 26 May 2014, Dan Melconian, Suggestion, "Edit-on-end" would be nice 26 May 2014, Dan Melconian, Suggestion, "Edit-on-end" would be nice
|
We use the "Edit-on-start" and it's great. But sometimes, something breaks
during the run, or you didn't realize you forgot to plug in a cable, or
whatever. It'd be nice to have an "Edit-on-end" where you could prompt the user
to answer simple questions (like "Was this a good run? [y/n]" or "Was the data
polarized? [y/n]") and/or add a quick summary of what happened that run.
Thanks in advance,
Dan |
 26 May 2014, Stefan Ritt, Suggestion, "Edit-on-end" would be nice 26 May 2014, Stefan Ritt, Suggestion, "Edit-on-end" would be nice
|
We have similar demands, and we solve it in the following:
We use a run database. In the simplest case, this can be a text file which gets written at the end of the file. The
mlogger has a built in SQL interface, so one can keep that table even inside a SQL interface. The per-run-
information then contains the run number, start/stop time, number of events, some run parameters and a "junk"
flag. So if a run has a problem, one can set the junk flag by accessing the database (or text file) and setting this
flag. In many cases you see that a run had a problem not at the end of the run, but a bit later. You mayby realize
that the last two or three runs had the problem. With the run database approach, you can flag any run as "junk"
later, which we need often, An edit-on-end would not make this possible.
So technically putting and edit-on-end is not a problem, but your life might be much easier if you use a run
database as outlined above.
Best regards,
Stefan |
|
28 Apr 2014, Tom Stuttard, Forum, Words written as zero in Midas bank
|
Hi,
I am having some trouble with the data in my Midas bank. I am filling a midas
bank in my frontend (one of several in my system), and this bank is then being
added to the overall event by the event builder.
I check the data as it enters the bank, and also check again after I close the
bank in my frontend (using pdata's original value), and in both cases my data is
as I expect.
However, when I view the data in the .mid file (using mdump), there is a
problem. The correct number of words are there, and the values are correct up
until the 148th word. However, all subsequent words are 0.
I have also noticed that if I change my word size from 32bit (DWORD) to 16bit
(WORD), I observe the same behaviour except that now the first 296 words are
correct and all others are zero.
Note that other frontends in the system are not suffering this issue.
Does anyone have any ideas about how to solve this problem? |
|
15 Apr 2014, Wes Gohn, Forum, C++11 error
|
I am having some trouble creating a frontend that interacts with some libraries that use C++11.
The flag I added to my MIDAS Makefile to get the C++11 part of the code to work is -std=c++0x. This
causes an error in the equipment description in the frontend code.
The error I get is:
frontend.cpp:149: error: narrowing conversion of �-0x00000000000000001� from �int� to �WORD� inside {
}
This corresponds to the following in the MIDAS frontend code.
EQUIPMENT equipment[] = {
{
"MWPC", /* equipment name */
{1, TRIGGER_ALL, /* event ID, trigger mask */
"BUF2", /* event buffer */
EQ_POLLED | EQ_EB, /* equipment type */
LAM_SOURCE(0, 0xFFFFFF), /* event source crate 0, all stations */
"MIDAS", /* format */
TRUE, /* enabled */
RO_RUNNING, /* read only when running */
1, /* poll for 1ms */
0, /* stop run after this event limit */
0, /* number of sub events */
0, /* don't log history */
"", "", "",},
read_trigger_event, /* readout routine */
},
{""}
}; <- this is line 149
#ifdef __cplusplus
}
#endif
Do you know a way to make this compatible with C++11?
Thanks! |
|
16 Apr 2014, Stefan Ritt, Forum, C++11 error
|
> I am having some trouble creating a frontend that interacts with some libraries that use C++11.
>
> The flag I added to my MIDAS Makefile to get the C++11 part of the code to work is -std=c++0x. This
> causes an error in the equipment description in the frontend code.
>
> The error I get is:
>
> frontend.cpp:149: error: narrowing conversion of �-0x00000000000000001� from �int� to �WORD� inside {
> }
>
> This corresponds to the following in the MIDAS frontend code.
>
> EQUIPMENT equipment[] = {
> {
> "MWPC", /* equipment name */
> {1, TRIGGER_ALL, /* event ID, trigger mask */
> "BUF2", /* event buffer */
> EQ_POLLED | EQ_EB, /* equipment type */
> LAM_SOURCE(0, 0xFFFFFF), /* event source crate 0, all stations */
> "MIDAS", /* format */
> TRUE, /* enabled */
> RO_RUNNING, /* read only when running */
> 1, /* poll for 1ms */
> 0, /* stop run after this event limit */
> 0, /* number of sub events */
> 0, /* don't log history */
> "", "", "",},
> read_trigger_event, /* readout routine */
> },
>
> {""}
> }; <- this is line 149
> #ifdef __cplusplus
> }
> #endif
>
> Do you know a way to make this compatible with C++11?
>
> Thanks!
Is this maybe related to the LAM_SOURCE(0, 0xFFFFFFFF) where 0xFFFFFFFF is -1. I guess you are not using CAMAC, so just replace the
LAM_SOURCE(...) with zero and try again.
/Stefan |
|
16 Apr 2014, Wes Gohn, Forum, C++11 error
|
> > I am having some trouble creating a frontend that interacts with some libraries that use C++11.
> >
> > The flag I added to my MIDAS Makefile to get the C++11 part of the code to work is -std=c++0x. This
> > causes an error in the equipment description in the frontend code.
> >
> > The error I get is:
> >
> > frontend.cpp:149: error: narrowing conversion of �-0x00000000000000001� from �int� to �WORD� inside {
> > }
> >
> > This corresponds to the following in the MIDAS frontend code.
> >
> > EQUIPMENT equipment[] = {
> > {
> > "MWPC", /* equipment name */
> > {1, TRIGGER_ALL, /* event ID, trigger mask */
> > "BUF2", /* event buffer */
> > EQ_POLLED | EQ_EB, /* equipment type */
> > LAM_SOURCE(0, 0xFFFFFF), /* event source crate 0, all stations */
> > "MIDAS", /* format */
> > TRUE, /* enabled */
> > RO_RUNNING, /* read only when running */
> > 1, /* poll for 1ms */
> > 0, /* stop run after this event limit */
> > 0, /* number of sub events */
> > 0, /* don't log history */
> > "", "", "",},
> > read_trigger_event, /* readout routine */
> > },
> >
> > {""}
> > }; <- this is line 149
> > #ifdef __cplusplus
> > }
> > #endif
> >
> > Do you know a way to make this compatible with C++11?
> >
> > Thanks!
>
> Is this maybe related to the LAM_SOURCE(0, 0xFFFFFFFF) where 0xFFFFFFFF is -1. I guess you are not using CAMAC, so just replace the
> LAM_SOURCE(...) with zero and try again.
>
> /Stefan
Thanks for the suggestion. It looks like it is instead the TRIGGER_ALL that is causing the problem. TRIGGER_ALL is defined as -1 in midas.h. If I replace TRIGGER_ALL with 0 in the
frontend, it compiles, but if I use -1, I get the same error. I do not think that I want my trigger mask set to 0. Do you have a suggestion of how to get around this?
