| ID |
Date |
Author |
Topic |
Subject |
|
2520
|
24 May 2023 |
Gennaro Tortone | Forum | pull request for PostgreSQL support |
Hi,
is there any news regarding this pull request ?
(https://bitbucket.org/tmidas/midas/pull-requests/30)
If you agree to merge I can resolve conflicts that now
(after two months) are listed...
Regards,
Gennaro
>
> Hi,
> I have updated the PR with a new one that includes TimescaleDB support and some
> changes to mhistory.js to support downsampling queries...
>
> Cheers,
> Gennaro
>
> > > some minutes ago I published a PR for PostgreSQL support I developed
> > > at INFN-Napoli for Darkside experiment...
> > >
> > > I don't know if you receive a notification about this PR and in doubt
> > > I wrote this message...
> >
> > Hi, Gennaro, thank you for the very useful contribution. I saw the previous version
> > of your pull request and everything looked quite good. But that pull request was
> > for an older version of midas and it would not have applied cleanly to the current
> > version. I will take a look at your updated pull request. In theory it should only
> > add the Postgres class and modify a few other places in history_schema.cxx and have
> > no changes to anything else. (if you need those changes, it should be a separate
> > pull request).
> >
> > Also I am curious what benefits and drawbacks of Postgres vs mysql/mariadb you have
> > observed for storing and using midas history data.
> >
> > K.O. |
|
2531
|
13 Jun 2023 |
Thomas Senger | Forum | Include subroutine through relative path in sequencer | Hi, I would like to restructure our sequencer scripts and the paths. Until now many things are not generic at all. I would like to ask if it is possible to include files through a relative path for example something like
INCLUDE ../chip/global_basic_functions
Maybe I just did not found how to do it. |
|
2532
|
13 Jun 2023 |
Stefan Ritt | Forum | Include subroutine through relative path in sequencer | > Hi, I would like to restructure our sequencer scripts and the paths. Until now many things are not generic at all. I would like to ask if it is possible to include files through a relative path for example something like
> INCLUDE ../chip/global_basic_functions
> Maybe I just did not found how to do it.
It was not there. I implemented it in the last commit.
Stefan |
|
2533
|
13 Jun 2023 |
Marco Francesconi | Forum | Include subroutine through relative path in sequencer | > > Hi, I would like to restructure our sequencer scripts and the paths. Until now many things are not generic at all. I would like to ask if it is possible to include files through a relative path for example something like
> > INCLUDE ../chip/global_basic_functions
> > Maybe I just did not found how to do it.
>
> It was not there. I implemented it in the last commit.
>
> Stefan
Hi Stefan,
when I did this job for MEG II we decided not to include relative paths and the ".." folder to avoid an exploit called "XML Entity Injection".
In short is to avoid leaking files outside the sequencer folders like /etc/password or private SSH keys.
I do not remember in this moment why we pushed for absolute paths instead but let's keep this in mind.
Marco |
|
2540
|
13 Jun 2023 |
Stefan Ritt | Forum | Include subroutine through relative path in sequencer | > when I did this job for MEG II we decided not to include relative paths and the ".." folder to avoid an exploit called "XML Entity Injection".
> In short is to avoid leaking files outside the sequencer folders like /etc/password or private SSH keys.
> I do not remember in this moment why we pushed for absolute paths instead but let's keep this in mind.
I thought about that. But before we had absolute paths in the sequencer INCLUDE statement. So having "../../../etc/passwd" is as bad as the
absolute path "/etc/passwd". So nothing really changed. What we really should prevent is to LOAD files into the sequencer from outside the
sequence subdirectory. And this is prevented by the file loader. Actually we will soon replace the file loaded with a modern JS dialog, and
the code restricts all operations to within the experiment directory and below.
