 11 Feb 2014, Andreas Suter, Bug Report, mhttpd, etc. 11 Feb 2014, Andreas Suter, Bug Report, mhttpd, etc. 
|
I found a couple of bugs in the current mhttpd, midas version: "93fa5ed"
This concerns all browser I checked (firefox, chrome, internet explorer, opera)
1) When trying to change a value of a frontend using a multi class driver (we
have a lot of them), the field for changing appears, but I cannot get it set!
Neither via the two set buttons (why 2?) nor via return.
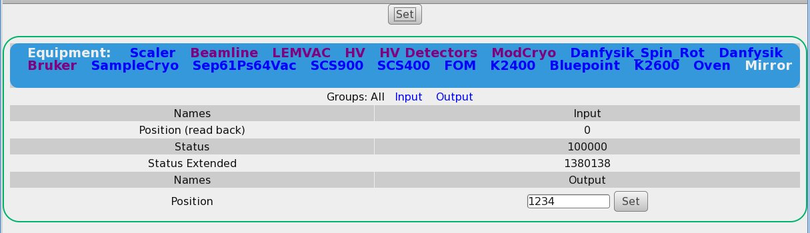
It also would be nice, if the css could be changed such that input/output for
multi-driver would be better separated; something along as suggested in
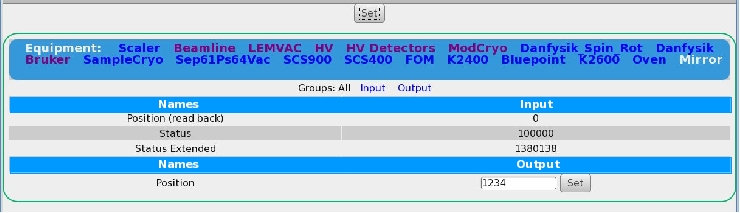
2) If I changing a value (generic/hv class driver), the index of the array
remains when chaning a value until the next update of the page

3) We are using a web-password. In the current version the password is plain visible when entering.
4) I just copied the header as described here: https://midas.triumf.ca/elog/Midas/908, but I get another result:
It looks like as a wrong cookie is filtered? |
 11 Feb 2014, Stefan Ritt, Bug Report, mhttpd, etc. 11 Feb 2014, Stefan Ritt, Bug Report, mhttpd, etc.
|
| Andreas Suter wrote: | | I found a couple of bugs in the current mhttpd, midas version: "93fa5ed" |
See my reply on the issue tracker:
https://bitbucket.org/tmidas/midas/issue/18/mhttpd-bugs |
|
15 Jan 2014, Konstantin Olchanski, Bug Report, MIDAS password protection is broken
|
If you follow the MIDAS documentation for setting up password protection, you will get strange messages:
ladd00:midas$ ./linux/bin/odbedit
[local:testexpt:S]/>passwd <---- setup a password
Password:
Retype password:
[local:testexpt:S]/> exit
ladd00:midas$ odbedit
Password: <---- enter correct password here
ss_semaphore_wait_for: semop/semtimedop(21135376) returned -1, errno 22 (Invalid argument)
ss_semaphore_release: semop/semtimedop(21135376) returned -1, errno 22 (Invalid argument)
[local:testexpt:S]/>ss_semaphore_wait_for: semop/semtimedop(21037069) returned -1, errno 43 (Identifier removed)
The same messages will appear from all other programs - mhttpd, etc. They will be printed about every 1 second.
So what do they mean? They mean what they say - the semaphore is not there, it is easy to check using "ipcs" that semaphores with
those ids do not exist. In fact all the semaphores are missing (the ODB semaphore is eventually recreated, so at least ODB works
correctly).
In this situation, MIDAS will not work correctly.
What is happening?
- cm_connect_experiment1() creates all the semaphores and remembers them in cm_set_experiment_semaphore()
- calls cm_set_client_info()
- cm_set_client_info() finds ODB /expt/sec/password, and returns CM_WRONG_PASSWORD
- before returning, it calls db_close_all_databases() and bm_close_all_buffers(), which delete all semaphores (put a print statement in
ss_semaphore_delete() to see this).
- (values saved by cm_set_experiment_semaphore() are stale now).
- (if by luck you have other midas programs still running, the semaphores will not be deleted)
- we are back to cm_connect_experiment1() which will ask for the password, call cm_set_client_info() again and continue as usual
- it will reopen ODB, recreating the ODB semaphore
- (but all the other semaphores are still deleted and values saved by cm_set_experiment_semaphore() are stale)
I through to improve this by fixing a bug in cm_msg_log() (where the messages are coming from) - it tries to lock the "MSG"
semaphore, but even if it could not lock it, it continues as usual and even calls an unlock at the end. (very bad). For catastrophic
locking failures like this (semaphore is deleted), we usually abort. But if I abort here, I get completely locked out from odb - odbedit
crashes right away and there is no way to do any corrective action other than delete odb and reload it from an xml file.
I know that some experiments use this password protection - why/how does it work there?
I think they are okey because they put critical programs like odbedit, mserver, mlogger and mhttpd into "/expt/sec/allowed
programs". In this case the pass the password check in cm_set_client_info() and the semaphores are not deleted. If any subsequent
program asks for the password, the semaphores survive because mlogger or mhttpd is already running and keeps semaphores from
being deleted.
What a mess.
K.O. |
|
15 Jan 2014, Konstantin Olchanski, Bug Report, MIDAS password protection is broken
|
> I through to improve this by fixing a bug in cm_msg_log() (where the messages are coming from)
The periodic messages about broken semaphore actually come from al_check(). I put some whining there, too.
K.O. |
|
05 Feb 2014, Stefan Ritt, Bug Report, MIDAS password protection is broken
|
> If you follow the MIDAS documentation for setting up password protection, you will get strange messages:
This is interesting. When I used it last time (some years ago...) it worked fine. I did not touch this, and now it's broken. Must be related to some modifications of the semaphore system.
Well, anyhow, the problem seems to me the db_close_all_databses() and the re-opening of the ODB. Apparently the db_close_database() call does not clean up the semaphores properly.
Actually there is absolutely no need to close and re-open the ODB upon a wrong password, so I just removed that code and now it works again.
/Stefan |
|
15 Jan 2014, Konstantin Olchanski, Bug Report, MIDAS Web password broken
|
The MIDAS Web password function is broken - with the web password enabled, I am not prompted for a
password when editing ODB. The password still partially works - I am prompted for the web password
when starting a run. K.O.
P.S. https://midas.triumf.ca/MidasWiki/index.php/Security says "web password" needed for "write access",
but does not specify if this includes editing odb. (I would think so, and I think I remember that it used to). |
|
05 Feb 2014, Stefan Ritt, Bug Report, MIDAS Web password broken
|
> The MIDAS Web password function is broken - with the web password enabled, I am not prompted for a
> password when editing ODB. The password still partially works - I am prompted for the web password
> when starting a run. K.O.
>
> P.S. https://midas.triumf.ca/MidasWiki/index.php/Security says "web password" needed for "write access",
> but does not specify if this includes editing odb. (I would think so, and I think I remember that it used to).
Didn't we agree to put those issues into the bitbucket issue tracker?
This functionality got broken when implementing the new inline edit functionality. Actually one has to "manually" check for the password. The old way
was that there web page asking for the web password, but if we do ODBSet via Ajax there is nobody who could fill out that form. So I added a
"manual" checking into ODBCheckWebPassword(). This will not work for custom pages, but they have their own way to define passwords.
/Stefan |
|
16 Jan 2014, Konstantin Olchanski, Info, MIDAS and "international characters", UTF-8 and Unicode.
|
I made some tests of MIDAS support for "international characters" and we seem to be in a reasonable
shape.