To answer the other questions, we are running on SLF6. I am building a frontend for a MWPC to read data from CAEN TDCs. |
|
17 Apr 2014, Stefan Ritt, Forum, C++11 error
|
> Thanks for the suggestion. It looks like it is instead the TRIGGER_ALL that is causing the problem. TRIGGER_ALL is defined as -1 in midas.h. If I replace TRIGGER_ALL with 0 in the
> frontend, it compiles, but if I use -1, I get the same error. I do not think that I want my trigger mask set to 0. Do you have a suggestion of how to get around this?
Ok, then it's clear. The trigger mask inside the EQUIPMENT_INFO is defined as 16-bit unsigned int (WORD). So the -1 gets expanded into a 64-bit signed int, then the compiler complains about truncating this to 16-bit.
Just try instead TRIGGER_ALL to write
(WORD)(-1)
or even
0xFFFF
that should do the job. Basically you want all 16 bits to be "1" if yo do not use this feature.
Best regards,
Stefan |
|
17 Mar 2014, Zhi Li, Forum, [need help] simple example frontend for CAEN VX1721
|
Dear guys,
I�m Zhi Li from China, and I�m now working on my graduation project, which now
basically gets stuck in the part of preparing the frontend for my FADC (CAEN
VX1721) using Midas.
Now the current set-up includes a VME crate, a CAEN v2718 (Optical Bridge and
Controller) and a CAEN VX1721(8ch 8bit 500MS/s Waveform digitizer). The hardware
set-up has been finished and I could capture the analog waveform using CAEN
software(wavedump).
Could anyone please tell me what are the basic things to do for using MIDAS?
I�ve installed MIDAS in PC and it works well for CAMAC, but do I need any extra
hardware module on using VME crate? Also, how to download
Universe-II VME driver?
Thanks,
Li |
|
17 Mar 2014, Pierre-Andre Amaudruz, Forum, [need help] simple example frontend for CAEN VX1721
|
Hi Li,
You mention that you've got the wavedump working. It suggests that you have a A3818
interface, can you confirm that?
If so, you can make a Midas frontend using the CAEN libraries to access your VX1721. I can provide you with a frontend example used for the V1720 or V1740. The
modifications for the VX1721 shouldn't be too hard as most of the CAEN digitizers
are fortunately based on a similar configuration mechanism.
If you have a Midas CAMAC frontend, the trick would be to replace the CAMAC calls by
the appropriate CAENComm_xxx() for the equivalent functionality.
Can you remind me what hardware do you have in your lab for acquisition?
CAMAC controller, VME controller etc.
Cheers, PAA
> Dear guys,
>
> I�m Zhi Li from China, and I�m now working on my graduation project, which now
> basically gets stuck in the part of preparing the frontend for my FADC (CAEN
> VX1721) using Midas.
>
> Now the current set-up includes a VME crate, a CAEN v2718 (Optical Bridge and
> Controller) and a CAEN VX1721(8ch 8bit 500MS/s Waveform digitizer). The hardware
> set-up has been finished and I could capture the analog waveform using CAEN
> software(wavedump).
>
> Could anyone please tell me what are the basic things to do for using MIDAS?
> I�ve installed MIDAS in PC and it works well for CAMAC, but do I need any extra
> hardware module on using VME crate? Also, how to download
> Universe-II VME driver?
>
> Thanks,
> Li |
|
17 Mar 2014, Zhi Li, Forum, [need help] simple example frontend for CAEN VX1721
|
Hi Pierre,
Thanks for your instructions. Before I run the wavedump software, I need to load a driver file for A2818, thus I think I've got this interface of A2818.
I would be grateful to have a look at the frontend example used for v1720 (closer to v1721 I suppose), would you be so kind to offer me the Makefile as well? I
really want to have a compilable/executable DAQ frontend for vme modules, and know better how to link to CAEN library in the Makefile.
About hardware currently used in the vme crate(A2818), there is a VME controller(V2718, CONET VME Bridge), and a FADC(VX1721 waveform digitizer). I'm now preparing
this DAQ system to compare relative quantum efficiency, timing resolution, 1 pe distribution of photomultipliers, also measure decay time of cosmic muons, and
electron spectrum. Humbly, I want to know your opinion on whether I need additional hardware to finish these experiments.
Thanks,
Li
> Hi Li,
>
> You mention that you've got the wavedump working. It suggests that you have a A3818
> interface, can you confirm that?
>
> If so, you can make a Midas frontend using the CAEN libraries to access your VX1721. I can provide you with a frontend example used for the V1720 or V1740. The
> modifications for the VX1721 shouldn't be too hard as most of the CAEN digitizers
> are fortunately based on a similar configuration mechanism.
> If you have a Midas CAMAC frontend, the trick would be to replace the CAMAC calls by
> the appropriate CAENComm_xxx() for the equivalent functionality.
>
> Can you remind me what hardware do you have in your lab for acquisition?
> CAMAC controller, VME controller etc.
>
> Cheers, PAA
>
> > Dear guys,
> >
> > I�m Zhi Li from China, and I�m now working on my graduation project, which now
> > basically gets stuck in the part of preparing the frontend for my FADC (CAEN
> > VX1721) using Midas.
> >
> > Now the current set-up includes a VME crate, a CAEN v2718 (Optical Bridge and
> > Controller) and a CAEN VX1721(8ch 8bit 500MS/s Waveform digitizer). The hardware
> > set-up has been finished and I could capture the analog waveform using CAEN
> > software(wavedump).
> >
> > Could anyone please tell me what are the basic things to do for using MIDAS?
> > I�ve installed MIDAS in PC and it works well for CAMAC, but do I need any extra
> > hardware module on using VME crate? Also, how to download
> > Universe-II VME driver?
> >
> > Thanks,
> > Li |
|
12 Mar 2014, Andreas Suter, Info, Windows support droped?
|
In the old SVN midas world it was typically such that the Windows dll's and
exe's were ready to be used when checking out. I am not so sure this is the case
for the current version, since when I use the packed dll's and exe's (e.g.
odbedit.exe) I get the warning that this is running midas 2.0.0 but the current
version (on the linux server) is 2.1.
What does this mean?
1) A little bug in the packed windows part, but up-to-date dll's and exe's?
2) The dll's and exe's are not bundled any more to up-to-date version?
If 2) is the case, I would like to get a hint how to build midas under Windows
(Windows 7), since we still have some few Windows clients. |
|
14 Mar 2014, Konstantin Olchanski, Info, Windows support droped?
|
> In the old SVN midas world it was typically such that the Windows dll's and
> exe's were ready to be used when checking out.
The Windows executables are no longer included in the midas git repository. Old versions are still available in
the git repository - they got pulled in during conversion from svn.
One reason for removing them is that neither myself, nor Pierre, nor Stefan have ready access to a Windows
development environment and we cannot keep Windows binaries up to date. Theoretically we can setup a
Windows machine just for compiling MIDAS, but then there is a question of which Windows we should use and
how much priority we should put into it. I do not think there is any demand for MIDAS on Windows at TRIUMF.
(Personally, I think Windows is no longer a viable platform for any business use - with Microsoft focusing on
"experiences", "tiles", touch screens, portable devices, and other gimmicks - rather than on providing a solid OS
to get work done)
> I am not so sure this is the case
> for the current version, since when I use the packed dll's and exe's (e.g.
> odbedit.exe) I get the warning that this is running midas 2.0.0 but the current
> version (on the linux server) is 2.1. What does this mean?
