| ID |
Date |
Author |
Topic |
Subject |
|
689
|
12 Dec 2009 |
Jimmy Ngai | Forum | Run multiple frontend on the same host | Dear Stefan,
I followed your suggestion to try the sample front-ends from the distribution and
they work fine. They also work fine with any one of my front-ends. Only my two
front-ends cannot run concurrently in the same directory. I later found that the
problem is in the CAEN HV wrapper library. The problem arises when the front-ends
are both linked to that library and it is solved now.
Thanks & Best Regards,
Jimmy
> Hi Jimmy,
>
> ok, now I understand. Well, I don't see your problem. I just tried with the
> current SVN
> version to start
>
> midas/examples/experiment/frontend
> midas/examples/slowcont/scfe
>
> in the same directory (without "-h localhost") and it works just fine (see
> attachemnt). I even started them from the same directory. Yes there are *.SHM
> files and they correspond to shared memory, but both front-ends use this shared
> memory together (that's why it's called 'shared').
>
> Your error message 'Semaphore already present' is strange. The string is not
> contained in any midas program, so it must come from somewhere else. Do you
> maybe try to access the same hardware with the two front-end programs?
>
> I would propose you do the following: Use the two front-ends from the
> distribution (see above). They do not access any hardware. See if you can run
> them with the current SVN version of midas. If not, report back to me.
>
> Best regards,
>
> Stefan
>
>
> > Dear Stefan,
> >
> > Thanks for the reply. I have tried your patch and it didn't solve my problem.
> Maybe I
> > have not written my question clearly. The two frontends could run on the same
> computer
> > if I use the remote method, i.e. by setting up the mserver and connect to the
> > experiment by specifying "-h localhost", also the frontend programs need to be
> put in
> > different directory. What I want to know is whether I can simply start
> multiple
> > frontends in the same directory without setting up the mserver etc. I noticed
> that
> > there are several *.SHM files, I'm not familiar with semaphore, but I guess
> they are
> > the key to the problem. Please correct me if I misunderstood something.
> >
> > Best Regards,
> > Jimmy
> >
> >
> > > > Dear All,
> > > >
> > > > I want to run two frontend programs (one for trigger and one for slow
> control)
> > > > concurrently on the same computer, but I failed. The second frontend said:
> > > >
> > > > Semaphore already present
> > > > There is another process using the semaphore.
> > > > Or a process using the semaphore exited abnormally.
> > > > In That case try to manually release the semaphore with:
> > > > ipcrm sem XXX.
> > > >
> > > > The two frontends are connected to the same experiment. Is there any way I
> can
> > > > overcome this problem?
> > >
> > > That might be related to the RPC mutex, which gets created system wide now.
> I
> > > modified this in midas.c rev. 4628, so there will be one mutex per process.
> Can you
> > > try that temporary patch and tell me if it works for you? |
|
688
|
08 Dec 2009 |
Stefan Ritt | Forum | Run multiple frontend on the same host | Hi Jimmy,
ok, now I understand. Well, I don't see your problem. I just tried with the
current SVN
version to start
midas/examples/experiment/frontend
midas/examples/slowcont/scfe
in the same directory (without "-h localhost") and it works just fine (see
attachemnt). I even started them from the same directory. Yes there are *.SHM
files and they correspond to shared memory, but both front-ends use this shared
memory together (that's why it's called 'shared').
Your error message 'Semaphore already present' is strange. The string is not
contained in any midas program, so it must come from somewhere else. Do you
maybe try to access the same hardware with the two front-end programs?
I would propose you do the following: Use the two front-ends from the
distribution (see above). They do not access any hardware. See if you can run
them with the current SVN version of midas. If not, report back to me.
Best regards,
Stefan
> Dear Stefan,
>
> Thanks for the reply. I have tried your patch and it didn't solve my problem.