The standard standard is UTF-8 encoding of Unicode and the MIDAS core is believed to be UTF-8 clean -
one can use "international characters" in ODB names, in ODB values, in filenames, etc.
The web interface had some problems with percent-encoding of ODB URLs, but as of current git version,
everything seems to work okey, as long as the web browser is in the UTF-8 encoding mode. The default
mode is "Western ISO-8859-1" and javascript encodeURIComponent() is mangling some stuff making the
ODB editor not work. Switching to UTF-8 mode seems to fix that.
Perhaps we should make the UTF-8 encoding the default for mhttpd-generated web pages. This should be
okey for TRIUMF - we use English language almost exclusively, but need to check with other labs before
making such a change. I especially worry about PSI because I am not sure if and how they any of the special
German-language characters.
On the minus side, odbedit does not seem to accept non-English characters at all. Maybe it is easy to fix.
K.O. |
|
15 Jan 2014, Konstantin Olchanski, Bug Fix, Fixed spurious symlinks to midas.log
|
In some experiments (i.e. DEAP), we see spurious symlinks to midas.log scattered just about everywhere. I
now traced this to an uninitialized variable in cm_msg_log() and it should be fixed now. K.O. |
|
17 Dec 2013, Stefan Ritt, Info, IEEE Real Time 2014 Call for Abstracts
|
Hello,
I'm co-organizing the upcoming Real Time Conference, which covers also the field of data acquisition, so it might be interesting for people working
with MIDAS. If you have something to report, you could also consider to send an abstract to this conference. It will be located in Nara, Japan. The conference
site is now open at http://rt2014.rcnp.osaka-u.ac.jp/
Best regards,
Stefan Ritt |
|
16 Dec 2013, Konstantin Olchanski, Bug Fix, Abolished SYNC and ASYNC defines
|
A few months ago, definitions of SYNC and ASYNC in midas.h have been changed away from "0" and "1",
and this caused problems with some event buffer management functions bm_xxx().
For example, when event buffers are getting full, bm_send_event(SYNC) unexpectedly started returning
BM_ASYNC_RETURN instead of waiting for free space, causing unexpected crashes of frontend programs.
Part of the problem was confusion between SYNC/ASYNC used by buffer management (bm_xxx) and by run
transition (cm_transition()) functions. Adding to confusion, documentation of bm_send_event() & co used
FALSE/TRUE while most actual calls used SYNC/ASYNC.
To sort this out, an executive decision was made to abolish the SYNC/ASYNC defines:
For buffer management calls bm_send_event(), bm_receive_event(), etc, please use:
SYNC -> BM_WAIT
ASYNC -> BM_NO_WAIT
For run transitions, please use:
SYNC -> TR_SYNC
ASYNC -> TR_ASYNC
MTHREAD -> TR_MTHREAD
DETACH -> TR_DETACH
K.O. |
|
16 Dec 2013, Konstantin Olchanski, Info, MIDAS on ARM
|
I added MIDAS Makefile rules for building ARM binaries: "make linuxarm" and "make cleanarm" will create
(and clean) object files, libraries and executables under "linux-arm" using the TI Sitara ARM SDK or the
Yocto SDK ARM cross-compilers (GCC 4.7.x and 4.8.x respectively). (Makefile rules for building PPC
binaries have existed for years).
The hardware we have at TRIUMF are "ARMv7" machines - TI Sitara 335x CPUs (google mityarm) and Altera
Cyclone 5 FPGA ARM (google sockit). (as opposed to the ARMv5 CPU on the RaspberryPi). The software
binary API standard settled by Fedora Linux is "hard float" (as opposed to "soft float" used by older SDKs).
So "ARMv7 hard float" is what we intend to use at TRIUMF, but ARMv5 and soft-float should also work ok,
so please report successes and/or problems to this forum.
K.O. |
|
28 Nov 2013, Konstantin Olchanski, Info, Audit of fixed size arrays
|
In one of the experiments, we hit a long time bug in mdump - there was an array of 32 equipments and if
there were more than 32 entries under /equipment, it would overrun and corrupt memory. Somehow this
only showed up after mdump was switched to c++. The solution was to use std::vector instead of fixed
size array.
Just in case, I checked other midas programs for fixed size arrays (other than fixed size strings) and found
none. (in midas.c, there is a fixed size array of TR_FIFO[10], but code inspection shows that it cannot
overrun).
I used this script. It can be modified to also identify any strange sized string arrays.
K.O.
#!/usr/bin/perl -w
while (1) {
my $in = <STDIN>;
last unless $in;
#print $in;
$in =~ s/^\s+//;
next if $in =~ /^char/;
next if $in =~ /^static char/;
my $a = $in =~ /(.*)[(\d+)\]/;
next unless $a;
my $a1 = $1;
my $a2 = $2;
next if $a2 == 0;
next if $a2 == 1;
next if $a2 == 2;
next if $a2 == 3;
#print "[$a] [$a1] [$a2]\n";
print "-> $a1[$a2]\n";
}
# end |
|
20 Nov 2013, Konstantin Olchanski, Bug Report, Too many bm_flush_cache() in mfe.c
|
I was looking at something in the mserver and noticed that for remote frontends, for every periodic event,
there are about 3 RPC calls to bm_flush_cache().
Sure enough, in mfe.c::send_event(), for every event sent, there are 2 calls to bm_flush_cache() (once for
the buffer we used, second for all buffers). Then, for a good measure, the mfe idle loop calls
bm_flush_cache() for all buffers about once per second (even if no events were generated).
So what is going on here? To allow good performance when processing many small events,
the MIDAS event buffer code (bm_send_event()) buffers small events internally, and only after this internal
buffer is full, the accumulated events are flushed into the shared memory event buffer,
where they become visible to the mlogger, mdump and other consumers.
Because of this internal buffering, infrequent small size periodic events can become
stuck for quite a long time, confusing the user: "my frontend is sending events, how come I do not
see them in mdump?"
To avoid this, mfe.c manually flushes these internal event buffers by calling bm_flush_buffer().
And I think that works just fine for frontends directly connected to the shared memory, one call to
bm_flush_buffer() should be sufficient.
But for remote fronends connected through the mserver, it turns out there is a race condition between
sending the event data on one tcp connection and sending the bm_flush_cache() rpc request on another
tcp connection.
I see that the mserver always reads the rpc connection before the event connection, so bm_flush_cache()
is done *before* the event is written into the buffer by bm_send_event(). So the newly
send event is stuck in the buffer until bm_flush_cache() for the *next* event shows up:
mfe.c: send_event1 -> flush -> ... wait until next event ... -> send_event2 -> flush
mserver: flush -> receive_event1 -> ... wait ... -> flush -> receive_event2 -> ... wait ...
mdump -> ... nothing ... -> ... nothing ... -> event1 -> ... nothing ...
Enter the 2nd call to bm_flush_cache in mfe.c (flush all buffers) - now because mserver seems to be
alternating between reading the rpc connection and the event connection, the race condition looks like
this:
mfe.c: send_event -> flush -> flush
mserver: flush -> receive_event -> flush
mdump: ... -> event -> ...
So in this configuration, everything works correctly, the data is not stuck anywhere - but by accident, and
at the price of an extra rpc call.
But what about the periodic 1/second bm_flush_cache() on all buffers? I think it does not quite work
either because the race condition is still there: we send an event, and the first flush may race it and only
the 2nd flush gets the job done, so the delay between sending the event and seeing it in mdump would be
around 1-2 seconds. (no more than 2 seconds, I think). Since users expect their events to show up "right
away", a 2 second delay is probably not very good.
