 02 Aug 2023, Stefan Ritt, Bug Report, Error accessing history files 02 Aug 2023, Stefan Ritt, Bug Report, Error accessing history files 
|
We sporadically (like once per few hours) have an error message when we access the
history plots through mhttpd:
07:21:35.109 2023/08/03 [mhttpd,ERROR]
[history_schema.cxx:2345:FileHistory::read_data,ERROR] Cannot read
'/data2/history/mhf_1690890685_20230801_dc_hv.dat', read() errno 2 (No such file
or directory)
When I log in to the machine, I properly see the file and also can access it
[meg@megon02 history]$ ls -l mhf_1690890685_20230801_dc_hv.dat
-rw-rw-r--. 1 meg meg 34176312 Aug 3 07:23 mhf_1690890685_20230801_dc_hv.dat
and I also can dump that file.
When I try again with mhttpd, I properly see that file.
Now in principle this is not a problem, but the error message is annoying, since this
is the only error we get in 24 hours. I attached a 24h log to see what I mean. If this
is an OS issue, I wonder if we should add code to retry the file access in case we get
that error.
Anybody seen a similar thing?
Best,
Stefan |
 09 Aug 2023, Konstantin Olchanski, Bug Report, Error accessing history files 09 Aug 2023, Konstantin Olchanski, Bug Report, Error accessing history files
|
I confirm I see same on the agmini system. Two problems: (a) error message is wrong, it's a
short read, not a read error (clue: read() syscall does not return "no such file"). (b)
mlogger is supposed to write history in record-size blocks, read in the same record size
blocks. UNIX file semantics require that both reader and writer see read() and write() as
atomic, even on NFS, so mhttpd should never see partially written history records. I can
debug this on the agmini system. Probably should.
Problem (a) fixed in commit bb423c8680cc67220312534403840442868f2b3b, if you update, you
should see error messages about "short read" and the read sizes it reports are very
interesting, please put them in the elog here.
K.O.
> We sporadically (like once per few hours) have an error message when we access the
> history plots through mhttpd:
>
> 07:21:35.109 2023/08/03 [mhttpd,ERROR]
> [history_schema.cxx:2345:FileHistory::read_data,ERROR] Cannot read
> '/data2/history/mhf_1690890685_20230801_dc_hv.dat', read() errno 2 (No such file
> or directory)
>
> When I log in to the machine, I properly see the file and also can access it
>
> [meg@megon02 history]$ ls -l mhf_1690890685_20230801_dc_hv.dat
> -rw-rw-r--. 1 meg meg 34176312 Aug 3 07:23 mhf_1690890685_20230801_dc_hv.dat
>
> and I also can dump that file.
>
> When I try again with mhttpd, I properly see that file.
>
> Now in principle this is not a problem, but the error message is annoying, since this
> is the only error we get in 24 hours. I attached a 24h log to see what I mean. If this
> is an OS issue, I wonder if we should add code to retry the file access in case we get
> that error.
>
> Anybody seen a similar thing?
>
> Best,
> Stefan |
|
17 Aug 2023, Stefan Ritt, Bug Report, Error accessing history files
|
Tonight we got another error of that type after the update:
04:17 - [mhttpd,ERROR] [history_schema.cxx:2913:FileHistory::read_data,ERROR] Cannot read
'/data2/history/mhf_1692128214_20230815_gassystem.dat', read() errno 2 (No such file or directory)
This morning I looked at the file, and it was there:
[meg@megon02 history]$ ls -alg mhf_1692128214_20230815_gassystem.dat
-rw-rw-r--. 1 meg 4663228 Aug 17 08:50 mhf_1692128214_20230815_gassystem.dat
[meg@megon02 history]$
Stefan |
|
17 Aug 2023, Konstantin Olchanski, Bug Report, Error accessing history files
|
Confirmed. The error message is wrong. It is printed after a short read(), but short read() does not
set errno, and errno reported by the error message is from some previous syscall. Corrected error
message is already committed. K.O.
> Tonight we got another error of that type after the update:
>
> 04:17 - [mhttpd,ERROR] [history_schema.cxx:2913:FileHistory::read_data,ERROR] Cannot read
> '/data2/history/mhf_1692128214_20230815_gassystem.dat', read() errno 2 (No such file or directory)
>
> This morning I looked at the file, and it was there:
>
> [meg@megon02 history]$ ls -alg mhf_1692128214_20230815_gassystem.dat
> -rw-rw-r--. 1 meg 4663228 Aug 17 08:50 mhf_1692128214_20230815_gassystem.dat
> [meg@megon02 history]$
>
>
> Stefan |
|
19 Aug 2023, Stefan Ritt, Bug Report, Error accessing history files
|
Still get the same error with the latest version:
3:28 [mhttpd,ERROR] [history_schema.cxx:2913:FileHistory::read_data,ERROR] Cannot read
'/data2/history/mhf_1692391703_20230818_hv_tc.dat', read() errno 2 (No such file or directory)
Stefan |
|
06 Oct 2023, Konstantin Olchanski, Bug Report, Error accessing history files
|
> Still get the same error with the latest version:
> 3:28 [mhttpd,ERROR] [history_schema.cxx:2913:FileHistory::read_data,ERROR] Cannot read
> '/data2/history/mhf_1692391703_20230818_hv_tc.dat', read() errno 2 (No such file or directory)
I figured it out. I claim defense of temporary insanity and old age senility.
1) I added the "short read" check in one place, missed the second place
2) writes of history were meant to be atomic, and they are atomic in my head, but not in the midas
code:
history_schema.cxx:HsFileSchema::write_event()
...
status = write(s->writer_fd, &t, 4);
if (status != 4) {
cm_msg(MERROR, "FileHistory::write_event", "Cannot write to \'%s\', write(timestamp) errno
%d (%s)", s->file_name.c_str(), errno, strerror(errno));
return HS_FILE_ERROR;
}
status = write(s->writer_fd, data, expected_size);
if (status != expected_size) {
cm_msg(MERROR, "FileHistory::write_event", "Cannot write to \'%s\', write(%d) errno %d
(%s)", s->file_name.c_str(), data_size, errno, strerror(errno));
return HS_FILE_ERROR;
}
...
that's not atomic, that's two separate writes. history reader hits the history file between the
two writes and gets a short read of 4 bytes timestamp instead of full record size. that's the
error message reported by mhttpd.
two fixes forthcoming:
a) check for short read in the 2nd place that I missed
b) two write() are replaced by 2 memcpy() to a preallocated buffer and 1 write()
Overall, I am pretty happy that this is the only bug in the FILE history code found in N years,
and it does not even cause data corruption...
K.O. |
|
06 Oct 2023, Konstantin Olchanski, Bug Report, Error accessing history files
|
> two fixes forthcoming:
> a) check for short read in the 2nd place that I missed
> b) two write() are replaced by 2 memcpy() to a preallocated buffer and 1 write()
commit 713ec4a583365d57ffcd700ceeb09dcc14518295
K.O. |
|
03 Oct 2023, Konstantin Olchanski, Bug Fix, wrong array size after loading xml or json file
|
both the xml and the json decoders have a bug (fix pending). loading saved odb
from xml and json file did not truncate arrays in odb to the size of arrays in
the file. for example, if /example/double_array has size 20 in odb, but size 5
in xml or json file, after loading the file, array size is still 20.
this is unexpected: after loading an odb save file we expect odb to return to
same state as when odb save file was created. we do not expect some arrays to
have half of their elements restored from file and half their elements left
unchanged.
save and restore from .odb file does not have this problem.
I think this is a bug and I committed (but did not yet push) a fix for both xml
and json odb decoder.
I have run this problem while writing the new history panel editor, where
deleting variables did not work because json rpc db_paste() was not truncating
any arrays.
I am still finishing up the last few bits of the new history panel editor, and
there is a bit of time to discuss and comment this odb change before I push it
to midas.
K.O. |
|
30 Sep 2023, Gennaro Tortone, Bug Report, ODB page and hex values
|
Hi,
I was playing with MIDAS devel branch and I realized that
if I set an ODB INT32 key to a value using new ODB web interface
it is reported in parenthesis always as (0xFFFFFFFF);
I tested with different browser and result is the same while this
never happens in OldODB web interface...
Cheers,
Gennaro |
|
01 Oct 2023, Stefan Ritt, Bug Report, ODB page and hex values
|
Thanks for reporting this bug, I fixed it in the last commit.
Best,
Stefan |
|
26 Sep 2023, Stefan Ritt, Info, mjsonrpc_db_save / mjsonrpc_db_load have been dropped
|
The JavaScript function
mjsonrpc_db_save / mjonrpc_db_load
have been dropped from the API because they were not considered safe. Users
should use now the new function
file_save_ascii()
and
file_load_ascii()
These function have the additional advantage that the file is not loaded
directly into the ODB but goes into the JavaScript code in the browser, which
can check or modify it before sending it to the ODB via mjsonrpc_db_paste().
Access of these functions is limited to <experiment>/userfiles/* where
<experiment> is the normal MIDAS experiment directory defined by "exptab" or
"MIDAS_DIR". This ensures that there is no access to e.g. system-level files. If
you need to access a directory not under "userfile", us symbolic links.
These files can be combined with file_picker(), which lets you select files on
the server interactively.
Stefan |
|
24 Sep 2023, Frederik Wauters, Suggestion, scroll when browsing for a link
|
Another small user experience request:
When making a link in the odb (web interface) a nice browser window pop's up. There is however not scrolling possible in the window. As a result, you can not reach a odb key if it is nested to deeply.
Trying to type out the Link target in the field only allows for 32 characters
context: we are setting up a bunch of Links in the History |
|
26 Sep 2023, Stefan Ritt, Suggestion, scroll when browsing for a link
|
> When making a link in the odb (web interface) a nice browser window pop's up. There is however not scrolling possible in the window. As a result, you can not reach a odb key if it is nested to deeply.
>
> Trying to type out the Link target in the field only allows for 32 characters
Thanks for reporting the bug with the pop-up not being able to scroll, I fixed that and committed the change.
I do however not understand the issue with 32 characters. The link NAME should not be more than 32 chars (which applies to all ODB keys).
But if I try I can write more than 32 chars in the link target.
Stefan |
|
19 Sep 2023, Frederik Wauters, Bug Report, epics fe "Start Command"
|
The epics frontend overwrites the "start command" odb after each start:
// set start command in ODB
midas::odb efe("/Programs/EPICS Frontend");
std::string p(__FILE__);
std::string s("build/epics_fe");
auto i = p.find("epics_fe.cxx");
p.replace(i, s.length(), s);
p = p.substr(0, i + s.length());
efe["Start command"].set_string_size(p, 256);
this should be set such that it only writes when the key is not there. It causes the following issue: on a pc with multiple experiments defined, you need to start the fe's with a "-e <name>" flag. |
|
20 Sep 2023, Stefan Ritt, Bug Report, epics fe "Start Command"
|
Thanks for reporting this problem. It has been fixed today, so the start command is only written if it's emtpy.
Stefan |
|
08 Sep 2023, Nick Hastings, Forum, Hide start and stop buttons
|
The wiki documents an odb variable to enable the hiding of the Start and Stop buttons on the mhttpd status page
https://daq00.triumf.ca/MidasWiki/index.php//Experiment_ODB_tree#Start-Stop_Buttons
However mhttpd states this option is obsolete. See commit:
https://bitbucket.org/tmidas/midas/commits/2366eefc6a216dc45154bc4594e329420500dcf7
I note that that commit also made mhttpd report that the "Pause-Resume Buttons" variable is also obsolete, however that code seems to have since been removed.
Is there now some other mechanism to hide the start and stop buttons?
Note that this is for a pure slow control system that does not take runs. |
|
08 Sep 2023, Nick Hastings, Forum, Hide start and stop buttons
|
> Is there now some other mechanism to hide the start and stop buttons?
> Note that this is for a pure slow control system that does not take runs.
Just wanted to add that I realize that this can be done by copying
status.html and/or midas.css to the experiment directory and then modifying
them/it, but wonder if the is some other preferred way. |
|
13 Sep 2023, Stefan Ritt, Forum, Hide start and stop buttons
|
Indeed the ODB settings are obsolete. Now that the status page is fully dynamic
(JavaScript), it's much more powerful to modify the status.html page directly. You
can not only hide the buttons, but also remove the run numbers, the running time,
and so on. This is much more flexible than steering things through the ODB.
If there is a general need for that, I can draft a "non-run" based status page, but
it's a bit hard to make a one-fits-all. Like some might even remove the logging
channels and the clients, but add certain things like if their slow control front-
end is running etc.
Best,
Stefan |
|
13 Sep 2023, Nick Hastings, Forum, Hide start and stop buttons
|
Hi Stefan,
> Indeed the ODB settings are obsolete.
I just applied for an account for the wiki.
I'll try add a note regarding this change.
> Now that the status page is fully dynamic
> (JavaScript), it's much more powerful to modify the status.html page directly. You
> can not only hide the buttons, but also remove the run numbers, the running time,
> and so on. This is much more flexible than steering things through the ODB.
Very true. Currently I copied the resources/midas.css into the experiment directory and appended:
#runNumberCell { display: none;}
#runStatusStartTime { display: none;}
#runStatusStopTime { display: none;}
#runStatusSequencer { display: none;}
#logChannel { display: none;}
See screenshot attached. :-)
But if feels a little clunky to copy the whole file just to add five lines.
It might be more elegant if status.html looked for a user css file in addition
to the default ones.
> If there is a general need for that, I can draft a "non-run" based status page, but
> it's a bit hard to make a one-fits-all. Like some might even remove the logging
> channels and the clients, but add certain things like if their slow control front-
> end is running etc.
