 13 Oct 2003, Stefan Ritt, , mhttpd: add Elog text to outgoing email. 13 Oct 2003, Stefan Ritt, , mhttpd: add Elog text to outgoing email.
|
> around to implement it, until now. I also added assert() traps for the most
> common array overruns in the Elog code.
In addition to the assert() one should use strlcat() and strlcpy() all over
the code to avoid buffer overruns. The ELOG standalone code does that already
properly.
- Stefan |
|
13 Oct 2003, Konstantin Olchanski, , mhttpd: add Elog text to outgoing email.
|
> > around to implement it, until now. I also added assert() traps for the most
> > common array overruns in the Elog code.
>
> In addition to the assert() one should use strlcat() and strlcpy() all over
> the code to avoid buffer overruns. The ELOG standalone code does that already
> properly.
>
> - Stefan
Yes, the original authors should have used strlcat(). Now that I uncovered this source of mhttpd
memory corruption, maybe some volunteer will fix it up properly.
K.O. |
|
13 Oct 2003, Stefan Ritt, , mhttpd: add Elog text to outgoing email.
|
> > > around to implement it, until now. I also added assert() traps for the
most
> > > common array overruns in the Elog code.
> >
> > In addition to the assert() one should use strlcat() and strlcpy() all
over
> > the code to avoid buffer overruns. The ELOG standalone code does that
already
> > properly.
> >
> > - Stefan
>
> Yes, the original authors should have used strlcat(). Now that I uncovered
this source of mhttpd
> memory corruption, maybe some volunteer will fix it up properly.
>
> K.O.
I am the original author and will fix all that once I merged mhttpd and elog.
Due to my current task list, this will happen probably in November.
- Stefan |
 02 Nov 2010, chris pearson, Info, mhttpd: Extra entries on status page 02 Nov 2010, chris pearson, Info, mhttpd: Extra entries on status page 
|
A couple of experiments at triumf wanted certain important odb variables
displayed on their status page. (There was already the possibility to show the
run comment)
A new folder "/Experiment/Status Items" was created containing links to the
variables of interest, these items are show on the status page, under the run
comment (if any), in 3 columns.
the code from mhttpd.c:show_status_page()
between
/*---- run comment ----*/
and
/*---- Equipment list ----*/
is attached |
|
14 Dec 2004, Konstantin Olchanski, Info, mhttpd: Commit local TWIST modifications
|
> > I am commiting MIDAS modification accumulated...
mhttpd changes:
- Renee's improvements on http transaction logging
- Implement "minimum" and "maximum" clamping for history graphs. Unfortunately
there is no GUI code for changing the "minimum" and "maximum" settings,
other than directly frobbing the odb.
- When making history graphs, detect NaNs in the history data.
(- status page code for the TWIST event builder (precursor of the standard
event builder) stays uncommited).
K.O. |
|
09 Sep 2015, Thomas Lindner, Info, mhttpd/SSL error message on MacOS
|
On my macbook (OS X 10.10.3) I get this error message when starting mhttpd with mongoose-SSL:
[mhttpd,ERROR] [mhttpd.cxx:17092:mongoose,ERROR] mongoose web server error: set_ssl_option:
openssl "modern cryptography" ECDH ciphers not available
mhttpd seems to start fine anyway and safari connects to the secure midas page without complaining
about the SSL (it complains about the certificate of course). So maybe this error message is
relatively harmless?
I don't get this error message with Scientific Linux 6.7. |
|
11 Sep 2015, Konstantin Olchanski, Info, mhttpd/SSL error message on MacOS
|
> On my macbook (OS X 10.10.3) I get this error message when starting mhttpd with mongoose-SSL:
>
> [mhttpd,ERROR] [mhttpd.cxx:17092:mongoose,ERROR] mongoose web server error: set_ssl_option:
> openssl "modern cryptography" ECDH ciphers not available
>
It means what it says - "modern cryptography" is not available (in google-chrome terms), different browsers report this
differently, same (apple safari) do not seem to care.