Because periodic events are usually not high rate, the current situation (4 network transactions to send 1
event - 1x send event, 3x flush buffer) is probably acceptable. But this definitely sets a limit on the
maximum rate to 3x (2x?) the mserver rpc latency - without the rpc calls to bm_flush_buffer() there
would be no limit - the events themselves are sent through a pipelined tcp connection without
handshaking.
One solution to this would be to implement periodic bm_flush_buffer() in the mserver, making all calls to
bm_flush_buffer() in mfe.c unnecessary (unless it's a direct connection to shared memory).
Another solution could be to send events with a special flag telling the mserver to "flush the buffer right
away".
P.S. Look ma!!! A race condition with no threads!!!
K.O. |
|
21 Nov 2013, Stefan Ritt, Bug Report, Too many bm_flush_cache() in mfe.c
|
> And I think that works just fine for frontends directly connected to the shared memory, one call to
> bm_flush_buffer() should be sufficient.
That's correct. What you want is once per second or so for polled events, and once per periodic event (which anyhow will typically come only every 10 seconds or so). If there are 3 calls
per event, this is certainly too much.
> But for remote fronends connected through the mserver, it turns out there is a race condition between
> sending the event data on one tcp connection and sending the bm_flush_cache() rpc request on another
> tcp connection.
>
> ...
>
> One solution to this would be to implement periodic bm_flush_buffer() in the mserver, making all calls to
> bm_flush_buffer() in mfe.c unnecessary (unless it's a direct connection to shared memory).
>
> Another solution could be to send events with a special flag telling the mserver to "flush the buffer right
> away".
That's a very good and useful observation. I never really thought about that.
Looking at your proposed solutions, I prefer the second one. mserver is just an interface for RPC calls, it should not do anything "by itself". This was a strategic decision at the beginning.
So sending a flag to punch through the cache on mserver seems to me has less side effects. Will just break binary compatibility :-)
/Stefan |
|
15 Nov 2013, Konstantin Olchanski, Bug Report, stuck data buffers
|
We have seen several times a problem with stuck data buffers. The symptoms are very confusing -
frontends cannot start, instead hang forever in a state very hard to kill. Also "mdump -s -d -z
BUF03" for the affected data buffers is stuck.
We have identified the source of this problem - the semaphore for the buffer is locked and nobody
will ever unlock it - MIDAS relies on a feature of SYSV semaphores where they are automatically
unlocked by the OS and cannot ever be stuck ever. (see man semop, SEM_UNDO function).
I think this SEM_UNDO function is broken in recent Linux kernels and sometimes the semaphore
remains locked after the process that locked it has died. MIDAS is not programmed to deal with this
situation and the stuck semaphore has to be cleared manually.
Here, "BUF3" is used as example, but we have seen "SYSTEM" and ODB with stuck semaphores, too.
Steps:
a) confirm that we are using SYSV semaphores: "ipcs" should show many semaphores
b) identify the stuck semaphore: "strace mdump -s -d -z BUF03".
c) here will be a large printout, but ultimately you will see repeated entries of
"semtimedop(9633800, {{0, -1, SEM_UNDO}}, 1, {1, 0}^C <unfinished ...>"
d) erase the stuck semaphore "ipcrm -s 9633800", where the number comes from semtimedop() in
the strace output.
e) try again: "mdump -s -d -z BUF03" should work now.
Ultimately, I think we should switch to POSIX semaphores - they are easier to manage (the strace
and ipcrm dance becomes "rm /dev/shm/deap_BUF03.sem" - but they do not have the SEM_UNDO
function, so detection of locked and stuck semaphores will have to be done by MIDAS. (Unless we
can find some library of semaphore functions that already provides such advanced functionality).
K.O. |
|
14 Nov 2013, Konstantin Olchanski, Bug Report, MacOS10.9 strlcpy() problem
|
On MacOS 10.9 MIDAS will crashes in strlcpy() somewhere inside odb.c. We think this is because strlcpy()
in MacOS 10.9 was changed to abort() if input and output strings overlap. For overlapping memory one is
supposed to use memmove(). This is fixed in current midas, for older versions, you can try this patch:
konstantin-olchanskis-macbook:midas olchansk$ git diff
diff --git a/src/odb.c b/src/odb.c
index 1589dfa..762e2ed 100755
--- a/src/odb.c
+++ b/src/odb.c
@@ -6122,7 +6122,10 @@ INT db_paste(HNDLE hDB, HNDLE hKeyRoot, const char *buffer)
pc++;
while ((*pc == ' ' || *pc == ':') && *pc)
pc++;
- strlcpy(data_str, pc, sizeof(data_str));
+
+ //strlcpy(data_str, pc, sizeof(data_str)); // MacOS 10.9 does not permit strlcpy() of overlapping
strings
+ assert(strlen(pc) < sizeof(data_str)); // "pc" points at a substring inside "data_str"
+ memmove(data_str, pc, strlen(pc)+1);
if (n_data > 1) {
data_str[0] = 0;
konstantin-olchanskis-macbook:midas olchansk$
As historical reference:
a) MacOS documentation says "behavior is undefined", which is no longer true, the behaviour is KABOOM!
https://developer.apple.com/library/mac/documentation/Darwin/Reference/ManPages/man3/strlcpy.3.h
tml
b) the original strlcpy paper from OpenBSD does not contain the word "overlap"
http://www.courtesan.com/todd/papers/strlcpy.html
c) the OpenBSD man page says the same as Apple man page (behaviour undefined)
http://www.openbsd.org/cgi-bin/man.cgi?query=strlcpy
d) the linux kernel strlcpy() uses memcpy() and is probably unsafe for overlapping strings
http://lxr.free-electrons.com/source/lib/string.c#L149
e) midas strlcpy() looks to be safe for overlapping strings.
K.O. |
|
09 Nov 2013, Razvan Stefan Gornea, Forum, Installation problem
|
Hi,
I run into problems while trying to install Midas on Slackware 14.0. In the past
I have easily installed Midas on many other versions of Slackware. I have a new
computer set up with Slackware 14.0 and I just got the Midas latest version from
https://bitbucket.org/tmidas/midas
Apparently there is a problem with a shared library which should be on the
system, I think make checks for /usr/include/mysql and then supposes that
libodbc.so should be on disk. I don't know why on my system it is not.
But I was wondering if I have some other problems (configuration problem?)
because I get a very large number of warnings. My last installation of Midas is
like from two years ago but I don't remember getting many warnings. Do I do
something obviously wrong? Here is uname -a output and I attached a file with
the output from make in midas folder (GNU Make 3.82 Built for
x86_64-slackware-linux-gnu). Thanks a lot!
Linux lheppc83 3.2.29 #2 SMP Mon Sep 17 14:19:22 CDT 2012 x86_64 Intel(R)
Xeon(R) CPU E5520 @ 2.27GHz GenuineIntel GNU/Linux |
|
11 Nov 2013, Stefan Ritt, Forum, Installation problem
|
Seems to me a problem with the ODBC library, so maybe Konstantin can comment.
/Stefan |
|
11 Nov 2013, Konstantin Olchanski, Forum, Installation problem
|
> I run into problems while trying to install Midas on Slackware 14.0.
Thank you for reporting this. We do not have any slackware computers so we cannot see these message usually.
We use SL/RHEL 5/6 and MacOS for most development, plus we now have an Ubuntu test machine, where I see a
whole different spew of compiler messages.
