| ID |
Date |
Author |
Topic |
Subject |
|
683
|
01 Dec 2009 |
Stefan Ritt | Info | Redesign of status page links | The custom and alias links in the standard midas status page were shown as HTML
links so far. If there are many links with names having spaces in their names,
it's a bit hard to distinguish between them. Therefore, they are packed now into
individual buttons (see attachment) starting from SVN revision 4633 on. This makes
also the look more homogeneous. If there is any problem with that, please report. |
| Attachment 1: Capture.png
|

|
|
684
|
04 Dec 2009 |
Stefan Ritt | Info | Redesign of status page columns | Since the column on the main midas status page with fraction of analyzed events is
barely used, I decided to drop it. Anyhow it does not make sense for all slow
control events. If this feature is required in some experiment, I propose to move it
into a custom page and calculate this ratio in JavaScript, where one has much more
flexibility.
This modification frees up more space on the status page for the "Status" column, where
front-end programs can report errors etc. |
| Attachment 1: Capture.png
|

|
|
685
|
04 Dec 2009 |
Stefan Ritt | Info | Custom page showing ROOT analyzer output | Many midas experiments work with ROOT based analyzers today. One problem there is that the graphical output of the root analyzer can only be seen through the X server and not through the web. At the MEG experiment, we solved this problem in an elegant way: The ROOT analyzer runs in the background, using a "virtual" X server called Xvfb. It plots its output (several panels) normally using this X server, then saves this panels every ten seconds into GIF files. These GIF files are then served through mhttpd using a custom page. The output looks like this:
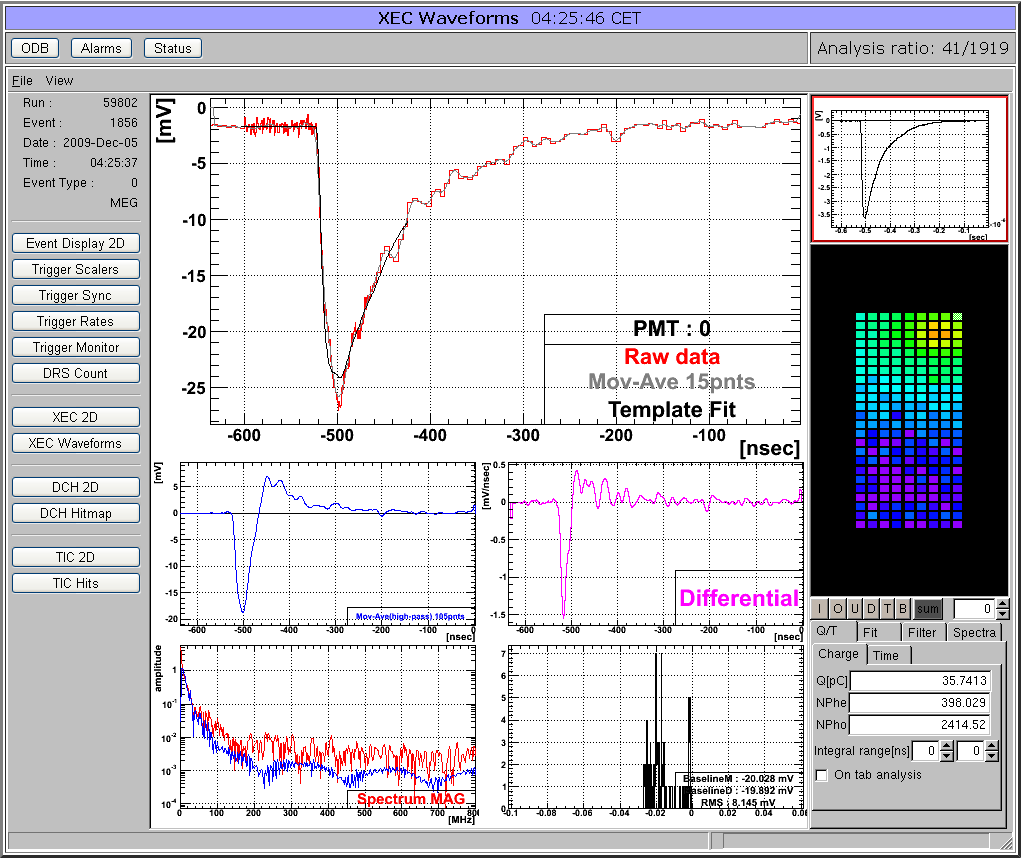
The buttons on the left sides are actually HTML buttons on that custom page overlaid to the GIF image, which in this case shows one of our 800 PMT channels digitized at 1.6 GSPS. With these buttons one can cycle through the different GIF images, which then automatically update ever ten seconds. Of course it is not possible to feed interaction back to the analyzer (like the waveform cannot be fitted interactively) but for monitoring an experiment in production mode this tools is extremely helpful, since it is seamlessly integrated into mhttpd. All the magic is done with JavaScript, and the buttons are overlaid to the graphics using CSS with absolute positioning. The analysis ratio on the top right is also done with JavaScript pulling the right info out of the ODB.
