 23 Apr 2020, Ivo Schulthess, Suggestion, Sequencer loop break 23 Apr 2020, Ivo Schulthess, Suggestion, Sequencer loop break
|
> You can do that with the "GOTO" statement, jumping to the first line after the loop.
>
> Here is a working example:
>
>
> LOOP runs, 5
> WAIT Seconds 3
> IF $runs > 2
> GOTO 7
> ENDIF
> ENDLOOP
> MESSAGE "Finished", 1
>
> Best,
> Stefan
Hoi Stefan
Thanks for your answer. As I understand it, this has to be in the sequence script before
running. So, in the end, it is not different than just saying "LOOP runs, 2" and
therefore the number of runs has do be known in advance as well. Or is there an option to
change the script on runtime? What I would like, is to start a sequence with "LOOP runs,
infinite" and when I come back to the experiment after falling asleep being able to break
the loop after the next iteration, but still execute everything after ENDLOOP, i.e. the
MESSAGE statement in your example. Because if I do a "Stop after current run", this seems
not to happen.
Best, Ivo |
|
23 Apr 2020, Stefan Ritt, Suggestion, Sequencer loop break
|
> > You can do that with the "GOTO" statement, jumping to the first line after the loop.
> >
> > Here is a working example:
> >
> >
> > LOOP runs, 5
> > WAIT Seconds 3
> > IF $runs > 2
> > GOTO 7
> > ENDIF
> > ENDLOOP
> > MESSAGE "Finished", 1
> >
> > Best,
> > Stefan
>
> Hoi Stefan
>
> Thanks for your answer. As I understand it, this has to be in the sequence script before
> running. So, in the end, it is not different than just saying "LOOP runs, 2" and
> therefore the number of runs has do be known in advance as well. Or is there an option to
> change the script on runtime? What I would like, is to start a sequence with "LOOP runs,
> infinite" and when I come back to the experiment after falling asleep being able to break
> the loop after the next iteration, but still execute everything after ENDLOOP, i.e. the
> MESSAGE statement in your example. Because if I do a "Stop after current run", this seems
> not to happen.
>
> Best, Ivo
First, you have the sequencer button "Stop after current run", but that does of course ot
execute anything after ENDLOOP.
Second, you can put anything in the IF statement. Like create a variable on the ODB like
/Experiment/Run parameters/Stop loop and set this to zero. Then put in your script:
...
ODBGET /Experiment/Run parameters/Stop loop, flag
IF $flag == 1
GOTO 7
...
So once you want to stop the loop, set the flag in the ODB to one.
Best,
Stefan |
|
25 Apr 2020, Konstantin Olchanski, Suggestion, Sequencer loop break
|
> LOOP runs, 5
> ...
> ENDLOOP
Classical loop constructs usually include "break" (exit the loop) and "continue" (loop again!)
constructs. I would say it is an unfortunate omission if they are not present in the midas sequencer.
But Stefan is right, of course, both commands are just funny names for "goto".
K.O. |
 19 Aug 2015, Pierre Gorel, Bug Report, Sequencer limits 19 Aug 2015, Pierre Gorel, Bug Report, Sequencer limits
|
While I know some of those limits/problems have been already been reported from
DEAP (and maybe corrected in the last version), I am recording them here:
Bugs (not working as it should):
- "SCRIPT" does not seem to take the parameters into account
- The operators for WAIT are incorrectly set:
the default ">=" and ">" are correct, but "<=", "<", "==" and "!=" are all using
">=" for the test.
Possible improvements:
- in LOOP, how can I get the index of the LOOP? I used an extra variable that I
increment, but it there a better way?
- PARAM is giving "string" (or a bool) whose size is set by the user input. The
side effect is that if I am making a loop starting at "1", the incrementation
will loop at "9" -> "1". If I start at "01", the incrementation will give "2.",
"3.",... "9.", "10"... The later is probably what most people would use.
- ODBGet (and ODBSet?) does seem to be able to take a variable as a path... I
was trying to use an array whose index would be incremented. |
|
19 Aug 2015, Pierre-Andre Amaudruz, Bug Report, Sequencer limits
|
These issues have been addressed by Stefan during his visit at Triumf last month.
The latest git has those fixes.