Most of the messages are:
a) useless compiler whining:
src/midas.c: In function 'cm_transition2':
src/midas.c:3769:74: warning: variable 'error' set but not used [-Wunused-but-set-variable]
b) an actual error in fal.c:
src/fal.c:131:0: warning: "EQUIPMENT_COMMON_STR" redefined [enabled by default]
c) actual error in fal.c: assignment into string constant is not permitted: char*x="aaa"; x[0]='c'; // core dump
src/fal.c:383:1: warning: deprecated conversion from string constant to 'char*' [-Wwrite-strings]
these are fixed by making sure all such pointers are "const char*" and the corresponding midas functions are
also "const char*".
d) maybe an error (gcc sometimes gets this one wrong)
./mscb/mscb.c: In function 'int mscb_info(int, short unsigned int, MSCB_INFO*)':
./mscb/mscb.c:1682:8: warning: 'size' may be used uninitialized in this function [-Wuninitialized]
> Apparently there is a problem with a shared library which should be on the
> system, I think make checks for /usr/include/mysql and then supposes that
> libodbc.so should be on disk. I don't know why on my system it is not.
g++ -g -O2 -Wall -Wno-strict-aliasing -Wuninitialized -Iinclude -Idrivers -I../mxml -I./mscb -Llinux/lib -
DHAVE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_MYSQL -I/usr/include/mysql -DHAVE_ODBC -DHAVE_SQLITE
-DHAVE_ROOT -pthread -m64 -I/home/exodaq/root_5.35.10/include -DHAVE_ZLIB -DHAVE_MSCB -DOS_LINUX
-fPIC -Wno-unused-function -o linux/bin/mhttpd linux/lib/mhttpd.o linux/lib/mgd.o linux/lib/mscb.o
linux/lib/sequencer.o linux/lib/libmidas.a linux/lib/libmidas.a -lodbc -lsqlite3 -lutil -lpthread -lrt -lz -lm
/usr/lib64/gcc/x86_64-slackware-linux/4.7.1/../../../../x86_64-slackware-linux/bin/ld: cannot find -lodbc
The ODBC library is not found (shared .so or static .a).
The Makefile check is for /usr/include/sql.h (usually part of the ODBC package). On the command line above,
HAVE_ODBC is set, and the rest of MIDAS compiled okey, so the ODBC header files at least are present. But why
the library is not found?
I do not know how slackware packages this stuff the way they do and I do not have a slackware system to check
how it should look like, so I cannot suggest anything other than commenting out "HAVE_ODBC := ..." in the
Makefile.
> But I was wondering if I have some other problems (configuration problem?)
> because I get a very large number of warnings. My last installation of Midas is
> like from two years ago but I don't remember getting many warnings.
There are no "many warnings". Mostly it's just one same warning repeated many times that complains about
perfectly valid code:
src/midas.c: In function 'cm_transition':
src/midas.c:4388:19: warning: variable 'tr_main' set but not used [-Wunused-but-set-variable]
They complain about code:
{ int i=foo(); ... } // yes, "i" is not used, yes, if you have to keep it if you want to be able to see the return value
of foo() in gdb.
> Do I do something obviously wrong?
No you. GCC people turned on one more noisy junk warning.
> Thanks a lot!
No idea about your missing ODBC library, I do not even know how to get a package listing on slackware (and
proud of it).
But if you do know how to get a package listing for your odbc package, please send it here. On RHEL/SL, I would
do:
rpm -qf /usr/include/sql.h ### find out the name of the package that owns this file
rpm -ql xxx ### list all files in this package
K.O. |
|
11 Nov 2013, Konstantin Olchanski, Forum, Installation problem
|
> > I run into problems while trying to install Midas on Slackware 14.0.
>
> b) an actual error in fal.c:
>
> src/fal.c:131:0: warning: "EQUIPMENT_COMMON_STR" redefined [enabled by default]
>
> c) actual error in fal.c: assignment into string constant is not permitted: char*x="aaa"; x[0]='c'; // core dump
>
> src/fal.c:383:1: warning: deprecated conversion from string constant to 'char*' [-Wwrite-strings]
>
> these are fixed by making sure all such pointers are "const char*" and the corresponding midas functions are
the warnings in fal.c are now fixed.
K.O. |
|
13 Nov 2013, Konstantin Olchanski, Forum, Installation problem
|
> > I run into problems while trying to install Midas on Slackware 14.0.
>
> Thank you for reporting this. We do not have any slackware computers so we cannot see these message usually.
>
>
> src/midas.c: In function 'cm_transition2':
> src/midas.c:3769:74: warning: variable 'error' set but not used [-Wunused-but-set-variable]
>
got around to look at compile messages on ubuntu: in addition to "variable 'error' set but not used" we have these:
warning: ignoring return value of 'ssize_t write(int, const void*, size_t)'
warning: ignoring return value of 'ssize_t read(int, void*, size_t)'
warning: ignoring return value of 'int setuid(__uid_t)'
and a few more of similar
K.O. |
|
14 Nov 2013, Stefan Ritt, Forum, Installation problem
|
> got around to look at compile messages on ubuntu: in addition to "variable 'error' set but not used" we have these:
>
> warning: ignoring return value of 'ssize_t write(int, const void*, size_t)'
> warning: ignoring return value of 'ssize_t read(int, void*, size_t)'
> warning: ignoring return value of 'int setuid(__uid_t)'
> and a few more of similar
Arghh, now it is getting even more picky. I can understand the "variable xyz set but not used" and I'm willing to remove all the variables. But checking the
return value from every function? Well, if the disk gets full, our code will silently ignore this for write(), so maybe it's not a bad idea to add a few checks. Also
for the read(), there could be some problem, where an explicit cm_msg() in case of an error would help. |
|
14 Nov 2013, Razvan Stefan Gornea, Forum, Installation problem
|
Hi, Thanks a lot for the response! Yes to search packages and list their content in Slackware it is pretty similar to your illustration. Slackware seems to use iODBC in which case it would link with -liodbc I guess.
root@lheppc83:~# slackpkg file-search sql.h
Looking for sql.h in package list. Please wait... DONE
The list below shows the packages that contains "sql\.h" file.
[ installed ] - libiodbc-3.52.7-x86_64-2
You can search specific packages using "slackpkg search package".
root@lheppc83:~# cat /var/log/packages/libiodbc-3.52.7-x86_64-2
PACKAGE NAME: libiodbc-3.52.7-x86_64-2
COMPRESSED PACKAGE SIZE: 255.0K
UNCOMPRESSED PACKAGE SIZE: 1.0M
PACKAGE LOCATION: /var/log/mount/slackware64/l/libiodbc-3.52.7-x86_64-2.txz
PACKAGE DESCRIPTION:
libiodbc: libiodbc (Independent Open DataBase Connectivity)
libiodbc:
libiodbc: iODBC is the acronym for Independent Open DataBase Connectivity,
libiodbc: an Open Source platform independent implementation of both the ODBC
libiodbc: and X/Open specifications. It allows for developing solutions
libiodbc: that are language, platform and database independent.
libiodbc:
libiodbc:
libiodbc:
libiodbc: Homepage: http://iodbc.org/
libiodbc:
FILE LIST:
./
usr/
usr/share/
usr/share/libiodbc/
usr/share/libiodbc/samples/
usr/share/libiodbc/samples/iodbctest.c
usr/share/libiodbc/samples/Makefile
usr/man/
usr/man/man1/
usr/man/man1/iodbc-config.1.gz
usr/man/man1/iodbctestw.1.gz
usr/man/man1/iodbctest.1.gz
usr/man/man1/iodbcadm-gtk.1.gz
usr/bin/
usr/bin/iodbctest
usr/bin/iodbcadm-gtk
usr/bin/iodbctestw
usr/bin/iodbc-config
usr/include/
usr/include/iodbcinst.h
usr/include/sqlext.h
usr/include/iodbcunix.h
usr/include/isqltypes.h
usr/include/sql.h
usr/include/iodbcext.h
usr/include/isql.h
usr/include/odbcinst.h
usr/include/isqlext.h
usr/include/sqlucode.h
usr/include/sqltypes.h
usr/lib64/
usr/lib64/libiodbc.la
usr/lib64/libdrvproxy.so.2.1.19
usr/lib64/libiodbcinst.la
usr/lib64/libiodbcadm.so.2.1.19
usr/lib64/libiodbcinst.so.2.1.19
usr/lib64/libiodbcadm.la
usr/lib64/pkgconfig/
usr/lib64/pkgconfig/libiodbc.pc
usr/lib64/libiodbc.so.2.1.19
usr/lib64/libdrvproxy.la
usr/doc/
usr/doc/libiodbc-3.52.7/
usr/doc/libiodbc-3.52.7/ChangeLog
usr/doc/libiodbc-3.52.7/README
usr/doc/libiodbc-3.52.7/COPYING
usr/doc/libiodbc-3.52.7/AUTHORS
usr/doc/libiodbc-3.52.7/INSTALL
install/
install/doinst.sh
install/slack-desc |
|
14 Nov 2013, Konstantin Olchanski, Forum, Installation problem
|
# slackpkg file-search sql.h
[ installed ] - libiodbc-3.52.7-x86_64-2
...