Stefan |
|
2553
|
11 Jul 2023 |
Anubhav Prakash | Forum | Possible ODB corruption! Webpages https://midptf01.triumf.ca/?cmd=Programs not loading! | The ODB server seems to have crashed/corrupted. I tried reloading the previous
working version of ODB(using the commands in folliwng image) but it didn't work.
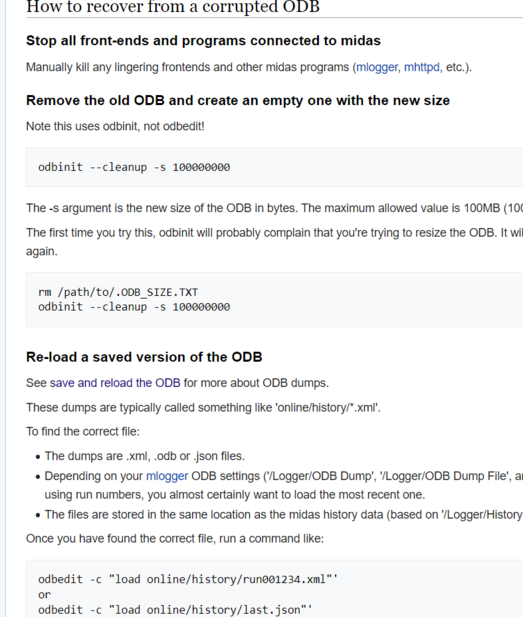
I have also attached the screenshot of the site https://midptf01.triumf.ca/?cmd=Programs. Any help to resolve this would be appreciated! Normally Prof. Thomas Lindner would solve such issues, but he is busy working at CERN till 17th of July, and we cannot afford to wait until then.
The following is the error: when I run bash /home/midptf/online/bin/start_daq.sh
[ODBEdit1,INFO] Fixing ODB "/Programs/ODBEdit" struct size mismatch (expected
316, odb size 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/ODBEdit" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/ODBEdit",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/ODBEdit"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/ODBEdit" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "ODBEdit", db_get_record1() status 319
[ODBEdit1,INFO] Fixing ODB "/Programs/mhttpd" struct size mismatch (expected
316, odb size 60)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/mhttpd" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/mhttpd",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/mhttpd"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/mhttpd" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "mhttpd", db_get_record1() status 319
[ODBEdit1,INFO] Fixing ODB "/Programs/Logger" struct size mismatch (expected
316, odb size 60)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/Logger" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/Logger",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/Logger"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/Logger" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "Logger", db_get_record1() status 319
14:54:29 [ODBEdit,ERROR] [odb.cxx:1763:db_validate_db,ERROR] Warning: database
data area is 100% full
14:54:29 [ODBEdit,ERROR] [odb.cxx:1283:db_validate_key,ERROR] hkey 643368, path
"/Alarms/Classes/<NULL>/Display BGColor", string value is not valid UTF-8
14:54:29 [ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot
malloc_data(256), called from db_set_link_data
14:54:29 [ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot
reallocate "/System/Tmp/140305391605888I/Start command" with new size 256 bytes,
online database full
14:54:29 [ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of
zero, set to 32, odb path "Start command"
14:54:29 [ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of
zero, set to 32, odb path "Start command" |
|
2554
|
11 Jul 2023 |
Thomas Lindner | Forum | Possible ODB corruption! Webpages https://midptf01.triumf.ca/?cmd=Programs not loading! | Hi Anubhav,
I have fixed the ODB corruption problem.
Cheers,
Thomas
| Anubhav Prakash wrote: | The ODB server seems to have crashed/corrupted. I tried reloading the previous
working version of ODB(using the commands in folliwng image) but it didn't work.
I have also attached the screenshot of the site https://midptf01.triumf.ca/?cmd=Programs. Any help to resolve this would be appreciated! Normally Prof. Thomas Lindner would solve such issues, but he is busy working at CERN till 17th of July, and we cannot afford to wait until then.