In practice if ECDH ciphers are not available, the https connection uses "obsolete cryptography" and (depending) it
probably not actually secure (might even be using RC4 ciphers).
The reason you get this error is the obsolete OpenSSL library shipped with MacOS (all version). (same on SL4 and SL5).
Reasonably up-to-date OpenSSL library that has ECDH support can be installed using MacPorts, this step should be
added to the MIDAS documentation.
>
> mhttpd seems to start fine anyway and safari connects to the secure midas page without complaining
> about the SSL (it complains about the certificate of course). So maybe this error message is
> relatively harmless?
>
Some browsers do not care about the quality of the connection - google-chrome seems to be the most conservative
and flags anything that is less than "most state of the art encryption".
Some browsers seem to be happy even if the connection is SSLv2 with RC4 encryption, even though it is not secure at
all by current thinking.
Is that harmless? (browser says "secure" when it is not?)
> I don't get this error message with Scientific Linux 6.7.
el6 has a reasonably recent OpenSSL library which supports "modern cryptography".
The best guide to this is to run the SSLlabs scanner and read through it's report.
K.O.
P.S. All this said, I hope my rationale to switching away from OpenSSL makes a bit more sense. If we use something
like PolarSSL, at least we get the same behaviour on all OSes.
K.O. |
|
14 Feb 2017, Konstantin Olchanski, Info, mhttpd.js split into midas.js, mhttpd.js and obsolete.js
|
As discussed before, the midas omnibus javascript file mhttpd.js has been split into three pieces:
midas.js - midas "public api" for building web pages that interact with midas
mhttpd.js - javascript functions used by mhttpd web pages
obsolete.js - functions still in use, but not recommended for new designs, mostly because of the deprecated "Synchronous XMLHttpRequest" business.
Consider these use cases:
a) completely standalone web pages served from some other web server (not mhttpd): loading midas.js, set the mhttpd location (base URL) via mjsonrpc_set_url(url) and issue
midas json-rpc requests as normal. (mhttpd fully supports the cross-site scripting (CORS) function).
b) custom pages loaded from mhttpd without midas styling: same as above, but no need to set the mhttpd base url.
c) custom pages loaded from mhttpd with midas styling: load midas.js, load mhttpd.js, load midas.css or mhttpd.css, see aaa_template.html or example.html to see how it all fits
together.
d) custom replacement for mhttpd standard web pages: to replace (for example) the standard "alarms" page, copy (or create a new one) alarms.html into the experiment directory
($MIDAS_DIR, same place as .ODB.SHM) and hack away. You can start from alarms.html, from aaa_template.html or from example.html.
K.O.
P.S. I am also reviewing mhttpd.css - the existing css file severely changes standard html formatting making it difficult to create custom web pages (all online tutorials and examples
look nothing like that are supposed to look like). The new CSS file midas.css fixes this by only changing formatting of html elements that explicitly ask for "midas styling", without
contaminating the standard html formatting. midas.css only works for example.html and aaa_template.html for now.