# slackpkg search package
...
# cat /var/log/packages/libiodbc-3.52.7-x86_64-2
usr/include/sql.h
...
usr/lib64/libiodbc.so.2.1.19
...
Thanks, I am saving the slackpkg commands for future reference. Looks like the immediate problem is
with the library name: libiodbc instead of libodbc. But the header file sql.h is the same.
I am not sure if it is worth making a generic solution for this: on MacOS, all ODBC functions are now
obsoleted, to be removed, and since we are stanardized on MySQL anyway, so I think I will rewrite the SQL
history driver to use the MySQL interface directly. Then all this ODBC extra layering will go away.
K.O. |
|
13 Nov 2013, Stefan Ritt, Forum, Installation problem
|
The warnings with the set but unused variables are real. While John O'Donnell proposed:
==========
somewhere I long the way I found an include file to help remove this kind of message. try something like:
#include "use.h"
int foo () { return 3; }
int main () {
{ USED int i=foo(); }
return 0;
}
with -Wall, and you will see the unused messages are gone.
==========
I would rather go and remove the unused variables to clean up the code a bit. Unfortunately my gcc version does
not yet bark on that. So once I get a new version and I got plenty of spare time (....) I will consider removing all
these variables.
/Stefan |
|
14 Nov 2013, Konstantin Olchanski, Forum, Installation problem
|
> #include "use.h"
> { USED int i=foo(); }
Sounds nifty, but google does not find use.h.
As for unused variables, some can be removed, others not so much, there is some code in there:
int i = blah...
#if 0
if (i=42) printf("wow, we got a 42!\n");
#endif
and
if (0) printf("debug: i=%d\n", i);
(difference is if you remove "i" or otherwise break the disabled debug code, "#if 0" will complain the next time you need that debugging code, "if (0)" will
complain right away).
Some of this disabled debug code I would rather not remove - so much debug scaffolding I have added, removed, added again, removed again, all in the same
places that I cannot be bothered with removing it anymore. I "#if 0" it and it stays there until I need it next time. But of course now gcc complains about it.
K.O. |
|
22 Oct 2013, Konstantin Olchanski, Info, midas programs "auto start", etc
|
MIDAS "programs" settings include: /programs/xxx/"auto start", "auto restart" and "auto stop". What do
they do?
"auto start":
if set to "y", the program's "start command" will be unconditionally executed at the beginning of the run
start transition.
Because there are no checks or tests, the "start command" will be executed even if the program is already
running. It means that this function cannot be used to start frontend programs - a new copy will be
started each time, and a previously running copy will be killed.
Also the timing of the program startup and run transition is wrong - in my tests, the program starts too
late to see the run transition. If the program is a frontend, it will never see the begin-of-run transition.
1st conclusion: "auto start" should be "n" for frontend programs and for any other programs that are
supposed to be continuously running (mlogger, lazylogger, etc).
2nd conclusion: "auto start" does the same thing as "/programs/execute on start run".
"auto stop":
if set to "y", the program will be stopped after the end of run. (using cm_shutdown).
"auto restart":
this has nothing to do with starting and stopping runs. Instead, it works in conjunction with the alarm
system and the "program is not running" alarm.
The alarm system periodically calls al_check(). al_check() checks all programs defined under /Programs to
see if they are running (using cm_exist()). If a program is not running and an alarm is defined, the alarm is
raised ("program is not running" alarm). If there is a start command and "auto restart" is set to "y", the
start command is executed.
When using these "auto start" and "auto restart" functions, one needs to be careful about the context
where the start command will be executed: midas clients may be running from different directories, under
different user names and on different computers.
In "auto start", the start command is executed from cm_transition. For remote clients, this will happen on
the remote computer. (against the expectation that the program will be started on the main computer).
In "auto restart", the start command is executed by al_check() which always runs locally (for remote
clients, it runs inside the mserver). So the started program will always run on the main computer, but
maybe not in the same directory as when started from the mhttpd "programs -> start" button.
Conclusion:
"programs auto start" : works but has strange interactions and side effects, do not use it.
"programs auto stop" : works, can be used to stop programs at the end of run (but what for?)
"programs auto restart" : works, seems to work correctly, can be used to auto restart mlogger, frontends,
etc.
K.O. |
|
06 Nov 2013, Stefan Ritt, Info, midas programs "auto start", etc
|
> "programs auto start" : works but has strange interactions and side effects, do not use it.
> "programs auto stop" : works, can be used to stop programs at the end of run (but what for?)
> "programs auto restart" : works, seems to work correctly, can be used to auto restart mlogger, frontends,
auto start and auto stop have been requested by PAA loooong time ago. Maybe he remembers if/where this has been used at all. I never used it. So if
this is the case for others, we can easily change it and won't break anything. Like auto start can be executed before the run transition happens, check
for a previous version of the program, and only continue when the program is actually running. Should be only a few lines of code. Auto restart is used
successfully here at PSI, for example for the lazy logger.
/Stefan |
|
25 Oct 2013, Konstantin Olchanski, Bug Fix, fixed mlogger run auto restart bug
|
A problem existed in midas for some time: when recording long data sets of time (or event) limited runs
with logger run auto restart set to "yes", the runs will automatically stop and restart as expected, but
sometimes the run will stop and never restart and beam will be lost until the experiment operator on shift
wakes up and restarts the run manually.
I have now traced this problem to a race condition inside the mlogger - when a run is being stopped from
the mlogger, the mlogger run transition handler (tr_stop) triggers an immediate attempt to start the next
run, without waiting for the run-stop transition to actually complete. If the run-stop transition does not
finish quickly enough, a safety check in start_the_run() will cause the run restart attempt to silently fail
without any error message.
This race condition is pretty rare but somehow I managed to replicate it while debugging the
multithreaded transitions. It is fixed by making mlogger wait until the run-stop transition completes.
https://bitbucket.org/tmidas/midas/commits/b2631fbed5f7b1ec80e8a6c8781ada0baed7702b
K.O. |
|
25 Oct 2013, Stefan Ritt, Bug Fix, fixed mlogger run auto restart bug
|
> A problem existed in midas for some time: when recording long data sets of time (or event) limited runs
> with logger run auto restart set to "yes", the runs will automatically stop and restart as expected, but
> sometimes the run will stop and never restart and beam will be lost until the experiment operator on shift
> wakes up and restarts the run manually.
>
> I have now traced this problem to a race condition inside the mlogger - when a run is being stopped from
> the mlogger, the mlogger run transition handler (tr_stop) triggers an immediate attempt to start the next
> run, without waiting for the run-stop transition to actually complete. If the run-stop transition does not
> finish quickly enough, a safety check in start_the_run() will cause the run restart attempt to silently fail
> without any error message.