The following is the error: when I run bash /home/midptf/online/bin/start_daq.sh
[ODBEdit1,INFO] Fixing ODB "/Programs/ODBEdit" struct size mismatch (expected
316, odb size 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/ODBEdit" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/ODBEdit",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/ODBEdit"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/ODBEdit" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "ODBEdit", db_get_record1() status 319
[ODBEdit1,INFO] Fixing ODB "/Programs/mhttpd" struct size mismatch (expected
316, odb size 60)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/mhttpd" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/mhttpd",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/mhttpd"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/mhttpd" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "mhttpd", db_get_record1() status 319
[ODBEdit1,INFO] Fixing ODB "/Programs/Logger" struct size mismatch (expected
316, odb size 60)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/Logger" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/Logger",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/Logger"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/Logger" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "Logger", db_get_record1() status 319
14:54:29 [ODBEdit,ERROR] [odb.cxx:1763:db_validate_db,ERROR] Warning: database
data area is 100% full
14:54:29 [ODBEdit,ERROR] [odb.cxx:1283:db_validate_key,ERROR] hkey 643368, path
"/Alarms/Classes/<NULL>/Display BGColor", string value is not valid UTF-8
14:54:29 [ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot
malloc_data(256), called from db_set_link_data
14:54:29 [ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot
reallocate "/System/Tmp/140305391605888I/Start command" with new size 256 bytes,
online database full
14:54:29 [ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of
zero, set to 32, odb path "Start command"
14:54:29 [ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of
zero, set to 32, odb path "Start command" |
|
|
2556
|
18 Jul 2023 |
Konstantin Olchanski | Forum | pull request for PostgreSQL support | > is there any news regarding this pull request ?
> (https://bitbucket.org/tmidas/midas/pull-requests/30)
apologies for taking a very long time to review the proposed changes.
the main problem with this pull request remains, it tangles together too many changes to the code and I cannot simply
say "this is okey", merge and commit it.
example of unrelated change is diff of mlogger.cxx, change of function in: "db_get_value(hDB, 0, "/Logger/Multithread
transitions" ... )". there is also unrelated changes to whitespace sprinkled around.
can you review your diffs again and try to remove as much unrelated and unnecessary changes as you can?
I could do this for you, and merge my version, but next time you merge base midas, you will have a collision.
unrelated change of function is introduction of something called "downsampling", what is the purpose of this? How is it
different from requesting binned data? Is it just a kludge to reduce the data size? Before we merge it, can you post a
description/discussion to this forum here? (as a separate topic, separate from discussion of PostgreSQL merge).
the changes to add PostgreSQL so fat look reasonable:
- CMakeLists, is always painful but if you do same a MySQL, should be okey, we always end up rejigging this several
times before it works everywhere.
- history.h, ok, minus changes for adding the "downsample" feature
- mlogger.cxx, changes are too tangled with "downsample" feature, cannot review
- SetDownsample() API is defective, should have separate Get() and Set() functions
- history_common.cxx, please do not add downsampling code to history providers that do not/will not support it.
- history_odbc.cxx, please do not change it. it does not support downsampling and never will.
- history.cxx, ditto
- mjsonrpc.cxx, history API is changed, we must know: is new JS compatible with old mhttpd? is old JS compatible with
new mhttpd? (mixed versions are very common in practice). if there is incompatibility, can you recoded it to be
compatible?
- history_schema.cxx: bitbucket diff is a dog's breakfast, cannot review. I will have to checkout your branch and diff
by hand.
changes to mhistory.js appear to be extensive and some explanation is needed for what is changed, what bugs/problems
are fixed, what new features are added.
to move forward, can you generate a pull requests that only adds pgsql to history_schema.cxx, history_common.cxx and
mlogger.cxx and does not add any other functions, features and does not change any whistespace?
K.O.
>
> If you agree to merge I can resolve conflicts that now
> (after two months) are listed...
