 08 Sep 2019, Vinzenz Bildstein, Bug Report, https redirect and ODB access 08 Sep 2019, Vinzenz Bildstein, Bug Report, https redirect and ODB access
|
I'm not sure if these issues are related or not, but I'm getting an error
message when I want to access the root of the ODB via the webserver:
[mhttpd,ERROR] [mhttpd.cxx:563:rread,ERROR] Cannot read file '/root', read of
4096 returned -1, errno 21 (Is a directory)
I also tried turning the re-direct from http to https off, but this does not
seem to work. I also noticed that the redirect changes the localhost into a
hostname. Where does mongoose take this hostname from?
EDIT: Seems that the change of the hostname is due to a setting in /etc/hosts,
i.e. all my fault ...
EDIT: I think there was some issue with the mhttpd. When I checked the output (I
used screen to run it), it was full of these messages:
ss_semaphore_wait_for: semop/semtimedop(2588679) returned -1, errno 43
(Identifier removed)
al_check: Something is wrong with our semaphore, ss_semaphore_wait_for()
returned 408, aborting.
al_check: Cannot abort - this will lock you out of odb. From this point, MIDAS
will not work correctly. Please read the discussion at
https://midas.triumf.ca/elog/Midas/945
Restarted it and it stopped redirecting. So accessing the root of the ODB via
the webserver is the only issue now. |
 16 Sep 2019, Konstantin Olchanski, Bug Report, https redirect and ODB access 16 Sep 2019, Konstantin Olchanski, Bug Report, https redirect and ODB access
|
> I'm not sure if these issues are related or not, but I'm getting an error
> message when I want to access the root of the ODB via the webserver:
> [mhttpd,ERROR] [mhttpd.cxx:563:rread,ERROR] Cannot read file '/root', read of
> 4096 returned -1, errno 21 (Is a directory)
This is an old bug. It was part of the "custom path" confusion. Fixed (I think) in all midas-2019
releases.
To confirm, which version are you using (run "odbedit ver" or look on the mhttpd "help" page)?
If you have an older version, I recommend that you update to midas-2019-03 (cd midas; git pull;
git checkout midas-2019-03; make clean; make).
If you feel adventurous, you can also update to the head of the development version
and see all the new features (cmake, c++11, new history pages).
If you do not feel adventurous, wait until we have midas-2019-09 ready, use midas-2019-03
until then.
K.O. |
07 Feb 2019, Stefan Ritt, Info, History panels in custom pages 
|
A new tag has been implemented to display history panels in custom pages, integrated in the
new custom page design from 2017. The full documentation can be found at
https://midas.triumf.ca/MidasWiki/index.php/New_Custom_Pages_(2017)#mhistory
Attached is a simple example of such a panel and the result. You have to rename triggerrate.txt to triggerrate.html if you want to use it (can't do it here since otherwise the browser wants to render it which does not work outside of midas).
Stefan |
|
08 Feb 2019, Thomas Lindner, Info, History panels in custom pages
|
> A new tag has been implemented to display history panels in custom pages, integrated in the
> new custom page design from 2017. The full documentation can be found at
>
As part of consolidating/cleaning the MIDAS Wiki documentation, the "New Custom Pages" was folded into the main "Custom Page". So to see a
description of Stefan's new functionality please go to
https://midas.triumf.ca/MidasWiki/index.php/Custom_Page#mhistory |
|
12 Sep 2019, Pintaudi Giorgio, Info, History panels in custom pages
|
> > A new tag has been implemented to display history panels in custom pages, integrated in the
> > new custom page design from 2017. The full documentation can be found at
> >
>
> As part of consolidating/cleaning the MIDAS Wiki documentation, the "New Custom Pages" was folded into the main "Custom Page". So to see a
> description of Stefan's new functionality please go to
>
> https://midas.triumf.ca/MidasWiki/index.php/Custom_Page#mhistory
Hello!
I am trying to use the new mhistory panels in the WAGASCI slow control custom page, but I cannot get them to work.
All I get is an empty frame. Anyway, in the History tab I can see the history plots correctly.
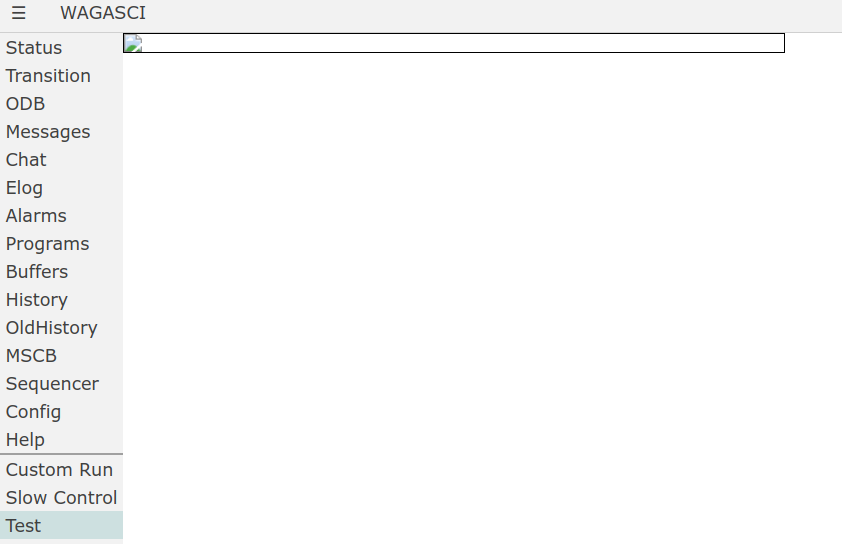
Here is a minimal example:<html>
<head>
<title>Test</title>
<link rel="stylesheet" href="midas.css">
<script src="controls.js"></script>
<script src="midas.js"></script>
<script src="mhttpd.js"></script>
</head>
<body class="mcss" onload="mhttpd_init('Test');">
<div id="mheader"></div>
<div id="msidenav"></div>
<div id="mmain">
<div name="mhistory" data-group="Test" data-panel="Test" data-scale="1m" style="width:600px;border:1px solid black;"></div>
</div>
</body>
</html>
Of course, the "Test" group and "Test" panel exist in the ODB and are correctly shown in the History tab. No error is shown in the console of the web browser.
I am using the latest version of MIDAS as of September 12.
Can you confirm that this feature is working in the latest MIDAS? If yes, how can I troubleshoot the problem?
Regards
Giorgio |
|
12 Sep 2019, Stefan Ritt, Info, History panels in custom pages
|
Indeed there was a bug in some JavaScript code, which I fixed here: https://bitbucket.org/tmidas/midas/commits/d2b1a783240e252820c622001e15c09c5d7798c0
Note that your code will bring you the "old style" history panels (with GIF images). If you want the new style (interactive canvas panels), you need the following:
1) Add
<script src="mhistory.js"></Script>
to the top of your custom page
2) Add "mhistory_init();" to the "onload" function of your page, like
<body class="mcss" onloas="mhttpd_init('Example');mhistory_init();">
3) Change the class of the panel from "mhistory" to "mjhistory", like
<div class="mjshistory" data-group=...>
Best regards,
Stefan |
|
13 Sep 2019, Pintaudi Giorgio, Info, History panels in custom pages
|
Dear Stefan,
thank you very much for the prompt reply. Your suggestions worked wonderfully. Now I can display all the plots that I want where I want.
The new JavaScript history plots are really a huge improvement over the old ones.
Thank you again
Giorgio
| Stefan Ritt wrote: | Indeed there was a bug in some JavaScript code, which I fixed here: https://bitbucket.org/tmidas/midas/commits/d2b1a783240e252820c622001e15c09c5d7798c0
Note that your code will bring you the "old style" history panels (with GIF images). If you want the new style (interactive canvas panels), you need the following:
1) Add
<script src="mhistory.js"></Script>
to the top of your custom page
2) Add "mhistory_init();" to the "onload" function of your page, like
<body class="mcss" onloas="mhttpd_init('Example');mhistory_init();">
3) Change the class of the panel from "mhistory" to "mjhistory", like
<div class="mjshistory" data-group=...>
Best regards,
Stefan |
|
|
07 Aug 2019, Paolo Baesso, Bug Report, ROOTANA bug?
|
Hi,
I posted on the ROOTANA elog but there seems to be little activity there...
Could someone confirm if this is a bug?
https://midas.triumf.ca/elog/Rootana/14
Another user replied that they are encountering the same issue, so I think it is unlikely it is just our installation.
While ROOTANA is unusable for us, I tried to use the example Frontend and Analyzer (under the Experiment source folder). The analyzer does not seem to do much though. A root file is produced but nothing is placed into it. Is that normal?
Any help would be welcome. |
|
07 Aug 2019, Thomas Lindner, Bug Report, ROOTANA bug?
|
Hi Paolo,
Sorry for the slow response. We were discussing this with Konstantin yesterday. He is aware of the problem now and will be working on a solution soon.
In the short term I found that it works if you just comment out the offending line:
indnerlt:rootana lindner$ git diff libMidasInterface/TMidasOnline.cxx
diff --git a/libMidasInterface/TMidasOnline.cxx b/libMidasInterface/TMidasOnline.cxx
index 92eb3e9..67da613 100644
--- a/libMidasInterface/TMidasOnline.cxx
+++ b/libMidasInterface/TMidasOnline.cxx
@@ -191,7 +191,7 @@ bool TMidasOnline::sleep(int mdelay)
#ifdef CH_IPC
ss_suspend_set_dispatch(CH_IPC, 0, NULL);
#else
- ss_suspend_set_dispatch_ipc(NULL);
+ // ss_suspend_set_dispatch_ipc(NULL);
#endif
int status = ss_suspend(mdelay, 0);
if (status == SS_SUCCESS)
This compiles and at least runs for me; so maybe that is helpful for you. But Konstantin will provide a longer term solution.
> Hi,
>
> I posted on the ROOTANA elog but there seems to be little activity there...
>
> Could someone confirm if this is a bug?
> https://midas.triumf.ca/elog/Rootana/14
>
> Another user replied that they are encountering the same issue, so I think it is unlikely it is just our installation.
>
> While ROOTANA is unusable for us, I tried to use the example Frontend and Analyzer (under the Experiment source folder). The analyzer does not seem to do much though. A root file is produced but nothing is placed into it. Is that normal?
>
> Any help would be welcome. |
|
08 Aug 2019, Lauren Manton, Bug Report, ROOTANA bug?
|
Hi,
Thank you, commenting out the line worked and we can now compile the code. However, when we try to run ana.exe or anaDisplay.exe, we get the following errors:
Error in <TCling::RegisterModule>: cannot find dictionary module TMainDisplayWindowDict_rdict.pcm
Error in <TCling::RegisterModule>: cannot find dictionary module TRootanaDisplayDict_rdict.pcm
Error in <TCling::RegisterModule>: cannot find dictionary module TFancyHistogramCanvasDict_rdict.pcm
We see that the files are in /rootana/obj but we cannot find a way to point the compiler to them.
Could you please advise how to proceed,
Many thanks
> Hi Paolo,
>
> Sorry for the slow response. We were discussing this with Konstantin yesterday. He is aware of the problem now and will be working on a solution soon.
>
> In the short term I found that it works if you just comment out the offending line:
>
> indnerlt:rootana lindner$ git diff libMidasInterface/TMidasOnline.cxx
> diff --git a/libMidasInterface/TMidasOnline.cxx b/libMidasInterface/TMidasOnline.cxx
> index 92eb3e9..67da613 100644
> --- a/libMidasInterface/TMidasOnline.cxx
> +++ b/libMidasInterface/TMidasOnline.cxx
> @@ -191,7 +191,7 @@ bool TMidasOnline::sleep(int mdelay)
> #ifdef CH_IPC
> ss_suspend_set_dispatch(CH_IPC, 0, NULL);
> #else
> - ss_suspend_set_dispatch_ipc(NULL);
> + // ss_suspend_set_dispatch_ipc(NULL);
> #endif
> int status = ss_suspend(mdelay, 0);
> if (status == SS_SUCCESS)
>
> This compiles and at least runs for me; so maybe that is helpful for you. But Konstantin will provide a longer term solution.
>
>
>
> > Hi,
> >
> > I posted on the ROOTANA elog but there seems to be little activity there...
> >
> > Could someone confirm if this is a bug?
> > https://midas.triumf.ca/elog/Rootana/14
> >
> > Another user replied that they are encountering the same issue, so I think it is unlikely it is just our installation.
> >
> > While ROOTANA is unusable for us, I tried to use the example Frontend and Analyzer (under the Experiment source folder). The analyzer does not seem to do much though. A root file is produced but nothing is placed into it. Is that normal?
> >
> > Any help would be welcome. |
|
08 Aug 2019, Konstantin Olchanski, Bug Report, ROOTANA bug?
|
> indnerlt:rootana lindner$ git diff libMidasInterface/TMidasOnline.cxx
> diff --git a/libMidasInterface/TMidasOnline.cxx b/libMidasInterface/TMidasOnline.cxx
> index 92eb3e9..67da613 100644
> --- a/libMidasInterface/TMidasOnline.cxx
> +++ b/libMidasInterface/TMidasOnline.cxx
> @@ -191,7 +191,7 @@ bool TMidasOnline::sleep(int mdelay)
> #ifdef CH_IPC
> ss_suspend_set_dispatch(CH_IPC, 0, NULL);
> #else
> - ss_suspend_set_dispatch_ipc(NULL);
> + // ss_suspend_set_dispatch_ipc(NULL);
> #endif
> int status = ss_suspend(mdelay, 0);
> if (status == SS_SUCCESS)
>
> This compiles and at least runs for me; so maybe that is helpful for you. But Konstantin will provide a longer term solution.
This is a problem with the latest development version of MIDAS. ss_suspend overrides have been removed from system.cxx
and there is no way for rootana to avoid the problem of recursive call to the event handler.
I recommend that instead of using the latest development version of MIDAS you use one of the recent released versions (use "git tag -l", midas-2019-06-b is the latest release).
All the released versions of midas have the ss_suspend overrides implemented and rootana will work correctly. For the next release of midas
I will restore the ss_suspend override and update the rootana code.
K.O. |
|
14 Aug 2019, Konstantin Olchanski, Bug Report, ROOTANA bug?
|
> - ss_suspend_set_dispatch_ipc(NULL);
> + // ss_suspend_set_dispatch_ipc(NULL);
>
> This compiles and at least runs for me; so maybe that is helpful for you. But Konstantin will provide a longer term solution.
I now understand why this fix worked. Around December 2018 timeframe, I reworked the MIDAS event buffer code
and one improvement was to only send UDP buffer notifications if somebody is waiting for them. This probably
reduced to zero the probability of recursive calls to the user event handler - the problem originally fixed by the monkey
work against the midas ipc handler.
After looking at it, I now understand that the correct solution is to call ss_suspend(MSG_BM), but it turns out
inside MIDAS, handling of MSG_BM was incomplete and recursive calls to the user event handler were still
possible. (but most likely not actually happening anymore because of those changes to the event buffer code).
So.
a) ss_suspend(MSG_BM) inside midas now works correctly, recursive call to the user event handler will not happen.
b) TMidasOnline::sleep() now calls ss_suspend(MSG_BM), monkey business with ss_suspend_set_dispatch_ipc() is removed.
The problem of recursive call to the analyzer event handler is now fixed, both rootana and manalyzer (both use the same TMidasOnline code).
Read more about this here:
https://midas.triumf.ca/elog/Midas/1663
K.O. |
|
14 Aug 2019, Konstantin Olchanski, Bug Fix, incorrect recursion in ss_suspend() via the user event handler
|
The ROOTANA midas analyzer uncovered a problem with recursive use of ss_suspend().
When running in graphical mode, the ROOT graphics main event loop was calling
ss_suspend(0) (no MSG_BM) which would sometimes call the user event handler (if a new
event arrives into the midas event buffer). Because this loop was already running in the
user event handler, there was a crash.
This is the calling sequence leading to the incorrect recursion: (from system.cxx comments
to ss_suspend())
analyzer ->
-> cm_yield() in the main loop
-> ss_suspend(0)
-> MSG_BM message arrives in the UDP socket
-> ss_suspend_process_ipc(0)
-> cm_dispatch_ipc()
-> bm_push_event()
-> bm_push_buffer()
-> bm_read_buffer()
-> bm_dispatch_event()
-> user event handler
-> user event handler ROOT graphics main loop needs to sleep
-> ss_suspend(0) <--- should be ss_suspend(MSG_BM)!!!
-> MSG_BM message arrives in the UDP socket
-> ss_suspend_process_ipc(0) <- should be ss_suspend_process_ipc(MSG_BM)!!!
-> cm_dispatch_ipc() <- without MSG_BM, calling cm_dispatch_ipc() again
-> bm_push_event()
-> bm_push_buffer()
-> bm_read_buffer()
-> bm_dispatch_event()
-> user event handler <---- called recursively, very bad!
The proper fix for this is to always call ss_suspend(MSG_BM) from the user event handler
and ss_suspend(MSG_ODB) from the user db_watch handler.
In this second case, ss_suspend(MSG_OBM) will lose/ignore/discard db_watch notifications,
if you do not want that, call ss_suspend(0) and be ready for recursive calls to your
db_watch handler. (this can happen in a frontend program that acts on changes in ODB and
where some of these actions may require sleeping via ss_suspend()).
ss_suspend(MSG_BM) will discard MSG_BM messages, which is not a problem as
bm_wait_for_events() and cm_yield() will immediately poll the event buffer and there will be
no delay in receiving new events.
Until commit 99d6e90 there were problems in ss_suspend(MSG_BM) and recursive calls to
the user event handler were still possible. It is now fixed in this and the previous commits.
K.O. |
|
05 Aug 2019, Stefan Ritt, Info, Precedence of equipment/common structure
|
Today I fixed a long-annoying problem. We have in each front-end an equipment structure
which defined the event id, event type, readout frequency etc. This is mapped to the ODB
subtree
/Equipment/<name>/Common
In the past, the ODB setting took precedence over the frontend structure. We defined this
like 25 years ago and I forgot what the exact reason was. It causes however many people
(including myself) to fall into this trap: You change something in the front-end EQUIPMENT
structure, you restart the front-end, but the new setting does not take effect since the
(old) ODB value took precedence. After some debugging you find out that you have to both
change the EQUIPMENT structure (which defines the default value for a fresh ODB) and the
ODB value itself.
So I changed it in the current develop tree that the front-end structure takes precedence.
You still have a hot-link, so if you want to change anything while the front-end is running
(like the readout period), you can do that in the ODB and it takes effect immediately. But
when you start the front-end the next time, the value from the EQUIPMENT structure is
taken again. So please be aware of this new feature.
Happy BC day,
Stefan |
|
06 Aug 2019, Thomas Lindner, Info, Precedence of equipment/common structure
|
Hi Stefan,
This change does not sound like a good idea to me. I think that this change will cause just as much confusion as before; probably more since you are changing established behaviour.
It is common that MIDAS frontends usually have a Settings directory in the ODB where details about the frontend behaviour are set. The Settings directory might get initialized from strings in the frontend code, but after initialization the Settings in the ODB have precedence and define how the frontend will behave. Indeed, most of my custom webpages are designed to control my frontend programs through their Settings ODB tree.
So you have created a situation where Frontend/Settings in the ODB has precedence and is the main place for changing frontend behaviour; but Frontend/Common in the ODB is essentially meaningless and will get overwritten the next time the frontend restarts. That seems likely to confuse people.
If you really want to make this change I suggest that you delete the Frontend/Common directory entirely; or make it read-only so that people aren't fooled into changing it.