Maybe I
> have not written my question clearly. The two frontends could run on the same
computer
> if I use the remote method, i.e. by setting up the mserver and connect to the
> experiment by specifying "-h localhost", also the frontend programs need to be
put in
> different directory. What I want to know is whether I can simply start
multiple
> frontends in the same directory without setting up the mserver etc. I noticed
that
> there are several *.SHM files, I'm not familiar with semaphore, but I guess
they are
> the key to the problem. Please correct me if I misunderstood something.
>
> Best Regards,
> Jimmy
>
>
> > > Dear All,
> > >
> > > I want to run two frontend programs (one for trigger and one for slow
control)
> > > concurrently on the same computer, but I failed. The second frontend said:
> > >
> > > Semaphore already present
> > > There is another process using the semaphore.
> > > Or a process using the semaphore exited abnormally.
> > > In That case try to manually release the semaphore with:
> > > ipcrm sem XXX.
> > >
> > > The two frontends are connected to the same experiment. Is there any way I
can
> > > overcome this problem?
> >
> > That might be related to the RPC mutex, which gets created system wide now.
I
> > modified this in midas.c rev. 4628, so there will be one mutex per process.
Can you
> > try that temporary patch and tell me if it works for you? |
| Attachment 1: Capture.png
|

|
|
687
|
07 Dec 2009 |
Jimmy Ngai | Forum | Run multiple frontend on the same host | Dear Stefan,
Thanks for the reply. I have tried your patch and it didn't solve my problem. Maybe I
have not written my question clearly. The two frontends could run on the same computer
if I use the remote method, i.e. by setting up the mserver and connect to the
experiment by specifying "-h localhost", also the frontend programs need to be put in
different directory. What I want to know is whether I can simply start multiple
frontends in the same directory without setting up the mserver etc. I noticed that
there are several *.SHM files, I'm not familiar with semaphore, but I guess they are
the key to the problem. Please correct me if I misunderstood something.
Best Regards,
Jimmy
> > Dear All,
> >
> > I want to run two frontend programs (one for trigger and one for slow control)
> > concurrently on the same computer, but I failed. The second frontend said:
> >
> > Semaphore already present
> > There is another process using the semaphore.
> > Or a process using the semaphore exited abnormally.
> > In That case try to manually release the semaphore with:
> > ipcrm sem XXX.
> >
> > The two frontends are connected to the same experiment. Is there any way I can
> > overcome this problem?
>
> That might be related to the RPC mutex, which gets created system wide now. I
> modified this in midas.c rev. 4628, so there will be one mutex per process. Can you
