| ID |
Date |
Author |
Topic |
Subject |
|
1396
|
24 Sep 2018 |
Devin Burke | Forum | Implementing MIDAS on a Satellite | Hello Everybody,
I am a member of a satellite team with a scientific payload and I am considering
coordinating the payload using MIDAS. This looks to be challenging since MIDAS
would be implemented on an Xilinx Spartan 6 FPGA with minimal hardware
resources. The idea would be to install a soft processor on the Spartan 6 and
run MIDAS through UCLinux either on the FPGA or boot it from SPI Flash. Does
anybody have any comments on how feasible this would be or perhaps have
experience implementing a similar system?
-Devin |
|
1401
|
25 Sep 2018 |
Stefan Ritt | Forum | Implementing MIDAS on a Satellite | > Hello Everybody,
>
> I am a member of a satellite team with a scientific payload and I am considering
> coordinating the payload using MIDAS. This looks to be challenging since MIDAS
> would be implemented on an Xilinx Spartan 6 FPGA with minimal hardware
> resources. The idea would be to install a soft processor on the Spartan 6 and
> run MIDAS through UCLinux either on the FPGA or boot it from SPI Flash. Does
> anybody have any comments on how feasible this would be or perhaps have
> experience implementing a similar system?
>
> -Devin
While some people successfully implemented a midas *client* in an FPGA softcore, the full midas
backend would probably not fit into a Spartan 6. Having done some FPGA programming and
working on satellites, I doubt that midas would be well suited for such an environment. It's
probably some kind of overkill. The complete GUI is likely useless since you want to minimize your
communication load on the satellite link.
Stefan |
|
1402
|
25 Sep 2018 |
Devin Burke | Forum | Implementing MIDAS on a Satellite | > > Hello Everybody,
> >
> > I am a member of a satellite team with a scientific payload and I am considering
> > coordinating the payload using MIDAS. This looks to be challenging since MIDAS
> > would be implemented on an Xilinx Spartan 6 FPGA with minimal hardware
> > resources. The idea would be to install a soft processor on the Spartan 6 and
> > run MIDAS through UCLinux either on the FPGA or boot it from SPI Flash. Does
> > anybody have any comments on how feasible this would be or perhaps have
> > experience implementing a similar system?
> >
> > -Devin
>
> While some people successfully implemented a midas *client* in an FPGA softcore, the full midas
> backend would probably not fit into a Spartan 6. Having done some FPGA programming and
> working on satellites, I doubt that midas would be well suited for such an environment. It's
> probably some kind of overkill. The complete GUI is likely useless since you want to minimize your
> communication load on the satellite link.
>
> Stefan
Thank you for your comment Stefan. We do have some hardware resources on the board such as RAM, ROM and
Flash storage so we wouldn't necessarily have to virtualize everything. Ideally we would like a
completed and compressed file to be produced on board and regularly sent back to ground without
requiring remote access. MIDAS is appealing to us because its easily automated but we wouldn't
necessarily need functions like a GUI or web interface. Part of the discussion now is whether or not a
microblaze processor would be sufficient or if we need a dedicted ARM processor.
Devin |
|
1421
|
26 Dec 2018 |
Konstantin Olchanski | Forum | Implementing MIDAS on a Satellite | >
> Thank you for your comment Stefan. We do have some hardware resources on the board such as RAM, ROM and
> Flash storage so we wouldn't necessarily have to virtualize everything. Ideally we would like a
> completed and compressed file to be produced on board and regularly sent back to ground without
> requiring remote access. MIDAS is appealing to us because its easily automated but we wouldn't
> necessarily need functions like a GUI or web interface. Part of the discussion now is whether or not a
> microblaze processor would be sufficient or if we need a dedicted ARM processor.
>
Hi, just recently I got a midas frontend to build and run on uclinux on a microblaze arm CPU (GRIFFIN CDM VME board).
It worked, but uncovered many problems inside midas - uclinux has no mmu, no multithreading, no recursive mutexes, no
some of the other stuff assumed always available.
The worst problem I ran into was with uclinux giving us a very small stack so code like "int main() { char buf[10*1024]; }
crashes right away and there is a lot of code like this in midas.
My feeling about the xilinx soft-core CPU, if you can run uclinux, you can also run a midas frontend. We do not require
memory beyond that needed to store one or two of your data events.