The logging channels are easily removed with the css (see attachment), but it might be
nice if the string "Run Status" table title was also configurable by css. For this
slow control system I'd probably change it to something like "GSC Status". Again
this is a minor thing, I could trivially do this by copying the resources/status.html
to the experiment directory and editing it.
Lots of fun new stuff migrating from circa 2012 midas to midas-2022-05-c :-)
Cheers,
Nick. |
|
14 Sep 2023, Stefan Ritt, Forum, Hide start and stop buttons
|
> Hi Stefan,
>
> > Indeed the ODB settings are obsolete.
>
> I just applied for an account for the wiki.
> I'll try add a note regarding this change.
Please coordinate with Ben Smith at TRIUMF <bsmith@triumf.ca>, who coordinates the documentation.
> Very true. Currently I copied the resources/midas.css into the experiment directory and appended:
>
> #runNumberCell { display: none;}
> #runStatusStartTime { display: none;}
> #runStatusStopTime { display: none;}
> #runStatusSequencer { display: none;}
> #logChannel { display: none;}
>
> See screenshot attached. :-)
>
> But if feels a little clunky to copy the whole file just to add five lines.
> It might be more elegant if status.html looked for a user css file in addition
> to the default ones.
I would not go to change the CSS file. You only can hide some tables. But in a while I'm sure you
want to ADD new things, which you only can do by editing the status.html file. You don't have to
change midas/resources/status.html, but can make your own "custom status", name it differently, and
link /Custom/Default in the ODB to it. This way it does not get overwritten if you pull midas.
> The logging channels are easily removed with the css (see attachment), but it might be
> nice if the string "Run Status" table title was also configurable by css. For this
> slow control system I'd probably change it to something like "GSC Status". Again
> this is a minor thing, I could trivially do this by copying the resources/status.html
> to the experiment directory and editing it.
See above. I agree that the status.html file is a bit complicated and not so easy to understand
as the CSS file, but you can do much more by editing it.
> Lots of fun new stuff migrating from circa 2012 midas to midas-2022-05-c :-)
I always advise people to frequently pull, they benefit from the newest features and avoid the
huge amount of work to migrate from a 10 year old version.
Best,
Stefan |
|
14 Sep 2023, Konstantin Olchanski, Forum, Hide start and stop buttons
|
I believe the original "hide run start / stop" was added specifically for ND280 GSC MIDAS. I do not know
why it was removed. "hide pause / resume" is still there. I will restore them. Hiding logger channel
section should probably be automatic of there is no /logger/channels, I can check if it works and what
happens if there is more than one logger channel. K.O. |
|
15 Sep 2023, Stefan Ritt, Forum, Hide start and stop buttons
|
> I believe the original "hide run start / stop" was added specifically for ND280 GSC MIDAS. I do not know
> why it was removed. "hide pause / resume" is still there. I will restore them. Hiding logger channel
> section should probably be automatic of there is no /logger/channels, I can check if it works and what
> happens if there is more than one logger channel. K.O.
Very likely it was "forgotten" when the status page was converted to a dynamic page by Shouyi Ma. Since he is
not around any more, it's up to us to adapt status.html if needed.
Stefan |
|
15 Sep 2023, Stefan Ritt, Forum, Hide start and stop buttons
|
> I believe the original "hide run start / stop" was added specifically for ND280 GSC MIDAS. I do not know
> why it was removed. "hide pause / resume" is still there. I will restore them. Hiding logger channel
> section should probably be automatic of there is no /logger/channels, I can check if it works and what
> happens if there is more than one logger channel. K.O.
Actually one thing is the functionality of the /Experiment/Start-Stop button in status.html, but the other is
the warning we get from mhttpd:
[mhttpd,ERROR] [mhttpd.cxx:1957:init_mhttpd_odb,ERROR] ODB "/Experiment/Start-Stop Buttons" is obsolete, please
delete it.
This was added by KO on Nov. 29, 2019 (commit 2366eefc). So we have to decide re-enable this feature (and
remove the warning above), or keep it dropped and work on changes of status.hmtl.
Stefan |
|
14 Sep 2023, Nick Hastings, Forum, Hide start and stop buttons
|
Hi
> > > Indeed the ODB settings are obsolete.
> >
> > I just applied for an account for the wiki.
> > I'll try add a note regarding this change.
>
> Please coordinate with Ben Smith at TRIUMF <bsmith@triumf.ca>, who coordinates the documentation.
I will tread lightly.
> I would not go to change the CSS file. You only can hide some tables. But in a while I'm sure you
> want to ADD new things, which you only can do by editing the status.html file. You don't have to
> change midas/resources/status.html, but can make your own "custom status", name it differently, and
> link /Custom/Default in the ODB to it. This way it does not get overwritten if you pull midas.
We have *many* custom pages. The submenus on the status page:
▸ FGD
▸ TPC
▸ TRIPt
hide custom pages with all sorts of good stuff.
> > The logging channels are easily removed with the css (see attachment), but it might be
> > nice if the string "Run Status" table title was also configurable by css. For this
> > slow control system I'd probably change it to something like "GSC Status". Again
> > this is a minor thing, I could trivially do this by copying the resources/status.html
> > to the experiment directory and editing it.
>
> See above. I agree that the status.html file is a bit complicated and not so easy to understand
> as the CSS file, but you can do much more by editing it.
I may end up doing this since the events and data columns do not provide particularly
useful information in this instance. But for now, the css route seems like a quick and
fairly clean way to remove irrelevant stuff from a prominent place at the top of the page.
> > Lots of fun new stuff migrating from circa 2012 midas to midas-2022-05-c :-)
>
> I always advise people to frequently pull, they benefit from the newest features and avoid the
> huge amount of work to migrate from a 10 year old version.
The long delay was not my choice. The group responsible for the system departed in 2018, and
and were not replaced by the experiment management. Lack of personnel/expertise resulted in
a "if it's not broken then don't fix it" situation. Eventually, the need to update the PCs/OSs
and the imminent introduction of new sub-detectors resulted people agreeing to the update.
Cheers,
Nick. |
|
12 Sep 2023, Maia Henriksson-Ward, Suggestion, Syntax highlighting for sequencer scripts
|
Recently I was trying to read sequencer scripts written by a previous student, and realized it would be easier to
quickly read/skim sequencer code with some form of syntax highlighting. I've been using Visual Studio Code as my
editor, so I made myself an extension for VS Code that provides basic syntax highlighting (with help from
ChatGPT-3.5). It's good enough for my purposes, but is missing some features you'd expect for full language
support. This got me wondering - does anything like this already exist, perhaps with more complete support?
If it doesn't already exist, and if there is interest, I could to publish mine
to vscode's "Extension Marketplace" for easy installations (I'd also welcome contributions for
more features). For now, I've installed it on my computer directly from the .vsix file, which I've put on my own
github at https://github.com/maia-hw/midas-sequencer-support . There is also a readme with screenshot showing what scripts
will look like with the highlighting |
|
12 Sep 2023, Stefan Ritt, Suggestion, Syntax highlighting for sequencer scripts
|
I like the idea of syntax highlighting, but your solution is just for one editor which not everybody
is using. It would be better if the editor built into mhttpd for MSL files would have the possibility.
I looked at highlighting in an HTML <textarea> tag, and found that we can do it with a
<div contenteditable="true" style="font-family: monospace"> ... </div>
tag where we can change the color of individual words. If you translate your existing rules of syntax
highlighting into JavaScript, I'm happy to put that into the mhttpd sequencer editor. So I would need
a function which receives a MSL text, then replaces all keywords with some color tagging, like
ODBSET -> <span style="color:red">ODBSET</span>
Best,
Stefan |
|
01 Jun 2023, Thomas Lindner, Info, MIDAS Workshop 2023
|
Dear MIDAS users,
We would like to arrange another MIDAS workshop, following on from previous successful workshops in 2015, 2017 and 2019. The
goals of the workshop would include:
- Getting updates from MIDAS developers on new features and other changes.
- Getting reports from MIDAS users on how they are using MIDAS, what is working and what is not
- Making plans for future MIDAS changes and improvements
This would be a one-day virtual workshop, planned for about 4 hours length. The workshop will probably be after another of
Stefan's visits to TRIUMF.
If you would be interested in participating in such a workshop, please help us choose the date by filling out this doodle poll:
https://doodle.com/meeting/organize/id/dBPVMQJa
Please fill in the poll by June 9, if you are interested. We will announce the date soon after that.
Thanks,
Thomas |
|
13 Jun 2023, Thomas Lindner, Info, MIDAS Workshop 2023 - Sept 13
|
Hi All,
Thanks to everyone who filled out the doodle poll.
Based on the results we will plan to have this workshop on September 13, at 9AM-1PM (Vancouver) / 6PM-10PM (Geneva). Apologies to
those for whom this is a bad time/day; in particular for MIDAS users in Asia.
If you would like to present a report at the workshop on your experiment's MIDAS experience, then please email me (lindner@triumf.ca).
It would be great to know this in advance so that we can start preparing an agenda. Feel free to also email me if there are topics
that you would like addressed at the workshop.
Thanks,
Thomas
> Dear MIDAS users,
>
> We would like to arrange another MIDAS workshop, following on from previous successful workshops in 2015, 2017 and 2019. The
> goals of the workshop would include:
>
> - Getting updates from MIDAS developers on new features and other changes.
> - Getting reports from MIDAS users on how they are using MIDAS, what is working and what is not
> - Making plans for future MIDAS changes and improvements
>
> This would be a one-day virtual workshop, planned for about 4 hours length. The workshop will probably be after another of
> Stefan's visits to TRIUMF.
>
> If you would be interested in participating in such a workshop, please help us choose the date by filling out this doodle poll:
>
> https://doodle.com/meeting/organize/id/dBPVMQJa
>
> Please fill in the poll by June 9, if you are interested. We will announce the date soon after that.
>
> Thanks,
> Thomas |
|
17 Aug 2023, Thomas Lindner, Info, MIDAS Workshop 2023 - Sept 12-13
|
Dear All,
A quick update on the MIDAS workshop. Based on the number of planned talks we have made the decision to switch to a two day workshop on Sept 12 and 13
(rather than just Sept 13). We decided 4 hours was not enough time to hear all the reports and have fruitful discussions; having a much longer meeting
on a single day was a bad idea given the time zones involved.
We have a tentative agenda planned for the workshop, which you can see here:
https://indico.psi.ch/event/15025/timetable/
We are still confirming some talks, so the agenda may still change a bit. But the baseline plan will be that the workshop will be
8:30AM-12:30PM (PDT) / 5:30PM-9:30PM (CEST)
on Sept 12-13. We hope that these times still work for everyone planning to attend.
Cheers,
Thomas
> Hi All,
>
> Thanks to everyone who filled out the doodle poll.
>
> Based on the results we will plan to have this workshop on September 13, at 9AM-1PM (Vancouver) / 6PM-10PM (Geneva). Apologies to
> those for whom this is a bad time/day; in particular for MIDAS users in Asia.
>
> If you would like to present a report at the workshop on your experiment's MIDAS experience, then please email me (lindner@triumf.ca).
> It would be great to know this in advance so that we can start preparing an agenda. Feel free to also email me if there are topics
> that you would like addressed at the workshop.
>
> Thanks,
> Thomas
>
>
> > Dear MIDAS users,
> >
> > We would like to arrange another MIDAS workshop, following on from previous successful workshops in 2015, 2017 and 2019. The
> > goals of the workshop would include:
> >
> > - Getting updates from MIDAS developers on new features and other changes.
> > - Getting reports from MIDAS users on how they are using MIDAS, what is working and what is not
> > - Making plans for future MIDAS changes and improvements
> >
> > This would be a one-day virtual workshop, planned for about 4 hours length. The workshop will probably be after another of
> > Stefan's visits to TRIUMF.
> >
> > If you would be interested in participating in such a workshop, please help us choose the date by filling out this doodle poll:
> >
> > https://doodle.com/meeting/organize/id/dBPVMQJa
> >
> > Please fill in the poll by June 9, if you are interested. We will announce the date soon after that.
> >
> > Thanks,
> > Thomas |
|
06 Sep 2023, Thomas Lindner, Info, MIDAS Workshop 2023 - Sept 12-13
|
Dear All,
A final reminder about the MIDAS workshop in 6 days. A (hopefully) finalized agenda is posted here:
https://indico.psi.ch/event/15025/timetable/
In the overview section of the indico page you will find the zoom link for the workshop.
We plan for the workshop to have a lot of time for discussion. This means that the exact schedule of the workshop is a little uncertain; hence the actual start
time of each talk will also have some uncertainty. We have scheduled that each day's session will be around 3.5 hours, but it is possible that the sessions will
be a little longer in reality. Stefan and Pierre will try to ensure that we stay roughly on schedule.
Looking forward to seeing people there.
Cheers,
Thomas
> Dear All,
>
> A quick update on the MIDAS workshop. Based on the number of planned talks we have made the decision to switch to a two day workshop on Sept 12 and 13
> (rather than just Sept 13). We decided 4 hours was not enough time to hear all the reports and have fruitful discussions; having a much longer meeting
> on a single day was a bad idea given the time zones involved.
>
> We have a tentative agenda planned for the workshop, which you can see here:
>
> https://indico.psi.ch/event/15025/timetable/
>
> We are still confirming some talks, so the agenda may still change a bit. But the baseline plan will be that the workshop will be
>
> 8:30AM-12:30PM (PDT) / 5:30PM-9:30PM (CEST)
>
> on Sept 12-13. We hope that these times still work for everyone planning to attend.
>
> Cheers,
> Thomas
>
>
> > Hi All,
> >
> > Thanks to everyone who filled out the doodle poll.
