 24 Apr 2024, Konstantin Olchanski, Info, MIDAS RPC add support for std::string and std::vector<char> 24 Apr 2024, Konstantin Olchanski, Info, MIDAS RPC add support for std::string and std::vector<char>
|
I now fully understand the MIDAS RPC code, had to add some debugging printfs,
write some test code (odbedit test_rpc), catch and fix a few bugs.
Fixes for the bugs are now committed.
Small refactor of rpc_execute() should be committed soon, this removes the
"goto" in the memory allocation of output buffer. Stefan's original code used a
fixed size buffer, I later added allocation "as-neeed" but did not fully
understand everything and implemented it as "if buffer too small, make it
bigger, goto start over again".
After that, I can implement support for std::string and std::vector<char>.
The way it looks right now, the on-the-wire data format is flexible enough to
make this change backward-compatible and allow MIDAS programs built with old
MIDAS to continue connecting to the new MIDAS and vice-versa.
MIDAS RPC support for std::string should let us improve security by removing
even more uses of fixed-size string buffers.
Support for std::vector<char> will allow removal of last places where
MAX_EVENT_SIZE is used and simplify memory allocation in other "give me data"
RPC calls, like RPC_JRPC and RPC_BRPC.
K.O. |
|
04 Apr 2024, Konstantin Olchanski, Info, MIDAS RPC data format
|
I am not sure I have seen this documented before. MIDAS RPC data format.
1) RPC request (from client to mserver), in rpc_call_encode()
1.1) header:
4 bytes NET_COMMAND.header.routine_id is the RPC routine ID
4 bytes NET_COMMAND.header.param_size is the size of following data, aligned to 8 bytes
1.2) followed by values of RPC_IN parameters:
arg_size is the actual data size
param_size = ALIGN8(arg_size)
for TID_STRING||TID_LINK, arg_size = 1+strlen()
for TID_STRUCT||RPC_FIXARRAY, arg_size is taken from RPC_LIST.param[i].n
for RPC_VARARRAY|RPC_OUT, arg_size is pointed to by the next argument
for RPC_VARARRAY, arg_size is the value of the next argument
otherwise arg_size = rpc_tid_size()
data encoding:
RPC_VARARRAY:
4 bytes of ALIGN8(arg_size)
4 bytes of padding
param_size bytes of data
TID_STRING||TID_LINK:
param_size of string data, zero terminated
otherwise:
param_size of data
2) RPC dispatch in rpc_execute
for each parameter, a pointer is placed into prpc_param[i]:
RPC_IN: points to the data inside the receive buffer
RPC_OUT: points to the data buffer allocated inside the send buffer
RPC_IN|RPC_OUT: data is copied from the receive buffer to the send buffer, prpc_param[i] is a pointer to the copy in the send buffer
prpc_param[] is passed to the user handler function.
user function reads RPC_IN parameters by using the CSTRING(i), etc macros to dereference prpc_param[i]
user function modifies RPC_IN|RPC_OUT parameters pointed to by prpc_param[i] (directly in the send buffer)
user function places RPC_OUT data directly to the send buffer pointed to by prpc_param[i]
size of RPC_VARARRAY|RPC_OUT data should be written into the next/following parameter.
3) RPC reply
3.1) header:
4 bytes NET_COMMAND.header.routine_id contains the value returned by the user function (RPC_SUCCESS)
4 bytes NET_COMMAND.header.param_size is the size of following data aligned to 8 bytes
3.2) followed by data for RPC_OUT parameters:
data sizes and encodings are the same as for RPC_IN parameters.
for variable-size RPC_OUT parameters, space is allocated in the send buffer according to the maximum data size
that the user code expects to receive:
RPC_VARARRAY||TID_STRING: max_size is taken from the first 4 bytes of the *next* parameter
otherwise: max_size is same as arg_size and param_size.
when encoding and sending RPC_VARARRAY data, actual data size is taken from the next parameter, which is expected to be
TID_INT32|RPC_IN|RPC_OUT.
4) Notes:
4.1) RPC_VARARRAY should always be sent using two parameters:
a) RPC_VARARRAY|RPC_IN is pointer to the data we are sending, next parameter must be TID_INT32|RPC_IN is data size
b) RPC_VARARRAY|RPC_OUT is pointer to the data buffer for received data, next parameter must be TID_INT32|RPC_IN|RPC_OUT before the call should
contain maximum data size we expect to receive (size of malloc() buffer), after the call it may contain the actual data size returned
c) RPC_VARARRAY|RPC_IN|RPC_OUT is pointer to the data we are sending, next parameter must be TID_INT32|RPC_IN|RPC_OUT containing the maximum
data size we are expected to receive.
4.2) during dispatching, RPC_VARARRAY|RPC_OUT and TID_STRING|RPC_OUT both have 8 bytes of special header preceeding the actual data, 4 bytes of
maximum data size and 4 bytes of padding. prpc_param[] points to the actual data and user does not see this special header.
4.3) when encoding outgoing data, this special 8 byte header is removed from TID_STRING|RPC_OUT parameters using memmove().
4.4) TID_STRING parameters:
TID_STRING|RPC_IN can be sent using oe parameter
TID_STRING|RPC_OUT must be sent using two parameters, second parameter should be TID_INT32|RPC_IN to specify maximum returned string length
TID_STRING|RPC_IN|RPC_OUT ditto, but not used anywhere inside MIDAS
4.5) TID_IN32|RPC_VARARRAY does not work, corrupts following parameters. MIDAS only uses TID_ARRAY|RPC_VARARRAY
4.6) TID_STRING|RPC_IN|RPC_OUT does not seem to work.
4.7) RPC_VARARRAY does not work is there is preceding TID_STRING|RPC_OUT that returned a short string. memmove() moves stuff in the send buffer,
this makes prpc_param[] pointers into the send buffer invalid. subsequent RPC_VARARRAY parameter refers to now-invalid prpc_param[i] pointer to
get param_size and gets the wrong value. MIDAS does not use this sequence of RPC parameters.
4.8) same bug is in the processing of TID_STRING|RPC_OUT parameters, where it refers to invalid prpc_param[i] to get the string length.
K.O. |
 24 Apr 2024, Konstantin Olchanski, Info, MIDAS RPC data format 24 Apr 2024, Konstantin Olchanski, Info, MIDAS RPC data format
|
> 4.5) TID_IN32|RPC_VARARRAY does not work, corrupts following parameters. MIDAS only uses TID_ARRAY|RPC_VARARRAY
fixed in commit 0f5436d901a1dfaf6da2b94e2d87f870e3611cf1, TID_ARRAY|RPC_VARARRAY was okey (i.e. db_get_value()), bug happened only if rpc_tid_size()
is not zero.
>
> 4.6) TID_STRING|RPC_IN|RPC_OUT does not seem to work.
>
> 4.7) RPC_VARARRAY does not work is there is preceding TID_STRING|RPC_OUT that returned a short string. memmove() moves stuff in the send buffer,
> this makes prpc_param[] pointers into the send buffer invalid. subsequent RPC_VARARRAY parameter refers to now-invalid prpc_param[i] pointer to
> get param_size and gets the wrong value. MIDAS does not use this sequence of RPC parameters.
>
> 4.8) same bug is in the processing of TID_STRING|RPC_OUT parameters, where it refers to invalid prpc_param[i] to get the string length.
fixed in commits e45de5a8fa81c75e826a6a940f053c0794c962f5 and dc08fe8425c7d7bfea32540592b2c3aec5bead9f
K.O. |
|
15 Apr 2024, Konstantin Olchanski, Bug Report, open MIDAS RPC ports
|
we had a bit of trouble with open network ports recently and I now think security of MIDAS RPC
ports needs to be tightened.
TL;DR, this is a non-trivial network configuration problem, TL required, DR up to you.
as background, right now we have two settings in ODB, "/expt/security/enable non-localhost
RPC" set to "no" (the default) and set to "yes". Set to "no" is very secure, all RPC sockets
listen only on the "localhost" interface (127.0.0.1) and do not accept connections from other
computers. Set to "yes", RPC sockets accept connections from everywhere in the world, but
immediately close them without reading any data unless connection origins are listed in ODB
"/expt/security/RPC hosts" (white-listed).
the problem, one. for security and robustness we place most equipments on a private network
(192.168.1.x). MIDAS frontends running on these equipments must connect to MIDAS running on
the main computer. This requires setting "enable non-localhost RPC" to "yes" and white-listing
all private network equipments. so far so good.
the problem, one, continued. in this configuration, the MIDAS main computer is usually also
the network gateway (with NAT, IP forwarding, DHCP, DNS, etc). so now MIDAS RPC ports are open
to all external connections (in the absence of restrictive firewall rules). one would hope for
security-through-obscurity and expect that "external threat actors" will try to bother them,
but in reality we eventually see large numbers of rejected unwanted connections logged in
midas.log (we log the first 10 rejected connections to help with maintaining the RPC
connections white-list).
the problem, two. central IT do not like open network ports. they run their scanners, discover
the MIDAS RPC ports, complain about them, require lengthy explanations, etc.
it would be much better if in the typical configuration, MIDAS RPC ports did not listen on
external interfaces (campus network). only listen on localhost and on private network
interfaces (192.168.1.x).
I am not yet of the simplest way to implement this. But I think this is the direction we
should go.
P.S. what about firewall rules? two problems: one: from statistic-of-one, I make mistakes
writing firewall rules, others also will make mistakes, a literally fool-proof protection of
MIDAS RPC ports is needed. two: RHEL-derived Linuxes by-default have restrictive firewall
rules, and this is good for security, except that there is a failure mode where at boot time
something can go wrong and firewall rules are not loaded at all. we have seen this happen.
this is a complete disaster on a system that depends on firewall rules for security. better to
have secure applications (TCP ports protected by design and by app internals) with firewall
rules providing a secondary layer of protection.
P.P.S. what about MIDAS frontend initial connection to the mserver? this is currently very
insecure, but the vulnerability window is very small. Ideally we should rework the mserver
connection to make it simpler, more secure and compatible with SSH tunneling.
P.P.S. Typical network diagram:
internet - campus firewall - campus network - MIDAS host (MIDAS) - 192.168.1.x network - power
supplies, digitizers, MIDAS frontends.
P.P.S. mserver connection sequence:
1) midas frontend opens 3 tcp sockets, connections permitted from anywhere
2) midas frontend opens tcp socket to main mserver, sends port numbers of the 3 tcp sockets
3) main mserver forks out a secondary (per-client) mserver
4) secondary mserver connects to the 3 tcp sockets of the midas frontend created in (1)
5) from here midas rpc works
6) midas frontend loads the RPC white-list
7) from here MIDAS RPC sockets are secure (protected by the white-list).