By design, the midas library can be built in a "minimal" configuration that only supports a frontend connected
to the mserver (no local ODB, no local event buffers, no local mhttpd/mlogger, etc).
As you have seen in the Makefile, there are provisions for cross-compilation and I cross-compile midas things quite often.
On the other side, if you have xilinx FPGA with build-in PowerPC CPU, most definitely you can run full linux
and you can run full midas on it, we have done this for the T2K/ND280 experiment in Japan.
K.O. |
|
2814
|
30 Aug 2024 |
Marius Koeppel | Suggestion | Improve Event Documentation | Hi,
I am writing a Rust based midas file reader however it was kind of hard to understand the full midas file
structure from the documentation.
Only at the end of the page
https://daq00.triumf.ca/MidasWiki/index.php/Event_Structure#MIDAS_Format_Event one finds under the
headline �tape format� that there are special events which mark the start and the end of the run. It would
be better to place this information more prominent maybe we a headline: �Special Events�. Maybe a link to
this section at the top of the page could help. Also at the mlogger page there is no information about this.
Best,
Marius |
|
2816
|
01 Sep 2024 |
Stefan Ritt | Suggestion | Improve Event Documentation | > Hi,
>
> I am writing a Rust based midas file reader however it was kind of hard to understand the full midas file
> structure from the documentation.
>
> Only at the end of the page
> https://daq00.triumf.ca/MidasWiki/index.php/Event_Structure#MIDAS_Format_Event one finds under the
> headline �tape format� that there are special events which mark the start and the end of the run. It would
> be better to place this information more prominent maybe we a headline: �Special Events�. Maybe a link to
> this section at the top of the page could help. Also at the mlogger page there is no information about this.
>
> Best,
> Marius
Ben was so kind to update the event documentation:
https://daq00.triumf.ca/MidasWiki/index.php/Event_Structure
Please have a look and let us know if that's better now.
Best,
Stefan |
|
2817
|
01 Sep 2024 |
Marius Koeppel | Suggestion | Improve Event Documentation | > > Hi,
> >
> > I am writing a Rust based midas file reader however it was kind of hard to understand the full midas file
> > structure from the documentation.
> >
> > Only at the end of the page
> > https://daq00.triumf.ca/MidasWiki/index.php/Event_Structure#MIDAS_Format_Event one finds under the
> > headline �tape format� that there are special events which mark the start and the end of the run. It would
> > be better to place this information more prominent maybe we a headline: �Special Events�. Maybe a link to
> > this section at the top of the page could help. Also at the mlogger page there is no information about this.
> >
> > Best,
> > Marius
>
> Ben was so kind to update the event documentation:
>
> https://daq00.triumf.ca/MidasWiki/index.php/Event_Structure
>
> Please have a look and let us know if that's better now.
>
> Best,
> Stefan
Thank you Ben! Now its super clear! |
|
2818
|
02 Sep 2024 |
Daniel Duque | Suggestion | Improve Event Documentation | > I am writing a Rust based midas file reader
You might find this library I wrote useful: https://crates.io/crates/midasio
It should "just work", and if it doesn't, I would be interested to know. |
|
2819
|
02 Sep 2024 |
Marius Koeppel | Suggestion | Improve Event Documentation | > > I am writing a Rust based midas file reader
>
> You might find this library I wrote useful: https://crates.io/crates/midasio
>
> It should "just work", and if it doesn't, I would be interested to know.
Nice! I did not know about this. I have now also one simple reader but yours looks much more advanced. My
overall idea here is to connect directly to midas so having some frontend features to analyze the data etc. do
you also have already a library for this? I can also extend your stuff.
Best,
Marius |
|
2820
|
02 Sep 2024 |
Daniel Duque | Suggestion | Improve Event Documentation | > My overall idea here is to connect directly to midas so having some frontend features to analyze the data etc. do
> you also have already a library for this? I can also extend your stuff.
No, sadly I don't have something like this yet. It has been on my "fun things to do at some point" list for too
long, but I haven't had the time.
If you start working on something like this, please keep me in the loop/link a repo here. I would be interested
on keeping an eye/contributing to something like this :) |
|
2835
|
11 Sep 2024 |
Konstantin Olchanski | Suggestion | Improve Event Documentation | > I am writing a Rust based midas file reader however it was kind of hard to understand the full midas file
> structure from the documentation.