>
> This race condition is pretty rare but somehow I managed to replicate it while debugging the
> multithreaded transitions. It is fixed by making mlogger wait until the run-stop transition completes.
>
> https://bitbucket.org/tmidas/midas/commits/b2631fbed5f7b1ec80e8a6c8781ada0baed7702b
>
> K.O.
More generally I kind of consider the mlogger auto restart facility as deprecated. It works in the background and the operator does not have a clue
what is going on. We use now the sequencer to achieve exactly the same functionality. It just requires a few lines of sequencer code:
LOOP INFINITE
TRANSITION start
WAIT events, 5000
TRANSITION stop
ENDLOOP
So the run start is only executed after the runs has been successfully stopped. You can do things in the sequencer like "stop run and sequence
immediately" or "stop after current run has finished" which are a bit hard to do with the old method. So people should move to the sequencer.
/Stefan |
|
28 Oct 2013, Konstantin Olchanski, Bug Fix, fixed mlogger run auto restart bug
|
>
> More generally I kind of consider the mlogger auto restart facility as deprecated. It works in the background and the operator does not have a clue
> what is going on. We use now the sequencer to achieve exactly the same functionality.
>
Before subruns were available, most experiments at TRIUMF have used the "auto restart" function. Now, I think most of them use subruns,
with the notable exception of PIENU where the analysis framework could not handle subruns. (PIENU is now shutdown and disassembled).
>
> It just requires a few lines of sequencer code:
>
> LOOP INFINITE
> TRANSITION start
> WAIT events, 5000
> TRANSITION stop
> ENDLOOP
>
Mouse click "auto restart" to "yes" is a little bit simpler than setting up a sequencer file, and it survives a crash of mhttpd.
Does the sequencer survive a crash or a restart of mhttpd?
K.O. |
|
28 Oct 2013, Stefan Ritt, Bug Fix, fixed mlogger run auto restart bug
|
> Does the sequencer survive a crash or a restart of mhttpd?
Yes. Of course runs will not be started/stopped when mhttpd is not running, but when you restart it gracefully continues where it stopped, since all variables such as event count or current line number of
the sequence are store in the ODB.
/Stefan |
|
01 Oct 2013, Konstantin Olchanski, Info, MacOS select() problem
|
The following code found in mhttpd does not work on MacOS (BSD UNIX).
On Linux, the do-loop will finish after 2 seconds as expected. On MacOS (and other BSD systems), it will
loop forever.
The cause is the MIDAS watchdog alarm() signal that fires every 1 second and always interrupts the 2
second sleep of select(). The Linux select() updates it's timeout argument to reflect time already slept, so
eventually we finish. The MacOS (BSD) select() does not update the timeout argument and select goes back
to sleep for another 2 seconds (to be again interrupted half-way through).
The POSIX standard (specification for select() & co) permits either behaviour. Compare "man select" on
MacOS and on Linux.
If the select() timeout were not 2 seconds, but 0.9 seconds; or if the MIDAS watchdog alarm fired every
2.1 seconds, this problem would also not exist.
I think there are several places in MIDAS with code like this. An audit is required.
{
FD_ZERO(&readfds);
FD_SET(_sock, &readfds);
timeout.tv_sec = 2;
timeout.tv_usec = 0;
do {
status = select(FD_SETSIZE, &readfds, NULL, NULL, &timeout);
/* if an alarm signal was cought, restart with reduced timeout */
} while (status == -1 && errno == EINTR);
}
K.O. |
|
25 Oct 2013, Konstantin Olchanski, Info, MacOS select() problem
|
> The following code found in mhttpd does not work on MacOS (BSD UNIX). ...
Because of this problem, on MacOS, run transitions can get stuck forever - most timeouts do not work. (Specifically, recv_string() never times out)
K.O. |
|
22 Oct 2013, Konstantin Olchanski, Info, audit of db_get_record()
|
Record-oriented ODB functions db_create_record(), db_get_record(), db_check_record() and
db_set_record() require special attention to the consistency between their "C struct"s (usually defined in
midas.h), their initialization strings (usually defined in midas.h) and the contents of ODB.
When these 3 items become inconsistent, the corresponding midas functions tend to break.
Unlike ODB internal structures and event buffer internal structures, these record-oriented functions are
not part of the midas binary-compatibility abi and they are not protected by db_validate_sizes().
From time to time, new items are added to some of these data structures. Usually this does not cause
problems, but recently we had some difficulty with the runinfo and equipment structures, prompting this
audit.
db_check_record: note: (C) means that this record is created there
alarm.c: alarm_odb_str(C)
mana.c: skipped
mfe.c: equipment_common_str, equipment_statistics_str(C), event_descrip(C), bank_list(C)
mhttpd.cxx: cgif_label_str(C), cgif_bar_str(C), runinfo_str(C), equipment_common_str(C)
mlogger.cxx: ch_settings_str(C)
sequencer.cxx: sequencer_str(C)
db_create_record:
alarm.c: alarm_odb_str, alarm_periodic_str, alarm_class_str
fal.c: skipped
mfe.c: equipment_common_str
midas.c: program_info_str (maybe)
odb.c: (maybe)
lazylogger.cxx: lazy_settings, lazy_statistics
mhttpd.cxx: runinfo_str
mlogger.cxx: chn_settings_str
db_get_record: (hard to do with grep, will have to check every db_get_record by hand)
alarm.c: alarm, class, program_info
fal.c: skipped
mana.c: skipped
midas.c: program_info
odb.c: (maybe)
lazylogger.cxx: lazyst
mhttpd.cxx: runinfo, equipment, ?hkeytemp?, chn_settings, chn_stats, ?label?, ?bar?
mlogger.cxx: ?, ?, chn_stats, chn, settings
sequencer.cxx: hkeyseq
db_set_record:
alarm.c: hkeyalarm, hkeyclass, ???, program_info
fal.c: skipped
mana.c: skipped
mfe.c: equipment_info, ?event structure?
odb.c: (maybe)
lazelogger.cxx: lazyst
mlogger.cxx: chn_stat
sequencer.cxx: seq
db_open_record: note: (W) means MODE_WRITE
fal.c: skipped
mana.c: skipped
mfe.c: equipment_info, equipment_stats(W)
midas.c: requested_transition
odbedit.c: key_update - generic test of hotlink
lazylogger.cxx: runstate, lazyst(W), lazy?
mlogger.cxx: history, chn_statistics, chn_settings
sequencer.cxx: seq
K.O. |
|
21 Aug 2013, Konstantin Olchanski, Info, Documentation for ODBGet() & co, Javascript and AJAX functions.
|
The bulk of the MIDAS AJAX and Javascript functions is now documented on the MIDAS Wiki:
https://midas.triumf.ca/MidasWiki/index.php/Mhttpd.js
https://midas.triumf.ca/MidasWiki/index.php/AJAX
Enjoy,
K.O. |
|
22 Aug 2013, Konstantin Olchanski, Info, Documentation for ODBGet() & co, Javascript and AJAX functions.
|
> The bulk of the MIDAS AJAX and Javascript functions is now documented on the MIDAS Wiki:
>
> https://midas.triumf.ca/MidasWiki/index.php/Mhttpd.js
> https://midas.triumf.ca/MidasWiki/index.php/AJAX
>
The documentation was updated again.
All functions and AJAX methods except jset, jget, jrpc (ODBGet, ODBSet, ODBRpc) and inline edit are now fully
documented. AJAX methods jset/jget and their javascript wrappers ODBSet/ODBGet/ODBMGet/ODBGetRecord() are
partially documented. Inline edit will have to be documented by Stefan.
When using these functions please read the "BUG" sections carefully.