Thomas
> Today I fixed a long-annoying problem. We have in each front-end an equipment structure
> which defined the event id, event type, readout frequency etc. This is mapped to the ODB
> subtree
>
> /Equipment/<name>/Common
>
> In the past, the ODB setting took precedence over the frontend structure. We defined this
> like 25 years ago and I forgot what the exact reason was. It causes however many people
> (including myself) to fall into this trap: You change something in the front-end EQUIPMENT
> structure, you restart the front-end, but the new setting does not take effect since the
> (old) ODB value took precedence. After some debugging you find out that you have to both
> change the EQUIPMENT structure (which defines the default value for a fresh ODB) and the
> ODB value itself.
>
> So I changed it in the current develop tree that the front-end structure takes precedence.
> You still have a hot-link, so if you want to change anything while the front-end is running
> (like the readout period), you can do that in the ODB and it takes effect immediately. But
> when you start the front-end the next time, the value from the EQUIPMENT structure is
> taken again. So please be aware of this new feature.
>
> Happy BC day,
> Stefan |
|
06 Aug 2019, Stefan Ritt, Info, Precedence of equipment/common structure
|
Hi Thomas,
the change only affects Eqipment/<name>/common not the Equipment/<name>/Settings.
The Common subtree is still hot-linked into the frontend, so when running things can be changed if needed. This mainly concerns the readout period of periodic events.
Sometimes you want to change this quickly without restarting the frontend. Changing the other settings are kind of dangerous. If you change the ID of an event on the fly
you won't be able to analyze your data. So having this read-only in the ODB might be a good idea (you still need it in the ODB for the status page), except for the values
you want to change (like the readout period).
Let's see what other people have to say.
Stefan
> Hi Stefan,
>
> This change does not sound like a good idea to me. I think that this change will cause just as much confusion as before; probably more since you are changing established behaviour.
>
> It is common that MIDAS frontends usually have a Settings directory in the ODB where details about the frontend behaviour are set. The Settings directory might get initialized from strings in the frontend code, but after initialization the Settings in the ODB have precedence and define how the frontend will behave. Indeed, most of my custom webpages are designed to control my frontend programs through their Settings ODB tree.
>
> So you have created a situation where Frontend/Settings in the ODB has precedence and is the main place for changing frontend behaviour; but Frontend/Common in the ODB is essentially meaningless and will get overwritten the next time the frontend restarts. That seems likely to confuse people.
>
> If you really want to make this change I suggest that you delete the Frontend/Common directory entirely; or make it read-only so that people aren't fooled into changing it.
>
> Thomas
>
>
>
> > Today I fixed a long-annoying problem. We have in each front-end an equipment structure
> > which defined the event id, event type, readout frequency etc. This is mapped to the ODB
> > subtree
> >
> > /Equipment/<name>/Common
> >
> > In the past, the ODB setting took precedence over the frontend structure. We defined this
> > like 25 years ago and I forgot what the exact reason was. It causes however many people
> > (including myself) to fall into this trap: You change something in the front-end EQUIPMENT
> > structure, you restart the front-end, but the new setting does not take effect since the
> > (old) ODB value took precedence. After some debugging you find out that you have to both
> > change the EQUIPMENT structure (which defines the default value for a fresh ODB) and the
> > ODB value itself.
> >
> > So I changed it in the current develop tree that the front-end structure takes precedence.
> > You still have a hot-link, so if you want to change anything while the front-end is running
> > (like the readout period), you can do that in the ODB and it takes effect immediately. But
> > when you start the front-end the next time, the value from the EQUIPMENT structure is
> > taken again. So please be aware of this new feature.
> >
> > Happy BC day,
> > Stefan |
|
06 Aug 2019, Stefan Ritt, Info, Precedence of equipment/common structure
|
After some internal discussion, I decided to undo my previous change again, in order not to break existing habits. Instead, I created a new function
set_odb_equipment_common(equipment, name);
which should be called from frontend_init() which explicitly copies all data from the equipment structure in the front-end into the ODB.
Stefan |
|
09 Aug 2019, Konstantin Olchanski, Info, Precedence of equipment/common structure
|
> Today I fixed a long-annoying problem. ...
> /Equipment/<name>/Common
> In the past, the ODB setting took precedence over the frontend structure...
> We defined this like 25 years ago and I forgot what the exact reason was.
> It causes however many people (including myself) to fall into this trap: ...
There is good number of confusions regarding entries in /eq/xxx/common:
- for some of them, the frontend code settings take precedence and overwrite settings in odb ("frontend file name")
- for some of them, ODB takes precedence and frontend code values are ignored ("read on" and "period")
- for some of them, changes in ODB take effect immediately (via db_watch) ("period")
- for some of them, frontend restart is required for changes to take effect (output event buffer name "buffer")
- some of them continuously update the odb values ("status", "status color")
I do not think there is a simple way to improve on this.
(One solution would replace the single "common" with several subdirectories, "per function",
one would have items where the code takes precedence, one would have items where odb takes
precedence (in effect, "standard settings"), one will have items that the frontend always updates
and that should not be changes via odb ("frontend name", etc). I am not sure this one solution
is necessarily an "improvement").
Lacking any ideas for improvements, I vote for the status quo. (plus a review of the documentation to ensure we have clearly
written up what each entry in "common" does and whether the user is permitted to edit it in odb).
K.O. |
|
13 Aug 2019, Stefan Ritt, Info, Precedence of equipment/common structure
|
> Lacking any ideas for improvements, I vote for the status quo. (plus a review of the documentation to ensure we have clearly
> written up what each entry in "common" does and whether the user is permitted to edit it in odb).
I agree with that.
Stefan |
|
22 Jul 2019, Hassan, Bug Report, Fetest History Plot
|
Hi,
We've been trying to run Fetest in the attempt of plotting the sine wave data on
the history page on the web server. However each time we've tried running a new
plot we have come across the error of 'no data' from the variables. In the
status page we are clearly obtaining data from the frontend and it is updating
the variable as expected in SLOW.
When setting up MIDAS we managed to produce a history plot from Fetest but are
unable to do so any longer. We did have a go at modifying the Fetest code but
created a backup before doing so and are now running the original backup.
What could be causing the Fetest data not to be showing in the history plot? |
|
24 Jul 2019, Pierre-Andre Amaudruz, Bug Report, Fetest History Plot
|
> Hi,
>
> We've been trying to run Fetest in the attempt of plotting the sine wave data on
> the history page on the web server. However each time we've tried running a new
> plot we have come across the error of 'no data' from the variables. In the
> status page we are clearly obtaining data from the frontend and it is updating
> the variable as expected in SLOW.
>
> When setting up MIDAS we managed to produce a history plot from Fetest but are
> unable to do so any longer. We did have a go at modifying the Fetest code but
> created a backup before doing so and are now running the original backup.
>
> What could be causing the Fetest data not to be showing in the history plot?
Is the logger running? (this application is handling the history data).
If yes: Did you change the variable names? If yes: restart the logger. |
|
26 Jul 2019, Hassan, Bug Report, Fetest History Plot
|
Hi, our logger was running. I have tried restarting mlogger (even though we haven't
changed variable names). We ran the following commands one after another and still no
luck with history plot. Is there anything else that could be causing these problems?
Kind regards,
Hassan
==================================================================================
[lm17773@it038146 ~]$ cd /opt/midas_software/midas/bin/
[lm17773@it038146 bin]$ mhttpd
[mhttpd,ERROR] [odb.cxx:1646:db_open_database,ERROR] Removed ODB client 'mhttpd',
index 0 because process pid 20094 does not exists
[mhttpd,ERROR] [odb.cxx:1646:db_open_database,ERROR] Removed ODB client 'Logger',
index 1 because process pid 20214 does not exists
[mhttpd,INFO] Removed open record flag from "/Experiment/Security/RPC hosts/Allowed hosts"
[mhttpd,INFO] Removed exclusive access mode from "/Experiment/Security/RPC
hosts/Allowed hosts"
[mhttpd,INFO] Removed open record flag from "/Experiment/Security/mhttpd hosts/Allowed
hosts"
[mhttpd,INFO] Removed exclusive access mode from "/Experiment/Security/mhttpd
hosts/Allowed hosts"
[mhttpd,INFO] Removed open record flag from "/Logger/History"
[mhttpd,INFO] Removed exclusive access mode from "/Logger/History"
[mhttpd,INFO] Removed open record flag from "/Sequencer/State"
[mhttpd,INFO] Removed exclusive access mode from "/Sequencer/State"
[mhttpd,INFO] Removed open record flag from "/History/LoggerHistoryChannel"
[mhttpd,INFO] Removed exclusive access mode from "/History/LoggerHistoryChannel"
[mhttpd,INFO] Removed open record flag from "/Equipment/slow/Variables"
[mhttpd,INFO] Removed exclusive access mode from "/Equipment/slow/Variables"
[mhttpd,INFO] Removed open record flag from "/Equipment/Trigger/Statistics/Events per
sec."
[mhttpd,INFO] Removed exclusive access mode from "/Equipment/Trigger/Statistics/Events
per sec."
[mhttpd,INFO] Removed open record flag from "/Equipment/Trigger/Statistics/kBytes per
sec."
[mhttpd,INFO] Removed exclusive access mode from "/Equipment/Trigger/Statistics/kBytes
per sec."
[mhttpd,INFO] Removed open record flag from "/Equipment/Periodic/Variables"
[mhttpd,INFO] Removed exclusive access mode from "/Equipment/Periodic/Variables"
[mhttpd,INFO] Removed open record flag from "/Equipment/Scaler/Variables"
[mhttpd,INFO] Removed exclusive access mode from "/Equipment/Scaler/Variables"
[mhttpd,INFO] Corrected 10 ODB entries
[mhttpd,INFO] Deleted entry '/System/Clients/20094' for client 'mhttpd' because it is
not connected to ODB
Mongoose web server will use SSL certificate file "/home/lm17773/online/ssl_cert.pem"
Mongoose web server will use authentication realm "sampleexpt", password file
"/home/lm17773/online/htpasswd.txt"
mongoose web server is redirecting HTTP port 8080 to
https://it038146.users.bris.ac.uk:8443
mongoose web server is listening on the HTTP port 8080
mongoose web server is listening on the HTTPS port 8443
====================================================================================
[lm17773@it038146 bin]$ mlogger
[Logger,INFO] Deleted entry '/System/Clients/20214' for client 'Logger' because it is
not connected to ODB
Log directory is /home/lm17773/online/
Data directory is same as Log unless specified in /Logger/channels/
History directory is same as Log unless specified in /Logger/history/
ELog directory is same as Log
SQL database is localhost/sampleexpt/Runlog
MIDAS logger started. Stop with "!"
====================================================================================
[lm17773@it038146 bin]$ fetest
Frontend name : fetest
Event buffer size : 10485760
User max event size : 4194304
User max frag. size : 4194304
# of events per buffer : 2
Connect to experiment sampleexpt...
OK
Init hardware...frontend_init!
Event size set to 10240 bytes
Ring buffer wait sleep 1 ms
OK
time 1564131394, data 97.814758
time 1564131395, data 96.592583
time 1564131396, data 95.105652
time 1564131397, data 93.358040
time 1564131398, data 91.354546
time 1564131399, data 89.100655
time 1564131400, data 86.602539
time 1564131401, data 83.867058
time 1564131402, data 80.901703
time 1564131403, data 77.714592
Warning: bank RND4 has zero size
time 1564131404, data 74.314484
time 1564131405, data 70.710678
time 1564131406, data 66.913063
time 1564131407, data 62.932041
====================================================================================
> > Hi,
> >
> > We've been trying to run Fetest in the attempt of plotting the sine wave data on
> > the history page on the web server. However each time we've tried running a new
> > plot we have come across the error of 'no data' from the variables. In the
> > status page we are clearly obtaining data from the frontend and it is updating
> > the variable as expected in SLOW.
> >
> > When setting up MIDAS we managed to produce a history plot from Fetest but are
> > unable to do so any longer. We did have a go at modifying the Fetest code but
> > created a backup before doing so and are now running the original backup.
> >
> > What could be causing the Fetest data not to be showing in the history plot?
>
> Is the logger running? (this application is handling the history data).
> If yes: Did you change the variable names? If yes: restart the logger. |
|
09 Aug 2019, Konstantin Olchanski, Bug Report, Fetest History Plot
|
> Hi, our logger was running.
One more thing is to check that the history files are actually being written to. Be default
the history files are written into the same directory where you have ODB, etc and
the file names are "*.hst".
Second thing, you can run "mlogger -v" and it will report that it is writing history events
into the history.
If all these things are happening,
Third, you can run "mhist" to see the data directly from the data files.
If all of these work, but you still get nothing in mhttpd, that would be very strange. If I remember
right, to see the sine wave, the history variable to plot is equipment "slow", variable "slow".
K.O.
> I have tried restarting mlogger (even though we haven't
> changed variable names). We ran the following commands one after another and still no
> luck with history plot. Is there anything else that could be causing these problems?
>
> Kind regards,
> Hassan
>
> ==================================================================================
>
> [lm17773@it038146 ~]$ cd /opt/midas_software/midas/bin/
> [lm17773@it038146 bin]$ mhttpd
> [mhttpd,ERROR] [odb.cxx:1646:db_open_database,ERROR] Removed ODB client 'mhttpd',
> index 0 because process pid 20094 does not exists
> [mhttpd,ERROR] [odb.cxx:1646:db_open_database,ERROR] Removed ODB client 'Logger',
> index 1 because process pid 20214 does not exists
> [mhttpd,INFO] Removed open record flag from "/Experiment/Security/RPC hosts/Allowed hosts"
> [mhttpd,INFO] Removed exclusive access mode from "/Experiment/Security/RPC
> hosts/Allowed hosts"
> [mhttpd,INFO] Removed open record flag from "/Experiment/Security/mhttpd hosts/Allowed
> hosts"
> [mhttpd,INFO] Removed exclusive access mode from "/Experiment/Security/mhttpd
> hosts/Allowed hosts"
> [mhttpd,INFO] Removed open record flag from "/Logger/History"
> [mhttpd,INFO] Removed exclusive access mode from "/Logger/History"
> [mhttpd,INFO] Removed open record flag from "/Sequencer/State"
> [mhttpd,INFO] Removed exclusive access mode from "/Sequencer/State"
> [mhttpd,INFO] Removed open record flag from "/History/LoggerHistoryChannel"
> [mhttpd,INFO] Removed exclusive access mode from "/History/LoggerHistoryChannel"
> [mhttpd,INFO] Removed open record flag from "/Equipment/slow/Variables"
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/slow/Variables"
> [mhttpd,INFO] Removed open record flag from "/Equipment/Trigger/Statistics/Events per
> sec."
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Trigger/Statistics/Events
> per sec."
> [mhttpd,INFO] Removed open record flag from "/Equipment/Trigger/Statistics/kBytes per
> sec."
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Trigger/Statistics/kBytes
> per sec."
> [mhttpd,INFO] Removed open record flag from "/Equipment/Periodic/Variables"
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Periodic/Variables"
> [mhttpd,INFO] Removed open record flag from "/Equipment/Scaler/Variables"
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Scaler/Variables"
> [mhttpd,INFO] Corrected 10 ODB entries
> [mhttpd,INFO] Deleted entry '/System/Clients/20094' for client 'mhttpd' because it is
> not connected to ODB
> Mongoose web server will use SSL certificate file "/home/lm17773/online/ssl_cert.pem"
> Mongoose web server will use authentication realm "sampleexpt", password file
> "/home/lm17773/online/htpasswd.txt"
> mongoose web server is redirecting HTTP port 8080 to
> https://it038146.users.bris.ac.uk:8443
> mongoose web server is listening on the HTTP port 8080
> mongoose web server is listening on the HTTPS port 8443
>
====================================================================================
>
> [lm17773@it038146 bin]$ mlogger
> [Logger,INFO] Deleted entry '/System/Clients/20214' for client 'Logger' because it is
> not connected to ODB
> Log directory is /home/lm17773/online/
> Data directory is same as Log unless specified in /Logger/channels/
> History directory is same as Log unless specified in /Logger/history/
> ELog directory is same as Log
> SQL database is localhost/sampleexpt/Runlog
> MIDAS logger started. Stop with "!"
>
====================================================================================
> [lm17773@it038146 bin]$ fetest
> Frontend name : fetest
> Event buffer size : 10485760
> User max event size : 4194304
> User max frag. size : 4194304
> # of events per buffer : 2
>
> Connect to experiment sampleexpt...
> OK
> Init hardware...frontend_init!
> Event size set to 10240 bytes
> Ring buffer wait sleep 1 ms
> OK
> time 1564131394, data 97.814758
> time 1564131395, data 96.592583
> time 1564131396, data 95.105652
> time 1564131397, data 93.358040
> time 1564131398, data 91.354546
> time 1564131399, data 89.100655
> time 1564131400, data 86.602539
> time 1564131401, data 83.867058
> time 1564131402, data 80.901703
> time 1564131403, data 77.714592
> Warning: bank RND4 has zero size
> time 1564131404, data 74.314484
> time 1564131405, data 70.710678
> time 1564131406, data 66.913063
> time 1564131407, data 62.932041
>
====================================================================================
>
>
>
>
>
>
> > > Hi,
> > >
> > > We've been trying to run Fetest in the attempt of plotting the sine wave data on
> > > the history page on the web server. However each time we've tried running a new
> > > plot we have come across the error of 'no data' from the variables. In the
> > > status page we are clearly obtaining data from the frontend and it is updating
> > > the variable as expected in SLOW.
> > >
> > > When setting up MIDAS we managed to produce a history plot from Fetest but are
> > > unable to do so any longer. We did have a go at modifying the Fetest code but
> > > created a backup before doing so and are now running the original backup.
> > >
> > > What could be causing the Fetest data not to be showing in the history plot?
> >
> > Is the logger running? (this application is handling the history data).
> > If yes: Did you change the variable names? If yes: restart the logger. |
|
09 Aug 2019, Konstantin Olchanski, Bug Report, Fetest History Plot
|
> Hi, our logger was running.
Please do these simple tests:
- run "mlogger -v", it should report that it is writing slow/slow data into the history with rate 1 Hz (fetest
should be running at this point, yes?)
- normally the history files are written into the experiment directory (where ODB is, etc) and have file names
"*.hst". Observe that the files are growing. Use "ls -ltr". (mlogger and fetest should be running at this point,
yes?)
- if all if this is happening, you can try to run "mhist" to see the history data
If all of the above works, but you still get nothing from the history plots in mhttpd, then we probably have a
bug in midas and we would like very much to fix it. For this we will need some more information from you. I
hope you have some time available to help us with this.
Hmm... the fetest history plots are not defined automatically, you have to create the history plot manually,
maybe this is where the problem happens. One thing to check here, the correct variable to plot
is "slow/slow", if I remember right.
K.O.
> I have tried restarting mlogger (even though we haven't
> changed variable names). We ran the following commands one after another and still no
> luck with history plot. Is there anything else that could be causing these problems?
>
> Kind regards,
> Hassan
>
>
================================================================================
==
>
> [lm17773@it038146 ~]$ cd /opt/midas_software/midas/bin/
> [lm17773@it038146 bin]$ mhttpd
> [mhttpd,ERROR] [odb.cxx:1646:db_open_database,ERROR] Removed ODB client 'mhttpd',
> index 0 because process pid 20094 does not exists
> [mhttpd,ERROR] [odb.cxx:1646:db_open_database,ERROR] Removed ODB client 'Logger',
> index 1 because process pid 20214 does not exists
> [mhttpd,INFO] Removed open record flag from "/Experiment/Security/RPC hosts/Allowed hosts"
> [mhttpd,INFO] Removed exclusive access mode from "/Experiment/Security/RPC
> hosts/Allowed hosts"
> [mhttpd,INFO] Removed open record flag from "/Experiment/Security/mhttpd hosts/Allowed
> hosts"
> [mhttpd,INFO] Removed exclusive access mode from "/Experiment/Security/mhttpd
> hosts/Allowed hosts"
> [mhttpd,INFO] Removed open record flag from "/Logger/History"
> [mhttpd,INFO] Removed exclusive access mode from "/Logger/History"
> [mhttpd,INFO] Removed open record flag from "/Sequencer/State"
> [mhttpd,INFO] Removed exclusive access mode from "/Sequencer/State"
> [mhttpd,INFO] Removed open record flag from "/History/LoggerHistoryChannel"
> [mhttpd,INFO] Removed exclusive access mode from "/History/LoggerHistoryChannel"
> [mhttpd,INFO] Removed open record flag from "/Equipment/slow/Variables"
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/slow/Variables"
> [mhttpd,INFO] Removed open record flag from "/Equipment/Trigger/Statistics/Events per
> sec."