> >
> > Based on the results we will plan to have this workshop on September 13, at 9AM-1PM (Vancouver) / 6PM-10PM (Geneva). Apologies to
> > those for whom this is a bad time/day; in particular for MIDAS users in Asia.
> >
> > If you would like to present a report at the workshop on your experiment's MIDAS experience, then please email me (lindner@triumf.ca).
> > It would be great to know this in advance so that we can start preparing an agenda. Feel free to also email me if there are topics
> > that you would like addressed at the workshop.
> >
> > Thanks,
> > Thomas
> >
> >
> > > Dear MIDAS users,
> > >
> > > We would like to arrange another MIDAS workshop, following on from previous successful workshops in 2015, 2017 and 2019. The
> > > goals of the workshop would include:
> > >
> > > - Getting updates from MIDAS developers on new features and other changes.
> > > - Getting reports from MIDAS users on how they are using MIDAS, what is working and what is not
> > > - Making plans for future MIDAS changes and improvements
> > >
> > > This would be a one-day virtual workshop, planned for about 4 hours length. The workshop will probably be after another of
> > > Stefan's visits to TRIUMF.
> > >
> > > If you would be interested in participating in such a workshop, please help us choose the date by filling out this doodle poll:
> > >
> > > https://doodle.com/meeting/organize/id/dBPVMQJa
> > >
> > > Please fill in the poll by June 9, if you are interested. We will announce the date soon after that.
> > >
> > > Thanks,
> > > Thomas |
|
16 May 2023, Konstantin Olchanski, Bug Report, excessive logging of http requests
|
Our default configuration of apache httpd logs every request. MIDAS custom web pages can easily make a huge number of RPC calls creating a
huge log file and filling system disk to 100% capacity
this example has around 100 RPC requests per second. reasonable/unreasonable? available hardware can handle it (web browser, network
httpd, mhttpd, etc), so we should try to get this to work. perhaps filter the apache httpd logs to exclude mjsonrpc requests? of course we
can ask the affected experiment why they make so many RPC calls, is there a bug?
[14/May/2023:03:49:01 -0700] 142.90.111.176 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 "POST /?mjsonrpc HTTP/1.1" 299
[14/May/2023:03:49:01 -0700] 142.90.111.176 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 "POST /?mjsonrpc HTTP/1.1" 299
[14/May/2023:03:49:01 -0700] 142.90.111.176 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 "POST /?mjsonrpc HTTP/1.1" 299
[14/May/2023:03:49:01 -0700] 142.90.111.176 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 "POST /?mjsonrpc HTTP/1.1" 299
[14/May/2023:03:49:01 -0700] 142.90.111.176 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 "POST /?mjsonrpc HTTP/1.1" 299
K.O. |
|
16 May 2023, Konstantin Olchanski, Bug Report, excessive logging of http requests
|
> Our default configuration of apache httpd logs every request. MIDAS custom web pages can easily make a huge number of RPC calls creating a
> huge log file and filling system disk to 100% capacity
perhaps use existing logrotate, add limit on file size (size) and limit of 2 old log files (rotate).
/etc/logrotate.d/httpd
/var/log/httpd/*log {
size 100M
rotate 2
missingok
notifempty
sharedscripts
delaycompress
postrotate
/bin/systemctl reload httpd.service > /dev/null 2>/dev/null || true
endscript
}
K.O. |
|
16 May 2023, Stefan Ritt, Bug Report, excessive logging of http requests
|
Maybe you remember the problems we had with a custom page in Japan loading it from TRIUMF. It took almost one minute since each RPC request took
about 1s round-trip. This got fixed by the modb* scheme where the framework actually collects all ODB variables in a custom page and puts them
into ONE rpc request (making the path an actual array of paths). That reduced the requests from 100 to 1 in the above example. Maybe the same
could be done in your current case. Pulling one ODB variable at a time is not very efficient.
Stefan |
|
02 Aug 2023, Konstantin Olchanski, Bug Report, excessive logging of http requests
|
> > Our default configuration of apache httpd logs every request. MIDAS custom web pages can easily make a huge number of RPC calls creating a
> > huge log file and filling system disk to 100% capacity
> perhaps use existing logrotate, add limit on file size (size) and limit of 2 old log files (rotate).
logrotate was ineffective.
following apache httpd config seems to disable logging of mjsonrpc requests. note that we cannot filter on the "mjsonrpc" string because
Request_URI excludes the query string (ouch!).
#SetEnvIf Request_URI "^POST /?mjsonrpc.*" nolog
SetEnvIf Request_Method "POST" envpost
SetEnvIf Request_URI "^\/$" envuri
SetEnvIfExpr "-T reqenv('envpost') && -T reqenv('envuri')" envnolog
CustomLog logs/ssl_request_log "%t %h %{SSL_PROTOCOL}x %{SSL_CIPHER}x \"%r\" %b" env=!envnolog
K.O. |
|
03 Aug 2023, Konstantin Olchanski, Bug Report, excessive logging of http requests
|
> > > Our default configuration of apache httpd logs every request. MIDAS custom web pages can easily make a huge number of RPC calls creating a
> > > huge log file and filling system disk to 100% capacity
> > perhaps use existing logrotate, add limit on file size (size) and limit of 2 old log files (rotate).
>
> CustomLog logs/ssl_request_log "%t %h %{SSL_PROTOCOL}x %{SSL_CIPHER}x \"%r\" %b" env=!envnolog
>
TransferLog is not conditional and has to be commented out to stop logging every jsonrpc request.
K.O. |
|
14 Aug 2023, Konstantin Olchanski, Bug Report, excessive logging of http requests
|
> Our default configuration of apache httpd logs every request.
> MIDAS custom web pages can easily make a huge number of RPC calls creating a
> huge log file and filling system disk to 100% capacity.
close but no cigar. mhttpd is not running and /var/log got filled to 100% capacity by http error messages. I do not see any apache facility to filter
error messages, hmm...
-rw-r--r-- 1 root root 1864421376 Aug 14 12:53 ssl_error_log
[Sun Aug 13 23:53:12.416247 2023] [proxy:error] [pid 18608] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.416538 2023] [proxy:error] [pid 19686] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.416603 2023] [proxy:error] [pid 19681] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.416775 2023] [proxy:error] [pid 19588] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.417022 2023] [proxy:error] [pid 19311] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.421864 2023] [proxy:error] [pid 18620] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.422051 2023] [proxy:error] [pid 19693] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.422199 2023] [proxy:error] [pid 19673] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.422222 2023] [proxy:error] [pid 18608] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.422230 2023] [proxy:error] [pid 19657] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.422259 2023] [proxy:error] [pid 18633] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.427513 2023] [proxy:error] [pid 19686] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.427549 2023] [proxy:error] [pid 19681] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.427645 2023] [proxy:error] [pid 19588] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.427774 2023] [proxy:error] [pid 19693] AH00940: HTTP: disabled connection for (localhost)
[Sun Aug 13 23:53:12.427800 2023] [proxy:error] [pid 18620] AH00940: HTTP: disabled connection for (localhost)
K.O. |
|
16 Aug 2023, Konstantin Olchanski, Bug Report, excessive logging of http requests
|
> > Our default configuration of apache httpd logs every request.
> > MIDAS custom web pages can easily make a huge number of RPC calls creating a
> > huge log file and filling system disk to 100% capacity.
added "daily" to /etc/logrotate.d/httpd, default was "weekly", not often enough.
K.O. |
|
17 Aug 2023, Konstantin Olchanski, Bug Report, excessive logging of http requests
|
> > > Our default configuration of apache httpd logs every request.
> > > MIDAS custom web pages can easily make a huge number of RPC calls creating a
> > > huge log file and filling system disk to 100% capacity.
> added "daily" to /etc/logrotate.d/httpd, default was "weekly", not often enough.
this should fix it good, make /var/log bigger:
[root@mpmt-test ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sdc2 52403200 52296356 106844 100% /
[root@mpmt-test ~]#
[root@mpmt-test ~]# xfs_growfs /
data blocks changed from 13107200 to 106367750
[root@mpmt-test ~]#
[root@mpmt-test ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sdc2 425445400 52300264 373145136 13% /
K.O. |
|
16 Aug 2023, Konstantin Olchanski, Bug Report, midas wants to show notification?
|
I started to get web browser popups about "midas wants to show notifications,
block/allow/x". is this a glitch or a new unannounced/undocumented feature?
google chrome on macos. K.O. |
|
16 Aug 2023, Stefan Ritt, Bug Report, midas wants to show notification?
|
> I started to get web browser popups about "midas wants to show notifications,
> block/allow/x". is this a glitch or a new unannounced/undocumented feature?
> google chrome on macos. K.O.
https://bitbucket.org/tmidas/midas/commits/e101dea764c647211c560a68db7ecda1834198db
I did not consider this a significant feature to be announced here. Just a few lines
of code. You can turn it on/off via the "Config" web page.
Stefan |
|
16 Aug 2023, Stefan Ritt, Bug Report, midas wants to show notification?
|
> > I started to get web browser popups about "midas wants to show notifications,
> > block/allow/x". is this a glitch or a new unannounced/undocumented feature?
> > google chrome on macos. K.O.
>
> https://bitbucket.org/tmidas/midas/commits/e101dea764c647211c560a68db7ecda1834198db
>
> I did not consider this a significant feature to be announced here. Just a few lines
> of code. You can turn it on/off via the "Config" web page.
>
> Stefan
Now as I look at it again I realized that the config check boxes had a bug. I fixed that
and now the disable should work correctly.
This feature was asked by some people who monitor an experiment and have the browser window
in the background, also have sound off (large office). So desktop notifications are a good
thing for them.
Stefan |
|
16 Aug 2023, Konstantin Olchanski, Bug Report, midas wants to show notification?
|
> This feature was asked by some people ...
"show notifications" popups are strongly associated with disreputable web sites (presumably to
push spam), it was surprising to see it from midas.
K.O. |
|
17 Aug 2023, Stefan Ritt, Bug Report, midas wants to show notification?
|
> > This feature was asked by some people ...
>
> "show notifications" popups are strongly associated with disreputable web sites (presumably to
> push spam), it was surprising to see it from midas.
>
> K.O.
I agree. But unlike emails (where you get lots of spam as well), you can nicely blacklist/whitelist
desktop notifications. I suppress all of them except the one for MIDAS. This allows me to watch our
experiment without staring on the web page all the time.
The main question here is maybe if the desktop notification should be on or off by default (for a
fresh browser). While you always can change that via the mhttpd "Config" page, the default value is
chosen by the system. I thought I put it to "on" so people can experience it, and then turn it off if
they don't like. Having them off by default, most people never would notice this possibility. But I'm
open to a discussion here.
Stefan |
|
15 Aug 2023, Konstantin Olchanski, Info, mlogger update
|
A bit of update to the mlogger. In preparation for more cleanup when Stefan is
here at TRIUMF.
1) fix overwrite of existing files if run number is reset (check for existing
files was missing in the LZ4, BZ2 & co data path)
2) made output files read-only (midas, json and checksum files)
3) commented out the old code paths
Currently active per-channel ODB settings:
Active - enable or disable mlogger channel
Type - NOT USED
Filename - output filename template, %d are replaced by run number and subrun
number, also pipe command for PIPE output
Format - NOT USED
Compression - NOT USED
ODB dump - enable/disable writing ODB dump to data file
ODB dump format - "json" is recommended for new experiments
Log messages - write log messages to output file, 0=off, -1=write all messages
Buffer - "SYSTEM" read events from this event buffer
EventID - "-1" for all events
Trigger Mask - "-1" for all events
Event Limit - stop run after so many events
Byte Limit - stop run after so many bytes
Subrun Byte limit - switch to next subrun file after writing so many bytes.
actual file size is longer than subrun_byte_limit because of ODB dumps.
Tape Capacity - NOT USED
Subdir Format - if not empty, output file name is DIR/SUBDIR/FILENAME, "%"
format things are expanded by strftime().
Current Filename - updated by mlogger, contains the currently written file name
Data checksum - checksum before compression, use CRC32C for maximum speed,
SHA512 for maximum security.
File checksum - checksum after compression, CRC32C is good against accidental
file corruption, SHA512 is cryptographically strong, good against purposeful
tampering.
Compress - use "lz4" for maximum speed, bzip2 or pbzip2 for maximum compression.
no compression and gzip are not recommended. (ZFS may apply lz4 compression to
uncompressed data).
Output - "NULL" do not write anything, "FILE" write to disk, "FTP" write to FTP
server, "ROOT" write via the mlogger ROOT writer (docs?), "PIPE" pipe data
through an external command (i.e. for bzip2 compression).
Gzip compression - gzip compression flags (see gzip docs, 1=max speed, 9=max
compression)
Bzip2 compression - if non-zero, bzip2 compression level (see "bzip2 -h", 1=max
speed, 9=max compression)
Pbzip2 num cpu - number of CPUs used by parallel bzip2 compression, pbzip2 -p
flag
Pbzip2 compression - if non-zero, pbzip2 compresison level (see "pbzip2 -h",
default is 9=max compression)
Pbzip2 options - any additional pbzip2 options, i.e. -l, -m, -p, etc.
Currently active /Logger options:
Data Dir - where to write all output files, if empty, cm_get_path() is used.
Message file date format - not used in mlogger
Message dir - not used in mlogger
Write data - if set to "no", midas file, runlog, etc will not be written.
ODB Dump - at run stop, save odb to disk
ODB Dump File - file name for "ODB Dump" save file. "%d" is replaced by run
number. "json" format is recommended for new experiments.
ODB Last Dump File - at run start, save ODB to disk. "json" format is
recommended for new experiments.