P.P.S. Here is the complete list of javascript functions in all 3 files:
8s-macbook-pro:resources 8ss$ grep ^function midas.js mhttpd.js obsolete.js
midas.js:function mjsonrpc_set_url(url)
midas.js:function mjsonrpc_send_request(req)
midas.js:function mjsonrpc_debug_alert(rpc) {
midas.js:function mjsonrpc_decode_error(error) {
midas.js:function mjsonrpc_error_alert(error) {
midas.js:function mjsonrpc_make_request(method, params, id)
midas.js:function mjsonrpc_call(method, params, id)
midas.js:function mjsonrpc_start_program(name, id) {
midas.js:function mjsonrpc_stop_program(name, unique, id) {
midas.js:function mjsonrpc_cm_exist(name, unique, id) {
midas.js:function mjsonrpc_al_reset_alarm(alarms, id) {
midas.js:function mjsonrpc_al_trigger_alarm(name, message, xclass, condition, type, id) {
midas.js:function mjsonrpc_db_copy(paths, id) {
midas.js:function mjsonrpc_db_get_values(paths, id) {
midas.js:function mjsonrpc_db_ls(paths, id) {
midas.js:function mjsonrpc_db_resize(paths, new_lengths, id) {
midas.js:function mjsonrpc_db_key(paths, id) {
midas.js:function mjsonrpc_db_delete(paths, id) {
midas.js:function mjsonrpc_db_paste(paths, values, id) {
midas.js:function mjsonrpc_db_create(paths, id) {
midas.js:function mjsonrpc_cm_msg(message, type, id) {
mhttpd.js:function ODBFinishInlineEdit(p, path, bracket)
mhttpd.js:function ODBInlineEditKeydown(event, p, path, bracket)
mhttpd.js:function ODBInlineEdit(p, odb_path, bracket)
mhttpd.js:function mhttpd_disable_button(button)
mhttpd.js:function mhttpd_enable_button(button)
mhttpd.js:function mhttpd_hide_button(button)
mhttpd.js:function mhttpd_unhide_button(button)
mhttpd.js:function mhttpd_init_overlay(overlay)
mhttpd.js:function mhttpd_hide_overlay(overlay)
mhttpd.js:function mhttpd_unhide_overlay(overlay)
mhttpd.js:function mhttpd_getParameterByName(name) {
mhttpd.js:function mhttpd_goto_page(page) {
mhttpd.js:function mhttpd_navigation_bar(current_page)
mhttpd.js:function mhttpd_page_footer()
mhttpd.js:function mhttpd_create_page_handle_create(mouseEvent)
mhttpd.js:function mhttpd_create_page_handle_cancel(mouseEvent)
mhttpd.js:function mhttpd_delete_page_handle_delete(mouseEvent)
mhttpd.js:function mhttpd_delete_page_handle_cancel(mouseEvent)
mhttpd.js:function mhttpd_start_run()
mhttpd.js:function mhttpd_stop_run()
mhttpd.js:function mhttpd_pause_run()
mhttpd.js:function mhttpd_resume_run()
mhttpd.js:function mhttpd_cancel_transition()
mhttpd.js:function mhttpd_reset_alarm(alarm_name)
mhttpd.js:function msg_load(f)
mhttpd.js:function msg_prepend(msg)
mhttpd.js:function msg_append(msg)
mhttpd.js:function findPos(obj) {
mhttpd.js:function msg_extend()
mhttpd.js:function alarm_load()
mhttpd.js:function aspeak_click(t)
mhttpd.js:function mhttpd_alarm_speak(t)
mhttpd.js:function chat_kp(e)
mhttpd.js:function rb()
mhttpd.js:function speak_click(t)
mhttpd.js:function chat_send()
mhttpd.js:function chat_load()
mhttpd.js:function chat_format(line)
mhttpd.js:function chat_prepend(msg)
mhttpd.js:function chat_append(msg)
mhttpd.js:function chat_reformat()
mhttpd.js:function chat_extend()
obsolete.js:function XMLHttpRequestGeneric()
obsolete.js:function ODBSetURL(url)
obsolete.js:function ODBSet(path, value, pwdname)
obsolete.js:function ODBGet(path, format, defval, len, type)
obsolete.js:function ODBMGet(paths, callback, formats)
obsolete.js:function ODBGetRecord(path)
obsolete.js:function ODBExtractRecord(record, key)
obsolete.js:function ODBKey(path)
obsolete.js:function ODBCopy(path, format)
obsolete.js:function ODBCall(url, callback)
obsolete.js:function ODBMCopy(paths, callback, encoding)
obsolete.js:function ODBMLs(paths, callback)
obsolete.js:function ODBMCreate(paths, types, arraylengths, stringlengths, callback)