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Trigger/Statistics/Events
> per sec."
> [mhttpd,INFO] Removed open record flag from "/Equipment/Trigger/Statistics/kBytes per
> sec."
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Trigger/Statistics/kBytes
> per sec."
> [mhttpd,INFO] Removed open record flag from "/Equipment/Periodic/Variables"
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Periodic/Variables"
> [mhttpd,INFO] Removed open record flag from "/Equipment/Scaler/Variables"
> [mhttpd,INFO] Removed exclusive access mode from "/Equipment/Scaler/Variables"
> [mhttpd,INFO] Corrected 10 ODB entries
> [mhttpd,INFO] Deleted entry '/System/Clients/20094' for client 'mhttpd' because it is
> not connected to ODB
> Mongoose web server will use SSL certificate file "/home/lm17773/online/ssl_cert.pem"
> Mongoose web server will use authentication realm "sampleexpt", password file
> "/home/lm17773/online/htpasswd.txt"
> mongoose web server is redirecting HTTP port 8080 to
> https://it038146.users.bris.ac.uk:8443
> mongoose web server is listening on the HTTP port 8080
> mongoose web server is listening on the HTTPS port 8443
>
================================================================================
====
>
> [lm17773@it038146 bin]$ mlogger
> [Logger,INFO] Deleted entry '/System/Clients/20214' for client 'Logger' because it is
> not connected to ODB
> Log directory is /home/lm17773/online/
> Data directory is same as Log unless specified in /Logger/channels/
> History directory is same as Log unless specified in /Logger/history/
> ELog directory is same as Log
> SQL database is localhost/sampleexpt/Runlog
> MIDAS logger started. Stop with "!"
>
================================================================================
====
> [lm17773@it038146 bin]$ fetest
> Frontend name : fetest
> Event buffer size : 10485760
> User max event size : 4194304
> User max frag. size : 4194304
> # of events per buffer : 2
>
> Connect to experiment sampleexpt...
> OK
> Init hardware...frontend_init!
> Event size set to 10240 bytes
> Ring buffer wait sleep 1 ms
> OK
> time 1564131394, data 97.814758
> time 1564131395, data 96.592583
> time 1564131396, data 95.105652
> time 1564131397, data 93.358040
> time 1564131398, data 91.354546
> time 1564131399, data 89.100655
> time 1564131400, data 86.602539
> time 1564131401, data 83.867058
> time 1564131402, data 80.901703
> time 1564131403, data 77.714592
> Warning: bank RND4 has zero size
> time 1564131404, data 74.314484
> time 1564131405, data 70.710678
> time 1564131406, data 66.913063
> time 1564131407, data 62.932041
>
================================================================================
====
>
>
>
>
>
>
> > > Hi,
> > >
> > > We've been trying to run Fetest in the attempt of plotting the sine wave data on
> > > the history page on the web server. However each time we've tried running a new
> > > plot we have come across the error of 'no data' from the variables. In the
> > > status page we are clearly obtaining data from the frontend and it is updating
> > > the variable as expected in SLOW.
> > >
> > > When setting up MIDAS we managed to produce a history plot from Fetest but are
> > > unable to do so any longer. We did have a go at modifying the Fetest code but
> > > created a backup before doing so and are now running the original backup.
> > >
> > > What could be causing the Fetest data not to be showing in the history plot?
> >
> > Is the logger running? (this application is handling the history data).
> > If yes: Did you change the variable names? If yes: restart the logger. |
|
08 Aug 2019, Art Olin, Suggestion, midas cmake migration
|
I want to report a bug in the ROOT build process that might be relevant to the midas implementation. I had an annoying failure to build root 6.18 (current pro version) with a misleading error message about a fault in the root code. It turned out this was a cmake problem, and the error was from my cmake version being older than 3.14, which is quite recent. Took a bit of searching to find this.
I recommend when the cmake version is distributed that the instructions include the required cmake version. Developers are generally working well ahead of what is available in the older OS's. |
|
08 Aug 2019, Stefan Ritt, Suggestion, midas cmake migration
|
Each CMakeLists.txt should specify which version of CMake it requires. The MIDAS CMakeLists.txt requires CMake 3.1 or later.
We deliberately stayed away from fancy cutting edge CMake features in order to make midas easier to compile. On top of that,
midas is a much simpler package compared to root, so things are not so complicated.
Stefan |
|
08 Aug 2019, Konstantin Olchanski, Suggestion, midas cmake migration
|
> Each CMakeLists.txt should specify which version of CMake it requires. The MIDAS CMakeLists.txt requires CMake 3.1 or later.
> We deliberately stayed away from fancy cutting edge CMake features in order to make midas easier to compile. On top of that,
> midas is a much simpler package compared to root, so things are not so complicated.
The oldest cmake I actually used is 3.6.1 (on SL6), so I do not know if cmake versions between 3.1 and 3.6 actually work for us. Perhaps we should set
the CMakefile requirement to 3.6.1 to match the oldest version we know works. If somebody has an older cmake, they have a choice of updating it or
trying it as as and reporting success/failure to the midas forum here.
K.O. |
|
08 Aug 2019, Stefan Ritt, Suggestion, midas cmake migration
|
I just tried CMake 3.1.0 and it worked with midas. So I believe all versions between 3.1.0 and 3.6.1 are ok.
Actually playing around with different versions I realized that 3.0.0 is also ok, so I changed the requirement of midas down to 3.0
Stefan |
|
07 Aug 2019, Pintaudi Giorgio, Suggestion, ROOT and multi-threading
|
Hello!
I am creating this thread to comment on an issue raised today during the MIDAS
workshop.
It was said that ROOT doesn't play well with multithreading ... and it is
definitely true. But since last year, many improvements have been done in ROOT
multi-threading support and now even the ROOT fitter can be made thread-safe.
I know this because recently I had to completely rewrite the calibration
software for the WAGASCI experiment and I wanted to use many ROOT analyzers in
parallel.
Getting ROOT to work in a multi-thread environment is not painless. It took me
many weeks to get to the end of it. But if using the latest ROOT version (from
about ROOT 6.12.00 onwards), it should be possible. Basically, you have to
compile ROOT with the Minuit2 minimizer support and then select it.
This is the thread on the ROOT forum where I have asked about and solved my
issues (I am LastStarDust): https://root-forum.cern.ch/t/root-crashes-in-multi-
threaded-environment/35407
You can also refer to this bug report: https://sft.its.cern.ch/jira/browse/ROOT-
7173
and this documentation page: https://root.cern.ch/how/how-express-parallelism-
many-cores
Hope it may help.
Giorgio |
|
21 May 2019, Thomas Lindner, Forum, MIDAS Workshop on Aug 7
|
Dear MIDAS users,
We would like to announce a third MIDAS workshop at TRIUMF on Aug 7, 2019.
Stefan Ritt will again be visiting TRIUMF at this time.
The overall goal of the workshop is to present new features in MIDAS, to discuss
future changes and to hear experiences from different experiments.
We expect that some participants will connect remotely to the workshop; we will
setup a video-conferencing option. The exact time of the workshop will be
decided later and will be optimized based on the geographic distribution of
remote attendees. So please let us know if you want to attend remotely. We are
also happy for people to come in person to TRIUMF.
A (very) preliminary agenda includes
- New default mhttpd pages and new APIs for custom pages
- Conversion of MIDAS to C++
- new C++ based frontend framework (tmfe and mvodb from ALPHA-g)
- MySQL/Postgres database for storing ODB configurations
- Plans for updating history plotting
- Using MIDAS with an online trigger farm
- new C++ multithreaded flow analyzer (manalyzer from ALPHA-g)
But please suggest other topics; we also hope to hear reports from particular
experiments.
Sincerely,
Thomas (on behalf of MIDAS developers) |
|
03 Jul 2019, Thomas Lindner, Forum, MIDAS Workshop on Aug 7
|
Dear MIDAS users,
Here's further information on the third MIDAS workshop:
1) Workshop will take place from 1PM-5PM (Vancouver time) on Aug 7.
2) A mostly finalized agenda for the workshop is posted here:
https://indico.triumf.ca/conferenceDisplay.py?confId=2438
People are still welcome to email me if they want to present something. We should be able to add it to the schedule.
3) For those who want to participate remotely, we will be using bluejeans. The webpage for the bluejeans meeting is here:
https://bluejeans.com/462865444
4) For those at TRIUMF I will confirm the meeting room closer to the date.
Thomas
> Dear MIDAS users,
>
> We would like to announce a third MIDAS workshop at TRIUMF on Aug 7, 2019.
> Stefan Ritt will again be visiting TRIUMF at this time.
>
> The overall goal of the workshop is to present new features in MIDAS, to discuss
> future changes and to hear experiences from different experiments.
>
> We expect that some participants will connect remotely to the workshop; we will
> setup a video-conferencing option. The exact time of the workshop will be
> decided later and will be optimized based on the geographic distribution of
> remote attendees. So please let us know if you want to attend remotely. We are
> also happy for people to come in person to TRIUMF.
>
> A (very) preliminary agenda includes
>
> - New default mhttpd pages and new APIs for custom pages
> - Conversion of MIDAS to C++
> - new C++ based frontend framework (tmfe and mvodb from ALPHA-g)
> - MySQL/Postgres database for storing ODB configurations
> - Plans for updating history plotting
> - Using MIDAS with an online trigger farm
> - new C++ multithreaded flow analyzer (manalyzer from ALPHA-g)
>
> But please suggest other topics; we also hope to hear reports from particular
> experiments.
>
> Sincerely,
> Thomas (on behalf of MIDAS developers) |
|
06 Aug 2019, Thomas Lindner, Forum, MIDAS Workshop on Aug 7
|
Dear MIDAS users,
A final reminder about the MIDAS workshop tomorrow. A couple reminders/notes:
1) Workshop will take place from 1PM-5:30PM (Vancouver time) on Aug 7.
2) A finalized agenda for the workshop is posted here:
https://indico.triumf.ca/conferenceDisplay.py?confId=2438
Speakers should email me their talks beforehand and I will post them.
3) For those who want to participate remotely, we will be using bluejeans. The webpage for the bluejeans meeting is here:
https://bluejeans.com/462865444
I will start the connection ~20min before the start of the session; people calling in remotely might want to call early, so we can test the sound quality.
4) For those at TRIUMF, the meeting will be in the ISAC-II conference room.
Thomas
> Dear MIDAS users,
>
> Here's further information on the third MIDAS workshop:
>
> 1) Workshop will take place from 1PM-5PM (Vancouver time) on Aug 7.
>
> 2) A mostly finalized agenda for the workshop is posted here:
>
> https://indico.triumf.ca/conferenceDisplay.py?confId=2438
>
> People are still welcome to email me if they want to present something. We should be able to add it to the schedule.
>
> 3) For those who want to participate remotely, we will be using bluejeans. The webpage for the bluejeans meeting is here:
>
> https://bluejeans.com/462865444
>
> 4) For those at TRIUMF I will confirm the meeting room closer to the date.
>
> Thomas
>
>
> > Dear MIDAS users,
> >
> > We would like to announce a third MIDAS workshop at TRIUMF on Aug 7, 2019.
> > Stefan Ritt will again be visiting TRIUMF at this time.
> >
> > The overall goal of the workshop is to present new features in MIDAS, to discuss
> > future changes and to hear experiences from different experiments.
> >
> > We expect that some participants will connect remotely to the workshop; we will
> > setup a video-conferencing option. The exact time of the workshop will be
> > decided later and will be optimized based on the geographic distribution of
> > remote attendees. So please let us know if you want to attend remotely. We are
> > also happy for people to come in person to TRIUMF.
> >
> > A (very) preliminary agenda includes
> >
> > - New default mhttpd pages and new APIs for custom pages
> > - Conversion of MIDAS to C++
> > - new C++ based frontend framework (tmfe and mvodb from ALPHA-g)
> > - MySQL/Postgres database for storing ODB configurations
> > - Plans for updating history plotting
> > - Using MIDAS with an online trigger farm
> > - new C++ multithreaded flow analyzer (manalyzer from ALPHA-g)
> >
> > But please suggest other topics; we also hope to hear reports from particular
> > experiments.
> >
> > Sincerely,
> > Thomas (on behalf of MIDAS developers) |
|
04 Jul 2019, Lukas Gerritzen, Info, Limitations of MSL
|
Hi,
I am missing a few features. Do any of the following exist and I have just
overlooked them?
- Arithmetics:
SET foo, 2
SET bar, 2
SET FOOBAR, $foo + $bar
-> FOOBAR is 2, not 4
- Vectors/arrays
As far as I understand, "SET" only allows for single variables and no
"scripting" in variable names, i. e. doing something like the following
scripted:
SET var_1, 0
SET var_2, 0
...
LOOP n, 10
...
IF something
SET var_${n}, 1
ENDIF
The only way I could think of doing something similar is via the ODB.
I don't know if it's good practice to fill the ODB with variables like this.
- Loading scripts at run time (see other bug)
That would allow for script manipulation, even though it's kind of dirty, it
might be useful in some cases.
- Obtaining results from external scripts
A way to pass things from external scripts would be the solution to all
problems. Something that is not implemented could be done in a bash or
python script instead.
Cheers
Lukas |
|
05 Jul 2019, Konstantin Olchanski, Info, Limitations of MSL
|
> I am missing a few features.
MSL did not start out as a fully featured programming language.
Rather than extending it until it becomes one, I think a better approach would be to take
one of the existing extensible scripting language libraries and extend it with midas functions.
For example, LUA (https://www.lua.org/about.html) seems to be popular.
There were also requests for a midas extension for PYTHON (actually this has been done before,
but never added to the midas repository. I still have that code and I suppose it could be resurrected).
K.O.
> Do any of the following exist and I have just
> overlooked them?
>
> - Arithmetics:
> SET foo, 2
> SET bar, 2
> SET FOOBAR, $foo + $bar
> -> FOOBAR is 2, not 4
>
> - Vectors/arrays
> As far as I understand, "SET" only allows for single variables and no
> "scripting" in variable names, i. e. doing something like the following
> scripted:
> SET var_1, 0
> SET var_2, 0
> ...
> LOOP n, 10
> ...
> IF something
> SET var_${n}, 1
> ENDIF
>
> The only way I could think of doing something similar is via the ODB.
> I don't know if it's good practice to fill the ODB with variables like this.
>
> - Loading scripts at run time (see other bug)
> That would allow for script manipulation, even though it's kind of dirty, it
> might be useful in some cases.
>
> - Obtaining results from external scripts
> A way to pass things from external scripts would be the solution to all
> problems. Something that is not implemented could be done in a bash or
> python script instead.
>
> Cheers
> Lukas |
|
08 Jul 2019, Stefan Ritt, Info, Limitations of MSL
|
Sure some existing scripting languages can be used, but they fall short of a few important items in larger experiments:
- they are typically run from a local terminal in the counting house. A remote observer of the experiment has no idea which script is running and at which state it is.
- if DAQ crashes during a script or is aborted, it has to be restarted from the beginning. If you run a sequence of let's say 100 runs taking 8 hours, and on run #98 something goes wrong, you are screwed if you have to start at run #1 again.
This are the main reasons why I developed the midas sequencer. Having everything web-based, everybody can watch remotely how far the sequence progressed. If the whole DAQ crashes, the sequence resumes from the crash point, not from the beginning. This is by saving the current state into the ODB. So even if the sequencer itself is stopped and restarted, that still works.
I agree that the MSL is missing a few calculations, and I was just waiting to get a few specific requests. I will either add new functions such as basic calculations like adding and subtracting variables, or I will create a way to call an external shell like bash to do calculations. I put this high on my todo list.
Stefan |
|
08 Jul 2019, Lukas Gerritzen, Info, Limitations of MSL
|
Thank you two!
Actually, both solutions would allow me to fix my problem and I can see use cases for both. Having everything web-based is useful in bigger setups. However, in a testbeam environment, a python script is probably the more straight-forward solution. This gives access to the whole system of ones DAQ PC for whatever tricks one would like to perform.
Konstantin, would you mind resurrecting and sharing the python code? So far, my workaround is to call odbedit, which is not ideal for many reasons.
Cheers
Lukas |
|
08 Jul 2019, Konstantin Olchanski, Info, Limitations of MSL
|
> Konstantin, would you mind resurrecting and sharing the python code?
Not until September or later.
I encourage you to start an "issue" in the bitbucket repository (a "request for improvement") and contact
Thomas L. to see if we can/should discuss it at the incoming midas workshop at TRIUMF.
> So far, my workaround is to call odbedit, which is not ideal for many reasons.
Yes, this has been the way to do it for years...
Also I was thinking of writing an command line tool to invoke midas json-rpc methods (via mhttpd),
then you can do from command line or from a script everything that a web page can do. (of course
you can do it today, by using "curl" to send http requests to mhttpd directly).
K.O. |
|
09 Jul 2019, Stefan Ritt, Info, Limitations of MSL
|
> Yes, this has been the way to do it for years...
Calling odbedit -c ... ist certainly not the most effective way, but it works. I just tried on my Mac and found that I can call odbedit about 150 times per second. So not so bad if you have a limited operations to perform.
Stefan |
|
08 Jul 2019, Konstantin Olchanski, Info, Limitations of MSL
|
Hi, Stefan, on second thought, I agree, I do not know of any scripting language implementation (packaged as a library or not) that
can store it's state in a file ("checkpoint the execution") and that can execute it's program "one line at a time", like the midas
sequencer does now. In the most severe case, one invocation of msequencer executes one line of the msl script.
K.O.
> Sure some existing scripting languages can be used, but they fall short of a few important items in larger experiments:
>
> - they are typically run from a local terminal in the counting house. A remote observer of the experiment has no idea which script is running and at which state it is.
>
> - if DAQ crashes during a script or is aborted, it has to be restarted from the beginning. If you run a sequence of let's say 100 runs taking 8 hours, and on run #98 something goes wrong, you are screwed if you have to start at run #1 again.
>
> This are the main reasons why I developed the midas sequencer. Having everything web-based, everybody can watch remotely how far the sequence progressed. If the whole DAQ crashes, the sequence resumes from the crash point, not from the beginning. This is by saving the current state into the ODB. So even if the sequencer itself is stopped and restarted, that still works.
>
> I agree that the MSL is missing a few calculations, and I was just waiting to get a few specific requests. I will either add new functions such as basic calculations like adding and subtracting variables, or I will create a way to call an external shell like bash to do calculations. I put this high on my todo list.
>
> Stefan |
|
16 Jul 2019, Lukas Gerritzen, Info, Limitations of MSL
|
Dear Stefan,
another thing which does not work is the comparison of floating point numbers.
The script:
IF 1.1 > 1.0
MESSAGE "foo"
ENDIF
Produces an error "Invalid number in comparison". This is due to isdigit() being used to find the numerical values in the condition at progs/msequencer.cxx:343.
Would it be possible to add something like the following?
343 if (!isdigit(value1_var[i]) && value1_var[i] != '.')
344 break;
Which would only leave open a problem with some string like "2.3.4"
Cheers
Lukas |
|
30 Jul 2019, Stefan Ritt, Info, Limitations of MSL
|
> Would it be possible to add something like the following?
> 343 if (!isdigit(value1_var[i]) && value1_var[i] != '.')