MIDAS is old-school, when the code was the documentation.
This is very noticeable when you try to document things MIDAS (as I have done many times).
For MIDAS data format, file level and bank level, best if you look at my midasio library (included with MIDAS
git clone) and translate it to Rust directly. I think a Rust version of C++ midasio would be very welcome.
Many data fields in MIDAS files are mysterious and I reverse-engineered them the best I could.
The main problems were:
- data padding
- "length" fields include padding or not?
- identification of big-endian vs little-endian data
- probably something I forget
K.O. |
|
494
|
04 Jul 2008 |
Stefan Ritt | Info | Improved alarm conditions implemented | I implemented improved alarm conditions in the alarm system. Now one can write
conditions like
/Equipment/HV/Variables/Input[*] < 100
or
/Equipment/HV/Variables/Input[2-3] < 100
to check all values from an array or a certain range. If one array element
fulfills the alarm condition, the alarm is trigger. In addition, bit-wise alarm
conditions are possible
/Equipment/Environment/Variables/Input[0] & 8
is triggered if bit #2 is set in Input[0].
The changes are committed to SVN revision 4242. |
|
492
|
17 Jun 2008 |
Stefan Ritt | Info | Improvement of custom pages | Some improvement of custom pages have been implemented. The idea behind is that
a custom page would contain a large background image containing indicators but
also controls. While indicators (values, bars) are already available, the field
of controls have been improved.
Edit boxes floating on top of a graphic
---------------------------------------
The first option has been there from the beginning, but was never documented. It
makes it possible to put an edit box right on top of a graphic by means of a CSS
style tag. The custom page code could look like this:
<div style="position:absolute; top:100px; left:50px;">
<odb src="/Runinfo/run number" edit=1>
</div>
<img src="cusgom.gif">
The "div" tag surrounding the "odb" tag places this directly on top of the
"custom.gif" image, where it can be clicked to be edited.
Password protection of an edit box
----------------------------------
Being able to control an experiment through a web interface of course rises the
question about safety. This is not so much about external access (for which we
have other protection schemes like host lists etc.) but it's about accidental
access by the normal shift crew. If a single click on a web page opens a
critical valve, this might be a problem. In order to restrict access to some
"experts", an additional password can be chosen for all or some controls on a
custom page. This is done by a new option in the "odb" tag and by adding a small
JavaScript function into the custom page:
<script type="text/javascript">
<!--
function promptpwd(path)
{
pwd = prompt('Please enter password', '');
document.cookie = "cpwd=" + pwd;
location.href = path;
}
//-->
</script>
...
<odb src="/..." edit=1 pwd="CustomPwd">
...
If the "pwd" option is present in the "odb" tag, mhttpd establishes a call to
the promptpwd() function if one click on the value. The password is then asked
from the user and submitted as a cookie. mhttpd then check this password against
the ODB entry
/Custom/Pwd/CustomPwd
and shows an error if they don't match. By using an explicit name ("CustomPwd"
in the above example) one can use a single password for all controls on a page,
or one could use several passwords on the same page. Like a shift crew password
for the less severe controls (/Custom/Pwd/ShiftPwd), and an "expert" password
(/Custom/Pwd/ExpertPwd) for the critical things. This password is of course not
secure in the sense that it's placed in plain text into the ODB, it's more to
prevent accidental modifications of things.
Area map to toggle values
-------------------------
Sometimes it's desirable to toggle a value, like the state of a valve. This can
be done now with a new function like this:
<map name="Custom1">
<area shape="rect" coords="40,200,100,300" alt="Main Valve"
href="Custom1?cmd=Toggle&odb=/Equipment/Environment/Variables/Output[2]">
</map>
<img src="cusgom.gif" usemap="#Custom1">
This defines a clickable map on top of the custom image. The area(s) should
match with some areas on the image like the box of a valve. By clicking on it,
the supplied path to the ODB is used (in this case
"/Equpiment/Environment/Variables[2]") and it's value is toggled (set to 0 if it
is 1, set to 0 if it is 1). If the valve value is then used in the image via a
"fill" statement to change the color of the valve, it can turn green or red
depending on it's state.