The used custom page file is attached. For details using Xvfb server, please contact Ryu Sawada <sawada@icepp.s.u-tokyo.ac.jp>. |
| Attachment 2: analyzer.html
|
|
686
|
04 Dec 2009 |
Stefan Ritt | Info | New '/Experiment/Menu buttons' | The mhttpd program shows some standard buttons in the top row for
starting/stopping runs, accessing the ODB, Alarms, etc. Since not all experiments
make use of all buttons, they have been customized. By default mhttpd creates
following entry in the ODB:
/Experiment/Menu Buttons = Start, ODB, Messages, ELog, Alarms, Programs, History,
Config, Help
Which is the standard set (except the old CNAF). People can customize this now by
removing unnecessary buttons or by changing their order. The "Start" entry above
actually causes the whole set of Start/Stop/Pause/Resume buttons to appear,
depending on the current run state. |
|
688
|
08 Dec 2009 |
Stefan Ritt | Forum | Run multiple frontend on the same host | Hi Jimmy,
ok, now I understand. Well, I don't see your problem. I just tried with the
current SVN
version to start
midas/examples/experiment/frontend
midas/examples/slowcont/scfe
in the same directory (without "-h localhost") and it works just fine (see
attachemnt). I even started them from the same directory. Yes there are *.SHM
files and they correspond to shared memory, but both front-ends use this shared
memory together (that's why it's called 'shared').
Your error message 'Semaphore already present' is strange. The string is not
contained in any midas program, so it must come from somewhere else. Do you
maybe try to access the same hardware with the two front-end programs?
I would propose you do the following: Use the two front-ends from the
distribution (see above). They do not access any hardware. See if you can run
them with the current SVN version of midas. If not, report back to me.
Best regards,
Stefan
> Dear Stefan,
>
> Thanks for the reply. I have tried your patch and it didn't solve my problem.
Maybe I
> have not written my question clearly. The two frontends could run on the same
computer
> if I use the remote method, i.e. by setting up the mserver and connect to the
> experiment by specifying "-h localhost", also the frontend programs need to be
put in
> different directory. What I want to know is whether I can simply start
multiple
> frontends in the same directory without setting up the mserver etc. I noticed
that
> there are several *.SHM files, I'm not familiar with semaphore, but I guess
they are
> the key to the problem. Please correct me if I misunderstood something.
>
> Best Regards,
> Jimmy
>
>
> > > Dear All,
> > >
> > > I want to run two frontend programs (one for trigger and one for slow
control)
> > > concurrently on the same computer, but I failed. The second frontend said:
> > >
> > > Semaphore already present
> > > There is another process using the semaphore.
> > > Or a process using the semaphore exited abnormally.
> > > In That case try to manually release the semaphore with:
> > > ipcrm sem XXX.
> > >
> > > The two frontends are connected to the same experiment. Is there any way I
can
> > > overcome this problem?
> >
> > That might be related to the RPC mutex, which gets created system wide now.
I
> > modified this in midas.c rev. 4628, so there will be one mutex per process.