> 344 break;
Actually isdigit() is completely wrong here, because it also fails the minus sign and the 'E' exponent, like in -1.2E-3
So I changed it to strchr("0123456789.+-Ee", var[i]) which should cover this case. If you put 1.2.3, it takes it as 1.2.
Stefan |
|
26 Jul 2019, Nik Berger, Bug Report, History/Endianness
|
Hi,
I have a bank of floats with slow control values that I store to the history and
ODB. When reading the history, both in the webbrowser and with mhist, the floats
get read with the wrong endianness; under /equipment/variables in the ODB they
however display correctly. System is a an intel OpenSuse linux box. Any ideas?
Thanks
Nik |
|
21 Jul 2019, Konstantin Olchanski, Info, error handling is hard
|
Happy summer to everybody.
When programming in general, and when programming MIDAS, there is always a struggle
with error handling. Too much? Too little? Visually, some MIDAS functions are 90% error handling, 10% useful work, if that.
What is the right way to do this?
Where is the balance?
Would c++ exceptions help or hinder?
How to make it better?
It turns out that the Go community have been struggling with exactly this for the last year or so.
Read the (ultimately rejected) proposal for improved error handling in Go. All the problems and difficulties
and struggles facing the programmer and the language designer spread right in front of us.
https://go.googlesource.com/proposal/+/master/design/go2draft-error-handling-overview.md
(To remember, Go is this: https://www.oreilly.com/library/view/the-go-programming/9780134190570/
The language designers are Brian W. Kernighan, Rob Pike, Ken Thompson and "some other people"
(Dennis Ritchie is no longer with us). These people gave us UNIX and C (and C++, the C++ guy was
their next-door-office mate), when that crowd speaks, I listen)
That write-up refers to some blogger's vivid illustration how correct error handling is hard,
with special focus on error handling in the presence of exceptions:
https://devblogs.microsoft.com/oldnewthing/?p=39683
https://devblogs.microsoft.com/oldnewthing/?p=36693
I read all this stuff and said, "wow, this is the reader's digest version of my life in computer programming".
The clincher from this last guy? "My point isn’t that exceptions are bad.
My point is that exceptions are too hard and I’m not smart
enough to handle them."
"back to writing some error handling code",
K.O. |
|
08 Jul 2019, Vinzenz Bildstein, Bug Report, Frontend killed at stop of run
|
I wrote a c++ frontend to read data from CAEN VX1730 digitizers which is used in
parallel with the GRIFFIN frontend to read out DESCANT.
After a long overnight run to check that the frontend runs smoothly for a longer
time, I stopped the run and the frontend was killed by midas. I am not sure why
this happened, as the end_of_run function returned successfully (at least the
print statement right before "return SUCCESS;" appeared right away). So
something else must have timed-out and caused it to be killed, I guess?
Any suggestions on where to look to find out what causes this?
Thanks in advance for your help! |
|
08 Jul 2019, Konstantin Olchanski, Bug Report, Frontend killed at stop of run
|
> After a long overnight run to check that the frontend runs smoothly for a longer
> time, I stopped the run and the frontend was killed by midas.
run the frontend inside gdb and post the stack trace after the crash?
if there is no crash (the program is stopped by exit()), you may need
to set a breakpoint in exit() or _exit() (not sure what it's latest name is)
then with luck your stack trace will show who/what called it from where.
if it is hard to start the frontend inside gdb, you can start it normally,
and attach gdb later, using a "gdb frontend.exe pid" command.
K.O.
> I am not sure why
> this happened, as the end_of_run function returned successfully (at least the
> print statement right before "return SUCCESS;" appeared right away). So
> something else must have timed-out and caused it to be killed, I guess?
>
> Any suggestions on where to look to find out what causes this?
>
> Thanks in advance for your help! |
|
08 Jul 2019, Vinzenz Bildstein, Bug Report, Frontend killed at stop of run
|
> run the frontend inside gdb and post the stack trace after the crash?
>
> if there is no crash (the program is stopped by exit()), you may need
> to set a breakpoint in exit() or _exit() (not sure what it's latest name is)
> then with luck your stack trace will show who/what called it from where.
>
If I remember correctly from the last time I tried that, it doesn't use the exit
function but gdb just reports that the program was terminated and no longer exists. I
can't set a breakpoint on SIGKILL as the point of SIGKILL is to kill the program and
gdb can't set a break at that point afaik. |
|
08 Jul 2019, Konstantin Olchanski, Bug Report, Frontend killed at stop of run
|
> > run the frontend inside gdb and post the stack trace after the crash?
> >
> > if there is no crash (the program is stopped by exit()), you may need
> > to set a breakpoint in exit() or _exit() (not sure what it's latest name is)
> > then with luck your stack trace will show who/what called it from where.
> >
>
> If I remember correctly from the last time I tried that, it doesn't use the exit
> function but gdb just reports that the program was terminated and no longer exists. I
> can't set a breakpoint on SIGKILL as the point of SIGKILL is to kill the program and
> gdb can't set a break at that point afaik.
For SIGKILL, my gdb reports "Program terminated with signal SIGKILL, Killed." and there is no stack
trace. Is this what you see?
If your program stops "normally", not from receiving some signal, set breakpoints on "exit" and
"_exit".
The normal stop sequence is to call exit(), which runs all the atexit() functions (the midas atexit()
function prints the message about "cm_disconnect_experiment not called at end of program") and
calls _exit() to stop the program.
So if you see the midas message "cm_disconnect_experiment not called at end of program", it is a
good indication that somebody (not mfe.c) called exit() on you. A breakpoint on "exit" should catch
who does it.
Good luck,
K.O. |
|
08 Jul 2019, Vinzenz Bildstein, Bug Report, Frontend killed at stop of run
|
> > > run the frontend inside gdb and post the stack trace after the crash?
> > >
> > > if there is no crash (the program is stopped by exit()), you may need
> > > to set a breakpoint in exit() or _exit() (not sure what it's latest name is)
> > > then with luck your stack trace will show who/what called it from where.
> > >
> >
> > If I remember correctly from the last time I tried that, it doesn't use the exit
> > function but gdb just reports that the program was terminated and no longer exists. I
> > can't set a breakpoint on SIGKILL as the point of SIGKILL is to kill the program and
> > gdb can't set a break at that point afaik.
>
> For SIGKILL, my gdb reports "Program terminated with signal SIGKILL, Killed." and there is no stack
> trace. Is this what you see?
Yes, that is exactly what I remember seeing.
>
> If your program stops "normally", not from receiving some signal, set breakpoints on "exit" and
> "_exit".
>
> The normal stop sequence is to call exit(), which runs all the atexit() functions (the midas atexit()
> function prints the message about "cm_disconnect_experiment not called at end of program") and
> calls _exit() to stop the program.
>
> So if you see the midas message "cm_disconnect_experiment not called at end of program", it is a
> good indication that somebody (not mfe.c) called exit() on you. A breakpoint on "exit" should catch
> who does it.
>
> Good luck,
> K.O.
So far I haven't seen the issue with the message "cm_disconnect_experiment not called at end of program"
again. Now I just have to restart the frontend after the run has (failed?) to stop. After restarting the
frontend everything seems to work again.
I haven't been writing data while doing these tests, so I can't say if there is any data missing or if the
runs were actually stopped properly (with a second dump of the ODB at the end). |
|
08 Jul 2019, Konstantin Olchanski, Bug Report, Frontend killed at stop of run
|
> >
> > For SIGKILL, my gdb reports "Program terminated with signal SIGKILL, Killed." and there is no stack
> > trace. Is this what you see?
>
> Yes, that is exactly what I remember seeing.
>
Where would a SIGKILL come from?!?
Look in the syslog (/var/log/messages). If the program was killed by the linux kernel, it would be logged there,
the usual cause is the machine runs out of memory and programs are killed by the OOM killer, this is logged
into the syslog, always.
MIDAS also can issue a SIGKILL sometimes, again this is always logged in midas.log. see src/midas.c, search for SIGKILL to see
the exact messages printed before it is sent out.
K.O. |
|
08 Jul 2019, Vinzenz Bildstein, Bug Report, Frontend killed at stop of run
|
> > >
> > > For SIGKILL, my gdb reports "Program terminated with signal SIGKILL, Killed." and there is no stack
> > > trace. Is this what you see?
> >
> > Yes, that is exactly what I remember seeing.
> >
>
> Where would a SIGKILL come from?!?
>
> Look in the syslog (/var/log/messages). If the program was killed by the linux kernel, it would be logged there,
> the usual cause is the machine runs out of memory and programs are killed by the OOM killer, this is logged
> into the syslog, always.
>
> MIDAS also can issue a SIGKILL sometimes, again this is always logged in midas.log. see src/midas.c, search for SIGKILL to see
> the exact messages printed before it is sent out.
>
> K.O.
I haven't been able to reproduce the error from the overnight run so far. I will try and leave this running in gdb overnight to see
if I can get that error again. |
|
10 Jul 2019, Vinzenz Bildstein, Bug Report, Frontend killed at stop of run
|
> > > >
> > > > For SIGKILL, my gdb reports "Program terminated with signal SIGKILL, Killed." and there is no stack
> > > > trace. Is this what you see?
> > >
> > > Yes, that is exactly what I remember seeing.
> > >
> >
> > Where would a SIGKILL come from?!?
> >
> > Look in the syslog (/var/log/messages). If the program was killed by the linux kernel, it would be logged there,
> > the usual cause is the machine runs out of memory and programs are killed by the OOM killer, this is logged
> > into the syslog, always.
> >
> > MIDAS also can issue a SIGKILL sometimes, again this is always logged in midas.log. see src/midas.c, search for SIGKILL to see
> > the exact messages printed before it is sent out.
> >
> > K.O.
>
> I haven't been able to reproduce the error from the overnight run so far. I will try and leave this running in gdb overnight to see
> if I can get that error again.
I was able to reproduce the error after an overnight run. gdb reported that the program received a SIGKILL, but no sign of it in
/var/log/messages. I've tried finding a current midas.log file, but it seems we don't have one? The most recent one was last updated
on May 24th this year. |
|
10 Jul 2019, Konstantin Olchanski, Bug Report, Frontend killed at stop of run
|
> ... finding a current midas.log file
On the "help" page, see "midas.log".
Same information is in ODB, the midas log file name is concatenation of "/Logger/Data dir" and "message file".
K.O. |
|
11 Jul 2019, Vinzenz Bildstein, Bug Report, Frontend killed at stop of run
|
> > ... finding a current midas.log file
>
> On the "help" page, see "midas.log".
>
> Same information is in ODB, the midas log file name is concatenation of "/Logger/Data dir" and "message file".
>
> K.O.
Sorry, should have found that myself ...
Anyway, the output from midas is
Tue Jul 9 07:24:06 2019 [mhttpd,INFO] Run #13456 started
Wed Jul 10 06:23:58 2019 [mhttpd,ERROR] [system.c:4580:ss_recv_net_command,ERROR] timeout receiving network
command header
Wed Jul 10 06:23:58 2019 [mhttpd,ERROR] [midas.c:10322:rpc_client_call,ERROR] call to "fedescant" on
"grsmid00.triumf.ca" RPC "rc_transition": timeout waiting for reply
Wed Jul 10 06:24:02 2019 [mhttpd,ERROR] [midas.c:5495:cm_shutdown,ERROR] Client 'fedescant' not responding to
shutdown command
Wed Jul 10 06:24:02 2019 [mhttpd,ERROR] [midas.c:5497:cm_shutdown,ERROR] Killing and Deleting client 'fedescant'
pid 31482
Wed Jul 10 06:24:02 2019 [Logger,INFO] Client 'fedescant' on buffer 'SYSMSG' removed by cm_watchdog because
process pid 31482 does not exist
Wed Jul 10 06:24:02 2019 [fegrifip09,INFO] Client 'fedescant' on buffer 'SYSTEM' removed by cm_watchdog because
process pid 31482 does not exist
Wed Jul 10 06:24:03 2019 [mhttpd,INFO] Run #13456 stopped
And I think I tracked down where this comes from with help from Thomas Lindner. It is a problem in the communication via the A3818 card from CAEN. This seems to block the frontend, even though it still reacts normal to a shutdown. So no issue with midas, even if it seemed that way at first. Thanks for all your help! |
|
11 Jul 2019, Konstantin Olchanski, Bug Report, Frontend killed at stop of run
|
> Wed Jul 10 06:23:58 2019 [mhttpd,ERROR] [system.c:4580:ss_recv_net_command,ERROR] timeout receiving network command header
> Wed Jul 10 06:23:58 2019 [mhttpd,ERROR] [midas.c:10322:rpc_client_call,ERROR] call to "fedescant" on "grsmid00.triumf.ca" RPC "rc_transition": timeout waiting for reply
We should have started debugging from here. The error messages mean: your frontend is not responding to run transition (RPC timeout).
> problem in the communication via the A3818 card from CAEN.
Yes, this has been problematic before.
K.O. |
|
16 Jul 2019, Konstantin Olchanski, Bug Report, a3818 and signals, Frontend killed at stop of run
|
Message from John M O'Donnell <odonnell@lanl.gov>
Folks,
The following might be related, if so great, if not sorry for the spam.
We had problems with MIDAS/CAEN_A3818 until two things happened:
1) CAEN found the root cause of a problem, as the A3818 and MIDAS both
used unix alarm signals, resulting in clashes. CAEN modified the
A3818 driver to have a "no alarm" option.
2) after downloading the modified driver, edit src/a3818.c to #define
USE_MIDAS 1 somewhere near the top.
Hope this helps,
John. |
|
16 Jul 2019, Konstantin Olchanski, Bug Report, a3818 and signals, Frontend killed at stop of run
|
> Message from John M O'Donnell <odonnell@lanl.gov>
>
> the A3818 and MIDAS both used unix alarm signals, resulting in clashes.
>
FWIW, current midas no longer uses alarm signals. See forum messages and git commits about
removal of cm_watchdog().
K.O. |
|
11 Jul 2019, Konstantin Olchanski, Bug Report, problems with the default mhttpd configuration
|
We installed recent mhttpd on a ubuntu machine and discovered a number of problems
with the default mhttpd settings.
We did follow the normal instructions to install and configure an apache https proxy
with a certbot certificate and password protection, this part worked ok. Big thanks
to Lars M. for providing the Ubuntu instructions for apache.
Then we started seeing errors from mhttpd about access to URLs like "manager/html"
(google "manager/html exploit") that did not go through the proxy.
It turns out that unlike CentOS-7, Ubuntu LTS 18.04 does not run a restrictive firewall
and access to mhttpd ports 8080 and 8443 is not blocked. Then, it turns out that by
default, the mhttpd access controls are also disabled, and it accepts http requests from
anywhere/everywhere. Also by default, the mhttpd password is also disabled.
As result, anybody from anywhere can access mhttpd without a password.
One fix for this is to activate the mhttpd access control list by setting ODB
/Experiment/Security/allowed hosts[0] to "localhost".
K.O. |
|
11 Jul 2019, Konstantin Olchanski, Bug Report, problems with the default mhttpd configuration, also elogd
|
> It turns out that unlike CentOS-7, Ubuntu LTS 18.04 does not run a restrictive firewall
> and access to mhttpd ports 8080 and 8443 is not blocked
>
> As result, anybody from anywhere can access mhttpd without a password.
>
elogd can suffer from the same problem, but not as badly, one can connect to elogd and attempt to run
exploits, but one cannot access elog entries without a password:
a) default configuration is to ask for a password
b) elogd almost immediately redirects to the https URL specified in the URL entry of the config file, which
normally points to the https proxy, which also immediately asks for a password.
In the absence of firewall protection (as on Ubuntu),
add "Interface = 127.0.0.1" to the elog config file or run elogd with "-n localhost",
per instructions at https://elog.psi.ch/elog/config.html
K.O. |
|
11 Jul 2019, Konstantin Olchanski, Bug Report, rework of mhttpd configuration
|
> Ubuntu LTS 18.04 does not run a restrictive firewall and access to mhttpd ports 8080 and 8443 is not
blocked.
Clearly, the present defaults settings of mhttpd are out of date.
The best I remember our internal discussions, we have converged on the following new default settings:
- mhttpd only listens on the localhost interface
- only accepts http (not https)
- password protection is off
These settings allow one to easily test midas on a laptop or on a single-user computer.
They also happen to be the correct settings when using an https proxy (i.e. apache httpd).
If the https proxy cannot be on the same computer, (i.e. ALPHA at CERN):
- one would enable mhttpd to listen on the external network interface
- this will enable the mhttpd access controls (ODB /expt/security/mhttpd hosts/allowed hosts)
- one would allow the https proxy machine access to mhttpd by adding it's hostname to "allowed hosts".
In the case where a separate https proxy cannot be used:
- one would enable https on the external network interface
- one would have to obtain an https certificate (there is possibility of adding certbot integration to mhttpd,
if there is demand for this)
- this will activate the mhttpd password protection, so one would have to define a username and password
in the .htdigest file (this is done by the mongoose web server library).
I was planning to implement these changes when I update the mongoose web server library to the latest
version (fixes a memory leak and improves/simplifies multithreading).
But maybe I should implement them sooner.
I am also thinking of adding a proxy function to mhttps (same as "ProxyPass" in apache httpd), set ODB
/Proxy/webcam to "http://webcam_on_private_network/magic_webcam_url", and access to
https://midas/webcam will return the data from the webcam without having to set this up in apache httpd
(requires root access, etc).
K.O. |
|
12 Jul 2019, Stefan Ritt, Bug Report, rework of mhttpd configuration
|
> - this will activate the mhttpd password protection, so one would have to define a username and password
> in the .htdigest file (this is done by the mongoose web server library).
Actually I'm thinking since a while to have user-level access to mhttpd, similarly to elog. Each user has to log in with a unique username/password. After some time of inactivity, you're logged out. This would have
the advantage that one knows who is active where, like when using the chat functionality in mhttpd. Or who started/stopped a run etc. This might not be necessary for simple local installations, but if you have 20
people controlling an experiment from three different continents simultaneously, this could be beneficial. Using the elog authentication libraries, one could even forward the login process to LDAP or KERBEROS,
so you could log in with out institutional account, and don't have to remember an additional password.
Just some food for thought.
Stefan |
|
12 Jul 2019, Konstantin Olchanski, Bug Report, rework of mhttpd configuration
|
> > - this will activate the mhttpd password protection, so one would have to define a username and password
> > in the .htdigest file (this is done by the mongoose web server library).
>
> Actually I'm thinking since a while to have user-level access to mhttpd, similarly to elog.
>
With per-user login, we have the possibility to add better permissions/access controls. In past
discussions we talked about 3 levels of user access:
- read-only user: can look, but cannot affect anything
- operator: same as read-only user, but can start/stop runs, can clear alarms, can push buttons on custom pages, can cause predefined scripts to run, etc.
- root user: can do everything
Technically, this is easy to implement in the mjsonrpc library: each username will be mapped to a privilege level,
and each rpc request handler will specify minimum required privilege: odb write rpc would require root level,
run start would require operator level, odb read permitted for everybody. This will be enforced inside mhttpd.
>
> Each user has to log in with a unique username/password. After some time of inactivity, you're logged out.
>
For now, we use the password protection built into the apache httpd web server.
It is known to be secure, but it does not have the "advanced" user management functions
that we take for granted with the elog, with wiki pages, with github, etc. Missing are self-registration
with approval, password reset and recovery and so forth.
On the other hand, apache httpd is supposed to be easy to integrate with "enterprise" user management
systems, like the CERN single-sign-on system. (We did not look yet at the integration with the TRIUMF
single-sign-on system, based on Microsoft AD).
(I see the nginx web server is gaining in popularity, but I do not know what features it has
for user and password management).
The elog software does have very good user and password management, and we could bring it into midas,
if we figure out how to ensure that it is actually secure. I know a professional security audit was done
for the elog software and I know that mhttpd will not pass such an audit.