>
> Regards,
> Gennaro
>
> >
> > Hi,
> > I have updated the PR with a new one that includes TimescaleDB support and some
> > changes to mhistory.js to support downsampling queries...
> >
> > Cheers,
> > Gennaro
> >
> > > > some minutes ago I published a PR for PostgreSQL support I developed
> > > > at INFN-Napoli for Darkside experiment...
> > > >
> > > > I don't know if you receive a notification about this PR and in doubt
> > > > I wrote this message...
> > >
> > > Hi, Gennaro, thank you for the very useful contribution. I saw the previous version
> > > of your pull request and everything looked quite good. But that pull request was
> > > for an older version of midas and it would not have applied cleanly to the current
> > > version. I will take a look at your updated pull request. In theory it should only
> > > add the Postgres class and modify a few other places in history_schema.cxx and have
> > > no changes to anything else. (if you need those changes, it should be a separate
> > > pull request).
> > >
> > > Also I am curious what benefits and drawbacks of Postgres vs mysql/mariadb you have
> > > observed for storing and using midas history data.
> > >
> > > K.O. |
|
2559
|
21 Jul 2023 |
Konstantin Olchanski | Forum | pull request for PostgreSQL support | > > is there any news regarding this pull request ?
> > (https://bitbucket.org/tmidas/midas/pull-requests/30)
>
> apologies for taking a very long time to review the proposed changes.
>
I merged the PgSql bits by hand - the automatic tools make a dog's breakfast from the history_schema.cxx diffs. Ouch.
history_schema.cxx merged pretty much cleanly, but I have one question about CreateSqlColumn() with sql_strict set to "true". Can you say
more why this is needed? Should this also be made the default for MySQL? The best I can tell the default values are only needed if we write
to SQL but forget to provide values that should not be NULL? But our code never does this? Or this is for reading from SQL, where NULL values
are replaced with the default values? I do not have time to look into this right now, I hope you can clarify it for me?
Also notice the fDownsample is set to zero and cannot be changed. I recommend we set it through the MakeMidasHistoryPgsql() factory method.
Please pull, merge, retest, update the pull request, check that there is no unrelated changes (changes in mlogger.cxx is a direct red flag!)
and we should be able to merge the rest of your stuff pronto.
K.O.
commit e85bb6d37c85f02fc4895cae340ba71ab36de906 (HEAD -> develop, origin/develop, origin/HEAD)
Author: Konstantin Olchanski <olchansk@triumf.ca>
Date: Fri Jul 21 09:45:08 2023 -0700
merge PQSQL history in history_schema.cxx
commit f254ebd60a23c6ee2d4870f3b6b5e8e95a8f1f09
Author: Konstantin Olchanski <olchansk@triumf.ca>
Date: Fri Jul 21 09:19:07 2023 -0700
add PGSQL Makefile bits
commit aa5a35ba221c6f87ae7a811236881499e3d8dcf7
Author: Konstantin Olchanski <olchansk@triumf.ca>
Date: Fri Jul 21 08:51:23 2023 -0700
merge PGSQL support from https://bitbucket.org/gtortone/midas/branch/feature/timescaledb_support except for history_schema.cxx |
|
2560
|
21 Jul 2023 |
Gennaro Tortone | Forum | pull request for PostgreSQL support |
Hi Konstantin,
thanks a lot for your work on PostgreSQL and TimescaleDB integration...
and sorry for unrelated changes on source code !
I will return on this task at end of this year (maybe October or November) because
I'm working on different tasks... but I will keep in mind your suggestions in order
to provide good source code.
Thanks,
Gennaro
>
> I merged the PgSql bits by hand - the automatic tools make a dog's breakfast from the history_schema.cxx diffs. Ouch.
>
> history_schema.cxx merged pretty much cleanly, but I have one question about CreateSqlColumn() with sql_strict set to "true". Can you say
> more why this is needed? Should this also be made the default for MySQL? The best I can tell the default values are only needed if we write
> to SQL but forget to provide values that should not be NULL? But our code never does this? Or this is for reading from SQL, where NULL values
> are replaced with the default values? I do not have time to look into this right now, I hope you can clarify it for me?