obsolete.js:function ODBMResize(paths, arraylengths, stringlengths, callback)
obsolete.js:function ODBMRename(paths, names, callback)
obsolete.js:function ODBMLink(paths, links, callback)
obsolete.js:function ODBMReorder(paths, indices, callback)
obsolete.js:function ODBMKey(paths, callback)
obsolete.js:function ODBMDelete(paths, callback)
obsolete.js:function ODBRpc_rev0(name, rpc, args)
obsolete.js:function ODBRpc_rev1(name, rpc, max_reply_length, args)
obsolete.js:function ODBRpc(program_name, command_name, arguments_string, callback, max_reply_length)
obsolete.js:function ODBGetMsg(facility, start, n)
obsolete.js:function ODBGenerateMsg(type,facility,user,msg)
obsolete.js:function ODBGetAlarms()
obsolete.js:function ODBEdit(path)
obsolete.js:function getMouseXY(e)
8s-macbook-pro:resources 8ss$
K.O. |
|
17 Jan 2009, Konstantin Olchanski, Info, mhttpd, mlogger updates
|
mhttpd and mlogger have been updated with potentially troublesome changes.
Before using these latest versions, please make a backup of your ODB. This is
svn revisions 4434 (mhttpd.c) and 4435 (mlogger.c).
These new features are now available:
- a "feature complete" implementation of "history in an SQL database". We use
this new code to write history data from the T2K test setup in the TRIUMF M11
beam line to a MySQL database (mlogger) and to make history plots directly from
this database (mhttpd). We still write normal midas history files and we have a
utility to import midas .hst files into an SQL database (utils/mh2sql). The code
is functional, but incomplete. For best SQL database data layout, you should
enable the "per variable history" (but backup your ODB before you do this!). All
are welcome to try it, kick the tires, report any problems. Documentation TBW.
- experimental implementation of "ODBRpc" added to the midas javascript library
(ODBSet, ODBGet & co). This permits buttons on midas "custom" web pages to
invoke RPC calls directly into user frontend programs, for example to turn
things on or off. Documentation TBW.
- the mlogger/mhttpd implementation of /History/Tags has proved troublesome and
we are moving away from it. The SQL database history implementation already does
not use it. During the present transition period:
- mlogger and mhttpd will now work without /History/Tags. This implementation
reads history tags directly from the history files themselves. Two downsides to
this: it is slower and tags become non-persistent: if some frontends have not
been running for a while, their variables may vanish from the history panel
editor. To run in this mode, set "/History/DisableTags" to "y". Existing
/History/Tags will be automatically deleted.
- for the above 2 reasons, I still recommend using /History/Tags, but the format
of the tags is now changed to simplify management and reduce odb size. mlogger
will automatically convert the tags to this new format (this is why you should
make a backup of your ODB).
- using old mlogger with new mhttpd is okey: new mhttpd understands both formats
of /History/Tags.
- using old mhttpd with new mlogger is okey: please set ODB
"/History/CreateOldTags" to "y" (type TID_BOOL/"boolean") before starting mlogger.
K.O. |
|
21 Jan 2009, Andreas Suter, Bug Report, mhttpd, mlogger updates
|
There is an obvious "unwanted feature" in this version of the mhttpd. It writes the
"plot time" into the gif (mhttpd, if-statement starting in line 8853).
Please check this obvious things more carefully in the future before submitting code. ;-)
> mhttpd and mlogger have been updated with potentially troublesome changes.
> Before using these latest versions, please make a backup of your ODB. This is
> svn revisions 4434 (mhttpd.c) and 4435 (mlogger.c).