(the 3 sockets are: RPC recv_sock, RPC send_sock and event_sock)
P.P.S. MIDAS UDP sockets used for event buffer and odb notifications are secure, they bind to
localhost interface and do not accept external connections.
K.O. |
|
15 Apr 2024, Stefan Ritt, Bug Report, open MIDAS RPC ports
|
One thing coming to my mind is the interface binding. If you have a midas host with two networks
("global" and "local"=192.168.x.x), you can tell to which interface a socket should bind.
By default it binds both interfaces, but we could restrict the socket only to bind to the local
interface 192.168.x.x. This way the open port would be invisible from the outside, but from
your local network everybody can connect easily without the need of a white list.
Stefan |
|
18 Mar 2024, Grzegorz Nieradka, Bug Report, Midas (manalyzer) + ROOT 6.31/01 - compilation error
|
I tried to update MIDAS installation on Ubuntu 22.04.1 to the latest commit at
the bitbucket.
I have update the ROOT from source the latest version ROOT 6.31/01.
During the MIDAS compilation I have error:
/usr/bin/ld: *some_path_to_ROOT*/libRIO.so: undefined reference to
`std::condition_variable::wait(std::unique_lock<std::mutex>&)@GLIBCXX_3.4.30'
The longer version of this error is below.
Has anybody knows some simple solution of this error?
Thanks, GN
Consolidate compiler generated dependencies of target manalyzer_main
[ 32%] Building CXX object
manalyzer/CMakeFiles/manalyzer_main.dir/manalyzer_main.cxx.o
[ 33%] Linking CXX static library libmanalyzer_main.a
[ 33%] Built target manalyzer_main
Consolidate compiler generated dependencies of target manalyzer_test.exe
[ 33%] Building CXX object
manalyzer/CMakeFiles/manalyzer_test.exe.dir/manalyzer_main.cxx.o
[ 34%] Linking CXX executable manalyzer_test.exe
/usr/bin/ld: /home/astrocent/workspace/root/root_install/lib/libRIO.so: undefined
reference to
`std::condition_variable::wait(std::unique_lock<std::mutex>&)@GLIBCXX_3.4.30'
collect2: error: ld returned 1 exit status
make[2]: *** [manalyzer/CMakeFiles/manalyzer_test.exe.dir/build.make:124:
manalyzer/manalyzer_test.exe] Error 1
make[1]: *** [CMakeFiles/Makefile2:780:
manalyzer/CMakeFiles/manalyzer_test.exe.dir/all] Error 2 |
|
18 Mar 2024, Konstantin Olchanski, Bug Report, Midas (manalyzer) + ROOT 6.31/01 - compilation error
|
> [ 34%] Linking CXX executable manalyzer_test.exe
> /usr/bin/ld: /home/astrocent/workspace/root/root_install/lib/libRIO.so: undefined
> reference to
> `std::condition_variable::wait(std::unique_lock<std::mutex>&)@GLIBCXX_3.4.30'
> collect2: error: ld returned 1 exit status
the error is actually in ROOT, libRIO does not find someting in the standard library.
one possible source of trouble is mismatched compilation flags, to debug this, please
use "make cmake" and email me (or post here) the full output. (standard cmake hides
all compiler information to make it easier to debug such problems).
since this is a prerelease of ROOT 6.32 (which in turn fixes major breakage on MacOS)
and you built it from sources, can you confirm for me that it actually works, you can
run "root -l somefile.root", open the tbrowser, look at some plots? this is to
eliminate the possibility that your ROOR is miscompiled.
hmm... also please run "make cmake -k", let's see is linking of rmlogger also fails.
K.O. |
19 Mar 2024, Grzegorz Nieradka, Bug Report, Midas (manalyzer) + ROOT 6.31/01 - compilation error 
|
Dear Konstantin,
Thank you for your interest in my problem.
What I did:
1. I installed the latest ROOT from source according tho the manual,
exactly as in this webpage (https://root.cern/install/).
ROOT sems work correctly, .demo from it is works and some example
file too. The manalyzer is not linking with this ROOT version installed from source.
2. I downgraded the ROOT to the lower version (6.30.04):
git checkout -b v6-30-04 v6-30-04
ROOT seems compiled, installed and run correctly. The manalyzer,
from the MIDAS is not linked.
3. I downoladed the latest version of ROOT:
https://root.cern/download/root_v6.30.04.Linux-ubuntu22.04-x86_64-gcc11.4.tar.gz
and I installed it simple by tar: tar -xzvf root_...
------------------------------------------------------------------
| Welcome to ROOT 6.30/04 https://root.cern |
| (c) 1995-2024, The ROOT Team; conception: R. Brun, F. Rademakers |
| Built for linuxx8664gcc on Jan 31 2024, 10:01:37 |
| From heads/master@tags/v6-30-04 |
| With c++ (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0 |
| Try '.help'/'.?', '.demo', '.license', '.credits', '.quit'/'.q' |
------------------------------------------------------------------
Again the ROOT sems work properly, the .demo from it is working, and example file
are working too. Manalyzer from MIDAS is failed to linking.
4. The midas with the option: cmake -D NO_ROOT=ON ..
is compliling, linking and even working.
5. When I try to build MIDAS with ROOT support threre is error:
[ 33%] Linking CXX executable manalyzer_test.exe
/usr/bin/ld: /home/astrocent/workspace/root/lib/libRIO.so: undefined reference to
`std::condition_variable::wait(std::unique_lock<std::mutex>&)@GLIBCXX_3.4.30
I'm trying to attach files:
cmake-midas-root -> My configuration of compiling MIDAS with ROOT
make-cmake-midas -> output of my the command make cmake in MIDAS directory
make-cmake-k -> output of my the command make cmake -k in MIDAS directory
And I'm stupid at this moment.
Regards,
Grzegorz Nieradka |
|
19 Mar 2024, Konstantin Olchanski, Bug Report, Midas (manalyzer) + ROOT 6.31/01 - compilation error
|
ok, thank you for your information. I cannot reproduce this problem, I use vanilla Ubuntu
LTS 22, ROOT binary kit root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4 from root.cern.ch
and latest midas from git.
something is wrong with your ubuntu or with your c++ standard library or with your ROOT.
a) can you try with root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4 from root.cern.ch
b) for the midas build, please run "make cclean; make cmake -k" and email me (or post
here) the complete output.
K.O. |
|
19 Mar 2024, Konstantin Olchanski, Bug Report, Midas (manalyzer) + ROOT 6.31/01 - compilation error
|
> ok, thank you for your information. I cannot reproduce this problem, I use vanilla Ubuntu
> LTS 22, ROOT binary kit root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4 from root.cern.ch
> and latest midas from git.
>
> something is wrong with your ubuntu or with your c++ standard library or with your ROOT.
>
> a) can you try with root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4 from root.cern.ch
> b) for the midas build, please run "make cclean; make cmake -k" and email me (or post
> here) the complete output.
also, please email me the output of these commands on your machine:
daq00:midas$ ls -l /lib/x86_64-linux-gnu/libstdc++*
lrwxrwxrwx 1 root root 19 May 13 2023 /lib/x86_64-linux-gnu/libstdc++.so.6 -> libstdc++.so.6.0.30
-rw-r--r-- 1 root root 2260296 May 13 2023 /lib/x86_64-linux-gnu/libstdc++.so.6.0.30
daq00:midas$
and
daq00:midas$ ldd $ROOTSYS/bin/rootreadspeed
linux-vdso.so.1 (0x00007ffe6c399000)
libTree.so => /daq/cern_root/root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4/lib/libTree.so (0x00007f67e53b5000)
libRIO.so => /daq/cern_root/root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4/lib/libRIO.so (0x00007f67e4fb9000)
libCore.so => /daq/cern_root/root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4/lib/libCore.so (0x00007f67e4b08000)
libstdc++.so.6 => /lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f67e48bd000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f67e489b000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f67e4672000)
libNet.so => /daq/cern_root/root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4/lib/libNet.so (0x00007f67e458b000)
libThread.so => /daq/cern_root/root_v6.30.02.Linux-ubuntu22.04-x86_64-gcc11.4/lib/libThread.so (0x00007f67e4533000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f67e444c000)
/lib64/ld-linux-x86-64.so.2 (0x00007f67e5599000)
libpcre.so.3 => /lib/x86_64-linux-gnu/libpcre.so.3 (0x00007f67e43d6000)
libz.so.1 => /lib/x86_64-linux-gnu/libz.so.1 (0x00007f67e43b8000)
liblzma.so.5 => /lib/x86_64-linux-gnu/liblzma.so.5 (0x00007f67e438d000)
libxxhash.so.0 => /lib/x86_64-linux-gnu/libxxhash.so.0 (0x00007f67e4378000)
liblz4.so.1 => /lib/x86_64-linux-gnu/liblz4.so.1 (0x00007f67e4358000)
libzstd.so.1 => /lib/x86_64-linux-gnu/libzstd.so.1 (0x00007f67e4289000)
libssl.so.3 => /lib/x86_64-linux-gnu/libssl.so.3 (0x00007f67e41e3000)
libcrypto.so.3 => /lib/x86_64-linux-gnu/libcrypto.so.3 (0x00007f67e3d9f000)
daq00:midas$
K.O. |
|
28 Mar 2024, Grzegorz Nieradka, Bug Report, Midas (manalyzer) + ROOT 6.31/01 - compilation error
|
I found solution for my trouble. With MIDAS and ROOT everything is OK,
the trobule was with my Ubuntu enviroment.
In this case the trobule was caused by earlier installed anaconda and hardcoded path
to anaconda libs folder in PATH enviroment variable.
In anaconda lib folder I have the libstdc++.so.6.0.29 and the hardcoded path
to this folder was added during the linking, by ld program, after the standard path location
of libstdc++.
So the linker tried to link to this version of libstdc++.
When I removed the path for anaconda libs from enviroment and the standard libs location
is /usr/lib/x86_64-linux-gnu/ and I have the libstdc++.so.6.0.32 version
of stdc++ library everything is compiling and linking smoothly without any errors.
Additionaly, everything works smoothly even with the newest ROOT version 6.30/04 compiled
from source.
Thanks for help.
BTW. I would like to take this opportunity to wish everyone a happy Easter and tasty eggs!
Regards,
Grzegorz Nieradka |
|
02 Apr 2024, Konstantin Olchanski, Bug Report, Midas (manalyzer) + ROOT 6.31/01 - compilation error
|
> I found solution for my trouble. With MIDAS and ROOT everything is OK,
> the trobule was with my Ubuntu enviroment.
Congratulations with figuring this out.