But with some extra work it is possible.
>
> This would have the advantage that one knows who is active where, like when using the chat functionality in mhttpd. Or who started/stopped a run etc. This might not be necessary for simple local installations, but if you have 20
> people controlling an experiment from three different continents simultaneously, this could be beneficial. Using the elog authentication libraries, one could even forward the login process to LDAP or KERBEROS,
> so you could log in with out institutional account, and don't have to remember an additional password.
>
> Just some food for thought.
>
Some of this food looks very good, indeed.
K.O. |
|
05 Jul 2019, Hassan, Bug Report, Header files missing when trying to compile rootana, roody and analyzer
|
First of all thank you for all the assistance provided so far, especially making
changes to the code in CMakeList file previously for our configuration.I am not
sure whether this is an appropriate Elog for this matter but we are getting the
following error when trying to make rootana, roody and analyzer on our 64 bit
DAQ machine.
At the bottom of this Elog entry I have provided information about the specifics
of our DAQ machine
Below are the 2 errors we are encountering:
=============================================================================
[hh19285@it038146 ~]$ cd packages/rootana/
[hh19285@it038146 rootana]$ ls
bitbucket-pipelines.yml Dockerfile Doxygen.cxx include libAnalyzer
libMidasInterface libNetDirectory libXmlServer Makefile.old obj
README.md thisrootana.sh
doc Doxyfile examples lib libAnalyzerDisplay
libMidasServer libUnpack Makefile manalyzer old_analyzer
thisrootana.csh
[hh19285@it038146 rootana]$ cd examples/
[hh19285@it038146 examples]$ make
g++ -o TV792Histogram.o -g -O2 -Wall -Wuninitialized -DHAVE_LIBZ
-I/home/hh19285/packages/rootana/include -DHAVE_ROOT -pthread -std=c++11 -m64
-I/usr/include/root -DHAVE_ROOT_XML -DHAVE_ROOT_HTTP -DHAVE_THTTP_SERVER
-DHAVE_MIDAS -DOS_LINUX -Dextname -I/home/hh19285/packages/midas/include -c
TV792Histogram.cxx
In file included from
/home/hh19285/packages/rootana/include/TRootanaDisplay.hxx:5:0,
from
/home/hh19285/packages/rootana/include/TCanvasHandleBase.hxx:13,
from
/home/hh19285/packages/rootana/include/THistogramArrayBase.h:9,
from TV792Histogram.h:5,
from TV792Histogram.cxx:1:
/home/hh19285/packages/rootana/include/TRootanaEventLoop.hxx:24:25: fatal error:
THttpServer.h: No such file or directory
#include "THttpServer.h"
^
compilation terminated.
make: *** [TV792Histogram.o] Error 1
[hh19285@it038146 examples]$
===============================================================================
[hh19285@it038146 analyzer]$ ls
ana.cxx midas2root.cxx TAgilentHistogram.h
TCamacADCHistogram.h TL2249Histogram.h TV1190Histogram.h
TV1720Waveform.h TV1730RawWaveform.h
anaDisplay.cxx README.txt TAnaManager.cxx
TDT724Waveform.cxx TTRB3Histogram.cxx TV1720Correlations.cxx
TV1730DppWaveform.cxx TV792Histogram.cxx
Makefile root_server.cxx TAnaManager.hxx TDT724Waveform.h
TTRB3Histogram.hxx TV1720Correlations.h TV1730DppWaveform.h
TV792Histogram.h
Makefile.old TAgilentHistogram.cxx TCamacADCHistogram.cxx
TL2249Histogram.cxx TV1190Histogram.cxx TV1720Waveform.cxx
TV1730RawWaveform.cxx
[hh19285@it038146 analyzer]$ make
g++ -o TV792Histogram.o -g -O2 -Wall -Wuninitialized -DHAVE_LIBZ -I../include
-DHAVE_ROOT -pthread -std=c++11 -m64 -I/usr/include/root -DHAVE_ROOT_XML
-DHAVE_ROOT_HTTP -DHAVE_THTTP_SERVER -DHAVE_MIDAS -DOS_LINUX -Dextname
-I/home/hh19285/packages/midas/include -c TV792Histogram.cxx
In file included from TV792Histogram.cxx:1:0:
TV792Histogram.h:5:33: fatal error: THistogramArrayBase.h: No such file or directory
#include "THistogramArrayBase.h"
^
compilation terminated.
make: *** [TV792Histogram.o] Error 1
===============================================================================
[hh19285@it038146 ~]$ cd $HOME/packages
[hh19285@it038146 packages]$ git clone https://bitbucket.org/tmidas/roody
Cloning into 'roody'...
remote: Counting objects: 1115, done.
remote: Compressing objects: 100% (470/470), done.
remote: Total 1115 (delta 662), reused 1063 (delta 631)
Receiving objects: 100% (1115/1115), 1.01 MiB | 2.12 MiB/s, done.
Resolving deltas: 100% (662/662), done.
[hh19285@it038146 packages]$ cd roody
[hh19285@it038146 roody]$ make
g++ -O2 -g -Wall -Wuninitialized -fPIC -pthread -std=c++11 -m64
-I/usr/include/root -DNEED_STRLCPY -I. -Iinclude -DHAVE_NETDIRECTORY
-I/home/hh19285/packages/rootana/include -c -MM src/*.cxx > Makefile.depends1
In file included from src/Roody.cxx:42:0:
include/TPeakFindPanel.h:46:23: fatal error: TSpectrum.h: No such file or directory
#include "TSpectrum.h"
^
compilation terminated.
In file included from src/TPeakFindPanel.cxx:12:0:
include/TPeakFindPanel.h:46:23: fatal error: TSpectrum.h: No such file or directory
#include "TSpectrum.h"
^
compilation terminated.
make: [depend] Error 1 (ignored)
sed 's#^#obj/#' Makefile.depends1 > Makefile.depends2
sed 's#^obj/ # #' Makefile.depends2 > Makefile.depends
rm -f Makefile.depends1 Makefile.depends2
mkdir -p bin
mkdir -p obj
mkdir -p lib
cd doxfiles; doxygen roodydox.cfg
Warning: Tag `USE_WINDOWS_ENCODING' at line 11 of file roodydox.cfg has become
obsolete.
To avoid this warning please remove this line from your configuration file or
upgrade it using "doxygen -u"
Warning: Tag `DETAILS_AT_TOP' at line 23 of file roodydox.cfg has become obsolete.
To avoid this warning please remove this line from your configuration file or
upgrade it using "doxygen -u"
Warning: Tag `SHOW_DIRECTORIES' at line 58 of file roodydox.cfg has become obsolete.
To avoid this warning please remove this line from your configuration file or
upgrade it using "doxygen -u"
Warning: Tag `HTML_ALIGN_MEMBERS' at line 122 of file roodydox.cfg has become
obsolete.
To avoid this warning please remove this line from your configuration file or
upgrade it using "doxygen -u"
Warning: Tag `MAX_DOT_GRAPH_WIDTH' at line 220 of file roodydox.cfg has become
obsolete.
To avoid this warning please remove this line from your configuration file or
upgrade it using "doxygen -u"
Warning: Tag `MAX_DOT_GRAPH_HEIGHT' at line 221 of file roodydox.cfg has become
obsolete.
To avoid this warning please remove this line from your configuration file or
upgrade it using "doxygen -u"
Searching for include files...
Searching for example files...
Searching for images...
Searching for dot files...
Searching for msc files...
Searching for files to exclude
Searching for files to process...
Searching for files in directory /home/hh19285/packages/roody/doxfiles
Reading and parsing tag files
Parsing files
Preprocessing /home/hh19285/packages/roody/doxfiles/features.dox...
Parsing file /home/hh19285/packages/roody/doxfiles/features.dox...
Preprocessing /home/hh19285/packages/roody/doxfiles/quickstart.dox...
Parsing file /home/hh19285/packages/roody/doxfiles/quickstart.dox...
Preprocessing /home/hh19285/packages/roody/doxfiles/roody.dox...
Parsing file /home/hh19285/packages/roody/doxfiles/roody.dox...
Preprocessing /home/hh19285/packages/roody/include/MTGListTree.h...
Parsing file /home/hh19285/packages/roody/include/MTGListTree.h...
Preprocessing /home/hh19285/packages/roody/include/Roody.h...
Parsing file /home/hh19285/packages/roody/include/Roody.h...
Preprocessing /home/hh19285/packages/roody/include/RoodyXML.h...
Parsing file /home/hh19285/packages/roody/include/RoodyXML.h...
Preprocessing /home/hh19285/packages/roody/include/TGTextDialog.h...
Parsing file /home/hh19285/packages/roody/include/TGTextDialog.h...
Preprocessing /home/hh19285/packages/roody/include/TPeakFindPanel.h...
Parsing file /home/hh19285/packages/roody/include/TPeakFindPanel.h...
Preprocessing /home/hh19285/packages/roody/src/MTGListTree.cxx...
Parsing file /home/hh19285/packages/roody/src/MTGListTree.cxx...
Preprocessing /home/hh19285/packages/roody/src/Roody.cxx...
Parsing file /home/hh19285/packages/roody/src/Roody.cxx...
Preprocessing /home/hh19285/packages/roody/src/RoodyXML.cxx...
Parsing file /home/hh19285/packages/roody/src/RoodyXML.cxx...
Preprocessing /home/hh19285/packages/roody/src/TGTextDialog.cxx...
Parsing file /home/hh19285/packages/roody/src/TGTextDialog.cxx...
Building group list...
Building directory list...
Building namespace list...
Building file list...
Building class list...
Associating documentation with classes...
Computing nesting relations for classes...
Building example list...
Searching for enumerations...
Searching for documented typedefs...
Searching for members imported via using declarations...
Searching for included using directives...
Searching for documented variables...
Building interface member list...
Building member list...
Searching for friends...
Searching for documented defines...
Computing class inheritance relations...
Computing class usage relations...
Flushing cached template relations that have become invalid...
Creating members for template instances...
Computing class relations...
Add enum values to enums...
Searching for member function documentation...
Building page list...
Search for main page...
Computing page relations...
Determining the scope of groups...
Sorting lists...
Freeing entry tree
Determining which enums are documented
Computing member relations...
Building full member lists recursively...
Adding members to member groups.
Computing member references...
Inheriting documentation...
Generating disk names...
Adding source references...
Adding xrefitems...
Sorting member lists...
Computing dependencies between directories...
Generating citations page...
Counting data structures...
Resolving user defined references...
Finding anchors and sections in the documentation...
Transferring function references...
Combining using relations...
Adding members to index pages...
Generating style sheet...
Generating search indices...
Generating example documentation...
Generating file sources...
Parsing code for file features.dox...
Generating code for file MTGListTree.cxx...
Generating code for file MTGListTree.h...
Parsing code for file quickstart.dox...
Generating code for file Roody.cxx...
Parsing code for file roody.dox...
Generating code for file Roody.h...
Generating code for file RoodyXML.cxx...
Generating code for file RoodyXML.h...
Generating code for file TGTextDialog.cxx...
Generating code for file TGTextDialog.h...
Generating code for file TPeakFindPanel.h...
Generating file documentation...
Generating docs for file features.dox...
Generating docs for file MTGListTree.cxx...
Generating docs for file MTGListTree.h...
Generating docs for file quickstart.dox...
Generating docs for file Roody.cxx...
Generating docs for file roody.dox...
Generating docs for file Roody.h...
Generating docs for file RoodyXML.cxx...
Generating docs for file RoodyXML.h...
Generating docs for file TGTextDialog.cxx...
Generating docs for file TGTextDialog.h...
Generating docs for file TPeakFindPanel.h...
Generating page documentation...
Generating docs for page features...
Generating docs for page quickstart...
Generating group documentation...
Generating class documentation...
Generating docs for compound MemDebug...
Generating docs for compound MTGListTree...
Generating docs for compound OptStatMenu...
Generating docs for compound PadObject...
Generating docs for compound PadObjectVec...
Generating docs for compound Roody...
Generating docs for compound RoodyXML...
Generating docs for compound TGTextDialog...
Generating docs for compound TPeakFindPanel...
Generating namespace index...
Generating graph info page...
Generating directory documentation...
Generating index page...
Generating page index...
Generating module index...
Generating namespace index...
Generating namespace member index...
Generating annotated compound index...
Generating alphabetical compound index...
Generating hierarchical class index...
Generating member index...
Generating file index...
Generating file member index...
Generating example index...
finalizing index lists...
lookup cache used 433/65536 hits=3757 misses=436
finished...
g++ -O2 -g -Wall -Wuninitialized -fPIC -pthread -std=c++11 -m64
-I/usr/include/root -DNEED_STRLCPY -I. -Iinclude -DHAVE_NETDIRECTORY
-I/home/hh19285/packages/rootana/include -c -o obj/main.o src/main.cxx
g++ -O2 -g -Wall -Wuninitialized -fPIC -pthread -std=c++11 -m64
-I/usr/include/root -DNEED_STRLCPY -I. -Iinclude -DHAVE_NETDIRECTORY
-I/home/hh19285/packages/rootana/include -c -o obj/DataSourceTDirectory.o
src/DataSourceTDirectory.cxx
g++ -O2 -g -Wall -Wuninitialized -fPIC -pthread -std=c++11 -m64
-I/usr/include/root -DNEED_STRLCPY -I. -Iinclude -DHAVE_NETDIRECTORY
-I/home/hh19285/packages/rootana/include -c -o obj/Roody.o src/Roody.cxx
In file included from src/Roody.cxx:42:0:
include/TPeakFindPanel.h:46:23: fatal error: TSpectrum.h: No such file or directory
#include "TSpectrum.h"
^
compilation terminated.
make: *** [obj/Roody.o] Error 1
================================================================================
For your reference here is the info about our DAQ machine
[hh19285@it038146 bin]$ uname -a
Linux it038146.users.bris.ac.uk 3.10.0-957.21.2.el7.x86_64 #1 SMP Wed Jun 5
14:26:44 UTC 2019 x86_64 x86_64
x86_64 GNU/Linux
[hh19285@it038146 bin]$ uname -a
Linux it038146.users.bris.ac.uk 3.10.0-957.21.2.el7.x86_64 #1 SMP Wed Jun 5
14:26:44 UTC 2019 x86_64 x86_64
x86_64 GNU/Linux
[hh19285@it038146 bin]$ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/lto-wrapper
Target: x86_64-redhat-linux
Configured with: ../configure --prefix=/usr --mandir=/usr/share/man
--infodir=/usr/share/info
--with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-bootstrap
--enable-shared --enable-threads=posix
--enable-checking=release --with-system-zlib --enable-__cxa_atexit
--disable-libunwind-exceptions
--enable-gnu-unique-object --enable-linker-build-id --with-linker-hash-style=gnu
--enable-languages=c,c++,objc,obj-c++,java,fortran,ada,go,lto --enable-plugin
--enable-initfini-array
--disable-libgcj
--with-isl=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/isl-install
--with-cloog=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/cloog-install
--enable-gnu-indirect-function --with-tune=generic --with-arch_32=x86-64
--build=x86_64-redhat-linux
Thread model: posix
gcc version 4.8.5 20150623 (Red Hat 4.8.5-36) (GCC)
[hh19285@it038146 bin]$ lsb_release -a
LSB Version: :core-4.1-amd64:core-4.1-noarch
Distributor ID: CentOS
Description: CentOS Linux release 7.6.1810 (Core)
Release: 7.6.1810
Codename: Core |
|
05 Jul 2019, Konstantin Olchanski, Bug Report, Header files missing when trying to compile rootana, roody and analyzer
|
> /home/hh19285/packages/rootana/include/TRootanaEventLoop.hxx:24:25: fatal error:
> THttpServer.h: No such file or directory
> #include "THttpServer.h"
>
> include/TPeakFindPanel.h:46:23: fatal error: TSpectrum.h: No such file or directory
> #include "TSpectrum.h"
>
Your ROOT is strange, missing some standard features. Also installed in a strange place, /usr/include/root.
Did you install ROOT from the EPEL RPM packages? In the last I have seen this ROOT built very strangely, with some standard features disabled for no obvious
reason.
For this reason, I recommend that you install ROOT from the binary distribution at root.cern.ch or build it from source.
For more debugging, please post the output of:
which root-config
root-config --version
root-config --features
root-config --cflags
For reference, here is my output for a typical CentOS7 machine:
daq16:~$ which root-config
/daq/daqshare/olchansk/root/root_v6.12.04_el74_64/bin/root-config
daq16:~$ root-config --version
6.12/04
daq16:~$ root-config --features
asimage astiff builtin_afterimage builtin_ftgl builtin_gl2ps builtin_glew builtin_llvm builtin_lz4 builtin_unuran cling cxx11 exceptions explicitlink fftw3 gdmlgenvector
http imt mathmore minuit2 opengl pch pgsql python roofit shared sqlite ssl thread tmva x11 xft xml
daq16:~$ root-config --cflags -pthread -std=c++11 -m64 -I/daq/daqshare/olchansk/root/root_v6.12.04_el74_64/include
The important one is the --features, see that "http" and "xml" are enabled. "spectrum" used to be an optional feature, I do not think it can be disabled these
days, so your missing "TSpectrum.h" is strange. (But I just think the EPEL ROOT RPMs are built wrong).
K.O. |
|
10 Jul 2019, Hassan, Bug Report, Header files missing when trying to compile rootana, roody and analyzer
|
Hi, we have now done a clean install of Root and after some dynamic linking we have been able to make Rootana and analyzer. However we get an error when we try to run analyzer.