>
> These new features are now available:
> - a "feature complete" implementation of "history in an SQL database". We use
> this new code to write history data from the T2K test setup in the TRIUMF M11
> beam line to a MySQL database (mlogger) and to make history plots directly from
> this database (mhttpd). We still write normal midas history files and we have a
> utility to import midas .hst files into an SQL database (utils/mh2sql). The code
> is functional, but incomplete. For best SQL database data layout, you should
> enable the "per variable history" (but backup your ODB before you do this!). All
> are welcome to try it, kick the tires, report any problems. Documentation TBW.
> - experimental implementation of "ODBRpc" added to the midas javascript library
> (ODBSet, ODBGet & co). This permits buttons on midas "custom" web pages to
> invoke RPC calls directly into user frontend programs, for example to turn
> things on or off. Documentation TBW.
> - the mlogger/mhttpd implementation of /History/Tags has proved troublesome and
> we are moving away from it. The SQL database history implementation already does
> not use it. During the present transition period:
> - mlogger and mhttpd will now work without /History/Tags. This implementation
> reads history tags directly from the history files themselves. Two downsides to
> this: it is slower and tags become non-persistent: if some frontends have not
> been running for a while, their variables may vanish from the history panel
> editor. To run in this mode, set "/History/DisableTags" to "y". Existing
> /History/Tags will be automatically deleted.
> - for the above 2 reasons, I still recommend using /History/Tags, but the format
> of the tags is now changed to simplify management and reduce odb size. mlogger
> will automatically convert the tags to this new format (this is why you should
> make a backup of your ODB).
> - using old mlogger with new mhttpd is okey: new mhttpd understands both formats
> of /History/Tags.
> - using old mhttpd with new mlogger is okey: please set ODB
> "/History/CreateOldTags" to "y" (type TID_BOOL/"boolean") before starting mlogger.
>
> K.O. |
|
11 Feb 2014, Andreas Suter, Bug Report, mhttpd, etc.
|
I found a couple of bugs in the current mhttpd, midas version: "93fa5ed"
This concerns all browser I checked (firefox, chrome, internet explorer, opera)
1) When trying to change a value of a frontend using a multi class driver (we
have a lot of them), the field for changing appears, but I cannot get it set!
Neither via the two set buttons (why 2?) nor via return.
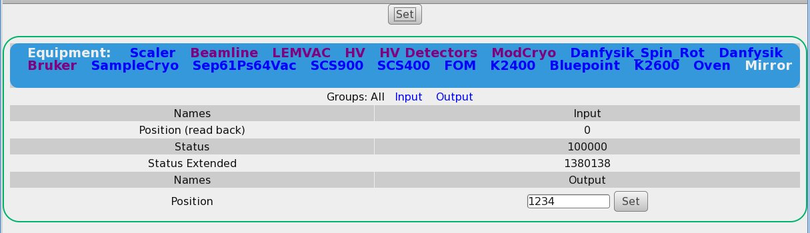
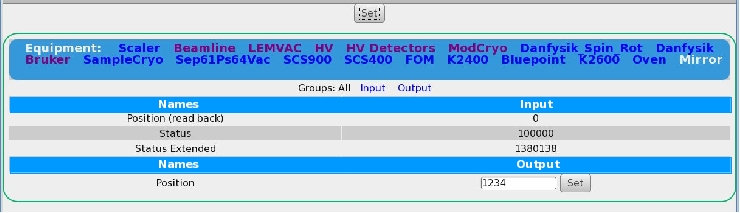
It also would be nice, if the css could be changed such that input/output for
multi-driver would be better separated; something along as suggested in
2) If I changing a value (generic/hv class driver), the index of the array
remains when chaning a value until the next update of the page

3) We are using a web-password. In the current version the password is plain visible when entering.