BTW, this is the 2nd case of contaminated linker environment I run into in the last 30 days. We
just had a problem of "cannot link MIDAS with ROOT" (resolving by "make cmake NO_ROOT=1 NO_CURL=1
NO_MYSQL=1").
This all seems to be a flaw in cmake, it reports "found ROOT at XXX", "found CURL at YYY", "found
MYSQL at ZZZ", then proceeds to link ROOT, CURL and MYSQL libraries from somewhere else,
resulting in shared library version mismatch.
With normal Makefiles, this is fixable by changing the link command from:
g++ -o rmlogger ... -LAAA/lib -LXXX/lib -LYYY/lib -lcurl -lmysql -lROOT
into explicit
g++ -o rmlogger ... -LAAA/lib XXX/lib/libcurl.a YYY/lib/libmysql.a ...
defeating the bogus CURL and MYSQL libraries in AAA.
With cmake, I do not think it is possible to make this transformation.
Maybe it is possible to add a cmake rules to at least detect this situation, i.e. compare library
paths reported by "ldd rmlogger" to those found and expected by cmake.
K.O. |
|
02 Apr 2024, Zaher Salman, Info, Sequencer editor
|
Dear all,
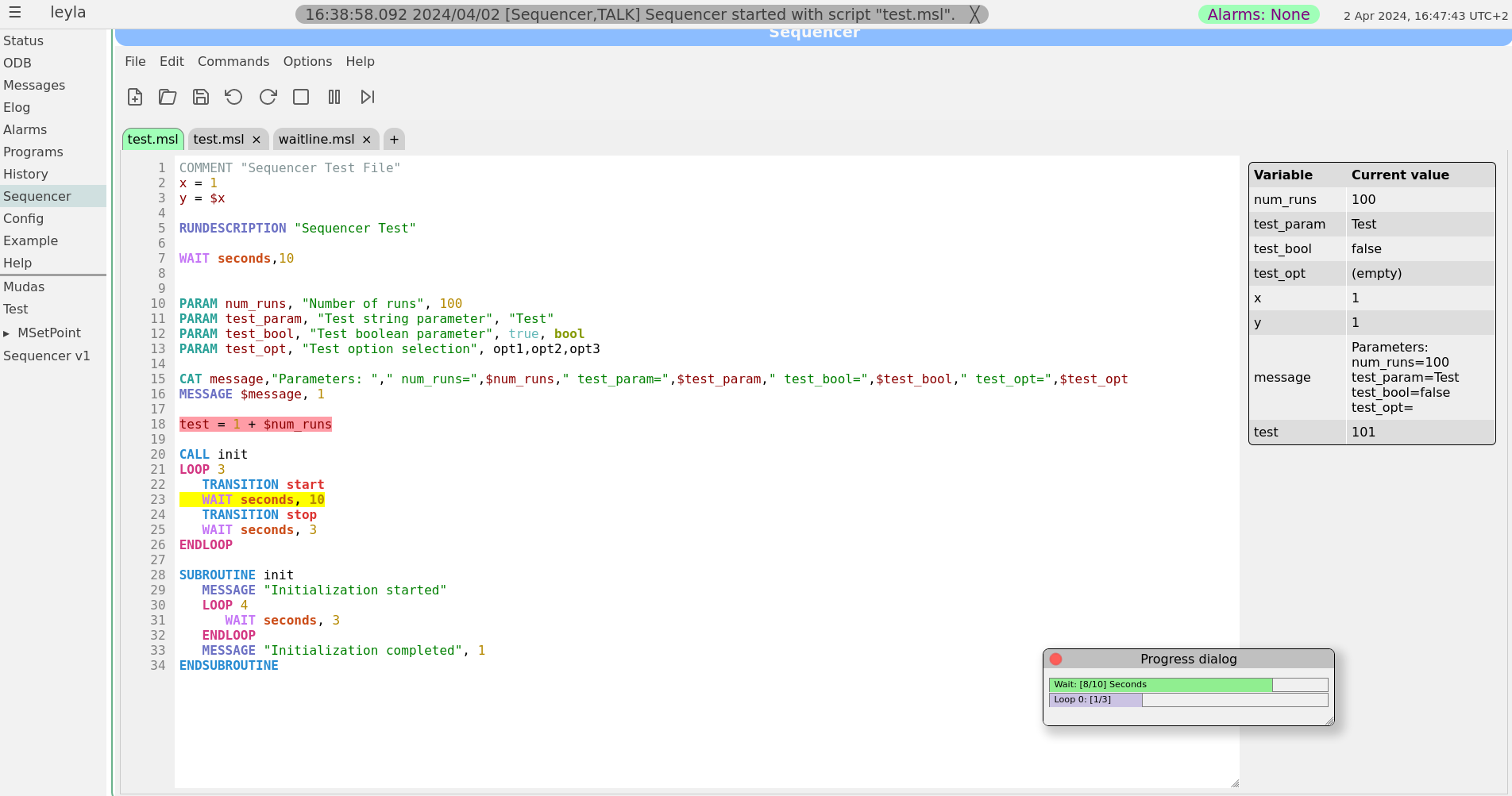
Stefan and I have been working on improving the sequencer editor to make it look and feel more like a standard editor. This sequencer v2 has been finally merged into the develop branch earlier today.
The sequencer page has now a main tab which is used as a "console" to show the loaded sequence and it's progress when running. All other tabs are used only for editing scripts. To edit a currently loaded sequence simply double click on the editing area of the main tab or load the file in a new tab. A couple of screen shots of the new editor are attached.
For those who would like to stay with the older sequencer version a bit longer, you may simply copy resources/sequencer_v1.html to resources/sequencer.html. However, this version is not being actively maintained and may become obsolete at some point. Please help us improve the new version instead by reporting bugs and feature requests on bitbucket or here.
Best regards,
Zaher
 |
|
02 Apr 2024, Konstantin Olchanski, Info, Sequencer editor
|
> Stefan and I have been working on improving the sequencer editor ...
Looks grand! Congratulations with getting it completed. The previous version was
my rewrite of the old generated-C pages into html+javascript, nothing to write
home about, I even kept the 1990-ies-style html formatting and styling as much as
possible.
K.O. |
|
01 Apr 2024, Konstantin Olchanski, Info, xz-utils bomb out, compression benchmarks
|
you may have heard the news of a major problem with the xz-utils project, authors of the popular "xz" file compression,
https://nvd.nist.gov/vuln/detail/CVE-2024-3094
the debian bug tracker is interesting reading on this topic, "750 commits or contributions to xz by Jia Tan, who backdoored it",
https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=1068024
and apparently there is problems with the deisng of the .xz file format, making it vulnerable to single-bit errors and unreliable checksums,
https://www.nongnu.org/lzip/xz_inadequate.html
this moved me to review status of file compression in MIDAS.
MIDAS does not use or recommend xz compression, MIDAS programs to not link to xz and lzma libraries provided by xz-utils.
mlogger has built-in support for:
- gzip-1, enabled by default, as the most safe and bog-standard compression method
- bzip2 and pbzip2, as providing the best compression
- lz4, for high data rate situations where gzip and bzip2 cannot keep up with the data
compression benchmarks on an AMD 7700 CPU (8-core, DDR5 RAM) confirm the usual speed-vs-compression tradeoff:
note: observe how both lz4 and pbzip2 compress time is the time it takes to read the file from ZFS cache, around 6 seconds.
note: decompression stacks up in the same order: lz4, gzip fastest, pbzip2 same speed using 10x CPU, bzip2 10x slower uses 1 CPU.
note: because of the fast decompression speed, gzip remains competitive.
no compression: 6 sec, 270 MiBytes/sec,
lz4, bpzip2: 6 sec, same, (pbzip2 uses 10 CPU vs lz4 uses 1 CPU)
gzip -1: 21 sec, 78 MiBytes/sec
bzip2: 70 sec, 23 MiBytes/sec (same speed as pbzip2, but using 1 CPU instead of 10 CPU)
file sizes:
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ ls -lSr test.mid*
-rw-r--r-- 1 dsdaqdev users 483319523 Apr 1 14:06 test.mid.bz2
-rw-r--r-- 1 dsdaqdev users 631575929 Apr 1 14:06 test.mid.gz
-rw-r--r-- 1 dsdaqdev users 1002432717 Apr 1 14:06 test.mid.lz4
-rw-r--r-- 1 dsdaqdev users 1729327169 Apr 1 14:06 test.mid
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$
actual benchmarks:
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time cat test.mid > /dev/null
0.00user 6.00system 0:06.00elapsed 99%CPU (0avgtext+0avgdata 1408maxresident)k
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time gzip -1 -k test.mid
14.70user 6.42system 0:21.14elapsed 99%CPU (0avgtext+0avgdata 1664maxresident)k
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time lz4 -k -f test.mid
2.90user 6.44system 0:09.39elapsed 99%CPU (0avgtext+0avgdata 7680maxresident)k
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time bzip2 -k -f test.mid
64.76user 8.81system 1:13.59elapsed 99%CPU (0avgtext+0avgdata 8448maxresident)k
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time pbzip2 -k -f test.mid
86.76user 15.39system 0:09.07elapsed 1125%CPU (0avgtext+0avgdata 114596maxresident)k
decompression benchmarks:
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time lz4cat test.mid.lz4 > /dev/null
0.68user 0.23system 0:00.91elapsed 99%CPU (0avgtext+0avgdata 7680maxresident)k
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time zcat test.mid.gz > /dev/null
6.61user 0.23system 0:06.85elapsed 99%CPU (0avgtext+0avgdata 1408maxresident)k
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time bzcat test.mid.bz2 > /dev/null
27.99user 1.59system 0:29.58elapsed 99%CPU (0avgtext+0avgdata 4656maxresident)k
(vslice) dsdaqdev@dsdaqgw:/zdata/vslice$ /usr/bin/time pbzip2 -dc test.mid.bz2 > /dev/null
37.32user 0.56system 0:02.75elapsed 1377%CPU (0avgtext+0avgdata 157036maxresident)k
K.O. |
|
10 Mar 2024, Zaher Salman, Bug Report, Autostart program
|
Hello everyone,
It seems that if a frontend is started automatically by using Program->Auto start then the status page does not show it as started. This is since the FE name has a number after the name. If I stop and start manually then the status page shows the correct state of the FE. Am I doing something wrong or is this a bug somewhere?
thanks,
Zaher |
|
11 Mar 2024, Konstantin Olchanski, Bug Report, Autostart program
|
> It seems that if a frontend is started automatically by using Program->Auto start then the status page does not show it as started. This is since the FE name has a number after the name. If I stop and start manually then the status page shows the correct state of the FE. Am I doing something wrong or is this a bug somewhere?