> try that temporary patch and tell me if it works for you? |
|
686
|
04 Dec 2009 |
Stefan Ritt | Info | New '/Experiment/Menu buttons' | The mhttpd program shows some standard buttons in the top row for
starting/stopping runs, accessing the ODB, Alarms, etc. Since not all experiments
make use of all buttons, they have been customized. By default mhttpd creates
following entry in the ODB:
/Experiment/Menu Buttons = Start, ODB, Messages, ELog, Alarms, Programs, History,
Config, Help
Which is the standard set (except the old CNAF). People can customize this now by
removing unnecessary buttons or by changing their order. The "Start" entry above
actually causes the whole set of Start/Stop/Pause/Resume buttons to appear,
depending on the current run state. |
|
685
|
04 Dec 2009 |
Stefan Ritt | Info | Custom page showing ROOT analyzer output | Many midas experiments work with ROOT based analyzers today. One problem there is that the graphical output of the root analyzer can only be seen through the X server and not through the web. At the MEG experiment, we solved this problem in an elegant way: The ROOT analyzer runs in the background, using a "virtual" X server called Xvfb. It plots its output (several panels) normally using this X server, then saves this panels every ten seconds into GIF files. These GIF files are then served through mhttpd using a custom page. The output looks like this:
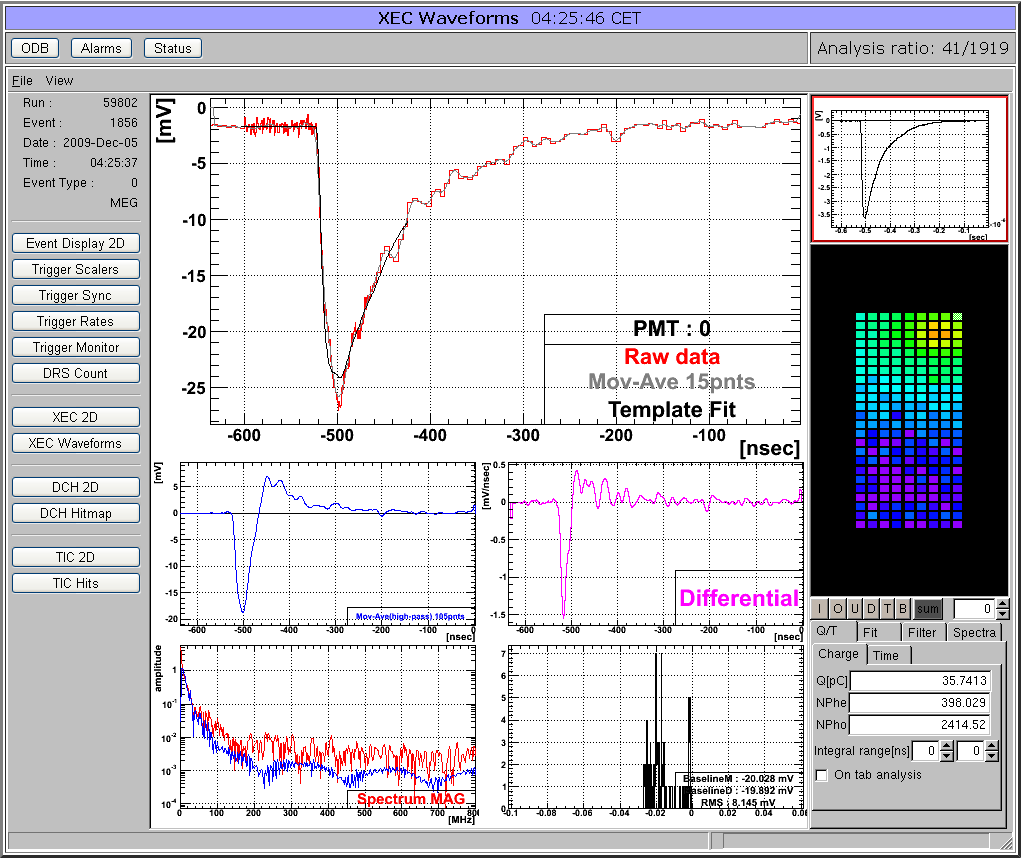
The buttons on the left sides are actually HTML buttons on that custom page overlaid to the GIF image, which in this case shows one of our 800 PMT channels digitized at 1.6 GSPS. With these buttons one can cycle through the different GIF images, which then automatically update ever ten seconds. Of course it is not possible to feed interaction back to the analyzer (like the waveform cannot be fitted interactively) but for monitoring an experiment in production mode this tools is extremely helpful, since it is seamlessly integrated into mhttpd. All the magic is done with JavaScript, and the buttons are overlaid to the graphics using CSS with absolute positioning. The analysis ratio on the top right is also done with JavaScript pulling the right info out of the ODB.
The used custom page file is attached. For details using Xvfb server, please contact Ryu Sawada <sawada@icepp.s.u-tokyo.ac.jp>. |
| Attachment 2: analyzer.html
|
|
684
|
04 Dec 2009 |
Stefan Ritt | Info | Redesign of status page columns | Since the column on the main midas status page with fraction of analyzed events is
barely used, I decided to drop it. Anyhow it does not make sense for all slow
control events. If this feature is required in some experiment, I propose to move it
into a custom page and calculate this ratio in JavaScript, where one has much more
flexibility.