You can ignore this message. Stefan incremented the MIDAS version when we migrated to git, but
there are no changes to the MIDAS RPC mechanism and we are still fully compatible with old versions,
at least in the MIDAS RPC and in the mserver.
So tools like odbedit.exe should still work okey when connecting from Windows to MIDAS running on Linux or
MacOS.
But old frontend programs may cause some trouble because the ODB layout changed somewhat with new things
added to /eq/xxx/common. Simplest is to try, if it works, it works.
> 1) A little bug in the packed windows part, but up-to-date dll's and exe's?
> 2) The dll's and exe's are not bundled any more to up-to-date version?
Case (2) is the case. Personally I do not have any capability to build Windows binaries. Same for Pierre and I think
for Stefan.
> If 2) is the case, I would like to get a hint how to build midas under Windows
> (Windows 7), since we still have some few Windows clients.
I do not think pre-built executables will ever return - the new way of things is to "cut-and-paste" the "git clone"
command from a web page, type "make", and be done with it. If your OS does not have "git", "make" & etc, you
should switch to a real OS.
On the MIDAS software side, we have no problem with supporting Windows - same as on any other platform,
please try to build and run it, report any problems, fixes, patches and improvements - we will commit them into
the midas repository.
K.O. |
|
17 Mar 2014, Stefan Ritt, Info, Windows support droped?
|
> The Windows executables are no longer included in the midas git repository. Old versions are still available in
> the git repository - they got pulled in during conversion from svn.
>
> One reason for removing them is that neither myself, nor Pierre, nor Stefan have ready access to a Windows
> development environment and we cannot keep Windows binaries up to date. Theoretically we can setup a
> Windows machine just for compiling MIDAS, but then there is a question of which Windows we should use and
> how much priority we should put into it. I do not think there is any demand for MIDAS on Windows at TRIUMF.
I double checked and can confirm that the executables in GIT are very old. So I tried to compile the current version for Windows. I found that I had to change lots
of places (basically all the new files written by KO) to make it work again, so it took me half a day, but now should be fine.
I'm not sure if it's a good idea to keep .exe files in GIT, maybe we should remove it some day, but for the moment I updated the executables to the current
version. Feedback welcome.
/Stefan |
|
11 Mar 2014, Andreas Suter, Forum, mlogger problem
|
I stumbled over a problem which I cannot pin point and would appreciate suggestions.
I set up an experiment, and all of a sudden I noticed the following behaviour.
I can start any number of frontends without any problems as long as mlogger is NOT running.
I can also start mlogger without any problems. However, as soon as I started the mlogger, I cannot start anything else any more (including odbedit). I get the following assertion:
16:07:06 [Logger,INFO] Program Logger on host lem00 started
[local:nemu:S]/>q
[nemu@lem00 2014]$ odbedit -e nemu
odbedit: src/odb.c:753: db_update_open_record: Assertion `xkey->notify_count == pkey->notify_count' failed.
Aborted
This is even happening if I stop all frontends, start only the mlogger and afterwards try to start odbedit.
I tried to see if this is a generic feature on a test experiment, but there I cannot reproduce it. It seems that there is either something wrong with the ODB, something wrong with hotlinks, ..., I don't know.
I would appreciated suggestions how pin point the issue. |
|
11 Mar 2014, Stefan Ritt, Forum, mlogger problem
|
| Andreas Suter wrote: | I stumbled over a problem which I cannot pin point and would appreciate suggestions.
I set up an experiment, and all of a sudden I noticed the following behaviour.
I can start any number of frontends without any problems as long as mlogger is NOT running.
I can also start mlogger without any problems. However, as soon as I started the mlogger, I cannot start anything else any more (including odbedit). I get the following assertion:
16:07:06 [Logger,INFO] Program Logger on host lem00 started
[local:nemu:S]/>q
[nemu@lem00 2014]$ odbedit -e nemu
odbedit: src/odb.c:753: db_update_open_record: Assertion `xkey->notify_count == pkey->notify_count' failed.
Aborted
This is even happening if I stop all frontends, start only the mlogger and afterwards try to start odbedit.
I tried to see if this is a generic feature on a test experiment, but there I cannot reproduce it. It seems that there is either something wrong with the ODB, something wrong with hotlinks, ..., I don't know.
I would appreciated suggestions how pin point the issue. |
K.O. put that in: https://bitbucket.org/tmidas/midas/commits/9d7b7c83b275a2bd3c846c4f265ff7f5d53f3426
He should have a look at it.
Have you tried to rebuild your ODB from scratch? (Save in XML, then delete .ODB.SHM, then load again form XML)?
/Stefan |
|
11 Mar 2014, Andreas Suter, Forum, mlogger problem
|
| Stefan Ritt wrote: |
| Andreas Suter wrote: | I stumbled over a problem which I cannot pin point and would appreciate suggestions.
I set up an experiment, and all of a sudden I noticed the following behaviour.
I can start any number of frontends without any problems as long as mlogger is NOT running.
I can also start mlogger without any problems. However, as soon as I started the mlogger, I cannot start anything else any more (including odbedit). I get the following assertion:
16:07:06 [Logger,INFO] Program Logger on host lem00 started
[local:nemu:S]/>q
[nemu@lem00 2014]$ odbedit -e nemu
odbedit: src/odb.c:753: db_update_open_record: Assertion `xkey->notify_count == pkey->notify_count' failed.
Aborted
This is even happening if I stop all frontends, start only the mlogger and afterwards try to start odbedit.
I tried to see if this is a generic feature on a test experiment, but there I cannot reproduce it. It seems that there is either something wrong with the ODB, something wrong with hotlinks, ..., I don't know.
I would appreciated suggestions how pin point the issue. |
K.O. put that in: https://bitbucket.org/tmidas/midas/commits/9d7b7c83b275a2bd3c846c4f265ff7f5d53f3426
He should have a look at it.
Have you tried to rebuild your ODB from scratch? (Save in XML, then delete .ODB.SHM, then load again form XML)?
/Stefan |
Yes, I could recover the ODB by falling back to a previous dump. Still, I would like to know what is the exact meaning of the above assertion. It might help to understand what are the likely cause which results in the assertion.
/Andreas |
|
14 Mar 2014, Konstantin Olchanski, Forum, mlogger problem
|
> I stumbled over a problem which I cannot pin point and would appreciate suggestions.
>
> [nemu@lem00 2014]$ odbedit -e nemu
> odbedit: src/odb.c:753: db_update_open_record: Assertion `xkey->notify_count == pkey-
>notify_count' failed.
> Aborted
I think this is a real bug in MIDAS - I will have to take a look to figure out where this is coming from. At the
least, if I cannot replace the assert with some corrective action, I may replace it with an error message.
I am glad you could recover by reloading odb.
K.O. |
|
14 Mar 2014, Konstantin Olchanski, Info, midas wiki updated to mediawiki 1.22.4
|
The midas wiki at https://midas.triumf.ca was updated to mediawiki 1.22.4 - the latest production version.
If you see any problems, please report them to this elog. K.O. |
27 Feb 2014, Andreas Suter, Suggestion, runlog is "ugly" 
|
I have a couple of questions and suggestions concerning the "new" CSS style of the mhttpd, especially related to the runlog
- If I am not mistaken, the mhttpd.css is hard coded (path/name) into the mhttpd. Wouldn't it be beneficial to have ODB entries where to get is from? This way people could change the look and feel more freely.