When using the Javascript functions (ODBGet, ODBSet, ODBMCopy, etc) please pay special attention to the rules for URI-
encoding function arguments - some functions require that some arguments be pre-encoded by
"encodeURIComponent()", some functions require some arguments to NOT be pre-encoded. The examples in
examples/javascript1/example.html are mostly correct.
Special confusion is created by special handling in mhttpd of URI-encoding of parameters named "format".
Special confusion is created by ODBSet(path, value), where "path" should be pre-encoded, while "value" is now encoded
internally, which is a recent change introduced with the inline edit function. Older versions of mhttpd.js still require that
"value" be URI-encoded.
Going forward, I hope to resolve most of the confusion by providing a cleaner interface for reading ODB
- ODBMCopy() already looks good with full async JSON/JSONP support (already implemented)
- ODBMKey() to read just the keys, with async JSON/JSONP support (to be added)
- ODBMCreate() to create ODB keys (RPC for db_create()) (to be added)
- ODBMSet() to write into ODB. (to be added)
K.O. |
|
25 Sep 2013, Konstantin Olchanski, Info, Documentation for ODBGet() & co, Javascript and AJAX functions.
|
> > The bulk of the MIDAS AJAX and Javascript functions is now documented on the MIDAS Wiki:
> >
> > https://midas.triumf.ca/MidasWiki/index.php/Mhttpd.js
> > https://midas.triumf.ca/MidasWiki/index.php/AJAX
> >
>
> The documentation was updated again.
>
Newly documented are the additional Javascript and AJAX functions present in the GIT branch "feature/ajax":
ODBMCreate(paths, types);
ODBMCreate(paths, types, arraylengths, stringlengths, callback);
ODBMResize(paths, arraylengths, stringlengths, callback);
ODBMRename(paths, names, callback);
ODBMLink(paths, links, callback);
ODBMReorder(paths, indices, callback);
ODBMKey(paths, callback);
ODBMDelete(paths, callback);
All these functions permit asynchronous use (with callback on completion) and the underlying AJAX functions permit JSON-P encoding.
ODBSetUrl("http://mhttpd.somewhere.com:8080") : this new function removes the restriction that custom scripts had to be loaded from the same mhttpd that they will
access. Together with the newly added CORS support in mhttpd, allows loading custom scripts from any web server, including local file, and having then access any one (or
any several) mhttpd data sources.
I think these new functions are now stable (I still had to make some changes to ODBMCreate() recently) and after some more testing this branch will be merged into
"develop".
To use this branch, do either:
a) git clone midas; git pull; git checkout feature/ajax
b) git clone midas; git checkout develop; git pull; git checkout -b ajaxtest; git merge feature/ajax;
(Option (b) creates a local branch with the latest "develop" and "feature/ajax" merged together).
K.O. |
|
13 Sep 2013, Thomas Lindner, Bug Report, mhttpd truncates string variables to 32 characters
|
I find that new mhttpd has strange behaviour for ODB strings.
- I create a new STRING variable in ODB through mhttpd. It defaults to size 32.
- I then edit the STRING variable through mhttpd, writing a new string larger
than 32 characters.
- Initially everything looks fine; it seems as if the new string value has been
accepted.
- But if you reload the page, or navigate back to the page, you realize that
mhttpd has silently truncated the string back to 32 characters.
You can reproduce this problem on a test page here:
http://midptf01.triumf.ca:8081/AnnMessage
Older versions of mhttpd (I'm testing one from 2 years ago) don't have this
'feature'. For older mhttpd the string variable would get resized when a larger
string was inputted. That definitely seems like the right behavior to me.
I am using fresh copy of midas from bitbucket as of this morning. (How do I get
a particular tag/hash of the version of midas that I am using?) |
|
13 Sep 2013, Konstantin Olchanski, Bug Report, mhttpd truncates string variables to 32 characters
|
I can confirm part of the problem - the new inline-edit function - after you finish editing - shows you what you
have typed, not what's actually in ODB - at the very end it should do an ODBGet() to load the actual ODB
contents and show *that* to the user.
The truncation to 32 characters - most likely it is a failure to resize the ODB string - is probably in mhttpd and
I can take a quick look into it.
There is a 3rd problem - the mhttpd ODB editor "create" function does not ask for the string length to create.
Actually, in ODB, "create" and "set string size" are two separate functions - db_create_key(TID_STRING) creates
a string of length zero, then db_set_data() creates an empty string of desired length.
In the new AJAX interface these two functions are separate (ODBCreate just calls db_create_key()).
In the present ODBSet() function the two are mixed together - and the ODB inline edit function uses ODBSet().
K.O.
> I find that new mhttpd has strange behaviour for ODB strings.
>
> - I create a new STRING variable in ODB through mhttpd. It defaults to size 32.
>
> - I then edit the STRING variable through mhttpd, writing a new string larger
> than 32 characters.
>
> - Initially everything looks fine; it seems as if the new string value has been
> accepted.
>
> - But if you reload the page, or navigate back to the page, you realize that
> mhttpd has silently truncated the string back to 32 characters.
>
> You can reproduce this problem on a test page here:
>
> http://midptf01.triumf.ca:8081/AnnMessage
>
> Older versions of mhttpd (I'm testing one from 2 years ago) don't have this
> 'feature'. For older mhttpd the string variable would get resized when a larger
> string was inputted. That definitely seems like the right behavior to me.
>
> I am using fresh copy of midas from bitbucket as of this morning. (How do I get
> a particular tag/hash of the version of midas that I am using?) |
|
18 Sep 2013, Konstantin Olchanski, Bug Report, mhttpd truncates string variables to 32 characters
|
I confirm the second part of the problem.
Inline edit uses ODBSet(), which uses the "jset" AJAX call to mhttpd which does not extend string variables.
This is the jset code. The best I can tell it truncates string variables to the existing size in ODB:
db_find_key(hDB, 0, str, &hkey)
db_get_key(hDB, hkey, &key);
memset(data, 0, sizeof(data));
size = sizeof(data);
db_sscanf(getparam("value"), data, &size, 0, key.type);
db_set_data_index(hDB, hkey, data, key.item_size, index, key.type);
These original jset/jget functions are a little bit too complicated and there is no documentation (what exists is done by me trying to read the existing code).
We now have a jcopy/ODBMCopy() as a sane replacement for jget, but nothing comparable for jset, yet.
I think this quirk of inline edit cannot be fixed in javascript - the mhttpd code for "jset" has to change.
K.O.
>
> I can confirm part of the problem - the new inline-edit function - after you finish editing - shows you what you
> have typed, not what's actually in ODB - at the very end it should do an ODBGet() to load the actual ODB
> contents and show *that* to the user.
>
> The truncation to 32 characters - most likely it is a failure to resize the ODB string - is probably in mhttpd and
> I can take a quick look into it.
>
> There is a 3rd problem - the mhttpd ODB editor "create" function does not ask for the string length to create.
>
> Actually, in ODB, "create" and "set string size" are two separate functions - db_create_key(TID_STRING) creates
> a string of length zero, then db_set_data() creates an empty string of desired length.
>
> In the new AJAX interface these two functions are separate (ODBCreate just calls db_create_key()).
>
> In the present ODBSet() function the two are mixed together - and the ODB inline edit function uses ODBSet().
>
> K.O.
>
>
>
> > I find that new mhttpd has strange behaviour for ODB strings.
> >
> > - I create a new STRING variable in ODB through mhttpd. It defaults to size 32.
> >
> > - I then edit the STRING variable through mhttpd, writing a new string larger
> > than 32 characters.
> >
> > - Initially everything looks fine; it seems as if the new string value has been
> > accepted.