This modification frees up more space on the status page for the "Status" column, where
front-end programs can report errors etc. |
| Attachment 1: Capture.png
|

|
|
683
|
01 Dec 2009 |
Stefan Ritt | Info | Redesign of status page links | The custom and alias links in the standard midas status page were shown as HTML
links so far. If there are many links with names having spaces in their names,
it's a bit hard to distinguish between them. Therefore, they are packed now into
individual buttons (see attachment) starting from SVN revision 4633 on. This makes
also the look more homogeneous. If there is any problem with that, please report. |
| Attachment 1: Capture.png
|

|
|
682
|
27 Nov 2009 |
Stefan Ritt | Forum | Run multiple frontend on the same host | > Dear All,
>
> I want to run two frontend programs (one for trigger and one for slow control)
> concurrently on the same computer, but I failed. The second frontend said:
>
> Semaphore already present
> There is another process using the semaphore.
> Or a process using the semaphore exited abnormally.
> In That case try to manually release the semaphore with:
> ipcrm sem XXX.
>
> The two frontends are connected to the same experiment. Is there any way I can
> overcome this problem?
That might be related to the RPC mutex, which gets created system wide now. I
modified this in midas.c rev. 4628, so there will be one mutex per process. Can you
try that temporary patch and tell me if it works for you? |
|
681
|
27 Nov 2009 |
Konstantin Olchanski | Bug Report | "mserver -s" is broken | >
> "mserver -s" is there for historical reasons and for debugging.
>
I confirm that my modification also works for "mserver -s". I also added an assert() to the
place in midas.c were it eventually crashes, to make it more obvious for the next guys.
K.O. |
|
680
|
27 Nov 2009 |
Stefan Ritt | Bug Report | "mserver -s" is broken | > I notice that "mserver -s" (a non-default mode of operation) does not work right
> - if I connect odbedit for the first time, all is okey, if I connect the second
> time, mserver crashes - because after the first connection closed,
> rpc_deregister_functions() was called, rpc_list is deleted and causes a crash
> later on. Because everybody uses the default "mserver -m" mode, I am not sure
> how important it is to fix this.
> K.O.
"mserver -s" is there for historical reasons and for debugging. I started originally
with a single process server back in the 90's, and only afterwards developed the multi
process scheme. The single process server now only works for one connection and then
crashes, as you described. But it can be used for debugging any server connection,
since you don't have to follow the creation of a subprocess with your debugger, and
therefore it's much easier. But after the first connection has been closed, you have
to restart that single server process. Maybe one could add some warning about that, or
even fix it, but it's nowhere used in production mode. |
|
679
|
26 Nov 2009 |
Konstantin Olchanski | Bug Fix | mserver network routing fix | mserver update svn rev 4625 fixes an anomaly in the MIDAS RPC network code where
in some network configurations MIDAS mserver connections work, but some RPC
transactions, such as starting and stopping runs, do not (use the wrong network
names or are routed over the wrong network).
The problem is a possible discrepancy between network addresses used to
establish the mserver connection and the value of "/System/Clients/xxx/Host"
which is ultimately set to the value of "hostname" of the remote client. This
ODB setting is then used to establish additional network connections, for
example to start or stop runs.
Use the client "hostname" setting works well for standard configurations, when
there is only one network interface in the machine, with only one IP address,
and with "hostname" set to the value that this IP address resolves to using DNS.
However, if there are private networks, multiple network interfaces, or multiple
network routes between machines, "/System/Clients/xxx/Host" may become set to an
undesirable value resulting in asymmetrical network routing or complete failure
to establish RPC connections.
Svn rev 4625 updates mserver.c to automatically set "/System/clients/xxx/Host"
to the same network name as was used to establish the original mserver connection.
As always with networking, any fix always breaks something somewhere for
somebody, in which case the old behavior can be restored by "setenv
MIDAS_MSERVER_DO_NOT_USE_CALLBACK_ADDR 1" before starting mserver.