- Especially the look and feel of the runlog is unsatisfactorily from my point of view. See
 . The old style was much more readable. I could recover the old style look and feel by slightly changing the mhttpd.cxx where I changed in show_rawfile(const char*) "dialogTable" to "runlogTable" in the table class. This way I could tinker around with the mhttpd.css by adding the following stuff there: . The old style was much more readable. I could recover the old style look and feel by slightly changing the mhttpd.cxx where I changed in show_rawfile(const char*) "dialogTable" to "runlogTable" in the table class. This way I could tinker around with the mhttpd.css by adding the following stuff there:
- adding .runlogTable in line 289 :

- adding some style information for the runlogTable :

This way the "old" runlog look and feel recovered : 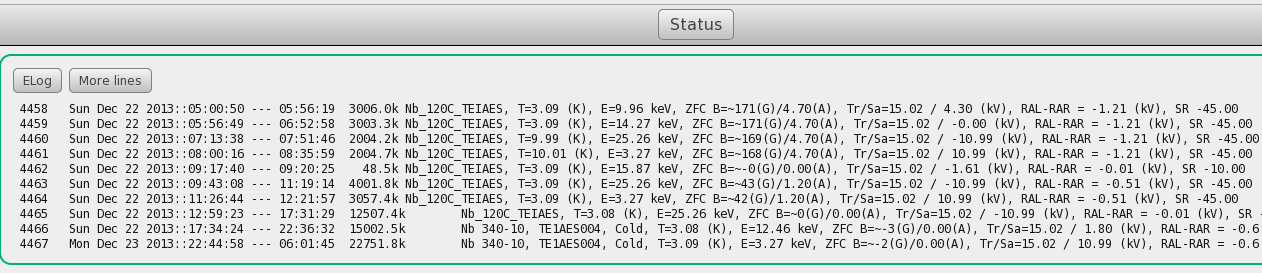 , which I think is much more readable. , which I think is much more readable.
If possible, I would love to have alternating background colors between the runs for readability reasons, but I am not sure how easy it would be to add something like this.
I not much experience with HTML/CSS yet, though a concrete implementation might be different. |
|
27 Feb 2014, Konstantin Olchanski, Suggestion, runlog is "ugly"
|
> If I am not mistaken, the mhttpd.css is hard coded (path/name) into the mhttpd.
mhttpd.css is served from $MIDASSYS/resources/mhttpd.css. The actual path is reported on the mhttpd
"help" page.
(I think the internal mhttpd.css and mhttpd.js should be removed as no longer useful - nothing will work
right if the real mhttpd.js and mhttpd.css cannot be served).
> Especially the look and feel of the runlog is unsatisfactorily from my point of view.
persons in charge of implementing the CSS stuff failed to convert quite a few pages, for example, the elog
and the history editor pages were left completely broken. (mostly fixed now).
so thank you for reporting the runlog breakage, I hope Stefan & co can fix it quickly. (I cannot do - I have
have no runlog pages on any of my test experiments).
> the old style was much more readable.
I think the new style is not too bad, except for a few visual artefacts here and there, the general comment
that CSS is too complicated and hard to debug and the fact that over-subtle colouring yields inconsistent
visuals between different monitors and ambient lighting conditions. (persons who select the colours always
respond that "but to me, it looks just fine on my laptop", making it hard to resolve any issues).
> I could recover the old style look and feel by slightly changing the mhttpd.cxx
If you post the patches that fix it for you, I can commit them to midas. (git diff | mail olchansk@triumf.ca).
K.O. |
|
28 Feb 2014, Andreas Suter, Suggestion, runlog is "ugly"
|
Understand me right, I mostly like the new style, except the runlog as reported.
Attached you will find the diff's you were asking for. But as pointed out, I
haven't worked so far on CSS and hence this should be checked!!
I understand that the mhttpd.js needs to be the default one, however, mhttpd.css
might be left to the end-user to adopt to their specific needs. I shortly
checked in the mhttpd demon. It checks for the resources path in the ODB. If it
also would check for a CSS name, mhttpd.css could be changed/adopted by the
end-users without breaking things (at least it would then be their one business).
> > If I am not mistaken, the mhttpd.css is hard coded (path/name) into the mhttpd.
>
> mhttpd.css is served from $MIDASSYS/resources/mhttpd.css. The actual path is
reported on the mhttpd
> "help" page.
>
> (I think the internal mhttpd.css and mhttpd.js should be removed as no longer
useful - nothing will work
> right if the real mhttpd.js and mhttpd.css cannot be served).
>
> > Especially the look and feel of the runlog is unsatisfactorily from my point
of view.
>
> persons in charge of implementing the CSS stuff failed to convert quite a few
pages, for example, the elog
> and the history editor pages were left completely broken. (mostly fixed now).
>
> so thank you for reporting the runlog breakage, I hope Stefan & co can fix it
quickly. (I cannot do - I have
> have no runlog pages on any of my test experiments).
>
> > the old style was much more readable.
>
> I think the new style is not too bad, except for a few visual artefacts here
and there, the general comment
> that CSS is too complicated and hard to debug and the fact that over-subtle
colouring yields inconsistent
> visuals between different monitors and ambient lighting conditions. (persons
who select the colours always
> respond that "but to me, it looks just fine on my laptop", making it hard to
resolve any issues).
>
> > I could recover the old style look and feel by slightly changing the mhttpd.cxx
>
> If you post the patches that fix it for you, I can commit them to midas. (git
diff | mail olchansk@triumf.ca).
>
> K.O. |
|
28 Feb 2014, Stefan Ritt, Suggestion, runlog is "ugly"
|
> If I am not mistaken, the mhttpd.css is hard coded (path/name) into the mhttpd.
I agree that this should be removed, Unfortunately I'm away right now, so I will fix it next week. Also will put in
Andreas' diffs.
/Stefan |
|
07 Mar 2014, Stefan Ritt, Suggestion, runlog is "ugly"
|
I put mhttpd.css and mhttpd.js into the ODB, so every experiment can change it. I put also Andreas' modifications of the CSS file for the runlog table and
committed the changes.
/Stefan |
|
11 Feb 2014, Randolf Pohl, Forum, Huge events (>10MB) every second or so
|
I'm looking into using MIDAS for an experiment that creates one large event
(20MB or more) every second.
Q1: It looks like I should use EQ_FRAGMENTED. Has this feature been in use
recently? Is it known to work/not work?
More specifically, the computer should initiate a 1 second data taking, start to
such the data out of the electronics (which may take a while), change some
experimental parameters, and start over.
Q2: What's the best way to do this? EQ_PERIODIC?
I cannot guarantee that the time required to read the hardware has an upper bound.
In a standalone-prog I would simply use a big loop and let the machine execute
it as fast as it can: 1.1s, 1.5s, 1.1s, 1.3s, 2.5s, ..... depending on the HW
deadtimes.
Will this work with EQ_PERIODIC?
(Sorry for these maybe stupid questions, but I have so far only used MIDAS for
externally generated events, with <32kB event size).
Thanks a lot,
Randolf |
|
11 Feb 2014, Stefan Ritt, Forum, Huge events (>10MB) every second or so
|
> I'm looking into using MIDAS for an experiment that creates one large event
> (20MB or more) every second.