Zaher, please read https://daq00.triumf.ca/elog-midas/Midas/919
K.O. |
|
08 Mar 2024, Konstantin Olchanski, Info, MIDAS frontend for WIENER L.V. P.S. and VME crates
|
Our MIDAS frontend for WIENER power supplies is now available as a standalone git repository.
https://bitbucket.org/ttriumfdaq/fewienerlvps/src/master/
This frontend use the snmpwalk and snmpset programs to talk to the power supply.
Also included is a simple custom web page to display power supply status and to turn things on and off.
This frontend was originally written for the T2K/ND280 experiment in Japan.
In addition to controlling Wiener low voltage power supplies, it was also used to control the ISEG MPOD high
voltage power supplies.
In Japan, ISEG MPOD was (still is) connected to the MicroMegas TPC and is operated in a special "spark counting"
mode. This spark counting code is still present in this MIDAS frontend and can be restored with a small amount of
work.
K.o. |
|
27 Feb 2024, Pavel Murat, Forum, displaying integers in hex format ?
|
Dear MIDAS Experts,
I'm having an odd problem when trying to display an integer stored in ODB on a custom
web page: the hex specifier, "%x", displays integers as if it were "%d" .
- attachment 1 shows the layout and the contents of the ODB sub-tree in question
- attachment 2 shows the web page as it is displayed
- attachment 3 shows the snippet of html/js producing the web page
I bet I'm missing smth trivial - an advice is greatly appreciated!
Also, is there an equivalent of a "0x%04x" specifier to have the output formatted
into a fixed length string ?
-- thanks, regards, Pasha |
|
27 Feb 2024, Stefan Ritt, Forum, displaying integers in hex format ?
|
Thanks for reporting that bug. I fixed it and committed the change to the develop branch.
Stefan |
|
27 Feb 2024, Pavel Murat, Forum, displaying integers in hex format ?
|
Hi Stefan (and Ben),
thanks for reacting so promptly - your commits on Bitbucket fixed the problem.
For those of us who knows little about how the web browsers work:
- picking up the fix required flushing the cache of the MIDAS client web browser - apparently the web browser
I'm using - Firefox 115.6 - cached the old version of midas.js but wouldn't report it cached and wouldn't load
the updated file on its own.
-- thanks again, regards, Pasha |
|
30 Mar 2016, Belina von Krosigk, Forum, mserver ERR message saying data area 100% full, though it is free
|
Hi,
I have just installed Midas and set-up the ODB for a SuperCDMS test-facility (on
a SL6.7 machine). All works fine except that I receive the following error message:
[mserver,ERROR] [odb.c:944:db_validate_db,ERROR] Warning: database data area is
100% full
Which is puzzling for the following reason:
-> I have created the ODB with: odbedit -s 4194304
-> Checking the size of the .ODB.SHM it says: 4.2M
-> When I save the ODB as .xml and check the file's size it says: 1.1M
-> When I start odbedit and check the memory usage issuing 'mem', it says:
...
Free Key area: 1982136 bytes out of 2097152 bytes
...
Free Data area: 2020072 bytes out of 2097152 bytes
Free: 1982136 (94.5%) keylist, 2020072 (96.3%) data
So it seems like nearly all memory is still free. As a test I created more
instances of one of our front-ends and checked 'mem' again. As expected the free
memory was decreasing. I did this ten times in fact, reaching
...
Free Key area: 1440976 bytes out of 2097152 bytes
...
Free Data area: 1861264 bytes out of 2097152 bytes
Free: 1440976 (68.7%) keylist, 1861264 (88.8%) data
So I could use another >20% of the database data area, which is according to the
error message 100% (resp. >95%) full. Am I misunderstanding the error message?
I'd appreciate any comments or ideas on that subject!
Thanks, Belina |
|
26 Feb 2024, Maia Henriksson-Ward, Forum, mserver ERR message saying data area 100% full, though it is free
|
> Hi,
>
> I have just installed Midas and set-up the ODB for a SuperCDMS test-facility (on
> a SL6.7 machine). All works fine except that I receive the following error message:
>
> [mserver,ERROR] [odb.c:944:db_validate_db,ERROR] Warning: database data area is
> 100% full
>
> Which is puzzling for the following reason:
>
> -> I have created the ODB with: odbedit -s 4194304
> -> Checking the size of the .ODB.SHM it says: 4.2M
> -> When I save the ODB as .xml and check the file's size it says: 1.1M
> -> When I start odbedit and check the memory usage issuing 'mem', it says:
> ...
> Free Key area: 1982136 bytes out of 2097152 bytes
> ...
> Free Data area: 2020072 bytes out of 2097152 bytes
> Free: 1982136 (94.5%) keylist, 2020072 (96.3%) data
>
> So it seems like nearly all memory is still free. As a test I created more
> instances of one of our front-ends and checked 'mem' again. As expected the free
> memory was decreasing. I did this ten times in fact, reaching
>
> ...
> Free Key area: 1440976 bytes out of 2097152 bytes
> ...
> Free Data area: 1861264 bytes out of 2097152 bytes
> Free: 1440976 (68.7%) keylist, 1861264 (88.8%) data
>
> So I could use another >20% of the database data area, which is according to the
> error message 100% (resp. >95%) full. Am I misunderstanding the error message?
> I'd appreciate any comments or ideas on that subject!
>
> Thanks, Belina
This is an old post, but I encountered the same error message recently and was looking for a
solution here. Here's how I solved it, for anyone else who finds this:
The size of .ODB.SHM was bigger than the maximum ODB size (4.2M > 4194304 in Belina's case). For us,
the very large odb size was in error and I suspect it happened because we forgot to shut down midas
cleanly before shutting the computer down. Using odbedit to load a previously saved copy of the ODB
did not help me to get .ODB.SHM back to a normal size. Following the instructions on the wiki for
recovery from a corrupted odb,
https://daq00.triumf.ca/MidasWiki/index.php/FAQ#How_to_recover_from_a_corrupted_ODB, (odbinit with --cleanup option) should
work, but didn't for me. Unfortunately I didn't save the output to figure out why. My solution was to manually delete/move/hide
the .ODB.SHM file, and an equally large file called .ODB.SHM.1701109528, then run odbedit again and reload that same saved copy of my ODB.
Manually changing files used by mserver is risky - for anyone who has the same problem, I suggest trying odbinit --cleanup -s
<yoursize> first. |
|
28 Jan 2024, Pavel Murat, Forum, number of entries in a given ODB subdirectory ?
|
Dear MIDAS experts,
- I have a detector configuration with a variable number of hardware components - FPGA's receiving data
from the detector. They are described in ODB using a set of keys ranging
from "/Detector/FPGAs/FPGA00" .... to "/Detector/FPGAs/FPGA68".
Each of "FPGAxx" corresponds to an ODB subdirectory containing parameters of a given FPGA.
The number of FPGAs in the detector configuration is variable - [independent] commissioning
of different detector subsystems involves different number of FPGAs.
In the beginning of the data taking one needs to loop over all of "FPGAxx",
parse the information there and initialize the corresponding FPGAs.
The actual question sounds rather trivial - what is the best way to implement a loop over them?
- it is certainly possible to have the number of FPGAs introduced as an additional configuration parameter,
say, "/Detector/Number_of_FPGAs", and this is what I have resorted to right now.
However, not only that loooks ugly, but it also opens a way to make a mistake
and have the Number_of_FPGAs, introduced separately, different from the actual number
of FPGA's in the detector configuration.
I therefore wonder if there could be a function, smth like
int db_get_n_keys(HNDLE hdb, HNDLE hKeyParent)
returning the number of ODB keys with a common parent, or, to put it simpler,
a number of ODB entries in a given subdirectory.
And if there were a better solution to the problem I'm dealing with, knowing it might be helpful
for more than one person - configuring detector readout may require to deal with a variable number
of very different parameters.
-- many thanks, regards, Pasha |
|
28 Jan 2024, Konstantin Olchanski, Forum, number of entries in a given ODB subdirectory ?
|
Very good question. It exposes a very nasty problem, the race condition between "ls" and "rm". While you are
looping over directory entries, somebody else is completely permitted to remove one of the files (or add more
files), making the output of "ls" incorrect (contains non-existant/removed files, does not contain newly added
files). even the simple count of number of files can be wrong.
Exactly the same problem exists in ODB. As you loop over directory entries, some other ODB client can remove or
add new entries.
To help with this, I considered adding an db_ls() function that would take the odb lock, atomically iterate over
a directory and return an std::vector<std::string> with names of all entries. (current odb iterator returns ODB
handles that may be invalid if corresponding entry was removed while we were iterating). Unfortunately the
delete/add race condition remains, some returned entries may be invalid or missing.
For your specific application, you can swear that you will never add/delete files "at the wrong time", and you
will not see this problem until one of your users writes a script that uses odbedit to add/remove subdirectory
entries exactly at the wrong time. (you run your "ls" in the BeginRun() handler of your frontend, they run their
"rm" from their's, so both run at the same time, a race condition.
Closer to your question, I think it is simplest to always iterate over the subdirectory, collect names of all
entries, then work with them:
std::vector<std::string> names;
iterate over odb {
names.push_back(name);
}
foreach (name in names)
work_on(name);
instead of:
size_t n = db_get_num_entries();
for (size_t i=0; i<n; i++) {
std::string name = sprintf("FPGA%d", i);
work_on(name);
}
K.O.
> Dear MIDAS experts,
>
> - I have a detector configuration with a variable number of hardware components - FPGA's receiving data
> from the detector. They are described in ODB using a set of keys ranging
> from "/Detector/FPGAs/FPGA00" .... to "/Detector/FPGAs/FPGA68".
> Each of "FPGAxx" corresponds to an ODB subdirectory containing parameters of a given FPGA.
>
> The number of FPGAs in the detector configuration is variable - [independent] commissioning
> of different detector subsystems involves different number of FPGAs.
>
> In the beginning of the data taking one needs to loop over all of "FPGAxx",
> parse the information there and initialize the corresponding FPGAs.
>
> The actual question sounds rather trivial - what is the best way to implement a loop over them?
>
> - it is certainly possible to have the number of FPGAs introduced as an additional configuration parameter,
> say, "/Detector/Number_of_FPGAs", and this is what I have resorted to right now.
>
> However, not only that loooks ugly, but it also opens a way to make a mistake
> and have the Number_of_FPGAs, introduced separately, different from the actual number
> of FPGA's in the detector configuration.
>
> I therefore wonder if there could be a function, smth like
>
> int db_get_n_keys(HNDLE hdb, HNDLE hKeyParent)
>
> returning the number of ODB keys with a common parent, or, to put it simpler,
> a number of ODB entries in a given subdirectory.