> While I know some of those limits/problems have been already been reported from
> DEAP (and maybe corrected in the last version), I am recording them here:
>
> Bugs (not working as it should):
> - "SCRIPT" does not seem to take the parameters into account
Fixed
> - The operators for WAIT are incorrectly set:
> the default ">=" and ">" are correct, but "<=", "<", "==" and "!=" are all using
> ">=" for the test.
Fixed
>
> Possible improvements:
> - in LOOP, how can I get the index of the LOOP? I used an extra variable that I
> increment, but it there a better way?
See LOOP doc
LOOP cnt, 10
ODBGET /foo/bflag, bb
IF $bb==1 THEN
SET cnt, 10
ELSE
...
> - PARAM is giving "string" (or a bool) whose size is set by the user input. The
> side effect is that if I am making a loop starting at "1", the incrementation
> will loop at "9" -> "1". If I start at "01", the incrementation will give "2.",
> "3.",... "9.", "10"... The later is probably what most people would use.
Fixed
> - ODBGet (and ODBSet?) does seem to be able to take a variable as a path... I
> was trying to use an array whose index would be incremented.
To be checked. |
|
19 Aug 2015, Konstantin Olchanski, Bug Report, Sequencer limits
|
>
> See LOOP doc
> LOOP cnt, 10
> ODBGET /foo/bflag, bb
> IF $bb==1 THEN
> SET cnt, 10
> ELSE
> ...
>
Looks like we have PE |
|
20 Aug 2015, Stefan Ritt, Bug Report, Sequencer limits
|
> > - ODBGet (and ODBSet?) does seem to be able to take a variable as a path... I
> > was trying to use an array whose index would be incremented.
>
> To be checked.
It does not take a variable as a path, but as an index. So you can do
LOOP i, 5
WAIT seconds, 3
ODBSET /System/Tmp/Test[$i], $i
ENDLOOP
And you will get
/System/Tmp/Test
[1] 1
[2] 2
[3] 3
[4] 4
[5] 5
/Stefan |
|
19 Nov 2021, Jacob Thorne, Forum, Sequencer error with ODB Inc
|
Hi,
I am having problems with the midas sequencer, here is my code:
1 COMMENT "Example to move a Standa stage"
2 RUNDESCRIPTION "Example movement sequence - each run is one position of a single stage
3
4 PARAM numRuns
5 PARAM sequenceNumber
6 PARAM RunNum
7
8 PARAM positionT2
9 PARAM deltapositionT2
10
11 ODBSet "/Runinfo/Run number", $RunNum
12 ODBSet "/Runinfo/Sequence number", $sequenceNumber
13
14 ODBSet "/Equipment/Neutron Detector/Settings/Detector/Type of Measurement", 2
15 ODBSet "/Equipment/Neutron Detector/Settings/Detector/Number of Time Bins", 10
16 ODBSet "/Equipment/Neutron Detector/Settings/Detector/Number of Sweeps", 1
17 ODBSet "/Equipment/Neutron Detector/Settings/Detector/Dwell Time", 100000
18
19 ODBSet "/Equipment/MTSC/Settings/Devices/Stage 2 Translation/Device Driver/Set Position", $positionT2
20
21 LOOP $numRuns
22 WAIT ODBvalue, "/Equipment/MTSC/Settings/Devices/Stage 2 Translation/Ready", ==, 1
23 TRANSITION START
24 WAIT ODBvalue, "/Equipment/Neutron Detector/Statistics/Events sent", >=, 1
25 WAIT ODBvalue, "/Runinfo/State", ==, 1
26 WAIT ODBvalue, "/Runinfo/Transition in progress", ==, 0
27 TRANSITION STOP
28 ODBInc "/Equipment/MTSC/Settings/Devices/Stage 2 Translation/Device Driver/Set Position", $deltapositionT2
29
30 ENDLOOP
31
32 ODBSet "/Runinfo/Sequence number", 0
The issue comes with line 28, the ODBInc does not work, regardless of what number I put I get the following error:
[Sequencer,ERROR] [odb.cxx:7046:db_set_data_index1,ERROR] "/Equipment/MTSC/Settings/Devices/Stage 2 Translation/Device Driver/Set Position" invalid element data size 32, expected 4
I don't see why this should happen, the format is correct and the number that I input is an int.
Sorry if this is a basic question.