Auto restart - run stopped by time limit or event limit is automatically
restarted
Auto restart delay - wair for some many seconds before restarting the run
Tape message - NOT USED
Run duration - stop the run after so many seconds
Next subrun - change from "no" to "yes" to force mlogger to open a new subrun
file (should this be per-channel?)
Subrun duration - open new subrun file after so many seconds (should this be
per-channel?)
History dir - not used in mlogger
Detached transition - "no" use the normal multithreaded transtions
(recommended), "yes" use mtransition helper to stop and restart runs. sometimes
files because mtransition is not in the user $PATH or wrong version of
mtransition is in the user $PATH.
K.O. |
|
09 Aug 2023, Konstantin Olchanski, Bug Fix, Stefan's improved ODB flush to disk
|
This is an important improvement, should have a post of it's own. K.O.
> > > RFE filed:
> > > https://bitbucket.org/tmidas/midas/issues/367/odb-should-be-saved-to-disk-
periodically
> >
> > Implemented and closed: https://bitbucket.org/tmidas/midas/issues/367/odb-
should-be-saved-to-disk-periodically
> >
> > Stefan
>
> Stefan's comments from the closed bug report:
>
> Ok I implemented some periodic flushing. Here is what I did:
>
> Created
>
> /System/Flush/Flush period : TID_UINT32 /System/Flush/Last flush : TID_UINT32
>
> which control the flushing to disk. The default value for �Flush period� is 60
seconds or one minute.
>
> All clients call db_flush_database() through their cm_yield() function
> db_flush_database() checks the �Last flush� and only flushes the ODB when the
period has expired. This test is
> done inside the ODB semaphore so that we don�t get a race condigiton
> If the period has expired, db_flush_database() calls ss_shm_flush()
> ss_shm_flush() tries to allocate a buffer of the shared memory. If the
allocation is not successful (out of
> memory), ss_shm_flush() writes directly to the binary file as before.
> If the allocation is successful, ss_shm_flush() copies the share memory to a
buffer and passes this buffer to a
> dedicated thread which writes the buffer to the binary file. This causes
ss_shm_flush() to return immediately and
> not block the calling program during the disk write operation.
> Added back the �if (destroy_flag) ss_shm_flush()� so that the ODB is flushed
for sure before the shared memory
> gets deleted.
> This means now that under normal circumstances, exiting programs like odbedit
do NOT flush the ODB. This allows to
> call many �odbedit -c� in a row without the flush penalty. Nevertheless, the
ODB then gets flushed by other
> clients latest 60 seconds (or whatever the flush period is) after odbedit
exits.
>
> Please note that ODB flushing has two purposes:
>
> When all programs exit, we need a persistent storage for the ODB. In most
experiments this only happens very
> seldom. Maybe at the end of a beam time period.
> If the computer crashes, a recent version of the ODB is kept on disk to
simplify recovery after the crash.
> Since crashes are not so often (during production periods we have maybe one
hardware failure every few years) the
> flushing of the ODB too often does not make sense and just consumes resources.
Flushing does also not help from
> corrupted ODBs, since the binary image will also get corrupted. So the only
reason for periodic flushes is to ease
> recovery after a total crash. I put the default to 60 seconds, but if people
are really paranoid they can decrease
> it to 10 seconds or so. Or increase it to 600 seconds if their system does not
crash every week and disks are
> slow.
>
> I made a dedicated branch feature/periodic_odb_flush so people can test the
new functionality. If there are no
> complaints within the next few days, I will merge that into develop.
>
> Stefan |
|
01 Apr 2022, Stefan Ritt, Suggestion, Maximum ODB size
|
Anybody some idea what the maximum ODB size can be? In the old days, the linux
kernels had a severe limit on shared memory of usually 8MB, but in the age of
64GB RAM being a standard, we should be able to grow bigger. Tried
odbinit -s 1024MB --cleanup
which went through without complain, even put that value in to .ODB_SIZE.TXT, but
when I started odbedit doing "mem", I only see a size of 1MB. Probably somewhere
deep inside we have a limit which prevents the user to create very large ODBs,
but this should be mentioned more prominently in odbinit. Like "size too large,
maximum allowd is xxx MB".
Stefan |
|
04 Apr 2022, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> Anybody some idea what the maximum ODB size can be?
It turns out ODB size limit is hardwired on db_open_database() at 100 Mbytes.
I now committed an improved error message for this.
I confirm that "odbinit -s 100MB" works and creates ODB with 50 Mbyte data area and 50
Mbyte key area.
> in the age of 64GB RAM being a standard, we should be able to grow bigger ...
I agree, I think we can safely bump the limit from 100 Mbytes to 1 Gbyte, maybe 1.5 or
1.99 Gbytes. Above that we run into 32-bit/31-bit cleanliness problems.
And creating extra large 1 GB ODB but using only a few megabytes will not waste any
RAM, because the .ODB.SHM file is demand-paged and non-used parts of ODB will not be
mapped into RAM. (It will waste disk space, file .ODB.SHM will be 1 GByte size).
However, 1 GByte (FPGA based) and 4-8 GByte (Raspberry Pi & co) machines are again
becoming popular and relevant for running MIDAS, and they have very slow "disk"
subsystems, with NAND, SD and USB flash, so we should not go crazy here.
> odbinit -s 1024MB --cleanup
there is a bug in odbinit, if initial odbinit fails, ODB with default size is creates,
and original rejected ODB size is written to .ODB_SIZE.TXT (an inconsistency).
bitbucket bug 328
> [ how do I resize ODB ??? ]
we need odbresize. bitbucket bug 329.
K.O. |
|
27 Apr 2023, Marius Koeppel, Suggestion, Maximum ODB size
|
Hi all,
> I agree, I think we can safely bump the limit from 100 Mbytes to 1 Gbyte, maybe 1.5 or
> 1.99 Gbytes. Above that we run into 32-bit/31-bit cleanliness problems.
We just went in and changed: int odb_size_limit = INT_MAX;//100*1000*1000; in odb.cxx. And we could create ODBs with 1GB and 1.5 GB.
Since the DecodeSize function in odbinit has also foreseen yottabytes ;) (const char units[] = {'k', 'M', 'G', 'T', 'P', 'E', 'Z', 'Y'};) we think going to GB for the maximum ODB size would be create.
> there is a bug in odbinit, if initial odbinit fails, ODB with default size is creates,
> and original rejected ODB size is written to .ODB_SIZE.TXT (an inconsistency).
Can#t we go with the maximum size here if the user inputs a larger size? So just below printf("Checking ODB size...\n"); one could check for the odb_size_limit. In general one could move the odb_size_limit to midas.h so its not only available in odb.cxx.
Best,
Marius |
|
27 Apr 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > I agree, I think we can safely bump the limit from 100 Mbytes to 1 Gbyte, maybe 1.5 or
> > 1.99 Gbytes. Above that we run into 32-bit/31-bit cleanliness problems.
>
> We just went in and changed: int odb_size_limit = INT_MAX;//100*1000*1000; in odb.cxx.
>
This is change is wrong. As I wrote, ODB is not 64-bit clean and it is not 32-bit clean. We think is is 31-bit clean, so maximum size would be slightly less than 2 Gbytes.
> And we could create ODBs with 1GB and 1.5 GB.
Congratulations. created != "it works". for proper test, you should fill it with 1.5 GB of stuff, save to json file, reload from json file, save to a different json file and compare that they have same contents (minus timestamps).
We could spend a lot of time making odb 32-bit clean and give you 4GB-max ODB, but would it be useful? For large ODB, "save to .json" already takes a long time ("save to .xml" is slower, "save to .odb" ditto, also buggy). We already have complaints that runs take forever to start because mlogger
takes a long time to write the ODB save file.
P.S. 64-bit clean ODB will be binary incompatible, all internal pointers are 32-bit right now.
K.O. |
|
27 Apr 2023, Marius Koeppel, Suggestion, Maximum ODB size
|
> This is change is wrong. As I wrote, ODB is not 64-bit clean and it is not 32-bit clean. We think is is 31-bit clean, so maximum size would be slightly less than 2 Gbytes.
I just wanted to show that changing it and creating bigger ODBs is in general possible.
My main intention was to trigger the discussion again. I also think in general 1GB is enough. But for our applications sometimes 100MB is just on the edge.
> Congratulations. created != "it works". for proper test, you should fill it with 1.5 GB of stuff, save to json file, reload from json file, save to a different json file and compare that they have same contents (minus timestamps).
You�re right we did not properly test it. I will run this test with a 1GB ODB.
> We could spend a lot of time making odb 32-bit clean and give you 4GB-max ODB, but would it be useful? For large ODB, "save to .json" already takes a long time ("save to .xml" is slower, "save to .odb" ditto, also buggy). We already have complaints that runs take forever to start because mlogger
> takes a long time to write the ODB save file.
I also agree that going in and making it 32-bit or even 64-bit clean is not worth the effort.
Also concerning the writing speed of the logger etc I am fully with you.
However, having the freedom to choose a bit bigger ODB would be great.
You said the writing into .odb is buggy. Do you mean it�s buggy in general or only in this specific case?
We save the ODB most of the time in the .odb format.
Cheers,
Marius |
|
27 Apr 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> You said the writing into .odb is buggy. Do you mean it�s buggy in general or only in this specific case?
> We save the ODB most of the time in the .odb format.
I recommend JSON. Main advantage is you can read it using JSON decoder available for any language, no need to write custom code.
Other than that, the main issue is encoding of strings. For ODB this is key names and string values.
JSON was the first to standardize escape characters what can encode all valid UTF-8 UNICODE strings,
the system of escape characters is clean, easy to understand and easy to implement. https://www.json.org/json-en.html
XML is not as well defined as JSON, i.e. go and try to find the XML BNF grammar. I am not sure if the MIDAS XML encoder
and decoder is fully UTF-8 clean, and if some unlucky combinations of characters break string encoding or decoding. This
is usually tested using a fuzzer (generates all possible, unlucky and unlikely string values). Most suspicious
would be quotes, and square and angle brackets. If some character combinations break encoding or decoding, likely
this cannot be fixed in MIDAS without breaking backwards self-compatibility (will not read old ODB files correctly).
Same applies for the ODB format, except that it is even more ad-hoc. Again, any problems are hard to fix without
breaking backward self-compatibility.
In addition, in the past, the ODB and XML decoders had trouble with very long strings, this has been
fixed some time ago.
K.O. |
|
27 Apr 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
my vote is to bump the ODB size limit to 1999*1000*1000 (not quite 2GB). but this needs to be tested. especially save and restore from ODB, XML and JSON files, including how long it takes to save and load a 1.9GB ODB. K.O. |
|
28 Apr 2023, Marius Koeppel, Suggestion, Maximum ODB size
|
> my vote is to bump the ODB size limit to 1999*1000*1000 (not quite 2GB). but this needs to be tested. especially save and restore from ODB, XML and JSON files, including how long it takes to save and load a 1.9GB ODB. K.O.
I had some fun with python and created a test script which can be executed in the MIDASSYS/online folder (test_odb.py). I did not really normalize the time so it will be different at different systems but I guess the trend is important (see create_time.pdf).
What is surprising to me is that even that I only write one STRING key to the time increases. Is this maybe related to what Stefan said about the run start - so that odbedit needs some time to load the bigger ODB?
Second thing is that also the creation / storing and load time is increasing. Should this be or is there a bug in the code I use or again is this related to the previous point?
The test of comparing the ODB after store / load / store already fails for the json format. I know I only test if the dicts are the same, so for timestamps this already fails.
But what is strange here is that sometimes the test works sometimes not and its different from run to run.
I will try to improve the test a bit more but for a short update this is how it looks so fare.
Best,
Marius |
|
28 Apr 2023, Stefan Ritt, Suggestion, Maximum ODB size
|
> Is this maybe related to what Stefan said about the run start - so that odbedit needs some time to load the bigger ODB?
At the run start mlogger writes the ODB to the .mid file. This needs conversion (binary ODB -> XML ASCII) which can take time.
This does NOT depend on the ODB size, but on the ODB *content*. Every key in the ODB takes time to convert. So if your ODB as 1.5 GB
but only a few keys, this is still fast. Only if you have 200 million keys int he ODB, then mlogger takes lots of time to convert
200 million values to XML or JSON strings.
Stefan |
|
28 Apr 2023, Marius Koeppel, Suggestion, Maximum ODB size
|
> At the run start mlogger writes the ODB to the .mid file. This needs conversion (binary ODB -> XML ASCII) which can take time.
> This does NOT depend on the ODB size, but on the ODB *content*. Every key in the ODB takes time to convert. So if your ODB as 1.5 GB
> but only a few keys, this is still fast. Only if you have 200 million keys int he ODB, then mlogger takes lots of time to convert
> 200 million values to XML or JSON strings.
This was also my assumption. Is this the same for odbedit -c save FILE?
Because this is what I tested with the script and there one can see in the plot that the time increases to write the file if the ODB size increases.
The content of the ODB is always the same - one STRING key in the directory Test.
Best,
Marius |
|
28 Apr 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > Is this maybe related to what Stefan said about the run start - so that odbedit needs some time to load the bigger ODB?
>
> At the run start mlogger writes the ODB to the .mid file. This needs conversion (binary ODB -> XML ASCII) which can take time.
> This does NOT depend on the ODB size, but on the ODB *content*.
>
Yes and no. They must be storing more than 100 Mbytes of stuff in ODB, if they are asking to bump ODB size from 100 Mbyte to 2 GByte ODB.
On the MIDAS, side, though, we have to plan for the worst case, if max ODB size 1.9 GB and it is full of data,
and mlogger (and odbedit save and load) take 10-30 seconds, then at least all timeouts (watchdog timeout, RPC timeout, etc)
must be increased accordingly.