4) I just copied the header as described here: https://midas.triumf.ca/elog/Midas/908, but I get another result:
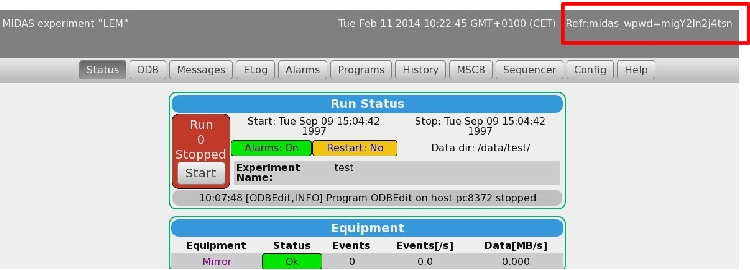
It looks like as a wrong cookie is filtered? |
|
11 Feb 2014, Stefan Ritt, Bug Report, mhttpd, etc.
|
| Andreas Suter wrote: | | I found a couple of bugs in the current mhttpd, midas version: "93fa5ed" |
See my reply on the issue tracker:
https://bitbucket.org/tmidas/midas/issue/18/mhttpd-bugs |
|
16 Apr 2026, Konstantin Olchanski, Suggestion, mhttpd user permissions
|
We had our periodic discussion on MIDAS web page user permissions. (I cannot
find the link to the previous discussions, ouch!)
Currently any logged in user can do anything - start stop runs, start/stop
programs, edit odb, etc.
Regularly, we have experiments that ask about "read-only" access to MIDAS and
about more granular user permissions.
In the past, I suggested a permissions scheme that is easy to implement
with the current code base. Permission level for each user can
be stored in ODB and allow:
level 0 - root user, as now
level 1 - experiment user, any restrictions are implemented in javascript, i.e.
all custom pages work as they do now, but (i.e.) the odb editor is read-only
level 2 - experiment operator, restrictions are implemented in the mjsonrpc
code, i.e. can start/stop runs, start/stop programs, but cannot make any
changes, i.e. cannot write to ODB
level 3 - read-only user - only mjsonrpc calls that do not change anything are
permitted.
(to implement level 2, obviously, the "start run" mjsonrpc call has to be
changed to accept the run comments, current code writes them to odb directly and
that would fail).
First step towards implementing this was made today. Ben and Derek figured out
the apache incantation to pass the logged user name to MIDAS and I added
decoding of this user name in mhttpd. I do not do anything with it, yet.
In apache config, one change is needed:
> For Apache, add this line in your VirtualHost section (tested as working):
> RequestHeader set X-Remote-User %{REMOTE_USER}s
https://daq00.triumf.ca/DaqWiki/index.php/Ubuntu#Install_apache_httpd_proxy_for_midas_and_elog
K.O. |
|
13 Sep 2013, Thomas Lindner, Bug Report, mhttpd truncates string variables to 32 characters
|
I find that new mhttpd has strange behaviour for ODB strings.
- I create a new STRING variable in ODB through mhttpd. It defaults to size 32.
- I then edit the STRING variable through mhttpd, writing a new string larger
than 32 characters.
- Initially everything looks fine; it seems as if the new string value has been
accepted.
- But if you reload the page, or navigate back to the page, you realize that
mhttpd has silently truncated the string back to 32 characters.
You can reproduce this problem on a test page here:
http://midptf01.triumf.ca:8081/AnnMessage
Older versions of mhttpd (I'm testing one from 2 years ago) don't have this
'feature'. For older mhttpd the string variable would get resized when a larger
string was inputted. That definitely seems like the right behavior to me.
I am using fresh copy of midas from bitbucket as of this morning. (How do I get
a particular tag/hash of the version of midas that I am using?) |
|
13 Sep 2013, Konstantin Olchanski, Bug Report, mhttpd truncates string variables to 32 characters
|
I can confirm part of the problem - the new inline-edit function - after you finish editing - shows you what you
have typed, not what's actually in ODB - at the very end it should do an ODBGet() to load the actual ODB
contents and show *that* to the user.
The truncation to 32 characters - most likely it is a failure to resize the ODB string - is probably in mhttpd and
I can take a quick look into it.
There is a 3rd problem - the mhttpd ODB editor "create" function does not ask for the string length to create.