Can you
> > try that temporary patch and tell me if it works for you? |
| Attachment 1: Capture.png
|

|
|
690
|
12 Dec 2009 |
Stefan Ritt | Info | New MSCB page implementation | A new page has been implemented in mhttpd. This allows web access to all devices from an MSCB system and their variables:
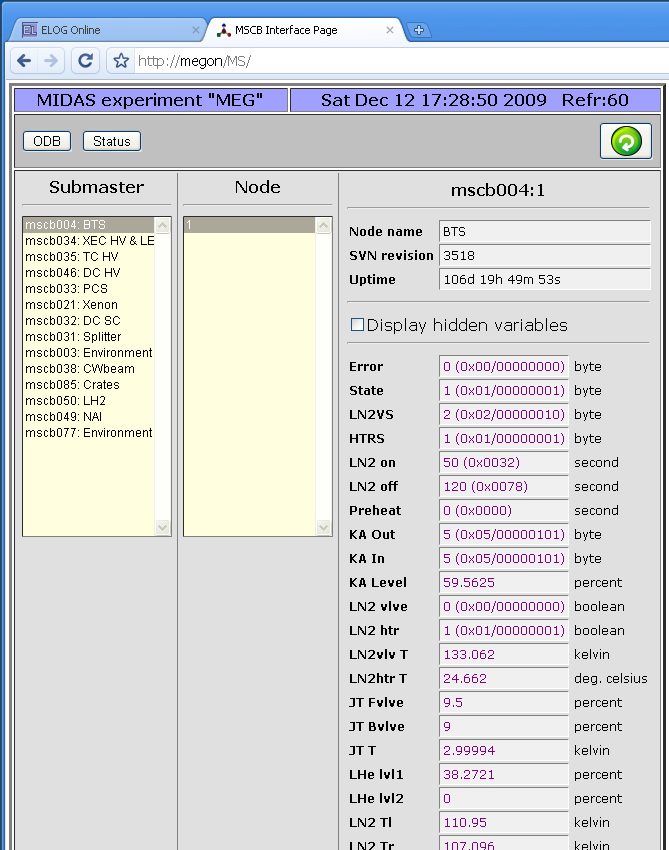
All you need to turn on the magic is to add a -DHAVE_MSCB to your Makefile for mhttpd. This is now the default in the Makefile from SVN, but it can be taken out for experiments not using MSCB. If it's present, mhttpd is linked against midas/mscb/mscb.c and gets direct access to all mscb ethernet submasters (USB access is currently disabled on purpose there). To show the MSCB button on the status page, you need following ODB entry:
/Experiment/Menu Buttons = Start, ODB, Messages, ELog, Alarms, Programs, History, MSCB, Config, Help
containing the "MSCB" entry in the list. If there is no "Menu Buttons" entry present in the ODB, mhttpd will create the above one, if it's compile with the -DHAVE_MSCB flag.
The MSCB page use the ODB Tree /MSCB/Submasters/... to get a list of all available submasters:
[local:MEG:R]/MSCB>ls -r
MSCB
Submaster
mscb004
Pwd xxxxx
Comment BTS
Address 1
mscb034
Pwd xxxxx
Comment XEC HV & LED
Address
0
1
2
Each submaster tree contains an optional password needed by that submaster, an optional comment (which just gets displayed on the 'Submaster' list on the web page), and an array of node addresses.
These trees can be created by hand, but they are also created automatically by mhttpd if the /MSCB/Submaster entry is not present in the ODB. In this case, the equipment list is scanned and all MSCB devices and addresses are collected from locations such as
/Equipment/<name>/Settings/Devices/Input/Device
or
/Equipment/<name>/Settings/Devices/<name>/MSCB Device
which are the locations for MSCB submasters used by the mscbdev.c and mscbhvr.c device drivers. Once the tree is created, it does not get touched again by mhttpd, so one can remove or reorder devices by hand.
The new system is currently successfully used at PSI, but I cannot guarantee that there are not issues. So in case of problems don't hesitate to contact me. |
|
692
|
11 Jan 2010 |
Stefan Ritt | Suggestion | Redesign of status page links | > > The custom and alias links in the standard midas status page were shown as HTML
> > links so far. If there are many links with names having spaces in their names,
> > it's a bit hard to distinguish between them. Therefore, they are packed now into
> > individual buttons (see attachment) starting from SVN revision 4633 on. This makes
> > also the look more homogeneous. If there is any problem with that, please report.
>
> Would you consider using a different colour for the alias buttons (or background
> colour)? At present it's hard to know whether a button is an alias link, a custom page
> link or a user-button especially if you are not familiar with the button layout.