K.O. |
|
27 Apr 2023, Stefan Ritt, Suggestion, Maximum ODB size
|
> Congratulations. created != "it works".
Two other tings to consider:
1) The ODB shared memory is dumped into a binary file (".ODB.SHM") after the last client finished and read if the first client starts, to get it persistent.
So this could slow down starting and stopping, but only the first client, so I guess it's not an issue.
2) Traditionally, the ODB gets dumped to the .mid file at the beginning and end of every run, so that one know the exact configuration of the experiment
for offline analysis. This can be turned off of course, but most experiments use it. If the ODB is dumped in any ASCII format, this can take quite long.
Assume it takes 10 seconds at the beginning of each run, and we take a run every five minutes. Then we loose 48 mins of precious beam time every day.
Best,
Stefan |
|
28 Apr 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > Congratulations. created != "it works".
>
> Two other tings to consider:
>
> 1) The ODB shared memory is dumped into a binary file (".ODB.SHM") after the last client finished and read if the first client starts, to get it persistent.
> So this could slow down starting and stopping, but only the first client, so I guess it's not an issue.
>
typical disk writing speed is 100-1000 Mbytes/sec, so writing 1 GB .ODB.SHM will take 1-10 seconds. NFS over 1gige network is 100 Mbytes/sec, so 10 seconds to
write .ODB.SHM. embedded ARM write speed to SD flash can be as low as 10 Mbytes/sec, so up to 100 seconds.
>
> 2) Traditionally, the ODB gets dumped to the .mid file at the beginning and end of every run, so that one know the exact configuration of the experiment
> for offline analysis. This can be turned off of course, but most experiments use it. If the ODB is dumped in any ASCII format, this can take quite long.
> Assume it takes 10 seconds at the beginning of each run, and we take a run every five minutes. Then we loose 48 mins of precious beam time every day.
>
new default is to save as JSON, (as of my last measurement) JSON encoder is faster than the XML (and ODB?) encoder, by default result is compressed by GZIP-1 (66
Mbytes/sec is my old benchmark, should remeasure on new DDR5 machines), compressed JSON is written .mid.gz file at disk speed (as above). Alternatively, use LZ4
compression, runs roughly at memcpy() speed, less compression, written to .mid.lz4 at disk speed.
if data storage is ZFS, ZFS built-in LZ4 compression is now enabled by default, so result writing uncompressed .mid file (no compression of ODB dump), should be
roughly same as when using MIDAS LZ4 compression and writing .mid.lz4.
bottom line, I need to remeasure gzip and lz4 compression speeds on new computers (DDR4 AMD 5000 series and DDR5 AMD 7000 series).
K.O. |
|
09 Jun 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > 1) The ODB shared memory is dumped into a binary file (".ODB.SHM") after the last client finished ...
correction: ODB shared memory is saved to .ODB.SHM each time a client stops, this is db_close_database().
I have just run into a problem with this in the DRAGON experiment. At begin and end of run they run
a script that does a large number of "odbedit" calls to read stuff from ODB and it was taking a very long time.
Each odbedit invocation was taking about 1 second, starting odbedit is quick, stopping odbedit takes about 1 second.
It turns out each invocation of odbedit saves .ODB.SHM, ODB was 100 Mbytes size, home disk is an HDD (~100-200 Mbytes/sec writing speed), so yes, about 1 second to
stop odbedit.
Solution was to reduce ODB size from 100 Mbytes to 10 Mbytes, odbedit now run quickly, begin and end of run scripts run quickly. problem solved.
K.O.
P.S. no, I am not the dragon experiment, no, I did not write those scripts, no, I will not rewrite them, persons who wrote them are long gone, no, the persons running
dragon today will not be rewriting them. |
|
12 Jun 2023, Stefan Ritt, Suggestion, Maximum ODB size
|
> correction: ODB shared memory is saved to .ODB.SHM each time a client stops, this is db_close_database().
The original design of the midas shared memory (back in the 1990's) was that the ODB shared memory file gets
only saved into the .ODB.SHM when the *last* client exits. This ensures to keep the ODB persistent when the
shared memory gets deleted. I vaguely remember I put something in like:
db_close_database()
...
destroy_flag = (pheader->num_clients == 0);
if (destroy_flag)
ss_shm_flush(pheader->name, pdb->shm_adr, pdb->shm_size, pdb->shm_handle);
...
Now I see that the "if (destory_flag)" is missing. Not sure if it was removed once, or if it actually never
was there. But I see no point in flushing the ODB when a client ends. We need the flushing only before the
shared memory gets deleted. We we have to ensure that the share memory and the binary dump file stay in sync
(like if all midas clients die at the same time), we could add some code to flush the ODB like once per minute,
but not attach it to db_close_database(). I know several experiments using "odbedit -c xxx" in vast quantities,
so all these experiments would then benefit.
Note: Mu3e at PSI also uses 100 MB ODB, and they really need it.
Thoughts and opinions?
Best,
Stefan |
|
12 Jun 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > correction: ODB shared memory is saved to .ODB.SHM each time a client stops, this is db_close_database().
>
> The original design of the midas shared memory (back in the 1990's) was that the ODB shared memory file gets
> only saved into the .ODB.SHM when the *last* client exits. This ensures to keep the ODB persistent when the
> shared memory gets deleted. I vaguely remember I put something in like:
>
> db_close_database()
> ...
> destroy_flag = (pheader->num_clients == 0);
>
> if (destroy_flag)
> ss_shm_flush(pheader->name, pdb->shm_adr, pdb->shm_size, pdb->shm_handle);
I remember the same, but I tracked it down in git to the very first commit, and there is no if() there,
odb is saved to .ODB.SHM on every client shutdown, not just the last client. I guess we both misremebered.
What's more, ss_shm_flush() is done while holding the ODB semaphore, so all other midas programs that try to access
odb at the same time (including the mserver) will stall until write() and close() return. at least we do not fsync(),
and there is no waiting until data is committed to physical media.
$ git annotate 3bb04af4d^ src/odb.c
...
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 875) destroy_flag = (pheader->num_clients == 0);
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 876)
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 877) /* flush shared memory to disk */
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 878) ss_flush_shm(pheader->name, pheader, sizeof(DATABASE_HEADER)+2*pheader->data_size);
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 879)
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 880) /* unmap shared memory, delete it if we are the last */
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 881) ss_close_shm(pheader->name, pheader,
ef8320177 (Stefan Ritt 1998-10-08 13:46:02 +0000 882) _database[hDB-1].shm_handle, destroy_flag);
...
K.O. |
|
13 Jun 2023, Stefan Ritt, Suggestion, Maximum ODB size
|
> I remember the same, but I tracked it down in git to the very first commit, and there is no if() there,
> odb is saved to .ODB.SHM on every client shutdown, not just the last client. I guess we both misremebered.
I confirm. Really strange how your mind can trick you. I'm absolutely sure I had this planned originally (1995?), but it got never implemented.
Well, never too late. So I added the "if" and committed to develop. I did a quick test and things seem to work fine here. Actually programs stop
a bit faster now. So please everybody give it a try and report back here.
BTW, how do I resize the ODB. I remember we discussed this some time ago, and concluded that odbedit needs a resize flag. Has this even been
done? If not, what is the "official" way to resize the ODB. We had some documentation about that some time ago, but I can't find it anymore.
Stefan |
|
13 Jun 2023, Marius Koeppel, Suggestion, Maximum ODB size
|
> BTW, how do I resize the ODB. I remember we discussed this some time ago, and concluded that odbedit needs a resize flag. Has this even been
> done? If not, what is the "official" way to resize the ODB. We had some documentation about that some time ago, but I can't find it anymore.
I guess this is still not done and the issue is still open: https://bitbucket.org/tmidas/midas/issues/329/need-odbresize
I guess if we touch this maybe the problem with the wrong size should be also fixed: https://bitbucket.org/tmidas/midas/issues/328/odbinit-s-1024mb-creates-odb-with-wrong
Best,
Marius |
|
13 Jun 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > BTW, how do I resize the ODB.
ODB cannot be resized "online". Everything has to stop, save content to odb.json, get rid of old ODB.SHM, ensure ODB shared memory is destroyed (SysV or POSIX shared memory),
create new ODB with new size, load odb.json. Feel free to punch this into chatgpt > odbresize.cxx, commit, test, push.
> I remember we discussed this some time ago, and concluded that odbedit needs a resize flag.
ODB cannot be resized online. ODB API has ODB clients holding ODB handles which are pointers (offsets) into ODB shared memory.
> Has this even been done?
> I guess this is still not done and the issue is still open: https://bitbucket.org/tmidas/midas/issues/329/need-odbresize
> I guess if we touch this maybe the problem with the wrong size should be also fixed: https://bitbucket.org/tmidas/midas/issues/328/odbinit-s-1024mb-creates-odb-with-wrong
please contribute 14 distraction-free days to my patreon. thanks in advance!
K.O. |
|
13 Jun 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > I remember the same, but I tracked it down in git to the very first commit, and there is no if() there,
> > odb is saved to .ODB.SHM on every client shutdown, not just the last client. I guess we both misremebered.
small problem. build an experiment, start taking data, observe how ODB is never saved to disk because the "last client" never stops. as bonus, crash
the computer, observe how all changes to ODB are now lost. if mlogger is configured to save odb.json at the end of run, and to write ODB dumps at
begin and end of every data file, you can recover some of the lost data.
for better effect, ODB should be dumped to disk at periodic intervals. but. current implementation writes odb to disk while holding the ODB
semaphore, which means all ODB access stops for the duration, specifically, there will be gaps in the history because mlogger cannot read history
data from ODB.
a better implementation could take the ODB lock, make a copy of ODB shared memory, release the ODB lock, complete writing to disk without holding the
lock. protection is needed against 100 midas programs trying to do this all at the same time. computers with 0.5 GB RAM (many ARM FPGA SoCs) will be
limited to ~100 Mbyte ODB). plus deal with memory allocation failures when taking a copy of a 2GB ODB.
in theory, the mmap() shared memory (already implemented in midas) does this automatically, but we lose control
over disk writes, we see some OSes write odb to disk "too often" and at wrong times, i.e. while we are in the middle
of creating or deleting something. current sequence of open(), atomic write() and close() ensures ODB.SHM always
contains a valid odb. (minus loss of OS and disk caches to crash or power loss).
K.O. |
|
13 Jun 2023, Stefan Ritt, Suggestion, Maximum ODB size
|
> small problem. build an experiment, start taking data, observe how ODB is never saved to disk because the "last client" never stops. as bonus, crash
> the computer, observe how all changes to ODB are now lost. if mlogger is configured to save odb.json at the end of run, and to write ODB dumps at
> begin and end of every data file, you can recover some of the lost
The new behavior is not much worse than before. Assume 10 programs running happily for days, computer crashes, all ODB changes lost.
So indeed a periodic flush without holding the lock might be best. Use a semaphore to prevent all programs flushing at the same time, or put
the flush only in the logger after an end of run.
Stefan |
|
13 Jun 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
>
> > small problem. build an experiment, start taking data, observe how ODB is never saved to disk because the "last client" never stops. as bonus, crash
> > the computer, observe how all changes to ODB are now lost. if mlogger is configured to save odb.json at the end of run, and to write ODB dumps at
> > begin and end of every data file, you can recover some of the lost
>
> The new behavior is not much worse than before. Assume 10 programs running happily for days, computer crashes, all ODB changes lost.
> So indeed a periodic flush without holding the lock might be best. Use a semaphore to prevent all programs flushing at the same time, or put
> the flush only in the logger after an end of run.
are you sure? when/how often does "last midas program finishes" happen? it does not happen on a system crash, not on power loss, not on "shutdown -r now"
(I am pretty sure). In the experiments you run, how often do you shut down all programs (and check that you did not forget one somehow)?
sanity check. dragon experiment, very active, .ODB.SHM timestamp is 1 second old. not-very-active agmini, today is June 13th, timestamp of .ODB.SHM is June
2nd. inactive TACTIC, timestamp of .ODB.SHM is May 16th.
so yes, not great, but in the new scheme, ODB.SHM timestamps would probably be from 2021 or 2020.
my vote is to undo this change, it is dangerous because it causes odb to be saved to ODB.SHM never.
K.O. |
|
13 Jun 2023, Stefan Ritt, Suggestion, Maximum ODB size
|
> are you sure? when/how often does "last midas program finishes" happen? it does not happen on a system crash, not on power loss, not on "shutdown -r now"
> (I am pretty sure). In the experiments you run, how often do you shut down all programs (and check that you did not forget one somehow)?
Indeed this is almost never the case, maybe once per months. On the other hand, we have a complete crash of the os maybe once a year. Most of the time the programs
run continuously (we do not need odbedit), so our timestamp is typically one or two days old, so not good either.
> my vote is to undo this change, it is dangerous because it causes odb to be saved to ODB.SHM never.
My vote is to flush the odb either periodically or after each run.
Stefan |
|
15 Jun 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
>
> > are you sure? when/how often does "last midas program finishes" happen? it does not happen on a system crash, not on power loss, not on "shutdown -r now"
> > (I am pretty sure). In the experiments you run, how often do you shut down all programs (and check that you did not forget one somehow)?
>
> Indeed this is almost never the case, maybe once per months. On the other hand, we have a complete crash of the os maybe once a year. Most of the time the programs
> run continuously (we do not need odbedit), so our timestamp is typically one or two days old, so not good either.
>
> > my vote is to undo this change, it is dangerous because it causes odb to be saved to ODB.SHM never.
>
> My vote is to flush the odb either periodically or after each run.