>
> Q1: It looks like I should use EQ_FRAGMENTED. Has this feature been in use
> recently? Is it known to work/not work?
>
> More specifically, the computer should initiate a 1 second data taking, start to
> such the data out of the electronics (which may take a while), change some
> experimental parameters, and start over.
>
> Q2: What's the best way to do this? EQ_PERIODIC?
> I cannot guarantee that the time required to read the hardware has an upper bound.
> In a standalone-prog I would simply use a big loop and let the machine execute
> it as fast as it can: 1.1s, 1.5s, 1.1s, 1.3s, 2.5s, ..... depending on the HW
> deadtimes.
> Will this work with EQ_PERIODIC?
>
> (Sorry for these maybe stupid questions, but I have so far only used MIDAS for
> externally generated events, with <32kB event size).
>
>
> Thanks a lot,
>
> Randolf
Hi Randolf,
EQ_FRAGMENTED is kind of historically, when computers had a few MB of memory and you have to play special tricks to get large data buffers through. Today I
would just use EQ_PERIODIC and increase the midas maximal event size to your needs. For details look here:
https://midas.triumf.ca/MidasWiki/index.php/Event_Buffer
The front-end scheduler is asynchronous, which means that your readout is called when the given period (1 second) is elapsed. If the readout takes longer
than 1s, the schedule will (hopefully) call your readout immediately after the event has been sent. So you get automatically your maximal data rate. At MEG, we
use 2 MB events with 10 Hz, so a 20 MB/sec data rate should not be a problem on decent computers.
Best,
Stefan |
|
18 Feb 2014, Konstantin Olchanski, Forum, Huge events (>10MB) every second or so
|
> I'm looking into using MIDAS for an experiment that creates one large event
> (20MB or more) every second.
Hi, there - 20 Mbyte event at 1/sec is not so large these days. (Well, depending on your hardware).
Using typical 1-2 year old PC hardware, 20 M/sec to local disk should work right away. Sending data from a
remote front end (through the mserver), or writing to a remote disk (NFS, etc) - will of course requre a GigE
network connection.
By default, MIDAS is configured for using about 1-2 Mbyte events, so for your case, you will need to:
- increase the event size limits in your frontend,
- increase /Experiment/MAX_EVENT_SIZE in ODB
- increase the size of the SYSTEM event buffer (/Experiment/Buffer sizes/SYSTEM in ODB)
I generally recommend sizing the SYSTEM event buffer to hold a few seconds worth of data (ot
accommodate any delays in writing to local disk - competing reads, internal delays of the disks, etc).
So for 20 M/s, the SYSTEM buffer size should be about 40-60 Mbytes.
For your case, you also want to buffer 3-5-10 events, so the SYSTEM buffer size would be between 100 and
200 MBytes.
Assuming you have between 8-16-32 GBytes of RAM, this should not be a problem.
One the other hand, if you are running on a low-power ("green") ARM system with 1 Gbyte of RAM and a
1GHz CPU, you should be able to handle the data rate of 20 Mbytes/sec, as long as your network and
storage can handle it - I see GigE ethernet running at about 30-40 Mbytes/sec, so you should be okey,
but local storage to SD flash is only about 10 Mbytes/sec - too slow. You can try USB-attached HDD or SSD,
this should run at up to 30-40 Mbytes/sec. I would expect no problems with this rate from MIDAS, as long
as you can fit into your 1 GByte of RAM - obviously your SYSTEM buffer will have to be a little smaller than
on a full-featured PC.
More information on MIDAS event size limits is here (as already reported by Stefan)
https://midas.triumf.ca/MidasWiki/index.php/Event_Buffer
Let us know how it works out for you.
K.O. |
|
01 Mar 2014, Randolf Pohl, Forum, Huge events (>10MB) every second or so
|
Works, and here is how I did it. The attached example is based on the standard MIDAS
example in "src/midas/examples/experiment".
My somewhat unsorted notes, haven't really tweaked the numbers. But it WORKS.
(1) mlogger writes "last.xml" (hard-coded!) which takes an awful amount of time
as it writes the complete ODB containing the 10MB bank!
just outcomment
// odb_save("last.xml");
in mlogger.cxx, function
INT tr_start(INT run_number, char *error)
(line ~3870 in mlogger rev. 5377, .cxx-file included)
(2) frontend.c:
* the most important declarations are
/* BIG_DATA_BYTES is the data in 1 bank
BIG_EVENT_SIZE is the event size. It's a bit larger than the bank size
because MIDAS needs to add some header bytes, I think
*/
#define BIG_DATA_BYTES (10*1024*1024) // 10 MB
#define BIG_EVENT_SIZE (BIG_DATA_BYTES + 100)
/* maximum event size produced by this frontend */
INT max_event_size = BIG_EVENT_SIZE;
/* maximum event size for fragmented events (EQ_FRAGMENTED) */
INT max_event_size_frag = 5 * BIG_EVENT_SIZE;
/* buffer size to hold 10 events */
INT event_buffer_size = 10 * BIG_EVENT_SIZE;
* bk_init() can hold at most 32kByte size events! Use bk_init32() instead.
* complete frontend.c is attached
(3) in an xterm do
# . setup.sh
# odbedit -s 41943040
(first invocation of odbedit must create large enough odb,
otherwise you'll get "odb full" errors)
(4) odbedit> load big.odb
(attached). Essentials are:
/Experiment/MAX_EVENT_SIZE = 20971520
/Experiment/Buffer sizes/SYSTEM = 41943040 <- at least 2 events!
To avoid excessive latecies when starting/stopping a run, do
/Logger/ODB Dump = no
/Logger/Channels/0/Settings/ODB Dump = no
and create an Equipment Tree to make the mlogger happy
(5) a few more xterms, always ". setup.sh":
# mlogger_patched (see (1))
# ./frontend (attched)
(6) in your odbedit (4) say "start". You should fill your disk rather quickly. |
|
01 Mar 2014, Stefan Ritt, Forum, Huge events (>10MB) every second or so
|
> Works, and here is how I did it. The attached example is based on the standard MIDAS
> example in "src/midas/examples/experiment".
If you have such huge events, it does not make sense to put them into the ODB. The size needs to be increased (as
you realized correctly) and the run stop takes long if you write last.xml. So just remove the RO_ODB flag in the
frontend program and you won't have these problems.
/Stefan |
|
23 Feb 2014, Andre Frankenthal, Bug Report, Installation failing on Mac OS X 10.9 -- related to strlcat and strlcpy
|
Hi,
I don't know if this actually fits the Bug Report category. I've been trying to install Midas on my Mac OS
Mavericks and I keep getting errors like "conflicting types for '___builtin____strlcpy_chk' ..." and similarly for
strlcat. I googled a bit and I think the problem might be that in Mavericks strlcat and strlcpy are already
defined in string.h, and so there might be a redundant definition somewhere. I'm not sure what the best
way to fix this would be though. Any help would be appreciated.
Thanks,
Andre |
|
27 Feb 2014, Konstantin Olchanski, Bug Report, Installation failing on Mac OS X 10.9 -- related to strlcat and strlcpy
|
>
> I don't know if this actually fits the Bug Report category. I've been trying to install Midas on my Mac OS
> Mavericks and I keep getting errors like "conflicting types for '___builtin____strlcpy_chk' ..." and similarly for
> strlcat. I googled a bit and I think the problem might be that in Mavericks strlcat and strlcpy are already
> defined in string.h, and so there might be a redundant definition somewhere. I'm not sure what the best
> way to fix this would be though. Any help would be appreciated.