--------------------------------------------------------------------------------------------------------------------------------------------------
First of all heres the information requested:
[hh19285@it038146 ~]$ which root-config
/software/root/v6.06.08/bin/root-config
[hh19285@it038146 ~]$ root-config --version
6.06/08
[hh19285@it038146 ~]$ root-config --features
asimage astiff builtin_afterimage builtin_fftw3 builtin_ftgl builtin_freetype builtin_glew builtin_pcre builtin_lzma builtin_davix builtin_gsl builtin_cfitsio builtin_xrootd
builtin_llvm cxx11 cling davix exceptions explicitlink fftw3 fitsio fortran gdml genvector http krb5 mathmore memstat minuit2 opengl pch python roofit shadowpw shared ssl
table thread tmva unuran vc vdt xft xml x11 xrootd
[hh19285@it038146 ~]$ root-config --cflags
-pthread -std=c++11 -Wno-deprecated-declarations -m64 -I/software/root/v6.06.08/include
------------------------------------------------------------------------------------------------------------------------------------------------------
[hh19285@it038146 ~]$ cd ~/online/build/
[hh19285@it038146 build]$ ls
analyzer CMakeCache.txt CMakeFiles cmake_install.cmake data.txt d.txt experimentaldata frontend ft232h.py f.txt iptable_state_2july19.txt Makefile midas.log
[hh19285@it038146 build]$ make
[ 71%] Built target analyzer
[100%] Built target frontend
[hh19285@it038146 build]$ ./analyzer
Warning in <TClassTable::Add>: class TApplication already in TClassTable
Warning in <TClassTable::Add>: class TApplicationImp already in TClassTable
Warning in <TClassTable::Add>: class TAttFill already in TClassTable
Warning in <TClassTable::Add>: class TAttLine already in TClassTable
Warning in <TClassTable::Add>: class TAttMarker already in TClassTable
Warning in <TClassTable::Add>: class TAttPad already in TClassTable
Warning in <TClassTable::Add>: class TAttAxis already in TClassTable
Warning in <TClassTable::Add>: class TAttText already in TClassTable
Warning in <TClassTable::Add>: class TAtt3D already in TClassTable
Warning in <TClassTable::Add>: class TAttBBox already in TClassTable
Warning in <TClassTable::Add>: class TAttBBox2D already in TClassTable
Warning in <TClassTable::Add>: class TBenchmark already in TClassTable
Warning in <TClassTable::Add>: class TBrowser already in TClassTable
Warning in <TClassTable::Add>: class TBrowserImp already in TClassTable
Warning in <TClassTable::Add>: class TBuffer already in TClassTable
Warning in <TClassTable::Add>: class TRootIOCtor already in TClassTable
Warning in <TClassTable::Add>: class TCanvasImp already in TClassTable
Warning in <TClassTable::Add>: class TColor already in TClassTable
Warning in <TClassTable::Add>: class TColorGradient already in TClassTable
Warning in <TClassTable::Add>: class TLinearGradient already in TClassTable
Warning in <TClassTable::Add>: class TRadialGradient already in TClassTable
Warning in <TClassTable::Add>: class TContextMenu already in TClassTable
Warning in <TClassTable::Add>: class TContextMenuImp already in TClassTable
Warning in <TClassTable::Add>: class TControlBarImp already in TClassTable
Warning in <TClassTable::Add>: class TInspectorImp already in TClassTable
Warning in <TClassTable::Add>: class TDatime already in TClassTable
Warning in <TClassTable::Add>: class TDirectory already in TClassTable
Warning in <TClassTable::Add>: class TEnv already in TClassTable
Warning in <TClassTable::Add>: class TEnvRec already in TClassTable
Warning in <TClassTable::Add>: class TFileHandler already in TClassTable
Warning in <TClassTable::Add>: class TGuiFactory already in TClassTable
Warning in <TClassTable::Add>: class TStyle already in TClassTable
Warning in <TClassTable::Add>: class TVirtualX already in TClassTable
Warning in <TClassTable::Add>: class TVirtualPad already in TClassTable
Warning in <TClassTable::Add>: class TVirtualViewer3D already in TClassTable
Warning in <TClassTable::Add>: class TBuffer3D already in TClassTable
Warning in <TClassTable::Add>: class TGLManager already in TClassTable
Warning in <TClassTable::Add>: class TVirtualGLPainter already in TClassTable
Warning in <TClassTable::Add>: class TVirtualGLManip already in TClassTable
Warning in <TClassTable::Add>: class TVirtualPS already in TClassTable
Warning in <TClassTable::Add>: class TGLPaintDevice already in TClassTable
Warning in <TClassTable::Add>: class TVirtualPadPainter already in TClassTable
Warning in <TClassTable::Add>: class TVirtualPadEditor already in TClassTable
Warning in <TClassTable::Add>: class TVirtualFFT already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<char*,string> already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<const char*,string> already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<string*,vector<string> > already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<const string*,vector<string> > already in TClassTable
Warning in <TClassTable::Add>: class reverse_iterator<__gnu_cxx::__normal_iterator<string*,vector<string> > > already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<TString*,vector<TString> > already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<const TString*,vector<TString> > already in TClassTable
Warning in <TClassTable::Add>: class reverse_iterator<__gnu_cxx::__normal_iterator<TString*,vector<TString> > > already in TClassTable
Warning in <TClassTable::Add>: class FileStat_t already in TClassTable
Warning in <TClassTable::Add>: class UserGroup_t already in TClassTable
Warning in <TClassTable::Add>: class SysInfo_t already in TClassTable
Warning in <TClassTable::Add>: class CpuInfo_t already in TClassTable
Warning in <TClassTable::Add>: class MemInfo_t already in TClassTable
Warning in <TClassTable::Add>: class ProcInfo_t already in TClassTable
Warning in <TClassTable::Add>: class RedirectHandle_t already in TClassTable
Warning in <TClassTable::Add>: class TExec already in TClassTable
Warning in <TClassTable::Add>: class TFolder already in TClassTable
Warning in <TClassTable::Add>: class TMacro already in TClassTable
Warning in <TClassTable::Add>: class TMD5 already in TClassTable
Warning in <TClassTable::Add>: class TMemberInspector already in TClassTable
Warning in <TClassTable::Add>: class TMessageHandler already in TClassTable
Warning in <TClassTable::Add>: class TNamed already in TClassTable
Warning in <TClassTable::Add>: class TObjString already in TClassTable
Warning in <TClassTable::Add>: class TObject already in TClassTable
Warning in <TClassTable::Add>: class TRemoteObject already in TClassTable
Warning in <TClassTable::Add>: class TPoint already in TClassTable
Warning in <TClassTable::Add>: class TProcessID already in TClassTable
Warning in <TClassTable::Add>: class TProcessUUID already in TClassTable
Warning in <TClassTable::Add>: class TProcessEventTimer already in TClassTable
Warning in <TClassTable::Add>: class TRef already in TClassTable
Warning in <TClassTable::Add>: class TROOT already in TClassTable
Warning in <TClassTable::Add>: class TRegexp already in TClassTable
Warning in <TClassTable::Add>: class TPRegexp already in TClassTable
Warning in <TClassTable::Add>: class TPMERegexp already in TClassTable
Warning in <TClassTable::Add>: class TRefCnt already in TClassTable
Warning in <TClassTable::Add>: class TSignalHandler already in TClassTable
Warning in <TClassTable::Add>: class TStdExceptionHandler already in TClassTable
Warning in <TClassTable::Add>: class TStopwatch already in TClassTable
Warning in <TClassTable::Add>: class TStorage already in TClassTable
Warning in <TClassTable::Add>: class TString already in TClassTable
Warning in <TClassTable::Add>: class TStringLong already in TClassTable
Warning in <TClassTable::Add>: class TStringToken already in TClassTable
Warning in <TClassTable::Add>: class TSubString already in TClassTable
Warning in <TClassTable::Add>: class TSysEvtHandler already in TClassTable
Warning in <TClassTable::Add>: class TSystem already in TClassTable
Warning in <TClassTable::Add>: class TSystemFile already in TClassTable
Warning in <TClassTable::Add>: class TSystemDirectory already in TClassTable
Warning in <TClassTable::Add>: class TTask already in TClassTable
Warning in <TClassTable::Add>: class TTime already in TClassTable
Warning in <TClassTable::Add>: class TTimer already in TClassTable
Warning in <TClassTable::Add>: class TQObject already in TClassTable
Warning in <TClassTable::Add>: class TQObjSender already in TClassTable
Warning in <TClassTable::Add>: class TQClass already in TClassTable
Warning in <TClassTable::Add>: class TQConnection already in TClassTable
Warning in <TClassTable::Add>: class TQCommand already in TClassTable
Warning in <TClassTable::Add>: class TQUndoManager already in TClassTable
Warning in <TClassTable::Add>: class TUUID already in TClassTable
Warning in <TClassTable::Add>: class TPluginHandler already in TClassTable
Warning in <TClassTable::Add>: class TPluginManager already in TClassTable
Warning in <TClassTable::Add>: class Event_t already in TClassTable
Warning in <TClassTable::Add>: class SetWindowAttributes_t already in TClassTable
Warning in <TClassTable::Add>: class WindowAttributes_t already in TClassTable
Warning in <TClassTable::Add>: class GCValues_t already in TClassTable
Warning in <TClassTable::Add>: class ColorStruct_t already in TClassTable
Warning in <TClassTable::Add>: class PictureAttributes_t already in TClassTable
Warning in <TClassTable::Add>: class Segment_t already in TClassTable
Warning in <TClassTable::Add>: class Point_t already in TClassTable
Warning in <TClassTable::Add>: class Rectangle_t already in TClassTable
Warning in <TClassTable::Add>: class timespec already in TClassTable
Warning in <TClassTable::Add>: class TTimeStamp already in TClassTable
Warning in <TClassTable::Add>: class TFileInfo already in TClassTable
Warning in <TClassTable::Add>: class TFileInfoMeta already in TClassTable
Warning in <TClassTable::Add>: class TFileCollection already in TClassTable
Warning in <TClassTable::Add>: class TVirtualAuth already in TClassTable
Warning in <TClassTable::Add>: class TVirtualMutex already in TClassTable
Warning in <TClassTable::Add>: class TLockGuard already in TClassTable
Warning in <TClassTable::Add>: class TRedirectOutputGuard already in TClassTable
Warning in <TClassTable::Add>: class TVirtualPerfStats already in TClassTable
Warning in <TClassTable::Add>: class TVirtualMonitoringWriter already in TClassTable
Warning in <TClassTable::Add>: class TVirtualMonitoringReader already in TClassTable
Warning in <TClassTable::Add>: class TObjectSpy already in TClassTable
Warning in <TClassTable::Add>: class TObjectRefSpy already in TClassTable
Warning in <TClassTable::Add>: class TUri already in TClassTable
Warning in <TClassTable::Add>: class TUrl already in TClassTable
Warning in <TClassTable::Add>: class TInetAddress already in TClassTable
Warning in <TClassTable::Add>: class TVirtualTableInterface already in TClassTable
Warning in <TClassTable::Add>: class TBase64 already in TClassTable
Warning in <TClassTable::Add>: class TParameter<bool> already in TClassTable
Warning in <TClassTable::Add>: class TParameter<float> already in TClassTable
Warning in <TClassTable::Add>: class TParameter<double> already in TClassTable
Warning in <TClassTable::Add>: class TParameter<int> already in TClassTable
Warning in <TClassTable::Add>: class TParameter<long> already in TClassTable
Warning in <TClassTable::Add>: class TParameter<Long64_t> already in TClassTable
Warning in <TClassTable::Add>: class TArray already in TClassTable
Warning in <TClassTable::Add>: class TArrayC already in TClassTable
Warning in <TClassTable::Add>: class TArrayD already in TClassTable
Warning in <TClassTable::Add>: class TArrayF already in TClassTable
Warning in <TClassTable::Add>: class TArrayI already in TClassTable
Warning in <TClassTable::Add>: class TArrayL already in TClassTable
Warning in <TClassTable::Add>: class TArrayL64 already in TClassTable
Warning in <TClassTable::Add>: class TArrayS already in TClassTable
Warning in <TClassTable::Add>: class TBits already in TClassTable
Warning in <TClassTable::Add>: class TCollection already in TClassTable
Warning in <TClassTable::Add>: class TBtree already in TClassTable
Warning in <TClassTable::Add>: class TBtreeIter already in TClassTable
Warning in <TClassTable::Add>: class TClassTable already in TClassTable
Warning in <TClassTable::Add>: class TClonesArray already in TClassTable
Warning in <TClassTable::Add>: class THashTable already in TClassTable
Warning in <TClassTable::Add>: class THashTableIter already in TClassTable
Warning in <TClassTable::Add>: class TIter already in TClassTable
Warning in <TClassTable::Add>: class TIterator already in TClassTable
Warning in <TClassTable::Add>: class TList already in TClassTable
Warning in <TClassTable::Add>: class TListIter already in TClassTable
Warning in <TClassTable::Add>: class THashList already in TClassTable
Warning in <TClassTable::Add>: class TMap already in TClassTable
Warning in <TClassTable::Add>: class TMapIter already in TClassTable
Warning in <TClassTable::Add>: class TPair already in TClassTable
Warning in <TClassTable::Add>: class TObjArray already in TClassTable
Warning in <TClassTable::Add>: class TObjArrayIter already in TClassTable
Warning in <TClassTable::Add>: class TObjectTable already in TClassTable
Warning in <TClassTable::Add>: class TOrdCollection already in TClassTable
Warning in <TClassTable::Add>: class TOrdCollectionIter already in TClassTable
Warning in <TClassTable::Add>: class TSeqCollection already in TClassTable
Warning in <TClassTable::Add>: class TSortedList already in TClassTable
Warning in <TClassTable::Add>: class TExMap already in TClassTable
Warning in <TClassTable::Add>: class TExMapIter already in TClassTable
Warning in <TClassTable::Add>: class TRefArray already in TClassTable
Warning in <TClassTable::Add>: class TRefArrayIter already in TClassTable
Warning in <TClassTable::Add>: class TRefTable already in TClassTable
Warning in <TClassTable::Add>: class TVirtualCollectionProxy already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<int*,vector<int> > already in TClassTable
Warning in <TClassTable::Add>: class __gnu_cxx::__normal_iterator<const int*,vector<int> > already in TClassTable
Warning in <TClassTable::Add>: class reverse_iterator<__gnu_cxx::__normal_iterator<int*,vector<int> > > already in TClassTable
Warning in <TClassTable::Add>: class TBits::TReference already in TClassTable
Warning in <TClassTable::Add>: class TBaseClass already in TClassTable
Warning in <TClassTable::Add>: class TClass already in TClassTable
Warning in <TClassTable::Add>: class TClassStreamer already in TClassTable
Warning in <TClassTable::Add>: class TMemberStreamer already in TClassTable
Warning in <TClassTable::Add>: class TDictAttributeMap already in TClassTable
Warning in <TClassTable::Add>: class TClassRef already in TClassTable
Warning in <TClassTable::Add>: class TClassGenerator already in TClassTable
Warning in <TClassTable::Add>: class TDataMember already in TClassTable
Warning in <TClassTable::Add>: class TOptionListItem already in TClassTable
Warning in <TClassTable::Add>: class TDataType already in TClassTable
Warning in <TClassTable::Add>: class TDictionary already in TClassTable
Warning in <TClassTable::Add>: class TEnumConstant already in TClassTable
Warning in <TClassTable::Add>: class TEnum already in TClassTable
Warning in <TClassTable::Add>: class TFunction already in TClassTable
Warning in <TClassTable::Add>: class TFunctionTemplate already in TClassTable
Warning in <TClassTable::Add>: class ROOT::TSchemaRule already in TClassTable
Warning in <TClassTable::Add>: class ROOT::TSchemaRule::TSources already in TClassTable
Warning in <TClassTable::Add>: class ROOT::Detail::TSchemaRuleSet already in TClassTable
Warning in <TClassTable::Add>: class TGlobal already in TClassTable
Warning in <TClassTable::Add>: class TMethod already in TClassTable
Warning in <TClassTable::Add>: class TMethodArg already in TClassTable
Warning in <TClassTable::Add>: class TMethodCall already in TClassTable
Warning in <TClassTable::Add>: class TInterpreter already in TClassTable
Warning in <TClassTable::Add>: class TClassMenuItem already in TClassTable
Warning in <TClassTable::Add>: class TVirtualIsAProxy already in TClassTable
Warning in <TClassTable::Add>: class TVirtualStreamerInfo already in TClassTable
Warning in <TClassTable::Add>: class TIsAProxy already in TClassTable
Warning in <TClassTable::Add>: class TProtoClass already in TClassTable
Warning in <TClassTable::Add>: class TProtoClass::TProtoRealData already in TClassTable
Warning in <TClassTable::Add>: class TRealData already in TClassTable
Warning in <TClassTable::Add>: class TStreamerArtificial already in TClassTable
Warning in <TClassTable::Add>: class TStreamerBase already in TClassTable
Warning in <TClassTable::Add>: class TStreamerBasicPointer already in TClassTable
Warning in <TClassTable::Add>: class TStreamerLoop already in TClassTable
Warning in <TClassTable::Add>: class TStreamerBasicType already in TClassTable
Warning in <TClassTable::Add>: class TStreamerObject already in TClassTable
Warning in <TClassTable::Add>: class TStreamerObjectAny already in TClassTable
Warning in <TClassTable::Add>: class TStreamerObjectPointer already in TClassTable
Warning in <TClassTable::Add>: class TStreamerObjectAnyPointer already in TClassTable
Warning in <TClassTable::Add>: class TStreamerString already in TClassTable
Warning in <TClassTable::Add>: class TStreamerSTL already in TClassTable
Warning in <TClassTable::Add>: class TStreamerSTLstring already in TClassTable
Warning in <TClassTable::Add>: class TStreamerElement already in TClassTable
Warning in <TClassTable::Add>: class TToggle already in TClassTable
Warning in <TClassTable::Add>: class TToggleGroup already in TClassTable
Warning in <TClassTable::Add>: class TFileMergeInfo already in TClassTable
Warning in <TClassTable::Add>: class TListOfFunctions already in TClassTable
Warning in <TClassTable::Add>: class TListOfFunctionsIter already in TClassTable
Warning in <TClassTable::Add>: class TListOfFunctionTemplates already in TClassTable
Warning in <TClassTable::Add>: class TListOfDataMembers already in TClassTable
Warning in <TClassTable::Add>: class TListOfEnums already in TClassTable
Warning in <TClassTable::Add>: class TListOfEnumsWithLock already in TClassTable
Warning in <TClassTable::Add>: class TListOfEnumsWithLockIter already in TClassTable
Warning in <TClassTable::Add>: class TUnixSystem already in TClassTable
Warning in <TClassTable::Add>: class TThread already in TClassTable
Warning in <TClassTable::Add>: class TConditionImp already in TClassTable
Warning in <TClassTable::Add>: class TCondition already in TClassTable
Warning in <TClassTable::Add>: class TMutex already in TClassTable
Warning in <TClassTable::Add>: class TMutexImp already in TClassTable
Warning in <TClassTable::Add>: class TPosixCondition already in TClassTable
Warning in <TClassTable::Add>: class TPosixMutex already in TClassTable
Warning in <TClassTable::Add>: class TPosixThread already in TClassTable
Warning in <TClassTable::Add>: class TPosixThreadFactory already in TClassTable
Warning in <TClassTable::Add>: class TSemaphore already in TClassTable
Warning in <TClassTable::Add>: class TThreadFactory already in TClassTable
Warning in <TClassTable::Add>: class TThreadImp already in TClassTable
Warning in <TClassTable::Add>: class TRWLock already in TClassTable
Warning in <TClassTable::Add>: class TAtomicCount already in TClassTable
Warning in <TClassTable::Add>: class TBufferFile already in TClassTable
Warning in <TClassTable::Add>: class TDirectoryFile already in TClassTable
Warning in <TClassTable::Add>: class TFile already in TClassTable
Warning in <TClassTable::Add>: class TFileCacheRead already in TClassTable
Warning in <TClassTable::Add>: class TFileCacheWrite already in TClassTable
Warning in <TClassTable::Add>: class TFileMerger already in TClassTable
Warning in <TClassTable::Add>: class TFree already in TClassTable
Warning in <TClassTable::Add>: class TKey already in TClassTable
Warning in <TClassTable::Add>: class TKeyMapFile already in TClassTable
Warning in <TClassTable::Add>: class TMapFile already in TClassTable
Warning in <TClassTable::Add>: class TMapRec already in TClassTable
Warning in <TClassTable::Add>: class TMemFile already in TClassTable
Warning in <TClassTable::Add>: class TArchiveFile already in TClassTable
Warning in <TClassTable::Add>: class TArchiveMember already in TClassTable
Warning in <TClassTable::Add>: class TZIPFile already in TClassTable
Warning in <TClassTable::Add>: class TZIPMember already in TClassTable
Warning in <TClassTable::Add>: class TLockFile already in TClassTable
Warning in <TClassTable::Add>: class TStreamerInfo already in TClassTable
Warning in <TClassTable::Add>: class TCollectionProxyFactory already in TClassTable
Warning in <TClassTable::Add>: class TEmulatedCollectionProxy already in TClassTable
Warning in <TClassTable::Add>: class TEmulatedMapProxy already in TClassTable
Warning in <TClassTable::Add>: class TGenCollectionProxy already in TClassTable
Warning in <TClassTable::Add>: class TGenCollectionProxy::Value already in TClassTable
Warning in <TClassTable::Add>: class TGenCollectionProxy::Method already in TClassTable
Warning in <TClassTable::Add>: class TCollectionStreamer already in TClassTable
Warning in <TClassTable::Add>: class TCollectionClassStreamer already in TClassTable
Warning in <TClassTable::Add>: class TCollectionMemberStreamer already in TClassTable
Warning in <TClassTable::Add>: class TVirtualObject already in TClassTable
Warning in <TClassTable::Add>: class TVirtualArray already in TClassTable
Warning in <TClassTable::Add>: class TFPBlock already in TClassTable
Warning in <TClassTable::Add>: class TFilePrefetch already in TClassTable
Warning in <TClassTable::Add>: class TStreamerInfoActions::TConfiguredAction already in TClassTable
Warning in <TClassTable::Add>: class TStreamerInfoActions::TActionSequence already in TClassTable
Warning in <TClassTable::Add>: class TStreamerInfoActions::TConfiguration already in TClassTable
*** Break *** segmentation violation
===========================================================
There was a crash.