>
So we are in agreement.
RFE filed:
https://bitbucket.org/tmidas/midas/issues/367/odb-should-be-saved-to-disk-periodically
Dangerous change reverted:
60e4c44ad66346b89ba057391acf7a02890049be
K.O.
bash-3.2$ git diff
diff --git a/src/odb.cxx b/src/odb.cxx
index 0d3b88c2..d104ff28 100644
--- a/src/odb.cxx
+++ b/src/odb.cxx
@@ -2199,7 +2199,14 @@ INT db_close_database(HNDLE hDB)
destroy_flag = (pheader->num_clients == 0);
/* flush shared memory to disk */
- if (destroy_flag)
+
+ /* if we save ODB to disk only after last client finishes, we will never save ODB to disk
+ in most experiments - none of them ever completely stop MIDAS in normal operation.
+ as result, all changes to ODB contents will be lost on system crash, power loss
+ or normal reboot. see https://daq00.triumf.ca/elog-midas/Midas/2539
+ K.O. June 2023. */
+
+ if (1 || destroy_flag)
ss_shm_flush(pheader->name, pdb->shm_adr, pdb->shm_size, pdb->shm_handle);
strlcpy(xname, pheader->name, sizeof(xname));
K.O. |
|
28 Jul 2023, Stefan Ritt, Suggestion, Maximum ODB size
|
> RFE filed:
> https://bitbucket.org/tmidas/midas/issues/367/odb-should-be-saved-to-disk-periodically
Implemented and closed: https://bitbucket.org/tmidas/midas/issues/367/odb-should-be-saved-to-disk-periodically
Stefan |
|
09 Aug 2023, Konstantin Olchanski, Suggestion, Maximum ODB size
|
> > RFE filed:
> > https://bitbucket.org/tmidas/midas/issues/367/odb-should-be-saved-to-disk-periodically
>
> Implemented and closed: https://bitbucket.org/tmidas/midas/issues/367/odb-should-be-saved-to-disk-periodically
>
> Stefan
Stefan's comments from the closed bug report:
Ok I implemented some periodic flushing. Here is what I did:
Created
/System/Flush/Flush period : TID_UINT32 /System/Flush/Last flush : TID_UINT32
which control the flushing to disk. The default value for �Flush period� is 60 seconds or one minute.
All clients call db_flush_database() through their cm_yield() function
db_flush_database() checks the �Last flush� and only flushes the ODB when the period has expired. This test is
done inside the ODB semaphore so that we don�t get a race condigiton
If the period has expired, db_flush_database() calls ss_shm_flush()
ss_shm_flush() tries to allocate a buffer of the shared memory. If the allocation is not successful (out of
memory), ss_shm_flush() writes directly to the binary file as before.
If the allocation is successful, ss_shm_flush() copies the share memory to a buffer and passes this buffer to a
dedicated thread which writes the buffer to the binary file. This causes ss_shm_flush() to return immediately and
not block the calling program during the disk write operation.
Added back the �if (destroy_flag) ss_shm_flush()� so that the ODB is flushed for sure before the shared memory
gets deleted.
This means now that under normal circumstances, exiting programs like odbedit do NOT flush the ODB. This allows to
call many �odbedit -c� in a row without the flush penalty. Nevertheless, the ODB then gets flushed by other
clients latest 60 seconds (or whatever the flush period is) after odbedit exits.
Please note that ODB flushing has two purposes:
When all programs exit, we need a persistent storage for the ODB. In most experiments this only happens very
seldom. Maybe at the end of a beam time period.
If the computer crashes, a recent version of the ODB is kept on disk to simplify recovery after the crash.
Since crashes are not so often (during production periods we have maybe one hardware failure every few years) the
flushing of the ODB too often does not make sense and just consumes resources. Flushing does also not help from
corrupted ODBs, since the binary image will also get corrupted. So the only reason for periodic flushes is to ease
recovery after a total crash. I put the default to 60 seconds, but if people are really paranoid they can decrease
it to 10 seconds or so. Or increase it to 600 seconds if their system does not crash every week and disks are
slow.
I made a dedicated branch feature/periodic_odb_flush so people can test the new functionality. If there are no
complaints within the next few days, I will merge that into develop.
Stefan |
|
06 Mar 2023, Gennaro Tortone, Forum, pull request for PostgreSQL support
|
Hi,
some minutes ago I published a PR for PostgreSQL support I developed
at INFN-Napoli for Darkside experiment...
I don't know if you receive a notification about this PR and in doubt
I wrote this message...
Thanks in advance,
Gennaro |
|
06 Mar 2023, Konstantin Olchanski, Forum, pull request for PostgreSQL support
|
> some minutes ago I published a PR for PostgreSQL support I developed
> at INFN-Napoli for Darkside experiment...
>
> I don't know if you receive a notification about this PR and in doubt
> I wrote this message...
Hi, Gennaro, thank you for the very useful contribution. I saw the previous version
of your pull request and everything looked quite good. But that pull request was
for an older version of midas and it would not have applied cleanly to the current
version. I will take a look at your updated pull request. In theory it should only
add the Postgres class and modify a few other places in history_schema.cxx and have
no changes to anything else. (if you need those changes, it should be a separate
pull request).
Also I am curious what benefits and drawbacks of Postgres vs mysql/mariadb you have
observed for storing and using midas history data.
K.O. |
|
06 Mar 2023, Gennaro Tortone, Forum, pull request for PostgreSQL support
|
Hi Konstantin,
thanks for this update |
My main interest for PostgreSQL is usage of TimescaleDB
(https://github.com/timescale/timescaledb) a PostgreSQL extension that
makes possible usage of downsampling functions on time-series...
here at INFN-Napoli we have a large history dataset that we manage
with MIDAS history and MySQL tables. We have a lot of issues
(wait time, browser hangs, crashes) when we use MIDAS history plot
pages on large time period because the Javascript web page try to
download million of records in order to display them on a plot of
(max) 2000 pixel width...
with native downsampling we can reduce a large dataset keeping the
"shape" of the curve using only the points needed by the plot area;
in TimescaleDB there is "lttb" ( Largest Triangle Three Bucket) a very
nice and impressive downsampling function that preserve very well the
shape of the series.
If you are interested to see a lttb at work on some data you can open this page:
https://www.base.is/flot
In next days I will work to add TimescaleDB backend to MIDAS history (it will be
similar to PostgreSQL backend) and we can discuss on how to add these
downsampling features to history plot web pages, I already developed some
solutions and I will be happy to share them with MIDAS community;
Cheers,
Gennaro
> > some minutes ago I published a PR for PostgreSQL support I developed
> > at INFN-Napoli for Darkside experiment...
> >
> > I don't know if you receive a notification about this PR and in doubt
> > I wrote this message...
>
> Hi, Gennaro, thank you for the very useful contribution. I saw the previous version
> of your pull request and everything looked quite good. But that pull request was
> for an older version of midas and it would not have applied cleanly to the current
> version. I will take a look at your updated pull request. In theory it should only
> add the Postgres class and modify a few other places in history_schema.cxx and have
> no changes to anything else. (if you need those changes, it should be a separate
> pull request).
>
> Also I am curious what benefits and drawbacks of Postgres vs mysql/mariadb you have
> observed for storing and using midas history data.
>
> K.O. |
|
20 Mar 2023, Gennaro Tortone, Forum, pull request for PostgreSQL support
|
Hi,
I have updated the PR with a new one that includes TimescaleDB support and some
changes to mhistory.js to support downsampling queries...
Cheers,
Gennaro
> > some minutes ago I published a PR for PostgreSQL support I developed
> > at INFN-Napoli for Darkside experiment...
> >
> > I don't know if you receive a notification about this PR and in doubt
> > I wrote this message...
>
> Hi, Gennaro, thank you for the very useful contribution. I saw the previous version
> of your pull request and everything looked quite good. But that pull request was
> for an older version of midas and it would not have applied cleanly to the current
> version. I will take a look at your updated pull request. In theory it should only
> add the Postgres class and modify a few other places in history_schema.cxx and have
> no changes to anything else. (if you need those changes, it should be a separate
> pull request).
>
> Also I am curious what benefits and drawbacks of Postgres vs mysql/mariadb you have
> observed for storing and using midas history data.
>
> K.O. |
|
24 May 2023, Gennaro Tortone, Forum, pull request for PostgreSQL support
|
Hi,
is there any news regarding this pull request ?
(https://bitbucket.org/tmidas/midas/pull-requests/30)
If you agree to merge I can resolve conflicts that now
(after two months) are listed...
Regards,
Gennaro
>
> Hi,
> I have updated the PR with a new one that includes TimescaleDB support and some
> changes to mhistory.js to support downsampling queries...
>
> Cheers,
> Gennaro
>
> > > some minutes ago I published a PR for PostgreSQL support I developed
> > > at INFN-Napoli for Darkside experiment...
> > >
> > > I don't know if you receive a notification about this PR and in doubt
> > > I wrote this message...
> >
> > Hi, Gennaro, thank you for the very useful contribution. I saw the previous version
> > of your pull request and everything looked quite good. But that pull request was
> > for an older version of midas and it would not have applied cleanly to the current
> > version. I will take a look at your updated pull request. In theory it should only
> > add the Postgres class and modify a few other places in history_schema.cxx and have
> > no changes to anything else. (if you need those changes, it should be a separate
> > pull request).
> >
> > Also I am curious what benefits and drawbacks of Postgres vs mysql/mariadb you have
> > observed for storing and using midas history data.
> >
> > K.O. |
|
18 Jul 2023, Konstantin Olchanski, Forum, pull request for PostgreSQL support
|
> is there any news regarding this pull request ?
> (https://bitbucket.org/tmidas/midas/pull-requests/30)
apologies for taking a very long time to review the proposed changes.
the main problem with this pull request remains, it tangles together too many changes to the code and I cannot simply
say "this is okey", merge and commit it.
example of unrelated change is diff of mlogger.cxx, change of function in: "db_get_value(hDB, 0, "/Logger/Multithread
transitions" ... )". there is also unrelated changes to whitespace sprinkled around.
can you review your diffs again and try to remove as much unrelated and unnecessary changes as you can?
I could do this for you, and merge my version, but next time you merge base midas, you will have a collision.
unrelated change of function is introduction of something called "downsampling", what is the purpose of this? How is it
different from requesting binned data? Is it just a kludge to reduce the data size? Before we merge it, can you post a
description/discussion to this forum here? (as a separate topic, separate from discussion of PostgreSQL merge).
the changes to add PostgreSQL so fat look reasonable:
- CMakeLists, is always painful but if you do same a MySQL, should be okey, we always end up rejigging this several
times before it works everywhere.
- history.h, ok, minus changes for adding the "downsample" feature
- mlogger.cxx, changes are too tangled with "downsample" feature, cannot review
- SetDownsample() API is defective, should have separate Get() and Set() functions
- history_common.cxx, please do not add downsampling code to history providers that do not/will not support it.
- history_odbc.cxx, please do not change it. it does not support downsampling and never will.
- history.cxx, ditto
- mjsonrpc.cxx, history API is changed, we must know: is new JS compatible with old mhttpd? is old JS compatible with
new mhttpd? (mixed versions are very common in practice). if there is incompatibility, can you recoded it to be
compatible?
- history_schema.cxx: bitbucket diff is a dog's breakfast, cannot review. I will have to checkout your branch and diff
by hand.
changes to mhistory.js appear to be extensive and some explanation is needed for what is changed, what bugs/problems
are fixed, what new features are added.
to move forward, can you generate a pull requests that only adds pgsql to history_schema.cxx, history_common.cxx and
mlogger.cxx and does not add any other functions, features and does not change any whistespace?
K.O.
>
> If you agree to merge I can resolve conflicts that now
> (after two months) are listed...
>
> Regards,
> Gennaro
>
> >
> > Hi,
> > I have updated the PR with a new one that includes TimescaleDB support and some
> > changes to mhistory.js to support downsampling queries...
> >
> > Cheers,
> > Gennaro
> >
> > > > some minutes ago I published a PR for PostgreSQL support I developed
> > > > at INFN-Napoli for Darkside experiment...
> > > >
> > > > I don't know if you receive a notification about this PR and in doubt
> > > > I wrote this message...
> > >
> > > Hi, Gennaro, thank you for the very useful contribution. I saw the previous version
> > > of your pull request and everything looked quite good. But that pull request was
> > > for an older version of midas and it would not have applied cleanly to the current
> > > version. I will take a look at your updated pull request. In theory it should only
> > > add the Postgres class and modify a few other places in history_schema.cxx and have
> > > no changes to anything else. (if you need those changes, it should be a separate
> > > pull request).
> > >
> > > Also I am curious what benefits and drawbacks of Postgres vs mysql/mariadb you have
> > > observed for storing and using midas history data.
> > >
> > > K.O. |
|
21 Jul 2023, Konstantin Olchanski, Forum, pull request for PostgreSQL support
|
> > is there any news regarding this pull request ?
> > (https://bitbucket.org/tmidas/midas/pull-requests/30)
>
> apologies for taking a very long time to review the proposed changes.
>
I merged the PgSql bits by hand - the automatic tools make a dog's breakfast from the history_schema.cxx diffs. Ouch.
history_schema.cxx merged pretty much cleanly, but I have one question about CreateSqlColumn() with sql_strict set to "true". Can you say
more why this is needed? Should this also be made the default for MySQL? The best I can tell the default values are only needed if we write
to SQL but forget to provide values that should not be NULL? But our code never does this? Or this is for reading from SQL, where NULL values
are replaced with the default values? I do not have time to look into this right now, I hope you can clarify it for me?