Jacob |
|
02 Dec 2021, Stefan Ritt, Forum, Sequencer error with ODB Inc
|
Thanks for reporting that bug. Indeed there was a problem in the sequencer code which I fixed now. Please try the updated develop branch.
Stefan |
02 Apr 2024, Zaher Salman, Info, Sequencer editor 
|
Dear all,
Stefan and I have been working on improving the sequencer editor to make it look and feel more like a standard editor. This sequencer v2 has been finally merged into the develop branch earlier today.
The sequencer page has now a main tab which is used as a "console" to show the loaded sequence and it's progress when running. All other tabs are used only for editing scripts. To edit a currently loaded sequence simply double click on the editing area of the main tab or load the file in a new tab. A couple of screen shots of the new editor are attached.
For those who would like to stay with the older sequencer version a bit longer, you may simply copy resources/sequencer_v1.html to resources/sequencer.html. However, this version is not being actively maintained and may become obsolete at some point. Please help us improve the new version instead by reporting bugs and feature requests on bitbucket or here.
Best regards,
Zaher
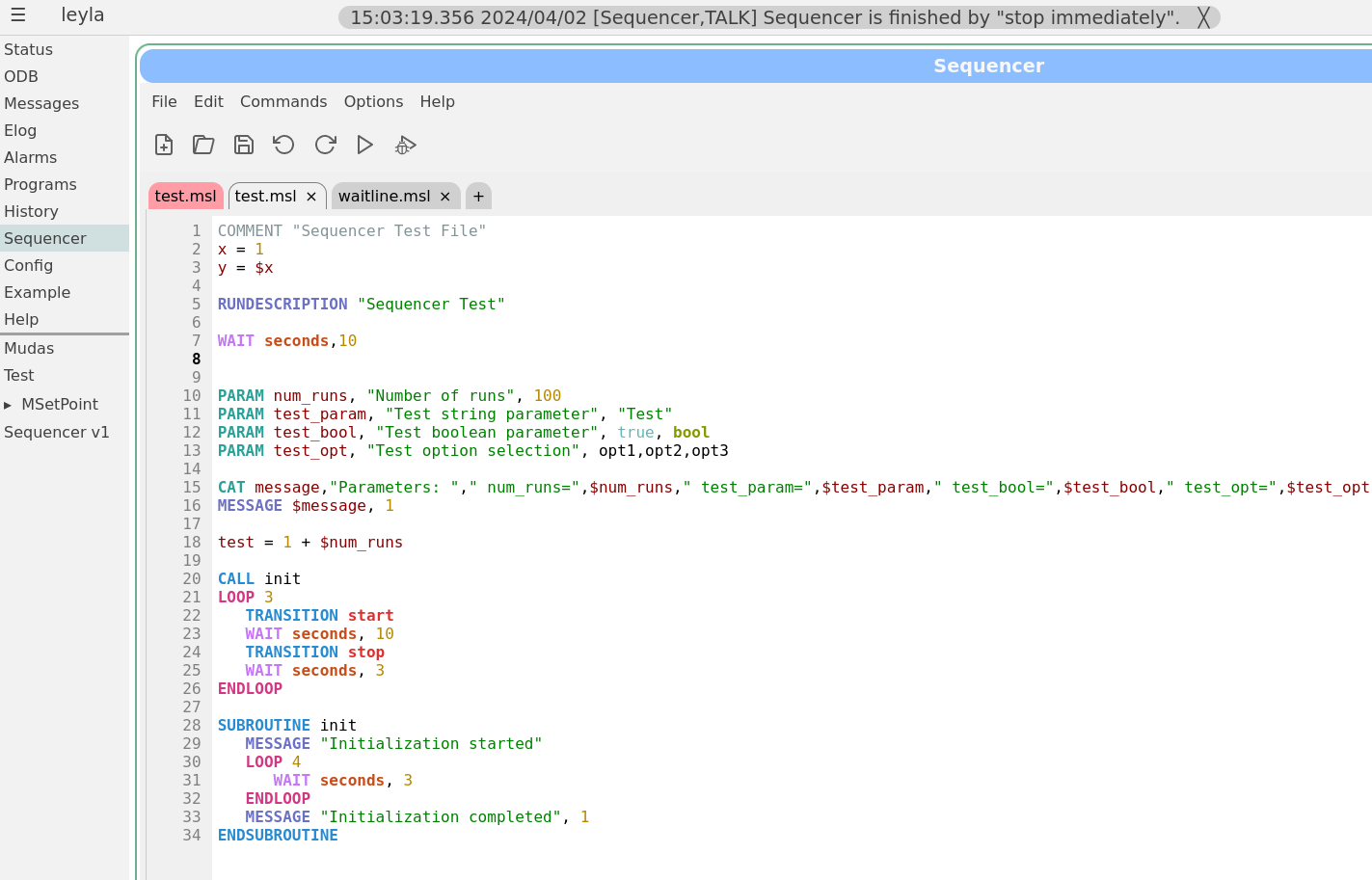
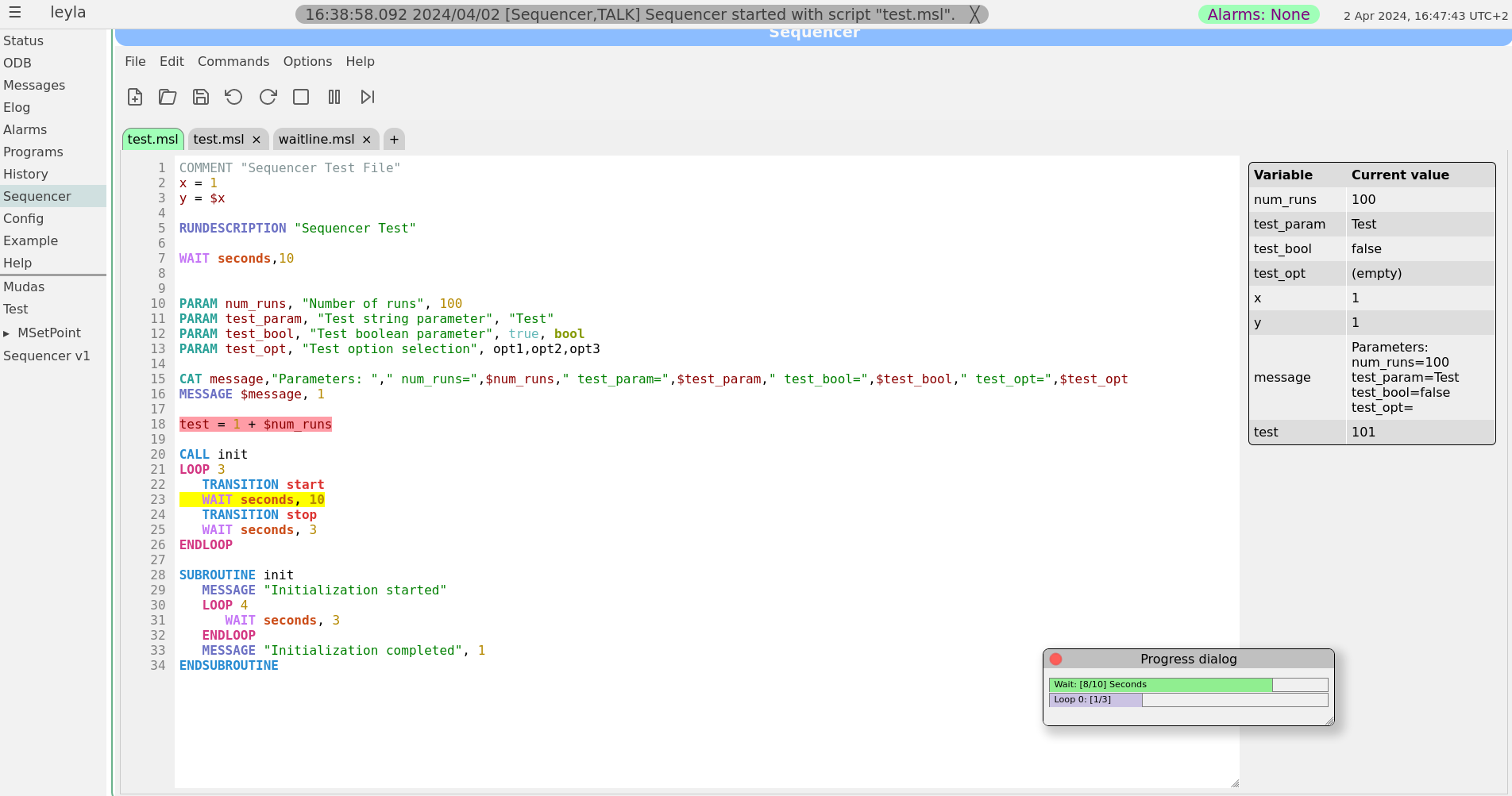 |
|
02 Apr 2024, Konstantin Olchanski, Info, Sequencer editor
|
> Stefan and I have been working on improving the sequencer editor ...