>
> Also notice the fDownsample is set to zero and cannot be changed. I recommend we set it through the MakeMidasHistoryPgsql() factory method.
>
> Please pull, merge, retest, update the pull request, check that there is no unrelated changes (changes in mlogger.cxx is a direct red flag!)
> and we should be able to merge the rest of your stuff pronto.
>
> K.O.
>
> commit e85bb6d37c85f02fc4895cae340ba71ab36de906 (HEAD -> develop, origin/develop, origin/HEAD)
> Author: Konstantin Olchanski <olchansk@triumf.ca>
> Date: Fri Jul 21 09:45:08 2023 -0700
>
> merge PQSQL history in history_schema.cxx
>
> commit f254ebd60a23c6ee2d4870f3b6b5e8e95a8f1f09
> Author: Konstantin Olchanski <olchansk@triumf.ca>
> Date: Fri Jul 21 09:19:07 2023 -0700
>
> add PGSQL Makefile bits
>
> commit aa5a35ba221c6f87ae7a811236881499e3d8dcf7
> Author: Konstantin Olchanski <olchansk@triumf.ca>
> Date: Fri Jul 21 08:51:23 2023 -0700
>
> merge PGSQL support from https://bitbucket.org/gtortone/midas/branch/feature/timescaledb_support except for history_schema.cxx |
|
2563
|
28 Jul 2023 |
Stefan Ritt | Forum | pull request for PostgreSQL support | The compilation of midas was broken by the last modification. The reason is that
Pgsql *fPgsql = NULL;
was not protected by
#ifdef HAVE_PGSQL
So I put all PGSQL code under a big #ifdef and now it compiles again. You might want to double check my modification at
https://bitbucket.org/tmidas/midas/commits/e3c7e73459265e0d7d7a236669d1d1f2d9292a74
Best,
Stefan |
|
2566
|
02 Aug 2023 |
Caleb Marshall | Forum | Issues with Universe II Driver | Hello,
At our lab we are currently in the process of migrating more of our systems over to Midas. However, all of our working systems are dependent on SBCs with the Tsi-148 chips of which we only have a handful. In order to have some backups and spares for testing, we have been attempting to get Midas working with some borrowed SBCs (Concurrent Technologies VX 40x/04x) with Universe-II chips. The SBC is running CentOS 7. I have tried to follow the instructions posted here. The universe-II kernel module appears to load correctly, dmesg gives:
[ 32.384826] VME: Board is system controller
[ 32.384875] VME: Driver compiled for SMP system
[ 32.384877] VME: Installed VME Universe module version: 3.6.KO6
However, running vmescan.exe fails with a segfault. Running with gdb shows:
vmic_mmap: Mapped VME AM 0x0d addr 0x00000000 size 0x00ffffff at address 0x80a01000
mvme_open:
Bus handle = 0x7
DMA handle = 0x6045d0
DMA area size = 1048576 bytes
DMA physical address = 0x7ffff7eea000
vmic_mmap: Mapped VME AM 0x2d addr 0x00000000 size 0x0000ffff at address 0x86ff0000
Program received signal SIGSEGV, Segmentation fault.
mvme_read_value (mvme=0x604010, vme_addr=<optimized out>)
at /home/jam/midas/packages/midas/drivers/vme/vmic/vmicvme.c:352
352 dst = *((WORD *)addr);
With the pointer addr originating from a call to vmic_mapcheck within the mvme_read_value functions in the vmicvme.c file. Help with where to go from here would be appreciated.
-Caleb
|
|
2567
|
02 Aug 2023 |
Konstantin Olchanski | Forum | Issues with Universe II Driver | I maintain the tsi148 and the universe-II drivers. I confirm -KO6 is my latest
version, last updated for 32-bit Debian-11, and we still use it at TRIUMF.