Ok, I changed the background colors for the button rows. There are now four different
colors: Main menu buttons, Scripts, Manually triggered events, Alias & Custom pages. Hope
this is ok. Of course one could have each button in a different color, but then it gets
complicated... In that case I would recommend to make a dedicated custom page with all these
buttons, which you can then tailor exactly to your needs. |
| Attachment 1: Capture.png
|

|
|
694
|
09 Feb 2010 |
Stefan Ritt | Forum | custom page - flashing filled area | | One possibility is to use small GIF images for each valve, which have several frames (called 'animated GIF'). Depending on the state you can use a static GIF or the flashing GIF. An alternate approach is to use a static background image, and display a valve with different color on top of the background in regular intervals using JavaScript. I tried that with the attached page. Just create a custom page
/Custom/Valve = valve.html
and put all three attachments into your mhttpd directory. The JavaScript displays the red valve on top of the background with a 3 Hz frequency. The only trick is to position the overlay image exactly on top of the background image. This is done using the 'absolute' position in the style sheet. It needs a bit playing to find the proper position, but then it works fine. |
| Attachment 1: valve.html
|
| Attachment 2: valve_back.gif
|

|
| Attachment 3: valve.gif
|

|
|
696
|
11 Mar 2010 |
Stefan Ritt | Info | New '/Experiment/Menu buttons' | > The mhttpd program shows some standard buttons in the top row for
> starting/stopping runs, accessing the ODB, Alarms, etc. Since not all experiments
> make use of all buttons, they have been customized. By default mhttpd creates
> following entry in the ODB:
>
> /Experiment/Menu Buttons = Start, ODB, Messages, ELog, Alarms, Programs, History,
> Config, Help
>
> Which is the standard set (except the old CNAF). People can customize this now by
> removing unnecessary buttons or by changing their order. The "Start" entry above
> actually causes the whole set of Start/Stop/Pause/Resume buttons to appear,
> depending on the current run state.
Upon request the set of Menu Buttons has been extended to
/Experiment/Menu Buttons = Start, Pause, ODB, Messages, ELog, Alarms, Programs,
History, Config, Help
by adding the additional "Pause" string. Without "Pause" being present in the list of
menu buttons, the run cannot be paused/resumed, but only started/stopped. This is
required by some experiments. If "/Experiment/Menu Buttons" is not present in the ODB,
it gets created with the above default. If it is there from the previous update, the
"Pause" string might be missing, so it must be added by hand if required. The
modification is committed as revision #4684. |
|
703
|
14 Jun 2010 |
Stefan Ritt | Forum | crash on start run | > I use fedora 12 and midas 4680. there is problem to start run when the frontend
> application runs fine.
I don't know exactly what is wrong, but I would check following things:
- does your feTCPPacketReceiver die during the start-of-run? Maybe you do some segfault
int he begin-of-run routine. Can you STOP a run?
- is there any network problem due to your two cards? When you try to stop your fe from
odbedit with
# odbedit -c "shutdown feTCPPacketReceiver"
do you then get the same error? The shutdown functionality uses the same RPC channel as
the start/stop run. Some people had firewall problems, on both sides (host AND client),
so make sure all firewalls are disabled.
- if you disable one network card, do you still get the same problem? |
|
709
|
28 Jun 2010 |
Stefan Ritt | Forum | Error connecting to back-end computer | > > Hi, there. I have not recently run mserver through inetd, and we usually do not do
> > that at TRIUMF. We do this:
> >
> > a) on the main computer: start mserver: "mserver -p 7070 -D" (note - use non-default
> > port - can use different ports for different experiments)
> > b) on remote computer: "odbedit -h main:7070" ("main" is the hostname of your main
> > computer). Use same "-h" switch for all other programs, including the frontends.
> >
> > This works well when all computers are on the same network, but if you have some
> > midas clients running on private networks you may get into trouble when they try to
> > connect to each other and fail because network routing is funny.
>
> Hi K.O.,
>
> Thanks for your reply. I have tried your way but I got the same error:
>
> [midas.c:8623:rpc_server_connect,ERROR] mserver subprocess could not be started
> (check path)
>
> My front-end and back-end computers are on the same network connected by a router. I
> have allowed port 7070 in the firewall and done the port forwarding in the router (for
> connecting from outside the network). From the error message it seems that some
> processes can not be started automatically. Could it be related to some security
> settings such as the SELinux?