>
We have run into this problem - MacOS 10.9 plays funny games with definitions of strlcpy() & co - and it has been fixed since last Summer.
For the record, current MIDAS builds just fine on MacOS 10.9.2.
For a pure test, try the instructions posted at midas.triumf.ca:
cd $HOME
mkdir packages
cd packages
git clone https://bitbucket.org/tmidas/midas
git clone https://bitbucket.org/tmidas/mscb
git clone https://bitbucket.org/tmidas/mxml
cd midas
make
K.O. |
|
27 Feb 2014, Andre Frankenthal, Bug Report, Installation failing on Mac OS X 10.9 -- related to strlcat and strlcpy
|
> >
> > I don't know if this actually fits the Bug Report category. I've been trying to install Midas on my Mac OS
> > Mavericks and I keep getting errors like "conflicting types for '___builtin____strlcpy_chk' ..." and similarly for
> > strlcat. I googled a bit and I think the problem might be that in Mavericks strlcat and strlcpy are already
> > defined in string.h, and so there might be a redundant definition somewhere. I'm not sure what the best
> > way to fix this would be though. Any help would be appreciated.
> >
>
> We have run into this problem - MacOS 10.9 plays funny games with definitions of strlcpy() & co - and it has been fixed since last Summer.
>
> For the record, current MIDAS builds just fine on MacOS 10.9.2.
>
> For a pure test, try the instructions posted at midas.triumf.ca:
>
> cd $HOME
> mkdir packages
> cd packages
> git clone https://bitbucket.org/tmidas/midas
> git clone https://bitbucket.org/tmidas/mscb
> git clone https://bitbucket.org/tmidas/mxml
> cd midas
> make
>
> K.O.
Thanks, it works like a charm now! I must have obtained an outdated version of Midas.
Andre |
|
23 Feb 2014, William Page, Forum, db_check_record() for verifying structure of ODB subtree
|
Hi,
I have been trying to use db_check_record() in order to verify that a subtree in the ODB has the correct
variables, variable order, and overall size. I'm going off the documentation
(https://midas.psi.ch/htmldoc/group__odbfunctionc.html) and use a string to compare against the ODB
structure. Since the string format is not specified for db_check_record(), I'm formatting my string
according to the db_create_record() example.
Instead of db_check_record() checking the entire ODB subtree against all the variables represented in the
string, I'm finding that only the first variable is checked. The later variables in the string can be
misspelled, out of order, or inexistent, and db_check_record() will still return 1.
Am I using db_check_record incorrectly?
Thank you for any help with this issue.
I also believe that some of the documentation for db_check_record is outdated. For example, init_string
is referenced in the documentation but isn't part of the function definition. |
|
21 Feb 2014, Konstantin Olchanski, Info, Javascript ODBMLs(), modified ODBMCopy() JSON encoding
|
I made a few minor modifications to the ODB JSON encoder and implemented a javascript "ls" function to
report full ODB directory information as available from odbedit "ls -l" and the mhttpd odb editor page.
Using the new ODBMLs(), the existing ODBMCreate(), ODBMDelete() & etc a complete ODB editor can be
written in Javascript (or in any other AJAX-capable language).
While implementing this function, I found some problems in the ODB JSON encoder when handling
symlinks, also some problems with handling symlinks in odbedit and in the mhttpd ODB editor - these are
now fixed.
Changes to the ODB JSON encoder:
- added the missing information to the ODB KEY (access_mode, notify_count)
- added symlink target information ("link")
- changed encoding of simple variable (i.e. jcopy of /experiment/name) - when possible (i.e. ODB KEY
information is omitted), they are encoded as bare values (before, they were always encoded as structures
with variable names, etc). This change makes it possible to implement ODBGet() and ODBMGet() using the
AJAX jcopy method with JSON data encoding. Bare value encoding in ODBMCopy()/AJAX jcopy is enabled by
using the "json-nokeys-nolastwritten" encoding option.
All these changes are supposed to be backward compatible (encoding used by ODBMCopy() for simple
values and "-nokeys-nolastwritten" was previously not documented).
Documentation was updated:
https://midas.triumf.ca/MidasWiki/index.php/Mhttpd.js
K.O. |
|
23 Sep 2013, Stefan Ritt, Info, Custom page header implemented
|
Due to popular request, I implemented a custom header for mhttpd. This allows to inject some HTML code
to be shown on top of the menu bar on all mhttpd pages. One possible application is to bring back the old
status line with the name of the current experiment, the actual time and the refresh interval.
To use this feature, one can put a new entry into the ODB under
/Custom/Header
which can be either a string (to show some short HTML code directly) or the name of a file containing some
HTML code. If /Custom/Path is present, that path is used to locate the header file. A simple header file to
recreate the GOT look (good-old-times) is here:
<div id="footerDiv" class="footerDiv">
<div style="display:inline; float:left;">MIDAS experiment "Test"</div>
<div id="refr" style="display:inline; float:right;"></div>
</div>
<script type="text/javascript">
var r = document.getElementById('refr');
var now = new Date();
var c = document.cookie.split('midas_refr=');
r.innerHTML = now.toString() + ' ' + 'Refr:' + c.pop().split(';').shift();
</script>
The JavaScript code is used to retrieve the midas_refr cookie which stores the refresh interval and displays
it together with the current time.
Another application of this feature might be to check certain values in the ODB (via the ODBGet function)
and some some important status or error condition.
/Stefan |
|
12 Feb 2014, Stefan Ritt, Info, Custom page header implemented
|
As reported in the bug tracker, the proposed header does not work if no specific (= different from the default 60 sec.) update period is specified,
since then no cookie is present. Here is the updated code which works for all cases:
<div id="footerDiv" class="footerDiv">
<div style="display:inline; float:left;">MIDAS experiment "Test"</div>
<div id="refr" style="display:inline; float:right;"></div>
</div>
<script type="text/javascript">
var r = document.getElementById('refr');
var now = new Date();
var refr;
if (document.cookie.search('midas_refr') == -1)
refr = 60;
else {
var c = document.cookie.split('midas_refr=');
refr = c.pop().split(';').shift();
}
r.innerHTML = now.toString() + ' ' + 'Refr:' + refr;
</script>
/Stefan |
|
18 Feb 2014, Konstantin Olchanski, Info, Custom page header implemented
|
I am not sure what to do with the javascript snippet - I understand it should be somehow connected to /Custom/Header, but if I create the /Custom/Header string, I cannot put this snippet
into this string using odbedit - if I try to cut&paste it into odbedit, it is truncated to the first line - nor using the mhttpd odb editor - when I cut&paste it into the odb editor text entry box, it
is truncated to the first 519 bytes (must be a hard limit somewhere). K.O.