Also notice the fDownsample is set to zero and cannot be changed. I recommend we set it through the MakeMidasHistoryPgsql() factory method.
Please pull, merge, retest, update the pull request, check that there is no unrelated changes (changes in mlogger.cxx is a direct red flag!)
and we should be able to merge the rest of your stuff pronto.
K.O.
commit e85bb6d37c85f02fc4895cae340ba71ab36de906 (HEAD -> develop, origin/develop, origin/HEAD)
Author: Konstantin Olchanski <olchansk@triumf.ca>
Date: Fri Jul 21 09:45:08 2023 -0700
merge PQSQL history in history_schema.cxx
commit f254ebd60a23c6ee2d4870f3b6b5e8e95a8f1f09
Author: Konstantin Olchanski <olchansk@triumf.ca>
Date: Fri Jul 21 09:19:07 2023 -0700
add PGSQL Makefile bits
commit aa5a35ba221c6f87ae7a811236881499e3d8dcf7
Author: Konstantin Olchanski <olchansk@triumf.ca>
Date: Fri Jul 21 08:51:23 2023 -0700
merge PGSQL support from https://bitbucket.org/gtortone/midas/branch/feature/timescaledb_support except for history_schema.cxx |
|
21 Jul 2023, Gennaro Tortone, Forum, pull request for PostgreSQL support
|
Hi Konstantin,
thanks a lot for your work on PostgreSQL and TimescaleDB integration...
and sorry for unrelated changes on source code !
I will return on this task at end of this year (maybe October or November) because
I'm working on different tasks... but I will keep in mind your suggestions in order
to provide good source code.
Thanks,
Gennaro
>
> I merged the PgSql bits by hand - the automatic tools make a dog's breakfast from the history_schema.cxx diffs. Ouch.
>
> history_schema.cxx merged pretty much cleanly, but I have one question about CreateSqlColumn() with sql_strict set to "true". Can you say
> more why this is needed? Should this also be made the default for MySQL? The best I can tell the default values are only needed if we write
> to SQL but forget to provide values that should not be NULL? But our code never does this? Or this is for reading from SQL, where NULL values
> are replaced with the default values? I do not have time to look into this right now, I hope you can clarify it for me?
>
> Also notice the fDownsample is set to zero and cannot be changed. I recommend we set it through the MakeMidasHistoryPgsql() factory method.
>
> Please pull, merge, retest, update the pull request, check that there is no unrelated changes (changes in mlogger.cxx is a direct red flag!)
> and we should be able to merge the rest of your stuff pronto.
>
> K.O.
>
> commit e85bb6d37c85f02fc4895cae340ba71ab36de906 (HEAD -> develop, origin/develop, origin/HEAD)
> Author: Konstantin Olchanski <olchansk@triumf.ca>
> Date: Fri Jul 21 09:45:08 2023 -0700
>
> merge PQSQL history in history_schema.cxx
>
> commit f254ebd60a23c6ee2d4870f3b6b5e8e95a8f1f09
> Author: Konstantin Olchanski <olchansk@triumf.ca>
> Date: Fri Jul 21 09:19:07 2023 -0700
>
> add PGSQL Makefile bits
>
> commit aa5a35ba221c6f87ae7a811236881499e3d8dcf7
> Author: Konstantin Olchanski <olchansk@triumf.ca>
> Date: Fri Jul 21 08:51:23 2023 -0700
>
> merge PGSQL support from https://bitbucket.org/gtortone/midas/branch/feature/timescaledb_support except for history_schema.cxx |
|
28 Jul 2023, Stefan Ritt, Forum, pull request for PostgreSQL support
|
The compilation of midas was broken by the last modification. The reason is that
Pgsql *fPgsql = NULL;
was not protected by
#ifdef HAVE_PGSQL
So I put all PGSQL code under a big #ifdef and now it compiles again. You might want to double check my modification at
https://bitbucket.org/tmidas/midas/commits/e3c7e73459265e0d7d7a236669d1d1f2d9292a74
Best,
Stefan |
|
09 Aug 2023, Konstantin Olchanski, Forum, pull request for PostgreSQL support
|
> The compilation of midas was broken by the last modification. The reason is that
> Pgsql *fPgsql = NULL;
> was not protected by #ifdef HAVE_PGSQL
confirmed, my mistake, I forgot to test with "make cmake NO_PGSQL". your fix is correct, thanks.
K.O. |
|
02 Aug 2023, Caleb Marshall, Forum, Issues with Universe II Driver
|
Hello,
At our lab we are currently in the process of migrating more of our systems over to Midas. However, all of our working systems are dependent on SBCs with the Tsi-148 chips of which we only have a handful. In order to have some backups and spares for testing, we have been attempting to get Midas working with some borrowed SBCs (Concurrent Technologies VX 40x/04x) with Universe-II chips. The SBC is running CentOS 7. I have tried to follow the instructions posted here. The universe-II kernel module appears to load correctly, dmesg gives:
[ 32.384826] VME: Board is system controller
[ 32.384875] VME: Driver compiled for SMP system
[ 32.384877] VME: Installed VME Universe module version: 3.6.KO6
However, running vmescan.exe fails with a segfault. Running with gdb shows:
vmic_mmap: Mapped VME AM 0x0d addr 0x00000000 size 0x00ffffff at address 0x80a01000
mvme_open:
Bus handle = 0x7
DMA handle = 0x6045d0
DMA area size = 1048576 bytes
DMA physical address = 0x7ffff7eea000
vmic_mmap: Mapped VME AM 0x2d addr 0x00000000 size 0x0000ffff at address 0x86ff0000
Program received signal SIGSEGV, Segmentation fault.
mvme_read_value (mvme=0x604010, vme_addr=<optimized out>)
at /home/jam/midas/packages/midas/drivers/vme/vmic/vmicvme.c:352
352 dst = *((WORD *)addr);
With the pointer addr originating from a call to vmic_mapcheck within the mvme_read_value functions in the vmicvme.c file. Help with where to go from here would be appreciated.
-Caleb
|
|
02 Aug 2023, Konstantin Olchanski, Forum, Issues with Universe II Driver
|
I maintain the tsi148 and the universe-II drivers. I confirm -KO6 is my latest
version, last updated for 32-bit Debian-11, and we still use it at TRIUMF.
It is good news that the vme_universe kernel module built, loaded and reported
correct stuff to dmesg.
It is not clear why mvme_read_value() crashed. We need to know the value of
vme_addr and addr, can you add printf()s for them using format "%08x" and try
again?
K.O.
<p> </p>
<table align="center" cellspacing="1" style="border:1px solid #486090;
width:98%">
<tbody>
<tr>
<td style="background-color:#486090">Caleb Marshall
wrote:</td>
</tr>
<tr>
<td style="background-color:#FFFFB0">
<p>Hello,</p>
<p>At our lab we are currently in the process of
migrating more of our systems over to Midas. However, all of our working systems
are dependent on SBCs with the Tsi-148 chips of which we only have a handful. In
order to have some backups and spares for testing, we have been attempting to
get Midas working with some borrowed SBCs (Concurrent Technologies VX 40x/04x)
with Universe-II chips. The SBC is running CentOS 7. I have tried to
follow the instructions posted <a
href="https://daq00.triumf.ca/DaqWiki/index.php/VME-
CPU#V7648_and_V7750_BIOS_Settings">here</a>. The universe-II kernel module
appears to load correctly, dmesg gives:</p>
<p>[ 32.384826] VME: Board is system
controller<br />
[ 32.384875] VME: Driver compiled for SMP
system<br />
[ 32.384877] VME: Installed VME Universe module
version: 3.6.KO6<br />
</p>
<p>However, running vmescan.exe fails with a segfault.
Running with gdb shows:</p>
<p>vmic_mmap: Mapped VME AM 0x0d addr 0x00000000 size
0x00ffffff at address 0x80a01000<br />
mvme_open:<br />
Bus handle
= 0x7<br />
DMA handle
= 0x6045d0<br />
DMA area size =
1048576 bytes<br />
DMA physical address = 0x7ffff7eea000<br />
vmic_mmap: Mapped VME AM 0x2d addr 0x00000000 size
0x0000ffff at address 0x86ff0000</p>
<p>Program received signal SIGSEGV, Segmentation fault.
<br />
mvme_read_value (mvme=0x604010, vme_addr=<optimized
out>)<br />
at
/home/jam/midas/packages/midas/drivers/vme/vmic/vmicvme.c:352<br />
352 dst = *((WORD
*)addr);<br />
</p>
<p>With the pointer addr originating from a call
to vmic_mapcheck within the mvme_read_value functions in the
vmicvme.c file. Help with where to go from here would be appreciated.</p>
<p>-Caleb </p>
<p> </p>
</td>
</tr>
</tbody>
</table>
<p> </p> |
|
03 Aug 2023, Caleb Marshall, Forum, Issues with Universe II Driver
|
Here is the output:
vmic_mmap: Mapped VME AM 0x0d addr 0x00000000 size 0x00ffffff at address 0x80a01000
mvme_open:
Bus handle = 0x3
DMA handle = 0x158f5d0
DMA area size = 1048576 bytes
DMA physical address = 0x7f91db553000
vmic_mmap: Mapped VME AM 0x2d addr 0x00000000 size 0x0000ffff at address 0x86ff0000
vme addr: 00000000
addr: db543000 |
|
03 Aug 2023, Konstantin Olchanski, Forum, Issues with Universe II Driver
|
> Here is the output:
>
> vmic_mmap: Mapped VME AM 0x0d addr 0x00000000 size 0x00ffffff at address 0x80a01000
> mvme_open:
> Bus handle = 0x3
> DMA handle = 0x158f5d0
> DMA area size = 1048576 bytes
> DMA physical address = 0x7f91db553000
> vmic_mmap: Mapped VME AM 0x2d addr 0x00000000 size 0x0000ffff at address 0x86ff0000
> vme addr: 00000000
> addr: db543000
I see the problem. A24 is mapped at 0x80xxxxxx, A16 is mapped at 0x86ffxxxx, but
mvme_read computed address 0xdb543000, out of range of either mapped vme address. ouch.
One more thing to check, AFAIK, this universe-II codes were never used on 64-bit CPU
before, we only have 32-bit Pentium-3 and Pentium-4 machines with these chips. The
tsi148 codes used to work both 32-bit and 64-bit, we used to have both flavours of
CPUs, but now only have 64-bit.
What is your output for "uname -a"? does it report 32-bit or 64-bit kernel?
If you feel adventurous, you can build 32-bit midas (cd .../midas; make linux32),
compile vmescan.o with "-m32" and link vmescan.exe against .../midas/linux-m32/lib, and
see if that works. Meanwhile, I can check if vmicvme.c is 64-bit clean. Checking if
kernel module is 64-bit clean would be more difficult...
K.O. |
|
03 Aug 2023, Caleb Marshall, Forum, Issues with Universe II Driver
|
I am looking into compiling the 32 bit midas.
In the meantime, here is the kernel info:
3.10.0-1160.11.1.el7.x86_64
Thank you for the help.
-Caleb |
|
04 Aug 2023, Caleb Marshall, Forum, Issues with Universe II Driver
|
I can compile 32 bit midas. Unless I am interpreting the linking error, I don't
think I can use the driver as built.
While trying to compile vme_scan, most of the programs fail with:
/usr/bin/ld: skipping incompatible /usr/lib/gcc/x86_64-redhat-
linux/4.8.5/../../../../lib/libvme.so when searching for -lvme
/usr/bin/ld: skipping incompatible /lib/../lib/libvme.so when searching for -lvme
/usr/bin/ld: skipping incompatible /usr/lib/../lib/libvme.so when searching for -
lvme
/usr/bin/ld: skipping incompatible /usr/lib/gcc/x86_64-redhat-
linux/4.8.5/../../../libvme.so when searching for -lvme
/usr/bin/ld: skipping incompatible //lib/libvme.so when searching for -lvme
/usr/bin/ld: skipping incompatible //usr/lib/libvme.so when searching for -lvme
with libvme.so being built by the universe-II driver. Not sure if I can get around
this without messing with the driver? Is it possible to build a 32 bit version of
that shared library without having to touch the actual kernel module?
-Caleb |
|
04 Aug 2023, Konstantin Olchanski, Forum, Issues with Universe II Driver
|
> I can compile 32 bit midas. Unless I am interpreting the linking error, I don't
> think I can use the driver as built.
I think you are right, Makefile from the Universe package does not build a -m32 version
of libvme.so. I think I can fix that...
K.O. |
|
12 May 2023, Stefan Ritt, Info, New environment variable MIDAS_EXPNAME
|
A new environment variable MIDAS_EXPNAME has been introduced. This must be
used for cases where people use MIDAS_DIR, and is then equivalent for the
experiment name and directory usually used in the exptab file. This fixes
and issue with creating and deleting shared memory in midas as described in
https://bitbucket.org/tmidas/midas/issues/363/deletion-of-shared-memory-fails
The documentation has been updated at
https://daq00.triumf.ca/MidasWiki/index.php/MIDAS_environment_variables#MIDAS_EXPN
AME
/Stefan |
|
12 May 2023, Konstantin Olchanski, Info, New environment variable MIDAS_EXPNAME
|
> A new environment variable MIDAS_EXPNAME has been introduced [to be used together with
MIDAS_DIR]
This is fixes an important buglet. If experiment uses MIDAS_DIR instead of exptab, at the time
of connecting to ODB, we do not know the experiment name and use name "Default" to create ODB
shared memory, instead of actual experiment name.
This creates an inconsistency, if some MIDAS programs in the same experiment use MIDAS_DIR while
others use exptab (this would be unusual, but not impossible) they would connect to two
different ODB shared memories, former using name "Default", latter using actual experiment name.