Looks grand! Congratulations with getting it completed. The previous version was
my rewrite of the old generated-C pages into html+javascript, nothing to write
home about, I even kept the 1990-ies-style html formatting and styling as much as
possible.
K.O. |
|
01 Apr 2025, Lukas Gerritzen, Suggestion, Sequencer ODBSET feature requests
|
I would like to request the following sequencer features if you find the ideas as sensible as I do:
- A "Reload File" button
- Support for patterns in ODBSET, e.g.:
-
ODBSET "/Path/value[1,3,5]", 1 -
ODBSET "/Path/value[1-5,7-9]", 1 - Arbitrary combinations of the above
- Support for variable substitution:
-
SET GOODCHANNELS, "1-5,7,9"; ODBSET "/Path/value[$GOODCHANNELS]", 1 -
SET BADCHANNELS, "6,8"; ODBSET "/Path/value[!$BADCHANNELS]", 1 -
ODBSET "/Path/value[0-100, except $BADCHANNELS]", 1
To add some context: I am using the sequencer for a voltage scan of several thousand channels. However, a few dozen of them have shorts, so I cannot simply set all demands to the voltage step. Currently, this is solved with a manually-created ODB file for each individual voltage step, but as you can imagine, this is quite difficult to maintain.
I also encountered a small annoyance in the current workflow of editing sequencer files in the browser:
- Load a file
- Double-click it to edit it, acknowledge the "To edit the sequence it must be opened in an editor tab" dialog
- A new tab opens
- Edit something, click "Start", acknowledge the "Save and start?" dialog (which pops up even if no changes are made)
- Run the script
- Double-click to make more changes -> another tab opens
After a while, many tabs with the same file are open. I understand this may be considered "user error", but perhaps the sequencer could avoid opening redundant tabs for the same file, or prompt before doing so?
Thanks for considering these suggestions! |
|
01 Apr 2025, Lukas Gerritzen, Suggestion, Sequencer ODBSET feature requests
|
While trying to simplify the existing spaghetti code, I encountered problems with type safety. Compare the following:SET v, "54"
SET file, "MPPCHV_$v.odb"
ODBLOAD $file -> successfully loads MPPCHV_54.odb
SET v, "54.2"
SET file, "MPPCHV_$v.odb"
ODBLOAD $file -> Error reading file "[...]/MPPCHV_54.200000.odb"
The "54.2" appears to be stored as a float rather than a string. Maybe "54" was stored as an integer? I don't know how to verify this in odbedit.
Actually, I would be fine with setting the value as a float, as it allows arithmetic. In that case, I would appreciate something like a SPRINTF function in MSL:SET v, 54.2
SPRINTF file, "MPPCHV_%f.odb", $v
ODBLOAD $file Or, maybe a bit more modern, something akin to Python's f-stringsODBLOAD f"MPPCHV_{v:.1f}.odb" |
|
01 Apr 2025, Stefan Ritt, Suggestion, Sequencer ODBSET feature requests
|
A new sequencer which understands Python is in the works. There you can use all features from that language.
Stefan |
|
01 Apr 2025, Stefan Ritt, Suggestion, Sequencer ODBSET feature requests
|
The extended ODBSET[x,y1-y2,z] could make sense to be implemented, since it then will match the alarm system which uses the same syntax.
The $GOODCHANNELS/$BADCHANNELS is however a very strange syntax which I haven't seen in any other computer language. It would take me probably several days to properly implement this, while it would take you much less time to explicitly use a few ODBSET statements to set the bad channels to zero.
For the file edit workflow, the author of the editor will have a look.