> As reported in the bug tracker, the proposed header does not work if no specific (= different from the default 60 sec.) update period is specified,
> since then no cookie is present. Here is the updated code which works for all cases:
>
>
>
> <div id="footerDiv" class="footerDiv">
> <div style="display:inline; float:left;">MIDAS experiment "Test"</div>
> <div id="refr" style="display:inline; float:right;"></div>
> </div>
> <script type="text/javascript">
> var r = document.getElementById('refr');
> var now = new Date();
> var refr;
> if (document.cookie.search('midas_refr') == -1)
> refr = 60;
> else {
> var c = document.cookie.split('midas_refr=');
> refr = c.pop().split(';').shift();
> }
> r.innerHTML = now.toString() + ' ' + 'Refr:' + refr;
> </script>
>
>
>
> /Stefan |
|
19 Feb 2014, Stefan Ritt, Info, Custom page header implemented
|
> I am not sure what to do with the javascript snippet
Just read elog:908, it tells you to put this into a file, name it header.html for example, and put into the ODB:
/Custom/Header [string32] = header.html
make sure that you put the file into the directory indicated by /Custom/Path.
Cheers,
Stefan |
|
29 Jan 2014, Konstantin Olchanski, Bug Fix, make dox
|
The capability to generate doxygen documentation of MIDAS was restored.
Use "make dox" and "make cleandox",
find generated documentation in ./html,
look at it via "firefox html/index.html".
The documentation is not generated by default - it takes quite a long time to build all the call graphs.
And the call graphs is what makes this documentation useful - without some visual graphical
representation it is quite difficult to understand some parts of MIDAS. Both caller and callee graphs are
generated.
Note that doxygen documentation for the javascript functions in mhttpd.js is also generated, making a
handy reference in addition to the full documentation on the MIDAS Wiki.
K.O. |
|
30 Jan 2014, Stefan Ritt, Bug Fix, make dox
|
> The capability to generate doxygen documentation of MIDAS was restored.
>
> Use "make dox" and "make cleandox",
> find generated documentation in ./html,
> look at it via "firefox html/index.html".
>
> The documentation is not generated by default - it takes quite a long time to build all the call graphs.
>
> And the call graphs is what makes this documentation useful - without some visual graphical
> representation it is quite difficult to understand some parts of MIDAS. Both caller and callee graphs are
> generated.
>
> Note that doxygen documentation for the javascript functions in mhttpd.js is also generated, making a
> handy reference in addition to the full documentation on the MIDAS Wiki.
>
> K.O.
To generate the files, you need doxygen installed which not everybody has. Is there a web site where one can see the generated graphs?
/Stefan |
|
18 Feb 2014, Konstantin Olchanski, Bug Fix, make dox
|
> > The capability to generate doxygen documentation of MIDAS was restored.
> >
> > Use "make dox" and "make cleandox",
> > find generated documentation in ./html,
> > look at it via "firefox html/index.html".
> >
>
> To generate the files, you need doxygen installed which not everybody has.
On most Linux systems, doxygen is easy to install. Red Hat instructions are here:
http://www.triumf.info/wiki/DAQwiki/index.php/SLinstall#Install_packages_needed_for_QUARTUS.2C_ROOT.2C_EPICS_and_MIDAS_DAQ
On MacOS, doxygen is easy to install via macports: sudo port install doxygen
> Is there a web site where one can see the generated graphs?
http://ladd00.triumf.ca/~olchansk/midas/index.html
there is no cron job to update this, but I may update it infrequently.
K.O. |
|
19 Feb 2014, Stefan Ritt, Bug Fix, make dox
|
> On most Linux systems, doxygen is easy to install. Red Hat instructions are here:
> http://www.triumf.info/wiki/DAQwiki/index.php/SLinstall#Install_packages_needed_for_QUARTUS.2C_ROOT.2C_EPICS_and_MIDAS_DAQ
>
> On MacOS, doxygen is easy to install via macports: sudo port install doxygen
>
> > Is there a web site where one can see the generated graphs?
>
> http://ladd00.triumf.ca/~olchansk/midas/index.html
>
> there is no cron job to update this, but I may update it infrequently.
>
> K.O.
Great, thanks a lot!
-Stefan |
|
31 Jan 2014, Stefan Ritt, Info, Separation of MSCB subtree
|
Since several projects at PSI need MSCB but not MIDAS, I decided to separate the two repositories. So if you
need MIDAS with MSCB support inside mhttpd, you have to clone MIDAS, MXML and MSCB from bitbucket
(or the local clone at TRIUMF) as described in
https://midas.triumf.ca/MidasWiki/index.php/Main_Page#Download
I tried to fix all Makefiles to link to the new locations, but I'm not sure if I got all. So if something does not
compile please let me know.
-Stefan |
|
18 Feb 2014, Konstantin Olchanski, Info, Separation of MSCB subtree
|
> Since several projects at PSI need MSCB but not MIDAS, I decided to separate the two repositories. So if you
> need MIDAS with MSCB support inside mhttpd, you have to clone MIDAS, MXML and MSCB from bitbucket
> (or the local clone at TRIUMF) as described in
>
> https://midas.triumf.ca/MidasWiki/index.php/Main_Page#Download
>
> I tried to fix all Makefiles to link to the new locations, but I'm not sure if I got all. So if something does not
> compile please let me know.
>
> -Stefan
After this split, Makefiles used to build experiment frontends need to be modified for the new location of the mscb tree:
replace
$(MIDASSYS)/mscb
with
$(MIDASSYS)/../mscb
K.O. |
|
11 Feb 2014, Andreas Suter, Bug Report, mhttpd, etc.
|
I found a couple of bugs in the current mhttpd, midas version: "93fa5ed"
This concerns all browser I checked (firefox, chrome, internet explorer, opera)
1) When trying to change a value of a frontend using a multi class driver (we
have a lot of them), the field for changing appears, but I cannot get it set!
Neither via the two set buttons (why 2?) nor via return.
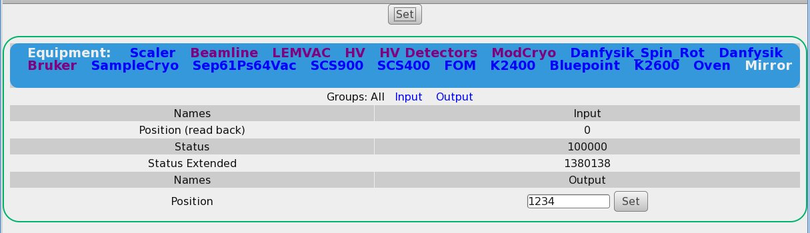
It also would be nice, if the css could be changed such that input/output for
multi-driver would be better separated; something along as suggested in
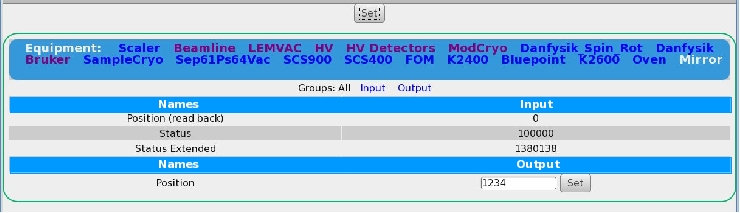
2) If I changing a value (generic/hv class driver), the index of the array
remains when chaning a value until the next update of the page

3) We are using a web-password. In the current version the password is plain visible when entering.