The specific problem fixed by this change is when the MIDAS client and server
are on machines connected by 2 separate networks ("client.triumf.ca" and
"client.daq"; "server.triumf.ca" and "server.daq"). The ".triumf.ca" network
carries the normal SSH, NFS, etc traffic, and the ".daq" network carries MIDAS
data traffic.
The client would use the "server.daq" name to connect to the server and this
traffic would go over the data network (good).
However, previously, the client "/System/Clients/xxx/Host" would be set to
"client.triumf.ca" and any reverse connections (i.e. RPC to start/stop runs)
would go over the normal ".triumf.ca" network (bad).
With this modification, mserver will set "/System/Clients/xxx/Host" to
"client.daq" (the IP address of the interface on the ".daq" network) and all
reverse connections would also go over the ".daq" network (good).
P.S. This modification definitely works only for the default "mserver -m" mode,
but I do not think this is a problem as using "-s" and "-t" modes is not
recommended, and the "-s" mode is definitely broken (see my previous message).
svn rev 4625
K.O. |
|
678
|
26 Nov 2009 |
Konstantin Olchanski | Bug Report | "mserver -s" is broken | I notice that "mserver -s" (a non-default mode of operation) does not work right
- if I connect odbedit for the first time, all is okey, if I connect the second
time, mserver crashes - because after the first connection closed,
rpc_deregister_functions() was called, rpc_list is deleted and causes a crash
later on. Because everybody uses the default "mserver -m" mode, I am not sure
how important it is to fix this.
K.O. |
|
677
|
26 Nov 2009 |
Konstantin Olchanski | Bug Fix | mdump max number of banks and dump of 32-bit banks | By request from Renee, I increased the MIDAS BANKLIST_MAX from 64 to 1024 and
after fixing a few buglets where YB_BANKLIST_MAX is used instead of (now bigger)
BANKLIST_MAX, I can do a full dump of ND280 FGD events (96 banks).
I also noticed that "mdump -b BANK" did not work, it turns out that it could not
handle 32bit-banks at all. This is now fixed, too.
svn rev 4624
K.O. |
|
676
|
25 Nov 2009 |
Konstantin Olchanski | Bug Report | once in 100 years midas shared memory bug | We were debugging a strange problem in the event builder, where out of 14
fragments, two fragments were always getting serial number mismatches and the
serial numbers were not sequentially increasing (the other 12 fragments were
just fine).
Then we noticed in the event builder debug output that these 2 fragments were
getting assigned the same buffer handle number, despite having different names -
BUF09 and BUFTPC.
Then we looked at "ipcs", counted the buffers, and there are only 13 buffers for
14 frontends.
Aha, we went, maybe we have unlucky buffer names, renamed BUFTPC to BUFAAA and
everything started to work just fine.
It turns out that the MIDAS ss_shm_open() function uses "ftok" to convert buffer
names to SystemV shared memory keys. This "ftok" function promises to create
unique keys, but I guess, just not today.
Using a short test program, I confirmed that indeed we have unlucky buffer names
and ftok() returns duplicate keys, see below.
Apparently ftok() uses the low 16 bits of the file inode number, but in our
case, the files are NFS mounted and inode numbers are faked inside NFS. When I
run my test program on a different computer, I get non-duplicate keys. So I
guess we are double unlucky.
Test program:
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
int main(int argc, char* argv[])
{
//key_t ftok(const char *pathname, int proj_id);
int k1 = ftok("/home/t2kdaq/midas/nd280/backend/.BUF09.SHM", 'M');
int k2 = ftok("/home/t2kdaq/midas/nd280/backend/.BUFTPC.SHM", 'M');
int k3 = ftok("/home/t2kdaq/midas/nd280/backend/.BUFFGD.SHM", 'M');
printf("key1: 0x%08x, key2: 0x%08x, key3: 0x%08x\n", k1, k2, k3);
return 0;
}
[t2kfgd@t2knd280logger ~/xxx]$ g++ -o ftok -Wall ftok.cxx
[t2kfgd@t2knd280logger ~/xxx]$ ./ftok
key1: 0x4d138154, key2: 0x4d138154, key3: 0x4d138152
Also:
[t2kfgd@t2knd280logger ~/xxx]$ ls -li ...