The way connections work under Midas is there is a callback scheme. The client starts
mserver on the back-end, then the back-end connects back to the front-end on three
different ports. These ports are assigned dynamically by the operating system and are
typically in the range 40000-60000. So you also have to allow the reverse connection on
your firewalls. |
|
717
|
08 Sep 2010 |
Stefan Ritt | Info | YBOS support now optional, disabled by default | > It looks like some example drivers in .../drivers/class want to link against YBOS libraries.
> This fails because ybos.o is missing from the MIDAS library.
I fixed the class drivers in meantime (SVN 4814).
There is however another problem: The lazylogger needs YBOS support compiled in if the FTP transfer mode is used.
At PSI we are stuck at the moment to FTP, so we still need YBOS there (although none of the data is in YBOS format).
Maybe there is a chance that this will be fixed some time and we can get rid of YBOS. |
|
721
|
20 Sep 2010 |
Stefan Ritt | Info | modified mhttpd history panel editor | Just some idea:
The ultimate solution to that would be to do that completely JavaScript driven. You load ONCE the list of all
variables into a local array, then sort this into your history panel LOCALLY. When I did the original mhttpd
history config page, there was not much JavaScript around, but today this would be the ultimate option. It
even supports drag-and-drop. So let's keep that in mind for the future.
- Stefan |
|
724
|
23 Sep 2010 |
Stefan Ritt | Info | Example javascript midas page | > We had javascript ODBGet() and ODBSet() functions for some time now, permitting
implementation of
> "page-reload-free" "self-updating" web pages. I finally got around to put all
the javascript bits together
> to actually implement such a page.
Unfortunately the page has tons of JavaScript errors, probably happened during
copy-and-paste to elog. Note that
such files are better places as attachment. I attached a screen dump from the JS
debugger inside Chrome which I
use normally to debug JS. |
| Attachment 1: js_error.png
|

|
|
725
|
23 Sep 2010 |
Stefan Ritt | Info | Another example of a JavaScript midas page | Please find attached another example of a JavaScript (JS) page using the
ODBGet/Set functions.
In contrast to the previous posting, the page is not constructed via the
document.writeln() function, but written directly in HTML and modified through the
"innerHTML = ..." functionality.
It is a control page for our beamline, which gets updated in the background. In
addition, the user can set the beamline to three predefined settings which are
stored in an array at the top of the page. As an little extra there is a progress
bar, which is updated locally via JS since changing the beamline takes a while.
The progress bar is implemented as a table with variable width, and dynamically
updated by the JS program. The second attachment is a screen dump from such a
switching process. Since only values in the ODB are changed, you can try it
yourself without actually modifying a PSI beam line ;-) |
| Attachment 1: beamline.html
|
| Attachment 2: beamline.png
|

|
|
727
|
24 Sep 2010 |
Stefan Ritt | Info | Example javascript midas page | > The attached errors all seem to be from cut-and-paste line breaks in the long "document.writeln()" statements.
> When the page runs, there are no errors from Firefox and Safari.
Then it would be good if you re-submit the file as an attachment so that other people can use it.
> This example uses "document.writeln()" because the number of PostAmp devices displayed in the table is not
> known in advance and is potentially read from ODB at page load time.
This was not a criticism but just to show that there are different ways of constructing such a page, depending on the
needs. So people have the choice. Anyhow I think it's very good to have some working examples for people to start
with. |
|
732
|
17 Nov 2010 |
Stefan Ritt | Bug Report | mhttpd "edit on start" breakage | > very recent mhttpd mangles spaces in URL encoding-decoding and I cannot create or delete entries in for
> example "/experiment/edit on start". For example attempt to delete "/experiment/Pedestals Run"
> produces:
> <h1>Cannot find key Experiment/edit%20on%20start/Pedestals run</h1>
> (notice "%20" instead of spaces. further navigation sometimes replaces the "%" sign with "%25" making it
> even more mangled)
>
> this used to work. looks like a call to URL unmangling went missing somewhere.
> K.O.
Thanks for reporting. Fixed in SVN revision 4882. Actually I outcommented the fix some time ago and forgot to
put it back. Now I hope that this does not blow anything else...