4) I just copied the header as described here: https://midas.triumf.ca/elog/Midas/908, but I get another result:
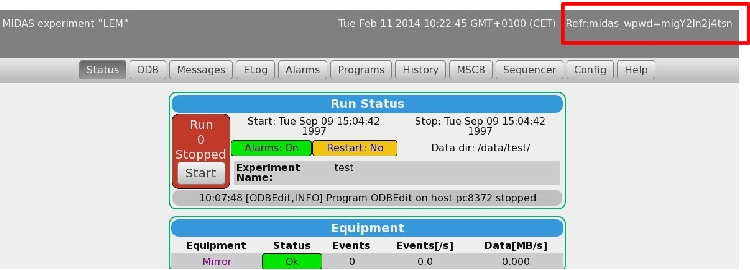
It looks like as a wrong cookie is filtered? |
|
11 Feb 2014, Stefan Ritt, Bug Report, mhttpd, etc.
|
| Andreas Suter wrote: | | I found a couple of bugs in the current mhttpd, midas version: "93fa5ed" |
See my reply on the issue tracker:
https://bitbucket.org/tmidas/midas/issue/18/mhttpd-bugs |
|
15 Jan 2014, Konstantin Olchanski, Bug Report, MIDAS password protection is broken
|
If you follow the MIDAS documentation for setting up password protection, you will get strange messages:
ladd00:midas$ ./linux/bin/odbedit
[local:testexpt:S]/>passwd <---- setup a password
Password:
Retype password:
[local:testexpt:S]/> exit
ladd00:midas$ odbedit
Password: <---- enter correct password here
ss_semaphore_wait_for: semop/semtimedop(21135376) returned -1, errno 22 (Invalid argument)
ss_semaphore_release: semop/semtimedop(21135376) returned -1, errno 22 (Invalid argument)
[local:testexpt:S]/>ss_semaphore_wait_for: semop/semtimedop(21037069) returned -1, errno 43 (Identifier removed)
The same messages will appear from all other programs - mhttpd, etc. They will be printed about every 1 second.
So what do they mean? They mean what they say - the semaphore is not there, it is easy to check using "ipcs" that semaphores with
those ids do not exist. In fact all the semaphores are missing (the ODB semaphore is eventually recreated, so at least ODB works
correctly).
In this situation, MIDAS will not work correctly.
What is happening?
- cm_connect_experiment1() creates all the semaphores and remembers them in cm_set_experiment_semaphore()
- calls cm_set_client_info()
- cm_set_client_info() finds ODB /expt/sec/password, and returns CM_WRONG_PASSWORD
- before returning, it calls db_close_all_databases() and bm_close_all_buffers(), which delete all semaphores (put a print statement in
ss_semaphore_delete() to see this).
- (values saved by cm_set_experiment_semaphore() are stale now).
- (if by luck you have other midas programs still running, the semaphores will not be deleted)
- we are back to cm_connect_experiment1() which will ask for the password, call cm_set_client_info() again and continue as usual
- it will reopen ODB, recreating the ODB semaphore
- (but all the other semaphores are still deleted and values saved by cm_set_experiment_semaphore() are stale)
I through to improve this by fixing a bug in cm_msg_log() (where the messages are coming from) - it tries to lock the "MSG"
semaphore, but even if it could not lock it, it continues as usual and even calls an unlock at the end. (very bad). For catastrophic
locking failures like this (semaphore is deleted), we usually abort. But if I abort here, I get completely locked out from odb - odbedit
crashes right away and there is no way to do any corrective action other than delete odb and reload it from an xml file.
I know that some experiments use this password protection - why/how does it work there?
I think they are okey because they put critical programs like odbedit, mserver, mlogger and mhttpd into "/expt/sec/allowed
programs". In this case the pass the password check in cm_set_client_info() and the semaphores are not deleted. If any subsequent
program asks for the password, the semaphores survive because mlogger or mhttpd is already running and keeps semaphores from
being deleted.
What a mess.
K.O. |
|
15 Jan 2014, Konstantin Olchanski, Bug Report, MIDAS password protection is broken
|
> I through to improve this by fixing a bug in cm_msg_log() (where the messages are coming from)
The periodic messages about broken semaphore actually come from al_check(). I put some whining there, too.
K.O. |
|
05 Feb 2014, Stefan Ritt, Bug Report, MIDAS password protection is broken
|
> If you follow the MIDAS documentation for setting up password protection, you will get strange messages:
This is interesting. When I used it last time (some years ago...) it worked fine. I did not touch this, and now it's broken. Must be related to some modifications of the semaphore system.
Well, anyhow, the problem seems to me the db_close_all_databses() and the re-opening of the ODB. Apparently the db_close_database() call does not clean up the semaphores properly.
Actually there is absolutely no need to close and re-open the ODB upon a wrong password, so I just removed that code and now it works again.
/Stefan |
|
15 Jan 2014, Konstantin Olchanski, Bug Report, MIDAS Web password broken
|
The MIDAS Web password function is broken - with the web password enabled, I am not prompted for a
password when editing ODB. The password still partially works - I am prompted for the web password
when starting a run. K.O.
P.S. https://midas.triumf.ca/MidasWiki/index.php/Security says "web password" needed for "write access",
but does not specify if this includes editing odb. (I would think so, and I think I remember that it used to). |
|
05 Feb 2014, Stefan Ritt, Bug Report, MIDAS Web password broken
|
> The MIDAS Web password function is broken - with the web password enabled, I am not prompted for a
> password when editing ODB. The password still partially works - I am prompted for the web password
> when starting a run. K.O.
>
> P.S. https://midas.triumf.ca/MidasWiki/index.php/Security says "web password" needed for "write access",
> but does not specify if this includes editing odb. (I would think so, and I think I remember that it used to).
Didn't we agree to put those issues into the bitbucket issue tracker?
This functionality got broken when implementing the new inline edit functionality. Actually one has to "manually" check for the password. The old way
was that there web page asking for the web password, but if we do ODBSet via Ajax there is nobody who could fill out that form. So I added a
"manual" checking into ODBCheckWebPassword(). This will not work for custom pages, but they have their own way to define passwords.
/Stefan |
|
16 Jan 2014, Konstantin Olchanski, Info, MIDAS and "international characters", UTF-8 and Unicode.
|
I made some tests of MIDAS support for "international characters" and we seem to be in a reasonable
shape.
The standard standard is UTF-8 encoding of Unicode and the MIDAS core is believed to be UTF-8 clean -
one can use "international characters" in ODB names, in ODB values, in filenames, etc.
The web interface had some problems with percent-encoding of ODB URLs, but as of current git version,
everything seems to work okey, as long as the web browser is in the UTF-8 encoding mode. The default
mode is "Western ISO-8859-1" and javascript encodeURIComponent() is mangling some stuff making the
ODB editor not work. Switching to UTF-8 mode seems to fix that.
Perhaps we should make the UTF-8 encoding the default for mhttpd-generated web pages. This should be
okey for TRIUMF - we use English language almost exclusively, but need to check with other labs before
making such a change. I especially worry about PSI because I am not sure if and how they any of the special
German-language characters.
On the minus side, odbedit does not seem to accept non-English characters at all. Maybe it is easy to fix.
K.O. |
|
15 Jan 2014, Konstantin Olchanski, Bug Fix, Fixed spurious symlinks to midas.log
|
In some experiments (i.e. DEAP), we see spurious symlinks to midas.log scattered just about everywhere. I
now traced this to an uninitialized variable in cm_msg_log() and it should be fixed now. K.O. |
|