As an indication that something is not right, when stopping MIDAS programs, there is an error
message about failure to delete shared ODB shared memory (because it was created using name
"Default" and delete using the correct experiment name fails).
Also it can cause co-mingling between two different experiments, depending on the type of shared
memory used by MIDAS (see $MIDAS_DIR/.SHM_TYPE.TXT):
POSIX - (usually not used) not affected (experiment name is not used)
POSIXv2 - (usually not used) affected (shm name is "$EXP_NAME_ODB")
POSIXv3 - used on MacOS - affected (shm name is "$UID_$EXP_NAME_ODB" so "$UID_Default_ODB" will
collide)
POSIXv4 - used on Linux - not affected (shm name includes $MIDAS_DIR which is different for
different experiments)
K.O. |
|
20 Jun 2023, Stefan Ritt, Info, New environment variable MIDAS_EXPNAME
|
I just realized that we had already MIDAS_EXPT_NAME, and now people get confused with
MIDAS_EXPT_NAME
and
MIDAS_EXPNAME
In trying to fix this confusion, I changed the name of the second variable to MIDAS_EXPT_NAME as well,
so we only have one variable now. If this causes any problems please report here.
Stefan |
|
28 Jul 2023, Stefan Ritt, Info, New environment variable MIDAS_EXPNAME
|
Concerning naming of shared memories I went one step further due to some requirement of a local experiment.
The experiment needs to change the experiment name shown on the web status page depending on the exact
configuration, but we do not want to change the whole midas experiment each time.
So I simple removed the check that the experiment name coming from the environment and used for the shared
memory gets checked against the experiment name in the ODB. The only connection there is that the ODB name
gets set to the environment name is it does not exist or is empty, just to have some default value. So for
most people nothing should change. If one changes however the name in the ODB (under /Experiment/Name),
nothing will change internally, just the web display via mhttpd changes its title.
I hope this has no bad side-effects, so please have a look if you see any issue in your experiment.
Stefan |
|
24 Jul 2023, Nick Hastings, Bug Report, Incompatible data types with mysql odbc interface
|
Hello,
I have recently set up a midas-2022-05-c instance and have been trying to configure
it to use the mysql odbc interface. Tables are being created for it but
the logger is issuing errors that some of the column types are incorrect. For example
in the log I see:
14:22:12.689 2023/07/25 [Logger,ERROR] [history_odbc.cxx:1531:hs_define_event,ERROR] Error: History event 'Run transitions': Incompatible data type for tag 'State' type 'UINT32', SQL column 'state' type 'INT UNSIGNED'
14:22:12.689 2023/07/25 [Logger,ERROR] [history_odbc.cxx:1531:hs_define_event,ERROR] Error: History event 'Run transitions': Incompatible data type for tag 'Run number' type 'UINT32', SQL column 'run_number' type 'INT UNSIGNED'
Checking the table in the database I see:
MariaDB [t2kgscND280]> describe run_transitions;
+------------+------------------+------+-----+---------------------+-------------------------------+
| Field | Type | Null | Key | Default | Extra |
+------------+------------------+------+-----+---------------------+-------------------------------+
| _t_time | timestamp | NO | MUL | current_timestamp() | on update current_timestamp() |
| _i_time | int(11) | NO | MUL | NULL | |
| state | int(10) unsigned | YES | | NULL | |
| run_number | int(10) unsigned | YES | | NULL | |
+------------+------------------+------+-----+---------------------+-------------------------------+
4 rows in set (0.000 sec)
Please note that this is not the only history variable that has this problem. There are multiple variables
for which:
Incompatible data type for tag 'Foo Bar' type 'UINT32', SQL column 'foo_bar' type 'INT UNSIGNED'
Checking history_odbc.cxx, I see:
static const char *sql_type_mysql[] = {
"xxxINVALIDxxxNULL", // TID_NULL
"tinyint unsigned", // TID_UINT8
"tinyint", // TID_INT8
"char", // TID_CHAR
"smallint unsigned", // TID_UINT16
"smallint", // TID_INT16
"integer unsigned", // TID_UINT32
"integer", // TID_INT32
"tinyint", // TID_BOOL
"float", // TID_FLOAT
"double", // TID_DOUBLE
"tinyint unsigned", // TID_BITFIELD
"VARCHAR", // TID_STRING
"xxxINVALIDxxxARRAY",
"xxxINVALIDxxxSTRUCT",
"xxxINVALIDxxxKEY",
"xxxINVALIDxxxLINK"
};
So it seems that unsigned int should map to UINT32.
The database is:
Server version: 10.5.16-MariaDB MariaDB Server
Please let me know if more information is needed.
Note that the choice of using the odbc interface is because we
plan to import an old database that was created using the odbc interface
with a previous version of midas (yes this is your old friend T2K/ND280).
Regards,
Nick. |
|
25 Jul 2023, Nick Hastings, Bug Report, Incompatible data types with mysql odbc interface
|
Hello,
wanted add few things:
1. I see the same problem for INT32
2. For now I've worked around these problems with https://bitbucket.org/nickhastings/midas/commits/e4776f7511de0647077c8c80d43c17bbfe2184fd
3. I'm using mariadb-connector-odbc-3.1.12-3.el9.x86_64 (System is AlmaLinux 9)
Regards,
Nick. |
|
18 Jul 2023, Gennaro Tortone, Bug Report, access to filesystem through mhttpd
|
Hi,
after some networks security scans I received some warnings because mhttpd expose
server filesystem through HTTP(S)...
in details a MIDAS user can access to /etc/passwd or download other files from
filesystem using a web browser:
(e.g. http://midas.host:8080/etc/passwd)
I know that /etc/passwd does not contain users password and mhttpd runs as an
unprivileged user but in principle this should be avoided in order to minimize
security risks: if I authorize a user to use MIDAS interface in order to handle
acquisition tasks this should not authorize the user to access the server filesystem...
but this access should be restricted to MIDAS web pages, custom pages etc.
What do you think about this ?
Cheers,
Gennaro |
|
18 Jul 2023, Konstantin Olchanski, Bug Report, access to filesystem through mhttpd
|
> (e.g. http://midas.host:8080/etc/passwd)
not again! I complained about this before, and I added a fix, but it must be broken again.
getting a copy of /etc/passwd is reasonably benign, but getting a copy of
/home/$USER/.ssh/id_rsa, id_rsa.pub, knownhosts and authorized_keys is a disaster.
(running mhttpd behind a web proxy does not solve the problem, number of attackers is
reduced to only the people who know the proxy password and to local users).
K.O. |
|
19 Jul 2023, Zaher Salman, Bug Report, access to filesystem through mhttpd
|
Have you actually been able to read /etc/passwd this way? I tested this on a few of our servers and it does not work. As far as I know, there is access to files in resources, custom pages etc.
Other possible ways to access the file system is via mjsonrpc calls, but again these are restricted to certain folders.
Can you please give us more details about this.
Zaher
> > (e.g. http://midas.host:8080/etc/passwd)
>
> not again! I complained about this before, and I added a fix, but it must be broken again.
>
> getting a copy of /etc/passwd is reasonably benign, but getting a copy of
> /home/$USER/.ssh/id_rsa, id_rsa.pub, knownhosts and authorized_keys is a disaster.
>
> (running mhttpd behind a web proxy does not solve the problem, number of attackers is
> reduced to only the people who know the proxy password and to local users).
>
> K.O. |
|
11 Jul 2023, Anubhav Prakash, Forum, Possible ODB corruption! Webpages https://midptf01.triumf.ca/?cmd=Programs not loading!
|
The ODB server seems to have crashed/corrupted. I tried reloading the previous
working version of ODB(using the commands in folliwng image) but it didn't work.
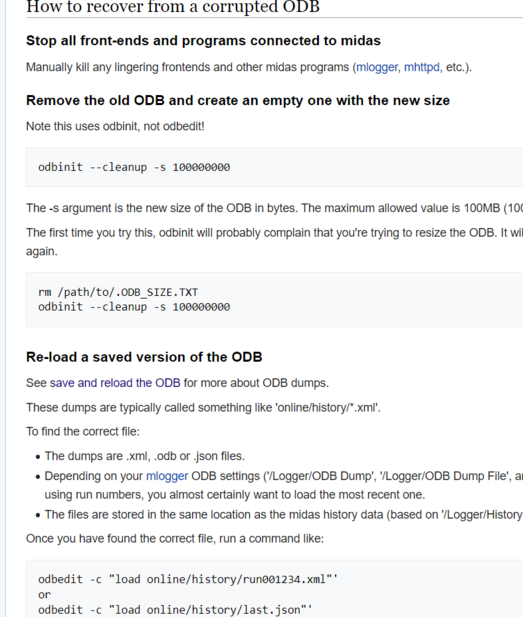
I have also attached the screenshot of the site https://midptf01.triumf.ca/?cmd=Programs. Any help to resolve this would be appreciated! Normally Prof. Thomas Lindner would solve such issues, but he is busy working at CERN till 17th of July, and we cannot afford to wait until then.
The following is the error: when I run bash /home/midptf/online/bin/start_daq.sh
[ODBEdit1,INFO] Fixing ODB "/Programs/ODBEdit" struct size mismatch (expected
316, odb size 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/ODBEdit" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/ODBEdit",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/ODBEdit"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/ODBEdit" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "ODBEdit", db_get_record1() status 319
[ODBEdit1,INFO] Fixing ODB "/Programs/mhttpd" struct size mismatch (expected
316, odb size 60)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/mhttpd" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/mhttpd",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/mhttpd"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/mhttpd" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "mhttpd", db_get_record1() status 319
[ODBEdit1,INFO] Fixing ODB "/Programs/Logger" struct size mismatch (expected
316, odb size 60)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/Logger" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/Logger",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/Logger"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/Logger" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "Logger", db_get_record1() status 319
14:54:29 [ODBEdit,ERROR] [odb.cxx:1763:db_validate_db,ERROR] Warning: database
data area is 100% full
14:54:29 [ODBEdit,ERROR] [odb.cxx:1283:db_validate_key,ERROR] hkey 643368, path
"/Alarms/Classes/<NULL>/Display BGColor", string value is not valid UTF-8
14:54:29 [ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot
malloc_data(256), called from db_set_link_data
14:54:29 [ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot
reallocate "/System/Tmp/140305391605888I/Start command" with new size 256 bytes,
online database full
14:54:29 [ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of
zero, set to 32, odb path "Start command"
14:54:29 [ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of
zero, set to 32, odb path "Start command" |
|
11 Jul 2023, Thomas Lindner, Forum, Possible ODB corruption! Webpages https://midptf01.triumf.ca/?cmd=Programs not loading!
|
Hi Anubhav,
I have fixed the ODB corruption problem.
Cheers,
Thomas
| Anubhav Prakash wrote: | The ODB server seems to have crashed/corrupted. I tried reloading the previous
working version of ODB(using the commands in folliwng image) but it didn't work.
I have also attached the screenshot of the site https://midptf01.triumf.ca/?cmd=Programs. Any help to resolve this would be appreciated! Normally Prof. Thomas Lindner would solve such issues, but he is busy working at CERN till 17th of July, and we cannot afford to wait until then.
The following is the error: when I run bash /home/midptf/online/bin/start_daq.sh
[ODBEdit1,INFO] Fixing ODB "/Programs/ODBEdit" struct size mismatch (expected
316, odb size 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/ODBEdit" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/ODBEdit",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/ODBEdit"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/ODBEdit" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "ODBEdit", db_get_record1() status 319
[ODBEdit1,INFO] Fixing ODB "/Programs/mhttpd" struct size mismatch (expected
316, odb size 60)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/mhttpd" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/mhttpd",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/mhttpd"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/mhttpd" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "mhttpd", db_get_record1() status 319
[ODBEdit1,INFO] Fixing ODB "/Programs/Logger" struct size mismatch (expected
316, odb size 60)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/Logger" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11381:db_get_record1,ERROR] after db_check_record()
still struct size mismatch (expected 316, odb size 92) of "/Programs/Logger",
calling db_create_record()
[ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot malloc_data(256),
called from db_set_link_data
[ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot reallocate
"/System/Tmp/140305391605888I/Start command" with new size 256 bytes, online
database full
[ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of zero, set
to 32, odb path "Start command"
[ODBEdit1,ERROR] [odb.cxx:11387:db_get_record1,ERROR] repaired struct size
mismatch of "/Programs/Logger"
[ODBEdit1,ERROR] [odb.cxx:11293:db_get_record,ERROR] struct size mismatch for
"/Programs/Logger" (expected size: 316, size in ODB: 92)
[ODBEdit1,ERROR] [alarm.cxx:702:al_check,ERROR] Cannot get program info record
for program "Logger", db_get_record1() status 319
14:54:29 [ODBEdit,ERROR] [odb.cxx:1763:db_validate_db,ERROR] Warning: database
data area is 100% full
14:54:29 [ODBEdit,ERROR] [odb.cxx:1283:db_validate_key,ERROR] hkey 643368, path
"/Alarms/Classes/<NULL>/Display BGColor", string value is not valid UTF-8
14:54:29 [ODBEdit1,ERROR] [odb.cxx:556:realloc_data,ERROR] cannot
malloc_data(256), called from db_set_link_data
14:54:29 [ODBEdit1,ERROR] [odb.cxx:6923:db_set_link_data,ERROR] Cannot
reallocate "/System/Tmp/140305391605888I/Start command" with new size 256 bytes,
online database full
14:54:29 [ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of
zero, set to 32, odb path "Start command"
14:54:29 [ODBEdit1,ERROR] [odb.cxx:8531:db_paste,ERROR] found string length of
zero, set to 32, odb path "Start command" |
|
|