- Stefan |
|
733
|
15 Dec 2010 |
Stefan Ritt | Info | New source file structure of MSCB tree | A long planned modification of the source file structure of the MSCB subsystem has been implemented. This is however only for those people who do actively participate in micro controller programming with MSCB. The idea behind this is tha the central include file mscbemb.h had a section for each new project. So whenever a new project was added, this file had to be modified which is clumsy and hard to maintain. Therefore I took the project specific sections out of this file and put it into a config.h file, which is separate for each project (very similar to VxWorks). So the folder tree now looks like this:
midas\mscb\embedded
\include <- place for framework include file mscbemb.h
\lib <- precompiled TCP/IP library for SCS-260 submaster
\src <- framework sources mscbmain.c and mscbutil.c
\<project1> <- separate folder for project1
config.h <- config file for project1
\<project2> <- separate folder for project2
config.h <- config file for project2
...
\experiment
\<experiment1>
\<experiment2>
So each project has it's own config.h, which is included from the central mscbemb.h and can be used to enable certain features of the framework without having to change the framework itself. The "projectx" folders contain devices which are used across several experiments and sometimes also between institutes (PSI and TRIUMF). If you make a device which is only used in a specific experiment, this should go under \experiment with the name of the device or the experiment as a subdirectory. I encourage everybody to submit even specific projects to the subversion system since they can sometimes be useful for others to look at some example code.
A few other things have to be changed in order to adapt to the new structure:
- The framework files mscbmain.c mscbutil.c and mscbemb.h have moved and therefore they have to be re-added to the projects in the Keil MicroVision Development Environment.
- The name of the device should not be defined under compiler settings (Project Options/C51/Preprocessor Symbols), but put directly into the config.h file associated with the project.
- The include paths in the compile have to be changed and point to \midas\mscb\embedded\include
- The file config.h has to be copied from a similar project and adjusted to fit the new project.
I did remove all project specific sections from mscbemb.h in the current SVN version, so certain projects (FDB_008 at TRIUMF, CRATE_MONITOR and PT100X8 at PSI) have to retrieve the settings (like LED ports etc.) from the old mscbemb.h and put it into the config.h file.
Furthermore there is a new STARTUP_VDDMON.A51 file in the src directory which should be added to each project. This was recommended by the micro controller manufacturer and fixes cases where the EEPROM contents of the CPU gets lost from time to time during power up.
The last thing is that PSI switched to MicroVision 4 as the development environment, so I added new project files (*.uvproj and *.uvopt instead *.Uv2), but I left the old ones there in case someone still has the uV2 environment. They are however not maintained any more.
If there is any problem with the new structure or you have some comments, please don't hesitate to contact me.
- Stefan |
|
752
|
17 Feb 2011 |
Stefan Ritt | Bug Report | Problems with midas history SVN 4936 | > uhm, mine might be completely unrelated to this, but it just so happened that the rev.
> 4936 was one that was used in a recent experiment, in which there was complaints about
> the responsiveness of the history plots. The history plots would take up to 30 seconds
> to respond, if the run was about 30-40 minutes old. When the run is about < 10 minutes
> old , the history plot was responsive to within 1-2 seconds.
Ah, that rings a bell. How big are your history files on disk? How much RAM do you have?
What I see in our experiment is that linux buffers everything I write to disk in a cache
located in RAM. But this cache is limited, so after a certain time it's overwritten. Now
this is handled by the OS, the application (mlogger in this case) has no influence on it.
Let's say you write 5 MB/minute of history, and your cache is 50 MB large. Then after 10
minutes you can still read the history data from the RAM cache which is ~10x faster than
your disk. But your older history data (30-40 min) is flushed out of the cache and has to be
re-read from disk. A typical symptom of this is that the first time you display this it
takes maybe 30 seconds, but if you do a "reload" of your page it goes much faster. In that
case the contents is cached again in RAM. If you observe this, you can almost be certain
that you see th "too small RAM cache" problem. In that case just add RAM and things should
run better (I use 16 GByte in my machine).
Best regards,
Stefan |
|
755
|
30 Mar 2011 |
Stefan Ritt | Forum | How large does "bank32" support? | > Reading an FADC buffer often needs large buffer size, especially while several
> FADCs work together. I want to know how large a bank32 can support.
The "32" in bank32 means 32-bits, so the bank holds 2^32=4 GBytes, hope that is enough for your ADC.
The "normal" bank has only a 16-bit header, so it can hold only 64 kBytes. But for small banks, the overhead
is therefore smaller. |
|