This is the entire stack trace of all threads:
===========================================================
#0 0x00007f7e8c322bbc in waitpid () from /lib64/libc.so.6
#1 0x00007f7e8c2a0ea2 in do_system () from /lib64/libc.so.6
#2 0x00007f7e911b21a4 in TUnixSystem::StackTrace() () from /usr/lib64/root/libCore.so.6.16
#3 0x00007f7e911b3fec in TUnixSystem::DispatchSignals(ESignals) () from /usr/lib64/root/libCore.so.6.16
#4 <signal handler called>
#5 0x00007f7e8c3cca81 in __strlen_sse2_pminub () from /lib64/libc.so.6
#6 0x00007f7e853e0c27 in TCling::TCling(char const*, char const*) () from /software/root/v6.06.08/lib/libCling.so
#7 0x00007f7e853e179e in CreateInterpreter () from /software/root/v6.06.08/lib/libCling.so
#8 0x00007f7e90feb1fc in TROOT::InitInterpreter() () from /usr/lib64/root/libCore.so.6.16
#9 0x00007f7e90feb806 in ROOT::Internal::GetROOT2() () from /usr/lib64/root/libCore.so.6.16
#10 0x00007f7e9107b32d in TApplication::TApplication(char const*, int*, char**, void*, int) () from /usr/lib64/root/libCore.so.6.16
#11 0x00007f7e8e71bdf4 in TRint::TRint(char const*, int*, char**, void*, int, bool) () from /usr/lib64/root/libRint.so.6.16
#12 0x000000000040d362 in main (argc=1, argv=0x7fff4d1d53b8) at /home/hh19285/packages/midas1/src/mana.cxx:5349
===========================================================
The lines below might hint at the cause of the crash.
You may get help by asking at the ROOT forum http://root.cern.ch/forum
Only if you are really convinced it is a bug in ROOT then please submit a
report at http://root.cern.ch/bugs Please post the ENTIRE stack trace
from above as an attachment in addition to anything else
that might help us fixing this issue.
===========================================================
#5 0x00007f7e8c3cca81 in __strlen_sse2_pminub () from /lib64/libc.so.6
#6 0x00007f7e853e0c27 in TCling::TCling(char const*, char const*) () from /software/root/v6.06.08/lib/libCling.so
#7 0x00007f7e853e179e in CreateInterpreter () from /software/root/v6.06.08/lib/libCling.so
#8 0x00007f7e90feb1fc in TROOT::InitInterpreter() () from /usr/lib64/root/libCore.so.6.16
#9 0x00007f7e90feb806 in ROOT::Internal::GetROOT2() () from /usr/lib64/root/libCore.so.6.16
#10 0x00007f7e9107b32d in TApplication::TApplication(char const*, int*, char**, void*, int) () from /usr/lib64/root/libCore.so.6.16
#11 0x00007f7e8e71bdf4 in TRint::TRint(char const*, int*, char**, void*, int, bool) () from /usr/lib64/root/libRint.so.6.16
#12 0x000000000040d362 in main (argc=1, argv=0x7fff4d1d53b8) at /home/hh19285/packages/midas1/src/mana.cxx:5349
===========================================================
> > /home/hh19285/packages/rootana/include/TRootanaEventLoop.hxx:24:25: fatal error:
> > THttpServer.h: No such file or directory
> > #include "THttpServer.h"
> >
> > include/TPeakFindPanel.h:46:23: fatal error: TSpectrum.h: No such file or directory
> > #include "TSpectrum.h"
> >
>
> Your ROOT is strange, missing some standard features. Also installed in a strange place, /usr/include/root.
>
> Did you install ROOT from the EPEL RPM packages? In the last I have seen this ROOT built very strangely, with some standard features disabled for no obvious
> reason.
>
> For this reason, I recommend that you install ROOT from the binary distribution at root.cern.ch or build it from source.
>
> For more debugging, please post the output of:
> which root-config
> root-config --version
> root-config --features
> root-config --cflags
>
> For reference, here is my output for a typical CentOS7 machine:
> daq16:~$ which root-config
> /daq/daqshare/olchansk/root/root_v6.12.04_el74_64/bin/root-config
> daq16:~$ root-config --version
> 6.12/04
> daq16:~$ root-config --features
> asimage astiff builtin_afterimage builtin_ftgl builtin_gl2ps builtin_glew builtin_llvm builtin_lz4 builtin_unuran cling cxx11 exceptions explicitlink fftw3 gdmlgenvector
> http imt mathmore minuit2 opengl pch pgsql python roofit shared sqlite ssl thread tmva x11 xft xml
> daq16:~$ root-config --cflags -pthread -std=c++11 -m64 -I/daq/daqshare/olchansk/root/root_v6.12.04_el74_64/include
>
> The important one is the --features, see that "http" and "xml" are enabled. "spectrum" used to be an optional feature, I do not think it can be disabled these
> days, so your missing "TSpectrum.h" is strange. (But I just think the EPEL ROOT RPMs are built wrong).
>
> K.O. |
|
10 Jul 2019, Konstantin Olchanski, Bug Report, Header files missing when trying to compile rootana, roody and analyzer
|
>> [hh19285@it038146 ~]$ which root-config
> /software/root/v6.06.08/bin/root-config
> [hh19285@it038146 ~]$ root-config --cflags
> -pthread -std=c++11 -Wno-deprecated-declarations -m64 -I/software/root/v6.06.08/include
>
> [hh19285@it038146 build]$ ./analyzer
> Warning in <TClassTable::Add>: class TApplication already in TClassTable
> ...
> ...
> #2 0x00007f7e911b21a4 in TUnixSystem::StackTrace() () from /usr/lib64/root/libCore.so.6.16
You have a mismatch. Your root-config thinks ROOT is installed in /software/..., but the crash
dump says your ROOT libraries are in /usr/lib64/root (not in /software/...).
You can confirm that you are linking against the correct ROOT by running cmake with VERBOSE=1
and examine the linker command line to see what library link path is specified for ROOT.
You can confirm which ROOT library is actually used when you run the analyzer
by running "ldd ./analyzer". You should see the same library paths as specified
to the linker (/software/.../lib*.so). A mismatch can be caused by the setting of LD_LIBRARY_PATH
and by 100 other reasons.
I suggest that you remove the "wrong" ROOT before you continue debugging this.
K.O. |
|
11 Jul 2019, Stefan Ritt, Bug Report, Header files missing when trying to compile rootana, roody and analyzer
|
> You can confirm that you are linking against the correct ROOT by running cmake with VERBOSE=1
> and examine the linker command line to see what library link path is specified for ROOT.
Actually you don't call cmake with the verbose flag but specify it during the make phase
$ make VERBOSE=1
to see the command lines.
Stefan |
|
11 Jul 2019, Konstantin Olchanski, Bug Report, Header files missing when trying to compile rootana, roody and analyzer
|
> > You can confirm that you are linking against the correct ROOT by running cmake with VERBOSE=1
> > and examine the linker command line to see what library link path is specified for ROOT.
>
> $ make VERBOSE=1
> to see the command lines.
>
Most likely, they forgot to rerun "cmake" after installing a new ROOT. The joys of a two-step build (cmake; make).
K.O. |
|
03 Jul 2019, Lukas Gerritzen, Bug Report, mhttpd crashes when including nonexistent script in msequencer
|
Hi,
the subject line describes the project already
Suppose you have a file foo.msl. Somewhere in the file, you have the line
INCLUDE bar.msl
Once you click save in the sequencer page, mhttpd crashes:
$ mhttpd
free(): double free detected in tcache 2
[1] 27590 abort (core dumped) mhttpd
GDB helps shed some light on the problem:
#0 0x00007ffff76b057f in raise () from /lib64/libc.so.6
#1 0x00007ffff769a895 in abort () from /lib64/libc.so.6
#2 0x00007ffff76f39d7 in __libc_message () from /lib64/libc.so.6
#3 0x00007ffff76fa2ec in malloc_printerr () from /lib64/libc.so.6
#4 0x00007ffff76fbdf5 in _int_free () from /lib64/libc.so.6
#5 0x00000000004b8b41 in mxml_parse_entity (buf=buf@entry=0x7fffffffc2c8,
file_name=file_name@entry=0x7fffffffc710
"/home/luk/packages/mutrig_daq/online/foo.xml",
error=error@entry=0x7fffffffcd24 "XML read error in file
\"/home/luk/packages/mutrig_daq/online/foo.xml\", line 2: bar.msl.xml is
missing", error_size=error_size@entry=256,
error_line=error_line@entry=0x7fffffffce24) at ../mxml/mxml.c:1996
#6 0x00000000004b966d in mxml_parse_file
(file_name=file_name@entry=0x7fffffffc710
"/home/luk/packages/mutrig_daq/online/foo.xml",
error=error@entry=0x7fffffffcd24 "XML read error in file
\"/home/luk/packages/mutrig_daq/online/foo.xml\", line 2: bar.msl.xml is
missing", error_size=error_size@entry=256,
error_line=error_line@entry=0x7fffffffce24) at ../mxml/mxml.c:2041
#7 0x000000000041d9c2 in init_sequencer () at src/mhttpd.cxx:14321
#8 0x000000000040c2b6 in main (argc=<optimized out>, argv=<optimized out>) at
src/mhttpd.cxx:18028
Cheers
Lukas
P. S. This problem reminds me of the old joke: A man goes to his doctor and says
"Doc, it hurts when I do this" to which the doctor replies "Then don't do that".
However, I think, mhttpd should not crash even if you're not supposed to include
non-existent scripts in msequencer. |
|
10 Jul 2019, Stefan Ritt, Bug Report, mhttpd crashes when including nonexistent script in msequencer
|
The bug has been fixed. It was actually in the mxml library. So you have to go to the midas/mxml
subdirectory and update that one via "git pull origin master".
Stefan
> Hi,
> the subject line describes the project already
> Suppose you have a file foo.msl. Somewhere in the file, you have the line
> INCLUDE bar.msl
>
> Once you click save in the sequencer page, mhttpd crashes:
> $ mhttpd
> free(): double free detected in tcache 2
> [1] 27590 abort (core dumped) mhttpd
>
>
> GDB helps shed some light on the problem:
>
> #0 0x00007ffff76b057f in raise () from /lib64/libc.so.6
> #1 0x00007ffff769a895 in abort () from /lib64/libc.so.6
> #2 0x00007ffff76f39d7 in __libc_message () from /lib64/libc.so.6
> #3 0x00007ffff76fa2ec in malloc_printerr () from /lib64/libc.so.6
> #4 0x00007ffff76fbdf5 in _int_free () from /lib64/libc.so.6
> #5 0x00000000004b8b41 in mxml_parse_entity (buf=buf@entry=0x7fffffffc2c8,
> file_name=file_name@entry=0x7fffffffc710
> "/home/luk/packages/mutrig_daq/online/foo.xml",
> error=error@entry=0x7fffffffcd24 "XML read error in file
> \"/home/luk/packages/mutrig_daq/online/foo.xml\", line 2: bar.msl.xml is
> missing", error_size=error_size@entry=256,
> error_line=error_line@entry=0x7fffffffce24) at ../mxml/mxml.c:1996
> #6 0x00000000004b966d in mxml_parse_file
> (file_name=file_name@entry=0x7fffffffc710
> "/home/luk/packages/mutrig_daq/online/foo.xml",
> error=error@entry=0x7fffffffcd24 "XML read error in file
> \"/home/luk/packages/mutrig_daq/online/foo.xml\", line 2: bar.msl.xml is
> missing", error_size=error_size@entry=256,
> error_line=error_line@entry=0x7fffffffce24) at ../mxml/mxml.c:2041
> #7 0x000000000041d9c2 in init_sequencer () at src/mhttpd.cxx:14321
> #8 0x000000000040c2b6 in main (argc=<optimized out>, argv=<optimized out>) at
> src/mhttpd.cxx:18028
>
> Cheers
> Lukas
>
> P. S. This problem reminds me of the old joke: A man goes to his doctor and says
> "Doc, it hurts when I do this" to which the doctor replies "Then don't do that".
> However, I think, mhttpd should not crash even if you're not supposed to include
> non-existent scripts in msequencer. |
|
02 Jul 2019, Lukas Gerritzen, Suggestion, my_global.h not present in my linux distribution (needed)
|
Hey,
while trying to compile Midas under openSUSE 15.0 with mysql support, I was
running into the problem that somehow the mysql header file my_global.h is not
included in the packages. This might be a bug that concerns the suse developers
more, but is it actually needed? Compilation worked fine with the include line
commented out.
If it's not needed, I would like to suggest to remove line 735 of
src/history_schema.cxx (where it's included)
Cheers
Lukas
mysql Ver 15.1 Distrib 10.2.22-MariaDB, for Linux (x86_64) using EditLine wrapper
Also, all mariadb development packages are installed |
|
02 Jul 2019, Konstantin Olchanski, Suggestion, my_global.h not present in my linux distribution (needed)
|
Confirmed. my_global.h is removed in MySQL 8.0 (gives a compile error) and deprecated in
MariaDB 10.2 (gives a #warning).
I removed include of my_global.h, it is not needed on el6, el7 and ubuntu.
Also added explicit support for mariadb via mariadb_config if it exists.
Note that the cmake build does not actually enable mysql, sqlite and odbc - it detects them, but
does not do anything about it. We will fix this shortly.
K.O.
> Hey,
>
> while trying to compile Midas under openSUSE 15.0 with mysql support, I was
> running into the problem that somehow the mysql header file my_global.h is not
> included in the packages. This might be a bug that concerns the suse developers
> more, but is it actually needed? Compilation worked fine with the include line
> commented out.
>
> If it's not needed, I would like to suggest to remove line 735 of
> src/history_schema.cxx (where it's included)
>
> Cheers
> Lukas
>
> mysql Ver 15.1 Distrib 10.2.22-MariaDB, for Linux (x86_64) using EditLine wrapper
> Also, all mariadb development packages are installed |
|
03 Jul 2019, Lukas Gerritzen, Suggestion, my_global.h not present in my linux distribution (needed)
|
Thanks! |
|
28 Jun 2019, Thorsten Lux, Bug Report, Status page reloads every second
|
Hello,
We observed a strange behavior, from our point of view:
After some issues with with a 100% full database and recovering from this by
creating a new odb file from a previous copy, the Midas status page started to
reload/refresh every second while on the other hand it solved the 100% full
issue.
There are no error messages and the pages looks like normal but it is impossible
to start a new run due to the permanent reloading.
It is possible to click for example on odb and check the settings.
Any idea what could be the problem and what the solution?
Thanks
Thorsten |
|
28 Jun 2019, Konstantin Olchanski, Bug Report, Status page reloads every second
|
> We observed a strange behavior, from our point of view:
> ... the Midas status page started to reload/refresh every second
What version of midas is this? Run the odbedit "ver" command please. Also which
browser on what OS is this? (chrome->about google chrome, firefox->about firefox).
The current versions of midas do not reload the status page ever, and I think
all the page-reload code has been removed and they cannot reload automatically.
Old versions of the midas status page were designed to reload every 60 seconds or so.
The reload interval is adjustable, but I do not think it was stored in ODB. It was
accessed from the status page "config" button and I think it stored the reload
period is a browser cookie.
This reload value may have gotten confused, and in this case, to fix it,
you can try to clear all the web cookies from the web page. Another test for this
would be to try an alternate web browser, which would presumable not have the bad cookie
and will not suffer from the reload problem.
You can also open the web page debugger (google chrome -> right click menu -> inspect ->>
console & etc) and see if anything shows up there. I think you can set a break point
on the page reload function and catch the place that causes the reload.
K.O. |
|
29 Jun 2019, Thorsten Lux, Bug Report, Status page reloads every second
|
I am sorry, yesterday evening I must have been a bit tired after a long day with a lot of
problems and error messages, so that I did not realize that yes, the frontend was finally
starting well again but by recovering the odb file from an old one, it was stuck in the
transition "stopping run" and this caused the continuous reloading of the status page.
A "obdedit -C stop" solved the problem.
Sorry for this!
> We observed a strange behavior, from our point of view:
> > ... the Midas status page started to reload/refresh every second
>
> What version of midas is this? Run the odbedit "ver" command please. Also which
> browser on what OS is this? (chrome->about google chrome, firefox->about firefox).
>
> The current versions of midas do not reload the status page ever, and I think
> all the page-reload code has been removed and they cannot reload automatically.
>
> Old versions of the midas status page were designed to reload every 60 seconds or so.
> The reload interval is adjustable, but I do not think it was stored in ODB. It was
> accessed from the status page "config" button and I think it stored the reload
> period is a browser cookie.
>
> This reload value may have gotten confused, and in this case, to fix it,
> you can try to clear all the web cookies from the web page. Another test for this
> would be to try an alternate web browser, which would presumable not have the bad cookie
> and will not suffer from the reload problem.
>
> You can also open the web page debugger (google chrome -> right click menu -> inspect ->>
> console & etc) and see if anything shows up there. I think you can set a break point
> on the page reload function and catch the place that causes the reload.
>
> K.O. |
|
24 Jun 2019, Hassan, Bug Report, ERROR INSTALLING 32BIT MIDAS LIBRARIES ON 64BIT HOST MACHINE
|
Hi, we are part of the Mu3e research based at University of Bristol. We have a
remote 32 bit frontend (raspberry pi) connected to a 64 bit Data Acquisition
system.we are following the instructions at installation/quickstart linux/Build
32-bit MIDAS libraries. when we execute the commands:
[mhostpc] cd /home/packages/midas
[mhostpc] make linux32
we get an error:
make NO_ROOT=1 NO_MYSQL=1 NO_ODBC=1 NO_SQLITE=1 OS_DIR=linux-m32 USERFLAGS=-m32
make[1]: Entering directory `/home/hh19285/packages/midas'
g++ -m32 -c -g -O2 -Wall -Wno-strict-aliasing -Wuninitialized -Iinclude -
Idrivers -Imxml -Imscb/include -DHAVE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_ZLIB -
DHAVE_MSCB -DHAVE_MONGOOSE6 -DMG_ENABLE_THREADS -DMG_DISABLE_CGI -DMG_ENABLE_SSL
-DOS_LINUX -fPIC -Wno-unused-function -o lib/crc32c.o src/crc32c.cxx
src/crc32c.cxx: In function ‘uint32_t crc32c_hw(uint32_t, const void*, size_t)’:
src/crc32c.cxx:283:66: error: ‘asm’ operand has impossible constraints
: "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
^
src/crc32c.cxx:303:66: error: ‘asm’ operand has impossible constraints
: "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
^
src/crc32c.cxx: In function ‘uint32_t crc32c(uint32_t, const void*, size_t)’:
src/crc32c.cxx:348:34: error: PIC register clobbered by ‘%ebx’ in ‘asm’
: "%ebx", "%edx"); \
^
src/crc32c.cxx:362:5: note: in expansion of macro ‘SSE42’
SSE42(sse42);
^
make[1]: *** [lib/crc32c.o] Error 1
make[1]: Leaving directory `/home/hh19285/packages/midas'
make: *** [linux32] Error 2
Could you please help with getting past this? otherwise we may need to change
our whole experimental setup.
Thank you in advance |
|
24 Jun 2019, Stefan Ritt, Bug Report, ERROR INSTALLING 32BIT MIDAS LIBRARIES ON 64BIT HOST MACHINE
|
Why don't your try the (yet undocumented) new installation procedure:
$ git clone https://bitbucket.com/tmidas/midas --recursive
$ cd midas
$ mkdir build
$ cd build
$ cmake ..