14385492 -rw-r--r-- 1 t2kdaq t2kdaq 8405052 Nov 24 17:42
/home/t2kdaq/midas/nd280/backend/.BUF09.SHM
36077906 -rw-r--r-- 1 t2kdaq t2kdaq 67125308 Nov 26 10:19
/home/t2kdaq/midas/nd280/backend/.BUFFGD.SHM
36077908 -rw-r--r-- 1 t2kdaq t2kdaq 8405052 Nov 25 15:53
/home/t2kdaq/midas/nd280/backend/.BUFTPC.SHM
(hint: print the inode numbers in hex and compare to shm keys printed by the
program)
K.O. |
|
675
|
25 Nov 2009 |
Konstantin Olchanski | Bug Fix | subrun file size | Please be aware of mlogger.c update rev 4566 on Sept 23rd 2009, when Stefan
fixed a buglet in the subrun file size computations. Before this fix, the first
subrun could be of a short length. If you use subruns, please update your
mlogger to at least rev 4566 (or newer, Stefan added the run and subrun time
limits just recently).
K.O. |
|
674
|
23 Nov 2009 |
Exaos Lee | Suggestion | Scripts for "midas-config" | Supposing you have installed MIDAS to some directory such as "/opt/MIDAS/r4621", you have to write some Makefile as the following while building some applications based on the version installed:
| Quote: |
CFLAGS += -I/opt/MIDAS/r4621/include -DOS_LINUX -g -O2 -Wall -fPIC
LIBS += -lutil -lpthread -lodbc -lz
....
|
Why not use a script to record your MIDAS building options? When you want to build something based on it, just type something such as
| Quote: |
M_CFLAGS := `midas-config --cflags`
M_LIBS := `midas-config --libs`
|
You needn't to check your installed options each time when you build something against it. Each time you install a new version of MIDAS, you only need to update the script called 'midas-config'. I wrote a sample script named "genconf.sh" in the first zipped attachment. The 2nd "midas-config" is a sampled generated by it. Also a diff of Makefile is included. I hope it may help.  |
| Attachment 1: genc.zip
|
| Attachment 2: midas-config
|
#!/bin/sh
prefix=/usr/local
cflags="-I/usr/local/include -g -O2 -Wall -Wuninitialized -DINCLUDE_FTPLIB -DOS_LINUX -fPIC -Wno-unused-function -DHAVE_ODBC -DHAVE_ZLIB"
st_libs="-lutil -lpthread -lodbc -lz /usr/local/lib/libmidas.a"
dyn_libs="-lutil -lpthread -lodbc -lz -L/usr/local/lib -lmidas"
incdir=/usr/local/include
libdir=/usr/local/lib
svnver=r4621
platform=linux
drvdir=/usr/local/share/drivers
camacdir=/usr/local/share/drivers/camac
vmedir=/usr/local/share/drivers/vme
srcdir=/usr/local/share/src
exampledir=/usr/local/share/examples
out=""
while test $# -gt 0; do
case "$1" in
-*=*) optarg=/usr/local ;;
*) optarg= ;;
esac
case $1 in
--prefix)
out="$out ${prefix}"
;;
--cflags|-c)
out="$out ${cflags}"
;;
--incdir|-dI)
out="$out ${incdir}"
;;
--libdir|-dL)
out="$out ${libdir}"
;;
--libs|--static-libs|-l)
out="$out ${st_libs}"
;;
--dyn-libs)
out="$out ${dyn_libs}"
;;
--platform)
out="$out ${platform}"
;;
--drvdir|-dD)
out="$out ${drvdir}"
;;
--camacdir|-dC)
out="$out ${camacdir}"
;;
--vmedir|-dV)
out="$out ${vmedir}"
;;
--srcdir|-dS)
out="$out ${srcdir}"
;;
--exampledir|-dE)
out="$out ${exampledir}"
;;
--version|-v)
out="$out ${svnver}"
;;
--help|-h)
echo "Usage: midas-config [options]"
echo "Options:"
echo " --prefix Display the installation prefix"
echo " --cflags,-c Display C/C++ flags using for compilation"
echo " --incdir,-dI Display midas header directory installed"
echo " --libdir,-dL Display midas library directory installed"
echo " --libs, -l"
echo " --static-libs Display link flags while linking with static midas library"
echo " --dyn-libs Display link flags while linking with dynamic library"