Stefan
| Lukas Gerritzen wrote: | I would like to request the following sequencer features if you find the ideas as sensible as I do:
- A "Reload File" button
- Support for patterns in ODBSET, e.g.:
-
ODBSET "/Path/value[1,3,5]", 1 -
ODBSET "/Path/value[1-5,7-9]", 1 - Arbitrary combinations of the above
- Support for variable substitution:
-
SET GOODCHANNELS, "1-5,7,9"; ODBSET "/Path/value[$GOODCHANNELS]", 1 -
SET BADCHANNELS, "6,8"; ODBSET "/Path/value[!$BADCHANNELS]", 1 -
ODBSET "/Path/value[0-100, except $BADCHANNELS]", 1
|
|
|
01 Apr 2025, Konstantin Olchanski, Suggestion, Sequencer ODBSET feature requests
|
> ODBSET "/Path/value[1,3,5]"
> ODBSET "/Path/value[1-5,7-9]"
we support this array index syntax in several places,
specifically, in javascript odb get and set mjsonrpc RPCs.
> SET GOODCHANNELS, "1-5,7,9"; ODBSET "/Path/value[$GOODCHANNELS]"
> SET BADCHANNELS, "6,8"; ODBSET "/Path/value[!$BADCHANNELS]"
> ODBSET "/Path/value[0-100, except $BADCHANNELS]"
this is very clever syntax, but I have not seen any programming
language actually implement it (not even perl).
there must be a good reason why nobody does this. probably we should not do it either.
but as Stefan said (and my opinion), the route of extending MIDAS sequencer
language until it becomes a superset of python, perl, tcl, bash, javascript
and algol is not a sustainable approach. I once looked at using LUA for this,
but I think basing off an full featured programming language like python
is better.
K.O. |
|
01 Apr 2025, Pavel Murat, Suggestion, Sequencer ODBSET feature requests
|
I once looked at using LUA for this,
> but I think basing off an full featured programming language like python
> is better.
if it came to a vote, my vote would go to Lua: it would allow to do everything needed,
with much less external dependencies and with much less motivation to over-use the interpreter.
The CMS experience was very teaching in this respect...
-- my 2c, regards, Pasha |
|
02 Apr 2025, Konstantin Olchanski, Suggestion, Sequencer ODBSET feature requests
|
> I once looked at using LUA for this
>
> > but I think basing off an full featured programming language like python
> > is better.
>
> if it came to a vote, my vote would go to Lua: it would allow to do everything needed,
> with much less external dependencies and with much less motivation to over-use the interpreter.
> The CMS experience was very teaching in this respect...
Unfortunately I am only slightly aware of Lua to say how nicve or how bad it is. And we are
not sure how well it supports the single-line-stepping that permits the nice graphical
visualization of Stefan's sequencer.
It looks like python has the single-line-stepping built-in as a standard feature
and python is a more popular and more versatile machine, so to me python looks
like a better choice compared to lua (obscure), perl ("nobody uses it anymore")
or bash (ugly syntax).
K.O. |
|
03 Apr 2025, Stefan Ritt, Suggestion, Sequencer ODBSET feature requests
|
And there is one more argument:
We have a Python expert in our development team who wrote already the Python-to-C bindings. That means when running a Python
script, we can already start/stop runs, write/read to the ODB etc. We only have to get the single stepping going which seems feasible to
me, since there are some libraries like inspect.currentframe() and traceback.extract_stack(). For single-stepping there are debug APIs
like debugpy. With Lua we really would have to start from scratch.
Stefan |
|
07 Apr 2025, Zaher Salman, Suggestion, Sequencer ODBSET feature requests
|
| Lukas Gerritzen wrote: |
I also encountered a small annoyance in the current workflow of editing sequencer files in the browser:
- Load a file
- Double-click it to edit it, acknowledge the "To edit the sequence it must be opened in an editor tab" dialog
- A new tab opens
- Edit something, click "Start", acknowledge the "Save and start?" dialog (which pops up even if no changes are made)
- Run the script
- Double-click to make more changes -> another tab opens
After a while, many tabs with the same file are open. I understand this may be considered "user error", but perhaps the sequencer could avoid opening redundant tabs for the same file, or prompt before doing so?
Thanks for considering these suggestions! |
The original reason the restricting edits in the first tab is that it is used to reflect the state of the sequencer, i.e. the file that is currently loaded in the ODB.
Imagine two users are working in parallel on the same file, each preparing their own sequence. One finishes editing and starts the sequencer. How would the second person know that by now the file was changed and is running?
I am open to suggestions to minimize the number of clicks and/or other options to make the first tab editable while making it safe and visible to all other users. Maybe a lock mechanism in the ODB can help here.
Zaher |
|