Are map with password check
---------------------------
The above area map can be combined with the password check. To do so, one needs:
<area shape="rect" coords="40,200,100,300" alt="Main Valve"
href="#"
onClick="promptpwd('Custom1?cmd=toggle&pnam=CustomPwd?odb=/Equipment/Environment/Variables/Output[2]')">
in combination with the JavaScript from above.
An example of the are map technology is shown in the attachment. This page from the MEG experiment at PSI
shows a complex gas system. The valves are represented as green circles. If they are clicked, they close
and become red (after the user successfully supplied the correct password). |
| Attachment 1: Capture.png
|

|
|
496
|
31 Jul 2008 |
Stefan Ritt | Info | Improvement of custom pages | Even more improvements have been implemented into custom pages recently, containing a complete JavaScript library for ODB communication. This JavaScript library relies on certain new commands built into mhttpd, and is therefore hardcoded into mhttpd. It can be seen by entering
http://<your mhttpd host>/mhttpd.js
To include it in your custom page, put following statement inside the <head>...</head> tag:
<script type="text/javascript" src="../mhttpd.js"></script>
It contains several functions:
Display of cursor location
When writing custom pages with large background images and labels placed on that image, it is hard to figure out X and Y coordinates of the labels. This can now be simplified by adding a new tag to the background image like
<img id="refimg" src="...">
If the "refimg" tag is present, the cursor changes into a crosshair and it's absolute and relative locations in respect to the reference image are shown in the status bar:
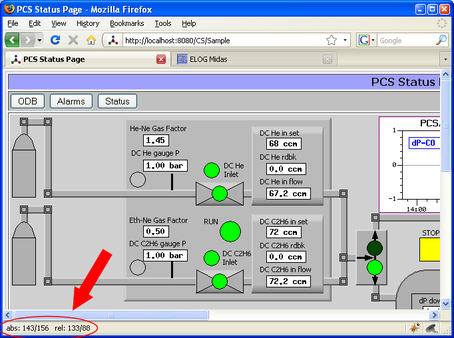
To make this work under Firefox, the user has to explicitly allow for status bar changes. To do so, enter about:config in the address bar. In the filter bar, enter status. Then locate dom.disable_window_status_change and set it to false.
Retrieving ODB values
Retrieving individual or array values from the ODB through the AJAX interface is now very simple. Just call:
ODBGet(<path>);
to obtain a value. If <path> points to an array in the ODB, an individual value can be retrieved by using an index, like
ODBGet('/Equipment/Environment/Variables/Input[3]');
or the complete array can be obtained with
ODBGet('/Equipment/Environment/Variables/Input[*]');
The function then returns a JavaScript array which can be used like
var a = ODBGet('/Equipment/Environment/Variables/Input[*]');
for (i=0 ; i<a.length ; i++)
alert(a[i]);
This functionality together with the window.setInterval() function can be used to update parts of the web page periodically such as:
window.setInterval("Refresh()", 10000);
function Refresh() {
document.getElementById("run_number").innerHTML = ODBGet('/Runinfo/Run number');
}
This function updates the current run number every 10 seconds in the background. The custom page has to contain an element with id="run_number", such as
<td id="run_number"></td>
The formatting of any number uses the internal default. If this should be changed, the format can directly appended in the ODB path such as:
ODBGet('/Equipment/Environment/Variables/Input[3]&format=%1.2lf');
the format %1.2lf is then directly passed to the sprintf() function.
Retrieving System Messages
A similar function ODBGetMsg(<n>) has been defined. It retrieves the last <n> system messages, which can then be displayed in some message area. If n=1 a single string is returned, if n>1 an array of strings is returned similar to ODB arrays.
Setting ODB values
Individual ODB values can be set in the background with
ODBSet(<path>,<value>);
or
ODBSet(<path>,<value>,<password_name>);
The password_name has the same meaning as described in elog:492. It must be defined under /Custom/Pwd/<password_name>. The function ODBSet can be used for example when one clicks on an checkbox for example:
<input type="checkbox" onClick="ODBSet('/Logger/Write data',this.checked?'1':'0')">
If used as above, the state of the checkbox must be initialized when the page is loaded. This can be either done with some JavaScript code called on initialization, which then uses ODBGet() as described above. Alternatively, the <odb> tag can be used like:
<odb src="/Logger/Write data" type="checkbox" edit="2" onclick="ODBSet('/Logger/Write data',this.checked?'1':'0')">
The special code edit="2" instructs mhttpd not to put any JavaScript code into the checkbox tag, since setting this value in the ODB is now handled by the user-supplied ODBSet() code. With edit="1" the internal JavaScript is activated, which uses the old form submission for sending the value to the ODB. |
|
2418
|
06 Aug 2022 |
Stefan Ritt | Info | Improvement of odbxx API | While the odbxx API has been successfully used since the last months, a potential
problem with large ODBs surfaced. If you have lots of data in the ODB and load it
into an object like
midas::odb o("/Equipment");
this might take quite long, since each ODB value is fetched separately, which is
very quick on a local machine but can take long over a client-server connection.