It is good news that the vme_universe kernel module built, loaded and reported
correct stuff to dmesg.
It is not clear why mvme_read_value() crashed. We need to know the value of
vme_addr and addr, can you add printf()s for them using format "%08x" and try
again?
K.O.
<p> </p>
<table align="center" cellspacing="1" style="border:1px solid #486090;
width:98%">
<tbody>
<tr>
<td style="background-color:#486090">Caleb Marshall
wrote:</td>
</tr>
<tr>
<td style="background-color:#FFFFB0">
<p>Hello,</p>
<p>At our lab we are currently in the process of
migrating more of our systems over to Midas. However, all of our working systems
are dependent on SBCs with the Tsi-148 chips of which we only have a handful. In
order to have some backups and spares for testing, we have been attempting to
get Midas working with some borrowed SBCs (Concurrent Technologies VX 40x/04x)
with Universe-II chips. The SBC is running CentOS 7. I have tried to
follow the instructions posted <a
href="https://daq00.triumf.ca/DaqWiki/index.php/VME-
CPU#V7648_and_V7750_BIOS_Settings">here</a>. The universe-II kernel module
appears to load correctly, dmesg gives:</p>
<p>[ 32.384826] VME: Board is system
controller<br />
[ 32.384875] VME: Driver compiled for SMP
system<br />
[ 32.384877] VME: Installed VME Universe module
version: 3.6.KO6<br />
</p>
<p>However, running vmescan.exe fails with a segfault.
Running with gdb shows:</p>
<p>vmic_mmap: Mapped VME AM 0x0d addr 0x00000000 size
0x00ffffff at address 0x80a01000<br />
mvme_open:<br />
Bus handle
= 0x7<br />
DMA handle
= 0x6045d0<br />
DMA area size =
1048576 bytes<br />
DMA physical address = 0x7ffff7eea000<br />
vmic_mmap: Mapped VME AM 0x2d addr 0x00000000 size
0x0000ffff at address 0x86ff0000</p>
<p>Program received signal SIGSEGV, Segmentation fault.
<br />
mvme_read_value (mvme=0x604010, vme_addr=<optimized
out>)<br />
at
/home/jam/midas/packages/midas/drivers/vme/vmic/vmicvme.c:352<br />
352 dst = *((WORD
*)addr);<br />
</p>
<p>With the pointer addr originating from a call
to vmic_mapcheck within the mvme_read_value functions in the
vmicvme.c file. Help with where to go from here would be appreciated.</p>
<p>-Caleb </p>
<p> </p>
</td>
</tr>
</tbody>
</table>
<p> </p> |
|
2570
|
03 Aug 2023 |
Caleb Marshall | Forum | Issues with Universe II Driver | Here is the output:
vmic_mmap: Mapped VME AM 0x0d addr 0x00000000 size 0x00ffffff at address 0x80a01000
mvme_open:
Bus handle = 0x3
DMA handle = 0x158f5d0
DMA area size = 1048576 bytes
DMA physical address = 0x7f91db553000
vmic_mmap: Mapped VME AM 0x2d addr 0x00000000 size 0x0000ffff at address 0x86ff0000
vme addr: 00000000
addr: db543000 |
|
2571
|
03 Aug 2023 |
Konstantin Olchanski | Forum | Issues with Universe II Driver | > Here is the output:
>
> vmic_mmap: Mapped VME AM 0x0d addr 0x00000000 size 0x00ffffff at address 0x80a01000
> mvme_open:
> Bus handle = 0x3
> DMA handle = 0x158f5d0
> DMA area size = 1048576 bytes
> DMA physical address = 0x7f91db553000
> vmic_mmap: Mapped VME AM 0x2d addr 0x00000000 size 0x0000ffff at address 0x86ff0000
> vme addr: 00000000
> addr: db543000
I see the problem. A24 is mapped at 0x80xxxxxx, A16 is mapped at 0x86ffxxxx, but
mvme_read computed address 0xdb543000, out of range of either mapped vme address. ouch.