echo " --platform Display installed platform"
echo " --drvdir,-dD Display the driver directory"
echo " --camacdir,-dC Display the directory including CAMAC APIs"
echo " --vmedir,-dV Display the directory including VME APIs"
echo " --srcdir,-dS Display the source directory"
echo " --exampledir,-dE Display the examples directory"
echo " --version, -v Show the subversion number"
echo " --help, -h Display this usage"
echo
exit 0
;;
*)
### Give an error
echo "Unknown argument \"/usr/local\"!" 1>&2
echo "${usage}" 1>&2
exit 1
;;
esac
shift
done
echo $out
|
|
673
|
20 Nov 2009 |
Konstantin Olchanski | Info | RPC.SHM gyration | > When using remote midas clients with mserver, you may have noticed the zero-size .RPC.SHM files
> these clients create in the directory where you run them.
Well, RPC.SHM bites. Please reread the parent message for full details, but in the nutshell, it is a global
semaphore that permits only one midas rpc client to talk to midas at a time (it was intended for local
locking between threads inside one midas application).
I have about 10 remote midas frontends started by ssh all in the same directory, so they all share the same
.RPC.SHM semaphore and do not live through the night - die from ODB timeouts because of RPC semaphore contention.
In a test version of MIDAS, I disabled the RPC.SHM semaphore, and now my clients live through the night, very
good.
Long term, we should fix this by using application-local mutexes (i.e. pthread_mutex, also works on MacOS, do
Windows have pthreads yet?).
This will also cleanup some of the ODB locking, which currently confuses pid's, tid's etc and is completely
broken on MacOS because some of these values are 64-bit and do not fit into the 32-bit data fields in MIDAS
shared memories.
Short term, I can add a flag for enabling and disabling the RPC semaphore from the user application: enabled
by default, but user can disable it if they do not use threads.
Alternatively, I can disable it by default, then enable it automatically if multiple threads are detected or
if ss_thread_create() is called.
Could also make it an environment variable.
Any preferences?
K.O. |
|
672
|
20 Nov 2009 |
Konstantin Olchanski | Bug Fix | disallow client names with slash '/' characters | > odb.c rev 4622 fixes ODB corruption by db_connect_database() if client_name is
> too long. Also fixed is potential ODB corruption by too long key names in
> db_create_key(). Problem kindly reported by Tim Nichols of T2K/ND280 experiment.
Related bug fix - db_connect_database() should not permit client names that contain
the slash (/) character. Names like "aaa/bbb" create entries /Programs/aaa/bbb (aaa
is a subdirectory) and names like "../aaa" create entries in the ODB root directory.
svn rev 4623.
K.O. |
|
671
|
20 Nov 2009 |
Konstantin Olchanski | Bug Fix | fix odb corruption from too long client names | odb.c rev 4622 fixes ODB corruption by db_connect_database() if client_name is
too long. Also fixed is potential ODB corruption by too long key names in
db_create_key(). Problem kindly reported by Tim Nichols of T2K/ND280 experiment.
K.O. |
|
670
|
10 Nov 2009 |
Stefan Ritt | Forum | It' better to fix this warnings | > This will cause "type conversion" warnings. I hope that "odbedit" can generate codes like this:
>
> #define EXPCVADC_COMMON_STR(_name) const char *_name[] = {\
> "[.]",\
>...
Ok, I changed that in odb.c rev. 4620, should be fine now. |
|