> >
> > - But if you reload the page, or navigate back to the page, you realize that
> > mhttpd has silently truncated the string back to 32 characters.
> >
> > You can reproduce this problem on a test page here:
> >
> > http://midptf01.triumf.ca:8081/AnnMessage
> >
> > Older versions of mhttpd (I'm testing one from 2 years ago) don't have this
> > 'feature'. For older mhttpd the string variable would get resized when a larger
> > string was inputted. That definitely seems like the right behavior to me.
> >
> > I am using fresh copy of midas from bitbucket as of this morning. (How do I get
> > a particular tag/hash of the version of midas that I am using?) |
|
24 Sep 2013, Stefan Ritt, Bug Report, mhttpd truncates string variables to 32 characters
|
> This is the jset code. The best I can tell it truncates string variables to the existing size in ODB:
>
> db_find_key(hDB, 0, str, &hkey)
> db_get_key(hDB, hkey, &key);
> memset(data, 0, sizeof(data));
> size = sizeof(data);
> db_sscanf(getparam("value"), data, &size, 0, key.type);
> db_set_data_index(hDB, hkey, data, key.item_size, index, key.type);
Correct. So I added some code which extends strings if necessary (NOT string arrays, they are more complicated to handle). |
|
24 Sep 2013, Stefan Ritt, Bug Report, mhttpd truncates string variables to 32 characters
|
Actually this was no bug, but a missing feature. Strings were never meant to be extended via the web interface.
Now I added that feature to the current version. Please check it.
/Stefan |
|
14 Sep 2013, Konstantin Olchanski, Info, mktime() and daylight savings time
|
I would like to share with you a silly problem with mktime() and daylight savings time (Summer
time/Winter time) that I have run into while working on the mhttpd history query page.
I am implementing 1 hour granularity for the queries (was 1 day granularity) and somehow all my queries
were off by 1 hour.
It turns out that the mktime() and localtime() functions for converting between time_t and normal time
units (days, hours) are not exact inverses of each other.
Daylight savings time (DST) is to blame.
While localtime() always applies the current DST, mktime() will return the wrong answer unless tm_isdst is
set correctly.
For tm_isdst, the default value 0 is wrong 50% of the time in most locations as it means "DST off" (whether
that's Summer time or Winter time depends on your location).
Today in Vancouver, BC, DST is in effect, and localtime(mktime()) is off by 1 hour.
If I were doing this in January, I would not see this problem.
"man mktime" talks about "tm_isdst" special value "-1" that is supposed to fix this. But the wording of
"man mktime" on Linux and on MacOS is different (I am amused by the talk about "attempting to divine
the DST setting"). Wording at http://pubs.opengroup.org/onlinepubs/007908799/xsh/mktime.html is
different again. MS Windows (Visual Studio) documentation says different things for different versions.
So for mhttpd I use the following code. First mktime() gets the approximate time, a call to localtime()
returns the DST setting in effect for that date, a second mktime() with the correct DST setting returns the
correct time. (By "correct" I mean that localtime(mktime(t)) == t).
time_t mktime_with_dst(const struct tm* ptms)
{
// this silly stuff is required to correctly handle daylight savings time (Summer time/Winter time)
// when we fill "struct tm" from user input, we cannot know if daylight savings time is in effect
// and we do not know how to initialize the value of tms->tm_isdst.
// This can cause the output of mktime() to be off by one hour.
// (Rules for daylight savings time are set by national and local govt and in some locations, changes
yearly)
// (There are no locations with 2 hour or half-hour daylight savings that I know of)
// (Yes, "man mktime" talks about using "tms->tm_isdst = -1")
//
// We assume the user is using local time and we convert in two steps:
//
// first we convert "struct tm" to "time_t" using mktime() with unknown tm_isdst
// second we convert "time_t" back to "struct tm" using localtime_r()
// this fills "tm_isdst" with correct value from the system time zone database
// then we reset all the time fields (except for sub-minute fields not affected by daylight savings)
// and call mktime() again, now with the correct value of "tm_isdst".
// K.O. 2013-09-14
struct tm tms = *ptms;
struct tm tms2;
time_t t1 = mktime(&tms);
localtime_r(&t1, &tms2);
tms2.tm_year = ptms->tm_year;
tms2.tm_mon = ptms->tm_mon;
tms2.tm_mday = ptms->tm_mday;
tms2.tm_hour = ptms->tm_hour;
tms2.tm_min = ptms->tm_min;
time_t t2 = mktime(&tms2);
//printf("t1 %.0f, t2 %.0f, diff %d\n", (double)t1, (double)t2, (int)(t1-t2));
return t2;
}
K.O. |
|
24 Sep 2013, Stefan Ritt, Info, mktime() and daylight savings time
|
I vaguely remember that I had a similar problem with ELOG. The solution was to call tzset() at the beginning of the program. The man page says that
this function is called automatically by programs using time zones, but apparently it is not. Can you try that? There is also the TZ environment
variable and /etc/localtime. I never understood the details, but playing with these things can influence mktime() and localtime().
/Stefan |
|
24 Sep 2013, Konstantin Olchanski, Info, mktime() and daylight savings time
|
> I vaguely remember that I had a similar problem with ELOG. The solution was to call tzset() at the beginning of the program. The man page says that
> this function is called automatically by programs using time zones, but apparently it is not. Can you try that? There is also the TZ environment
> variable and /etc/localtime. I never understood the details, but playing with these things can influence mktime() and localtime().
I confirm that the timezone is set correctly - I do get the correct time eventually - so there is no missing call to tzet().
K.O. |
|
24 Sep 2013, Stefan Ritt, Info, mktime() and daylight savings time
|
> > I vaguely remember that I had a similar problem with ELOG. The solution was to call tzset() at the beginning of the program. The man page says that
> > this function is called automatically by programs using time zones, but apparently it is not. Can you try that? There is also the TZ environment
> > variable and /etc/localtime. I never understood the details, but playing with these things can influence mktime() and localtime().
>
> I confirm that the timezone is set correctly - I do get the correct time eventually - so there is no missing call to tzet().
>
> K.O.
tzset() not only sets the time zone, but also DST. |
|
24 Sep 2013, Stefan Ritt, Info, mktime() and daylight savings time
|
> > > I vaguely remember that I had a similar problem with ELOG. The solution was to call tzset() at the beginning of the program. The man page says that
> > > this function is called automatically by programs using time zones, but apparently it is not. Can you try that? There is also the TZ environment
> > > variable and /etc/localtime. I never understood the details, but playing with these things can influence mktime() and localtime().
> >
> > I confirm that the timezone is set correctly - I do get the correct time eventually - so there is no missing call to tzet().
> >
> > K.O.
>
> tzset() not only sets the time zone, but also DST.
I found following code in elogd.c, maybe it helps:
/* workaround for wong timezone under MAX OSX */
long my_timezone()
{
#if defined(OS_MACOSX) || defined(__FreeBSD__) || defined(__OpenBSD__)
time_t tp;
time(&tp);
return -localtime(&tp)->tm_gmtoff;
#else
return timezone;
#endif
}
void get_rfc2822_date(char *date, int size, time_t ltime)
{
time_t now;
char buf[256];
int offset;
struct tm *ts;
/* switch locale temporarily back to english to comply with RFC2822 date format */
setlocale(LC_ALL, "C");
if (ltime == 0)
time(&now);
else
now = ltime;
ts = localtime(&now);
assert(ts);
strftime(buf, sizeof(buf), "%a, %d %b %Y %H:%M:%S", ts);
offset = (-(int) my_timezone());
if (ts->tm_isdst)
offset += 3600;
snprintf(date, size - 1, "%s %+03d%02d", buf, (int) (offset / 3600),
(int) ((abs((int) offset) / 60) % 60));
} |
|