$ make
$ make install
In case your RPi does not have cmake pre-installed, you need
$ sudo apt-get install cmake.
Works for my RPi.
Best,
Stefan |
|
25 Jun 2019, Stefan Ritt, Bug Report, ERROR INSTALLING 32BIT MIDAS LIBRARIES ON 64BIT HOST MACHINE
|
Update: "make" instead of "make linux32" should also work. I believe the "linux32" target came
from some special case at TRIUMF for some FPGA embedded linux, which is not applicable for
the Raspberry Pi.
Note that the build process has to be initiated on the Raspberry Pi, NOT a host PC.
Stefan |
|
25 Jun 2019, Konstantin Olchanski, Bug Report, ERROR INSTALLING 32BIT MIDAS LIBRARIES ON 64BIT HOST MACHINE
|
Yikes, the error is in the CRC library. The assembly-optimized crc32c function fails to build, and the
error does not look familiar to me. I do not see this error here. What is your host system ("uname -
a") and what is your gcc ("gcc -v")?
BTW, "make linux32" will build an Intel 32-bit version (see "-m32" in "man gcc"). For ARM 32-bit
you need a different switch, I think, also depending how you are cross-compiling it.
For straight cross-compilation, look at the Makefile target "make linuxarm" (you will need to change
the location of your ARM gcc cross-compiler).
For running MIDAS frontend on the Raspberry Pi 3, I build MIDAS on the Pi3 itself, the machine is big
enough to run CentOS7 linux and gcc to build the full MIDAS.
But if you have a different cross-compilation scheme, I am happy to help you and to add your
scheme to the MIDAS Makefile. We can start by looking at "uname -a" and "gcc -v" and "lsb_release
-a" (if you have it).
K.O.
> Hi, we are part of the Mu3e research based at University of Bristol. We have a
> remote 32 bit frontend (raspberry pi) connected to a 64 bit Data Acquisition
> system.we are following the instructions at installation/quickstart linux/Build
> 32-bit MIDAS libraries. when we execute the commands:
> [mhostpc] cd /home/packages/midas
> [mhostpc] make linux32
>
> we get an error:
>
> make NO_ROOT=1 NO_MYSQL=1 NO_ODBC=1 NO_SQLITE=1 OS_DIR=linux-m32 USERFLAGS=-
m32
> make[1]: Entering directory `/home/hh19285/packages/midas'
> g++ -m32 -c -g -O2 -Wall -Wno-strict-aliasing -Wuninitialized -Iinclude -
> Idrivers -Imxml -Imscb/include -DHAVE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_ZLIB -
> DHAVE_MSCB -DHAVE_MONGOOSE6 -DMG_ENABLE_THREADS -DMG_DISABLE_CGI -
DMG_ENABLE_SSL
> -DOS_LINUX -fPIC -Wno-unused-function -o lib/crc32c.o src/crc32c.cxx
> src/crc32c.cxx: In function ‘uint32_t crc32c_hw(uint32_t, const void*, size_t)’:
> src/crc32c.cxx:283:66: error: ‘asm’ operand has impossible constraints
> : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> ^
> src/crc32c.cxx:303:66: error: ‘asm’ operand has impossible constraints
> : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> ^
> src/crc32c.cxx: In function ‘uint32_t crc32c(uint32_t, const void*, size_t)’:
> src/crc32c.cxx:348:34: error: PIC register clobbered by ‘%ebx’ in ‘asm’
> : "%ebx", "%edx"); \
> ^
> src/crc32c.cxx:362:5: note: in expansion of macro ‘SSE42’
> SSE42(sse42);
> ^
> make[1]: *** [lib/crc32c.o] Error 1
> make[1]: Leaving directory `/home/hh19285/packages/midas'
> make: *** [linux32] Error 2
>
> Could you please help with getting past this? otherwise we may need to change
> our whole experimental setup.
>
> Thank you in advance |
|
26 Jun 2019, Hassan, Bug Report, ERROR INSTALLING 32BIT MIDAS LIBRARIES ON 64BIT HOST MACHINE
|
Thanks for your advice. We now have Midas installed on both our machines (remote machine-Rpi &
hostmachine-Centos).
=========================================================================================================
One the host machine:
[hh19285@it038146 bin]$ uname -a
Linux it038146.users.bris.ac.uk 3.10.0-957.21.2.el7.x86_64 #1 SMP Wed Jun 5 14:26:44 UTC 2019 x86_64 x86_64
x86_64 GNU/Linux
[hh19285@it038146 bin]$ uname -a
Linux it038146.users.bris.ac.uk 3.10.0-957.21.2.el7.x86_64 #1 SMP Wed Jun 5 14:26:44 UTC 2019 x86_64 x86_64
x86_64 GNU/Linux
[hh19285@it038146 bin]$ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/lto-wrapper
Target: x86_64-redhat-linux
Configured with: ../configure --prefix=/usr --mandir=/usr/share/man --infodir=/usr/share/info
--with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-bootstrap --enable-shared --enable-threads=posix
--enable-checking=release --with-system-zlib --enable-__cxa_atexit --disable-libunwind-exceptions
--enable-gnu-unique-object --enable-linker-build-id --with-linker-hash-style=gnu
--enable-languages=c,c++,objc,obj-c++,java,fortran,ada,go,lto --enable-plugin --enable-initfini-array
--disable-libgcj --with-isl=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/isl-install
--with-cloog=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/cloog-install
--enable-gnu-indirect-function --with-tune=generic --with-arch_32=x86-64 --build=x86_64-redhat-linux
Thread model: posix
gcc version 4.8.5 20150623 (Red Hat 4.8.5-36) (GCC)
[hh19285@it038146 bin]$ lsb_release -a
LSB Version: :core-4.1-amd64:core-4.1-noarch
Distributor ID: CentOS
Description: CentOS Linux release 7.6.1810 (Core)
Release: 7.6.1810
Codename: Core
===========================================================================================================
On remote machine:
pi@raspberrypi:~/packages/midas/bin $ uname -a
Linux raspberrypi 4.19.42-v7+ #1219 SMP Tue May 14 21:20:58 BST 2019 armv7l GNU/Linux
pi@raspberrypi:~/packages/midas/bin $ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/arm-linux-gnueabihf/6/lto-wrapper
Target: arm-linux-gnueabihf
Configured with: ../src/configure -v --with-pkgversion='Raspbian 6.3.0-18+rpi1+deb9u1'
--with-bugurl=file:///usr/share/doc/gcc-6/README.Bugs
--enable-languages=c,ada,c++,java,go,d,fortran,objc,obj-c++ --prefix=/usr --program-suffix=-6
--program-prefix=arm-linux-gnueabihf- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib
--without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --with-sysroot=/
--enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new
--enable-gnu-unique-object --disable-libitm --disable-libquadmath --enable-plugin --with-system-zlib
--disable-browser-plugin --enable-java-awt=gtk --enable-gtk-cairo
--with-java-home=/usr/lib/jvm/java-1.5.0-gcj-6-armhf/jre --enable-java-home
--with-jvm-root-dir=/usr/lib/jvm/java-1.5.0-gcj-6-armhf
--with-jvm-jar-dir=/usr/lib/jvm-exports/java-1.5.0-gcj-6-armhf --with-arch-directory=arm
--with-ecj-jar=/usr/share/java/eclipse-ecj.jar --with-target-system-zlib --enable-objc-gc=auto
--enable-multiarch --disable-sjlj-exceptions --with-arch=armv6 --with-fpu=vfp --with-float=hard
--enable-checking=release --build=arm-linux-gnueabihf --host=arm-linux-gnueabihf --target=arm-linux-gnueabihf
Thread model: posix
gcc version 6.3.0 20170516 (Raspbian 6.3.0-18+rpi1+deb9u1)
pi@raspberrypi:~/packages/midas/bin $ lsb_release -a
No LSB modules are available.
Distributor ID: Raspbian
Description: Raspbian GNU/Linux 9.9 (stretch)
Release: 9.9
Codename: stretch
> Yikes, the error is in the CRC library. The assembly-optimized crc32c function fails to build, and the
> error does not look familiar to me. I do not see this error here. What is your host system ("uname -
> a") and what is your gcc ("gcc -v")?
>
> BTW, "make linux32" will build an Intel 32-bit version (see "-m32" in "man gcc"). For ARM 32-bit
> you need a different switch, I think, also depending how you are cross-compiling it.
>
> For straight cross-compilation, look at the Makefile target "make linuxarm" (you will need to change
> the location of your ARM gcc cross-compiler).
>
> For running MIDAS frontend on the Raspberry Pi 3, I build MIDAS on the Pi3 itself, the machine is big
> enough to run CentOS7 linux and gcc to build the full MIDAS.
>
> But if you have a different cross-compilation scheme, I am happy to help you and to add your
> scheme to the MIDAS Makefile. We can start by looking at "uname -a" and "gcc -v" and "lsb_release
> -a" (if you have it).
>
> K.O.
>
>
> > Hi, we are part of the Mu3e research based at University of Bristol. We have a
> > remote 32 bit frontend (raspberry pi) connected to a 64 bit Data Acquisition
> > system.we are following the instructions at installation/quickstart linux/Build
> > 32-bit MIDAS libraries. when we execute the commands:
> > [mhostpc] cd /home/packages/midas
> > [mhostpc] make linux32
> >
> > we get an error:
> >
> > make NO_ROOT=1 NO_MYSQL=1 NO_ODBC=1 NO_SQLITE=1 OS_DIR=linux-m32 USERFLAGS=-
> m32
> > make[1]: Entering directory `/home/hh19285/packages/midas'
> > g++ -m32 -c -g -O2 -Wall -Wno-strict-aliasing -Wuninitialized -Iinclude -
> > Idrivers -Imxml -Imscb/include -DHAVE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_ZLIB -
> > DHAVE_MSCB -DHAVE_MONGOOSE6 -DMG_ENABLE_THREADS -DMG_DISABLE_CGI -
> DMG_ENABLE_SSL
> > -DOS_LINUX -fPIC -Wno-unused-function -o lib/crc32c.o src/crc32c.cxx
> > src/crc32c.cxx: In function ‘uint32_t crc32c_hw(uint32_t, const void*, size_t)’:
> > src/crc32c.cxx:283:66: error: ‘asm’ operand has impossible constraints
> > : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> > ^
> > src/crc32c.cxx:303:66: error: ‘asm’ operand has impossible constraints
> > : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> > ^
> > src/crc32c.cxx: In function ‘uint32_t crc32c(uint32_t, const void*, size_t)’:
> > src/crc32c.cxx:348:34: error: PIC register clobbered by ‘%ebx’ in ‘asm’
> > : "%ebx", "%edx"); \
> > ^
> > src/crc32c.cxx:362:5: note: in expansion of macro ‘SSE42’
> > SSE42(sse42);
> > ^
> > make[1]: *** [lib/crc32c.o] Error 1
> > make[1]: Leaving directory `/home/hh19285/packages/midas'
> > make: *** [linux32] Error 2
> >
> > Could you please help with getting past this? otherwise we may need to change
> > our whole experimental setup.
> >
> > Thank you in advance |
|
27 Jun 2019, Konstantin Olchanski, Bug Report, make linux32 bombs on el7 in crc32c.c, ERROR INSTALLING 32BIT MIDAS LIBRARIES ON 64BIT HOST MACHINE
|
Reproduced on el7 (CentOS7). Same thing works on el6 (SL6).
The error is in the SSE4.2-assembly-accelerated library for computing crc32c checksums. I do
not understand this assembly stuff enough to tell what goes wrong.
In any case, "make linux32" is intended for VME processors that cannot run 64-bit code. These
processors also happen to not have the SSE4.2 instructions needed for this code to actually
work, so one solution would be to always disable crc32c SSE4.2-assembly-acceleration for the
linux32 target.
Note that the original reported was running "make linux32" with the idea of generating code for
the 32-bit ARM processor.
Here the situation is like this: the required CRC32C instructions are present on 64-bit capable
ARM processors (RPi3, etc) and probably work in 32-bit mode, and I found the assembly-
language crc32c library that uses them. It needs to be added to MIDAS and tested.
For the older 32-bit-only ARM processors (Cyclone5 FPGA, Rpi2 and older) I do not see any
hardware accelerated crc32c implementations, so it uses software computed CRC32 always.
(P.S.: I see the current linux kernels have a hardware accelerated library for CRC32C, not sure if
it can be imported into MIDAS easily).
K.O.
> $ make linux32 ...
> g++ -m32 -c -g -O2 -Wall -Wno-strict-aliasing -Wuninitialized -Iinclude -
> Idrivers -Imxml -Imscb/include -DHAVE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_ZLIB -
> DHAVE_MSCB -DHAVE_MONGOOSE6 -DMG_ENABLE_THREADS -DMG_DISABLE_CGI -
DMG_ENABLE_SSL
> -DOS_LINUX -fPIC -Wno-unused-function -o lib/crc32c.o src/crc32c.cxx
> src/crc32c.cxx: In function ‘uint32_t crc32c_hw(uint32_t, const void*, size_t)’:
> src/crc32c.cxx:283:66: error: ‘asm’ operand has impossible constraints
> : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> ^
> src/crc32c.cxx:303:66: error: ‘asm’ operand has impossible constraints
> : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> ^
> src/crc32c.cxx: In function ‘uint32_t crc32c(uint32_t, const void*, size_t)’:
> src/crc32c.cxx:348:34: error: PIC register clobbered by ‘%ebx’ in ‘asm’
> : "%ebx", "%edx"); \
> ^
> src/crc32c.cxx:362:5: note: in expansion of macro ‘SSE42’
> SSE42(sse42);
> ^
> make[1]: *** [lib/crc32c.o] Error 1
> make[1]: Leaving directory `/home/hh19285/packages/midas'
> make: *** [linux32] Error 2
>
> Could you please help with getting past this? otherwise we may need to change
> our whole experimental setup.
>
> Thank you in advance |
|
28 Jun 2019, Konstantin Olchanski, Bug Report, make linux32 bombs on el7 in crc32c.c, ERROR INSTALLING 32BIT MIDAS LIBRARIES ON 64BIT HOST MACHINE
|
> Reproduced on el7 (CentOS7). Same thing works on el6 (SL6).
Fixed in commit dd937e6. Only enable SSE4.2 crc32c for 64-bit compilation. Still not sure why it worked for 32-bit
compilation on el6 (SL6).
K.O.
>
> The error is in the SSE4.2-assembly-accelerated library for computing crc32c checksums. I do
> not understand this assembly stuff enough to tell what goes wrong.
>
> In any case, "make linux32" is intended for VME processors that cannot run 64-bit code. These
> processors also happen to not have the SSE4.2 instructions needed for this code to actually
> work, so one solution would be to always disable crc32c SSE4.2-assembly-acceleration for the
> linux32 target.
>
> Note that the original reported was running "make linux32" with the idea of generating code for
> the 32-bit ARM processor.
>
> Here the situation is like this: the required CRC32C instructions are present on 64-bit capable
> ARM processors (RPi3, etc) and probably work in 32-bit mode, and I found the assembly-
> language crc32c library that uses them. It needs to be added to MIDAS and tested.
>
> For the older 32-bit-only ARM processors (Cyclone5 FPGA, Rpi2 and older) I do not see any
> hardware accelerated crc32c implementations, so it uses software computed CRC32 always.
> (P.S.: I see the current linux kernels have a hardware accelerated library for CRC32C, not sure if
> it can be imported into MIDAS easily).
>
> K.O.
>
>
> > $ make linux32 ...
> > g++ -m32 -c -g -O2 -Wall -Wno-strict-aliasing -Wuninitialized -Iinclude -
> > Idrivers -Imxml -Imscb/include -DHAVE_FTPLIB -D_LARGEFILE64_SOURCE -DHAVE_ZLIB -
> > DHAVE_MSCB -DHAVE_MONGOOSE6 -DMG_ENABLE_THREADS -DMG_DISABLE_CGI -
> DMG_ENABLE_SSL
> > -DOS_LINUX -fPIC -Wno-unused-function -o lib/crc32c.o src/crc32c.cxx
> > src/crc32c.cxx: In function ‘uint32_t crc32c_hw(uint32_t, const void*, size_t)’:
> > src/crc32c.cxx:283:66: error: ‘asm’ operand has impossible constraints
> > : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> > ^
> > src/crc32c.cxx:303:66: error: ‘asm’ operand has impossible constraints
> > : "r"(next), "0"(crc0), "1"(crc1), "2"(crc2));
> > ^
> > src/crc32c.cxx: In function ‘uint32_t crc32c(uint32_t, const void*, size_t)’:
> > src/crc32c.cxx:348:34: error: PIC register clobbered by ‘%ebx’ in ‘asm’
> > : "%ebx", "%edx"); \
> > ^
> > src/crc32c.cxx:362:5: note: in expansion of macro ‘SSE42’
> > SSE42(sse42);
> > ^
> > make[1]: *** [lib/crc32c.o] Error 1
> > make[1]: Leaving directory `/home/hh19285/packages/midas'
> > make: *** [linux32] Error 2
> >
> > Could you please help with getting past this? otherwise we may need to change
> > our whole experimental setup.
> >
> > Thank you in advance |
|
27 Jun 2019, Hassan, Bug Report, Getting an error when trying to compile a frontend file
|
When we run the following commands on the hostname(DAQ machine) and the remote
frontend(Rpi):
cd $HOME/online
cp $MIDASSYS/examples/experiment/* .
make
We get errors such as
=================
On Rpi:
pi@raspberrypi:~/online/fe_test $ make
...
Missing definition of environment variable 'ROOTSYS' !
=================
On host machine
inking CXX executable frontend
/usr/bin/ld: cannot find -lmfe
/usr/bin/ld: cannot find -lmidas
collect2: error: ld returned 1 exit status
make[2]: *** [frontend] Error 1
make[1]: *** [CMakeFiles/frontend.dir/all] Error 2
make: *** [all] Error 2
The Rpi(32bit) doesn't have root installed but the host machine(64bit) does.
What can we do to fix this?
Thank you this forum has been of great help. |
|
27 Jun 2019, Konstantin Olchanski, Bug Report, Getting an error when trying to compile a frontend file
|
If the latest midas does not work, try the previous release versions. "git tags" and "git branch -
a" will show you what exists. Look for branch and tag names in the form "midas-YYYY-MM".
As shortcut, the latest release candidate is midas-2019-06, the latest release branch is midas-
2019-03, latest release tag midas-2019-03-h.
Read the messages in this thread for more information:
https://midas.triumf.ca/elog/Midas/1513
>
> When we run the following commands ...
> make[1]: *** [CMakeFiles/frontend.dir/all] Error 2
>
I do not understand cmake well enough to debug this. Falling back to midas-2019-03 may help
you as it uses normal make and with luck you know how to debug normal Makefiles if you see
the same problem.
K.O. |
|
27 Jun 2019, Stefan Ritt, Bug Report, Getting an error when trying to compile a frontend file
|
Note that the example experiment compiles a simple example frontend and a root-based analyzer. If you don't have
ROOT installed, you of course cannot compile the analyzer. If you don't need the analyzer, remove it from the
Makefile/CMakeLists.txt
It's not clear to me why the frontend did not compile on our server machine. You did not post the command how you
initiated the build. Note that there are now two parallel build schemes: the traditional Makefile and the new
CMakeFiles.txt. We try to maintain both of them, so you have to specify which one you use when you get an error.
I realize now that the CMakeLists.txt in the experiment example directory builds nicely under midas, but when you move
it to another directory and extract it from the normal build scheme it breaks. I rewrote the CMakeLists.txt now that it
looks for MIDASSYS and also build at different locations. Do
cd $HOME/online
cp $MIDASSYS/examples/experiment/* .
mkdir build
cd build
cmake ..
make
and it should work. Of course first pull the current develop version.
Stefan |
|