Actually, in ODB, "create" and "set string size" are two separate functions - db_create_key(TID_STRING) creates
a string of length zero, then db_set_data() creates an empty string of desired length.
In the new AJAX interface these two functions are separate (ODBCreate just calls db_create_key()).
In the present ODBSet() function the two are mixed together - and the ODB inline edit function uses ODBSet().
K.O.
> I find that new mhttpd has strange behaviour for ODB strings.
>
> - I create a new STRING variable in ODB through mhttpd. It defaults to size 32.
>
> - I then edit the STRING variable through mhttpd, writing a new string larger
> than 32 characters.
>
> - Initially everything looks fine; it seems as if the new string value has been
> accepted.
>
> - But if you reload the page, or navigate back to the page, you realize that
> mhttpd has silently truncated the string back to 32 characters.
>
> You can reproduce this problem on a test page here:
>
> http://midptf01.triumf.ca:8081/AnnMessage
>
> Older versions of mhttpd (I'm testing one from 2 years ago) don't have this
> 'feature'. For older mhttpd the string variable would get resized when a larger
> string was inputted. That definitely seems like the right behavior to me.
>
> I am using fresh copy of midas from bitbucket as of this morning. (How do I get
> a particular tag/hash of the version of midas that I am using?) |
|
18 Sep 2013, Konstantin Olchanski, Bug Report, mhttpd truncates string variables to 32 characters
|
I confirm the second part of the problem.
Inline edit uses ODBSet(), which uses the "jset" AJAX call to mhttpd which does not extend string variables.
This is the jset code. The best I can tell it truncates string variables to the existing size in ODB:
db_find_key(hDB, 0, str, &hkey)
db_get_key(hDB, hkey, &key);
memset(data, 0, sizeof(data));
size = sizeof(data);
db_sscanf(getparam("value"), data, &size, 0, key.type);
db_set_data_index(hDB, hkey, data, key.item_size, index, key.type);
These original jset/jget functions are a little bit too complicated and there is no documentation (what exists is done by me trying to read the existing code).
We now have a jcopy/ODBMCopy() as a sane replacement for jget, but nothing comparable for jset, yet.
I think this quirk of inline edit cannot be fixed in javascript - the mhttpd code for "jset" has to change.
K.O.
>
> I can confirm part of the problem - the new inline-edit function - after you finish editing - shows you what you
> have typed, not what's actually in ODB - at the very end it should do an ODBGet() to load the actual ODB
> contents and show *that* to the user.
>
> The truncation to 32 characters - most likely it is a failure to resize the ODB string - is probably in mhttpd and
> I can take a quick look into it.
>
> There is a 3rd problem - the mhttpd ODB editor "create" function does not ask for the string length to create.
>
> Actually, in ODB, "create" and "set string size" are two separate functions - db_create_key(TID_STRING) creates
> a string of length zero, then db_set_data() creates an empty string of desired length.
>
> In the new AJAX interface these two functions are separate (ODBCreate just calls db_create_key()).
>
> In the present ODBSet() function the two are mixed together - and the ODB inline edit function uses ODBSet().
>
> K.O.
>
>
>
> > I find that new mhttpd has strange behaviour for ODB strings.
> >
> > - I create a new STRING variable in ODB through mhttpd. It defaults to size 32.
> >
> > - I then edit the STRING variable through mhttpd, writing a new string larger
> > than 32 characters.
> >
> > - Initially everything looks fine; it seems as if the new string value has been
> > accepted.
> >
> > - But if you reload the page, or navigate back to the page, you realize that
> > mhttpd has silently truncated the string back to 32 characters.
> >
> > You can reproduce this problem on a test page here:
> >
> > http://midptf01.triumf.ca:8081/AnnMessage
> >
> > Older versions of mhttpd (I'm testing one from 2 years ago) don't have this
> > 'feature'. For older mhttpd the string variable would get resized when a larger
> > string was inputted. That definitely seems like the right behavior to me.