>
> And if there were a better solution to the problem I'm dealing with, knowing it might be helpful
> for more than one person - configuring detector readout may require to deal with a variable number
> of very different parameters.
>
> -- many thanks, regards, Pasha |
|
28 Jan 2024, Stefan Ritt, Forum, number of entries in a given ODB subdirectory ?
|
I guess you won't change your FPGA configuration just when you start a run, so I don't consider the race
condition very crucial (although KO is correct, it it there).
I guess rather than any pseudo code you want to see real working code (db_get_num_entries() does not exist!), right?
The easiest these day is to ask ChatGPT. MIDAS has been open source since a long time, so it has been used
to train modern Large Language Models. Attached is the result. Here is the direct link from where you can
copy the code:
https://chat.openai.com/share/d927c78d-9914-4413-ab5e-3b0e5d173132
Please note that you never can be 100% sure that the code from a LLM is correct, so always compile and debug it.
But nevertheless, it's always easier to start from some existing code, even if there is a danger that it's not perfect.
Best,
Stefan |
|
29 Jan 2024, Pavel Murat, Forum, number of entries in a given ODB subdirectory ?
|
Hi Stefan, Konstantin,
thanks a lot for your responses - they are very teaching and it is good to have them archived in the forum.
Konstantin, as Stefan already noticed, in this particular case the race condition is not really a concern.
Stefan, the ChatGPT-generated code snippet is awesome! (teach a man how to fish ...)
-- regards, Pasha |
|
29 Jan 2024, Konstantin Olchanski, Forum, number of entries in a given ODB subdirectory ?
|
> https://chat.openai.com/share/d927c78d-9914-4413-ab5e-3b0e5d173132
>
> Please note that you never can be 100% sure that the code from a LLM is correct
yup, it's wrong allright. it should be looping until db_enum_key() returns "no more keys",
not from 0 to N. this is same as iterating over unix filesystem directory entries, opendir(),
loop readdir() until it returns EOF, closedir().
K.O. |
|
03 Feb 2024, Pavel Murat, Forum, number of entries in a given ODB subdirectory ?
|
Konstantin is right: KEY.num_values is not the same as the number of subkeys (should it be ?)
For those looking for an example in the future, I attach a working piece of code converted
from the ChatGPT example, together with its printout.
-- regards, Pasha |
|
08 Feb 2024, Stefan Ritt, Forum, number of entries in a given ODB subdirectory ?
|
> Konstantin is right: KEY.num_values is not the same as the number of subkeys (should it be ?)
For ODB keys of type TID_KEY, the value num_values IS the number of subkeys. The only issue here is
what KO mentioned already. If you obtain num_values, start iterating, then someone else might
change the number of subkeys, then your (old) num_values is off. Therefore it's always good to
check the return status of all subkey accesses. To do a truely atomic access to a subtree, you need
db_copy(), but then you have to parse the JSON yourself, and again you have no guarantee that the
ODB hasn't changed in meantime.
Stefan |
|
11 Feb 2024, Pavel Murat, Forum, number of entries in a given ODB subdirectory ?
|
> For ODB keys of type TID_KEY, the value num_values IS the number of subkeys.
this logic makes sense, however it doesn't seem to be consistent with the printout of the test example
at the end of https://daq00.triumf.ca/elog-midas/Midas/240203_095803/a.cc . The printout reports
key.num_values = 1, but the actual number of subkeys = 6, and all subkeys being of TID_KEY type
I'm certain that the ODB subtree in question was not accessed concurrently during the test.
-- regards, Pasha |
|
13 Feb 2024, Stefan Ritt, Forum, number of entries in a given ODB subdirectory ?
|
> > For ODB keys of type TID_KEY, the value num_values IS the number of subkeys.
>
> this logic makes sense, however it doesn't seem to be consistent with the printout of the test example
> at the end of https://daq00.triumf.ca/elog-midas/Midas/240203_095803/a.cc . The printout reports
>
> key.num_values = 1, but the actual number of subkeys = 6, and all subkeys being of TID_KEY type
>
> I'm certain that the ODB subtree in question was not accessed concurrently during the test.
You are right, num_values is always 1 for TID_KEYS. The number of subkeys is stored in
((KEYLIST *) ((char *)pheader + pkey->data))->num_keys
Maybe we should add a function to return this. But so far db_enum_key() was enough.
Stefan |
|
15 Feb 2024, Konstantin Olchanski, Forum, number of entries in a given ODB subdirectory ?
|
> > > For ODB keys of type TID_KEY, the value num_values IS the number of subkeys.
> >
> > this logic makes sense, however it doesn't seem to be consistent with the printout of the test example
> > at the end of https://daq00.triumf.ca/elog-midas/Midas/240203_095803/a.cc . The printout reports
> >
> > key.num_values = 1, but the actual number of subkeys = 6, and all subkeys being of TID_KEY type
> >
> > I'm certain that the ODB subtree in question was not accessed concurrently during the test.
>
> You are right, num_values is always 1 for TID_KEYS. The number of subkeys is stored in
>
> ((KEYLIST *) ((char *)pheader + pkey->data))->num_keys
>
> Maybe we should add a function to return this. But so far db_enum_key() was enough.
>
> Stefan
I would rather add a function that atomically returns an std::vector<KEY>. number of entries
is vector size, entry names are in key.name. If you need to do something with an entry,
like iterate a subdirectory, you have to go by name (not by HNDLE), and if somebody deleted
it, you get an error "entry deleted, tough!", (HNDLE becomes invalid without any error message about it,
subsequent db_get_data() likely returns gibberish, subsequent db_set_data() likely corrupts ODB).
K.O. |
|
15 Feb 2024, Konstantin Olchanski, Forum, number of entries in a given ODB subdirectory ?
|
> > You are right, num_values is always 1 for TID_KEYS. The number of subkeys is stored in
> > ((KEYLIST *) ((char *)pheader + pkey->data))->num_keys
> > Maybe we should add a function to return this. But so far db_enum_key() was enough.
Hmm... is there any use case where you want to know the number of directory entries, but you will not iterate
over them later?
K.O. |
|
15 Feb 2024, Stefan Ritt, Forum, number of entries in a given ODB subdirectory ?
|
> Hmm... is there any use case where you want to know the number of directory entries, but you will not iterate
> over them later?
I agree.
One more way to iterate over subkeys by name is by using the new odbxx API:
midas::odb tree("/Test/Settings");
for (midas::odb& key : tree)
std::cout << key.get_name() << std::endl;
Stefan |
|
19 Feb 2024, Pavel Murat, Forum, number of entries in a given ODB subdirectory ?
|
> > Hmm... is there any use case where you want to know the number of directory entries, but you will not iterate
> > over them later?
>
> I agree.
here comes the use case:
I have a slow control frontend which monitors several DAQ components - software processes.
The components are listed in the system configuration stored in ODB, a subkey per component.
Each component has its own driver, so the length of the driver list, defined by the number of components,
needs to be determined at run time.
I calculate the number of components by iterating over the list of component subkeys in the system configuration,
allocate space for the driver list, and store the pointer to the driver list in the equipment record.
The approach works, but it does require pre-calculating the number of subkeys of a given key.
-- regards, Pasha |
|
15 Jan 2024, Frederik Wauters, Forum, dump history FILE files
|
We switched from the history files from MIDAS to FILE, so we have *.dat files now (per variable), instead of the old *.hst.
How shoul
d one now extract data from these data files? With the old *,hst files I can e.g. mhdump -E 102 231010.hst
but with the new *.dat files I get
...2023/history$ mhdump -E 0 -T "Run number" mhf_1697445335_20231016_run_transitions.dat | head -n 15
event name: [Run transitions], time [1697445335]
tag: tag: /DWORD 1 4 /timestamp
tag: tag: UINT32 1 4 State
tag: tag: UINT32 1 4 Run number
record size: 12, data offset: 1024
record 0, time 1697557722, incr 112387
record 1, time 1697557783, incr 61
record 2, time 1697557804, incr 21
record 3, time 1697557834, incr 30
record 4, time 1697557888, incr 54
record 5, time 1697558318, incr 430
record 6, time 1697558323, incr 5
record 7, time 1697558659, incr 336
record 8, time 1697558668, incr 9
record 9, time 1697558753, incr 85
not very intelligible
Yes, I can do csv export on the webpage. But it would be nice to be able to extract from just the files. Also, the webpage export only saves the data shown ( range limited and/or downsampled) |
|
28 Jan 2024, Konstantin Olchanski, Forum, dump history FILE files
|
$ cat mhf_1697445335_20231016_run_transitions.dat
event name: [Run transitions], time [1697445335]
tag: tag: /DWORD 1 4 /timestamp
tag: tag: UINT32 1 4 State
tag: tag: UINT32 1 4 Run number
record size: 12, data offset: 1024
...
data is in fixed-length record format. from the file header, you read "record size" is 12 and data starts at offset 1024.
the 12 bytes of the data record are described by the tags:
4 bytes of timestamp (DWORD, unix time)
4 bytes of State (UINT32)
4 bytes of "Run number" (UINT32)
endianess is "local endian", which means "little endian" as we have no big-endian hardware anymore to test endian conversions.
file format is designed for reading using read() or mmap().
and you are right mhdump, does not work on these files, I guess I can write another utility that does what I just described and spews the numbers to stdout.
K.O. |
|
18 Feb 2024, Frederik Wauters, Forum, dump history FILE files
|
> $ cat mhf_1697445335_20231016_run_transitions.dat
> event name: [Run transitions], time [1697445335]
> tag: tag: /DWORD 1 4 /timestamp
> tag: tag: UINT32 1 4 State
> tag: tag: UINT32 1 4 Run number
> record size: 12, data offset: 1024
> ...
>
> data is in fixed-length record format. from the file header, you read "record size" is 12 and data starts at offset 1024.
>
> the 12 bytes of the data record are described by the tags:
> 4 bytes of timestamp (DWORD, unix time)
> 4 bytes of State (UINT32)
> 4 bytes of "Run number" (UINT32)
>
> endianess is "local endian", which means "little endian" as we have no big-endian hardware anymore to test endian conversions.
>
> file format is designed for reading using read() or mmap().
>
> and you are right mhdump, does not work on these files, I guess I can write another utility that does what I just described and spews the numbers to stdout.
>
> K.O.
Thanks for the answer. As this FILE system is advertised as the new default (eog:2617), this format does merit some more WIKI info. |
|
14 Feb 2024, Konstantin Olchanski, Info, bitbucket permissions
|
I pushed some buttons in bitbucket user groups and permissions to make it happy
wrt recent changes.
The intended configuration is this:
- two user groups: admins and developers
- admins has full control over the workspace, project and repositories ("Admin"
permission)
- developers have push permission for all repositories (not the "create
repository" permission, this is limited to admins) ("Write" permission).