For large experiments this can take up to minutes (!).
To get rid of this problem, the underlying object model has been modified. When an
object is instantiated like above, then the whole ODB tree is fetched in an XML
buffer in a single transfer, which even for large ODBs usually takes much less
than a second. Then the XML buffer is decomposed on the client side and converted
into the proper midas::odb objects. In one case this gave an improvement from 35
seconds to 0.5 seconds which is significant. To enable the new method, the object
can be created with a flag like
midas::odb o("/Equipment", true);
which then switches to the new method. One has to take care not to fool oneself
(like I did) by printing the object like
midas::odb o("/Equipment", true);
std::cout << o << std::endl;
because each read access to any sub-object of o causes a separate read request to
the server which again can take long. Therefore, one has to switch off the auto
refresh via
midas::odb o("/Equipment", true);
o.set_auto_refresh_read(false);
std::cout << o << std::endl;
Accessing any sub-object of o then does not cause a client-server request, which
is not necessary if all objects just have been pulled from the server before. If
one keeps the object however for a long time in memory, one has to be aware that
it only contains "old" values from the time if instantiation. If one needs more
current ODB values, the auto read refresh has to be turned on again.
Stefan |
|
2419
|
08 Aug 2022 |
Stefan Ritt | Info | Improvement of odbxx API | After some thought, I changed the API again and removed the flag in the constructor,
so the system now automatically choses the best algorithm depending if the client
is connected to a local or a remote API. So in all cases you use again the old syntax:
midas::odb o("/Equipment");
Stefan |
|
2061
|
17 Dec 2020 |
Amy Roberts | Suggestion | Improving variable functionality in Sequencer? | We're using the sequencer to manage runs, and this typically looks something like:
1. save ODB keys to variables via ODBGET
2. set ODB keys to new values for a "pre-run" process
3. return ODB keys to values created in line 1
4. take data
The problem I'm running into is that the list of ODB keys to save is pretty
unwieldy. I'm wondering if there are sequencer features that exist or that I could
request that might make this easier.
For example, having a way to list ODB keys, save ODB directories, and load ODB
directories would be much more concise way for me to write my script.
Another option might be to have some version of the ODBSET wildcards for ODBGET.
Although for this, setting the variable names might be tricky.
In any case, even being able to ODBGET an array and set that to one variable name
would be a big improvement. |
|
2065
|
05 Jan 2021 |
Amy Roberts | Suggestion | Improving variable functionality in Sequencer? | Hello, just wanted to re-ping on this question now that folks are starting to get back from
the holidays. |
|
2067
|
06 Jan 2021 |
Stefan Ritt | Suggestion | Improving variable functionality in Sequencer? | I guess you use a wrong pattern here. There is no need to copy ODB values to local variables,
then change them, then write them back. You can rather directly write values to the ODB. We run
all our experiments in that way and we can do what we want. So most of our scripts have sections
like
ODBSUBDIR "/Equipment/Laser/Variables"
ODBSET "Setting[*]", 0, 0
ODBSET "Output[1]", 0, 0
ODBSET "Output[2]", 1, 0
ODBSET "Output[3]", 0, 0
ODBSET "Output[4]", 1, 1
ENDODBSUBDIR
Note that both the path and the indices can contain wild cards, making this pattern more
flexible. Wildcards are however not (yet) supported for local variables, that's why we use
directly the ODBSET directive.
I attach a larger example from the MEG experiment here for your reference.