One more thing to check, AFAIK, this universe-II codes were never used on 64-bit CPU
before, we only have 32-bit Pentium-3 and Pentium-4 machines with these chips. The
tsi148 codes used to work both 32-bit and 64-bit, we used to have both flavours of
CPUs, but now only have 64-bit.
What is your output for "uname -a"? does it report 32-bit or 64-bit kernel?
If you feel adventurous, you can build 32-bit midas (cd .../midas; make linux32),
compile vmescan.o with "-m32" and link vmescan.exe against .../midas/linux-m32/lib, and
see if that works. Meanwhile, I can check if vmicvme.c is 64-bit clean. Checking if
kernel module is 64-bit clean would be more difficult...
K.O. |
|
2572
|
03 Aug 2023 |
Caleb Marshall | Forum | Issues with Universe II Driver | I am looking into compiling the 32 bit midas.
In the meantime, here is the kernel info:
3.10.0-1160.11.1.el7.x86_64
Thank you for the help.
-Caleb |
|
2574
|
04 Aug 2023 |
Caleb Marshall | Forum | Issues with Universe II Driver | I can compile 32 bit midas. Unless I am interpreting the linking error, I don't
think I can use the driver as built.
While trying to compile vme_scan, most of the programs fail with:
/usr/bin/ld: skipping incompatible /usr/lib/gcc/x86_64-redhat-
linux/4.8.5/../../../../lib/libvme.so when searching for -lvme
/usr/bin/ld: skipping incompatible /lib/../lib/libvme.so when searching for -lvme
/usr/bin/ld: skipping incompatible /usr/lib/../lib/libvme.so when searching for -
lvme
/usr/bin/ld: skipping incompatible /usr/lib/gcc/x86_64-redhat-
linux/4.8.5/../../../libvme.so when searching for -lvme
/usr/bin/ld: skipping incompatible //lib/libvme.so when searching for -lvme
/usr/bin/ld: skipping incompatible //usr/lib/libvme.so when searching for -lvme
with libvme.so being built by the universe-II driver. Not sure if I can get around
this without messing with the driver? Is it possible to build a 32 bit version of
that shared library without having to touch the actual kernel module?
-Caleb |
|
2575
|
04 Aug 2023 |
Konstantin Olchanski | Forum | Issues with Universe II Driver | > I can compile 32 bit midas. Unless I am interpreting the linking error, I don't
> think I can use the driver as built.
I think you are right, Makefile from the Universe package does not build a -m32 version
of libvme.so. I think I can fix that...
K.O. |
|
2576
|
09 Aug 2023 |
Konstantin Olchanski | Forum | pull request for PostgreSQL support | > The compilation of midas was broken by the last modification. The reason is that
> Pgsql *fPgsql = NULL;
> was not protected by #ifdef HAVE_PGSQL
confirmed, my mistake, I forgot to test with "make cmake NO_PGSQL". your fix is correct, thanks.
K.O. |
|
2595
|
08 Sep 2023 |
Nick Hastings | Forum | Hide start and stop buttons | The wiki documents an odb variable to enable the hiding of the Start and Stop buttons on the mhttpd status page
https://daq00.triumf.ca/MidasWiki/index.php//Experiment_ODB_tree#Start-Stop_Buttons
However mhttpd states this option is obsolete. See commit:
https://bitbucket.org/tmidas/midas/commits/2366eefc6a216dc45154bc4594e329420500dcf7
I note that that commit also made mhttpd report that the "Pause-Resume Buttons" variable is also obsolete, however that code seems to have since been removed.
Is there now some other mechanism to hide the start and stop buttons?
Note that this is for a pure slow control system that does not take runs. |
|