- there seems to be a quirk, admins also need to be in the developers group or
some things do not work (like "run pipeline", which set me off into doing all
this).
- admins "Admin" permission is set at the "workspace" level and is inherited
down to project and repository level.
- developers "Write" permission is set at the "project" level and is inherited
down to repository level.
- individual repositories in the "MIDAS" project also seem to have explicit
(non-inhertited) permissions, I think this is redundant and I will probably
remove them at some point (not today).
K.O. |
|
03 Feb 2024, Pavel Murat, Bug Report, string --> int64 conversion in the python interface ?
|
Dear MIDAS experts,
I gave a try to the MIDAS python interface and ran all tests available in midas/python/tests.
Two Int64 tests from test_odb.py had failed (see below), everthong else - succeeded
I'm using a ~ 2.5 weeks-old commit and python 3.9 on SL7 Linux platform.
commit c19b4e696400ee437d8790b7d3819051f66da62d (HEAD -> develop, origin/develop, origin/HEAD)
Author: Zaher Salman <zaher.salman@gmail.com>
Date: Sun Jan 14 13:18:48 2024 +0100
The symptoms are consistent with a string --> int64 conversion not happening
where it is needed.
Perhaps the issue have already been fixed?
-- many thanks, regards, Pasha
-------------------------------------------------------------------------------------------
Traceback (most recent call last):
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 178, in testInt64
self.set_and_readback_from_parent_dir("/pytest", "int64_2", [123, 40000000000000000], midas.TID_INT64, True)
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 130, in set_and_readback_from_parent_dir
self.validate_readback(value, retval[key_name], expected_key_type)
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 87, in validate_readback
self.assert_equal(val, retval[i], expected_key_type)
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 60, in assert_equal
self.assertEqual(val1, val2)
AssertionError: 123 != '123'
with the test on line 178 commented out, the test on the next line fails in a similar way:
Traceback (most recent call last):
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 179, in testInt64
self.set_and_readback_from_parent_dir("/pytest", "int64_2", 37, midas.TID_INT64, True)
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 130, in set_and_readback_from_parent_dir
self.validate_readback(value, retval[key_name], expected_key_type)
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 102, in validate_readback
self.assert_equal(value, retval, expected_key_type)
File "/home/mu2etrk/test_stand/pasha_020/midas/python/tests/test_odb.py", line 60, in assert_equal
self.assertEqual(val1, val2)
AssertionError: 37 != '37'
--------------------------------------------------------------------------- |
|
05 Feb 2024, Ben Smith, Bug Fix, string --> int64 conversion in the python interface ?
|
> The symptoms are consistent with a string --> int64 conversion not happening
> where it is needed.
Thanks for the report Pasha. Indeed I was missing a conversion in one place. Fixed now!
Ben |
|
13 Feb 2024, Konstantin Olchanski, Bug Fix, string --> int64 conversion in the python interface ?
|
> > The symptoms are consistent with a string --> int64 conversion not happening
> > where it is needed.
>
> Thanks for the report Pasha. Indeed I was missing a conversion in one place. Fixed now!
>
Are we running these tests as part of the nightly build on bitbucket? They would be part of
the "make test" target. Correct python dependancies may need to be added to the bitbucket OS
image in bitbucket-pipelines.yml. (This is a PITA to get right).
K.O. |
|
14 Feb 2024, Konstantin Olchanski, Bug Fix, added ubuntu-22 to nightly build on bitbucket, now need python!
|
> Are we running these tests as part of the nightly build on bitbucket? They would be part of
> the "make test" target. Correct python dependancies may need to be added to the bitbucket OS
> image in bitbucket-pipelines.yml. (This is a PITA to get right).
I added ubuntu-22 to the nightly builds.
but I notice the build says "no python" and I am not sure what packages I need to install for
midas python to work.
Ben, can you help me with this?
https://bitbucket.org/tmidas/midas/pipelines/results/1106/steps/%7B9ef2cf97-bd9f-4fd3-9ca2-9c6aa5e20828%7D
K.O. |
|
05 Feb 2024, Pavel Murat, Forum, forbidden equipment names ?
|
Dear MIDAS experts,
I have multiple daq nodes with two data receiving FPGAs on the PCIe bus each.
The FPGAs come under the names of DTC0 and DTC1. Both FPGAs are managed by the same slow control frontend.
To distinguish FPGAs of different nodes from each other, I included the hostname to the equipment name,
so for node=mu2edaq09 the FPGA names are 'mu2edaq09:DTC0' and 'mu2edaq09:DTC1'.
The history system didn't like the names, complaining that
21:26:06.334 2024/02/05 [Logger,ERROR] [mlogger.cxx:5142:open_history,ERROR] Equipment name 'mu2edaq09:DTC1'
contains characters ':', this may break the history system
So the question is : what are the safe equipment/driver naming rules and what characters
are not allowed in them? - I think this is worth documenting, and the current MIDAS docs at
https://daq00.triumf.ca/MidasWiki/index.php/Equipment_List_Parameters#Equipment_Name
don't say much about it.
-- many thanks, regards, Pasha |
|
13 Feb 2024, Konstantin Olchanski, Forum, forbidden equipment names ?
|
> equipment names are 'mu2edaq09:DTC0' and 'mu2edaq09:DTC1'
I think all names permitted for ODB keys are allowed as equipment names, any valid UTF-8,
forbidden chars are "/" (ODB path separator) and "\0" (C string terminator). Maximum length
is 31 byte (plus "\0" string terminator). (Fixed length 32-byte names with implied terminator
are no longer permitted).
The ":" character is used in history plot definitions and we are likely eventually change that,
history event names used to be pairs of "equipment_name:tag_name" but these days with per-variable
history, they are triplets "equipment_name,variable_name,tag_name". The history plot editor
and the corresponding ODB entries need to be updated for this. Then, ":" will again be a valid
equipment name.
I think if you disable the history for your equipments, MIDAS will stop complaining about ":" in the name.
K.O. |
|
12 Feb 2024, Konstantin Olchanski, Info, MIDAS and ROOT 6.30
|
Starting around ROOT 6.30, there is a new dependency requirement for nlohmann-json3-dev from https://github.com/nlohmann/json.
If you use a Ubuntu-22 ROOT binary kit from root.cern.ch, MIDAS build will bomb with errors: Could not find a package configuration file provided by "nlohmann_json"
Per https://root.cern/install/dependencies/ install it:
apt install nlohmann-json3-dev
After this MIDAS builds ok.
K.O. |
|
16 Jan 2024, Pavel Murat, Forum, a scroll option for "add history variables" window?
|
Dear all,
I have a "slow control" frontend which reads out 100 slow control parameters.
When I'm interactively adding a parameter to a history plot,
a nice "Add history variable" pops up .. , but with 100 parameters in the list,
it doesn't fit within the screen...
The browser becomes passive, and I didn't find any easy way of scrolling.
In the attached example, adding a channel 32 variable becomes rather cumbersome,
not speaking about channel 99.
Two questions:
a) how do people get around this "no-scrolling" issue? - perhaps there is a workaround
b) how big of a deal is it to add a scroll bar to the "Add history variables" popup ?
- I do not know javascript myself, but could find help to contribute..
-- many thanks, regards, Pasha |
|
16 Jan 2024, Stefan Ritt, Forum, a scroll option for "add history variables" window?
|
Have you updated to the current midas version? This issue has been fixed a while ago. Below
you see a screenshot of a long list scrolled all the way to the bottom.
Revision: Thu Dec 7 14:26:37 2023 +0100 - midas-2022-05-c-762-g1eb9f627-dirty on branch
develop
Chrome on MacOSX 14.2.1
The fix is actually in "controls.js", so make sure your browser does not cache an old
version of that file. I usually have to clear my browser history to get the new file from
mhttpd.
Best regards,
Stefan |
|
17 Jan 2024, Pavel Murat, Forum, a scroll option for "add history variables" window?
|
> Have you updated to the current midas version? This issue has been fixed a while ago.
Hi Stefan, thanks a lot! I pulled from the head, and the scrolling works now. -- regards, Pasha |
|
28 Jan 2024, Konstantin Olchanski, Forum, a scroll option for "add history variables" window?
|
> > Have you updated to the current midas version? This issue has been fixed a while ago.
>
> Hi Stefan, thanks a lot! I pulled from the head, and the scrolling works now. -- regards, Pasha
Right, I remember running into this problem, too.
If you have some ideas on how to better present 100500 history variables, please shout out!
K.O. |
|
29 Jan 2024, Pavel Murat, Forum, a scroll option for "add history variables" window?
|
> If you have some ideas on how to better present 100500 history variables, please shout out!
let me share some thoughts. In a particular case which lead to the original posting,
I was using a multi-threaded driver and monitoring several pieces of equipment with different device drivers.
In fact, it was not even hardware, but processes running on different nodes of a distributed computer farm.
To reduce the number of frontends, I was combining together the output of what could've been implemented
as multiple slow control drivers and got 100+ variables in the list - hence the scrolling experience.
At the same time, a list of control variables per driver could've been kept relatively short.
So if a list of control variables of a slow control frontend were split in a History GUI not only by the
equipment piece, but within the equipment "folder", also by the driver, that might help improving
the scalability of the graphical interface.
May be that is already implemented and it is just a matter of me not finding the right base class / example
in the MIDAS code
-- regards, Pasha |
|
29 Jan 2024, Konstantin Olchanski, Forum, a scroll option for "add history variables" window?
|
familiar situation, "too much data", you dice t or slice it, still too much. BTW, you can try to generate history
plot ODB entries from your program instead of from the history plot editor. K.O. |
|
22 Jan 2024, Ben Smith, Bug Report, Warnings about ODB keys that haven't been touched for 10+ years
|
We have an experiment that's been running for a long time and has some ODB keys that haven't been touched in ages. Mostly related to features that we don't use like the elog and lazylogger, or things that don't change often (like the logger data directory).
When we start any program, we now got dozens of error messages in the log with lines like:
hkey 297088, path "/Elog/Display run number", invalid pkey->last_written time 1377040124
That timestamp is reasonable though, as the experiment was set up in 2013!
What's the best way to make these messages go away?
- Change the logic in db_validate_and_repair_key_wlocked() to not worry if keys are 10+ years old?
- Write a script to "touch" all the old keys so they've been modified recently?
- Something else? |
|
22 Jan 2024, Stefan Ritt, Bug Report, Warnings about ODB keys that haven't been touched for 10+ years
|
> What's the best way to make these messages go away?
> - Change the logic in db_validate_and_repair_key_wlocked() to not worry if keys are 10+ years old?