Stefan |
| Attachment 1: laser.msl
|
COMMENT "TC laser run"
# include XEC setting script
INCLUDE xec_settings
RUNDESCRIPTION "TC laser run"
SET Nrun, 1
SET Freq, 1200
ODBSET "/Experiment/Run Parameters/SQL/SPX/SPXConfId", 79, 0
ODBGET "/Sequencer/Variables/Freq", Freq
ODBSET "/Sequencer/Variables/Freq", 1200, 1
SET Power, 12
SET Temp, 15
SET LaserFreq, 40
SET Nevent, 3000
ODBGET "/Sequencer/Variables/Nevent", Nevent
ODBSET "/Sequencer/Variables/Nevent", 3000, 1
SET Gain, 100
SET PzcLevel, 7
# Reset XEC setting
CALL setup_ADC, 0
CALL setup_DRS, 0
ODBSUBDIR "/Equipment/Trigger/Settings/WaveDAQ/"
ODBSET "AUXCrate/AUX-13/SamplingFrequency", $Freq, 0
ODBSET "AUXCrate/AUX-13/FrontendPzcLevel", 3, 0
ODBSET "AUXCrate/AUX-13/FrontendGain[14]", 1, 0
ODBSET "AUXCrate/AUX-13/FrontendPzc[14]", n, 0
ODBSET "AUXCrate/AUX-13/FrontendGain[15]", 1, 0
ODBSET "AUXCrate/AUX-13/FrontendPzc[15]", y, 0
ODBSET "AUXCrate/AUX-13/DRSChannelTxEnable", 0x3FFFFx,0
ODBSET "AUXCrate/AUX-13/ZeroSuppressionEnable", n, 0
ODBSET "TCUS1Crate/TU1-*/SamplingFrequency", $Freq, 0
ODBSET "TCUS1Crate/TU1-*/FrontendPzcLevel", $PzcLevel, 0
ODBSET "TCUS1Crate/TU1-*/FrontendPzc[*]", y, 0
ODBSET "TCUS1Crate/TU1-*/DRSChannelTxEnable", 0x3FFFF,0
ODBSET "TCUS1Crate/TU1-*/ZeroSuppressionEnable", n, 0
ODBSET "TCUS1Crate/TU1-*/FrontendGain[*]", $Gain, 0
ODBSET "TCUS1Crate/TU1-6/FrontendGain[*]", 50, 0
ODBSET "TCUS1Crate/TU1-*/TDCChannelTxEnable", 0,0
ENDODBSUBDIR
ODBSUBDIR "/Equipment/Trigger/Settings/WaveDAQ"
ODBSET "Trigger/MASTER/TriggerPrescaling[*]", 0, 0
ODBSET "Trigger/MASTER/TriggerEnable[*]", n, 0
ODBSET "Trigger/MASTER/TriggerPrescaling[63]", 1, 0
ODBSET "Trigger/MASTER/TriggerEnable[63]", y, 0
ODBSET "Trigger/MASTER/Write TRGC", y, 0
ODBSET "Trigger/MASTER/Write TGEN", y, 0
ODBSET "Trigger/MASTER/Write XEC", n, 0
ODBSet "Trigger/TC/Write SPX", n, 0
ENDODBSUBDIR
ODBSUBDIR ""
ENDODBSUBDIR
ODBSET "/Equipment/Trigger/Settings/Reload all", y, 1
WAIT ODBValue, "/Equipment/Trigger/Variables/Config busy", ==, 0
WAIT seconds, 2
ODBSUBDIR "/Equipment/Trigger/Settings/WaveDAQ"
ODBSET "Trigger/MASTER/TriggerPrescaling[*]", 0, 0
ODBSET "Trigger/MASTER/TriggerEnable[*]", n, 0
ODBSET "Trigger/MASTER/TriggerPrescaling[63]", 100, 0
ODBSET "Trigger/MASTER/TriggerEnable[63]", y, 1
ENDODBSUBDIR
ODBSUBDIR ""
ENDODBSUBDIR
CAT description, "TC pedestal"
ODBSET "/Experiment/Run Parameters/Run description", $description, 1
LOOP $Nrun
TRANSITION start
WAIT events, 1000
TRANSITION stop
ENDLOOP
ODBSUBDIR "/Equipment/Trigger/Settings/WaveDAQ"
ODBSET "Trigger/MASTER/TriggerPrescaling[*]", 0, 0
ODBSET "Trigger/MASTER/TriggerEnable[*]", n, 0
ODBSET "Trigger/MASTER/TriggerPrescaling[23]", 1, 0
ODBSET "Trigger/MASTER/TriggerEnable[23]", y, 1
ENDODBSUBDIR
ODBSUBDIR "/Equipment/Laser/Variables/"
ODBSET "Output[0]", $LaserFreq, 0