> >
> > I am using fresh copy of midas from bitbucket as of this morning. (How do I get
> > a particular tag/hash of the version of midas that I am using?) |
|
24 Sep 2013, Stefan Ritt, Bug Report, mhttpd truncates string variables to 32 characters
|
Actually this was no bug, but a missing feature. Strings were never meant to be extended via the web interface.
Now I added that feature to the current version. Please check it.
/Stefan |
|
24 Sep 2013, Stefan Ritt, Bug Report, mhttpd truncates string variables to 32 characters
|
> This is the jset code. The best I can tell it truncates string variables to the existing size in ODB:
>
> db_find_key(hDB, 0, str, &hkey)
> db_get_key(hDB, hkey, &key);
> memset(data, 0, sizeof(data));
> size = sizeof(data);
> db_sscanf(getparam("value"), data, &size, 0, key.type);
> db_set_data_index(hDB, hkey, data, key.item_size, index, key.type);
Correct. So I added some code which extends strings if necessary (NOT string arrays, they are more complicated to handle). |
|
17 Sep 2019, Richard Longland, Forum, mhttpd start and stop redirect to Transition page
|
I recently upgraded to MIDAS version midas-2019-06-b. I had to make a few changes
to get our custom page running again, but am a little confused on starting and
stopping runs. When I click on my "Start" button, it now redirects to a
Transition page rather than reloading the status page. The standard MIDAS status
page does the same. Could someone explain the reasoning for the current behavior?
Furthermore my "Stop" button is now broken with the following error:
Error: Invalid URL "CS/EngeRun&" or query "cmd=Stop&redir=EngeRun%26" or command
"Stop"
I looked through the mhttpd.js code and managed to get the start button to load
the status page, at least, but the stop button seems to be written differently.
For example, start calls:
location.search = "cmd=Transition";
whereas stop does:
mhttpd_goto_page("Transition"); // DOES NOT RETURN
Can anyone offer any insights or advice? I can change the former to "cmd=Status", but
the latter doesn't allow it. |
|
27 Sep 2019, Konstantin Olchanski, Forum, mhttpd start and stop redirect to Transition page
|
> I recently upgraded to MIDAS version midas-2019-06-b. I had to make a few changes
> to get our custom page running again, but am a little confused on starting and
> stopping runs.
So far so good.
> When I click on my "Start" button, it now redirects to a
> Transition page rather than reloading the status page.
Are you sure? The "start" button redirects to the "start" page (start.html) which redirects
to the "transition" page (transition.html), which does not redirect anywhere so you can see
the result of the transition.
> Could someone explain the reasoning for the current behavior?
It's been like this for years now. Stefan suggest that we implement the "start" page
and the "transition" page as overlays on top of the status page, but it did not happen yet.
> Furthermore my "Stop" button is now broken with the following error:
> Error: Invalid URL "CS/EngeRun&" or query "cmd=Stop&redir=EngeRun%26" or command "Stop"
I grep for "EngeRun" and I do not see it anywhere in the midas sources. Can you grep for it
to see if it is coming from one of your pages?
If you want to start/stop runs from your custom page, look at start.html and transition.html - you will
need to make the run transition RPC calls (cut-and-paste the code to your page) and (obviously)
you will not have any redirects to some strange pages.
> For example, start calls:
> location.search = "cmd=Transition";
> whereas stop does:
> mhttpd_goto_page("Transition"); // DOES NOT RETURN
It's the same thing, look at mhttpd_goto_page().
> Can anyone offer any insights or advice? I can change the former to "cmd=Status", but
> the latter doesn't allow it.
I am not sure what you are trying to do. If you need the "start" button on the status page
to do something different from what it does now, just hack status.html until it does so.
If you need some specific help with that, I am happy to help. I think I answered all questions
you asked so far.
K.O. |
|