> - Write a script to "touch" all the old keys so they've been modified recently?
> - Something else?
The function db_validate_and_repair_key_wlocked() has been written by KO so he should reply here.
In my opinion, I would go with the first one. Changing the function is easier than to write a script
and teach everybody how to use it. This would be one more thing not to forget.
Now changing the function is not so obvious. We could extend the check to let's say 20 years, but
then we meet here again in ten years. Maybe the best choice would be to just check that the time
is not in the future.
Anyhow, most people don't realize, but we all will have fun on Jan 19, 2038, when the Unix time
overflows in 32-bit signed integers. I don't know if midas will be around by then (I will be 74 years),
but before that date one has to worry about many places in midas where we use Unix time. At that time
your date stamps from 2013 would be 25 years old, so we either remove the date check (just keep
the check of not being in the future), or extend it to 26 years.
Stefan |
|
23 Jan 2024, Nick Hastings, Bug Report, Warnings about ODB keys that haven't been touched for 10+ years
|
Hi,
> What's the best way to make these messages go away?
1.
> - Change the logic in db_validate_and_repair_key_wlocked() to not worry if keys are 10+ years old?
2.
> - Write a script to "touch" all the old keys so they've been modified recently?
3.
> - Something else?
I wondered about this just under a year ago, and Konstantin forwarded my query here:
https://daq00.triumf.ca/elog-midas/Midas/2470
I am now of the opinion that 2 is not a good approach since it removes potentially
useful information.
I think some version of 1. is the correct choice. Whatever it fix is, I think it
should not care that timestamps of when variables are set are "old" (or at least
it should be user configurable via some odb setting).
Nick. |
|
24 Jan 2024, Pavel Murat, Bug Report, Warnings about ODB keys that haven't been touched for 10+ years
|
I don't immediately see a reason for saying that if a DB key is older than 10 yrs, it may not be valid.
However, it would be worth learning what was the logic behind choosing 10 yrs as a threshold.
If 10 is just a more or less arbitrary number, changing 10 --> 100 seems to be the way to go.
-- regards, Pasha |
|
28 Jan 2024, Konstantin Olchanski, Bug Report, Warnings about ODB keys that haven't been touched for 10+ years
|
> I don't immediately see a reason for saying that if a DB key is older than 10 yrs, it may not be valid.
>
> However, it would be worth learning what was the logic behind choosing 10 yrs as a threshold.
> If 10 is just a more or less arbitrary number, changing 10 --> 100 seems to be the way to go.
Please run "git blame" to find out who added that check.
If I remember right, it was added to complain/correct dates in the future.
I think the oldest experiment at TRIUMF where we still can load an odb into current MIDAS is TWIST,
now about 25 years old. the purpose of loading odb would be to test the history function
to see if we can look at 10-15 year old histories. (TWIST history is in the latest FILE format,
so it will load).
I think this age check should be removed, but there must be *some* check for invalid/bogus timestamps. Or
not, we should check if MIDAS cares about timestamps at all, if ODB functions never use/look at timestamp,
maybe we are okey with bogus timestamps. They may look funny in the odb editor, but that's it.
K.O. |
|
28 Jan 2024, Stefan Ritt, Bug Report, Warnings about ODB keys that haven't been touched for 10+ years
|
> Please run "git blame" to find out who added that check.
OK ok, was me. But actually 2003. I hope that this being more than 20y ago excuses me not remembering it ;-)
> I think this age check should be removed, but there must be *some* check for invalid/bogus timestamps. Or
> not, we should check if MIDAS cares about timestamps at all, if ODB functions never use/look at timestamp,
> maybe we are okey with bogus timestamps. They may look funny in the odb editor, but that's it.
I changed the code to only check for timestamps more than 1h in the future and then complain. This should
avoid glitches when switching daylight savings time.
Stefan |
|
11 Dec 2023, Pavel Murat, Forum, the logic of handling history variables ? 11x
|
Dear MIDAS developers,
I'm trying to understand handling of the history (slow control) variables in MIDAS,
and it seems that the behavior I'm observing is somewhat counterintuitive.
Most likely, I just do not understand the implemented logic.
As it it rather difficult to report on the behavior of the interactive program,
I'll describe what I'm doing and illustrate the report with the series of attached
screenshots showing the history plots and the status of the run control at different
consecutive points in time.
Starting with the landscape:
- I'm running MIDAS, git commit=30a03c4c (the latest, as of today).
- I have built the midas/examples/slowcont frontend with the following modifications.
(the diffs are enclosed below):
1) the frequency of the history updates is increased from 60sec/10sec to 6sec/1sec
and, in hope to have updates continuos, I replaced (RO_RUNNING | RO_TRANSITIONS)
with RO_ALWAYS.
2) for convenience of debugging, midas/drivers/nulldrv.cxx is replaced with its clone,
which instead of returning zeroes in each channel, generates a sine curve:
V(t) = 100*sin(t/60)+10*channel
- an active channel in /Logger/History is chosen to be FILE
- /History/LoggerHistoryChannel is also set to FILE
- I'm running mlogger and modified, as described, 'scfe' frontend from midas/examples/slowcont
- the attached history plots include three (0,4 and 7) HV:MEASURED channels
Now, the observations:
1) the history plots are updated only when a new run starts, no matter how hard
I'm trying to update them by clicking on various buttons.
The attached screenshots show the timing sequence of the run control states
(with the times printed) and the corresponding history plots.
The "measured voltages" change only when the next run starts - the voltage graphs
break only at the times corresponding to the vertical green lines.
2) No matter for how long I wait within the run, the history updates are not happening.
3) if the time difference between the two run starts gets too large,
the plotted time dependence starts getting discontinuities
4) finally, if I switch the logging channel from FILE to MIDAS (activate the MIDAS
channel in /Logger/History and set /History/LoggerHistoryChannel to MIDAS),
the updates of the history plots simply stop.
MIDAS feels as a great DAQ framework, so I would appreciate any suggestion on
what I could be doing wrong. I'd also be happy to give a demo in real time
(via ZOOM/SKYPE etc).
-- much appreciate your time, thanks, regards, Pasha
------------------------------------------------------------------------------
diff --git a/examples/slowcont/scfe.cxx b/examples/slowcont/scfe.cxx
index 11f09042..c98d37e8 100644
--- a/examples/slowcont/scfe.cxx
+++ b/examples/slowcont/scfe.cxx
@@ -24,9 +24,10 @@
#include "mfe.h"
#include "class/hv.h"
#include "class/multi.h"
-#include "device/nulldev.h"
#include "bus/null.h"
+#include "nulldev.h"
+
/*-- Globals -------------------------------------------------------*/
/* The frontend name (client name) as seen by other MIDAS clients */
@@ -74,11 +75,11 @@ EQUIPMENT equipment[] = {
0, /* event source */
"FIXED", /* format */
TRUE, /* enabled */
- RO_RUNNING | RO_TRANSITIONS, /* read when running and on transitions */
- 60000, /* read every 60 sec */
+ RO_ALWAYS, /* read when running and on transitions */
+ 6000, /* read every 6 sec */
0, /* stop run after this event limit */
0, /* number of sub events */
- 10000, /* log history at most every ten seconds */
+ 1000, /* log history at most every one second */
"", "", ""} ,
cd_hv_read, /* readout routine */
cd_hv, /* class driver main routine */
@@ -93,8 +94,8 @@ EQUIPMENT equipment[] = {
0, /* event source */
"FIXED", /* format */
TRUE, /* enabled */
- RO_RUNNING | RO_TRANSITIONS, /* read when running and on transitions */
- 60000, /* read every 60 sec */
+ RO_ALWAYS, /* read when running and on transitions */
+ 6000, /* read every 6 sec */
0, /* stop run after this event limit */
0, /* number of sub events */
1, /* log history every event as often as it changes (max 1 Hz) */
------------------------------------------------------------------------------
[test_001]$ diff ../midas/examples/slowcont/nulldev.cxx ../midas/drivers/device/nulldev.cxx
13d12
< #include <math.h>
150,154c149,150
< if (channel < info->num_channels) {
< // *pvalue = info->array[channel];
< time_t t = time(NULL);;
< *pvalue = 100*sin(M_PI*t/60)+10*channel;
< }
---
> if (channel < info->num_channels)
> *pvalue = info->array[channel];
------------------------------------------------------------------------------ |
|
11 Dec 2023, Stefan Ritt, Forum, the logic of handling history variables ?
|
First of all it's important to understand that the slow control system has nothing to do
with events. So if you look at event statistics, these are the events with the slow control
data sent to the midas data file, not the history database. So the logging period (the one you
decreased from 60s to 10s to 6s) only affect the generation of events.
What is important in your case is the number of events sent to the ODB. You see these in the
screen output of the slow control frontend (see attachment). This number show increase every
second.
I tried your modification (change nulldev with a sine function), and left the sc_fe.cxx
otherwise untouched. I then started with a fresh ODB ("rm /"). Started logger, mhttpd, sc_fe
and started a run. In the attachments is what I see. So I don't understand what your problem
is. |
|
12 Dec 2023, Pavel Murat, Forum, the logic of handling history variables ?
|
Hi Sfefan, thanks a lot for taking time to reproduce the issue!
Here comes the resolution, and of course, it was something deeply trivial :
the definition of the HV equipment in midas/examples/slowcont/scfe.cxx has
the history logging time in seconds, however the comment suggests milliseconds (see below),
and for a few days I believed to the comment (:smile:)
Easy to fix.
Also, I think that having a sine wave displayed by midas/examples/slowcont/scfe.cxx
would make this example even more helpful.
-- thanks again, regards, Pasha
--------------------------------------------------------------------------------------------------------
EQUIPMENT equipment[] = {
{"HV", /* equipment name */
{3, 0, /* event ID, trigger mask */
"SYSTEM", /* event buffer */
EQ_SLOW, /* equipment type */
0, /* event source */
"FIXED", /* format */
TRUE, /* enabled */
RO_RUNNING | RO_TRANSITIONS, /* read when running and on transitions */
60000, /* read every 60 sec */
0, /* stop run after this event limit */
0, /* number of sub events */
10000, /* log history at most every ten seconds */ // <------------ this is 10^4 seconds, not 10 seconds
"", "", ""} ,
cd_hv_read, /* readout routine */
cd_hv, /* class driver main routine */
hv_driver, /* device driver list */
NULL, /* init string */
},
https://bitbucket.org/tmidas/midas/src/7f0147eb7bc7395f262b3ae90dd0d2af0625af39/examples/slowcont/scfe.cxx#lines-81 |
|
13 Dec 2023, Stefan Ritt, Forum, the logic of handling history variables ?
|
> Also, I think that having a sine wave displayed by midas/examples/slowcont/scfe.cxx
> would make this example even more helpful.