ODBSET "Output[1]", 1, 0
ODBSET "Output[2]", 1, 0
ODBSET "Output[3]", 1, 0
ODBSET "Output[4]", 0, 1
ENDODBSUBDIR
WAIT seconds, 10
ODBSUBDIR ""
ENDODBSUBDIR
CAT description, "Laser run, sector: 4, frequency: ", $Freq, ", clock: square, power: ", $Power, ", attenuator: 0, temperature: ", $Temp
ODBSET "/Experiment/Run Parameters/Run description", $description, 1
LOOP $Nrun
TRANSITION start
WAIT events, $Nevent
TRANSITION stop
ENDLOOP
ODBSUBDIR "/Equipment/Laser/Variables/"
ODBSET "Output[1]", 1, 0
ODBSET "Output[2]", 0, 0
ODBSET "Output[3]", 0, 0
ODBSET "Output[4]", 1, 1
ENDODBSUBDIR
WAIT seconds, 10
ODBSUBDIR ""
ENDODBSUBDIR
CAT description, "Laser run, sector: 5, frequency: ", $Freq, ", clock: square, power: ", $Power, ", attenuator: 0, temperature: ", $Temp
ODBSET "/Experiment/Run Parameters/Run description", $description, 1
LOOP $Nrun
TRANSITION start
WAIT events, $Nevent
TRANSITION stop
ENDLOOP
ODBSUBDIR "/Equipment/Laser/Variables"
ODBSET "Output[1]", 0, 0
ODBSET "Output[2]", 1, 0
ODBSET "Output[3]", 0, 0
ODBSET "Output[4]", 1, 1
ENDODBSUBDIR
WAIT seconds, 10
ODBSUBDIR ""
ENDODBSUBDIR
CAT description, "Laser run, sector: 6, frequency: ", $Freq, ", clock: square, power: ", $Power, ", attenuator: 0, temperature: ", $Temp
ODBSET "/Experiment/Run Parameters/Run description", $description, 1
LOOP $Nrun
TRANSITION start
WAIT events, $Nevent
TRANSITION stop
ENDLOOP
ODBSUBDIR "/Equipment/Laser/Variables"
ODBSET "Output[1]", 1, 0
ODBSET "Output[2]", 1, 0
ODBSET "Output[3]", 0, 0
ODBSET "Output[4]", 1, 1
ENDODBSUBDIR
WAIT seconds, 10
ODBSUBDIR ""
ENDODBSUBDIR
CAT description, "Laser run, sector: 7, frequency: ", $Freq, ", clock: square, power: ", $Power, ", attenuator: 0, temperature: ", $Temp
ODBSET "/Experiment/Run Parameters/Run description", $description, 1
LOOP $Nrun
TRANSITION start
WAIT events, $Nevent
TRANSITION stop
ENDLOOP
ODBSUBDIR "/Equipment/Laser/Variables"
ODBSET "Output[0]", 0, 0
ODBSET "Output[1]", 1, 0
ODBSET "Output[2]", 0, 0
ODBSET "Output[3]", 0, 0
ODBSET "Output[4]", 0, 1
ENDODBSUBDIR
ODBSUBDIR "/Equipment/Trigger/Settings/WaveDAQ"
ODBSET "AUXCrate/AUX-13/SamplingFrequency", 1200, 0
ODBSET "AUXCrate/AUX-13/FrontendPzcLevel", 7, 0
ODBSET "AUXCrate/AUX-13/FrontendGain[14]", 1, 0
ODBSET "AUXCrate/AUX-13/FrontendPzc[14]", n, 0
ODBSET "AUXCrate/AUX-13/FrontendGain[15]", 1, 0
ODBSET "AUXCrate/AUX-13/FrontendPzc[15]", n, 1
ENDODBSUBDIR
|
|
2531
|
13 Jun 2023 |
Thomas Senger | Forum | Include subroutine through relative path in sequencer | Hi, I would like to restructure our sequencer scripts and the paths. Until now many things are not generic at all. I would like to ask if it is possible to include files through a relative path for example something like
INCLUDE ../chip/global_basic_functions
Maybe I just did not found how to do it. |
|