Indeed. I reworked the example to have a out-of-the-box sine wave plotter, including the
automatic creation of a history panel. Thanks for the hint.
Best,
Stefan |
|
28 Jan 2024, Konstantin Olchanski, Forum, the logic of handling history variables ?
|
MIDAS history is very simple:
from your frontend, your write your history data to ODB /eq/xxx/variables (see below)
mlogger has a hotlink to all /eq/*/variables and it will "see" the new data, write it to history file (see below)
you should see the history file grow using "ls"
history web page in your browser sends a "give me more data" JSON-RPC request to mhttpd
mhttpd looks at the history file, if there is new data (file got bigger) it send it to the web page
web page shows the new data.
where things usually go wrong:
- mlogger only looks for new history variables on startup and on begin-of-run. if you add new stuff in your frontend, you
will not see it until you restart mlogger or start a new run.
- mlogger only looks at history data if corresponding "/eq/xxx/common/log history" is non-zero. for best effect, set it to
"1". (or "0" to turn history off).
- history file is not growing, likely mlogger does not "see" your new data
- timestamps of stuff in /eq/xxx/variables are not getting updated, likely frontend is not writing them, and there is no
new data for mlogger to "see" and write to file.
Frontend has several ways of writing to /eq/xxx/variables:
- write to ODB directly using ODB API db_set_data(), mvodb->Wx(), etc. this is the most foolproof method. use in
conjunction with a printf() statement to make sure you actually do write to ODB. Sometimes your frontend event loop fails
to run, a bug/failure that has nothing to do with midas history.
- generate a midas event and set the per-equipment "write event to ODB" flag (RO_ODB for mfe.c frontends), the mfe/tmfe
framework will write event data to ODB, each data bank will be written to /eq/xxx/variables/BANKNAME, data type is taken
from the event data bank definition.
This second method sometimes malfunctions, typical problems are missing RO_ODB in the equipment table, equipment table in
ODB overwriting the value in source code (this is confusing in mfe.c frontends).
Least likely failure is "/eq/xxx/common/log history" set to bogus value. Normal values are 0=history disabled, 1=history
enabled, other values are only needed if you do not want mlogger to record history as often as you generate it, i.e. you
update /eq/xxx/variables every 1/sec, but you want mlogger to only record it 1/minute.
I hope this helps.
P.S. I notice your equipment tables do not have RO_ODB, so if you use the 2nd method, write history via event data banks,
it will not work.
K.O.
> Dear MIDAS developers,
>
> I'm trying to understand handling of the history (slow control) variables in MIDAS,
> and it seems that the behavior I'm observing is somewhat counterintuitive.
> Most likely, I just do not understand the implemented logic.
>
> As it it rather difficult to report on the behavior of the interactive program,
> I'll describe what I'm doing and illustrate the report with the series of attached
> screenshots showing the history plots and the status of the run control at different
> consecutive points in time.
>
> Starting with the landscape:
>
> - I'm running MIDAS, git commit=30a03c4c (the latest, as of today).
>
> - I have built the midas/examples/slowcont frontend with the following modifications.
> (the diffs are enclosed below):
>
> 1) the frequency of the history updates is increased from 60sec/10sec to 6sec/1sec
> and, in hope to have updates continuos, I replaced (RO_RUNNING | RO_TRANSITIONS)
> with RO_ALWAYS.
>
> 2) for convenience of debugging, midas/drivers/nulldrv.cxx is replaced with its clone,
> which instead of returning zeroes in each channel, generates a sine curve:
>
> V(t) = 100*sin(t/60)+10*channel
>
> - an active channel in /Logger/History is chosen to be FILE
>
> - /History/LoggerHistoryChannel is also set to FILE
>
> - I'm running mlogger and modified, as described, 'scfe' frontend from midas/examples/slowcont
>
> - the attached history plots include three (0,4 and 7) HV:MEASURED channels
>
>
> Now, the observations:
>
> 1) the history plots are updated only when a new run starts, no matter how hard
> I'm trying to update them by clicking on various buttons.
>
> The attached screenshots show the timing sequence of the run control states
> (with the times printed) and the corresponding history plots.
>
> The "measured voltages" change only when the next run starts - the voltage graphs
> break only at the times corresponding to the vertical green lines.
>
> 2) No matter for how long I wait within the run, the history updates are not happening.
>
> 3) if the time difference between the two run starts gets too large,
> the plotted time dependence starts getting discontinuities
>
> 4) finally, if I switch the logging channel from FILE to MIDAS (activate the MIDAS
> channel in /Logger/History and set /History/LoggerHistoryChannel to MIDAS),
> the updates of the history plots simply stop.
>
> MIDAS feels as a great DAQ framework, so I would appreciate any suggestion on
> what I could be doing wrong. I'd also be happy to give a demo in real time
> (via ZOOM/SKYPE etc).
>
> -- much appreciate your time, thanks, regards, Pasha
>
> ------------------------------------------------------------------------------
> diff --git a/examples/slowcont/scfe.cxx b/examples/slowcont/scfe.cxx
> index 11f09042..c98d37e8 100644
> --- a/examples/slowcont/scfe.cxx
> +++ b/examples/slowcont/scfe.cxx
> @@ -24,9 +24,10 @@
> #include "mfe.h"
> #include "class/hv.h"
> #include "class/multi.h"
> -#include "device/nulldev.h"
> #include "bus/null.h"
>
> +#include "nulldev.h"
> +
> /*-- Globals -------------------------------------------------------*/
>
> /* The frontend name (client name) as seen by other MIDAS clients */
> @@ -74,11 +75,11 @@ EQUIPMENT equipment[] = {
> 0, /* event source */
> "FIXED", /* format */
> TRUE, /* enabled */
> - RO_RUNNING | RO_TRANSITIONS, /* read when running and on transitions */
> - 60000, /* read every 60 sec */
> + RO_ALWAYS, /* read when running and on transitions */
> + 6000, /* read every 6 sec */
> 0, /* stop run after this event limit */
> 0, /* number of sub events */
> - 10000, /* log history at most every ten seconds */
> + 1000, /* log history at most every one second */
> "", "", ""} ,
> cd_hv_read, /* readout routine */
> cd_hv, /* class driver main routine */
> @@ -93,8 +94,8 @@ EQUIPMENT equipment[] = {
> 0, /* event source */
> "FIXED", /* format */
> TRUE, /* enabled */
> - RO_RUNNING | RO_TRANSITIONS, /* read when running and on transitions */
> - 60000, /* read every 60 sec */
> + RO_ALWAYS, /* read when running and on transitions */
> + 6000, /* read every 6 sec */
> 0, /* stop run after this event limit */
> 0, /* number of sub events */
> 1, /* log history every event as often as it changes (max 1 Hz) */
> ------------------------------------------------------------------------------
> [test_001]$ diff ../midas/examples/slowcont/nulldev.cxx ../midas/drivers/device/nulldev.cxx
> 13d12
> < #include <math.h>
> 150,154c149,150
> < if (channel < info->num_channels) {
> < // *pvalue = info->array[channel];
> < time_t t = time(NULL);;
> < *pvalue = 100*sin(M_PI*t/60)+10*channel;
> < }
> ---
> > if (channel < info->num_channels)
> > *pvalue = info->array[channel];
> ------------------------------------------------------------------------------ |
|
10 Jan 2024, Pavel Murat, Forum, slow control frontends - how much do they sleep and how often their drivers are called?
|
Dear all,
I have implemented a number of slow control frontends which are directed to update the
history once in every 10 sec, and they do just that.
I expected that such frontends would be spending most of the time sleeping and waking up
once in ten seconds to call their respective drivers and send the data to the server.
However I observe that each frontend process consumes almost 100% of a single core CPU time
and the frontend driver is called many times per second.
Is that the expected behavior ?
So far, I couldn't find the place in the system part of the frontend code (is that the right
place to look for?) which regulates the frequency of the frontend driver calls, so I'd greatly
appreciate if someone could point me to that place.
I'm using the following commit:
commit 30a03c4c develop origin/develop Make sure line numbers and sequence lines are aligned.
-- many thanks, regards, Pasha |
|
11 Jan 2024, Stefan Ritt, Forum, slow control frontends - how much do they sleep and how often their drivers are called?
|
Put a
ss_sleep(10);
into your frontend_loop(), then you should be fine.
The event loop runs as fast as possible in order not to miss any (triggered) event, so no seep in the
event loop, because this would limit the (triggered) event rate to 100 Hz (minimum sleep is 10 ms).
Therefore, you have to slow down the event loop manually with the method described above.
Best,
Stefan |
|
11 Jan 2024, Pavel Murat, Forum, slow control frontends - how much do they sleep and how often their drivers are called?
|
Hi Stefan, thanks a lot !
I just thought that for the EQ_SLOW type equipment calls to sleep() could be hidden in mfe.cxx
and handled based on the requested frequency of the history updates.
Doing the same in the user side is straighforward - the important part is to know where the
responsibility line goes (: smile :)
-- regards, Pasha |
|
12 Jan 2024, Stefan Ritt, Forum, slow control frontends - how much do they sleep and how often their drivers are called?
|
> Hi Stefan, thanks a lot !
>
> I just thought that for the EQ_SLOW type equipment calls to sleep() could be hidden in mfe.cxx
> and handled based on the requested frequency of the history updates.
Most people combine EQ_SLOW with EQ_POLLED, so they want to read out as quickly as possible. Since
the framework cannot "guess" what the users want there, I removed all sleep() in the framework.
> Doing the same in the user side is straighforward - the important part is to know where the
> responsibility line goes (: smile :)
Pushing this to the user gives you more freedom. Like you can add sleep() for some frontends, but not
for others, only when the run is stopped and more.
Stefan |
|
28 Jan 2024, Konstantin Olchanski, Forum, slow control frontends - how much do they sleep and how often their drivers are called?
|
> I have implemented a number of slow control frontends which are directed to update the
> history once in every 10 sec, and they do just that.
I suggest that you switch from the old mfe.c frontend framework to the new tmfe framework that was
designed to solve exactly this type of problems.
Look at .../midas/progs/tmfe_example*.cxx
You have a choice of:
- single threaded frontend, most robust, no race conditions, but readout is interrupted during
begin/end of run.
- two-threaded frontend, your periodic equipments run in one thread, midas loop and rpc run in a
different thread, you have to handle locking yourself.
- you can run each of your equipments in it's own thread without help from the framework, it is
obvious how to do it if you can program c++ threads, "new std::thread" to create/start a thread,
stop threads using a binary flag, thread->join() to reap them at the end (or thread sanitizer will
complain).
K.O. |
|